 +
+
+
+ +
+
+## المحتويات
+
+ينقسم التوثيق إلى خمسة أقسام:
+
+- **ابدأ** تقدم جولة سريعة في المكتبة وتعليمات التثبيت للبدء.
+- **الدروس التعليمية** هي مكان رائع للبدء إذا كنت مبتدئًا. سيساعدك هذا القسم على اكتساب المهارات الأساسية التي تحتاجها للبدء في استخدام المكتبة.
+- **أدلة كيفية الاستخدام** تُظهر لك كيفية تحقيق هدف محدد، مثل ضبط نموذج مسبق التدريب لنمذجة اللغة أو كيفية كتابة ومشاركة نموذج مخصص.
+- **الأدلة المفاهيمية** تقدم مناقشة وتفسيرًا أكثر للأفكار والمفاهيم الأساسية وراء النماذج والمهام وفلسفة التصميم في 🤗 Transformers.
+- **واجهة برمجة التطبيقات (API)** تصف جميع الفئات والوظائف:
+
+ - **الفئات الرئيسية** تشرح الفئات الأكثر أهمية مثل التكوين والنمذجة والتحليل النصي وخط الأنابيب.
+ - **النماذج** تشرح الفئات والوظائف المتعلقة بكل نموذج يتم تنفيذه في المكتبة.
+ - **المساعدون الداخليون** يشرحون فئات ووظائف المساعدة التي يتم استخدامها داخليًا.
+
+
+## النماذج والأطر المدعومة
+
+يمثل الجدول أدناه الدعم الحالي في المكتبة لكل من هذه النماذج، وما إذا كان لديها محلل نحوي Python (يُسمى "بطيء"). محلل نحوي "سريع" مدعوم بمكتبة 🤗 Tokenizers، وما إذا كان لديها دعم في Jax (عبر Flax) و/أو PyTorch و/أو TensorFlow.
+
+
+# Hugging Face Hub: قائمة النماذج
+
+آخر تحديث: 06/08/2024
+
+| النموذج | دعم PyTorch | دعم TensorFlow | دعم Flax |
+| :----: | :---------: | :------------: | :-------: |
+| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
+| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
+| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
+| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
+| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
+| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
+| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
+| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
+| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
+| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
+| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
+| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
+| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
+| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
+| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
+| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
+| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
+| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
+| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
+| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
+| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
+| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
+| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
+| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
+| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
+| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
+| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
+| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+# النماذج Models
+
+| النموذج/المهمة | التصنيف Classification | استخراج المعلومات Information Extraction | توليد Generation |
+| :-----: | :----: | :----: | :----: |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+| [Chameleon](model_doc/chameleon) | ✅ | ❌ | ❌ |
+| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
+| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
+| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
+| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
+| [CLVP](model_doc/clvp) | ✅ | ❌ | ❌ |
+| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
+| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ✅ |
+| [Cohere](model_doc/cohere) | ✅ | ❌ | ❌ |
+| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
+| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
+| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
+| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ✅ | ❌ |
+| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
+| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
+| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
+| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
+| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
+| [DBRX](model_doc/dbrx) | ✅ | ❌ | ❌ |
+| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
+| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
+| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
+| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
+| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
+| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
+| [Depth Anything](model_doc/depth_anything) | ✅ | ❌ | ❌ |
+| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
+| [DETR](model_doc/detr) | | | |
+# قائمة النماذج
+
+| الاسم باللغة الإنجليزية | الوصف باللغة الإنجليزية | الوصف باللغة العربية |
+| :--------------------- | :---------------------- | :------------------- |
+| [DiT](model_doc/dit) | ✅ | |
+| [DonutSwin](model_doc/donut) | ✅ | |
+| [DPT](model_doc/dpt) | ✅ | |
+| [EfficientFormer](model_doc/efficientformer) | ✅ | |
+| [EnCodec](model_doc/encodec) | ✅ | |
+| [ErnieM](model_doc/ernie_m) | ✅ | |
+| [FNet](model_doc/fnet) | ✅ | |
+| [FocalNet](model_doc/focalnet) | ✅ | |
+| [Fuyu](model_doc/fuyu) | ✅ | |
+| [Gemma2](model_doc/gemma2) | ✅ | |
+| [GIT](model_doc/git) | ✅ | |
+# النماذج المدعومة حالياً
+
+| النموذج | النص | الصور | الصوت |
+|-------------|--------|---------|-------|
+| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
+| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
+| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
+| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
+| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
+| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
+| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
+| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
+| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
+| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
+| [Grounding DINO](model_doc/grounding-dino) | ✅ | ❌ | ❌ |
+| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
+| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
+| [Hiera](model_doc/hiera) | ✅ | ❌ | ❌ |
+| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
+| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
+| [IDEFICS](model_doc/idefics) | ✅ | ✅ | ❌ |
+| [Idefics2](model_doc/idefics2) | ✅ | ❌ | ❌ |
+| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
+| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
+| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
+| [InstructBlipVideo](model_doc/instructblipvideo) | ✅ | ❌ | ❌ |
+| [Jamba](model_doc/jamba) | ✅ | ❌ | ❌ |
+| [JetMoe](model_doc/jetmoe) | ✅ | ❌ | ❌ |
+| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
+| [KOSMOS-2](model_doc/kosmos-2) | ✅ | ❌ | ❌ |
+| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
+| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
+| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
+| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+# Hugging Face Models
+
+مرحباً! هذه قائمة بالنماذج المتاحة في Hugging Face Hub. تم تحديثها مؤخراً لتشمل أحدث النماذج وأكثرها شعبية.
+
+| الاسم | النص | الصورة | الصوت |
+| --- | --- | --- | --- |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
+| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
+| [LLaMA](model_doc/llama) | ✅ | ❌ | ✅ |
+| [Llama2](model_doc/llama2) | ✅ | ❌ | ✅ |
+| [Llama3](model_doc/llama3) | ✅ | ❌ | ✅ |
+| [LLaVa](model_doc/llava) | ✅ | ❌ | ❌ |
+| [LLaVA-NeXT](model_doc/llava_next) | ✅ | ❌ | ❌ |
+| [LLaVa-NeXT-Video](model_doc/llava-next-video) | ✅ | ❌ | ❌ |
+| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
+| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
+| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
+| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
+| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
+| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
+| [MADLAD-400](model_doc/madlad-400) | ✅ | ✅ | ✅ |
+| [Mamba](model_doc/mamba) | ✅ | ❌ | ❌ |
+| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
+| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
+| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
+| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
+| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
+| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
+| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
+| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
+| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
+| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
+| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
+| [Mistral](model_doc/mistral) | ✅ | ✅ | ✅ |
+| [Mixtral](model_doc/mixtral) | ✅ | ❌ | ❌ |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+# Hugging Face Models
+
+نموذج Hugging Face هو تمثيل لخوارزمية تعلم الآلة التي يمكن تدريبها على بيانات محددة لأداء مهام مختلفة مثل تصنيف النصوص أو توليد الصور. توفر Hugging Face مجموعة واسعة من النماذج التي يمكن استخدامها مباشرة أو تخصيصها لمهمة محددة.
+
+## نظرة عامة على النماذج
+
+| الاسم | النص | الصورة/الكائن | الصوت |
+| ---------------------------------------- | ----------- | ------------- | --------- |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
+| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
+| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
+| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
+| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
+| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
+| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
+| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
+| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
+| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
+| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
+| [MusicGen Melody](model_doc/musicgen_melody) | ✅ | ❌ | ❌ |
+| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
+| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
+| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
+| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
+| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
+| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
+| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
+| [OLMo](model_doc/olmo) | ✅ | ❌ | ❌ |
+| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
+| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
+| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
+| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
+| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
+| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
+| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
+| [PaliGemma](model_doc/paligemma) | ✅ | ❌ | ❌ |
+| [PatchTSMixer](model_doc/patchtsmixer) | ✅ | ❌ | ❌ |
+| [PatchTST](model_doc/patchtst) | ✅ | ❌ | ❌ |
+# النماذج المدعومة
+
+| الاسم | التصنيف | التوليد | استخراج المعلومات |
+| --- | --- | --- | --- |
+| [PatchTST](model_doc/patchtst) | ✅ | ❌ | ❌ |
+| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
+| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
+| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
+| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
+| [Phi](model_doc/phi) | ✅ | ❌ | ❌ |
+| [Phi3](model_doc/phi3) | ✅ | ❌ | ❌ |
+| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
+| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
+| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
+| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
+| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
+| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
+| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
+| [PVTv2](model_doc/pvt_v2) | ✅ | ❌ | ❌ |
+| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
+| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
+| [Qwen2MoE](model_doc/qwen2_moe) | ✅ | ❌ | ❌ |
+| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
+| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
+| [RecurrentGemma](model_doc/recurrent_gemma) | ✅ | ❌ | ❌ |
+| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
+| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
+| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
+| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
+| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
+| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
+| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
+| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
+| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
+| [RT-DETR](model_doc/rt_detr) | ✅ | ❌ | ❌ |
+# النماذج المدعومة
+
+| الاسم | التصنيف | الكشف | التتبع |
+| ---------------------------------------------------------------------------------------------------------------------------------------------------- | :-----: | :-----: | :------: |
+| [RT-DETR](model_doc/rt_detr) | ✅ | ❌ | ❌ |
+| [RT-DETR-ResNet](model_doc/rt_detr_resnet) | ✅ | ❌ | ❌ |
+| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
+| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
+| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
+| [SeamlessM4Tv2](model_doc/seamless_m4t_v2) | ✅ | ❌ | ❌ |
+| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
+| [SegGPT](model_doc/seggpt) | ✅ | ❌ | ❌ |
+| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
+| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
+| [SigLIP](model_doc/siglip) | ✅ | ❌ | ❌ |
+| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
+| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
+| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
+| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
+| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
+| [StableLm](model_doc/stablelm) | ✅ | ❌ | ❌ |
+| [Starcoder2](model_doc/starcoder2) | ✅ | ❌ | ❌ |
+| [SuperPoint](model_doc/superpoint) | ✅ | ❌ | ❌ |
+| [SwiftFormer](model_doc/swiftformer) | ✅ | ✅ | ❌ |
+| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
+| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
+| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
+| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
+| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
+| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
+| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
+| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
+| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
+| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+# قائمة النماذج المدعومة
+
+| الاسم | التصنيف | النص | الصورة |
+| -------------------------------------- | ------ | -------- | --------- |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
+| ... | ... | ... | ... |
+
+# تفاصيل النموذج
+
+يرجى الرجوع إلى [README.md](README.md#model-zoo) للحصول على تفاصيل حول كيفية إضافة نموذج جديد.
+
+# النماذج المدعومة
+
+## النص
+
+| الاسم | التصنيف | النص-النص | النص-الصورة | النص-الفيديو |
+| -------------------------------------------- | ------ | --------- | ----------- | ------------ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ | ❌ |
+| ... | ... | ... | ... | ... |
+
+## الصورة
+
+| الاسم | التصنيف | النص-الصورة | الصورة-الصورة |
+| ---------------------------------------- | ------ | ----------- | ------------- |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
+| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
+| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
+| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
+| ... | ... | ... | ... |
+
+## الفيديو
+
+| الاسم | التصنيف | النص-الفيديو | الفيديو-الفيديو |
+| ---------------------------------------- | ------ | ------------ | -------------- |
+| [VideoLlava](model_doc/video_llava) | ✅ | ❌ | ❌ |
+| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
+| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
+| [VipLlava](model_doc/vipllava) | ✅ | ❌ | ❌ |
+| ... | ... | ... | ... |
+# النماذج المدعومة
+
+| الاسم | الصوت | النص | الصورة |
+| ------------------------------------------------------------------- | ----- | ---- | ------ |
+| [Wav2Vec2-BERT](model_doc/wav2vec2-bert) | ✅ | ❌ | ❌ |
+| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
+| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
+| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
+| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
+| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
+| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
+| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
+| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
+| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
+| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
+| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
+| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
+| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
+| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
+| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
+| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
+| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
+| [ZoeDepth](model_doc/zoedepth) | ✅ | ❌ | ❌ |
+
\ No newline at end of file
From 72f5aa7b6b0b8c50f4614fb30631dafd7a55dd09 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:09 +0300
Subject: [PATCH 011/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/installation.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/installation.md | 246 +++++++++++++++++++++++++++++++++
1 file changed, 246 insertions(+)
create mode 100644 docs/source/ar/installation.md
diff --git a/docs/source/ar/installation.md b/docs/source/ar/installation.md
new file mode 100644
index 00000000000000..855308f733ea44
--- /dev/null
+++ b/docs/source/ar/installation.md
@@ -0,0 +1,246 @@
+## التثبيت
+
+قم بتثبيت مكتبة 🤗 Transformers لمكتبة التعلم العميق التي تعمل معها، وقم بإعداد ذاكرة التخزين المؤقت الخاصة بك، وقم بإعداد 🤗 Transformers للعمل دون اتصال (اختياري).
+
+تم اختبار 🤗 Transformers على Python 3.6+، وPyTorch 1.1.0+، وTensorFlow 2.0+، وFlax. اتبع تعليمات التثبيت أدناه لمكتبة التعلم العميق التي تستخدمها:
+
+* تعليمات تثبيت [PyTorch](https://pytorch.org/get-started/locally/).
+* تعليمات تثبيت [TensorFlow 2.0](https://www.tensorflow.org/install/pip).
+* تعليمات تثبيت [Flax](https://flax.readthedocs.io/en/latest/).
+
+## التثبيت باستخدام pip
+
+يجب عليك تثبيت 🤗 Transformers في [بيئة افتراضية](https://docs.python.org/3/library/venv.html). إذا لم تكن معتادًا على البيئات الافتراضية في Python، فراجع هذا [الدليل](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). تجعل البيئة الافتراضية من السهل إدارة المشاريع المختلفة، وتجنب مشكلات التوافق بين التبعيات.
+
+ابدأ بإنشاء بيئة افتراضية في دليل مشروعك:
+
+```bash
+python -m venv .env
+```
+
+قم بتنشيط البيئة الافتراضية. على Linux وMacOs:
+
+```bash
+source .env/bin/activate
+```
+
+قم بتنشيط البيئة الافتراضية على Windows:
+
+```bash
+.env/Scripts/activate
+```
+
+الآن أنت مستعد لتثبيت 🤗 Transformers باستخدام الأمر التالي:
+
+```bash
+pip install transformers
+```
+
+للحصول على الدعم الخاص بـ CPU فقط، يمكنك تثبيت 🤗 Transformers ومكتبة التعلم العميق في خطوة واحدة. على سبيل المثال، قم بتثبيت 🤗 Transformers وPyTorch باستخدام:
+
+```bash
+pip install 'transformers[torch]'
+```
+
+🤗 Transformers وTensorFlow 2.0:
+
+```bash
+pip install 'transformers[tf-cpu]'
+```
+
+
+
+
+## المحتويات
+
+ينقسم التوثيق إلى خمسة أقسام:
+
+- **ابدأ** تقدم جولة سريعة في المكتبة وتعليمات التثبيت للبدء.
+- **الدروس التعليمية** هي مكان رائع للبدء إذا كنت مبتدئًا. سيساعدك هذا القسم على اكتساب المهارات الأساسية التي تحتاجها للبدء في استخدام المكتبة.
+- **أدلة كيفية الاستخدام** تُظهر لك كيفية تحقيق هدف محدد، مثل ضبط نموذج مسبق التدريب لنمذجة اللغة أو كيفية كتابة ومشاركة نموذج مخصص.
+- **الأدلة المفاهيمية** تقدم مناقشة وتفسيرًا أكثر للأفكار والمفاهيم الأساسية وراء النماذج والمهام وفلسفة التصميم في 🤗 Transformers.
+- **واجهة برمجة التطبيقات (API)** تصف جميع الفئات والوظائف:
+
+ - **الفئات الرئيسية** تشرح الفئات الأكثر أهمية مثل التكوين والنمذجة والتحليل النصي وخط الأنابيب.
+ - **النماذج** تشرح الفئات والوظائف المتعلقة بكل نموذج يتم تنفيذه في المكتبة.
+ - **المساعدون الداخليون** يشرحون فئات ووظائف المساعدة التي يتم استخدامها داخليًا.
+
+
+## النماذج والأطر المدعومة
+
+يمثل الجدول أدناه الدعم الحالي في المكتبة لكل من هذه النماذج، وما إذا كان لديها محلل نحوي Python (يُسمى "بطيء"). محلل نحوي "سريع" مدعوم بمكتبة 🤗 Tokenizers، وما إذا كان لديها دعم في Jax (عبر Flax) و/أو PyTorch و/أو TensorFlow.
+
+
+# Hugging Face Hub: قائمة النماذج
+
+آخر تحديث: 06/08/2024
+
+| النموذج | دعم PyTorch | دعم TensorFlow | دعم Flax |
+| :----: | :---------: | :------------: | :-------: |
+| [ALBERT](model_doc/albert) | ✅ | ✅ | ✅ |
+| [ALIGN](model_doc/align) | ✅ | ❌ | ❌ |
+| [AltCLIP](model_doc/altclip) | ✅ | ❌ | ❌ |
+| [Audio Spectrogram Transformer](model_doc/audio-spectrogram-transformer) | ✅ | ❌ | ❌ |
+| [Autoformer](model_doc/autoformer) | ✅ | ❌ | ❌ |
+| [Bark](model_doc/bark) | ✅ | ❌ | ❌ |
+| [BART](model_doc/bart) | ✅ | ✅ | ✅ |
+| [BARThez](model_doc/barthez) | ✅ | ✅ | ✅ |
+| [BARTpho](model_doc/bartpho) | ✅ | ✅ | ✅ |
+| [BEiT](model_doc/beit) | ✅ | ❌ | ✅ |
+| [BERT](model_doc/bert) | ✅ | ✅ | ✅ |
+| [Bert Generation](model_doc/bert-generation) | ✅ | ❌ | ❌ |
+| [BertJapanese](model_doc/bert-japanese) | ✅ | ✅ | ✅ |
+| [BERTweet](model_doc/bertweet) | ✅ | ✅ | ✅ |
+| [BigBird](model_doc/big_bird) | ✅ | ❌ | ✅ |
+| [BigBird-Pegasus](model_doc/bigbird_pegasus) | ✅ | ❌ | ❌ |
+| [BioGpt](model_doc/biogpt) | ✅ | ❌ | ❌ |
+| [BiT](model_doc/bit) | ✅ | ❌ | ❌ |
+| [Blenderbot](model_doc/blenderbot) | ✅ | ✅ | ✅ |
+| [BlenderbotSmall](model_doc/blenderbot-small) | ✅ | ✅ | ✅ |
+| [BLIP](model_doc/blip) | ✅ | ✅ | ❌ |
+| [BLIP-2](model_doc/blip-2) | ✅ | ❌ | ❌ |
+| [BLOOM](model_doc/bloom) | ✅ | ❌ | ✅ |
+| [BORT](model_doc/bort) | ✅ | ✅ | ✅ |
+| [BridgeTower](model_doc/bridgetower) | ✅ | ❌ | ❌ |
+| [BROS](model_doc/bros) | ✅ | ❌ | ❌ |
+| [ByT5](model_doc/byt5) | ✅ | ✅ | ✅ |
+| [CamemBERT](model_doc/camembert) | ✅ | ✅ | ❌ |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+# النماذج Models
+
+| النموذج/المهمة | التصنيف Classification | استخراج المعلومات Information Extraction | توليد Generation |
+| :-----: | :----: | :----: | :----: |
+| [CANINE](model_doc/canine) | ✅ | ❌ | ❌ |
+| [Chameleon](model_doc/chameleon) | ✅ | ❌ | ❌ |
+| [Chinese-CLIP](model_doc/chinese_clip) | ✅ | ❌ | ❌ |
+| [CLAP](model_doc/clap) | ✅ | ❌ | ❌ |
+| [CLIP](model_doc/clip) | ✅ | ✅ | ✅ |
+| [CLIPSeg](model_doc/clipseg) | ✅ | ❌ | ❌ |
+| [CLVP](model_doc/clvp) | ✅ | ❌ | ❌ |
+| [CodeGen](model_doc/codegen) | ✅ | ❌ | ❌ |
+| [CodeLlama](model_doc/code_llama) | ✅ | ❌ | ✅ |
+| [Cohere](model_doc/cohere) | ✅ | ❌ | ❌ |
+| [Conditional DETR](model_doc/conditional_detr) | ✅ | ❌ | ❌ |
+| [ConvBERT](model_doc/convbert) | ✅ | ✅ | ❌ |
+| [ConvNeXT](model_doc/convnext) | ✅ | ✅ | ❌ |
+| [ConvNeXTV2](model_doc/convnextv2) | ✅ | ✅ | ❌ |
+| [CPM](model_doc/cpm) | ✅ | ✅ | ✅ |
+| [CPM-Ant](model_doc/cpmant) | ✅ | ❌ | ❌ |
+| [CTRL](model_doc/ctrl) | ✅ | ✅ | ❌ |
+| [CvT](model_doc/cvt) | ✅ | ✅ | ❌ |
+| [Data2VecAudio](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecText](model_doc/data2vec) | ✅ | ❌ | ❌ |
+| [Data2VecVision](model_doc/data2vec) | ✅ | ✅ | ❌ |
+| [DBRX](model_doc/dbrx) | ✅ | ❌ | ❌ |
+| [DeBERTa](model_doc/deberta) | ✅ | ✅ | ❌ |
+| [DeBERTa-v2](model_doc/deberta-v2) | ✅ | ✅ | ❌ |
+| [Decision Transformer](model_doc/decision_transformer) | ✅ | ❌ | ❌ |
+| [Deformable DETR](model_doc/deformable_detr) | ✅ | ❌ | ❌ |
+| [DeiT](model_doc/deit) | ✅ | ✅ | ❌ |
+| [DePlot](model_doc/deplot) | ✅ | ❌ | ❌ |
+| [Depth Anything](model_doc/depth_anything) | ✅ | ❌ | ❌ |
+| [DETA](model_doc/deta) | ✅ | ❌ | ❌ |
+| [DETR](model_doc/detr) | | | |
+# قائمة النماذج
+
+| الاسم باللغة الإنجليزية | الوصف باللغة الإنجليزية | الوصف باللغة العربية |
+| :--------------------- | :---------------------- | :------------------- |
+| [DiT](model_doc/dit) | ✅ | |
+| [DonutSwin](model_doc/donut) | ✅ | |
+| [DPT](model_doc/dpt) | ✅ | |
+| [EfficientFormer](model_doc/efficientformer) | ✅ | |
+| [EnCodec](model_doc/encodec) | ✅ | |
+| [ErnieM](model_doc/ernie_m) | ✅ | |
+| [FNet](model_doc/fnet) | ✅ | |
+| [FocalNet](model_doc/focalnet) | ✅ | |
+| [Fuyu](model_doc/fuyu) | ✅ | |
+| [Gemma2](model_doc/gemma2) | ✅ | |
+| [GIT](model_doc/git) | ✅ | |
+# النماذج المدعومة حالياً
+
+| النموذج | النص | الصور | الصوت |
+|-------------|--------|---------|-------|
+| [GIT](model_doc/git) | ✅ | ❌ | ❌ |
+| [GLPN](model_doc/glpn) | ✅ | ❌ | ❌ |
+| [GPT Neo](model_doc/gpt_neo) | ✅ | ❌ | ✅ |
+| [GPT NeoX](model_doc/gpt_neox) | ✅ | ❌ | ❌ |
+| [GPT NeoX Japanese](model_doc/gpt_neox_japanese) | ✅ | ❌ | ❌ |
+| [GPT-J](model_doc/gptj) | ✅ | ✅ | ✅ |
+| [GPT-Sw3](model_doc/gpt-sw3) | ✅ | ✅ | ✅ |
+| [GPTBigCode](model_doc/gpt_bigcode) | ✅ | ❌ | ❌ |
+| [GPTSAN-japanese](model_doc/gptsan-japanese) | ✅ | ❌ | ❌ |
+| [Graphormer](model_doc/graphormer) | ✅ | ❌ | ❌ |
+| [Grounding DINO](model_doc/grounding-dino) | ✅ | ❌ | ❌ |
+| [GroupViT](model_doc/groupvit) | ✅ | ✅ | ❌ |
+| [HerBERT](model_doc/herbert) | ✅ | ✅ | ✅ |
+| [Hiera](model_doc/hiera) | ✅ | ❌ | ❌ |
+| [Hubert](model_doc/hubert) | ✅ | ✅ | ❌ |
+| [I-BERT](model_doc/ibert) | ✅ | ❌ | ❌ |
+| [IDEFICS](model_doc/idefics) | ✅ | ✅ | ❌ |
+| [Idefics2](model_doc/idefics2) | ✅ | ❌ | ❌ |
+| [ImageGPT](model_doc/imagegpt) | ✅ | ❌ | ❌ |
+| [Informer](model_doc/informer) | ✅ | ❌ | ❌ |
+| [InstructBLIP](model_doc/instructblip) | ✅ | ❌ | ❌ |
+| [InstructBlipVideo](model_doc/instructblipvideo) | ✅ | ❌ | ❌ |
+| [Jamba](model_doc/jamba) | ✅ | ❌ | ❌ |
+| [JetMoe](model_doc/jetmoe) | ✅ | ❌ | ❌ |
+| [Jukebox](model_doc/jukebox) | ✅ | ❌ | ❌ |
+| [KOSMOS-2](model_doc/kosmos-2) | ✅ | ❌ | ❌ |
+| [LayoutLM](model_doc/layoutlm) | ✅ | ✅ | ❌ |
+| [LayoutLMv2](model_doc/layoutlmv2) | ✅ | ❌ | ❌ |
+| [LayoutLMv3](model_doc/layoutlmv3) | ✅ | ✅ | ❌ |
+| [LayoutXLM](model_doc/layoutxlm) | ✅ | ❌ | ❌ |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+# Hugging Face Models
+
+مرحباً! هذه قائمة بالنماذج المتاحة في Hugging Face Hub. تم تحديثها مؤخراً لتشمل أحدث النماذج وأكثرها شعبية.
+
+| الاسم | النص | الصورة | الصوت |
+| --- | --- | --- | --- |
+| [LED](model_doc/led) | ✅ | ✅ | ❌ |
+| [LeViT](model_doc/levit) | ✅ | ❌ | ❌ |
+| [LiLT](model_doc/lilt) | ✅ | ❌ | ❌ |
+| [LLaMA](model_doc/llama) | ✅ | ❌ | ✅ |
+| [Llama2](model_doc/llama2) | ✅ | ❌ | ✅ |
+| [Llama3](model_doc/llama3) | ✅ | ❌ | ✅ |
+| [LLaVa](model_doc/llava) | ✅ | ❌ | ❌ |
+| [LLaVA-NeXT](model_doc/llava_next) | ✅ | ❌ | ❌ |
+| [LLaVa-NeXT-Video](model_doc/llava-next-video) | ✅ | ❌ | ❌ |
+| [Longformer](model_doc/longformer) | ✅ | ✅ | ❌ |
+| [LongT5](model_doc/longt5) | ✅ | ❌ | ✅ |
+| [LUKE](model_doc/luke) | ✅ | ❌ | ❌ |
+| [LXMERT](model_doc/lxmert) | ✅ | ✅ | ❌ |
+| [M-CTC-T](model_doc/mctct) | ✅ | ❌ | ❌ |
+| [M2M100](model_doc/m2m_100) | ✅ | ❌ | ❌ |
+| [MADLAD-400](model_doc/madlad-400) | ✅ | ✅ | ✅ |
+| [Mamba](model_doc/mamba) | ✅ | ❌ | ❌ |
+| [Marian](model_doc/marian) | ✅ | ✅ | ✅ |
+| [MarkupLM](model_doc/markuplm) | ✅ | ❌ | ❌ |
+| [Mask2Former](model_doc/mask2former) | ✅ | ❌ | ❌ |
+| [MaskFormer](model_doc/maskformer) | ✅ | ❌ | ❌ |
+| [MatCha](model_doc/matcha) | ✅ | ❌ | ❌ |
+| [mBART](model_doc/mbart) | ✅ | ✅ | ✅ |
+| [mBART-50](model_doc/mbart50) | ✅ | ✅ | ✅ |
+| [MEGA](model_doc/mega) | ✅ | ❌ | ❌ |
+| [Megatron-BERT](model_doc/megatron-bert) | ✅ | ❌ | ❌ |
+| [Megatron-GPT2](model_doc/megatron_gpt2) | ✅ | ✅ | ✅ |
+| [MGP-STR](model_doc/mgp-str) | ✅ | ❌ | ❌ |
+| [Mistral](model_doc/mistral) | ✅ | ✅ | ✅ |
+| [Mixtral](model_doc/mixtral) | ✅ | ❌ | ❌ |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+# Hugging Face Models
+
+نموذج Hugging Face هو تمثيل لخوارزمية تعلم الآلة التي يمكن تدريبها على بيانات محددة لأداء مهام مختلفة مثل تصنيف النصوص أو توليد الصور. توفر Hugging Face مجموعة واسعة من النماذج التي يمكن استخدامها مباشرة أو تخصيصها لمهمة محددة.
+
+## نظرة عامة على النماذج
+
+| الاسم | النص | الصورة/الكائن | الصوت |
+| ---------------------------------------- | ----------- | ------------- | --------- |
+| [mLUKE](model_doc/mluke) | ✅ | ❌ | ❌ |
+| [MMS](model_doc/mms) | ✅ | ✅ | ✅ |
+| [MobileBERT](model_doc/mobilebert) | ✅ | ✅ | ❌ |
+| [MobileNetV1](model_doc/mobilenet_v1) | ✅ | ❌ | ❌ |
+| [MobileNetV2](model_doc/mobilenet_v2) | ✅ | ❌ | ❌ |
+| [MobileViT](model_doc/mobilevit) | ✅ | ✅ | ❌ |
+| [MobileViTV2](model_doc/mobilevitv2) | ✅ | ❌ | ❌ |
+| [MPNet](model_doc/mpnet) | ✅ | ✅ | ❌ |
+| [MPT](model_doc/mpt) | ✅ | ❌ | ❌ |
+| [MRA](model_doc/mra) | ✅ | ❌ | ❌ |
+| [MT5](model_doc/mt5) | ✅ | ✅ | ✅ |
+| [MusicGen](model_doc/musicgen) | ✅ | ❌ | ❌ |
+| [MusicGen Melody](model_doc/musicgen_melody) | ✅ | ❌ | ❌ |
+| [MVP](model_doc/mvp) | ✅ | ❌ | ❌ |
+| [NAT](model_doc/nat) | ✅ | ❌ | ❌ |
+| [Nezha](model_doc/nezha) | ✅ | ❌ | ❌ |
+| [NLLB](model_doc/nllb) | ✅ | ❌ | ❌ |
+| [NLLB-MOE](model_doc/nllb-moe) | ✅ | ❌ | ❌ |
+| [Nougat](model_doc/nougat) | ✅ | ✅ | ✅ |
+| [Nyströmformer](model_doc/nystromformer) | ✅ | ❌ | ❌ |
+| [OLMo](model_doc/olmo) | ✅ | ❌ | ❌ |
+| [OneFormer](model_doc/oneformer) | ✅ | ❌ | ❌ |
+| [OpenAI GPT](model_doc/openai-gpt) | ✅ | ✅ | ❌ |
+| [OpenAI GPT-2](model_doc/gpt2) | ✅ | ✅ | ✅ |
+| [OpenLlama](model_doc/open-llama) | ✅ | ❌ | ❌ |
+| [OPT](model_doc/opt) | ✅ | ✅ | ✅ |
+| [OWL-ViT](model_doc/owlvit) | ✅ | ❌ | ❌ |
+| [OWLv2](model_doc/owlv2) | ✅ | ❌ | ❌ |
+| [PaliGemma](model_doc/paligemma) | ✅ | ❌ | ❌ |
+| [PatchTSMixer](model_doc/patchtsmixer) | ✅ | ❌ | ❌ |
+| [PatchTST](model_doc/patchtst) | ✅ | ❌ | ❌ |
+# النماذج المدعومة
+
+| الاسم | التصنيف | التوليد | استخراج المعلومات |
+| --- | --- | --- | --- |
+| [PatchTST](model_doc/patchtst) | ✅ | ❌ | ❌ |
+| [Pegasus](model_doc/pegasus) | ✅ | ✅ | ✅ |
+| [PEGASUS-X](model_doc/pegasus_x) | ✅ | ❌ | ❌ |
+| [Perceiver](model_doc/perceiver) | ✅ | ❌ | ❌ |
+| [Persimmon](model_doc/persimmon) | ✅ | ❌ | ❌ |
+| [Phi](model_doc/phi) | ✅ | ❌ | ❌ |
+| [Phi3](model_doc/phi3) | ✅ | ❌ | ❌ |
+| [PhoBERT](model_doc/phobert) | ✅ | ✅ | ✅ |
+| [Pix2Struct](model_doc/pix2struct) | ✅ | ❌ | ❌ |
+| [PLBart](model_doc/plbart) | ✅ | ❌ | ❌ |
+| [PoolFormer](model_doc/poolformer) | ✅ | ❌ | ❌ |
+| [Pop2Piano](model_doc/pop2piano) | ✅ | ❌ | ❌ |
+| [ProphetNet](model_doc/prophetnet) | ✅ | ❌ | ❌ |
+| [PVT](model_doc/pvt) | ✅ | ❌ | ❌ |
+| [PVTv2](model_doc/pvt_v2) | ✅ | ❌ | ❌ |
+| [QDQBert](model_doc/qdqbert) | ✅ | ❌ | ❌ |
+| [Qwen2](model_doc/qwen2) | ✅ | ❌ | ❌ |
+| [Qwen2MoE](model_doc/qwen2_moe) | ✅ | ❌ | ❌ |
+| [RAG](model_doc/rag) | ✅ | ✅ | ❌ |
+| [REALM](model_doc/realm) | ✅ | ❌ | ❌ |
+| [RecurrentGemma](model_doc/recurrent_gemma) | ✅ | ❌ | ❌ |
+| [Reformer](model_doc/reformer) | ✅ | ❌ | ❌ |
+| [RegNet](model_doc/regnet) | ✅ | ✅ | ✅ |
+| [RemBERT](model_doc/rembert) | ✅ | ✅ | ❌ |
+| [ResNet](model_doc/resnet) | ✅ | ✅ | ✅ |
+| [RetriBERT](model_doc/retribert) | ✅ | ❌ | ❌ |
+| [RoBERTa](model_doc/roberta) | ✅ | ✅ | ✅ |
+| [RoBERTa-PreLayerNorm](model_doc/roberta-prelayernorm) | ✅ | ✅ | ✅ |
+| [RoCBert](model_doc/roc_bert) | ✅ | ❌ | ❌ |
+| [RoFormer](model_doc/roformer) | ✅ | ✅ | ✅ |
+| [RT-DETR](model_doc/rt_detr) | ✅ | ❌ | ❌ |
+# النماذج المدعومة
+
+| الاسم | التصنيف | الكشف | التتبع |
+| ---------------------------------------------------------------------------------------------------------------------------------------------------- | :-----: | :-----: | :------: |
+| [RT-DETR](model_doc/rt_detr) | ✅ | ❌ | ❌ |
+| [RT-DETR-ResNet](model_doc/rt_detr_resnet) | ✅ | ❌ | ❌ |
+| [RWKV](model_doc/rwkv) | ✅ | ❌ | ❌ |
+| [SAM](model_doc/sam) | ✅ | ✅ | ❌ |
+| [SeamlessM4T](model_doc/seamless_m4t) | ✅ | ❌ | ❌ |
+| [SeamlessM4Tv2](model_doc/seamless_m4t_v2) | ✅ | ❌ | ❌ |
+| [SegFormer](model_doc/segformer) | ✅ | ✅ | ❌ |
+| [SegGPT](model_doc/seggpt) | ✅ | ❌ | ❌ |
+| [SEW](model_doc/sew) | ✅ | ❌ | ❌ |
+| [SEW-D](model_doc/sew-d) | ✅ | ❌ | ❌ |
+| [SigLIP](model_doc/siglip) | ✅ | ❌ | ❌ |
+| [Speech Encoder decoder](model_doc/speech-encoder-decoder) | ✅ | ❌ | ✅ |
+| [Speech2Text](model_doc/speech_to_text) | ✅ | ✅ | ❌ |
+| [SpeechT5](model_doc/speecht5) | ✅ | ❌ | ❌ |
+| [Splinter](model_doc/splinter) | ✅ | ❌ | ❌ |
+| [SqueezeBERT](model_doc/squeezebert) | ✅ | ❌ | ❌ |
+| [StableLm](model_doc/stablelm) | ✅ | ❌ | ❌ |
+| [Starcoder2](model_doc/starcoder2) | ✅ | ❌ | ❌ |
+| [SuperPoint](model_doc/superpoint) | ✅ | ❌ | ❌ |
+| [SwiftFormer](model_doc/swiftformer) | ✅ | ✅ | ❌ |
+| [Swin Transformer](model_doc/swin) | ✅ | ✅ | ❌ |
+| [Swin Transformer V2](model_doc/swinv2) | ✅ | ❌ | ❌ |
+| [Swin2SR](model_doc/swin2sr) | ✅ | ❌ | ❌ |
+| [SwitchTransformers](model_doc/switch_transformers) | ✅ | ❌ | ❌ |
+| [T5](model_doc/t5) | ✅ | ✅ | ✅ |
+| [T5v1.1](model_doc/t5v1.1) | ✅ | ✅ | ✅ |
+| [Table Transformer](model_doc/table-transformer) | ✅ | ❌ | ❌ |
+| [TAPAS](model_doc/tapas) | ✅ | ✅ | ❌ |
+| [TAPEX](model_doc/tapex) | ✅ | ✅ | ✅ |
+| [Time Series Transformer](model_doc/time_series_transformer) | ✅ | ❌ | ❌ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+# قائمة النماذج المدعومة
+
+| الاسم | التصنيف | النص | الصورة |
+| -------------------------------------- | ------ | -------- | --------- |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [Wav2Vec2](model_doc/wav2vec2) | ✅ | ✅ | ✅ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ |
+| ... | ... | ... | ... |
+
+# تفاصيل النموذج
+
+يرجى الرجوع إلى [README.md](README.md#model-zoo) للحصول على تفاصيل حول كيفية إضافة نموذج جديد.
+
+# النماذج المدعومة
+
+## النص
+
+| الاسم | التصنيف | النص-النص | النص-الصورة | النص-الفيديو |
+| -------------------------------------------- | ------ | --------- | ----------- | ------------ |
+| [TimeSformer](model_doc/timesformer) | ✅ | ❌ | ❌ | ❌ |
+| [Trajectory Transformer](model_doc/trajectory_transformer) | ✅ | ❌ | ❌ | ❌ |
+| [Transformer-XL](model_doc/transfo-xl) | ✅ | ✅ | ❌ | ❌ |
+| ... | ... | ... | ... | ... |
+
+## الصورة
+
+| الاسم | التصنيف | النص-الصورة | الصورة-الصورة |
+| ---------------------------------------- | ------ | ----------- | ------------- |
+| [UL2](model_doc/ul2) | ✅ | ✅ | ✅ |
+| [ViT](model_doc/vit) | ✅ | ✅ | ✅ |
+| [ViT Hybrid](model_doc/vit_hybrid) | ✅ | ❌ | ❌ |
+| [VitDet](model_doc/vitdet) | ✅ | ❌ | ❌ |
+| [ViTMAE](model_doc/vit_mae) | ✅ | ✅ | ❌ |
+| ... | ... | ... | ... |
+
+## الفيديو
+
+| الاسم | التصنيف | النص-الفيديو | الفيديو-الفيديو |
+| ---------------------------------------- | ------ | ------------ | -------------- |
+| [VideoLlava](model_doc/video_llava) | ✅ | ❌ | ❌ |
+| [VideoMAE](model_doc/videomae) | ✅ | ❌ | ❌ |
+| [ViLT](model_doc/vilt) | ✅ | ❌ | ❌ |
+| [VipLlava](model_doc/vipllava) | ✅ | ❌ | ❌ |
+| ... | ... | ... | ... |
+# النماذج المدعومة
+
+| الاسم | الصوت | النص | الصورة |
+| ------------------------------------------------------------------- | ----- | ---- | ------ |
+| [Wav2Vec2-BERT](model_doc/wav2vec2-bert) | ✅ | ❌ | ❌ |
+| [Wav2Vec2-Conformer](model_doc/wav2vec2-conformer) | ✅ | ❌ | ❌ |
+| [Wav2Vec2Phoneme](model_doc/wav2vec2_phoneme) | ✅ | ✅ | ✅ |
+| [WavLM](model_doc/wavlm) | ✅ | ❌ | ❌ |
+| [Whisper](model_doc/whisper) | ✅ | ✅ | ✅ |
+| [X-CLIP](model_doc/xclip) | ✅ | ❌ | ❌ |
+| [X-MOD](model_doc/xmod) | ✅ | ❌ | ❌ |
+| [XGLM](model_doc/xglm) | ✅ | ✅ | ✅ |
+| [XLM](model_doc/xlm) | ✅ | ✅ | ❌ |
+| [XLM-ProphetNet](model_doc/xlm-prophetnet) | ✅ | ❌ | ❌ |
+| [XLM-RoBERTa](model_doc/xlm-roberta) | ✅ | ✅ | ✅ |
+| [XLM-RoBERTa-XL](model_doc/xlm-roberta-xl) | ✅ | ❌ | ❌ |
+| [XLM-V](model_doc/xlm-v) | ✅ | ✅ | ✅ |
+| [XLNet](model_doc/xlnet) | ✅ | ✅ | ❌ |
+| [XLS-R](model_doc/xls_r) | ✅ | ✅ | ✅ |
+| [XLSR-Wav2Vec2](model_doc/xlsr_wav2vec2) | ✅ | ✅ | ✅ |
+| [YOLOS](model_doc/yolos) | ✅ | ❌ | ❌ |
+| [YOSO](model_doc/yoso) | ✅ | ❌ | ❌ |
+| [ZoeDepth](model_doc/zoedepth) | ✅ | ❌ | ❌ |
+
\ No newline at end of file
From 72f5aa7b6b0b8c50f4614fb30631dafd7a55dd09 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:09 +0300
Subject: [PATCH 011/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/installation.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/installation.md | 246 +++++++++++++++++++++++++++++++++
1 file changed, 246 insertions(+)
create mode 100644 docs/source/ar/installation.md
diff --git a/docs/source/ar/installation.md b/docs/source/ar/installation.md
new file mode 100644
index 00000000000000..855308f733ea44
--- /dev/null
+++ b/docs/source/ar/installation.md
@@ -0,0 +1,246 @@
+## التثبيت
+
+قم بتثبيت مكتبة 🤗 Transformers لمكتبة التعلم العميق التي تعمل معها، وقم بإعداد ذاكرة التخزين المؤقت الخاصة بك، وقم بإعداد 🤗 Transformers للعمل دون اتصال (اختياري).
+
+تم اختبار 🤗 Transformers على Python 3.6+، وPyTorch 1.1.0+، وTensorFlow 2.0+، وFlax. اتبع تعليمات التثبيت أدناه لمكتبة التعلم العميق التي تستخدمها:
+
+* تعليمات تثبيت [PyTorch](https://pytorch.org/get-started/locally/).
+* تعليمات تثبيت [TensorFlow 2.0](https://www.tensorflow.org/install/pip).
+* تعليمات تثبيت [Flax](https://flax.readthedocs.io/en/latest/).
+
+## التثبيت باستخدام pip
+
+يجب عليك تثبيت 🤗 Transformers في [بيئة افتراضية](https://docs.python.org/3/library/venv.html). إذا لم تكن معتادًا على البيئات الافتراضية في Python، فراجع هذا [الدليل](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). تجعل البيئة الافتراضية من السهل إدارة المشاريع المختلفة، وتجنب مشكلات التوافق بين التبعيات.
+
+ابدأ بإنشاء بيئة افتراضية في دليل مشروعك:
+
+```bash
+python -m venv .env
+```
+
+قم بتنشيط البيئة الافتراضية. على Linux وMacOs:
+
+```bash
+source .env/bin/activate
+```
+
+قم بتنشيط البيئة الافتراضية على Windows:
+
+```bash
+.env/Scripts/activate
+```
+
+الآن أنت مستعد لتثبيت 🤗 Transformers باستخدام الأمر التالي:
+
+```bash
+pip install transformers
+```
+
+للحصول على الدعم الخاص بـ CPU فقط، يمكنك تثبيت 🤗 Transformers ومكتبة التعلم العميق في خطوة واحدة. على سبيل المثال، قم بتثبيت 🤗 Transformers وPyTorch باستخدام:
+
+```bash
+pip install 'transformers[torch]'
+```
+
+🤗 Transformers وTensorFlow 2.0:
+
+```bash
+pip install 'transformers[tf-cpu]'
+```
+
+ +
+  +
+
+يمكنك تصور كيفية عمل فك تشفير البحث الشعاعي في [هذا العرض التوضيحي التفاعلي](https://huggingface.co/spaces/m-ric/beam_search_visualizer): اكتب جملتك المدخلة، ولعب مع المعلمات لمشاهدة كيفية تغيير حزم فك التشفير.
+
+لتمكين استراتيجية فك التشفير هذه، حدد `num_beams` (أي عدد الفرضيات التي يجب تتبعها) أكبر من 1.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> prompt = "It is astonishing how one can"
+>>> checkpoint = "openai-community/gpt2-medium"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+
+>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
+time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
+```
+
+### معاينة شعاع متعددة الحدود
+
+كما يوحي الاسم، تجمع استراتيجية فك التشفير هذه بين البحث الشعاعي والمعاينة متعددة الحدود. يجب عليك تحديد
+`num_beams` أكبر من 1، وتعيين `do_sample=True` لاستخدام استراتيجية فك التشفير هذه.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
+>>> set_seed(0) # من أجل إمكانية إعادة الإنتاج
+
+>>> prompt = "translate English to German: The house is wonderful."
+>>> checkpoint = "google-t5/t5-small"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+
+>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'Das Haus ist wunderbar.'
+```
+
+### فك تشفير البحث الشعاعي المتنوع
+
+استراتيجية فك تشفير البحث الشعاعي المتنوع هي امتداد لاستراتيجية البحث الشعاعي التي تتيح توليد مجموعة أكثر تنوعًا
+من تسلسلات الشعاع للاختيار من بينها. لمعرفة كيفية عمله، راجع [بحث شعاعي متنوع: فك تشفير حلول متنوعة من نماذج التسلسل العصبي](https://arxiv.org/pdf/1610.02424.pdf).
+
+لدى هذا النهج ثلاثة معلمات رئيسية: `num_beams`، `num_beam_groups`، و`diversity_penalty`.
+تضمن عقوبة التنوع تميز الإخراج عبر المجموعات، ويتم استخدام البحث الشعاعي داخل كل مجموعة.
+
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+>>> checkpoint = "google/pegasus-xsum"
+>>> prompt = (
+... "The Permaculture Design Principles are a set of universal design principles "
+... "that can be applied to any location, climate and culture, and they allow us to design "
+... "the most efficient and sustainable human habitation and food production systems. "
+... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
+... "as ecology, landscape design, environmental science and energy conservation, and the "
+... "Permaculture design principles are drawn from these various disciplines. Each individual "
+... "design principle itself embodies a complete conceptual framework based on sound "
+... "scientific principles. When we bring all these separate principles together, we can "
+... "create a design system that both looks at whole systems, the parts that these systems "
+... "consist of, and how those parts interact with each other to create a complex, dynamic, "
+... "living system. Each design principle serves as a tool that allows us to integrate all "
+... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
+... "whole system, where the elements harmoniously interact and work together in the most "
+... "efficient way possible."
+... )
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+
+>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'The Design Principles are a set of universal design principles that can be applied to any location, climate and
+culture, and they allow us to design the'
+```
+يوضح هذا الدليل المعلمات الرئيسية التي تمكن استراتيجيات فك التشفير المختلفة. هناك معلمات أكثر تقدمًا لـ
+طريقة [`generate`]، والتي تمنحك مزيدًا من التحكم في سلوك طريقة [`generate`].
+
+للاطلاع على القائمة الكاملة للمعلمات المتاحة، راجع [توثيق API](./main_classes/text_generation.md).
+
+### فك التشفير التخميني
+
+فك التشفير التخميني (المعروف أيضًا باسم فك التشفير بمساعدة) هو تعديل لاستراتيجيات فك التشفير المذكورة أعلاه، والذي يستخدم
+نموذج مساعد (يفضل أن يكون أصغر بكثير) بنفس المعالج اللغوي، لتوليد بعض الرموز المرشحة. ثم يقوم النموذج الرئيسي
+بتحقق من الرموز المرشحة في تمرير توجيهي واحد، والذي يسرع عملية فك التشفير. إذا
+`do_sample=True`، يتم استخدام التحقق من الرمز مع إعادة المعاينة المقدمة في
+[ورقة فك التشفير التخميني](https://arxiv.org/pdf/2211.17192.pdf).
+
+حاليًا، يتم دعم البحث الشره والمعاينة فقط مع فك التشفير بمساعدة، ولا يدعم فك التشفير بمساعدة الإدخالات المجمعة.
+لمعرفة المزيد حول فك التشفير بمساعدة، تحقق من [هذه التدوينة](https://huggingface.co/blog/assisted-generation).
+
+لتمكين فك التشفير بمساعدة، قم بتعيين وسيط `assistant_model` بنموذج.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> prompt = "Alice and Bob"
+>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
+>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
+>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
+```
+
+عند استخدام فك التشفير بمساعدة مع طرق المعاينة، يمكنك استخدام وسيط `temperature` للتحكم في العشوائية،
+تمامًا كما هو الحال في المعاينة متعددة الحدود. ومع ذلك، في فك التشفير بمساعدة، قد يساعد تقليل درجة الحرارة في تحسين الكمون.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
+>>> set_seed(42) # من أجل إمكانية إعادة الإنتاج
+
+>>> prompt = "Alice and Bob"
+>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
+>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
+>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Alice and Bob, a couple of friends of mine, who are both in the same office as']
+```
+
+بدلاً من ذلك، يمكنك أيضًا تعيين `prompt_lookup_num_tokens` لتشغيل فك التشفير بمساعدة n-gram، بدلاً من
+فك التشفير بمساعدة النماذج. يمكنك قراءة المزيد عنه [هنا](https://twitter.com/joao_gante/status/1747322413006643259).
+### فك تشفير DoLa
+
+**D** فك التشفير عن طريق تباين **La** فك تشفير الطبقات (DoLa) هو استراتيجية فك تشفير تبايني لتحسين الواقعية والحد من
+الهلوسة في LLMs، كما هو موضح في هذه الورقة ICLR 2024 [DoLa: فك تشفير الطبقات التبايني يحسن الواقعية في نماذج اللغة الكبيرة](https://arxiv.org/abs/2309.03883).
+
+يتم تحقيق DoLa من خلال تضخيم الاختلافات في logits التي تم الحصول عليها من الطبقات النهائية
+مقابل الطبقات السابقة، وبالتالي تضخيم المعرفة الواقعية الموضعية في جزء معين من طبقات المحول.
+يتم تحقيق DoLa من خلال تضخيم الاختلافات في logits التي تم الحصول عليها من الطبقات النهائية
+مقابل الطبقات السابقة، وبالتالي تضخيم المعرفة الواقعية الموضعية في جزء معين من طبقات المحول.
+
+اتبع الخطوتين التاليتين لتنشيط فك تشفير DoLa عند استدعاء وظيفة `model.generate`:
+
+1. قم بتعيين وسيط `dola_layers`، والذي يمكن أن يكون إما سلسلة أو قائمة من الأعداد الصحيحة.
+ - إذا تم تعيينه على سلسلة، فيمكن أن يكون أحد `low`، `high`.
+ - إذا تم تعيينه على قائمة من الأعداد الصحيحة، فيجب أن يكون قائمة بمؤشرات الطبقات بين 0 والعدد الإجمالي للطبقات في النموذج. طبقة 0 هي طبقة تضمين الكلمات، والطبقة 1 هي أول طبقة محول، وهكذا.
+2. يُقترح تعيين `repetition_penalty = 1.2` لتقليل التكرار في فك تشفير DoLa.
+
+راجع الأمثلة التالية لفك تشفير DoLa باستخدام نموذج LLaMA-7B المكون من 32 طبقة.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b")
+>>> model = AutoModelForCausalLM.from_pretrained("huggyllama/llama-7b", torch_dtype=torch.float16)
+>>> device = 'cuda' if torch.cuda.is_available() else 'cpu'
+>>> model.to(device)
+>>> set_seed(42)
+
+>>> text = "On what date was the Declaration of Independence officially signed?"
+>>> inputs = tokenizer(text, return_tensors="pt").to(device)
+
+# Vanilla greddy decoding
+>>> vanilla_output = model.generate(**inputs, do_sample=False, max_new_tokens=50)
+>>> tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
+['\nThe Declaration of Independence was signed on July 4, 1776.\nWhat was the date of the signing of the Declaration of Independence?\nThe Declaration of Independence was signed on July 4,']
+
+# DoLa decoding with contrasting higher part of layers (layers 16,18,...,30)
+>>> dola_high_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers='high')
+>>> tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
+['\nJuly 4, 1776, when the Continental Congress voted to separate from Great Britain. The 56 delegates to the Continental Congress signed the Declaration on August 2, 1776.']
+
+# DoLa decoding with contrasting specific layers (layers 28 and 30)
+>>> dola_custom_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers=[28,30], repetition_penalty=1.2)
+>>> tokenizer.batch_decode(dola_custom_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
+['\nIt was officially signed on 2 August 1776, when 56 members of the Second Continental Congress, representing the original 13 American colonies, voted unanimously for the resolution for independence. The 2']
+```
+
+#### فهم معاملات 'dola_layers'
+
+يمثل 'dola_layers' طبقات المرشح في الاختيار المبكر للطبقة، كما هو موضح في ورقة DoLa. ستتم مقارنة الطبقة المبكرة المحددة بالطبقة النهائية.
+
+يؤدي تعيين 'dola_layers' إلى 'low' أو 'high' إلى تحديد الجزء السفلي أو العلوي من الطبقات للمقارنة، على التوالي.
+
+- بالنسبة لنماذج 'N-layer' مع 'N <= 40' layer، يتم استخدام الطبقات من 'range(0، N // 2، 2)' و'range(N // 2، N، 2)' لـ 'low' و 'high' layers، على التوالي.
+
+- بالنسبة للنماذج التي تحتوي على 'N > 40' layer، يتم استخدام الطبقات من 'range(0، 20، 2)' و'range(N - 20، N، 2)' لـ 'low' و 'high' layers، على التوالي.
+
+- إذا كان للنموذج تعليقات توضيحية مرتبطة بالكلمات، فإننا نتخطى طبقة التعليقات التوضيحية للكلمات (الطبقة 0) ونبدأ من الطبقة الثانية، نظرًا لأن الخروج المبكر من التعليقات التوضيحية للكلمات سيصبح دالة الهوية.
+
+- قم بتعيين 'dola_layers' إلى قائمة من الأعداد الصحيحة لفهرسة الطبقات لمقارنة الطبقات المحددة يدويًا. على سبيل المثال، يؤدي تعيين 'dola_layers=[28،30]' إلى مقارنة الطبقة النهائية (الطبقة 32) بالطبقات 28 و30.
+
+اقترحت الورقة أن مقارنة الطبقات 'العالية' لتحسين مهام الإجابات القصيرة مثل TruthfulQA، ومقارنة الطبقات 'المنخفضة' لتحسين جميع مهام الاستدلال بالإجابات الطويلة الأخرى، مثل GSM8K وStrategyQA وFACTOR وVicunaQA. لا يوصى بتطبيق DoLa على النماذج الأصغر مثل GPT-2، كما هو موضح في الملحق N من الورقة.
\ No newline at end of file
From a920aead6967f0b8fe15482b50a5c1a12957f85f Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:29 +0300
Subject: [PATCH 022/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/gguf.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/gguf.md | 66 ++++++++++++++++++++++++++++++++++++++++++
1 file changed, 66 insertions(+)
create mode 100644 docs/source/ar/gguf.md
diff --git a/docs/source/ar/gguf.md b/docs/source/ar/gguf.md
new file mode 100644
index 00000000000000..aeacd3b1bcd978
--- /dev/null
+++ b/docs/source/ar/gguf.md
@@ -0,0 +1,66 @@
+# GGUF وتفاعلها مع المحولات
+
+تُستخدم صيغة ملف GGUF لتخزين النماذج للاستنتاج مع [GGML](https://github.com/ggerganov/ggml) والمكتبات الأخرى التي تعتمد عليها، مثل [llama.cpp](https://github.com/ggerganov/llama.cpp) أو [whisper.cpp](https://github.com/ggerganov/whisper.cpp) الشهيرة جدًا.
+
+إنها صيغة ملف [مدعومة من قبل Hugging Face Hub](https://huggingface.co/docs/hub/en/gguf) مع ميزات تسمح بالتفتيش السريع للتوابع والبيانات الوصفية داخل الملف.
+
+تم تصميم تنسيق الملف هذا كـ "تنسيق ملف واحد" حيث يحتوي ملف واحد عادةً على كل من سمات التكوين ومفردات المحلل اللغوي والسمات الأخرى، بالإضافة إلى جميع التوابع التي سيتم تحميلها في النموذج. تأتي هذه الملفات بتنسيقات مختلفة وفقًا لنوع التكميم في الملف. نلقي نظرة موجزة على بعضها [هنا](https://huggingface.co/docs/hub/en/gguf#quantization-types).
+
+## الدعم داخل المحولات
+
+أضفنا القدرة على تحميل ملفات `gguf` داخل `المحولات` لتوفير قدرات تدريب/ضبط إضافية لنماذج gguf، قبل إعادة تحويل تلك النماذج إلى `gguf` لاستخدامها داخل نظام بيئي `ggml`. عند تحميل نموذج، نقوم أولاً بإلغاء تكميمه إلى fp32، قبل تحميل الأوزان لاستخدامها في PyTorch.
+
+> [!ملاحظة]
+> لا يزال الدعم استكشافيًا للغاية ونرحب بالمساهمات لتثبيته عبر أنواع التكميم وبنيات النماذج.
+
+فيما يلي، بنيات النماذج وأنواع التكميم المدعومة:
+
+### أنواع التكميم المدعومة
+
+تُحدد أنواع التكميم المدعومة مبدئيًا وفقًا لملفات التكميم الشائعة التي تمت مشاركتها على Hub.
+
+- F32
+- Q2_K
+- Q3_K
+- Q4_0
+- Q4_K
+- Q5_K
+- Q6_K
+- Q8_0
+
+نأخذ مثالاً من المحلل الممتاز [99991/pygguf](https://github.com/99991/pygguf) Python لإلغاء تكميم الأوزان.
+
+### بنيات النماذج المدعومة
+
+في الوقت الحالي، بنيات النماذج المدعومة هي البنيات التي كانت شائعة جدًا على Hub، وهي:
+
+- LLaMa
+- ميسترال
+- Qwen2
+
+## مثال الاستخدام
+
+لتحميل ملفات `gguf` في `المحولات`، يجب تحديد وسيط `gguf_file` لأساليب `from_pretrained` لكل من المحللات اللغوية والنماذج. فيما يلي كيفية تحميل محلل لغوي ونموذج، يمكن تحميلهما من نفس الملف بالضبط:
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
+filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
+
+tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
+model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)
+```
+
+الآن لديك حق الوصول إلى الإصدار الكامل غير المكمم للنموذج في نظام PyTorch البيئي، حيث يمكنك دمجه مع مجموعة من الأدوات الأخرى.
+
+لإعادة التحويل إلى ملف `gguf`، نوصي باستخدام ملف [`convert-hf-to-gguf.py`](https://github.com/ggerganov/llama.cpp/blob/master/convert-hf-to-gguf.py) من llama.cpp.
+
+فيما يلي كيفية إكمال البرنامج النصي أعلاه لحفظ النموذج وتصديره مرة أخرى إلى `gguf`:
+
+```py
+tokenizer.save_pretrained('directory')
+model.save_pretrained('directory')
+
+!python ${path_to_llama_cpp}/convert-hf-to-gguf.py ${directory}
+```
\ No newline at end of file
From 5ef35eb5fa810f31a1835f34fafd0c8639088b5f Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:31 +0300
Subject: [PATCH 023/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/llm=5Foptims.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/llm_optims.md | 291 +++++++++++++++++++++++++++++++++++
1 file changed, 291 insertions(+)
create mode 100644 docs/source/ar/llm_optims.md
diff --git a/docs/source/ar/llm_optims.md b/docs/source/ar/llm_optims.md
new file mode 100644
index 00000000000000..7cb865fac7dd19
--- /dev/null
+++ b/docs/source/ar/llm_optims.md
@@ -0,0 +1,291 @@
+# تحسين الاستنتاج لنماذج اللغة الضخمة
+
+دفعت نماذج اللغة الضخمة (LLMs) تطبيقات توليد النصوص، مثل نماذج الدردشة واستكمال الأكواد، إلى المستوى التالي من خلال إنتاج نصوص تظهر مستوى عاليًا من الفهم والطلاقة. ولكن ما يجعل نماذج اللغة الضخمة قوية - أي حجمها - يطرح أيضًا تحديات للاستنتاج.
+
+الاستنتاج الأساسي بطيء لأن نماذج اللغة الضخمة يجب أن تُستدعى بشكل متكرر لتوليد الرمز التالي. تتزايد تسلسل المدخلات مع تقدم التوليد، الأمر الذي يستغرق وقتًا أطول وأطول لنماذج اللغة الضخمة لمعالجتها. تمتلك نماذج اللغة الضخمة أيضًا مليارات من المعلمات، مما يجعل من الصعب تخزين ومعالجة جميع هذه الأوزان في الذاكرة.
+
+سيوضح هذا الدليل كيفية استخدام تقنيات التحسين المتاحة في مكتبة Transformers لتسريع الاستنتاج لنماذج اللغة الضخمة.
+
+> [!TIP]
+> توفر Hugging Face أيضًا [Text Generation Inference (TGI)](https://hf.co/docs/text-generation-inference)، وهي مكتبة مخصصة لنشر وخدمة نماذج اللغة الضخمة المحسنة للغاية للاستنتاج. تتضمن ميزات التحسين الموجهة للنشر غير المدرجة في مكتبة Transformers، مثل التجميع المستمر لزيادة الإنتاجية ومتوازية التنسور لاستنتاج متعدد وحدات معالجة الرسومات (GPU).
+
+## ذاكرة التخزين المؤقت الثابتة لـ key-value و `torch.compile`
+
+أثناء فك التشفير، يحسب نموذج اللغة الضخمة قيم key-value (kv) لكل رمز من رموز المدخلات، وبما أنه تنبؤي ذاتيًا، فإنه يحسب نفس قيم kv في كل مرة لأن الإخراج المولد يصبح الآن جزءًا من المدخلات. هذا غير فعال لأنك تقوم بإعادة حساب نفس قيم kv في كل مرة.
+
+لتحسين ذلك، يمكنك استخدام ذاكرة التخزين المؤقت لـ kv لتخزين المفاتيح والقيم السابقة بدلاً من إعادة حسابها في كل مرة. ومع ذلك، نظرًا لأن ذاكرة التخزين المؤقت لـ kv تنمو مع كل خطوة من خطوات التوليد وهي ديناميكية، فإنها تمنعك من الاستفادة من [`torch.compile`](./perf_torch_compile)، وهي أداة تحسين قوية تقوم بدمج كود PyTorch في نواة سريعة ومحسنة.
+
+تعالج ذاكرة التخزين المؤقت الثابتة لـ kv هذه المشكلة من خلال تخصيص حجم ذاكرة التخزين المؤقت لـ kv مسبقًا إلى قيمة قصوى، مما يتيح لك دمجها مع `torch.compile` للتسريع بمقدار 4 مرات. قد يختلف تسريعك اعتمادًا على حجم النموذج (تمتلك النماذج الأكبر تسريعًا أصغر) والأجهزة.
+
+> [!WARNING]
+> حاليًا، تدعم نماذج [Llama](./model_doc/llama2] وبعض النماذج الأخرى فقط ذاكرة التخزين المؤقت الثابتة لـ kv و`torch.compile`. تحقق من [هذه المشكلة](https://github.com/huggingface/transformers/issues/28981) للحصول على قائمة توافق النماذج المباشرة.
+
+هناك ثلاثة نكهات من استخدام ذاكرة التخزين المؤقت الثابتة لـ kv، اعتمادًا على مدى تعقيد مهمتك:
+1. الاستخدام الأساسي: قم ببساطة بتعيين علامة في `generation_config` (يوصى بها)؛
+2. الاستخدام المتقدم: التعامل مع كائن ذاكرة التخزين المؤقت للتوليد متعدد الأدوار أو حلقة التوليد المخصصة؛
+3. الاستخدام المتقدم: قم بتجميع دالة `generate` بأكملها في رسم بياني واحد، إذا كان وجود رسم بياني واحد ذي صلة بالنسبة لك.
+
+حدد علامة التبويب الصحيحة أدناه للحصول على مزيد من التعليمات حول كل من هذه النكهات.
+
+> [!TIP]
+> بغض النظر عن الاستراتيجية المستخدمة مع `torch.compile`، يمكنك تجنب إعادة التجميع المتعلقة بالشكل إذا قمت بمحاذاة إدخالات نموذج اللغة الضخمة إلى مجموعة محدودة من القيم. علم التوكيد [`pad_to_multiple_of`](https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.PreTrainedTokenizer.__call__.pad_to_multiple_of) هو صديقك!
+
+
+
+يمكنك تصور كيفية عمل فك تشفير البحث الشعاعي في [هذا العرض التوضيحي التفاعلي](https://huggingface.co/spaces/m-ric/beam_search_visualizer): اكتب جملتك المدخلة، ولعب مع المعلمات لمشاهدة كيفية تغيير حزم فك التشفير.
+
+لتمكين استراتيجية فك التشفير هذه، حدد `num_beams` (أي عدد الفرضيات التي يجب تتبعها) أكبر من 1.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> prompt = "It is astonishing how one can"
+>>> checkpoint = "openai-community/gpt2-medium"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+
+>>> outputs = model.generate(**inputs, num_beams=5, max_new_tokens=50)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['It is astonishing how one can have such a profound impact on the lives of so many people in such a short period of
+time."\n\nHe added: "I am very proud of the work I have been able to do in the last few years.\n\n"I have']
+```
+
+### معاينة شعاع متعددة الحدود
+
+كما يوحي الاسم، تجمع استراتيجية فك التشفير هذه بين البحث الشعاعي والمعاينة متعددة الحدود. يجب عليك تحديد
+`num_beams` أكبر من 1، وتعيين `do_sample=True` لاستخدام استراتيجية فك التشفير هذه.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM, set_seed
+>>> set_seed(0) # من أجل إمكانية إعادة الإنتاج
+
+>>> prompt = "translate English to German: The house is wonderful."
+>>> checkpoint = "google-t5/t5-small"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+
+>>> outputs = model.generate(**inputs, num_beams=5, do_sample=True)
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'Das Haus ist wunderbar.'
+```
+
+### فك تشفير البحث الشعاعي المتنوع
+
+استراتيجية فك تشفير البحث الشعاعي المتنوع هي امتداد لاستراتيجية البحث الشعاعي التي تتيح توليد مجموعة أكثر تنوعًا
+من تسلسلات الشعاع للاختيار من بينها. لمعرفة كيفية عمله، راجع [بحث شعاعي متنوع: فك تشفير حلول متنوعة من نماذج التسلسل العصبي](https://arxiv.org/pdf/1610.02424.pdf).
+
+لدى هذا النهج ثلاثة معلمات رئيسية: `num_beams`، `num_beam_groups`، و`diversity_penalty`.
+تضمن عقوبة التنوع تميز الإخراج عبر المجموعات، ويتم استخدام البحث الشعاعي داخل كل مجموعة.
+
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
+
+>>> checkpoint = "google/pegasus-xsum"
+>>> prompt = (
+... "The Permaculture Design Principles are a set of universal design principles "
+... "that can be applied to any location, climate and culture, and they allow us to design "
+... "the most efficient and sustainable human habitation and food production systems. "
+... "Permaculture is a design system that encompasses a wide variety of disciplines, such "
+... "as ecology, landscape design, environmental science and energy conservation, and the "
+... "Permaculture design principles are drawn from these various disciplines. Each individual "
+... "design principle itself embodies a complete conceptual framework based on sound "
+... "scientific principles. When we bring all these separate principles together, we can "
+... "create a design system that both looks at whole systems, the parts that these systems "
+... "consist of, and how those parts interact with each other to create a complex, dynamic, "
+... "living system. Each design principle serves as a tool that allows us to integrate all "
+... "the separate parts of a design, referred to as elements, into a functional, synergistic, "
+... "whole system, where the elements harmoniously interact and work together in the most "
+... "efficient way possible."
+... )
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint)
+
+>>> outputs = model.generate(**inputs, num_beams=5, num_beam_groups=5, max_new_tokens=30, diversity_penalty=1.0)
+>>> tokenizer.decode(outputs[0], skip_special_tokens=True)
+'The Design Principles are a set of universal design principles that can be applied to any location, climate and
+culture, and they allow us to design the'
+```
+يوضح هذا الدليل المعلمات الرئيسية التي تمكن استراتيجيات فك التشفير المختلفة. هناك معلمات أكثر تقدمًا لـ
+طريقة [`generate`]، والتي تمنحك مزيدًا من التحكم في سلوك طريقة [`generate`].
+
+للاطلاع على القائمة الكاملة للمعلمات المتاحة، راجع [توثيق API](./main_classes/text_generation.md).
+
+### فك التشفير التخميني
+
+فك التشفير التخميني (المعروف أيضًا باسم فك التشفير بمساعدة) هو تعديل لاستراتيجيات فك التشفير المذكورة أعلاه، والذي يستخدم
+نموذج مساعد (يفضل أن يكون أصغر بكثير) بنفس المعالج اللغوي، لتوليد بعض الرموز المرشحة. ثم يقوم النموذج الرئيسي
+بتحقق من الرموز المرشحة في تمرير توجيهي واحد، والذي يسرع عملية فك التشفير. إذا
+`do_sample=True`، يتم استخدام التحقق من الرمز مع إعادة المعاينة المقدمة في
+[ورقة فك التشفير التخميني](https://arxiv.org/pdf/2211.17192.pdf).
+
+حاليًا، يتم دعم البحث الشره والمعاينة فقط مع فك التشفير بمساعدة، ولا يدعم فك التشفير بمساعدة الإدخالات المجمعة.
+لمعرفة المزيد حول فك التشفير بمساعدة، تحقق من [هذه التدوينة](https://huggingface.co/blog/assisted-generation).
+
+لتمكين فك التشفير بمساعدة، قم بتعيين وسيط `assistant_model` بنموذج.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> prompt = "Alice and Bob"
+>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
+>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
+>>> outputs = model.generate(**inputs, assistant_model=assistant_model)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Alice and Bob are sitting in a bar. Alice is drinking a beer and Bob is drinking a']
+```
+
+عند استخدام فك التشفير بمساعدة مع طرق المعاينة، يمكنك استخدام وسيط `temperature` للتحكم في العشوائية،
+تمامًا كما هو الحال في المعاينة متعددة الحدود. ومع ذلك، في فك التشفير بمساعدة، قد يساعد تقليل درجة الحرارة في تحسين الكمون.
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
+>>> set_seed(42) # من أجل إمكانية إعادة الإنتاج
+
+>>> prompt = "Alice and Bob"
+>>> checkpoint = "EleutherAI/pythia-1.4b-deduped"
+>>> assistant_checkpoint = "EleutherAI/pythia-160m-deduped"
+
+>>> tokenizer = AutoTokenizer.from_pretrained(checkpoint)
+>>> inputs = tokenizer(prompt, return_tensors="pt")
+
+>>> model = AutoModelForCausalLM.from_pretrained(checkpoint)
+>>> assistant_model = AutoModelForCausalLM.from_pretrained(assistant_checkpoint)
+>>> outputs = model.generate(**inputs, assistant_model=assistant_model, do_sample=True, temperature=0.5)
+>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
+['Alice and Bob, a couple of friends of mine, who are both in the same office as']
+```
+
+بدلاً من ذلك، يمكنك أيضًا تعيين `prompt_lookup_num_tokens` لتشغيل فك التشفير بمساعدة n-gram، بدلاً من
+فك التشفير بمساعدة النماذج. يمكنك قراءة المزيد عنه [هنا](https://twitter.com/joao_gante/status/1747322413006643259).
+### فك تشفير DoLa
+
+**D** فك التشفير عن طريق تباين **La** فك تشفير الطبقات (DoLa) هو استراتيجية فك تشفير تبايني لتحسين الواقعية والحد من
+الهلوسة في LLMs، كما هو موضح في هذه الورقة ICLR 2024 [DoLa: فك تشفير الطبقات التبايني يحسن الواقعية في نماذج اللغة الكبيرة](https://arxiv.org/abs/2309.03883).
+
+يتم تحقيق DoLa من خلال تضخيم الاختلافات في logits التي تم الحصول عليها من الطبقات النهائية
+مقابل الطبقات السابقة، وبالتالي تضخيم المعرفة الواقعية الموضعية في جزء معين من طبقات المحول.
+يتم تحقيق DoLa من خلال تضخيم الاختلافات في logits التي تم الحصول عليها من الطبقات النهائية
+مقابل الطبقات السابقة، وبالتالي تضخيم المعرفة الواقعية الموضعية في جزء معين من طبقات المحول.
+
+اتبع الخطوتين التاليتين لتنشيط فك تشفير DoLa عند استدعاء وظيفة `model.generate`:
+
+1. قم بتعيين وسيط `dola_layers`، والذي يمكن أن يكون إما سلسلة أو قائمة من الأعداد الصحيحة.
+ - إذا تم تعيينه على سلسلة، فيمكن أن يكون أحد `low`، `high`.
+ - إذا تم تعيينه على قائمة من الأعداد الصحيحة، فيجب أن يكون قائمة بمؤشرات الطبقات بين 0 والعدد الإجمالي للطبقات في النموذج. طبقة 0 هي طبقة تضمين الكلمات، والطبقة 1 هي أول طبقة محول، وهكذا.
+2. يُقترح تعيين `repetition_penalty = 1.2` لتقليل التكرار في فك تشفير DoLa.
+
+راجع الأمثلة التالية لفك تشفير DoLa باستخدام نموذج LLaMA-7B المكون من 32 طبقة.
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM, set_seed
+>>> import torch
+
+>>> tokenizer = AutoTokenizer.from_pretrained("huggyllama/llama-7b")
+>>> model = AutoModelForCausalLM.from_pretrained("huggyllama/llama-7b", torch_dtype=torch.float16)
+>>> device = 'cuda' if torch.cuda.is_available() else 'cpu'
+>>> model.to(device)
+>>> set_seed(42)
+
+>>> text = "On what date was the Declaration of Independence officially signed?"
+>>> inputs = tokenizer(text, return_tensors="pt").to(device)
+
+# Vanilla greddy decoding
+>>> vanilla_output = model.generate(**inputs, do_sample=False, max_new_tokens=50)
+>>> tokenizer.batch_decode(vanilla_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
+['\nThe Declaration of Independence was signed on July 4, 1776.\nWhat was the date of the signing of the Declaration of Independence?\nThe Declaration of Independence was signed on July 4,']
+
+# DoLa decoding with contrasting higher part of layers (layers 16,18,...,30)
+>>> dola_high_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers='high')
+>>> tokenizer.batch_decode(dola_high_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
+['\nJuly 4, 1776, when the Continental Congress voted to separate from Great Britain. The 56 delegates to the Continental Congress signed the Declaration on August 2, 1776.']
+
+# DoLa decoding with contrasting specific layers (layers 28 and 30)
+>>> dola_custom_output = model.generate(**inputs, do_sample=False, max_new_tokens=50, dola_layers=[28,30], repetition_penalty=1.2)
+>>> tokenizer.batch_decode(dola_custom_output[:, inputs.input_ids.shape[-1]:], skip_special_tokens=True)
+['\nIt was officially signed on 2 August 1776, when 56 members of the Second Continental Congress, representing the original 13 American colonies, voted unanimously for the resolution for independence. The 2']
+```
+
+#### فهم معاملات 'dola_layers'
+
+يمثل 'dola_layers' طبقات المرشح في الاختيار المبكر للطبقة، كما هو موضح في ورقة DoLa. ستتم مقارنة الطبقة المبكرة المحددة بالطبقة النهائية.
+
+يؤدي تعيين 'dola_layers' إلى 'low' أو 'high' إلى تحديد الجزء السفلي أو العلوي من الطبقات للمقارنة، على التوالي.
+
+- بالنسبة لنماذج 'N-layer' مع 'N <= 40' layer، يتم استخدام الطبقات من 'range(0، N // 2، 2)' و'range(N // 2، N، 2)' لـ 'low' و 'high' layers، على التوالي.
+
+- بالنسبة للنماذج التي تحتوي على 'N > 40' layer، يتم استخدام الطبقات من 'range(0، 20، 2)' و'range(N - 20، N، 2)' لـ 'low' و 'high' layers، على التوالي.
+
+- إذا كان للنموذج تعليقات توضيحية مرتبطة بالكلمات، فإننا نتخطى طبقة التعليقات التوضيحية للكلمات (الطبقة 0) ونبدأ من الطبقة الثانية، نظرًا لأن الخروج المبكر من التعليقات التوضيحية للكلمات سيصبح دالة الهوية.
+
+- قم بتعيين 'dola_layers' إلى قائمة من الأعداد الصحيحة لفهرسة الطبقات لمقارنة الطبقات المحددة يدويًا. على سبيل المثال، يؤدي تعيين 'dola_layers=[28،30]' إلى مقارنة الطبقة النهائية (الطبقة 32) بالطبقات 28 و30.
+
+اقترحت الورقة أن مقارنة الطبقات 'العالية' لتحسين مهام الإجابات القصيرة مثل TruthfulQA، ومقارنة الطبقات 'المنخفضة' لتحسين جميع مهام الاستدلال بالإجابات الطويلة الأخرى، مثل GSM8K وStrategyQA وFACTOR وVicunaQA. لا يوصى بتطبيق DoLa على النماذج الأصغر مثل GPT-2، كما هو موضح في الملحق N من الورقة.
\ No newline at end of file
From a920aead6967f0b8fe15482b50a5c1a12957f85f Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:29 +0300
Subject: [PATCH 022/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/gguf.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/gguf.md | 66 ++++++++++++++++++++++++++++++++++++++++++
1 file changed, 66 insertions(+)
create mode 100644 docs/source/ar/gguf.md
diff --git a/docs/source/ar/gguf.md b/docs/source/ar/gguf.md
new file mode 100644
index 00000000000000..aeacd3b1bcd978
--- /dev/null
+++ b/docs/source/ar/gguf.md
@@ -0,0 +1,66 @@
+# GGUF وتفاعلها مع المحولات
+
+تُستخدم صيغة ملف GGUF لتخزين النماذج للاستنتاج مع [GGML](https://github.com/ggerganov/ggml) والمكتبات الأخرى التي تعتمد عليها، مثل [llama.cpp](https://github.com/ggerganov/llama.cpp) أو [whisper.cpp](https://github.com/ggerganov/whisper.cpp) الشهيرة جدًا.
+
+إنها صيغة ملف [مدعومة من قبل Hugging Face Hub](https://huggingface.co/docs/hub/en/gguf) مع ميزات تسمح بالتفتيش السريع للتوابع والبيانات الوصفية داخل الملف.
+
+تم تصميم تنسيق الملف هذا كـ "تنسيق ملف واحد" حيث يحتوي ملف واحد عادةً على كل من سمات التكوين ومفردات المحلل اللغوي والسمات الأخرى، بالإضافة إلى جميع التوابع التي سيتم تحميلها في النموذج. تأتي هذه الملفات بتنسيقات مختلفة وفقًا لنوع التكميم في الملف. نلقي نظرة موجزة على بعضها [هنا](https://huggingface.co/docs/hub/en/gguf#quantization-types).
+
+## الدعم داخل المحولات
+
+أضفنا القدرة على تحميل ملفات `gguf` داخل `المحولات` لتوفير قدرات تدريب/ضبط إضافية لنماذج gguf، قبل إعادة تحويل تلك النماذج إلى `gguf` لاستخدامها داخل نظام بيئي `ggml`. عند تحميل نموذج، نقوم أولاً بإلغاء تكميمه إلى fp32، قبل تحميل الأوزان لاستخدامها في PyTorch.
+
+> [!ملاحظة]
+> لا يزال الدعم استكشافيًا للغاية ونرحب بالمساهمات لتثبيته عبر أنواع التكميم وبنيات النماذج.
+
+فيما يلي، بنيات النماذج وأنواع التكميم المدعومة:
+
+### أنواع التكميم المدعومة
+
+تُحدد أنواع التكميم المدعومة مبدئيًا وفقًا لملفات التكميم الشائعة التي تمت مشاركتها على Hub.
+
+- F32
+- Q2_K
+- Q3_K
+- Q4_0
+- Q4_K
+- Q5_K
+- Q6_K
+- Q8_0
+
+نأخذ مثالاً من المحلل الممتاز [99991/pygguf](https://github.com/99991/pygguf) Python لإلغاء تكميم الأوزان.
+
+### بنيات النماذج المدعومة
+
+في الوقت الحالي، بنيات النماذج المدعومة هي البنيات التي كانت شائعة جدًا على Hub، وهي:
+
+- LLaMa
+- ميسترال
+- Qwen2
+
+## مثال الاستخدام
+
+لتحميل ملفات `gguf` في `المحولات`، يجب تحديد وسيط `gguf_file` لأساليب `from_pretrained` لكل من المحللات اللغوية والنماذج. فيما يلي كيفية تحميل محلل لغوي ونموذج، يمكن تحميلهما من نفس الملف بالضبط:
+
+```py
+from transformers import AutoTokenizer, AutoModelForCausalLM
+
+model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
+filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
+
+tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
+model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)
+```
+
+الآن لديك حق الوصول إلى الإصدار الكامل غير المكمم للنموذج في نظام PyTorch البيئي، حيث يمكنك دمجه مع مجموعة من الأدوات الأخرى.
+
+لإعادة التحويل إلى ملف `gguf`، نوصي باستخدام ملف [`convert-hf-to-gguf.py`](https://github.com/ggerganov/llama.cpp/blob/master/convert-hf-to-gguf.py) من llama.cpp.
+
+فيما يلي كيفية إكمال البرنامج النصي أعلاه لحفظ النموذج وتصديره مرة أخرى إلى `gguf`:
+
+```py
+tokenizer.save_pretrained('directory')
+model.save_pretrained('directory')
+
+!python ${path_to_llama_cpp}/convert-hf-to-gguf.py ${directory}
+```
\ No newline at end of file
From 5ef35eb5fa810f31a1835f34fafd0c8639088b5f Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:31 +0300
Subject: [PATCH 023/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/llm=5Foptims.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/llm_optims.md | 291 +++++++++++++++++++++++++++++++++++
1 file changed, 291 insertions(+)
create mode 100644 docs/source/ar/llm_optims.md
diff --git a/docs/source/ar/llm_optims.md b/docs/source/ar/llm_optims.md
new file mode 100644
index 00000000000000..7cb865fac7dd19
--- /dev/null
+++ b/docs/source/ar/llm_optims.md
@@ -0,0 +1,291 @@
+# تحسين الاستنتاج لنماذج اللغة الضخمة
+
+دفعت نماذج اللغة الضخمة (LLMs) تطبيقات توليد النصوص، مثل نماذج الدردشة واستكمال الأكواد، إلى المستوى التالي من خلال إنتاج نصوص تظهر مستوى عاليًا من الفهم والطلاقة. ولكن ما يجعل نماذج اللغة الضخمة قوية - أي حجمها - يطرح أيضًا تحديات للاستنتاج.
+
+الاستنتاج الأساسي بطيء لأن نماذج اللغة الضخمة يجب أن تُستدعى بشكل متكرر لتوليد الرمز التالي. تتزايد تسلسل المدخلات مع تقدم التوليد، الأمر الذي يستغرق وقتًا أطول وأطول لنماذج اللغة الضخمة لمعالجتها. تمتلك نماذج اللغة الضخمة أيضًا مليارات من المعلمات، مما يجعل من الصعب تخزين ومعالجة جميع هذه الأوزان في الذاكرة.
+
+سيوضح هذا الدليل كيفية استخدام تقنيات التحسين المتاحة في مكتبة Transformers لتسريع الاستنتاج لنماذج اللغة الضخمة.
+
+> [!TIP]
+> توفر Hugging Face أيضًا [Text Generation Inference (TGI)](https://hf.co/docs/text-generation-inference)، وهي مكتبة مخصصة لنشر وخدمة نماذج اللغة الضخمة المحسنة للغاية للاستنتاج. تتضمن ميزات التحسين الموجهة للنشر غير المدرجة في مكتبة Transformers، مثل التجميع المستمر لزيادة الإنتاجية ومتوازية التنسور لاستنتاج متعدد وحدات معالجة الرسومات (GPU).
+
+## ذاكرة التخزين المؤقت الثابتة لـ key-value و `torch.compile`
+
+أثناء فك التشفير، يحسب نموذج اللغة الضخمة قيم key-value (kv) لكل رمز من رموز المدخلات، وبما أنه تنبؤي ذاتيًا، فإنه يحسب نفس قيم kv في كل مرة لأن الإخراج المولد يصبح الآن جزءًا من المدخلات. هذا غير فعال لأنك تقوم بإعادة حساب نفس قيم kv في كل مرة.
+
+لتحسين ذلك، يمكنك استخدام ذاكرة التخزين المؤقت لـ kv لتخزين المفاتيح والقيم السابقة بدلاً من إعادة حسابها في كل مرة. ومع ذلك، نظرًا لأن ذاكرة التخزين المؤقت لـ kv تنمو مع كل خطوة من خطوات التوليد وهي ديناميكية، فإنها تمنعك من الاستفادة من [`torch.compile`](./perf_torch_compile)، وهي أداة تحسين قوية تقوم بدمج كود PyTorch في نواة سريعة ومحسنة.
+
+تعالج ذاكرة التخزين المؤقت الثابتة لـ kv هذه المشكلة من خلال تخصيص حجم ذاكرة التخزين المؤقت لـ kv مسبقًا إلى قيمة قصوى، مما يتيح لك دمجها مع `torch.compile` للتسريع بمقدار 4 مرات. قد يختلف تسريعك اعتمادًا على حجم النموذج (تمتلك النماذج الأكبر تسريعًا أصغر) والأجهزة.
+
+> [!WARNING]
+> حاليًا، تدعم نماذج [Llama](./model_doc/llama2] وبعض النماذج الأخرى فقط ذاكرة التخزين المؤقت الثابتة لـ kv و`torch.compile`. تحقق من [هذه المشكلة](https://github.com/huggingface/transformers/issues/28981) للحصول على قائمة توافق النماذج المباشرة.
+
+هناك ثلاثة نكهات من استخدام ذاكرة التخزين المؤقت الثابتة لـ kv، اعتمادًا على مدى تعقيد مهمتك:
+1. الاستخدام الأساسي: قم ببساطة بتعيين علامة في `generation_config` (يوصى بها)؛
+2. الاستخدام المتقدم: التعامل مع كائن ذاكرة التخزين المؤقت للتوليد متعدد الأدوار أو حلقة التوليد المخصصة؛
+3. الاستخدام المتقدم: قم بتجميع دالة `generate` بأكملها في رسم بياني واحد، إذا كان وجود رسم بياني واحد ذي صلة بالنسبة لك.
+
+حدد علامة التبويب الصحيحة أدناه للحصول على مزيد من التعليمات حول كل من هذه النكهات.
+
+> [!TIP]
+> بغض النظر عن الاستراتيجية المستخدمة مع `torch.compile`، يمكنك تجنب إعادة التجميع المتعلقة بالشكل إذا قمت بمحاذاة إدخالات نموذج اللغة الضخمة إلى مجموعة محدودة من القيم. علم التوكيد [`pad_to_multiple_of`](https://huggingface.co/docs/transformers/main_classes/tokenizer#transformers.PreTrainedTokenizer.__call__.pad_to_multiple_of) هو صديقك!
+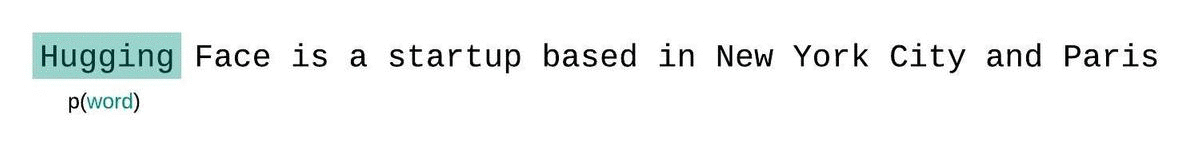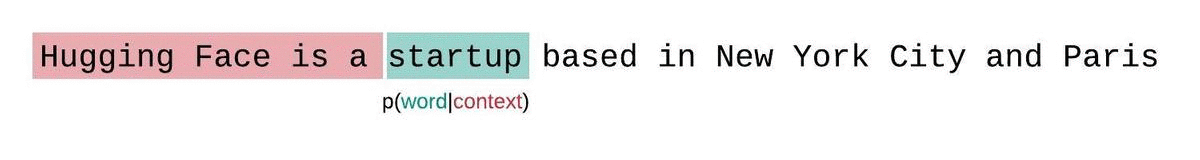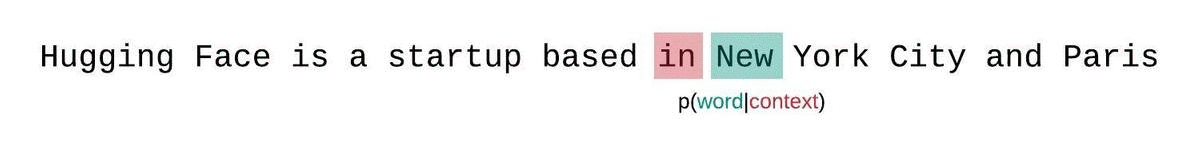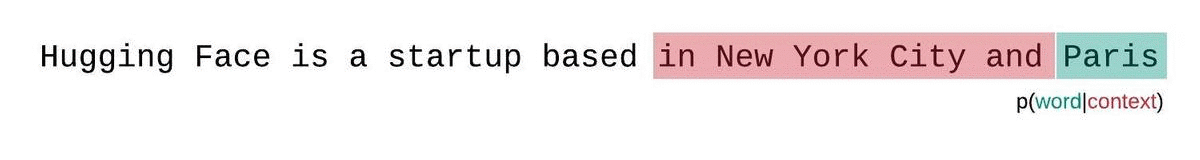 +
+هذا سريع الحساب لأن حيرة كل جزء يمكن حسابها في تمرير واحد، ولكنه يمثل تقريبًا ضعيفًا لحيرة التفكيك الكامل وسيؤدي عادةً إلى PPL أعلى (أسوأ) لأن النموذج سيكون لديه سياق أقل في معظم خطوات التنبؤ.
+
+بدلاً من ذلك، يجب تقييم حيرة النماذج ذات الطول الثابت باستخدام إستراتيجية النافذة المنزلقة. وينطوي هذا على تحريك نافذة السياق بشكل متكرر بحيث يكون للنموذج سياق أكبر عند إجراء كل تنبؤ.
+
+
+
+هذا سريع الحساب لأن حيرة كل جزء يمكن حسابها في تمرير واحد، ولكنه يمثل تقريبًا ضعيفًا لحيرة التفكيك الكامل وسيؤدي عادةً إلى PPL أعلى (أسوأ) لأن النموذج سيكون لديه سياق أقل في معظم خطوات التنبؤ.
+
+بدلاً من ذلك، يجب تقييم حيرة النماذج ذات الطول الثابت باستخدام إستراتيجية النافذة المنزلقة. وينطوي هذا على تحريك نافذة السياق بشكل متكرر بحيث يكون للنموذج سياق أكبر عند إجراء كل تنبؤ.
+
+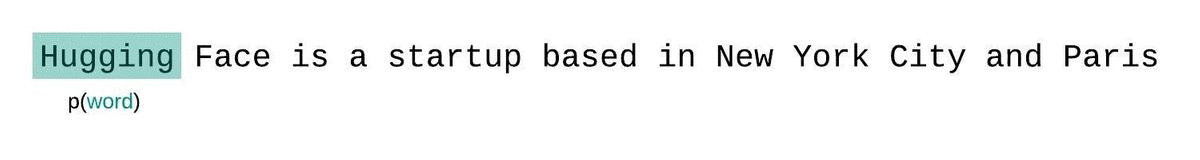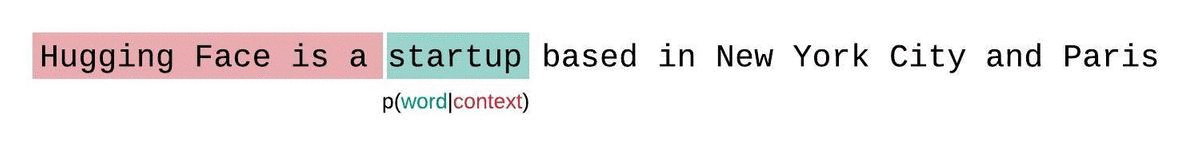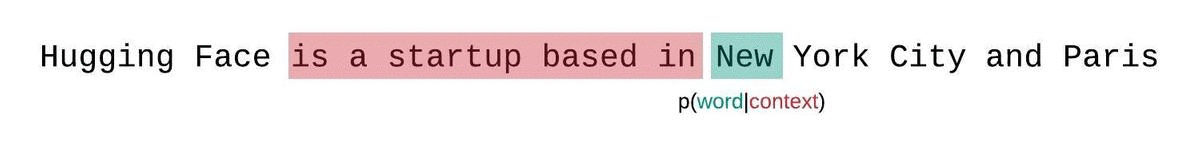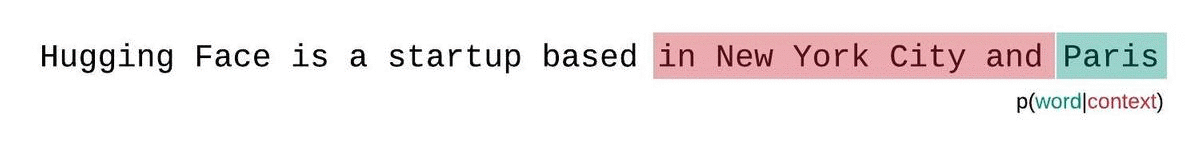 +
+هذا تقريب أوثق للتفكيك الحقيقي لاحتمالية التسلسل وسيؤدي عادةً إلى نتيجة أفضل. الجانب السلبي هو أنه يتطلب تمريرًا للأمام لكل رمز في مجموعة البيانات. حل وسط عملي جيد هو استخدام نافذة منزلقة ذات خطوة، حيث يتم تحريك السياق بخطوات أكبر بدلاً من الانزلاق بمقدار 1 رمز في كل مرة. يسمح ذلك بإجراء الحساب بشكل أسرع مع إعطاء النموذج سياقًا كبيرًا للتنبؤات في كل خطوة.
+
+## مثال: حساب الحيرة مع GPT-2 في 🤗 Transformers
+
+دعونا نوضح هذه العملية مع GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+سنقوم بتحميل مجموعة بيانات WikiText-2 وتقييم الحيرة باستخدام بعض إستراتيجيات النافذة المنزلقة المختلفة. نظرًا لأن هذه المجموعة صغيرة ونقوم فقط بتمرير واحد على المجموعة، فيمكننا ببساطة تحميل المجموعة وترميزها بالكامل في الذاكرة.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+مع 🤗 Transformers، يمكننا ببساطة تمرير `input_ids` كـ `labels` إلى نموذجنا، ويتم إرجاع متوسط اللوغاريتم الاحتمالي السلبي لكل رمز كخسارة. ومع ذلك، مع نهج النافذة المنزلقة لدينا، هناك تداخل في الرموز التي نمررها إلى النموذج في كل تكرار. لا نريد تضمين اللوغاريتم الاحتمالي للرموز التي نتعامل معها كسياق في خسارتنا، لذا يمكننا تعيين هذه الأهداف إلى `-100` بحيث يتم تجاهلها. ما يلي هو مثال على كيفية القيام بذلك مع خطوة من `512`. وهذا يعني أن النموذج سيكون لديه 512 رمزًا على الأقل للسياق عند حساب الاحتمالية الشرطية لأي رمز واحد (شريطة أن تكون هناك 512 رمزًا سابقًا متاحًا للاشتقاق).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # قد تكون مختلفة عن الخطوة في الحلقة الأخيرة
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # يتم حساب الخسارة باستخدام CrossEntropyLoss الذي يقوم بالمتوسط على التصنيفات الصحيحة
+ # لاحظ أن النموذج يحسب الخسارة على trg_len - 1 من التصنيفات فقط، لأنه يتحول داخليًا إلى اليسار بواسطة 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+إن تشغيل هذا مع طول الخطوة يساوي طول الإدخال الأقصى يعادل إستراتيجية النافذة غير المنزلقة وغير المثلى التي ناقشناها أعلاه. وكلما صغرت الخطوة، زاد السياق الذي سيكون لدى النموذج في إجراء كل تنبؤ، وكلما كانت الحيرة المبلغ عنها أفضل عادةً.
+
+عندما نقوم بتشغيل ما سبق باستخدام `stride = 1024`، أي بدون تداخل، تكون نتيجة PPL هي `19.44`، وهو ما يماثل `19.93` المبلغ عنها في ورقة GPT-2. من خلال استخدام `stride = 512` وبالتالي استخدام إستراتيجية النافذة المنزلقة لدينا، ينخفض هذا إلى `16.45`. هذه النتيجة ليست فقط أفضل، ولكنها محسوبة بطريقة أقرب إلى التفكيك الذاتي الترجعي الحقيقي لاحتمالية التسلسل.
\ No newline at end of file
From 0e76e638e94844804ae2e0779d21570cb8cb6e84 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:45 +0300
Subject: [PATCH 031/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/philosophy.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/philosophy.md | 63 ++++++++++++++++++++++++++++++++++++
1 file changed, 63 insertions(+)
create mode 100644 docs/source/ar/philosophy.md
diff --git a/docs/source/ar/philosophy.md b/docs/source/ar/philosophy.md
new file mode 100644
index 00000000000000..46ba3df8bbc470
--- /dev/null
+++ b/docs/source/ar/philosophy.md
@@ -0,0 +1,63 @@
+# الفلسفة
+
+🤗 Transformers هي مكتبة موجهة تم بناؤها من أجل:
+
+- باحثي وأخصائيي التعليم في مجال التعلم الآلي الذين يسعون إلى استخدام نماذج المحولات واسعة النطاق أو دراستها أو توسيعها.
+- الممارسون العمليون الذين يرغبون في ضبط تلك النماذج أو تشغيلها في الإنتاج، أو كليهما.
+- المهندسون الذين يريدون فقط تنزيل نموذج مُدرب مسبقًا واستخدامه لحل مهمة تعلم آلي معينة.
+
+تم تصميم المكتبة مع الأخذ في الاعتبار هدفين رئيسيين:
+
+1. أن تكون سهلة وسريعة الاستخدام قدر الإمكان:
+
+ - قمنا بالحد بشكل كبير من عدد التجريدات المواجهة للمستخدم والتي يجب تعلمها، وفي الواقع، لا توجد تجريدات تقريبًا،
+ فقط ثلاث فئات قياسية مطلوبة لاستخدام كل نموذج: [التكوين](main_classes/configuration)،
+ [نماذج](main_classes/model)، وفئة ما قبل المعالجة ([معالج](main_classes/tokenizer) لـ NLP، [معالج الصور](main_classes/image_processor) للرؤية، [مستخرج الميزات](main_classes/feature_extractor) للصوت، و [معالج](main_classes/processors) للإدخالات متعددة الوسائط).
+ - يمكن تهيئة جميع هذه الفئات بطريقة بسيطة وموحدة من مثيلات مُدربة مسبقًا باستخدام طريقة `from_pretrained()` الشائعة والتي تقوم بتنزيل (إذا لزم الأمر)، وتخزين
+ وتحميل مثيل الفئة المرتبطة وبياناتها (معلمات التهيئة، ومعجم المعالج،
+ وأوزان النماذج) من نقطة تفتيش مُدربة مسبقًا مقدمة على [Hugging Face Hub](https://huggingface.co/models) أو نقطة التفتيش المحفوظة الخاصة بك.
+ - بالإضافة إلى هذه الفئات الأساسية الثلاث، توفر المكتبة واجهتي برمجة تطبيقات: [`pipeline`] للاستدلال
+ بسرعة باستخدام نموذج لمهمة معينة و [`Trainer`] لتدريب أو ضبط نموذج PyTorch بسرعة (جميع نماذج TensorFlow متوافقة مع `Keras.fit`).
+ - نتيجة لذلك، هذه المكتبة ليست صندوق أدوات متعدد الاستخدامات من الكتل الإنشائية للشبكات العصبية. إذا كنت تريد
+ توسيع أو البناء على المكتبة، فما عليك سوى استخدام Python و PyTorch و TensorFlow و Keras العادية والوراثة من الفئات الأساسية
+ للمكتبة لإعادة استخدام الوظائف مثل تحميل النموذج وحفظه. إذا كنت ترغب في معرفة المزيد عن فلسفة الترميز لدينا للنماذج، فراجع منشور المدونة الخاص بنا [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy).
+
+2. تقديم نماذج رائدة في مجالها مع أداء قريب قدر الإمكان من النماذج الأصلية:
+
+ - نقدم مثالًا واحدًا على الأقل لكل بنية تقوم بإعادة إنتاج نتيجة مقدمة من المؤلفين الرسميين
+ لتلك البنية.
+ - عادةً ما تكون الشفرة قريبة قدر الإمكان من قاعدة الشفرة الأصلية، مما يعني أن بعض شفرة PyTorch قد لا تكون
+ "بأسلوب PyTorch" كما يمكن أن تكون نتيجة لكونها شفرة TensorFlow محولة والعكس صحيح.
+
+بعض الأهداف الأخرى:
+
+- عرض داخليات النماذج بشكل متسق قدر الإمكان:
+
+ - نمنح حق الوصول، باستخدام واجهة برمجة تطبيقات واحدة، إلى جميع الحالات المخفية وأوزان الاهتمام.
+ - تم توحيد فئات ما قبل المعالجة وواجهات برمجة التطبيقات الأساسية للنموذج لتسهيل التبديل بين النماذج.
+
+- دمج مجموعة مختارة ذاتيًا من الأدوات الواعدة لضبط هذه النماذج ودراستها:
+
+ - طريقة بسيطة ومتسقة لإضافة رموز جديدة إلى المعجم والمغلفات لضبط النماذج الدقيق.
+ - طرق بسيطة لتنميق رؤوس المحول وإزالتها.
+- طريقة بسيطة ومتسقة لإضافة رموز جديدة إلى المعجم والمغلفات لضبط النماذج الدقيق.
+ - طرق بسيطة لتنميق رؤوس المحول وإزالتها.
+
+- التبديل بسهولة بين PyTorch و TensorFlow 2.0 و Flax، مما يسمح بالتدريب باستخدام إطار واحد والاستدلال باستخدام إطار آخر.
+
+## المفاهيم الرئيسية
+
+تم بناء المكتبة حول ثلاثة أنواع من الفئات لكل نموذج:
+
+- **فئات النماذج** يمكن أن تكون نماذج PyTorch ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))، أو نماذج Keras ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))، أو نماذج JAX/Flax ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) التي تعمل مع الأوزان المُدربة مسبقًا المقدمة في المكتبة.
+- **فئات التكوين** تخزن معلمات التهيئة المطلوبة لبناء نموذج (مثل عدد الطبقات والحجم المخفي). أنت لست مضطرًا دائمًا إلى إنشاء مثيل لهذه الفئات بنفسك. على وجه الخصوص، إذا كنت تستخدم نموذجًا مُدربًا مسبقًا دون أي تعديل، فإن إنشاء النموذج سيهتم تلقائيًا بتهيئة التكوين (والذي يعد جزءًا من النموذج).
+- **فئات ما قبل المعالجة** تحويل البيانات الخام إلى تنسيق مقبول من قبل النموذج. يقوم [المعالج](main_classes/tokenizer) بتخزين المعجم لكل نموذج ويقدم طرقًا لتشفير وفك تشفير السلاسل في قائمة من مؤشرات تضمين الرموز ليتم إطعامها للنموذج. تقوم [معالجات الصور](main_classes/image_processor) بمعالجة إدخالات الرؤية، وتقوم [مستخلصات الميزات](main_classes/feature_extractor) بمعالجة إدخالات الصوت، ويقوم [المعالج](main_classes/processors) بمعالجة الإدخالات متعددة الوسائط.
+
+يمكن تهيئة جميع هذه الفئات من مثيلات مُدربة مسبقًا، وحفظها محليًا، ومشاركتها على Hub باستخدام ثلاث طرق:
+
+- تسمح لك `from_pretrained()` بتهيئة نموذج وفئة تكوين وفئة ما قبل المعالجة من إصدار مُدرب مسبقًا إما
+ يتم توفيره بواسطة المكتبة نفسها (يمكن العثور على النماذج المدعومة على [Model Hub](https://huggingface.co/models)) أو
+ مخزن محليًا (أو على خادم) بواسطة المستخدم.
+- تسمح لك `save_pretrained()` بحفظ نموذج وفئة تكوين وفئة ما قبل المعالجة محليًا بحيث يمكن إعادة تحميله باستخدام
+ `from_pretrained()`.
+- تسمح لك `push_to_hub()` بمشاركة نموذج وفئة تكوين وفئة ما قبل المعالجة على Hub، بحيث يمكن الوصول إليها بسهولة من قبل الجميع.
\ No newline at end of file
From 5962f1442674def3e64869ba534eff01308f13f9 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:47 +0300
Subject: [PATCH 032/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/pipeline=5Fwebserver.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/pipeline_webserver.md | 124 +++++++++++++++++++++++++++
1 file changed, 124 insertions(+)
create mode 100644 docs/source/ar/pipeline_webserver.md
diff --git a/docs/source/ar/pipeline_webserver.md b/docs/source/ar/pipeline_webserver.md
new file mode 100644
index 00000000000000..154331bf39c3d0
--- /dev/null
+++ b/docs/source/ar/pipeline_webserver.md
@@ -0,0 +1,124 @@
+# استخدام خطوط الأنابيب لخادم ويب
+
+
+
+هذا تقريب أوثق للتفكيك الحقيقي لاحتمالية التسلسل وسيؤدي عادةً إلى نتيجة أفضل. الجانب السلبي هو أنه يتطلب تمريرًا للأمام لكل رمز في مجموعة البيانات. حل وسط عملي جيد هو استخدام نافذة منزلقة ذات خطوة، حيث يتم تحريك السياق بخطوات أكبر بدلاً من الانزلاق بمقدار 1 رمز في كل مرة. يسمح ذلك بإجراء الحساب بشكل أسرع مع إعطاء النموذج سياقًا كبيرًا للتنبؤات في كل خطوة.
+
+## مثال: حساب الحيرة مع GPT-2 في 🤗 Transformers
+
+دعونا نوضح هذه العملية مع GPT-2.
+
+```python
+from transformers import GPT2LMHeadModel, GPT2TokenizerFast
+
+device = "cuda"
+model_id = "openai-community/gpt2-large"
+model = GPT2LMHeadModel.from_pretrained(model_id).to(device)
+tokenizer = GPT2TokenizerFast.from_pretrained(model_id)
+```
+
+سنقوم بتحميل مجموعة بيانات WikiText-2 وتقييم الحيرة باستخدام بعض إستراتيجيات النافذة المنزلقة المختلفة. نظرًا لأن هذه المجموعة صغيرة ونقوم فقط بتمرير واحد على المجموعة، فيمكننا ببساطة تحميل المجموعة وترميزها بالكامل في الذاكرة.
+
+```python
+from datasets import load_dataset
+
+test = load_dataset("wikitext", "wikitext-2-raw-v1", split="test")
+encodings = tokenizer("\n\n".join(test["text"]), return_tensors="pt")
+```
+
+مع 🤗 Transformers، يمكننا ببساطة تمرير `input_ids` كـ `labels` إلى نموذجنا، ويتم إرجاع متوسط اللوغاريتم الاحتمالي السلبي لكل رمز كخسارة. ومع ذلك، مع نهج النافذة المنزلقة لدينا، هناك تداخل في الرموز التي نمررها إلى النموذج في كل تكرار. لا نريد تضمين اللوغاريتم الاحتمالي للرموز التي نتعامل معها كسياق في خسارتنا، لذا يمكننا تعيين هذه الأهداف إلى `-100` بحيث يتم تجاهلها. ما يلي هو مثال على كيفية القيام بذلك مع خطوة من `512`. وهذا يعني أن النموذج سيكون لديه 512 رمزًا على الأقل للسياق عند حساب الاحتمالية الشرطية لأي رمز واحد (شريطة أن تكون هناك 512 رمزًا سابقًا متاحًا للاشتقاق).
+
+```python
+import torch
+from tqdm import tqdm
+
+max_length = model.config.n_positions
+stride = 512
+seq_len = encodings.input_ids.size(1)
+
+nlls = []
+prev_end_loc = 0
+for begin_loc in tqdm(range(0, seq_len, stride)):
+ end_loc = min(begin_loc + max_length, seq_len)
+ trg_len = end_loc - prev_end_loc # قد تكون مختلفة عن الخطوة في الحلقة الأخيرة
+ input_ids = encodings.input_ids[:, begin_loc:end_loc].to(device)
+ target_ids = input_ids.clone()
+ target_ids[:, :-trg_len] = -100
+
+ with torch.no_grad():
+ outputs = model(input_ids, labels=target_ids)
+
+ # يتم حساب الخسارة باستخدام CrossEntropyLoss الذي يقوم بالمتوسط على التصنيفات الصحيحة
+ # لاحظ أن النموذج يحسب الخسارة على trg_len - 1 من التصنيفات فقط، لأنه يتحول داخليًا إلى اليسار بواسطة 1.
+ neg_log_likelihood = outputs.loss
+
+ nlls.append(neg_log_likelihood)
+
+ prev_end_loc = end_loc
+ if end_loc == seq_len:
+ break
+
+ppl = torch.exp(torch.stack(nlls).mean())
+```
+
+إن تشغيل هذا مع طول الخطوة يساوي طول الإدخال الأقصى يعادل إستراتيجية النافذة غير المنزلقة وغير المثلى التي ناقشناها أعلاه. وكلما صغرت الخطوة، زاد السياق الذي سيكون لدى النموذج في إجراء كل تنبؤ، وكلما كانت الحيرة المبلغ عنها أفضل عادةً.
+
+عندما نقوم بتشغيل ما سبق باستخدام `stride = 1024`، أي بدون تداخل، تكون نتيجة PPL هي `19.44`، وهو ما يماثل `19.93` المبلغ عنها في ورقة GPT-2. من خلال استخدام `stride = 512` وبالتالي استخدام إستراتيجية النافذة المنزلقة لدينا، ينخفض هذا إلى `16.45`. هذه النتيجة ليست فقط أفضل، ولكنها محسوبة بطريقة أقرب إلى التفكيك الذاتي الترجعي الحقيقي لاحتمالية التسلسل.
\ No newline at end of file
From 0e76e638e94844804ae2e0779d21570cb8cb6e84 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:45 +0300
Subject: [PATCH 031/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/philosophy.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/philosophy.md | 63 ++++++++++++++++++++++++++++++++++++
1 file changed, 63 insertions(+)
create mode 100644 docs/source/ar/philosophy.md
diff --git a/docs/source/ar/philosophy.md b/docs/source/ar/philosophy.md
new file mode 100644
index 00000000000000..46ba3df8bbc470
--- /dev/null
+++ b/docs/source/ar/philosophy.md
@@ -0,0 +1,63 @@
+# الفلسفة
+
+🤗 Transformers هي مكتبة موجهة تم بناؤها من أجل:
+
+- باحثي وأخصائيي التعليم في مجال التعلم الآلي الذين يسعون إلى استخدام نماذج المحولات واسعة النطاق أو دراستها أو توسيعها.
+- الممارسون العمليون الذين يرغبون في ضبط تلك النماذج أو تشغيلها في الإنتاج، أو كليهما.
+- المهندسون الذين يريدون فقط تنزيل نموذج مُدرب مسبقًا واستخدامه لحل مهمة تعلم آلي معينة.
+
+تم تصميم المكتبة مع الأخذ في الاعتبار هدفين رئيسيين:
+
+1. أن تكون سهلة وسريعة الاستخدام قدر الإمكان:
+
+ - قمنا بالحد بشكل كبير من عدد التجريدات المواجهة للمستخدم والتي يجب تعلمها، وفي الواقع، لا توجد تجريدات تقريبًا،
+ فقط ثلاث فئات قياسية مطلوبة لاستخدام كل نموذج: [التكوين](main_classes/configuration)،
+ [نماذج](main_classes/model)، وفئة ما قبل المعالجة ([معالج](main_classes/tokenizer) لـ NLP، [معالج الصور](main_classes/image_processor) للرؤية، [مستخرج الميزات](main_classes/feature_extractor) للصوت، و [معالج](main_classes/processors) للإدخالات متعددة الوسائط).
+ - يمكن تهيئة جميع هذه الفئات بطريقة بسيطة وموحدة من مثيلات مُدربة مسبقًا باستخدام طريقة `from_pretrained()` الشائعة والتي تقوم بتنزيل (إذا لزم الأمر)، وتخزين
+ وتحميل مثيل الفئة المرتبطة وبياناتها (معلمات التهيئة، ومعجم المعالج،
+ وأوزان النماذج) من نقطة تفتيش مُدربة مسبقًا مقدمة على [Hugging Face Hub](https://huggingface.co/models) أو نقطة التفتيش المحفوظة الخاصة بك.
+ - بالإضافة إلى هذه الفئات الأساسية الثلاث، توفر المكتبة واجهتي برمجة تطبيقات: [`pipeline`] للاستدلال
+ بسرعة باستخدام نموذج لمهمة معينة و [`Trainer`] لتدريب أو ضبط نموذج PyTorch بسرعة (جميع نماذج TensorFlow متوافقة مع `Keras.fit`).
+ - نتيجة لذلك، هذه المكتبة ليست صندوق أدوات متعدد الاستخدامات من الكتل الإنشائية للشبكات العصبية. إذا كنت تريد
+ توسيع أو البناء على المكتبة، فما عليك سوى استخدام Python و PyTorch و TensorFlow و Keras العادية والوراثة من الفئات الأساسية
+ للمكتبة لإعادة استخدام الوظائف مثل تحميل النموذج وحفظه. إذا كنت ترغب في معرفة المزيد عن فلسفة الترميز لدينا للنماذج، فراجع منشور المدونة الخاص بنا [Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy).
+
+2. تقديم نماذج رائدة في مجالها مع أداء قريب قدر الإمكان من النماذج الأصلية:
+
+ - نقدم مثالًا واحدًا على الأقل لكل بنية تقوم بإعادة إنتاج نتيجة مقدمة من المؤلفين الرسميين
+ لتلك البنية.
+ - عادةً ما تكون الشفرة قريبة قدر الإمكان من قاعدة الشفرة الأصلية، مما يعني أن بعض شفرة PyTorch قد لا تكون
+ "بأسلوب PyTorch" كما يمكن أن تكون نتيجة لكونها شفرة TensorFlow محولة والعكس صحيح.
+
+بعض الأهداف الأخرى:
+
+- عرض داخليات النماذج بشكل متسق قدر الإمكان:
+
+ - نمنح حق الوصول، باستخدام واجهة برمجة تطبيقات واحدة، إلى جميع الحالات المخفية وأوزان الاهتمام.
+ - تم توحيد فئات ما قبل المعالجة وواجهات برمجة التطبيقات الأساسية للنموذج لتسهيل التبديل بين النماذج.
+
+- دمج مجموعة مختارة ذاتيًا من الأدوات الواعدة لضبط هذه النماذج ودراستها:
+
+ - طريقة بسيطة ومتسقة لإضافة رموز جديدة إلى المعجم والمغلفات لضبط النماذج الدقيق.
+ - طرق بسيطة لتنميق رؤوس المحول وإزالتها.
+- طريقة بسيطة ومتسقة لإضافة رموز جديدة إلى المعجم والمغلفات لضبط النماذج الدقيق.
+ - طرق بسيطة لتنميق رؤوس المحول وإزالتها.
+
+- التبديل بسهولة بين PyTorch و TensorFlow 2.0 و Flax، مما يسمح بالتدريب باستخدام إطار واحد والاستدلال باستخدام إطار آخر.
+
+## المفاهيم الرئيسية
+
+تم بناء المكتبة حول ثلاثة أنواع من الفئات لكل نموذج:
+
+- **فئات النماذج** يمكن أن تكون نماذج PyTorch ([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))، أو نماذج Keras ([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))، أو نماذج JAX/Flax ([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html)) التي تعمل مع الأوزان المُدربة مسبقًا المقدمة في المكتبة.
+- **فئات التكوين** تخزن معلمات التهيئة المطلوبة لبناء نموذج (مثل عدد الطبقات والحجم المخفي). أنت لست مضطرًا دائمًا إلى إنشاء مثيل لهذه الفئات بنفسك. على وجه الخصوص، إذا كنت تستخدم نموذجًا مُدربًا مسبقًا دون أي تعديل، فإن إنشاء النموذج سيهتم تلقائيًا بتهيئة التكوين (والذي يعد جزءًا من النموذج).
+- **فئات ما قبل المعالجة** تحويل البيانات الخام إلى تنسيق مقبول من قبل النموذج. يقوم [المعالج](main_classes/tokenizer) بتخزين المعجم لكل نموذج ويقدم طرقًا لتشفير وفك تشفير السلاسل في قائمة من مؤشرات تضمين الرموز ليتم إطعامها للنموذج. تقوم [معالجات الصور](main_classes/image_processor) بمعالجة إدخالات الرؤية، وتقوم [مستخلصات الميزات](main_classes/feature_extractor) بمعالجة إدخالات الصوت، ويقوم [المعالج](main_classes/processors) بمعالجة الإدخالات متعددة الوسائط.
+
+يمكن تهيئة جميع هذه الفئات من مثيلات مُدربة مسبقًا، وحفظها محليًا، ومشاركتها على Hub باستخدام ثلاث طرق:
+
+- تسمح لك `from_pretrained()` بتهيئة نموذج وفئة تكوين وفئة ما قبل المعالجة من إصدار مُدرب مسبقًا إما
+ يتم توفيره بواسطة المكتبة نفسها (يمكن العثور على النماذج المدعومة على [Model Hub](https://huggingface.co/models)) أو
+ مخزن محليًا (أو على خادم) بواسطة المستخدم.
+- تسمح لك `save_pretrained()` بحفظ نموذج وفئة تكوين وفئة ما قبل المعالجة محليًا بحيث يمكن إعادة تحميله باستخدام
+ `from_pretrained()`.
+- تسمح لك `push_to_hub()` بمشاركة نموذج وفئة تكوين وفئة ما قبل المعالجة على Hub، بحيث يمكن الوصول إليها بسهولة من قبل الجميع.
\ No newline at end of file
From 5962f1442674def3e64869ba534eff01308f13f9 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 21:41:47 +0300
Subject: [PATCH 032/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/pipeline=5Fwebserver.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/pipeline_webserver.md | 124 +++++++++++++++++++++++++++
1 file changed, 124 insertions(+)
create mode 100644 docs/source/ar/pipeline_webserver.md
diff --git a/docs/source/ar/pipeline_webserver.md b/docs/source/ar/pipeline_webserver.md
new file mode 100644
index 00000000000000..154331bf39c3d0
--- /dev/null
+++ b/docs/source/ar/pipeline_webserver.md
@@ -0,0 +1,124 @@
+# استخدام خطوط الأنابيب لخادم ويب
+
+ +
+ +
+
+
+ +
+ +
+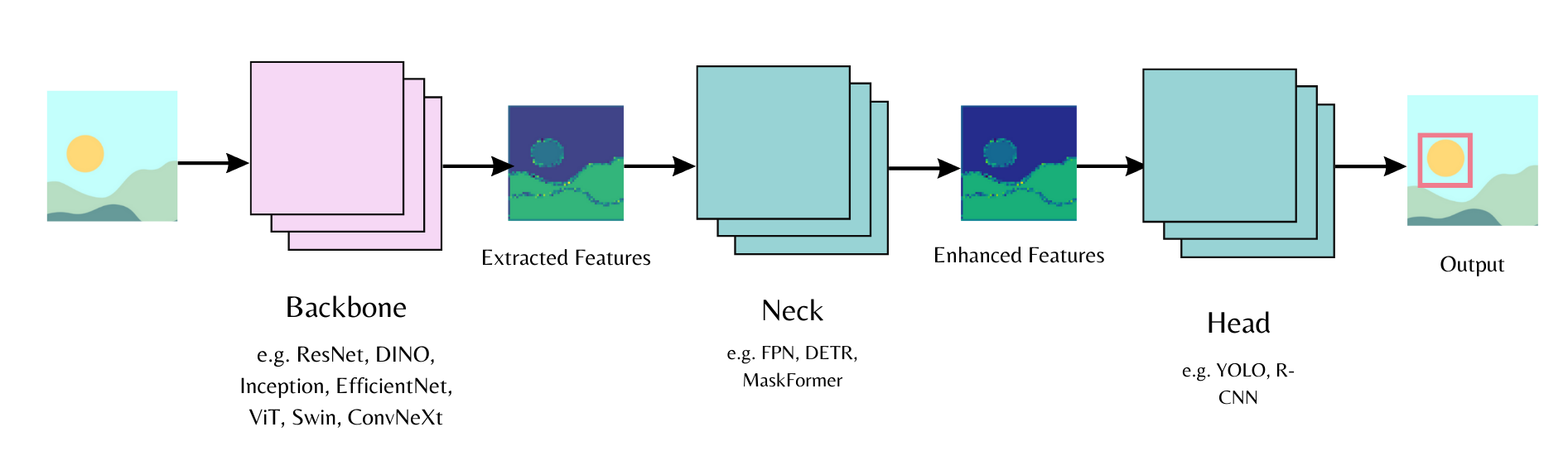 +
+ +
+  +
+  +
+ 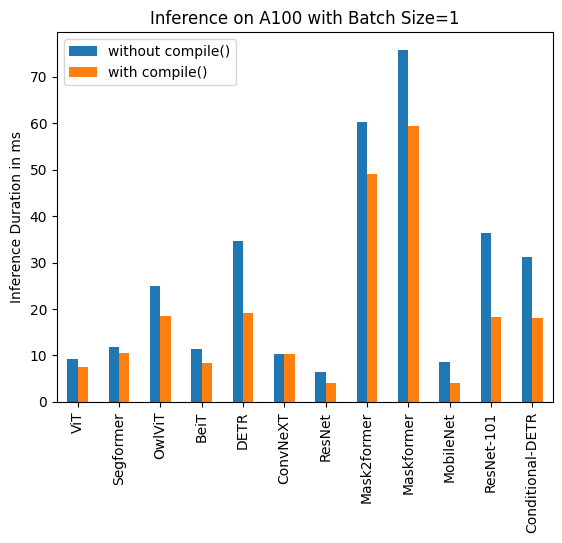 +
+ 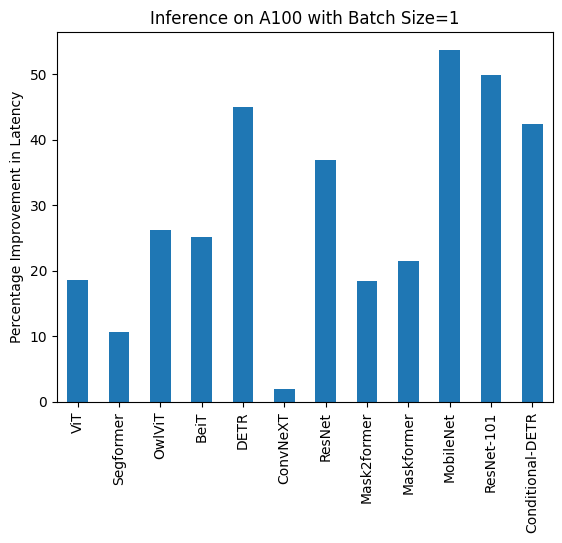 +
+ python run_qa.py \ +--model_name_or_path google-bert/bert-base-uncased \ +--dataset_name squad \ +--do_train \ +--do_eval \ +--per_device_train_batch_size 12 \ +--learning_rate 3e-5 \ +--num_train_epochs 2 \ +--max_seq_length 384 \ +--doc_stride 128 \ +--output_dir /tmp/debug_squad/ \ +--use_ipex \ +--bf16 \ +--use_cpu+ +إذا كنت تريد تمكين `use_ipex` و`bf16` في نصك البرمجي، فقم بإضافة هذه المعلمات إلى `TrainingArguments` على النحو التالي: +```diff +training_args = TrainingArguments( + output_dir=args.output_path, ++ bf16=True, ++ use_ipex=True, ++ use_cpu=True, + **kwargs +) +``` + +### مثال عملي + +مقال المدونة: [تسريع تحويلات PyTorch باستخدام Intel Sapphire Rapids](https://huggingface.co/blog/intel-sapphire-rapids) \ No newline at end of file From bcb7d31561074d94abde3e510d29559f2231b1c3 Mon Sep 17 00:00:00 2001 From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com> Date: Wed, 7 Aug 2024 21:42:22 +0300 Subject: [PATCH 050/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?= =?UTF-8?q?ource/ar/perf=5Ftrain=5Ftpu=5Ftf.md?= MIME-Version: 1.0 Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: 8bit --- docs/source/ar/perf_train_tpu_tf.md | 152 ++++++++++++++++++++++++++++ 1 file changed, 152 insertions(+) create mode 100644 docs/source/ar/perf_train_tpu_tf.md diff --git a/docs/source/ar/perf_train_tpu_tf.md b/docs/source/ar/perf_train_tpu_tf.md new file mode 100644 index 00000000000000..f463bbf5395d36 --- /dev/null +++ b/docs/source/ar/perf_train_tpu_tf.md @@ -0,0 +1,152 @@ +# التدريب على وحدة معالجة tensor (TPU) باستخدام TensorFlow + +
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+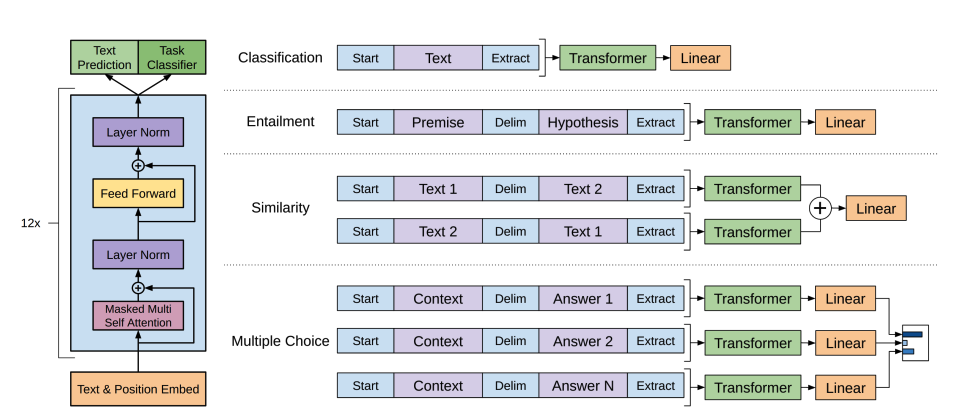 +
+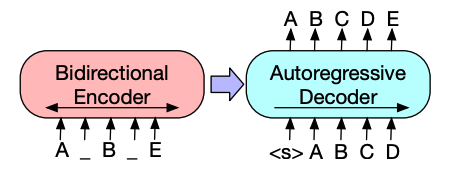 +
+ +
+  +
+ 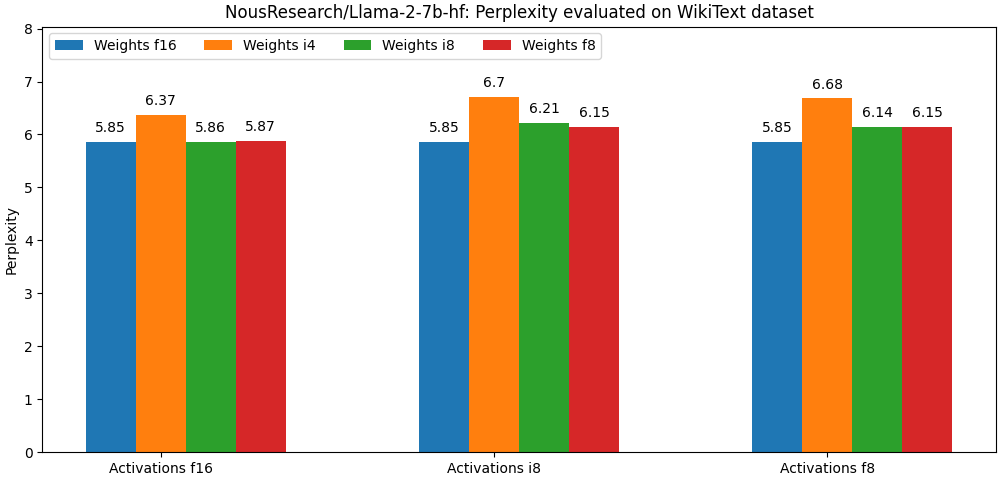 +
+  +
+  +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+
+
+ +
+ +
+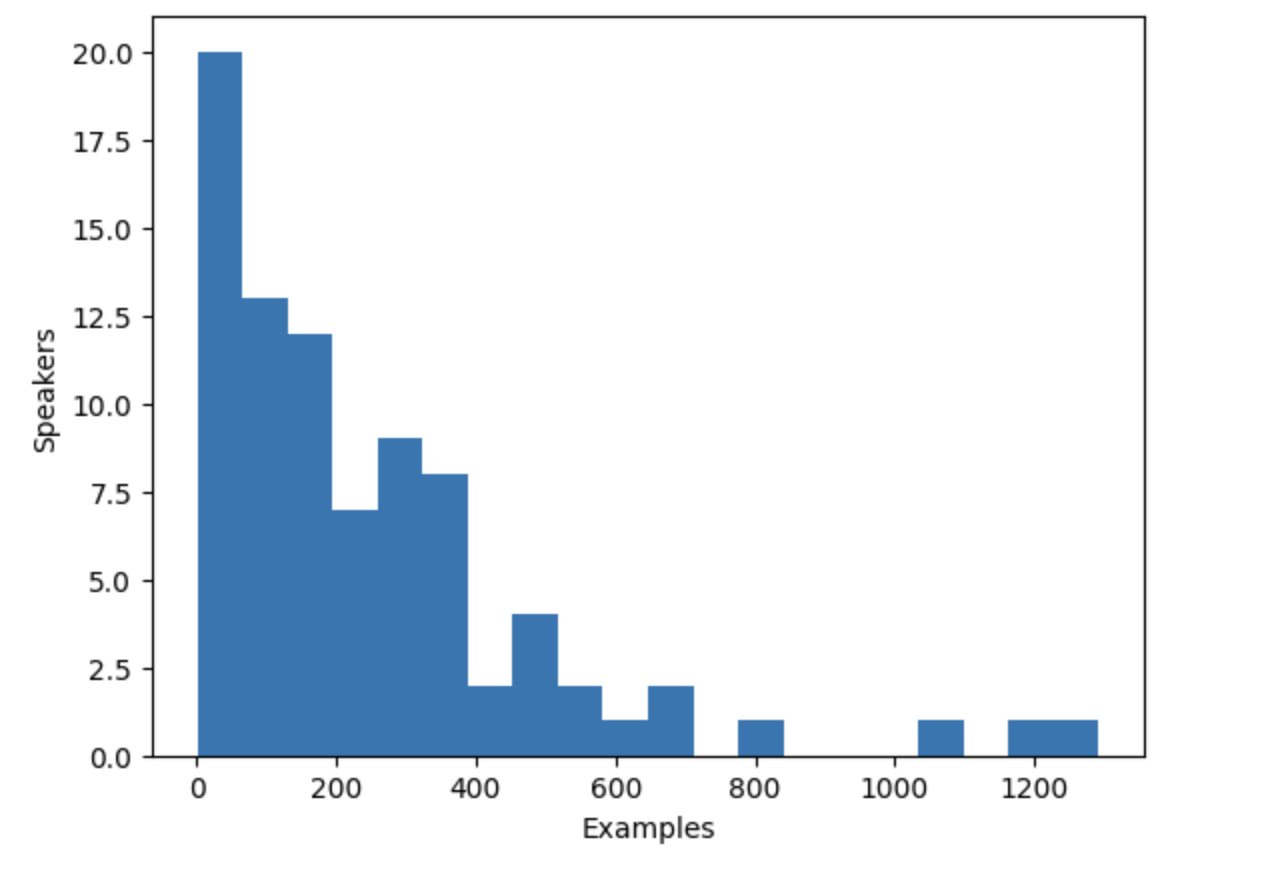 +
+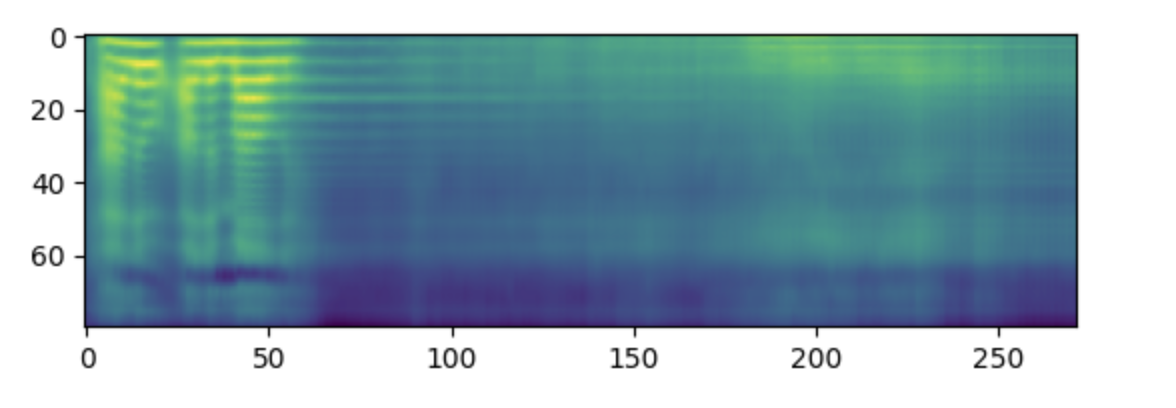 +
+ +
+ +
+ +
+ +
+ +
+
+
+ +
+ +
+ +
+| Epoch | +Training Loss | +Validation Loss | +Map | +Map 50 | +Map 75 | +Map Small | +Map Medium | +Map Large | +Mar 1 | +Mar 10 | +Mar 100 | +Mar Small | +Mar Medium | +Mar Large | +Map Coverall | +Mar 100 Coverall | +Map Face Shield | +Mar 100 Face Shield | +Map Gloves | +Mar 100 Gloves | +Map Goggles | +Mar 100 Goggles | +Map Mask | +Mar 100 Mask | +
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | +No log | +2.629903 | +0.008900 | +0.023200 | +0.006500 | +0.001300 | +0.002800 | +0.020500 | +0.021500 | +0.070400 | +0.101400 | +0.007600 | +0.106200 | +0.096100 | +0.036700 | +0.232000 | +0.000300 | +0.019000 | +0.003900 | +0.125400 | +0.000100 | +0.003100 | +0.003500 | +0.127600 | +
| 2 | +No log | +3.479864 | +0.014800 | +0.034600 | +0.010800 | +0.008600 | +0.011700 | +0.012500 | +0.041100 | +0.098700 | +0.130000 | +0.056000 | +0.062200 | +0.111900 | +0.053500 | +0.447300 | +0.010600 | +0.100000 | +0.000200 | +0.022800 | +0.000100 | +0.015400 | +0.009700 | +0.064400 | +
| 3 | +No log | +2.107622 | +0.041700 | +0.094000 | +0.034300 | +0.024100 | +0.026400 | +0.047400 | +0.091500 | +0.182800 | +0.225800 | +0.087200 | +0.199400 | +0.210600 | +0.150900 | +0.571200 | +0.017300 | +0.101300 | +0.007300 | +0.180400 | +0.002100 | +0.026200 | +0.031000 | +0.250200 | +
| 4 | +No log | +2.031242 | +0.055900 | +0.120600 | +0.046900 | +0.013800 | +0.038100 | +0.090300 | +0.105900 | +0.225600 | +0.266100 | +0.130200 | +0.228100 | +0.330000 | +0.191000 | +0.572100 | +0.010600 | +0.157000 | +0.014600 | +0.235300 | +0.001700 | +0.052300 | +0.061800 | +0.313800 | +
| 5 | +3.889400 | +1.883433 | +0.089700 | +0.201800 | +0.067300 | +0.022800 | +0.065300 | +0.129500 | +0.136000 | +0.272200 | +0.303700 | +0.112900 | +0.312500 | +0.424600 | +0.300200 | +0.585100 | +0.032700 | +0.202500 | +0.031300 | +0.271000 | +0.008700 | +0.126200 | +0.075500 | +0.333800 | +
| 6 | +3.889400 | +1.807503 | +0.118500 | +0.270900 | +0.090200 | +0.034900 | +0.076700 | +0.152500 | +0.146100 | +0.297800 | +0.325400 | +0.171700 | +0.283700 | +0.545900 | +0.396900 | +0.554500 | +0.043000 | +0.262000 | +0.054500 | +0.271900 | +0.020300 | +0.230800 | +0.077600 | +0.308000 | +
| 7 | +3.889400 | +1.716169 | +0.143500 | +0.307700 | +0.123200 | +0.045800 | +0.097800 | +0.258300 | +0.165300 | +0.327700 | +0.352600 | +0.140900 | +0.336700 | +0.599400 | +0.442900 | +0.620700 | +0.069400 | +0.301300 | +0.081600 | +0.292000 | +0.011000 | +0.230800 | +0.112700 | +0.318200 | +
| 8 | +3.889400 | +1.679014 | +0.153000 | +0.355800 | +0.127900 | +0.038700 | +0.115600 | +0.291600 | +0.176000 | +0.322500 | +0.349700 | +0.135600 | +0.326100 | +0.643700 | +0.431700 | +0.582900 | +0.069800 | +0.265800 | +0.088600 | +0.274600 | +0.028300 | +0.280000 | +0.146700 | +0.345300 | +
| 9 | +3.889400 | +1.618239 | +0.172100 | +0.375300 | +0.137600 | +0.046100 | +0.141700 | +0.308500 | +0.194000 | +0.356200 | +0.386200 | +0.162400 | +0.359200 | +0.677700 | +0.469800 | +0.623900 | +0.102100 | +0.317700 | +0.099100 | +0.290200 | +0.029300 | +0.335400 | +0.160200 | +0.364000 | +
| 10 | +1.599700 | +1.572512 | +0.179500 | +0.400400 | +0.147200 | +0.056500 | +0.141700 | +0.316700 | +0.213100 | +0.357600 | +0.381300 | +0.197900 | +0.344300 | +0.638500 | +0.466900 | +0.623900 | +0.101300 | +0.311400 | +0.104700 | +0.279500 | +0.051600 | +0.338500 | +0.173000 | +0.353300 | +
| 11 | +1.599700 | +1.528889 | +0.192200 | +0.415000 | +0.160800 | +0.053700 | +0.150500 | +0.378000 | +0.211500 | +0.371700 | +0.397800 | +0.204900 | +0.374600 | +0.684800 | +0.491900 | +0.632400 | +0.131200 | +0.346800 | +0.122000 | +0.300900 | +0.038400 | +0.344600 | +0.177500 | +0.364400 | +
| 12 | +1.599700 | +1.517532 | +0.198300 | +0.429800 | +0.159800 | +0.066400 | +0.162900 | +0.383300 | +0.220700 | +0.382100 | +0.405400 | +0.214800 | +0.383200 | +0.672900 | +0.469000 | +0.610400 | +0.167800 | +0.379700 | +0.119700 | +0.307100 | +0.038100 | +0.335400 | +0.196800 | +0.394200 | +
| 13 | +1.599700 | +1.488849 | +0.209800 | +0.452300 | +0.172300 | +0.094900 | +0.171100 | +0.437800 | +0.222000 | +0.379800 | +0.411500 | +0.203800 | +0.397300 | +0.707500 | +0.470700 | +0.620700 | +0.186900 | +0.407600 | +0.124200 | +0.306700 | +0.059300 | +0.355400 | +0.207700 | +0.367100 | +
| 14 | +1.599700 | +1.482210 | +0.228900 | +0.482600 | +0.187800 | +0.083600 | +0.191800 | +0.444100 | +0.225900 | +0.376900 | +0.407400 | +0.182500 | +0.384800 | +0.700600 | +0.512100 | +0.640100 | +0.175000 | +0.363300 | +0.144300 | +0.300000 | +0.083100 | +0.363100 | +0.229900 | +0.370700 | +
| 15 | +1.326800 | +1.475198 | +0.216300 | +0.455600 | +0.174900 | +0.088500 | +0.183500 | +0.424400 | +0.226900 | +0.373400 | +0.404300 | +0.199200 | +0.396400 | +0.677800 | +0.496300 | +0.633800 | +0.166300 | +0.392400 | +0.128900 | +0.312900 | +0.085200 | +0.312300 | +0.205000 | +0.370200 | +
| 16 | +1.326800 | +1.459697 | +0.233200 | +0.504200 | +0.192200 | +0.096000 | +0.202000 | +0.430800 | +0.239100 | +0.382400 | +0.412600 | +0.219500 | +0.403100 | +0.670400 | +0.485200 | +0.625200 | +0.196500 | +0.410100 | +0.135700 | +0.299600 | +0.123100 | +0.356900 | +0.225300 | +0.371100 | +
| 17 | +1.326800 | +1.407340 | +0.243400 | +0.511900 | +0.204500 | +0.121000 | +0.215700 | +0.468000 | +0.246200 | +0.394600 | +0.424200 | +0.225900 | +0.416100 | +0.705200 | +0.494900 | +0.638300 | +0.224900 | +0.430400 | +0.157200 | +0.317900 | +0.115700 | +0.369200 | +0.224200 | +0.365300 | +
| 18 | +1.326800 | +1.419522 | +0.245100 | +0.521500 | +0.210000 | +0.116100 | +0.211500 | +0.489900 | +0.255400 | +0.391600 | +0.419700 | +0.198800 | +0.421200 | +0.701400 | +0.501800 | +0.634200 | +0.226700 | +0.410100 | +0.154400 | +0.321400 | +0.105900 | +0.352300 | +0.236700 | +0.380400 | +
| 19 | +1.158600 | +1.398764 | +0.253600 | +0.519200 | +0.213600 | +0.135200 | +0.207700 | +0.491900 | +0.257300 | +0.397300 | +0.428000 | +0.241400 | +0.401800 | +0.703500 | +0.509700 | +0.631100 | +0.236700 | +0.441800 | +0.155900 | +0.330800 | +0.128100 | +0.352300 | +0.237500 | +0.384000 | +
| 20 | +1.158600 | +1.390591 | +0.248800 | +0.520200 | +0.216600 | +0.127500 | +0.211400 | +0.471900 | +0.258300 | +0.407000 | +0.429100 | +0.240300 | +0.407600 | +0.708500 | +0.505800 | +0.623400 | +0.235500 | +0.431600 | +0.150000 | +0.325000 | +0.125700 | +0.375400 | +0.227200 | +0.390200 | +
| 21 | +1.158600 | +1.360608 | +0.262700 | +0.544800 | +0.222100 | +0.134700 | +0.230000 | +0.487500 | +0.269500 | +0.413300 | +0.436300 | +0.236200 | +0.419100 | +0.709300 | +0.514100 | +0.637400 | +0.257200 | +0.450600 | +0.165100 | +0.338400 | +0.139400 | +0.372300 | +0.237700 | +0.382700 | +
| 22 | +1.158600 | +1.368296 | +0.262800 | +0.542400 | +0.236400 | +0.137400 | +0.228100 | +0.498500 | +0.266500 | +0.409000 | +0.433000 | +0.239900 | +0.418500 | +0.697500 | +0.520500 | +0.641000 | +0.257500 | +0.455700 | +0.162600 | +0.334800 | +0.140200 | +0.353800 | +0.233200 | +0.379600 | +
| 23 | +1.158600 | +1.368176 | +0.264800 | +0.541100 | +0.233100 | +0.138200 | +0.223900 | +0.498700 | +0.272300 | +0.407400 | +0.434400 | +0.233100 | +0.418300 | +0.702000 | +0.524400 | +0.642300 | +0.262300 | +0.444300 | +0.159700 | +0.335300 | +0.140500 | +0.366200 | +0.236900 | +0.384000 | +
| 24 | +1.049700 | +1.355271 | +0.269700 | +0.549200 | +0.239100 | +0.134700 | +0.229900 | +0.519200 | +0.274800 | +0.412700 | +0.437600 | +0.245400 | +0.417200 | +0.711200 | +0.523200 | +0.644100 | +0.272100 | +0.440500 | +0.166700 | +0.341500 | +0.137700 | +0.373800 | +0.249000 | +0.388000 | +
| 25 | +1.049700 | +1.355180 | +0.272500 | +0.547900 | +0.243800 | +0.149700 | +0.229900 | +0.523100 | +0.272500 | +0.415700 | +0.442200 | +0.256200 | +0.420200 | +0.705800 | +0.523900 | +0.639600 | +0.271700 | +0.451900 | +0.166300 | +0.346900 | +0.153700 | +0.383100 | +0.247000 | +0.389300 | +
| 26 | +1.049700 | +1.349337 | +0.275600 | +0.556300 | +0.246400 | +0.146700 | +0.234800 | +0.516300 | +0.274200 | +0.418300 | +0.440900 | +0.248700 | +0.418900 | +0.705800 | +0.523200 | +0.636500 | +0.274700 | +0.440500 | +0.172400 | +0.349100 | +0.155600 | +0.384600 | +0.252300 | +0.393800 | +
| 27 | +1.049700 | +1.350782 | +0.275200 | +0.548700 | +0.246800 | +0.147300 | +0.236400 | +0.527200 | +0.280100 | +0.416200 | +0.442600 | +0.253400 | +0.424000 | +0.710300 | +0.526600 | +0.640100 | +0.273200 | +0.445600 | +0.167000 | +0.346900 | +0.160100 | +0.387700 | +0.249200 | +0.392900 | +
| 28 | +1.049700 | +1.346533 | +0.277000 | +0.552800 | +0.252900 | +0.147400 | +0.240000 | +0.527600 | +0.280900 | +0.420900 | +0.444100 | +0.255500 | +0.424500 | +0.711200 | +0.530200 | +0.646800 | +0.277400 | +0.441800 | +0.170900 | +0.346900 | +0.156600 | +0.389200 | +0.249600 | +0.396000 | +
| 29 | +0.993700 | +1.346575 | +0.277100 | +0.554800 | +0.252900 | +0.148400 | +0.239700 | +0.523600 | +0.278400 | +0.420000 | +0.443300 | +0.256300 | +0.424000 | +0.705600 | +0.529600 | +0.647300 | +0.273900 | +0.439200 | +0.174300 | +0.348700 | +0.157600 | +0.386200 | +0.250100 | +0.395100 | +
| 30 | +0.993700 | +1.346446 | +0.277400 | +0.554700 | +0.252700 | +0.147900 | +0.240800 | +0.523600 | +0.278800 | +0.420400 | +0.443300 | +0.256100 | +0.424200 | +0.705500 | +0.530100 | +0.646800 | +0.275600 | +0.440500 | +0.174500 | +0.348700 | +0.157300 | +0.386200 | +0.249200 | +0.394200 | +
+ +إذا قمت بتعيين `push_to_hub` إلى `True` في `training_args`، يتم دفع نقاط تثبيت التدريب إلى +Hub الخاص بـ Hugging Face. عند اكتمال التدريب، قم أيضًا بدفع النموذج النهائي إلى Hub عن طريق استدعاء طريقة [`~transformers.Trainer.push_to_hub`]. + +```py +>>> trainer.push_to_hub() +``` + +## تقييم + +```py +>>> from pprint import pprint + +>>> metrics = trainer.evaluate(eval_dataset=cppe5["test"], metric_key_prefix="test") +>>> pprint(metrics) +{'epoch': 30.0، + 'test_loss': 1.0877351760864258، + 'test_map': 0.4116، + 'test_map_50': 0.741، + 'test_map_75': 0.3663، + 'test_map_Coverall': 0.5937، + 'test_map_Face_Shield': 0.5863، + 'test_map_Gloves': 0.3416، + 'test_map_Goggles': 0.1468، + 'test_map_Mask': 0.3894، + 'test_map_large': 0.5637، + 'test_map_medium': 0.3257، + 'test_map_small': 0.3589، + 'test_mar_1': 0.323، + 'test_mar_10': 0.5237، + 'test_mar_100': 0.5587، + 'test_mar_100_Coverall': 0.6756، + 'test_mar_100_Face_Shield': 0.7294، + 'test_mar_100_Gloves': 0.4721، + 'test_mar_100_Goggles': 0.4125، + 'test_mar_100_Mask': 0.5038، + 'test_mar_large': 0.7283، + 'test_mar_medium': 0.4901، + 'test_mar_small': 0.4469، + 'test_runtime': 1.6526، + 'test_samples_per_second': 17.548، + 'test_steps_per_second': 2.42} +``` + +يمكن تحسين هذه النتائج عن طريق ضبط فرط المعلمات في [`TrainingArguments`]. جربه! + +## الاستنتاج + +الآن بعد أن قمت بضبط نموذج، وتقييمه، وتحميله إلى Hub الخاص بـ Hugging Face، يمكنك استخدامه للاستنتاج. + +```py +>>> import torch +>>> import requests + +>>> from PIL import Image, ImageDraw +>>> from transformers import AutoImageProcessor, AutoModelForObjectDetection + +>>> url = "https://images.pexels.com/photos/8413299/pexels-photo-8413299.jpeg?auto=compress&cs=tinysrgb&w=630&h=375&dpr=2" +>>> image = Image.open(requests.get(url, stream=True).raw) +``` + +قم بتحميل النموذج ومعالج الصور من Hub الخاص بـ Hugging Face (تخطي لاستخدام ما تم تدريبه بالفعل في هذه الجلسة): +```py +>>> device = "cuda" +>>> model_repo = "qubvel-hf/detr_finetuned_cppe5" + +>>> image_processor = AutoImageProcessor.from_pretrained(model_repo) +>>> model = AutoModelForObjectDetection.from_pretrained(model_repo) +>>> model = model.to(device) +``` + +وكشف حدود الصناديق: + +```py + +>>> with torch.no_grad(): +... inputs = image_processor(images=[image], return_tensors="pt") +... outputs = model(**inputs.to(device)) +... target_sizes = torch.tensor([[image.size[1], image.size[0]]]) +... results = image_processor.post_process_object_detection(outputs, threshold=0.3, target_sizes=target_sizes)[0] + +>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]): +... box = [round(i, 2) for i in box.tolist()] +... print( +... f"Detected {model.config.id2label[label.item()]} with confidence " +... f"{round(score.item(), 3)} at location {box}" +... ) +تم الكشف عن القفازات بثقة 0.683 في الموقع [244.58، 124.33، 300.35، 185.13] +تم الكشف عن قناع بثقة 0.517 في الموقع [143.73، 64.58، 219.57، 125.89] +تم الكشف عن القفازات بثقة 0.425 في الموقع [179.15، 155.57، 262.4، 226.35] +تم الكشف عن رداء واقي بثقة 0.407 في الموقع [307.13، -1.18، 477.82، 318.06] +تم الكشف عن رداء واقي بثقة 0.391 في الموقع [68.61، 126.66، 309.03، 318.89] +``` + +دعونا نرسم النتيجة: + +```py +>>> draw = ImageDraw.Draw(image) + +>>> for score, label, box in zip(results["scores"], results["labels"], results["boxes"]): +... box = [round(i, 2) for i in box.tolist()] +... x, y, x2, y2 = tuple(box) +... draw.rectangle((x, y, x2, y2), outline="red", width=1) +... draw.text((x, y), model.config.id2label[label.item()], fill="white") + +>>> image +``` + +
 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+From d08fbfe2bfcab9b2afbcb70ef08d9de8b08c15cc Mon Sep 17 00:00:00 2001 From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com> Date: Wed, 7 Aug 2024 23:05:56 +0300 Subject: [PATCH 221/653] =?UTF-8?q?=D8=AA=D8=AD=D8=AF=D9=8A=D8=AB=20i18n/R?= =?UTF-8?q?EADME=5Fte.md?= MIME-Version: 1.0 Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: 8bit --- i18n/README_te.md | 1 + 1 file changed, 1 insertion(+) diff --git a/i18n/README_te.md b/i18n/README_te.md index 13fd0ade17cd48..6bd4bb48bacbc9 100644 --- a/i18n/README_te.md +++ b/i18n/README_te.md @@ -50,6 +50,7 @@ limitations under the License. Français | Deutsch | Tiếng Việt | + العربية |
From f110ce8af046faaf07010d883740ab00483d7b48 Mon Sep 17 00:00:00 2001 From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com> Date: Wed, 7 Aug 2024 23:05:58 +0300 Subject: [PATCH 222/653] =?UTF-8?q?=D8=AA=D8=AD=D8=AF=D9=8A=D8=AB=20i18n/R?= =?UTF-8?q?EADME=5Fvi.md?= MIME-Version: 1.0 Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: 8bit --- i18n/README_vi.md | 1 + 1 file changed, 1 insertion(+) diff --git a/i18n/README_vi.md b/i18n/README_vi.md index 4a48edf7eb0be1..9efd63968e17e3 100644 --- a/i18n/README_vi.md +++ b/i18n/README_vi.md @@ -47,6 +47,7 @@ limitations under the License. తెలుగు | Français | Deutsch | + العربية | Tiếng việt | From 98dac09baeb934a51d2325c701b8858551526ed9 Mon Sep 17 00:00:00 2001 From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com> Date: Wed, 7 Aug 2024 23:05:59 +0300 Subject: [PATCH 223/653] =?UTF-8?q?=D8=AA=D8=AD=D8=AF=D9=8A=D8=AB=20i18n/R?= =?UTF-8?q?EADME=5Fzh-hans.md?= MIME-Version: 1.0 Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: 8bit --- i18n/README_zh-hans.md | 1 + 1 file changed, 1 insertion(+) diff --git a/i18n/README_zh-hans.md b/i18n/README_zh-hans.md index ef059dd0b0f0ea..f55058c9e70923 100644 --- a/i18n/README_zh-hans.md +++ b/i18n/README_zh-hans.md @@ -68,6 +68,7 @@ checkpoint: 检查点 Français | Deutsch | Tiếng Việt | + العربية | From 8e1af6278cd5a48c4187e5819ae14d3a4fb20179 Mon Sep 17 00:00:00 2001 From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com> Date: Wed, 7 Aug 2024 23:06:01 +0300 Subject: [PATCH 224/653] =?UTF-8?q?=D8=AA=D8=AD=D8=AF=D9=8A=D8=AB=20i18n/R?= =?UTF-8?q?EADME=5Fzh-hant.md?= MIME-Version: 1.0 Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: 8bit --- i18n/README_zh-hant.md | 1 + 1 file changed, 1 insertion(+) diff --git a/i18n/README_zh-hant.md b/i18n/README_zh-hant.md index 1dceb5cb9027ce..ec58206ee7a7d7 100644 --- a/i18n/README_zh-hant.md +++ b/i18n/README_zh-hant.md @@ -80,6 +80,7 @@ user: 使用者 Français | Deutsch | Tiếng Việt | + العربية | From da7ca5aad9abf44af93dcf5c119167cdff5ce5ae Mon Sep 17 00:00:00 2001 From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com> Date: Wed, 7 Aug 2024 23:06:03 +0300 Subject: [PATCH 225/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20i18n/?= =?UTF-8?q?=E2=80=8F=E2=80=8FREADME=5Far.md?= MIME-Version: 1.0 Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: 8bit --- "i18n/\342\200\217\342\200\217README_ar.md" | 317 ++++++++++++++++++++ 1 file changed, 317 insertions(+) create mode 100644 "i18n/\342\200\217\342\200\217README_ar.md" diff --git "a/i18n/\342\200\217\342\200\217README_ar.md" "b/i18n/\342\200\217\342\200\217README_ar.md" new file mode 100644 index 00000000000000..8e602b23eb3b93 --- /dev/null +++ "b/i18n/\342\200\217\342\200\217README_ar.md" @@ -0,0 +1,317 @@ + + +
+ ![]() +
+
+
+
+ 
 +
+  +
+  +
+ ![]() +
+ ![]() +
+
+ English | + 简体中文 | + 繁體中文 | + 한국어 | + Español | + 日本語 | + हिन्दी | + Русский | + Рortuguês | + తెలుగు | + Français | + Deutsch | + Tiếng Việt | + العربية | +
+ + +أحدث تقنيات التعلم الآلي لـ JAX وPyTorch وTensorFlow
+ + + +
+
+
+ +
+  +
+ +
+[[autodoc]] get_cosine_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_schedule_with_warmup
+
+ +
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+
+
+[[autodoc]] get_cosine_with_hard_restarts_schedule_with_warmup
+
+ +
+[[autodoc]] get_linear_schedule_with_warmup
+
+
+
+[[autodoc]] get_linear_schedule_with_warmup
+
+ +
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+[[autodoc]] get_wsd_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## استراتيجيات التدرج
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
\ No newline at end of file
From 9505cfbca87daed32962caf754fb4bdc71ce1fe7 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:22:49 +0300
Subject: [PATCH 355/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/main=5Fclasses/output.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/main_classes/output.md | 294 ++++++++++++++++++++++++++
1 file changed, 294 insertions(+)
create mode 100644 docs/source/ar/main_classes/output.md
diff --git a/docs/source/ar/main_classes/output.md b/docs/source/ar/main_classes/output.md
new file mode 100644
index 00000000000000..cc6f8599e35422
--- /dev/null
+++ b/docs/source/ar/main_classes/output.md
@@ -0,0 +1,294 @@
+# مخرجات النموذج
+
+تمتلك جميع النماذج مخرجات هي عبارة عن حالات من الفئات الفرعية لـ [`~utils.ModelOutput`]. وهذه عبارة عن هياكل بيانات تحتوي على جميع المعلومات التي يرجعها النموذج، ولكن يمكن استخدامها أيضًا كمجموعات أو قواميس.
+
+دعونا نرى كيف يبدو هذا في مثال:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # حجم الدفعة 1
+outputs = model(**inputs, labels=labels)
+```
+
+إن كائن `outputs` هو [`~ modeling_outputs.SequenceClassifierOutput`]، كما يمكننا أن نرى في توثيق تلك الفئة أدناه، وهذا يعني أنه يحتوي على خاصية `loss` اختيارية، و`logits`، و`hidden_states` اختيارية، و`attentions` اختيارية. هنا لدينا `loss` لأننا مررنا `labels`، لكننا لا نملك `hidden_states` و`attentions` لأننا لم نمرر `output_hidden_states=True` أو `output_attentions=True`.
+
+
+
+[[autodoc]] get_polynomial_decay_schedule_with_warmup
+
+[[autodoc]] get_inverse_sqrt_schedule
+
+[[autodoc]] get_wsd_schedule
+
+### Warmup (TensorFlow)
+
+[[autodoc]] WarmUp
+
+## استراتيجيات التدرج
+
+### GradientAccumulator (TensorFlow)
+
+[[autodoc]] GradientAccumulator
\ No newline at end of file
From 9505cfbca87daed32962caf754fb4bdc71ce1fe7 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:22:49 +0300
Subject: [PATCH 355/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/main=5Fclasses/output.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/main_classes/output.md | 294 ++++++++++++++++++++++++++
1 file changed, 294 insertions(+)
create mode 100644 docs/source/ar/main_classes/output.md
diff --git a/docs/source/ar/main_classes/output.md b/docs/source/ar/main_classes/output.md
new file mode 100644
index 00000000000000..cc6f8599e35422
--- /dev/null
+++ b/docs/source/ar/main_classes/output.md
@@ -0,0 +1,294 @@
+# مخرجات النموذج
+
+تمتلك جميع النماذج مخرجات هي عبارة عن حالات من الفئات الفرعية لـ [`~utils.ModelOutput`]. وهذه عبارة عن هياكل بيانات تحتوي على جميع المعلومات التي يرجعها النموذج، ولكن يمكن استخدامها أيضًا كمجموعات أو قواميس.
+
+دعونا نرى كيف يبدو هذا في مثال:
+
+```python
+from transformers import BertTokenizer, BertForSequenceClassification
+import torch
+
+tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
+model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
+
+inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+labels = torch.tensor([1]).unsqueeze(0) # حجم الدفعة 1
+outputs = model(**inputs, labels=labels)
+```
+
+إن كائن `outputs` هو [`~ modeling_outputs.SequenceClassifierOutput`]، كما يمكننا أن نرى في توثيق تلك الفئة أدناه، وهذا يعني أنه يحتوي على خاصية `loss` اختيارية، و`logits`، و`hidden_states` اختيارية، و`attentions` اختيارية. هنا لدينا `loss` لأننا مررنا `labels`، لكننا لا نملك `hidden_states` و`attentions` لأننا لم نمرر `output_hidden_states=True` أو `output_attentions=True`.
+
+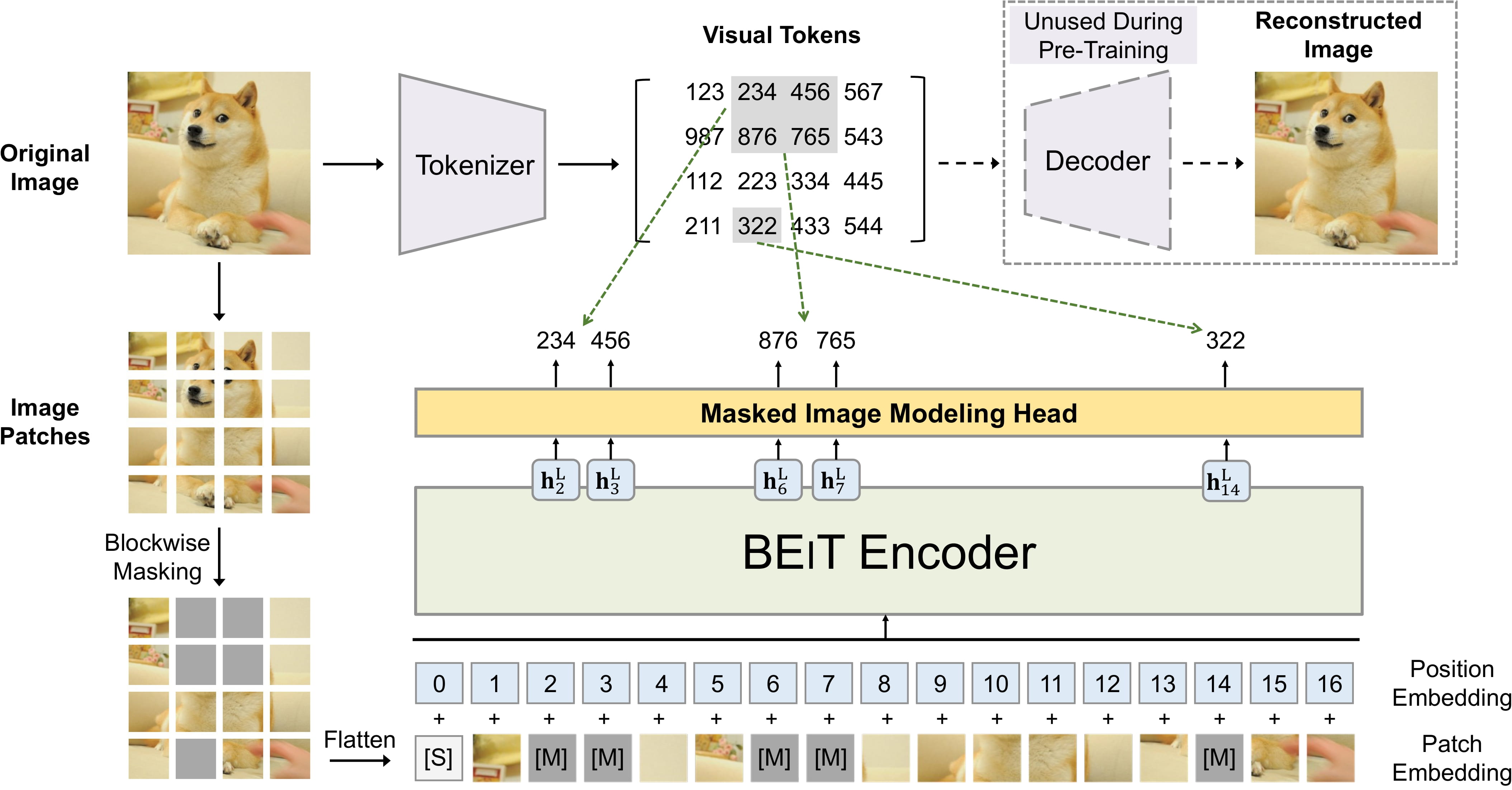 +
+ مرحلة ما قبل التدريب BEiT. مأخوذة من الورقة البحثية الأصلية.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام BEiT.
+
+
+
+ مرحلة ما قبل التدريب BEiT. مأخوذة من الورقة البحثية الأصلية.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام BEiT.
+
+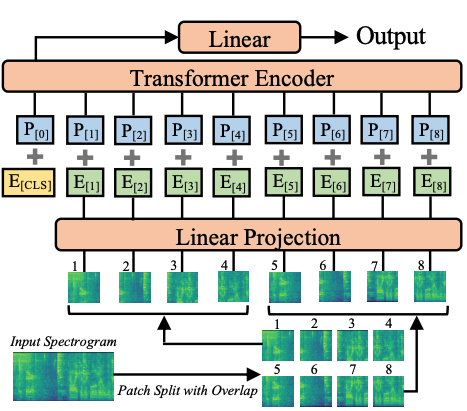 +
+ بنية محول المخطط الطيفي الصوتي. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/YuanGongND/ast).
+
+## نصائح الاستخدام
+
+- عند ضبط نموذج محول المخطط الطيفي الصوتي (AST) على مجموعة البيانات الخاصة بك، يوصى بالاهتمام بتطبيع الإدخال (للتأكد من أن الإدخال له متوسط 0 وانحراف معياري 0.5). ويتولى [`ASTFeatureExtractor`] العناية بهذا. لاحظ أنه يستخدم متوسط ومجموعة AudioSet بشكل افتراضي. يمكنك التحقق من [`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py) لمعرفة كيفية حساب المؤلفين للإحصاءات لمجموعة بيانات أسفل البث.
+
+- لاحظ أن AST يحتاج إلى معدل تعلم منخفض (يستخدم المؤلفون معدل تعلم أقل بعشر مرات مقارنة بنموذج الشبكة العصبية التلافيفية الذي اقترحوه في ورقة [PSLA](https://arxiv.org/abs/2102.01243)) ويصل إلى التقارب بسرعة، لذا يرجى البحث عن معدل تعلم مناسب ومخطط جدولة معدل التعلم لمهمتك.
+
+### استخدام الانتباه المنتج المرجح بالبقعة (SDPA)
+
+تتضمن PyTorch مشغل اهتمام منتج مرجح بالبقعة (SDPA) أصلي كجزء من `torch.nn.functional`. تشمل هذه الوظيفة عدة تطبيقات يمكن تطبيقها اعتمادًا على الإدخالات والأجهزة المستخدمة. راجع [الوثائق الرسمية](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html) أو صفحة [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) لمزيد من المعلومات.
+
+يتم استخدام SDPA بشكل افتراضي لـ `torch>=2.1.1` عندما يكون التنفيذ متاحًا، ولكن يمكنك أيضًا تعيين `attn_implementation="sdpa"` في `from_pretrained()` لطلب استخدام SDPA بشكل صريح.
+
+```
+from transformers import ASTForAudioClassification
+model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+للحصول على أفضل التحسينات، نوصي بتحميل النموذج بنصف الدقة (على سبيل المثال `torch.float16` أو `torch.bfloat16`).
+
+في معيار محلي (A100-40GB، PyTorch 2.3.0، OS Ubuntu 22.04) مع `float32` ونموذج `MIT/ast-finetuned-audioset-10-10-0.4593`، رأينا التحسينات التالية أثناء الاستدلال.
+
+| حجم الدفعة | متوسط وقت الاستدلال (ميلي ثانية)، وضع التقييم | متوسط وقت الاستدلال (ميلي ثانية)، نموذج SDPA | تسريع، SDPA / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 27 | 6 | 4.5 |
+| 2 | 12 | 6 | 2 |
+| 4 | 21 | 8 | 2.62 |
+| 8 | 40 | 14 | 2.86 |
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام محول المخطط الطيفي الصوتي.
+
+
+
+ بنية محول المخطط الطيفي الصوتي. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/YuanGongND/ast).
+
+## نصائح الاستخدام
+
+- عند ضبط نموذج محول المخطط الطيفي الصوتي (AST) على مجموعة البيانات الخاصة بك، يوصى بالاهتمام بتطبيع الإدخال (للتأكد من أن الإدخال له متوسط 0 وانحراف معياري 0.5). ويتولى [`ASTFeatureExtractor`] العناية بهذا. لاحظ أنه يستخدم متوسط ومجموعة AudioSet بشكل افتراضي. يمكنك التحقق من [`ast/src/get_norm_stats.py`](https://github.com/YuanGongND/ast/blob/master/src/get_norm_stats.py) لمعرفة كيفية حساب المؤلفين للإحصاءات لمجموعة بيانات أسفل البث.
+
+- لاحظ أن AST يحتاج إلى معدل تعلم منخفض (يستخدم المؤلفون معدل تعلم أقل بعشر مرات مقارنة بنموذج الشبكة العصبية التلافيفية الذي اقترحوه في ورقة [PSLA](https://arxiv.org/abs/2102.01243)) ويصل إلى التقارب بسرعة، لذا يرجى البحث عن معدل تعلم مناسب ومخطط جدولة معدل التعلم لمهمتك.
+
+### استخدام الانتباه المنتج المرجح بالبقعة (SDPA)
+
+تتضمن PyTorch مشغل اهتمام منتج مرجح بالبقعة (SDPA) أصلي كجزء من `torch.nn.functional`. تشمل هذه الوظيفة عدة تطبيقات يمكن تطبيقها اعتمادًا على الإدخالات والأجهزة المستخدمة. راجع [الوثائق الرسمية](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html) أو صفحة [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) لمزيد من المعلومات.
+
+يتم استخدام SDPA بشكل افتراضي لـ `torch>=2.1.1` عندما يكون التنفيذ متاحًا، ولكن يمكنك أيضًا تعيين `attn_implementation="sdpa"` في `from_pretrained()` لطلب استخدام SDPA بشكل صريح.
+
+```
+from transformers import ASTForAudioClassification
+model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+للحصول على أفضل التحسينات، نوصي بتحميل النموذج بنصف الدقة (على سبيل المثال `torch.float16` أو `torch.bfloat16`).
+
+في معيار محلي (A100-40GB، PyTorch 2.3.0، OS Ubuntu 22.04) مع `float32` ونموذج `MIT/ast-finetuned-audioset-10-10-0.4593`، رأينا التحسينات التالية أثناء الاستدلال.
+
+| حجم الدفعة | متوسط وقت الاستدلال (ميلي ثانية)، وضع التقييم | متوسط وقت الاستدلال (ميلي ثانية)، نموذج SDPA | تسريع، SDPA / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 27 | 6 | 4.5 |
+| 2 | 12 | 6 | 2 |
+| 4 | 21 | 8 | 2.62 |
+| 8 | 40 | 14 | 2.86 |
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام محول المخطط الطيفي الصوتي.
+
+ +
+ +
+ هندسة BLIP-2. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+
+## نصائح الاستخدام
+
+- يمكن استخدام BLIP-2 للتوليد النصي الشرطي بناءً على صورة وطلب نص اختياري. في وقت الاستدلال، يوصى باستخدام طريقة [`generate`] .
+- يمكن للمرء استخدام [`Blip2Processor`] لتحضير الصور للنموذج، وفك رموز معرّفات الرموز المتوقعة مرة أخرى إلى نص.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام BLIP-2.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ BLIP-2 لتعليق الصور، والإجابة على الأسئلة المرئية (VQA) والمحادثات الشبيهة بالدردشة [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2).
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يوضح المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## Blip2Config
+
+[[autodoc]] Blip2Config
+
+- from_vision_qformer_text_configs
+
+## Blip2VisionConfig
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel
+
+[[autodoc]] Blip2VisionModel
+
+- forward
+
+## Blip2QFormerModel
+
+[[autodoc]] Blip2QFormerModel
+
+- forward
+
+## Blip2Model
+
+[[autodoc]] Blip2Model
+
+- forward
+- get_text_features
+- get_image_features
+- get_qformer_features
+
+## Blip2ForConditionalGeneration
+
+[[autodoc]] Blip2ForConditionalGeneration
+
+- forward
+- generate
\ No newline at end of file
From 4227829a4fe00a7e1f49d6ef28c8c85d9ced08a8 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:23:42 +0300
Subject: [PATCH 384/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/blip.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/blip.md | 137 +++++++++++++++++++++++++++++++
1 file changed, 137 insertions(+)
create mode 100644 docs/source/ar/model_doc/blip.md
diff --git a/docs/source/ar/model_doc/blip.md b/docs/source/ar/model_doc/blip.md
new file mode 100644
index 00000000000000..10e904786c9f8e
--- /dev/null
+++ b/docs/source/ar/model_doc/blip.md
@@ -0,0 +1,137 @@
+# BLIP
+
+## نظرة عامة
+تم اقتراح نموذج BLIP في [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) بواسطة Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
+
+BLIP هو نموذج قادر على أداء مهام متعددة الوسائط المختلفة بما في ذلك:
+
+- الإجابة على الأسئلة البصرية
+- استرجاع الصور والنصوص (مطابقة الصور والنصوص)
+- وضع تعليقات توضيحية على الصور
+
+ملخص الورقة البحثية هو كما يلي:
+
+*أدى التدريب المسبق للرؤية واللغة (VLP) إلى تقدم الأداء في العديد من مهام الرؤية واللغة. ومع ذلك، فإن معظم النماذج التي تم تدريبها مسبقًا لا تتفوق إلا في مهام الفهم أو المهام القائمة على التوليد. علاوة على ذلك، تم تحقيق تحسين الأداء إلى حد كبير عن طريق توسيع نطاق مجموعة البيانات باستخدام أزواج من الصور والنصوص الضخمة التي تم جمعها من الويب، والتي تعد مصدرًا غير مثاليًا للإشراف. في هذه الورقة، نقترح BLIP، وهو إطار عمل جديد لـ VLP ينتقل بمرونة إلى مهام الفهم وتوليد الرؤية واللغة. يستخدم BLIP البيانات الضخمة من الويب بشكل فعال من خلال تعزيز التعليقات التوضيحية، حيث تقوم أداة إنشاء التعليقات التوضيحية بتوليد تعليقات توضيحية اصطناعية وتقوم أداة الترشيح بإزالة غير النظيفة منها. نحقق نتائج متقدمة في مجموعة واسعة من مهام الرؤية واللغة، مثل استرجاع الصور والنصوص (+2.7% في متوسط الاستدعاء@1)، ووضع تعليقات توضيحية على الصور (+2.8% في CIDEr)، والإجابة على الأسئلة البصرية (+1.6% في درجة VQA). كما يظهر BLIP قدرة تعميم قوية عند نقله مباشرة إلى مهام اللغة المرئية بطريقة الصفر. تم إصدار الكود والنماذج ومجموعات البيانات.*
+
+
+
+تمت المساهمة بهذا النموذج بواسطة [ybelkada](https://huggingface.co/ybelkada). يمكن العثور على الكود الأصلي [هنا](https://github.com/salesforce/BLIP).
+
+## الموارد
+
+- [دفتر Jupyter](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) حول كيفية ضبط نموذج BLIP لوضع تعليقات توضيحية على الصور باستخدام مجموعة بيانات مخصصة
+
+## BlipConfig
+
+[[autodoc]] BlipConfig
+
+- from_text_vision_configs
+
+## BlipTextConfig
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor
+
+[[autodoc]] BlipImageProcessor
+
+- preprocess
+
+
+
+ هندسة BLIP-2. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/salesforce/LAVIS/tree/5ee63d688ba4cebff63acee04adaef2dee9af207).
+
+## نصائح الاستخدام
+
+- يمكن استخدام BLIP-2 للتوليد النصي الشرطي بناءً على صورة وطلب نص اختياري. في وقت الاستدلال، يوصى باستخدام طريقة [`generate`] .
+- يمكن للمرء استخدام [`Blip2Processor`] لتحضير الصور للنموذج، وفك رموز معرّفات الرموز المتوقعة مرة أخرى إلى نص.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام BLIP-2.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ BLIP-2 لتعليق الصور، والإجابة على الأسئلة المرئية (VQA) والمحادثات الشبيهة بالدردشة [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BLIP-2).
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يوضح المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## Blip2Config
+
+[[autodoc]] Blip2Config
+
+- from_vision_qformer_text_configs
+
+## Blip2VisionConfig
+
+[[autodoc]] Blip2VisionConfig
+
+## Blip2QFormerConfig
+
+[[autodoc]] Blip2QFormerConfig
+
+## Blip2Processor
+
+[[autodoc]] Blip2Processor
+
+## Blip2VisionModel
+
+[[autodoc]] Blip2VisionModel
+
+- forward
+
+## Blip2QFormerModel
+
+[[autodoc]] Blip2QFormerModel
+
+- forward
+
+## Blip2Model
+
+[[autodoc]] Blip2Model
+
+- forward
+- get_text_features
+- get_image_features
+- get_qformer_features
+
+## Blip2ForConditionalGeneration
+
+[[autodoc]] Blip2ForConditionalGeneration
+
+- forward
+- generate
\ No newline at end of file
From 4227829a4fe00a7e1f49d6ef28c8c85d9ced08a8 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:23:42 +0300
Subject: [PATCH 384/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/blip.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/blip.md | 137 +++++++++++++++++++++++++++++++
1 file changed, 137 insertions(+)
create mode 100644 docs/source/ar/model_doc/blip.md
diff --git a/docs/source/ar/model_doc/blip.md b/docs/source/ar/model_doc/blip.md
new file mode 100644
index 00000000000000..10e904786c9f8e
--- /dev/null
+++ b/docs/source/ar/model_doc/blip.md
@@ -0,0 +1,137 @@
+# BLIP
+
+## نظرة عامة
+تم اقتراح نموذج BLIP في [BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) بواسطة Junnan Li, Dongxu Li, Caiming Xiong, Steven Hoi.
+
+BLIP هو نموذج قادر على أداء مهام متعددة الوسائط المختلفة بما في ذلك:
+
+- الإجابة على الأسئلة البصرية
+- استرجاع الصور والنصوص (مطابقة الصور والنصوص)
+- وضع تعليقات توضيحية على الصور
+
+ملخص الورقة البحثية هو كما يلي:
+
+*أدى التدريب المسبق للرؤية واللغة (VLP) إلى تقدم الأداء في العديد من مهام الرؤية واللغة. ومع ذلك، فإن معظم النماذج التي تم تدريبها مسبقًا لا تتفوق إلا في مهام الفهم أو المهام القائمة على التوليد. علاوة على ذلك، تم تحقيق تحسين الأداء إلى حد كبير عن طريق توسيع نطاق مجموعة البيانات باستخدام أزواج من الصور والنصوص الضخمة التي تم جمعها من الويب، والتي تعد مصدرًا غير مثاليًا للإشراف. في هذه الورقة، نقترح BLIP، وهو إطار عمل جديد لـ VLP ينتقل بمرونة إلى مهام الفهم وتوليد الرؤية واللغة. يستخدم BLIP البيانات الضخمة من الويب بشكل فعال من خلال تعزيز التعليقات التوضيحية، حيث تقوم أداة إنشاء التعليقات التوضيحية بتوليد تعليقات توضيحية اصطناعية وتقوم أداة الترشيح بإزالة غير النظيفة منها. نحقق نتائج متقدمة في مجموعة واسعة من مهام الرؤية واللغة، مثل استرجاع الصور والنصوص (+2.7% في متوسط الاستدعاء@1)، ووضع تعليقات توضيحية على الصور (+2.8% في CIDEr)، والإجابة على الأسئلة البصرية (+1.6% في درجة VQA). كما يظهر BLIP قدرة تعميم قوية عند نقله مباشرة إلى مهام اللغة المرئية بطريقة الصفر. تم إصدار الكود والنماذج ومجموعات البيانات.*
+
+
+
+تمت المساهمة بهذا النموذج بواسطة [ybelkada](https://huggingface.co/ybelkada). يمكن العثور على الكود الأصلي [هنا](https://github.com/salesforce/BLIP).
+
+## الموارد
+
+- [دفتر Jupyter](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) حول كيفية ضبط نموذج BLIP لوضع تعليقات توضيحية على الصور باستخدام مجموعة بيانات مخصصة
+
+## BlipConfig
+
+[[autodoc]] BlipConfig
+
+- from_text_vision_configs
+
+## BlipTextConfig
+
+[[autodoc]] BlipTextConfig
+
+## BlipVisionConfig
+
+[[autodoc]] BlipVisionConfig
+
+## BlipProcessor
+
+[[autodoc]] BlipProcessor
+
+## BlipImageProcessor
+
+[[autodoc]] BlipImageProcessor
+
+- preprocess
+
+ +
+ بنية BridgeTower. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل أناهيتا بهيوانديوالا، وتييب لي، وشاويين تسنغ. ويمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/BridgeTower).
+
+## نصائح الاستخدام وأمثلة
+
+يتكون BridgeTower من مشفر بصري ومشفر نصي ومشفر متعدد الأنماط مع طبقات جسر خفيفة متعددة. ويهدف هذا النهج إلى بناء جسر بين كل مشفر أحادي النمط والمشفر متعدد الأنماط لتمكين التفاعل الشامل والمفصل في كل طبقة من المشفر متعدد الأنماط.
+
+من حيث المبدأ، يمكن تطبيق أي مشفر بصري أو نصي أو متعدد الأنماط في البنية المقترحة.
+
+يغلف [`BridgeTowerProcessor`] كلاً من [`RobertaTokenizer`] و [`BridgeTowerImageProcessor`] في مثيل واحد لتشفير النص وإعداد الصور على التوالي.
+
+يوضح المثال التالي كيفية تشغيل التعلم التبايني باستخدام [`BridgeTowerProcessor`] و [`BridgeTowerForContrastiveLearning`].
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+يوضح المثال التالي كيفية تشغيل الاسترجاع الصوري النصي باستخدام [`BridgeTowerProcessor`] و [`BridgeTowerForImageAndTextRetrieval`].
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+يوضح المثال التالي كيفية تشغيل نمذجة اللغة المقنعة باستخدام [`BridgeTowerProcessor`] و [`BridgeTowerForMaskedLM`].
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a
+
+ بنية BridgeTower. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل أناهيتا بهيوانديوالا، وتييب لي، وشاويين تسنغ. ويمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/BridgeTower).
+
+## نصائح الاستخدام وأمثلة
+
+يتكون BridgeTower من مشفر بصري ومشفر نصي ومشفر متعدد الأنماط مع طبقات جسر خفيفة متعددة. ويهدف هذا النهج إلى بناء جسر بين كل مشفر أحادي النمط والمشفر متعدد الأنماط لتمكين التفاعل الشامل والمفصل في كل طبقة من المشفر متعدد الأنماط.
+
+من حيث المبدأ، يمكن تطبيق أي مشفر بصري أو نصي أو متعدد الأنماط في البنية المقترحة.
+
+يغلف [`BridgeTowerProcessor`] كلاً من [`RobertaTokenizer`] و [`BridgeTowerImageProcessor`] في مثيل واحد لتشفير النص وإعداد الصور على التوالي.
+
+يوضح المثال التالي كيفية تشغيل التعلم التبايني باستخدام [`BridgeTowerProcessor`] و [`BridgeTowerForContrastiveLearning`].
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs
+```
+
+يوضح المثال التالي كيفية تشغيل الاسترجاع الصوري النصي باستخدام [`BridgeTowerProcessor`] و [`BridgeTowerForImageAndTextRetrieval`].
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
+>>> import requests
+>>> from PIL import Image
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
+
+>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
+
+>>> # forward pass
+>>> scores = dict()
+>>> for text in texts:
+... # prepare inputs
+... encoding = processor(image, text, return_tensors="pt")
+... outputs = model(**encoding)
+... scores[text] = outputs.logits[0, 1].item()
+```
+
+يوضح المثال التالي كيفية تشغيل نمذجة اللغة المقنعة باستخدام [`BridgeTowerProcessor`] و [`BridgeTowerForMaskedLM`].
+
+```python
+>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+>>> text = "a  +
+نظرة عامة على CLIPSeg. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/timojl/clipseg).
+
+## نصائح الاستخدام
+
+- [`CLIPSegForImageSegmentation`] يضيف فك تشفير أعلى [`CLIPSegModel`]. هذا الأخير متطابق مع [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] يمكنه إنشاء تجزئات الصور بناءً على مطالبات تعسفية في وقت الاختبار. يمكن أن يكون المطالبة إما نصًا (مقدمًا إلى النموذج على أنه `input_ids`) أو صورة (مقدمة إلى النموذج على أنها `conditional_pixel_values`). يمكنك أيضًا توفير تضمينات شرطية مخصصة (مقدمة إلى النموذج على أنها `conditional_embeddings`).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام CLIPSeg. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يوضح المورد بشكل مثالي شيء جديد بدلاً من تكرار مورد موجود.
+
+
+
+نظرة عامة على CLIPSeg. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/timojl/clipseg).
+
+## نصائح الاستخدام
+
+- [`CLIPSegForImageSegmentation`] يضيف فك تشفير أعلى [`CLIPSegModel`]. هذا الأخير متطابق مع [`CLIPModel`].
+- [`CLIPSegForImageSegmentation`] يمكنه إنشاء تجزئات الصور بناءً على مطالبات تعسفية في وقت الاختبار. يمكن أن يكون المطالبة إما نصًا (مقدمًا إلى النموذج على أنه `input_ids`) أو صورة (مقدمة إلى النموذج على أنها `conditional_pixel_values`). يمكنك أيضًا توفير تضمينات شرطية مخصصة (مقدمة إلى النموذج على أنها `conditional_embeddings`).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام CLIPSeg. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يوضح المورد بشكل مثالي شيء جديد بدلاً من تكرار مورد موجود.
+
+ +
+ يظهر Conditional DETR تقاربًا أسرع بكثير مقارنة بـ DETR الأصلي. مأخوذ من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [DepuMeng](https://huggingface.co/DepuMeng). ويمكن العثور على الكود الأصلي [هنا](https://github.com/Atten4Vis/ConditionalDETR).
+
+## الموارد
+
+- يمكن العثور على البرامج النصية لضبط نموذج [`ConditionalDetrForObjectDetection`] باستخدام [`Trainer`] أو [Accelerate](https://huggingface.co/docs/accelerate/index) [هنا](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- راجع أيضًا: [دليل مهمة كشف الأشياء](../tasks/object_detection).
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+
+- preprocess
+- post_process_object_detection
+- post_process_instance_segmentation
+- post_process_semantic_segmentation
+- post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+
+- __call__
+- post_process_object_detection
+- post_process_instance_segmentation
+- post_process_semantic_segmentation
+- post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+
+- forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+
+- forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+
+- forward
\ No newline at end of file
From 34f13d2095e54f8f11fe62eb08daf22e3080b96e Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:24:12 +0300
Subject: [PATCH 401/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/convbert.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/convbert.md | 121 +++++++++++++++++++++++++++
1 file changed, 121 insertions(+)
create mode 100644 docs/source/ar/model_doc/convbert.md
diff --git a/docs/source/ar/model_doc/convbert.md b/docs/source/ar/model_doc/convbert.md
new file mode 100644
index 00000000000000..e520fcb34e2269
--- /dev/null
+++ b/docs/source/ar/model_doc/convbert.md
@@ -0,0 +1,121 @@
+# ConvBERT
+
+## نظرة عامة
+
+اقتُرح نموذج ConvBERT في [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) بواسطة Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+
+مقدمة الورقة البحثية هي التالية:
+
+*حققت نماذج اللغة المُدربة مسبقًا مثل BERT ومتغيراته أداءً مثيرًا للإعجاب في العديد من مهام فهم اللغة الطبيعية. ومع ذلك، يعتمد BERT بشكل كبير على كتلة الاهتمام الذاتي العالمي، وبالتالي يعاني من آثار ذاكرة كبيرة وتكلفة حوسبة عالية. على الرغم من أن جميع رؤوس اهتمامه تستفسر عن التسلسل الكامل للإدخال لإنشاء خريطة الاهتمام من منظور عالمي، إلا أننا نلاحظ أن بعض الرؤوس تحتاج فقط إلى تعلم التبعيات المحلية، مما يعني وجود حوسبة زائدة. لذلك، نقترح حوسبة ديناميكية جديدة تعتمد على النطاق لاستبدال رؤوس الاهتمام الذاتي هذه لنمذجة التبعيات المحلية مباشرةً. تشكل رؤوس الحوسبة الجديدة، جنبًا إلى جنب مع بقية رؤوس الاهتمام الذاتي، كتلة اهتمام مختلطة أكثر كفاءة في تعلم السياق العالمي والمحلي. نقوم بتجهيز BERT بتصميم الاهتمام المختلط هذا وبناء نموذج ConvBERT. وقد أظهرت التجارب أن ConvBERT يتفوق بشكل كبير على BERT ومتغيراته في مهام مختلفة، بتكلفة تدريب أقل وعدد أقل من معلمات النموذج. ومن المثير للاهتمام أن نموذج ConvBERTbase يحقق نتيجة 86.4 في اختبار GLUE، أي أعلى بـ 0.7 من نموذج ELECTRAbase، مع استخدام أقل من ربع تكلفة التدريب. سيتم إطلاق الكود والنماذج المُدربة مسبقًا.*
+
+تمت المساهمة بهذا النموذج من قبل [abhishek](https://huggingface.co/abhishek). ويمكن العثور على التنفيذ الأصلي هنا: https://github.com/yitu-opensource/ConvBert
+
+## نصائح الاستخدام
+
+نصائح تدريب ConvBERT مماثلة لتلك الخاصة بـ BERT. للاطلاع على نصائح الاستخدام، يرجى الرجوع إلى [توثيق BERT](bert).
+
+## الموارد
+
+- [دليل مهمة تصنيف النصوص](../tasks/sequence_classification)
+- [دليل مهمة تصنيف الرموز](../tasks/token_classification)
+- [دليل مهمة الإجابة على الأسئلة](../tasks/question_answering)
+- [دليل مهمة نمذجة اللغة المعقدة](../tasks/masked_language_modeling)
+- [دليل المهمة متعددة الخيارات](../tasks/multiple_choice)
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+
+
+ يظهر Conditional DETR تقاربًا أسرع بكثير مقارنة بـ DETR الأصلي. مأخوذ من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [DepuMeng](https://huggingface.co/DepuMeng). ويمكن العثور على الكود الأصلي [هنا](https://github.com/Atten4Vis/ConditionalDETR).
+
+## الموارد
+
+- يمكن العثور على البرامج النصية لضبط نموذج [`ConditionalDetrForObjectDetection`] باستخدام [`Trainer`] أو [Accelerate](https://huggingface.co/docs/accelerate/index) [هنا](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- راجع أيضًا: [دليل مهمة كشف الأشياء](../tasks/object_detection).
+
+## ConditionalDetrConfig
+
+[[autodoc]] ConditionalDetrConfig
+
+## ConditionalDetrImageProcessor
+
+[[autodoc]] ConditionalDetrImageProcessor
+
+- preprocess
+- post_process_object_detection
+- post_process_instance_segmentation
+- post_process_semantic_segmentation
+- post_process_panoptic_segmentation
+
+## ConditionalDetrFeatureExtractor
+
+[[autodoc]] ConditionalDetrFeatureExtractor
+
+- __call__
+- post_process_object_detection
+- post_process_instance_segmentation
+- post_process_semantic_segmentation
+- post_process_panoptic_segmentation
+
+## ConditionalDetrModel
+
+[[autodoc]] ConditionalDetrModel
+
+- forward
+
+## ConditionalDetrForObjectDetection
+
+[[autodoc]] ConditionalDetrForObjectDetection
+
+- forward
+
+## ConditionalDetrForSegmentation
+
+[[autodoc]] ConditionalDetrForSegmentation
+
+- forward
\ No newline at end of file
From 34f13d2095e54f8f11fe62eb08daf22e3080b96e Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:24:12 +0300
Subject: [PATCH 401/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/convbert.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/convbert.md | 121 +++++++++++++++++++++++++++
1 file changed, 121 insertions(+)
create mode 100644 docs/source/ar/model_doc/convbert.md
diff --git a/docs/source/ar/model_doc/convbert.md b/docs/source/ar/model_doc/convbert.md
new file mode 100644
index 00000000000000..e520fcb34e2269
--- /dev/null
+++ b/docs/source/ar/model_doc/convbert.md
@@ -0,0 +1,121 @@
+# ConvBERT
+
+## نظرة عامة
+
+اقتُرح نموذج ConvBERT في [ConvBERT: Improving BERT with Span-based Dynamic Convolution](https://arxiv.org/abs/2008.02496) بواسطة Zihang Jiang, Weihao Yu, Daquan Zhou, Yunpeng Chen, Jiashi Feng, Shuicheng Yan.
+
+مقدمة الورقة البحثية هي التالية:
+
+*حققت نماذج اللغة المُدربة مسبقًا مثل BERT ومتغيراته أداءً مثيرًا للإعجاب في العديد من مهام فهم اللغة الطبيعية. ومع ذلك، يعتمد BERT بشكل كبير على كتلة الاهتمام الذاتي العالمي، وبالتالي يعاني من آثار ذاكرة كبيرة وتكلفة حوسبة عالية. على الرغم من أن جميع رؤوس اهتمامه تستفسر عن التسلسل الكامل للإدخال لإنشاء خريطة الاهتمام من منظور عالمي، إلا أننا نلاحظ أن بعض الرؤوس تحتاج فقط إلى تعلم التبعيات المحلية، مما يعني وجود حوسبة زائدة. لذلك، نقترح حوسبة ديناميكية جديدة تعتمد على النطاق لاستبدال رؤوس الاهتمام الذاتي هذه لنمذجة التبعيات المحلية مباشرةً. تشكل رؤوس الحوسبة الجديدة، جنبًا إلى جنب مع بقية رؤوس الاهتمام الذاتي، كتلة اهتمام مختلطة أكثر كفاءة في تعلم السياق العالمي والمحلي. نقوم بتجهيز BERT بتصميم الاهتمام المختلط هذا وبناء نموذج ConvBERT. وقد أظهرت التجارب أن ConvBERT يتفوق بشكل كبير على BERT ومتغيراته في مهام مختلفة، بتكلفة تدريب أقل وعدد أقل من معلمات النموذج. ومن المثير للاهتمام أن نموذج ConvBERTbase يحقق نتيجة 86.4 في اختبار GLUE، أي أعلى بـ 0.7 من نموذج ELECTRAbase، مع استخدام أقل من ربع تكلفة التدريب. سيتم إطلاق الكود والنماذج المُدربة مسبقًا.*
+
+تمت المساهمة بهذا النموذج من قبل [abhishek](https://huggingface.co/abhishek). ويمكن العثور على التنفيذ الأصلي هنا: https://github.com/yitu-opensource/ConvBert
+
+## نصائح الاستخدام
+
+نصائح تدريب ConvBERT مماثلة لتلك الخاصة بـ BERT. للاطلاع على نصائح الاستخدام، يرجى الرجوع إلى [توثيق BERT](bert).
+
+## الموارد
+
+- [دليل مهمة تصنيف النصوص](../tasks/sequence_classification)
+- [دليل مهمة تصنيف الرموز](../tasks/token_classification)
+- [دليل مهمة الإجابة على الأسئلة](../tasks/question_answering)
+- [دليل مهمة نمذجة اللغة المعقدة](../tasks/masked_language_modeling)
+- [دليل المهمة متعددة الخيارات](../tasks/multiple_choice)
+
+## ConvBertConfig
+
+[[autodoc]] ConvBertConfig
+
+## ConvBertTokenizer
+
+[[autodoc]] ConvBertTokenizer
+
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## ConvBertTokenizerFast
+
+[[autodoc]] ConvBertTokenizerFast
+
+ +
+هندسة ConvNeXT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة في هذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). تمت المساهمة في إصدار TensorFlow من النموذج بواسطة [ariG23498](https://github.com/ariG23498) و [gante](https://github.com/gante) و [sayakpaul](https://github.com/sayakpaul) (مساهمة متساوية). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/ConvNeXt).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام ConvNeXT.
+
+
+
+هندسة ConvNeXT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة في هذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). تمت المساهمة في إصدار TensorFlow من النموذج بواسطة [ariG23498](https://github.com/ariG23498) و [gante](https://github.com/gante) و [sayakpaul](https://github.com/sayakpaul) (مساهمة متساوية). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/ConvNeXt).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام ConvNeXT.
+
+ +
+هندسة ConvNeXt V2. مأخوذة من الورقة الأصلية.
+
+ساهم بهذا النموذج [adirik](https://huggingface.co/adirik). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/ConvNeXt-V2).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام ConvNeXt V2.
+
+
+
+هندسة ConvNeXt V2. مأخوذة من الورقة الأصلية.
+
+ساهم بهذا النموذج [adirik](https://huggingface.co/adirik). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/ConvNeXt-V2).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام ConvNeXt V2.
+
+ +
+ بنية Deformable DETR. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). ويمكن العثور على الكود الأصلي [هنا](https://github.com/fundamentalvision/Deformable-DETR).
+
+## نصائح الاستخدام
+
+- تدريب Deformable DETR مكافئ لتدريب نموذج [DETR](detr) الأصلي. راجع قسم [الموارد](#الموارد) أدناه لمفكرات الملاحظات التوضيحية.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام Deformable DETR.
+
+
+
+ بنية Deformable DETR. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). ويمكن العثور على الكود الأصلي [هنا](https://github.com/fundamentalvision/Deformable-DETR).
+
+## نصائح الاستخدام
+
+- تدريب Deformable DETR مكافئ لتدريب نموذج [DETR](detr) الأصلي. راجع قسم [الموارد](#الموارد) أدناه لمفكرات الملاحظات التوضيحية.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام Deformable DETR.
+
+ +
+نظرة عامة على Depth Anything. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/LiheYoung/Depth-Anything).
+
+## مثال على الاستخدام
+
+هناك طريقتان رئيسيتان لاستخدام Depth Anything: إما باستخدام واجهة برمجة التطبيقات الخاصة بالخطوط الأنابيب، والتي تُبسِّط جميع التعقيدات لك، أو باستخدام فئة `DepthAnythingForDepthEstimation` بنفسك.
+
+### واجهة برمجة التطبيقات الخاصة بالخطوط الأنابيب
+
+تسمح واجهة برمجة التطبيقات باستخدام النموذج في بضع سطور من الكود:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # تحميل الأنبوب
+>>> pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
+
+>>> # تحميل الصورة
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # الاستنتاج
+>>> depth = pipe(image)["depth"]
+```
+
+### استخدام النموذج بنفسك
+
+إذا كنت تريد القيام بالمعالجة المسبقة واللاحقة بنفسك، فهذا هو كيفية القيام بذلك:
+
+```python
+>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+>>> import torch
+>>> import numpy as np
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-small-hf")
+>>> model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
+
+>>> # إعداد الصورة للنموذج
+>>> inputs = image_processor(images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+... predicted_depth = outputs.predicted_depth
+
+>>> # الاستيفاء إلى الحجم الأصلي
+>>> prediction = torch.nn.functional.interpolate(
+... predicted_depth.unsqueeze(1),
+... size=image.size[::-1],
+... mode="bicubic",
+... align_corners=False,
+... )
+
+>>> # تصور التنبؤ
+>>> output = prediction.squeeze().cpu().numpy()
+>>> formatted = (output * 255 / np.max(output)).astype("uint8")
+>>> depth = Image.fromarray(formatted)
+```
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام Depth Anything.
+
+- [دليل مهام تقدير العمق أحادي العين](../tasks/depth_estimation)
+- يمكن العثور على دفتر ملاحظات يُظهر الاستدلال باستخدام [`DepthAnythingForDepthEstimation`] [هنا](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Depth%20Anything/Predicting_depth_in_an_image_with_Depth_Anything.ipynb). 🌎
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## DepthAnythingConfig
+
+[[autodoc]] DepthAnythingConfig
+
+## DepthAnythingForDepthEstimation
+
+[[autodoc]] DepthAnythingForDepthEstimation
+
+- forward
\ No newline at end of file
From 868e766493eac024ca74f9cfaae2f7fb7e2aeb63 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:24:44 +0300
Subject: [PATCH 418/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/deta.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/deta.md | 52 ++++++++++++++++++++++++++++++++
1 file changed, 52 insertions(+)
create mode 100644 docs/source/ar/model_doc/deta.md
diff --git a/docs/source/ar/model_doc/deta.md b/docs/source/ar/model_doc/deta.md
new file mode 100644
index 00000000000000..8696d25882d67e
--- /dev/null
+++ b/docs/source/ar/model_doc/deta.md
@@ -0,0 +1,52 @@
+# DETA
+
+> هذا النموذج في وضع الصيانة فقط، ولا نقبل أي طلبات سحب جديدة لتغيير شفرته. إذا واجهتك أي مشكلات أثناء تشغيل هذا النموذج، يرجى إعادة تثبيت الإصدار الأخير الذي يدعم هذا النموذج: v4.40.2. يمكنك القيام بذلك عن طريق تشغيل الأمر التالي: `pip install -U transformers==4.40.2`.
+
+## نظرة عامة
+
+اقترح نموذج DETA في ورقة بحثية بعنوان [NMS Strikes Back](https://arxiv.org/abs/2212.06137) من قبل Jeffrey Ouyang-Zhang وJang Hyun Cho وXingyi Zhou وPhilipp Krähenbühl.
+
+يحسن DETA (اختصار لـ Detection Transformers with Assignment) [Deformable DETR](deformable_detr) عن طريق استبدال مطابقة Hungarian الثنائية المتماثلة بخسارة تعيين التسميات من واحد إلى كثير المستخدمة في أجهزة الكشف التقليدية مع الحد الأقصى لقمع غير أقصى (NMS). يؤدي هذا إلى مكاسب كبيرة تصل إلى 2.5 mAP.
+
+الملخص من الورقة هو كما يلي:
+
+> يحول محول الكشف (DETR) الاستعلامات مباشرة إلى كائنات فريدة من خلال استخدام المطابقة الثنائية المتماثلة أثناء التدريب ويمكّن الكشف عن الكائنات من النهاية إلى النهاية. مؤخرًا، تفوقت هذه النماذج على أجهزة الكشف التقليدية على COCO بأسلوب لا يمكن إنكاره. ومع ذلك، فإنها تختلف عن أجهزة الكشف التقليدية في العديد من التصميمات، بما في ذلك بنية النموذج وجداول التدريب، وبالتالي فإن فعالية المطابقة المتماثلة غير مفهومة تمامًا. في هذا العمل، نجري مقارنة صارمة بين المطابقة المتماثلة لـ Hungarian في DETRs وتعيينات التسميات من واحد إلى كثير في أجهزة الكشف التقليدية مع الإشراف غير الأقصى الأقصى (NMS). ومما يثير الدهشة أننا نلاحظ أن التعيينات من واحد إلى كثير مع NMS تتفوق باستمرار على المطابقة المتماثلة القياسية في نفس الإعداد، مع مكسب كبير يصل إلى 2.5 mAP. حقق مكتشفنا الذي يدرب Deformable-DETR مع تعيين التسمية المستندة إلى IoU 50.2 COCO mAP في غضون 12 فترة (جدول 1x) مع العمود الفقري ResNet50، متفوقًا على جميع أجهزة الكشف التقليدية أو القائمة على المحول الموجودة في هذا الإعداد. على مجموعات بيانات متعددة وجداول ومعماريات، نُظهر باستمرار أن المطابقة الثنائية غير ضرورية لمحولات الكشف القابلة للأداء. علاوة على ذلك، نعزو نجاح محولات الكشف إلى بنية المحول التعبيري.
+
+
+
+نظرة عامة على Depth Anything. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/LiheYoung/Depth-Anything).
+
+## مثال على الاستخدام
+
+هناك طريقتان رئيسيتان لاستخدام Depth Anything: إما باستخدام واجهة برمجة التطبيقات الخاصة بالخطوط الأنابيب، والتي تُبسِّط جميع التعقيدات لك، أو باستخدام فئة `DepthAnythingForDepthEstimation` بنفسك.
+
+### واجهة برمجة التطبيقات الخاصة بالخطوط الأنابيب
+
+تسمح واجهة برمجة التطبيقات باستخدام النموذج في بضع سطور من الكود:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # تحميل الأنبوب
+>>> pipe = pipeline(task="depth-estimation", model="LiheYoung/depth-anything-small-hf")
+
+>>> # تحميل الصورة
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # الاستنتاج
+>>> depth = pipe(image)["depth"]
+```
+
+### استخدام النموذج بنفسك
+
+إذا كنت تريد القيام بالمعالجة المسبقة واللاحقة بنفسك، فهذا هو كيفية القيام بذلك:
+
+```python
+>>> from transformers import AutoImageProcessor, AutoModelForDepthEstimation
+>>> import torch
+>>> import numpy as np
+>>> from PIL import Image
+>>> import requests
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> image_processor = AutoImageProcessor.from_pretrained("LiheYoung/depth-anything-small-hf")
+>>> model = AutoModelForDepthEstimation.from_pretrained("LiheYoung/depth-anything-small-hf")
+
+>>> # إعداد الصورة للنموذج
+>>> inputs = image_processor(images=image, return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+... predicted_depth = outputs.predicted_depth
+
+>>> # الاستيفاء إلى الحجم الأصلي
+>>> prediction = torch.nn.functional.interpolate(
+... predicted_depth.unsqueeze(1),
+... size=image.size[::-1],
+... mode="bicubic",
+... align_corners=False,
+... )
+
+>>> # تصور التنبؤ
+>>> output = prediction.squeeze().cpu().numpy()
+>>> formatted = (output * 255 / np.max(output)).astype("uint8")
+>>> depth = Image.fromarray(formatted)
+```
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام Depth Anything.
+
+- [دليل مهام تقدير العمق أحادي العين](../tasks/depth_estimation)
+- يمكن العثور على دفتر ملاحظات يُظهر الاستدلال باستخدام [`DepthAnythingForDepthEstimation`] [هنا](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Depth%20Anything/Predicting_depth_in_an_image_with_Depth_Anything.ipynb). 🌎
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## DepthAnythingConfig
+
+[[autodoc]] DepthAnythingConfig
+
+## DepthAnythingForDepthEstimation
+
+[[autodoc]] DepthAnythingForDepthEstimation
+
+- forward
\ No newline at end of file
From 868e766493eac024ca74f9cfaae2f7fb7e2aeb63 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:24:44 +0300
Subject: [PATCH 418/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/deta.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/deta.md | 52 ++++++++++++++++++++++++++++++++
1 file changed, 52 insertions(+)
create mode 100644 docs/source/ar/model_doc/deta.md
diff --git a/docs/source/ar/model_doc/deta.md b/docs/source/ar/model_doc/deta.md
new file mode 100644
index 00000000000000..8696d25882d67e
--- /dev/null
+++ b/docs/source/ar/model_doc/deta.md
@@ -0,0 +1,52 @@
+# DETA
+
+> هذا النموذج في وضع الصيانة فقط، ولا نقبل أي طلبات سحب جديدة لتغيير شفرته. إذا واجهتك أي مشكلات أثناء تشغيل هذا النموذج، يرجى إعادة تثبيت الإصدار الأخير الذي يدعم هذا النموذج: v4.40.2. يمكنك القيام بذلك عن طريق تشغيل الأمر التالي: `pip install -U transformers==4.40.2`.
+
+## نظرة عامة
+
+اقترح نموذج DETA في ورقة بحثية بعنوان [NMS Strikes Back](https://arxiv.org/abs/2212.06137) من قبل Jeffrey Ouyang-Zhang وJang Hyun Cho وXingyi Zhou وPhilipp Krähenbühl.
+
+يحسن DETA (اختصار لـ Detection Transformers with Assignment) [Deformable DETR](deformable_detr) عن طريق استبدال مطابقة Hungarian الثنائية المتماثلة بخسارة تعيين التسميات من واحد إلى كثير المستخدمة في أجهزة الكشف التقليدية مع الحد الأقصى لقمع غير أقصى (NMS). يؤدي هذا إلى مكاسب كبيرة تصل إلى 2.5 mAP.
+
+الملخص من الورقة هو كما يلي:
+
+> يحول محول الكشف (DETR) الاستعلامات مباشرة إلى كائنات فريدة من خلال استخدام المطابقة الثنائية المتماثلة أثناء التدريب ويمكّن الكشف عن الكائنات من النهاية إلى النهاية. مؤخرًا، تفوقت هذه النماذج على أجهزة الكشف التقليدية على COCO بأسلوب لا يمكن إنكاره. ومع ذلك، فإنها تختلف عن أجهزة الكشف التقليدية في العديد من التصميمات، بما في ذلك بنية النموذج وجداول التدريب، وبالتالي فإن فعالية المطابقة المتماثلة غير مفهومة تمامًا. في هذا العمل، نجري مقارنة صارمة بين المطابقة المتماثلة لـ Hungarian في DETRs وتعيينات التسميات من واحد إلى كثير في أجهزة الكشف التقليدية مع الإشراف غير الأقصى الأقصى (NMS). ومما يثير الدهشة أننا نلاحظ أن التعيينات من واحد إلى كثير مع NMS تتفوق باستمرار على المطابقة المتماثلة القياسية في نفس الإعداد، مع مكسب كبير يصل إلى 2.5 mAP. حقق مكتشفنا الذي يدرب Deformable-DETR مع تعيين التسمية المستندة إلى IoU 50.2 COCO mAP في غضون 12 فترة (جدول 1x) مع العمود الفقري ResNet50، متفوقًا على جميع أجهزة الكشف التقليدية أو القائمة على المحول الموجودة في هذا الإعداد. على مجموعات بيانات متعددة وجداول ومعماريات، نُظهر باستمرار أن المطابقة الثنائية غير ضرورية لمحولات الكشف القابلة للأداء. علاوة على ذلك، نعزو نجاح محولات الكشف إلى بنية المحول التعبيري.
+
+ +
+نظرة عامة على DETA. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/jozhang97/DETA).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام DETA.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ DETA [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA).
+- يمكن العثور على البرامج النصية لتدريب النماذج الدقيقة [`DetaForObjectDetection`] مع [`Trainer`] أو [Accelerate](https://huggingface.co/docs/accelerate/index) [هنا](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- راجع أيضًا: [دليل مهام الكشف عن الأشياء](../tasks/object_detection).
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## DetaConfig
+
+[[autodoc]] DetaConfig
+
+## DetaImageProcessor
+
+[[autodoc]] DetaImageProcessor
+
+- preprocess
+- post_process_object_detection
+
+## DetaModel
+
+[[autodoc]] DetaModel
+
+- forward
+
+## DetaForObjectDetection
+
+[[autodoc]] DetaForObjectDetection
+
+- forward
\ No newline at end of file
From cf114a4201a982396040c08cf7b12ead4f3cae4a Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:24:46 +0300
Subject: [PATCH 419/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/detr.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/detr.md | 150 +++++++++++++++++++++++++++++++
1 file changed, 150 insertions(+)
create mode 100644 docs/source/ar/model_doc/detr.md
diff --git a/docs/source/ar/model_doc/detr.md b/docs/source/ar/model_doc/detr.md
new file mode 100644
index 00000000000000..57f9cbcab5516a
--- /dev/null
+++ b/docs/source/ar/model_doc/detr.md
@@ -0,0 +1,150 @@
+# DETR
+
+## نظرة عامة
+
+اقتُرح نموذج DETR في ورقة "End-to-End Object Detection with Transformers" بواسطة Nicolas Carion وآخرين. يتكون نموذج DETR من شبكة عصبية تعاقبية تليها محول تشفير وفك تشفير يمكن تدريبهما من البداية إلى النهاية للكشف عن الأشياء. إنه يبسط كثيرًا من تعقيدات النماذج مثل Faster-R-CNN وMask-R-CNN، والتي تستخدم أشياء مثل اقتراحات المناطق، وإجراءات القمع غير القصوى، وتوليد المراسي. علاوة على ذلك، يمكن أيضًا توسيع نموذج DETR بشكل طبيعي لأداء التجزئة الشاملة، وذلك ببساطة عن طريق إضافة رأس قناع أعلى مخرجات فك التشفير.
+
+مقتطف من الورقة البحثية على النحو التالي:
+
+> "نقدم طريقة جديدة تنظر إلى الكشف عن الأشياء كمشكلة تنبؤ مجموعة مباشرة. يبسط نهجنا خط أنابيب الكشف، مما يزيل فعليًا الحاجة إلى العديد من المكونات المصممة يدويًا مثل إجراءات القمع غير القصوى أو توليد المرساة التي تشفر صراحة معرفتنا المسبقة بالمهمة. المكونات الرئيسية للإطار الجديد، المسمى محول الكشف أو DETR، هي خسارة عالمية قائمة على المجموعة تجبر التنبؤات الفريدة من خلال المطابقة الثنائية، وبنية محول الترميز وفك الترميز. بالنظر إلى مجموعة صغيرة ثابتة من استفسارات الكائن المُعلم، يُجري DETR استدلالًا حول علاقات الأشياء وسياق الصورة العالمي لإخراج مجموعة التنبؤات النهائية بالتوازي. النموذج الجديد مفهوميًا بسيط ولا يتطلب مكتبة متخصصة، على عكس العديد من الكاشفات الحديثة الأخرى. يُظهر DETR دقة وأداء وقت التشغيل على قدم المساواة مع خط الأساس Faster RCNN الراسخ والمحسّن جيدًا في مجموعة بيانات COCO الصعبة للكشف عن الأشياء. علاوة على ذلك، يمكن تعميم DETR بسهولة لإنتاج التجزئة الشاملة بطريقة موحدة. نُظهر أنه يتفوق بشكل كبير على خطوط الأساس التنافسية."
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/detr).
+
+## كيف يعمل DETR
+
+فيما يلي ملخص يوضح كيفية عمل [`~transformers.DetrForObjectDetection`].
+
+أولاً، يتم إرسال صورة عبر شبكة عصبية تعاقبية مُعلمة مسبقًا (في الورقة، يستخدم المؤلفون ResNet-50/ResNet-101). لنفترض أننا أضفنا أيضًا بُعد الدفعة. وهذا يعني أن المدخلات إلى الشبكة العصبية التعاقبية هي مصفوفة ذات شكل `(batch_size، 3، height، width)`، مع افتراض أن الصورة تحتوي على 3 قنوات لونية (RGB). تقوم الشبكة العصبية التعاقبية بإخراج خريطة ميزات ذات دقة أقل، عادةً ذات شكل `(batch_size، 2048، height/32، width/32)`. يتم بعد ذلك إسقاطها لمطابقة البعد المخفي لمحول DETR، والذي يكون `256` بشكل افتراضي، باستخدام طبقة `nn.Conv2D`. لذا، لدينا الآن مصفوفة ذات شكل `(batch_size، 256، height/32، width/32)`. بعد ذلك، يتم تسطيح خريطة الميزات وتعديلها للحصول على مصفوفة ذات شكل `(batch_size، seq_len، d_model)` = `(batch_size، width/32*height/32، 256)`. لذا، فإن أحد الاختلافات مع نماذج معالجة اللغات الطبيعية هو أن طول التسلسل أطول من المعتاد، ولكن مع `d_model` أصغر (والذي يكون عادةً 768 أو أعلى في نماذج معالجة اللغات الطبيعية).
+
+بعد ذلك، يتم إرسال هذا إلى المشفر، مما يؤدي إلى إخراج `encoder_hidden_states` بنفس الشكل (يمكن اعتبارها ميزات صورة). بعد ذلك، يتم إرسال ما يسمى بـ **استعلامات الكائن** عبر فك التشفير. هذه مصفوفة ذات شكل `(batch_size، num_queries، d_model)`، مع `num_queries` يتم تعيينها عادةً إلى 100 وإعدادها إلى الصفر. هذه المدخلات هي ترميزات موضع مُعلمة يشير إليها المؤلفون باستعلامات الكائن، وعلى غرار المشفر، يتم إضافتها إلى إدخال كل طبقة اهتمام. سيبحث كل استعلام كائن عن كائن معين في الصورة. يقوم فك التشفير بتحديث هذه الترميزات من خلال طبقات اهتمام ذاتية واهتمام بتشفير وفك تشفير متعددة لإخراج `decoder_hidden_states` بنفس الشكل: `(batch_size، num_queries، d_model)`. بعد ذلك، يتم إضافة رأسين لأعلى للكشف عن الأشياء: طبقة خطية لتصنيف كل استعلام كائن إلى أحد الأشياء أو "لا شيء"، وMLP للتنبؤ بحدود الإحداثيات لكل استعلام.
+
+يتم تدريب النموذج باستخدام **خسارة المطابقة الثنائية**: لذا ما نفعله بالفعل هو مقارنة الفئات المتنبأ بها + حدود الإحداثيات لكل من استعلامات N = 100 مع التعليقات التوضيحية الأرضية الحقيقة، مع توسيع نطاقها إلى نفس الطول N (لذا، إذا كانت الصورة تحتوي على 4 أشياء فقط، فستحتوي 96 تعليق توضيحي فقط على "لا شيء" كفئة و"لا حدود إحداثيات" كحدود إحداثيات). يتم استخدام خوارزمية المطابقة الهنغارية للعثور على خريطة واحدة لواحدة مثالية لكل من الاستعلامات N والتعليقات N. بعد ذلك، يتم استخدام الانحدار اللوغاريتمي (للطبقات) ومزيج خطي من L1 و [خسارة IoU العامة](https://giou.stanford.edu/) (لحدود الإحداثيات) لتحسين معلمات النموذج.
+
+يمكن توسيع نموذج DETR بشكل طبيعي لأداء التجزئة الشاملة (التي توحد التجزئة الدلالية وتجزئة المثيل). يضيف [`~transformers.DetrForSegmentation`] رأس قناع أعلى [`~transformers.DetrForObjectDetection`]. يمكن تدريب رأس القناع إما بشكل مشترك، أو في عملية من خطوتين، حيث يتم أولاً تدريب نموذج [`~transformers.DetrForObjectDetection`] للكشف عن حدود الإحداثيات حول كل من "الأشياء" (المثيلات) و"الأشياء" (أشياء الخلفية مثل الأشجار والطرق والسماء)، ثم يتم تجميد جميع الأوزان وتدريب رأس القناع فقط لمدة 25 حقبة. تجريبياً، تعطي هاتان المقاربتان نتائج مماثلة. لاحظ أن التنبؤ بالحدود مطلوب لإمكانية التدريب، حيث يتم حساب المطابقة الهنغارية باستخدام المسافات بين الحدود.
+
+## نصائح الاستخدام
+
+- يستخدم نموذج DETR ما يسمى بـ **استعلامات الكائن** للكشف عن الأشياء في صورة. يحدد عدد الاستعلامات العدد الأقصى للأشياء التي يمكن اكتشافها في صورة واحدة، وهو مضبوط على 100 بشكل افتراضي (راجع معلمة `num_queries` من [`~transformers.DetrConfig`]). لاحظ أنه من الجيد أن يكون هناك بعض المرونة (في COCO، استخدم المؤلفون 100، في حين أن العدد الأقصى للأشياء في صورة COCO هو ~70).
+
+- يقوم فك تشفير نموذج DETR بتحديث ترميزات الاستعلام بالتوازي. هذا يختلف عن نماذج اللغة مثل GPT-2، والتي تستخدم فك تشفير ذاتي الرجوع بدلاً من ذلك. وبالتالي، لا يتم استخدام قناع اهتمام سببي.
+
+- يضيف نموذج DETR ترميزات الموضع إلى الحالات المخفية في كل طبقة اهتمام ذاتي واهتمام متعدد قبل إسقاطها إلى استعلامات ومفاتيح. بالنسبة لترميزات موضع الصورة، يمكن للمرء أن يختار بين ترميزات موضع ثابتة أو تعلمية. بشكل افتراضي، يتم ضبط معلمة `position_embedding_type` من [`~transformers.DetrConfig`] على `"sine"`.
+
+- أثناء التدريب، وجد مؤلفو نموذج DETR أنه من المفيد استخدام خسائر مساعدة في فك التشفير، خاصة لمساعدة النموذج على إخراج العدد الصحيح من الأشياء لكل فئة. إذا قمت بتعيين معلمة `auxiliary_loss` من [`~transformers.DetrConfig`] إلى `True`، فسيتم إضافة شبكات عصبية أمامية وخسائر هنغارية بعد كل طبقة فك تشفير (مع مشاركة FFNs للمعلمات).
+
+- إذا كنت تريد تدريب النموذج في بيئة موزعة عبر عدة عقد، فيجب عليك تحديث متغير _num_boxes_ في فئة _DetrLoss_ من _modeling_detr.py_. عند التدريب على عدة عقد، يجب تعيين هذا إلى متوسط عدد الصناديق المستهدفة عبر جميع العقد، كما هو موضح في التنفيذ الأصلي [هنا](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232).
+
+- يمكن تهيئة [`~transformers.DetrForObjectDetection`] و [`~transformers.DetrForSegmentation`] بأي شبكة عصبية تعاقبية متوفرة في [مكتبة timm](https://github.com/rwightman/pytorch-image-models). يمكن تهيئة نموذج مع شبكة عصبية تعاقبية MobileNet على سبيل المثال عن طريق تعيين سمة `backbone` من [`~transformers.DetrConfig`] إلى `"tf_mobilenetv3_small_075"`، ثم تهيئة النموذج باستخدام هذا التكوين.
+
+- يقوم نموذج DETR بتغيير حجم الصور المدخلة بحيث يكون الجانب الأقصر على الأقل عددًا معينًا من البكسلات في حين أن الأطول هو 1333 بكسل كحد أقصى. أثناء التدريب، يتم استخدام زيادة حجم المقياس بحيث يكون الجانب الأقصر عشوائيًا على الأقل 480 بكسل وكحد أقصى 800 بكسل. أثناء الاستدلال، يتم تعيين الجانب الأقصر إلى 800. يمكن استخدام [`~transformers.DetrImageProcessor`] لإعداد الصور (والتعليقات التوضيحية الاختيارية بتنسيق COCO) للنموذج. نظرًا لهذا التغيير في الحجم، يمكن أن يكون للصور في دفعة أحجام مختلفة. يحل نموذج DETR هذه المشكلة عن طريق إضافة صور إلى الحجم الأكبر في دفعة، وعن طريق إنشاء قناع بكسل يشير إلى البكسلات الحقيقية/الوسادات. بدلاً من ذلك، يمكن للمرء أيضًا تحديد دالة تجميع مخصصة من أجل تجميع الصور معًا، باستخدام [`~transformers.DetrImageProcessor.pad_and_create_pixel_mask`].
+
+- سيحدد حجم الصور مقدار الذاكرة المستخدمة، وبالتالي سيحدد `batch_size`. يُنصح باستخدام حجم دفعة يبلغ 2 لكل GPU. راجع [خيط GitHub](https://github.com/facebookresearch/detr/issues/150) هذا لمزيد من المعلومات.
+
+هناك ثلاث طرق لتهيئة نموذج DETR (حسب تفضيلك):
+
+الخيار 1: تهيئة نموذج DETR بأوزان مُعلمة مسبقًا للنموذج بالكامل
+
+```py
+>>> from transformers import DetrForObjectDetection
+
+>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
+```
+
+الخيار 2: تهيئة نموذج DETR بأوزان مُعلمة مسبقًا للشبكة العصبية التعاقبية، ولكن بأوزان مُعلمة مسبقًا لمحول الترميز وفك الترميز
+
+```py
+>>> from transformers import DetrConfig, DetrForObjectDetection
+
+>>> config = DetrConfig()
+>>> model = DetrForObjectDetection(config)
+```
+
+الخيار 3: تهيئة نموذج DETR بأوزان مُعلمة مسبقًا للشبكة العصبية التعاقبية + محول الترميز وفك الترميز
+
+```py
+>>> config = DetrConfig(use_pretrained_backbone=False)
+>>> model = DetrForObjectDetection(config)
+```
+
+كملخص، ضع في اعتبارك الجدول التالي:
+
+| المهمة | الكشف عن الأشياء | تجزئة المثيل | التجزئة الشاملة |
+|------|------------------|-----------------------|-----------------------|
+| **الوصف** | التنبؤ بحدود الإحداثيات وتصنيفات الفئات حول الأشياء في صورة | التنبؤ بأقنعة حول الأشياء (أي المثيلات) في صورة | التنبؤ بأقنعة حول كل من الأشياء (أي المثيلات) وكذلك "الأشياء" (أي أشياء الخلفية مثل الأشجار والطرق) في صورة |
+| **النموذج** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
+| **مجموعة البيانات النموذجية** | COCO detection | COCO detection، COCO panoptic | COCO panoptic |
+| **تنسيق التعليقات التوضيحية لتوفيرها إلى** [`~transformers.DetrImageProcessor`] | {'image_id': `int`، 'annotations': `List [Dict]`} كل Dict عبارة عن تعليق توضيحي لكائن COCO | {'image_id': `int`، 'annotations': `List [Dict]`} (في حالة الكشف عن COCO) أو {'file_name': `str`، 'image_id': `int`، 'segments_info': `List [Dict]`} (في حالة COCO panoptic) | {'file_name': `str`، 'image_id': `int`، 'segments_info': `List [Dict]`} و masks_path (مسار إلى الدليل الذي يحتوي على ملفات PNG للأقنعة) |
+| **ما بعد المعالجة** (أي تحويل إخراج النموذج إلى تنسيق Pascal VOC) | [`~transformers.DetrImageProcessor.post_process`] | [`~transformers.DetrImageProcessor.post_process_segmentation`] | [`~transformers.DetrImageProcessor.post_process_segmentation`]`، [`~transformers.DetrImageProcessor.post_process_panoptic`] |
+| **المقيمون** | `CocoEvaluator` مع `iou_types="bbox"` | `CocoEvaluator` مع `iou_types="bbox"` أو `"segm"` | `CocoEvaluator` مع `iou_tupes="bbox"` أو `"segm"`، `PanopticEvaluator` |
+
+باختصار، يجب إعداد البيانات بتنسيق COCO detection أو COCO panoptic، ثم استخدام [`~transformers.DetrImageProcessor`] لإنشاء `pixel_values`، `pixel_mask`، والتعليقات التوضيحية الاختيارية `labels`، والتي يمكن بعد ذلك استخدامها لتدريب (أو ضبط دقيق) نموذج. للتقويم، يجب أولاً تحويل مخرجات النموذج باستخدام إحدى طرق ما بعد المعالجة من [`~transformers.DetrImageProcessor`]. يمكن بعد ذلك توفير هذه المخرجات إلى `CocoEvaluator` أو `PanopticEvaluator`، والتي تتيح لك حساب مقاييس مثل متوسط الدقة (mAP) والجودة الشاملة (PQ). يتم تنفيذ هذه الكائنات في [المستودع الأصلي](https://github.com/facebookresearch/detr). راجع [دفاتر الملاحظات التوضيحية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) للحصول على مزيد من المعلومات حول التقييم.
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (يشار إليها برمز 🌎) لمساعدتك في البدء مع DETR.
+
+
+نظرة عامة على DETA. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/jozhang97/DETA).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام DETA.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ DETA [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETA).
+- يمكن العثور على البرامج النصية لتدريب النماذج الدقيقة [`DetaForObjectDetection`] مع [`Trainer`] أو [Accelerate](https://huggingface.co/docs/accelerate/index) [هنا](https://github.com/huggingface/transformers/tree/main/examples/pytorch/object-detection).
+- راجع أيضًا: [دليل مهام الكشف عن الأشياء](../tasks/object_detection).
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## DetaConfig
+
+[[autodoc]] DetaConfig
+
+## DetaImageProcessor
+
+[[autodoc]] DetaImageProcessor
+
+- preprocess
+- post_process_object_detection
+
+## DetaModel
+
+[[autodoc]] DetaModel
+
+- forward
+
+## DetaForObjectDetection
+
+[[autodoc]] DetaForObjectDetection
+
+- forward
\ No newline at end of file
From cf114a4201a982396040c08cf7b12ead4f3cae4a Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:24:46 +0300
Subject: [PATCH 419/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/detr.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/detr.md | 150 +++++++++++++++++++++++++++++++
1 file changed, 150 insertions(+)
create mode 100644 docs/source/ar/model_doc/detr.md
diff --git a/docs/source/ar/model_doc/detr.md b/docs/source/ar/model_doc/detr.md
new file mode 100644
index 00000000000000..57f9cbcab5516a
--- /dev/null
+++ b/docs/source/ar/model_doc/detr.md
@@ -0,0 +1,150 @@
+# DETR
+
+## نظرة عامة
+
+اقتُرح نموذج DETR في ورقة "End-to-End Object Detection with Transformers" بواسطة Nicolas Carion وآخرين. يتكون نموذج DETR من شبكة عصبية تعاقبية تليها محول تشفير وفك تشفير يمكن تدريبهما من البداية إلى النهاية للكشف عن الأشياء. إنه يبسط كثيرًا من تعقيدات النماذج مثل Faster-R-CNN وMask-R-CNN، والتي تستخدم أشياء مثل اقتراحات المناطق، وإجراءات القمع غير القصوى، وتوليد المراسي. علاوة على ذلك، يمكن أيضًا توسيع نموذج DETR بشكل طبيعي لأداء التجزئة الشاملة، وذلك ببساطة عن طريق إضافة رأس قناع أعلى مخرجات فك التشفير.
+
+مقتطف من الورقة البحثية على النحو التالي:
+
+> "نقدم طريقة جديدة تنظر إلى الكشف عن الأشياء كمشكلة تنبؤ مجموعة مباشرة. يبسط نهجنا خط أنابيب الكشف، مما يزيل فعليًا الحاجة إلى العديد من المكونات المصممة يدويًا مثل إجراءات القمع غير القصوى أو توليد المرساة التي تشفر صراحة معرفتنا المسبقة بالمهمة. المكونات الرئيسية للإطار الجديد، المسمى محول الكشف أو DETR، هي خسارة عالمية قائمة على المجموعة تجبر التنبؤات الفريدة من خلال المطابقة الثنائية، وبنية محول الترميز وفك الترميز. بالنظر إلى مجموعة صغيرة ثابتة من استفسارات الكائن المُعلم، يُجري DETR استدلالًا حول علاقات الأشياء وسياق الصورة العالمي لإخراج مجموعة التنبؤات النهائية بالتوازي. النموذج الجديد مفهوميًا بسيط ولا يتطلب مكتبة متخصصة، على عكس العديد من الكاشفات الحديثة الأخرى. يُظهر DETR دقة وأداء وقت التشغيل على قدم المساواة مع خط الأساس Faster RCNN الراسخ والمحسّن جيدًا في مجموعة بيانات COCO الصعبة للكشف عن الأشياء. علاوة على ذلك، يمكن تعميم DETR بسهولة لإنتاج التجزئة الشاملة بطريقة موحدة. نُظهر أنه يتفوق بشكل كبير على خطوط الأساس التنافسية."
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/detr).
+
+## كيف يعمل DETR
+
+فيما يلي ملخص يوضح كيفية عمل [`~transformers.DetrForObjectDetection`].
+
+أولاً، يتم إرسال صورة عبر شبكة عصبية تعاقبية مُعلمة مسبقًا (في الورقة، يستخدم المؤلفون ResNet-50/ResNet-101). لنفترض أننا أضفنا أيضًا بُعد الدفعة. وهذا يعني أن المدخلات إلى الشبكة العصبية التعاقبية هي مصفوفة ذات شكل `(batch_size، 3، height، width)`، مع افتراض أن الصورة تحتوي على 3 قنوات لونية (RGB). تقوم الشبكة العصبية التعاقبية بإخراج خريطة ميزات ذات دقة أقل، عادةً ذات شكل `(batch_size، 2048، height/32، width/32)`. يتم بعد ذلك إسقاطها لمطابقة البعد المخفي لمحول DETR، والذي يكون `256` بشكل افتراضي، باستخدام طبقة `nn.Conv2D`. لذا، لدينا الآن مصفوفة ذات شكل `(batch_size، 256، height/32، width/32)`. بعد ذلك، يتم تسطيح خريطة الميزات وتعديلها للحصول على مصفوفة ذات شكل `(batch_size، seq_len، d_model)` = `(batch_size، width/32*height/32، 256)`. لذا، فإن أحد الاختلافات مع نماذج معالجة اللغات الطبيعية هو أن طول التسلسل أطول من المعتاد، ولكن مع `d_model` أصغر (والذي يكون عادةً 768 أو أعلى في نماذج معالجة اللغات الطبيعية).
+
+بعد ذلك، يتم إرسال هذا إلى المشفر، مما يؤدي إلى إخراج `encoder_hidden_states` بنفس الشكل (يمكن اعتبارها ميزات صورة). بعد ذلك، يتم إرسال ما يسمى بـ **استعلامات الكائن** عبر فك التشفير. هذه مصفوفة ذات شكل `(batch_size، num_queries، d_model)`، مع `num_queries` يتم تعيينها عادةً إلى 100 وإعدادها إلى الصفر. هذه المدخلات هي ترميزات موضع مُعلمة يشير إليها المؤلفون باستعلامات الكائن، وعلى غرار المشفر، يتم إضافتها إلى إدخال كل طبقة اهتمام. سيبحث كل استعلام كائن عن كائن معين في الصورة. يقوم فك التشفير بتحديث هذه الترميزات من خلال طبقات اهتمام ذاتية واهتمام بتشفير وفك تشفير متعددة لإخراج `decoder_hidden_states` بنفس الشكل: `(batch_size، num_queries، d_model)`. بعد ذلك، يتم إضافة رأسين لأعلى للكشف عن الأشياء: طبقة خطية لتصنيف كل استعلام كائن إلى أحد الأشياء أو "لا شيء"، وMLP للتنبؤ بحدود الإحداثيات لكل استعلام.
+
+يتم تدريب النموذج باستخدام **خسارة المطابقة الثنائية**: لذا ما نفعله بالفعل هو مقارنة الفئات المتنبأ بها + حدود الإحداثيات لكل من استعلامات N = 100 مع التعليقات التوضيحية الأرضية الحقيقة، مع توسيع نطاقها إلى نفس الطول N (لذا، إذا كانت الصورة تحتوي على 4 أشياء فقط، فستحتوي 96 تعليق توضيحي فقط على "لا شيء" كفئة و"لا حدود إحداثيات" كحدود إحداثيات). يتم استخدام خوارزمية المطابقة الهنغارية للعثور على خريطة واحدة لواحدة مثالية لكل من الاستعلامات N والتعليقات N. بعد ذلك، يتم استخدام الانحدار اللوغاريتمي (للطبقات) ومزيج خطي من L1 و [خسارة IoU العامة](https://giou.stanford.edu/) (لحدود الإحداثيات) لتحسين معلمات النموذج.
+
+يمكن توسيع نموذج DETR بشكل طبيعي لأداء التجزئة الشاملة (التي توحد التجزئة الدلالية وتجزئة المثيل). يضيف [`~transformers.DetrForSegmentation`] رأس قناع أعلى [`~transformers.DetrForObjectDetection`]. يمكن تدريب رأس القناع إما بشكل مشترك، أو في عملية من خطوتين، حيث يتم أولاً تدريب نموذج [`~transformers.DetrForObjectDetection`] للكشف عن حدود الإحداثيات حول كل من "الأشياء" (المثيلات) و"الأشياء" (أشياء الخلفية مثل الأشجار والطرق والسماء)، ثم يتم تجميد جميع الأوزان وتدريب رأس القناع فقط لمدة 25 حقبة. تجريبياً، تعطي هاتان المقاربتان نتائج مماثلة. لاحظ أن التنبؤ بالحدود مطلوب لإمكانية التدريب، حيث يتم حساب المطابقة الهنغارية باستخدام المسافات بين الحدود.
+
+## نصائح الاستخدام
+
+- يستخدم نموذج DETR ما يسمى بـ **استعلامات الكائن** للكشف عن الأشياء في صورة. يحدد عدد الاستعلامات العدد الأقصى للأشياء التي يمكن اكتشافها في صورة واحدة، وهو مضبوط على 100 بشكل افتراضي (راجع معلمة `num_queries` من [`~transformers.DetrConfig`]). لاحظ أنه من الجيد أن يكون هناك بعض المرونة (في COCO، استخدم المؤلفون 100، في حين أن العدد الأقصى للأشياء في صورة COCO هو ~70).
+
+- يقوم فك تشفير نموذج DETR بتحديث ترميزات الاستعلام بالتوازي. هذا يختلف عن نماذج اللغة مثل GPT-2، والتي تستخدم فك تشفير ذاتي الرجوع بدلاً من ذلك. وبالتالي، لا يتم استخدام قناع اهتمام سببي.
+
+- يضيف نموذج DETR ترميزات الموضع إلى الحالات المخفية في كل طبقة اهتمام ذاتي واهتمام متعدد قبل إسقاطها إلى استعلامات ومفاتيح. بالنسبة لترميزات موضع الصورة، يمكن للمرء أن يختار بين ترميزات موضع ثابتة أو تعلمية. بشكل افتراضي، يتم ضبط معلمة `position_embedding_type` من [`~transformers.DetrConfig`] على `"sine"`.
+
+- أثناء التدريب، وجد مؤلفو نموذج DETR أنه من المفيد استخدام خسائر مساعدة في فك التشفير، خاصة لمساعدة النموذج على إخراج العدد الصحيح من الأشياء لكل فئة. إذا قمت بتعيين معلمة `auxiliary_loss` من [`~transformers.DetrConfig`] إلى `True`، فسيتم إضافة شبكات عصبية أمامية وخسائر هنغارية بعد كل طبقة فك تشفير (مع مشاركة FFNs للمعلمات).
+
+- إذا كنت تريد تدريب النموذج في بيئة موزعة عبر عدة عقد، فيجب عليك تحديث متغير _num_boxes_ في فئة _DetrLoss_ من _modeling_detr.py_. عند التدريب على عدة عقد، يجب تعيين هذا إلى متوسط عدد الصناديق المستهدفة عبر جميع العقد، كما هو موضح في التنفيذ الأصلي [هنا](https://github.com/facebookresearch/detr/blob/a54b77800eb8e64e3ad0d8237789fcbf2f8350c5/models/detr.py#L227-L232).
+
+- يمكن تهيئة [`~transformers.DetrForObjectDetection`] و [`~transformers.DetrForSegmentation`] بأي شبكة عصبية تعاقبية متوفرة في [مكتبة timm](https://github.com/rwightman/pytorch-image-models). يمكن تهيئة نموذج مع شبكة عصبية تعاقبية MobileNet على سبيل المثال عن طريق تعيين سمة `backbone` من [`~transformers.DetrConfig`] إلى `"tf_mobilenetv3_small_075"`، ثم تهيئة النموذج باستخدام هذا التكوين.
+
+- يقوم نموذج DETR بتغيير حجم الصور المدخلة بحيث يكون الجانب الأقصر على الأقل عددًا معينًا من البكسلات في حين أن الأطول هو 1333 بكسل كحد أقصى. أثناء التدريب، يتم استخدام زيادة حجم المقياس بحيث يكون الجانب الأقصر عشوائيًا على الأقل 480 بكسل وكحد أقصى 800 بكسل. أثناء الاستدلال، يتم تعيين الجانب الأقصر إلى 800. يمكن استخدام [`~transformers.DetrImageProcessor`] لإعداد الصور (والتعليقات التوضيحية الاختيارية بتنسيق COCO) للنموذج. نظرًا لهذا التغيير في الحجم، يمكن أن يكون للصور في دفعة أحجام مختلفة. يحل نموذج DETR هذه المشكلة عن طريق إضافة صور إلى الحجم الأكبر في دفعة، وعن طريق إنشاء قناع بكسل يشير إلى البكسلات الحقيقية/الوسادات. بدلاً من ذلك، يمكن للمرء أيضًا تحديد دالة تجميع مخصصة من أجل تجميع الصور معًا، باستخدام [`~transformers.DetrImageProcessor.pad_and_create_pixel_mask`].
+
+- سيحدد حجم الصور مقدار الذاكرة المستخدمة، وبالتالي سيحدد `batch_size`. يُنصح باستخدام حجم دفعة يبلغ 2 لكل GPU. راجع [خيط GitHub](https://github.com/facebookresearch/detr/issues/150) هذا لمزيد من المعلومات.
+
+هناك ثلاث طرق لتهيئة نموذج DETR (حسب تفضيلك):
+
+الخيار 1: تهيئة نموذج DETR بأوزان مُعلمة مسبقًا للنموذج بالكامل
+
+```py
+>>> from transformers import DetrForObjectDetection
+
+>>> model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50")
+```
+
+الخيار 2: تهيئة نموذج DETR بأوزان مُعلمة مسبقًا للشبكة العصبية التعاقبية، ولكن بأوزان مُعلمة مسبقًا لمحول الترميز وفك الترميز
+
+```py
+>>> from transformers import DetrConfig, DetrForObjectDetection
+
+>>> config = DetrConfig()
+>>> model = DetrForObjectDetection(config)
+```
+
+الخيار 3: تهيئة نموذج DETR بأوزان مُعلمة مسبقًا للشبكة العصبية التعاقبية + محول الترميز وفك الترميز
+
+```py
+>>> config = DetrConfig(use_pretrained_backbone=False)
+>>> model = DetrForObjectDetection(config)
+```
+
+كملخص، ضع في اعتبارك الجدول التالي:
+
+| المهمة | الكشف عن الأشياء | تجزئة المثيل | التجزئة الشاملة |
+|------|------------------|-----------------------|-----------------------|
+| **الوصف** | التنبؤ بحدود الإحداثيات وتصنيفات الفئات حول الأشياء في صورة | التنبؤ بأقنعة حول الأشياء (أي المثيلات) في صورة | التنبؤ بأقنعة حول كل من الأشياء (أي المثيلات) وكذلك "الأشياء" (أي أشياء الخلفية مثل الأشجار والطرق) في صورة |
+| **النموذج** | [`~transformers.DetrForObjectDetection`] | [`~transformers.DetrForSegmentation`] | [`~transformers.DetrForSegmentation`] |
+| **مجموعة البيانات النموذجية** | COCO detection | COCO detection، COCO panoptic | COCO panoptic |
+| **تنسيق التعليقات التوضيحية لتوفيرها إلى** [`~transformers.DetrImageProcessor`] | {'image_id': `int`، 'annotations': `List [Dict]`} كل Dict عبارة عن تعليق توضيحي لكائن COCO | {'image_id': `int`، 'annotations': `List [Dict]`} (في حالة الكشف عن COCO) أو {'file_name': `str`، 'image_id': `int`، 'segments_info': `List [Dict]`} (في حالة COCO panoptic) | {'file_name': `str`، 'image_id': `int`، 'segments_info': `List [Dict]`} و masks_path (مسار إلى الدليل الذي يحتوي على ملفات PNG للأقنعة) |
+| **ما بعد المعالجة** (أي تحويل إخراج النموذج إلى تنسيق Pascal VOC) | [`~transformers.DetrImageProcessor.post_process`] | [`~transformers.DetrImageProcessor.post_process_segmentation`] | [`~transformers.DetrImageProcessor.post_process_segmentation`]`، [`~transformers.DetrImageProcessor.post_process_panoptic`] |
+| **المقيمون** | `CocoEvaluator` مع `iou_types="bbox"` | `CocoEvaluator` مع `iou_types="bbox"` أو `"segm"` | `CocoEvaluator` مع `iou_tupes="bbox"` أو `"segm"`، `PanopticEvaluator` |
+
+باختصار، يجب إعداد البيانات بتنسيق COCO detection أو COCO panoptic، ثم استخدام [`~transformers.DetrImageProcessor`] لإنشاء `pixel_values`، `pixel_mask`، والتعليقات التوضيحية الاختيارية `labels`، والتي يمكن بعد ذلك استخدامها لتدريب (أو ضبط دقيق) نموذج. للتقويم، يجب أولاً تحويل مخرجات النموذج باستخدام إحدى طرق ما بعد المعالجة من [`~transformers.DetrImageProcessor`]. يمكن بعد ذلك توفير هذه المخرجات إلى `CocoEvaluator` أو `PanopticEvaluator`، والتي تتيح لك حساب مقاييس مثل متوسط الدقة (mAP) والجودة الشاملة (PQ). يتم تنفيذ هذه الكائنات في [المستودع الأصلي](https://github.com/facebookresearch/detr). راجع [دفاتر الملاحظات التوضيحية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR) للحصول على مزيد من المعلومات حول التقييم.
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (يشار إليها برمز 🌎) لمساعدتك في البدء مع DETR.
+ +
+ ملخص النهج. مأخوذ من [الورقة الأصلية](https://arxiv.org/abs/2203.02378).
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/unilm/tree/master/dit).
+
+## نصائح الاستخدام
+
+يمكن للمرء استخدام أوزان DiT مباشرة مع واجهة برمجة تطبيقات AutoModel:
+
+```python
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("microsoft/dit-base")
+```
+
+سيؤدي هذا إلى تحميل النموذج الذي تم تدريبه مسبقًا على نمذجة الصور المقنعة. لاحظ أن هذا لن يتضمن رأس نمذجة اللغة في الأعلى، والذي يستخدم للتنبؤ بالرموز البصرية.
+
+لإدراج الرأس، يمكنك تحميل الأوزان في نموذج `BeitForMaskedImageModeling`، كما هو موضح أدناه:
+
+```python
+from transformers import BeitForMaskedImageModeling
+
+model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
+```
+
+يمكنك أيضًا تحميل نموذج مدرب من [المحور](https://huggingface.co/models?other=dit)، كما هو موضح أدناه:
+
+```python
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
+```
+
+تم ضبط نقطة التحقق هذه بشكل دقيق على [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/)، وهو معيار مرجعي مهم لتصنيف صورة المستند.
+
+يمكن العثور على دفتر الملاحظات الذي يوضح الاستدلال لتصنيف صورة المستند [هنا](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام DiT.
+
+
+
+ ملخص النهج. مأخوذ من [الورقة الأصلية](https://arxiv.org/abs/2203.02378).
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/unilm/tree/master/dit).
+
+## نصائح الاستخدام
+
+يمكن للمرء استخدام أوزان DiT مباشرة مع واجهة برمجة تطبيقات AutoModel:
+
+```python
+from transformers import AutoModel
+
+model = AutoModel.from_pretrained("microsoft/dit-base")
+```
+
+سيؤدي هذا إلى تحميل النموذج الذي تم تدريبه مسبقًا على نمذجة الصور المقنعة. لاحظ أن هذا لن يتضمن رأس نمذجة اللغة في الأعلى، والذي يستخدم للتنبؤ بالرموز البصرية.
+
+لإدراج الرأس، يمكنك تحميل الأوزان في نموذج `BeitForMaskedImageModeling`، كما هو موضح أدناه:
+
+```python
+from transformers import BeitForMaskedImageModeling
+
+model = BeitForMaskedImageModeling.from_pretrained("microsoft/dit-base")
+```
+
+يمكنك أيضًا تحميل نموذج مدرب من [المحور](https://huggingface.co/models?other=dit)، كما هو موضح أدناه:
+
+```python
+from transformers import AutoModelForImageClassification
+
+model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
+```
+
+تم ضبط نقطة التحقق هذه بشكل دقيق على [RVL-CDIP](https://www.cs.cmu.edu/~aharley/rvl-cdip/)، وهو معيار مرجعي مهم لتصنيف صورة المستند.
+
+يمكن العثور على دفتر الملاحظات الذي يوضح الاستدلال لتصنيف صورة المستند [هنا](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/DiT/Inference_with_DiT_(Document_Image_Transformer)_for_document_image_classification.ipynb).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام DiT.
+
+ +
+نظرة عامة عالية المستوى لنموذج Donut. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). ويمكن العثور على الكود الأصلي [هنا](https://github.com/clovaai/donut).
+
+## نصائح الاستخدام
+
+- أسرع طريقة للبدء في استخدام نموذج Donut هي من خلال الاطلاع على [دفاتر الملاحظات التعليمية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Donut)، والتي توضح كيفية استخدام النموذج في مرحلة الاستدلال وكذلك الضبط الدقيق على بيانات مخصصة.
+
+- يتم استخدام نموذج Donut دائمًا ضمن إطار عمل [VisionEncoderDecoder](vision-encoder-decoder).
+
+## أمثلة الاستدلال
+
+يقبل نموذج [`VisionEncoderDecoder`] في نموذج Donut الصور كمدخلات ويستخدم [`~generation.GenerationMixin.generate`] لتوليد النص تلقائيًا بناءً على صورة المدخلات.
+
+تتولى فئة [`DonutImageProcessor`] مسؤولية معالجة صورة المدخلات، ويقوم [`XLMRobertaTokenizer`/`XLMRobertaTokenizerFast`] بفك ترميز رموز الهدف المتوقعة إلى سلسلة الهدف. وتجمع فئة [`DonutProcessor`] بين [`DonutImageProcessor`] و [`XLMRobertaTokenizer`/`XLMRobertaTokenizerFast`] في مثيل واحد لاستخراج ميزات المدخلات وفك ترميز رموز الهدف المتوقعة.
+
+- خطوة بخطوة لتصنيف صورة المستند:
+
+```py
+>>> import re
+
+>>> from transformers import DonutProcessor, VisionEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
+>>> model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model.to(device) # doctest: +IGNORE_RESULT
+
+>>> # تحميل صورة المستند
+>>> dataset = load_dataset("hf-internal-testing/example-documents", split="test")
+>>> image = dataset[1]["image"]
+
+>>> # إعداد مدخلات فك الترميز
+>>> task_prompt = "
+
+نظرة عامة عالية المستوى لنموذج Donut. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). ويمكن العثور على الكود الأصلي [هنا](https://github.com/clovaai/donut).
+
+## نصائح الاستخدام
+
+- أسرع طريقة للبدء في استخدام نموذج Donut هي من خلال الاطلاع على [دفاتر الملاحظات التعليمية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Donut)، والتي توضح كيفية استخدام النموذج في مرحلة الاستدلال وكذلك الضبط الدقيق على بيانات مخصصة.
+
+- يتم استخدام نموذج Donut دائمًا ضمن إطار عمل [VisionEncoderDecoder](vision-encoder-decoder).
+
+## أمثلة الاستدلال
+
+يقبل نموذج [`VisionEncoderDecoder`] في نموذج Donut الصور كمدخلات ويستخدم [`~generation.GenerationMixin.generate`] لتوليد النص تلقائيًا بناءً على صورة المدخلات.
+
+تتولى فئة [`DonutImageProcessor`] مسؤولية معالجة صورة المدخلات، ويقوم [`XLMRobertaTokenizer`/`XLMRobertaTokenizerFast`] بفك ترميز رموز الهدف المتوقعة إلى سلسلة الهدف. وتجمع فئة [`DonutProcessor`] بين [`DonutImageProcessor`] و [`XLMRobertaTokenizer`/`XLMRobertaTokenizerFast`] في مثيل واحد لاستخراج ميزات المدخلات وفك ترميز رموز الهدف المتوقعة.
+
+- خطوة بخطوة لتصنيف صورة المستند:
+
+```py
+>>> import re
+
+>>> from transformers import DonutProcessor, VisionEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> processor = DonutProcessor.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
+>>> model = VisionEncoderDecoderModel.from_pretrained("naver-clova-ix/donut-base-finetuned-rvlcdip")
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model.to(device) # doctest: +IGNORE_RESULT
+
+>>> # تحميل صورة المستند
+>>> dataset = load_dataset("hf-internal-testing/example-documents", split="test")
+>>> image = dataset[1]["image"]
+
+>>> # إعداد مدخلات فك الترميز
+>>> task_prompt = " +
+هندسة DPT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/isl-org/DPT).
+
+## نصائح الاستخدام
+يتوافق DPT مع فئة [`AutoBackbone`]. يسمح ذلك باستخدام إطار عمل DPT مع العمود الفقري لرؤية الكمبيوتر المختلفة المتاحة في المكتبة، مثل [`VitDetBackbone`] أو [`Dinov2Backbone`]. يمكن إنشاؤه على النحو التالي:
+
+```python
+from transformers import Dinov2Config, DPTConfig, DPTForDepthEstimation
+
+# initialize with a Transformer-based backbone such as DINOv2
+# in that case, we also specify `reshape_hidden_states=False` to get feature maps of shape (batch_size, num_channels, height, width)
+backbone_config = Dinov2Config.from_pretrained("facebook/dinov2-base", out_features=["stage1", "stage2", "stage3", "stage4"], reshape_hidden_states=False)
+
+config = DPTConfig(backbone_config=backbone_config)
+model = DPTForDepthEstimation(config=config)
+```
+
+## الموارد
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام DPT.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ [`DPTForDepthEstimation`] [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DPT).
+- [دليل مهام التجزئة الدلالية](../tasks/semantic_segmentation)
+- [دليل مهام تقدير العمق الأحادي](../tasks/monocular_depth_estimation)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يوضح المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## DPTConfig
+
+[[autodoc]] DPTConfig
+
+## DPTFeatureExtractor
+
+[[autodoc]] DPTFeatureExtractor
+
+- __call__
+- post_process_semantic_segmentation
+
+## DPTImageProcessor
+
+[[autodoc]] DPTImageProcessor
+
+- preprocess
+- post_process_semantic_segmentation
+
+## DPTModel
+
+[[autodoc]] DPTModel
+
+- forward
+
+## DPTForDepthEstimation
+
+[[autodoc]] DPTForDepthEstimation
+
+- forward
+
+## DPTForSemanticSegmentation
+
+[[autodoc]] DPTForSemanticSegmentation
+
+- forward
\ No newline at end of file
From 5769073b1ccbb6aa8a65ad0fe51affc809e12754 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:02 +0300
Subject: [PATCH 428/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/graphormer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/graphormer.md | 36 ++++++++++++++++++++++++++
1 file changed, 36 insertions(+)
create mode 100644 docs/source/ar/model_doc/graphormer.md
diff --git a/docs/source/ar/model_doc/graphormer.md b/docs/source/ar/model_doc/graphormer.md
new file mode 100644
index 00000000000000..f6aa9a46c9c31d
--- /dev/null
+++ b/docs/source/ar/model_doc/graphormer.md
@@ -0,0 +1,36 @@
+# Graphormer
+
+> **ملاحظة:**
+> هذا النموذج في وضع الصيانة فقط، ولن نقبل أي طلبات سحب (Pull Requests) جديدة لتغيير شفرته. إذا واجهتك أي مشكلات أثناء تشغيل هذا النموذج، يرجى إعادة تثبيت الإصدار الأخير الذي يدعم هذا النموذج: v4.40.2. يمكنك القيام بذلك عن طريق تشغيل الأمر التالي: `pip install -U transformers==4.40.2`.
+
+## نظرة عامة
+
+اقتُرح نموذج Graphormer في الورقة البحثية [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) من قبل Chengxuan Ying وآخرين. وهو نموذج محول رسومي (Graph Transformer) معدل للسماح بإجراء الحسابات على الرسوم البيانية بدلاً من تسلسلات النص من خلال توليد التضمينات (embeddings) والسمات ذات الاهتمام أثناء المعالجة المسبقة والجمع، ثم استخدام انتباه معدل.
+
+هذا هو الملخص من الورقة:
+
+> أصبحت بنية المحول (Transformer) اختيارًا مهيمنًا في العديد من المجالات، مثل معالجة اللغة الطبيعية والرؤية الحاسوبية. ومع ذلك، لم يحقق أداءً تنافسيًا في لوحات القيادة الشائعة للتنبؤ على مستوى الرسم البياني مقارنة بالمتغيرات الشائعة لشبكات الرسوم البيانية العصبية (GNN). لذلك، يظل الأمر لغزًا كيف يمكن أن تؤدي المحولات أداءً جيدًا لتعلم تمثيل الرسم البياني. في هذه الورقة، نقوم بحل هذا اللغز من خلال تقديم Graphormer، والذي تم بناؤه بناءً على بنية المحول القياسية، ويمكنه تحقيق نتائج ممتازة في مجموعة واسعة من مهام تعلم تمثيل الرسم البياني، خاصة في تحدي OGB Large-Scale Challenge الأخير. تتمثل رؤيتنا الأساسية لاستخدام المحول في الرسم البياني في ضرورة ترميز المعلومات الهيكلية للرسم البياني بشكل فعال في النموذج. ولهذه الغاية، نقترح عدة طرق ترميز هيكلية بسيطة وفعالة لمساعدة Graphormer على نمذجة البيانات المبنية على الرسوم البيانية بشكل أفضل. بالإضافة إلى ذلك، نحدد الخصائص التعبيرية لـ Graphormer ونظهر أنه مع طرقنا لترميز المعلومات الهيكلية للرسوم البيانية، يمكن تغطية العديد من المتغيرات الشائعة لشبكات GNN كحالات خاصة لـ Graphormer.
+
+تمت المساهمة بهذا النموذج من قبل [clefourrier](https://huggingface.co/clefourrier). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/Graphormer).
+
+## نصائح الاستخدام
+
+لن يعمل هذا النموذج بشكل جيد على الرسوم البيانية الكبيرة (أكثر من 100 عقدة/حافة)، حيث سيؤدي ذلك إلى انفجار الذاكرة. يمكنك تقليل حجم الدفعة، أو زيادة ذاكرة الوصول العشوائي (RAM)، أو تقليل معلمة `UNREACHABLE_NODE_DISTANCE` في ملف `algos_graphormer.pyx`، ولكن سيكون من الصعب تجاوز 700 عقدة/حافة.
+
+لا يستخدم هذا النموذج رمزًا مميزًا (tokenizer)، ولكنه يستخدم بدلاً من ذلك مجمعًا (collator) خاصًا أثناء التدريب.
+
+## GraphormerConfig
+
+[[autodoc]] GraphormerConfig
+
+## GraphormerModel
+
+[[autodoc]] GraphormerModel
+
+- forward
+
+## GraphormerForGraphClassification
+
+[[autodoc]] GraphormerForGraphClassification
+
+- forward
\ No newline at end of file
From 4b626cf1c6d547a6b271a21155579c33473d1fb7 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:04 +0300
Subject: [PATCH 429/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/efficientnet.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/efficientnet.md | 34 ++++++++++++++++++++++++
1 file changed, 34 insertions(+)
create mode 100644 docs/source/ar/model_doc/efficientnet.md
diff --git a/docs/source/ar/model_doc/efficientnet.md b/docs/source/ar/model_doc/efficientnet.md
new file mode 100644
index 00000000000000..c90d206d3a5c03
--- /dev/null
+++ b/docs/source/ar/model_doc/efficientnet.md
@@ -0,0 +1,34 @@
+# EfficientNet
+
+## نظرة عامة
+تم اقتراح نموذج EfficientNet في ورقة [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) بواسطة Mingxing Tan و Quoc V. Le. تعد EfficientNets عائلة من نماذج تصنيف الصور، والتي تحقق دقة عالية، مع كونها أصغر وأسرع من النماذج السابقة.
+
+ملخص الورقة البحثية هو كما يلي:
+
+*تُطور شبكات العصبونات التلافيفية (ConvNets) عادةً بميزانية موارد ثابتة، ثم يتم توسيعها للحصول على دقة أفضل إذا كانت هناك موارد إضافية متاحة. في هذه الورقة، نقوم بدراسة منهجية لقياس النموذج وتحديد أن الموازنة الدقيقة بين عمق الشبكة وعرضها ودقتها يمكن أن تؤدي إلى أداء أفضل. وبناءً على هذه الملاحظة، نقترح طريقة جديدة لقياس النطاق الذي يوسع جميع أبعاد العمق/العرض/الدقة باستخدام معامل مركب بسيط ولكنه فعال للغاية. نثبت فعالية هذه الطريقة في توسيع MobileNets و ResNet.
+
+وللمضي قدما، نستخدم البحث المعماري العصبي لتصميم شبكة أساس جديدة وتوسيعها للحصول على عائلة من النماذج، تسمى EfficientNets، والتي تحقق دقة وكفاءة أفضل بكثير من ConvNets السابقة. على وجه الخصوص، يحقق نموذجنا EfficientNet-B7 دقة أعلى بنسبة 84.3٪ في تصنيف الصور ImageNet، بينما يكون أصغر 8.4 مرة وأسرع 6.1 مرة في الاستدلال من أفضل ConvNet موجود. كما أن نماذج EfficientNets الخاصة بنا تنتقل بشكل جيد وتحقق دقة عالية على مجموعات بيانات التعلم بالانتقال CIFAR-100 (91.7٪) و Flowers (98.8٪) وخمس مجموعات بيانات أخرى للتعلم بالانتقال، مع عدد أقل من المعلمات.*
+
+تمت المساهمة بهذا النموذج من قبل [adirik](https://huggingface.co/adirik). يمكن العثور على الكود الأصلي [هنا](https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet).
+
+## EfficientNetConfig
+
+[[autodoc]] EfficientNetConfig
+
+## EfficientNetImageProcessor
+
+[[autodoc]] EfficientNetImageProcessor
+
+- preprocess
+
+## EfficientNetModel
+
+[[autodoc]] EfficientNetModel
+
+- forward
+
+## EfficientNetForImageClassification
+
+[[autodoc]] EfficientNetForImageClassification
+
+- forward
\ No newline at end of file
From 1df4a1b5e6d70821899a6764bca10959e8aecb9d Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:06 +0300
Subject: [PATCH 430/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/electra.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/electra.md | 198 ++++++++++++++++++++++++++++
1 file changed, 198 insertions(+)
create mode 100644 docs/source/ar/model_doc/electra.md
diff --git a/docs/source/ar/model_doc/electra.md b/docs/source/ar/model_doc/electra.md
new file mode 100644
index 00000000000000..4d0d2a2bcf8c60
--- /dev/null
+++ b/docs/source/ar/model_doc/electra.md
@@ -0,0 +1,198 @@
+# ELECTRA
+
+## نظرة عامة
+
+تم اقتراح نموذج ELECTRA في الورقة البحثية [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than
+Generators](https://openreview.net/pdf?id=r1xMH1BtvB). ELECTRA هو أسلوب جديد للتعليم المسبق يقوم بتدريب نموذجين من نوع المحول: المولد والمحقق. يتمثل دور المولد في استبدال الرموز في تسلسل، وبالتالي يتم تدريبه كنموذج لغة مقنعة. أما المحقق، وهو النموذج الذي يهمنا، فيحاول تحديد الرموز التي استبدلها المولد في التسلسل.
+
+ملخص الورقة البحثية هو كما يلي:
+
+> تقوم طرق التعليم المسبق لـ MLM (Masked Language Modeling) مثل BERT بإفساد الإدخال عن طريق استبدال بعض الرموز بـ [MASK] ثم تدريب نموذج لإعادة بناء الرموز الأصلية. وعلى الرغم من أنها تنتج نتائج جيدة عند نقلها إلى مهام NLP لأسفل، إلا أنها تتطلب عمومًا كميات كبيرة من الحساب لتكون فعالة. وبدلاً من ذلك، نقترح مهمة تعليم مسبق أكثر كفاءة في العينات تسمى كشف الرمز المُستبدل. بدلاً من قناع الإدخال، يقوم نهجنا بإفساده عن طريق استبدال بعض الرموز ببدائل مقنعة يتم أخذ عينات منها من شبكة مولد صغيرة. ثم، بدلاً من تدريب نموذج يتنبأ بالهويات الأصلية للرموز الفاسدة، نقوم بتدريب نموذج تمييزي يتنبأ بما إذا كان كل رمز في الإدخال الفاسد قد تم استبداله بواسطة عينة من المولد أم لا. تُظهر التجارب الشاملة أن مهمة التعليم المسبق الجديدة هذه أكثر كفاءة من MLM لأن المهمة محددة لجميع رموز الإدخال بدلاً من المجموعة الفرعية الصغيرة التي تم قناعها. ونتيجة لذلك، فإن التمثيلات السياقية التي تعلمها نهجنا تتفوق بشكل كبير على تلك التي تعلمها BERT نظرًا لنفس حجم النموذج والبيانات والحساب. وتكون المكاسب قوية بشكل خاص بالنسبة للنماذج الصغيرة؛ على سبيل المثال، نقوم بتدريب نموذج على وحدة معالجة رسومات واحدة لمدة 4 أيام تتفوق على GPT (تم تدريبه باستخدام 30 ضعف الحساب) في معيار الفهم اللغوي GLUE. كما يعمل نهجنا بشكل جيد على نطاق واسع، حيث يؤدي أداءً مماثلاً لـ RoBERTa و XLNet باستخدام أقل من 1/4 من حساباتهما ويتفوق عليهما عند استخدام نفس الكمية من الحساب.
+
+تمت المساهمة بهذا النموذج من قبل [lysandre](https://huggingface.co/lysandre). يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/electra).
+
+## نصائح الاستخدام
+
+- ELECTRA هو نهج التعليم المسبق، وبالتالي لا يوجد أي تغييرات تقريبًا في النموذج الأساسي: BERT. التغيير الوحيد هو فصل حجم تضمين وحجم المخفي: حجم التضمين أصغر عمومًا، في حين أن حجم المخفي أكبر. تُستخدم طبقة إسقاط إضافية (خطية) لإسقاط التضمينات من حجم التضمين إلى حجم المخفي. في الحالة التي يكون فيها حجم التضمين هو نفسه حجم المخفي، لا تُستخدم أي طبقة إسقاط.
+
+- ELECTRA هو نموذج محول مُدرب مسبقًا باستخدام نموذج لغة مقنع آخر (صغير). يتم إفساد الإدخالات بواسطة نموذج اللغة هذا، والذي يأخذ نصًا مقنعًا عشوائيًا كإدخال ويقوم بإخراج نص يجب على ELECTRA التنبؤ به والذي هو رمز أصلي والذي تم استبداله. مثل تدريب GAN، يتم تدريب نموذج اللغة الصغيرة لبضع خطوات (ولكن باستخدام النصوص الأصلية كهدف، وليس خداع نموذج ELECTRA كما هو الحال في إعداد GAN التقليدي) ثم يتم تدريب نموذج ELECTRA لبضع خطوات.
+
+- تحتوي نقاط تفتيش ELECTRA المحفوظة باستخدام [تنفيذ Google Research](https://github.com/google-research/electra) على كل من المولد والمحقق. يتطلب برنامج التحويل من المستخدم تسمية النموذج الذي سيتم تصديره إلى الهندسة المعمارية الصحيحة. بمجرد تحويلها إلى تنسيق HuggingFace، يمكن تحميل هذه نقاط التفتيش في جميع نماذج ELECTRA المتاحة، ومع ذلك. وهذا يعني أنه يمكن تحميل المحقق في نموذج [`ElectraForMaskedLM`]، ويمكن تحميل المولد في نموذج [`ElectraForPreTraining`] (سيتم تهيئة رأس التصنيف بشكل عشوائي لأنه غير موجود في المولد).
+
+## الموارد
+
+- [دليل مهام تصنيف النصوص](../tasks/sequence_classification)
+- [دليل مهام تصنيف الرموز](../tasks/token_classification)
+- [دليل مهام الإجابة على الأسئلة](../tasks/question_answering)
+- [دليل مهام نمذجة اللغة السببية](../tasks/language_modeling)
+- [دليل مهام نمذجة اللغة المقنعة](../tasks/masked_language_modeling)
+- [دليل مهام الاختيار المتعدد](../tasks/multiple_choice)
+
+## ElectraConfig
+
+[[autodoc]] ElectraConfig
+
+## ElectraTokenizer
+
+[[autodoc]] ElectraTokenizer
+
+## ElectraTokenizerFast
+
+[[autodoc]] ElectraTokenizerFast
+
+## المخرجات الخاصة بـ Electra
+
+[[autodoc]] models.electra.modeling_electra.ElectraForPreTrainingOutput
+
+[[autodoc]] models.electra.modeling_tf_electra.TFElectraForPreTrainingOutput
+
+
+
+هندسة DPT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/isl-org/DPT).
+
+## نصائح الاستخدام
+يتوافق DPT مع فئة [`AutoBackbone`]. يسمح ذلك باستخدام إطار عمل DPT مع العمود الفقري لرؤية الكمبيوتر المختلفة المتاحة في المكتبة، مثل [`VitDetBackbone`] أو [`Dinov2Backbone`]. يمكن إنشاؤه على النحو التالي:
+
+```python
+from transformers import Dinov2Config, DPTConfig, DPTForDepthEstimation
+
+# initialize with a Transformer-based backbone such as DINOv2
+# in that case, we also specify `reshape_hidden_states=False` to get feature maps of shape (batch_size, num_channels, height, width)
+backbone_config = Dinov2Config.from_pretrained("facebook/dinov2-base", out_features=["stage1", "stage2", "stage3", "stage4"], reshape_hidden_states=False)
+
+config = DPTConfig(backbone_config=backbone_config)
+model = DPTForDepthEstimation(config=config)
+```
+
+## الموارد
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام DPT.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ [`DPTForDepthEstimation`] [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DPT).
+- [دليل مهام التجزئة الدلالية](../tasks/semantic_segmentation)
+- [دليل مهام تقدير العمق الأحادي](../tasks/monocular_depth_estimation)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يوضح المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## DPTConfig
+
+[[autodoc]] DPTConfig
+
+## DPTFeatureExtractor
+
+[[autodoc]] DPTFeatureExtractor
+
+- __call__
+- post_process_semantic_segmentation
+
+## DPTImageProcessor
+
+[[autodoc]] DPTImageProcessor
+
+- preprocess
+- post_process_semantic_segmentation
+
+## DPTModel
+
+[[autodoc]] DPTModel
+
+- forward
+
+## DPTForDepthEstimation
+
+[[autodoc]] DPTForDepthEstimation
+
+- forward
+
+## DPTForSemanticSegmentation
+
+[[autodoc]] DPTForSemanticSegmentation
+
+- forward
\ No newline at end of file
From 5769073b1ccbb6aa8a65ad0fe51affc809e12754 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:02 +0300
Subject: [PATCH 428/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/graphormer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/graphormer.md | 36 ++++++++++++++++++++++++++
1 file changed, 36 insertions(+)
create mode 100644 docs/source/ar/model_doc/graphormer.md
diff --git a/docs/source/ar/model_doc/graphormer.md b/docs/source/ar/model_doc/graphormer.md
new file mode 100644
index 00000000000000..f6aa9a46c9c31d
--- /dev/null
+++ b/docs/source/ar/model_doc/graphormer.md
@@ -0,0 +1,36 @@
+# Graphormer
+
+> **ملاحظة:**
+> هذا النموذج في وضع الصيانة فقط، ولن نقبل أي طلبات سحب (Pull Requests) جديدة لتغيير شفرته. إذا واجهتك أي مشكلات أثناء تشغيل هذا النموذج، يرجى إعادة تثبيت الإصدار الأخير الذي يدعم هذا النموذج: v4.40.2. يمكنك القيام بذلك عن طريق تشغيل الأمر التالي: `pip install -U transformers==4.40.2`.
+
+## نظرة عامة
+
+اقتُرح نموذج Graphormer في الورقة البحثية [Do Transformers Really Perform Bad for Graph Representation?](https://arxiv.org/abs/2106.05234) من قبل Chengxuan Ying وآخرين. وهو نموذج محول رسومي (Graph Transformer) معدل للسماح بإجراء الحسابات على الرسوم البيانية بدلاً من تسلسلات النص من خلال توليد التضمينات (embeddings) والسمات ذات الاهتمام أثناء المعالجة المسبقة والجمع، ثم استخدام انتباه معدل.
+
+هذا هو الملخص من الورقة:
+
+> أصبحت بنية المحول (Transformer) اختيارًا مهيمنًا في العديد من المجالات، مثل معالجة اللغة الطبيعية والرؤية الحاسوبية. ومع ذلك، لم يحقق أداءً تنافسيًا في لوحات القيادة الشائعة للتنبؤ على مستوى الرسم البياني مقارنة بالمتغيرات الشائعة لشبكات الرسوم البيانية العصبية (GNN). لذلك، يظل الأمر لغزًا كيف يمكن أن تؤدي المحولات أداءً جيدًا لتعلم تمثيل الرسم البياني. في هذه الورقة، نقوم بحل هذا اللغز من خلال تقديم Graphormer، والذي تم بناؤه بناءً على بنية المحول القياسية، ويمكنه تحقيق نتائج ممتازة في مجموعة واسعة من مهام تعلم تمثيل الرسم البياني، خاصة في تحدي OGB Large-Scale Challenge الأخير. تتمثل رؤيتنا الأساسية لاستخدام المحول في الرسم البياني في ضرورة ترميز المعلومات الهيكلية للرسم البياني بشكل فعال في النموذج. ولهذه الغاية، نقترح عدة طرق ترميز هيكلية بسيطة وفعالة لمساعدة Graphormer على نمذجة البيانات المبنية على الرسوم البيانية بشكل أفضل. بالإضافة إلى ذلك، نحدد الخصائص التعبيرية لـ Graphormer ونظهر أنه مع طرقنا لترميز المعلومات الهيكلية للرسوم البيانية، يمكن تغطية العديد من المتغيرات الشائعة لشبكات GNN كحالات خاصة لـ Graphormer.
+
+تمت المساهمة بهذا النموذج من قبل [clefourrier](https://huggingface.co/clefourrier). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/Graphormer).
+
+## نصائح الاستخدام
+
+لن يعمل هذا النموذج بشكل جيد على الرسوم البيانية الكبيرة (أكثر من 100 عقدة/حافة)، حيث سيؤدي ذلك إلى انفجار الذاكرة. يمكنك تقليل حجم الدفعة، أو زيادة ذاكرة الوصول العشوائي (RAM)، أو تقليل معلمة `UNREACHABLE_NODE_DISTANCE` في ملف `algos_graphormer.pyx`، ولكن سيكون من الصعب تجاوز 700 عقدة/حافة.
+
+لا يستخدم هذا النموذج رمزًا مميزًا (tokenizer)، ولكنه يستخدم بدلاً من ذلك مجمعًا (collator) خاصًا أثناء التدريب.
+
+## GraphormerConfig
+
+[[autodoc]] GraphormerConfig
+
+## GraphormerModel
+
+[[autodoc]] GraphormerModel
+
+- forward
+
+## GraphormerForGraphClassification
+
+[[autodoc]] GraphormerForGraphClassification
+
+- forward
\ No newline at end of file
From 4b626cf1c6d547a6b271a21155579c33473d1fb7 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:04 +0300
Subject: [PATCH 429/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/efficientnet.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/efficientnet.md | 34 ++++++++++++++++++++++++
1 file changed, 34 insertions(+)
create mode 100644 docs/source/ar/model_doc/efficientnet.md
diff --git a/docs/source/ar/model_doc/efficientnet.md b/docs/source/ar/model_doc/efficientnet.md
new file mode 100644
index 00000000000000..c90d206d3a5c03
--- /dev/null
+++ b/docs/source/ar/model_doc/efficientnet.md
@@ -0,0 +1,34 @@
+# EfficientNet
+
+## نظرة عامة
+تم اقتراح نموذج EfficientNet في ورقة [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946) بواسطة Mingxing Tan و Quoc V. Le. تعد EfficientNets عائلة من نماذج تصنيف الصور، والتي تحقق دقة عالية، مع كونها أصغر وأسرع من النماذج السابقة.
+
+ملخص الورقة البحثية هو كما يلي:
+
+*تُطور شبكات العصبونات التلافيفية (ConvNets) عادةً بميزانية موارد ثابتة، ثم يتم توسيعها للحصول على دقة أفضل إذا كانت هناك موارد إضافية متاحة. في هذه الورقة، نقوم بدراسة منهجية لقياس النموذج وتحديد أن الموازنة الدقيقة بين عمق الشبكة وعرضها ودقتها يمكن أن تؤدي إلى أداء أفضل. وبناءً على هذه الملاحظة، نقترح طريقة جديدة لقياس النطاق الذي يوسع جميع أبعاد العمق/العرض/الدقة باستخدام معامل مركب بسيط ولكنه فعال للغاية. نثبت فعالية هذه الطريقة في توسيع MobileNets و ResNet.
+
+وللمضي قدما، نستخدم البحث المعماري العصبي لتصميم شبكة أساس جديدة وتوسيعها للحصول على عائلة من النماذج، تسمى EfficientNets، والتي تحقق دقة وكفاءة أفضل بكثير من ConvNets السابقة. على وجه الخصوص، يحقق نموذجنا EfficientNet-B7 دقة أعلى بنسبة 84.3٪ في تصنيف الصور ImageNet، بينما يكون أصغر 8.4 مرة وأسرع 6.1 مرة في الاستدلال من أفضل ConvNet موجود. كما أن نماذج EfficientNets الخاصة بنا تنتقل بشكل جيد وتحقق دقة عالية على مجموعات بيانات التعلم بالانتقال CIFAR-100 (91.7٪) و Flowers (98.8٪) وخمس مجموعات بيانات أخرى للتعلم بالانتقال، مع عدد أقل من المعلمات.*
+
+تمت المساهمة بهذا النموذج من قبل [adirik](https://huggingface.co/adirik). يمكن العثور على الكود الأصلي [هنا](https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet).
+
+## EfficientNetConfig
+
+[[autodoc]] EfficientNetConfig
+
+## EfficientNetImageProcessor
+
+[[autodoc]] EfficientNetImageProcessor
+
+- preprocess
+
+## EfficientNetModel
+
+[[autodoc]] EfficientNetModel
+
+- forward
+
+## EfficientNetForImageClassification
+
+[[autodoc]] EfficientNetForImageClassification
+
+- forward
\ No newline at end of file
From 1df4a1b5e6d70821899a6764bca10959e8aecb9d Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:06 +0300
Subject: [PATCH 430/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/electra.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/electra.md | 198 ++++++++++++++++++++++++++++
1 file changed, 198 insertions(+)
create mode 100644 docs/source/ar/model_doc/electra.md
diff --git a/docs/source/ar/model_doc/electra.md b/docs/source/ar/model_doc/electra.md
new file mode 100644
index 00000000000000..4d0d2a2bcf8c60
--- /dev/null
+++ b/docs/source/ar/model_doc/electra.md
@@ -0,0 +1,198 @@
+# ELECTRA
+
+## نظرة عامة
+
+تم اقتراح نموذج ELECTRA في الورقة البحثية [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than
+Generators](https://openreview.net/pdf?id=r1xMH1BtvB). ELECTRA هو أسلوب جديد للتعليم المسبق يقوم بتدريب نموذجين من نوع المحول: المولد والمحقق. يتمثل دور المولد في استبدال الرموز في تسلسل، وبالتالي يتم تدريبه كنموذج لغة مقنعة. أما المحقق، وهو النموذج الذي يهمنا، فيحاول تحديد الرموز التي استبدلها المولد في التسلسل.
+
+ملخص الورقة البحثية هو كما يلي:
+
+> تقوم طرق التعليم المسبق لـ MLM (Masked Language Modeling) مثل BERT بإفساد الإدخال عن طريق استبدال بعض الرموز بـ [MASK] ثم تدريب نموذج لإعادة بناء الرموز الأصلية. وعلى الرغم من أنها تنتج نتائج جيدة عند نقلها إلى مهام NLP لأسفل، إلا أنها تتطلب عمومًا كميات كبيرة من الحساب لتكون فعالة. وبدلاً من ذلك، نقترح مهمة تعليم مسبق أكثر كفاءة في العينات تسمى كشف الرمز المُستبدل. بدلاً من قناع الإدخال، يقوم نهجنا بإفساده عن طريق استبدال بعض الرموز ببدائل مقنعة يتم أخذ عينات منها من شبكة مولد صغيرة. ثم، بدلاً من تدريب نموذج يتنبأ بالهويات الأصلية للرموز الفاسدة، نقوم بتدريب نموذج تمييزي يتنبأ بما إذا كان كل رمز في الإدخال الفاسد قد تم استبداله بواسطة عينة من المولد أم لا. تُظهر التجارب الشاملة أن مهمة التعليم المسبق الجديدة هذه أكثر كفاءة من MLM لأن المهمة محددة لجميع رموز الإدخال بدلاً من المجموعة الفرعية الصغيرة التي تم قناعها. ونتيجة لذلك، فإن التمثيلات السياقية التي تعلمها نهجنا تتفوق بشكل كبير على تلك التي تعلمها BERT نظرًا لنفس حجم النموذج والبيانات والحساب. وتكون المكاسب قوية بشكل خاص بالنسبة للنماذج الصغيرة؛ على سبيل المثال، نقوم بتدريب نموذج على وحدة معالجة رسومات واحدة لمدة 4 أيام تتفوق على GPT (تم تدريبه باستخدام 30 ضعف الحساب) في معيار الفهم اللغوي GLUE. كما يعمل نهجنا بشكل جيد على نطاق واسع، حيث يؤدي أداءً مماثلاً لـ RoBERTa و XLNet باستخدام أقل من 1/4 من حساباتهما ويتفوق عليهما عند استخدام نفس الكمية من الحساب.
+
+تمت المساهمة بهذا النموذج من قبل [lysandre](https://huggingface.co/lysandre). يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/electra).
+
+## نصائح الاستخدام
+
+- ELECTRA هو نهج التعليم المسبق، وبالتالي لا يوجد أي تغييرات تقريبًا في النموذج الأساسي: BERT. التغيير الوحيد هو فصل حجم تضمين وحجم المخفي: حجم التضمين أصغر عمومًا، في حين أن حجم المخفي أكبر. تُستخدم طبقة إسقاط إضافية (خطية) لإسقاط التضمينات من حجم التضمين إلى حجم المخفي. في الحالة التي يكون فيها حجم التضمين هو نفسه حجم المخفي، لا تُستخدم أي طبقة إسقاط.
+
+- ELECTRA هو نموذج محول مُدرب مسبقًا باستخدام نموذج لغة مقنع آخر (صغير). يتم إفساد الإدخالات بواسطة نموذج اللغة هذا، والذي يأخذ نصًا مقنعًا عشوائيًا كإدخال ويقوم بإخراج نص يجب على ELECTRA التنبؤ به والذي هو رمز أصلي والذي تم استبداله. مثل تدريب GAN، يتم تدريب نموذج اللغة الصغيرة لبضع خطوات (ولكن باستخدام النصوص الأصلية كهدف، وليس خداع نموذج ELECTRA كما هو الحال في إعداد GAN التقليدي) ثم يتم تدريب نموذج ELECTRA لبضع خطوات.
+
+- تحتوي نقاط تفتيش ELECTRA المحفوظة باستخدام [تنفيذ Google Research](https://github.com/google-research/electra) على كل من المولد والمحقق. يتطلب برنامج التحويل من المستخدم تسمية النموذج الذي سيتم تصديره إلى الهندسة المعمارية الصحيحة. بمجرد تحويلها إلى تنسيق HuggingFace، يمكن تحميل هذه نقاط التفتيش في جميع نماذج ELECTRA المتاحة، ومع ذلك. وهذا يعني أنه يمكن تحميل المحقق في نموذج [`ElectraForMaskedLM`]، ويمكن تحميل المولد في نموذج [`ElectraForPreTraining`] (سيتم تهيئة رأس التصنيف بشكل عشوائي لأنه غير موجود في المولد).
+
+## الموارد
+
+- [دليل مهام تصنيف النصوص](../tasks/sequence_classification)
+- [دليل مهام تصنيف الرموز](../tasks/token_classification)
+- [دليل مهام الإجابة على الأسئلة](../tasks/question_answering)
+- [دليل مهام نمذجة اللغة السببية](../tasks/language_modeling)
+- [دليل مهام نمذجة اللغة المقنعة](../tasks/masked_language_modeling)
+- [دليل مهام الاختيار المتعدد](../tasks/multiple_choice)
+
+## ElectraConfig
+
+[[autodoc]] ElectraConfig
+
+## ElectraTokenizer
+
+[[autodoc]] ElectraTokenizer
+
+## ElectraTokenizerFast
+
+[[autodoc]] ElectraTokenizerFast
+
+## المخرجات الخاصة بـ Electra
+
+[[autodoc]] models.electra.modeling_electra.ElectraForPreTrainingOutput
+
+[[autodoc]] models.electra.modeling_tf_electra.TFElectraForPreTrainingOutput
+
+ +
+بنية GIT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/GenerativeImage2Text).
+
+## نصائح الاستخدام
+
+- تم تنفيذ GIT بطريقة مشابهة جدًا لـ GPT-2، والفرق الوحيد هو أن النموذج مشروط أيضًا بـ `pixel_values`.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام GIT.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية المتعلقة بالاستدلال + الضبط الدقيق لـ GIT على بيانات مخصصة [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GIT).
+- راجع أيضًا: [دليل مهمة نمذجة اللغة السببية](../tasks/language_modeling)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه. يجب أن يوضح المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## GitVisionConfig
+
+[[autodoc]] GitVisionConfig
+
+## GitVisionModel
+
+[[autodoc]] GitVisionModel
+
+- forward
+
+## GitConfig
+
+[[autodoc]] GitConfig
+
+- all
+
+## GitProcessor
+
+[[autodoc]] GitProcessor
+
+- __call__
+
+## GitModel
+
+[[autodoc]] GitModel
+
+- forward
+
+## GitForCausalLM
+
+[[autodoc]] GitForCausalLM
+
+- forward
\ No newline at end of file
From b0cadf3f330e6cef575d7f0386993d6104a95182 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:39 +0300
Subject: [PATCH 449/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/glpn.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/glpn.md | 59 ++++++++++++++++++++++++++++++++
1 file changed, 59 insertions(+)
create mode 100644 docs/source/ar/model_doc/glpn.md
diff --git a/docs/source/ar/model_doc/glpn.md b/docs/source/ar/model_doc/glpn.md
new file mode 100644
index 00000000000000..763cef1538602b
--- /dev/null
+++ b/docs/source/ar/model_doc/glpn.md
@@ -0,0 +1,59 @@
+# GLPN
+
+
+
+ ملخص النهج. مأخوذ من <[الأوراق الأصلية](https://arxiv.org/abs/2201.07436)>
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/vinvino02/GLPDepth).
+
+## الموارد
+
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام GLPN.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ [`GLPNForDepthEstimation`] [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GLPN).
+- [دليل مهام تقدير العمق أحادي العين](../tasks/monocular_depth_estimation)
+
+## GLPNConfig
+
+[[autodoc]] GLPNConfig
+
+## GLPNFeatureExtractor
+
+[[autodoc]] GLPNFeatureExtractor
+
+- __call__
+
+## GLPNImageProcessor
+
+[[autodoc]] GLPNImageProcessor
+
+- preprocess
+
+## GLPNModel
+
+[[autodoc]] GLPNModel
+
+- forward
+
+## GLPNForDepthEstimation
+
+[[autodoc]] GLPNForDepthEstimation
+
+- forward
\ No newline at end of file
From 51139c4f3ab99e54dceda6c399dac9b458bb87f5 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:41 +0300
Subject: [PATCH 450/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/gpt-sw3.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/gpt-sw3.md | 47 +++++++++++++++++++++++++++++
1 file changed, 47 insertions(+)
create mode 100644 docs/source/ar/model_doc/gpt-sw3.md
diff --git a/docs/source/ar/model_doc/gpt-sw3.md b/docs/source/ar/model_doc/gpt-sw3.md
new file mode 100644
index 00000000000000..e1acb32d6e7e74
--- /dev/null
+++ b/docs/source/ar/model_doc/gpt-sw3.md
@@ -0,0 +1,47 @@
+# GPT-Sw3
+
+## نظرة عامة
+
+اقترح نموذج GPT-Sw3 لأول مرة في ورقة "الدروس المستفادة من GPT-SW3: بناء أول نموذج لغوي توليدي واسع النطاق للغة السويدية" من قبل أرييل إكغرين، وأمارو كوبا جيلينستن، وإيفانجيليا جوجولو، وأليس هايمان، وسيفيرين فيرليندن، وجوي أوهمان، وفريدريك كارلسون، وماغنوس ساهلجرين.
+
+ومنذ تلك الورقة الأولى، وسع المؤلفون عملهم ودربوا نماذج جديدة على مجموعات بياناتهم الجديدة التي تبلغ 1.2 تيرابايت والتي تسمى The Nordic Pile.
+
+GPT-Sw3 عبارة عن مجموعة من نماذج المحول اللغوي فك التشفير فقط كبيرة الحجم التي تم تطويرها بواسطة AI Sweden بالتعاون مع RISE و WASP WARA for Media and Language. تم تدريب GPT-Sw3 على مجموعة بيانات تحتوي على 320 مليار رمز في السويدية والنرويجية والدانماركية والإيسلندية والإنجليزية، ورموز البرمجة. تم تدريب النموذج المسبق باستخدام هدف نمذجة اللغة السببية (CLM) باستخدام تنفيذ NeMo Megatron GPT.
+
+تمت المساهمة بهذا النموذج من قبل [نماذج AI Sweden](https://huggingface.co/AI-Sweden-Models).
+
+## مثال على الاستخدام
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM
+
+>>> tokenizer = AutoTokenizer.from_pretrained("AI-Sweden-Models/gpt-sw3-356m")
+>>> model = AutoModelForCausalLM.from_pretrained("AI-Sweden-Models/gpt-sw3-352m")
+
+>>> input_ids = tokenizer("Träd är fina för att", return_tensors="pt")["input_ids"]
+
+>>> generated_token_ids = model.generate(inputs=input_ids, max_new_tokens=10, do_sample=True)[0]
+
+>>> print(tokenizer.decode(generated_token_ids))
+Träd är fina för att de är färgstarka. Men ibland är det fint
+```
+
+## الموارد
+
+- [دليل مهمة تصنيف النصوص](../tasks/sequence_classification)
+- [دليل مهمة تصنيف الرموز](../tasks/token_classification)
+- [دليل نمذجة اللغة السببية](../tasks/language_modeling)
+
+
+
+بنية GIT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/GenerativeImage2Text).
+
+## نصائح الاستخدام
+
+- تم تنفيذ GIT بطريقة مشابهة جدًا لـ GPT-2، والفرق الوحيد هو أن النموذج مشروط أيضًا بـ `pixel_values`.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام GIT.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية المتعلقة بالاستدلال + الضبط الدقيق لـ GIT على بيانات مخصصة [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GIT).
+- راجع أيضًا: [دليل مهمة نمذجة اللغة السببية](../tasks/language_modeling)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه. يجب أن يوضح المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## GitVisionConfig
+
+[[autodoc]] GitVisionConfig
+
+## GitVisionModel
+
+[[autodoc]] GitVisionModel
+
+- forward
+
+## GitConfig
+
+[[autodoc]] GitConfig
+
+- all
+
+## GitProcessor
+
+[[autodoc]] GitProcessor
+
+- __call__
+
+## GitModel
+
+[[autodoc]] GitModel
+
+- forward
+
+## GitForCausalLM
+
+[[autodoc]] GitForCausalLM
+
+- forward
\ No newline at end of file
From b0cadf3f330e6cef575d7f0386993d6104a95182 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:39 +0300
Subject: [PATCH 449/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/glpn.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/glpn.md | 59 ++++++++++++++++++++++++++++++++
1 file changed, 59 insertions(+)
create mode 100644 docs/source/ar/model_doc/glpn.md
diff --git a/docs/source/ar/model_doc/glpn.md b/docs/source/ar/model_doc/glpn.md
new file mode 100644
index 00000000000000..763cef1538602b
--- /dev/null
+++ b/docs/source/ar/model_doc/glpn.md
@@ -0,0 +1,59 @@
+# GLPN
+
+
+
+ ملخص النهج. مأخوذ من <[الأوراق الأصلية](https://arxiv.org/abs/2201.07436)>
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/vinvino02/GLPDepth).
+
+## الموارد
+
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام GLPN.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ [`GLPNForDepthEstimation`] [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/GLPN).
+- [دليل مهام تقدير العمق أحادي العين](../tasks/monocular_depth_estimation)
+
+## GLPNConfig
+
+[[autodoc]] GLPNConfig
+
+## GLPNFeatureExtractor
+
+[[autodoc]] GLPNFeatureExtractor
+
+- __call__
+
+## GLPNImageProcessor
+
+[[autodoc]] GLPNImageProcessor
+
+- preprocess
+
+## GLPNModel
+
+[[autodoc]] GLPNModel
+
+- forward
+
+## GLPNForDepthEstimation
+
+[[autodoc]] GLPNForDepthEstimation
+
+- forward
\ No newline at end of file
From 51139c4f3ab99e54dceda6c399dac9b458bb87f5 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:41 +0300
Subject: [PATCH 450/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/gpt-sw3.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/gpt-sw3.md | 47 +++++++++++++++++++++++++++++
1 file changed, 47 insertions(+)
create mode 100644 docs/source/ar/model_doc/gpt-sw3.md
diff --git a/docs/source/ar/model_doc/gpt-sw3.md b/docs/source/ar/model_doc/gpt-sw3.md
new file mode 100644
index 00000000000000..e1acb32d6e7e74
--- /dev/null
+++ b/docs/source/ar/model_doc/gpt-sw3.md
@@ -0,0 +1,47 @@
+# GPT-Sw3
+
+## نظرة عامة
+
+اقترح نموذج GPT-Sw3 لأول مرة في ورقة "الدروس المستفادة من GPT-SW3: بناء أول نموذج لغوي توليدي واسع النطاق للغة السويدية" من قبل أرييل إكغرين، وأمارو كوبا جيلينستن، وإيفانجيليا جوجولو، وأليس هايمان، وسيفيرين فيرليندن، وجوي أوهمان، وفريدريك كارلسون، وماغنوس ساهلجرين.
+
+ومنذ تلك الورقة الأولى، وسع المؤلفون عملهم ودربوا نماذج جديدة على مجموعات بياناتهم الجديدة التي تبلغ 1.2 تيرابايت والتي تسمى The Nordic Pile.
+
+GPT-Sw3 عبارة عن مجموعة من نماذج المحول اللغوي فك التشفير فقط كبيرة الحجم التي تم تطويرها بواسطة AI Sweden بالتعاون مع RISE و WASP WARA for Media and Language. تم تدريب GPT-Sw3 على مجموعة بيانات تحتوي على 320 مليار رمز في السويدية والنرويجية والدانماركية والإيسلندية والإنجليزية، ورموز البرمجة. تم تدريب النموذج المسبق باستخدام هدف نمذجة اللغة السببية (CLM) باستخدام تنفيذ NeMo Megatron GPT.
+
+تمت المساهمة بهذا النموذج من قبل [نماذج AI Sweden](https://huggingface.co/AI-Sweden-Models).
+
+## مثال على الاستخدام
+
+```python
+>>> from transformers import AutoTokenizer, AutoModelForCausalLM
+
+>>> tokenizer = AutoTokenizer.from_pretrained("AI-Sweden-Models/gpt-sw3-356m")
+>>> model = AutoModelForCausalLM.from_pretrained("AI-Sweden-Models/gpt-sw3-352m")
+
+>>> input_ids = tokenizer("Träd är fina för att", return_tensors="pt")["input_ids"]
+
+>>> generated_token_ids = model.generate(inputs=input_ids, max_new_tokens=10, do_sample=True)[0]
+
+>>> print(tokenizer.decode(generated_token_ids))
+Träd är fina för att de är färgstarka. Men ibland är det fint
+```
+
+## الموارد
+
+- [دليل مهمة تصنيف النصوص](../tasks/sequence_classification)
+- [دليل مهمة تصنيف الرموز](../tasks/token_classification)
+- [دليل نمذجة اللغة السببية](../tasks/language_modeling)
+
+ +
+ +
+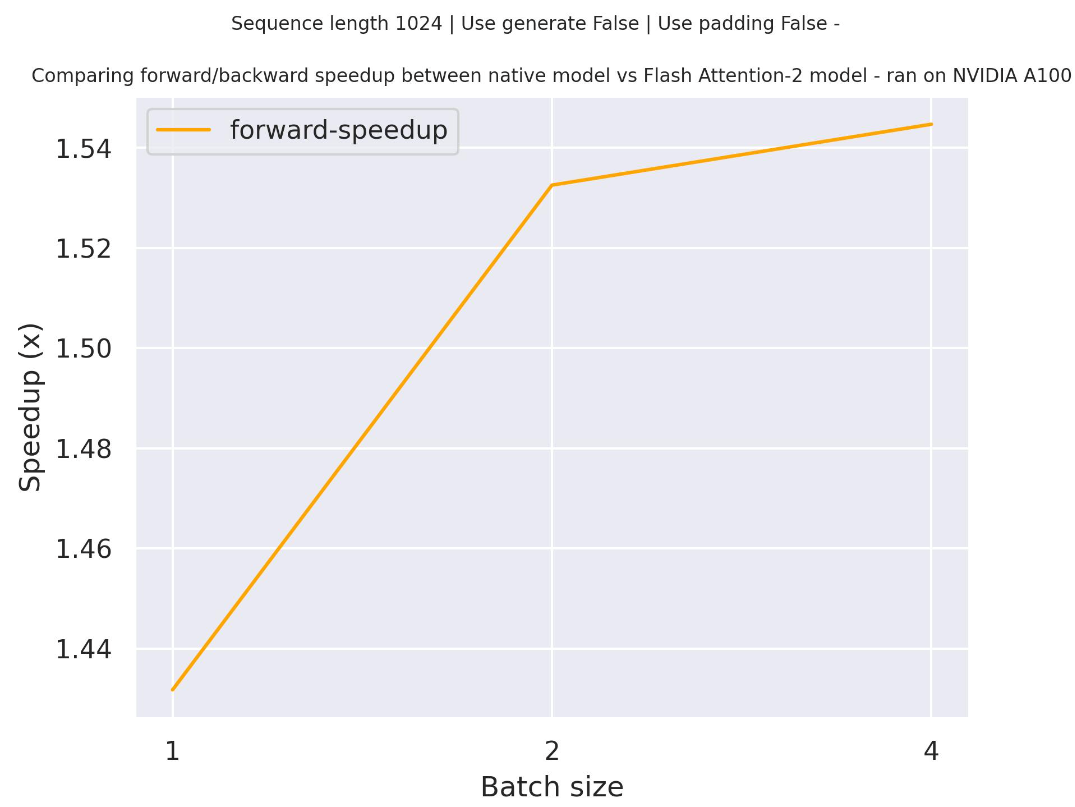 +
+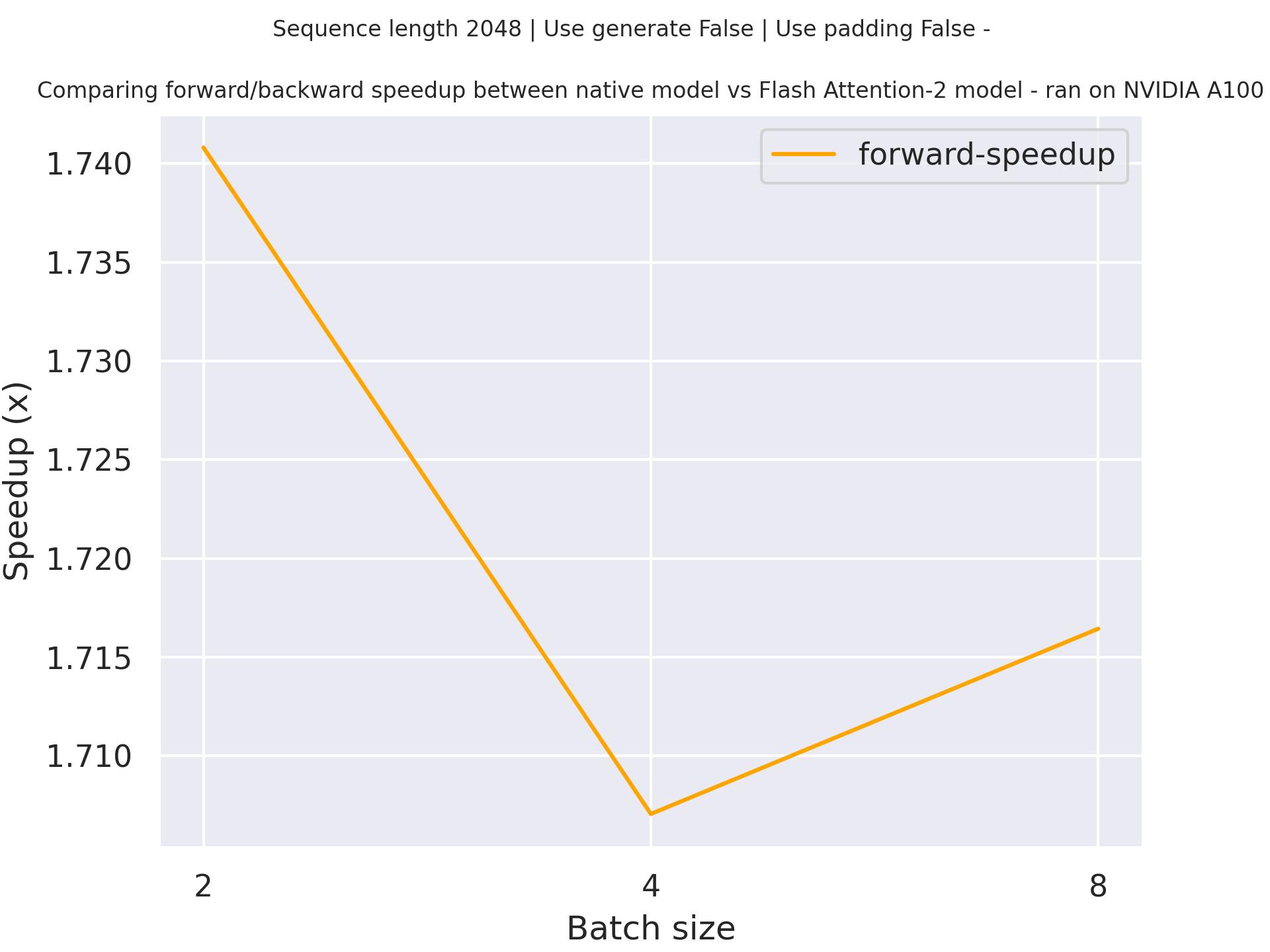 +
+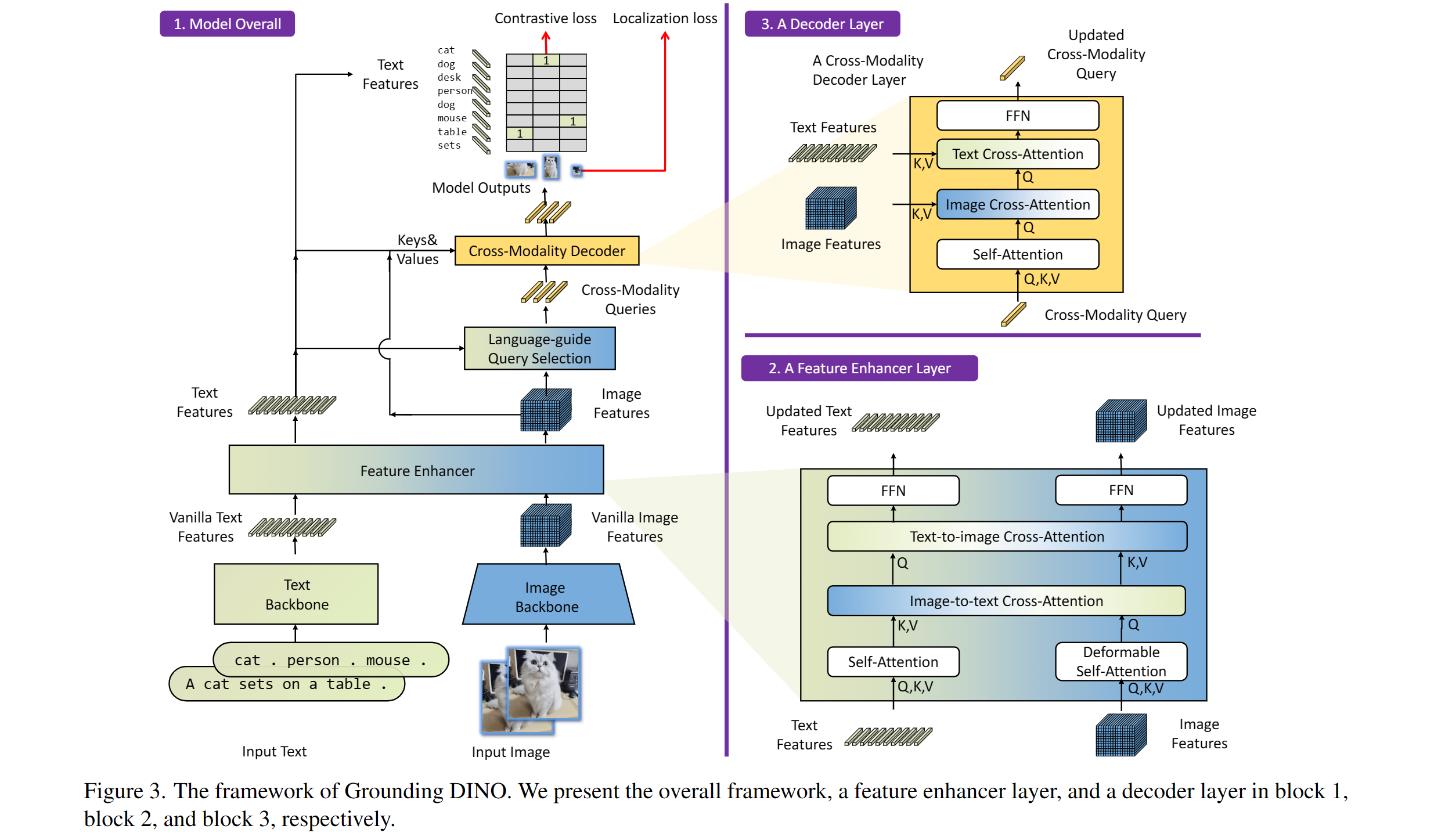 +
+ نظرة عامة على Grounding DINO. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل EduardoPacheco وnielsr. يمكن العثور على الكود الأصلي [هنا](https://github.com/IDEA-Research/GroundingDINO).
+
+## نصائح الاستخدام
+
+- يمكن استخدام [`GroundingDinoProcessor`] لإعداد أزواج الصور والنصوص للنموذج.
+- لفصل الفئات في النص، استخدم فترة، على سبيل المثال "قطة. كلب."
+- عند استخدام فئات متعددة (على سبيل المثال "قطة. كلب.")، استخدم `post_process_grounded_object_detection` من [`GroundingDinoProcessor`] لمعالجة الإخراج. نظرًا لأن التسميات التي تم إرجاعها من `post_process_object_detection` تمثل المؤشرات من بُعد النموذج حيث تكون الاحتمالية أكبر من العتبة.
+
+فيما يلي كيفية استخدام النموذج للكشف عن الكائنات بدون الإشراف:
+
+```python
+import requests
+
+import torch
+from PIL import Image
+from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection,
+
+model_id = "IDEA-Research/grounding-dino-tiny"
+
+processor = AutoProcessor.from_pretrained(model_id)
+model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
+
+image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(image_url, stream=True).raw)
+# Check for cats and remote controls
+text = "a cat. a remote control."
+
+inputs = processor(images=image, text=text, return_tensors="pt").to(device)
+with torch.no_grad():
+ outputs = model(**inputs)
+
+results = processor.post_process_grounded_object_detection(
+ outputs,
+ inputs.input_ids,
+ box_threshold=0.4,
+ text_threshold=0.3,
+ target_sizes=[image.size[::-1]]
+)
+```
+
+## Grounded SAM
+
+يمكنك دمج Grounding DINO مع نموذج [Segment Anything](sam) للتنقيب القائم على النص كما هو مقدم في ورقة "Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks". يمكنك الرجوع إلى هذا [دفتر الملاحظات التوضيحي](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 للحصول على التفاصيل.
+
+
+
+ نظرة عامة على Grounding DINO. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل EduardoPacheco وnielsr. يمكن العثور على الكود الأصلي [هنا](https://github.com/IDEA-Research/GroundingDINO).
+
+## نصائح الاستخدام
+
+- يمكن استخدام [`GroundingDinoProcessor`] لإعداد أزواج الصور والنصوص للنموذج.
+- لفصل الفئات في النص، استخدم فترة، على سبيل المثال "قطة. كلب."
+- عند استخدام فئات متعددة (على سبيل المثال "قطة. كلب.")، استخدم `post_process_grounded_object_detection` من [`GroundingDinoProcessor`] لمعالجة الإخراج. نظرًا لأن التسميات التي تم إرجاعها من `post_process_object_detection` تمثل المؤشرات من بُعد النموذج حيث تكون الاحتمالية أكبر من العتبة.
+
+فيما يلي كيفية استخدام النموذج للكشف عن الكائنات بدون الإشراف:
+
+```python
+import requests
+
+import torch
+from PIL import Image
+from transformers import AutoProcessor, AutoModelForZeroShotObjectDetection,
+
+model_id = "IDEA-Research/grounding-dino-tiny"
+
+processor = AutoProcessor.from_pretrained(model_id)
+model = AutoModelForZeroShotObjectDetection.from_pretrained(model_id).to(device)
+
+image_url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(image_url, stream=True).raw)
+# Check for cats and remote controls
+text = "a cat. a remote control."
+
+inputs = processor(images=image, text=text, return_tensors="pt").to(device)
+with torch.no_grad():
+ outputs = model(**inputs)
+
+results = processor.post_process_grounded_object_detection(
+ outputs,
+ inputs.input_ids,
+ box_threshold=0.4,
+ text_threshold=0.3,
+ target_sizes=[image.size[::-1]]
+)
+```
+
+## Grounded SAM
+
+يمكنك دمج Grounding DINO مع نموذج [Segment Anything](sam) للتنقيب القائم على النص كما هو مقدم في ورقة "Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks". يمكنك الرجوع إلى هذا [دفتر الملاحظات التوضيحي](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Grounding%20DINO/GroundingDINO_with_Segment_Anything.ipynb) 🌍 للحصول على التفاصيل.
+
+ +
+ نظرة عامة على Grounded SAM. مأخوذة من المستودع الأصلي.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام Grounding DINO. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد بشكل مثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية المتعلقة بالاستدلال باستخدام Grounding DINO، وكذلك دمجه مع [SAM](sam) [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Grounding%20DINO). 🌎
+
+## GroundingDinoImageProcessor
+
+[[autodoc]] GroundingDinoImageProcessor
+
+- preprocess
+- post_process_object_detection
+
+## GroundingDinoProcessor
+
+[[autodoc]] GroundingDinoProcessor
+
+- post_process_grounded_object_detection
+
+## GroundingDinoConfig
+
+[[autodoc]] GroundingDinoConfig
+
+## GroundingDinoModel
+
+[[autodoc]] GroundingDinoModel
+
+- forward
+
+## GroundingDinoForObjectDetection
+
+[[autodoc]] GroundingDinoForObjectDetection
+
+- forward
\ No newline at end of file
From 7e2f1e5dcc2ae55e663054568419b90bb390d05b Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:57 +0300
Subject: [PATCH 459/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/groupvit.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/groupvit.md | 98 ++++++++++++++++++++++++++++
1 file changed, 98 insertions(+)
create mode 100644 docs/source/ar/model_doc/groupvit.md
diff --git a/docs/source/ar/model_doc/groupvit.md b/docs/source/ar/model_doc/groupvit.md
new file mode 100644
index 00000000000000..f63b72f252035d
--- /dev/null
+++ b/docs/source/ar/model_doc/groupvit.md
@@ -0,0 +1,98 @@
+# GroupViT
+
+## نظرة عامة
+
+اقترح نموذج GroupViT في [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) بواسطة Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+
+استوحى من [CLIP](clip)، GroupViT هو نموذج للرؤية اللغوية يمكنه أداء تجزئة دلالية بدون الإشراف على أي فئات معجمية معينة.
+
+المستخلص من الورقة هو ما يلي:
+
+*يعد التجميع والتعرف على المكونات المهمة لفهم المشهد المرئي، على سبيل المثال، للكشف عن الأشياء والتجزئة الدلالية. مع أنظمة التعلم العميق من البداية إلى النهاية، يحدث تجميع مناطق الصورة عادة بشكل ضمني عبر الإشراف من أعلى إلى أسفل من علامات التعرف على مستوى البكسل. بدلاً من ذلك، في هذه الورقة، نقترح إعادة آلية التجميع إلى الشبكات العصبية العميقة، والتي تسمح للشرائح الدلالية بالظهور تلقائيًا مع الإشراف النصي فقط. نقترح مجموعة هرمية من محول الرؤية (GroupViT)، والتي تتجاوز تمثيل هيكل الشبكة المنتظمة وتتعلم تجميع مناطق الصورة في شرائح ذات أشكال تعسفية أكبر تدريجيًا. نقوم بتدريب GroupViT بشكل مشترك مع مشفر نصي على مجموعة بيانات نصية للصور واسعة النطاق عبر الخسائر التباينية. بدون أي ملاحظات على مستوى البكسل، يتعلم GroupViT تجميع المناطق الدلالية معًا وينتقل بنجاح إلى مهمة التجزئة الدلالية بطريقة بدون إشراف، أي بدون أي ضبط دقيق إضافي. يحقق دقة بدون إشراف تبلغ 52.3% mIoU على مجموعة بيانات PASCAL VOC 2012 و22.4% mIoU على مجموعة بيانات PASCAL Context، وينافس طرق التعلم عن طريق النقل التي تتطلب مستويات أعلى من الإشراف.*
+
+ساهم بهذا النموذج [xvjiarui](https://huggingface.co/xvjiarui). ساهم في إصدار TensorFlow بواسطة [ariG23498](https://huggingface.co/ariG23498) بمساعدة [Yih-Dar SHIEH](https://huggingface.co/ydshieh) و[Amy Roberts](https://huggingface.co/amyeroberts) و[Joao Gante](https://huggingface.co/joaogante).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/NVlabs/GroupViT).
+
+## نصائح الاستخدام
+
+- يمكنك تحديد `output_segmentation=True` في الأمام من `GroupViTModel` للحصول على logits التجزئة للنصوص المدخلة.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية والمجتمعية (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام GroupViT.
+
+- أسرع طريقة للبدء في استخدام GroupViT هي التحقق من [دفاتر الملاحظات التوضيحية](https://github.com/xvjiarui/GroupViT/blob/main/demo/GroupViT_hf_inference_notebook.ipynb) (والتي تعرض الاستدلال على التجزئة بدون إشراف).
+
+- يمكنك أيضًا الاطلاع على [تجربة HuggingFace Spaces](https://huggingface.co/spaces/xvjiarui/GroupViT) للعب مع GroupViT.
+
+## GroupViTConfig
+
+[[autodoc]] GroupViTConfig
+
+- from_text_vision_configs
+
+## GroupViTTextConfig
+
+[[autodoc]] GroupViTTextConfig
+
+## GroupViTVisionConfig
+
+[[autodoc]] GroupViTVisionConfig
+
+
+
+ نظرة عامة على Grounded SAM. مأخوذة من المستودع الأصلي.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام Grounding DINO. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد بشكل مثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية المتعلقة بالاستدلال باستخدام Grounding DINO، وكذلك دمجه مع [SAM](sam) [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Grounding%20DINO). 🌎
+
+## GroundingDinoImageProcessor
+
+[[autodoc]] GroundingDinoImageProcessor
+
+- preprocess
+- post_process_object_detection
+
+## GroundingDinoProcessor
+
+[[autodoc]] GroundingDinoProcessor
+
+- post_process_grounded_object_detection
+
+## GroundingDinoConfig
+
+[[autodoc]] GroundingDinoConfig
+
+## GroundingDinoModel
+
+[[autodoc]] GroundingDinoModel
+
+- forward
+
+## GroundingDinoForObjectDetection
+
+[[autodoc]] GroundingDinoForObjectDetection
+
+- forward
\ No newline at end of file
From 7e2f1e5dcc2ae55e663054568419b90bb390d05b Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:25:57 +0300
Subject: [PATCH 459/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/groupvit.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/groupvit.md | 98 ++++++++++++++++++++++++++++
1 file changed, 98 insertions(+)
create mode 100644 docs/source/ar/model_doc/groupvit.md
diff --git a/docs/source/ar/model_doc/groupvit.md b/docs/source/ar/model_doc/groupvit.md
new file mode 100644
index 00000000000000..f63b72f252035d
--- /dev/null
+++ b/docs/source/ar/model_doc/groupvit.md
@@ -0,0 +1,98 @@
+# GroupViT
+
+## نظرة عامة
+
+اقترح نموذج GroupViT في [GroupViT: Semantic Segmentation Emerges from Text Supervision](https://arxiv.org/abs/2202.11094) بواسطة Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang.
+
+استوحى من [CLIP](clip)، GroupViT هو نموذج للرؤية اللغوية يمكنه أداء تجزئة دلالية بدون الإشراف على أي فئات معجمية معينة.
+
+المستخلص من الورقة هو ما يلي:
+
+*يعد التجميع والتعرف على المكونات المهمة لفهم المشهد المرئي، على سبيل المثال، للكشف عن الأشياء والتجزئة الدلالية. مع أنظمة التعلم العميق من البداية إلى النهاية، يحدث تجميع مناطق الصورة عادة بشكل ضمني عبر الإشراف من أعلى إلى أسفل من علامات التعرف على مستوى البكسل. بدلاً من ذلك، في هذه الورقة، نقترح إعادة آلية التجميع إلى الشبكات العصبية العميقة، والتي تسمح للشرائح الدلالية بالظهور تلقائيًا مع الإشراف النصي فقط. نقترح مجموعة هرمية من محول الرؤية (GroupViT)، والتي تتجاوز تمثيل هيكل الشبكة المنتظمة وتتعلم تجميع مناطق الصورة في شرائح ذات أشكال تعسفية أكبر تدريجيًا. نقوم بتدريب GroupViT بشكل مشترك مع مشفر نصي على مجموعة بيانات نصية للصور واسعة النطاق عبر الخسائر التباينية. بدون أي ملاحظات على مستوى البكسل، يتعلم GroupViT تجميع المناطق الدلالية معًا وينتقل بنجاح إلى مهمة التجزئة الدلالية بطريقة بدون إشراف، أي بدون أي ضبط دقيق إضافي. يحقق دقة بدون إشراف تبلغ 52.3% mIoU على مجموعة بيانات PASCAL VOC 2012 و22.4% mIoU على مجموعة بيانات PASCAL Context، وينافس طرق التعلم عن طريق النقل التي تتطلب مستويات أعلى من الإشراف.*
+
+ساهم بهذا النموذج [xvjiarui](https://huggingface.co/xvjiarui). ساهم في إصدار TensorFlow بواسطة [ariG23498](https://huggingface.co/ariG23498) بمساعدة [Yih-Dar SHIEH](https://huggingface.co/ydshieh) و[Amy Roberts](https://huggingface.co/amyeroberts) و[Joao Gante](https://huggingface.co/joaogante).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/NVlabs/GroupViT).
+
+## نصائح الاستخدام
+
+- يمكنك تحديد `output_segmentation=True` في الأمام من `GroupViTModel` للحصول على logits التجزئة للنصوص المدخلة.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية والمجتمعية (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام GroupViT.
+
+- أسرع طريقة للبدء في استخدام GroupViT هي التحقق من [دفاتر الملاحظات التوضيحية](https://github.com/xvjiarui/GroupViT/blob/main/demo/GroupViT_hf_inference_notebook.ipynb) (والتي تعرض الاستدلال على التجزئة بدون إشراف).
+
+- يمكنك أيضًا الاطلاع على [تجربة HuggingFace Spaces](https://huggingface.co/spaces/xvjiarui/GroupViT) للعب مع GroupViT.
+
+## GroupViTConfig
+
+[[autodoc]] GroupViTConfig
+
+- from_text_vision_configs
+
+## GroupViTTextConfig
+
+[[autodoc]] GroupViTTextConfig
+
+## GroupViTVisionConfig
+
+[[autodoc]] GroupViTVisionConfig
+
+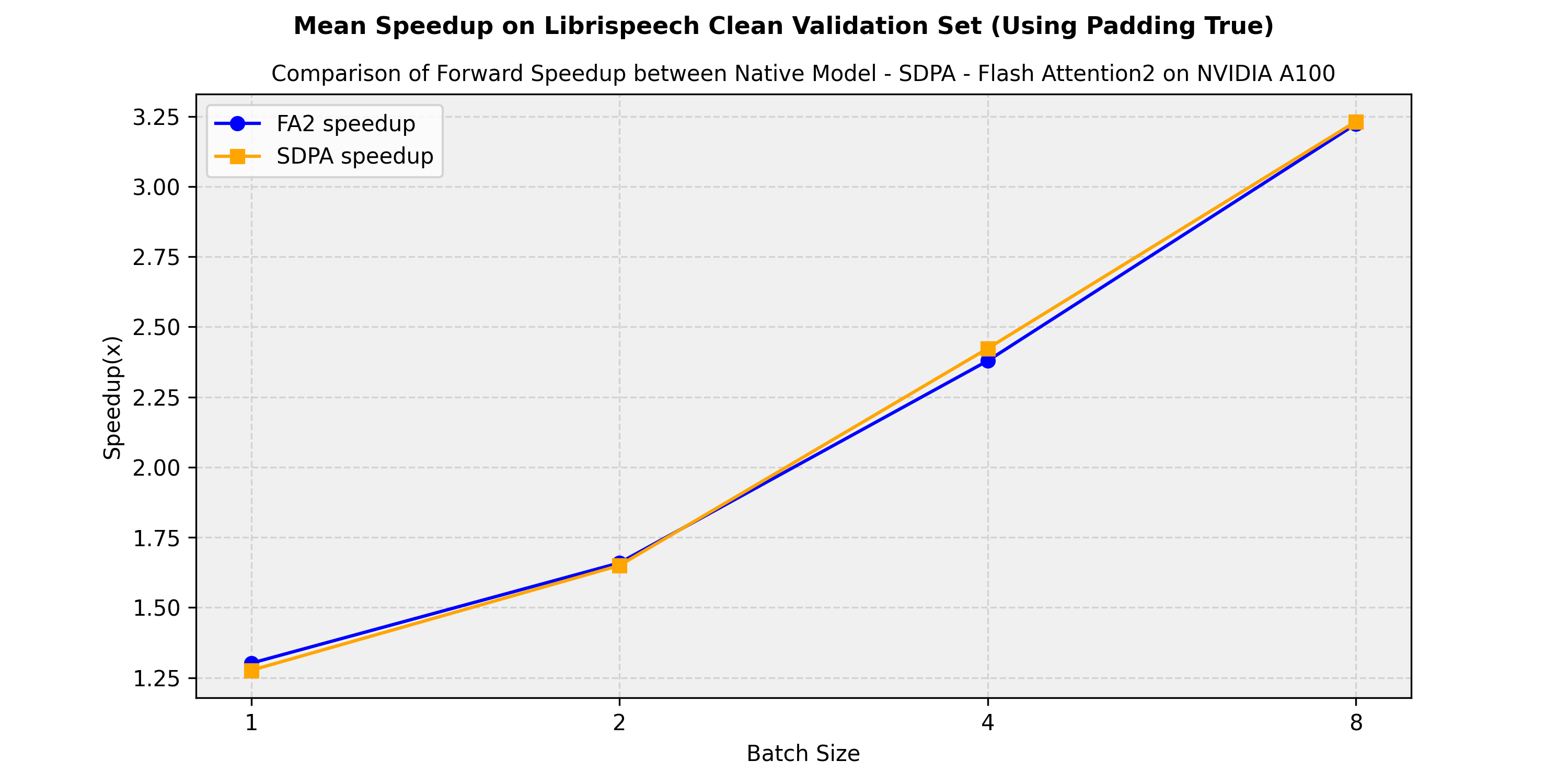 +
+ +
+هندسة Idefics2. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [amyeroberts](https://huggingface.co/amyeroberts).
+يمكن العثور على الكود الأصلي [هنا](https://huggingface.co/HuggingFaceM4/idefics2).
+
+## نصائح الاستخدام
+
+- يمكن أن يحتوي كل عينة على صور متعددة، ويمكن أن يختلف عدد الصور بين العينات. وسوف يقوم المعالج بملء إدخالات إلى العدد الأقصى من الصور في دفعة للإدخال إلى النموذج.
+- يوجد لدى المعالج خيار `do_image_splitting`. إذا كان `True`، فسيتم تقسيم كل صورة إدخال إلى 4 صور فرعية، وسيتم دمجها مع الأصل لتشكيل 5 صور. هذا مفيد لزيادة أداء النموذج. تأكد من تعيين `processor.image_processor.do_image_splitting` على `False` إذا لم يتم تدريب النموذج باستخدام هذا الخيار.
+- يجب أن يكون `text` الذي تم تمريره إلى المعالج رموز `
+
+هندسة Idefics2. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [amyeroberts](https://huggingface.co/amyeroberts).
+يمكن العثور على الكود الأصلي [هنا](https://huggingface.co/HuggingFaceM4/idefics2).
+
+## نصائح الاستخدام
+
+- يمكن أن يحتوي كل عينة على صور متعددة، ويمكن أن يختلف عدد الصور بين العينات. وسوف يقوم المعالج بملء إدخالات إلى العدد الأقصى من الصور في دفعة للإدخال إلى النموذج.
+- يوجد لدى المعالج خيار `do_image_splitting`. إذا كان `True`، فسيتم تقسيم كل صورة إدخال إلى 4 صور فرعية، وسيتم دمجها مع الأصل لتشكيل 5 صور. هذا مفيد لزيادة أداء النموذج. تأكد من تعيين `processor.image_processor.do_image_splitting` على `False` إذا لم يتم تدريب النموذج باستخدام هذا الخيار.
+- يجب أن يكون `text` الذي تم تمريره إلى المعالج رموز ` +
+ ملخص النهج. مأخوذ من [الورقة الأصلية](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr)، بناءً على [هذه القضية](https://github.com/openai/image-gpt/issues/7). يمكن العثور على الكود الأصلي [هنا](https://github.com/openai/image-gpt).
+
+## نصائح الاستخدام
+
+- ImageGPT هو نفسه تقريبًا مثل [GPT-2](gpt2)، باستثناء استخدام دالة تنشيط مختلفة (وهي "quick gelu")، ولا تقوم طبقات التطبيع الطبقي بمركز متوسط المدخلات. كما أن ImageGPT لا يحتوي على تضمين إدخال وإخراج مربوط.
+
+- نظرًا لأن متطلبات الوقت والذاكرة لآلية اهتمام المحولات تتناسب تربيعيًا مع طول التسلسل، قام المؤلفون بتدريب ImageGPT مسبقًا على دقات إدخال أصغر، مثل 32x32 و64x64. ومع ذلك، فإن إدخال تسلسل من 32x32x3=3072 رمزًا من 0..255 في محول لا يزال كبيرًا جدًا. لذلك، طبق المؤلفون التجميع k-means على قيم البكسل (R,G,B) مع k=512. بهذه الطريقة، لدينا تسلسل يبلغ طوله 32*32 = 1024، ولكنه الآن من الأعداد الصحيحة في النطاق 0..511. لذلك، نقوم بتقليص طول التسلسل على حساب مصفوفة تضمين أكبر. وبعبارة أخرى، يبلغ حجم مفردات ImageGPT 512، + 1 لعلامة "بداية الجملة" (SOS) الخاصة، والتي يتم استخدامها في بداية كل تسلسل. يمكن للمرء استخدام [`ImageGPTImageProcessor`] لتحضير الصور للنموذج.
+
+- على الرغم من التدريب المسبق تمامًا بدون إشراف (أي بدون استخدام أي ملصقات)، فإن ImageGPT ينتج ميزات صورة جيدة الأداء مفيدة للمهام اللاحقة، مثل تصنيف الصور. أظهر المؤلفون أن الميزات الموجودة في منتصف الشبكة هي الأكثر أداءً، ويمكن استخدامها كما هي لتدريب نموذج خطي (مثل نموذج الانحدار اللوجستي sklearn على سبيل المثال). يُشار إلى هذا أيضًا باسم "الاستجواب الخطي". يمكن الحصول على الميزات بسهولة عن طريق تمرير الصورة أولاً عبر النموذج، ثم تحديد `output_hidden_states=True`، ثم تجميع المتوسط للدول المخفية في أي طبقة تريدها.
+
+- بدلاً من ذلك، يمكن للمرء مواصلة الضبط الدقيق للنموذج بالكامل على مجموعة بيانات تابعة، على غرار BERT. للقيام بذلك، يمكنك استخدام [`ImageGPTForImageClassification`].
+
+- يأتي ImageGPT بأحجام مختلفة: هناك ImageGPT-small، وImageGPT-medium، وImageGPT-large. قام المؤلفون أيضًا بتدريب متغير XL، لكنهم لم يطلقوه. يتم تلخيص الاختلافات في الحجم في الجدول التالي:
+
+| **متغير النموذج** | **الأعماق** | **الأحجام المخفية** | **حجم فك تشفير المخفية** | **بارامترات (م)** | **ImageNet-1k Top 1** |
+|---|---|---|---|---|---|
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام ImageGPT.
+
+
+
+ ملخص النهج. مأخوذ من [الورقة الأصلية](https://cdn.openai.com/papers/Generative_Pretraining_from_Pixels_V2.pdf).
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr)، بناءً على [هذه القضية](https://github.com/openai/image-gpt/issues/7). يمكن العثور على الكود الأصلي [هنا](https://github.com/openai/image-gpt).
+
+## نصائح الاستخدام
+
+- ImageGPT هو نفسه تقريبًا مثل [GPT-2](gpt2)، باستثناء استخدام دالة تنشيط مختلفة (وهي "quick gelu")، ولا تقوم طبقات التطبيع الطبقي بمركز متوسط المدخلات. كما أن ImageGPT لا يحتوي على تضمين إدخال وإخراج مربوط.
+
+- نظرًا لأن متطلبات الوقت والذاكرة لآلية اهتمام المحولات تتناسب تربيعيًا مع طول التسلسل، قام المؤلفون بتدريب ImageGPT مسبقًا على دقات إدخال أصغر، مثل 32x32 و64x64. ومع ذلك، فإن إدخال تسلسل من 32x32x3=3072 رمزًا من 0..255 في محول لا يزال كبيرًا جدًا. لذلك، طبق المؤلفون التجميع k-means على قيم البكسل (R,G,B) مع k=512. بهذه الطريقة، لدينا تسلسل يبلغ طوله 32*32 = 1024، ولكنه الآن من الأعداد الصحيحة في النطاق 0..511. لذلك، نقوم بتقليص طول التسلسل على حساب مصفوفة تضمين أكبر. وبعبارة أخرى، يبلغ حجم مفردات ImageGPT 512، + 1 لعلامة "بداية الجملة" (SOS) الخاصة، والتي يتم استخدامها في بداية كل تسلسل. يمكن للمرء استخدام [`ImageGPTImageProcessor`] لتحضير الصور للنموذج.
+
+- على الرغم من التدريب المسبق تمامًا بدون إشراف (أي بدون استخدام أي ملصقات)، فإن ImageGPT ينتج ميزات صورة جيدة الأداء مفيدة للمهام اللاحقة، مثل تصنيف الصور. أظهر المؤلفون أن الميزات الموجودة في منتصف الشبكة هي الأكثر أداءً، ويمكن استخدامها كما هي لتدريب نموذج خطي (مثل نموذج الانحدار اللوجستي sklearn على سبيل المثال). يُشار إلى هذا أيضًا باسم "الاستجواب الخطي". يمكن الحصول على الميزات بسهولة عن طريق تمرير الصورة أولاً عبر النموذج، ثم تحديد `output_hidden_states=True`، ثم تجميع المتوسط للدول المخفية في أي طبقة تريدها.
+
+- بدلاً من ذلك، يمكن للمرء مواصلة الضبط الدقيق للنموذج بالكامل على مجموعة بيانات تابعة، على غرار BERT. للقيام بذلك، يمكنك استخدام [`ImageGPTForImageClassification`].
+
+- يأتي ImageGPT بأحجام مختلفة: هناك ImageGPT-small، وImageGPT-medium، وImageGPT-large. قام المؤلفون أيضًا بتدريب متغير XL، لكنهم لم يطلقوه. يتم تلخيص الاختلافات في الحجم في الجدول التالي:
+
+| **متغير النموذج** | **الأعماق** | **الأحجام المخفية** | **حجم فك تشفير المخفية** | **بارامترات (م)** | **ImageNet-1k Top 1** |
+|---|---|---|---|---|---|
+| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام ImageGPT.
+
+ +
+ بنية InstructBLIP. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+
+## نصائح الاستخدام
+يستخدم InstructBLIP نفس البنية مثل [BLIP-2](blip2) مع اختلاف بسيط ولكنه مهم: فهو أيضًا يغذي موجه النص (التعليمات) إلى Q-Former.
+
+## InstructBlipConfig
+
+[[autodoc]] InstructBlipConfig
+
+- from_vision_qformer_text_configs
+
+## InstructBlipVisionConfig
+
+[[autodoc]] InstructBlipVisionConfig
+
+## InstructBlipQFormerConfig
+
+[[autodoc]] InstructBlipQFormerConfig
+
+## InstructBlipProcessor
+
+[[autodoc]] InstructBlipProcessor
+
+## InstructBlipVisionModel
+
+[[autodoc]] InstructBlipVisionModel
+
+- forward
+
+## InstructBlipQFormerModel
+
+[[autodoc]] InstructBlipQFormerModel
+
+- forward
+
+## InstructBlipForConditionalGeneration
+
+[[autodoc]] InstructBlipForConditionalGeneration
+
+- forward
+
+- generate
\ No newline at end of file
From 73f0ceb19857715c5ab722bf3c4ce8d23b73359a Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:26:14 +0300
Subject: [PATCH 468/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/jamba.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/jamba.md | 115 ++++++++++++++++++++++++++++++
1 file changed, 115 insertions(+)
create mode 100644 docs/source/ar/model_doc/jamba.md
diff --git a/docs/source/ar/model_doc/jamba.md b/docs/source/ar/model_doc/jamba.md
new file mode 100644
index 00000000000000..c14e99001097b5
--- /dev/null
+++ b/docs/source/ar/model_doc/jamba.md
@@ -0,0 +1,115 @@
+# Jamba
+
+## نظرة عامة
+
+Jamba عبارة عن شبكة عصبية هجينة SSM-Transformer LLM رائدة في مجالها. إنه أول تطبيق لمقياس Mamba، والذي يفتح فرصًا مثيرة للبحث والتطبيق. في حين أن هذه التجربة الأولية تظهر مكاسب مشجعة، فإننا نتوقع أن يتم تعزيزها بشكل أكبر مع الاستكشافات والتحسينات المستقبلية.
+
+للحصول على التفاصيل الكاملة حول هذا النموذج، يرجى قراءة [منشور المدونة](https://www.ai21.com/blog/announcing-jamba) الخاص بالإصدار.
+
+### تفاصيل النموذج
+
+Jamba هو نموذج نصي تنبئي مسبق التدريب، يعتمد على مزيج من الخبراء (MoE)، ويحتوي على 12 بليون معامل نشط و52 بليون معامل إجمالي عبر جميع الخبراء. يدعم النموذج طول سياق يصل إلى 256 ألفًا، ويمكنه استيعاب ما يصل إلى 140 ألف رمز على وحدة معالجة رسومية (GPU) واحدة بسعة 80 جيجابايت.
+
+كما هو موضح في الرسم البياني أدناه، تتميز بنية Jamba بنهج الكتل والطبقات الذي يسمح لـ Jamba بدمج بنيات Transformer وMamba بنجاح. تحتوي كل كتلة من Jamba إما على طبقة اهتمام أو طبقة Mamba، تليها شبكة عصبية متعددة الطبقات (MLP)، مما ينتج عنه نسبة إجمالية تبلغ طبقة Transformer واحدة من كل ثماني طبقات إجمالية.
+
+
+
+## الاستخدام
+
+### المتطلبات الأساسية
+
+يتطلب Jamba استخدام إصدار `transformers` 4.39.0 أو أعلى:
+
+```bash
+pip install transformers>=4.39.0
+```
+
+لتشغيل تطبيقات Mamba المحسّنة، يجب أولاً تثبيت `mamba-ssm` و`causal-conv1d`:
+
+```bash
+pip install mamba-ssm causal-conv1d>=1.2.0
+```
+
+يجب أيضًا أن يكون لديك النموذج على جهاز CUDA.
+
+يمكنك تشغيل النموذج دون استخدام نوى Mamba المحسنة، ولكن لا يوصى بذلك لأنه سيؤدي إلى انخفاض كبير في الكمون. للقيام بذلك، ستحتاج إلى تحديد `use_mamba_kernels=False` عند تحميل النموذج.
+
+### تشغيل النموذج
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
+tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
+
+input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
+
+outputs = model.generate(input_ids, max_new_tokens=216)
+
+print(tokenizer.batch_decode(outputs))
+# ["<|startoftext|>In the recent Super Bowl LVIII, the Kansas City Chiefs emerged victorious, defeating the San Francisco 49ers in a thrilling overtime showdown. The game was a nail-biter, with both teams showcasing their skills and determination.\n\nThe Chiefs, led by their star quarterback Patrick Mahomes, displayed their offensive prowess, while the 49ers, led by their strong defense, put up a tough fight. The game went into overtime, with the Chiefs ultimately securing the win with a touchdown.\n\nThe victory marked the Chiefs' second Super Bowl win in four years, solidifying their status as one of the top teams in the NFL. The game was a testament to the skill and talent of both teams, and a thrilling end to the NFL season.\n\nThe Super Bowl is not just about the game itself, but also about the halftime show and the commercials. This year's halftime show featured a star-studded lineup, including Usher, Alicia Keys, and Lil Jon. The show was a spectacle of music and dance, with the performers delivering an energetic and entertaining performance.\n"]
+```
+
+
+
+ بنية InstructBLIP. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/salesforce/LAVIS/tree/main/projects/instructblip).
+
+## نصائح الاستخدام
+يستخدم InstructBLIP نفس البنية مثل [BLIP-2](blip2) مع اختلاف بسيط ولكنه مهم: فهو أيضًا يغذي موجه النص (التعليمات) إلى Q-Former.
+
+## InstructBlipConfig
+
+[[autodoc]] InstructBlipConfig
+
+- from_vision_qformer_text_configs
+
+## InstructBlipVisionConfig
+
+[[autodoc]] InstructBlipVisionConfig
+
+## InstructBlipQFormerConfig
+
+[[autodoc]] InstructBlipQFormerConfig
+
+## InstructBlipProcessor
+
+[[autodoc]] InstructBlipProcessor
+
+## InstructBlipVisionModel
+
+[[autodoc]] InstructBlipVisionModel
+
+- forward
+
+## InstructBlipQFormerModel
+
+[[autodoc]] InstructBlipQFormerModel
+
+- forward
+
+## InstructBlipForConditionalGeneration
+
+[[autodoc]] InstructBlipForConditionalGeneration
+
+- forward
+
+- generate
\ No newline at end of file
From 73f0ceb19857715c5ab722bf3c4ce8d23b73359a Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:26:14 +0300
Subject: [PATCH 468/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/jamba.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/jamba.md | 115 ++++++++++++++++++++++++++++++
1 file changed, 115 insertions(+)
create mode 100644 docs/source/ar/model_doc/jamba.md
diff --git a/docs/source/ar/model_doc/jamba.md b/docs/source/ar/model_doc/jamba.md
new file mode 100644
index 00000000000000..c14e99001097b5
--- /dev/null
+++ b/docs/source/ar/model_doc/jamba.md
@@ -0,0 +1,115 @@
+# Jamba
+
+## نظرة عامة
+
+Jamba عبارة عن شبكة عصبية هجينة SSM-Transformer LLM رائدة في مجالها. إنه أول تطبيق لمقياس Mamba، والذي يفتح فرصًا مثيرة للبحث والتطبيق. في حين أن هذه التجربة الأولية تظهر مكاسب مشجعة، فإننا نتوقع أن يتم تعزيزها بشكل أكبر مع الاستكشافات والتحسينات المستقبلية.
+
+للحصول على التفاصيل الكاملة حول هذا النموذج، يرجى قراءة [منشور المدونة](https://www.ai21.com/blog/announcing-jamba) الخاص بالإصدار.
+
+### تفاصيل النموذج
+
+Jamba هو نموذج نصي تنبئي مسبق التدريب، يعتمد على مزيج من الخبراء (MoE)، ويحتوي على 12 بليون معامل نشط و52 بليون معامل إجمالي عبر جميع الخبراء. يدعم النموذج طول سياق يصل إلى 256 ألفًا، ويمكنه استيعاب ما يصل إلى 140 ألف رمز على وحدة معالجة رسومية (GPU) واحدة بسعة 80 جيجابايت.
+
+كما هو موضح في الرسم البياني أدناه، تتميز بنية Jamba بنهج الكتل والطبقات الذي يسمح لـ Jamba بدمج بنيات Transformer وMamba بنجاح. تحتوي كل كتلة من Jamba إما على طبقة اهتمام أو طبقة Mamba، تليها شبكة عصبية متعددة الطبقات (MLP)، مما ينتج عنه نسبة إجمالية تبلغ طبقة Transformer واحدة من كل ثماني طبقات إجمالية.
+
+
+
+## الاستخدام
+
+### المتطلبات الأساسية
+
+يتطلب Jamba استخدام إصدار `transformers` 4.39.0 أو أعلى:
+
+```bash
+pip install transformers>=4.39.0
+```
+
+لتشغيل تطبيقات Mamba المحسّنة، يجب أولاً تثبيت `mamba-ssm` و`causal-conv1d`:
+
+```bash
+pip install mamba-ssm causal-conv1d>=1.2.0
+```
+
+يجب أيضًا أن يكون لديك النموذج على جهاز CUDA.
+
+يمكنك تشغيل النموذج دون استخدام نوى Mamba المحسنة، ولكن لا يوصى بذلك لأنه سيؤدي إلى انخفاض كبير في الكمون. للقيام بذلك، ستحتاج إلى تحديد `use_mamba_kernels=False` عند تحميل النموذج.
+
+### تشغيل النموذج
+
+```python
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+model = AutoModelForCausalLM.from_pretrained("ai21labs/Jamba-v0.1")
+tokenizer = AutoTokenizer.from_pretrained("ai21labs/Jamba-v0.1")
+
+input_ids = tokenizer("In the recent Super Bowl LVIII,", return_tensors='pt').to(model.device)["input_ids"]
+
+outputs = model.generate(input_ids, max_new_tokens=216)
+
+print(tokenizer.batch_decode(outputs))
+# ["<|startoftext|>In the recent Super Bowl LVIII, the Kansas City Chiefs emerged victorious, defeating the San Francisco 49ers in a thrilling overtime showdown. The game was a nail-biter, with both teams showcasing their skills and determination.\n\nThe Chiefs, led by their star quarterback Patrick Mahomes, displayed their offensive prowess, while the 49ers, led by their strong defense, put up a tough fight. The game went into overtime, with the Chiefs ultimately securing the win with a touchdown.\n\nThe victory marked the Chiefs' second Super Bowl win in four years, solidifying their status as one of the top teams in the NFL. The game was a testament to the skill and talent of both teams, and a thrilling end to the NFL season.\n\nThe Super Bowl is not just about the game itself, but also about the halftime show and the commercials. This year's halftime show featured a star-studded lineup, including Usher, Alicia Keys, and Lil Jon. The show was a spectacle of music and dance, with the performers delivering an energetic and entertaining performance.\n"]
+```
+
+ +
+نظرة عامة على المهام التي يمكن أن يتعامل معها KOSMOS-2. مأخوذة من الورقة البحثية الأصلية.
+
+## مثال
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
+
+>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
+>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
+
+>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> prompt = "
+
+نظرة عامة على المهام التي يمكن أن يتعامل معها KOSMOS-2. مأخوذة من الورقة البحثية الأصلية.
+
+## مثال
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, Kosmos2ForConditionalGeneration
+
+>>> model = Kosmos2ForConditionalGeneration.from_pretrained("microsoft/kosmos-2-patch14-224")
+>>> processor = AutoProcessor.from_pretrained("microsoft/kosmos-2-patch14-224")
+
+>>> url = "https://huggingface.co/microsoft/kosmos-2-patch14-224/resolve/main/snowman.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> prompt = " +
+ تصميم LayoutLMv3. مأخوذ من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). تمت إضافة إصدار TensorFlow من هذا النموذج بواسطة [chriskoo](https://huggingface.co/chriskoo)، و [tokec](https://huggingface.co/tokec)، و [lre](https://huggingface.co/lre). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+
+## نصائح الاستخدام
+
+- من حيث معالجة البيانات، فإن LayoutLMv3 مطابق لسلفه [LayoutLMv2](layoutlmv2)، باستثناء ما يلي:
+
+- يجب تغيير حجم الصور وتطبيعها مع القنوات بتنسيق RGB العادي. من ناحية أخرى، يقوم LayoutLMv2 بتطبيع الصور داخليًا ويتوقع القنوات بتنسيق BGR.
+
+- يتم توكين النص باستخدام الترميز ثنائي البايت (BPE)، على عكس WordPiece.
+
+بسبب هذه الاختلافات في معالجة البيانات الأولية، يمكن استخدام [`LayoutLMv3Processor`] الذي يجمع داخليًا بين [`LayoutLMv3ImageProcessor`] (لطريقة الصورة) و [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (لطريقة النص) لإعداد جميع البيانات للنموذج.
+
+- فيما يتعلق باستخدام [`LayoutLMv3Processor`]]، نشير إلى [دليل الاستخدام](layoutlmv2#usage-layoutlmv2processor) لسلفه.
+
+## الموارد
+
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام LayoutLMv3. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب Pull Request وسنقوم بمراجعته! يجب أن يوضح المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+
+
+ تصميم LayoutLMv3. مأخوذ من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). تمت إضافة إصدار TensorFlow من هذا النموذج بواسطة [chriskoo](https://huggingface.co/chriskoo)، و [tokec](https://huggingface.co/tokec)، و [lre](https://huggingface.co/lre). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/unilm/tree/master/layoutlmv3).
+
+## نصائح الاستخدام
+
+- من حيث معالجة البيانات، فإن LayoutLMv3 مطابق لسلفه [LayoutLMv2](layoutlmv2)، باستثناء ما يلي:
+
+- يجب تغيير حجم الصور وتطبيعها مع القنوات بتنسيق RGB العادي. من ناحية أخرى، يقوم LayoutLMv2 بتطبيع الصور داخليًا ويتوقع القنوات بتنسيق BGR.
+
+- يتم توكين النص باستخدام الترميز ثنائي البايت (BPE)، على عكس WordPiece.
+
+بسبب هذه الاختلافات في معالجة البيانات الأولية، يمكن استخدام [`LayoutLMv3Processor`] الذي يجمع داخليًا بين [`LayoutLMv3ImageProcessor`] (لطريقة الصورة) و [`LayoutLMv3Tokenizer`]/[`LayoutLMv3TokenizerFast`] (لطريقة النص) لإعداد جميع البيانات للنموذج.
+
+- فيما يتعلق باستخدام [`LayoutLMv3Processor`]]، نشير إلى [دليل الاستخدام](layoutlmv2#usage-layoutlmv2processor) لسلفه.
+
+## الموارد
+
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام LayoutLMv3. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب Pull Request وسنقوم بمراجعته! يجب أن يوضح المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+ +
+هندسة LeViT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [anugunj](https://huggingface.co/anugunj). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/LeViT).
+
+## نصائح الاستخدام
+
+- مقارنة بـ ViT، تستخدم نماذج LeViT رأس تقطير إضافي للتعلم الفعال من المعلم (والذي، في ورقة LeViT، هو نموذج مشابه لـ ResNet). يتم تعلم رأس التقطير من خلال الانتشار الخلفي تحت إشراف نموذج مشابه لـ ResNet. كما يستلهمون الإلهام من شبكات التلفيف العصبية لاستخدام خرائط تنشيط ذات دقة متناقصة لزيادة الكفاءة.
+
+- هناك طريقتان لضبط النماذج المقطرة، إما (1) بالطريقة الكلاسيكية، عن طريق وضع رأس تنبؤ فقط أعلى حالة الإخفاء النهائية وعدم استخدام رأس التقطير، أو (2) عن طريق وضع رأس تنبؤ ورأس تقطير أعلى حالة الإخفاء النهائية. في هذه الحالة، يتم تدريب رأس التنبؤ باستخدام الانتشارية العادية بين تنبؤ الرأس والملصق الأرضي، في حين يتم تدريب رأس التقطير التنبؤي باستخدام التقطير الصعب (الانتشارية بين تنبؤ رأس التقطير والملصق الذي تنبأ به المعلم). في وقت الاستدلال، يتم أخذ متوسط التنبؤ بين كلا الرأسين كتنبؤ نهائي. (2) يُطلق عليه أيضًا "الضبط الدقيق مع التقطير"، لأنه يعتمد على معلم تم ضبطه بالفعل على مجموعة البيانات النهائية. من حيث النماذج، (1) يقابل [`LevitForImageClassification`] و (2) يقابل [`LevitForImageClassificationWithTeacher`].
+
+- تم ضبط جميع نقاط التحقق الصادرة مسبقًا والضبط الدقيق على [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (يشار إليها أيضًا باسم ILSVRC 2012، وهي عبارة عن مجموعة من 1.3 مليون صورة و1000 فئة). لم يتم استخدام أي بيانات خارجية. وهذا يتعارض مع نموذج ViT الأصلي، والذي استخدم بيانات خارجية مثل مجموعة بيانات JFT-300M/Imagenet-21k للضبط المسبق.
+
+- أصدر مؤلفو LeViT 5 نماذج LeViT مدربة، والتي يمكنك توصيلها مباشرة في [`LevitModel`] أو [`LevitForImageClassification`]. تم استخدام تقنيات مثل زيادة البيانات والتحسين والتنظيم لمحاكاة التدريب على مجموعة بيانات أكبر بكثير (مع استخدام ImageNet-1k فقط للضبط المسبق). المتغيرات الخمسة المتاحة هي (جميعها مدربة على صور بحجم 224x224): *facebook/levit-128S*، *facebook/levit-128*، *facebook/levit-192*، *facebook/levit-256* و*facebook/levit-384*. لاحظ أنه يجب استخدام [`LevitImageProcessor`] لتحضير الصور للنموذج.
+
+- يدعم [`LevitForImageClassificationWithTeacher`] حاليًا الاستدلال فقط وليس التدريب أو الضبط الدقيق.
+
+- يمكنك الاطلاع على دفاتر الملاحظات التجريبية المتعلقة بالاستدلال وكذلك الضبط الدقيق على البيانات المخصصة [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (يمكنك فقط استبدال [`ViTFeatureExtractor`] بـ [`LevitImageProcessor`] و [`ViTForImageClassification`] بـ [`LevitForImageClassification`] أو [`LevitForImageClassificationWithTeacher`]).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام LeViT.
+
+
+
+هندسة LeViT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [anugunj](https://huggingface.co/anugunj). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/LeViT).
+
+## نصائح الاستخدام
+
+- مقارنة بـ ViT، تستخدم نماذج LeViT رأس تقطير إضافي للتعلم الفعال من المعلم (والذي، في ورقة LeViT، هو نموذج مشابه لـ ResNet). يتم تعلم رأس التقطير من خلال الانتشار الخلفي تحت إشراف نموذج مشابه لـ ResNet. كما يستلهمون الإلهام من شبكات التلفيف العصبية لاستخدام خرائط تنشيط ذات دقة متناقصة لزيادة الكفاءة.
+
+- هناك طريقتان لضبط النماذج المقطرة، إما (1) بالطريقة الكلاسيكية، عن طريق وضع رأس تنبؤ فقط أعلى حالة الإخفاء النهائية وعدم استخدام رأس التقطير، أو (2) عن طريق وضع رأس تنبؤ ورأس تقطير أعلى حالة الإخفاء النهائية. في هذه الحالة، يتم تدريب رأس التنبؤ باستخدام الانتشارية العادية بين تنبؤ الرأس والملصق الأرضي، في حين يتم تدريب رأس التقطير التنبؤي باستخدام التقطير الصعب (الانتشارية بين تنبؤ رأس التقطير والملصق الذي تنبأ به المعلم). في وقت الاستدلال، يتم أخذ متوسط التنبؤ بين كلا الرأسين كتنبؤ نهائي. (2) يُطلق عليه أيضًا "الضبط الدقيق مع التقطير"، لأنه يعتمد على معلم تم ضبطه بالفعل على مجموعة البيانات النهائية. من حيث النماذج، (1) يقابل [`LevitForImageClassification`] و (2) يقابل [`LevitForImageClassificationWithTeacher`].
+
+- تم ضبط جميع نقاط التحقق الصادرة مسبقًا والضبط الدقيق على [ImageNet-1k](https://huggingface.co/datasets/imagenet-1k) (يشار إليها أيضًا باسم ILSVRC 2012، وهي عبارة عن مجموعة من 1.3 مليون صورة و1000 فئة). لم يتم استخدام أي بيانات خارجية. وهذا يتعارض مع نموذج ViT الأصلي، والذي استخدم بيانات خارجية مثل مجموعة بيانات JFT-300M/Imagenet-21k للضبط المسبق.
+
+- أصدر مؤلفو LeViT 5 نماذج LeViT مدربة، والتي يمكنك توصيلها مباشرة في [`LevitModel`] أو [`LevitForImageClassification`]. تم استخدام تقنيات مثل زيادة البيانات والتحسين والتنظيم لمحاكاة التدريب على مجموعة بيانات أكبر بكثير (مع استخدام ImageNet-1k فقط للضبط المسبق). المتغيرات الخمسة المتاحة هي (جميعها مدربة على صور بحجم 224x224): *facebook/levit-128S*، *facebook/levit-128*، *facebook/levit-192*، *facebook/levit-256* و*facebook/levit-384*. لاحظ أنه يجب استخدام [`LevitImageProcessor`] لتحضير الصور للنموذج.
+
+- يدعم [`LevitForImageClassificationWithTeacher`] حاليًا الاستدلال فقط وليس التدريب أو الضبط الدقيق.
+
+- يمكنك الاطلاع على دفاتر الملاحظات التجريبية المتعلقة بالاستدلال وكذلك الضبط الدقيق على البيانات المخصصة [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/VisionTransformer) (يمكنك فقط استبدال [`ViTFeatureExtractor`] بـ [`LevitImageProcessor`] و [`ViTForImageClassification`] بـ [`LevitForImageClassification`] أو [`LevitForImageClassificationWithTeacher`]).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام LeViT.
+
+ +
+هندسة LiLT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/jpwang/lilt).
+
+## نصائح الاستخدام
+
+- للجمع بين محول التخطيط المستقل عن اللغة ونقطة تفتيش جديدة من RoBERTa من [hub](https://huggingface.co/models?search=roberta)، راجع [هذا الدليل](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
+سينتج البرنامج النصي عن ملفي `config.json` و`pytorch_model.bin` المخزنين محليًا. بعد القيام بذلك، يمكنك القيام بما يلي (بافتراض أنك قمت بتسجيل الدخول باستخدام حساب HuggingFace الخاص بك):
+
+```python
+from transformers import LiltModel
+
+model = LiltModel.from_pretrained("path_to_your_files")
+model.push_to_hub("name_of_repo_on_the_hub")
+```
+
+- عند إعداد البيانات للنموذج، تأكد من استخدام مفردات الرموز التي تتوافق مع نقطة تفتيش RoBERTa التي قمت بدمجها مع محول التخطيط.
+- نظرًا لأن [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) يستخدم نفس المفردات مثل [LayoutLMv3](layoutlmv3)، فيمكن استخدام [`LayoutLMv3TokenizerFast`] لإعداد البيانات للنموذج.
+وينطبق الشيء نفسه على [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): يمكن استخدام [`LayoutXLMTokenizerFast`] لهذا النموذج.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام LiLT.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ LiLT [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
+
+**موارد التوثيق**
+
+- [دليل مهمة تصنيف النصوص](../tasks/sequence_classification)
+- [دليل مهمة تصنيف الرموز](../tasks/token_classification)
+- [دليل مهمة الإجابة على الأسئلة](../tasks/question_answering)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يوضح المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## LiltConfig
+
+[[autodoc]] LiltConfig
+
+## LiltModel
+
+[[autodoc]] LiltModel
+
+- forward
+
+## LiltForSequenceClassification
+
+[[autodoc]] LiltForSequenceClassification
+
+- forward
+
+## LiltForTokenClassification
+
+[[autodoc]] LiltForTokenClassification
+
+- forward
+
+## LiltForQuestionAnswering
+
+[[autodoc]] LiltForQuestionAnswering
+
+- forward
\ No newline at end of file
From 1717e6901e0d42677b67942ad2b198dab54d2f3e Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:26:34 +0300
Subject: [PATCH 479/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/llama.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/llama.md | 133 ++++++++++++++++++++++++++++++
1 file changed, 133 insertions(+)
create mode 100644 docs/source/ar/model_doc/llama.md
diff --git a/docs/source/ar/model_doc/llama.md b/docs/source/ar/model_doc/llama.md
new file mode 100644
index 00000000000000..c5804d38a270fa
--- /dev/null
+++ b/docs/source/ar/model_doc/llama.md
@@ -0,0 +1,133 @@
+# LLaMA
+
+## نظرة عامة
+اقترح نموذج LLaMA في [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) بواسطة Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. وهي مجموعة من نماذج اللغة الأساسية التي تتراوح من 7B إلى 65B من المعلمات.
+
+الملخص من الورقة هو ما يلي:
+
+*نحن نقدم LLaMA، وهي مجموعة من نماذج اللغة الأساسية التي تتراوح من 7B إلى 65B من المعلمات. نقوم بتدريب نماذجنا على تريليونات من الرموز، ونظهر أنه من الممكن تدريب نماذج متقدمة باستخدام مجموعات البيانات المتاحة للجمهور حصريًا، دون اللجوء إلى مجموعات البيانات المملوكة وغير المتاحة. وعلى وجه الخصوص، يتفوق LLaMA-13B على GPT-3 (175B) في معظم المعايير، وينافس LLaMA-65B أفضل النماذج، Chinchilla-70B و PaLM-540B. نقوم بإطلاق جميع نماذجنا لمجتمع البحث.*
+
+تمت المساهمة بهذا النموذج من قبل [zphang](https://huggingface.co/zphang) بمساهمات من [BlackSamorez](https://huggingface.co/BlackSamorez). يعتمد كود التنفيذ في Hugging Face على GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). يمكن العثور على الكود الأصلي للمؤلفين [here](https://github.com/facebookresearch/llama).
+
+## نصائح الاستخدام
+
+- يمكن الحصول على أوزان نماذج LLaMA من خلال ملء [هذا النموذج](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform?usp=send_form)
+
+- بعد تنزيل الأوزان، سيتعين تحويلها إلى تنسيق Hugging Face Transformers باستخدام [Script التحويل](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py). يمكن استدعاء النص البرمجي باستخدام الأمر التالي (كمثال):
+
+```bash
+python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
+```
+
+- بعد التحويل، يمكن تحميل النموذج ومحول الرموز باستخدام ما يلي:
+
+```python
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+tokenizer = LlamaTokenizer.from_pretrained("/output/path")
+model = LlamaForCausalLM.from_pretrained("/output/path")
+```
+
+ملاحظة: يتطلب تنفيذ النص البرمجي مساحة كافية من ذاكرة الوصول العشوائي CPU لاستضافة النموذج بالكامل في دقة float16 (حتى إذا كانت الإصدارات الأكبر تأتي في عدة نقاط مرجعية، فإن كل منها يحتوي على جزء من كل وزن للنموذج، لذلك نحتاج إلى تحميلها جميعًا في ذاكرة الوصول العشوائي). بالنسبة للنموذج 65B، نحتاج إلى 130 جيجابايت من ذاكرة الوصول العشوائي.
+
+- محول رموز LLaMA هو نموذج BPE يعتمد على [sentencepiece](https://github.com/google/sentencepiece). إحدى ميزات sentencepiece هي أنه عند فك تشفير تسلسل، إذا كان الرمز الأول هو بداية الكلمة (مثل "Banana")، فإن المحلل اللغوي لا يسبق المسافة البادئة إلى السلسلة.
+
+تمت المساهمة بهذا النموذج من قبل [zphang](https://huggingface.co/zphang) بمساهمات من [BlackSamorez](https://huggingface.co/BlackSamorez). يعتمد كود التنفيذ في Hugging Face على GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). يمكن العثور على الكود الأصلي للمؤلفين [here](https://github.com/facebookresearch/llama). تم تقديم إصدار Flax من التنفيذ من قبل [afmck](https://huggingface.co/afmck) مع الكود في التنفيذ بناءً على Flax GPT-Neo من Hugging Face.
+
+بناءً على نموذج LLaMA الأصلي، أصدرت Meta AI بعض الأعمال اللاحقة:
+
+- **Llama2**: Llama2 هو إصدار محسن من Llama مع بعض التعديلات المعمارية (Grouped Query Attention)، وهو مُدرب مسبقًا على 2 تريليون رمز. راجع وثائق Llama2 التي يمكن العثور عليها [here](llama2).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام LLaMA. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+
+
+هندسة LiLT. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/jpwang/lilt).
+
+## نصائح الاستخدام
+
+- للجمع بين محول التخطيط المستقل عن اللغة ونقطة تفتيش جديدة من RoBERTa من [hub](https://huggingface.co/models?search=roberta)، راجع [هذا الدليل](https://github.com/jpWang/LiLT#or-generate-your-own-checkpoint-optional).
+سينتج البرنامج النصي عن ملفي `config.json` و`pytorch_model.bin` المخزنين محليًا. بعد القيام بذلك، يمكنك القيام بما يلي (بافتراض أنك قمت بتسجيل الدخول باستخدام حساب HuggingFace الخاص بك):
+
+```python
+from transformers import LiltModel
+
+model = LiltModel.from_pretrained("path_to_your_files")
+model.push_to_hub("name_of_repo_on_the_hub")
+```
+
+- عند إعداد البيانات للنموذج، تأكد من استخدام مفردات الرموز التي تتوافق مع نقطة تفتيش RoBERTa التي قمت بدمجها مع محول التخطيط.
+- نظرًا لأن [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-roberta-en-base) يستخدم نفس المفردات مثل [LayoutLMv3](layoutlmv3)، فيمكن استخدام [`LayoutLMv3TokenizerFast`] لإعداد البيانات للنموذج.
+وينطبق الشيء نفسه على [lilt-roberta-en-base](https://huggingface.co/SCUT-DLVCLab/lilt-infoxlm-base): يمكن استخدام [`LayoutXLMTokenizerFast`] لهذا النموذج.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام LiLT.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ LiLT [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LiLT).
+
+**موارد التوثيق**
+
+- [دليل مهمة تصنيف النصوص](../tasks/sequence_classification)
+- [دليل مهمة تصنيف الرموز](../tasks/token_classification)
+- [دليل مهمة الإجابة على الأسئلة](../tasks/question_answering)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يوضح المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## LiltConfig
+
+[[autodoc]] LiltConfig
+
+## LiltModel
+
+[[autodoc]] LiltModel
+
+- forward
+
+## LiltForSequenceClassification
+
+[[autodoc]] LiltForSequenceClassification
+
+- forward
+
+## LiltForTokenClassification
+
+[[autodoc]] LiltForTokenClassification
+
+- forward
+
+## LiltForQuestionAnswering
+
+[[autodoc]] LiltForQuestionAnswering
+
+- forward
\ No newline at end of file
From 1717e6901e0d42677b67942ad2b198dab54d2f3e Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:26:34 +0300
Subject: [PATCH 479/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/llama.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/llama.md | 133 ++++++++++++++++++++++++++++++
1 file changed, 133 insertions(+)
create mode 100644 docs/source/ar/model_doc/llama.md
diff --git a/docs/source/ar/model_doc/llama.md b/docs/source/ar/model_doc/llama.md
new file mode 100644
index 00000000000000..c5804d38a270fa
--- /dev/null
+++ b/docs/source/ar/model_doc/llama.md
@@ -0,0 +1,133 @@
+# LLaMA
+
+## نظرة عامة
+اقترح نموذج LLaMA في [LLaMA: Open and Efficient Foundation Language Models](https://arxiv.org/abs/2302.13971) بواسطة Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. وهي مجموعة من نماذج اللغة الأساسية التي تتراوح من 7B إلى 65B من المعلمات.
+
+الملخص من الورقة هو ما يلي:
+
+*نحن نقدم LLaMA، وهي مجموعة من نماذج اللغة الأساسية التي تتراوح من 7B إلى 65B من المعلمات. نقوم بتدريب نماذجنا على تريليونات من الرموز، ونظهر أنه من الممكن تدريب نماذج متقدمة باستخدام مجموعات البيانات المتاحة للجمهور حصريًا، دون اللجوء إلى مجموعات البيانات المملوكة وغير المتاحة. وعلى وجه الخصوص، يتفوق LLaMA-13B على GPT-3 (175B) في معظم المعايير، وينافس LLaMA-65B أفضل النماذج، Chinchilla-70B و PaLM-540B. نقوم بإطلاق جميع نماذجنا لمجتمع البحث.*
+
+تمت المساهمة بهذا النموذج من قبل [zphang](https://huggingface.co/zphang) بمساهمات من [BlackSamorez](https://huggingface.co/BlackSamorez). يعتمد كود التنفيذ في Hugging Face على GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). يمكن العثور على الكود الأصلي للمؤلفين [here](https://github.com/facebookresearch/llama).
+
+## نصائح الاستخدام
+
+- يمكن الحصول على أوزان نماذج LLaMA من خلال ملء [هذا النموذج](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform?usp=send_form)
+
+- بعد تنزيل الأوزان، سيتعين تحويلها إلى تنسيق Hugging Face Transformers باستخدام [Script التحويل](https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/convert_llama_weights_to_hf.py). يمكن استدعاء النص البرمجي باستخدام الأمر التالي (كمثال):
+
+```bash
+python src/transformers/models/llama/convert_llama_weights_to_hf.py \
+--input_dir /path/to/downloaded/llama/weights --model_size 7B --output_dir /output/path
+```
+
+- بعد التحويل، يمكن تحميل النموذج ومحول الرموز باستخدام ما يلي:
+
+```python
+from transformers import LlamaForCausalLM, LlamaTokenizer
+
+tokenizer = LlamaTokenizer.from_pretrained("/output/path")
+model = LlamaForCausalLM.from_pretrained("/output/path")
+```
+
+ملاحظة: يتطلب تنفيذ النص البرمجي مساحة كافية من ذاكرة الوصول العشوائي CPU لاستضافة النموذج بالكامل في دقة float16 (حتى إذا كانت الإصدارات الأكبر تأتي في عدة نقاط مرجعية، فإن كل منها يحتوي على جزء من كل وزن للنموذج، لذلك نحتاج إلى تحميلها جميعًا في ذاكرة الوصول العشوائي). بالنسبة للنموذج 65B، نحتاج إلى 130 جيجابايت من ذاكرة الوصول العشوائي.
+
+- محول رموز LLaMA هو نموذج BPE يعتمد على [sentencepiece](https://github.com/google/sentencepiece). إحدى ميزات sentencepiece هي أنه عند فك تشفير تسلسل، إذا كان الرمز الأول هو بداية الكلمة (مثل "Banana")، فإن المحلل اللغوي لا يسبق المسافة البادئة إلى السلسلة.
+
+تمت المساهمة بهذا النموذج من قبل [zphang](https://huggingface.co/zphang) بمساهمات من [BlackSamorez](https://huggingface.co/BlackSamorez). يعتمد كود التنفيذ في Hugging Face على GPT-NeoX [here](https://github.com/EleutherAI/gpt-neox). يمكن العثور على الكود الأصلي للمؤلفين [here](https://github.com/facebookresearch/llama). تم تقديم إصدار Flax من التنفيذ من قبل [afmck](https://huggingface.co/afmck) مع الكود في التنفيذ بناءً على Flax GPT-Neo من Hugging Face.
+
+بناءً على نموذج LLaMA الأصلي، أصدرت Meta AI بعض الأعمال اللاحقة:
+
+- **Llama2**: Llama2 هو إصدار محسن من Llama مع بعض التعديلات المعمارية (Grouped Query Attention)، وهو مُدرب مسبقًا على 2 تريليون رمز. راجع وثائق Llama2 التي يمكن العثور عليها [here](llama2).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام LLaMA. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+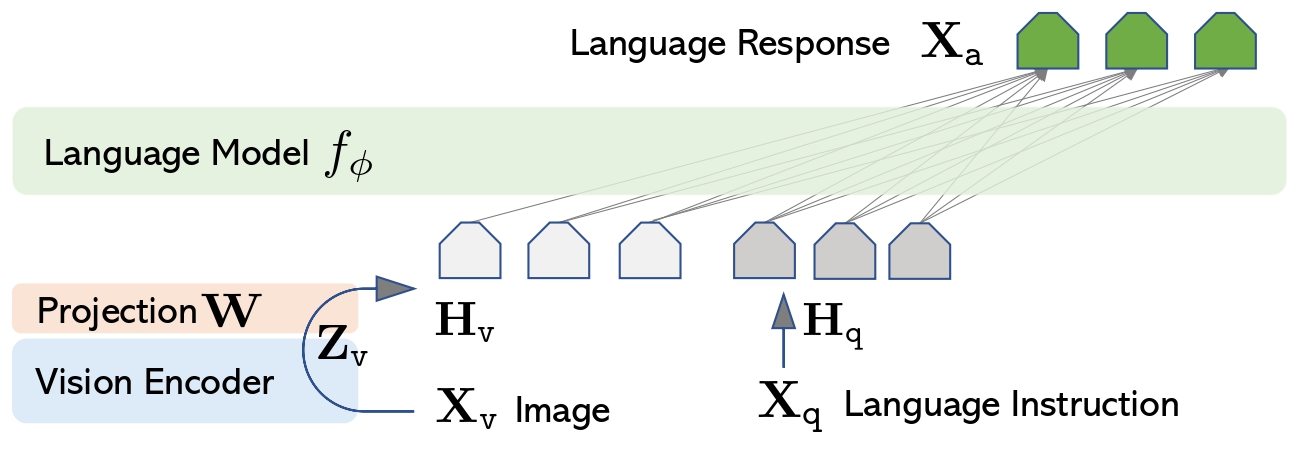 +
+بنية LLaVa. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [ArthurZ](https://huggingface.co/ArthurZ) و[ybelkada](https://huggingface.co/ybelkada).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/haotian-liu/LLaVA/tree/main/llava).
+
+## نصائح الاستخدام
+
+- ننصح المستخدمين باستخدام `padding_side="left"` عند حساب التوليد الدفعي حيث يؤدي إلى نتائج أكثر دقة. كل ما عليك التأكد من هو استدعاء `processor.tokenizer.padding_side = "left"` قبل التوليد.
+
+- لاحظ أن النموذج لم يتم تدريبه بشكل صريح لمعالجة صور متعددة في نفس المطالبة، على الرغم من أن هذا ممكن من الناحية الفنية، فقد تواجه نتائج غير دقيقة.
+
+- للحصول على نتائج أفضل، نوصي المستخدمين بتزويد النموذج بتنسيق المطالبة الصحيح:
+
+```bash
+"USER:
+
+بنية LLaVa. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [ArthurZ](https://huggingface.co/ArthurZ) و[ybelkada](https://huggingface.co/ybelkada).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/haotian-liu/LLaVA/tree/main/llava).
+
+## نصائح الاستخدام
+
+- ننصح المستخدمين باستخدام `padding_side="left"` عند حساب التوليد الدفعي حيث يؤدي إلى نتائج أكثر دقة. كل ما عليك التأكد من هو استدعاء `processor.tokenizer.padding_side = "left"` قبل التوليد.
+
+- لاحظ أن النموذج لم يتم تدريبه بشكل صريح لمعالجة صور متعددة في نفس المطالبة، على الرغم من أن هذا ممكن من الناحية الفنية، فقد تواجه نتائج غير دقيقة.
+
+- للحصول على نتائج أفضل، نوصي المستخدمين بتزويد النموذج بتنسيق المطالبة الصحيح:
+
+```bash
+"USER: 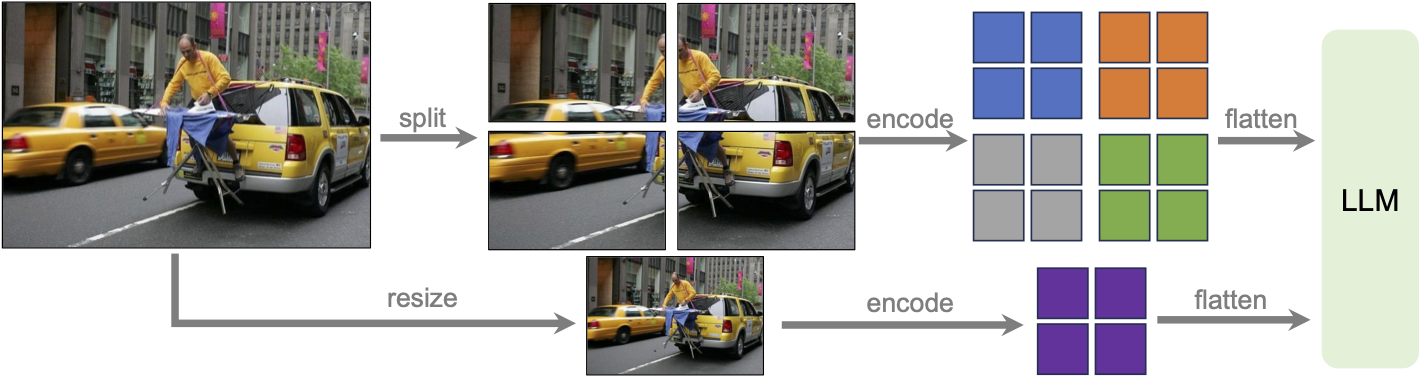 +
+ يدمج LLaVa-NeXT دقة إدخال أعلى عن طريق ترميز رقع مختلفة من صورة الإدخال. مأخوذة من الورقة الأصلية.
+
+ساهم بهذا النموذج [nielsr](https://huggingface.co/nielsr).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/haotian-liu/LLaVA/tree/main).
+
+## نصائح الاستخدام
+
+- ننصح المستخدمين باستخدام `padding_side="left"` عند حساب التوليد الدفعي لأنه يؤدي إلى نتائج أكثر دقة. تأكد ببساطة من استدعاء `processor.tokenizer.padding_side = "left"` قبل التوليد.
+
+- لاحظ أن كل نقطة تفتيش تم تدريبها بتنسيق موجه محدد، اعتمادًا على نموذج اللغة الكبير (LLM) المستخدم. أدناه، نقوم بإدراج تنسيقات الموجه الصحيحة لاستخدامها في موجه النص "What is shown in this image؟":
+
+[llava-v1.6-mistral-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf) يتطلب التنسيق التالي:
+
+```bash
+"[INST]
+
+ يدمج LLaVa-NeXT دقة إدخال أعلى عن طريق ترميز رقع مختلفة من صورة الإدخال. مأخوذة من الورقة الأصلية.
+
+ساهم بهذا النموذج [nielsr](https://huggingface.co/nielsr).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/haotian-liu/LLaVA/tree/main).
+
+## نصائح الاستخدام
+
+- ننصح المستخدمين باستخدام `padding_side="left"` عند حساب التوليد الدفعي لأنه يؤدي إلى نتائج أكثر دقة. تأكد ببساطة من استدعاء `processor.tokenizer.padding_side = "left"` قبل التوليد.
+
+- لاحظ أن كل نقطة تفتيش تم تدريبها بتنسيق موجه محدد، اعتمادًا على نموذج اللغة الكبير (LLM) المستخدم. أدناه، نقوم بإدراج تنسيقات الموجه الصحيحة لاستخدامها في موجه النص "What is shown in this image؟":
+
+[llava-v1.6-mistral-7b-hf](https://huggingface.co/llava-hf/llava-v1.6-mistral-7b-hf) يتطلب التنسيق التالي:
+
+```bash
+"[INST] 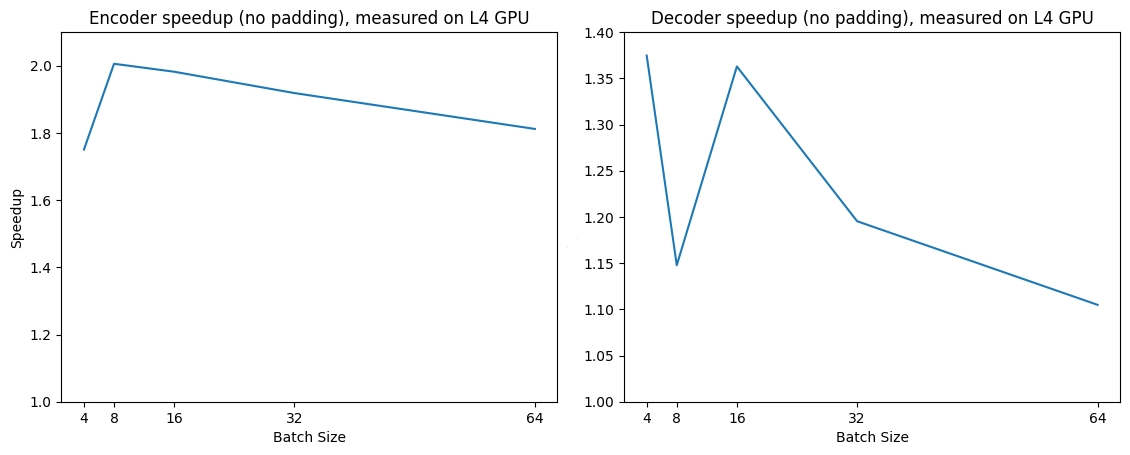 +
+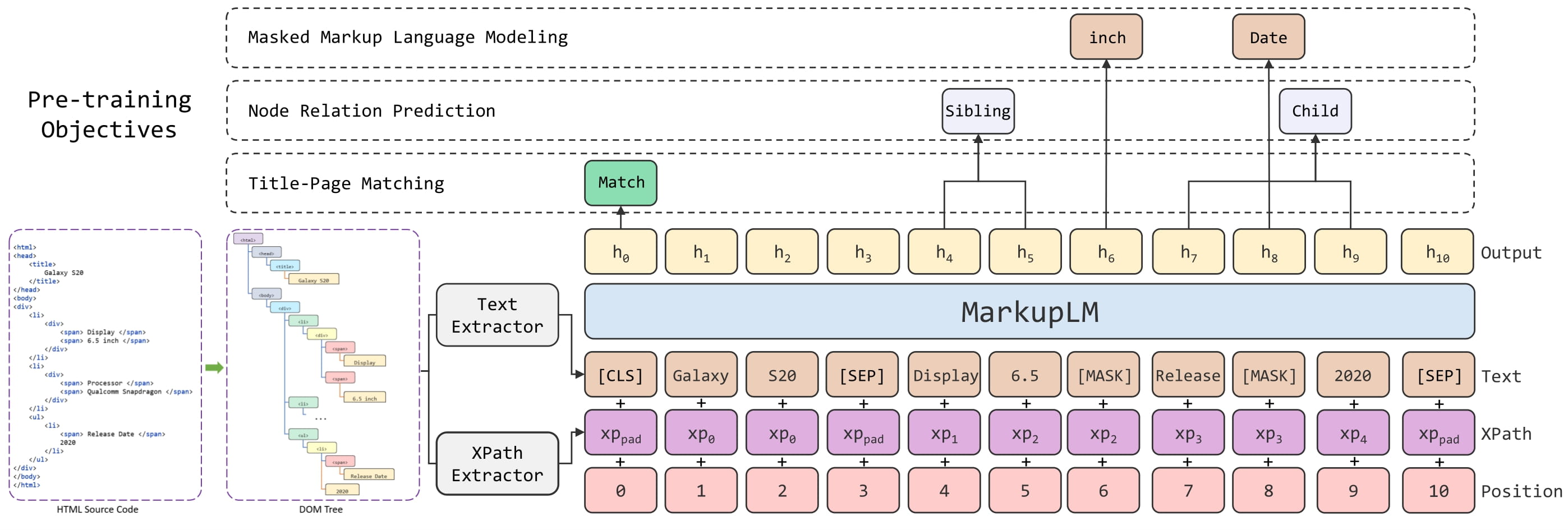 +
+ بنية نموذج MarkupLM. مأخوذة من الورقة البحثية الأصلية.
+
+## الاستخدام: MarkupLMProcessor
+
+أسهل طريقة لإعداد البيانات للنموذج هي استخدام [`MarkupLMProcessor`]، والذي يجمع بين مستخرج الميزات ([`MarkupLMFeatureExtractor`]) ومُرمز ([`MarkupLMTokenizer`] أو [`MarkupLMTokenizerFast`]) داخليًا. ويستخدم مستخرج الميزات لاستخراج جميع العقد ومسارات لغة الترميز الموحدة (XPath) من سلاسل HTML، والتي يتم توفيرها بعد ذلك إلى المرمز، والذي يحولها إلى إدخالات على مستوى الرموز للنموذج (`input_ids`، إلخ). لاحظ أنه يمكنك استخدام مستخرج الميزات والمرمز بشكل منفصل إذا كنت تريد التعامل مع إحدى المهمتين فقط.
+
+```python
+from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
+
+feature_extractor = MarkupLMFeatureExtractor()
+tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
+processor = MarkupLMProcessor(feature_extractor, tokenizer)
+```
+
+وباختصار، يمكنك توفير سلاسل HTML (وربما بيانات إضافية) إلى [`MarkupLMProcessor`]، وسينشئ الإدخالات التي يتوقعها النموذج. داخليًا، يستخدم المعالج أولاً [`MarkupLMFeatureExtractor`] للحصول على قائمة العقد ومسارات لغة الترميز الموحدة (XPath) المقابلة. ثم يتم توفير العقد ومسارات لغة الترميز الموحدة (XPath) إلى [`MarkupLMTokenizer`] أو [`MarkupLMTokenizerFast`]، والذي يحولها إلى `input_ids` على مستوى الرموز و`attention_mask` و`token_type_ids` و`xpath_subs_seq` و`xpath_tags_seq`.
+
+اختياريًا، يمكنك توفير تسميات العقد للمعالج، والتي يتم تحويلها إلى `labels` على مستوى الرموز.
+
+يستخدم [`MarkupLMFeatureExtractor`] مكتبة [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/)، وهي مكتبة بايثون لاستخراج البيانات من ملفات HTML وXML، في الخلفية. لاحظ أنه يمكنك استخدام حل التوصيل الخاص بك وتوفير العقد ومسارات لغة الترميز الموحدة (XPath) بنفسك إلى [`MarkupLMTokenizer`] أو [`MarkupLMTokenizerFast`].
+
+هناك خمس حالات استخدام مدعومة من قبل المعالج. فيما يلي قائمة بها جميعًا. لاحظ أن كل حالة من هذه الحالات الاستخدامية تعمل مع الإدخالات المجمعة وغير المجمعة (نوضحها لإدخالات غير مجمعة).
+
+**حالة الاستخدام 1: تصنيف صفحات الويب (التدريب والاستنتاج) + تصنيف الرموز (الاستنتاج)، parse_html = True**
+
+هذه هي الحالة الأكثر بساطة، والتي سيستخدم فيها المعالج مستخرج الميزات للحصول على جميع العقد ومسارات لغة الترميز الموحدة (XPath) من HTML.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+
+>>> html_string = """
+...
+...
+...
+...
+
+ بنية نموذج MarkupLM. مأخوذة من الورقة البحثية الأصلية.
+
+## الاستخدام: MarkupLMProcessor
+
+أسهل طريقة لإعداد البيانات للنموذج هي استخدام [`MarkupLMProcessor`]، والذي يجمع بين مستخرج الميزات ([`MarkupLMFeatureExtractor`]) ومُرمز ([`MarkupLMTokenizer`] أو [`MarkupLMTokenizerFast`]) داخليًا. ويستخدم مستخرج الميزات لاستخراج جميع العقد ومسارات لغة الترميز الموحدة (XPath) من سلاسل HTML، والتي يتم توفيرها بعد ذلك إلى المرمز، والذي يحولها إلى إدخالات على مستوى الرموز للنموذج (`input_ids`، إلخ). لاحظ أنه يمكنك استخدام مستخرج الميزات والمرمز بشكل منفصل إذا كنت تريد التعامل مع إحدى المهمتين فقط.
+
+```python
+from transformers import MarkupLMFeatureExtractor, MarkupLMTokenizerFast, MarkupLMProcessor
+
+feature_extractor = MarkupLMFeatureExtractor()
+tokenizer = MarkupLMTokenizerFast.from_pretrained("microsoft/markuplm-base")
+processor = MarkupLMProcessor(feature_extractor, tokenizer)
+```
+
+وباختصار، يمكنك توفير سلاسل HTML (وربما بيانات إضافية) إلى [`MarkupLMProcessor`]، وسينشئ الإدخالات التي يتوقعها النموذج. داخليًا، يستخدم المعالج أولاً [`MarkupLMFeatureExtractor`] للحصول على قائمة العقد ومسارات لغة الترميز الموحدة (XPath) المقابلة. ثم يتم توفير العقد ومسارات لغة الترميز الموحدة (XPath) إلى [`MarkupLMTokenizer`] أو [`MarkupLMTokenizerFast`]، والذي يحولها إلى `input_ids` على مستوى الرموز و`attention_mask` و`token_type_ids` و`xpath_subs_seq` و`xpath_tags_seq`.
+
+اختياريًا، يمكنك توفير تسميات العقد للمعالج، والتي يتم تحويلها إلى `labels` على مستوى الرموز.
+
+يستخدم [`MarkupLMFeatureExtractor`] مكتبة [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup/bs4/doc/)، وهي مكتبة بايثون لاستخراج البيانات من ملفات HTML وXML، في الخلفية. لاحظ أنه يمكنك استخدام حل التوصيل الخاص بك وتوفير العقد ومسارات لغة الترميز الموحدة (XPath) بنفسك إلى [`MarkupLMTokenizer`] أو [`MarkupLMTokenizerFast`].
+
+هناك خمس حالات استخدام مدعومة من قبل المعالج. فيما يلي قائمة بها جميعًا. لاحظ أن كل حالة من هذه الحالات الاستخدامية تعمل مع الإدخالات المجمعة وغير المجمعة (نوضحها لإدخالات غير مجمعة).
+
+**حالة الاستخدام 1: تصنيف صفحات الويب (التدريب والاستنتاج) + تصنيف الرموز (الاستنتاج)، parse_html = True**
+
+هذه هي الحالة الأكثر بساطة، والتي سيستخدم فيها المعالج مستخرج الميزات للحصول على جميع العقد ومسارات لغة الترميز الموحدة (XPath) من HTML.
+
+```python
+>>> from transformers import MarkupLMProcessor
+
+>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base")
+
+>>> html_string = """
+...
+...
+...
+... My name is Niels.
+... +... """ + +>>> question = "What's his name?" +>>> encoding = processor(html_string, questions=question, return_tensors="pt") +>>> print(encoding.keys()) +dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq']) +``` + +**حالة الاستخدام 5: الإجابة على أسئلة صفحات الويب (الاستنتاج)، parse_html=False** + +لمهام الإجابة على الأسئلة (مثل WebSRC)، يمكنك توفير سؤال للمعالج. إذا قمت باستخراج جميع العقد ومسارات لغة الترميز الموحدة (XPath) بنفسك، فيمكنك توفيرها مباشرة إلى المعالج. تأكد من تعيين `parse_html` إلى `False`. + +```python +>>> from transformers import MarkupLMProcessor + +>>> processor = MarkupLMProcessor.from_pretrained("microsoft/markuplm-base") +>>> processor.parse_html = False + +>>> nodes = ["hello", "world", "how", "are"] +>>> xpaths = ["/html/body/div/li[1]/div/span", "/html/body/div/li[1]/div/span", "html/body", "html/body/div"] +>>> question = "What's his name?" +>>> encoding = processor(nodes=nodes, xpaths=xpaths, questions=question, return_tensors="pt") +>>> print(encoding.keys()) +dict_keys(['input_ids', 'token_type_ids', 'attention_mask', 'xpath_tags_seq', 'xpath_subs_seq']) +``` + +## الموارد + +- [دفاتر الملاحظات التوضيحية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MarkupLM) +- [دليل مهام تصنيف النصوص](../tasks/sequence_classification) +- [دليل مهام تصنيف الرموز](../tasks/token_classification) +- [دليل مهام الإجابة على الأسئلة](../tasks/question_answering) + +## MarkupLMConfig + +[[autodoc]] MarkupLMConfig +- all + +## MarkupLMFeatureExtractor + +[[autodoc]] MarkupLMFeatureExtractor +- __call__ + +## MarkupLMTokenizer + +[[autodoc]] MarkupLMTokenizer +- build_inputs_with_special_tokens +- get_special_tokens_mask +- create_token_type_ids_from_sequences +- save_vocabulary + +## MarkupLMTokenizerFast + +[[autodoc]] MarkupLMTokenizerFast +- all + +## MarkupLMProcessor + +[[autodoc]] MarkupLMProcessor +- __call__ + +## MarkupLMModel + +[[autodoc]] MarkupLMModel +- forward + +## MarkupLMForSequenceClassification + +[[autodoc]] MarkupLMForSequenceClassification +- forward + +## MarkupLMForTokenClassification + +[[autodoc]] MarkupLMForTokenClassification +- forward + +## MarkupLMForQuestionAnswering + +[[autodoc]] MarkupLMForQuestionAnswering +- forward \ No newline at end of file From a54d32c532e7bac22129c3a2b6b3dd2d523673e1 Mon Sep 17 00:00:00 2001 From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com> Date: Wed, 7 Aug 2024 23:27:01 +0300 Subject: [PATCH 494/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?= =?UTF-8?q?ource/ar/model=5Fdoc/mask2former.md?= MIME-Version: 1.0 Content-Type: text/plain; charset=UTF-8 Content-Transfer-Encoding: 8bit --- docs/source/ar/model_doc/mask2former.md | 69 +++++++++++++++++++++++++ 1 file changed, 69 insertions(+) create mode 100644 docs/source/ar/model_doc/mask2former.md diff --git a/docs/source/ar/model_doc/mask2former.md b/docs/source/ar/model_doc/mask2former.md new file mode 100644 index 00000000000000..b819d87a0dee86 --- /dev/null +++ b/docs/source/ar/model_doc/mask2former.md @@ -0,0 +1,69 @@ +# Mask2Former + +## نظرة عامة +اقترح نموذج Mask2Former في [Masked-attention Mask Transformer for Universal Image Segmentation](https://arxiv.org/abs/2112.01527) بواسطة Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, Rohit Girdhar. Mask2Former هو إطار موحد لقطاعات panoptic و instance و semantic ويتميز بتحسينات كبيرة في الأداء والكفاءة على [MaskFormer](maskformer). + +مقدمة الورقة هي التالية: + +*يقوم تجميع الصور بتجزئة البكسلات ذات الدلالات المختلفة، على سبيل المثال، فئة أو عضوية مثيل. كل خيار +تعرف الدلالات مهمة. في حين أن دلاليات كل مهمة تختلف فقط، يركز البحث الحالي على تصميم هندسات متخصصة لكل مهمة. نقدم Masked-attention Mask Transformer (Mask2Former)، وهو تصميم جديد قادر على معالجة أي مهمة تجزئة صور (panoptic أو instance أو semantic). تشمل مكوناته الرئيسية الانتباه المقنع، والذي يستخرج ميزات محلية عن طريق تقييد الانتباه المتقاطع داخل مناطق القناع المتوقعة. بالإضافة إلى تقليل جهد البحث ثلاث مرات على الأقل، فإنه يتفوق على أفضل العمارات المتخصصة بهامش كبير في أربع مجموعات بيانات شائعة. والأهم من ذلك، أن Mask2Former يحدد حالة جديدة لتقسيم الصور الفائقة (57.8 PQ على COCO) وتجزئة مثيلات (50.1 AP على COCO) وتجزئة دلالية (57.7 mIoU على ADE20K).* + + +
+ هندسة Mask2Former. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [Shivalika Singh](https://huggingface.co/shivi) و [Alara Dirik](https://huggingface.co/adirik). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/Mask2Former).
+
+## نصائح الاستخدام
+
+- يستخدم Mask2Former نفس خطوات المعالجة المسبقة والمعالجة اللاحقة مثل [MaskFormer](maskformer). استخدم [`Mask2FormerImageProcessor`] أو [`AutoImageProcessor`] لإعداد الصور والأهداف الاختيارية للنموذج.
+
+- للحصول على التجزئة النهائية، اعتمادًا على المهمة، يمكنك استدعاء [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] أو [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] أو [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. يمكن حل المهام الثلاث جميعها باستخدام إخراج [`Mask2FormerForUniversalSegmentation`]، ويقبل تجزئة panoptic حجة اختيارية `label_ids_to_fuse` لدمج مثيلات الكائن المستهدف (مثل السماء) معًا.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء في استخدام Mask2Former.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية المتعلقة بالاستدلال + ضبط Mask2Former على بيانات مخصصة [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Mask2Former).
+
+- يمكن العثور على البرامج النصية لضبط [`Mask2Former`] باستخدام [`Trainer`] أو [Accelerate](https://huggingface.co/docs/accelerate/index) [هنا](https://github.com/huggingface/transformers/tree/main/examples/pytorch/instance-segmentation).
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فلا تتردد في فتح طلب سحب وسنراجعه.
+
+يجب أن يوضح المورد بشكل مثالي شيء جديد بدلاً من تكرار مورد موجود.
+
+## Mask2FormerConfig
+
+[[autodoc]] Mask2FormerConfig
+
+## مخرجات خاصة بـ MaskFormer
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
+
+## Mask2FormerModel
+
+[[autodoc]] Mask2FormerModel
+
+- forword
+
+## Mask2FormerForUniversalSegmentation
+
+[[autodoc]] Mask2FormerForUniversalSegmentation
+
+- forword
+
+## Mask2FormerImageProcessor
+
+[[autodoc]] Mask2FormerImageProcessor
+
+- preprocess
+
+- encode_inputs
+
+- post_process_semantic_segmentation
+
+- post_process_instance_segmentation
+
+- post_process_panoptic_segmentation
\ No newline at end of file
From 86a33144c3f18be4ce786d4e91010d15cf6ec273 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:27:03 +0300
Subject: [PATCH 495/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/maskformer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/maskformer.md | 75 ++++++++++++++++++++++++++
1 file changed, 75 insertions(+)
create mode 100644 docs/source/ar/model_doc/maskformer.md
diff --git a/docs/source/ar/model_doc/maskformer.md b/docs/source/ar/model_doc/maskformer.md
new file mode 100644
index 00000000000000..7d40a39db3c2da
--- /dev/null
+++ b/docs/source/ar/model_doc/maskformer.md
@@ -0,0 +1,75 @@
+# MaskFormer
+
+> هذا نموذج تم تقديمه مؤخرًا، لذلك لم يتم اختبار واجهة برمجة التطبيقات الخاصة به بشكل مكثف. قد تكون هناك بعض الأخطاء أو التغييرات الطفيفة التي قد تسبب كسر التعليمات البرمجية في المستقبل. إذا لاحظت شيئًا غريبًا، فقم بإنشاء [قضية على GitHub](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+## نظرة عامة
+
+تم اقتراح نموذج MaskFormer في ورقة "Per-Pixel Classification is Not All You Need for Semantic Segmentation" بواسطة Bowen Cheng و Alexander G. Schwing و Alexander Kirillov. يعالج MaskFormer التجزئة الدلالية باستخدام نموذج تصنيف الأقنعة بدلاً من إجراء التصنيف الكلاسيكي على مستوى البكسل.
+
+ملخص الورقة هو كما يلي:
+
+> "تقوم الأساليب الحديثة بشكل نموذجي بصياغة التجزئة الدلالية كمهمة تصنيف لكل بكسل، في حين يتم التعامل مع التجزئة على مستوى المثيل باستخدام تصنيف الأقنعة كبديل. رؤيتنا الأساسية هي: تصنيف الأقنعة عام بما يكفي لحل مهام التجزئة الدلالية ومستوى المثيل بطريقة موحدة باستخدام نفس النموذج والخسارة وإجراء التدريب بالضبط. بناءً على هذه الملاحظة، نقترح MaskFormer، وهو نموذج تصنيف أقنعة بسيط يتوقع مجموعة من الأقنعة الثنائية، وكل منها مرتبط بتوقع تسمية فئة عالمية واحدة. بشكل عام، تبسط طريقة التصنيف القائمة على الأقنعة المقترحة مشهد الأساليب الفعالة لمهام التجزئة الدلالية والكلية، وتحقق نتائج تجريبية ممتازة. على وجه الخصوص، نلاحظ أن MaskFormer يتفوق على خطوط الأساس لتصنيف البكسل عندما يكون عدد الفئات كبيرًا. تتفوق طريقة التصنيف المستندة إلى الأقنعة الخاصة بنا على أحدث نماذج التجزئة الدلالية (55.6 mIoU على ADE20K) والتجزئة الكلية (52.7 PQ على COCO) على حد سواء."
+
+يوضح الشكل أدناه بنية MaskFormer. مأخوذة من [الورقة الأصلية](https://arxiv.org/abs/2107.06278).
+
+
+
+تمت المساهمة بهذا النموذج من قبل [francesco](https://huggingface.co/francesco). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/MaskFormer).
+
+## نصائح الاستخدام
+
+- إن فك تشفير المحول في MaskFormer مطابق لفك تشفير [DETR](detr). أثناء التدريب، وجد مؤلفو DETR أنه من المفيد استخدام خسائر مساعدة في فك التشفير، خاصة لمساعدة النموذج على إخراج العدد الصحيح من الكائنات لكل فئة. إذا قمت بتعيين معلمة `use_auxiliary_loss` من [`MaskFormerConfig`] إلى `True`، فسيتم إضافة شبكات عصبية أمامية للتنبؤ وخسائر الهنغاري بعد كل طبقة فك تشفير (مع مشاركة FFNs للبارامترات).
+
+- إذا كنت تريد تدريب النموذج في بيئة موزعة عبر عدة عقد، فيجب عليك تحديث وظيفة `get_num_masks` داخل فئة `MaskFormerLoss` من `modeling_maskformer.py`. عند التدريب على عدة عقد، يجب تعيين هذا إلى متوسط عدد الأقنعة المستهدفة عبر جميع العقد، كما هو موضح في التنفيذ الأصلي [هنا](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
+
+- يمكنك استخدام [`MaskFormerImageProcessor`] لتحضير الصور للنموذج والأهداف الاختيارية للنموذج.
+
+- للحصول على التجزئة النهائية، اعتمادًا على المهمة، يمكنك استدعاء [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] أو [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. يمكن حل كلتا المهمتين باستخدام إخراج [`MaskFormerForInstanceSegmentation`]، ويقبل التجزئة الكلية حجة `label_ids_to_fuse` الاختيارية لدمج مثيلات الكائن المستهدف (مثل السماء) معًا.
+
+## الموارد
+
+- يمكن العثور على جميع دفاتر الملاحظات التي توضح الاستدلال وكذلك الضبط الدقيق على البيانات المخصصة باستخدام MaskFormer [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MaskFormer).
+
+- يمكن العثور على البرامج النصية للضبط الدقيق لـ [`MaskFormer`] باستخدام [`Trainer`] أو [Accelerate](https://huggingface.co/docs/accelerate/index) [هنا](https://github.com/huggingface/transformers/tree/main/examples/pytorch/instance-segmentation).
+
+## مخرجات MaskFormer المحددة
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerModelOutput
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerForInstanceSegmentationOutput
+
+## MaskFormerConfig
+
+[[autodoc]] MaskFormerConfig
+
+## MaskFormerImageProcessor
+
+[[autodoc]] MaskFormerImageProcessor
+
+- preprocess
+- encode_inputs
+- post_process_semantic_segmentation
+- post_process_instance_segmentation
+- post_process_panoptic_segmentation
+
+## MaskFormerFeatureExtractor
+
+[[autodoc]] MaskFormerFeatureExtractor
+
+- __call__
+- encode_inputs
+- post_process_semantic_segmentation
+- post_process_instance_segmentation
+- post_process_panoptic_segmentation
+
+## MaskFormerModel
+
+[[autodoc]] MaskFormerModel
+
+- forward
+
+## MaskFormerForInstanceSegmentation
+
+[[autodoc]] MaskFormerForInstanceSegmentation
+
+- forward
\ No newline at end of file
From 3df92f77b81c874ac133e193e8712a7fdc359fa2 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:27:05 +0300
Subject: [PATCH 496/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/matcha.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/matcha.md | 62 ++++++++++++++++++++++++++++++
1 file changed, 62 insertions(+)
create mode 100644 docs/source/ar/model_doc/matcha.md
diff --git a/docs/source/ar/model_doc/matcha.md b/docs/source/ar/model_doc/matcha.md
new file mode 100644
index 00000000000000..53511e373aa46c
--- /dev/null
+++ b/docs/source/ar/model_doc/matcha.md
@@ -0,0 +1,62 @@
+# MatCha
+
+## نظرة عامة
+
+اقتُرح MatCha في الورقة البحثية [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662)، من تأليف Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
+
+يوضح ملخص الورقة البحثية ما يلي:
+
+> تنتشر البيانات المرئية اللغوية مثل الرسوم البيانية والمخططات والرسوم المعلوماتية انتشاراً واسعاً في العالم البشري. ومع ذلك، لا تؤدي النماذج اللغوية المرئية المتقدمة حالياً أداءً جيداً على هذه البيانات. نقترح MatCha (التدريب المسبق على الاستدلال الرياضي وإلغاء عرض المخططات) لتعزيز قدرات النماذج اللغوية المرئية في النمذجة المشتركة للمخططات/الرسوم البيانية والبيانات اللغوية. وعلى وجه التحديد، نقترح عدة مهام للتدريب المسبق تغطي تفكيك المخطط والاستدلال العددي، والتي تعد قدرات رئيسية في النمذجة اللغوية المرئية. ونقوم بالتدريب المسبق لـ MatCha انطلاقاً من Pix2Struct، وهو نموذج لغوي مرئي للصور النصية تم اقتراحه مؤخراً. وعلى المعايير القياسية مثل PlotQA وChartQA، يتفوق نموذج MatCha على الطرق الحالية بأداء أفضل يصل إلى 20%. كما نقوم بفحص مدى جودة نقل التدريب المسبق لـ MatCha إلى مجالات مثل لقطات الشاشة، ومخططات الكتب المدرسية، ورسوم الوثائق، ونلاحظ تحسناً عاماً، مما يؤكد فائدة التدريب المسبق لـ MatCha على المهام اللغوية المرئية الأوسع نطاقاً.
+
+## وصف النموذج
+
+MatCha هو نموذج تم تدريبه باستخدام بنية `Pix2Struct`. يمكنك العثور على مزيد من المعلومات حول `Pix2Struct` في [وثائق Pix2Struct](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct).
+
+MatCha هو مجموعة فرعية من الأسئلة البصرية والإجابة عليها في بنية `Pix2Struct`. فهو يقوم برسم السؤال المدخل على الصورة والتنبؤ بالإجابة.
+
+## الاستخدام
+
+تتوفر حالياً 6 نقاط تفتيش لـ MatCha:
+
+- `google/matcha`: نموذج MatCha الأساسي، المستخدم لتعديل نموذج MatCha لمهام تالية
+- `google/matcha-chartqa`: نموذج MatCha المعدل لبيانات ChartQA. يمكن استخدامه للإجابة على الأسئلة حول المخططات.
+- `google/matcha-plotqa-v1`: نموذج MatCha المعدل لبيانات PlotQA. يمكن استخدامه للإجابة على الأسئلة حول الرسوم البيانية.
+- `google/matcha-plotqa-v2`: نموذج MatCha المعدل لبيانات PlotQA. يمكن استخدامه للإجابة على الأسئلة حول الرسوم البيانية.
+- `google/matcha-chart2text-statista`: نموذج MatCha المعدل لمجموعة بيانات Statista.
+- `google/matcha-chart2text-pew`: نموذج MatCha المعدل لمجموعة بيانات Pew.
+
+تكون النماذج المعدلة على `chart2text-pew` و`chart2text-statista` أكثر ملاءمة للتلخيص، في حين أن النماذج المعدلة على `plotqa` و`chartqa` تكون أكثر ملاءمة للإجابة على الأسئلة.
+
+يمكنك استخدام هذه النماذج على النحو التالي (مثال على مجموعة بيانات ChatQA):
+
+```python
+from transformers import AutoProcessor, Pix2StructForConditionalGeneration
+import requests
+from PIL import Image
+
+model = Pix2StructForConditionalGeneration.from_pretrained("google/matcha-chartqa").to(0)
+processor = AutoProcessor.from_pretrained("google/matcha-chartqa")
+url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/20294671002019.png"
+image = Image.open(requests.get(url, stream=True).raw)
+
+inputs = processor(images=image, text="Is the sum of all 4 places greater than Laos?", return_tensors="pt").to(0)
+predictions = model.generate(**inputs, max_new_tokens=512)
+print(processor.decode(predictions[0], skip_special_tokens=True))
+```
+
+## الضبط الدقيق
+
+لضبط نموذج MatCha بدقة، راجع دفتر الملاحظات [fine-tuning notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb). بالنسبة لنماذج `Pix2Struct`، وجدنا أن ضبط النموذج بدقة باستخدام Adafactor وجدول التعلم بمعدل ثابت يؤدي إلى تقارب أسرع:
+
+```python
+from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
+
+optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
+scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
+```
+
+
+
+ هندسة Mask2Former. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [Shivalika Singh](https://huggingface.co/shivi) و [Alara Dirik](https://huggingface.co/adirik). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/Mask2Former).
+
+## نصائح الاستخدام
+
+- يستخدم Mask2Former نفس خطوات المعالجة المسبقة والمعالجة اللاحقة مثل [MaskFormer](maskformer). استخدم [`Mask2FormerImageProcessor`] أو [`AutoImageProcessor`] لإعداد الصور والأهداف الاختيارية للنموذج.
+
+- للحصول على التجزئة النهائية، اعتمادًا على المهمة، يمكنك استدعاء [`~Mask2FormerImageProcessor.post_process_semantic_segmentation`] أو [`~Mask2FormerImageProcessor.post_process_instance_segmentation`] أو [`~Mask2FormerImageProcessor.post_process_panoptic_segmentation`]. يمكن حل المهام الثلاث جميعها باستخدام إخراج [`Mask2FormerForUniversalSegmentation`]، ويقبل تجزئة panoptic حجة اختيارية `label_ids_to_fuse` لدمج مثيلات الكائن المستهدف (مثل السماء) معًا.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء في استخدام Mask2Former.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية المتعلقة بالاستدلال + ضبط Mask2Former على بيانات مخصصة [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Mask2Former).
+
+- يمكن العثور على البرامج النصية لضبط [`Mask2Former`] باستخدام [`Trainer`] أو [Accelerate](https://huggingface.co/docs/accelerate/index) [هنا](https://github.com/huggingface/transformers/tree/main/examples/pytorch/instance-segmentation).
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فلا تتردد في فتح طلب سحب وسنراجعه.
+
+يجب أن يوضح المورد بشكل مثالي شيء جديد بدلاً من تكرار مورد موجود.
+
+## Mask2FormerConfig
+
+[[autodoc]] Mask2FormerConfig
+
+## مخرجات خاصة بـ MaskFormer
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerModelOutput
+
+[[autodoc]] models.mask2former.modeling_mask2former.Mask2FormerForUniversalSegmentationOutput
+
+## Mask2FormerModel
+
+[[autodoc]] Mask2FormerModel
+
+- forword
+
+## Mask2FormerForUniversalSegmentation
+
+[[autodoc]] Mask2FormerForUniversalSegmentation
+
+- forword
+
+## Mask2FormerImageProcessor
+
+[[autodoc]] Mask2FormerImageProcessor
+
+- preprocess
+
+- encode_inputs
+
+- post_process_semantic_segmentation
+
+- post_process_instance_segmentation
+
+- post_process_panoptic_segmentation
\ No newline at end of file
From 86a33144c3f18be4ce786d4e91010d15cf6ec273 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:27:03 +0300
Subject: [PATCH 495/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/maskformer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/maskformer.md | 75 ++++++++++++++++++++++++++
1 file changed, 75 insertions(+)
create mode 100644 docs/source/ar/model_doc/maskformer.md
diff --git a/docs/source/ar/model_doc/maskformer.md b/docs/source/ar/model_doc/maskformer.md
new file mode 100644
index 00000000000000..7d40a39db3c2da
--- /dev/null
+++ b/docs/source/ar/model_doc/maskformer.md
@@ -0,0 +1,75 @@
+# MaskFormer
+
+> هذا نموذج تم تقديمه مؤخرًا، لذلك لم يتم اختبار واجهة برمجة التطبيقات الخاصة به بشكل مكثف. قد تكون هناك بعض الأخطاء أو التغييرات الطفيفة التي قد تسبب كسر التعليمات البرمجية في المستقبل. إذا لاحظت شيئًا غريبًا، فقم بإنشاء [قضية على GitHub](https://github.com/huggingface/transformers/issues/new?assignees=&labels=&template=bug-report.md&title).
+
+## نظرة عامة
+
+تم اقتراح نموذج MaskFormer في ورقة "Per-Pixel Classification is Not All You Need for Semantic Segmentation" بواسطة Bowen Cheng و Alexander G. Schwing و Alexander Kirillov. يعالج MaskFormer التجزئة الدلالية باستخدام نموذج تصنيف الأقنعة بدلاً من إجراء التصنيف الكلاسيكي على مستوى البكسل.
+
+ملخص الورقة هو كما يلي:
+
+> "تقوم الأساليب الحديثة بشكل نموذجي بصياغة التجزئة الدلالية كمهمة تصنيف لكل بكسل، في حين يتم التعامل مع التجزئة على مستوى المثيل باستخدام تصنيف الأقنعة كبديل. رؤيتنا الأساسية هي: تصنيف الأقنعة عام بما يكفي لحل مهام التجزئة الدلالية ومستوى المثيل بطريقة موحدة باستخدام نفس النموذج والخسارة وإجراء التدريب بالضبط. بناءً على هذه الملاحظة، نقترح MaskFormer، وهو نموذج تصنيف أقنعة بسيط يتوقع مجموعة من الأقنعة الثنائية، وكل منها مرتبط بتوقع تسمية فئة عالمية واحدة. بشكل عام، تبسط طريقة التصنيف القائمة على الأقنعة المقترحة مشهد الأساليب الفعالة لمهام التجزئة الدلالية والكلية، وتحقق نتائج تجريبية ممتازة. على وجه الخصوص، نلاحظ أن MaskFormer يتفوق على خطوط الأساس لتصنيف البكسل عندما يكون عدد الفئات كبيرًا. تتفوق طريقة التصنيف المستندة إلى الأقنعة الخاصة بنا على أحدث نماذج التجزئة الدلالية (55.6 mIoU على ADE20K) والتجزئة الكلية (52.7 PQ على COCO) على حد سواء."
+
+يوضح الشكل أدناه بنية MaskFormer. مأخوذة من [الورقة الأصلية](https://arxiv.org/abs/2107.06278).
+
+
+
+تمت المساهمة بهذا النموذج من قبل [francesco](https://huggingface.co/francesco). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/MaskFormer).
+
+## نصائح الاستخدام
+
+- إن فك تشفير المحول في MaskFormer مطابق لفك تشفير [DETR](detr). أثناء التدريب، وجد مؤلفو DETR أنه من المفيد استخدام خسائر مساعدة في فك التشفير، خاصة لمساعدة النموذج على إخراج العدد الصحيح من الكائنات لكل فئة. إذا قمت بتعيين معلمة `use_auxiliary_loss` من [`MaskFormerConfig`] إلى `True`، فسيتم إضافة شبكات عصبية أمامية للتنبؤ وخسائر الهنغاري بعد كل طبقة فك تشفير (مع مشاركة FFNs للبارامترات).
+
+- إذا كنت تريد تدريب النموذج في بيئة موزعة عبر عدة عقد، فيجب عليك تحديث وظيفة `get_num_masks` داخل فئة `MaskFormerLoss` من `modeling_maskformer.py`. عند التدريب على عدة عقد، يجب تعيين هذا إلى متوسط عدد الأقنعة المستهدفة عبر جميع العقد، كما هو موضح في التنفيذ الأصلي [هنا](https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/modeling/criterion.py#L169).
+
+- يمكنك استخدام [`MaskFormerImageProcessor`] لتحضير الصور للنموذج والأهداف الاختيارية للنموذج.
+
+- للحصول على التجزئة النهائية، اعتمادًا على المهمة، يمكنك استدعاء [`~MaskFormerImageProcessor.post_process_semantic_segmentation`] أو [`~MaskFormerImageProcessor.post_process_panoptic_segmentation`]. يمكن حل كلتا المهمتين باستخدام إخراج [`MaskFormerForInstanceSegmentation`]، ويقبل التجزئة الكلية حجة `label_ids_to_fuse` الاختيارية لدمج مثيلات الكائن المستهدف (مثل السماء) معًا.
+
+## الموارد
+
+- يمكن العثور على جميع دفاتر الملاحظات التي توضح الاستدلال وكذلك الضبط الدقيق على البيانات المخصصة باستخدام MaskFormer [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/MaskFormer).
+
+- يمكن العثور على البرامج النصية للضبط الدقيق لـ [`MaskFormer`] باستخدام [`Trainer`] أو [Accelerate](https://huggingface.co/docs/accelerate/index) [هنا](https://github.com/huggingface/transformers/tree/main/examples/pytorch/instance-segmentation).
+
+## مخرجات MaskFormer المحددة
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerModelOutput
+
+[[autodoc]] models.maskformer.modeling_maskformer.MaskFormerForInstanceSegmentationOutput
+
+## MaskFormerConfig
+
+[[autodoc]] MaskFormerConfig
+
+## MaskFormerImageProcessor
+
+[[autodoc]] MaskFormerImageProcessor
+
+- preprocess
+- encode_inputs
+- post_process_semantic_segmentation
+- post_process_instance_segmentation
+- post_process_panoptic_segmentation
+
+## MaskFormerFeatureExtractor
+
+[[autodoc]] MaskFormerFeatureExtractor
+
+- __call__
+- encode_inputs
+- post_process_semantic_segmentation
+- post_process_instance_segmentation
+- post_process_panoptic_segmentation
+
+## MaskFormerModel
+
+[[autodoc]] MaskFormerModel
+
+- forward
+
+## MaskFormerForInstanceSegmentation
+
+[[autodoc]] MaskFormerForInstanceSegmentation
+
+- forward
\ No newline at end of file
From 3df92f77b81c874ac133e193e8712a7fdc359fa2 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:27:05 +0300
Subject: [PATCH 496/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/matcha.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/matcha.md | 62 ++++++++++++++++++++++++++++++
1 file changed, 62 insertions(+)
create mode 100644 docs/source/ar/model_doc/matcha.md
diff --git a/docs/source/ar/model_doc/matcha.md b/docs/source/ar/model_doc/matcha.md
new file mode 100644
index 00000000000000..53511e373aa46c
--- /dev/null
+++ b/docs/source/ar/model_doc/matcha.md
@@ -0,0 +1,62 @@
+# MatCha
+
+## نظرة عامة
+
+اقتُرح MatCha في الورقة البحثية [MatCha: Enhancing Visual Language Pretraining with Math Reasoning and Chart Derendering](https://arxiv.org/abs/2212.09662)، من تأليف Fangyu Liu, Francesco Piccinno, Syrine Krichene, Chenxi Pang, Kenton Lee, Mandar Joshi, Yasemin Altun, Nigel Collier, Julian Martin Eisenschlos.
+
+يوضح ملخص الورقة البحثية ما يلي:
+
+> تنتشر البيانات المرئية اللغوية مثل الرسوم البيانية والمخططات والرسوم المعلوماتية انتشاراً واسعاً في العالم البشري. ومع ذلك، لا تؤدي النماذج اللغوية المرئية المتقدمة حالياً أداءً جيداً على هذه البيانات. نقترح MatCha (التدريب المسبق على الاستدلال الرياضي وإلغاء عرض المخططات) لتعزيز قدرات النماذج اللغوية المرئية في النمذجة المشتركة للمخططات/الرسوم البيانية والبيانات اللغوية. وعلى وجه التحديد، نقترح عدة مهام للتدريب المسبق تغطي تفكيك المخطط والاستدلال العددي، والتي تعد قدرات رئيسية في النمذجة اللغوية المرئية. ونقوم بالتدريب المسبق لـ MatCha انطلاقاً من Pix2Struct، وهو نموذج لغوي مرئي للصور النصية تم اقتراحه مؤخراً. وعلى المعايير القياسية مثل PlotQA وChartQA، يتفوق نموذج MatCha على الطرق الحالية بأداء أفضل يصل إلى 20%. كما نقوم بفحص مدى جودة نقل التدريب المسبق لـ MatCha إلى مجالات مثل لقطات الشاشة، ومخططات الكتب المدرسية، ورسوم الوثائق، ونلاحظ تحسناً عاماً، مما يؤكد فائدة التدريب المسبق لـ MatCha على المهام اللغوية المرئية الأوسع نطاقاً.
+
+## وصف النموذج
+
+MatCha هو نموذج تم تدريبه باستخدام بنية `Pix2Struct`. يمكنك العثور على مزيد من المعلومات حول `Pix2Struct` في [وثائق Pix2Struct](https://huggingface.co/docs/transformers/main/en/model_doc/pix2struct).
+
+MatCha هو مجموعة فرعية من الأسئلة البصرية والإجابة عليها في بنية `Pix2Struct`. فهو يقوم برسم السؤال المدخل على الصورة والتنبؤ بالإجابة.
+
+## الاستخدام
+
+تتوفر حالياً 6 نقاط تفتيش لـ MatCha:
+
+- `google/matcha`: نموذج MatCha الأساسي، المستخدم لتعديل نموذج MatCha لمهام تالية
+- `google/matcha-chartqa`: نموذج MatCha المعدل لبيانات ChartQA. يمكن استخدامه للإجابة على الأسئلة حول المخططات.
+- `google/matcha-plotqa-v1`: نموذج MatCha المعدل لبيانات PlotQA. يمكن استخدامه للإجابة على الأسئلة حول الرسوم البيانية.
+- `google/matcha-plotqa-v2`: نموذج MatCha المعدل لبيانات PlotQA. يمكن استخدامه للإجابة على الأسئلة حول الرسوم البيانية.
+- `google/matcha-chart2text-statista`: نموذج MatCha المعدل لمجموعة بيانات Statista.
+- `google/matcha-chart2text-pew`: نموذج MatCha المعدل لمجموعة بيانات Pew.
+
+تكون النماذج المعدلة على `chart2text-pew` و`chart2text-statista` أكثر ملاءمة للتلخيص، في حين أن النماذج المعدلة على `plotqa` و`chartqa` تكون أكثر ملاءمة للإجابة على الأسئلة.
+
+يمكنك استخدام هذه النماذج على النحو التالي (مثال على مجموعة بيانات ChatQA):
+
+```python
+from transformers import AutoProcessor, Pix2StructForConditionalGeneration
+import requests
+from PIL import Image
+
+model = Pix2StructForConditionalGeneration.from_pretrained("google/matcha-chartqa").to(0)
+processor = AutoProcessor.from_pretrained("google/matcha-chartqa")
+url = "https://raw.githubusercontent.com/vis-nlp/ChartQA/main/ChartQA%20Dataset/val/png/20294671002019.png"
+image = Image.open(requests.get(url, stream=True).raw)
+
+inputs = processor(images=image, text="Is the sum of all 4 places greater than Laos?", return_tensors="pt").to(0)
+predictions = model.generate(**inputs, max_new_tokens=512)
+print(processor.decode(predictions[0], skip_special_tokens=True))
+```
+
+## الضبط الدقيق
+
+لضبط نموذج MatCha بدقة، راجع دفتر الملاحظات [fine-tuning notebook](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_pix2struct.ipynb). بالنسبة لنماذج `Pix2Struct`، وجدنا أن ضبط النموذج بدقة باستخدام Adafactor وجدول التعلم بمعدل ثابت يؤدي إلى تقارب أسرع:
+
+```python
+from transformers.optimization import Adafactor, get_cosine_schedule_with_warmup
+
+optimizer = Adafactor(self.parameters(), scale_parameter=False, relative_step=False, lr=0.01, weight_decay=1e-05)
+scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=1000, num_training_steps=40000)
+```
+
+ +
+هندسة MGP-STR. مأخوذة من الورقة الأصلية.
+
+تم تدريب MGP-STR على مجموعتين من البيانات الاصطناعية [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) و[SynthText](http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) بدون ضبط دقيق على مجموعات بيانات أخرى. ويحقق نتائج رائدة على ستة معايير قياسية لنص المشهد اللاتيني، بما في ذلك 3 مجموعات بيانات نص عادية (IC13، SVT، IIIT) و3 مجموعات بيانات غير منتظمة (IC15، SVTP، CUTE).
+
+تمت المساهمة بهذا النموذج بواسطة [yuekun](https://huggingface.co/yuekun). يمكن العثور على الكود الأصلي [هنا](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
+
+## مثال الاستنتاج
+
+يقبل [`MgpstrModel`] الصور كمدخلات وينشئ ثلاثة أنواع من التنبؤات، والتي تمثل معلومات نصية بمستويات دقة مختلفة.
+
+يتم دمج الأنواع الثلاثة من التنبؤات لإعطاء نتيجة التنبؤ النهائية.
+
+تكون فئة [`ViTImageProcessor`] مسؤولة عن معالجة الصورة المدخلة، ويقوم [`MgpstrTokenizer`] بفك رموز الرموز المميزة المولدة إلى السلسلة المستهدفة.
+
+يغلف [`MgpstrProcessor`] [`ViTImageProcessor`] و [`MgpstrTokenizer`] في مثيل واحد لاستخراج ميزات الإدخال وفك تشفير معرّفات الرموز المميزة المتوقعة.
+
+- التعرف الضوئي على الأحرف خطوة بخطوة (OCR)
+
+```py
+>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
+>>> import requests
+>>> from PIL import Image
+
+>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
+>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
+
+>>> # تحميل الصورة من مجموعة بيانات IIIT-5k
+>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+
+>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
+>>> outputs = model(pixel_values)
+
+>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']
+```
+
+## MgpstrConfig
+
+[[autodoc]] MgpstrConfig
+
+## MgpstrTokenizer
+
+[[autodoc]] MgpstrTokenizer
+
+- save_vocabulary
+
+## MgpstrProcessor
+
+[[autodoc]] MgpstrProcessor
+
+- __call__
+
+- batch_decode
+
+## MgpstrModel
+
+[[autodoc]] MgpstrModel
+
+- forward
+
+## MgpstrForSceneTextRecognition
+
+[[autodoc]] MgpstrForSceneTextRecognition
+
+- forward
\ No newline at end of file
From 9e3e73a05c8a24d5dc9b98c9c216f15ee12dc1cd Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:27:17 +0300
Subject: [PATCH 503/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/mistral.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/mistral.md | 235 ++++++++++++++++++++++++++++
1 file changed, 235 insertions(+)
create mode 100644 docs/source/ar/model_doc/mistral.md
diff --git a/docs/source/ar/model_doc/mistral.md b/docs/source/ar/model_doc/mistral.md
new file mode 100644
index 00000000000000..f374404fe95e6e
--- /dev/null
+++ b/docs/source/ar/model_doc/mistral.md
@@ -0,0 +1,235 @@
+# Mistral
+
+## نظرة عامة
+تم تقديم ميسترال في [هذه التدوينة](https://mistral.ai/news/announcing-mistral-7b/) بواسطة ألبرت جيانج، وألكسندر سابليرولز، وأرثر مينش، وكريس بامفورد، وديفندرا سينغ تشابلوت، ودييجو دي لاس كاساس، وفلوريان بريساند، وجيانا لينجيل، وجيوم لابل، وليليو رينارد لافو، ولوسيل سولنييه، وماري-آن لاشو، وبيير ستوك، وتيفين لو سكاو، وتيبو لافري، وتوماس وانج، وتيموتي لاكروا، وويليام إل سيد.
+
+تقول مقدمة التدوينة:
+
+> *يفتخر فريق Mistral AI بتقديم Mistral 7B، أقوى نموذج لغوي حتى الآن بحجمه.*
+
+ميسترال-7B هو أول نموذج لغوي كبير (LLM) أصدره [mistral.ai](https://mistral.ai/).
+
+### التفاصيل المعمارية
+
+ميسترال-7B هو محول فك تشفير فقط مع خيارات التصميم المعماري التالية:
+
+- Sliding Window Attention - تم تدريبه باستخدام طول سياق 8k وحجم ذاكرة التخزين المؤقت الثابت، مع نطاق اهتمام نظري يبلغ 128K رمزًا
+
+- GQA (Grouped Query Attention) - يسمح بإجراء استدلال أسرع وحجم ذاكرة تخزين مؤقت أقل.
+
+- Byte-fallback BPE tokenizer - يضمن عدم تعيين الأحرف مطلقًا إلى رموز خارج المفردات.
+
+للحصول على مزيد من التفاصيل، يرجى الرجوع إلى [تدوينة الإصدار](https://mistral.ai/news/announcing-mistral-7b/).
+
+### الترخيص
+
+تم إصدار `Mistral-7B` بموجب ترخيص Apache 2.0.
+
+## نصائح الاستخدام
+
+أصدر فريق ميسترال 3 نقاط تفتيش:
+
+- نموذج أساسي، [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)، تم تدريبه مسبقًا للتنبؤ بالرمز التالي على بيانات بحجم الإنترنت.
+
+- نموذج ضبط التعليمات، [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)، وهو النموذج الأساسي الذي تم تحسينه لأغراض الدردشة باستخدام الضبط الدقيق المُشرف (SFT) والتحسين المباشر للأفضليات (DPO).
+
+- نموذج ضبط تعليمات محسن، [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)، والذي يحسن الإصدار 1.
+
+يمكن استخدام النموذج الأساسي على النحو التالي:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"My favourite condiment is to ..."
+```
+
+يمكن استخدام نموذج ضبط التعليمات على النحو التالي:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
+
+>>> messages = [
+... {"role": "user", "content": "What is your favourite condiment?"},
+... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
+... {"role": "user", "content": "Do you have mayonnaise recipes?"}
+... ]
+
+>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
+
+>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"Mayonnaise can be made as follows: (...)"
+```
+
+كما هو موضح، يتطلب نموذج ضبط التعليمات [قالب دردشة](../chat_templating) للتأكد من إعداد المدخلات بتنسيق صحيح.
+
+## تسريع ميسترال باستخدام Flash Attention
+
+توضح مقتطفات الشفرة أعلاه الاستدلال بدون أي حيل للتحسين. ومع ذلك، يمكن للمرء تسريع النموذج بشكل كبير من خلال الاستفادة من [Flash Attention](../perf_train_gpu_one.md#flash-attention-2)، وهو تنفيذ أسرع لآلية الاهتمام المستخدمة داخل النموذج.
+
+أولاً، تأكد من تثبيت أحدث إصدار من Flash Attention 2 لتضمين ميزة نافذة الانزلاق.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+تأكد أيضًا من أن لديك أجهزة متوافقة مع Flash-Attention 2. اقرأ المزيد عنها في الوثائق الرسمية لـ [مستودع الاهتمام بالوميض](https://github.com/Dao-AILab/flash-attention). تأكد أيضًا من تحميل نموذجك في نصف الدقة (على سبيل المثال `torch.float16`)
+
+للتحميل وتشغيل نموذج باستخدام Flash Attention-2، راجع المقتطف أدناه:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"My favourite condiment is to (...)"
+```
+
+### تسريع متوقع
+
+فيما يلي رسم بياني للتسريع المتوقع الذي يقارن وقت الاستدلال النقي بين التنفيذ الأصلي في المحولات باستخدام نقطة تفتيش `mistralai/Mistral-7B-v0.1` وإصدار Flash Attention 2 من النموذج.
+
+
+
+هندسة MGP-STR. مأخوذة من الورقة الأصلية.
+
+تم تدريب MGP-STR على مجموعتين من البيانات الاصطناعية [MJSynth]((http://www.robots.ox.ac.uk/~vgg/data/text/)) (MJ) و[SynthText](http://www.robots.ox.ac.uk/~vgg/data/scenetext/) (ST) بدون ضبط دقيق على مجموعات بيانات أخرى. ويحقق نتائج رائدة على ستة معايير قياسية لنص المشهد اللاتيني، بما في ذلك 3 مجموعات بيانات نص عادية (IC13، SVT، IIIT) و3 مجموعات بيانات غير منتظمة (IC15، SVTP، CUTE).
+
+تمت المساهمة بهذا النموذج بواسطة [yuekun](https://huggingface.co/yuekun). يمكن العثور على الكود الأصلي [هنا](https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR).
+
+## مثال الاستنتاج
+
+يقبل [`MgpstrModel`] الصور كمدخلات وينشئ ثلاثة أنواع من التنبؤات، والتي تمثل معلومات نصية بمستويات دقة مختلفة.
+
+يتم دمج الأنواع الثلاثة من التنبؤات لإعطاء نتيجة التنبؤ النهائية.
+
+تكون فئة [`ViTImageProcessor`] مسؤولة عن معالجة الصورة المدخلة، ويقوم [`MgpstrTokenizer`] بفك رموز الرموز المميزة المولدة إلى السلسلة المستهدفة.
+
+يغلف [`MgpstrProcessor`] [`ViTImageProcessor`] و [`MgpstrTokenizer`] في مثيل واحد لاستخراج ميزات الإدخال وفك تشفير معرّفات الرموز المميزة المتوقعة.
+
+- التعرف الضوئي على الأحرف خطوة بخطوة (OCR)
+
+```py
+>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
+>>> import requests
+>>> from PIL import Image
+
+>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
+>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
+
+>>> # تحميل الصورة من مجموعة بيانات IIIT-5k
+>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
+>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+
+>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
+>>> outputs = model(pixel_values)
+
+>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']
+```
+
+## MgpstrConfig
+
+[[autodoc]] MgpstrConfig
+
+## MgpstrTokenizer
+
+[[autodoc]] MgpstrTokenizer
+
+- save_vocabulary
+
+## MgpstrProcessor
+
+[[autodoc]] MgpstrProcessor
+
+- __call__
+
+- batch_decode
+
+## MgpstrModel
+
+[[autodoc]] MgpstrModel
+
+- forward
+
+## MgpstrForSceneTextRecognition
+
+[[autodoc]] MgpstrForSceneTextRecognition
+
+- forward
\ No newline at end of file
From 9e3e73a05c8a24d5dc9b98c9c216f15ee12dc1cd Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:27:17 +0300
Subject: [PATCH 503/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/mistral.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/mistral.md | 235 ++++++++++++++++++++++++++++
1 file changed, 235 insertions(+)
create mode 100644 docs/source/ar/model_doc/mistral.md
diff --git a/docs/source/ar/model_doc/mistral.md b/docs/source/ar/model_doc/mistral.md
new file mode 100644
index 00000000000000..f374404fe95e6e
--- /dev/null
+++ b/docs/source/ar/model_doc/mistral.md
@@ -0,0 +1,235 @@
+# Mistral
+
+## نظرة عامة
+تم تقديم ميسترال في [هذه التدوينة](https://mistral.ai/news/announcing-mistral-7b/) بواسطة ألبرت جيانج، وألكسندر سابليرولز، وأرثر مينش، وكريس بامفورد، وديفندرا سينغ تشابلوت، ودييجو دي لاس كاساس، وفلوريان بريساند، وجيانا لينجيل، وجيوم لابل، وليليو رينارد لافو، ولوسيل سولنييه، وماري-آن لاشو، وبيير ستوك، وتيفين لو سكاو، وتيبو لافري، وتوماس وانج، وتيموتي لاكروا، وويليام إل سيد.
+
+تقول مقدمة التدوينة:
+
+> *يفتخر فريق Mistral AI بتقديم Mistral 7B، أقوى نموذج لغوي حتى الآن بحجمه.*
+
+ميسترال-7B هو أول نموذج لغوي كبير (LLM) أصدره [mistral.ai](https://mistral.ai/).
+
+### التفاصيل المعمارية
+
+ميسترال-7B هو محول فك تشفير فقط مع خيارات التصميم المعماري التالية:
+
+- Sliding Window Attention - تم تدريبه باستخدام طول سياق 8k وحجم ذاكرة التخزين المؤقت الثابت، مع نطاق اهتمام نظري يبلغ 128K رمزًا
+
+- GQA (Grouped Query Attention) - يسمح بإجراء استدلال أسرع وحجم ذاكرة تخزين مؤقت أقل.
+
+- Byte-fallback BPE tokenizer - يضمن عدم تعيين الأحرف مطلقًا إلى رموز خارج المفردات.
+
+للحصول على مزيد من التفاصيل، يرجى الرجوع إلى [تدوينة الإصدار](https://mistral.ai/news/announcing-mistral-7b/).
+
+### الترخيص
+
+تم إصدار `Mistral-7B` بموجب ترخيص Apache 2.0.
+
+## نصائح الاستخدام
+
+أصدر فريق ميسترال 3 نقاط تفتيش:
+
+- نموذج أساسي، [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)، تم تدريبه مسبقًا للتنبؤ بالرمز التالي على بيانات بحجم الإنترنت.
+
+- نموذج ضبط التعليمات، [Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1)، وهو النموذج الأساسي الذي تم تحسينه لأغراض الدردشة باستخدام الضبط الدقيق المُشرف (SFT) والتحسين المباشر للأفضليات (DPO).
+
+- نموذج ضبط تعليمات محسن، [Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2)، والذي يحسن الإصدار 1.
+
+يمكن استخدام النموذج الأساسي على النحو التالي:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"My favourite condiment is to ..."
+```
+
+يمكن استخدام نموذج ضبط التعليمات على النحو التالي:
+
+```python
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.2")
+
+>>> messages = [
+... {"role": "user", "content": "What is your favourite condiment?"},
+... {"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
+... {"role": "user", "content": "Do you have mayonnaise recipes?"}
+... ]
+
+>>> model_inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
+
+>>> generated_ids = model.generate(model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"Mayonnaise can be made as follows: (...)"
+```
+
+كما هو موضح، يتطلب نموذج ضبط التعليمات [قالب دردشة](../chat_templating) للتأكد من إعداد المدخلات بتنسيق صحيح.
+
+## تسريع ميسترال باستخدام Flash Attention
+
+توضح مقتطفات الشفرة أعلاه الاستدلال بدون أي حيل للتحسين. ومع ذلك، يمكن للمرء تسريع النموذج بشكل كبير من خلال الاستفادة من [Flash Attention](../perf_train_gpu_one.md#flash-attention-2)، وهو تنفيذ أسرع لآلية الاهتمام المستخدمة داخل النموذج.
+
+أولاً، تأكد من تثبيت أحدث إصدار من Flash Attention 2 لتضمين ميزة نافذة الانزلاق.
+
+```bash
+pip install -U flash-attn --no-build-isolation
+```
+
+تأكد أيضًا من أن لديك أجهزة متوافقة مع Flash-Attention 2. اقرأ المزيد عنها في الوثائق الرسمية لـ [مستودع الاهتمام بالوميض](https://github.com/Dao-AILab/flash-attention). تأكد أيضًا من تحميل نموذجك في نصف الدقة (على سبيل المثال `torch.float16`)
+
+للتحميل وتشغيل نموذج باستخدام Flash Attention-2، راجع المقتطف أدناه:
+
+```python
+>>> import torch
+>>> from transformers import AutoModelForCausalLM, AutoTokenizer
+
+>>> model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-v0.1", torch_dtype=torch.float16, attn_implementation="flash_attention_2", device_map="auto")
+>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
+
+>>> prompt = "My favourite condiment is"
+
+>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
+>>> model.to(device)
+
+>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
+>>> tokenizer.batch_decode(generated_ids)[0]
+"My favourite condiment is to (...)"
+```
+
+### تسريع متوقع
+
+فيما يلي رسم بياني للتسريع المتوقع الذي يقارن وقت الاستدلال النقي بين التنفيذ الأصلي في المحولات باستخدام نقطة تفتيش `mistralai/Mistral-7B-v0.1` وإصدار Flash Attention 2 من النموذج.
+
+ +
+ +
+
+
+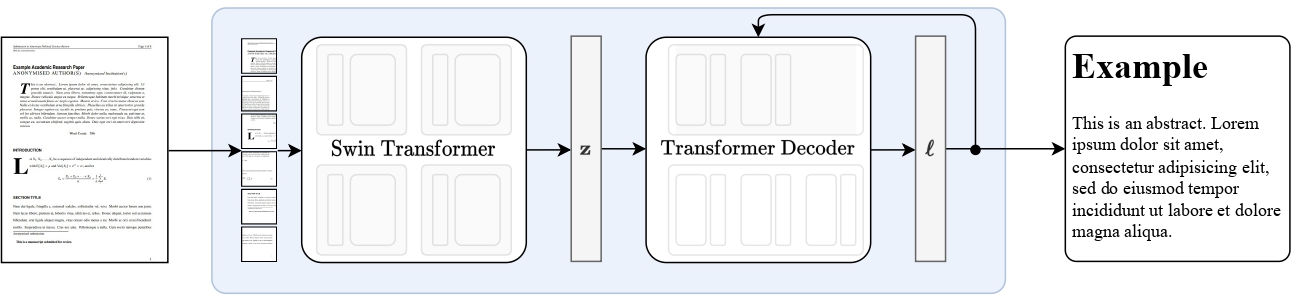 +
+نظرة عامة عالية المستوى على Nougat. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). ويمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/nougat).
+
+## نصائح الاستخدام
+
+- أسرع طريقة للبدء مع Nougat هي التحقق من [دفاتر الملاحظات التعليمية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Nougat)، والتي توضح كيفية استخدام النموذج في وقت الاستدلال وكذلك الضبط الدقيق على البيانات المخصصة.
+
+- يتم استخدام Nougat دائمًا ضمن إطار عمل [VisionEncoderDecoder](vision-encoder-decoder). النموذج مطابق لـ [Donut](donut) من حيث البنية المعمارية.
+
+## الاستنتاج
+
+يقبل نموذج [`VisionEncoderDecoder`] في Nougat الصور كمدخلات ويستخدم [`~generation.GenerationMixin.generate`] لتوليد النص تلقائيًا بناءً على صورة المدخلات.
+
+تتولى فئة [`NougatImageProcessor`] معالجة الصورة المدخلة، بينما تقوم فئة [`NougatTokenizerFast`] بفك ترميز رموز الهدف المولدة إلى سلسلة الهدف. وتجمع فئة [`NougatProcessor`] بين فئتي [`NougatImageProcessor`] و [`NougatTokenizerFast`] في مثيل واحد لاستخراج ميزات المدخلات وفك ترميز رموز الهدف المتوقعة.
+
+- نسخ المستندات خطوة بخطوة من ملفات PDF
+
+```py
+>>> from huggingface_hub import hf_hub_download
+>>> import re
+>>> from PIL import Image
+
+>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
+>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model.to(device) # doctest: +IGNORE_RESULT
+
+>>> # prepare PDF image for the model
+>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
+>>> image = Image.open(filepath)
+>>> pixel_values = processor(image, return_tensors="pt").pixel_values
+
+>>> # generate transcription (here we only generate 30 tokens)
+>>> outputs = model.generate(
+... pixel_values.to(device),
+... min_length=1,
+... max_new_tokens=30,
+... bad_words_ids=[[processor.tokenizer.unk_token_id]],
+... )
+
+>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
+>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
+>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
+>>> print(repr(sequence))
+'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'
+```
+
+راجع [مركز النماذج](https://huggingface.co/models?filter=nougat) للبحث عن نقاط تفتيش Nougat.
+
+
+
+نظرة عامة عالية المستوى على Nougat. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). ويمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/nougat).
+
+## نصائح الاستخدام
+
+- أسرع طريقة للبدء مع Nougat هي التحقق من [دفاتر الملاحظات التعليمية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Nougat)، والتي توضح كيفية استخدام النموذج في وقت الاستدلال وكذلك الضبط الدقيق على البيانات المخصصة.
+
+- يتم استخدام Nougat دائمًا ضمن إطار عمل [VisionEncoderDecoder](vision-encoder-decoder). النموذج مطابق لـ [Donut](donut) من حيث البنية المعمارية.
+
+## الاستنتاج
+
+يقبل نموذج [`VisionEncoderDecoder`] في Nougat الصور كمدخلات ويستخدم [`~generation.GenerationMixin.generate`] لتوليد النص تلقائيًا بناءً على صورة المدخلات.
+
+تتولى فئة [`NougatImageProcessor`] معالجة الصورة المدخلة، بينما تقوم فئة [`NougatTokenizerFast`] بفك ترميز رموز الهدف المولدة إلى سلسلة الهدف. وتجمع فئة [`NougatProcessor`] بين فئتي [`NougatImageProcessor`] و [`NougatTokenizerFast`] في مثيل واحد لاستخراج ميزات المدخلات وفك ترميز رموز الهدف المتوقعة.
+
+- نسخ المستندات خطوة بخطوة من ملفات PDF
+
+```py
+>>> from huggingface_hub import hf_hub_download
+>>> import re
+>>> from PIL import Image
+
+>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
+>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
+
+>>> device = "cuda" if torch.cuda.is_available() else "cpu"
+>>> model.to(device) # doctest: +IGNORE_RESULT
+
+>>> # prepare PDF image for the model
+>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
+>>> image = Image.open(filepath)
+>>> pixel_values = processor(image, return_tensors="pt").pixel_values
+
+>>> # generate transcription (here we only generate 30 tokens)
+>>> outputs = model.generate(
+... pixel_values.to(device),
+... min_length=1,
+... max_new_tokens=30,
+... bad_words_ids=[[processor.tokenizer.unk_token_id]],
+... )
+
+>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
+>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
+>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
+>>> print(repr(sequence))
+'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'
+```
+
+راجع [مركز النماذج](https://huggingface.co/models?filter=nougat) للبحث عن نقاط تفتيش Nougat.
+
+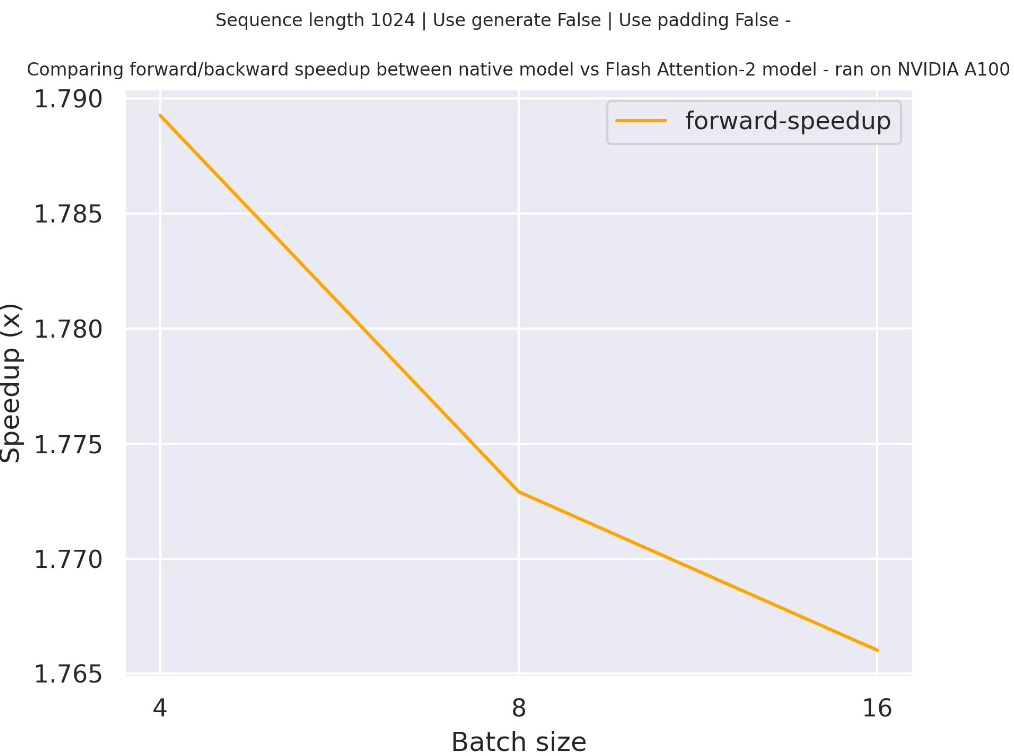 +
+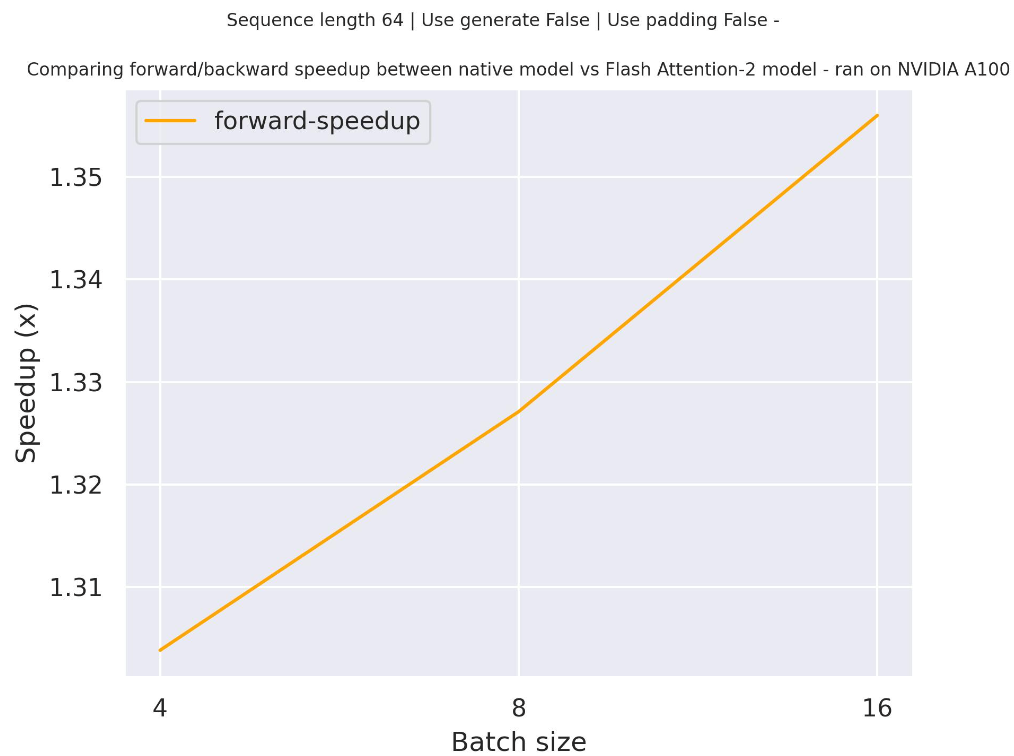 +
+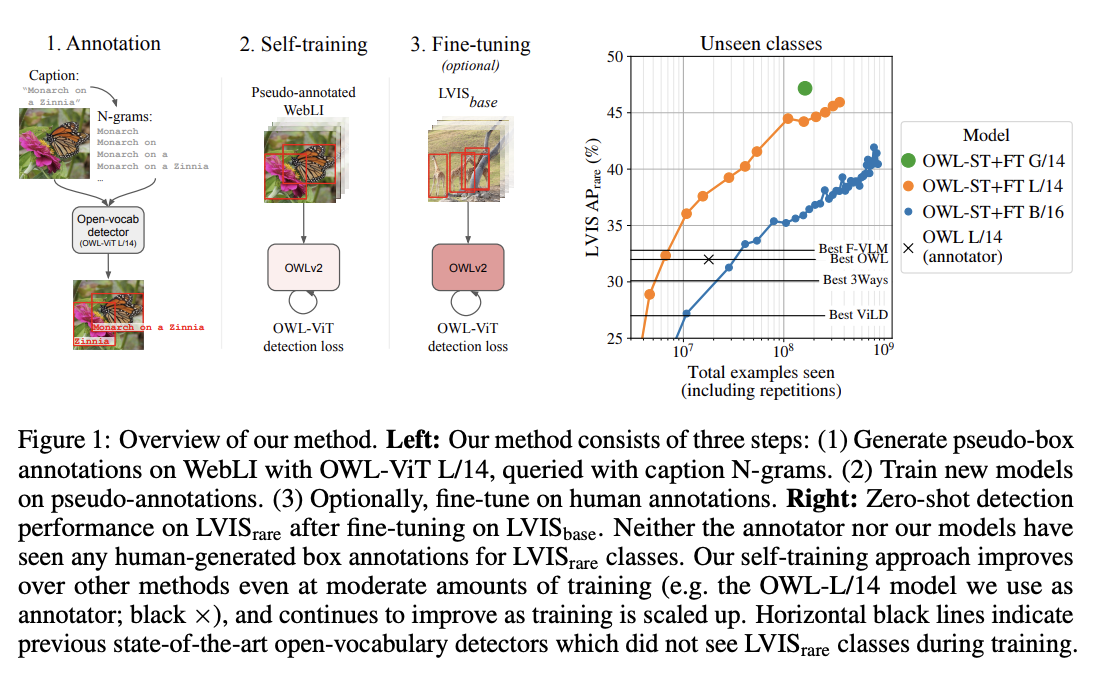 +
+نظرة عامة عالية المستوى على OWLv2. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## مثال على الاستخدام
+OWLv2 هو، مثل سابقه OWL-ViT، نموذج الكشف عن الأشياء المشروط بالنص بدون الصفر. يستخدم OWL-ViT CLIP كعمود فقري متعدد الوسائط، مع محول يشبه ViT للحصول على الميزات المرئية ونموذج اللغة السببية للحصول على الميزات النصية. لاستخدام CLIP للكشف، يزيل OWL-ViT طبقة تجميع الرموز النهائية لنموذج الرؤية ويرفق رأس تصنيف وخزان خفيفين بكل رمز إخراج محول. يتم تمكين التصنيف مفتوح المفردات عن طريق استبدال أوزان طبقة التصنيف الثابتة برموز تضمين اسم الفئة التي يتم الحصول عليها من نموذج النص. يقوم المؤلفون أولاً بتدريب CLIP من الصفر وتدريبه بشكل شامل مع رؤوس التصنيف والصندوق على مجموعات بيانات الكشف القياسية باستخدام خسارة المطابقة الثنائية. يمكن استخدام استعلام نصي واحد أو أكثر لكل صورة للكشف عن الأشياء المشروطة بالنص بدون الصفر.
+
+يمكن استخدام [`Owlv2ImageProcessor`] لإعادة تحديد حجم الصور (أو إعادة تحجيمها) وتطبيعها للنموذج، ويستخدم [`CLIPTokenizer`] لترميز النص. [`Owlv2Processor`] يجمع [`Owlv2ImageProcessor`] و [`CLIPTokenizer`] في مثيل واحد لترميز النص وإعداد الصور. يوضح المثال التالي كيفية إجراء الكشف عن الأشياء باستخدام [`Owlv2Processor`] و [`Owlv2ForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import Owlv2Processor, Owlv2ForObjectDetection
+
+>>> processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16-ensemble")
+>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=texts, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.Tensor([image.size[::-1]])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC Format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.1)
+>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
+>>> text = texts[i]
+>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
+>>> for box, score, label in zip(boxes, scores, labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.614 at location [341.67, 23.39, 642.32, 371.35]
+Detected a photo of a cat with confidence 0.665 at location [6.75, 51.96, 326.62, 473.13]
+```
+
+## الموارد
+- يمكن العثور على دفتر ملاحظات توضيحي حول استخدام OWLv2 للكشف عن الصفر واللقطة الواحدة (التي يوجهها الصور) [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [دليل مهام الكشف عن الأشياء ذات الصفر](../tasks/zero_shot_object_detection)
+
+
+
+نظرة عامة عالية المستوى على OWLv2. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## مثال على الاستخدام
+OWLv2 هو، مثل سابقه OWL-ViT، نموذج الكشف عن الأشياء المشروط بالنص بدون الصفر. يستخدم OWL-ViT CLIP كعمود فقري متعدد الوسائط، مع محول يشبه ViT للحصول على الميزات المرئية ونموذج اللغة السببية للحصول على الميزات النصية. لاستخدام CLIP للكشف، يزيل OWL-ViT طبقة تجميع الرموز النهائية لنموذج الرؤية ويرفق رأس تصنيف وخزان خفيفين بكل رمز إخراج محول. يتم تمكين التصنيف مفتوح المفردات عن طريق استبدال أوزان طبقة التصنيف الثابتة برموز تضمين اسم الفئة التي يتم الحصول عليها من نموذج النص. يقوم المؤلفون أولاً بتدريب CLIP من الصفر وتدريبه بشكل شامل مع رؤوس التصنيف والصندوق على مجموعات بيانات الكشف القياسية باستخدام خسارة المطابقة الثنائية. يمكن استخدام استعلام نصي واحد أو أكثر لكل صورة للكشف عن الأشياء المشروطة بالنص بدون الصفر.
+
+يمكن استخدام [`Owlv2ImageProcessor`] لإعادة تحديد حجم الصور (أو إعادة تحجيمها) وتطبيعها للنموذج، ويستخدم [`CLIPTokenizer`] لترميز النص. [`Owlv2Processor`] يجمع [`Owlv2ImageProcessor`] و [`CLIPTokenizer`] في مثيل واحد لترميز النص وإعداد الصور. يوضح المثال التالي كيفية إجراء الكشف عن الأشياء باستخدام [`Owlv2Processor`] و [`Owlv2ForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import Owlv2Processor, Owlv2ForObjectDetection
+
+>>> processor = Owlv2Processor.from_pretrained("google/owlv2-base-patch16-ensemble")
+>>> model = Owlv2ForObjectDetection.from_pretrained("google/owlv2-base-patch16-ensemble")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=texts, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.Tensor([image.size[::-1]])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC Format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.1)
+>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
+>>> text = texts[i]
+>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
+>>> for box, score, label in zip(boxes, scores, labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.614 at location [341.67, 23.39, 642.32, 371.35]
+Detected a photo of a cat with confidence 0.665 at location [6.75, 51.96, 326.62, 473.13]
+```
+
+## الموارد
+- يمكن العثور على دفتر ملاحظات توضيحي حول استخدام OWLv2 للكشف عن الصفر واللقطة الواحدة (التي يوجهها الصور) [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/OWLv2).
+- [دليل مهام الكشف عن الأشياء ذات الصفر](../tasks/zero_shot_object_detection)
+
+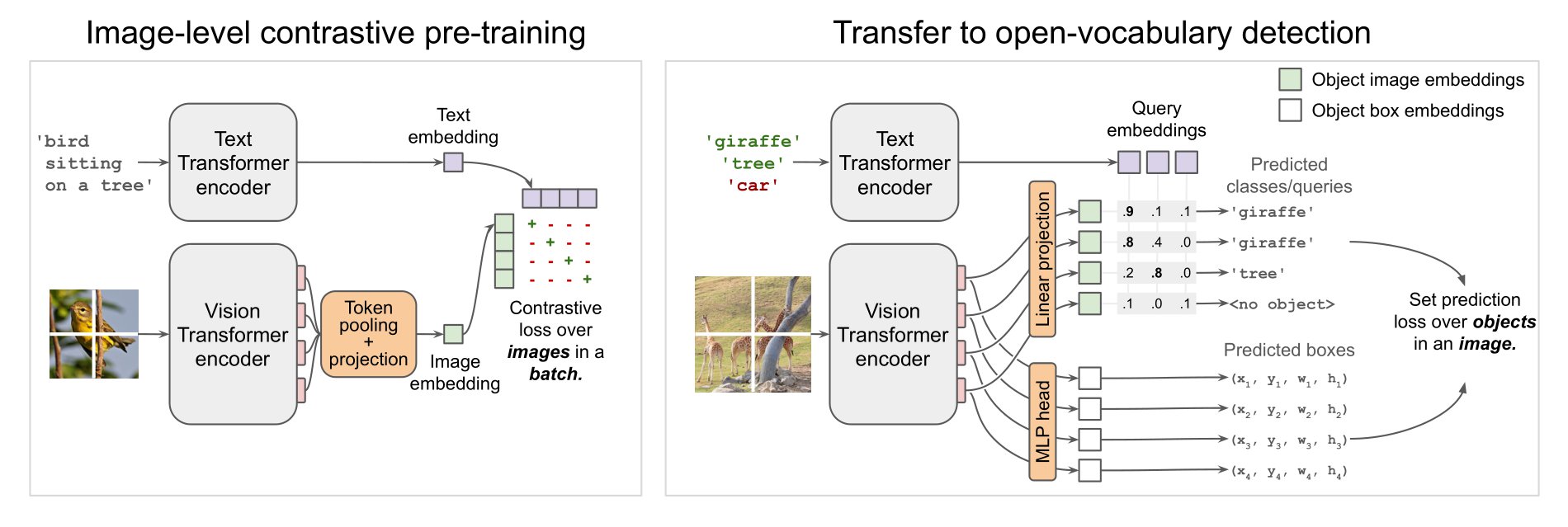 +
+بنية OWL-ViT. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [adirik](https://huggingface.co/adirik). يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## نصائح الاستخدام
+OWL-ViT هو نموذج كشف كائنات مشروط بالنص بدون بيانات تدريب. يستخدم OWL-ViT [CLIP](clip) كعمود فقري متعدد الوسائط، مع محول تشابهي مثل ViT للحصول على الميزات المرئية ونموذج لغة سببي للحصول على ميزات النص. لاستخدام CLIP للكشف، يزيل OWL-ViT طبقة تجميع الرموز النهائية من نموذج الرؤية ويرفق رأس تصنيف وخزان خفيف الوزن بكل رمز إخراج محول. يتم تمكين التصنيف مفتوح المفردات عن طريق استبدال أوزان طبقة التصنيف الثابتة برموز تضمين اسم الفئة التي يتم الحصول عليها من نموذج النص. يقوم المؤلفون أولاً بتدريب CLIP من الصفر وضبطها الدقيق من النهاية إلى النهاية مع رؤوس التصنيف والخزان على مجموعات بيانات الكشف القياسية باستخدام خسارة المطابقة الثنائية. يمكن استخدام استعلام نصي واحد أو أكثر لكل صورة لأداء الكشف عن الكائنات المشروط بالنص بدون بيانات تدريب.
+
+يمكن استخدام [`OwlViTImageProcessor`] لإعادة تحديد حجم الصور (أو إعادة تحجيمها) وتطبيعها للنموذج، ويستخدم [`CLIPTokenizer`] لترميز النص. [`OwlViTProcessor`] يجمع [`OwlViTImageProcessor`] و [`CLIPTokenizer`] في مثيل واحد لترميز النص وإعداد الصور. يوضح المثال التالي كيفية تنفيذ الكشف عن الكائنات باستخدام [`OwlViTProcessor`] و [`OwlViTForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import OwlViTProcessor, OwlViTForObjectDetection
+
+>>> processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
+>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=texts, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.Tensor([image.size[::-1]])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.1)
+>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
+>>> text = texts[i]
+>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
+>>> for box, score, label in zip(boxes, scores, labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.58, 373.29]
+Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
+```
+
+## الموارد
+يمكن العثور على دفتر ملاحظات توضيحي حول استخدام OWL-ViT للكشف عن الكائنات بدون بيانات تدريب وبدليل الصور [هنا](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb).
+
+## OwlViTConfig
+
+[[autodoc]] OwlViTConfig
+
+- from_text_vision_configs
+
+## OwlViTTextConfig
+
+[[autodoc]] OwlViTTextConfig
+
+## OwlViTVisionConfig
+
+[[autodoc]] OwlViTVisionConfig
+
+## OwlViTImageProcessor
+
+[[autodoc]] OwlViTImageProcessor
+
+- preprocess
+
+- post_process_object_detection
+
+- post_process_image_guided_detection
+
+## OwlViTFeatureExtractor
+
+[[autodoc]] OwlViTFeatureExtractor
+
+- __call__
+
+- post_process
+
+- post_process_image_guided_detection
+
+## OwlViTProcessor
+
+[[autodoc]] OwlViTProcessor
+
+## OwlViTModel
+
+[[autodoc]] OwlViTModel
+
+- forward
+
+- get_text_features
+
+- get_image_features
+
+## OwlViTTextModel
+
+[[autodoc]] OwlViTTextModel
+
+- forward
+
+## OwlViTVisionModel
+
+
+[[autodoc]] OwlViTVisionModel
+
+- forward
+
+## OwlViTForObjectDetection
+
+[[autodoc]] OwlViTForObjectDetection
+
+- forward
+
+- image_guided_detection
\ No newline at end of file
From 997a35f54d63c4434108ab3e32ca1ae629a10056 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:28:10 +0300
Subject: [PATCH 532/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/paligemma.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/paligemma.md | 66 +++++++++++++++++++++++++++
1 file changed, 66 insertions(+)
create mode 100644 docs/source/ar/model_doc/paligemma.md
diff --git a/docs/source/ar/model_doc/paligemma.md b/docs/source/ar/model_doc/paligemma.md
new file mode 100644
index 00000000000000..59cc1c36ae83f9
--- /dev/null
+++ b/docs/source/ar/model_doc/paligemma.md
@@ -0,0 +1,66 @@
+# PaliGemma
+
+## نظرة عامة
+
+اقترح نموذج PaliGemma في [PaliGemma – Google's Cutting-Edge Open Vision Language Model](https://huggingface.co/blog/paligemma) بواسطة Google. إنه نموذج للرؤية اللغوية يبلغ حجمه 3B، ويتكون من [SigLIP](siglip) encoder للرؤية وفك تشفير اللغة [Gemma](gemma) متصلين بواسطة إسقاط خطي متعدد الوسائط. ويقطع الصورة إلى عدد ثابت من رموز VIT ويضيفها إلى موجه اختياري. ومن خصوصياته أن النموذج يستخدم انتباه الكتلة الكاملة على جميع رموز الصورة بالإضافة إلى رموز النص المدخلة. وهو متوفر بثلاثة دقات، 224x224 و448x448 و896x896 مع 3 نماذج أساسية، و55 نسخة مُعدّلة مسبقًا لمهمام مختلفة، ونموذجين مختلطين.
+
+
+
+بنية OWL-ViT. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [adirik](https://huggingface.co/adirik). يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/scenic/tree/main/scenic/projects/owl_vit).
+
+## نصائح الاستخدام
+OWL-ViT هو نموذج كشف كائنات مشروط بالنص بدون بيانات تدريب. يستخدم OWL-ViT [CLIP](clip) كعمود فقري متعدد الوسائط، مع محول تشابهي مثل ViT للحصول على الميزات المرئية ونموذج لغة سببي للحصول على ميزات النص. لاستخدام CLIP للكشف، يزيل OWL-ViT طبقة تجميع الرموز النهائية من نموذج الرؤية ويرفق رأس تصنيف وخزان خفيف الوزن بكل رمز إخراج محول. يتم تمكين التصنيف مفتوح المفردات عن طريق استبدال أوزان طبقة التصنيف الثابتة برموز تضمين اسم الفئة التي يتم الحصول عليها من نموذج النص. يقوم المؤلفون أولاً بتدريب CLIP من الصفر وضبطها الدقيق من النهاية إلى النهاية مع رؤوس التصنيف والخزان على مجموعات بيانات الكشف القياسية باستخدام خسارة المطابقة الثنائية. يمكن استخدام استعلام نصي واحد أو أكثر لكل صورة لأداء الكشف عن الكائنات المشروط بالنص بدون بيانات تدريب.
+
+يمكن استخدام [`OwlViTImageProcessor`] لإعادة تحديد حجم الصور (أو إعادة تحجيمها) وتطبيعها للنموذج، ويستخدم [`CLIPTokenizer`] لترميز النص. [`OwlViTProcessor`] يجمع [`OwlViTImageProcessor`] و [`CLIPTokenizer`] في مثيل واحد لترميز النص وإعداد الصور. يوضح المثال التالي كيفية تنفيذ الكشف عن الكائنات باستخدام [`OwlViTProcessor`] و [`OwlViTForObjectDetection`].
+
+```python
+>>> import requests
+>>> from PIL import Image
+>>> import torch
+
+>>> from transformers import OwlViTProcessor, OwlViTForObjectDetection
+
+>>> processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
+>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+>>> texts = [["a photo of a cat", "a photo of a dog"]]
+>>> inputs = processor(text=texts, images=image, return_tensors="pt")
+>>> outputs = model(**inputs)
+
+>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
+>>> target_sizes = torch.Tensor([image.size[::-1]])
+>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
+>>> results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.1)
+>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
+>>> text = texts[i]
+>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
+>>> for box, score, label in zip(boxes, scores, labels):
+... box = [round(i, 2) for i in box.tolist()]
+... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
+Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.58, 373.29]
+Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
+```
+
+## الموارد
+يمكن العثور على دفتر ملاحظات توضيحي حول استخدام OWL-ViT للكشف عن الكائنات بدون بيانات تدريب وبدليل الصور [هنا](https://github.com/huggingface/notebooks/blob/main/examples/zeroshot_object_detection_with_owlvit.ipynb).
+
+## OwlViTConfig
+
+[[autodoc]] OwlViTConfig
+
+- from_text_vision_configs
+
+## OwlViTTextConfig
+
+[[autodoc]] OwlViTTextConfig
+
+## OwlViTVisionConfig
+
+[[autodoc]] OwlViTVisionConfig
+
+## OwlViTImageProcessor
+
+[[autodoc]] OwlViTImageProcessor
+
+- preprocess
+
+- post_process_object_detection
+
+- post_process_image_guided_detection
+
+## OwlViTFeatureExtractor
+
+[[autodoc]] OwlViTFeatureExtractor
+
+- __call__
+
+- post_process
+
+- post_process_image_guided_detection
+
+## OwlViTProcessor
+
+[[autodoc]] OwlViTProcessor
+
+## OwlViTModel
+
+[[autodoc]] OwlViTModel
+
+- forward
+
+- get_text_features
+
+- get_image_features
+
+## OwlViTTextModel
+
+[[autodoc]] OwlViTTextModel
+
+- forward
+
+## OwlViTVisionModel
+
+
+[[autodoc]] OwlViTVisionModel
+
+- forward
+
+## OwlViTForObjectDetection
+
+[[autodoc]] OwlViTForObjectDetection
+
+- forward
+
+- image_guided_detection
\ No newline at end of file
From 997a35f54d63c4434108ab3e32ca1ae629a10056 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:28:10 +0300
Subject: [PATCH 532/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/paligemma.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/paligemma.md | 66 +++++++++++++++++++++++++++
1 file changed, 66 insertions(+)
create mode 100644 docs/source/ar/model_doc/paligemma.md
diff --git a/docs/source/ar/model_doc/paligemma.md b/docs/source/ar/model_doc/paligemma.md
new file mode 100644
index 00000000000000..59cc1c36ae83f9
--- /dev/null
+++ b/docs/source/ar/model_doc/paligemma.md
@@ -0,0 +1,66 @@
+# PaliGemma
+
+## نظرة عامة
+
+اقترح نموذج PaliGemma في [PaliGemma – Google's Cutting-Edge Open Vision Language Model](https://huggingface.co/blog/paligemma) بواسطة Google. إنه نموذج للرؤية اللغوية يبلغ حجمه 3B، ويتكون من [SigLIP](siglip) encoder للرؤية وفك تشفير اللغة [Gemma](gemma) متصلين بواسطة إسقاط خطي متعدد الوسائط. ويقطع الصورة إلى عدد ثابت من رموز VIT ويضيفها إلى موجه اختياري. ومن خصوصياته أن النموذج يستخدم انتباه الكتلة الكاملة على جميع رموز الصورة بالإضافة إلى رموز النص المدخلة. وهو متوفر بثلاثة دقات، 224x224 و448x448 و896x896 مع 3 نماذج أساسية، و55 نسخة مُعدّلة مسبقًا لمهمام مختلفة، ونموذجين مختلطين.
+
+ +
+ هندسة PaliGemma. مأخوذة من منشور المدونة.
+
+تمت المساهمة بهذا النموذج بواسطة [Molbap](https://huggingface.co/Molbap).
+
+## نصائح الاستخدام
+
+يمكن إجراء الاستنتاج باستخدام PaliGemma على النحو التالي:
+
+```python
+from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
+
+model_id = "google/paligemma-3b-mix-224"
+model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
+processor = AutoProcessor.from_pretrained(model_id)
+
+prompt = "What is on the flower?"
+image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
+raw_image = Image.open(requests.get(image_file, stream=True).raw)
+inputs = processor(prompt, raw_image, return_tensors="pt")
+output = model.generate(**inputs, max_new_tokens=20)
+
+print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
+```
+
+- لا يقصد بـ PaliGemma الاستخدام المحادثي، وهو يعمل بشكل أفضل عند الضبط الدقيق لحالة استخدام محددة. بعض المهام النهائية التي يمكن ضبط PaliGemma الدقيق لها تشمل إنشاء تعليقات توضيحية للصور، والإجابة على الأسئلة المرئية (VQA)، وكشف الأجسام، وتحديد أجزاء الكلام، وفهم المستندات.
+
+- يمكن استخدام `PaliGemmaProcessor` لإعداد الصور والنص والعلامات الاختيارية للنموذج. عند الضبط الدقيق لنموذج PaliGemma، يمكن تمرير وسيط `suffix` إلى المعالج الذي يقوم بإنشاء `labels` للنموذج:
+
+```python
+prompt = "What is on the flower?"
+answer = "a bee"
+inputs = processor(text=prompt, images=raw_image, suffix=answer, return_tensors="pt")
+```
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية والمجتمعية (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام PaliGemma. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب Pull Request وسنراجعه! ويفضل أن يُظهر المورد شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+- يمكن العثور على منشور مدونة يقدم جميع ميزات PaliGemma [هنا](https://huggingface.co/blog/paligemma).
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية حول كيفية الضبط الدقيق لـ PaliGemma لـ VQA باستخدام واجهة برمجة تطبيقات Trainer إلى جانب الاستنتاج [هنا](https://github.com/huggingface/notebooks/tree/main/examples/paligemma).
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية حول كيفية الضبط الدقيق لـ PaliGemma على مجموعة بيانات مخصصة (صورة الإيصال -> JSON) إلى جانب الاستنتاج [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/PaliGemma). 🌎
+
+## PaliGemmaConfig
+
+[[autodoc]] PaliGemmaConfig
+
+## PaliGemmaProcessor
+
+[[autodoc]] PaliGemmaProcessor
+
+## PaliGemmaForConditionalGeneration
+
+[[autodoc]] PaliGemmaForConditionalGeneration
+
+- forward
\ No newline at end of file
From 41a23c49d6361cc53dba7062d363fe449937e48c Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:28:11 +0300
Subject: [PATCH 533/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/patchtsmixer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/patchtsmixer.md | 70 ++++++++++++++++++++++++
1 file changed, 70 insertions(+)
create mode 100644 docs/source/ar/model_doc/patchtsmixer.md
diff --git a/docs/source/ar/model_doc/patchtsmixer.md b/docs/source/ar/model_doc/patchtsmixer.md
new file mode 100644
index 00000000000000..84e69cb9f00603
--- /dev/null
+++ b/docs/source/ar/model_doc/patchtsmixer.md
@@ -0,0 +1,70 @@
+# PatchTSMixer
+
+## نظرة عامة
+
+اقتُرح نموذج PatchTSMixer في ورقة بحثية بعنوان [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) بواسطة Vijay Ekambaram وArindam Jati وNam Nguyen وPhanwadee Sinthong وJayant Kalagnanam.
+
+PatchTSMixer هو نهج نمذجة سلسلة زمنية خفيف الوزن يعتمد على بنية MLP-Mixer. وفي هذا التنفيذ من HuggingFace، نوفر قدرات PatchTSMixer لتسهيل المزج الخفيف عبر الرقع والقنوات والميزات المخفية لنمذجة السلاسل الزمنية متعددة المتغيرات بشكل فعال. كما يدعم العديد من آليات الانتباه بدءًا من الانتباه المبسط المحكوم إلى كتل الانتباه الذاتي الأكثر تعقيدًا التي يمكن تخصيصها وفقًا لذلك. يمكن تدريب النموذج مسبقًا ثم استخدامه لاحقًا في مهام مختلفة مثل التنبؤ والتصنيف والرجعية.
+
+الملخص من الورقة هو كما يلي:
+
+*TSMixer هو بنية عصبية خفيفة الوزن تتكون حصريًا من وحدات متعددة الطبقات (MLP) مصممة للتنبؤ والتعلم التمثيلي متعدد المتغيرات على السلاسل الزمنية المرقعة. يستلهم نموذجنا الإلهام من نجاح نماذج MLP-Mixer في رؤية الكمبيوتر. نحن نبرهن على التحديات التي ينطوي عليها تكييف رؤية MLP-Mixer للسلاسل الزمنية ونقدم مكونات تم التحقق من صحتها تجريبيًا لتحسين الدقة. ويشمل ذلك طريقة تصميم جديدة تتمثل في ربط رؤوس التسوية عبر الإنترنت مع العمود الفقري لـ MLP-Mixer، لنمذجة خصائص السلاسل الزمنية بشكل صريح مثل التسلسل الهرمي والارتباطات بين القنوات. كما نقترح نهجًا هجينًا لنمذجة القنوات للتعامل بفعالية مع تفاعلات القنوات الضجيج والتعميم عبر مجموعات بيانات متنوعة، وهو تحدٍ شائع في طرق مزج قنوات الرقع الموجودة. بالإضافة إلى ذلك، تم تقديم آلية اهتمام محكومة بسيطة في العمود الفقري لإعطاء الأولوية للميزات المهمة. من خلال دمج هذه المكونات الخفيفة، نحسن بشكل كبير من قدرة التعلم لهياكل MLP البسيطة، متجاوزين نماذج المحول المعقدة باستخدام الحد الأدنى من الاستخدام الحسابي. علاوة على ذلك، تمكن التصميم النمطي لـ TSMixer من التوافق مع كل من طرق التعلم الخاضعة للإشراف والتعلم الذاتي المقنع، مما يجعله كتلة بناء واعدة لنماذج الأساس الخاصة بالسلاسل الزمنية. يتفوق TSMixer على أحدث نماذج MLP و Transformer في التنبؤ بهامش كبير يتراوح بين 8-60%. كما يتفوق على أحدث المعايير القوية لنماذج Patch-Transformer (بنسبة 1-2%) مع تقليل كبير في الذاكرة ووقت التشغيل (2-3X).*
+
+تمت المساهمة بهذا النموذج من قبل [ajati](https://huggingface.co/ajati)، [vijaye12](https://huggingface.co/vijaye12)، [gsinthong](https://huggingface.co/gsinthong)، [namctin](https://huggingface.co/namctin)، [wmgifford](https://huggingface.co/wmgifford)، [kashif](https://huggingface.co/kashif).
+
+## مثال على الاستخدام
+
+توضح مقتطفات الأكواد أدناه كيفية تهيئة نموذج PatchTSMixer بشكل عشوائي. النموذج متوافق مع [Trainer API](../trainer.md).
+
+```python
+from transformers import PatchTSMixerConfig, PatchTSMixerForPrediction
+from transformers import Trainer, TrainingArguments,
+
+config = PatchTSMixerConfig(context_length = 512, prediction_length = 96)
+model = PatchTSMixerForPrediction(config)
+trainer = Trainer(model=model, args=training_args, train_dataset=train_dataset, eval_dataset=valid_dataset)
+trainer.train()
+results = trainer.evaluate(test_dataset)
+```
+
+## نصائح الاستخدام
+
+يمكن أيضًا استخدام النموذج لتصنيف السلاسل الزمنية والرجعية الزمنية. راجع فئات [`PatchTSMixerForTimeSeriesClassification`] و [`PatchTSMixerForRegression`] على التوالي.
+
+## الموارد
+
+- يمكن العثور على منشور مدونة يشرح PatchTSMixer بالتفصيل [هنا](https://huggingface.co/blog/patchtsmixer). يمكن أيضًا فتح المدونة في Google Colab.
+
+## PatchTSMixerConfig
+
+[[autodoc]] PatchTSMixerConfig
+
+## PatchTSMixerModel
+
+[[autodoc]] PatchTSMixerModel
+
+- forward
+
+## PatchTSMixerForPrediction
+
+[[autodoc]] PatchTSMixerForPrediction
+
+- forward
+
+## PatchTSMixerForTimeSeriesClassification
+
+[[autodoc]] PatchTSMixerForTimeSeriesClassification
+
+- forward
+
+## PatchTSMixerForPretraining
+
+[[autodoc]] PatchTSMixerForPretraining
+
+- forward
+
+## PatchTSMixerForRegression
+
+[[autodoc]] PatchTSMixerForRegression
+
+- forward
\ No newline at end of file
From 7fb8b7b90599fae698fb18b9f2e71943f9ec89e5 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:28:13 +0300
Subject: [PATCH 534/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/patchtst.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/patchtst.md | 52 ++++++++++++++++++++++++++++
1 file changed, 52 insertions(+)
create mode 100644 docs/source/ar/model_doc/patchtst.md
diff --git a/docs/source/ar/model_doc/patchtst.md b/docs/source/ar/model_doc/patchtst.md
new file mode 100644
index 00000000000000..ae224084f04d23
--- /dev/null
+++ b/docs/source/ar/model_doc/patchtst.md
@@ -0,0 +1,52 @@
+# PatchTST
+
+## نظرة عامة
+تم اقتراح نموذج PatchTST في ورقة بحثية بعنوان "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers" بواسطة Yuqi Nie و Nam H. Nguyen و Phanwadee Sinthong و Jayant Kalagnanam.
+
+بشكل عام، يقوم النموذج بتقطيع السلاسل الزمنية إلى رقع ذات حجم معين وترميز تسلسل المتجهات الناتج عبر محول (Transformer) يقوم بعد ذلك بإخراج توقع طول التنبؤ عبر رأس مناسب. يتم توضيح النموذج في الشكل التالي:
+
+يقدم الملخص التالي من الورقة:
+
+"نقترح تصميمًا فعالًا لنماذج المحولات القائمة على السلاسل الزمنية متعددة المتغيرات والتعلم التمثيلي الخاضع للإشراف الذاتي. يعتمد على مكونين رئيسيين: (1) تقسيم السلاسل الزمنية إلى رقع على مستوى السلاسل الفرعية والتي يتم استخدامها كرموز دخول إلى المحول؛ (2) الاستقلالية القناة حيث تحتوي كل قناة على سلسلة زمنية أحادية المتغيرات تشترك في نفس التضمين وأوزان المحول عبر جميع السلاسل. يحتوي التصميم التصحيح بشكل طبيعي على فائدة ثلاثية: يتم الاحتفاظ بالمعلومات الدلالية المحلية في التضمين؛ يتم تقليل استخدام الذاكرة والحساب لخرائط الاهتمام بشكل رباعي نظرًا لنفس نافذة النظر إلى الوراء؛ ويمكن للنموذج الاهتمام بتاريخ أطول. يمكن لمحولنا المستقل عن القناة لتصحيح السلاسل الزمنية (PatchTST) تحسين دقة التنبؤ على المدى الطويل بشكل كبير عند مقارنته بنماذج المحولات المستندة إلى SOTA. نطبق نموذجنا أيضًا على مهام التدريب المسبق الخاضعة للإشراف الذاتي ونحقق أداء ضبط دقيق ممتازًا، والذي يتفوق على التدريب الخاضع للإشراف على مجموعات البيانات الكبيرة. كما أن نقل التمثيل المقنع مسبقًا من مجموعة بيانات إلى أخرى ينتج أيضًا دقة تنبؤية على مستوى SOTA."
+
+تمت المساهمة بهذا النموذج من قبل namctin و gsinthong و diepi و vijaye12 و wmgifford و kashif. يمكن العثور على الكود الأصلي [هنا](https://github.com/yuqinie98/PatchTST).
+
+## نصائح الاستخدام
+يمكن أيضًا استخدام النموذج لتصنيف السلاسل الزمنية والانحدار الزمني. راجع فئات [`PatchTSTForClassification`] و [`PatchTSTForRegression`] الخاصة بكل منهما.
+
+## الموارد
+- يمكن العثور على منشور المدونة الذي يشرح PatchTST بالتفصيل [هنا](https://huggingface.co/blog/patchtst). يمكن أيضًا فتح المدونة في Google Colab.
+
+## PatchTSTConfig
+
+[[autodoc]] PatchTSTConfig
+
+## PatchTSTModel
+
+[[autodoc]] PatchTSTModel
+
+- forward
+
+## PatchTSTForPrediction
+
+[[autodoc]] PatchTSTForPrediction
+
+- forward
+
+## PatchTSTForClassification
+
+[[autodoc]] PatchTSTForClassification
+
+- forward
+
+## PatchTSTForPretraining
+
+[[autodoc]] PatchTSTForPretraining
+
+- forward
+
+## PatchTSTForRegression
+
+[[autodoc]] PatchTSTForRegression
+
+- forward
\ No newline at end of file
From 84779b9e5f984bd5fe699a42bbb355429205e9b5 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:28:15 +0300
Subject: [PATCH 535/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/pegasus.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/pegasus.md | 145 ++++++++++++++++++++++++++++
1 file changed, 145 insertions(+)
create mode 100644 docs/source/ar/model_doc/pegasus.md
diff --git a/docs/source/ar/model_doc/pegasus.md b/docs/source/ar/model_doc/pegasus.md
new file mode 100644
index 00000000000000..3852d3f9a6df62
--- /dev/null
+++ b/docs/source/ar/model_doc/pegasus.md
@@ -0,0 +1,145 @@
+# Pegasus
+
+## نظرة عامة
+
+اقتُرح نموذج Pegasus في ورقة بحثية بعنوان: "PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization" من قبل جينغكينغ جانغ، وياو تشاو، ومحمد صالح، وبيتر ج. ليو في 18 ديسمبر 2019.
+
+وفقًا للملخص، فإن:
+
+- مهمة التدريب المسبق لـ Pegasus متشابهة عن قصد مع الملخص: تتم إزالة/حجب جمل مهمة من وثيقة الإدخال، ثم يتم توليدها معًا كتسلسل إخراج واحد من الجمل المتبقية، على غرار الملخص الاستخلاصي.
+- يحقق Pegasus أداءً متميزًا في مهام الملخص على جميع المهام الفرعية الـ 12، وفقًا لتقييم ROUGE والتقييم البشري.
+
+تمت المساهمة بهذا النموذج من قبل [sshleifer](https://huggingface.co/sshleifer). ويمكن العثور على كود المؤلفين [هنا](https://github.com/google-research/pegasus).
+
+## نصائح الاستخدام
+
+- يعد Pegasus نموذجًا تسلسليًا تسلسليًا له نفس بنية الترميز فك الترميز مثل BART. تم تدريب Pegasus بشكل مسبق بشكل مشترك على دالتين للهدف ذاتي الإشراف: Masked Language Modeling (MLM) ودالة تدريب مسبق محددة للملخص تسمى Gap Sentence Generation (GSG).
+
+* MLM: يتم استبدال رموز الإدخال للترميز بشكل عشوائي برموز قناع، ويجب التنبؤ بها بواسطة الترميز (مثل BERT)
+* GSG: يتم استبدال جمل إدخال الترميز بالكامل برمز قناع ثانوي وإدخالها إلى فك الترميز، ولكن مع قناع سببي لإخفاء الكلمات المستقبلية مثل فك تشفير محول ذاتي الانحدار منتظم.
+
+- لا يتم دعم FP16 (يتم تقدير المساعدة/الأفكار حول هذا الموضوع!).
+- يوصى باستخدام محسن adafactor لضبط نموذج Pegasus بشكل دقيق.
+
+## نقاط التفتيش
+
+تم ضبط جميع [نقاط التفتيش](https://huggingface.co/models?search=pegasus) مسبقًا للتلخيص، باستثناء *pegasus-large*، حيث يتم ضبط نقاط التفتيش الأخرى:
+
+- يحتل كل نقطة تفتيش مساحة 2.2 جيجابايت على القرص و568 مليون معلمة.
+- لا يتم دعم FP16 (يتم تقدير المساعدة/الأفكار حول هذا الموضوع!).
+- يستغرق تلخيص xsum في fp32 حوالي 400 مللي ثانية/عينة، مع معلمات افتراضية على وحدة معالجة الرسومات v100.
+- يمكن العثور على نتائج الاستنساخ الكامل والبيانات المعالجة بشكل صحيح في هذه [القضية](https://github.com/huggingface/transformers/issues/6844#issue-689259666).
+- يتم وصف [نقاط التفتيش المقطرة](https://huggingface.co/models?search=distill-pegasus) في هذه [الورقة](https://arxiv.org/abs/2010.13002).
+
+## ملاحظات التنفيذ
+
+- جميع النماذج هي محولات الترميز فك الترميز مع 16 طبقة في كل مكون.
+- تم استلهام التنفيذ بالكامل من [`BartForConditionalGeneration`]
+- بعض الاختلافات الرئيسية في التكوين:
+- مواضع ثابتة، تضمينية جيبية
+- يبدأ النموذج في التوليد باستخدام pad_token_id (الذي يحتوي على 0 token_embedding) كبادئة.
+- يتم استخدام المزيد من الحزم (`num_beams=8`)
+- جميع نقاط تفتيش Pegasus المسبقة التدريب متطابقة باستثناء ثلاث سمات: `tokenizer.model_max_length` (حجم الإدخال الأقصى)، و`max_length` (العدد الأقصى من الرموز المولدة)، و`length_penalty`.
+- يمكن العثور على الكود لتحويل نقاط التفتيش المدربة في مستودع المؤلفين [هنا](https://github.com/google-research/pegasus) في `convert_pegasus_tf_to_pytorch.py`.
+
+## مثال على الاستخدام
+
+```python
+>>> from transformers import PegasusForConditionalGeneration, PegasusTokenizer
+>>> import torch
+
+>>> src_text = [
+... """ PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."""
+... ]
+
+... model_name = "google/pegasus-xsum"
+... device = "cuda" if torch.cuda.is_available() else "cpu"
+... tokenizer = PegasusTokenizer.from_pretrained(model_name)
+... model = PegasusForConditionalGeneration.from_pretrained(model_name).to(device)
+... batch = tokenizer(src_text, truncation=True, padding="longest", return_tensors="pt").to(device)
+... translated = model.generate(**batch)
+... tgt_text = tokenizer.batch_decode(translated, skip_special_tokens=True)
+... assert (
+... tgt_text[0]
+... == "California's largest electricity provider has turned off power to hundreds of thousands of customers."
+... )
+```
+
+## الموارد
+
+- [سكريبت](https://github.com/huggingface/transformers/tree/main/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh) لضبط نموذج Pegasus بشكل دقيق على مجموعة بيانات XSUM. تعليمات تنزيل البيانات في [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+- [دليل مهام نمذجة اللغة السببية](../tasks/language_modeling)
+- [دليل مهام الترجمة](../tasks/translation)
+- [دليل مهام الملخص](../tasks/summarization)
+
+## PegasusConfig
+
+[[autodoc]] PegasusConfig
+
+## PegasusTokenizer
+
+تحذير: `add_tokens` لا يعمل في الوقت الحالي.
+
+[[autodoc]] PegasusTokenizer
+
+## PegasusTokenizerFast
+
+[[autodoc]] PegasusTokenizerFast
+
+
+
+ هندسة PaliGemma. مأخوذة من منشور المدونة.
+
+تمت المساهمة بهذا النموذج بواسطة [Molbap](https://huggingface.co/Molbap).
+
+## نصائح الاستخدام
+
+يمكن إجراء الاستنتاج باستخدام PaliGemma على النحو التالي:
+
+```python
+from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
+
+model_id = "google/paligemma-3b-mix-224"
+model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
+processor = AutoProcessor.from_pretrained(model_id)
+
+prompt = "What is on the flower?"
+image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
+raw_image = Image.open(requests.get(image_file, stream=True).raw)
+inputs = processor(prompt, raw_image, return_tensors="pt")
+output = model.generate(**inputs, max_new_tokens=20)
+
+print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
+```
+
+- لا يقصد بـ PaliGemma الاستخدام المحادثي، وهو يعمل بشكل أفضل عند الضبط الدقيق لحالة استخدام محددة. بعض المهام النهائية التي يمكن ضبط PaliGemma الدقيق لها تشمل إنشاء تعليقات توضيحية للصور، والإجابة على الأسئلة المرئية (VQA)، وكشف الأجسام، وتحديد أجزاء الكلام، وفهم المستندات.
+
+- يمكن استخدام `PaliGemmaProcessor` لإعداد الصور والنص والعلامات الاختيارية للنموذج. عند الضبط الدقيق لنموذج PaliGemma، يمكن تمرير وسيط `suffix` إلى المعالج الذي يقوم بإنشاء `labels` للنموذج:
+
+```python
+prompt = "What is on the flower?"
+answer = "a bee"
+inputs = processor(text=prompt, images=raw_image, suffix=answer, return_tensors="pt")
+```
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية والمجتمعية (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام PaliGemma. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب Pull Request وسنراجعه! ويفضل أن يُظهر المورد شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+- يمكن العثور على منشور مدونة يقدم جميع ميزات PaliGemma [هنا](https://huggingface.co/blog/paligemma).
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية حول كيفية الضبط الدقيق لـ PaliGemma لـ VQA باستخدام واجهة برمجة تطبيقات Trainer إلى جانب الاستنتاج [هنا](https://github.com/huggingface/notebooks/tree/main/examples/paligemma).
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية حول كيفية الضبط الدقيق لـ PaliGemma على مجموعة بيانات مخصصة (صورة الإيصال -> JSON) إلى جانب الاستنتاج [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/PaliGemma). 🌎
+
+## PaliGemmaConfig
+
+[[autodoc]] PaliGemmaConfig
+
+## PaliGemmaProcessor
+
+[[autodoc]] PaliGemmaProcessor
+
+## PaliGemmaForConditionalGeneration
+
+[[autodoc]] PaliGemmaForConditionalGeneration
+
+- forward
\ No newline at end of file
From 41a23c49d6361cc53dba7062d363fe449937e48c Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:28:11 +0300
Subject: [PATCH 533/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/patchtsmixer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/patchtsmixer.md | 70 ++++++++++++++++++++++++
1 file changed, 70 insertions(+)
create mode 100644 docs/source/ar/model_doc/patchtsmixer.md
diff --git a/docs/source/ar/model_doc/patchtsmixer.md b/docs/source/ar/model_doc/patchtsmixer.md
new file mode 100644
index 00000000000000..84e69cb9f00603
--- /dev/null
+++ b/docs/source/ar/model_doc/patchtsmixer.md
@@ -0,0 +1,70 @@
+# PatchTSMixer
+
+## نظرة عامة
+
+اقتُرح نموذج PatchTSMixer في ورقة بحثية بعنوان [TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting](https://arxiv.org/pdf/2306.09364.pdf) بواسطة Vijay Ekambaram وArindam Jati وNam Nguyen وPhanwadee Sinthong وJayant Kalagnanam.
+
+PatchTSMixer هو نهج نمذجة سلسلة زمنية خفيف الوزن يعتمد على بنية MLP-Mixer. وفي هذا التنفيذ من HuggingFace، نوفر قدرات PatchTSMixer لتسهيل المزج الخفيف عبر الرقع والقنوات والميزات المخفية لنمذجة السلاسل الزمنية متعددة المتغيرات بشكل فعال. كما يدعم العديد من آليات الانتباه بدءًا من الانتباه المبسط المحكوم إلى كتل الانتباه الذاتي الأكثر تعقيدًا التي يمكن تخصيصها وفقًا لذلك. يمكن تدريب النموذج مسبقًا ثم استخدامه لاحقًا في مهام مختلفة مثل التنبؤ والتصنيف والرجعية.
+
+الملخص من الورقة هو كما يلي:
+
+*TSMixer هو بنية عصبية خفيفة الوزن تتكون حصريًا من وحدات متعددة الطبقات (MLP) مصممة للتنبؤ والتعلم التمثيلي متعدد المتغيرات على السلاسل الزمنية المرقعة. يستلهم نموذجنا الإلهام من نجاح نماذج MLP-Mixer في رؤية الكمبيوتر. نحن نبرهن على التحديات التي ينطوي عليها تكييف رؤية MLP-Mixer للسلاسل الزمنية ونقدم مكونات تم التحقق من صحتها تجريبيًا لتحسين الدقة. ويشمل ذلك طريقة تصميم جديدة تتمثل في ربط رؤوس التسوية عبر الإنترنت مع العمود الفقري لـ MLP-Mixer، لنمذجة خصائص السلاسل الزمنية بشكل صريح مثل التسلسل الهرمي والارتباطات بين القنوات. كما نقترح نهجًا هجينًا لنمذجة القنوات للتعامل بفعالية مع تفاعلات القنوات الضجيج والتعميم عبر مجموعات بيانات متنوعة، وهو تحدٍ شائع في طرق مزج قنوات الرقع الموجودة. بالإضافة إلى ذلك، تم تقديم آلية اهتمام محكومة بسيطة في العمود الفقري لإعطاء الأولوية للميزات المهمة. من خلال دمج هذه المكونات الخفيفة، نحسن بشكل كبير من قدرة التعلم لهياكل MLP البسيطة، متجاوزين نماذج المحول المعقدة باستخدام الحد الأدنى من الاستخدام الحسابي. علاوة على ذلك، تمكن التصميم النمطي لـ TSMixer من التوافق مع كل من طرق التعلم الخاضعة للإشراف والتعلم الذاتي المقنع، مما يجعله كتلة بناء واعدة لنماذج الأساس الخاصة بالسلاسل الزمنية. يتفوق TSMixer على أحدث نماذج MLP و Transformer في التنبؤ بهامش كبير يتراوح بين 8-60%. كما يتفوق على أحدث المعايير القوية لنماذج Patch-Transformer (بنسبة 1-2%) مع تقليل كبير في الذاكرة ووقت التشغيل (2-3X).*
+
+تمت المساهمة بهذا النموذج من قبل [ajati](https://huggingface.co/ajati)، [vijaye12](https://huggingface.co/vijaye12)، [gsinthong](https://huggingface.co/gsinthong)، [namctin](https://huggingface.co/namctin)، [wmgifford](https://huggingface.co/wmgifford)، [kashif](https://huggingface.co/kashif).
+
+## مثال على الاستخدام
+
+توضح مقتطفات الأكواد أدناه كيفية تهيئة نموذج PatchTSMixer بشكل عشوائي. النموذج متوافق مع [Trainer API](../trainer.md).
+
+```python
+from transformers import PatchTSMixerConfig, PatchTSMixerForPrediction
+from transformers import Trainer, TrainingArguments,
+
+config = PatchTSMixerConfig(context_length = 512, prediction_length = 96)
+model = PatchTSMixerForPrediction(config)
+trainer = Trainer(model=model, args=training_args, train_dataset=train_dataset, eval_dataset=valid_dataset)
+trainer.train()
+results = trainer.evaluate(test_dataset)
+```
+
+## نصائح الاستخدام
+
+يمكن أيضًا استخدام النموذج لتصنيف السلاسل الزمنية والرجعية الزمنية. راجع فئات [`PatchTSMixerForTimeSeriesClassification`] و [`PatchTSMixerForRegression`] على التوالي.
+
+## الموارد
+
+- يمكن العثور على منشور مدونة يشرح PatchTSMixer بالتفصيل [هنا](https://huggingface.co/blog/patchtsmixer). يمكن أيضًا فتح المدونة في Google Colab.
+
+## PatchTSMixerConfig
+
+[[autodoc]] PatchTSMixerConfig
+
+## PatchTSMixerModel
+
+[[autodoc]] PatchTSMixerModel
+
+- forward
+
+## PatchTSMixerForPrediction
+
+[[autodoc]] PatchTSMixerForPrediction
+
+- forward
+
+## PatchTSMixerForTimeSeriesClassification
+
+[[autodoc]] PatchTSMixerForTimeSeriesClassification
+
+- forward
+
+## PatchTSMixerForPretraining
+
+[[autodoc]] PatchTSMixerForPretraining
+
+- forward
+
+## PatchTSMixerForRegression
+
+[[autodoc]] PatchTSMixerForRegression
+
+- forward
\ No newline at end of file
From 7fb8b7b90599fae698fb18b9f2e71943f9ec89e5 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:28:13 +0300
Subject: [PATCH 534/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/patchtst.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/patchtst.md | 52 ++++++++++++++++++++++++++++
1 file changed, 52 insertions(+)
create mode 100644 docs/source/ar/model_doc/patchtst.md
diff --git a/docs/source/ar/model_doc/patchtst.md b/docs/source/ar/model_doc/patchtst.md
new file mode 100644
index 00000000000000..ae224084f04d23
--- /dev/null
+++ b/docs/source/ar/model_doc/patchtst.md
@@ -0,0 +1,52 @@
+# PatchTST
+
+## نظرة عامة
+تم اقتراح نموذج PatchTST في ورقة بحثية بعنوان "A Time Series is Worth 64 Words: Long-term Forecasting with Transformers" بواسطة Yuqi Nie و Nam H. Nguyen و Phanwadee Sinthong و Jayant Kalagnanam.
+
+بشكل عام، يقوم النموذج بتقطيع السلاسل الزمنية إلى رقع ذات حجم معين وترميز تسلسل المتجهات الناتج عبر محول (Transformer) يقوم بعد ذلك بإخراج توقع طول التنبؤ عبر رأس مناسب. يتم توضيح النموذج في الشكل التالي:
+
+يقدم الملخص التالي من الورقة:
+
+"نقترح تصميمًا فعالًا لنماذج المحولات القائمة على السلاسل الزمنية متعددة المتغيرات والتعلم التمثيلي الخاضع للإشراف الذاتي. يعتمد على مكونين رئيسيين: (1) تقسيم السلاسل الزمنية إلى رقع على مستوى السلاسل الفرعية والتي يتم استخدامها كرموز دخول إلى المحول؛ (2) الاستقلالية القناة حيث تحتوي كل قناة على سلسلة زمنية أحادية المتغيرات تشترك في نفس التضمين وأوزان المحول عبر جميع السلاسل. يحتوي التصميم التصحيح بشكل طبيعي على فائدة ثلاثية: يتم الاحتفاظ بالمعلومات الدلالية المحلية في التضمين؛ يتم تقليل استخدام الذاكرة والحساب لخرائط الاهتمام بشكل رباعي نظرًا لنفس نافذة النظر إلى الوراء؛ ويمكن للنموذج الاهتمام بتاريخ أطول. يمكن لمحولنا المستقل عن القناة لتصحيح السلاسل الزمنية (PatchTST) تحسين دقة التنبؤ على المدى الطويل بشكل كبير عند مقارنته بنماذج المحولات المستندة إلى SOTA. نطبق نموذجنا أيضًا على مهام التدريب المسبق الخاضعة للإشراف الذاتي ونحقق أداء ضبط دقيق ممتازًا، والذي يتفوق على التدريب الخاضع للإشراف على مجموعات البيانات الكبيرة. كما أن نقل التمثيل المقنع مسبقًا من مجموعة بيانات إلى أخرى ينتج أيضًا دقة تنبؤية على مستوى SOTA."
+
+تمت المساهمة بهذا النموذج من قبل namctin و gsinthong و diepi و vijaye12 و wmgifford و kashif. يمكن العثور على الكود الأصلي [هنا](https://github.com/yuqinie98/PatchTST).
+
+## نصائح الاستخدام
+يمكن أيضًا استخدام النموذج لتصنيف السلاسل الزمنية والانحدار الزمني. راجع فئات [`PatchTSTForClassification`] و [`PatchTSTForRegression`] الخاصة بكل منهما.
+
+## الموارد
+- يمكن العثور على منشور المدونة الذي يشرح PatchTST بالتفصيل [هنا](https://huggingface.co/blog/patchtst). يمكن أيضًا فتح المدونة في Google Colab.
+
+## PatchTSTConfig
+
+[[autodoc]] PatchTSTConfig
+
+## PatchTSTModel
+
+[[autodoc]] PatchTSTModel
+
+- forward
+
+## PatchTSTForPrediction
+
+[[autodoc]] PatchTSTForPrediction
+
+- forward
+
+## PatchTSTForClassification
+
+[[autodoc]] PatchTSTForClassification
+
+- forward
+
+## PatchTSTForPretraining
+
+[[autodoc]] PatchTSTForPretraining
+
+- forward
+
+## PatchTSTForRegression
+
+[[autodoc]] PatchTSTForRegression
+
+- forward
\ No newline at end of file
From 84779b9e5f984bd5fe699a42bbb355429205e9b5 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:28:15 +0300
Subject: [PATCH 535/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/pegasus.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/pegasus.md | 145 ++++++++++++++++++++++++++++
1 file changed, 145 insertions(+)
create mode 100644 docs/source/ar/model_doc/pegasus.md
diff --git a/docs/source/ar/model_doc/pegasus.md b/docs/source/ar/model_doc/pegasus.md
new file mode 100644
index 00000000000000..3852d3f9a6df62
--- /dev/null
+++ b/docs/source/ar/model_doc/pegasus.md
@@ -0,0 +1,145 @@
+# Pegasus
+
+## نظرة عامة
+
+اقتُرح نموذج Pegasus في ورقة بحثية بعنوان: "PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization" من قبل جينغكينغ جانغ، وياو تشاو، ومحمد صالح، وبيتر ج. ليو في 18 ديسمبر 2019.
+
+وفقًا للملخص، فإن:
+
+- مهمة التدريب المسبق لـ Pegasus متشابهة عن قصد مع الملخص: تتم إزالة/حجب جمل مهمة من وثيقة الإدخال، ثم يتم توليدها معًا كتسلسل إخراج واحد من الجمل المتبقية، على غرار الملخص الاستخلاصي.
+- يحقق Pegasus أداءً متميزًا في مهام الملخص على جميع المهام الفرعية الـ 12، وفقًا لتقييم ROUGE والتقييم البشري.
+
+تمت المساهمة بهذا النموذج من قبل [sshleifer](https://huggingface.co/sshleifer). ويمكن العثور على كود المؤلفين [هنا](https://github.com/google-research/pegasus).
+
+## نصائح الاستخدام
+
+- يعد Pegasus نموذجًا تسلسليًا تسلسليًا له نفس بنية الترميز فك الترميز مثل BART. تم تدريب Pegasus بشكل مسبق بشكل مشترك على دالتين للهدف ذاتي الإشراف: Masked Language Modeling (MLM) ودالة تدريب مسبق محددة للملخص تسمى Gap Sentence Generation (GSG).
+
+* MLM: يتم استبدال رموز الإدخال للترميز بشكل عشوائي برموز قناع، ويجب التنبؤ بها بواسطة الترميز (مثل BERT)
+* GSG: يتم استبدال جمل إدخال الترميز بالكامل برمز قناع ثانوي وإدخالها إلى فك الترميز، ولكن مع قناع سببي لإخفاء الكلمات المستقبلية مثل فك تشفير محول ذاتي الانحدار منتظم.
+
+- لا يتم دعم FP16 (يتم تقدير المساعدة/الأفكار حول هذا الموضوع!).
+- يوصى باستخدام محسن adafactor لضبط نموذج Pegasus بشكل دقيق.
+
+## نقاط التفتيش
+
+تم ضبط جميع [نقاط التفتيش](https://huggingface.co/models?search=pegasus) مسبقًا للتلخيص، باستثناء *pegasus-large*، حيث يتم ضبط نقاط التفتيش الأخرى:
+
+- يحتل كل نقطة تفتيش مساحة 2.2 جيجابايت على القرص و568 مليون معلمة.
+- لا يتم دعم FP16 (يتم تقدير المساعدة/الأفكار حول هذا الموضوع!).
+- يستغرق تلخيص xsum في fp32 حوالي 400 مللي ثانية/عينة، مع معلمات افتراضية على وحدة معالجة الرسومات v100.
+- يمكن العثور على نتائج الاستنساخ الكامل والبيانات المعالجة بشكل صحيح في هذه [القضية](https://github.com/huggingface/transformers/issues/6844#issue-689259666).
+- يتم وصف [نقاط التفتيش المقطرة](https://huggingface.co/models?search=distill-pegasus) في هذه [الورقة](https://arxiv.org/abs/2010.13002).
+
+## ملاحظات التنفيذ
+
+- جميع النماذج هي محولات الترميز فك الترميز مع 16 طبقة في كل مكون.
+- تم استلهام التنفيذ بالكامل من [`BartForConditionalGeneration`]
+- بعض الاختلافات الرئيسية في التكوين:
+- مواضع ثابتة، تضمينية جيبية
+- يبدأ النموذج في التوليد باستخدام pad_token_id (الذي يحتوي على 0 token_embedding) كبادئة.
+- يتم استخدام المزيد من الحزم (`num_beams=8`)
+- جميع نقاط تفتيش Pegasus المسبقة التدريب متطابقة باستثناء ثلاث سمات: `tokenizer.model_max_length` (حجم الإدخال الأقصى)، و`max_length` (العدد الأقصى من الرموز المولدة)، و`length_penalty`.
+- يمكن العثور على الكود لتحويل نقاط التفتيش المدربة في مستودع المؤلفين [هنا](https://github.com/google-research/pegasus) في `convert_pegasus_tf_to_pytorch.py`.
+
+## مثال على الاستخدام
+
+```python
+>>> from transformers import PegasusForConditionalGeneration, PegasusTokenizer
+>>> import torch
+
+>>> src_text = [
+... """ PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."""
+... ]
+
+... model_name = "google/pegasus-xsum"
+... device = "cuda" if torch.cuda.is_available() else "cpu"
+... tokenizer = PegasusTokenizer.from_pretrained(model_name)
+... model = PegasusForConditionalGeneration.from_pretrained(model_name).to(device)
+... batch = tokenizer(src_text, truncation=True, padding="longest", return_tensors="pt").to(device)
+... translated = model.generate(**batch)
+... tgt_text = tokenizer.batch_decode(translated, skip_special_tokens=True)
+... assert (
+... tgt_text[0]
+... == "California's largest electricity provider has turned off power to hundreds of thousands of customers."
+... )
+```
+
+## الموارد
+
+- [سكريبت](https://github.com/huggingface/transformers/tree/main/examples/research_projects/seq2seq-distillation/finetune_pegasus_xsum.sh) لضبط نموذج Pegasus بشكل دقيق على مجموعة بيانات XSUM. تعليمات تنزيل البيانات في [examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
+- [دليل مهام نمذجة اللغة السببية](../tasks/language_modeling)
+- [دليل مهام الترجمة](../tasks/translation)
+- [دليل مهام الملخص](../tasks/summarization)
+
+## PegasusConfig
+
+[[autodoc]] PegasusConfig
+
+## PegasusTokenizer
+
+تحذير: `add_tokens` لا يعمل في الوقت الحالي.
+
+[[autodoc]] PegasusTokenizer
+
+## PegasusTokenizerFast
+
+[[autodoc]] PegasusTokenizerFast
+
+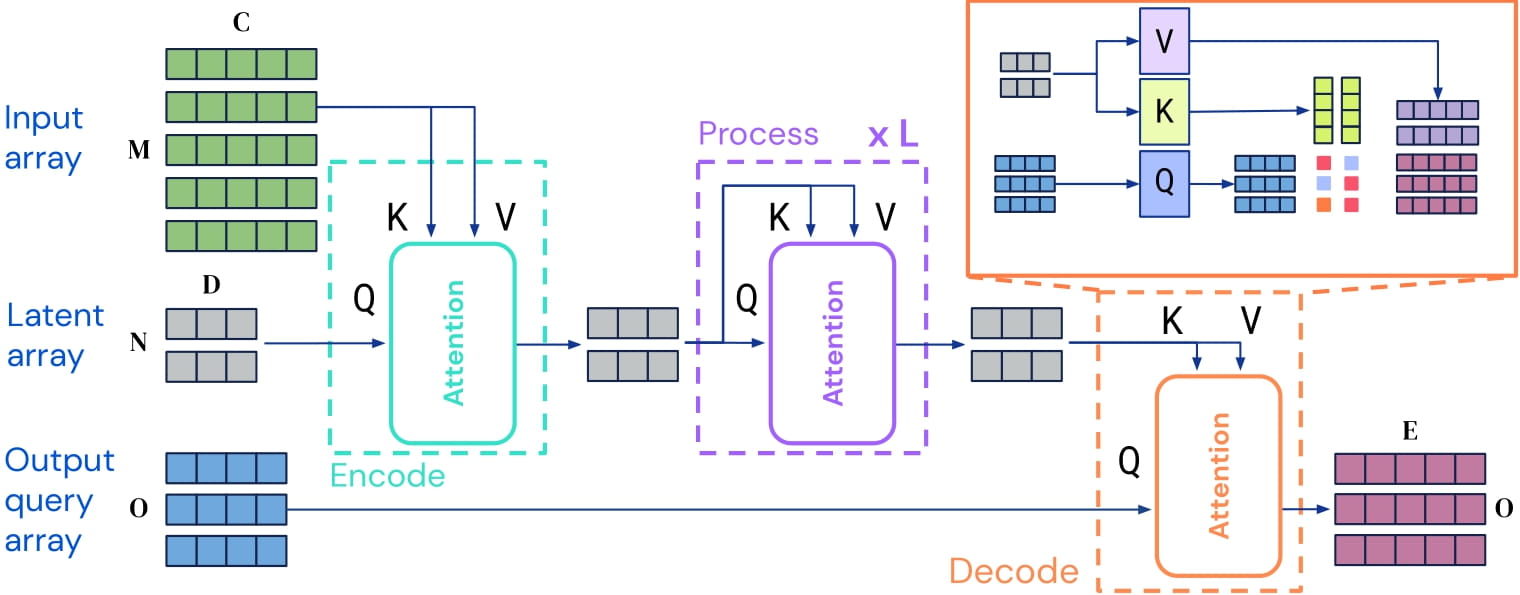 +
+ تم المساهم بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
+
+
+
+ تم المساهم بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يمكن العثور على الكود الأصلي [هنا](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
+
+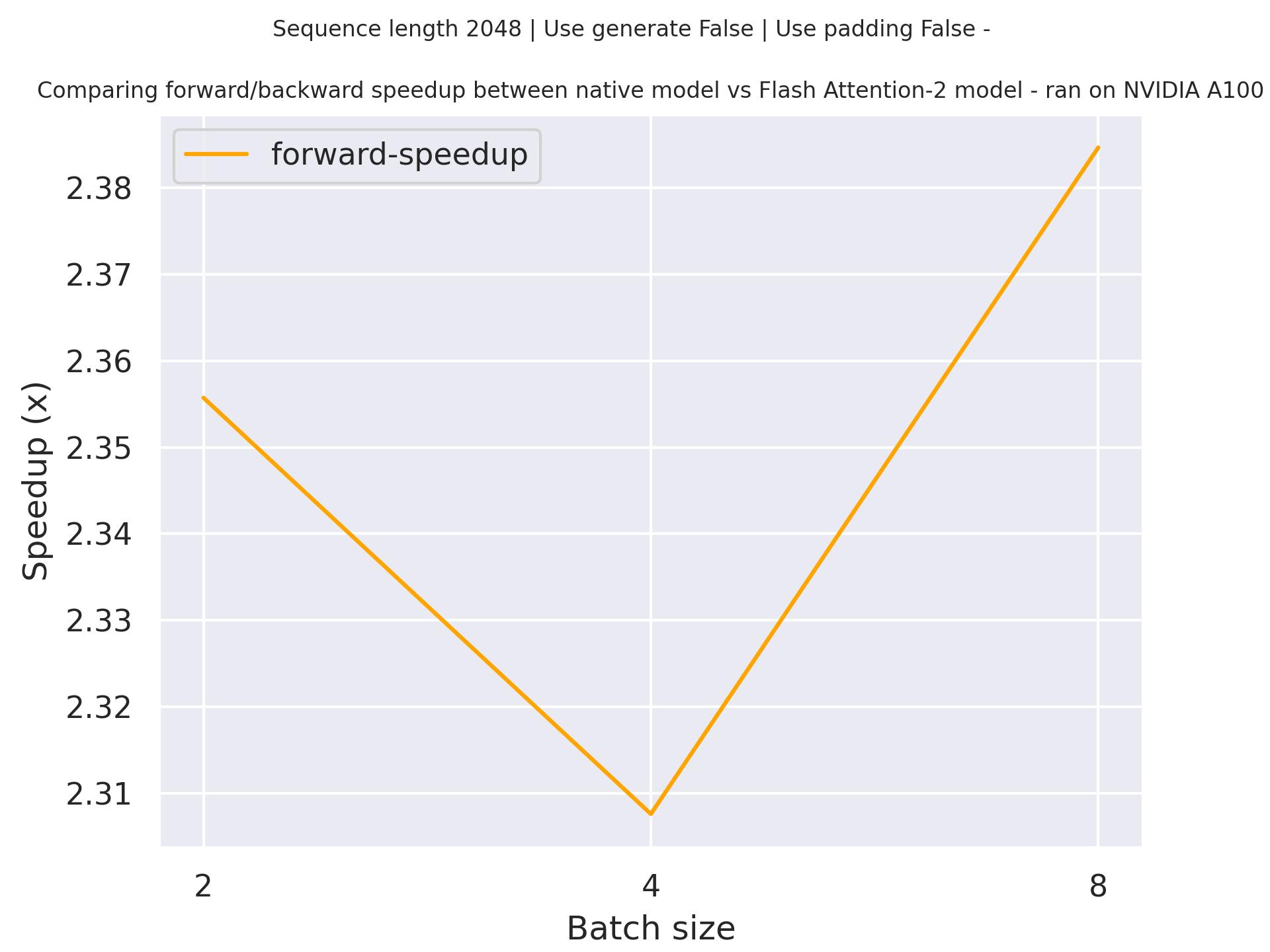 +
+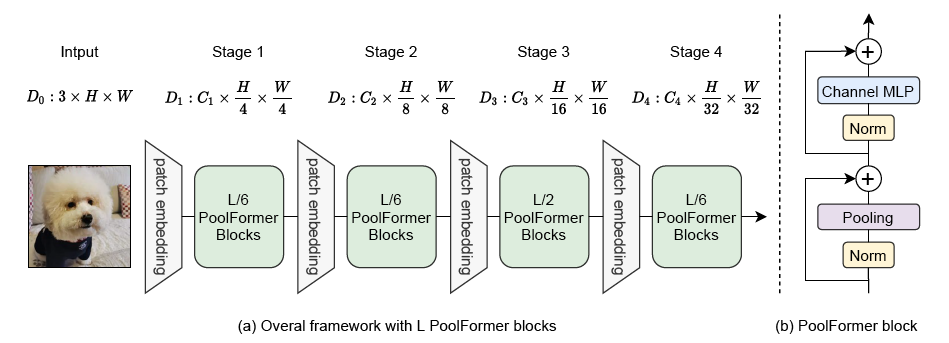 +
+تمت المساهمة بهذا النموذج من قبل [heytanay](https://huggingface.co/heytanay). يمكن العثور على الكود الأصلي [هنا](https://github.com/sail-sg/poolformer).
+
+## نصائح الاستخدام
+
+- يحتوي PoolFormer على بنية هرمية، حيث توجد طبقة تجميع متوسطة بسيطة بدلاً من الاهتمام. يمكن العثور على جميع نقاط تفتيش النموذج على [hub](https://huggingface.co/models?other=poolformer).
+
+- يمكن للمرء استخدام [`PoolFormerImageProcessor`] لتحضير الصور للنموذج.
+
+- مثل معظم النماذج، يأتي PoolFormer بأحجام مختلفة، يمكن العثور على تفاصيلها في الجدول أدناه.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
+| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
+| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
+| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
+| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
+| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام PoolFormer.
+
+
+
+تمت المساهمة بهذا النموذج من قبل [heytanay](https://huggingface.co/heytanay). يمكن العثور على الكود الأصلي [هنا](https://github.com/sail-sg/poolformer).
+
+## نصائح الاستخدام
+
+- يحتوي PoolFormer على بنية هرمية، حيث توجد طبقة تجميع متوسطة بسيطة بدلاً من الاهتمام. يمكن العثور على جميع نقاط تفتيش النموذج على [hub](https://huggingface.co/models?other=poolformer).
+
+- يمكن للمرء استخدام [`PoolFormerImageProcessor`] لتحضير الصور للنموذج.
+
+- مثل معظم النماذج، يأتي PoolFormer بأحجام مختلفة، يمكن العثور على تفاصيلها في الجدول أدناه.
+
+| **Model variant** | **Depths** | **Hidden sizes** | **Params (M)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :------------: | :-------------------: |
+| s12 | [2, 2, 6, 2] | [64, 128, 320, 512] | 12 | 77.2 |
+| s24 | [4, 4, 12, 4] | [64, 128, 320, 512] | 21 | 80.3 |
+| s36 | [6, 6, 18, 6] | [64, 128, 320, 512] | 31 | 81.4 |
+| m36 | [6, 6, 18, 6] | [96, 192, 384, 768] | 56 | 82.1 |
+| m48 | [8, 8, 24, 8] | [96, 192, 384, 768] | 73 | 82.5 |
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام PoolFormer.
+
+ +
+تمت المساهمة بهذا النموذج بواسطة [Francesco](https://huggingface.co/Francesco). تمت إضافة إصدار TensorFlow من هذا النموذج بواسطة [amyeroberts](https://huggingface.co/amyeroberts). يمكن العثور على الكود الأصلي [هنا](https://github.com/KaimingHe/deep-residual-networks).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية والمجتمعية (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام ResNet.
+
+
+
+ نظرة عامة على Grounded SAM. مأخوذة من المستودع الأصلي.
+
+## SamConfig
+
+[[autodoc]] SamConfig
+
+## SamVisionConfig
+
+[[autodoc]] SamVisionConfig
+
+## SamMaskDecoderConfig
+
+[[autodoc]] SamMaskDecoderConfig
+
+## SamPromptEncoderConfig
+
+[[autodoc]] SamPromptEncoderConfig
+
+## SamProcessor
+
+[[autodoc]] SamProcessor
+
+## SamImageProcessor
+
+[[autodoc]] SamImageProcessor
+
+## SamModel
+
+[[autodoc]] SamModel
+
+- forward
+
+## TFSamModel
+
+[[autodoc]] TFSamModel
+
+- call
\ No newline at end of file
From 5bb6f72180d7218489e5a8385f789b1058f4253e Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:11 +0300
Subject: [PATCH 566/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/seamless=5Fm4t.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/seamless_m4t.md | 207 +++++++++++++++++++++++
1 file changed, 207 insertions(+)
create mode 100644 docs/source/ar/model_doc/seamless_m4t.md
diff --git a/docs/source/ar/model_doc/seamless_m4t.md b/docs/source/ar/model_doc/seamless_m4t.md
new file mode 100644
index 00000000000000..157c205d080243
--- /dev/null
+++ b/docs/source/ar/model_doc/seamless_m4t.md
@@ -0,0 +1,207 @@
+# SeamlessM4T
+
+## نظرة عامة
+
+اقترح نموذج SeamlessM4T في [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) بواسطة فريق Seamless Communication من Meta AI.
+
+هذا هو إصدار **الإصدار 1** من النموذج. للإصدار المحدث **الإصدار 2**، راجع [Seamless M4T v2 docs](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2).
+
+SeamlessM4T عبارة عن مجموعة من النماذج المصممة لتوفير ترجمة عالية الجودة، مما يسمح للأفراد من مجتمعات لغوية مختلفة بالتواصل بسلاسة من خلال الكلام والنص.
+
+تمكّن SeamlessM4T من تنفيذ مهام متعددة دون الاعتماد على نماذج منفصلة:
+
+- الترجمة من الكلام إلى الكلام (S2ST)
+- الترجمة من الكلام إلى النص (S2TT)
+- الترجمة من النص إلى الكلام (T2ST)
+- الترجمة من نص إلى نص (T2TT)
+- التعرف التلقائي على الكلام (ASR)
+
+يمكن لـ [`SeamlessM4TModel`] تنفيذ جميع المهام المذكورة أعلاه، ولكن لكل مهمة أيضًا نموذجها الفرعي المخصص.
+
+المقتطف من الورقة هو ما يلي:
+
+*ما الذي يتطلبه الأمر لخلق سمكة بابل، وهي أداة يمكن أن تساعد الأفراد على ترجمة الكلام بين أي لغتين؟ في حين أن الاختراقات الأخيرة في النماذج القائمة على النص دفعت بتغطية الترجمة الآلية إلى ما بعد 200 لغة، إلا أن نماذج الترجمة الموحدة من الكلام إلى الكلام لم تحقق بعد قفزات مماثلة. على وجه التحديد، تعتمد أنظمة الترجمة التقليدية من الكلام إلى الكلام على الأنظمة المتتالية التي تؤدي الترجمة تدريجيًا، مما يجعل الأنظمة الموحدة عالية الأداء بعيدة المنال. لمعالجة هذه الفجوات، نقدم SeamlessM4T، وهو نموذج واحد يدعم الترجمة من الكلام إلى الكلام، والترجمة من الكلام إلى النص، والترجمة من النص إلى الكلام، والترجمة من نص إلى نص، والتعرف التلقائي على الكلام لما يصل إلى 100 لغة. لبناء هذا، استخدمنا مليون ساعة من بيانات الصوت المفتوحة لتعلم التمثيلات الصوتية ذاتية الإشراف باستخدام w2v-BERT 2.0. بعد ذلك، قمنا بإنشاء مجموعة بيانات متعددة الوسائط من ترجمات الكلام المحاذاة تلقائيًا. بعد التصفية والدمج مع البيانات التي تحمل علامات بشرية وبيانات ذات علامات زائفة، قمنا بتطوير أول نظام متعدد اللغات قادر على الترجمة من وإلى اللغة الإنجليزية لكل من الكلام والنص. في FLEURS، يحدد SeamlessM4T معيارًا جديدًا للترجمات إلى لغات متعددة مستهدفة، محققًا تحسنًا بنسبة 20% في BLEU مقارنة بـ SOTA السابق في الترجمة المباشرة من الكلام إلى النص. مقارنة بالنماذج المتتالية القوية، يحسن SeamlessM4T جودة الترجمة إلى اللغة الإنجليزية بمقدار 1.3 نقطة BLEU في الترجمة من الكلام إلى النص وبمقدار 2.6 نقطة ASR-BLEU في الترجمة من الكلام إلى الكلام. تم اختبار نظامنا للمتانة، ويؤدي أداءً أفضل ضد الضوضاء الخلفية وتغيرات المتحدث في مهام الترجمة من الكلام إلى النص مقارنة بنموذج SOTA الحالي. من الناحية الحرجة، قمنا بتقييم SeamlessM4T على التحيز بين الجنسين والسمية المضافة لتقييم سلامة الترجمة. أخيرًا، جميع المساهمات في هذا العمل مفتوحة المصدر ومتاحة على https://github.com/facebookresearch/seamless_communication*
+
+## الاستخدام
+
+أولاً، قم بتحميل المعالج ونقطة تفتيش للنموذج:
+
+```python
+>>> from transformers import AutoProcessor, SeamlessM4TModel
+
+>>> processor = AutoProcessor.from_pretrained("facebook/hf-seamless-m4t-medium")
+>>> model = SeamlessM4TModel.from_pretrained("facebook/hf-seamless-m4t-medium")
+```
+
+يمكنك استخدام هذا النموذج بسلاسة على النص أو الصوت، لإنشاء نص مترجم أو صوت مترجم.
+
+فيما يلي كيفية استخدام المعالج لمعالجة النص والصوت:
+
+```python
+>>> # دعنا نحمل عينة صوتية من مجموعة بيانات خطاب عربي
+>>> from datasets import load_dataset
+>>> dataset = load_dataset("arabic_speech_corpus", split="test", streaming=True)
+>>> audio_sample = next(iter(dataset))["audio"]
+
+>>> # الآن، قم بمعالجته
+>>> audio_inputs = processor(audios=audio_sample["array"], return_tensors="pt")
+
+>>> # الآن، قم بمعالجة بعض النصوص الإنجليزية أيضًا
+>>> text_inputs = processor(text="Hello, my dog is cute", src_lang="eng", return_tensors="pt")
+```
+
+### الكلام
+
+يمكن لـ [`SeamlessM4TModel`] *بسلاسة* إنشاء نص أو كلام مع عدد قليل من التغييرات أو بدونها. دعنا نستهدف الترجمة الصوتية الروسية:
+
+```python
+>>> audio_array_from_text = model.generate(**text_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+>>> audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+```
+
+بنفس الرمز تقريبًا، قمت بترجمة نص إنجليزي وكلام عربي إلى عينات كلام روسية.
+
+### نص
+
+وبالمثل، يمكنك إنشاء نص مترجم من ملفات الصوت أو من النص باستخدام نفس النموذج. كل ما عليك فعله هو تمرير `generate_speech=False` إلى [`SeamlessM4TModel.generate`].
+
+هذه المرة، دعنا نترجم إلى الفرنسية.
+
+```python
+>>> # من الصوت
+>>> output_tokens = model.generate(**audio_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_audio = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+
+>>> # من النص
+>>> output_tokens = model.generate(**text_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_partum_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+```
+
+### نصائح
+
+#### 1. استخدم النماذج المخصصة
+
+[`SeamlessM4TModel`] هو نموذج المستوى الأعلى في المحولات لإنشاء الكلام والنص، ولكن يمكنك أيضًا استخدام النماذج المخصصة التي تؤدي المهمة دون مكونات إضافية، مما يقلل من بصمة الذاكرة.
+
+على سبيل المثال، يمكنك استبدال جزء الرمز الخاص بإنشاء الصوت باستخدام النموذج المخصص لمهمة S2ST، وبقية الرمز هو نفسه بالضبط:
+
+```python
+>>> from transformers import SeamlessM4TForSpeechToSpeech
+>>> model = SeamlessM4TForSpeechToSpeech.from_pretrained("facebook/hf-seamless-m4t-medium")
+```
+
+أو يمكنك استبدال جزء الرمز الخاص بإنشاء النص باستخدام النموذج المخصص لمهمة T2TT، وكل ما عليك فعله هو إزالة `generate_speech=False`.
+
+```python
+>>> from transformers import SeamlessM4TForTextToText
+>>> model = SeamlessM4TForTextToText.from_pretrained("facebook/hf-seamless-m4t-medium")
+```
+
+لا تتردد في تجربة [`SeamlessM4TForSpeechToText`] و [`SeamlessM4TForTextToSpeech`] أيضًا.
+
+#### 2. تغيير هوية المتحدث
+
+لديك إمكانية تغيير المتحدث المستخدم للتخليق الصوتي باستخدام حجة `spkr_id`. تعمل بعض قيم `spkr_id` بشكل أفضل من غيرها لبعض اللغات!
+
+#### 3. تغيير استراتيجية التوليد
+
+يمكنك استخدام استراتيجيات [توليد](./generation_strategies) مختلفة للكلام وتوليد النص، على سبيل المثال `.generate(input_ids=input_ids، text_num_beams=4، speech_do_sample=True)` والذي سيؤدي فك تشفير شعاع على النموذج النصي، وعينة متعددة الحدود على النموذج الصوتي.
+
+#### 4. قم بتوليد الكلام والنص في نفس الوقت
+
+استخدم `return_intermediate_token_ids=True` مع [`SeamlessM4TModel`] لإرجاع كل من الكلام والنص!
+
+## بنية النموذج
+
+تتميز SeamlessM4T ببنية مرنة تتعامل بسلاسة مع التوليد التسلسلي للنص والكلام. يتضمن هذا الإعداد نموذجين تسلسليين (seq2seq). يترجم النموذج الأول الطريقة المدخلة إلى نص مترجم، بينما يقوم النموذج الثاني بتوليد رموز الكلام، والمعروفة باسم "رموز الوحدة"، من النص المترجم.
+
+لدى كل طريقة مشفر خاص بها ببنية فريدة. بالإضافة إلى ذلك، بالنسبة لإخراج الكلام، يوجد جهاز فك ترميز مستوحى من بنية [HiFi-GAN](https://arxiv.org/abs/2010.05646) أعلى نموذج seq2seq الثاني.
+
+فيما يلي كيفية عمل عملية التوليد:
+
+- تتم معالجة النص أو الكلام المدخل من خلال مشفر محدد.
+- يقوم فك التشفير بإنشاء رموز نصية باللغة المطلوبة.
+- إذا كانت هناك حاجة إلى توليد الكلام، يقوم نموذج seq2seq الثاني، باتباع بنية مشفر-فك تشفير قياسية، بتوليد رموز الوحدة.
+- يتم بعد ذلك تمرير رموز الوحدة هذه عبر فك التشفير النهائي لإنتاج الكلام الفعلي.
+
+تمت المساهمة بهذا النموذج بواسطة [ylacombe](https://huggingface.co/ylacombe). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/seamless_communication).
+
+## SeamlessM4TModel
+
+[[autodoc]] SeamlessM4TModel
+
+- generate
+
+## SeamlessM4TForTextToSpeech
+
+[[autodoc]] SeamlessM4TForTextToSpeech
+
+- generate
+
+## SeamlessM4TForSpeechToSpeech
+
+[[autodoc]] SeamlessM4TForSpeechToSpeech
+
+- generate
+
+## SeamlessM4TForTextToText
+
+[[autodoc]] transformers.SeamlessM4TForTextToText
+
+- forward
+- generate
+
+## SeamlessM4TForSpeechToText
+
+[[autodoc]] transformers.SeamlessM4TForSpeechToText
+
+- forward
+- generate
+
+## SeamlessM4TConfig
+
+[[autodoc]] SeamlessM4TConfig
+
+## SeamlessM4TTokenizer
+
+[[autodoc]] SeamlessM4TTokenizer
+
+- __call__
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## SeamlessM4TTokenizerFast
+
+[[autodoc]] SeamlessM4TTokenizerFast
+
+- __call__
+
+## SeamlessM4TFeatureExtractor
+
+[[autodoc]] SeamlessM4TFeatureExtractor
+
+- __call__
+
+## SeamlessM4TProcessor
+
+[[autodoc]] SeamlessM4TProcessor
+
+- __call__
+
+## SeamlessM4TCodeHifiGan
+
+[[autodoc]] SeamlessM4TCodeHifiGan
+
+## SeamlessM4THifiGan
+
+[[autodoc]] SeamlessM4THifiGan
+
+## SeamlessM4TTextToUnitModel
+
+[[autodoc]] SeamlessM4TTextToUnitModel
+
+## SeamlessM4TTextToUnitForConditionalGeneration
+
+[[autodoc]] SeamlessM4TTextToUnitForConditionalGeneration
\ No newline at end of file
From ae192f8b50314b515c053b9de4bb92b065c276c2 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:13 +0300
Subject: [PATCH 567/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/seamless=5Fm4t=5Fv2.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/seamless_m4t_v2.md | 185 ++++++++++++++++++++
1 file changed, 185 insertions(+)
create mode 100644 docs/source/ar/model_doc/seamless_m4t_v2.md
diff --git a/docs/source/ar/model_doc/seamless_m4t_v2.md b/docs/source/ar/model_doc/seamless_m4t_v2.md
new file mode 100644
index 00000000000000..255f4f2c110970
--- /dev/null
+++ b/docs/source/ar/model_doc/seamless_m4t_v2.md
@@ -0,0 +1,185 @@
+# SeamlessM4T-v2
+
+## نظرة عامة
+
+اقترح فريق Seamless Communication من Meta AI نموذج SeamlessM4T-v2 في [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/).
+
+SeamlessM4T-v2 عبارة عن مجموعة من النماذج المصممة لتوفير ترجمة عالية الجودة، مما يسمح للناس من مجتمعات لغوية مختلفة بالتواصل بسلاسة من خلال الكلام والنص. إنه تحسين على [الإصدار السابق](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t). لمزيد من التفاصيل حول الاختلافات بين الإصدارين v1 و v2، راجع القسم [الاختلاف مع SeamlessM4T-v1](#difference-with-seamlessm4t-v1).
+
+يتيح SeamlessM4T-v2 مهام متعددة دون الاعتماد على نماذج منفصلة:
+
+- الترجمة الكلامية النصية (S2ST)
+- الترجمة الكلامية النصية (S2TT)
+- الترجمة النصية الكلامية (T2ST)
+- الترجمة النصية النصية (T2TT)
+- التعرف التلقائي على الكلام (ASR)
+
+يمكن لـ [`SeamlessM4Tv2Model`] تنفيذ جميع المهام المذكورة أعلاه، ولكن لكل مهمة أيضًا نموذج فرعي مخصص لها.
+
+المقتطف من الورقة هو ما يلي:
+
+*حققت التطورات الأخيرة في الترجمة الكلامية التلقائية توسعًا كبيرًا في تغطية اللغة، وتحسين القدرات متعددة الوسائط، وتمكين مجموعة واسعة من المهام والوظائف. ومع ذلك، تفتقر أنظمة الترجمة الكلامية التلقائية واسعة النطاق اليوم إلى ميزات رئيسية تساعد في جعل التواصل بوساطة الآلة سلسًا عند مقارنته بالحوار بين البشر. في هذا العمل، نقدم عائلة من النماذج التي تمكّن الترجمات التعبيرية والمتعددة اللغات بطريقة متواصلة. أولاً، نساهم في تقديم نسخة محسّنة من نموذج SeamlessM4T متعدد اللغات والوسائط بشكل كبير - SeamlessM4T v2. تم تدريب هذا النموذج الأحدث، الذي يتضمن إطار عمل UnitY2 المحدث، على المزيد من بيانات اللغات منخفضة الموارد. تضيف النسخة الموسعة من SeamlessAlign 114,800 ساعة من البيانات المحاذاة تلقائيًا لما مجموعه 76 لغة. يوفر SeamlessM4T v2 الأساس الذي تقوم عليه أحدث نماذجنا، SeamlessExpressive و SeamlessStreaming. يمكّن SeamlessExpressive الترجمة التي تحافظ على الأساليب الصوتية والتنغيم. مقارنة بالجهود السابقة في أبحاث الكلام التعبيري، يعالج عملنا بعض الجوانب الأقل استكشافًا للتنغيم، مثل معدل الكلام والتوقفات، مع الحفاظ على أسلوب صوت الشخص. أما بالنسبة لـ SeamlessStreaming، فإن نموذجنا يستفيد من آلية Efficient Monotonic Multihead Attention (EMMA) لتوليد ترجمات مستهدفة منخفضة الكمون دون انتظار نطق المصدر الكامل. يعد SeamlessStreaming الأول من نوعه، حيث يمكّن الترجمة الكلامية/النصية المتزامنة للغات المصدر والهدف المتعددة. لفهم أداء هذه النماذج، قمنا بدمج الإصدارات الجديدة والمعدلة من المقاييس التلقائية الموجودة لتقييم التنغيم والكمون والمتانة. وبالنسبة للتقييمات البشرية، قمنا بتكييف البروتوكولات الموجودة المصممة لقياس أكثر السمات ملاءمة في الحفاظ على المعنى والطبيعية والتعبير. ولضمان إمكانية استخدام نماذجنا بشكل آمن ومسؤول، قمنا بتنفيذ أول جهد معروف للفريق الأحمر للترجمة الآلية متعددة الوسائط، ونظام للكشف عن السمية المضافة والتخفيف منها، وتقييم منهجي للتحيز بين الجنسين، وآلية ترميز علامات مائية محلية غير مسموعة مصممة للتخفيف من تأثير مقاطع الفيديو المزيفة. وبالتالي، فإننا نجمع المكونات الرئيسية من SeamlessExpressive و SeamlessStreaming لتشكيل Seamless، وهو أول نظام متاح للجمهور يفتح التواصل التعبيري متعدد اللغات في الوقت الفعلي. في الختام، يمنحنا Seamless نظرة محورية على الأساس التقني اللازم لتحويل المترجم الشفوي العالمي من مفهوم الخيال العلمي إلى تكنولوجيا الواقع. وأخيرًا، يتم إطلاق المساهمات في هذا العمل - بما في ذلك النماذج والشفرة وكاشف العلامات المائية - علنًا ويمكن الوصول إليها من خلال الرابط أدناه.*
+
+## الاستخدام
+
+في المثال التالي، سنقوم بتحميل عينة صوت عربية وعينة نص إنجليزي وتحويلهما إلى كلام روسي ونص فرنسي.
+
+أولاً، قم بتحميل المعالج ونقطة تفتيش للنموذج:
+
+```python
+>>> from transformers import AutoProcessor, SeamlessM4Tv2Model
+
+>>> processor = AutoProcessor.from_pretrained("facebook/seamless-m4t-v2-large")
+>>> model = SeamlessM4Tv2Model.from_pretrained("facebook/seamless-m4t-v2-large")
+```
+
+يمكنك استخدام هذا النموذج بسلاسة على النص أو الصوت، لتوليد نص مترجم أو صوت مترجم.
+
+هكذا تستخدم المعالج لمعالجة النص والصوت:
+
+```python
+>>> # دعنا نحمل عينة صوت من مجموعة بيانات كلام عربية
+>>> from datasets import load_dataset
+>>> dataset = load_dataset("arabic_speech_corpus", split="test", streaming=True)
+>>> audio_sample = next(iter(dataset))["audio"]
+
+>>> # الآن، قم بمعالجته
+>>> audio_inputs = processor(audios=audio_sample["array"], return_tensors="pt")
+
+>>> # الآن، قم بمعالجة بعض النصوص الإنجليزية أيضًا
+>>> text_inputs = processor(text="Hello, my dog is cute", src_lang="eng", return_tensors="pt")
+```
+
+### الكلام
+
+يمكن لـ [`SeamlessM4Tv2Model`] *بسلاسة* توليد نص أو كلام مع عدد قليل من التغييرات أو بدونها. دعنا نستهدف الترجمة الصوتية الروسية:
+
+```python
+>>> audio_array_from_text = model.generate(**text_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+>>> audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+```
+
+بنفس الكود تقريبًا، قمت بترجمة نص إنجليزي وكلام عربي إلى عينات كلام روسية.
+
+### النص
+
+وبالمثل، يمكنك توليد نص مترجم من ملفات الصوت أو النص باستخدام نفس النموذج. عليك فقط تمرير `generate_speech=False` إلى [`SeamlessM4Tv2Model.generate`].
+
+هذه المرة، دعنا نقوم بالترجمة إلى الفرنسية.
+
+```python
+>>> # من الصوت
+>>> output_tokens = model.generate(**audio_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_audio = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+
+>>> # من النص
+>>> output_tokens = model.generate(**text_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+```
+
+### نصائح
+
+#### 1. استخدم النماذج المخصصة
+
+[`SeamlessM4Tv2Model`] هو نموذج المستوى الأعلى في برنامج Transformers لتوليد الكلام والنص، ولكن يمكنك أيضًا استخدام النماذج المخصصة التي تؤدي المهمة دون مكونات إضافية، مما يقلل من بصمة الذاكرة.
+
+على سبيل المثال، يمكنك استبدال جزء التعليمات البرمجية لتوليد الصوت بالنموذج المخصص لمهمة S2ST، والباقي هو نفس الكود بالضبط:
+
+```python
+>>> from transformers import SeamlessM4Tv2ForSpeechToSpeech
+>>> model = SeamlessM4Tv2ForSpeechToSpeech.from_pretrained("facebook/seamless-m4t-v2-large")
+```
+
+أو يمكنك استبدال جزء التعليمات البرمجية لتوليد النص بالنموذج المخصص لمهمة T2TT، عليك فقط إزالة `generate_speech=False`.
+
+```python
+>>> from transformers import SeamlessM4Tv2ForTextToText
+>>> model = SeamlessM4Tv2ForTextToText.from_pretrained("facebook/seamless-m4t-v2-large")
+```
+
+لا تتردد في تجربة [`SeamlessM4Tv2ForSpeechToText`] و [`SeamlessM4Tv2ForTextToSpeech`] أيضًا.
+
+#### 2. تغيير هوية المتحدث
+
+لديك إمكانية تغيير المتحدث المستخدم للتخليق الصوتي باستخدام وسيط `speaker_id`. تعمل بعض قيم `speaker_id` بشكل أفضل من غيرها لبعض اللغات!
+
+#### 3. تغيير استراتيجية التوليد
+
+يمكنك استخدام استراتيجيات [توليد](../generation_strategies) مختلفة للنص، على سبيل المثال `.generate(input_ids=input_ids, text_num_beams=4, text_do_sample=True)` والتي ستؤدي فك تشفير شعاع متعدد الحدود على النموذج النصي. لاحظ أن توليد الكلام يدعم فقط الجشع - بشكل افتراضي - أو العينات متعددة الحدود، والتي يمكن استخدامها مع `.generate(..., speech_do_sample=True, speech_temperature=0.6)`.
+
+#### 4. قم بتوليد الكلام والنص في نفس الوقت
+
+استخدم `return_intermediate_token_ids=True` مع [`SeamlessM4Tv2Model`] لإرجاع كل من الكلام والنص!
+
+## بنية النموذج
+
+يتميز SeamlessM4T-v2 ببنية مرنة تتعامل بسلاسة مع التوليد التسلسلي للنص والكلام. يتضمن هذا الإعداد نموذجين تسلسليين (seq2seq). يقوم النموذج الأول بترجمة المدخلات إلى نص مترجم، بينما يقوم النموذج الثاني بتوليد رموز الكلام، المعروفة باسم "رموز الوحدة"، من النص المترجم.
+
+لدى كل وسيطة مشفرها الخاص ببنية فريدة. بالإضافة إلى ذلك، بالنسبة لخرج الكلام، يوجد محول ترميز مستوحى من بنية [HiFi-GAN](https://arxiv.org/abs/2010.05646) أعلى نموذج seq2seq الثاني.
+
+### الاختلاف مع SeamlessM4T-v1
+
+تختلف بنية هذه النسخة الجديدة عن الإصدار الأول في بعض الجوانب:
+
+#### التحسينات على نموذج المرور الثاني
+
+نموذج seq2seq الثاني، المسمى نموذج النص إلى وحدة، غير تلقائي الآن، مما يعني أنه يحسب الوحدات في **تمريرة أمامية واحدة**. أصبح هذا الإنجاز ممكنًا من خلال:
+
+- استخدام **تضمين مستوى الأحرف**، مما يعني أن لكل حرف من النص المترجم المتنبأ به تضمينه الخاص، والذي يتم استخدامه بعد ذلك للتنبؤ برموز الوحدة.
+- استخدام مُنبئ المدة الوسيطة، الذي يتنبأ بمدة الكلام على مستوى **الشخصية** في النص المترجم المتنبأ به.
+- استخدام فك تشفير النص إلى وحدة جديد يمزج بين التعرّف على التعرّف والاهتمام الذاتي للتعامل مع السياق الأطول.
+
+#### الاختلاف في مشفر الكلام
+
+يختلف مشفر الكلام، الذي يتم استخدامه أثناء عملية توليد المرور الأول للتنبؤ بالنص المترجم، بشكل أساسي عن مشفر الكلام السابق من خلال هذه الآليات:
+
+- استخدام قناع اهتمام مجزأ لمنع الاهتمام عبر المقاطع، وضمان أن يحضر كل موضع فقط إلى المواضع الموجودة داخل مقطعته وعدد ثابت من المقاطع السابقة.
+- استخدام التضمينات الموضعية النسبية التي لا تأخذ في الاعتبار سوى المسافة بين عناصر التسلسل بدلاً من المواضع المطلقة. يرجى الرجوع إلى [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155) لمزيد من التفاصيل.
+- استخدام التعرّف المتعمق السببي بدلاً من غير السببي.
+
+### عملية التوليد
+
+هكذا تعمل عملية التوليد:
+
+- تتم معالجة النص أو الكلام المدخل من خلال مشفر محدد.
+- يقوم فك التشفير بإنشاء رموز نصية باللغة المطلوبة.
+- إذا كانت هناك حاجة إلى توليد الكلام، فإن نموذج seq2seq الثاني يقوم بتوليد رموز الوحدة بطريقة غير تلقائية.
+- يتم بعد ذلك تمرير رموز الوحدة هذه عبر محول الترميز النهائي لإنتاج الكلام الفعلي.
+
+تمت المساهمة بهذا النموذج من قبل [ylacombe](https://huggingface.co/ylacombe). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/seamless_communication).
+
+## SeamlessM4Tv2Model
+
+[[autodoc]] SeamlessM4Tv2Model
+
+- generate
+
+## SeamlessM4Tv2ForTextToSpeech
+
+[[autodoc]] SeamlessM4Tv2ForTextToSpeech
+
+- generate
+
+## SeamlessM4Tv2ForSpeechToSpeech
+
+[[autodoc]] SeamlessM4Tv2ForSpeechToSpeech
+
+- generate
+
+## SeamlessM4Tv2ForTextToText
+
+[[autodoc]] transformers.SeamlessM4Tv2ForTextToText
+
+- forward
+- generate
+
+## SeamlessM4Tv2ForSpeechToText
+
+[[autodoc]] transformers.SeamlessM4Tv2ForSpeechToText
+
+- forward
+- generate
+
+## SeamlessM4Tv2Config
+
+[[autodoc]] SeamlessM4Tv2Config
\ No newline at end of file
From a635d0bea5d84d6d766fd558e2e98d9a90ade592 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:15 +0300
Subject: [PATCH 568/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/segformer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/segformer.md | 143 ++++++++++++++++++++++++++
1 file changed, 143 insertions(+)
create mode 100644 docs/source/ar/model_doc/segformer.md
diff --git a/docs/source/ar/model_doc/segformer.md b/docs/source/ar/model_doc/segformer.md
new file mode 100644
index 00000000000000..7871e2d69620ab
--- /dev/null
+++ b/docs/source/ar/model_doc/segformer.md
@@ -0,0 +1,143 @@
+# SegFormer
+
+## نظرة عامة
+
+اقترح نموذج SegFormer في ورقة "SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers" بواسطة Enze Xie وآخرون. يتكون النموذج من ترميز Transformer هرمي ورأس فك تشفير خفيف الوزن يعتمد بالكامل على MLP لتحقيق نتائج ممتازة في معايير تصنيف الصور مثل ADE20K وCityscapes.
+
+الملخص من الورقة هو ما يلي:
+
+> "نقدم SegFormer، وهو إطار عمل لتصنيف الصور البسيط والفعال والقوي الذي يوحد المحولات مع فك ترميز الإدراك متعدد الطبقات (MLP) خفيف الوزن. يتميز SegFormer بميزتين جذابتين: 1) يتكون SegFormer من ترميز محول هرمي هيكلي جديد ينتج ميزات متعددة المقاييس. لا يحتاج إلى ترميز الموضع، وبالتالي يتجنب الاستيفاء لرموز الموضعية التي تؤدي إلى انخفاض الأداء عندما يختلف القرار عند الاختبار عن التدريب. 2) يتجنب SegFormer فك الترميز المعقد. يقوم فك ترميز MLP المقترح بتجميع المعلومات من طبقات مختلفة، وبالتالي الجمع بين كل من الاهتمام المحلي والعالمي لتصيير تمثيلات قوية. نُظهر أن هذا التصميم البسيط والخفيف هو المفتاح لتصنيف الكفاءة على المحولات. نقوم بزيادة مقياس نهجنا للحصول على سلسلة من النماذج من SegFormer-B0 إلى SegFormer-B5، مما يحقق أداءً وكفاءة أفضل بكثير من النظائر السابقة. على سبيل المثال، يحقق SegFormer-B4 نسبة 50.3% mIoU على ADE20K مع 64 مليون معامل، وهو أصغر 5 مرات وأفضل بنسبة 2.2% من الطريقة الأفضل السابقة. ويحقق نموذجنا الأفضل، SegFormer-B5، نسبة 84.0% mIoU على مجموعة التحقق من Cityscapes ويظهر متانة ممتازة للتصنيف الصفري على Cityscapes-C."
+
+يوضح الشكل أدناه بنية SegFormer. مأخوذة من الورقة الأصلية.
+
+
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). تمت المساهمة في إصدار TensorFlow من النموذج بواسطة [sayakpaul](https://huggingface.co/sayakpaul). يمكن العثور على الكود الأصلي [هنا](https://github.com/NVlabs/SegFormer).
+
+## نصائح الاستخدام
+
+- يتكون SegFormer من ترميز محول هرمي ورأس فك تشفير خفيف الوزن يعتمد بالكامل على MLP. [`SegformerModel`] هو ترميز المحول الهرمي (الذي يشار إليه أيضًا في الورقة باسم Mix Transformer أو MiT). يضيف [`SegformerForSemanticSegmentation`] رأس فك تشفير MLP بالكامل لأداء التصنيف الدلالي للصور. بالإضافة إلى ذلك، هناك [`SegformerForImageClassification`] الذي يمكن استخدامه - كما هو متوقع - لتصنيف الصور. قام مؤلفو SegFormer أولاً بتدريب المحول الترميزي مسبقًا على ImageNet-1k لتصنيف الصور. بعد ذلك، يقومون بحذف رأس التصنيف، واستبداله برأس فك تشفير MLP. بعد ذلك، يقومون بتدريب النموذج بالكامل على ADE20K وCityscapes وCOCO-stuff، والتي تعد معايير مرجعية مهمة لتصنيف الصور. يمكن العثور على جميع نقاط التفتيش على [المركز](https://huggingface.co/models?other=segformer).
+
+- أسرع طريقة للبدء مع SegFormer هي التحقق من [دفاتر الملاحظات التوضيحية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (التي تعرض كل من الاستدلال والتدريب الدقيق على البيانات المخصصة). يمكن للمرء أيضًا الاطلاع على [منشور المدونة](https://huggingface.co/blog/fine-tune-segformer) الذي يقدم SegFormer ويوضح كيفية ضبطه بدقة على بيانات مخصصة.
+
+- يجب أن يشير مستخدمو TensorFlow إلى [هذا المستودع](https://github.com/deep-diver/segformer-tf-transformers) الذي يوضح الاستدلال والضبط الدقيق خارج الصندوق.
+
+- يمكن للمرء أيضًا الاطلاع على [هذا العرض التوضيحي التفاعلي على Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers) لتجربة نموذج SegFormer على الصور المخصصة.
+
+- يعمل SegFormer مع أي حجم إدخال، حيث يقوم بتقسيم الإدخال ليكون قابلاً للقسمة على `config.patch_sizes`.
+
+- يمكن للمرء استخدام [`SegformerImageProcessor`] لإعداد الصور وخرائط التجزئة المقابلة للنموذج. لاحظ أن معالج الصور هذا أساسي إلى حد ما ولا يتضمن جميع عمليات زيادة البيانات المستخدمة في الورقة الأصلية. يمكن العثور على خطوط المعالجة المسبقة الأصلية (لمجموعة بيانات ADE20k على سبيل المثال) [هنا](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). تتمثل أهم خطوة للمعالجة المسبقة في اقتصاص الصور وخرائط التجزئة عشوائيًا وإضافتها إلى نفس الحجم، مثل 512x512 أو 640x640، ثم يتم تطبيعها.
+
+- هناك شيء إضافي يجب مراعاته وهو أنه يمكن تهيئة [`SegformerImageProcessor`] باستخدام `do_reduce_labels` على `True` أو `False`. في بعض مجموعات البيانات (مثل ADE20k)، يتم استخدام الفهرس 0 في خرائط التجزئة المشروحة للخلفية. ومع ذلك، لا تتضمن مجموعة بيانات ADE20k فئة "الخلفية" في علاماتها البالغ عددها 150. لذلك، يتم استخدام `do_reduce_labels` لخفض جميع العلامات بمقدار 1، والتأكد من عدم حساب أي خسارة لفئة "الخلفية" (أي أنها تستبدل 0 في الخرائط المشروحة بـ 255، وهو *ignore_index* لدالة الخسارة المستخدمة بواسطة [`SegformerForSemanticSegmentation`]). ومع ذلك، تستخدم مجموعات بيانات أخرى الفهرس 0 كفئة خلفية وتتضمن هذه الفئة كجزء من جميع العلامات. في هذه الحالة، يجب تعيين `do_reduce_labels` على `False`، حيث يجب أيضًا حساب الخسارة لفئة الخلفية.
+
+- مثل معظم النماذج، يأتي SegFormer بأحجام مختلفة، يمكن العثور على تفاصيلها في الجدول أدناه (مأخوذ من الجدول 7 من [الورقة الأصلية](https://arxiv.org/abs/2105.15203)).
+
+| **متغير النموذج** | **الأعماق** | **أحجام المخفية** | **حجم مخفي فك الترميز** | **المعلمات (م)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
+| MiT-b0 | [2، 2، 2، 2] | [32، 64، 160، 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2، 2، 2، 2] | [64، 128، 320، 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3، 4، 6، 3] | [64، 128، 320، 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3، 4، 18، 3] | [64، 128، 320، 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3، 8، 27، 3] | [64، 128، 320، 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3، 6، 40، 3] | [64، 128، 320، 512] | 768 | 82.0 | 83.8 |
+
+لاحظ أن MiT في الجدول أعلاه يشير إلى العمود الفقري لترميز المحول المختلط المقدم في SegFormer. للحصول على نتائج SegFormer على مجموعات بيانات التجزئة مثل ADE20k، راجع [الورقة](https://arxiv.org/abs/2105.15203).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام SegFormer.
+
+- [`SegformerForImageClassification`] مدعوم بواسطة [نص البرنامج النصي التوضيحي](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) و [دفتر الملاحظات](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+- [دليل مهام تصنيف الصور](../tasks/image_classification)
+
+التصنيف الدلالي:
+
+- [`SegformerForSemanticSegmentation`] مدعوم بواسطة [نص البرنامج النصي التوضيحي](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation).
+
+- يمكن العثور على مدونة حول الضبط الدقيق لـ SegFormer على مجموعة بيانات مخصصة [هنا](https://huggingface.co/blog/fine-tune-segformer).
+
+- يمكن العثور على المزيد من دفاتر الملاحظات التوضيحية حول SegFormer (الاستدلال + الضبط الدقيق على مجموعة بيانات مخصصة) [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer).
+
+- [`TFSegformerForSemanticSegmentation`] مدعوم بواسطة [دفتر الملاحظات التوضيحي هذا](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb).
+
+- [دليل مهام التجزئة الدلالية](../tasks/semantic_segmentation)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يوضح المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## SegformerConfig
+
+[[autodoc]] SegformerConfig
+
+## SegformerFeatureExtractor
+
+[[autodoc]] SegformerFeatureExtractor
+
+- __call__
+
+- post_process_semantic_segmentation
+
+## SegformerImageProcessor
+
+[[autodoc]] SegformerImageProcessor
+
+- preprocess
+
+- post_process_semantic_segmentation
+
+
+
+تمت المساهمة بهذا النموذج بواسطة [Francesco](https://huggingface.co/Francesco). تمت إضافة إصدار TensorFlow من هذا النموذج بواسطة [amyeroberts](https://huggingface.co/amyeroberts). يمكن العثور على الكود الأصلي [هنا](https://github.com/KaimingHe/deep-residual-networks).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية والمجتمعية (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام ResNet.
+
+
+
+ نظرة عامة على Grounded SAM. مأخوذة من المستودع الأصلي.
+
+## SamConfig
+
+[[autodoc]] SamConfig
+
+## SamVisionConfig
+
+[[autodoc]] SamVisionConfig
+
+## SamMaskDecoderConfig
+
+[[autodoc]] SamMaskDecoderConfig
+
+## SamPromptEncoderConfig
+
+[[autodoc]] SamPromptEncoderConfig
+
+## SamProcessor
+
+[[autodoc]] SamProcessor
+
+## SamImageProcessor
+
+[[autodoc]] SamImageProcessor
+
+## SamModel
+
+[[autodoc]] SamModel
+
+- forward
+
+## TFSamModel
+
+[[autodoc]] TFSamModel
+
+- call
\ No newline at end of file
From 5bb6f72180d7218489e5a8385f789b1058f4253e Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:11 +0300
Subject: [PATCH 566/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/seamless=5Fm4t.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/seamless_m4t.md | 207 +++++++++++++++++++++++
1 file changed, 207 insertions(+)
create mode 100644 docs/source/ar/model_doc/seamless_m4t.md
diff --git a/docs/source/ar/model_doc/seamless_m4t.md b/docs/source/ar/model_doc/seamless_m4t.md
new file mode 100644
index 00000000000000..157c205d080243
--- /dev/null
+++ b/docs/source/ar/model_doc/seamless_m4t.md
@@ -0,0 +1,207 @@
+# SeamlessM4T
+
+## نظرة عامة
+
+اقترح نموذج SeamlessM4T في [SeamlessM4T — Massively Multilingual & Multimodal Machine Translation](https://dl.fbaipublicfiles.com/seamless/seamless_m4t_paper.pdf) بواسطة فريق Seamless Communication من Meta AI.
+
+هذا هو إصدار **الإصدار 1** من النموذج. للإصدار المحدث **الإصدار 2**، راجع [Seamless M4T v2 docs](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t_v2).
+
+SeamlessM4T عبارة عن مجموعة من النماذج المصممة لتوفير ترجمة عالية الجودة، مما يسمح للأفراد من مجتمعات لغوية مختلفة بالتواصل بسلاسة من خلال الكلام والنص.
+
+تمكّن SeamlessM4T من تنفيذ مهام متعددة دون الاعتماد على نماذج منفصلة:
+
+- الترجمة من الكلام إلى الكلام (S2ST)
+- الترجمة من الكلام إلى النص (S2TT)
+- الترجمة من النص إلى الكلام (T2ST)
+- الترجمة من نص إلى نص (T2TT)
+- التعرف التلقائي على الكلام (ASR)
+
+يمكن لـ [`SeamlessM4TModel`] تنفيذ جميع المهام المذكورة أعلاه، ولكن لكل مهمة أيضًا نموذجها الفرعي المخصص.
+
+المقتطف من الورقة هو ما يلي:
+
+*ما الذي يتطلبه الأمر لخلق سمكة بابل، وهي أداة يمكن أن تساعد الأفراد على ترجمة الكلام بين أي لغتين؟ في حين أن الاختراقات الأخيرة في النماذج القائمة على النص دفعت بتغطية الترجمة الآلية إلى ما بعد 200 لغة، إلا أن نماذج الترجمة الموحدة من الكلام إلى الكلام لم تحقق بعد قفزات مماثلة. على وجه التحديد، تعتمد أنظمة الترجمة التقليدية من الكلام إلى الكلام على الأنظمة المتتالية التي تؤدي الترجمة تدريجيًا، مما يجعل الأنظمة الموحدة عالية الأداء بعيدة المنال. لمعالجة هذه الفجوات، نقدم SeamlessM4T، وهو نموذج واحد يدعم الترجمة من الكلام إلى الكلام، والترجمة من الكلام إلى النص، والترجمة من النص إلى الكلام، والترجمة من نص إلى نص، والتعرف التلقائي على الكلام لما يصل إلى 100 لغة. لبناء هذا، استخدمنا مليون ساعة من بيانات الصوت المفتوحة لتعلم التمثيلات الصوتية ذاتية الإشراف باستخدام w2v-BERT 2.0. بعد ذلك، قمنا بإنشاء مجموعة بيانات متعددة الوسائط من ترجمات الكلام المحاذاة تلقائيًا. بعد التصفية والدمج مع البيانات التي تحمل علامات بشرية وبيانات ذات علامات زائفة، قمنا بتطوير أول نظام متعدد اللغات قادر على الترجمة من وإلى اللغة الإنجليزية لكل من الكلام والنص. في FLEURS، يحدد SeamlessM4T معيارًا جديدًا للترجمات إلى لغات متعددة مستهدفة، محققًا تحسنًا بنسبة 20% في BLEU مقارنة بـ SOTA السابق في الترجمة المباشرة من الكلام إلى النص. مقارنة بالنماذج المتتالية القوية، يحسن SeamlessM4T جودة الترجمة إلى اللغة الإنجليزية بمقدار 1.3 نقطة BLEU في الترجمة من الكلام إلى النص وبمقدار 2.6 نقطة ASR-BLEU في الترجمة من الكلام إلى الكلام. تم اختبار نظامنا للمتانة، ويؤدي أداءً أفضل ضد الضوضاء الخلفية وتغيرات المتحدث في مهام الترجمة من الكلام إلى النص مقارنة بنموذج SOTA الحالي. من الناحية الحرجة، قمنا بتقييم SeamlessM4T على التحيز بين الجنسين والسمية المضافة لتقييم سلامة الترجمة. أخيرًا، جميع المساهمات في هذا العمل مفتوحة المصدر ومتاحة على https://github.com/facebookresearch/seamless_communication*
+
+## الاستخدام
+
+أولاً، قم بتحميل المعالج ونقطة تفتيش للنموذج:
+
+```python
+>>> from transformers import AutoProcessor, SeamlessM4TModel
+
+>>> processor = AutoProcessor.from_pretrained("facebook/hf-seamless-m4t-medium")
+>>> model = SeamlessM4TModel.from_pretrained("facebook/hf-seamless-m4t-medium")
+```
+
+يمكنك استخدام هذا النموذج بسلاسة على النص أو الصوت، لإنشاء نص مترجم أو صوت مترجم.
+
+فيما يلي كيفية استخدام المعالج لمعالجة النص والصوت:
+
+```python
+>>> # دعنا نحمل عينة صوتية من مجموعة بيانات خطاب عربي
+>>> from datasets import load_dataset
+>>> dataset = load_dataset("arabic_speech_corpus", split="test", streaming=True)
+>>> audio_sample = next(iter(dataset))["audio"]
+
+>>> # الآن، قم بمعالجته
+>>> audio_inputs = processor(audios=audio_sample["array"], return_tensors="pt")
+
+>>> # الآن، قم بمعالجة بعض النصوص الإنجليزية أيضًا
+>>> text_inputs = processor(text="Hello, my dog is cute", src_lang="eng", return_tensors="pt")
+```
+
+### الكلام
+
+يمكن لـ [`SeamlessM4TModel`] *بسلاسة* إنشاء نص أو كلام مع عدد قليل من التغييرات أو بدونها. دعنا نستهدف الترجمة الصوتية الروسية:
+
+```python
+>>> audio_array_from_text = model.generate(**text_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+>>> audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+```
+
+بنفس الرمز تقريبًا، قمت بترجمة نص إنجليزي وكلام عربي إلى عينات كلام روسية.
+
+### نص
+
+وبالمثل، يمكنك إنشاء نص مترجم من ملفات الصوت أو من النص باستخدام نفس النموذج. كل ما عليك فعله هو تمرير `generate_speech=False` إلى [`SeamlessM4TModel.generate`].
+
+هذه المرة، دعنا نترجم إلى الفرنسية.
+
+```python
+>>> # من الصوت
+>>> output_tokens = model.generate(**audio_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_audio = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+
+>>> # من النص
+>>> output_tokens = model.generate(**text_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_partum_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+```
+
+### نصائح
+
+#### 1. استخدم النماذج المخصصة
+
+[`SeamlessM4TModel`] هو نموذج المستوى الأعلى في المحولات لإنشاء الكلام والنص، ولكن يمكنك أيضًا استخدام النماذج المخصصة التي تؤدي المهمة دون مكونات إضافية، مما يقلل من بصمة الذاكرة.
+
+على سبيل المثال، يمكنك استبدال جزء الرمز الخاص بإنشاء الصوت باستخدام النموذج المخصص لمهمة S2ST، وبقية الرمز هو نفسه بالضبط:
+
+```python
+>>> from transformers import SeamlessM4TForSpeechToSpeech
+>>> model = SeamlessM4TForSpeechToSpeech.from_pretrained("facebook/hf-seamless-m4t-medium")
+```
+
+أو يمكنك استبدال جزء الرمز الخاص بإنشاء النص باستخدام النموذج المخصص لمهمة T2TT، وكل ما عليك فعله هو إزالة `generate_speech=False`.
+
+```python
+>>> from transformers import SeamlessM4TForTextToText
+>>> model = SeamlessM4TForTextToText.from_pretrained("facebook/hf-seamless-m4t-medium")
+```
+
+لا تتردد في تجربة [`SeamlessM4TForSpeechToText`] و [`SeamlessM4TForTextToSpeech`] أيضًا.
+
+#### 2. تغيير هوية المتحدث
+
+لديك إمكانية تغيير المتحدث المستخدم للتخليق الصوتي باستخدام حجة `spkr_id`. تعمل بعض قيم `spkr_id` بشكل أفضل من غيرها لبعض اللغات!
+
+#### 3. تغيير استراتيجية التوليد
+
+يمكنك استخدام استراتيجيات [توليد](./generation_strategies) مختلفة للكلام وتوليد النص، على سبيل المثال `.generate(input_ids=input_ids، text_num_beams=4، speech_do_sample=True)` والذي سيؤدي فك تشفير شعاع على النموذج النصي، وعينة متعددة الحدود على النموذج الصوتي.
+
+#### 4. قم بتوليد الكلام والنص في نفس الوقت
+
+استخدم `return_intermediate_token_ids=True` مع [`SeamlessM4TModel`] لإرجاع كل من الكلام والنص!
+
+## بنية النموذج
+
+تتميز SeamlessM4T ببنية مرنة تتعامل بسلاسة مع التوليد التسلسلي للنص والكلام. يتضمن هذا الإعداد نموذجين تسلسليين (seq2seq). يترجم النموذج الأول الطريقة المدخلة إلى نص مترجم، بينما يقوم النموذج الثاني بتوليد رموز الكلام، والمعروفة باسم "رموز الوحدة"، من النص المترجم.
+
+لدى كل طريقة مشفر خاص بها ببنية فريدة. بالإضافة إلى ذلك، بالنسبة لإخراج الكلام، يوجد جهاز فك ترميز مستوحى من بنية [HiFi-GAN](https://arxiv.org/abs/2010.05646) أعلى نموذج seq2seq الثاني.
+
+فيما يلي كيفية عمل عملية التوليد:
+
+- تتم معالجة النص أو الكلام المدخل من خلال مشفر محدد.
+- يقوم فك التشفير بإنشاء رموز نصية باللغة المطلوبة.
+- إذا كانت هناك حاجة إلى توليد الكلام، يقوم نموذج seq2seq الثاني، باتباع بنية مشفر-فك تشفير قياسية، بتوليد رموز الوحدة.
+- يتم بعد ذلك تمرير رموز الوحدة هذه عبر فك التشفير النهائي لإنتاج الكلام الفعلي.
+
+تمت المساهمة بهذا النموذج بواسطة [ylacombe](https://huggingface.co/ylacombe). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/seamless_communication).
+
+## SeamlessM4TModel
+
+[[autodoc]] SeamlessM4TModel
+
+- generate
+
+## SeamlessM4TForTextToSpeech
+
+[[autodoc]] SeamlessM4TForTextToSpeech
+
+- generate
+
+## SeamlessM4TForSpeechToSpeech
+
+[[autodoc]] SeamlessM4TForSpeechToSpeech
+
+- generate
+
+## SeamlessM4TForTextToText
+
+[[autodoc]] transformers.SeamlessM4TForTextToText
+
+- forward
+- generate
+
+## SeamlessM4TForSpeechToText
+
+[[autodoc]] transformers.SeamlessM4TForSpeechToText
+
+- forward
+- generate
+
+## SeamlessM4TConfig
+
+[[autodoc]] SeamlessM4TConfig
+
+## SeamlessM4TTokenizer
+
+[[autodoc]] SeamlessM4TTokenizer
+
+- __call__
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## SeamlessM4TTokenizerFast
+
+[[autodoc]] SeamlessM4TTokenizerFast
+
+- __call__
+
+## SeamlessM4TFeatureExtractor
+
+[[autodoc]] SeamlessM4TFeatureExtractor
+
+- __call__
+
+## SeamlessM4TProcessor
+
+[[autodoc]] SeamlessM4TProcessor
+
+- __call__
+
+## SeamlessM4TCodeHifiGan
+
+[[autodoc]] SeamlessM4TCodeHifiGan
+
+## SeamlessM4THifiGan
+
+[[autodoc]] SeamlessM4THifiGan
+
+## SeamlessM4TTextToUnitModel
+
+[[autodoc]] SeamlessM4TTextToUnitModel
+
+## SeamlessM4TTextToUnitForConditionalGeneration
+
+[[autodoc]] SeamlessM4TTextToUnitForConditionalGeneration
\ No newline at end of file
From ae192f8b50314b515c053b9de4bb92b065c276c2 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:13 +0300
Subject: [PATCH 567/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/seamless=5Fm4t=5Fv2.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/seamless_m4t_v2.md | 185 ++++++++++++++++++++
1 file changed, 185 insertions(+)
create mode 100644 docs/source/ar/model_doc/seamless_m4t_v2.md
diff --git a/docs/source/ar/model_doc/seamless_m4t_v2.md b/docs/source/ar/model_doc/seamless_m4t_v2.md
new file mode 100644
index 00000000000000..255f4f2c110970
--- /dev/null
+++ b/docs/source/ar/model_doc/seamless_m4t_v2.md
@@ -0,0 +1,185 @@
+# SeamlessM4T-v2
+
+## نظرة عامة
+
+اقترح فريق Seamless Communication من Meta AI نموذج SeamlessM4T-v2 في [Seamless: Multilingual Expressive and Streaming Speech Translation](https://ai.meta.com/research/publications/seamless-multilingual-expressive-and-streaming-speech-translation/).
+
+SeamlessM4T-v2 عبارة عن مجموعة من النماذج المصممة لتوفير ترجمة عالية الجودة، مما يسمح للناس من مجتمعات لغوية مختلفة بالتواصل بسلاسة من خلال الكلام والنص. إنه تحسين على [الإصدار السابق](https://huggingface.co/docs/transformers/main/model_doc/seamless_m4t). لمزيد من التفاصيل حول الاختلافات بين الإصدارين v1 و v2، راجع القسم [الاختلاف مع SeamlessM4T-v1](#difference-with-seamlessm4t-v1).
+
+يتيح SeamlessM4T-v2 مهام متعددة دون الاعتماد على نماذج منفصلة:
+
+- الترجمة الكلامية النصية (S2ST)
+- الترجمة الكلامية النصية (S2TT)
+- الترجمة النصية الكلامية (T2ST)
+- الترجمة النصية النصية (T2TT)
+- التعرف التلقائي على الكلام (ASR)
+
+يمكن لـ [`SeamlessM4Tv2Model`] تنفيذ جميع المهام المذكورة أعلاه، ولكن لكل مهمة أيضًا نموذج فرعي مخصص لها.
+
+المقتطف من الورقة هو ما يلي:
+
+*حققت التطورات الأخيرة في الترجمة الكلامية التلقائية توسعًا كبيرًا في تغطية اللغة، وتحسين القدرات متعددة الوسائط، وتمكين مجموعة واسعة من المهام والوظائف. ومع ذلك، تفتقر أنظمة الترجمة الكلامية التلقائية واسعة النطاق اليوم إلى ميزات رئيسية تساعد في جعل التواصل بوساطة الآلة سلسًا عند مقارنته بالحوار بين البشر. في هذا العمل، نقدم عائلة من النماذج التي تمكّن الترجمات التعبيرية والمتعددة اللغات بطريقة متواصلة. أولاً، نساهم في تقديم نسخة محسّنة من نموذج SeamlessM4T متعدد اللغات والوسائط بشكل كبير - SeamlessM4T v2. تم تدريب هذا النموذج الأحدث، الذي يتضمن إطار عمل UnitY2 المحدث، على المزيد من بيانات اللغات منخفضة الموارد. تضيف النسخة الموسعة من SeamlessAlign 114,800 ساعة من البيانات المحاذاة تلقائيًا لما مجموعه 76 لغة. يوفر SeamlessM4T v2 الأساس الذي تقوم عليه أحدث نماذجنا، SeamlessExpressive و SeamlessStreaming. يمكّن SeamlessExpressive الترجمة التي تحافظ على الأساليب الصوتية والتنغيم. مقارنة بالجهود السابقة في أبحاث الكلام التعبيري، يعالج عملنا بعض الجوانب الأقل استكشافًا للتنغيم، مثل معدل الكلام والتوقفات، مع الحفاظ على أسلوب صوت الشخص. أما بالنسبة لـ SeamlessStreaming، فإن نموذجنا يستفيد من آلية Efficient Monotonic Multihead Attention (EMMA) لتوليد ترجمات مستهدفة منخفضة الكمون دون انتظار نطق المصدر الكامل. يعد SeamlessStreaming الأول من نوعه، حيث يمكّن الترجمة الكلامية/النصية المتزامنة للغات المصدر والهدف المتعددة. لفهم أداء هذه النماذج، قمنا بدمج الإصدارات الجديدة والمعدلة من المقاييس التلقائية الموجودة لتقييم التنغيم والكمون والمتانة. وبالنسبة للتقييمات البشرية، قمنا بتكييف البروتوكولات الموجودة المصممة لقياس أكثر السمات ملاءمة في الحفاظ على المعنى والطبيعية والتعبير. ولضمان إمكانية استخدام نماذجنا بشكل آمن ومسؤول، قمنا بتنفيذ أول جهد معروف للفريق الأحمر للترجمة الآلية متعددة الوسائط، ونظام للكشف عن السمية المضافة والتخفيف منها، وتقييم منهجي للتحيز بين الجنسين، وآلية ترميز علامات مائية محلية غير مسموعة مصممة للتخفيف من تأثير مقاطع الفيديو المزيفة. وبالتالي، فإننا نجمع المكونات الرئيسية من SeamlessExpressive و SeamlessStreaming لتشكيل Seamless، وهو أول نظام متاح للجمهور يفتح التواصل التعبيري متعدد اللغات في الوقت الفعلي. في الختام، يمنحنا Seamless نظرة محورية على الأساس التقني اللازم لتحويل المترجم الشفوي العالمي من مفهوم الخيال العلمي إلى تكنولوجيا الواقع. وأخيرًا، يتم إطلاق المساهمات في هذا العمل - بما في ذلك النماذج والشفرة وكاشف العلامات المائية - علنًا ويمكن الوصول إليها من خلال الرابط أدناه.*
+
+## الاستخدام
+
+في المثال التالي، سنقوم بتحميل عينة صوت عربية وعينة نص إنجليزي وتحويلهما إلى كلام روسي ونص فرنسي.
+
+أولاً، قم بتحميل المعالج ونقطة تفتيش للنموذج:
+
+```python
+>>> from transformers import AutoProcessor, SeamlessM4Tv2Model
+
+>>> processor = AutoProcessor.from_pretrained("facebook/seamless-m4t-v2-large")
+>>> model = SeamlessM4Tv2Model.from_pretrained("facebook/seamless-m4t-v2-large")
+```
+
+يمكنك استخدام هذا النموذج بسلاسة على النص أو الصوت، لتوليد نص مترجم أو صوت مترجم.
+
+هكذا تستخدم المعالج لمعالجة النص والصوت:
+
+```python
+>>> # دعنا نحمل عينة صوت من مجموعة بيانات كلام عربية
+>>> from datasets import load_dataset
+>>> dataset = load_dataset("arabic_speech_corpus", split="test", streaming=True)
+>>> audio_sample = next(iter(dataset))["audio"]
+
+>>> # الآن، قم بمعالجته
+>>> audio_inputs = processor(audios=audio_sample["array"], return_tensors="pt")
+
+>>> # الآن، قم بمعالجة بعض النصوص الإنجليزية أيضًا
+>>> text_inputs = processor(text="Hello, my dog is cute", src_lang="eng", return_tensors="pt")
+```
+
+### الكلام
+
+يمكن لـ [`SeamlessM4Tv2Model`] *بسلاسة* توليد نص أو كلام مع عدد قليل من التغييرات أو بدونها. دعنا نستهدف الترجمة الصوتية الروسية:
+
+```python
+>>> audio_array_from_text = model.generate(**text_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+>>> audio_array_from_audio = model.generate(**audio_inputs, tgt_lang="rus")[0].cpu().numpy().squeeze()
+```
+
+بنفس الكود تقريبًا، قمت بترجمة نص إنجليزي وكلام عربي إلى عينات كلام روسية.
+
+### النص
+
+وبالمثل، يمكنك توليد نص مترجم من ملفات الصوت أو النص باستخدام نفس النموذج. عليك فقط تمرير `generate_speech=False` إلى [`SeamlessM4Tv2Model.generate`].
+
+هذه المرة، دعنا نقوم بالترجمة إلى الفرنسية.
+
+```python
+>>> # من الصوت
+>>> output_tokens = model.generate(**audio_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_audio = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+
+>>> # من النص
+>>> output_tokens = model.generate(**text_inputs, tgt_lang="fra", generate_speech=False)
+>>> translated_text_from_text = processor.decode(output_tokens[0].tolist()[0], skip_special_tokens=True)
+```
+
+### نصائح
+
+#### 1. استخدم النماذج المخصصة
+
+[`SeamlessM4Tv2Model`] هو نموذج المستوى الأعلى في برنامج Transformers لتوليد الكلام والنص، ولكن يمكنك أيضًا استخدام النماذج المخصصة التي تؤدي المهمة دون مكونات إضافية، مما يقلل من بصمة الذاكرة.
+
+على سبيل المثال، يمكنك استبدال جزء التعليمات البرمجية لتوليد الصوت بالنموذج المخصص لمهمة S2ST، والباقي هو نفس الكود بالضبط:
+
+```python
+>>> from transformers import SeamlessM4Tv2ForSpeechToSpeech
+>>> model = SeamlessM4Tv2ForSpeechToSpeech.from_pretrained("facebook/seamless-m4t-v2-large")
+```
+
+أو يمكنك استبدال جزء التعليمات البرمجية لتوليد النص بالنموذج المخصص لمهمة T2TT، عليك فقط إزالة `generate_speech=False`.
+
+```python
+>>> from transformers import SeamlessM4Tv2ForTextToText
+>>> model = SeamlessM4Tv2ForTextToText.from_pretrained("facebook/seamless-m4t-v2-large")
+```
+
+لا تتردد في تجربة [`SeamlessM4Tv2ForSpeechToText`] و [`SeamlessM4Tv2ForTextToSpeech`] أيضًا.
+
+#### 2. تغيير هوية المتحدث
+
+لديك إمكانية تغيير المتحدث المستخدم للتخليق الصوتي باستخدام وسيط `speaker_id`. تعمل بعض قيم `speaker_id` بشكل أفضل من غيرها لبعض اللغات!
+
+#### 3. تغيير استراتيجية التوليد
+
+يمكنك استخدام استراتيجيات [توليد](../generation_strategies) مختلفة للنص، على سبيل المثال `.generate(input_ids=input_ids, text_num_beams=4, text_do_sample=True)` والتي ستؤدي فك تشفير شعاع متعدد الحدود على النموذج النصي. لاحظ أن توليد الكلام يدعم فقط الجشع - بشكل افتراضي - أو العينات متعددة الحدود، والتي يمكن استخدامها مع `.generate(..., speech_do_sample=True, speech_temperature=0.6)`.
+
+#### 4. قم بتوليد الكلام والنص في نفس الوقت
+
+استخدم `return_intermediate_token_ids=True` مع [`SeamlessM4Tv2Model`] لإرجاع كل من الكلام والنص!
+
+## بنية النموذج
+
+يتميز SeamlessM4T-v2 ببنية مرنة تتعامل بسلاسة مع التوليد التسلسلي للنص والكلام. يتضمن هذا الإعداد نموذجين تسلسليين (seq2seq). يقوم النموذج الأول بترجمة المدخلات إلى نص مترجم، بينما يقوم النموذج الثاني بتوليد رموز الكلام، المعروفة باسم "رموز الوحدة"، من النص المترجم.
+
+لدى كل وسيطة مشفرها الخاص ببنية فريدة. بالإضافة إلى ذلك، بالنسبة لخرج الكلام، يوجد محول ترميز مستوحى من بنية [HiFi-GAN](https://arxiv.org/abs/2010.05646) أعلى نموذج seq2seq الثاني.
+
+### الاختلاف مع SeamlessM4T-v1
+
+تختلف بنية هذه النسخة الجديدة عن الإصدار الأول في بعض الجوانب:
+
+#### التحسينات على نموذج المرور الثاني
+
+نموذج seq2seq الثاني، المسمى نموذج النص إلى وحدة، غير تلقائي الآن، مما يعني أنه يحسب الوحدات في **تمريرة أمامية واحدة**. أصبح هذا الإنجاز ممكنًا من خلال:
+
+- استخدام **تضمين مستوى الأحرف**، مما يعني أن لكل حرف من النص المترجم المتنبأ به تضمينه الخاص، والذي يتم استخدامه بعد ذلك للتنبؤ برموز الوحدة.
+- استخدام مُنبئ المدة الوسيطة، الذي يتنبأ بمدة الكلام على مستوى **الشخصية** في النص المترجم المتنبأ به.
+- استخدام فك تشفير النص إلى وحدة جديد يمزج بين التعرّف على التعرّف والاهتمام الذاتي للتعامل مع السياق الأطول.
+
+#### الاختلاف في مشفر الكلام
+
+يختلف مشفر الكلام، الذي يتم استخدامه أثناء عملية توليد المرور الأول للتنبؤ بالنص المترجم، بشكل أساسي عن مشفر الكلام السابق من خلال هذه الآليات:
+
+- استخدام قناع اهتمام مجزأ لمنع الاهتمام عبر المقاطع، وضمان أن يحضر كل موضع فقط إلى المواضع الموجودة داخل مقطعته وعدد ثابت من المقاطع السابقة.
+- استخدام التضمينات الموضعية النسبية التي لا تأخذ في الاعتبار سوى المسافة بين عناصر التسلسل بدلاً من المواضع المطلقة. يرجى الرجوع إلى [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155) لمزيد من التفاصيل.
+- استخدام التعرّف المتعمق السببي بدلاً من غير السببي.
+
+### عملية التوليد
+
+هكذا تعمل عملية التوليد:
+
+- تتم معالجة النص أو الكلام المدخل من خلال مشفر محدد.
+- يقوم فك التشفير بإنشاء رموز نصية باللغة المطلوبة.
+- إذا كانت هناك حاجة إلى توليد الكلام، فإن نموذج seq2seq الثاني يقوم بتوليد رموز الوحدة بطريقة غير تلقائية.
+- يتم بعد ذلك تمرير رموز الوحدة هذه عبر محول الترميز النهائي لإنتاج الكلام الفعلي.
+
+تمت المساهمة بهذا النموذج من قبل [ylacombe](https://huggingface.co/ylacombe). يمكن العثور على الكود الأصلي [هنا](https://github.com/facebookresearch/seamless_communication).
+
+## SeamlessM4Tv2Model
+
+[[autodoc]] SeamlessM4Tv2Model
+
+- generate
+
+## SeamlessM4Tv2ForTextToSpeech
+
+[[autodoc]] SeamlessM4Tv2ForTextToSpeech
+
+- generate
+
+## SeamlessM4Tv2ForSpeechToSpeech
+
+[[autodoc]] SeamlessM4Tv2ForSpeechToSpeech
+
+- generate
+
+## SeamlessM4Tv2ForTextToText
+
+[[autodoc]] transformers.SeamlessM4Tv2ForTextToText
+
+- forward
+- generate
+
+## SeamlessM4Tv2ForSpeechToText
+
+[[autodoc]] transformers.SeamlessM4Tv2ForSpeechToText
+
+- forward
+- generate
+
+## SeamlessM4Tv2Config
+
+[[autodoc]] SeamlessM4Tv2Config
\ No newline at end of file
From a635d0bea5d84d6d766fd558e2e98d9a90ade592 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:15 +0300
Subject: [PATCH 568/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/segformer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/segformer.md | 143 ++++++++++++++++++++++++++
1 file changed, 143 insertions(+)
create mode 100644 docs/source/ar/model_doc/segformer.md
diff --git a/docs/source/ar/model_doc/segformer.md b/docs/source/ar/model_doc/segformer.md
new file mode 100644
index 00000000000000..7871e2d69620ab
--- /dev/null
+++ b/docs/source/ar/model_doc/segformer.md
@@ -0,0 +1,143 @@
+# SegFormer
+
+## نظرة عامة
+
+اقترح نموذج SegFormer في ورقة "SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers" بواسطة Enze Xie وآخرون. يتكون النموذج من ترميز Transformer هرمي ورأس فك تشفير خفيف الوزن يعتمد بالكامل على MLP لتحقيق نتائج ممتازة في معايير تصنيف الصور مثل ADE20K وCityscapes.
+
+الملخص من الورقة هو ما يلي:
+
+> "نقدم SegFormer، وهو إطار عمل لتصنيف الصور البسيط والفعال والقوي الذي يوحد المحولات مع فك ترميز الإدراك متعدد الطبقات (MLP) خفيف الوزن. يتميز SegFormer بميزتين جذابتين: 1) يتكون SegFormer من ترميز محول هرمي هيكلي جديد ينتج ميزات متعددة المقاييس. لا يحتاج إلى ترميز الموضع، وبالتالي يتجنب الاستيفاء لرموز الموضعية التي تؤدي إلى انخفاض الأداء عندما يختلف القرار عند الاختبار عن التدريب. 2) يتجنب SegFormer فك الترميز المعقد. يقوم فك ترميز MLP المقترح بتجميع المعلومات من طبقات مختلفة، وبالتالي الجمع بين كل من الاهتمام المحلي والعالمي لتصيير تمثيلات قوية. نُظهر أن هذا التصميم البسيط والخفيف هو المفتاح لتصنيف الكفاءة على المحولات. نقوم بزيادة مقياس نهجنا للحصول على سلسلة من النماذج من SegFormer-B0 إلى SegFormer-B5، مما يحقق أداءً وكفاءة أفضل بكثير من النظائر السابقة. على سبيل المثال، يحقق SegFormer-B4 نسبة 50.3% mIoU على ADE20K مع 64 مليون معامل، وهو أصغر 5 مرات وأفضل بنسبة 2.2% من الطريقة الأفضل السابقة. ويحقق نموذجنا الأفضل، SegFormer-B5، نسبة 84.0% mIoU على مجموعة التحقق من Cityscapes ويظهر متانة ممتازة للتصنيف الصفري على Cityscapes-C."
+
+يوضح الشكل أدناه بنية SegFormer. مأخوذة من الورقة الأصلية.
+
+
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr). تمت المساهمة في إصدار TensorFlow من النموذج بواسطة [sayakpaul](https://huggingface.co/sayakpaul). يمكن العثور على الكود الأصلي [هنا](https://github.com/NVlabs/SegFormer).
+
+## نصائح الاستخدام
+
+- يتكون SegFormer من ترميز محول هرمي ورأس فك تشفير خفيف الوزن يعتمد بالكامل على MLP. [`SegformerModel`] هو ترميز المحول الهرمي (الذي يشار إليه أيضًا في الورقة باسم Mix Transformer أو MiT). يضيف [`SegformerForSemanticSegmentation`] رأس فك تشفير MLP بالكامل لأداء التصنيف الدلالي للصور. بالإضافة إلى ذلك، هناك [`SegformerForImageClassification`] الذي يمكن استخدامه - كما هو متوقع - لتصنيف الصور. قام مؤلفو SegFormer أولاً بتدريب المحول الترميزي مسبقًا على ImageNet-1k لتصنيف الصور. بعد ذلك، يقومون بحذف رأس التصنيف، واستبداله برأس فك تشفير MLP. بعد ذلك، يقومون بتدريب النموذج بالكامل على ADE20K وCityscapes وCOCO-stuff، والتي تعد معايير مرجعية مهمة لتصنيف الصور. يمكن العثور على جميع نقاط التفتيش على [المركز](https://huggingface.co/models?other=segformer).
+
+- أسرع طريقة للبدء مع SegFormer هي التحقق من [دفاتر الملاحظات التوضيحية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (التي تعرض كل من الاستدلال والتدريب الدقيق على البيانات المخصصة). يمكن للمرء أيضًا الاطلاع على [منشور المدونة](https://huggingface.co/blog/fine-tune-segformer) الذي يقدم SegFormer ويوضح كيفية ضبطه بدقة على بيانات مخصصة.
+
+- يجب أن يشير مستخدمو TensorFlow إلى [هذا المستودع](https://github.com/deep-diver/segformer-tf-transformers) الذي يوضح الاستدلال والضبط الدقيق خارج الصندوق.
+
+- يمكن للمرء أيضًا الاطلاع على [هذا العرض التوضيحي التفاعلي على Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers) لتجربة نموذج SegFormer على الصور المخصصة.
+
+- يعمل SegFormer مع أي حجم إدخال، حيث يقوم بتقسيم الإدخال ليكون قابلاً للقسمة على `config.patch_sizes`.
+
+- يمكن للمرء استخدام [`SegformerImageProcessor`] لإعداد الصور وخرائط التجزئة المقابلة للنموذج. لاحظ أن معالج الصور هذا أساسي إلى حد ما ولا يتضمن جميع عمليات زيادة البيانات المستخدمة في الورقة الأصلية. يمكن العثور على خطوط المعالجة المسبقة الأصلية (لمجموعة بيانات ADE20k على سبيل المثال) [هنا](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). تتمثل أهم خطوة للمعالجة المسبقة في اقتصاص الصور وخرائط التجزئة عشوائيًا وإضافتها إلى نفس الحجم، مثل 512x512 أو 640x640، ثم يتم تطبيعها.
+
+- هناك شيء إضافي يجب مراعاته وهو أنه يمكن تهيئة [`SegformerImageProcessor`] باستخدام `do_reduce_labels` على `True` أو `False`. في بعض مجموعات البيانات (مثل ADE20k)، يتم استخدام الفهرس 0 في خرائط التجزئة المشروحة للخلفية. ومع ذلك، لا تتضمن مجموعة بيانات ADE20k فئة "الخلفية" في علاماتها البالغ عددها 150. لذلك، يتم استخدام `do_reduce_labels` لخفض جميع العلامات بمقدار 1، والتأكد من عدم حساب أي خسارة لفئة "الخلفية" (أي أنها تستبدل 0 في الخرائط المشروحة بـ 255، وهو *ignore_index* لدالة الخسارة المستخدمة بواسطة [`SegformerForSemanticSegmentation`]). ومع ذلك، تستخدم مجموعات بيانات أخرى الفهرس 0 كفئة خلفية وتتضمن هذه الفئة كجزء من جميع العلامات. في هذه الحالة، يجب تعيين `do_reduce_labels` على `False`، حيث يجب أيضًا حساب الخسارة لفئة الخلفية.
+
+- مثل معظم النماذج، يأتي SegFormer بأحجام مختلفة، يمكن العثور على تفاصيلها في الجدول أدناه (مأخوذ من الجدول 7 من [الورقة الأصلية](https://arxiv.org/abs/2105.15203)).
+
+| **متغير النموذج** | **الأعماق** | **أحجام المخفية** | **حجم مخفي فك الترميز** | **المعلمات (م)** | **ImageNet-1k Top 1** |
+| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
+| MiT-b0 | [2، 2، 2، 2] | [32، 64، 160، 256] | 256 | 3.7 | 70.5 |
+| MiT-b1 | [2، 2، 2، 2] | [64، 128، 320، 512] | 256 | 14.0 | 78.7 |
+| MiT-b2 | [3، 4، 6، 3] | [64، 128، 320، 512] | 768 | 25.4 | 81.6 |
+| MiT-b3 | [3، 4، 18، 3] | [64، 128، 320، 512] | 768 | 45.2 | 83.1 |
+| MiT-b4 | [3، 8، 27، 3] | [64، 128، 320، 512] | 768 | 62.6 | 83.6 |
+| MiT-b5 | [3، 6، 40، 3] | [64، 128، 320، 512] | 768 | 82.0 | 83.8 |
+
+لاحظ أن MiT في الجدول أعلاه يشير إلى العمود الفقري لترميز المحول المختلط المقدم في SegFormer. للحصول على نتائج SegFormer على مجموعات بيانات التجزئة مثل ADE20k، راجع [الورقة](https://arxiv.org/abs/2105.15203).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام SegFormer.
+
+- [`SegformerForImageClassification`] مدعوم بواسطة [نص البرنامج النصي التوضيحي](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) و [دفتر الملاحظات](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
+
+- [دليل مهام تصنيف الصور](../tasks/image_classification)
+
+التصنيف الدلالي:
+
+- [`SegformerForSemanticSegmentation`] مدعوم بواسطة [نص البرنامج النصي التوضيحي](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation).
+
+- يمكن العثور على مدونة حول الضبط الدقيق لـ SegFormer على مجموعة بيانات مخصصة [هنا](https://huggingface.co/blog/fine-tune-segformer).
+
+- يمكن العثور على المزيد من دفاتر الملاحظات التوضيحية حول SegFormer (الاستدلال + الضبط الدقيق على مجموعة بيانات مخصصة) [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer).
+
+- [`TFSegformerForSemanticSegmentation`] مدعوم بواسطة [دفتر الملاحظات التوضيحي هذا](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb).
+
+- [دليل مهام التجزئة الدلالية](../tasks/semantic_segmentation)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يوضح المورد في الوضع المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## SegformerConfig
+
+[[autodoc]] SegformerConfig
+
+## SegformerFeatureExtractor
+
+[[autodoc]] SegformerFeatureExtractor
+
+- __call__
+
+- post_process_semantic_segmentation
+
+## SegformerImageProcessor
+
+[[autodoc]] SegformerImageProcessor
+
+- preprocess
+
+- post_process_semantic_segmentation
+
+ +
+ نتائج تقييم SigLIP مقارنة بـ CLIP. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/big_vision/tree/main).
+
+## مثال الاستخدام
+
+هناك طريقتان رئيسيتان لاستخدام SigLIP: إما باستخدام واجهة برمجة التطبيقات الخاصة بالخطوط الأنابيب، والتي تُجرِّد كل التعقيد من أجلك، أو باستخدام فئة `SiglipModel` بنفسك.
+
+### واجهة برمجة التطبيقات الخاصة بالخطوط الأنابيب
+
+تسمح واجهة برمجة التطبيقات باستخدام النموذج في بضع سطور من الكود:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # تحميل الأنبوب
+>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
+
+>>> # تحميل الصورة
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # الاستنتاج
+>>> outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+### استخدام النموذج بنفسك
+
+إذا كنت تريد القيام بالمعالجة المسبقة واللاحقة بنفسك، فهذا هو ما يجب فعله:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
+>>> # من المهم: نمرر `padding=max_length` حيث تم تدريب النموذج بهذه الطريقة
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # هذه هي الاحتمالات
+>>> print(f"{probs[0][0]:.1%} احتمال أن تكون الصورة 0 هي '{texts[0]}'")
+31.9% احتمال أن تكون الصورة 0 هي 'a photo of 2 cats'
+```
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام SigLIP.
+
+- [دليل مهام التصنيف الصوري بدون إشراف](../tasks/zero_shot_image_classification_md)
+
+- يمكن العثور على دفاتر الملاحظات التجريبية لـ SigLIP [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SigLIP). 🌎
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد بشكل مثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## SiglipConfig
+
+[[autodoc]] SiglipConfig
+
+- from_text_vision_configs
+
+## SiglipTextConfig
+
+[[autodoc]] SiglipTextConfig
+
+## SiglipVisionConfig
+
+[[autodoc]] SiglipVisionConfig
+
+## SiglipTokenizer
+
+[[autodoc]] SiglipTokenizer
+
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## SiglipImageProcessor
+
+[[autodoc]] SiglipImageProcessor
+
+- preprocess
+
+## SiglipProcessor
+
+[[autodoc]] SiglipProcessor
+
+## SiglipModel
+
+[[autodoc]] SiglipModel
+
+- forward
+- get_text_features
+- get_image_features
+
+## SiglipTextModel
+
+[[autodoc]] SiglipTextModel
+
+- forward
+
+## SiglipVisionModel
+
+[[autodoc]] SiglipVisionModel
+
+- forward
+
+## SiglipForImageClassification
+
+[[autodoc]] SiglipForImageClassification
+
+- forward
\ No newline at end of file
From 37cffebc170edbdc2d5486b5803a6adb45e7f95d Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:23 +0300
Subject: [PATCH 573/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/speech-encoder-decoder.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../ar/model_doc/speech-encoder-decoder.md | 117 ++++++++++++++++++
1 file changed, 117 insertions(+)
create mode 100644 docs/source/ar/model_doc/speech-encoder-decoder.md
diff --git a/docs/source/ar/model_doc/speech-encoder-decoder.md b/docs/source/ar/model_doc/speech-encoder-decoder.md
new file mode 100644
index 00000000000000..9015e27cd94dfe
--- /dev/null
+++ b/docs/source/ar/model_doc/speech-encoder-decoder.md
@@ -0,0 +1,117 @@
+# نماذج الترميز فك الترميز الصوتي
+
+يمكن استخدام [`SpeechEncoderDecoderModel`] لتهيئة نموذج تحويل الكلام إلى نص باستخدام أي نموذج ترميز ذاتي التعلم مسبقًا للكلام كترميز (*e.g.* [Wav2Vec2](wav2vec2)، [Hubert](hubert)) وأي نموذج توليدي مسبق التدريب كفك تشفير.
+
+وقد تم إثبات فعالية تهيئة النماذج التسلسلية للكلام إلى تسلسلات نصية باستخدام نقاط تفتيش مسبقة التدريب للتعرف على الكلام وترجمته على سبيل المثال في [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) بواسطة Changhan Wang وAnne Wu وJuan Pino وAlexei Baevski وMichael Auli وAlexis Conneau.
+
+يمكن الاطلاع على مثال حول كيفية استخدام [`SpeechEncoderDecoderModel`] للاستنتاج في [Speech2Text2](speech_to_text_2).
+
+## تهيئة `SpeechEncoderDecoderModel` بشكل عشوائي من تكوينات النموذج.
+
+يمكن تهيئة [`SpeechEncoderDecoderModel`] بشكل عشوائي من تكوين الترميز وفك الترميز. في المثال التالي، نوضح كيفية القيام بذلك باستخدام تكوين [`Wav2Vec2Model`] الافتراضي للترميز
+وتكوين [`BertForCausalLM`] الافتراضي لفك الترميز.
+
+```python
+>>> from transformers import BertConfig, Wav2Vec2Config, SpeechEncoderDecoderConfig, SpeechEncoderDecoderModel
+
+>>> config_encoder = Wav2Vec2Config()
+>>> config_decoder = BertConfig()
+
+>>> config = SpeechEncoderDecoderConfig.from_encoder_decoder_configs(config_encoder, config_decoder)
+>>> model = SpeechEncoderDecoderModel(config=config)
+```
+
+## تهيئة `SpeechEncoderDecoderModel` من ترميز وفك تشفير مُدرَّب مسبقًا.
+
+يمكن تهيئة [`SpeechEncoderDecoderModel`] من نقطة تفتيش ترميز مُدرَّب مسبقًا ونقطة تفتيش فك تشفير مُدرَّب مسبقًا. لاحظ أن أي نموذج كلام قائم على Transformer، مثل [Wav2Vec2](wav2vec2) أو [Hubert](hubert) يمكن أن يعمل كترميز، في حين يمكن استخدام كل من النماذج الذاتية الترميز المُدرَّبة مسبقًا، مثل BERT، ونماذج اللغة السببية المُدرَّبة مسبقًا، مثل GPT2، بالإضافة إلى الجزء المدرَّب مسبقًا من فك تشفير نماذج التسلسل إلى تسلسل، مثل فك تشفير BART، كفك تشفير.
+
+اعتمادًا على البنية التي تختارها كفك تشفير، قد يتم تهيئة طبقات الاهتمام المتقاطع بشكل عشوائي.
+
+تتطلب تهيئة [`SpeechEncoderDecoderModel`] من نقطة تفتيش ترميز وفك تشفير مُدرَّب مسبقًا تهيئة النموذج الدقيقة على مهمة أسفل النهر، كما هو موضح في [منشور المدونة *Warm-starting-encoder-decoder*](https://huggingface.co/blog/warm-starting-encoder-decoder).
+
+للقيام بذلك، توفر فئة `SpeechEncoderDecoderModel` طريقة [`SpeechEncoderDecoderModel.from_encoder_decoder_pretrained`].
+
+```python
+>>> from transformers import SpeechEncoderDecoderModel
+
+>>> model = SpeechEncoderDecoderModel.from_encoder_decoder_pretrained(
+... "facebook/hubert-large-ll60k", "google-bert/bert-base-uncased"
+... )
+```
+
+## تحميل نقطة تفتيش `SpeechEncoderDecoderModel` موجودة والقيام بالاستدلال.
+
+لتحميل نقاط تفتيش مُدرَّبة دقيقة من فئة `SpeechEncoderDecoderModel`، توفر [`SpeechEncoderDecoderModel`] طريقة `from_pretrained(...)` مثل أي بنية نموذج أخرى في Transformers.
+
+للقيام بالاستدلال، يمكنك استخدام طريقة [`generate`]، والتي تسمح بتوليد النص بشكل تلقائي. تدعم هذه الطريقة أشكالًا مختلفة من فك التشفير، مثل الجشع، وبحث الشعاع، وأخذ العينات متعددة الحدود.
+
+```python
+>>> from transformers import Wav2Vec2Processor, SpeechEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> # تحميل نموذج ترجمة كلام مُدرَّب دقيق ومعالج مطابق
+>>> model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
+>>> processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
+
+>>> # لنقم بالاستدلال على قطعة من الكلام باللغة الإنجليزية (والتي سنترجمها إلى الألمانية)
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
+
+>>> # توليد النسخ النصي تلقائيًا (يستخدم فك التشفير الجشع بشكل افتراضي)
+>>> generated_ids = model.generate(input_values)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+>>> print(generated_text)
+Mr. Quilter ist der Apostel der Mittelschicht und wir freuen uns, sein Evangelium willkommen heißen zu können.
+```
+
+## التدريب
+
+بمجرد إنشاء النموذج، يمكن ضبطه بشكل دقيق مثل BART أو T5 أو أي نموذج ترميز وفك تشفير آخر على مجموعة بيانات من أزواج (كلام، نص).
+
+كما ترى، يلزم إدخالان فقط للنموذج من أجل حساب الخسارة: `input_values` (وهي إدخالات الكلام) و`labels` (وهي `input_ids` للتسلسل المستهدف المشفر).
+
+```python
+>>> from transformers import AutoTokenizer, AutoFeatureExtractor, SpeechEncoderDecoderModel
+>>> from datasets import load_dataset
+
+>>> encoder_id = "facebook/wav2vec2-base-960h" # ترميز النموذج الصوتي
+>>> decoder_id = "google-bert/bert-base-uncased" # فك تشفير النص
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(encoder_id)
+>>> tokenizer = AutoTokenizer.from_pretrained(decoder_id)
+>>> # دمج الترميز المُدرَّب مسبقًا وفك الترميز المُدرَّب مسبقًا لتشكيل نموذج تسلسل إلى تسلسل
+>>> model = SpeechEncoderDecoderModel.from_encoder_decoder_pretrained(encoder_id, decoder_id)
+
+>>> model.config.decoder_start_token_id = tokenizer.cls_token_
+>>> model.config.pad_token_id = tokenizer.pad_token_id
+
+>>> # تحميل إدخال صوتي ومعالجته مسبقًا (تطبيع المتوسط/الانحراف المعياري إلى 0/1)
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> input_values = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt").input_values
+
+>>> # تحميل النسخ النصي المقابل له وتشفيره لإنشاء العلامات
+>>> labels = tokenizer(ds[0]["text"], return_tensors="pt").input_ids
+
+>>> # تقوم دالة التقديم تلقائيًا بإنشاء decoder_input_ids الصحيحة
+>>> loss = model(input_values=input_values, labels=labels).loss
+>>> loss.backward()
+```
+
+## SpeechEncoderDecoderConfig
+
+[[autodoc]] SpeechEncoderDecoderConfig
+
+## SpeechEncoderDecoderModel
+
+[[autodoc]] SpeechEncoderDecoderModel
+
+- forward
+- from_encoder_decoder_pretrained
+
+## FlaxSpeechEncoderDecoderModel
+
+[[autodoc]] FlaxSpeechEncoderDecoderModel
+
+- __call__
+- from_encoder_decoder_pretrained
\ No newline at end of file
From 30997d5c614fa5baff8cbf734c7a29ed6a6d9b23 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:25 +0300
Subject: [PATCH 574/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/speecht5.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/speecht5.md | 87 ++++++++++++++++++++++++++++
1 file changed, 87 insertions(+)
create mode 100644 docs/source/ar/model_doc/speecht5.md
diff --git a/docs/source/ar/model_doc/speecht5.md b/docs/source/ar/model_doc/speecht5.md
new file mode 100644
index 00000000000000..083fb4365dff7b
--- /dev/null
+++ b/docs/source/ar/model_doc/speecht5.md
@@ -0,0 +1,87 @@
+# SpeechT5
+
+## نظرة عامة
+
+اقترح نموذج SpeechT5 في بحث "SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing" من قبل Junyi Ao وآخرون.
+
+ملخص البحث هو كما يلي:
+
+*انطلاقًا من نجاح نموذج T5 (Text-To-Text Transfer Transformer) في معالجة اللغات الطبيعية المدَربة مسبقًا، نقترح إطار عمل SpeechT5 الموحد للطريقة الذي يستكشف التدريب المسبق للترميز فك الترميز للتعلم الذاتي التمثيل اللغوي المنطوق/المكتوب. ويتكون إطار عمل SpeechT5 من شبكة ترميز وفك ترميز مشتركة وست شبكات محددة للطريقة (منطوقة/مكتوبة) للمراحل السابقة/اللاحقة. وبعد معالجة المدخلات المنطوقة/المكتوبة من خلال المراحل السابقة، تقوم شبكة الترميز وفك الترميز المشتركة بنمذجة التحويل من سلسلة إلى أخرى، ثم تقوم المراحل اللاحقة بتوليد المخرجات في طريقة الكلام/النص بناءً على مخرجات فك الترميز. وباستخدام البيانات الكبيرة غير الموسومة للكلام والنص، نقوم بتدريب SpeechT5 مسبقًا لتعلم تمثيل موحد للطريقة، على أمل تحسين قدرة النمذجة لكل من الكلام والنص. ولمواءمة المعلومات النصية والمنطوقة في هذه المساحة الدلالية الموحدة، نقترح نهجًا للتحليل الكمي متعدد الطرق الذي يخلط عشوائيًا حالات الكلام/النص مع الوحدات الكامنة كوسيط بين الترميز وفك الترميز. وتظهر التقييمات الشاملة تفوق إطار عمل SpeechT5 المقترح في مجموعة واسعة من مهام معالجة اللغة المنطوقة، بما في ذلك التعرف التلقائي على الكلام، وتوليف الكلام، وترجمة الكلام، وتحويل الصوت، وتحسين الكلام، والتعرف على المتحدث.*
+
+تمت المساهمة بهذا النموذج من قبل [Matthijs](https://huggingface.co/Matthijs). ويمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/SpeechT5).
+
+## SpeechT5Config
+
+[[autodoc]] SpeechT5Config
+
+## SpeechT5HifiGanConfig
+
+[[autodoc]] SpeechT5HifiGanConfig
+
+## SpeechT5Tokenizer
+
+[[autodoc]] SpeechT5Tokenizer
+
+- __call__
+
+- save_vocabulary
+
+- decode
+
+- batch_decode
+
+## SpeechT5FeatureExtractor
+
+[[autodoc]] SpeechT5FeatureExtractor
+
+- __call__
+
+## SpeechT5Processor
+
+[[autodoc]] SpeechT5Processor
+
+- __call__
+
+- pad
+
+- from_pretrained
+
+- save_pretrained
+
+- batch_decode
+
+- decode
+
+## SpeechT5Model
+
+[[autodoc]] SpeechT5Model
+
+- forward
+
+## SpeechT5ForSpeechToText
+
+[[autodoc]] SpeechT5ForSpeechToText
+
+- forward
+
+## SpeechT5ForTextToSpeech
+
+[[autodoc]] SpeechT5ForTextToSpeech
+
+- forward
+
+- generate
+
+## SpeechT5ForSpeechToSpeech
+
+[[autodoc]] SpeechT5ForSpeechToSpeech
+
+- forward
+
+- generate_speech
+
+## SpeechT5HifiGan
+
+[[autodoc]] SpeechT5HifiGan
+
+- forward
\ No newline at end of file
From 0e796c4a31c75e2ba28d419563efb00b5b74a9d7 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:27 +0300
Subject: [PATCH 575/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/speech=5Fto=5Ftext.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/speech_to_text.md | 126 +++++++++++++++++++++
1 file changed, 126 insertions(+)
create mode 100644 docs/source/ar/model_doc/speech_to_text.md
diff --git a/docs/source/ar/model_doc/speech_to_text.md b/docs/source/ar/model_doc/speech_to_text.md
new file mode 100644
index 00000000000000..b08bf16bffc74c
--- /dev/null
+++ b/docs/source/ar/model_doc/speech_to_text.md
@@ -0,0 +1,126 @@
+# Speech2Text
+
+## نظرة عامة
+تم اقتراح نموذج Speech2Text في [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) بواسطة Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. وهو عبارة عن نموذج تسلسل إلى تسلسل (ترميز فك الترميز) يعتمد على المحول المصمم للتعرف التلقائي على الكلام (ASR) وترجمة الكلام (ST). يستخدم مخفضًا للتعرّف على الشكل لتقصير طول إدخالات الكلام بمقدار 3/4 قبل إدخالها في الترميز. يتم تدريب النموذج باستخدام خسارة ذاتي الارتباط عبر الإنتروبيا القياسية ويولد النسخ/الترجمات ذاتيًا. تم ضبط نموذج Speech2Text بشكل دقيق على العديد من مجموعات البيانات لـ ASR و ST: [LibriSpeech](http://www.openslr.org/12)، [CoVoST 2](https://github.com/facebookresearch/covost)، [MuST-C](https://ict.fbk.eu/must-c/).
+
+تمت المساهمة بهذا النموذج من قبل [valhalla](https://huggingface.co/valhalla). يمكن العثور على الكود الأصلي [هنا](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text).
+
+## الاستنتاج
+Speech2Text هو نموذج كلام يقبل Tensor عائمًا لميزات بنك التصفية اللوغاريتمية المستخرجة من إشارة الكلام. إنه نموذج تسلسل إلى تسلسل يعتمد على المحول، لذلك يتم إنشاء النسخ/الترجمات ذاتيًا. يمكن استخدام طريقة `generate()` للاستدلال.
+
+تعد فئة [`Speech2TextFeatureExtractor`] مسؤولة عن استخراج ميزات بنك التصفية اللوغاريتمية. يجمع [`Speech2TextProcessor`] [`Speech2TextFeatureExtractor`] و [`Speech2TextTokenizer`] في مثيل واحد لاستخراج ميزات الإدخال وفك تشفير معرّفات الرموز المتوقعة.
+
+يعتمد المستخرج المميز على `torchaudio` ويعتمد الرمز المميز على `sentencepiece`، لذا تأكد من تثبيت هذه الحزم قبل تشغيل الأمثلة. يمكنك تثبيت تلك الحزم كاعتمادات كلام إضافية مع `pip install transformers"[speech, sentencepiece]"` أو تثبيت الحزم بشكل منفصل باستخدام `pip install torchaudio sentencepiece`. يتطلب `torchaudio` أيضًا الإصدار التنموي من حزمة [libsndfile](http://www.mega-nerd.com/libsndfile/) والتي يمكن تثبيتها عبر مدير حزم النظام. على Ubuntu، يمكن تثبيته على النحو التالي: `apt install libsndfile1-dev`
+
+- التعرف على الكلام وترجمة الكلام
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
+
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
+
+>>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> transcription
+['mister quilter is the apostle of the middle classes and we are glad to welcome his gospel']
+```
+
+- ترجمة الكلام متعددة اللغات
+
+بالنسبة لنماذج ترجمة الكلام متعددة اللغات، يتم استخدام `eos_token_id` كـ `decoder_start_token_id`
+ويتم فرض معرف لغة الهدف كرابع رمز مولد. لفرض معرف لغة الهدف كرابع رمز مولد، قم بتمرير معلمة `forced_bos_token_id` إلى طريقة `generate()`. يوضح المثال التالي كيفية ترجمة الكلام باللغة الإنجليزية إلى نص باللغة الفرنسية باستخدام نقطة تفتيش *facebook/s2t-medium-mustc-multilingual-st*.
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(
+... inputs["input_features"],
+... attention_mask=inputs["attention_mask"],
+... forced_bos_token_id=processor.tokenizer.lang_code_to_id["fr"],
+... )
+
+>>> translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> translation
+["(Vidéo) Si M. Kilder est l'apossible des classes moyennes, et nous sommes heureux d'être accueillis dans son évangile."]
+```
+
+راجع [نموذج المركز](https://huggingface.co/models؟filter=speech_to_text) للبحث عن نقاط تفتيش Speech2Text.
+
+## Speech2TextConfig
+
+[[autodoc]] Speech2TextConfig
+
+## Speech2TextTokenizer
+
+[[autodoc]] Speech2TextTokenizer
+
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## Speech2TextFeatureExtractor
+
+[[autodoc]] Speech2TextFeatureExtractor
+
+- __call__
+
+## Speech2TextProcessor
+
+[[autodoc]] Speech2TextProcessor
+
+- __call__
+- from_pretrained
+- save_pretrained
+- batch_decode
+- decode
+
+
+
+ نتائج تقييم SigLIP مقارنة بـ CLIP. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/big_vision/tree/main).
+
+## مثال الاستخدام
+
+هناك طريقتان رئيسيتان لاستخدام SigLIP: إما باستخدام واجهة برمجة التطبيقات الخاصة بالخطوط الأنابيب، والتي تُجرِّد كل التعقيد من أجلك، أو باستخدام فئة `SiglipModel` بنفسك.
+
+### واجهة برمجة التطبيقات الخاصة بالخطوط الأنابيب
+
+تسمح واجهة برمجة التطبيقات باستخدام النموذج في بضع سطور من الكود:
+
+```python
+>>> from transformers import pipeline
+>>> from PIL import Image
+>>> import requests
+
+>>> # تحميل الأنبوب
+>>> image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-base-patch16-224")
+
+>>> # تحميل الصورة
+>>> url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> # الاستنتاج
+>>> outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
+>>> outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
+>>> print(outputs)
+[{'score': 0.1979, 'label': '2 cats'}, {'score': 0.0, 'label': 'a remote'}, {'score': 0.0, 'label': 'a plane'}]
+```
+
+### استخدام النموذج بنفسك
+
+إذا كنت تريد القيام بالمعالجة المسبقة واللاحقة بنفسك، فهذا هو ما يجب فعله:
+
+```python
+>>> from PIL import Image
+>>> import requests
+>>> from transformers import AutoProcessor, AutoModel
+>>> import torch
+
+>>> model = AutoModel.from_pretrained("google/siglip-base-patch16-224")
+>>> processor = AutoProcessor.from_pretrained("google/siglip-base-patch16-224")
+
+>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+>>> image = Image.open(requests.get(url, stream=True).raw)
+
+>>> texts = ["a photo of 2 cats", "a photo of 2 dogs"]
+>>> # من المهم: نمرر `padding=max_length` حيث تم تدريب النموذج بهذه الطريقة
+>>> inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
+
+>>> with torch.no_grad():
+... outputs = model(**inputs)
+
+>>> logits_per_image = outputs.logits_per_image
+>>> probs = torch.sigmoid(logits_per_image) # هذه هي الاحتمالات
+>>> print(f"{probs[0][0]:.1%} احتمال أن تكون الصورة 0 هي '{texts[0]}'")
+31.9% احتمال أن تكون الصورة 0 هي 'a photo of 2 cats'
+```
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام SigLIP.
+
+- [دليل مهام التصنيف الصوري بدون إشراف](../tasks/zero_shot_image_classification_md)
+
+- يمكن العثور على دفاتر الملاحظات التجريبية لـ SigLIP [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SigLIP). 🌎
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنراجعه! يجب أن يُظهر المورد بشكل مثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## SiglipConfig
+
+[[autodoc]] SiglipConfig
+
+- from_text_vision_configs
+
+## SiglipTextConfig
+
+[[autodoc]] SiglipTextConfig
+
+## SiglipVisionConfig
+
+[[autodoc]] SiglipVisionConfig
+
+## SiglipTokenizer
+
+[[autodoc]] SiglipTokenizer
+
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## SiglipImageProcessor
+
+[[autodoc]] SiglipImageProcessor
+
+- preprocess
+
+## SiglipProcessor
+
+[[autodoc]] SiglipProcessor
+
+## SiglipModel
+
+[[autodoc]] SiglipModel
+
+- forward
+- get_text_features
+- get_image_features
+
+## SiglipTextModel
+
+[[autodoc]] SiglipTextModel
+
+- forward
+
+## SiglipVisionModel
+
+[[autodoc]] SiglipVisionModel
+
+- forward
+
+## SiglipForImageClassification
+
+[[autodoc]] SiglipForImageClassification
+
+- forward
\ No newline at end of file
From 37cffebc170edbdc2d5486b5803a6adb45e7f95d Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:23 +0300
Subject: [PATCH 573/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/speech-encoder-decoder.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
.../ar/model_doc/speech-encoder-decoder.md | 117 ++++++++++++++++++
1 file changed, 117 insertions(+)
create mode 100644 docs/source/ar/model_doc/speech-encoder-decoder.md
diff --git a/docs/source/ar/model_doc/speech-encoder-decoder.md b/docs/source/ar/model_doc/speech-encoder-decoder.md
new file mode 100644
index 00000000000000..9015e27cd94dfe
--- /dev/null
+++ b/docs/source/ar/model_doc/speech-encoder-decoder.md
@@ -0,0 +1,117 @@
+# نماذج الترميز فك الترميز الصوتي
+
+يمكن استخدام [`SpeechEncoderDecoderModel`] لتهيئة نموذج تحويل الكلام إلى نص باستخدام أي نموذج ترميز ذاتي التعلم مسبقًا للكلام كترميز (*e.g.* [Wav2Vec2](wav2vec2)، [Hubert](hubert)) وأي نموذج توليدي مسبق التدريب كفك تشفير.
+
+وقد تم إثبات فعالية تهيئة النماذج التسلسلية للكلام إلى تسلسلات نصية باستخدام نقاط تفتيش مسبقة التدريب للتعرف على الكلام وترجمته على سبيل المثال في [Large-Scale Self- and Semi-Supervised Learning for Speech Translation](https://arxiv.org/abs/2104.06678) بواسطة Changhan Wang وAnne Wu وJuan Pino وAlexei Baevski وMichael Auli وAlexis Conneau.
+
+يمكن الاطلاع على مثال حول كيفية استخدام [`SpeechEncoderDecoderModel`] للاستنتاج في [Speech2Text2](speech_to_text_2).
+
+## تهيئة `SpeechEncoderDecoderModel` بشكل عشوائي من تكوينات النموذج.
+
+يمكن تهيئة [`SpeechEncoderDecoderModel`] بشكل عشوائي من تكوين الترميز وفك الترميز. في المثال التالي، نوضح كيفية القيام بذلك باستخدام تكوين [`Wav2Vec2Model`] الافتراضي للترميز
+وتكوين [`BertForCausalLM`] الافتراضي لفك الترميز.
+
+```python
+>>> from transformers import BertConfig, Wav2Vec2Config, SpeechEncoderDecoderConfig, SpeechEncoderDecoderModel
+
+>>> config_encoder = Wav2Vec2Config()
+>>> config_decoder = BertConfig()
+
+>>> config = SpeechEncoderDecoderConfig.from_encoder_decoder_configs(config_encoder, config_decoder)
+>>> model = SpeechEncoderDecoderModel(config=config)
+```
+
+## تهيئة `SpeechEncoderDecoderModel` من ترميز وفك تشفير مُدرَّب مسبقًا.
+
+يمكن تهيئة [`SpeechEncoderDecoderModel`] من نقطة تفتيش ترميز مُدرَّب مسبقًا ونقطة تفتيش فك تشفير مُدرَّب مسبقًا. لاحظ أن أي نموذج كلام قائم على Transformer، مثل [Wav2Vec2](wav2vec2) أو [Hubert](hubert) يمكن أن يعمل كترميز، في حين يمكن استخدام كل من النماذج الذاتية الترميز المُدرَّبة مسبقًا، مثل BERT، ونماذج اللغة السببية المُدرَّبة مسبقًا، مثل GPT2، بالإضافة إلى الجزء المدرَّب مسبقًا من فك تشفير نماذج التسلسل إلى تسلسل، مثل فك تشفير BART، كفك تشفير.
+
+اعتمادًا على البنية التي تختارها كفك تشفير، قد يتم تهيئة طبقات الاهتمام المتقاطع بشكل عشوائي.
+
+تتطلب تهيئة [`SpeechEncoderDecoderModel`] من نقطة تفتيش ترميز وفك تشفير مُدرَّب مسبقًا تهيئة النموذج الدقيقة على مهمة أسفل النهر، كما هو موضح في [منشور المدونة *Warm-starting-encoder-decoder*](https://huggingface.co/blog/warm-starting-encoder-decoder).
+
+للقيام بذلك، توفر فئة `SpeechEncoderDecoderModel` طريقة [`SpeechEncoderDecoderModel.from_encoder_decoder_pretrained`].
+
+```python
+>>> from transformers import SpeechEncoderDecoderModel
+
+>>> model = SpeechEncoderDecoderModel.from_encoder_decoder_pretrained(
+... "facebook/hubert-large-ll60k", "google-bert/bert-base-uncased"
+... )
+```
+
+## تحميل نقطة تفتيش `SpeechEncoderDecoderModel` موجودة والقيام بالاستدلال.
+
+لتحميل نقاط تفتيش مُدرَّبة دقيقة من فئة `SpeechEncoderDecoderModel`، توفر [`SpeechEncoderDecoderModel`] طريقة `from_pretrained(...)` مثل أي بنية نموذج أخرى في Transformers.
+
+للقيام بالاستدلال، يمكنك استخدام طريقة [`generate`]، والتي تسمح بتوليد النص بشكل تلقائي. تدعم هذه الطريقة أشكالًا مختلفة من فك التشفير، مثل الجشع، وبحث الشعاع، وأخذ العينات متعددة الحدود.
+
+```python
+>>> from transformers import Wav2Vec2Processor, SpeechEncoderDecoderModel
+>>> from datasets import load_dataset
+>>> import torch
+
+>>> # تحميل نموذج ترجمة كلام مُدرَّب دقيق ومعالج مطابق
+>>> model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
+>>> processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
+
+>>> # لنقم بالاستدلال على قطعة من الكلام باللغة الإنجليزية (والتي سنترجمها إلى الألمانية)
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
+
+>>> # توليد النسخ النصي تلقائيًا (يستخدم فك التشفير الجشع بشكل افتراضي)
+>>> generated_ids = model.generate(input_values)
+>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+>>> print(generated_text)
+Mr. Quilter ist der Apostel der Mittelschicht und wir freuen uns, sein Evangelium willkommen heißen zu können.
+```
+
+## التدريب
+
+بمجرد إنشاء النموذج، يمكن ضبطه بشكل دقيق مثل BART أو T5 أو أي نموذج ترميز وفك تشفير آخر على مجموعة بيانات من أزواج (كلام، نص).
+
+كما ترى، يلزم إدخالان فقط للنموذج من أجل حساب الخسارة: `input_values` (وهي إدخالات الكلام) و`labels` (وهي `input_ids` للتسلسل المستهدف المشفر).
+
+```python
+>>> from transformers import AutoTokenizer, AutoFeatureExtractor, SpeechEncoderDecoderModel
+>>> from datasets import load_dataset
+
+>>> encoder_id = "facebook/wav2vec2-base-960h" # ترميز النموذج الصوتي
+>>> decoder_id = "google-bert/bert-base-uncased" # فك تشفير النص
+
+>>> feature_extractor = AutoFeatureExtractor.from_pretrained(encoder_id)
+>>> tokenizer = AutoTokenizer.from_pretrained(decoder_id)
+>>> # دمج الترميز المُدرَّب مسبقًا وفك الترميز المُدرَّب مسبقًا لتشكيل نموذج تسلسل إلى تسلسل
+>>> model = SpeechEncoderDecoderModel.from_encoder_decoder_pretrained(encoder_id, decoder_id)
+
+>>> model.config.decoder_start_token_id = tokenizer.cls_token_
+>>> model.config.pad_token_id = tokenizer.pad_token_id
+
+>>> # تحميل إدخال صوتي ومعالجته مسبقًا (تطبيع المتوسط/الانحراف المعياري إلى 0/1)
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+>>> input_values = feature_extractor(ds[0]["audio"]["array"], return_tensors="pt").input_values
+
+>>> # تحميل النسخ النصي المقابل له وتشفيره لإنشاء العلامات
+>>> labels = tokenizer(ds[0]["text"], return_tensors="pt").input_ids
+
+>>> # تقوم دالة التقديم تلقائيًا بإنشاء decoder_input_ids الصحيحة
+>>> loss = model(input_values=input_values, labels=labels).loss
+>>> loss.backward()
+```
+
+## SpeechEncoderDecoderConfig
+
+[[autodoc]] SpeechEncoderDecoderConfig
+
+## SpeechEncoderDecoderModel
+
+[[autodoc]] SpeechEncoderDecoderModel
+
+- forward
+- from_encoder_decoder_pretrained
+
+## FlaxSpeechEncoderDecoderModel
+
+[[autodoc]] FlaxSpeechEncoderDecoderModel
+
+- __call__
+- from_encoder_decoder_pretrained
\ No newline at end of file
From 30997d5c614fa5baff8cbf734c7a29ed6a6d9b23 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:25 +0300
Subject: [PATCH 574/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/speecht5.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/speecht5.md | 87 ++++++++++++++++++++++++++++
1 file changed, 87 insertions(+)
create mode 100644 docs/source/ar/model_doc/speecht5.md
diff --git a/docs/source/ar/model_doc/speecht5.md b/docs/source/ar/model_doc/speecht5.md
new file mode 100644
index 00000000000000..083fb4365dff7b
--- /dev/null
+++ b/docs/source/ar/model_doc/speecht5.md
@@ -0,0 +1,87 @@
+# SpeechT5
+
+## نظرة عامة
+
+اقترح نموذج SpeechT5 في بحث "SpeechT5: Unified-Modal Encoder-Decoder Pre-Training for Spoken Language Processing" من قبل Junyi Ao وآخرون.
+
+ملخص البحث هو كما يلي:
+
+*انطلاقًا من نجاح نموذج T5 (Text-To-Text Transfer Transformer) في معالجة اللغات الطبيعية المدَربة مسبقًا، نقترح إطار عمل SpeechT5 الموحد للطريقة الذي يستكشف التدريب المسبق للترميز فك الترميز للتعلم الذاتي التمثيل اللغوي المنطوق/المكتوب. ويتكون إطار عمل SpeechT5 من شبكة ترميز وفك ترميز مشتركة وست شبكات محددة للطريقة (منطوقة/مكتوبة) للمراحل السابقة/اللاحقة. وبعد معالجة المدخلات المنطوقة/المكتوبة من خلال المراحل السابقة، تقوم شبكة الترميز وفك الترميز المشتركة بنمذجة التحويل من سلسلة إلى أخرى، ثم تقوم المراحل اللاحقة بتوليد المخرجات في طريقة الكلام/النص بناءً على مخرجات فك الترميز. وباستخدام البيانات الكبيرة غير الموسومة للكلام والنص، نقوم بتدريب SpeechT5 مسبقًا لتعلم تمثيل موحد للطريقة، على أمل تحسين قدرة النمذجة لكل من الكلام والنص. ولمواءمة المعلومات النصية والمنطوقة في هذه المساحة الدلالية الموحدة، نقترح نهجًا للتحليل الكمي متعدد الطرق الذي يخلط عشوائيًا حالات الكلام/النص مع الوحدات الكامنة كوسيط بين الترميز وفك الترميز. وتظهر التقييمات الشاملة تفوق إطار عمل SpeechT5 المقترح في مجموعة واسعة من مهام معالجة اللغة المنطوقة، بما في ذلك التعرف التلقائي على الكلام، وتوليف الكلام، وترجمة الكلام، وتحويل الصوت، وتحسين الكلام، والتعرف على المتحدث.*
+
+تمت المساهمة بهذا النموذج من قبل [Matthijs](https://huggingface.co/Matthijs). ويمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/SpeechT5).
+
+## SpeechT5Config
+
+[[autodoc]] SpeechT5Config
+
+## SpeechT5HifiGanConfig
+
+[[autodoc]] SpeechT5HifiGanConfig
+
+## SpeechT5Tokenizer
+
+[[autodoc]] SpeechT5Tokenizer
+
+- __call__
+
+- save_vocabulary
+
+- decode
+
+- batch_decode
+
+## SpeechT5FeatureExtractor
+
+[[autodoc]] SpeechT5FeatureExtractor
+
+- __call__
+
+## SpeechT5Processor
+
+[[autodoc]] SpeechT5Processor
+
+- __call__
+
+- pad
+
+- from_pretrained
+
+- save_pretrained
+
+- batch_decode
+
+- decode
+
+## SpeechT5Model
+
+[[autodoc]] SpeechT5Model
+
+- forward
+
+## SpeechT5ForSpeechToText
+
+[[autodoc]] SpeechT5ForSpeechToText
+
+- forward
+
+## SpeechT5ForTextToSpeech
+
+[[autodoc]] SpeechT5ForTextToSpeech
+
+- forward
+
+- generate
+
+## SpeechT5ForSpeechToSpeech
+
+[[autodoc]] SpeechT5ForSpeechToSpeech
+
+- forward
+
+- generate_speech
+
+## SpeechT5HifiGan
+
+[[autodoc]] SpeechT5HifiGan
+
+- forward
\ No newline at end of file
From 0e796c4a31c75e2ba28d419563efb00b5b74a9d7 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:27 +0300
Subject: [PATCH 575/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/speech=5Fto=5Ftext.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/speech_to_text.md | 126 +++++++++++++++++++++
1 file changed, 126 insertions(+)
create mode 100644 docs/source/ar/model_doc/speech_to_text.md
diff --git a/docs/source/ar/model_doc/speech_to_text.md b/docs/source/ar/model_doc/speech_to_text.md
new file mode 100644
index 00000000000000..b08bf16bffc74c
--- /dev/null
+++ b/docs/source/ar/model_doc/speech_to_text.md
@@ -0,0 +1,126 @@
+# Speech2Text
+
+## نظرة عامة
+تم اقتراح نموذج Speech2Text في [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) بواسطة Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. وهو عبارة عن نموذج تسلسل إلى تسلسل (ترميز فك الترميز) يعتمد على المحول المصمم للتعرف التلقائي على الكلام (ASR) وترجمة الكلام (ST). يستخدم مخفضًا للتعرّف على الشكل لتقصير طول إدخالات الكلام بمقدار 3/4 قبل إدخالها في الترميز. يتم تدريب النموذج باستخدام خسارة ذاتي الارتباط عبر الإنتروبيا القياسية ويولد النسخ/الترجمات ذاتيًا. تم ضبط نموذج Speech2Text بشكل دقيق على العديد من مجموعات البيانات لـ ASR و ST: [LibriSpeech](http://www.openslr.org/12)، [CoVoST 2](https://github.com/facebookresearch/covost)، [MuST-C](https://ict.fbk.eu/must-c/).
+
+تمت المساهمة بهذا النموذج من قبل [valhalla](https://huggingface.co/valhalla). يمكن العثور على الكود الأصلي [هنا](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text).
+
+## الاستنتاج
+Speech2Text هو نموذج كلام يقبل Tensor عائمًا لميزات بنك التصفية اللوغاريتمية المستخرجة من إشارة الكلام. إنه نموذج تسلسل إلى تسلسل يعتمد على المحول، لذلك يتم إنشاء النسخ/الترجمات ذاتيًا. يمكن استخدام طريقة `generate()` للاستدلال.
+
+تعد فئة [`Speech2TextFeatureExtractor`] مسؤولة عن استخراج ميزات بنك التصفية اللوغاريتمية. يجمع [`Speech2TextProcessor`] [`Speech2TextFeatureExtractor`] و [`Speech2TextTokenizer`] في مثيل واحد لاستخراج ميزات الإدخال وفك تشفير معرّفات الرموز المتوقعة.
+
+يعتمد المستخرج المميز على `torchaudio` ويعتمد الرمز المميز على `sentencepiece`، لذا تأكد من تثبيت هذه الحزم قبل تشغيل الأمثلة. يمكنك تثبيت تلك الحزم كاعتمادات كلام إضافية مع `pip install transformers"[speech, sentencepiece]"` أو تثبيت الحزم بشكل منفصل باستخدام `pip install torchaudio sentencepiece`. يتطلب `torchaudio` أيضًا الإصدار التنموي من حزمة [libsndfile](http://www.mega-nerd.com/libsndfile/) والتي يمكن تثبيتها عبر مدير حزم النظام. على Ubuntu، يمكن تثبيته على النحو التالي: `apt install libsndfile1-dev`
+
+- التعرف على الكلام وترجمة الكلام
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
+
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
+
+>>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> transcription
+['mister quilter is the apostle of the middle classes and we are glad to welcome his gospel']
+```
+
+- ترجمة الكلام متعددة اللغات
+
+بالنسبة لنماذج ترجمة الكلام متعددة اللغات، يتم استخدام `eos_token_id` كـ `decoder_start_token_id`
+ويتم فرض معرف لغة الهدف كرابع رمز مولد. لفرض معرف لغة الهدف كرابع رمز مولد، قم بتمرير معلمة `forced_bos_token_id` إلى طريقة `generate()`. يوضح المثال التالي كيفية ترجمة الكلام باللغة الإنجليزية إلى نص باللغة الفرنسية باستخدام نقطة تفتيش *facebook/s2t-medium-mustc-multilingual-st*.
+
+```python
+>>> import torch
+>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
+>>> from datasets import load_dataset
+
+>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
+
+>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
+
+>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
+>>> generated_ids = model.generate(
+... inputs["input_features"],
+... attention_mask=inputs["attention_mask"],
+... forced_bos_token_id=processor.tokenizer.lang_code_to_id["fr"],
+... )
+
+>>> translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
+>>> translation
+["(Vidéo) Si M. Kilder est l'apossible des classes moyennes, et nous sommes heureux d'être accueillis dans son évangile."]
+```
+
+راجع [نموذج المركز](https://huggingface.co/models؟filter=speech_to_text) للبحث عن نقاط تفتيش Speech2Text.
+
+## Speech2TextConfig
+
+[[autodoc]] Speech2TextConfig
+
+## Speech2TextTokenizer
+
+[[autodoc]] Speech2TextTokenizer
+
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## Speech2TextFeatureExtractor
+
+[[autodoc]] Speech2TextFeatureExtractor
+
+- __call__
+
+## Speech2TextProcessor
+
+[[autodoc]] Speech2TextProcessor
+
+- __call__
+- from_pretrained
+- save_pretrained
+- batch_decode
+- decode
+
+ +
+نظرة عامة على SuperPoint. مأخوذة من الورقة البحثية الأصلية.
+
+## نصائح الاستخدام
+
+فيما يلي مثال سريع على استخدام النموذج للكشف عن نقاط الاهتمام في صورة:
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(image, return_tensors="pt")
+outputs = model(**inputs)
+```
+
+تحتوي الإخراجات على قائمة إحداثيات نقاط الاهتمام مع درجاتها ووصفها (متجه بطول 256).
+
+يمكنك أيضًا إدخال صور متعددة إلى النموذج. وبسبب طبيعة SuperPoint، لإخراج عدد متغير من نقاط الاهتمام، ستحتاج إلى استخدام خاصية القناع (mask) لاسترجاع المعلومات المقابلة:
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url_image_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image_1 = Image.open(requests.get(url_image_1, stream=True).raw)
+url_image_2 = "http://images.cocodataset.org/test-stuff2017/000000000568.jpg"
+image_2 = Image.open(requests.get(url_image_2, stream=True).raw)
+
+images = [image_1, image_2]
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(images, return_tensors="pt")
+outputs = model(**inputs)
+
+for i in range(len(images)):
+ image_mask = outputs.mask[i]
+ image_indices = torch.nonzero(image_mask).squeeze()
+ image_keypoints = outputs.keypoints[i][image_indices]
+ image_scores = outputs.scores[i][image_indices]
+ image_descriptors = outputs.descriptors[i][image_indices]
+```
+
+بعد ذلك، يمكنك طباعة نقاط الاهتمام على الصورة لتصور النتيجة:
+
+```python
+import cv2
+for keypoint, score in zip(image_keypoints, image_scores):
+ keypoint_x, keypoint_y = int(keypoint[0].item()), int(keypoint[1].item())
+ color = tuple([score.item() * 255] * 3)
+ image = cv2.circle(image, (keypoint_x, keypoint_y), 2, color)
+cv2.imwrite("output_image.png", image)
+```
+
+تمت المساهمة بهذا النموذج من قبل [stevenbucaille](https://huggingface.co/stevenbucaille). ويمكن العثور على الكود الأصلي [هنا](https://github.com/magicleap/SuperPointPretrainedNetwork).
+
+## الموارد
+
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها برمز 🌎) لمساعدتك في البدء باستخدام SuperPoint. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب (Pull Request) وسنقوم بمراجعته! ويفضل أن يُظهر المورد شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+- يمكن العثور على دفتر ملاحظات يُظهر الاستنتاج والتصور باستخدام SuperPoint [هنا](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SuperPoint/Inference_with_SuperPoint_to_detect_interest_points_in_an_image.ipynb). 🌎
+
+## SuperPointConfig
+
+[[autodoc]] SuperPointConfig
+
+## SuperPointImageProcessor
+
+[[autodoc]] SuperPointImageProcessor
+
+- preprocess
+
+## SuperPointForKeypointDetection
+
+[[autodoc]] SuperPointForKeypointDetection
+
+- forward
\ No newline at end of file
From 7fd5340238d4109448ea7dd1bd97343e7939e916 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:39 +0300
Subject: [PATCH 582/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/swiftformer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/swiftformer.md | 41 +++++++++++++++++++++++++
1 file changed, 41 insertions(+)
create mode 100644 docs/source/ar/model_doc/swiftformer.md
diff --git a/docs/source/ar/model_doc/swiftformer.md b/docs/source/ar/model_doc/swiftformer.md
new file mode 100644
index 00000000000000..b5133e2e9e2f54
--- /dev/null
+++ b/docs/source/ar/model_doc/swiftformer.md
@@ -0,0 +1,41 @@
+# SwiftFormer
+
+## نظرة عامة
+
+اقترح نموذج SwiftFormer في ورقة "SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications" بواسطة Abdelrahman Shaker وآخرون. يقدم هذا البحث آلية اهتمام إضافية فعالة تحل محل عمليات الضرب المعقدة في المصفوفات التربيعية في حساب الاهتمام الذاتي بعمليات ضرب العناصر الخطية. وبناءً على ذلك، تم بناء سلسلة من النماذج تسمى "SwiftFormer" والتي حققت أداءً متميزًا من حيث الدقة وسرعة الاستدلال على الأجهزة المحمولة. حتى أن متغيرها الصغير يحقق دقة أعلى من 78.5٪ مع تأخير 0.8 مللي ثانية فقط على iPhone 14، وهو أكثر دقة وسرعة مقارنة بـ MobileViT-v2.
+
+فيما يلي الملخص من الورقة:
+
+> "أصبح الاهتمام الذاتي خيارًا فعليًا لالتقاط السياق العالمي في مختلف تطبيقات الرؤية. ومع ذلك، فإن تعقيده الحسابي التربيعي فيما يتعلق بدقة الصورة يحد من استخدامه في التطبيقات في الوقت الفعلي، خاصة عند نشره على الأجهزة المحمولة المقيدة بالموارد. على الرغم من اقتراح الأساليب الهجينة لدمج مزايا التحويلات والاهتمام الذاتي من أجل تحقيق توازن أفضل بين السرعة والدقة، إلا أن عمليات ضرب المصفوفات المكلفة في الاهتمام الذاتي لا تزال تشكل عنق زجاجة. في هذا العمل، نقدم آلية اهتمام إضافية فعالة تحل بشكل فعال محل عمليات ضرب المصفوفات التربيعية بعمليات ضرب العناصر الخطية. ويظهر تصميمها أنه يمكن استبدال التفاعل بين المفتاح والقيمة بطبقة خطية دون التضحية بأي دقة. على عكس الأساليب المتميزة السابقة، يمكّن صيغتنا الفعالة للاهتمام الذاتي من استخدامها في جميع مراحل الشبكة. باستخدام الاهتمام الإضافي الفعال المقترح، نقوم ببناء سلسلة من النماذج تسمى "SwiftFormer" والتي تحقق أداءً متميزًا من حيث الدقة وسرعة الاستدلال على الأجهزة المحمولة. يحقق متغيرنا الصغير دقة أعلى من 78.5٪ في ImageNet-1K مع تأخير 0.8 مللي ثانية فقط على iPhone 14، وهو أكثر دقة وسرعة مقارنة بـ MobileViT-v2."
+
+تمت المساهمة بهذا النموذج بواسطة [shehan97](https://huggingface.co/shehan97). تمت المساهمة في إصدار TensorFlow بواسطة [joaocmd](https://huggingface.co/joaocmd).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/Amshaker/SwiftFormer).
+
+## SwiftFormerConfig
+
+[[autodoc]] SwiftFormerConfig
+
+## SwiftFormerModel
+
+[[autodoc]] SwiftFormerModel
+
+- forward
+
+## SwiftFormerForImageClassification
+
+[[autodoc]] SwiftFormerForImageClassification
+
+- forward
+
+## TFSwiftFormerModel
+
+[[autodoc]] TFSwiftFormerModel
+
+- call
+
+## TFSwiftFormerForImageClassification
+
+[[autodoc]] TFSwiftFormerForImageClassification
+
+- call
\ No newline at end of file
From 5291b09f5a16cb2433723bcd93d3ddade9b84bac Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:41 +0300
Subject: [PATCH 583/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/swin.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/swin.md | 83 ++++++++++++++++++++++++++++++++
1 file changed, 83 insertions(+)
create mode 100644 docs/source/ar/model_doc/swin.md
diff --git a/docs/source/ar/model_doc/swin.md b/docs/source/ar/model_doc/swin.md
new file mode 100644
index 00000000000000..dc0a90ab75df9d
--- /dev/null
+++ b/docs/source/ar/model_doc/swin.md
@@ -0,0 +1,83 @@
+# Swin Transformer
+
+## نظرة عامة
+
+تم اقتراح محول Swin في [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) بواسطة Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+
+الملخص من الورقة هو ما يلي:
+
+*تقدم هذه الورقة محول رؤية جديد، يسمى Swin Transformer، والذي يمكن أن يعمل كعمود فقري للأغراض العامة في مجال الرؤية الحاسوبية. تنشأ التحديات في تكييف المحول من اللغة إلى الرؤية من الاختلافات بين المجالين، مثل الاختلافات الكبيرة في مقاييس الكيانات المرئية ودقة بكسلات الصور مقارنة بالكلمات في النص. لمعالجة هذه الاختلافات، نقترح محولًا هرميًا يتم حساب تمثيله باستخدام نوافذ منزاحة. يجلب نظام النوافذ المنزاحة كفاءة أكبر من خلال الحد من حساب الاهتمام الذاتي إلى نوافذ محلية غير متداخلة مع السماح أيضًا بالاتصال عبر النوافذ. يتميز هذا التصميم الهرمي بالمرونة في النمذجة على نطاقات مختلفة وله تعقيد حسابي خطي فيما يتعلق بحجم الصورة. تجعل هذه الخصائص من محول Swin متوافقًا مع مجموعة واسعة من مهام الرؤية، بما في ذلك تصنيف الصور (87.3 دقة أعلى-1 على ImageNet-1K) ومهام التنبؤ الكثيفة مثل اكتشاف الأجسام (58.7 AP للصندوق و51.1 AP للقناع على COCO test-dev) والتجزئة الدلالية (53.5 mIoU على ADE20K val). تتفوق أداءه على الحالة السابقة للفن بهامش كبير يبلغ +2.7 AP للصندوق و+2.6 AP للقناع على COCO، و+3.2 mIoU على ADE20K، مما يثبت الإمكانات الكبيرة للنماذج المستندة إلى المحول كعمود فقري للرؤية. كما أثبت التصميم الهرمي ونهج النافذة المنزاحة فائدتهما لتصميمات MLP بالكامل.*
+
+
+
+نظرة عامة على SuperPoint. مأخوذة من الورقة البحثية الأصلية.
+
+## نصائح الاستخدام
+
+فيما يلي مثال سريع على استخدام النموذج للكشف عن نقاط الاهتمام في صورة:
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image = Image.open(requests.get(url, stream=True).raw)
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(image, return_tensors="pt")
+outputs = model(**inputs)
+```
+
+تحتوي الإخراجات على قائمة إحداثيات نقاط الاهتمام مع درجاتها ووصفها (متجه بطول 256).
+
+يمكنك أيضًا إدخال صور متعددة إلى النموذج. وبسبب طبيعة SuperPoint، لإخراج عدد متغير من نقاط الاهتمام، ستحتاج إلى استخدام خاصية القناع (mask) لاسترجاع المعلومات المقابلة:
+
+```python
+from transformers import AutoImageProcessor, SuperPointForKeypointDetection
+import torch
+from PIL import Image
+import requests
+
+url_image_1 = "http://images.cocodataset.org/val2017/000000039769.jpg"
+image_1 = Image.open(requests.get(url_image_1, stream=True).raw)
+url_image_2 = "http://images.cocodataset.org/test-stuff2017/000000000568.jpg"
+image_2 = Image.open(requests.get(url_image_2, stream=True).raw)
+
+images = [image_1, image_2]
+
+processor = AutoImageProcessor.from_pretrained("magic-leap-community/superpoint")
+model = SuperPointForKeypointDetection.from_pretrained("magic-leap-community/superpoint")
+
+inputs = processor(images, return_tensors="pt")
+outputs = model(**inputs)
+
+for i in range(len(images)):
+ image_mask = outputs.mask[i]
+ image_indices = torch.nonzero(image_mask).squeeze()
+ image_keypoints = outputs.keypoints[i][image_indices]
+ image_scores = outputs.scores[i][image_indices]
+ image_descriptors = outputs.descriptors[i][image_indices]
+```
+
+بعد ذلك، يمكنك طباعة نقاط الاهتمام على الصورة لتصور النتيجة:
+
+```python
+import cv2
+for keypoint, score in zip(image_keypoints, image_scores):
+ keypoint_x, keypoint_y = int(keypoint[0].item()), int(keypoint[1].item())
+ color = tuple([score.item() * 255] * 3)
+ image = cv2.circle(image, (keypoint_x, keypoint_y), 2, color)
+cv2.imwrite("output_image.png", image)
+```
+
+تمت المساهمة بهذا النموذج من قبل [stevenbucaille](https://huggingface.co/stevenbucaille). ويمكن العثور على الكود الأصلي [هنا](https://github.com/magicleap/SuperPointPretrainedNetwork).
+
+## الموارد
+
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها برمز 🌎) لمساعدتك في البدء باستخدام SuperPoint. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب (Pull Request) وسنقوم بمراجعته! ويفضل أن يُظهر المورد شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+- يمكن العثور على دفتر ملاحظات يُظهر الاستنتاج والتصور باستخدام SuperPoint [هنا](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SuperPoint/Inference_with_SuperPoint_to_detect_interest_points_in_an_image.ipynb). 🌎
+
+## SuperPointConfig
+
+[[autodoc]] SuperPointConfig
+
+## SuperPointImageProcessor
+
+[[autodoc]] SuperPointImageProcessor
+
+- preprocess
+
+## SuperPointForKeypointDetection
+
+[[autodoc]] SuperPointForKeypointDetection
+
+- forward
\ No newline at end of file
From 7fd5340238d4109448ea7dd1bd97343e7939e916 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:39 +0300
Subject: [PATCH 582/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/swiftformer.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/swiftformer.md | 41 +++++++++++++++++++++++++
1 file changed, 41 insertions(+)
create mode 100644 docs/source/ar/model_doc/swiftformer.md
diff --git a/docs/source/ar/model_doc/swiftformer.md b/docs/source/ar/model_doc/swiftformer.md
new file mode 100644
index 00000000000000..b5133e2e9e2f54
--- /dev/null
+++ b/docs/source/ar/model_doc/swiftformer.md
@@ -0,0 +1,41 @@
+# SwiftFormer
+
+## نظرة عامة
+
+اقترح نموذج SwiftFormer في ورقة "SwiftFormer: Efficient Additive Attention for Transformer-based Real-time Mobile Vision Applications" بواسطة Abdelrahman Shaker وآخرون. يقدم هذا البحث آلية اهتمام إضافية فعالة تحل محل عمليات الضرب المعقدة في المصفوفات التربيعية في حساب الاهتمام الذاتي بعمليات ضرب العناصر الخطية. وبناءً على ذلك، تم بناء سلسلة من النماذج تسمى "SwiftFormer" والتي حققت أداءً متميزًا من حيث الدقة وسرعة الاستدلال على الأجهزة المحمولة. حتى أن متغيرها الصغير يحقق دقة أعلى من 78.5٪ مع تأخير 0.8 مللي ثانية فقط على iPhone 14، وهو أكثر دقة وسرعة مقارنة بـ MobileViT-v2.
+
+فيما يلي الملخص من الورقة:
+
+> "أصبح الاهتمام الذاتي خيارًا فعليًا لالتقاط السياق العالمي في مختلف تطبيقات الرؤية. ومع ذلك، فإن تعقيده الحسابي التربيعي فيما يتعلق بدقة الصورة يحد من استخدامه في التطبيقات في الوقت الفعلي، خاصة عند نشره على الأجهزة المحمولة المقيدة بالموارد. على الرغم من اقتراح الأساليب الهجينة لدمج مزايا التحويلات والاهتمام الذاتي من أجل تحقيق توازن أفضل بين السرعة والدقة، إلا أن عمليات ضرب المصفوفات المكلفة في الاهتمام الذاتي لا تزال تشكل عنق زجاجة. في هذا العمل، نقدم آلية اهتمام إضافية فعالة تحل بشكل فعال محل عمليات ضرب المصفوفات التربيعية بعمليات ضرب العناصر الخطية. ويظهر تصميمها أنه يمكن استبدال التفاعل بين المفتاح والقيمة بطبقة خطية دون التضحية بأي دقة. على عكس الأساليب المتميزة السابقة، يمكّن صيغتنا الفعالة للاهتمام الذاتي من استخدامها في جميع مراحل الشبكة. باستخدام الاهتمام الإضافي الفعال المقترح، نقوم ببناء سلسلة من النماذج تسمى "SwiftFormer" والتي تحقق أداءً متميزًا من حيث الدقة وسرعة الاستدلال على الأجهزة المحمولة. يحقق متغيرنا الصغير دقة أعلى من 78.5٪ في ImageNet-1K مع تأخير 0.8 مللي ثانية فقط على iPhone 14، وهو أكثر دقة وسرعة مقارنة بـ MobileViT-v2."
+
+تمت المساهمة بهذا النموذج بواسطة [shehan97](https://huggingface.co/shehan97). تمت المساهمة في إصدار TensorFlow بواسطة [joaocmd](https://huggingface.co/joaocmd).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/Amshaker/SwiftFormer).
+
+## SwiftFormerConfig
+
+[[autodoc]] SwiftFormerConfig
+
+## SwiftFormerModel
+
+[[autodoc]] SwiftFormerModel
+
+- forward
+
+## SwiftFormerForImageClassification
+
+[[autodoc]] SwiftFormerForImageClassification
+
+- forward
+
+## TFSwiftFormerModel
+
+[[autodoc]] TFSwiftFormerModel
+
+- call
+
+## TFSwiftFormerForImageClassification
+
+[[autodoc]] TFSwiftFormerForImageClassification
+
+- call
\ No newline at end of file
From 5291b09f5a16cb2433723bcd93d3ddade9b84bac Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:41 +0300
Subject: [PATCH 583/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/swin.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/swin.md | 83 ++++++++++++++++++++++++++++++++
1 file changed, 83 insertions(+)
create mode 100644 docs/source/ar/model_doc/swin.md
diff --git a/docs/source/ar/model_doc/swin.md b/docs/source/ar/model_doc/swin.md
new file mode 100644
index 00000000000000..dc0a90ab75df9d
--- /dev/null
+++ b/docs/source/ar/model_doc/swin.md
@@ -0,0 +1,83 @@
+# Swin Transformer
+
+## نظرة عامة
+
+تم اقتراح محول Swin في [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030) بواسطة Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
+
+الملخص من الورقة هو ما يلي:
+
+*تقدم هذه الورقة محول رؤية جديد، يسمى Swin Transformer، والذي يمكن أن يعمل كعمود فقري للأغراض العامة في مجال الرؤية الحاسوبية. تنشأ التحديات في تكييف المحول من اللغة إلى الرؤية من الاختلافات بين المجالين، مثل الاختلافات الكبيرة في مقاييس الكيانات المرئية ودقة بكسلات الصور مقارنة بالكلمات في النص. لمعالجة هذه الاختلافات، نقترح محولًا هرميًا يتم حساب تمثيله باستخدام نوافذ منزاحة. يجلب نظام النوافذ المنزاحة كفاءة أكبر من خلال الحد من حساب الاهتمام الذاتي إلى نوافذ محلية غير متداخلة مع السماح أيضًا بالاتصال عبر النوافذ. يتميز هذا التصميم الهرمي بالمرونة في النمذجة على نطاقات مختلفة وله تعقيد حسابي خطي فيما يتعلق بحجم الصورة. تجعل هذه الخصائص من محول Swin متوافقًا مع مجموعة واسعة من مهام الرؤية، بما في ذلك تصنيف الصور (87.3 دقة أعلى-1 على ImageNet-1K) ومهام التنبؤ الكثيفة مثل اكتشاف الأجسام (58.7 AP للصندوق و51.1 AP للقناع على COCO test-dev) والتجزئة الدلالية (53.5 mIoU على ADE20K val). تتفوق أداءه على الحالة السابقة للفن بهامش كبير يبلغ +2.7 AP للصندوق و+2.6 AP للقناع على COCO، و+3.2 mIoU على ADE20K، مما يثبت الإمكانات الكبيرة للنماذج المستندة إلى المحول كعمود فقري للرؤية. كما أثبت التصميم الهرمي ونهج النافذة المنزاحة فائدتهما لتصميمات MLP بالكامل.*
+
+ +
+هندسة محول Swin. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [novice03](https://huggingface.co/novice03). تمت المساهمة في إصدار Tensorflow من هذا النموذج بواسطة [amyeroberts](https://huggingface.co/amyeroberts). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/Swin-Transformer).
+
+## نصائح الاستخدام
+
+- يقوم Swin بتبطين المدخلات التي تدعم أي ارتفاع وعرض للإدخال (إذا كان قابلاً للقسمة على `32`).
+- يمكن استخدام Swin كـ *عمود فقري*. عندما تكون `output_hidden_states = True`، فإنه سيخرج كلاً من `hidden_states` و`reshaped_hidden_states`. تحتوي `reshaped_hidden_states` على شكل `(batch, num_channels, height, width)` بدلاً من `(batch_size, sequence_length, num_channels)`.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام محول Swin.
+
+
+
+هندسة محول Swin. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [novice03](https://huggingface.co/novice03). تمت المساهمة في إصدار Tensorflow من هذا النموذج بواسطة [amyeroberts](https://huggingface.co/amyeroberts). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/Swin-Transformer).
+
+## نصائح الاستخدام
+
+- يقوم Swin بتبطين المدخلات التي تدعم أي ارتفاع وعرض للإدخال (إذا كان قابلاً للقسمة على `32`).
+- يمكن استخدام Swin كـ *عمود فقري*. عندما تكون `output_hidden_states = True`، فإنه سيخرج كلاً من `hidden_states` و`reshaped_hidden_states`. تحتوي `reshaped_hidden_states` على شكل `(batch, num_channels, height, width)` بدلاً من `(batch_size, sequence_length, num_channels)`.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام محول Swin.
+
+ +
+ بنية Swin2SR. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/mv-lab/swin2sr).
+
+## الموارد
+
+يمكن العثور على دفاتر الملاحظات التجريبية لـ Swin2SR [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR).
+
+يمكن العثور على مساحة تجريبية لاستعادة الدقة الفائقة للصور باستخدام SwinSR [هنا](https://huggingface.co/spaces/jjourney1125/swin2sr).
+
+## Swin2SRImageProcessor
+
+[[autodoc]] Swin2SRImageProcessor
+
+- preprocess
+
+## Swin2SRConfig
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel
+
+[[autodoc]] Swin2SRModel
+
+- forward
+
+## Swin2SRForImageSuperResolution
+
+[[autodoc]] Swin2SRForImageSuperResolution
+
+- forward
\ No newline at end of file
From 799d689fb65d247102aa2868e72acd7275318d65 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:45 +0300
Subject: [PATCH 585/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/swinv2.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/swinv2.md | 49 ++++++++++++++++++++++++++++++
1 file changed, 49 insertions(+)
create mode 100644 docs/source/ar/model_doc/swinv2.md
diff --git a/docs/source/ar/model_doc/swinv2.md b/docs/source/ar/model_doc/swinv2.md
new file mode 100644
index 00000000000000..976caae32d9e22
--- /dev/null
+++ b/docs/source/ar/model_doc/swinv2.md
@@ -0,0 +1,49 @@
+# Swin Transformer V2
+
+## نظرة عامة
+
+اقتُرح نموذج Swin Transformer V2 في ورقة بحثية بعنوان [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) بواسطة Ze Liu و Han Hu و Yutong Lin و Zhuliang Yao و Zhenda Xie و Yixuan Wei و Jia Ning و Yue Cao و Zheng Zhang و Li Dong و Furu Wei و Baining Guo.
+
+وفيما يلي الملخص المستخرج من الورقة البحثية:
+
+*أظهرت النماذج اللغوية واسعة النطاق تحسناً ملحوظاً في الأداء على المهام اللغوية دون أي مؤشرات على التشبع. كما أنها تُظهر قدرات مذهلة على التعلم القليل مثل قدرات البشر. تهدف هذه الورقة إلى استكشاف النماذج واسعة النطاق في رؤية الكمبيوتر. نتناول ثلاث قضايا رئيسية في تدريب وتطبيق النماذج البصرية واسعة النطاق، بما في ذلك عدم استقرار التدريب، والفجوات في الدقة بين التدريب الأولي والضبط الدقيق، والحاجة إلى البيانات المُوسمة. تم اقتراح ثلاث تقنيات رئيسية: 1) طريقة residual-post-norm مُجمعة مع انتباه كوسين لتحسين استقرار التدريب؛ 2) طريقة log-spaced continuous position bias لنقل النماذج المُدربة مسبقًا باستخدام صور منخفضة الدقة بشكل فعال إلى مهام التدفق السفلي مع إدخالات عالية الدقة؛ 3) طريقة pre-training ذاتية الإشراف، SimMIM، لتقليل الحاجة إلى الصور المُوسمة الكبيرة. من خلال هذه التقنيات، نجحت هذه الورقة في تدريب نموذج Swin Transformer V2 الذي يحتوي على 3 مليار معامل، وهو أكبر نموذج رؤية كثيف حتى الآن، وجعله قادرًا على التدريب باستخدام صور يصل حجمها إلى 1,536×1,536. حقق هذا النموذج سجلات أداء جديدة في 4 مهام رؤية تمثيلية، بما في ذلك تصنيف الصور ImageNet-V2، وكشف الأجسام COCO، والتجزئة الدلالية ADE20K، وتصنيف إجراءات الفيديو Kinetics-400.*
+
+تمت المساهمة بهذا النموذج من قبل [nandwalritik](https://huggingface.co/nandwalritik). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/Swin-Transformer).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام Swin Transformer v2.
+
+
+
+ بنية Swin2SR. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/mv-lab/swin2sr).
+
+## الموارد
+
+يمكن العثور على دفاتر الملاحظات التجريبية لـ Swin2SR [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/Swin2SR).
+
+يمكن العثور على مساحة تجريبية لاستعادة الدقة الفائقة للصور باستخدام SwinSR [هنا](https://huggingface.co/spaces/jjourney1125/swin2sr).
+
+## Swin2SRImageProcessor
+
+[[autodoc]] Swin2SRImageProcessor
+
+- preprocess
+
+## Swin2SRConfig
+
+[[autodoc]] Swin2SRConfig
+
+## Swin2SRModel
+
+[[autodoc]] Swin2SRModel
+
+- forward
+
+## Swin2SRForImageSuperResolution
+
+[[autodoc]] Swin2SRForImageSuperResolution
+
+- forward
\ No newline at end of file
From 799d689fb65d247102aa2868e72acd7275318d65 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:29:45 +0300
Subject: [PATCH 585/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/swinv2.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/swinv2.md | 49 ++++++++++++++++++++++++++++++
1 file changed, 49 insertions(+)
create mode 100644 docs/source/ar/model_doc/swinv2.md
diff --git a/docs/source/ar/model_doc/swinv2.md b/docs/source/ar/model_doc/swinv2.md
new file mode 100644
index 00000000000000..976caae32d9e22
--- /dev/null
+++ b/docs/source/ar/model_doc/swinv2.md
@@ -0,0 +1,49 @@
+# Swin Transformer V2
+
+## نظرة عامة
+
+اقتُرح نموذج Swin Transformer V2 في ورقة بحثية بعنوان [Swin Transformer V2: Scaling Up Capacity and Resolution](https://arxiv.org/abs/2111.09883) بواسطة Ze Liu و Han Hu و Yutong Lin و Zhuliang Yao و Zhenda Xie و Yixuan Wei و Jia Ning و Yue Cao و Zheng Zhang و Li Dong و Furu Wei و Baining Guo.
+
+وفيما يلي الملخص المستخرج من الورقة البحثية:
+
+*أظهرت النماذج اللغوية واسعة النطاق تحسناً ملحوظاً في الأداء على المهام اللغوية دون أي مؤشرات على التشبع. كما أنها تُظهر قدرات مذهلة على التعلم القليل مثل قدرات البشر. تهدف هذه الورقة إلى استكشاف النماذج واسعة النطاق في رؤية الكمبيوتر. نتناول ثلاث قضايا رئيسية في تدريب وتطبيق النماذج البصرية واسعة النطاق، بما في ذلك عدم استقرار التدريب، والفجوات في الدقة بين التدريب الأولي والضبط الدقيق، والحاجة إلى البيانات المُوسمة. تم اقتراح ثلاث تقنيات رئيسية: 1) طريقة residual-post-norm مُجمعة مع انتباه كوسين لتحسين استقرار التدريب؛ 2) طريقة log-spaced continuous position bias لنقل النماذج المُدربة مسبقًا باستخدام صور منخفضة الدقة بشكل فعال إلى مهام التدفق السفلي مع إدخالات عالية الدقة؛ 3) طريقة pre-training ذاتية الإشراف، SimMIM، لتقليل الحاجة إلى الصور المُوسمة الكبيرة. من خلال هذه التقنيات، نجحت هذه الورقة في تدريب نموذج Swin Transformer V2 الذي يحتوي على 3 مليار معامل، وهو أكبر نموذج رؤية كثيف حتى الآن، وجعله قادرًا على التدريب باستخدام صور يصل حجمها إلى 1,536×1,536. حقق هذا النموذج سجلات أداء جديدة في 4 مهام رؤية تمثيلية، بما في ذلك تصنيف الصور ImageNet-V2، وكشف الأجسام COCO، والتجزئة الدلالية ADE20K، وتصنيف إجراءات الفيديو Kinetics-400.*
+
+تمت المساهمة بهذا النموذج من قبل [nandwalritik](https://huggingface.co/nandwalritik). يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/Swin-Transformer).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام Swin Transformer v2.
+
+ +
+ بنية نموذج TrOCR. مأخوذة من الورقة البحثية الأصلية.
+
+يرجى الرجوع إلى فئة [`VisionEncoderDecoder`] لمعرفة كيفية استخدام هذا النموذج.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). ويمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/unilm/tree/6f60612e7cc86a2a1ae85c47231507a587ab4e01/trocr).
+
+## نصائح الاستخدام
+
+- أسرع طريقة للبدء في استخدام TrOCR هي من خلال الاطلاع على [دفاتر الملاحظات التعليمية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR)، والتي توضح كيفية استخدام النموذج في وقت الاستدلال، بالإضافة إلى الضبط الدقيق على بيانات مخصصة.
+
+- يتم تدريب نموذج TrOCR مسبقًا على مرحلتين قبل ضبط دقته على مجموعات بيانات خاصة بمهمة معينة. ويحقق نتائج متميزة في كل من التعرف على النص المطبوع (مثل مجموعة بيانات SROIE) والمكتوب بخط اليد (مثل مجموعة بيانات IAM Handwriting dataset). لمزيد من المعلومات، يرجى الاطلاع على [النماذج الرسمية](https://huggingface.co/models?other=trocr>).
+
+- يتم استخدام نموذج TrOCR دائمًا ضمن إطار عمل [VisionEncoderDecoder](vision-encoder-decoder).
+
+## الموارد
+
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء في استخدام TrOCR. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب (Pull Request) وسنقوم بمراجعته! ويفضل أن يظهر المورد شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+
+
+ بنية نموذج TrOCR. مأخوذة من الورقة البحثية الأصلية.
+
+يرجى الرجوع إلى فئة [`VisionEncoderDecoder`] لمعرفة كيفية استخدام هذا النموذج.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). ويمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/unilm/tree/6f60612e7cc86a2a1ae85c47231507a587ab4e01/trocr).
+
+## نصائح الاستخدام
+
+- أسرع طريقة للبدء في استخدام TrOCR هي من خلال الاطلاع على [دفاتر الملاحظات التعليمية](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/TrOCR)، والتي توضح كيفية استخدام النموذج في وقت الاستدلال، بالإضافة إلى الضبط الدقيق على بيانات مخصصة.
+
+- يتم تدريب نموذج TrOCR مسبقًا على مرحلتين قبل ضبط دقته على مجموعات بيانات خاصة بمهمة معينة. ويحقق نتائج متميزة في كل من التعرف على النص المطبوع (مثل مجموعة بيانات SROIE) والمكتوب بخط اليد (مثل مجموعة بيانات IAM Handwriting dataset). لمزيد من المعلومات، يرجى الاطلاع على [النماذج الرسمية](https://huggingface.co/models?other=trocr>).
+
+- يتم استخدام نموذج TrOCR دائمًا ضمن إطار عمل [VisionEncoderDecoder](vision-encoder-decoder).
+
+## الموارد
+
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء في استخدام TrOCR. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فيرجى فتح طلب سحب (Pull Request) وسنقوم بمراجعته! ويفضل أن يظهر المورد شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+
+
+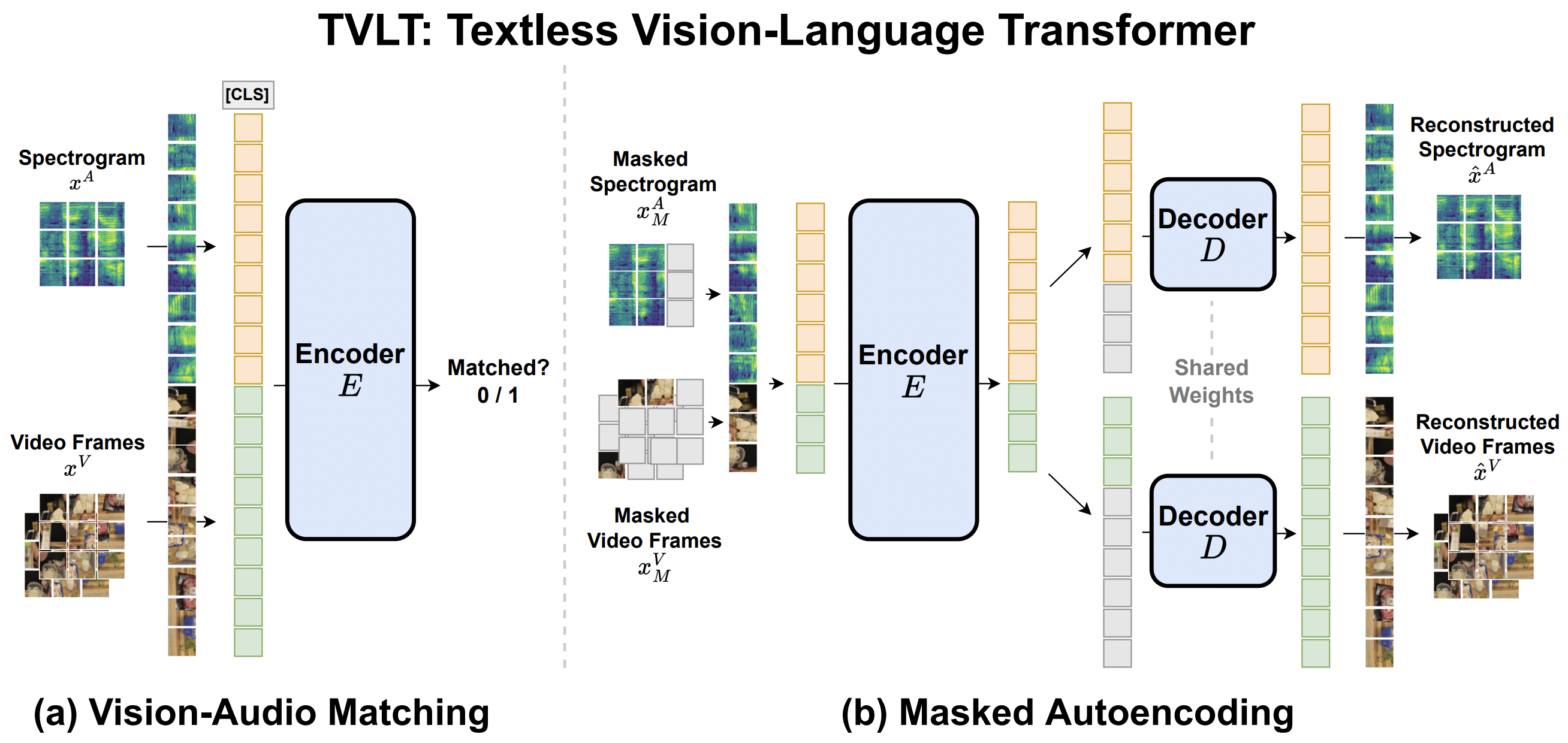 +
+
+
+
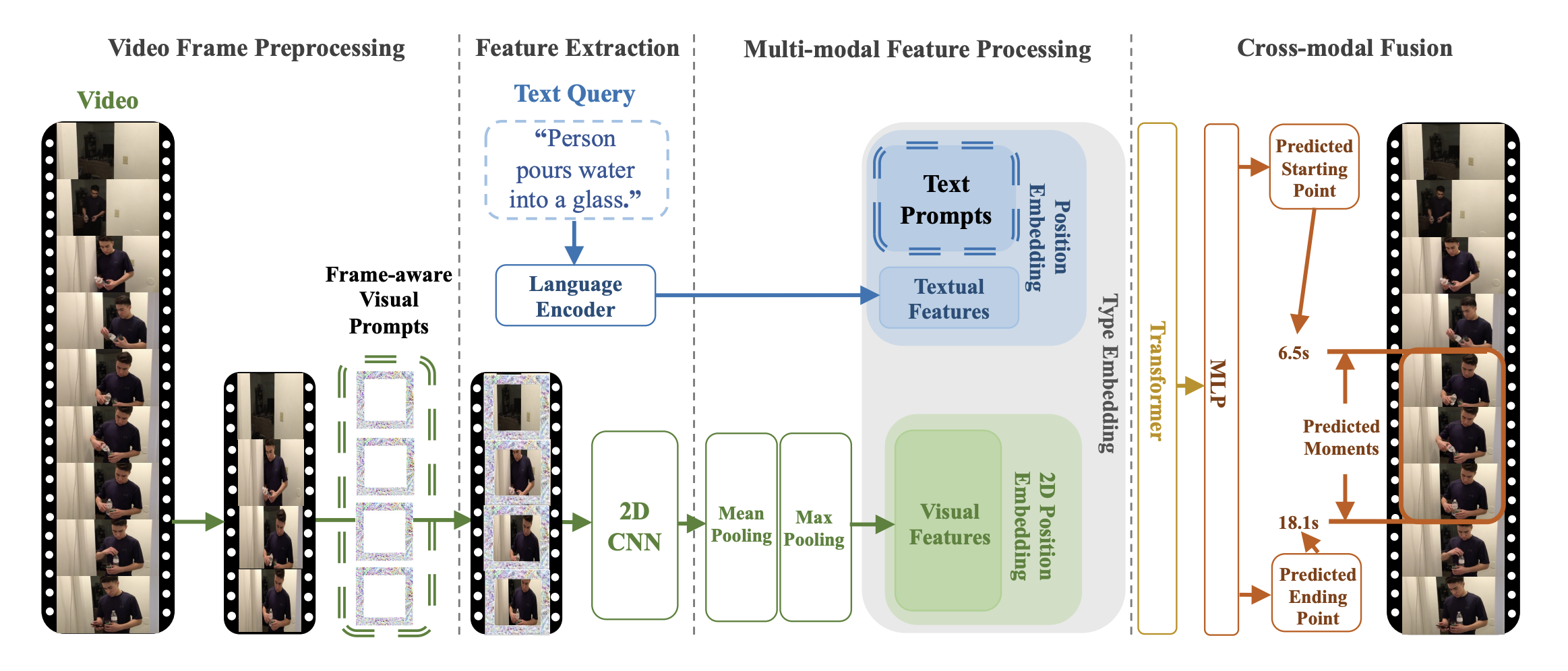 +
+ تصميم TVP. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [Jiqing Feng](https://huggingface.co/Jiqing). ويمكن العثور على الكود الأصلي [هنا](https://github.com/intel/TVP).
+
+## نصائح وأمثلة الاستخدام
+
+"Prompts" هي أنماط اضطراب محسنة، سيتم إضافتها إلى إطارات الفيديو أو الميزات النصية. تشير "المجموعة الشاملة" إلى استخدام نفس المجموعة المحددة من الـ "prompts" لأي مدخلات، وهذا يعني أن هذه الـ "prompts" يتم إضافتها باستمرار إلى جميع إطارات الفيديو والميزات النصية، بغض النظر عن محتوى الإدخال.
+
+يتكون TVP من مشفر بصري ومشفر متعدد الوسائط. يتم دمج مجموعة شاملة من الـ "prompts" البصرية والنصية في إطارات الفيديو والعناصر النصية التي تم أخذ عينات منها، على التوالي. وبشكل خاص، يتم تطبيق مجموعة من الـ "prompts" البصرية المختلفة على إطارات الفيديو التي تم أخذ عينات منها بشكل موحد من فيديو واحد غير محدد الطول بالترتيب.
+
+هدف هذا النموذج هو دمج الـ "prompts" القابلة للتدريب في كل من المدخلات المرئية والميزات النصية لمشاكل التحديد الزمني للفيديو (TVG).
+
+من حيث المبدأ، يمكن تطبيق أي مشفر بصري أو متعدد الوسائط في تصميم TVP المقترح.
+
+يقوم [`TvpProcessor`] بتغليف [`BertTokenizer`] و [`TvpImageProcessor`] في مثيل واحد لتشفير النص وإعداد الصور على التوالي.
+
+يوضح المثال التالي كيفية تشغيل التحديد الزمني للفيديو باستخدام [`TvpProcessor`] و [`TvpForVideoGrounding`].
+
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+## نصائح:
+
+- يستخدم هذا التنفيذ لـ TVP [`BertTokenizer`] لتوليد تضمين نصي ونموذج Resnet-50 لحساب التضمين المرئي.
+- تم إصدار نقاط مرجعية للنموذج المُدرب مسبقًا [tvp-base](https://huggingface.co/Intel/tvp-base).
+- يرجى الرجوع إلى [الجدول 2](https://arxiv.org/pdf/2303.04995.pdf) لأداء TVP على مهمة التحديد الزمني للفيديو.
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+
+- preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+
+- __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+
+- forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+
+- forward
\ No newline at end of file
From cf5cf51df5b53c491780819d6e69e14923a0f5c6 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:30:10 +0300
Subject: [PATCH 599/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/udop.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/udop.md | 98 ++++++++++++++++++++++++++++++++
1 file changed, 98 insertions(+)
create mode 100644 docs/source/ar/model_doc/udop.md
diff --git a/docs/source/ar/model_doc/udop.md b/docs/source/ar/model_doc/udop.md
new file mode 100644
index 00000000000000..d535cb06d486ea
--- /dev/null
+++ b/docs/source/ar/model_doc/udop.md
@@ -0,0 +1,98 @@
+# UDOP
+
+## نظرة عامة
+تم اقتراح نموذج UDOP في [توحيد الرؤية والنص والتخطيط لمعالجة المستندات الشاملة](https://arxiv.org/abs/2212.02623) بواسطة Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
+
+يعتمد UDOP على بنية Transformer الترميزية فك الترميز المستندة إلى [T5](t5) لمهام الذكاء الاصطناعي للمستندات مثل تصنيف صور المستندات، وتحليل المستندات، والأسئلة والأجوبة البصرية للمستندات.
+
+ملخص الورقة هو ما يلي:
+
+نقترح معالجة المستندات الشاملة (UDOP)، وهي نموذج Document AI أساسي يوحد أوضاع النص والصورة والتخطيط معًا بتنسيقات مهام متنوعة، بما في ذلك فهم المستندات وتوليد المستندات. يستفيد UDOP من الارتباط المكاني بين المحتوى النصي وصورة المستند لنمذجة أوضاع الصورة والنص والتخطيط باستخدام تمثيل موحد. باستخدام محول Vision-Text-Layout المبتكر، يوحد UDOP بين المعالجة المسبقة ومهام المجال المتعدد لأسفل البنية المستندة إلى التسلسل. يتم المعالجة المسبقة لـ UDOP على كل من مجموعات البيانات الوثائقية واسعة النطاق غير الموسومة باستخدام أهداف ذاتية الإشراف مبتكرة وبيانات موسومة متنوعة. يتعلم UDOP أيضًا إنشاء صور المستندات من أوضاع النص والتخطيط عبر إعادة بناء الصورة المقنعة. على حد علمنا، هذه هي المرة الأولى في مجال الذكاء الاصطناعي للمستندات التي يحقق فيها نموذج واحد في نفس الوقت تحرير المستندات العصبية وتخصيص المحتوى بجودة عالية. تحدد طريقتنا الحالة الراهنة لـ 9 مهام AI للمستندات، على سبيل المثال فهم المستندات والأسئلة والأجوبة، عبر مجالات البيانات المتنوعة مثل تقارير التمويل والأوراق الأكاديمية والمواقع الإلكترونية. يحتل UDOP المرتبة الأولى في لوحة القيادة الخاصة بمعيار فهم المستندات (DUE).
+
+
+
+ تصميم TVP. مأخوذة من الورقة البحثية الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [Jiqing Feng](https://huggingface.co/Jiqing). ويمكن العثور على الكود الأصلي [هنا](https://github.com/intel/TVP).
+
+## نصائح وأمثلة الاستخدام
+
+"Prompts" هي أنماط اضطراب محسنة، سيتم إضافتها إلى إطارات الفيديو أو الميزات النصية. تشير "المجموعة الشاملة" إلى استخدام نفس المجموعة المحددة من الـ "prompts" لأي مدخلات، وهذا يعني أن هذه الـ "prompts" يتم إضافتها باستمرار إلى جميع إطارات الفيديو والميزات النصية، بغض النظر عن محتوى الإدخال.
+
+يتكون TVP من مشفر بصري ومشفر متعدد الوسائط. يتم دمج مجموعة شاملة من الـ "prompts" البصرية والنصية في إطارات الفيديو والعناصر النصية التي تم أخذ عينات منها، على التوالي. وبشكل خاص، يتم تطبيق مجموعة من الـ "prompts" البصرية المختلفة على إطارات الفيديو التي تم أخذ عينات منها بشكل موحد من فيديو واحد غير محدد الطول بالترتيب.
+
+هدف هذا النموذج هو دمج الـ "prompts" القابلة للتدريب في كل من المدخلات المرئية والميزات النصية لمشاكل التحديد الزمني للفيديو (TVG).
+
+من حيث المبدأ، يمكن تطبيق أي مشفر بصري أو متعدد الوسائط في تصميم TVP المقترح.
+
+يقوم [`TvpProcessor`] بتغليف [`BertTokenizer`] و [`TvpImageProcessor`] في مثيل واحد لتشفير النص وإعداد الصور على التوالي.
+
+يوضح المثال التالي كيفية تشغيل التحديد الزمني للفيديو باستخدام [`TvpProcessor`] و [`TvpForVideoGrounding`].
+
+```python
+import av
+import cv2
+import numpy as np
+import torch
+from huggingface_hub import hf_hub_download
+from transformers import AutoProcessor, TvpForVideoGrounding
+
+
+def pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Convert the video from its original fps to the target_fps and decode the video with PyAV decoder.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video. Return None if the no
+ video stream was found.
+ fps (float): the number of frames per second of the video.
+ '''
+ video = container.streams.video[0]
+ fps = float(video.average_rate)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ delta = max(num_frames - clip_size, 0)
+ start_idx = delta * clip_idx / num_clips
+ end_idx = start_idx + clip_size - 1
+ timebase = video.duration / num_frames
+ video_start_pts = int(start_idx * timebase)
+ video_end_pts = int(end_idx * timebase)
+ seek_offset = max(video_start_pts - 1024, 0)
+ container.seek(seek_offset, any_frame=False, backward=True, stream=video)
+ frames = {}
+ for frame in container.decode(video=0):
+ if frame.pts < video_start_pts:
+ continue
+ frames[frame.pts] = frame
+ if frame.pts > video_end_pts:
+ break
+ frames = [frames[pts] for pts in sorted(frames)]
+ return frames, fps
+
+
+def decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps):
+ '''
+ Decode the video and perform temporal sampling.
+ Args:
+ container (container): pyav container.
+ sampling_rate (int): frame sampling rate (interval between two sampled frames).
+ num_frames (int): number of frames to sample.
+ clip_idx (int): if clip_idx is -1, perform random temporal sampling.
+ If clip_idx is larger than -1, uniformly split the video to num_clips
+ clips, and select the clip_idx-th video clip.
+ num_clips (int): overall number of clips to uniformly sample from the given video.
+ target_fps (int): the input video may have different fps, convert it to
+ the target video fps before frame sampling.
+ Returns:
+ frames (tensor): decoded frames from the video.
+ '''
+ assert clip_idx >= -2, "Not a valied clip_idx {}".format(clip_idx)
+ frames, fps = pyav_decode(container, sampling_rate, num_frames, clip_idx, num_clips, target_fps)
+ clip_size = sampling_rate * num_frames / target_fps * fps
+ index = np.linspace(0, clip_size - 1, num_frames)
+ index = np.clip(index, 0, len(frames) - 1).astype(np.int64)
+ frames = np.array([frames[idx].to_rgb().to_ndarray() for idx in index])
+ frames = frames.transpose(0, 3, 1, 2)
+ return frames
+
+
+file = hf_hub_download(repo_id="Intel/tvp_demo", filename="AK2KG.mp4", repo_type="dataset")
+model = TvpForVideoGrounding.from_pretrained("Intel/tvp-base")
+
+decoder_kwargs = dict(
+ container=av.open(file, metadata_errors="ignore"),
+ sampling_rate=1,
+ num_frames=model.config.num_frames,
+ clip_idx=0,
+ num_clips=1,
+ target_fps=3,
+)
+raw_sampled_frms = decode(**decoder_kwargs)
+
+text = "a person is sitting on a bed."
+processor = AutoProcessor.from_pretrained("Intel/tvp-base")
+model_inputs = processor(
+ text=[text], videos=list(raw_sampled_frms), return_tensors="pt", max_text_length=100#, size=size
+)
+
+model_inputs["pixel_values"] = model_inputs["pixel_values"].to(model.dtype)
+output = model(**model_inputs)
+
+def get_video_duration(filename):
+ cap = cv2.VideoCapture(filename)
+ if cap.isOpened():
+ rate = cap.get(5)
+ frame_num = cap.get(7)
+ duration = frame_num/rate
+ return duration
+ return -1
+
+duration = get_video_duration(file)
+start, end = processor.post_process_video_grounding(output.logits, duration)
+
+print(f"The time slot of the video corresponding to the text \"{text}\" is from {start}s to {end}s")
+```
+
+## نصائح:
+
+- يستخدم هذا التنفيذ لـ TVP [`BertTokenizer`] لتوليد تضمين نصي ونموذج Resnet-50 لحساب التضمين المرئي.
+- تم إصدار نقاط مرجعية للنموذج المُدرب مسبقًا [tvp-base](https://huggingface.co/Intel/tvp-base).
+- يرجى الرجوع إلى [الجدول 2](https://arxiv.org/pdf/2303.04995.pdf) لأداء TVP على مهمة التحديد الزمني للفيديو.
+
+## TvpConfig
+
+[[autodoc]] TvpConfig
+
+## TvpImageProcessor
+
+[[autodoc]] TvpImageProcessor
+
+- preprocess
+
+## TvpProcessor
+
+[[autodoc]] TvpProcessor
+
+- __call__
+
+## TvpModel
+
+[[autodoc]] TvpModel
+
+- forward
+
+## TvpForVideoGrounding
+
+[[autodoc]] TvpForVideoGrounding
+
+- forward
\ No newline at end of file
From cf5cf51df5b53c491780819d6e69e14923a0f5c6 Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:30:10 +0300
Subject: [PATCH 599/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/udop.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/udop.md | 98 ++++++++++++++++++++++++++++++++
1 file changed, 98 insertions(+)
create mode 100644 docs/source/ar/model_doc/udop.md
diff --git a/docs/source/ar/model_doc/udop.md b/docs/source/ar/model_doc/udop.md
new file mode 100644
index 00000000000000..d535cb06d486ea
--- /dev/null
+++ b/docs/source/ar/model_doc/udop.md
@@ -0,0 +1,98 @@
+# UDOP
+
+## نظرة عامة
+تم اقتراح نموذج UDOP في [توحيد الرؤية والنص والتخطيط لمعالجة المستندات الشاملة](https://arxiv.org/abs/2212.02623) بواسطة Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal.
+
+يعتمد UDOP على بنية Transformer الترميزية فك الترميز المستندة إلى [T5](t5) لمهام الذكاء الاصطناعي للمستندات مثل تصنيف صور المستندات، وتحليل المستندات، والأسئلة والأجوبة البصرية للمستندات.
+
+ملخص الورقة هو ما يلي:
+
+نقترح معالجة المستندات الشاملة (UDOP)، وهي نموذج Document AI أساسي يوحد أوضاع النص والصورة والتخطيط معًا بتنسيقات مهام متنوعة، بما في ذلك فهم المستندات وتوليد المستندات. يستفيد UDOP من الارتباط المكاني بين المحتوى النصي وصورة المستند لنمذجة أوضاع الصورة والنص والتخطيط باستخدام تمثيل موحد. باستخدام محول Vision-Text-Layout المبتكر، يوحد UDOP بين المعالجة المسبقة ومهام المجال المتعدد لأسفل البنية المستندة إلى التسلسل. يتم المعالجة المسبقة لـ UDOP على كل من مجموعات البيانات الوثائقية واسعة النطاق غير الموسومة باستخدام أهداف ذاتية الإشراف مبتكرة وبيانات موسومة متنوعة. يتعلم UDOP أيضًا إنشاء صور المستندات من أوضاع النص والتخطيط عبر إعادة بناء الصورة المقنعة. على حد علمنا، هذه هي المرة الأولى في مجال الذكاء الاصطناعي للمستندات التي يحقق فيها نموذج واحد في نفس الوقت تحرير المستندات العصبية وتخصيص المحتوى بجودة عالية. تحدد طريقتنا الحالة الراهنة لـ 9 مهام AI للمستندات، على سبيل المثال فهم المستندات والأسئلة والأجوبة، عبر مجالات البيانات المتنوعة مثل تقارير التمويل والأوراق الأكاديمية والمواقع الإلكترونية. يحتل UDOP المرتبة الأولى في لوحة القيادة الخاصة بمعيار فهم المستندات (DUE).
+
+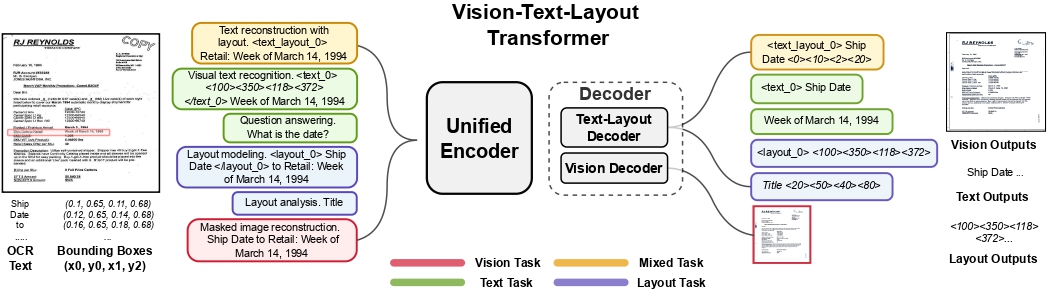 +
+ هندسة UDOP. مأخوذة من الورقة الأصلية.
+
+## نصائح الاستخدام
+
+- بالإضافة إلى *input_ids*، يتوقع [`UdopForConditionalGeneration`] أيضًا إدخال `bbox`، وهو عبارة عن صناديق حدود (أي مواضع ثنائية الأبعاد) للرموز المميزة للإدخال. يمكن الحصول على هذه باستخدام محرك OCR خارجي مثل [Tesseract](https://github.com/tesseract-ocr/tesseract) من Google (يتوفر [غلاف Python](https://pypi.org/project/pytesseract/)). يجب أن يكون كل صندوق حد في تنسيق (x0، y0، x1، y1)، حيث يتوافق (x0، y0) مع موضع الركن العلوي الأيسر في صندوق الحد، ويمثل (x1، y1) موضع الركن السفلي الأيمن. لاحظ أنه يجب عليك أولاً تطبيع صناديق الحدود لتكون على مقياس 0-1000. لتطبيع، يمكنك استخدام الدالة التالية:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+هنا، `width` و`height` يقابلان عرض وارتفاع المستند الأصلي الذي يحدث فيه الرمز المميز. يمكن الحصول على تلك باستخدام مكتبة Python Image Library (PIL)، على سبيل المثال، كما يلي:
+
+```python
+from PIL import Image
+
+# يمكن أن تكون الوثيقة png أو jpg، إلخ. يجب تحويل ملفات PDF إلى صور.
+image = Image.open(name_of_your_document).convert("RGB")
+
+width, height = image.size
+```
+
+يمكنك استخدام [`UdopProcessor`] لتحضير الصور والنص للنموذج، والذي يتولى كل ذلك. بشكل افتراضي، تستخدم هذه الفئة محرك Tesseract لاستخراج قائمة بالكلمات والصناديق (الإحداثيات) من مستند معين. وظيفتها مكافئة لتلك الموجودة في [`LayoutLMv3Processor`]، وبالتالي فهي تدعم تمرير إما `apply_ocr=False` في حالة تفضيلك لاستخدام محرك OCR الخاص بك أو `apply_ocr=true` في حالة رغبتك في استخدام محرك OCR الافتراضي. راجع دليل الاستخدام لـ [LayoutLMv2](layoutlmv2#usage-layoutlmv2processor) فيما يتعلق بجميع حالات الاستخدام الممكنة (تكون وظيفة `UdopProcessor` متطابقة).
+
+- إذا كنت تستخدم محرك OCR الخاص بك، فإن إحدى التوصيات هي واجهة برمجة تطبيقات القراءة من Azure [Read API](https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/how-to/call-read-api)، والتي تدعم ما يسمى بقطاعات الخطوط. يؤدي استخدام تضمينات موضع القطاع عادةً إلى أداء أفضل.
+- أثناء الاستدلال، يوصى باستخدام طريقة `generate` لتوليد النص تلقائيًا بالنظر إلى صورة المستند.
+- تم المعالجة المسبقة للنموذج لكل من الأهداف الخاضعة للإشراف الذاتي. يمكنك استخدام بادئات المهام المختلفة (المطالبات) المستخدمة أثناء المعالجة المسبقة لاختبار القدرات الجاهزة للاستخدام. على سبيل المثال، يمكن مطالبة النموذج بـ "الأسئلة والأجوبة. ما هو التاريخ؟"، حيث "الأسئلة والأجوبة." هو بادئة المهمة المستخدمة أثناء المعالجة المسبقة لـ DocVQA. راجع [الورقة](https://arxiv.org/abs/2212.02623) (الجدول 1) لجميع بادئات المهام.
+- يمكنك أيضًا ضبط [`UdopEncoderModel`]، وهو الجزء الترميز فقط من UDOP، والذي يمكن اعتباره محول ترميز LayoutLMv3. بالنسبة إلى المهام التمييزية، يمكنك ببساطة إضافة مصنف خطي في الأعلى وضبطه على مجموعة بيانات موسومة.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/UDOP).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام UDOP. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنقوم بمراجعته! يجب أن يوضح المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية المتعلقة بـ UDOP [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UDOP) والتي توضح كيفية ضبط UDOP على مجموعة بيانات مخصصة بالإضافة إلى الاستدلال. 🌎
+- [دليل مهام الأسئلة والأجوبة للمستندات](../tasks/document_question_answering)
+
+## UdopConfig
+
+[[autodoc]] UdopConfig
+
+## UdopTokenizer
+
+[[autodoc]] UdopTokenizer
+
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## UdopTokenizerFast
+
+[[autodoc]] UdopTokenizerFast
+
+## UdopProcessor
+
+[[autodoc]] UdopProcessor
+
+- __call__
+
+## UdopModel
+
+[[autodoc]] UdopModel
+
+- forward
+
+## UdopForConditionalGeneration
+
+[[autodoc]] UdopForConditionalGeneration
+
+- forward
+
+## UdopEncoderModel
+
+[[autodoc]] UdopEncoderModel
+
+- forward
\ No newline at end of file
From 68b1432e19426576976be94b908fb89d6ebf3c0c Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:30:12 +0300
Subject: [PATCH 600/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/ul2.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/ul2.md | 20 ++++++++++++++++++++
1 file changed, 20 insertions(+)
create mode 100644 docs/source/ar/model_doc/ul2.md
diff --git a/docs/source/ar/model_doc/ul2.md b/docs/source/ar/model_doc/ul2.md
new file mode 100644
index 00000000000000..9ff0b56c5e481c
--- /dev/null
+++ b/docs/source/ar/model_doc/ul2.md
@@ -0,0 +1,20 @@
+# UL2
+
+## نظرة عامة
+تم تقديم نموذج T5 في ورقة [Unifying Language Learning Paradigms](https://arxiv.org/pdf/2205.05131v1.pdf) بواسطة Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
+
+مقدمة الورقة البحثية هي كما يلي:
+
+> *"تُصمم النماذج المُدربة مسبقًا الحالية بشكل عام لفئة معينة من المشكلات. حتى الآن، يبدو أنه لا يوجد إجماع على ماهية البنية الصحيحة وإعداد التدريب المسبق. تقدم هذه الورقة إطار عمل موحد لنماذج التدريب المسبق التي تكون فعالة عالميًا عبر مجموعات البيانات وإعدادات مختلفة. نبدأ بفك تشابك النماذج المعمارية مع أهداف التدريب المسبق - وهما مفهومان يتم خلطهما عادة. بعد ذلك، نقدم منظورًا موحدًا وعامًا للإشراف الذاتي في معالجة اللغات الطبيعية ونُظهر كيف يمكن صياغة أهداف التدريب المسبق المختلفة على أنها مكافئة لبعضها البعض، وكيف يمكن أن يكون التداخل بين الأهداف المختلفة فعالًا. بعد ذلك، نقترح Mixture-of-Denoisers (MoD)، وهو هدف تدريب مسبق يجمع بين نماذج التدريب المسبق المتنوعة معًا. نقدم أيضًا مفهوم تبديل الوضع، حيث يرتبط الضبط الدقيق لأسفل البئر بمخططات التدريب المسبق المحددة. نجري تجارب استقصائية مكثفة لمقارنة أهداف التدريب المسبق المتعددة ونجد أن طريقة Pareto-frontier تتفوق على النماذج الشبيهة بـ T5 و/أو GPT عبر إعدادات متنوعة متعددة. وأخيرًا، من خلال زيادة حجم نموذج UL2 إلى 20 مليار معامل، حققنا أداءً متميزًا في 50 مهمة NLP خاضعة للإشراف جيدًا تتراوح من توليد اللغة (مع التقييم الآلي والبشري)، وفهم اللغة، وتصنيف النصوص، والأسئلة والأجوبة، والاستدلال بالمنطق العام، والاستدلال بالنصوص الطويلة، وتأطير المعرفة المنظمة واسترجاع المعلومات. كما يحقق نموذج UL2 نتائج قوية في التعلم في السياق، متجاوزًا نموذج GPT-3 بحجم 175 مليار في التعلم الصفري على مجموعة SuperGLUE، ومضاعفة أداء T5-XXL ثلاث مرات في الملخص بنهج التعلم بالتصوير."*
+
+تمت المساهمة بهذا النموذج بواسطة [DanielHesslow](https://huggingface.co/Seledorn). يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/google-research/tree/master/ul2).
+
+## نصائح الاستخدام
+
+- UL2 هو نموذج ترميز وفك ترميز تم تدريبه مسبقًا على مزيج من وظائف إزالة التشويش، بالإضافة إلى الضبط الدقيق على مجموعة من المهام النهائية.
+- يستخدم UL2 نفس البنية المعمارية لـ [T5v1.1](t5v1.1) ولكنه يستخدم دالة التنشيط Gated-SiLU بدلاً من Gated-GELU.
+- قام المؤلفون بإطلاق نقاط تفتيش لمعمارية واحدة يمكن الاطلاع عليها [هنا](https://huggingface.co/google/ul2)
+
+
+
+ هندسة UDOP. مأخوذة من الورقة الأصلية.
+
+## نصائح الاستخدام
+
+- بالإضافة إلى *input_ids*، يتوقع [`UdopForConditionalGeneration`] أيضًا إدخال `bbox`، وهو عبارة عن صناديق حدود (أي مواضع ثنائية الأبعاد) للرموز المميزة للإدخال. يمكن الحصول على هذه باستخدام محرك OCR خارجي مثل [Tesseract](https://github.com/tesseract-ocr/tesseract) من Google (يتوفر [غلاف Python](https://pypi.org/project/pytesseract/)). يجب أن يكون كل صندوق حد في تنسيق (x0، y0، x1، y1)، حيث يتوافق (x0، y0) مع موضع الركن العلوي الأيسر في صندوق الحد، ويمثل (x1، y1) موضع الركن السفلي الأيمن. لاحظ أنه يجب عليك أولاً تطبيع صناديق الحدود لتكون على مقياس 0-1000. لتطبيع، يمكنك استخدام الدالة التالية:
+
+```python
+def normalize_bbox(bbox, width, height):
+ return [
+ int(1000 * (bbox[0] / width)),
+ int(1000 * (bbox[1] / height)),
+ int(1000 * (bbox[2] / width)),
+ int(1000 * (bbox[3] / height)),
+ ]
+```
+
+هنا، `width` و`height` يقابلان عرض وارتفاع المستند الأصلي الذي يحدث فيه الرمز المميز. يمكن الحصول على تلك باستخدام مكتبة Python Image Library (PIL)، على سبيل المثال، كما يلي:
+
+```python
+from PIL import Image
+
+# يمكن أن تكون الوثيقة png أو jpg، إلخ. يجب تحويل ملفات PDF إلى صور.
+image = Image.open(name_of_your_document).convert("RGB")
+
+width, height = image.size
+```
+
+يمكنك استخدام [`UdopProcessor`] لتحضير الصور والنص للنموذج، والذي يتولى كل ذلك. بشكل افتراضي، تستخدم هذه الفئة محرك Tesseract لاستخراج قائمة بالكلمات والصناديق (الإحداثيات) من مستند معين. وظيفتها مكافئة لتلك الموجودة في [`LayoutLMv3Processor`]، وبالتالي فهي تدعم تمرير إما `apply_ocr=False` في حالة تفضيلك لاستخدام محرك OCR الخاص بك أو `apply_ocr=true` في حالة رغبتك في استخدام محرك OCR الافتراضي. راجع دليل الاستخدام لـ [LayoutLMv2](layoutlmv2#usage-layoutlmv2processor) فيما يتعلق بجميع حالات الاستخدام الممكنة (تكون وظيفة `UdopProcessor` متطابقة).
+
+- إذا كنت تستخدم محرك OCR الخاص بك، فإن إحدى التوصيات هي واجهة برمجة تطبيقات القراءة من Azure [Read API](https://learn.microsoft.com/en-us/azure/ai-services/computer-vision/how-to/call-read-api)، والتي تدعم ما يسمى بقطاعات الخطوط. يؤدي استخدام تضمينات موضع القطاع عادةً إلى أداء أفضل.
+- أثناء الاستدلال، يوصى باستخدام طريقة `generate` لتوليد النص تلقائيًا بالنظر إلى صورة المستند.
+- تم المعالجة المسبقة للنموذج لكل من الأهداف الخاضعة للإشراف الذاتي. يمكنك استخدام بادئات المهام المختلفة (المطالبات) المستخدمة أثناء المعالجة المسبقة لاختبار القدرات الجاهزة للاستخدام. على سبيل المثال، يمكن مطالبة النموذج بـ "الأسئلة والأجوبة. ما هو التاريخ؟"، حيث "الأسئلة والأجوبة." هو بادئة المهمة المستخدمة أثناء المعالجة المسبقة لـ DocVQA. راجع [الورقة](https://arxiv.org/abs/2212.02623) (الجدول 1) لجميع بادئات المهام.
+- يمكنك أيضًا ضبط [`UdopEncoderModel`]، وهو الجزء الترميز فقط من UDOP، والذي يمكن اعتباره محول ترميز LayoutLMv3. بالنسبة إلى المهام التمييزية، يمكنك ببساطة إضافة مصنف خطي في الأعلى وضبطه على مجموعة بيانات موسومة.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr).
+
+يمكن العثور على الكود الأصلي [هنا](https://github.com/microsoft/UDOP).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام UDOP. إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنقوم بمراجعته! يجب أن يوضح المورد المثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية المتعلقة بـ UDOP [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UDOP) والتي توضح كيفية ضبط UDOP على مجموعة بيانات مخصصة بالإضافة إلى الاستدلال. 🌎
+- [دليل مهام الأسئلة والأجوبة للمستندات](../tasks/document_question_answering)
+
+## UdopConfig
+
+[[autodoc]] UdopConfig
+
+## UdopTokenizer
+
+[[autodoc]] UdopTokenizer
+
+- build_inputs_with_special_tokens
+- get_special_tokens_mask
+- create_token_type_ids_from_sequences
+- save_vocabulary
+
+## UdopTokenizerFast
+
+[[autodoc]] UdopTokenizerFast
+
+## UdopProcessor
+
+[[autodoc]] UdopProcessor
+
+- __call__
+
+## UdopModel
+
+[[autodoc]] UdopModel
+
+- forward
+
+## UdopForConditionalGeneration
+
+[[autodoc]] UdopForConditionalGeneration
+
+- forward
+
+## UdopEncoderModel
+
+[[autodoc]] UdopEncoderModel
+
+- forward
\ No newline at end of file
From 68b1432e19426576976be94b908fb89d6ebf3c0c Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:30:12 +0300
Subject: [PATCH 600/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/ul2.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/ul2.md | 20 ++++++++++++++++++++
1 file changed, 20 insertions(+)
create mode 100644 docs/source/ar/model_doc/ul2.md
diff --git a/docs/source/ar/model_doc/ul2.md b/docs/source/ar/model_doc/ul2.md
new file mode 100644
index 00000000000000..9ff0b56c5e481c
--- /dev/null
+++ b/docs/source/ar/model_doc/ul2.md
@@ -0,0 +1,20 @@
+# UL2
+
+## نظرة عامة
+تم تقديم نموذج T5 في ورقة [Unifying Language Learning Paradigms](https://arxiv.org/pdf/2205.05131v1.pdf) بواسطة Yi Tay, Mostafa Dehghani, Vinh Q. Tran, Xavier Garcia, Dara Bahri, Tal Schuster, Huaixiu Steven Zheng, Neil Houlsby, Donald Metzler.
+
+مقدمة الورقة البحثية هي كما يلي:
+
+> *"تُصمم النماذج المُدربة مسبقًا الحالية بشكل عام لفئة معينة من المشكلات. حتى الآن، يبدو أنه لا يوجد إجماع على ماهية البنية الصحيحة وإعداد التدريب المسبق. تقدم هذه الورقة إطار عمل موحد لنماذج التدريب المسبق التي تكون فعالة عالميًا عبر مجموعات البيانات وإعدادات مختلفة. نبدأ بفك تشابك النماذج المعمارية مع أهداف التدريب المسبق - وهما مفهومان يتم خلطهما عادة. بعد ذلك، نقدم منظورًا موحدًا وعامًا للإشراف الذاتي في معالجة اللغات الطبيعية ونُظهر كيف يمكن صياغة أهداف التدريب المسبق المختلفة على أنها مكافئة لبعضها البعض، وكيف يمكن أن يكون التداخل بين الأهداف المختلفة فعالًا. بعد ذلك، نقترح Mixture-of-Denoisers (MoD)، وهو هدف تدريب مسبق يجمع بين نماذج التدريب المسبق المتنوعة معًا. نقدم أيضًا مفهوم تبديل الوضع، حيث يرتبط الضبط الدقيق لأسفل البئر بمخططات التدريب المسبق المحددة. نجري تجارب استقصائية مكثفة لمقارنة أهداف التدريب المسبق المتعددة ونجد أن طريقة Pareto-frontier تتفوق على النماذج الشبيهة بـ T5 و/أو GPT عبر إعدادات متنوعة متعددة. وأخيرًا، من خلال زيادة حجم نموذج UL2 إلى 20 مليار معامل، حققنا أداءً متميزًا في 50 مهمة NLP خاضعة للإشراف جيدًا تتراوح من توليد اللغة (مع التقييم الآلي والبشري)، وفهم اللغة، وتصنيف النصوص، والأسئلة والأجوبة، والاستدلال بالمنطق العام، والاستدلال بالنصوص الطويلة، وتأطير المعرفة المنظمة واسترجاع المعلومات. كما يحقق نموذج UL2 نتائج قوية في التعلم في السياق، متجاوزًا نموذج GPT-3 بحجم 175 مليار في التعلم الصفري على مجموعة SuperGLUE، ومضاعفة أداء T5-XXL ثلاث مرات في الملخص بنهج التعلم بالتصوير."*
+
+تمت المساهمة بهذا النموذج بواسطة [DanielHesslow](https://huggingface.co/Seledorn). يمكن العثور على الكود الأصلي [هنا](https://github.com/google-research/google-research/tree/master/ul2).
+
+## نصائح الاستخدام
+
+- UL2 هو نموذج ترميز وفك ترميز تم تدريبه مسبقًا على مزيج من وظائف إزالة التشويش، بالإضافة إلى الضبط الدقيق على مجموعة من المهام النهائية.
+- يستخدم UL2 نفس البنية المعمارية لـ [T5v1.1](t5v1.1) ولكنه يستخدم دالة التنشيط Gated-SiLU بدلاً من Gated-GELU.
+- قام المؤلفون بإطلاق نقاط تفتيش لمعمارية واحدة يمكن الاطلاع عليها [هنا](https://huggingface.co/google/ul2)
+
+ +
+إطار عمل UPerNet. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يعتمد الكود الأصلي على OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
+
+## أمثلة الاستخدام
+
+UPerNet هو إطار عام للتجزئة الدلالية. يمكن استخدامه مع أي عمود رؤية، مثل ما يلي:
+
+```py
+from transformers import SwinConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = SwinConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+لاستخدام عمود رؤية آخر، مثل [ConvNeXt](convnext)، قم ببساطة بإنشاء مثيل للنموذج مع العمود الفقري المناسب:
+
+```py
+from transformers import ConvNextConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = ConvNextConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+لاحظ أن هذا سيقوم بإنشاء جميع أوزان النموذج بشكل عشوائي.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية والمجتمعية (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام UPerNet.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ UPerNet [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
+- يتم دعم [`UperNetForSemanticSegmentation`] بواسطة [نص البرنامج النصي](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) و [دفتر الملاحظات](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb) هذا.
+- راجع أيضًا: [دليل مهام التجزئة الدلالية](../tasks/semantic_segmentation)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنقوم بمراجعته! يجب أن يُظهر المورد بشكل مثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## UperNetConfig
+
+[[autodoc]] UperNetConfig
+
+## UperNetForSemanticSegmentation
+
+[[autodoc]] UperNetForSemanticSegmentation
+
+- forward
\ No newline at end of file
From 80b8b28616668a7fbdd31c1c5945769ff0b08e3d Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:30:23 +0300
Subject: [PATCH 606/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/van.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/van.md | 52 +++++++++++++++++++++++++++++++++
1 file changed, 52 insertions(+)
create mode 100644 docs/source/ar/model_doc/van.md
diff --git a/docs/source/ar/model_doc/van.md b/docs/source/ar/model_doc/van.md
new file mode 100644
index 00000000000000..8139ebb4770961
--- /dev/null
+++ b/docs/source/ar/model_doc/van.md
@@ -0,0 +1,52 @@
+# VAN
+
+
+
+إطار عمل UPerNet. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج من قبل [nielsr](https://huggingface.co/nielsr). يعتمد الكود الأصلي على OpenMMLab's mmsegmentation [here](https://github.com/open-mmlab/mmsegmentation/blob/master/mmseg/models/decode_heads/uper_head.py).
+
+## أمثلة الاستخدام
+
+UPerNet هو إطار عام للتجزئة الدلالية. يمكن استخدامه مع أي عمود رؤية، مثل ما يلي:
+
+```py
+from transformers import SwinConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = SwinConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+لاستخدام عمود رؤية آخر، مثل [ConvNeXt](convnext)، قم ببساطة بإنشاء مثيل للنموذج مع العمود الفقري المناسب:
+
+```py
+from transformers import ConvNextConfig, UperNetConfig, UperNetForSemanticSegmentation
+
+backbone_config = ConvNextConfig(out_features=["stage1", "stage2", "stage3", "stage4"])
+
+config = UperNetConfig(backbone_config=backbone_config)
+model = UperNetForSemanticSegmentation(config)
+```
+
+لاحظ أن هذا سيقوم بإنشاء جميع أوزان النموذج بشكل عشوائي.
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية والمجتمعية (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام UPerNet.
+
+- يمكن العثور على دفاتر الملاحظات التوضيحية لـ UPerNet [هنا](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/UPerNet).
+- يتم دعم [`UperNetForSemanticSegmentation`] بواسطة [نص البرنامج النصي](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation) و [دفتر الملاحظات](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/semantic_segmentation.ipynb) هذا.
+- راجع أيضًا: [دليل مهام التجزئة الدلالية](../tasks/semantic_segmentation)
+
+إذا كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب وسنقوم بمراجعته! يجب أن يُظهر المورد بشكل مثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+## UperNetConfig
+
+[[autodoc]] UperNetConfig
+
+## UperNetForSemanticSegmentation
+
+[[autodoc]] UperNetForSemanticSegmentation
+
+- forward
\ No newline at end of file
From 80b8b28616668a7fbdd31c1c5945769ff0b08e3d Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:30:23 +0300
Subject: [PATCH 606/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/van.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/van.md | 52 +++++++++++++++++++++++++++++++++
1 file changed, 52 insertions(+)
create mode 100644 docs/source/ar/model_doc/van.md
diff --git a/docs/source/ar/model_doc/van.md b/docs/source/ar/model_doc/van.md
new file mode 100644
index 00000000000000..8139ebb4770961
--- /dev/null
+++ b/docs/source/ar/model_doc/van.md
@@ -0,0 +1,52 @@
+# VAN
+
+ +
+تمت المساهمة بهذا النموذج من قبل [فرانشيسكو](https://huggingface.co/Francesco). يمكن العثور على الكود الأصلي [هنا](https://github.com/Visual-Attention-Network/VAN-Classification).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام VAN.
+
+
+
+تمت المساهمة بهذا النموذج من قبل [فرانشيسكو](https://huggingface.co/Francesco). يمكن العثور على الكود الأصلي [هنا](https://github.com/Visual-Attention-Network/VAN-Classification).
+
+## الموارد
+
+قائمة بموارد Hugging Face الرسمية وموارد المجتمع (المشار إليها بـ 🌎) لمساعدتك في البدء باستخدام VAN.
+
+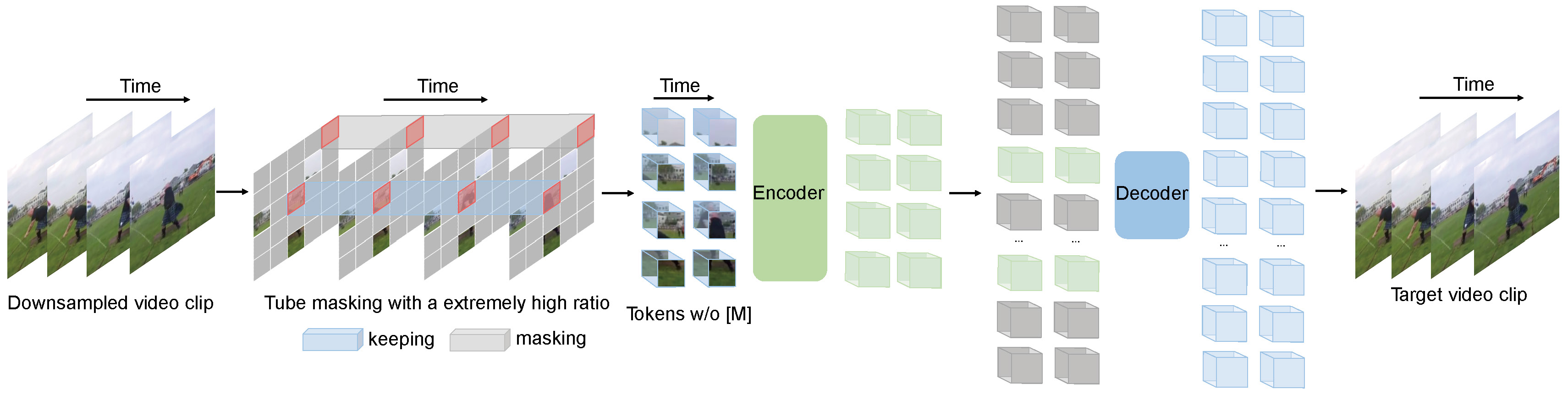 +
+التدريب المسبق لـ VideoMAE. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/MCG-NJU/VideoMAE).
+
+## استخدام Scaled Dot Product Attention (SDPA)
+تتضمن PyTorch مشغل اهتمام المنتج النقطي المميز (SDPA) الأصلي كجزء من `torch.nn.functional`. تشمل هذه الوظيفة عدة تطبيقات يمكن تطبيقها اعتمادًا على المدخلات والأجهزة المستخدمة. راجع [الوثائق الرسمية](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+أو صفحة [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+لمزيد من المعلومات.
+
+يتم استخدام SDPA بشكل افتراضي لـ `torch>=2.1.1` عند توفر التطبيق، ولكن يمكنك أيضًا تعيين
+`attn_implementation="sdpa"` في `from_pretrained()` لطلب استخدام SDPA بشكل صريح.
+
+```py
+from transformers import VideoMAEForVideoClassification
+model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+للحصول على أفضل التحسينات، نوصي بتحميل النموذج بنصف الدقة (على سبيل المثال `torch.float16` أو `torch.bfloat16`).
+
+على معيار محلي (A100-40GB، PyTorch 2.3.0، نظام التشغيل Ubuntu 22.04) مع `float32` ونموذج `MCG-NJU/videomae-base-finetuned-kinetics`، رأينا التحسينات التالية أثناء الاستدلال.
+
+| حجم الدفعة | متوسط وقت الاستدلال (مللي ثانية)، وضع Eager | متوسط وقت الاستدلال (مللي ثانية)، نموذج SDPA | تسريع، SDPA / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 37 | 10 | 3.7 |
+| 2 | 24 | 18 | 1.33 |
+| 4 | 43 | 32 | 1.34 |
+| 8 | 84 | 60 | 1.4 |
+
+## الموارد
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام VideoMAE. إذا
+كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب Pull Request وسنراجعه! يجب أن يُظهر المورد بشكل مثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+**تصنيف الفيديو**
+- [دفتر ملاحظات](https://github.com/huggingface/notebooks/blob/main/examples/video_classification.ipynb) يُظهر كيفية
+ضبط نموذج VideoMAE على مجموعة بيانات مخصصة.
+- [دليل مهمة تصنيف الفيديو](../tasks/video_classification)
+- [مساحة 🤗](https://huggingface.co/spaces/sayakpaul/video-classification-ucf101-subset) تُظهر كيفية إجراء الاستدلال باستخدام نموذج تصنيف الفيديو.
+
+## VideoMAEConfig
+[[autodoc]] VideoMAEConfig
+
+## VideoMAEFeatureExtractor
+
+[[autodoc]] VideoMAEFeatureExtractor
+- __call__
+
+## VideoMAEImageProcessor
+
+[[autodoc]] VideoMAEImageProcessor
+- preprocess
+
+## VideoMAEModel
+
+[[autodoc]] VideoMAEModel
+- forward
+
+## VideoMAEForPreTraining
+
+يتضمن `VideoMAEForPreTraining` فك التشفير في الأعلى للتدريب المسبق ذاتي الإشراف.
+
+[[autodoc]] transformers.VideoMAEForPreTraining
+- forward
+
+## VideoMAEForVideoClassification
+
+[[autodoc]] transformers.VideoMAEForVideoClassification
+- forward
\ No newline at end of file
From 1cd029d11b52d8496c4aec0a8ce0edff5fdad6dc Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:30:27 +0300
Subject: [PATCH 608/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/video=5Fllava.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/video_llava.md | 162 ++++++++++++++++++++++++
1 file changed, 162 insertions(+)
create mode 100644 docs/source/ar/model_doc/video_llava.md
diff --git a/docs/source/ar/model_doc/video_llava.md b/docs/source/ar/model_doc/video_llava.md
new file mode 100644
index 00000000000000..059508175dde75
--- /dev/null
+++ b/docs/source/ar/model_doc/video_llava.md
@@ -0,0 +1,162 @@
+# Video-LLaVA
+
+## نظرة عامة
+Video-LLaVa هو نموذج لغة مفتوح المصدر متعدد الوسائط تم تدريبه عن طريق الضبط الدقيق لـ LlamA/Vicuna على بيانات اتباع التعليمات متعددة الوسائط التي تم إنشاؤها بواسطة Llava1.5 وVideChat. وهو نموذج لغة تنازلي، يعتمد على بنية المحول (transformer architecture). يوحد Video-LLaVa التمثيلات المرئية في مساحة ميزات اللغة، ويمكّن نموذج لغة اللغة من أداء قدرات الاستدلال المرئي على الصور ومقاطع الفيديو في نفس الوقت.
+
+تم اقتراح نموذج Video-LLaVA في ورقة "Video-LLaVA: Learning United Visual Representation by Alignment Before Projection" من قبل Bin Lin وYang Ye وBin Zhu وJiaxi Cui وMunang Ning وPeng Jin وLi Yuan.
+
+ملخص الورقة هو كما يلي:
+
+*"عزز نموذج اللغة والرؤية الكبير (LVLM) أداء مختلف مهام التدفق السفلي في فهم اللغة والرؤية. تقوم معظم الطرق الحالية بتشفير الصور ومقاطع الفيديو في مساحات ميزات منفصلة، والتي يتم تغذيتها بعد ذلك كمدخلات لنماذج اللغة الكبيرة. ومع ذلك، بسبب عدم وجود توحيد لعملية تمثيل الصور ومقاطع الفيديو، أي عدم الاتساق قبل الإسقاط، يصبح من الصعب على نموذج لغة اللغة الكبيرة (LLM) تعلم التفاعلات متعددة الوسائط من عدة طبقات إسقاط رديئة. في هذا العمل، نوحد التمثيل المرئي في مساحة ميزات اللغة للانتقال بنموذج LLM الأساسي نحو LVLM موحد. ونتيجة لذلك، أنشأنا خط أساس بسيطًا ولكنه قويًا لـ LVLM، وهو Video-LLaVA، والذي يتعلم من مجموعة بيانات مختلطة من الصور ومقاطع الفيديو، مما يعزز كل منهما الآخر. يحقق Video-LLaVA أداءً متفوقًا في مجموعة واسعة من معايير الصور التي تغطي 5 مجموعات بيانات لأسئلة الصور و4 مجموعات أدوات معايير الصور. بالإضافة إلى ذلك، يتفوق نموذجنا Video-LLaVA أيضًا على Video-ChatGPT بنسبة 5.8٪ و9.9٪ و18.6٪ و10.1٪ على مجموعات بيانات MSRVTT وMSVD وTGIF وActivityNet على التوالي. وتجدر الإشارة إلى أن التجارب الواسعة توضح أن Video-LLaVA يفيد الصور ومقاطع الفيديو بشكل متبادل في إطار تمثيل مرئي موحد، متفوقًا على النماذج المصممة خصيصًا للصور أو مقاطع الفيديو. نهدف من خلال هذا العمل إلى تقديم رؤى متواضعة حول المدخلات متعددة الوسائط لنموذج اللغة."*
+
+## نصائح الاستخدام:
+
+- نوصي المستخدمين باستخدام padding_side="left" عند حساب التوليد الدفعي لأنه يؤدي إلى نتائج أكثر دقة. فقط تأكد من استدعاء processor.tokenizer.padding_side = "left" قبل التوليد.
+
+- لاحظ أن النموذج لم يتم تدريبه صراحةً لمعالجة عدة صور/مقاطع فيديو في نفس المطالبة، على الرغم من أن هذا ممكن من الناحية الفنية، فقد تواجه نتائج غير دقيقة.
+
+- لاحظ أن مدخلات الفيديو يجب أن تحتوي على 8 إطارات بالضبط، حيث تم تدريب النماذج في هذا الإعداد.
+
+تمت المساهمة بهذا النموذج من قبل [RaushanTurganbay](https://huggingface.co/RaushanTurganbay). يمكن العثور على الكود الأصلي [هنا](https://github.com/PKU-YuanGroup/Video-LLaVA).
+
+## مثال الاستخدام
+
+### وضع الوسائط الفردية
+
+يمكن للنموذج قبول كل من الصور ومقاطع الفيديو كمدخلات. فيما يلي مثال على التعليمات البرمجية للاستنتاج في الدقة النصفية (`torch.float16`):
+
+```python
+import av
+import torch
+import numpy as np
+from transformers import VideoLlavaForConditionalGeneration, VideoLlavaProcessor
+
+def read_video_pyav(container, indices):
+ '''
+ Decode the video with PyAV decoder.
+ Args:
+ container (`av.container.input.InputContainer`): PyAV container.
+ indices (`List[int]`): List of frame indices to decode.
+ Returns:
+ result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
+ '''
+ frames = []
+ container.seek(0)
+ start_index = indices[0]
+ end_index = indices[-1]
+ for i, frame in enumerate(container.decode(video=0)):
+ if i > end_index:
+ break
+ if i >= start_index and i in indices:
+ frames.append(frame)
+ return np.stack([x.to_ndarray(format="rgb24") for x in frames])
+
+# Load the model in half-precision
+model = VideoLlavaForConditionalGeneration.from_pretrained("LanguageBind/Video-LLaVA-7B-hf", torch_dtype=torch.float16, device_map="auto")
+processor = VideoLlavaProcessor.from_pretrained("LanguageBind/Video-LLaVA-7B-hf")
+
+# Load the video as an np.arrau, sampling uniformly 8 frames
+video_path = hf_hub_download(repo_id="raushan-testing-hf/videos-test", filename="sample_demo_1.mp4", repo_type="dataset")
+container = av.open(video_path)
+total_frames = container.streams.video[0].frames
+indices = np.arange(0, total_frames, total_frames / 8).astype(int)
+video = read_video_pyav(container, indices)
+
+# For better results, we recommend to prompt the model in the following format
+prompt = "USER:
+
+التدريب المسبق لـ VideoMAE. مأخوذة من الورقة الأصلية.
+
+تمت المساهمة بهذا النموذج بواسطة [nielsr](https://huggingface.co/nielsr).
+يمكن العثور على الكود الأصلي [هنا](https://github.com/MCG-NJU/VideoMAE).
+
+## استخدام Scaled Dot Product Attention (SDPA)
+تتضمن PyTorch مشغل اهتمام المنتج النقطي المميز (SDPA) الأصلي كجزء من `torch.nn.functional`. تشمل هذه الوظيفة عدة تطبيقات يمكن تطبيقها اعتمادًا على المدخلات والأجهزة المستخدمة. راجع [الوثائق الرسمية](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html)
+أو صفحة [GPU Inference](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention)
+لمزيد من المعلومات.
+
+يتم استخدام SDPA بشكل افتراضي لـ `torch>=2.1.1` عند توفر التطبيق، ولكن يمكنك أيضًا تعيين
+`attn_implementation="sdpa"` في `from_pretrained()` لطلب استخدام SDPA بشكل صريح.
+
+```py
+from transformers import VideoMAEForVideoClassification
+model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics", attn_implementation="sdpa", torch_dtype=torch.float16)
+...
+```
+
+للحصول على أفضل التحسينات، نوصي بتحميل النموذج بنصف الدقة (على سبيل المثال `torch.float16` أو `torch.bfloat16`).
+
+على معيار محلي (A100-40GB، PyTorch 2.3.0، نظام التشغيل Ubuntu 22.04) مع `float32` ونموذج `MCG-NJU/videomae-base-finetuned-kinetics`، رأينا التحسينات التالية أثناء الاستدلال.
+
+| حجم الدفعة | متوسط وقت الاستدلال (مللي ثانية)، وضع Eager | متوسط وقت الاستدلال (مللي ثانية)، نموذج SDPA | تسريع، SDPA / Eager (x) |
+|--------------|-------------------------------------------|-------------------------------------------|------------------------------|
+| 1 | 37 | 10 | 3.7 |
+| 2 | 24 | 18 | 1.33 |
+| 4 | 43 | 32 | 1.34 |
+| 8 | 84 | 60 | 1.4 |
+
+## الموارد
+فيما يلي قائمة بموارد Hugging Face الرسمية وموارد المجتمع (مشار إليها بـ 🌎) لمساعدتك في البدء باستخدام VideoMAE. إذا
+كنت مهتمًا بتقديم مورد لإدراجه هنا، فالرجاء فتح طلب سحب Pull Request وسنراجعه! يجب أن يُظهر المورد بشكل مثالي شيئًا جديدًا بدلاً من تكرار مورد موجود.
+
+**تصنيف الفيديو**
+- [دفتر ملاحظات](https://github.com/huggingface/notebooks/blob/main/examples/video_classification.ipynb) يُظهر كيفية
+ضبط نموذج VideoMAE على مجموعة بيانات مخصصة.
+- [دليل مهمة تصنيف الفيديو](../tasks/video_classification)
+- [مساحة 🤗](https://huggingface.co/spaces/sayakpaul/video-classification-ucf101-subset) تُظهر كيفية إجراء الاستدلال باستخدام نموذج تصنيف الفيديو.
+
+## VideoMAEConfig
+[[autodoc]] VideoMAEConfig
+
+## VideoMAEFeatureExtractor
+
+[[autodoc]] VideoMAEFeatureExtractor
+- __call__
+
+## VideoMAEImageProcessor
+
+[[autodoc]] VideoMAEImageProcessor
+- preprocess
+
+## VideoMAEModel
+
+[[autodoc]] VideoMAEModel
+- forward
+
+## VideoMAEForPreTraining
+
+يتضمن `VideoMAEForPreTraining` فك التشفير في الأعلى للتدريب المسبق ذاتي الإشراف.
+
+[[autodoc]] transformers.VideoMAEForPreTraining
+- forward
+
+## VideoMAEForVideoClassification
+
+[[autodoc]] transformers.VideoMAEForVideoClassification
+- forward
\ No newline at end of file
From 1cd029d11b52d8496c4aec0a8ce0edff5fdad6dc Mon Sep 17 00:00:00 2001
From: Ahmed almaghz <53489256+ahmedalmaghz@users.noreply.github.com>
Date: Wed, 7 Aug 2024 23:30:27 +0300
Subject: [PATCH 608/653] =?UTF-8?q?=D8=A5=D8=B6=D8=A7=D9=81=D8=A9=20docs/s?=
=?UTF-8?q?ource/ar/model=5Fdoc/video=5Fllava.md?=
MIME-Version: 1.0
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: 8bit
---
docs/source/ar/model_doc/video_llava.md | 162 ++++++++++++++++++++++++
1 file changed, 162 insertions(+)
create mode 100644 docs/source/ar/model_doc/video_llava.md
diff --git a/docs/source/ar/model_doc/video_llava.md b/docs/source/ar/model_doc/video_llava.md
new file mode 100644
index 00000000000000..059508175dde75
--- /dev/null
+++ b/docs/source/ar/model_doc/video_llava.md
@@ -0,0 +1,162 @@
+# Video-LLaVA
+
+## نظرة عامة
+Video-LLaVa هو نموذج لغة مفتوح المصدر متعدد الوسائط تم تدريبه عن طريق الضبط الدقيق لـ LlamA/Vicuna على بيانات اتباع التعليمات متعددة الوسائط التي تم إنشاؤها بواسطة Llava1.5 وVideChat. وهو نموذج لغة تنازلي، يعتمد على بنية المحول (transformer architecture). يوحد Video-LLaVa التمثيلات المرئية في مساحة ميزات اللغة، ويمكّن نموذج لغة اللغة من أداء قدرات الاستدلال المرئي على الصور ومقاطع الفيديو في نفس الوقت.
+
+تم اقتراح نموذج Video-LLaVA في ورقة "Video-LLaVA: Learning United Visual Representation by Alignment Before Projection" من قبل Bin Lin وYang Ye وBin Zhu وJiaxi Cui وMunang Ning وPeng Jin وLi Yuan.
+
+ملخص الورقة هو كما يلي:
+
+*"عزز نموذج اللغة والرؤية الكبير (LVLM) أداء مختلف مهام التدفق السفلي في فهم اللغة والرؤية. تقوم معظم الطرق الحالية بتشفير الصور ومقاطع الفيديو في مساحات ميزات منفصلة، والتي يتم تغذيتها بعد ذلك كمدخلات لنماذج اللغة الكبيرة. ومع ذلك، بسبب عدم وجود توحيد لعملية تمثيل الصور ومقاطع الفيديو، أي عدم الاتساق قبل الإسقاط، يصبح من الصعب على نموذج لغة اللغة الكبيرة (LLM) تعلم التفاعلات متعددة الوسائط من عدة طبقات إسقاط رديئة. في هذا العمل، نوحد التمثيل المرئي في مساحة ميزات اللغة للانتقال بنموذج LLM الأساسي نحو LVLM موحد. ونتيجة لذلك، أنشأنا خط أساس بسيطًا ولكنه قويًا لـ LVLM، وهو Video-LLaVA، والذي يتعلم من مجموعة بيانات مختلطة من الصور ومقاطع الفيديو، مما يعزز كل منهما الآخر. يحقق Video-LLaVA أداءً متفوقًا في مجموعة واسعة من معايير الصور التي تغطي 5 مجموعات بيانات لأسئلة الصور و4 مجموعات أدوات معايير الصور. بالإضافة إلى ذلك، يتفوق نموذجنا Video-LLaVA أيضًا على Video-ChatGPT بنسبة 5.8٪ و9.9٪ و18.6٪ و10.1٪ على مجموعات بيانات MSRVTT وMSVD وTGIF وActivityNet على التوالي. وتجدر الإشارة إلى أن التجارب الواسعة توضح أن Video-LLaVA يفيد الصور ومقاطع الفيديو بشكل متبادل في إطار تمثيل مرئي موحد، متفوقًا على النماذج المصممة خصيصًا للصور أو مقاطع الفيديو. نهدف من خلال هذا العمل إلى تقديم رؤى متواضعة حول المدخلات متعددة الوسائط لنموذج اللغة."*
+
+## نصائح الاستخدام:
+
+- نوصي المستخدمين باستخدام padding_side="left" عند حساب التوليد الدفعي لأنه يؤدي إلى نتائج أكثر دقة. فقط تأكد من استدعاء processor.tokenizer.padding_side = "left" قبل التوليد.
+
+- لاحظ أن النموذج لم يتم تدريبه صراحةً لمعالجة عدة صور/مقاطع فيديو في نفس المطالبة، على الرغم من أن هذا ممكن من الناحية الفنية، فقد تواجه نتائج غير دقيقة.
+
+- لاحظ أن مدخلات الفيديو يجب أن تحتوي على 8 إطارات بالضبط، حيث تم تدريب النماذج في هذا الإعداد.
+
+تمت المساهمة بهذا النموذج من قبل [RaushanTurganbay](https://huggingface.co/RaushanTurganbay). يمكن العثور على الكود الأصلي [هنا](https://github.com/PKU-YuanGroup/Video-LLaVA).
+
+## مثال الاستخدام
+
+### وضع الوسائط الفردية
+
+يمكن للنموذج قبول كل من الصور ومقاطع الفيديو كمدخلات. فيما يلي مثال على التعليمات البرمجية للاستنتاج في الدقة النصفية (`torch.float16`):
+
+```python
+import av
+import torch
+import numpy as np
+from transformers import VideoLlavaForConditionalGeneration, VideoLlavaProcessor
+
+def read_video_pyav(container, indices):
+ '''
+ Decode the video with PyAV decoder.
+ Args:
+ container (`av.container.input.InputContainer`): PyAV container.
+ indices (`List[int]`): List of frame indices to decode.
+ Returns:
+ result (np.ndarray): np array of decoded frames of shape (num_frames, height, width, 3).
+ '''
+ frames = []
+ container.seek(0)
+ start_index = indices[0]
+ end_index = indices[-1]
+ for i, frame in enumerate(container.decode(video=0)):
+ if i > end_index:
+ break
+ if i >= start_index and i in indices:
+ frames.append(frame)
+ return np.stack([x.to_ndarray(format="rgb24") for x in frames])
+
+# Load the model in half-precision
+model = VideoLlavaForConditionalGeneration.from_pretrained("LanguageBind/Video-LLaVA-7B-hf", torch_dtype=torch.float16, device_map="auto")
+processor = VideoLlavaProcessor.from_pretrained("LanguageBind/Video-LLaVA-7B-hf")
+
+# Load the video as an np.arrau, sampling uniformly 8 frames
+video_path = hf_hub_download(repo_id="raushan-testing-hf/videos-test", filename="sample_demo_1.mp4", repo_type="dataset")
+container = av.open(video_path)
+total_frames = container.streams.video[0].frames
+indices = np.arange(0, total_frames, total_frames / 8).astype(int)
+video = read_video_pyav(container, indices)
+
+# For better results, we recommend to prompt the model in the following format
+prompt = "USER: