

Author
Patrick Nguyen (University of Information Technology, Vietnam)
References from Tensorflow docs and bunch of places on the internet!
Tensors are the most lowest-level units that you have to work on if you want to build any kind of Neural Network using Tensorflow.
Outputs random values from a distribution.
# Create a normally distributed tensor with the shape of (12,48,48)
normal_tensor = tf.random.normal((12,48,48), mean=1, stddev=1.0) # Create a uniformly distributed tensor with the shape of (12,48,48)
uniform_tensor = tf.random.uniform((12,48,48))# Create a u gamma-ly distributed tensor with the shape of (12,48,48)
uniform_tensor = tf.random.gamma((12,48,48))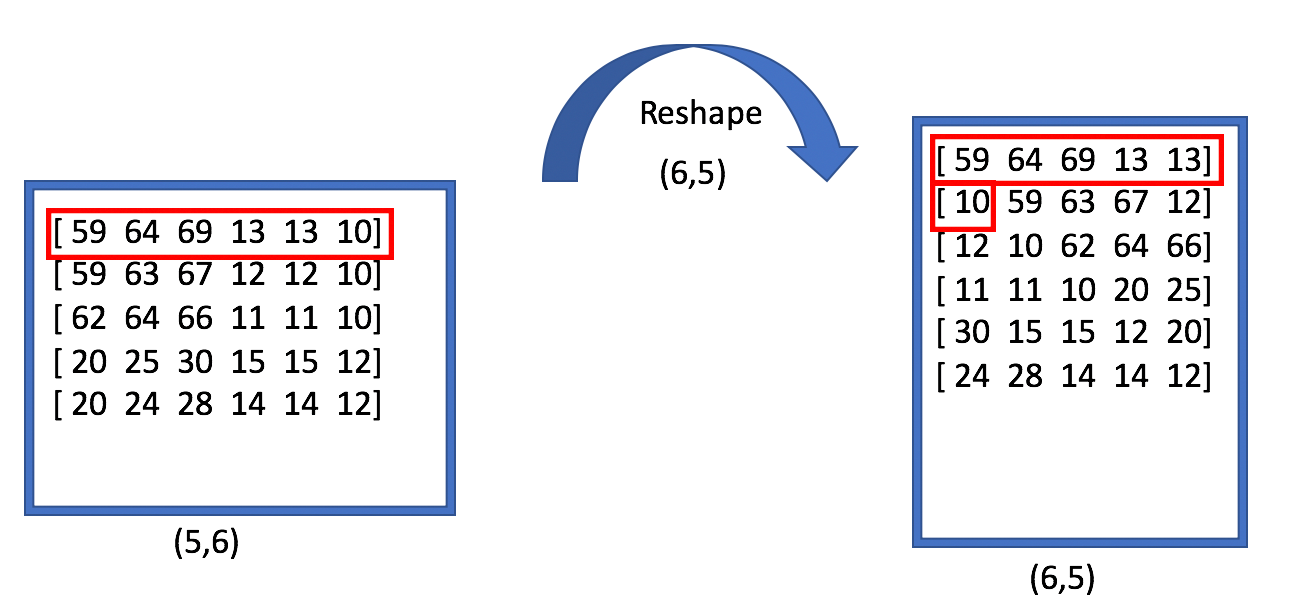
Given tensor, this operation returns a tensor that has the same values as tensor with shape shape
# tensor 't' is [1, 2, 3, 4, 5, 6, 7, 8, 9]
# tensor 't' has shape [9]
reshape(t, [3, 3]) # [[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]]
# tensor 't' is [[[1, 1], [2, 2]],
# [[3, 3], [4, 4]]]
# tensor 't' has shape [2, 2, 2]
reshape(t, [2, 4]) # [[1, 1, 2, 2],
# [3, 3, 4, 4]]Inserts a dimension of 1 into a tensor's shape.
# 't' is a tensor of shape [2, 3, 5]
(tf.expand_dims(t, 0)).shape # [1, 2, 3, 5]
(tf.expand_dims(t, 2)).shape # [2, 3, 1, 5]
(tf.expand_dims(t, 3)).shape # [2, 3, 5, 1]Returns the index with the largest value across dimensions of a tensor.
import tensorflow as tf
a = tf.convert_to_tensor([[1, 10, 7],
[3, 4, 9]])
tf.argmax(a,axis=1) # [1,2]Returns the index with the largest value across dimensions of a tensor.
import tensorflow as tf
a = tf.convert_to_tensor([[1, 10, 7],
[3, 4, 9]])
tf.argmin(a,axis=1) # [0,0]Return the sum of all elements in the tensor or sum of the tensor along specified axis
a = tf.convert_to_tensor([[1, 10, 7],
[3, 4, 9]])
tf.reduce_sum(a) # 34
tf.reduce_sum(a,axis = 0) # [4,14,16]
tf.reduce_sum(a,axis = 1) # [18,16]Return the product of all elements in the tensor or product of the tensor along specified axis
a = tf.convert_to_tensor([[1, 10, 7],
[3, 4, 9]])
tf.reduce_prod(a) # 7560
tf.reduce_prod(a,axis = 0) # [3,40,63]
tf.reduce_prod(a,axis = 1) # [70,108]Return the product of all elements in the tensor or product of the tensor along specified axis.
a = tf.convert_to_tensor([[1, 10, 7],
[3, 4, 9]])
tf.reduce_mean(a) # 7560
tf.reduce_mean(a,axis = 0) # [3,40,63]
tf.reduce_(a,axis = 1) # [70,108]Return the max of all elements in the tensor or product of the tensor along specified axis.
a = tf.convert_to_tensor([[1, 10, 7],
[3, 4, 9]])
tf.reduce_max(a) # 10
tf.reduce_max(a,axis = 0) # [3,10,9]
tf.reduce_max(a,axis = 1) # [70,108]Return the min of all elements in the tensor or product of the tensor along specified axis.
a = tf.convert_to_tensor([[1, 10, 7],
[3, 4, 9]])
tf.reduce_min(a) # 1
tf.reduce_min(a,axis = 0) # [1,4,7]
tf.reduce_min(a,axis = 1) # [1,3]a module for manage and load batches of dataset at training & test time
Creates a Dataset whose elements are slices of the given tensors.
image_dataset = tf.data.Dataset.from_tensor_slices(unique_image_urls)After create a dataset from_tensor_slices(), you can then transform this dataset using a mapping function. For e.g:
# Mapping function
def load_image(image_path):
image = tf.io.read_file(image_path)
image = tf.image.decode_jpeg(image,channels = 3)
image = tf.image.resize(image,(299,299))
image = tf.keras.applications.inception_v3.preprocess_input(image)
return image, image_path
# Transform dataset
image_dataset = image_dataset.map(
load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE).batch(16)
# Then you can iterate
for img, path in image_dataset:
batch_features = feature_extractor_model(img)
....This module allows you to download a file via a link and put that to a specified folder. You can extract the file if you wish!
data_path = os.path.abspath('.') + "/my_data_folder/"
train_zip_url = 'http://images.cocodataset.org/zips/train2014.zip'
name_of_zip = "my_train_data.zip"
train_zip = tf.keras.utils.get_file(name_of_zip,
cache_subdir=data_path,
origin = train_zip_url ,
extract = True)shortcut GlobalMaxPool1D
shortcut
Turns positive integers (indexes) into dense vectors of fixed size.
Inherits From: Layer
e.g. [[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]]
vocab_size = 5000
embedding_dim = 256
my_input = tf.Variable([Tokenizer.word_index['dog']] *3) # value: [64,64,64] shape: [3]
Embedding_Layer = tf.keras.layers.Embedding(vocab_size, embedding_dim)
Embedding_Layer(my_input) # shape: [3,256]Create a model that is linearly stacked with layers
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, Dense, Flatten, Dropout
model = Sequential()
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu', input_shape=x_train.shape[1:]))
model.add(Conv2D(filters=32, kernel_size=(5,5), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(Conv2D(filters=64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(rate=0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(rate=0.5))
model.add(Dense(10, activation='softmax'))If you want to create your own custom layers, you can inherit from tf.keras.layers.Layer class then create your own using atomic tensorflow operations.
class MyDenseLayer(tf.keras.layers.Layer):
def __init__(self, num_outputs):
super(MyDenseLayer, self).__init__()
self.num_outputs = num_outputs
def build(self, input_shape):
self.kernel = self.add_variable("kernel",
shape=[int(input_shape[-1]),
self.num_outputs])
def call(self, input):
return tf.matmul(input, self.kernel)
layer = MyDenseLayer(10)So if you want to be able to call .fit(), .evaluate(), or .predict() on those blocks or you want to be able to save and load those blocks separately or something you should use the Model class. A model should contain multiple layers while layer contains only 1 pass-through from input to output (theoretically speaking).
class ResnetIdentityBlock(tf.keras.Model):
def __init__(self, kernel_size, filters):
super(ResnetIdentityBlock, self).__init__(name='')
filters1, filters2, filters3 = filters
self.conv2a = tf.keras.layers.Conv2D(filters1, (1, 1))
self.bn2a = tf.keras.layers.BatchNormalization()
.....
self.bn2c = tf.keras.layers.BatchNormalization()
def call(self, input_tensor, training=False):
x = self.conv2a(input_tensor)
x = self.bn2a(x, training=training)
x = tf.nn.relu(x)
.....
x = self.conv2c(x)
x = self.bn2c(x, training=training)
x += input_tensor
return tf.nn.relu(x)In tensorflow 2, Gradient Tape is born for the sake of automatic differentiation - computing the gradient of a computation with respect to its input variables. Tensorflow "records" all operations executed inside the context of a tf.GradientTape onto a "tape".
def f(w1, w2):
return 3 * w1 ** 2 + 2 * w1 * w2
w1, w2 = tf.Variable(5.), tf.Variable(3.)
with tf.GradientTape() as tape:
z = f(w1, w2)
gradients = tape.gradient(z, [w1, w2])You can also using tf.GradientTape() to compute gradient corresponded to a chain of computation with respected to some variables, and then apply these gradients to variables via a declared optimizer.
# Init loss
loss = 0
with tf.GradientTape() as tape:
# Put through CNN encoder
features = encoder(image_tensor)
.....
for i in range(target.shape[1])
# Get output and hidden from decoder
x, hidden, _ = decoder(x, features, hidden)
# Compute loss function
loss += loss_func(target[i], x)
....
.....
train_params = encoder.trainable_variables + decoder.trainable_variables # Grab all trainable variables
gradients = tape.gradient(loss,train_params) # calculate gradient respected to param
optimizer.apply_gradients(zip(gradients,train_params)) # apply gradientsOptimizer that implements the Adam algorithm.
Optimizer that implements the Adagrad algorithm.
Optimizer that implements the Adadelta algorithm.
Optimizer that implements the Adamax algorithm.
Optimizer that implements the FTRL algorithm.
Optimizer that implements the NAdam algorithm.
Optimizer that implements the RMSprop algorithm.
Stochastic gradient descent and momentum optimizer.
Tensorflow's doc https://www.tensorflow.org/tutorials/eager/