From 77930f8a01d5a18af88335c60b86068f10b647f7 Mon Sep 17 00:00:00 2001
From: Steven Liu <59462357+stevhliu@users.noreply.github.com>
Date: Tue, 31 Oct 2023 09:44:51 -0700
Subject: [PATCH] [docs] Update CPU/GPU inference docs (#26881)
* first draft
* remove non-existent paths
* edits
* feedback
* feedback and optimum
* Apply suggestions from code review
Co-authored-by: regisss <15324346+regisss@users.noreply.github.com>
Co-authored-by: Ella Charlaix <80481427+echarlaix@users.noreply.github.com>
* redirect to correct doc
* _redirects.yml
---------
Co-authored-by: regisss <15324346+regisss@users.noreply.github.com>
Co-authored-by: Ella Charlaix <80481427+echarlaix@users.noreply.github.com>
---
docs/source/en/_redirects.yml | 3 +
docs/source/en/_toctree.yml | 8 +-
docs/source/en/perf_infer_cpu.md | 108 +++++---
docs/source/en/perf_infer_gpu_many.md | 124 ----------
docs/source/en/perf_infer_gpu_one.md | 342 ++++++++++----------------
docs/source/en/perf_infer_special.md | 18 --
docs/source/en/performance.md | 2 +-
src/transformers/utils/logging.py | 4 +-
utils/not_doctested.txt | 2 -
9 files changed, 215 insertions(+), 396 deletions(-)
create mode 100644 docs/source/en/_redirects.yml
delete mode 100644 docs/source/en/perf_infer_gpu_many.md
delete mode 100644 docs/source/en/perf_infer_special.md
diff --git a/docs/source/en/_redirects.yml b/docs/source/en/_redirects.yml
new file mode 100644
index 00000000000000..0dd4d2bfb34b2f
--- /dev/null
+++ b/docs/source/en/_redirects.yml
@@ -0,0 +1,3 @@
+# Optimizing inference
+
+perf_infer_gpu_many: perf_infer_gpu_one
\ No newline at end of file
diff --git a/docs/source/en/_toctree.yml b/docs/source/en/_toctree.yml
index 1a76762d160f88..4d434b7a18c154 100644
--- a/docs/source/en/_toctree.yml
+++ b/docs/source/en/_toctree.yml
@@ -155,13 +155,9 @@
title: Efficient training techniques
- sections:
- local: perf_infer_cpu
- title: Inference on CPU
+ title: CPU inference
- local: perf_infer_gpu_one
- title: Inference on one GPU
- - local: perf_infer_gpu_many
- title: Inference on many GPUs
- - local: perf_infer_special
- title: Inference on Specialized Hardware
+ title: GPU inference
title: Optimizing inference
- local: big_models
title: Instantiating a big model
diff --git a/docs/source/en/perf_infer_cpu.md b/docs/source/en/perf_infer_cpu.md
index a7a524ae1ef039..f10fc01e7ca6f1 100644
--- a/docs/source/en/perf_infer_cpu.md
+++ b/docs/source/en/perf_infer_cpu.md
@@ -13,46 +13,48 @@ rendered properly in your Markdown viewer.
-->
-# Efficient Inference on CPU
+# CPU inference
-This guide focuses on inferencing large models efficiently on CPU.
+With some optimizations, it is possible to efficiently run large model inference on a CPU. One of these optimization techniques involves compiling the PyTorch code into an intermediate format for high-performance environments like C++. The other technique fuses multiple operations into one kernel to reduce the overhead of running each operation separately.
-## `BetterTransformer` for faster inference
+You'll learn how to use [BetterTransformer](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/) for faster inference, and how to convert your PyTorch code to [TorchScript](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html). If you're using an Intel CPU, you can also use [graph optimizations](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features.html#graph-optimization) from [Intel Extension for PyTorch](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/index.html) to boost inference speed even more. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime or OpenVINO (if you're using an Intel CPU).
-We have recently integrated `BetterTransformer` for faster inference on CPU for text, image and audio models. Check the documentation about this integration [here](https://huggingface.co/docs/optimum/bettertransformer/overview) for more details.
+## BetterTransformer
-## PyTorch JIT-mode (TorchScript)
-TorchScript is a way to create serializable and optimizable models from PyTorch code. Any TorchScript program can be saved from a Python process and loaded in a process where there is no Python dependency.
-Comparing to default eager mode, jit mode in PyTorch normally yields better performance for model inference from optimization methodologies like operator fusion.
+BetterTransformer accelerates inference with its fastpath (native PyTorch specialized implementation of Transformer functions) execution. The two optimizations in the fastpath execution are:
-For a gentle introduction to TorchScript, see the Introduction to [PyTorch TorchScript tutorial](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html#tracing-modules).
+1. fusion, which combines multiple sequential operations into a single "kernel" to reduce the number of computation steps
+2. skipping the inherent sparsity of padding tokens to avoid unnecessary computation with nested tensors
-### IPEX Graph Optimization with JIT-mode
-Intel® Extension for PyTorch provides further optimizations in jit mode for Transformers series models. It is highly recommended for users to take advantage of Intel® Extension for PyTorch with jit mode. Some frequently used operator patterns from Transformers models are already supported in Intel® Extension for PyTorch with jit mode fusions. Those fusion patterns like Multi-head-attention fusion, Concat Linear, Linear+Add, Linear+Gelu, Add+LayerNorm fusion and etc. are enabled and perform well. The benefit of the fusion is delivered to users in a transparent fashion. According to the analysis, ~70% of most popular NLP tasks in question-answering, text-classification, and token-classification can get performance benefits with these fusion patterns for both Float32 precision and BFloat16 Mixed precision.
+BetterTransformer also converts all attention operations to use the more memory-efficient [scaled dot product attention](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention).
-Check more detailed information for [IPEX Graph Optimization](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html).
+
-#### IPEX installation:
+BetterTransformer is not supported for all models. Check this [list](https://huggingface.co/docs/optimum/bettertransformer/overview#supported-models) to see if a model supports BetterTransformer.
-IPEX release is following PyTorch, check the approaches for [IPEX installation](https://intel.github.io/intel-extension-for-pytorch/).
+
-### Usage of JIT-mode
-To enable JIT-mode in Trainer for evaluaion or prediction, users should add `jit_mode_eval` in Trainer command arguments.
+Before you start, make sure you have 🤗 Optimum [installed](https://huggingface.co/docs/optimum/installation).
-
+Enable BetterTransformer with the [`PreTrainedModel.to_bettertransformer`] method:
-for PyTorch >= 1.14.0. JIT-mode could benefit any models for prediction and evaluaion since dict input is supported in jit.trace
+```py
+from transformers import AutoModelForCausalLM
-for PyTorch < 1.14.0. JIT-mode could benefit models whose forward parameter order matches the tuple input order in jit.trace, like question-answering model
-In the case where the forward parameter order does not match the tuple input order in jit.trace, like text-classification models, jit.trace will fail and we are capturing this with the exception here to make it fallback. Logging is used to notify users.
+model = AutoModelForCausalLM.from_pretrained("bigcode/starcoder")
+model.to_bettertransformer()
+```
-
+## TorchScript
+
+TorchScript is an intermediate PyTorch model representation that can be run in production environments where performance is important. You can train a model in PyTorch and then export it to TorchScript to free the model from Python performance constraints. PyTorch [traces](https://pytorch.org/docs/stable/generated/torch.jit.trace.html) a model to return a [`ScriptFunction`] that is optimized with just-in-time compilation (JIT). Compared to the default eager mode, JIT mode in PyTorch typically yields better performance for inference using optimization techniques like operator fusion.
-Take an example of the use cases on [Transformers question-answering](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)
+For a gentle introduction to TorchScript, see the [Introduction to PyTorch TorchScript](https://pytorch.org/tutorials/beginner/Intro_to_TorchScript_tutorial.html) tutorial.
+With the [`Trainer`] class, you can enable JIT mode for CPU inference by setting the `--jit_mode_eval` flag:
-- Inference using jit mode on CPU:
-python run_qa.py \
+```bash
+python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
@@ -60,10 +62,31 @@ Take an example of the use cases on [Transformers question-answering](https://gi
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
---jit_mode_eval
+--jit_mode_eval
+```
+
+
+
+For PyTorch >= 1.14.0, JIT-mode could benefit any model for prediction and evaluaion since the dict input is supported in `jit.trace`.
+
+For PyTorch < 1.14.0, JIT-mode could benefit a model if its forward parameter order matches the tuple input order in `jit.trace`, such as a question-answering model. If the forward parameter order does not match the tuple input order in `jit.trace`, like a text classification model, `jit.trace` will fail and we are capturing this with the exception here to make it fallback. Logging is used to notify users.
+
+
+
+## IPEX graph optimization
+
+Intel® Extension for PyTorch (IPEX) provides further optimizations in JIT mode for Intel CPUs, and we recommend combining it with TorchScript for even faster performance. The IPEX [graph optimization](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/features/graph_optimization.html) fuses operations like Multi-head attention, Concat Linear, Linear + Add, Linear + Gelu, Add + LayerNorm, and more.
+
+To take advantage of these graph optimizations, make sure you have IPEX [installed](https://intel.github.io/intel-extension-for-pytorch/cpu/latest/tutorials/installation.html):
+
+```bash
+pip install intel_extension_for_pytorch
+```
-- Inference with IPEX using jit mode on CPU:
-python run_qa.py \
+Set the `--use_ipex` and `--jit_mode_eval` flags in the [`Trainer`] class to enable JIT mode with the graph optimizations:
+
+```bash
+python run_qa.py \
--model_name_or_path csarron/bert-base-uncased-squad-v1 \
--dataset_name squad \
--do_eval \
@@ -71,5 +94,34 @@ Take an example of the use cases on [Transformers question-answering](https://gi
--doc_stride 128 \
--output_dir /tmp/ \
--no_cuda \
---use_ipex \
---jit_mode_eval
+--use_ipex \
+--jit_mode_eval
+```
+
+## 🤗 Optimum
+
+
+
+Learn more details about using ORT with 🤗 Optimum in the [Optimum Inference with ONNX Runtime](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/models) guide. This section only provides a brief and simple example.
+
+
+
+ONNX Runtime (ORT) is a model accelerator that runs inference on CPUs by default. ORT is supported by 🤗 Optimum which can be used in 🤗 Transformers, without making too many changes to your code. You only need to replace the 🤗 Transformers `AutoClass` with its equivalent [`~optimum.onnxruntime.ORTModel`] for the task you're solving, and load a checkpoint in the ONNX format.
+
+For example, if you're running inference on a question answering task, load the [optimum/roberta-base-squad2](https://huggingface.co/optimum/roberta-base-squad2) checkpoint which contains a `model.onnx` file:
+
+```py
+from transformers import AutoTokenizer, pipeline
+from optimum.onnxruntime import ORTModelForQuestionAnswering
+
+model = ORTModelForQuestionAnswering.from_pretrained("optimum/roberta-base-squad2")
+tokenizer = AutoTokenizer.from_pretrained("deepset/roberta-base-squad2")
+
+onnx_qa = pipeline("question-answering", model=model, tokenizer=tokenizer)
+
+question = "What's my name?"
+context = "My name is Philipp and I live in Nuremberg."
+pred = onnx_qa(question, context)
+```
+
+If you have an Intel CPU, take a look at 🤗 [Optimum Intel](https://huggingface.co/docs/optimum/intel/index) which supports a variety of compression techniques (quantization, pruning, knowledge distillation) and tools for converting models to the [OpenVINO](https://huggingface.co/docs/optimum/intel/inference) format for higher performance inference.
diff --git a/docs/source/en/perf_infer_gpu_many.md b/docs/source/en/perf_infer_gpu_many.md
deleted file mode 100644
index 2118b5ddb40431..00000000000000
--- a/docs/source/en/perf_infer_gpu_many.md
+++ /dev/null
@@ -1,124 +0,0 @@
-
-
-# Efficient Inference on a Multiple GPUs
-
-This document contains information on how to efficiently infer on a multiple GPUs.
-
-
-Note: A multi GPU setup can use the majority of the strategies described in the [single GPU section](./perf_infer_gpu_one). You must be aware of simple techniques, though, that can be used for a better usage.
-
-
-
-## Flash Attention 2
-
-Flash Attention 2 integration also works in a multi-GPU setup, check out the appropriate section in the [single GPU section](./perf_infer_gpu_one#Flash-Attention-2)
-
-## BetterTransformer
-
-[BetterTransformer](https://huggingface.co/docs/optimum/bettertransformer/overview) converts 🤗 Transformers models to use the PyTorch-native fastpath execution, which calls optimized kernels like Flash Attention under the hood.
-
-BetterTransformer is also supported for faster inference on single and multi-GPU for text, image, and audio models.
-
-
-
-Flash Attention can only be used for models using fp16 or bf16 dtype. Make sure to cast your model to the appropriate dtype before using BetterTransformer.
-
-
-
-### Decoder models
-
-For text models, especially decoder-based models (GPT, T5, Llama, etc.), the BetterTransformer API converts all attention operations to use the [`torch.nn.functional.scaled_dot_product_attention` operator](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) (SDPA) that is only available in PyTorch 2.0 and onwards.
-
-To convert a model to BetterTransformer:
-
-```python
-from transformers import AutoModelForCausalLM
-
-model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m")
-# convert the model to BetterTransformer
-model.to_bettertransformer()
-
-# Use it for training or inference
-```
-
-SDPA can also call [Flash Attention](https://arxiv.org/abs/2205.14135) kernels under the hood. To enable Flash Attention or to check that it is available in a given setting (hardware, problem size), use [`torch.backends.cuda.sdp_kernel`](https://pytorch.org/docs/master/backends.html#torch.backends.cuda.sdp_kernel) as a context manager:
-
-
-```diff
-import torch
-from transformers import AutoModelForCausalLM, AutoTokenizer
-
-tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
-model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m").to("cuda")
-# convert the model to BetterTransformer
-model.to_bettertransformer()
-
-input_text = "Hello my dog is cute and"
-inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
-
-+ with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
- outputs = model.generate(**inputs)
-
-print(tokenizer.decode(outputs[0], skip_special_tokens=True))
-```
-
-If you see a bug with a traceback saying
-
-```bash
-RuntimeError: No available kernel. Aborting execution.
-```
-
-try using the PyTorch nightly version, which may have a broader coverage for Flash Attention:
-
-```bash
-pip3 install -U --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu118
-```
-
-Have a look at this [blog post](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about what is possible with the BetterTransformer + SDPA API.
-
-### Encoder models
-
-For encoder models during inference, BetterTransformer dispatches the forward call of encoder layers to an equivalent of [`torch.nn.TransformerEncoderLayer`](https://pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html) that will execute the fastpath implementation of the encoder layers.
-
-Because `torch.nn.TransformerEncoderLayer` fastpath does not support training, it is dispatched to `torch.nn.functional.scaled_dot_product_attention` instead, which does not leverage nested tensors but can use Flash Attention or Memory-Efficient Attention fused kernels.
-
-More details about BetterTransformer performance can be found in this [blog post](https://medium.com/pytorch/bettertransformer-out-of-the-box-performance-for-huggingface-transformers-3fbe27d50ab2), and you can learn more about BetterTransformer for encoder models in this [blog](https://pytorch.org/blog/a-better-transformer-for-fast-transformer-encoder-inference/).
-
-
-## Advanced usage: mixing FP4 (or Int8) and BetterTransformer
-
-You can combine the different methods described above to get the best performance for your model. For example, you can use BetterTransformer with FP4 mixed-precision inference + flash attention:
-
-```py
-import torch
-from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
-
-quantization_config = BitsAndBytesConfig(
- load_in_4bit=True,
- bnb_4bit_compute_dtype=torch.float16
-)
-
-tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
-model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", quantization_config=quantization_config)
-
-input_text = "Hello my dog is cute and"
-inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
-
-with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
- outputs = model.generate(**inputs)
-
-print(tokenizer.decode(outputs[0], skip_special_tokens=True))
-```
\ No newline at end of file
diff --git a/docs/source/en/perf_infer_gpu_one.md b/docs/source/en/perf_infer_gpu_one.md
index 39f2ca22b1f040..06e91c5502266e 100644
--- a/docs/source/en/perf_infer_gpu_one.md
+++ b/docs/source/en/perf_infer_gpu_one.md
@@ -13,40 +13,38 @@ rendered properly in your Markdown viewer.
-->
-# Efficient Inference on a Single GPU
+# GPU inference
-In addition to this guide, relevant information can be found as well in [the guide for training on a single GPU](perf_train_gpu_one) and [the guide for inference on CPUs](perf_infer_cpu).
-
-## Flash Attention 2
+GPUs are the standard choice of hardware for machine learning, unlike CPUs, because they are optimized for memory bandwidth and parallelism. To keep up with the larger sizes of modern models or to run these large models on existing and older hardware, there are several optimizations you can use to speed up GPU inference. In this guide, you'll learn how to use FlashAttention-2 (a more memory-efficient attention mechanism), BetterTransformer (a PyTorch native fastpath execution), and bitsandbytes to quantize your model to a lower precision. Finally, learn how to use 🤗 Optimum to accelerate inference with ONNX Runtime on Nvidia GPUs.
-Note that this feature is experimental and might considerably change in future versions. For instance, the Flash Attention 2 API might migrate to `BetterTransformer` API in the near future.
+The majority of the optimizations described here also apply to multi-GPU setups!
-Flash Attention 2 can considerably speed up transformer-based models' training and inference speed. Flash Attention 2 has been introduced in the [official Flash Attention repository](https://github.com/Dao-AILab/flash-attention) by Tri Dao et al. The scientific paper on Flash Attention can be found [here](https://arxiv.org/abs/2205.14135).
+## FlashAttention-2
-Make sure to follow the installation guide on the repository mentioned above to properly install Flash Attention 2. Once that package is installed, you can benefit from this feature.
+
-We natively support Flash Attention 2 for the following models:
+FlashAttention-2 is experimental and may change considerably in future versions.
-- Llama
-- Mistral
-- Falcon
-- [GPTBigCode (Starcoder)](model_doc/gpt_bigcode#)
+
-You can request to add Flash Attention 2 support for more models by opening an issue on GitHub, and even open a Pull Request to integrate the changes. The supported models can be used for inference and training, including training with padding tokens - *which is currently not supported for `BetterTransformer` API below.*
+[FlashAttention-2](https://huggingface.co/papers/2205.14135) is a faster and more efficient implementation of the standard attention mechanism that can significantly speedup inference by:
-
+1. additionally parallelizing the attention computation over sequence length
+2. partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them
-Flash Attention 2 can only be used when the models' dtype is `fp16` or `bf16` and runs only on NVIDIA-GPU devices. Make sure to cast your model to the appropriate dtype and load them on a supported device before using that feature.
-
-
+FlashAttention-2 supports inference with Llama, Mistral, and Falcon models. You can request to add FlashAttention-2 support for another model by opening a GitHub Issue or Pull Request.
-### Quick usage
+Before you begin, make sure you have FlashAttention-2 installed (see the [installation](https://github.com/Dao-AILab/flash-attention?tab=readme-ov-file#installation-and-features) guide for more details about prerequisites):
-To enable Flash Attention 2 in your model, add `use_flash_attention_2` in the `from_pretrained` arguments:
+```bash
+pip install flash-attn --no-build-isolation
+```
+
+To enable FlashAttention-2, add the `use_flash_attention_2` parameter to [`~AutoModelForCausalLM.from_pretrained`]:
```python
import torch
@@ -62,74 +60,29 @@ model = AutoModelForCausalLM.from_pretrained(
)
```
-And use it for generation or fine-tuning.
-
-### Expected speedups
-
-You can benefit from considerable speedups for fine-tuning and inference, especially for long sequences. However, since Flash Attention does not support computing attention scores with padding tokens under the hood, we must manually pad / unpad the attention scores for batched inference when the sequence contains padding tokens. This leads to a significant slowdown for batched generations with padding tokens.
-
-To overcome this, one should use Flash Attention without padding tokens in the sequence for training (e.g., by packing a dataset, i.e., concatenating sequences until reaching the maximum sequence length. An example is provided [here](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm.py#L516).
-
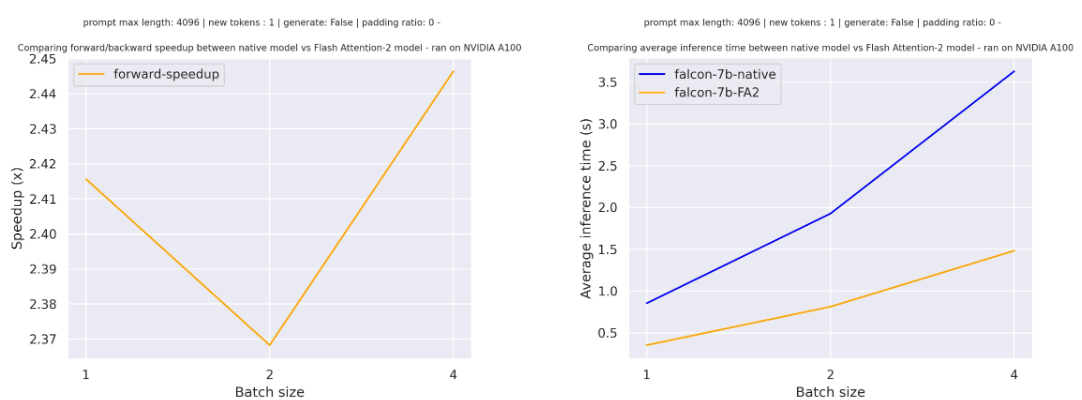
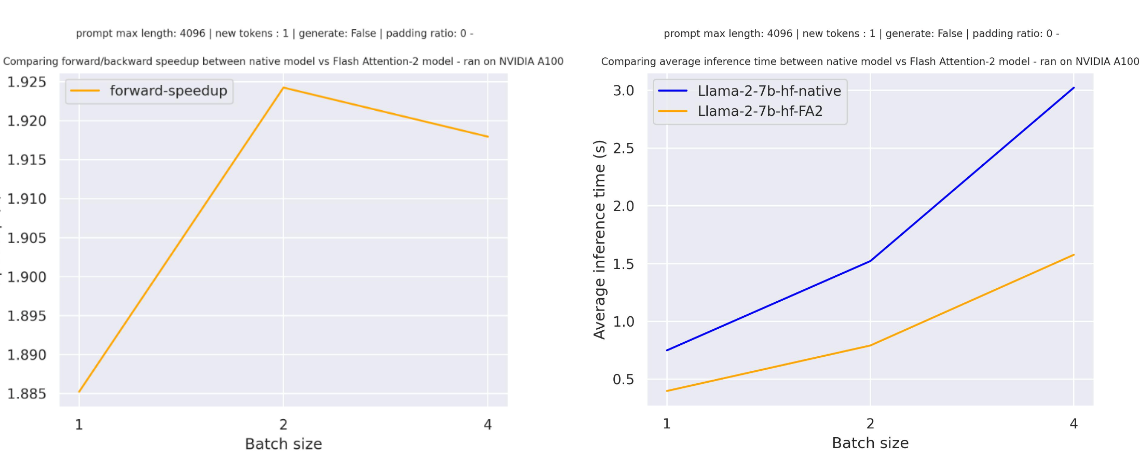
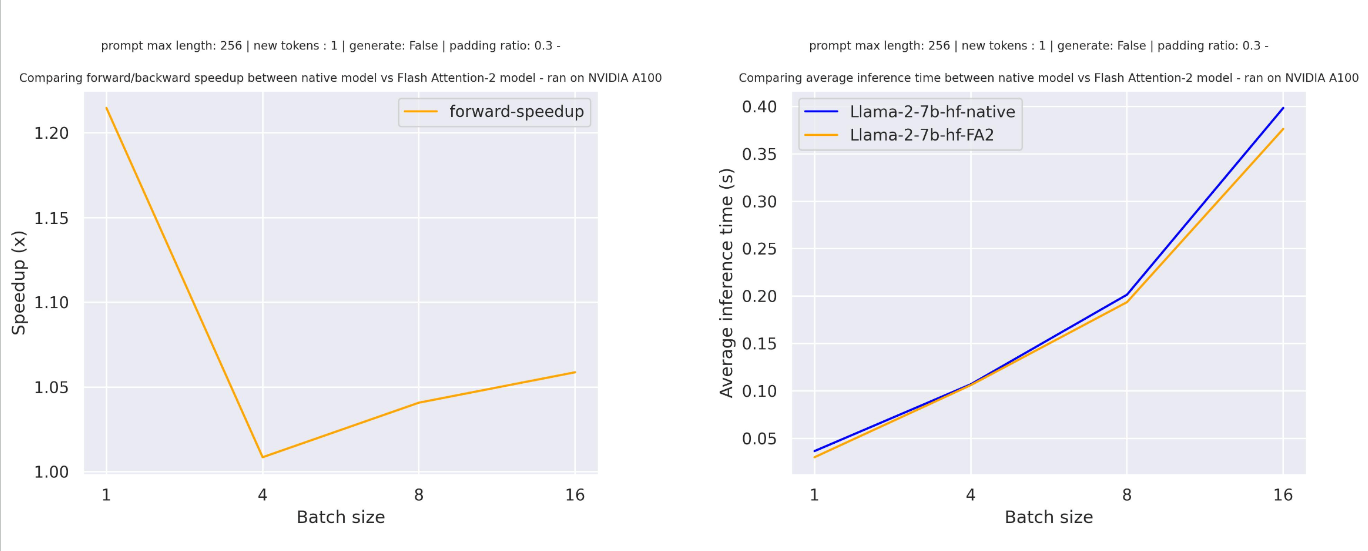
-Below is the expected speedup you can get for a simple forward pass on [tiiuae/falcon-7b](https://hf.co/tiiuae/falcon-7b) with a sequence length of 4096 and various batch sizes, without padding tokens:
-
-
-
-
-
-
-
-
-

-
+
+
+
+
+
+
+
+