+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+ 实验日期:2023/9/18
+地点:东3-406
+
这些电阻为五道色环对应读数
+| 电阻标称阻值 | +标称允许误差 | +测量值 | +实际误差 | +是否在容许误差内 | +
|---|---|---|---|---|
| 2KΩ(红黑黑棕200*10^1^) | +±1% | +1.992KΩ | +0.40% | +是 | +
| 510Ω(绿棕黑黑510*10^0^) | +±1% | +505.8Ω | +0.82% | +是 | +
使用万用表欧姆档所测量的电阻阻值与标称阻值略有偏差,但均在允许误差范围内。
+打开万用表并选择电阻测量模式,将红色连接线连结到Ω测量口,黑色链接COM输入口。
+选择合适的量程,由于我们选择的是10KΩ的电位器,所以将欧姆表调为60KΩ档位。
+将黑色表笔插入电位器位于中心的孔,红表笔插入两旁的孔。
+
我们观察到阻值从8.71KΩ,变至10.15KΩ。
+

调换红表笔至另一端的插孔,发现读书变为0,反方向旋转电位器,示数增大。
+将红黑表笔插入电位器两端接口,发现示数即为之前所得最大值10.15KΩ。
+旋转电位器,能够改变电位器的阻值。中心头应该起到调节短路部分电阻的作用,从而使得电位器阻值发生变化。
+理想电容在充满电的情况下,应该完全绝缘,但实际情况并非如此,仍有一定量的电流通过,说明此时电容存在一个电阻,这个电阻被称为漏电阻。从以上分析也可以知道,电容的漏电阻应该非常大,所以选取的万用表欧姆最大档进行测量。在测验过程中,也选择过较小档位,但是,很快就会出现OL显示,说明电容的漏电阻非常大。
+| 电容量/最大工作耐压 | +测试结果 | +分析 | +
|---|---|---|
| 100µF/25V | +未知,>8.3MΩ | +由于万用表中的阻值也非常大,充电时间非常长,示数一直在增大,所以未知实际漏电电阻为多少 | +
| 1000µF/25V | +>8.61MΩ | +等待电容充完电后,万用表示数,保持稳定,该大电容的示数也一直在增大,但增大速度小于100µF的电容,根据t=CR,可以猜想,所需要的充电时间更长,充电速度更慢,因此相应的欧姆表示数跳大的速率也比较小。 | +


想要输出-12V,实际上只需要交换正常的输出方式即可
+AutoScale按钮,将波形稳定地显示在屏幕上。Meas按钮进行数据测量。
| 波形 | +频率 | +峰峰值 | +周期 | +上升沿时间 | +下降沿时间 | +
|---|---|---|---|---|---|
| 方波 | +1.0002kHz | +2.61V | +999.78µs | +1.95µs | +1.95µs | +
output按键输出信号。AutoScale按钮,等待示波器调节好波形,并利用Horizontal Vertical部分的旋钮,将波形调至合适的显示尺寸,如果波形仍然不稳定,调节Trigger部分按键(触发模式和触发电平)得到想要的稳定的波形。Meas按钮进行数据测量。



| 信号源输出电压及频率 | +峰峰值 | +有效值 | +周期 | +频率 | +
|---|---|---|---|---|
| 25kHz 正弦波 80mV,偏移量 20mV | +88mV | +28.545mV | +39.973us | +25.017kHz | +
| 1kHz 方波5V,偏移口,占空比40% | +6.03V | +2.4837V | +1.0000ms | +1.0000kHz | +
| 2kHz 锯齿5V,偏移1V,对称性20% | +5.03V | +1.4080V | +501.1us | +1.9955kHz | +
| IkHz脉冲3V,偏移1V,占空比50%,边沿t50ns | +3.62V | +1.5232V | +1.0000ms | +1.0000kHz | +
可见,信号源输出有一定误差,当然示波器检测也有一定的误差,导致测量值与所设想不同。
+
实验电路图如上。调节信号源为正弦函数,并且将信号频率分别调至10, 10^2^, 10^3^, 10^4^, 10^5^, 10^6^kHz,并将示波器探测头两端并联在阻值R处,利用自带的测试工具,测量出U~R~的有效值,并绘图,得出结论。
+Output按钮。
实验过程中发现,当频率为10Hz时,示波器中显示的波形噪声非常大(如上图显示),因此,使用了trigger按键中,降低噪声的按钮,从而能够较好地测量出有效值,而非显示屏数字一直上下跳动。
+| 频率(Hz) | +10 | +10^1.5 | +100 | +10^2.5 | +1000 | +10^3.5 | +10^4 | +10^4.5 | +10^5 | +10^5.5 | +10^6 | +
|---|---|---|---|---|---|---|---|---|---|---|---|
| 电压有效值(mV) | +6.727 | +20.133 | +64.68 | +200.49 | +543.5 | +895.9 | +986.1 | +990.4 | +985.8 | +990.6 | +1004.1 | +
根据以上数据,绘制出数据图
+
电阻两端的有效值随着信号源频率的升高先是缓慢上升,然后在10^2^~10^4^区间快速上升,最后趋于平缓,直至近似于电压源的有效值。体现出电容“隔直流,通交流”或者“通高频,阻低频”的特性。
+探究万用表电流档(以6mA和60mA为例)内部阻值对测量结果的影响。
+
结果如下:
+| 电流表档位 | +6mA | +60mA | +差 | +
|---|---|---|---|
| 万用表示数 | +2.862mA | +2.98mA | +0.118mA | +
| \(R_总=\dfrac{U}{I}\),电路内电阻和 | +2096.4Ω | +2013.4Ω | +83Ω | +
| 估算得\(R_A=R_总-R\) | +96.4Ω | +13.4Ω | +83Ω | +
可以看到,电流档两档的测量相差了0.118mA。所以,如果想利用伏安法测量电阻阻值,得到的电阻值将相差83Ω,所以电流表内阻对测量有非常大的影响。
+
| 电流表档位 | +6mA | +60mA | +
|---|---|---|
| 阻值 | +99.8Ω | +11.2Ω | +
该方法存在系统误差,并不能很准确地代表电流表的阻值,但是经过一定改进的方法,使得测量值非常接近于真实阻值,原理如下:
+我们在使用半偏法的时候,假定整体电流并没有发生变化,但实际上,由于新电阻的并联,电路中的总阻值变小,外部电流\(I\)变大。如果想要\(R_B\)的阻值等同于\(R_A\),那么万用表所显示的电流应该要更大(\(I_A=I_B=\dfrac{1}{2}I_2\))。然而实际上,\(I_A\)的电流仍然为 \(\dfrac{1}{2}I_1<\dfrac{1}{2}I_2\),因此,经过\(R_B\)的电流大于\(R_A\),\(R_B<R_A\),测量值小于真实值。
+但是再分析,
+情况1:
+情况2:
+可以列出方程
+解得,
+根据(5)中的2式,可以看出,当\(R_A<<R_H\)时,\(R_B≈R_A\)。
+所以,在已经确定电流表阻值和电流的情况下,扩大\(R_H\)的阻值显得非常必要。我们可以通过扩大电压源电压的方法,来增大
+\(R_H\)的阻值,所以电压源选择了20V。
+以60mA为例,分析其中误差: +$$ +R_A=\dfrac{R_B\cdot{R_H}}{R_H-R_B}\ +相对误差: +1-\dfrac{R_B}{R_A}=\dfrac{R_B}{R_H}≈2.88\% +$$ +由于约为10Ω左右,所以相差0.3Ω左右的阻值,在可接受范围内。
+而6mA的误差只会更小,所以可以考虑选用半偏法进行测量。
+最后我们发现,60mA档的6mA档内部的阻值相差十倍。因此在平时选用合理档位测量电路中的电流时应该妥善选择量程。
+结合电流表的组装,即将一个微小电流表和分流电阻并连的结构可知,量程越大相对应的阻值越小。
+
学会利用示波器上的Acquire键,调节出两个信号源合并之后的李萨如图像。
AutoScale按钮,然后发现两列波稳定地显示在屏幕上。
Acquire按钮,然后将时间模式调为XY显示,随后,发现示波器界面并没有变成预想的直线,后意识到,输出的波形并没有同相位,因此只要在信号源中点按同相位即可。
实验日期:2023/9/26
+地点:东3-406
+本实验首先掌握判断二极管好坏的方法。接着采用三种方法绘制二极管VA特性曲线。具体流程如下:
+⽤万⽤表粗略判别⼆极管好坏。
+采⽤逐点测量法测量⼆极管的VA特性。
+采⽤扫描测量法测量⼆极管的VA特性,并双踪观察信号源与⼆极管两端电压(注意其击穿值)。
+采⽤扫描测量法测量稳压管的VA特性,并双踪观察信号源与⼆极管两端电压(注意其击穿值)。
+

将黑表笔插入COM口,红表笔插入二极管测试对应二极管测试插口,并将档位调至二极管测量档位。由于蜂鸣器档位和二极管是同一档位,点按左上角Select按钮,切换至二极管档位。
将万用表红表笔接入1N4007正级,黑色接负极,此时万用表显示二极管导通电压。如下图所示,测得1N4007的正向导通电压约为0.568V。
+



首先通过万用表可以很好地对二极管进行检测,如检验其是否被击穿。同时可以看到,在同样的测量条件下,稳压二极管比整流二极管正向导通电压要高。可以与课上所给的VA特性曲线相联系,万用表所提供的电压为三伏,稳压二极管导通后,电压将保持0.7V左右,而整流二极管的曲线类似于大电阻,因而万用表显示的电压值在0.568V。
+采用以下电路,利用欧姆定律对二极管在每一点电压下的阻值进行测量。最后利用excel对数据进行处理,绘制曲线。
+
由于万用表的安培表阻值在该测试条件下(mA级别),视为短路;而相反,电压表的阻值足够大,可以视为开路,所以实验中只使用电压表来进行测量,将电压表并联在R~1~两端。并且利用电压源的示数,通过计算得出二极管两端电压与电流。
+
将万用表并联在电阻两端,测得电压示数。将此示数和电压源示数,一起记录到excel表格中。
+逐渐增大电压源输出电压,并重复步骤2。
+使用excel处理数据,并且绘制曲线,在变化较为剧烈处,增加多组数据测量,从而得到更为光滑、准确的曲线。
+| 电压源输出电压(V) | +R1两端电压(V) | +二极管两端电压(=A#-B#) | +电流(=B#/1000) | +
|---|---|---|---|
| 0 | +0 | +0 | +0 | +
| 0.3 | +0.0014 | +0.2986 | +0.0000014 | +
| 0.403 | +0.0134 | +0.3896 | +0.0000134 | +
| 0.452 | +0.0302 | +0.4218 | +0.0000302 | +
| 0.502 | +0.0554 | +0.4466 | +0.0000554 | +
| 0.55 | +0.085 | +0.465 | +0.000085 | +
| 0.602 | +0.1209 | +0.4811 | +0.0001209 | +
| 0.703 | +0.1979 | +0.5051 | +0.0001979 | +
| 0.803 | +0.281 | +0.522 | +0.000281 | +
| 0.903 | +0.3678 | +0.5352 | +0.0003678 | +
| 1.102 | +0.5481 | +0.5539 | +0.0005481 | +
| 1.202 | +0.645 | +0.557 | +0.000645 | +
| 1.3 | +0.739 | +0.561 | +0.000739 | +
| 1.551 | +0.976 | +0.575 | +0.000976 | +
| 1.751 | +1.169 | +0.582 | +0.001169 | +
| 1.851 | +1.265 | +0.586 | +0.001265 | +
| 1.951 | +1.362 | +0.589 | +0.001362 | +
| 2.151 | +1.557 | +0.594 | +0.001557 | +
| 2.451 | +1.851 | +0.6 | +0.001851 | +
| 2.751 | +2.147 | +0.604 | +0.002147 | +
| 2.951 | +2.344 | +0.607 | +0.002344 | +
| 3.551 | +2.938 | +0.613 | +0.002938 | +
| 4.551 | +3.931 | +0.62 | +0.003931 | +
| 5.551 | +4.928 | +0.623 | +0.004928 | +
| 7.65 | +7.02 | +0.63 | +0.00702 | +
| 9.55 | +8.92 | +0.63 | +0.00892 | +
| 11.049 | +10.42 | +0.629 | +0.01042 | +

并将信号源设置为1kHz,10Vp的锯齿波。通过信号源的XY显示,展示VA特性曲线直观样式。由于\(U_{diode}=U_{ch1}-U_{ch2},I_{diode}=\dfrac{U_{ch1}}{51Ω}\),因此,XY曲线一定程度上反映了最终结果的图线。
+后通过matlab等数据处理,生成正确的曲线。
+
连接电路(二极管选择1N4007整流二极管,电阻选择51Ω),调节信号源、示波器,观察图样。
+利用示波器的USB接口,将图样信息和数据保存。
+利用Matlab处理信息,生成图像。
+Matlab代码如下:
+
观察到以下几个特殊的地方:
+截止时,电流不完全为0,由于R~1~两端存在一个非常小的电压,该曲线在截止部分的电流不为0。
+该曲线在导通与截止部分,存在两条曲线,上面那条曲线一般认为是理想情况下的VA特性曲线。而下面那条曲线说明,二极管存在一个反向的电流。再经过数据分析可知,在截止与导通部分,当二极管两端电压逐渐增大时,即由截止切换到导通模式时,电流增大;而当电压减小时,即由导通切换为截止模式时,存在一个反向电流。后经过资料查询可知,二极管存在一个特性:
+二极管方向恢复电流(Reverse Recovery Current) 在二极管由导通状态转变为截止状态时,电流反向流动的现象。当二极管从正向导通状态切换到反向截止状态时,载流子需要一定时间来清除。在这个短暂的时间内,二极管中的电流会反向流动,这就是方向恢复电流。方向恢复电流的大小和持续时间取决于二极管的特性和工作条件。
+
可以观察到,稳压二极管的截止电压约为5.2V左右,与标称的5V/1W相匹配,同时可以观察到,稳压二极管相比于整流二极管,在两端电压增大的情况下,能保持一个较为稳定的电压值,约为0.76V左右。
+利用Multisim平台搭建电路,利用扫描法绘制二极管曲线。
+Multisim平台一定需要一个接地端,同时示波器的接地端并不影响电路中的电位,因而实验电路如下:
+
示波器A接口为二极管两端电压,B接口为R1两端电压。利用示波器的B/A按钮,定性地显示VA特性曲线,再利用Matlab处理输出的数据。
+根据不同曲线的特点,采用了以下两种方式进行数据拟合:
+| Matlab | |
|---|---|


可以看出,由导通到截止这一部分,二极管的性质并不是非常稳定,所以曲线几乎填满了该段区域。
+
观察上面的黄色曲线,会发现,当二极管导通后,峰值电压骤降。而分析可知,Channel1所测的是信号源两端电压,而电压骤降说明了信号源内部有电阻,进行分压,导致其峰值减小。现测量信号源两端的电阻大小。
+采用以下电路,利用欧姆定律对其进行测量。通过测量峰值电压的变化,得出信号源内部电阻大小
+



计算得到,信号源内阻为51.7Ω,查阅说明书,得知Channel1输出的内阻在50Ω左右,因此可知测量基本准确。
+信号源内部有50Ω左右的阻值,所以,以后在定量测量的时候,需要将内阻考虑在内,以免影响最后结果的准确性。
实验日期:2023/10/9
+地点:东3-406
+用QUARTUS软件和DE10开发板设计并实现如下逻辑功能
+输入是三位二进制数A,B,C,要求当输入是2或3的倍数时输出等于逻辑1,其它情况,输出等于0。
+设计并实现一位二进制全加器(输入是一位二进制加数、被加教和低位进位,共3个逻辑变量)。
+【探究】某客厅四周有4个房间,每个房间门口有一个开关,客厅中间有一盏灯A。试设计一个逻辑电路,要求每个开关都能控制
+灯A的亮灭,并在DE10开发板上模拟此逻辑电路的功能。
+| num | +A | +B | +C | +Z | +
|---|---|---|---|---|
| 0 | +0 | +0 | +0 | +1 | +
| 1 | +0 | +0 | +1 | +0 | +
| 2 | +0 | +1 | +0 | +1 | +
| 3 | +0 | +1 | +1 | +1 | +
| 4 | +1 | +0 | +0 | +1 | +
| 5 | +1 | +0 | +1 | +0 | +
| 6 | +1 | +1 | +0 | +1 | +
| 7 | +1 | +1 | +1 | +0 | +
由于总情况较少,所以选择打表的方式列写代码。
+
根据波形图结果,可知,该元件的代码编写正确,可以进行下一操作。
+

点按步骤如下:
+




与预期一致,所以可以进行下一步操作
+编译输出,得到以下逻辑图
pin planner
+

上图对应A=0, B=0, C0=0的情况,输出C=0,Z=0的情况。
+
上图对应A=0, B=1, C0=0的情况,输出C=0,Z=1的情况。
+
上图对应A=1, B=1, C0=0的情况,输出C=1,Z=0的情况。
+
上图对应A=1, B=1, C0=1的情况,输出C=1,Z=1的情况。
+ABCD作为四个开关,任意的改变状态都将改变电灯的状态,不同于上面的电路,该电路没有真值表。
+
任意改变ABCD四个开关中任意状态,Z就会输出与原来相反的结果,仿真结果正确。
+
Pin Planner
+ABCD对应四个开关
+结果分析,由于这个代码的问题,也就是在芯片最开始执行结构体部分的代码时,由于mA与A并不一定相匹配,所以刚刚开始,Z的灯可能混乱闪烁。但是一段时间后,也就是当所有mA,mB,mC,mD都已经与现实情况相匹配以后,就能够正常显示。
实验日期:2023/10/9
+地点:东3-406
+


根据以上表格可以判断,该三极管中间的端口为b基极,且为NPN型三极管。
+

将万用表切换到HFE档,通过对三极管的放大倍数的测量,判断三极管的e和c极。已知正常的ß应该在100~300之间。
+将三极管中间的极脚插入b口,两端分别插入e和c。可见当示数显示为249时,e,b,c脚插入正确,放大倍数ß=249。从而可判断三极管的三只脚的极性:当平面对向自己时,从左到右三只脚分别为e,b,c。
+
调整V2的大小,即调整V~CE~的大小分别为0V和15V。调整直流输出源V1的大小,用万用表测量R1两端电压,从而得出V~BE~和I~B~的大小。
+利用Matlab绘制伏安特性曲线。
+实验数据如下:
+









我们发现,当I~b~=2.5uA时ce的压降使得Ic到达饱和区时,放大电流随着压降增大而减小。
+
而当I~b~=10uA时,放大电流随着V~CE~增加增大。这种现象,可能也恰好反映了基极电流会随着CE两端电压的大小变化而发生变化,但是所造成的变化并不明显,所以上述实验可以通过保持V1不变控制I~b~不变。
+

仿真->直流扫描功能,改变所要调节的参数,获得所要的特性曲线。
固定Vce
+




调节2脚的电位,使用万用表测量2脚以及输出端电压。
+记录数据,并根据数据绘制图线。
+


调节信号源为0V~5V锯齿波,对称性为50%,频率为10Hz。
+调节示波器至显示清晰稳定图像。
+

根据XY显示,实际上,从高电位变到低点位,临界值偏大;而当低点位变到高电位过程中,临界值偏小。所以,在进行万用表测量时,正反两次调节电压所获数据不同属于是正常现象。
+根据示波器读数,当电位在2.3V到3.5V之间时,输入并不是准确的高电位抑或低电位,此处的引脚输出也并不是准确的高电位/低点位。因此在实际使用过程中,应该避免引脚输入处于这个值之间。
+


200Ω作为保护电阻,保护电路
+用万用表欧姆档测量R~L~阻值,并将R~L~调节为合适大小。后连接电路利用万用表测量电压,并记录数据。
+计算出集成门电路的输出负载电流,在坐标系中画出输出端负载特性曲线。
+注意:每次测量电阻RL的值时须断电,并将R~L~两端中的任意一端从电路中断开,以免连接的电路影响电阻的测量值。
+

可以看到与非门输出在外端串联电阻时,尤其是小电阻,输出并不是标准的高电平或者低电平。与非门内部呈现一定的定值电阻特性(由两段曲线呈现直线可以看出)。经过一定的计算,可以得出与非门内部的电阻可以近似估计为0.02Ω。
+
实验日期:2023/10/23
+地点:东3-406
+万用表(HY63)
+实验室配备小车
+
我们主要讨论R17的阻值,R19的阻值和W5为什么为大电阻(10k)。
+使直流电压源输出稳定15V电压,给小车供电。
+将小车的红外探测仪置于不同表面,使用万用表6V电压档测量电路各参数。
+##### 【1.1 分析红外光电检测电路参数设计】
+| Led05 | +11脚输入/V | +10脚输入/V | +13脚输出/V | +灯 | +V~R19~/V | +V~R20~/V | +V~R17~/V | +V~R18~/V | +5V实际输入电压/V | +3.3V实际输入电压/V | +
|---|---|---|---|---|---|---|---|---|---|---|
| 桌面白 | +0.200 | +1.992 | +0.153 | +亮 | +1.253 | +3.168 | +3.708 | +4.721 | +4.933 | +3.329 | +
| 桌面黑 | +3.655 | +1.992 | +3.320 | +暗 | +0.000 | +0.000 | +3.709 | +1.340 | +~ | +~ | +
R19与R20
+这两个电阻位于发光电路之中。R19作为LED灯的限流电阻,R20作为LED的并联电阻。 + $$ + \begin{array}{l} + I_{19}=\dfrac{U_{R_{19}}}{R_{19}} = 1.253/680mA=1.84mA\ + U_{LED}=V_{I}-U_{R_{19}}=3.329-1.253=2.076V + \end{array} + $$
+
根据上述图表,同时根据我们的二极管为绿色二极管可知,当选用3.3V的发光二极管时,已经能够较好地体现发光特性,电流以毫安级别通过。
+R20作为并联电阻,搜索资料得知,在LED两端并联大电阻,当有反向电流流过时,能稳定LED两端电压,避免所有分压在一个LED灯上,导致LED灯反向击穿;同时,能够很好的释放LED内部存储的能量,使得LED灯快速熄灭。
+W5,10脚输入电压
+W5采用10kΩ大电阻,在控制电位压降的同时,也很好地控制进入比较器的电流大小,,一般要将输入比较器的电流控制在10mA以下。
+红外检测电路部分R17,R18
+R17作为红外发光二极管的限流电阻,控制流过二极管的电流大小。 + $$ + I_{R_{17}}=U_{R_{17}}/R_{17}=3.708/150=24.72mA + $$ + 同样根据fig2,可以看到,将红外发光二极管维持在20mA左右的电流通过,能使其更好地发挥作用。
+R18作为检测支路上的电阻,与光电二极管构成了一个为11脚提供电位的之路。 + $$ + \begin{array}{l} + 1. 当光电二极管接收红外光线,产生电流时,等于光电二极管导通:\ + I_{R_{18}}=U_{R_{18}}/R_{18}=4.721/10k=0.47mA\ + U_d=U_s-U_{R_{18}}=0.2V\ + \ + 2. 当光电二极管未接收到红外光线,等于光电二极管截止:\ + I_{R_{18}}=U_{R_{18}}/R_{18}=0.13mA\ + U_d=U_s-U_{R_{18}}=3.655V\ + \end{array} + $$ + 当然,接收到的红外光线越少,光电二极管两端电压越大,11脚电位越高。
+比较器的使用
+11脚电位比10脚电位低,则输出低电压,稳定在0.153V。
+11脚电位比10脚电位高,这输出高电压,稳定在3.320V。
+| LED06 | +11脚输入/V | +10脚输入/V | +13脚输出/V | +灯 | +V~R19~/V | +V~R20~/V | +V~R17~/V | +V~R18~/V | +
|---|---|---|---|---|---|---|---|---|
| 白 | +0.193 | +1.965 | +0.152 | +亮 | +1.249 | +3.169 | +3.712 | +4.711 | +
| 黑 | +3.201 | +1.965 | +3.320 | +暗 | +0 | +0 | +3.713 | +1.728 | +
测量LED06阻值两端的电压与LED05所得结果基本相似。
+
根据实验结果,可以得到以下结论:反射表面对红外线吸收能力越强,光电管反射电压越高。
+随着反射表面对红外线能力的吸收增强,光电管两端电压增加,当超过另外一只引脚的输入电压后,比较器输出相反的性质。
+


测量不同输入直流电压时,经过小车上的电机的电流。
+

对集成H桥各端口输入不同情况下的电压,检验芯片各端口的输出特性,验证电机的转动情况。
+
该电路分为三个模块:
+通过IN1,IN2等各接口输入电压,当输入高电位后,控制灯光发亮,光电管接收到光信号导通,集成H桥芯片中的IN1脚变为高电位。
+这样子利用光电控制的好处在于,低电流控制高电流,将控制电路与高电压、大电流驱动电路分开,避免高电压、高电流出问题后,造成控制电路的损坏。
+有输入端4四个,其中IN1、IN2和OUT1、OUT2控制一个电机的两端,IN3、IN4和OUT3、OUT4控制另外一个电机。
+电机有两个端口,两端的电压差驱动电机的转动。
+
将输入脚ENA总控制开关,IN1、IN2等输入引脚与3.3V或者GND脚连接,以控制输入电位的高低。
+
观察电机正转/反转时,小车的运动情况。
+
实验日期:2023/10/30
+地点:东3-406
+测量轨道部分数据,选择合适的红外检测管,作为本次试验作为判定的光电管。
+轨道经测量,约为两指宽。所以,选择中间两盏小灯作为沿轨道行进判定,和间隔一个旁边的小灯作为转弯判定。
+
分析输出端口电位
+根据上一次实验,得知地面为黑色,比较器出高,灯熄灭;地面为白色,比较器出低,灯发光。
+编写程序,并进行编译仿真。
+根据第一步的分析,我们需要一个以下有5个接口,7个输出口的逻辑芯片。
+
开关设计,利用FPGA板上的开关键Switch0,来控制实体的运作与否。
+| Vhdl | |
|---|---|
小车直线循轨
+四个探测器,从左到右分别为inp1, inc1, inc2, inp2
+左轮为in1,in2控制,右轮为in3,in4控制
+当左轮转动时,in1输出1,in2输出0
+当左轮转动时,in3输出1,in4输出0
+
| Vhdl | |
|---|---|
小车遇到岔路判断
+

小车直角转弯
+
当小车回到轨道后,由于光电管并不一定稳定运行,所以利用之前的发光判断,小车会自行沿着轨道左转或者右转。
+小车停止运行
+当小车四个光电管均位于停车处的黑框时,即tmp=0000时,小车停止运行
+| Vhdl | |
|---|---|
根据以上示意图,先物理上连接各引脚的输入输出。
+后在Quartus软件上,对FPGA进行pin planner
+
在Quartars中编译文件,成功运行并导入FPGA板中。
+| Vhdl | |
|---|---|
修改后,小车能够顺利转弯。
+即要从逻辑上分析小车运动的情况,也要根据实验中具体出现的问题进行调整。这也说明,在未来的实验中,不光光要从理论上严谨分析,也要从具体实际中实践,修改,然后完善。
以下代码有些许语法错误
+电院实验课本身内容并不复杂,具体操作老师基本上会给出,但是完成实验并得到效果还是一个比较繁琐的内容,再加上对实验报告有一定的要求,所以会觉得这2学分的课实在是性价比过高。
+综合实验报告成绩和两次考核成绩,本人最终成绩为94,所以可以以此为基准参考需要的努力程度。
+综合一年的实验感受,实验报告总的完成以下两点要求差不多就可以拿到一个不错的成绩:
+秋学期:综合实验,各类内容均有涉及,主要目的是了解实验器材,然后对”电“有一定的概念。祁才军老师负责,但应该教完我们这一届就退休了。期末考试内容涉及PPT内容较多,认真阅读PPT,对期末考试有较大帮助。
+冬学期:电路原理部分实验。实际上涉及较多模电实验的内容。姚缨英老师主要负责。姚老师虽然看上去事情很多,实际上事情也是真的多。PPT上的实验内容也比较杂乱,但可以根据往届的实验报告推测老师的实验要求。同时有任何不理解的内容和要求,也建议主动问姚老师。姚老师会非常耐心地解答。
+秋学期:期末考试以笔试形式考察秋学期的所有实验内容,认真阅读PPT
+冬学期:姚老师基本上会以各种方式提示期末考试的内容
仿真所用文件在这里: Lab5 PSpice仿真.zip
+Lab6所使用仿真软件 Lab6 PSpice仿真.zip
+Lab7中所使用的仿真文件: Lab7PSpice仿真.zip
+Lab9中所使用的Multisim仿真文件: Lab9 Multisim.zip
+编写者为ZJU 22级电子信息工程专业学生,由于加入爱迪生班,所以内容主要面向爱迪生班专业内容(爱迪生班内容会在后面标注\(\alpha\))。
+这里作为我对本专业的回顾,以及一些经验~
+专业课大致内容如下:(打勾内容为已更新)
+各类通识课:
+Principal Component Analysis (PCA):
+PCA 是一种用于降维和数据压缩的线性技术。它的目标是找到数据中最重要的方向,即方差最大的方向,然后将数据投影到这些方向上。这些方向被称为主成分。通过选择最重要的主成分,我们可以保留数据中的大部分信息,同时降低数据的维度。
+PCA 在数据压缩、特征提取和可视化等领域广泛应用。
+t-distributed Stochastic Neighbor Embedding (t-SNE):
+t-SNE 是一种非线性降维算法,主要用于可视化高维数据。它能够保留数据点之间的相对距离,特别适用于发现数据中的聚类结构。
+t-SNE 通常用于可视化高维数据,尤其在发现聚类结构方面表现出色。然而,需要注意的是,t-SNE 对于不同的初始化可能会导致不同的结果,因此在解释结果时需要谨慎。
+Image compression using PCA (Principal Component Analysis) involves applying PCA to the pixel values of an image and retaining only the most significant principal components. The basic idea is to reduce the dimensionality of the image while preserving as much information as possible. Here's a step-by-step guide on how to perform image compression using PCA:
+
generative model 生成式模型和非生成式模型
+linear model/none linear model
+
生成模型(Generative Model)和判别模型(Discriminative Model)是机器学习中两种不同类型的模型,它们的主要区别在于它们对数据的建模方式和应用领域。
+总结来说,生成模型和判别模型的关键区别在于其建模目标。生成模型试图理解整个数据分布并生成新数据,而判别模型关注的是对数据的分类或标记。在实际应用中,选择生成模型还是判别模型通常取决于具体问题和任务的性质。有时,这两种类型的模型可以结合使用,以实现更复杂的机器学习任务。
+
linear feature+nonlinear model/ nonlinear feature+linear model是什么意思
+ChatGPT
+"线性特征 + 非线性模型" 和 "非线性特征 + 线性模型" 是机器学习中的两种不同方法,用于处理数据和建立预测模型。它们可以在特征工程和模型选择方面用于处理非线性关系。
+这两种方法通常用于处理不同类型的数据和问题。选择哪种方法通常取决于问题的性质以及数据的分布。在某些情况下,可以尝试两种方法,然后根据模型性能来选择最佳方法。
+需要注意的是,"非线性特征 + 线性模型" 也可以被看作是一种"线性特征 + 非线性模型"的特殊情况,因为线性模型本身可以学习非线性关系,只要特征经过适当的非线性变换。这种灵活性使得线性模型成为许多机器学习问题的有力工具。
+| Truth/Prediction | +Positive | ++ |
|---|---|---|
| Positive | +TP | ++ |
| Negative | +FP | ++ |
| + | + | + |

mean-squared error
+

logic theorist
+expert system
+automated theoroem proving
+transformers
+recurrent neural networks
+convolution neural netorks
+Neyman-Pearson方法是统计学中的一种假设检验方法,由Jerzy Neyman和Egon Pearson命名。它在频率主义统计学中被广泛应用,用于根据观察到的数据在两个竞争性假设之间做出决策。该方法着重于控制第一类错误的概率,即当真实的零假设被错误拒绝时发生的错误。
+以下是Neyman-Pearson方法的关键要点:
+Neyman-Pearson方法通过在控制显著性水平的同时最小化第二类错误的概率,提供了一种强假设检验的框架。这种方法在实际应用中对于需要明确控制错误率的问题非常有用。
+这个表达式表示了后验概率的计算方式,其中beta.pdf(p, a, b)表示了一个Beta分布的概率密度函数(probability density function,PDF)。在这个表达式中,p是概率的取值,a和b是Beta分布的参数。
Beta分布是一个常用的概率分布,它在概率论和统计学中经常被用于描述随机变量的取值范围在[0, 1]之间的情况。它的概率密度函数可以表示为:
+其中,$$ \text{Beta}(p|a, b)$$是Beta函数(Beta function),用于归一化Beta分布。在后验概率的计算中,通常会假设先验分布为Beta分布,并结合观测数据,通过贝叶斯定理计算得到后验分布。这里的beta.pdf(p, a, b)就是计算给定参数a和b的Beta分布在概率值p处的概率密度。
因此,posterior = beta.pdf(p, a, b)表示计算后验概率,即给定先验分布和观测数据,通过Beta分布的概率密度函数计算在概率值p处的后验概率密度。
Metropolis-Hastings算法是一种用于从目标分布中抽样的马尔可夫链蒙特卡罗(MCMC)方法。这个算法允许我们在无法直接从目标分布中抽样的情况下,通过构建一个马尔可夫链来间接地生成样本。以下是一个通俗的解释:
+总体而言,Metropolis-Hastings算法通过引入提议步骤和接受/拒绝步骤,利用马尔可夫链的性质,逐步探索并逼近目标分布,从而实现从目标分布中抽样的目的。这种方法在贝叶斯统计学、统计物理学等领域中广泛应用。

广播机制
+降维
+| Python | |
|---|---|
轴(axis)就是张量的维度
+torch.arange(a): 生成从0~a-1的一个向量
+torch.dot
+输出的y是x的多元函数,对\(x_i\)求偏导的格式为:
+
例如\(y=2X^TX\)
+y是标量,x是一个向量
+引入激活函数的理由:
+1.各层级之间的线性操作可以直接等价于一层线性操作
+2.由于线性组合相当于是对原始参数矩阵张成的空间进行伸缩,旋转和剪切
+但是可能真实世界有些原始数据本身就是线性不可分的,必须要对原始空间进行一定的非线性操作(对原空间进行一定的扭曲?)
+对于回归问题也可以同样运用高数的思维,把回归看成分类问题的无限细分,当极限存在时,分类也就成为了回归问题。
+激活函数应该具有的特征 +避免梯度消失的特性,造成网络更新过慢 +输出最好关于0对称,这样就不会造成梯度向特定方向移动 +激活函数应该为神经网络引入非线性 +激活函数应该是可微的,使得满足各层之间梯度下降的计算(至少部分可微) +梯度的计算不应该太复杂,影响网络性能
+


上图是论文中 Transformer 的内部结构图,左侧为 Encoder block,右侧为 Decoder block。红色圈中的部分为 Multi-Head Attention,是由多个 Self-Attention组成的,可以看到 Encoder block 包含一个 Multi-Head Attention,而 Decoder block 包含两个 Multi-Head Attention (其中有一个用到 Masked)。Multi-Head Attention 上方还包括一个 Add & Norm 层,Add 表示残差连接 (Residual Connection) 用于防止网络退化,Norm 表示 Layer Normalization,用于对每一层的激活值进行归一化。
+masked multi-head attention
+batch norm 和layer norm的区别
+ChatGPT
+ChatGPT
+Batch Normalization(批归一化,简称 Batch Norm)和 Layer Normalization(层归一化,简称 Layer Norm)是用于神经网络中的正则化技术,它们有一些关键的区别:
+总体而言,Batch Normalization 和 Layer Normalization都是用于加速神经网络训练、防止梯度消失和梯度爆炸的方法,但它们的实现和应用场景有所不同。
+残差连接(Residual Connection)是一种神经网络中的建模技术,旨在解决深度神经网络训练过程中的梯度消失和梯度爆炸问题。这一技术最初由何恺明等人提出,并在2016年的论文 "Deep Residual Learning for Image Recognition" 中首次引入。
+在残差连接中,网络的某些层(通常是卷积层)的输入直接通过跳跃连接(skip connection)添加到网络的输出中。这样的连接使得网络可以直接学习残差,而不是完整地学习特征映射。残差连接的数学表达如下:
+输出=输入+残差输出=输入+残差
+具体而言,如果 �(�)F(x) 表示网络的映射函数(例如卷积层和激活函数的组合),那么残差块的输出为:
+输出=�(�)+�输出=F(x)+x
+其中,�x 是输入。
+残差连接的主要优势包括:
+残差连接在许多深度学习任务中都取得了显著的成功,并被广泛用于各种架构,如 ResNet、DenseNet 等。
+
将query和key-value对
+output是value的加权和
+value的加权和是query和key的相似度算出的
+key是名字,query是想查谁的名字,也是一个名字,value是key对应的值
+假设进行了n次query,dk为key的特征维度数,dv为单词特征维数,一般来说dk和dv相同
+一般来说Query,Key,Value矩阵的形状一致
+Query矩阵 n行dk列
+Key矩阵 m行dk列
+weight矩阵 n行m列,每一行都是一次query,对应一个单词
+value矩阵,m行dv列,每一列是一个单词,dv是单词特征的维度
+output矩阵,n行dv列,n次query,输出了
+multi-head 多头注意力机制,拆开来再合并
+如下图,在第一次multi-head-attention之后,实际上整个序列的信息已经通过attention层,把不同的query和position encoding被拆解成独立的部分,和RNN不同
+
很深的神经网络误差变大的问题
+不是过拟合造成的
+"Identity mapping" 是深度学习领域中一个重要的概念,通常与残差网络(Residual Networks,简称 ResNets)相关。
+在深度卷积神经网络中,当模型变得非常深时,训练变得更加困难。梯度消失和梯度爆炸是训练深度网络时常见的问题之一。为了解决这个问题,ResNet 引入了残差块(Residual Block),其中的关键部分就是 "identity mapping"。
+Identity Mapping 的定义:
+在 ResNet 的残差块中,通过引入跳跃连接(skip connection)和 "identity mapping",使得网络可以直接学习残差(residual)。具体而言,对于一个残差块,其输出可以表示为:
+Output=F(Input)+Input
+其中,F(Input) 是经过残差块内部操作的结果,Input 是输入。上式中的 "input" 就是 "identity mapping",它允许模型学习对输入进行恒等映射(即不进行任何变换)。
+作用和优势:
+总体而言,"identity mapping" 在深度学习中的应用是为了提高模型的训练稳定性和深度网络的可训练性。
+
在深度学习中,"downsample" 和 "upsample" 是指改变输入数据的空间分辨率的操作。
+这两个操作在深度学习中经常用于神经网络的不同层次和任务:
+这些操作在神经网络中的使用可以根据任务和网络结构的需求而变化。
+
"LR" 在深度学习领域中通常指的是逻辑回归(Logistic Regression),是一种用于二分类问题的模型。对于逻辑回归模型,通常使用二元交叉熵损失函数(Binary Cross Entropy Loss)作为损失函数,而不是传统的均方误差损失。
+逻辑回归的损失函数为:
+\(\text{Binary Cross Entropy Loss} = - \frac{1}{N} \sum_{i=1}^{N} \left[ y_i \log(p_i) + (1 - y_i) \log(1 - p_i) \right]\)
+其中:
+优化损失函数的过程通常使用梯度下降法或其变种。梯度下降法的基本思想是通过迭代调整模型参数,使损失函数最小化。
+参数更新: 使用梯度下降法或其他优化算法更新模型参数。更新规则通常为 \(\theta_{\text{new}} = \theta_{\text{old}} - \alpha \nabla L\),其中 \(\alpha\) 是学习率,▽L 是损失函数关于模型参数的梯度。
+迭代: 重复上述步骤,直到满足停止条件,如达到最大迭代次数或梯度接近零。
+对于逻辑回归,由于损失函数是凸函数,梯度下降法通常能够收敛到全局最小值。学习率的选择很重要,过大的学习率可能导致不稳定的训练,而过小的学习率可能导致收敛缓慢。
+在 PyTorch 中,你可以使用自动微分和优化器来实现梯度下降。例如:
+怎样才是最好的分割:
+“分的清,没有含糊不清的点”:各点离平面的距离设为\(r_i\),求使得所有\(r_i\)的最小值最大的一个分割
+ + +| Python | |
|---|---|
| Python | |
|---|---|
把PIL Image 或者 numpy.ndarray转换为tensor类型
+| Python | |
|---|---|
标准数据集网址:Datasets — Torchvision 0.16 documentation (pytorch.org)
+torchvision — Torchvision master documentation (pytorch.org)
+tensorboard使用:
+commandline:tensorboard --logdir = "mydirname"
或在vscode中启动tensorboard会话也可
+把dataset中的数据一个个加载到神经网络中
+dataloader类属性:
+ dataset,from which to load the data
+ batch_size,每次抓几张牌
+ shuffle ,每个epoch是否重新加载
+ num_workers 主进程加载,=0,>0对windows可能有问题,broken pipes
+ drop_last 舍去最后一份牌,是否保留整数
+
| Python | |
|---|---|

层的参数设置:
+| Python | |
|---|---|

VGG 网络结构示意
+我们以图像的每个像素为中心生成不同形状的锚框。 +• 交并比(IoU)也被称为杰卡德系数,用于衡量两个边界框的相似性。它是相交面积与相并面积的比率。 +• 在训练集中,我们需要给每个锚框两种类型的标签。一个是与锚框中目标检测的类别,另一个是锚框真 +实相对于边界框的偏移量。 +• 预测期间可以使用非极大值抑制(NMS)来移除类似的预测边界框,从而简化输出。
+NMS(非极大值抑制,Non-Maximum Suppression)是一种常用于目标检测任务的技术,用于从一组重叠的候选框中选择最符合条件的框。其主要原理是消除多余的、与最终选择框高度重叠的候选框,以确保最终输出的框具有最佳的质量和非重叠性。
+以下是NMS的基本原理:
+这样,NMS 确保了最终输出的框具有较高的得分,并且彼此之间有较低的重叠度。这对于目标检测任务很重要,因为它可以防止在同一个目标上产生多个高度重叠的检测结果,从而提高检测的准确性。
+"单发多框检测"(Single Shot Multibox Detection,SSD)是一种用于目标检测的深度学习架构,旨在实现快速而准确的目标检测。SSD是一种多尺度、多框架的检测方法,能够在一次前向传播中检测图像中的多个目标。
+以下是SSD的主要特点和原理:
+SSD的设计使得它在准确性和速度之间取得了平衡,使其成为在实际应用中广泛使用的目标检测框架之一。它适用于各种尺寸和形状的目标,并且在复杂的场景中表现良好
+
特化的AI前端界面,语法非常轻量级,采用很多block搭建交互式的web UI
+Zero-shot image classification is a computer vision task to classify images into one of several classes, without any prior training or knowledge of the classes. Zero shot image classification works by transferring knowledge learnt during training of one model, to classify novel classes that was not present in the training data.
+
目前的视觉识别任务通常是在一个预先定义好的类别范围内进行的,这样限制了其在真实场景中的扩展。CLIP的出现打破了这一限制,CLIP利用image-text对进行训练,从而使得模型可以根据文字prompt识别任意类别。关于CLIP的详细介绍可以看我的文章:深度解读CLIP:打破文字与图像之间的壁垒。CLIP适用于分类任务,而GLIP尝试将这一技术应用于目标检测等更加复杂的任务中。
+ +在多模态网络(Multimodal Network)中,通常会使用类似于单模态网络的结构,但在设计上进行了一些调整以处理多个模态(例如图像、文本、声音等)的输入。其中,backbone、neck 和 head 是网络的不同部分,各自有不同的功能。
+总体而言,backbone 负责提取共享的特征,neck 负责整合多模态特征,而 head 则专注于执行具体的任务。多模态网络的设计需要考虑如何在这三个部分中合理地处理不同模态的信息,以实现对多模态输入的有效建模。不同的应用场景和任务可能需要不同的架构设计。
+

“Segment and Track Anything” 利用自动和交互式方法。主要使用的算法包括 SAM(Segment Anything Models)用于自动/交互式关键帧分割,以及 DeAOT(Decoupling features in Associating Objects with Transformers)(NeurIPS2022)用于高效的多目标跟踪和传播。SAM-Track 管道实现了 SAM 的动态自动检测和分割新物体,而 DeAOT 负责跟踪所有识别到的物体。
+
DeAOT achieves promising results on various benchmarks. However, as a semi-supervised video segmentation model, DeAOT requires reference frame annotations for initialization, which limits its application.
+半监督视频目标分割
+vision transformer
+把目标检测从视觉端移除?
+用预训练的目标检测器去抽取视觉特征的时候会有很多局限性
+视觉特征:patch embedding?
+模态融合部分非常大
+推理时间和训练时间复杂度?
+模型推理过程
+模型的推理时间指的是使用训练好的机器学习或深度学习模型进行实际预测或推断的时间。在模型训练之后,模型通常需要通过输入数据进行推理,即根据学到的规律或模式对新的未见过的数据进行预测或分类。
+推理时间是衡量模型性能的一个重要指标,尤其是在实际应用中,对于需要快速响应的场景,推理时间的效率至关重要。推理时间的快慢受到多个因素的影响,包括但不限于:
+因此,模型的推理时间是在实际部署或使用过程中,模型处理输入数据所需的时间,直接关系到模型在实际应用中的实用性和性能。
+CLIP是典型的双塔模型,特征
+VE TE MI
+VE: Visual embedding
+TE: Text embedding
+MI: modality interaction
+VQA,VR,VE
+VQA(Visual Question Answering)、VR(Visual Reasoning)和VE(Visual Explanation)是三个涉及多模态(图像和文本)的任务,它们在计算机视觉和自然语言处理领域中有着不同的目标和侧重点。
+这些任务都涉及到图像和文本之间的跨模态理解和交互,要求计算机系统能够处理视觉信息和自然语言信息的复杂关系。这些任务在推动计算机视觉和自然语言处理交叉研究的发展,使计算机能够更全面地理解和处理多模态信息。
+视觉特征在图像处理中比文本特征要重要
+模态融合部分也非常关键
+Visual Encoder > Modality Interaction > Text Encoder
+目标函数总结:
+CLIP使用的 ITC lost :image text contrasting
+(word patch alignment WPA lost训练起来非常慢)
+masked laguage modeling :MLM lost, 完形填空
+image text matching lost: ITM lost
+
多模态大模型综述(插图)
+vision and language representation learning with momentum distillation
+不需要使用bounding box annotation(锚框定位及标注)
+momentum distilliation
+momentum encoder
+自训练模型
+1. 解释SVM的工作原理。
+SVM,全称支持向量机(Support Vector Machine),是一种有监督学习算法,主要用于解决数据挖掘或模式识别领域中的数据分类问题。
+SVM的工作原理是建立一个最优决策超平面,使得该平面两侧距平面最近的两类样本之间的距离最大化,从而对分类问题提供良好的泛化力(推广能力)。这里的“支持向量”是指训练集中的某些训练点,这些点最靠近分类决策面,是最难分类的数据点。
+SVM可以处理二类分类问题,也可以扩展到多类分类问题。在二类分类问题中,SVM寻找一个最优超平面,将两类样本分隔开。这个最优超平面需要满足间隔最大化的条件,即两侧距平面最近的两类样本之间的距离最大化。当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机。当训练数据近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性支持向量机。当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
+SVM使用核函数来处理非线性可分的情况。核函数的定义是K(x,y)=<ϕ(x),ϕ(y)>,即在特征空间的内积等于它们在原始样本空间中通过核函数K计算的结果。通过使用核函数,SVM可以将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
+2. k-means和k-means++算法有什么区别?
+两者之间的唯一区别是初始化质心的方式。在k-means算法中,质心从给定点随机初始化。这种方法存在一个缺点,即有时这种随机初始化会导致非优化的聚类,这是由于两个聚类的初始化可能彼此接近。
+为了解决这个问题,k-means++算法应运而生。在k-means++中,第一个质心从数据点中随机选择。后续质心的选择基于它们与初始质心的分离。一个点被选为下一个质心的概率与该点和已经被选择的最近质心之间的平方距离成比例。这保证了质心均匀地分散开,并降低了收敛到不理想聚类的可能性。这有助于算法达到全局最小值,而不是陷入局部最小值。
+3. 解释机器学习中常用的一些相似性度量。
+一些最常用的相似性度量如下:
+4. 当数据分布右偏和左偏时,均值、中位数和众数会发生什么变化?
+标准正态分布特征:均值=中位数=众数
+左偏态特征:众数>中位数>均值
+右偏态特征:均值>中位数>众数
+右偏分布
+
左偏分布,
+
5. 对于离群值,决策树和随机森林谁的鲁棒性更强。
+决策树和随机森林对离群值都相对稳健。随机森林模型是多个决策树的集成,因此,随机森林模型的输出是多个决策树的聚合。因此,当我们对结果进行平均时,过拟合的可能性就会降低。因此,我们可以说随机森林模型对离群值更具鲁棒性。
+6. L1正则化和L2正则化有什么区别?它们的意义是什么?
+L1正则化:在L1正则化中,也被称为Lasso正则化,其中我们在损失函数中添加模型权重的绝对值之和。
+在L1正则化中,那些根本不重要的特征的权重被惩罚为零,因此,反过来,我们通过使用L1正则化技术来获得特征选择。
+L2正则化:在L2正则化中,也称为岭正则化,我们将权重的平方添加到损失函数中。在这两种正则化方法中,权重都是不利的,但它们帮助实现的目标之间存在细微的差异。
+在L2正则化中,权重不会被惩罚为0,但对于不相关的特征,它们接近于零。它通常用于通过将权重缩小到零来防止过拟合,特别是当有许多特征并且数据有噪声时。
+7. 什么是径向基函数?解释它的用途。
+RBF(径向基函数)是一种用于机器学习的实值函数,其值仅取决于输入和称为中心的固定点。径向基函数的公式如下:
+
机器学习系统经常将RBF函数用于各种函数,包括:
+它是SVM算法中通常使用的非常著名的内核之一,用于将低维数据映射到高维平面,因此,我们可以确定一个边界,该边界可以将这些平面的不同区域中的类以尽可能多的余量分开。
+8. 解释用于处理数据不平衡的SMOTE方法。
+SMOTE是用来处理数据集中数据不平衡问题的方法之一。在这种方法中,基于现有的少数类,我们通过使用线性插值合成新的数据点。使用这种方法的优点是模型不会在相同的数据上进行训练。但是使用这种方法的缺点是它向数据集添加了不需要的噪声,并且可能对模型的性能产生负面影响。
+9. 准确率得分是否总是衡量分类模型性能的良好指标?
+不,有时候我们在不平衡的数据集上训练模型时,准确度分数并不是衡量模型性能的好指标。在这种情况下,我们使用查准率和查全率来衡量分类模型的性能。此外,f1-score是另一个可用于衡量性能的指标,但最终,f1-score也是使用精确度和召回率计算的,因为f1-score只是精确度和召回率的调和平均值。
+10. 什么是 KNN 插值填充?
+我们通常通过数据的描述性统计测量(如平均值、众数或中位数)来估算空值,但KNN 插值是一种更复杂的填补空值的方法。在该方法中还使用距离参数,其也被称为k参数。这项工作在某种程度上类似于聚类算法。缺失值是参照缺失值的邻域点进行插补的。
+11. 解释XGB模型的工作流程。
+XGB模型是机器学习集成技术的一个例子,在这种方法中,权重通过将它们传递到决策树来以顺序的方式进行优化。在每一遍之后,权重变得越来越好,因为每棵树都试图优化权重,最终,我们获得了手头问题的最佳权重。像正则化梯度和小批量梯度下降这样的技术已经被用来实现这个算法,所以它以非常快速和优化的方式工作。
+12. 将给定数据集拆分为训练和验证数据的目的是什么?
+主要目的是保留一些模型尚未训练的剩余数据,以便我们可以在训练后评估机器学习模型的性能。此外,有时我们使用验证数据集在多个先进的机器学习模型中进行选择。就像我们首先训练一些模型一样,比如LogisticRegression,XGBoost或任何其他模型,而不是使用验证数据测试它们的性能,并选择验证和训练精度之间差异较小的模型。
+13. 解释一些处理数据中缺失值的方法。
+处理缺失值的一些方法如下:
+14. k-means和KNN算法有什么区别?
+k-means算法是用于聚类目的的流行的无监督机器学习算法之一。但KNN是一种通常用于分类任务的模型,是一种有监督的机器学习算法。k-means算法通过在数据集中形成聚类来帮助我们标记数据。
+15. 什么是LDA线性判别分析?
+LDA是一种有监督的机器学习降维技术,因为它也使用目标变量进行降维。它通常用于分类问题。LDA主要致力于两个目标:
+16. 如何在二维中可视化高维数据?
+最常用和有效的方法之一是使用t-SNE算法。该算法采用了一些非线性的复合形方法对给定的数据进行降维。我们还可以使用PCA或LDA将n维数据转换为2维,以便我们可以绘制它以获得更好的分析视觉效果。但是PCA和t-SNE之间的区别在于前者试图保持数据集的方差,而t-SNE试图保持数据集中的局部相似性。
+17. 维度灾难背后的原因是什么?
+随着输入数据的维度增加,概括或学习数据中存在的模式所需的数据量也增加。对于模型,很难从有限数量的数据集中识别每个特征的模式,或者我们可以说,由于数据的高维性和用于训练模型的有限数量的示例,权重没有得到适当的优化。由于这一点,在输入数据的维数达到一定的阈值后,我们不得不面对维数灾难。
+18. 度量MAE或MSE或RMSE, 哪个对离群值有更好的鲁棒性。
+在上述三个指标中,与MSE或RMSE相比,MAE对离群值具有鲁棒性。这背后的主要原因是因为平方误差值。在离群值的情况下,误差值已经很高,然后我们将其平方,这导致误差值的爆炸超过预期,并为梯度产生误导性结果。
+19. 为什么删除高度相关的特征被认为是一种良好的做法?
+当两个特征高度相关时,它们可能向模型提供类似的信息,这可能导致过拟合。如果数据集中存在高度相关的特征,那么它们不必要地增加了特征空间的维数,有时会产生维数灾难的问题。如果特征空间的维数很高,那么模型训练可能需要比预期更多的时间,这将增加模型的复杂性和出错的机会。这在某种程度上也有助于我们实现数据压缩,因为这些功能已经被删除,而没有太多的数据丢失。
+20. 推荐系统中基于内容的过滤算法和协同过滤算法有什么区别?
+在一个基于内容的推荐系统中,内容和服务的相似性进行评估,然后通过使用这些相似性措施,从过去的数据,我们推荐产品给用户。但另一方面,在协同过滤中,我们根据相似用户的偏好推荐内容和服务。例如,如果一个用户过去已经使用了A和B服务,并且新用户已经使用了服务A,则将基于另一用户的偏好向他推荐服务A。
labs & hw review quickly!
+ + + + + + + + + + + + + + + + + + + + + + +第8章
+集成学习算法之Boosting - 知乎 (zhihu.com)
+一文看懂决策树(Decision Tree) - 知乎 (zhihu.com)
+【机器学习】Bootstrap详解 - 知乎 (zhihu.com)
+KMeans(K均值)和KNN(K最近邻)是两种不同的机器学习算法,它们在任务和实现上有很大的区别。
+总体而言,KMeans 和 KNN 是两种不同类型的算法,用于解决不同的问题。 KMeans 是一种无监督学习算法,用于聚类,而 KNN 通常用于监督学习中的分类和回归任务
+监督学习和无监督学习是机器学习中两种不同类型的学习范式,它们之间的主要区别在于训练数据的标签信息。
+无监督学习通常用于在数据中发现隐藏的结构,而监督学习则用于构建输入和输出之间的映射关系。这两者在解决不同类型的问题时发挥着重要的作用。
+一步干四件事情:
+输入新的输入信息和上一个状态的cell state和hidden state,输出hidden state和cell state
+根据当前新的输入,选择从上个状态的cell state中要忘记的内容,
+根据当前新的输入,选择从上个状态的cell state中要更新的内容
+根据更新后的状态和当前新的输入,更新hidden state的内容
+Softmax、ReLU(Rectified Linear Unit)、和Sigmoid是常用的激活函数,它们在深度学习中用于不同的场景。以下是它们的函数表达式和主要应用情形:
+这些激活函数的选择通常取决于任务的性质和网络的结构。一般而言,Softmax适用于多类别分类,ReLU适用于隐藏层以增加模型的非线性表达能力,而Sigmoid适用于二元分类。
+week 9
+word embedding 词嵌入
+Convert words into numerical form (e.g., vector). +例如,Embed words into a mathematical space.
+one-hot编码的优点和缺点:维度太高,无法表征相似(靠近)程度
+distributional representation 分布式表示方法
+distributional hypothesis指出,应该用这个词所处的语境来生成词向量
+word2vec is used for distributional representation
+inference based methods:在自然语言处理(NLP)中,skip-gram和CBOW(Continuous Bag of Words)是两种用于学习词向量表示的模型,它们被称为“inference based methods”(基于推理的方法)的原因主要与它们的训练目标和方法有关。
+这两种模型都是基于推断(inference)的方法,因为它们的核心目标是通过观察词汇之间的上下文关系来推断每个词的词向量表示。具体而言:
+这两种方法之所以被称为“inference based methods”,是因为它们的核心任务是从给定的上下文信息中推断单词的表示。这与一些其他方法,如计数方法(count-based methods)不同,后者主要关注的是统计词汇的共现信息而不是直接推断词向量。
+总的来说,skip-gram和CBOW模型被称为基于推理的方法,因为它们通过观察上下文关系来推断词汇的语义表示,从而实现更好的词向量学习。
+Predict one word (target word) from multiple words (context). +The convergence rate is fast. +The distributional representation (word vector) is relatively inferior.
+Predict multiple words (context) from one word (target word). +The convergence rate is slow. +The distributional representation (word vector) is relatively superior.
+CBOW(Continuous Bag of Words)和Skip-gram是自然语言处理(NLP)中用于生成词向量的两种流行模型。关于CBOW的词向量相对较差的说法可能受到一些因素的影响,但需要注意的是,这些模型的性能可能取决于具体的任务、数据集和训练参数。
+以下是CBOW的词向量在某些情境下被认为相对较差的一些原因:
+值得注意的是,在CBOW和Skip-gram之间的选择通常取决于数据集的具体特性以及下游任务的需求。在实践中,研究人员和从业者可能会尝试使用这两种模型,以确定哪种模型更适合其特定的用例。此外,诸如基于Transformer的更近期的词向量模型等技术的进步在各种NLP应用中超越了传统方法,如CBOW和Skip-gram。
+
"RNN能够Correlate temporal information" 表示循环神经网络(Recurrent Neural Network,RNN)能够关联或捕捉时间上的信息。在这种上下文中,"temporal information" 指的是与时间相关的数据、模式或序列。
+RNN是一种具有循环结构的神经网络,它在处理序列数据时表现出色。这意味着它能够考虑先前的时间步信息,从而更好地理解和预测序列中的模式。RNN的循环结构允许信息在网络中传递,使得网络能够捕捉和利用时间上的依赖关系。
+具体而言,RNN中的隐藏状态允许网络在处理序列时保留过去的信息,并在当前时间步使用。这种机制使得RNN能够关联不同时间步的输入,从而更好地理解序列中的动态模式。这样,RNN就能够在处理时间序列数据时有效地"correlate temporal information",也就是关联或捕捉时间上的信息。
+然而,传统的RNN在处理长序列时可能会面临梯度消失或梯度爆炸的问题,为了解决这一问题,一些改进的结构,如长短时记忆网络(LSTM)和门控循环单元(GRU)等,被提出来以更有效地捕捉和利用时间信息。这些改进的结构在处理长期依赖性时表现更好。
+Large models, especially those based on transformer architectures like OpenAI's GPT-3, have shown significant advancements in various natural language processing (NLP) and machine learning tasks. These models are known for their ability to capture complex patterns in data, generate coherent and contextually relevant outputs, and achieve state-of-the-art performance in multiple benchmarks.
+Here are some considerations regarding the future of large models:
+Increased Model Size: There is a trend of increasing model sizes to improve performance. Researchers continue to explore even larger models with more parameters to push the boundaries of what's possible in terms of understanding and generating natural language.
+Broader Applicability: Large models are being adapted and fine-tuned for a broader range of tasks beyond NLP, including computer vision, reinforcement learning, and more. This trend may continue as researchers aim to develop models with general intelligence.
+Resource Intensiveness: Training and deploying large models require substantial computational resources, which may limit accessibility. Future developments might focus on making these models more efficient and accessible, allowing a wider range of researchers and applications to benefit from them.
+Ethical Considerations: As large models become more powerful, there's a growing need to address ethical concerns, including issues related to biases in training data, potential misuse, and the environmental impact of training such models.
+Hybrid Models: Future research might explore hybrid models that combine the strengths of large pre-trained models with more task-specific architectures. This approach could enhance efficiency and performance for specific applications.
+agents
+It's important to note that the field of machine learning is dynamic, and new developments may occur beyond my last update. The future of large models will likely depend on ongoing research, technological advancements, and societal considerations.
+贝叶斯分类器:
+训练样本为 特征 对应 分类
+需要预测的是:某特征x下对应的分类y,求出最大可能性的y,argmax p(y|x)
+训练方法是:
google colab
+使用模型,想一个应用场景
+视频剪辑
第一遍:标题摘要结论。可以看一眼exp中的图表,瞄一眼method
+第二遍:对整个文章过一遍,证明公式忽略,图表要细看,和其他人工作的对比,圈出引用的文章。
+第三遍:每句话都要理解,如果是我来做应该怎么做,哪些地方可以往前做
打补丁法
+以MAE为例:
+
第一个想法:“遮住更多的图片块”就是给图片加很强的噪声,相当于数据增强,数据增强是为了使模型不过拟合,但是坏处就是训练很慢,收敛速度极慢,考虑在更大数据集或更大架构上做MAE成本过大。因此可以考虑其他的数据增强,使得效果不差且训练速度快
+第二个想法:对于ViT,可以考虑使用新的model,例如自注意力、MLP都是可以替换的;
+第三个想法:对于BERT,使用的是完形填空和句子对匹配,是否可以增加额外的一个损失函数,例如contrast learning
+打补丁逻辑要串起来
+打补丁要找一篇脑洞比较大的
+Momemtum Contrast for Unsupervised Visual Represententation Learning
+MoCo是CV领域使用对比学习的里程碑工作
+无监督,在分类任务上逼近有监督的基线模型,而且在其他任务中甚至超越了有监督的预训练模型
+动量:指数移动平均。\(y_t\)是当前输出,\(y_{t-1}\)是上一次输出,\(m\)是超参数动量,\(x_t\)是当前输入。当\(m\)趋向于1的时候函数变化慢 + $$ + y_t=m\cdot y_{t-1}+(1-m)\cdot x_t,m\in[0,1] + $$
+NLP领域的无监督学习效果很好,但是CV领域不行,原因可能是两者的信号空间不同。语言任务是离散的信号空间(词、词缀等),容易建立tokenized字典(表示某个词表示某个特征)。视觉是高维连续信息,没有很强语义信息,比较难浓缩,不简洁,不适合建字典
+结构图:
+红色的字是对比学习范式内容。我们将\(X_1\)通过不同的变换\(T_1,T_2\)形成\(X_1^1,X_1^2\),前者是anchor锚点,后者是正样本positive,其他样本是负样本negative。锚点和正样本分别通过编码器\(E_{11}\)和\(E_{12}\)得到特征\(f_{11}\)和\(f_{12}\)(这里的Encoder可以不一样,所以标号不同,但也可以一样,MoCo中不一样),然后负样本通过\(E_{12}\)得到\(f_2,f_3,\dots,f_n\)
+
字典要
+大:包含更多视觉信息
+一致:字典中的key要用相同或相似的编码器得到
+框架:
+和对比学习最大的不同是queue队列。队列可以很大,但是每次更新可以只更新一个batch size。最旧的mini batch出队列,新的mini batch进入队列
+为了保持一直性,所有的key都通过相似的encoder,所以这里使用动量编码器。假设encoder的参数为\(\theta_q\),动量编码器的参数是\(\theta_k=m\cdot \theta_{k-1}+(1-m)\cdot\theta_q\)
+

Softmax: + $$ + \frac{\exp(z_+)}{\sum\limits_{i=0}^k\exp(z_i)} + $$ + 交叉熵: + $$ + -\log\frac{\exp(z_+)}{\sum\limits_{i=0}^k\exp(z_i)} + $$ + 以上的 \(k\) 表示数据集的类别。在代理任务 instance discrimination 中 \(k\) 会达到几百万(ImageNet)
+NCE简化类别数量为两类,一个是data一个是noise,同时做估计近似(E表示estimation),字典越大能提供越好的近似。InfoNCE觉得二分类不够,所以就使用如下公式:
+
\(\tau\)是温度超参数,用来控制分布形状,\(\tau\)大的时候分布变peek就越集中。温度太大,所有负样本都一视同仁,学习没有轻重;反之过小就会只关注特别特别困难的样本,导致模型很难收敛学到的特征不好泛化。这里的\(K\)是负样本的数量。
+队列字典
+字典是队列的数据结构,每个mini batch编码后放进来,最老的就出去,这意味着字典里面的key有的是用不同的encoder编码的
+动量更新
+当字典很大的时候,很难通过反向传播去更新key encoder(不理解)
+++GPT(不一定准确):
+当字典很大时,key encoder的参数数量会非常庞大,导致反向传播需要计算大量的梯度,计算量非常大。此外,由于key encoder是不可微的,因此无法通过自动微分来计算其梯度,而需要使用其他方法,如近似梯度或离散化梯度等。这些方法的精度和效率都不如自动微分,因此更新key encoder的效率会受到很大的限制。
+
query encoder一直在更新,但是key encoder不更新,所以简单的方法是将query encoder复制到key encoder中,但结果不好,作者认为是快速改变的key encoder破坏了一致性
+所以使用动量更新:
+
探讨之前的架构存在的dictionary size和consistency的问题
+端到端:字典大小和batch size相等,可以梯度回传,优点编码器实时更新一致性好,缺点是字典不能过大
+
memory bank:对整个数据集都抽特征(ImageNet有128万个样本,每个特征128维,仅需要600M大小),训练时随机抽样当做字典。
+训练的逻辑:128万维的memory bank中随机抽取几个key然后求loss反向传播更新key encoder,然后再重新算key更新memory中那几个key的值,导致一致性很低。同时memory bank过大导致训练每个epoch(遍历128万的特征)后再选的key是非常老的key。
+
伪代码:注意交叉熵这里有个labes = zeros(N)是因为0号位置上的是ground truth \(k_+\)。

InstDisc
+标题:Unsupervised Feature Learning via Non-Parametric Instance Discrimination
+个体判别任务+Memory Bank
+想法:在有监督学习中,很多图片就是很相似,没有语义便签也可以
+学习到特征,然后让不同类别的图像在语义空间中尽可能分开
+
InvaSpread
+标题:Unsupervised Embedding Learning via Invariant and Spreading Instance Feature
+被认为是SimCLR的前身
+MoCo中提到的端到端的学习方式,只用一个编码器,在一个minibatch中找正负样本
+Invariant相似图片特征不变形,Spreading不同图片特征不同
+
也使用InstDisc个体判别的代理任务,主要是看正负样本的选择
+
没有SimCLR效果好的原因:字典不够大
+CPC
+标题:Representation Learning with Contrastive Predictive Coding
+新的代理任务,个体判别是判别式任务,那一定存在生成式任务
+音频、图片、文字、强化学习都可以用
+思路:将之前的输入通过encoder变成特征\(z_{t-3},z_{t-2},\dots,z_{t}\),然后喂给自回归的模型例如RNN或者LSTM,然后得到\(c_t\)(context representation,代表上下文的特征),这个上下文的特征应该可以预测\(z_{t+1}\)。
+对比学习:预测是query,未来时刻编码后的\(z_{t+1}\)等是正样本,任意输入通过编码器都是负样本
+
CMC
+标题:Contrastive Multiview Coding
+一个物体的很多视角都可以当做是正样本
+摘要很好:人感知世界有非常多方式,视觉听觉等,我们希望能学习其中强大的mutual information(所有视角下的关键因素)
+
例子:使用NYU RGBD数据集,其中包括原始图片、深度图、分割图等,这些互为正样本
+
很早做多视角的对比学习,证明多视角和多模态的可行性,后来OpenAI出了CLIP模型,图片和文本是正样本对。CMC原班人马做了一篇蒸馏的工作,无论使用什么样的网络,同一个图片都应该得到类似的特征,我们希望让teacher模型和student模型的输出尽可能相似,使teacher和student形成一个正样本对
+使用几个视角可能得配几个编码器,但是CLIP使用的是BERT+ViT(底层都是Transformer),所以可能Transformer能够统一处理不同类型的数据
+MoCo
+将对比学习转化成字典查询问题
+使用Res50等
+SimCLR
+标题:A Simple Framework for Contrastive Learning of Visual Representations
+方法:和InvaSpread非常类似,对于batch size \(N\),正样本是数据增强的,负样本是数据增强和没有数据增强的,主要的不同是加了个投影层\(g(\cdot)\),其实就是MLP,但是这一个层让效果提升10个点,但是这个projection只在训练的时候用,在下游任务的时候把projection去掉了
+
和InvaSpread的区别
+
投影层:
+MLP中是FC+ReLU是Non-Linear,只有FC是Linear,都不用是None,可以看到效果对比
+
MoCo v2
+标题:Improved Baselines with Momentum Contrastive Learning
+作者发现SimCLR中的东西是即插即用的,所以直接加上,主要是MLP head和数据增强
+数据:
+

