| title | date | order | categories | tags | permalink | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Tomcat 快速入门 |
2022-02-17 14:34:30 -0800 |
1 |
|
|
/pages/4a4c02/ |
🎁 版本说明
当前最新版本:Tomcat 8.5.24
环境要求:JDK7+
Tomcat 是由 Apache 开发的一个 Servlet 容器,实现了对 Servlet 和 JSP 的支持,并提供了作为 Web 服务器的一些特有功能,如 Tomcat 管理和控制平台、安全域管理和 Tomcat 阀等。
由于 Tomcat 本身也内含了一个 HTTP 服务器,它也可以被视作一个单独的 Web 服务器。但是,不能将 Tomcat 和 Apache HTTP 服务器混淆,Apache HTTP 服务器是一个用 C 语言实现的 HTTP Web 服务器;这两个 HTTP web server 不是捆绑在一起的。Tomcat 包含了一个配置管理工具,也可以通过编辑 XML 格式的配置文件来进行配置。
- /bin - Tomcat 脚本存放目录(如启动、关闭脚本)。
*.sh文件用于 Unix 系统;*.bat文件用于 Windows 系统。 - /conf - Tomcat 配置文件目录。
- /logs - Tomcat 默认日志目录。
- /webapps - webapp 运行的目录。
一般 web 项目路径结构
|-- webapp # 站点根目录
|-- META-INF # META-INF 目录
| `-- MANIFEST.MF # 配置清单文件
|-- WEB-INF # WEB-INF 目录
| |-- classes # class文件目录
| | |-- *.class # 程序需要的 class 文件
| | `-- *.xml # 程序需要的 xml 文件
| |-- lib # 库文件夹
| | `-- *.jar # 程序需要的 jar 包
| `-- web.xml # Web应用程序的部署描述文件
|-- <userdir> # 自定义的目录
|-- <userfiles> # 自定义的资源文件
-
webapp:工程发布文件夹。其实每个 war 包都可以视为 webapp 的压缩包。 -
META-INF:META-INF 目录用于存放工程自身相关的一些信息,元文件信息,通常由开发工具,环境自动生成。 -
WEB-INF:Java web 应用的安全目录。所谓安全就是客户端无法访问,只有服务端可以访问的目录。 -
/WEB-INF/classes:存放程序所需要的所有 Java class 文件。 -
/WEB-INF/lib:存放程序所需要的所有 jar 文件。 -
/WEB-INF/web.xml:web 应用的部署配置文件。它是工程中最重要的配置文件,它描述了 servlet 和组成应用的其它组件,以及应用初始化参数、安全管理约束等。
Tomcat 支持的 I/O 模型有:
- NIO:非阻塞 I/O,采用 Java NIO 类库实现。
- NIO2:异步 I/O,采用 JDK 7 最新的 NIO2 类库实现。
- APR:采用 Apache 可移植运行库实现,是 C/C++ 编写的本地库。
Tomcat 支持的应用层协议有:
- HTTP/1.1:这是大部分 Web 应用采用的访问协议。
- AJP:用于和 Web 服务器集成(如 Apache)。
- HTTP/2:HTTP 2.0 大幅度的提升了 Web 性能。
前提条件
Tomcat 8.5 要求 JDK 版本为 1.7 以上。
进入 Tomcat 官方下载地址 选择合适版本下载,并解压到本地。
Windows
添加环境变量 CATALINA_HOME ,值为 Tomcat 的安装路径。
进入安装目录下的 bin 目录,运行 startup.bat 文件,启动 Tomcat
Linux / Unix
下面的示例以 8.5.24 版本为例,包含了下载、解压、启动操作。
# 下载解压到本地
wget http://mirrors.hust.edu.cn/apache/tomcat/tomcat-8/v8.5.24/bin/apache-tomcat-8.5.24.tar.gz
tar -zxf apache-tomcat-8.5.24.tar.gz
# 启动 Tomcat
./apache-tomcat-8.5.24/bin/startup.sh启动后,访问 http://localhost:8080 ,可以看到 Tomcat 安装成功的测试页面。
本节将列举一些重要、常见的配置项。详细的 Tomcat8 配置可以参考 Tomcat 8 配置官方参考文档 。
Server 元素表示整个 Catalina servlet 容器。
因此,它必须是
conf/server.xml配置文件中的根元素。它的属性代表了整个 servlet 容器的特性。
属性表
| 属性 | 描述 | 备注 |
|---|---|---|
| className | 这个类必须实现 org.apache.catalina.Server 接口。 | 默认 org.apache.catalina.core.StandardServer |
| address | 服务器等待关机命令的 TCP / IP 地址。如果没有指定地址,则使用 localhost。 | |
| port | 服务器等待关机命令的 TCP / IP 端口号。设置为-1 以禁用关闭端口。 | |
| shutdown | 必须通过 TCP / IP 连接接收到指定端口号的命令字符串,以关闭 Tomcat。 |
Service 元素表示一个或多个连接器组件的组合,这些组件共享一个用于处理传入请求的引擎组件。Server 中可以有多个 Service。
属性表
| 属性 | 描述 | 备注 |
|---|---|---|
| className | 这个类必须实现org.apache.catalina.Service接口。 |
默认 org.apache.catalina.core.StandardService |
| name | 此服务的显示名称,如果您使用标准 Catalina 组件,将包含在日志消息中。与特定服务器关联的每个服务的名称必须是唯一的。 |
实例 - conf/server.xml 配置文件示例
<?xml version="1.0" encoding="UTF-8"?>
<Server port="8080" shutdown="SHUTDOWN">
<Service name="xxx">
