[NEW] Reaching 1 million requests per second on a single Valkey instance #22
Comments
|
@touitou-dan was still working on this with @uriyage. I'm planning on syncing with them internally to see what their status is and how we can port the changes here. |
|
We are developing an application that went through a series of big architectural changes. Initially it was many threads, each with its own Redis connection.
|
|
I think there's a divide between two basic use cases which changes development priorities:
Most of the "Redis panic" is around hosting providers just wanting to continue servicing easy use cases, but there's a lot of room for "bug fixes and performance enhancements" too for much more advanced use cases. Let me continue bringing up the work I've spent 10,000 hours implementing most of these fixes already, but I'm afraid to release publicly because if I see more of my high performance code get deployed on tens of millions of computers without compensation I'll just have to walk into the ocean. db rewrite details: https://matt.sh/best-database-ever |
|
Really look forward to this io-threads refactor, speaking of the
BTW, I also noticed the memory latency before, below is the disassembly code of
|

|
Yeah I will take a look. Btw, a few of us are at the Linux open source summit this week so our response would be a bit slower than usual. |
|
@lipzhu, I am still waiting for the detailed design. Here is my understanding of what we are trying to achieve here (but @madolson @touitou-dan can let me know if I am mistaken). With this proposal,
IF this is the proposal (even with just step 1 and 2), I don't see the optimization proposed in #111 getting carried over. |
|
@PingXie Maybe I confused you, #111 is inspired from redis/redis#12305 (comment). For existing io-threads implementation, user may found that with the same client requests pressure, server with more CPU allocated and io-threads number configured have lower QPS than server with little io-threads configured, this doesn't make sense. Test scenario is updated in #111 (comment) |
|
Those are all logical steps. Very similar to when I worked out a multi-threaded archietcture a couple years ago: Be careful though because eventually you just end up implementing a full programming language virtual machine to solve the problem. You'll end up with a full internal bytecode/IR mapping for translating all client commands into more detailed internal features because you need to manage: command distribution, a work queue, letting some workers sleep (so then you also need to implement a scheduler), then the replies have to be happy; then you also have to check if your TLS library supports isolating readers and writers concurrently or if you have to lock them all down simultaneously, etc. |
My understanding is that the slow access is a result of idx = h & DICTHT_SIZE_MASK(d->ht_size_exp[table]);
he = d->ht_table[table][idx];
while(he) {
Yeah, I also think this will increase the cache hit rate. |
Understood. I was thinking more along the line of "longevity" for #111. From a quick look at the PR, I think it is pretty contained and the change makes sense to me. If it doesn't increase our tech debts (which doesn't look like the case right now), I agree it makes sense to continue improving the status quo. I will take a close look at #111 next. |
Good point @mattsta. I wonder if there is a way to materialize this proposal in phases. We will need a more concrete design first. |
Look forward to your help :) |
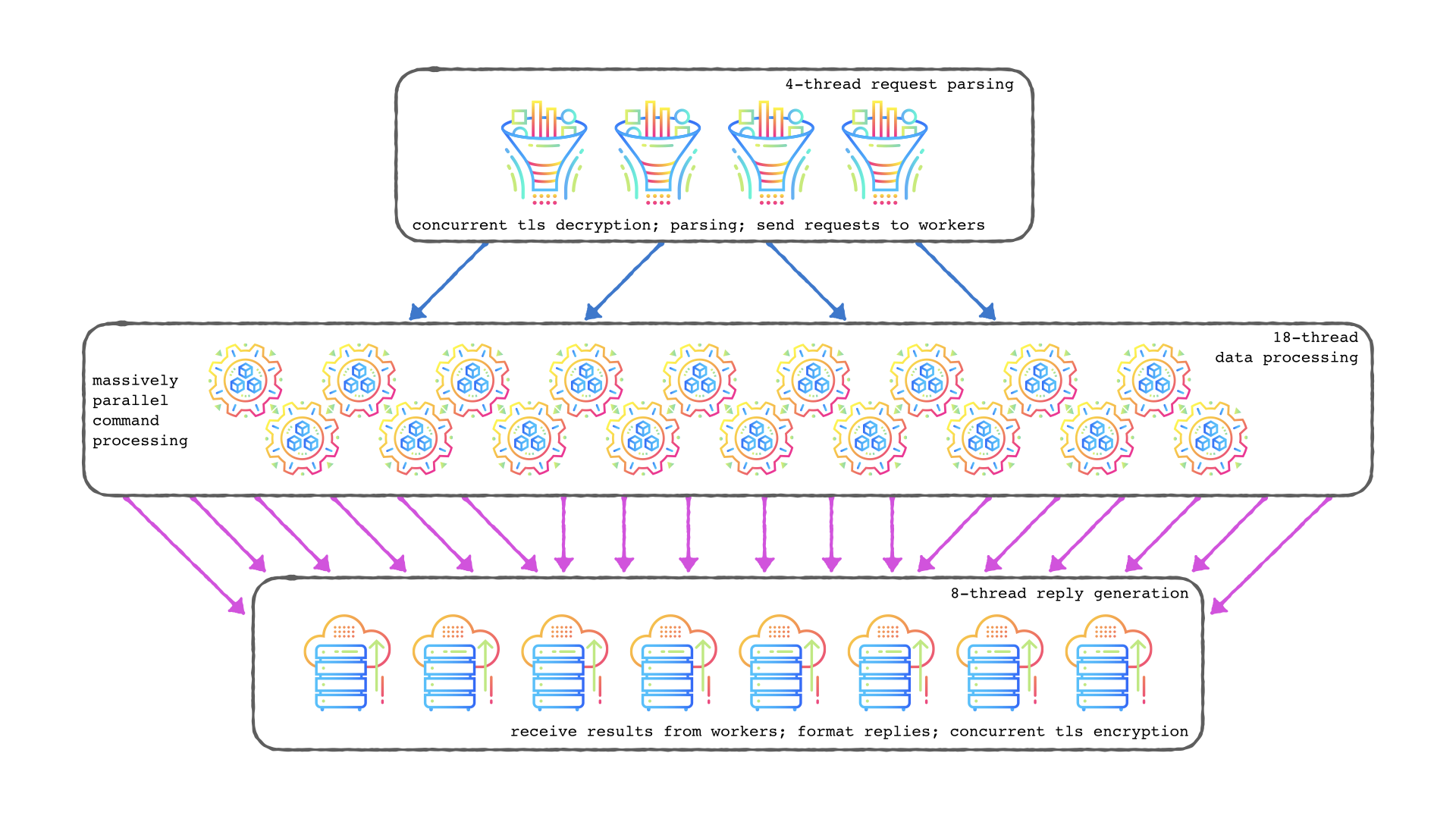
This PR is 1 of 3 PRs intended to achieve the goal of 1 million requests per second, as detailed by [dan touitou](https://github.com/touitou-dan) in #22. This PR modifies the IO threads to be fully asynchronous, which is a first and necessary step to allow more work offloading and better utilization of the IO threads. ### Current IO threads state: Valkey IO threads were introduced in Redis 6.0 to allow better utilization of multi-core machines. Before this, Redis was single-threaded and could only use one CPU core for network and command processing. The introduction of IO threads helps in offloading the IO operations to multiple threads. **Current IO Threads flow:** 1. Initialization: When Redis starts, it initializes a specified number of IO threads. These threads are in addition to the main thread, each thread starts with an empty list, the main thread will populate that list in each event-loop with pending-read-clients or pending-write-clients. 2. Read Phase: The main thread accepts incoming connections and reads requests from clients. The reading of requests are offloaded to IO threads. The main thread puts the clients ready-to-read in a list and set the global io_threads_op to IO_THREADS_OP_READ, the IO threads pick the clients up, perform the read operation and parse the first incoming command. 3. Command Processing: After reading the requests, command processing is still single-threaded and handled by the main thread. 4. Write Phase: Similar to the read phase, the write phase is also be offloaded to IO threads. The main thread prepares the response in the clients’ output buffer then the main thread puts the client in the list, and sets the global io_threads_op to the IO_THREADS_OP_WRITE. The IO threads then pick the clients up and perform the write operation to send the responses back to clients. 5. Synchronization: The main-thread communicate with the threads on how many jobs left per each thread with atomic counter. The main-thread doesn’t access the clients while being handled by the IO threads. **Issues with current implementation:** * Underutilized Cores: The current implementation of IO-threads leads to the underutilization of CPU cores. * The main thread remains responsible for a significant portion of IO-related tasks that could be offloaded to IO-threads. * When the main-thread is processing client’s commands, the IO threads are idle for a considerable amount of time. * Notably, the main thread's performance during the IO-related tasks is constrained by the speed of the slowest IO-thread. * Limited Offloading: Currently, Since the Main-threads waits synchronously for the IO threads, the Threads perform only read-parse, and write operations, with parsing done only for the first command. If the threads can do work asynchronously we may offload more work to the threads reducing the load from the main-thread. * TLS: Currently, we don't support IO threads with TLS (where offloading IO would be more beneficial) since TLS read/write operations are not thread-safe with the current implementation. ### Suggested change Non-blocking main thread - The main thread and IO threads will operate in parallel to maximize efficiency. The main thread will not be blocked by IO operations. It will continue to process commands independently of the IO thread's activities. **Implementation details** **Inter-thread communication.** * We use a static, lock-free ring buffer of fixed size (2048 jobs) for the main thread to send jobs and for the IO to receive them. If the ring buffer fills up, the main thread will handle the task itself, acting as back pressure (in case IO operations are more expensive than command processing). A static ring buffer is a better candidate than a dynamic job queue as it eliminates the need for allocation/freeing per job. * An IO job will be in the format: ` [void* function-call-back | void *data] `where data is either a client to read/write from and the function-ptr is the function to be called with the data for example readQueryFromClient using this format we can use it later to offload other types of works to the IO threads. * The Ring buffer is one way from the main-thread to the IO thread, Upon read/write event the main thread will send a read/write job then in before sleep it will iterate over the pending read/write clients to checking for each client if the IO threads has already finished handling it. The IO thread signals it has finished handling a client read/write by toggling an atomic flag read_state / write_state on the client struct. **Thread Safety** As suggested in this solution, the IO threads are reading from and writing to the clients' buffers while the main thread may access those clients. We must ensure no race conditions or unsafe access occurs while keeping the Valkey code simple and lock free. Minimal Action in the IO Threads The main change is to limit the IO thread operations to the bare minimum. The IO thread will access only the client's struct and only the necessary fields in this struct. The IO threads will be responsible for the following: * Read Operation: The IO thread will only read and parse a single command. It will not update the server stats, handle read errors, or parsing errors. These tasks will be taken care of by the main thread. * Write Operation: The IO thread will only write the available data. It will not free the client's replies, handle write errors, or update the server statistics. To achieve this without code duplication, the read/write code has been refactored into smaller, independent components: * Functions that perform only the read/parse/write calls. * Functions that handle the read/parse/write results. This refactor accounts for the majority of the modifications in this PR. **Client Struct Safe Access** As we ensure that the IO threads access memory only within the client struct, we need to ensure thread safety only for the client's struct's shared fields. * Query Buffer * Command parsing - The main thread will not try to parse a command from the query buffer when a client is offloaded to the IO thread. * Client's memory checks in client-cron - The main thread will not access the client query buffer if it is offloaded and will handle the querybuf grow/shrink when the client is back. * CLIENT LIST command - The main thread will busy-wait for the IO thread to finish handling the client, falling back to the current behavior where the main thread waits for the IO thread to finish their processing. * Output Buffer * The IO thread will not change the client's bufpos and won't free the client's reply lists. These actions will be done by the main thread on the client's return from the IO thread. * bufpos / block→used: As the main thread may change the bufpos, the reply-block→used, or add/delete blocks to the reply list while the IO thread writes, we add two fields to the client struct: io_last_bufpos and io_last_reply_block. The IO thread will write until the io_last_bufpos, which was set by the main-thread before sending the client to the IO thread. If more data has been added to the cob in between, it will be written in the next write-job. In addition, the main thread will not trim or merge reply blocks while the client is offloaded. * Parsing Fields * Client's cmd, argc, argv, reqtype, etc., are set during parsing. * The main thread will indicate to the IO thread not to parse a cmd if the client is not reset. In this case, the IO thread will only read from the network and won't attempt to parse a new command. * The main thread won't access the c→cmd/c→argv in the CLIENT LIST command as stated before it will busy wait for the IO threads. * Client Flags * c→flags, which may be changed by the main thread in multiple places, won't be accessed by the IO thread. Instead, the main thread will set the c→io_flags with the information necessary for the IO thread to know the client's state. * Client Close * On freeClient, the main thread will busy wait for the IO thread to finish processing the client's read/write before proceeding to free the client. * Client's Memory Limits * The IO thread won't handle the qb/cob limits. In case a client crosses the qb limit, the IO thread will stop reading for it, letting the main thread know that the client crossed the limit. **TLS** TLS is currently not supported with IO threads for the following reasons: 1. Pending reads - If SSL has pending data that has already been read from the socket, there is a risk of not calling the read handler again. To handle this, a list is used to hold the pending clients. With IO threads, multiple threads can access the list concurrently. 2. Event loop modification - Currently, the TLS code registers/unregisters the file descriptor from the event loop depending on the read/write results. With IO threads, multiple threads can modify the event loop struct simultaneously. 3. The same client can be sent to 2 different threads concurrently (redis/redis#12540). Those issues were handled in the current PR: 1. The IO thread only performs the read operation. The main thread will check for pending reads after the client returns from the IO thread and will be the only one to access the pending list. 2. The registering/unregistering of events will be similarly postponed and handled by the main thread only. 3. Each client is being sent to the same dedicated thread (c→id % num_of_threads). **Sending Replies Immediately with IO threads.** Currently, after processing a command, we add the client to the pending_writes_list. Only after processing all the clients do we send all the replies. Since the IO threads are now working asynchronously, we can send the reply immediately after processing the client’s requests, reducing the command latency. However, if we are using AOF=always, we must wait for the AOF buffer to be written, in which case we revert to the current behavior. **IO threads dynamic adjustment** Currently, we use an all-or-nothing approach when activating the IO threads. The current logic is as follows: if the number of pending write clients is greater than twice the number of threads (including the main thread), we enable all threads; otherwise, we enable none. For example, if 8 IO threads are defined, we enable all 8 threads if there are 16 pending clients; else, we enable none. It makes more sense to enable partial activation of the IO threads. If we have 10 pending clients, we will enable 5 threads, and so on. This approach allows for a more granular and efficient allocation of resources based on the current workload. In addition, the user will now be able to change the number of I/O threads at runtime. For example, when decreasing the number of threads from 4 to 2, threads 3 and 4 will be closed after flushing their job queues. **Tests** Currently, we run the io-threads tests with 4 IO threads (https://github.com/valkey-io/valkey/blob/443d80f1686377ad42cbf92d98ecc6d240325ee1/.github/workflows/daily.yml#L353). This means that we will not activate the IO threads unless there are 8 (threads * 2) pending write clients per single loop, which is unlikely to happened in most of tests, meaning the IO threads are not currently being tested. To enforce the main thread to always offload work to the IO threads, regardless of the number of pending events, we add an events-per-io-thread configuration with a default value of 2. When set to 0, this configuration will force the main thread to always offload work to the IO threads. When we offload every single read/write operation to the IO threads, the IO-threads are running with 100% CPU when running multiple tests concurrently some tests fail as a result of larger than expected command latencies. To address this issue, we have to add some after or wait_for calls to some of the tests to ensure they pass with IO threads as well. Signed-off-by: Uri Yagelnik <[email protected]>
This PR is 1 of 3 PRs intended to achieve the goal of 1 million requests per second, as detailed by [dan touitou](https://github.com/touitou-dan) in valkey-io#22. This PR modifies the IO threads to be fully asynchronous, which is a first and necessary step to allow more work offloading and better utilization of the IO threads. ### Current IO threads state: Valkey IO threads were introduced in Redis 6.0 to allow better utilization of multi-core machines. Before this, Redis was single-threaded and could only use one CPU core for network and command processing. The introduction of IO threads helps in offloading the IO operations to multiple threads. **Current IO Threads flow:** 1. Initialization: When Redis starts, it initializes a specified number of IO threads. These threads are in addition to the main thread, each thread starts with an empty list, the main thread will populate that list in each event-loop with pending-read-clients or pending-write-clients. 2. Read Phase: The main thread accepts incoming connections and reads requests from clients. The reading of requests are offloaded to IO threads. The main thread puts the clients ready-to-read in a list and set the global io_threads_op to IO_THREADS_OP_READ, the IO threads pick the clients up, perform the read operation and parse the first incoming command. 3. Command Processing: After reading the requests, command processing is still single-threaded and handled by the main thread. 