MoCo比SimCLR的优越性,就是硬件
+
SimCLR v2
+标题:Big Self-Supervised Models are Strong Semi-Supervised Learners
+大的自监督模型适合做半监督学习
+架构图
+
++Task-agnostic在机器学习中指的是一种算法或模型,它不针对特定的任务进行优化,而是具有通用性和适应性,可以应用于多种不同的任务和领域。这种算法或模型通常具有更广泛的适用性和更好的泛化能力,因为它们不会过度拟合任何特定任务的特定数据集。例如,一些常见的task-agnostic模型包括线性回归、决策树、随机森林等。
+
和SimCLR v1的区别
+SwAV
+标题:Unsupervised Learning of Visual Features by Contrasting Cluster Assignment
+Sw是Swap,A是Assignment,V是Views
+希望用一个视角的特征去预测另一个视角的特征
+对比学习+聚类
+架构图
+之前的负样本只是近似(例如MoCo从128万个特征中取65536个做负样本),所以可以考虑和聚类中心比。
+聚类中心是Prototypes \(c\),大小 \(D\times K\)(\(D\)是特征维度,\(K\)是聚类中心个数),\(z\)大小\(B\times D\),\(q\)大小\(B\times K\)。
+
聚类的方法使用的是deep cluster、deep cluster 2
+使用到一个trick:multi-crop,正样本取多个crop,现在取2个长宽160和4个长宽96的可以有提高
+CPC v2
+BYOL
+标题:Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning
+Bootstrap改造,Latent特征。自己跟自己学,左脚踩右脚
+不使用负样本。在一般的对比学习中,如果没有负样本,那Loss Function的目的就是让所有正样本都相似,那么就存在一个捷径解,即无论给任何输入都返回相同输出,此时所有正样本一定相似,一旦模型躺平就称为model collapse / learning collapse。
+架构图
+
SimCLR使用了BN且有两个
+
MoCo没有BN
+
BYOL:只有一个BN
+
消融实验证明是BN的效果
+
BN的效果是算Batch的均值方差,这意味着你在算某个正样本Loss的时候其实也看到了别的样本的特征,造成信息泄漏。所以BYOL也是对比学习,它的任务是正样本和平均图片之间的差异(相当于SwAV中的聚类中心)
+但是后来原作者又发了新的文章:BYOL works even without batch statistics
+
当-/BN/-的时候训练失败;-/-的时候SimCLR也失败了,即用了负样本也训不出来
后来达成一致:BN增加训练稳健性
+作者发现一开始初始化比较好不使用BN也可以。使用了Group Norm和Weight Standardization初始化,在BEiT中提出的,也是ResNet v2初始化方法
+SimSam
+标题:Exploring Simple Siamese(孪生网络) Representation Learning
+没有负样本、不需要大的batch size、没有动量编码器
+
孪生网络:编码器结构相同且共享参数
+和BYOL的区别,没有用动量编码器
+伪代码:\(D\)函数是计算MSE,可以用p1预测z2,也可以用p2预测z1
+
主要是stop gradient的操作
+作者认为是EM算法,接近聚类
+
动量编码器很可以提点,分类任务最强的是BYOL
+迁移学习是MoCo v2和SimSam最好,推荐用MoCo v2做基线模型,训练快训练稳
+MoCo v3
+标题:An Empirical Study of Training Self-Supervised Vision Transformers
+主要内容是如何提高ViT的训练稳定性
+MoCo v3相当于v2和SimSam的合体
+
两个编码器,query和key,后者是动量编码器,loss用的是对比学习的loss,看起来是MoCo v2。而query编码器还用了projection和prediction,相当于BYOL和SimSam。同时backbone骨干网络从残差网络换成了ViT
+batchsize大的时候会突然下降
+
作者检查了梯度,发现是ViT第一层patch projection发生梯度的波峰。相当于tokenization阶段,如何将图片打成patch然后给他一个特征,就是一个MLP,所以直接给一个random patch projecion层然后freeze,问题就解决了,发现这个trick对MoCo v3和BYOL都可以用
+如果不改Transformer,那就只有一开始的tokenization和最后的目标函数能改
+DINO
+标题:Emerging Properties in Self-Supervised Vision Transformers
+

归因技术是 gradient saliency,计算输出关于输入的梯度,如果比较大就说明该特征比较重要
+
略
+
ViT使用16倍的下采样率,虽然使用全局自注意力,但是对多尺度特征提取能力就差一些
+下游任务如检测和分割(密集预测任务),多尺寸特征是至关重要的。目标检测用的最广的方法是FPN,feature pyramid network。物体分割最常用的是UNet。都会使用不同尺寸上的特征
+
CNN中使用池化来增大感受野,SwinTransformer使用PatchMerging将相邻小patch合成大patch
+有了多尺度特征就可以输给一个FPN做检测,或者扔给UNet做分割
+移动窗口:灰色是小patch(4*4),红色框内是有7*7个小patch(下图仅为示意图),
+


作者最后直接用全局池化操作 global average pooling 将最后 \(7*7\) 变成了 \(1*1\) 来做分类
+计算复杂度
+
上式是标准的多头自注意力,而下式是窗口多头自注意力
+架构图中右侧是两个block合成一个计算单元,分别使用窗口自注意力和移动窗口自注意力
+移动窗口的问题:移动之后变得不规则了(4个窗口变成了9个窗口),解决方法之一是直接pad但是计算复杂度变大了
+作者提出的方法:循环移位,窗口数量始终是4个,但是问题是ABC所在窗口内的patch有的是从很远的地方搬过来的并不相关,这里作者使用mask来处理,最后还要使用循环移位来变回去
+
掩码操作:假设窗口是14*14的大小,对于3和6区域,我们首先将3区域内的所有patch拉直,得到28*C个向量,然后再接6号区域21*C个向量拼在一起,然后转置相乘算自注意力,得到的结果中左上和右下区域是不需要的,最后会加上一个Mask矩阵,Mask矩阵的左上和右下都是很大的负数,经过softmax之后就没了
+


另外还有一个回收机制,将编码器和解码器的输出都加入到编码器的输入,回收机制不参与梯度回传,降低训练压力
+编码器
+和Transformer类似,区别是Pair会传到MSA,而MSA也会传到Pair。同时因为是二维矩阵,所以会处理按行信息以及按列信息
+
补充材料:row-wise gated self-attention with pair bias
+上图中第一行的第二个block:
+row-wise表示按行,所以特征长度是\(c_m\)
+gated表示除了qkv之外加了一个linear+Sigmoid使之在0-1之间然后做一个按元素点乘实现门的效果(输出门)
+pair表示:假设计算第\(i\)个氨基酸为query,\(j\)个氨基酸为key,那么可以在pair representation中取第\(i\)行第\(j\)列通过线性投影到一维然后加上去(表示氨基酸之间的预设关系)
+

编码器图第一行的第三个block:对列的特征提取
+
编码器第一行第四个block:MLP
+
编码器第一行和第二行之间的紫色模块
+
在MSA中两个氨基酸对是一个矩阵,每个氨基酸是一个\(s*c_m\)的矩阵;在Pair矩阵中每个氨基酸对是一个\(c_m\)的向量,所以要把两个矩阵变成一个向量。
+这里outer product是将两个矩阵分别扩成 \((s,c,1)\) 和 \((s,1,c)\) 然后外积得到 \((s,c,c)\)。
+编码器第二行第4/5个block
+

这里称为 Triangular,是因为这里使用了 \(i,j,k\) 三个氨基酸之间的关系
+
这里矩阵是不对称的
+编码器第二行第2/3个block
+
为了计算\(i\)和\(j\)之间的关系,使用了所有\(i,k\)和\(k,j\)之间的关系,和图神经网络类似
+
outgoing和incoming,相当于汇聚出去和进来的边两种结构
+解码器
+氨基酸在3D中的位置表示使用的是相对位置,即每个氨基酸的位置相对于上一个的相对位置
+\(Y^{3\times 1}=R^{3\times 3}X^{3\times 1}+t^{3\times1}\),因此主要需要预测 \(R\) 和 \(t\)。
+需要符合生物和物理规则
+结构:先预测Backbone即蛋白质主干网络位置,然后预测枝干网络
+
IPA拿到氨基酸对信息、不断更新的序列信息、主干网旋转平移信息
+类似RNN
+IPA模块的算法:不动点的注意力
+
后面太复杂了……略了
+Learning Transferable Visual Models From Natural Language Supervision
+利用自然语言监督的信号来训练一个可迁移的视觉模型
+输入是文字和图片的配对,各自通过一个encoder得到特征,然后做对比学习(只需要有正样本和负样本的定义即可,配对的样本是正样本,即矩阵中对角线是正样本)
+
正常的CLIP是没有分类头的,因此要额外进行prompt template,即将类别转成一个句子(例如This is a dog)然后抽取文本特征,图片抽取特征,然后计算相似度
+zero shot:能够预测出不在ImageNet中的类别
+将图片语义和文本语义联系起来,所以迁移效果非常好
+我们的想法一点也不新,但是之前的工作说法混淆、规模不够大、NLP模型不够好,当Transformer解决NLP大一统问题之后容易获得语义特征了
+多模态特征适合zero shot迁移
+数据集:WIT(WebImage Text)
+之前的预训练工作在ImageNet1K上就需要数十个GPU/TPU年的训练时间,而OpenAI注重效率,所以选择对比学习。而其他OpenAI工作都基于GPT,仅有CLIP基于对比学习
+一开始采用类似VirTex,图像CNN文本Transformer,给定图片预测其对应文本。但是图片的描述有很多可能,所以预训练非常慢
+当把预测型任务换成对比型任务,判断图片与文本是否是配对就比较简单(生成式变判别式),效率提高4倍
+伪代码
+第一步抽取特征。第二步中会点乘一个\(W\),这个投影是为了将单模态信息转成多模态信息,然后归一化。第三步算相似度。第四步算loss,正样本是对角线上,对称式的loss函数
+作者没有使用非线性投影层(之前的对比学习中提升了近10个点)因为作者发现多模态中提升不大
+只做了随机裁剪的数据增强
+
之前的自监督无监督学习到一个特征之后,还需要对下游任务做有监督的微调
+图
+
prompt engineering and ensembling
+prompt的重要性:ImageNet中有两个类construction crane(起重机)和crane(鹤),文本多义性可能导致问题;另外输入输出要尽可能保持一致,避免distribution gap
+A phot of {label},还可以加一些例如A photo of {label}, a type of petensemble,用多种提示模板,CLIP使用了80个模板
+大规模迁移学习结果:
+这里是Linear Probe表示将前面的模型freeze掉只从中抽特征,然后训练一个FC来做分类任务。普通物体zero shot任务比较好,但是比较难的任务(DTD纹理分类,CLEVRCounts物体计数)。
+
Few Shot的结果:BiT为Big Transfer本身就是谷歌为了迁移学习设计的
+
所有数据:略
+Two-Stream Convolutional Networks for Action Recognition in Videos
+我们对视频中的动作识别比较感兴趣、收集容易、落地场景多
+结构:
+作者认为卷积神经网络适合学习局部规律,但是不适合学习物体移动规律(Motion Information)
+由于物体不会学,那就教你学,直接先把运动信息抽取好(光流抽取),然后去学习映射
+上面一只为空间流CNN,下一只为时间流CNN
+
空间流使用单张frame,从静止的图片中做动作识别,其实就是图像分类,但是图像分类本身就和动作识别强相关(例如出现钢琴、篮球等),所以空间流已经非常有竞争力。甚至空间流可以做预训练
+时间流
+

双向光流:Bidirectional,同时计算前向光流和后向光流,即上面的向量可以取反向(一半帧计算正向,一半帧计算反向)
+最后光流图的大小是 \(W\times H\times 2L\),如果视频帧是 \(L+1\),作者一般使用的是11帧
+最后两个流使用的是softmax得到值取平均相加
+测试方法
+对于空间流:每次等间距取,一共取25帧。数据增强:一帧上crop取5块,然后翻转再crop出5块,每帧得到10张图(250view),这250个图结果取平均得到空间流结果
+对于时间流:取25帧每帧位置后面11帧,得到250张光流图
+后来测试方法取view数就很多样了,3D网络30view,Transformer有使用4或3view的
+预处理光流
+机器耗时,数据dense占用空间(每个位置都有值)
+作者的方法是将数据rescale到0-255整数然后存成JPEG
+消融实验
+空间流
+
时间流
+
总对比
+时间流得到的正确率很高(不使用Pretraining),甚至超过空间流
+
标题:Improving Language Understanding by Generative Pre-Training
+方法
+无监督预训练
+
微调
+
下游任务
+
分类:判断一段话的标号(例如评价是正面还是负面的),方法是前面加个start后面加个extract然后放到Transformer中,然后将extract的输出接linear
+蕴涵:判断premise中是否蕴涵hypothesis中假设的东西(例如premise是a给了b玫瑰花,hypothesis是a喜欢b,那么就是支持),其实是三分类问题,支持或反对或中立
+相似:对称关系
+多选题
+标题:Language Models are Few-Shot Learners
+导言
+NLP预训练的问题:需要一个下游数据集做微调
+方法
+不做模型更新:所谓zero-shot / one-shot / few-shot都是in-context learning,直接在prompt里给
+
大模型不容易过拟合
+数据集收集
+将Reddit上的网页(精选)定义为正类,Common Crawl(多但脏)上的网页定义为负类,然后做二分类,获得更多的正类网页
+标题:ImageNet Classification with Deep Convolutional Neural Networks,ImageNet是当时最大的图片数据集
+作者:Hinton当时机器学习的大牛
+
Abstract:重点介绍了AlexNet的效果,有点像技术报告
+
结尾不是Conclusion而是Discussion:提出深度和网络效果正相关,因为五层去掉一层效果降低2%(实际上是调参没调好,去掉一层影响不大,但是前面提到的深度和网络效果正相关是正确的,另外宽度也很重要)。使用Supervised Training(但是当时Hinton和LeCun都认为无监督学习才是最重要的,最近BERT和GAN让人对无监督又开始感兴趣起来了)。未来希望能够在video数据上训练(在video上一直都比较慢)。
+
图:
+
右边的图片是最后一层输出的向量,在数据集中找最相邻的图片,可以看到基本相似。这是最重要的一点,相似的图经过神经网络在语义空间里是相近的
+
由于该工作的正确率非常高,因此决定继续往下读。
+introduction:
+++在深度学习中,正则化(regularization)是一种用于减少模型过拟合的技术。正则化通过在损失函数中添加一个惩罚项,来限制模型参数的值域,使其不能过大,从而降低过拟合的风险。
+正则化通常被应用于优化算法的损失函数中。它的目的是在保持良好的拟合能力的同时,降低模型的复杂度。常见的正则化方法包括:
++
+- L1正则化:在损失函数中添加L1范数惩罚项,使得模型的参数稀疏化,即将一些参数缩减为0,从而降低模型的复杂度。
+- L2正则化:在损失函数中添加L2范数惩罚项,使得模型的参数权重被限制在一个较小的范围内,从而降低模型的过拟合风险。
+- Dropout正则化:在模型的训练过程中,以一定的概率随机忽略掉一些神经元,从而使得模型不依赖于某些特定的神经元,提高模型的泛化能力。
+正则化方法的选择取决于具体的问题和数据集。
+L1范数和L2范数是向量空间中常见的两种范数,它们都可以用来衡量向量的大小。在深度学习中,L1范数和L2范数通常被用来作为正则化方法的惩罚项。
+L1范数是指向量中各个元素的绝对值之和,也就是说,对于一个n维向量x,它的L1范数为:
+||x||₁ = ∑|xᵢ|
+其中,|xᵢ|表示向量x中第i个元素的绝对值。
+L2范数是指向量中各个元素的平方和的开方,也就是说,对于一个n维向量x,它的L2范数为:
+||x||₂ = √(∑xᵢ²)
+其中,xᵢ²表示向量x中第i个元素的平方。
+可以看出,L1范数和L2范数都可以衡量向量的大小,但是它们的数值大小和性质不同。L1范数倾向于使得向量中某些元素变为0,从而得到一个稀疏的向量,适用于特征选择等需要稀疏性的场景。而L2范数倾向于使得向量中每个元素都变小,但不会减为0,适用于需要平滑性的场景。
+在深度学习中,L2范数通常被用作权重衰减(weight decay)的惩罚项,以避免过拟合问题。L1范数也可以用作正则化方法,但由于它的导数在0点处不连续,不利于优化算法的求解,因此通常需要使用一些特殊的算法进行优化。
+
Dataset:
+Architecture:
+我们使用了ReLU,一般用的是Sigmod和tanh。在当时更快一些,但是目前换成其他的也无所谓
+多卡训练:工程细节可以忽略
+Local Response Normalization:避免饱和(饱和此时不理解),实际上目前有更好的Normalizatio的方法
+Overlapping Pooling:Pooling是什么?对传统Pooling做了一些修改
+Overall Architecture:
+CNN的长宽减小代表压缩信息,一个像素代表之前多个像素。通道数增加,代表观察的模式类型增加
+
有两块GPU,将一张图分成两个部分分别卷积,在第2层和第3层之间做一次GPU通信。模型并行在AlexNet之后的七八年没有受到关注,但是最近也有收到关注(因为太大)
+Reducing Overfitting:
+Details of learning:
+Result:
+经常混用val和test,一般来说val是能一直调参的,而test只能提交几次
+作者说GPU0上和color有关,而GPU1上和color无关,实际上这可能是随机发生的
+基于GPT,使用GitHub微调
+将Python的docstrings(注释)翻译成code,作者自己实现了一个数据集HumanEval用来判断Code的正确性
+训练集也进行了额外的收集,为了和测试集的输入类似,相当于增加一个带标准答案的数据集
+考虑一个新的任务:从代码生成文档或函数名等,BERT可以但是GPT是前向的,所以他们重新做了一个训练数据集,这个数据集里注释在最后
+
CV
+Image
+ImageNet:使用额外训练数据有更好的结果
+STL-10数据集:使用FID分数评价生成图片和真实图片之间的区别
+Deepfake Detection
+姿势识别
+语义分割
+...
+Video
+Kinetics数据集、ActivityNet数据集(标出几秒到几秒是什么动作)
+COCO数据集
+NLP
+文本理解
+机器翻译
+语言
+语言识别
+推荐系统
+强化学习
+硬件系统
+机器人
+各种方法对比
+a:将每个帧通过CNN抽取特征,然后将特征放入LSTM加上时序信息,效果不好
+
inflate
+将2D直接变成3D网络,不需要设计网咯
+bootstrap 引导
+用已经训练好的网络参数来做初始化,一般是两个完全一样的网络结构
+作者的方法是:如果两个模型的输入相同且输出也相同说明两个模型初始化一致,因此作者将图片复制很多帧形成视频,然后将图片喂给2D网络,给视频喂给3D网络
+具体结构:最初使用Inception模型,因为当时比ResNet好一点,但是后来也换回ResNet了。Pooling层做了修改,时间维度上不要做下采样,即输入64帧输出64帧
+
测试的时候10s视频最好都囊括在内
+
光流始终能提点
+整体微调效果会更好
+效果:
+可以不使用IDT等传统特征
+
Large-scale Video Classification with Convolutional Neural Networks
+提出Sports-1M数据集
+不同方法
+
Single Frame就是图片分类,后面三种使用到了时序信息。Late Fusion是两帧分别通过CNN然后将特征结合起来通过FC,Early Fusion是多帧一开始就直接叠加然后通过CNN,Slow Fusion是一开始四帧叠加进入CNN之后慢慢合并
+实际上不同方法效果差不多,同时在小数据集上训练之后比不过手工特征
+多分辨率CNN
+
fovea流的输入是图片中间的信息,context流是全局信息,效果研究不够好,迁移学习效果远不如手工特征
+之前的双流光流网络
+Late Fusion,是否能够尝试别的Fusion方法
+单帧和光流图片还是比较短,需要针对长时间视频
+Beyond Short Snippets: Deep Networks for Video Classification
+架构图
+
抽取特征之后使用哪种Pooling,本文进行了深入的探索,发现Conv Pooling效果最好
+使用LSTM发现效果提升有限
+LSTM:最底层是CNN抽取出的特征,然后接5层LSTM,最后Softmax输出
+
LSTM的输入必须有一定变化才能学到时间上的改变,如果视频比较短,那就没有效果了
+Convolutional Two-Stream Network Fusion for Video Action Recognition
+本文详细探索了不同Fusion的效果
+Spatial Fusion
+保证时间流和空间流特征图在同一个位置产生的通道Response是能联系起来的,这样才算Early Fusion
+包括 Max Fusion / Concatenation Fusion / Conv Fusion / Bilinear Fusion / Sum Fusion,表现最好的是Conv Fusion
+Fusion的阶段
+
作者总结了两种比较好的Fusion时机
+Temporal Fusion
+作者尝试了3D Pooling和3D Conv+3D Pooling
+结论
+
作者的网络有两个分支,一个包括时空信息,而另一种只包含时间信息
+推理的时候用两个loss late fusion
+证明了early fusion和3D Conv的效果
+TSN
+标题:Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
+能处理更长时间的视频,同时确定了很多很好用的技巧即Towards Good Practices
+长时间视频就先分段,然后在每段里随机抽取一帧,然后在之后几帧中计算光流,然后再通过共享参数的双流网络。作者认为虽然图片不同但是最高层语义信息相同,所以将空间流进行一个Segmental Consensus,可以做加法、乘法、LSTM等,然后两个Consensus做一个加权平均
+
技巧
+由于提前抽取光流非常耗时,不能支持实时光流抽取
+C3D
+标题:Learning Spatiotemporal Features with 3D Convolutional Networks
+最主要特点是使用大型数据集Sports-1M,网络更加深
+就是3D版本的VGG
+结构:作者发现FineTune效果并不好,不如直接从FC6抽取特征然后训练SVM,C3D特征指的就是FC6抽取出的特征
+
后来很多任务都直接使用FC6特征然后做下游任务
+I3D
+降低了网络训练难度
+I3D还是用到了光流,且带来了提升,所以光流有用
+Non-local Neural Networks
+摘要:卷积和递归都是在局部区域中的feature,而非局部的信息可能对泛化有很多好处,所以这里实现一个Non-local的算子,这是一个即插即用的block,作用就是建模长距离信息,在各种任务中都很有效
+结构:
+时空算子,其实是标准的attention以及残差连接,为了适配3D所以这里2D操作都变成了3D
+
消融实验比较重要
+之后大家更不用LSTM了,Non-Local成为重要算子
+R(2+1)D
+标题:A Closer Look at Spatiotemporal Convolutions for Action Recognition
+测试2D和3D各种网络,最后发现将3D卷积拆分成空间上的2D和时间上的1D效果最好
+架构比较
+
R(2+1)D
+
比之前好的原因
+但是最终结果在UCF101和HMDB51比I3D差,在K400上单独的RGB / Flow效果比较好,但是合起来就比I3D差
+输入是112*112而I3D的输入是224*224,且前者不需要使用ImageNet预训练模型,同时R(2+1)D训练更容易
+SlowFast
+标题:SlowFast Networks for Video Recognition
+借鉴双流模型,但是不使用光流作为输入
+作者说来源于人有p细胞和m细胞,前者捕捉静态信息后者捕捉高频运动信息,前者占80%后者占20%,所以作者设计了两只网络,一个是Slow网络(I3D)输入少但是参数量大,另一个是Fast网络输入多但是参数量小
+
具体网络结构
+
快分支每16帧取1帧,慢分支2帧取一帧,所以快分支的通道数少很多,另外时间维度上不下采样
+Timesformer
+标题:Is space-time attention all you need for video understanding?
+实验性论文,探索如何将Transformer迁到视频领域
+架构对比
+
更详细的attention设计方案
+
最后最好的方案是Divided Space-Time Attention
+分布式算法
+Task Scheduler负责通知Worker做计算
+
注意图中的训练数据可能是稀疏的,所以它有些 \(w\) 参数是不需要pull到的
+
架构图
+多个worker group的目的是可以训练多个有交集的任务、或者提供多个线上服务例如inference接口
+
参数服务器对参数的抽象是 (Key, Value)
+key简单认为是参数\(w\)的下标,但是下标不一定连续,往往是hash值
+所以可以使用BLAS库等写矩阵乘法
+Range Push and Pull
+相当于参数可以将某个range内的key发送出去(或接受)
+server端用户设计函数
+服务器代码非常重要,挂了就很危险
+提供了一个接口,在安全性基础上,用户可以设置\(w\)怎么更新
+异步任务
+一个任务通过一个RPC触发,这里会异步地触发任务,即让Worker0执行WorkerIterate,不等它执行完直接让Worker1执行WorkIterate
+
顺序图 DAG 有向无环图
+
用户定义过滤器
+我们需要发送大量数据,但是某些数据发送是没有必要的,我们会通过一些过滤器让它少发一些东西
+向量钟
+server需要维护每个节点访问参数 \(w\) 的时间
+可以记录每个层的时间(利用上面提到的Range Push and Pull)
+通信
+内容:如果数据在上一轮没有改变就不用发,就是看hash之后的key是否有改变
+
一致性hash ring
+Key Ring:所有参数按照hash值排列成环,每个server占用一部分同时保存下两段的replica。因此允许两个server挂掉;如果要加一个节点,只需要在某段上加一个节点然后将原段分成两个
+
流程:
+左边图表示:当worker获得ack的时候,它的server和备份节点都接收到了
+右边图表示:为了提高带宽可以做汇聚,将多个梯度累加然后不着急备份,但是延迟会增加
+机器学习关注带宽不关注延迟
+
worker management
+容灾比较简单,如果挂了,server就ping一下,ping不到就直接发任务给别的worker
+++编排层是计算机网络中的一种抽象层级,主要负责对网络数据进行编排和排序,以保证数据在传输过程中的正确性和完整性。编排层通常包括以下功能:
++
+- 数据分段:将大块数据分成较小的数据块,以便在传输过程中更好地管理和控制。
+- 数据排序:对分段后的数据进行排序,以保证数据在传输过程中的正确性和完整性。
+- 流量控制:通过控制数据发送速率和接收速率,避免网络拥塞和数据丢失。
+- 错误检测和纠正:对传输过程中出现的错误进行检测和纠正,以保证数据的完整性和正确性。
+- 重传机制:在数据传输过程中,如果发生数据丢失或错误,可以通过重传机制重新发送数据,以保证数据的完整性和正确性。
+编排层通常是网络协议栈中的一个重要组成部分,常见的编排协议包括TCP、UDP、SCTP等。
+
本系统Pathways将被未来的ML所需要
+当前的系统都是SPMD(Single Program Multiple Data),每台机器用一样的代码,算完自己的梯度然后调用AllReduce函数(MPI函数),等待所有机器都执行完这一步,然后将所有的梯度相加,BSP模型
+
BSP模型会在新的语言任务上出现问题,数据在一个加速器上放不下,需要用Pipeline;另外模型有稀疏性
+单台机器上的TPU/GPU比较快,但是不同机器之间数据传输比较慢,同时有异构存在,然后大家追求MPMD(不同机器的代码不同,调度优化不同)
+Foundation模型很大,且推理和训练可能同时使用
+图(a)中Host表示CPU,Dev表示GPU
+图(b)中ctrl会派送任务到不同机器,报错信息比较难看
+图(c)即本文架构,用ctrl向不同节点派送不同任务,系统上称作dataflow。在dataflow中计算表示成图,每个计算为一个节点,箭头表示依赖。
+Transformer中矩阵乘法数量远超CNN,但是单个计算复杂度又不高,导致整个计算图多了很多边,通信成本增加非常多,本文希望在(c)架构上提升性能
+
pathways提供额外的函数,能够分配虚拟TPU,然后计算逻辑先编译成计算图,然后发给TPU运行
+@pw.program将多个计算合并成一个program,可以直接编译成大的模块

资源管理器
+蓝色小块就是一个TPU核,它和邻居之间(上下左右前后)高速连接,然后一堆蓝色小块连在一起就是一个Pod(一个Pod最多2048核);Pod之间的网络带宽低很多;jax和TensorFlow一般会在Pod内划出一块矩形来运算,这样通信速度比较快
+
Pathways希望让多个pod之间的通信加速。我们称A/B/C为一个岛,我们目标是在三个岛上有效执行。
+资源管理器就是根据用户代码中的虚拟TPU要求去请求物理TPU,然后将虚拟TPU映射到物理TPU上,Pathways就先简单地直接分配然后一对一映射,未来可以支持动态加减
+将代码编译到某个IR然后再优化?
+

图(a)的流程:TPU0获得程序开始编译并执行,然后发送给TPU1要求它创建一块内存来等待接受TPU0的输出,同时TPU1也让TPU2开内存。当TPU0计算完的时候会send给TPU2,中间会有一个stall。
+图(b)的流程:客户端会有提前的调度同时发送给其他TPU开内存
+
GPipe基于Lingvo,后者是TensorFlow上的一个库(注重可重复性、可复现性,它会保存所有配置项)
+假设神经网络是 \(L\)层,GPipe允许用户设置切的块数 \(K\),然后开始做计算
+第 \(K\) 块放在第 \(K\) 个加速器上——最简单的模型并行
+模型并行和数据并行
+模型并行就是将不同层分给不同GPU,然后数据和梯度相互传递
+数据并行就是将输入的数据分成块然后在每个GPU上通过所有的层,最后加起来
+
图(b)模型并行和单GPU运算是相同的,因为其他时间都在等待,其实就是内存翻4倍但是计算没有翻4倍
+图(c)就是流水线,具体就是数据切开成微批量,相当于数据并行和模型并行同时做,当切的微批量越多的时候就能让效率提的更高。注意使用批量归一化的时候需要对整个批量做一个均值和方差,而现在是做微批量,而Transformer是层归一化就无所谓了
+
BubbleTime为 \(O(\frac{K-1}{M+K-1})\),其中 \(K\) 是流水线级数,\(M\) 是指令数。作者发现 \(M\ge 4\times K\)的时候就可以忽略不计了
+前向过程中中间值不能被丢掉,因为后面回传的时候可能会用到,导致activation memory比较大。GPipe使用 re-materialization 或者 active checkpoint
+在没有做re-materialization的时候,需要保存的数据量是 \(O(\frac{L}{K}\cdot N)\)(N是批量大小),做了re-materializaion之后只需要保留一开始的输入 \(N\),而每层只需要保留微批量大小 \(\frac{L}{K}\cdot \frac{N}{M}\),所以最后是 \(O(N+\frac{L}{M}\cdot \frac{N}{M})\)
+代价是慢一些,但是内存降低
+
Megatron-LM: Training Multi-Billion Parameter Language Model Using Model Parallelism
+针对特别大的语言模型,题目是模型并行,但是本文其实是张量并行
+内存不够,本文提出层内模型并行,不需要新的包或者新的编译器,和之前的Pipeline是互补正交关系
+之前的工作需要一个编译器或者一个framework,但是本文实现更加简单;但是牺牲的是通用性,本文只适合Transformer
+X是输入,A和B分别是两个隐藏层,本文探讨的问题是A和B很大需要拆分,所以就将A竖着拆分成两个模块,分别在GPU0和GPU1上,输入X在两块GPU上;然后各自得到一半的\(XA\),然后将\(B\)横着拆分成两块在GPU0和GPU1上,然后各自计算,得到各自的\(Y\),最后的结果就是两个\(Y\)相加即可。如果不考虑初始的\(X\)获取,两个GPU的通信之后最后的\(Y\)相加
+
多头就在不同的GPU上做运算,然后到MLP的时候就和上面一样
+
输入是\(b\times l\),然后去\(v\times k\)的词典里查询,每个词会对应一个\(k\)的向量,所以得到\(b\times l\times k\),整个词典可以放在不同的GPU上,然后各自查询如果查询到就是\(k\)否则就是\(0\),然后all reduce加起来就能得到词向量表示。
+输出的时候是\(b\times l\times k\),然后也去查字典,得到 \(b\times l\times v\),因为每个词会得到\(v\)长度的logits(表示和每个word的相似程度),然后要做 softmax,可以在两个GPU上分别做 exp以及求和,然后得到的竖着的向量再all reduce相加就可以得到最后的 softmax
+
每一层做一次all reduce,通讯量为 \(O(b\times l\times k\times n)\)
之前使用proposals / anchor / window center 等将问题变成回归和分类问题,导致会出现冗余的框(重复预测),然后就得用NMS来抑制掉这些框
+架构
+训练:
+推理:去掉上面第四步,取置信度大于0.7的物体
+
集合目标函数
+模型生成100个框,而gound truth只有几个框,解决匹配问题——二分图匹配问题
+二分图匹配问题:
+例子,假如有3个员工和3个工作,每个员工对于不同工作有不同的cost(cost matrix),目标是进行分配之后总cost最低
+可以使用scipy.linear_sum_assignment解决这种问题,所以需要确定cost matrix中的cost怎么填,使用如下的公式:

++二分图匹配问题是指在一个二分图中,找到一种最大匹配方案,使得尽可能多的节点能够匹配成功。二分图是指一个图中的节点可以分为两部分,使得同一部分内的节点之间没有边相连,不同部分的节点之间有边相连。匹配是指将图中的边和节点配对,使得每个节点只能和一个边匹配,每个边也只能和一个节点匹配。最大匹配是指在所有匹配方案中,能够匹配成功的节点最多的方案。
+二分图匹配问题可以通过匈牙利算法解决。匈牙利算法是一种增广路算法,通过寻找增广路来增加匹配的数量。具体步骤如下:
++
+- 初始时,所有节点都还没有匹配。
+- 从未匹配的节点开始,按照某种顺序遍历所有未匹配的节点,对于每个未匹配的节点,尝试与其相邻的未匹配的节点进行匹配。
+- 如果相邻节点还没有匹配,直接将它们匹配起来。
+- 如果相邻节点已经匹配,那么就尝试将相邻节点的匹配对象换成当前节点。如果能够成功,就将原来的匹配关系断开,将当前节点和相邻节点匹配起来。
+- 如果不能成功,就继续尝试与下一个相邻节点匹配。
+- 如果所有相邻节点都尝试过了,还是没有匹配成功,就将当前节点标记为已经匹配过了,并返回上一层继续寻找未匹配的节点。
+- 最终,所有节点都将被匹配或者标记为无法匹配。
+通过匈牙利算法,可以求得二分图的最大匹配方案。
+
最后的loss函数
+
最优匹配之后再算loss
+DETR结构
+
object query也是一个可学习的参数
+Abstrat:深的神经网络训练很困难,我们使用残差网络来ease深度学习。深度152层,8倍于VGG,但是计算复杂度降低了。赢得了ImageNet和COCO第一,COCO是物体检测中最大的数据集
+没有conclusion:因为CVPR限制论文在8页之内
+图(一般第一页会放上好看的图,CG甚至会在标题上面放图):
+
提出当深度增加的时候,error反而很高
+
Introduction:
+++Batch Normalization(批归一化)是一种用于深度神经网络中加速训练和减轻过拟合的技术。它通过对每个batch的数据进行归一化操作,使得模型的训练更加稳定和快速。
+Batch Normalization的基本思想是对每个batch的输入数据进行归一化处理,使得它们的均值为0,方差为1,从而使得输入数据分布更加稳定。具体来说,Batch Normalization包括以下几个步骤:
++
+- 对每个batch的输入数据进行归一化,使得其均值为0,方差为1。
+- 对归一化后的数据进行线性变换,包括缩放和偏移操作,使得模型可以学习到不同的特征组合。
+- 将线性变换后的数据输入到激活函数中进行非线性变换,从而得到网络的输出。
+Batch Normalization可以应用于网络的任意层,包括卷积层、全连接层等,可以有效地加速训练,减轻过拟合,同时可以使得学习率更大,从而更快地收敛。
+Batch Normalization的一个重要特点是可以减少对超参数的敏感性,例如学习率和权重初始化等。此外,Batch Normalization还可以被视为一种正则化方法,因为它对每个batch的数据进行了限制,从而使得模型更加健壮。
+
当网络深的时候观察到train和test的error都提高了,说明并不是overfitting
+照理来说深的网络一定包含了浅的网络,直接做identical mapping,所以显示构造identical mapping
+shortcut connection
+
Related Work:
+Deep Residual Learning:
+
++在随机梯度下降(Stochastic Gradient Descent,SGD)算法中,batch指的是一批次(subset)的训练数据。具体来说,SGD将所有的训练样本分成若干个batch,每个batch包含了一定数量的训练样本,通常是2的幂次方,如32、64、128等。
+在每次迭代中,SGD会从训练集中随机选择一个batch的数据进行训练,计算其梯度并更新模型参数。这样做的好处是可以减少训练过程中的内存占用,同时也可以提高训练速度,因为每个batch的数据量相对较小,计算梯度的时间更短,模型参数也更容易更新。
+batch size的大小通常是根据硬件设备的内存大小和训练集的大小来确定的。如果batch size太小,训练过程中的噪声会更大,但是可以更频繁地更新模型参数;如果batch size太大,训练过程中的噪声会更小,但是每次更新模型参数的时间会更长,训练速度也会减慢。
+需要注意的是,SGD在每个batch上计算的梯度只是整个训练集上梯度的一个无偏估计,因此可能会存在一定程度上的不稳定性。为了解决这个问题,可以采用一些优化的算法,如Momentum、Adagrad、RMSProp和Adam等。
+
Experiments
+

注意:ResNet中的通道数是一直在增加的
+

+++

ResNet计算快的原因:加法后面的梯度相对比较大 + $$ + \frac{\partial (f(g(x))+g(x))}{\partial x}=\frac{\partial (f(g(x))}{\partial x}+\frac{\partial g(x)}{\partial x}=\frac{\partial (f(g(x))}{\partial g(x)}\cdot\frac{\partial g(x)}{\partial x}+\frac{\partial g(x)}{\partial x} + $$
+Failure is another way of convergence。SGD一般都能收敛但是要收敛到一个小的值,就是要一直有梯度,能跑得动。所以一般梯度够大就有比较好的结果
+为什么ResNet在CIFAR10小的数据集上没有过拟合还是一个open question,可能是加了resnet降低了模型的复杂度,所以就会找到一个更简单的模型去学而不过拟合
+参数和梯度用fp16保存,这里需要使用\(4\Psi\)字节,另外Adam里需要用fp32保存,需要\(12\Psi\)
+

三种分割方法:\(P_{os},P_{g},P_{p}\),一般称为 \(Zero_1,Zero_2,Zero_3\)
+\(Zero_1,Zero_2\)
+假设两张卡(卡数记为\(N_d=2\)),一层网络。状态用fp32存(\(12\Psi\)),fp16的梯度(\(2\Psi\)),fp16的梯度(\(2\Psi\))。
+将整个状态切成两半,一半留在GPU0(斜线部分),一半留在GPU1,另一半是不需要的,这称为\(Zero_1\),所以内存开销为 \(12\Psi/N_d\)
+fp16的梯度切成两半,称为\(Zero_2\),开销为 \(2\Psi/N_d\)
+假设 \(w\) 是都保存在内存中,那么此时可以计算出一般状态对应的梯度,然后将这个梯度的一半发给另一个GPU的梯度加起来做all reduce。状态更新也是更新一半然后发给对方的参数
+

CLIP学到的特征很稳健,扩散模型多样性比较好且保真度一直在提高
+结构
+虚线上方是CLIP模型,左边图片是文本通过Encoder到文本特征,右边图片通过Encoder得到图像特征,两者构成正样本;CLIP模型是锁住的
+用CLIP中的图像特征做Ground Truth,做预测任务
+本文称自己为unCLIP,相当于CLIP的反过程
+
GAN
+问题是训练不稳定,生成多样性不高
+AutoEncoder
+原理:自己预测自己
+
DAE先给输入一个打乱然后再给Encoder,让结果去重建原始的\(x\),而不是扰动后的\(x_c\),效果很好比较稳健。图片信息比较稳健,加一些noise不会有太多问题,和MAE原理类似
+VAE架构:和之前的架构不同之处,在于之前的工作是学习Bottleneck中的特征,而本文是学习分布。作者假设是高斯分布,将Encoder输出的特征通过几个FC层来预测高斯分布,即均值和方差,然后采样出一个\(z\)然后做生成
+
VQ-VAE
+VQ的含义是vector quantised,即给VAE做量化。VAE模型尺寸不好做大,分布不好学,所以不去做Distribution的预测,而是用Codebook代替,可以理解为\(K\)个聚类中心。然后将Encoder出来的特征图和Codebook中的聚类中心看距离的接近程度,选择接近的聚类中心放到\(Z\)中,然后用这些聚类中心形成新的特征图\(f_a\)
+这里特征是从Codebook中拿到的,所以不能做随机采样,因此不能生成,必须加一个Prior网络来做生成。这些特征本来是做high level任务的,例如分类检测等
+
VQ-VAE2:模型变成层级式,除了局部建模还做全局建模,加上了attention。然后根据Codebook学了一个Prior网络(pixelCNN,这是一个自回归模型),生成效果很好
+++自回归模型(Autoregressive Model)是一种时间序列预测模型,它假设当前时刻的值与前面若干个时刻的值有关。具体来说,自回归模型将当前时刻的值看做是前面p个时刻的值的线性组合,其中p称为模型的阶数。自回归模型常用的表示形式是AR(p),其中p表示模型的阶数。自回归模型可以用于预测时间序列的未来值,也可以用于时间序列的分析和建模。
+
DALLE
+
OpenAI将上面的自回归模型pixelCNN换成GPT
+扩散模型
+架构:前向过程,每次加一点噪声,如果\(T\)无穷大,那么就会得到各向同性的正太分布。
+
reverse diffusion使用的网络模型是UNet
+
DDPM
+之前是从\(x_t\)预测\(x_{t-1}\),作者认为可以只预测噪声\(\epsilon\)。UNet中要加上time embedding(正弦的位置编码或者傅里叶特征),我们希望反向过程中可以先学习低频信息生成物体轮廓coarse,然后最后学习到高频信息,而所有模型是共享参数的,所以需要用time Embedding来提醒模型做到哪一步了
+
预测正太分布其实都不需要学习方差,只学习均值就已经很好了,进一步降低了训练难度
+Improved DDPM:继续学习方差发现效果不错;添加噪声的schedule从线性的schedule改成了余弦的schedule;Diffusion scale很好
+Diffusion beats GAN:更大网络;新的归一化方式,adaptive group normalization,根据步数做自适应的归一化;使用classifier guidance的方法来引导模型采样和生成,加速反向生成过程
+
在训练模型的时候加了一个分类器(简单的图像分类器,可以在ImageNet上预训练,但加了很多噪声),每次\(x_t\)都经过分类器算一个交叉熵然后算梯度再给\(x_{t-1}\),目的是使其更接近某种物体,增加逼真度。
+其他guidance:除了使用简单的分类器做guidance,可以换成使用CLIP模型,另外可以在图像上做特征级别的引导、风格层面的引导,文本可以用LLM。这些引导都是下式中的 \(y\)
+
缺陷是需要使用其他模型,要么自己训要么用预训练模型
+后续工作classifier free guidance(GLIDE,DALLE2):假设我用text做guidance(下式中\(y\)),但是我随机去掉这个guidance(下式中为\(\empty\)),然后会有两个分布,我就可以得到一个方向,然后最后反向扩散的时候如果没有guidance也可以生成。但是这个方法很贵。
+
Decoder(图像特征到图像):基于GLIDE,classifier guidance和classifier-free guidance都用到了
+Prior(文本特征到图像特征):作者尝试了两种方法,自回归和扩散(两者都用到了classifier-free guidance,效果很好)。
+前者训练效率很低(输入是文本特征,有CLIP的图像特征做GT,然后就可以把图片遮住做自回归的预测);
+后者在反向扩散的时候使用了Transformer的Decoder(因为输入输出都是Embedding所以直接Transformer,用UNet不太合适)。模型输入:文本、CLIP文本特征、步数Embedding、加过噪声的图像特征、Transformer自身的Embedding(例如CLS Token),而这个CLS Token就拿去预测没有加过噪声的CLIP图像特征。从DDPM开始大家都是预测噪声,但是本文发现预测图像特征在这个任务里效果更好
+DALLE2使用上述两阶段生成,但是ImageGen里用一个阶段且只用UNet效果也很好
+Scale Matters
+不能很好地将物体和属性结合起来,例如方向位置等。可能是CLIP模型的问题,CLIP模型只看物体相似性,不了解方向等抽象概念
+生成文字不对,可能是因为使用BPE编码导致,因为这是对词根词缀编码的
+ViLT:Vision-and-Language Transformer Without Convolution or Region Supervision
+将目标检测从多模态学习框架中去除
+架构
+之前的模型一般都是文本处理比较简单直接将文本变成Embedding,然后直接和图片特征放到Transformer里做模态融合
+之前的工作Region Feature就像目标检测一样是抽取局部特征,先用CNN Backbone,然后再经过Region Operations获得很多框(使用目标检测的任务)
+
之前的Region Feature在视觉这边占用时间极长
+
ViLT的训练成本很贵且效果一般,但是运行时间非常快
+VLP模型分类
+
上图VE表示视觉Embedding,TE是文本Embedding,MI是模态融合
+CLIP适合抽特征,但是融合比较轻量就不太适合做下游任务,因为它的融合是不可学习的简单的点乘
+前两年主要研究的是方法c,模态融合也使用Transformer
+作者认为抽特征影响不大,模态融合比较重要
+模态融合
+single-stream:两个序列直接compact然后放到模型里
+作者认为第二种方法比较贵
+语言特征抽取:一般都使用预训练的BERT
+视觉特征抽取
+区域学习 Region Feature:Backbone抽特征(ResNet)+ RPN网络抽ROI,然后用NMS将ROI降低到固定数量 + RoI Head将bounding box变成一维向量
+++RPN网络是一种用于目标检测的神经网络,全称为Region Proposal Network。它是在Faster R-CNN模型中提出的一种新型网络结构,用于生成候选区域并对其进行分类,以提高目标检测的准确性和效率。RPN网络可以在一张图像中生成多个候选区域,每个区域都有可能包含目标物体,然后再通过后续的网络结构对这些候选区域进行分类和定位。RPN网络通常使用卷积神经网络(CNN)来提取特征,具有较高的计算效率和准确性。
+ROI(Region of Interest)在目标检测中是指感兴趣区域,即图像中可能包含目标的区域。在目标检测中,先通过一些预处理方法(如边缘检测、图像分割等)找到图像中的ROI,然后对这些ROI进行特征提取、分类等操作,以判断其中是否包含目标物体。ROI的准确性和有效性对目标检测的结果影响很大。
+
Grid Feature:比较贵且性能下降极大
+Patch Projection:借鉴ViT,只使用patch
+模型结构:Transformer Encoder
+将图片和文本变成Embedding之后需要在前面加一些指示Flag,因为single-stream不能区分图像文本,所以需要在前面加0/1表示文本或图像;文本和图像最前面需要加CLS Token;另外需要加position embedding;注意这里三个Embedding是相加的而不是拼接
+
loss:Image Text Matching + Masked Language Modeling + Word Patch Alignment,最后一种用的人比较少,也是想算文本和图像特征相似度,利用Optimal Transport最优运输理论,简单理解是输出的文本特征和图像特征各有一个概率分布,作者计算了两个分布之间的距离。第二种loss就是BERT的完型填空
+Whole Word Masking
+之前用的是WordPiece Token,就是将一个word切成几份,如果中间mask掉一个的话,模型可以根据首尾几个字母直接猜出来,而不用去从图像中学,相当于一个Shortcut。所以直接将整个word去掉
+这个trick很有效
+数据增强
+RandAugment,但是不使用Color inversion和cutout
+
分割和分类很像,相当于像素级别上的分类。Paperwithcode上分割论文最多,因为分类任务都能直接在分割上用
+Language-Driven Semantic Segmentation
+架构:和CLIP非常像。图像特征变成了dense feature密集特征,然后做点积做融合
+图像Encoder使用的是DPT,相当于ViT+Decoder,将原图降维一些。不看上面的文本信息其实和分割模型是一样的。
+说是zero-shot但是是有监督的学习,不是对比学习(无监督学习)的loss
+
训练:文本编码器就是用的CLIP,并且由于分割数据集小,所以freeze了整个文本编码器。图像编码器使用CLIP反而不行,用ViT更好,很难解释
+Zero-Shot的效果比之前用ResNet的OneShot的效果差很多,提升空间很大
+CLIP其实关注算图像和文本之间的相似性,所以如果把上面的标签other换成一些抽象的虚词也可以替代原来的other的效果,并不是真正的分类
+Group ViT: Semantic Segmantation Emerges from Text Supervision
+上面的工作还依赖于手工标注,如何做到无监督训练是更被关注的
+架构
+之前做无监督分割的时候经常用一种方法叫Grouping,如果有一些聚类中心点,然后从这个点开始发散,然后逐步扩充成一个Group,自下而上的方法,这个Group就相当于一个segmentation mask
+作者在ViT的框架中加上Grouping Block以及可学习的Group Tokens,在浅层的分割效果一般,但到上层效果就很好了
+一开始Group Tokens维度是64表示一开始有64个聚类中心(替代了之前一个CLS,因为之前想用一个Token来代表整个图片),384是ViT模型特征长度
+经过6个Transformer Layers之后然后进入Group Block,Group Block的作用是将图像特征进行一次Assign,相当于将图像特征cluster到一个聚类中心去,所以得到64个Segmentation Token
+
具体的Group Block如下:类似自注意力。聚类中心的分配是不可导的(?),所以这里用一个gumbel softmax将此过程转变为可导的
+
之后再加新的Group Tokens,来进一步减少聚类中心,最后得到8个聚类中心
+loss使用CLIP的对比学习,文本直接得到文本特征,图像最后8个特征经过平均池化加MLP得到图像特征
+zero-shot推理:就是图像有8个特征,然后文本一个特征算相似性,最大的局限是最多只有8类
+
背景类:设置前景的阈值,如果所有的Embedding都小于阈值则将其分给背景类。导致的问题就是如果图像内类别很多置信度就不够高。作者发现Group ViT分割做的很好,但是语义分割不太好,可能是因为CLIP只能学到物体语义信息非常明确的物体
+Open-Vocabulary Object Detection Via Vision and Language Knowledge Distillation
+CLIP当老师蒸馏网络,open-vocabulary就是任意类别
+
方法
+

++目标检测中的proposal是指对输入图像中可能包含目标的区域进行预测和筛选,生成一组候选框,即候选区域。这些候选区域通常是在输入图像中的各个位置和尺度上生成的,可以包含目标或不包含目标。目标检测算法会在这些候选框中寻找目标,并进行分类和定位。生成proposal的方法有很多种,常见的包括滑动窗口、选择性搜索、快速RCNN中的候选框网络等。
+



模型总览图
+
GLIP
+标题:Grounded Language-Image Pre-training
+作者找到一类任务是Vision Grounding,将一句话中的物体在图片中找到,和目标检测类似,但是多一个文本信息,作者发现可以把Detection和Phrase Grounding任务融合起来从而获得了更大的数据集,另外可以使用伪标签等技术可以在没有标注过的图像文本对上生成Bounding Box标签从而扩大数据集数量
+背景:Vision Grouding任务和目标检测的任务的联系,目标检测的loss是分类loss+定位loss,Vision Grounding的定位loss是一样,但是分类loss不一样。目标检测的标签是一个或两个词,是one-hot标签,而Vision Grounding是句子
+目标检测的分类Loss:\(O\)是图片每个Bounding Box的特征 \(N\times d\),\(W\)是分类器矩阵,得到\(S\)是logits,最后算一个Loss
+
Vision Grounding的分类Loss:计算图片区域和句子中的word匹配分数\(S_{ground}\)
+
Img通过Encoder得到Region Embedding,Prompt通过Encoder得到文本Embedding,然后算相似度。这块和ViLD-text一样
+接下来的任务就是如何将这两个任务统一起来,只要做一个小小改动即上面时候算是positive match,什么时候是negative match
+作者发现GLIP可以迁移到任何一个目标检测的数据集上,接下来就是看如何扩大数据集
+作者既使用Detection数据集又使用Grounding数据集做预训练。Detection用的是Object365,在Object365上做预训练然后在COCO上做微调一般都会非常好;Grounding用的是GoldG,有Bounding Box Annotation。作者还想要更大的数据集,于是引入unlabeled的Cap24M(图像文本对),但是需要知道Bounding Box和Box内物体的信息,所以作者使用伪标签,直接使用小模型(GLIP-T(C))给这些图像文本对做推理打标签(Self-Training)。伪标签一般效果会更好
+++Bounding Box Annotation是指在图像或视频中对目标物体进行框选标记的过程,通常用于目标检测、物体识别、跟踪等计算机视觉任务中。这种标记通常用矩形框或正方形框来表示目标的位置和大小。在深度学习中,Bounding Box Annotation是训练物体检测和识别模型的重要步骤之一。对于每个目标,需要标注出其在图像中的位置、大小和类别等信息,以便模型能够从图像中正确地识别和定位目标。
+
总体框架
+下图Matrix里是监督学习,我知道每个Bounding Box对应的文本,所以可以算相似度的Alignment Loss,另外有Ground Truth可以做Localization Loss。
+Deep Fusion阶段本来是获得了两种Embedding就直接算相似度矩阵,但是这里多加一些层数来使其进行融合,本文使用Cross Attention。这种Deep Fusion可以用到分割中,比如GroupViT有两个分支可以做EarlyFusion
+检测和分割都属于稠密预测,很多方法可以互相借鉴
+
GLIP v2: Unifying Localization and VL Understanding
+融合更多的任务和更多的数据集,将所有带定位(分割检测)和Vision-Language的任务都融合起来(VQA、Vision Grounding、Vision Caption)
+架构:统一框架,融合更多文本任务、数据集、模态
+
CLIPasson: Semantically-Aware Object Sketching(SIGGRAPH)
+CLIP+毕加索,保持语义信息的物体速写
+之前的工作就是data-driven,抽象程度由数据集控制,数据集有如下:
+
但里面最大的数据集也就是QuickDraw,只有300多类
+CLIP对物体的语义信息抓取的特别好,同时zero-shot能力很强,文献中提到CLIP抽取的特征特别稳健,不光在自然图像上,于是作者认为可以运用到简笔画上
+++CLIP is exceptional at encoding the semantic meaning of visual depictions, regardless of their style
+https://distill.pub/2021/multimodal-neurons
+
本文可以根据笔画的多少来决定抽象的程度
+架构
+每张图是由Sketch组成的(\(S_i\)表示Sketch),每个Sketch是一条贝塞尔曲线,每条曲线由4个点决定
+本文主要的贡献是最初的初始化以及最后的训练,中间的光栅化器是之前的工作。主要思想也是利用CLIP特征的稳健性来进行知识蒸馏,作者认为风格改变不会影响前后两张图的语义信息,所以我需要将这两个特征尽可能接近,所以设计了第一个loss函数 \(L_s\) 即 基于语义的特征;另外还需要几何上的一些限制即 \(L_g\),用ResNet50前几层的图像做几何上的Loss,因为前面的特征图还有长宽概念,所以可以来做几何上的限制,而后面的特征已经只剩下语义特征了。
+
作者发现初始化非常重要,所以作者提出基于saliency的初始化方式,使用ViT最后一层多头自注意力取一个加权平均得到saliency map然后看哪些区域更显著,在这些显著的区域行采点。其实就是已经知道物体的边界,在沿着边界画点了
+作者还加了一个后处理,每次生成3张简笔画,然后根据\(L_g / L_s\)然后返回最好的画
+局限性
+CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
+任务是Video Text Retrieval,CLIP天生适合Retrieve / Ranking / Matching 相关任务,因为CLIP就是算Video和Text的相似性
+双塔结构
+图像和文本编码器分开,得到特征之后做点乘得到相似度,扩展性比较好,可以提前将大的数据集的特征先抽取好
+
文本直接放到Transformer得到一个CLS Token,图像多帧依次放入得到多个CLS Token。原来是一个文本特征对应一个图像特征直接做点乘计算相似度,现在是一文本特征对应十个图像特征,本文是empirical study,所以就尝试了各种方法来看哪个效果最好
+
平均池化(作者称为Parameter Free):简单,但是没有考虑时序信息,例如做下和站起取平均是一样的,接受度最高
+LSTM 或 Transformer+Positional Embedding
+Early Fusion(作者称为Tight Type),之前的方法是Late Fusion即抽完特征考虑如何融合,这里是一开始就融合,直接用同一个Transformer
+++机器学习中的Video Text Retrieval(视频文本检索)任务是指在视频中检索与文本查询相关的视频片段。具体来说,给定一个查询文本,该任务的目标是找到与该文本相关的视频片段。这些视频片段可以是包含查询文本中的关键词的视频,或者与查询文本语义相似的视频。该任务在视频内容分析、视频搜索和视频推荐等领域具有广泛的应用。
+在机器学习和信息检索中,Recall(召回率)是指在所有相关文档中,被正确检索出来的文档数与所有相关文档总数之比。换句话说,召回率表示了检索系统能够找到多少与查询相关的文档。
+公式表示为:
+Recall = TP / (TP + FN)
+其中,TP表示真正例(被正确检索出来的相关文档数),FN表示假反例(未被检索出来的相关文档数)。
+召回率越高,说明检索系统能够找到更多的相关文档,但同时可能会将一些不相关的文档也检索出来。因此,召回率与准确率(Precision)一起被用来评估检索系统的性能。
+
实验
+Insight
+ActionCLIP: A New Paradigm for Video Action Recognition
+视频领域更火的任务:动作识别,其实就是分类任务但是加上额外的时序信息
+之前的方法:
+视频通过Video Encoder得到输出,然后和Ground Truth做对比,然后就可以算起loss,但是问题是视频理解的标签不好标,one-hot label比较难代表其全部语义,动作识别的label是一个短语,label space很大,导致遇到新类效果不好。所以最理想是先学一个很好的特征,然后zero-shot或者few-shot去做下游任务是最理想的
+作者提出的方法和CLIP很像,VideoEncoder和CLIP4Clip很像;在batch比较大的时候同一行同一列里可能有多个正样本对
+
模型
+
实验
+AudioCLIP: Extending CLIP to Image, Text and Audio
+架构:仿照CLIP做对比学习,加入Audio模态
+
PointCLIP: Point Cloud Understanding by CLIP
+CLIP学习到了很好的2D特征,作者想迁移到3D
+架构:将3D点云投影到2D深度图,由于CLIP支持各种风格,所以这种深度图也能支持。文本prompt改成了point clound depth map of
+
Can Language Understand Depth?
+深度估计任务
+CLIP对概念理解不太好,因为对比学习不适合学概念,而深度信息就是概念。所以之前做optical flow和depth estimation和主流CV不太一样,往往不做初始化
+流程图
+作者将深度估计任务从回归问题看成分类问题,强制将深度分成了几类,和LSeg很像
+
++回归问题和分类问题是机器学习中两种不同的问题类型。
+回归问题是指预测连续值的问题,例如房价预测、股票价格预测等。回归问题的目标是预测一个数值,通常是一个实数值。
+分类问题是指将数据分为不同的类别的问题,例如垃圾邮件分类、图像分类等。分类问题的目标是将每个数据点分为一个或多个已知的类别中的一个。
+回归问题和分类问题的区别在于它们的输出类型不同。回归问题的输出是一个连续值,而分类问题的输出是一个或多个离散的类别。此外,回归问题通常涉及到连续的输入变量,而分类问题通常涉及到离散的输入变量。
+
CLIP的使用场景:
+Prompt类型
+Zero-Shot
+
Zero-Shot-CoT
+
Manual-CoT:手动构造样例
+
Auto-CoT:Self-Training,先用Let's think step by step得到样例输入然后拼接在一起作为样例,然后接输入
+
数据处理
+使用过滤器去除机器生成的label;
+先训练一个模型然后去推理,检查正确率低的样本发现很多语音和文本是对不上的,就把这些去掉
+架构:就是Transformer,一开始使用卷积来抽取局部特征
+

不同任务用的是不同token来区别,共用输出层:
+
zero-shot,为了符合某些数据集test的要求,手动做了一些normalize
+比较:虽然是LibriSpeech上的WER别的模型已经刷到非常低了,但是迁移到别的数据集错误率非常高,而Whisper的迁移能力很强
+

ALBEF
+标题:Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
+架构:
+图像使用12层Transformer编码器,文本把12层的BERT切成两个部分先6层Encoder然后6层多模态融合,符合:图像Encoder大于文本Encoder;模态融合模型要大
+Loss用的也是上面提到的 MLM / ITM / ITC
+
摘要:
+方法:
+图片用的是就是ViT,而文本这边本来可以直接用BERT然后再在后面加个大的多模态Encoder,但是为了保持最优配比,即图像部分模型和多模态模型要大,所以这边就把BERT劈成两半,初始化用的就是BERT
+另外有一个Momentum Model,它的参数是旧的ALBEF参数,动量更新,moving average设的很高0.995使之不会很快更新,从而使得产生的特征更加稳定
+Align阶段:抽完特征之后和MoCo一模一样,先downsample和normalization,然后将正负样本对比进行第一阶段的学习
+
最后ITM其实就是二分类任务,在ALBEF后面加个FC来检查输入文本\(T\)和输入图像\(I\)是否是一对,但是这个任务难度很低,负样本和正样本的区别很大(可能经过ITC),很快就能让准确度提很高,所以这里给负样本加constraint,其实就是选择最接近正样本的负样本,选择的方法是选择同一个batch里在ITC中相似度最高的negative(称之hard negative,即已经非常相似我仍然认为其是negative)
+MLM:完型填空,将文本masked之后变成\(T'\),所以会发现该模型要做两次前向过程。多模态学习往往要做多种Loss所以可能要做多次前向过程来得到不同的Loss
+
由于伪标签是Softmax Score,所以算的是KL散度,例如 ITC 的更新:
+
ITM 没有使用动量更新,是因为 ITM 是二分类任务,就是需要知道Ground Truth
+实验:测试了五个下游任务,检索(图搜文、文搜图、图搜图、文搜文、看Recall,有R1 R5 R10)、视觉蕴涵Visual Entailment(前后两句话之间的关系,蕴涵矛盾中立,三分类问题)、视觉问答Visual Question Answering(有两种,闭集VQA即选答案,开集VQA即生成答案,用的是闭集VQA)、Visual Reasoning(一个文本能否同时描述一对图片,二分类任务)、Visual Grounding
+VLMo: Unified Vision-Language Pre-training with Mixture-of-Modality-Experts
+研究动机1:目前主流有两种结构
+研究动机2:使用的目标函数也是上面三种,需要大量数据,但是当时多模态的数据不多,所以作者使用stagewise pre-training strategy,因为单模态的数据非常多,所以就让vision expert和language expert分别在各自数据集上训练,之后再在多模态上做训练,效果就很好
+架构:
+每个Block和Transformer Block很像,之是最后用不同的FFN(Feed-forward Network),三个不同的FFN是不share weights,但是自注意力层是share weights(说明自注意力不挑输入形式,适合多模态学习)
+ITC就是CLIP,ITM是Fusion Encoder形式
+好处就是灵活
+
| Text Only | |
|---|---|
1 +2 +3 +4 +5 +6 +7 +8 +9 | |
++因此,可以说FFN和FC是MLP的组成部分,MLP包含了多个FC层和激活函数,而FFN是一种特殊的MLP,只包含一个输入层、一个输出层和若干个隐藏层。
+
Vision Pre-training使用自己的BEiT(Masked Image Modeling),Language Pre-training用的是Masked Language Modeling,最后VL Pretraining用的是上面提到的三个函数
+注意哪些是frozen的:一开始全部打开很正常,Language训练阶段注意自注意力层被frozen了直接用 Image 上训练的自注意力层(反过来不行,这个可以探索),最后就都打开了
+
BeiT——VLMo——VL-BeiT——BeiT v2——BeiT v3
+
BLIP:Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
+关键词:Bootstrap和Unified。Bootstrap表示从noisy data中训练一个模型然后通过一些方法得到更干净的数据,然后用更干净的数据train出更好的模型;Unified表示应用在多种任务上,包括Understanding任务(Retrieval / VQA / VR / VE)和Generation(Image Captioning生成字幕)生成式任务
+研究动机
+模型:之前的Encoder模型不能运用到生成任务中,而Encoder-Decoder不能做Image-text Retrieval的任务,这个动机和VLMo是一样的
+数据:通过数据集变大可以提高效果,但是在Noisy的数据集上预训练还是不好的(suboptimal,不是最优解),作者提出两个模块 caption 生成字幕,Filter删除不匹配的图像文本对
+
背景:之前的ALBEF和VLMo,后者更加简单
+
架构
+图像就是一个ViT,文本使用三个模型。不看文本的第三个,其实就是个ALBEF,只是文本Encoder更大且可以共享参数(借鉴VLMo)而不是劈开成两个;生成模型就是第三个文本模型,但是文本不能直接看全部,因为就是要生成这种文本(任务是像GPT一样的LM,不是MLM完形填空),所以使用causal self-attention因果自注意力层,使用相同参数会导致性能下降,因为这是在做不同任务
+prompt在最前面加上了CLS / Encode / Decode

Captioner-Filter
+网络下载的文本\(T_w\)质量差,而手工标注的\(T_h\)质量较好
+Filter就是将ITC和ITM部分的模型拿过来然后在COCO手工数据集上做Finetune作为Filter,进行数据清洗
+Captioner:作者发现Decoder能力很强,所以就在COCO上做微调然后变成Captioner,然后生成一些图像文本对
+生成Caption很有效
+
实验:
+应用:
+Stable Diffusion生成Pokeman,有图但没label,用BLIP生成效果很好
+LAION COCO数据集:从LAION 4B中取英语然后用一个BLIP两个CLIP做Cap-Filter得到COCO 600M。先用BLIP生成40个Caption,然后CLIP选最好的5个然后再用更大的CLIP选最好的。
+CLIP做Ranking / Retrieval 效果都挺好
+
CoCa: Contrastive Captioners are Image-Text Foundation Models
+看标题就知道使用了两种Loss:Contrastive Loss和Captioning Loss
+架构:
+和ALBEF很像,但是文本使用的是Decoder
+图像这一支用的是attentional pooling,是可学习的
+文本最后使用captioning loss,所以一开始的self-attention都是casual的(就是masked self-attention)。作者没有使用ITM Loss,是因为之前的工作要Forward很多次,训练时间过长,这里为了只Forward一次,所以输入的文本都是masked。由于模型在几十亿的数据上训练所以怎么masked都可以
+
++Casual self-attention layer是一种神经网络层,用于处理序列数据,例如自然语言文本。它是自我注意力机制的一种形式,允许模型在处理序列时关注先前的位置,但不允许模型查看未来的位置。这使得模型可以在处理序列时更好地捕捉上下文信息,同时避免了信息泄漏问题。Casual self-attention layer通常用于Transformer模型中,是其核心组件之一。
+
效果
+
BeiTv3
+标题:Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
+多边形图:超越CoCa
+Public Dataset,只用一个Loss。所以不是更多Loss做Regularization就更好,需要看各种Loss是否有弥补性,另外就是当模型变大的时候是否需要其他的Loss函数,另外数据量也不是越多越好,CoCa的数据量是几十倍于BeiTv3的,所以数据质量很重要
+引言(做多模态必读):Language / Vision / Multimodal 都出现Big Convergence趋势,大模型成为Foundation Model。讨论目前的多模态模型架构,作者认为目前的架构仍然需要根据下游任务做调整,所以作者希望能够进一步实现大一统。作者将图像看做一种foreign language,称为Imglish
+架构:就是VLMo,完型填空
+


