From c7c104cb7ccc353faa10667853ed210e042f1be8 Mon Sep 17 00:00:00 2001
From: Jianghai <72591262+CjhHa1@users.noreply.github.com>
Date: Mon, 29 Jan 2024 16:21:06 +0800
Subject: [PATCH] [DOC] Update inference readme (#5280)
* add readme
* add readme
* 1
* update engine
* finish readme
* add readme
---
colossalai/inference/README.md | 81 +++++++++++++++++++++++++++--
colossalai/inference/core/engine.py | 1 +
2 files changed, 79 insertions(+), 3 deletions(-)
diff --git a/colossalai/inference/README.md b/colossalai/inference/README.md
index 2773a7ff4eda..ed8e2d1ce42d 100644
--- a/colossalai/inference/README.md
+++ b/colossalai/inference/README.md
@@ -13,18 +13,92 @@
## 📌 Introduction
-
ColossalAI-Inference is a library which offers acceleration to Transformers models, especially LLMs. In ColossalAI-Inference, we leverage high-performance kernels, KV cache, paged attention, continous batching and other techniques to accelerate the inference of LLMs. We also provide a unified interface for users to easily use our library.
## 🛠 Design and Implementation
-To be added.
+### :book: Overview
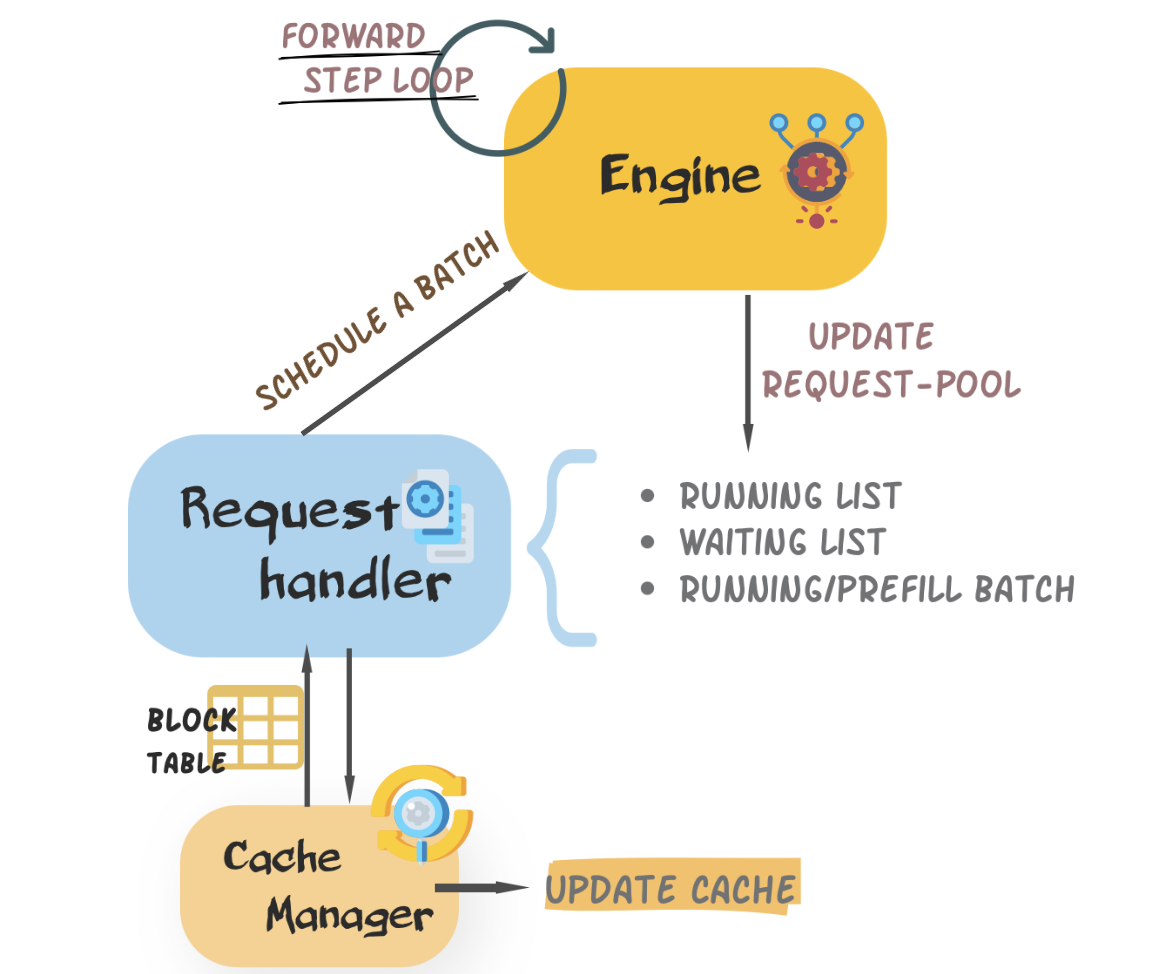
+We build ColossalAI-Inference based on **Four** core components: `engine`,`request handler`,`cache manager(block cached)`, `hand crafted modeling`. **Engine** controls inference step, it recives `requests`, calls `request handler` to schedule a decoding batch and runs `modeling` to perform a iteration and returns finished `requests`. **Cache manager** is bound with `request handler`, updates cache blocks and logical block tables during schedule.
+
+The interaction between different components are shown below, you can also checkout detailed introduction below.:
+
+
+
+
+
+### :mailbox_closed: Design of engine
+Engine is designed as starter of inference loop. User can easily instantialize an infer engine with config and execute requests. We provids apis below in engine, you can refer to source code for more information:
+- `generate`: main function, handle inputs and return outputs
+- `add_request`: add request to waitting list
+- `step`: perform one decoding iteration
+ - first, `request handler` schedules a batch to do prefill/decode
+ - then, invoke a model to generate a batch of token
+ - after that, do logit processing and sampling, check and decode finished requests
+
+### :game_die: Design of request_handler
+Request handler is responsible manage requests and schedule a proper batch from exisiting requests. According to existing work and experiments, we do believe that it is beneficial to increase the length of decoding sequences. In our design, we partition requests into three priorities depending on their lengths, the longer sequences are first considered.
+
+
+
+
+
+### :radio: Design of KV cache and cache manager
+We design a unified blocked type cache and cache manager to distribute memory. The physical memory is allocated before decoding and represented by a logical block table. During decoding process, cache manager administrate physical memory through `block table` and other components(i.e. engine) can focus on the light-weighted `block table`. Their details are introduced below.
+- `cache block` We group physical memory into different memory blocks. A typical cache block is shaped `(num_kv_heads, head_size, block_size)`. We decide block number beforehand. The memory allocation and computation are executed with the granularity of memory block.
+- `block table` Block table is the logical representation of cache blocks. Concretely, a block table of a single sequence is a 1D tensor, with each element holding a block id of allocated id or `-1` for non allocated. Each iteration we pass through a batch block table to the corresponding model. For more information, you can checkout the source code.
+
+
+
+
+
+ Example of Batch Block Table
+
+
+
+
+### :railway_car: Modeling
+Modeling contains models and layers, which are hand-crafted for better performance easier usage. Deeply integrated with `shardformer`, we also construct policy for our models. In order to minimize users' learning costs, our models are aligned with [Transformers](https://github.com/huggingface/transformers)
## 🕹 Usage
+### :arrow_right: Quick Start
+You can enjoy your fast generation journey within three step
+```python
+# First, create a model in "transformers" way, you can provide a model config or use the default one.
+model = transformers.LlamaForCausalLM(config).cuda()
+# Second, create an inference_config
+inference_config = InferenceConfig(
+ dtype=args.dtype,
+ max_batch_size=args.max_batch_size,
+ max_input_len=args.seq_len,
+ max_output_len=args.output_len,
+ )
+# Third, create an engine with model and config
+engine = InferenceEngine(model, tokenizer, inference_config, verbose=True)
+
+# Try fast infrence now!
+prompts = {'Nice to meet you, Colossal-Inference!'}
+engine.generate(prompts)
-To be added.
+```
+### :bookmark: Customize your inference engine
+Besides the basic fast-start inference, you can also customize your inference engine via modifying config or upload your own model or decoding components (logit processors or sampling strategies).
+#### Inference Config
+Inference Config is a unified api for generation process. You can define the value of args to control the generation, like `max_batch_size`,`max_output_len`,`dtype` to decide the how many sequences can be handled at a time, and how many tokens to output. Refer to the source code for more detail.
+#### Generation Config
+In colossal-inference, Generation config api is inherited from [Transformers](https://github.com/huggingface/transformers). Usage is aligned. By default, it is automatically generated by our system and you don't bother to construct one. If you have such demand, you can also create your own and send it to your engine.
+
+#### Logit Processors
+Logit Processosr receives logits and return processed ones, take the following step to make your own.
+```python
+@register_logit_processor("name")
+def xx_logit_processor(logits, args):
+ logits = do_some_process(logits)
+ return logits
+```
+#### Sampling Strategies
+We offer 3 main sampling strategies now (i.e. `greedy sample`, `multinomial sample`, `beam_search sample`), you can refer to [sampler](/ColossalAI/colossalai/inference/sampler.py) for more details. We would strongly appreciate if you can contribute your varities.
## 🪅 Support Matrix
| Model | KV Cache | Paged Attention | Kernels | Tensor Parallelism | Speculative Decoding |
@@ -44,6 +118,7 @@ Notations:
- [x] High-Performance Kernels
- [x] Llama Modelling
- [ ] Tensor Parallelism
+- [ ] Beam Search
- [ ] Speculative Decoding
- [ ] Continuous Batching
- [ ] Online Inference
diff --git a/colossalai/inference/core/engine.py b/colossalai/inference/core/engine.py
index 9c49a60a0438..a9686f07c8d6 100644
--- a/colossalai/inference/core/engine.py
+++ b/colossalai/inference/core/engine.py
@@ -242,6 +242,7 @@ def step(self) -> List[str]:
finished_sequences = self.request_handler.update()
# Decode completed sentences.
+ # TODO : update decoding step
for seq in finished_sequences:
output_str = self.tokenizer.decode(seq.input_token_id + seq.output_token_id, skip_special_tokens=True)
output_list.append(output_str)
 +
+  +
+  +
+