##第一部分、快速排序 关于快速排序算法,本人已经写了3篇文章(可参见其中的两篇: 1、十二、快速排序算法之所有版本的c/c++实现, 2、一之续、快速排序算法的深入分析),
为何又要旧事重提列?正如很多事物都有相似的地方,而咱们面临的问题--快速选择算法中的划分过程等同于快速排序,所以,在分析快速选择SELECT算法之前,咱们先再来简单回顾和分析下快速排序,ok,今天看到Mark的数据结构与算法分析-c语言描述一书上对快速排序也有不错的介绍,所以为了增加点新鲜感,就不用自己以前的文章而改为直接引用Mark的叙述了:
As its name implies, quicksort is the fastest known sorting algorithm in practice. Its average running time is O(n log n)(快速排序是实践中已知的最快的排序算法,他的平均运行时间为O(N*logN)). It is very fast, mainly due to a very tight and highly optimized inner loop. It has O(n2) worst-case performance(最坏情形的性能为O(N^2)), but this can be made exponentially unlikely with a little effort.
The quicksort algorithm is simple to understand and prove correct, although for many years it had the reputation of being an algorithm that could in theory be highly optimized but in practice was impossible to code correctly (no doubt because of FORTRAN).
Like mergesort, quicksort is a divide-and-conquer recursive algorithm(像归并排序一样,快速排序也是一种采取分治方法的递归算法). The basic algorithm to sort an array S consists of the following four easy steps(通过下面的4个步骤将数组S排序的算法如下):
- If the number of elements in S is 0 or 1, then return(如果S中元素个数是0或1,则返回).
- Pick any element v in S. This is called the pivot(取S中任一元素v,作为枢纽元).
- Partition S - {v} (the remaining elements in S) into two disjoint groups(枢纽元v将S中其余的元素分成两个不相交的集合): S1 = {x(- S-{v}| x <= v}, and S2 = {x(- S-{v}| x >= v}.
- Return { quicksort(S1) followed by v followed by quicksort(S2)}.
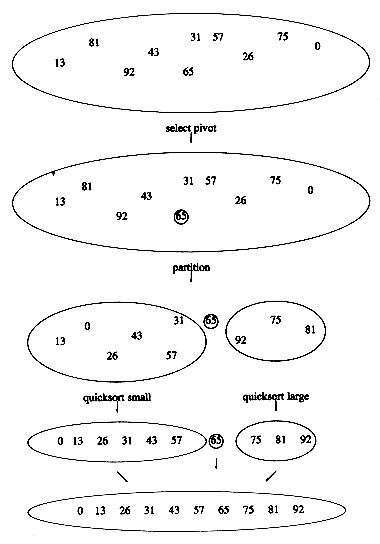
下面依据上述步骤对序列13,81,92,43,65,31,57,26,75,0 进行第一趟划分处理,可得到如下图所示的过程:
@TODO: add http://hi.csdn.net/attachment/201105/18/8394323_1305736981tvZN.jpg
{kind=link}
1.2、选取枢纽元的几种方法 1、糟糕的方法 通常的做法是选择数组中第一个元素作为枢纽元,如果输入是随机的,那么这是可以接受的。但是,如果输入序列是预排序的或者是反序的,那么依据这样的枢纽元进行划分则会出现相当糟糕的情况,因为可能所有的元素不是被划入S1,就是都被划入S2中。 2、较好的方法 一个比较好的做法是随机选取枢纽元,一般来说,这种策略是比较妥当的。 3、三数取取中值方法 例如,输入序列为 8, 1, 4, 9, 6, 3, 5, 2, 7, 0 ,它的左边元素为8,右边元素为0,中间位置|left+right)/2|上的元素为6,于是枢纽元为6.显然,使用三数中值分割法消除了预排序输入的坏情形,并且减少了快速排序大约5%(此为前人实验所得数据,无法具体证明)的运行时间。
1.3、划分过程 下面,我们再对序列8, 1, 4, 9, 6, 3, 5, 2, 7, 0进行第一趟划分,我们要达到的划分目的就是为了把所有小于枢纽元(据三数取中分割法取元素6为枢纽元)的元素移到数组的左边,而把所有大于枢纽元的元素全部移到数组的右边。
此过程,如下述几个图所示:
8 1 4 9 0 3 5 2 7 6
i j
8 1 4 9 0 3 5 2 7 6
i j
emsp; emsp; After First Swap:
----------------------------
2 1 4 9 0 3 5 8 7 6
i j
emsp; emsp; Before Second Swap:
----------------------------
2 1 4 9 0 3 5 8 7 6
i j
emsp; emsp; After Second Swap:
----------------------------
2 1 4 5 0 3 9 8 7 6
i j
emsp; emsp;Before Third Swap
----------------------------
2 1 4 5 0 3 9 8 7 6
j i //i,j在元素3处碰头之后,i++指向了9,最后与6交换后,得到:
2 1 4 5 0 3 6 8 7 9
i pivot
至此,第一趟划分过程结束,枢纽元6将整个序列划分成了左小右大两个部分。
1.4、四个细节
下面,是4个值得你注意的细节问题: 1、我们要考虑一下,就是如何处理那些等于枢纽元的元素,问题在于当i遇到第一个等于枢纽元的关键字时,是否应该停止移动i,或者当j遇到一个等于枢纽元的元素时是否应该停止移动j。 答案是:如果i,j遇到等于枢纽元的元素,那么我们就让i和j都停止移动。 2、对于很小的数组,如数组的大小N<=20时,快速排序不如插入排序好。 3、只通过元素间进行比较达到排序目的的任何排序算法都需要进行O(NlogN)次比较,如快速排序算法(最坏O(N^2),最好O(NlogN)),归并排序算法(最坏O(N*logN,不过归并排序的问题在于合并两个待排序的序列需要附加线性内存,在整个算法中,还要将数据拷贝到临时数组再拷贝回来这样一些额外的开销,放慢了归并排序的速度)等。 4、下面是实现三数取中的划分方法的程序:
//三数取中分割法
input_type median3( input_type a[], int left, int right )
//下面的快速排序算法实现之一,及通过三数取中分割法寻找最小的k个数的快速选择SELECT算法都要调用这个median3函数
{
int center;
center = (left + right) / 2;
if( a[left] > a[center] )
swap( &a[left], &a[center] );
if( a[left] > a[right] )
swap( &a[left], &a[right] );
if( a[center] > a[right] )
swap( &a[center], &a[right] );
/* invariant: a[left] <= a[center] <= a[right] */
swap( &a[center], &a[right-1] ); /* hide pivot */
return a[right-1]; /* return pivot */
}下面的程序是利用上面的三数取中分割法而运行的快速排序算法:
//快速排序的实现之一
void q_sort( input_type a[], int left, int right )
{
int i, j;
input_type pivot;
if( left + CUTOFF <= right )
{
pivot = median3( a, left, right ); //调用上面的实现三数取中分割法的median3函数
i=left; j=right-1; //第8句
for(;;)
{
while( a[++i] < pivot );
while( a[--j] > pivot );
if( i < j )
swap( &a[i], &a[j] );
else
break; //第16句
}
swap( &a[i], &a[right-1] ); /*restore pivot*/
q_sort( a, left, i-1 );
q_sort( a, i+1, right );
//如上所见,在划分过程(partition)后,快速排序需要两次递归,一次对左边递归
//一次对右边递归。下面,你将看到,快速选择SELECT算法始终只对一边进行递归。
//这从直观上也能反应出:此快速排序算法(O(N*logN))明显会比
//下面第二节中的快速选择SELECT算法(O(N))平均花费更多的运行时间。
}
}如果上面的第8-16句,改写成以下这样:
i=left+1; j=right-2;
for(;;)
{
while( a[i] < pivot ) i++;
while( a[j] > pivot ) j--;
if( i < j )
swap( &a[i], &a[j] );
else
break;
}那么,当a[i] = a[j] = pivot则会产生无限,即死循环(相信,不用我多余解释,:D)。ok,接下来,咱们将进入正题--快速选择SELECT算法。
##第二部分、线性期望时间的快速选择SELECT算法 2.1、快速选择SELECT算法的介绍
Quicksort can be modified to solve the selection problem, which we have seen in chapters 1 and 6. Recall that by using a priority queue, we can find the kth largest (or smallest) element in O(n + k log n)(以用最小堆初始化数组,然后取这个优先队列前k个值,复杂度O(n)+kO(log n)。实际上,最好采用最大堆寻找最小的k个数,那样,此时复杂度为nlogk。更多详情,请参见:狂想曲系列第三章、寻找最小的k个数). For the special case of finding the median, this gives an O(n log n) algorithm.
Since we can sort the file in O(nlog n) time, one might expect to obtain a better time bound for selection. The algorithm we present to find the kth smallest element in a set S is almost identical to quicksort. In fact, the first three steps are the same. We will call this algorithm quickselect(叫做快速选择). Let |Si| denote the number of elements in Si(令|Si|为Si中元素的个数). The steps of quickselect are:
- If |S| = 1, then k = 1 and return the elements in S as the answer. If a cutoff for small files is being used and |S| <=CUTOFF, then sort S and return the kth smallest element.
- Pick a pivot element, v (- S.(选取一个枢纽元v属于S)
- Partition S - {v} into S1 and S2, as was done with quicksort. ( > 集合S-{v}分割成S1和S2,就像我们在快速排序中所作的那样)
- If k <= |S1|, then the kth smallest element must be in S1. In this case, return quickselect (S1, k). If k = 1 + |S1|, then the pivot is the kth smallest element and we can return it as the answer. Otherwise, the kth smallest element lies in S2, and it is the (k - |S1| - 1)st smallest element in S2. We make a recursive call and return quickselect (S2, k - |S1| - 1). ( > 果k<=|S1|,那么第k个最小元素必然在S1中。在这种情况下,返回quickselect(S1,k)。如果k=1+|S1|,那么枢纽元素就是第k个最小元素,即找到,直接返回它。否则,这第k个最小元素就在S2中,即S2中的第(k-|S1|-1)个最小元素,我们递归调用并返回quickselect(S2,k-|S1|-1))(下面几节的程序关于k的表述可能会有所出入,但无碍,抓住原理即ok)。
In contrast to quicksort, quickselect makes only one recursive call instead of two. The worst case of quickselect is identical to that of quicksort and is O(n2). Intuitively, this is because quicksort's worst case is when one of S1 and S2 is empty; thus, quickselect(快速选择) is not really saving a recursive call. The average running time, however, is O(n)(不过,其平均运行时间为O(N)。看到了没,就是平均复杂度为O(N)这句话). The analysis is similar to quicksort's and is left as an exercise.
The implementation of quickselect is even simpler than the abstract description might imply. The code to do this shown in Figure 7.16. When the algorithm terminates, the kth smallest element is in position k. This destroys the original ordering; if this is not desirable, then a copy must be made.
2.2、三数中值分割法寻找第k小的元素
第一节,已经介绍过此三数中值分割法,有个细节,你要注意,即数组元素索引是从“0...i”开始计数的,所以第k小的元素应该是返回a[i]=a[k-1].即k-1=i。换句话就是说,第k小元素,实际上应该在数组中对应下标为k-1。ok,下面给出三数中值分割法寻找第k小的元素的程序的两个代码实现:
//代码实现一
//copyright@ mark allen weiss
//July、updated,2011.05.05凌晨.
//三数中值分割法寻找第k小的元素的快速选择SELECT算法
void q_select( input_type a[], int k, int left, int right )
{
int i, j;
input_type pivot;
if( left /*+ CUTOFF*/ <= right ) //去掉CUTOFF常量,无用
{
pivot = median3( a, left, right ); //调用1、4节里的实现三数取中分割法的median3函数
//取三数中值作为枢纽元,可以消除最坏情况而保证此算法是O(N)的。不过,这还只局限在理论意义上。
//稍后,您将看到另一种选取枢纽元的方法。
i=left; j=right-1;
for(;;) //此句到下面的九行代码,即为快速排序中的partition过程的实现之一
{
while( a[++i] < pivot ){}
while( a[--j] > pivot ){}
if (i < j )
swap( &a[i], &a[j] );
else
break;
}
swap( &a[i], &a[right-1] ); /* restore pivot */
if( k < i)
q_select( a, k, left, i-1 );
else
if( k-1 > i ) //此条语句相当于:if(k>i+1)
q-select( a, k, i+1, right );
//1、希望你已经看到,通过上面的if-else语句表明,此快速选择SELECT算法始终只对数组的一边进行递归,
//这也是其与第一节中的快速排序算法的本质性区别。
//2、这个区别则直接决定了:快速排序算法最快能达到O(N*logN),
//而快速选择SELECT算法则最坏亦能达到O(N)的线性时间复杂度。
//3、而确保快速选择算法最坏情况下能做到O(N)的根本保障在于枢纽元元素的选取,
//即采取稍后的2.3节里的五分化中项的中项,或2.4节里的中位数的中外位数的枢纽元选择方法达到O(N)的目的。
//后天老爸生日,孩儿深深祝福。July、updated,2011.05.19。
}
else
insert_sort(a, left, right-left+1 );
}//代码实现二
//copyright @ 飞羽
//July、updated,2011.05.11。
//三数中值分割法寻找第k小的元素
bool median_select(int array[], int left, int right, int k)
{
//第k小元素,实际上应该在数组中下标为k-1
if (k-1 > right || k-1 < left)
return false;
//三数中值作为枢纽元方法,关键代码就是下述六行:
int midIndex=(left+right)/2;
if(array[left]<array[midIndex])
swap(array[left],array[midIndex]);
if(array[right]<array[midIndex])
swap(array[right],array[midIndex]);
if(array[right]<array[left])
swap(array[right],array[left]);
swap(array[midIndex], array[right]);
int pos = partition(array, left, right);
if (pos == k-1) //第k小元素,实际上应该在数组中下标为k-1
return true;
else if (pos > k-1)
return median_select(array, left, pos-1, k);
else return median_select(array, pos+1, right, k);
}上述程序使用三数中值作为枢纽元的方法可以使得最坏情况发生的概率几乎可以忽略不计。然而,稍后,您将看到:通过一种更好的方法,如“五分化中项的中项”,或“中位数的中位数”等方法选取枢纽元,我们将能彻底保证在最坏情况下依然是线性O(N)的复杂度。即,如稍后2.3节所示。
2.3、五分化中项的中项,确保O(N)
The selection problem requires us to find the kth smallest element in a list S of n elements(要求我们找出含N个元素的表S中的第k个最小的元素). Of particular interest is the special case of finding the median. This occurs when k = |-n/2-|(向上取整).(我们对找出中间元素的特殊情况有着特别的兴趣,这种情况发生在k=|-n/2-|的时候)
In Chapters 1, 6, 7 we have seen several solutions to the selection problem. The solution in Chapter 7 uses a variation of quicksort and runs in O(n) average time(第7章中的解法,即本文上面第1节所述的思路4,用到快速排序的变体并以平均时间O(N)运行). Indeed, it is described in Hoare's original paper on quicksort.
Although this algorithm runs in linear average time, it has a worst case of O (n2)(但它有一个O(N^2)的最快情况). Selection can easily be solved in O(n log n) worst-case time by sorting the elements, but for a long time it was unknown whether or not selection could be accomplished in O(n) worst-case time. The quickselect algorithm outlined in Section 7.7.6 is quite efficient in practice, so this was mostly a question of theoretical interest.
Recall that the basic algorithm is a simple recursive strategy. Assuming that n is larger than the cutoff point where elements are simply sorted, an element v, known as the pivot, is chosen. The remaining elements are placed into two sets, S1 and S2. S1 contains elements that are guaranteed to be no larger than v, and S2 contains elements that are no smaller than v. Finally, if k <= |S1|, then the kth smallest element in S can be found by recursively computing the kth smallest element in S1. If k = |S1| + 1, then the pivot is the kth smallest element. Otherwise, the kth smallest element in S is the (k - |S1| -1 )st smallest element in S2. The main difference between this algorithm and quicksort is that there is only one subproblem to solve instead of two(这个快速选择算法与快速排序之间的主要区别在于,这里求解的只有一个子问题,而不是两个子问题)。
定理10.9
> The running time of quickselect using median-of-median-of-five partitioning is O(n)。
> The basic idea is still useful. Indeed, we will see that we can use it to improve the expected number of comparisons that quickselect makes. To get a good worst case, however, the key idea is to use one more level of indirection. Instead of finding the median from a sample of random elements, we will find the median from a sample of medians.
> The basic pivot selection algorithm is as follows:
> 1. Arrange the n elements into |_n/5_| groups of 5 elements, ignoring the (at most four) extra elements.
> 2. Find the median of each group. This gives a list M of |_n/5_| medians.
> 3. Find the median of M. Return this as the pivot, v.