目前有两种模型想做更General的框架:
+retrieval:找到query相关的所有的文档;ranking:给一个更加精确的分数。ranking阶段常常会用深度学习来预测query和文档的相关性,但是这比较贵,所以retrieval阶段需要比较高的召回
+文档检索有两种方法:
+term-based:倒排索引,高效但是语义搜索能力不强
+semantic-based:query和document映射成一个向量,往往使用two-tower模型。然后搜索的时候用近似的K近邻算法,不适合exact match
+


用了个trick,除了Transformer本来的Decoder,这里另外加了AdaptiveDecoder
+

GPT的目标函数是预测下一个词,但是人类希望的是正确且安全地输出,所以作者认为语言模型的目标函数没有align
+作者使用RLHF,原因可能是OpenAI是做强化学习出家的
+方法
+第一阶段:SFT,Supervised FineTune,标注一些对话
+第二阶段:类似伪标签,让GPT生成多种输出让用户来选 Beam Search,人类进行答案排序,称为 RM 奖励模型
+++Beam Search是一种搜索算法,用于在图形或树形结构中寻找最佳解决方案。它是一种贪心算法,每次扩展搜索树时只保留一定数量的最优解,而不是全部扩展。这个数量称为Beam Width或Beam Size,通常设置为一个较小的常数。
+Beam Search的基本思想是在搜索过程中维护一个集合,该集合包含最有可能的解。这个集合会随着搜索的进行而不断扩大,但是集合中的解的数量不会超过Beam Width。每次扩展搜索树时,会考虑所有可能的扩展,然后选择一些最有可能的解作为下一步的搜索。这些解会被添加到集合中,并且根据它们的得分进行排序。然后,集合中的解就是下一步搜索的候选解。这个过程会一直重复,直到找到一个满足条件的解。
+Beam Search的优点是它能够在短时间内找到一个较好的解决方案,而不需要搜索整个解空间。缺点是它可能会陷入局部最优解,因为它只保留了一部分解。
+
第三阶段:用一个新的prompt生成output给reward model计算reward,然后提高分数
+
数据集
+首先用人标主的信息实现一个InstructGPT,标准包括:
+
然后放到Playground里,然后收集用户的问题,然后再,过滤掉个人信息,并且训练的时候不使用同一个人文的很多问题(最多200个)
+三个dataset:SFT / RM / PPO,第三个数据集没有human label
+
模型
+SFT:FineTune GPT3,用人工标注的数据,因为只有13K,所以只用了16epoch,但是发现只扫一边就过拟合了,但是这是为了初始化后面的模型,所以过拟合也没太大问题
+RM:
+目的是训练另一个模型,拟合人对于prompt+reponse的评价(排序)
+使用6B的模型,从SFT开始去掉最后的Unbedding层(可能就是去除Softmax层,然后直接用线性层投影成一个值,将这个标量输出看作是reward),输入是prompt及其response。作者发现大模型不稳定,所以使用小的模型
+输入是排序而不是一个值,所以需要把顺序变成值,使用Pairwise Ranking Loss,简单的想法就是如果一个response比另一个的排序更高就让它的reward和另一个差更远。这里排序答案数量\(K=9\),因为发现排序读题的时间更长,当\(K\)越大,得到的排序关系就越多;同时下式中\(r_{\theta}\)最贵,但是只用做\(K\)次RM,所以\(K\)越大省更多时间
+
RL:PPO是之前OpenAI的工作,就是在下面的目标函数上做梯度下降
+
在强化学习中,模型称为Policy。我们要学习\(\pi_{\phi}^{RL}\),初始化成\(\pi^{SFT}\),\(E_{(x,y)}\)中的\((x,y)\)就是第三个PPO数据集里的prompt \(x\) 及其reponse \(y\)(\(y\)是用当前模型 \(\pi_{\phi}^{RL}\) 算出来的),当模型数据更新之后,\(y\)是会改变的(即环境发生变化)。然后将\((x,y)\)丢到RM模型里来算reward分数,我们希望让这个分数最大。
+RM模型其实相当于做一个AI判分,替代了人工判分,本来RLHF阶段应该是\(x\)通过模型得到\(y\)然后停下人工排序然后给分数,再更新模型,这里RM模型直接跳过人工排序步骤(在线)。如果人能直接标出\(y\)那就变成了有监督,可以放到SFT阶段
+但是\(r_{\theta}\)是基于\(\pi^{SFT}\)的,当\(\pi^{RL}\)在训练的时候会让输出\(y\)分布变化,使得\(r\)的分数估算逐渐变得不准,所以第一个中括号中的第二项使得新模型和之前的模型不要跑太远,其实就是KL散度,看两个模型输入同一个\(x\)输出\(y\)的概率值的KL散度(这个就是PPO思想)。最后一项是不光注重RLHF、防止遗忘之前的训练参数、多偏向原始数据,其实就是原始的GPT3的目标函数,加上最后一项称为PPO-ptx
++++
+
https://datawhalechina.github.io/easy-rl/#/chapter5/chapter5
+



左边是编码器右边是解码器,解码器之前的输出作为当前的输入(所以这里最下面写的是output)
+Nx表示由N个Block构成,每个block里面有一个多头注意力层+前馈神经网络(基本是MLP)并使用ResNet。
+++MLP(Multilayer Perceptron,多层感知器)是一种基本的前馈神经网络,由多个全连接层组成。在每个全连接层中,每个神经元都与前一层的所有神经元相连,通过学习权重和偏置,实现对输入数据的非线性映射。
+MLP通常用于解决分类和回归问题,可以处理非线性数据,具有很强的适应能力和泛化能力。在训练过程中,MLP通过反向传播算法来更新权重和偏置,使得模型可以逐渐逼近真实数据的分布。
+MLP的网络结构通常包括输入层、隐藏层和输出层。输入层接收原始数据,并将其传递给第一个隐藏层;每个隐藏层通过学习非线性映射,将输入转换为更高层次的特征表示,并将其传递给下一个隐藏层或输出层;输出层根据不同的任务,可以采用不同的激活函数,如sigmoid、softmax等,将特征转换为输出结果。
+MLP在深度学习中具有重要的地位,是其他深度学习算法的基础。它可以通过堆叠多个隐藏层来构建深层神经网络,从而实现更强大的特征提取和学习能力。同时,MLP还可以与其他深度学习技术相结合,如卷积神经网络和循环神经网络等,构建更加复杂的神经网络模型。
+
解码器中多了Masked Multi-head Attention
+与传统的Encoder-Decoder的架构的区别是Block的架构以及中间从Encoder到Decoder的输入。
+

LayerNorm与BatchNorm,在变长的情况(文本不是统一长度)不使用BatchNorm
+对于BatchNorm,在train的时候,一般是取小批量里的均值和方差,在预测的时候用的是全局的均值和方差。什么是批标准化 (Batch Normalization) - 知乎 (zhihu.com)。二维情况(每个样本对应一个feature)在下图中BatchNorm是下图左边,LayerNorm的下图右边。
+
三维情况(batch由样本组成,每个样本是seq长度的向量,每个词由一个feature向量来描述,feature长度是d,transformer中是512),蓝色是BatchNorm,黄色是LayerNorm。
+
句子长度是不同的,对于BatchNorm有很多零,导致均值方差抖动大,并且不一定能适合于长句子
+

解码器:其中的masked multi-head attention,输入的时候在\(t\)时间不会看到\(t\)时间之后的输入(注意力机制中是可以看到完整输入的,所以要加masked)
+


上面黄色和绿色表示query,和蓝色越接近,对应的权重就越大
+将query和key的内积作为相似度(cos),如果为0说明正交。第二段是矩阵运算来加速的方法
+
query的数量可能有\(n\)个,key-value的数量是\(m\)个,但是query和key的长度都是\(d_k\)。最后结果每一行都是一个结果
+
其他人使用的注意力机制:additive attention(处理query和key不等长的情况)和dot-product attention(和本文相同,除了本文除了\(\sqrt{d_k}\))
+
除以这个数的原因是:当\(d_k\)比较大的时候,算出来的加权value值差距较大,经过softmax有些值变成1有些值变成0,所以要除
+
上图masked表示对于\(t\)时间的query \(q_t\),应该只看\(k_1,k_2,\dots,k_{t-1}\)。这里的解决方法是:将\(k_t,\dots\)换成非常大的负数,使得通过softmax都是0
+


Transformer输入输出维度一直是512,这里\(h\)用的是8,所以这里就让投影之后为64维,之后拼起来变成512维
+实现的时候可以一个矩阵乘法实现
+
第一个自注意力层:输入\(n\)个(句子中词的数量)长为\(d\)(每个词的feature)的向量。自注意力表示输入同时作为query和key和value。假设不考虑多头,那么会得到\(n\)个长为\(d\)的结果,每个结果都是所有value的加权和,而这个权重里,最大的就是自己和自己的权重
+

第二个自注意力层:和上面基本一致,除了masked,所以上图中黄色画的线都要置成0
+
第三个注意力层:key和value(\(n\)个长为\(d\))来自Encoder,query(\(m\)个长为\(d\))来自Decoder。例如Encoder中Hello和World分别对应一个长为\(d\)的向量即value,那么结果一定是这些value的加权求和,而这权重就是Decoder中query和对应key的相似度,例如“你”可能和"Hello"比较接近则权重更大。
+就是MLP。特点是“applied to each position separately and identically”。下面\(x\)是512的向量,\(W_1\)将其投影到2048,\(W_2\)将其投影回到512,即单隐藏层的MLP。
+

下面的红色是attention层,上面是对每个position做MLP(尽管画了多个方块,但是每个position的MLP是相同的)。attention的作用是aggregate汇聚我所有感兴趣的信息,即完成了序列信息的汇聚,所以可以分开MLP
+
右边其实和RNN很像,但是用的是attention抽取的序列信息。
+
attention没有时序信息,句子打乱之后值不会变,这有问题。所以这里将位置1,2,3,4,5...加到句子里面。
+公式:
+
使用上面的公式编码数字,然后加到Embedding之后的向量里。由于是使用sin和cos,这个位置编码是在-1到1之间的,所以上面的embedding要乘一个常数使其大致在-1到1之间
+
Parameter-Efficient Transfer Learning for NLP
+Adapter就是一个下采样的FC层+非线性层+上采样的FC层,在模型微调的过程是不会动Transformer Block中的其他模块的参数
+
Lora就使用了PFET方法
+相关论文:Towards A Unified View of Parameter-Efficient Transfer Learning
+文本Prompt相关技术
+论文:CoOp(Context Optimization)
+标题:Learning to Prompt for Vision-Language Models
+
CLIP的分类任务的推理,就是用各种标签(Prompt)和图片算相似度,这种Prompt可以修改格式,从而大幅影响模型的准确率
+人工写死的Prompt是hard prompt,而本文提出soft prompt可学习的prompt,就是一个learnable vector。将模型参数锁住,然后学习这个learnable vector
+架构:和CLIP不同的是text的输入是一个可学习的向量
+
视觉Prompt相关技术
+论文:VPT(Visual-Prompt Tuning)
+标题:Visual-Prompt Tuning
+架构
+
AIM: Adapting Image Models for Efficient Video Action Recognition
+视频动作识别
+之前有两种方法:首先我们都要有一个预训练的Image模型(2D)
+时空一起做
+时空一起做(3D),使用3D网络(输入是3D的,模型也是3D的),例如 I3D 等
+这两种方法成本都比较大,需要在视频数据上做FineTune,但视频数据集很大,数据 IO 有Bottleneck,导致训练时间极长,这些还已经是在预训练模型上FineTune,其他train from scratch的就更耗费时间了
+
作者认为强大的图像模型抽取的视频特征已经很强了,同时下游任务数据集不够强可能会导致模型过拟合或灾难性遗忘,所以就打算直接锁住Image Model,然后在上面加Adapters
+本文提出三种Adaptation:
+(e)就是一个ViT Block,重复12次得到Vit-Base
+
发现如果Image Foundation Model变强,性能也会大幅提高
+zero shot > few shot > pretaining
+Unsupervised Semantic Segmentation With Self-Supervised Object-Centric Representations
+语义分割任务
+Self-Supervised:使用预训练好的DINO网络等,不需要额外训练
+Object-Centric Representation:比较新的赛道。之前大家关注图像整体层面的特征,这个赛道是提取物体层面的特征,因为人会先观察人再观察物体然后观察人与物体之间的交互。本文关注如何无监督或自监督地学习物体特征。
+首先先用DeepUSPS(给定图片会提取出显著物体的Mask)抽取saliency mask label,如此解决定位问题;然后解决分类问题,将扣出的这些图形之后然后resize成224*224扔给DINO网络,得到representations;然后做无监督的聚类,得到pseudo masks(即能告诉你每个东西是类0或是类1或是类2,只是一个id);有了图像和mask label就可以有监督地训练一个semantic segmentation network(例如DeepLab v3)
+
最近该方向卷起来了,因为有CLIP的Language Guided Segmentation
+关注一些新的topic包括因果学习、Feedforward Network(FFNet)、In-Context Learning、Chain of Thought Prompting
+



哪些问题有图结构的data
+图层面任务:例如判断一个图是否有环,可以不使用机器学习即可
+顶点层面的任务:两个顶点代表的人决裂之后,其他和他们两个有社交关系的人决定是否和他们一起
+
边层面的任务:先对图进行语义分割,然后用图神经网络学习其关系
+
机器学习中使用图的挑战
+点、边、全局信息都是向量比较好处理,但是连通性如果用邻接矩阵开销就过于大了
+邻接矩阵可以有多种表达
+


最后一层的输出得到预测值
+例:对每个顶点做预测。每个顶点都是一个向量,如果做二分类,就通过一个输出维度为2的全连接层,然后加个softmax得到输出
+
Pooling,如果某个点没有向量,那么就取它所有相邻边的向量以及全局向量相加,
+
所以如果没有边的向量信息,那么可以用点的向量信息来聚合Pooling。反之亦然
+

网络结构:不同属性经过GNN层得到变化之后的图,然后用聚合操作得到希望预测的属性,然后通过全连接层得到最后的Prediction
+
上述结构存在问题,点与点的相邻关系等都没有包含进去
+Message passing信息传递
+进入MLP之前,输入点相邻的点也要输入到MLP中
+
信息传递最简单的是一近邻。
+
另外可以不在最后一层做Pooling,可以提前在前面的层先汇聚起来
+例子:\(\rho(V_n\rightarrow E_n)\)表示将顶点信息汇聚到边上
+
全局信息
+某些点相距较远,需要比较长时间才能传递到
+加入一个虚拟的点 master node或者叫 context vector
+
略
+采样
+CNN中会使用随机采样。GNN中使用的是如下策略
+
GNN的假设:图的连通性
+GCN:图卷积神经网络,带汇聚的GNN
+
++深度生成模型的影响较小,这是由于在最大似然估计和相关策略中出现了许多难以近似的概率计算,并且很难利用分段线性单元在生成环境中的优势。我们提出了一种新的生成模型估计过程,可以避开这些困难。
+
生成模型:造假者;判别模型:警察
+生成模型是一个MLP,通过随机噪音生成sample;判别模型也用MLP
+++对数似然函数是一种用于最大似然估计的函数。最大似然估计是一种统计推断方法,用于估计参数值,使得给定观测数据的条件下,该参数下的概率密度函数或概率质量函数最大化。
+在数学中,给定数据样本集合,对数似然函数是指这个样本集合的概率密度函数或概率质量函数的对数形式,这个函数的值越大,表示该参数估计值越优。
+通常情况下,对数似然函数的形式是一个关于参数的函数,用参数的估计值代入函数中得到的结果最大化,即是最大似然估计的结果。
+对数似然函数的使用可以简化计算,因为将似然函数取对数后,可以将连乘变为连加,减少了数值计算的复杂度。此外,对数似然函数还有其它一些优点,如避免数值下溢、易于求导等。
+生成模型是一种机器学习模型,用于学习样本数据的概率分布函数。与生成模型相对应的是判别模型,判别模型直接从输入到输出映射,不考虑数据的分布情况。
+生成模型通常基于概率分布函数,用于生成与样本数据类似的新数据。因此,生成模型需要对样本数据的概率分布进行建模,以便生成新的数据。
+对数似然函数可以被用来评估概率分布函数的质量,因为它是衡量模型对样本数据拟合的常用指标。通常,生成模型使用对数似然函数作为目标函数进行优化,以最大化对数似然函数的值。
+具体来说,最大化对数似然函数可以使得生成模型的输出更加接近于样本数据的真实分布,从而提高模型的生成能力。此外,对数似然函数的优化通常可以通过梯度下降等优化算法进行,因此,可以使用数值优化方法来求解最优的模型参数,以最大化对数似然函数的值。
+因此,生成模型通常会构造概率分布函数,并通过最大化对数似然函数来训练模型,以便生成与样本数据类似的新数据。
+
本文是构造一个模型来近似一个分布,坏处是不知道分布是什么样子
+理论基础:对期望的求导等于对f的求导
+
一个比喻:现在有个游戏,它的画面是800万像素的图像,我要用生成器近似生成出这个游戏。生成器是一个概率分布\(p_g\)(即我们学出来的“假”游戏),800万像素的图片是目标 \(x\),每个像素都来自于这个\(p_g\)。我们首先在一个输入噪音 \(z\) (\(z\) 可以是一个100维的向量,其中元素均值为0方差为1的高斯噪音)上定义一个先验的概率 \(p_z(z)\),生成模型就是将 \(z\) 映射成 \(x\)(我认为一个100维的变量就决定了这个游戏逻辑,实际上不知道真实游戏的代码),它有一个可学习的参数 \(\theta_g\),我们可以将生成器定义为 \(G(z;\theta_g)\)。所以每次都随机一个 \(z\) 去看生成的效果。
+判别器是MLP到1或0的函数,1表示是真图,0表示假图
+所以\(G\)要最小化 \(\log (1-D(G(z)))\),让\(D\)尽量犯错,不让他分辨出来。
+目标:\(x\sim p_{data}(x)\) 表示 \(x\) 是采样真实分布,第一项如果 \(D\) 是完美的那么 \(D(x)=1,\log D(x)=0\),否则为负数;第二项,采样噪音,如果 \(D\) 是完美的,那么 \(D(G(z))=0,\log(1-D(G(z)))=0\),否则为负数,所以要 \(\max\limits_{D}\)。
+
达到均衡就是纳什均衡
+例子:下图黑点线\(p_x\)是数据真实分布,绿色线\(p_g\)是生成器的分布,蓝色点线是\(D\)是判别器的分布。图(b)中可以看到接近黑点线的时候,判别器靠近1,接近绿线靠近0,(c)中将绿线往黑点线靠近,使得判别器对两个区分很困难,最后图(d)中判别器永远给出0.5
+
这里\(k\)是超参数,如果对\(D\)没有足够好的更新,那么下面一项中\(D\)没有升级,\(G\)的升级就没有意义反正总能糊弄过去;但是如果\(D\)更新的太完美,就会导致结果为0,没有梯度
+判断收敛比较难。
+



注意:\(g(z)=x\)
+
对 \(a\log(y)+b\log (1-y)\)求导即可得最大值,它是凸函数
+
首先要学习一下 KL 散度(暂时不会),\(KL(p||q)=E_{x\sim p}\log\frac{p(x)}{q(x)}\),表示在知道 \(p\) 的情况下至少要多少比特才能将 \(q\) 描述出来
+两个KL散度可以拼成JS散度,KL散度是非对称的,JS散度是对称的
+
有人说因为GAN使用了对称散度所以训练简单,未来还有工作用更简单的目标函数
+证明二:
+
目前使用预训练模型到下游任务的有两种思路
+feature-based
+例如ELMo,将预训练表示作为额外的特征输入到模型中。使用了双向信息但是用的是老的RNN
+++预训练模型中的feature-based指的是使用预训练模型的中间层(通常是最后一层)的输出作为特征来进行下游任务。这些特征通常被称为“预训练特征”或“表示”。
+预训练模型通过在大规模未标注数据上进行预训练来学习通用的特征表示,这些表示可以被用于各种下游任务,如文本分类、命名实体识别、情感分析等。在使用预训练模型进行下游任务时,可以将预训练模型的中间层输出作为输入特征,然后将这些特征提供给下游模型,如传统的机器学习算法或者其他神经网络模型,以完成具体的任务。
+
fine-tuning
+例如GPT,微调参数。只用了单向信息。
+这两种方法都使用相同的目标函数,并且是单向的
+很多语言任务并不一定是从左看到右,文本两个方向的信息都有用
+BERT思路:用mask掩码盖住部分文本做完型填空,可以看左右的信息;另外还训练了判断两个给定句子在原文中是否相邻
+




BERT输入是一个句子或者句子对(例如答案和回答作为一对输入),称为sequence。而Transformer是一个sequence对,因为encoder和decoder各需要一个sequence。
+切词的方法是WordPiece。如果按空格切词,那么会导致嵌入层的参数量过大
+++WordPiece是一种用于自然语言处理中的分词方法,它将单词拆分成较小的子词或标记,这些子词或标记被称为WordPieces。WordPiece模型在训练过程中会根据语料库的频率和语言模型选择最优的WordPieces,这样可以更好地处理未知词汇和罕见词汇。WordPiece已被广泛应用于机器翻译、语音识别和文本分类等任务中。
+以英语单词"unbelievable"为例,使用WordPiece分词方法可以将其拆分成较小的子词或标记,如下所示:
+un- ##be- ##liev- ##able
+其中,"##"表示这是一个WordPiece的一部分。这样,单词"unbelievable"就被拆分成了四个WordPieces,这些WordPieces可以更好地处理未知词汇和罕见词汇,从而提高自然语言处理的效果。
+
[CLS]的特殊标记表示Classification,在两个句子中间加上了[SEP]。将每个词都embed之后然后输入BERT,得到输出\(C,T_1,\dots,T_N,T_{[SEP]},T_1',\dots,T_M'\),然后再接输出层。
++嵌入层(Embedding Layer)是深度学习模型中的一种常见层类型,用于将离散的输入数据(如单词、类别等)转换为连续的向量表示。它的作用类似于字典,将每个离散数据映射到一个唯一的向量,从而使得数据可以被神经网络处理。嵌入层的输出向量是根据输入数据在训练过程中学习到的,因此可以捕捉到数据之间的语义关系,例如相似性和相关性。在自然语言处理、推荐系统等领域中,嵌入层是非常常用的。
+

对WordPiece生成的词元,有15%的概率随机替换成一个掩码\([MASK]\),让BERT来预测。而微调的时候没有这个掩码,可能会导致一些问题(不匹配)。解决方法:对于15%选中token。有时候并不是真的替换这个词为\([MASK]\)(80%概率),剩下10%替换成一个随机token,剩下10%不变。
+两种情况,A和B是相邻的,标上IsNext;A和B不相邻,标上NotNext。这能提高QA和推理的效果

不能像Transformer一样做机器翻译
整体架构图
+加入位置编码
+[CLS]标记也就是下图中的0*,然后看这个token的最后结果,当做整个模型的输出
上面的全连接层称为 \(E\),维度是 768*768(图片原大小是224*224,切成16*16方格得到14*14个patch即196,768是16*16*3是每个patch的大小)
+每张图片(共196张)变成768长度的向量,前面再加一个CLS,得到Transformer输入长度197*768
位置编码也是768长度的向量,然后相加,而不是拼接
+位置编码选用1D和2D发现效果类似
+CLS的使用
+在Res50中,最后得到一个14*14的特征图,然后会通过一个GAP(Global Average Pooling)得到一个向量来分类,为什么ViT不做GAP而用CLS?
+通过实验发现这两个方法都可以,但是作者是Transformer原教旨主义
+位置编码
+1D位置编码
+通过结果发现以上三种效果类似
+微调
+预训练好的模型不太好调输入图片的尺寸,一旦图片增大序列长度就会增大(patch大小不变),虽然基本能用,但是提前训练的位置编码就没用了。
+自监督效果还可以,后来MAE使用自监督来训练ViT效果非常好
+命名方法:
+
ViT-L16表示,ViT-Large模型且patch size是16*16
+和CNN大模型比,分数都很高,而Transformer训练成本相对低一些
+最重要的图:在小的数据集上ViT不如ResNet,在大数据集上相近
+

架构图
+这里Encoder画的比Decoder高,表示计算量主要在Encoder这里
+
1、从仿真角度来说,HDL语言面对的是编译器,相当于使用软件思路,此时:
+| Text Only | |
|---|---|
1 +2 +3 | |
2、从综合角度,HDL语言面对的是综合器,相当于从电路角度来思考,此时:
+| Text Only | |
|---|---|
1 +2 +3 +4 +5 +6 +7 | |
3、设计中,输入信号一般来说不能判断出上一级是寄存器输出还是组合逻辑输出,对于本级来说,就当成一根导线,即wire型。而输出信号则由自己来决定是reg还是组合逻辑输出,wire和reg型都可以。但一般的,整个设计的外部输出(即最顶层模块的输出),要求是reg输出,这比较稳定、扇出能力好。
+4、Verilog中何时要定义成wire型?
+| Text Only | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
情况二:元件实例化时必须用wire型
+| Text Only | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 | |
5、何时用reg、何时用wire?
+| Text Only | |
|---|---|
1 +2 +3 +4 +5 +6 +7 | |
6、reg和wire的区别:
+| Text Only | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 | |
7、过程赋值语句always@和连续赋值语句assign的区别:
+| Text Only | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 | |
以下为个人书写规范,方便个人统一格式,与行业规范有所不符
+| Verilog | |
|---|---|
在这段代码中a是不会综合出寄存器的,而b却会,原因在于a是中间变量,就是一条线,所以综合出来的不是寄存器,而是一条线。而在condtion不满足的情况下b要保值,所以b会综合成寄存器。(引用BruceX的回答)
+6t
+SOP:sum of minterms
+对函数求complement
+product term obtained by combining adjacent squares in the map into a rectangle with the number of squares a power of 2.
+A Prime Implicant is a product term obtained by combining the maximum possible number of adjacent squares in the map into a rectangle with the number of squares a power of 2.
+A prime implicant is called an Essential Prime Implicant if it is the only prime implicant that covers (includes) one or more minterms.
+1.3 implicant +蕴含项其实就是我们文章最开始提到的“圈”,每一种可能的圈就是一个蕴含项
+
上图中就有7个一次蕴含项,6个二次蕴含项和1个四次蕴含项,共计14个蕴含项
+1.4 prime implicant +质蕴含项就是不能与其它蕴含项合并的蕴含项,在1.3中,我们发现四次蕴含项中有4个二次蕴含项,那么它们就不是质蕴含项
+
可以看到上图中的每一个圈都不能和其它圈合并,所以上图有共计4个质蕴含项
+1.5 essential prime implicant +实质本源蕴含项中必须含有至少一个没被包含在其它蕴含项中的项,而且不能被更大的圈包裹
+
上图中有三个实质本源蕴含项,而我们找到最简SOP的方式就是找到所有的实质本源蕴含项
+propagation : 传输
+

三个串联?四个可以吗
+74LS00与非门传输延迟测量:3个74LS00门串联,4个可以吗?
+\((\overline{A B})\)
+
2-12怎么化简
+4位全加器的延时较长
+因此采用carry look ahead adder
+16位加法器使用4个CLA串联
+64位 组超前进位
+将G0~3, P0~3传给下一层?
+C4 = G3 +P3G2 + P3P2G1+P3P2P1G0+P3P2P1P0C0
+ = G0~3 + P0~3*C0
+C8 = G4~7 + P4~7*C4
+同理,C12 = G8~11+ P8~11*C8
+C16 = G12~15+ P12~15*C12
+依赖关系和4位的CLA相似
+
4变量的卡诺图,16个格子,圈的大小为8->1个变量
+

发现只要是在这个文件结构下的图片都会正常显示
+因为实际上typora编辑器的设置中拷贝图片时会将assets会单独复制一份
+
然而,拷贝后进行缩放,就是改为了html格式,就不能够正常渲染?
+

对应的英文名词
+上课ppt,重点章节回放,guahao实验指导网页,小测ppt,
+时钟空翻问题
+D锁存器
+和时钟长度有关、D锁存器延时有关
+Triggered SR 主从触发器
+一次性采样问题
+小的毛刺,干扰
+英文电子书pdf搜索找到名词,中文纸质书理解
+BCD码,gray code 余三码
+SOP,POS 最大项,最小项,卡诺图化简,
+高阻输出 三态门和传输门
+多级电路,二级电路
+门输入成本?gate input cost
+PLD: programmable logic devices
+PLD includes ROM,PAL,PLA
+ROM:与门固定,或门阵列可编程
+PAL:或门固定,与门阵列可编程
+


PLA:与门和或门均可编程
+CPLD, FPGA, *LUT
+第二章 组合逻辑电路 +布尔代数(Boolean)的概念
+与、或门的开、关门特点,异或的同相、反相性质 +逻辑函数的化简.
+公式化简、最小项,最大项、卡诺图化简、蕴涵项,任意项。 不同函数形式的变换及与最小项的关系 +函数的五种表示形式
+功能模块化设计
+译码器和与或门
+encoder&decoder
+多路复用器(加反相器?)
+加减法器:算数函数:+-*,增量函数及运算
+补码运算
+半加器及全加器电路设计
+多位全加器,全减器设计 异或门
+超前进位
+进位传递与延迟,进位函数:generate,Gi,propagate
+ALU设计
+触发器 JK,SR, D
+一次性采样问题
+主从触发器和边沿触发器
+脉冲触发器
+SR 锁存器 R=1 S=0 复位 Q=0, R=0,S=1 置位 Q=1,
+\(\overline{S}\overline{R}\) 锁存器 $$$$$$$$$
+D 锁存器
+模三累加器
+输出只依赖状态
+输出画到弧线上面
+脉冲(主从)触发器
+边沿触发器 edge triggered 有一次性采样问题?
+J-K T flip-flops
+状态图化简注意未定义状态利用态进行化简
+所谓setup time就是在negedge或posedge发生前信号要有稳定的一段时间
+所谓hold time就是在negedge或posedge发生后信号要有稳定的一段时间
+mealy 状态是抽象的数字编号(000,001,010........111// 0,1,2,3,4,5),状态转移曲线上画的是input/output
+current state到next state的状态转移就是从一个圆圈到下一个圆圈
+moore 圆圈里画的是状态/输出,因为输出仅仅和当前的状态有关,不依赖于输入,输入仅仅影响状态转移,所以画在状态转移曲线上
+电路延时分析
+时序问题
+锁存器与触发器 +S-R锁存器的原理、特征表、特征方程,内部电路分析,不确定状态的原因及出现条件 +D锁存器、D触发器的原理、特征表、特征方程 +内部电路分析JK触发器、T触发器的行为、特征表、特征方程 +霍荣馨答势盗菌触发的概念,脉冲触发的一次性采样行为的原因 +锁存器和触发器的时序,建立时间、保持时间、传输延时等时序成分
+各种触发器的图形符号
+纹波计数器
+低位的进位输出到高位的计数EN端口
+和同步计数器
+存储器基础:
+地址线重合选择
+计算所需内存位数
+猝发读写?
+ +寻址方式:DRAM需要通过行地址和列地址来寻址,而SRAM则只需要一个地址就可以了。
+Refresh Controller and Refresh Counter(刷新控制器和刷新计数器):
+SRAM和DRAM的区别:
+总体而言,SRAM适用于需要高性能和不需要频繁刷新的场景,而DRAM适用于需要高密度存储和较低成本的场景。
+画出状态机所对应的电路图:
+mealy状态机的下一状态由当前状态和输入决定
+可以画很多条竖线
+接口定义:输入EN,clk,输出Q0-Q3,CO 四个D flip-flop
+ripple counter是asynchronous counter,是 将一个不断自反的 FF 的输出直接或间接作为下一个 FF 的时钟脉冲。由于形成一次脉冲需要一对 0&1,所以前一个 FF 取反两次才能引起下一个 FF 取反一次,如果下一个 FF 是在上一个 FF 的输出从 1 变 0 时触发,那两个 FF 的变化刚好对应于二进制自增的进位规律:(0,0),(0,1),(1,0),(1,1),(0,0),...
ring counter是移位寄存器的代表,
+4-bit “synchronous(同步)”计数器,分为serial gating 和 parallel gating,区别在于逻辑门之间的延时parallel gating小一些
+4-bit binary counter with parallel load 就是将LD信号和LD非信号输入,LD非信号和clk与一下,使得LD==1时就不count,直接并行输入数据
+BCD counter就是在Q0和Q3都为1时(数到9的时候)要回到0,那么LD=1时并行输入0,且LD信号就是Q0andQ3
+radix = 50/256 counter 需要使用两块74LS161芯片(16进制adder,同步四位2进制计数器)连接实现,一般clk信号是直接接入的,而CTp和CTt信号可以作为使能,使用异步清零(CR非)来实现mod N计数器,异步清零不是通过LD新的数来实现的,异步清零和clk是同等地位的信号(always @posedge clk or negedge CRn begin)
+下图输出50(0011 0010)时重置
+
arbitrary counter需要使用状态图和状态机实现
+半加器,全加器
+half adder的逻辑就是S = X非Y+Y非X,C = XY
+full adder考虑了低位向高位进位的操作: S = X,Y,Ci-1三者奇数个为1,决定当前位,Ci = XY+Ci-1*( X非Y+Y非X)决定当前位给出的进位,通常使用异或门,S是三个亦或, X非Y+Y非X是X异或Y
+full adder可由两个half adder叠加搭建
+4-bit ripple adder的过程就是正常加法进位的过程
+
4位加法器的抽象表示
+
4位加减法器的抽象表示,S是运算符
+
针对无移位操作的寄存器cell 设计:
+Give two register transfer operations (R1 unchanged except for the following cases):
+C1: R1<-- R1 + R2
+(~C1)C2: R1<--R1 - 1
+Use two 4-bits registers, one 4-bit adder, and other necessary gates to implement the above operations.
+source register的值作为输入和控制信号一并接到D FF的输入端,D FF的输出端接给destination register
+LD = C1+C1非 = 1
+Di = C1(R1+R2)+非C1(R1-1)
+有移位操作的寄存器cell
+即只涉及输入的控制信号,不涉及当前状态的逻辑值组合可以被重复利用
+化简的方法:一般两个操作数,两个寄存器设为Ai,Bi,状态记作At,Bt,下一状态为At+1,Bt+1,当前的寄存器的值
+还是用卡诺图化简的
+serial transfer就是像主从触发器一样接起来,n位需要n个上升沿才能传输完毕
+serial addition与4位carry adder的直接实现是space and time的tradeoff
+
8-1 multiplexer可以实现任意3输入的逻辑函数
+8-1 multiplexer由3-8 decoder先将3位的控制信号译码成8个单独的信号,再在8个信号中选一个
+

+
+ + +is .
+If the postorder and inorder traversal sequences of a binary tree are the same, then none of the nodes in the tree has a right child.
+The best "worst-case time complexity" for any algorithm that sorts by comparisons only must be .
+If the most commonly used operations are to visit a random position and to insert and delete the last element in a linear list, then sequential storage works the fastest.
+Given the input sequence onto a stack as {1, 2, 3, ..., }. If the first output is , then the -th output must be .
+Given a tree of degree 4. Suppose that the numbers of nodes of degrees 2, 3 and 4 are 4, 2 and 1, respectively. Then the number of leaf nodes must be:
+Suppose that an array of size m is used to store a circular queue. If the front position is front and the current size is size, then the rear element must be at:
Insert {5, 2, 7, 3, 4, 1, 6} one by one into an initially empty min-heap. The preorder traversal sequence of the resulting tree is:
+Among the following methods, which one's time complexity is always , no matter what the initial condition is?
+Suppose that the height of a binary tree is (the height of a leaf node is defined to be 1), and it has only the nodes of degrees 0 and 2. Then the minimum and maximum possible total numbers of nodes are:
+Suppose that the level-order traversal sequence of a min-heap is {1, 3, 2, 5, 4, 7, 6}. Use the linear algorithm to adjust this min-heap into a max-heap. The inorder traversal sequence of the resulting tree is:
+To delete p from a doubly linked list, we must do:
If on the 9th level of a complete binary tree (assume that the root is on the 1st level) there are 100 leaf nodes, then the maximum number of nodes of this tree must be:
+The array representation of a disjoint set containing numbers 0 to 8 is given by { 1, -4, 1, 1, -3, 4, 4, 8, -2 }. Then to union the two sets which contain 6 and 8 (with union-by-size), the index of the resulting root and the value stored at the root are:
+For a binary search tree, in which order of traversal that we can obtain a non-decreasing sequence?
+Given input { 321, 156, 57, 46, 28, 7, 331, 33, 34, 63 }. Which one of the following is the result after the 1st run of the Least Signification Digit (LSD) radix sort?
+Which one of the following relations is correct about the extra space taken by heap sort, quick sort and merge sort?
+Given the pushing sequence of a stack as {1, 2, 3, 4, 5}. If the first number being popped out is 4, then the last one out must be:
+The function is to increase the value of the integer key at position P by a positive amount D in a max-heap H.
void IncreaseKey( int P, int D, PriorityQueue H )
+{
+ int i, key;
+ key = H->Elements[P] + D;
+ for ( i = (3分); H->Elements[i/2] < key; i/=2 )
+ (3分);
+ H->Elements[i] = key;
+}
| 序号 | 结果 | 测试点得分 |
|---|---|---|
| 0 | 编译错误 | 0 |
| 1 | 未作答 | 0 |
You are supposed to output, in decreasing order, all the elements no greater than X in a binary search tree T.
void Print_NGT( Tree T, int X );
where Tree is defined as the following:
typedef struct TreeNode *Tree;
+struct TreeNode {
+ int Element;
+ Tree Left;
+ Tree Right;
+};
The function is supposed to use Output(X) to print X.
#include <stdio.h>
+#include <stdlib.h>
+
+typedef struct TreeNode *Tree;
+struct TreeNode {
+ int Element;
+ Tree Left;
+ Tree Right;
+};
+
+Tree BuildTree(); /* details omitted */
+void Output( int X ); /* details omitted */
+
+void Print_NGT( Tree T, int X );
+
+int main()
+{
+ Tree T;
+ int X;
+
+ T = BuildTree();
+ scanf("%d", &X);
+ Print_NGT( T, X );
+ printf("End\n");
+
+ return 0;
+}
+
+/* Your function will be put here */
+
91 90 85 81 80 55 End
End
void Print_NGT( Tree T, int X ) {
+ return;
+}a.c: In function ‘BuildTree’:
+a.c:33:6: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result]
+ scanf("%d", &n);
+ ^~~~~~~~~~~~~~~
+a.c:35:10: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result]
+ scanf("%d", &x);
+ ^~~~~~~~~~~~~~~
+a.c: In function ‘main’:
+a.c:52:5: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result]
+ scanf("%d", &X);
+ ^~~~~~~~~~~~~~~| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 0 | 答案错误 | 0 | 4.00 ms | 312 KB |
| 1 | 答案正确 | 3 | 4.00 ms | 432 KB |
| 2 | 答案错误 | 0 | 4.00 ms | 336 KB |
| 3 | 答案正确 | 2 | 4.00 ms | 352 KB |
| 4 | 答案错误 | 0 | 4.00 ms | 384 KB |
+
+ + +In a binary search tree, the keys on the same level from left to right must be in sorted (non-decreasing) order.
+For a sequentially stored linear list of length , the time complexities for query and insertion are and , respectively.
+and have the same speed of growth.
+In a directed graph, the sum of the in-degrees must be equal to the sum of the out-degrees of all the vertices.
+If keys are pushed onto a stack in the order {1, 2, 3, 4, 5}, then it is impossible to obtain the output sequence {3, 4, 1, 2, 5}.
+Suppose that an array of size m is used to store a circular queue. If the front position is front and the current size is size, then the rear element must be at:
The result of performing three DeleteMin operations in the min-heap {1,3,2,6,7,5,4,15,14,12,9,10,11,13,8} is:
+In a complete binary tree with 1102 nodes, there must be __ leaf nodes.
+Use Dijkstra algorithm to find the shortest paths from 1 to every other vertices. In which order that the destinations must be obtained?
+Given a directed graph G=(V, E) where V = {v1, v2, v3, v4, v5, v6} and E = {<v1,v2>, <v1,v4>, <v2,v6>, <v3,v1>, <v3,v4>, <v4,v5>, <v5,v2>, <v5,v6>}. Then the topological order of G is:
In a weighted graph, if the length of the shortest path from b to a is 10, and there exists an edge of weight 3 between c and b, then how many of the following statements is/are TRUE?
c to a must be 13.c to a must be 7.c to a must be no greater than 13.c to a must be no less than 7.The array representation of a disjoint set is given by { 4, 6, 5, 2, -3, -4, 3 }. If the elements are numbered from 1 to 7, the resulting array after invoking Union(Find(7),Find(1)) with union-by-size and path-compression is:
Given a quadtree(四叉树) with 3 nodes of degree 2, 2 nodes of degree 3, 4 nodes of degree 4. The number of leaf nodes in this tree is __.
+What is a critical path in an AOE network?
+Insert { 6, 9, 12, 3, 4, 8 } one by one into an initially empty binary search tree. The post-order traversal sequence of the resulting tree is:
+To insert s after p in a doubly linked circular list, we must do:
If an undirected graph G = (V, E) contains 7 vertices. Then to guarantee that G is connected in any cases, there has to be at least ____ edges.
+The function is to lower the value of the integer key at position P by a positive amount D in a min-heap H.
void DecreaseKey( int P, int D, PriorityQueue H )
+{
+ int i, key;
+ key = H->Elements[P] - D;
+ for ( i = (5分); H->Elements[i/2] > key; i/=2 )
+ (5分);
+ H->Elements[i] = key;
+}
Please fill in the blanks in the program which performs Find as a Union/Find operation with path compression.
SetType Find ( ElementType X, DisjSet S )
+{
+ ElementType root, trail, lead;
+
+ for ( root = X; S[root] > 0; (5分) ) ;
+ for ( trail = X; trail != root; trail = lead ) {
+ lead = S[trail] ;
+ (5分);
+ }
+ return root;
+}
| 序号 | 结果 | 测试点得分 |
|---|---|---|
| 0 | 答案正确 | 5 |
| 1 | 未作答 | 0 |
+
+ + +If keys are pushed onto a stack in the order {1, 2, 3, 4, 5}, then it is impossible to obtain the output sequence {3, 4, 1, 2, 5}.
+For a sequentially stored linear list of length , the time complexities for deleting the first element and inserting the last element are and , respectively.
+The sum of the degrees of all the vertices in a connected graph must be an even number.
+In a binary search tree, the keys on the same level from left to right must be in sorted (non-decreasing) order.
+and have the same speed of growth.
+How many leaf node does a complete binary tree with 2435 nodes have?
+The result of performing three DeleteMin operations in the min-heap {1,3,2,6,7,5,4,15,14,12,9,10,11,13,8} is:
+The array representation of a disjoint set is given by { 4, 6, 5, 2, -3, -4, 3 }. If the elements are numbered from 1 to 7, the resulting array after invoking Union(Find(7),Find(1)) with union-by-size and path-compression is:
Insert { 6, 9, 12, 3, 4, 8 } one by one into an initially empty binary search tree. The post-order traversal sequence of the resulting tree is:
+In-order traversal of a binary tree can be done iteratively. Given the stack operation sequence as the following:
+push(1), push(2), push(3), pop(), push(4), pop(), pop(), push(5), pop(), pop(), push(6), pop()
Which one of the following statements is TRUE?
+The recurrent equations for the time complexities of programs P1 and P2 are:
+Then the best conclusion about their time complexities is:
+From the given graph shown by the figure, how many different topological orders can we obtain?
+If an undirected graph G = (V, E) contains 7 vertices. Then to guarantee that G is connected in any cases, there has to be at least ____ edges.
+To delete p from a doubly linked list, we must do:
Which of the following statements is TRUE about topological sorting?
+Given a quadtree(四叉树) with 4 nodes of degree 2, 4 nodes of degree 3, 3 nodes of degree 4. The number of leaf nodes in this tree is __.
+Suppose that an array of size m is used to store a circular queue. If the front position is front and the current size is size, then the rear element must be at:
The function is to find the K-th largest element in a list A of N elements. The function BuildMinHeap(H, K) is to arrange elements H[1] ... H[K] into a min-heap. Please complete the following program.
ElementType FindKthLargest ( int A[], int N, int K )
+{ /* it is assumed that K<=N */
+ ElementType *H;
+ int i, next, child;
+
+ H = (ElementType *)malloc((K+1)*sizeof(ElementType));
+ for ( i=1; i<=K; i++ ) H[i] = A[i-1];
+ BuildMinHeap(H, K);
+
+ for ( next=K; next<N; next++ ) {
+ H[0] = A[next];
+ if ( H[0] > H[1] ) {
+ for ( i=1; i*2<=K; i=child ) {
+ child = i*2;
+ if ( child!=K && (5分) ) child++;
+ if ( (5分) )
+ H[i] = H[child];
+ else break;
+ }
+ H[i] = H[0];
+ }
+ }
+ return H[1];
+}
+
| 序号 | 结果 | 测试点得分 |
|---|---|---|
| 0 | 编译错误 | 0 |
| 1 | 未作答 | 0 |
Please fill in the blanks in the program which performs Find as a Union/Find operation with path compression.
SetType Find ( ElementType X, DisjSet S )
+{
+ ElementType root, trail, lead;
+
+ for ( root = X; S[root] > 0; (5分) ) ;
+ for ( trail = X; trail != root; trail = lead ) {
+ lead = S[trail] ;
+ (5分);
+ }
+ return root;
+}
| 序号 | 结果 | 测试点得分 |
|---|---|---|
| 0 | 编译错误 | 0 |
| 1 | 未作答 | 0 |
+
+ + +and have the same speed of growth.
+If keys are pushed onto a stack in the order {1, 2, 3, 4, 5}, then it is impossible to obtain the output sequence {3, 4, 1, 2, 5}.
+If there are less than 20 inversions in an integer array, then Insertion Sort will be the best method among Quick Sort, Heap Sort and Insertion Sort.
+For a sequentially stored linear list of length , the time complexities for query and insertion are and , respectively.
+In a binary search tree, the keys on the same level from left to right must be in sorted (non-decreasing) order.
+The recurrent equations for the time complexities of programs P1 and P2 are:
+Then the best conclusion about their time complexities is:
+To delete p from a doubly linked list, we must do:
Given input {15, 9, 7, 8, 20, -1, 4}. If the result of the 1st run of Shell sort is {15, -1, 4, 8, 20, 9, 7}, then the initial increment must be:
+In-order traversal of a binary tree can be done iteratively. Given the stack operation sequence as the following:
+push(1), push(2), push(3), pop(), push(4), pop(), pop(), push(5), pop(), pop(), push(6), pop()
Which one of the following statements is TRUE?
+How many leaf node does a complete binary tree with 2435 nodes have?
+Suppose that an array of size m is used to store a circular queue. If the head pointer front and the current size variable size are used to represent the range of the queue instead of front and rear, then the maximum capacity of this queue can be:
Given input { 4321, 56, 57, 46, 28, 7, 331, 33, 234, 63 }. Which one of the following is the result after the 1st run of the Least Signification Digit (LSD) radix sort?
+Given a quadtree(四叉树) with 4 nodes of degree 2, 4 nodes of degree 3, 3 nodes of degree 4. The number of leaf nodes in this tree is __.
+For an in-order threaded binary tree, if the pre-order and in-order traversal sequences are B E A C F D and A E C B D F respectively, which pair of nodes' left links are both threads?
The result of performing three DeleteMin operations in the min-heap {1,3,2,12,6,4,8,15,14,9,7,5,11,13,10} is:
+For the quicksort implementation with the left pointer stops at an element with the same key as the pivot during the partitioning, but the right pointer does not stop in a similar case, what is the running time when all keys are equal?
+Among the following sorting methods, which ones will be slowed down if we store the elements in a linked structure instead of a sequential structure?
+Insert { 3, 8, 9, 1, 2, 6 } one by one into an initially empty binary search tree. The post-order traversal sequence of the resulting tree is:
+The function is to find the K-th smallest element in a list A of N elements. The function BuildMaxHeap(H, K) is to arrange elements H[1] ... H[K] into a max-heap. Please complete the following program.
ElementType FindKthSmallest ( int A[], int N, int K )
+{ /* it is assumed that K<=N */
+ ElementType *H;
+ int i, next, child;
+
+ H = (ElementType *)malloc((K+1)*sizeof(ElementType));
+ for ( i=1; i<=K; i++ ) H[i] = A[i-1];
+ BuildMaxHeap(H, K);
+
+ for ( next=K; next<N; next++ ) {
+ H[0] = A[next];
+ if ( H[0] < H[1] ) {
+ for ( i=1; i*2<=K; i=child ) {
+ child = i*2;
+ if ( child!=K && (3分) ) child++;
+ if ( (3分) )
+ H[i] = H[child];
+ else break;
+ }
+ H[i] = H[0];
+ }
+ }
+ return H[1];
+}
+
| 序号 | 结果 | 测试点得分 |
|---|---|---|
| 0 | 编译错误 | 0 |
| 1 | 未作答 | 0 |
The function is to sort the list { r[1] … r[n] } in non-decreasing order. Unlike selection sort which places only the minimum unsorted element in its correct position, this algorithm finds both the minimum and the maximum unsorted elements and places them into their final positions.
void sort( list r[], int n )
+{
+ int i, j, mini, maxi;
+
+ for (i=1; i<n-i+1; i++) {
+ mini = maxi = i;
+ for( j=i+1; (3分); ++j ){
+ if( (3分) ) mini = j;
+ else if(r[j]->key > r[maxi]->key) maxi = j;
+ }
+ if( mini != i ) swap(&r[mini], &r[i]);
+ if( maxi != n-i+1 ){
+ if( (3分) ) swap(&r[mini], &r[n-i+1]);
+ else swap(&r[maxi], &r[n-i+1]);
+ }
+ }
+}
You are supposed to output, in decreasing order, all the elements no less than X in a binary search tree T.
void Print_NLT( Tree T, int X );
where Tree is defined as the following:
typedef struct TreeNode *Tree;
+struct TreeNode {
+ int Element;
+ Tree Left;
+ Tree Right;
+};
The function is supposed to use Output(X) to print X.
#include <stdio.h>
+#include <stdlib.h>
+
+typedef struct TreeNode *Tree;
+struct TreeNode {
+ int Element;
+ Tree Left;
+ Tree Right;
+};
+
+Tree BuildTree(); /* details omitted */
+void Output( int X ); /* details omitted */
+
+void Print_NLT( Tree T, int X );
+
+int main()
+{
+ Tree T;
+ int X;
+
+ T = BuildTree();
+ scanf("%d", &X);
+ Print_NLT( T, X );
+ printf("End\n");
+
+ return 0;
+}
+
+/* Your function will be put here */
+
92 91 90 85 81 80 End
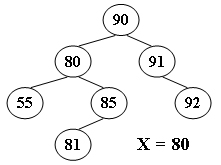
End
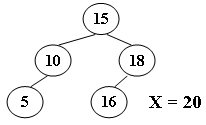
void Print_NLT( Tree T, int X ) {
+ return;
+}a.c: In function ‘BuildTree’:
+a.c:33:6: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result]
+ scanf("%d", &n);
+ ^~~~~~~~~~~~~~~
+a.c:35:10: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result]
+ scanf("%d", &x);
+ ^~~~~~~~~~~~~~~
+a.c: In function ‘main’:
+a.c:52:5: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result]
+ scanf("%d", &X);
+ ^~~~~~~~~~~~~~~| 测试点 | 结果 | 测试点得分 | 耗时 | 内存 |
|---|---|---|---|---|
| 0 | 答案错误 | 0 | 5.00 ms | 316 KB |
| 1 | 答案正确 | 1 | 4.00 ms | 384 KB |
| 2 | 答案错误 | 0 | 5.00 ms | 356 KB |
| 3 | 答案正确 | 1 | 4.00 ms | 324 KB |
| 4 | 答案错误 | 0 | 5.00 ms | 400 KB |
+
+ + +is .
+In Union/Find algorithm, if Unions are done by size, the depth of any node must be no more than , but not .
+If a linear list is represented by a 1-dimensional array, the addresses of the elements in the memory must be consecutive.
+ADT is the abbreviation for Abstract Data Type in the textbook of data structures.
+In a directed graph, the sum of the in-degrees must be equal to the sum of the out-degrees of all the vertices.
+If a binary search tree of nodes is also a complete binary tree, then among the following, which one is FALSE?
+The following figure shows the AOE network of a project with 8 activities. The earliest and the latest start times of the activity d are __, respectively.
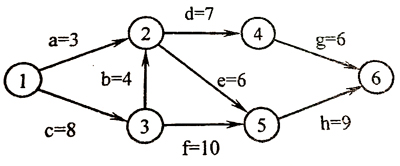

Which one of the following is the data structure that is best represented by the above picture?
+For a sequentially stored linear list of length , the time complexities for query and insertion are:
+If graph G is NOT connected and has 27 edges, then it must have at least ____ vertices.
+A full tree of degree 3 is a tree in which every node other than the leaves has 3 children. How many leaves does a full tree of degree 3 have if it has 127 nodes?
+Since the speed of a printer cannot match the speed of a computer, a buffer is designed to temperarily store the data from a computer so that later the printer can retrieve data in order. Then the proper structure of the buffer shall be a:
+Let be a non-negative integer representing the size of input. The time complexity of the following piece of code is:
+x = 0;
+while ( n >= (x+1)*(x+1) )
+ x = x+1;
From the given graph shown by the figure, how many different topological orders can we obtain?
+If besides finding the shortest path from S to every other vertices, we also need to count the number of different shortest paths, we can modify the Dijkstra algorithm in the following way: add an array count[] so that count[V] records the number of different shortest paths from S to V. Then count[V] shall be initialized as:
Given the shape of a binary tree shown by the figure below. If its postorder traversal sequence is { e, a, c, b, d, f }, then the node on the same level of b must be:
The array representation of the disjoint sets is given by {2, –4, 2, 3, -3, 5, 6, 9, -2}. Keep in mind that the elements are numbered from 1 to 9. After invoking Union(Find(4), Find(6)) with union-by-size, which elements will be changed in the resulting array?
+Given the popping sequence of a stack as {1, 2, 3, 4, 5}. Among the following, the impossible pushing sequence is:
+The function Dijkstra is to find the shortest path from Vertex S to every other vertices in a given Graph. The distances are stored in dist[], and path[] records the paths. The MGraph is defined as the following:
typedef struct GNode *PtrToGNode;
+struct GNode{
+ int Nv; /* Number of vertices */
+ int Ne; /* Number of edges */
+ WeightType G[MaxVertexNum][MaxVertexNum]; /* adjacency matrix */
+};
+typedef PtrToGNode MGraph;
void Dijkstra( MGraph Graph, int dist[], int path[], Vertex S )
+{
+ int collected[MaxVertexNum];
+ Vertex V, W;
+
+ for ( V=0; V<Graph->Nv; V++ ) {
+ dist[V] = Graph->G[S][V];
+ path[V] = -1;
+ collected[V] = false;
+ }
+ dist[S] = 0;
+ collected[S] = true;
+
+ while (1) {
+ V = FindMinDist( Graph, dist, collected );
+ if ( V==ERROR ) break;
+ collected[V] = true;
+ for( W=0; W<Graph->Nv; W++ )
+ if ( collected[W]==false && Graph->G[V][W]<INFINITY ) {
+ if ( (4分) ) {
+ dist[W] = (3分);
+ path[W] = (3分);
+ }
+ }
+ } /* end while */
+}
The function is to return the reverse linked list of L, with a dummy header.
List Reverse( List L )
+{
+ Position Old_head, New_head, Temp;
+ New_head = NULL;
+ Old_head = L->Next;
+
+ while ( Old_head ) {
+ Temp = Old_head->Next;
+ (3分);
+ New_head = Old_head;
+ Old_head = Temp;
+ }
+ (3分);
+ return L;
+}
Please fill in the blanks in the program which deletes a given element at position p from a max-heap H.
Deletion ( PriorityQueue H, int p ) /* delete the element H->Elements[p] */
+{
+ ElementType temp;
+ int child;
+
+ temp = H-> Elements[ H->Size-- ];
+ if ( temp > H->Elements[p] ) {
+ while ( (p != 1) && (temp > H->Elements[p/2]) ) {
+ (3分);
+ p /= 2;
+ }
+ }
+ else {
+ while( (child = 2*p) <= H->Size) {
+ if ( child != H->Size && (3分) )
+ child ++;
+ if ( (3分) ) {
+ H->Elements[p] = H->Elements[child];
+ p = child;
+ }
+ else
+ break;
+ }
+ }
+ H->Elements[p] = temp;
+}
来看看什么是逆天奇才
+| C | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 +148 +149 +150 +151 +152 +153 +154 +155 +156 +157 +158 +159 +160 +161 +162 +163 +164 +165 +166 +167 +168 +169 +170 +171 +172 +173 +174 +175 +176 +177 +178 +179 +180 +181 +182 +183 +184 +185 +186 | |
少用全局变量
+全局初始化时
+qsort用法
+qsort 是C语言标准库中的一个函数,用于对数组进行快速排序。它的声明如下:
| Text Only | |
|---|---|
base:指向要排序的数组的指针。nmemb:数组中元素的数量。size:每个元素的大小(以字节为单位)。compar:比较函数的指针,用于定义排序顺序。比较函数 compar 应该接受两个参数,每个参数是数组中的一个元素,函数返回一个整数表示它们的相对顺序。返回值的含义如下:
下面是一个简单的例子,演示如何使用 qsort 对整数数组进行升序排序:
在这个例子中,compare 函数用于升序排序整数数组。你可以根据需要修改比较函数来改变排序的顺序或者适应不同类型的数据。
先写出int compare(const void *a,const void *b).
a和b进行类型强转,如果是整形就改为(int*)a,最后访问时要加*,*(int*)a,否则访问的是指针的地址
如果是结构体如edge,则改为(edge*)a->weight,这整个是访问的元素
Given the relations of all the activities of a project, you are supposed to find the earliest completion time of the project. +Input Specification:
+Each input file contains one test case. Each case starts with a line containing two positive integers N (<=100), the number of activity check points (hence it is assumed that the check points are numbered from 0 to N-1), and M, the number of activities. +Then M lines follow, each gives the description of an activity. For the i-th activity, three non-negative numbers are given: S[i], E[i], and L[i], where S[i] is the index of the starting check point, E[i] of the ending check point, and L[i] the lasting time of the activity. The numbers in a line are separated by a space. +Output Specification: +For each test case, if the scheduling is possible, print in a line its earliest completion time; or simply output "Impossible*
+example:
+9 12
+0 1 6
+0 2 4
+0 3 5
+$$ + T=O(|V|^2+|E|) = O(|V|^2) + $$
+$$ + T=O(|V|+|E|) + $$
+\(注意E的范围 最小 V 最大 |V|^2\)
+回溯算法(Backtracking)和深度优先搜索算法(DFS)之间存在关系,但它们有一些主要的不同之处。
+尽管有这些不同,DFS算法实际上可以看作是回溯算法的一种特例,因为回溯算法也可以使用深度优先搜索的方式进行实现。在许多情况下,这两个术语可以交替使用,具体取决于上下文和问题的特性
+| C | |
|---|---|
注意复习:填空题,以下内容均可能作为填空
+
四种遍历顺序
+层序 1 11 5 12 17 8 20 15
+中序 12 11 20 17 1 15 8 5
+前序 1 11 12 17 20 5 8 15
+后序 12 20 17 11 15 8 5 1
+| C | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 | |
前序的第一个元素和后序的最后一个元素为根节点
+中序从左到右,实际上的根节点将数组分成了完整的两个部分,因此只要确定当前的根节点,就能找出左、右子树的区间
+形象一点:一遍过后:
+中序 (左子树:12 11 20 17 )【1】 (右子树:15 8 5)
+后序 (12 20 17 11)( 15 8 5)【1】
+两遍后:
+中序 ((12) 11 (20 17) )【1】 ((15 8 ){5}())
+后序 ((12) (20 17) {11})( (15 8) {5})【1】
+中序 (12 11 20 17) 【1】 (15 8 5)
+前序【1】 (11 12 17 20)( 5 8 15)
+| C | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 +10 +11 +12 +13 +14 +15 +16 +17 +18 +19 +20 +21 +22 +23 +24 +25 +26 +27 +28 +29 +30 +31 +32 +33 +34 +35 +36 +37 +38 +39 +40 +41 +42 +43 +44 +45 +46 +47 +48 +49 +50 +51 +52 +53 +54 +55 +56 +57 +58 +59 +60 +61 +62 +63 +64 +65 +66 +67 +68 +69 +70 +71 +72 +73 +74 +75 +76 +77 +78 +79 +80 +81 | |
链表实现
+| C | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 | |
数组实现
+| C | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 | |
链表实现
+| C | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 | |
数组实现
+| C | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 | |
二分法的细节加细节 你真的应该搞懂!!!_二分算法-CSDN博客
+折半查找判定树——(快速判断某棵树是否为折半查找判定树)_折半查找树_叫我蘑菇先生的博客-CSDN博客
+对任意无序序列可建立完全二叉查找树
+先对序列排序,排序后得到升序序列为中序遍历顺序
+已知父节点i,可求出子节点下标2i和 2i+1
+| C | |
|---|---|
直接找到越界为止

程序填空:排序
+编程题:图,树
+1.O(N)是上界,Ω(N)为下界,Θ(N)为常数倍
+2.注意循环的条件,以及N^2^还是N^N^,还是N*N
+比较 \(N^{1.5}和NlogN\)
+1.链表中的二分法复杂度大于O(NlogN)
+2.sequentially stored linear list这个是顺序存储的线性表,就是和数组差不多,不是链表。链表:linked list
+链表相关操作,考填空
+array implementation of stack
+非递归实现,写一写
+topological sort 指定使用stack实现
+balancing symbol
+模拟入栈,出栈序列
+infix inorder traversal的非递归实现
+1.prefix和infix和postfix是树的三种遍历方式,变量在叶子结点,而运算符号在非叶子结点。
+index->postfix:遇到字母直接输出,遇到符号:要求栈顶的优先级是最高的,如果不能满足,就出栈,直到满足为止。然后该符号入栈。
+括号的优先级栈外最高,栈内最低。遇到右括号,出栈直到左括号
+2.问不可能的弹出序列,问栈至少多大,都模拟一下栈即可。注意出栈以后可以在该元素的旁边写数字表示入栈,不是在上方。
+3.Circle queue:出入队列操作以后,有可能出现尾节点小于头节点的情况。但是它们之间的差不会大于n。尾节点其实是n+尾节点的位置。因此计算个数的时候就加回去。
+Circle queue最多可以容纳的元素是数组的大小-1个元素。
+circlular queue?装满,满和空是无法区分的?
+how to convert general tree into binary tree
+expression tree evaluation
+preorder和postorder在完全二叉树情况下可以建树
+inorder序列must/may
+a.将当前结点的左结点压入栈,直到没有左节点。
+b.弹出一个点,将这个点的右节点压入栈,
+c.重复b直到遍历完成
+a.当前结点所有孩子入队列。
+b.弹出一个,将孩子入队列,直到队列空
+已知degree为1,2的点有几个这种,需要用公式:\(∑degree=2e\),但是degree定义不同,需要+1,求和后需要-1,因为根节点没有父节点。
+如果有两个degree的点个数不知道,直接当作0就可以。必须能够约掉,否则算不出来。
+(与叶节点相关的计算)
+
给一个序列。把bst建出来
+construct BST recursively
+节点下标关系
+建堆
+建并查集return s[x]=find(s[x],S)
+insertion deletion
+T(N)=2T(N/2)+1,解一下是O(N)
+后序遍历:必须最后一个是根,前面必须有一个序列完全小于根,后面一个序列完全大于根。然后再在子序列里找。
+节点为\(1 + 2 + 2 2 + . . . 2 k + m = 2 k + 1 − 1 + m = n 1+2+2^2+...2^k+m=2^{k+1}-1+m=n1+2+2 +2 + +...2 +k + +m=2 +k+1 + −1+m=n\)
+m是最下面一层的孩子。最下面一层的孩子的的一半+完整的k阶二叉树的孩子个数就是总孩子个数。
+4.二叉树最方便的方法就是画一个特例验证
+5.二叉搜索树不一定是完全的,因此和二分查找是不一样的。二分查找相当于在完全二叉树里找
+6.二叉搜索的时间复杂度为:T(N)=T(N/2)+1,如果不是二分,则是N/K,但是复杂度还是O(NlogN)
+7.二叉树7,9同级,则8一定共同的祖先,但是不一定是共同的父结点。
+下标问题:从0开始还是从1开始
+heapsort从1开始的
+下标性质比较重要
+1.建堆是从低N/2个元素开始,一个一个往前走,每个执行precdown。precdown是指将该结点和最小的孩子比较,如果大于最小的孩子,则交换,直到小于所有的孩子。
+2.建堆最大比较2N-2次
+
复杂度是多少
+union-by-size 因为每个节点
+\(O(log_2N+1)\)
+Proved by induction. Each element can have its set name changed at most \(\log_2N\) times.
+N union and M find (M>N):对于有path compression和union by rank的算法,
+\(T(M,N)=M\alpha(M,N)=Mlog^*(N)\)
+kruskal为什么是ElogE
+akammen
+横着看竖着看
+边(Edge)
+顶点(Vertex)
+度:相连边的个数,不同与树的子节点数(少 1)。
+\(∑ d e g r e e = 2 e\)是对所有的图都成立,和是否联通没有关系
+二维数组:表示边的方向、权。
+无向:使用单一数组,多重链表(共用存储,用多链串起每个元素)
+有向:邻接链表,十字链表(共用存储,分别用两链串起出入)
+关键信息在顶点(AOV,Activity On Vertex)
+单源最短路问题,即选出一个原点,其他所有点到这个原点的最小距离,并找出获得这个最小距离需要走哪条路
+两种BFS求无权图最短路的写法,一种是外面一个遍历所有节点的循环,维护一个curdist变量对每个点都判断,若距离=curdist,则更新与该节点相邻的所有节点的dist为curdist+1,如果图退化为线性的则复杂度为\(O(N^2)\)
+一种维护了一个队列,也就是BFS最经典的结构,先将原点入队,......直到队空,复杂度降为\(O(|V|+|E|)\)
+每次在unknown的节点中找一个dist最小的节点加入known数组中,更新与之相邻的所有节点的dist,当所有节点都在known中时终止
+有很多更新动作:走一条跳数更多的路径可能最后更短
+每次找dist的动作:线性扫描 复杂度为\(O(|V^2|+|E|)\), 对稠密图好,由于\(V<E<V^2\)
+邻接矩阵,邻接表实现,复杂度
+维护堆:
+堆优化
+Keep distances in a priority queue and call DeleteMin to find the smallest unknown distance vertex.——\(O(\log|V|)\)
更新的处理方法
+Method 1 : DecreaseKey——\(O(\log|V|)\)
\(T=O(|V|\log|V|+|E|\log|V|)=O(|E|\log|V|)\)
+Method 2 : insert W with updated Dist into the priority queue
+Must keep doing DeleteMin until an unknown vertex emerges
\(T=O(|E|\log|V|)\) but requires \(|E|\) DeleteMin with |E| space
Good if the graph is sparse
+复杂度:\(O(|V|×|E|)\)?
+combine the update move of weighted graph and the queue of unweighted
+循环V-1轮,遍历每条边E,看看对于已经访问过的节点(dist!=INT_MAX)是否能继续更新与之相邻节点的dist
+V-1轮对于遍历每条边更新是肯定够的,就算是考虑退化为一条单链表,也只需要V-1次
+判断有负权环的条件是,如果在第V-1次迭代后,还能继续松弛,则说明有负权环
+使用队列实现,对于出现了更新的顶点,都将其入队,每个顶点最多入队V次,而非发现时的一次,使用邻接表时复杂度为\(O(|V|×|E|)\),比dijkstra的\(O(|E|\log|V|)\)高非常多
+任意顶点第V+1出队时终止while循环
+activity on edges,边是重点动作,顶点只是指示该动作完成了,像一个检查点
+拓扑排序复杂度:\(O(|E|+|V|)\)
+从v到w的边
由松弛时间(slack time)==0的路径构成的通路为critical path
+在AOE网络中有一个源头顶点和目的顶点。 从源头顶点开始,执行各边上事件的行动,到目的顶点完成为止,所需的时间为所有事件完成的时间总花费。 AOE完成所需的时间是由一条或数条关键路径(Critical Path)所控制的。 所谓关键路径,就是AOE有向图从源头顶点到目的顶点之间,所需花费时间最长的一条有方向性的路径。 当有一条以上的路径时间相等并且都是最长,则这些路径都称为此AOE有向图的关键路径。
+The all-pairs shortest path problem is the determination of the shortest graph distances between every pair of vertices in a given graph. The problem can be solved using V applications of Dijkstra's algorithm or all at once using the Floyd-Warshall algorithm.
+Dijkstra算法重复用V次可达\(O(∣V∣^3 )\),优先级队列实现的话可以简化至\(O(|V|×|E|×log|V|)\),
+对于稀疏图比较好
+| C | |
|---|---|
手动算网络流要小心:模拟最大流,计算残余网络(residual graph)
+过程: Gf是最终流的情况,Gr是剩余容量的情况,开始Gf=0,Gr=原图
+注意是在残余网络中添加反方向的边
+An augmenting path can be found by an unweighted shortest path algorithm.
+\(T=O(f×|E|)\) where \(f\) is the maximum flow.
+Always choose the augmenting path that allows the largest increase in flow
+对Dijkstra算法进行单线(single-line)修改来寻找增长通路
+$$ + T=T_{augmentation}\times T_{find_a_path}\ + =O(|E|\log cap_{max})\times O(|E|\log|V|)\ + =O(|E|^2\log|V|\log cap_{max})\ + dijkstra算法,邻接表+堆的实现复杂度为O(|E|log|V|) + $$
+Always choose the augmenting path that has the least number of edges
+使用无权最短路算法来寻找增长路径
+$$ + T=T_{augmentation}\times T_{find_a_path}\ + =O(|E||V|)\times O(|E|)\ + =O(|E|^2|V|) + $$
+++Note :
++
+- If every \(v \notin \{ s, t \}\) has either a single incoming edge of capacity 1 or a single outgoing edge of capacity 1, then time bound is reduced to \(O( |E| |V|^{1/2} )\).
+- The min-cost flow problem is to find, among all maximum flows, the one flow of minimum cost provided that each edge has a cost per unit of flow.
+
kruskal 使用并查集?
+prim和kruskal \(|E|log|V|, Elog|E|?\),
+n 节点连通且无回路:n-1 条边
+由某点开始扩展树,选取最小路径,类 Dijkstra
+将边从小到大排序,每次取出最小边,不构成回路则放入。使用事先排序或堆。使用并查集优化环路判别
+权值相同的必须都添加(不能构成环)
+1.对图中的每一条边,扫描其他边,如果存在相同权值的边,则对此边做标记。
+2.然后使用Kruskal(或者prim)算法求出最小生成树。
+3.如果这时候的最小生成树没有包含未被标记的边,即可判定最小生成树唯一。如果包含了标记的边,那么依次去掉这些边,再求最小生成树,如果求得的最小生成树的权值和原来的最小生成树的权值相同,即可判断最小生成树不唯一。
+递归,访问所有未标记已访问的相邻顶点
+遍历非连通图:对每个节点,若未标记已访问,调用深度优先遍历。可由此获得 Component 数
+为获得唯一顺序,考试将使用图的具体表示进行考察
+articulation point 判断:
+
根节点有两个子节点,则一定是关节点
+不是根节点的点,至少有一个叶子节点,且不能够往下通过背向边(back edge)回到父亲
+
一笔画问题(边不重复)
+欧拉遍历:不重复遍历所有边,要求图有两个节点度奇数,则从一奇数回到另一奇数
+欧拉回路:不重复遍历所有边并回到起点,要求所有节点度为偶数。
+其他:哈密顿回路(点不重复)
+优先考虑是否是联通的。比如成环的一定是强联通,但是不联通的就错。如果边的度数为偶,但是没说是联通图,则不是欧拉图
+shell sort's increment 的决定因素
+shell’s increments
+shell 增量:for ( Increment = N / 2; Increment > 0; Increment /= 2 )
+
最差\(O(N^2)\),平均\(O(nlogn)\)
+hibbard 增量 \(h_k=2^k-1\)最差\(O(N^{3/2})\),平均\(O(N^{5/4})\)
+sedgewick 增量 最差 \(O(N^{4/3})\),平均\(O(N^{7/6})\)
+堆排序不用外部维护,可以原地排序,mergesort是唯一外部排序
+1.排序复杂度:
+归并:归并:O(N),总复杂度:O(NlogN)
+快排:平均和一般情况:O(BNlogN),最坏O(N^2)
+堆排:O(NlogN)
+
插入:O(N^2)
+桶排:O(N+M),M为桶数
+所有排序最坏情况必须为O(N)
+2.Heap和quick不用额外空间,Merge需要O(N)空间,外部排序
+
通常需要\(O(N)\)复杂度的额外空间
+During the sorting, processing every element which is not yet at its final position is called a "run". Which of the following cannot be the result after the second run of quicksort? +A.5, 2, 16, 12, 28, 60, 32, 72
+B.2, 16, 5, 28, 12, 60, 32, 72
+C.2, 12, 16, 5, 28, 32, 72, 60
+D.5, 2, 12, 28, 16, 32, 72, 60
+每一个run可以确定一个pivot的位置,两次递归可以确定1+2=3个。
+但是要注意,如果在末尾的pivot使得递归只在之前进行,所以也可以
+loading factor?
+loading density
+probing methods
+collision / overflow
+如果冲突太多还不如树,树至少有logN
+double hashing 和 rehashing是不一样
+模拟哈希
+冲突处理
+字符串:转换为 32 进制整数,与散列表大小取模。
+
如果是empty,则key没有定义,先判断会出错。
+假设探测步数i不超过TS/2+1步,即假设表<50%。这时CurrentPos+2i-1 <= 2TS-1,所以可以用减法。
+分离连接法(桶)
+开放地址法
+线性探测:线性向下查找空位。
+二次探测:
+必须tablesize=prime,使用二次探测,则
+解决查找不存在映射的效率,因不成功搜索需要查找至空位,而平方可较快地避开聚集。
+在删除时需要使用标记,使得查找可以在标记位置继续,而插入也可以正常工作。
+2021-2022
+quicksort shellsort 的步长
+double hashing和quadratic probing的关系
+kruskal
+二叉查找树子树所有元素对父节点大小关系均相同,因此判断是否为二叉查找序列可按顺序更新允许的最小值和最大值。
+堆排序使用最大堆。
+快速排序空间复杂度非 O(1),而是堆栈引入的 O(NlogN)~O(N)。
+由广度优先遍历构建二叉树:寻找根(前序前,后序后),确定两子树,递归。
+由元素构建二叉查找树:按图形确定树根和两子树,递归。
+单向列表导致尾部不能直接删除
+入/出堆栈/队列须判断空/满
+队列 Front 可指在队列头前一以使当 Front Rear 重合时队列为满
+中缀表达式转后缀表达式,数字直接输出,符号:当已知符号优先级大于等于当前符号已知出栈,之后当前符号入栈。括号处理:左括号在栈外优先级最高(直接入栈),在栈内优先级最低(不出栈),只在遇到右括号时弹出。
+二叉树:n0=n2+1,叶子数为双儿子父亲数加一。
+二叉查找树插入、删除实现使用返回值式递归,函数总是返回参数节点的元素(可能改变),调用者将该节点用返回值覆盖。
+d堆:父节点位于 [(i + d − 2) / d],儿子节点在 (i − 1)d + 2, ..., id + 1.
+森林:根节点右兄弟为其他根节点
+开放地址法二次探测要求表大小为素数且最多有 [表的大小/2] (向下取整)个位置被占用。
+DAG:Directed Acyclic Graph
+无环连通图为树
+稳定性 +稳定的排序 +冒泡排序 O(n2) +插入排序 O(n2) +桶排序 O(n);需要O(k)额外空间 +归并排序 O(n log n);需要O(n)额外空间 +原地归并排序 O(n2) +基数排序 O(n·k);需要O(n)额外空间
+不稳定的排序 +选择排序 O(n2) +希尔排序(shell sort)—O(n log2 n)如果使用最佳的现在版本 +堆排序(heap sort)—O(n log n) +快速排序(quick sort)—O(n log n)期望时间, O(n2)最坏情况;对于大的、乱数列表一般相信是最快的已知排序
+平均时间复杂度由高到低为: +冒泡排序O(n2) +选择排序O(n2) +插入排序O(n2) +希尔排序O(n1.25) +堆排序O(n log n) +归并排序O(n log n) +快速排序O(n log n) +基数排序O(n)
int **graph,int graphsize表示graph二维数组有多少行
+int* graphcolsize表示每行有多少列
+验证二叉搜索树:用中序遍历
+230
+给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序)
graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点 graph[i][j]存在一条有向边)。
分治思想:
+回溯注重边的选择,撤销在for循环内
+和DFS一样,先看是否走通了一条路径/走到头了一条路径
+如果没有,就将当前位置相邻的下一层所有的可能性都遍历一遍
+举个例子,比如两个经典排序算法 快速排序 和 归并排序,对于它俩,你有什么理解?
+如果你告诉我,快速排序就是个二叉树的前序遍历,归并排序就是个二叉树的后序遍历,那么我就知道你是个算法高手了。
+为什么快速排序和归并排序能和二叉树扯上关系?我们来简单分析一下他们的算法思想和代码框架:
+快速排序的逻辑是,若要对 nums[lo..hi] 进行排序,我们先找一个分界点 p,通过交换元素使得 nums[lo..p-1] 都小于等于 nums[p],且 nums[p+1..hi] 都大于 nums[p],然后递归地去 nums[lo..p-1] 和 nums[p+1..hi] 中寻找新的分界点,最后整个数组就被排序了。
快速排序的代码框架如下:
+| Java | |
|---|---|
先构造分界点,然后去左右子数组构造分界点,你看这不就是一个二叉树的前序遍历吗?
+再说说归并排序的逻辑,若要对 nums[lo..hi] 进行排序,我们先对 nums[lo..mid] 排序,再对 nums[mid+1..hi] 排序,最后把这两个有序的子数组合并,整个数组就排好序了。
归并排序的代码框架如下:
+先对左右子数组排序,然后合并(类似合并有序链表的逻辑),你看这是不是二叉树的后序遍历框架?另外,这不就是传说中的分治算法嘛,不过如此呀。
+如果你一眼就识破这些排序算法的底细,还需要背这些经典算法吗?不需要。你可以手到擒来,从二叉树遍历框架就能扩展出算法了。
+说了这么多,旨在说明,二叉树的算法思想的运用广泛,甚至可以说,只要涉及递归,都可以抽象成二叉树的问题。
+原因:对于高度为h,有\(2^{h+1}-1\)个节点的完全二叉树,节点的高度之和为\(2^{h+1}-h-1\)
+N union + M find \(O(N+Mlog_2N)\) union by size,因为find大于等于union
+循环链表 To delete p from a doubly linked list, we must do:
p->prior->next = p->next;p->next->prior=p->prior
指针比较多,注意调试不要打印或者访问NULL的某个属性,避免越界等段错误
+因此所有的find percolate insert都先判断是否为NULL节点,再访问节点的left/right
+堆下标从1开始
+从二叉树中删除节点:
+先找到元素,找到NULL则说明要删除的元素不存在
+再看有几个子节点,若0或1个则直接替换(用Null)替换也可
+若有两个则用左子树中的最大节点或右子树中最小的节点替换,替换过程中只先改变根节点的数值,再执行delete那个底下的重复节点
+插入新元素
+插在最后,向上percolate,注意percolate up自然是不用比较大小的,down需要比较大小
+Percolate
+弹出最小值(DeleteMin)并维护堆的性质:
+用最后一个元素替换堆顶元素,并进行minHeapify
+minHeapify过程,就是percolate down的过程
+递归传递的参数为堆指针和当前节点的下标i,首先计算出左右节点下标(2i,2i+1),比较左右节点选出较小值与根节点交换,递归持续进行到越界或最小值就是i结束。
+

| C | |
|---|---|
最坏情况复杂度达到\(O(N^2)\)!!!!
+Proved by induction. Each element can have its set name changed at most \(\log_2N\) times.
+Time complexity of \(N\) Union and \(M\) Find operations is now \(O(N+M\log_2N)\).
+原因:被链接的树的大小至少翻倍
+| C | |
|---|---|
使用S[root]保存树的深度的相反数,都是负数,绝对值越大越深
+| C | |
|---|---|
普通的find
+ +带路径压缩的find:
+| C | |
|---|---|
这两种是一样的
+| C | |
|---|---|
递归改写为迭代形式的find,相当于遍历两遍
+| C | |
|---|---|

| C | |
|---|---|
| C | |
|---|---|
1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 + 9 + 10 + 11 + 12 + 13 + 14 + 15 + 16 + 17 + 18 + 19 + 20 + 21 + 22 + 23 + 24 + 25 + 26 + 27 + 28 + 29 + 30 + 31 + 32 + 33 + 34 + 35 + 36 + 37 + 38 + 39 + 40 + 41 + 42 + 43 + 44 + 45 + 46 + 47 + 48 + 49 + 50 + 51 + 52 + 53 + 54 + 55 + 56 + 57 + 58 + 59 + 60 + 61 + 62 + 63 + 64 + 65 + 66 + 67 + 68 + 69 + 70 + 71 + 72 + 73 + 74 + 75 + 76 + 77 + 78 + 79 + 80 + 81 + 82 + 83 + 84 + 85 + 86 + 87 + 88 + 89 + 90 + 91 + 92 + 93 + 94 + 95 + 96 + 97 + 98 + 99 +100 +101 +102 +103 +104 +105 +106 +107 +108 +109 +110 +111 +112 +113 +114 +115 +116 +117 +118 +119 +120 +121 +122 +123 +124 +125 +126 +127 +128 +129 +130 +131 +132 +133 +134 +135 +136 +137 +138 +139 +140 +141 +142 +143 +144 +145 +146 +147 | |
insertion sequence序列不同,构建出的二叉树形状可能有多种
+
建立二叉搜索树的顺序
+先判断当前节点是否为NULL,若是,则建立新节点(data = x,left=right=NULL)
+若不是,则递归向下,若大于当前,则Insert(x,tree->left),小于前,则Insert(x,tree->right)
+作业错题
+环形队列 数组实现
+Suppose that an array of size m is used to store a circular queue. If the front position is front and the current size is size, then the rear element must be at:
| Text Only | |
|---|---|
| Text Only | |
|---|---|
| Text Only | |
|---|---|
| Text Only | |
|---|---|


disjoint sets
+
对于某个序列,如3,2,1,7,5,6,4,栈的大小为5
+预设flag=1,假设是合法出栈序列
+初始化栈顶指针为-1,先将1入栈,因为1一定是第一个入栈,使用i记录下一个将要入栈的元素
+栈顶不能超过M,且还未遍历完(使用\(num[j]\)保存如果是合法出栈序列即将出栈的元素)
+若\(栈顶元素==num[j]\)则弹出,\(j\)向后遍历
+若到最后栈不为空则error
+polish
+infix操作
+
C
+计算机只能在将中缀表达式转换为前缀或后缀表达式后才能进行运算
+计算机在计算后缀表达式时只需从左到右线性扫描,遇到操作数压入栈,遇到运算符则依次取出栈顶的两个操作数计算后将结果重新压回栈中。
+因此将中缀表达式转换为前缀或后缀表达式比较关键
+一般使用两个栈进行此操作,在转换时不进行运算,只是将运算符和操作数重新排列
+最后输出时一般是倒序输出
+注意,只有S1栈顶运算符优先级小于当前运算符时,才将当前运算符压入S1,否则直接压入中间结果栈S2
+S2不叫操作数栈,因为最后结果从S2中逆序输出得到
+

倒序输出为ABC+*DEF+/-
+操作数顺序不会变化,一定是叶子节点
+
模板1相当于 左闭右闭区间 left=0,right=length-1,
+模板2相当于 左闭右开区间 left=0,right=length,
+模板3相当于 左开右开区间 left=-1,right=length/ left=0,right=length-1,
+2和3找的是\(>=\)target的第一个数
+模板 #1 (left <= right):
模板 #2 (left < right):
模板 #3 (left + 1 < right):
在N个元素的数组中找第K大的数:
+N个元素的前K个先做minHeapify,后面的元素依次插入堆的对应位置:
+方法:insert,如果比H[1](堆顶元素,下标从1开始)小,则不插入堆中,因为堆顶就是第K个大的数
+若比H[1]大,则percolate down,沿途子节点向上替换父节点,也就是H[1]被替换
+将余下的K+1~N个元素全部判断并插入后,最终堆顶元素就是N个数中第K大的数
+No Greater Than X in BST
+(20分)
+You are supposed to output, in decreasing order, all the elements no greater than X in a binary search tree T.




默写内容
+树:delete(BST),insert(BST)
+堆:deletemin,minheapify,percolate(up/down),
+栈:infix->prefix/postfix, evaluate postfix
+| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
Given any weighted undirected graph, there exists at least one minimum spanning tree (MST) if the graph is connected. Sometimes the MST may not be unique though. Here you are supposed to calculate the minimum total weight of the MST, and also tell if it is unique or not.
+Each input file contains one test case. Each case starts with a line containing 2 numbers N (≤ 500), and M, which are the total number of vertices, and the number of edges, respectively. Then M lines follow, each describes an edge by 3 integers:
+| Text Only | |
|---|---|
where V1 and V2 are the two ends of the edge (the vertices are numbered from 1 to N), and Weight is the positive weight on that edge. It is guaranteed that the total weight of the graph will not exceed 230.
For each test case, first print in a line the total weight of the minimum spanning tree if there exists one, or else print No MST instead. Then if the MST exists, print in the next line Yes if the tree is unique, or No otherwise. There there is no MST, print the number of connected components instead.
注意circuit是回路,要回去到起点的,euler tour可以不用回到起点,但经过每条边
+判断是否存在欧拉回路主要就是看有没有度为奇数的边
+A.判断欧拉通路是否存在的方法
+有向图:图连通,有一个顶点出度大入度1,有一个顶点入度大出度1,其余都是出度=入度。
+无向图:图连通,只有两个顶点是奇数度,其余都是偶数度的。
+B.判断欧拉回路是否存在的方法
+有向图:图连通,所有的顶点出度=入度。
+无向图:图连通,所有顶点都是偶数度。
+若图中有负权环路,则会产生无穷循环,最短路不存在
+求强连通分量的Tarjan算法
+| C | |
|---|---|



Input : There are zero or more quantities that are externally supplied.
+Output : At least one quantity is produced.
+Definiteness : Each instruction is clear and unambiguous.
+Finiteness : the algorithm terminates after finite number of steps
+Effectiveness : basic enough to be carried out ; feasible
+A program does not have to be finite. (eg. an operation system)
+An algorithm can be described by human languages, flow charts, some programming languages, or pseudocode.
+| Text Only | |
|---|---|
Machine and compiler-dependent run times.
+Time and space complexities : machine and compiler independent.
+Assumptions:
++++
+- +
+instructions are executed sequentially 顺序执行
+- +
+each instruction is simple, and takes exactly one time unit
+- integer size is fixed and we have infinite memory
+
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
But it takes more time to compute each step.
+\(2N+3=O(N)=O(N^{k\geq1})=O(2^N)=\ldots\) take the smallest \(f(N)\)
+\(2^N+N^2=\Omega(2^N)=\Omega(N^2)=\Omega(N)=\Omega(1)=\ldots\) take the largest \(g(N)\)
+Rules of Asymptotic Notation
++++
+- If \(T_1(N)=O(f(N))\) and \(T_2=O(g(N))\), then
+(1) \(T_1(N)+T_2(N)=max(O(f(N)),O(g(N)))\)
+(2) \(T_1(N)*T_2(N)=O(f(N)*g(N))\)
++
+- +
+若\(T(N)\)是一个\(k\)次多项式,则\(T(N)=\Theta(N^k)\)
+- +
+\(log_kN=O(N)\) for any constant \(k\) (logarithms grow very slowly)
+


| C | |
|---|---|
+++
+- +
+For loops : The running time of a for loop is at most the running time of the statements inside the for loop (including tests) times the number of iterations.
+- +
+Nested for loops : The total running time of a statement inside a group of nested loops is the running time of the statements multiplied by the product of the sizes of all the for loops.
+- +
+Consecutive statements : These just add (which means that the maximum is the one that counts).
+- +
+If/else : For the fragment + if ( Condition ) S1; + else S2;
+The running time is never more than the running time of the test plus the larger of the running time of S1 and S2.
++
+
+- Recursions :
+[Example] Fibonacci number + $$ + Fib(0)=Fib(1)=1, Fib(n)=Fib(n-1)+Fib(n-2) + $$
++
C $$ + T(N)=T(N-1)+T(N-2)+2\geq Fib(N)\ + \left(\frac{3}{2} \right)^n\leq Fib(N)\leq\left(\frac{5}{3}\right)^n + $$
+时间复杂度:\(O(2^N)\) \(T(N)\) grows exponentially
+空间复杂度:\(O(N)\)
+\(O(N)\)
+
\(O(N)\)
+Algorithm 1
+Algotithm 2
+Algorithm 3 Divide and Conquer 分治法
+$$ +\because T(N)=2T(\frac N2)+cN\quad T(1)=O(1)\ +T(\frac N2)=2T(\frac N {2^2})+c\frac N2\ +\cdots\ +T(1)=2T(\frac N{2^k})+c\frac N{2^{k-1}}\ +\therefore T(N)=2^kT(\frac N{2^k})+kcN=N\cdot O(1)+cN\log N +$$ +Algorithm 4 On-line Algorithm 在线算法
+| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
When \(T(N)=O(N)\), check if \(T(2N)/T(N)\approx2\)
+When \(T(N)=O(N^2)\), check if \(T(2N)/T(N)\approx4\)
+When \(T(N)=O(N^3)\), check if \(T(2N)/T(N)\approx8\)
+When \(T(N)=O(f(N))\), check if $\lim\limits_{N\rightarrow\infty}\frac{T(N)}{f(N)}\approx C $
+Sequential mapping 连续存储,访问快
+Find_Kth take \(O(1)\) time.
+MaxSize has to be estimated.
+Insertion and Deletion not only take \(O(N)\) times, but also involve a lot of data movements which takes time.
+
Query 查询
+Location of nodes may change on differrent runs.
+Insertion 先连后断
+Deletion 先连后释放
+频繁malloc和free系统开销较大
+Finding take \(O(N)\) times.
+| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|

The correct answer is D.
+The Polynomial ADT
+Objects :
+Operations :
+Multiplication
+Differentiation
+[Representation 1]
+| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
只存储非零项
+Multilists
+
#blender エイサー・パルマタム || Acer Palmatum - selescha.arts的插画 - pixiv
1、栈的链表实现,push,pop和top语句
+2、
+
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
The stack model must be well encapsulated(封装). That is, no part of your code, except for the stack routines, can attempt to access the Array or TopOfStack variable.
+Error check must be done before Push or Pop (Top).
+| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
检查括号是否平衡
+Postfix Evaluation 后缀表达式
+Infix to Postfix Conversion
+读到一个操作数时立即把它放到输出中
+Exponentiation associates right to left.
+Function Calls (System Stack)
+
++Note : Recursion can always be completely removed. Non recursive programs are generally faster than equivalent recursive programs. However, recursive programs are in general much simpler and easier to understand.
+
| C | |
|---|---|
Circular Queue :
+

++Note : Adding a Size field can avoid wasting one empty space to distinguish “full” from “empty”.
+
大纲:
+树的定义是递归的,有根节点和从其出发的有向边,连向所有的子树
+树的性质,n个节点n-1条边有根节点
+二叉树:
+树的遍历 四种遍历顺序,层序遍历
+Subtrees must not connect together. Therefore every node in the tree is the root of some subtree.
+There are N-1 edges in a tree with N nodes
++++
+- degree of a node : 结点的子树个数
+- degree of a tree : 结点的度的最大值
+- parent : 有子树的结点
+- children : the roots of the subtrees of a parent
+- siblings : children of the same parent
+- leaf(terminal node) : a node with degree 0(no children)
+- path from \(n_1\) to \(n_k\) : a unique sequence of nodes \(n_1,n_2,\cdots,n_k\) such that \(n_i\) is the parent of \(n_{i+1}\) for \(1\leq i<k\)
+- length of path : 路径上边的条数
+- depth of \(n_i\) : 从根结点到\(n_i\)结点的路径的长度(\(Depth(root)=0\))
+- height of \(n_i\) : 从\(n_i\)结点到叶结点的最长路径的长度(\(Height(leaf)=0\))
+- height/depth of a tree : 根结点的高度/最深的叶结点的深度
+- ancestors of a node : 从此结点到根结点的路径上的所有结点
+- descendants of a node : 此结点的子树中的所有结点
+

The correct answer is T.
+
线性复杂度\(O(n)\),因为每个节点只访问一次
+遍历不改变操作数的顺序
+visit(可以是print)
+| Text Only | |
|---|---|
| Text Only | |
|---|---|
| Text Only | |
|---|---|
| Text Only | |
|---|---|
Iterative Program : 使用自己定义的栈替换系统的栈,实现中序遍历
+leftmost 的左节点和rightmost的右节点都是NULL
+| Text Only | |
|---|---|

A full binary tree with \(n\) nodes has \(2n\) links, and \(n+1\) of them are NULL.
+Replace the NULL links by “threads” which will make traversals easier.
+Rules :
++++
+- If Tree->Left is null, replace it with a pointer to the inorder predecessor(中序前驱) of Tree.
+- leftmost的left指针由于没有中序前驱(中序遍历中最先返回的节点),所以指向head node
+- If Tree->Right is null, replace it with a pointer to the inorder successor(中序后继) of Tree.
+- 同理,rightmost的right由于没有中序后继(中序遍历中最后返回的节点),所以也指向head node
+- There must not be any loose threads. Therefore a threaded binary tree must have a head node of which the left child points to the first node.(右节点指针指向自身)
+

| C | |
|---|---|
+++
+- The maximum number of nodes on level \(i\) is \(2^{i-1},i\geq1\).
+- The maximum number of nodes in a binary tree of depth \(k\) is \(2^k-1,k\geq1\).
+- For any nonempty binary tree, \(n_0 = n_2 + 1\) where \(n_0\) is the number of leaf nodes and \(n_2\) is the number of nodes of degree 2.
+proof: 假设该二叉树总共有n个结点(\(n =n_0+n_1+n_2\)),则该二叉树总共会有n-1条边,度为2的结点会延伸出两条边,
+同理,度为1的结点会延伸出一条边,则可列公式:$n-1 = 2n_2 + n_1 $,
+合并两个式子可得:\(2n_2 + n_1 +1 =n_0 + n_1 + n_2\) ,则计算可知 \(n_0=n_2+1\)
+
Iterative program :
+| Text Only | |
|---|---|
| Text Only | |
|---|---|
\(T(N)=O(d)\)
+Delete
+Delete a leaf node : Reset its parent link to NULL
+++Note : If there are not many deletions, then lazy deletion may be employed: add a flag field to each node, to mark if a node is active or is deleted. Therefore we can delete a node without actually freeing the space of that node. If a deleted key is reinserted, we won’t have to call malloc again.
+
Average-Case Analysis
+The average depth over all nodes in a tree is \(O(logN)\) on the assumption that all trees are equally likely.
+
The correct answer is A.
+Insertion — add one item at the end ~\(\Theta(1)\)
+Deletion — find the largest / smallest key ~\(\Theta(n)\)
+ remove the item and shift array ~\(O(n)\)
+Insertion — add to the front of the chain ~\(\Theta(1)\)
+Deletion — find the largest / smallest key ~\(\Theta(n)\)
+ remove the item ~\(\Theta(1)\)
+ shift array and add the item ~\(O(n)\)
+ add the item ~\(\Theta(1)\)
+[Definition] A binary tree with \(n\) nodes and height \(h\) is complete if its nodes correspond to the nodes numbered from \(1\) to \(n\) in the perfect binary tree of height \(h\).
+A complete binary tree of height \(h\) has between \(2^h\) and \(2^{h+1}-1\) nodes.
+\(h=\lfloor\log N\rfloor\)
+Array Representation : BT[n + 1] ( BT[0] is not used)
+
[Lemma]
+[Definition] A min tree is a tree in which the key value in each node is no larger than the key values in its children (if any). A min heap is a complete binary tree that is also a min tree.
+$$ + T(N)=O(\log N) + $$
+查找除最小值之外的值需要对整个堆进行线性扫描
+DecreaseKey — Percolate up
+IncreaseKey — Percolate down
+Delete
+BuildHeap
+将N 个关键字以任意顺序放入树中,保持结构特性,再执行下滤
+ +$$ + T(N)=O(N) + $$
+[Theorem] For the perfect binary tree of height \(h\) containing \(2^{h+1}-1\) nodes, the sum of the heights of the nodes is \(2^{h+1}-1-(h+1)\).
+
The function is to find the K-th smallest element in a list A of N elements. The function BuildMaxHeap(H, K) is to arrange elements H[1] ... H[K] into a max-heap.
Note :
++++
+- DeleteMin will take \(d-1\) comparisons to find the smallest child. Hence the total time complexity would be \(O(d \log_d N)\).
+- 2 or /2 is merely *a bit shift**, but *d or /d is not.
+- When the priority queue is too large to fit entirely in main memory, a d-heap will become interesting.
+


正确答案是4,注意“in the process”
+关系的几种类型 +自反关系(reflexive) +设 R是 A上的一个二元关系,若对于 A中的每一个元素 a, (a,a)都属于 R,则称 R为自反关系。
+非自反关系(irreflexive) +设R是A上的关系。若对所有a∈A,均有(a,a)∈ R,则称R是A上的一个自反关系
+对称关系(symmetric) +集合A上的二元关系R,对任何a,b∈A,当aRb时有bRa
+非对称关系(asymmetric) +集合A上的二元关系R,对任何a,b∈A,当aRb时有bR a
+反对称关系(antisymmetric)
+
Operations :
+Union( \(i, j\) ) = Replace \(S_i\) and \(S_j\) by \(S=S_i\bigcup S_j\)
+Make \(S_i\) a subtree of \(S_j\), or vice versa, that is to set the parent pointer of one of the roots to the other root.
+Implementation 1 :
+
Implementation 2 :
+The elements are numbered from 1 to N, hence they can be used as indices of an array.
+S[ element ] = the element’s parent
+Note : S[ root ] = 0 and set name = root index
+

| Text Only | |
|---|---|
Always change the smaller tree
+S[Root] = -size, initialized to be -1
+[Lemma] Let T be a tree created by union-by-size with N nodes, then \(height(T)\leq\lfloor\log_2N\rfloor+1\).
+Proved by induction. Each element can have its set name changed at most \(\log_2N\) times.
+| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
$$ + A(2,4)=2^{2^{2^{2^2}}}=2^{65536} + $$
+\(\log^*N\) (inverse Ackermann function) = number of times the logarithm is applied to \(N\) until the result \(\leq1\).
+一共有五种算法,注意看清题设
+No smart union
+Union-by-size
+Union-by-height
+Union-by-size + Path Compression
+Union-by-height + Path Compression
+



number of edges incident to v
+For a directed G, we have in-degree and out-degree.
+Given G with \(n\) vertices and \(e\) edges, then + $$ + e=(\sum_{i=0}^{n-1}d_i)/2\quad where\quad d_i=degree(v_i) + $$
+
++Note : If G is undirected, then adj_mat[][] is symmetric. Thus we can save space by storing only half of the matrix.
+

This representation wastes space if the graph has a lot of vertices but very few edges.
+To find out whether or not \(G\) is connected, we’ll have to examine all edges. In this case \(T\) and \(S\) are both \(O( n^2 )\).
+
++Note : The order of nodes in each list does not matter.
+


++Note : If the precedence relation is reflexive, then there must be an \(i\) such that \(i\) is a predecessor of \(i\). That is, \(i\) must be done before \(i\) is started. Therefore if a project is feasible, it must be irreflexive.
+
++Note : The topological orders may not be unique for a network.
+
\(注意E的范围 最小 V 最大 |V|^2\)
Given a digraph \(G = ( V, E )\), and a cost function \(c( e )\) for \(e \in E( G )\).
+The length of a path \(P\) from source to destination is \(\sum_{e_i\subset P} c(e_i)\)(also called weighted path length).
+Given as input a weighted graph, \(G = ( V, E )\), and a distinguished vertex \(s\), find the shortest weighted path from \(s\) to every other vertex in \(G\).
+++Note: If there is no negative-cost cycle, the shortest path from \(s\) to \(s\) is defined to be zero.
+
Implementation :
+The worst case :
+ +$$
+T(N)=O(|V|^2)
+$$
+Improvement :
+$$
+T(N)=O(|V|^2)
+$$
+Improvement :
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|
堆优化
+Keep distances in a priority queue and call DeleteMin to find the smallest unknown distance vertex.——\(O(\log|V|)\)
更新的处理方法
+Method 1 : DecreaseKey——\(O(\log|V|)\)
\(T=O(|V|\log|V|+|E|\log|V|)=O(|E|\log|V|)\)
+Method 2 : insert W with updated Dist into the priority queue
+Must keep doing DeleteMin until an unknown vertex emerges
\(T=O(|E|\log|V|)\) but requires \(|E|\) DeleteMin with |E| space
Good if the graph is sparse
+++Note : Negative-cost cycle will cause indefinite loop
+




