-
Notifications
You must be signed in to change notification settings - Fork 971
3.2 采集器高级用法
[TOC]
本节内容有些零散,不需要通读,可根据标题快速检索需要的内容。
XPath可以非常灵活,例如:
- //@src 可匹配所有src标签
- //title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。
还可以通过|对多个表达式进行混合,Hawk支持了完整的XPath语法,因此不论是网页采集器以及数据清洗的XPath转换器,都能极其灵活地实现各种需求。 强烈建议自学XPath语法。
多数情况下,使用XPath就能解决问题,但是CSSSelector更简洁,且鲁棒性更强,为什么不用呢?关于它的介绍,可参考
当然,大部分情况不需要那么复杂,只要记住以下几点:
-
.name获取所有id为name的元素 -
#name获取所有class为name的元素 -
p获取所有p元素 -
ul > li获取所有父节点是ul的li元素。 这非常符合
主要是沙漠君对css选择器也不太属性,就不班门弄斧了。
你可以在Hawk中混合使用XPath和CSS,例如列表节点路径用CSS,属性路径用XPath,按需求获得更灵活的配置。
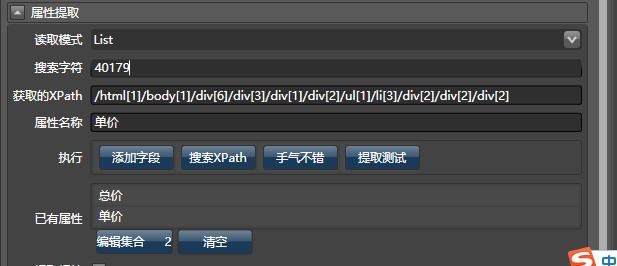
在List模式下,为了保证软件获取数据的稳定性,便有了列表根路径.什么是列表根路径?
通过列表根路径,我们能定位到所有子节点的路径,考虑这个表达式: //ul/li,它会获取所有以li结尾的多个元素。
可参考如下教程
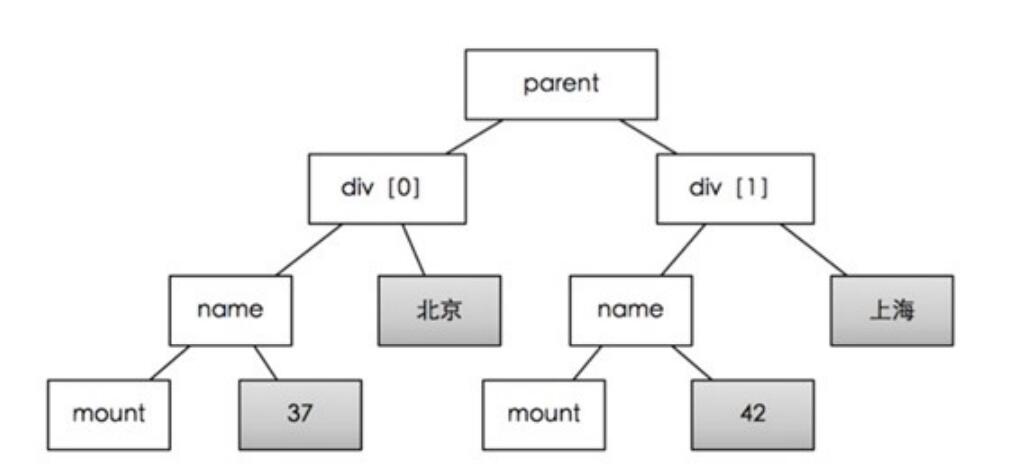
