性能优化是把双刃剑,有好的一面也有坏的一面。好的一面就是能提升网站性能,坏的一面就是配置麻烦,或者要遵守的规则太多。并且某些性能优化规则并不适用所有场景,需要谨慎使用,请读者带着批判性的眼光来阅读本文。
本文相关的优化建议的引用资料出处均会在建议后面给出,或者放在文末。
一个完整的 HTTP 请求需要经历 DNS 查找,TCP 握手,浏览器发出 HTTP 请求,服务器接收请求,服务器处理请求并发回响应,浏览器接收响应等过程。接下来看一个具体的例子帮助理解 HTTP :
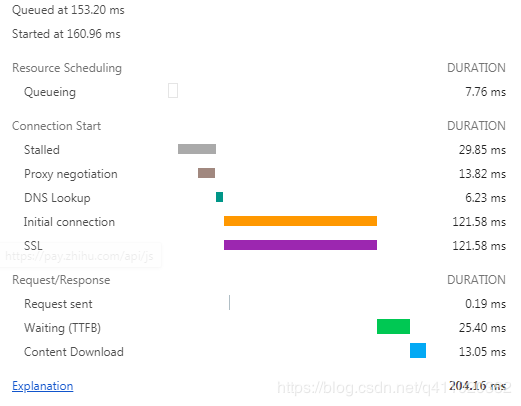
这是一个 HTTP 请求,请求的文件大小为 28.4KB。
名词解释:
- Queueing: 在请求队列中的时间。
- Stalled: 从TCP 连接建立完成,到真正可以传输数据之间的时间差,此时间包括代理协商时间。
- Proxy negotiation: 与代理服务器连接进行协商所花费的时间。
- DNS Lookup: 执行DNS查找所花费的时间,页面上的每个不同的域都需要进行DNS查找。
- Initial Connection / Connecting: 建立连接所花费的时间,包括TCP握手/重试和协商SSL。
- SSL: 完成SSL握手所花费的时间。
- Request sent: 发出网络请求所花费的时间,通常为一毫秒的时间。
- Waiting(TFFB): TFFB 是发出页面请求到接收到应答数据第一个字节的时间。
- Content Download: 接收响应数据所花费的时间。
从这个例子可以看出,真正下载数据的时间占比为 13.05 / 204.16 = 6.39%,文件越小,这个比例越小,文件越大,比例就越高。这就是为什么要建议将多个小文件合并为一个大文件,从而减少 HTTP 请求次数的原因。
参考资料:
HTTP2 相比 HTTP1.1 有如下几个优点:
服务器解析 HTTP1.1 的请求时,必须不断地读入字节,直到遇到分隔符 CRLF 为止。而解析 HTTP2 的请求就不用这么麻烦,因为 HTTP2 是基于帧的协议,每个帧都有表示帧长度的字段。
HTTP1.1 如果要同时发起多个请求,就得建立多个 TCP 连接,因为一个 TCP 连接同时只能处理一个 HTTP1.1 的请求。
在 HTTP2 上,多个请求可以共用一个 TCP 连接,这称为多路复用。同一个请求和响应用一个流来表示,并有唯一的流 ID 来标识。 多个请求和响应在 TCP 连接中可以乱序发送,到达目的地后再通过流 ID 重新组建。
HTTP2 提供了首部压缩功能。
例如有如下两个请求:
:authority: unpkg.zhimg.com
:method: GET
:path: /[email protected]/dist/zap.js
:scheme: https
accept: */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
cache-control: no-cache
pragma: no-cache
referer: https://www.zhihu.com/
sec-fetch-dest: script
sec-fetch-mode: no-cors
sec-fetch-site: cross-site
user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
:authority: zz.bdstatic.com
:method: GET
:path: /linksubmit/push.js
:scheme: https
accept: */*
accept-encoding: gzip, deflate, br
accept-language: zh-CN,zh;q=0.9
cache-control: no-cache
pragma: no-cache
referer: https://www.zhihu.com/
sec-fetch-dest: script
sec-fetch-mode: no-cors
sec-fetch-site: cross-site
user-agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36
从上面两个请求可以看出来,有很多数据都是重复的。如果可以把相同的首部存储起来,仅发送它们之间不同的部分,就可以节省不少的流量,加快请求的时间。
HTTP/2 在客户端和服务器端使用“首部表”来跟踪和存储之前发送的键-值对,对于相同的数据,不再通过每次请求和响应发送。
下面再来看一个简化的例子,假设客户端按顺序发送如下请求首部:
Header1:foo
Header2:bar
Header3:bat
当客户端发送请求时,它会根据首部值创建一张表:
| 索引 | 首部名称 | 值 |
|---|---|---|
| 62 | Header1 | foo |
| 63 | Header2 | bar |
| 64 | Header3 | bat |
