On sparsity and the best way to compute indices of non zero elements. #204
Comments
12 tasks
|
For AVX512VBMI the following code could be considered too: |
|
Other thing to consider - don't do the FT "transform" and work directly on the int16 output, as the sparse implementation doesn't need the clippedrelu to actually be performed on it (though needs somehow to efficiently do |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
I tried implementing affine transform that takes advantage of sparse inputs in stockfish for some experiments and I have found that computing the indices of non-zero elements is actually quite a costly operation. I tried computing them lazily like cfish does, and storing them in a local array - both resulted in similar performance and stall issues. However the version with a local array allows for less branching in the actual dot product computations. Let's look at some data first.
I've investigated the sparsity of the feature transformer output for feature transformers of various size. The number of non-zero inputs is almost constant, regardless of the size. That means that density decreases rapidly with size. Here is the plot that shows the density (on y axis) for chosen nets (on x axis), grouped by size of the feature transformer (top). Data comes from low depth bench. Box corresponds to [0.25, 0.75] range, whiskers to [0.01, 0.99] range, the circles are outliers.
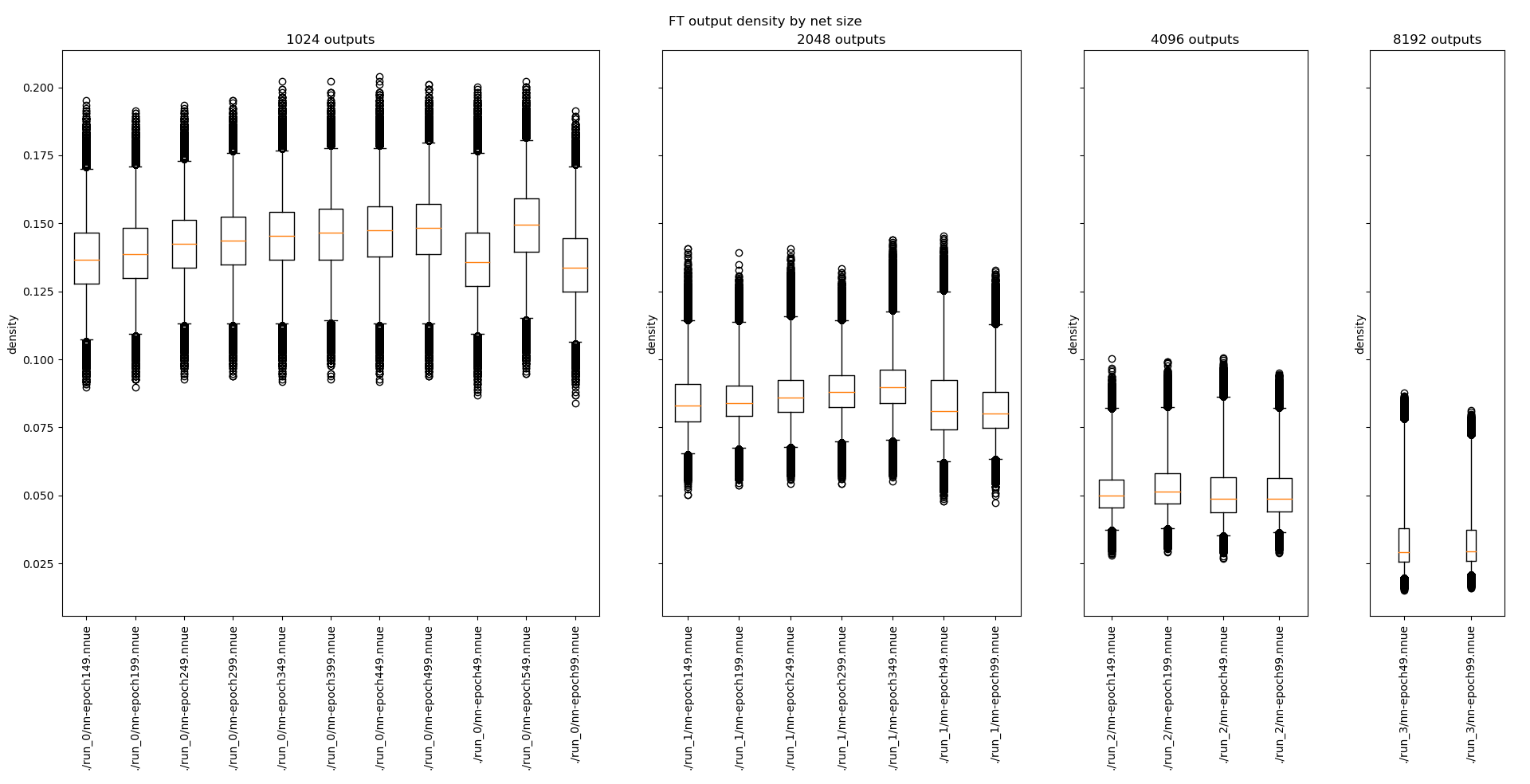
We can see that the current architecture (as of official-stockfish/Stockfish@e8d64af) has density of about 15%, and the 1024x2 has density of about 8%. I have no gathered the data for the 256x2 case but it's reasonable to assume it's around 25%. This also means that, with the right inference code, it might be possible to have feature transformer of size 1024x2 in Stockfish, though I won't delve into this here.
I've also implemented a few variants of the way indices of non-zero inputs are computed. I focused on the AVX2 implementation as it's by far the most popular (some cool tricks possible in AVX512, but I didn't bother implementing anything there). The code can be found here https://godbolt.org/z/z5xTYv4e1. The benchmark is over multiple different densities. The input array of size 2048 and is filled randomly with the desired average density. 64 input sets are generated and the benchmark goes over them 10000 times. Warmup is performed on all input sets once. The total time in seconds is reported. I've ran this benchmark on an Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz, compiled with GCC 9.3, with
g++ -std=c++17 -mavx2 -O3 -DNDEBUG. The results are as follows:Cfish currently uses the implementation similar to
non_zero_indices_1. The implementationnon_zero_indices_6is about 4-5x faster than the current cfish implementation for the case of 10-20% density. Implementationnon_zero_indices_4might be a good middle ground not to trash the cache with the larger lookup table.Also one more thing. It should be possible to utilize VNNI by taking 4 inputs at a time, and interleaving 4 weight rows. It's slightly easier to manage in the case of having the indices in a local array instead of computing them lazily.
The text was updated successfully, but these errors were encountered: