diff --git a/README.md b/README.md
index cbfa3e7b..5ecc3603 100644
--- a/README.md
+++ b/README.md
@@ -36,7 +36,7 @@ Lux is a Python library that facilitate fast and easy data exploration by automa
Here is a [1-min video](https://www.youtube.com/watch?v=qmnYP-LmbNU) introducing Lux, and [slides](http://dorisjunglinlee.com/files/Zillow_07_2020_Slide.pdf) from a more extended talk.
-Check out our [notebook gallery](https://lux-api.readthedocs.io/en/latest/source/reference/gallery.html) with examples of how Lux can be used with a variety of dataset and analysis scenarios.
+Check out our [notebook gallery](https://lux-api.readthedocs.io/en/latest/source/reference/gallery.html) with examples of how Lux can be used with different datasets and analyses.
Or try out Lux on your own in a [live Jupyter Notebook](https://mybinder.org/v2/gh/lux-org/lux-binder/master?urlpath=tree/demo/employee_demo.ipynb)!
# Getting Started
@@ -48,26 +48,22 @@ import lux
import pandas as pd
```
-Then, Lux can be used as-is, without modifying any of your existing Pandas code. Here, we use Pandas's [read_csv](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html) command to load in a [dataset of colleges](https://github.com/lux-org/lux-datasets/blob/master/data/college.csv) and their properties.
+Lux can be used without modifying any existing Pandas code. Here, we use Pandas's [read_csv](https://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_csv.html) command to load in a [dataset of colleges](https://github.com/lux-org/lux-datasets/blob/master/data/college.csv) and their properties.
```python
df = pd.read_csv("https://raw.githubusercontent.com/lux-org/lux-datasets/master/data/college.csv")
df
```
-
+When the dataframe is printed out, Lux automatically recommends a set of visualizations highlighting interesting trends and patterns in the dataset.
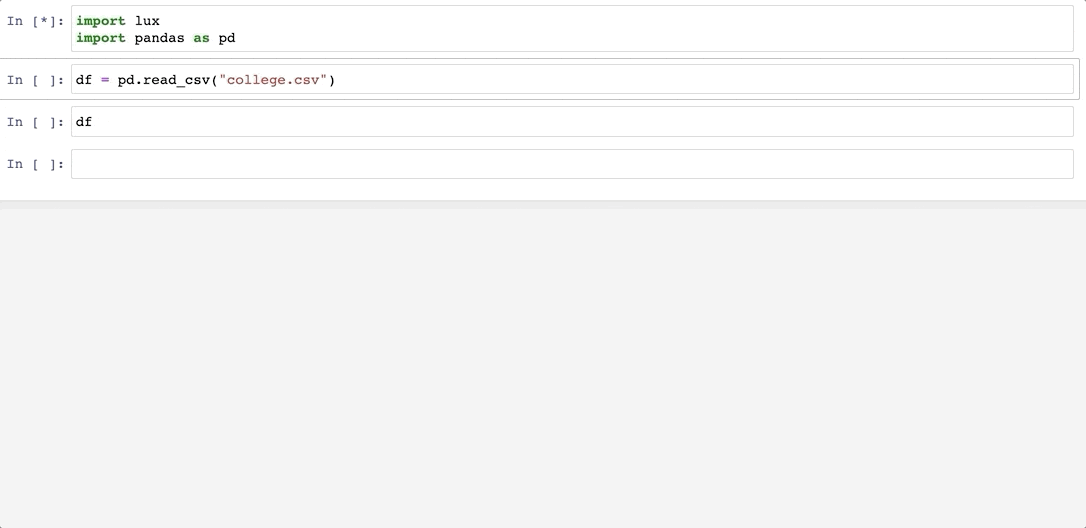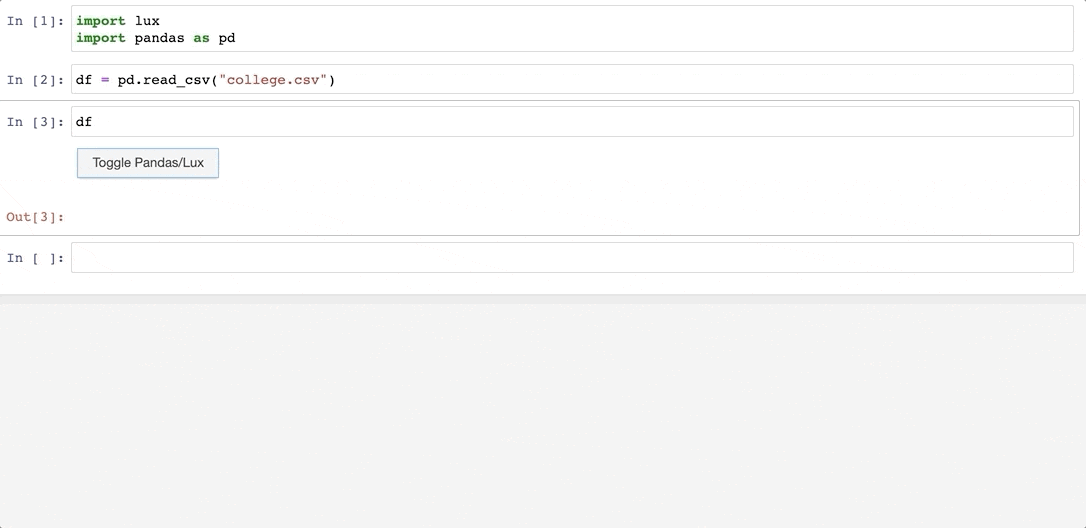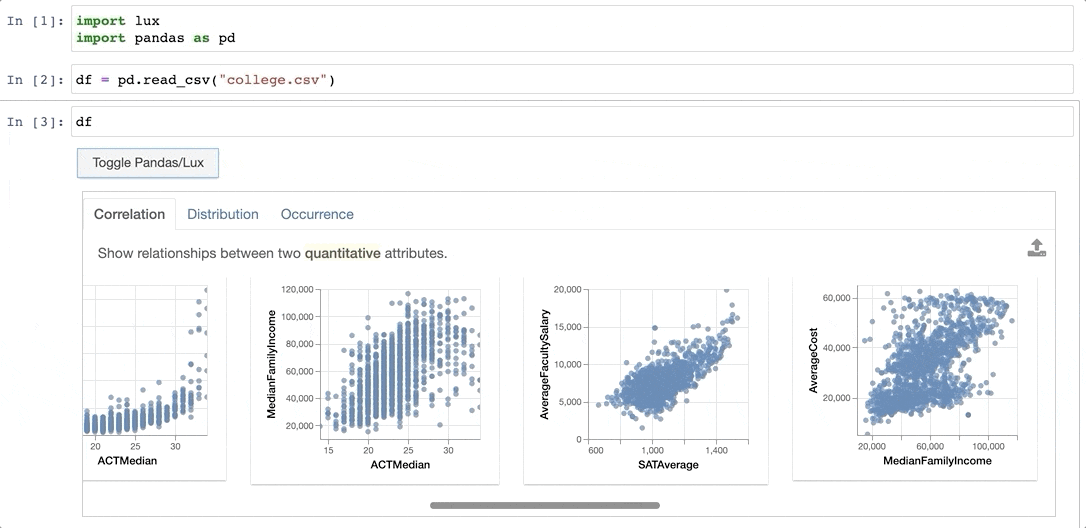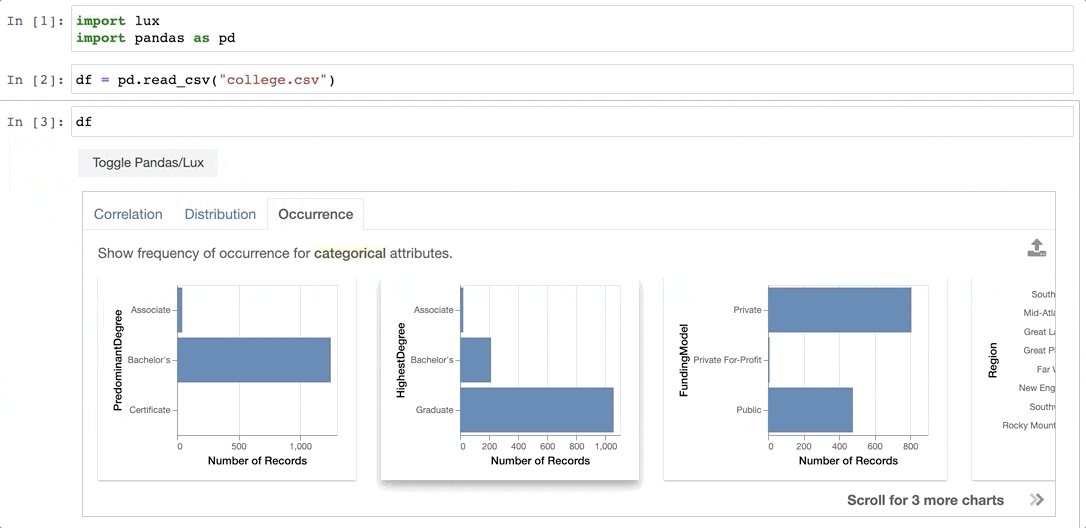 Voila! Here's a set of visualizations that you can now use to explore your dataset further!
-
-
-
### Next-step recommendations based on user intent:
-In addition to dataframe visualizations at every step in the exploration, you can specify in Lux the attributes and values you're interested in. Based on this intent, Lux guides users towards potential next-steps in their exploration.
+In addition to dataframe visualizations at every step in the exploration, you can specify to Lux the attributes and values you're interested in. Based on this intent, Lux guides users towards potential next-steps in their exploration.
For example, we might be interested in the attributes `AverageCost` and `SATAverage`.
@@ -122,7 +118,7 @@ Vis(["Region=New England","MedianEarnings"],df)
Lux provides a powerful abstraction for working with collections of visualizations based on a partially specified queries. Users can provide a list or a wildcard to iterate over combinations of filter or attribute values and quickly browse through large numbers of visualizations. The partial specification is inspired by existing work on visualization query languages, including [ZQL](https://github.com/vega/compassql) and [CompassQL](https://github.com/vega/compassql).
-For example, we might be interested in looking at how the `AverageCost` distribution differs across different `Region`s.
+For example, we are interested in how the `AverageCost` distribution differs across different `Region`s.
```python
from lux.vis.VisList import VisList
diff --git a/lux/_version.py b/lux/_version.py
index 71ffb3e0..d16c3697 100644
--- a/lux/_version.py
+++ b/lux/_version.py
@@ -1,5 +1,5 @@
#!/usr/bin/env python
# coding: utf-8
-version_info = (0, 2, 3)
+version_info = (0, 2, 4)
__version__ = ".".join(map(str, version_info))
Voila! Here's a set of visualizations that you can now use to explore your dataset further!
-
-
-
### Next-step recommendations based on user intent:
-In addition to dataframe visualizations at every step in the exploration, you can specify in Lux the attributes and values you're interested in. Based on this intent, Lux guides users towards potential next-steps in their exploration.
+In addition to dataframe visualizations at every step in the exploration, you can specify to Lux the attributes and values you're interested in. Based on this intent, Lux guides users towards potential next-steps in their exploration.
For example, we might be interested in the attributes `AverageCost` and `SATAverage`.
@@ -122,7 +118,7 @@ Vis(["Region=New England","MedianEarnings"],df)
Lux provides a powerful abstraction for working with collections of visualizations based on a partially specified queries. Users can provide a list or a wildcard to iterate over combinations of filter or attribute values and quickly browse through large numbers of visualizations. The partial specification is inspired by existing work on visualization query languages, including [ZQL](https://github.com/vega/compassql) and [CompassQL](https://github.com/vega/compassql).
-For example, we might be interested in looking at how the `AverageCost` distribution differs across different `Region`s.
+For example, we are interested in how the `AverageCost` distribution differs across different `Region`s.
```python
from lux.vis.VisList import VisList
diff --git a/lux/_version.py b/lux/_version.py
index 71ffb3e0..d16c3697 100644
--- a/lux/_version.py
+++ b/lux/_version.py
@@ -1,5 +1,5 @@
#!/usr/bin/env python
# coding: utf-8
-version_info = (0, 2, 3)
+version_info = (0, 2, 4)
__version__ = ".".join(map(str, version_info))