Portkey is the Control Panel for AI apps, offering an AI Gateway and Observability Suite that enables teams to build reliable, cost-efficient, and fast applications. This guide will walk you through integrating Portkey with Groq, allowing you to leverage Groq's powerful LLMs through Portkey's unified API and advanced features.
With Portkey, you can:
- Connect to 250+ models through a unified API
- Monitor 42+ metrics & logs for all requests
- Enable semantic caching to reduce latency & costs
- Implement reliability features like conditional routing, retries & fallbacks
- Add custom tags to requests for better tracking and analysis
- Guardrails and more
Install the Portkey SDK in your environment:
pip install portkey-aiTo use Groq with Portkey, you'll need two keys:
- Portkey API Key: Sign up at app.portkey.ai and copy your API key.
- Groq API Key: Create a free account on GroqCloud and generate your Groq API Key.
Create a Virtual Key in Portkey to securely store your Groq API key:
- Navigate to the Virtual Keys tab in Portkey, and create a new key for Groq
- Use the Virtual Key in your code:
from portkey_ai import Portkey
portkey = Portkey(
api_key="YOUR_PORTKEY_API_KEY",
virtual_key="YOUR_GROQ_VIRTUAL_KEY"
)You can also make API calls without using virtual key, learn more here
Now you can make calls to models powered by Groq for fast inference speed and low latency through Portkey:
completion = portkey.chat.completions.create(
messages=[{"role": "user", "content": "Say this is a test"}],
model="llama-3.1-8b-instant"
)
print(completion)Portkey automatically logs all requests, making debugging and monitoring simple. View detailed logs and traces in the Portkey dashboard.
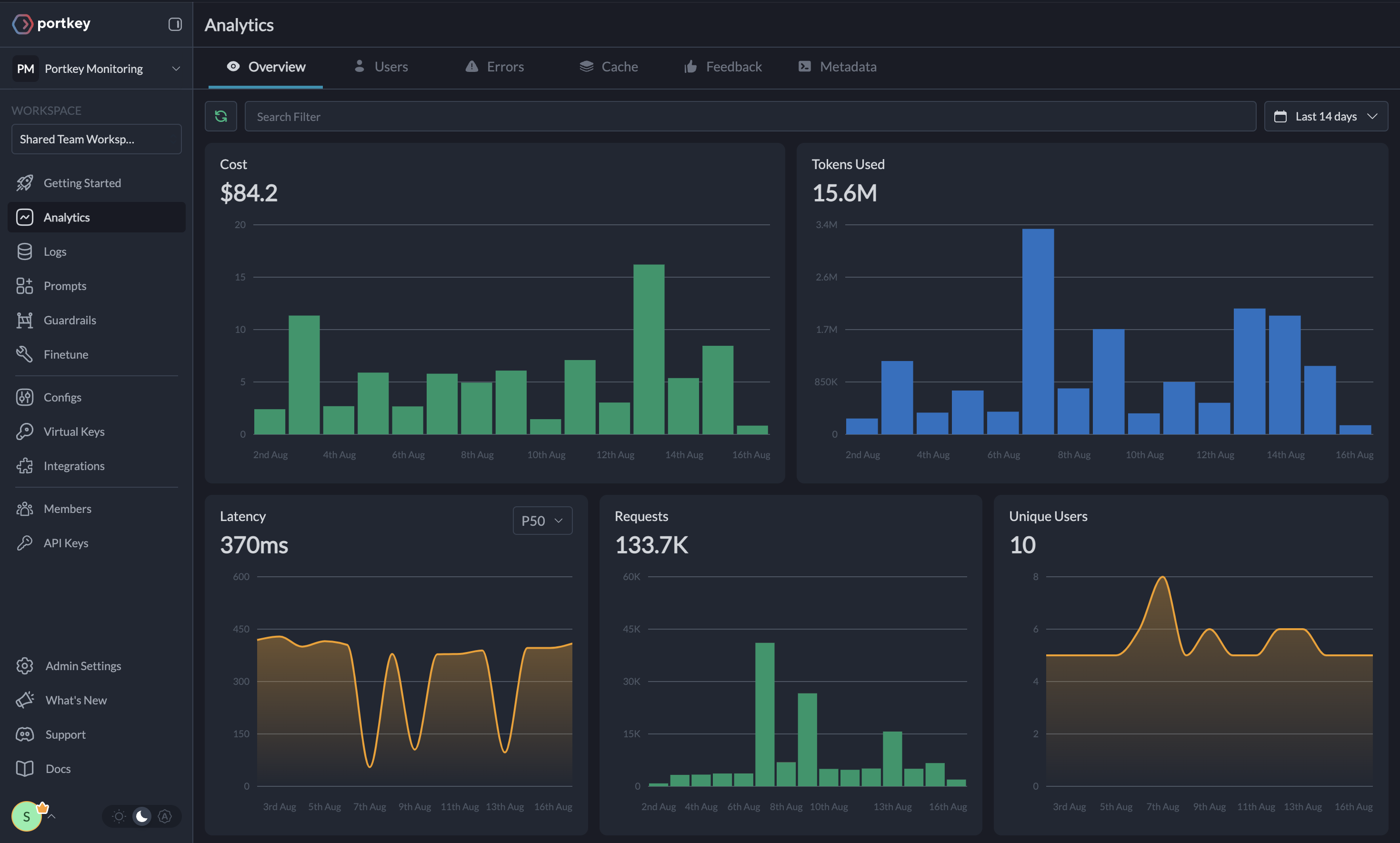
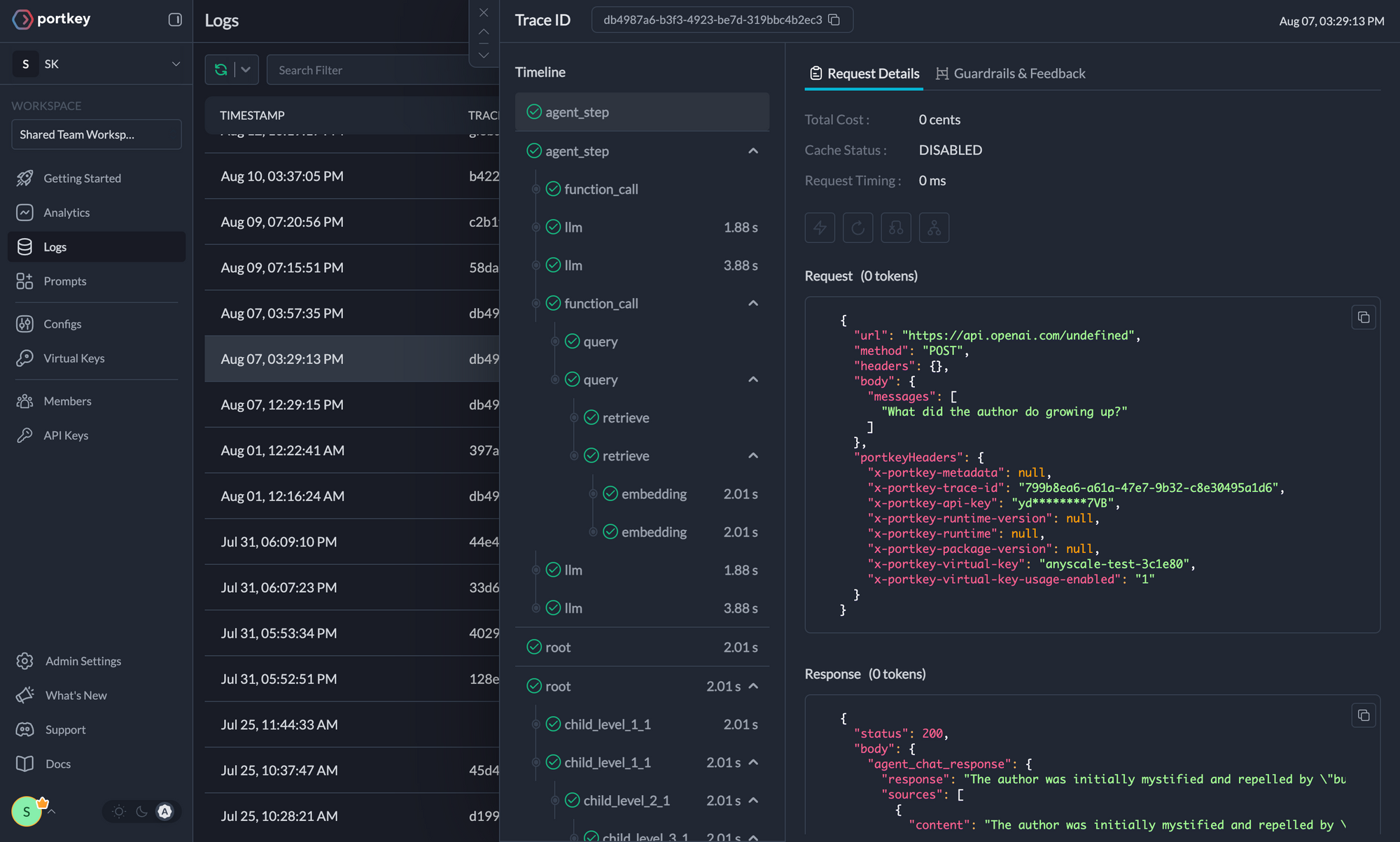
One of Portkey's strengths is the ability to easily switch between different LLM providers. To do so, simply change the virtual key.
portkey = Portkey(
api_key="YOUR_PORTKEY_API_KEY",
virtual_key="VIRTUAL_KEY",
)You can send custom metadata along with your requests in Portkey, which can later be used for auditing or filtering logs. You can pass any number of keys, all values should be of type string with max-length as 128 characters.
portkey = Portkey(
api_key="PORTKEY_API_KEY",
virtual_key="GROQ_VIRTUAL_KEY"
)
response = portkey.with_options(
metadata = {
"environment": "production",
"prompt": "test_prompt",
"session_id": "1729"
}).chat.completions.create(
messages = [{ "role": 'user', "content": 'What is 1729' }],
model = 'llama-3.1-8b-instant'
)
print(response.choices[0].message)Portkey config is a JSON object that defines how Portkey should handle your API requests. Configs allow you to customize various aspects of your API calls, including routing, caching, and reliability features. You can apply configs globally when initializing the Portkey client.
Here's a basic structure of a Portkey config:
portkey = Portkey(
api_key="YOUR_PORTKEY_API_KEY",
virtual_key="YOUR_GROQ_VIRTUAL_KEY",
config=test_config, # Example Configs of features like load-balance, guardrails, routing are given below.
model="llama-3.1-8b-instant"
)Portkey offers sophisticated routing capabilities to enhance the reliability and flexibility of your LLM integrations. Here are some key routing features:
- Retries: Automatically retry failed requests.
- Fallbacks: Specify alternative models or providers if the primary option fails.
- Conditional Routing: Route requests based on specific conditions.
- Load Balancing: Distribute requests across multiple models or providers.
Let's explore some of these features with examples:
Portkey’s Guardrails allow you to verify your LLM inputs AND outputs, adhering to your specifed checks. You can orchestrate your request - with actions ranging from denying the request, logging the guardrail result, creating an evals dataset, falling back to another LLM or prompt, retrying the request, and more.
guardrails_config = {
"before_request_hooks": [{
"id": "input-guardrail-id-xx"
}],
"after_request_hooks": [{
"id": "output-guardrail-id-xx"
}]
}Enable semantic caching to reduce latency and costs:
test_config = {
"cache": {
"mode": "semantic", # Choose between simple and semantic
}
}retry_fallback_config = {
"retry": {
"attempts": 3,
},
"fallback": {
"targets": [
{"virtual_key": "openai-virtual-key"},
{"virtual_key": "groq-virtual-key"}
]
}
}This configuration attempts to retry the request up to 3 times if a timeout or rate limit error occurs. If all retries fail, it will fallback to OpenAI's GPT-3.5 Turbo, and if that fails, to Anthropic's Claude 2.
test_config = {
"strategy": {
"mode": "conditional",
"conditions": [
{
"query": { "metadata.user_plan": { "$eq": "paid" } },
"then": "free-model"
},
{
"query": { "metadata.user_plan": { "$eq": "free" } },
"then": "paid-model"
}
],
"default": "free-model"
},
"targets": [
{
"name": "free-model",
"virtual_key": "groq-virtual-key",
"override_params": {"model": "mixtral-8x7b-32768"},
},
{
"name": "paid-model",
"virtual_key": "groq-virtual-key",
"override_params": {"model": "llama-3.1-8b-instant"},
},
]
}This configuration routes requests to Groq's Mixtral model for paid and to OpenAI's GPT-3.5 Turbo for free, based on the user_plan metadata.
test_config = {
"strategy": {
"mode": "loadbalance"
},
"targets": [{
"virtual_key": "groq-virtual-key",
"override_params": {"model": "mixtral-8x7b-32768"},
"weight": 0.7
}, {
"virtual_key": "groq-virtual-key",
"override_params": {"model": "llama-3.1-8b-instant"},
"weight": 0.3
}]
}This configuration distributes 70% of traffic to Mixtral and 30% to LLaMA 2, both hosted on Groq.
- Portkey Observability Documentation
- AI Gateway Documentation
- Prompt Library Documentation
- Open Source AI Gateway
For detailed information on each feature and how to use it, please refer to the Portkey documentation.
If you have any questions or need further assistance, reach out to us on Discord or via email at [email protected].