> We will use the term median-of-median-of-five partitioning to describe the quickselect algorithm that uses the pivot selection rule given above. (我们将用术语“五分化中项的中项”来描述使用上面给出的枢纽元选择法的快速选择算法)。We will now show that median-of-median-of-five partitioning guarantees that each recursive subproblem is at most roughly 70 percent as large as the original(现在我们要证明,“五分化中项的中项”,得保证每个递归子问题的大小最多为原问题的大约70%). We will also show that the pivot can be computed quickly enough to guarantee an O (n) running time for the entire selection algorithm(我们还要证明,对于整个选择算法,枢纽元可以足够快的算出,以确保O(N)的运行时间。看到了没,这再次佐证了我们的类似快速排序的partition过程的分治方法为O(N)的观点)(更多详细的证明,请参考:第三章、寻找最小的k个数)。
2.4、中位数的中位数,O(N)的再次论证
以下内容来自算法导论第九章第9.3节全部内容(最坏情况线性时间的选择),如下(我酌情对之参考原中文版做了翻译,下文中括号内的中文解释,为我个人添加):
9.3 Selection in worst-case linear time(最坏情况下线性时间的选择算法)
We now examine a selection algorithm whose running time is O(n) in the worst case(现在来看,一个最坏情况运行时间为O(N)的选择算法SELECT). Like RANDOMIZED-SELECT, the algorithm SELECT finds the desired element by recursively partitioning the input array. The idea behind the algorithm, however, is to guarantee a good split when the array is partitioned. SELECT uses the deterministic partitioning algorithm PARTITION from quicksort (see Section 7.1), modified to take the element to partition around as an input parameter(像RANDOMIZED-SELECT一样,SELECTT通过输入数组的递归划分来找出所求元素,但是,该算法的基本思想是要保证对数组的划分是个好的划分。SECLECT采用了取自快速排序的确定性划分算法partition,并做了修改,把划分主元元素作为其参数). The SELECT algorithm determines the ith smallest of an input array of n > 1 elements by executing the following steps. (If n = 1, then SELECT merely returns its only input value as the ith smallest.)(算法SELECT通过执行下列步骤来确定一个有n>1个元素的输入数组中的第i小的元素。(如果n=1,则SELECT返回它的唯一输入数值作为第i个最小值。)) Divide the n elements of the input array into ⌊n/5⌋ groups of 5 elements each and at most one group made up of the remaining n mod 5 elements. Find the median of each of the ⌈n/5⌉ groups by first insertion sorting the elements of each group (of which there are at most 5) and then picking the median from the sorted list of group elements. Use SELECT recursively to find the median x of the ⌈n/5⌉ medians found in step 2. (If there are an even number of medians, then by our convention, x is the lower median.) Partition the input array around the median-of-medians x using the modified version of PARTITION. Let k be one more than the number of elements on the low side of the partition, so that x is the kth smallest element and there are n-k elements on the high side of the partition.(利用修改过的partition过程,按中位数的中位数x对输入数组进行划分,让k比划低去的元素数目多1,所以,x是第k小的元素,并且有n-k个元素在划分的高区) If i = k, then return x. Otherwise, use SELECT recursively to find the ith smallest element on the low side if i < k, or the (i - k)th smallest element on the high side if i > k.(如果要找的第i小的元素等于程序返回的k,即i=k,则返回x。否则,如果i<k,则在低区递归调用SELECT以找出第i小的元素,如果i>k,则在高区间找第(i-k)个最小元素)
(以上五个步骤,即本文上面的第四节末中所提到的所谓“五分化中项的中项”的方法。)
To analyze the running time of SELECT, we first determine a lower bound on the number of elements that are greater than the partitioning element x. (为了分析SELECT的运行时间,先来确定大于划分主元元素x的的元素数的一个下界)Figure 9.1 is helpful in visualizing this bookkeeping. At least half of the medians found in step 2 are greater than[1] the median-of-medians x. Thus, at least half of the ⌈n/5⌉ groups contribute 3 elements that are greater than x, except for the one group that has fewer than 5 elements if 5 does not divide n exactly, and the one group containing x itself. Discounting these two groups, it follows that the number of elements greater than x is at least:
(Figure 9.1: 对上图的解释或称对SELECT算法的分析:n个元素由小圆圈来表示,并且每一个组占一纵列。组的中位数用白色表示,而各中位数的中位数x也被标出。(当寻找偶数数目元素的中位数时,使用下中位数)。箭头从比较大的元素指向较小的元素,从中可以看出,在x的右边,每一个包含5个元素的组中都有3个元素大于x,在x的左边,每一个包含5个元素的组中有3个元素小于x。大于x的元素以阴影背景表示。 )
Similarly, the number of elements that are less than x is at least 3n/10 - 6. Thus, in the worst case, SELECT is called recursively on at most 7n/10 + 6 elements in step 5.
We can now develop a recurrence for the worst-case running time T(n) of the algorithm SELECT. Steps 1, 2, and 4 take O(n) time. (Step 2 consists of O(n) calls of insertion sort on sets of size O(1).) Step 3 takes time T(⌈n/5⌉), and step 5 takes time at most T(7n/10+ 6), assuming that T is monotonically increasing. We make the assumption, which seems unmotivated at first, that any input of 140 or fewer elements requires O(1) time; the origin of the magic constant 140 will be clear shortly. We can therefore obtain the recurrence:
We show that the running time is linear by substitution. More specifically, we will show that T(n) ≤ cn for some suitably large constant c and all n > 0. We begin by assuming that T(n) ≤ cn for some suitably large constant c and all n ≤ 140; this assumption holds if c is large enough. We also pick a constant a such that the function described by the O(n) term above (which describes the non-recursive component of the running time of the algorithm) is bounded above by an for all n > 0. Substituting this inductive hypothesis into the right-hand side of the recurrence yields
```
T(n) ≤ c[n/5] + c(7n/10 + 6) + an
≤ cn/5 + c + 7cn/10 + 6c + an
= 9cn/10 + 7c + an
= cn + (-cn/10 + 7c + an) ,
```
which is at most cn if
@todo: wget http://hi.csdn.net/attachment/201105/5/8394323_1304568935P0Zp.jpg
Inequality (9.2) is equivalent to the inequality c ≥ 10a(n/(n - 70)) when n > 70. Because we assume that n ≥ 140, we have n/(n - 70) ≤ 2, and so choosing c ≥ 20a will satisfy inequality (9.2). (Note that there is nothing special about the constant 140; we could replace it by any integer strictly greater than 70 and then choose c accordingly.) The worst-case running time of SELECT is therefore linear(因此,此SELECT的最坏情况的运行时间是线性的).
As in a comparison sort (see Section 8.1), SELECT and RANDOMIZED-SELECT determine information about the relative order of elements only by comparing elements. Recall from Chapter 8 that sorting requires Ω(n lg n) time in the comparison model, even on average (see Problem 8-1). The linear-time sorting algorithms in Chapter 8 make assumptions about the input. In contrast, the linear-time selection algorithms in this chapter do not require any assumptions about the input. They are not subject to the Ω(n lg n) lower bound because they manage to solve the selection problem without sorting.
(与比较排序(算法导论8.1节)中的一样,SELECT和RANDOMIZED-SELECT仅通过元素间的比较来确定它们之间的相对次序。在算法导论第8章中,我们知道在比较模型中,即使在平均情况下,排序仍然要O(nlogn)的时间。第8章得线性时间排序算法在输入上做了假设。相反地,本节提到的此类似partition过程的SELECT算法不需要关于输入的任何假设,它们不受下界O(nlogn)的约束,因为它们没有使用排序就解决了选择问题(看到了没,道出了此算法的本质阿)) Thus, the running time is linear because these algorithms do not sort; the linear-time behavior is not a result of assumptions about the input, as was the case for the sorting algorithms in Chapter 8. Sorting requires Ω(n lg n) time in the comparison model, even on average (see Problem 8-1), and thus the method of sorting and indexing presented in the introduction to this chapter is asymptotically inefficient.(所以,本节中的选择算法之所以具有线性运行时间,是因为这些算法没有进行排序;线性时间的结论并不需要在输入上所任何假设,即可得到。.....)
##第三部分、快速选择SELECT算法的实现 本节,咱们将依据下图所示的步骤,采取中位数的中位数选取枢纽元的方法来实现此SELECT算法,
不过,在实现之前,有个细节我还是必须要提醒你,即上文中2.2节开头处所述,“数组元素索引是从“0...i”开始计数的,所以第k小的元素应该是返回a[i]=a[k-1].即k-1=i。换句话就是说,第k小元素,实际上应该在数组中对应下标为k-1”这句话,我想,你应该明白了:返回数组中第k小的元素,实际上就是返回数组中的元素array[i],即array[k-1]。ok,最后请看此快速选择SELECT算法的完整代码实现(据我所知,在此之前,从没有人采取中位数的中位数选取枢纽元的方法来实现过这个SELECT算法):
//copyright@ yansha && July && 飞羽
//July、updated,2011.05.19.清晨。
//版权所有,引用必须注明出处:http://blog.csdn.net/v_JULY_v。
#include <iostream>
#include <time.h>
using namespace std;
const int num_array = 13;
const int num_med_array = num_array / 5 + 1;
int array[num_array];
int midian_array[num_med_array];
//冒泡排序(晚些时候将修正为插入排序)
/*void insert_sort(int array[], int left, int loop_times, int compare_times)
{
for (int i = 0; i < loop_times; i++)
{
for (int j = 0; j < compare_times - i; j++)
{
if (array[left + j] > array[left + j + 1])
swap(array[left + j], array[left + j + 1]);
}
}
}/*
//插入排序算法伪代码
INSERTION-SORT(A) cost times
1 for j ← 2 to length[A] c1 n
2 do key ← A[j] c2 n - 1
3 Insert A[j] into the sorted sequence A[1 ‥ j - 1]. 0...n - 1
4 i ← j - 1 c4 n - 1
5 while i > 0 and A[i] > key c5
6 do A[i + 1] ← A[i] c6
7 i ← i - 1 c7
8 A[i + 1] ← key c8 n - 1
*/
//已修正为插入排序,如下:
void insert_sort(int array[], int left, int loop_times)
{
for (int j = left; j < left+loop_times; j++)
{
int key = array[j];
int i = j-1;
while ( i>left && array[i]>key )
{
array[i+1] = array[i];
i--;
}
array[i+1] = key;
}
}
int find_median(int array[], int left, int right)
{
if (left == right)
return array[left];
int index;
for (index = left; index < right - 5; index += 5)
{
insert_sort(array, index, 4);
int num = index - left;
midian_array[num / 5] = array[index + 2];
}
// 处理剩余元素
int remain_num = right - index + 1;
if (remain_num > 0)
{
insert_sort(array, index, remain_num - 1);
int num = index - left;
midian_array[num / 5] = array[index + remain_num / 2];
}
int elem_aux_array = (right - left) / 5 - 1;
if ((right - left) % 5 != 0)
elem_aux_array++;
// 如果剩余一个元素返回,否则继续递归
if (elem_aux_array == 0)
return midian_array[0];
else
return find_median(midian_array, 0, elem_aux_array);
}
// 寻找中位数的所在位置
int find_index(int array[], int left, int right, int median)
{
for (int i = left; i <= right; i++)
{
if (array[i] == median)
return i;
}
return -1;
}
int q_select(int array[], int left, int right, int k)
{
// 寻找中位数的中位数
int median = find_median(array, left, right);
// 将中位数的中位数与最右元素交换
int index = find_index(array, left, right, median);
swap(array[index], array[right]);
int pivot = array[right];
// 申请两个移动指针并初始化
int i = left;
int j = right - 1;
// 根据枢纽元素的值对数组进行一次划分
while (true)
{
while(array[i] < pivot)
i++;
while(array[j] > pivot)
j--;
if (i < j)
swap(array[i], array[j]);
else
break;
}
swap(array[i], array[right]);
/* 对三种情况进行处理:(m = i - left + 1)
1、如果m=k,即返回的主元即为我们要找的第k小的元素,那么直接返回主元a[i]即可;
2、如果m>k,那么接下来要到低区间A[0....m-1]中寻找,丢掉高区间;
3、如果m<k,那么接下来要到高区间A[m+1...n-1]中寻找,丢掉低区间。
*/
int m = i - left + 1;
if (m == k)
return array[i];
else if(m > k)
//上条语句相当于if( (i-left+1) >k),即if( (i-left) > k-1 ),于此就与2.2节里的代码实现一、二相对应起来了。
return q_select(array, left, i - 1, k);
else
return q_select(array, i + 1, right, k - m);
}
int main()
{
//srand(unsigned(time(NULL)));
//for (int j = 0; j < num_array; j++)
//array[j] = rand();
int array[num_array]={0,45,78,55,47,4,1,2,7,8,96,36,45};
// 寻找第k最小数
int k = 4;
int i = q_select(array, 0, num_array - 1, k);
cout << i << endl;
return 0;
}