[Core][Frontend] Add faster-outlines as guided decoding backend #10277
Conversation
|
👋 Hi! Thank you for contributing to the vLLM project. Once the PR is approved and ready to go, your PR reviewer(s) can run CI to test the changes comprehensively before merging. To run CI, PR reviewers can do one of these:
🚀 |
|
@unaidedelf8777 Thank you for this thorough and well-documented PR! The amount of work you've put into both the implementation and testing methodology is great. The performance improvements shown (90-94% faster compilation, significant TTFT reductions) are remarkable, so I'm looking forward to further validate with my benchmarking. Regarding platform support - I see from PyPI that faster-outlines currently provides wheels for:
This covers most of vLLM's current deployment scenarios, though we'd need Python 3.9 support added for full compatibility. Would you be open to adding Python 3.9 wheels to ensure we can support the full range of vLLM deployments? In the best possible scenario, you would be able to use the My main consideration is around adding another compiled binary dependency to the common requirements. While the performance benefits are compelling, we want to ensure we're not creating deployment challenges for the many hardware backends we have. That said, the existing wheel coverage should be good for now. A few quick questions:
|
|
I did some benchmarking using the modified throughput script here #10046 (comment) All benchmarks were done on a single H100 80GB HBM3. Each prompt is about 580 tokens. Online throughput scenario (10 prompts of 2048 output length without warmup):Here you can see the advantage of faster-outlines better TTFT and FSM index creation, almost 3x output token improvement. Offline throughput scenario (100 prompts of 2048 output length with warmup):Here we unfortunately see a regression in token throughput when having a large batch size. This probably isn't an issue with faster-outlines itself, but rather vLLM's structure for guided decoding. Curious to hear your thoughts |
|
@mgoin Thanks for taking a look!
PyPi wheels are no problem I'm sure. I'll take a look into the ci setup, and get the wheels pushed soon as I can ( likely tommorow / saturday ). The only reason it is labeled to support >=3.10 is because that is what I have installed locally.
Right now, the only algorithmic difference is that unlike outlines it cannot generate multi-byte sequences, but that should be fixed in a later update.
I have some rough estimates based on objects within the code from tests earlier, and the sizes should not have changed since that, because I am using the same dtypes still ( basically u32 for everything ). when I did that the peek size I saw was around 30mb for a very large (~200 state fsm). Overall, The lib is 90% zero copy, since it just uses Arc's ( reference counted multi-thread container ) to hold most things which need to be saved. From the test I just ran, the size of the same FSM as a outlines FSM is roughly 100mb, I would assume because python's default int seems to be 28 bytes long ( or at least 28 bytes per integer object ). I used the function from here to get the size of the outlines FSM's If the python integer is in fact 28 bytes long, then faster-outlines will be using massively less memory than outlines, simply because each integer is 4 bytes instead of 28. The only other memory overhead which is capable of growing large enough to be noticed would be the cache. But the cache size can be controlled by the env var
Currently, if you need to do multi-byte sequences in the regex, then you would need to use outlines. But other than that there is no difference in the outputs compared to outlines. It is the exact same algorithms, just with much better memory management, and of-course async. |
|
I think the main problem atm is that logit_processor is currently applying row-wise blocking I will share a draft wrt design proposal a bit later (currently working on it atm) |
|
Python 3.9 wheels are working and pushed to pypi. The wheels were compiled with the "abi3" feature of pyo3, which uses only the python-limited-api as requested. I'll push to the fork in a few to update the version minimum. (edit: done) |
Re-released faster-outlines to pypi in order to compile for python3.9 and above; Updating the version in requirements-common.txt in order to comply with vllm being based on python3.9
|
Is there anything else I can do to make this more mergeable? And are you able to review / merge, or do I need to contact somebody for that? |
|
We will have a meeting tmr to discuss steps moving forward wrt guided decoding plans. Will update you |
Cool. Keep Me posted. |
Adds support for faster-outlines as a guided decoding backend.
Hello all,
The last few months I have been porting the algorithms of the outlines library to Rust, and making them significantly faster ( Note: I started this port long before the outlines team actually did it themselves ). The implementation is specifically tailored to high throughput inference setups, which cannot know the JSON schema/regex's ahead of time.
One of the specific optimizations which I made in order to reduce TTFT is to make the index compilation parallel with the computation for model inference. Without getting into the nitty gritty of it, it follows a model where we allocate a shared memory block, then launch a thread to compute the tokenizer based FSM index, reporting back the results of each FSM state immediately once it is finished and notifying state status via Atomics.
This parallel computation reduces the TTFT for nearly all requests to only slightly longer than it takes to compile the FSM based on the regex.
In terms of VLLM implementation specifics, it parses the regex pattern, translate it to an FSM, and reduce that FSM inside of the server process. Then this FSM is serialized and sent over via pickle to the inference process, where the FSM is used to instantiate a
LazyFSMIndexobject, which is the core of the lazy / parallel computation of the index. On instantiation theLazyFSMIndexobject launches the index compilation thread using the aforementioned method for sharing state, and then the objects initialization function returns immediately. This whole instantiation process takes less than a millisecond (of course, it could take more than that since it is launching threads, and thus is at the mercy of the OS). From this point on, the object acts as a normaloutlinesguide, implementing an identical guide API, and abstracting any state awaiting / special implementation logic away to Rust. In terms of state awaiting, it usually does not incur overhead, as states are normally computed by the time they are needed by the inference thread, and awaiting only consistently happens in the cases of state machines with 200+ states. The awaiting mechanism is also very fast, using atomics andFUTEXsys calls to wake all waiters when a state is ready.In terms of caching, The implementation delegates this to Rust as well for performance. The cache stores FSM's based on the hashes of both the input regex pattern and the tokenizer to avoid issues. On the event of a cache hit, the object bypasses all state awaiting mechanisms and assumes that all states are computed in order to decrease the overhead of the object to as little as possible.
The library has been thoroughly tested, and has a small tests in the Rust code, and a main smoke test for all functionality in the codebase, which has a list of regex patterns which need to be compiled and a tokenizer, and then randomly walks the allowed token id's of the FSM in order to try and break it. If at the end of the mock generation loop in the test the decoded token IDs do not match the regex pattern, it fails. For each regex pattern this test is performed 50 times to be absolutely sure of results, and the overall test fails if less than 100% match rate occurs.
Below is a comparison between faster-outlines's state machine compilation time and the time of
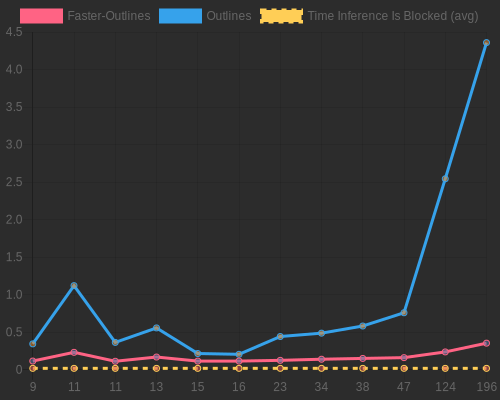
outlines-core(the outlines team's Rust port)The benchmark code used to generate this graph can be found in the repository
In this test the index object is forced to wait for the compilation of the index to finish before the timer stops and time is saved.
For all tested regex's, faster-outlines registers at roughly 90% faster for all, with a peek speed up of 94%.
Below are benchmarks showing the TTFT improvements over outlines, and overall request time reduction for unseen regex patterns. All benchmarks performed with default inference settings and dtype, on an L40S.
The
Totalfield in the graphs below represents the total time roundtrip for the request.For llama-3.2-1b-Instruct
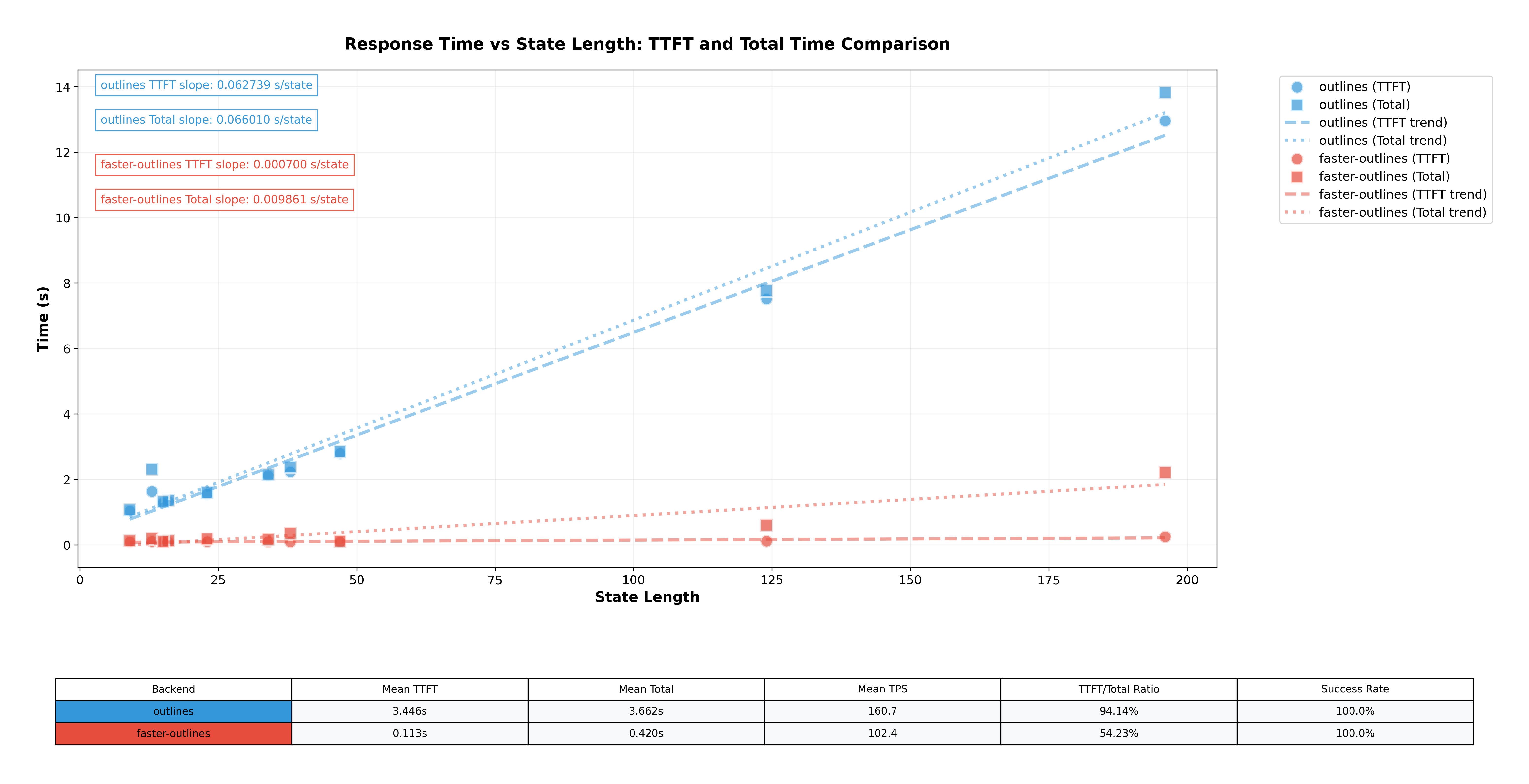
For llama-3-8b-Instruct
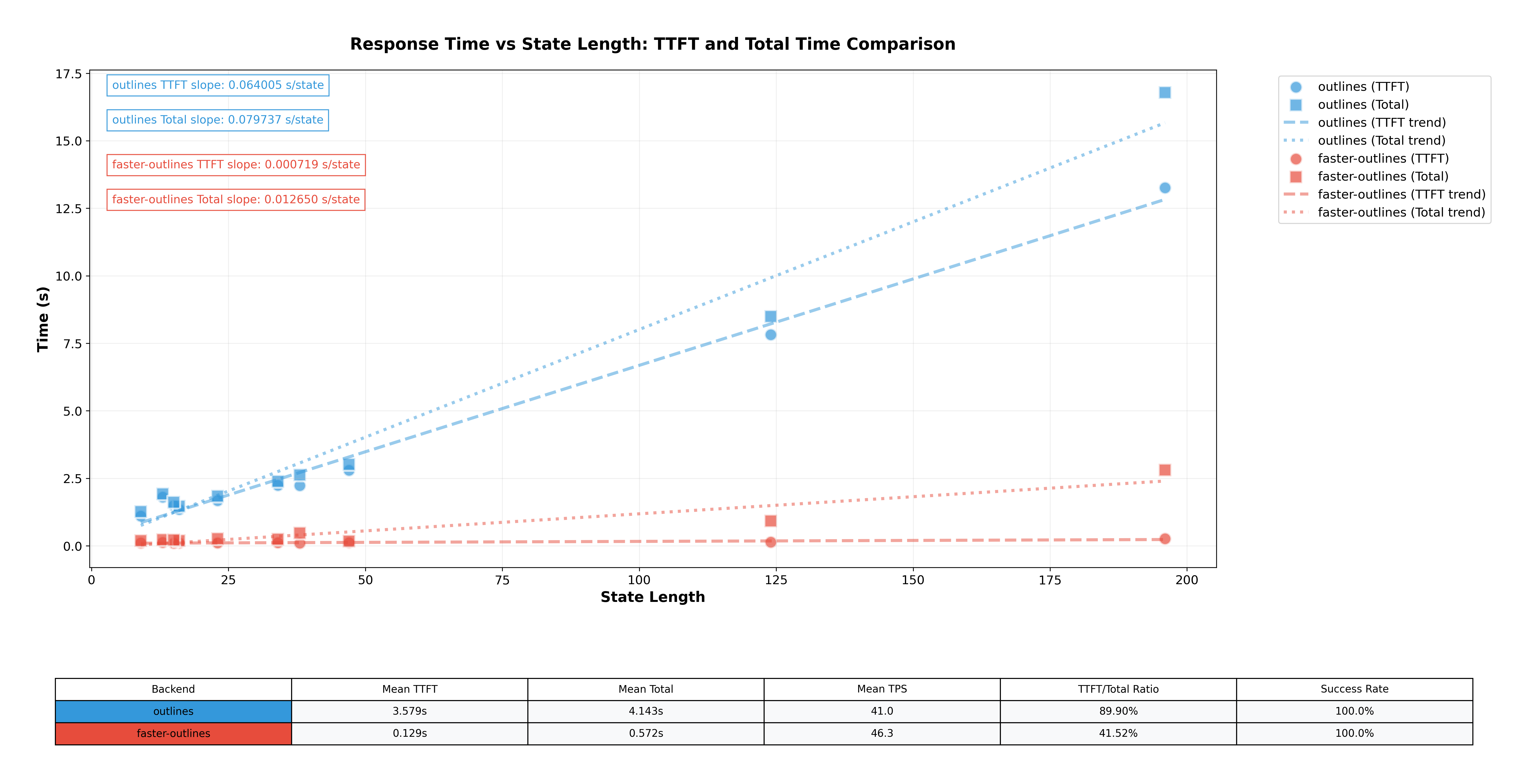
The benchmark code used to make these two graphs is located in the repository as well at this file
In terms of the integration as a
guided_decoding_backend, the implementation is a single file, and is quite similar to the one implemented for outlines, just with unnecessary code stripped away and some changes to reduce overhead.