++Note : Total coming in (\(v\)) = Total going out (\(v\)) where \(v \notin \{ s, t \}\)
+
++Step 1 : Find any path from \(s\) to \(t\) in \(G_r\) , which is called augmenting path(增长通路).
+Step 2 : Take the minimum edge on this path as the amount of flow and add to \(G_f\).
+Step 3 : Update \(G_r\) and remove the 0 flow edges.
+Step 4 : If there is a path from \(s\) to \(t\) in \(G_r\) then go to Step 1, or end the algorithm.
+
++Note : The algorithm works for \(G\) with cycles as well.
+
An augmenting path can be found by an unweighted shortest path algorithm.
+\(T=O(f|E|)\) where \(f\) is the maximum flow.
+Always choose the augmenting path that allows the largest increase in flow
+对Dijkstra算法进行单线(single-line)修改来寻找增长通路
+$$ + T=T_{augmentation}\times T_{find_a_path}\ + =O(|E|\log cap_{max})\times O(|E|\log|V|)\ + =O(|E|^2\log|V|\log cap_{max}) + $$
+Always choose the augmenting path that has the least number of edges
+使用无权最短路算法来寻找增长路径
+$$ + T=T_{augmentation}\times T_{find_a_path}\ + =O(|E||V|)\times O(|E|)\ + =O(|E|^2|V|) + $$
+++Note :
++
+- If every \(v \notin \{ s, t \}\) has either a single incoming edge of capacity 1 or a single outgoing edge of capacity 1, then time bound is reduced to \(O( |E| |V|^{1/2} )\).
+- The min-cost flow problem is to find, among all maximum flows, the one flow of minimum cost provided that each edge has a cost per unit of flow.
+
++Note :
++
+- The minimum spanning tree is a tree since it is acyclic, the number of edges is \(|V|-1\)
+- It is minimum for the total cost of edges is minimized.
+- It is spanning because it covers every vertex.
+- A minimum spanning tree exists if \(G\) is connected.
+- Adding a non-tree edge to a spanning tree, we obtain a cycle.
+
Make the best decision for each stage, under the following constrains :
++++
+- we must use only edges within the graph
+- we must use exactly \(|V|-1\) edges
+- we may not use edges that would produce a cycle
+
Prim’s Algorithm
+在算法的任一时刻,都可以看到一个已经添加到树上的顶点集,而其余顶点尚未加到这棵树中
+算法在每一阶段都可以通过选择边\((u, v)\),使得\((u,v)\)的值是所有\(u\) 在树上但\(v\)不在树上的边的值中的最小者,而找出一个新的顶点并把它添加到这棵树中
+Kruskal’s Algorithm
+连续地按照最小的权选择边,,并且当所选的边不产生环时就把它作为取定的边
+$$ + T=O(|E|\log|E|) + $$
+
| C | |
|---|---|
| C | |
|---|---|
| C | |
|---|---|


++Note : No edges can be shared by two or more biconnected components. Hence \(E(G)\) is partitioned by the biconnected components of \(G\).
+
Finding the biconnected components of a connected undirected \(G\) :
++++
+- Use depth first search to obtain a spanning tree of \(G\)
++
+
+
+- Depth first number(\(Num\)) 先序编号
+- Back edges(背向边) = \((u,v)\notin\) tree and \(u\) is an ancestor of \(v\).
+++Note : If \(u\) is an ancestor of \(v\), then \(Num(u)<Num(v)\).
++
+- Find the articulation points in \(G\)
+- The root is an articulation point if it has at least 2 children.
+- Any other vertex \(u\) is an articulation point if \(u\) has at least 1 child, and it is impossible to move down at least 1 step and then jump up to \(u\)‘s ancestor
+
| Text Only | |
|---|---|
++Note:
++
+- The path should be maintained as a linked list.
+- For each adjacency list, maintain a pointer to the last edge scanned.
+- \(T=O(|E|+|V|)\)
+
| C | |
|---|---|
The worst case : Input A[ ] is in reverse order + $$ + T(N)=O(N^2) + $$
+The best case : Input A[ ] is in sorted order + $$ + T(N)=O(N) + $$
+Swapping two adjacent elements that are out of place removes exactly one inversion.
+\(T(N,I)=O(I+N)\) where \(I\) is the number of inversions in the original array.
+
Define an \(h_k\)-sort at each phase for \(k = t, t - 1,\cdots, 1\)
+最后一轮就是Insertion Sort
+++Note : An \(h_k\)-sorted file that is then \(h_{k-1}\)-sorted remains \(h_k\)-sorted.
+
| C | |
|---|---|
| C | |
|---|---|
++Note : Although Heapsort gives the best average time, in practice it is slower than a version of Shellsort that uses Sedgewick’s increment sequence.
+
++Note : Mergesort requires linear extra memory, and copying an array is slow. It is hardly ever used for internal sorting, but is quite useful for external sorting.
+
qsort非递归实现,自然语言描述(ppt第一页),qsort程序填空
+不要只注意i++,j--
+| Text Only | |
|---|---|
| C | |
|---|---|
++Note : If set i = Left+1 and j = Right-2, there will be an infinite loop if A[i] = A[j] = pivot.
+如果出现arr[i]=arr[j]=pivot情况,for循环将进入死循环,因为每次检查到arr[i]=pivot和arr[j]=pivot就会终止循环,并且i<j,相互交换,还都是pivot,无法终止。
+ 一个改进的方法就是,我们在每次swap之后,修改i和j的值,对i自加,对j自减,这种操作是可行的,因为当前i和j元素交换,满足i元素小于等于pivot,j元素大于等于pivot。改进如下:
++
C
\(i\) is the number of the elements in \(S_1\).
+The Worst Case + $$ + T(N)=T(N-1)+cN + $$
+$$ + T(N-1)=T(N-2)+c(N-1) + $$
+$$ + \cdots + $$
+$$ + T(2)=T(1)+2c + $$
+$$ + T(N)=T(1)+c\sum^N_{i=2}i=O(N^2) + $$
+$$ + \frac{T(N)}{N}=\frac{T(N/2)}{N/2}+c + $$
+$$ + \frac{T(N/2)}{N/2}=\frac{T(N/4)}{N/4}+c + $$
+$$ + \cdots + $$
+$$ + \frac{T(2)}{2}=\frac{T(1)}{1}+c + $$
+$$ + \frac{T(N)}{N}=\frac{T(1)}{1}+c\log N\frac{T(N)}{N}=\frac{T(1)}{1}+c\log N + $$
+$$ + T(N)=cN\log N+N=O(N\log N) + $$
+The Average Case
+Assume the average value of \(T( i )\) for any \(i\) is \(\frac{1}{N}\left[\sum^{N-1}_{j=0}T(j)\right]\) + $$ + T(N)=\frac{2}{N}\left[\sum^{N-1}_{j=0}T(j)\right]+cN + $$
+$$ + NT(N)=2\left[\sum^{N-1}_{j=0}T(j)\right]+cN^2 + $$
+$$ + (N-1)T(N-1)=2\left[\sum^{N-2}_{j=0}T(j)\right]+c(N-1)^2 + $$
+$$ + NT(N)-(N-1)T(N-1)=2T(N-1)+2cN-c + $$
+$$ + NT(N)=(N+1)T(N-1)+2cN + $$
+$$ + \frac{T(N)}{N+1}=\frac{T(N-1)}{N}+\frac{2c}{N+1} + $$
+$$ + \frac{T(N-1)}{N}=\frac{T(N-2)}{N-1}+\frac{2c}{N} + $$
+$$ + \cdots + $$
+$$ + \frac{T(2)}{3}=\frac{T(1)}{2}+\frac{2c}{3} + $$
+$$ + \frac{T(N)}{N+1}=\frac{T(1)}{2}+2c\sum^{N+1}_{i=3}\frac{1}{i} + $$
+$$ + T(N)=O(N\log N) + $$
+
正确答案是D
+
| Text Only | |
|---|---|







| C | |
|---|---|
++Note : Make the TableSize about as large as the number of keys expected (i.e. to make the loading density factor \(\lambda\approx\)1).
+
++Note : Generally \(\lambda<0.5\).
+

++Note : If the table size is a prime of the form \(4k + 3\), then the quadratic probing \(f(i) = \pm i^2\) can probe the entire table.
+
| C | |
|---|---|
++Note :
++
+- Insertion will be seriously slowed down if there are too many deletions intermixed with insertions.
+- Although primary clustering is solved, secondary clustering occurs, that is, keys that hash to the same position will probe the same alternative cells.
+
++Note :
++
+- If double hashing is correctly implemented, simulations imply that the expected number of probes is almost the same as for a random collision resolution strategy.
+- Quadratic probing does not require the use of a second hash function and is thus likely to be simpler and faster in practice.
+
++Note : Usually there should have been N/2 insertions before rehash, so O(N) rehash only adds a constant cost to each insertion. However, in an interactive system, the unfortunate user whose insertion caused a rehash could see a slowdown.
+
 +
+ +
+ +
+
This is my personal notes for The Foundation of Data Structure course in Zhejiang University.
+Since it’s the first time I’ve learned data structure systematically, I wish I could detail the information which will make it easier for me to review in the future.
+Also hope that my notes can help someone else a little bit.
教授内容以图像基本概念、基本操作为基础,围绕图像合成与编辑核心,并介绍了当前数字图像处理的现状、发展和一些关键技术。 主要知识点为:
+卷面(60%)+ 作业(40%)
+一学期大概会有 5~7 次作业,要使用 C/C++ 编程,不可调用 OpenCV 等图形处理库。
+矢量图格式
+BITMAPFILEHEADER
+BITMAPINFOHEDER
+morphing 变形、映射
+bilateral filter 双边滤波
+guided filter
+数字图像基本处理——空间滤波(spatial filtering) - Bracer - 博客园 (cnblogs.com)
+图像信息处理的应用: image retrieval, scene classification
+Object recognition: face detection
+Interactive image retrieval: Mindfinder-> 根据sketch和附加的prompt(颜色,文本)来找网上的图片
+▪Grayscale image and color image representation
+▪Color space transfer
+▪Image format
+


▪Data structure of image: some typical ones
+▪Programming for image processing
+▪An image in computer: array(s)
+▪Image file: its format and read/write
+▪Access DIB: some Windows APIs
+▪An image processing example for VC++
+▪Image processing in Matlab: some typical instructions
+▪Popular image processing softwares
+光圈的大小与景深有密切关系
+对于给定的主体取景和相机位置,DOF 受镜头光圈直径的控制,光圈直径通常指定为 f 数,即镜头焦距与光圈直径的比值。减小光圈直径(增大 f 值)可以增大景深;但同时也会减小透射光的数量,并增加衍射,这就对通过减小光圈直径来增大景深的程度施加了实际限制。
+焦点前后各有一个容许弥散圆,他们之间的距离叫做景深。景深随镜头的焦距、光圈值、拍摄距离而变化
+](1)、镜头光圈: + 光圈越大,景深越小;光圈越小,景深越大; + (2)、镜头焦距 + 镜头焦距越长,景深越小;焦距越短,景深越大; + (3)、拍摄距离 + 距离越远,景深越大;距离越近,景深越小
+For a given subject framing and camera position, the DOF is controlled by the lens aperture diameter, which is usually specified as the f-number, the ratio of lens focal length to aperture diameter. Reducing the aperture diameter (increasing the f-number) increases the DOF; however, it also reduces the amount of light transmitted, and increases diffraction, placing a practical limit on the extent to which DOF can be increased by reducing the aperture diameter.
+对于给定的主体取景和相机位置,景深受镜头光圈直径的控制,光圈直径通常指定为 f 数,即镜头焦距与光圈直径的比值。减小光圈直径(增大 f 值)可以增大景深;但同时也会减小透射光的数量,并增加衍射,这就对通过减小光圈直径来增大景深的程度施加了实际限制。
+–Binary image
+–How to obtain a binary image: binarization
+–Image morphological operation
+–Definition of ‘set’
+–Erosion
+–Dilation
+–‘Open’ operation
+–‘Close’ operation
+–Hit-or-miss transform
+–Grayscale image transform
+•Visibility of image
+•Visibility enhancement: Logarithm
+•Histogram of image
+•Histogram equalization
+•Etc.
+–Simple geometric transform
+旋转
+–Interpolation
+–Application
+这里讨论的Morph变形不同于一般的几何变换(Warp)。
+Morph变形指景物的形体变化,它是使一幅图像逐步变化到另一幅图像的处理方法。
+这是一种较复杂的二维图像处理,需要对各像素点的颜色、位置作变换。
+变形的起始图像和结束图像分别为两幅关键帧,从起始形状变化到结束形状的关键在于自动地生成中间形状,也即自动生成中间帧。
+大小相同的两幅图的转换作静态变换。从一幅图a逐渐变化成第二幅图b。
+原理:让图a中每个像素的颜色,逐渐变成图b相同位置像素的颜色。
+方法:根据变换的快慢,设置相应的步长,将图a每一点的RGB逐渐变成图b相同位置象素的RGB。可以选择等比或等差的方式,或其它方式让:ra-->rb。
+对于灰度图像,可以直接用等比或等差级数定义步长,使颜色从原图变到目标图。
+基于特征点的变形涉及识别两幅原始图像中的特定特征或标志,例如面部变形时脸部的关键点。这些特征点被用作变形过程的参考点,确保在转换过程中保留重要的视觉元素。
+基于网格的变形,也称为基于格的变形,将图像分成网格或格点。这些点作为控制顶点,可以被操纵以使图像发生变形。通过平滑地插值这些网格点的移动,从第一幅图像到第二幅图像,实现了图像的变形,使得变形更加灵活和详细。
+总之,图像变形涉及通过一系列中间图像将一幅图像转换成另一幅图像。静态变形关注单一、静态的转换,而动态变形考虑了时间上的转换。基于特征点的变形依赖于特定的标志来进行变形,而基于网格的变形使用一系列点来进行更加灵活和详细的变形。每种方法都提供了独特的方式来实现视觉上引人注目的图像转换。
+–1-D convolution
+–Property of convolution
+–Discrete convolution
+–Smoothing
+–Sharpening
+–Bilateral filter
+–Guided filter (Optional)
+去除噪音 image smoothing
+高斯模糊
+Split an image into:
+large-scale features, structure
+small-scale features, texture
+An image has two main characteristics
+▪The space domain S, which is the set of possible positions in an image. This is related to the resolution, i.e., the number of rows and columns in the image.
+▪The intensity domain R, which is the set of possible pixel values. The number of bits used to represent the pixel value may vary. Common pixel representations are unsigned bytes (0 to 255) and floating point.
+Every sample is replaced by a weighted average of its neighbors,
+These weights reflect two forces
+▪How close are the neighbor and the center sample, so that larger weight to closer samples,
+▪How similar are the neighbor and the center sample – larger weight to similar samples.
+All the weights should be normalized to preserve the local mean.
+回顾高斯模糊的问题:确实使图片更平滑了,但是没有保留边缘信息,
+Does smooth images But smooths too much: edges are blurred.
+▪Only spatial distance matters
+▪No edge term
+Space and Intensity Parameters
+◼space \(\sigma_s\) : spatial extent of the kernel, size of the considered neighborhood.
+◼intensity \(\sigma_r\) : amplitude extent of an edge
+
\(\sigma_{r}\)趋于无穷,就是高斯模糊(整个图都考虑,相当于没考虑)
+\(\sigma_{s}\)变大的时候边界内部的纹理被模糊的程度加深,但边界被保留
+选择参数取决于应用场景
+For instance:
+space parameter: proportional to image size e.g., 2% of image diagonal
+intensity parameter: proportional to edge amplitude
+e.g., mean or median of image gradients independent of resolution and exposure
+图像灰度梯度的中位数/平均数受极端情况影响较小,能够反映图像整体边缘纹理特征的强烈程度,不受分辨率和曝光程度影响
+降噪选择小的spatial \(\sigma_{s}\)不用加速操作,Adapt intensity sigma \(\sigma_{s}\) to noise level
+导向滤波:guided filtering 输入一个guided image
+解决gradient reversal的问题
+在导向滤波(guided filtering)中,导向图像(guided image)通常是从输入图像中得到的。导向图像用于指导滤波器以更好地保留图像的细节和边缘信息。
+一种常见的方法是使用输入图像本身作为导向图像。这意味着在进行滤波时,输入图像的某个版本(通常是平滑版本)被用作自身的引导。这种方法有助于确保在进行滤波时保留原始图像中的细节和结构。
+另一种方法是通过使用与输入图像相关的其他信息来生成导向图像。例如,可以使用输入图像的梯度信息或者其他相关图像的信息作为导向图像,以便在滤波过程中更好地保留特定的细节和结构。
+总的来说,导向图像的获取方式取决于具体的应用场景和对图像细节保留的要求。
+◼Read a color bmp;
+◼RGB->YUV;
+◼Color to gray: gray=Y in YUV color space;
+◼Rearrange gray intensity to lie between [0,255];
+◼Write a grayscale bmp;
+◼Change the luminance value Y;
+◼YUV->RGB;
+◼Write a color bmp.
+图像文件头,信息头格式,读写操作
+图像增强技术
+–Fourier and his work
+–Background of Fourier transform
+–Fourier transform
+–Discrete Fourier transform (1D)
+–FFT
+–FFT in Matlab
+–2D Fourier transform
+–SIFT
+–SURF
+–Deep feature
+引入卷积神经网络(CNN)可以大规模减少权重参数训练量的主要原因如下:
+综上所述,引入CNN可以通过参数共享、稀疏连接和平移不变性等特性,大规模减少权重参数训练量,从而使得神经网络在处理图像等二维数据时更加高效。
对于每个不同尺度的图片,还是使用harris corner detector 来检测可能的特殊点
+在不同尺度上检查特殊点,使用Laplace算子,也就是两个二次偏导和的形式,这个值产生峰值的地方,且在不同大小的图片中产生峰值的地方就是特殊点blob可能出现的位置
+DoG:difference of guassian:高斯函数的差分值
+Maxima and minima
+Compare x with its 26 neighbors at 3 scales
+基本思想
+

完整版:
+SIFT Feature
+SIFT 特征可以对图像进行分类 +Bag of visual words 提取SIFT特征,将特征做一个聚类(kmeans),将每个聚类中心称为 visual word 视觉单词
+Conclusion of SIFT
+创建直方图的作用是为了对关键点周围的梯度方向进行统计,以便后续确定关键点的主导方向。这种方向直方图的创建有助于实现SIFT算法的方向不变性,具体包括以下步骤:
+通过这种方向直方图的创建和主导方向的选择,SIFT算法实现了对于图像局部特征的方向不变性,使得检测到的关键点能够在一定程度上抵抗图像的旋转变换。
+SURF相比SIFT的进步之处在于以下几个方面:
+关于Integral Image 允许我们对滤波器进行上采样而不是对图像进行下采样的意思是,积分图像的使用允许我们通过对滤波器进行上采样来实现尺度不变性,而不是像SIFT那样通过对图像进行下采样来实现尺度不变性。这种方法使得算法更快速,因为上采样可以通过积分图像直接实现,而无需对原始图像进行复杂的操作。
+至于为什么SURF需要计算二阶导数,这是因为SURF中的描述符计算涉及对Hessian矩阵的计算,而Hessian矩阵包括二阶导数信息,这对于确定特征点的局部特征形状非常重要。
+接下来,对于9x9滤波器的情况,l0 = 3 表示在导数方向上正负半轴的长度。为了保持中心像素,必须至少增加2个像素,因此必须将 l0 增加至少2个像素,这意味着需要增加6个像素的滤波器维度。因此,滤波器的尺寸为:9x9, 15x15, 21x21, 27x27。
+这些内容的具体含义是,SURF算法通过使用积分图像实现了对滤波器的上采样,从而实现了尺度不变性,同时利用二阶导数信息来计算特征点的局部特征形状,这些都是SURF相对于SIFT的改进之处。
+Hessian矩阵在图像处理中扮演着重要的角色,特别是在特征检测和特征描述方面。其作用主要体现在以下两个方面:
+至于为什么要进行插值,这是因为在实际图像中,特征点的位置通常不会精确地落在像素的中心点上,而是落在像素之间的某个位置。为了更准确地计算Hessian矩阵,需要对局部图像区域进行插值,以便在子像素级别上计算梯度和曲率信息。通过插值,可以更精确地估计局部特征点的梯度和曲率,从而提高特征点检测和描述的精度。
+Harris角点检测算法使用Hessian矩阵的特征值来判断图像中的角点。在该算法中,使用λ1和λ2中的较小值作为检测依据的原因如下:
+综上所述,Harris角点检测中使用λ1和λ2的较小值作为检测依据,主要是为了确保检测到的特征更可能代表角点而非边缘,同时提高算法对噪声的鲁棒性,并捕捉局部结构的变化。
高斯滤波、均值滤波和中值滤波是常见的图像滤波技术,它们在图像处理中有不同的应用场景和效果特点。
+
p=2时为均值滤波,p=1时是中值滤波
+p值足够小:能够保边
+HDR compression
+保证梯度不会逆转
能够保边,但不能保方向
+存在梯度逆转问题
+

sigma s 一般设为图像对角线的2%这么大 +sigma r 一般设为gradient的均值或中位值?
+the halo nightmare
+HDR压缩到标准动态范围
+通过感受野压缩图像 从低到高
+residual 感受野的大小带来的残差
+高频,低频
+简述光圈和景深的关系;相机是如何调整光圈的;简述数码相机的原理。
+光圈和景深的关系:
+### 2.
+### 1. 计算机里灰度用几位表示,一共几个灰度梯度;
+### 2. 写出至少五种颜色空间,并解释两种颜色空间每一维的含义;
+### 3. 用于表示加色和减色的颜色空间是什么,解释这两个空间每一维的含义,并说明它们的应用场合。
+应用场合:
+减色空间的应用场合: 用于印刷行业,因为印刷是通过减少光的反射来呈现图像的,使用CMYK颜色空间可以更好地控制颜色和浓度,以适应印刷机的特性。
+BMP 图像的图像数据(bitmap data)部分中,每一行的数据存储有什么要求?如果想要存储 12 34 56 78 9A BC(具体数据不是这个,忘了,不过没差- -),应该怎样存储? (我不知道描述清楚了没有- -应该问的是四字节对齐的事情...)
+给出一个结构元和一个二值图像,问这个结构元和二值图像进行膨胀操作后的结果是什么,并简述膨胀操作的物理意义。
+当一张灰度图像的光照变化比较大时,简单的全局阈值二值化方法可能无法很好地处理图像。在这种情况下,可以考虑使用自适应阈值二值化方法,例如局部自适应阈值二值化。这种方法允许根据图像的局部特征来确定每个像素的阈值,从而更好地处理光照变化较大的图像。
+你可以使用一些常见的算法,如基于局部均值的方法(如Sauvola算法),基于局部高斯模型的方法(如Niblack算法),或者基于局部中值的方法(如Otsu算法)来进行局部自适应阈值二值化。
+给一个 8 个梯度的灰度分布,求灰度均衡化后的结果,并简述步骤(我记得这题的数据和 ppt 上的好像是一样的)。
+给一张 5 × 5 的灰度图,求用 3 × 3 的 mask 进行中值滤波后的结果,忽略图像边界。
+简述用 ratio image 将 source 人脸的表情转移到 target 人脸上的步骤。
+给出双边滤波的公式,简述双边滤波的基本思想,并解释公式里各符号的意义。
+简述如何用 log algorithm 增强图像的可视性。
+选择图像信息处理的一种应用,尽量详细地说明原理。
+++注:题目是中英对照的,回答用中文或英文均可
+
Digital image (or video stream) 数字图像 is the main form to present information. For human beings, more than 60% of information is obtained through vision 视觉.
+设备相关的颜色空间:(RGB)(YUV)(CMYK)
+设备无关的颜色空间:(sRGB)(CIEXYZ)(Lab)
+Image Data 要求每一行必须是 4 的倍数,例如 13 A1 17 19 18 15 在文件中存储为:(13 A1 17 19)(18 15 00 00)
BMP图像的文件结构:(文件头)(位图信息头)(调色板)(图像数据)
+给了PPT上那张图
+压缩策略:根据压缩比要求,从高频到低频逐步削减信息
+优势:高频信息占用存储空间大,减少高频信息更容易获得高压缩比;低频信息可以保留物体的基本轮廓和色彩分布,最大限度维持图像质量;适合用于互联网的视觉媒体。
+不同格式的图像压缩方式可以分为有损压缩和无损压缩两种。以下是几种常见图像格式(JPEG、TIFF、BMP、JPG)的压缩方式:
+总的来说,选择图像格式和压缩方式取决于应用需求。无损压缩适合需要保持图像质量的场景,而有损压缩适合对图像质量要求较低但需要节省存储空间或加快传输速度的场景。
引导滤波,基本思想
+导向滤波是一种图像处理技术,主要用于图像去噪和增强的目的。其基本原理是利用一个附加的辅助图像(称为导向图像)的信息来引导滤波过程,从而更好地保留图像中的细节和结构。
+以下是导向滤波的基本原理和作用:
+总体而言,导向滤波通过结合导向图像的信息,使得滤波过程更具方向性和适应性,从而在图像处理中取得更好的效果。
+暴力双边滤波迭代次数非常大
+
解决双边滤波中的梯度反转、计算缓慢问题,能够保边、非迭代 +I是guide,p是输入图,q是输出图。输出是I的线性表达 +$$ + min\sum(aI_i+b-p_i)^2+\epsilon a^2\ + q_i=\hat a_iI_i+\hat b_i +$$ +
+
answer = get_string()
+print("hello,",answer) 两个参数中间自动加括号
+print(f"hello,{answer}")
+f为formatted string 格式化字符串
+数据类型
+删去了c中的 long double
+只有bool float int str
+加了range list tuple dict set
+
所谓oop就是有内置的函数
+s.lower() 要非常注意python中的浅拷贝和深拷贝
+
| Python | |
|---|---|
全局帧是程序的顶层帧,包含了全局范围内定义的变量。这些变量被称为全局变量,因为它们可以在整个程序的任何地方访问。全局帧中的变量对整个程序都是可见的。
+每当你调用一个函数,Python会为该函数创建一个局部帧。这个局部帧包含了函数中定义的局部变量和参数。这些变量只能在函数内部访问,而在函数执行完毕后,局部帧也会被销毁。这有助于保持变量的隔离性,防止不同函数之间的变量名冲突。
+举例来说,如果你在Python中定义一个函数,函数内的变量会存在于该函数的局部帧中。同时,如果你在函数外定义一个变量,它会存在于全局帧中。这种分层的帧结构有助于组织和管理变量,使其具有适当的作用域。局部帧和全局帧的交互是Python中变量作用域的核心概念,它确保了变量在程序中的合理可见性和隔离性。
+以交互式命令行运行python,可以通过键入变量值查看执行完成后的各个变量,无需print
+运行docstring所指定的示例,如果没有输出则直接返回
+打印输出所有的docstring测试结果,相当于自测情况
+def嵌套定义
+




lambda x : f(x)==y 返回一个x
+
control statements
+
用数归!
+1.base case
+2.假设n-1的情况正确执行,正确返回,如何利用n-1的情况得出n
+

上面是循环,迭代
+下面是递归!
+迭代每次while循环内的赋值变成了递归调用时的参数
+| Python | |
|---|---|
分清楚base case和else
+


怎么分解问题比较关键
+counting partitions
+


python列表(list)和元组(tuple)详解_木子林_的博客-CSDN博客
+一篇讲list和tuple区别的blog,非常细致,可以细看
+ +method :和instance绑定的函数
+method的第一个隐形的参数是self,调用的方式是dot(.)
+instance有属性,但是class也可以有自己的属性
+类名.函数名
+Account.deposit(account_john,10)属于直接访问类的method
+面向对象编程中,所有东西是object:对象
+在oop python中,所有东西(object)都有属性(attributes),以键值对(name-value pairs)表示
+类(classes)也是object:对象,因此类有自己的属性
+实例的属性:初始化的实例具有的属性
+类的属性:初始化的实例所属的类所具有的属性
+类的def方法定义的method/函数返回不返回(return有没有内容视情况需要,如果在实际实例化调用类时需要将初始化过的东西接收,例如a = open_account("john",5),则需要返回,否则不一定需要写return什么
+has-a和is-a关系
+Nested Code Blocks
+ +Another List
+ +nested code block
+note
+  +
+  +
+  +
+ 
语法格式:
+tab间隔,建议在vscode/typora原格式(raw)下编辑,可以选中tab
+alt text形式是直接采用在md文件的同目录下插入,可以在nested tab中插入
+

发现只要是在这个文件结构下的图片都会正常显示
+因为实际上typora编辑器的设置中拷贝图片时会将assets会单独复制一份
+
然而,拷贝后进行缩放,就是改为了html格式,就不能够正常渲染?
+
aliyun服务器: ssh root@101.201.46.135
+宝塔面板
+最后还是采用ssh的方法
+SSH免密登录(SSH Public Key Authentication)是一种通过使用密钥对而不是密码进行SSH登录的方法,提高了安全性并简化了登录过程。以下是SSH免密登录的配置过程:
+使用以下命令生成密钥对:
+ +这会在~/.ssh/目录下生成id_rsa(私钥)和id_rsa.pub(公钥)文件。
~/.ssh/authorized_keys文件中。可以使用ssh-copy-id命令,它会自动将公钥添加到目标用户的authorized_keys文件中。如果ssh-copy-id命令不可用,可以手动将公钥内容追加到远程服务器的~/.ssh/authorized_keys文件中。
~/.ssh/ 目录和 ~/.ssh/authorized_keys 文件的权限正确。权限设置对于SSH的安全性至关重要。如果一切设置正确,你将可以无密码登录到远程服务器。
+请注意,为了安全起见,私钥文件(id_rsa)应该保持在本地机器上,并且不应该分享给其他人。同时,公钥文件(id_rsa.pub)需要传输到需要访问的远程服务器。
[Linux]创建新用户及用户权限 - 知乎 (zhihu.com)
+| C | |
|---|---|
服务器改名
+找到/etc/hosts sudo vim hosts 添加一行 101.201.46.135 server_jy 再在ssh时重新add一下这个别名,完成
+以后就叫server_jy了~
+监听端口
+安全组
+查找命令
+```[root@iZ2ze72tpnr9ta1r8uvbujZ /]# find / -name nginx +[root@iZ2ze72tpnr9ta1r8uvbujZ /]# find / -name nginx +/www/server/nginx +/www/server/nginx/src/objs/nginx +/www/server/nginx/sbin/nginx +/www/server/panel/rewrite/nginx +/www/server/panel/vhost/nginx +/www/server/panel/vhost/template/nginx +/etc/rc.d/init.d/nginx +/usr/bin/nginx +/usr/local/nginx +[root@iZ2ze72tpnr9ta1r8uvbujZ /]# +
grep是一个在文本中搜索模式的强大命令行工具。它的名字来源于全局正则表达式打印(Global Regular Expression Print)。
下面是grep命令的基本用法和一些常见选项:
pattern:要搜索的模式,可以是字符串或正则表达式。file:要在其中搜索模式的文件。如果没有提供文件名,grep将从标准输入中读取。常见选项:
+-i:忽略大小写。-r或-R:递归搜索子目录。-n:显示匹配行的行号。-v:反向选择,显示不匹配的行。-l:只显示包含匹配项的文件名。-c:只显示匹配的行数而不显示匹配的内容。-A,-B,-C:显示匹配行的上下文行。-e:指定多个模式。示例:
+这只是一些grep命令的基本用法和选项,grep有很多其他选项和功能,你可以通过man grep查看grep的手册页以获取更多详细信息。\
竟然没有apt-get??
+| C | |
|---|---|
为什么命令查找不到是bash打头
+| C | |
|---|---|
如果你在使用命令时遇到 "命令找不到" 的错误,这可能有多个原因。一种可能性是系统无法找到或识别该命令,这可能与环境变量或命令的位置有关。以下是一些可能的原因和解决方法:
+PATH环境变量中。PATH环境变量包含一组目录,系统在这些目录中查找可执行文件。你可以使用以下命令查看PATH:如果命令所在的目录不在PATH中,你可以将其添加到PATH。例如:
在这里,将/path/to/your/command替换为包含你的命令的实际路径。
命令未安装: 确保你尝试运行的命令已经安装在系统上。有些命令可能需要单独安装。你可以使用系统的包管理器安装它们。
+文件权限问题: 检查命令文件的权限,确保你有执行权限。你可以使用ls -l命令查看文件权限,例如:
如果没有执行权限,可以使用chmod命令添加执行权限:
如果你能提供更具体的错误信息或命令示例,我可以提供更详细的帮助。
+| Text Only | |
|---|---|
发行版问题
+没有apt-get
+| C | |
|---|---|
wordpress建站 ok
+mysql数据库使用
+域名只不过是将101.201.46.135之类的ip地址用DNS服务器映射到可记忆的字符串?
+是的,域名系统(DNS)的主要作用是将易于记忆的域名映射到计算机网络中的IP地址。IP地址是互联网上计算机的唯一标识符,通过将域名映射到IP地址,人们可以使用容易记忆的名称来访问网站、服务器或其他网络服务,而不必记住复杂的数字地址。
+例如,将域名 "example.com" 映射到 IP 地址 "101.201.46.135"。当你在浏览器中键入 "example.com" 时,计算机首先会查询DNS服务器,获取与 "example.com" 相关联的IP地址,然后使用这个IP地址建立连接到相应的服务器。
+DNS使用一个层次化的结构,包括顶级域(如.com、.org)、二级域(如example.com)、子域等。这个结构允许全球范围内唯一地标识不同的域名,并通过分布式的DNS服务器系统来管理这些映射关系。
+总的来说,域名的作用是提供一个便于记忆和使用的方式来访问互联网上的资源,而不必记住它们的具体IP地址。
+自行建站有很多选择,取决于你的技术水平、需求、预算和个人偏好。以下是一些常见的自行建站工具和平台:
+选择哪个工具取决于你的具体需求和技术偏好。对于初学者,使用WordPress、Wix或Squarespace可能是更容易上手的选择。对于有一些编程经验的人来说,静态网站生成器如Jekyll、Hugo或VuePress可能是一个不错的选择。
+
2023_DD是guahao老师在github上的仓库的全部内容,其中并未包括node_modules,src/assets/javascripts文件的内容,请问
+github.io建站过程
+使用
+