如果服务器收到了请求,它会照样创建一张表。 当客户端发送下一个请求的时候,如果首部相同,它可以直接发送这样的首部块:
62 63 64
服务器会查找先前建立的表格,并把这些数字还原成索引对应的完整首部。
HTTP2 可以对比较紧急的请求设置一个较高的优先级,服务器在收到这样的请求后,可以优先处理。
由于一个 TCP 连接流量带宽(根据客户端到服务器的网络带宽而定)是固定的,当有多个请求并发时,一个请求占的流量多,另一个请求占的流量就会少。流量控制可以对不同的流的流量进行精确控制。
HTTP2 新增的一个强大的新功能,就是服务器可以对一个客户端请求发送多个响应。换句话说,除了对最初请求的响应外,服务器还可以额外向客户端推送资源,而无需客户端明确地请求。
例如当浏览器请求一个网站时,除了返回 HTML 页面外,服务器还可以根据 HTML 页面中的资源的 URL,来提前推送资源。
现在有很多网站已经开始使用 HTTP2 了,例如知乎:
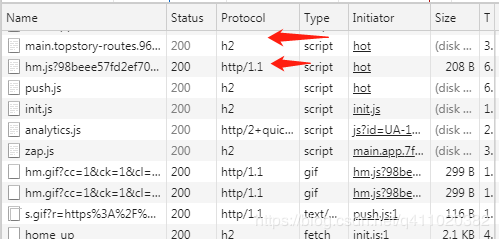
其中 h2 是指 HTTP2 协议,http/1.1 则是指 HTTP1.1 协议。
参考资料:
客户端渲染: 获取 HTML 文件,根据需要下载 JavaScript 文件,运行文件,生成 DOM,再渲染。
服务端渲染:服务端返回 HTML 文件,客户端只需解析 HTML。
- 优点:首屏渲染快,SEO 好。
- 缺点:配置麻烦,增加了服务器的计算压力。
下面我用 Vue SSR 做示例,简单的描述一下 SSR 过程。
- 访问客户端渲染的网站。
- 服务器返回一个包含了引入资源语句和
<div id="app"></div>的 HTML 文件。 - 客户端通过 HTTP 向服务器请求资源,当必要的资源都加载完毕后,执行
new Vue()开始实例化并渲染页面。
- 访问服务端渲染的网站。
- 服务器会查看当前路由组件需要哪些资源文件,然后将这些文件的内容填充到 HTML 文件。如果有 ajax 请求,就会执行它进行数据预取并填充到 HTML 文件里,最后返回这个 HTML 页面。
- 当客户端接收到这个 HTML 页面时,可以马上就开始渲染页面。与此同时,页面也会加载资源,当必要的资源都加载完毕后,开始执行
new Vue()开始实例化并接管页面。
从上述两个过程中可以看出,区别就在于第二步。客户端渲染的网站会直接返回 HTML 文件,而服务端渲染的网站则会渲染完页面再返回这个 HTML 文件。
这样做的好处是什么?是更快的内容到达时间 (time-to-content)。
假设你的网站需要加载完 abcd 四个文件才能渲染完毕。并且每个文件大小为 1 M。
这样一算:客户端渲染的网站需要加载 4 个文件和 HTML 文件才能完成首页渲染,总计大小为 4M(忽略 HTML 文件大小)。而服务端渲染的网站只需要加载一个渲染完毕的 HTML 文件就能完成首页渲染,总计大小为已经渲染完毕的 HTML 文件(这种文件不会太大,一般为几百K,我的个人博客网站(SSR)加载的 HTML 文件为 400K)。这就是服务端渲染更快的原因。
参考资料:
内容分发网络(CDN)是一组分布在多个不同地理位置的 Web 服务器。我们都知道,当服务器离用户越远时,延迟越高。CDN 就是为了解决这一问题,在多个位置部署服务器,让用户离服务器更近,从而缩短请求时间。
当用户访问一个网站时,如果没有 CDN,过程是这样的:
- 浏览器要将域名解析为 IP 地址,所以需要向本地 DNS 发出请求。
- 本地 DNS 依次向根服务器、顶级域名服务器、权限服务器发出请求,得到网站服务器的 IP 地址。
- 本地 DNS 将 IP 地址发回给浏览器,浏览器向网站服务器 IP 地址发出请求并得到资源。
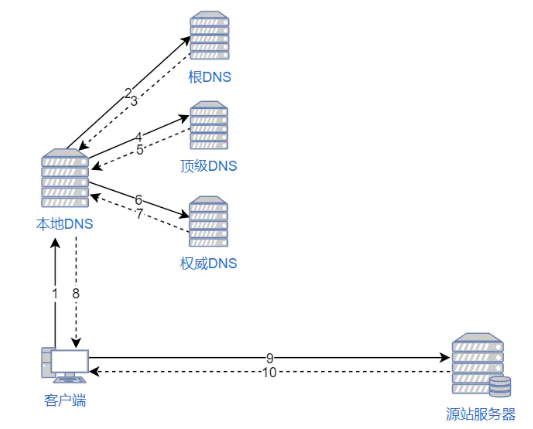
如果用户访问的网站部署了 CDN,过程是这样的:
- 浏览器要将域名解析为 IP 地址,所以需要向本地 DNS 发出请求。
- 本地 DNS 依次向根服务器、顶级域名服务器、权限服务器发出请求,得到全局负载均衡系统(GSLB)的 IP 地址。
- 本地 DNS 再向 GSLB 发出请求,GSLB 的主要功能是根据本地 DNS 的 IP 地址判断用户的位置,筛选出距离用户较近的本地负载均衡系统(SLB),并将该 SLB 的 IP 地址作为结果返回给本地 DNS。
- 本地 DNS 将 SLB 的 IP 地址发回给浏览器,浏览器向 SLB 发出请求。
- SLB 根据浏览器请求的资源和地址,选出最优的缓存服务器发回给浏览器。
- 浏览器再根据 SLB 发回的地址重定向到缓存服务器。
- 如果缓存服务器有浏览器需要的资源,就将资源发回给浏览器。如果没有,就向源服务器请求资源,再发给浏览器并缓存在本地。

参考资料:
所有放在 head 标签里的 CSS 和 JS 文件都会堵塞渲染。如果这些 CSS 和 JS 需要加载和解析很久的话,那么页面就空白了。所以 JS 文件要放在底部,等 HTML 解析完了再加载 JS 文件。
那为什么 CSS 文件还要放在头部呢?
因为先加载 HTML 再加载 CSS,会让用户第一时间看到的页面是没有样式的、“丑陋”的,为了避免这种情况发生,就要将 CSS 文件放在头部了。
另外,JS 文件也不是不可以放在头部,只要给 script 标签加上 defer 属性就可以了,异步下载,延迟执行。
字体图标就是将图标制作成一个字体,使用时就跟字体一样,可以设置属性,例如 font-size、color 等等,非常方便。并且字体图标是矢量图,不会失真。还有一个优点是生成的文件特别小。
使用 fontmin-webpack 插件对字体文件进行压缩(感谢前端小伟提供)。
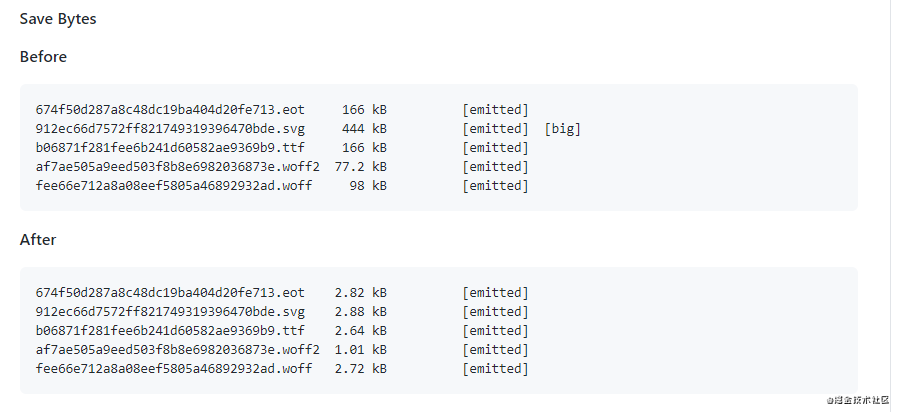
参考资料:
为了避免用户每次访问网站都得请求文件,我们可以通过添加 Expires 或 max-age 来控制这一行为。Expires 设置了一个时间,只要在这个时间之前,浏览器都不会请求文件,而是直接使用缓存。而 max-age 是一个相对时间,建议使用 max-age 代替 Expires 。
不过这样会产生一个问题,当文件更新了怎么办?怎么通知浏览器重新请求文件?
可以通过更新页面中引用的资源链接地址,让浏览器主动放弃缓存,加载新资源。
具体做法是把资源地址 URL 的修改与文件内容关联起来,也就是说,只有文件内容变化,才会导致相应 URL 的变更,从而实现文件级别的精确缓存控制。什么东西与文件内容相关呢?我们会很自然的联想到利用数据摘要要算法对文件求摘要信息,摘要信息与文件内容一一对应,就有了一种可以精确到单个文件粒度的缓存控制依据了。
参考资料:
压缩文件可以减少文件下载时间,让用户体验性更好。
得益于 webpack 和 node 的发展,现在压缩文件已经非常方便了。
在 webpack 可以使用如下插件进行压缩:
- JavaScript:UglifyPlugin
- CSS :MiniCssExtractPlugin
- HTML:HtmlWebpackPlugin
其实,我们还可以做得更好。那就是使用 gzip 压缩。可以通过向 HTTP 请求头中的 Accept-Encoding 头添加 gzip 标识来开启这一功能。当然,服务器也得支持这一功能。
gzip 是目前最流行和最有效的压缩方法。举个例子,我用 Vue 开发的项目构建后生成的 app.js 文件大小为 1.4MB,使用 gzip 压缩后只有 573KB,体积减少了将近 60%。
附上 webpack 和 node 配置 gzip 的使用方法。
下载插件
npm install compression-webpack-plugin --save-dev
npm install compression
webpack 配置
const CompressionPlugin = require('compression-webpack-plugin');
module.exports = {
plugins: [new CompressionPlugin()],
}
node 配置
const compression = require('compression')
// 在其他中间件前使用
app.use(compression())
在页面中,先不给图片设置路径,只有当图片出现在浏览器的可视区域时,才去加载真正的图片,这就是延迟加载。对于图片很多的网站来说,一次性加载全部图片,会对用户体验造成很大的影响,所以需要使用图片延迟加载。
首先可以将图片这样设置,在页面不可见时图片不会加载:
<img data-src="https://avatars0.githubusercontent.com/u/22117876?s=460&u=7bd8f32788df6988833da6bd155c3cfbebc68006&v=4">等页面可见时,使用 JS 加载图片:
const img = document.querySelector('img')
img.src = img.dataset.src这样图片就加载出来了,完整的代码可以看一下参考资料。
参考资料:
响应式图片的优点是浏览器能够根据屏幕大小自动加载合适的图片。
通过 picture 实现
<picture>
<source srcset="banner_w1000.jpg" media="(min-width: 801px)">
<source srcset="banner_w800.jpg" media="(max-width: 800px)">
<img src="banner_w800.jpg" alt="">
</picture>通过 @media 实现
@media (min-width: 769px) {
.bg {
background-image: url(bg1080.jpg);
}
}
@media (max-width: 768px) {
.bg {
background-image: url(bg768.jpg);
}
}例如,你有一个 1920 * 1080 大小的图片,用缩略图的方式展示给用户,并且当用户鼠标悬停在上面时才展示全图。如果用户从未真正将鼠标悬停在缩略图上,则浪费了下载图片的时间。
所以,我们可以用两张图片来实行优化。一开始,只加载缩略图,当用户悬停在图片上时,才加载大图。还有一种办法,即对大图进行延迟加载,在所有元素都加载完成后手动更改大图的 src 进行下载。
例如 JPG 格式的图片,100% 的质量和 90% 质量的通常看不出来区别,尤其是用来当背景图的时候。我经常用 PS 切背景图时, 将图片切成 JPG 格式,并且将它压缩到 60% 的质量,基本上看不出来区别。
压缩方法有两种,一是通过 webpack 插件 image-webpack-loader,二是通过在线网站进行压缩。
以下附上 webpack 插件 image-webpack-loader 的用法。
npm i -D image-webpack-loader
webpack 配置
{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
use:[
{
loader: 'url-loader',
options: {
limit: 10000, /* 图片大小小于1000字节限制时会自动转成 base64 码引用*/
name: utils.assetsPath('img/[name].[hash:7].[ext]')
}
},
/*对图片进行压缩*/
{
loader: 'image-webpack-loader',
options: {
bypassOnDebug: true,
}
}
]
}有很多图片使用 CSS 效果(渐变、阴影等)就能画出来,这种情况选择 CSS3 效果更好。因为代码大小通常是图片大小的几分之一甚至几十分之一。
参考资料:
WebP 的优势体现在它具有更优的图像数据压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量;同时具备了无损和有损的压缩模式、Alpha 透明以及动画的特性,在 JPEG 和 PNG 上的转化效果都相当优秀、稳定和统一。
参考资料:
懒加载或者按需加载,是一种很好的优化网页或应用的方式。这种方式实际上是先把你的代码在一些逻辑断点处分离开,然后在一些代码块中完成某些操作后,立即引用或即将引用另外一些新的代码块。这样加快了应用的初始加载速度,减轻了它的总体体积,因为某些代码块可能永远不会被加载。
通过配置 output 的 filename 属性可以实现这个需求。filename 属性的值选项中有一个 [contenthash],它将根据文件内容创建出唯一 hash。当文件内容发生变化时,[contenthash] 也会发生变化。
output: {
filename: '[name].[contenthash].js',
chunkFilename: '[name].[contenthash].js',
path: path.resolve(__dirname, '../dist'),
},由于引入的第三方库一般都比较稳定,不会经常改变。所以将它们单独提取出来,作为长期缓存是一个更好的选择。 这里需要使用 webpack4 的 splitChunk 插件 cacheGroups 选项。
optimization: {
runtimeChunk: {
name: 'manifest' // 将 webpack 的 runtime 代码拆分为一个单独的 chunk。
},
splitChunks: {
cacheGroups: {
vendor: {
name: 'chunk-vendors',
test: /[\\/]node_modules[\\/]/,
priority: -10,
chunks: 'initial'
},
common: {
name: 'chunk-common',
minChunks: 2,
priority: -20,
chunks: 'initial',
reuseExistingChunk: true
}
},
}
},- test: 用于控制哪些模块被这个缓存组匹配到。原封不动传递出去的话,它默认会选择所有的模块。可以传递的值类型:RegExp、String和Function;
- priority:表示抽取权重,数字越大表示优先级越高。因为一个 module 可能会满足多个 cacheGroups 的条件,那么抽取到哪个就由权重最高的说了算;
- reuseExistingChunk:表示是否使用已有的 chunk,如果为 true 则表示如果当前的 chunk 包含的模块已经被抽取出去了,那么将不会重新生成新的。
- minChunks(默认是1):在分割之前,这个代码块最小应该被引用的次数(译注:保证代码块复用性,默认配置的策略是不需要多次引用也可以被分割)
- chunks (默认是async) :initial、async和all
- name(打包的chunks的名字):字符串或者函数(函数可以根据条件自定义名字)
Babel 转化后的代码想要实现和原来代码一样的功能需要借助一些帮助函数,比如:
class Person {}会被转换为:
"use strict";
function _classCallCheck(instance, Constructor) {
if (!(instance instanceof Constructor)) {
throw new TypeError("Cannot call a class as a function");
}
}
var Person = function Person() {
_classCallCheck(this, Person);
};这里 _classCallCheck 就是一个 helper 函数,如果在很多文件里都声明了类,那么就会产生很多个这样的 helper 函数。
这里的 @babel/runtime 包就声明了所有需要用到的帮助函数,而 @babel/plugin-transform-runtime 的作用就是将所有需要 helper 函数的文件,从 @babel/runtime包 引进来:
"use strict";
var _classCallCheck2 = require("@babel/runtime/helpers/classCallCheck");
var _classCallCheck3 = _interopRequireDefault(_classCallCheck2);
function _interopRequireDefault(obj) {
return obj && obj.__esModule ? obj : { default: obj };
}
var Person = function Person() {
(0, _classCallCheck3.default)(this, Person);
};这里就没有再编译出 helper 函数 classCallCheck 了,而是直接引用了 @babel/runtime 中的 helpers/classCallCheck。
安装
npm i -D @babel/plugin-transform-runtime @babel/runtime
使用
在 .babelrc 文件中
"plugins": [
"@babel/plugin-transform-runtime"
]
参考资料:
浏览器渲染过程
- 解析HTML生成DOM树。
- 解析CSS生成CSSOM规则树。
- 将DOM树与CSSOM规则树合并在一起生成渲染树。
- 遍历渲染树开始布局,计算每个节点的位置大小信息。
- 将渲染树每个节点绘制到屏幕。
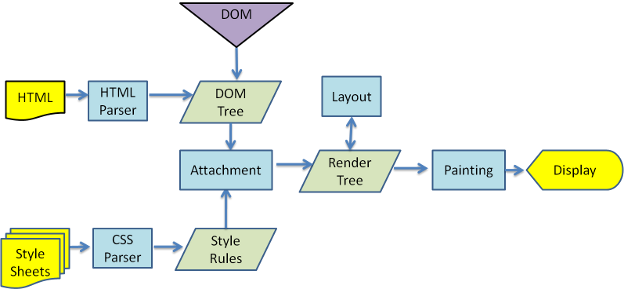
重排
当改变 DOM 元素位置或大小时,会导致浏览器重新生成渲染树,这个过程叫重排。
重绘
当重新生成渲染树后,就要将渲染树每个节点绘制到屏幕,这个过程叫重绘。不是所有的动作都会导致重排,例如改变字体颜色,只会导致重绘。记住,重排会导致重绘,重绘不会导致重排 。
重排和重绘这两个操作都是非常昂贵的,因为 JavaScript 引擎线程与 GUI 渲染线程是互斥,它们同时只能一个在工作。
什么操作会导致重排?
- 添加或删除可见的 DOM 元素
- 元素位置改变
- 元素尺寸改变
- 内容改变
- 浏览器窗口尺寸改变
如何减少重排重绘?
- 用 JavaScript 修改样式时,最好不要直接写样式,而是替换 class 来改变样式。
- 如果要对 DOM 元素执行一系列操作,可以将 DOM 元素脱离文档流,修改完成后,再将它带回文档。推荐使用隐藏元素(display:none)或文档碎片(DocumentFragement),都能很好的实现这个方案。
事件委托利用了事件冒泡,只指定一个事件处理程序,就可以管理某一类型的所有事件。所有用到按钮的事件(多数鼠标事件和键盘事件)都适合采用事件委托技术, 使用事件委托可以节省内存。
<ul>
<li>苹果</li>
<li>香蕉</li>
<li>凤梨</li>
</ul>
// good
document.querySelector('ul').onclick = (event) => {
const target = event.target
if (target.nodeName === 'LI') {
console.log(target.innerHTML)
}
}
// bad
document.querySelectorAll('li').forEach((e) => {
e.onclick = function() {
console.log(this.innerHTML)
}
}) 一个编写良好的计算机程序常常具有良好的局部性,它们倾向于引用最近引用过的数据项附近的数据项,或者最近引用过的数据项本身,这种倾向性,被称为局部性原理。有良好局部性的程序比局部性差的程序运行得更快。
局部性通常有两种不同的形式:
- 时间局部性:在一个具有良好时间局部性的程序中,被引用过一次的内存位置很可能在不远的将来被多次引用。
- 空间局部性 :在一个具有良好空间局部性的程序中,如果一个内存位置被引用了一次,那么程序很可能在不远的将来引用附近的一个内存位置。
时间局部性示例
function sum(arry) {
let i, sum = 0
let len = arry.length
for (i = 0; i < len; i++) {
sum += arry[i]
}
return sum
}在这个例子中,变量sum在每次循环迭代中被引用一次,因此,对于sum来说,具有良好的时间局部性
空间局部性示例
具有良好空间局部性的程序
// 二维数组
function sum1(arry, rows, cols) {
let i, j, sum = 0
for (i = 0; i < rows; i++) {
for (j = 0; j < cols; j++) {
sum += arry[i][j]
}
}
return sum
}空间局部性差的程序
// 二维数组
function sum2(arry, rows, cols) {
let i, j, sum = 0
for (j = 0; j < cols; j++) {
for (i = 0; i < rows; i++) {
sum += arry[i][j]
}
}
return sum
}看一下上面的两个空间局部性示例,像示例中从每行开始按顺序访问数组每个元素的方式,称为具有步长为1的引用模式。 如果在数组中,每隔k个元素进行访问,就称为步长为k的引用模式。 一般而言,随着步长的增加,空间局部性下降。
这两个例子有什么区别?区别在于第一个示例是按行扫描数组,每扫描完一行再去扫下一行;第二个示例是按列来扫描数组,扫完一行中的一个元素,马上就去扫下一行中的同一列元素。
数组在内存中是按照行顺序来存放的,结果就是逐行扫描数组的示例得到了步长为 1 引用模式,具有良好的空间局部性;而另一个示例步长为 rows,空间局部性极差。
运行环境:
- cpu: i5-7400
- 浏览器: chrome 70.0.3538.110
对一个长度为9000的二维数组(子数组长度也为9000)进行10次空间局部性测试,时间(毫秒)取平均值,结果如下:
所用示例为上述两个空间局部性示例
| 步长为 1 | 步长为 9000 |
|---|---|
| 124 | 2316 |
从以上测试结果来看,步长为 1 的数组执行时间比步长为 9000 的数组快了一个数量级。
总结:
- 重复引用相同变量的程序具有良好的时间局部性
- 对于具有步长为 k 的引用模式的程序,步长越小,空间局部性越好;而在内存中以大步长跳来跳去的程序空间局部性会很差
参考资料:
当判断条件数量越来越多时,越倾向于使用 switch 而不是 if-else。
if (color == 'blue') {
} else if (color == 'yellow') {
} else if (color == 'white') {
} else if (color == 'black') {
} else if (color == 'green') {
} else if (color == 'orange') {
} else if (color == 'pink') {
}
switch (color) {
case 'blue':
break
case 'yellow':
break
case 'white':
break
case 'black':
break
case 'green':
break
case 'orange':
break
case 'pink':
break
}像以上这种情况,使用 switch 是最好的。假设 color 的值为 pink,则 if-else 语句要进行 7 次判断,switch 只需要进行一次判断。 从可读性来说,switch 语句也更好。
从使用时机来说,当条件值大于两个的时候,使用 switch 更好。不过 if-else 也有 switch 无法做到的事情,例如有多个判断条件的情况下,无法使用 switch。
当条件语句特别多时,使用 switch 和 if-else 不是最佳的选择,这时不妨试一下查找表。查找表可以使用数组和对象来构建。
switch (index) {
case '0':
return result0
case '1':
return result1
case '2':
return result2
case '3':
return result3
case '4':
return result4
case '5':
return result5
case '6':
return result6
case '7':
return result7
case '8':
return result8
case '9':
return result9
case '10':
return result10
case '11':
return result11
}可以将这个 switch 语句转换为查找表
const results = [result0,result1,result2,result3,result4,result5,result6,result7,result8,result9,result10,result11]
return results[index]如果条件语句不是数值而是字符串,可以用对象来建立查找表
const map = {
red: result0,
green: result1,
}
return map[color]60fps 与设备刷新率
目前大多数设备的屏幕刷新率为 60 次/秒。因此,如果在页面中有一个动画或渐变效果,或者用户正在滚动页面,那么浏览器渲染动画或页面的每一帧的速率也需要跟设备屏幕的刷新率保持一致。 其中每个帧的预算时间仅比 16 毫秒多一点 (1 秒/ 60 = 16.66 毫秒)。但实际上,浏览器有整理工作要做,因此您的所有工作需要在 10 毫秒内完成。如果无法符合此预算,帧率将下降,并且内容会在屏幕上抖动。 此现象通常称为卡顿,会对用户体验产生负面影响。

假如你用 JavaScript 修改了 DOM,并触发样式修改,经历重排重绘最后画到屏幕上。如果这其中任意一项的执行时间过长,都会导致渲染这一帧的时间过长,平均帧率就会下降。假设这一帧花了 50 ms,那么此时的帧率为 1s / 50ms = 20fps,页面看起来就像卡顿了一样。
对于一些长时间运行的 JavaScript,我们可以使用定时器进行切分,延迟执行。
for (let i = 0, len = arry.length; i < len; i++) {
process(arry[i])
}假设上面的循环结构由于 process() 复杂度过高或数组元素太多,甚至两者都有,可以尝试一下切分。
const todo = arry.concat()
setTimeout(function() {
process(todo.shift())
if (todo.length) {
setTimeout(arguments.callee, 25)
} else {
callback(arry)
}
}, 25)如果有兴趣了解更多,可以查看一下高性能JavaScript第 6 章和高效前端:Web高效编程与优化实践第 3 章。
参考资料:
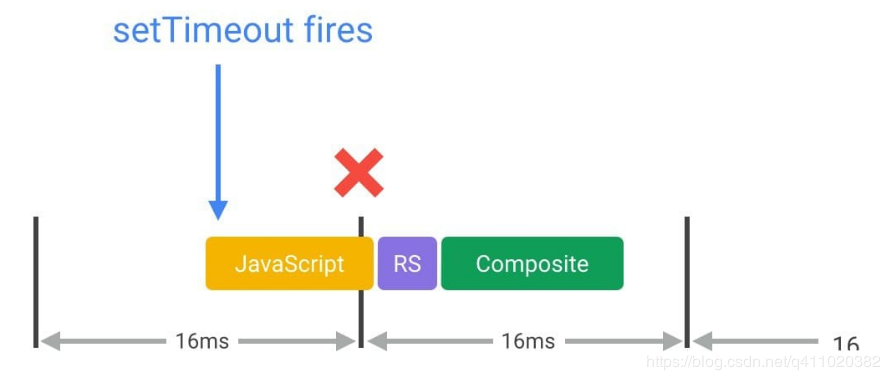
从第 16 点我们可以知道,大多数设备屏幕刷新率为 60 次/秒,也就是说每一帧的平均时间为 16.66 毫秒。在使用 JavaScript 实现动画效果的时候,最好的情况就是每次代码都是在帧的开头开始执行。而保证 JavaScript 在帧开始时运行的唯一方式是使用 requestAnimationFrame。
/**
* If run as a requestAnimationFrame callback, this
* will be run at the start of the frame.
*/
function updateScreen(time) {
// Make visual updates here.
}
requestAnimationFrame(updateScreen);如果采取 setTimeout 或 setInterval 来实现动画的话,回调函数将在帧中的某个时点运行,可能刚好在末尾,而这可能经常会使我们丢失帧,导致卡顿。
参考资料:
Web Worker 使用其他工作线程从而独立于主线程之外,它可以执行任务而不干扰用户界面。一个 worker 可以将消息发送到创建它的 JavaScript 代码, 通过将消息发送到该代码指定的事件处理程序(反之亦然)。
Web Worker 适用于那些处理纯数据,或者与浏览器 UI 无关的长时间运行脚本。
创建一个新的 worker 很简单,指定一个脚本的 URI 来执行 worker 线程(main.js):
var myWorker = new Worker('worker.js');
// 你可以通过postMessage() 方法和onmessage事件向worker发送消息。
first.onchange = function() {
myWorker.postMessage([first.value,second.value]);
console.log('Message posted to worker');
}
second.onchange = function() {
myWorker.postMessage([first.value,second.value]);
console.log('Message posted to worker');
}在 worker 中接收到消息后,我们可以写一个事件处理函数代码作为响应(worker.js):
onmessage = function(e) {
console.log('Message received from main script');
var workerResult = 'Result: ' + (e.data[0] * e.data[1]);
console.log('Posting message back to main script');
postMessage(workerResult);
}onmessage处理函数在接收到消息后马上执行,代码中消息本身作为事件的data属性进行使用。这里我们简单的对这2个数字作乘法处理并再次使用postMessage()方法,将结果回传给主线程。
回到主线程,我们再次使用onmessage以响应worker回传的消息:
myWorker.onmessage = function(e) {
result.textContent = e.data;
console.log('Message received from worker');
}在这里我们获取消息事件的data,并且将它设置为result的textContent,所以用户可以直接看到运算的结果。
不过在worker内,不能直接操作DOM节点,也不能使用window对象的默认方法和属性。然而你可以使用大量window对象之下的东西,包括WebSockets,IndexedDB以及FireFox OS专用的Data Store API等数据存储机制。
参考资料:
JavaScript 中的数字都使用 IEEE-754 标准以 64 位格式存储。但是在位操作中,数字被转换为有符号的 32 位格式。即使需要转换,位操作也比其他数学运算和布尔操作快得多。
由于偶数的最低位为 0,奇数为 1,所以取模运算可以用位操作来代替。
if (value % 2) {
// 奇数
} else {
// 偶数
}
// 位操作
if (value & 1) {
// 奇数
} else {
// 偶数
}~~10.12 // 10
~~10 // 10
~~'1.5' // 1
~~undefined // 0
~~null // 0const a = 1
const b = 2
const c = 4
const options = a | b | c通过定义这些选项,可以用按位与操作来判断 a/b/c 是否在 options 中。
// 选项 b 是否在选项中
if (b & options) {
...
}无论你的 JavaScript 代码如何优化,都比不上原生方法。因为原生方法是用低级语言写的(C/C++),并且被编译成机器码,成为浏览器的一部分。当原生方法可用时,尽量使用它们,特别是数学运算和 DOM 操作。
看个示例
#block .text p {
color: red;
}- 查找所有 P 元素。
- 查找结果 1 中的元素是否有类名为 text 的父元素
- 查找结果 2 中的元素是否有 id 为 block 的父元素
内联 > ID选择器 > 类选择器 > 标签选择器
根据以上两个信息可以得出结论。
- 选择器越短越好。
- 尽量使用高优先级的选择器,例如 ID 和类选择器。
- 避免使用通配符 *。
最后要说一句,据我查找的资料所得,CSS 选择器没有优化的必要,因为最慢和慢快的选择器性能差别非常小。
参考资料:
在早期的 CSS 布局方式中我们能对元素实行绝对定位、相对定位或浮动定位。而现在,我们有了新的布局方式 flexbox,它比起早期的布局方式来说有个优势,那就是性能比较好。
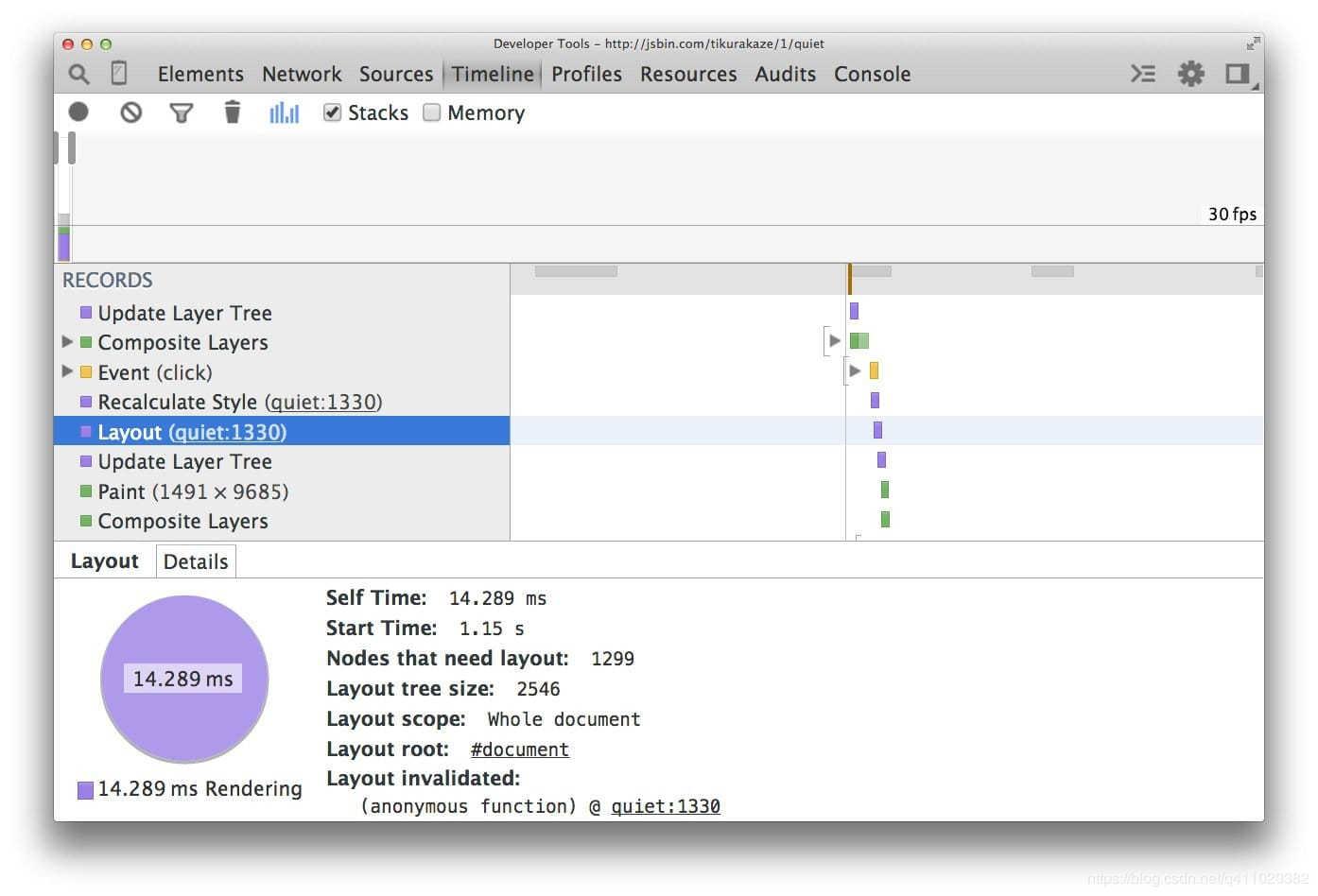
下面的截图显示了在 1300 个框上使用浮动的布局开销:
然后我们用 flexbox 来重现这个例子:
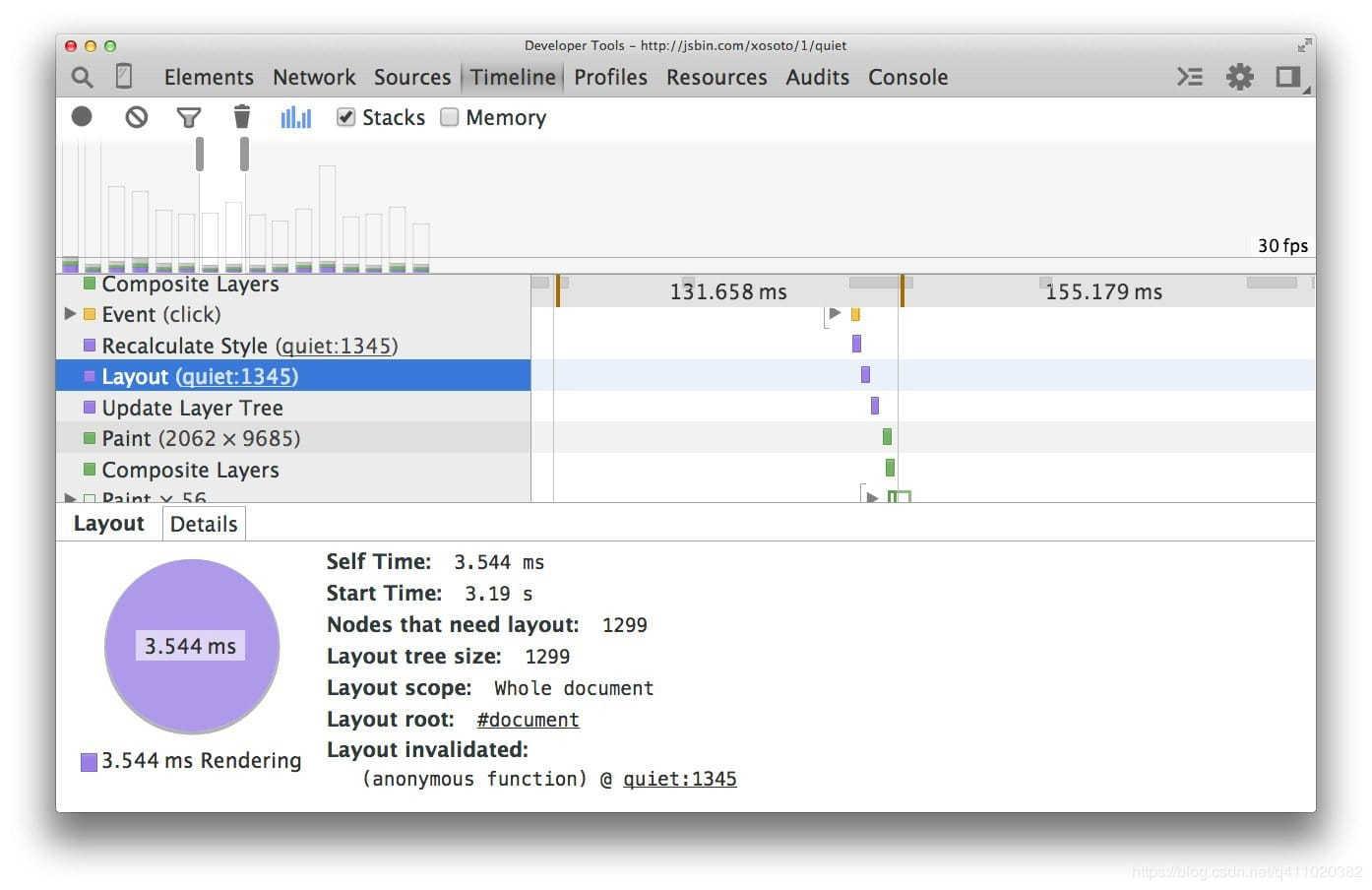
现在,对于相同数量的元素和相同的视觉外观,布局的时间要少得多(本例中为分别 3.5 毫秒和 14 毫秒)。
不过 flexbox 兼容性还是有点问题,不是所有浏览器都支持它,所以要谨慎使用。
各浏览器兼容性:
- Chrome 29+
- Firefox 28+
- Internet Explorer 11
- Opera 17+
- Safari 6.1+ (prefixed with -webkit-)
- Android 4.4+
