{kind=link}
{kind=link}
This is a streamlit-based NLP application powering the Explore the World demo, it's easy to change and extend and can be used to try out Haystack's capabilities.
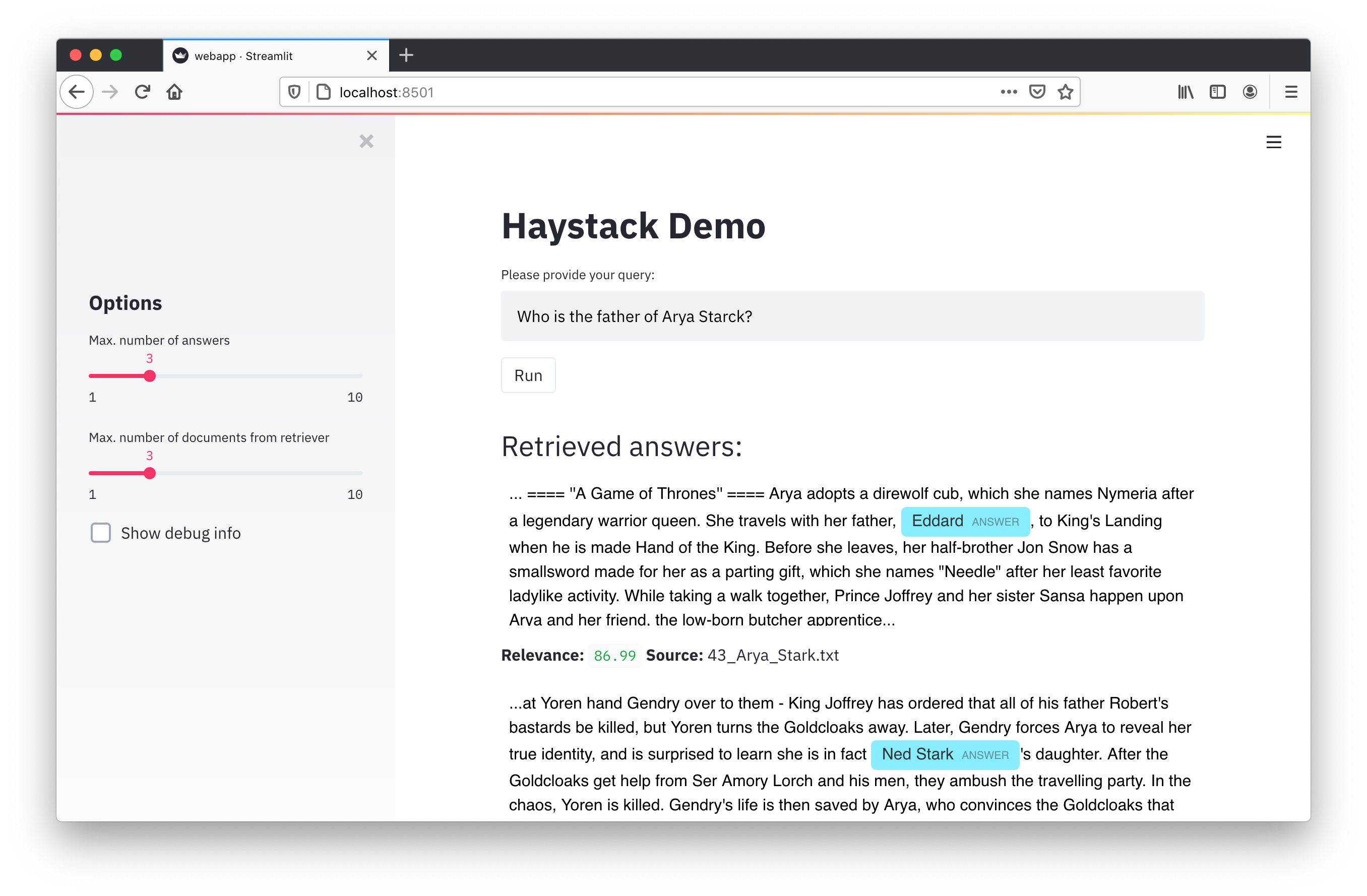
To get started with Haystack please visit the README or check out our tutorials.
The easiest way to run the application is through Docker compose. From this folder, just run:
docker-compose up -dDocker will start three containers:
elasticsearch, running an Elasticsearch instance with some data pre-loaded.haystack-api, running a pre-loaded Haystack pipeline behind a RESTful API.ui, running the streamlit application showing the UI and querying Haystack under the hood.
Once all the containers are up and running, you can open the user interface pointing your browser to http://localhost:8501.
The evaluation mode leverages the feedback REST API endpoint of haystack. The user has the options "Wrong answer", "Wrong answer and wrong passage" and "Wrong answer and wrong passage" to give feedback.
In order to use the UI in evaluation mode, you need an ElasticSearch instance with pre-indexed files and the Haystack REST API. You can set the environment up via docker images. For ElasticSearch, you can check out our documentation and for setting up the REST API this [link](https://github.com/deepset-ai/haystack/blob/main/README. md#7-rest-api).
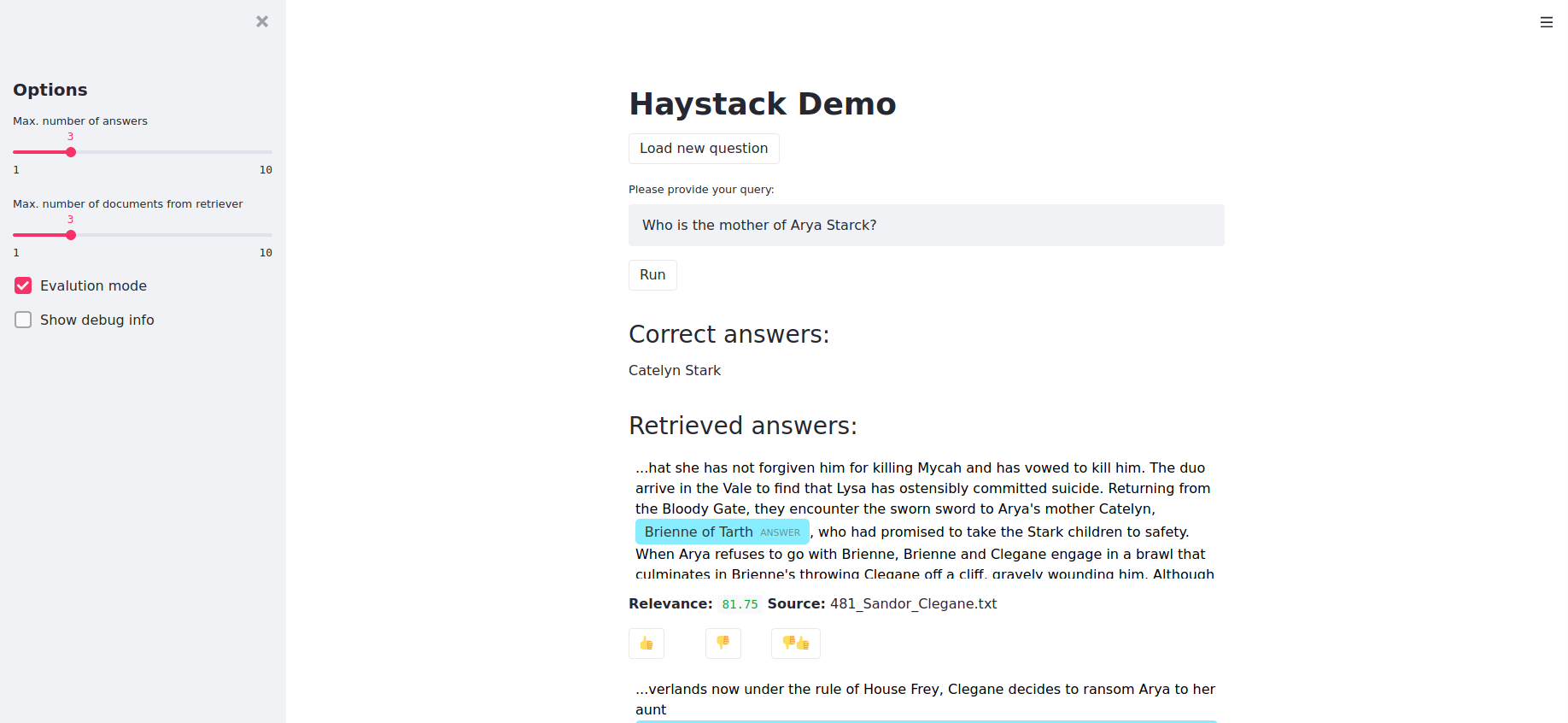
To enter the evaluation mode, select the checkbox "Evaluation mode" in the sidebar. The UI will load
the predefined questions from the file [eval_labels_examples](https://raw.githubusercontent.com/
deepset-ai/haystack/main/ui/ui/eval_labels_example.csv). The file needs to be prefilled with your
data. This way, the user will get a random question from the set and can give his feedback with the
buttons below the questions. To load a new question, click the button "Get random question".
The file just needs to have two columns separated by semicolon. You can add more columns but the UI will ignore them. Every line represents a questions answer pair. The columns with the questions needs to be named “Question Text” and the answer column “Answer” so that they can be loaded correctly. Currently, the easiest way to create the file is manually by adding question answer pairs.
The feedback can be exported with the API endpoint export-doc-qa-feedback. To learn more about
finetuning a model with user feedback, please check out our [docs](https://haystack.deepset.ai/usage/
domain-adaptation#user-feedback).
If you want to use this application to query a different corpus, the easiest way is to build the Elasticsearch image, load your own text data and then use the same Compose file to run all the three containers needed. This will require Docker to be properly installed on your machine.
The build script supports the following environment variables which you can set for your own deployment:
| Var | Use |
|---|---|
| DATA_IMAGE_NAME | Elastic docker image, default is deepset/elasticsearch-countries-and-capitals |
| DATASET_DIR | Data/Corpus directory, default is dataset |
| HAYSTACK_IMAGE_NAME | Haystack build image, default is deepset/haystack:cpu-main |
| NETWORK | Docker network name, default is explore_the_world |
First of all, replace all the content in the ./data/dataset folder or create a separate directory
with all of the text files you want to query and specify the DATASET directory.
You can read about how it's better to organize your data in this section of the Haystack docs
Once the text files are in place, from the ./data folder you can just run:
DATA_IMAGE_NAME=my-docker-acct/elasticsearch-custom DATASET_DIR=dataset NETWORK=explore_the_world ./build.shThis will build a new Docker image locally, pre-filled with your data. The script will start all the required services and index the text files one by one; this process might take a while, depending on the number and size of your corpus and the overall performance of your computer.
Once done, modify the elasticsearch section in the docker-compose.yml file, changing this line:
image: "deepset/elasticsearch-countries-and-capitals"to:
image: "my-docker-acct/elasticsearch-custom"Finally, run the compose file as usual:
docker-compose upIf you want to change the streamlit application, you need to setup your Python environment first. From a virtual environment, run:
pip install -e .The app requires the Haystack RESTful API to be ready and accepting connections at http://localhost:8000, you can use Docker compose to start only the required containers:
docker-compose up elasticsearch haystack-apiAt this point you should be able to make changes and run the streamlit application with:
streamlit run ui/webapp.py