This is the code for the NeurIPS 2019 article available here: https://arxiv.org/abs/1906.10169.
This paper was written by Rémi Cadene, Corentin Dancette, Hedi Ben Younes, Matthieu Cord and Devi Parikh.
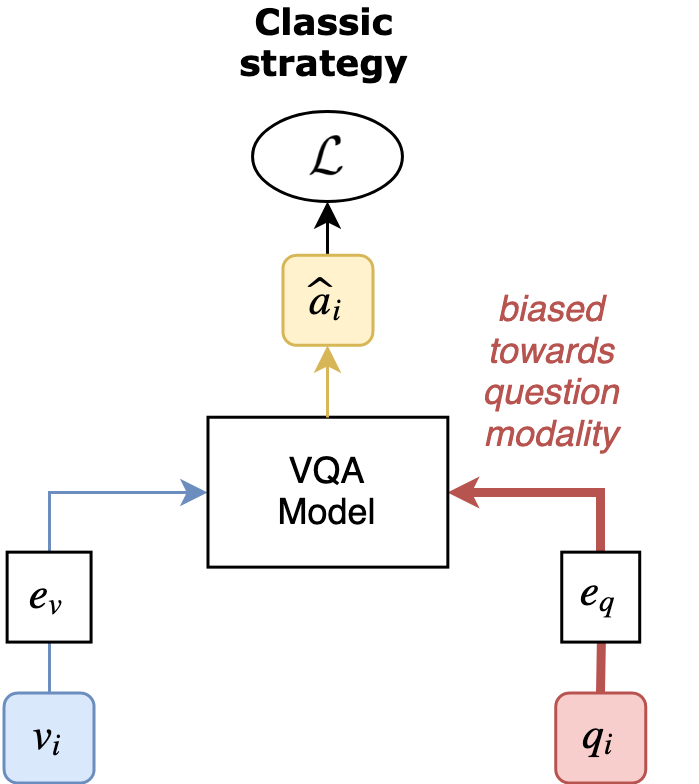
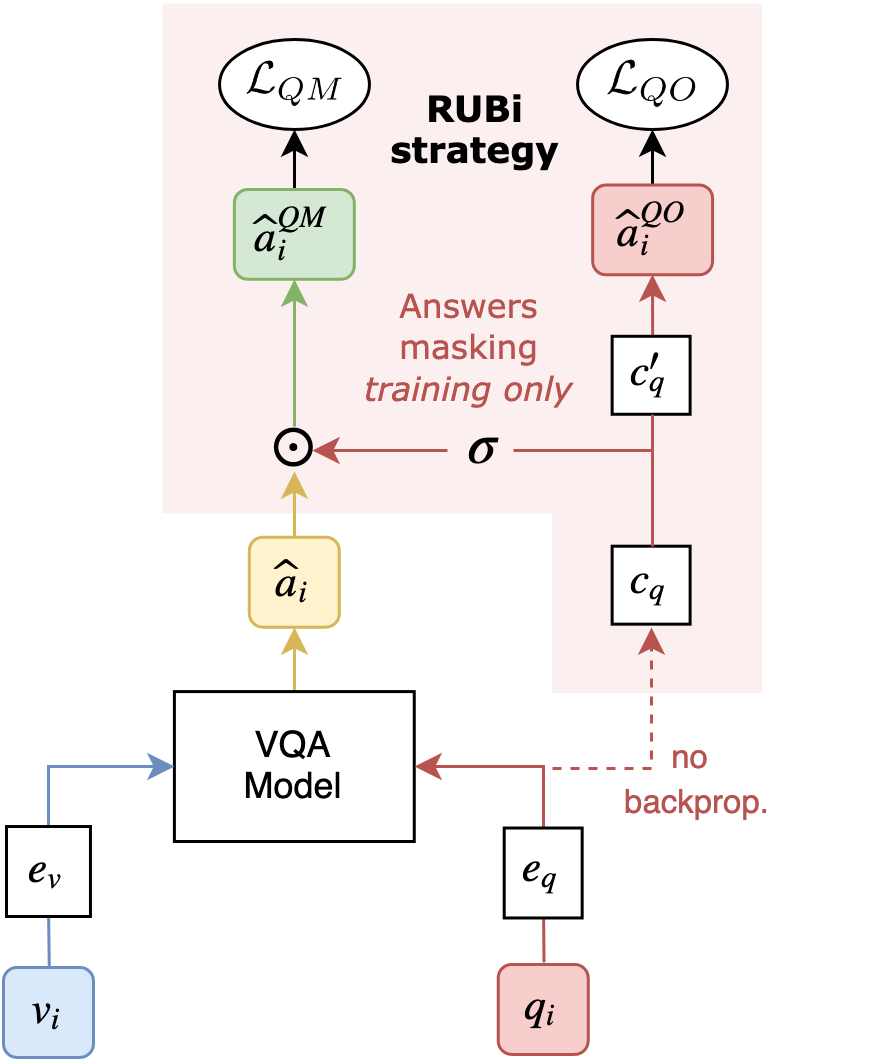
RUBi is a learning strategy to reduce biases in VQA models. It relies on a question-only branch plugged at the end of a VQA model.
We don't provide support for python 2. We advise you to install python 3 with Anaconda. Then, you can create an environment.
conda create --name rubi python=3.7
source activate rubi
git clone --recursive https://github.com/cdancette/rubi.bootstrap.pytorch.git
cd rubi.bootstrap.pytorch
pip install -r requirements.txt
To install the library
git clone https://github.com/cdancette/rubi.bootstrap.pytorch.git
python setup.py install
Then by importing the rubi python module, you can access datasets and models in a simple way.
from rubi.models.networks.rubi import RUBiNetNote: This repo is built on top of block.bootstrap.pytorch. We import VQA2, TDIUC, VGenome from this library.
Download annotations, images and features for VQA experiments:
bash rubi/datasets/scripts/download_vqa2.sh
bash rubi/datasets/scripts/download_vqacp2.sh
The main model is RUBi.
from rubi.models.networks.rubi import RUBiNetRUBi takes as input another VQA model, adds a question branch around it. The question predictions are merged with the original predictions. RUBi returns the new predictions that are used to train the VQA model.
For an example base model, you can check the baseline model. The model must return the raw predictions (before softmax) in a dictionnary, with the key logits.
The boostrap/run.py file load the options contained in a yaml file, create the corresponding experiment directory and start the training procedure. For instance, you can train our best model on VQA2 by running:
python -m bootstrap.run -o rubi/options/vqacp2/rubi.yaml
Then, several files are going to be created in logs/vqa2/rubi:
- options.yaml (copy of options)
- logs.txt (history of print)
- logs.json (batchs and epochs statistics)
- view.html (learning curves)
- ckpt_last_engine.pth.tar (checkpoints of last epoch)
- ckpt_last_model.pth.tar
- ckpt_last_optimizer.pth.tar
- ckpt_best_eval_epoch.accuracy_top1_engine.pth.tar (checkpoints of best epoch)
- ckpt_best_eval_epoch.accuracy_top1_model.pth.tar
- ckpt_best_eval_epoch.accuracy_top1_optimizer.pth.tar
Many options are available in the options directory.
There is no testing set on VQA-CP v2, our main dataset. The evaluation is done on the validation set.
For a model trained on VQA v2, you can evaluate your model on the testing set. In this example, boostrap/run.py load the options from your experiment directory, resume the best checkpoint on the validation set and start an evaluation on the testing set instead of the validation set while skipping the training set (train_split is empty). Thanks to --misc.logs_name, the logs will be written in the new logs_predicate.txt and logs_predicate.json files, instead of being appended to the logs.txt and logs.json files.
python -m bootstrap.run \
-o logs/vqa2/rubi/baseline.yaml \
--exp.resume best_accuracy_top1 \
--dataset.train_split \
--dataset.eval_split test \
--misc.logs_name test
Use this simple setup to reproduce our results on the valset of VQA-CP v2.
Baseline:
python -m bootstrap.run \
-o rubi/options/vqacp2/baseline.yaml \
--exp.dir logs/vqacp2/baselineRUBi :
python -m bootstrap.run \
-o rubi/options/vqacp2/rubi.yaml \
--exp.dir logs/vqacp2/rubiYou can compare experiments by displaying their best metrics on the valset.
python -m rubi.compare_vqacp2_rubi -d logs/vqacp2/rubi logs/vqacp2/baseline
Baseline:
python -m bootstrap.run \
-o rubi/options/vqa2/baseline.yaml \
--exp.dir logs/vqa2/baselineRUBi :
python -m bootstrap.run \
-o rubi/options/vqa2/rubi.yaml \
--exp.dir logs/vqa2/rubiYou can compare experiments by displaying their best metrics on the valset.
python -m rubi.compare_vqa2_rubi_val -d logs/vqa2/rubi logs/vqa2/baseline
python -m bootstrap.run \
-o logs/vqa2/rubi/options.yaml \
--exp.resume best_eval_epoch.accuracy_top1 \
--dataset.train_split '' \
--dataset.eval_split test \
--misc.logs_name testThe weights for the model trained on VQA-CP v2 can be downloaded here : http://webia.lip6.fr/~cadene/rubi/ckpt_last_model.pth.tar
To use it :
- Run this command once to create the experiment folder. Cancel it when the training starts
python -m bootstrap.run \
-o rubi/options/vqacp2/rubi.yaml \
--exp.dir logs/vqacp2/rubi- Move the downloaded file to the experiment folder, and use the flag
--exp.resume lastto use this checkpoint :
python -m bootstrap.run \
-o logs/vqacp2/rubi/options.yaml \
--exp.resume lastInstead of creating a view.html file, a tensorboard file will be created:
python -m bootstrap.run -o rubi/options/vqacp2/rubi.yaml \
--view.name tensorboard
tensorboard --logdir=logs/vqa2
You can use plotly and tensorboard at the same time by updating the yaml file like this one.
For a specific experiment:
CUDA_VISIBLE_DEVICES=0 python -m boostrap.run -o rubi/options/vqacp2/rubi.yaml
For the current terminal session:
export CUDA_VISIBLE_DEVICES=0
The boostrap.pytorch framework makes it easy to overwrite a hyperparameter. In this example, we run an experiment with a non-default learning rate. Thus, I also overwrite the experiment directory path:
python -m bootstrap.run -o rubi/options/vqacp2/rubi.yaml \
--optimizer.lr 0.0003 \
--exp.dir logs/vqacp2/rubi_lr,0.0003
If a problem occurs, it is easy to resume the last epoch by specifying the options file from the experiment directory while overwritting the exp.resume option (default is None):
python -m bootstrap.run -o logs/vqacp2/rubi/options.yaml \
--exp.resume last
This code was made available by Corentin Dancette and Rémi Cadene
Special thanks to the authors of VQA2, TDIUC, VisualGenome and VQACP2, the datasets used in this research project.