...
</Service>
</Server>Executor 表示可以在 Tomcat 中的组件之间共享的线程池。
属性表
| 属性 | 描述 | 备注 |
|---|---|---|
| className | 这个类必须实现org.apache.catalina.Executor接口。 |
默认 org.apache.catalina.core.StandardThreadExecutor |
| name | 线程池名称。 | 要求唯一, 供 Connector 元素的 executor 属性使用 |
| namePrefix | 线程名称前缀。 | |
| maxThreads | 最大活跃线程数。 | 默认 200 |
| minSpareThreads | 最小活跃线程数。 | 默认 25 |
| maxIdleTime | 当前活跃线程大于 minSpareThreads 时,空闲线程关闭的等待最大时间。 | 默认 60000ms |
| maxQueueSize | 线程池满情况下的请求排队大小。 | 默认 Integer.MAX_VALUE |
<Service name="xxx">
<Executor name="tomcatThreadPool" namePrefix="catalina-exec-" maxThreads="300" minSpareThreads="25"/>
</Service>Connector 代表连接组件。Tomcat 支持三种协议:HTTP/1.1、HTTP/2.0、AJP。
属性表
| 属性 | 说明 | 备注 |
|---|---|---|
| asyncTimeout | Servlet3.0 规范中的异步请求超时 | 默认 30s |
| port | 请求连接的 TCP Port | 设置为 0,则会随机选取一个未占用的端口号 |
| protocol | 协议. 一般情况下设置为 HTTP/1.1,这种情况下连接模型会在 NIO 和 APR/native 中自动根据配置选择 | |
| URIEncoding | 对 URI 的编码方式. | 如果设置系统变量 org.apache.catalina.STRICT_SERVLET_COMPLIANCE 为 true,使用 ISO-8859-1 编码;如果未设置此系统变量且未设置此属性, 使用 UTF-8 编码 |
| useBodyEncodingForURI | 是否采用指定的 contentType 而不是 URIEncoding 来编码 URI 中的请求参数 |
以下属性在标准的 Connector(NIO, NIO2 和 APR/native)中有效:
| 属性 | 说明 | 备注 |
|---|---|---|
| acceptCount | 当最大请求连接 maxConnections 满时的最大排队大小 | 默认 100,注意此属性和 Executor 中属性 maxQueueSize 的区别.这个指的是请求连接满时的堆栈大小,Executor 的 maxQueueSize 指的是处理线程满时的堆栈大小 |
| connectionTimeout | 请求连接超时 | 默认 60000ms |
| executor | 指定配置的线程池名称 | |
| keepAliveTimeout | keeAlive 超时时间 | 默认值为 connectionTimeout 配置值.-1 表示不超时 |
| maxConnections | 最大连接数 | 连接满时后续连接放入最大为 acceptCount 的队列中. 对 NIO 和 NIO2 连接,默认值为 10000;对 APR/native,默认值为 8192 |
| maxThreads | 如果指定了 Executor, 此属性忽略;否则为 Connector 创建的内部线程池最大值 | 默认 200 |
| minSpareThreads | 如果指定了 Executor, 此属性忽略;否则为 Connector 创建线程池的最小活跃线程数 | 默认 10 |
| processorCache | 协议处理器缓存 Processor 对象的大小 | -1 表示不限制.当不使用 servlet3.0 的异步处理情况下: 如果配置 Executor,配置为 Executor 的 maxThreads;否则配置为 Connnector 的 maxThreads. 如果使用 Serlvet3.0 异步处理, 取 maxThreads 和 maxConnections 的最大值 |
Context 元素表示一个 Web 应用程序,它在特定的虚拟主机中运行。每个 Web 应用程序都基于 Web 应用程序存档(WAR)文件,或者包含相应的解包内容的相应目录,如 Servlet 规范中所述。
属性表
| 属性 | 说明 | 备注 |
|---|---|---|
| altDDName | web.xml 部署描述符路径 | 默认 /WEB-INF/web.xml |
| docBase | Context 的 Root 路径 | 和 Host 的 appBase 相结合, 可确定 web 应用的实际目录 |
| failCtxIfServletStartFails | 同 Host 中的 failCtxIfServletStartFails, 只对当前 Context 有效 | 默认为 false |
| logEffectiveWebXml | 是否日志打印 web.xml 内容(web.xml 由默认的 web.xml 和应用中的 web.xml 组成) | 默认为 false |
| path | web 应用的 context path | 如果为根路径,则配置为空字符串(""), 不能不配置 |
| privileged | 是否使用 Tomcat 提供的 manager servlet | |
| reloadable | /WEB-INF/classes/ 和/WEB-INF/lib/ 目录中 class 文件发生变化是否自动重新加载 | 默认为 false |
| swallowOutput | true 情况下, System.out 和 System.err 输出将被定向到 web 应用日志中 | 默认为 false |
Engine 元素表示与特定的 Catalina 服务相关联的整个请求处理机器。它接收并处理来自一个或多个连接器的所有请求,并将完成的响应返回给连接器,以便最终传输回客户端。
属性表
| 属性 | 描述 | 备注 |
|---|---|---|
| defaultHost | 默认主机名,用于标识将处理指向此服务器上主机名称但未在此配置文件中配置的请求的主机。 | 这个名字必须匹配其中一个嵌套的主机元素的名字属性。 |
| name | 此引擎的逻辑名称,用于日志和错误消息。 | 在同一服务器中使用多个服务元素时,每个引擎必须分配一个唯一的名称。 |
Host 元素表示一个虚拟主机,它是一个服务器的网络名称(如“www.mycompany.com”)与运行 Tomcat 的特定服务器的关联。
属性表
| 属性 | 说明 | 备注 |
|---|---|---|
| name | 名称 | 用于日志输出 |
| appBase | 虚拟主机对应的应用基础路径 | 可以是个绝对路径, 或${CATALINA_BASE}相对路径 |
| xmlBase | 虚拟主机 XML 基础路径,里面应该有 Context xml 配置文件 | 可以是个绝对路径, 或${CATALINA_BASE}相对路径 |
| createDirs | 当 appBase 和 xmlBase 不存在时,是否创建目录 | 默认为 true |
| autoDeploy | 是否周期性的检查 appBase 和 xmlBase 并 deploy web 应用和 context 描述符 | 默认为 true |
| deployIgnore | 忽略 deploy 的正则 | |
| deployOnStartup | Tomcat 启动时是否自动 deploy | 默认为 true |
| failCtxIfServletStartFails | 配置为 true 情况下,任何 load-on-startup >=0 的 servlet 启动失败,则其对应的 Contxt 也启动失败 | 默认为 false |
由于在实际开发中,我从未用过 Tomcat 集群配置,所以没研究。
这种方式要求本地必须安装 Tomcat 。
将打包好的 war 包放在 Tomcat 安装目录下的 webapps 目录下,然后在 bin 目录下执行 startup.bat 或 startup.sh ,Tomcat 会自动解压 webapps 目录下的 war 包。
成功后,可以访问 http://localhost:8080/xxx (xxx 是 war 包文件名)。
注意
以上步骤是最简单的示例。步骤中的 war 包解压路径、启动端口以及一些更多的功能都可以修改配置文件来定制 (主要是
server.xml或context.xml文件)。
在 pom.xml 中添加依赖
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-core</artifactId>
<version>8.5.24</version>
</dependency>添加 SimpleEmbedTomcatServer.java 文件,内容如下:
import java.util.Optional;
import org.apache.catalina.startup.Tomcat;
public class SimpleTomcatServer {
private static final int PORT = 8080;
private static final String CONTEXT_PATH = "/javatool-server";
public static void main(String[] args) throws Exception {
// 设定 profile
Optional<String> profile = Optional.ofNullable(System.getProperty("spring.profiles.active"));
System.setProperty("spring.profiles.active", profile.orElse("develop"));
Tomcat tomcat = new Tomcat();
tomcat.setPort(PORT);
tomcat.getHost().setAppBase(".");
tomcat.addWebapp(CONTEXT_PATH, getAbsolutePath() + "src/main/webapp");
tomcat.start();
tomcat.getServer().await();
}
private static String getAbsolutePath() {
String path = null;
String folderPath = SimpleEmbedTomcatServer.class.getProtectionDomain().getCodeSource().getLocation().getPath()
.substring(1);
if (folderPath.indexOf("target") > 0) {
path = folderPath.substring(0, folderPath.indexOf("target"));
}
return path;
}
}成功后,可以访问 http://localhost:8080/javatool-server 。
说明
本示例是使用
org.apache.tomcat.embed启动嵌入式 Tomcat 的最简示例。这个示例中使用的是 Tomcat 默认的配置,但通常,我们需要对 Tomcat 配置进行一些定制和调优。为了加载配置文件,启动类就要稍微再复杂一些。这里不想再贴代码,有兴趣的同学可以参考:
不推荐理由:这种方式启动 maven 虽然最简单,但是有一个很大的问题是,真的很久很久没发布新版本了(最新版本发布时间:2013-11-11)。且貌似只能找到 Tomcat6 、Tomcat7 插件。
使用方法
在 pom.xml 中引入插件
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.2</version>
<configuration>
<port>8080</port>
<path>/${project.artifactId}</path>
<uriEncoding>UTF-8</uriEncoding>
</configuration>
</plugin>运行 mvn tomcat7:run 命令,启动 Tomcat。
成功后,可以访问 http://localhost:8080/xxx (xxx 是 ${project.artifactId} 指定的项目名)。
常见 Java IDE 一般都有对 Tomcat 的支持。
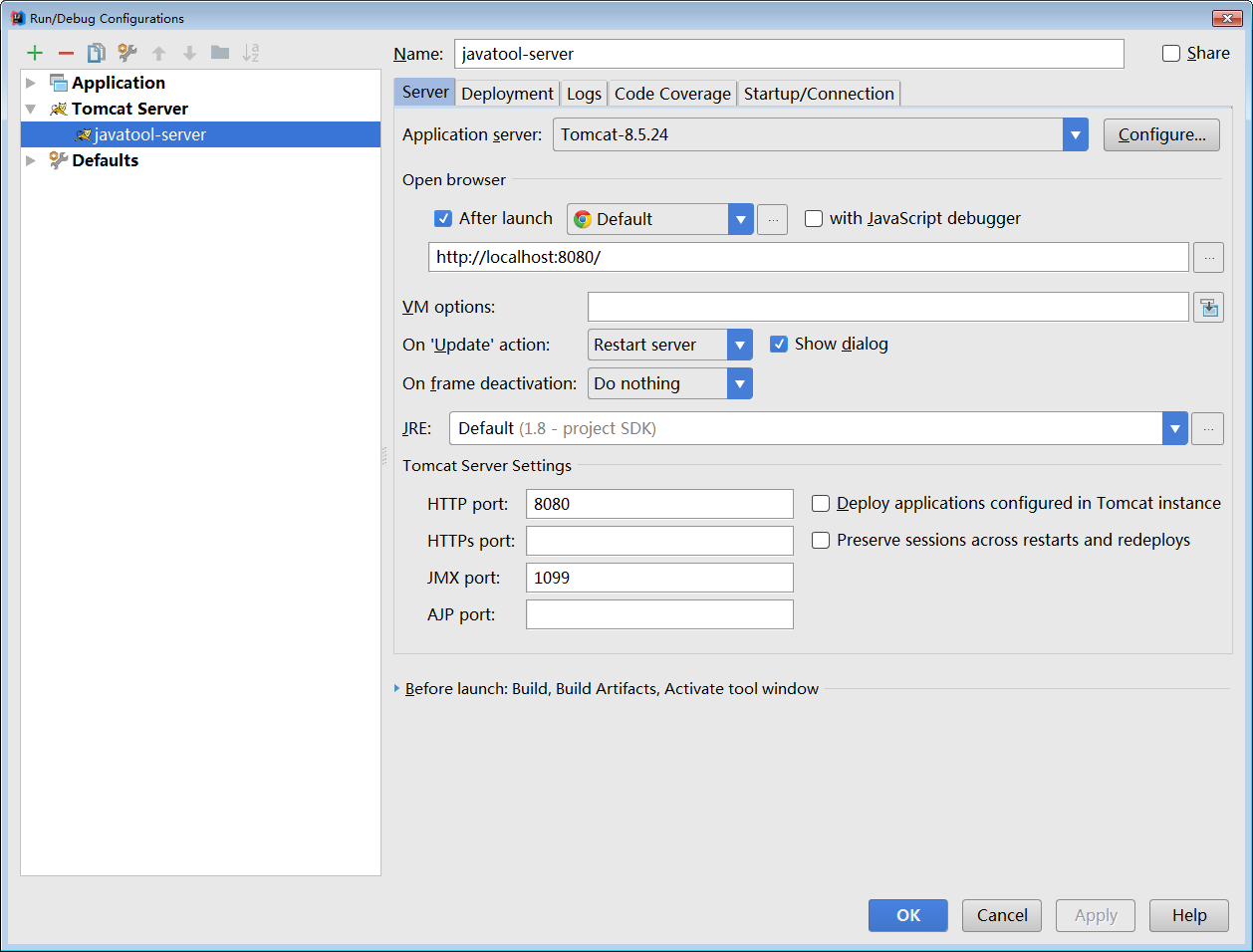
以 Intellij IDEA 为例,提供了 Tomcat and TomEE Integration 插件(一般默认会安装)。
使用步骤
- 点击 Run/Debug Configurations > New Tomcat Server > local ,打开 Tomcat 配置页面。
- 点击 Confiure... 按钮,设置 Tomcat 安装路径。
- 点击 Deployment 标签页,设置要启动的应用。
- 设置启动应用的端口、JVM 参数、启动浏览器等。
- 成功后,可以访问
http://localhost:8080/(当然,你也可以在 url 中设置上下文名称)。
说明
个人认为这个插件不如 Eclipse 的 Tomcat 插件好用,Eclipse 的 Tomcat 插件支持对 Tomcat xml 配置文件进行配置。而这里,你只能自己去 Tomcat 安装路径下修改配置文件。
文中的嵌入式启动示例可以参考我的示例项目
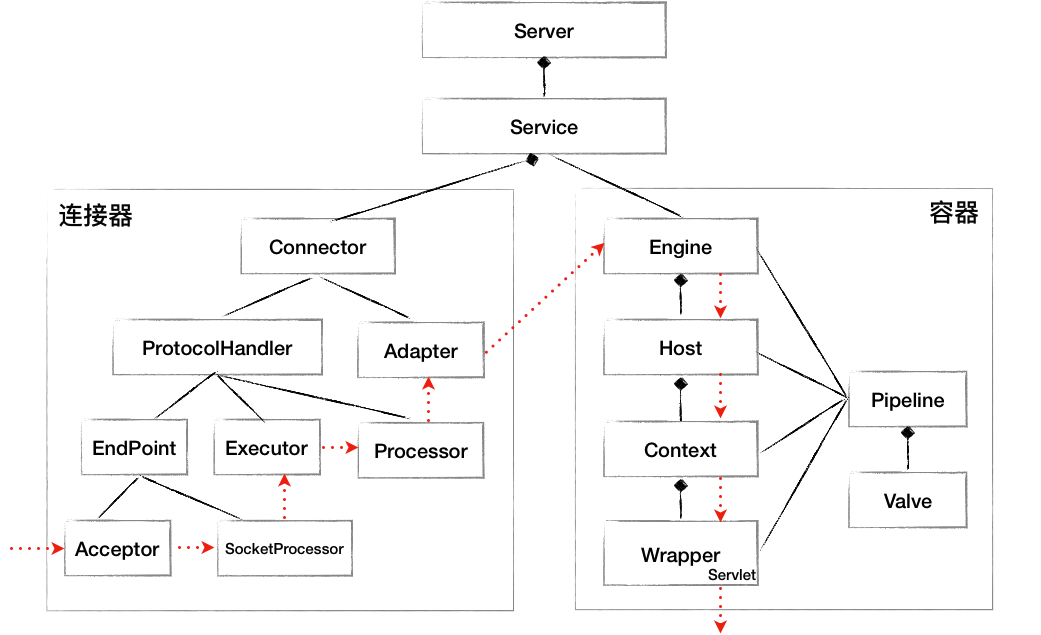
Tomcat 要实现 2 个核心功能:
- 处理 Socket 连接,负责网络字节流与 Request 和 Response 对象的转化。
- 加载和管理 Servlet,以及处理具体的 Request 请求。
为此,Tomcat 设计了两个核心组件:
- 连接器(Connector):负责和外部通信
- 容器(Container):负责内部处理
Tomcat 支持的 I/O 模型有:
- NIO:非阻塞 I/O,采用 Java NIO 类库实现。
- NIO2:异步 I/O,采用 JDK 7 最新的 NIO2 类库实现。
- APR:采用 Apache 可移植运行库实现,是 C/C++ 编写的本地库。
Tomcat 支持的应用层协议有:
- HTTP/1.1:这是大部分 Web 应用采用的访问协议。
- AJP:用于和 Web 服务器集成(如 Apache)。
- HTTP/2:HTTP 2.0 大幅度的提升了 Web 性能。
Tomcat 支持多种 I/O 模型和应用层协议。为了实现这点,一个容器可能对接多个连接器。但是,单独的连接器或容器都不能对外提供服务,需要把它们组装起来才能工作,组装后这个整体叫作 Service 组件。Tomcat 内可能有多个 Service,通过在 Tomcat 中配置多个 Service,可以实现通过不同的端口号来访问同一台机器上部署的不同应用。
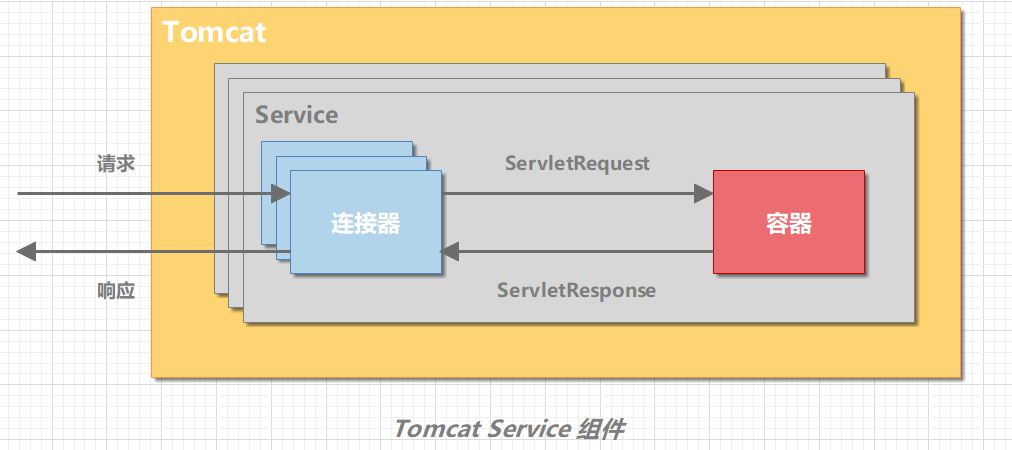
一个 Tomcat 实例有一个或多个 Service;一个 Service 有多个 Connector 和 Container。Connector 和 Container 之间通过标准的 ServletRequest 和 ServletResponse 通信。
连接器对 Servlet 容器屏蔽了协议及 I/O 模型等的区别,无论是 HTTP 还是 AJP,在容器中获取到的都是一个标准的 ServletRequest 对象。
连接器的主要功能是:
- 网络通信
- 应用层协议解析
- Tomcat Request/Response 与 ServletRequest/ServletResponse 的转化
Tomcat 设计了 3 个组件来实现这 3 个功能,分别是 EndPoint、Processor 和 Adapter。
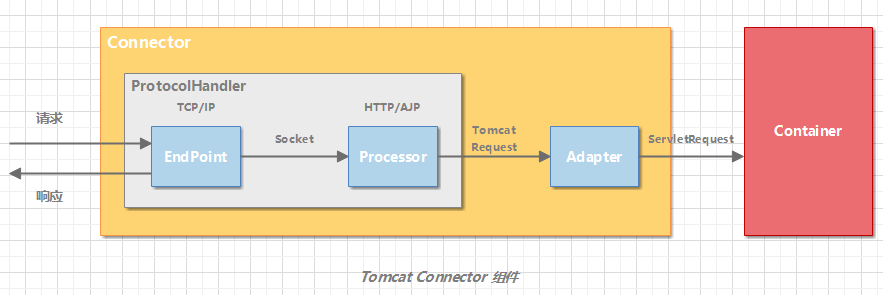
组件间通过抽象接口交互。这样做还有一个好处是**封装变化。**这是面向对象设计的精髓,将系统中经常变化的部分和稳定的部分隔离,有助于增加复用性,并降低系统耦合度。网络通信的 I/O 模型是变化的,可能是非阻塞 I/O、异步 I/O 或者 APR。应用层协议也是变化的,可能是 HTTP、HTTPS、AJP。浏览器端发送的请求信息也是变化的。但是整体的处理逻辑是不变的,EndPoint 负责提供字节流给 Processor,Processor 负责提供 Tomcat Request 对象给 Adapter,Adapter 负责提供 ServletRequest 对象给容器。
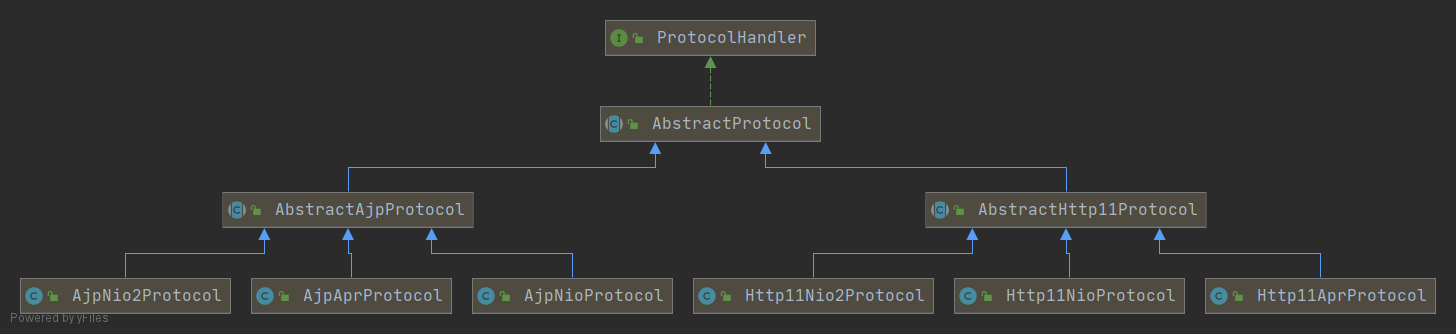
如果要支持新的 I/O 方案、新的应用层协议,只需要实现相关的具体子类,上层通用的处理逻辑是不变的。由于 I/O 模型和应用层协议可以自由组合,比如 NIO + HTTP 或者 NIO2 + AJP。Tomcat 的设计者将网络通信和应用层协议解析放在一起考虑,设计了一个叫 ProtocolHandler 的接口来封装这两种变化点。各种协议和通信模型的组合有相应的具体实现类。比如:Http11NioProtocol 和 AjpNioProtocol。
连接器用 ProtocolHandler 接口来封装通信协议和 I/O 模型的差异。ProtocolHandler 内部又分为 EndPoint 和 Processor 模块,EndPoint 负责底层 Socket 通信,Proccesor 负责应用层协议解析。
EndPoint 是通信端点,即通信监听的接口,是具体的 Socket 接收和发送处理器,是对传输层的抽象,因此 EndPoint 是用来实现 TCP/IP 协议的。
EndPoint 是一个接口,对应的抽象实现类是 AbstractEndpoint,而 AbstractEndpoint 的具体子类,比如在 NioEndpoint 和 Nio2Endpoint 中,有两个重要的子组件:Acceptor 和 SocketProcessor。
其中 Acceptor 用于监听 Socket 连接请求。SocketProcessor 用于处理接收到的 Socket 请求,它实现 Runnable 接口,在 Run 方法里调用协议处理组件 Processor 进行处理。为了提高处理能力,SocketProcessor 被提交到线程池来执行。而这个线程池叫作执行器(Executor)。
如果说 EndPoint 是用来实现 TCP/IP 协议的,那么 Processor 用来实现 HTTP 协议,Processor 接收来自 EndPoint 的 Socket,读取字节流解析成 Tomcat Request 和 Response 对象,并通过 Adapter 将其提交到容器处理,Processor 是对应用层协议的抽象。
Processor 是一个接口,定义了请求的处理等方法。它的抽象实现类 AbstractProcessor 对一些协议共有的属性进行封装,没有对方法进行实现。具体的实现有 AJPProcessor、HTTP11Processor 等,这些具体实现类实现了特定协议的解析方法和请求处理方式。
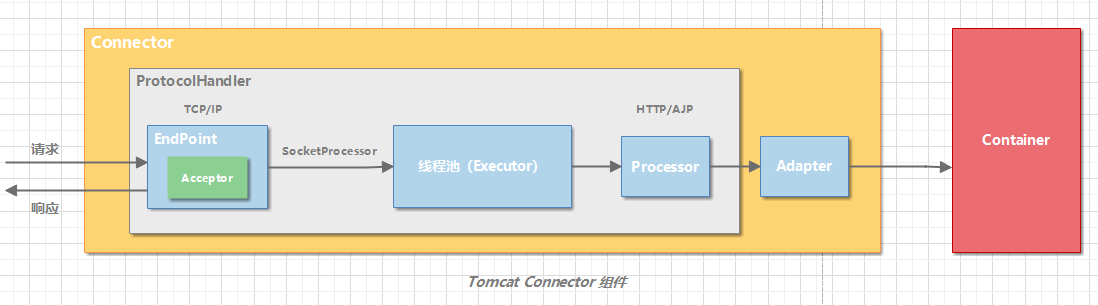
从图中我们看到,EndPoint 接收到 Socket 连接后,生成一个 SocketProcessor 任务提交到线程池去处理,SocketProcessor 的 Run 方法会调用 Processor 组件去解析应用层协议,Processor 通过解析生成 Request 对象后,会调用 Adapter 的 Service 方法。
连接器通过适配器 Adapter 调用容器。
由于协议不同,客户端发过来的请求信息也不尽相同,Tomcat 定义了自己的 Request 类来适配这些请求信息。
ProtocolHandler 接口负责解析请求并生成 Tomcat Request 类。但是这个 Request 对象不是标准的 ServletRequest,也就意味着,不能用 Tomcat Request 作为参数来调用容器。Tomcat 的解决方案是引入 CoyoteAdapter,这是适配器模式的经典运用,连接器调用 CoyoteAdapter 的 Sevice 方法,传入的是 Tomcat Request 对象,CoyoteAdapter 负责将 Tomcat Request 转成 ServletRequest,再调用容器的 Service 方法。
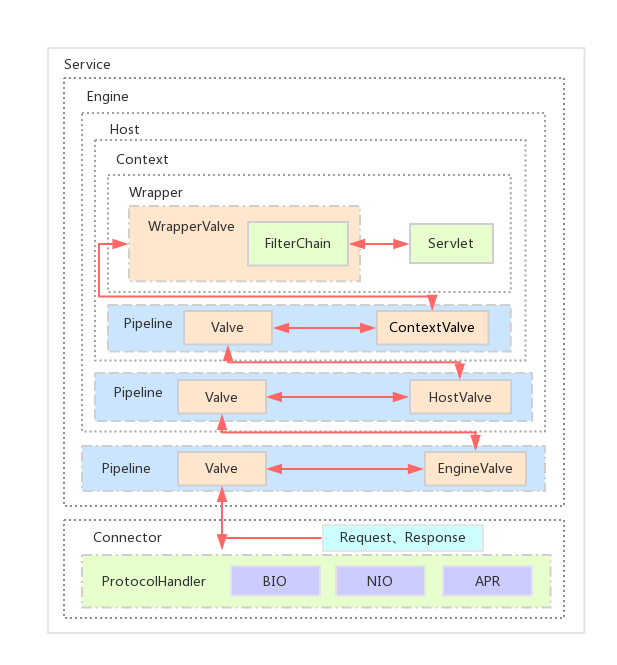
Tomcat 设计了 4 种容器,分别是 Engine、Host、Context 和 Wrapper。
- Engine - Servlet 的顶层容器,包含一 个或多个 Host 子容器;
- Host - 虚拟主机,负责 web 应用的部署和 Context 的创建;
- Context - Web 应用上下文,包含多个 Wrapper,负责 web 配置的解析、管理所有的 Web 资源;
- Wrapper - 最底层的容器,是对 Servlet 的封装,负责 Servlet 实例的创 建、执行和销毁。
Tomcat 是怎么确定请求是由哪个 Wrapper 容器里的 Servlet 来处理的呢?答案是,Tomcat 是用 Mapper 组件来完成这个任务的。
举例来说,假如有一个网购系统,有面向网站管理人员的后台管理系统,还有面向终端客户的在线购物系统。这两个系统跑在同一个 Tomcat 上,为了隔离它们的访问域名,配置了两个虚拟域名:manage.shopping.com和user.shopping.com,网站管理人员通过manage.shopping.com域名访问 Tomcat 去管理用户和商品,而用户管理和商品管理是两个单独的 Web 应用。终端客户通过user.shopping.com域名去搜索商品和下订单,搜索功能和订单管理也是两个独立的 Web 应用。如下所示,演示了 url 应声 Servlet 的处理流程。
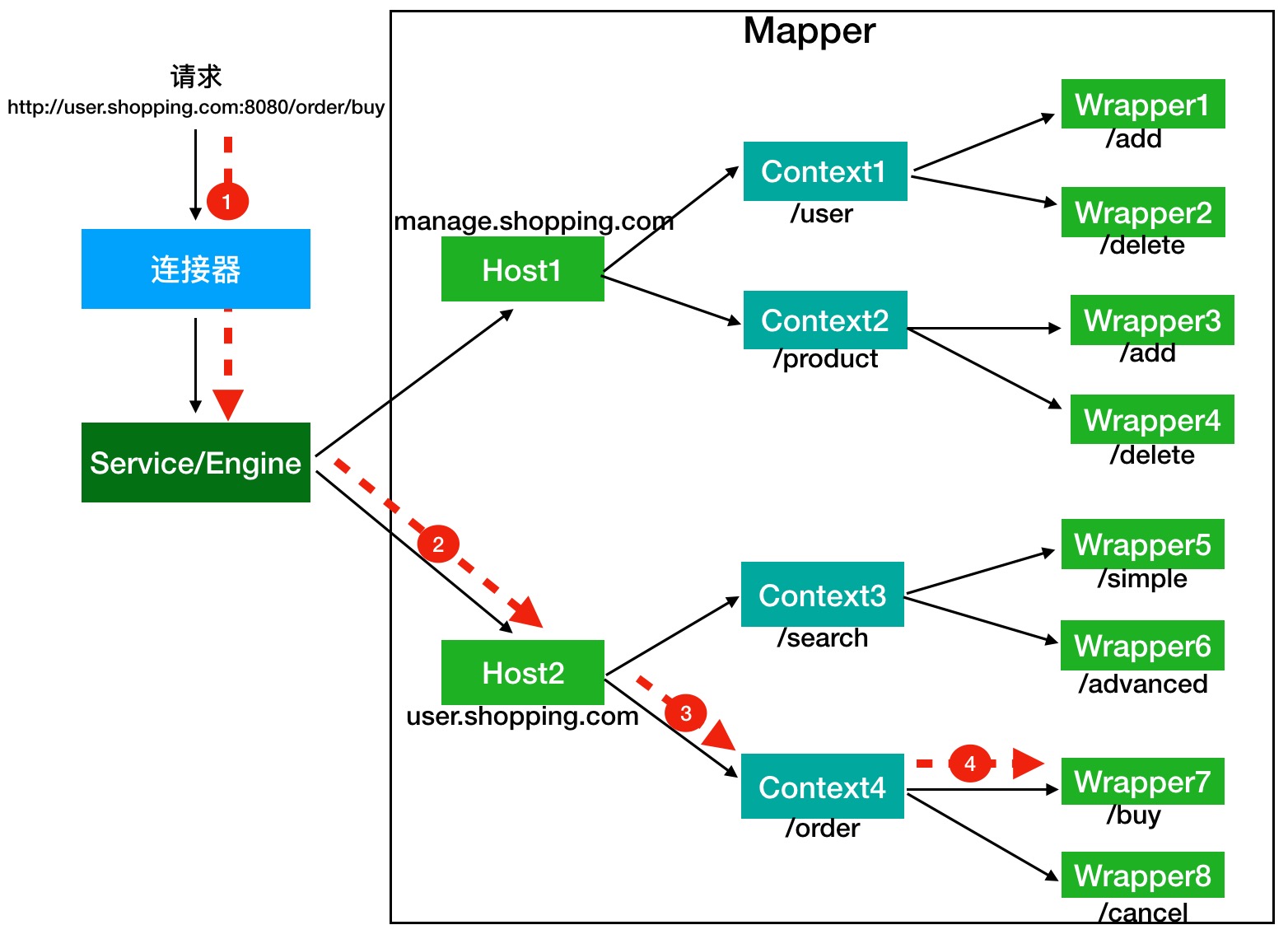
假如有用户访问一个 URL,比如图中的http://user.shopping.com:8080/order/buy,Tomcat 如何将这个 URL 定位到一个 Servlet 呢?
- 首先,根据协议和端口号选定 Service 和 Engine。
- 然后,根据域名选定 Host。
- 之后,根据 URL 路径找到 Context 组件。
- 最后,根据 URL 路径找到 Wrapper(Servlet)。
这个路由分发过程具体是怎么实现的呢?答案是使用 Pipeline-Valve 管道。
Pipeline 可以理解为现实中的管道,Valve 为管道中的阀门,Request 和 Response 对象在管道中经过各个阀门的处理和控制。
Pipeline-Valve 是责任链模式,责任链模式是指在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将再调用下一个处理者继续处理。Valve 表示一个处理点,比如权限认证和记录日志。
先来了解一下 Valve 和 Pipeline 接口的设计:
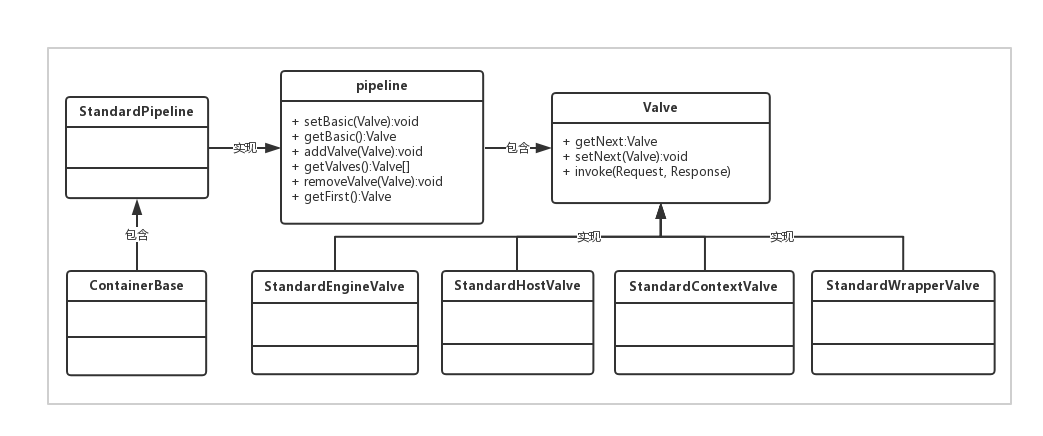
- 每一个容器都有一个 Pipeline 对象,只要触发这个 Pipeline 的第一个 Valve,这个容器里 Pipeline 中的 Valve 就都会被调用到。但是,不同容器的 Pipeline 是怎么链式触发的呢,比如 Engine 中 Pipeline 需要调用下层容器 Host 中的 Pipeline。
- 这是因为 Pipeline 中还有个 getBasic 方法。这个 BasicValve 处于 Valve 链表的末端,它是 Pipeline 中必不可少的一个 Valve,负责调用下层容器的 Pipeline 里的第一个 Valve。
- Pipeline 中有 addValve 方法。Pipeline 中维护了 Valve 链表,Valve 可以插入到 Pipeline 中,对请求做某些处理。我们还发现 Pipeline 中没有 invoke 方法,因为整个调用链的触发是 Valve 来完成的,Valve 完成自己的处理后,调用
getNext.invoke()来触发下一个 Valve 调用。 - Valve 中主要的三个方法:
setNext、getNext、invoke。Valve 之间的关系是单向链式结构,本身invoke方法中会调用下一个 Valve 的invoke方法。 - 各层容器对应的 basic valve 分别是
StandardEngineValve、StandardHostValve、StandardContextValve、StandardWrapperValve。 - 由于 Valve 是一个处理点,因此 invoke 方法就是来处理请求的。注意到 Valve 中有 getNext 和 setNext 方法,因此我们大概可以猜到有一个链表将 Valve 链起来了。
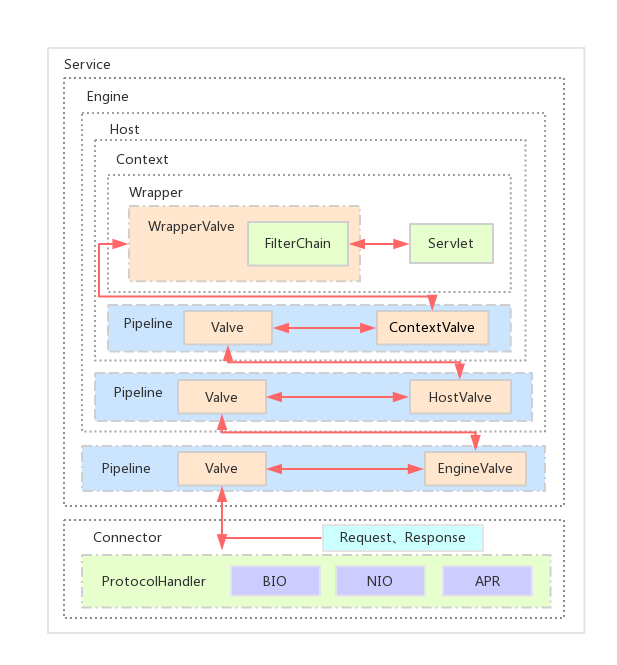
整个调用过程由连接器中的 Adapter 触发的,它会调用 Engine 的第一个 Valve:
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);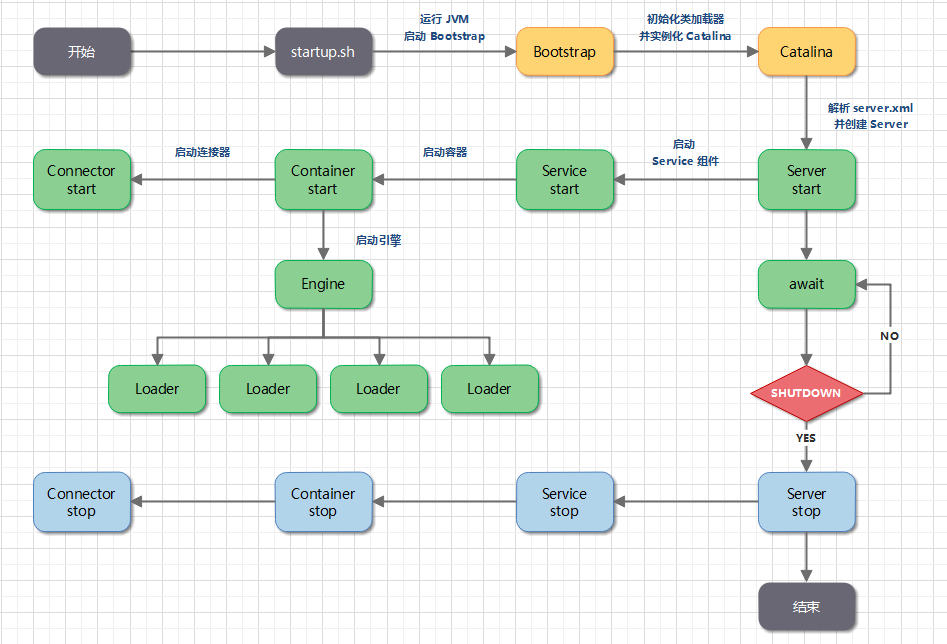
- Tomcat 是一个 Java 程序,它的运行从执行
startup.sh脚本开始。startup.sh会启动一个 JVM 来运行 Tomcat 的启动类Bootstrap。 Bootstrap会初始化 Tomcat 的类加载器并实例化Catalina。Catalina会通过 Digester 解析server.xml,根据其中的配置信息来创建相应组件,并调用Server的start方法。Server负责管理Service组件,它会调用Service的start方法。Service负责管理Connector和顶层容器Engine,它会调用Connector和Engine的start方法。
Catalina 的职责就是解析 server.xml 配置,并据此实例化 Server。接下来,调用 Server 组件的 init 方法和 start 方法,将 Tomcat 启动起来。
Catalina 还需要处理各种“异常”情况,比如当我们通过“Ctrl + C”关闭 Tomcat 时,Tomcat 将如何优雅的停止并且清理资源呢?因此 Catalina 在 JVM 中注册一个“关闭钩子”。
public void start() {
//1. 如果持有的 Server 实例为空,就解析 server.xml 创建出来
if (getServer() == null) {
load();
}
//2. 如果创建失败,报错退出
if (getServer() == null) {
log.fatal(sm.getString("catalina.noServer"));
return;
}
//3. 启动 Server
try {
getServer().start();
} catch (LifecycleException e) {
return;
}
// 创建并注册关闭钩子
if (useShutdownHook) {
if (shutdownHook == null) {
shutdownHook = new CatalinaShutdownHook();
}
Runtime.getRuntime().addShutdownHook(shutdownHook);
}
// 用 await 方法监听停止请求
if (await) {
await();
stop();
}
}为什么需要关闭钩子?
如果我们需要在 JVM 关闭时做一些清理工作,比如将缓存数据刷到磁盘上,或者清理一些临时文件,可以向 JVM 注册一个“关闭钩子”。“关闭钩子”其实就是一个线程,JVM 在停止之前会尝试执行这个线程的 run 方法。
Tomcat 的“关闭钩子”—— CatalinaShutdownHook 做了些什么呢?
protected class CatalinaShutdownHook extends Thread {
@Override
public void run() {
try {
if (getServer() != null) {
Catalina.this.stop();
}
} catch (Throwable ex) {
...
}
}
}Tomcat 的“关闭钩子”实际上就执行了 Server 的 stop 方法,Server 的 stop 方法会释放和清理所有的资源。
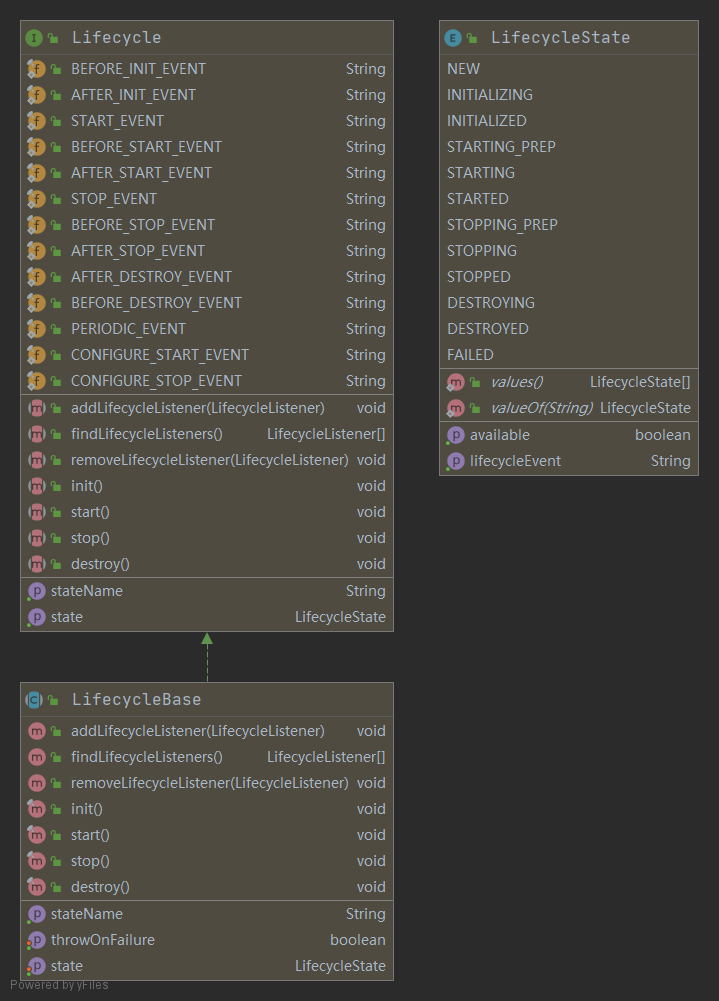
Server 组件的具体实现类是 StandardServer,Server 继承了 LifeCycleBase,它的生命周期被统一管理,并且它的子组件是 Service,因此它还需要管理 Service 的生命周期,也就是说在启动时调用 Service 组件的启动方法,在停止时调用它们的停止方法。Server 在内部维护了若干 Service 组件,它是以数组来保存的。
@Override
public void addService(Service service) {
service.setServer(this);
synchronized (servicesLock) {
// 创建一个长度 +1 的新数组
Service results[] = new Service[services.length + 1];
// 将老的数据复制过去
System.arraycopy(services, 0, results, 0, services.length);
results[services.length] = service;
services = results;
// 启动 Service 组件
if (getState().isAvailable()) {
try {
service.start();
} catch (LifecycleException e) {
// Ignore
}
}
// 触发监听事件
support.firePropertyChange("service", null, service);
}
}Server 并没有一开始就分配一个很长的数组,而是在添加的过程中动态地扩展数组长度,当添加一个新的 Service 实例时,会创建一个新数组并把原来数组内容复制到新数组,这样做的目的其实是为了节省内存空间。
除此之外,Server 组件还有一个重要的任务是启动一个 Socket 来监听停止端口,这就是为什么你能通过 shutdown 命令来关闭 Tomcat。不知道你留意到没有,上面 Caralina 的启动方法的最后一行代码就是调用了 Server 的 await 方法。
在 await 方法里会创建一个 Socket 监听 8005 端口,并在一个死循环里接收 Socket 上的连接请求,如果有新的连接到来就建立连接,然后从 Socket 中读取数据;如果读到的数据是停止命令“SHUTDOWN”,就退出循环,进入 stop 流程。
Service 组件的具体实现类是 StandardService。
【源码】StandardService 源码定义
public class StandardService extends LifecycleBase implements Service {
// 名字
private String name = null;
//Server 实例
private Server server = null;
// 连接器数组
protected Connector connectors[] = new Connector[0];
private final Object connectorsLock = new Object();
// 对应的 Engine 容器
private Engine engine = null;
// 映射器及其监听器
protected final Mapper mapper = new Mapper();
protected final MapperListener mapperListener = new MapperListener(this);
// ...
}StandardService 继承了 LifecycleBase 抽象类。
StandardService 维护了一个 MapperListener 用于支持 Tomcat 热部署。当 Web 应用的部署发生变化时,Mapper 中的映射信息也要跟着变化,MapperListener 就是一个监听器,它监听容器的变化,并把信息更新到 Mapper 中,这是典型的观察者模式。
作为“管理”角色的组件,最重要的是维护其他组件的生命周期。此外在启动各种组件时,要注意它们的依赖关系,也就是说,要注意启动的顺序。
protected void startInternal() throws LifecycleException {
//1. 触发启动监听器
setState(LifecycleState.STARTING);
//2. 先启动 Engine,Engine 会启动它子容器
if (engine != null) {
synchronized (engine) {
engine.start();
}
}
//3. 再启动 Mapper 监听器
mapperListener.start();
//4. 最后启动连接器,连接器会启动它子组件,比如 Endpoint
synchronized (connectorsLock) {
for (Connector connector: connectors) {
if (connector.getState() != LifecycleState.FAILED) {
connector.start();
}
}
}
}从启动方法可以看到,Service 先启动了 Engine 组件,再启动 Mapper 监听器,最后才是启动连接器。这很好理解,因为内层组件启动好了才能对外提供服务,才能启动外层的连接器组件。而 Mapper 也依赖容器组件,容器组件启动好了才能监听它们的变化,因此 Mapper 和 MapperListener 在容器组件之后启动。组件停止的顺序跟启动顺序正好相反的,也是基于它们的依赖关系。
Engine 本质是一个容器,因此它继承了 ContainerBase 基类,并且实现了 Engine 接口。
注:catalina.home:安装目录;catalina.base:工作目录;默认值 user.dir
- Server.xml 配置 Host 元素,指定 appBase 属性,默认$catalina.base/webapps/
- Server.xml 配置 Context 元素,指定 docBase,元素,指定 web 应用的路径
- 自定义配置:在$catalina.base/EngineName/HostName/XXX.xml 配置 Context 元素
HostConfig 监听了 StandardHost 容器的事件,在 start 方法中解析上述配置文件:
- 扫描 appbase 路径下的所有文件夹和 war 包,解析各个应用的 META-INF/context.xml,并 创建 StandardContext,并将 Context 加入到 Host 的子容器中。
- 解析$catalina.base/EngineName/HostName/下的所有 Context 配置,找到相应 web 应 用的位置,解析各个应用的 META-INF/context.xml,并创建 StandardContext,并将 Context 加入到 Host 的子容器中。
注:
- HostConfig 并没有实际解析 Context.xml,而是在 ContextConfig 中进行的。
- HostConfig 中会定期检查 watched 资源文件(context.xml 配置文件)
ContextConfig 解析 context.xml 顺序:
- 先解析全局的配置 config/context.xml
- 然后解析 Host 的默认配置 EngineName/HostName/context.xml.default
- 最后解析应用的 META-INF/context.xml
ContextConfig 解析 web.xml 顺序:
- 先解析全局的配置 config/web.xml
- 然后解析 Host 的默认配置 EngineName/HostName/web.xml.default 接着解析应用的 MEB-INF/web.xml
- 扫描应用 WEB-INF/lib/下的 jar 文件,解析其中的 META-INF/web-fragment.xml 最后合并 xml 封装成 WebXml,并设置 Context
注:
- 扫描 web 应用和 jar 中的注解(Filter、Listener、Servlet)就是上述步骤中进行的。
- 容器的定期执行:backgroundProcess,由 ContainerBase 来实现的,并且只有在顶层容器 中才会开启线程。(backgroundProcessorDelay=10 标志位来控制)
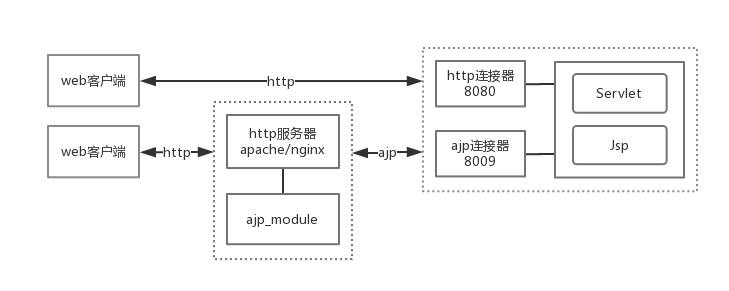
- 根据 server.xml 配置的指定的 connector 以及端口监听 http、或者 ajp 请求
- 请求到来时建立连接,解析请求参数,创建 Request 和 Response 对象,调用顶层容器 pipeline 的 invoke 方法
- 容器之间层层调用,最终调用业务 servlet 的 service 方法
- Connector 将 response 流中的数据写到 socket 中
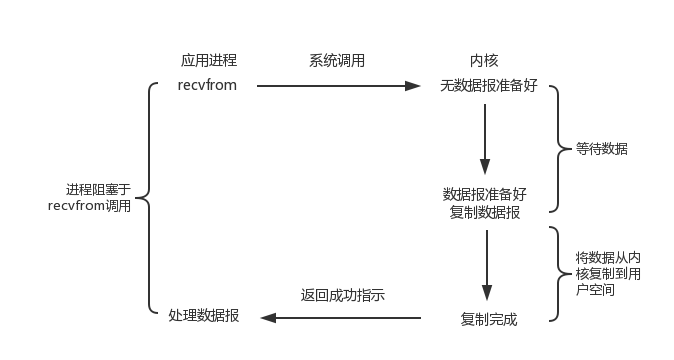
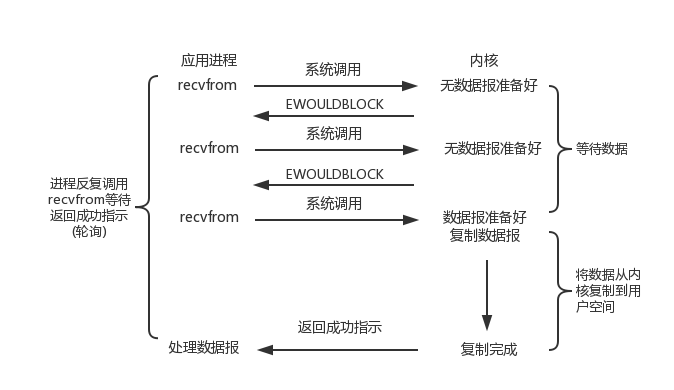
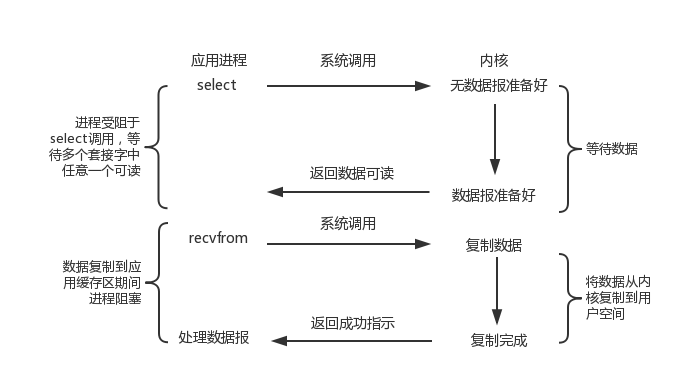
阻塞与非阻塞的区别在于进行读操作和写操作的系统调用时,如果此时内核态没有数据可读或者没有缓冲空间可写时,是否阻塞。
IO 多路复用的好处在于可同时监听多个 socket 的可读和可写事件,这样就能使得应用可以同时监听多个 socket,释放了应用线程资源。

- JIO:用 java.io 编写的 TCP 模块,阻塞 IO
- NIO:用 java.nio 编写的 TCP 模块,非阻塞 IO,(IO 多路复用)
- APR:全称 Apache Portable Runtime,使用 JNI 的方式来进行读取文件以及进行网络传输
Apache Portable Runtime 是一个高度可移植的库,它是 Apache HTTP Server 2.x 的核心。 APR 具有许多用途,包括访问高级 IO 功能(如 sendfile,epoll 和 OpenSSL),操作系统级功能(随机数生成,系统状态等)和本地进程处理(共享内存,NT 管道和 Unix 套接字)。
表格中字段含义说明:
- Support Polling - 是否支持基于 IO 多路复用的 socket 事件轮询
- Polling Size - 轮询的最大连接数
- Wait for next Request - 在等待下一个请求时,处理线程是否释放,BIO 是没有释放的,所以在 keep-alive=true 的情况下处理的并发连接数有限
- Read Request Headers - 由于 request header 数据较少,可以由容器提前解析完毕,不需要阻塞
- Read Request Body - 读取 request body 的数据是应用业务逻辑的事情,同时 Servlet 的限制,是需要阻塞读取的
- Write Response - 跟读取 request body 的逻辑类似,同样需要阻塞写
NIO 处理相关类
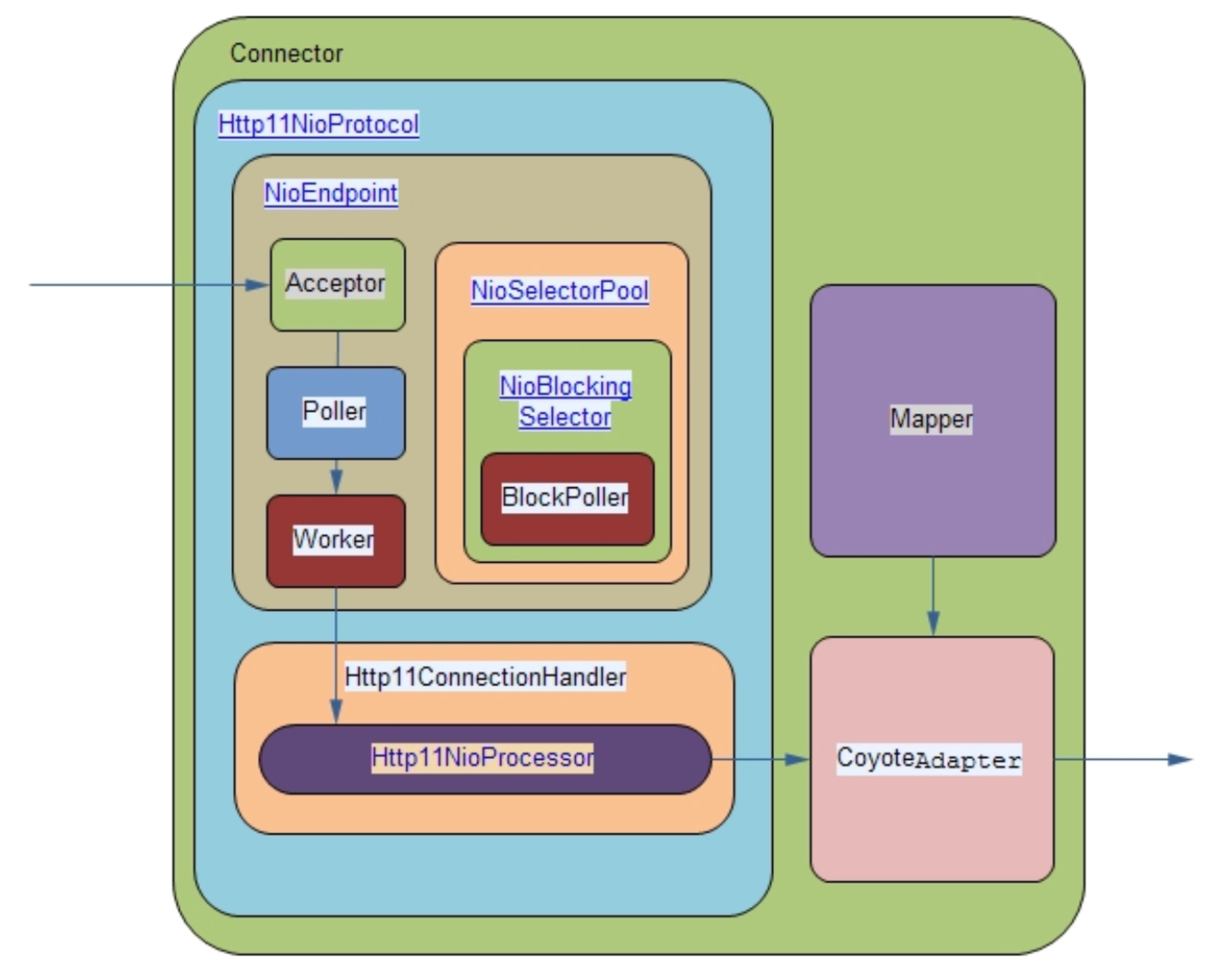
Poller 线程从 EventQueue 获取 PollerEvent,并执行 PollerEvent 的 run 方法,调用 Selector 的 select 方法,如果有可读的 Socket 则创建 Http11NioProcessor,放入到线程池中执行;
CoyoteAdapter 是 Connector 到 Container 的适配器,Http11NioProcessor 调用其提供的 service 方法,内部创建 Request 和 Response 对象,并调用最顶层容器的 Pipeline 中的第一个 Valve 的 invoke 方法
Mapper 主要处理 http url 到 servlet 的映射规则的解析,对外提供 map 方法
Comet 是一种用于 web 的推送技术,能使服务器实时地将更新的信息传送到客户端,而无须客户端发出请求 在 WebSocket 出来之前,如果不适用 comet,只能通过浏览器端轮询 Server 来模拟实现服务器端推送。 Comet 支持 servlet 异步处理 IO,当连接上数据可读时触发事件,并异步写数据(阻塞)
Tomcat 要实现 Comet,只需继承 HttpServlet 同时,实现 CometProcessor 接口
- Begin:新的请求连接接入调用,可进行与 Request 和 Response 相关的对象初始化操作,并保存 response 对象,用于后续写入数据
- Read:请求连接有数据可读时调用
- End:当数据可用时,如果读取到文件结束或者 response 被关闭时则被调用
- Error:在连接上发生异常时调用,数据读取异常、连接断开、处理异常、socket 超时
Note:
- Read:在 post 请求有数据,但在 begin 事件中没有处理,则会调用 read,如果 read 没有读取数据,在会触发 Error 回调,关闭 socket
- End:当 socket 超时,并且 response 被关闭时也会调用;server 被关闭时调用
- Error:除了 socket 超时不会关闭 socket,其他都会关闭 socket
- End 和 Error 时间触发时应关闭当前 comet 会话,即调用 CometEvent 的 close 方法 Note:在事件触发时要做好线程安全的操作
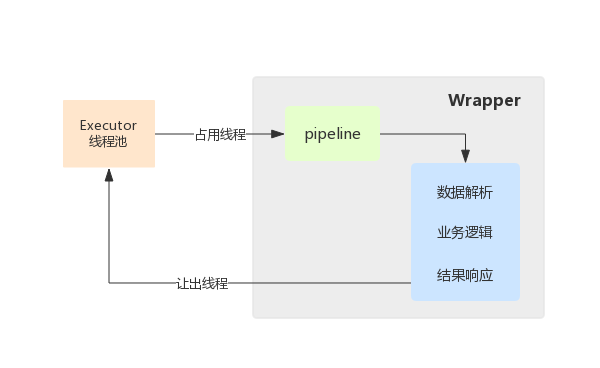
传统流程:
- 首先,Servlet 接收到请求之后,request 数据解析;
- 接着,调用业务接口的某些方法,以完成业务处理;
- 最后,根据处理的结果提交响应,Servlet 线程结束
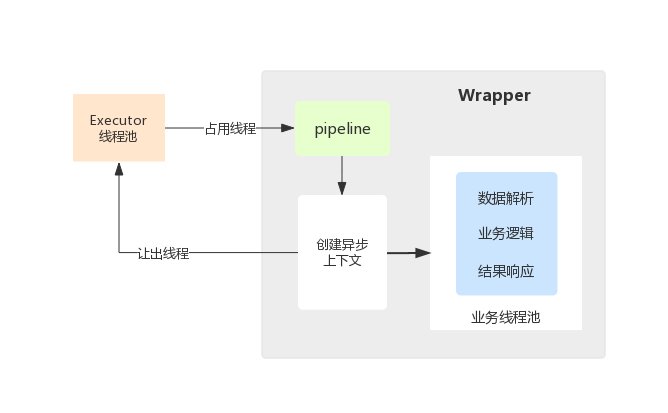
异步处理流程:
- 客户端发送一个请求
- Servlet 容器分配一个线程来处理容器中的一个 servlet
- servlet 调用 request.startAsync(),保存 AsyncContext, 然后返回
- 任何方式存在的容器线程都将退出,但是 response 仍然保持开放
- 业务线程使用保存的 AsyncContext 来完成响应(线程池)
- 客户端收到响应
Servlet 线程将请求转交给一个异步线程来执行业务处理,线程本身返回至容器,此时 Servlet 还没有生成响应数据,异步线程处理完业务以后,可以直接生成响应数据(异步线程拥有 ServletRequest 和 ServletResponse 对象的引用)
为什么 web 应用中支持异步?
推出异步,主要是针对那些比较耗时的请求:比如一次缓慢的数据库查询,一次外部 REST API 调用, 或者是其他一些 I/O 密集型操作。这种耗时的请求会很快的耗光 Servlet 容器的线程池,继而影响可扩展性。
Note:从客户端的角度来看,request 仍然像任何其他的 HTTP 的 request-response 交互一样,只是耗费了更长的时间而已
异步事件监听
- onStartAsync:Request 调用 startAsync 方法时触发
- onComplete:syncContext 调用 complete 方法时触发
- onError:处理请求的过程出现异常时触发
- onTimeout:socket 超时触发
Note : onError/ onTimeout 触发后,会紧接着回调 onComplete onComplete 执行后,就不可再操作 request 和 response