Le but de ce document est de formaliser un mode de travail permettant le développement et la mise en production rapide de nouveaux modèles pour le projet Signaux Faibles.
Nous utilisons une version simplifiée du Git Flow:
mainest la branche qui contient la seule et unique version du modèle signaux-faibles de production. En théorie, le modèle/code présent sur cette branche devrait pouvoir être utilisé pas n'importe qui (développeur, DevOps, data scientist) sans avoir à se concerter avec le data scientist responsable du modèle. Cette branche a donc vocation à être :- stable : seuls les modèles qui apportent une amélioration claire, documentée et testée sont mergés dans
main. Cette branche contient du code fonctionnel et qui ne cassera pas la production. - versionée : les différentes releases sont taggées en suivant le format
YY.MMcorrespondant au mois de prédiction du modèle. - documentée : un modèle utilisé en production doit nécéssairement avoir une documentation à jour. Il est également bon d'utiliser un
changelogafin d'expliciter les changements apportés aux différentes versions du modèle. - protégée : il est impossible de pousser des changements directement dans
main. Le seul moyen de la faire évoluer est de merger une pull request ayant été revue et validée par un.e pair.e — idéalement depuisdevelop(voir ci-dessous).
- stable : seuls les modèles qui apportent une amélioration claire, documentée et testée sont mergés dans
developest la branche sur laquelle les data scientists travaillent ensemble. Elle est moins stable quemainet contient la prochaine release du modèle (dont elle peut être considerée comme une version "beta"). Une fois qu'assez de changements ont été apportés àdevelop, elle est mergée dansmain(et taggée!). Cette branche doit être:- relativement stable: cette branche est testée, la chaine d'intégration continue doit passer, le modèle qu'elle contient doit être utilisable et documenté.
- protégée : il est impossible de pousser des changements directement dans
develop— le seul moyen de la faire évoluer et de merger une pull request ayant été revue et validée par un.e pair.e — idéalement depuis les feature branches (voir ci-dessous). - par défault : le repo GitHub doit être configuré pour que la branche par défault du repo (pour les pull requests par exemple) soit
developet non pasmain
feat/<nom_de_la_feature>sont les branches de travail pour les data scientists. Elle peuvent contenir des améliorations/évolutions du modèle, du code, des tests, etc. Elle doivent être:- atomiques et ne contenir qu'une seule évolution par rapport à develop. Par exemple,
feat/better_hyperparam_tuningse concentrera sur une amélioration du modèle existant alors quefeat/new_test_train_splitconcernera une évolution des fonctions d'aides du repo. Il faut impérativement séparer ces deux chantiers sur deux branches différentes (quitte à travailler sur les 2 en parallèle) afin de pouvoir merger une branche indépendamment de l'autre. - exploratoires : une branche de feature est un espace de travail ou les data scientists peuvent casser et changer le code à loisir. NB: il est cependant recommandé de synchroniser régulièrement sa branche avec
developafin de bénéficier de certains changements déjà réalisés par d'autres - éphémères : une branche de feature n'est pas faite pour "stocker" du code sur de la longue durée, et a avant tout pour vocation d'être mergée dans
developsur le moyen terme. Cette rêgle peut être adaptée dans le cadre de travaux exploratoires sur des modèles de data science — auquel cas il serait bon de convenir d'une convention de nommage pour ces branches (par exemple,modele/<model_name>).
- atomiques et ne contenir qu'une seule évolution par rapport à develop. Par exemple,
hotfix/<nom_du_fix>est une branche dite de "hotfix". Elle peut être mergée directement en production (main) dans le cas ou cette dernière est cassée.- ne doit être ouverte que le temps de la résolution d'un bug en production
- ne doit contenir que le code minimum nécessaire à la résolution du bug + le cas échéant, un test permettant de s'assurer que le bug ne réapparaitra pas
- ne doit (évidemment) pas introduire de nouveaux bugs ou de régression, et doit donc à minima passer la CI
Ce schéma résume notre git flow (NB: l'utilisation du terme main est aujourd'hui préféré à celui, plus connoté, de master):
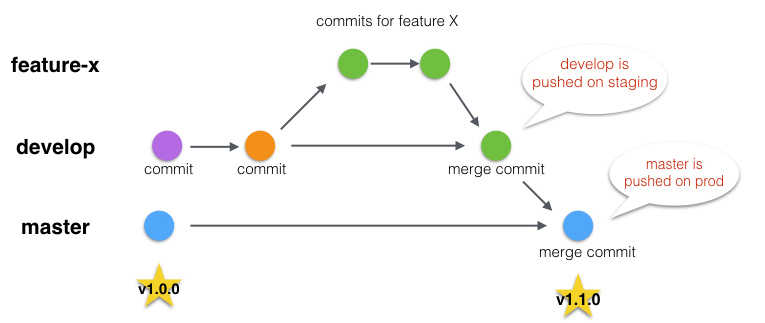
(Les branches de hotfix partent et poussent dans main).
Le respect de certaines conventions de nommage permet de s'assurer de la bonne santée du projet.
Pour une nouvelle feature
feat/<name_of_feature>
Pour un nouveau modèle
model/<name_of_model>
Pour une correction de bug en production
hotfix/<description>
Pour une refactorisation du code
refacto/<description>
Pour des correctifs non urgents
fix/<description>
Dans l'esprit, se référer à : conventionalcommits
Un commit doit idéalement respecter ce format:
git commit -m '{TYPE}: MESSAGE'
{TYPE}: decrit le type de commit;fixbug fixfeatrajout d'une featurerefactoune amélioration (refacto, factorisation, simplification, etc.)cleannettoyage du codedocajout de documentationconfigchangement de la configuration du projettestrajout ou mise-à-jour des testsMpour les changements majeurs (commit initial, nouveau modèle, résolution d'un gros bug)
Il est possible de rajouter un BODY et un FOOTER à ses messages de commit
git commit -m '{TYPE}: {MESSAGE}' -m '{BODY}' -m '{FOOTER}'Qui peuvent servir a rajouter des information utiles à l'automatisation de taches par GitHub (par exemple, fermer des issues):
git commit -m 'feat: change test train proportion' \
-m 'move value from .5 to .75' \
-m 'closes #17 and #19'Certains outils permettent de s'assurer de la pérénité et de la stabilité du code produit.
Nous utilisons le package pytest.
L'intérêt d'utiliser un outil de formattage automatique de code est qu'il permet d'assurer une cohérence au sein du repo en termes de style et de règles. Cela permet une meilleure compréhension du code, moins d'erreurs, et des revues de code plus rapides.
- Nous utilisons le formatter
black
Un linter s'assure que le code produit adhère aux bonnes pratiques de style et de syntaxe.
- Nous utilisons
pylint
Les git hooks permettent de s'assurer que certains scripts tournent automatiquement avant un commit ou un push. Ils sont stockés dans .git/hooks/ et doivent être ajoutés localement avec la commande python -m python_githooks.
.git/hooks/pre-commitblacktous les fichiers .pypylinttous les fichiers .py
.git/hooks/pre-pushpytest- faire tourner et évaluer le modèle (ça peut juste être un rappel si c'est trop lourd)
L'évaluation du modèle peut produire un artefact "model_evaluation.json", versionné dans git avec chaque nouvelle version du modèle.
Une documentation du code peut être générée automatiquement grâce à sphinx (voir README.md). Celle-ci se base sur les «docstrings» des modules, classes et autres objets pythons du code, il est donc très utile de bien les documenter !
Le format napoleon (variante google) est employé. Un exemple de ce format est disponible ici. Quelques éléments importants du format des docstrings :
- La première ligne est une courte description de l'objet.
- Des sauts de lignes séparent la première ligne, la description plus longue, les arguments, la valeur renvoyée.
- Si la ligne de description d'un argument dépasse la longueur maximale autorisée, on indente la ligne suivante de deux espaces.
- On préférera indiquer les types des variables d'entrée et de sortie directement dans la signature d'une fonction plutôt que dans la docstring.
- Il est possible d'intégrer des équations à l'aide de la directive
:math:.
- Les notebooks Jupyter doivent être commités non-executés. Toujours s'assurer que de la donnée sensible n'est pas contenue dans ce dépot.
- Le code poussé dans
predictsignauxfaiblesne doit jamais contenir l'URI MongoDb