使用手气不错后,嗅探器会找到列表节点的父节点,以及挂载在父节点上的多个子节点,从而形成一个树状结构
{kind=link}
{kind=link}
{kind=link}
{kind=link}
每个节点要抽取下面的属性:
为了能获取父节点下所有的div子节点,因此列表根路径就是/html/div[2]/div[3]/div[4]/div。 注意:父节点Path路径末尾是不带序号的,这样才能获取多个子节点。可以这么理解,列表根路径就是不带结尾数字的父节点路径。
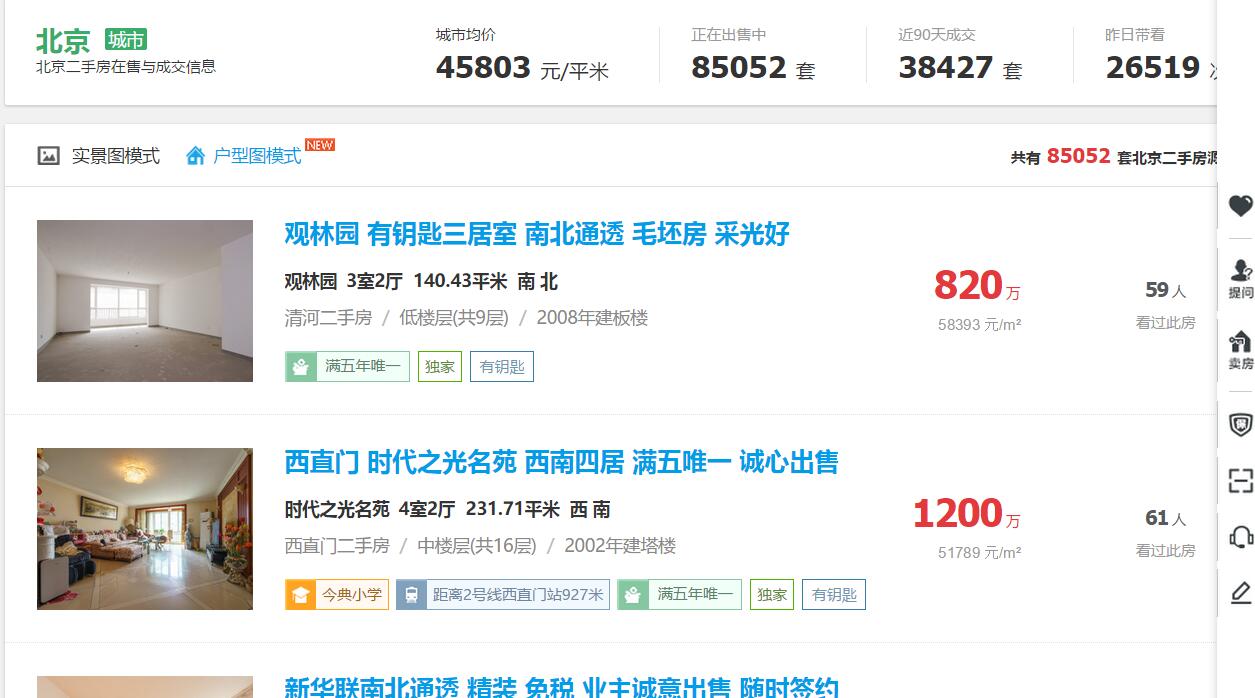
有时候,父节点的xpath是不稳定的,举个例子,北京上海的二手房页面,上海会在列表上面增加一个广告banner,从而真正的父节点就会发生变化,比如向后偏移了div[1]变成了div[2]。为了应对这种变化,通常的做法是手工修改【列表根路径】
继续举例子,父节点的id为house_list,且在网页中全局唯一,你就可以使用另外一种父节点表示法//*[@id='house_list']/li(写法可以参考其他XPath教程),而子节点表达式不变。这样会让程序变得更加鲁棒。
这个功能在遇到数据分布在网页多个位置的情形下非常有用。 具体可参考1.6入门5,XPath|优酷列表
为了抓取一个网站的不同数据,我们需要多个网页采集器。但是访问网站需要登录和cookie,难不成每个采集器都要设置对应的请求参数吗?
采集器的属性对话框中,可以设置共享源,也就是要共享的网页采集器的名称。例如设置为链家采集器,那么本采集器的请求参数,都会在执行时,动态地从链家采集器中获得。这样就极大地简化了配置过程。
Hawk提供了有限的代理支持,具体可参考常见问题章节。
//增加图片和配置思路