4. Write Phase: Similar to the read phase, the write phase is also be offloaded to IO threads. The main thread prepares the response in the clients’ output buffer then the main thread puts the client in the list, and sets the global io_threads_op to the IO_THREADS_OP_WRITE. The IO threads then pick the clients up and perform the write operation to send the responses back to clients. 5. Synchronization: The main-thread communicate with the threads on how many jobs left per each thread with atomic counter. The main-thread doesn’t access the clients while being handled by the IO threads. **Issues with current implementation:** * Underutilized Cores: The current implementation of IO-threads leads to the underutilization of CPU cores. * The main thread remains responsible for a significant portion of IO-related tasks that could be offloaded to IO-threads. * When the main-thread is processing client’s commands, the IO threads are idle for a considerable amount of time. * Notably, the main thread's performance during the IO-related tasks is constrained by the speed of the slowest IO-thread. * Limited Offloading: Currently, Since the Main-threads waits synchronously for the IO threads, the Threads perform only read-parse, and write operations, with parsing done only for the first command. If the threads can do work asynchronously we may offload more work to the threads reducing the load from the main-thread. * TLS: Currently, we don't support IO threads with TLS (where offloading IO would be more beneficial) since TLS read/write operations are not thread-safe with the current implementation. ### Suggested change Non-blocking main thread - The main thread and IO threads will operate in parallel to maximize efficiency. The main thread will not be blocked by IO operations. It will continue to process commands independently of the IO thread's activities. **Implementation details** **Inter-thread communication.** * We use a static, lock-free ring buffer of fixed size (2048 jobs) for the main thread to send jobs and for the IO to receive them. If the ring buffer fills up, the main thread will handle the task itself, acting as back pressure (in case IO operations are more expensive than command processing). A static ring buffer is a better candidate than a dynamic job queue as it eliminates the need for allocation/freeing per job. * An IO job will be in the format: ` [void* function-call-back | void *data] `where data is either a client to read/write from and the function-ptr is the function to be called with the data for example readQueryFromClient using this format we can use it later to offload other types of works to the IO threads. * The Ring buffer is one way from the main-thread to the IO thread, Upon read/write event the main thread will send a read/write job then in before sleep it will iterate over the pending read/write clients to checking for each client if the IO threads has already finished handling it. The IO thread signals it has finished handling a client read/write by toggling an atomic flag read_state / write_state on the client struct. **Thread Safety** As suggested in this solution, the IO threads are reading from and writing to the clients' buffers while the main thread may access those clients. We must ensure no race conditions or unsafe access occurs while keeping the Valkey code simple and lock free. Minimal Action in the IO Threads The main change is to limit the IO thread operations to the bare minimum. The IO thread will access only the client's struct and only the necessary fields in this struct. The IO threads will be responsible for the following: * Read Operation: The IO thread will only read and parse a single command. It will not update the server stats, handle read errors, or parsing errors. These tasks will be taken care of by the main thread. * Write Operation: The IO thread will only write the available data. It will not free the client's replies, handle write errors, or update the server statistics. To achieve this without code duplication, the read/write code has been refactored into smaller, independent components: * Functions that perform only the read/parse/write calls. * Functions that handle the read/parse/write results. This refactor accounts for the majority of the modifications in this PR. **Client Struct Safe Access** As we ensure that the IO threads access memory only within the client struct, we need to ensure thread safety only for the client's struct's shared fields. * Query Buffer * Command parsing - The main thread will not try to parse a command from the query buffer when a client is offloaded to the IO thread. * Client's memory checks in client-cron - The main thread will not access the client query buffer if it is offloaded and will handle the querybuf grow/shrink when the client is back. * CLIENT LIST command - The main thread will busy-wait for the IO thread to finish handling the client, falling back to the current behavior where the main thread waits for the IO thread to finish their processing. * Output Buffer * The IO thread will not change the client's bufpos and won't free the client's reply lists. These actions will be done by the main thread on the client's return from the IO thread. * bufpos / block→used: As the main thread may change the bufpos, the reply-block→used, or add/delete blocks to the reply list while the IO thread writes, we add two fields to the client struct: io_last_bufpos and io_last_reply_block. The IO thread will write until the io_last_bufpos, which was set by the main-thread before sending the client to the IO thread. If more data has been added to the cob in between, it will be written in the next write-job. In addition, the main thread will not trim or merge reply blocks while the client is offloaded. * Parsing Fields * Client's cmd, argc, argv, reqtype, etc., are set during parsing. * The main thread will indicate to the IO thread not to parse a cmd if the client is not reset. In this case, the IO thread will only read from the network and won't attempt to parse a new command. * The main thread won't access the c→cmd/c→argv in the CLIENT LIST command as stated before it will busy wait for the IO threads. * Client Flags * c→flags, which may be changed by the main thread in multiple places, won't be accessed by the IO thread. Instead, the main thread will set the c→io_flags with the information necessary for the IO thread to know the client's state. * Client Close * On freeClient, the main thread will busy wait for the IO thread to finish processing the client's read/write before proceeding to free the client. * Client's Memory Limits * The IO thread won't handle the qb/cob limits. In case a client crosses the qb limit, the IO thread will stop reading for it, letting the main thread know that the client crossed the limit. **TLS** TLS is currently not supported with IO threads for the following reasons: 1. Pending reads - If SSL has pending data that has already been read from the socket, there is a risk of not calling the read handler again. To handle this, a list is used to hold the pending clients. With IO threads, multiple threads can access the list concurrently. 2. Event loop modification - Currently, the TLS code registers/unregisters the file descriptor from the event loop depending on the read/write results. With IO threads, multiple threads can modify the event loop struct simultaneously. 3. The same client can be sent to 2 different threads concurrently (redis/redis#12540). Those issues were handled in the current PR: 1. The IO thread only performs the read operation. The main thread will check for pending reads after the client returns from the IO thread and will be the only one to access the pending list. 2. The registering/unregistering of events will be similarly postponed and handled by the main thread only. 3. Each client is being sent to the same dedicated thread (c→id % num_of_threads). **Sending Replies Immediately with IO threads.** Currently, after processing a command, we add the client to the pending_writes_list. Only after processing all the clients do we send all the replies. Since the IO threads are now working asynchronously, we can send the reply immediately after processing the client’s requests, reducing the command latency. However, if we are using AOF=always, we must wait for the AOF buffer to be written, in which case we revert to the current behavior. **IO threads dynamic adjustment** Currently, we use an all-or-nothing approach when activating the IO threads. The current logic is as follows: if the number of pending write clients is greater than twice the number of threads (including the main thread), we enable all threads; otherwise, we enable none. For example, if 8 IO threads are defined, we enable all 8 threads if there are 16 pending clients; else, we enable none. It makes more sense to enable partial activation of the IO threads. If we have 10 pending clients, we will enable 5 threads, and so on. This approach allows for a more granular and efficient allocation of resources based on the current workload. In addition, the user will now be able to change the number of I/O threads at runtime. For example, when decreasing the number of threads from 4 to 2, threads 3 and 4 will be closed after flushing their job queues. **Tests** Currently, we run the io-threads tests with 4 IO threads (https://github.com/valkey-io/valkey/blob/443d80f1686377ad42cbf92d98ecc6d240325ee1/.github/workflows/daily.yml#L353). This means that we will not activate the IO threads unless there are 8 (threads * 2) pending write clients per single loop, which is unlikely to happened in most of tests, meaning the IO threads are not currently being tested. To enforce the main thread to always offload work to the IO threads, regardless of the number of pending events, we add an events-per-io-thread configuration with a default value of 2. When set to 0, this configuration will force the main thread to always offload work to the IO threads. When we offload every single read/write operation to the IO threads, the IO-threads are running with 100% CPU when running multiple tests concurrently some tests fail as a result of larger than expected command latencies. To address this issue, we have to add some after or wait_for calls to some of the tests to ensure they pass with IO threads as well. Signed-off-by: Uri Yagelnik <[email protected]> Signed-off-by: hwware <[email protected]>
This PR is 1 of 3 PRs intended to achieve the goal of 1 million requests per second, as detailed by [dan touitou](https://github.com/touitou-dan) in valkey-io#22. This PR modifies the IO threads to be fully asynchronous, which is a first and necessary step to allow more work offloading and better utilization of the IO threads. ### Current IO threads state: Valkey IO threads were introduced in Redis 6.0 to allow better utilization of multi-core machines. Before this, Redis was single-threaded and could only use one CPU core for network and command processing. The introduction of IO threads helps in offloading the IO operations to multiple threads. **Current IO Threads flow:** 1. Initialization: When Redis starts, it initializes a specified number of IO threads. These threads are in addition to the main thread, each thread starts with an empty list, the main thread will populate that list in each event-loop with pending-read-clients or pending-write-clients. 