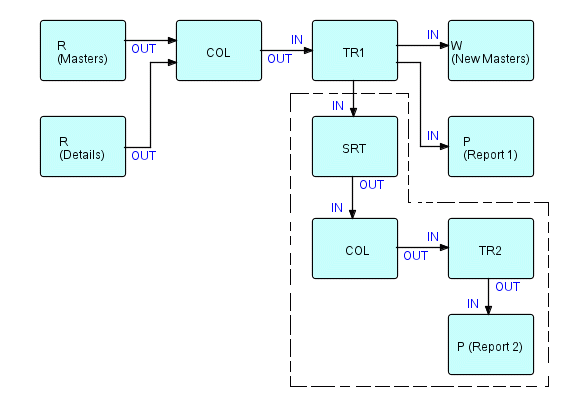
В этой главе мы будем работать с более сложным примером — программе по статистике продаж, описанной в Ливенвортом в 1977. В его документе описывается приложение, где отсортированный файл сведений о продажах продуктов сравнивается с "мастер-файлом" продукта, создавая "обновленный мастер-файл" и два отчета: сводку по продуктам и сводку по районам и продавцам. Рисунок на следующей странице, который первоначально появился в моей статье в 1978, показывает сеть FBP-процессов для этого приложения.
При традиционном подходе к созданию этого приложения мы сначала разделили бы сводку по району/продавцу на отдельный этап работы, которому предшествовала бы сортировка. Получилась бы функция, которая принимает два входных файла и генерирует три выходных (обновленный мастер, сводка продукта и ввод для сортировки, также называемый расширенными деталями). Эта функция должна передавать сведения о мастер-файлах, учитывать, что один из файлов обычно заканчивается раньше другого и обрабатывать возможные прерывания, обнаруживать нарушения последовательности и т.д. и т.п.
Как мы говорили в предыдущей главе, компонент Collate является ключом к упрощению такого рода приложений. Результирующая диаграмма выглядит следующим образом:
Фрагмент 10.7
Где:
Rкомпонент чтения.W— компонент записи.COL— обобщенныйCollate, который объединяет два или более потоков на основе заданных контрольных полей и вставляет IP-скобки между IP с разными значениями в контрольных полях. (Если используется только с одним потоком, то просто вставляет IP скобок — это случай второгоCOLна диаграмме).Pкомпонент печати.TR1иTR2соответствуютTran-1иTran-2соответственно в статье Б. Ливенворта.SRT- обобщенныйSORT, который сортирует расширенные сведения, поступающие изTran-1, по продавцам в пределах округа.
Выходные данные Collate состоят из последовательностей групп, называемых «подпотоками», каждая из которых состоит из открывающей скобки, "мастера", нуля или более деталей и закрывающей скобки.
Схематично это можно показать следующим образом:
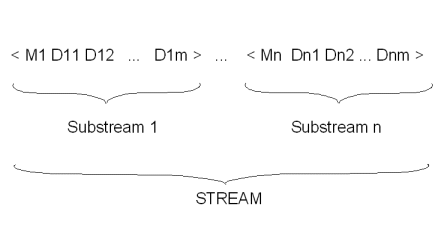
Фрагмент 10.2
J-D. Warnier (1974) использует вертикальную форму приведенной выше диаграммы для определения входных и выходных файлов приложения и использует ее для определения структуры кода, который должен их обрабатывать. К сожалению, программирование с управлением потока требует, чтобы один из файлов становился "драйвером" с точки зрения общей структуры программы, так что, если между структурами разных файлов есть какие-либо существенные различия, структуру программы становится все труднее и труднее понимать и, как следствие, поддерживать. В FBP эта структура сообщает нам важные вещи именно о тех компонентах, которые получают или отправляют этот конкретный поток и потому остается чрезвычайно полезным средством для понимания логики приложения.
Входной поток для TR1 показан с использованием расширения нотации J-D Warnier:
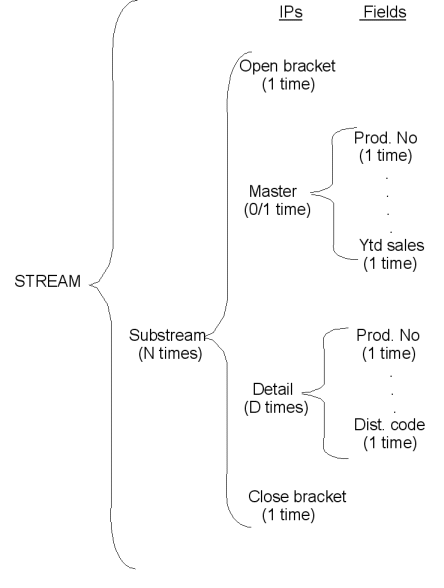
Фрагмент 10.3
Конечно, в книге Warnier'а приведенный выше тип диаграммы используется для описания реальных файлов, а не FBP-потоков, но он довольно хорошо переносится на IP, потоки и подпотоки. Последний столбец, конечно же, это поля внутри IP.
Другой методологией, тесно связанной с методологией Warnier'а, является методология Джексона, о которой уже упоминалось. Он использует горизонтальную версию этой записи, используя звездочки для обозначения повторяющихся элементов. Используя его нотацию, эта диаграмма может выглядеть так:
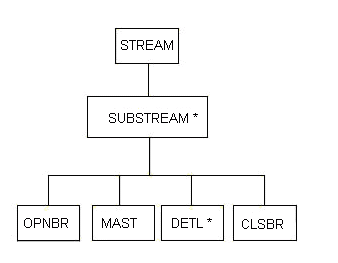
Фрагмент 10.4
Теперь, возвращаясь к нашему примеру, TR1 генерирует три потока вывода: один из обновленных мастер-записей, один из записей-сводок, которые похожи на мастер-записи, но имеют другой формат (предназначены для компонента печати отчетов), и один поток "расширенных" деталей: добавлены подробные записи с полем "расширенная цена" (количество умноженное на цену за единицу).
Должны быть выполнены следующие расчеты:
extended price (in detail) :=
quantity from detail * unit price from corresponding master record
product total (in summary) :=
sum of extended prices over the details relating to one product master
year-to-date sales (in summary and updated master) :=
year-to-date sales from incoming master record + product total
Фигура 10.5
Ранее мы говорили об использовании non-loopers со стеками для обработки вложенных потоков и подпотоков. Если мы добавим стек к нашим компонентам TR1, мы получим следующее «раздутое» изображение TR1 (стек не показан в определении сети — я просто показываю его, потому что он «внешний» по отношению к процессу):
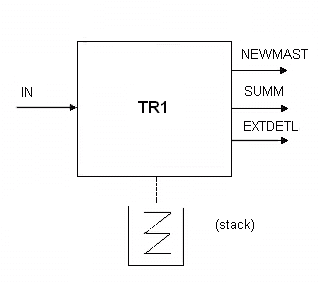
Фрагмент 10.6
Вот логика, которую нужно выполнить для каждого входящего IP (как видите, она очень похожа на логику, которую мы показали в предыдущей главе):
- Открытая скобка
- создать контрольный IP
- очистить поле
total quantityв этом IP - положить этот IP на вершину стека
- Мастер-запись
- взять контрольный IP со стека
- скопировать из входящего мастер-IP информацию, такую как
unit price,year-to-date sales, и т.д. - отбросить входящий мастер-IP
- заменить контрольный IP на вершине стека (надо убрать IP со стека, перед тем как обрабатывать его)
- Запись с деталями
- взять контрольный IP со стека
- обновить
total quantityнаquantityв IP деталей - вычислить
extended priceдля деталей - отправить IP расширенных деталей на специальный выходной порт
- вернуть контрольный IP на стек
- Закрытая скобка
- взять контрольный IP со стека
- создать отчёт
- вычислить общую сумму (в долларах)
- отформатировать IP с отчётом и отправить на выходной порт для отчётов
- создать мастер-IP с информацией из контрольного IP и отправить на выходной порт "обновлённый мастер"
- отбросить контрольный IP
- стек теперь пуст, а когда прибудет новая открытая скобка, новый контрольный IP может быть положен на стек, сохранив глубину стека
- Конец данных
- процесс закрывается, закрываются его выходные порты, что позволяет нисходящим процессам начать своё собственное завершение.
Обратите внимание, что IP сводок и обновленных "мастеров" не выводятся до «времени закрытия скобки», так как сначала необходимо обработать все "детали" для данного мастера.
FBP в основном занимается динамическими IP, а не переменными. Хотя на первый взгляд может показаться, что это приведет к недисциплинированному использованию и модификации данных, на самом деле мы лучше контролируем данные, потому что каждый IP отслеживается индивидуально с момента создания до момента его окончательного уничтожения, и он не может просто исчезать или дублироваться без какой-либо компоненты, выдающей для этого специальную команду. Во время прохождения IP через систему он может одновременно принадлежать только одному процессу, поэтому нет возможности, чтобы два процесса одновременно модифицировали один IP. На самом деле мы отслеживаем это во время выполнения, помечая IP идентификатором процесса-владельца: действие по присвоению IP, в случае успеха, предоставляет «владение» этим IP выполняющему его процессу.
На самом деле в этом примере почти все изменяемые данные находятся в IP, а глобальных данных нет вообще. FBP не требовал глобальных окружений в первые годы своего существования, и, хотя они и были добавлен в некоторые его диалекты, они до сих пор используется очень редко.
Мы также можем использовать рис. 10.1, чтобы проиллюстрировать, как легко модифицировать такую сеть, для удовлетворения бизнес-требований, повышения производительности или по какой-либо другой причине. Вот что я сказал в своей статье (Morrison 1978) о том, как можно изменить эту диаграмму (в этой статье используется термин DSLM для группы концепций, которую мы теперь называем FBP):
«Можно возразить, что сортировка — это всего лишь один из способов упорядочивания информации и что решение о точной методике не следует принимать слишком рано. Дело в том, что DSLM позволяет разработчику сосредоточиться на потоке данных и фактически делает доступные варианты более наглядными и управляемыми. Например, в приведенном выше примере дизайнер может решить, что по каким-то причинам он предпочитает строить таблицу итогов и кодов районов с продавцами, которые будут обновляться случайным образом по мере того, как расширенные детали выходят из TR1».
Прошу прощения за использование "он" и "продавец", но это было 15 лет назад (книга написана в 1994)! Затем я предложил заменить подсеть, обозначенную точками на приведенной ниже диаграмме, сетью, которая случайным образом обновляет итоговые значения, а затем сигнализирует функции сканирования и отчета для отображения результирующих итоговых значений, т.е.
Фрагмент 10.7
Можно заменить на:
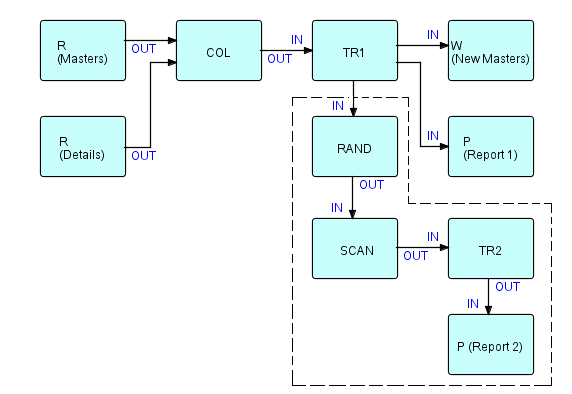
Фрагмент 10.8
Где RAND — это компонент, который случайным образом обновляет итоги в таблице, тогда как SCAN просматривает все итоги в конце задания, генерируя строки отчета.
Как запускается SCAN и как после запуска он получает доступ к таблице, созданной с помощью RAND? Что ж, поскольку в FBP все, что передается через соединения, является дескрипторами IP, почему бы не использовать RAND, чтобы просто "отправить" всю таблицу!? Это гарантирует, что SCAN не запустится до тех пор, пока не завершится RAND, а также, что SCAN получит доступ к таблице в нужное время! В обычном программировании таблицы не перемещаются - и, собственно, в FBP тоже, но иногда удобно сделать вид!
Выше я упомянул компонент «генерация отчета». Вы увидите, что это важно для ваших пакетных бизнес-приложений и иллюстрирует силу FBP, а также способность FBP помочь вам разделить функции на управляемые компоненты. Мы обнаружили, что почти для всех бизнес-приложений нам нужен компонент, который будет принимать отформатированные строки и объединять их в страницы отчета. Вышестоящий процесс может выполнять работу по созданию отформатированных строк, и этот тип функций следует отделять от форматирования страницы. FBP — это инструмент переиспользования "чёрных ящиков", и фактически ваш компонент «Генератор отчетов» может использоваться вашими приложениями как черный ящик. Таким образом, он может реализовать ваши стандарты для отчетов, что может облегчить программистам соответствие этим стандартам, уменьшив их работу (определенно, лучший способ поощрения соблюдения стандартов)! Пока всё хорошо. Тем не менее, у каждой компании есть свой стандарт отчетности, поэтому вам придется создать свой собственный черный ящик, чтобы воплотить свои эти стандарты. К счастью, легко создавать новые компоненты, используя вызовы FBP API. Если мы решим, что хотим распространять компонент более широко, то, похоже, потребуется другой метод распространения: либо в формате исходного кода, либо как чистый черный ящик, но с выходами, предоставляемыми установкой, либо как черный ящик с поддержкой мини-языка. Возможно, нам следует назвать это «серым ящиком».
Вот список возможностей, которые мы предоставили в генераторе отчетов, который использовали с DFDM в нашем магазине:
- принять две строки постоянной информации о заголовке в качестве параметров времени выполнения и объединить их с информацией о дате в стандартном для установки формате.
- принять две даты для выполнения: фактическую дату и дату вступления в силу ("по состоянию на" дату)
- принимать дополнительную информацию о заголовке из дополнительного потока IP, который может быть изменен динамически (при получении сигнала «изменить заголовок»)
- генерировать номера страниц
- принять сигнал для сброса номера страницы
- создать поле «конец отчета» в конце отчета (это позволяет человеку, получающему отчет, знать, что он завершен)
- создать поле «отчет прерван» в отчете по запросу
- поддерживать все вышеперечисленные функции на английском, французском или двуязычном английском и французском языках (под контролем опции).
Это может показаться длинным списком, но в основном он воплощал ранее существовавший набор заводских стандартов, некоторые из которых поддерживались подпрограммами, а некоторые нет. Теперь, вместо того, чтобы навязывать стандарт, в котором люди видели дополнительную работой, у нас был компонент, который делал это «автоматически». По нашему опыту, гораздо проще внедрить стандарт, который экономит людям время. Если они будут использовать ваш компонент, их отчеты будут соответствовать заводским стандартам, а ваши системы будут более надежными и дешевыми в создании и обслуживании. Вы можете сказать своим разработчикам: «Мы не возражаем, если вы не будете следовать стандартам, но это будет стоить вам денег, и если вы не уложитесь в сроки, мы попросим объяснений!». Та же самая философия применялась на заре разработки аппаратного обеспечения. Дизайнеры были совершенно свободны в создании новых компонентов, но все расходы по разработке, тестированию и т.д. они должны были нести сами. Сегодня не случайно подавляющее большинство персональных компьютеров построено на очень небольшом количестве различных процессорных микросхем. Это вариант точки зрения, к которой мы будем часто возвращаться — только изменив экономику разработки приложений, мы получим то поведение, которое пытаемся поощрять.
Последний момент может показаться очевидным на первый взгляд: этот генератор отчетов предполагает, что его входные IP это полностью отформатированные строки отчета. Форматирование этих строк можно логически разделить на отдельные компоненты. Теперь программисты, укоренившиеся в традиционном программировании, могут думать, что такое жесткое разделение невозможно, но у них нет опыта использования отдельного компонента, который делает такое разделение привлекательным как с экономической, так и с логической точек зрения. Как только такая вещь существует, люди обнаруживают, что они могут принимать разумные решения, балансируя эстетические соображения с экономическими. Без такого компонента у вас даже выбора нет!
Такой компонент, как генератор отчетов, можно добавлять в ваше приложение постепенно, т. е. вы сначала заставляете свое приложение работать с простым компонентом построчного вывода, а затем заменяете его компонентом генерации отчетов, чтобы получить красивый отчет. Хотя вы добавляете больше функций в свое приложение, вы можете очень точно предсказать, сколько времени это займет. В традиционном программировании многие авторы отмечали экспоненциальную зависимость между размером приложения и ресурсами для его разработки. Этот график обычно имеет следующий вид:
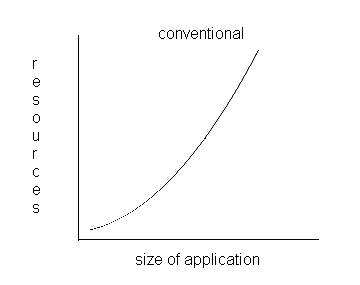
Фрагмент 10.9
Разработка с FBP показывает по существу линейную зависимость, а именно:

Фрагмент 10.10
Сопоставив два графика (даже если мы допускаем возможность, что начальные затраты могут быть немного выше — в FBP вы, как правило, заранее выполняете больше проектных работ), мы получаем следующую картину:
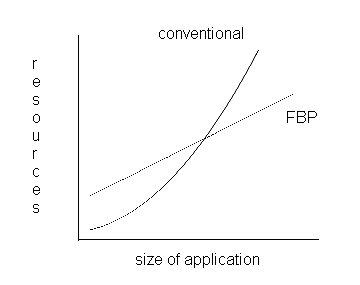
Фрагмент 10.11
Ясно, что в какой-то момент (и мы обнаружили, что это происходит даже с удивительно маленькими приложениями) производительность FBP начинает превосходить производительность программ с контролем потока исполнения, и тем сильнее, чем больше приложение. FBP расширяется! Моему коллеге Чаку (он работал над приложением с 200 процессами) не нужно было беспокоиться о том, что его приложение будет становиться все труднее и что всё труднее будет отлаживать его по мере роста — он просто создавал его методично, шаг за шагом — и с тех пор у него один из самых низких показателей ошибок среди всех приложений в магазине. Наконец, если вы думаете, что это сработало только потому, что он был единственным человеком, который мог держать все это в своей голове, спросите себя, каковы требования для успешного управления большим проектом. Конечно, некоторые из наиболее важных из них — это именно то, что так хорошо обеспечивает FBP: единообразное представление, чистые интерфейсы и компоненты с четко определенными функциями.