- iOS 7.1+ (prefixed with -webkit-)
参考资料:
在 CSS 中,transforms 和 opacity 这两个属性更改不会触发重排与重绘,它们是可以由合成器(composite)单独处理的属性。

参考资料:
性能优化主要分为两类:
- 加载时优化
- 运行时优化
上述 23 条建议中,属于加载时优化的是前面 10 条建议,属于运行时优化的是后面 13 条建议。通常来说,没有必要 23 条性能优化规则都用上,根据网站用户群体来做针对性的调整是最好的,节省精力,节省时间。
在解决问题之前,得先找出问题,否则无从下手。所以在做性能优化之前,最好先调查一下网站的加载性能和运行性能。
一个网站加载性能如何主要看白屏时间和首屏时间。
- 白屏时间:指从输入网址,到页面开始显示内容的时间。
- 首屏时间:指从输入网址,到页面完全渲染的时间。
将以下脚本放在 </head> 前面就能获取白屏时间。
<script>
new Date() - performance.timing.navigationStart
</script>在 window.onload 事件里执行 new Date() - performance.timing.navigationStart 即可获取首屏时间。
配合 chrome 的开发者工具,我们可以查看网站在运行时的性能。
打开网站,按 F12 选择 performance,点击左上角的灰色圆点,变成红色就代表开始记录了。这时可以模仿用户使用网站,在使用完毕后,点击 stop,然后你就能看到网站运行期间的性能报告。如果有红色的块,代表有掉帧的情况;如果是绿色,则代表 FPS 很好。performance 的具体使用方法请用搜索引擎搜索一下,毕竟篇幅有限。
通过检查加载和运行性能,相信你对网站性能已经有了大概了解。所以这时候要做的事情,就是使用上述 23 条建议尽情地去优化你的网站,加油!
参考资料: