List of Reviewed Articles
- DeepGlobe 2018: A Challenge to Parse the Earth through Satellite Images (https://arxiv.org/pdf/1805.06561.pdf)
- Learning Aerial Image Segmentation from Online Maps (https://arxiv.org/pdf/1707.06879.pdf)
- Faster R-CNN (https://arxiv.org/pdf/1506.01497.pdf)
- YOLO (https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf)
- Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN (https://www.mdpi.com/2076-3417/8/5/813)
- R-CNN for Small Object Detection (https://www.merl.com/publications/docs/TR2016-144.pdf)
- Geospatial Object Detection in High Resolution Satellite Images Based on Multi-Scale Convolutional Neural Network (https://www.mdpi.com/2072-4292/10/1/131/htm)
- Using Convolutional Networks and Satellite Imagery to Identify Patterns in Urban Environments at a Large Scale (https://dl.acm.org/citation.cfm?id=3098070)
This paper introduces DeepGlobe 2018: three new challenges focusing on segmentation, detection, and classification tasks on satellite images. Provides a synopsis on several different datasets used for each task. Specifically, the challenges are road extraction, building detection, and land cover classification. For each task, the paper covers:
- The datasets being used
- The evaluation criteria of the competitions
- Baselines for each task
The DeepGlobe competition uses the DigitalGlobe +Vivid Images for the road extraction task. The data is sampled from both urban and rural areas. GIS experts then crop the images to extract useful and relevant subregions.
For building detection, DeepGlobe uses SpaceNet Building Detection Dataset. Unlike previous competitions, the SpaceNet dataset uses large areas, which are mainly urban or suburban. A DigitalGlobe team fully annotated each scene, identifying and providing a bounding polygon for each building to the published specification, which were extracted to best represent the building outline. There are around 300,000 total building labels. Each area is also a single satellite image, so the light and atmospheric conditions do not vary. It’s also publicly available on AWS.
DeepGlobe created a new dataset for the land cover classification challenge. The dataset focuses on rural areas. Each satellite image contains RGB data with a pixel resolution of 50cm. Each image is paired with a pixel-wise mask image for land cover annotation, where the mask is an RGB image with 7 classes.
The road extraction challenge is a binary classification task. They expect an output mask for each image input, and the outputs will be evaluated using pixel-wise IoU.
The building detection challenge is considered a binary segmentation task, where the output is a list of building polygons. The output will be an F1 with the matching algorithm inspired by Algorithm 2 in this paper[insert link]. The metric emphasizes accurate detection and complete identification of building outlines. During the tiling process, a tile boundary can cut a building into multiple parts, so they ignore buildings with a pixel area of 20 pixels or less. They consider a true positive to be when a detected building and a ground truth building have an IoU greater than .5.
Land cover classification is considered a multi-class segmentation task. The expected output is an RGB mask. Again, IoU is used, but it’s defined slightly different for each of the 7 classes.
For road extraction, the state-of-the-art models that were tested were:
- SegNet
- DeepLab
- Deep ResNet
- U-Net The best results were obtained by training a modified version of DeepLab architecture with a ResNet18 backbone and Focal Loss (with simple augmentation, no post-processing). Using DeepLab, they got a .545 IoU after training 100 epochs.
For building classification, they covered a few past and current approaches to the task:
- Mnih used two locally connected NN layers followed by fully connected layer.
- Conv. layers of AlexNet fed into SVM
- CNN based approach
- FCN-8 segmentation network analyzing IR, R and G data with 5 convolutional layers and augmentation with a model based on nDSM (normalized Digital Surface Model) and NDVI.
- U-Net or SegNet approaches to segmentation
For the baseline, they selected a winner from recent competition on SpaceNet. The competitor used an ensemble of 3 U-Net models to segment an 8-band multi-spectral image, with the additional use of OpenStreetMap data. They then extracted building footprints from the segmentation. During the competition, this approach produced IoU larger than .8, but it struggles with small objects and close buildings.
Attempts to reduce the computational bottleneck of region proposal methods in the RCNN architecture. Specifically, replacing selective search with a deep CNN drastically improves cost. Introduces RPNs (regional proposal networks) that share convolutional layers with object detection networks that have been showed to perform well.
Design
Uses the feature maps created by Fast- RCNN to generate the region proposals. Then, simultaneously regressing on the bounds of the region and the object-ness scores on each location, region proposals are predicted.
Switches between fine-tuning for object detection and for generating the region proposals, thus sharing the convolutional features between both tasks.
Generating the region proposals: slide small network over CNN feature map, produce k anchor boxes at each window. Therefore, we have 2k scores for the box-classification layer, and 4k coordinates for the box regression layer.

- Translation Invariant
- Much faster, no extra cost for scale, since single image is used from RCNN architecture
- Anchor boxes replace the much slower selective search
- Still uses regression (linear?)
- Still has to output k anchors for every every sliding window position (discards the irrelevant one only in Loss computation)
- Not specific to satellite imagery (but possibly good for small objects)
YOLO approaches object detection as a regression problem. It is a fast and relatively simple network that is used primarily for real-time object detection. YOLO tends to be less accurate and make more localization errors than state of the art techniques, but it is faster, better at generalizing, and less prone to detect false positives than other top architectures.
Design
YOLO first divides the input image into an SxS grid, where each grid cell is responsible for detecting objects whose centers lie in that cell. Each grid cell predicts B bounding boxes and confidence scores for each box. The confidence scores reflect the "objectness" of the box and the predicted accuracy of the bounding box. Each grid cell also predicts C conditional class probabilities. By multiplying this and the original confidence scores together, class-specific confidence scores can be assigned to each grid cell.
The architecture of this network is inspired by the GoogLeNet model. 24 convolutional layers for feature extraction are followed by 2 fully connected layers for outputting coordinates and object probabilities.

- Fast
- YOLO is a single network, whereas other methods have separate parts that need to be trained and optimized separately
- Learns very general representations of objects (better at generalizing than R-CNN, good for geographically different areas?)
- Sees entire image during training and test time so it's better able to encode contextual information about classes. Because of this, YOLO detects fewer false positives than R-CNNs
- More localization errors than other methods, accuracy worse than state of the art methods. This is because loss is the same for large vs small bounding boxes and while small errors for large boxes are insignificant, small errors in localizing small boxes can be significant.
- Has an especially difficult time with small objects
- The number of objects YOLO can detect is limited
YOLT was created to address the difficulties of detecting small objects in high resolution satellite images. Often satellite images can encompass areas many square kilometers in size with hundreds of millions of pixels. Objects in these images can be tiny (10-100 pixels), which makes them very difficult for many other algorithms to detect. YOLT evaluates satellite images of arbitrary size at a rate of 0.5 square km/second. This paper claims that YOLT can localize objects only 5 pixels in size with high confidence. This paper is very vague but there is code we can look at and use. See h�ps://github.com/CosmiQ/yolt
Requirements
Because of the unique challenges faced when working with satellite images, object detection algorithms must take into account (1) small spatial extent of objects, (2) complete rotation invariance, (3) small amounts of training data, and (4) very high resolution inputs.
Architecture
YOLT uses a 22 layer architecture that downsamples by a factor of 16. Inputting a 416x416 grid would yield a 26x26 prediction grid. YOLT's architecture is inspired by YOLO, but optimized for small, densely packed objects. A passthrough layer (similar to identity mappings in ResNet) to preserve fine grained features, and each convolutional layer besides the last is batch normalized with leaky relu activation. The last layer predicts bounding boxes and classes. The default number of boxes per grid cell is 5.
Training Data
Training data is collected from small chips of large images. Some hyperparameters: 5 boxes per grid cell, initial learning rate of 10^-3, weight decay of 0.0005, momentum of 0.9. Training took 2-3 days on a single NVIDIA Titan X GPU.
Test Procedure . Images of arbitrary size can be partitioned and individually run through a trained model.
- Can evaluate images of arbitrary size
- Fast
- Can detect tiny objects in HRES satellite images
- Not optimized for building detection (maybe something we could add)
The paper claims to improve object detection for small objects by making the following five modifications to the standard Faster R-CNN architecture:
- Feature map fusion before anchor boxes are proposed
- Shrinking anchor box sizes to match dataset statistics
- Network module to incorporate context
- Random rotations for data pre-processing
- Balanced sampling to combat class imbalance
Feature map fusion before anchor boxes are proposed: Draws inspiration from feature pyramid networks. In a normal scenario, there is a feature map upon which one would propose anchor boxes. That feature map would be the last layer of some pre-trained network backbone (e.g. ResNet-50). This paper proposes that we take the last few layers of that pre-trained backbone and fuse them together through addition (and the necessary 1x1 convolutions to reduce the dimensions so that we can add feature maps of different dimensions). One would then propose anchor boxes on this fused feature map. The idea is that we can combine high-resolution information with semantically meaningful features, which is important for accurately capturing features for extremely small objects.
Shrinking anchor box sizes to match dataset statistics: The anchor box sizes for standard object detection benchmarks are designed to catch large objects; this paper’s response is to choose better anchor box sizes based on the range of object sizes in the specific problem that the algorithm is facing. This experimentally improves accuracy.
Network module to incorporate context: Idea is that context can help with object recognition. Essentially, for each anchor box proposal they also extract a context proposal which encapsulates the anchor box proposal. Both of these proposals are fed through a combination of ROI layers and some fully connected layers to get the final classifications and coordinates.
Random rotations for data processing: Empirically show that their “RR” method improves accuracy. However, unclear how it is different than standard rotations in data augmentation.
Balanced sampling to combat class imbalance: Irrelevant to our problem for now because we do not expect class imbalance.
The paper claims to improve object detection for small objects by making the following 2 modifications to the standard R-CNN architecture:
- Shrink anchor box sizes
- Context module
Shrink anchor box sizes: Same reasoning as above paper.
Context module: For each proposal, also include a context region which is essentially a larger region enclosing proposal. Feed both regions into network, and at some point later in the network, concatenate the two different feature maps together.
Geospatial Object Detection in High Resolution Satellite Images Based on Multi-Scale Convolutional Neural Network
This paper describes a multi-scale convolutional neural network for detecting objects of all sizes in high resolution satellite (HRS) images. While several effective methods have been used for bounding box object detection in the past, none are particularly well-suited for detecting small objects within HRS images. This architecture is R-CNN inspired, with a few key improvements given below
- Shared Multi-Scale Base Network
- Multi-Scale Object Proposal Network
- Multi-Scale Object Detection Network
Shared Multi-Scale Base Network
One major problem Faster R-CNNs have in detecting objects of different scales has to do with their base feature maps. Traditionally, Faster R-CNN feature maps do not have strong semantic representations for objects of all scales. However, in order to be able to detect small objects in large images, feature maps with strong semantic representations for a variety of differently-sized objects is required. To produce feature maps with strong semantic representations on all scales, a shared multi-scale base network was used.
This shared multi-scale base network is built from a "bottom up" section and a "top down" section. The bottom up architecture is a VGG-16 net, and it is used to produce several initial feature maps with different levels of semantic representation. In the top down part of the architecture, feature maps are taken from several places in the middle of the bottom up portion and combined (using element-wise addition and deconvolutional layers) with other feature maps produced at the end and in the middle of the VGG-16 network. The multi-scale base network outputs several differently-sized feature maps with receptive fields of 8, 16, 32, and 64 pixels with respect to the original image.

Multi-Scale Object Proposal Network
To detect multi-scale objects in images, a region proposal network (RPN) is used on each feature map. The RPN takes feature maps as inputs and proposes bounding boxes of 2 scales and 5 aspect ratios for each feature map, outputting an "objectness" score and the coordinates of each bounding box. Because there will be so many more bounding boxes that do not surround objects than ones that do, a classifier is also trained to supress a large portion of the negative samples. This classifier, which is composed of convolutional layers followed by softmax, gives proposal scores for each bounding box. Boxes with scores below 0.5 are discarded.
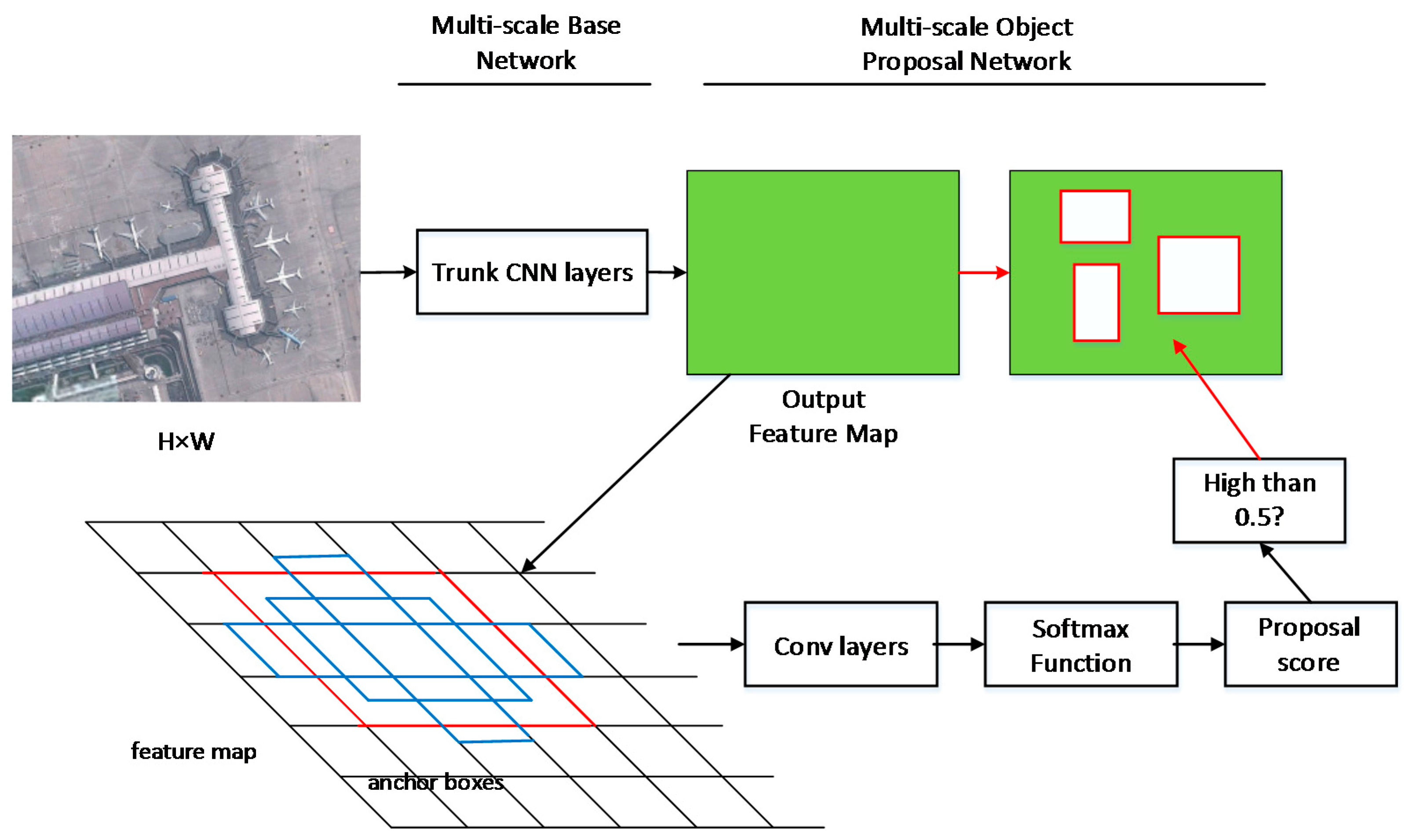
Multi-Scale Object Detection Network
After generating feature maps and object proposals, the next step is to determine what objects are in the object proposal bounding boxes, if any, and adjust the bounding boxes to more closely fit any objects that might be inside of them. In this paper, two 3×3 convolutional layers were applied to the feature maps to obtain classification and bounding box regression results. While different layers could be used in this step, such as residual or inception units, this paper simply used 3x3 convolutional layers for simplicity. The architecture was trained and tested on the VHR-10 dataset and achieved a 89.6% mAP value.
- Accurate, well suited for detecting smaller objects as well as bigger ones
- Intuitive
- Slow
- Not specialized enough for detecting smaller objects, might waste a lot of resources unless we revise it to be more specific.
Using Convolutional Networks and Satellite Imagery to Identify Patterns in Urban Environments at a Large Scale
Addresses the problem of scalability; for models models trained in one city, how good are they in different cities? Study how different classes compare across cities.
Design
- Models: ResNet and VGG-16
- Features extracted from these models to perform large scale comparison of urban environments (across cities)
- Ground truth labels from Urban Atlas
- Images from Google Maps static API
- 10 cities in Europe with 10 land use classes
- Why not OSM: Because the labels are too specific (e.g.:baseball diamonds, churches, roundabouts). Also Urban Atlas is for Europe.
- Why Urban Atlas: Comprehensive and consistent, large scale, curated by experts, used over the last decade. Also the land use classes reflect higher functions (socio-economic, cultural) functions of the land as used in applications.

- Is able to recognise class probability for agricultural lands, industrial, public, commercial land and airports, sports and leisure facilities quite well.
- Is able to recognise features and similarities between different cities, pointing to quantitive similarities of classes between cities.
- Not that great at roads (since roads have different functional classification for urban planning purposes.
- Labels used were high-level, more abstract (low density urban fabric and sports and leisure facilities)
- Better results when architecture was trained over a mixture of cities then if trained on one city and tested on another.