-->Package installed- NLKT
- NLTK stands for 'Natural Language Tool Kit'. It consists of the most common algorithms such as tokenizing, part-of-speech tagging, stemming, sentiment analysis, topic segmentation, and named entity recognition. NLTK helps the computer to analysis, preprocess, and understand the written text.
--> Pandas
- pandas is a library where your data can be stored, analyzed and processed in row and column representation
--> from sklearn.feature_extraction.text import CountVectorizer
- Scikit-learn's CountVectorizer is used to convert a collection of text documents to a vector of term/token counts. It also enables the pre-processing of text data prior to generating the vector representation. This functionality makes it a highly flexible feature representation module for text.
- Input the sentences you would like to vectorize.
- The script will tokenize the sentences.
- It will transform the text to vectors where each word and its count is a feature.
- Then the bag of word model is ready.
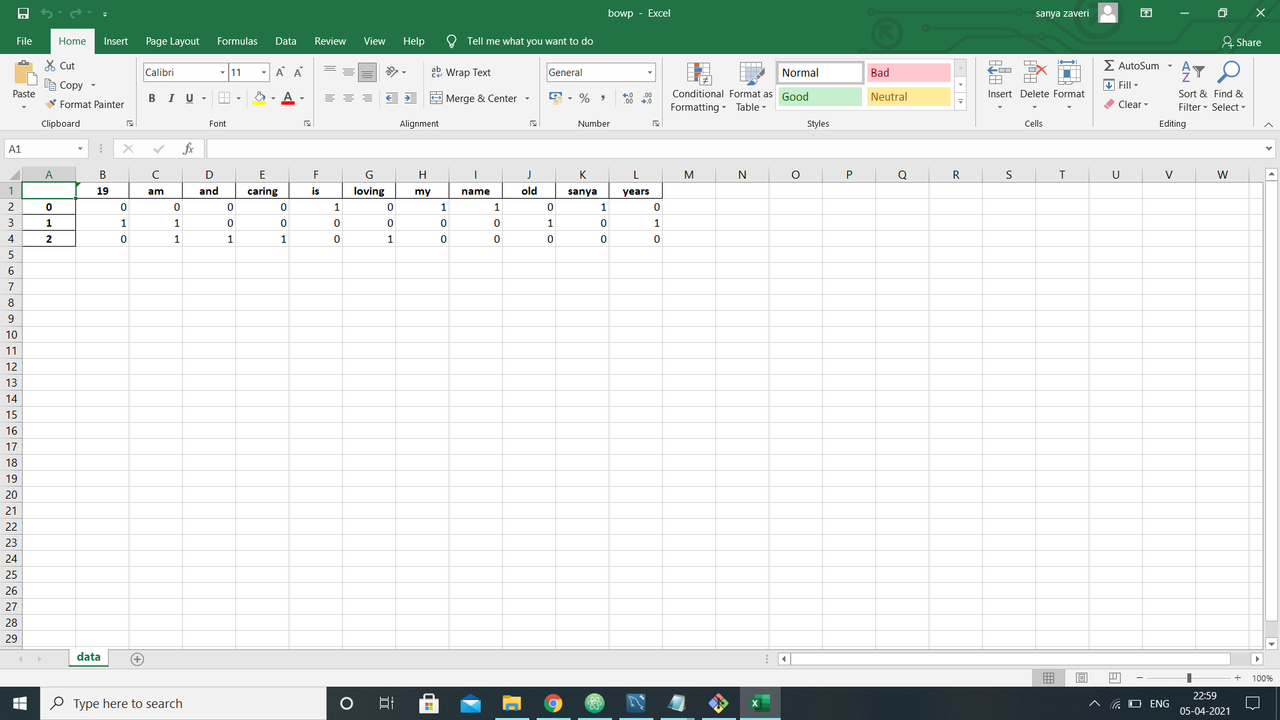
- create dataframe where dataFrame is an analogy to excel-spreadsheet.
- Open excel and check the 'bowp.xlsx' where sheet name is 'data'. The dataframe will be stored over there.
- This code is written by Sanya Devansh Zaveri
There are no disclaimers for this script.