2. Read Phase: The main thread accepts incoming connections and reads requests from clients. The reading of requests are offloaded to IO threads. The main thread puts the clients ready-to-read in a list and set the global io_threads_op to IO_THREADS_OP_READ, the IO threads pick the clients up, perform the read operation and parse the first incoming command. 3. Command Processing: After reading the requests, command processing is still single-threaded and handled by the main thread. 4. Write Phase: Similar to the read phase, the write phase is also be offloaded to IO threads. The main thread prepares the response in the clients’ output buffer then the main thread puts the client in the list, and sets the global io_threads_op to the IO_THREADS_OP_WRITE. The IO threads then pick the clients up and perform the write operation to send the responses back to clients. 5. Synchronization: The main-thread communicate with the threads on how many jobs left per each thread with atomic counter. The main-thread doesn’t access the clients while being handled by the IO threads. **Issues with current implementation:** * Underutilized Cores: The current implementation of IO-threads leads to the underutilization of CPU cores. * The main thread remains responsible for a significant portion of IO-related tasks that could be offloaded to IO-threads. * When the main-thread is processing client’s commands, the IO threads are idle for a considerable amount of time. * Notably, the main thread's performance during the IO-related tasks is constrained by the speed of the slowest IO-thread. * Limited Offloading: Currently, Since the Main-threads waits synchronously for the IO threads, the Threads perform only read-parse, and write operations, with parsing done only for the first command. If the threads can do work asynchronously we may offload more work to the threads reducing the load from the main-thread. * TLS: Currently, we don't support IO threads with TLS (where offloading IO would be more beneficial) since TLS read/write operations are not thread-safe with the current implementation. ### Suggested change Non-blocking main thread - The main thread and IO threads will operate in parallel to maximize efficiency. The main thread will not be blocked by IO operations. It will continue to process commands independently of the IO thread's activities. **Implementation details** **Inter-thread communication.** * We use a static, lock-free ring buffer of fixed size (2048 jobs) for the main thread to send jobs and for the IO to receive them. If the ring buffer fills up, the main thread will handle the task itself, acting as back pressure (in case IO operations are more expensive than command processing). A static ring buffer is a better candidate than a dynamic job queue as it eliminates the need for allocation/freeing per job. * An IO job will be in the format: ` [void* function-call-back | void *data] `where data is either a client to read/write from and the function-ptr is the function to be called with the data for example readQueryFromClient using this format we can use it later to offload other types of works to the IO threads. * The Ring buffer is one way from the main-thread to the IO thread, Upon read/write event the main thread will send a read/write job then in before sleep it will iterate over the pending read/write clients to checking for each client if the IO threads has already finished handling it. The IO thread signals it has finished handling a client read/write by toggling an atomic flag read_state / write_state on the client struct. **Thread Safety** As suggested in this solution, the IO threads are reading from and writing to the clients' buffers while the main thread may access those clients. We must ensure no race conditions or unsafe access occurs while keeping the Valkey code simple and lock free. Minimal Action in the IO Threads The main change is to limit the IO thread operations to the bare minimum. The IO thread will access only the client's struct and only the necessary fields in this struct. The IO threads will be responsible for the following: * Read Operation: The IO thread will only read and parse a single command. It will not update the server stats, handle read errors, or parsing errors. These tasks will be taken care of by the main thread. * Write Operation: The IO thread will only write the available data. It will not free the client's replies, handle write errors, or update the server statistics. To achieve this without code duplication, the read/write code has been refactored into smaller, independent components: * Functions that perform only the read/parse/write calls. * Functions that handle the read/parse/write results. This refactor accounts for the majority of the modifications in this PR. **Client Struct Safe Access** As we ensure that the IO threads access memory only within the client struct, we need to ensure thread safety only for the client's struct's shared fields. * Query Buffer * Command parsing - The main thread will not try to parse a command from the query buffer when a client is offloaded to the IO thread. * Client's memory checks in client-cron - The main thread will not access the client query buffer if it is offloaded and will handle the querybuf grow/shrink when the client is back. * CLIENT LIST command - The main thread will busy-wait for the IO thread to finish handling the client, falling back to the current behavior where the main thread waits for the IO thread to finish their processing. * Output Buffer * The IO thread will not change the client's bufpos and won't free the client's reply lists. These actions will be done by the main thread on the client's return from the IO thread. * bufpos / block→used: As the main thread may change the bufpos, the reply-block→used, or add/delete blocks to the reply list while the IO thread writes, we add two fields to the client struct: io_last_bufpos and io_last_reply_block. The IO thread will write until the io_last_bufpos, which was set by the main-thread before sending the client to the IO thread. If more data has been added to the cob in between, it will be written in the next write-job. In addition, the main thread will not trim or merge reply blocks while the client is offloaded. * Parsing Fields * Client's cmd, argc, argv, reqtype, etc., are set during parsing. * The main thread will indicate to the IO thread not to parse a cmd if the client is not reset. In this case, the IO thread will only read from the network and won't attempt to parse a new command. * The main thread won't access the c→cmd/c→argv in the CLIENT LIST command as stated before it will busy wait for the IO threads. * Client Flags * c→flags, which may be changed by the main thread in multiple places, won't be accessed by the IO thread. Instead, the main thread will set the c→io_flags with the information necessary for the IO thread to know the client's state. * Client Close * On freeClient, the main thread will busy wait for the IO thread to finish processing the client's read/write before proceeding to free the client. * Client's Memory Limits * The IO thread won't handle the qb/cob limits. In case a client crosses the qb limit, the IO thread will stop reading for it, letting the main thread know that the client crossed the limit. **TLS** TLS is currently not supported with IO threads for the following reasons: 1. Pending reads - If SSL has pending data that has already been read from the socket, there is a risk of not calling the read handler again. To handle this, a list is used to hold the pending clients. With IO threads, multiple threads can access the list concurrently. 2. Event loop modification - Currently, the TLS code registers/unregisters the file descriptor from the event loop depending on the read/write results. With IO threads, multiple threads can modify the event loop struct simultaneously. 3. The same client can be sent to 2 different threads concurrently (redis/redis#12540). Those issues were handled in the current PR: 1. The IO thread only performs the read operation. The main thread will check for pending reads after the client returns from the IO thread and will be the only one to access the pending list. 2. The registering/unregistering of events will be similarly postponed and handled by the main thread only. 3. Each client is being sent to the same dedicated thread (c→id % num_of_threads). **Sending Replies Immediately with IO threads.** Currently, after processing a command, we add the client to the pending_writes_list. Only after processing all the clients do we send all the replies. Since the IO threads are now working asynchronously, we can send the reply immediately after processing the client’s requests, reducing the command latency. However, if we are using AOF=always, we must wait for the AOF buffer to be written, in which case we revert to the current behavior. **IO threads dynamic adjustment** Currently, we use an all-or-nothing approach when activating the IO threads. The current logic is as follows: if the number of pending write clients is greater than twice the number of threads (including the main thread), we enable all threads; otherwise, we enable none. For example, if 8 IO threads are defined, we enable all 8 threads if there are 16 pending clients; else, we enable none. It makes more sense to enable partial activation of the IO threads. If we have 10 pending clients, we will enable 5 threads, and so on. This approach allows for a more granular and efficient allocation of resources based on the current workload. In addition, the user will now be able to change the number of I/O threads at runtime. For example, when decreasing the number of threads from 4 to 2, threads 3 and 4 will be closed after flushing their job queues. **Tests** Currently, we run the io-threads tests with 4 IO threads (https://github.com/valkey-io/valkey/blob/443d80f1686377ad42cbf92d98ecc6d240325ee1/.github/workflows/daily.yml#L353). This means that we will not activate the IO threads unless there are 8 (threads * 2) pending write clients per single loop, which is unlikely to happened in most of tests, meaning the IO threads are not currently being tested. To enforce the main thread to always offload work to the IO threads, regardless of the number of pending events, we add an events-per-io-thread configuration with a default value of 2. When set to 0, this configuration will force the main thread to always offload work to the IO threads. When we offload every single read/write operation to the IO threads, the IO-threads are running with 100% CPU when running multiple tests concurrently some tests fail as a result of larger than expected command latencies. To address this issue, we have to add some after or wait_for calls to some of the tests to ensure they pass with IO threads as well. Signed-off-by: Uri Yagelnik <[email protected]>
|
I suppose the bulk of this work is now merged and we have a specific followups. So going to close it. |
|
summary:This problem was solved by the following three PRs.
more follow-up are |
This is a true gem :). The proposal was originally brought up by @touitou-dan and below is a verbatim copy of redis/redis#12489
The following is a proposal to accelerate Redis performance by:
Improving io-thread efficiency by totally offloading network layer from main thread.
Reducing load on main thread remaining functionality by moving memory management and response formatting to the io-threads.
Amortizing memory access latency by batching dictionary searches.
We believe than by implementing these steps, a single Redis instance running on a multicore machine will deliver more than 1 million rps, up from under 400K rps as it is today.
Introduction
Io-threads were added to version 6.0 in order to split the network and some part of the application representation layer processing load among two or more cores. Io-threads can be used for both incoming requests and outgoing responses. When used on incoming traffic, io-threads not only read from the socket but also attempt to parse the first incoming request in the input buffer. In both directions, the main thread operates in a similar way, it balances the io tasks equally between the io-threads and itself, executes its part of the tasks and waits for others to complete their part before processing commands. This fan-out/fan-in approach keeps the solution simple has it requires no complex synchronization except from a barrier between the main and io threads.
We measured the performance of Redis (version 7.0) with and without io-threads. All tests were performed on an EC2 Graviton 3 instance with 8 cores (r7g.2xl) with no replica and no TLS. In this test we first populated the DB with 3 million keys of size 512 bytes and sent GET/SET requests from 500 clients. The GET and SET distribution was 80 and 20% respectively. We measured the following performance numbers:
Without io-threads 205K rps
With 6 additional io-threads (“—io-threads 7”) 295K rps
With 6 additional io-threads doing also read 390K rps
When analyzing the performance we found the following issues:
a. Underutilized cores - despite the 2x performance acceleration io-threads provide, Redis main thread still spends only 57% (processPendingCommandAndInputBuffer) of time executing commands. This implies that 1. The io-threads are practically idle 57% of the time and that 2. the main thread is spending 43% of the time executing io related functionality that could and should be executed by the io-threads. In addition, out of the 57% spent on executing commands, more than 9 percent (addReplyBulk ) are spent on translating objects into responses.
b. Memory management – Redis main thread spends more than 7% freeing object that have been allocated mostly by the io-threads. Such discordance between allocators and freers may cause lock contention on the jemalloc arenas and reduce efficiency.
c. Memory pattern access – Redis dictionary is a straightforward but inefficient chained hash implementation. While traversing the hash linked lists, every access to either a dictEntry structure, pointer to key or a value object requires with high probability an expensive external memory access. In our tests we found that the main thread spent more that 26% on dictionary related operations.
Our suggestions:
Io-threads
We suggest to totally offload all network layer functionality from main thread to io-threads. Our preferred approach would be to divide the client layer into two halves. The first half, handled by the io-thread will be the “stream layer” which includes socket layer as well as parsing requests and formatting responses while the second part, handled by main thread, maintains the client execution’s state (blocked, watching, subscribing etc). Based on this, io-threads handle read/write/epoll on the sockets, parse and allocate commands and append the ready to be executed commands on one or more queues. The main thread extract commands from the queues, executes them in the client context and appends responses on the queues which the io-threads extract, format and transmit on the sockets. In addition to the standard Redis commands and responses, internal control commands will be exchange between io-threads and main thread such as creating and erasing client states, pausing read from client sockets, requests to free previously allocated memory etc..
Dictionary memory access
Redis de facto executes commands in batches. We suggest that before executing a batch of commands we must ensure that all memory locations needed for dictionary operations will be find in the (L1/2/3) caches and avoid the latency associated with external memory accesses. This is done by searching in the dictionary all keys from a batch of commands before executing them. Searching the dictionary with more than on key at a time, when using prefetch instructions properly, allows to amortize memory access latency. From our experience, up to 65 % of the time spent on dictionary operations can be reduced this way.
Alternative solutions
An alternative approach to increase parallelism would be to allow main and io threads run in parallel on an unmodified client layer and prevent conflicting accesses between the io and main thread with locks. Such approach, while theoretically simpler, may require considerable testing to ensure consistency as well as avoiding lock related issues such as contention and deadlocks.
Dictionary inefficiencies can be solved by replacing the hash table implementation with a more "cache friendly" one that amortizes memory access by storing entire buckets in one or more adjacent cache lines. This approach has the advantage of being more "neighbor friendly" as it issues considerably less requests to the memory channels. However since Redis dictionary deliver a non standard programmatic interface ("key to dictEntry" mapping rather than "key to value" mapping) , replacing the hash implementation requires a much bigger coding and testing effort than the proposed alternative.
The text was updated successfully, but these errors were encountered: