Implementation and extension of Score-Based Generative Modeling through Stochastic Differential Equations (Song++20) and Maximum Likelihood Training of Score-Based Diffusion Models (Song++21) in jax and equinox.
This repository provides a lightweight library of models, sampling and likelihood routines. Suitable for likelihood-free or emulation based approaches. Tested and typed code to ensure reliable and benchmarkable training and inference.
Warning
🏗️ Note this repository is under construction, expect changes. 🏗️
Diffusion models are deep hierarchical models for data that use neural networks to model the reverse of a diffusion process that adds a sequence of noise perturbations to the data.
Modern cutting-edge diffusion models (see citations) express both the forward and reverse diffusion processes as a Stochastic Differential Equation (SDE).

A diagram showing how to map data to a noise distribution (the prior) with an SDE, and reverse this SDE for generative modeling. One can also reverse the associated probability flow ODE, which yields a deterministic process that samples from the same distribution as the SDE. Both the reverse-time SDE and probability flow ODE can be obtained by estimating the score.
For any SDE of the form
the reverse of the SDE from noise to data is given by
For every SDE there exists an associated ordinary differential equation (ODE)
where the trajectories of the SDE and ODE have the same marginal PDFs
The Stein score of the marginal probability distributions over
For each SDE there exists a deterministic ODE with marginal likelihoods
The continuous normalizing flow formalism allows the ODE to be expressed as
which gives the log-likelihood of a datapoint
Note that maximum-likelihood training is prohibitively expensive for SDE based diffusion models.
Install via
pip install sbgm
See examples.
To run on the cifar10 image dataset, try something like
import sbgm
import data
import configs
datasets_path = "."
root_dir = "."
config = configs.cifar10_config()
key = jr.key(config.seed)
data_key, model_key, train_key = jr.split(key, 3)
dataset = data.cifar10(datasets_path, data_key)
sharding = sbgm.shard.get_sharding()
# Diffusion model
model = sbgm.models.get_model(
model_key,
config.model.model_type,
dataset.data_shape,
dataset.context_shape,
dataset.parameter_dim,
config
)
# Stochastic differential equation (SDE)
sde = sbgm.sde.get_sde(config.sde)
# Fit model to dataset
model = sbgm.train.train(
train_key,
model,
sde,
dataset,
config,
sharding=sharding,
save_dir=root_dir
)- Parallelised exact and approximate log-likelihood calculations,
- UNet and transformer score network implementations,
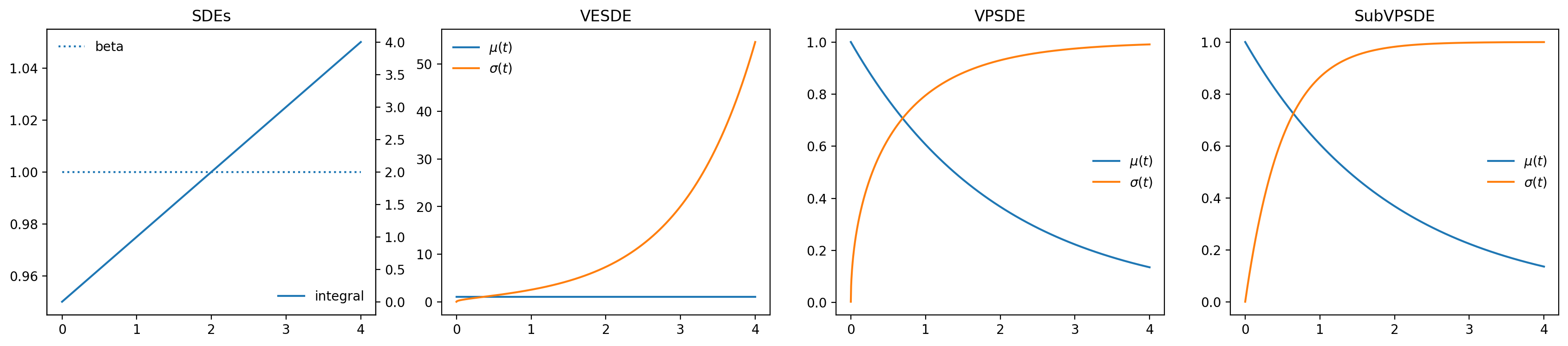
- VP, SubVP and VE SDEs (neural network
$\beta(t)$ and$\sigma(t)$ functions are on the list!), - Multi-modal conditioning (basically just optional parameter and image conditioning methods),
- Checkpointing optimiser and model,
- Multi-device training and sampling.
Note
I haven't optimised any training/architecture hyperparameters or trained long enough here, you could do a lot better.
Euler-Marayama sampling

ODE sampling

Euler-Marayama sampling

ODE sampling

@misc{song2021scorebasedgenerativemodelingstochastic,
title={Score-Based Generative Modeling through Stochastic Differential Equations},
author={Yang Song and Jascha Sohl-Dickstein and Diederik P. Kingma and Abhishek Kumar and Stefano Ermon and Ben Poole},
year={2021},
eprint={2011.13456},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2011.13456},
}@misc{song2021maximumlikelihoodtrainingscorebased,
title={Maximum Likelihood Training of Score-Based Diffusion Models},
author={Yang Song and Conor Durkan and Iain Murray and Stefano Ermon},
year={2021},
eprint={2101.09258},
archivePrefix={arXiv},
primaryClass={stat.ML},
url={https://arxiv.org/abs/2101.09258},
}