diff --git a/.github/ISSUE_TEMPLATE/request-for-help.md b/.github/ISSUE_TEMPLATE/request-for-help.md
index 7b312c8d8..5f9b94e51 100644
--- a/.github/ISSUE_TEMPLATE/request-for-help.md
+++ b/.github/ISSUE_TEMPLATE/request-for-help.md
@@ -13,7 +13,7 @@ Before asking questions, you can
search the previous issues or discussions
check [Manual](https://github.com/deepmodeling/dpgen).
-Please **do not** post requests for help (e.g. with installing or using dpgen) here.
+Please **do not** post requests for help (e.g. with installing or using dpgen) here.
Instead go to [discussions](https://github.com/deepmodeling/dpgen/discussions).
This issue tracker is for tracking dpgen development related issues only.
diff --git a/.github/workflows/test.yml b/.github/workflows/test.yml
index c52ab1cfe..ebe9bdff4 100644
--- a/.github/workflows/test.yml
+++ b/.github/workflows/test.yml
@@ -10,7 +10,6 @@ jobs:
strategy:
matrix:
python-version: [3.8, 3.9]
- PYMATGEN_VERSION: [2022.7.19]
steps:
- uses: actions/checkout@v2
@@ -19,12 +18,16 @@ jobs:
with:
python-version: ${{ matrix.python-version }}
- name: Install dependencies
- run: pip install coverage pymatgen==${{ matrix.PYMATGEN_VERSION }} -e .
+ run: pip install coverage git+https://github.com/materialsproject/pymatgen@b56698019098247ff54f50997a67c562b4375fc3 -e .
- name: Test
run: coverage run --source=./dpgen -m unittest -v && coverage report
- uses: codecov/codecov-action@v3
pass:
needs: [build]
runs-on: ubuntu-latest
+ if: always()
steps:
- - run: echo "All jobs passed"
+ - name: Decide whether the needed jobs succeeded or failed
+ uses: re-actors/alls-green@release/v1
+ with:
+ jobs: ${{ toJSON(needs) }}
diff --git a/.gitignore b/.gitignore
index ecfb6d73e..936bfd426 100644
--- a/.gitignore
+++ b/.gitignore
@@ -42,4 +42,3 @@ dbconfig.json
_build
tests/generator/calypso_test_path
doc/api/
-
diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
new file mode 100644
index 000000000..b5ce6e9c2
--- /dev/null
+++ b/.pre-commit-config.yaml
@@ -0,0 +1,38 @@
+# See https://pre-commit.com for more information
+# See https://pre-commit.com/hooks.html for more hooks
+repos:
+- repo: https://github.com/pre-commit/pre-commit-hooks
+ rev: v4.4.0
+ hooks:
+ # there are many log files in tests
+ # TODO: seperate py files and log files
+ - id: trailing-whitespace
+ exclude: "^tests/.*$"
+ - id: end-of-file-fixer
+ exclude: "^tests/.*$"
+ - id: check-yaml
+ exclude: "^conda/.*$"
+ #- id: check-json
+ - id: check-added-large-files
+ - id: check-merge-conflict
+ - id: check-symlinks
+ exclude: "^tests/tools/run_report_test_output/.*$"
+ - id: check-toml
+# Python
+- repo: https://github.com/psf/black
+ rev: 22.12.0
+ hooks:
+ - id: black-jupyter
+- repo: https://github.com/charliermarsh/ruff-pre-commit
+ rev: v0.0.253
+ hooks:
+ - id: ruff
+ args: ["--fix"]
+# numpydoc
+- repo: https://github.com/Carreau/velin
+ rev: 0.0.12
+ hooks:
+ - id: velin
+ args: ["--write"]
+ci:
+ autoupdate_branch: devel
diff --git a/README.md b/README.md
index 200a8cc3b..d2734fd9a 100644
--- a/README.md
+++ b/README.md
@@ -1,8 +1,12 @@
+
+
+--------------------------------------------------------------------------------
+
# DP-GEN: A concurrent learning platform for the generation of reliable deep learning based potential energy models
[](https://github.com/deepmodeling/dpgen/releases/)
[](https://doi.org/10.1016/j.cpc.2020.107206)
-
+[](https://badge.dimensions.ai/details/doi/10.1016/j.cpc.2020.107206)
[](https://anaconda.org/conda-forge/dpgen)
[](https://pypi.org/project/dpgen)
diff --git a/codecov.yml b/codecov.yml
new file mode 100644
index 000000000..fe16b8945
--- /dev/null
+++ b/codecov.yml
@@ -0,0 +1,10 @@
+ignore:
+ - "tests"
+coverage:
+ status:
+ project:
+ default:
+ threshold: 100%
+ patch:
+ default:
+ threshold: 100%
diff --git a/conda/conda_build_config.yaml b/conda/conda_build_config.yaml
index 2cb7c1896..9c44fb84b 100644
--- a/conda/conda_build_config.yaml
+++ b/conda/conda_build_config.yaml
@@ -1,5 +1,5 @@
-channel_sources:
+channel_sources:
- defaults
- conda-forge
-channel_targets:
+channel_targets:
- deepmodeling
diff --git a/conda/construct.yaml b/conda/construct.yaml
index c3c6005de..020ae1f56 100644
--- a/conda/construct.yaml
+++ b/conda/construct.yaml
@@ -11,7 +11,7 @@ channels:
specs:
- python 3.8
- pip
- - dpgen {{ version }}
+ - dpgen {{ version }}
ignore_duplicate_files: True
diff --git a/doc/autotest/Auto-test.md b/doc/autotest/Auto-test.md
index b49d28516..7ecd36286 100644
--- a/doc/autotest/Auto-test.md
+++ b/doc/autotest/Auto-test.md
@@ -15,7 +15,7 @@ If, for some reasons, the main program terminated at stage `run`, one can easily
`relax.json` is the parameter file. An example for `deepmd` relaxation is given as:
```json
{
- "structures": "confs/mp-*",
+ "structures": ["confs/mp-*"],
"interaction": {
"type": "deepmd",
"model": "frozen_model.pb",
@@ -30,8 +30,8 @@ where the key `structures` provides the structures to relax. `interaction` is pr
### Task type
There are now six task types implemented in the package: `vasp`, `abacus`, `deepmd`, `meam`, `eam_fs`, and `eam_alloy`. An `inter.json` file in json format containing the interaction parameters will be written in the directory of each task after `make`. We give input examples of the `interaction` part for each type below:
-**VASP**:
-
+**VASP**:
+
The default of `potcar_prefix` is "".
```json
"interaction": {
@@ -41,8 +41,8 @@ The default of `potcar_prefix` is "".
"potcars": {"Al": "POTCAR.al", "Mg": "POTCAR.mg"}
}
```
-**ABACUS**:
-
+**ABACUS**:
+
The default of `potcar_prefix` is "". The path of potcars/orb_files/deepks_desc is `potcar_prefix` + `potcars`/`orb_files`/`deepks_desc`.
```json
"interaction": {
@@ -62,7 +62,7 @@ The default of `potcar_prefix` is "". The path of potcars/orb_files/deepks_desc
```json
"interaction": {
"type": "deepmd",
- "model": "frozen_model.pb",
+ "model": "frozen_model.pb",
"type_map": {"Al": 0, "Mg": 1}
}
```
@@ -81,8 +81,8 @@ Please make sure the [USER-MEAMC package](https://lammps.sandia.gov/doc/Packages
Please make sure the [MANYBODY package](https://lammps.sandia.gov/doc/Packages_details.html#pkg-manybody) has already been installed in LAMMPS
```json
"interaction": {
- "type": "eam_fs (eam_alloy)",
- "model": "AlMg.eam.fs (AlMg.eam.alloy)",
+ "type": "eam_fs (eam_alloy)",
+ "model": "AlMg.eam.fs (AlMg.eam.alloy)",
"type_map": {"Al": 1, "Mg": 2}
}
```
@@ -96,9 +96,9 @@ Now the supported property types are `eos`, `elastic`, `vacancy`, `interstitial`
There are three operations in auto test package, namely `make`, `run`, and `post`. Here we take `eos` property as an example for property type.
### Make
-The `INCAR`, `POSCAR`, `POTCAR` input files for VASP or `in.lammps`, `conf.lmp`, and the interatomic potential files for LAMMPS will be generated in the directory `confs/mp-*/relaxation/relax_task` for relaxation or `confs/mp-*/eos_00/task.[0-9]*[0-9]` for EOS. The `machine.json` file is not needed for `make`. Example:
+The `INCAR`, `POSCAR`, `POTCAR` input files for VASP or `in.lammps`, `conf.lmp`, and the interatomic potential files for LAMMPS will be generated in the directory `confs/mp-*/relaxation/relax_task` for relaxation or `confs/mp-*/eos_00/task.[0-9]*[0-9]` for EOS. The `machine.json` file is not needed for `make`. Example:
```bash
-dpgen autotest make relaxation.json
+dpgen autotest make relaxation.json
```
### Run
@@ -110,5 +110,5 @@ dpgen autotest run relaxation.json machine.json
### Post
The post process of calculation results would be performed. `result.json` in json format will be generated in `confs/mp-*/relaxation/relax_task` for relaxation and `result.json` in json format and `result.out` in txt format in `confs/mp-*/eos_00` for EOS. The `machine.json` file is also not needed for `post`. Example:
```bash
-dpgen autotest post relaxation.json
+dpgen autotest post relaxation.json
```
diff --git a/doc/autotest/index.rst b/doc/autotest/index.rst
index 4c393354b..0d18a0b55 100644
--- a/doc/autotest/index.rst
+++ b/doc/autotest/index.rst
@@ -9,13 +9,13 @@ Auto test
:caption: Guidelines
Auto-test
-
+
.. _Main-components::
.. toctree::
:maxdepth: 2
:caption: Main components
-
+
Task-type
Property-type
Make-run-and-post
@@ -25,7 +25,7 @@ Auto test
.. toctree::
:maxdepth: 2
:caption: Structure relaxation
-
+
relaxation/index.rst
.. _Property::
@@ -41,7 +41,7 @@ Auto test
.. toctree::
:maxdepth: 2
:caption: Refine
-
+
refine/index.rst
.. _Reproduce::
@@ -49,5 +49,5 @@ Auto test
.. toctree::
:maxdepth: 2
:caption: Reproduce
-
+
reproduce/index.rst
diff --git a/doc/autotest/property/Property-get-started-and-input-examples.md b/doc/autotest/property/Property-get-started-and-input-examples.md
index 0e1cc9a7d..d8082be0d 100644
--- a/doc/autotest/property/Property-get-started-and-input-examples.md
+++ b/doc/autotest/property/Property-get-started-and-input-examples.md
@@ -61,7 +61,7 @@ Key words | data structure | example | description
**type** | String | "eos" | property type
skip | Boolean | true | whether to skip current property or not
start_confs_path | String | "../vasp/confs" | start from the equilibrium configuration in other path only for the current property type
-cal_setting["input_prop"] | String | "lammps_input/lammps_high" |input commands file
+cal_setting["input_prop"] | String | "lammps_input/lammps_high" |input commands file
cal_setting["overwrite_interaction"] | Dict | | overwrite the interaction in the `interaction` part only for the current property type
other parameters in `cal_setting` and `cal_type` in `relaxation` also apply in `property`.
@@ -116,4 +116,4 @@ Key words | data structure | example | description
supercell_size | List of Int | [1,1,10] | the supercell to be constructed, default = [1,1,5]
min_vacuum_size | Int or Float | 10 | minimum size of vacuum width, default = 20
add_fix | List of String | ['true','true','false'] | whether to fix atoms in the direction, default = ['true','true','false'] (standard method)
-n_steps | Int | 20 | Number of points for gamma-line calculation, default = 10
\ No newline at end of file
+n_steps | Int | 20 | Number of points for gamma-line calculation, default = 10
diff --git a/doc/autotest/property/Property-post.md b/doc/autotest/property/Property-post.md
index 5b31b1806..0af4710c3 100644
--- a/doc/autotest/property/Property-post.md
+++ b/doc/autotest/property/Property-post.md
@@ -4,4 +4,4 @@ Use command
```bash
dpgen autotest post property.json
```
-to post results as `result.json` and `result.out` in each property's path.
\ No newline at end of file
+to post results as `result.json` and `result.out` in each property's path.
diff --git a/doc/autotest/property/index.rst b/doc/autotest/property/index.rst
index dbf433cba..a2798fa6d 100644
--- a/doc/autotest/property/index.rst
+++ b/doc/autotest/property/index.rst
@@ -9,4 +9,4 @@ Property
Property-make
Property-run
Property-post
- properties/index.rst
\ No newline at end of file
+ properties/index.rst
diff --git a/doc/autotest/property/properties/EOS-make.md b/doc/autotest/property/properties/EOS-make.md
index 97f7c1215..8d9875788 100644
--- a/doc/autotest/property/properties/EOS-make.md
+++ b/doc/autotest/property/properties/EOS-make.md
@@ -1,10 +1,10 @@
## EOS make
-**Step 1.** Before `make` in EOS, the equilibrium configuration `CONTCAR` must be present in `confs/mp-*/relaxation`.
+**Step 1.** Before `make` in EOS, the equilibrium configuration `CONTCAR` must be present in `confs/mp-*/relaxation`.
-**Step 2.** For the input example in the previous section, when we do `make`, 40 tasks would be generated as `confs/mp-*/eos_00/task.000000, confs/mp-*/eos_00/task.000001, ... , confs/mp-*/eos_00/task.000039`. The suffix `00` is used for possible `refine` later.
+**Step 2.** For the input example in the previous section, when we do `make`, 40 tasks would be generated as `confs/mp-*/eos_00/task.000000, confs/mp-*/eos_00/task.000001, ... , confs/mp-*/eos_00/task.000039`. The suffix `00` is used for possible `refine` later.
-**Step 3.** If the task directory, for example `confs/mp-*/eos_00/task.000000` is not empty, the old input files in it including `INCAR`, `POSCAR`, `POTCAR`, `conf.lmp`, `in.lammps` would be deleted.
+**Step 3.** If the task directory, for example `confs/mp-*/eos_00/task.000000` is not empty, the old input files in it including `INCAR`, `POSCAR`, `POTCAR`, `conf.lmp`, `in.lammps` would be deleted.
**Step 4.** In each task directory, `POSCAR.orig` would link to `confs/mp-*/relaxation/CONTCAR`. Then the `scale` parameter can be calculated as:
@@ -14,4 +14,4 @@ scale = (vol_current / vol_equi) ** (1. / 3.)
`vol_current` is the corresponding volume per atom of the current task and `vol_equi` is the volume per atom of the equilibrium configuration. Then the `poscar_scale` function in `dpgen.auto_test.lib.vasp` module would help to generate `POSCAR` file with `vol_current` in `confs/mp-*/eos_00/task.[0-9]*[0-9]`.
-**Step 5.** According to the task type, the input file including `INCAR`, `POTCAR` or `conf.lmp`, `in.lammps` would be written in every `confs/mp-*/eos_00/task.[0-9]*[0-9]`.
\ No newline at end of file
+**Step 5.** According to the task type, the input file including `INCAR`, `POTCAR` or `conf.lmp`, `in.lammps` would be written in every `confs/mp-*/eos_00/task.[0-9]*[0-9]`.
diff --git a/doc/autotest/property/properties/EOS-post.md b/doc/autotest/property/properties/EOS-post.md
index b6c1ccd45..e6e62540c 100644
--- a/doc/autotest/property/properties/EOS-post.md
+++ b/doc/autotest/property/properties/EOS-post.md
@@ -31,5 +31,3 @@ onf_dir: /root/auto_test_example/deepmd/confs/std-fcc/eos_00
... ...
17.935 -3.7088
```
-
-
diff --git a/doc/autotest/property/properties/Interstitial-make.md b/doc/autotest/property/properties/Interstitial-make.md
index 98ee4627a..0d732e6d2 100644
--- a/doc/autotest/property/properties/Interstitial-make.md
+++ b/doc/autotest/property/properties/Interstitial-make.md
@@ -4,4 +4,4 @@
**Step 2.** If `refine` is `True`, we do [refine process](../../refine/Refine-get-started-and-input-examples). If `reprod-opt` is `True` (the default is **False**), we do [reproduce process](../../reproduce/Reproduce-get-started-and-input-examples). Else, the vacancy structure (`POSCAR`) and supercell information (`supercell.out`) are written in the task directory, for example, in `confs/mp-*/interstitial_00/task.000000` with the check and possible removing of the old input files like before.
-**Step 3.** In `interstitial` by VASP, `ISIF = 3`. In `interstitial` by LAMMPS, the same `in.lammps` as that in [EOS (change_box is True)](./EOS-make) would be generated with `scale` set to one.
+**Step 3.** In `interstitial` by VASP, `ISIF = 3`. In `interstitial` by LAMMPS, the same `in.lammps` as that in [EOS (change_box is True)](./EOS-make) would be generated with `scale` set to one.
diff --git a/doc/autotest/property/properties/Interstitial-post.md b/doc/autotest/property/properties/Interstitial-post.md
index 37c650352..5ec9446b1 100644
--- a/doc/autotest/property/properties/Interstitial-post.md
+++ b/doc/autotest/property/properties/Interstitial-post.md
@@ -1,6 +1,6 @@
## Interstitial post
-For `Interstitial`, we need to calculate the energy difference between a crystal structure with and without atom added in.
+For `Interstitial`, we need to calculate the energy difference between a crystal structure with and without atom added in.
The examples of the output files `result.json` in json format and `result.out` in txt format are given below.
#### result.json
diff --git a/doc/autotest/property/properties/Surface-get-started-and-input-examples.md b/doc/autotest/property/properties/Surface-get-started-and-input-examples.md
index 9c10cc059..ba8269ab6 100644
--- a/doc/autotest/property/properties/Surface-get-started-and-input-examples.md
+++ b/doc/autotest/property/properties/Surface-get-started-and-input-examples.md
@@ -1,6 +1,6 @@
## Surface get started and input examples
-`Surface` calculates the surface energy. We need to give the information of `min_slab_size`, `min_vacuum_size`, `max_miller` (default value is 2), and `pert_xz` which means perturbations in xz and will help work around vasp bug.
+`Surface` calculates the surface energy. We need to give the information of `min_slab_size`, `min_vacuum_size`, `max_miller` (default value is 2), and `pert_xz` which means perturbations in xz and will help work around vasp bug.
#### An example of the input file for Surface by deepmd:
@@ -18,7 +18,7 @@
"min_slab_size": 10,
"min_vacuum_size":11,
"max_miller": 2,
- "cal_type": "static"
+ "cal_type": "static"
}
]
}
diff --git a/doc/autotest/property/properties/Surface-make.md b/doc/autotest/property/properties/Surface-make.md
index b305e9086..d43f50819 100644
--- a/doc/autotest/property/properties/Surface-make.md
+++ b/doc/autotest/property/properties/Surface-make.md
@@ -1,5 +1,5 @@
## Surface make
-**Step 1.** Based on the equilibrium configuration, `generate_all_slabs` module in [pymatgen.core.surface](https://pymatgen.org/pymatgen.core.surface.html) would help to generate surface structure list with using `max_miller`, `min_slab_size`, and `min_vacuum_size` parameters.
+**Step 1.** Based on the equilibrium configuration, `generate_all_slabs` module in [pymatgen.core.surface](https://pymatgen.org/pymatgen.core.surface.html) would help to generate surface structure list with using `max_miller`, `min_slab_size`, and `min_vacuum_size` parameters.
**Step 2.** If `refine` is True, we do [refine process](../../refine/Refine-get-started-and-input-examples). If `reprod-opt` is True (the default is False), we do [reproduce process](../../reproduce/Reproduce-get-started-and-input-examples). Otherwise, the surface structure (`POSCAR`) with perturbations in xz and miller index information (`miller.out`) are written in the task directory, for example, in `confs/mp-*/interstitial_00/task.000000` with the check and possible removing of the old input files like before.
diff --git a/doc/autotest/property/properties/Vacancy-make.md b/doc/autotest/property/properties/Vacancy-make.md
index c11062d03..7ea906b75 100644
--- a/doc/autotest/property/properties/Vacancy-make.md
+++ b/doc/autotest/property/properties/Vacancy-make.md
@@ -1,7 +1,7 @@
## Vacancy make
-**Step 1.** The `VacancyGenerator` module in [pymatgen.analysis.defects.generators](https://pymatgen.org/pymatgen.analysis.defects.generators.html) is used to generate a set of structures with vacancy.
+**Step 1.** The `VacancyGenerator` module in [pymatgen.analysis.defects.generators](https://pymatgen.org/pymatgen.analysis.defects.generators.html) is used to generate a set of structures with vacancy.
**Step 2.** If there are `init_from_suffix` and `output_suffix` parameter in the `properties` part, the [refine process](../../refine/Refine-get-started-and-input-examples) follows. If reproduce is evoked, the [reproduce process](../../reproduce/Reproduce-get-started-and-input-examples) follows. Otherwise, the vacancy structure (`POSCAR`) and supercell information (`supercell.out`) are written in the task directory, for example, in `confs/mp-*/vacancy_00/task.000000` with the check and possible removing of the old input files like before.
-**Step 3.** When doing `vacancy` by VASP, `ISIF = 3`. When doing `vacancy` by LAMMPS, the same `in.lammps` as that in [EOS (change_box is True)](./EOS-make) would be generated with `scale` set to one.
+**Step 3.** When doing `vacancy` by VASP, `ISIF = 3`. When doing `vacancy` by LAMMPS, the same `in.lammps` as that in [EOS (change_box is True)](./EOS-make) would be generated with `scale` set to one.
diff --git a/doc/autotest/property/properties/Vacancy-post.md b/doc/autotest/property/properties/Vacancy-post.md
index 36476d298..a513ac68d 100644
--- a/doc/autotest/property/properties/Vacancy-post.md
+++ b/doc/autotest/property/properties/Vacancy-post.md
@@ -1,6 +1,6 @@
## Vacancy post
-For `Vacancy`, we need to calculate the energy difference between a crystal structure with and without a vacancy.
+For `Vacancy`, we need to calculate the energy difference between a crystal structure with and without a vacancy.
The examples of the output files `result.json` in json format and `result.out` in txt format are given below.
#### result.json
diff --git a/doc/autotest/property/properties/index.rst b/doc/autotest/property/properties/index.rst
index 697489780..a62719af9 100644
--- a/doc/autotest/property/properties/index.rst
+++ b/doc/autotest/property/properties/index.rst
@@ -24,4 +24,4 @@ Properties
Surface-get-started-and-input-examples
Surface-make
Surface-run
- Surface-post
\ No newline at end of file
+ Surface-post
diff --git a/doc/autotest/refine/Refine-get-started-and-input-examples.md b/doc/autotest/refine/Refine-get-started-and-input-examples.md
index 1dd6e88a7..d4bd5e212 100644
--- a/doc/autotest/refine/Refine-get-started-and-input-examples.md
+++ b/doc/autotest/refine/Refine-get-started-and-input-examples.md
@@ -1,6 +1,6 @@
## Refine get started and input examples
-Sometimes we want to refine the calculation of a property from previous results. For example, when higher convergence criteria `EDIFF` and `EDIFFG` are necessary in VASP, the new VASP calculation is desired to start from the previous output configuration, rather than starting from scratch.
+Sometimes we want to refine the calculation of a property from previous results. For example, when higher convergence criteria `EDIFF` and `EDIFFG` are necessary in VASP, the new VASP calculation is desired to start from the previous output configuration, rather than starting from scratch.
An example of the input file `refine.json` is given below:
diff --git a/doc/autotest/refine/index.rst b/doc/autotest/refine/index.rst
index d2fd8a3b3..4893d829c 100644
--- a/doc/autotest/refine/index.rst
+++ b/doc/autotest/refine/index.rst
@@ -4,8 +4,8 @@ Refine
.. toctree::
:maxdepth: 2
-
+
Refine-get-started-and-input-examples
Refine-make
Refine-run
- Refine-post
\ No newline at end of file
+ Refine-post
diff --git a/doc/autotest/relaxation/Relaxation-get-started-and-input-examples.md b/doc/autotest/relaxation/Relaxation-get-started-and-input-examples.md
index 8ac37847c..84c683f9b 100644
--- a/doc/autotest/relaxation/Relaxation-get-started-and-input-examples.md
+++ b/doc/autotest/relaxation/Relaxation-get-started-and-input-examples.md
@@ -1,8 +1,8 @@
## Relaxation get started and input examples
-The relaxation of a structure should be carried out before calculating all other properties.
+The relaxation of a structure should be carried out before calculating all other properties.
-First, we need input parameter file and we name it `relax.json` here. All the relaxation calculations should be taken either by `VASP`, `ABACUS`, or `LAMMPS`. Here are two input examples for `VASP` and `LAMMPS` respectively.
+First, we need input parameter file and we name it `relax.json` here. All the relaxation calculations should be taken either by `VASP`, `ABACUS`, or `LAMMPS`. Here are two input examples for `VASP` and `LAMMPS` respectively.
An example of the input file for relaxation by VASP:
@@ -81,5 +81,3 @@ maxiter | Int | 5000 | max iterations of minimizer
maxeval | Int | 500000 | max number of force/energy evaluations
For LAMMPS relaxation and all the property calculations, **package will help to generate `in.lammps` file for user automatically** according to the property type. We can also make the final changes in the `minimize` setting (`minimize etol ftol maxiter maxeval`) in `in.lammps`. In addition, users can apply the input file for lammps commands in the `interaction` part. For further information of the LAMMPS relaxation, we refer users to [minimize command](https://lammps.sandia.gov/doc/minimize.html).
-
-
diff --git a/doc/autotest/relaxation/Relaxation-make.md b/doc/autotest/relaxation/Relaxation-make.md
index 0d8d2786a..51b3f8858 100644
--- a/doc/autotest/relaxation/Relaxation-make.md
+++ b/doc/autotest/relaxation/Relaxation-make.md
@@ -96,7 +96,3 @@ print "Final Stress (xx yy zz xy xz yz) = ${Pxx} ${Pyy} ${Pzz} ${Pxy} ${Pxz} ${P
If user provides lammps input command file `in.lammps`, the `thermo_style` and `dump` commands should be the same as the above file.
**interatomic potential model**: the `frozen_model.pb` in `confs/mp-*/relaxation` would link to the `frozen_model.pb` file given in the input.
-
-
-
-
diff --git a/doc/autotest/relaxation/Relaxation-run.md b/doc/autotest/relaxation/Relaxation-run.md
index d9f2af56f..cb3db76fa 100644
--- a/doc/autotest/relaxation/Relaxation-run.md
+++ b/doc/autotest/relaxation/Relaxation-run.md
@@ -1,6 +1,6 @@
## Relaxation run
-The work path of each task should be in the form like `confs/mp-*/relaxation` and all task is in the form like `confs/mp-*/relaxation/relax_task`.
+The work path of each task should be in the form like `confs/mp-*/relaxation` and all task is in the form like `confs/mp-*/relaxation/relax_task`.
The `machine.json` file should be applied in this process and the machine parameters (eg. GPU or CPU) are determined according to the task type (VASP or LAMMPS). Then in each work path, the corresponding tasks would be submitted and the results would be sent back through [make_dispatcher](https://github.com/deepmodeling/dpgen/blob/devel/dpgen/dispatcher/Dispatcher.py).
diff --git a/doc/autotest/reproduce/Reproduce-get-started-and-input-examples.md b/doc/autotest/reproduce/Reproduce-get-started-and-input-examples.md
index 815cfbcf3..0f87be1c8 100644
--- a/doc/autotest/reproduce/Reproduce-get-started-and-input-examples.md
+++ b/doc/autotest/reproduce/Reproduce-get-started-and-input-examples.md
@@ -22,8 +22,8 @@ Sometimes we want to reproduce the initial results with the same configurations
}
```
-`reproduce` denotes whether to do `reproduce` or not and the default value is False.
+`reproduce` denotes whether to do `reproduce` or not and the default value is False.
-`init_data_path` is the path of VASP or LAMMPS initial data to be reproduced. `init_from_suffix` is the suffix of the initial data and the default value is "00". In this case, the VASP Interstitial results are stored in `../vasp/confs/std-*/interstitial_00` and the reproduced Interstitial results would be in `deepmd/confs/std-*/interstitial_reprod`.
+`init_data_path` is the path of VASP or LAMMPS initial data to be reproduced. `init_from_suffix` is the suffix of the initial data and the default value is "00". In this case, the VASP Interstitial results are stored in `../vasp/confs/std-*/interstitial_00` and the reproduced Interstitial results would be in `deepmd/confs/std-*/interstitial_reprod`.
-`reprod_last_frame` denotes if only the last frame is used in reproduce. The default value is True for eos and surface, but is False for vacancy and interstitial.
\ No newline at end of file
+`reprod_last_frame` denotes if only the last frame is used in reproduce. The default value is True for eos and surface, but is False for vacancy and interstitial.
diff --git a/doc/autotest/reproduce/index.rst b/doc/autotest/reproduce/index.rst
index fa49af926..29c00bd7e 100644
--- a/doc/autotest/reproduce/index.rst
+++ b/doc/autotest/reproduce/index.rst
@@ -4,8 +4,8 @@ Reproduce
.. toctree::
:maxdepth: 2
-
+
Reproduce-get-started-and-input-examples
Reproduce-make
Reproduce-run
- Reproduce-post
\ No newline at end of file
+ Reproduce-post
diff --git a/doc/conf.py b/doc/conf.py
index 48b4b53d0..358c2a9b0 100644
--- a/doc/conf.py
+++ b/doc/conf.py
@@ -11,19 +11,19 @@
# documentation root, use os.path.abspath to make it absolute, like shown here.
#
import os
-import sys
import subprocess
+import sys
from datetime import date
+
# import sys
import recommonmark
from recommonmark.transform import AutoStructify
-
# -- Project information -----------------------------------------------------
-project = 'DP-GEN'
-copyright = '2020-%d, DeepModeling' % date.today().year
-author = 'DeepModeling'
+project = "DP-GEN"
+copyright = "2020-%d, DeepModeling" % date.today().year
+author = "DeepModeling"
# -- General configuration ---------------------------------------------------
@@ -40,33 +40,33 @@
# ]
extensions = [
- 'deepmodeling_sphinx',
- 'dargs.sphinx',
+ "deepmodeling_sphinx",
+ "dargs.sphinx",
"sphinx_rtd_theme",
- 'myst_parser',
- 'sphinx.ext.autosummary',
- 'sphinx.ext.viewcode',
- 'sphinxarg.ext',
- 'numpydoc',
+ "myst_parser",
+ "sphinx.ext.autosummary",
+ "sphinx.ext.viewcode",
+ "sphinxarg.ext",
+ "numpydoc",
]
# Tell sphinx what the primary language being documented is.
-primary_domain = 'py'
+primary_domain = "py"
# Tell sphinx what the pygments highlight language should be.
-highlight_language = 'py'
+highlight_language = "py"
-#
+#
myst_heading_anchors = 4
# Add any paths that contain templates here, relative to this directory.
-templates_path = ['_templates']
+templates_path = ["_templates"]
# List of patterns, relative to source directory, that match files and
# directories to ignore when looking for source files.
# This pattern also affects html_static_path and html_extra_path.
-exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
+exclude_patterns = ["_build", "Thumbs.db", ".DS_Store"]
# -- Options for HTML output -------------------------------------------------
@@ -74,7 +74,8 @@
# The theme to use for HTML and HTML Help pages. See the documentation for
# a list of builtin themes.
#
-html_theme = 'sphinx_rtd_theme'
+html_theme = "sphinx_rtd_theme"
+html_logo = "logo.svg"
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
@@ -82,15 +83,18 @@
# html_static_path = ['_static']
# html_css_files = ['css/custom.css']
-autodoc_default_flags = ['members']
+autodoc_default_flags = ["members"]
autosummary_generate = True
-master_doc = 'index'
+master_doc = "index"
intersphinx_mapping = {
"python": ("https://docs.python.org/", None),
"dargs": ("https://docs.deepmodeling.com/projects/dargs/en/latest/", None),
"dpdata": ("https://docs.deepmodeling.com/projects/dpdata/en/latest/", None),
- "dpdispatcher": ("https://docs.deepmodeling.com/projects/dpdispatcher/en/latest/", None),
+ "dpdispatcher": (
+ "https://docs.deepmodeling.com/projects/dpdispatcher/en/latest/",
+ None,
+ ),
"ase": ("https://wiki.fysik.dtu.dk/ase/", None),
"numpy": ("https://docs.scipy.org/doc/numpy/", None),
"pamatgen": ("https://pymatgen.org/", None),
@@ -103,11 +107,24 @@
def run_apidoc(_):
from sphinx.ext.apidoc import main
- sys.path.append(os.path.join(os.path.dirname(__file__), '..'))
+
+ sys.path.append(os.path.join(os.path.dirname(__file__), ".."))
cur_dir = os.path.abspath(os.path.dirname(__file__))
module = os.path.join(cur_dir, "..", "dpgen")
- main(['-M', '--tocfile', 'api', '-H', 'DP-GEN API', '-o', os.path.join(cur_dir, "api"), module, '--force'])
+ main(
+ [
+ "-M",
+ "--tocfile",
+ "api",
+ "-H",
+ "DP-GEN API",
+ "-o",
+ os.path.join(cur_dir, "api"),
+ module,
+ "--force",
+ ]
+ )
def setup(app):
- app.connect('builder-inited', run_apidoc)
+ app.connect("builder-inited", run_apidoc)
diff --git a/doc/contributing-guide/contributing-guide.md b/doc/contributing-guide/contributing-guide.md
index 325148173..b843f6629 100644
--- a/doc/contributing-guide/contributing-guide.md
+++ b/doc/contributing-guide/contributing-guide.md
@@ -10,9 +10,9 @@ Firstly, fork in DP-GEN repository. Then you can clone the repository, build a n
## How to contribute to DP-GEN
-Welcome to the repository of [DP-GEN](https://github.com/deepmodeling/dpgen)
+Welcome to the repository of [DP-GEN](https://github.com/deepmodeling/dpgen)
-DP-GEN adopts the same convention as other software in DeepModeling Community.
+DP-GEN adopts the same convention as other software in DeepModeling Community.
You can first refer to DeePMD-kit's
[Contributing guide](https://github.com/deepmodeling/deepmd-kit/blob/master/CONTRIBUTING.md)
@@ -21,7 +21,7 @@ and [Developer guide](https://docs.deepmodeling.com/projects/deepmd/en/master/de
You can also read relative chapters on [Github Docs](https://docs.github.com/en/pull-requests/collaborating-with-pull-requests/proposing-changes-to-your-work-with-pull-requests/creating-a-pull-request).
If you have no idea how to fix your problem or where to find the relative source code, please check [Code Structure](../overview/code-structure) of the DP-GEN repository on this website.
-
+
### Use command line
You can use git with the command line, or open the repository on Github Desktop. Here is a video as a demo of making changes to DP-GEN and publishing it with command line.
@@ -30,8 +30,8 @@ You can use git with the command line, or open the repository on Github Desktop.
> If you have never used Github before, remember to generate your ssh key and configure the public key in Github Settings.
-> If you can't configure your username and password, please use token.
-> The explanation from Github see [Github Blog: token authentication requirements for git operations](https://github.blog/2020-12-15-token-authentication-requirements-for-git-operations/). [A discussion on StaskOverflow](https://stackoverflow.com/questions/68775869/message-support-for-password-authentication-was-removed-please-use-a-personal) can solve this problem.
+> If you can't configure your username and password, please use token.
+> The explanation from Github see [Github Blog: token authentication requirements for git operations](https://github.blog/2020-12-15-token-authentication-requirements-for-git-operations/). [A discussion on StaskOverflow](https://stackoverflow.com/questions/68775869/message-support-for-password-authentication-was-removed-please-use-a-personal) can solve this problem.
### Use Github Desktop
Also, you can use Github Desktop to make PR.
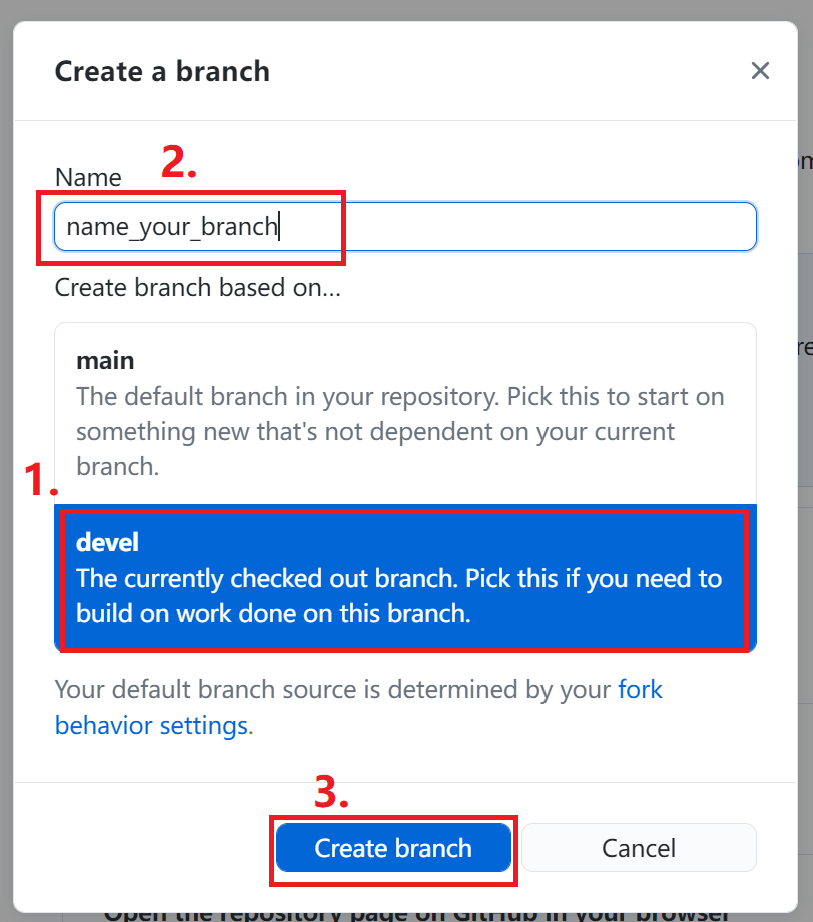
@@ -48,10 +48,10 @@ Firstly, create your new branch based on devel branch.
-Secondly, add your doc to the certain directory in your local repository, and add its name into index.
+Secondly, add your doc to the certain directory in your local repository, and add its name into index.
-Here is an [example](https://github.com/deepmodeling/tutorials/pull/43).
-Remember to add the filename of your doc into index!
+Here is an [example](https://github.com/deepmodeling/tutorials/pull/43).
+Remember to add the filename of your doc into index!
Thirdly, select the changes that you what to push, and commit to it. Press "Publish branch" to push your origin repository to the remote branch.
@@ -59,7 +59,7 @@ Thirdly, select the changes that you what to push, and commit to it. Press "Publ
Finally, you can check it on github and make a pull request. Press "Compare & pull request" to make a PR.
-(Note: please commit pr to the devel branch)
+(Note: please commit pr to the devel branch)
@@ -69,14 +69,14 @@ Welcome to [the documents of DP-GEN](https://github.com/deepmodeling/dpgen/tree/
- If you want to add a new directory for a new category of instructions, make a new directory and add it in doc/index.rst.
Also welcome to [Tutorials repository](https://github.com/deepmodeling/tutorials)
-You can find the structure of tutorials and preparations before writing a document in [Writing Tips](https://tutorials.deepmodeling.com/en/devel/Resources/writingTips.html#).
+You can find the structure of tutorials and preparations before writing a document in [Writing Tips](https://tutorials.deepmodeling.com/en/devel/Resources/writingTips.html#).
The latest page of DP-GEN Docs
### Examples of contributions
-- [Example 1](https://github.com/deepmodeling/dpgen/pull/758)
+- [Example 1](https://github.com/deepmodeling/dpgen/pull/758)
- [Example 2](https://github.com/deepmodeling/dpgen/pull/844) (a simple one for beginner)
### 1. Push your doc
@@ -106,19 +106,19 @@ dpdispatcher and dpdata are dependencies of DP-GEN. dpdispatcher is related to t
## About the update of the parameter file
You may have noticed that there are arginfo.py files in many folders. This is a file used to generate parameter documentation.
If you add or modify a parameter in DP-GEN and intend to export it to the main repository, please sync your changes in arginfo.
-
+
## Tips
-
+
1. Please try to submit a PR after finishing all the changes
-
+
2. Please briefly describe what you do with `git commit -m ""`! "No description provided." will make the maintainer feel confused.
3. It is not recommended to make changes directly in the `devel` branch. It is recommended to pull a branch from devel: `git checkout -b `
-
+
4. When switching branches, remember to check if you want to bring the changes to the next branch!
5. Please fix the errors reported by the unit test. You can firstly test on your local machine before pushing commits. Hint: The way to test the code is to go from the main directory to the tests directory, and use the command `python3 -m unittest`. You can watch the demo video for review. Sometimes you may fail unit tests due to your local circumstance. You can check whether the error reported is related to the part you modified to eliminate this problem. After submitting, as long as there is a green check mark after the PR title on the webpage, it means that the test has been passed.
-6. Pay attention to whether there are comments under your PR. If there is a change request, you need to check and modify the code. If there are conflicts, you need to solve them manually.
+6. Pay attention to whether there are comments under your PR. If there is a change request, you need to check and modify the code. If there are conflicts, you need to solve them manually.
---
-After successfully making a PR, developers will check it and give comments. It will be merged after everything done. Then CONGRATULATIONS! You become a first-time contributor to DP-GEN!
+After successfully making a PR, developers will check it and give comments. It will be merged after everything done. Then CONGRATULATIONS! You become a first-time contributor to DP-GEN!
diff --git a/doc/contributing-guide/index.rst b/doc/contributing-guide/index.rst
index c758deb8d..c47f2001f 100644
--- a/doc/contributing-guide/index.rst
+++ b/doc/contributing-guide/index.rst
@@ -4,5 +4,5 @@ Contributing Guide
.. toctree::
:maxdepth: 2
-
- ./contributing-guide
\ No newline at end of file
+
+ ./contributing-guide
diff --git a/doc/credits.rst b/doc/credits.rst
index a72b83e5a..54fd98842 100644
--- a/doc/credits.rst
+++ b/doc/credits.rst
@@ -1,4 +1,4 @@
Authors
=======
-.. git-shortlog-authors::
\ No newline at end of file
+.. git-shortlog-authors::
diff --git a/doc/index.rst b/doc/index.rst
index 75d87ee52..e8eb8b380 100644
--- a/doc/index.rst
+++ b/doc/index.rst
@@ -16,7 +16,7 @@ DPGEN's documentation
.. toctree::
:maxdepth: 2
- :caption: Workflow
+ :caption: Workflow
run/index.rst
init/index.rst
@@ -28,7 +28,7 @@ DPGEN's documentation
.. toctree::
:maxdepth: 2
:caption: Tutorial
- :glob:
+ :glob:
Tutorials
Publications
@@ -64,5 +64,5 @@ How to get help from the community
* :ref:`modindex`
* :ref:`search`
-.. _feedback:
-.. _affiliated packages:
+.. _feedback:
+.. _affiliated packages:
diff --git a/doc/init/index.rst b/doc/init/index.rst
index b248bcc4f..1d22ae222 100644
--- a/doc/init/index.rst
+++ b/doc/init/index.rst
@@ -6,7 +6,7 @@ Init
.. toctree::
:maxdepth: 2
-
+
init-bulk.md
init-bulk-jdata
init-bulk-mdata
@@ -15,4 +15,4 @@ Init
init-surf-mdata
init-reaction
init-reaction-jdata
- init-reaction-mdata
\ No newline at end of file
+ init-reaction-mdata
diff --git a/doc/init/init-bulk-jdata.rst b/doc/init/init-bulk-jdata.rst
index 82ed65322..8d37484bd 100644
--- a/doc/init/init-bulk-jdata.rst
+++ b/doc/init/init-bulk-jdata.rst
@@ -1,6 +1,9 @@
dpgen init_bulk parameters
======================================
+.. note::
+ One can load, modify, and export the input file by using our effective web-based tool `DP-GUI `_. All parameters below can be set in DP-GUI. By clicking "SAVE JSON", one can download the input file.
+
.. dargs::
:module: dpgen.data.arginfo
:func: init_bulk_jdata_arginfo
diff --git a/doc/init/init-bulk-mdata.rst b/doc/init/init-bulk-mdata.rst
index b3098e906..79f29a4de 100644
--- a/doc/init/init-bulk-mdata.rst
+++ b/doc/init/init-bulk-mdata.rst
@@ -1,6 +1,9 @@
dpgen init_bulk machine parameters
==================================
+.. note::
+ One can load, modify, and export the input file by using our effective web-based tool `DP-GUI `_. All parameters below can be set in DP-GUI. By clicking "SAVE JSON", one can download the input file.
+
.. dargs::
:module: dpgen.data.arginfo
:func: init_bulk_mdata_arginfo
diff --git a/doc/init/init-bulk.md b/doc/init/init-bulk.md
index 6974979ca..d14b858a9 100644
--- a/doc/init/init-bulk.md
+++ b/doc/init/init-bulk.md
@@ -47,6 +47,6 @@ If you want to specify a structure as starting point for `init_bulk`, you may se
"from_poscar": true,
"from_poscar_path": "....../C_mp-47_conventional.POSCAR",
```
-`init_bulk` supports both VASP and ABACUS for first-principle calculation. You can choose the software by specifying the key {dargs:argument}`init_fp_style `. If {dargs:argument}`init_fp_style ` is not specified, the default software will be VASP.
+`init_bulk` supports both VASP and ABACUS for first-principle calculation. You can choose the software by specifying the key {dargs:argument}`init_fp_style `. If {dargs:argument}`init_fp_style ` is not specified, the default software will be VASP.
When using ABACUS for {dargs:argument}`init_fp_style `, the keys of the paths of `INPUT` files for relaxation and MD simulations are the same as `INCAR` for VASP, which are {dargs:argument}`relax_incar ` and {dargs:argument}`md_incar ` respectively. Use {dargs:argument}`relax_kpt ` and {dargs:argument}`md_kpt ` for the relative path for `KPT` files of relaxation and MD simulations. They two can be omitted if `kspacing` (in unit of 1/Bohr) or `gamma_only` has been set in corresponding INPUT files. If {dargs:argument}`from_poscar ` is set to `false`, you have to specify {dargs:argument}`atom_masses ` in the same order as `elements`.
diff --git a/doc/init/init-reaction-jdata.rst b/doc/init/init-reaction-jdata.rst
index 253cae682..2c1f2480f 100644
--- a/doc/init/init-reaction-jdata.rst
+++ b/doc/init/init-reaction-jdata.rst
@@ -1,6 +1,9 @@
dpgen init_reaction parameters
======================================
+.. note::
+ One can load, modify, and export the input file by using our effective web-based tool `DP-GUI `_. All parameters below can be set in DP-GUI. By clicking "SAVE JSON", one can download the input file.
+
.. dargs::
:module: dpgen.data.arginfo
:func: init_reaction_jdata_arginfo
diff --git a/doc/init/init-reaction-mdata.rst b/doc/init/init-reaction-mdata.rst
index 2fe35a0d8..74f39dfd7 100644
--- a/doc/init/init-reaction-mdata.rst
+++ b/doc/init/init-reaction-mdata.rst
@@ -1,6 +1,9 @@
dpgen init_reaction machine parameters
======================================
+.. note::
+ One can load, modify, and export the input file by using our effective web-based tool `DP-GUI `_. All parameters below can be set in DP-GUI. By clicking "SAVE JSON", one can download the input file.
+
.. dargs::
:module: dpgen.data.arginfo
:func: init_reaction_mdata_arginfo
diff --git a/doc/init/init-surf-jdata.rst b/doc/init/init-surf-jdata.rst
index 7fe2c4273..aa61245d9 100644
--- a/doc/init/init-surf-jdata.rst
+++ b/doc/init/init-surf-jdata.rst
@@ -1,6 +1,9 @@
dpgen init_surf parameters
======================================
+.. note::
+ One can load, modify, and export the input file by using our effective web-based tool `DP-GUI `_. All parameters below can be set in DP-GUI. By clicking "SAVE JSON", one can download the input file.
+
.. dargs::
:module: dpgen.data.arginfo
:func: init_surf_jdata_arginfo
diff --git a/doc/init/init-surf-mdata.rst b/doc/init/init-surf-mdata.rst
index 35e8e322f..d1f6e7c4c 100644
--- a/doc/init/init-surf-mdata.rst
+++ b/doc/init/init-surf-mdata.rst
@@ -1,6 +1,9 @@
dpgen init_surf machine parameters
==================================
+.. note::
+ One can load, modify, and export the input file by using our effective web-based tool `DP-GUI `_. All parameters below can be set in DP-GUI. By clicking "SAVE JSON", one can download the input file.
+
.. dargs::
:module: dpgen.data.arginfo
:func: init_surf_mdata_arginfo
diff --git a/doc/init/init_surf.md b/doc/init/init_surf.md
index e4e82588a..72c0e4656 100644
--- a/doc/init/init_surf.md
+++ b/doc/init/init_surf.md
@@ -7,7 +7,7 @@ dpgen init_surf PARAM [MACHINE]
```
The MACHINE configure file is optional. If this parameter exists, then the optimization
tasks or MD tasks will be submitted automatically according to MACHINE.json. That is to say, if one only wants to prepare `surf-xxx/sys-xxx` folders for the second stage but wants to skip relaxation, `dpgen init_surf PARAM` should be used (without `MACHINE`).
-"stages" and "skip_relax" in `PARAM` should be set as:
+"stages" and "skip_relax" in `PARAM` should be set as:
```json
"stages": [1,2],
"skip_relax": true,
@@ -19,15 +19,15 @@ Basically `init_surf` can be divided into two parts , denoted as {dargs:argument
All stages must be **in order**.
-Generally, `init_surf` does not run AIMD but only generates a lot of configurations. Compared with `init_bulk`, which runs DFT calculations twice, init_surf does once. Usually, we do `init_bulk`, run many rounds of DP-GEN iterations, collect enough data for the bulk system, and do `init_surf` after that. At this point, the lattice constant has been determined, and the lattice constant required for the initial configuration of `init_surf` can be used directly. These configurations made by `init_surf` are prepared for `01.model_devi`. Candidates will do DFT calculation in `02.fp`.
+Generally, `init_surf` does not run AIMD but only generates a lot of configurations. Compared with `init_bulk`, which runs DFT calculations twice, init_surf does once. Usually, we do `init_bulk`, run many rounds of DP-GEN iterations, collect enough data for the bulk system, and do `init_surf` after that. At this point, the lattice constant has been determined, and the lattice constant required for the initial configuration of `init_surf` can be used directly. These configurations made by `init_surf` are prepared for `01.model_devi`. Candidates will do DFT calculation in `02.fp`.
- Generate vacuum layers
According to [the source code of pert_scaled](https://github.com/deepmodeling/dpgen/blob/8dea29ef125f66be9641afe5ac4970433a9c9ce1/dpgen/data/surf.py#L484), init_surf will generate a series of surface structures with specified separations between the sample layer and its periodic image. There are two ways to specify the interval in generating the vacuum layers: 1) to set the interval value and 2) to set the number of intervals.
-You can use {dargs:argument}`layer_numb ` (the number of layers of the slab) or {dargs:argument}`z_min ` (the total thickness) to specify the thickness of the atoms below. Then `vacuum_*` parameters specify the vacuum layers above. `dpgen init_surf` will make a series of structures with the thickness of vacuum layers from {dargs:argument}`vacuum_min ` to {dargs:argument}`vacuum_max `. The number of vacuum layers is controlled by the parameter {dargs:argument}`vacuum_resol `.
+You can use {dargs:argument}`layer_numb ` (the number of layers of the slab) or {dargs:argument}`z_min ` (the total thickness) to specify the thickness of the atoms below. Then `vacuum_*` parameters specify the vacuum layers above. `dpgen init_surf` will make a series of structures with the thickness of vacuum layers from {dargs:argument}`vacuum_min ` to {dargs:argument}`vacuum_max `. The number of vacuum layers is controlled by the parameter {dargs:argument}`vacuum_resol `.
-The layers will be generated even when the size of {dargs:argument}`vacuum_resol ` is 1. When the size of {dargs:argument}`vacuum_resol ` is 2 or it is empty, the whole interval range is divided into the nearby region with denser intervals (head region) and the far-away region with sparser intervals (tail region), which are divided by {dargs:argument}`mid_point `.
+The layers will be generated even when the size of {dargs:argument}`vacuum_resol ` is 1. When the size of {dargs:argument}`vacuum_resol ` is 2 or it is empty, the whole interval range is divided into the nearby region with denser intervals (head region) and the far-away region with sparser intervals (tail region), which are divided by {dargs:argument}`mid_point `.
When the size of {dargs:argument}`vacuum_resol ` is 2, two elements respectively decide the number of intervals in head region and tail region.
@@ -35,7 +35,7 @@ When {dargs:argument}`vacuum_resol ` is empty, the
- Attach files in the task path
-One can use the machine parameter `forward_files` to upload other files besides POSCAR, INCAR, and POTCAR. For example, "vdw_kernal.bindat" for each task.
+One can use the machine parameter `forward_files` to upload other files besides POSCAR, INCAR, and POTCAR. For example, "vdw_kernal.bindat" for each task.
See [the document of task parameters](https://docs.deepmodeling.com/projects/dpdispatcher/en/latest/task.html#argument:task/forward_files).
@@ -95,7 +95,7 @@ Following is an example for `PARAM`, which generates data from a typical structu
}
```
-Another example is `from_poscar` method. Here you need to specify the POSCAR file.
+Another example is `from_poscar` method. Here you need to specify the POSCAR file.
```json
{
diff --git a/doc/logo.svg b/doc/logo.svg
new file mode 100644
index 000000000..09764a8dc
--- /dev/null
+++ b/doc/logo.svg
@@ -0,0 +1 @@
+
diff --git a/doc/overview/code-structure.md b/doc/overview/code-structure.md
index 11abf211c..b8be78b42 100644
--- a/doc/overview/code-structure.md
+++ b/doc/overview/code-structure.md
@@ -47,8 +47,8 @@ Most of the code related to DP-GEN functions is in the `dpgen` directory. Open t
- `database` is the source code for collecting data generated by DP-GEN and interface with database.
- `simplify` corresponds to `dpgen simplify`.
- `remote` and `dispatcher` : source code for automatically submiting scripts,maintaining job queues and collecting results.
- **Notice this part hase been integrated into [dpdispatcher](https://github.com/deepmodeling/dpdispatcher)**
-`generator` is the core part of DP-GEN. It's for main process of deep generator. Let's open this folder.
+ **Notice this part hase been integrated into [dpdispatcher](https://github.com/deepmodeling/dpdispatcher)**
+`generator` is the core part of DP-GEN. It's for main process of deep generator. Let's open this folder.
````
├── arginfo.py
@@ -58,5 +58,3 @@ Most of the code related to DP-GEN functions is in the `dpgen` directory. Open t
└── run.py
````
`run.py` is the core of DP-GEN, corresponding to `dpgen run`. We can find `make_train`, `run_train`, ... `post_fp`, and other steps related functions here.
-
-
diff --git a/doc/overview/overview.md b/doc/overview/overview.md
index b0fd31e56..801370e5f 100644
--- a/doc/overview/overview.md
+++ b/doc/overview/overview.md
@@ -23,14 +23,14 @@ Yuzhi Zhang, Haidi Wang, Weijie Chen, Jinzhe Zeng, Linfeng Zhang, Han Wang, and
DP-GEN only supports Python 3.8 and above.
-Please follow our [GitHub](https://github.com/deepmodeling/dpgen) webpage to download the [latest released version](https://github.com/deepmodeling/dpgen/tree/master) and [development version](https://github.com/deepmodeling/dpgen/tree/devel).
+Please follow our [GitHub](https://github.com/deepmodeling/dpgen) webpage to download the [latest released version](https://github.com/deepmodeling/dpgen/tree/master) and [development version](https://github.com/deepmodeling/dpgen/tree/devel).
One can download the source code of dpgen by
```bash
git clone https://github.com/deepmodeling/dpgen.git
```
DP-GEN offers multiple installation methods. It is recommend using easily methods like:
-- offline packages: find them in [releases](https://github.com/deepmodeling/dpgen/releases/),
+- offline packages: find them in [releases](https://github.com/deepmodeling/dpgen/releases/),
- pip: use `pip install dpgen`, see [dpgen-PyPI](https://pypi.org/project/dpgen/)
- conda: use `conda install -c deepmodeling dpgen`, see [dpgen-conda](https://anaconda.org/deepmodeling/dpgen)
@@ -57,19 +57,19 @@ Before starting a new Deep Potential (DP) project, we suggest people (especially
- [Convergence-Test](https://tutorials.deepmodeling.com/en/latest/CaseStudies/Convergence-Test/index.html)
-to ensure the data quality, the reliability of the final model, as well as the feasibility of the project, a convergence test should be done first.
+to ensure the data quality, the reliability of the final model, as well as the feasibility of the project, a convergence test should be done first.
- [Gas-phase](https://tutorials.deepmodeling.com/en/latest/CaseStudies/Gas-phase/index.html)
-In this tutorial, we will take the simulation of methane combustion as an example and introduce the procedure of DP-based MD simulation.
+In this tutorial, we will take the simulation of methane combustion as an example and introduce the procedure of DP-based MD simulation.
- [Mg-Y_alloy](https://tutorials.deepmodeling.com/en/latest/CaseStudies/Mg-Y_alloy/index.html)
-
+
We will briefly analyze the candidate configurational space of a metallic system by taking Mg-based Mg-Y binary alloy as an example. The task is divided into steps during the DP-GEN process.
- [Transfer-learning](https://tutorials.deepmodeling.com/en/latest/CaseStudies/Transfer-learning/index.html)
-
- This tutorial will introduce how to implement potential energy surface (PES) transfer-learning by using the DP-GEN software. In DP-GEN (version > 0.8.0), the “simplify” module is designed for this purpose.
+
+ This tutorial will introduce how to implement potential energy surface (PES) transfer-learning by using the DP-GEN software. In DP-GEN (version > 0.8.0), the “simplify” module is designed for this purpose.
## License
The project dpgen is licensed under [GNU LGPLv3.0](https://github.com/deepmodeling/dpgen/blob/master/LICENSE)
diff --git a/doc/run/example-of-machine.md b/doc/run/example-of-machine.md
index 0f0cd83b2..e277e1256 100644
--- a/doc/run/example-of-machine.md
+++ b/doc/run/example-of-machine.md
@@ -2,13 +2,13 @@
## DPDispatcher Update Note
-DPDispatcher has updated and the api of machine.json is changed. DP-GEN will use the new DPDispatcher if the value of key {dargs:argument}`api_version ` in machine.json is equal to or large than 1.0. And for now, DPDispatcher is maintained on a separate repo (https://github.com/deepmodeling/dpdispatcher). Please check the documents (https://deepmd.readthedocs.io/projects/dpdispatcher/en/latest/) for more information about the new DPDispatcher.
+DPDispatcher has updated and the api of machine.json is changed. DP-GEN will use the new DPDispatcher if the value of key {dargs:argument}`api_version ` in machine.json is equal to or large than 1.0. And for now, DPDispatcher is maintained on a separate repo (https://github.com/deepmodeling/dpdispatcher). Please check the documents (https://deepmd.readthedocs.io/projects/dpdispatcher/en/latest/) for more information about the new DPDispatcher.
DP-GEN will use the old DPDispatcher if the key {dargs:argument}`api_version ` is not specified in machine.json or the {dargs:argument}`api_version ` is smaller than 1.0. This gurantees that the old machine.json still works.
## New DPDispatcher
-Each iteration in the run process of DP-GEN is composed of three steps: exploration, labeling, and training. Accordingly, machine.json is composed of three parts: train, model_devi, and fp. Each part is a list of dicts. Each dict can be considered as an independent environment for calculation.
+Each iteration in the run process of DP-GEN is composed of three steps: exploration, labeling, and training. Accordingly, machine.json is composed of three parts: train, model_devi, and fp. Each part is a list of dicts. Each dict can be considered as an independent environment for calculation.
In this section, we will show you how to perform train task at a local workstation, model_devi task at a local Slurm cluster, and fp task at a remote PBS cluster using the new DPDispatcher. For each task, three types of keys are needed:
- Command: provides the command used to execute each step.
@@ -108,7 +108,7 @@ In this example, we perform the fp task at a remote PBS cluster that can be acce
VASP code is used for fp task and mpi is used for parallel computing, so "mpirun -n 32" is added to specify the number of parallel threads.
-In the machine parameter, {dargs:argument}`context_type ` is modified to "SSHContext" and {dargs:argument}`batch_type ` is modified to "PBS". It is worth noting that {dargs:argument}`remote_root ` should be set to an accessible path on the remote PBS cluster. {dargs:argument}`remote_profile ` is added to specify the information used to connect the remote cluster, including hostname, username, port, etc.
+In the machine parameter, {dargs:argument}`context_type ` is modified to "SSHContext" and {dargs:argument}`batch_type ` is modified to "PBS". It is worth noting that {dargs:argument}`remote_root ` should be set to an accessible path on the remote PBS cluster. {dargs:argument}`remote_profile ` is added to specify the information used to connect the remote cluster, including hostname, username, port, etc.
In the resources parameter, we set {dargs:argument}`gpu_per_node ` to 0 since it is cost-effective to use the CPU for VASP calculations.
diff --git a/doc/run/example-of-param.md b/doc/run/example-of-param.md
index b5015c30b..0c5cac191 100644
--- a/doc/run/example-of-param.md
+++ b/doc/run/example-of-param.md
@@ -17,7 +17,7 @@ The basics related keys in param.json are given as follows
],
```
-The basics related keys specify the basic information about the system. {dargs:argument}`type_map ` gives the atom types, i.e. "H" and "C". {dargs:argument}`mass_map ` gives the standard atom weights, i.e. "1" and "12".
+The basics related keys specify the basic information about the system. {dargs:argument}`type_map ` gives the atom types, i.e. "H" and "C". {dargs:argument}`mass_map ` gives the standard atom weights, i.e. "1" and "12".
## data
@@ -40,9 +40,9 @@ The data related keys in param.json are given as follows
],
```
-The data related keys specify the init data for training initial DP models and structures used for model_devi calculations. {dargs:argument}`init_data_prefix ` and {dargs:argument}`init_data_sys ` specify the location of the init data. {dargs:argument}`sys_configs_prefix ` and {dargs:argument}`sys_configs ` specify the location of the structures.
+The data related keys specify the init data for training initial DP models and structures used for model_devi calculations. {dargs:argument}`init_data_prefix ` and {dargs:argument}`init_data_sys ` specify the location of the init data. {dargs:argument}`sys_configs_prefix ` and {dargs:argument}`sys_configs ` specify the location of the structures.
-Here, the init data is provided at "...... /init/CH4.POSCAR.01x01x01/02.md/sys-0004-0001/deepmd". These structures are divided into two groups and provided at "....../init/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale*/00000*/POSCAR" and "....../init/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale*/00001*/POSCAR".
+Here, the init data is provided at "...... /init/CH4.POSCAR.01x01x01/02.md/sys-0004-0001/deepmd". These structures are divided into two groups and provided at "....../init/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale*/00000*/POSCAR" and "....../init/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale*/00001*/POSCAR".
## training
@@ -53,7 +53,7 @@ The training related keys in param.json are given as follows
"default_training_param": {
},
```
-The training related keys specify the details of training tasks. {dargs:argument}`numb_models ` specifies the number of models to be trained. "default_training_param" specifies the training parameters for `deepmd-kit`.
+The training related keys specify the details of training tasks. {dargs:argument}`numb_models ` specifies the number of models to be trained. "default_training_param" specifies the training parameters for `deepmd-kit`.
Here, 4 DP models will be trained in `00.train`. A detailed explanation of training parameters can be found in DeePMD-kit’s documentation (https://docs.deepmodeling.com/projects/deepmd/en/master/).
@@ -104,7 +104,7 @@ The exploration related keys specify the details of exploration tasks. {dargs:ar
Here, MD simulations are performed at the temperature of 100 K and the pressure of 1.0 Bar with an integrator time of 2 fs under the nvt ensemble. Two iterations are set in {dargs:argument}`model_devi_jobs `. MD simulations are run for 300 and 3000 time steps with the first and second groups of structures in {dargs:argument}`sys_configs ` in 00 and 01 iterations. We choose to save all structures generated in MD simulations and have set {dargs:argument}`trj_freq ` as 10, so 30 and 300 structures are saved in 00 and 01 iterations. If the "max_devi_f" of saved structure falls between 0.05 and 0.15, DP-GEN will treat the structure as a candidate. We choose to clean traj folders in MD since they are too large. If you want to save the most recent n iterations of traj folders, you can set {dargs:argument}`model_devi_clean_traj ` to be an integer.
-## labeling
+## labeling
The labeling related keys in param.json are given as follows
@@ -122,6 +122,6 @@ The labeling related keys in param.json are given as follows
The labeling related keys specify the details of labeling tasks. {dargs:argument}`fp_style ` specifies software for First Principles. {dargs:argument}`fp_task_max ` and {dargs:argument}`fp_task_min ` specify the minimum and maximum of structures to be calculated in `02.fp` of each iteration. {dargs:argument}`fp_pp_path ` and {dargs:argument}`fp_pp_files ` specify the location of the psuedo-potential file to be used for 02.fp. {dargs:argument}`run_jdata[fp_style=vasp]/fp_incar` specifies input file for VASP. INCAR must specify KSPACING and KGAMMA.
-Here, a minimum of 1 and a maximum of 20 structures will be labeled using the VASP code with the INCAR provided at "....../INCAR_methane" and POTCAR provided at "....../methane/POTCAR" in each iteration. Note that the order of elements in POTCAR should correspond to the order in {dargs:argument}`type_map `.
+Here, a minimum of 1 and a maximum of 20 structures will be labeled using the VASP code with the INCAR provided at "....../INCAR_methane" and POTCAR provided at "....../methane/POTCAR" in each iteration. Note that the order of elements in POTCAR should correspond to the order in {dargs:argument}`type_map `.
All the keys of the DP-GEN are explained in detail in the section Parameters.
diff --git a/doc/run/index.rst b/doc/run/index.rst
index 957109889..04e304892 100644
--- a/doc/run/index.rst
+++ b/doc/run/index.rst
@@ -4,7 +4,7 @@ Run
.. toctree::
:maxdepth: 2
-
+
overview-of-the-run-process.md
example-of-param.md
example-of-machine.md
diff --git a/doc/run/overview-of-the-run-process.md b/doc/run/overview-of-the-run-process.md
index 691b6a2dd..590312ff3 100644
--- a/doc/run/overview-of-the-run-process.md
+++ b/doc/run/overview-of-the-run-process.md
@@ -8,7 +8,7 @@ The run process contains a series of successive iterations, undertaken in order
02.fp : Selected structures will be calculated by first-principles methods(default VASP). DP-GEN will obtain some new data and put them together with initial data and data generated in previous iterations. After that, new training will be set up and DP-GEN will enter the next iteration!
-In the run process of the DP-GEN, we need to specify the basic information about the system, the initial data, and details of the training, exploration, and labeling tasks. In addition, we need to specify the software, machine environment, and computing resource and enable the process of job generation, submission, query, and collection automatically. We can perform the run process as we expect by specifying the keywords in param.json and machine.json, and they will be introduced in detail in the following sections.
+In the run process of the DP-GEN, we need to specify the basic information about the system, the initial data, and details of the training, exploration, and labeling tasks. In addition, we need to specify the software, machine environment, and computing resource and enable the process of job generation, submission, query, and collection automatically. We can perform the run process as we expect by specifying the keywords in param.json and machine.json, and they will be introduced in detail in the following sections.
Here, we give a general description of the run process. We can execute the run process of DP-GEN easily by:
@@ -36,13 +36,13 @@ In folder iter.000000/ 00.train:
In folder iter.000000/ 01.model_devi:
-- Folder confs contains the initial configurations for LAMMPS MD converted from POSCAR you set in {dargs:argument}`sys_configs ` of param.json.
+- Folder confs contains the initial configurations for LAMMPS MD converted from POSCAR you set in {dargs:argument}`sys_configs ` of param.json.
- Folder task.000.00000x contains the input and output files of the LAMMPS. In folder task.000.00000x, file model_devi.out records the model deviation of concerned labels, energy and force in MD. It serves as the criterion for selecting which structures and doing first-principle calculations.
In folder iter.000000/ 02.fp:
- candidate.shuffle.000.out records which structures will be selected from last step 01.model_devi. There are always far more candidates than the maximum you expect to calculate at one time. In this condition, DP-GEN will randomly choose up to {dargs:argument}`fp_task_max ` structures and form the folder task.*.
-- rest_accurate.shuffle.000.out records the other structures where our model is accurate (`max_devi_f` is less than {dargs:argument}`model_devi_f_trust_lo `, no need to calculate any more),
+- rest_accurate.shuffle.000.out records the other structures where our model is accurate (`max_devi_f` is less than {dargs:argument}`model_devi_f_trust_lo `, no need to calculate any more),
- rest_failed.shuffled.000.out records the other structures where our model is too inaccurate (larger than {dargs:argument}`model_devi_f_trust_hi `, there may be some error).
- data.000: After first-principle calculations, DP-GEN will collect these data and change them into the format DeePMD-kit needs. In the next iteration's 00.train, these data will be trained together as well as the initial data.
diff --git a/doc/run/param.rst b/doc/run/param.rst
index 592f8f31c..6b99446f3 100644
--- a/doc/run/param.rst
+++ b/doc/run/param.rst
@@ -2,6 +2,9 @@
dpgen run param parameters
=============================
+.. note::
+ One can load, modify, and export the input file by using our effective web-based tool `DP-GUI `_. All parameters below can be set in DP-GUI. By clicking "SAVE JSON", one can download the input file.
+
.. dargs::
:module: dpgen.generator.arginfo
:func: run_jdata_arginfo
diff --git a/doc/simplify/index.rst b/doc/simplify/index.rst
index 22733d19f..45bfbee89 100644
--- a/doc/simplify/index.rst
+++ b/doc/simplify/index.rst
@@ -4,7 +4,7 @@ Simplify
.. toctree::
:maxdepth: 2
-
+
simplify
simplify-jdata
- simplify-mdata
\ No newline at end of file
+ simplify-mdata
diff --git a/doc/simplify/simplify-jdata.rst b/doc/simplify/simplify-jdata.rst
index 520c889ab..3933566dd 100644
--- a/doc/simplify/simplify-jdata.rst
+++ b/doc/simplify/simplify-jdata.rst
@@ -1,6 +1,9 @@
dpgen simplify parameters
=========================
+.. note::
+ One can load, modify, and export the input file by using our effective web-based tool `DP-GUI `_. All parameters below can be set in DP-GUI. By clicking "SAVE JSON", one can download the input file.
+
.. dargs::
:module: dpgen.simplify.arginfo
:func: simplify_jdata_arginfo
diff --git a/doc/simplify/simplify-mdata.rst b/doc/simplify/simplify-mdata.rst
index 995fc90f8..40edfc201 100644
--- a/doc/simplify/simplify-mdata.rst
+++ b/doc/simplify/simplify-mdata.rst
@@ -1,6 +1,9 @@
dpgen simplify machine parameters
=================================
+.. note::
+ One can load, modify, and export the input file by using our effective web-based tool `DP-GUI `_. All parameters below can be set in DP-GUI. By clicking "SAVE JSON", one can download the input file.
+
.. dargs::
:module: dpgen.simplify.arginfo
:func: simplify_mdata_arginfo
diff --git a/doc/simplify/simplify.md b/doc/simplify/simplify.md
index 86dd06d17..c462c85df 100644
--- a/doc/simplify/simplify.md
+++ b/doc/simplify/simplify.md
@@ -119,4 +119,3 @@ Here is an example of `param.json` for QM7 dataset:
```
Here {dargs:argument}`pick_data ` is the directory to data to simplify where the program recursively detects systems `System` with `deepmd/npy` format. {dargs:argument}`init_pick_number ` and {dargs:argument}`iter_pick_number ` are the numbers of picked frames. {dargs:argument}`model_devi_f_trust_lo ` and {dargs:argument}`model_devi_f_trust_hi ` mean the range of the max deviation of atomic forces in a frame. {dargs:argument}`fp_style ` can be either `gaussian` or `vasp` currently. Other parameters are as the same as those of generator.
-
diff --git a/doc/user-guide/common-errors.md b/doc/user-guide/common-errors.md
index 022194faa..7efab1d9c 100644
--- a/doc/user-guide/common-errors.md
+++ b/doc/user-guide/common-errors.md
@@ -17,8 +17,8 @@ If you find this error occurs, please check your initial data. Your model will n
Your `.json` file is incorrect. It may be a mistake in syntax or a missing comma.
## OSError: [Error cannot find valid a data system] Please check your setting for data systems
-Check if the path to the dataset in the parameter file is set correctly. Note that `init_data_sys` is a list, while `sys_configs` should be a two-dimensional list. The first dimension corresponds to `sys_idx`, and the second level are some poscars under each group. Refer to the [sample file](https://github.com/deepmodeling/dpgen/blob/master/examples/run/dp2.x-lammps-vasp/param_CH4_deepmd-kit-2.0.1.json ).
-
+Check if the path to the dataset in the parameter file is set correctly. Note that `init_data_sys` is a list, while `sys_configs` should be a two-dimensional list. The first dimension corresponds to `sys_idx`, and the second level are some poscars under each group. Refer to the [sample file](https://github.com/deepmodeling/dpgen/blob/master/examples/run/dp2.x-lammps-vasp/param_CH4_deepmd-kit-2.0.1.json ).
+
## RuntimeError: job:xxxxxxx failed 3 times
```
RuntimeError: job:xxxxxxx failed 3 times
@@ -30,9 +30,9 @@ Debug information: remote_root==xxxxxx
Debug information: submission_hash==xxxxxx
Please check the dirs and scripts in remote_root. The job information mentioned above may help.
```
-If a user finds an error like this, he or she is advised to check the files on the remote server. It shows that your job has failed 3 times, but has not shown the reason.
-
-To find the reason, you can check the log on the remote root. For example, you can check train.log, which is generated by DeePMD-kit. It can tell you more details.
+If a user finds an error like this, he or she is advised to check the files on the remote server. It shows that your job has failed 3 times, but has not shown the reason.
+
+To find the reason, you can check the log on the remote root. For example, you can check train.log, which is generated by DeePMD-kit. It can tell you more details.
If it doesn't help, you can manually run the `.sub` script, whose path is shown in `Debug information: remote_root==xxxxxx`
Some common reasons are as follows:
@@ -40,10 +40,10 @@ Some common reasons are as follows:
2. You may have something wrong in your input files, which causes the process to fail.
## RuntimeError: find too many unsuccessfully terminated jobs.
-The ratio of failed jobs is larger than ratio_failure. You can set a high value for ratio_failure or check if there is something wrong with your input files.
+The ratio of failed jobs is larger than ratio_failure. You can set a high value for ratio_failure or check if there is something wrong with your input files.
## ValueError: Cannot load file containing picked data when allow_picked=False
-Please ensure that you write the correct path of the dataset with no excess files.
+Please ensure that you write the correct path of the dataset with no excess files.
## warnings.warn("Some Gromacs commands were NOT found; "
-You can ignore this warning if you don't need Gromacs. It just show that Gromacs is not installed in you environment.
\ No newline at end of file
+You can ignore this warning if you don't need Gromacs. It just show that Gromacs is not installed in you environment.
diff --git a/doc/user-guide/get-help-from-com.md b/doc/user-guide/get-help-from-com.md
index b551add48..60738f35a 100644
--- a/doc/user-guide/get-help-from-com.md
+++ b/doc/user-guide/get-help-from-com.md
@@ -3,31 +3,30 @@
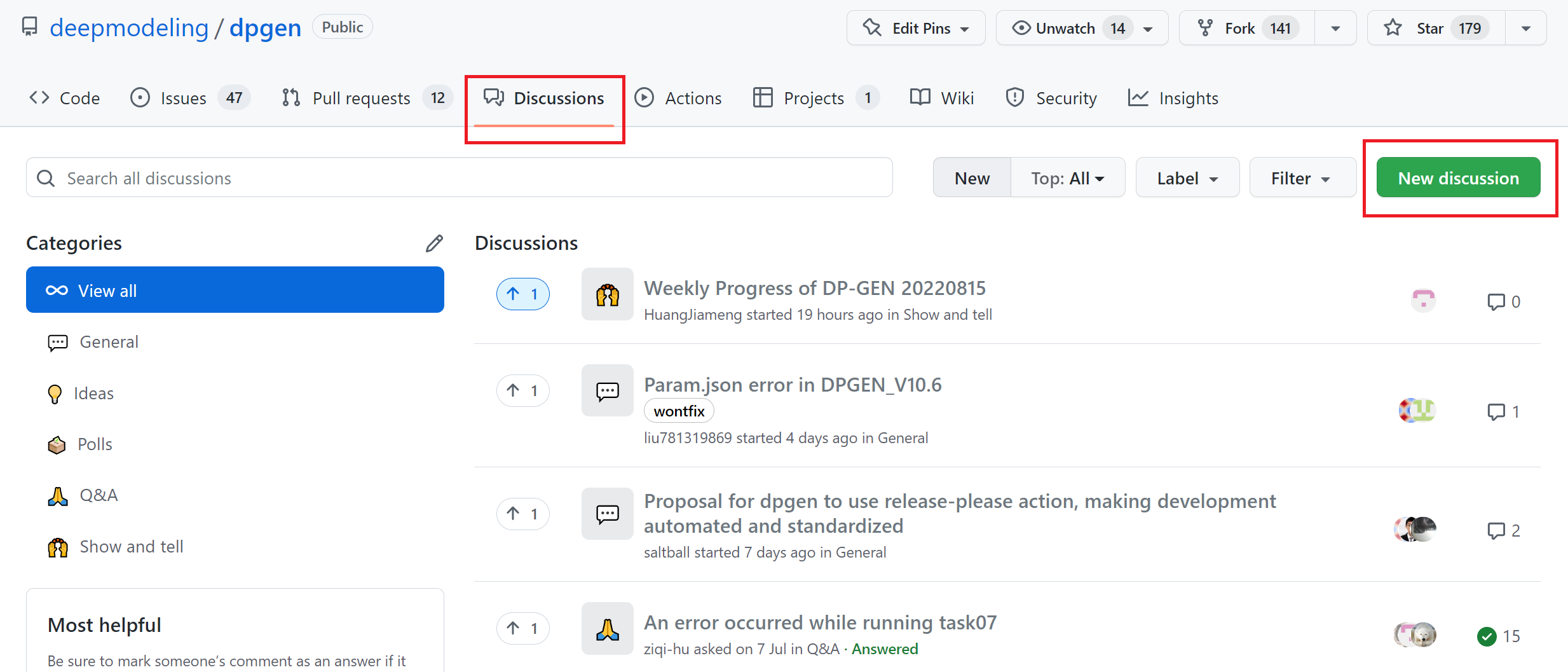
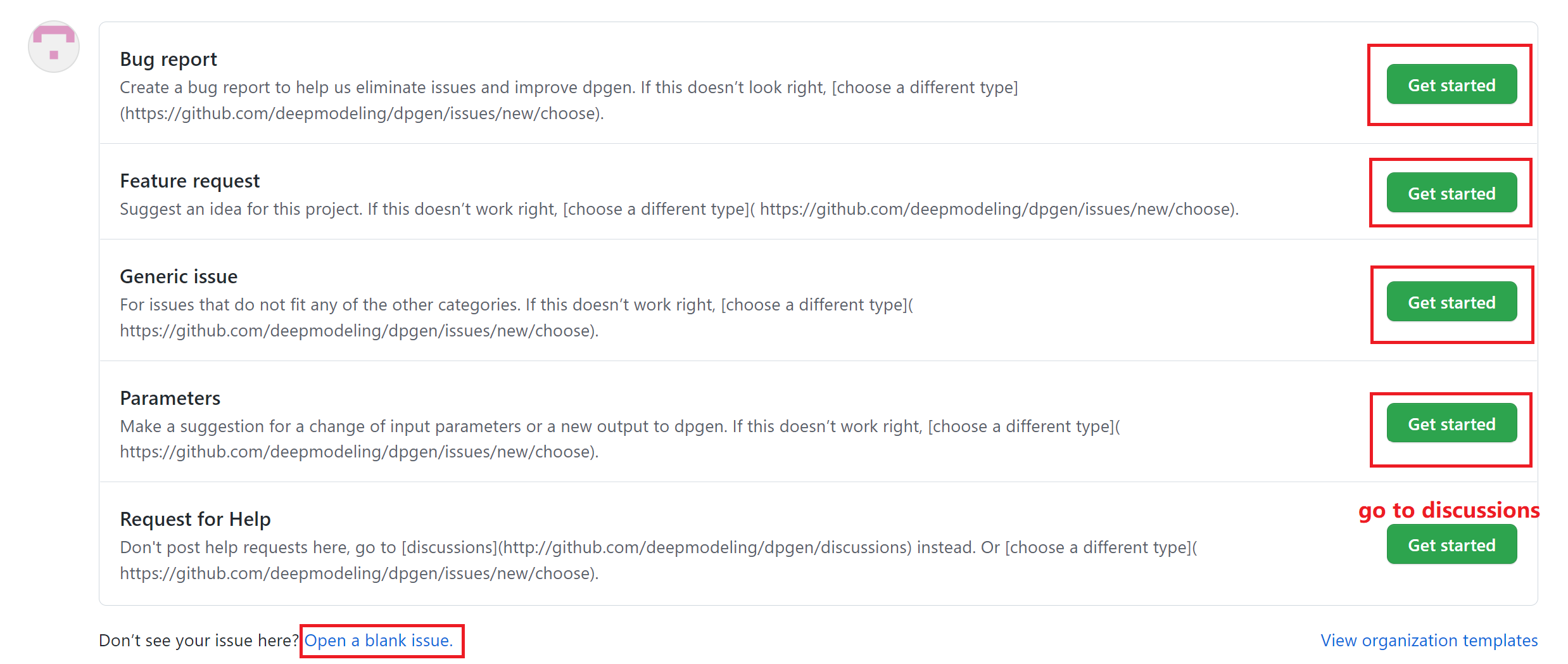
Welcome everyone to participate in the discussion about DP-GEN in the [discussion](https://github.com/deepmodeling/dpgen/discussions) module. You can ask for help, share an idea or anything to discuss here.
-Note: before you raise a question, please check TUTORIAL/FAQs and search history discussions to find solutions.
+Note: before you raise a question, please check TUTORIAL/FAQs and search history discussions to find solutions.
## Issue:
-
-
-If you want to make a bug report or a request for new features, you can make an issue in the issue module.
+
-
-
-Here are the types you can choose. A proper type can help developer figure out what you need. Also, you can assign yourself to solve the issue. Your contribution is welcome!
+If you want to make a bug report or a request for new features, you can make an issue in the issue module.
-Note: before you raise a question, please check TUTORIAL/FAQs and search history issues to find solutions.
-
-## Tutorials
+
+
+Here are the types you can choose. A proper type can help developer figure out what you need. Also, you can assign yourself to solve the issue. Your contribution is welcome!
+
+Note: before you raise a question, please check TUTORIAL/FAQs and search history issues to find solutions.
+
+## Tutorials
Tutorials can be found [here](https://tutorials.deepmodeling.com/en/latest/Tutorials/DP-GEN/index.html).
## Example for parameters
-
+
If you have no idea how to prepare a `PARAM` for your task, you can find examples of PARAM for different tasks in [examples](https://github.com/deepmodeling/dpgen/tree/master/examples).
-
+
For example, if you want to set specific template for LAMMPS, you can find an example [here](https://github.com/deepmodeling/dpgen/blob/master/examples/run/dp-lammps-enhance_sampling/param.json)
-
+
If you want to learn more about Machine parameters, please check [docs for dpdispatcher](https://docs.deepmodeling.com/projects/dpdispatcher/en/latest/)
-
-## [Pull requests - How to contribute](../contributing-guide/contributing-guide)
+## [Pull requests - How to contribute](../contributing-guide/contributing-guide)
diff --git a/doc/user-guide/troubleshooting.md b/doc/user-guide/troubleshooting.md
index 306cc71c9..69722cada 100644
--- a/doc/user-guide/troubleshooting.md
+++ b/doc/user-guide/troubleshooting.md
@@ -6,11 +6,10 @@
- Size of `sel_a` and actual types of atoms in your system.
- Index of `sys_configs` and `sys_idx`.
-2. Please verify the directories of `sys_configs`. If there isn't any POSCAR for `01.model_devi` in one iteration, it may happen that you write the false path of `sys_configs`. Note that `init_data_sys` is a list, while `sys_configs` should be a two-dimensional list. The first dimension corresponds to `sys_idx`, and the second level are some poscars under each group. Refer to the [sample file](https://github.com/deepmodeling/dpgen/blob/master/examples/run/dp2.x-lammps-vasp/param_CH4_deepmd-kit-2.0.1.json ).
+2. Please verify the directories of `sys_configs`. If there isn't any POSCAR for `01.model_devi` in one iteration, it may happen that you write the false path of `sys_configs`. Note that `init_data_sys` is a list, while `sys_configs` should be a two-dimensional list. The first dimension corresponds to `sys_idx`, and the second level are some poscars under each group. Refer to the [sample file](https://github.com/deepmodeling/dpgen/blob/master/examples/run/dp2.x-lammps-vasp/param_CH4_deepmd-kit-2.0.1.json ).
3. Correct format of JSON file.
4. The frames of one system should be larger than `batch_size` and `numb_test` in `default_training_param`. It happens that one iteration adds only a few structures and causes error in next iteration's training. In this condition, you may let `fp_task_min` be larger than `numb_test`.
5. If you found the dpgen with the same version on two machines behaves differently, you may have modified the code in one of them.
-
diff --git a/dpgen/__init__.py b/dpgen/__init__.py
index bd778d617..927705f25 100644
--- a/dpgen/__init__.py
+++ b/dpgen/__init__.py
@@ -1,54 +1,69 @@
-from __future__ import unicode_literals, print_function
+from __future__ import print_function, unicode_literals
+
import logging
import os
-
-ROOT_PATH=__path__[0]
-NAME="dpgen"
-SHORT_CMD="dpgen"
+ROOT_PATH = __path__[0]
+NAME = "dpgen"
+SHORT_CMD = "dpgen"
dlog = logging.getLogger(__name__)
dlog.setLevel(logging.INFO)
-dlogf = logging.FileHandler(os.getcwd()+os.sep+SHORT_CMD+'.log', delay=True)
-dlogf_formatter=logging.Formatter('%(asctime)s - %(levelname)s : %(message)s')
-#dlogf_formatter=logging.Formatter('%(asctime)s - %(name)s - [%(filename)s:%(funcName)s - %(lineno)d ] - %(levelname)s \n %(message)s')
+dlogf = logging.FileHandler(os.getcwd() + os.sep + SHORT_CMD + ".log", delay=True)
+dlogf_formatter = logging.Formatter("%(asctime)s - %(levelname)s : %(message)s")
+# dlogf_formatter=logging.Formatter('%(asctime)s - %(name)s - [%(filename)s:%(funcName)s - %(lineno)d ] - %(levelname)s \n %(message)s')
dlogf.setFormatter(dlogf_formatter)
dlog.addHandler(dlogf)
-__author__ = "Han Wang"
+__author__ = "Han Wang"
__copyright__ = "Copyright 2019"
-__status__ = "Development"
+__status__ = "Development"
try:
from ._version import version as __version__
except ImportError:
- __version__ = 'unkown'
+ __version__ = "unkown"
+
def info():
+ (
+ """
+ Show basic information about """
+ + NAME
+ + """, its location and version.
"""
- Show basic information about """+NAME+""", its location and version.
- """
+ )
- print('DeepModeling\n------------')
- print('Version: ' + __version__)
- print('Path: ' + ROOT_PATH)
- print('')
- print('Dependency')
- print('------------')
- for modui in ['numpy', 'dpdata', 'pymatgen', 'monty', 'ase', 'paramiko', 'custodian' ]:
+ print("DeepModeling\n------------")
+ print("Version: " + __version__)
+ print("Path: " + ROOT_PATH)
+ print("")
+ print("Dependency")
+ print("------------")
+ for modui in [
+ "numpy",
+ "dpdata",
+ "pymatgen",
+ "monty",
+ "ase",
+ "paramiko",
+ "custodian",
+ ]:
try:
mm = __import__(modui)
- print('%10s %10s %s' % (modui, mm.__version__, mm.__path__[0]))
+ print("%10s %10s %s" % (modui, mm.__version__, mm.__path__[0]))
except ImportError:
- print('%10s %10s Not Found' % (modui, ''))
+ print("%10s %10s Not Found" % (modui, ""))
except AttributeError:
- print('%10s %10s unknown version or path' %(modui, ''))
+ print("%10s %10s unknown version or path" % (modui, ""))
print()
# reference
- print("""Reference
+ print(
+ """Reference
------------
Please cite:
Yuzhi Zhang, Haidi Wang, Weijie Chen, Jinzhe Zeng, Linfeng Zhang, Han Wang, and Weinan E,
DP-GEN: A concurrent learning platform for the generation of reliable deep learning
based potential energy models, Computer Physics Communications, 2020, 107206.
------------
-""")
+"""
+ )
diff --git a/dpgen/arginfo.py b/dpgen/arginfo.py
index 52f966316..63405bfdd 100644
--- a/dpgen/arginfo.py
+++ b/dpgen/arginfo.py
@@ -14,25 +14,33 @@ def general_mdata_arginfo(name: str, tasks: Tuple[str]) -> Argument:
mdata name
tasks : tuple[str]
tuple of task keys, e.g. ("train", "model_devi", "fp")
-
+
Returns
-------
Argument
arginfo
"""
-
+
doc_api_version = "Please set to 1.0"
doc_deepmd_version = "DeePMD-kit version, e.g. 2.1.3"
doc_run_mdata = "machine.json file"
- arg_api_version = Argument("api_version", str, optional=False, doc=doc_api_version)
+ arg_api_version = Argument(
+ "api_version", str, default="1.0", optional=True, doc=doc_api_version
+ )
arg_deepmd_version = Argument(
- "deepmd_version", str, optional=True, default="2", doc=doc_deepmd_version)
+ "deepmd_version", str, optional=True, default="2", doc=doc_deepmd_version
+ )
sub_fields = [arg_api_version, arg_deepmd_version]
doc_mdata = "Parameters of command, machine, and resources for %s"
for task in tasks:
- sub_fields.append(Argument(
- task, dict, optional=False, sub_fields=mdata_arginfo(),
- doc=doc_mdata % task,
- ))
+ sub_fields.append(
+ Argument(
+ task,
+ dict,
+ optional=False,
+ sub_fields=mdata_arginfo(),
+ doc=doc_mdata % task,
+ )
+ )
return Argument(name, dict, sub_fields=sub_fields, doc=doc_run_mdata)
diff --git a/dpgen/auto_test/ABACUS.py b/dpgen/auto_test/ABACUS.py
index 252962c3f..ed246b19f 100644
--- a/dpgen/auto_test/ABACUS.py
+++ b/dpgen/auto_test/ABACUS.py
@@ -1,201 +1,213 @@
import os
-from dpgen import dlog
-from dpgen.util import sepline
-import dpgen.auto_test.lib.abacus as abacus
-import dpgen.generator.lib.abacus_scf as abacus_scf
-from dpgen.auto_test.Task import Task
+import numpy as np
from dpdata import LabeledSystem
from monty.serialization import dumpfn
-import numpy as np
+
+import dpgen.auto_test.lib.abacus as abacus
+import dpgen.generator.lib.abacus_scf as abacus_scf
+from dpgen import dlog
+from dpgen.auto_test.Task import Task
+from dpgen.util import sepline
class ABACUS(Task):
- def __init__(self,
- inter_parameter,
- path_to_poscar):
+ def __init__(self, inter_parameter, path_to_poscar):
self.inter = inter_parameter
- self.inter_type = inter_parameter['type']
- self.incar = inter_parameter.get('incar',{})
- self.potcar_prefix = inter_parameter.get('potcar_prefix', '')
- self.potcars = inter_parameter.get('potcars',None)
- self.orbfile = inter_parameter.get('orb_files',None)
- self.deepks = inter_parameter.get('deepks_desc',None)
+ self.inter_type = inter_parameter["type"]
+ self.incar = inter_parameter.get("incar", {})
+ self.potcar_prefix = inter_parameter.get("potcar_prefix", "")
+ self.potcars = inter_parameter.get("potcars", None)
+ self.orbfile = inter_parameter.get("orb_files", None)
+ self.deepks = inter_parameter.get("deepks_desc", None)
self.path_to_poscar = path_to_poscar
self.if_define_orb_file = False if self.orbfile == None else True
- def make_potential_files(self,
- output_dir):
- stru = os.path.abspath(os.path.join(output_dir, 'STRU'))
+ def make_potential_files(self, output_dir):
+ stru = os.path.abspath(os.path.join(output_dir, "STRU"))
if not os.path.isfile(stru):
raise FileNotFoundError("No file %s" % stru)
stru_data = abacus_scf.get_abacus_STRU(stru)
- atom_names = stru_data['atom_names']
- orb_files = stru_data['orb_files']
- pp_files = stru_data["pp_files"]
- dpks_descriptor = stru_data['dpks_descriptor']
-
- if os.path.islink(os.path.join(output_dir, 'STRU')):
- stru_path,tmpf = os.path.split(os.readlink(os.path.join(output_dir, 'STRU')))
+ atom_names = stru_data["atom_names"]
+ orb_files = stru_data["orb_files"]
+ pp_files = stru_data["pp_files"]
+ dpks_descriptor = stru_data["dpks_descriptor"]
+
+ if os.path.islink(os.path.join(output_dir, "STRU")):
+ stru_path, tmpf = os.path.split(
+ os.readlink(os.path.join(output_dir, "STRU"))
+ )
else:
stru_path = output_dir
if pp_files == None:
- raise RuntimeError("No pseudopotential information in STRU file")
+ raise RuntimeError("No pseudopotential information in STRU file")
pp_dir = os.path.abspath(self.potcar_prefix)
cwd = os.getcwd()
os.chdir(output_dir)
- if not os.path.isdir("./pp_orb"): os.mkdir("./pp_orb")
+ if not os.path.isdir("./pp_orb"):
+ os.mkdir("./pp_orb")
for i in range(len(atom_names)):
- pp_orb_file = [[pp_files[i],self.potcars]]
+ pp_orb_file = [[pp_files[i], self.potcars]]
if orb_files != None:
- pp_orb_file.append([orb_files[i],self.orbfile])
+ pp_orb_file.append([orb_files[i], self.orbfile])
elif self.orbfile != None:
- assert(atom_names[i] in self.orbfile),"orb_file of %s is not defined" % atom_names[i]
- pp_orb_file.append([self.orbfile[atom_names[i]],self.orbfile])
+ assert atom_names[i] in self.orbfile, (
+ "orb_file of %s is not defined" % atom_names[i]
+ )
+ pp_orb_file.append([self.orbfile[atom_names[i]], self.orbfile])
if dpks_descriptor != None:
- pp_orb_file.append([dpks_descriptor[i],self.deepks])
+ pp_orb_file.append([dpks_descriptor[i], self.deepks])
elif self.deepks != None:
- pp_orb_file.append([self.deepks,self.deepks])
+ pp_orb_file.append([self.deepks, self.deepks])
- for tmpf,tmpdict in pp_orb_file:
+ for tmpf, tmpdict in pp_orb_file:
atom = atom_names[i]
- if os.path.isfile(os.path.join(stru_path,tmpf)):
- linked_file = os.path.join(stru_path,tmpf)
- elif tmpdict != None and os.path.isfile(os.path.join(pp_dir,tmpdict[atom])):
- linked_file = os.path.join(pp_dir,tmpdict[atom])
+ if os.path.isfile(os.path.join(stru_path, tmpf)):
+ linked_file = os.path.join(stru_path, tmpf)
+ elif tmpdict != None and os.path.isfile(
+ os.path.join(pp_dir, tmpdict[atom])
+ ):
+ linked_file = os.path.join(pp_dir, tmpdict[atom])
else:
- raise RuntimeError("Can not find file %s" % tmpf.split('/')[-1])
- target_file = os.path.join("./pp_orb/",tmpf.split('/')[-1])
+ raise RuntimeError("Can not find file %s" % tmpf.split("/")[-1])
+ target_file = os.path.join("./pp_orb/", tmpf.split("/")[-1])
if os.path.isfile(target_file):
os.remove(target_file)
os.symlink(linked_file, target_file)
os.chdir(cwd)
- dumpfn(self.inter, os.path.join(output_dir, 'inter.json'), indent=4)
+ dumpfn(self.inter, os.path.join(output_dir, "inter.json"), indent=4)
- def modify_input(self,incar,x,y):
+ def modify_input(self, incar, x, y):
if x in incar and incar[x] != y:
- dlog.info("setting %s to %s" % (x,y))
+ dlog.info("setting %s to %s" % (x, y))
incar[x] = y
- def make_input_file(self,
- output_dir,
- task_type,
- task_param):
+ def make_input_file(self, output_dir, task_type, task_param):
sepline(ch=output_dir)
- dumpfn(task_param, os.path.join(output_dir, 'task.json'), indent=4)
+ dumpfn(task_param, os.path.join(output_dir, "task.json"), indent=4)
- assert (os.path.exists(self.incar)), 'no INPUT file for relaxation'
+ assert os.path.exists(self.incar), "no INPUT file for relaxation"
relax_incar_path = os.path.abspath(self.incar)
incar_relax = abacus_scf.get_abacus_input_parameters(relax_incar_path)
# deal with relaxation
- cal_type = task_param['cal_type']
- cal_setting = task_param['cal_setting']
+ cal_type = task_param["cal_type"]
+ cal_setting = task_param["cal_setting"]
# user input INCAR for property calculation
- if 'input_prop' in cal_setting and os.path.isfile(cal_setting['input_prop']):
- incar_prop = os.path.abspath(cal_setting['input_prop'])
+ if "input_prop" in cal_setting and os.path.isfile(cal_setting["input_prop"]):
+ incar_prop = os.path.abspath(cal_setting["input_prop"])
incar = abacus_scf.get_abacus_input_parameters(incar_prop)
- dlog.info("Detected 'input_prop' in 'relaxation', use %s as INPUT, and ignore 'cal_setting'" % incar_prop)
+ dlog.info(
+ "Detected 'input_prop' in 'relaxation', use %s as INPUT, and ignore 'cal_setting'"
+ % incar_prop
+ )
# revise INCAR based on the INCAR provided in the "interaction"
else:
incar = incar_relax
for key in cal_setting:
- if key in ['relax_pos','relax_shape','relax_vol','K_POINTS','']:continue
- if key[0] == '_' : continue
- if 'interaction' in key.lower():continue
+ if key in ["relax_pos", "relax_shape", "relax_vol", "K_POINTS", ""]:
+ continue
+ if key[0] == "_":
+ continue
+ if "interaction" in key.lower():
+ continue
incar[key.lower()] = cal_setting[key]
- fix_atom = [False,False,False]
- if cal_type == 'relaxation':
- relax_pos = cal_setting['relax_pos']
- relax_shape = cal_setting['relax_shape']
- relax_vol = cal_setting['relax_vol']
+ fix_atom = [False, False, False]
+ if cal_type == "relaxation":
+ relax_pos = cal_setting["relax_pos"]
+ relax_shape = cal_setting["relax_shape"]
+ relax_vol = cal_setting["relax_vol"]
if [relax_pos, relax_shape, relax_vol] == [True, False, False]:
- self.modify_input(incar,'calculation','relax')
+ self.modify_input(incar, "calculation", "relax")
elif [relax_pos, relax_shape, relax_vol] == [True, True, True]:
- self.modify_input(incar,'calculation','cell-relax')
+ self.modify_input(incar, "calculation", "cell-relax")
elif [relax_pos, relax_shape, relax_vol] == [True, True, False]:
- self.modify_input(incar,'calculation','cell-relax')
- self.modify_input(incar,'fixed_axes','volume')
+ self.modify_input(incar, "calculation", "cell-relax")
+ self.modify_input(incar, "fixed_axes", "volume")
elif [relax_pos, relax_shape, relax_vol] == [False, True, False]:
- self.modify_input(incar,'calculation','cell-relax')
- self.modify_input(incar,'fixed_axes','volume')
- fix_atom = [True,True,True]
+ self.modify_input(incar, "calculation", "cell-relax")
+ self.modify_input(incar, "fixed_axes", "volume")
+ fix_atom = [True, True, True]
elif [relax_pos, relax_shape, relax_vol] == [False, True, True]:
- self.modify_input(incar,'calculation','cell-relax')
- fix_atom = [True,True,True]
+ self.modify_input(incar, "calculation", "cell-relax")
+ fix_atom = [True, True, True]
elif [relax_pos, relax_shape, relax_vol] == [False, False, True]:
- raise RuntimeError("relax volume but fix shape is not supported for ABACUS")
+ raise RuntimeError(
+ "relax volume but fix shape is not supported for ABACUS"
+ )
elif [relax_pos, relax_shape, relax_vol] == [False, False, False]:
- self.modify_input(incar,'calculation','scf')
+ self.modify_input(incar, "calculation", "scf")
else:
raise RuntimeError("not supported calculation setting for ABACUS")
- elif cal_type == 'static':
- self.modify_input(incar,'calculation','scf')
+ elif cal_type == "static":
+ self.modify_input(incar, "calculation", "scf")
else:
raise RuntimeError("not supported calculation type for ABACUS")
- #modify STRU file base on the value of fix_atom
- abacus.stru_fix_atom(os.path.join(output_dir, 'STRU'),fix_atom)
+ # modify STRU file base on the value of fix_atom
+ abacus.stru_fix_atom(os.path.join(output_dir, "STRU"), fix_atom)
- if 'basis_type' not in incar:
+ if "basis_type" not in incar:
dlog.info("'basis_type' is not defined, set to be 'pw'!")
- self.modify_input(incar,'basis_type','pw')
- if 'ntype' not in incar:
- raise RuntimeError("ntype is not defined in INPUT")
- if 'lcao' in incar['basis_type'].lower() and not self.if_define_orb_file:
- mess = "The basis_type is %s, but not define orbital file!!!" % incar['basis_type']
+ self.modify_input(incar, "basis_type", "pw")
+ if "lcao" in incar["basis_type"].lower() and not self.if_define_orb_file:
+ mess = (
+ "The basis_type is %s, but not define orbital file!!!"
+ % incar["basis_type"]
+ )
raise RuntimeError(mess)
- abacus.write_input(os.path.join(output_dir, '../INPUT'),incar)
+ abacus.write_input(os.path.join(output_dir, "../INPUT"), incar)
cwd = os.getcwd()
os.chdir(output_dir)
- if not os.path.islink('INPUT'):
- os.symlink('../INPUT', 'INPUT')
- elif not '../INPUT' == os.readlink('INPUT'):
- os.remove('INPUT')
- os.symlink('../INPUT', 'INPUT')
+ if not os.path.islink("INPUT"):
+ os.symlink("../INPUT", "INPUT")
+ elif not "../INPUT" == os.readlink("INPUT"):
+ os.remove("INPUT")
+ os.symlink("../INPUT", "INPUT")
os.chdir(cwd)
- if 'kspacing' in incar:
- kspacing = float(incar['kspacing'])
- if os.path.isfile(os.path.join(output_dir, 'STRU')):
- kpt = abacus.make_kspacing_kpt(os.path.join(output_dir, 'STRU'),kspacing)
- kpt += [0,0,0]
+ if "kspacing" in incar:
+ kspacing = float(incar["kspacing"])
+ if os.path.isfile(os.path.join(output_dir, "STRU")):
+ kpt = abacus.make_kspacing_kpt(
+ os.path.join(output_dir, "STRU"), kspacing
+ )
+ kpt += [0, 0, 0]
else:
- kpt = [1,1,1,0,0,0]
- elif 'K_POINTS' in cal_setting:
- kpt = cal_setting['K_POINTS']
+ kpt = [1, 1, 1, 0, 0, 0]
+ elif "K_POINTS" in cal_setting:
+ kpt = cal_setting["K_POINTS"]
else:
- mess = "K point information is not defined\n"
+ mess = "K point information is not defined\n"
mess += "You can set key word 'kspacing' (unit in 1/bohr) as a float value in INPUT\n"
mess += "or set key word 'K_POINTS' as a list in 'cal_setting', e.g. [1,2,3,0,0,0]\n"
raise RuntimeError(mess)
- abacus.write_kpt(os.path.join(output_dir, 'KPT'),kpt)
-
- def compute(self,
- output_dir):
- if not os.path.isfile(os.path.join(output_dir,'INPUT')):
- dlog.warning("cannot find INPUT in " + output_dir + " skip")
- return None
- ls = LabeledSystem(output_dir,fmt='abacus/relax')
+ abacus.write_kpt(os.path.join(output_dir, "KPT"), kpt)
+
+ def compute(self, output_dir):
+ if not os.path.isfile(os.path.join(output_dir, "INPUT")):
+ dlog.warning("cannot find INPUT in " + output_dir + " skip")
+ return None
+ ls = LabeledSystem(output_dir, fmt="abacus/relax")
outcar_dict = ls.as_dict()
return outcar_dict
- def forward_files(self, property_type='relaxation'):
- return ['INPUT', 'STRU', 'KPT', 'pp_orb']
+ def forward_files(self, property_type="relaxation"):
+ return ["INPUT", "STRU", "KPT", "pp_orb"]
- def forward_common_files(self, property_type='relaxation'):
+ def forward_common_files(self, property_type="relaxation"):
return []
- def backward_files(self, property_type='relaxation'):
+ def backward_files(self, property_type="relaxation"):
return []
diff --git a/dpgen/auto_test/EOS.py b/dpgen/auto_test/EOS.py
index a41200c47..6ccd60fb8 100644
--- a/dpgen/auto_test/EOS.py
+++ b/dpgen/auto_test/EOS.py
@@ -4,178 +4,235 @@
import re
import numpy as np
-from monty.serialization import loadfn, dumpfn
+from monty.serialization import dumpfn, loadfn
+import dpgen.auto_test.lib.abacus as abacus
import dpgen.auto_test.lib.vasp as vasp
+import dpgen.generator.lib.abacus_scf as abacus_scf
from dpgen import dlog
from dpgen.auto_test.Property import Property
from dpgen.auto_test.refine import make_refine
-from dpgen.auto_test.reproduce import make_repro
-from dpgen.auto_test.reproduce import post_repro
+from dpgen.auto_test.reproduce import make_repro, post_repro
-import dpgen.generator.lib.abacus_scf as abacus_scf
-import dpgen.auto_test.lib.abacus as abacus
class EOS(Property):
- def __init__(self,
- parameter,inter_param=None):
- parameter['reproduce'] = parameter.get('reproduce', False)
- self.reprod = parameter['reproduce']
+ def __init__(self, parameter, inter_param=None):
+ parameter["reproduce"] = parameter.get("reproduce", False)
+ self.reprod = parameter["reproduce"]
if not self.reprod:
- if not ('init_from_suffix' in parameter and 'output_suffix' in parameter):
- self.vol_start = parameter['vol_start']
- self.vol_end = parameter['vol_end']
- self.vol_step = parameter['vol_step']
- parameter['vol_abs'] = parameter.get('vol_abs', False)
- self.vol_abs = parameter['vol_abs']
- parameter['cal_type'] = parameter.get('cal_type', 'relaxation')
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": True,
- "relax_shape": True,
- "relax_vol": False}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ if not ("init_from_suffix" in parameter and "output_suffix" in parameter):
+ self.vol_start = parameter["vol_start"]
+ self.vol_end = parameter["vol_end"]
+ self.vol_step = parameter["vol_step"]
+ parameter["vol_abs"] = parameter.get("vol_abs", False)
+ self.vol_abs = parameter["vol_abs"]
+ parameter["cal_type"] = parameter.get("cal_type", "relaxation")
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": False,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
else:
- parameter['cal_type'] = 'static'
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": False,
- "relax_shape": False,
- "relax_vol": False}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["cal_type"] = "static"
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": False,
+ "relax_shape": False,
+ "relax_vol": False,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
- parameter['init_from_suffix'] = parameter.get('init_from_suffix', '00')
- self.init_from_suffix = parameter['init_from_suffix']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
+ parameter["init_from_suffix"] = parameter.get("init_from_suffix", "00")
+ self.init_from_suffix = parameter["init_from_suffix"]
self.parameter = parameter
- self.inter_param = inter_param if inter_param != None else {'type': 'vasp'}
+ self.inter_param = inter_param if inter_param != None else {"type": "vasp"}
- def make_confs(self,
- path_to_work,
- path_to_equi,
- refine=False):
+ def make_confs(self, path_to_work, path_to_equi, refine=False):
path_to_work = os.path.abspath(path_to_work)
if os.path.exists(path_to_work):
- dlog.warning('%s already exists' % path_to_work)
+ dlog.warning("%s already exists" % path_to_work)
else:
os.makedirs(path_to_work)
path_to_equi = os.path.abspath(path_to_equi)
- if 'start_confs_path' in self.parameter and os.path.exists(self.parameter['start_confs_path']):
- init_path_list = glob.glob(os.path.join(self.parameter['start_confs_path'], '*'))
+ if "start_confs_path" in self.parameter and os.path.exists(
+ self.parameter["start_confs_path"]
+ ):
+ init_path_list = glob.glob(
+ os.path.join(self.parameter["start_confs_path"], "*")
+ )
struct_init_name_list = []
for ii in init_path_list:
- struct_init_name_list.append(ii.split('/')[-1])
- struct_output_name = path_to_work.split('/')[-2]
+ struct_init_name_list.append(ii.split("/")[-1])
+ struct_output_name = path_to_work.split("/")[-2]
assert struct_output_name in struct_init_name_list
- path_to_equi = os.path.abspath(os.path.join(self.parameter['start_confs_path'],
- struct_output_name, 'relaxation', 'relax_task'))
+ path_to_equi = os.path.abspath(
+ os.path.join(
+ self.parameter["start_confs_path"],
+ struct_output_name,
+ "relaxation",
+ "relax_task",
+ )
+ )
cwd = os.getcwd()
task_list = []
if self.reprod:
- print('eos reproduce starts')
- if 'init_data_path' not in self.parameter:
+ print("eos reproduce starts")
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- task_list = make_repro(self.inter_param,init_data_path, self.init_from_suffix,
- path_to_work, self.parameter.get('reprod_last_frame', True))
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ task_list = make_repro(
+ self.inter_param,
+ init_data_path,
+ self.init_from_suffix,
+ path_to_work,
+ self.parameter.get("reprod_last_frame", True),
+ )
os.chdir(cwd)
else:
if refine:
- print('eos refine starts')
- task_list = make_refine(self.parameter['init_from_suffix'],
- self.parameter['output_suffix'],
- path_to_work)
+ print("eos refine starts")
+ task_list = make_refine(
+ self.parameter["init_from_suffix"],
+ self.parameter["output_suffix"],
+ path_to_work,
+ )
os.chdir(cwd)
- init_from_path = re.sub(self.parameter['output_suffix'][::-1],
- self.parameter['init_from_suffix'][::-1],
- path_to_work[::-1], count=1)[::-1]
+ init_from_path = re.sub(
+ self.parameter["output_suffix"][::-1],
+ self.parameter["init_from_suffix"][::-1],
+ path_to_work[::-1],
+ count=1,
+ )[::-1]
task_list_basename = list(map(os.path.basename, task_list))
for ii in task_list_basename:
init_from_task = os.path.join(init_from_path, ii)
output_task = os.path.join(path_to_work, ii)
os.chdir(output_task)
- if os.path.isfile('eos.json'):
- os.remove('eos.json')
- if os.path.islink('eos.json'):
- os.remove('eos.json')
- os.symlink(os.path.relpath(os.path.join(init_from_task, 'eos.json')), 'eos.json')
+ if os.path.isfile("eos.json"):
+ os.remove("eos.json")
+ if os.path.islink("eos.json"):
+ os.remove("eos.json")
+ os.symlink(
+ os.path.relpath(os.path.join(init_from_task, "eos.json")),
+ "eos.json",
+ )
os.chdir(cwd)
else:
- print('gen eos from ' + str(self.vol_start) + ' to ' + str(self.vol_end) + ' by every ' + str(self.vol_step))
- if self.vol_abs :
- dlog.info('treat vol_start and vol_end as absolute volume')
- else :
- dlog.info('treat vol_start and vol_end as relative volume')
-
- if self.inter_param['type'] == 'abacus':
- equi_contcar = os.path.join(path_to_equi,abacus.final_stru(path_to_equi))
+ print(
+ "gen eos from "
+ + str(self.vol_start)
+ + " to "
+ + str(self.vol_end)
+ + " by every "
+ + str(self.vol_step)
+ )
+ if self.vol_abs:
+ dlog.info("treat vol_start and vol_end as absolute volume")
else:
- equi_contcar = os.path.join(path_to_equi, 'CONTCAR')
+ dlog.info("treat vol_start and vol_end as relative volume")
+
+ if self.inter_param["type"] == "abacus":
+ equi_contcar = os.path.join(
+ path_to_equi, abacus.final_stru(path_to_equi)
+ )
+ else:
+ equi_contcar = os.path.join(path_to_equi, "CONTCAR")
if not os.path.isfile(equi_contcar):
- raise RuntimeError("Can not find %s, please do relaxation first" % equi_contcar)
+ raise RuntimeError(
+ "Can not find %s, please do relaxation first" % equi_contcar
+ )
- if self.inter_param['type'] == 'abacus':
- stru_data = abacus_scf.get_abacus_STRU(equi_contcar)
- vol_to_poscar = abs(np.linalg.det(stru_data['cells'])) / np.array(stru_data['atom_numbs']).sum()
+ if self.inter_param["type"] == "abacus":
+ stru_data = abacus_scf.get_abacus_STRU(equi_contcar)
+ vol_to_poscar = (
+ abs(np.linalg.det(stru_data["cells"]))
+ / np.array(stru_data["atom_numbs"]).sum()
+ )
else:
- vol_to_poscar = vasp.poscar_vol(equi_contcar) / vasp.poscar_natoms(equi_contcar)
- self.parameter['scale2equi'] = []
+ vol_to_poscar = vasp.poscar_vol(equi_contcar) / vasp.poscar_natoms(
+ equi_contcar
+ )
+ self.parameter["scale2equi"] = []
task_num = 0
while self.vol_start + self.vol_step * task_num < self.vol_end:
- # for vol in np.arange(int(self.vol_start * 100), int(self.vol_end * 100), int(self.vol_step * 100)):
+ # for vol in np.arange(int(self.vol_start * 100), int(self.vol_end * 100), int(self.vol_step * 100)):
# vol = vol / 100.0
vol = self.vol_start + task_num * self.vol_step
- #task_num = int((vol - self.vol_start) / self.vol_step)
- output_task = os.path.join(path_to_work, 'task.%06d' % task_num)
+ # task_num = int((vol - self.vol_start) / self.vol_step)
+ output_task = os.path.join(path_to_work, "task.%06d" % task_num)
os.makedirs(output_task, exist_ok=True)
os.chdir(output_task)
- if self.inter_param['type'] == 'abacus':
- POSCAR = 'STRU'
- POSCAR_orig = 'STRU.orig'
+ if self.inter_param["type"] == "abacus":
+ POSCAR = "STRU"
+ POSCAR_orig = "STRU.orig"
scale_func = abacus.stru_scale
else:
- POSCAR = 'POSCAR'
- POSCAR_orig = 'POSCAR.orig'
+ POSCAR = "POSCAR"
+ POSCAR_orig = "POSCAR.orig"
scale_func = vasp.poscar_scale
- for ii in ['INCAR', 'POTCAR', POSCAR_orig, POSCAR, 'conf.lmp', 'in.lammps']:
+ for ii in [
+ "INCAR",
+ "POTCAR",
+ POSCAR_orig,
+ POSCAR,
+ "conf.lmp",
+ "in.lammps",
+ ]:
if os.path.exists(ii):
os.remove(ii)
task_list.append(output_task)
os.symlink(os.path.relpath(equi_contcar), POSCAR_orig)
# scale = (vol / vol_to_poscar) ** (1. / 3.)
- if self.vol_abs :
- scale = (vol / vol_to_poscar) ** (1. / 3.)
- eos_params = {'volume': vol, 'scale': scale}
- else :
- scale = vol ** (1. / 3.)
- eos_params = {'volume': vol * vol_to_poscar, 'scale': scale}
- dumpfn(eos_params, 'eos.json', indent=4)
- self.parameter['scale2equi'].append(scale) # 06/22
- scale_func(POSCAR_orig,POSCAR,scale)
+ if self.vol_abs:
+ scale = (vol / vol_to_poscar) ** (1.0 / 3.0)
+ eos_params = {"volume": vol, "scale": scale}
+ else:
+ scale = vol ** (1.0 / 3.0)
+ eos_params = {"volume": vol * vol_to_poscar, "scale": scale}
+ dumpfn(eos_params, "eos.json", indent=4)
+ self.parameter["scale2equi"].append(scale) # 06/22
+ scale_func(POSCAR_orig, POSCAR, scale)
task_num += 1
os.chdir(cwd)
return task_list
@@ -184,37 +241,44 @@ def post_process(self, task_list):
pass
def task_type(self):
- return self.parameter['type']
+ return self.parameter["type"]
def task_param(self):
return self.parameter
- def _compute_lower(self,
- output_file,
- all_tasks,
- all_res):
+ def _compute_lower(self, output_file, all_tasks, all_res):
output_file = os.path.abspath(output_file)
res_data = {}
ptr_data = "conf_dir: " + os.path.dirname(output_file) + "\n"
if not self.reprod:
- ptr_data += ' VpA(A^3) EpA(eV)\n'
+ ptr_data += " VpA(A^3) EpA(eV)\n"
for ii in range(len(all_tasks)):
# vol = self.vol_start + ii * self.vol_step
- vol = loadfn(os.path.join(all_tasks[ii], 'eos.json'))['volume']
+ vol = loadfn(os.path.join(all_tasks[ii], "eos.json"))["volume"]
task_result = loadfn(all_res[ii])
- res_data[vol] = task_result['energies'][-1] / sum(task_result['atom_numbs'])
- ptr_data += '%7.3f %8.4f \n' % (vol, task_result['energies'][-1] / sum(task_result['atom_numbs']))
+ res_data[vol] = task_result["energies"][-1] / sum(
+ task_result["atom_numbs"]
+ )
+ ptr_data += "%7.3f %8.4f \n" % (
+ vol,
+ task_result["energies"][-1] / sum(task_result["atom_numbs"]),
+ )
# res_data[vol] = all_res[ii]['energy'] / len(all_res[ii]['force'])
# ptr_data += '%7.3f %8.4f \n' % (vol, all_res[ii]['energy'] / len(all_res[ii]['force']))
else:
- if 'init_data_path' not in self.parameter:
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- res_data, ptr_data = post_repro(init_data_path, self.parameter['init_from_suffix'],
- all_tasks, ptr_data, self.parameter.get('reprod_last_frame', True))
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ res_data, ptr_data = post_repro(
+ init_data_path,
+ self.parameter["init_from_suffix"],
+ all_tasks,
+ ptr_data,
+ self.parameter.get("reprod_last_frame", True),
+ )
- with open(output_file, 'w') as fp:
+ with open(output_file, "w") as fp:
json.dump(res_data, fp, indent=4)
return res_data, ptr_data
diff --git a/dpgen/auto_test/Elastic.py b/dpgen/auto_test/Elastic.py
index 9ce3da6bb..0c98e44ab 100644
--- a/dpgen/auto_test/Elastic.py
+++ b/dpgen/auto_test/Elastic.py
@@ -1,84 +1,94 @@
import glob
import os
-from shutil import copyfile
import re
+from shutil import copyfile
-from monty.serialization import loadfn, dumpfn
+from monty.serialization import dumpfn, loadfn
from pymatgen.analysis.elasticity.elastic import ElasticTensor
from pymatgen.analysis.elasticity.strain import DeformedStructureSet, Strain
from pymatgen.analysis.elasticity.stress import Stress
from pymatgen.core.structure import Structure
from pymatgen.io.vasp import Incar, Kpoints
+import dpgen.auto_test.lib.abacus as abacus
import dpgen.auto_test.lib.vasp as vasp
+import dpgen.generator.lib.abacus_scf as abacus_scf
from dpgen import dlog
from dpgen.auto_test.Property import Property
from dpgen.auto_test.refine import make_refine
from dpgen.generator.lib.vasp import incar_upper
-import dpgen.auto_test.lib.abacus as abacus
-import dpgen.generator.lib.abacus_scf as abacus_scf
class Elastic(Property):
- def __init__(self,
- parameter,inter_param=None):
- if not ('init_from_suffix' in parameter and 'output_suffix' in parameter):
+ def __init__(self, parameter, inter_param=None):
+ if not ("init_from_suffix" in parameter and "output_suffix" in parameter):
default_norm_def = 1e-2
default_shear_def = 1e-2
- parameter['norm_deform'] = parameter.get('norm_deform', default_norm_def)
- self.norm_deform = parameter['norm_deform']
- parameter['shear_deform'] = parameter.get('shear_deform', default_shear_def)
- self.shear_deform = parameter['shear_deform']
- parameter['cal_type'] = parameter.get('cal_type', 'relaxation')
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": True,
- "relax_shape": False,
- "relax_vol": False}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["norm_deform"] = parameter.get("norm_deform", default_norm_def)
+ self.norm_deform = parameter["norm_deform"]
+ parameter["shear_deform"] = parameter.get("shear_deform", default_shear_def)
+ self.shear_deform = parameter["shear_deform"]
+ parameter["cal_type"] = parameter.get("cal_type", "relaxation")
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": True,
+ "relax_shape": False,
+ "relax_vol": False,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting["relax_pos"]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting["relax_vol"]
+ self.cal_setting = parameter["cal_setting"]
# parameter['reproduce'] = False
# self.reprod = parameter['reproduce']
self.parameter = parameter
- self.inter_param = inter_param if inter_param != None else {'type': 'vasp'}
+ self.inter_param = inter_param if inter_param != None else {"type": "vasp"}
- def make_confs(self,
- path_to_work,
- path_to_equi,
- refine=False):
+ def make_confs(self, path_to_work, path_to_equi, refine=False):
path_to_work = os.path.abspath(path_to_work)
if os.path.exists(path_to_work):
- dlog.warning('%s already exists' % path_to_work)
+ dlog.warning("%s already exists" % path_to_work)
else:
os.makedirs(path_to_work)
path_to_equi = os.path.abspath(path_to_equi)
- if 'start_confs_path' in self.parameter and os.path.exists(self.parameter['start_confs_path']):
- init_path_list = glob.glob(os.path.join(self.parameter['start_confs_path'], '*'))
+ if "start_confs_path" in self.parameter and os.path.exists(
+ self.parameter["start_confs_path"]
+ ):
+ init_path_list = glob.glob(
+ os.path.join(self.parameter["start_confs_path"], "*")
+ )
struct_init_name_list = []
for ii in init_path_list:
- struct_init_name_list.append(ii.split('/')[-1])
- struct_output_name = path_to_work.split('/')[-2]
+ struct_init_name_list.append(ii.split("/")[-1])
+ struct_output_name = path_to_work.split("/")[-2]
assert struct_output_name in struct_init_name_list
- path_to_equi = os.path.abspath(os.path.join(self.parameter['start_confs_path'],
- struct_output_name, 'relaxation', 'relax_task'))
+ path_to_equi = os.path.abspath(
+ os.path.join(
+ self.parameter["start_confs_path"],
+ struct_output_name,
+ "relaxation",
+ "relax_task",
+ )
+ )
task_list = []
cwd = os.getcwd()
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
CONTCAR = abacus.final_stru(path_to_equi)
- POSCAR = 'STRU'
+ POSCAR = "STRU"
else:
- CONTCAR = 'CONTCAR'
- POSCAR = 'POSCAR'
+ CONTCAR = "CONTCAR"
+ POSCAR = "POSCAR"
equi_contcar = os.path.join(path_to_equi, CONTCAR)
@@ -91,36 +101,41 @@ def make_confs(self,
# task_poscar = os.path.join(output, 'POSCAR')
# stress, deal with unsupported stress in dpdata
- #with open(os.path.join(path_to_equi, 'result.json')) as fin:
+ # with open(os.path.join(path_to_equi, 'result.json')) as fin:
# equi_result = json.load(fin)
- #equi_stress = np.array(equi_result['stress']['data'])[-1]
- equi_result = loadfn(os.path.join(path_to_equi, 'result.json'))
- equi_stress = equi_result['stress'][-1]
- dumpfn(equi_stress, 'equi.stress.json', indent=4)
+ # equi_stress = np.array(equi_result['stress']['data'])[-1]
+ equi_result = loadfn(os.path.join(path_to_equi, "result.json"))
+ equi_stress = equi_result["stress"][-1]
+ dumpfn(equi_stress, "equi.stress.json", indent=4)
os.chdir(cwd)
if refine:
- print('elastic refine starts')
- task_list = make_refine(self.parameter['init_from_suffix'],
- self.parameter['output_suffix'],
- path_to_work)
+ print("elastic refine starts")
+ task_list = make_refine(
+ self.parameter["init_from_suffix"],
+ self.parameter["output_suffix"],
+ path_to_work,
+ )
# record strain
# df = Strain.from_deformation(dfm_ss.deformations[idid])
# dumpfn(df.as_dict(), 'strain.json', indent=4)
- init_from_path = re.sub(self.parameter['output_suffix'][::-1],
- self.parameter['init_from_suffix'][::-1],
- path_to_work[::-1], count=1)[::-1]
+ init_from_path = re.sub(
+ self.parameter["output_suffix"][::-1],
+ self.parameter["init_from_suffix"][::-1],
+ path_to_work[::-1],
+ count=1,
+ )[::-1]
task_list_basename = list(map(os.path.basename, task_list))
for ii in task_list_basename:
init_from_task = os.path.join(init_from_path, ii)
output_task = os.path.join(path_to_work, ii)
os.chdir(output_task)
- if os.path.isfile('strain.json'):
- os.remove('strain.json')
- copyfile(os.path.join(init_from_task, 'strain.json'), 'strain.json')
- #os.symlink(os.path.relpath(
+ if os.path.isfile("strain.json"):
+ os.remove("strain.json")
+ copyfile(os.path.join(init_from_task, "strain.json"), "strain.json")
+ # os.symlink(os.path.relpath(
# os.path.join((re.sub(self.parameter['output_suffix'], self.parameter['init_from_suffix'], ii)),
# 'strain.json')),
# 'strain.json')
@@ -134,74 +149,87 @@ def make_confs(self,
if not os.path.exists(equi_contcar):
raise RuntimeError("please do relaxation first")
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
ss = abacus.stru2Structure(equi_contcar)
else:
ss = Structure.from_file(equi_contcar)
- dfm_ss = DeformedStructureSet(ss,
- symmetry=False,
- norm_strains=norm_strains,
- shear_strains=shear_strains)
+ dfm_ss = DeformedStructureSet(
+ ss,
+ symmetry=False,
+ norm_strains=norm_strains,
+ shear_strains=shear_strains,
+ )
n_dfm = len(dfm_ss)
- print('gen with norm ' + str(norm_strains))
- print('gen with shear ' + str(shear_strains))
+ print("gen with norm " + str(norm_strains))
+ print("gen with shear " + str(shear_strains))
for ii in range(n_dfm):
- output_task = os.path.join(path_to_work, 'task.%06d' % ii)
+ output_task = os.path.join(path_to_work, "task.%06d" % ii)
os.makedirs(output_task, exist_ok=True)
os.chdir(output_task)
- for jj in ['INCAR', 'POTCAR', 'POSCAR', 'conf.lmp', 'in.lammps','STRU']:
+ for jj in [
+ "INCAR",
+ "POTCAR",
+ "POSCAR",
+ "conf.lmp",
+ "in.lammps",
+ "STRU",
+ ]:
if os.path.exists(jj):
os.remove(jj)
task_list.append(output_task)
- dfm_ss.deformed_structures[ii].to('POSCAR', 'POSCAR')
- if self.inter_param['type'] == 'abacus':
- abacus.poscar2stru("POSCAR",self.inter_param,"STRU")
- os.remove('POSCAR')
+ dfm_ss.deformed_structures[ii].to("POSCAR", "POSCAR")
+ if self.inter_param["type"] == "abacus":
+ abacus.poscar2stru("POSCAR", self.inter_param, "STRU")
+ os.remove("POSCAR")
# record strain
df = Strain.from_deformation(dfm_ss.deformations[ii])
- dumpfn(df.as_dict(), 'strain.json', indent=4)
+ dumpfn(df.as_dict(), "strain.json", indent=4)
os.chdir(cwd)
return task_list
def post_process(self, task_list):
- if self.inter_param['type'] == 'abacus':
- POSCAR = 'STRU'
- INCAR = 'INPUT'
- KPOINTS = 'KPT'
+ if self.inter_param["type"] == "abacus":
+ POSCAR = "STRU"
+ INCAR = "INPUT"
+ KPOINTS = "KPT"
else:
- POSCAR = 'POSCAR'
- INCAR = 'INCAR'
- KPOINTS = 'KPOINTS'
+ POSCAR = "POSCAR"
+ INCAR = "INCAR"
+ KPOINTS = "KPOINTS"
cwd = os.getcwd()
- poscar_start = os.path.abspath(os.path.join(task_list[0], '..', POSCAR))
- os.chdir(os.path.join(task_list[0], '..'))
+ poscar_start = os.path.abspath(os.path.join(task_list[0], "..", POSCAR))
+ os.chdir(os.path.join(task_list[0], ".."))
if os.path.isfile(os.path.join(task_list[0], INCAR)):
- if self.inter_param['type'] == 'abacus':
- input_aba = abacus_scf.get_abacus_input_parameters('INPUT')
- if 'kspacing' in input_aba:
- kspacing = float(input_aba['kspacing'])
- kpt = abacus.make_kspacing_kpt(poscar_start,kspacing)
- kpt += [0,0,0]
- abacus.write_kpt('KPT',kpt)
- del input_aba['kspacing']
- os.remove('INPUT')
- abacus.write_input('INPUT',input_aba)
+ if self.inter_param["type"] == "abacus":
+ input_aba = abacus_scf.get_abacus_input_parameters("INPUT")
+ if "kspacing" in input_aba:
+ kspacing = float(input_aba["kspacing"])
+ kpt = abacus.make_kspacing_kpt(poscar_start, kspacing)
+ kpt += [0, 0, 0]
+ abacus.write_kpt("KPT", kpt)
+ del input_aba["kspacing"]
+ os.remove("INPUT")
+ abacus.write_input("INPUT", input_aba)
else:
- os.rename(os.path.join(task_list[0], 'KPT'),'./KPT')
+ os.rename(os.path.join(task_list[0], "KPT"), "./KPT")
else:
- incar = incar_upper(Incar.from_file(os.path.join(task_list[0], 'INCAR')))
- kspacing = incar.get('KSPACING')
- kgamma = incar.get('KGAMMA', False)
+ incar = incar_upper(
+ Incar.from_file(os.path.join(task_list[0], "INCAR"))
+ )
+ kspacing = incar.get("KSPACING")
+ kgamma = incar.get("KGAMMA", False)
ret = vasp.make_kspacing_kpoints(poscar_start, kspacing, kgamma)
kp = Kpoints.from_string(ret)
- if os.path.isfile('KPOINTS'):
- os.remove('KPOINTS')
+ if os.path.isfile("KPOINTS"):
+ os.remove("KPOINTS")
kp.write_file("KPOINTS")
os.chdir(cwd)
- kpoints_universal = os.path.abspath(os.path.join(task_list[0], '..', KPOINTS))
+ kpoints_universal = os.path.abspath(
+ os.path.join(task_list[0], "..", KPOINTS)
+ )
for ii in task_list:
if os.path.isfile(os.path.join(ii, KPOINTS)):
os.remove(os.path.join(ii, KPOINTS))
@@ -213,49 +241,50 @@ def post_process(self, task_list):
os.chdir(cwd)
def task_type(self):
- return self.parameter['type']
+ return self.parameter["type"]
def task_param(self):
return self.parameter
- def _compute_lower(self,
- output_file,
- all_tasks,
- all_res):
+ def _compute_lower(self, output_file, all_tasks, all_res):
output_file = os.path.abspath(output_file)
res_data = {}
- ptr_data = os.path.dirname(output_file) + '\n'
- equi_stress = Stress(loadfn(os.path.join(os.path.dirname(output_file), 'equi.stress.json')))
+ ptr_data = os.path.dirname(output_file) + "\n"
+ equi_stress = Stress(
+ loadfn(os.path.join(os.path.dirname(output_file), "equi.stress.json"))
+ )
equi_stress *= -1000
lst_strain = []
lst_stress = []
for ii in all_tasks:
- strain = loadfn(os.path.join(ii, 'strain.json'))
+ strain = loadfn(os.path.join(ii, "strain.json"))
# stress, deal with unsupported stress in dpdata
- #with open(os.path.join(ii, 'result_task.json')) as fin:
+ # with open(os.path.join(ii, 'result_task.json')) as fin:
# task_result = json.load(fin)
- #stress = np.array(task_result['stress']['data'])[-1]
- stress = loadfn(os.path.join(ii, 'result_task.json'))['stress'][-1]
+ # stress = np.array(task_result['stress']['data'])[-1]
+ stress = loadfn(os.path.join(ii, "result_task.json"))["stress"][-1]
lst_strain.append(strain)
lst_stress.append(Stress(stress * -1000))
- et = ElasticTensor.from_independent_strains(lst_strain, lst_stress, eq_stress=equi_stress, vasp=False)
- res_data['elastic_tensor'] = []
+ et = ElasticTensor.from_independent_strains(
+ lst_strain, lst_stress, eq_stress=equi_stress, vasp=False
+ )
+ res_data["elastic_tensor"] = []
for ii in range(6):
for jj in range(6):
- res_data['elastic_tensor'].append(et.voigt[ii][jj] / 1e4)
+ res_data["elastic_tensor"].append(et.voigt[ii][jj] / 1e4)
ptr_data += "%7.2f " % (et.voigt[ii][jj] / 1e4)
- ptr_data += '\n'
+ ptr_data += "\n"
BV = et.k_voigt / 1e4
GV = et.g_voigt / 1e4
EV = 9 * BV * GV / (3 * BV + GV)
uV = 0.5 * (3 * BV - 2 * GV) / (3 * BV + GV)
- res_data['BV'] = BV
- res_data['GV'] = GV
- res_data['EV'] = EV
- res_data['uV'] = uV
+ res_data["BV"] = BV
+ res_data["GV"] = GV
+ res_data["EV"] = EV
+ res_data["uV"] = uV
ptr_data += "# Bulk Modulus BV = %.2f GPa\n" % BV
ptr_data += "# Shear Modulus GV = %.2f GPa\n" % GV
ptr_data += "# Youngs Modulus EV = %.2f GPa\n" % EV
diff --git a/dpgen/auto_test/Gamma.py b/dpgen/auto_test/Gamma.py
index 5361a7712..97eed3b1b 100644
--- a/dpgen/auto_test/Gamma.py
+++ b/dpgen/auto_test/Gamma.py
@@ -5,158 +5,197 @@
import dpdata
import numpy as np
-from monty.serialization import loadfn, dumpfn
-from pymatgen.core.structure import Structure
-from pymatgen.core.surface import SlabGenerator
-from pymatgen.io.ase import AseAtomsAdaptor
from ase.lattice.cubic import BodyCenteredCubic as bcc
from ase.lattice.cubic import FaceCenteredCubic as fcc
from ase.lattice.hexagonal import HexagonalClosedPacked as hcp
+from monty.serialization import dumpfn, loadfn
+from pymatgen.core.structure import Structure
+from pymatgen.core.surface import SlabGenerator
+from pymatgen.io.ase import AseAtomsAdaptor
+import dpgen.auto_test.lib.abacus as abacus
import dpgen.auto_test.lib.vasp as vasp
from dpgen import dlog
from dpgen.auto_test.Property import Property
from dpgen.auto_test.refine import make_refine
-from dpgen.auto_test.reproduce import make_repro
-from dpgen.auto_test.reproduce import post_repro
-
-import dpgen.auto_test.lib.abacus as abacus
+from dpgen.auto_test.reproduce import make_repro, post_repro
class Gamma(Property):
"""
Calculation of common gamma lines for bcc and fcc
"""
- def __init__(self,
- parameter,inter_param=None):
- parameter['reproduce'] = parameter.get('reproduce', False)
- self.reprod = parameter['reproduce']
+
+ def __init__(self, parameter, inter_param=None):
+ parameter["reproduce"] = parameter.get("reproduce", False)
+ self.reprod = parameter["reproduce"]
if not self.reprod:
- if not ('init_from_suffix' in parameter and 'output_suffix' in parameter):
- self.miller_index = parameter['miller_index']
- self.displace_direction = parameter['displace_direction']
- self.lattice_type = parameter['lattice_type']
- parameter['supercell_size'] = parameter.get('supercell_size', (1,1,5))
- self.supercell_size = parameter['supercell_size']
- parameter['min_vacuum_size'] = parameter.get('min_vacuum_size', 20)
- self.min_vacuum_size = parameter['min_vacuum_size']
- parameter['add_fix'] = parameter.get('add_fix', ['true','true','false']) # standard method
- self.add_fix = parameter['add_fix']
- parameter['n_steps'] = parameter.get('n_steps', 10)
- self.n_steps = parameter['n_steps']
+ if not ("init_from_suffix" in parameter and "output_suffix" in parameter):
+ self.miller_index = parameter["miller_index"]
+ self.displace_direction = parameter["displace_direction"]
+ self.lattice_type = parameter["lattice_type"]
+ parameter["supercell_size"] = parameter.get("supercell_size", (1, 1, 5))
+ self.supercell_size = parameter["supercell_size"]
+ parameter["min_vacuum_size"] = parameter.get("min_vacuum_size", 20)
+ self.min_vacuum_size = parameter["min_vacuum_size"]
+ parameter["add_fix"] = parameter.get(
+ "add_fix", ["true", "true", "false"]
+ ) # standard method
+ self.add_fix = parameter["add_fix"]
+ parameter["n_steps"] = parameter.get("n_steps", 10)
+ self.n_steps = parameter["n_steps"]
self.atom_num = None
- parameter['cal_type'] = parameter.get('cal_type', 'relaxation')
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": True,
- "relax_shape": False,
- "relax_vol": False}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["cal_type"] = parameter.get("cal_type", "relaxation")
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": True,
+ "relax_shape": False,
+ "relax_vol": False,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
else:
- parameter['cal_type'] = 'static'
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": False,
- "relax_shape": False,
- "relax_vol": False}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["cal_type"] = "static"
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": False,
+ "relax_shape": False,
+ "relax_vol": False,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
- parameter['init_from_suffix'] = parameter.get('init_from_suffix', '00')
- self.init_from_suffix = parameter['init_from_suffix']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
+ parameter["init_from_suffix"] = parameter.get("init_from_suffix", "00")
+ self.init_from_suffix = parameter["init_from_suffix"]
self.parameter = parameter
- self.inter_param = inter_param if inter_param != None else {'type': 'vasp'}
+ self.inter_param = inter_param if inter_param != None else {"type": "vasp"}
- def make_confs(self,
- path_to_work,
- path_to_equi,
- refine=False):
+ def make_confs(self, path_to_work, path_to_equi, refine=False):
path_to_work = os.path.abspath(path_to_work)
if os.path.exists(path_to_work):
- dlog.warning('%s already exists' % path_to_work)
+ dlog.warning("%s already exists" % path_to_work)
else:
os.makedirs(path_to_work)
path_to_equi = os.path.abspath(path_to_equi)
- if 'start_confs_path' in self.parameter and os.path.exists(self.parameter['start_confs_path']):
- init_path_list = glob.glob(os.path.join(self.parameter['start_confs_path'], '*'))
+ if "start_confs_path" in self.parameter and os.path.exists(
+ self.parameter["start_confs_path"]
+ ):
+ init_path_list = glob.glob(
+ os.path.join(self.parameter["start_confs_path"], "*")
+ )
struct_init_name_list = []
for ii in init_path_list:
- struct_init_name_list.append(ii.split('/')[-1])
- struct_output_name = path_to_work.split('/')[-2]
+ struct_init_name_list.append(ii.split("/")[-1])
+ struct_output_name = path_to_work.split("/")[-2]
assert struct_output_name in struct_init_name_list
- path_to_equi = os.path.abspath(os.path.join(self.parameter['start_confs_path'],
- struct_output_name, 'relaxation', 'relax_task'))
+ path_to_equi = os.path.abspath(
+ os.path.join(
+ self.parameter["start_confs_path"],
+ struct_output_name,
+ "relaxation",
+ "relax_task",
+ )
+ )
task_list = []
cwd = os.getcwd()
if self.reprod:
- print('gamma line reproduce starts')
- if 'init_data_path' not in self.parameter:
+ print("gamma line reproduce starts")
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- task_list = make_repro(init_data_path, self.init_from_suffix,
- path_to_work, self.parameter.get('reprod_last_frame', True))
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ task_list = make_repro(
+ init_data_path,
+ self.init_from_suffix,
+ path_to_work,
+ self.parameter.get("reprod_last_frame", True),
+ )
os.chdir(cwd)
else:
if refine:
- print('gamma line refine starts')
- task_list = make_refine(self.parameter['init_from_suffix'],
- self.parameter['output_suffix'],
- path_to_work)
+ print("gamma line refine starts")
+ task_list = make_refine(
+ self.parameter["init_from_suffix"],
+ self.parameter["output_suffix"],
+ path_to_work,
+ )
os.chdir(cwd)
# record miller
- init_from_path = re.sub(self.parameter['output_suffix'][::-1],
- self.parameter['init_from_suffix'][::-1],
- path_to_work[::-1], count=1)[::-1]
+ init_from_path = re.sub(
+ self.parameter["output_suffix"][::-1],
+ self.parameter["init_from_suffix"][::-1],
+ path_to_work[::-1],
+ count=1,
+ )[::-1]
task_list_basename = list(map(os.path.basename, task_list))
for ii in task_list_basename:
init_from_task = os.path.join(init_from_path, ii)
output_task = os.path.join(path_to_work, ii)
os.chdir(output_task)
- if os.path.isfile('miller.json'):
- os.remove('miller.json')
- if os.path.islink('miller.json'):
- os.remove('miller.json')
- os.symlink(os.path.relpath(os.path.join(init_from_task, 'miller.json')), 'miller.json')
+ if os.path.isfile("miller.json"):
+ os.remove("miller.json")
+ if os.path.islink("miller.json"):
+ os.remove("miller.json")
+ os.symlink(
+ os.path.relpath(os.path.join(init_from_task, "miller.json")),
+ "miller.json",
+ )
os.chdir(cwd)
else:
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
CONTCAR = abacus.final_stru(path_to_equi)
- POSCAR = 'STRU'
+ POSCAR = "STRU"
else:
- CONTCAR = 'CONTCAR'
- POSCAR = 'POSCAR'
+ CONTCAR = "CONTCAR"
+ POSCAR = "POSCAR"
equi_contcar = os.path.join(path_to_equi, CONTCAR)
if not os.path.exists(equi_contcar):
raise RuntimeError("please do relaxation first")
- print('we now only support gamma line calculation for BCC and FCC metals')
- print('supported slip systems are planes/direction: 100/010, 110/111, 111/110, 111/112, 112/111, and 123/111')
-
- if self.inter_param['type'] == 'abacus':
+ print(
+ "we now only support gamma line calculation for BCC and FCC metals"
+ )
+ print(
+ "supported slip systems are planes/direction: 100/010, 110/111, 111/110, 111/112, 112/111, and 123/111"
+ )
+
+ if self.inter_param["type"] == "abacus":
stru = dpdata.System(equi_contcar, fmt="stru")
- stru.to('contcar','CONTCAR.tmp')
- ptypes = vasp.get_poscar_types('CONTCAR.tmp')
- ss = Structure.from_file('CONTCAR.tmp')
- os.remove('CONTCAR.tmp')
+ stru.to("contcar", "CONTCAR.tmp")
+ ptypes = vasp.get_poscar_types("CONTCAR.tmp")
+ ss = Structure.from_file("CONTCAR.tmp")
+ os.remove("CONTCAR.tmp")
else:
ptypes = vasp.get_poscar_types(equi_contcar)
# read structure from relaxed CONTCAR
@@ -164,17 +203,18 @@ def make_confs(self,
# rewrite new CONTCAR with direct coords
os.chdir(path_to_equi)
- ss.to('POSCAR', 'CONTCAR.direct')
+ ss.to("CONTCAR.direct", "POSCAR")
# re-read new CONTCAR
- ss = Structure.from_file('CONTCAR.direct')
+ ss = Structure.from_file("CONTCAR.direct")
relax_a = ss.lattice.a
relax_b = ss.lattice.b
relax_c = ss.lattice.c
# gen initial slab
- slab = self.__gen_slab_ase(symbol=ptypes[0],
- lat_param=[relax_a,relax_b,relax_c])
+ slab = self.__gen_slab_ase(
+ symbol=ptypes[0], lat_param=[relax_a, relax_b, relax_c]
+ )
# define displace vectors
- disp_vector = (1/self.supercell_size[0], 0, 0)
+ disp_vector = (1 / self.supercell_size[0], 0, 0)
# displace structure
all_slabs = self.__displace_slab(slab, disp_vector=disp_vector)
self.atom_num = len(all_slabs[0].sites)
@@ -187,25 +227,29 @@ def make_confs(self,
os.symlink(os.path.relpath(equi_contcar), POSCAR)
# task_poscar = os.path.join(output, 'POSCAR')
for ii in range(len(all_slabs)):
- output_task = os.path.join(path_to_work, 'task.%06d' % ii)
+ output_task = os.path.join(path_to_work, "task.%06d" % ii)
os.makedirs(output_task, exist_ok=True)
os.chdir(output_task)
- for jj in ['INCAR', 'POTCAR', POSCAR, 'conf.lmp', 'in.lammps']:
+ for jj in ["INCAR", "POTCAR", POSCAR, "conf.lmp", "in.lammps"]:
if os.path.exists(jj):
os.remove(jj)
task_list.append(output_task)
- #print("# %03d generate " % ii, output_task)
- print("# %03d generate " % ii, output_task, " \t %d atoms" % self.atom_num)
+ # print("# %03d generate " % ii, output_task)
+ print(
+ "# %03d generate " % ii,
+ output_task,
+ " \t %d atoms" % self.atom_num,
+ )
# make confs
- all_slabs[ii].to('POSCAR', 'POSCAR.tmp')
- vasp.regulate_poscar('POSCAR.tmp', 'POSCAR')
- vasp.sort_poscar('POSCAR', 'POSCAR', ptypes)
- if self.inter_param['type'] == 'abacus':
- abacus.poscar2stru("POSCAR",self.inter_param,"STRU")
- os.remove('POSCAR')
+ all_slabs[ii].to("POSCAR.tmp", "POSCAR")
+ vasp.regulate_poscar("POSCAR.tmp", "POSCAR")
+ vasp.sort_poscar("POSCAR", "POSCAR", ptypes)
+ if self.inter_param["type"] == "abacus":
+ abacus.poscar2stru("POSCAR", self.inter_param, "STRU")
+ os.remove("POSCAR")
# vasp.perturb_xz('POSCAR', 'POSCAR', self.pert_xz)
# record miller
- dumpfn(self.miller_index, 'miller.json')
+ dumpfn(self.miller_index, "miller.json")
os.chdir(cwd)
return task_list
@@ -214,58 +258,67 @@ def make_confs(self,
def centralize_slab(slab) -> None:
z_pos_list = list(set([site.position[2] for site in slab]))
z_pos_list.sort()
- central_atoms = (z_pos_list[-1] - z_pos_list[0])/2
- central_cell = slab.cell[2][2]/2
+ central_atoms = (z_pos_list[-1] - z_pos_list[0]) / 2
+ central_cell = slab.cell[2][2] / 2
disp_length = central_cell - central_atoms
for site in slab:
site.position[2] += disp_length
def return_direction(self):
- miller_str = ''
- direct_str = ''
+ miller_str = ""
+ direct_str = ""
for ii in range(len(self.miller_index)):
miller_str += str(self.miller_index[ii])
for ii in range(len(self.displace_direction)):
direct_str += str(self.displace_direction[ii])
- search_key = miller_str + '/' + direct_str
+ search_key = miller_str + "/" + direct_str
# define specific cell vectors
dict_directions = {
- '100/010': [(0,1,0), (0,0,1), (1,0,0)],
- '110/111': [(-1,1,1), (1,-1,1), (1,1,0)],
- '111/110': [(-1,1,0), (-1,-1,2), (1,1,1)],
- '111/112': [(1,1,-2), (-1,1,0), (1,1,1)],
- '112/111': [(-1,-1,1), (1,-1,0), (1,1,2)],
- '123/111': [(-1,-1,1), (2,-1,0), (1,2,3)]
+ "100/010": [(0, 1, 0), (0, 0, 1), (1, 0, 0)],
+ "110/111": [(-1, 1, 1), (1, -1, 1), (1, 1, 0)],
+ "111/110": [(-1, 1, 0), (-1, -1, 2), (1, 1, 1)],
+ "111/112": [(1, 1, -2), (-1, 1, 0), (1, 1, 1)],
+ "112/111": [(-1, -1, 1), (1, -1, 0), (1, 1, 2)],
+ "123/111": [(-1, -1, 1), (2, -1, 0), (1, 2, 3)],
}
try:
directions = dict_directions[search_key]
except KeyError:
- raise RuntimeError(f'Unsupported input combination of miller index and displacement direction: '
- f'{miller_str}:{direct_str}')
+ raise RuntimeError(
+ f"Unsupported input combination of miller index and displacement direction: "
+ f"{miller_str}:{direct_str}"
+ )
return directions
- def __gen_slab_ase(self,
- symbol, lat_param):
+ def __gen_slab_ase(self, symbol, lat_param):
if not self.lattice_type:
- raise RuntimeError('Error! Please provide the input lattice type!')
- elif self.lattice_type == 'bcc':
- slab_ase = bcc(symbol=symbol, size=self.supercell_size, latticeconstant=lat_param[0],
- directions=self.return_direction())
- elif self.lattice_type == 'fcc':
- slab_ase = fcc(symbol=symbol, size=self.supercell_size, latticeconstant=lat_param[0],
- directions=self.return_direction())
- elif self.lattice_type == 'hcp':
+ raise RuntimeError("Error! Please provide the input lattice type!")
+ elif self.lattice_type == "bcc":
+ slab_ase = bcc(
+ symbol=symbol,
+ size=self.supercell_size,
+ latticeconstant=lat_param[0],
+ directions=self.return_direction(),
+ )
+ elif self.lattice_type == "fcc":
+ slab_ase = fcc(
+ symbol=symbol,
+ size=self.supercell_size,
+ latticeconstant=lat_param[0],
+ directions=self.return_direction(),
+ )
+ elif self.lattice_type == "hcp":
pass
else:
- raise RuntimeError(f'unsupported lattice type: {self.lattice_type}')
+ raise RuntimeError(f"unsupported lattice type: {self.lattice_type}")
self.centralize_slab(slab_ase)
if self.min_vacuum_size > 0:
- slab_ase.center(vacuum=self.min_vacuum_size/2, axis=2)
+ slab_ase.center(vacuum=self.min_vacuum_size / 2, axis=2)
slab_pymatgen = AseAtomsAdaptor.get_structure(slab_ase)
return slab_pymatgen
# leave this function to later use
- #def __gen_slab_pmg(self,
+ # def __gen_slab_pmg(self,
# pmg_struc):
# slabGen = SlabGenerator(pmg_struc, miller_index=self.miller_index,
# min_slab_size=self.supercell_size[2],
@@ -276,142 +329,173 @@ def __gen_slab_ase(self,
# slab_pmg.make_supercell(scaling_matrix=[self.supercell_size[0],self.supercell_size[1],1])
# return slab_pmg
- def __displace_slab(self,
- slab, disp_vector):
+ def __displace_slab(self, slab, disp_vector):
# return a list of displaced slab objects
all_slabs = [slab.copy()]
for ii in list(range(self.n_steps)):
frac_disp = 1 / self.n_steps
unit_vector = frac_disp * np.array(disp_vector)
# return list of atoms number to be displaced which above 0.5 z
- disp_atoms_list = np.where(slab.frac_coords[:,2]>0.5)[0]
- slab.translate_sites(indices=disp_atoms_list, vector=unit_vector,
- frac_coords=True, to_unit_cell=True)
+ disp_atoms_list = np.where(slab.frac_coords[:, 2] > 0.5)[0]
+ slab.translate_sites(
+ indices=disp_atoms_list,
+ vector=unit_vector,
+ frac_coords=True,
+ to_unit_cell=True,
+ )
all_slabs.append(slab.copy())
return all_slabs
def __poscar_fix(self, poscar) -> None:
# add position fix condition of x and y in POSCAR
insert_pos = -self.atom_num
- fix_dict = {
- 'true': 'F',
- 'false': 'T'
- }
- add_fix_str = ' ' + fix_dict[self.add_fix[0]] + \
- ' ' + fix_dict[self.add_fix[1]] + \
- ' ' + fix_dict[self.add_fix[2]] + '\n'
- with open(poscar, 'r') as fin1:
+ fix_dict = {"true": "F", "false": "T"}
+ add_fix_str = (
+ " "
+ + fix_dict[self.add_fix[0]]
+ + " "
+ + fix_dict[self.add_fix[1]]
+ + " "
+ + fix_dict[self.add_fix[2]]
+ + "\n"
+ )
+ with open(poscar, "r") as fin1:
contents = fin1.readlines()
- contents.insert(insert_pos-1, 'Selective dynamics\n')
+ contents.insert(insert_pos - 1, "Selective dynamics\n")
for ii in range(insert_pos, 0, 1):
- contents[ii] = contents[ii].replace('\n', '')
+ contents[ii] = contents[ii].replace("\n", "")
contents[ii] += add_fix_str
- with open(poscar, 'w') as fin2:
+ with open(poscar, "w") as fin2:
for ii in range(len(contents)):
fin2.write(contents[ii])
- def __stru_fix(self,stru) -> None:
- fix_dict = {
- 'true': True,
- 'false': False
- }
+ def __stru_fix(self, stru) -> None:
+ fix_dict = {"true": True, "false": False}
fix_xyz = [fix_dict[i] for i in self.addfix]
- abacus.stru_fix_atom(stru,fix_atom=fix_xyz)
+ abacus.stru_fix_atom(stru, fix_atom=fix_xyz)
def __inLammpes_fix(self, inLammps) -> None:
# add position fix condition of x and y of in.lammps
- fix_dict = {
- 'true': '0',
- 'false': 'NULL'
- }
- add_fix_str = 'fix 1 all setforce' + \
- ' ' + fix_dict[self.add_fix[0]] + \
- ' ' + fix_dict[self.add_fix[1]] + \
- ' ' + fix_dict[self.add_fix[2]] + '\n'
- with open(inLammps, 'r') as fin1:
+ fix_dict = {"true": "0", "false": "NULL"}
+ add_fix_str = (
+ "fix 1 all setforce"
+ + " "
+ + fix_dict[self.add_fix[0]]
+ + " "
+ + fix_dict[self.add_fix[1]]
+ + " "
+ + fix_dict[self.add_fix[2]]
+ + "\n"
+ )
+ with open(inLammps, "r") as fin1:
contents = fin1.readlines()
for ii in range(len(contents)):
upper = re.search("variable N equal count\(all\)", contents[ii])
lower = re.search("min_style cg", contents[ii])
if lower:
lower_id = ii
- #print(lower_id)
+ # print(lower_id)
elif upper:
upper_id = ii
- #print(upper_id)
- del contents[lower_id+1:upper_id-1]
- contents.insert(lower_id+1, add_fix_str)
- with open(inLammps, 'w') as fin2:
+ # print(upper_id)
+ del contents[lower_id + 1 : upper_id - 1]
+ contents.insert(lower_id + 1, add_fix_str)
+ with open(inLammps, "w") as fin2:
for ii in range(len(contents)):
fin2.write(contents[ii])
- def post_process(self,
- task_list):
+ def post_process(self, task_list):
if self.add_fix:
count = 0
for ii in task_list:
count += 1
- inter = os.path.join(ii, 'inter.json')
- poscar = os.path.join(ii, 'POSCAR')
- calc_type = loadfn(inter)['type']
- if calc_type == 'vasp':
+ inter = os.path.join(ii, "inter.json")
+ poscar = os.path.join(ii, "POSCAR")
+ calc_type = loadfn(inter)["type"]
+ if calc_type == "vasp":
self.__poscar_fix(poscar)
- elif calc_type == 'abacus':
- self.__stru_fix(os.path.join(ii, 'STRU'))
+ elif calc_type == "abacus":
+ self.__stru_fix(os.path.join(ii, "STRU"))
else:
- inLammps = os.path.join(ii, 'in.lammps')
+ inLammps = os.path.join(ii, "in.lammps")
if count == 1:
self.__inLammpes_fix(inLammps)
-
def task_type(self):
- return self.parameter['type']
+ return self.parameter["type"]
def task_param(self):
return self.parameter
- def _compute_lower(self,
- output_file,
- all_tasks,
- all_res):
+ def _compute_lower(self, output_file, all_tasks, all_res):
output_file = os.path.abspath(output_file)
res_data = {}
- ptr_data = os.path.dirname(output_file) + '\n'
+ ptr_data = os.path.dirname(output_file) + "\n"
if not self.reprod:
- ptr_data += str(tuple(self.miller_index)) + ' plane along ' + str(self.displace_direction)
+ ptr_data += (
+ str(tuple(self.miller_index))
+ + " plane along "
+ + str(self.displace_direction)
+ )
ptr_data += "No_task: \tDisplacement \tStacking_Fault_E(J/m^2) EpA(eV) slab_equi_EpA(eV)\n"
all_tasks.sort()
- task_result_slab_equi = loadfn(os.path.join(all_tasks[0], 'result_task.json'))
+ task_result_slab_equi = loadfn(
+ os.path.join(all_tasks[0], "result_task.json")
+ )
for ii in all_tasks:
- task_result = loadfn(os.path.join(ii, 'result_task.json'))
- natoms = np.sum(task_result['atom_numbs'])
- epa = task_result['energies'][-1] / natoms
- equi_epa_slab = task_result_slab_equi['energies'][-1] / natoms
- AA = np.linalg.norm(np.cross(task_result['cells'][0][0], task_result['cells'][0][1]))
-
- equi_path = os.path.abspath(os.path.join(os.path.dirname(output_file), '../relaxation/relax_task'))
- equi_result = loadfn(os.path.join(equi_path, 'result.json'))
- equi_epa = equi_result['energies'][-1] / np.sum(equi_result['atom_numbs'])
+ task_result = loadfn(os.path.join(ii, "result_task.json"))
+ natoms = np.sum(task_result["atom_numbs"])
+ epa = task_result["energies"][-1] / natoms
+ equi_epa_slab = task_result_slab_equi["energies"][-1] / natoms
+ AA = np.linalg.norm(
+ np.cross(task_result["cells"][0][0], task_result["cells"][0][1])
+ )
+
+ equi_path = os.path.abspath(
+ os.path.join(
+ os.path.dirname(output_file), "../relaxation/relax_task"
+ )
+ )
+ equi_result = loadfn(os.path.join(equi_path, "result.json"))
+ equi_epa = equi_result["energies"][-1] / np.sum(
+ equi_result["atom_numbs"]
+ )
structure_dir = os.path.basename(ii)
Cf = 1.60217657e-16 / 1e-20 * 0.001
- sfe = (task_result['energies'][-1] - task_result_slab_equi['energies'][-1]) / AA * Cf
-
- miller_index = loadfn(os.path.join(ii, 'miller.json'))
+ sfe = (
+ (
+ task_result["energies"][-1]
+ - task_result_slab_equi["energies"][-1]
+ )
+ / AA
+ * Cf
+ )
+
+ miller_index = loadfn(os.path.join(ii, "miller.json"))
ptr_data += "%-25s %7.2f %7.3f %8.3f %8.3f\n" % (
- str(miller_index) + '-' + structure_dir + ':', int(ii[-4:])/self.n_steps, sfe, epa, equi_epa_slab)
- res_data[int(ii[-4:])/self.n_steps] = [sfe, epa, equi_epa]
-
+ str(miller_index) + "-" + structure_dir + ":",
+ int(ii[-4:]) / self.n_steps,
+ sfe,
+ epa,
+ equi_epa_slab,
+ )
+ res_data[int(ii[-4:]) / self.n_steps] = [sfe, epa, equi_epa]
else:
- if 'init_data_path' not in self.parameter:
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- res_data, ptr_data = post_repro(init_data_path, self.parameter['init_from_suffix'],
- all_tasks, ptr_data, self.parameter.get('reprod_last_frame', True))
-
- with open(output_file, 'w') as fp:
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ res_data, ptr_data = post_repro(
+ init_data_path,
+ self.parameter["init_from_suffix"],
+ all_tasks,
+ ptr_data,
+ self.parameter.get("reprod_last_frame", True),
+ )
+
+ with open(output_file, "w") as fp:
json.dump(res_data, fp, indent=4)
return res_data, ptr_data
diff --git a/dpgen/auto_test/Interstitial.py b/dpgen/auto_test/Interstitial.py
index 70560418c..b98f18d15 100644
--- a/dpgen/auto_test/Interstitial.py
+++ b/dpgen/auto_test/Interstitial.py
@@ -2,171 +2,217 @@
import json
import os
import re
-import numpy as np
-from monty.serialization import loadfn, dumpfn
+import numpy as np
+from monty.serialization import dumpfn, loadfn
from pymatgen.analysis.defects.generators import InterstitialGenerator
from pymatgen.core.structure import Structure
+import dpgen.auto_test.lib.abacus as abacus
import dpgen.auto_test.lib.lammps as lammps
+import dpgen.generator.lib.abacus_scf as abacus_scf
from dpgen.auto_test.Property import Property
from dpgen.auto_test.refine import make_refine
-from dpgen.auto_test.reproduce import make_repro
-from dpgen.auto_test.reproduce import post_repro
+from dpgen.auto_test.reproduce import make_repro, post_repro
-import dpgen.auto_test.lib.abacus as abacus
-import dpgen.generator.lib.abacus_scf as abacus_scf
class Interstitial(Property):
- def __init__(self,
- parameter,inter_param=None):
- parameter['reproduce'] = parameter.get('reproduce', False)
- self.reprod = parameter['reproduce']
+ def __init__(self, parameter, inter_param=None):
+ parameter["reproduce"] = parameter.get("reproduce", False)
+ self.reprod = parameter["reproduce"]
if not self.reprod:
- if not ('init_from_suffix' in parameter and 'output_suffix' in parameter):
+ if not ("init_from_suffix" in parameter and "output_suffix" in parameter):
default_supercell = [1, 1, 1]
- parameter['supercell'] = parameter.get('supercell', default_supercell)
- self.supercell = parameter['supercell']
- self.insert_ele = parameter['insert_ele']
- parameter['cal_type'] = parameter.get('cal_type', 'relaxation')
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": True,
- "relax_shape": True,
- "relax_vol": True}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["supercell"] = parameter.get("supercell", default_supercell)
+ self.supercell = parameter["supercell"]
+ self.insert_ele = parameter["insert_ele"]
+ parameter["cal_type"] = parameter.get("cal_type", "relaxation")
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": True,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
else:
- parameter['cal_type'] = 'static'
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": False,
- "relax_shape": False,
- "relax_vol": False}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["cal_type"] = "static"
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": False,
+ "relax_shape": False,
+ "relax_vol": False,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
- parameter['init_from_suffix'] = parameter.get('init_from_suffix', '00')
- self.init_from_suffix = parameter['init_from_suffix']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
+ parameter["init_from_suffix"] = parameter.get("init_from_suffix", "00")
+ self.init_from_suffix = parameter["init_from_suffix"]
self.parameter = parameter
- self.inter_param = inter_param if inter_param != None else {'type': 'vasp'}
+ self.inter_param = inter_param if inter_param != None else {"type": "vasp"}
- def make_confs(self,
- path_to_work,
- path_to_equi,
- refine=False):
+ def make_confs(self, path_to_work, path_to_equi, refine=False):
path_to_work = os.path.abspath(path_to_work)
path_to_equi = os.path.abspath(path_to_equi)
- if 'start_confs_path' in self.parameter and os.path.exists(self.parameter['start_confs_path']):
- init_path_list = glob.glob(os.path.join(self.parameter['start_confs_path'], '*'))
+ if "start_confs_path" in self.parameter and os.path.exists(
+ self.parameter["start_confs_path"]
+ ):
+ init_path_list = glob.glob(
+ os.path.join(self.parameter["start_confs_path"], "*")
+ )
struct_init_name_list = []
for ii in init_path_list:
- struct_init_name_list.append(ii.split('/')[-1])
- struct_output_name = path_to_work.split('/')[-2]
+ struct_init_name_list.append(ii.split("/")[-1])
+ struct_output_name = path_to_work.split("/")[-2]
assert struct_output_name in struct_init_name_list
- path_to_equi = os.path.abspath(os.path.join(self.parameter['start_confs_path'],
- struct_output_name, 'relaxation', 'relax_task'))
+ path_to_equi = os.path.abspath(
+ os.path.join(
+ self.parameter["start_confs_path"],
+ struct_output_name,
+ "relaxation",
+ "relax_task",
+ )
+ )
task_list = []
cwd = os.getcwd()
if self.reprod:
- print('interstitial reproduce starts')
- if 'init_data_path' not in self.parameter:
+ print("interstitial reproduce starts")
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- task_list = make_repro(self.inter_param,init_data_path, self.init_from_suffix,
- path_to_work, self.parameter.get('reprod_last_frame', False))
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ task_list = make_repro(
+ self.inter_param,
+ init_data_path,
+ self.init_from_suffix,
+ path_to_work,
+ self.parameter.get("reprod_last_frame", False),
+ )
os.chdir(cwd)
else:
if refine:
- print('interstitial refine starts')
- task_list = make_refine(self.parameter['init_from_suffix'],
- self.parameter['output_suffix'],
- path_to_work)
-
- init_from_path = re.sub(self.parameter['output_suffix'][::-1],
- self.parameter['init_from_suffix'][::-1],
- path_to_work[::-1], count=1)[::-1]
+ print("interstitial refine starts")
+ task_list = make_refine(
+ self.parameter["init_from_suffix"],
+ self.parameter["output_suffix"],
+ path_to_work,
+ )
+
+ init_from_path = re.sub(
+ self.parameter["output_suffix"][::-1],
+ self.parameter["init_from_suffix"][::-1],
+ path_to_work[::-1],
+ count=1,
+ )[::-1]
task_list_basename = list(map(os.path.basename, task_list))
os.chdir(path_to_work)
- if os.path.isfile('element.out'):
- os.remove('element.out')
- if os.path.islink('element.out'):
- os.remove('element.out')
- os.symlink(os.path.relpath(os.path.join(init_from_path, 'element.out')), 'element.out')
+ if os.path.isfile("element.out"):
+ os.remove("element.out")
+ if os.path.islink("element.out"):
+ os.remove("element.out")
+ os.symlink(
+ os.path.relpath(os.path.join(init_from_path, "element.out")),
+ "element.out",
+ )
os.chdir(cwd)
for ii in task_list_basename:
init_from_task = os.path.join(init_from_path, ii)
output_task = os.path.join(path_to_work, ii)
os.chdir(output_task)
- if os.path.isfile('supercell.json'):
- os.remove('supercell.json')
- if os.path.islink('supercell.json'):
- os.remove('supercell.json')
- os.symlink(os.path.relpath(os.path.join(init_from_task, 'supercell.json')), 'supercell.json')
+ if os.path.isfile("supercell.json"):
+ os.remove("supercell.json")
+ if os.path.islink("supercell.json"):
+ os.remove("supercell.json")
+ os.symlink(
+ os.path.relpath(os.path.join(init_from_task, "supercell.json")),
+ "supercell.json",
+ )
os.chdir(cwd)
else:
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
CONTCAR = abacus.final_stru(path_to_equi)
- POSCAR = 'STRU'
+ POSCAR = "STRU"
else:
- CONTCAR = 'CONTCAR'
- POSCAR = 'POSCAR'
+ CONTCAR = "CONTCAR"
+ POSCAR = "POSCAR"
equi_contcar = os.path.join(path_to_equi, CONTCAR)
if not os.path.exists(equi_contcar):
raise RuntimeError("please do relaxation first")
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
ss = abacus.stru2Structure(equi_contcar)
else:
ss = Structure.from_file(equi_contcar)
# gen defects
dss = []
- insert_element_task = os.path.join(path_to_work, 'element.out')
+ insert_element_task = os.path.join(path_to_work, "element.out")
if os.path.isfile(insert_element_task):
os.remove(insert_element_task)
for ii in self.insert_ele:
pre_vds = InterstitialGenerator()
- vds = pre_vds.generate(ss, {ii: [[0.1,0.1,0.1]]})
+ vds = pre_vds.generate(ss, {ii: [[0.1, 0.1, 0.1]]})
for jj in vds:
- temp = jj.get_supercell_structure(sc_mat=np.diag(self.supercell, k=0))
+ temp = jj.get_supercell_structure(
+ sc_mat=np.diag(self.supercell, k=0)
+ )
smallest_distance = list(set(temp.distance_matrix.ravel()))[1]
- if 'conf_filters' in self.parameter and 'min_dist' in self.parameter['conf_filters']:
- min_dist = self.parameter['conf_filters']['min_dist']
+ if (
+ "conf_filters" in self.parameter
+ and "min_dist" in self.parameter["conf_filters"]
+ ):
+ min_dist = self.parameter["conf_filters"]["min_dist"]
if smallest_distance >= min_dist:
dss.append(temp)
- with open(insert_element_task, 'a+') as fout:
+ with open(insert_element_task, "a+") as fout:
print(ii, file=fout)
else:
dss.append(temp)
- with open(insert_element_task, 'a+') as fout:
+ with open(insert_element_task, "a+") as fout:
print(ii, file=fout)
# dss.append(jj.generate_defect_structure(self.supercell))
print(
- 'gen interstitial with supercell ' + str(self.supercell) + ' with element ' + str(self.insert_ele))
+ "gen interstitial with supercell "
+ + str(self.supercell)
+ + " with element "
+ + str(self.insert_ele)
+ )
os.chdir(path_to_work)
if os.path.isfile(POSCAR):
os.remove(POSCAR)
@@ -176,220 +222,335 @@ def make_confs(self,
# task_poscar = os.path.join(output, 'POSCAR')
for ii in range(len(dss)):
- output_task = os.path.join(path_to_work, 'task.%06d' % ii)
+ output_task = os.path.join(path_to_work, "task.%06d" % ii)
os.makedirs(output_task, exist_ok=True)
os.chdir(output_task)
- for jj in ['INCAR', 'POTCAR', 'POSCAR', 'conf.lmp', 'in.lammps','STRU']:
+ for jj in [
+ "INCAR",
+ "POTCAR",
+ "POSCAR",
+ "conf.lmp",
+ "in.lammps",
+ "STRU",
+ ]:
if os.path.exists(jj):
os.remove(jj)
task_list.append(output_task)
- dss[ii].to('POSCAR', 'POSCAR')
+ dss[ii].to("POSCAR", "POSCAR")
# np.savetxt('supercell.out', self.supercell, fmt='%d')
- dumpfn(self.supercell, 'supercell.json')
+ dumpfn(self.supercell, "supercell.json")
os.chdir(cwd)
-
- if 'bcc_self' in self.parameter and self.parameter['bcc_self']:
- super_size = self.supercell[0] * self.supercell[1] * self.supercell[2]
+ if "bcc_self" in self.parameter and self.parameter["bcc_self"]:
+ super_size = (
+ self.supercell[0] * self.supercell[1] * self.supercell[2]
+ )
num_atom = super_size * 2
chl = -num_atom - 2
os.chdir(path_to_work)
- with open('POSCAR', 'r') as fin:
+ with open("POSCAR", "r") as fin:
fin.readline()
scale = float(fin.readline().split()[0])
latt_param = float(fin.readline().split()[0])
latt_param *= scale
-
- if not os.path.isfile('task.000000/POSCAR'):
+
+ if not os.path.isfile("task.000000/POSCAR"):
raise RuntimeError("need task.000000 structure as reference")
- with open('task.000000/POSCAR', 'r') as fin:
- pos_line = fin.read().split('\n')
+ with open("task.000000/POSCAR", "r") as fin:
+ pos_line = fin.read().split("\n")
super_latt_param = float(pos_line[2].split()[0])
- output_task1 = os.path.join(path_to_work, 'task.%06d' % (len(dss)))
+ output_task1 = os.path.join(path_to_work, "task.%06d" % (len(dss)))
os.makedirs(output_task1, exist_ok=True)
os.chdir(output_task1)
task_list.append(output_task1)
- with open(insert_element_task, 'a+') as fout:
+ with open(insert_element_task, "a+") as fout:
print(self.insert_ele[0], file=fout)
- dumpfn(self.supercell, 'supercell.json')
- pos_line[chl] = '%.6f' % float(latt_param/4/super_latt_param) + ' ' + '%.6f' % float(latt_param/2/super_latt_param) + ' 0.000000 ' + self.insert_ele[0]
- with open('POSCAR', 'w+') as fout:
+ dumpfn(self.supercell, "supercell.json")
+ pos_line[chl] = (
+ "%.6f" % float(latt_param / 4 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 2 / super_latt_param)
+ + " 0.000000 "
+ + self.insert_ele[0]
+ )
+ with open("POSCAR", "w+") as fout:
for ii in pos_line:
- print(ii, file=fout)
- print('gen bcc tetrahedral')
+ print(ii, file=fout)
+ print("gen bcc tetrahedral")
os.chdir(cwd)
- output_task2 = os.path.join(path_to_work, 'task.%06d' % (len(dss)+1))
+ output_task2 = os.path.join(
+ path_to_work, "task.%06d" % (len(dss) + 1)
+ )
os.makedirs(output_task2, exist_ok=True)
os.chdir(output_task2)
task_list.append(output_task2)
- with open(insert_element_task, 'a+') as fout:
+ with open(insert_element_task, "a+") as fout:
print(self.insert_ele[0], file=fout)
- dumpfn(self.supercell, 'supercell.json')
- pos_line[chl] = '%.6f' % float(latt_param/2/super_latt_param) + ' ' + '%.6f' % float(latt_param/2/super_latt_param) + ' 0.000000 ' + self.insert_ele[0]
- with open('POSCAR', 'w+') as fout:
+ dumpfn(self.supercell, "supercell.json")
+ pos_line[chl] = (
+ "%.6f" % float(latt_param / 2 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 2 / super_latt_param)
+ + " 0.000000 "
+ + self.insert_ele[0]
+ )
+ with open("POSCAR", "w+") as fout:
for ii in pos_line:
- print(ii, file=fout)
- print('gen bcc octahedral')
+ print(ii, file=fout)
+ print("gen bcc octahedral")
os.chdir(cwd)
- output_task3 = os.path.join(path_to_work, 'task.%06d' % (len(dss)+2))
+ output_task3 = os.path.join(
+ path_to_work, "task.%06d" % (len(dss) + 2)
+ )
os.makedirs(output_task3, exist_ok=True)
os.chdir(output_task3)
task_list.append(output_task3)
- with open(insert_element_task, 'a+') as fout:
+ with open(insert_element_task, "a+") as fout:
print(self.insert_ele[0], file=fout)
- dumpfn(self.supercell, 'supercell.json')
- pos_line[chl] = '%.6f' % float(latt_param/4/super_latt_param) + ' ' + '%.6f' % float(latt_param/4/super_latt_param) + ' ' + '%.6f' % float(latt_param/4/super_latt_param) + ' ' + self.insert_ele[0]
- with open('POSCAR', 'w+') as fout:
+ dumpfn(self.supercell, "supercell.json")
+ pos_line[chl] = (
+ "%.6f" % float(latt_param / 4 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 4 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 4 / super_latt_param)
+ + " "
+ + self.insert_ele[0]
+ )
+ with open("POSCAR", "w+") as fout:
for ii in pos_line:
- print(ii, file=fout)
- print('gen bcc crowdion')
+ print(ii, file=fout)
+ print("gen bcc crowdion")
os.chdir(cwd)
for idx, ii in enumerate(pos_line):
ss = ii.split()
if len(ss) > 3:
- if abs(latt_param/2/super_latt_param - float(ss[0])) < 1e-5 and abs(latt_param/2/super_latt_param - float(ss[1])) < 1e-5 and abs(latt_param/2/super_latt_param - float(ss[2])) < 1e-5:
+ if (
+ abs(latt_param / 2 / super_latt_param - float(ss[0]))
+ < 1e-5
+ and abs(
+ latt_param / 2 / super_latt_param - float(ss[1])
+ )
+ < 1e-5
+ and abs(
+ latt_param / 2 / super_latt_param - float(ss[2])
+ )
+ < 1e-5
+ ):
replace_label = idx
- output_task4 = os.path.join(path_to_work, 'task.%06d' % (len(dss)+3))
+ output_task4 = os.path.join(
+ path_to_work, "task.%06d" % (len(dss) + 3)
+ )
os.makedirs(output_task4, exist_ok=True)
os.chdir(output_task4)
task_list.append(output_task4)
- with open(insert_element_task, 'a+') as fout:
+ with open(insert_element_task, "a+") as fout:
print(self.insert_ele[0], file=fout)
- dumpfn(self.supercell, 'supercell.json')
- pos_line[chl] = '%.6f' % float(latt_param/3/super_latt_param) + ' ' + '%.6f' % float(latt_param/3/super_latt_param) + ' ' + '%.6f' % float(latt_param/3/super_latt_param) + ' ' + self.insert_ele[0]
- pos_line[replace_label] = '%.6f' % float(latt_param/3*2/super_latt_param) + ' ' + '%.6f' % float(latt_param/3*2/super_latt_param) + ' ' + '%.6f' % float(latt_param/3*2/super_latt_param) + ' ' + self.insert_ele[0]
-
- with open('POSCAR', 'w+') as fout:
+ dumpfn(self.supercell, "supercell.json")
+ pos_line[chl] = (
+ "%.6f" % float(latt_param / 3 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 3 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 3 / super_latt_param)
+ + " "
+ + self.insert_ele[0]
+ )
+ pos_line[replace_label] = (
+ "%.6f" % float(latt_param / 3 * 2 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 3 * 2 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 3 * 2 / super_latt_param)
+ + " "
+ + self.insert_ele[0]
+ )
+
+ with open("POSCAR", "w+") as fout:
for ii in pos_line:
- print(ii, file=fout)
- print('gen bcc <111> dumbbell')
+ print(ii, file=fout)
+ print("gen bcc <111> dumbbell")
os.chdir(cwd)
- output_task5 = os.path.join(path_to_work, 'task.%06d' % (len(dss)+4))
+ output_task5 = os.path.join(
+ path_to_work, "task.%06d" % (len(dss) + 4)
+ )
os.makedirs(output_task5, exist_ok=True)
os.chdir(output_task5)
task_list.append(output_task5)
- with open(insert_element_task, 'a+') as fout:
+ with open(insert_element_task, "a+") as fout:
print(self.insert_ele[0], file=fout)
- dumpfn(self.supercell, 'supercell.json')
- pos_line[chl] = '%.6f' % float((latt_param+2.1/2**0.5)/2/super_latt_param) + ' ' + '%.6f' % float((latt_param-2.1/2**0.5)/2/super_latt_param) + ' ' + '%.6f' % float(latt_param/2/super_latt_param) + ' ' + self.insert_ele[0]
- pos_line[replace_label] = '%.6f' % float((latt_param-2.1/2**0.5)/2/super_latt_param) + ' ' + '%.6f' % float((latt_param+2.1/2**0.5)/2/super_latt_param) + ' ' + '%.6f' % float(latt_param/2/super_latt_param) + ' ' + self.insert_ele[0]
-
- with open('POSCAR', 'w+') as fout:
+ dumpfn(self.supercell, "supercell.json")
+ pos_line[chl] = (
+ "%.6f"
+ % float((latt_param + 2.1 / 2**0.5) / 2 / super_latt_param)
+ + " "
+ + "%.6f"
+ % float((latt_param - 2.1 / 2**0.5) / 2 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 2 / super_latt_param)
+ + " "
+ + self.insert_ele[0]
+ )
+ pos_line[replace_label] = (
+ "%.6f"
+ % float((latt_param - 2.1 / 2**0.5) / 2 / super_latt_param)
+ + " "
+ + "%.6f"
+ % float((latt_param + 2.1 / 2**0.5) / 2 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 2 / super_latt_param)
+ + " "
+ + self.insert_ele[0]
+ )
+
+ with open("POSCAR", "w+") as fout:
for ii in pos_line:
- print(ii, file=fout)
- print('gen bcc <110> dumbbell')
+ print(ii, file=fout)
+ print("gen bcc <110> dumbbell")
os.chdir(cwd)
- output_task6 = os.path.join(path_to_work, 'task.%06d' % (len(dss)+5))
+ output_task6 = os.path.join(
+ path_to_work, "task.%06d" % (len(dss) + 5)
+ )
os.makedirs(output_task6, exist_ok=True)
os.chdir(output_task6)
task_list.append(output_task6)
- with open(insert_element_task, 'a+') as fout:
+ with open(insert_element_task, "a+") as fout:
print(self.insert_ele[0], file=fout)
- dumpfn(self.supercell, 'supercell.json')
- pos_line[chl] = '%.6f' % float(latt_param/2/super_latt_param) + ' ' + '%.6f' % float(latt_param/2/super_latt_param) + ' ' + '%.6f' % float((latt_param-2.1)/2/super_latt_param) + ' ' + self.insert_ele[0]
- pos_line[replace_label] = '%.6f' % float(latt_param/2/super_latt_param) + ' ' + '%.6f' % float(latt_param/2/super_latt_param) + ' ' + '%.6f' % float((latt_param+2.1)/2/super_latt_param) + ' ' + self.insert_ele[0]
-
- with open('POSCAR', 'w+') as fout:
+ dumpfn(self.supercell, "supercell.json")
+ pos_line[chl] = (
+ "%.6f" % float(latt_param / 2 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 2 / super_latt_param)
+ + " "
+ + "%.6f" % float((latt_param - 2.1) / 2 / super_latt_param)
+ + " "
+ + self.insert_ele[0]
+ )
+ pos_line[replace_label] = (
+ "%.6f" % float(latt_param / 2 / super_latt_param)
+ + " "
+ + "%.6f" % float(latt_param / 2 / super_latt_param)
+ + " "
+ + "%.6f" % float((latt_param + 2.1) / 2 / super_latt_param)
+ + " "
+ + self.insert_ele[0]
+ )
+
+ with open("POSCAR", "w+") as fout:
for ii in pos_line:
- print(ii, file=fout)
- print('gen bcc <100> dumbbell')
+ print(ii, file=fout)
+ print("gen bcc <100> dumbbell")
os.chdir(cwd)
- total_task = len(dss)+6
+ total_task = len(dss) + 6
else:
total_task = len(dss)
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
for ii in range(total_task):
- output_task = os.path.join(path_to_work, 'task.%06d' % ii)
+ output_task = os.path.join(path_to_work, "task.%06d" % ii)
os.chdir(output_task)
- abacus.poscar2stru("POSCAR",self.inter_param,"STRU")
- os.remove('POSCAR')
+ abacus.poscar2stru("POSCAR", self.inter_param, "STRU")
+ os.remove("POSCAR")
os.chdir(cwd)
return task_list
def post_process(self, task_list):
if True:
- fin1 = open(os.path.join(task_list[0], '..', 'element.out'), 'r')
+ fin1 = open(os.path.join(task_list[0], "..", "element.out"), "r")
for ii in task_list:
- conf = os.path.join(ii, 'conf.lmp')
- inter = os.path.join(ii, 'inter.json')
+ conf = os.path.join(ii, "conf.lmp")
+ inter = os.path.join(ii, "inter.json")
insert_ele = fin1.readline().split()[0]
if os.path.isfile(conf):
- with open(conf, 'r') as fin2:
- conf_line = fin2.read().split('\n')
+ with open(conf, "r") as fin2:
+ conf_line = fin2.read().split("\n")
insert_line = conf_line[-2]
- type_map = loadfn(inter)['type_map']
+ type_map = loadfn(inter)["type_map"]
type_map_list = lammps.element_list(type_map)
if int(insert_line.split()[1]) > len(type_map_list):
type_num = type_map[insert_ele] + 1
- conf_line[2] = str(len(type_map_list)) + ' atom types'
- conf_line[-2] = '%6.d' % int(insert_line.split()[0]) + '%7.d' % type_num + \
- '%16.10f' % float(insert_line.split()[2]) + \
- '%16.10f' % float(insert_line.split()[3]) + \
- '%16.10f' % float(insert_line.split()[4])
- with open(conf, 'w+') as fout:
+ conf_line[2] = str(len(type_map_list)) + " atom types"
+ conf_line[-2] = (
+ "%6.d" % int(insert_line.split()[0])
+ + "%7.d" % type_num
+ + "%16.10f" % float(insert_line.split()[2])
+ + "%16.10f" % float(insert_line.split()[3])
+ + "%16.10f" % float(insert_line.split()[4])
+ )
+ with open(conf, "w+") as fout:
for jj in conf_line:
print(jj, file=fout)
fin1.close()
def task_type(self):
- return self.parameter['type']
+ return self.parameter["type"]
def task_param(self):
return self.parameter
- def _compute_lower(self,
- output_file,
- all_tasks,
- all_res):
+ def _compute_lower(self, output_file, all_tasks, all_res):
output_file = os.path.abspath(output_file)
res_data = {}
- ptr_data = os.path.dirname(output_file) + '\n'
+ ptr_data = os.path.dirname(output_file) + "\n"
if not self.reprod:
- with open(os.path.join(os.path.dirname(output_file), 'element.out'), 'r') as fin:
- fc = fin.read().split('\n')
+ with open(
+ os.path.join(os.path.dirname(output_file), "element.out"), "r"
+ ) as fin:
+ fc = fin.read().split("\n")
ptr_data += "Insert_ele-Struct: Inter_E(eV) E(eV) equi_E(eV)\n"
idid = -1
for ii in all_tasks:
idid += 1
structure_dir = os.path.basename(ii)
task_result = loadfn(all_res[idid])
- natoms = task_result['atom_numbs'][0]
- equi_path = os.path.abspath(os.path.join(os.path.dirname(output_file), '../relaxation/relax_task'))
- equi_result = loadfn(os.path.join(equi_path, 'result.json'))
- equi_epa = equi_result['energies'][-1] / equi_result['atom_numbs'][0]
- evac = task_result['energies'][-1] - equi_epa * natoms
-
- supercell_index = loadfn(os.path.join(ii, 'supercell.json'))
+ natoms = task_result["atom_numbs"][0]
+ equi_path = os.path.abspath(
+ os.path.join(
+ os.path.dirname(output_file), "../relaxation/relax_task"
+ )
+ )
+ equi_result = loadfn(os.path.join(equi_path, "result.json"))
+ equi_epa = equi_result["energies"][-1] / equi_result["atom_numbs"][0]
+ evac = task_result["energies"][-1] - equi_epa * natoms
+
+ supercell_index = loadfn(os.path.join(ii, "supercell.json"))
# insert_ele = loadfn(os.path.join(ii, 'task.json'))['insert_ele'][0]
insert_ele = fc[idid]
ptr_data += "%s: %7.3f %7.3f %7.3f \n" % (
- insert_ele + '-' + str(supercell_index) + '-' + structure_dir, evac,
- task_result['energies'][-1], equi_epa * natoms)
- res_data[insert_ele + '-' + str(supercell_index) + '-' + structure_dir] = [evac,
- task_result['energies'][-1],
- equi_epa * natoms]
+ insert_ele + "-" + str(supercell_index) + "-" + structure_dir,
+ evac,
+ task_result["energies"][-1],
+ equi_epa * natoms,
+ )
+ res_data[
+ insert_ele + "-" + str(supercell_index) + "-" + structure_dir
+ ] = [evac, task_result["energies"][-1], equi_epa * natoms]
else:
- if 'init_data_path' not in self.parameter:
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- res_data, ptr_data = post_repro(init_data_path, self.parameter['init_from_suffix'],
- all_tasks, ptr_data, self.parameter.get('reprod_last_frame', False))
-
- with open(output_file, 'w') as fp:
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ res_data, ptr_data = post_repro(
+ init_data_path,
+ self.parameter["init_from_suffix"],
+ all_tasks,
+ ptr_data,
+ self.parameter.get("reprod_last_frame", False),
+ )
+
+ with open(output_file, "w") as fp:
json.dump(res_data, fp, indent=4)
return res_data, ptr_data
diff --git a/dpgen/auto_test/Lammps.py b/dpgen/auto_test/Lammps.py
index d77b32716..1a3693807 100644
--- a/dpgen/auto_test/Lammps.py
+++ b/dpgen/auto_test/Lammps.py
@@ -1,26 +1,31 @@
import os
import warnings
+
+from monty.serialization import dumpfn, loadfn
+
import dpgen.auto_test.lib.lammps as lammps
from dpgen import dlog
-from monty.serialization import loadfn, dumpfn
+from dpgen.auto_test.lib.lammps import (
+ inter_deepmd,
+ inter_eam_alloy,
+ inter_eam_fs,
+ inter_meam,
+)
from dpgen.auto_test.Task import Task
-from dpgen.auto_test.lib.lammps import inter_deepmd, inter_meam, inter_eam_fs, inter_eam_alloy
-supported_inter = ["deepmd", 'meam', 'eam_fs', 'eam_alloy']
+supported_inter = ["deepmd", "meam", "eam_fs", "eam_alloy"]
class Lammps(Task):
- def __init__(self,
- inter_parameter,
- path_to_poscar):
+ def __init__(self, inter_parameter, path_to_poscar):
self.inter = inter_parameter
- self.inter_type = inter_parameter['type']
- self.type_map = inter_parameter['type_map']
- self.in_lammps = inter_parameter.get('in_lammps', 'auto')
- if self.inter_type == 'meam':
- self.model = list(map(os.path.abspath, inter_parameter['model']))
+ self.inter_type = inter_parameter["type"]
+ self.type_map = inter_parameter["type_map"]
+ self.in_lammps = inter_parameter.get("in_lammps", "auto")
+ if self.inter_type == "meam":
+ self.model = list(map(os.path.abspath, inter_parameter["model"]))
else:
- self.model = os.path.abspath(inter_parameter['model'])
+ self.model = os.path.abspath(inter_parameter["model"])
self.path_to_poscar = path_to_poscar
assert self.inter_type in supported_inter
self.set_inter_type_func()
@@ -30,10 +35,10 @@ def set_inter_type_func(self):
if self.inter_type == "deepmd":
self.inter_func = inter_deepmd
- elif self.inter_type == 'meam':
+ elif self.inter_type == "meam":
self.inter_func = inter_meam
- elif self.inter_type == 'eam_fs':
+ elif self.inter_type == "eam_fs":
self.inter_func = inter_eam_fs
else:
@@ -44,25 +49,24 @@ def set_model_param(self):
if self.inter_type == "deepmd":
model_name = os.path.basename(self.model)
deepmd_version = self.inter.get("deepmd_version", "1.2.0")
- self.model_param = {'model_name': [model_name],
- 'param_type': self.type_map,
- 'deepmd_version': deepmd_version}
- elif self.inter_type == 'meam':
+ self.model_param = {
+ "model_name": [model_name],
+ "param_type": self.type_map,
+ "deepmd_version": deepmd_version,
+ }
+ elif self.inter_type == "meam":
model_name = list(map(os.path.basename, self.model))
- self.model_param = {'model_name': [model_name],
- 'param_type': self.type_map}
+ self.model_param = {"model_name": [model_name], "param_type": self.type_map}
else:
model_name = os.path.basename(self.model)
- self.model_param = {'model_name': [model_name],
- 'param_type': self.type_map}
+ self.model_param = {"model_name": [model_name], "param_type": self.type_map}
- def make_potential_files(self,
- output_dir):
+ def make_potential_files(self, output_dir):
cwd = os.getcwd()
- if self.inter_type == 'meam':
+ if self.inter_type == "meam":
model_lib = os.path.basename(self.model[0])
model_file = os.path.basename(self.model[1])
- os.chdir(os.path.join(output_dir, '../'))
+ os.chdir(os.path.join(output_dir, "../"))
if os.path.islink(model_lib):
link_lib = os.readlink(model_lib)
if not os.path.abspath(link_lib) == self.model[0]:
@@ -80,21 +84,21 @@ def make_potential_files(self,
os.symlink(os.path.relpath(self.model[1]), model_file)
os.chdir(output_dir)
if not os.path.islink(model_lib):
- os.symlink(os.path.join('..', model_lib), model_lib)
- elif not os.path.join('..', model_lib) == os.readlink(model_lib):
+ os.symlink(os.path.join("..", model_lib), model_lib)
+ elif not os.path.join("..", model_lib) == os.readlink(model_lib):
os.remove(model_lib)
- os.symlink(os.path.join('..', model_lib), model_lib)
+ os.symlink(os.path.join("..", model_lib), model_lib)
if not os.path.islink(model_file):
- os.symlink(os.path.join('..', model_file), model_file)
- elif not os.path.join('..', model_file) == os.readlink(model_file):
+ os.symlink(os.path.join("..", model_file), model_file)
+ elif not os.path.join("..", model_file) == os.readlink(model_file):
os.remove(model_file)
- os.symlink(os.path.join('..', model_file), model_file)
+ os.symlink(os.path.join("..", model_file), model_file)
os.chdir(cwd)
else:
model_file = os.path.basename(self.model)
- os.chdir(os.path.join(output_dir, '../'))
+ os.chdir(os.path.join(output_dir, "../"))
if os.path.islink(model_file):
link_file = os.readlink(model_file)
if not os.path.abspath(link_file) == self.model:
@@ -104,19 +108,20 @@ def make_potential_files(self,
os.symlink(os.path.relpath(self.model), model_file)
os.chdir(output_dir)
if not os.path.islink(model_file):
- os.symlink(os.path.join('..', model_file), model_file)
- elif not os.path.join('..', model_file) == os.readlink(model_file):
+ os.symlink(os.path.join("..", model_file), model_file)
+ elif not os.path.join("..", model_file) == os.readlink(model_file):
os.remove(model_file)
- os.symlink(os.path.join('..', model_file), model_file)
+ os.symlink(os.path.join("..", model_file), model_file)
os.chdir(cwd)
- dumpfn(self.inter, os.path.join(output_dir, 'inter.json'), indent=4)
+ dumpfn(self.inter, os.path.join(output_dir, "inter.json"), indent=4)
- def make_input_file(self,
- output_dir,
- task_type,
- task_param):
- lammps.cvt_lammps_conf(os.path.join(output_dir, 'POSCAR'), os.path.join(output_dir, 'conf.lmp'), lammps.element_list(self.type_map))
+ def make_input_file(self, output_dir, task_type, task_param):
+ lammps.cvt_lammps_conf(
+ os.path.join(output_dir, "POSCAR"),
+ os.path.join(output_dir, "conf.lmp"),
+ lammps.element_list(self.type_map),
+ )
# dumpfn(task_param, os.path.join(output_dir, 'task.json'), indent=4)
@@ -128,92 +133,161 @@ def make_input_file(self,
bp = 0
ntypes = len(self.type_map)
- cal_type = task_param['cal_type']
- cal_setting = task_param['cal_setting']
+ cal_type = task_param["cal_type"]
+ cal_setting = task_param["cal_setting"]
self.set_model_param()
# deal with user input in.lammps for relaxation
- if os.path.isfile(self.in_lammps) and task_type == 'relaxation':
- with open(self.in_lammps, 'r') as fin:
+ if os.path.isfile(self.in_lammps) and task_type == "relaxation":
+ with open(self.in_lammps, "r") as fin:
fc = fin.read()
# user input in.lammps for property calculation
- if 'input_prop' in cal_setting and os.path.isfile(cal_setting['input_prop']):
- with open(os.path.abspath(cal_setting['input_prop']), 'r') as fin:
+ if "input_prop" in cal_setting and os.path.isfile(cal_setting["input_prop"]):
+ with open(os.path.abspath(cal_setting["input_prop"]), "r") as fin:
fc = fin.read()
else:
- if 'etol' in cal_setting:
- dlog.info("%s setting etol to %s" % (self.make_input_file.__name__, cal_setting['etol']))
- etol = cal_setting['etol']
- if 'ftol' in cal_setting:
- dlog.info("%s setting ftol to %s" % (self.make_input_file.__name__, cal_setting['ftol']))
- ftol = cal_setting['ftol']
- if 'maxiter' in cal_setting:
- dlog.info("%s setting maxiter to %s" % (self.make_input_file.__name__, cal_setting['maxiter']))
- maxiter = cal_setting['maxiter']
- if 'maxeval' in cal_setting:
- dlog.info("%s setting maxeval to %s" % (self.make_input_file.__name__, cal_setting['maxeval']))
- maxeval = cal_setting['maxeval']
-
- if cal_type == 'relaxation':
- relax_pos = cal_setting['relax_pos']
- relax_shape = cal_setting['relax_shape']
- relax_vol = cal_setting['relax_vol']
+ if "etol" in cal_setting:
+ dlog.info(
+ "%s setting etol to %s"
+ % (self.make_input_file.__name__, cal_setting["etol"])
+ )
+ etol = cal_setting["etol"]
+ if "ftol" in cal_setting:
+ dlog.info(
+ "%s setting ftol to %s"
+ % (self.make_input_file.__name__, cal_setting["ftol"])
+ )
+ ftol = cal_setting["ftol"]
+ if "maxiter" in cal_setting:
+ dlog.info(
+ "%s setting maxiter to %s"
+ % (self.make_input_file.__name__, cal_setting["maxiter"])
+ )
+ maxiter = cal_setting["maxiter"]
+ if "maxeval" in cal_setting:
+ dlog.info(
+ "%s setting maxeval to %s"
+ % (self.make_input_file.__name__, cal_setting["maxeval"])
+ )
+ maxeval = cal_setting["maxeval"]
+
+ if cal_type == "relaxation":
+ relax_pos = cal_setting["relax_pos"]
+ relax_shape = cal_setting["relax_shape"]
+ relax_vol = cal_setting["relax_vol"]
if [relax_pos, relax_shape, relax_vol] == [True, False, False]:
- fc = lammps.make_lammps_equi('conf.lmp', self.type_map, self.inter_func, self.model_param,
- etol, ftol, maxiter, maxeval, False)
+ fc = lammps.make_lammps_equi(
+ "conf.lmp",
+ self.type_map,
+ self.inter_func,
+ self.model_param,
+ etol,
+ ftol,
+ maxiter,
+ maxeval,
+ False,
+ )
elif [relax_pos, relax_shape, relax_vol] == [True, True, True]:
- fc = lammps.make_lammps_equi('conf.lmp', self.type_map, self.inter_func, self.model_param,
- etol, ftol, maxiter, maxeval, True)
- elif [relax_pos, relax_shape, relax_vol] == [True, True, False] and not task_type == 'eos':
- if 'scale2equi' in task_param:
- scale2equi = task_param['scale2equi']
- fc = lammps.make_lammps_press_relax('conf.lmp', self.type_map, scale2equi[int(output_dir[-6:])],
- self.inter_func,
- self.model_param, B0, bp, etol, ftol, maxiter, maxeval)
+ fc = lammps.make_lammps_equi(
+ "conf.lmp",
+ self.type_map,
+ self.inter_func,
+ self.model_param,
+ etol,
+ ftol,
+ maxiter,
+ maxeval,
+ True,
+ )
+ elif [relax_pos, relax_shape, relax_vol] == [
+ True,
+ True,
+ False,
+ ] and not task_type == "eos":
+ if "scale2equi" in task_param:
+ scale2equi = task_param["scale2equi"]
+ fc = lammps.make_lammps_press_relax(
+ "conf.lmp",
+ self.type_map,
+ scale2equi[int(output_dir[-6:])],
+ self.inter_func,
+ self.model_param,
+ B0,
+ bp,
+ etol,
+ ftol,
+ maxiter,
+ maxeval,
+ )
else:
- fc = lammps.make_lammps_equi('conf.lmp', self.type_map, self.inter_func, self.model_param,
- etol, ftol, maxiter, maxeval, True)
- elif [relax_pos, relax_shape, relax_vol] == [True, True, False] and task_type == 'eos':
- task_param['cal_setting']['relax_shape'] = False
- fc = lammps.make_lammps_equi('conf.lmp', self.type_map, self.inter_func, self.model_param,
- etol, ftol, maxiter, maxeval, False)
+ fc = lammps.make_lammps_equi(
+ "conf.lmp",
+ self.type_map,
+ self.inter_func,
+ self.model_param,
+ etol,
+ ftol,
+ maxiter,
+ maxeval,
+ True,
+ )
+ elif [relax_pos, relax_shape, relax_vol] == [
+ True,
+ True,
+ False,
+ ] and task_type == "eos":
+ task_param["cal_setting"]["relax_shape"] = False
+ fc = lammps.make_lammps_equi(
+ "conf.lmp",
+ self.type_map,
+ self.inter_func,
+ self.model_param,
+ etol,
+ ftol,
+ maxiter,
+ maxeval,
+ False,
+ )
elif [relax_pos, relax_shape, relax_vol] == [False, False, False]:
- fc = lammps.make_lammps_eval('conf.lmp', self.type_map, self.inter_func, self.model_param)
+ fc = lammps.make_lammps_eval(
+ "conf.lmp", self.type_map, self.inter_func, self.model_param
+ )
else:
raise RuntimeError("not supported calculation setting for LAMMPS")
- elif cal_type == 'static':
- fc = lammps.make_lammps_eval('conf.lmp', self.type_map, self.inter_func, self.model_param)
+ elif cal_type == "static":
+ fc = lammps.make_lammps_eval(
+ "conf.lmp", self.type_map, self.inter_func, self.model_param
+ )
else:
raise RuntimeError("not supported calculation type for LAMMPS")
- dumpfn(task_param, os.path.join(output_dir, 'task.json'), indent=4)
+ dumpfn(task_param, os.path.join(output_dir, "task.json"), indent=4)
- in_lammps_not_link_list = ['eos']
+ in_lammps_not_link_list = ["eos"]
if task_type not in in_lammps_not_link_list:
- with open(os.path.join(output_dir, '../in.lammps'), 'w') as fp:
+ with open(os.path.join(output_dir, "../in.lammps"), "w") as fp:
fp.write(fc)
cwd = os.getcwd()
os.chdir(output_dir)
- if not (os.path.islink('in.lammps') or os.path.isfile('in.lammps')):
- os.symlink('../in.lammps', 'in.lammps')
+ if not (os.path.islink("in.lammps") or os.path.isfile("in.lammps")):
+ os.symlink("../in.lammps", "in.lammps")
else:
- os.remove('in.lammps')
- os.symlink('../in.lammps', 'in.lammps')
+ os.remove("in.lammps")
+ os.symlink("../in.lammps", "in.lammps")
os.chdir(cwd)
else:
- with open(os.path.join(output_dir, 'in.lammps'), 'w') as fp:
+ with open(os.path.join(output_dir, "in.lammps"), "w") as fp:
fp.write(fc)
- def compute(self,
- output_dir):
- log_lammps = os.path.join(output_dir, 'log.lammps')
- dump_lammps = os.path.join(output_dir, 'dump.relax')
+ def compute(self, output_dir):
+ log_lammps = os.path.join(output_dir, "log.lammps")
+ dump_lammps = os.path.join(output_dir, "dump.relax")
if not os.path.isfile(log_lammps):
warnings.warn("cannot find log.lammps in " + output_dir + " skip")
return None
@@ -228,11 +302,11 @@ def compute(self,
force = []
virial = []
stress = []
- with open(dump_lammps, 'r') as fin:
- dump = fin.read().split('\n')
+ with open(dump_lammps, "r") as fin:
+ dump = fin.read().split("\n")
dumptime = []
for idx, ii in enumerate(dump):
- if ii == 'ITEM: TIMESTEP':
+ if ii == "ITEM: TIMESTEP":
box.append([])
coord.append([])
force.append([])
@@ -247,7 +321,11 @@ def compute(self,
zlo = float(dump[idx + 7].split()[0])
zhi = float(dump[idx + 7].split()[1])
yz = float(dump[idx + 7].split()[2])
- xx = xhi_bound - max([0, xy, xz, xy + xz]) - (xlo_bound - min([0, xy, xz, xy + xz]))
+ xx = (
+ xhi_bound
+ - max([0, xy, xz, xy + xz])
+ - (xlo_bound - min([0, xy, xz, xy + xz]))
+ )
yy = yhi_bound - max([0, yz]) - (ylo_bound - min([0, yz]))
zz = zhi - zlo
box[-1].append([xx, 0.0, 0.0])
@@ -257,12 +335,16 @@ def compute(self,
type_list = []
for jj in range(natom):
type_list.append(int(dump[idx + 9 + jj].split()[1]) - 1)
- if 'xs ys zs' in dump[idx + 8]:
- a_x = float(dump[idx + 9 + jj].split()[2]) * xx + float(
- dump[idx + 9 + jj].split()[3]) * xy \
- + float(dump[idx + 9 + jj].split()[4]) * xz
- a_y = float(dump[idx + 9 + jj].split()[3]) * yy + float(
- dump[idx + 9 + jj].split()[4]) * yz
+ if "xs ys zs" in dump[idx + 8]:
+ a_x = (
+ float(dump[idx + 9 + jj].split()[2]) * xx
+ + float(dump[idx + 9 + jj].split()[3]) * xy
+ + float(dump[idx + 9 + jj].split()[4]) * xz
+ )
+ a_y = (
+ float(dump[idx + 9 + jj].split()[3]) * yy
+ + float(dump[idx + 9 + jj].split()[4]) * yz
+ )
a_z = float(dump[idx + 9 + jj].split()[4]) * zz
else:
a_x = float(dump[idx + 9 + jj].split()[2])
@@ -274,13 +356,13 @@ def compute(self,
fz = float(dump[idx + 9 + jj].split()[7])
force[-1].append([fx, fy, fz])
- with open(log_lammps, 'r') as fp:
- if 'Total wall time:' not in fp.read():
+ with open(log_lammps, "r") as fp:
+ if "Total wall time:" not in fp.read():
warnings.warn("lammps not finished " + log_lammps + " skip")
return None
else:
fp.seek(0)
- lines = fp.read().split('\n')
+ lines = fp.read().split("\n")
idid = -1
for ii in dumptime:
idid += 1
@@ -295,16 +377,51 @@ def compute(self,
virial.append([])
energy.append(float(line[1]))
# virials = stress * vol * 1e5 *1e-30 * 1e19/1.6021766208
- stress[-1].append([float(line[2]) / 1000.0, float(line[5]) / 1000.0, float(line[6]) / 1000.0])
- stress[-1].append([float(line[5]) / 1000.0, float(line[3]) / 1000.0, float(line[7]) / 1000.0])
- stress[-1].append([float(line[6]) / 1000.0, float(line[7]) / 1000.0, float(line[4]) / 1000.0])
- stress_to_virial = vol[idid] * 1e5 * 1e-30 * 1e19 / 1.6021766208
- virial[-1].append([float(line[2]) * stress_to_virial, float(line[5]) * stress_to_virial,
- float(line[6]) * stress_to_virial])
- virial[-1].append([float(line[5]) * stress_to_virial, float(line[3]) * stress_to_virial,
- float(line[7]) * stress_to_virial])
- virial[-1].append([float(line[6]) * stress_to_virial, float(line[7]) * stress_to_virial,
- float(line[4]) * stress_to_virial])
+ stress[-1].append(
+ [
+ float(line[2]) / 1000.0,
+ float(line[5]) / 1000.0,
+ float(line[6]) / 1000.0,
+ ]
+ )
+ stress[-1].append(
+ [
+ float(line[5]) / 1000.0,
+ float(line[3]) / 1000.0,
+ float(line[7]) / 1000.0,
+ ]
+ )
+ stress[-1].append(
+ [
+ float(line[6]) / 1000.0,
+ float(line[7]) / 1000.0,
+ float(line[4]) / 1000.0,
+ ]
+ )
+ stress_to_virial = (
+ vol[idid] * 1e5 * 1e-30 * 1e19 / 1.6021766208
+ )
+ virial[-1].append(
+ [
+ float(line[2]) * stress_to_virial,
+ float(line[5]) * stress_to_virial,
+ float(line[6]) * stress_to_virial,
+ ]
+ )
+ virial[-1].append(
+ [
+ float(line[5]) * stress_to_virial,
+ float(line[3]) * stress_to_virial,
+ float(line[7]) * stress_to_virial,
+ ]
+ )
+ virial[-1].append(
+ [
+ float(line[6]) * stress_to_virial,
+ float(line[7]) * stress_to_virial,
+ float(line[4]) * stress_to_virial,
+ ]
+ )
break
_tmp = self.type_map
@@ -323,71 +440,87 @@ def compute(self,
# d_dump = dpdata.System(dump_lammps, fmt='lammps/dump', type_map=type_map_list)
# d_dump.to('vasp/poscar', contcar, frame_idx=-1)
- result_dict = {"@module": "dpdata.system", "@class": "LabeledSystem", "data": {"atom_numbs": atom_numbs,
- "atom_names": type_map_list,
- "atom_types": {
- "@module": "numpy",
- "@class": "array",
- "dtype": "int64",
- "data": type_list},
- "orig": {"@module": "numpy",
- "@class": "array",
- "dtype": "int64",
- "data": [0, 0, 0]},
- "cells": {"@module": "numpy",
- "@class": "array",
- "dtype": "float64",
- "data": box},
- "coords": {
- "@module": "numpy",
- "@class": "array",
- "dtype": "float64",
- "data": coord},
- "energies": {
- "@module": "numpy",
- "@class": "array",
- "dtype": "float64",
- "data": energy},
- "forces": {
- "@module": "numpy",
- "@class": "array",
- "dtype": "float64",
- "data": force},
- "virials": {
- "@module": "numpy",
- "@class": "array",
- "dtype": "float64",
- "data": virial},
- "stress": {
- "@module": "numpy",
- "@class": "array",
- "dtype": "float64",
- "data": stress}}}
-
- contcar = os.path.join(output_dir, 'CONTCAR')
+ result_dict = {
+ "@module": "dpdata.system",
+ "@class": "LabeledSystem",
+ "data": {
+ "atom_numbs": atom_numbs,
+ "atom_names": type_map_list,
+ "atom_types": {
+ "@module": "numpy",
+ "@class": "array",
+ "dtype": "int64",
+ "data": type_list,
+ },
+ "orig": {
+ "@module": "numpy",
+ "@class": "array",
+ "dtype": "int64",
+ "data": [0, 0, 0],
+ },
+ "cells": {
+ "@module": "numpy",
+ "@class": "array",
+ "dtype": "float64",
+ "data": box,
+ },
+ "coords": {
+ "@module": "numpy",
+ "@class": "array",
+ "dtype": "float64",
+ "data": coord,
+ },
+ "energies": {
+ "@module": "numpy",
+ "@class": "array",
+ "dtype": "float64",
+ "data": energy,
+ },
+ "forces": {
+ "@module": "numpy",
+ "@class": "array",
+ "dtype": "float64",
+ "data": force,
+ },
+ "virials": {
+ "@module": "numpy",
+ "@class": "array",
+ "dtype": "float64",
+ "data": virial,
+ },
+ "stress": {
+ "@module": "numpy",
+ "@class": "array",
+ "dtype": "float64",
+ "data": stress,
+ },
+ },
+ }
+
+ contcar = os.path.join(output_dir, "CONTCAR")
dumpfn(result_dict, contcar, indent=4)
d_dump = loadfn(contcar)
- d_dump.to('vasp/poscar', contcar, frame_idx=-1)
+ d_dump.to("vasp/poscar", contcar, frame_idx=-1)
return result_dict
- def forward_files(self, property_type='relaxation'):
- if self.inter_type == 'meam':
- return ['conf.lmp', 'in.lammps'] + list(map(os.path.basename, self.model))
+ def forward_files(self, property_type="relaxation"):
+ if self.inter_type == "meam":
+ return ["conf.lmp", "in.lammps"] + list(map(os.path.basename, self.model))
else:
- return ['conf.lmp', 'in.lammps', os.path.basename(self.model)]
+ return ["conf.lmp", "in.lammps", os.path.basename(self.model)]
- def forward_common_files(self, property_type='relaxation'):
- if property_type not in ['eos']:
- if self.inter_type == 'meam':
- return ['in.lammps'] + list(map(os.path.basename, self.model))
+ def forward_common_files(self, property_type="relaxation"):
+ if property_type not in ["eos"]:
+ if self.inter_type == "meam":
+ return ["in.lammps"] + list(map(os.path.basename, self.model))
else:
- return ['in.lammps', os.path.basename(self.model)]
+ return ["in.lammps", os.path.basename(self.model)]
else:
- if self.inter_type == 'meam':
+ if self.inter_type == "meam":
return list(map(os.path.basename, self.model))
else:
return [os.path.basename(self.model)]
- def backward_files(self, property_type='relaxation'):
- return ['log.lammps', 'outlog', 'dump.relax']
+ def backward_files(self, property_type="relaxation"):
+ return ["log.lammps", "outlog", "dump.relax"]
diff --git a/dpgen/auto_test/Property.py b/dpgen/auto_test/Property.py
index 3d1de3350..e0fb4d3c1 100644
--- a/dpgen/auto_test/Property.py
+++ b/dpgen/auto_test/Property.py
@@ -10,42 +10,38 @@
class Property(ABC):
@abstractmethod
- def __init__(self,
- parameter):
+ def __init__(self, parameter):
"""
Constructor
Parameters
----------
- parameters : dict
- A dict that defines the property.
+ parameter : dict
+ A dict that defines the property.
"""
pass
@abstractmethod
- def make_confs(self,
- path_to_work,
- path_to_equi,
- refine=False):
+ def make_confs(self, path_to_work, path_to_equi, refine=False):
"""
- Make configurations needed to compute the property.
+ Make configurations needed to compute the property.
The tasks directory will be named as path_to_work/task.xxxxxx
IMPORTANT: handel the case when the directory exists.
Parameters
----------
path_to_work : str
- The path where the tasks for the property are located
+ The path where the tasks for the property are located
path_to_equi : str
- -refine == False: The path to the directory that equilibrated the configuration.
- -refine == True: The path to the directory that has property confs.
- refine: str
- To refine existing property confs or generate property confs from a equilibrated conf
-
+ -refine == False: The path to the directory that equilibrated the configuration.
+ -refine == True: The path to the directory that has property confs.
+ refine : str
+ To refine existing property confs or generate property confs from a equilibrated conf
+
Returns
-------
task_list: list of str
- The list of task directories.
+ The list of task directories.
"""
pass
@@ -72,10 +68,7 @@ def task_param(self):
"""
pass
- def compute(self,
- output_file,
- print_file,
- path_to_work):
+ def compute(self, output_file, print_file, path_to_work):
"""
Postprocess the finished tasks to compute the property.
Output the result to a json database
@@ -83,57 +76,53 @@ def compute(self,
Parameters
----------
output_file:
- The file to output the property in json format
+ The file to output the property in json format
print_file:
- The file to output the property in txt format
+ The file to output the property in txt format
path_to_work:
- The working directory where the computational tasks locate.
+ The working directory where the computational tasks locate.
"""
path_to_work = os.path.abspath(path_to_work)
- task_dirs = glob.glob(os.path.join(path_to_work, 'task.[0-9]*[0-9]'))
+ task_dirs = glob.glob(os.path.join(path_to_work, "task.[0-9]*[0-9]"))
task_dirs.sort()
all_res = []
for ii in task_dirs:
- with open(os.path.join(ii, 'inter.json')) as fp:
+ with open(os.path.join(ii, "inter.json")) as fp:
idata = json.load(fp)
- poscar = os.path.join(ii, 'POSCAR')
+ poscar = os.path.join(ii, "POSCAR")
task = make_calculator(idata, poscar)
res = task.compute(ii)
- dumpfn(res, os.path.join(ii, 'result_task.json'), indent=4)
+ dumpfn(res, os.path.join(ii, "result_task.json"), indent=4)
# all_res.append(res)
- all_res.append(os.path.join(ii, 'result_task.json'))
+ all_res.append(os.path.join(ii, "result_task.json"))
# cwd = os.getcwd()
# os.chdir(path_to_work)
res, ptr = self._compute_lower(output_file, task_dirs, all_res)
# with open(output_file, 'w') as fp:
# json.dump(fp, res, indent=4)
- with open(print_file, 'w') as fp:
+ with open(print_file, "w") as fp:
fp.write(ptr)
# os.chdir(cwd)
@abstractmethod
- def _compute_lower(self,
- output_file,
- all_tasks,
- all_res):
+ def _compute_lower(self, output_file, all_tasks, all_res):
"""
Compute the property.
Parameters
----------
output_file:
- The file to output the property
+ The file to output the property
all_tasks : list of str
- The list of directories to the tasks
+ The list of directories to the tasks
all_res : list of str
- The list of results
-
+ The list of results
Returns:
-------
- res_data: dist
- The dict storing the result of the property
- ptr_data: str
- The result printed in string format
+ res_data : dist
+ The dict storing the result of the property
+ ptr_data : str
+ The result printed in string format
"""
pass
diff --git a/dpgen/auto_test/Surface.py b/dpgen/auto_test/Surface.py
index 5078f61ad..da5770598 100644
--- a/dpgen/auto_test/Surface.py
+++ b/dpgen/auto_test/Surface.py
@@ -5,152 +5,190 @@
import dpdata
import numpy as np
-from monty.serialization import loadfn, dumpfn
+from monty.serialization import dumpfn, loadfn
from pymatgen.core.structure import Structure
from pymatgen.core.surface import generate_all_slabs
+import dpgen.auto_test.lib.abacus as abacus
import dpgen.auto_test.lib.vasp as vasp
+import dpgen.generator.lib.abacus_scf as abacus_scf
from dpgen import dlog
from dpgen.auto_test.Property import Property
from dpgen.auto_test.refine import make_refine
-from dpgen.auto_test.reproduce import make_repro
-from dpgen.auto_test.reproduce import post_repro
+from dpgen.auto_test.reproduce import make_repro, post_repro
-import dpgen.auto_test.lib.abacus as abacus
-import dpgen.generator.lib.abacus_scf as abacus_scf
class Surface(Property):
- def __init__(self,
- parameter,inter_param=None):
- parameter['reproduce'] = parameter.get('reproduce', False)
- self.reprod = parameter['reproduce']
+ def __init__(self, parameter, inter_param=None):
+ parameter["reproduce"] = parameter.get("reproduce", False)
+ self.reprod = parameter["reproduce"]
if not self.reprod:
- if not ('init_from_suffix' in parameter and 'output_suffix' in parameter):
- self.min_slab_size = parameter['min_slab_size']
- self.min_vacuum_size = parameter['min_vacuum_size']
- parameter['pert_xz'] = parameter.get('pert_xz', 0.01)
- self.pert_xz = parameter['pert_xz']
+ if not ("init_from_suffix" in parameter and "output_suffix" in parameter):
+ self.min_slab_size = parameter["min_slab_size"]
+ self.min_vacuum_size = parameter["min_vacuum_size"]
+ parameter["pert_xz"] = parameter.get("pert_xz", 0.01)
+ self.pert_xz = parameter["pert_xz"]
default_max_miller = 2
- parameter['max_miller'] = parameter.get('max_miller', default_max_miller)
- self.miller = parameter['max_miller']
- parameter['cal_type'] = parameter.get('cal_type', 'relaxation')
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": True,
- "relax_shape": True,
- "relax_vol": False}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["max_miller"] = parameter.get(
+ "max_miller", default_max_miller
+ )
+ self.miller = parameter["max_miller"]
+ parameter["cal_type"] = parameter.get("cal_type", "relaxation")
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": False,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
else:
- parameter['cal_type'] = 'static'
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": False,
- "relax_shape": False,
- "relax_vol": False}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["cal_type"] = "static"
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": False,
+ "relax_shape": False,
+ "relax_vol": False,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
- parameter['init_from_suffix'] = parameter.get('init_from_suffix', '00')
- self.init_from_suffix = parameter['init_from_suffix']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
+ parameter["init_from_suffix"] = parameter.get("init_from_suffix", "00")
+ self.init_from_suffix = parameter["init_from_suffix"]
self.parameter = parameter
- self.inter_param = inter_param if inter_param != None else {'type': 'vasp'}
+ self.inter_param = inter_param if inter_param != None else {"type": "vasp"}
- def make_confs(self,
- path_to_work,
- path_to_equi,
- refine=False):
+ def make_confs(self, path_to_work, path_to_equi, refine=False):
path_to_work = os.path.abspath(path_to_work)
if os.path.exists(path_to_work):
- dlog.warning('%s already exists' % path_to_work)
+ dlog.warning("%s already exists" % path_to_work)
else:
os.makedirs(path_to_work)
path_to_equi = os.path.abspath(path_to_equi)
- if 'start_confs_path' in self.parameter and os.path.exists(self.parameter['start_confs_path']):
- init_path_list = glob.glob(os.path.join(self.parameter['start_confs_path'], '*'))
+ if "start_confs_path" in self.parameter and os.path.exists(
+ self.parameter["start_confs_path"]
+ ):
+ init_path_list = glob.glob(
+ os.path.join(self.parameter["start_confs_path"], "*")
+ )
struct_init_name_list = []
for ii in init_path_list:
- struct_init_name_list.append(ii.split('/')[-1])
- struct_output_name = path_to_work.split('/')[-2]
+ struct_init_name_list.append(ii.split("/")[-1])
+ struct_output_name = path_to_work.split("/")[-2]
assert struct_output_name in struct_init_name_list
- path_to_equi = os.path.abspath(os.path.join(self.parameter['start_confs_path'],
- struct_output_name, 'relaxation', 'relax_task'))
+ path_to_equi = os.path.abspath(
+ os.path.join(
+ self.parameter["start_confs_path"],
+ struct_output_name,
+ "relaxation",
+ "relax_task",
+ )
+ )
task_list = []
cwd = os.getcwd()
if self.reprod:
- print('surface reproduce starts')
- if 'init_data_path' not in self.parameter:
+ print("surface reproduce starts")
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- task_list = make_repro(self.inter_param,init_data_path, self.init_from_suffix,
- path_to_work, self.parameter.get('reprod_last_frame', True))
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ task_list = make_repro(
+ self.inter_param,
+ init_data_path,
+ self.init_from_suffix,
+ path_to_work,
+ self.parameter.get("reprod_last_frame", True),
+ )
os.chdir(cwd)
else:
if refine:
- print('surface refine starts')
- task_list = make_refine(self.parameter['init_from_suffix'],
- self.parameter['output_suffix'],
- path_to_work)
+ print("surface refine starts")
+ task_list = make_refine(
+ self.parameter["init_from_suffix"],
+ self.parameter["output_suffix"],
+ path_to_work,
+ )
os.chdir(cwd)
# record miller
- init_from_path = re.sub(self.parameter['output_suffix'][::-1],
- self.parameter['init_from_suffix'][::-1],
- path_to_work[::-1], count=1)[::-1]
+ init_from_path = re.sub(
+ self.parameter["output_suffix"][::-1],
+ self.parameter["init_from_suffix"][::-1],
+ path_to_work[::-1],
+ count=1,
+ )[::-1]
task_list_basename = list(map(os.path.basename, task_list))
for ii in task_list_basename:
init_from_task = os.path.join(init_from_path, ii)
output_task = os.path.join(path_to_work, ii)
os.chdir(output_task)
- if os.path.isfile('miller.json'):
- os.remove('miller.json')
- if os.path.islink('miller.json'):
- os.remove('miller.json')
- os.symlink(os.path.relpath(os.path.join(init_from_task, 'miller.json')), 'miller.json')
+ if os.path.isfile("miller.json"):
+ os.remove("miller.json")
+ if os.path.islink("miller.json"):
+ os.remove("miller.json")
+ os.symlink(
+ os.path.relpath(os.path.join(init_from_task, "miller.json")),
+ "miller.json",
+ )
os.chdir(cwd)
else:
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
CONTCAR = abacus.final_stru(path_to_equi)
- POSCAR = 'STRU'
+ POSCAR = "STRU"
else:
- CONTCAR = 'CONTCAR'
- POSCAR = 'POSCAR'
+ CONTCAR = "CONTCAR"
+ POSCAR = "POSCAR"
equi_contcar = os.path.join(path_to_equi, CONTCAR)
if not os.path.exists(equi_contcar):
raise RuntimeError("please do relaxation first")
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
stru = dpdata.System(equi_contcar, fmt="stru")
- stru.to('contcar','CONTCAR.tmp')
- ptypes = vasp.get_poscar_types('CONTCAR.tmp')
- ss = Structure.from_file('CONTCAR.tmp')
- os.remove('CONTCAR.tmp')
- else:
+ stru.to("contcar", "CONTCAR.tmp")
+ ptypes = vasp.get_poscar_types("CONTCAR.tmp")
+ ss = Structure.from_file("CONTCAR.tmp")
+ os.remove("CONTCAR.tmp")
+ else:
ptypes = vasp.get_poscar_types(equi_contcar)
# gen structure
ss = Structure.from_file(equi_contcar)
# gen slabs
- all_slabs = generate_all_slabs(ss, self.miller, self.min_slab_size, self.min_vacuum_size)
+ all_slabs = generate_all_slabs(
+ ss, self.miller, self.min_slab_size, self.min_vacuum_size
+ )
os.chdir(path_to_work)
if os.path.isfile(POSCAR):
@@ -160,24 +198,35 @@ def make_confs(self,
os.symlink(os.path.relpath(equi_contcar), POSCAR)
# task_poscar = os.path.join(output, 'POSCAR')
for ii in range(len(all_slabs)):
- output_task = os.path.join(path_to_work, 'task.%06d' % ii)
+ output_task = os.path.join(path_to_work, "task.%06d" % ii)
os.makedirs(output_task, exist_ok=True)
os.chdir(output_task)
- for jj in ['INCAR', 'POTCAR', 'POSCAR', 'conf.lmp', 'in.lammps','STRU']:
+ for jj in [
+ "INCAR",
+ "POTCAR",
+ "POSCAR",
+ "conf.lmp",
+ "in.lammps",
+ "STRU",
+ ]:
if os.path.exists(jj):
os.remove(jj)
task_list.append(output_task)
- print("# %03d generate " % ii, output_task, " \t %d atoms" % len(all_slabs[ii].sites))
+ print(
+ "# %03d generate " % ii,
+ output_task,
+ " \t %d atoms" % len(all_slabs[ii].sites),
+ )
# make confs
- all_slabs[ii].to('POSCAR', 'POSCAR.tmp')
- vasp.regulate_poscar('POSCAR.tmp', 'POSCAR')
- vasp.sort_poscar('POSCAR', 'POSCAR', ptypes)
- vasp.perturb_xz('POSCAR', 'POSCAR', self.pert_xz)
- if self.inter_param['type'] == 'abacus':
- abacus.poscar2stru("POSCAR",self.inter_param,"STRU")
- os.remove('POSCAR')
+ all_slabs[ii].to("POSCAR.tmp", "POSCAR")
+ vasp.regulate_poscar("POSCAR.tmp", "POSCAR")
+ vasp.sort_poscar("POSCAR", "POSCAR", ptypes)
+ vasp.perturb_xz("POSCAR", "POSCAR", self.pert_xz)
+ if self.inter_param["type"] == "abacus":
+ abacus.poscar2stru("POSCAR", self.inter_param, "STRU")
+ os.remove("POSCAR")
# record miller
- dumpfn(all_slabs[ii].miller_index, 'miller.json')
+ dumpfn(all_slabs[ii].miller_index, "miller.json")
os.chdir(cwd)
return task_list
@@ -186,48 +235,66 @@ def post_process(self, task_list):
pass
def task_type(self):
- return self.parameter['type']
+ return self.parameter["type"]
def task_param(self):
return self.parameter
- def _compute_lower(self,
- output_file,
- all_tasks,
- all_res):
+ def _compute_lower(self, output_file, all_tasks, all_res):
output_file = os.path.abspath(output_file)
res_data = {}
- ptr_data = os.path.dirname(output_file) + '\n'
+ ptr_data = os.path.dirname(output_file) + "\n"
if not self.reprod:
ptr_data += "Miller_Indices: \tSurf_E(J/m^2) EpA(eV) equi_EpA(eV)\n"
for ii in all_tasks:
- task_result = loadfn(os.path.join(ii, 'result_task.json'))
- natoms = np.sum(task_result['atom_numbs'])
- epa = task_result['energies'][-1] / natoms
- AA = np.linalg.norm(np.cross(task_result['cells'][0][0], task_result['cells'][0][1]))
-
- equi_path = os.path.abspath(os.path.join(os.path.dirname(output_file), '../relaxation/relax_task'))
- equi_result = loadfn(os.path.join(equi_path, 'result.json'))
- equi_epa = equi_result['energies'][-1] / np.sum(equi_result['atom_numbs'])
+ task_result = loadfn(os.path.join(ii, "result_task.json"))
+ natoms = np.sum(task_result["atom_numbs"])
+ epa = task_result["energies"][-1] / natoms
+ AA = np.linalg.norm(
+ np.cross(task_result["cells"][0][0], task_result["cells"][0][1])
+ )
+
+ equi_path = os.path.abspath(
+ os.path.join(
+ os.path.dirname(output_file), "../relaxation/relax_task"
+ )
+ )
+ equi_result = loadfn(os.path.join(equi_path, "result.json"))
+ equi_epa = equi_result["energies"][-1] / np.sum(
+ equi_result["atom_numbs"]
+ )
structure_dir = os.path.basename(ii)
Cf = 1.60217657e-16 / (1e-20 * 2) * 0.001
- evac = (task_result['energies'][-1] - equi_epa * natoms) / AA * Cf
+ evac = (task_result["energies"][-1] - equi_epa * natoms) / AA * Cf
- miller_index = loadfn(os.path.join(ii, 'miller.json'))
+ miller_index = loadfn(os.path.join(ii, "miller.json"))
ptr_data += "%-25s %7.3f %8.3f %8.3f\n" % (
- str(miller_index) + '-' + structure_dir + ':', evac, epa, equi_epa)
- res_data[str(miller_index) + '-' + structure_dir] = [evac, epa, equi_epa]
+ str(miller_index) + "-" + structure_dir + ":",
+ evac,
+ epa,
+ equi_epa,
+ )
+ res_data[str(miller_index) + "-" + structure_dir] = [
+ evac,
+ epa,
+ equi_epa,
+ ]
else:
- if 'init_data_path' not in self.parameter:
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- res_data, ptr_data = post_repro(init_data_path, self.parameter['init_from_suffix'],
- all_tasks, ptr_data, self.parameter.get('reprod_last_frame', True))
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ res_data, ptr_data = post_repro(
+ init_data_path,
+ self.parameter["init_from_suffix"],
+ all_tasks,
+ ptr_data,
+ self.parameter.get("reprod_last_frame", True),
+ )
- with open(output_file, 'w') as fp:
+ with open(output_file, "w") as fp:
json.dump(res_data, fp, indent=4)
return res_data, ptr_data
diff --git a/dpgen/auto_test/Task.py b/dpgen/auto_test/Task.py
index c04aac586..848a8bebd 100644
--- a/dpgen/auto_test/Task.py
+++ b/dpgen/auto_test/Task.py
@@ -3,46 +3,43 @@
class Task(ABC):
@abstractmethod
- def __init__(self,
- inter_parameter,
- path_to_poscar):
+ def __init__(self, inter_parameter, path_to_poscar):
"""
Constructor
Parameters
----------
inter_parameter : dict
- A dict that specifies the interaction.
+ A dict that specifies the interaction.
path_to_poscar : str
- The path to POSCAR. Indicating in which system the task will be initialized.
+ The path to POSCAR. Indicating in which system the task will be initialized.
"""
pass
@abstractmethod
- def make_potential_files(self,
- output_dir):
+ def make_potential_files(self, output_dir):
"""
Prepare potential files for a computational task.
- For example, the VASP prepares POTCAR.
+ For example, the VASP prepares POTCAR.
DeePMD prepares frozen model(s).
IMPORTANT: Interaction should be stored in output_dir/inter.json
Parameters
----------
output_dir : str
- The directory storing the potential files.
- Outputs
- -------
+ The directory storing the potential files.
+
+ Notes
+ -----
+ The following files are generated:
+
inter.json: output file
The task information is stored in `output_dir/inter.json`
"""
pass
@abstractmethod
- def make_input_file(self,
- output_dir,
- task_type,
- task_param):
+ def make_input_file(self, output_dir, task_type, task_param):
"""
Prepare input files for a computational task
For example, the VASP prepares INCAR.
@@ -51,38 +48,38 @@ def make_input_file(self,
Parameters
----------
output_dir : str
- The directory storing the input files.
+ The directory storing the input files.
task_type : str
- Can be
- - "relaxation:": structure relaxation
- - "static": static computation calculates the energy, force... of a strcture
- task_parame: dict
- The parameters of the task.
- For example the VASP interaction can be provided with
- { "ediff": 1e-6, "ediffg": 1e-5 }
+ Can be
+ - "relaxation:": structure relaxation
+ - "static": static computation calculates the energy, force... of a strcture
+ task_param : dict
+ The parameters of the task.
+ For example the VASP interaction can be provided with
+ { "ediff": 1e-6, "ediffg": 1e-5 }
"""
pass
@abstractmethod
- def compute(self,
- output_dir):
+ def compute(self, output_dir):
"""
- Compute output of the task.
+ Compute output of the task.
IMPORTANT: The output configuration should be converted and stored in a CONTCAR file.
Parameters
----------
output_dir : str
- The directory storing the input and output files.
+ The directory storing the input and output files.
Returns
-------
result_dict: dict
- A dict that storing the result. For example:
- { "energy": xxx, "force": [xxx] }
+ A dict that storing the result. For example:
+ { "energy": xxx, "force": [xxx] }
- Outputs
- -------
+ Notes
+ -----
+ The following files are generated:
CONTCAR: output file
The output configuration is converted to CONTCAR and stored in the `output_dir`
"""
diff --git a/dpgen/auto_test/VASP.py b/dpgen/auto_test/VASP.py
index 61cbeb931..cf317a438 100644
--- a/dpgen/auto_test/VASP.py
+++ b/dpgen/auto_test/VASP.py
@@ -1,35 +1,34 @@
import os
-from dpgen import dlog
-from dpgen.util import sepline
-import dpgen.auto_test.lib.vasp as vasp
-from dpgen.auto_test.Task import Task
-from dpgen.generator.lib.vasp import incar_upper
+
from dpdata import LabeledSystem
from monty.serialization import dumpfn
-from pymatgen.io.vasp import Incar, Kpoints
from pymatgen.core.structure import Structure
+from pymatgen.io.vasp import Incar, Kpoints
+
+import dpgen.auto_test.lib.vasp as vasp
+from dpgen import dlog
+from dpgen.auto_test.Task import Task
+from dpgen.generator.lib.vasp import incar_upper
+from dpgen.util import sepline
class VASP(Task):
- def __init__(self,
- inter_parameter,
- path_to_poscar):
+ def __init__(self, inter_parameter, path_to_poscar):
self.inter = inter_parameter
- self.inter_type = inter_parameter['type']
- self.incar = inter_parameter['incar']
- self.potcar_prefix = inter_parameter.get('potcar_prefix', '')
- self.potcars = inter_parameter['potcars']
+ self.inter_type = inter_parameter["type"]
+ self.incar = inter_parameter["incar"]
+ self.potcar_prefix = inter_parameter.get("potcar_prefix", "")
+ self.potcars = inter_parameter["potcars"]
self.path_to_poscar = path_to_poscar
- def make_potential_files(self,
- output_dir):
- potcar_not_link_list = ['vacancy', 'interstitial']
- task_type = output_dir.split('/')[-2].split('_')[0]
+ def make_potential_files(self, output_dir):
+ potcar_not_link_list = ["vacancy", "interstitial"]
+ task_type = output_dir.split("/")[-2].split("_")[0]
ele_pot_list = [key for key in self.potcars.keys()]
- poscar = os.path.abspath(os.path.join(output_dir, 'POSCAR'))
+ poscar = os.path.abspath(os.path.join(output_dir, "POSCAR"))
pos_str = Structure.from_file(poscar)
- ele_pos_list_tmp = list(ii.as_dict()['element'] for ii in pos_str.species)
+ ele_pos_list_tmp = list(ii.as_dict()["element"] for ii in pos_str.species)
ele_pos_list = [ele_pos_list_tmp[0]]
for ii in range(1, len(ele_pos_list_tmp)):
@@ -37,62 +36,64 @@ def make_potential_files(self,
ele_pos_list.append(ele_pos_list_tmp[ii])
if task_type in potcar_not_link_list:
- with open(os.path.join(output_dir, 'POTCAR'), 'w') as fp:
+ with open(os.path.join(output_dir, "POTCAR"), "w") as fp:
for ii in ele_pos_list:
for jj in ele_pot_list:
if ii == jj:
- with open(os.path.join(self.potcar_prefix, self.potcars[jj]), 'r') as fin:
+ with open(
+ os.path.join(self.potcar_prefix, self.potcars[jj]), "r"
+ ) as fin:
for line in fin:
- print(line.strip('\n'), file=fp)
+ print(line.strip("\n"), file=fp)
else:
- if not os.path.isfile(os.path.join(output_dir, '../POTCAR')):
- with open(os.path.join(output_dir, '../POTCAR'), 'w') as fp:
+ if not os.path.isfile(os.path.join(output_dir, "../POTCAR")):
+ with open(os.path.join(output_dir, "../POTCAR"), "w") as fp:
for ii in ele_pos_list:
for jj in ele_pot_list:
if ii == jj:
- with open(os.path.join(self.potcar_prefix, self.potcars[jj]), 'r') as fin:
+ with open(
+ os.path.join(self.potcar_prefix, self.potcars[jj]),
+ "r",
+ ) as fin:
for line in fin:
- print(line.strip('\n'), file=fp)
+ print(line.strip("\n"), file=fp)
cwd = os.getcwd()
os.chdir(output_dir)
- if not os.path.islink('POTCAR'):
- os.symlink('../POTCAR', 'POTCAR')
- elif not '../POTCAR' == os.readlink('POTCAR'):
- os.remove('POTCAR')
- os.symlink('../POTCAR', 'POTCAR')
+ if not os.path.islink("POTCAR"):
+ os.symlink("../POTCAR", "POTCAR")
+ elif not "../POTCAR" == os.readlink("POTCAR"):
+ os.remove("POTCAR")
+ os.symlink("../POTCAR", "POTCAR")
os.chdir(cwd)
- dumpfn(self.inter, os.path.join(output_dir, 'inter.json'), indent=4)
+ dumpfn(self.inter, os.path.join(output_dir, "inter.json"), indent=4)
- def make_input_file(self,
- output_dir,
- task_type,
- task_param):
+ def make_input_file(self, output_dir, task_type, task_param):
sepline(ch=output_dir)
- dumpfn(task_param, os.path.join(output_dir, 'task.json'), indent=4)
+ dumpfn(task_param, os.path.join(output_dir, "task.json"), indent=4)
- assert (os.path.exists(self.incar)), 'no INCAR file for relaxation'
+ assert os.path.exists(self.incar), "no INCAR file for relaxation"
relax_incar_path = os.path.abspath(self.incar)
incar_relax = incar_upper(Incar.from_file(relax_incar_path))
# deal with relaxation
- cal_type = task_param['cal_type']
- cal_setting = task_param['cal_setting']
+ cal_type = task_param["cal_type"]
+ cal_setting = task_param["cal_setting"]
# user input INCAR for property calculation
- if 'input_prop' in cal_setting and os.path.isfile(cal_setting['input_prop']):
- incar_prop = os.path.abspath(cal_setting['input_prop'])
+ if "input_prop" in cal_setting and os.path.isfile(cal_setting["input_prop"]):
+ incar_prop = os.path.abspath(cal_setting["input_prop"])
incar = incar_upper(Incar.from_file(incar_prop))
# revise INCAR based on the INCAR provided in the "interaction"
else:
incar = incar_relax
- if cal_type == 'relaxation':
- relax_pos = cal_setting['relax_pos']
- relax_shape = cal_setting['relax_shape']
- relax_vol = cal_setting['relax_vol']
+ if cal_type == "relaxation":
+ relax_pos = cal_setting["relax_pos"]
+ relax_shape = cal_setting["relax_shape"]
+ relax_vol = cal_setting["relax_vol"]
if [relax_pos, relax_shape, relax_vol] == [True, False, False]:
isif = 2
elif [relax_pos, relax_shape, relax_vol] == [True, True, True]:
@@ -108,81 +109,102 @@ def make_input_file(self,
elif [relax_pos, relax_shape, relax_vol] == [False, False, False]:
nsw = 0
isif = 2
- if not ('NSW' in incar and incar.get('NSW') == nsw):
- dlog.info("%s setting NSW to %d" % (self.make_input_file.__name__, nsw))
- incar['NSW'] = nsw
+ if not ("NSW" in incar and incar.get("NSW") == nsw):
+ dlog.info(
+ "%s setting NSW to %d"
+ % (self.make_input_file.__name__, nsw)
+ )
+ incar["NSW"] = nsw
else:
raise RuntimeError("not supported calculation setting for VASP")
- if not ('ISIF' in incar and incar.get('ISIF') == isif):
- dlog.info("%s setting ISIF to %d" % (self.make_input_file.__name__, isif))
- incar['ISIF'] = isif
+ if not ("ISIF" in incar and incar.get("ISIF") == isif):
+ dlog.info(
+ "%s setting ISIF to %d" % (self.make_input_file.__name__, isif)
+ )
+ incar["ISIF"] = isif
- elif cal_type == 'static':
+ elif cal_type == "static":
nsw = 0
- if not ('NSW' in incar and incar.get('NSW') == nsw):
- dlog.info("%s setting NSW to %d" % (self.make_input_file.__name__, nsw))
- incar['NSW'] = nsw
+ if not ("NSW" in incar and incar.get("NSW") == nsw):
+ dlog.info(
+ "%s setting NSW to %d" % (self.make_input_file.__name__, nsw)
+ )
+ incar["NSW"] = nsw
else:
raise RuntimeError("not supported calculation type for VASP")
- if 'ediff' in cal_setting:
- dlog.info("%s setting EDIFF to %s" % (self.make_input_file.__name__, cal_setting['ediff']))
- incar['EDIFF'] = cal_setting['ediff']
-
- if 'ediffg' in cal_setting:
- dlog.info("%s setting EDIFFG to %s" % (self.make_input_file.__name__, cal_setting['ediffg']))
- incar['EDIFFG'] = cal_setting['ediffg']
-
- if 'encut' in cal_setting:
- dlog.info("%s setting ENCUT to %s" % (self.make_input_file.__name__, cal_setting['encut']))
- incar['ENCUT'] = cal_setting['encut']
-
- if 'kspacing' in cal_setting:
- dlog.info("%s setting KSPACING to %s" % (self.make_input_file.__name__, cal_setting['kspacing']))
- incar['KSPACING'] = cal_setting['kspacing']
-
- if 'kgamma' in cal_setting:
- dlog.info("%s setting KGAMMA to %s" % (self.make_input_file.__name__, cal_setting['kgamma']))
- incar['KGAMMA'] = cal_setting['kgamma']
+ if "ediff" in cal_setting:
+ dlog.info(
+ "%s setting EDIFF to %s"
+ % (self.make_input_file.__name__, cal_setting["ediff"])
+ )
+ incar["EDIFF"] = cal_setting["ediff"]
+
+ if "ediffg" in cal_setting:
+ dlog.info(
+ "%s setting EDIFFG to %s"
+ % (self.make_input_file.__name__, cal_setting["ediffg"])
+ )
+ incar["EDIFFG"] = cal_setting["ediffg"]
+
+ if "encut" in cal_setting:
+ dlog.info(
+ "%s setting ENCUT to %s"
+ % (self.make_input_file.__name__, cal_setting["encut"])
+ )
+ incar["ENCUT"] = cal_setting["encut"]
+
+ if "kspacing" in cal_setting:
+ dlog.info(
+ "%s setting KSPACING to %s"
+ % (self.make_input_file.__name__, cal_setting["kspacing"])
+ )
+ incar["KSPACING"] = cal_setting["kspacing"]
+
+ if "kgamma" in cal_setting:
+ dlog.info(
+ "%s setting KGAMMA to %s"
+ % (self.make_input_file.__name__, cal_setting["kgamma"])
+ )
+ incar["KGAMMA"] = cal_setting["kgamma"]
try:
- kspacing = incar.get('KSPACING')
+ kspacing = incar.get("KSPACING")
except KeyError:
raise RuntimeError("KSPACING must be given in INCAR")
- if 'KGAMMA' in incar:
- kgamma = incar.get('KGAMMA')
+ if "KGAMMA" in incar:
+ kgamma = incar.get("KGAMMA")
else:
kgamma = False
- incar.write_file(os.path.join(output_dir, '../INCAR'))
+ incar.write_file(os.path.join(output_dir, "../INCAR"))
cwd = os.getcwd()
os.chdir(output_dir)
- if not os.path.islink('INCAR'):
- os.symlink('../INCAR', 'INCAR')
- elif not '../INCAR' == os.readlink('INCAR'):
- os.remove('INCAR')
- os.symlink('../INCAR', 'INCAR')
+ if not os.path.islink("INCAR"):
+ os.symlink("../INCAR", "INCAR")
+ elif not "../INCAR" == os.readlink("INCAR"):
+ os.remove("INCAR")
+ os.symlink("../INCAR", "INCAR")
os.chdir(cwd)
ret = vasp.make_kspacing_kpoints(self.path_to_poscar, kspacing, kgamma)
kp = Kpoints.from_string(ret)
kp.write_file(os.path.join(output_dir, "KPOINTS"))
- def compute(self,
- output_dir):
- outcar = os.path.join(output_dir, 'OUTCAR')
+ def compute(self, output_dir):
+ outcar = os.path.join(output_dir, "OUTCAR")
if not os.path.isfile(outcar):
dlog.warning("cannot find OUTCAR in " + output_dir + " skip")
return None
else:
ls = LabeledSystem(outcar)
stress = []
- with open(outcar, 'r') as fin:
- lines = fin.read().split('\n')
+ with open(outcar, "r") as fin:
+ lines = fin.read().split("\n")
for line in lines:
- if 'in kB' in line:
+ if "in kB" in line:
stress_xx = float(line.split()[2])
stress_yy = float(line.split()[3])
stress_zz = float(line.split()[4])
@@ -195,21 +217,26 @@ def compute(self,
stress[-1].append([stress_zx, stress_yz, stress_zz])
outcar_dict = ls.as_dict()
- outcar_dict['data']['stress'] = {"@module": "numpy", "@class": "array", "dtype": "float64", "data": stress}
+ outcar_dict["data"]["stress"] = {
+ "@module": "numpy",
+ "@class": "array",
+ "dtype": "float64",
+ "data": stress,
+ }
return outcar_dict
- def forward_files(self, property_type='relaxation'):
- return ['INCAR', 'POSCAR', 'KPOINTS', 'POTCAR']
+ def forward_files(self, property_type="relaxation"):
+ return ["INCAR", "POSCAR", "KPOINTS", "POTCAR"]
- def forward_common_files(self, property_type='relaxation'):
- potcar_not_link_list = ['vacancy', 'interstitial']
- if property_type == 'elastic':
- return ['INCAR', 'KPOINTS', 'POTCAR']
+ def forward_common_files(self, property_type="relaxation"):
+ potcar_not_link_list = ["vacancy", "interstitial"]
+ if property_type == "elastic":
+ return ["INCAR", "KPOINTS", "POTCAR"]
elif property_type in potcar_not_link_list:
- return ['INCAR']
+ return ["INCAR"]
else:
- return ['INCAR', 'POTCAR']
+ return ["INCAR", "POTCAR"]
- def backward_files(self, property_type='relaxation'):
- return ['OUTCAR', 'outlog', 'CONTCAR', 'OSZICAR', 'XDATCAR']
+ def backward_files(self, property_type="relaxation"):
+ return ["OUTCAR", "outlog", "CONTCAR", "OSZICAR", "XDATCAR"]
diff --git a/dpgen/auto_test/Vacancy.py b/dpgen/auto_test/Vacancy.py
index ddce3117b..06a65d728 100644
--- a/dpgen/auto_test/Vacancy.py
+++ b/dpgen/auto_test/Vacancy.py
@@ -2,135 +2,169 @@
import json
import os
import re
-import numpy as np
-from monty.serialization import loadfn, dumpfn
+import numpy as np
+from monty.serialization import dumpfn, loadfn
from pymatgen.analysis.defects.generators import VacancyGenerator
from pymatgen.core.structure import Structure
+import dpgen.auto_test.lib.abacus as abacus
+import dpgen.generator.lib.abacus_scf as abacus_scf
from dpgen import dlog
from dpgen.auto_test.Property import Property
from dpgen.auto_test.refine import make_refine
-from dpgen.auto_test.reproduce import make_repro
-from dpgen.auto_test.reproduce import post_repro
+from dpgen.auto_test.reproduce import make_repro, post_repro
-import dpgen.auto_test.lib.abacus as abacus
-import dpgen.generator.lib.abacus_scf as abacus_scf
class Vacancy(Property):
- def __init__(self,
- parameter,inter_param=None):
- parameter['reproduce'] = parameter.get('reproduce', False)
- self.reprod = parameter['reproduce']
+ def __init__(self, parameter, inter_param=None):
+ parameter["reproduce"] = parameter.get("reproduce", False)
+ self.reprod = parameter["reproduce"]
if not self.reprod:
- if not ('init_from_suffix' in parameter and 'output_suffix' in parameter):
+ if not ("init_from_suffix" in parameter and "output_suffix" in parameter):
default_supercell = [1, 1, 1]
- parameter['supercell'] = parameter.get('supercell', default_supercell)
- self.supercell = parameter['supercell']
- parameter['cal_type'] = parameter.get('cal_type', 'relaxation')
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": True,
- "relax_shape": True,
- "relax_vol": True}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["supercell"] = parameter.get("supercell", default_supercell)
+ self.supercell = parameter["supercell"]
+ parameter["cal_type"] = parameter.get("cal_type", "relaxation")
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": True,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
else:
- parameter['cal_type'] = 'static'
- self.cal_type = parameter['cal_type']
- default_cal_setting = {"relax_pos": False,
- "relax_shape": False,
- "relax_vol": False}
- if 'cal_setting' not in parameter:
- parameter['cal_setting'] = default_cal_setting
+ parameter["cal_type"] = "static"
+ self.cal_type = parameter["cal_type"]
+ default_cal_setting = {
+ "relax_pos": False,
+ "relax_shape": False,
+ "relax_vol": False,
+ }
+ if "cal_setting" not in parameter:
+ parameter["cal_setting"] = default_cal_setting
else:
- if "relax_pos" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_pos'] = default_cal_setting['relax_pos']
- if "relax_shape" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_shape'] = default_cal_setting['relax_shape']
- if "relax_vol" not in parameter['cal_setting']:
- parameter['cal_setting']['relax_vol'] = default_cal_setting['relax_vol']
- self.cal_setting = parameter['cal_setting']
- parameter['init_from_suffix'] = parameter.get('init_from_suffix', '00')
- self.init_from_suffix = parameter['init_from_suffix']
+ if "relax_pos" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_pos"] = default_cal_setting[
+ "relax_pos"
+ ]
+ if "relax_shape" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_shape"] = default_cal_setting[
+ "relax_shape"
+ ]
+ if "relax_vol" not in parameter["cal_setting"]:
+ parameter["cal_setting"]["relax_vol"] = default_cal_setting[
+ "relax_vol"
+ ]
+ self.cal_setting = parameter["cal_setting"]
+ parameter["init_from_suffix"] = parameter.get("init_from_suffix", "00")
+ self.init_from_suffix = parameter["init_from_suffix"]
self.parameter = parameter
- self.inter_param = inter_param if inter_param != None else {'type': 'vasp'}
+ self.inter_param = inter_param if inter_param != None else {"type": "vasp"}
- def make_confs(self,
- path_to_work,
- path_to_equi,
- refine=False):
+ def make_confs(self, path_to_work, path_to_equi, refine=False):
path_to_work = os.path.abspath(path_to_work)
if os.path.exists(path_to_work):
- dlog.warning('%s already exists' % path_to_work)
+ dlog.warning("%s already exists" % path_to_work)
else:
os.makedirs(path_to_work)
path_to_equi = os.path.abspath(path_to_equi)
- if 'start_confs_path' in self.parameter and os.path.exists(self.parameter['start_confs_path']):
- init_path_list = glob.glob(os.path.join(self.parameter['start_confs_path'], '*'))
+ if "start_confs_path" in self.parameter and os.path.exists(
+ self.parameter["start_confs_path"]
+ ):
+ init_path_list = glob.glob(
+ os.path.join(self.parameter["start_confs_path"], "*")
+ )
struct_init_name_list = []
for ii in init_path_list:
- struct_init_name_list.append(ii.split('/')[-1])
- struct_output_name = path_to_work.split('/')[-2]
+ struct_init_name_list.append(ii.split("/")[-1])
+ struct_output_name = path_to_work.split("/")[-2]
assert struct_output_name in struct_init_name_list
- path_to_equi = os.path.abspath(os.path.join(self.parameter['start_confs_path'],
- struct_output_name, 'relaxation', 'relax_task'))
+ path_to_equi = os.path.abspath(
+ os.path.join(
+ self.parameter["start_confs_path"],
+ struct_output_name,
+ "relaxation",
+ "relax_task",
+ )
+ )
task_list = []
cwd = os.getcwd()
if self.reprod:
- print('vacancy reproduce starts')
- if 'init_data_path' not in self.parameter:
+ print("vacancy reproduce starts")
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- task_list = make_repro(self.inter_param,init_data_path, self.init_from_suffix,
- path_to_work, self.parameter.get('reprod_last_frame', False))
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ task_list = make_repro(
+ self.inter_param,
+ init_data_path,
+ self.init_from_suffix,
+ path_to_work,
+ self.parameter.get("reprod_last_frame", False),
+ )
os.chdir(cwd)
else:
if refine:
- print('vacancy refine starts')
- task_list = make_refine(self.parameter['init_from_suffix'],
- self.parameter['output_suffix'],
- path_to_work)
-
- init_from_path = re.sub(self.parameter['output_suffix'][::-1],
- self.parameter['init_from_suffix'][::-1],
- path_to_work[::-1], count=1)[::-1]
+ print("vacancy refine starts")
+ task_list = make_refine(
+ self.parameter["init_from_suffix"],
+ self.parameter["output_suffix"],
+ path_to_work,
+ )
+
+ init_from_path = re.sub(
+ self.parameter["output_suffix"][::-1],
+ self.parameter["init_from_suffix"][::-1],
+ path_to_work[::-1],
+ count=1,
+ )[::-1]
task_list_basename = list(map(os.path.basename, task_list))
for ii in task_list_basename:
init_from_task = os.path.join(init_from_path, ii)
output_task = os.path.join(path_to_work, ii)
os.chdir(output_task)
- if os.path.isfile('supercell.json'):
- os.remove('supercell.json')
- if os.path.islink('supercell.json'):
- os.remove('supercell.json')
- os.symlink(os.path.relpath(os.path.join(init_from_task, 'supercell.json')), 'supercell.json')
+ if os.path.isfile("supercell.json"):
+ os.remove("supercell.json")
+ if os.path.islink("supercell.json"):
+ os.remove("supercell.json")
+ os.symlink(
+ os.path.relpath(os.path.join(init_from_task, "supercell.json")),
+ "supercell.json",
+ )
os.chdir(cwd)
else:
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
CONTCAR = abacus.final_stru(path_to_equi)
- POSCAR = 'STRU'
+ POSCAR = "STRU"
else:
- CONTCAR = 'CONTCAR'
- POSCAR = 'POSCAR'
+ CONTCAR = "CONTCAR"
+ POSCAR = "POSCAR"
equi_contcar = os.path.join(path_to_equi, CONTCAR)
if not os.path.exists(equi_contcar):
raise RuntimeError("please do relaxation first")
- if self.inter_param['type'] == 'abacus':
+ if self.inter_param["type"] == "abacus":
ss = abacus.stru2Structure(equi_contcar)
else:
ss = Structure.from_file(equi_contcar)
@@ -139,9 +173,11 @@ def make_confs(self,
vds = pre_vds.generate(ss)
dss = []
for jj in vds:
- dss.append(jj.get_supercell_structure(sc_mat=np.diag(self.supercell, k=0)))
+ dss.append(
+ jj.get_supercell_structure(sc_mat=np.diag(self.supercell, k=0))
+ )
- print('gen vacancy with supercell ' + str(self.supercell))
+ print("gen vacancy with supercell " + str(self.supercell))
os.chdir(path_to_work)
if os.path.isfile(POSCAR):
os.remove(POSCAR)
@@ -151,19 +187,26 @@ def make_confs(self,
# task_poscar = os.path.join(output, 'POSCAR')
for ii in range(len(dss)):
- output_task = os.path.join(path_to_work, 'task.%06d' % ii)
+ output_task = os.path.join(path_to_work, "task.%06d" % ii)
os.makedirs(output_task, exist_ok=True)
os.chdir(output_task)
- for jj in ['INCAR', 'POTCAR', 'POSCAR', 'conf.lmp', 'in.lammps','STRU']:
+ for jj in [
+ "INCAR",
+ "POTCAR",
+ "POSCAR",
+ "conf.lmp",
+ "in.lammps",
+ "STRU",
+ ]:
if os.path.exists(jj):
os.remove(jj)
task_list.append(output_task)
- dss[ii].to('POSCAR', 'POSCAR')
- if self.inter_param['type'] == 'abacus':
- abacus.poscar2stru("POSCAR",self.inter_param,"STRU")
- os.remove('POSCAR')
+ dss[ii].to("POSCAR", "POSCAR")
+ if self.inter_param["type"] == "abacus":
+ abacus.poscar2stru("POSCAR", self.inter_param, "STRU")
+ os.remove("POSCAR")
# np.savetxt('supercell.out', self.supercell, fmt='%d')
- dumpfn(self.supercell, 'supercell.json')
+ dumpfn(self.supercell, "supercell.json")
os.chdir(cwd)
return task_list
@@ -171,18 +214,15 @@ def post_process(self, task_list):
pass
def task_type(self):
- return self.parameter['type']
+ return self.parameter["type"]
def task_param(self):
return self.parameter
- def _compute_lower(self,
- output_file,
- all_tasks,
- all_res):
+ def _compute_lower(self, output_file, all_tasks, all_res):
output_file = os.path.abspath(output_file)
res_data = {}
- ptr_data = os.path.dirname(output_file) + '\n'
+ ptr_data = os.path.dirname(output_file) + "\n"
if not self.reprod:
ptr_data += "Structure: \tVac_E(eV) E(eV) equi_E(eV)\n"
@@ -191,26 +231,42 @@ def _compute_lower(self,
idid += 1
structure_dir = os.path.basename(ii)
task_result = loadfn(all_res[idid])
- natoms = task_result['atom_numbs'][0]
- equi_path = os.path.abspath(os.path.join(os.path.dirname(output_file), '../relaxation/relax_task'))
- equi_result = loadfn(os.path.join(equi_path, 'result.json'))
- equi_epa = equi_result['energies'][-1] / equi_result['atom_numbs'][0]
- evac = task_result['energies'][-1] - equi_epa * natoms
-
- supercell_index = loadfn(os.path.join(ii, 'supercell.json'))
- ptr_data += "%s: %7.3f %7.3f %7.3f \n" % (str(supercell_index) + '-' + structure_dir,
- evac, task_result['energies'][-1], equi_epa * natoms)
- res_data[str(supercell_index) + '-' + structure_dir] = [evac, task_result['energies'][-1],
- equi_epa * natoms]
+ natoms = task_result["atom_numbs"][0]
+ equi_path = os.path.abspath(
+ os.path.join(
+ os.path.dirname(output_file), "../relaxation/relax_task"
+ )
+ )
+ equi_result = loadfn(os.path.join(equi_path, "result.json"))
+ equi_epa = equi_result["energies"][-1] / equi_result["atom_numbs"][0]
+ evac = task_result["energies"][-1] - equi_epa * natoms
+
+ supercell_index = loadfn(os.path.join(ii, "supercell.json"))
+ ptr_data += "%s: %7.3f %7.3f %7.3f \n" % (
+ str(supercell_index) + "-" + structure_dir,
+ evac,
+ task_result["energies"][-1],
+ equi_epa * natoms,
+ )
+ res_data[str(supercell_index) + "-" + structure_dir] = [
+ evac,
+ task_result["energies"][-1],
+ equi_epa * natoms,
+ ]
else:
- if 'init_data_path' not in self.parameter:
+ if "init_data_path" not in self.parameter:
raise RuntimeError("please provide the initial data path to reproduce")
- init_data_path = os.path.abspath(self.parameter['init_data_path'])
- res_data, ptr_data = post_repro(init_data_path, self.parameter['init_from_suffix'],
- all_tasks, ptr_data, self.parameter.get('reprod_last_frame', False))
+ init_data_path = os.path.abspath(self.parameter["init_data_path"])
+ res_data, ptr_data = post_repro(
+ init_data_path,
+ self.parameter["init_from_suffix"],
+ all_tasks,
+ ptr_data,
+ self.parameter.get("reprod_last_frame", False),
+ )
- with open(output_file, 'w') as fp:
+ with open(output_file, "w") as fp:
json.dump(res_data, fp, indent=4)
return res_data, ptr_data
diff --git a/dpgen/auto_test/calculator.py b/dpgen/auto_test/calculator.py
index b936351ec..90e800371 100644
--- a/dpgen/auto_test/calculator.py
+++ b/dpgen/auto_test/calculator.py
@@ -1,22 +1,21 @@
-from dpgen.auto_test.VASP import VASP
from dpgen.auto_test.ABACUS import ABACUS
from dpgen.auto_test.Lammps import Lammps
+from dpgen.auto_test.VASP import VASP
-def make_calculator(inter_parameter,
- path_to_poscar):
+def make_calculator(inter_parameter, path_to_poscar):
"""
Make an instance of Task
"""
- inter_type = inter_parameter['type']
- if inter_type == 'vasp':
+ inter_type = inter_parameter["type"]
+ if inter_type == "vasp":
return VASP(inter_parameter, path_to_poscar)
- elif inter_type == 'abacus':
+ elif inter_type == "abacus":
return ABACUS(inter_parameter, path_to_poscar)
- elif inter_type in ['deepmd', 'meam', 'eam_fs', 'eam_alloy']:
+ elif inter_type in ["deepmd", "meam", "eam_fs", "eam_alloy"]:
return Lammps(inter_parameter, path_to_poscar)
# if inter_type == 'siesta':
# return Siesta(inter_parameter, path_to_poscar)
# pass
else:
- raise RuntimeError(f'unsupported interaction {inter_type}')
+ raise RuntimeError(f"unsupported interaction {inter_type}")
diff --git a/dpgen/auto_test/common_equi.py b/dpgen/auto_test/common_equi.py
index f456be083..2c0bfbf8e 100644
--- a/dpgen/auto_test/common_equi.py
+++ b/dpgen/auto_test/common_equi.py
@@ -2,36 +2,34 @@
import os
import shutil
import warnings
-from monty.serialization import dumpfn
from multiprocessing import Pool
+from monty.serialization import dumpfn
+from packaging.version import Version
+
+import dpgen.auto_test.lib.abacus as abacus
import dpgen.auto_test.lib.crys as crys
import dpgen.auto_test.lib.util as util
-import dpgen.auto_test.lib.abacus as abacus
from dpgen import dlog
from dpgen.auto_test.calculator import make_calculator
+from dpgen.auto_test.lib.utils import create_path
from dpgen.auto_test.mpdb import get_structure
-from dpgen.dispatcher.Dispatcher import make_dispatcher
-from distutils.version import LooseVersion
from dpgen.dispatcher.Dispatcher import make_submission
from dpgen.remote.decide_machine import convert_mdata
-from dpgen.auto_test.lib.utils import create_path
-lammps_task_type = ['deepmd', 'meam', 'eam_fs', 'eam_alloy']
+lammps_task_type = ["deepmd", "meam", "eam_fs", "eam_alloy"]
-def make_equi(confs,
- inter_param,
- relax_param):
+def make_equi(confs, inter_param, relax_param):
# find all POSCARs and their name like mp-xxx
# ...
- dlog.debug('debug info make equi')
- if 'type_map' in inter_param:
- ele_list = [key for key in inter_param['type_map'].keys()]
+ dlog.debug("debug info make equi")
+ if "type_map" in inter_param:
+ ele_list = [key for key in inter_param["type_map"].keys()]
else:
- ele_list = [key for key in inter_param['potcars'].keys()]
+ ele_list = [key for key in inter_param["potcars"].keys()]
# ele_list = inter_param['type_map']
- dlog.debug("ele_list %s" % ':'.join(ele_list))
+ dlog.debug("ele_list %s" % ":".join(ele_list))
conf_dirs = []
for conf in confs:
conf_dirs.extend(glob.glob(conf))
@@ -41,67 +39,71 @@ def make_equi(confs,
# ...
cwd = os.getcwd()
# generate poscar for single element crystal
- if len(ele_list) == 1 or 'single' in inter_param:
- if 'single' in inter_param:
- element_label = int(inter_param['single'])
+ if len(ele_list) == 1 or "single" in inter_param:
+ if "single" in inter_param:
+ element_label = int(inter_param["single"])
else:
element_label = 0
for ii in conf_dirs:
os.chdir(ii)
- crys_type = ii.split('/')[-1]
- dlog.debug('crys_type: %s' % crys_type)
- dlog.debug('pwd: %s' % os.getcwd())
- if crys_type == 'std-fcc':
- if not os.path.exists('POSCAR'):
- crys.fcc1(ele_list[element_label]).to('POSCAR', 'POSCAR')
- elif crys_type == 'std-hcp':
- if not os.path.exists('POSCAR'):
- crys.hcp(ele_list[element_label]).to('POSCAR', 'POSCAR')
- elif crys_type == 'std-dhcp':
- if not os.path.exists('POSCAR'):
- crys.dhcp(ele_list[element_label]).to('POSCAR', 'POSCAR')
- elif crys_type == 'std-bcc':
- if not os.path.exists('POSCAR'):
- crys.bcc(ele_list[element_label]).to('POSCAR', 'POSCAR')
- elif crys_type == 'std-diamond':
- if not os.path.exists('POSCAR'):
- crys.diamond(ele_list[element_label]).to('POSCAR', 'POSCAR')
- elif crys_type == 'std-sc':
- if not os.path.exists('POSCAR'):
- crys.sc(ele_list[element_label]).to('POSCAR', 'POSCAR')
-
- if inter_param['type'] == "abacus" and not os.path.exists('STRU'):
- abacus.poscar2stru("POSCAR",inter_param,"STRU")
- os.remove('POSCAR')
-
+ crys_type = ii.split("/")[-1]
+ dlog.debug("crys_type: %s" % crys_type)
+ dlog.debug("pwd: %s" % os.getcwd())
+ if crys_type == "std-fcc":
+ if not os.path.exists("POSCAR"):
+ crys.fcc1(ele_list[element_label]).to("POSCAR", "POSCAR")
+ elif crys_type == "std-hcp":
+ if not os.path.exists("POSCAR"):
+ crys.hcp(ele_list[element_label]).to("POSCAR", "POSCAR")
+ elif crys_type == "std-dhcp":
+ if not os.path.exists("POSCAR"):
+ crys.dhcp(ele_list[element_label]).to("POSCAR", "POSCAR")
+ elif crys_type == "std-bcc":
+ if not os.path.exists("POSCAR"):
+ crys.bcc(ele_list[element_label]).to("POSCAR", "POSCAR")
+ elif crys_type == "std-diamond":
+ if not os.path.exists("POSCAR"):
+ crys.diamond(ele_list[element_label]).to("POSCAR", "POSCAR")
+ elif crys_type == "std-sc":
+ if not os.path.exists("POSCAR"):
+ crys.sc(ele_list[element_label]).to("POSCAR", "POSCAR")
+
+ if inter_param["type"] == "abacus" and not os.path.exists("STRU"):
+ abacus.poscar2stru("POSCAR", inter_param, "STRU")
+ os.remove("POSCAR")
+
os.chdir(cwd)
task_dirs = []
# make task directories like mp-xxx/relaxation/relax_task
# if mp-xxx/exists then print a warning and exit.
# ...
for ii in conf_dirs:
- crys_type = ii.split('/')[-1]
- dlog.debug('crys_type: %s' % crys_type)
-
- if 'mp-' in crys_type and not os.path.exists(os.path.join(ii, 'POSCAR')):
- get_structure(crys_type).to('POSCAR', os.path.join(ii, 'POSCAR'))
- if inter_param['type'] == "abacus" and not os.path.exists('STRU'):
- abacus.poscar2stru(os.path.join(ii, 'POSCAR'),inter_param,os.path.join(ii, 'STRU'))
- os.remove(os.path.join(ii, 'POSCAR'))
-
- poscar = os.path.abspath(os.path.join(ii, 'POSCAR'))
- POSCAR = 'POSCAR'
- if inter_param['type'] == "abacus":
- shutil.copyfile(os.path.join(ii, 'STRU'),os.path.join(ii, 'STRU.bk'))
- abacus.modify_stru_path(os.path.join(ii, 'STRU'),'pp_orb/')
- poscar = os.path.abspath(os.path.join(ii, 'STRU'))
- POSCAR = 'STRU'
+ crys_type = ii.split("/")[-1]
+ dlog.debug("crys_type: %s" % crys_type)
+
+ if "mp-" in crys_type and not os.path.exists(os.path.join(ii, "POSCAR")):
+ get_structure(crys_type).to("POSCAR", os.path.join(ii, "POSCAR"))
+ if inter_param["type"] == "abacus" and not os.path.exists("STRU"):
+ abacus.poscar2stru(
+ os.path.join(ii, "POSCAR"), inter_param, os.path.join(ii, "STRU")
+ )
+ os.remove(os.path.join(ii, "POSCAR"))
+
+ poscar = os.path.abspath(os.path.join(ii, "POSCAR"))
+ POSCAR = "POSCAR"
+ if inter_param["type"] == "abacus":
+ shutil.copyfile(os.path.join(ii, "STRU"), os.path.join(ii, "STRU.bk"))
+ abacus.modify_stru_path(os.path.join(ii, "STRU"), "pp_orb/")
+ poscar = os.path.abspath(os.path.join(ii, "STRU"))
+ POSCAR = "STRU"
if not os.path.exists(poscar):
- raise FileNotFoundError('no configuration for autotest')
- if os.path.exists(os.path.join(ii, 'relaxation', 'jr.json')):
- os.remove(os.path.join(ii, 'relaxation', 'jr.json'))
+ raise FileNotFoundError("no configuration for autotest")
+ if os.path.exists(os.path.join(ii, "relaxation", "jr.json")):
+ os.remove(os.path.join(ii, "relaxation", "jr.json"))
- relax_dirs = os.path.abspath(os.path.join(ii, 'relaxation', 'relax_task')) # to be consistent with property in make dispatcher
+ relax_dirs = os.path.abspath(
+ os.path.join(ii, "relaxation", "relax_task")
+ ) # to be consistent with property in make dispatcher
create_path(relax_dirs)
task_dirs.append(relax_dirs)
os.chdir(relax_dirs)
@@ -113,31 +115,30 @@ def make_equi(confs,
os.chdir(cwd)
task_dirs.sort()
# generate task files
- relax_param['cal_type'] = 'relaxation'
- if 'cal_setting' not in relax_param:
- relax_param['cal_setting'] = {"relax_pos": True,
- "relax_shape": True,
- "relax_vol": True}
+ relax_param["cal_type"] = "relaxation"
+ if "cal_setting" not in relax_param:
+ relax_param["cal_setting"] = {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": True,
+ }
else:
- if "relax_pos" not in relax_param['cal_setting']:
- relax_param['cal_setting']['relax_pos'] = True
- if "relax_shape" not in relax_param['cal_setting']:
- relax_param['cal_setting']['relax_shape'] = True
- if "relax_vol" not in relax_param['cal_setting']:
- relax_param['cal_setting']['relax_vol'] = True
+ if "relax_pos" not in relax_param["cal_setting"]:
+ relax_param["cal_setting"]["relax_pos"] = True
+ if "relax_shape" not in relax_param["cal_setting"]:
+ relax_param["cal_setting"]["relax_shape"] = True
+ if "relax_vol" not in relax_param["cal_setting"]:
+ relax_param["cal_setting"]["relax_vol"] = True
for ii in task_dirs:
- poscar = os.path.join(ii, 'POSCAR')
- dlog.debug('task_dir %s' % ii)
+ poscar = os.path.join(ii, "POSCAR")
+ dlog.debug("task_dir %s" % ii)
inter = make_calculator(inter_param, poscar)
inter.make_potential_files(ii)
- inter.make_input_file(ii, 'relaxation', relax_param)
-
+ inter.make_input_file(ii, "relaxation", relax_param)
-def run_equi(confs,
- inter_param,
- mdata):
+def run_equi(confs, inter_param, mdata):
# find all POSCARs and their name like mp-xxx
# ...
conf_dirs = []
@@ -151,20 +152,20 @@ def run_equi(confs,
# ...
work_path_list = []
for ii in conf_dirs:
- work_path_list.append(os.path.join(ii, 'relaxation'))
+ work_path_list.append(os.path.join(ii, "relaxation"))
all_task = []
for ii in work_path_list:
- all_task.append(os.path.join(ii, 'relax_task'))
+ all_task.append(os.path.join(ii, "relax_task"))
run_tasks = all_task
- inter_type = inter_param['type']
+ inter_type = inter_param["type"]
# vasp
- if inter_type in ["vasp","abacus"]:
+ if inter_type in ["vasp", "abacus"]:
mdata = convert_mdata(mdata, ["fp"])
elif inter_type in lammps_task_type:
mdata = convert_mdata(mdata, ["model_devi"])
else:
raise RuntimeError("unknown task %s, something wrong" % inter_type)
-
+
# dispatch the tasks
# POSCAR here is useless
virtual_calculator = make_calculator(inter_param, "POSCAR")
@@ -176,23 +177,13 @@ def run_equi(confs,
work_path = os.getcwd()
print("%s --> Runing... " % (work_path))
- api_version = mdata.get('api_version', '0.9')
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- disp = make_dispatcher(machine, resources, work_path, run_tasks, group_size)
- disp.run_jobs(resources,
- command,
- work_path,
- run_tasks,
- group_size,
- forward_common_files,
- forward_files,
- backward_files,
- outlog='outlog',
- errlog='errlog')
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
-
+ api_version = mdata.get("api_version", "1.0")
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+ elif Version(api_version) >= Version("1.0"):
+
submission = make_submission(
mdata_machine=machine,
mdata_resources=resources,
@@ -203,12 +194,11 @@ def run_equi(confs,
forward_common_files=forward_common_files,
forward_files=forward_files,
backward_files=backward_files,
- outlog='outlog',
- errlog='errlog'
+ outlog="outlog",
+ errlog="errlog",
)
submission.run_submission()
-
-
+
def post_equi(confs, inter_param):
# find all POSCARs and their name like mp-xxx
@@ -219,7 +209,7 @@ def post_equi(confs, inter_param):
conf_dirs.sort()
task_dirs = []
for ii in conf_dirs:
- task_dirs.append(os.path.abspath(os.path.join(ii, 'relaxation', 'relax_task')))
+ task_dirs.append(os.path.abspath(os.path.join(ii, "relaxation", "relax_task")))
task_dirs.sort()
# generate a list of task names like mp-xxx/relaxation
@@ -227,7 +217,7 @@ def post_equi(confs, inter_param):
# dump the relaxation result.
for ii in task_dirs:
- poscar = os.path.join(ii, 'POSCAR')
+ poscar = os.path.join(ii, "POSCAR")
inter = make_calculator(inter_param, poscar)
res = inter.compute(ii)
- dumpfn(res, os.path.join(ii, 'result.json'), indent=4)
+ dumpfn(res, os.path.join(ii, "result.json"), indent=4)
diff --git a/dpgen/auto_test/common_prop.py b/dpgen/auto_test/common_prop.py
index e0a3645e6..1f3ea3461 100644
--- a/dpgen/auto_test/common_prop.py
+++ b/dpgen/auto_test/common_prop.py
@@ -1,49 +1,49 @@
-from distutils.version import LooseVersion
import glob
import os
import warnings
from multiprocessing import Pool
+
+from packaging.version import Version
+
import dpgen.auto_test.lib.util as util
from dpgen import dlog
-from dpgen.util import sepline
-from dpgen.auto_test.EOS import EOS
+from dpgen.auto_test.calculator import make_calculator
from dpgen.auto_test.Elastic import Elastic
+from dpgen.auto_test.EOS import EOS
+from dpgen.auto_test.Gamma import Gamma
from dpgen.auto_test.Interstitial import Interstitial
+from dpgen.auto_test.lib.utils import create_path
from dpgen.auto_test.Surface import Surface
from dpgen.auto_test.Vacancy import Vacancy
-from dpgen.auto_test.Gamma import Gamma
-from dpgen.auto_test.calculator import make_calculator
-from dpgen.dispatcher.Dispatcher import make_dispatcher
from dpgen.dispatcher.Dispatcher import make_submission
from dpgen.remote.decide_machine import convert_mdata
-from dpgen.auto_test.lib.utils import create_path
-lammps_task_type = ['deepmd', 'meam', 'eam_fs', 'eam_alloy']
+from dpgen.util import sepline
+lammps_task_type = ["deepmd", "meam", "eam_fs", "eam_alloy"]
-def make_property_instance(parameters,inter_param):
+
+def make_property_instance(parameters, inter_param):
"""
Make an instance of Property
"""
- prop_type = parameters['type']
- if prop_type == 'eos':
- return EOS(parameters,inter_param)
- elif prop_type == 'elastic':
- return Elastic(parameters,inter_param)
- elif prop_type == 'vacancy':
- return Vacancy(parameters,inter_param)
- elif prop_type == 'interstitial':
- return Interstitial(parameters,inter_param)
- elif prop_type == 'surface':
- return Surface(parameters,inter_param)
- elif prop_type == 'gamma':
- return Gamma(parameters,inter_param)
+ prop_type = parameters["type"]
+ if prop_type == "eos":
+ return EOS(parameters, inter_param)
+ elif prop_type == "elastic":
+ return Elastic(parameters, inter_param)
+ elif prop_type == "vacancy":
+ return Vacancy(parameters, inter_param)
+ elif prop_type == "interstitial":
+ return Interstitial(parameters, inter_param)
+ elif prop_type == "surface":
+ return Surface(parameters, inter_param)
+ elif prop_type == "gamma":
+ return Gamma(parameters, inter_param)
else:
- raise RuntimeError(f'unknown property type {prop_type}')
+ raise RuntimeError(f"unknown property type {prop_type}")
-def make_property(confs,
- inter_param,
- property_list):
+def make_property(confs, inter_param, property_list):
# find all POSCARs and their name like mp-xxx
# ...
# conf_dirs = glob.glob(confs)
@@ -57,15 +57,15 @@ def make_property(confs,
for jj in property_list:
if jj.get("skip", False):
continue
- if 'init_from_suffix' and 'output_suffix' in jj:
+ if "init_from_suffix" and "output_suffix" in jj:
do_refine = True
- suffix = jj['output_suffix']
- elif 'reproduce' in jj and jj['reproduce']:
+ suffix = jj["output_suffix"]
+ elif "reproduce" in jj and jj["reproduce"]:
do_refine = False
- suffix = 'reprod'
+ suffix = "reprod"
else:
do_refine = False
- suffix = '00'
+ suffix = "00"
# generate working directory like mp-xxx/eos_00 if jj['type'] == 'eos'
# handel the exception that the working directory exists
# ...
@@ -73,33 +73,32 @@ def make_property(confs,
# determine the suffix: from scratch or refine
# ...
- property_type = jj['type']
- path_to_equi = os.path.join(ii, 'relaxation', 'relax_task')
- path_to_work = os.path.join(ii, property_type + '_' + suffix)
+ property_type = jj["type"]
+ path_to_equi = os.path.join(ii, "relaxation", "relax_task")
+ path_to_work = os.path.join(ii, property_type + "_" + suffix)
create_path(path_to_work)
inter_param_prop = inter_param
- if 'cal_setting' in jj and 'overwrite_interaction' in jj['cal_setting']:
- inter_param_prop = jj['cal_setting']['overwrite_interaction']
+ if "cal_setting" in jj and "overwrite_interaction" in jj["cal_setting"]:
+ inter_param_prop = jj["cal_setting"]["overwrite_interaction"]
- prop = make_property_instance(jj,inter_param_prop)
- task_list = prop.make_confs(path_to_work, path_to_equi, do_refine)
+ prop = make_property_instance(jj, inter_param_prop)
+ task_list = prop.make_confs(path_to_work, path_to_equi, do_refine)
for kk in task_list:
- poscar = os.path.join(kk, 'POSCAR')
+ poscar = os.path.join(kk, "POSCAR")
inter = make_calculator(inter_param_prop, poscar)
inter.make_potential_files(kk)
dlog.debug(prop.task_type()) ### debug
inter.make_input_file(kk, prop.task_type(), prop.task_param())
- prop.post_process(task_list) # generate same KPOINTS file for elastic when doing VASP
+ prop.post_process(
+ task_list
+ ) # generate same KPOINTS file for elastic when doing VASP
-def run_property(confs,
- inter_param,
- property_list,
- mdata):
+def run_property(confs, inter_param, property_list, mdata):
# find all POSCARs and their name like mp-xxx
# ...
# conf_dirs = glob.glob(confs)
@@ -121,36 +120,40 @@ def run_property(confs,
# ...
if jj.get("skip", False):
continue
- if 'init_from_suffix' and 'output_suffix' in jj:
- suffix = jj['output_suffix']
- elif 'reproduce' in jj and jj['reproduce']:
- suffix = 'reprod'
+ if "init_from_suffix" and "output_suffix" in jj:
+ suffix = jj["output_suffix"]
+ elif "reproduce" in jj and jj["reproduce"]:
+ suffix = "reprod"
else:
- suffix = '00'
+ suffix = "00"
- property_type = jj['type']
- path_to_work = os.path.abspath(os.path.join(ii, property_type + '_' + suffix))
+ property_type = jj["type"]
+ path_to_work = os.path.abspath(
+ os.path.join(ii, property_type + "_" + suffix)
+ )
work_path_list.append(path_to_work)
- tmp_task_list = glob.glob(os.path.join(path_to_work, 'task.[0-9]*[0-9]'))
+ tmp_task_list = glob.glob(os.path.join(path_to_work, "task.[0-9]*[0-9]"))
tmp_task_list.sort()
task_list.append(tmp_task_list)
inter_param_prop = inter_param
- if 'cal_setting' in jj and 'overwrite_interaction' in jj['cal_setting']:
- inter_param_prop = jj['cal_setting']['overwrite_interaction']
+ if "cal_setting" in jj and "overwrite_interaction" in jj["cal_setting"]:
+ inter_param_prop = jj["cal_setting"]["overwrite_interaction"]
# dispatch the tasks
# POSCAR here is useless
virtual_calculator = make_calculator(inter_param_prop, "POSCAR")
forward_files = virtual_calculator.forward_files(property_type)
- forward_common_files = virtual_calculator.forward_common_files(property_type)
+ forward_common_files = virtual_calculator.forward_common_files(
+ property_type
+ )
backward_files = virtual_calculator.backward_files(property_type)
# backward_files += logs
# ...
- inter_type = inter_param_prop['type']
+ inter_type = inter_param_prop["type"]
# vasp
- if inter_type in ["vasp","abacus"]:
+ if inter_type in ["vasp", "abacus"]:
mdata = convert_mdata(mdata, ["fp"])
elif inter_type in lammps_task_type:
mdata = convert_mdata(mdata, ["model_devi"])
@@ -163,14 +166,18 @@ def run_property(confs,
if len(run_tasks) == 0:
continue
else:
- ret = pool.apply_async(worker, (work_path,
- all_task,
- forward_common_files,
- forward_files,
- backward_files,
- mdata,
- inter_type,
- ))
+ ret = pool.apply_async(
+ worker,
+ (
+ work_path,
+ all_task,
+ forward_common_files,
+ forward_files,
+ backward_files,
+ mdata,
+ inter_type,
+ ),
+ )
multiple_ret.append(ret)
pool.close()
pool.join()
@@ -178,52 +185,43 @@ def run_property(confs,
if not multiple_ret[ii].successful():
print("ERROR:", multiple_ret[ii].get())
raise RuntimeError("Job %d is not successful!" % ii)
- print('%d jobs are finished' % len(multiple_ret))
+ print("%d jobs are finished" % len(multiple_ret))
-def worker(work_path,
- all_task,
- forward_common_files,
- forward_files,
- backward_files,
- mdata,
- inter_type):
+def worker(
+ work_path,
+ all_task,
+ forward_common_files,
+ forward_files,
+ backward_files,
+ mdata,
+ inter_type,
+):
run_tasks = [os.path.basename(ii) for ii in all_task]
machine, resources, command, group_size = util.get_machine_info(mdata, inter_type)
- api_version = mdata.get('api_version', '0.9')
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- disp = make_dispatcher(machine, resources, work_path, run_tasks, group_size)
- disp.run_jobs(resources,
- command,
- work_path,
- run_tasks,
- group_size,
- forward_common_files,
- forward_files,
- backward_files,
- outlog='outlog',
- errlog='errlog')
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ api_version = mdata.get("api_version", "1.0")
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+ elif Version(api_version) >= Version("1.0"):
submission = make_submission(
- mdata_machine=machine,
- mdata_resources=resources,
- commands=[command],
- work_path=work_path,
- run_tasks=run_tasks,
- group_size=group_size,
- forward_common_files=forward_common_files,
- forward_files=forward_files,
- backward_files=backward_files,
- outlog = 'outlog',
- errlog = 'errlog'
- )
+ mdata_machine=machine,
+ mdata_resources=resources,
+ commands=[command],
+ work_path=work_path,
+ run_tasks=run_tasks,
+ group_size=group_size,
+ forward_common_files=forward_common_files,
+ forward_files=forward_files,
+ backward_files=backward_files,
+ outlog="outlog",
+ errlog="errlog",
+ )
submission.run_submission()
-def post_property(confs,
- inter_param,
- property_list):
+
+def post_property(confs, inter_param, property_list):
# find all POSCARs and their name like mp-xxx
# ...
# task_list = []
@@ -239,19 +237,22 @@ def post_property(confs,
# ...
if jj.get("skip", False):
continue
- if 'init_from_suffix' and 'output_suffix' in jj:
- suffix = jj['output_suffix']
- elif 'reproduce' in jj and jj['reproduce']:
- suffix = 'reprod'
+ if "init_from_suffix" and "output_suffix" in jj:
+ suffix = jj["output_suffix"]
+ elif "reproduce" in jj and jj["reproduce"]:
+ suffix = "reprod"
else:
- suffix = '00'
+ suffix = "00"
inter_param_prop = inter_param
- if 'cal_setting' in jj and 'overwrite_interaction' in jj['cal_setting']:
- inter_param_prop = jj['cal_setting']['overwrite_interaction']
+ if "cal_setting" in jj and "overwrite_interaction" in jj["cal_setting"]:
+ inter_param_prop = jj["cal_setting"]["overwrite_interaction"]
- property_type = jj['type']
- path_to_work = os.path.join(ii, property_type + '_' + suffix)
- prop = make_property_instance(jj,inter_param_prop)
- prop.compute(os.path.join(path_to_work, 'result.json'), os.path.join(path_to_work, 'result.out'),
- path_to_work)
+ property_type = jj["type"]
+ path_to_work = os.path.join(ii, property_type + "_" + suffix)
+ prop = make_property_instance(jj, inter_param_prop)
+ prop.compute(
+ os.path.join(path_to_work, "result.json"),
+ os.path.join(path_to_work, "result.out"),
+ path_to_work,
+ )
diff --git a/dpgen/auto_test/gen_confs.py b/dpgen/auto_test/gen_confs.py
index fee3ca785..29cc02ba8 100755
--- a/dpgen/auto_test/gen_confs.py
+++ b/dpgen/auto_test/gen_confs.py
@@ -1,131 +1,147 @@
#!/usr/bin/env python3
-import os, re, argparse
-import dpgen.auto_test.lib.crys as crys
-from pymatgen.ext.matproj import MPRester, Composition
+import argparse
+import os
+import re
+
from pymatgen.analysis.structure_matcher import StructureMatcher
+from pymatgen.ext.matproj import Composition, MPRester
+
+import dpgen.auto_test.lib.crys as crys
global_std_crystal = {
- 'fcc' : crys.fcc,
- 'hcp' : crys.hcp,
- 'dhcp' : crys.dhcp,
- 'bcc' : crys.bcc,
- 'diamond' : crys.diamond,
- 'sc' : crys.sc
+ "fcc": crys.fcc,
+ "hcp": crys.hcp,
+ "dhcp": crys.dhcp,
+ "bcc": crys.bcc,
+ "diamond": crys.diamond,
+ "sc": crys.sc,
}
-def test_fit(struct, data) :
- m = StructureMatcher()
- for ii in data :
- if m.fit(ii['structure'], struct) :
+
+def test_fit(struct, data):
+ m = StructureMatcher()
+ for ii in data:
+ if m.fit(ii["structure"], struct):
return True
return False
-def make_path_mp(ii) :
- pf = ii['pretty_formula']
- pf = re.sub('\d+', '', pf)
- task_id = ii['task_id']
- work_path = 'confs'
+
+def make_path_mp(ii):
+ pf = ii["pretty_formula"]
+ pf = re.sub("\d+", "", pf)
+ task_id = ii["task_id"]
+ work_path = "confs"
work_path = os.path.join(work_path, pf)
work_path = os.path.join(work_path, task_id)
return work_path
+
def gen_ele_std(ele_name, ctype):
struct = global_std_crystal[ctype](ele_name)
- work_path = 'confs'
+ work_path = "confs"
work_path = os.path.join(work_path, ele_name)
- work_path = os.path.join(work_path, 'std-'+ctype)
- os.makedirs(work_path, exist_ok = True)
- fposcar = os.path.join(work_path, 'POSCAR')
- fjson = os.path.join(work_path, 'data.json')
- struct.to('poscar', fposcar)
+ work_path = os.path.join(work_path, "std-" + ctype)
+ os.makedirs(work_path, exist_ok=True)
+ fposcar = os.path.join(work_path, "POSCAR")
+ fjson = os.path.join(work_path, "data.json")
+ struct.to("poscar", fposcar)
return struct
-def gen_element(ele_name,key) :
- assert(type(ele_name) == str)
+
+def gen_element(ele_name, key):
+ assert type(ele_name) == str
mpr = MPRester(key)
- data = mpr.query({'elements':[ele_name], 'nelements':1},
- properties=["task_id",
- "pretty_formula",
- 'formula',
- "anonymous_formula",
- 'formation_energy_per_atom',
- 'energy_per_atom',
- 'structure'])
- for ii in data :
+ data = mpr.query(
+ {"elements": [ele_name], "nelements": 1},
+ properties=[
+ "task_id",
+ "pretty_formula",
+ "formula",
+ "anonymous_formula",
+ "formation_energy_per_atom",
+ "energy_per_atom",
+ "structure",
+ ],
+ )
+ for ii in data:
work_path = make_path_mp(ii)
- os.makedirs(work_path, exist_ok = True)
- fposcar = os.path.join(work_path, 'POSCAR')
- fjson = os.path.join(work_path, 'data.json')
- ii['structure'].to('poscar', fposcar)
- ii['structure'].to('json', fjson)
-
- m = StructureMatcher()
- for ii in global_std_crystal.keys() :
+ os.makedirs(work_path, exist_ok=True)
+ fposcar = os.path.join(work_path, "POSCAR")
+ fjson = os.path.join(work_path, "data.json")
+ ii["structure"].to("poscar", fposcar)
+ ii["structure"].to("json", fjson)
+
+ m = StructureMatcher()
+ for ii in global_std_crystal.keys():
ss = gen_ele_std(ele_name, ii)
find = False
for jj in data:
- if m.fit(ss,jj['structure']) :
+ if m.fit(ss, jj["structure"]):
find = True
break
- if find :
+ if find:
work_path = make_path_mp(jj)
- with open(os.path.join(work_path,'std-crys'), 'w') as fp :
- fp.write(ii+'\n')
+ with open(os.path.join(work_path, "std-crys"), "w") as fp:
+ fp.write(ii + "\n")
-def gen_element_std(ele_name) :
- assert(type(ele_name) == str)
- for ii in global_std_crystal.keys() :
+
+def gen_element_std(ele_name):
+ assert type(ele_name) == str
+ for ii in global_std_crystal.keys():
ss = gen_ele_std(ele_name, ii)
-def gen_alloy(eles,key) :
-
+
+def gen_alloy(eles, key):
+
mpr = MPRester(key)
- data = mpr.query({'elements':{'$all': eles}, 'nelements':len(eles)},
- properties=["task_id",
- "pretty_formula",
- 'formula',
- "anonymous_formula",
- 'formation_energy_per_atom',
- 'energy_per_atom',
- 'structure'])
- if len(data) == 0 :
+ data = mpr.query(
+ {"elements": {"$all": eles}, "nelements": len(eles)},
+ properties=[
+ "task_id",
+ "pretty_formula",
+ "formula",
+ "anonymous_formula",
+ "formation_energy_per_atom",
+ "energy_per_atom",
+ "structure",
+ ],
+ )
+ if len(data) == 0:
return
-
+
alloy_file = make_path_mp(data[0])
- os.makedirs(alloy_file, exist_ok = True)
- alloy_file = os.path.join(alloy_file, '..')
- alloy_file = os.path.join(alloy_file, 'alloy')
- with open(alloy_file, 'w') as fp :
- None
-
- for ii in data :
+ os.makedirs(alloy_file, exist_ok=True)
+ alloy_file = os.path.join(alloy_file, "..")
+ alloy_file = os.path.join(alloy_file, "alloy")
+ with open(alloy_file, "w") as fp:
+ None
+
+ for ii in data:
work_path = make_path_mp(ii)
- os.makedirs(work_path, exist_ok = True)
- fposcar = os.path.join(work_path, 'POSCAR')
- fjson = os.path.join(work_path, 'data.json')
- ii['structure'].to('poscar', fposcar)
- ii['structure'].to('json', fjson)
-
-def _main() :
- parser = argparse.ArgumentParser(
- description="gen structures")
- parser.add_argument('key', type=str,
- help='key id of material project')
- parser.add_argument('elements',
- type=str,
- nargs = '+',
- help="the list of appeared elements")
+ os.makedirs(work_path, exist_ok=True)
+ fposcar = os.path.join(work_path, "POSCAR")
+ fjson = os.path.join(work_path, "data.json")
+ ii["structure"].to("poscar", fposcar)
+ ii["structure"].to("json", fjson)
+
+
+def _main():
+ parser = argparse.ArgumentParser(description="gen structures")
+ parser.add_argument("key", type=str, help="key id of material project")
+ parser.add_argument(
+ "elements", type=str, nargs="+", help="the list of appeared elements"
+ )
args = parser.parse_args()
- print('generate %s' % (args.elements))
- if len(args.elements) == 1 :
- gen_element(args.elements[0],key)
+ print("generate %s" % (args.elements))
+ if len(args.elements) == 1:
+ gen_element(args.elements[0], key)
# gen_element_std(args.elements[0])
- else :
- gen_alloy(args.elements,key)
+ else:
+ gen_alloy(args.elements, key)
-if __name__ == '__main__' :
- _main()
+if __name__ == "__main__":
+ _main()
diff --git a/dpgen/auto_test/lib/BatchJob.py b/dpgen/auto_test/lib/BatchJob.py
deleted file mode 100644
index 6d68497df..000000000
--- a/dpgen/auto_test/lib/BatchJob.py
+++ /dev/null
@@ -1,81 +0,0 @@
-#!/usr/bin/env python3
-
-import os
-import sys
-from enum import Enum
-from subprocess import Popen, PIPE
-
-class JobStatus (Enum) :
- unsubmitted = 1
- waiting = 2
- running = 3
- terminated = 4
- finished = 5
- unknow = 100
-
-class BatchJob (object):
- """
- Abstract class of a batch job
- It submit a job (leave the id in file tag_jobid)
- It check the status of the job (return JobStatus)
- NOTICE: I assume that when a job finishes, a tag file named tag_finished should be touched by the user.
- TYPICAL USAGE:
- job = DERIVED_BatchJob (dir, script)
- job.submit ()
- stat = job.check_status ()
- """
- def __init__ (self,
- job_dir = "", # dir of the job
- job_script = "", # name of the job script
- job_finish_tag = "tag_finished", # name of the tag for finished job
- job_id_file = "tag_jobid") : # job id if making an existing job
- self.job_dir = job_dir
- self.job_script = job_script
- self.job_id_file = job_dir + "/" + job_id_file
- self.job_finish_tag = job_dir + "/" + job_finish_tag
- self.cwd = os.getcwd()
- self.submit_cmd = str(self.submit_command())
- def get_job_id (self) :
- if True == os.path.exists (self.job_id_file) :
- fp = open (self.job_id_file, 'r')
- job_id = fp.read ()
- return str(job_id)
- else :
- return ""
- def submit_command (self) :
- """
- submission is
- $ [command] [script]
- """
- raise RuntimeError ("submit_command not implemented")
- def check_status (self):
- raise RuntimeError ("check_status not implemented")
- def submit (self) :
- if self.get_job_id () != "" :
- stat = self.check_status()
- if stat != JobStatus.terminated :
- if stat == JobStatus.unknow :
- raise RuntimeError ("unknown job status, terminate!")
- print ("# job %s, dir %s already submitted (waiting, running or finished), would not submit again" %
- (self.get_job_id(), self.job_dir))
- return self.get_job_id()
- else :
- print ("# find terminated job " + self.get_job_id() + ", submit again")
- if (False == os.path.isdir (self.job_dir) ) :
- raise RuntimeError ("cannot find job dir " + self.job_dir)
- abs_job_script = self.job_dir + "/" + self.job_script
- if False == os.path.exists (abs_job_script) :
- raise RuntimeError ("cannot find job script " + abs_job_script)
- cwd = os.getcwd()
- os.chdir (self.job_dir)
- ret = Popen([self.submit_cmd + " " + self.job_script], stdout=PIPE, stderr=PIPE, shell = True)
- stdout, stderr = ret.communicate()
- if str(stderr, encoding='ascii') != "":
- raise RuntimeError (stderr)
- job_id = str(stdout, encoding='ascii').replace('\n','').split()[-1]
- print ("# job %s submitted, dir %s " % (job_id, self.job_dir))
- fp = open (self.job_id_file, 'w')
- fp.write (job_id)
- fp.close()
- os.chdir (cwd)
- return self.get_job_id()
diff --git a/dpgen/auto_test/lib/RemoteJob.py b/dpgen/auto_test/lib/RemoteJob.py
deleted file mode 100644
index e66df1351..000000000
--- a/dpgen/auto_test/lib/RemoteJob.py
+++ /dev/null
@@ -1,565 +0,0 @@
-#!/usr/bin/env python3
-
-import os, sys, paramiko, json, uuid, tarfile, time, stat
-from enum import Enum
-
-class JobStatus (Enum) :
- unsubmitted = 1
- waiting = 2
- running = 3
- terminated = 4
- finished = 5
- unknow = 100
-
-def _default_item(resources, key, value) :
- if key not in resources :
- resources[key] = value
-
-def _set_default_resource(res) :
- if res == None :
- res = {}
- _default_item(res, 'numb_node', 1)
- _default_item(res, 'task_per_node', 1)
- _default_item(res, 'numb_gpu', 0)
- _default_item(res, 'time_limit', '1:0:0')
- _default_item(res, 'mem_limit', -1)
- _default_item(res, 'partition', '')
- _default_item(res, 'account', '')
- _default_item(res, 'qos', '')
- _default_item(res, 'constraint_list', [])
- _default_item(res, 'license_list', [])
- _default_item(res, 'exclude_list', [])
- _default_item(res, 'module_unload_list', [])
- _default_item(res, 'module_list', [])
- _default_item(res, 'source_list', [])
- _default_item(res, 'envs', None)
- _default_item(res, 'with_mpi', False)
-
-
-class SSHSession (object) :
- def __init__ (self, jdata) :
- self.remote_profile = jdata
- # with open(remote_profile) as fp :
- # self.remote_profile = json.load(fp)
- self.remote_host = self.remote_profile['hostname']
- self.remote_port = self.remote_profile['port']
- self.remote_uname = self.remote_profile['username']
- self.remote_password = self.remote_profile['password']
- self.remote_workpath = self.remote_profile['work_path']
- self.ssh = self._setup_ssh(self.remote_host, self.remote_port, username = self.remote_uname,password=self.remote_password)
-
- def _setup_ssh(self,
- hostname,
- port,
- username = None,
- password = None):
- ssh_client = paramiko.SSHClient()
- ssh_client.load_system_host_keys()
- ssh_client.set_missing_host_key_policy(paramiko.WarningPolicy)
- ssh_client.connect(hostname, port=port, username=username, password=password)
- assert(ssh_client.get_transport().is_active())
- return ssh_client
-
- def get_ssh_client(self) :
- return self.ssh
-
- def get_session_root(self) :
- return self.remote_workpath
-
- def close(self) :
- self.ssh.close()
-
-
-class RemoteJob (object):
- def __init__ (self,
- ssh_session,
- local_root
- ) :
-
- self.local_root = os.path.abspath(local_root)
- self.job_uuid = str(uuid.uuid4())
- # self.job_uuid = 'a21d0017-c9f1-4d29-9a03-97df06965cef'
- self.remote_root = os.path.join(ssh_session.get_session_root(), self.job_uuid)
- print("local_root is ", local_root)
- print("remote_root is", self.remote_root)
- self.ssh = ssh_session.get_ssh_client()
- sftp = self.ssh.open_sftp()
- sftp.mkdir(self.remote_root)
- sftp.close()
- # open('job_uuid', 'w').write(self.job_uuid)
-
- def get_job_root(self) :
- return self.remote_root
-
- def upload(self,
- job_dirs,
- local_up_files,
- dereference = True) :
- cwd = os.getcwd()
- os.chdir(self.local_root)
- file_list = []
- for ii in job_dirs :
- for jj in local_up_files :
- file_list.append(os.path.join(ii,jj))
- self._put_files(file_list, dereference = dereference)
- os.chdir(cwd)
-
- def download(self,
- job_dirs,
- remote_down_files) :
- cwd = os.getcwd()
- os.chdir(self.local_root)
- file_list = []
- for ii in job_dirs :
- for jj in remote_down_files :
- file_list.append(os.path.join(ii,jj))
- self._get_files(file_list)
- os.chdir(cwd)
-
- def block_checkcall(self,
- cmd) :
- stdin, stdout, stderr = self.ssh.exec_command(('cd %s ;' % self.remote_root) + cmd)
- exit_status = stdout.channel.recv_exit_status()
- if exit_status != 0:
- raise RuntimeError("Get error code %d in calling through ssh with job: %s ", (exit_status, self.job_uuid))
- return stdin, stdout, stderr
-
- def block_call(self,
- cmd) :
- stdin, stdout, stderr = self.ssh.exec_command(('cd %s ;' % self.remote_root) + cmd)
- exit_status = stdout.channel.recv_exit_status()
- return exit_status, stdin, stdout, stderr
-
- def clean(self) :
- sftp = self.ssh.open_sftp()
- self._rmtree(sftp, self.remote_root)
- sftp.close()
-
- def _rmtree(self, sftp, remotepath, level=0, verbose = False):
- for f in sftp.listdir_attr(remotepath):
- rpath = os.path.join(remotepath, f.filename)
- if stat.S_ISDIR(f.st_mode):
- self._rmtree(sftp, rpath, level=(level + 1))
- else:
- rpath = os.path.join(remotepath, f.filename)
- if verbose: print('removing %s%s' % (' ' * level, rpath))
- sftp.remove(rpath)
- if verbose: print('removing %s%s' % (' ' * level, remotepath))
- sftp.rmdir(remotepath)
-
- def _put_files(self,
- files,
- dereference = True) :
- of = self.job_uuid + '.tgz'
- # local tar
- cwd = os.getcwd()
- os.chdir(self.local_root)
- if os.path.isfile(of) :
- os.remove(of)
- with tarfile.open(of, "w:gz", dereference = dereference) as tar:
- for ii in files :
- tar.add(ii)
- os.chdir(cwd)
- # trans
- from_f = os.path.join(self.local_root, of)
- to_f = os.path.join(self.remote_root, of)
- sftp = self.ssh.open_sftp()
- sftp.put(from_f, to_f)
- # remote extract
- self.block_checkcall('tar xf %s' % of)
- # clean up
- os.remove(from_f)
- sftp.remove(to_f)
- sftp.close()
-
- def _get_files(self,
- files) :
- of = self.job_uuid + '.tgz'
- flist = ""
- for ii in files :
- flist += " " + ii
- # remote tar
- self.block_checkcall('tar czf %s %s' % (of, flist))
- # trans
- from_f = os.path.join(self.remote_root, of)
- to_f = os.path.join(self.local_root, of)
- if os.path.isfile(to_f) :
- os.remove(to_f)
- sftp = self.ssh.open_sftp()
- sftp.get(from_f, to_f)
- # extract
- cwd = os.getcwd()
- os.chdir(self.local_root)
- with tarfile.open(of, "r:gz") as tar:
- def is_within_directory(directory, target):
-
- abs_directory = os.path.abspath(directory)
- abs_target = os.path.abspath(target)
-
- prefix = os.path.commonprefix([abs_directory, abs_target])
-
- return prefix == abs_directory
-
- def safe_extract(tar, path=".", members=None, *, numeric_owner=False):
-
- for member in tar.getmembers():
- member_path = os.path.join(path, member.name)
- if not is_within_directory(path, member_path):
- raise Exception("Attempted Path Traversal in Tar File")
-
- tar.extractall(path, members, numeric_owner=numeric_owner)
-
-
- safe_extract(tar)
- os.chdir(cwd)
- # cleanup
- os.remove(to_f)
- sftp.remove(from_f)
-
-class CloudMachineJob (RemoteJob) :
- def submit(self,
- job_dirs,
- cmd,
- args = None,
- resources = None) :
-
- #print("Current path is",os.getcwd())
-
- #for ii in job_dirs :
- # if not os.path.isdir(ii) :
- # raise RuntimeError("cannot find dir %s" % ii)
- # print(self.remote_root)
- script_name = self._make_script(job_dirs, cmd, args, resources)
- self.stdin, self.stdout, self.stderr = self.ssh.exec_command(('cd %s; bash %s' % (self.remote_root, script_name)))
- # print(self.stderr.read().decode('utf-8'))
- # print(self.stdout.read().decode('utf-8'))
-
- def check_status(self) :
- if not self._check_finish(self.stdout) :
- return JobStatus.running
- elif self._get_exit_status(self.stdout) == 0 :
- return JobStatus.finished
- else :
- return JobStatus.terminated
-
- def _check_finish(self, stdout) :
- return stdout.channel.exit_status_ready()
-
- def _get_exit_status(self, stdout) :
- return stdout.channel.recv_exit_status()
-
- def _make_script(self,
- job_dirs,
- cmd,
- args = None,
- resources = None) :
- _set_default_resource(resources)
- envs = resources['envs']
- module_list = resources['module_list']
- module_unload_list = resources['module_unload_list']
- task_per_node = resources['task_per_node']
-
- script_name = 'run.sh'
- if args == None :
- args = []
- for ii in job_dirs:
- args.append('')
- script = os.path.join(self.remote_root, script_name)
- sftp = self.ssh.open_sftp()
- with sftp.open(script, 'w') as fp :
- fp.write('#!/bin/bash\n\n')
- # fp.write('set -euo pipefail\n')
- if envs != None :
- for key in envs.keys() :
- fp.write('export %s=%s\n' % (key, envs[key]))
- fp.write('\n')
- if module_unload_list is not None :
- for ii in module_unload_list :
- fp.write('module unload %s\n' % ii)
- fp.write('\n')
- if module_list is not None :
- for ii in module_list :
- fp.write('module load %s\n' % ii)
- fp.write('\n')
- for ii,jj in zip(job_dirs, args) :
- fp.write('cd %s\n' % ii)
- fp.write('test $? -ne 0 && exit\n')
- if resources['with_mpi'] == True :
- fp.write('mpirun -n %d %s %s\n'
- % (task_per_node, cmd, jj))
- else :
- fp.write('%s %s\n' % (cmd, jj))
- fp.write('test $? -ne 0 && exit\n')
- fp.write('cd %s\n' % self.remote_root)
- fp.write('test $? -ne 0 && exit\n')
- fp.write('\ntouch tag_finished\n')
- sftp.close()
- return script_name
-
-
-class SlurmJob (RemoteJob) :
- def submit(self,
- job_dirs,
- cmd,
- args = None,
- resources = None) :
- script_name = self._make_script(job_dirs, cmd, args, res = resources)
- stdin, stdout, stderr = self.block_checkcall(('cd %s; sbatch %s' % (self.remote_root, script_name)))
- subret = (stdout.readlines())
- job_id = subret[0].split()[-1]
- sftp = self.ssh.open_sftp()
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'w') as fp:
- fp.write(job_id)
- sftp.close()
-
- def check_status(self) :
- job_id = self._get_job_id()
- if job_id == "" :
- raise RuntimeError("job %s is has not been submitted" % self.remote_root)
- ret, stdin, stdout, stderr\
- = self.block_call ("squeue --job " + job_id)
- err_str = stderr.read().decode('utf-8')
- if (ret != 0) :
- if str("Invalid job id specified") in err_str :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- raise RuntimeError\
- ("status command squeue fails to execute\nerror message:%s\nreturn code %d\n" % (err_str, ret))
- status_line = stdout.read().decode('utf-8').split ('\n')[-2]
- status_word = status_line.split ()[-4]
- if status_word in ["PD","CF","S"] :
- return JobStatus.waiting
- elif status_word in ["R","CG"] :
- return JobStatus.running
- elif status_word in ["C","E","K","BF","CA","CD","F","NF","PR","SE","ST","TO"] :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- return JobStatus.unknown
-
- def _get_job_id(self) :
- sftp = self.ssh.open_sftp()
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'r') as fp:
- ret = fp.read().decode('utf-8')
- sftp.close()
- return ret
-
- def _check_finish_tag(self) :
- sftp = self.ssh.open_sftp()
- try:
- sftp.stat(os.path.join(self.remote_root, 'tag_finished'))
- ret = True
- except IOError:
- ret = False
- sftp.close()
- return ret
-
- def _make_script(self,
- job_dirs,
- cmd,
- args = None,
- res = None) :
- _set_default_resource(res)
- ret = ''
- ret += "#!/bin/bash -l\n"
- ret += "#SBATCH -N %d\n" % res['numb_node']
- ret += "#SBATCH --ntasks-per-node %d\n" % res['task_per_node']
- ret += "#SBATCH -t %s\n" % res['time_limit']
- if res['mem_limit'] > 0 :
- ret += "#SBATCH --mem %dG \n" % res['mem_limit']
- if len(res['account']) > 0 :
- ret += "#SBATCH --account %s \n" % res['account']
- if len(res['partition']) > 0 :
- ret += "#SBATCH --partition %s \n" % res['partition']
- if len(res['qos']) > 0 :
- ret += "#SBATCH --qos %s \n" % res['qos']
- if res['numb_gpu'] > 0 :
- ret += "#SBATCH --gres=gpu:%d\n" % res['numb_gpu']
- for ii in res['constraint_list'] :
- ret += '#SBATCH -C %s \n' % ii
- for ii in res['license_list'] :
- ret += '#SBATCH -L %s \n' % ii
- for ii in res['exclude_list'] :
- ret += '#SBATCH --exclude %s \n' % ii
- ret += "\n"
- # ret += 'set -euo pipefail\n\n'
- for ii in res['module_unload_list'] :
- ret += "module unload %s\n" % ii
- for ii in res['module_list'] :
- ret += "module load %s\n" % ii
- ret += "\n"
- for ii in res['source_list'] :
- ret += "source %s\n" %ii
- ret += "\n"
- envs = res['envs']
- if envs != None :
- for key in envs.keys() :
- ret += 'export %s=%s\n' % (key, envs[key])
- ret += '\n'
-
- if args == None :
- args = []
- for ii in job_dirs:
- args.append('')
- for ii,jj in zip(job_dirs, args) :
- ret += 'cd %s\n' % ii
- ret += 'test $? -ne 0 && exit\n'
- if res['with_mpi'] :
- ret += 'mpirun -n %d %s %s\n' % (res['task_per_node'],cmd, jj)
- else :
- ret += '%s %s\n' % (cmd, jj)
- ret += 'test $? -ne 0 && exit\n'
- ret += 'cd %s\n' % self.remote_root
- ret += 'test $? -ne 0 && exit\n'
- ret += '\ntouch tag_finished\n'
-
- script_name = 'run.sub'
- script = os.path.join(self.remote_root, script_name)
- sftp = self.ssh.open_sftp()
- with sftp.open(script, 'w') as fp :
- fp.write(ret)
- sftp.close()
-
- return script_name
-
-
-class PBSJob (RemoteJob) :
- def submit(self,
- job_dirs,
- cmd,
- args = None,
- resources = None) :
- script_name = self._make_script(job_dirs, cmd, args, res = resources)
- stdin, stdout, stderr = self.block_checkcall(('cd %s; qsub %s' % (self.remote_root, script_name)))
- subret = (stdout.readlines())
- job_id = subret[0].split()[0]
- sftp = self.ssh.open_sftp()
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'w') as fp:
- fp.write(job_id)
- sftp.close()
-
- def check_status(self) :
- job_id = self._get_job_id()
- if job_id == "" :
- raise RuntimeError("job %s is has not been submitted" % self.remote_root)
- ret, stdin, stdout, stderr\
- = self.block_call ("qstat " + job_id)
- err_str = stderr.read().decode('utf-8')
- if (ret != 0) :
- if str("qstat: Unknown Job Id") in err_str :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- raise RuntimeError ("status command qstat fails to execute. erro info: %s return code %d"
- % (err_str, ret))
- status_line = stdout.read().decode('utf-8').split ('\n')[-2]
- status_word = status_line.split ()[-2]
-# print (status_word)
- if status_word in ["Q","H"] :
- return JobStatus.waiting
- elif status_word in ["R"] :
- return JobStatus.running
- elif status_word in ["C","E","K"] :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- return JobStatus.unknown
-
- def _get_job_id(self) :
- sftp = self.ssh.open_sftp()
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'r') as fp:
- ret = fp.read().decode('utf-8')
- sftp.close()
- return ret
-
- def _check_finish_tag(self) :
- sftp = self.ssh.open_sftp()
- try:
- sftp.stat(os.path.join(self.remote_root, 'tag_finished'))
- ret = True
- except IOError:
- ret = False
- sftp.close()
- return ret
-
- def _make_script(self,
- job_dirs,
- cmd,
- args = None,
- res = None) :
- _set_default_resource(res)
- ret = ''
- ret += "#!/bin/bash -l\n"
- if res['numb_gpu'] == 0:
- ret += '#PBS -l nodes=%d:ppn=%d\n' % (res['numb_node'], res['task_per_node'])
- else :
- ret += '#PBS -l nodes=%d:ppn=%d:gpus=%d\n' % (res['numb_node'], res['task_per_node'], res['numb_gpu'])
- ret += '#PBS -l walltime=%s\n' % (res['time_limit'])
- if res['mem_limit'] > 0 :
- ret += "#PBS -l mem=%dG \n" % res['mem_limit']
- ret += '#PBS -j oe\n'
- if len(res['partition']) > 0 :
- ret += '#PBS -q %s\n' % res['partition']
- ret += "\n"
- for ii in res['module_unload_list'] :
- ret += "module unload %s\n" % ii
- for ii in res['module_list'] :
- ret += "module load %s\n" % ii
- ret += "\n"
- for ii in res['source_list'] :
- ret += "source %s\n" %ii
- ret += "\n"
- envs = res['envs']
- if envs != None :
- for key in envs.keys() :
- ret += 'export %s=%s\n' % (key, envs[key])
- ret += '\n'
- ret += 'cd $PBS_O_WORKDIR\n\n'
-
- if args == None :
- args = []
- for ii in job_dirs:
- args.append('')
- for ii,jj in zip(job_dirs, args) :
- ret += 'cd %s\n' % ii
- ret += 'test $? -ne 0 && exit\n'
- if res['with_mpi'] :
- ret += 'mpirun -machinefile $PBS_NODEFILE -n %d %s %s\n' % (res['numb_node'] * res['task_per_node'], cmd, jj)
- else :
- ret += '%s %s\n' % (cmd, jj)
- ret += 'test $? -ne 0 && exit\n'
- ret += 'cd %s\n' % self.remote_root
- ret += 'test $? -ne 0 && exit\n'
- ret += '\ntouch tag_finished\n'
-
- script_name = 'run.sub'
- script = os.path.join(self.remote_root, script_name)
- sftp = self.ssh.open_sftp()
- with sftp.open(script, 'w') as fp :
- fp.write(ret)
- sftp.close()
-
- return script_name
-
-
-# ssh_session = SSHSession('localhost.json')
-# rjob = CloudMachineJob(ssh_session, '.')
-# # can upload dirs and normal files
-# rjob.upload(['job0', 'job1'], ['batch_exec.py', 'test'])
-# rjob.submit(['job0', 'job1'], 'touch a; sleep 2')
-# while rjob.check_status() == JobStatus.running :
-# print('checked')
-# time.sleep(2)
-# print(rjob.check_status())
-# # can download dirs and normal files
-# rjob.download(['job0', 'job1'], ['a'])
-# # rjob.clean()
diff --git a/dpgen/auto_test/lib/SlurmJob.py b/dpgen/auto_test/lib/SlurmJob.py
deleted file mode 100644
index 3fc49088d..000000000
--- a/dpgen/auto_test/lib/SlurmJob.py
+++ /dev/null
@@ -1,55 +0,0 @@
-#!/usr/bin/env python3
-
-import os
-import sys
-from enum import Enum
-from subprocess import Popen, PIPE
-from dpgen.auto_test.lib.BatchJob import BatchJob
-from dpgen.auto_test.lib.BatchJob import JobStatus
-
-class SlurmJob (BatchJob) :
- def submit_command (self):
- return "sbatch"
- def check_status (self):
- job_id = self.get_job_id ()
- if len(job_id) == 0 :
- return JobStatus.unsubmitted
- ret = Popen (["squeue --job " + job_id], shell=True, stdout=PIPE, stderr=PIPE)
- stdout, stderr = ret.communicate()
- if (ret.returncode != 0) :
- if str("Invalid job id specified") in str(stderr, encoding='ascii') :
- if os.path.exists (self.job_finish_tag) :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- Logger.error ("status command " + "squeue" + " fails to execute")
- Logger.error ("erro info: " + str(stderr, encoding='ascii'))
- Logger.error ("return code: " + str(ret.returncode))
- sys.exit ()
- status_line = str(stdout, encoding='ascii').split ('\n')[-2]
- status_word = status_line.split ()[4]
-# status_word = status_line.split ()[-4]
-# print ("status line: " + status_line)
-# print ("status word: " + status_word)
-# print (status_word)
- if status_word in ["PD","CF","S"] :
- return JobStatus.waiting
- elif status_word in ["R","CG"] :
- return JobStatus.running
- elif status_word in ["C","E","K","BF","CA","CD","F","NF","PR","SE","ST","TO"] :
- if os.path.exists (self.job_finish_tag) :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- return JobStatus.unknown
-
-if __name__ == "__main__" :
- job = SlurmJob ("/home/han.wang/data/test/string/test", "cu01.sleep")
- job.submit ()
- print ("submit done")
- stat = job.check_status ()
- print ("check done")
- print (stat)
-
diff --git a/dpgen/auto_test/lib/abacus.py b/dpgen/auto_test/lib/abacus.py
index 0428066f1..b72eec33a 100644
--- a/dpgen/auto_test/lib/abacus.py
+++ b/dpgen/auto_test/lib/abacus.py
@@ -1,236 +1,500 @@
#!/usr/bin/python3
-import os,sys
+import os
+import sys
from unicodedata import numeric
+
import dpdata
-import dpgen.generator.lib.abacus_scf as abacus_scf
import numpy as np
from pymatgen.core.structure import Structure
+import dpgen.generator.lib.abacus_scf as abacus_scf
+
A2BOHR = 1.8897261254578281
-MASS_DICT = {"H":1.0079,"He":4.0026,"Li":6.941,"Be":9.0122,"B":10.811,"C":12.0107,"N":14.0067,\
- "O":15.9994,"F":18.9984,"Ne":20.1797,"Na":22.9897,"Mg":24.305,"Al":26.9815,"Si":28.0855,\
- "P":30.9738,"S":32.065,"Cl":35.453,"K":39.0983,"Ar":39.948,"Ca":40.078,"Sc":44.9559,\
- "Ti":47.867,"V":50.9415,"Cr":51.9961,"Mn":54.938,"Fe":55.845,"Ni":58.6934,"Co":58.9332,\
- "Cu":63.546,"Zn":65.39,"Ga":69.723,"Ge":72.64,"As":74.9216,"Se":78.96,"Br":79.904,"Kr":83.8,\
- "Rb":85.4678,"Sr":87.62,"Y":88.9059,"Zr":91.224,"Nb":92.9064,"Mo":95.94,"Tc":98,"Ru":101.07,\
- "Rh":102.9055,"Pd":106.42,"Ag":107.8682,"Cd":112.411,"In":114.818,"Sn":118.71,"Sb":121.76,"I":126.9045,\
- "Te":127.6,"Xe":131.293,"Cs":132.9055,"Ba":137.327,"La":138.9055,"Ce":140.116,"Pr":140.9077,"Nd":144.24,\
- "Pm":145,"Sm":150.36,"Eu":151.964,"Gd":157.25,"Tb":158.9253,"Dy":162.5,"Ho":164.9303,"Er":167.259,\
- "Tm":168.9342,"Yb":173.04,"Lu":174.967,"Hf":178.49,"Ta":180.9479,"W":183.84,"Re":186.207,"Os":190.23,\
- "Ir":192.217,"Pt":195.078,"Au":196.9665,"Hg":200.59,"Tl":204.3833,"Pb":207.2,"Bi":208.9804,"Po":209,\
- "At":210,"Rn":222,"Fr":223,"Ra":226,"Ac":227,"Pa":231.0359,"Th":232.0381,"Np":237,"U":238.0289,"Am":243,\
- "Pu":244,"Cm":247,"Bk":247,"Cf":251,"Es":252,"Fm":257,"Md":258,"No":259,"Rf":261,"Lr":262,"Db":262,"Bh":264,\
- "Sg":266,"Mt":268,"Rg":272,"Hs":277,"H":1.0079,"He":4.0026,"Li":6.941,"Be":9.0122,"B":10.811,"C":12.0107,\
- "N":14.0067,"O":15.9994,"F":18.9984,"Ne":20.1797,"Na":22.9897,"Mg":24.305,"Al":26.9815,"Si":28.0855,"P":30.9738,\
- "S":32.065,"Cl":35.453,"K":39.0983,"Ar":39.948,"Ca":40.078,"Sc":44.9559,"Ti":47.867,"V":50.9415,"Cr":51.9961,\
- "Mn":54.938,"Fe":55.845,"Ni":58.6934,"Co":58.9332,"Cu":63.546,"Zn":65.39,"Ga":69.723,"Ge":72.64,"As":74.9216,\
- "Se":78.96,"Br":79.904,"Kr":83.8,"Rb":85.4678,"Sr":87.62,"Y":88.9059,"Zr":91.224,"Nb":92.9064,"Mo":95.94,"Tc":98,\
- "Ru":101.07,"Rh":102.9055,"Pd":106.42,"Ag":107.8682,"Cd":112.411,"In":114.818,"Sn":118.71,"Sb":121.76,\
- "I":126.9045,"Te":127.6,"Xe":131.293,"Cs":132.9055,"Ba":137.327,"La":138.9055,"Ce":140.116,"Pr":140.9077,\
- "Nd":144.24,"Pm":145,"Sm":150.36,"Eu":151.964,"Gd":157.25,"Tb":158.9253,"Dy":162.5,"Ho":164.9303,"Er":167.259,\
- "Tm":168.9342,"Yb":173.04,"Lu":174.967,"Hf":178.49,"Ta":180.9479,"W":183.84,"Re":186.207,"Os":190.23,"Ir":192.217,\
- "Pt":195.078,"Au":196.9665,"Hg":200.59,"Tl":204.3833,"Pb":207.2,"Bi":208.9804,"Po":209,"At":210,"Rn":222,"Fr":223,\
- "Ra":226,"Ac":227,"Pa":231.0359,"Th":232.0381,"Np":237,"U":238.0289,"Am":243,"Pu":244,"Cm":247,"Bk":247,"Cf":251,\
- "Es":252,"Fm":257,"Md":258,"No":259,"Rf":261,"Lr":262,"Db":262,"Bh":264,"Sg":266,"Mt":268,"Rg":272,"Hs":277}
-key_words_list = ["ATOMIC_SPECIES", "NUMERICAL_ORBITAL", "LATTICE_CONSTANT", "LATTICE_VECTORS", "ATOMIC_POSITIONS", "NUMERICAL_DESCRIPTOR"]
-
-def poscar2stru(poscar,inter_param,stru):
- '''
- - poscar: POSCAR for input
- - inter_param: dictionary of 'interaction' from param.json
- some key words for ABACUS are:
- - atom_masses: a dictionary of atoms' masses
- - orb_files: a dictionary of orbital files
- - deepks_desc: a string of deepks descriptor file
- - stru: output filename, usally is 'STRU'
- '''
- stru = dpdata.System(poscar, fmt = 'vasp/poscar')
+MASS_DICT = {
+ "H": 1.0079,
+ "He": 4.0026,
+ "Li": 6.941,
+ "Be": 9.0122,
+ "B": 10.811,
+ "C": 12.0107,
+ "N": 14.0067,
+ "O": 15.9994,
+ "F": 18.9984,
+ "Ne": 20.1797,
+ "Na": 22.9897,
+ "Mg": 24.305,
+ "Al": 26.9815,
+ "Si": 28.0855,
+ "P": 30.9738,
+ "S": 32.065,
+ "Cl": 35.453,
+ "K": 39.0983,
+ "Ar": 39.948,
+ "Ca": 40.078,
+ "Sc": 44.9559,
+ "Ti": 47.867,
+ "V": 50.9415,
+ "Cr": 51.9961,
+ "Mn": 54.938,
+ "Fe": 55.845,
+ "Ni": 58.6934,
+ "Co": 58.9332,
+ "Cu": 63.546,
+ "Zn": 65.39,
+ "Ga": 69.723,
+ "Ge": 72.64,
+ "As": 74.9216,
+ "Se": 78.96,
+ "Br": 79.904,
+ "Kr": 83.8,
+ "Rb": 85.4678,
+ "Sr": 87.62,
+ "Y": 88.9059,
+ "Zr": 91.224,
+ "Nb": 92.9064,
+ "Mo": 95.94,
+ "Tc": 98,
+ "Ru": 101.07,
+ "Rh": 102.9055,
+ "Pd": 106.42,
+ "Ag": 107.8682,
+ "Cd": 112.411,
+ "In": 114.818,
+ "Sn": 118.71,
+ "Sb": 121.76,
+ "I": 126.9045,
+ "Te": 127.6,
+ "Xe": 131.293,
+ "Cs": 132.9055,
+ "Ba": 137.327,
+ "La": 138.9055,
+ "Ce": 140.116,
+ "Pr": 140.9077,
+ "Nd": 144.24,
+ "Pm": 145,
+ "Sm": 150.36,
+ "Eu": 151.964,
+ "Gd": 157.25,
+ "Tb": 158.9253,
+ "Dy": 162.5,
+ "Ho": 164.9303,
+ "Er": 167.259,
+ "Tm": 168.9342,
+ "Yb": 173.04,
+ "Lu": 174.967,
+ "Hf": 178.49,
+ "Ta": 180.9479,
+ "W": 183.84,
+ "Re": 186.207,
+ "Os": 190.23,
+ "Ir": 192.217,
+ "Pt": 195.078,
+ "Au": 196.9665,
+ "Hg": 200.59,
+ "Tl": 204.3833,
+ "Pb": 207.2,
+ "Bi": 208.9804,
+ "Po": 209,
+ "At": 210,
+ "Rn": 222,
+ "Fr": 223,
+ "Ra": 226,
+ "Ac": 227,
+ "Pa": 231.0359,
+ "Th": 232.0381,
+ "Np": 237,
+ "U": 238.0289,
+ "Am": 243,
+ "Pu": 244,
+ "Cm": 247,
+ "Bk": 247,
+ "Cf": 251,
+ "Es": 252,
+ "Fm": 257,
+ "Md": 258,
+ "No": 259,
+ "Rf": 261,
+ "Lr": 262,
+ "Db": 262,
+ "Bh": 264,
+ "Sg": 266,
+ "Mt": 268,
+ "Rg": 272,
+ "Hs": 277,
+ "H": 1.0079,
+ "He": 4.0026,
+ "Li": 6.941,
+ "Be": 9.0122,
+ "B": 10.811,
+ "C": 12.0107,
+ "N": 14.0067,
+ "O": 15.9994,
+ "F": 18.9984,
+ "Ne": 20.1797,
+ "Na": 22.9897,
+ "Mg": 24.305,
+ "Al": 26.9815,
+ "Si": 28.0855,
+ "P": 30.9738,
+ "S": 32.065,
+ "Cl": 35.453,
+ "K": 39.0983,
+ "Ar": 39.948,
+ "Ca": 40.078,
+ "Sc": 44.9559,
+ "Ti": 47.867,
+ "V": 50.9415,
+ "Cr": 51.9961,
+ "Mn": 54.938,
+ "Fe": 55.845,
+ "Ni": 58.6934,
+ "Co": 58.9332,
+ "Cu": 63.546,
+ "Zn": 65.39,
+ "Ga": 69.723,
+ "Ge": 72.64,
+ "As": 74.9216,
+ "Se": 78.96,
+ "Br": 79.904,
+ "Kr": 83.8,
+ "Rb": 85.4678,
+ "Sr": 87.62,
+ "Y": 88.9059,
+ "Zr": 91.224,
+ "Nb": 92.9064,
+ "Mo": 95.94,
+ "Tc": 98,
+ "Ru": 101.07,
+ "Rh": 102.9055,
+ "Pd": 106.42,
+ "Ag": 107.8682,
+ "Cd": 112.411,
+ "In": 114.818,
+ "Sn": 118.71,
+ "Sb": 121.76,
+ "I": 126.9045,
+ "Te": 127.6,
+ "Xe": 131.293,
+ "Cs": 132.9055,
+ "Ba": 137.327,
+ "La": 138.9055,
+ "Ce": 140.116,
+ "Pr": 140.9077,
+ "Nd": 144.24,
+ "Pm": 145,
+ "Sm": 150.36,
+ "Eu": 151.964,
+ "Gd": 157.25,
+ "Tb": 158.9253,
+ "Dy": 162.5,
+ "Ho": 164.9303,
+ "Er": 167.259,
+ "Tm": 168.9342,
+ "Yb": 173.04,
+ "Lu": 174.967,
+ "Hf": 178.49,
+ "Ta": 180.9479,
+ "W": 183.84,
+ "Re": 186.207,
+ "Os": 190.23,
+ "Ir": 192.217,
+ "Pt": 195.078,
+ "Au": 196.9665,
+ "Hg": 200.59,
+ "Tl": 204.3833,
+ "Pb": 207.2,
+ "Bi": 208.9804,
+ "Po": 209,
+ "At": 210,
+ "Rn": 222,
+ "Fr": 223,
+ "Ra": 226,
+ "Ac": 227,
+ "Pa": 231.0359,
+ "Th": 232.0381,
+ "Np": 237,
+ "U": 238.0289,
+ "Am": 243,
+ "Pu": 244,
+ "Cm": 247,
+ "Bk": 247,
+ "Cf": 251,
+ "Es": 252,
+ "Fm": 257,
+ "Md": 258,
+ "No": 259,
+ "Rf": 261,
+ "Lr": 262,
+ "Db": 262,
+ "Bh": 264,
+ "Sg": 266,
+ "Mt": 268,
+ "Rg": 272,
+ "Hs": 277,
+}
+key_words_list = [
+ "ATOMIC_SPECIES",
+ "NUMERICAL_ORBITAL",
+ "LATTICE_CONSTANT",
+ "LATTICE_VECTORS",
+ "ATOMIC_POSITIONS",
+ "NUMERICAL_DESCRIPTOR",
+]
+
+
+def poscar2stru(poscar, inter_param, stru):
+ """
+ - poscar: POSCAR for input
+ - inter_param: dictionary of 'interaction' from param.json
+ some key words for ABACUS are:
+ - atom_masses: a dictionary of atoms' masses
+ - orb_files: a dictionary of orbital files
+ - deepks_desc: a string of deepks descriptor file
+ - stru: output filename, usally is 'STRU'
+ """
+ stru = dpdata.System(poscar, fmt="vasp/poscar")
stru_data = stru.data
atom_mass = []
pseudo = None
orb = None
- deepks_desc = None
+ deepks_desc = None
- if 'atom_masses' not in inter_param:
- atom_mass_dict = {i:1.0 if i not in MASS_DICT else MASS_DICT[i] for i in stru_data['atom_names']}
+ if "atom_masses" not in inter_param:
+ atom_mass_dict = {
+ i: 1.0 if i not in MASS_DICT else MASS_DICT[i]
+ for i in stru_data["atom_names"]
+ }
else:
- atom_mass_dict = inter_param['atom_masses']
- for atom in stru_data['atom_names']:
- assert(atom in atom_mass_dict), "the mass of %s is not defined in interaction:atom_masses" % atom
- atom_mass.append(atom_mass_dict[atom])
+ atom_mass_dict = inter_param["atom_masses"]
+ for atom in stru_data["atom_names"]:
+ assert atom in atom_mass_dict, (
+ "the mass of %s is not defined in interaction:atom_masses" % atom
+ )
+ atom_mass.append(atom_mass_dict[atom])
- if 'potcars' in inter_param:
+ if "potcars" in inter_param:
pseudo = []
- for atom in stru_data['atom_names']:
- assert(atom in inter_param['potcars']), "the pseudopotential of %s is not defined in interaction:potcars" % atom
- pseudo.append("./pp_orb/" + inter_param['potcars'][atom].split('/')[-1])
+ for atom in stru_data["atom_names"]:
+ assert atom in inter_param["potcars"], (
+ "the pseudopotential of %s is not defined in interaction:potcars" % atom
+ )
+ pseudo.append("./pp_orb/" + inter_param["potcars"][atom].split("/")[-1])
- if 'orb_files' in inter_param:
+ if "orb_files" in inter_param:
orb = []
- for atom in stru_data['atom_names']:
- assert(atom in inter_param['orb_files']), "orbital file of %s is not defined in interaction:orb_files" % atom
- orb.append("./pp_orb/" + inter_param['orb_files'][atom].split('/')[-1])
-
- if 'deepks_desc' in inter_param:
- deepks_desc ="./pp_orb/%s\n" % inter_param['deepks_desc']
-
- stru.to("stru", "STRU", mass = atom_mass, pp_file = pseudo, numerical_orbital = orb, numerical_descriptor = deepks_desc)
-
-
-def stru_fix_atom(struf,fix_atom = [True,True,True]):
- '''
-...
-ATOMIC_POSITIONS
-Cartesian #Cartesian(Unit is LATTICE_CONSTANT)
-Si #Name of element
-0.0 #Magnetic for this element.
-2 #Number of atoms
-0.00 0.00 0.00 0 0 0 #x,y,z, move_x, move_y, move_z
-0.25 0.25 0.25 0 0 0
- '''
- fix_xyz = ['0' if i else '1' for i in fix_atom ]
+ for atom in stru_data["atom_names"]:
+ assert atom in inter_param["orb_files"], (
+ "orbital file of %s is not defined in interaction:orb_files" % atom
+ )
+ orb.append("./pp_orb/" + inter_param["orb_files"][atom].split("/")[-1])
+
+ if "deepks_desc" in inter_param:
+ deepks_desc = "./pp_orb/%s\n" % inter_param["deepks_desc"]
+
+ stru.to(
+ "stru",
+ "STRU",
+ mass=atom_mass,
+ pp_file=pseudo,
+ numerical_orbital=orb,
+ numerical_descriptor=deepks_desc,
+ )
+
+
+def stru_fix_atom(struf, fix_atom=[True, True, True]):
+ """
+ ...
+ ATOMIC_POSITIONS
+ Cartesian #Cartesian(Unit is LATTICE_CONSTANT)
+ Si #Name of element
+ 0.0 #Magnetic for this element.
+ 2 #Number of atoms
+ 0.00 0.00 0.00 0 0 0 #x,y,z, move_x, move_y, move_z
+ 0.25 0.25 0.25 0 0 0
+ """
+ fix_xyz = ["0" if i else "1" for i in fix_atom]
if os.path.isfile(struf):
- with open(struf) as f1: lines = f1.readlines()
+ with open(struf) as f1:
+ lines = f1.readlines()
for i in range(len(lines)):
- if "ATOMIC_POSITIONS" in lines[i]: break
+ if "ATOMIC_POSITIONS" in lines[i]:
+ break
i += 1
flag_read_coord_type = False
flag_read_atom_number = 2
flag_atom_number = 0
while i < len(lines):
- if lines[i].strip() == '':pass
- elif lines[i].split()[0] in key_words_list: break
- elif not flag_read_coord_type:
+ if lines[i].strip() == "":
+ pass
+ elif lines[i].split()[0] in key_words_list:
+ break
+ elif not flag_read_coord_type:
flag_read_coord_type = True
elif flag_atom_number:
flag_atom_number -= 1
- x,y,z = lines[i].split()[:3]
- lines[i] = "%s %s %s %s %s %s\n" % tuple([x,y,z] + fix_xyz)
+ x, y, z = lines[i].split()[:3]
+ lines[i] = "%s %s %s %s %s %s\n" % tuple([x, y, z] + fix_xyz)
elif flag_read_coord_type and flag_read_atom_number:
flag_read_atom_number -= 1
elif not flag_read_atom_number:
flag_read_atom_number = 2
flag_atom_number = int(lines[i].split()[0])
i += 1
- with open(struf,'w') as f1: f1.writelines(lines)
+ with open(struf, "w") as f1:
+ f1.writelines(lines)
else:
- raise RuntimeError("Error: Try to modify struc file %s, but can not find it" % struf)
+ raise RuntimeError(
+ "Error: Try to modify struc file %s, but can not find it" % struf
+ )
-def stru_scale (stru_in, stru_out, scale) :
- with open(stru_in, 'r') as fin : lines = fin.readlines()
+
+def stru_scale(stru_in, stru_out, scale):
+ with open(stru_in, "r") as fin:
+ lines = fin.readlines()
for i in range(len(lines)):
if "LATTICE_CONSTANT" in lines[i]:
- lines[i+1] = str(float(lines[i+1].strip())*scale) + '\n'
+ lines[i + 1] = str(float(lines[i + 1].strip()) * scale) + "\n"
break
- with open(stru_out,'w') as f1: f1.writelines(lines)
+ with open(stru_out, "w") as f1:
+ f1.writelines(lines)
-def write_kpt(kptf,kptlist):
+def write_kpt(kptf, kptlist):
context = "K_POINTS\n0\nGamma\n"
- for i in kptlist: context += str(i) + " "
- with open(kptf,'w') as f1: f1.write(context)
+ for i in kptlist:
+ context += str(i) + " "
+ with open(kptf, "w") as f1:
+ f1.write(context)
+
-def write_input(inputf,inputdict):
+def write_input(inputf, inputdict):
context = "INPUT_PARAMETERS\n"
for key in inputdict.keys():
- if key[0] in ['_','#']:continue
+ if key[0] in ["_", "#"]:
+ continue
context += key + " " + str(inputdict[key]) + "\n"
- with open(inputf,'w') as f1: f1.write(context)
+ with open(inputf, "w") as f1:
+ f1.write(context)
+
-def make_kspacing_kpt(struf,kspacing):
+def make_kspacing_kpt(struf, kspacing):
stru_data = abacus_scf.get_abacus_STRU(struf)
- cell = stru_data['cells'] / abacus_scf.bohr2ang
- volume = abs(cell[0].dot(np.cross(cell[1],cell[2])))
+ cell = stru_data["cells"] / abacus_scf.bohr2ang
+ volume = abs(cell[0].dot(np.cross(cell[1], cell[2])))
coef = 2 * np.pi / volume / kspacing
- kpt = [max(1,int(np.linalg.norm(np.cross(cell[x],cell[y]))*coef+1)) for x,y in [[1,2],[2,0],[0,1]] ]
+ kpt = [
+ max(1, int(np.linalg.norm(np.cross(cell[x], cell[y])) * coef + 1))
+ for x, y in [[1, 2], [2, 0], [0, 1]]
+ ]
return kpt
+
def check_finished(fname):
- with open(fname, 'r') as fp:
- return 'Total Time :' in fp.read()
+ with open(fname, "r") as fp:
+ return "Total Time :" in fp.read()
+
def final_stru(abacus_path):
- with open(os.path.join(abacus_path, 'INPUT')) as f1: lines = f1.readlines()
- suffix = 'ABACUS'
- calculation = 'scf'
+ with open(os.path.join(abacus_path, "INPUT")) as f1:
+ lines = f1.readlines()
+ suffix = "ABACUS"
+ calculation = "scf"
out_stru = False
for line in lines:
- if 'suffix' in line and line.split()[0] == 'suffix':
+ if "suffix" in line and line.split()[0] == "suffix":
suffix = line.split()[1]
- elif 'calculation' in line and line.split()[0] == 'calculation':
+ elif "calculation" in line and line.split()[0] == "calculation":
calculation = line.split()[1]
- elif 'out_stru' in line and line.split()[0] == 'out_stru':
+ elif "out_stru" in line and line.split()[0] == "out_stru":
out_stru = bool(line.split()[1])
- logf = os.path.join(abacus_path, 'OUT.%s/running_%s.log'%(suffix,calculation))
- if calculation in ['relax','cell-relax']:
+ logf = os.path.join(abacus_path, "OUT.%s/running_%s.log" % (suffix, calculation))
+ if calculation in ["relax", "cell-relax"]:
if not out_stru:
- return 'OUT.%s/STRU_ION_D' % suffix
+ return "OUT.%s/STRU_ION_D" % suffix
else:
- with open(logf) as f1: lines = f1.readlines()
- for i in range(1,len(lines)):
- if lines[-i][36:41] == 'istep':
+ with open(logf) as f1:
+ lines = f1.readlines()
+ for i in range(1, len(lines)):
+ if lines[-i][36:41] == "istep":
max_step = int(lines[-i].split()[-1])
break
- return 'OUT.%s/STRU_ION%d_D' % (suffix,max_step)
- elif calculation == 'md':
- with open(logf) as f1: lines = f1.readlines()
- for i in range(1,len(lines)):
- if lines[-i][1:27] == 'STEP OF MOLECULAR DYNAMICS':
+ return "OUT.%s/STRU_ION%d_D" % (suffix, max_step)
+ elif calculation == "md":
+ with open(logf) as f1:
+ lines = f1.readlines()
+ for i in range(1, len(lines)):
+ if lines[-i][1:27] == "STEP OF MOLECULAR DYNAMICS":
max_step = int(lines[-i].split()[-1])
break
- return 'OUT.%s/STRU_MD_%d' % (suffix,max_step)
- elif calculation == 'scf':
- return 'STRU'
+ return "OUT.%s/STRU_MD_%d" % (suffix, max_step)
+ elif calculation == "scf":
+ return "STRU"
else:
print("Unrecognized calculation type in %s/INPUT" % abacus_path)
- return 'STRU'
+ return "STRU"
+
def stru2Structure(struf):
stru = dpdata.System(struf, fmt="stru")
- stru.to('poscar','POSCAR.tmp')
- ss = Structure.from_file('POSCAR.tmp')
- os.remove('POSCAR.tmp')
+ stru.to("poscar", "POSCAR.tmp")
+ ss = Structure.from_file("POSCAR.tmp")
+ os.remove("POSCAR.tmp")
return ss
-def check_stru_fixed(struf,fixed):
+
+def check_stru_fixed(struf, fixed):
block = {}
- with open(struf) as f1: lines = f1.readlines()
+ with open(struf) as f1:
+ lines = f1.readlines()
for line in lines:
- if line.strip() == '':continue
+ if line.strip() == "":
+ continue
elif line.split()[0] in key_words_list:
key = line.split()[0]
block[key] = []
else:
block[key].append(line)
i = 3
- while i < len(block['ATOMIC_POSITIONS']):
- natom = int(block['ATOMIC_POSITIONS'][i])
+ while i < len(block["ATOMIC_POSITIONS"]):
+ natom = int(block["ATOMIC_POSITIONS"][i])
for j in range(natom):
i += 1
- for k in block['ATOMIC_POSITIONS'][i].split()[3:6]:
- if fixed and bool(int(k)):return False
- elif not fixed and not bool(int(k)): return False
+ for k in block["ATOMIC_POSITIONS"][i].split()[3:6]:
+ if fixed and bool(int(k)):
+ return False
+ elif not fixed and not bool(int(k)):
+ return False
i += 1
return True
-def modify_stru_path(strucf,tpath):
- if tpath[-1] != '/':tpath += '/'
- with open(strucf) as f1: lines = f1.readlines()
- for i,line in enumerate(lines):
+
+def modify_stru_path(strucf, tpath):
+ if tpath[-1] != "/":
+ tpath += "/"
+ with open(strucf) as f1:
+ lines = f1.readlines()
+ for i, line in enumerate(lines):
if "ATOMIC_SPECIES" in line and line.split()[0] == "ATOMIC_SPECIES":
file_numb = 2
- elif ("NUMERICAL_ORBITAL" in line and line.split()[0] == "NUMERICAL_ORBITAL") or \
- ("NUMERICAL_DESCRIPTOR" in line and line.split()[0] == "NUMERICAL_DESCRIPTOR"):
- file_numb = 0
- else:continue
-
- for j in range(i+1,len(lines)):
- if lines[j].strip() in key_words_list: break
- elif lines[j].strip() == '':continue
- ppfile = tpath + os.path.split(lines[j].split()[file_numb])[1]
- tmp_line = ''
- for k in range(file_numb): tmp_line += lines[j].split()[k] + ' '
- lines[j] = tmp_line + ppfile + '\n'
+ elif (
+ "NUMERICAL_ORBITAL" in line and line.split()[0] == "NUMERICAL_ORBITAL"
+ ) or (
+ "NUMERICAL_DESCRIPTOR" in line and line.split()[0] == "NUMERICAL_DESCRIPTOR"
+ ):
+ file_numb = 0
+ else:
+ continue
- with open(strucf,'w') as f1: f1.writelines(lines)
+ for j in range(i + 1, len(lines)):
+ if lines[j].strip() in key_words_list:
+ break
+ elif lines[j].strip() == "":
+ continue
+ ppfile = tpath + os.path.split(lines[j].split()[file_numb])[1]
+ tmp_line = ""
+ for k in range(file_numb):
+ tmp_line += lines[j].split()[k] + " "
+ lines[j] = tmp_line + ppfile + "\n"
+ with open(strucf, "w") as f1:
+ f1.writelines(lines)
diff --git a/dpgen/auto_test/lib/crys.py b/dpgen/auto_test/lib/crys.py
index 96656296a..9961d217e 100644
--- a/dpgen/auto_test/lib/crys.py
+++ b/dpgen/auto_test/lib/crys.py
@@ -2,87 +2,81 @@
from pymatgen.core.lattice import Lattice
from pymatgen.core.structure import Structure
-def fcc (ele_name = 'ele', a = 4.05) :
- box = np.array([ [0.0, 0.5, 0.5],
- [0.5, 0.0, 0.5],
- [0.5, 0.5, 0.0] ] )
+
+def fcc(ele_name="ele", a=4.05):
+ box = np.array([[0.0, 0.5, 0.5], [0.5, 0.0, 0.5], [0.5, 0.5, 0.0]])
box *= a
- return Structure(box,
- [ele_name],
- [[0, 0, 0]]
- )
+ return Structure(box, [ele_name], [[0, 0, 0]])
+
-def fcc1 (ele_name = 'ele', a = 4.05) :
+def fcc1(ele_name="ele", a=4.05):
latt = Lattice.cubic(a)
- return Structure(latt,
- [ele_name, ele_name, ele_name, ele_name],
- [[0, 0, 0],
- [0, 0.5, 0.5],
- [0.5, 0, 0.5],
- [0.5, 0.5, 0]]
+ return Structure(
+ latt,
+ [ele_name, ele_name, ele_name, ele_name],
+ [[0, 0, 0], [0, 0.5, 0.5], [0.5, 0, 0.5], [0.5, 0.5, 0]],
)
-def sc (ele_name = 'ele', a = 2.551340126037118) :
+
+def sc(ele_name="ele", a=2.551340126037118):
latt = Lattice.cubic(a)
- return Structure(latt,
- [ele_name],
- [[0, 0, 0]]
- )
+ return Structure(latt, [ele_name], [[0, 0, 0]])
-def bcc (ele_name = 'ele', a = 3.2144871302356037) :
+
+def bcc(ele_name="ele", a=3.2144871302356037):
latt = Lattice.cubic(a)
- return Structure(latt,
- [ele_name, ele_name],
- [[0, 0, 0],
- [0.5, 0.5, 0.5],
- ]
+ return Structure(
+ latt,
+ [ele_name, ele_name],
+ [
+ [0, 0, 0],
+ [0.5, 0.5, 0.5],
+ ],
)
-def hcp (ele_name = 'ele',
- a = 4.05 / np.sqrt(2),
- c = 4.05 / np.sqrt(2) * 2. * np.sqrt(2./3.)) :
- box = np.array ([[ 1, 0, 0],
- [0.5, 0.5 * np.sqrt(3), 0],
- [0, 0, 1]])
+
+def hcp(
+ ele_name="ele", a=4.05 / np.sqrt(2), c=4.05 / np.sqrt(2) * 2.0 * np.sqrt(2.0 / 3.0)
+):
+ box = np.array([[1, 0, 0], [0.5, 0.5 * np.sqrt(3), 0], [0, 0, 1]])
box[0] *= a
box[1] *= a
box[2] *= c
latt = Lattice(box)
- return Structure(latt, [ele_name, ele_name],
- [[0, 0, 0],
- [1./3, 1./3, 1./2]]
+ return Structure(
+ latt, [ele_name, ele_name], [[0, 0, 0], [1.0 / 3, 1.0 / 3, 1.0 / 2]]
)
-def dhcp (ele_name = 'ele',
- a = 4.05 / np.sqrt(2),
- c = 4.05 / np.sqrt(2) * 4. * np.sqrt(2./3.)) :
- box = np.array ([[ 1, 0, 0],
- [0.5, 0.5 * np.sqrt(3), 0],
- [0, 0, 1]])
+
+def dhcp(
+ ele_name="ele", a=4.05 / np.sqrt(2), c=4.05 / np.sqrt(2) * 4.0 * np.sqrt(2.0 / 3.0)
+):
+ box = np.array([[1, 0, 0], [0.5, 0.5 * np.sqrt(3), 0], [0, 0, 1]])
box[0] *= a
box[1] *= a
box[2] *= c
latt = Lattice(box)
- return Structure(latt, [ele_name, ele_name, ele_name, ele_name],
- [
- [0, 0, 0],
- [1./3., 1./3., 1./4.],
- [0, 0, 1./2.],
- [2./3., 2./3., 3./4.],
- ]
+ return Structure(
+ latt,
+ [ele_name, ele_name, ele_name, ele_name],
+ [
+ [0, 0, 0],
+ [1.0 / 3.0, 1.0 / 3.0, 1.0 / 4.0],
+ [0, 0, 1.0 / 2.0],
+ [2.0 / 3.0, 2.0 / 3.0, 3.0 / 4.0],
+ ],
)
-def diamond(ele_name = 'ele',
- a = 2.551340126037118) :
- box = np.array([[0.0, 1.0, 1.0],
- [1.0, 0.0, 1.0],
- [1.0, 1.0, 0.0]])
+
+def diamond(ele_name="ele", a=2.551340126037118):
+ box = np.array([[0.0, 1.0, 1.0], [1.0, 0.0, 1.0], [1.0, 1.0, 0.0]])
box *= a
latt = Lattice(box)
- return Structure(latt, [ele_name, ele_name],
- [
- [0.12500000000000, 0.12500000000000, 0.12500000000000],
- [0.87500000000000, 0.87500000000000, 0.87500000000000]
- ]
+ return Structure(
+ latt,
+ [ele_name, ele_name],
+ [
+ [0.12500000000000, 0.12500000000000, 0.12500000000000],
+ [0.87500000000000, 0.87500000000000, 0.87500000000000],
+ ],
)
-
diff --git a/dpgen/auto_test/lib/lammps.py b/dpgen/auto_test/lib/lammps.py
index a47fcfeb6..cb27a8e98 100644
--- a/dpgen/auto_test/lib/lammps.py
+++ b/dpgen/auto_test/lib/lammps.py
@@ -1,35 +1,41 @@
#!/usr/bin/env python3
-import random, os, sys
-import dpdata
+import os
+import random
import subprocess as sp
-import dpgen.auto_test.lib.util as util
-from distutils.version import LooseVersion
+import sys
+
+import dpdata
from dpdata.periodic_table import Element
+from packaging.version import Version
+
+import dpgen.auto_test.lib.util as util
-def cvt_lammps_conf(fin, fout, type_map, ofmt='lammps/data'):
+def cvt_lammps_conf(fin, fout, type_map, ofmt="lammps/data"):
"""
Format convert from fin to fout, specify the output format by ofmt
Imcomplete situation
"""
- supp_ofmt = ['lammps/dump', 'lammps/data', 'vasp/poscar']
- supp_exts = ['dump', 'lmp', 'poscar/POSCAR']
-
- if 'dump' in fout:
- ofmt = 'lammps/dump'
- elif 'lmp' in fout:
- ofmt = 'lammps/data'
- elif 'poscar' in fout or 'POSCAR' in fout:
- ofmt = 'vasp/poscar'
+ supp_ofmt = ["lammps/dump", "lammps/data", "vasp/poscar"]
+ supp_exts = ["dump", "lmp", "poscar/POSCAR"]
+
+ if "dump" in fout:
+ ofmt = "lammps/dump"
+ elif "lmp" in fout:
+ ofmt = "lammps/data"
+ elif "poscar" in fout or "POSCAR" in fout:
+ ofmt = "vasp/poscar"
if not ofmt in supp_ofmt:
- raise RuntimeError("output format " + ofmt + " is not supported. use one of " + str(supp_ofmt))
+ raise RuntimeError(
+ "output format " + ofmt + " is not supported. use one of " + str(supp_ofmt)
+ )
- if 'lmp' in fout:
- d_poscar = dpdata.System(fin, fmt='vasp/poscar', type_map=type_map)
+ if "lmp" in fout:
+ d_poscar = dpdata.System(fin, fmt="vasp/poscar", type_map=type_map)
d_poscar.to_lammps_lmp(fout, frame_idx=0)
- elif 'poscar' in fout or 'POSCAR' in fout:
- d_dump = dpdata.System(fin, fmt='lammps/dump', type_map=type_map)
+ elif "poscar" in fout or "POSCAR" in fout:
+ d_dump = dpdata.System(fin, fmt="lammps/dump", type_map=type_map)
d_dump.to_vasp_poscar(fout, frame_idx=-1)
@@ -42,15 +48,15 @@ def apply_type_map(conf_file, deepmd_type_map, ptypes):
"""
natoms = _get_conf_natom(conf_file)
ntypes = len(deepmd_type_map)
- with open(conf_file, 'r') as fp:
- lines = fp.read().split('\n')
+ with open(conf_file, "r") as fp:
+ lines = fp.read().split("\n")
# with open(conf_file+'.bk', 'w') as fp:
# fp.write("\n".join(lines))
new_lines = lines
# revise ntypes
idx_ntypes = -1
for idx, ii in enumerate(lines):
- if 'atom types' in ii:
+ if "atom types" in ii:
idx_ntypes = idx
if idx_ntypes == -1:
raise RuntimeError("cannot find the entry 'atom types' in ", conf_file)
@@ -60,7 +66,7 @@ def apply_type_map(conf_file, deepmd_type_map, ptypes):
# find number of atoms
idx_atom_entry = -1
for idx, ii in enumerate(lines):
- if 'Atoms' in ii:
+ if "Atoms" in ii:
idx_atom_entry = idx
if idx_atom_entry == -1:
raise RuntimeError("cannot find the entry 'Atoms' in ", conf_file)
@@ -68,19 +74,19 @@ def apply_type_map(conf_file, deepmd_type_map, ptypes):
for idx in range(idx_atom_entry + 2, idx_atom_entry + 2 + natoms):
ii = lines[idx]
words = ii.split()
- assert (len(words) >= 5)
+ assert len(words) >= 5
old_id = int(words[1])
new_id = deepmd_type_map.index(ptypes[old_id - 1]) + 1
words[1] = str(new_id)
ii = " ".join(words)
new_lines[idx] = ii
- with open(conf_file, 'w') as fp:
+ with open(conf_file, "w") as fp:
fp.write("\n".join(new_lines))
def _get_ntype(conf):
- with open(conf, 'r') as fp:
- lines = fp.read().split('\n')
+ with open(conf, "r") as fp:
+ lines = fp.read().split("\n")
for ii in lines:
if "atom types" in ii:
return int(ii.split()[0])
@@ -88,8 +94,8 @@ def _get_ntype(conf):
def _get_conf_natom(conf):
- with open(conf, 'r') as fp:
- lines = fp.read().split('\n')
+ with open(conf, "r") as fp:
+ lines = fp.read().split("\n")
for ii in lines:
if "atoms" in ii:
return int(ii.split()[0])
@@ -103,18 +109,18 @@ def inter_deepmd(param):
model_list = ""
for ii in models:
model_list += ii + " "
- if LooseVersion(deepmd_version) < LooseVersion('1'):
+ if Version(deepmd_version) < Version("1"):
## DeePMD-kit version == 0.x
if len(models) > 1:
- ret += '%s 10 model_devi.out\n' % model_list
+ ret += "%s 10 model_devi.out\n" % model_list
else:
- ret += models[0] + '\n'
+ ret += models[0] + "\n"
else:
## DeePMD-kit version >= 1
if len(models) > 1:
ret += "%s out_freq 10 out_file model_devi.out\n" % model_list
else:
- ret += models[0] + '\n'
+ ret += models[0] + "\n"
ret += "pair_coeff * *\n"
return ret
@@ -122,13 +128,13 @@ def inter_deepmd(param):
def inter_meam(param):
ret = ""
line = "pair_style meam \n"
- line += "pair_coeff * * %s " % param['model_name'][0]
- for ii in param['param_type']:
- line += ii + ' '
- line += "%s " % param['model_name'][1]
- for ii in param['param_type']:
- line += ii + ' '
- line += '\n'
+ line += "pair_coeff * * %s " % param["model_name"][0]
+ for ii in param["param_type"]:
+ line += ii + " "
+ line += "%s " % param["model_name"][1]
+ for ii in param["param_type"]:
+ line += ii + " "
+ line += "\n"
ret += line
return ret
@@ -136,10 +142,10 @@ def inter_meam(param):
def inter_eam_fs(param): # 06/08 eam.fs interaction
ret = ""
line = "pair_style eam/fs \n"
- line += "pair_coeff * * %s " % param['model_name'][0]
- for ii in param['param_type']:
- line += ii + ' '
- line += '\n'
+ line += "pair_coeff * * %s " % param["model_name"][0]
+ for ii in param["param_type"]:
+ line += ii + " "
+ line += "\n"
ret += line
return ret
@@ -147,10 +153,10 @@ def inter_eam_fs(param): # 06/08 eam.fs interaction
def inter_eam_alloy(param): # 06/08 eam.alloy interaction
ret = ""
line = "pair_style eam/alloy \n"
- line += "pair_coeff * * %s " % param['model_name']
- for ii in param['param_type']:
- line += ii + ' '
- line += '\n'
+ line += "pair_coeff * * %s " % param["model_name"]
+ for ii in param["param_type"]:
+ line += ii + " "
+ line += "\n"
ret += line
return ret
@@ -185,12 +191,14 @@ def make_lammps_eval(conf, type_map, interaction, param):
ret += interaction(param)
ret += "compute mype all pe\n"
ret += "thermo 100\n"
- ret += "thermo_style custom step pe pxx pyy pzz pxy pxz pyz lx ly lz vol c_mype\n"
+ ret += (
+ "thermo_style custom step pe pxx pyy pzz pxy pxz pyz lx ly lz vol c_mype\n"
+ )
ret += "dump 1 all custom 100 dump.relax id type xs ys zs fx fy fz\n" # 06/09 give dump.relax
ret += "run 0\n"
ret += "variable N equal count(all)\n"
ret += "variable V equal vol\n"
- ret += "variable E equal \"c_mype\"\n"
+ ret += 'variable E equal "c_mype"\n'
ret += "variable tmplx equal lx\n"
ret += "variable tmply equal ly\n"
ret += "variable Pxx equal pxx\n"
@@ -202,19 +210,26 @@ def make_lammps_eval(conf, type_map, interaction, param):
ret += "variable Epa equal ${E}/${N}\n"
ret += "variable Vpa equal ${V}/${N}\n"
ret += "variable AA equal (${tmplx}*${tmply})\n"
- ret += "print \"All done\"\n"
- ret += "print \"Total number of atoms = ${N}\"\n"
- ret += "print \"Final energy per atoms = ${Epa}\"\n"
- ret += "print \"Final volume per atoms = ${Vpa}\"\n"
- ret += "print \"Final Base area = ${AA}\"\n"
- ret += "print \"Final Stress (xx yy zz xy xz yz) = ${Pxx} ${Pyy} ${Pzz} ${Pxy} ${Pxz} ${Pyz}\"\n"
+ ret += 'print "All done"\n'
+ ret += 'print "Total number of atoms = ${N}"\n'
+ ret += 'print "Final energy per atoms = ${Epa}"\n'
+ ret += 'print "Final volume per atoms = ${Vpa}"\n'
+ ret += 'print "Final Base area = ${AA}"\n'
+ ret += 'print "Final Stress (xx yy zz xy xz yz) = ${Pxx} ${Pyy} ${Pzz} ${Pxy} ${Pxz} ${Pyz}"\n'
return ret
-def make_lammps_equi(conf, type_map, interaction, param,
- etol=0, ftol=1e-10,
- maxiter=5000, maxeval=500000,
- change_box=True):
+def make_lammps_equi(
+ conf,
+ type_map,
+ interaction,
+ param,
+ etol=0,
+ ftol=1e-10,
+ maxiter=5000,
+ maxeval=500000,
+ change_box=True,
+):
type_map_list = element_list(type_map)
"""
@@ -234,7 +249,9 @@ def make_lammps_equi(conf, type_map, interaction, param,
ret += interaction(param)
ret += "compute mype all pe\n"
ret += "thermo 100\n"
- ret += "thermo_style custom step pe pxx pyy pzz pxy pxz pyz lx ly lz vol c_mype\n"
+ ret += (
+ "thermo_style custom step pe pxx pyy pzz pxy pxz pyz lx ly lz vol c_mype\n"
+ )
ret += "dump 1 all custom 100 dump.relax id type xs ys zs fx fy fz\n"
ret += "min_style cg\n"
if change_box:
@@ -246,7 +263,7 @@ def make_lammps_equi(conf, type_map, interaction, param,
ret += "minimize %e %e %d %d\n" % (etol, ftol, maxiter, maxeval)
ret += "variable N equal count(all)\n"
ret += "variable V equal vol\n"
- ret += "variable E equal \"c_mype\"\n"
+ ret += 'variable E equal "c_mype"\n'
ret += "variable tmplx equal lx\n"
ret += "variable tmply equal ly\n"
ret += "variable Pxx equal pxx\n"
@@ -258,18 +275,18 @@ def make_lammps_equi(conf, type_map, interaction, param,
ret += "variable Epa equal ${E}/${N}\n"
ret += "variable Vpa equal ${V}/${N}\n"
ret += "variable AA equal (${tmplx}*${tmply})\n"
- ret += "print \"All done\"\n"
- ret += "print \"Total number of atoms = ${N}\"\n"
- ret += "print \"Final energy per atoms = ${Epa}\"\n"
- ret += "print \"Final volume per atoms = ${Vpa}\"\n"
- ret += "print \"Final Base area = ${AA}\"\n"
- ret += "print \"Final Stress (xx yy zz xy xz yz) = ${Pxx} ${Pyy} ${Pzz} ${Pxy} ${Pxz} ${Pyz}\"\n"
+ ret += 'print "All done"\n'
+ ret += 'print "Total number of atoms = ${N}"\n'
+ ret += 'print "Final energy per atoms = ${Epa}"\n'
+ ret += 'print "Final volume per atoms = ${Vpa}"\n'
+ ret += 'print "Final Base area = ${AA}"\n'
+ ret += 'print "Final Stress (xx yy zz xy xz yz) = ${Pxx} ${Pyy} ${Pzz} ${Pxy} ${Pxz} ${Pyz}"\n'
return ret
-def make_lammps_elastic(conf, type_map, interaction, param,
- etol=0, ftol=1e-10,
- maxiter=5000, maxeval=500000):
+def make_lammps_elastic(
+ conf, type_map, interaction, param, etol=0, ftol=1e-10, maxiter=5000, maxeval=500000
+):
type_map_list = element_list(type_map)
"""
@@ -289,13 +306,15 @@ def make_lammps_elastic(conf, type_map, interaction, param,
ret += interaction(param)
ret += "compute mype all pe\n"
ret += "thermo 100\n"
- ret += "thermo_style custom step pe pxx pyy pzz pxy pxz pyz lx ly lz vol c_mype\n"
+ ret += (
+ "thermo_style custom step pe pxx pyy pzz pxy pxz pyz lx ly lz vol c_mype\n"
+ )
ret += "dump 1 all custom 100 dump.relax id type xs ys zs fx fy fz\n"
ret += "min_style cg\n"
ret += "minimize %e %e %d %d\n" % (etol, ftol, maxiter, maxeval)
ret += "variable N equal count(all)\n"
ret += "variable V equal vol\n"
- ret += "variable E equal \"c_mype\"\n"
+ ret += 'variable E equal "c_mype"\n'
ret += "variable Pxx equal pxx\n"
ret += "variable Pyy equal pyy\n"
ret += "variable Pzz equal pzz\n"
@@ -304,18 +323,27 @@ def make_lammps_elastic(conf, type_map, interaction, param,
ret += "variable Pyz equal pyz\n"
ret += "variable Epa equal ${E}/${N}\n"
ret += "variable Vpa equal ${V}/${N}\n"
- ret += "print \"All done\"\n"
- ret += "print \"Total number of atoms = ${N}\"\n"
- ret += "print \"Final energy per atoms = ${Epa}\"\n"
- ret += "print \"Final volume per atoms = ${Vpa}\"\n"
- ret += "print \"Final Stress (xx yy zz xy xz yz) = ${Pxx} ${Pyy} ${Pzz} ${Pxy} ${Pxz} ${Pyz}\"\n"
+ ret += 'print "All done"\n'
+ ret += 'print "Total number of atoms = ${N}"\n'
+ ret += 'print "Final energy per atoms = ${Epa}"\n'
+ ret += 'print "Final volume per atoms = ${Vpa}"\n'
+ ret += 'print "Final Stress (xx yy zz xy xz yz) = ${Pxx} ${Pyy} ${Pzz} ${Pxy} ${Pxz} ${Pyz}"\n'
return ret
-def make_lammps_press_relax(conf, type_map, scale2equi, interaction, param,
- B0=70, bp=0,
- etol=0, ftol=1e-10,
- maxiter=5000, maxeval=500000):
+def make_lammps_press_relax(
+ conf,
+ type_map,
+ scale2equi,
+ interaction,
+ param,
+ B0=70,
+ bp=0,
+ etol=0,
+ ftol=1e-10,
+ maxiter=5000,
+ maxeval=500000,
+):
type_map_list = element_list(type_map)
"""
@@ -329,7 +357,9 @@ def make_lammps_press_relax(conf, type_map, scale2equi, interaction, param,
ret += "variable bp equal %f\n" % bp
ret += "variable xx equal %f\n" % scale2equi
ret += "variable yeta equal 1.5*(${bp}-1)\n"
- ret += "variable Px0 equal 3*${B0}*(1-${xx})/${xx}^2*exp(${yeta}*(1-${xx}))\n"
+ ret += (
+ "variable Px0 equal 3*${B0}*(1-${xx})/${xx}^2*exp(${yeta}*(1-${xx}))\n"
+ )
ret += "variable Px equal ${Px0}*${GPa2bar}\n"
ret += "units metal\n"
ret += "dimension 3\n"
@@ -343,7 +373,9 @@ def make_lammps_press_relax(conf, type_map, scale2equi, interaction, param,
ret += interaction(param)
ret += "compute mype all pe\n"
ret += "thermo 100\n"
- ret += "thermo_style custom step pe pxx pyy pzz pxy pxz pyz lx ly lz vol c_mype\n"
+ ret += (
+ "thermo_style custom step pe pxx pyy pzz pxy pxz pyz lx ly lz vol c_mype\n"
+ )
ret += "dump 1 all custom 100 dump.relax id type xs ys zs fx fy fz\n"
ret += "min_style cg\n"
ret += "fix 1 all box/relax iso ${Px} \n"
@@ -352,7 +384,7 @@ def make_lammps_press_relax(conf, type_map, scale2equi, interaction, param,
ret += "minimize %e %e %d %d\n" % (etol, ftol, maxiter, maxeval)
ret += "variable N equal count(all)\n"
ret += "variable V equal vol\n"
- ret += "variable E equal \"c_mype\"\n"
+ ret += 'variable E equal "c_mype"\n'
ret += "variable Pxx equal pxx\n"
ret += "variable Pyy equal pyy\n"
ret += "variable Pzz equal pzz\n"
@@ -361,18 +393,18 @@ def make_lammps_press_relax(conf, type_map, scale2equi, interaction, param,
ret += "variable Pyz equal pyz\n"
ret += "variable Epa equal ${E}/${N}\n"
ret += "variable Vpa equal ${V}/${N}\n"
- ret += "print \"All done\"\n"
- ret += "print \"Total number of atoms = ${N}\"\n"
- ret += "print \"Relax at Press = ${Px} Bar\"\n"
- ret += "print \"Final energy per atoms = ${Epa} eV\"\n"
- ret += "print \"Final volume per atoms = ${Vpa} A^3\"\n"
- ret += "print \"Final Stress (xx yy zz xy xz yz) = ${Pxx} ${Pyy} ${Pzz} ${Pxy} ${Pxz} ${Pyz}\"\n"
+ ret += 'print "All done"\n'
+ ret += 'print "Total number of atoms = ${N}"\n'
+ ret += 'print "Relax at Press = ${Px} Bar"\n'
+ ret += 'print "Final energy per atoms = ${Epa} eV"\n'
+ ret += 'print "Final volume per atoms = ${Vpa} A^3"\n'
+ ret += 'print "Final Stress (xx yy zz xy xz yz) = ${Pxx} ${Pyy} ${Pzz} ${Pxy} ${Pxz} ${Pyz}"\n'
return ret
-def make_lammps_phonon(conf, masses, interaction, param,
- etol=0, ftol=1e-10,
- maxiter=5000, maxeval=500000):
+def make_lammps_phonon(
+ conf, masses, interaction, param, etol=0, ftol=1e-10, maxiter=5000, maxeval=500000
+):
"""
make lammps input for elastic calculation
"""
@@ -394,31 +426,37 @@ def make_lammps_phonon(conf, masses, interaction, param,
def _get_epa(lines):
for ii in lines:
- if ("Final energy per atoms" in ii) and (not 'print' in ii):
- return float(ii.split('=')[1].split()[0])
- raise RuntimeError("cannot find key \"Final energy per atoms\" in lines, something wrong")
+ if ("Final energy per atoms" in ii) and (not "print" in ii):
+ return float(ii.split("=")[1].split()[0])
+ raise RuntimeError(
+ 'cannot find key "Final energy per atoms" in lines, something wrong'
+ )
def _get_vpa(lines):
for ii in lines:
- if ("Final volume per atoms" in ii) and (not 'print' in ii):
- return float(ii.split('=')[1].split()[0])
- raise RuntimeError("cannot find key \"Final volume per atoms\" in lines, something wrong")
+ if ("Final volume per atoms" in ii) and (not "print" in ii):
+ return float(ii.split("=")[1].split()[0])
+ raise RuntimeError(
+ 'cannot find key "Final volume per atoms" in lines, something wrong'
+ )
def _get_natoms(lines):
for ii in lines:
- if ("Total number of atoms" in ii) and (not 'print' in ii):
- return int(ii.split('=')[1].split()[0])
- raise RuntimeError("cannot find key \"Total number of atoms\" in lines, something wrong")
+ if ("Total number of atoms" in ii) and (not "print" in ii):
+ return int(ii.split("=")[1].split()[0])
+ raise RuntimeError(
+ 'cannot find key "Total number of atoms" in lines, something wrong'
+ )
def get_nev(log):
"""
get natoms, energy_per_atom and volume_per_atom from lammps log
"""
- with open(log, 'r') as fp:
- lines = fp.read().split('\n')
+ with open(log, "r") as fp:
+ lines = fp.read().split("\n")
epa = _get_epa(lines)
vpa = _get_vpa(lines)
natoms = _get_natoms(lines)
@@ -429,22 +467,22 @@ def get_base_area(log):
"""
get base area
"""
- with open(log, 'r') as fp:
- lines = fp.read().split('\n')
+ with open(log, "r") as fp:
+ lines = fp.read().split("\n")
for ii in lines:
- if ("Final Base area" in ii) and (not 'print' in ii):
- return float(ii.split('=')[1].split()[0])
+ if ("Final Base area" in ii) and (not "print" in ii):
+ return float(ii.split("=")[1].split()[0])
def get_stress(log):
"""
get stress from lammps log
"""
- with open(log, 'r') as fp:
- lines = fp.read().split('\n')
+ with open(log, "r") as fp:
+ lines = fp.read().split("\n")
for ii in lines:
- if ('Final Stress' in ii) and (not 'print' in ii):
- vstress = [float(jj) for jj in ii.split('=')[1].split()]
+ if ("Final Stress" in ii) and (not "print" in ii):
+ vstress = [float(jj) for jj in ii.split("=")[1].split()]
stress = util.voigt_to_stress(vstress)
return stress
@@ -453,36 +491,36 @@ def poscar_from_last_dump(dump, poscar_out, deepmd_type_map):
"""
get poscar from the last frame of a lammps MD traj (dump format)
"""
- with open(dump, 'r') as fp:
- lines = fp.read().split('\n')
+ with open(dump, "r") as fp:
+ lines = fp.read().split("\n")
step_idx = -1
for idx, ii in enumerate(lines):
- if 'ITEM: TIMESTEP' in ii:
+ if "ITEM: TIMESTEP" in ii:
step_idx = idx
if step_idx == -1:
raise RuntimeError("cannot find timestep in lammps dump, something wrong")
- with open('tmp_dump', 'w') as fp:
+ with open("tmp_dump", "w") as fp:
fp.write("\n".join(lines[step_idx:]))
- cvt_lammps_conf('tmp_dump', poscar_out, ofmt='vasp')
- os.remove('tmp_dump')
- with open(poscar_out, 'r') as fp:
- lines = fp.read().split('\n')
- types = [deepmd_type_map[int(ii.split('_')[1])] for ii in lines[5].split()]
+ cvt_lammps_conf("tmp_dump", poscar_out, ofmt="vasp")
+ os.remove("tmp_dump")
+ with open(poscar_out, "r") as fp:
+ lines = fp.read().split("\n")
+ types = [deepmd_type_map[int(ii.split("_")[1])] for ii in lines[5].split()]
lines[5] = " ".join(types)
- with open(poscar_out, 'w') as fp:
+ with open(poscar_out, "w") as fp:
lines = fp.write("\n".join(lines))
def check_finished_new(fname, keyword):
- with open(fname, 'r') as fp:
- lines = fp.read().split('\n')
+ with open(fname, "r") as fp:
+ lines = fp.read().split("\n")
flag = False
for jj in lines:
- if (keyword in jj) and (not 'print' in jj):
+ if (keyword in jj) and (not "print" in jj):
flag = True
return flag
def check_finished(fname):
- with open(fname, 'r') as fp:
- return 'Total wall time:' in fp.read()
+ with open(fname, "r") as fp:
+ return "Total wall time:" in fp.read()
diff --git a/dpgen/auto_test/lib/lmp.py b/dpgen/auto_test/lib/lmp.py
index 22fd74cfb..15705ec8a 100644
--- a/dpgen/auto_test/lib/lmp.py
+++ b/dpgen/auto_test/lib/lmp.py
@@ -2,171 +2,196 @@
import numpy as np
-def _get_block (lines, keys) :
- for idx in range(len(lines)) :
- if keys in lines[idx] :
+
+def _get_block(lines, keys):
+ for idx in range(len(lines)):
+ if keys in lines[idx]:
break
if idx == len(lines) - 1:
return None
- idx_s = idx+2
+ idx_s = idx + 2
idx = idx_s
ret = []
- while True :
- if len(lines[idx].split()) == 0 :
+ while True:
+ if len(lines[idx].split()) == 0:
break
- else :
+ else:
ret.append(lines[idx])
idx += 1
return ret
-def lmpbox2box(lohi, tilt) :
+
+def lmpbox2box(lohi, tilt):
xy = tilt[0]
xz = tilt[1]
yz = tilt[2]
orig = np.array([lohi[0][0], lohi[1][0], lohi[2][0]])
lens = []
- for dd in range(3) :
+ for dd in range(3):
lens.append(lohi[dd][1] - lohi[dd][0])
xx = [lens[0], 0, 0]
yy = [xy, lens[1], 0]
- zz= [xz, yz, lens[2]]
+ zz = [xz, yz, lens[2]]
return orig, np.array([xx, yy, zz])
-def box2lmpbox(orig, box) :
- lohi = np.zeros([3,2])
- for dd in range(3) :
+
+def box2lmpbox(orig, box):
+ lohi = np.zeros([3, 2])
+ for dd in range(3):
lohi[dd][0] = orig[dd]
tilt = np.zeros(3)
tilt[0] = box[1][0]
tilt[1] = box[2][0]
tilt[2] = box[2][1]
- lens = np.zeros(3)
+ lens = np.zeros(3)
lens[0] = box[0][0]
lens[1] = box[1][1]
lens[2] = box[2][2]
- for dd in range(3) :
+ for dd in range(3):
lohi[dd][1] = lohi[dd][0] + lens[dd]
return lohi, tilt
-def get_atoms(lines) :
- return _get_block(lines, 'Atoms')
-def get_natoms(lines) :
- for ii in lines :
- if 'atoms' in ii :
+def get_atoms(lines):
+ return _get_block(lines, "Atoms")
+
+
+def get_natoms(lines):
+ for ii in lines:
+ if "atoms" in ii:
return int(ii.split()[0])
return None
-def get_natomtypes(lines) :
- for ii in lines :
- if 'atom types' in ii :
+
+def get_natomtypes(lines):
+ for ii in lines:
+ if "atom types" in ii:
return int(ii.split()[0])
return None
-def _atom_info_mol(line) :
+
+def _atom_info_mol(line):
vec = line.split()
# idx, mole_type, atom_type, charge, x, y, z
- return int(vec[0]), int(vec[1]), int(vec[2]), float(vec[3]), float(vec[4]), float(vec[5]), float(vec[6])
-
-def _atom_info_atom(line) :
+ return (
+ int(vec[0]),
+ int(vec[1]),
+ int(vec[2]),
+ float(vec[3]),
+ float(vec[4]),
+ float(vec[5]),
+ float(vec[6]),
+ )
+
+
+def _atom_info_atom(line):
vec = line.split()
# idx, atom_type, x, y, z
return int(vec[0]), int(vec[1]), float(vec[2]), float(vec[3]), float(vec[4])
-def get_natoms_vec(lines) :
+
+def get_natoms_vec(lines):
atype = get_atype(lines)
natoms_vec = []
natomtypes = get_natomtypes(lines)
- for ii in range(natomtypes) :
- natoms_vec.append(sum(atype == ii+1))
- assert (sum(natoms_vec) == get_natoms(lines))
+ for ii in range(natomtypes):
+ natoms_vec.append(sum(atype == ii + 1))
+ assert sum(natoms_vec) == get_natoms(lines)
return natoms_vec
-def get_atype(lines) :
- alines = get_atoms(lines)
+
+def get_atype(lines):
+ alines = get_atoms(lines)
atype = []
- for ii in alines :
+ for ii in alines:
# idx, mt, at, q, x, y, z = _atom_info_mol(ii)
idx, at, x, y, z = _atom_info_atom(ii)
atype.append(at)
- return np.array(atype, dtype = int)
+ return np.array(atype, dtype=int)
+
-def get_posi(lines) :
+def get_posi(lines):
atom_lines = get_atoms(lines)
posis = []
- for ii in atom_lines :
+ for ii in atom_lines:
# posis.append([float(jj) for jj in ii.split()[4:7]])
posis.append([float(jj) for jj in ii.split()[2:5]])
return np.array(posis)
-def get_lmpbox(lines) :
+
+def get_lmpbox(lines):
box_info = []
tilt = np.zeros(3)
- for ii in lines :
- if 'xlo' in ii and 'xhi' in ii :
+ for ii in lines:
+ if "xlo" in ii and "xhi" in ii:
box_info.append([float(ii.split()[0]), float(ii.split()[1])])
break
- for ii in lines :
- if 'ylo' in ii and 'yhi' in ii :
+ for ii in lines:
+ if "ylo" in ii and "yhi" in ii:
box_info.append([float(ii.split()[0]), float(ii.split()[1])])
break
- for ii in lines :
- if 'zlo' in ii and 'zhi' in ii :
+ for ii in lines:
+ if "zlo" in ii and "zhi" in ii:
box_info.append([float(ii.split()[0]), float(ii.split()[1])])
break
- for ii in lines :
- if 'xy' in ii and 'xz' in ii and 'yz' in ii :
+ for ii in lines:
+ if "xy" in ii and "xz" in ii and "yz" in ii:
tilt = np.array([float(jj) for jj in ii.split()[0:3]])
return box_info, tilt
-def system_data(lines) :
+def system_data(lines):
system = {}
- system['atom_numbs'] = get_natoms_vec(lines)
- system['atom_names'] = []
- for ii in range(len(system['atom_numbs'])) :
- system['atom_names'].append('Type_%d' % ii)
+ system["atom_numbs"] = get_natoms_vec(lines)
+ system["atom_names"] = []
+ for ii in range(len(system["atom_numbs"])):
+ system["atom_names"].append("Type_%d" % ii)
lohi, tilt = get_lmpbox(lines)
orig, cell = lmpbox2box(lohi, tilt)
- system['orig'] = np.array(orig)
- system['cell'] = np.array(cell)
- natoms = sum(system['atom_numbs'])
- system['atom_types'] = get_atype(lines)
- system['coordinates'] = get_posi(lines)
+ system["orig"] = np.array(orig)
+ system["cell"] = np.array(cell)
+ natoms = sum(system["atom_numbs"])
+ system["atom_types"] = get_atype(lines)
+ system["coordinates"] = get_posi(lines)
return system
-def to_system_data(lines) :
+
+def to_system_data(lines):
return system_data(lines)
-def from_system_data(system) :
- ret = ''
- ret += '\n'
- natoms = sum(system['atom_numbs'])
- ntypes = len(system['atom_numbs'])
- ret += '%d atoms\n' % natoms
- ret += '%d atom types\n' % ntypes
- ret += '0 %f xlo xhi\n' % system['cell'][0][0]
- ret += '0 %f ylo yhi\n' % system['cell'][1][1]
- ret += '0 %f zlo zhi\n' % system['cell'][2][2]
- ret += '%f %f %f xy xz yz\n' % \
- (system['cell'][1][0], system['cell'][2][0], system['cell'][2][1])
- ret += '\n'
- ret += 'Atoms # atomic\n'
- ret += '\n'
- for ii in range(natoms) :
- ret += '%d %d %f %f %f\n' % \
- (ii+1,
- system['atom_types'][ii],
- system['coordinates'][ii][0] - system['orig'][0],
- system['coordinates'][ii][1] - system['orig'][1],
- system['coordinates'][ii][2] - system['orig'][2]
+
+def from_system_data(system):
+ ret = ""
+ ret += "\n"
+ natoms = sum(system["atom_numbs"])
+ ntypes = len(system["atom_numbs"])
+ ret += "%d atoms\n" % natoms
+ ret += "%d atom types\n" % ntypes
+ ret += "0 %f xlo xhi\n" % system["cell"][0][0]
+ ret += "0 %f ylo yhi\n" % system["cell"][1][1]
+ ret += "0 %f zlo zhi\n" % system["cell"][2][2]
+ ret += "%f %f %f xy xz yz\n" % (
+ system["cell"][1][0],
+ system["cell"][2][0],
+ system["cell"][2][1],
+ )
+ ret += "\n"
+ ret += "Atoms # atomic\n"
+ ret += "\n"
+ for ii in range(natoms):
+ ret += "%d %d %f %f %f\n" % (
+ ii + 1,
+ system["atom_types"][ii],
+ system["coordinates"][ii][0] - system["orig"][0],
+ system["coordinates"][ii][1] - system["orig"][1],
+ system["coordinates"][ii][2] - system["orig"][2],
)
return ret
-if __name__ == '__main__' :
- fname = 'water-SPCE.data'
- lines = open(fname).read().split('\n')
+if __name__ == "__main__":
+ fname = "water-SPCE.data"
+ lines = open(fname).read().split("\n")
bonds, tilt = get_lmpbox(lines)
# print(bonds, tilt)
orig, box = lmpbox2box(bonds, tilt)
diff --git a/dpgen/auto_test/lib/localhost.json b/dpgen/auto_test/lib/localhost.json
deleted file mode 100644
index f2feaed5d..000000000
--- a/dpgen/auto_test/lib/localhost.json
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "hostname" : "localhost",
- "port" : 22,
- "username": "wanghan",
- "work_path" : "/home/wanghan/tmp",
- "_comment" : "that's all"
-}
diff --git a/dpgen/auto_test/lib/mfp_eosfit.py b/dpgen/auto_test/lib/mfp_eosfit.py
index 78d8b72e0..148c9b5f8 100755
--- a/dpgen/auto_test/lib/mfp_eosfit.py
+++ b/dpgen/auto_test/lib/mfp_eosfit.py
@@ -1,69 +1,77 @@
#!/usr/bin/env python3
from __future__ import division
+
+import argparse
import os
import sys
-import argparse
+import matplotlib.pyplot as plt
import numpy as np
-from scipy.optimize import leastsq, root, fsolve, curve_fit
-from scipy.optimize import minimize
-from scipy.misc import derivative
-from scipy.interpolate import *
import scipy.integrate as INT
-import matplotlib.pyplot as plt
+from scipy.interpolate import *
+from scipy.misc import derivative
+from scipy.optimize import curve_fit, fsolve, leastsq, minimize, root
kb = 1.3806488e-23 # J K^-1
kb_ev = 8.6173324e-05 # eV K^-1
-h = 6.62606957e-34 # J.s
+h = 6.62606957e-34 # J.s
h_ev = 4.135667516e-15 # eV s
hb = 1.054571726e-34 # J.s
hb_ev = 6.58211928e-16 # eV s
mu = 1.660538921e-27 # kg
me = 9.1093821545e-31 # kg
-NA = 6.02214129e+23 # number per mol
+NA = 6.02214129e23 # number per mol
-eV2GPa = 1.602176565e+2
+eV2GPa = 1.602176565e2
eV2mol = 9.648455461e4 # eV/K --> J/mol/K
def __version__():
- return '1.2.5'
+ return "1.2.5"
def get_eos_list_4p():
eos_list_4p = [
- 'murnaghan', 'birch',
- 'BM4', 'mBM4', 'mBM4poly', 'rBM4',
- 'rPT4', 'LOG4',
- 'vinet', 'Li4p', 'universal',
- 'morse', 'morse_AB', 'mie', 'mie_simple',
- 'SJX_v2'
+ "murnaghan",
+ "birch",
+ "BM4",
+ "mBM4",
+ "mBM4poly",
+ "rBM4",
+ "rPT4",
+ "LOG4",
+ "vinet",
+ "Li4p",
+ "universal",
+ "morse",
+ "morse_AB",
+ "mie",
+ "mie_simple",
+ "SJX_v2",
]
return eos_list_4p
def get_eos_list_5p():
- eos_list_5p = [
- 'BM5', 'mBM5', 'rBM5', 'mBM5poly',
- 'rPT5', 'LOG5',
- 'TEOS', 'SJX_5p']
+ eos_list_5p = ["BM5", "mBM5", "rBM5", "mBM5poly", "rPT5", "LOG5", "TEOS", "SJX_5p"]
return eos_list_5p
def get_eos_list_6p():
- eos_list_6p = ['morse_6p']
+ eos_list_6p = ["morse_6p"]
return eos_list_6p
def get_eos_list_3p():
- eos_list_3p = ['morse_3p']
+ eos_list_3p = ["morse_3p"]
return eos_list_3p
def get_eos_list():
- LIST_ALL = get_eos_list_3p() + get_eos_list_4p() + \
- get_eos_list_5p() + get_eos_list_6p()
+ LIST_ALL = (
+ get_eos_list_3p() + get_eos_list_4p() + get_eos_list_5p() + get_eos_list_6p()
+ )
return LIST_ALL
@@ -82,7 +90,7 @@ def murnaghan(vol, pars):
bp = pars[2]
v0 = pars[3]
- xx = (v0 / vol)**bp
+ xx = (v0 / vol) ** bp
A = e0 - b0 * v0 / (bp - 1)
B = b0 * vol / bp
ee = A + B * (1 + xx / (bp - 1))
@@ -91,6 +99,7 @@ def murnaghan(vol, pars):
return ee
+
# ----------------------------------------------------------------------------------------
@@ -111,8 +120,11 @@ def birch(v, parameters):
bp = parameters[2]
v0 = parameters[3]
- e = (e0 + 9.0 / 8.0 * b0 * v0 * ((v0 / v) ** (2.0 / 3.0) - 1.0) ** 2
- + 9.0 / 16.0 * b0 * v0 * (bp - 4.) * ((v0 / v) ** (2.0 / 3.0) - 1.0) ** 3)
+ e = (
+ e0
+ + 9.0 / 8.0 * b0 * v0 * ((v0 / v) ** (2.0 / 3.0) - 1.0) ** 2
+ + 9.0 / 16.0 * b0 * v0 * (bp - 4.0) * ((v0 / v) ** (2.0 / 3.0) - 1.0) ** 3
+ )
return e
@@ -142,14 +154,14 @@ def mBM4(vol, pars):
bp = pars[2]
v0 = pars[3]
- a = e0 + 9 * b0 * v0 * (4 - bp) / 2.
- b = -9 * b0 * v0 ** (4. / 3) * (11 - 3 * bp) / 2.
- c = 9 * b0 * v0 ** (5. / 3) * (10 - 3 * bp) / 2.
- d = -9 * b0 * v0 ** 2 * (3 - bp) / 2.
+ a = e0 + 9 * b0 * v0 * (4 - bp) / 2.0
+ b = -9 * b0 * v0 ** (4.0 / 3) * (11 - 3 * bp) / 2.0
+ c = 9 * b0 * v0 ** (5.0 / 3) * (10 - 3 * bp) / 2.0
+ d = -9 * b0 * v0**2 * (3 - bp) / 2.0
n = 1 # 1 as mBM, 2 as BM
VV = np.power(vol, -n / 3)
- ee = a + b * VV + c * VV ** 2 + d * VV ** 3
+ ee = a + b * VV + c * VV**2 + d * VV**3
return ee
@@ -168,24 +180,23 @@ def mBM5(vol, pars):
v0 = pars[3]
b2p = pars[4]
- '''
+ """
# copy from ShunLi's matlab scripts.
a = (8 * e0 + 3 * b0 * (122 + 9 * b0 * b2p - 57 * bp + 9 * bp * bp) * v0) / 8
b = (-3 * b0 * (107 + 9 * b0 * b2p - 54 * bp + 9 * bp * bp) * v0 ** (4 / 3)) / 2
c = (9 * b0 * (94 + 9 * b0 * b2p - 51 * bp + 9 * bp * bp) * v0 ** (5 / 3)) / 4
d = (-3 * b0 * (83 + 9 * b0 * b2p - 48 * bp + 9 * bp * bp) * v0 ** 2) / 2
e = (3 * b0 * (74 + 9 * b0 * b2p - 45 * bp + 9 * bp * bp) * v0 ** (7 / 3)) / 8
- '''
+ """
# retype according to formula in the article
a = e0 + 3 * b0 * v0 * (122 + 9 * b0 * b2p - 57 * bp + 9 * bp * bp) / 8
- b = -3 * b0 * v0**(4 / 3) * (107 + 9 * b0 *
- b2p - 54 * bp + 9 * bp * bp) / 2
- c = 9 * b0 * v0**(5 / 3) * (94 + 9 * b0 * b2p - 51 * bp + 9 * bp * bp) / 4
+ b = -3 * b0 * v0 ** (4 / 3) * (107 + 9 * b0 * b2p - 54 * bp + 9 * bp * bp) / 2
+ c = 9 * b0 * v0 ** (5 / 3) * (94 + 9 * b0 * b2p - 51 * bp + 9 * bp * bp) / 4
d = -3 * b0 * v0**2 * (83 + 9 * b0 * b2p - 48 * bp + 9 * bp * bp) / 2
- e = 3 * b0 * v0**(7 / 3) * (74 + 9 * b0 * b2p - 45 * bp + 9 * bp * bp) / 8
+ e = 3 * b0 * v0 ** (7 / 3) * (74 + 9 * b0 * b2p - 45 * bp + 9 * bp * bp) / 8
VV = np.power(vol, -1 / 3)
- ee = a + b * VV + c * VV ** 2 + d * VV ** 3 + e * VV ** 4
+ ee = a + b * VV + c * VV**2 + d * VV**3 + e * VV**4
return ee
@@ -207,7 +218,7 @@ def mBM4poly(vol, parameters):
n = 1 # 1 as mBM, 2 as BM
VV = np.power(vol, -1 / 3)
- E = a + b * VV + c * VV ** 2 + d * VV ** 3 + e * VV ** 4
+ E = a + b * VV + c * VV**2 + d * VV**3 + e * VV**4
return E
@@ -218,8 +229,12 @@ def calc_v0_mBM4poly(x, pars):
d = pars[3]
e = 0
- f = ((4 * e) / (3 * x ** (7 / 3)) + d / x ** 2 + (2 * c) /
- (3 * x ** (5 / 3)) + b / (3 * x ** (4 / 3))) * eV2GPa
+ f = (
+ (4 * e) / (3 * x ** (7 / 3))
+ + d / x**2
+ + (2 * c) / (3 * x ** (5 / 3))
+ + b / (3 * x ** (4 / 3))
+ ) * eV2GPa
return f
@@ -230,23 +245,37 @@ def calc_props_mBM4poly(pars):
d = pars[3]
e = 0
- v0 = 4 * c ** 3 - 9 * b * c * d + \
- np.sqrt((c ** 2 - 3 * b * d) * (4 * c ** 2 - 3 * b * d) ** 2)
- v0 = -v0 / b ** 3
- b0 = ((28 * e) / (9 * v0 ** (10 / 3)) +
- (2 * d) / v0 ** 3 + (10 * c) / (9 * v0 ** (8 / 3)) +
- (4 * b) / (9 * v0 ** (7 / 3))) * v0
- bp = (98 * e + 54 * d * v0 ** (1 / 3) + 25 * c * v0 ** (2 / 3) + 8 * b * v0) / \
- (42 * e + 27 * d * v0 ** (1 / 3) + 15 * c * v0 ** (2 / 3) + 6 * b * v0)
- b2p = (v0**(8 / 3) * (9 * d * (14 * e + 5 * c * v0**(2 / 3) + 8 * b * v0) +
- 2 * v0**(1 / 3) * (126 * b * e * v0 ** (1 / 3) + 5 * c * (28 * e + b * v0)))) / \
- (2 * (14 * e + 9 * d * v0**(1 / 3) + 5 * c * v0**(2 / 3) + 2 * b * v0)**3)
+ v0 = (
+ 4 * c**3
+ - 9 * b * c * d
+ + np.sqrt((c**2 - 3 * b * d) * (4 * c**2 - 3 * b * d) ** 2)
+ )
+ v0 = -v0 / b**3
+ b0 = (
+ (28 * e) / (9 * v0 ** (10 / 3))
+ + (2 * d) / v0**3
+ + (10 * c) / (9 * v0 ** (8 / 3))
+ + (4 * b) / (9 * v0 ** (7 / 3))
+ ) * v0
+ bp = (98 * e + 54 * d * v0 ** (1 / 3) + 25 * c * v0 ** (2 / 3) + 8 * b * v0) / (
+ 42 * e + 27 * d * v0 ** (1 / 3) + 15 * c * v0 ** (2 / 3) + 6 * b * v0
+ )
+ b2p = (
+ v0 ** (8 / 3)
+ * (
+ 9 * d * (14 * e + 5 * c * v0 ** (2 / 3) + 8 * b * v0)
+ + 2
+ * v0 ** (1 / 3)
+ * (126 * b * e * v0 ** (1 / 3) + 5 * c * (28 * e + b * v0))
+ )
+ ) / (2 * (14 * e + 9 * d * v0 ** (1 / 3) + 5 * c * v0 ** (2 / 3) + 2 * b * v0) ** 3)
e0 = mBM4poly(v0, pars)
props = [e0, b0, bp, v0, b2p]
return props
-#---------------------------------
+
+# ---------------------------------
def res_mBM5poly(pars, y, x):
@@ -265,7 +294,7 @@ def mBM5poly(vol, pars):
n = 1 # 1 as mBM, 2 as BM
VV = np.power(vol, -1 / 3)
- E = a + b * VV + c * VV ** 2 + d * VV ** 3 + e * VV ** 4
+ E = a + b * VV + c * VV**2 + d * VV**3 + e * VV**4
return E
@@ -276,8 +305,12 @@ def calc_v0_mBM5poly(x, pars):
d = pars[3]
e = pars[4]
- f = ((4 * e) / (3 * x ** (7 / 3)) + d / x ** 2 + (2 * c) /
- (3 * x ** (5 / 3)) + b / (3 * x ** (4 / 3))) * eV2GPa
+ f = (
+ (4 * e) / (3 * x ** (7 / 3))
+ + d / x**2
+ + (2 * c) / (3 * x ** (5 / 3))
+ + b / (3 * x ** (4 / 3))
+ ) * eV2GPa
return f
@@ -299,16 +332,26 @@ def calc_props_mBM5poly(pars):
sol = fsolve(calc_v0_mBM5poly, vg, args=pars)
v0 = sol
- b0 = ((28 * e) / (9 * v0 ** (10 / 3)) +
- (2 * d) / v0 ** 3 + (10 * c) / (9 * v0 ** (8 / 3)) +
- (4 * b) / (9 * v0 ** (7 / 3))) * v0
- bp = (98 * e + 54 * d * v0 ** (1 / 3) + 25 * c * v0 ** (2 / 3) + 8 * b * v0) / \
- (42 * e + 27 * d * v0 ** (1 / 3) + 15 * c * v0 ** (2 / 3) + 6 * b * v0)
- b2p = (v0**(8 / 3) * (9 * d * (14 * e + 5 * c * v0**(2 / 3) + 8 * b * v0) +
- 2 * v0**(1 / 3) * (126 * b * e * v0 ** (1 / 3) + 5 * c * (28 * e + b * v0)))) / \
- (2 * (14 * e + 9 * d * v0**(1 / 3) + 5 * c * v0**(2 / 3) + 2 * b * v0)**3)
+ b0 = (
+ (28 * e) / (9 * v0 ** (10 / 3))
+ + (2 * d) / v0**3
+ + (10 * c) / (9 * v0 ** (8 / 3))
+ + (4 * b) / (9 * v0 ** (7 / 3))
+ ) * v0
+ bp = (98 * e + 54 * d * v0 ** (1 / 3) + 25 * c * v0 ** (2 / 3) + 8 * b * v0) / (
+ 42 * e + 27 * d * v0 ** (1 / 3) + 15 * c * v0 ** (2 / 3) + 6 * b * v0
+ )
+ b2p = (
+ v0 ** (8 / 3)
+ * (
+ 9 * d * (14 * e + 5 * c * v0 ** (2 / 3) + 8 * b * v0)
+ + 2
+ * v0 ** (1 / 3)
+ * (126 * b * e * v0 ** (1 / 3) + 5 * c * (28 * e + b * v0))
+ )
+ ) / (2 * (14 * e + 9 * d * v0 ** (1 / 3) + 5 * c * v0 ** (2 / 3) + 2 * b * v0) ** 3)
- '''
+ """
dEdV = -b / 3 * v0**(-4 / 3) - 2 / 3 * c * \
v0**(-5 / 3) - d * v0**(-2) - 4 / 3 * e * v0**(-7 / 3)
dEdV2 = 4 / 9 * b * v0**(-7 / 3) + 10 / 9 * c * \
@@ -328,7 +371,7 @@ def calc_props_mBM5poly(pars):
b0 = v0 * dEdV2
bp = dBdV / dPdV
b2p = (dBdV2 * dPdV - dPdV2 * dBdV) / dPdV**3
- '''
+ """
e0 = mBM5poly(v0, pars)
props = [e0, b0, bp, v0, b2p]
return props
@@ -360,9 +403,10 @@ def BM4(vol, pars):
bp = pars[2]
v0 = pars[3]
- eta = (v0 / vol) ** (1. / 3.)
- e = e0 + 9. * b0 * v0 / 16 * \
- (eta ** 2 - 1) ** 2 * (6 + bp * (eta ** 2 - 1.) - 4. * eta ** 2)
+ eta = (v0 / vol) ** (1.0 / 3.0)
+ e = e0 + 9.0 * b0 * v0 / 16 * (eta**2 - 1) ** 2 * (
+ 6 + bp * (eta**2 - 1.0) - 4.0 * eta**2
+ )
return e
@@ -381,30 +425,37 @@ def BM5(vol, pars):
v0 = pars[3]
b0pp = pars[4]
- t1 = (v0 / vol) ** (1. / 3.)
- t2 = t1 ** 2
- t3 = t2 - 1.
- t4 = t3 ** 2 / 4.
- t5 = b0p ** 2
-
- ee = e0 + 3. / 8. * b0 * v0 * t4 * (9. * t4 * b0 * b0pp +
- 9. * t4 * t5 - 63. * t4 * b0p + 143. * t4 + 6. * b0p * t3 - 24. * t2 + 36.)
+ t1 = (v0 / vol) ** (1.0 / 3.0)
+ t2 = t1**2
+ t3 = t2 - 1.0
+ t4 = t3**2 / 4.0
+ t5 = b0p**2
+
+ ee = e0 + 3.0 / 8.0 * b0 * v0 * t4 * (
+ 9.0 * t4 * b0 * b0pp
+ + 9.0 * t4 * t5
+ - 63.0 * t4 * b0p
+ + 143.0 * t4
+ + 6.0 * b0p * t3
+ - 24.0 * t2
+ + 36.0
+ )
return ee
def rBM4(vol, pars):
- '''
+ """
Implementions as Alberto Otero-de-la-Roza, i.e. rBM4 is used here
Comput Physics Comm, 2011, 182: 1708-1720
- '''
+ """
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
v0 = pars[3]
x = v0 / vol
- f = 0.5 * (x**(2. / 3) - 1)
+ f = 0.5 * (x ** (2.0 / 3) - 1)
E = e0 + 4.5 * v0 * b0 * f**2 * (1 + (bp - 4) * f)
return E
@@ -415,19 +466,19 @@ def res_rBM4(pars, y, x):
def rBM4_pv(vol, pars):
- '''
+ """
Implementions as Alberto Otero-de-la-Roza, i.e. rBM4 is used here
Comput Physics Comm, 2011, 182: 1708-1720
Fit for V-P relations
- '''
+ """
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
v0 = pars[3]
x = v0 / vol
- f = 0.5 * (x**(2. / 3) - 1)
- P = 1.5 * b0 * (2 * f + 1)**(2.5) * (2 + 3 * (bp - 4) * f)
+ f = 0.5 * (x ** (2.0 / 3) - 1)
+ P = 1.5 * b0 * (2 * f + 1) ** (2.5) * (2 + 3 * (bp - 4) * f)
return P
@@ -437,10 +488,10 @@ def res_rBM4_pv(par, y, x):
def rBM5(vol, pars):
- '''
+ """
Implementions as Alberto Otero-de-la-Roza, i.e. rBM5 is used here
Comput Physics Comm, 2011, 182: 1708-1720
- '''
+ """
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
@@ -448,11 +499,12 @@ def rBM5(vol, pars):
bpp = pars[4]
x = v0 / vol
- f = 0.5 * (x**(2. / 3) - 1)
+ f = 0.5 * (x ** (2.0 / 3) - 1)
H = b0 * bpp + b0 * b0
- E = e0 + 3 / 8 * v0 * b0 * f**2 * \
- ((9 * H - 63 * bp + 143) * f**2 + 12 * (bp - 4) * f + 12)
+ E = e0 + 3 / 8 * v0 * b0 * f**2 * (
+ (9 * H - 63 * bp + 143) * f**2 + 12 * (bp - 4) * f + 12
+ )
return E
@@ -462,11 +514,11 @@ def res_rBM5(pars, y, x):
def rBM5_pv(vol, pars):
- '''
+ """
Implementions as Alberto Otero-de-la-Roza, i.e. rBM5 is used here
Comput Physics Comm, 2011, 182: 1708-1720
Fit for V-P relations
- '''
+ """
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
@@ -474,11 +526,15 @@ def rBM5_pv(vol, pars):
bpp = pars[4]
x = v0 / vol
- f = 0.5 * (x**(2. / 3) - 1)
+ f = 0.5 * (x ** (2.0 / 3) - 1)
H = b0 * bpp + b0 * b0
- P = 0.5 * b0 * (2 * f + 1)**(2.5) * \
- ((9 * H - 63 * bp + 143) * f**2 + 9 * (bp - 4) * f + 6)
+ P = (
+ 0.5
+ * b0
+ * (2 * f + 1) ** (2.5)
+ * ((9 * H - 63 * bp + 143) * f**2 + 9 * (bp - 4) * f + 6)
+ )
return P
@@ -504,13 +560,16 @@ def universal(vol, parameters):
v0 = parameters[3]
t1 = b0 * v0
- t2 = bp - 1.
- t3 = (vol / v0) ** (1. / 3.)
- t4 = np.exp(-3. / 2. * t2 * (-1. + t3))
- t5 = t2 ** 2
- t6 = 1. / t5
- e = e0 - 2. * t1 * t4 * \
- (3. * t3 * bp - 3. * t3 + 5. - 3. * bp) * t6 + 4. * t1 * t6
+ t2 = bp - 1.0
+ t3 = (vol / v0) ** (1.0 / 3.0)
+ t4 = np.exp(-3.0 / 2.0 * t2 * (-1.0 + t3))
+ t5 = t2**2
+ t6 = 1.0 / t5
+ e = (
+ e0
+ - 2.0 * t1 * t4 * (3.0 * t3 * bp - 3.0 * t3 + 5.0 - 3.0 * bp) * t6
+ + 4.0 * t1 * t6
+ )
return e
@@ -521,10 +580,10 @@ def res_LOG4(pars, y, x):
def LOG4(vol, pars):
- '''
+ """
Natrual strain (Poirier-Tarantola)EOS with 4 paramters
Seems only work in near-equillibrium range.
- '''
+ """
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
@@ -532,10 +591,10 @@ def LOG4(vol, pars):
t1 = b0 * v0
t2 = np.log(v0 / vol)
- t3 = t2 ** 2
+ t3 = t2**2
t4 = t3 * t2
- ee = e0 + t1 * t3 / 2. + t1 * t4 * bp / 6. - t1 * t4 / 3.
- '''
+ ee = e0 + t1 * t3 / 2.0 + t1 * t4 * bp / 6.0 - t1 * t4 / 3.0
+ """
# write follows ShunLi's
xx = np.log(v0)
a = e0 + b0 * v0 * (3 * xx**2 + (bp - 2) * xx**3) / 6
@@ -544,7 +603,7 @@ def LOG4(vol, pars):
d = -b0 * v0 * (bp - 2) / 6
VV = np.log(vol)
ee = a + b * VV + c * VV**2 + d * VV**3
- '''
+ """
return ee
@@ -558,18 +617,19 @@ def calc_props_LOG4(pars):
props = [e0, b0, bp, v0, bpp]
return props
+
# ----------------------------------------------------------------------------------------
def rPT4(vol, pars):
- '''
+ """
Natrual strain EOS with 4 paramters
Seems only work in near-equillibrium range.
Implementions as Alberto Otero-de-la-Roza, i.e. rPT4 is used here
Comput Physics Comm, 2011, 182: 1708-1720,
in their article, labeled as PT3 (3-order), however, we mention it as
rPT4 for 4-parameters EOS.
- '''
+ """
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
@@ -587,20 +647,20 @@ def res_rPT4(pars, y, x):
def rPT4_pv(vol, pars):
- '''
+ """
Natrual strain (Poirier-Tarantola)EOS with 4 paramters
Seems only work in near-equillibrium range.
Implementions as Alberto Otero-de-la-Roza, i.e. rPT4 is used here
Comput Physics Comm, 2011, 182: 1708-1720,
in their article, labeled as PT3 (3-order), however, we mention it as
rPT4 for 4-parameters EOS.
- '''
+ """
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
v0 = pars[3]
- x = (vol / v0)
+ x = vol / v0
fn = 1 / 3 * np.log(x)
P = -1.5 * b0 * fn * np.exp(-3 * fn) * (-3 * (bp - 2) * fn + 1)
return P
@@ -617,9 +677,9 @@ def res_LOG5(pars, y, x):
def LOG5(vol, parameters):
- '''
+ """
Natrual strain (Poirier-Tarantola)EOS with 5 paramters
- '''
+ """
e0 = parameters[0]
b0 = parameters[1]
b0p = parameters[2]
@@ -628,38 +688,47 @@ def LOG5(vol, parameters):
t1 = b0 * v0
t2 = np.log(v0 / vol)
- t3 = t2 ** 2
- t4 = t3 ** 2
- t5 = b0 ** 2
- t6 = b0p ** 2
+ t3 = t2**2
+ t4 = t3**2
+ t5 = b0**2
+ t6 = b0p**2
t7 = t3 * t2
- e = e0 + t1 * t4 / 8. + t5 * v0 * t4 * b0pp / 24. - t1 * t4 * b0p / 8. + \
- t1 * t4 * t6 / 24. + t1 * t7 * b0p / 6. - t1 * t7 / 3. + t1 * t3 / 2.
+ e = (
+ e0
+ + t1 * t4 / 8.0
+ + t5 * v0 * t4 * b0pp / 24.0
+ - t1 * t4 * b0p / 8.0
+ + t1 * t4 * t6 / 24.0
+ + t1 * t7 * b0p / 6.0
+ - t1 * t7 / 3.0
+ + t1 * t3 / 2.0
+ )
return e
def rPT5(vol, pars):
- '''
+ """
Natrual strain EOS with 4 paramters
Seems only work in near-equillibrium range.
Implementions as Alberto Otero-de-la-Roza, i.e. rPT5 is used here
Comput Physics Comm, 2011, 182: 1708-1720,
in their article, labeled as PT3 (3-order), however, we mention it as
rPT5 for 4-parameters EOS.
- '''
+ """
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
v0 = pars[3]
bpp = pars[4]
- x = (vol / v0)
+ x = vol / v0
fn = 1 / 3 * np.log(x)
H = b0 * bpp + bp * bp
- E = e0 + 9 / 8 * b0 * v0 * fn**2 * \
- (-3 * (H + 3 * bp - 3) * fn**2 - 4 * (bp - 2) * fn + 4)
+ E = e0 + 9 / 8 * b0 * v0 * fn**2 * (
+ -3 * (H + 3 * bp - 3) * fn**2 - 4 * (bp - 2) * fn + 4
+ )
return E
@@ -669,26 +738,30 @@ def res_rPT5(pars, y, x):
def rPT5_pv(vol, pars):
- '''
+ """
Natrual strain (Poirier-Tarantola)EOS with 5 paramters
Implementions as Alberto Otero-de-la-Roza, i.e. rPT5 is used here
Comput Physics Comm, 2011, 182: 1708-1720,
in their article, labeled as PT3 (3-order), however, we mention it as
rPT5 for 4-parameters EOS.
- '''
+ """
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
v0 = pars[3]
bpp = pars[4]
- x = (vol / v0)
+ x = vol / v0
fn = 1 / 3 * np.log(x)
H = b0 * bpp + bp * bp
- P = -1.5 * b0 * fn * \
- np.exp(-3 * fn) * (-3 * (H + 3 * bp - 3)
- * fn**2 - 3 * (bp - 2) * fn + 2)
+ P = (
+ -1.5
+ * b0
+ * fn
+ * np.exp(-3 * fn)
+ * (-3 * (H + 3 * bp - 3) * fn**2 - 3 * (bp - 2) * fn + 2)
+ )
return P
@@ -726,7 +799,7 @@ def vinet(vol, pars):
eta = (vol / v0) ** (1 / 3)
Y = 1.5 * (bp - 1) * (1 - eta)
- Z = 4 * b0 * v0 / (bp - 1)**2
+ Z = 4 * b0 * v0 / (bp - 1) ** 2
ee = e0 + Z - Z * (1 - Y) * np.exp(Y)
return ee
@@ -750,19 +823,19 @@ def res_vinet_pv(par, y, x):
# ----------------------------------------------------------------------------------------
def Li4p(V, parameters):
- ''' Li JH, APL, 87, 194111 (2005) '''
+ """Li JH, APL, 87, 194111 (2005)"""
E0 = parameters[0]
B0 = parameters[1]
BP = parameters[2]
V0 = parameters[3]
# In fact, it is just a small modified version of Rose or Vinet EOS.
- x = (V / V0) ** (1. / 3.)
+ x = (V / V0) ** (1.0 / 3.0)
eta = np.sqrt(-9 * B0 * V0 / E0)
- astar = eta * (x - 1.)
- delta = (BP - 1.) / (2 * eta) - 1. / 3.
+ astar = eta * (x - 1.0)
+ delta = (BP - 1.0) / (2 * eta) - 1.0 / 3.0
- E = E0 * (1 + astar + delta * astar ** 3) * np.exp(-astar)
+ E = E0 * (1 + astar + delta * astar**3) * np.exp(-astar)
return E
@@ -773,7 +846,7 @@ def res_Li4p(p, y, x):
# ----------------------------------------------------------------------------------------
def morse(v, pars):
- ''' Reproduce from ShunliShang's matlab script. '''
+ """Reproduce from ShunliShang's matlab script."""
e0 = pars[0]
b0 = pars[1]
bp = pars[2]
@@ -784,10 +857,13 @@ def morse(v, pars):
a = e0 + (9 * b0 * v0) / (2 * (-1 + bp) * (-1 + bp))
b = (-9 * b0 * np.exp(-1 + bp) * v0) / (-1 + bp) / (-1 + bp)
c = (9 * b0 * np.exp(-2 + 2 * bp) * v0) / (2 * (-1 + bp) * (-1 + bp))
- d = (1 - bp) / (v0 ** (1. / 3))
+ d = (1 - bp) / (v0 ** (1.0 / 3))
- ee = a + b * np.exp(d * np.power(v, 1. / 3)) + \
- c * np.exp(2 * d * np.power(v, 1. / 3))
+ ee = (
+ a
+ + b * np.exp(d * np.power(v, 1.0 / 3))
+ + c * np.exp(2 * d * np.power(v, 1.0 / 3))
+ )
return ee
@@ -808,17 +884,22 @@ def res_morse(p, en, volume):
def morse_AB(volume, p):
- '''
+ """
morse_AB EOS formula from Song's FVT souces
- '''
+ """
# p0 = [e0, b0, bp, v0, bpp]
E0 = p[0]
A = p[1]
B = p[2]
V0 = p[3]
xx = (volume / V0) ** (1 / 3)
- E = 1.5 * V0 * A * (np.exp(B * (1. - 2.0 * xx)) -
- 2.0 * np.exp(-B * xx) + np.exp(-B)) + E0
+ E = (
+ 1.5
+ * V0
+ * A
+ * (np.exp(B * (1.0 - 2.0 * xx)) - 2.0 * np.exp(-B * xx) + np.exp(-B))
+ + E0
+ )
return E
@@ -828,18 +909,23 @@ def res_morse_AB(p, en, volume):
def morse_3p(volume, p):
- '''
+ """
morse_AB EOS formula from Song's FVT souces
A= 0.5*B
- '''
+ """
# p0 = [e0, b0, bp, v0, bpp]
E0 = p[0]
A = p[1]
V0 = p[2]
B = 0.5 * A
xx = (volume / V0) ** (1 / 3)
- E = 1.5 * V0 * A * (np.exp(B * (1. - 2.0 * xx)) -
- 2.0 * np.exp(-B * xx) + np.exp(-B)) + E0
+ E = (
+ 1.5
+ * V0
+ * A
+ * (np.exp(B * (1.0 - 2.0 * xx)) - 2.0 * np.exp(-B * xx) + np.exp(-B))
+ + E0
+ )
return E
@@ -849,11 +935,11 @@ def res_morse_3p(p, en, volume):
def morse_6p(vol, par):
- '''
+ """
Generalized Morse EOS proposed by Qin, see:
Qin et al. Phys Rev B, 2008, 78, 214108.
Qin et al. Phys Rev B, 2008, 77, 220103(R).
- '''
+ """
# p0 = [e0, b0, bp, v0, bpp]
e0 = par[0]
b0 = par[1]
@@ -868,8 +954,12 @@ def morse_6p(vol, par):
B = 9 * b0 * v0 * (p + m) / C
x = (vol / v0) ** (1 / 3)
- ee = A * np.exp(-p * (x - 1)) / (x ** m) - \
- B * (x ** n) * np.exp(-q * (x - 1)) + e0 - (A - B)
+ ee = (
+ A * np.exp(-p * (x - 1)) / (x**m)
+ - B * (x**n) * np.exp(-q * (x - 1))
+ + e0
+ - (A - B)
+ )
return ee
@@ -895,9 +985,9 @@ def res_morse_6p(p, en, volume):
# ----------------------------------------------------------------------------------------
def mie(v, p):
- '''
+ """
Mie model for song's FVT
- '''
+ """
# p0 = [e0, b0, bp, v0, bpp]
E0 = p[0]
m = p[1]
@@ -905,7 +995,7 @@ def mie(v, p):
V0 = p[3]
xx = (V0 / v) ** (1 / 3)
- E = E0 / (n - m) * (n * (xx ** m) - m * (xx ** n))
+ E = E0 / (n - m) * (n * (xx**m) - m * (xx**n))
return E
@@ -916,9 +1006,9 @@ def res_mie(p, e, v):
def mie_simple(v, p):
- '''
+ """
Mie_simple model for song's FVT
- '''
+ """
# p0 = [e0, b0, bp, v0, bpp]
E0 = p[0]
m = 4
@@ -926,7 +1016,7 @@ def mie_simple(v, p):
V0 = p[3]
xx = (V0 / v) ** (1 / 3)
- E = E0 / (n - m) * (n * (xx ** m) - m * (xx ** n))
+ E = E0 / (n - m) * (n * (xx**m) - m * (xx**n))
return E
@@ -938,10 +1028,10 @@ def res_mie_simple(p, e, v):
# ----------------------------------------------------------------------------------------
def TEOS(v, par):
- '''
+ """
Holland, et al, Journal of Metamorphic Geology, 2011, 29(3): 333-383
Modified Tait equation of Huang & Chow
- '''
+ """
e0 = par[0]
b0 = par[1]
bp = par[2]
@@ -950,7 +1040,7 @@ def TEOS(v, par):
a = (1 + bp) / (1 + bp + b0 * bpp)
b = bp / b0 - bpp / (1 + bp)
- c = (1 + bp + b0 * bpp) / (bp ** 2 + bp - b0 * bpp)
+ c = (1 + bp + b0 * bpp) / (bp**2 + bp - b0 * bpp)
t1 = (v / v0) + a - 1
P = 1 / b * ((t1 / a) ** (-1 / c) - 1)
@@ -966,24 +1056,28 @@ def res_TEOS(p, e, v):
# ----------------------------------------------------------------------------------------
def SJX_v2(vol, par):
- '''
+ """
Sun Jiuxun, et al. J phys Chem Solids, 2005, 66: 773-782.
They said it is satified for the limiting condition at high pressure.
- '''
+ """
e0 = par[0]
b0 = par[1]
bp = par[2]
v0 = par[3]
- Y = (v0 / vol)**(1 / 3) - 1
+ Y = (v0 / vol) ** (1 / 3) - 1
alpha = 1 / 4 * (3 * bp - 1)
beta = 1 - 1 / alpha
a = alpha
b = beta
- ee = e0 + 3 / 10 * a**4 * b0 * v0 * (2 * (b**5 + 1 / a**5) * (1 - (Y + 1)**(-3))
- - 15 * b**4 * (1 - (Y + 1)**(-2))
- - 60 * b**3 * (1 - (Y + 1)**(-1))
- + 60 * b**2 * np.log(Y + 1) + 3 * Y * (Y + 2) - 30 * b * Y)
+ ee = e0 + 3 / 10 * a**4 * b0 * v0 * (
+ 2 * (b**5 + 1 / a**5) * (1 - (Y + 1) ** (-3))
+ - 15 * b**4 * (1 - (Y + 1) ** (-2))
+ - 60 * b**3 * (1 - (Y + 1) ** (-1))
+ + 60 * b**2 * np.log(Y + 1)
+ + 3 * Y * (Y + 2)
+ - 30 * b * Y
+ )
return ee
@@ -993,9 +1087,9 @@ def res_SJX_v2(p, e, v):
def SJX_5p(vol, par):
- '''
+ """
SJX_5p's five parameters EOS, Physica B: Condens Mater, 2011, 406: 1276-1282
- '''
+ """
e0 = par[0]
a = par[1]
b = par[2]
@@ -1003,8 +1097,8 @@ def SJX_5p(vol, par):
n = par[4]
X = (vol / v0) ** (1 / 3)
- C1 = n * b * np.exp(a * (1 - X) + b * (1 - X ** n))
- C2 = (-n * b - a) * np.exp(b * (1 - X ** n))
+ C1 = n * b * np.exp(a * (1 - X) + b * (1 - X**n))
+ C2 = (-n * b - a) * np.exp(b * (1 - X**n))
ee = e0 / a * (C1 + C2)
return ee
@@ -1028,13 +1122,14 @@ def calc_props_SJX_5p(par):
props = [e0, b0, bp, v0, n]
return props
+
# ----------------------------------------------------------------------------------------
# some utility functions
def read_ve(fin):
if not os.path.exists(fin):
- print('Could not find input file: [%s]' % fin)
+ print("Could not find input file: [%s]" % fin)
os.sys.exit(-1)
lines = open(fin).readlines()
nline = len(lines)
@@ -1056,7 +1151,7 @@ def read_ve(fin):
def read_vlp(fin, fstart, fend):
if not os.path.exists(fin):
- print('>> Could not find input file: [%s]' % fin)
+ print(">> Could not find input file: [%s]" % fin)
os.sys.exit(-1)
lines = open(fin).readlines()
nline = len(lines)
@@ -1096,20 +1191,25 @@ def read_vlp(fin, fstart, fend):
print("\n** Vmin = %f, Vmax = %f" % (min(vol), max(vol)))
# some special conditions
- if (fstart <= 0):
- print('\n** Data range input parameters must be positive values!')
+ if fstart <= 0:
+ print("\n** Data range input parameters must be positive values!")
os.sys.exit(-1)
if fstart > fend:
if fend != -1:
tmp = fstart
fstart = fend
fend = tmp
- if (fend > nline):
+ if fend > nline:
print(
- '\n** EoSfit fit range exceed available data numbers, Reset it to be %d now.' % nline)
+ "\n** EoSfit fit range exceed available data numbers, Reset it to be %d now."
+ % nline
+ )
fend = nline
- if (fstart > nline):
- print('EoSfit fit range exceed available data numbers, Reset it to be 1: %d now.' % nline)
+ if fstart > nline:
+ print(
+ "EoSfit fit range exceed available data numbers, Reset it to be 1: %d now."
+ % nline
+ )
fstart = 1
fend = -1
@@ -1136,7 +1236,7 @@ def read_vlp(fin, fstart, fend):
def read_velp(fin, fstart, fend):
if not os.path.exists(fin):
- print('>> Could not find input file: [%s]' % fin)
+ print(">> Could not find input file: [%s]" % fin)
os.sys.exit(-1)
lines = open(fin).readlines()
nline = len(lines)
@@ -1171,20 +1271,25 @@ def read_velp(fin, fstart, fend):
print("\n** Vmin = %f, Vmax = %f" % (min(vol), max(vol)))
# some special conditions
- if (fstart <= 0):
- print('\n** Data range input parameters must be positive values!')
+ if fstart <= 0:
+ print("\n** Data range input parameters must be positive values!")
os.sys.exit(-1)
if fstart > fend:
if fend != -1:
tmp = fstart
fstart = fend
fend = tmp
- if (fend > nline):
+ if fend > nline:
print(
- '\n** EoSfit fit range exceed available data numbers, Reset it to be %d now.' % nline)
+ "\n** EoSfit fit range exceed available data numbers, Reset it to be %d now."
+ % nline
+ )
fend = -1
- if (fstart > nline):
- print('EoSfit fit range exceed available data numbers, Reset it to be 1: %d now.' % nline)
+ if fstart > nline:
+ print(
+ "EoSfit fit range exceed available data numbers, Reset it to be 1: %d now."
+ % nline
+ )
fstart = 1
fend = -1
@@ -1215,7 +1320,7 @@ def init_guess(fin):
a, b, c = np.polyfit(v, e, 2) # this comes from pylab
# initial guesses.
v0 = np.abs(-b / (2 * a))
- e0 = a * v0 ** 2 + b * v0 + c
+ e0 = a * v0**2 + b * v0 + c
b0 = 2 * a * v0
bp = 3.0
bpp = 1 * eV2GPa
@@ -1243,28 +1348,29 @@ def repro_vp(func, vol_i, pars):
return Press
-def ext_vec(func, fin, p0, fs, fe, vols=None, vole=None, ndata=101, refit=0, show_fig=False):
- '''
+def ext_vec(
+ func, fin, p0, fs, fe, vols=None, vole=None, ndata=101, refit=0, show_fig=False
+):
+ """
extrapolate the data points for E-V based on the fitted parameters in small or
very large volume range.
- '''
+ """
# read fitted-parameters
# pars = np.loadtxt(fin, dtype=float)
- fout = 'EoSfit.out'
+ fout = "EoSfit.out"
pars = lsqfit_eos(func, fin, p0, fs, fe, fout, refit=refit)
vol, eng, cella, cellb, cellc, cellba, cellca = read_velp(fin, fs, fe)
sca = ext_splint(vol, cellca)
# define extrapolate range
- print("\n** Vext_start = %f, Vext_end = %f, N_ext = %d" %
- (vols, vole, ndata))
+ print("\n** Vext_start = %f, Vext_end = %f, N_ext = %d" % (vols, vole, ndata))
vol_ext = np.linspace(vols, vole, ndata)
en_ext = eval(func)(vol_ext, pars)
# en_ext = np.zeros(ndata)
- fout = 'ext_ve_' + func + '.dat'
- fw = open(fout, 'w+')
+ fout = "ext_ve_" + func + ".dat"
+ fw = open(fout, "w+")
fw.write("%d\n" % ndata)
for i in range(ndata):
vx = vol_ext[i]
@@ -1281,11 +1387,11 @@ def ext_vec(func, fin, p0, fs, fe, vols=None, vole=None, ndata=101, refit=0, sho
# plot the results
vol, en = read_ve(fin)
- plt.plot(vol, en, 'o-', vol_ext, en_ext, 'rd')
- plt.legend(['dft_calc', func + '_ext'], loc='best')
- plt.savefig('ext_ve_' + func + '.png')
+ plt.plot(vol, en, "o-", vol_ext, en_ext, "rd")
+ plt.legend(["dft_calc", func + "_ext"], loc="best")
+ plt.savefig("ext_ve_" + func + ".png")
if show_fig:
- plt.show()
+ plt.show()
plt.close()
print("\n>> Storing the extrapolate results in %s\n" % fout)
print("\n>> DONE!")
@@ -1293,17 +1399,17 @@ def ext_vec(func, fin, p0, fs, fe, vols=None, vole=None, ndata=101, refit=0, sho
return
-def ext_splint(xp, yp, order=3, method='unispl'):
- if method == 'interp1d':
+def ext_splint(xp, yp, order=3, method="unispl"):
+ if method == "interp1d":
# old-implement of 1-D interpolation
# could not used in extrapolate
SPLINT = interp1d
return SPLINT(xp, yp, order, bounds_error=False)
- elif method == 'piecepoly':
+ elif method == "piecepoly":
SPLINT = PiecewisePolynomial
return SPLINT(xp, yp, order)
else:
- if method == 'unispl':
+ if method == "unispl":
# 1-D smoothing spline fit to a given set of data
SPLINT = UnivariateSpline
else:
@@ -1311,17 +1417,26 @@ def ext_splint(xp, yp, order=3, method='unispl'):
return SPLINT(xp, yp, k=order)
-def ext_velp(fin, fstart, fend, vols, vole, ndata, order=3, method='unispl', fout='ext_velp.dat', show_fig=False):
- '''
+def ext_velp(
+ fin,
+ fstart,
+ fend,
+ vols,
+ vole,
+ ndata,
+ order=3,
+ method="unispl",
+ fout="ext_velp.dat",
+ show_fig=False,
+):
+ """
extrapolate the lattice parameters based on input data
- '''
+ """
# read file
- vol, eng, cella, cellb, cellc, cellba, cellca = read_velp(
- fin, fstart, fend)
+ vol, eng, cella, cellb, cellc, cellba, cellca = read_velp(fin, fstart, fend)
# define extrapolate range
- print("\n** Vext_start = %f, Vext_end = %f, N_ext = %d" %
- (vols, vole, ndata))
+ print("\n** Vext_start = %f, Vext_end = %f, N_ext = %d" % (vols, vole, ndata))
vv = np.linspace(vols, vole, ndata)
# spline order = 3 by default
@@ -1342,29 +1457,49 @@ def ext_velp(fin, fstart, fend, vols, vole, ndata, order=3, method='unispl', fou
# plot the extrapolate results
nfigure = 6
lp_ext = [ee, cellaa, cellbb, cellcc, cellbaba, cellcaca, cellca_cal]
- lp_ori = [eng, cella, cellb, cellc, cellba,
- cellca, np.array(cellc) / np.array(cella)]
- lp_ylabel = ['E(eV)', 'a(A)', 'b(A)', 'c(A)', 'b/a', 'c/a', 'c_ext/a_ext']
+ lp_ori = [
+ eng,
+ cella,
+ cellb,
+ cellc,
+ cellba,
+ cellca,
+ np.array(cellc) / np.array(cella),
+ ]
+ lp_ylabel = ["E(eV)", "a(A)", "b(A)", "c(A)", "b/a", "c/a", "c_ext/a_ext"]
for i in range(nfigure):
plt.subplot(nfigure, 1, i + 1)
plt.ylabel(lp_ylabel[i])
- plt.plot(vol, lp_ori[i], 'o-', vv, lp_ext[i], 'rd')
+ plt.plot(vol, lp_ori[i], "o-", vv, lp_ext[i], "rd")
if i == 0:
- plt.legend(['ori', 'ext'], loc='best')
- plt.xlabel('Volume (A**3)')
- plt.savefig('ext_velp.png')
+ plt.legend(["ori", "ext"], loc="best")
+ plt.xlabel("Volume (A**3)")
+ plt.savefig("ext_velp.png")
if show_fig:
- plt.show()
+ plt.show()
plt.close()
# save the fit data
# get vba.dat
- fw = open(fout, 'w+')
- fw.write('#%12s\t%12s\t%12s\t%12s\t%12s\t%12s\t%12s\t%12s\n' %
- ('volume', 'eng', 'cella', 'cellb', 'cellc', 'b/a', 'c/a', 'cext/aext'))
+ fw = open(fout, "w+")
+ fw.write(
+ "#%12s\t%12s\t%12s\t%12s\t%12s\t%12s\t%12s\t%12s\n"
+ % ("volume", "eng", "cella", "cellb", "cellc", "b/a", "c/a", "cext/aext")
+ )
for i in range(ndata):
- fw.write('%12.6f\t%12.6f\t%12.6f\t%12.6f\t%12.6f\t%12.6f\t%12.6f\t%12.6f\n' %
- (vv[i], ee[i], cellaa[i], cellbb[i], cellcc[i], cellbaba[i], cellcaca[i], cellca_cal[i]))
+ fw.write(
+ "%12.6f\t%12.6f\t%12.6f\t%12.6f\t%12.6f\t%12.6f\t%12.6f\t%12.6f\n"
+ % (
+ vv[i],
+ ee[i],
+ cellaa[i],
+ cellbb[i],
+ cellcc[i],
+ cellbaba[i],
+ cellcaca[i],
+ cellca_cal[i],
+ )
+ )
fw.flush()
fw.close()
print("\n>> Storing the extrapolate results in %s\n" % fout)
@@ -1372,38 +1507,40 @@ def ext_velp(fin, fstart, fend, vols, vole, ndata, order=3, method='unispl', fou
return
-def lsqfit_eos(func, fin, par, fstart, fend, show_fig=False, fout='EoSfit.out', refit=-1):
+def lsqfit_eos(
+ func, fin, par, fstart, fend, show_fig=False, fout="EoSfit.out", refit=-1
+):
# make the screen output better.
- print('\n')
+ print("\n")
print("\t>> We are using [ %s ] to fit the V-E relationship << \t" % func)
- print('\n')
+ print("\n")
fs = fstart
fe = fend
p = par
if fs < 0:
- print('start fitting range index must be a positive integer!')
+ print("start fitting range index must be a positive integer!")
os.sys.exit(-1)
# p0 = [e0, b0, bp, v0, bpp]
if refit == -1:
- if (func == 'morse_AB') or (func == 'morse_3p'):
+ if (func == "morse_AB") or (func == "morse_3p"):
A = 6
B = 0.5 * A
- if func == 'morse_AB':
+ if func == "morse_AB":
p0 = [p[0], A, B, p[3]]
else:
p0 = [p[0], A, p[3]]
- elif func in ['mie', 'mie_simple']:
+ elif func in ["mie", "mie_simple"]:
p0 = [p[0], 4, 6, p[3]]
- elif func == 'morse_6p':
+ elif func == "morse_6p":
P = 1
Q = 2
m = 1
n = 1
p0 = [p[0], p[1], P, p[3], Q, m, n]
- elif func == 'SJX_5p':
+ elif func == "SJX_5p":
alpha = 1
beta = 1
n = 1
@@ -1411,11 +1548,11 @@ def lsqfit_eos(func, fin, par, fstart, fend, show_fig=False, fout='EoSfit.out',
else:
p0 = p
print(
- '>> use initial guess of fitted-paramters by polynomial fitting results:\n')
+ ">> use initial guess of fitted-paramters by polynomial fitting results:\n"
+ )
else:
p0 = np.loadtxt(fout)
- print(
- '>> use initial guess of fitted-paramters by last fitting results:\n')
+ print(">> use initial guess of fitted-paramters by last fitting results:\n")
print(p0)
vol, en = read_ve(fin)
@@ -1424,90 +1561,108 @@ def lsqfit_eos(func, fin, par, fstart, fend, show_fig=False, fout='EoSfit.out',
if fe > ndata:
fe = ndata
print(
- '\n[WARNING]: f_end exceed available data numbers, Reset it to be %d now.' % ndata)
+ "\n[WARNING]: f_end exceed available data numbers, Reset it to be %d now."
+ % ndata
+ )
if fs > ndata:
print(
- '\n[WARNING]: f_start exceed available data numbers, Reset it to be 1: %d now.' % ndata)
- print('and Reset f_end to be %d now.' % ndata)
+ "\n[WARNING]: f_start exceed available data numbers, Reset it to be 1: %d now."
+ % ndata
+ )
+ print("and Reset f_end to be %d now." % ndata)
fs = 1
fe = ndata
if fe == -1:
- print('\n[ATTENTIONS]: fend = -1')
+ print("\n[ATTENTIONS]: fend = -1")
num = ndata - fs + 1
else:
num = fe - fs + 1
- vol = vol[fs - 1: fe]
- en = en[fs - 1: fe]
- print('\n%d/%d data was used in the fitting ...\n' % (num, ndata))
+ vol = vol[fs - 1 : fe]
+ en = en[fs - 1 : fe]
+ print("\n%d/%d data was used in the fitting ...\n" % (num, ndata))
- #*************************************************************************
+ # *************************************************************************
# fit it: step 1.
popt, pcov, infodict, mesg, ier = leastsq(
- eval('res_' + func), p0, args=(en, vol), full_output=1, maxfev=(len(p0) + 1) * 400)
- nfev = infodict['nfev']
- fvec = infodict['fvec']
+ eval("res_" + func),
+ p0,
+ args=(en, vol),
+ full_output=1,
+ maxfev=(len(p0) + 1) * 400,
+ )
+ nfev = infodict["nfev"]
+ fvec = infodict["fvec"]
- '''
+ """
psi_i = sum(fvec**2)
psi_min = min(fvec)
pfactor = np.zeros(num)
wi = (4 + 1) / num * psi_i / psi_min
pfi = np.exp(-wi * wi)
- '''
+ """
if ier not in [1, 2, 3, 4]:
raise RuntimeError("Optimal parameters not found: " + mesg)
- #*************************************************************************
+ # *************************************************************************
- print('*' * 80)
+ print("*" * 80)
print(">> fitted parameters (with %d iterations):" % nfev)
# p0 = [e0, b0, bp, v0, bpp]
- if func == 'morse_AB':
+ if func == "morse_AB":
e0, A, B, v0 = popt
- print("%12s\t%12s\t%12s\t%12s" % ('V0(A**3)', 'A', 'B', 'E0(eV)'))
- print('%12f\t%12f\t%12f\t%12f\n' % (v0, A, B, e0))
- elif func == 'morse_3p':
+ print("%12s\t%12s\t%12s\t%12s" % ("V0(A**3)", "A", "B", "E0(eV)"))
+ print("%12f\t%12f\t%12f\t%12f\n" % (v0, A, B, e0))
+ elif func == "morse_3p":
e0, A, v0 = popt
B = 0.5 * A
- print("%12s\t%12s\t%12s\t%12s" % ('V0(A**3)', 'A', 'B', 'E0(eV)'))
- print('%12f\t%12f\t%12f\t%12f\n' % (v0, A, B, e0))
- elif func in ['mie', 'mie_simple']:
+ print("%12s\t%12s\t%12s\t%12s" % ("V0(A**3)", "A", "B", "E0(eV)"))
+ print("%12f\t%12f\t%12f\t%12f\n" % (v0, A, B, e0))
+ elif func in ["mie", "mie_simple"]:
e0, m, n, v0 = popt
- print("%12s\t%12s\t%12s\t%12s" % ('V0(A**3)', 'm', 'n', 'E0(eV)'))
- print('%12f\t%12f\t%12f\t%12f\n' % (v0, m, n, e0))
- elif func == 'morse_6p':
+ print("%12s\t%12s\t%12s\t%12s" % ("V0(A**3)", "m", "n", "E0(eV)"))
+ print("%12f\t%12f\t%12f\t%12f\n" % (v0, m, n, e0))
+ elif func == "morse_6p":
e0, b0, bp, v0, bpp, m, n = calc_props_morse_6p(popt)
b0 = eV2GPa * b0
bpp = bpp / eV2GPa
- print("%12s\t%12s\t%12s\t%12s\t%12s\t%12s\t%12s" %
- ('V0(A**3)', 'B0(GPa)', 'Bp', 'E0(eV)', 'Bpp(1/GPa)', 'm', 'n'))
- print('%12f\t%12f\t%12f\t%12f\t%12f\t%12f\t%12f\n' %
- (v0, b0, bp, e0, bpp, m, n))
- elif func == 'SJX_5p':
+ print(
+ "%12s\t%12s\t%12s\t%12s\t%12s\t%12s\t%12s"
+ % ("V0(A**3)", "B0(GPa)", "Bp", "E0(eV)", "Bpp(1/GPa)", "m", "n")
+ )
+ print(
+ "%12f\t%12f\t%12f\t%12f\t%12f\t%12f\t%12f\n" % (v0, b0, bp, e0, bpp, m, n)
+ )
+ elif func == "SJX_5p":
e0, b0, bp, v0, n = calc_props_SJX_5p(popt)
b0 = eV2GPa * b0
- print("%12s\t%12s\t%12s\t%12s\t%12s" %
- ('V0(A**3)', 'B0(GPa)', 'Bp', 'E0(eV)', 'n'))
- print('%12f\t%12f\t%12f\t%12f\t%12f\n' % (v0, b0, bp, e0, n))
- elif func in ['mBM4poly', 'mBM5poly', 'mBM4', 'LOG4', 'vinet', 'morse', 'BM4']:
- prop_func = eval('calc_props_' + func)
+ print(
+ "%12s\t%12s\t%12s\t%12s\t%12s"
+ % ("V0(A**3)", "B0(GPa)", "Bp", "E0(eV)", "n")
+ )
+ print("%12f\t%12f\t%12f\t%12f\t%12f\n" % (v0, b0, bp, e0, n))
+ elif func in ["mBM4poly", "mBM5poly", "mBM4", "LOG4", "vinet", "morse", "BM4"]:
+ prop_func = eval("calc_props_" + func)
e0, b0, bp, v0, bpp = prop_func(popt)
b0 = eV2GPa * b0
bpp = bpp / eV2GPa
- print("%12s\t%12s\t%12s\t%12s\t%12s" %
- ('V0(A**3)', 'B0(GPa)', 'Bp', 'E0(eV)', 'Bpp(1/GPa)'))
- print('%12f\t%12f\t%12f\t%12f\t%12f\n' % (v0, b0, bp, e0, bpp))
+ print(
+ "%12s\t%12s\t%12s\t%12s\t%12s"
+ % ("V0(A**3)", "B0(GPa)", "Bp", "E0(eV)", "Bpp(1/GPa)")
+ )
+ print("%12f\t%12f\t%12f\t%12f\t%12f\n" % (v0, b0, bp, e0, bpp))
else:
e0, b0, bp, v0, bpp = popt
b0 = eV2GPa * b0
bpp = bpp / eV2GPa
- print("%12s\t%12s\t%12s\t%12s\t%12s" %
- ('V0(A**3)', 'B0(GPa)', 'Bp', 'E0(eV)', 'Bpp(1/GPa)'))
- print('%12f\t%12f\t%12f\t%12f\t%12f\n' % (v0, b0, bp, e0, bpp))
+ print(
+ "%12s\t%12s\t%12s\t%12s\t%12s"
+ % ("V0(A**3)", "B0(GPa)", "Bp", "E0(eV)", "Bpp(1/GPa)")
+ )
+ print("%12f\t%12f\t%12f\t%12f\t%12f\n" % (v0, b0, bp, e0, bpp))
# write the fitted results in fit.out
- fw = open(fout, 'w+')
+ fw = open(fout, "w+")
for i in range(len(popt)):
fw.write("%f\n" % popt[i])
fw.flush()
@@ -1517,11 +1672,11 @@ def lsqfit_eos(func, fin, par, fstart, fend, show_fig=False, fout='EoSfit.out',
vol_i = np.linspace(min(vol) * 0.95, max(vol) * 1.05, len(vol) * 2)
en_i = repro_ve(func, vol_i, popt)
- print('*' * 80)
+ print("*" * 80)
# calculate fitted residuals and square errors
res_opt = np.zeros(len(vol))
for i in range(len(vol)):
- res_opt[i] = (fvec[i])**2
+ res_opt[i] = (fvec[i]) ** 2
fit_res = sum(res_opt)
fit_var = np.var(fvec)
fit_std = np.std(fvec)
@@ -1531,33 +1686,38 @@ def lsqfit_eos(func, fin, par, fstart, fend, show_fig=False, fout='EoSfit.out',
# if fit_res > 1e-4:
# print("\n>> Residuals seems too large, please refit it by swithing argument --refit 1!\n")
# show = 'F' # reset show tag, not to show the figure.
- plt.plot(vol, en, 'o', vol_i, en_i)
- plt.title('EoS fitted by: %s model' % str(func))
- plt.legend(['calc', func + '-fit'], loc='best')
- plt.xlabel('Volume (A**3)')
- plt.ylabel('Energy (eV)')
- plt.savefig('EoSfit_' + func + '.png')
+ plt.plot(vol, en, "o", vol_i, en_i)
+ plt.title("EoS fitted by: %s model" % str(func))
+ plt.legend(["calc", func + "-fit"], loc="best")
+ plt.xlabel("Volume (A**3)")
+ plt.ylabel("Energy (eV)")
+ plt.savefig("EoSfit_" + func + ".png")
if show_fig:
plt.show()
- print('*' * 80)
+ print("*" * 80)
plt.close()
# reproduce data by the popt and write it into files.
repro_en = repro_ve(func, vol, popt)
repro_press = repro_vp(func, vol, popt)
- fve = open(func + '_ve_fit.dat', 'w+')
- fvp = open(func + '_vp_fit.dat', 'w+')
- fve.write('#%20s\t%20s\t%20s\t%20s\n' %
- ('volume(A**3)', 'energy(fit)', 'energy(cal)', 'dE(%)'))
- fvp.write('#%20s\t%20s\t%20s\t%20s\n'
- % ('volume(A**3)', 'pressure(GPa)', 'pressure(Mbar)', 'pressure(kbar)'))
+ fve = open(func + "_ve_fit.dat", "w+")
+ fvp = open(func + "_vp_fit.dat", "w+")
+ fve.write(
+ "#%20s\t%20s\t%20s\t%20s\n"
+ % ("volume(A**3)", "energy(fit)", "energy(cal)", "dE(%)")
+ )
+ fvp.write(
+ "#%20s\t%20s\t%20s\t%20s\n"
+ % ("volume(A**3)", "pressure(GPa)", "pressure(Mbar)", "pressure(kbar)")
+ )
for i in range(len(vol)):
- fve.write('%20f\t%20f\t%20f\t%20f\n' %
- (vol[i], repro_en[i], en[i], 100 * np.abs((en[i] - repro_en[i]) / en[i])))
+ fve.write(
+ "%20f\t%20f\t%20f\t%20f\n"
+ % (vol[i], repro_en[i], en[i], 100 * np.abs((en[i] - repro_en[i]) / en[i]))
+ )
fve.flush()
p_tmp = repro_press[i]
- fvp.write('%20f\t%20f\t%20f\t%20f\n' %
- (vol[i], p_tmp, p_tmp / 100, p_tmp * 10))
+ fvp.write("%20f\t%20f\t%20f\t%20f\n" % (vol[i], p_tmp, p_tmp / 100, p_tmp * 10))
fvp.flush()
fve.close()
fvp.close()
@@ -1566,32 +1726,64 @@ def lsqfit_eos(func, fin, par, fstart, fend, show_fig=False, fout='EoSfit.out',
def parse_argument():
parser = argparse.ArgumentParser(
- description=" Script to fit EOS in MTP calculations")
- parser.add_argument('choice', help='to run mfp, ext_vec, ext_velp?')
+ description=" Script to fit EOS in MTP calculations"
+ )
+ parser.add_argument("choice", help="to run mfp, ext_vec, ext_velp?")
+ parser.add_argument("infile", help="input ve.dat, vec.dat, velp.dat, or vlp.dat")
+ parser.add_argument(
+ "-eos",
+ "--eos",
+ default="morse_AB",
+ help="Please choose one of the EOS name in: " + str(get_eos_list()),
+ )
+ parser.add_argument(
+ "--show", default="T", help="to show the fitted results[T] or not[F]?"
+ )
+ parser.add_argument(
+ "-vr",
+ "--vrange",
+ type=float,
+ nargs=3,
+ default=[30, 50, 101],
+ help="extend range used for ext, e.g. [vols, vole, ndata]: 1 10 31",
+ )
+ parser.add_argument(
+ "-fr",
+ "--frange",
+ type=int,
+ nargs=2,
+ default=[1, 1000],
+ help="data range to be fitted, e.g. [ns, ne]",
+ )
parser.add_argument(
- 'infile', help='input ve.dat, vec.dat, velp.dat, or vlp.dat')
- parser.add_argument('-eos', '--eos', default='morse_AB',
- help='Please choose one of the EOS name in: ' + str(get_eos_list()))
+ "--refit",
+ type=int,
+ default=-1,
+ help="fit the data with last fitted parameters as initial guess",
+ )
parser.add_argument(
- '--show', default='T', help='to show the fitted results[T] or not[F]?')
- parser.add_argument('-vr', '--vrange', type=float, nargs=3,
- default=[30, 50, 101], help="extend range used for ext, e.g. [vols, vole, ndata]: 1 10 31")
+ "-eord",
+ "--extorder",
+ type=int,
+ default=3,
+ help="spline order used in extrapolate",
+ )
parser.add_argument(
- '-fr', '--frange', type=int, nargs=2, default=[1, 1000], help='data range to be fitted, e.g. [ns, ne]')
- parser.add_argument('--refit', type=int, default=-1,
- help='fit the data with last fitted parameters as initial guess')
- parser.add_argument('-eord', '--extorder', type=int,
- default=3, help='spline order used in extrapolate')
- parser.add_argument('-enum', '--extnum', type=int, default=20,
- help='number of data to be extrapolate')
+ "-enum",
+ "--extnum",
+ type=int,
+ default=20,
+ help="number of data to be extrapolate",
+ )
parser.add_argument(
- '-v', '--version', action='version', version='%(prog)s ' + __version__())
+ "-v", "--version", action="version", version="%(prog)s " + __version__()
+ )
args = parser.parse_args()
- return(args)
+ return args
# main
-if __name__ == '__main__':
+if __name__ == "__main__":
args = parse_argument()
cho = args.choice
fin = args.infile
@@ -1616,11 +1808,10 @@ def parse_argument():
print("ERROR, start range index must be a positive integer!")
os.sys.exit(-1)
- if cho == 'mfp':
+ if cho == "mfp":
p0 = init_guess(fin)
- lsqfit_eos(
- func, fin, p0, fs, fe, SHOW, refit=REFIT)
- elif cho == 'ext_vec':
+ lsqfit_eos(func, fin, p0, fs, fe, SHOW, refit=REFIT)
+ elif cho == "ext_vec":
# used in ext choice
ExtVS = args.vrange[0]
ExtVE = args.vrange[1]
@@ -1634,7 +1825,7 @@ def parse_argument():
# ExtNum = ExtNum + 1
p0 = init_guess(fin)
ext_vec(func, fin, p0, fs, fe, ExtVS, ExtVE, ExtNum, refit=REFIT)
- elif cho == 'ext_velp':
+ elif cho == "ext_velp":
EORDER = args.extorder
ExtVS = args.vrange[0]
ExtVE = args.vrange[1]
@@ -1643,11 +1834,9 @@ def parse_argument():
print("ERROR, range setting must be a positive value!")
exit(1)
if ExtNum % 2 == 0:
- print("[WARNING]: ndata = %d, reset it to be %d" %
- (ExtNum, ExtNum + 1))
+ print("[WARNING]: ndata = %d, reset it to be %d" % (ExtNum, ExtNum + 1))
ExtNum = ExtNum + 1
- ext_velp(fin, fs, fe, ExtVS, ExtVE, ExtNum,
- order=EORDER, method='unispl')
+ ext_velp(fin, fs, fe, ExtVS, ExtVE, ExtNum, order=EORDER, method="unispl")
else:
- print('Unkown Choice, abort now ... ...')
+ print("Unkown Choice, abort now ... ...")
os.sys.exit(-1)
diff --git a/dpgen/auto_test/lib/pwscf.py b/dpgen/auto_test/lib/pwscf.py
index ca54def1c..d3844497b 100644
--- a/dpgen/auto_test/lib/pwscf.py
+++ b/dpgen/auto_test/lib/pwscf.py
@@ -1,13 +1,15 @@
-#!/usr/bin/python3
+#!/usr/bin/python3
import numpy as np
+
# from lib.vasp import system_from_poscar
-def _make_pwscf_01_runctrl(sys_data, ecut, ediff, smearing, degauss) :
- tot_natoms = sum(sys_data['atom_numbs'])
- ntypes = len(sys_data['atom_names'])
+
+def _make_pwscf_01_runctrl(sys_data, ecut, ediff, smearing, degauss):
+ tot_natoms = sum(sys_data["atom_numbs"])
+ ntypes = len(sys_data["atom_names"])
ret = ""
- ret += '&control\n'
+ ret += "&control\n"
ret += "calculation='scf',\n"
ret += "restart_mode='from_scratch',\n"
ret += "pseudo_dir='./',\n"
@@ -24,38 +26,40 @@ def _make_pwscf_01_runctrl(sys_data, ecut, ediff, smearing, degauss) :
ret += "ecutwfc = %f,\n" % ecut
ret += "ts_vdw_econv_thr=%e,\n" % ediff
ret += "nosym = .TRUE.,\n"
- if degauss is not None :
- ret += 'degauss = %f,\n' % degauss
- if smearing is not None :
- ret += 'smearing = \'%s\',\n' % (smearing.lower())
+ if degauss is not None:
+ ret += "degauss = %f,\n" % degauss
+ if smearing is not None:
+ ret += "smearing = '%s',\n" % (smearing.lower())
ret += "/\n"
ret += "&electrons\n"
ret += "conv_thr = %e,\n" % ediff
ret += "/\n"
return ret
-def _make_pwscf_02_species(sys_data, pps) :
- atom_names = (sys_data['atom_names'])
- if 'atom_masses' in sys_data:
- atom_masses = (sys_data['atom_masses'])
- else :
+
+def _make_pwscf_02_species(sys_data, pps):
+ atom_names = sys_data["atom_names"]
+ if "atom_masses" in sys_data:
+ atom_masses = sys_data["atom_masses"]
+ else:
atom_masses = [1 for ii in atom_names]
ret = ""
ret += "ATOMIC_SPECIES\n"
ntypes = len(atom_names)
- assert(ntypes == len(atom_names))
- assert(ntypes == len(atom_masses))
- assert(ntypes == len(pps))
- for ii in range(ntypes) :
+ assert ntypes == len(atom_names)
+ assert ntypes == len(atom_masses)
+ assert ntypes == len(pps)
+ for ii in range(ntypes):
ret += "%s %d %s\n" % (atom_names[ii], atom_masses[ii], pps[ii])
return ret
-
-def _make_pwscf_03_config(sys_data) :
- cell = sys_data['cell']
- cell = np.reshape(cell, [3,3])
- coordinates = sys_data['coordinates']
- atom_names = (sys_data['atom_names'])
- atom_numbs = (sys_data['atom_numbs'])
+
+
+def _make_pwscf_03_config(sys_data):
+ cell = sys_data["cell"]
+ cell = np.reshape(cell, [3, 3])
+ coordinates = sys_data["coordinates"]
+ atom_names = sys_data["atom_names"]
+ atom_numbs = sys_data["atom_numbs"]
ntypes = len(atom_names)
ret = ""
ret += "CELL_PARAMETERS { angstrom }\n"
@@ -67,53 +71,60 @@ def _make_pwscf_03_config(sys_data) :
ret += "ATOMIC_POSITIONS { angstrom }\n"
cc = 0
for ii in range(ntypes):
- for jj in range(atom_numbs[ii]):
- ret += "%s %f %f %f\n" % (atom_names[ii],
- coordinates[cc][0],
- coordinates[cc][1],
- coordinates[cc][2])
+ for jj in range(atom_numbs[ii]):
+ ret += "%s %f %f %f\n" % (
+ atom_names[ii],
+ coordinates[cc][0],
+ coordinates[cc][1],
+ coordinates[cc][2],
+ )
cc += 1
return ret
-def _kshift(nkpt) :
- if (nkpt//2) * 2 == nkpt :
+
+def _kshift(nkpt):
+ if (nkpt // 2) * 2 == nkpt:
return 1
- else :
+ else:
return 0
-
+
+
def _make_pwscf_04_kpoints(sys_data, kspacing):
- cell = sys_data['cell']
- cell = np.reshape(cell, [3,3])
+ cell = sys_data["cell"]
+ cell = np.reshape(cell, [3, 3])
rcell = np.linalg.inv(cell)
rcell = rcell.T
- kpoints = [(np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int))
- for ii in rcell]
+ kpoints = [
+ (np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int)) for ii in rcell
+ ]
ret = ""
ret += "K_POINTS { automatic }\n"
- for ii in range(3) :
+ for ii in range(3):
ret += "%d " % kpoints[ii]
- for ii in range(3) :
+ for ii in range(3):
ret += "%d " % _kshift(kpoints[ii])
ret += "\n"
return ret
-def _make_smearing(fp_params) :
+
+def _make_smearing(fp_params):
smearing = None
- degauss = None
- if 'smearing' in fp_params :
- smearing = (fp_params['smearing']).lower()
- if 'sigma' in fp_params :
- degauss = fp_params['sigma']
- if (smearing is not None) and (smearing.split(':')[0] == 'mp') :
- smearing = 'mp'
- if not (smearing in [None, 'gauss', 'mp', 'fd']) :
+ degauss = None
+ if "smearing" in fp_params:
+ smearing = (fp_params["smearing"]).lower()
+ if "sigma" in fp_params:
+ degauss = fp_params["sigma"]
+ if (smearing is not None) and (smearing.split(":")[0] == "mp"):
+ smearing = "mp"
+ if not (smearing in [None, "gauss", "mp", "fd"]):
raise RuntimeError("unknow smearing method " + smearing)
return smearing, degauss
-def make_pwscf_input(sys_data, fp_pp_files, fp_params) :
- ecut = fp_params['ecut']
- ediff = fp_params['ediff']
- kspacing = fp_params['kspacing']
+
+def make_pwscf_input(sys_data, fp_pp_files, fp_params):
+ ecut = fp_params["ecut"]
+ ediff = fp_params["ediff"]
+ kspacing = fp_params["kspacing"]
smearing, degauss = _make_smearing(fp_params)
ret = ""
ret += _make_pwscf_01_runctrl(sys_data, ecut, ediff, smearing, degauss)
@@ -125,7 +136,7 @@ def make_pwscf_input(sys_data, fp_pp_files, fp_params) :
ret += _make_pwscf_04_kpoints(sys_data, kspacing)
ret += "\n"
return ret
-
+
# sys_data = system_from_poscar('POSCAR')
# ret = ""
diff --git a/dpgen/auto_test/lib/siesta.py b/dpgen/auto_test/lib/siesta.py
index 84618cec1..9c1be6144 100644
--- a/dpgen/auto_test/lib/siesta.py
+++ b/dpgen/auto_test/lib/siesta.py
@@ -2,56 +2,62 @@
from dpdata.periodic_table import Element
-
def _make_siesta_01_common(sys_data, ecut, ediff, mixingWeight, NumberPulay):
- tot_natoms = sum(sys_data['atom_numbs'])
- ntypes = len(sys_data['atom_names'])
+ tot_natoms = sum(sys_data["atom_numbs"])
+ ntypes = len(sys_data["atom_names"])
ret = ""
- ret += 'SystemName system\n'
- ret += 'SystemLabel system\n'
- ret += 'NumberOfAtoms %d' % tot_natoms
- ret += '\nNumberOfSpecies %d\n' % ntypes
- ret += '\n'
- ret += 'WriteForces T\n'
- ret += 'WriteCoorStep T\n'
- ret += 'WriteCoorXmol T\n'
- ret += 'WriteMDXmol T\n'
- ret += 'WriteMDHistory T\n\n'
-
- ret += 'MeshCutoff %s' % str(ecut)
- ret += ' Ry\n'
- ret += 'DM.MixingWeight %f\n' % mixingWeight
- ret += 'DM.Tolerance %e\n' % ediff
- ret += 'DM.UseSaveDM true\n'
- ret += 'DM.NumberPulay %d\n' % NumberPulay
- ret += 'MD.UseSaveXV T\n\n'
-
- ret += 'XC.functional GGA\n'
- ret += 'XC.authors PBE\n'
- ret += 'DM.UseSaveDM F\n'
- ret += 'WriteDM F\n'
- ret += 'WriteDM.NetCDF F\n'
- ret += 'WriteDMHS.NetCDF F\n'
+ ret += "SystemName system\n"
+ ret += "SystemLabel system\n"
+ ret += "NumberOfAtoms %d" % tot_natoms
+ ret += "\nNumberOfSpecies %d\n" % ntypes
+ ret += "\n"
+ ret += "WriteForces T\n"
+ ret += "WriteCoorStep T\n"
+ ret += "WriteCoorXmol T\n"
+ ret += "WriteMDXmol T\n"
+ ret += "WriteMDHistory T\n\n"
+
+ ret += "MeshCutoff %s" % str(ecut)
+ ret += " Ry\n"
+ ret += "DM.MixingWeight %f\n" % mixingWeight
+ ret += "DM.Tolerance %e\n" % ediff
+ ret += "DM.UseSaveDM true\n"
+ ret += "DM.NumberPulay %d\n" % NumberPulay
+ ret += "MD.UseSaveXV T\n\n"
+
+ ret += "XC.functional GGA\n"
+ ret += "XC.authors PBE\n"
+ ret += "DM.UseSaveDM F\n"
+ ret += "WriteDM F\n"
+ ret += "WriteDM.NetCDF F\n"
+ ret += "WriteDMHS.NetCDF F\n"
return ret
def _make_siesta_02_species(sys_data, pps):
- atom_nums = sys_data['atom_numbs']
- atom_names = sys_data['atom_names']
+ atom_nums = sys_data["atom_numbs"]
+ atom_names = sys_data["atom_names"]
ntypes = len(atom_nums)
- assert (ntypes == len(atom_names))
- assert (ntypes == len(pps))
- ret = ''
- ret += '%block Chemical_Species_label\n'
+ assert ntypes == len(atom_names)
+ assert ntypes == len(pps)
+ ret = ""
+ ret += "%block Chemical_Species_label\n"
for i in range(0, len(atom_names)):
- ret += str(i + 1) + '\t' + str(Element(atom_names[i]).Z) + '\t' + atom_names[i] + '\n'
- ret += '%endblock Chemical_Species_label\n'
+ ret += (
+ str(i + 1)
+ + "\t"
+ + str(Element(atom_names[i]).Z)
+ + "\t"
+ + atom_names[i]
+ + "\n"
+ )
+ ret += "%endblock Chemical_Species_label\n"
return ret
# ## kpoints !!! can not understand
def _make_siesta_03_kpoint(sys_data, kspacing):
- cell = sys_data['cells'][0]
+ cell = sys_data["cells"][0]
cell = np.reshape(cell, [3, 3])
## np.linalg.inv():矩阵求逆
rcell = np.linalg.inv(cell)
@@ -59,32 +65,33 @@ def _make_siesta_03_kpoint(sys_data, kspacing):
rcell = rcell.T
# np.ceil()是向上取整,与四舍五入无关 -5.6 --> -5
# np.linalg.norm:进行范数运算,范数是对向量(或者矩阵)的度量,是一个标量(scalar)
- kpoints = [(np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int))
- for ii in rcell]
+ kpoints = [
+ (np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int)) for ii in rcell
+ ]
ret = ""
- ret += '%block kgrid_Monkhorst_Pack\n'
- ret += '%d' % kpoints[0]
- ret += '\t0\t0\t0.0\n'
+ ret += "%block kgrid_Monkhorst_Pack\n"
+ ret += "%d" % kpoints[0]
+ ret += "\t0\t0\t0.0\n"
- ret += '0\t'
- ret += '%d' % kpoints[1]
- ret += '\t0\t0.0\n'
+ ret += "0\t"
+ ret += "%d" % kpoints[1]
+ ret += "\t0\t0.0\n"
- ret += '0\t0\t'
- ret += '%d' % kpoints[2]
- ret += '\t0.0\n'
+ ret += "0\t0\t"
+ ret += "%d" % kpoints[2]
+ ret += "\t0.0\n"
- ret += '%endblock kgrid_Monkhorst_Pack\n'
+ ret += "%endblock kgrid_Monkhorst_Pack\n"
return ret
### coordinate
def _make_siesta_04_ucVectorCoord(sys_data):
- cell = sys_data['cells'][0]
+ cell = sys_data["cells"][0]
cell = np.reshape(cell, [3, 3])
- coordinates = sys_data['coords'][0]
- atom_names = (sys_data['atom_names'])
- atom_numbs = (sys_data['atom_numbs'])
+ coordinates = sys_data["coords"][0]
+ atom_names = sys_data["atom_names"]
+ atom_numbs = sys_data["atom_numbs"]
ntypes = len(atom_names)
ret = ""
ret += "LatticeConstant try_input_output.00 Ang\n"
@@ -101,21 +108,24 @@ def _make_siesta_04_ucVectorCoord(sys_data):
cc = 0
for ii in range(ntypes):
for jj in range(atom_numbs[ii]):
- ret += "%f %f %f %d %s\n" % (coordinates[cc][0],
- coordinates[cc][1],
- coordinates[cc][2],
- ii + 1,
- atom_names[ii])
+ ret += "%f %f %f %d %s\n" % (
+ coordinates[cc][0],
+ coordinates[cc][1],
+ coordinates[cc][2],
+ ii + 1,
+ atom_names[ii],
+ )
cc += 1
ret += "%endblock AtomicCoordinatesAndAtomicSpecies"
return ret
+
def make_siesta_input(sys_data, fp_pp_files, fp_params):
- ecut = fp_params['ecut']
- ediff = fp_params['ediff']
- mixingWeight = fp_params['mixingWeight']
- NumberPulay = fp_params['NumberPulay']
- kspacing = fp_params['kspacing']
+ ecut = fp_params["ecut"]
+ ediff = fp_params["ediff"]
+ mixingWeight = fp_params["mixingWeight"]
+ NumberPulay = fp_params["NumberPulay"]
+ kspacing = fp_params["kspacing"]
ret = ""
ret += _make_siesta_01_common(sys_data, ecut, ediff, mixingWeight, NumberPulay)
ret += "\n"
@@ -126,4 +136,3 @@ def make_siesta_input(sys_data, fp_pp_files, fp_params):
ret += _make_siesta_04_ucVectorCoord(sys_data)
ret += "\n"
return ret
-
diff --git a/dpgen/auto_test/lib/util.py b/dpgen/auto_test/lib/util.py
index 221e2e9ed..62d5285a0 100644
--- a/dpgen/auto_test/lib/util.py
+++ b/dpgen/auto_test/lib/util.py
@@ -1,16 +1,18 @@
+import os
+import re
+
import numpy as np
import requests
-import os,re
+
from dpgen import dlog
-from dpgen.auto_test.lib import vasp
-from dpgen.auto_test.lib import lammps
-from dpgen.auto_test.lib import abacus
+from dpgen.auto_test.lib import abacus, lammps, vasp
from dpgen.auto_test.lib.utils import cmd_append_log
-lammps_task_type=['deepmd','meam','eam_fs','eam_alloy'] # 06/13 revised
+lammps_task_type = ["deepmd", "meam", "eam_fs", "eam_alloy"] # 06/13 revised
+
-def voigt_to_stress(inpt) :
- ret = np.zeros((3,3))
+def voigt_to_stress(inpt):
+ ret = np.zeros((3, 3))
ret[0][0] = inpt[0]
ret[1][1] = inpt[1]
ret[2][2] = inpt[2]
@@ -22,89 +24,94 @@ def voigt_to_stress(inpt) :
ret[2][1] = ret[1][2]
return ret
-def insert_data(task,task_type,username,file_name):
- assert task in ['eos','elastic','surf']
- assert task_type in ['vasp','deepmd']
- url='http://115.27.161.2:5000/insert_test_data?username=%s&expr_type=%s&data_type=%s' % (username,task_type,task)
+
+def insert_data(task, task_type, username, file_name):
+ assert task in ["eos", "elastic", "surf"]
+ assert task_type in ["vasp", "deepmd"]
+ url = (
+ "http://115.27.161.2:5000/insert_test_data?username=%s&expr_type=%s&data_type=%s"
+ % (username, task_type, task)
+ )
res = requests.post(url, data=open(file_name).read())
- print('Successful upload!')
+ print("Successful upload!")
-def make_work_path(jdata,task,reprod_opt,static,user):
+def make_work_path(jdata, task, reprod_opt, static, user):
- task_type=jdata['task_type']
- conf_dir=jdata['conf_dir']
+ task_type = jdata["task_type"]
+ conf_dir = jdata["conf_dir"]
conf_path = os.path.abspath(conf_dir)
- task_path = re.sub('confs', task, conf_path)
+ task_path = re.sub("confs", task, conf_path)
- if task_type=="vasp":
+ if task_type == "vasp":
if user:
- work_path=os.path.join(task_path, 'vasp-user_incar')
- assert(os.path.isdir(work_path))
+ work_path = os.path.join(task_path, "vasp-user_incar")
+ assert os.path.isdir(work_path)
return work_path
if static:
- if 'scf_incar' in jdata.keys():
- task_type=task_type+'-static-scf_incar'
+ if "scf_incar" in jdata.keys():
+ task_type = task_type + "-static-scf_incar"
else:
- kspacing = jdata['vasp_params']['kspacing']
- task_type=task_type+'-static-k%.2f' % (kspacing)
+ kspacing = jdata["vasp_params"]["kspacing"]
+ task_type = task_type + "-static-k%.2f" % (kspacing)
else:
- if 'relax_incar' in jdata.keys():
- task_type=task_type+'-relax_incar'
+ if "relax_incar" in jdata.keys():
+ task_type = task_type + "-relax_incar"
else:
- kspacing = jdata['vasp_params']['kspacing']
- task_type=task_type+'-k%.2f' % (kspacing)
+ kspacing = jdata["vasp_params"]["kspacing"]
+ task_type = task_type + "-k%.2f" % (kspacing)
elif task_type in lammps_task_type:
if static:
- task_type=task_type+'-static'
- elif reprod_opt :
- if 'relax_incar' in jdata.keys():
- task_type=task_type+'-reprod-relax_incar'
+ task_type = task_type + "-static"
+ elif reprod_opt:
+ if "relax_incar" in jdata.keys():
+ task_type = task_type + "-reprod-relax_incar"
else:
- kspacing = jdata['vasp_params']['kspacing']
- task_type=task_type+'-reprod-k%.2f'% (kspacing)
+ kspacing = jdata["vasp_params"]["kspacing"]
+ task_type = task_type + "-reprod-k%.2f" % (kspacing)
- work_path=os.path.join(task_path, task_type)
- assert(os.path.isdir(work_path))
+ work_path = os.path.join(task_path, task_type)
+ assert os.path.isdir(work_path)
return work_path
-def get_machine_info(mdata,task_type):
- if task_type in ["vasp","abacus"]:
- vasp_exec=mdata['fp_command']
- group_size = mdata['fp_group_size']
- resources = mdata['fp_resources']
- machine=mdata['fp_machine']
+def get_machine_info(mdata, task_type):
+ if task_type in ["vasp", "abacus"]:
+ vasp_exec = mdata["fp_command"]
+ group_size = mdata["fp_group_size"]
+ resources = mdata["fp_resources"]
+ machine = mdata["fp_machine"]
command = vasp_exec
command = cmd_append_log(command, "log")
elif task_type in lammps_task_type:
- model_devi_exec = mdata['model_devi_command']
- group_size = mdata['model_devi_group_size']
- resources = mdata['model_devi_resources']
- machine=mdata['model_devi_machine']
+ model_devi_exec = mdata["model_devi_command"]
+ group_size = mdata["model_devi_group_size"]
+ resources = mdata["model_devi_resources"]
+ machine = mdata["model_devi_machine"]
command = model_devi_exec + " -i in.lammps"
command = cmd_append_log(command, "model_devi.log")
return machine, resources, command, group_size
-def collect_task(all_task,task_type):
- if task_type == 'vasp':
- output_file ='OUTCAR'
+def collect_task(all_task, task_type):
+
+ if task_type == "vasp":
+ output_file = "OUTCAR"
check_finished = vasp.check_finished
elif task_type in lammps_task_type:
- output_file = 'log.lammps'
+ output_file = "log.lammps"
check_finished = lammps.check_finished
- elif task_type == 'abacus':
- output_file = 'OUT.ABACUS/running_relax.log'
+ elif task_type == "abacus":
+ output_file = "OUT.ABACUS/running_relax.log"
check_finished = abacus.check_finished
run_tasks_ = []
for ii in all_task:
fres = os.path.join(ii, output_file)
- if os.path.isfile(fres) :
+ if os.path.isfile(fres):
if not check_finished(fres):
run_tasks_.append(ii)
- else :
+ else:
run_tasks_.append(ii)
run_tasks = [os.path.basename(ii) for ii in run_tasks_]
diff --git a/dpgen/auto_test/lib/utils.py b/dpgen/auto_test/lib/utils.py
index 60f33e145..cba2f25fc 100644
--- a/dpgen/auto_test/lib/utils.py
+++ b/dpgen/auto_test/lib/utils.py
@@ -1,63 +1,74 @@
#!/usr/bin/env python3
-import os, re, shutil, logging
+import logging
+import os
+import re
+import shutil
iter_format = "%s"
task_format = "%s"
log_iter_head = "task type: " + iter_format + " task: " + task_format + " process: "
-def make_iter_name (iter_index) :
+
+def make_iter_name(iter_index):
return "task type:" + (iter_format)
-def create_path (path) :
- path += '/'
- if os.path.isdir(path) :
- dirname = os.path.dirname(path)
+
+def create_path(path):
+ path += "/"
+ if os.path.isdir(path):
+ dirname = os.path.dirname(path)
counter = 0
- while True :
+ while True:
bk_dirname = dirname + ".bk%03d" % counter
- if not os.path.isdir(bk_dirname) :
- shutil.move (dirname, bk_dirname)
+ if not os.path.isdir(bk_dirname):
+ shutil.move(dirname, bk_dirname)
break
counter += 1
- os.makedirs (path)
-
-def replace (file_name, pattern, subst) :
- file_handel = open (file_name, 'r')
- file_string = file_handel.read ()
- file_handel.close ()
- file_string = ( re.sub (pattern, subst, file_string) )
- file_handel = open (file_name, 'w')
- file_handel.write (file_string)
- file_handel.close ()
-
-def copy_file_list (file_list, from_path, to_path) :
- for jj in file_list :
- if os.path.isfile(os.path.join(from_path, jj)) :
- shutil.copy (os.path.join(from_path, jj), to_path)
- elif os.path.isdir(os.path.join(from_path, jj)) :
- shutil.copytree (os.path.join(from_path, jj), os.path.join(to_path, jj))
-
-def cmd_append_log (cmd,
- log_file) :
+ os.makedirs(path)
+
+
+def replace(file_name, pattern, subst):
+ file_handel = open(file_name, "r")
+ file_string = file_handel.read()
+ file_handel.close()
+ file_string = re.sub(pattern, subst, file_string)
+ file_handel = open(file_name, "w")
+ file_handel.write(file_string)
+ file_handel.close()
+
+
+def copy_file_list(file_list, from_path, to_path):
+ for jj in file_list:
+ if os.path.isfile(os.path.join(from_path, jj)):
+ shutil.copy(os.path.join(from_path, jj), to_path)
+ elif os.path.isdir(os.path.join(from_path, jj)):
+ shutil.copytree(os.path.join(from_path, jj), os.path.join(to_path, jj))
+
+
+def cmd_append_log(cmd, log_file):
ret = cmd
ret = ret + " 1> " + log_file
ret = ret + " 2> " + log_file
return ret
-def log_iter (task, ii, jj) :
- logging.info ((log_iter_head + "%s") % (ii, jj, task))
+
+def log_iter(task, ii, jj):
+ logging.info((log_iter_head + "%s") % (ii, jj, task))
+
def repeat_to_length(string_to_expand, length):
ret = ""
- for ii in range (length) :
+ for ii in range(length):
ret += string_to_expand
return ret
-def log_task (message) :
- header = repeat_to_length (" ", len(log_iter_head % (0, 0)))
- logging.info (header + message)
-def record_iter (record, confs, ii, jj) :
- with open (record, "a") as frec :
- frec.write ("%s %s %s\n" % (confs, ii, jj))
+def log_task(message):
+ header = repeat_to_length(" ", len(log_iter_head % (0, 0)))
+ logging.info(header + message)
+
+
+def record_iter(record, confs, ii, jj):
+ with open(record, "a") as frec:
+ frec.write("%s %s %s\n" % (confs, ii, jj))
diff --git a/dpgen/auto_test/lib/vasp.py b/dpgen/auto_test/lib/vasp.py
index 2e234b3c1..1aa0793b7 100644
--- a/dpgen/auto_test/lib/vasp.py
+++ b/dpgen/auto_test/lib/vasp.py
@@ -1,15 +1,19 @@
#!/usr/bin/python3
import os
import warnings
+
import numpy as np
+from pymatgen.io.vasp import Incar, Kpoints, Potcar
+
import dpgen.auto_test.lib.lammps as lammps
import dpgen.auto_test.lib.util as util
from dpgen.generator.lib.vasp import incar_upper
-from pymatgen.io.vasp import Incar,Kpoints,Potcar
+
class OutcarItemError(Exception):
pass
+
# def get_poscar(conf_dir) :
# conf_path = os.path.abspath(conf_dir)
# poscar_out = os.path.join(conf_path, 'POSCAR')
@@ -24,78 +28,82 @@ class OutcarItemError(Exception):
# dump_file = lmp_dump[0]
# lammps.poscar_from_last_dump(dump_file, task_poscar, deepmd_type_map)
-def regulate_poscar(poscar_in, poscar_out) :
- with open(poscar_in, 'r') as fp:
- lines = fp.read().split('\n')
+
+def regulate_poscar(poscar_in, poscar_out):
+ with open(poscar_in, "r") as fp:
+ lines = fp.read().split("\n")
names = lines[5].split()
counts = [int(ii) for ii in lines[6].split()]
- assert(len(names) == len(counts))
+ assert len(names) == len(counts)
uniq_name = []
- for ii in names :
- if not (ii in uniq_name) :
+ for ii in names:
+ if not (ii in uniq_name):
uniq_name.append(ii)
- uniq_count = np.zeros(len(uniq_name), dtype = int)
- for nn,cc in zip(names,counts) :
+ uniq_count = np.zeros(len(uniq_name), dtype=int)
+ for nn, cc in zip(names, counts):
uniq_count[uniq_name.index(nn)] += cc
natoms = np.sum(uniq_count)
- posis = lines[8:8+natoms]
+ posis = lines[8 : 8 + natoms]
all_lines = []
for ele in uniq_name:
ele_lines = []
- for ii in posis :
+ for ii in posis:
ele_name = ii.split()[-1]
- if ele_name == ele :
+ if ele_name == ele:
ele_lines.append(ii)
all_lines += ele_lines
- all_lines.append('')
+ all_lines.append("")
ret = lines[0:5]
ret.append(" ".join(uniq_name))
ret.append(" ".join([str(ii) for ii in uniq_count]))
ret.append("Direct")
ret += all_lines
- with open(poscar_out, 'w') as fp:
+ with open(poscar_out, "w") as fp:
fp.write("\n".join(ret))
-def sort_poscar(poscar_in, poscar_out, new_names) :
- with open(poscar_in, 'r') as fp:
- lines = fp.read().split('\n')
+
+def sort_poscar(poscar_in, poscar_out, new_names):
+ with open(poscar_in, "r") as fp:
+ lines = fp.read().split("\n")
names = lines[5].split()
counts = [int(ii) for ii in lines[6].split()]
- new_counts = np.zeros(len(counts), dtype = int)
- for nn,cc in zip(names,counts) :
+ new_counts = np.zeros(len(counts), dtype=int)
+ for nn, cc in zip(names, counts):
new_counts[new_names.index(nn)] += cc
natoms = np.sum(new_counts)
- posis = lines[8:8+natoms]
+ posis = lines[8 : 8 + natoms]
all_lines = []
for ele in new_names:
ele_lines = []
- for ii in posis :
+ for ii in posis:
ele_name = ii.split()[-1]
- if ele_name == ele :
+ if ele_name == ele:
ele_lines.append(ii)
all_lines += ele_lines
- all_lines.append('')
+ all_lines.append("")
ret = lines[0:5]
ret.append(" ".join(new_names))
ret.append(" ".join([str(ii) for ii in new_counts]))
ret.append("Direct")
ret += all_lines
- with open(poscar_out, 'w') as fp:
+ with open(poscar_out, "w") as fp:
fp.write("\n".join(ret))
-def perturb_xz (poscar_in, poscar_out, pert = 0.01) :
- with open(poscar_in, 'r') as fp:
- lines = fp.read().split('\n')
+
+def perturb_xz(poscar_in, poscar_out, pert=0.01):
+ with open(poscar_in, "r") as fp:
+ lines = fp.read().split("\n")
zz = lines[4]
az = [float(ii) for ii in zz.split()]
az[0] += pert
zz = [str(ii) for ii in az]
zz = " ".join(zz)
lines[4] = zz
- with open(poscar_out, 'w') as fp:
+ with open(poscar_out, "w") as fp:
fp.write("\n".join(lines))
-def reciprocal_box(box) :
+
+def reciprocal_box(box):
rbox = np.linalg.inv(box)
rbox = rbox.T
# rbox = rbox / np.linalg.det(box)
@@ -103,117 +111,132 @@ def reciprocal_box(box) :
# print(rbox)
return rbox
-def make_kspacing_kpoints(poscar, kspacing, kgamma) :
+
+def make_kspacing_kpoints(poscar, kspacing, kgamma):
if type(kspacing) is not list:
kspacing = [kspacing, kspacing, kspacing]
- with open(poscar, 'r') as fp:
- lines = fp.read().split('\n')
+ with open(poscar, "r") as fp:
+ lines = fp.read().split("\n")
scale = float(lines[1])
box = []
- for ii in range(2,5) :
+ for ii in range(2, 5):
box.append([float(jj) for jj in lines[ii].split()[0:3]])
box = np.array(box)
box *= scale
rbox = reciprocal_box(box)
- kpoints = [max(1,(np.ceil(2 * np.pi * np.linalg.norm(ii) / ks).astype(int))) for ii,ks in zip(rbox,kspacing)]
+ kpoints = [
+ max(1, (np.ceil(2 * np.pi * np.linalg.norm(ii) / ks).astype(int)))
+ for ii, ks in zip(rbox, kspacing)
+ ]
ret = make_vasp_kpoints(kpoints, kgamma)
return ret
-def get_energies (fname) :
+
+def get_energies(fname):
if not check_finished(fname):
- warnings.warn("incomplete outcar: "+fname)
- with open(fname, 'r') as fp:
- lines = fp.read().split('\n')
- try :
+ warnings.warn("incomplete outcar: " + fname)
+ with open(fname, "r") as fp:
+ lines = fp.read().split("\n")
+ try:
ener = _get_energies(lines)
return ener
- except OutcarItemError :
+ except OutcarItemError:
return None
-def get_boxes (fname) :
+
+def get_boxes(fname):
if not check_finished(fname):
- warnings.warn("incomplete outcar: "+fname)
- with open(fname, 'r') as fp:
- lines = fp.read().split('\n')
- try :
+ warnings.warn("incomplete outcar: " + fname)
+ with open(fname, "r") as fp:
+ lines = fp.read().split("\n")
+ try:
ener = _get_boxes(lines)
return ener
- except OutcarItemError :
+ except OutcarItemError:
return None
-def get_nev(fname) :
+
+def get_nev(fname):
if not check_finished(fname):
- warnings.warn("incomplete outcar: "+fname)
- with open(fname, 'r') as fp:
- lines = fp.read().split('\n')
+ warnings.warn("incomplete outcar: " + fname)
+ with open(fname, "r") as fp:
+ lines = fp.read().split("\n")
try:
natoms = _get_natoms(lines)
vol = _get_volumes(lines)[-1]
ener = _get_energies(lines)[-1]
- return natoms, ener/natoms, vol/natoms
+ return natoms, ener / natoms, vol / natoms
except OutcarItemError:
raise OutcarItemError("cannot find the result, please check the OUTCAR")
# print(fname, natoms, vol, ener)
-def get_stress(fname) :
+
+def get_stress(fname):
if not check_finished(fname):
- warnings.warn("incomplete outcar: "+fname)
- with open(fname, 'r') as fp:
- lines = fp.read().split('\n')
+ warnings.warn("incomplete outcar: " + fname)
+ with open(fname, "r") as fp:
+ lines = fp.read().split("\n")
try:
stress = _get_stress(lines)[-1]
return stress
except OutcarItemError:
return None
-def check_finished(fname) :
- with open(fname, 'r') as fp:
- return 'Elapsed time (sec):' in fp.read()
-def _get_natoms(lines) :
+def check_finished(fname):
+ with open(fname, "r") as fp:
+ return "Elapsed time (sec):" in fp.read()
+
+
+def _get_natoms(lines):
ipt = None
for ii in lines:
- if 'ions per type' in ii :
+ if "ions per type" in ii:
ipt = [int(jj) for jj in ii.split()[4:]]
return sum(ipt)
raise OutcarItemError("cannot find item 'ions per type'")
-def _get_energies(lines) :
+
+def _get_energies(lines):
items = []
for ii in lines:
- if 'free energy TOTEN' in ii:
- items.append(float (ii.split()[4]))
+ if "free energy TOTEN" in ii:
+ items.append(float(ii.split()[4]))
if len(items) == 0:
raise OutcarItemError("cannot find item 'free energy TOTEN'")
return items
-def _split_box_line(line) :
+
+def _split_box_line(line):
return [float(line[0:16]), float(line[16:29]), float(line[29:42])]
-def _get_boxes(lines) :
+
+def _get_boxes(lines):
items = []
- for idx,ii in enumerate(lines):
+ for idx, ii in enumerate(lines):
tmp_box = []
- if 'direct lattice vectors' in ii :
- tmp_box.append(_split_box_line(lines[idx+1]))
- tmp_box.append(_split_box_line(lines[idx+2]))
- tmp_box.append(_split_box_line(lines[idx+3]))
+ if "direct lattice vectors" in ii:
+ tmp_box.append(_split_box_line(lines[idx + 1]))
+ tmp_box.append(_split_box_line(lines[idx + 2]))
+ tmp_box.append(_split_box_line(lines[idx + 3]))
items.append(tmp_box)
return np.array(items)
-def _get_volumes(lines) :
+
+def _get_volumes(lines):
items = []
for ii in lines:
- if 'volume of cell' in ii:
- items.append(float (ii.split()[4]))
+ if "volume of cell" in ii:
+ items.append(float(ii.split()[4]))
if len(items) == 0:
raise OutcarItemError("cannot find item 'volume of cell'")
return items
-def _get_stress(lines) :
+
+def _get_stress(lines):
items = []
for ii in lines:
- if 'in kB' in ii:
+ if "in kB" in ii:
sv = [float(jj) for jj in ii.split()[2:8]]
tmp = sv[4]
sv[4] = sv[5]
@@ -223,164 +246,176 @@ def _get_stress(lines) :
raise OutcarItemError("cannot find item 'in kB'")
return items
-def _compute_isif (relax_ions,
- relax_shape,
- relax_volume) :
- if (relax_ions) and (not relax_shape) and (not relax_volume) :
+
+def _compute_isif(relax_ions, relax_shape, relax_volume):
+ if (relax_ions) and (not relax_shape) and (not relax_volume):
isif = 2
- elif (relax_ions) and (relax_shape) and (relax_volume) :
+ elif (relax_ions) and (relax_shape) and (relax_volume):
isif = 3
- elif (relax_ions) and (relax_shape) and (not relax_volume) :
+ elif (relax_ions) and (relax_shape) and (not relax_volume):
isif = 4
- elif (not relax_ions) and (relax_shape) and (not relax_volume) :
+ elif (not relax_ions) and (relax_shape) and (not relax_volume):
isif = 5
- elif (not relax_ions) and (relax_shape) and (relax_volume) :
+ elif (not relax_ions) and (relax_shape) and (relax_volume):
isif = 6
- elif (not relax_ions) and (not relax_shape) and (relax_volume) :
+ elif (not relax_ions) and (not relax_shape) and (relax_volume):
isif = 7
- else :
+ else:
raise ValueError("unknow relax style")
return isif
-def make_vasp_static_incar (ecut, ediff,
- npar, kpar,
- kspacing = 0.5, kgamma = True,
- ismear = 1, sigma = 0.2) :
+
+def make_vasp_static_incar(
+ ecut, ediff, npar, kpar, kspacing=0.5, kgamma=True, ismear=1, sigma=0.2
+):
isif = 2
- ret = ''
- ret += 'PREC=A\n'
- ret += 'ENCUT=%d\n' % ecut
- ret += '# ISYM=0\n'
- ret += 'ALGO=normal\n'
- ret += 'EDIFF=%e\n' % ediff
- ret += 'EDIFFG=-0.01\n'
- ret += 'LREAL=A\n'
- ret += 'NPAR=%d\n' % npar
- ret += 'KPAR=%d\n' % kpar
+ ret = ""
+ ret += "PREC=A\n"
+ ret += "ENCUT=%d\n" % ecut
+ ret += "# ISYM=0\n"
+ ret += "ALGO=normal\n"
+ ret += "EDIFF=%e\n" % ediff
+ ret += "EDIFFG=-0.01\n"
+ ret += "LREAL=A\n"
+ ret += "NPAR=%d\n" % npar
+ ret += "KPAR=%d\n" % kpar
ret += "\n"
- ret += 'ISMEAR=%d\n' % ismear
- ret += 'SIGMA=%f\n' % sigma
+ ret += "ISMEAR=%d\n" % ismear
+ ret += "SIGMA=%f\n" % sigma
ret += "\n"
- ret += 'ISTART=0\n'
- ret += 'ICHARG=2\n'
- ret += 'NELMIN=6\n'
- ret += 'ISIF=%d\n' % isif
- ret += 'IBRION=-1\n'
+ ret += "ISTART=0\n"
+ ret += "ICHARG=2\n"
+ ret += "NELMIN=6\n"
+ ret += "ISIF=%d\n" % isif
+ ret += "IBRION=-1\n"
ret += "\n"
- ret += 'NSW=0\n'
+ ret += "NSW=0\n"
ret += "\n"
- ret += 'LWAVE=F\n'
- ret += 'LCHARG=F\n'
- ret += 'PSTRESS=0\n'
+ ret += "LWAVE=F\n"
+ ret += "LCHARG=F\n"
+ ret += "PSTRESS=0\n"
ret += "\n"
- if kspacing is not None :
- ret += 'KSPACING=%f\n' % kspacing
- if kgamma is not None :
+ if kspacing is not None:
+ ret += "KSPACING=%f\n" % kspacing
+ if kgamma is not None:
if kgamma:
- ret += 'KGAMMA=T\n'
- else :
- ret += 'KGAMMA=F\n'
+ ret += "KGAMMA=T\n"
+ else:
+ ret += "KGAMMA=F\n"
return ret
-def make_vasp_relax_incar (ecut, ediff,
- relax_ion, relax_shape, relax_volume,
- npar, kpar,
- kspacing = 0.5, kgamma = True,
- ismear = 1, sigma = 0.22) :
+
+def make_vasp_relax_incar(
+ ecut,
+ ediff,
+ relax_ion,
+ relax_shape,
+ relax_volume,
+ npar,
+ kpar,
+ kspacing=0.5,
+ kgamma=True,
+ ismear=1,
+ sigma=0.22,
+):
isif = _compute_isif(relax_ion, relax_shape, relax_volume)
- ret = ''
- ret += 'PREC=A\n'
- ret += 'ENCUT=%d\n' % ecut
- ret += '# ISYM=0\n'
- ret += 'ALGO=normal\n'
- ret += 'EDIFF=%e\n' % ediff
- ret += 'EDIFFG=-0.01\n'
- ret += 'LREAL=A\n'
- ret += 'NPAR=%d\n' % npar
- ret += 'KPAR=%d\n' % kpar
+ ret = ""
+ ret += "PREC=A\n"
+ ret += "ENCUT=%d\n" % ecut
+ ret += "# ISYM=0\n"
+ ret += "ALGO=normal\n"
+ ret += "EDIFF=%e\n" % ediff
+ ret += "EDIFFG=-0.01\n"
+ ret += "LREAL=A\n"
+ ret += "NPAR=%d\n" % npar
+ ret += "KPAR=%d\n" % kpar
ret += "\n"
- ret += 'ISMEAR=%d\n' % ismear
- ret += 'SIGMA=%f\n' % sigma
+ ret += "ISMEAR=%d\n" % ismear
+ ret += "SIGMA=%f\n" % sigma
ret += "\n"
- ret += 'ISTART=0\n'
- ret += 'ICHARG=2\n'
- ret += 'NELM=100\n'
- ret += 'NELMIN=6\n'
- ret += 'ISIF=%d\n' % isif
- ret += 'IBRION=2\n'
+ ret += "ISTART=0\n"
+ ret += "ICHARG=2\n"
+ ret += "NELM=100\n"
+ ret += "NELMIN=6\n"
+ ret += "ISIF=%d\n" % isif
+ ret += "IBRION=2\n"
ret += "\n"
- ret += 'NSW=50\n'
+ ret += "NSW=50\n"
ret += "\n"
- ret += 'LWAVE=F\n'
- ret += 'LCHARG=F\n'
- ret += 'PSTRESS=0\n'
+ ret += "LWAVE=F\n"
+ ret += "LCHARG=F\n"
+ ret += "PSTRESS=0\n"
ret += "\n"
- if kspacing is not None :
- ret += 'KSPACING=%f\n' % kspacing
- if kgamma is not None :
+ if kspacing is not None:
+ ret += "KSPACING=%f\n" % kspacing
+ if kgamma is not None:
if kgamma:
- ret += 'KGAMMA=T\n'
- else :
- ret += 'KGAMMA=F\n'
+ ret += "KGAMMA=T\n"
+ else:
+ ret += "KGAMMA=F\n"
return ret
-def make_vasp_phonon_incar (ecut, ediff,
- npar, kpar,
- kspacing = 0.5, kgamma = True,
- ismear = 1, sigma = 0.2) :
+
+def make_vasp_phonon_incar(
+ ecut, ediff, npar, kpar, kspacing=0.5, kgamma=True, ismear=1, sigma=0.2
+):
isif = 2
- ret = ''
- ret += 'PREC=A\n'
- ret += 'ENCUT=%d\n' % ecut
- ret += '# ISYM=0\n'
- ret += 'ALGO=normal\n'
- ret += 'EDIFF=%e\n' % ediff
- ret += 'EDIFFG=-0.01\n'
- ret += 'LREAL=A\n'
- #ret += 'NPAR=%d\n' % npar
- ret += 'KPAR=%d\n' % kpar
+ ret = ""
+ ret += "PREC=A\n"
+ ret += "ENCUT=%d\n" % ecut
+ ret += "# ISYM=0\n"
+ ret += "ALGO=normal\n"
+ ret += "EDIFF=%e\n" % ediff
+ ret += "EDIFFG=-0.01\n"
+ ret += "LREAL=A\n"
+ # ret += 'NPAR=%d\n' % npar
+ ret += "KPAR=%d\n" % kpar
ret += "\n"
- ret += 'ISMEAR=%d\n' % ismear
- ret += 'SIGMA=%f\n' % sigma
+ ret += "ISMEAR=%d\n" % ismear
+ ret += "SIGMA=%f\n" % sigma
ret += "\n"
- ret += 'ISTART=0\n'
- ret += 'ICHARG=2\n'
- ret += 'NELMIN=4\n'
- ret += 'ISIF=%d\n' % isif
- ret += 'IBRION=8\n'
+ ret += "ISTART=0\n"
+ ret += "ICHARG=2\n"
+ ret += "NELMIN=4\n"
+ ret += "ISIF=%d\n" % isif
+ ret += "IBRION=8\n"
ret += "\n"
- ret += 'NSW=1\n'
+ ret += "NSW=1\n"
ret += "\n"
- ret += 'LWAVE=F\n'
- ret += 'LCHARG=F\n'
- ret += 'PSTRESS=0\n'
+ ret += "LWAVE=F\n"
+ ret += "LCHARG=F\n"
+ ret += "PSTRESS=0\n"
ret += "\n"
- if kspacing is not None :
- ret += 'KSPACING=%f\n' % kspacing
- if kgamma is not None :
+ if kspacing is not None:
+ ret += "KSPACING=%f\n" % kspacing
+ if kgamma is not None:
if kgamma:
- ret += 'KGAMMA=T\n'
- else :
- ret += 'KGAMMA=F\n'
+ ret += "KGAMMA=T\n"
+ else:
+ ret += "KGAMMA=F\n"
return ret
-def get_poscar_types (fname) :
- with open(fname, 'r') as fp :
- lines = fp.read().split('\n')
+
+def get_poscar_types(fname):
+ with open(fname, "r") as fp:
+ lines = fp.read().split("\n")
return lines[5].split()
-def get_poscar_natoms (fname) :
- with open(fname, 'r') as fp :
- lines = fp.read().split('\n')
+
+def get_poscar_natoms(fname):
+ with open(fname, "r") as fp:
+ lines = fp.read().split("\n")
return [int(ii) for ii in lines[6].split()]
-def _poscar_natoms(lines) :
+
+def _poscar_natoms(lines):
numb_atoms = 0
- for ii in lines[6].split() :
+ for ii in lines[6].split():
numb_atoms += int(ii)
return numb_atoms
-def _poscar_scale_direct (str_in, scale) :
+
+def _poscar_scale_direct(str_in, scale):
lines = str_in.copy()
numb_atoms = _poscar_natoms(lines)
pscale = float(lines[1])
@@ -388,45 +423,49 @@ def _poscar_scale_direct (str_in, scale) :
lines[1] = str(pscale) + "\n"
return lines
-def _poscar_scale_cartesian (str_in, scale) :
+
+def _poscar_scale_cartesian(str_in, scale):
lines = str_in.copy()
numb_atoms = _poscar_natoms(lines)
# scale box
- for ii in range(2,5) :
+ for ii in range(2, 5):
boxl = lines[ii].split()
boxv = [float(ii) for ii in boxl]
boxv = np.array(boxv) * scale
lines[ii] = "%.16e %.16e %.16e\n" % (boxv[0], boxv[1], boxv[2])
# scale coord
- for ii in range(8, 8+numb_atoms) :
+ for ii in range(8, 8 + numb_atoms):
cl = lines[ii].split()
cv = [float(ii) for ii in cl]
cv = np.array(cv) * scale
lines[ii] = "%.16e %.16e %.16e\n" % (cv[0], cv[1], cv[2])
return lines
-def poscar_natoms(poscar_in) :
- with open(poscar_in, 'r') as fin :
+
+def poscar_natoms(poscar_in):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
return _poscar_natoms(lines)
-def poscar_scale (poscar_in, poscar_out, scale) :
- with open(poscar_in, 'r') as fin :
+
+def poscar_scale(poscar_in, poscar_out, scale):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
- if 'D' == lines[7][0] or 'd' == lines[7][0] :
+ if "D" == lines[7][0] or "d" == lines[7][0]:
lines = _poscar_scale_direct(lines, scale)
- elif 'C' == lines[7][0] or 'c' == lines[7][0] :
+ elif "C" == lines[7][0] or "c" == lines[7][0]:
lines = _poscar_scale_cartesian(lines, scale)
- else :
+ else:
raise RuntimeError("Unknow poscar coord style at line 7: %s" % lines[7])
- with open(poscar_out, 'w') as fout:
+ with open(poscar_out, "w") as fout:
fout.write("".join(lines))
-def poscar_vol (poscar_in) :
- with open(poscar_in, 'r') as fin :
+
+def poscar_vol(poscar_in):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
box = []
- for ii in range(2,5) :
+ for ii in range(2, 5):
words = lines[ii].split()
vec = [float(jj) for jj in words]
box.append(vec)
@@ -435,6 +474,7 @@ def poscar_vol (poscar_in) :
box *= scale
return np.linalg.det(box)
+
def _make_vasp_kp_gamma(kpoints):
ret = ""
ret += "Automatic mesh\n"
@@ -444,6 +484,7 @@ def _make_vasp_kp_gamma(kpoints):
ret += "0 0 0\n"
return ret
+
def _make_vasp_kp_mp(kpoints):
ret = ""
ret += "K-Points\n"
@@ -453,45 +494,46 @@ def _make_vasp_kp_mp(kpoints):
ret += " 0 0 0\n"
return ret
-def make_vasp_kpoints (kpoints, kgamma = False) :
- if kgamma :
+
+def make_vasp_kpoints(kpoints, kgamma=False):
+ if kgamma:
ret = _make_vasp_kp_gamma(kpoints)
- else :
+ else:
ret = _make_vasp_kp_mp(kpoints)
return ret
-def make_vasp_kpoints_from_incar(work_dir,jdata):
- cwd=os.getcwd()
- fp_aniso_kspacing = jdata.get('fp_aniso_kspacing')
+def make_vasp_kpoints_from_incar(work_dir, jdata):
+ cwd = os.getcwd()
+ fp_aniso_kspacing = jdata.get("fp_aniso_kspacing")
os.chdir(work_dir)
# get kspacing and kgamma from incar
- assert(os.path.exists('INCAR'))
- with open('INCAR') as fp:
+ assert os.path.exists("INCAR")
+ with open("INCAR") as fp:
incar = fp.read()
standard_incar = incar_upper(Incar.from_string(incar))
if fp_aniso_kspacing is None:
try:
- kspacing = standard_incar['KSPACING']
+ kspacing = standard_incar["KSPACING"]
except KeyError:
- raise RuntimeError ("KSPACING must be given in INCAR")
- else :
+ raise RuntimeError("KSPACING must be given in INCAR")
+ else:
kspacing = fp_aniso_kspacing
try:
- gamma = standard_incar['KGAMMA']
- if isinstance(gamma,bool):
+ gamma = standard_incar["KGAMMA"]
+ if isinstance(gamma, bool):
pass
else:
- if gamma[0].upper()=="T":
- gamma=True
+ if gamma[0].upper() == "T":
+ gamma = True
else:
- gamma=False
+ gamma = False
except KeyError:
- raise RuntimeError ("KGAMMA must be given in INCAR")
+ raise RuntimeError("KGAMMA must be given in INCAR")
# check poscar
- assert(os.path.exists('POSCAR'))
+ assert os.path.exists("POSCAR")
# make kpoints
- ret=make_kspacing_kpoints('POSCAR', kspacing, gamma)
- kp=Kpoints.from_string(ret)
+ ret = make_kspacing_kpoints("POSCAR", kspacing, gamma)
+ kp = Kpoints.from_string(ret)
kp.write_file("KPOINTS")
os.chdir(cwd)
diff --git a/dpgen/auto_test/mpdb.py b/dpgen/auto_test/mpdb.py
index fa91d72fb..c6409013a 100644
--- a/dpgen/auto_test/mpdb.py
+++ b/dpgen/auto_test/mpdb.py
@@ -1,25 +1,29 @@
import os
-from dpgen import dlog
-from pymatgen.ext.matproj import MPRester, MPRestError
+
from pymatgen.core import Structure
+from pymatgen.ext.matproj import MPRester, MPRestError
+
+from dpgen import dlog
+
+web = "materials.org"
-web="materials.org"
def check_apikey():
try:
- apikey=os.environ['MAPI_KEY']
+ apikey = os.environ["MAPI_KEY"]
except KeyError:
- print("You have to get a MAPI_KEY from "+web)
- print("and execute following command:")
- print('echo "export MAPI_KEY=yourkey">> ~/.bashrc')
- print("source ~/.bashrc")
- os._exit(0)
+ print("You have to get a MAPI_KEY from " + web)
+ print("and execute following command:")
+ print('echo "export MAPI_KEY=yourkey">> ~/.bashrc')
+ print("source ~/.bashrc")
+ os._exit(0)
try:
- return MPRester(apikey)
+ return MPRester(apikey)
except MPRestError:
- dlog.info("MPRester Error, you need to prepare POSCAR manually")
- os._exit(0)
+ dlog.info("MPRester Error, you need to prepare POSCAR manually")
+ os._exit(0)
+
def get_structure(mp_id):
- mpr=check_apikey()
+ mpr = check_apikey()
return mpr.get_structure_by_material_id(mp_id)
diff --git a/dpgen/auto_test/refine.py b/dpgen/auto_test/refine.py
index ae6bd438c..d44bd15d7 100644
--- a/dpgen/auto_test/refine.py
+++ b/dpgen/auto_test/refine.py
@@ -1,39 +1,55 @@
import glob
import os
import re
+
import dpgen.auto_test.lib.abacus as abacus
+
def make_refine(init_from_suffix, output_suffix, path_to_work):
cwd = os.getcwd()
- init_from = re.sub(output_suffix[::-1], init_from_suffix[::-1], path_to_work[::-1], count=1)[::-1]
+ init_from = re.sub(
+ output_suffix[::-1], init_from_suffix[::-1], path_to_work[::-1], count=1
+ )[::-1]
if not os.path.exists(init_from):
raise FileNotFoundError("the initial directory does not exist for refine")
output = path_to_work
- init_from_task_tot = glob.glob(os.path.join(init_from, 'task.[0-9]*[0-9]'))
+ init_from_task_tot = glob.glob(os.path.join(init_from, "task.[0-9]*[0-9]"))
task_num = len(init_from_task_tot)
task_list = []
for ii in range(task_num):
- output_task = os.path.join(output, 'task.%06d' % ii)
+ output_task = os.path.join(output, "task.%06d" % ii)
os.makedirs(output_task, exist_ok=True)
os.chdir(output_task)
- for jj in ['INCAR', 'POTCAR', 'POSCAR.orig', 'POSCAR', 'conf.lmp', 'in.lammps','STRU']:
+ for jj in [
+ "INCAR",
+ "POTCAR",
+ "POSCAR.orig",
+ "POSCAR",
+ "conf.lmp",
+ "in.lammps",
+ "STRU",
+ ]:
if os.path.exists(jj):
os.remove(jj)
task_list.append(output_task)
- init_from_task = os.path.join(init_from, 'task.%06d' % ii)
+ init_from_task = os.path.join(init_from, "task.%06d" % ii)
if not os.path.exists(init_from_task):
- raise FileNotFoundError("the initial task directory does not exist for refine")
+ raise FileNotFoundError(
+ "the initial task directory does not exist for refine"
+ )
- if os.path.isfile(os.path.join(init_from_task, 'INPUT')) and os.path.isfile(os.path.join(init_from_task, 'STRU')):
- #if there has INPUT and STRU files in this path, we believe this is a ABACUS job
+ if os.path.isfile(os.path.join(init_from_task, "INPUT")) and os.path.isfile(
+ os.path.join(init_from_task, "STRU")
+ ):
+ # if there has INPUT and STRU files in this path, we believe this is a ABACUS job
CONTCAR = abacus.final_stru(init_from_task)
- POSCAR = 'STRU'
+ POSCAR = "STRU"
else:
- CONTCAR = 'CONTCAR'
- POSCAR = 'POSCAR'
+ CONTCAR = "CONTCAR"
+ POSCAR = "POSCAR"
contcar = os.path.join(init_from_task, CONTCAR)
init_poscar = os.path.join(init_from_task, POSCAR)
if os.path.exists(contcar):
@@ -41,7 +57,9 @@ def make_refine(init_from_suffix, output_suffix, path_to_work):
elif os.path.exists(init_poscar):
os.symlink(os.path.relpath(init_poscar), POSCAR)
else:
- raise FileNotFoundError("no %s or %s in the init_from directory" % (CONTCAR,POSCAR))
+ raise FileNotFoundError(
+ "no %s or %s in the init_from directory" % (CONTCAR, POSCAR)
+ )
os.chdir(cwd)
return task_list
diff --git a/dpgen/auto_test/reproduce.py b/dpgen/auto_test/reproduce.py
index a1e15914f..ce4c7483c 100644
--- a/dpgen/auto_test/reproduce.py
+++ b/dpgen/auto_test/reproduce.py
@@ -3,19 +3,25 @@
import numpy as np
from monty.serialization import loadfn
+
import dpgen.auto_test.lib.abacus as abacus
-def make_repro(inter_param,init_data_path, init_from_suffix, path_to_work, reprod_last_frame=True):
+
+def make_repro(
+ inter_param, init_data_path, init_from_suffix, path_to_work, reprod_last_frame=True
+):
path_to_work = os.path.abspath(path_to_work)
- property_type = path_to_work.split('/')[-1].split('_')[0]
- init_data_path = os.path.join(init_data_path, '*', property_type + '_' + init_from_suffix)
+ property_type = path_to_work.split("/")[-1].split("_")[0]
+ init_data_path = os.path.join(
+ init_data_path, "*", property_type + "_" + init_from_suffix
+ )
init_data_path_list = glob.glob(init_data_path)
init_data_path_list.sort()
cwd = os.getcwd()
struct_init_name_list = []
for ii in init_data_path_list:
- struct_init_name_list.append(ii.split('/')[-2])
- struct_output_name = path_to_work.split('/')[-2]
+ struct_init_name_list.append(ii.split("/")[-2])
+ struct_output_name = path_to_work.split("/")[-2]
assert struct_output_name in struct_init_name_list
@@ -25,69 +31,85 @@ def make_repro(inter_param,init_data_path, init_from_suffix, path_to_work, repro
init_data_path_todo = init_data_path_list[label]
- init_data_task_todo = glob.glob(os.path.join(init_data_path_todo, 'task.[0-9]*[0-9]'))
- assert len(init_data_task_todo) > 0, "There is no task in previous calculations path"
+ init_data_task_todo = glob.glob(
+ os.path.join(init_data_path_todo, "task.[0-9]*[0-9]")
+ )
+ assert (
+ len(init_data_task_todo) > 0
+ ), "There is no task in previous calculations path"
init_data_task_todo.sort()
task_list = []
task_num = 0
- if property_type == 'interstitial':
- if os.path.exists(os.path.join(path_to_work, 'element.out')):
- os.remove(os.path.join(path_to_work, 'element.out'))
- fout_element = open(os.path.join(path_to_work, 'element.out'), 'a+')
- fin_element = open(os.path.join(init_data_path_todo, 'element.out'), 'r')
+ if property_type == "interstitial":
+ if os.path.exists(os.path.join(path_to_work, "element.out")):
+ os.remove(os.path.join(path_to_work, "element.out"))
+ fout_element = open(os.path.join(path_to_work, "element.out"), "a+")
+ fin_element = open(os.path.join(init_data_path_todo, "element.out"), "r")
for ii in init_data_task_todo:
# get frame number
- task_result = loadfn(os.path.join(ii, 'result_task.json'))
+ task_result = loadfn(os.path.join(ii, "result_task.json"))
if reprod_last_frame:
nframe = 1
else:
- nframe = len(task_result['energies'])
- if property_type == 'interstitial':
+ nframe = len(task_result["energies"])
+ if property_type == "interstitial":
insert_element = fin_element.readline().split()[0]
for jj in range(nframe):
- if property_type == 'interstitial':
+ if property_type == "interstitial":
print(insert_element, file=fout_element)
- output_task = os.path.join(path_to_work, 'task.%06d' % task_num)
+ output_task = os.path.join(path_to_work, "task.%06d" % task_num)
task_num += 1
task_list.append(output_task)
os.makedirs(output_task, exist_ok=True)
os.chdir(output_task)
# clear dir
- for kk in ['INCAR', 'POTCAR', 'POSCAR.orig', 'POSCAR', 'conf.lmp', 'in.lammps','STRU']:
+ for kk in [
+ "INCAR",
+ "POTCAR",
+ "POSCAR.orig",
+ "POSCAR",
+ "conf.lmp",
+ "in.lammps",
+ "STRU",
+ ]:
if os.path.exists(kk):
os.remove(kk)
# make conf
if reprod_last_frame:
- task_result.to('vasp/poscar', 'POSCAR', frame_idx=-1)
+ task_result.to("vasp/poscar", "POSCAR", frame_idx=-1)
else:
- task_result.to('vasp/poscar', 'POSCAR', frame_idx=jj)
- if inter_param['type'] == 'abacus':
- abacus.poscar2stru("POSCAR",inter_param,"STRU")
- os.remove('POSCAR')
+ task_result.to("vasp/poscar", "POSCAR", frame_idx=jj)
+ if inter_param["type"] == "abacus":
+ abacus.poscar2stru("POSCAR", inter_param, "STRU")
+ os.remove("POSCAR")
os.chdir(cwd)
- if property_type == 'interstitial':
+ if property_type == "interstitial":
fout_element.close()
fin_element.close()
return task_list
-def post_repro(init_data_path, init_from_suffix, all_tasks, ptr_data, reprod_last_frame=True):
+def post_repro(
+ init_data_path, init_from_suffix, all_tasks, ptr_data, reprod_last_frame=True
+):
ptr_data += "Reproduce: Initial_path Init_E(eV/atom) Reprod_E(eV/atom) Difference(eV/atom)\n"
- struct_output_name = all_tasks[0].split('/')[-3]
- property_type = all_tasks[0].split('/')[-2].split('_')[0]
- init_data_path = os.path.join(init_data_path, '*', property_type + '_' + init_from_suffix)
+ struct_output_name = all_tasks[0].split("/")[-3]
+ property_type = all_tasks[0].split("/")[-2].split("_")[0]
+ init_data_path = os.path.join(
+ init_data_path, "*", property_type + "_" + init_from_suffix
+ )
init_data_path_list = glob.glob(init_data_path)
init_data_path_list.sort()
# cwd = os.getcwd()
struct_init_name_list = []
for ii in init_data_path_list:
- struct_init_name_list.append(ii.split('/')[-2])
+ struct_init_name_list.append(ii.split("/")[-2])
assert struct_output_name in struct_init_name_list
@@ -97,8 +119,12 @@ def post_repro(init_data_path, init_from_suffix, all_tasks, ptr_data, reprod_las
init_data_path_todo = init_data_path_list[label]
- init_data_task_todo = glob.glob(os.path.join(init_data_path_todo, 'task.[0-9]*[0-9]'))
- assert len(init_data_task_todo) > 0, "There is no task in previous calculations path"
+ init_data_task_todo = glob.glob(
+ os.path.join(init_data_path_todo, "task.[0-9]*[0-9]")
+ )
+ assert (
+ len(init_data_task_todo) > 0
+ ), "There is no task in previous calculations path"
init_data_task_todo.sort()
idid = 0
@@ -107,27 +133,32 @@ def post_repro(init_data_path, init_from_suffix, all_tasks, ptr_data, reprod_las
res_data = {}
for ii in init_data_task_todo:
- init_task_result = loadfn(os.path.join(ii, 'result_task.json'))
+ init_task_result = loadfn(os.path.join(ii, "result_task.json"))
if reprod_last_frame:
nframe = 1
else:
- nframe = len(init_task_result['energies'])
+ nframe = len(init_task_result["energies"])
# idid += nframe
- natoms = init_task_result['atom_numbs'][0]
+ natoms = np.sum(init_task_result["atom_numbs"])
if reprod_last_frame:
- init_ener = init_task_result['energies'][-1:]
+ init_ener = init_task_result["energies"][-1:]
else:
- init_ener = init_task_result['energies']
+ init_ener = init_task_result["energies"]
init_ener_tot.extend(list(init_ener))
output_ener = []
for jj in range(idid, idid + nframe):
- output_task_result = loadfn(os.path.join(all_tasks[jj], 'result_task.json'))
- output_epa = output_task_result['energies'] / natoms
+ output_task_result = loadfn(os.path.join(all_tasks[jj], "result_task.json"))
+ output_epa = output_task_result["energies"] / natoms
output_ener.append(output_epa)
- output_ener_tot.extend(output_task_result['energies'])
+ output_ener_tot.extend(output_task_result["energies"])
init_epa = init_ener[jj - idid] / natoms
- ptr_data += '%s %7.3f %7.3f %7.3f\n' % (ii, init_epa, output_epa, output_epa - init_epa)
+ ptr_data += "%s %7.3f %7.3f %7.3f\n" % (
+ ii,
+ init_epa,
+ output_epa,
+ output_epa - init_epa,
+ )
idid += nframe
output_ener = np.array(output_ener)
output_ener = np.reshape(output_ener, [-1, 1])
@@ -140,7 +171,7 @@ def post_repro(init_data_path, init_from_suffix, all_tasks, ptr_data, reprod_las
diff = output_ener - init_ener
diff = diff[error_start:]
error = np.linalg.norm(diff) / np.sqrt(np.size(output_ener) - error_start)
- res_data[ii] = {'nframes': len(init_ener), 'error': error}
+ res_data[ii] = {"nframes": len(init_ener), "error": error}
if not len(init_ener_tot) == len(output_ener_tot):
raise RuntimeError("reproduce tasks not equal to init")
diff --git a/dpgen/auto_test/run.py b/dpgen/auto_test/run.py
index 87b5fecae..696f831bd 100644
--- a/dpgen/auto_test/run.py
+++ b/dpgen/auto_test/run.py
@@ -5,50 +5,51 @@
from monty.serialization import loadfn
from dpgen import dlog
-from dpgen.auto_test.common_equi import make_equi, run_equi, post_equi
-from dpgen.auto_test.common_prop import make_property, run_property, post_property
+from dpgen.auto_test.common_equi import make_equi, post_equi, run_equi
+from dpgen.auto_test.common_prop import make_property, post_property, run_property
+# lammps_task_type = ['deepmd', 'meam', 'eam_fs', 'eam_alloy']
-#lammps_task_type = ['deepmd', 'meam', 'eam_fs', 'eam_alloy']
def run_task(step, param_file, machine_file=None):
- jdata=loadfn(param_file)
- confs = jdata['structures']
- inter_parameter = jdata['interaction']
+ jdata = loadfn(param_file)
+ confs = jdata["structures"]
+ inter_parameter = jdata["interaction"]
if machine_file:
- mdata=loadfn(machine_file)
+ mdata = loadfn(machine_file)
- if step == 'make' and 'relaxation' in jdata:
- relax_param = jdata['relaxation']
+ if step == "make" and "relaxation" in jdata:
+ relax_param = jdata["relaxation"]
make_equi(confs, inter_parameter, relax_param)
- elif step == 'make' and 'properties' in jdata:
- property_list = jdata['properties']
+ elif step == "make" and "properties" in jdata:
+ property_list = jdata["properties"]
make_property(confs, inter_parameter, property_list)
- elif step == 'run' and 'relaxation' in jdata:
+ elif step == "run" and "relaxation" in jdata:
if machine_file is None:
- print('Please supply the machine.json, exit now!')
- return
+ print("Please supply the machine.json, exit now!")
+ return
run_equi(confs, inter_parameter, mdata)
- elif step == 'run' and 'properties' in jdata:
+ elif step == "run" and "properties" in jdata:
if machine_file is None:
- print('Please supply the machine.json, exit now!')
- return
- property_list = jdata['properties']
+ print("Please supply the machine.json, exit now!")
+ return
+ property_list = jdata["properties"]
run_property(confs, inter_parameter, property_list, mdata)
- elif step == 'post' and 'relaxation' in jdata:
+ elif step == "post" and "relaxation" in jdata:
post_equi(confs, inter_parameter)
- elif step == 'post' and 'properties' in jdata:
- property_list = jdata['properties']
- post_property(confs,inter_parameter, property_list)
+ elif step == "post" and "properties" in jdata:
+ property_list = jdata["properties"]
+ post_property(confs, inter_parameter, property_list)
else:
- raise RuntimeError('unknown tasks')
+ raise RuntimeError("unknown tasks")
+
def gen_test(args):
dlog.info("start auto-testing")
@@ -56,6 +57,3 @@ def gen_test(args):
dlog.setLevel(logging.DEBUG)
run_task(args.TASK, args.PARAM, args.MACHINE)
dlog.info("finished!")
-
-
-
diff --git a/dpgen/auto_test/template/elastic/lmp/displace.mod b/dpgen/auto_test/template/elastic/lmp/displace.mod
index 9664fa8d0..822f03066 100644
--- a/dpgen/auto_test/template/elastic/lmp/displace.mod
+++ b/dpgen/auto_test/template/elastic/lmp/displace.mod
@@ -4,17 +4,17 @@
# Find which reference length to use
if "${dir} == 1" then &
- "variable len0 equal ${lx0}"
+ "variable len0 equal ${lx0}"
if "${dir} == 2" then &
- "variable len0 equal ${ly0}"
+ "variable len0 equal ${ly0}"
if "${dir} == 3" then &
- "variable len0 equal ${lz0}"
+ "variable len0 equal ${lz0}"
if "${dir} == 4" then &
- "variable len0 equal ${lz0}"
+ "variable len0 equal ${lz0}"
if "${dir} == 5" then &
- "variable len0 equal ${lz0}"
+ "variable len0 equal ${lz0}"
if "${dir} == 6" then &
- "variable len0 equal ${ly0}"
+ "variable len0 equal ${ly0}"
# Reset box and simulation parameters
@@ -47,7 +47,7 @@ if "${dir} == 6" then &
minimize ${etol} ${ftol} ${maxiter} ${maxeval}
# Obtain new stress tensor
-
+
variable tmp equal pxx
variable pxx1 equal ${tmp}
variable tmp equal pyy
@@ -101,7 +101,7 @@ if "${dir} == 6" then &
minimize ${etol} ${ftol} ${maxiter} ${maxeval}
# Obtain new stress tensor
-
+
variable tmp equal pe
variable e1 equal ${tmp}
variable tmp equal press
@@ -128,7 +128,7 @@ variable C4pos equal ${d4}
variable C5pos equal ${d5}
variable C6pos equal ${d6}
-# Combine positive and negative
+# Combine positive and negative
variable C1${dir} equal 0.5*(${C1neg}+${C1pos})
variable C2${dir} equal 0.5*(${C2neg}+${C2pos})
diff --git a/dpgen/auto_test/template/elastic/lmp/in.elastic b/dpgen/auto_test/template/elastic/lmp/in.elastic
index 07d5d28ad..6b290fc70 100644
--- a/dpgen/auto_test/template/elastic/lmp/in.elastic
+++ b/dpgen/auto_test/template/elastic/lmp/in.elastic
@@ -6,31 +6,31 @@
#
# init.mod (must be modified for different crystal structures)
# Define units, deformation parameters and initial
-# configuration of the atoms and simulation cell.
+# configuration of the atoms and simulation cell.
#
#
# potential.mod (must be modified for different pair styles)
-# Define pair style and other attributes
+# Define pair style and other attributes
# not stored in restart file
#
#
# displace.mod (displace.mod should not need to be modified)
-# Perform positive and negative box displacements
-# in direction ${dir} and size ${up}.
-# It uses the resultant changes
+# Perform positive and negative box displacements
+# in direction ${dir} and size ${up}.
+# It uses the resultant changes
# in stress to compute one
# row of the elastic stiffness tensor
-#
+#
# Inputs variables:
-# dir = the Voigt deformation component
-# (1,2,3,4,5,6)
+# dir = the Voigt deformation component
+# (1,2,3,4,5,6)
# Global constants:
# up = the deformation magnitude (strain units)
-# cfac = conversion from LAMMPS pressure units to
-# output units for elastic constants
+# cfac = conversion from LAMMPS pressure units to
+# output units for elastic constants
#
#
-# To run this on a different system, it should only be necessary to
+# To run this on a different system, it should only be necessary to
# modify the files init.mod and potential.mod. In order to calculate
# the elastic constants correctly, care must be taken to specify
# the correct units in init.mod (units, cfac and cunits). It is also
@@ -39,8 +39,8 @@
# One indication of this is that the elastic constants are insensitive
# to the choice of the variable ${up} in init.mod. Another is to check
# the final max and two-norm forces reported in the log file. If you know
-# that minimization is not required, you can set maxiter = 0.0 in
-# init.mod.
+# that minimization is not required, you can set maxiter = 0.0 in
+# init.mod.
#
include init.mod
@@ -71,7 +71,7 @@ variable tmp equal lz
variable lz0 equal ${tmp}
# These formulas define the derivatives w.r.t. strain components
-# Constants uses $, variables use v_
+# Constants uses $, variables use v_
variable d1 equal -(v_pxx1-${pxx0})/(v_delta/v_len0)*${cfac}
variable d2 equal -(v_pyy1-${pyy0})/(v_delta/v_len0)*${cfac}
variable d3 equal -(v_pzz1-${pzz0})/(v_delta/v_len0)*${cfac}
@@ -268,4 +268,3 @@ print "EV (Youngs Modulus) = ${EV} ${cunits}"
print "uV (Poisson Ratio) = ${uV}"
print ""
-
diff --git a/dpgen/auto_test/template/elastic/lmp/init.mod b/dpgen/auto_test/template/elastic/lmp/init.mod
index 8ba1f25a3..544fa4071 100644
--- a/dpgen/auto_test/template/elastic/lmp/init.mod
+++ b/dpgen/auto_test/template/elastic/lmp/init.mod
@@ -1,11 +1,11 @@
-# NOTE: This script can be modified for different atomic structures,
+# NOTE: This script can be modified for different atomic structures,
# units, etc. See in.elastic for more info.
#
# Define the finite deformation size. Try several values of this
# variable to verify that results do not depend on it.
variable up equal 1.0e-3
-
+
# Define the amount of random jiggle for atoms
# This prevents atoms from staying on saddle points
variable atomjiggle equal 1.0e-5
@@ -29,7 +29,7 @@ variable cunits string GPa
#variable cunits string GPa
# Define minimization parameters
-variable etol equal 0.0
+variable etol equal 0.0
variable ftol equal 1.0e-10
variable maxiter equal 10000
variable maxeval equal 10000
@@ -57,4 +57,3 @@ create_atoms 1 box
mass 1 27
reset_timestep 0
-
diff --git a/dpgen/auto_test/template/elastic/lmp/potential.mod b/dpgen/auto_test/template/elastic/lmp/potential.mod
index 3ad5b0e1f..9c296f47b 100644
--- a/dpgen/auto_test/template/elastic/lmp/potential.mod
+++ b/dpgen/auto_test/template/elastic/lmp/potential.mod
@@ -1,4 +1,4 @@
-# NOTE: This script can be modified for different pair styles
+# NOTE: This script can be modified for different pair styles
# See in.elastic for more info.
# ================= Choose potential ========================
@@ -11,7 +11,7 @@ neigh_modify every 1 delay 0 check yes
# Setup minimization style
min_style cg
-min_modify dmax ${dmax}
+min_modify dmax ${dmax}
# Setup output
thermo 10
diff --git a/dpgen/collect/collect.py b/dpgen/collect/collect.py
index 25f96c23b..faadf6336 100644
--- a/dpgen/collect/collect.py
+++ b/dpgen/collect/collect.py
@@ -1,47 +1,59 @@
#!/usr/bin/env python3
-import os,sys,json,glob,argparse,dpdata
+import argparse
+import glob
+import json
+import os
+import sys
+
+import dpdata
import numpy as np
+
from dpgen.generator.run import data_system_fmt
-def collect_data(target_folder, param_file, output,
- verbose = True,
- shuffle = True,
- merge = True) :
+
+def collect_data(
+ target_folder, param_file, output, verbose=True, shuffle=True, merge=True
+):
target_folder = os.path.abspath(target_folder)
output = os.path.abspath(output)
- # goto input
+ # goto input
cwd = os.getcwd()
os.chdir(target_folder)
jdata = json.load(open(param_file))
- sys_configs_prefix = jdata.get('sys_configs_prefix', '')
- sys_configs = jdata.get('sys_configs', [])
- if verbose :
+ sys_configs_prefix = jdata.get("sys_configs_prefix", "")
+ sys_configs = jdata.get("sys_configs", [])
+ if verbose:
max_str_len = max([len(str(ii)) for ii in sys_configs])
max_form_len = 16
- ptr_fmt = '%%%ds %%%ds natoms %%6d nframes %%6d' % (max_str_len+5, max_form_len)
+ ptr_fmt = "%%%ds %%%ds natoms %%6d nframes %%6d" % (
+ max_str_len + 5,
+ max_form_len,
+ )
# init systems
init_data = []
- init_data_prefix = jdata.get('init_data_prefix', '')
- init_data_sys = jdata.get('init_data_sys', [])
+ init_data_prefix = jdata.get("init_data_prefix", "")
+ init_data_sys = jdata.get("init_data_sys", [])
for ii in init_data_sys:
- init_data.append(dpdata.LabeledSystem(os.path.join(init_data_prefix, ii), fmt='deepmd/npy'))
- # collect systems from iter dirs
+ init_data.append(
+ dpdata.LabeledSystem(os.path.join(init_data_prefix, ii), fmt="deepmd/npy")
+ )
+ # collect systems from iter dirs
coll_data = {}
numb_sys = len(sys_configs)
- model_devi_jobs = jdata.get('model_devi_jobs', {})
+ model_devi_jobs = jdata.get("model_devi_jobs", {})
numb_jobs = len(model_devi_jobs)
- iters = ['iter.%06d' % ii for ii in range(numb_jobs)]
+ iters = ["iter.%06d" % ii for ii in range(numb_jobs)]
# loop over iters to collect data
- for ii in range(len(iters)) :
- iter_data = glob.glob(os.path.join(iters[ii], '02.fp', 'data.[0-9]*[0-9]'))
+ for ii in range(len(iters)):
+ iter_data = glob.glob(os.path.join(iters[ii], "02.fp", "data.[0-9]*[0-9]"))
iter_data.sort()
- for jj in iter_data :
- sys = dpdata.LabeledSystem(jj, fmt = 'deepmd/npy')
+ for jj in iter_data:
+ sys = dpdata.LabeledSystem(jj, fmt="deepmd/npy")
if merge:
sys_str = sys.formula
else:
- sys_str = (os.path.basename(jj).split('.')[-1])
+ sys_str = os.path.basename(jj).split(".")[-1]
if sys_str in coll_data.keys():
coll_data[sys_str].append(sys)
else:
@@ -49,63 +61,90 @@ def collect_data(target_folder, param_file, output,
# print information
if verbose:
for ii in range(len(init_data)):
- print(ptr_fmt % (str(init_data_sys[ii]),
- init_data[ii].formula,
- init_data[ii].get_natoms(),
- init_data[ii].get_nframes() ))
+ print(
+ ptr_fmt
+ % (
+ str(init_data_sys[ii]),
+ init_data[ii].formula,
+ init_data[ii].get_natoms(),
+ init_data[ii].get_nframes(),
+ )
+ )
keys = list(coll_data.keys())
keys.sort()
for ii in keys:
if merge:
sys_str = ii
- else :
+ else:
sys_str = str(sys_configs[int(ii)])
- print(ptr_fmt % (sys_str,
- coll_data[ii].formula,
- coll_data[ii].get_natoms(),
- coll_data[ii].get_nframes() ))
+ print(
+ ptr_fmt
+ % (
+ sys_str,
+ coll_data[ii].formula,
+ coll_data[ii].get_natoms(),
+ coll_data[ii].get_nframes(),
+ )
+ )
# shuffle system data
if shuffle:
for kk in coll_data.keys():
coll_data[kk].shuffle()
# create output dir
os.chdir(cwd)
- os.makedirs(output, exist_ok = True)
+ os.makedirs(output, exist_ok=True)
# dump init data
- for idx,ii in enumerate(init_data):
- out_dir = 'init.' + (data_system_fmt % idx)
- ii.to('deepmd/npy', os.path.join(output, out_dir))
+ for idx, ii in enumerate(init_data):
+ out_dir = "init." + (data_system_fmt % idx)
+ ii.to("deepmd/npy", os.path.join(output, out_dir))
# dump iter data
for kk in coll_data.keys():
- out_dir = 'sys.%s' % kk
+ out_dir = "sys.%s" % kk
nframes = coll_data[kk].get_nframes()
- coll_data[kk].to('deepmd/npy', os.path.join(output, out_dir), set_size = nframes)
+ coll_data[kk].to("deepmd/npy", os.path.join(output, out_dir), set_size=nframes)
# coll_data[kk].to('deepmd/npy', os.path.join(output, out_dir))
+
def gen_collect(args):
- collect_data(args.JOB_DIR, args.parameter, args.OUTPUT,
- verbose = args.verbose,
- shuffle = args.shuffle,
- merge = args.merge)
+ collect_data(
+ args.JOB_DIR,
+ args.parameter,
+ args.OUTPUT,
+ verbose=args.verbose,
+ shuffle=args.shuffle,
+ merge=args.merge,
+ )
+
-def _main() :
- parser = argparse.ArgumentParser(description='Collect data from DP-GEN iterations')
- parser.add_argument("JOB_DIR", type=str,
- help="the directory of the DP-GEN job")
- parser.add_argument("OUTPUT", type=str,
- help="the output directory of data")
- parser.add_argument('-p',"--parameter", type=str, default = 'param.json',
- help="the json file provides DP-GEN paramters, should be located in JOB_DIR")
- parser.add_argument('-v',"--verbose", action = 'store_true',
- help="print number of data in each system")
- parser.add_argument('-m',"--merge", action = 'store_true',
- help="merge the systems with the same chemical formula")
- parser.add_argument('-s',"--shuffle", action = 'store_true',
- help="shuffle the data systems")
+def _main():
+ parser = argparse.ArgumentParser(description="Collect data from DP-GEN iterations")
+ parser.add_argument("JOB_DIR", type=str, help="the directory of the DP-GEN job")
+ parser.add_argument("OUTPUT", type=str, help="the output directory of data")
+ parser.add_argument(
+ "-p",
+ "--parameter",
+ type=str,
+ default="param.json",
+ help="the json file provides DP-GEN paramters, should be located in JOB_DIR",
+ )
+ parser.add_argument(
+ "-v",
+ "--verbose",
+ action="store_true",
+ help="print number of data in each system",
+ )
+ parser.add_argument(
+ "-m",
+ "--merge",
+ action="store_true",
+ help="merge the systems with the same chemical formula",
+ )
+ parser.add_argument(
+ "-s", "--shuffle", action="store_true", help="shuffle the data systems"
+ )
args = parser.parse_args()
gen_collect(args)
-if __name__ == '__main__':
- _main()
-
+if __name__ == "__main__":
+ _main()
diff --git a/dpgen/data/arginfo.py b/dpgen/data/arginfo.py
index 27511de38..6bbcd3fa1 100644
--- a/dpgen/data/arginfo.py
+++ b/dpgen/data/arginfo.py
@@ -1,12 +1,13 @@
-from dargs import Argument, ArgumentEncoder, Variant
from typing import Dict, List
+from dargs import Argument, ArgumentEncoder, Variant
+
from dpgen.arginfo import general_mdata_arginfo
def init_bulk_mdata_arginfo() -> Argument:
"""Generate arginfo for dpgen init_bulk mdata.
-
+
Returns
-------
Argument
@@ -17,7 +18,7 @@ def init_bulk_mdata_arginfo() -> Argument:
def init_surf_mdata_arginfo() -> Argument:
"""Generate arginfo for dpgen init_surf mdata.
-
+
Returns
-------
Argument
@@ -28,7 +29,7 @@ def init_surf_mdata_arginfo() -> Argument:
def init_reaction_mdata_arginfo() -> Argument:
"""Generate arginfo for dpgen init_reaction mdata.
-
+
Returns
-------
Argument
@@ -36,9 +37,11 @@ def init_reaction_mdata_arginfo() -> Argument:
"""
return general_mdata_arginfo("init_reaction_mdata", ("reaxff", "build", "fp"))
+
def init_bulk_vasp_args() -> List[Argument]:
return []
+
def init_bulk_abacus_args() -> List[Argument]:
doc_relax_kpt = 'Path of `KPT` file for relaxation in stage 1. Only useful if `init_fp_style` is "ABACUS".'
doc_md_kpt = 'Path of `KPT` file for MD simulations in stage 3. Only useful if `init_fp_style` is "ABACUS".'
@@ -48,19 +51,32 @@ def init_bulk_abacus_args() -> List[Argument]:
Argument("md_kpt", str, optional=True, doc=doc_md_kpt),
Argument("atom_masses", list, optional=True, doc=doc_atom_masses),
]
-
+
def init_bulk_variant_type_args() -> List[Variant]:
doc_init_fp_style = "First-principle software. If this key is absent."
- return [Variant("init_fp_style", [
- Argument("VASP", dict, init_bulk_vasp_args(), doc="No more parameters is needed to be added."),
- Argument("ABACUS", dict, init_bulk_abacus_args(), doc="ABACUS"),
- ], default_tag="VASP", optional=True, doc=doc_init_fp_style)]
+ return [
+ Variant(
+ "init_fp_style",
+ [
+ Argument(
+ "VASP",
+ dict,
+ init_bulk_vasp_args(),
+ doc="No more parameters is needed to be added.",
+ ),
+ Argument("ABACUS", dict, init_bulk_abacus_args(), doc="ABACUS"),
+ ],
+ default_tag="VASP",
+ optional=True,
+ doc=doc_init_fp_style,
+ )
+ ]
def init_bulk_jdata_arginfo() -> Argument:
"""Generate arginfo for dpgen init_bulk jdata.
-
+
Returns
-------
Argument
@@ -83,32 +99,42 @@ def init_bulk_jdata_arginfo() -> Argument:
doc_pert_atom = "Perturbation of atom coordinates (Angstrom). Random perturbations are performed on three coordinates of each atom by adding values randomly sampled from a uniform distribution in the range [-pert_atom, pert_atom]."
doc_md_nstep = "Steps of AIMD in stage 3. If it's not equal to settings via `NSW` in `md_incar`, DP-GEN will follow `NSW`."
doc_coll_ndata = "Maximal number of collected data."
- doc_type_map = "The indices of elements in deepmd formats will be set in this order."
-
- return Argument("init_bulk_jdata", dict, [
- Argument("stages", list, optional=False, doc=doc_stages),
- Argument("elements", list, optional=False, doc=doc_elements),
- Argument("potcars", list, optional=True, doc=doc_potcars),
- Argument("cell_type", str, optional=True, doc=doc_cell_type),
- Argument("super_cell", list, optional=False, doc=doc_super_cell),
- Argument("from_poscar", bool, optional=True, default=False, doc=doc_from_poscar),
- Argument("from_poscar_path", str, optional=True, doc=doc_from_poscar_path),
- Argument("relax_incar", str, optional=True, doc=doc_relax_incar),
- Argument("md_incar", str, optional=True, doc=doc_md_incar),
- Argument("scale", list, optional=False, doc=doc_scale),
- Argument("skip_relax", bool, optional=False, doc=doc_skip_relax),
- Argument("pert_numb", int, optional=False, doc=doc_pert_numb),
- Argument("pert_box", float, optional=False, doc=doc_pert_box),
- Argument("pert_atom", float, optional=False, doc=doc_pert_atom),
- Argument("md_nstep", int, optional=False, doc=doc_md_nstep),
- Argument("coll_ndata", int, optional=False, doc=doc_coll_ndata),
- Argument("type_map", list, optional=True, doc=doc_type_map),
- ], sub_variants=init_bulk_variant_type_args(),
- doc=doc_init_bulk)
+ doc_type_map = (
+ "The indices of elements in deepmd formats will be set in this order."
+ )
+
+ return Argument(
+ "init_bulk_jdata",
+ dict,
+ [
+ Argument("stages", list, optional=False, doc=doc_stages),
+ Argument("elements", list, optional=False, doc=doc_elements),
+ Argument("potcars", list, optional=True, doc=doc_potcars),
+ Argument("cell_type", str, optional=True, doc=doc_cell_type),
+ Argument("super_cell", list, optional=False, doc=doc_super_cell),
+ Argument(
+ "from_poscar", bool, optional=True, default=False, doc=doc_from_poscar
+ ),
+ Argument("from_poscar_path", str, optional=True, doc=doc_from_poscar_path),
+ Argument("relax_incar", str, optional=True, doc=doc_relax_incar),
+ Argument("md_incar", str, optional=True, doc=doc_md_incar),
+ Argument("scale", list, optional=False, doc=doc_scale),
+ Argument("skip_relax", bool, optional=False, doc=doc_skip_relax),
+ Argument("pert_numb", int, optional=False, doc=doc_pert_numb),
+ Argument("pert_box", float, optional=False, doc=doc_pert_box),
+ Argument("pert_atom", float, optional=False, doc=doc_pert_atom),
+ Argument("md_nstep", int, optional=False, doc=doc_md_nstep),
+ Argument("coll_ndata", int, optional=False, doc=doc_coll_ndata),
+ Argument("type_map", list, optional=True, doc=doc_type_map),
+ ],
+ sub_variants=init_bulk_variant_type_args(),
+ doc=doc_init_bulk,
+ )
+
def init_surf_jdata_arginfo() -> Argument:
"""Generate arginfo for dpgen init_surf jdata.
-
+
Returns
-------
Argument
@@ -128,57 +154,73 @@ def init_surf_jdata_arginfo() -> Argument:
doc_vacuum_max = "Maximal thickness of vacuum (Angstrom)."
doc_vacuum_min = "Minimal thickness of vacuum (Angstrom). Default value is 2 times atomic radius."
doc_vacuum_resol = "Interval of thickness of vacuum. If size of `vacuum_resol` is 1, the interval is fixed to its value. If size of `vacuum_resol` is 2, the interval is `vacuum_resol[0]` before `mid_point`, otherwise `vacuum_resol[1]` after `mid_point`."
- doc_vacuum_numb = "The total number of vacuum layers **Necessary** if vacuum_resol is empty."
+ doc_vacuum_numb = (
+ "The total number of vacuum layers **Necessary** if vacuum_resol is empty."
+ )
doc_mid_point = "The mid point separating head region and tail region. **Necessary** if the size of vacuum_resol is 2 or 0."
- doc_head_ratio = "Ratio of vacuum layers in the nearby region with denser intervals(head region). **Necessary** if vacuum_resol is empty."
+ doc_head_ratio = "Ratio of vacuum layers in the nearby region with denser intervals(head region). **Necessary** if vacuum_resol is empty."
doc_millers = "Miller indices."
- doc_relax_incar = "Path of INCAR for relaxation in VASP. **Necessary** if `stages` include 1."
+ doc_relax_incar = (
+ "Path of INCAR for relaxation in VASP. **Necessary** if `stages` include 1."
+ )
doc_scale = "Scales for isotropic transforming cells."
doc_skip_relax = "If it's true, you may directly run stage 2 (perturb and scale) using an unrelaxed POSCAR."
doc_pert_numb = "Number of perturbations for each scaled (key `scale`) POSCAR."
doc_pert_box = "Anisotropic Perturbation for cells (independent changes of lengths of three box vectors as well as angel among) in decimal formats. 9 elements of the 3x3 perturbation matrix will be randomly sampled from a uniform distribution (default) in the range [-pert_box, pert_box]. Such a perturbation matrix adds the identity matrix gives the actual transformation matrix for this perturbation operation."
doc_pert_atom = "Perturbation of atom coordinates (Angstrom). Random perturbations are performed on three coordinates of each atom by adding values randomly sampled from a uniform distribution in the range [-pert_atom, pert_atom]."
doc_coll_ndata = "Maximal number of collected data."
- return Argument("init_surf_jdata", dict, [
- Argument("stages", list, optional=False, doc=doc_stages),
- Argument("elements", list, optional=False, doc=doc_elements),
- Argument("potcars", list, optional=True, doc=doc_potcars),
- Argument("cell_type", str, optional=True, doc=doc_cell_type),
- Argument("super_cell", list, optional=False, doc=doc_super_cell),
- Argument("from_poscar", bool, optional=True, default=False, doc=doc_from_poscar),
- Argument("from_poscar_path", str, optional=True, doc=doc_from_poscar_path),
- Argument("latt", float, optional=False, doc=doc_latt),
- Argument("layer_numb", int, optional=True, doc=doc_layer_numb),
- Argument("z_min", int, optional=True, doc=doc_z_min),
- Argument("vacuum_max", float, optional=False, doc=doc_vacuum_max),
- Argument("vacuum_min", float, optional=True, doc=doc_vacuum_min),
- Argument("vacuum_resol", list, optional=False, doc=doc_vacuum_resol),
- Argument("vacuum_numb", int, optional=True, doc=doc_vacuum_numb),
- Argument("mid_point", float, optional=True, doc=doc_mid_point),
- Argument("head_ratio", float, optional=True, doc=doc_head_ratio),
- Argument("millers", list, optional=False, doc=doc_millers),
- Argument("relax_incar", str, optional=True, doc=doc_relax_incar),
- Argument("scale", list, optional=False, doc=doc_scale),
- Argument("skip_relax", bool, optional=False, doc=doc_skip_relax),
- Argument("pert_numb", int, optional=False, doc=doc_pert_numb),
- Argument("pert_box", float, optional=False, doc=doc_pert_box),
- Argument("pert_atom", float, optional=False, doc=doc_pert_atom),
- Argument("coll_ndata", int, optional=False, doc=doc_coll_ndata),
- ], doc=doc_init_surf)
+ return Argument(
+ "init_surf_jdata",
+ dict,
+ [
+ Argument("stages", list, optional=False, doc=doc_stages),
+ Argument("elements", list, optional=False, doc=doc_elements),
+ Argument("potcars", list, optional=True, doc=doc_potcars),
+ Argument("cell_type", str, optional=True, doc=doc_cell_type),
+ Argument("super_cell", list, optional=False, doc=doc_super_cell),
+ Argument(
+ "from_poscar", bool, optional=True, default=False, doc=doc_from_poscar
+ ),
+ Argument("from_poscar_path", str, optional=True, doc=doc_from_poscar_path),
+ Argument("latt", float, optional=False, doc=doc_latt),
+ Argument("layer_numb", int, optional=True, doc=doc_layer_numb),
+ Argument("z_min", int, optional=True, doc=doc_z_min),
+ Argument("vacuum_max", float, optional=False, doc=doc_vacuum_max),
+ Argument("vacuum_min", float, optional=True, doc=doc_vacuum_min),
+ Argument("vacuum_resol", list, optional=False, doc=doc_vacuum_resol),
+ Argument("vacuum_numb", int, optional=True, doc=doc_vacuum_numb),
+ Argument("mid_point", float, optional=True, doc=doc_mid_point),
+ Argument("head_ratio", float, optional=True, doc=doc_head_ratio),
+ Argument("millers", list, optional=False, doc=doc_millers),
+ Argument("relax_incar", str, optional=True, doc=doc_relax_incar),
+ Argument("scale", list, optional=False, doc=doc_scale),
+ Argument("skip_relax", bool, optional=False, doc=doc_skip_relax),
+ Argument("pert_numb", int, optional=False, doc=doc_pert_numb),
+ Argument("pert_box", float, optional=False, doc=doc_pert_box),
+ Argument("pert_atom", float, optional=False, doc=doc_pert_atom),
+ Argument("coll_ndata", int, optional=False, doc=doc_coll_ndata),
+ ],
+ doc=doc_init_surf,
+ )
+
def init_reaction_jdata_arginfo() -> Argument:
"""Generate arginfo for dpgen init_reaction jdata.
-
+
Returns
-------
Argument
dpgen init_reaction jdata arginfo
"""
doc_init_reaction = "Generate initial data for reactive systems for small gas-phase molecules, from a ReaxFF NVT MD trajectory."
- doc_type_map = "Type map, which should match types in the initial data. e.g. [\"C\", \"H\", \"O\"]"
+ doc_type_map = (
+ 'Type map, which should match types in the initial data. e.g. ["C", "H", "O"]'
+ )
doc_reaxff = "Parameters for ReaxFF NVT MD."
doc_data = "Path to initial LAMMPS data file. The atom_style should be charge."
- doc_ff = "Path to ReaxFF force field file. Available in the lammps/potentials directory."
+ doc_ff = (
+ "Path to ReaxFF force field file. Available in the lammps/potentials directory."
+ )
doc_control = "Path to ReaxFF control file."
doc_temp = "Target Temperature for the NVT MD simulation. Unit: K."
doc_dt = "Real time for every time step. Unit: fs."
@@ -187,21 +229,31 @@ def init_reaction_jdata_arginfo() -> Argument:
doc_nstep = "Total steps to run the ReaxFF MD simulation."
doc_cutoff = "Cutoff radius to take clusters from the trajectory. Note that only a complete molecule or free radical will be taken."
doc_dataset_size = "Collected dataset size for each bond type."
- doc_qmkeywords = "Gaussian keywords for first-principle calculations. e.g. force mn15/6-31g** Geom=PrintInputOrient. Note that \"force\" job is necessary to collect data. Geom=PrintInputOrient should be used when there are more than 50 atoms in a cluster."
-
- return Argument("init_reaction_jdata", dict, [
- Argument("type_map", list, doc=doc_type_map),
- Argument("reaxff", dict, [
- Argument("data", str, doc=doc_data),
- Argument("ff", str, doc=doc_ff),
- Argument("control", str, doc=doc_control),
- Argument("temp", [float, int], doc=doc_temp),
- Argument("dt", [float, int], doc=doc_dt),
- Argument("tau_t", [float, int], doc=doc_tau_t),
- Argument("dump_freq", int, doc=doc_dump_frep),
- Argument("nstep", int, doc=doc_nstep),
- ], doc=doc_reaxff),
- Argument("cutoff", float, doc=doc_cutoff),
- Argument("dataset_size", int, doc=doc_dataset_size),
- Argument("qmkeywords", str, doc=doc_qmkeywords),
- ], doc=doc_init_reaction)
+ doc_qmkeywords = 'Gaussian keywords for first-principle calculations. e.g. force mn15/6-31g** Geom=PrintInputOrient. Note that "force" job is necessary to collect data. Geom=PrintInputOrient should be used when there are more than 50 atoms in a cluster.'
+
+ return Argument(
+ "init_reaction_jdata",
+ dict,
+ [
+ Argument("type_map", list, doc=doc_type_map),
+ Argument(
+ "reaxff",
+ dict,
+ [
+ Argument("data", str, doc=doc_data),
+ Argument("ff", str, doc=doc_ff),
+ Argument("control", str, doc=doc_control),
+ Argument("temp", [float, int], doc=doc_temp),
+ Argument("dt", [float, int], doc=doc_dt),
+ Argument("tau_t", [float, int], doc=doc_tau_t),
+ Argument("dump_freq", int, doc=doc_dump_frep),
+ Argument("nstep", int, doc=doc_nstep),
+ ],
+ doc=doc_reaxff,
+ ),
+ Argument("cutoff", float, doc=doc_cutoff),
+ Argument("dataset_size", int, doc=doc_dataset_size),
+ Argument("qmkeywords", str, doc=doc_qmkeywords),
+ ],
+ doc=doc_init_reaction,
+ )
diff --git a/dpgen/data/gen.py b/dpgen/data/gen.py
index 9f9d6f0f5..14314ada8 100644
--- a/dpgen/data/gen.py
+++ b/dpgen/data/gen.py
@@ -1,68 +1,75 @@
-#!/usr/bin/env python3
+#!/usr/bin/env python3
-import os
-import re
-import sys
import argparse
import glob
import json
-import random
import logging
-import warnings
+import os
+import random
+import re
import shutil
+import subprocess as sp
+import sys
import time
+import warnings
+
import dpdata
import numpy as np
-from dpgen import dlog
-import subprocess as sp
-import dpgen.data.tools.hcp as hcp
-import dpgen.data.tools.fcc as fcc
+from packaging.version import Version
+from pymatgen.core import Structure
+from pymatgen.io.vasp import Incar
+
import dpgen.data.tools.bcc as bcc
import dpgen.data.tools.diamond as diamond
+import dpgen.data.tools.fcc as fcc
+import dpgen.data.tools.hcp as hcp
import dpgen.data.tools.sc as sc
-from distutils.version import LooseVersion
-from dpgen.generator.lib.vasp import incar_upper
+from dpgen import ROOT_PATH, dlog
+from dpgen.dispatcher.Dispatcher import make_submission
+from dpgen.generator.lib.abacus_scf import (
+ get_abacus_input_parameters,
+ get_abacus_STRU,
+ make_abacus_scf_kpt,
+ make_abacus_scf_stru,
+ make_kspacing_kpoints_stru,
+ make_supercell_abacus,
+)
from dpgen.generator.lib.utils import symlink_user_forward_files
-from dpgen.generator.lib.abacus_scf import get_abacus_input_parameters, get_abacus_STRU, make_supercell_abacus, make_abacus_scf_stru\
- , make_kspacing_kpoints_stru, make_abacus_scf_kpt
-from pymatgen.core import Structure
-from pymatgen.io.vasp import Incar
-from dpgen.remote.decide_machine import convert_mdata
-from dpgen import ROOT_PATH
-from dpgen.dispatcher.Dispatcher import Dispatcher, make_dispatcher, make_submission
-
-
+from dpgen.generator.lib.vasp import incar_upper
+from dpgen.remote.decide_machine import convert_mdata
-def create_path (path,back=False) :
- if path[-1] != "/":
- path += '/'
- if os.path.isdir(path) :
+def create_path(path, back=False):
+ if path[-1] != "/":
+ path += "/"
+ if os.path.isdir(path):
if back:
- dirname = os.path.dirname(path)
- counter = 0
- while True :
- bk_dirname = dirname + ".bk%03d" % counter
- if not os.path.isdir(bk_dirname) :
- shutil.move (dirname, bk_dirname)
- break
- counter += 1
- os.makedirs (path)
- return path
+ dirname = os.path.dirname(path)
+ counter = 0
+ while True:
+ bk_dirname = dirname + ".bk%03d" % counter
+ if not os.path.isdir(bk_dirname):
+ shutil.move(dirname, bk_dirname)
+ break
+ counter += 1
+ os.makedirs(path)
+ return path
else:
- return path
+ return path
- os.makedirs (path)
+ os.makedirs(path)
return path
-def replace (file_name, pattern, subst) :
- file_handel = open (file_name, 'r')
- file_string = file_handel.read ()
- file_handel.close ()
- file_string = ( re.sub (pattern, subst, file_string) )
- file_handel = open (file_name, 'w')
- file_handel.write (file_string)
- file_handel.close ()
+
+def replace(file_name, pattern, subst):
+ file_handel = open(file_name, "r")
+ file_string = file_handel.read()
+ file_handel.close()
+ file_string = re.sub(pattern, subst, file_string)
+ file_handel = open(file_name, "w")
+ file_handel.write(file_string)
+ file_handel.close()
+
"""
0, make unit cell
@@ -71,122 +78,141 @@ def replace (file_name, pattern, subst) :
3, relax
4, perturb
"""
-global_dirname_02 = '00.place_ele'
-global_dirname_03 = '01.scale_pert'
-global_dirname_04 = '02.md'
+global_dirname_02 = "00.place_ele"
+global_dirname_03 = "01.scale_pert"
+global_dirname_04 = "02.md"
+
-def out_dir_name(jdata) :
- elements = jdata['elements']
- super_cell = jdata['super_cell']
- from_poscar = jdata.get('from_poscar', False)
+def out_dir_name(jdata):
+ elements = jdata["elements"]
+ super_cell = jdata["super_cell"]
+ from_poscar = jdata.get("from_poscar", False)
if from_poscar:
- from_poscar_path = jdata['from_poscar_path']
+ from_poscar_path = jdata["from_poscar_path"]
poscar_name = os.path.basename(from_poscar_path)
cell_str = "%02d" % (super_cell[0])
- for ii in range(1,len(super_cell)) :
+ for ii in range(1, len(super_cell)):
cell_str = cell_str + ("x%02d" % super_cell[ii])
- return poscar_name + '.' + cell_str
- else :
- cell_type = jdata['cell_type']
+ return poscar_name + "." + cell_str
+ else:
+ cell_type = jdata["cell_type"]
ele_str = ""
for ii in elements:
ele_str = ele_str + ii.lower()
cell_str = "%02d" % (super_cell[0])
- for ii in range(1,len(super_cell)) :
+ for ii in range(1, len(super_cell)):
cell_str = cell_str + ("x%02d" % super_cell[ii])
- return ele_str + '.' + cell_type + '.' + cell_str
+ return ele_str + "." + cell_type + "." + cell_str
-def class_cell_type(jdata) :
- ct = jdata['cell_type']
- if ct == "hcp" :
+
+def class_cell_type(jdata):
+ ct = jdata["cell_type"]
+ if ct == "hcp":
cell_type = hcp
- elif ct == "fcc" :
+ elif ct == "fcc":
cell_type = fcc
- elif ct == "diamond" :
+ elif ct == "diamond":
cell_type = diamond
- elif ct == "sc" :
+ elif ct == "sc":
cell_type = sc
- elif ct == "bcc" :
+ elif ct == "bcc":
cell_type = bcc
- else :
+ else:
raise RuntimeError("unknown cell type %s" % ct)
return cell_type
-def poscar_ele(poscar_in, poscar_out, eles, natoms) :
+
+def poscar_ele(poscar_in, poscar_out, eles, natoms):
ele_line = ""
natom_line = ""
- for ii in eles :
+ for ii in eles:
ele_line += str(ii) + " "
- for ii in natoms :
+ for ii in natoms:
natom_line += str(ii) + " "
- with open(poscar_in, 'r') as fin :
+ with open(poscar_in, "r") as fin:
lines = list(fin)
lines[5] = ele_line + "\n"
lines[6] = natom_line + "\n"
- with open(poscar_out, 'w') as fout :
+ with open(poscar_out, "w") as fout:
fout.write("".join(lines))
+
def stru_ele(supercell_stru, stru_out, eles, natoms, jdata, path_work):
supercell_stru["types"] = []
supercell_stru["atom_numbs"] = list(natoms)
for iele in range(len(natoms)):
for iatom in range(natoms[iele]):
supercell_stru["types"].append(iele)
- pp_file_names = [os.path.basename(a) for a in jdata['potcars']]
+ pp_file_names = [os.path.basename(a) for a in jdata["potcars"]]
orb_file_names = None
dpks_descriptor_name = None
- if 'orb_files' in jdata:
- orb_file_names = [os.path.basename(a) for a in jdata['orb_files']]
- if 'dpks_descriptor' in jdata:
- dpks_descriptor_name = os.path.basename(jdata['dpks_descriptor'])
+ if "orb_files" in jdata:
+ orb_file_names = [os.path.basename(a) for a in jdata["orb_files"]]
+ if "dpks_descriptor" in jdata:
+ dpks_descriptor_name = os.path.basename(jdata["dpks_descriptor"])
supercell_stru["atom_masses"] = jdata["atom_masses"]
supercell_stru["atom_names"] = eles
- stru_text = make_abacus_scf_stru(supercell_stru, pp_file_names, orb_file_names, dpks_descriptor_name)
+ stru_text = make_abacus_scf_stru(
+ supercell_stru,
+ pp_file_names,
+ orb_file_names,
+ dpks_descriptor_name,
+ type_map=jdata["elements"],
+ )
with open(stru_out, "w") as f:
f.write(stru_text)
absolute_pp_file_path = [os.path.abspath(a) for a in jdata["potcars"]]
- if 'orb_files' in jdata:
- absolute_orb_file_path = [os.path.abspath(a) for a in jdata['orb_files']]
- if 'dpks_descriptor' in jdata:
- absolute_dpks_descriptor_path = os.path.abspath(jdata['dpks_descriptor'])
+ if "orb_files" in jdata:
+ absolute_orb_file_path = [os.path.abspath(a) for a in jdata["orb_files"]]
+ if "dpks_descriptor" in jdata:
+ absolute_dpks_descriptor_path = os.path.abspath(jdata["dpks_descriptor"])
for ipp, pp_file in enumerate(absolute_pp_file_path):
os.symlink(pp_file, os.path.join(path_work, pp_file_names[ipp]))
- if 'orb_files' in jdata:
- os.symlink(absolute_orb_file_path[ipp], os.path.join(path_work, orb_file_names[ipp]))
- if 'dpks_descriptor' in jdata:
- os.symlink(absolute_dpks_descriptor_path, os.path.join(path_work, dpks_descriptor_name))
-
-def poscar_natoms(lines) :
+ if "orb_files" in jdata:
+ os.symlink(
+ absolute_orb_file_path[ipp],
+ os.path.join(path_work, orb_file_names[ipp]),
+ )
+ if "dpks_descriptor" in jdata:
+ os.symlink(
+ absolute_dpks_descriptor_path, os.path.join(path_work, dpks_descriptor_name)
+ )
+
+
+def poscar_natoms(lines):
numb_atoms = 0
- for ii in lines[6].split() :
+ for ii in lines[6].split():
numb_atoms += int(ii)
return numb_atoms
-def poscar_shuffle(poscar_in, poscar_out) :
- with open(poscar_in, 'r') as fin :
+
+def poscar_shuffle(poscar_in, poscar_out):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
numb_atoms = poscar_natoms(lines)
- idx = np.arange(8, 8+numb_atoms)
+ idx = np.arange(8, 8 + numb_atoms)
np.random.shuffle(idx)
out_lines = lines[0:8]
- for ii in range(numb_atoms) :
+ for ii in range(numb_atoms):
out_lines.append(lines[idx[ii]])
- with open(poscar_out, 'w') as fout:
+ with open(poscar_out, "w") as fout:
fout.write("".join(out_lines))
+
def shuffle_stru_data(supercell_stru):
atom_numb = sum(supercell_stru["atom_numbs"])
- assert(np.shape(supercell_stru["coords"]) == (atom_numb, 3))
+ assert np.shape(supercell_stru["coords"]) == (atom_numb, 3)
new_coord = np.zeros([atom_numb, 3])
order = np.arange(0, atom_numb)
np.random.shuffle(order)
for idx in range(atom_numb):
new_coord[idx] = supercell_stru["coords"][order[idx]]
- supercell_stru['coords'] = new_coord
+ supercell_stru["coords"] = new_coord
return supercell_stru
-def poscar_scale_direct (str_in, scale) :
+
+def poscar_scale_direct(str_in, scale):
lines = str_in.copy()
numb_atoms = poscar_natoms(lines)
pscale = float(lines[1])
@@ -194,153 +220,160 @@ def poscar_scale_direct (str_in, scale) :
lines[1] = str(pscale) + "\n"
return lines
-def poscar_scale_cartesian (str_in, scale) :
+
+def poscar_scale_cartesian(str_in, scale):
lines = str_in.copy()
numb_atoms = poscar_natoms(lines)
# scale box
- for ii in range(2,5) :
+ for ii in range(2, 5):
boxl = lines[ii].split()
boxv = [float(ii) for ii in boxl]
boxv = np.array(boxv) * scale
lines[ii] = "%.16e %.16e %.16e\n" % (boxv[0], boxv[1], boxv[2])
# scale coord
- for ii in range(8, 8+numb_atoms) :
+ for ii in range(8, 8 + numb_atoms):
cl = lines[ii].split()
cv = [float(ii) for ii in cl]
cv = np.array(cv) * scale
lines[ii] = "%.16e %.16e %.16e\n" % (cv[0], cv[1], cv[2])
- return lines
+ return lines
+
-def poscar_scale (poscar_in, poscar_out, scale) :
- with open(poscar_in, 'r') as fin :
+def poscar_scale(poscar_in, poscar_out, scale):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
- if 'D' == lines[7][0] or 'd' == lines[7][0]:
+ if "D" == lines[7][0] or "d" == lines[7][0]:
lines = poscar_scale_direct(lines, scale)
- elif 'C' == lines[7][0] or 'c' == lines[7][0] :
+ elif "C" == lines[7][0] or "c" == lines[7][0]:
lines = poscar_scale_cartesian(lines, scale)
- else :
+ else:
raise RuntimeError("Unknow poscar style at line 7: %s" % lines[7])
- with open(poscar_out, 'w') as fout:
+ with open(poscar_out, "w") as fout:
fout.write("".join(lines))
+
def poscar_scale_abacus(poscar_in, poscar_out, scale, jdata):
- stru = get_abacus_STRU(poscar_in, n_ele=len(jdata["elements"]))
+ stru = get_abacus_STRU(poscar_in)
stru["cells"] *= scale
stru["coords"] *= scale
- pp_files = [os.path.basename(a) for a in jdata['potcars']]
+ pp_files = [os.path.basename(a) for a in jdata["potcars"]]
orb_file_names = None
dpks_descriptor_name = None
- if 'orb_files' in jdata:
- orb_file_names = [os.path.basename(a) for a in jdata['orb_files']]
- if 'dpks_descriptor' in jdata:
- dpks_descriptor_name = os.path.basename(jdata['dpks_descriptor'])
- ret = make_abacus_scf_stru(stru, pp_files, orb_file_names, dpks_descriptor_name)
- #ret = make_abacus_scf_stru(stru, pp_files)
+ if "orb_files" in jdata:
+ orb_file_names = [os.path.basename(a) for a in jdata["orb_files"]]
+ if "dpks_descriptor" in jdata:
+ dpks_descriptor_name = os.path.basename(jdata["dpks_descriptor"])
+ ret = make_abacus_scf_stru(
+ stru, pp_files, orb_file_names, dpks_descriptor_name, type_map=jdata["elements"]
+ )
+ # ret = make_abacus_scf_stru(stru, pp_files)
with open(poscar_out, "w") as fp:
fp.write(ret)
-
-def make_unit_cell (jdata) :
- latt = jdata['latt']
- out_dir = jdata['out_dir']
+
+def make_unit_cell(jdata):
+ latt = jdata["latt"]
+ out_dir = jdata["out_dir"]
path_uc = os.path.join(out_dir, global_dirname_02)
cell_type = class_cell_type(jdata)
- cwd = os.getcwd()
+ cwd = os.getcwd()
# for ii in scale :
# path_work = create_path(os.path.join(path_uc, '%.3f' % ii))
- path_work = create_path(path_uc)
+ path_work = create_path(path_uc)
os.chdir(path_work)
- with open('POSCAR.unit', 'w') as fp:
- fp.write (cell_type.poscar_unit(latt))
- os.chdir(cwd)
+ with open("POSCAR.unit", "w") as fp:
+ fp.write(cell_type.poscar_unit(latt))
+ os.chdir(cwd)
+
-def make_unit_cell_ABACUS (jdata) :
- latt = jdata['latt']
- out_dir = jdata['out_dir']
+def make_unit_cell_ABACUS(jdata):
+ latt = jdata["latt"]
+ out_dir = jdata["out_dir"]
path_uc = os.path.join(out_dir, global_dirname_02)
cell_type = class_cell_type(jdata)
- cwd = os.getcwd()
+ cwd = os.getcwd()
path_work = create_path(path_uc)
os.chdir(path_work)
- with open('POSCAR.unit', 'w') as fp:
- fp.write (cell_type.poscar_unit(latt))
- stru_data = dpdata.System("POSCAR.unit", fmt = 'vasp/poscar').data
- os.chdir(cwd)
- stru_data['coords'] = np.squeeze(stru_data['coords'])
- stru_data['cells'] = np.squeeze(stru_data['cells'])
+ with open("POSCAR.unit", "w") as fp:
+ fp.write(cell_type.poscar_unit(latt))
+ stru_data = dpdata.System("POSCAR.unit", fmt="vasp/poscar").data
+ os.chdir(cwd)
+ stru_data["coords"] = np.squeeze(stru_data["coords"])
+ stru_data["cells"] = np.squeeze(stru_data["cells"])
del stru_data["atom_names"]
return stru_data
-
-def make_super_cell (jdata) :
- out_dir = jdata['out_dir']
- super_cell = jdata['super_cell']
+
+def make_super_cell(jdata):
+ out_dir = jdata["out_dir"]
+ super_cell = jdata["super_cell"]
path_uc = os.path.join(out_dir, global_dirname_02)
path_sc = os.path.join(out_dir, global_dirname_02)
- assert(os.path.isdir(path_uc)), "path %s should exists" % path_uc
- assert(os.path.isdir(path_sc)), "path %s should exists" % path_sc
+ assert os.path.isdir(path_uc), "path %s should exists" % path_uc
+ assert os.path.isdir(path_sc), "path %s should exists" % path_sc
# for ii in scale :
from_path = path_uc
- from_file = os.path.join(from_path, 'POSCAR.unit')
+ from_file = os.path.join(from_path, "POSCAR.unit")
to_path = path_sc
- to_file = os.path.join(to_path, 'POSCAR')
+ to_file = os.path.join(to_path, "POSCAR")
- #minor bug for element symbol behind the coordinates
- from_struct=Structure.from_file(from_file)
+ # minor bug for element symbol behind the coordinates
+ from_struct = Structure.from_file(from_file)
from_struct.make_supercell(super_cell)
- from_struct.to('poscar',to_file)
+ from_struct.to(to_file, "poscar")
+
-def make_super_cell_ABACUS (jdata, stru_data) :
- out_dir = jdata['out_dir']
- super_cell = jdata['super_cell']
+def make_super_cell_ABACUS(jdata, stru_data):
+ out_dir = jdata["out_dir"]
+ super_cell = jdata["super_cell"]
path_uc = os.path.join(out_dir, global_dirname_02)
path_sc = os.path.join(out_dir, global_dirname_02)
- assert(os.path.isdir(path_uc)), "path %s should exists" % path_uc
- assert(os.path.isdir(path_sc)), "path %s should exists" % path_sc
+ assert os.path.isdir(path_uc), "path %s should exists" % path_uc
+ assert os.path.isdir(path_sc), "path %s should exists" % path_sc
# for ii in scale :
- #from_path = path_uc
- #from_file = os.path.join(from_path, 'POSCAR.unit')
- #to_path = path_sc
- #to_file = os.path.join(to_path, 'POSCAR')
-
- #minor bug for element symbol behind the coordinates
- #from_struct=Structure.from_file(from_file)
- #from_struct.make_supercell(super_cell)
- #from_struct.to('poscar',to_file)
+ # from_path = path_uc
+ # from_file = os.path.join(from_path, 'POSCAR.unit')
+ # to_path = path_sc
+ # to_file = os.path.join(to_path, 'POSCAR')
+
+ # minor bug for element symbol behind the coordinates
+ # from_struct=Structure.from_file(from_file)
+ # from_struct.make_supercell(super_cell)
+ # from_struct.to('poscar',to_file)
supercell_stru = make_supercell_abacus(stru_data, super_cell)
return supercell_stru
-def make_super_cell_poscar(jdata) :
- out_dir = jdata['out_dir']
- super_cell = jdata['super_cell']
- path_sc = os.path.join(out_dir, global_dirname_02)
+def make_super_cell_poscar(jdata):
+ out_dir = jdata["out_dir"]
+ super_cell = jdata["super_cell"]
+ path_sc = os.path.join(out_dir, global_dirname_02)
create_path(path_sc)
- from_poscar_path = jdata['from_poscar_path']
- assert(os.path.isfile(from_poscar_path)), "file %s should exists" % from_poscar_path
-
- from_file = os.path.join(path_sc, 'POSCAR.copied')
+ from_poscar_path = jdata["from_poscar_path"]
+ assert os.path.isfile(from_poscar_path), "file %s should exists" % from_poscar_path
+
+ from_file = os.path.join(path_sc, "POSCAR.copied")
shutil.copy2(from_poscar_path, from_file)
to_path = path_sc
- to_file = os.path.join(to_path, 'POSCAR')
-
- #minor bug for element symbol behind the coordinates
- from_struct=Structure.from_file(from_file)
+ to_file = os.path.join(to_path, "POSCAR")
+
+ # minor bug for element symbol behind the coordinates
+ from_struct = Structure.from_file(from_file)
from_struct.make_supercell(super_cell)
- from_struct.to('poscar',to_file)
+ from_struct.to(to_file, "poscar")
# make system dir (copy)
- lines = open(to_file, 'r').read().split('\n')
+ lines = open(to_file, "r").read().split("\n")
natoms_str = lines[6]
natoms_list = [int(ii) for ii in natoms_str.split()]
dlog.info(natoms_list)
comb_name = "sys-"
- for idx,ii in enumerate(natoms_list) :
+ for idx, ii in enumerate(natoms_list):
comb_name += "%04d" % ii
- if idx != len(natoms_list)-1 :
+ if idx != len(natoms_list) - 1:
comb_name += "-"
path_work = os.path.join(path_sc, comb_name)
create_path(path_work)
@@ -348,266 +381,286 @@ def make_super_cell_poscar(jdata) :
to_file = os.path.abspath(to_file)
os.chdir(path_work)
try:
- os.symlink(os.path.relpath(to_file), 'POSCAR')
+ os.symlink(os.path.relpath(to_file), "POSCAR")
except FileExistsError:
pass
os.chdir(cwd)
-def make_super_cell_STRU(jdata) :
- out_dir = jdata['out_dir']
- super_cell = jdata['super_cell']
- path_sc = os.path.join(out_dir, global_dirname_02)
+
+def make_super_cell_STRU(jdata):
+ out_dir = jdata["out_dir"]
+ super_cell = jdata["super_cell"]
+ path_sc = os.path.join(out_dir, global_dirname_02)
create_path(path_sc)
- from_poscar_path = jdata['from_poscar_path']
- assert(os.path.isfile(from_poscar_path)), "file %s should exists" % from_poscar_path
+ from_poscar_path = jdata["from_poscar_path"]
+ assert os.path.isfile(from_poscar_path), "file %s should exists" % from_poscar_path
- from_file = os.path.join(path_sc, 'STRU.copied')
+ from_file = os.path.join(path_sc, "STRU.copied")
shutil.copy2(from_poscar_path, from_file)
to_path = path_sc
- to_file = os.path.join(to_path, 'STRU')
+ to_file = os.path.join(to_path, "STRU")
- from_struct=get_abacus_STRU(from_file, n_ele=len(jdata["elements"]))
+ from_struct = get_abacus_STRU(from_file)
from_struct = make_supercell_abacus(from_struct, super_cell)
- pp_file_names = [os.path.basename(a) for a in jdata['potcars']]
+ pp_file_names = [os.path.basename(a) for a in jdata["potcars"]]
orb_file_names = None
dpks_descriptor_name = None
- if 'orb_files' in jdata:
- orb_file_names = [os.path.basename(a) for a in jdata['orb_files']]
- if 'dpks_descriptor' in jdata:
- dpks_descriptor_name = os.path.basename(jdata['dpks_descriptor'])
- stru_text = make_abacus_scf_stru(from_struct, pp_file_names, orb_file_names, dpks_descriptor_name)
+ if "orb_files" in jdata:
+ orb_file_names = [os.path.basename(a) for a in jdata["orb_files"]]
+ if "dpks_descriptor" in jdata:
+ dpks_descriptor_name = os.path.basename(jdata["dpks_descriptor"])
+ stru_text = make_abacus_scf_stru(
+ from_struct,
+ pp_file_names,
+ orb_file_names,
+ dpks_descriptor_name,
+ type_map=jdata["elements"],
+ )
with open(to_file, "w") as fp:
- fp.write(stru_text)
+ fp.write(stru_text)
# make system dir (copy)
- natoms_list = from_struct['atom_numbs']
+ natoms_list = from_struct["atom_numbs"]
dlog.info(natoms_list)
comb_name = "sys-"
- for idx,ii in enumerate(natoms_list) :
+ for idx, ii in enumerate(natoms_list):
comb_name += "%04d" % ii
- if idx != len(natoms_list)-1 :
+ if idx != len(natoms_list) - 1:
comb_name += "-"
path_work = os.path.join(path_sc, comb_name)
create_path(path_work)
cwd = os.getcwd()
- absolute_pp_file_path = [os.path.abspath(a) for a in jdata['potcars']]
- if 'orb_files' in jdata:
- absolute_orb_file_path = [os.path.abspath(a) for a in jdata['orb_files']]
- if 'dpks_descriptor' in jdata:
- absolute_dpks_descriptor_path = os.path.abspath(jdata['dpks_descriptor'])
+ absolute_pp_file_path = [os.path.abspath(a) for a in jdata["potcars"]]
+ if "orb_files" in jdata:
+ absolute_orb_file_path = [os.path.abspath(a) for a in jdata["orb_files"]]
+ if "dpks_descriptor" in jdata:
+ absolute_dpks_descriptor_path = os.path.abspath(jdata["dpks_descriptor"])
to_file = os.path.abspath(to_file)
os.chdir(path_work)
try:
- os.symlink(os.path.relpath(to_file), 'STRU')
+ os.symlink(os.path.relpath(to_file), "STRU")
for ipp, pp_file in enumerate(absolute_pp_file_path):
- os.symlink(pp_file, pp_file_names[ipp]) # create pseudo-potential files
- if 'orb_files' in jdata:
+ os.symlink(pp_file, pp_file_names[ipp]) # create pseudo-potential files
+ if "orb_files" in jdata:
os.symlink(absolute_orb_file_path[ipp], orb_file_names[ipp])
- if 'dpks_descriptor' in jdata:
+ if "dpks_descriptor" in jdata:
os.symlink(absolute_dpks_descriptor_path, dpks_descriptor_name)
except FileExistsError:
pass
os.chdir(cwd)
-def make_combines (dim, natoms) :
- if dim == 1 :
+
+def make_combines(dim, natoms):
+ if dim == 1:
return [[natoms]]
- else :
+ else:
res = []
- for ii in range(natoms+1) :
+ for ii in range(natoms + 1):
rest = natoms - ii
- tmp_combines = make_combines(dim-1, rest)
- for jj in tmp_combines :
+ tmp_combines = make_combines(dim - 1, rest)
+ for jj in tmp_combines:
jj.append(ii)
- if len(res) == 0 :
+ if len(res) == 0:
res = tmp_combines
- else :
+ else:
res += tmp_combines
return res
-def place_element (jdata) :
- out_dir = jdata['out_dir']
- super_cell = jdata['super_cell']
+
+def place_element(jdata):
+ out_dir = jdata["out_dir"]
+ super_cell = jdata["super_cell"]
cell_type = class_cell_type(jdata)
natoms = np.cumprod(super_cell)[-1] * cell_type.numb_atoms()
- elements = jdata['elements']
+ elements = jdata["elements"]
path_sc = os.path.join(out_dir, global_dirname_02)
- path_pe = os.path.join(out_dir, global_dirname_02)
- combines = np.array(make_combines(len(elements), natoms), dtype = int)
-
- assert(os.path.isdir(path_pe))
+ path_pe = os.path.join(out_dir, global_dirname_02)
+ combines = np.array(make_combines(len(elements), natoms), dtype=int)
+
+ assert os.path.isdir(path_pe)
cwd = os.getcwd()
- for ii in combines :
- if any(ii == 0) :
+ for ii in combines:
+ if any(ii == 0):
continue
comb_name = "sys-"
- for idx,jj in enumerate(ii) :
+ for idx, jj in enumerate(ii):
comb_name += "%04d" % jj
- if idx != len(ii)-1 :
+ if idx != len(ii) - 1:
comb_name += "-"
path_pos_in = path_sc
path_work = os.path.join(path_pe, comb_name)
create_path(path_work)
- pos_in = os.path.join(path_pos_in, 'POSCAR')
- pos_out = os.path.join(path_work, 'POSCAR')
+ pos_in = os.path.join(path_pos_in, "POSCAR")
+ pos_out = os.path.join(path_work, "POSCAR")
poscar_ele(pos_in, pos_out, elements, ii)
poscar_shuffle(pos_out, pos_out)
+
def place_element_ABACUS(jdata, supercell_stru):
- out_dir = jdata['out_dir']
- super_cell = jdata['super_cell']
+ out_dir = jdata["out_dir"]
+ super_cell = jdata["super_cell"]
cell_type = class_cell_type(jdata)
- natoms = sum(supercell_stru['atom_numbs'])
- elements = jdata['elements']
- #path_sc = os.path.join(out_dir, global_dirname_02)
- path_pe = os.path.join(out_dir, global_dirname_02)
- combines = np.array(make_combines(len(elements), natoms), dtype = int)
- assert(os.path.isdir(path_pe))
+ natoms = sum(supercell_stru["atom_numbs"])
+ elements = jdata["elements"]
+ # path_sc = os.path.join(out_dir, global_dirname_02)
+ path_pe = os.path.join(out_dir, global_dirname_02)
+ combines = np.array(make_combines(len(elements), natoms), dtype=int)
+ assert os.path.isdir(path_pe)
cwd = os.getcwd()
- for ii in combines :
- if any(ii == 0) :
+ for ii in combines:
+ if any(ii == 0):
continue
comb_name = "sys-"
- for idx,jj in enumerate(ii) :
+ for idx, jj in enumerate(ii):
comb_name += "%04d" % jj
- if idx != len(ii)-1 :
+ if idx != len(ii) - 1:
comb_name += "-"
- #path_pos_in = path_sc
+ # path_pos_in = path_sc
path_work = os.path.join(path_pe, comb_name)
create_path(path_work)
- #pos_in = os.path.join(path_pos_in, 'POSCAR')
- pos_out = os.path.join(path_work, 'STRU')
+ # pos_in = os.path.join(path_pos_in, 'POSCAR')
+ pos_out = os.path.join(path_work, "STRU")
supercell_stru = shuffle_stru_data(supercell_stru)
stru_ele(supercell_stru, pos_out, elements, ii, jdata, path_work)
-
-def make_vasp_relax (jdata, mdata) :
- out_dir = jdata['out_dir']
- potcars = jdata['potcars']
+
+def make_vasp_relax(jdata, mdata):
+ out_dir = jdata["out_dir"]
+ potcars = jdata["potcars"]
cwd = os.getcwd()
work_dir = os.path.join(out_dir, global_dirname_02)
- assert (os.path.isdir(work_dir))
+ assert os.path.isdir(work_dir)
work_dir = os.path.abspath(work_dir)
- if os.path.isfile(os.path.join(work_dir, 'INCAR' )) :
- os.remove(os.path.join(work_dir, 'INCAR' ))
- if os.path.isfile(os.path.join(work_dir, 'POTCAR')) :
- os.remove(os.path.join(work_dir, 'POTCAR'))
- shutil.copy2( jdata['relax_incar'],
- os.path.join(work_dir, 'INCAR'))
-
- out_potcar = os.path.join(work_dir, 'POTCAR')
- with open(out_potcar, 'w') as outfile:
+ if os.path.isfile(os.path.join(work_dir, "INCAR")):
+ os.remove(os.path.join(work_dir, "INCAR"))
+ if os.path.isfile(os.path.join(work_dir, "POTCAR")):
+ os.remove(os.path.join(work_dir, "POTCAR"))
+ shutil.copy2(jdata["relax_incar"], os.path.join(work_dir, "INCAR"))
+
+ out_potcar = os.path.join(work_dir, "POTCAR")
+ with open(out_potcar, "w") as outfile:
for fname in potcars:
with open(fname) as infile:
outfile.write(infile.read())
-
+
os.chdir(work_dir)
-
- sys_list = glob.glob('sys-*')
+
+ sys_list = glob.glob("sys-*")
for ss in sys_list:
os.chdir(ss)
- ln_src = os.path.relpath(os.path.join(work_dir,'INCAR'))
+ ln_src = os.path.relpath(os.path.join(work_dir, "INCAR"))
try:
- os.symlink(ln_src, 'INCAR')
+ os.symlink(ln_src, "INCAR")
except FileExistsError:
- pass
- ln_src = os.path.relpath(os.path.join(work_dir,'POTCAR'))
+ pass
+ ln_src = os.path.relpath(os.path.join(work_dir, "POTCAR"))
try:
- os.symlink(ln_src, 'POTCAR')
+ os.symlink(ln_src, "POTCAR")
except FileExistsError:
- pass
+ pass
is_cvasp = False
- if 'cvasp' in mdata['fp_resources'].keys():
- is_cvasp = mdata['fp_resources']['cvasp']
+ if "cvasp" in mdata["fp_resources"].keys():
+ is_cvasp = mdata["fp_resources"]["cvasp"]
if is_cvasp:
- cvasp_file = os.path.join(ROOT_PATH, 'generator/lib/cvasp.py')
- shutil.copyfile(cvasp_file, 'cvasp.py')
+ cvasp_file = os.path.join(ROOT_PATH, "generator/lib/cvasp.py")
+ shutil.copyfile(cvasp_file, "cvasp.py")
os.chdir(work_dir)
os.chdir(cwd)
- symlink_user_forward_files(mdata=mdata, task_type="fp",
- work_path=os.path.join(os.path.basename(out_dir),global_dirname_02),
- task_format= {"fp" : "sys-*"})
-
-def make_abacus_relax (jdata, mdata) :
- relax_incar = jdata['relax_incar']
- standard_incar = get_abacus_input_parameters(relax_incar) # a dictionary in which all of the values are strings
+ symlink_user_forward_files(
+ mdata=mdata,
+ task_type="fp",
+ work_path=os.path.join(os.path.basename(out_dir), global_dirname_02),
+ task_format={"fp": "sys-*"},
+ )
+
+
+def make_abacus_relax(jdata, mdata):
+ relax_incar = jdata["relax_incar"]
+ standard_incar = get_abacus_input_parameters(
+ relax_incar
+ ) # a dictionary in which all of the values are strings
if "kspacing" not in standard_incar:
if "gamma_only" in standard_incar:
- if type(standard_incar["gamma_only"])==str:
+ if type(standard_incar["gamma_only"]) == str:
standard_incar["gamma_only"] = int(eval(standard_incar["gamma_only"]))
if standard_incar["gamma_only"] == 0:
if "relax_kpt" not in jdata:
raise RuntimeError("Cannot find any k-points information.")
else:
- md_kpt_path = jdata['relax_kpt']
- assert(os.path.isfile(relax_kpt_path)), "file %s should exists" % relax_kpt_path
+ relax_kpt_path = jdata["relax_kpt"]
+ assert os.path.isfile(relax_kpt_path), (
+ "file %s should exists" % relax_kpt_path
+ )
else:
- gamma_param = {"k_points":[1,1,1,0,0,0]}
+ gamma_param = {"k_points": [1, 1, 1, 0, 0, 0]}
ret_kpt = make_abacus_scf_kpt(gamma_param)
else:
if "relax_kpt" not in jdata:
raise RuntimeError("Cannot find any k-points information.")
else:
- relax_kpt_path = jdata['relax_kpt']
- assert(os.path.isfile(relax_kpt_path)), "file %s should exists" % relax_kpt_path
+ relax_kpt_path = jdata["relax_kpt"]
+ assert os.path.isfile(relax_kpt_path), (
+ "file %s should exists" % relax_kpt_path
+ )
- out_dir = jdata['out_dir']
+ out_dir = jdata["out_dir"]
cwd = os.getcwd()
work_dir = os.path.join(out_dir, global_dirname_02)
- assert (os.path.isdir(work_dir))
+ assert os.path.isdir(work_dir)
work_dir = os.path.abspath(work_dir)
- if os.path.isfile(os.path.join(work_dir, 'INPUT' )) :
- os.remove(os.path.join(work_dir, 'INPUT' ))
- shutil.copy2( jdata['relax_incar'],
- os.path.join(work_dir, 'INPUT'))
+ if os.path.isfile(os.path.join(work_dir, "INPUT")):
+ os.remove(os.path.join(work_dir, "INPUT"))
+ shutil.copy2(jdata["relax_incar"], os.path.join(work_dir, "INPUT"))
-
if "kspacing" not in standard_incar:
- if os.path.isfile(os.path.join(work_dir, 'KPT' )) :
- os.remove(os.path.join(work_dir, 'KPT' ))
- if "gamma_only" in standard_incar and standard_incar["gamma_only"]==1:
- with open(os.path.join(work_dir,'KPT'),"w") as fp:
+ if os.path.isfile(os.path.join(work_dir, "KPT")):
+ os.remove(os.path.join(work_dir, "KPT"))
+ if "gamma_only" in standard_incar and standard_incar["gamma_only"] == 1:
+ with open(os.path.join(work_dir, "KPT"), "w") as fp:
fp.write(ret_kpt)
else:
- jdata['relax_kpt'] = os.path.relpath(jdata['relax_kpt'])
- shutil.copy2(jdata['relax_kpt'],os.path.join(work_dir, 'KPT'))
-
+ jdata["relax_kpt"] = os.path.relpath(jdata["relax_kpt"])
+ shutil.copy2(jdata["relax_kpt"], os.path.join(work_dir, "KPT"))
+
if "dpks_model" in jdata:
dpks_model_absolute_path = os.path.abspath(jdata["dpks_model"])
- assert(os.path.isfile(dpks_model_absolute_path))
+ assert os.path.isfile(dpks_model_absolute_path)
dpks_model_name = os.path.basename(jdata["dpks_model"])
- shutil.copy2( dpks_model_absolute_path,
- os.path.join(work_dir, dpks_model_name))
+ shutil.copy2(dpks_model_absolute_path, os.path.join(work_dir, dpks_model_name))
os.chdir(work_dir)
-
- sys_list = glob.glob('sys-*')
+
+ sys_list = glob.glob("sys-*")
for ss in sys_list:
os.chdir(ss)
- ln_src = os.path.relpath(os.path.join(work_dir,'INPUT'))
+ ln_src = os.path.relpath(os.path.join(work_dir, "INPUT"))
if "kspacing" not in standard_incar:
- kpt_src = os.path.relpath(os.path.join(work_dir,'KPT'))
+ kpt_src = os.path.relpath(os.path.join(work_dir, "KPT"))
if "dpks_model" in jdata:
- ksmd_src = os.path.relpath(os.path.join(work_dir,dpks_model_name))
+ ksmd_src = os.path.relpath(os.path.join(work_dir, dpks_model_name))
try:
- os.symlink(ln_src, 'INPUT')
+ os.symlink(ln_src, "INPUT")
if "kspacing" not in standard_incar:
- os.symlink(kpt_src, 'KPT')
+ os.symlink(kpt_src, "KPT")
if "dpks_model" in jdata:
os.symlink(ksmd_src, dpks_model_name)
except FileExistsError:
pass
os.chdir(work_dir)
os.chdir(cwd)
- symlink_user_forward_files(mdata=mdata, task_type="fp",
- work_path=os.path.join(os.path.basename(out_dir),global_dirname_02),
- task_format= {"fp" : "sys-*"})
+ symlink_user_forward_files(
+ mdata=mdata,
+ task_type="fp",
+ work_path=os.path.join(os.path.basename(out_dir), global_dirname_02),
+ task_format={"fp": "sys-*"},
+ )
+
def make_scale(jdata):
- out_dir = jdata['out_dir']
- scale = jdata['scale']
- skip_relax = jdata['skip_relax']
+ out_dir = jdata["out_dir"]
+ scale = jdata["scale"]
+ skip_relax = jdata["skip_relax"]
cwd = os.getcwd()
init_path = os.path.join(out_dir, global_dirname_02)
@@ -619,28 +672,31 @@ def make_scale(jdata):
os.chdir(cwd)
create_path(work_path)
- for ii in init_sys :
- for jj in scale :
- if skip_relax :
- pos_src = os.path.join(os.path.join(init_path, ii), 'POSCAR')
- assert(os.path.isfile(pos_src))
- else :
+ for ii in init_sys:
+ for jj in scale:
+ if skip_relax:
+ pos_src = os.path.join(os.path.join(init_path, ii), "POSCAR")
+ assert os.path.isfile(pos_src)
+ else:
try:
- pos_src = os.path.join(os.path.join(init_path, ii), 'CONTCAR')
- assert(os.path.isfile(pos_src))
+ pos_src = os.path.join(os.path.join(init_path, ii), "CONTCAR")
+ assert os.path.isfile(pos_src)
except Exception:
- raise RuntimeError("not file %s, vasp relaxation should be run before scale poscar")
+ raise RuntimeError(
+ "not file %s, vasp relaxation should be run before scale poscar"
+ )
scale_path = os.path.join(work_path, ii)
scale_path = os.path.join(scale_path, "scale-%.3f" % jj)
create_path(scale_path)
- os.chdir(scale_path)
- poscar_scale(pos_src, 'POSCAR', jj)
+ os.chdir(scale_path)
+ poscar_scale(pos_src, "POSCAR", jj)
os.chdir(cwd)
+
def make_scale_ABACUS(jdata):
- out_dir = jdata['out_dir']
- scale = jdata['scale']
- skip_relax = jdata['skip_relax']
+ out_dir = jdata["out_dir"]
+ scale = jdata["scale"]
+ skip_relax = jdata["skip_relax"]
cwd = os.getcwd()
init_path = os.path.join(out_dir, global_dirname_02)
@@ -652,81 +708,90 @@ def make_scale_ABACUS(jdata):
os.chdir(cwd)
create_path(work_path)
- for ii in init_sys :
- for jj in scale :
- if skip_relax :
- pos_src = os.path.join(os.path.join(init_path, ii), 'STRU')
- assert(os.path.isfile(pos_src))
- else :
+ for ii in init_sys:
+ for jj in scale:
+ if skip_relax:
+ pos_src = os.path.join(os.path.join(init_path, ii), "STRU")
+ assert os.path.isfile(pos_src)
+ else:
try:
- pos_src = os.path.join(os.path.join(init_path, ii), 'OUT.ABACUS/STRU_ION_D')
- assert(os.path.isfile(pos_src))
+ pos_src = os.path.join(
+ os.path.join(init_path, ii), "OUT.ABACUS/STRU_ION_D"
+ )
+ assert os.path.isfile(pos_src)
except Exception:
- raise RuntimeError("not file %s, vasp relaxation should be run before scale poscar")
+ raise RuntimeError(
+ "not file %s, vasp relaxation should be run before scale poscar"
+ )
scale_path = os.path.join(work_path, ii)
scale_path = os.path.join(scale_path, "scale-%.3f" % jj)
create_path(scale_path)
- os.chdir(scale_path)
- poscar_scale_abacus(pos_src, 'STRU', jj, jdata)
+ os.chdir(scale_path)
+ poscar_scale_abacus(pos_src, "STRU", jj, jdata)
os.chdir(cwd)
-
-def pert_scaled(jdata) :
+def pert_scaled(jdata):
if "init_fp_style" not in jdata:
jdata["init_fp_style"] = "VASP"
- out_dir = jdata['out_dir']
- scale = jdata['scale']
- pert_box = jdata['pert_box']
- pert_atom = jdata['pert_atom']
- pert_numb = jdata['pert_numb']
- pp_file = [os.path.basename(a) for a in jdata['potcars']]
+ out_dir = jdata["out_dir"]
+ scale = jdata["scale"]
+ pert_box = jdata["pert_box"]
+ pert_atom = jdata["pert_atom"]
+ pert_numb = jdata["pert_numb"]
+ pp_file = [os.path.basename(a) for a in jdata["potcars"]]
orb_file_names = None
dpks_descriptor_name = None
- if 'orb_files' in jdata:
- orb_file_names = [os.path.basename(a) for a in jdata['orb_files']]
- if 'dpks_descriptor' in jdata:
- dpks_descriptor_name = os.path.basename(jdata['dpks_descriptor'])
- from_poscar = False
- if 'from_poscar' in jdata :
- from_poscar = jdata['from_poscar']
-
+ if "orb_files" in jdata:
+ orb_file_names = [os.path.basename(a) for a in jdata["orb_files"]]
+ if "dpks_descriptor" in jdata:
+ dpks_descriptor_name = os.path.basename(jdata["dpks_descriptor"])
+ from_poscar = False
+ if "from_poscar" in jdata:
+ from_poscar = jdata["from_poscar"]
+
cwd = os.getcwd()
path_sp = os.path.join(out_dir, global_dirname_03)
- assert(os.path.isdir(path_sp))
+ assert os.path.isdir(path_sp)
os.chdir(path_sp)
- sys_pe = glob.glob('sys-*')
+ sys_pe = glob.glob("sys-*")
sys_pe.sort()
- os.chdir(cwd)
+ os.chdir(cwd)
pert_cmd = os.path.dirname(__file__)
- pert_cmd = os.path.join(pert_cmd, 'tools')
- pert_cmd = os.path.join(pert_cmd, 'create_random_disturb.py')
+ pert_cmd = os.path.join(pert_cmd, "tools")
+ pert_cmd = os.path.join(pert_cmd, "create_random_disturb.py")
fp_style = "vasp"
poscar_name = "POSCAR"
- if jdata['init_fp_style'] == "ABACUS":
+ if jdata["init_fp_style"] == "ABACUS":
fp_style = "abacus"
poscar_name = "STRU"
- pert_cmd = 'python3 ' + pert_cmd + ' -etmax %f -ofmt %s %s %d %f > /dev/null' %(pert_box, fp_style, poscar_name, pert_numb, pert_atom)
- for ii in sys_pe :
- for jj in scale :
+ pert_cmd = (
+ sys.executable
+ + " "
+ + pert_cmd
+ + " -etmax %f -ofmt %s %s %d %f > /dev/null"
+ % (pert_box, fp_style, poscar_name, pert_numb, pert_atom)
+ )
+ for ii in sys_pe:
+ for jj in scale:
path_work = path_sp
path_work = os.path.join(path_work, ii)
- path_work = os.path.join(path_work, 'scale-%.3f' % jj)
- assert(os.path.isdir(path_work))
+ path_work = os.path.join(path_work, "scale-%.3f" % jj)
+ assert os.path.isdir(path_work)
os.chdir(path_work)
- sp.check_call(pert_cmd, shell = True)
- for kk in range(pert_numb) :
+ sp.check_call(pert_cmd, shell=True)
+ for kk in range(pert_numb):
if fp_style == "vasp":
- pos_in = 'POSCAR%d.vasp' % (kk+1)
+ pos_in = "POSCAR%d.vasp" % (kk + 1)
elif fp_style == "abacus":
- pos_in = 'STRU%d.abacus' % (kk+1)
- dir_out = '%06d' % (kk+1)
+ pos_in = "STRU%d.abacus" % (kk + 1)
+ dir_out = "%06d" % (kk + 1)
create_path(dir_out)
if fp_style == "vasp":
- pos_out = os.path.join(dir_out, 'POSCAR')
+ pos_out = os.path.join(dir_out, "POSCAR")
elif fp_style == "abacus":
- pos_out = os.path.join(dir_out, 'STRU')
+ pos_out = os.path.join(dir_out, "STRU")
if not from_poscar:
if fp_style == "vasp":
poscar_shuffle(pos_in, pos_out)
@@ -734,21 +799,29 @@ def pert_scaled(jdata) :
stru_in = get_abacus_STRU(pos_in)
stru_out = shuffle_stru_data(stru_in)
with open(pos_out, "w") as fp:
- fp.write(make_abacus_scf_stru(stru_out, pp_file, orb_file_names, dpks_descriptor_name))
- else :
+ fp.write(
+ make_abacus_scf_stru(
+ stru_out,
+ pp_file,
+ orb_file_names,
+ dpks_descriptor_name,
+ type_map=jdata["elements"],
+ )
+ )
+ else:
shutil.copy2(pos_in, pos_out)
os.remove(pos_in)
kk = -1
if fp_style == "vasp":
- pos_in = 'POSCAR'
+ pos_in = "POSCAR"
elif fp_style == "abacus":
- pos_in = 'STRU'
- dir_out = '%06d' % (kk+1)
+ pos_in = "STRU"
+ dir_out = "%06d" % (kk + 1)
create_path(dir_out)
if fp_style == "vasp":
- pos_out = os.path.join(dir_out, 'POSCAR')
+ pos_out = os.path.join(dir_out, "POSCAR")
elif fp_style == "abacus":
- pos_out = os.path.join(dir_out, 'STRU')
+ pos_out = os.path.join(dir_out, "STRU")
if not from_poscar:
if fp_style == "vasp":
poscar_shuffle(pos_in, pos_out)
@@ -756,328 +829,353 @@ def pert_scaled(jdata) :
stru_in = get_abacus_STRU(pos_in)
stru_out = shuffle_stru_data(stru_in)
with open(pos_out, "w") as fp:
- fp.write(make_abacus_scf_stru(stru_out, pp_file, orb_file_names, dpks_descriptor_name))
- else :
+ fp.write(
+ make_abacus_scf_stru(
+ stru_out,
+ pp_file,
+ orb_file_names,
+ dpks_descriptor_name,
+ type_map=jdata["elements"],
+ )
+ )
+ else:
shutil.copy2(pos_in, pos_out)
os.chdir(cwd)
-def make_vasp_md(jdata, mdata) :
- out_dir = jdata['out_dir']
- potcars = jdata['potcars']
- scale = jdata['scale']
- pert_numb = jdata['pert_numb']
- md_nstep = jdata['md_nstep']
+
+def make_vasp_md(jdata, mdata):
+ out_dir = jdata["out_dir"]
+ potcars = jdata["potcars"]
+ scale = jdata["scale"]
+ pert_numb = jdata["pert_numb"]
+ md_nstep = jdata["md_nstep"]
cwd = os.getcwd()
path_ps = os.path.join(out_dir, global_dirname_03)
path_ps = os.path.abspath(path_ps)
- assert(os.path.isdir(path_ps))
+ assert os.path.isdir(path_ps)
os.chdir(path_ps)
- sys_ps = glob.glob('sys-*')
+ sys_ps = glob.glob("sys-*")
sys_ps.sort()
- os.chdir(cwd)
+ os.chdir(cwd)
path_md = os.path.join(out_dir, global_dirname_04)
path_md = os.path.abspath(path_md)
create_path(path_md)
- shutil.copy2(jdata['md_incar'],
- os.path.join(path_md, 'INCAR'))
- out_potcar = os.path.join(path_md, 'POTCAR')
- with open(out_potcar, 'w') as outfile:
+ shutil.copy2(jdata["md_incar"], os.path.join(path_md, "INCAR"))
+ out_potcar = os.path.join(path_md, "POTCAR")
+ with open(out_potcar, "w") as outfile:
for fname in potcars:
with open(fname) as infile:
outfile.write(infile.read())
os.chdir(path_md)
os.chdir(cwd)
-
-
- for ii in sys_ps :
- for jj in scale :
- for kk in range(pert_numb+1) :
+ for ii in sys_ps:
+ for jj in scale:
+ for kk in range(pert_numb + 1):
path_work = path_md
path_work = os.path.join(path_work, ii)
path_work = os.path.join(path_work, "scale-%.3f" % jj)
path_work = os.path.join(path_work, "%06d" % kk)
create_path(path_work)
- os.chdir(path_work)
+ os.chdir(path_work)
path_pos = path_ps
path_pos = os.path.join(path_pos, ii)
path_pos = os.path.join(path_pos, "scale-%.3f" % jj)
path_pos = os.path.join(path_pos, "%06d" % kk)
- init_pos = os.path.join(path_pos, 'POSCAR')
- shutil.copy2 (init_pos, 'POSCAR')
- file_incar = os.path.join(path_md, 'INCAR')
- file_potcar = os.path.join(path_md, 'POTCAR')
+ init_pos = os.path.join(path_pos, "POSCAR")
+ shutil.copy2(init_pos, "POSCAR")
+ file_incar = os.path.join(path_md, "INCAR")
+ file_potcar = os.path.join(path_md, "POTCAR")
try:
- os.symlink(os.path.relpath(file_incar), 'INCAR')
+ os.symlink(os.path.relpath(file_incar), "INCAR")
except FileExistsError:
pass
try:
- os.symlink(os.path.relpath(file_potcar), 'POTCAR')
+ os.symlink(os.path.relpath(file_potcar), "POTCAR")
except FileExistsError:
pass
is_cvasp = False
- if 'cvasp' in mdata['fp_resources'].keys():
- is_cvasp = mdata['fp_resources']['cvasp']
+ if "cvasp" in mdata["fp_resources"].keys():
+ is_cvasp = mdata["fp_resources"]["cvasp"]
if is_cvasp:
- cvasp_file = os.path.join(ROOT_PATH, 'generator/lib/cvasp.py')
- shutil.copyfile(cvasp_file, 'cvasp.py')
-
+ cvasp_file = os.path.join(ROOT_PATH, "generator/lib/cvasp.py")
+ shutil.copyfile(cvasp_file, "cvasp.py")
+
os.chdir(cwd)
-
- symlink_user_forward_files(mdata=mdata, task_type="fp",
- work_path=os.path.join(os.path.basename(out_dir),global_dirname_04),
- task_format= {"fp" :"sys-*/scale*/00*"})
-
-def make_abacus_md(jdata, mdata) :
- md_incar = jdata['md_incar']
- standard_incar = get_abacus_input_parameters(md_incar) # a dictionary in which all of the values are strings
- #assert("md_kpt" in jdata or "kspacing" in standard_incar or "gamma_only" in standard_incar) \
+
+ symlink_user_forward_files(
+ mdata=mdata,
+ task_type="fp",
+ work_path=os.path.join(os.path.basename(out_dir), global_dirname_04),
+ task_format={"fp": "sys-*/scale*/00*"},
+ )
+
+
+def make_abacus_md(jdata, mdata):
+ md_incar = jdata["md_incar"]
+ standard_incar = get_abacus_input_parameters(
+ md_incar
+ ) # a dictionary in which all of the values are strings
+ # assert("md_kpt" in jdata or "kspacing" in standard_incar or "gamma_only" in standard_incar) \
# "Cannot find any k-points information."
if "kspacing" not in standard_incar:
if "gamma_only" in standard_incar:
- if type(standard_incar["gamma_only"])==str:
+ if type(standard_incar["gamma_only"]) == str:
standard_incar["gamma_only"] = int(eval(standard_incar["gamma_only"]))
if standard_incar["gamma_only"] == 0:
if "md_kpt" not in jdata:
raise RuntimeError("Cannot find any k-points information.")
else:
- md_kpt_path = jdata['md_kpt']
- assert(os.path.isfile(md_kpt_path)), "file %s should exists" % md_kpt_path
+ md_kpt_path = jdata["md_kpt"]
+ assert os.path.isfile(md_kpt_path), (
+ "file %s should exists" % md_kpt_path
+ )
else:
- ret_kpt = make_abacus_scf_kpt({"k_points":[1,1,1,0,0,0]})
+ ret_kpt = make_abacus_scf_kpt({"k_points": [1, 1, 1, 0, 0, 0]})
else:
if "md_kpt" not in jdata:
raise RuntimeError("Cannot find any k-points information.")
else:
- md_kpt_path = jdata['md_kpt']
- assert(os.path.isfile(md_kpt_path)), "file %s should exists" % md_kpt_path
+ md_kpt_path = jdata["md_kpt"]
+ assert os.path.isfile(md_kpt_path), (
+ "file %s should exists" % md_kpt_path
+ )
- out_dir = jdata['out_dir']
- potcars = jdata['potcars']
- scale = jdata['scale']
- pert_numb = jdata['pert_numb']
- md_nstep = jdata['md_nstep']
+ out_dir = jdata["out_dir"]
+ potcars = jdata["potcars"]
+ scale = jdata["scale"]
+ pert_numb = jdata["pert_numb"]
+ md_nstep = jdata["md_nstep"]
cwd = os.getcwd()
path_ps = os.path.join(out_dir, global_dirname_03)
path_ps = os.path.abspath(path_ps)
- assert(os.path.isdir(path_ps))
+ assert os.path.isdir(path_ps)
os.chdir(path_ps)
- sys_ps = glob.glob('sys-*')
+ sys_ps = glob.glob("sys-*")
sys_ps.sort()
- os.chdir(cwd)
+ os.chdir(cwd)
path_md = os.path.join(out_dir, global_dirname_04)
path_md = os.path.abspath(path_md)
create_path(path_md)
- shutil.copy2(jdata['md_incar'],
- os.path.join(path_md, 'INPUT'))
+ shutil.copy2(jdata["md_incar"], os.path.join(path_md, "INPUT"))
if "kspacing" not in standard_incar:
- if "gamma_only" in standard_incar and standard_incar["gamma_only"]==1:
- with open(os.path.join(path_md,"KPT"),"w") as fp:
+ if "gamma_only" in standard_incar and standard_incar["gamma_only"] == 1:
+ with open(os.path.join(path_md, "KPT"), "w") as fp:
fp.write(ret_kpt)
else:
- shutil.copy2(jdata['md_kpt'],os.path.join(path_md, 'KPT'))
+ shutil.copy2(jdata["md_kpt"], os.path.join(path_md, "KPT"))
orb_file_names = None
orb_file_abspath = None
dpks_descriptor_name = None
dpks_descriptor_abspath = None
dpks_model_name = None
dpks_model_abspath = None
- if 'orb_files' in jdata:
- orb_file_names = [os.path.basename(a) for a in jdata['orb_files']]
- orb_file_abspath = [os.path.abspath(a) for a in jdata['orb_files']]
+ if "orb_files" in jdata:
+ orb_file_names = [os.path.basename(a) for a in jdata["orb_files"]]
+ orb_file_abspath = [os.path.abspath(a) for a in jdata["orb_files"]]
for iorb, orb_file in enumerate(orb_file_names):
- shutil.copy2(orb_file_abspath[iorb],
- os.path.join(path_md, orb_file))
- if 'dpks_descriptor' in jdata:
- dpks_descriptor_name = os.path.basename(jdata['dpks_descriptor'])
- dpks_descriptor_abspath = os.path.abspath(jdata['dpks_descriptor'])
- shutil.copy2(dpks_descriptor_abspath,
- os.path.join(path_md, dpks_descriptor_name))
- if 'dpks_model' in jdata:
- dpks_model_name = os.path.basename(jdata['dpks_model'])
- dpks_model_abspath = os.path.abspath(jdata['dpks_model'])
- shutil.copy2(dpks_model_abspath,
- os.path.join(path_md, dpks_model_name))
- for pp_file in jdata['potcars']:
- shutil.copy2(pp_file,
- os.path.join(path_md, os.path.basename(pp_file)))
+ shutil.copy2(orb_file_abspath[iorb], os.path.join(path_md, orb_file))
+ if "dpks_descriptor" in jdata:
+ dpks_descriptor_name = os.path.basename(jdata["dpks_descriptor"])
+ dpks_descriptor_abspath = os.path.abspath(jdata["dpks_descriptor"])
+ shutil.copy2(
+ dpks_descriptor_abspath, os.path.join(path_md, dpks_descriptor_name)
+ )
+ if "dpks_model" in jdata:
+ dpks_model_name = os.path.basename(jdata["dpks_model"])
+ dpks_model_abspath = os.path.abspath(jdata["dpks_model"])
+ shutil.copy2(dpks_model_abspath, os.path.join(path_md, dpks_model_name))
+ for pp_file in jdata["potcars"]:
+ shutil.copy2(pp_file, os.path.join(path_md, os.path.basename(pp_file)))
os.chdir(path_md)
os.chdir(cwd)
-
-
- for ii in sys_ps :
- for jj in scale :
- for kk in range(pert_numb+1) :
+ for ii in sys_ps:
+ for jj in scale:
+ for kk in range(pert_numb + 1):
path_work = path_md
path_work = os.path.join(path_work, ii)
path_work = os.path.join(path_work, "scale-%.3f" % jj)
path_work = os.path.join(path_work, "%06d" % kk)
create_path(path_work)
- os.chdir(path_work)
+ os.chdir(path_work)
path_pos = path_ps
path_pos = os.path.join(path_pos, ii)
path_pos = os.path.join(path_pos, "scale-%.3f" % jj)
path_pos = os.path.join(path_pos, "%06d" % kk)
- init_pos = os.path.join(path_pos, 'STRU')
+ init_pos = os.path.join(path_pos, "STRU")
if "kspacing" not in standard_incar:
- file_kpt = os.path.join(path_md, 'KPT')
- shutil.copy2 (init_pos, 'STRU')
- file_incar = os.path.join(path_md, 'INPUT')
+ file_kpt = os.path.join(path_md, "KPT")
+ shutil.copy2(init_pos, "STRU")
+ file_incar = os.path.join(path_md, "INPUT")
try:
- os.symlink(os.path.relpath(file_incar), 'INPUT')
+ os.symlink(os.path.relpath(file_incar), "INPUT")
if "kspacing" not in standard_incar:
- os.symlink(os.path.relpath(file_kpt), 'KPT')
+ os.symlink(os.path.relpath(file_kpt), "KPT")
except FileExistsError:
pass
try:
- for pp_file in [os.path.basename(a) for a in jdata['potcars']]:
- os.symlink(os.path.relpath(os.path.join(path_md, pp_file)), pp_file)
- if 'orb_files' in jdata:
+ for pp_file in [os.path.basename(a) for a in jdata["potcars"]]:
+ os.symlink(
+ os.path.relpath(os.path.join(path_md, pp_file)), pp_file
+ )
+ if "orb_files" in jdata:
for orb_file in orb_file_names:
- os.symlink(os.path.relpath(os.path.join(path_md, orb_file)), orb_file)
- if 'dpks_model' in jdata:
- os.symlink(os.path.relpath(os.path.join(path_md, dpks_model_name)), dpks_model_name)
- if 'dpks_descriptor' in jdata:
- os.symlink(os.path.relpath(os.path.join(path_md, dpks_descriptor_name)), dpks_descriptor_name)
+ os.symlink(
+ os.path.relpath(os.path.join(path_md, orb_file)),
+ orb_file,
+ )
+ if "dpks_model" in jdata:
+ os.symlink(
+ os.path.relpath(os.path.join(path_md, dpks_model_name)),
+ dpks_model_name,
+ )
+ if "dpks_descriptor" in jdata:
+ os.symlink(
+ os.path.relpath(
+ os.path.join(path_md, dpks_descriptor_name)
+ ),
+ dpks_descriptor_name,
+ )
except FileExistsError:
pass
-
+
os.chdir(cwd)
-
- symlink_user_forward_files(mdata=mdata, task_type="fp",
- work_path=os.path.join(os.path.basename(out_dir),global_dirname_04),
- task_format= {"fp" :"sys-*/scale*/00*"})
-
-
-def coll_vasp_md(jdata) :
- out_dir = jdata['out_dir']
- md_nstep = jdata['md_nstep']
- scale = jdata['scale']
- pert_numb = jdata['pert_numb']
- coll_ndata = jdata['coll_ndata']
+
+ symlink_user_forward_files(
+ mdata=mdata,
+ task_type="fp",
+ work_path=os.path.join(os.path.basename(out_dir), global_dirname_04),
+ task_format={"fp": "sys-*/scale*/00*"},
+ )
+
+
+def coll_vasp_md(jdata):
+ out_dir = jdata["out_dir"]
+ md_nstep = jdata["md_nstep"]
+ scale = jdata["scale"]
+ pert_numb = jdata["pert_numb"]
+ coll_ndata = jdata["coll_ndata"]
cwd = os.getcwd()
path_md = os.path.join(out_dir, global_dirname_04)
path_md = os.path.abspath(path_md)
- assert(os.path.isdir(path_md)), "md path should exists"
+ assert os.path.isdir(path_md), "md path should exists"
os.chdir(path_md)
- sys_md = glob.glob('sys-*')
+ sys_md = glob.glob("sys-*")
sys_md.sort()
- for ii in sys_md :
+ for ii in sys_md:
os.chdir(ii)
# convert outcars
valid_outcars = []
- for jj in scale :
- for kk in range(pert_numb) :
+ for jj in scale:
+ for kk in range(pert_numb):
path_work = os.path.join("scale-%.3f" % jj, "%06d" % kk)
- outcar = os.path.join(path_work, 'OUTCAR')
- #dlog.info("OUTCAR",outcar)
- if os.path.isfile(outcar) :
- #dlog.info("*"*40)
- with open(outcar, 'r') as fin:
- nforce = fin.read().count('TOTAL-FORCE')
- #dlog.info("nforce is", nforce)
- #dlog.info("md_nstep", md_nstep)
- if nforce == md_nstep :
+ outcar = os.path.join(path_work, "OUTCAR")
+ # dlog.info("OUTCAR",outcar)
+ if os.path.isfile(outcar):
+ # dlog.info("*"*40)
+ with open(outcar, "r") as fin:
+ nforce = fin.read().count("TOTAL-FORCE")
+ # dlog.info("nforce is", nforce)
+ # dlog.info("md_nstep", md_nstep)
+ if nforce == md_nstep:
valid_outcars.append(outcar)
- elif md_nstep == 0 and nforce == 1 :
+ elif md_nstep == 0 and nforce == 1:
valid_outcars.append(outcar)
else:
- dlog.info("WARNING : in directory %s nforce in OUTCAR is not equal to settings in INCAR"%(os.getcwd()))
+ dlog.info(
+ "WARNING : in directory %s nforce in OUTCAR is not equal to settings in INCAR"
+ % (os.getcwd())
+ )
arg_cvt = " "
if len(valid_outcars) == 0:
- raise RuntimeError("MD dir: %s: find no valid outcar in sys %s, "
- "check if your vasp md simulation is correctly done"
- % (path_md, ii))
+ raise RuntimeError(
+ "MD dir: %s: find no valid outcar in sys %s, "
+ "check if your vasp md simulation is correctly done" % (path_md, ii)
+ )
- flag=True
+ flag = True
if ("type_map" in jdata) and isinstance(jdata["type_map"], list):
type_map = jdata["type_map"]
else:
- type_map = None
- for oo in valid_outcars :
+ type_map = None
+ for oo in valid_outcars:
if flag:
- _sys = dpdata.LabeledSystem(oo, type_map= type_map)
- if len(_sys)>0:
- all_sys=_sys
- flag=False
+ _sys = dpdata.LabeledSystem(oo, type_map=type_map)
+ if len(_sys) > 0:
+ all_sys = _sys
+ flag = False
else:
- pass
+ pass
else:
- _sys = dpdata.LabeledSystem(oo, type_map= type_map)
- if len(_sys)>0:
- all_sys.append(_sys)
+ _sys = dpdata.LabeledSystem(oo, type_map=type_map)
+ if len(_sys) > 0:
+ all_sys.append(_sys)
# create deepmd data
- if all_sys.get_nframes() >= coll_ndata :
+ if all_sys.get_nframes() >= coll_ndata:
all_sys = all_sys.sub_system(np.arange(coll_ndata))
- all_sys.to_deepmd_raw('deepmd')
- all_sys.to_deepmd_npy('deepmd', set_size = all_sys.get_nframes())
+ all_sys.to_deepmd_raw("deepmd")
+ all_sys.to_deepmd_npy("deepmd", set_size=all_sys.get_nframes())
os.chdir(path_md)
os.chdir(cwd)
-def _vasp_check_fin (ii) :
- if os.path.isfile(os.path.join(ii, 'OUTCAR')) :
- with open(os.path.join(ii, 'OUTCAR'), 'r') as fp :
+
+def _vasp_check_fin(ii):
+ if os.path.isfile(os.path.join(ii, "OUTCAR")):
+ with open(os.path.join(ii, "OUTCAR"), "r") as fp:
content = fp.read()
- count = content.count('Elapse')
- if count != 1 :
+ count = content.count("Elapse")
+ if count != 1:
return False
- else :
+ else:
return False
return True
+
def run_vasp_relax(jdata, mdata):
- fp_command = mdata['fp_command']
- fp_group_size = mdata['fp_group_size']
- fp_resources = mdata['fp_resources']
- #machine_type = mdata['fp_machine']['machine_type']
- work_dir = os.path.join(jdata['out_dir'], global_dirname_02)
-
+ fp_command = mdata["fp_command"]
+ fp_group_size = mdata["fp_group_size"]
+ fp_resources = mdata["fp_resources"]
+ # machine_type = mdata['fp_machine']['machine_type']
+ work_dir = os.path.join(jdata["out_dir"], global_dirname_02)
+
forward_files = ["POSCAR", "INCAR", "POTCAR"]
user_forward_files = mdata.get("fp" + "_user_forward_files", [])
forward_files += [os.path.basename(file) for file in user_forward_files]
- backward_files = ["OUTCAR","CONTCAR"]
+ backward_files = ["OUTCAR", "CONTCAR"]
backward_files += mdata.get("fp" + "_user_backward_files", [])
forward_common_files = []
- if 'cvasp' in mdata['fp_resources']:
- if mdata['fp_resources']['cvasp']:
- forward_files +=['cvasp.py']
+ if "cvasp" in mdata["fp_resources"]:
+ if mdata["fp_resources"]["cvasp"]:
+ forward_files += ["cvasp.py"]
relax_tasks = glob.glob(os.path.join(work_dir, "sys-*"))
relax_tasks.sort()
- #dlog.info("work_dir",work_dir)
- #dlog.info("relax_tasks",relax_tasks)
+ # dlog.info("work_dir",work_dir)
+ # dlog.info("relax_tasks",relax_tasks)
if len(relax_tasks) == 0:
return
relax_run_tasks = relax_tasks
- #for ii in relax_tasks :
+ # for ii in relax_tasks :
# if not _vasp_check_fin(ii):
# relax_run_tasks.append(ii)
run_tasks = [os.path.basename(ii) for ii in relax_run_tasks]
- api_version = mdata.get('api_version', '0.9')
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher = make_dispatcher(mdata['fp_machine'], mdata['fp_resources'], work_dir, run_tasks, fp_group_size)
- dispatcher.run_jobs(fp_resources,
- [fp_command],
- work_dir,
- run_tasks,
- fp_group_size,
- forward_common_files,
- forward_files,
- backward_files)
-
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ api_version = mdata.get("api_version", "1.0")
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+
+ elif Version(api_version) >= Version("1.0"):
submission = make_submission(
- mdata['fp_machine'],
- mdata['fp_resources'],
+ mdata["fp_machine"],
+ mdata["fp_resources"],
commands=[fp_command],
work_path=work_dir,
run_tasks=run_tasks,
@@ -1085,95 +1183,107 @@ def run_vasp_relax(jdata, mdata):
forward_common_files=forward_common_files,
forward_files=forward_files,
backward_files=backward_files,
- outlog = 'fp.log',
- errlog = 'fp.log')
+ outlog="fp.log",
+ errlog="fp.log",
+ )
submission.run_submission()
-def coll_abacus_md(jdata) :
- out_dir = jdata['out_dir']
- md_nstep = jdata['md_nstep']
- scale = jdata['scale']
- pert_numb = jdata['pert_numb']
- coll_ndata = jdata['coll_ndata']
+
+def coll_abacus_md(jdata):
+ out_dir = jdata["out_dir"]
+ md_nstep = jdata["md_nstep"]
+ scale = jdata["scale"]
+ pert_numb = jdata["pert_numb"]
+ coll_ndata = jdata["coll_ndata"]
cwd = os.getcwd()
path_md = os.path.join(out_dir, global_dirname_04)
path_md = os.path.abspath(path_md)
- assert(os.path.isdir(path_md)), "md path should exists"
+ assert os.path.isdir(path_md), "md path should exists"
os.chdir(path_md)
- sys_md = glob.glob('sys-*')
+ sys_md = glob.glob("sys-*")
sys_md.sort()
- for ii in sys_md :
+ for ii in sys_md:
os.chdir(ii)
# convert outcars
valid_outcars = []
- for jj in scale :
- for kk in range(pert_numb+1) :
+ for jj in scale:
+ for kk in range(pert_numb + 1):
path_work = os.path.join("scale-%.3f" % jj, "%06d" % kk)
- print("path_work = %s" %path_work)
- #outcar = os.path.join(path_work, 'OUT.ABACUS/')
+ print("path_work = %s" % path_work)
+ # outcar = os.path.join(path_work, 'OUT.ABACUS/')
outcar = path_work
- #dlog.info("OUTCAR",outcar)
- if os.path.exists(os.path.join(outcar, "OUT.ABACUS/running_md.log")) :
+ # dlog.info("OUTCAR",outcar)
+ if os.path.exists(os.path.join(outcar, "OUT.ABACUS/running_md.log")):
with open(os.path.join(outcar, "OUT.ABACUS/running_md.log")) as fp:
if "!FINAL_ETOT_IS" in fp.read():
valid_outcars.append(outcar)
print(outcar)
else:
- dlog.info("WARNING : file %s does not have !FINAL_ETOT_IS note. MD simulation is not completed normally."%os.path.join(outcar, "OUT.ABACUS/running_md.log"))
+ dlog.info(
+ "WARNING : file %s does not have !FINAL_ETOT_IS note. MD simulation is not completed normally."
+ % os.path.join(outcar, "OUT.ABACUS/running_md.log")
+ )
else:
- dlog.info("WARNING : in directory %s NO running_md.log file found."%(os.getcwd()))
+ dlog.info(
+ "WARNING : in directory %s NO running_md.log file found."
+ % (os.getcwd())
+ )
arg_cvt = " "
if len(valid_outcars) == 0:
- raise RuntimeError("MD dir: %s: find no valid OUT.ABACUS in sys %s, "
- "check if your abacus md simulation is correctly done."
- % (path_md, ii))
+ raise RuntimeError(
+ "MD dir: %s: find no valid OUT.ABACUS in sys %s, "
+ "check if your abacus md simulation is correctly done." % (path_md, ii)
+ )
- flag=True
+ flag = True
if ("type_map" in jdata) and isinstance(jdata["type_map"], list):
type_map = jdata["type_map"]
else:
- type_map = None
- for oo in valid_outcars :
+ type_map = None
+ for oo in valid_outcars:
if flag:
- _sys = dpdata.LabeledSystem(oo, type_map= type_map, fmt='abacus/md')
- if len(_sys)>0:
- all_sys=_sys
- flag=False
+ _sys = dpdata.LabeledSystem(oo, type_map=type_map, fmt="abacus/md")
+ if len(_sys) > 0:
+ all_sys = _sys
+ flag = False
else:
- pass
+ pass
else:
- _sys = dpdata.LabeledSystem(oo, type_map= type_map, fmt='abacus/md')
- if len(_sys)>0:
- all_sys.append(_sys)
+ _sys = dpdata.LabeledSystem(oo, type_map=type_map, fmt="abacus/md")
+ if len(_sys) > 0:
+ all_sys.append(_sys)
# create deepmd data
- if all_sys.get_nframes() >= coll_ndata :
+ if all_sys.get_nframes() >= coll_ndata:
all_sys = all_sys.sub_system(np.arange(coll_ndata))
print(all_sys.get_nframes())
- all_sys.to_deepmd_raw('deepmd')
- all_sys.to_deepmd_npy('deepmd', set_size = all_sys.get_nframes())
+ all_sys.to_deepmd_raw("deepmd")
+ all_sys.to_deepmd_npy("deepmd", set_size=all_sys.get_nframes())
os.chdir(path_md)
os.chdir(cwd)
+
def run_abacus_relax(jdata, mdata):
- fp_command = mdata['fp_command']
- fp_group_size = mdata['fp_group_size']
- fp_resources = mdata['fp_resources']
- #machine_type = mdata['fp_machine']['machine_type']
- work_dir = os.path.join(jdata['out_dir'], global_dirname_02)
+ fp_command = mdata["fp_command"]
+ fp_group_size = mdata["fp_group_size"]
+ fp_resources = mdata["fp_resources"]
+ # machine_type = mdata['fp_machine']['machine_type']
+ work_dir = os.path.join(jdata["out_dir"], global_dirname_02)
pp_files = [os.path.basename(a) for a in jdata["potcars"]]
orb_file_names = []
dpks_descriptor_name = []
dpks_model_name = []
- if 'orb_files' in jdata:
- orb_file_names = [os.path.basename(a) for a in jdata['orb_files']]
- if 'dpks_descriptor' in jdata:
- dpks_descriptor_name = [os.path.basename(jdata['dpks_descriptor'])]
- if 'dpks_model' in jdata:
- dpks_model_name = [os.path.basename(jdata['dpks_model'])]
- relax_incar = jdata['relax_incar']
- standard_incar = get_abacus_input_parameters(relax_incar) # a dictionary in which all of the values are strings
+ if "orb_files" in jdata:
+ orb_file_names = [os.path.basename(a) for a in jdata["orb_files"]]
+ if "dpks_descriptor" in jdata:
+ dpks_descriptor_name = [os.path.basename(jdata["dpks_descriptor"])]
+ if "dpks_model" in jdata:
+ dpks_model_name = [os.path.basename(jdata["dpks_model"])]
+ relax_incar = jdata["relax_incar"]
+ standard_incar = get_abacus_input_parameters(
+ relax_incar
+ ) # a dictionary in which all of the values are strings
forward_files = ["STRU", "INPUT"]
if "kspacing" not in standard_incar:
forward_files = ["STRU", "INPUT", "KPT"]
@@ -1185,35 +1295,27 @@ def run_abacus_relax(jdata, mdata):
forward_common_files = []
relax_tasks = glob.glob(os.path.join(work_dir, "sys-*"))
relax_tasks.sort()
- #dlog.info("work_dir",work_dir)
- #dlog.info("relax_tasks",relax_tasks)
+ # dlog.info("work_dir",work_dir)
+ # dlog.info("relax_tasks",relax_tasks)
if len(relax_tasks) == 0:
return
relax_run_tasks = relax_tasks
- #for ii in relax_tasks :
+ # for ii in relax_tasks :
# if not _vasp_check_fin(ii):
# relax_run_tasks.append(ii)
run_tasks = [os.path.basename(ii) for ii in relax_run_tasks]
- api_version = mdata.get('api_version', '0.9')
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher = make_dispatcher(mdata['fp_machine'], mdata['fp_resources'], work_dir, run_tasks, fp_group_size)
- dispatcher.run_jobs(fp_resources,
- [fp_command],
- work_dir,
- run_tasks,
- fp_group_size,
- forward_common_files,
- forward_files,
- backward_files)
-
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ api_version = mdata.get("api_version", "1.0")
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+
+ elif Version(api_version) >= Version("1.0"):
submission = make_submission(
- mdata['fp_machine'],
- mdata['fp_resources'],
+ mdata["fp_machine"],
+ mdata["fp_resources"],
commands=[fp_command],
work_path=work_dir,
run_tasks=run_tasks,
@@ -1221,19 +1323,21 @@ def run_abacus_relax(jdata, mdata):
forward_common_files=forward_common_files,
forward_files=forward_files,
backward_files=backward_files,
- outlog = 'fp.log',
- errlog = 'fp.log')
+ outlog="fp.log",
+ errlog="fp.log",
+ )
submission.run_submission()
+
def run_vasp_md(jdata, mdata):
- fp_command = mdata['fp_command']
- fp_group_size = mdata['fp_group_size']
- fp_resources = mdata['fp_resources']
- #machine_type = mdata['fp_machine']['machine_type']
- work_dir = os.path.join(jdata['out_dir'], global_dirname_04)
- scale = jdata['scale']
- pert_numb = jdata['pert_numb']
- md_nstep = jdata['md_nstep']
+ fp_command = mdata["fp_command"]
+ fp_group_size = mdata["fp_group_size"]
+ fp_resources = mdata["fp_resources"]
+ # machine_type = mdata['fp_machine']['machine_type']
+ work_dir = os.path.join(jdata["out_dir"], global_dirname_04)
+ scale = jdata["scale"]
+ pert_numb = jdata["pert_numb"]
+ md_nstep = jdata["md_nstep"]
forward_files = ["POSCAR", "INCAR", "POTCAR"]
user_forward_files = mdata.get("fp" + "_user_forward_files", [])
@@ -1241,46 +1345,38 @@ def run_vasp_md(jdata, mdata):
backward_files = ["OUTCAR"]
backward_files += mdata.get("fp" + "_user_backward_files", [])
forward_common_files = []
- if 'cvasp' in mdata['fp_resources']:
- if mdata['fp_resources']['cvasp']:
- forward_files +=['cvasp.py']
+ if "cvasp" in mdata["fp_resources"]:
+ if mdata["fp_resources"]["cvasp"]:
+ forward_files += ["cvasp.py"]
path_md = work_dir
path_md = os.path.abspath(path_md)
cwd = os.getcwd()
- assert(os.path.isdir(path_md)), "md path should exists"
- md_tasks = glob.glob(os.path.join(work_dir, 'sys-*/scale*/00*'))
+ assert os.path.isdir(path_md), "md path should exists"
+ md_tasks = glob.glob(os.path.join(work_dir, "sys-*/scale*/00*"))
md_tasks.sort()
if len(md_tasks) == 0:
return
md_run_tasks = md_tasks
- #for ii in md_tasks :
+ # for ii in md_tasks :
# if not _vasp_check_fin(ii):
# md_run_tasks.append(ii)
- run_tasks = [ii.replace(work_dir+"/", "") for ii in md_run_tasks]
- #dlog.info("md_work_dir", work_dir)
- #dlog.info("run_tasks",run_tasks)
- api_version = mdata.get('api_version', '0.9')
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher = make_dispatcher(mdata['fp_machine'], mdata['fp_resources'], work_dir, run_tasks, fp_group_size)
- dispatcher.run_jobs(fp_resources,
- [fp_command],
- work_dir,
- run_tasks,
- fp_group_size,
- forward_common_files,
- forward_files,
- backward_files)
-
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ run_tasks = [ii.replace(work_dir + "/", "") for ii in md_run_tasks]
+ # dlog.info("md_work_dir", work_dir)
+ # dlog.info("run_tasks",run_tasks)
+ api_version = mdata.get("api_version", "1.0")
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+
+ elif Version(api_version) >= Version("1.0"):
submission = make_submission(
- mdata['fp_machine'],
- mdata['fp_resources'],
+ mdata["fp_machine"],
+ mdata["fp_resources"],
commands=[fp_command],
work_path=work_dir,
run_tasks=run_tasks,
@@ -1288,36 +1384,40 @@ def run_vasp_md(jdata, mdata):
forward_common_files=forward_common_files,
forward_files=forward_files,
backward_files=backward_files,
- outlog = 'fp.log',
- errlog = 'fp.log')
+ outlog="fp.log",
+ errlog="fp.log",
+ )
submission.run_submission()
+
def run_abacus_md(jdata, mdata):
- fp_command = mdata['fp_command']
- fp_group_size = mdata['fp_group_size']
- fp_resources = mdata['fp_resources']
- #machine_type = mdata['fp_machine']['machine_type']
- work_dir = os.path.join(jdata['out_dir'], global_dirname_04)
- scale = jdata['scale']
- pert_numb = jdata['pert_numb']
- md_nstep = jdata['md_nstep']
+ fp_command = mdata["fp_command"]
+ fp_group_size = mdata["fp_group_size"]
+ fp_resources = mdata["fp_resources"]
+ # machine_type = mdata['fp_machine']['machine_type']
+ work_dir = os.path.join(jdata["out_dir"], global_dirname_04)
+ scale = jdata["scale"]
+ pert_numb = jdata["pert_numb"]
+ md_nstep = jdata["md_nstep"]
orb_file_names = []
dpks_descriptor_name = []
dpks_model_name = []
- if 'orb_files' in jdata:
- orb_file_names = [os.path.basename(a) for a in jdata['orb_files']]
- if 'dpks_descriptor' in jdata:
- dpks_descriptor_name = [os.path.basename(jdata['dpks_descriptor'])]
- if 'dpks_model' in jdata:
- dpks_model_name = [os.path.basename(jdata['dpks_model'])]
- md_incar = jdata['md_incar']
- standard_incar = get_abacus_input_parameters(md_incar) # a dictionary in which all of the values are strings
+ if "orb_files" in jdata:
+ orb_file_names = [os.path.basename(a) for a in jdata["orb_files"]]
+ if "dpks_descriptor" in jdata:
+ dpks_descriptor_name = [os.path.basename(jdata["dpks_descriptor"])]
+ if "dpks_model" in jdata:
+ dpks_model_name = [os.path.basename(jdata["dpks_model"])]
+ md_incar = jdata["md_incar"]
+ standard_incar = get_abacus_input_parameters(
+ md_incar
+ ) # a dictionary in which all of the values are strings
forward_files = ["STRU", "INPUT"]
if "kspacing" not in standard_incar:
forward_files = ["STRU", "INPUT", "KPT"]
forward_files += orb_file_names + dpks_descriptor_name + dpks_model_name
- for pp_file in [os.path.basename(a) for a in jdata['potcars']]:
+ for pp_file in [os.path.basename(a) for a in jdata["potcars"]]:
forward_files.append(pp_file)
user_forward_files = mdata.get("fp" + "_user_forward_files", [])
forward_files += [os.path.basename(file) for file in user_forward_files]
@@ -1328,39 +1428,31 @@ def run_abacus_md(jdata, mdata):
path_md = work_dir
path_md = os.path.abspath(path_md)
cwd = os.getcwd()
- assert(os.path.isdir(path_md)), "md path should exists"
- md_tasks = glob.glob(os.path.join(work_dir, 'sys-*/scale*/00*'))
+ assert os.path.isdir(path_md), "md path should exists"
+ md_tasks = glob.glob(os.path.join(work_dir, "sys-*/scale*/00*"))
md_tasks.sort()
if len(md_tasks) == 0:
return
md_run_tasks = md_tasks
- #for ii in md_tasks :
+ # for ii in md_tasks :
# if not _vasp_check_fin(ii):
# md_run_tasks.append(ii)
- run_tasks = [ii.replace(work_dir+"/", "") for ii in md_run_tasks]
- #dlog.info("md_work_dir", work_dir)
- #dlog.info("run_tasks",run_tasks)
- api_version = mdata.get('api_version', '0.9')
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher = make_dispatcher(mdata['fp_machine'], mdata['fp_resources'], work_dir, run_tasks, fp_group_size)
- dispatcher.run_jobs(fp_resources,
- [fp_command],
- work_dir,
- run_tasks,
- fp_group_size,
- forward_common_files,
- forward_files,
- backward_files)
-
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ run_tasks = [ii.replace(work_dir + "/", "") for ii in md_run_tasks]
+ # dlog.info("md_work_dir", work_dir)
+ # dlog.info("run_tasks",run_tasks)
+ api_version = mdata.get("api_version", "1.0")
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+
+ elif Version(api_version) >= Version("1.0"):
submission = make_submission(
- mdata['fp_machine'],
- mdata['fp_resources'],
+ mdata["fp_machine"],
+ mdata["fp_resources"],
commands=[fp_command],
work_path=work_dir,
run_tasks=run_tasks,
@@ -1368,144 +1460,157 @@ def run_abacus_md(jdata, mdata):
forward_common_files=forward_common_files,
forward_files=forward_files,
backward_files=backward_files,
- outlog = 'fp.log',
- errlog = 'fp.log')
+ outlog="fp.log",
+ errlog="fp.log",
+ )
submission.run_submission()
-def gen_init_bulk(args) :
+
+def gen_init_bulk(args):
try:
- import ruamel
- from monty.serialization import loadfn,dumpfn
- warnings.simplefilter('ignore', ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
- jdata=loadfn(args.PARAM)
- if args.MACHINE is not None:
- mdata=loadfn(args.MACHINE)
+ import ruamel
+ from monty.serialization import dumpfn, loadfn
+
+ warnings.simplefilter("ignore", ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
+ jdata = loadfn(args.PARAM)
+ if args.MACHINE is not None:
+ mdata = loadfn(args.MACHINE)
except Exception:
- with open (args.PARAM, 'r') as fp :
- jdata = json.load (fp)
- if args.MACHINE is not None:
- with open (args.MACHINE, "r") as fp:
- mdata = json.load(fp)
+ with open(args.PARAM, "r") as fp:
+ jdata = json.load(fp)
+ if args.MACHINE is not None:
+ with open(args.MACHINE, "r") as fp:
+ mdata = json.load(fp)
if args.MACHINE is not None:
- # Selecting a proper machine
- mdata = convert_mdata(mdata, ["fp"])
- #disp = make_dispatcher(mdata["fp_machine"])
+ # Selecting a proper machine
+ mdata = convert_mdata(mdata, ["fp"])
+ # disp = make_dispatcher(mdata["fp_machine"])
# Decide work path
out_dir = out_dir_name(jdata)
- jdata['out_dir'] = out_dir
- dlog.info ("# working dir %s" % out_dir)
+ jdata["out_dir"] = out_dir
+ dlog.info("# working dir %s" % out_dir)
# Decide whether to use a given poscar
- from_poscar = jdata.get('from_poscar', False)
+ from_poscar = jdata.get("from_poscar", False)
# Verify md_nstep
md_nstep_jdata = jdata["md_nstep"]
- if 'init_fp_style' not in jdata:
- jdata['init_fp_style'] = "VASP"
+ if "init_fp_style" not in jdata:
+ jdata["init_fp_style"] = "VASP"
try:
- md_incar = jdata['md_incar']
+ md_incar = jdata["md_incar"]
if os.path.isfile(md_incar):
- if jdata['init_fp_style'] == "VASP":
+ if jdata["init_fp_style"] == "VASP":
standard_incar = incar_upper(Incar.from_file(md_incar))
nsw_flag = False
if "NSW" in standard_incar:
- nsw_flag = True
- nsw_steps = standard_incar['NSW']
- #dlog.info("nsw_steps is", nsw_steps)
- #dlog.info("md_nstep_jdata is", md_nstep_jdata)
- elif jdata['init_fp_style'] == "ABACUS":
- standard_incar = get_abacus_input_parameters(md_incar) # a dictionary in which all of the values are strings
+ nsw_flag = True
+ nsw_steps = standard_incar["NSW"]
+ # dlog.info("nsw_steps is", nsw_steps)
+ # dlog.info("md_nstep_jdata is", md_nstep_jdata)
+ elif jdata["init_fp_style"] == "ABACUS":
+ standard_incar = get_abacus_input_parameters(
+ md_incar
+ ) # a dictionary in which all of the values are strings
nsw_flag = False
if "md_nstep" in standard_incar:
- nsw_flag = True
- nsw_steps = int(standard_incar['md_nstep'])
+ nsw_flag = True
+ nsw_steps = int(standard_incar["md_nstep"])
if nsw_flag:
- if (nsw_steps != md_nstep_jdata):
- dlog.info("WARNING: your set-up for MD steps in PARAM and md_incar are not consistent!")
- dlog.info("MD steps in PARAM is %d"%(md_nstep_jdata))
- dlog.info("MD steps in md_incar is %d"%(nsw_steps))
+ if nsw_steps != md_nstep_jdata:
+ dlog.info(
+ "WARNING: your set-up for MD steps in PARAM and md_incar are not consistent!"
+ )
+ dlog.info("MD steps in PARAM is %d" % (md_nstep_jdata))
+ dlog.info("MD steps in md_incar is %d" % (nsw_steps))
dlog.info("DP-GEN will use settings in md_incar!")
- jdata['md_nstep'] = nsw_steps
+ jdata["md_nstep"] = nsw_steps
except KeyError:
pass
- ## correct element name
+ ## correct element name
temp_elements = []
- for ele in jdata['elements']:
+ for ele in jdata["elements"]:
temp_elements.append(ele[0].upper() + ele[1:])
- jdata['elements'] = temp_elements
- dlog.info("Elements are %s"% ' '.join(jdata['elements']))
+ jdata["elements"] = temp_elements
+ dlog.info("Elements are %s" % " ".join(jdata["elements"]))
- ## Iteration
- stage_list = [int(i) for i in jdata['stages']]
+ ## Iteration
+ stage_list = [int(i) for i in jdata["stages"]]
for stage in stage_list:
- if stage == 1 :
+ if stage == 1:
dlog.info("Current stage is 1, relax")
create_path(out_dir)
- shutil.copy2(args.PARAM, os.path.join(out_dir, 'param.json'))
- if from_poscar :
- if jdata['init_fp_style'] == "VASP":
+ shutil.copy2(args.PARAM, os.path.join(out_dir, "param.json"))
+ if from_poscar:
+ if jdata["init_fp_style"] == "VASP":
make_super_cell_poscar(jdata)
- elif jdata['init_fp_style'] == "ABACUS":
+ elif jdata["init_fp_style"] == "ABACUS":
make_super_cell_STRU(jdata)
- else :
- if jdata['init_fp_style'] == "VASP":
+ else:
+ if jdata["init_fp_style"] == "VASP":
make_unit_cell(jdata)
make_super_cell(jdata)
place_element(jdata)
- elif jdata['init_fp_style'] == "ABACUS":
+ elif jdata["init_fp_style"] == "ABACUS":
stru_data = make_unit_cell_ABACUS(jdata)
supercell_stru = make_super_cell_ABACUS(jdata, stru_data)
place_element_ABACUS(jdata, supercell_stru)
if args.MACHINE is not None:
- if jdata['init_fp_style'] == "VASP":
- make_vasp_relax(jdata, mdata)
- run_vasp_relax(jdata, mdata)
- elif jdata['init_fp_style'] == "ABACUS":
+ if jdata["init_fp_style"] == "VASP":
+ make_vasp_relax(jdata, mdata)
+ run_vasp_relax(jdata, mdata)
+ elif jdata["init_fp_style"] == "ABACUS":
make_abacus_relax(jdata, mdata)
run_abacus_relax(jdata, mdata)
else:
- if jdata['init_fp_style'] == "VASP":
- make_vasp_relax(jdata, {"fp_resources":{}})
- elif jdata['init_fp_style'] == "ABACUS":
- make_abacus_relax(jdata, {"fp_resources":{}})
- elif stage == 2 :
+ if jdata["init_fp_style"] == "VASP":
+ make_vasp_relax(jdata, {"fp_resources": {}})
+ elif jdata["init_fp_style"] == "ABACUS":
+ make_abacus_relax(jdata, {"fp_resources": {}})
+ elif stage == 2:
dlog.info("Current stage is 2, perturb and scale")
- if jdata['init_fp_style'] == "VASP":
+ if jdata["init_fp_style"] == "VASP":
make_scale(jdata)
pert_scaled(jdata)
- elif jdata['init_fp_style'] == "ABACUS":
+ elif jdata["init_fp_style"] == "ABACUS":
make_scale_ABACUS(jdata)
pert_scaled(jdata)
- elif stage == 3 :
+ elif stage == 3:
dlog.info("Current stage is 3, run a short md")
if args.MACHINE is not None:
- if jdata['init_fp_style'] == "VASP":
+ if jdata["init_fp_style"] == "VASP":
make_vasp_md(jdata, mdata)
run_vasp_md(jdata, mdata)
- elif jdata['init_fp_style'] == "ABACUS":
+ elif jdata["init_fp_style"] == "ABACUS":
make_abacus_md(jdata, mdata)
run_abacus_md(jdata, mdata)
else:
- if jdata['init_fp_style'] == "VASP":
- make_vasp_md(jdata, {"fp_resources":{}})
- elif jdata['init_fp_style'] == "ABACUS":
- make_abacus_md(jdata, {"fp_resources":{}})
-
- elif stage == 4 :
+ if jdata["init_fp_style"] == "VASP":
+ make_vasp_md(jdata, {"fp_resources": {}})
+ elif jdata["init_fp_style"] == "ABACUS":
+ make_abacus_md(jdata, {"fp_resources": {}})
+
+ elif stage == 4:
dlog.info("Current stage is 4, collect data")
- if jdata['init_fp_style'] == "VASP":
+ if jdata["init_fp_style"] == "VASP":
coll_vasp_md(jdata)
- elif jdata['init_fp_style'] == "ABACUS":
+ elif jdata["init_fp_style"] == "ABACUS":
coll_abacus_md(jdata)
- else :
+ else:
raise RuntimeError("unknown stage %d" % stage)
+
if __name__ == "__main__":
parser = argparse.ArgumentParser(
- description="Generating initial data for bulk systems.")
- parser.add_argument('PARAM', type=str,
- help="parameter file, json/yaml format")
- parser.add_argument('MACHINE', type=str,default=None,nargs="?",
- help="machine file, json/yaml format")
+ description="Generating initial data for bulk systems."
+ )
+ parser.add_argument("PARAM", type=str, help="parameter file, json/yaml format")
+ parser.add_argument(
+ "MACHINE",
+ type=str,
+ default=None,
+ nargs="?",
+ help="machine file, json/yaml format",
+ )
args = parser.parse_args()
gen_init_bulk(args)
diff --git a/dpgen/data/jsons/almg.diamond.111.json b/dpgen/data/jsons/almg.diamond.111.json
index 4683084ab..c41b905be 100644
--- a/dpgen/data/jsons/almg.diamond.111.json
+++ b/dpgen/data/jsons/almg.diamond.111.json
@@ -3,7 +3,7 @@
"latt": 2.5,
"super_cell": [1, 1, 1],
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/almg.diamond.222.json b/dpgen/data/jsons/almg.diamond.222.json
index d9fb465a5..b94c24b06 100644
--- a/dpgen/data/jsons/almg.diamond.222.json
+++ b/dpgen/data/jsons/almg.diamond.222.json
@@ -3,7 +3,7 @@
"latt": 2.5,
"super_cell": [2, 2, 2],
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/almg.fcc.111.json b/dpgen/data/jsons/almg.fcc.111.json
index 163775c98..e6fb8d951 100644
--- a/dpgen/data/jsons/almg.fcc.111.json
+++ b/dpgen/data/jsons/almg.fcc.111.json
@@ -3,7 +3,7 @@
"latt": 4.3,
"super_cell": [1, 1, 1],
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/almg.fcc.222.json b/dpgen/data/jsons/almg.fcc.222.json
index 0f510a92d..dab0caf8f 100644
--- a/dpgen/data/jsons/almg.fcc.222.json
+++ b/dpgen/data/jsons/almg.fcc.222.json
@@ -3,7 +3,7 @@
"latt": 4.3,
"super_cell": [2, 2, 2],
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/almg.hcp.111.json b/dpgen/data/jsons/almg.hcp.111.json
index e7804667b..9ef72bd4c 100644
--- a/dpgen/data/jsons/almg.hcp.111.json
+++ b/dpgen/data/jsons/almg.hcp.111.json
@@ -3,7 +3,7 @@
"latt": 4.3,
"super_cell": [1, 1, 1],
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/almg.hcp.222.json b/dpgen/data/jsons/almg.hcp.222.json
index 530abe8aa..1abe49cc5 100644
--- a/dpgen/data/jsons/almg.hcp.222.json
+++ b/dpgen/data/jsons/almg.hcp.222.json
@@ -3,7 +3,7 @@
"latt": 4.3,
"super_cell": [2, 2, 2],
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/almg.hcp.332.json b/dpgen/data/jsons/almg.hcp.332.json
index cbcbf1750..024c1eb21 100644
--- a/dpgen/data/jsons/almg.hcp.332.json
+++ b/dpgen/data/jsons/almg.hcp.332.json
@@ -3,7 +3,7 @@
"latt": 4.3,
"super_cell": [3, 3, 2],
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/almg.sc.222.json b/dpgen/data/jsons/almg.sc.222.json
index a19ded3d6..c27f9fd82 100644
--- a/dpgen/data/jsons/almg.sc.222.json
+++ b/dpgen/data/jsons/almg.sc.222.json
@@ -3,7 +3,7 @@
"latt": 2.5,
"super_cell": [2, 2, 2],
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/almg.sc.333.json b/dpgen/data/jsons/almg.sc.333.json
index 8a1f0e33d..31bf2e42c 100644
--- a/dpgen/data/jsons/almg.sc.333.json
+++ b/dpgen/data/jsons/almg.sc.333.json
@@ -3,7 +3,7 @@
"latt": 2.5,
"super_cell": [3, 3, 3],
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/surf.almg.fcc.json b/dpgen/data/jsons/surf.almg.fcc.json
index b40dde0cb..c1cc480cb 100644
--- a/dpgen/data/jsons/surf.almg.fcc.json
+++ b/dpgen/data/jsons/surf.almg.fcc.json
@@ -7,7 +7,7 @@
"vacuum_resol": 0.2,
"lmp_cmd": "/home/wanghan/Soft/lammps/lammps-16Mar18/src/lmp_mpi",
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/surf.almg.hcp.json b/dpgen/data/jsons/surf.almg.hcp.json
index 4d8a44fc4..bb83686a5 100644
--- a/dpgen/data/jsons/surf.almg.hcp.json
+++ b/dpgen/data/jsons/surf.almg.hcp.json
@@ -7,7 +7,7 @@
"vacuum_resol": 0.2,
"lmp_cmd": "/home/wanghan/Soft/lammps/lammps-16Mar18/src/lmp_mpi",
"elements": ["Al", "Mg"],
- "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
+ "potcars": ["/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Al/POTCAR",
"/home/wanghan/Soft/vasp/potcar.unknown/potpaw_PBE/Mg/POTCAR"
],
"encut": 600,
diff --git a/dpgen/data/jsons/water.111.json b/dpgen/data/jsons/water.111.json
index ee5abef69..4f5733a90 100644
--- a/dpgen/data/jsons/water.111.json
+++ b/dpgen/data/jsons/water.111.json
@@ -6,10 +6,10 @@
"_comment": "if set from poscar, the options above will be ignored",
"from_poscar": true,
"from_poscar_path": "ice6.POSCAR",
-
+
"_comment": "",
"super_cell": [1, 1, 1],
- "potcars": [ "/home/wanghan/Soft/vasp/potcar.52/potpaw_PBE.52/O/POTCAR",
+ "potcars": [ "/home/wanghan/Soft/vasp/potcar.52/potpaw_PBE.52/O/POTCAR",
"/home/wanghan/Soft/vasp/potcar.52/potpaw_PBE.52/H/POTCAR"
],
"encut": 900,
diff --git a/dpgen/data/reaction.py b/dpgen/data/reaction.py
index 51be3b111..2df183796 100644
--- a/dpgen/data/reaction.py
+++ b/dpgen/data/reaction.py
@@ -7,18 +7,20 @@
output: data
"""
-import warnings
import glob
import json
import os
import random
+import warnings
import dpdata
+
from dpgen import dlog
from dpgen.dispatcher.Dispatcher import make_submission_compat
-from dpgen.remote.decide_machine import convert_mdata
from dpgen.generator.run import create_path, make_fp_task_name
-from dpgen.util import sepline, normalize
+from dpgen.remote.decide_machine import convert_mdata
+from dpgen.util import normalize, sepline
+
from .arginfo import init_reaction_jdata_arginfo
reaxff_path = "00.reaxff"
@@ -39,19 +41,24 @@ def link_reaxff(jdata):
task_path = os.path.join(reaxff_path, "task.000")
create_path(task_path)
- rdata = jdata['reaxff']
- os.symlink(os.path.abspath(rdata["data"]), os.path.abspath(
- os.path.join(task_path, data_init_path)))
- os.symlink(os.path.abspath(rdata["ff"]), os.path.abspath(
- os.path.join(task_path, ff_path)))
- os.symlink(os.path.abspath(rdata["control"]), os.path.abspath(
- os.path.join(task_path, control_path)))
- with open(os.path.join(task_path, lmp_path), 'w') as f:
+ rdata = jdata["reaxff"]
+ os.symlink(
+ os.path.abspath(rdata["data"]),
+ os.path.abspath(os.path.join(task_path, data_init_path)),
+ )
+ os.symlink(
+ os.path.abspath(rdata["ff"]), os.path.abspath(os.path.join(task_path, ff_path))
+ )
+ os.symlink(
+ os.path.abspath(rdata["control"]),
+ os.path.abspath(os.path.join(task_path, control_path)),
+ )
+ with open(os.path.join(task_path, lmp_path), "w") as f:
f.write(make_lmp(jdata))
def make_lmp(jdata):
- rdata = jdata['reaxff']
+ rdata = jdata["reaxff"]
lmp_string = """units real
atom_style charge
read_data data.init
@@ -60,17 +67,17 @@ def make_lmp(jdata):
velocity all create {temp} {rand}
fix 1 all nvt temp {temp} {temp} {tau_t}
fix 2 all qeq/reax 1 0.0 10.0 1.0e-6 reax/c
-dump 1 all custom {dump_freq} lammpstrj id type x y z
+dump 1 all custom {dump_freq} lammpstrj id type x y z
timestep {dt}
run {nstep}
""".format(
- type_map=" ".join(jdata['type_map']),
- temp=rdata['temp'],
- rand=random.randrange(1000000-1)+1,
- tau_t=rdata['tau_t'],
- dump_freq=rdata['dump_freq'],
- dt=rdata['dt'],
- nstep=rdata['nstep']
+ type_map=" ".join(jdata["type_map"]),
+ temp=rdata["temp"],
+ rand=random.randrange(1000000 - 1) + 1,
+ tau_t=rdata["tau_t"],
+ dump_freq=rdata["dump_freq"],
+ dt=rdata["dt"],
+ nstep=rdata["nstep"],
)
return lmp_string
@@ -78,22 +85,24 @@ def make_lmp(jdata):
def run_reaxff(jdata, mdata, log_file="reaxff_log"):
work_path = reaxff_path
reaxff_command = "{} -in {}".format(mdata["reaxff_command"], lmp_path)
- run_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ run_tasks = glob.glob(os.path.join(work_path, "task.*"))
run_tasks.sort()
run_tasks = [os.path.basename(ii) for ii in run_tasks]
- make_submission_compat(mdata['reaxff_machine'],
- mdata['reaxff_resources'],
- [reaxff_command],
- work_path,
- run_tasks,
- 1,
- [],
- [ff_path, data_init_path, control_path, lmp_path],
- [trj_path],
- outlog=log_file,
- errlog=log_file,
- api_version=mdata.get("api_version", "0.9"))
+ make_submission_compat(
+ mdata["reaxff_machine"],
+ mdata["reaxff_resources"],
+ [reaxff_command],
+ work_path,
+ run_tasks,
+ 1,
+ [],
+ [ff_path, data_init_path, control_path, lmp_path],
+ [trj_path],
+ outlog=log_file,
+ errlog=log_file,
+ api_version=mdata.get("api_version", "0.9"),
+ )
def link_trj(jdata):
@@ -102,16 +111,22 @@ def link_trj(jdata):
task_path = os.path.join(build_path, "task.000")
create_path(task_path)
- os.symlink(os.path.abspath(os.path.join(reaxff_path, "task.000", trj_path)), os.path.abspath(
- os.path.join(task_path, trj_path)))
+ os.symlink(
+ os.path.abspath(os.path.join(reaxff_path, "task.000", trj_path)),
+ os.path.abspath(os.path.join(task_path, trj_path)),
+ )
def run_build_dataset(jdata, mdata, log_file="build_log"):
work_path = build_path
# compatible with new dpdispatcher and old dpgen.dispatcher
- build_ntasks = mdata["build_resources"].get("cpu_per_node", mdata["build_resources"]["task_per_node"])
- fp_ntasks = mdata["fp_resources"].get("cpu_per_node", mdata["fp_resources"]["task_per_node"])
- build_command = "{cmd} -n {dataset_name} -a {type_map} -d {lammpstrj} -c {cutoff} -s {dataset_size} -k \"{qmkeywords}\" --nprocjob {nprocjob} --nproc {nproc}".format(
+ build_ntasks = mdata["build_resources"].get(
+ "cpu_per_node", mdata["build_resources"]["task_per_node"]
+ )
+ fp_ntasks = mdata["fp_resources"].get(
+ "cpu_per_node", mdata["fp_resources"]["task_per_node"]
+ )
+ build_command = '{cmd} -n {dataset_name} -a {type_map} -d {lammpstrj} -c {cutoff} -s {dataset_size} -k "{qmkeywords}" --nprocjob {nprocjob} --nproc {nproc}'.format(
cmd=mdata["build_command"],
type_map=" ".join(jdata["type_map"]),
lammpstrj=trj_path,
@@ -120,48 +135,49 @@ def run_build_dataset(jdata, mdata, log_file="build_log"):
qmkeywords=jdata["qmkeywords"],
nprocjob=fp_ntasks,
nproc=build_ntasks,
- dataset_name=dataset_name
+ dataset_name=dataset_name,
)
- run_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ run_tasks = glob.glob(os.path.join(work_path, "task.*"))
run_tasks.sort()
run_tasks = [os.path.basename(ii) for ii in run_tasks]
- make_submission_compat(mdata['build_machine'],
- mdata['build_resources'],
- [build_command],
- work_path,
- run_tasks,
- 1,
- [],
- [trj_path],
- [f"dataset_{dataset_name}_gjf"],
- outlog=log_file,
- errlog=log_file,
- api_version=mdata.get("api_version", "0.9"))
+ make_submission_compat(
+ mdata["build_machine"],
+ mdata["build_resources"],
+ [build_command],
+ work_path,
+ run_tasks,
+ 1,
+ [],
+ [trj_path],
+ [f"dataset_{dataset_name}_gjf"],
+ outlog=log_file,
+ errlog=log_file,
+ api_version=mdata.get("api_version", "0.9"),
+ )
def link_fp_input():
- all_input_file = glob.glob(os.path.join(
- build_path, "task.*", f"dataset_{dataset_name}_gjf", "*", "*.gjf"))
+ all_input_file = glob.glob(
+ os.path.join(build_path, "task.*", f"dataset_{dataset_name}_gjf", "*", "*.gjf")
+ )
work_path = fp_path
create_path(work_path)
for ii, fin in enumerate(all_input_file):
dst_path = os.path.join(work_path, make_fp_task_name(0, ii))
create_path(dst_path)
- os.symlink(os.path.abspath(fin), os.path.abspath(
- os.path.join(dst_path, "input")))
+ os.symlink(
+ os.path.abspath(fin), os.path.abspath(os.path.join(dst_path, "input"))
+ )
-def run_fp(jdata,
- mdata,
- log_file="output",
- forward_common_files=[]):
- fp_command = mdata['fp_command']
- fp_group_size = mdata['fp_group_size']
+def run_fp(jdata, mdata, log_file="output", forward_common_files=[]):
+ fp_command = mdata["fp_command"]
+ fp_group_size = mdata["fp_group_size"]
work_path = fp_path
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
if len(fp_tasks) == 0:
return
@@ -170,24 +186,30 @@ def run_fp(jdata,
run_tasks = [os.path.basename(ii) for ii in fp_run_tasks]
- make_submission_compat(mdata['fp_machine'],
- mdata['fp_resources'],
- [fp_command],
- work_path,
- run_tasks,
- fp_group_size,
- [],
- ["input"],
- [log_file],
- outlog=log_file,
- errlog=log_file,
- api_version=mdata.get("api_version", "0.9"))
+ make_submission_compat(
+ mdata["fp_machine"],
+ mdata["fp_resources"],
+ [fp_command],
+ work_path,
+ run_tasks,
+ fp_group_size,
+ [],
+ ["input"],
+ [log_file],
+ outlog=log_file,
+ errlog=log_file,
+ api_version=mdata.get("api_version", "0.9"),
+ )
def convert_data(jdata):
- s = dpdata.MultiSystems(*[dpdata.LabeledSystem(x, fmt="gaussian/log")
- for x in glob.glob(os.path.join(fp_path, "*", "output"))],
- type_map=jdata["type_map"])
+ s = dpdata.MultiSystems(
+ *[
+ dpdata.LabeledSystem(x, fmt="gaussian/log")
+ for x in glob.glob(os.path.join(fp_path, "*", "output"))
+ ],
+ type_map=jdata["type_map"],
+ )
s.to_deepmd_npy(data_path)
dlog.info("Initial data is avaiable in %s" % os.path.abspath(data_path))
@@ -195,14 +217,14 @@ def convert_data(jdata):
def gen_init_reaction(args):
try:
import ruamel
- from monty.serialization import loadfn, dumpfn
- warnings.simplefilter(
- 'ignore', ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
+ from monty.serialization import dumpfn, loadfn
+
+ warnings.simplefilter("ignore", ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
jdata = loadfn(args.PARAM)
if args.MACHINE is not None:
mdata = loadfn(args.MACHINE)
except Exception:
- with open(args.PARAM, 'r') as fp:
+ with open(args.PARAM, "r") as fp:
jdata = json.load(fp)
if args.MACHINE is not None:
with open(args.MACHINE, "r") as fp:
@@ -221,7 +243,7 @@ def gen_init_reaction(args):
iter_rec = int(line.strip())
dlog.info("continue from task %02d" % iter_rec)
for ii in range(numb_task):
- sepline(str(ii), '-')
+ sepline(str(ii), "-")
if ii <= iter_rec:
continue
elif ii == 0:
@@ -239,4 +261,4 @@ def gen_init_reaction(args):
elif ii == 6:
convert_data(jdata)
with open(record, "a") as frec:
- frec.write(str(ii)+'\n')
+ frec.write(str(ii) + "\n")
diff --git a/dpgen/data/surf.py b/dpgen/data/surf.py
index 59883f2cb..da1042bba 100644
--- a/dpgen/data/surf.py
+++ b/dpgen/data/surf.py
@@ -1,50 +1,61 @@
-#!/usr/bin/env python3
-
+#!/usr/bin/env python3
+
+import argparse
+import glob
+import json
+import os
+import re
+import shutil
+import subprocess as sp
+import sys
import warnings
-import os,json,shutil,re,glob,argparse
+
import numpy as np
-import subprocess as sp
-import dpgen.data.tools.hcp as hcp
-import dpgen.data.tools.fcc as fcc
+from ase.build import general_surface
+
+# -----ASE-------
+from ase.io import read
+from pymatgen.core import Element, Structure
+from pymatgen.io.ase import AseAtomsAdaptor
+
+# -----PMG---------
+from pymatgen.io.vasp import Poscar
+
+import dpgen.data.tools.bcc as bcc
import dpgen.data.tools.diamond as diamond
+import dpgen.data.tools.fcc as fcc
+import dpgen.data.tools.hcp as hcp
import dpgen.data.tools.sc as sc
-import dpgen.data.tools.bcc as bcc
-from dpgen import dlog
-from dpgen import ROOT_PATH
-from dpgen.remote.decide_machine import convert_mdata
+from dpgen import ROOT_PATH, dlog
from dpgen.dispatcher.Dispatcher import make_submission_compat
from dpgen.generator.lib.utils import symlink_user_forward_files
-#-----PMG---------
-from pymatgen.io.vasp import Poscar
-from pymatgen.core import Structure, Element
-from pymatgen.io.ase import AseAtomsAdaptor
-#-----ASE-------
-from ase.io import read
-from ase.build import general_surface
+from dpgen.remote.decide_machine import convert_mdata
-def create_path (path) :
- path += '/'
- if os.path.isdir(path) :
- dirname = os.path.dirname(path)
+def create_path(path):
+ path += "/"
+ if os.path.isdir(path):
+ dirname = os.path.dirname(path)
counter = 0
- while True :
+ while True:
bk_dirname = dirname + ".bk%03d" % counter
- if not os.path.isdir(bk_dirname) :
- shutil.move (dirname, bk_dirname)
+ if not os.path.isdir(bk_dirname):
+ shutil.move(dirname, bk_dirname)
break
counter += 1
- os.makedirs (path)
+ os.makedirs(path)
return path
-def replace (file_name, pattern, subst) :
- file_handel = open (file_name, 'r')
- file_string = file_handel.read ()
- file_handel.close ()
- file_string = ( re.sub (pattern, subst, file_string) )
- file_handel = open (file_name, 'w')
- file_handel.write (file_string)
- file_handel.close ()
+
+def replace(file_name, pattern, subst):
+ file_handel = open(file_name, "r")
+ file_string = file_handel.read()
+ file_handel.close()
+ file_string = re.sub(pattern, subst, file_string)
+ file_handel = open(file_name, "w")
+ file_handel.write(file_string)
+ file_handel.close()
+
"""
1 make unit cell
@@ -58,91 +69,98 @@ def replace (file_name, pattern, subst) :
3a vasp md
4 collect md data
"""
-global_dirname_02 = '00.place_ele'
-global_dirname_03 = '01.scale_pert'
-global_dirname_04 = '02.md'
+global_dirname_02 = "00.place_ele"
+global_dirname_03 = "01.scale_pert"
+global_dirname_04 = "02.md"
max_layer_numb = 50
-def out_dir_name(jdata) :
- super_cell = jdata['super_cell']
- from_poscar= jdata.get('from_poscar',False)
+def out_dir_name(jdata):
+ super_cell = jdata["super_cell"]
- if from_poscar:
- from_poscar_path = jdata['from_poscar_path']
+ from_poscar = jdata.get("from_poscar", False)
+
+ if from_poscar:
+ from_poscar_path = jdata["from_poscar_path"]
poscar_name = os.path.basename(from_poscar_path)
cell_str = "%02d" % (super_cell[0])
- for ii in range(1,len(super_cell)) :
+ for ii in range(1, len(super_cell)):
cell_str = cell_str + ("x%02d" % super_cell[ii])
- return poscar_name + '.' + cell_str
+ return poscar_name + "." + cell_str
else:
- cell_type = jdata['cell_type']
- elements = jdata['elements']
- super_cell = jdata['super_cell']
+ cell_type = jdata["cell_type"]
+ elements = jdata["elements"]
+ super_cell = jdata["super_cell"]
ele_str = "surf."
for ii in elements:
ele_str = ele_str + ii.lower()
cell_str = "%02d" % (super_cell[0])
- for ii in range(1,len(super_cell)) :
+ for ii in range(1, len(super_cell)):
cell_str = cell_str + ("x%02d" % super_cell[ii])
- return ele_str + '.' + cell_type + '.' + cell_str
+ return ele_str + "." + cell_type + "." + cell_str
-def class_cell_type(jdata) :
- ct = jdata['cell_type']
- if ct == "hcp" :
+
+def class_cell_type(jdata):
+ ct = jdata["cell_type"]
+ if ct == "hcp":
cell_type = hcp
- elif ct == "fcc" :
+ elif ct == "fcc":
cell_type = fcc
- elif ct == "diamond" :
+ elif ct == "diamond":
cell_type = diamond
- elif ct == "sc" :
+ elif ct == "sc":
cell_type = sc
- elif ct == "bcc" :
+ elif ct == "bcc":
cell_type = bcc
- else :
+ else:
raise RuntimeError("unknow cell type %s" % ct)
return cell_type
-def poscar_ele(poscar_in, poscar_out, eles, natoms) :
+
+def poscar_ele(poscar_in, poscar_out, eles, natoms):
ele_line = ""
natom_line = ""
- for ii in eles :
+ for ii in eles:
ele_line += str(ii) + " "
- for ii in natoms :
+ for ii in natoms:
natom_line += str(ii) + " "
- with open(poscar_in, 'r') as fin :
+ with open(poscar_in, "r") as fin:
lines = list(fin)
lines[5] = ele_line + "\n"
lines[6] = natom_line + "\n"
- with open(poscar_out, 'w') as fout :
+ with open(poscar_out, "w") as fout:
fout.write("".join(lines))
-def _poscar_natoms(lines) :
+
+def _poscar_natoms(lines):
numb_atoms = 0
- for ii in lines[6].split() :
+ for ii in lines[6].split():
numb_atoms += int(ii)
return numb_atoms
-def poscar_natoms(poscar_in) :
- with open(poscar_in, 'r') as fin :
+
+def poscar_natoms(poscar_in):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
return _poscar_natoms(lines)
-def poscar_shuffle(poscar_in, poscar_out) :
- with open(poscar_in, 'r') as fin :
+
+def poscar_shuffle(poscar_in, poscar_out):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
numb_atoms = _poscar_natoms(lines)
- idx = np.arange(8, 8+numb_atoms)
+ idx = np.arange(8, 8 + numb_atoms)
np.random.shuffle(idx)
out_lines = lines[0:8]
- for ii in range(numb_atoms) :
+ for ii in range(numb_atoms):
out_lines.append(lines[idx[ii]])
- with open(poscar_out, 'w') as fout:
+ with open(poscar_out, "w") as fout:
fout.write("".join(out_lines))
-def poscar_scale_direct (str_in, scale) :
+
+def poscar_scale_direct(str_in, scale):
lines = str_in.copy()
numb_atoms = _poscar_natoms(lines)
pscale = float(lines[1])
@@ -150,242 +168,256 @@ def poscar_scale_direct (str_in, scale) :
lines[1] = str(pscale) + "\n"
return lines
-def poscar_scale_cartesian (str_in, scale) :
+
+def poscar_scale_cartesian(str_in, scale):
lines = str_in.copy()
numb_atoms = _poscar_natoms(lines)
# scale box
- for ii in range(2,5) :
+ for ii in range(2, 5):
boxl = lines[ii].split()
boxv = [float(ii) for ii in boxl]
boxv = np.array(boxv) * scale
lines[ii] = "%.16e %.16e %.16e\n" % (boxv[0], boxv[1], boxv[2])
# scale coord
- for ii in range(8, 8+numb_atoms) :
+ for ii in range(8, 8 + numb_atoms):
cl = lines[ii].split()
cv = [float(ii) for ii in cl]
cv = np.array(cv) * scale
lines[ii] = "%.16e %.16e %.16e\n" % (cv[0], cv[1], cv[2])
- return lines
+ return lines
+
-def poscar_scale (poscar_in, poscar_out, scale) :
- with open(poscar_in, 'r') as fin :
+def poscar_scale(poscar_in, poscar_out, scale):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
- if 'D' == lines[7][0] or 'd' == lines[7][0]:
+ if "D" == lines[7][0] or "d" == lines[7][0]:
lines = poscar_scale_direct(lines, scale)
- elif 'C' == lines[7][0] or 'c' == lines[7][0] :
+ elif "C" == lines[7][0] or "c" == lines[7][0]:
lines = poscar_scale_cartesian(lines, scale)
- else :
+ else:
raise RuntimeError("Unknow poscar style at line 7: %s" % lines[7])
- with open(poscar_out, 'w') as fout:
+ with open(poscar_out, "w") as fout:
fout.write("".join(lines))
-def poscar_elong (poscar_in, poscar_out, elong, shift_center=True) :
- with open(poscar_in, 'r') as fin :
+
+def poscar_elong(poscar_in, poscar_out, elong, shift_center=True):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
- if lines[7][0].upper() != 'C' :
+ if lines[7][0].upper() != "C":
raise RuntimeError("only works for Cartesian POSCAR")
sboxz = lines[4].split()
boxz = np.array([float(sboxz[0]), float(sboxz[1]), float(sboxz[2])])
boxzl = np.linalg.norm(boxz)
elong_ratio = elong / boxzl
- boxz = boxz * (1. + elong_ratio)
- lines[4] = '%.16e %.16e %.16e\n' % (boxz[0],boxz[1],boxz[2])
+ boxz = boxz * (1.0 + elong_ratio)
+ lines[4] = "%.16e %.16e %.16e\n" % (boxz[0], boxz[1], boxz[2])
if shift_center:
- poscar_str="".join(lines)
- st=Structure.from_str(poscar_str,fmt='poscar')
- cart_coords=st.cart_coords
- z_mean=cart_coords[:,2].mean()
- z_shift=st.lattice.c/2-z_mean
- cart_coords[:,2]=cart_coords[:,2]+z_shift
- nst=Structure(st.lattice,st.species,coords=cart_coords,coords_are_cartesian=True)
- nst.to('poscar',poscar_out)
+ poscar_str = "".join(lines)
+ st = Structure.from_str(poscar_str, fmt="poscar")
+ cart_coords = st.cart_coords
+ z_mean = cart_coords[:, 2].mean()
+ z_shift = st.lattice.c / 2 - z_mean
+ cart_coords[:, 2] = cart_coords[:, 2] + z_shift
+ nst = Structure(
+ st.lattice, st.species, coords=cart_coords, coords_are_cartesian=True
+ )
+ nst.to(poscar_out, "poscar")
else:
- with open(poscar_out, 'w') as fout:
+ with open(poscar_out, "w") as fout:
fout.write("".join(lines))
-def make_unit_cell (jdata) :
- from_poscar= jdata.get('from_poscar',False)
+def make_unit_cell(jdata):
+
+ from_poscar = jdata.get("from_poscar", False)
if not from_poscar:
- latt = jdata['latt']
- cell_type = class_cell_type(jdata)
+ latt = jdata["latt"]
+ cell_type = class_cell_type(jdata)
- out_dir = jdata['out_dir']
+ out_dir = jdata["out_dir"]
path_uc = os.path.join(out_dir, global_dirname_02)
- cwd = os.getcwd()
+ cwd = os.getcwd()
# for ii in scale :
# path_work = create_path(os.path.join(path_uc, '%.3f' % ii))
- path_work = create_path(path_uc)
+ path_work = create_path(path_uc)
os.chdir(path_work)
if not from_poscar:
- with open('POSCAR.unit', 'w') as fp:
- fp.write (cell_type.poscar_unit(latt))
- os.chdir(cwd)
+ with open("POSCAR.unit", "w") as fp:
+ fp.write(cell_type.poscar_unit(latt))
+ os.chdir(cwd)
+
-def make_super_cell_pymatgen (jdata) :
+def make_super_cell_pymatgen(jdata):
make_unit_cell(jdata)
- out_dir = jdata['out_dir']
+ out_dir = jdata["out_dir"]
path_uc = os.path.join(out_dir, global_dirname_02)
-
- elements=[Element(ii) for ii in jdata['elements']]
- if 'vacuum_min' in jdata:
- vacuum_min=jdata['vacuum_min']
+
+ elements = [Element(ii) for ii in jdata["elements"]]
+ if "vacuum_min" in jdata:
+ vacuum_min = jdata["vacuum_min"]
else:
- vacuum_min=max([float(ii.atomic_radius) for ii in elements])
+ vacuum_min = max([float(ii.atomic_radius) for ii in elements])
- from_poscar= jdata.get('from_poscar',False)
+ from_poscar = jdata.get("from_poscar", False)
if from_poscar:
- from_poscar_path = jdata['from_poscar_path']
+ from_poscar_path = jdata["from_poscar_path"]
poscar_name = os.path.basename(from_poscar_path)
ss = Structure.from_file(poscar_name)
else:
from_path = path_uc
- from_file = os.path.join(from_path, 'POSCAR.unit')
+ from_file = os.path.join(from_path, "POSCAR.unit")
ss = Structure.from_file(from_file)
# ase only support X type element
for i in range(len(ss)):
- ss[i]='X'
+ ss[i] = "X"
- ss=AseAtomsAdaptor.get_atoms(ss)
+ ss = AseAtomsAdaptor.get_atoms(ss)
- all_millers = jdata['millers']
+ all_millers = jdata["millers"]
path_sc = os.path.join(out_dir, global_dirname_02)
-
- user_layer_numb = None # set default value
- z_min = None
- if 'layer_numb' in jdata:
- user_layer_numb = jdata['layer_numb']
+
+ user_layer_numb = None # set default value
+ z_min = None
+ if "layer_numb" in jdata:
+ user_layer_numb = jdata["layer_numb"]
else:
- z_min = jdata['z_min']
+ z_min = jdata["z_min"]
- super_cell = jdata['super_cell']
+ super_cell = jdata["super_cell"]
- cwd = os.getcwd()
- path_work = (path_sc)
+ cwd = os.getcwd()
+ path_work = path_sc
path_work = os.path.abspath(path_work)
os.chdir(path_work)
for miller in all_millers:
- miller_str=""
- for ii in miller :
- miller_str += str(ii)
- path_cur_surf = create_path('surf-'+miller_str)
+ miller_str = ""
+ for ii in miller:
+ miller_str += str(ii)
+ path_cur_surf = create_path("surf-" + miller_str)
os.chdir(path_cur_surf)
- #slabgen = SlabGenerator(ss, miller, z_min, 1e-3)
+ # slabgen = SlabGenerator(ss, miller, z_min, 1e-3)
if user_layer_numb:
- slab=general_surface.surface(ss,indices=miller,vacuum=vacuum_min,layers=user_layer_numb)
+ slab = general_surface.surface(
+ ss, indices=miller, vacuum=vacuum_min, layers=user_layer_numb
+ )
else:
- # build slab according to z_min value
- for layer_numb in range( 1,max_layer_numb+1):
- slab=general_surface.surface(ss,indices=miller,vacuum=vacuum_min,layers=layer_numb)
- if slab.cell.lengths()[-1] >= z_min:
- break
- if layer_numb == max_layer_numb:
- raise RuntimeError("can't build the required slab")
- #all_slabs = slabgen.get_slabs()
+ # build slab according to z_min value
+ for layer_numb in range(1, max_layer_numb + 1):
+ slab = general_surface.surface(
+ ss, indices=miller, vacuum=vacuum_min, layers=layer_numb
+ )
+ if slab.cell.lengths()[-1] >= z_min:
+ break
+ if layer_numb == max_layer_numb:
+ raise RuntimeError("can't build the required slab")
+ # all_slabs = slabgen.get_slabs()
dlog.info(os.getcwd())
- #dlog.info("Miller %s: The slab has %s termination, use the first one" %(str(miller), len(all_slabs)))
- #all_slabs[0].to('POSCAR', 'POSCAR')
- slab.write('POSCAR',vasp5=True)
- if super_cell[0] > 1 or super_cell[1] > 1 :
- st=Structure.from_file('POSCAR')
+ # dlog.info("Miller %s: The slab has %s termination, use the first one" %(str(miller), len(all_slabs)))
+ # all_slabs[0].to('POSCAR', 'POSCAR')
+ slab.write("POSCAR", vasp5=True)
+ if super_cell[0] > 1 or super_cell[1] > 1:
+ st = Structure.from_file("POSCAR")
st.make_supercell([super_cell[0], super_cell[1], 1])
- st.to('POSCAR','POSCAR')
+ st.to("POSCAR", "POSCAR")
os.chdir(path_work)
- os.chdir(cwd)
+ os.chdir(cwd)
+
-def make_combines (dim, natoms) :
- if dim == 1 :
+def make_combines(dim, natoms):
+ if dim == 1:
return [[natoms]]
- else :
+ else:
res = []
- for ii in range(natoms+1) :
+ for ii in range(natoms + 1):
rest = natoms - ii
- tmp_combines = make_combines(dim-1, rest)
- for jj in tmp_combines :
+ tmp_combines = make_combines(dim - 1, rest)
+ for jj in tmp_combines:
jj.append(ii)
- if len(res) == 0 :
+ if len(res) == 0:
res = tmp_combines
- else :
+ else:
res += tmp_combines
return res
-def place_element (jdata) :
- out_dir = jdata['out_dir']
- super_cell = jdata['super_cell']
+
+def place_element(jdata):
+ out_dir = jdata["out_dir"]
+ super_cell = jdata["super_cell"]
cell_type = class_cell_type(jdata)
- elements = jdata['elements']
- from_poscar= jdata.get('from_poscar',False)
+ elements = jdata["elements"]
+ from_poscar = jdata.get("from_poscar", False)
path_sc = os.path.join(out_dir, global_dirname_02)
- path_pe = os.path.join(out_dir, global_dirname_02)
+ path_pe = os.path.join(out_dir, global_dirname_02)
path_sc = os.path.abspath(path_sc)
path_pe = os.path.abspath(path_pe)
-
- assert(os.path.isdir(path_sc))
- assert(os.path.isdir(path_pe))
+
+ assert os.path.isdir(path_sc)
+ assert os.path.isdir(path_pe)
cwd = os.getcwd()
os.chdir(path_sc)
- surf_list = glob.glob('surf-*')
+ surf_list = glob.glob("surf-*")
surf_list.sort()
os.chdir(cwd)
for ss in surf_list:
- path_surf = os.path.join(path_sc, ss)
- pos_in = os.path.join(path_surf, 'POSCAR')
+ path_surf = os.path.join(path_sc, ss)
+ pos_in = os.path.join(path_surf, "POSCAR")
natoms = poscar_natoms(pos_in)
- combines = np.array(make_combines(len(elements), natoms), dtype = int)
- for ii in combines :
- if any(ii == 0) :
+ combines = np.array(make_combines(len(elements), natoms), dtype=int)
+ for ii in combines:
+ if any(ii == 0):
continue
comb_name = "sys-"
- for idx,jj in enumerate(ii) :
+ for idx, jj in enumerate(ii):
comb_name += "%04d" % jj
- if idx != len(ii)-1 :
+ if idx != len(ii) - 1:
comb_name += "-"
path_work = os.path.join(path_surf, comb_name)
create_path(path_work)
- pos_out = os.path.join(path_work, 'POSCAR')
+ pos_out = os.path.join(path_work, "POSCAR")
if from_poscar:
- shutil.copy2( pos_in, pos_out)
+ shutil.copy2(pos_in, pos_out)
else:
- poscar_ele(pos_in, pos_out, elements, ii)
+ poscar_ele(pos_in, pos_out, elements, ii)
poscar_shuffle(pos_out, pos_out)
-def make_vasp_relax (jdata) :
- out_dir = jdata['out_dir']
- potcars = jdata['potcars']
+
+def make_vasp_relax(jdata):
+ out_dir = jdata["out_dir"]
+ potcars = jdata["potcars"]
cwd = os.getcwd()
work_dir = os.path.join(out_dir, global_dirname_02)
- assert (os.path.isdir(work_dir))
+ assert os.path.isdir(work_dir)
work_dir = os.path.abspath(work_dir)
- if os.path.isfile(os.path.join(work_dir, 'INCAR' )) :
- os.remove(os.path.join(work_dir, 'INCAR' ))
- if os.path.isfile(os.path.join(work_dir, 'POTCAR')) :
- os.remove(os.path.join(work_dir, 'POTCAR'))
- shutil.copy2( jdata['relax_incar'],
- os.path.join(work_dir, 'INCAR'))
- out_potcar = os.path.join(work_dir, 'POTCAR')
- with open(out_potcar, 'w') as outfile:
+ if os.path.isfile(os.path.join(work_dir, "INCAR")):
+ os.remove(os.path.join(work_dir, "INCAR"))
+ if os.path.isfile(os.path.join(work_dir, "POTCAR")):
+ os.remove(os.path.join(work_dir, "POTCAR"))
+ shutil.copy2(jdata["relax_incar"], os.path.join(work_dir, "INCAR"))
+ out_potcar = os.path.join(work_dir, "POTCAR")
+ with open(out_potcar, "w") as outfile:
for fname in potcars:
with open(fname) as infile:
outfile.write(infile.read())
-
+
os.chdir(work_dir)
-
- sys_list = glob.glob(os.path.join('surf-*', 'sys-*'))
+
+ sys_list = glob.glob(os.path.join("surf-*", "sys-*"))
for ss in sys_list:
os.chdir(ss)
- ln_src = os.path.relpath(os.path.join(work_dir,'INCAR'))
- os.symlink(ln_src, 'INCAR')
- ln_src = os.path.relpath(os.path.join(work_dir,'POTCAR'))
- os.symlink(ln_src, 'POTCAR')
+ ln_src = os.path.relpath(os.path.join(work_dir, "INCAR"))
+ os.symlink(ln_src, "INCAR")
+ ln_src = os.path.relpath(os.path.join(work_dir, "POTCAR"))
+ os.symlink(ln_src, "POTCAR")
os.chdir(work_dir)
os.chdir(cwd)
-def poscar_scale_direct (str_in, scale) :
+
+def poscar_scale_direct(str_in, scale):
lines = str_in.copy()
numb_atoms = _poscar_natoms(lines)
pscale = float(lines[1])
@@ -393,243 +425,278 @@ def poscar_scale_direct (str_in, scale) :
lines[1] = str(pscale) + "\n"
return lines
-def poscar_scale_cartesian (str_in, scale) :
+
+def poscar_scale_cartesian(str_in, scale):
lines = str_in.copy()
numb_atoms = _poscar_natoms(lines)
# scale box
- for ii in range(2,5) :
+ for ii in range(2, 5):
boxl = lines[ii].split()
boxv = [float(ii) for ii in boxl]
boxv = np.array(boxv) * scale
lines[ii] = "%.16e %.16e %.16e\n" % (boxv[0], boxv[1], boxv[2])
# scale coord
- for ii in range(8, 8+numb_atoms) :
+ for ii in range(8, 8 + numb_atoms):
cl = lines[ii].split()
cv = [float(ii) for ii in cl]
cv = np.array(cv) * scale
lines[ii] = "%.16e %.16e %.16e\n" % (cv[0], cv[1], cv[2])
return lines
-def poscar_scale (poscar_in, poscar_out, scale) :
- with open(poscar_in, 'r') as fin :
+
+def poscar_scale(poscar_in, poscar_out, scale):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
- if 'D' == lines[7][0] or 'd' == lines[7][0]:
+ if "D" == lines[7][0] or "d" == lines[7][0]:
lines = poscar_scale_direct(lines, scale)
- elif 'C' == lines[7][0] or 'c' == lines[7][0] :
+ elif "C" == lines[7][0] or "c" == lines[7][0]:
lines = poscar_scale_cartesian(lines, scale)
- else :
+ else:
raise RuntimeError("Unknow poscar style at line 7: %s" % lines[7])
- poscar=Poscar.from_string("".join(lines))
- with open(poscar_out, 'w') as fout:
+ poscar = Poscar.from_string("".join(lines))
+ with open(poscar_out, "w") as fout:
fout.write(poscar.get_string(direct=False))
+
def make_scale(jdata):
- out_dir = jdata['out_dir']
- scale = jdata['scale']
- skip_relax = jdata['skip_relax']
+ out_dir = jdata["out_dir"]
+ scale = jdata["scale"]
+ skip_relax = jdata["skip_relax"]
cwd = os.getcwd()
init_path = os.path.join(out_dir, global_dirname_02)
init_path = os.path.abspath(init_path)
work_path = os.path.join(out_dir, global_dirname_03)
os.chdir(init_path)
- init_sys = glob.glob(os.path.join('surf-*', 'sys-*'))
+ init_sys = glob.glob(os.path.join("surf-*", "sys-*"))
init_sys.sort()
os.chdir(cwd)
create_path(work_path)
- for ii in init_sys :
- for jj in scale :
- if skip_relax :
- pos_src = os.path.join(os.path.join(init_path, ii), 'POSCAR')
- assert(os.path.isfile(pos_src))
- else :
+ for ii in init_sys:
+ for jj in scale:
+ if skip_relax:
+ pos_src = os.path.join(os.path.join(init_path, ii), "POSCAR")
+ assert os.path.isfile(pos_src)
+ else:
try:
- pos_src = os.path.join(os.path.join(init_path, ii), 'CONTCAR')
- assert(os.path.isfile(pos_src))
+ pos_src = os.path.join(os.path.join(init_path, ii), "CONTCAR")
+ assert os.path.isfile(pos_src)
except Exception:
- raise RuntimeError("not file %s, vasp relaxation should be run before scale poscar")
+ raise RuntimeError(
+ "not file %s, vasp relaxation should be run before scale poscar"
+ )
scale_path = os.path.join(work_path, ii)
scale_path = os.path.join(scale_path, "scale-%.3f" % jj)
create_path(scale_path)
os.chdir(scale_path)
- poscar_scale(pos_src, 'POSCAR', jj)
+ poscar_scale(pos_src, "POSCAR", jj)
os.chdir(cwd)
-def pert_scaled(jdata) :
- out_dir = jdata['out_dir']
- scale = jdata['scale']
- pert_box = jdata['pert_box']
- pert_atom = jdata['pert_atom']
- pert_numb = jdata['pert_numb']
- vacuum_max = jdata['vacuum_max']
- vacuum_resol = jdata.get('vacuum_resol',[])
+
+def pert_scaled(jdata):
+ out_dir = jdata["out_dir"]
+ scale = jdata["scale"]
+ pert_box = jdata["pert_box"]
+ pert_atom = jdata["pert_atom"]
+ pert_numb = jdata["pert_numb"]
+ vacuum_max = jdata["vacuum_max"]
+ vacuum_resol = jdata.get("vacuum_resol", [])
if vacuum_resol:
- if len(vacuum_resol)==1:
- elongs = np.arange(vacuum_resol[0], vacuum_max, vacuum_resol[0])
- elif len(vacuum_resol)==2:
- mid_point = jdata.get('mid_point')
- head_elongs = np.arange(vacuum_resol[0], mid_point, vacuum_resol[0]).tolist()
- tail_elongs = np.arange(mid_point, vacuum_max, vacuum_resol[1]).tolist()
- elongs = np.unique(head_elongs+tail_elongs).tolist()
- else:
- raise RuntimeError("the length of vacuum_resol must equal 1 or 2")
-
- else:
- vacuum_num = jdata['vacuum_numb'] # the total number of vacuum layers
- head_ratio = jdata['head_ratio'] # deciding the mid_point by vacum_max * head_ratio, which point separates the nearby region with denser intervals (head region) and the far-away region with sparser intervals (tail region).
- mid_point = jdata['mid_point'] # the mid point of head region and tail region
- head_numb = int(vacuum_num*head_ratio)
- tail_numb = vacuum_num - head_numb
- head_elongs = np.linspace(0,mid_point,head_numb).tolist()
- tail_elongs = np.linspace(mid_point,vacuum_max,tail_numb+1).tolist() # the far-away region with sparser intervals (tail region)
- elongs = np.unique(head_elongs+tail_elongs).tolist()
-
+ if len(vacuum_resol) == 1:
+ elongs = np.arange(vacuum_resol[0], vacuum_max, vacuum_resol[0])
+ elif len(vacuum_resol) == 2:
+ mid_point = jdata.get("mid_point")
+ head_elongs = np.arange(
+ vacuum_resol[0], mid_point, vacuum_resol[0]
+ ).tolist()
+ tail_elongs = np.arange(mid_point, vacuum_max, vacuum_resol[1]).tolist()
+ elongs = np.unique(head_elongs + tail_elongs).tolist()
+ else:
+ raise RuntimeError("the length of vacuum_resol must equal 1 or 2")
+
+ else:
+ vacuum_num = jdata["vacuum_numb"] # the total number of vacuum layers
+ head_ratio = jdata[
+ "head_ratio"
+ ] # deciding the mid_point by vacum_max * head_ratio, which point separates the nearby region with denser intervals (head region) and the far-away region with sparser intervals (tail region).
+ mid_point = jdata["mid_point"] # the mid point of head region and tail region
+ head_numb = int(vacuum_num * head_ratio)
+ tail_numb = vacuum_num - head_numb
+ head_elongs = np.linspace(0, mid_point, head_numb).tolist()
+ tail_elongs = np.linspace(
+ mid_point, vacuum_max, tail_numb + 1
+ ).tolist() # the far-away region with sparser intervals (tail region)
+ elongs = np.unique(head_elongs + tail_elongs).tolist()
+
cwd = os.getcwd()
path_sp = os.path.join(out_dir, global_dirname_03)
- assert(os.path.isdir(path_sp))
+ assert os.path.isdir(path_sp)
path_sp = os.path.abspath(path_sp)
os.chdir(path_sp)
- sys_pe = glob.glob(os.path.join('surf-*', 'sys-*'))
+ sys_pe = glob.glob(os.path.join("surf-*", "sys-*"))
sys_pe.sort()
- os.chdir(cwd)
+ os.chdir(cwd)
- pert_cmd = "python "+os.path.join(ROOT_PATH, 'data/tools/create_random_disturb.py')
- pert_cmd += ' -etmax %f -ofmt vasp POSCAR %d %f > /dev/null' %(pert_box, pert_numb, pert_atom)
- for ii in sys_pe :
- for jj in scale :
+ pert_cmd = (
+ sys.executable
+ + " "
+ + os.path.join(ROOT_PATH, "data/tools/create_random_disturb.py")
+ )
+ pert_cmd += " -etmax %f -ofmt vasp POSCAR %d %f > /dev/null" % (
+ pert_box,
+ pert_numb,
+ pert_atom,
+ )
+ for ii in sys_pe:
+ for jj in scale:
path_scale = path_sp
path_scale = os.path.join(path_scale, ii)
- path_scale = os.path.join(path_scale, 'scale-%.3f' % jj)
- assert(os.path.isdir(path_scale))
+ path_scale = os.path.join(path_scale, "scale-%.3f" % jj)
+ assert os.path.isdir(path_scale)
os.chdir(path_scale)
dlog.info(os.getcwd())
- poscar_in = os.path.join(path_scale, 'POSCAR')
- assert(os.path.isfile(poscar_in))
+ poscar_in = os.path.join(path_scale, "POSCAR")
+ assert os.path.isfile(poscar_in)
for ll in elongs:
path_elong = path_scale
- path_elong = os.path.join(path_elong, 'elong-%3.3f' % ll)
+ path_elong = os.path.join(path_elong, "elong-%3.3f" % ll)
create_path(path_elong)
os.chdir(path_elong)
- poscar_elong(poscar_in, 'POSCAR', ll)
- sp.check_call(pert_cmd, shell = True)
- for kk in range(pert_numb) :
- pos_in = 'POSCAR%d.vasp' % (kk+1)
- dir_out = '%06d' % (kk+1)
+ poscar_elong(poscar_in, "POSCAR", ll)
+ sp.check_call(pert_cmd, shell=True)
+ for kk in range(pert_numb):
+ pos_in = "POSCAR%d.vasp" % (kk + 1)
+ dir_out = "%06d" % (kk + 1)
create_path(dir_out)
- pos_out = os.path.join(dir_out, 'POSCAR')
+ pos_out = os.path.join(dir_out, "POSCAR")
poscar_shuffle(pos_in, pos_out)
os.remove(pos_in)
kk = -1
- pos_in = 'POSCAR'
- dir_out = '%06d' % (kk+1)
+ pos_in = "POSCAR"
+ dir_out = "%06d" % (kk + 1)
create_path(dir_out)
- pos_out = os.path.join(dir_out, 'POSCAR')
+ pos_out = os.path.join(dir_out, "POSCAR")
poscar_shuffle(pos_in, pos_out)
os.chdir(cwd)
-def _vasp_check_fin (ii) :
- if os.path.isfile(os.path.join(ii, 'OUTCAR')) :
- with open(os.path.join(ii, 'OUTCAR'), 'r') as fp :
+
+
+def _vasp_check_fin(ii):
+ if os.path.isfile(os.path.join(ii, "OUTCAR")):
+ with open(os.path.join(ii, "OUTCAR"), "r") as fp:
content = fp.read()
- count = content.count('Elapse')
- if count != 1 :
+ count = content.count("Elapse")
+ if count != 1:
return False
- else :
+ else:
return False
return True
+
def run_vasp_relax(jdata, mdata):
- fp_command = mdata['fp_command']
- fp_group_size = mdata['fp_group_size']
- fp_resources = mdata['fp_resources']
+ fp_command = mdata["fp_command"]
+ fp_group_size = mdata["fp_group_size"]
+ fp_resources = mdata["fp_resources"]
# machine_type = mdata['fp_machine']['machine_type']
- work_dir = os.path.join(jdata['out_dir'], global_dirname_02)
-
+ work_dir = os.path.join(jdata["out_dir"], global_dirname_02)
+
forward_files = ["POSCAR", "INCAR", "POTCAR"]
- backward_files = ["OUTCAR","CONTCAR"]
+ backward_files = ["OUTCAR", "CONTCAR"]
forward_common_files = []
work_path_list = glob.glob(os.path.join(work_dir, "surf-*"))
- task_format = {"fp" : "sys-*"}
- for work_path in work_path_list :
- symlink_user_forward_files(mdata=mdata, task_type="fp", work_path=work_path, task_format=task_format)
+ task_format = {"fp": "sys-*"}
+ for work_path in work_path_list:
+ symlink_user_forward_files(
+ mdata=mdata, task_type="fp", work_path=work_path, task_format=task_format
+ )
user_forward_files = mdata.get("fp" + "_user_forward_files", [])
forward_files += [os.path.basename(file) for file in user_forward_files]
backward_files += mdata.get("fp" + "_user_backward_files", [])
- #if 'cvasp' in mdata['fp_resources']:
+ # if 'cvasp' in mdata['fp_resources']:
# if mdata['fp_resources']['cvasp']:
# forward_common_files=['cvasp.py']
- relax_tasks = glob.glob(os.path.join(work_dir, "surf-*/","sys-*"))
+ relax_tasks = glob.glob(os.path.join(work_dir, "surf-*/", "sys-*"))
relax_tasks.sort()
- #dlog.info("work_dir",work_dir)
- #dlog.info("relax_tasks",relax_tasks)
+ # dlog.info("work_dir",work_dir)
+ # dlog.info("relax_tasks",relax_tasks)
if len(relax_tasks) == 0:
return
relax_run_tasks = []
- for ii in relax_tasks :
+ for ii in relax_tasks:
if not _vasp_check_fin(ii):
relax_run_tasks.append(ii)
- run_tasks = [ii.replace(work_dir+"/", "") for ii in relax_run_tasks]
-
- #dlog.info(run_tasks)
- make_submission_compat(mdata['fp_machine'],
- fp_resources,
- [fp_command],
- work_dir,
- run_tasks,
- fp_group_size,
- forward_common_files,
- forward_files,
- backward_files,
- api_version=mdata.get("api_version", "0.9"))
+ run_tasks = [ii.replace(work_dir + "/", "") for ii in relax_run_tasks]
+
+ # dlog.info(run_tasks)
+ make_submission_compat(
+ mdata["fp_machine"],
+ fp_resources,
+ [fp_command],
+ work_dir,
+ run_tasks,
+ fp_group_size,
+ forward_common_files,
+ forward_files,
+ backward_files,
+ api_version=mdata.get("api_version", "0.9"),
+ )
+
def gen_init_surf(args):
try:
- import ruamel
- from monty.serialization import loadfn,dumpfn
- warnings.simplefilter('ignore', ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
- jdata=loadfn(args.PARAM)
- if args.MACHINE is not None:
- mdata=loadfn(args.MACHINE)
+ import ruamel
+ from monty.serialization import dumpfn, loadfn
+
+ warnings.simplefilter("ignore", ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
+ jdata = loadfn(args.PARAM)
+ if args.MACHINE is not None:
+ mdata = loadfn(args.MACHINE)
except Exception:
- with open (args.PARAM, 'r') as fp :
- jdata = json.load (fp)
+ with open(args.PARAM, "r") as fp:
+ jdata = json.load(fp)
if args.MACHINE is not None:
- with open (args.MACHINE, "r") as fp:
+ with open(args.MACHINE, "r") as fp:
mdata = json.load(fp)
out_dir = out_dir_name(jdata)
- jdata['out_dir'] = out_dir
- dlog.info ("# working dir %s" % out_dir)
-
+ jdata["out_dir"] = out_dir
+ dlog.info("# working dir %s" % out_dir)
+
if args.MACHINE is not None:
- # Decide a proper machine
- mdata = convert_mdata(mdata, ["fp"])
- # disp = make_dispatcher(mdata["fp_machine"])
+ # Decide a proper machine
+ mdata = convert_mdata(mdata, ["fp"])
+ # disp = make_dispatcher(mdata["fp_machine"])
- #stage = args.STAGE
- stage_list = [int(i) for i in jdata['stages']]
+ # stage = args.STAGE
+ stage_list = [int(i) for i in jdata["stages"]]
for stage in stage_list:
- if stage == 1 :
+ if stage == 1:
create_path(out_dir)
make_super_cell_pymatgen(jdata)
place_element(jdata)
make_vasp_relax(jdata)
if args.MACHINE is not None:
- run_vasp_relax(jdata, mdata)
- elif stage == 2 :
+ run_vasp_relax(jdata, mdata)
+ elif stage == 2:
make_scale(jdata)
pert_scaled(jdata)
- else :
+ else:
raise RuntimeError("unknown stage %d" % stage)
-
+
+
if __name__ == "__main__":
- parser = argparse.ArgumentParser(
- description="Generating initial data for surface systems.")
- parser.add_argument('PARAM', type=str,
- help="parameter file, json/yaml format")
- parser.add_argument('MACHINE', type=str,default=None,nargs="?",
- help="machine file, json/yaml format")
- args = parser.parse_args()
- gen_init_surf(args)
+ parser = argparse.ArgumentParser(
+ description="Generating initial data for surface systems."
+ )
+ parser.add_argument("PARAM", type=str, help="parameter file, json/yaml format")
+ parser.add_argument(
+ "MACHINE",
+ type=str,
+ default=None,
+ nargs="?",
+ help="machine file, json/yaml format",
+ )
+ args = parser.parse_args()
+ gen_init_surf(args)
diff --git a/dpgen/data/tools/bcc.py b/dpgen/data/tools/bcc.py
index fb96333d5..a48baef07 100644
--- a/dpgen/data/tools/bcc.py
+++ b/dpgen/data/tools/bcc.py
@@ -1,14 +1,17 @@
import numpy as np
-def numb_atoms () :
+
+def numb_atoms():
return 2
-def gen_box () :
+
+def gen_box():
return np.eye(3)
-def poscar_unit (latt) :
+
+def poscar_unit(latt):
box = gen_box()
- ret = ""
+ ret = ""
ret += "BCC : a = %f \n" % latt
ret += "%.16f\n" % (latt)
ret += "%.16f %.16f %.16f\n" % (box[0][0], box[0][1], box[0][2])
diff --git a/dpgen/data/tools/cessp2force_lin.py b/dpgen/data/tools/cessp2force_lin.py
index ceaa3b775..aa6c91c3a 100755
--- a/dpgen/data/tools/cessp2force_lin.py
+++ b/dpgen/data/tools/cessp2force_lin.py
@@ -40,24 +40,22 @@
def get_outcar_files(directory, recursive):
# walk directory (recursively) and return all OUTCAR* files
# return list of outcars' path
- sys.stderr.write(
- 'Searching directory %s for OUTCAR* files ...\n' % directory)
+ sys.stderr.write("Searching directory %s for OUTCAR* files ...\n" % directory)
outcars = []
if not recursive:
for item in os.listdir(directory):
- if item.startswith('OUTCAR'):
+ if item.startswith("OUTCAR"):
outcars.append(os.path.join(directory, item))
else:
for root, SubFolders, files in os.walk(directory):
for item in files:
- if item.startswith('OUTCAR'):
+ if item.startswith("OUTCAR"):
outcars.append(os.path.join(root, item))
if len(outcars) == 0:
- sys.stderr.write(
- 'Could not find any OUTCAR files in this directory.\n')
+ sys.stderr.write("Could not find any OUTCAR files in this directory.\n")
else:
- sys.stderr.write('Found the following files:\n')
- sys.stderr.write(' {}\n'.format(('\n ').join(outcars)))
+ sys.stderr.write("Found the following files:\n")
+ sys.stderr.write(" {}\n".format(("\n ").join(outcars)))
return outcars
return outcars
@@ -82,18 +80,17 @@ def scan_outcar_file(file_handle):
potcar = []
ipt = []
for line in file_handle:
- if line.startswith('|'):
+ if line.startswith("|"):
continue
- if 'TOTAL-FORCE' in line:
+ if "TOTAL-FORCE" in line:
configs += 1
- if 'VRHFIN' in line:
- atom_types.append(
- line.split()[1].replace('=', '').replace(':', ''))
- if 'title' in line:
+ if "VRHFIN" in line:
+ atom_types.append(line.split()[1].replace("=", "").replace(":", ""))
+ if "title" in line:
title.append(line.split()[3][0:2])
- if 'POTCAR' in line:
+ if "POTCAR" in line:
potcar.append(line.split()[2][0:2])
- if 'ions per type' in line:
+ if "ions per type" in line:
ipt = [int(s) for s in line.split()[4:]]
potcar = uniq(potcar)
@@ -105,34 +102,42 @@ def scan_outcar_file(file_handle):
elif potcar:
return [configs, potcar, ipt]
else:
- sys.stderr.write(
- 'Could not determine atom types in file %s.\n' % filename)
+ sys.stderr.write("Could not determine atom types in file %s.\n" % filename)
sys.exit()
-def process_outcar_file_v5_dev(outcars, data, numbers, types, max_types, elements=None, windex=None, fout='potfit.configs'):
- fw = open(fout, 'w')
+def process_outcar_file_v5_dev(
+ outcars,
+ data,
+ numbers,
+ types,
+ max_types,
+ elements=None,
+ windex=None,
+ fout="potfit.configs",
+):
+ fw = open(fout, "w")
for i in range(len(outcars)):
- if outcars[i].endswith('.gz'):
- f = gzip.open(outcars[i], 'rb')
+ if outcars[i].endswith(".gz"):
+ f = gzip.open(outcars[i], "rb")
else:
- f = open(outcars[i], 'r')
+ f = open(outcars[i], "r")
# Writing current OUTCAR's information into potfit format files.
nconfs = data[i][0]
natoms = sum(data[i][2]) # ipt
if windex == None:
windex = range(nconfs)
- if windex == 'final':
+ if windex == "final":
windex = [nconfs - 1]
# reading current OUTCAR
print("Reading %s ..." % outcars[i])
count = -1
line = f.readline()
- while line != '':
+ while line != "":
line = f.readline()
- if 'Iteration' in line:
+ if "Iteration" in line:
energy = 0
box_x = []
box_y = []
@@ -142,55 +147,67 @@ def process_outcar_file_v5_dev(outcars, data, numbers, types, max_types, element
# if 'energy without' in line:
# # appears in each electronic-iteration steps
# energy = float(line.split()[6]) / natoms
- if 'free energy TOTEN' in line:
- energy = float (line.split()[4]) / natoms
+ if "free energy TOTEN" in line:
+ energy = float(line.split()[4]) / natoms
if count in windex:
fw.write("#N %s 1\n" % natoms)
- fw.write('#C ')
+ fw.write("#C ")
if elements:
fw.write("%s " % numbers[0])
for j in range(1, max_types):
- fw.write('%s\t' % numbers[j])
+ fw.write("%s\t" % numbers[j])
else:
fw.write(" %s" % data[i][1][0])
for j in range(1, max_types):
- fw.write(' %s' % data[i][1][j])
+ fw.write(" %s" % data[i][1][j])
fw.write("\n")
- fw.write("## force file generated from file %s config %d\n" % (
- outcars[i], count))
- fw.write("#X %13.8f %13.8f %13.8f\n" %
- (box_x[0], box_x[1], box_x[2]))
- fw.write("#Y %13.8f %13.8f %13.8f\n" %
- (box_y[0], box_y[1], box_y[2]))
- fw.write("#Z %13.8f %13.8f %13.8f\n" %
- (box_z[0], box_z[1], box_z[2]))
+ fw.write(
+ "## force file generated from file %s config %d\n"
+ % (outcars[i], count)
+ )
+ fw.write(
+ "#X %13.8f %13.8f %13.8f\n" % (box_x[0], box_x[1], box_x[2])
+ )
+ fw.write(
+ "#Y %13.8f %13.8f %13.8f\n" % (box_y[0], box_y[1], box_y[2])
+ )
+ fw.write(
+ "#Z %13.8f %13.8f %13.8f\n" % (box_z[0], box_z[1], box_z[2])
+ )
fw.write("#W %f\n" % (args.weight))
fw.write("#E %.10f\n" % (energy))
if stress:
fw.write("#S ")
for num in range(6):
- fw.write('%8.7g\t' % (stress[num]))
- fw.write('\n')
+ fw.write("%8.7g\t" % (stress[num]))
+ fw.write("\n")
fw.write("#F\n")
fw.flush()
for adata in atom_data:
- fw.write("%d %11.7g %11.7g %11.7g %11.7g %11.7g %11.7g\n" %
- (adata[0], adata[1], adata[2], adata[3], adata[4], adata[5], adata[6]))
- if 'VOLUME and BASIS' in line:
+ fw.write(
+ "%d %11.7g %11.7g %11.7g %11.7g %11.7g %11.7g\n"
+ % (
+ adata[0],
+ adata[1],
+ adata[2],
+ adata[3],
+ adata[4],
+ adata[5],
+ adata[6],
+ )
+ )
+ if "VOLUME and BASIS" in line:
for do in range(5):
# SKIP 5 lines
line = f.readline()
- box_x = [float(s)
- for s in line.replace('-', ' -').split()[0:3]]
+ box_x = [float(s) for s in line.replace("-", " -").split()[0:3]]
line = f.readline()
- box_y = [float(s)
- for s in line.replace('-', ' -').split()[0:3]]
+ box_y = [float(s) for s in line.replace("-", " -").split()[0:3]]
line = f.readline()
- box_z = [float(s)
- for s in line.replace('-', ' -').split()[0:3]]
- if 'in kB' in line:
+ box_z = [float(s) for s in line.replace("-", " -").split()[0:3]]
+ if "in kB" in line:
stress = [float(s) / 1602 for s in line.split()[2:8]]
- if 'TOTAL-FORCE' in line:
+ if "TOTAL-FORCE" in line:
# only appears in Ion-iteration steps
line = f.readline() # skip 1 line
adata = [0] * 7
@@ -215,26 +232,48 @@ def process_outcar_file_v5_dev(outcars, data, numbers, types, max_types, element
def Parser():
parser = argparse.ArgumentParser(
- description='''Converts vasp output data into potfit reference configurations.''')
+ description="""Converts vasp output data into potfit reference configurations."""
+ )
- parser.add_argument('-c', type=str, required=False,
- help='list of chemical species to use, e.g. -c Mg=0,Zn=1')
parser.add_argument(
- '-e', type=str, required=False, help='file with single atom energies (NYI)')
- parser.add_argument('-r', '--recursive', action='store_true',
- help='scan recursively for OUTCAR files')
- parser.add_argument('-f', '--final', action='store_true',
- help='use only the final configuration from OUTCAR')
- parser.add_argument('-sr', '--configs_range', type=str,
- help='range of the configurations to use')
- parser.add_argument('-w', '--weight', type=float, default=1.0,
- help='set configuration weight for all configurations')
+ "-c",
+ type=str,
+ required=False,
+ help="list of chemical species to use, e.g. -c Mg=0,Zn=1",
+ )
parser.add_argument(
- 'files', type=str, nargs='*', help='list of OUTCAR files (plain or gzipped)')
+ "-e", type=str, required=False, help="file with single atom energies (NYI)"
+ )
+ parser.add_argument(
+ "-r",
+ "--recursive",
+ action="store_true",
+ help="scan recursively for OUTCAR files",
+ )
+ parser.add_argument(
+ "-f",
+ "--final",
+ action="store_true",
+ help="use only the final configuration from OUTCAR",
+ )
+ parser.add_argument(
+ "-sr", "--configs_range", type=str, help="range of the configurations to use"
+ )
+ parser.add_argument(
+ "-w",
+ "--weight",
+ type=float,
+ default=1.0,
+ help="set configuration weight for all configurations",
+ )
+ parser.add_argument(
+ "files", type=str, nargs="*", help="list of OUTCAR files (plain or gzipped)"
+ )
args = parser.parse_args()
return args
+
#
if __name__ == "__main__":
# Check for sane arguments
@@ -246,7 +285,7 @@ def Parser():
# determine all OUTCAR files
outcars = []
if not args.files:
- outcars = get_outcar_files('.', args.recursive)
+ outcars = get_outcar_files(".", args.recursive)
for item in args.files:
if os.path.isdir(item):
@@ -261,10 +300,10 @@ def Parser():
data = []
max_types = 1
for item in outcars:
- if item.endswith('.gz'):
- f = gzip.open(item, 'rb')
+ if item.endswith(".gz"):
+ f = gzip.open(item, "rb")
else:
- f = open(item, 'r')
+ f = open(item, "r")
data.append(scan_outcar_file(f))
f.close()
max_types = max(max_types, len(data[-1][1]))
@@ -273,37 +312,38 @@ def Parser():
types = dict()
numbers = dict()
if args.c:
- if len(args.c.split(',')) > max_types:
- sys.stderr.write(
- "\nERROR: There are too many items in you -c string!\n")
+ if len(args.c.split(",")) > max_types:
+ sys.stderr.write("\nERROR: There are too many items in you -c string!\n")
sys.exit()
- if len(args.c.split(',')) < max_types:
- sys.stderr.write(
- "\nERROR: There are not enough items in you -c string!\n")
+ if len(args.c.split(",")) < max_types:
+ sys.stderr.write("\nERROR: There are not enough items in you -c string!\n")
sys.exit()
- for item in args.c.split(','):
- if len(item.split('=')) != 2:
+ for item in args.c.split(","):
+ if len(item.split("=")) != 2:
sys.stderr.write("\nERROR: Could not read the -c string.\n")
sys.stderr.write("Maybe a missing or extra '=' sign?\n")
sys.exit()
else:
try:
- name = str(item.split('=')[0])
- number = int(item.split('=')[1])
+ name = str(item.split("=")[0])
+ number = int(item.split("=")[1])
except Exception:
sys.stderr.write("\nERROR: Could not read the -c string\n")
sys.exit()
if number >= max_types:
sys.stderr.write(
- "\nERROR: The atom type for %s is invalid!\n" % name)
+ "\nERROR: The atom type for %s is invalid!\n" % name
+ )
sys.exit()
if name in types:
sys.stderr.write(
- "\nERROR: Duplicate atom type found in -c string\n")
+ "\nERROR: Duplicate atom type found in -c string\n"
+ )
sys.exit()
if number in numbers:
sys.stderr.write(
- "\nERROR: Duplicate atom number found in -c string\n")
+ "\nERROR: Duplicate atom number found in -c string\n"
+ )
sys.exit()
types[name] = number
numbers[number] = name
@@ -319,7 +359,8 @@ def Parser():
windex = range(sr0, sr1 + 1)
if args.final:
- windex = 'final'
+ windex = "final"
process_outcar_file_v5_dev(
- outcars, data, numbers, types, max_types, windex=windex, fout='test.configs')
+ outcars, data, numbers, types, max_types, windex=windex, fout="test.configs"
+ )
diff --git a/dpgen/data/tools/clean.sh b/dpgen/data/tools/clean.sh
index 2cbad547a..781bf0ee3 100755
--- a/dpgen/data/tools/clean.sh
+++ b/dpgen/data/tools/clean.sh
@@ -15,4 +15,3 @@ do
mv $ii bk.$ii
fi
done
-
diff --git a/dpgen/data/tools/create_random_disturb.py b/dpgen/data/tools/create_random_disturb.py
index 4c2aa1064..b8fb47dfa 100755
--- a/dpgen/data/tools/create_random_disturb.py
+++ b/dpgen/data/tools/create_random_disturb.py
@@ -1,26 +1,27 @@
#!/usr/bin/env python3
-import sys
+import argparse
+import glob
import os
import shutil
-import glob
-import argparse
+import sys
-import numpy as np
import ase.io
-import dpgen.data.tools.io_lammps as io_lammps
+import numpy as np
+import dpgen.data.tools.io_lammps as io_lammps
from dpgen.generator.lib.abacus_scf import get_abacus_STRU, make_abacus_scf_stru
+
def create_disturbs_atomsk(fin, nfile, dmax=1.0, ofmt="lmp"):
# removing the exists files
- flist = glob.glob('*.' + ofmt)
+ flist = glob.glob("*." + ofmt)
for f in flist:
os.remove(f)
# Based on our tests, we find it always creates a disturb by
# constant value of dmax for atomsk
for i in range(1, nfile + 1):
- fout = fin + str(i) + '.' + ofmt
+ fout = fin + str(i) + "." + ofmt
cmd = "atomsk " + fin + " -disturb " + str(dmax) + " -wrap -ow " + fout
os.system(cmd)
return
@@ -31,12 +32,12 @@ def random_range(a, b, ndata=1):
return data
-def gen_random_disturb(dmax, a, b, dstyle='uniform'):
+def gen_random_disturb(dmax, a, b, dstyle="uniform"):
d0 = np.random.rand(3) * (b - a) + a
dnorm = np.linalg.norm(d0)
- if dstyle == 'normal':
+ if dstyle == "normal":
dmax = np.random.standard_normal(0, 0.5) * dmax
- elif dstyle == 'constant':
+ elif dstyle == "constant":
pass
else:
# use if we just wanna a disturb in a range of [0, dmax),
@@ -45,9 +46,11 @@ def gen_random_disturb(dmax, a, b, dstyle='uniform'):
return dr
-def create_disturbs_ase(fin, nfile, dmax=1.0, ofmt="lmp", dstyle='uniform', write_d=False):
+def create_disturbs_ase(
+ fin, nfile, dmax=1.0, ofmt="lmp", dstyle="uniform", write_d=False
+):
# removing the exists files
- flist = glob.glob('*.' + ofmt)
+ flist = glob.glob("*." + ofmt)
for f in flist:
os.remove(f)
@@ -61,30 +64,29 @@ def create_disturbs_ase(fin, nfile, dmax=1.0, ofmt="lmp", dstyle='uniform', writ
dpos = np.zeros((natoms, 3))
atoms_d = atoms.copy()
if write_d:
- fw = open('disp-' + str(fid) + '.dat', 'w')
+ fw = open("disp-" + str(fid) + ".dat", "w")
for i in range(natoms):
# Use copy(), otherwise it will modify the input atoms every time.
dr = gen_random_disturb(dmax, -0.5, 0.5, dstyle)
- '''
+ """
if i == 1:
print(dr)
print(np.linalg.norm(dr))
- '''
+ """
dpos[i, :] = dr
if write_d:
dnorm = np.linalg.norm(dr)
- fw.write('%d\t%f\t%f\t%f\t%f\n' %
- (i + 1, dr[0], dr[1], dr[2], dnorm))
+ fw.write("%d\t%f\t%f\t%f\t%f\n" % (i + 1, dr[0], dr[1], dr[2], dnorm))
fw.flush()
pos = pos0 + dpos
atoms_d.set_positions(pos)
- fout = fin + str(fid) + '.' + ofmt
+ fout = fin + str(fid) + "." + ofmt
print("Creating %s ..." % fout)
- if ofmt in ['lmp', 'lammps_data']:
+ if ofmt in ["lmp", "lammps_data"]:
# for lammps, use my personal output functions
io_lammps.ase2lammpsdata(atoms_d, fout)
else:
- ase.io.write(fout, atoms_d, ofmt, vasp5 = True)
+ ase.io.write(fout, atoms_d, ofmt, vasp5=True)
if write_d:
fw.close()
return
@@ -99,17 +101,21 @@ def gen_random_emat(etmax, diag=0):
# isotropic behavior
e[3], e[4], e[5] = 0, 0, 0
emat = np.array(
- [[e[0], 0.5 * e[5], 0.5 * e[4]],
- [0.5 * e[5], e[1], 0.5 * e[3]],
- [0.5 * e[4], 0.5 * e[3], e[2]]]
+ [
+ [e[0], 0.5 * e[5], 0.5 * e[4]],
+ [0.5 * e[5], e[1], 0.5 * e[3]],
+ [0.5 * e[4], 0.5 * e[3], e[2]],
+ ]
)
emat = emat + np.eye(3)
return emat
-def create_disturbs_ase_dev(fin, nfile, dmax=1.0, etmax=0.1, ofmt="lmp", dstyle='uniform', write_d=False, diag=0):
+def create_disturbs_ase_dev(
+ fin, nfile, dmax=1.0, etmax=0.1, ofmt="lmp", dstyle="uniform", write_d=False, diag=0
+):
# removing the exists files
- flist = glob.glob('*.' + ofmt)
+ flist = glob.glob("*." + ofmt)
for f in flist:
os.remove(f)
@@ -125,23 +131,22 @@ def create_disturbs_ase_dev(fin, nfile, dmax=1.0, etmax=0.1, ofmt="lmp", dstyle=
# random flux for atomic positions
if write_d:
- fw = open('disp-' + str(fid) + '.dat', 'w')
+ fw = open("disp-" + str(fid) + ".dat", "w")
dpos = np.zeros((natoms, 3))
for i in range(natoms):
dr = gen_random_disturb(dmax, -0.5, 0.5, dstyle)
dpos[i, :] = dr
if write_d:
dnorm = np.linalg.norm(dr)
- fw.write('%d\t%f\t%f\t%f\t%f\n' %
- (i + 1, dr[0], dr[1], dr[2], dnorm))
+ fw.write("%d\t%f\t%f\t%f\t%f\n" % (i + 1, dr[0], dr[1], dr[2], dnorm))
fw.flush()
# random flux for volumes
cell = np.dot(cell0, gen_random_emat(etmax, diag))
atoms_d.set_cell(cell, scale_atoms=True)
if write_d:
- fout_c = 'cell-' + str(fid) + '.dat'
- np.savetxt(fout_c, cell, '%f')
+ fout_c = "cell-" + str(fid) + ".dat"
+ np.savetxt(fout_c, cell, "%f")
# determine new cell & atomic positions randomiziations
pos = atoms_d.get_positions() + dpos
@@ -149,36 +154,46 @@ def create_disturbs_ase_dev(fin, nfile, dmax=1.0, etmax=0.1, ofmt="lmp", dstyle=
# pre-converting the Atoms to be in low tri-angular cell matrix
cell_new = io_lammps.convert_cell(cell)
- #pos_new = io_lammps.convert_positions(pos, cell, cell_new)
+ # pos_new = io_lammps.convert_positions(pos, cell, cell_new)
atoms_d.set_cell(cell_new, scale_atoms=True)
# atoms_d.set_positions(pos_new)
# Writing it
- fout = fin + str(fid) + '.' + ofmt
+ fout = fin + str(fid) + "." + ofmt
print("Creating %s ..." % fout)
- if ofmt in ['lmp', 'lammps_data']:
+ if ofmt in ["lmp", "lammps_data"]:
# for lammps, use my personal output functions
io_lammps.ase2lammpsdata(atoms_d, fout=fout)
else:
- ase.io.write(fout, atoms_d, ofmt, vasp5 = True)
+ ase.io.write(fout, atoms_d, ofmt, vasp5=True)
if write_d:
fw.close()
return
-def create_disturbs_abacus_dev(fin, nfile, dmax=1.0, etmax=0.1, ofmt="abacus", dstyle='uniform', write_d=False, diag=0):
+
+def create_disturbs_abacus_dev(
+ fin,
+ nfile,
+ dmax=1.0,
+ etmax=0.1,
+ ofmt="abacus",
+ dstyle="uniform",
+ write_d=False,
+ diag=0,
+):
# removing the exists files
- flist = glob.glob('*.' + ofmt)
+ flist = glob.glob("*." + ofmt)
for f in flist:
os.remove(f)
# read-in by ase
- #atoms = ase.io.read(fin)
- #natoms = atoms.get_number_of_atoms()
- #cell0 = atoms.get_cell()
-
+ # atoms = ase.io.read(fin)
+ # natoms = atoms.get_number_of_atoms()
+ # cell0 = atoms.get_cell()
+
stru = get_abacus_STRU(fin)
natoms = sum(stru["atom_numbs"])
- cell0 = stru['cells']
+ cell0 = stru["cells"]
# creat nfile ofmt files.
for fid in range(1, nfile + 1):
@@ -187,40 +202,40 @@ def create_disturbs_abacus_dev(fin, nfile, dmax=1.0, etmax=0.1, ofmt="abacus", d
# random flux for atomic positions
if write_d:
- fw = open('disp-' + str(fid) + '.dat', 'w')
+ fw = open("disp-" + str(fid) + ".dat", "w")
dpos = np.zeros((natoms, 3))
for i in range(natoms):
dr = gen_random_disturb(dmax, -0.5, 0.5, dstyle)
dpos[i, :] = dr
if write_d:
dnorm = np.linalg.norm(dr)
- fw.write('%d\t%f\t%f\t%f\t%f\n' %
- (i + 1, dr[0], dr[1], dr[2], dnorm))
+ fw.write("%d\t%f\t%f\t%f\t%f\n" % (i + 1, dr[0], dr[1], dr[2], dnorm))
fw.flush()
# random flux for volumes
cell = np.dot(cell0, gen_random_emat(etmax, diag))
- stru_d['cells'] = cell
+ stru_d["cells"] = cell
if write_d:
- fout_c = 'cell-' + str(fid) + '.dat'
- np.savetxt(fout_c, cell, '%f')
+ fout_c = "cell-" + str(fid) + ".dat"
+ np.savetxt(fout_c, cell, "%f")
# determine new cell & atomic positions randomiziations
- stru_d['coords'] += dpos
+ stru_d["coords"] += dpos
# pre-converting the Atoms to be in low tri-angular cell matrix
cell_new = io_lammps.convert_cell(cell)
- #pos_new = io_lammps.convert_positions(pos, cell, cell_new)
- stru_d['cells'] = cell_new
+ # pos_new = io_lammps.convert_positions(pos, cell, cell_new)
+ stru_d["cells"] = cell_new
convert_mat = np.linalg.inv(cell).dot(cell_new)
- stru_d['coords'] = np.matmul(stru_d['coords'], convert_mat)
-
+ stru_d["coords"] = np.matmul(stru_d["coords"], convert_mat)
# Writing it
- fout = fin + str(fid) + '.' + ofmt
+ fout = fin + str(fid) + "." + ofmt
print("Creating %s ..." % fout)
- ret = make_abacus_scf_stru(stru_d, stru_d['pp_files'], stru_d['orb_files'], stru_d['dpks_descriptor'])
+ ret = make_abacus_scf_stru(
+ stru_d, stru_d["pp_files"], stru_d["orb_files"], stru_d["dpks_descriptor"]
+ )
with open(fout, "w") as fp:
fp.write(ret)
if write_d:
@@ -228,10 +243,10 @@ def create_disturbs_abacus_dev(fin, nfile, dmax=1.0, etmax=0.1, ofmt="abacus", d
return
-def create_random_alloys(fin, alloy_dist, ifmt='vasp', ofmt='vasp'):
- '''
+def create_random_alloys(fin, alloy_dist, ifmt="vasp", ofmt="vasp"):
+ """
In fact, atomsk also gives us the convinient tool to do this
- '''
+ """
# alloy_dist = {'Zr': 0.80, 'Nb': 0.20}
atomic_symbols = alloy_dist.keys()
atomic_ratios = alloy_dist.values()
@@ -270,28 +285,44 @@ def create_random_alloys(fin, alloy_dist, ifmt='vasp', ofmt='vasp'):
atoms.set_chemical_symbols(new_chemical_symbols)
# write it as ofmt
- fout = fin.split(',')[0] + '_random' + ofmt
- ase.io.write(fout, atoms, format=ofmt, vasp5 = True)
+ fout = fin.split(",")[0] + "_random" + ofmt
+ ase.io.write(fout, atoms, format=ofmt, vasp5=True)
return
def RandomDisturbParser():
parser = argparse.ArgumentParser(
- description="Script to generate random disturb configurations")
- parser.add_argument('fin', type=str, help="input file name")
- parser.add_argument('nfile', type=int,
- help='number of files to be created')
- parser.add_argument('dmax', type=float, help='dmax')
- parser.add_argument('-etmax', type=float, default=0,
- help='etmax for random strain tensor generations')
- parser.add_argument('-diag', type=int, default=0,
- help='only diagonal elements of strain tensors are randomized?')
- parser.add_argument('-ofmt', type=str, default='lmp',
- help='output fileformat')
- parser.add_argument('-dstyle', type=str, default='uniform',
- help='random distribution style [uniform?]')
- parser.add_argument('-wd', '--write_disp', type=int,
- default=0, help='write displacement information?')
+ description="Script to generate random disturb configurations"
+ )
+ parser.add_argument("fin", type=str, help="input file name")
+ parser.add_argument("nfile", type=int, help="number of files to be created")
+ parser.add_argument("dmax", type=float, help="dmax")
+ parser.add_argument(
+ "-etmax",
+ type=float,
+ default=0,
+ help="etmax for random strain tensor generations",
+ )
+ parser.add_argument(
+ "-diag",
+ type=int,
+ default=0,
+ help="only diagonal elements of strain tensors are randomized?",
+ )
+ parser.add_argument("-ofmt", type=str, default="lmp", help="output fileformat")
+ parser.add_argument(
+ "-dstyle",
+ type=str,
+ default="uniform",
+ help="random distribution style [uniform?]",
+ )
+ parser.add_argument(
+ "-wd",
+ "--write_disp",
+ type=int,
+ default=0,
+ help="write displacement information?",
+ )
return parser.parse_args()
@@ -313,11 +344,9 @@ def RandomDisturbParser():
write_d = True
# main program
- #create_disturbs_atomsk(fin, nfile, dmax, ofmt)
- #create_disturbs_ase(fin, nfile, dmax, ofmt, dstyle, write_d)
+ # create_disturbs_atomsk(fin, nfile, dmax, ofmt)
+ # create_disturbs_ase(fin, nfile, dmax, ofmt, dstyle, write_d)
if ofmt == "vasp":
- create_disturbs_ase_dev(fin, nfile, dmax, etmax,
- ofmt, dstyle, write_d, diag)
+ create_disturbs_ase_dev(fin, nfile, dmax, etmax, ofmt, dstyle, write_d, diag)
elif ofmt == "abacus":
- create_disturbs_abacus_dev(fin, nfile, dmax, etmax,
- ofmt, dstyle, write_d, diag)
\ No newline at end of file
+ create_disturbs_abacus_dev(fin, nfile, dmax, etmax, ofmt, dstyle, write_d, diag)
diff --git a/dpgen/data/tools/diamond.py b/dpgen/data/tools/diamond.py
index 4674ef737..312872851 100644
--- a/dpgen/data/tools/diamond.py
+++ b/dpgen/data/tools/diamond.py
@@ -1,18 +1,22 @@
import numpy as np
-def numb_atoms () :
+
+def numb_atoms():
return 2
-def gen_box () :
- box = [[0.000000, 1.000000, 1.000000],
- [1.000000, 0.000000, 1.000000],
- [1.000000, 1.000000, 0.000000]
+
+def gen_box():
+ box = [
+ [0.000000, 1.000000, 1.000000],
+ [1.000000, 0.000000, 1.000000],
+ [1.000000, 1.000000, 0.000000],
]
return np.array(box)
-def poscar_unit (latt) :
+
+def poscar_unit(latt):
box = gen_box()
- ret = ""
+ ret = ""
ret += "DIAMOND\n"
ret += "%.16f\n" % (latt)
ret += "%.16f %.16f %.16f\n" % (box[0][0], box[0][1], box[0][2])
@@ -21,6 +25,14 @@ def poscar_unit (latt) :
ret += "Type\n"
ret += "%d\n" % numb_atoms()
ret += "Direct\n"
- ret += "%.16f %.16f %.16f\n" % (0.12500000000000, 0.12500000000000, 0.12500000000000)
- ret += "%.16f %.16f %.16f\n" % (0.87500000000000, 0.87500000000000, 0.87500000000000)
+ ret += "%.16f %.16f %.16f\n" % (
+ 0.12500000000000,
+ 0.12500000000000,
+ 0.12500000000000,
+ )
+ ret += "%.16f %.16f %.16f\n" % (
+ 0.87500000000000,
+ 0.87500000000000,
+ 0.87500000000000,
+ )
return ret
diff --git a/dpgen/data/tools/fcc.py b/dpgen/data/tools/fcc.py
index ca4640bc1..f4576e3c4 100644
--- a/dpgen/data/tools/fcc.py
+++ b/dpgen/data/tools/fcc.py
@@ -1,14 +1,17 @@
import numpy as np
-def numb_atoms () :
+
+def numb_atoms():
return 4
-def gen_box () :
+
+def gen_box():
return np.eye(3)
-def poscar_unit (latt) :
+
+def poscar_unit(latt):
box = gen_box()
- ret = ""
+ ret = ""
ret += "FCC : a = %f \n" % latt
ret += "%.16f\n" % (latt)
ret += "%.16f %.16f %.16f\n" % (box[0][0], box[0][1], box[0][2])
diff --git a/dpgen/data/tools/hcp.py b/dpgen/data/tools/hcp.py
index b2a47ace9..60c15f8aa 100644
--- a/dpgen/data/tools/hcp.py
+++ b/dpgen/data/tools/hcp.py
@@ -1,17 +1,20 @@
import numpy as np
-def numb_atoms () :
+
+def numb_atoms():
return 2
-def gen_box () :
- box = np.array ([[ 1, 0, 0],
- [0.5, 0.5 * np.sqrt(3), 0],
- [0, 0, 2. * np.sqrt(2./3.)]])
+
+def gen_box():
+ box = np.array(
+ [[1, 0, 0], [0.5, 0.5 * np.sqrt(3), 0], [0, 0, 2.0 * np.sqrt(2.0 / 3.0)]]
+ )
return box
-def poscar_unit (latt) :
+
+def poscar_unit(latt):
box = gen_box()
- ret = ""
+ ret = ""
ret += "HCP : a = %f / sqrt(2)\n" % latt
ret += "%.16f\n" % (latt / np.sqrt(2))
ret += "%.16f %.16f %.16f\n" % (box[0][0], box[0][1], box[0][2])
@@ -21,5 +24,5 @@ def poscar_unit (latt) :
ret += "%d\n" % numb_atoms()
ret += "Direct\n"
ret += "%.16f %.16f %.16f\n" % (0, 0, 0)
- ret += "%.16f %.16f %.16f\n" % (1./3, 1./3, 1./2)
+ ret += "%.16f %.16f %.16f\n" % (1.0 / 3, 1.0 / 3, 1.0 / 2)
return ret
diff --git a/dpgen/data/tools/io_lammps.py b/dpgen/data/tools/io_lammps.py
index 2c8a5a596..35223c68b 100755
--- a/dpgen/data/tools/io_lammps.py
+++ b/dpgen/data/tools/io_lammps.py
@@ -7,11 +7,10 @@
"""
+import ase.io
import numpy as np
from numpy.linalg import norm
-import ase.io
-
def dir2car(v, A):
"""Direct to cartesian coordinates"""
@@ -49,9 +48,11 @@ def is_upper_triangular(mat):
test if 3x3 matrix is upper triangular
LAMMPS has a rule for cell matrix definition
"""
+
def near0(x):
"""Test if a float is within .00001 of 0"""
return abs(x) < 0.00001
+
return near0(mat[1, 0]) and near0(mat[2, 0]) and near0(mat[2, 1])
@@ -63,7 +64,7 @@ def convert_cell(ase_cell):
"""
# if ase_cell is lower triangular, cell is upper tri-angular
- cell = np.matrix.transpose(ase_cell)
+ cell = np.matrix.transpose(ase_cell)
if not is_upper_triangular(cell):
# rotate bases into triangular matrix
@@ -85,7 +86,7 @@ def convert_cell(ase_cell):
trans = np.array([np.cross(B, C), np.cross(C, A), np.cross(A, B)])
trans = trans / volume
coord_transform = tri_mat * trans
- return tri_mat.T # return the lower-tri-angular
+ return tri_mat.T # return the lower-tri-angular
else:
return ase_cell
@@ -97,12 +98,12 @@ def convert_positions(pos0, cell0, cell_new, direct=False):
cell0_inv = np.linalg.inv(cell0)
R = np.dot(cell_new, cell0_inv)
pos = np.dot(pos0, R)
- '''
+ """
print(R)
print(R.T)
print(np.linalg.inv(R))
print(np.linalg.det(R))
- '''
+ """
return pos
@@ -158,23 +159,23 @@ def get_typeid(typeids, csymbol):
return typeids[csymbol]
-def ase2lammpsdata(atoms, typeids=None, fout='out.lmp'):
+def ase2lammpsdata(atoms, typeids=None, fout="out.lmp"):
# atoms: ase.Atoms
# typeids: eg. {'Zr': 1, 'Nb': 2, 'Hf': 3}, should start with 1 and continuous
# fout: output file name
- fw = open(fout, 'w')
- fw.write('# LAMMPS data written by PotGen-ASE\n')
- fw.write('\n')
+ fw = open(fout, "w")
+ fw.write("# LAMMPS data written by PotGen-ASE\n")
+ fw.write("\n")
# write number of atoms
natoms = atoms.get_number_of_atoms()
- fw.write('%d atoms\n' % natoms)
- fw.write('\n')
+ fw.write("%d atoms\n" % natoms)
+ fw.write("\n")
# write number of types
ntypes = get_atoms_ntypes(atoms)
fw.write("%d atom types\n" % ntypes)
- fw.write('\n')
+ fw.write("\n")
# write cell information
# transfer the cell into lammps' style
@@ -193,27 +194,27 @@ def ase2lammpsdata(atoms, typeids=None, fout='out.lmp'):
fw.write("%f\t%f\t ylo yhi\n" % (0, yhi))
fw.write("%f\t%f\t zlo zhi\n" % (0, zhi))
fw.write("%f\t%f\t%f\t xy xz yz\n" % (xy, xz, yz))
- fw.write('\n')
+ fw.write("\n")
# write mases
masses = np.unique(atoms.get_masses())
- fw.write('Masses\n')
- fw.write('\n')
+ fw.write("Masses\n")
+ fw.write("\n")
for i in range(ntypes):
- fw.write('%d\t%f\n' % (i + 1, masses[i]))
+ fw.write("%d\t%f\n" % (i + 1, masses[i]))
fw.flush()
- fw.write('\n')
+ fw.write("\n")
# convert positions
atoms.set_cell(cell, scale_atoms=True)
pos = atoms.get_positions()
- '''
+ """
pos0 = atoms.get_positions()
pos = convert_positions(pos0, cell0, cell) # positions in new cellmatrix
- '''
+ """
# === Write postions ===
- fw.write('Atoms\n')
- fw.write('\n')
+ fw.write("Atoms\n")
+ fw.write("\n")
symbols = atoms.get_chemical_symbols()
if typeids is None:
typeids = set_atoms_typeids(atoms)
@@ -222,21 +223,24 @@ def ase2lammpsdata(atoms, typeids=None, fout='out.lmp'):
typeid = get_typeid(typeids, cs) # typeid start from 1~N
# typeid = ase.data.atomic_numbers[cs] # typeid as their atomic
# numbers
- fw.write('%d\t%d\t%f\t%f\t%f\n' %
- (i + 1, typeid, pos[i][0], pos[i][1], pos[i][2]))
+ fw.write(
+ "%d\t%d\t%f\t%f\t%f\n" % (i + 1, typeid, pos[i][0], pos[i][1], pos[i][2])
+ )
fw.flush()
fw.close()
return
+
# test
if __name__ == "__main__":
import sys
+
fin = sys.argv[1]
ATOMS = ase.io.read(fin)
ase2lammpsdata(ATOMS)
- ase2lammpsdata(ATOMS, typeids={'Al': 1}, fout=fin + '.lmp')
+ ase2lammpsdata(ATOMS, typeids={"Al": 1}, fout=fin + ".lmp")
- sep = '=' * 40
+ sep = "=" * 40
pos0 = ATOMS.get_positions()
cell0 = ATOMS.get_cell()
@@ -244,24 +248,24 @@ def ase2lammpsdata(atoms, typeids=None, fout='out.lmp'):
print(pos0)
print(sep)
- '''
+ """
cell_new = np.eye(3)*4.05
- '''
+ """
delta = 4.05 * 0.02
- '''
+ """
cell_new = 4.05*np.array([[1, delta, 0],
[delta, 1, 0],
[0, 0, 1 / (1 - delta**2)]])
- '''
- cell_new = 4.05 * np.array([[1 + delta, 0, 0],
- [0, 1 + delta, 0],
- [0, 0, 1 / (1 + delta**2)]])
+ """
+ cell_new = 4.05 * np.array(
+ [[1 + delta, 0, 0], [0, 1 + delta, 0], [0, 0, 1 / (1 + delta**2)]]
+ )
pos = convert_positions(pos0, cell0, cell_new)
print(cell0)
print(cell_new)
- #print(np.linalg.det(cell0), np.linalg.det(cell_new))
+ # print(np.linalg.det(cell0), np.linalg.det(cell_new))
print(pos)
print(sep)
@@ -270,13 +274,12 @@ def ase2lammpsdata(atoms, typeids=None, fout='out.lmp'):
pos = convert_positions(pos0, cell0, cell_new)
print(cell0)
print(cell_new)
- #print(np.linalg.det(cell0), np.linalg.det(cell_new))
+ # print(np.linalg.det(cell0), np.linalg.det(cell_new))
print(pos)
print(sep)
# test for stress tensor transformation
- stress0 = np.array([0.000593 , 0.000593, 0.000593 ,
- 0., 0.00, 0.00])
+ stress0 = np.array([0.000593, 0.000593, 0.000593, 0.0, 0.00, 0.00])
stress_new = convert_stress(stress0, cell0, cell_new)
print(stress0)
print(stress_new)
diff --git a/dpgen/data/tools/ovito_file_convert.py b/dpgen/data/tools/ovito_file_convert.py
index aa88fa457..5b3f19c7c 100755
--- a/dpgen/data/tools/ovito_file_convert.py
+++ b/dpgen/data/tools/ovito_file_convert.py
@@ -1,49 +1,57 @@
#!/usr/bin/env ovitos
-'''
+"""
This Script is adapted from Alexander Stukowski, the author of OVITO.
See: http://forum.ovito.org/index.php?topic=131.0 for details.
-'''
+"""
+import argparse
import os
import sys
-import argparse
-import numpy as np
+import numpy as np
from ovito.io import *
-supp_ofmt = ['lammps_dump', 'lammps_data', 'vasp']
-supp_exts = ['dump', 'lmp', 'poscar/POSCAR']
+supp_ofmt = ["lammps_dump", "lammps_data", "vasp"]
+supp_exts = ["dump", "lmp", "poscar/POSCAR"]
parser = argparse.ArgumentParser()
-parser.add_argument("-m", "--ofmt", type=str,
- help="the output format, supported: " + str(supp_ofmt))
-parser.add_argument("INPUT", type=str,
- help="the input file")
-parser.add_argument("OUTPUT", type=str,
- help="the output file, supported ext: " + str(supp_exts))
+parser.add_argument(
+ "-m", "--ofmt", type=str, help="the output format, supported: " + str(supp_ofmt)
+)
+parser.add_argument("INPUT", type=str, help="the input file")
+parser.add_argument(
+ "OUTPUT", type=str, help="the output file, supported ext: " + str(supp_exts)
+)
args = parser.parse_args()
fin = args.INPUT
fout = args.OUTPUT
-if args.ofmt is not None :
+if args.ofmt is not None:
ofmt = args.ofmt
-else :
- ext = fout.split('.')[-1]
- if ext == 'dump' :
- ofmt = 'lammps_dump'
- elif ext == 'lmp' :
- ofmt = 'lammps_data'
- elif ext == 'poscar' or ext == 'POSCAR' :
- ofmt = 'vasp'
-if not ofmt in supp_ofmt :
- raise RuntimeError ("output format " + ofmt + " is not supported. use one of " + str(supp_ofmt))
+else:
+ ext = fout.split(".")[-1]
+ if ext == "dump":
+ ofmt = "lammps_dump"
+ elif ext == "lmp":
+ ofmt = "lammps_data"
+ elif ext == "poscar" or ext == "POSCAR":
+ ofmt = "vasp"
+if not ofmt in supp_ofmt:
+ raise RuntimeError(
+ "output format " + ofmt + " is not supported. use one of " + str(supp_ofmt)
+ )
columns = None
-if ofmt == "lammps_dump" :
- columns=["Particle Identifier", "Particle Type", "Position.X", "Position.Y", "Position.Z"]
+if ofmt == "lammps_dump":
+ columns = [
+ "Particle Identifier",
+ "Particle Type",
+ "Position.X",
+ "Position.Y",
+ "Position.Z",
+ ]
node = import_file(fin)
-if columns is not None :
- export_file(node, fout, ofmt, columns = columns)
-else :
+if columns is not None:
+ export_file(node, fout, ofmt, columns=columns)
+else:
export_file(node, fout, ofmt)
-
diff --git a/dpgen/data/tools/poscar_copy.py b/dpgen/data/tools/poscar_copy.py
index 19db01962..24aab403b 100755
--- a/dpgen/data/tools/poscar_copy.py
+++ b/dpgen/data/tools/poscar_copy.py
@@ -1,36 +1,37 @@
#!/usr/bin/env ovitos
+import argparse
+
+import numpy as np
from ovito.io import *
from ovito.modifiers import *
-import numpy as np
-import argparse
-def copy_system (ncopy, fin, fout) :
+def copy_system(ncopy, fin, fout):
nx = ncopy[0]
ny = ncopy[1]
nz = ncopy[2]
node = import_file(fin)
- pbc = ShowPeriodicImagesModifier(adjust_box = True,
- num_x = nx,
- num_y = ny,
- num_z = nz,
- replicate_x = True,
- replicate_y = True,
- replicate_z = True
+ pbc = ShowPeriodicImagesModifier(
+ adjust_box=True,
+ num_x=nx,
+ num_y=ny,
+ num_z=nz,
+ replicate_x=True,
+ replicate_y=True,
+ replicate_z=True,
)
node.modifiers.append(pbc)
node.compute()
- export_file(node, fout, 'vasp')
+ export_file(node, fout, "vasp")
+
-parser = argparse.ArgumentParser(
- description="Copy system")
-parser.add_argument('-n', '--ncopy', type=int, nargs = 3,
- help="the number of copies in each direction")
-parser.add_argument('INPUT', type=str,
- help="the input file")
-parser.add_argument('OUTPUT', type=str,
- help="the output file")
+parser = argparse.ArgumentParser(description="Copy system")
+parser.add_argument(
+ "-n", "--ncopy", type=int, nargs=3, help="the number of copies in each direction"
+)
+parser.add_argument("INPUT", type=str, help="the input file")
+parser.add_argument("OUTPUT", type=str, help="the output file")
args = parser.parse_args()
copy_system(args.ncopy, args.INPUT, args.OUTPUT)
diff --git a/dpgen/data/tools/sc.py b/dpgen/data/tools/sc.py
index 3e1c33d54..2c2c0671a 100644
--- a/dpgen/data/tools/sc.py
+++ b/dpgen/data/tools/sc.py
@@ -1,14 +1,17 @@
import numpy as np
-def numb_atoms () :
+
+def numb_atoms():
return 1
-def gen_box () :
+
+def gen_box():
return np.eye(3)
-def poscar_unit (latt) :
+
+def poscar_unit(latt):
box = gen_box()
- ret = ""
+ ret = ""
ret += "SC : a = %f \n" % latt
ret += "%.16f\n" % (latt)
ret += "%.16f %.16f %.16f\n" % (box[0][0], box[0][1], box[0][2])
diff --git a/dpgen/data/tools/test.sh b/dpgen/data/tools/test.sh
index 021135e13..58b01ebe4 100755
--- a/dpgen/data/tools/test.sh
+++ b/dpgen/data/tools/test.sh
@@ -1,4 +1,3 @@
#!/bin/bash
for ii in *; do ll=`grep -i 'total-force' $ii/OUTCAR | wc -l`; echo $ii $ll; done
-
diff --git a/dpgen/database/__init__.py b/dpgen/database/__init__.py
index e8b92ae34..fadd65267 100644
--- a/dpgen/database/__init__.py
+++ b/dpgen/database/__init__.py
@@ -1,2 +1,2 @@
from .entry import Entry
-from .vasp import VaspInput,DPPotcar
+from .vasp import DPPotcar, VaspInput
diff --git a/dpgen/database/entry.py b/dpgen/database/entry.py
index e881f45dd..41da89320 100644
--- a/dpgen/database/entry.py
+++ b/dpgen/database/entry.py
@@ -1,14 +1,16 @@
-#/usr/bin/env python
+# /usr/bin/env python
# coding: utf-8
# Copyright (c) The Dpmodeling Team.
import json
import warnings
from uuid import uuid4
-from dpdata import System,LabeledSystem
-from dpgen.database.vasp import VaspInput
+
+from dpdata import LabeledSystem, System
+from monty.json import MontyDecoder, MontyEncoder, MSONable
from pymatgen.core.composition import Composition
-from monty.json import MontyEncoder, MontyDecoder, MSONable
+
+from dpgen.database.vasp import VaspInput
"""
This module implements equivalents of the basic Entry objects, which
@@ -21,12 +23,20 @@
class Entry(MSONable):
"""
An lightweight Entry object containing key computed data
- for storing purpose.
+ for storing purpose.
"""
- def __init__(self, composition, calculator, inputs,
- data, entry_id=None, attribute=None, tag=None):
+ def __init__(
+ self,
+ composition,
+ calculator,
+ inputs,
+ data,
+ entry_id=None,
+ attribute=None,
+ tag=None,
+ ):
"""
Initializes a Entry.
@@ -47,15 +57,15 @@ def __init__(self, composition, calculator, inputs,
but must be MSONable.
"""
self.composition = Composition(composition)
- self.calculator = calculator
+ self.calculator = calculator
self.inputs = inputs
- self.data = data
+ self.data = data
self.entry_id = entry_id
self.name = self.composition.reduced_formula
self.attribute = attribute
self.tag = tag
- #def __eq__(self,other):
+ # def __eq__(self,other):
# if not self.composition == other.composition:
# return False
# if not self.calculator == other.calculator:
@@ -77,9 +87,10 @@ def number_element(self):
return len(self.composition)
def __repr__(self):
- output = ["Entry {} - {}".format(self.entry_id, self.composition.formula),
- "calculator: {}".format(self.calculator)
- ]
+ output = [
+ "Entry {} - {}".format(self.entry_id, self.composition.formula),
+ "calculator: {}".format(self.calculator),
+ ]
return "\n".join(output)
def __str__(self):
@@ -88,24 +99,25 @@ def __str__(self):
@classmethod
def from_dict(cls, d):
dec = MontyDecoder()
- return cls(d["composition"], d["calculator"],
- inputs={k: dec.process_decoded(v)
- for k, v in d.get("inputs", {}).items()},
- data={k: dec.process_decoded(v)
- for k, v in d.get("data", {}).items()},
- entry_id=d.get("entry_id", None),
- attribute=d["attribute"] if "attribute" in d else None,
- tag=d["tag"] if "tag" in d else None
- )
+ return cls(
+ d["composition"],
+ d["calculator"],
+ inputs={k: dec.process_decoded(v) for k, v in d.get("inputs", {}).items()},
+ data={k: dec.process_decoded(v) for k, v in d.get("data", {}).items()},
+ entry_id=d.get("entry_id", None),
+ attribute=d["attribute"] if "attribute" in d else None,
+ tag=d["tag"] if "tag" in d else None,
+ )
def as_dict(self):
- return {"@module": self.__class__.__module__,
- "@class": self.__class__.__name__,
- "composition": self.composition.as_dict(),
- "calculator": self.calculator,
- "inputs": json.loads(json.dumps(self.inputs,
- cls=MontyEncoder)),
- "data": json.loads(json.dumps(self.data, cls=MontyEncoder)),
- "entry_id": self.entry_id,
- "attribute": self.attribute,
- "tag": self.tag}
+ return {
+ "@module": self.__class__.__module__,
+ "@class": self.__class__.__name__,
+ "composition": self.composition.as_dict(),
+ "calculator": self.calculator,
+ "inputs": json.loads(json.dumps(self.inputs, cls=MontyEncoder)),
+ "data": json.loads(json.dumps(self.data, cls=MontyEncoder)),
+ "entry_id": self.entry_id,
+ "attribute": self.attribute,
+ "tag": self.tag,
+ }
diff --git a/dpgen/database/run.py b/dpgen/database/run.py
index f66e4c56f..722028b10 100644
--- a/dpgen/database/run.py
+++ b/dpgen/database/run.py
@@ -1,36 +1,39 @@
-#/usr/bin/env python
+# /usr/bin/env python
# coding: utf-8
# Copyright (c) The Dpmodeling Team.
+import json
import os
import time
-import json
-from uuid import uuid4
-from threading import Thread
+import traceback
from glob import glob
-from dpgen import dlog
-from dpgen import SHORT_CMD
+from threading import Thread
+from uuid import uuid4
+
+import numpy as np
+from dpdata import LabeledSystem, System
+from monty.serialization import dumpfn, loadfn
+
+from dpgen import SHORT_CMD, dlog
from dpgen.database.entry import Entry
from dpgen.database.vasp import VaspInput
-from dpdata import System,LabeledSystem
-from monty.serialization import loadfn,dumpfn
-import numpy as np
-import traceback
-OUTPUT=SHORT_CMD+'_db.json'
-SUPPORTED_CACULATOR=['vasp','pwscf','gaussian']
-ITERS_PAT="iter.*/02.fp/task*"
-INIT_PAT="init/*/02.md/sys-*/scale-*/*"
+OUTPUT = SHORT_CMD + "_db.json"
+SUPPORTED_CACULATOR = ["vasp", "pwscf", "gaussian"]
+ITERS_PAT = "iter.*/02.fp/task*"
+INIT_PAT = "init/*/02.md/sys-*/scale-*/*"
+
def db_run(args):
- dlog.info ("collecting data")
- #print(args.ID_PREFIX)
+ dlog.info("collecting data")
+ # print(args.ID_PREFIX)
_main(args.PARAM)
- dlog.info ("finished")
+ dlog.info("finished")
+
def _main(param):
with open(param, "r") as fp:
- jdata = json.load(fp)
+ jdata = json.load(fp)
calculator = jdata["calculator"]
path = jdata["path"]
calulator = jdata["calculator"]
@@ -39,123 +42,128 @@ def _main(param):
id_prefix = jdata["id_prefix"]
skip_init = False
if "skip_init" in jdata:
- skip_init = jdata["skip_init"]
+ skip_init = jdata["skip_init"]
## The mapping from sys_info to sys_configs
assert calculator.lower() in SUPPORTED_CACULATOR
- dlog.info('data collection from: %s'%path)
+ dlog.info("data collection from: %s" % path)
if calculator == "vasp":
- parsing_vasp(path,config_info_dict,skip_init, output,id_prefix)
- elif calculator == 'gaussian':
- parsing_gaussian(path,output)
+ parsing_vasp(path, config_info_dict, skip_init, output, id_prefix)
+ elif calculator == "gaussian":
+ parsing_gaussian(path, output)
else:
- parsing_pwscf(path,output)
+ parsing_pwscf(path, output)
+
-def parsing_vasp(path,config_info_dict, skip_init, output=OUTPUT,id_prefix=None):
-
- fp_iters=os.path.join(path,ITERS_PAT)
+def parsing_vasp(path, config_info_dict, skip_init, output=OUTPUT, id_prefix=None):
+
+ fp_iters = os.path.join(path, ITERS_PAT)
dlog.debug(fp_iters)
- f_fp_iters=glob(fp_iters)
- dlog.info("len iterations data: %s"%len(f_fp_iters))
- fp_init=os.path.join(path,INIT_PAT)
+ f_fp_iters = glob(fp_iters)
+ dlog.info("len iterations data: %s" % len(f_fp_iters))
+ fp_init = os.path.join(path, INIT_PAT)
dlog.debug(fp_init)
- f_fp_init=glob(fp_init)
+ f_fp_init = glob(fp_init)
if skip_init:
- entries = _parsing_vasp(f_fp_iters,config_info_dict, id_prefix)
- dlog.info("len collected data: %s"%len(entries))
+ entries = _parsing_vasp(f_fp_iters, config_info_dict, id_prefix)
+ dlog.info("len collected data: %s" % len(entries))
else:
- dlog.info("len initialization data: %s"%len(f_fp_init))
- entries=_parsing_vasp(f_fp_init,config_info_dict, id_prefix,iters=False)
- entries.extend(_parsing_vasp(f_fp_iters,config_info_dict, id_prefix))
- dlog.info("len collected data: %s"%len(entries))
- #print(output)
- #print(entries)
- dumpfn(entries,output,indent=4)
-
-def _parsing_vasp(paths,config_info_dict, id_prefix,iters=True):
- entries=[]
- icount=0
+ dlog.info("len initialization data: %s" % len(f_fp_init))
+ entries = _parsing_vasp(f_fp_init, config_info_dict, id_prefix, iters=False)
+ entries.extend(_parsing_vasp(f_fp_iters, config_info_dict, id_prefix))
+ dlog.info("len collected data: %s" % len(entries))
+ # print(output)
+ # print(entries)
+ dumpfn(entries, output, indent=4)
+
+
+def _parsing_vasp(paths, config_info_dict, id_prefix, iters=True):
+ entries = []
+ icount = 0
if iters:
- iter_record = []
- iter_record_new = []
- try:
- with open ("record.database", "r") as f_record:
- iter_record = [i.split()[0] for i in f_record.readlines()]
- iter_record.sort()
- dlog.info("iter_record")
- dlog.info(iter_record)
- except Exception:
- pass
+ iter_record = []
+ iter_record_new = []
+ try:
+ with open("record.database", "r") as f_record:
+ iter_record = [i.split()[0] for i in f_record.readlines()]
+ iter_record.sort()
+ dlog.info("iter_record")
+ dlog.info(iter_record)
+ except Exception:
+ pass
for path in paths:
- try:
- f_outcar = os.path.join(path,'OUTCAR')
- f_job = os.path.join(path,'job.json')
- tmp_iter = path.split('/')[-3]
- if (tmp_iter in iter_record) and (tmp_iter != iter_record[-1]):
- continue
- if tmp_iter not in iter_record_new:
- iter_record_new.append(tmp_iter)
- vi = VaspInput.from_directory(path)
- if os.path.isfile(f_job):
- attrib=loadfn(f_job)
- else:
- attrib={}
-
- if iters and attrib:
- # generator/Cu/iter.000031/02.fp/task.007.000000
- tmp_=path.split('/')[-1]
- #config_info=tmp_.split('.')[1]
- task_info=tmp_.split('.')[-1]
- tmp_iter = path.split('/')[-3]
- iter_info = tmp_iter.split('.')[-1]
- sys_info = path.split('/')[-4]
- config_info_int = int(tmp_.split('.')[1])
- for (key, value) in config_info_dict.items():
- if config_info_int in value:
- config_info = key
- attrib['config_info']=config_info
- attrib['task_info']=task_info
- attrib['iter_info']=iter_info
- attrib['sys_info']=sys_info
- with open(f_outcar , "r") as fin_outcar:
- infile_outcar = fin_outcar.readlines()
- for line in infile_outcar:
- if "running on" in line:
- attrib["core"] = int(line.split()[2])
- if "Elapse" in line:
- attrib["wall_time"] = float(line.split()[-1])
- if "executed on" in line:
- attrib["date"] = line.split()[-2]
- attrib["clocktime"] = line.split()[-1]
- dlog.info("Attrib")
- dlog.info(attrib)
- comp=vi['POSCAR'].structure.composition
- ls = LabeledSystem(f_outcar)
- lss=ls.to_list()
- for ls in lss:
- if id_prefix:
- eid=id_prefix+"_"+str(icount)
- else:
- eid = str(uuid4())
- entry=Entry(comp,'vasp',vi.as_dict(),ls.as_dict(),attribute=attrib,entry_id=eid)
- entries.append(entry)
- icount+=1
- except Exception:
- #dlog.info(str(Exception))
- dlog.info("failed for %s"%(path))
- #pass
+ try:
+ f_outcar = os.path.join(path, "OUTCAR")
+ f_job = os.path.join(path, "job.json")
+ tmp_iter = path.split("/")[-3]
+ if (tmp_iter in iter_record) and (tmp_iter != iter_record[-1]):
+ continue
+ if tmp_iter not in iter_record_new:
+ iter_record_new.append(tmp_iter)
+ vi = VaspInput.from_directory(path)
+ if os.path.isfile(f_job):
+ attrib = loadfn(f_job)
+ else:
+ attrib = {}
+
+ if iters and attrib:
+ # generator/Cu/iter.000031/02.fp/task.007.000000
+ tmp_ = path.split("/")[-1]
+ # config_info=tmp_.split('.')[1]
+ task_info = tmp_.split(".")[-1]
+ tmp_iter = path.split("/")[-3]
+ iter_info = tmp_iter.split(".")[-1]
+ sys_info = path.split("/")[-4]
+ config_info_int = int(tmp_.split(".")[1])
+ for (key, value) in config_info_dict.items():
+ if config_info_int in value:
+ config_info = key
+ attrib["config_info"] = config_info
+ attrib["task_info"] = task_info
+ attrib["iter_info"] = iter_info
+ attrib["sys_info"] = sys_info
+ with open(f_outcar, "r") as fin_outcar:
+ infile_outcar = fin_outcar.readlines()
+ for line in infile_outcar:
+ if "running on" in line:
+ attrib["core"] = int(line.split()[2])
+ if "Elapse" in line:
+ attrib["wall_time"] = float(line.split()[-1])
+ if "executed on" in line:
+ attrib["date"] = line.split()[-2]
+ attrib["clocktime"] = line.split()[-1]
+ dlog.info("Attrib")
+ dlog.info(attrib)
+ comp = vi["POSCAR"].structure.composition
+ ls = LabeledSystem(f_outcar)
+ lss = ls.to_list()
+ for ls in lss:
+ if id_prefix:
+ eid = id_prefix + "_" + str(icount)
+ else:
+ eid = str(uuid4())
+ entry = Entry(
+ comp, "vasp", vi.as_dict(), ls.as_dict(), attribute=attrib, entry_id=eid
+ )
+ entries.append(entry)
+ icount += 1
+ except Exception:
+ # dlog.info(str(Exception))
+ dlog.info("failed for %s" % (path))
+ # pass
if iters:
- iter_record.sort()
- iter_record_new.sort()
- with open("record.database" , "w") as fw:
- for line in iter_record:
- fw.write(line + "\n")
- for line in iter_record_new:
- fw.write(line + "\n")
+ iter_record.sort()
+ iter_record_new.sort()
+ with open("record.database", "w") as fw:
+ for line in iter_record:
+ fw.write(line + "\n")
+ for line in iter_record_new:
+ fw.write(line + "\n")
return entries
-def parsing_pwscf(path,output=OUTPUT):
- pass
-def parsing_gaussian(path,output=OUTPUT):
+def parsing_pwscf(path, output=OUTPUT):
pass
+
+def parsing_gaussian(path, output=OUTPUT):
+ pass
diff --git a/dpgen/database/vasp.py b/dpgen/database/vasp.py
index add777e6d..dcbef299d 100644
--- a/dpgen/database/vasp.py
+++ b/dpgen/database/vasp.py
@@ -1,96 +1,98 @@
-#/usr/bin/env python
+# /usr/bin/env python
# coding: utf-8
# Copyright (c) PThe Dpmodeling Team.
import os
import warnings
+
from monty.io import zopen
+from monty.json import MontyDecoder, MSONable
from monty.os.path import zpath
-from monty.json import MSONable, MontyDecoder
-from pymatgen.io.vasp import Potcar,Incar,Kpoints,Poscar,PotcarSingle
+from pymatgen.io.vasp import Incar, Kpoints, Poscar, Potcar, PotcarSingle
+
"""
Classes for reading/manipulating/writing VASP input files. All major VASP input
files.
"""
+
class DPPotcar(MSONable):
- def __init__(self,symbols=None,functional="PBE",pp_file=None,pp_lists=None):
+ def __init__(self, symbols=None, functional="PBE", pp_file=None, pp_lists=None):
if pp_lists and pp_file is None:
- for pp in pp_lists:
- assert isinstance(pp,PotcarSingle)
- self.potcars=pp_lists
- elif pp_file and pp_list is None:
- self.potcars=Potcar.from_file(pp_file)
+ for pp in pp_lists:
+ assert isinstance(pp, PotcarSingle)
+ self.potcars = pp_lists
+ elif pp_file and pp_list is None:
+ self.potcars = Potcar.from_file(pp_file)
elif pp_file and pp_list:
- self.potcars=Potcar.from_file(pp_file)
+ self.potcars = Potcar.from_file(pp_file)
else:
- try:
- self.potcars=Potcar(symbols=symbols, functional=functional)
- except Exception:
- warnings.warn ("""Inproperly configure of POTCAR !""")
- self.potcars=None
-
+ try:
+ self.potcars = Potcar(symbols=symbols, functional=functional)
+ except Exception:
+ warnings.warn("""Inproperly configure of POTCAR !""")
+ self.potcars = None
+
if self.potcars is not None:
- self.symbols = [pp.symbol for pp in self.potcars]
- self.functional = list(set([pp.functional for pp in self.potcars]))[0]
- self.hashs = [pp.get_potcar_hash() for pp in self.potcars]
+ self.symbols = [pp.symbol for pp in self.potcars]
+ self.functional = list(set([pp.functional for pp in self.potcars]))[0]
+ self.hashs = [pp.get_potcar_hash() for pp in self.potcars]
else:
- self.symbols=symbols
- self.functional=functional
- self.hashs = ''
+ self.symbols = symbols
+ self.functional = functional
+ self.hashs = ""
self.elements = self._get_elements()
-
+
def __repr__(self):
return str(self)
def __str__(self):
if self.potcars is not None:
- return str(self.potcars)
+ return str(self.potcars)
else:
- ret ="Functional: %s\n"%self.functional
- ret +=" ".join(self.symbols)+"\n"
- return ret
+ ret = "Functional: %s\n" % self.functional
+ ret += " ".join(self.symbols) + "\n"
+ return ret
def _get_elements(self):
- elements=[]
+ elements = []
for el in self.symbols:
- if '_' in el:
- elements.append(el.split('_')[0])
+ if "_" in el:
+ elements.append(el.split("_")[0])
else:
- elements.append(el)
+ elements.append(el)
return elements
@classmethod
- def from_dict(cls,d):
- return cls(symbols=d['symbols'],functional=d['functional'])
+ def from_dict(cls, d):
+ return cls(symbols=d["symbols"], functional=d["functional"])
def as_dict(self):
- d={}
+ d = {}
d["@module"] = self.__class__.__module__
d["@class"] = self.__class__.__name__
- d['symbols']=self.symbols
- d['elements']=self.elements
- d['hashs']=self.hashs
- d['functional']=self.functional
+ d["symbols"] = self.symbols
+ d["elements"] = self.elements
+ d["hashs"] = self.hashs
+ d["functional"] = self.functional
return d
@classmethod
- def from_file(cls,filename):
+ def from_file(cls, filename):
try:
- potcars=Potcar.from_file(filename)
- return cls(pp_lists=potcars)
+ potcars = Potcar.from_file(filename)
+ return cls(pp_lists=potcars)
except Exception:
- with open(filename,'r') as f:
- content=f.readlines()
- functional=content[0].strip().split(':')[-1].strip()
- symbols=content[1].strip().split()
- return cls(symbols=symbols,functional=functional)
-
+ with open(filename, "r") as f:
+ content = f.readlines()
+ functional = content[0].strip().split(":")[-1].strip()
+ symbols = content[1].strip().split()
+ return cls(symbols=symbols, functional=functional)
- def write_file(self,filename):
- with open(filename,'w') as f:
- f.write(str(self))
+ def write_file(self, filename):
+ with open(filename, "w") as f:
+ f.write(str(self))
class VaspInput(dict, MSONable):
@@ -107,15 +109,14 @@ class VaspInput(dict, MSONable):
conventions in implementing a as_dict() and from_dict method.
"""
- def __init__(self, incar, poscar, potcar, kpoints=None, optional_files=None,
- **kwargs):
+ def __init__(
+ self, incar, poscar, potcar, kpoints=None, optional_files=None, **kwargs
+ ):
super().__init__(**kwargs)
-
- self.update({'INCAR': incar,
- 'POSCAR': poscar,
- 'POTCAR': potcar})
+
+ self.update({"INCAR": incar, "POSCAR": poscar, "POTCAR": potcar})
if kpoints:
- self.update({'KPOINTS': kpoints})
+ self.update({"KPOINTS": kpoints})
if optional_files is not None:
self.update(optional_files)
@@ -126,7 +127,7 @@ def __str__(self):
output.append(str(v))
output.append("")
return "\n".join(output)
-
+
def as_dict(self):
d = {k: v.as_dict() for k, v in self.items()}
d["@module"] = self.__class__.__module__
@@ -175,20 +176,27 @@ def from_directory(input_dir, optional_files=None):
"""
sub_d = {}
try:
- for fname, ftype in [("INCAR", Incar), ("KPOINTS", Kpoints),
- ("POSCAR", Poscar), ("POTCAR", DPPotcar)]:
+ for fname, ftype in [
+ ("INCAR", Incar),
+ ("KPOINTS", Kpoints),
+ ("POSCAR", Poscar),
+ ("POTCAR", DPPotcar),
+ ]:
fullzpath = zpath(os.path.join(input_dir, fname))
sub_d[fname.lower()] = ftype.from_file(fullzpath)
except Exception:
- for fname, ftype in [("INCAR", Incar),
- ("POSCAR", Poscar), ("POTCAR", DPPotcar)]:
+ for fname, ftype in [
+ ("INCAR", Incar),
+ ("POSCAR", Poscar),
+ ("POTCAR", DPPotcar),
+ ]:
fullzpath = zpath(os.path.join(input_dir, fname))
sub_d[fname.lower()] = ftype.from_file(fullzpath)
sub_d["optional_files"] = {}
if optional_files is not None:
for fname, ftype in optional_files.items():
- sub_d["optional_files"][fname] = \
- ftype.from_file(os.path.join(input_dir, fname))
+ sub_d["optional_files"][fname] = ftype.from_file(
+ os.path.join(input_dir, fname)
+ )
return VaspInput(**sub_d)
-
diff --git a/dpgen/dispatcher/ALI.py b/dpgen/dispatcher/ALI.py
deleted file mode 100644
index 2a01ab378..000000000
--- a/dpgen/dispatcher/ALI.py
+++ /dev/null
@@ -1,514 +0,0 @@
-from aliyunsdkecs.request.v20140526.DescribeInstancesRequest import DescribeInstancesRequest
-from aliyunsdkcore.client import AcsClient
-import aliyunsdkcore.request
-aliyunsdkcore.request.set_default_protocol_type("https")
-from aliyunsdkcore.acs_exception.exceptions import ClientException
-from aliyunsdkcore.acs_exception.exceptions import ServerException
-from aliyunsdkecs.request.v20140526.RunInstancesRequest import RunInstancesRequest
-from aliyunsdkecs.request.v20140526.DeleteInstancesRequest import DeleteInstancesRequest
-from aliyunsdkecs.request.v20140526.DescribeAutoProvisioningGroupInstancesRequest import DescribeAutoProvisioningGroupInstancesRequest
-from aliyunsdkecs.request.v20140526.CreateAutoProvisioningGroupRequest import CreateAutoProvisioningGroupRequest
-from aliyunsdkecs.request.v20140526.DeleteAutoProvisioningGroupRequest import DeleteAutoProvisioningGroupRequest
-from aliyunsdkecs.request.v20140526.ModifyAutoProvisioningGroupRequest import ModifyAutoProvisioningGroupRequest
-from aliyunsdkecs.request.v20140526.DeleteLaunchTemplateRequest import DeleteLaunchTemplateRequest
-from aliyunsdkvpc.request.v20160428.DescribeVpcsRequest import DescribeVpcsRequest
-from aliyunsdkecs.request.v20140526.DescribeLaunchTemplatesRequest import DescribeLaunchTemplatesRequest
-from aliyunsdkecs.request.v20140526.CreateLaunchTemplateRequest import CreateLaunchTemplateRequest
-from aliyunsdkecs.request.v20140526.DescribeImagesRequest import DescribeImagesRequest
-from aliyunsdkecs.request.v20140526.DescribeSecurityGroupsRequest import DescribeSecurityGroupsRequest
-from aliyunsdkvpc.request.v20160428.DescribeVSwitchesRequest import DescribeVSwitchesRequest
-import time, json, os, glob, string, random, sys
-from dpgen.dispatcher.Dispatcher import Dispatcher, _split_tasks, JobRecord
-from dpgen.dispatcher.SSHContext import SSHSession
-from dpgen.dispatcher.DispatcherList import DispatcherList, Entity
-from os.path import join
-from dpgen import dlog
-from hashlib import sha1
-
-# cloud_resources = {"AccessKey_ID":"",
-# "AccessKey_Secret":"",
-# "regionID": "cn-shenzhen",
-# "img_name": "kit",
-# "machine_type_price": [
-# {"machine_type": "ecs.gn6v-c8g1.2xlarge", "price_limit": 20.00, "numb": 1, "priority": 0},
-# {"machine_type": "ecs.gn5-c4g1.xlarge", "price_limit": 20.00, "numb": 1, "priority": 1}
-# ],
-# "instance_name": "CH4_test_username",
-# "pay_strategy": "spot"
-# "apg_id": apg_id,
-# "template_id": template_id,
-# "vsw_id": vsw_id,
-# "region_id": region_id,
-# "client": client}
-
-def manual_create(stage, num):
- '''running this function in your project root path, which contains machine-ali.json.
- please ensure your machine name is machine-ali.json
- This will create a subdir named manual, which includes apg_id.json'''
- root_path = os.getcwd()
- fp = open("machine-ali.json")
- data = json.load(fp)
- if not os.path.exists("manual"):
- os.mkdir("manual")
- os.chdir("manual")
- mdata_machine = data[stage][0]["machine"]
- mdata_resources = data[stage][0]["resources"]
- cloud_resources = mdata_machine["cloud_resources"]
- ali = ALI(mdata_machine, mdata_resources, "work_path", [1], 1, cloud_resources)
- img_id = ali.get_image_id(ali.cloud_resources["img_name"])
- sg_id, vpc_id = ali.get_sg_vpc_id()
- ali.cloud_resources["template_id"] = ali.create_template(img_id, sg_id, vpc_id)
- ali.cloud_resources["vsw_id"] = ali.get_vsw_id(vpc_id)
- ali.nchunks_limit = num
- ali.cloud_resources["apg_id"] = ali.create_apg()
- time.sleep(90)
- instance_list = ali.describe_apg_instances()
- ip_list = ali.get_ip(instance_list)
- print(instance_list)
- print(ip_list)
-
-def manual_delete(stage):
- '''running this function in your project root path, which contains machine-ali.json. '''
- if os.path.exists("manual"):
- fp = open("machine-ali.json")
- data = json.load(fp)
- mdata_machine = data[stage][0]["machine"]
- mdata_resources = data[stage][0]["resources"]
- cloud_resources = mdata_machine["cloud_resources"]
- ali = ALI(mdata_machine, mdata_resources, "work_path", [1], 1, cloud_resources)
- os.chdir("manual")
- fp = open("apg_id.json")
- data = json.load(fp)
- ali.cloud_resources["apg_id"] = data["apg_id"]
- ali.delete_apg()
- os.remove("apg_id.json")
- print("delete successfully!")
-
-def delete_apg(stage):
- fp = open("machine-ali.json")
- data = json.load(fp)
- mdata_machine = data[stage][0]["machine"]
- mdata_resources = data[stage][0]["resources"]
- cloud_resources = mdata_machine["cloud_resources"]
- ali = ALI(mdata_machine, mdata_resources, "work_path", [1], 1, cloud_resources)
- fp = open("apg_id.json")
- data = json.load(fp)
- ali.cloud_resources["apg_id"] = data["apg_id"]
- ali.delete_apg()
- os.remove("apg_id.json")
- print("delete successfully!")
-
-
-class ALI(DispatcherList):
- def __init__(self, mdata_machine, mdata_resources, work_path, run_tasks, group_size, cloud_resources=None):
- super().__init__(mdata_machine, mdata_resources, work_path, run_tasks, group_size, cloud_resources)
- self.client = AcsClient(cloud_resources["AccessKey_ID"], cloud_resources["AccessKey_Secret"], cloud_resources["regionID"])
-
- def init(self):
- self.prepare()
- for ii in range(self.nchunks):
- self.create(ii)
-
- def create(self, ii):
- if self.dispatcher_list[ii]["dispatcher_status"] == "unallocated" and len(self.ip_pool) > 0:
- self.dispatcher_list[ii]["entity"] = Entity(self.ip_pool.pop(0), self.server_pool.pop(0))
- self.make_dispatcher(ii)
-
- # Derivate
- def delete(self, ii):
- '''delete one machine'''
- request = DeleteInstancesRequest()
- request.set_accept_format('json')
- request.set_InstanceIds([self.dispatcher_list[ii]["entity"].instance_id])
- request.set_Force(True)
- count = 0
- flag = 0
- while count < 10:
- try:
- response = self.client.do_action_with_exception(request)
- flag = 1
- break
- except ServerException as e:
- time.sleep(10)
- count += 1
-
- if flag:
- status_list = [item["dispatcher_status"] for item in self.dispatcher_list]
- running_num = status_list.count("running")
- running_num += status_list.count("unsubmitted")
- self.change_apg_capasity(running_num)
- else:
- dlog.info("delete failed, exit")
- sys.exit()
-
- def update(self):
- self.server_pool = self.get_server_pool()
- self.ip_pool = self.get_ip(self.server_pool)
-
- # Derivate
- def catch_dispatcher_exception(self, ii):
- '''everything is okay: return 0
- ssh not active : return 1
- machine callback : return 2'''
- if self.check_spot_callback(self.dispatcher_list[ii]["entity"].instance_id):
- dlog.info("machine %s callback, ip: %s" % (self.dispatcher_list[ii]["entity"].instance_id, self.dispatcher_list[ii]["entity"].ip))
- return 2
- elif not self.dispatcher_list[ii]["dispatcher"].session._check_alive():
- try:
- self.dispatcher_list[ii]["dispatcher"].session.ensure_alive()
- return 0
- except RuntimeError:
- return 1
- else: return 0
-
- def get_server_pool(self):
- running_server = self.describe_apg_instances()
- allocated_server = []
- for ii in range(self.nchunks):
- if self.dispatcher_list[ii]["dispatcher_status"] == "running" or self.dispatcher_list[ii]["dispatcher_status"] == "unsubmitted":
- allocated_server.append(self.dispatcher_list[ii]["entity"].instance_id)
- return list(set(running_server) - set(allocated_server))
-
- def clean(self):
- self.delete_apg()
- self.delete_template()
- os.remove("apg_id.json")
-
- def prepare(self):
- restart = False
- if os.path.exists('apg_id.json'):
- with open('apg_id.json') as fp:
- apg = json.load(fp)
- self.cloud_resources["apg_id"] = apg["apg_id"]
- task_chunks_str = ['+'.join(ii) for ii in self.task_chunks]
- task_hashes = [sha1(ii.encode('utf-8')).hexdigest() for ii in task_chunks_str]
- for ii in range(self.nchunks):
- fn = 'jr.%.06d.json' % ii
- if os.path.exists(os.path.join(os.path.abspath(self.work_path), fn)):
- cur_hash = task_hashes[ii]
- job_record = JobRecord(self.work_path, self.task_chunks[ii], fn)
- if not job_record.check_finished(cur_hash):
- if not self.check_spot_callback(job_record.record[cur_hash]['context']['instance_id']):
- self.dispatcher_list[ii]["entity"] = Entity(job_record.record[cur_hash]['context']['ip'], job_record.record[cur_hash]['context']['instance_id'], job_record)
- self.make_dispatcher(ii)
- self.dispatcher_list[ii]["dispatcher_status"] = "unsubmitted"
- else:
- os.remove(os.path.join(os.path.abspath(self.work_path), fn))
- else:
- self.dispatcher_list[ii]["dispatcher_status"] = "finished"
- self.server_pool = self.get_server_pool()
- self.ip_pool = self.get_ip(self.server_pool)
- restart = True
- img_id = self.get_image_id(self.cloud_resources["img_name"])
- sg_id, vpc_id = self.get_sg_vpc_id()
- self.cloud_resources["template_id"] = self.create_template(img_id, sg_id, vpc_id)
- self.cloud_resources["vsw_id"] = self.get_vsw_id(vpc_id)
- if not restart:
- dlog.info("begin to create apg")
- self.cloud_resources["apg_id"] = self.create_apg()
- time.sleep(120)
- self.server_pool = self.get_server_pool()
- self.ip_pool = self.get_ip(self.server_pool)
- else: dlog.info("restart dpgen")
-
- def delete_apg(self):
- request = DeleteAutoProvisioningGroupRequest()
- request.set_accept_format('json')
- request.set_AutoProvisioningGroupId(self.cloud_resources["apg_id"])
- request.set_TerminateInstances(True)
- count = 0
- flag = 0
- while count < 10:
- try:
- response = self.client.do_action_with_exception(request)
- flag = 1
- break
- except ServerException as e:
- time.sleep(10)
- count += 1
- if not flag:
- dlog.info("delete apg failed, exit")
- sys.exit()
-
-
- def create_apg(self):
- request = CreateAutoProvisioningGroupRequest()
- request.set_accept_format('json')
- request.set_TotalTargetCapacity(str(self.nchunks_limit))
- request.set_LaunchTemplateId(self.cloud_resources["template_id"])
- request.set_AutoProvisioningGroupName(self.cloud_resources["instance_name"] + ''.join(random.choice(string.ascii_uppercase) for _ in range(20)))
- request.set_AutoProvisioningGroupType("maintain")
- request.set_SpotAllocationStrategy("lowest-price")
- request.set_SpotInstanceInterruptionBehavior("terminate")
- request.set_SpotInstancePoolsToUseCount(1)
- request.set_ExcessCapacityTerminationPolicy("termination")
- request.set_TerminateInstances(True)
- request.set_PayAsYouGoTargetCapacity("0")
- request.set_SpotTargetCapacity(str(self.nchunks_limit))
- config = self.generate_config()
- request.set_LaunchTemplateConfigs(config)
-
- try:
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- with open('apg_id.json', 'w') as fp:
- json.dump({'apg_id': response["AutoProvisioningGroupId"]}, fp, indent=4)
- return response["AutoProvisioningGroupId"]
- except ServerException as e:
- dlog.info("create apg failed, err msg: %s" % e)
- sys.exit()
- except ClientException as e:
- dlog.info("create apg failed, err msg: %s" % e)
- sys.exit()
-
- def describe_apg_instances(self):
- request = DescribeAutoProvisioningGroupInstancesRequest()
- request.set_accept_format('json')
- request.set_AutoProvisioningGroupId(self.cloud_resources["apg_id"])
- request.set_PageSize(100)
- iteration = self.nchunks // 100
- instance_list = []
- for i in range(iteration + 1):
- request.set_PageNumber(i+1)
- count = 0
- flag = 0
- err_msg = 0
- while count < 10:
- try:
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- for ins in response["Instances"]["Instance"]:
- instance_list.append(ins["InstanceId"])
- flag = 1
- break
- except ServerException as e:
- # dlog.info(e)
- err_msg = e
- count += 1
- except ClientException as e:
- # dlog.info(e)
- err_msg = e
- count += 1
- if not flag:
- dlog.info("describe_apg_instances failed, err msg: %s" %err_msg)
- sys.exit()
- return instance_list
-
- def generate_config(self):
- machine_config = self.cloud_resources["machine_type_price"]
- config = []
- for conf in machine_config:
- for vsw in self.cloud_resources["vsw_id"]:
- tmp = {
- "InstanceType": conf["machine_type"],
- "MaxPrice": str(conf["price_limit"] * conf["numb"]),
- "VSwitchId": vsw,
- "WeightedCapacity": "1",
- "Priority": str(conf["priority"])
- }
- config.append(tmp)
- return config
-
- def create_template(self, image_id, sg_id, vpc_id):
- request = CreateLaunchTemplateRequest()
- request.set_accept_format('json')
- request.set_LaunchTemplateName(''.join(random.choice(string.ascii_uppercase) for _ in range(20)))
- request.set_ImageId(image_id)
- request.set_ImageOwnerAlias("self")
- request.set_PasswordInherit(True)
- if "address" in self.cloud_resources and self.cloud_resources['address'] == "public":
- request.set_InternetMaxBandwidthIn(100)
- request.set_InternetMaxBandwidthOut(100)
- request.set_InstanceType("ecs.c6.large")
- request.set_InstanceName(self.cloud_resources["instance_name"])
- request.set_SecurityGroupId(sg_id)
- request.set_VpcId(vpc_id)
- request.set_SystemDiskCategory("cloud_efficiency")
- request.set_SystemDiskSize(70)
- request.set_IoOptimized("optimized")
- request.set_InstanceChargeType("PostPaid")
- request.set_NetworkType("vpc")
- request.set_SpotStrategy("SpotWithPriceLimit")
- request.set_SpotPriceLimit(100)
- try:
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- return response["LaunchTemplateId"]
- except ServerException as e:
- dlog.info(e)
- sys.exit()
- except ClientException as e:
- dlog.info(e)
- sys.exit()
-
- def delete_template(self):
- request = DeleteLaunchTemplateRequest()
- request.set_accept_format('json')
- count = 0
- flag = 0
- while count < 10:
- try:
- request.set_LaunchTemplateId(self.cloud_resources["template_id"])
- response = self.client.do_action_with_exception(request)
- flag = 1
- break
- except Exception:
- count += 1
- # count = 10 and still failed, continue
-
- def get_image_id(self, img_name):
- request = DescribeImagesRequest()
- request.set_accept_format('json')
- request.set_ImageOwnerAlias("self")
- request.set_PageSize(20)
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- totalcount = response["TotalCount"]
-
- iteration = totalcount // 20
- if iteration * 20 < totalcount:
- iteration += 1
-
- for ii in range(1, iteration+1):
- count = 0
- flag = 0
- request.set_PageNumber(ii)
- while count < 10:
- try:
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- for img in response["Images"]["Image"]:
- if img["ImageName"] == img_name:
- return img["ImageId"]
- flag = 1
- break
- except Exception:
- count += 1
- time.sleep(10)
- if not flag:
- dlog.info("get image failed, exit")
- sys.exit()
-
- def get_sg_vpc_id(self):
- request = DescribeSecurityGroupsRequest()
- request.set_accept_format('json')
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- for sg in response["SecurityGroups"]["SecurityGroup"]:
- if sg["SecurityGroupName"] == "sg":
- return sg["SecurityGroupId"], sg["VpcId"]
-
- def get_vsw_id(self, vpc_id):
- request = DescribeVpcsRequest()
- request.set_accept_format('json')
- request.set_VpcId(vpc_id)
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- for vpc in response["Vpcs"]["Vpc"]:
- if vpc["VpcId"] == vpc_id:
- vswitchids = vpc["VSwitchIds"]["VSwitchId"]
- break
- vswitchid_option = []
- if "zone" in self.cloud_resources and self.cloud_resources['zone']:
- for zone in self.cloud_resources['zone']:
- for vswitchid in vswitchids:
- request = DescribeVSwitchesRequest()
- request.set_accept_format('json')
- request.set_VSwitchId(vswitchid)
- zoneid = self.cloud_resources['regionID']+"-"+zone
- request.set_ZoneId(zoneid)
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- if(response["TotalCount"] == 1):
- vswitchid_option.append(vswitchid)
- continue
- if(vswitchid_option):
- return vswitchid_option
- else:
- return vswitchids
-
- def change_apg_capasity(self, capasity):
- request = ModifyAutoProvisioningGroupRequest()
- request.set_accept_format('json')
- request.set_AutoProvisioningGroupId(self.cloud_resources["apg_id"])
- request.set_TotalTargetCapacity(str(capasity))
- request.set_SpotTargetCapacity(str(capasity))
- request.set_PayAsYouGoTargetCapacity("0")
- count = 0
- flag = 0
- while count < 10:
- try:
- response = self.client.do_action_with_exception(request)
- flag = 1
- break
- except Exception:
- count += 1
- time.sleep(10)
- if not flag:
- dlog.info("change_apg_capasity failed, exit")
- sys.exit()
-
- def check_spot_callback(self, instance_id):
- request = DescribeInstancesRequest()
- request.set_accept_format('json')
- request.set_InstanceIds([instance_id])
- status = False
- count = 0
- while count < 10:
- try:
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- if len(response["Instances"]["Instance"]) == 1 and "Recycling" in response["Instances"]["Instance"][0]["OperationLocks"]["LockReason"]:
- status = True
- if instance_id not in self.describe_apg_instances():
- status = True
- break
- except ServerException as e:
- # dlog.info(e)
- count += 1
- time.sleep(10)
- except ClientException as e:
- # dlog.info(e)
- count += 1
- time.sleep(10)
- return status
-
- def get_ip(self, instance_list):
- request = DescribeInstancesRequest()
- request.set_accept_format('json')
- ip_list = []
- if len(instance_list) == 0: return ip_list
- try:
- if len(instance_list) <= 10:
- for i in range(len(instance_list)):
- request.set_InstanceIds([instance_list[i]])
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- if "address" in self.cloud_resources and self.cloud_resources['address'] == "public":
- ip_list.append(response["Instances"]["Instance"][0]["PublicIpAddress"]["IpAddress"][0])
- else:
- ip_list.append(response["Instances"]["Instance"][0]["VpcAttributes"]["PrivateIpAddress"]['IpAddress'][0])
- # ip_list.append(response["Instances"]["Instance"][0]["PublicIpAddress"]["IpAddress"][0])
- else:
- iteration = len(instance_list) // 10
- for i in range(iteration):
- for j in range(10):
- request.set_InstanceIds([instance_list[i*10+j]])
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- if "address" in self.cloud_resources and self.cloud_resources['address'] == "public":
- ip_list.append(response["Instances"]["Instance"][0]["PublicIpAddress"]["IpAddress"][0])
- else:
- ip_list.append(response["Instances"]["Instance"][0]["VpcAttributes"]["PrivateIpAddress"]['IpAddress'][0])
- if len(instance_list) - iteration * 10 != 0:
- for j in range(len(instance_list) - iteration * 10):
- request.set_InstanceIds([instance_list[iteration*10+j]])
- response = self.client.do_action_with_exception(request)
- response = json.loads(response)
- if "address" in self.cloud_resources and self.cloud_resources['address'] == "public":
- ip_list.append(response["Instances"]["Instance"][0]["PublicIpAddress"]["IpAddress"][0])
- else:
- ip_list.append(response["Instances"]["Instance"][0]["VpcAttributes"]["PrivateIpAddress"]['IpAddress'][0])
- return ip_list
- except Exception: return []
-
diff --git a/dpgen/dispatcher/AWS.py b/dpgen/dispatcher/AWS.py
deleted file mode 100644
index 84f2b7cbf..000000000
--- a/dpgen/dispatcher/AWS.py
+++ /dev/null
@@ -1,142 +0,0 @@
-import os,getpass,time
-from datetime import datetime
-from itertools import zip_longest
-from dpgen.dispatcher.Batch import Batch
-from dpgen.dispatcher.JobStatus import JobStatus
-from dpgen import dlog
-
-
-class AWS(Batch):
- _query_time_interval = 30
- _job_id_map_status = {}
- _jobQueue = ""
- _query_next_allow_time = datetime.now().timestamp()
-
- def __init__(self, context, uuid_names=True):
- import boto3
- self.batch_client = boto3.client('batch')
- super().__init__(context, uuid_names)
-
- @staticmethod
- def map_aws_status_to_dpgen_status(aws_status):
- map_dict = {'SUBMITTED': JobStatus.waiting,
- 'PENDING': JobStatus.waiting,
- 'RUNNABLE': JobStatus.waiting,
- 'STARTING': JobStatus.waiting,
- 'RUNNING': JobStatus.running,
- 'SUCCEEDED': JobStatus.finished,
- 'FAILED': JobStatus.terminated,
- 'UNKNOWN': JobStatus.unknown}
- return map_dict.get(aws_status, JobStatus.unknown)
-
- @classmethod
- def AWS_check_status(cls, job_id=""):
- """
- to aviod query jobStatus too often, set a time interval
- query_dict example:
- {job_id: JobStatus}
-
- {'40fb24b2-d0ca-4443-8e3a-c0906ea03622': ,
- '41bda50c-0a23-4372-806c-87d16a680d85': }
-
- """
- query_dict ={}
- if datetime.now().timestamp() > cls._query_next_allow_time:
- cls._query_next_allow_time=datetime.now().timestamp()+cls._query_time_interval
- for status in ['SUBMITTED', 'PENDING', 'RUNNABLE', 'STARTING', 'RUNNING','SUCCEEDED', 'FAILED']:
- nextToken = ''
- while nextToken is not None:
- status_response = self.batch_client.list_jobs(jobQueue=cls._jobQueue, jobStatus=status, maxResults=100, nextToken=nextToken)
- status_list=status_response.get('jobSummaryList')
- nextToken = status_response.get('nextToken', None)
- for job_dict in status_list:
- cls._job_id_map_status.update({job_dict['jobId']: cls.map_aws_status_to_dpgen_status(job_dict['status'])})
- dlog.debug('20000:_map: %s' %(cls._job_id_map_status))
- dlog.debug('62000:job_id:%s, _query: %s, _map: %s' %(job_id, query_dict, cls._job_id_map_status))
- if job_id:
- return cls._job_id_map_status.get(job_id)
-
- return cls._job_id_map_status
-
- @property
- def job_id(self):
- try:
- self._job_id
- except AttributeError:
- if self.context.check_file_exists(self.job_id_name):
- self._job_id = self.context.read_file(self.job_id_name)
- response_list = self.batch_client.describe_jobs(jobs=[self._job_id]).get('jobs')
- try:
- response = response_list[0]
- jobQueue = response['jobQueue']
- except IndexError:
- pass
- else:
- self.job_id = (response, jobQueue)
- return self._job_id
- dlog.debug("50000, self._job_id:%s,_Queue:%s,_map:%s,"%(self._job_id, self.__class__._jobQueue, self.__class__._job_id_map_status ))
- return ""
- return self._job_id
-
- @job_id.setter
- def job_id(self, values):
- response, jobQueue = values
- self._job_id = response['jobId']
- self._job_name = response['jobName']
- self.__class__._jobQueue = jobQueue
- self.__class__._job_id_map_status[self._job_id] = self.map_aws_status_to_dpgen_status(response.get('status', 'SUBMITTED'))
- self.context.write_file(self.job_id_name, self._job_id)
- dlog.debug("15000, _job_id:%s, _job_name:%s, _map:%s, _Queue:%s" % (self._job_id, self._job_name, self.__class__._job_id_map_status, self.__class__._jobQueue))
-
- def check_status(self):
- return self.__class__.AWS_check_status(job_id=self.job_id)
-
- def sub_script(self, job_dirs, cmd, args, res, outlog, errlog):
- if args is None:
- args=[]
- multi_command = ""
- for job_dir in job_dirs:
- for idx,t in enumerate(zip_longest(cmd, args, fillvalue='')):
- c_str = f"cd {self.context.remote_root}/{job_dir} && ( test -f tag_{idx}_finished || ( ({t[0]} {t[1]} && touch tag_{idx}_finished 2>>{errlog} || exit 52 ) | tee -a {outlog}) ) || exit 51;"
- multi_command += c_str
- multi_command +="exit 0;"
- dlog.debug("10000, %s" % multi_command)
- return multi_command
-
- def default_resources(self, res):
- if res == None:
- res = {}
- else:
- # res.setdefault(jobDefinition)
- res.setdefault('cpu_num', 32)
- res.setdefault('memory_size', 120000)
- res.setdefault('jobQueue', 'deepmd_m5_v1_7')
- return res
-
- def do_submit(self,
- job_dirs,
- cmd,
- args = None,
- res = None,
- outlog = 'log',
- errlog = 'err'):
-
- res = self.default_resources(res)
- dlog.debug("2000, params=(%s, %s, %s, %s, %s, %s, )" % (job_dirs, cmd, args, res, outlog, errlog ))
- dlog.debug('2200, self.context.remote_root: %s , self.context.local_root: %s' % (self.context.remote_root, self.context.local_root))
- # concreate_command =
- script_str = self.sub_script(job_dirs, cmd, args=args, res=res, outlog=outlog, errlog=errlog)
- dlog.debug('2300, script_str: %s, self.sub_script_name: %s' % (script_str, self.sub_script_name))
- """
- jobName example:
- home-ec2-user-Ag_init-run_gen-iter_000000-01_model_devi-task_000_000048
- """
- jobName = os.path.join(self.context.remote_root,job_dirs.pop())[1:].replace('/','-').replace('.','_')
- jobName += ("_" + str(self.context.job_uuid))
- response = self.batch_client.submit_job(jobName=jobName,
- jobQueue=res['jobQueue'],
- jobDefinition=res['jobDefinition'],
- parameters={'task_command':script_str},
- containerOverrides={'vcpus':res['cpu_num'], 'memory':res['memory_size']})
- dlog.debug('4000, response:%s' % response)
- self.job_id = (response, res['jobQueue'])
diff --git a/dpgen/dispatcher/Batch.py b/dpgen/dispatcher/Batch.py
deleted file mode 100644
index 1240be9f7..000000000
--- a/dpgen/dispatcher/Batch.py
+++ /dev/null
@@ -1,166 +0,0 @@
-import os,sys,time
-
-from dpgen.dispatcher.JobStatus import JobStatus
-from dpgen import dlog
-
-
-class Batch(object) :
- def __init__ (self,
- context,
- uuid_names = True) :
- self.context = context
- self.uuid_names = uuid_names
- if uuid_names:
- self.upload_tag_name = '%s_tag_upload' % self.context.job_uuid
- self.finish_tag_name = '%s_tag_finished' % self.context.job_uuid
- self.sub_script_name = '%s.sub' % self.context.job_uuid
- self.job_id_name = '%s_job_id' % self.context.job_uuid
- else:
- self.upload_tag_name = 'tag_upload'
- self.finish_tag_name = 'tag_finished'
- self.sub_script_name = 'run.sub'
- self.job_id_name = 'job_id'
-
- def check_status(self) :
- raise RuntimeError('abstract method check_status should be implemented by derived class')
-
- def default_resources(self, res) :
- raise RuntimeError('abstract method sub_script_head should be implemented by derived class')
-
- def sub_script_head(self, res) :
- raise RuntimeError('abstract method sub_script_head should be implemented by derived class')
-
- def sub_script_cmd(self, cmd, res):
- raise RuntimeError('abstract method sub_script_cmd should be implemented by derived class')
-
- def do_submit(self,
- job_dirs,
- cmd,
- args = None,
- res = None,
- outlog = 'log',
- errlog = 'err'):
- '''
- submit a single job, assuming that no job is running there.
- '''
- raise RuntimeError('abstract method check_status should be implemented by derived class')
-
- def sub_script(self,
- job_dirs,
- cmd,
- args = None,
- res = None,
- outlog = 'log',
- errlog = 'err') :
- """
- make submit script
-
- job_dirs(list): directories of jobs. size: n_job
- cmd(list): commands to be executed. size: n_cmd
- args(list of list): args of commands. size of n_cmd x n_job
- can be None
- res(dict): resources available
- outlog(str): file name for output
- errlog(str): file name for error
- """
- res = self.default_resources(res)
- ret = self.sub_script_head(res)
- if not isinstance(cmd, list):
- cmd = [cmd]
- if args == None :
- args = []
- for ii in cmd:
- _args = []
- for jj in job_dirs:
- _args.append('')
- args.append(_args)
- # loop over commands
- self.cmd_cnt = 0
- try:
- self.manual_cuda_devices = res['manual_cuda_devices']
- except KeyError:
- self.manual_cuda_devices = 0
- try:
- self.manual_cuda_multiplicity = res['manual_cuda_multiplicity']
- except KeyError:
- self.manual_cuda_multiplicity = 1
- for ii in range(len(cmd)):
- # for one command
- ret += self._sub_script_inner(job_dirs,
- cmd[ii],
- args[ii],
- ii,
- res,
- outlog=outlog,
- errlog=errlog)
- ret += '\ntouch %s\n' % self.finish_tag_name
- return ret
-
- def submit(self,
- job_dirs,
- cmd,
- args = None,
- res = None,
- restart = False,
- outlog = 'log',
- errlog = 'err'):
- if restart:
- dlog.debug('restart task')
- status = self.check_status()
- if status in [ JobStatus.unsubmitted, JobStatus.unknown, JobStatus.terminated ]:
- dlog.debug('task restart point !!!')
- self.do_submit(job_dirs, cmd, args, res, outlog=outlog, errlog=errlog)
- elif status==JobStatus.waiting:
- dlog.debug('task is waiting')
- elif status==JobStatus.running:
- dlog.debug('task is running')
- elif status==JobStatus.finished:
- dlog.debug('task is finished')
- else:
- raise RuntimeError('unknow job status, must be wrong')
- else:
- dlog.debug('new task')
- self.do_submit(job_dirs, cmd, args, res, outlog=outlog, errlog=errlog)
- if res is None:
- sleep = 0
- else:
- sleep = res.get('submit_wait_time', 0)
- time.sleep(sleep) # For preventing the crash of the tasks while submitting
-
- def check_finish_tag(self) :
- return self.context.check_file_exists(self.finish_tag_name)
-
- def _sub_script_inner(self,
- job_dirs,
- cmd,
- args,
- idx,
- res,
- outlog = 'log',
- errlog = 'err') :
- ret = ""
- allow_failure = res.get('allow_failure', False)
- for ii,jj in zip(job_dirs, args) :
- ret += 'cd %s\n' % ii
- ret += 'test $? -ne 0 && exit 1\n\n'
- if self.manual_cuda_devices > 0:
- # set CUDA_VISIBLE_DEVICES
- ret += 'export CUDA_VISIBLE_DEVICES=%d\n' % (self.cmd_cnt % self.manual_cuda_devices)
- ret += '{ if [ ! -f tag_%d_finished ] ;then\n' % idx
- ret += ' %s 1>> %s 2>> %s \n' % (self.sub_script_cmd(cmd, jj, res), outlog, errlog)
- if res['allow_failure'] is False:
- ret += ' if test $? -ne 0; then exit 1; else touch tag_%d_finished; fi \n' % idx
- else :
- ret += ' if test $? -ne 0; then touch tag_failure_%d; fi \n' % idx
- ret += ' touch tag_%d_finished \n' % idx
- ret += 'fi }'
- if self.manual_cuda_devices > 0:
- ret += '&'
- self.cmd_cnt += 1
- ret += '\n\n'
- ret += 'cd %s\n' % self.context.remote_root
- ret += 'test $? -ne 0 && exit 1\n'
- if self.manual_cuda_devices > 0 and self.cmd_cnt % (self.manual_cuda_devices * self.manual_cuda_multiplicity) == 0:
- ret += '\nwait\n\n'
- ret += '\nwait\n\n'
- return ret
diff --git a/dpgen/dispatcher/Dispatcher.py b/dpgen/dispatcher/Dispatcher.py
index cb2db0986..c15c1f498 100644
--- a/dpgen/dispatcher/Dispatcher.py
+++ b/dpgen/dispatcher/Dispatcher.py
@@ -1,376 +1,48 @@
+import os
from distutils.version import LooseVersion
-import os,sys,time,random,json,glob
-import warnings
from typing import List
-from dpdispatcher import Task, Submission, Resources, Machine
-from dpgen.dispatcher.LocalContext import LocalSession
-from dpgen.dispatcher.LocalContext import LocalContext
-from dpgen.dispatcher.LazyLocalContext import LazyLocalContext
-from dpgen.dispatcher.SSHContext import SSHSession
-from dpgen.dispatcher.SSHContext import SSHContext
-from dpgen.dispatcher.Slurm import Slurm
-from dpgen.dispatcher.LSF import LSF
-from dpgen.dispatcher.PBS import PBS
-from dpgen.dispatcher.Shell import Shell
-from dpgen.dispatcher.AWS import AWS
-from dpgen.dispatcher.JobStatus import JobStatus
-from dpgen import dlog
-from hashlib import sha1
+
# import dargs
from dargs.dargs import Argument
-
-def _split_tasks(tasks,
- group_size):
- ntasks = len(tasks)
- ngroups = ntasks // group_size
- if ngroups * group_size < ntasks:
- ngroups += 1
- chunks = [[]] * ngroups
- tot = 0
- for ii in range(ngroups) :
- chunks[ii] = (tasks[ii::ngroups])
- tot += len(chunks[ii])
- assert(tot == len(tasks))
- return chunks
-
-
-class Dispatcher(object):
- def __init__ (self,
- remote_profile,
- context_type = 'local',
- batch_type = 'slurm',
- job_record = 'jr.json'):
- self.remote_profile = remote_profile
-
- if context_type == 'local':
- self.session = LocalSession(remote_profile)
- self.context = LocalContext
- self.uuid_names = True
- elif context_type == 'lazy-local':
- self.session = None
- self.context = LazyLocalContext
- self.uuid_names = True
- elif context_type == 'ssh':
- self.session = SSHSession(remote_profile)
- self.context = SSHContext
- self.uuid_names = True
- else :
- raise RuntimeError('unknown context')
- if batch_type == 'slurm':
- self.batch = Slurm
- elif batch_type == 'lsf':
- self.batch = LSF
- elif batch_type == 'pbs':
- self.batch = PBS
- elif batch_type == 'shell':
- self.batch = Shell
- elif batch_type == 'aws':
- self.batch = AWS
- else :
- raise RuntimeError('unknown batch ' + batch_type)
- self.jrname = job_record
-
- def run_jobs(self,
- resources,
- command,
- work_path,
- tasks,
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference = True,
- mark_failure = False,
- outlog = 'log',
- errlog = 'err') :
- job_handler = self.submit_jobs(resources,
- command,
- work_path,
- tasks,
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference,
- outlog,
- errlog)
- while not self.all_finished(job_handler, mark_failure) :
- time.sleep(60)
- # delete path map file when job finish
- # _pmap.delete()
-
-
- def submit_jobs(self,
- resources,
- command,
- work_path,
- tasks,
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference = True,
- outlog = 'log',
- errlog = 'err') :
- self.backward_task_files = backward_task_files
- # task_chunks = [
- # [os.path.basename(j) for j in tasks[i:i + group_size]] \
- # for i in range(0, len(tasks), group_size)
- # ]
- task_chunks = _split_tasks(tasks, group_size)
- task_chunks_str = ['+'.join(ii) for ii in task_chunks]
- task_hashes = [sha1(ii.encode('utf-8')).hexdigest() for ii in task_chunks_str]
- job_record = JobRecord(work_path, task_chunks, fname = self.jrname)
- job_record.dump()
- nchunks = len(task_chunks)
-
- job_list = []
- for ii in range(nchunks) :
- cur_chunk = task_chunks[ii]
- cur_hash = task_hashes[ii]
- if not job_record.check_finished(cur_hash):
- # chunk is not finished
- # check if chunk is submitted
- submitted = job_record.check_submitted(cur_hash)
- if not submitted:
- job_uuid = None
- else :
- job_uuid = job_record.get_uuid(cur_hash)
- dlog.debug("load uuid %s for chunk %s" % (job_uuid, cur_hash))
- # communication context, bach system
- context = self.context(work_path, self.session, job_uuid)
- batch = self.batch(context, uuid_names = self.uuid_names)
- rjob = {'context':context, 'batch':batch}
- # upload files
- if not rjob['context'].check_file_exists(rjob['batch'].upload_tag_name):
- rjob['context'].upload('.',
- forward_common_files)
- rjob['context'].upload(cur_chunk,
- forward_task_files,
- dereference = forward_task_deference)
-
- rjob['context'].write_file(rjob['batch'].upload_tag_name, '')
- dlog.debug('uploaded files for %s' % task_chunks_str[ii])
- # submit new or recover old submission
- if not submitted:
- rjob['batch'].submit(cur_chunk, command, res = resources, outlog=outlog, errlog=errlog)
- job_uuid = rjob['context'].job_uuid
- dlog.debug('assigned uuid %s for %s ' % (job_uuid, task_chunks_str[ii]))
- dlog.info('new submission of %s for chunk %s' % (job_uuid, cur_hash))
- else:
- rjob['batch'].submit(cur_chunk, command, res = resources, outlog=outlog, errlog=errlog, restart = True)
- dlog.info('restart from old submission %s for chunk %s' % (job_uuid, cur_hash))
- # record job and its remote context
- job_list.append(rjob)
- ip = None
- instance_id = None
- if 'cloud_resources' in self.remote_profile:
- ip = self.remote_profile['hostname']
- instance_id = self.remote_profile['instance_id']
- job_record.record_remote_context(cur_hash,
- context.local_root,
- context.remote_root,
- job_uuid,
- ip,
- instance_id)
- job_record.dump()
- else :
- # finished job, append a None to list
- job_list.append(None)
- assert(len(job_list) == nchunks)
- job_handler = {
- 'task_chunks': task_chunks,
- 'job_list': job_list,
- 'job_record': job_record,
- 'command': command,
- 'resources': resources,
- 'outlog': outlog,
- 'errlog': errlog,
- 'backward_task_files': backward_task_files
- }
- return job_handler
-
-
- def all_finished(self,
- job_handler,
- mark_failure,
- clean=True):
- task_chunks = job_handler['task_chunks']
- task_chunks_str = ['+'.join(ii) for ii in task_chunks]
- task_hashes = [sha1(ii.encode('utf-8')).hexdigest() for ii in task_chunks_str]
- job_list = job_handler['job_list']
- job_record = job_handler['job_record']
- command = job_handler['command']
- tag_failure_list = ['tag_failure_%d' % ii for ii in range(len(command))]
- resources = job_handler['resources']
- outlog = job_handler['outlog']
- errlog = job_handler['errlog']
- backward_task_files = job_handler['backward_task_files']
- dlog.debug('checking jobs')
- nchunks = len(task_chunks)
- for idx in range(nchunks) :
- cur_hash = task_hashes[idx]
- rjob = job_list[idx]
- if not job_record.check_finished(cur_hash) :
- # chunk not finished according to record
- status = rjob['batch'].check_status()
- job_uuid = rjob['context'].job_uuid
- dlog.debug('checked job %s' % job_uuid)
- if status == JobStatus.terminated :
- job_record.increase_nfail(cur_hash)
- if job_record.check_nfail(cur_hash) > 3:
- raise RuntimeError('Job %s failed for more than 3 times' % job_uuid)
- dlog.info('job %s terminated, submit again'% job_uuid)
- dlog.debug('try %s times for %s'% (job_record.check_nfail(cur_hash), job_uuid))
- rjob['batch'].submit(task_chunks[idx], command, res = resources, outlog=outlog, errlog=errlog,restart=True)
- elif status == JobStatus.finished :
- dlog.info('job %s finished' % job_uuid)
- if mark_failure:
- rjob['context'].download(task_chunks[idx], tag_failure_list, check_exists = True, mark_failure = False)
- rjob['context'].download(task_chunks[idx], backward_task_files, check_exists = True)
- else:
- rjob['context'].download(task_chunks[idx], backward_task_files)
- if clean:
- rjob['context'].clean()
- job_record.record_finish(cur_hash)
- job_record.dump()
- job_record.dump()
- return job_record.check_all_finished()
-
-
-class JobRecord(object):
- def __init__ (self, path, task_chunks, fname = 'job_record.json', ip=None):
- self.path = os.path.abspath(path)
- self.fname = os.path.join(self.path, fname)
- self.task_chunks = task_chunks
- if not os.path.exists(self.fname):
- self._new_record()
- else :
- self.load()
-
- def check_submitted(self, chunk_hash):
- self.valid_hash(chunk_hash)
- return self.record[chunk_hash]['context'] is not None
-
- def record_remote_context(self,
- chunk_hash,
- local_root,
- remote_root,
- job_uuid,
- ip=None,
- instance_id=None):
- self.valid_hash(chunk_hash)
- # self.record[chunk_hash]['context'] = [local_root, remote_root, job_uuid, ip, instance_id]
- self.record[chunk_hash]['context'] = {}
- self.record[chunk_hash]['context']['local_root'] = local_root
- self.record[chunk_hash]['context']['remote_root'] = remote_root
- self.record[chunk_hash]['context']['job_uuid'] = job_uuid
- self.record[chunk_hash]['context']['ip'] = ip
- self.record[chunk_hash]['context']['instance_id'] = instance_id
-
- def get_uuid(self, chunk_hash):
- self.valid_hash(chunk_hash)
- return self.record[chunk_hash]['context']['job_uuid']
-
- def check_finished(self, chunk_hash):
- self.valid_hash(chunk_hash)
- return self.record[chunk_hash]['finished']
-
- def check_all_finished(self):
- flist = [self.record[ii]['finished'] for ii in self.record]
- return all(flist)
-
- def record_finish(self, chunk_hash):
- self.valid_hash(chunk_hash)
- self.record[chunk_hash]['finished'] = True
-
- def check_nfail(self,chunk_hash):
- self.valid_hash(chunk_hash)
- return self.record[chunk_hash]['fail_count']
-
- def increase_nfail(self,chunk_hash):
- self.valid_hash(chunk_hash)
- self.record[chunk_hash]['fail_count'] += 1
-
- def valid_hash(self, chunk_hash):
- if chunk_hash not in self.record.keys():
- raise RuntimeError('chunk hash %s not in record, a invalid record may be used, please check file %s' % (chunk_hash, self.fname))
-
- def dump(self):
- with open(self.fname, 'w') as fp:
- json.dump(self.record, fp, indent=4)
-
- def load(self):
- with open(self.fname) as fp:
- self.record = json.load(fp)
-
- def _new_record(self):
- task_chunks_str=['+'.join(ii) for ii in self.task_chunks]
- task_hash = [sha1(ii.encode('utf-8')).hexdigest() for ii in task_chunks_str]
- self.record = {}
- for ii,jj in zip(task_hash, self.task_chunks):
- self.record[ii] = {
- 'context': None,
- 'finished': False,
- 'fail_count': 0,
- 'task_chunk': jj,
- }
-
-
-def make_dispatcher(mdata, mdata_resource=None, work_path=None, run_tasks=None, group_size=None):
- if 'cloud_resources' in mdata:
- if mdata['cloud_resources']['cloud_platform'] == 'ali':
- from dpgen.dispatcher.ALI import ALI
- dispatcher = ALI(mdata, mdata_resource, work_path, run_tasks, group_size, mdata['cloud_resources'])
- dispatcher.init()
- return dispatcher
- elif mdata['cloud_resources']['cloud_platform'] == 'ucloud':
- pass
- else:
- hostname = mdata.get('hostname', None)
- #use_uuid = mdata.get('use_uuid', False)
- if hostname:
- context_type = 'ssh'
- else:
- context_type = 'local'
- try:
- batch_type = mdata['batch']
- except Exception:
- dlog.info('cannot find key "batch" in machine file, try to use deprecated key "machine_type"')
- batch_type = mdata['machine_type']
- lazy_local = (mdata.get('lazy-local', False)) or (mdata.get('lazy_local', False))
- if lazy_local and context_type == 'local':
- dlog.info('Dispatcher switches to the lazy local mode')
- context_type = 'lazy-local'
- disp = Dispatcher(mdata, context_type=context_type, batch_type=batch_type)
- return disp
-
-def make_submission(mdata_machine, mdata_resources, commands, work_path, run_tasks, group_size,
- forward_common_files, forward_files, backward_files, outlog, errlog):
-
- if mdata_machine['local_root'] != './':
+from dpdispatcher import Machine, Resources, Submission, Task
+
+
+def make_submission(
+ mdata_machine,
+ mdata_resources,
+ commands,
+ work_path,
+ run_tasks,
+ group_size,
+ forward_common_files,
+ forward_files,
+ backward_files,
+ outlog,
+ errlog,
+):
+
+ if mdata_machine["local_root"] != "./":
raise RuntimeError(f"local_root must be './' in dpgen's machine.json.")
-
- abs_local_root = os.path.abspath('./')
+
+ abs_local_root = os.path.abspath("./")
abs_mdata_machine = mdata_machine.copy()
- abs_mdata_machine['local_root'] = abs_local_root
+ abs_mdata_machine["local_root"] = abs_local_root
machine = Machine.load_from_dict(abs_mdata_machine)
resources = Resources.load_from_dict(mdata_resources)
-
command = "&&".join(commands)
task_list = []
for ii in run_tasks:
task = Task(
- command=command,
+ command=command,
task_work_path=ii,
forward_files=forward_files,
backward_files=backward_files,
outlog=outlog,
- errlog=errlog
+ errlog=errlog,
)
task_list.append(task)
@@ -380,7 +52,7 @@ def make_submission(mdata_machine, mdata_resources, commands, work_path, run_tas
resources=resources,
task_list=task_list,
forward_common_files=forward_common_files,
- backward_common_files=[]
+ backward_common_files=[],
)
return submission
@@ -390,7 +62,7 @@ def mdata_arginfo() -> List[Argument]:
A submission requires the following keys: command, machine,
and resources.
-
+
Returns
-------
list[Argument]
@@ -404,33 +76,39 @@ def mdata_arginfo() -> List[Argument]:
machine_arginfo.name = "machine"
resources_arginfo = Resources.arginfo()
resources_arginfo.name = "resources"
- user_forward_files_arginfo = Argument("user_forward_files", list, optional=True, doc=doc_user_forward_files)
- user_backward_files_arginfo = Argument("user_backward_files", list, optional=True, doc=doc_user_backward_files)
+ user_forward_files_arginfo = Argument(
+ "user_forward_files", list, optional=True, doc=doc_user_forward_files
+ )
+ user_backward_files_arginfo = Argument(
+ "user_backward_files", list, optional=True, doc=doc_user_backward_files
+ )
return [
- command_arginfo, machine_arginfo, resources_arginfo,
+ command_arginfo,
+ machine_arginfo,
+ resources_arginfo,
user_forward_files_arginfo,
user_backward_files_arginfo,
]
def make_submission_compat(
- machine: dict,
- resources: dict,
- commands: List[str],
- work_path: str,
- run_tasks: List[str],
- group_size: int,
- forward_common_files: List[str],
- forward_files: List[str],
- backward_files: List[str],
- outlog: str="log",
- errlog: str="err",
- api_version: str="0.9",
- ) -> None:
+ machine: dict,
+ resources: dict,
+ commands: List[str],
+ work_path: str,
+ run_tasks: List[str],
+ group_size: int,
+ forward_common_files: List[str],
+ forward_files: List[str],
+ backward_files: List[str],
+ outlog: str = "log",
+ errlog: str = "err",
+ api_version: str = "1.0",
+) -> None:
"""Make submission with compatibility of both dispatcher API v0 and v1.
- If `api_version` is less than 1.0, use `make_dispatcher`. If
+ If `api_version` is less than 1.0, raise RuntimeError. If
`api_version` is large than 1.0, use `make_submission`.
Parameters
@@ -457,25 +135,15 @@ def make_submission_compat(
path to log from stdout
errlog : str, default=err
path to log from stderr
- api_version : str, default=0.9
- API version. 1.0 is recommended
+ api_version : str, default=1.0
+ API version. 1.0 is required
"""
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher = make_dispatcher(machine, resources, work_dir, run_tasks, group_size)
- dispatcher.run_jobs(resources,
- commands,
- work_path,
- run_tasks,
- group_size,
- forward_common_files,
- forward_files,
- backward_files,
- outlog=outlog,
- errlog=errlog)
+ if LooseVersion(api_version) < LooseVersion("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ elif LooseVersion(api_version) >= LooseVersion("1.0"):
submission = make_submission(
machine,
resources,
@@ -487,6 +155,6 @@ def make_submission_compat(
forward_files=forward_files,
backward_files=backward_files,
outlog=outlog,
- errlog=errlog)
+ errlog=errlog,
+ )
submission.run_submission()
-
diff --git a/dpgen/dispatcher/DispatcherList.py b/dpgen/dispatcher/DispatcherList.py
deleted file mode 100644
index 22b77fd50..000000000
--- a/dpgen/dispatcher/DispatcherList.py
+++ /dev/null
@@ -1,227 +0,0 @@
-from dpgen.dispatcher.Dispatcher import Dispatcher, _split_tasks, JobRecord
-from paramiko.ssh_exception import NoValidConnectionsError
-import os, time
-from dpgen import dlog
-class Entity():
- def __init__(self, ip, instance_id, job_record=None, job_handler=None):
- self.ip = ip
- self.instance_id = instance_id
- self.job_record = job_record
- self.job_handler = job_handler
-
-class DispatcherList():
- def __init__(self, mdata_machine, mdata_resources, work_path, run_tasks, group_size, cloud_resources=None):
- self.mdata_machine = mdata_machine
- self.mdata_resources = mdata_resources
- self.task_chunks = _split_tasks(run_tasks, group_size)
- self.nchunks = len(self.task_chunks)
- self.nchunks_limit = int(self.mdata_machine.get("machine_upper_bound", self.nchunks))
- if(self.nchunks_limit > self.nchunks):
- self.nchunks_limit = self.nchunks
- self.work_path = work_path
- self.cloud_resources = cloud_resources
- self.server_pool = []
- self.ip_pool = []
- self.dispatcher_list = list({"dispatcher": None,
- "dispatcher_status": "unallocated",
- "entity": None} for ii in range(self.nchunks))
- # Derivate
- def init(self):
- # do something necessary
- for ii in range(self.nchunks):
- self.create(ii)
-
- # Base
- def run_jobs(self,
- resources,
- command,
- work_path,
- tasks,
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference = True,
- mark_failure = False,
- outlog = 'log',
- errlog = 'err'):
- ratio_failure = self.mdata_resources.get("ratio_failure", 0)
- while True:
- if self.check_all_dispatchers_finished(ratio_failure):
- self.clean()
- break
- self.exception_handling(ratio_failure)
- jj = self.nchunks - 1
- for ii in range(self.nchunks):
- dispatcher_status = self.check_dispatcher_status(ii)
- if dispatcher_status == "unsubmitted":
- dlog.info(self.dispatcher_list[ii]["entity"].ip)
- self.dispatcher_list[ii]["entity"].job_handler = self.dispatcher_list[ii]["dispatcher"].submit_jobs(resources,
- command,
- work_path,
- self.task_chunks[ii],
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference,
- outlog,
- errlog)
- self.dispatcher_list[ii]["entity"].job_record = self.dispatcher_list[ii]["entity"].job_handler["job_record"]
- self.dispatcher_list[ii]["dispatcher_status"] = "running"
- elif dispatcher_status == "finished" and self.dispatcher_list[ii]["entity"]:
- # no jobs in queue, delete current machine
- # else add current machine to server_pool
- entity = self.dispatcher_list[ii]["entity"]
- status_list = [item["dispatcher_status"] for item in self.dispatcher_list]
- flag = "unallocated" in status_list
- if not flag:
- self.delete(ii)
- self.dispatcher_list[ii]["entity"] = None
- else:
- self.dispatcher_list[ii]["entity"] = None
- self.server_pool.append(entity.instance_id)
- self.ip_pool.append(entity.ip)
- while(jj>=ii):
- if(self.dispatcher_list[jj]["dispatcher_status"] == "unallocated"):
- self.create(jj)
- if(self.dispatcher_list[jj]["dispatcher_status"] == "unsubmitted"):
- dlog.info(self.dispatcher_list[jj]["entity"].ip)
- self.dispatcher_list[jj]["entity"].job_handler = self.dispatcher_list[jj]["dispatcher"].submit_jobs(resources,
- command,
- work_path,
- self.task_chunks[jj],
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference,
- outlog,
- errlog)
- self.dispatcher_list[jj]["entity"].job_record = self.dispatcher_list[jj]["entity"].job_handler["job_record"]
- self.dispatcher_list[jj]["dispatcher_status"] = "running"
- break
- jj -=1
- elif dispatcher_status == "running":
- pass
- elif dispatcher_status == "unallocated":
- # if len(server_pool) > 0: make_dispatcher
- # else: pass
- self.create(ii)
- if self.dispatcher_list[ii]["dispatcher_status"] == "unsubmitted":
- dlog.info(self.dispatcher_list[ii]["entity"].ip)
- self.dispatcher_list[ii]["entity"].job_handler = self.dispatcher_list[ii]["dispatcher"].submit_jobs(resources,
- command,
- work_path,
- self.task_chunks[ii],
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference,
- outlog,
- errlog)
- self.dispatcher_list[ii]["entity"].job_record = self.dispatcher_list[ii]["entity"].job_handler["job_record"]
- self.dispatcher_list[ii]["dispatcher_status"] = "running"
- elif dispatcher_status == "terminated":
- pass
- self.update()
- time.sleep(10)
-
- # Derivate
- def create(self, ii):
- '''case1: use existed machine(finished) to make_dispatcher
- case2: create one machine, then make_dispatcher, change status from unallocated to unsubmitted'''
- pass
-
- # Derivate
- def delete(self, ii):
- '''delete one machine
- if entity is none, means this machine is used by another dispatcher, shouldn't be deleted'''
- pass
-
- # Derivate, delete config like templates, etc.
- def clean(self):
- pass
-
- # Derivate
- def update():
- pass
-
- # Base
- def check_all_dispatchers_finished(self, ratio_failure):
- status_list = [item["dispatcher_status"] for item in self.dispatcher_list]
- finished_num = status_list.count("finished")
- if finished_num / self.nchunks < (1 - ratio_failure): return False
- else: return True
-
- # Base
- def exception_handling(self, ratio_failure):
- status_list = [item["dispatcher_status"] for item in self.dispatcher_list]
- terminated_num = status_list.count("terminated")
- if terminated_num / self.nchunks > ratio_failure:
- # self.dispatcher_list = [lambda item["dispatcher_status"]: "finished" for item in self.dispatcher_list if item["dispatcher_status"] == "terminated"]
- for ii in range(self.nchunks):
- if self.dispatcher_list[ii]["dispatcher_status"] == "terminated":
- self.dispatcher_list[ii]["dispatcher_status"] = "unallocated"
- # Base
- def make_dispatcher(self, ii):
- entity = self.dispatcher_list[ii]["entity"]
- profile = self.mdata_machine.copy()
- profile['hostname'] = entity.ip
- profile['instance_id'] = entity.instance_id
- count = 0
- flag = 0
- while count < 3:
- try:
- self.dispatcher_list[ii]["dispatcher"] = Dispatcher(profile, context_type='ssh', batch_type='shell', job_record='jr.%.06d.json' % ii)
- self.dispatcher_list[ii]["dispatcher_status"] = "unsubmitted"
- flag = 1
- break
- except Exception:
- count += 1
- time.sleep(60)
- if not flag:
- # give up this machine, wait other machine in sever_pool.
- # this machine will be append into server_pool next time when update apg_instances.
- self.dispatcher_list[ii]["entity"] = None
-
-
- # Base
- def check_dispatcher_status(self, ii, allow_failure=False):
- '''catch running dispatcher exception
- if no exception occured, check finished'''
- if self.dispatcher_list[ii]["dispatcher_status"] == "running":
- status = self.catch_dispatcher_exception(ii)
- if status == 0:
- # param clean: delete remote work_dir or not.
- clean = self.mdata_resources.get("clean", False)
- try:
- # avoid raising ssh exception in download proceess
- finished = self.dispatcher_list[ii]["dispatcher"].all_finished(self.dispatcher_list[ii]["entity"].job_handler, allow_failure, clean)
- if finished:
- self.dispatcher_list[ii]["dispatcher_status"] = "finished"
- except Exception:
- pass
- elif status == 1:
- # self.dispatcher_list[ii]["dispatcher_status"] = "terminated"
- pass
- elif status == 2:
- self.dispatcher_list[ii]["dispatcher"] = None
- self.dispatcher_list[ii]["dispatcher_status"] = "terminated"
- self.dispatcher_list[ii]["entity"] = None
- os.remove(os.path.join(self.work_path, "jr.%.06d.json" % ii))
- return self.dispatcher_list[ii]["dispatcher_status"]
-
- # Derivate
- def catch_dispatcher_exception(self, ii):
- '''everything is okay: return 0
- ssh not active : return 1
- machine callback : return 2'''
- pass
-
-
-
-
-
-
diff --git a/dpgen/dispatcher/JobStatus.py b/dpgen/dispatcher/JobStatus.py
deleted file mode 100644
index f649e36a0..000000000
--- a/dpgen/dispatcher/JobStatus.py
+++ /dev/null
@@ -1,11 +0,0 @@
-from enum import Enum
-
-class JobStatus (Enum) :
- unsubmitted = 1
- waiting = 2
- running = 3
- terminated = 4
- finished = 5
- completing = 6
- unknown = 100
-
diff --git a/dpgen/dispatcher/LSF.py b/dpgen/dispatcher/LSF.py
deleted file mode 100644
index dfde7c5e3..000000000
--- a/dpgen/dispatcher/LSF.py
+++ /dev/null
@@ -1,190 +0,0 @@
-import os,getpass,time
-from dpgen.dispatcher.Batch import Batch
-from dpgen.dispatcher.JobStatus import JobStatus
-
-def _default_item(resources, key, value) :
- if key not in resources :
- resources[key] = value
-
-class LSF(Batch) :
-
- def check_status(self):
- try:
- job_id = self._get_job_id()
- except Exception:
- return JobStatus.terminated
- if job_id == "" :
- raise RuntimeError("job %s has not been submitted" % self.context.remote_root)
- ret, stdin, stdout, stderr\
- = self.context.block_call ("bjobs " + job_id)
- err_str = stderr.read().decode('utf-8')
- if ("Job <%s> is not found" % job_id) in err_str :
- if self.check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- elif ret != 0 :
- raise RuntimeError ("status command bjobs fails to execute. erro info: %s return code %d"
- % (err_str, ret))
- status_out = stdout.read().decode('utf-8').split('\n')
- if len(status_out) < 2:
- return JobStatus.unknown
- else:
- status_line = status_out[1]
- status_word = status_line.split()[2]
-
- # ref: https://www.ibm.com/support/knowledgecenter/en/SSETD4_9.1.2/lsf_command_ref/bjobs.1.html
- if status_word in ["PEND", "WAIT", "PSUSP"] :
- return JobStatus.waiting
- elif status_word in ["RUN", "USUSP"] :
- return JobStatus.running
- elif status_word in ["DONE","EXIT"] :
- if self.check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- return JobStatus.unknown
-
-
- def do_submit(self,
- job_dirs,
- cmd,
- args = None,
- res = None,
- outlog = 'log',
- errlog = 'err'):
- if res == None:
- res = self.default_resources(res)
- if 'task_max' in res and res['task_max'] > 0:
- while self._check_sub_limit(task_max=res['task_max']):
- time.sleep(60)
- script_str = self.sub_script(job_dirs, cmd, args=args, res=res, outlog=outlog, errlog=errlog)
- self.context.write_file(self.sub_script_name, script_str)
- stdin, stdout, stderr = self.context.block_checkcall('cd %s && %s < %s' % (self.context.remote_root, 'bsub', self.sub_script_name))
- subret = (stdout.readlines())
- job_id = subret[0].split()[1][1:-1]
- self.context.write_file(self.job_id_name, job_id)
-
-
- def default_resources(self, res_) :
- """
- set default value if a key in res_ is not fhound
- """
- if res_ == None :
- res = {}
- else:
- res = res_
- _default_item(res, 'node_cpu', 1)
- _default_item(res, 'numb_node', 1)
- _default_item(res, 'task_per_node', 1)
- _default_item(res, 'cpus_per_task', -1)
- _default_item(res, 'numb_gpu', 0)
- _default_item(res, 'time_limit', '1:0:0')
- _default_item(res, 'mem_limit', -1)
- _default_item(res, 'partition', '')
- _default_item(res, 'account', '')
- _default_item(res, 'qos', '')
- _default_item(res, 'constraint_list', [])
- _default_item(res, 'license_list', [])
- _default_item(res, 'exclude_list', [])
- _default_item(res, 'module_unload_list', [])
- _default_item(res, 'module_list', [])
- _default_item(res, 'source_list', [])
- _default_item(res, 'envs', None)
- _default_item(res, 'with_mpi', False)
- _default_item(res, 'cuda_multi_tasks', False)
- _default_item(res, 'allow_failure', False)
- _default_item(res, 'cvasp', False)
- return res
-
- def sub_script_head(self, res):
- ret = ''
- ret += "#!/bin/bash -l\n#BSUB -e %J.err\n#BSUB -o %J.out\n"
- if res['numb_gpu'] == 0:
- ret += '#BSUB -n %d\n#BSUB -R span[ptile=%d]\n' % (
- res['numb_node'] * res['task_per_node'], res['node_cpu'])
- else:
- if res['node_cpu']:
- ret += '#BSUB -R span[ptile=%d]\n' % res['node_cpu']
- if res.get('new_lsf_gpu', False):
- # supported in LSF >= 10.1.0.3
- # ref: https://www.ibm.com/support/knowledgecenter/en/SSWRJV_10.1.0
- # /lsf_resource_sharing/use_gpu_res_reqs.html
- if res.get('exclusive', False):
- j_exclusive = "no"
- else:
- j_exclusive = "yes"
- ret += '#BSUB -n %d\n#BSUB -gpu "num=%d:mode=shared:j_exclusive=%s"\n' % (
- res['task_per_node'], res['numb_gpu'], j_exclusive)
- else:
- ret += '#BSUB -n %d\n#BSUB -R "select[ngpus >0] rusage[ngpus_excl_p=%d]"\n' % (
- res['task_per_node'], res['numb_gpu'])
- if res['time_limit']:
- ret += '#BSUB -W %s\n' % (res['time_limit'].split(':')[
- 0] + ':' + res['time_limit'].split(':')[1])
- if res['mem_limit'] > 0 :
- ret += "#BSUB -M %d \n" % (res['mem_limit'])
- ret += '#BSUB -J %s\n' % (res['job_name'] if 'job_name' in res else 'dpgen')
- if len(res['partition']) > 0 :
- ret += '#BSUB -q %s\n' % res['partition']
- if len(res['exclude_list']) > 0:
- ret += '#BSUB -R "select['
- temp_exclude = []
- for ii in res['exclude_list']:
- temp_exclude.append('hname != %s' % ii)
- ret += ' && '.join(temp_exclude)
- ret += ']"\n'
- ret += "\n"
- for ii in res['module_unload_list'] :
- ret += "module unload %s\n" % ii
- for ii in res['module_list'] :
- ret += "module load %s\n" % ii
- ret += "\n"
- for ii in res['source_list'] :
- ret += "source %s\n" %ii
- ret += "\n"
- envs = res['envs']
- if envs != None :
- for key in envs.keys() :
- ret += 'export %s=%s\n' % (key, envs[key])
- ret += '\n'
- return ret
-
-
- def sub_script_cmd(self,
- cmd,
- arg,
- res) :
- if res['with_mpi']:
- ret = 'mpirun -machinefile $LSB_DJOB_HOSTFILE -n %d %s %s' % (
- res['numb_node'] * res['task_per_node'], cmd, arg)
- else :
- ret = '%s %s' % (cmd, arg)
- return ret
-
-
- def _get_job_id(self) :
- if self.context.check_file_exists(self.job_id_name) :
- return self.context.read_file(self.job_id_name)
- else:
- return ""
-
-
- def _check_sub_limit(self, task_max, **kwarg) :
- stdin_run, stdout_run, stderr_run = self.context.block_checkcall("bjobs | grep RUN | wc -l")
- njobs_run = int(stdout_run.read().decode('utf-8').split ('\n')[0])
- stdin_pend, stdout_pend, stderr_pend = self.context.block_checkcall("bjobs | grep PEND | wc -l")
- njobs_pend = int(stdout_pend.read().decode('utf-8').split ('\n')[0])
- if (njobs_pend + njobs_run) < task_max:
- return False
- else:
- return True
-
-
- def _make_squeue(self, mdata1, res):
- ret = ''
- ret += 'bjobs -u %s ' % mdata1['username']
- ret += '-q %s ' % res['partition']
- ret += '| grep PEND '
- return ret
diff --git a/dpgen/dispatcher/LazyLocalContext.py b/dpgen/dispatcher/LazyLocalContext.py
deleted file mode 100644
index 0b66335f2..000000000
--- a/dpgen/dispatcher/LazyLocalContext.py
+++ /dev/null
@@ -1,135 +0,0 @@
-import os,shutil,uuid
-import subprocess as sp
-from glob import glob
-from dpgen import dlog
-
-class SPRetObj(object) :
- def __init__ (self,
- ret) :
- self.data = ret
-
- def read(self) :
- return self.data
-
- def readlines(self) :
- lines = self.data.decode('utf-8').splitlines()
- ret = []
- for aa in lines:
- ret.append(aa+'\n')
- return ret
-
-class LazyLocalContext(object) :
- def __init__ (self,
- local_root,
- work_profile = None,
- job_uuid = None) :
- """
- work_profile:
- local_root:
- """
- assert(type(local_root) == str)
- self.local_root = os.path.abspath(local_root)
- self.remote_root = self.local_root
- if job_uuid:
- self.job_uuid=job_uuid
- else:
- self.job_uuid = str(uuid.uuid4())
-
- def get_job_root(self) :
- return self.local_root
-
- def upload(self,
- job_dirs,
- local_up_files,
- dereference = True) :
- pass
-
- def download(self,
- job_dirs,
- remote_down_files,
- check_exists = False,
- mark_failure = True,
- back_error=False) :
- for ii in job_dirs :
- for jj in remote_down_files :
- fname = os.path.join(self.local_root, ii, jj)
- exists = os.path.exists(fname)
- if not exists:
- if check_exists:
- if mark_failure:
- with open(os.path.join(self.local_root, ii, 'tag_failure_download_%s' % jj), 'w') as fp: pass
- else:
- pass
- else:
- raise OSError('do not find download file ' + fname)
-
-
- def block_checkcall(self,
- cmd) :
- cwd = os.getcwd()
- os.chdir(self.local_root)
- proc = sp.Popen(cmd, shell=True, stdout = sp.PIPE, stderr = sp.PIPE)
- o, e = proc.communicate()
- stdout = SPRetObj(o)
- stderr = SPRetObj(e)
- code = proc.returncode
- if code != 0:
- os.chdir(cwd)
- raise RuntimeError("Get error code %d in locally calling %s with job: %s ", (code, cmd, self.job_uuid))
- os.chdir(cwd)
- return None, stdout, stderr
-
- def block_call(self, cmd) :
- cwd = os.getcwd()
- os.chdir(self.local_root)
- proc = sp.Popen(cmd, shell=True, stdout = sp.PIPE, stderr = sp.PIPE)
- o, e = proc.communicate()
- stdout = SPRetObj(o)
- stderr = SPRetObj(e)
- code = proc.returncode
- os.chdir(cwd)
- return code, None, stdout, stderr
-
- def clean(self) :
- pass
-
- def write_file(self, fname, write_str):
- with open(os.path.join(self.local_root, fname), 'w') as fp :
- fp.write(write_str)
-
- def read_file(self, fname):
- with open(os.path.join(self.local_root, fname), 'r') as fp:
- ret = fp.read()
- return ret
-
- def check_file_exists(self, fname):
- return os.path.isfile(os.path.join(self.local_root, fname))
-
- def call(self, cmd) :
- cwd = os.getcwd()
- os.chdir(self.local_root)
- proc = sp.Popen(cmd, shell=True, stdout = sp.PIPE, stderr = sp.PIPE)
- os.chdir(cwd)
- return proc
-
- def kill(self, proc):
- proc.kill()
-
- def check_finish(self, proc):
- return (proc.poll() != None)
-
- def get_return(self, proc):
- ret = proc.poll()
- if ret is None:
- return None, None, None
- else :
- try:
- o, e = proc.communicate()
- stdout = SPRetObj(o)
- stderr = SPRetObj(e)
- except ValueError:
- stdout = None
- stderr = None
- return ret, stdout, stderr
-
-
diff --git a/dpgen/dispatcher/LocalContext.py b/dpgen/dispatcher/LocalContext.py
deleted file mode 100644
index 81fbd5007..000000000
--- a/dpgen/dispatcher/LocalContext.py
+++ /dev/null
@@ -1,210 +0,0 @@
-import os,shutil,uuid,hashlib
-import subprocess as sp
-from glob import glob
-from dpgen import dlog
-
-class LocalSession (object) :
- def __init__ (self, jdata) :
- self.work_path = os.path.abspath(jdata['work_path'])
- assert(os.path.exists(self.work_path))
-
- def get_work_root(self) :
- return self.work_path
-
-class SPRetObj(object) :
- def __init__ (self,
- ret) :
- self.data = ret
-
- def read(self) :
- return self.data
-
- def readlines(self) :
- lines = self.data.decode('utf-8').splitlines()
- ret = []
- for aa in lines:
- ret.append(aa+'\n')
- return ret
-
-def _check_file_path(fname) :
- dirname = os.path.dirname(fname)
- if dirname != "":
- os.makedirs(dirname, exist_ok=True)
-
-def _identical_files(fname0, fname1) :
- with open(fname0) as fp:
- code0 = hashlib.sha1(fp.read().encode('utf-8')).hexdigest()
- with open(fname1) as fp:
- code1 = hashlib.sha1(fp.read().encode('utf-8')).hexdigest()
- return code0 == code1
-
-
-class LocalContext(object) :
- def __init__ (self,
- local_root,
- work_profile,
- job_uuid = None) :
- """
- work_profile:
- local_root:
- """
- assert(type(local_root) == str)
- self.local_root = os.path.abspath(local_root)
- if job_uuid:
- self.job_uuid=job_uuid
- else:
- self.job_uuid = str(uuid.uuid4())
-
- self.remote_root = os.path.join(work_profile.get_work_root(), self.job_uuid)
- dlog.debug("local_root is %s"% local_root)
- dlog.debug("remote_root is %s"% self.remote_root)
-
- os.makedirs(self.remote_root, exist_ok = True)
-
- def get_job_root(self) :
- return self.remote_root
-
- def upload(self,
- job_dirs,
- local_up_files,
- dereference = True) :
- cwd = os.getcwd()
- for ii in job_dirs :
- local_job = os.path.join(self.local_root, ii)
- remote_job = os.path.join(self.remote_root, ii)
- os.makedirs(remote_job, exist_ok = True)
- os.chdir(remote_job)
- for jj in local_up_files :
- if not os.path.exists(os.path.join(local_job, jj)):
- os.chdir(cwd)
- raise OSError('cannot find upload file ' + os.path.join(local_job, jj))
- if os.path.exists(os.path.join(remote_job, jj)) :
- os.remove(os.path.join(remote_job, jj))
- _check_file_path(jj)
- os.symlink(os.path.join(local_job, jj),
- os.path.join(remote_job, jj))
- os.chdir(cwd)
-
- def download(self,
- job_dirs,
- remote_down_files,
- check_exists = False,
- mark_failure = True,
- back_error=False) :
- cwd = os.getcwd()
- for ii in job_dirs :
- local_job = os.path.join(self.local_root, ii)
- remote_job = os.path.join(self.remote_root, ii)
- flist = remote_down_files
- if back_error :
- os.chdir(remote_job)
- flist += glob('error*')
- os.chdir(cwd)
- for jj in flist :
- rfile = os.path.join(remote_job, jj)
- lfile = os.path.join(local_job, jj)
- if not os.path.realpath(rfile) == os.path.realpath(lfile) :
- if (not os.path.exists(rfile)) and (not os.path.exists(lfile)):
- if check_exists :
- if mark_failure:
- with open(os.path.join(self.local_root, ii, 'tag_failure_download_%s' % jj), 'w') as fp: pass
- else :
- pass
- else :
- raise RuntimeError('do not find download file ' + rfile)
- elif (not os.path.exists(rfile)) and (os.path.exists(lfile)) :
- # already downloaded
- pass
- elif (os.path.exists(rfile)) and (not os.path.exists(lfile)) :
- # trivial case, download happily
- # If the file to be downloaded is a softlink, `cp` should be performed instead of `mv`.
- # Otherwise, `lfile` is still a file linked to some original file,
- # and when this file's removed, `lfile` will be invalid.
- if os.path.islink(rfile):
- shutil.copyfile(rfile,lfile)
- else:
- shutil.move(rfile, lfile)
- elif (os.path.exists(rfile)) and (os.path.exists(lfile)) :
- # both exists, replace!
- dlog.info('find existing %s, replacing by %s' % (lfile, rfile))
- if os.path.isdir(lfile):
- shutil.rmtree(lfile, ignore_errors=True)
- elif os.path.isfile(lfile) or os.path.islink(lfile):
- os.remove(lfile)
- shutil.move(rfile, lfile)
- else :
- raise RuntimeError('should not reach here!')
- else :
- # no nothing in the case of linked files
- pass
- os.chdir(cwd)
-
- def block_checkcall(self,
- cmd) :
- cwd = os.getcwd()
- os.chdir(self.remote_root)
- proc = sp.Popen(cmd, shell=True, stdout = sp.PIPE, stderr = sp.PIPE)
- o, e = proc.communicate()
- stdout = SPRetObj(o)
- stderr = SPRetObj(e)
- code = proc.returncode
- if code != 0:
- os.chdir(cwd)
- raise RuntimeError("Get error code %d in locally calling %s with job: %s ", (code, cmd, self.job_uuid))
- os.chdir(cwd)
- return None, stdout, stderr
-
- def block_call(self, cmd) :
- cwd = os.getcwd()
- os.chdir(self.remote_root)
- proc = sp.Popen(cmd, shell=True, stdout = sp.PIPE, stderr = sp.PIPE)
- o, e = proc.communicate()
- stdout = SPRetObj(o)
- stderr = SPRetObj(e)
- code = proc.returncode
- os.chdir(cwd)
- return code, None, stdout, stderr
-
- def clean(self) :
- shutil.rmtree(self.remote_root, ignore_errors=True)
-
- def write_file(self, fname, write_str):
- with open(os.path.join(self.remote_root, fname), 'w') as fp :
- fp.write(write_str)
-
- def read_file(self, fname):
- with open(os.path.join(self.remote_root, fname), 'r') as fp:
- ret = fp.read()
- return ret
-
- def check_file_exists(self, fname):
- return os.path.isfile(os.path.join(self.remote_root, fname))
-
- def call(self, cmd) :
- cwd = os.getcwd()
- os.chdir(self.remote_root)
- proc = sp.Popen(cmd, shell=True, stdout = sp.PIPE, stderr = sp.PIPE)
- os.chdir(cwd)
- return proc
-
- def kill(self, proc):
- proc.kill()
-
- def check_finish(self, proc):
- return (proc.poll() != None)
-
- def get_return(self, proc):
- ret = proc.poll()
- if ret is None:
- return None, None, None
- else :
- try:
- o, e = proc.communicate()
- stdout = SPRetObj(o)
- stderr = SPRetObj(e)
- except ValueError:
- stdout = None
- stderr = None
- return ret, stdout, stderr
-
-
diff --git a/dpgen/dispatcher/PBS.py b/dpgen/dispatcher/PBS.py
deleted file mode 100644
index 0fed5a888..000000000
--- a/dpgen/dispatcher/PBS.py
+++ /dev/null
@@ -1,137 +0,0 @@
-import os,getpass,time
-from dpgen.dispatcher.Batch import Batch
-from dpgen.dispatcher.JobStatus import JobStatus
-
-def _default_item(resources, key, value) :
- if key not in resources :
- resources[key] = value
-
-class PBS(Batch) :
-
- def check_status(self) :
- job_id = self._get_job_id()
- if job_id == "" :
- return JobStatus.unsubmitted
- ret, stdin, stdout, stderr\
- = self.context.block_call ("qstat " + job_id)
- err_str = stderr.read().decode('utf-8')
- if (ret != 0) :
- if str("qstat: Unknown Job Id") in err_str or str("Job has finished") in err_str:
- if self.check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- raise RuntimeError ("status command qstat fails to execute. erro info: %s return code %d"
- % (err_str, ret))
- status_line = stdout.read().decode('utf-8').split ('\n')[-2]
- status_word = status_line.split ()[-2]
- # dlog.info (status_word)
- if status_word in ["Q","H"] :
- return JobStatus.waiting
- elif status_word in ["R"] :
- return JobStatus.running
- elif status_word in ["C","E","K"] :
- if self.check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- return JobStatus.unknown
-
- def do_submit(self,
- job_dirs,
- cmd,
- args = None,
- res = None,
- outlog = 'log',
- errlog = 'err'):
- if res == None:
- res = self.default_resources(res)
- # if 'task_max' in res and res['task_max'] > 0:
- # while self._check_sub_limit(task_max=res['task_max']):
- # time.sleep(60)
- script_str = self.sub_script(job_dirs, cmd, args=args, res=res, outlog=outlog, errlog=errlog)
- self.context.write_file(self.sub_script_name, script_str)
- stdin, stdout, stderr = self.context.block_checkcall('cd %s && %s %s' % (self.context.remote_root, 'qsub', self.sub_script_name))
- subret = (stdout.readlines())
- job_id = subret[0].split()[0]
- self.context.write_file(self.job_id_name, job_id)
-
- def default_resources(self, res_) :
- """
- set default value if a key in res_ is not fhound
- """
- if res_ == None :
- res = {}
- else:
- res = res_
- _default_item(res, 'numb_node', 1)
- _default_item(res, 'task_per_node', 1)
- _default_item(res, 'cpus_per_task', -1)
- _default_item(res, 'numb_gpu', 0)
- _default_item(res, 'time_limit', '1:0:0')
- _default_item(res, 'mem_limit', -1)
- _default_item(res, 'partition', '')
- _default_item(res, 'account', '')
- _default_item(res, 'qos', '')
- _default_item(res, 'constraint_list', [])
- _default_item(res, 'license_list', [])
- _default_item(res, 'exclude_list', [])
- _default_item(res, 'module_unload_list', [])
- _default_item(res, 'module_list', [])
- _default_item(res, 'source_list', [])
- _default_item(res, 'envs', None)
- _default_item(res, 'with_mpi', False)
- _default_item(res, 'cuda_multi_tasks', False)
- _default_item(res, 'allow_failure', True)
- _default_item(res, 'cvasp', False)
- return res
-
- def sub_script_head(self, res):
- ret = ''
- ret += "#!/bin/bash -l\n"
- if res['numb_gpu'] == 0:
- ret += '#PBS -l nodes=%d:ppn=%d\n' % (res['numb_node'], res['task_per_node'])
- else :
- ret += '#PBS -l nodes=%d:ppn=%d:gpus=%d\n' % (res['numb_node'], res['task_per_node'], res['numb_gpu'])
- ret += '#PBS -l walltime=%s\n' % (res['time_limit'])
- if res['mem_limit'] > 0 :
- ret += "#PBS -l mem=%dG \n" % res['mem_limit']
- ret += '#PBS -j oe\n'
- if len(res['partition']) > 0 :
- ret += '#PBS -q %s\n' % res['partition']
- ret += "\n"
- for ii in res['module_unload_list'] :
- ret += "module unload %s\n" % ii
- for ii in res['module_list'] :
- ret += "module load %s\n" % ii
- ret += "\n"
- for ii in res['source_list'] :
- ret += "source %s\n" %ii
- ret += "\n"
- envs = res['envs']
- if envs != None :
- for key in envs.keys() :
- ret += 'export %s=%s\n' % (key, envs[key])
- ret += '\n'
- ret += 'cd $PBS_O_WORKDIR\n\n'
- return ret
-
- def sub_script_cmd(self,
- cmd,
- arg,
- res) :
- if res['with_mpi']:
- ret = 'mpirun -machinefile $PBS_NODEFILE -n %d %s %s' % (
- res['numb_node'] * res['task_per_node'], cmd, arg)
- else :
- ret = '%s %s' % (cmd, arg)
- return ret
-
- def _get_job_id(self) :
- if self.context.check_file_exists(self.job_id_name) :
- return self.context.read_file(self.job_id_name)
- else:
- return ""
-
diff --git a/dpgen/dispatcher/SSHContext.py b/dpgen/dispatcher/SSHContext.py
deleted file mode 100644
index 7f614f31b..000000000
--- a/dpgen/dispatcher/SSHContext.py
+++ /dev/null
@@ -1,359 +0,0 @@
-#!/usr/bin/env python
-# coding: utf-8
-
-import os, sys, paramiko, json, uuid, tarfile, time, stat, shutil
-from glob import glob
-from dpgen import dlog
-
-class SSHSession (object) :
- def __init__ (self, jdata) :
- self.remote_profile = jdata
- # with open(remote_profile) as fp :
- # self.remote_profile = json.load(fp)
- self.remote_host = self.remote_profile['hostname']
- self.remote_uname = self.remote_profile['username']
- self.remote_port = self.remote_profile.get('port', 22)
- self.remote_password = self.remote_profile.get('password', None)
- self.local_key_filename = self.remote_profile.get('key_filename', None)
- self.remote_timeout = self.remote_profile.get('timeout', None)
- self.local_key_passphrase = self.remote_profile.get('passphrase', None)
- self.remote_workpath = self.remote_profile['work_path']
- self.ssh = None
- self._setup_ssh(hostname=self.remote_host,
- port=self.remote_port,
- username=self.remote_uname,
- password=self.remote_password,
- key_filename=self.local_key_filename,
- timeout=self.remote_timeout,
- passphrase=self.local_key_passphrase)
-
- def ensure_alive(self,
- max_check = 10,
- sleep_time = 10):
- count = 1
- while not self._check_alive():
- if count == max_check:
- raise RuntimeError('cannot connect ssh after %d failures at interval %d s' %
- (max_check, sleep_time))
- dlog.info('connection check failed, try to reconnect to ' + self.remote_host)
- self._setup_ssh(hostname=self.remote_host,
- port=self.remote_port,
- username=self.remote_uname,
- password=self.remote_password,
- key_filename=self.local_key_filename,
- timeout=self.remote_timeout,
- passphrase=self.local_key_passphrase)
- count += 1
- time.sleep(sleep_time)
-
- def _check_alive(self):
- if self.ssh == None:
- return False
- try :
- transport = self.ssh.get_transport()
- transport.send_ignore()
- return True
- except EOFError:
- return False
-
- def _setup_ssh(self,
- hostname,
- port=22,
- username=None,
- password=None,
- key_filename=None,
- timeout=None,
- passphrase=None):
- self.ssh = paramiko.SSHClient()
- # ssh_client.load_system_host_keys()
- self.ssh.set_missing_host_key_policy(paramiko.WarningPolicy)
- self.ssh.connect(hostname=hostname, port=port,
- username=username, password=password,
- key_filename=key_filename, timeout=timeout, passphrase=passphrase)
- assert(self.ssh.get_transport().is_active())
- transport = self.ssh.get_transport()
- transport.set_keepalive(60)
- # reset sftp
- self._sftp = None
-
- def get_ssh_client(self) :
- return self.ssh
-
- def get_session_root(self) :
- return self.remote_workpath
-
- def close(self) :
- self.ssh.close()
-
- def exec_command(self, cmd, retry = 0):
- """Calling self.ssh.exec_command but has an exception check."""
- try:
- return self.ssh.exec_command(cmd)
- except paramiko.ssh_exception.SSHException:
- # SSH session not active
- # retry for up to 3 times
- if retry < 3:
- dlog.warning("SSH session not active in calling %s, retry the command..." % cmd)
- # ensure alive
- self.ensure_alive()
- return self.exec_command(cmd, retry = retry+1)
- raise RuntimeError("SSH session not active")
-
- @property
- def sftp(self):
- """Returns sftp. Open a new one if not existing."""
- if self._sftp is None:
- self.ensure_alive()
- self._sftp = self.ssh.open_sftp()
- return self._sftp
-
-
-class SSHContext (object):
- def __init__ (self,
- local_root,
- ssh_session,
- job_uuid=None,
- ) :
- assert(type(local_root) == str)
- self.local_root = os.path.abspath(local_root)
- if job_uuid:
- self.job_uuid=job_uuid
- else:
- self.job_uuid = str(uuid.uuid4())
- self.remote_root = os.path.join(ssh_session.get_session_root(), self.job_uuid)
- self.ssh_session = ssh_session
- self.ssh_session.ensure_alive()
- try:
- self.sftp.mkdir(self.remote_root)
- except Exception:
- pass
-
- @property
- def ssh(self):
- return self.ssh_session.get_ssh_client()
-
- @property
- def sftp(self):
- return self.ssh_session.sftp
-
- def close(self):
- self.ssh_session.close()
-
- def get_job_root(self) :
- return self.remote_root
-
- def upload(self,
- job_dirs,
- local_up_files,
- dereference = True) :
- self.ssh_session.ensure_alive()
- cwd = os.getcwd()
- os.chdir(self.local_root)
- file_list = []
- for ii in job_dirs :
- for jj in local_up_files :
- file_list.append(os.path.join(ii,jj))
- self._put_files(file_list, dereference = dereference)
- os.chdir(cwd)
-
- def download(self,
- job_dirs,
- remote_down_files,
- check_exists = False,
- mark_failure = True,
- back_error=False) :
- self.ssh_session.ensure_alive()
- cwd = os.getcwd()
- os.chdir(self.local_root)
- file_list = []
- for ii in job_dirs :
- for jj in remote_down_files :
- file_name = os.path.join(ii,jj)
- if check_exists:
- if self.check_file_exists(file_name):
- file_list.append(file_name)
- elif mark_failure :
- with open(os.path.join(self.local_root, ii, 'tag_failure_download_%s' % jj), 'w') as fp: pass
- else:
- pass
- else:
- file_list.append(file_name)
- if back_error:
- errors=glob(os.path.join(ii,'error*'))
- file_list.extend(errors)
- if len(file_list) > 0:
- self._get_files(file_list)
- os.chdir(cwd)
-
- def block_checkcall(self,
- cmd,
- retry=0) :
- self.ssh_session.ensure_alive()
- stdin, stdout, stderr = self.ssh_session.exec_command(('cd %s ;' % self.remote_root) + cmd)
- exit_status = stdout.channel.recv_exit_status()
- if exit_status != 0:
- if retry<3:
- # sleep 60 s
- dlog.warning("Get error code %d in calling %s through ssh with job: %s . message: %s" %
- (exit_status, cmd, self.job_uuid, stderr.read().decode('utf-8')))
- dlog.warning("Sleep 60 s and retry the command...")
- time.sleep(60)
- return self.block_checkcall(cmd, retry=retry+1)
- raise RuntimeError("Get error code %d in calling %s through ssh with job: %s . message: %s" %
- (exit_status, cmd, self.job_uuid, stderr.read().decode('utf-8')))
- return stdin, stdout, stderr
-
- def block_call(self,
- cmd) :
- self.ssh_session.ensure_alive()
- stdin, stdout, stderr = self.ssh_session.exec_command(('cd %s ;' % self.remote_root) + cmd)
- exit_status = stdout.channel.recv_exit_status()
- return exit_status, stdin, stdout, stderr
-
- def clean(self) :
- self.ssh_session.ensure_alive()
- sftp = self.ssh.open_sftp()
- self._rmtree(sftp, self.remote_root)
- sftp.close()
-
- def write_file(self, fname, write_str):
- self.ssh_session.ensure_alive()
- with self.sftp.open(os.path.join(self.remote_root, fname), 'w') as fp :
- fp.write(write_str)
-
- def read_file(self, fname):
- self.ssh_session.ensure_alive()
- with self.sftp.open(os.path.join(self.remote_root, fname), 'r') as fp:
- ret = fp.read().decode('utf-8')
- return ret
-
- def check_file_exists(self, fname):
- self.ssh_session.ensure_alive()
- try:
- self.sftp.stat(os.path.join(self.remote_root, fname))
- ret = True
- except IOError:
- ret = False
- return ret
-
- def call(self, cmd):
- stdin, stdout, stderr = self.ssh_session.exec_command(cmd)
- # stdin, stdout, stderr = self.ssh.exec_command('echo $$; exec ' + cmd)
- # pid = stdout.readline().strip()
- # print(pid)
- return {'stdin':stdin, 'stdout':stdout, 'stderr':stderr}
-
- def check_finish(self, cmd_pipes):
- return cmd_pipes['stdout'].channel.exit_status_ready()
-
-
- def get_return(self, cmd_pipes):
- if not self.check_finish(cmd_pipes):
- return None, None, None
- else :
- retcode = cmd_pipes['stdout'].channel.recv_exit_status()
- return retcode, cmd_pipes['stdout'], cmd_pipes['stderr']
-
- def kill(self, cmd_pipes) :
- raise RuntimeError('dose not work! we do not know how to kill proc through paramiko.SSHClient')
- self.block_checkcall('kill -15 %s' % cmd_pipes['pid'])
-
-
- def _rmtree(self, sftp, remotepath, level=0, verbose = False):
- for f in sftp.listdir_attr(remotepath):
- rpath = os.path.join(remotepath, f.filename)
- if stat.S_ISDIR(f.st_mode):
- self._rmtree(sftp, rpath, level=(level + 1))
- else:
- rpath = os.path.join(remotepath, f.filename)
- if verbose: dlog.info('removing %s%s' % (' ' * level, rpath))
- sftp.remove(rpath)
- if verbose: dlog.info('removing %s%s' % (' ' * level, remotepath))
- sftp.rmdir(remotepath)
-
- def _put_files(self,
- files,
- dereference = True) :
- of = self.job_uuid + '.tgz'
- # local tar
- cwd = os.getcwd()
- os.chdir(self.local_root)
- if os.path.isfile(of) :
- os.remove(of)
- with tarfile.open(of, "w:gz", dereference = dereference, compresslevel=6) as tar:
- for ii in files :
- tar.add(ii)
- os.chdir(cwd)
- # trans
- from_f = os.path.join(self.local_root, of)
- to_f = os.path.join(self.remote_root, of)
- try:
- self.sftp.put(from_f, to_f)
- except FileNotFoundError:
- raise FileNotFoundError("from %s to %s Error!"%(from_f,to_f))
- # remote extract
- self.block_checkcall('tar xf %s' % of)
- # clean up
- os.remove(from_f)
- self.sftp.remove(to_f)
-
- def _get_files(self,
- files) :
- of = self.job_uuid + '.tar.gz'
- # remote tar
- # If the number of files are large, we may get "Argument list too long" error.
- # Thus, we may run tar commands for serveral times and tar only 100 files for
- # each time.
- per_nfile = 100
- ntar = len(files) // per_nfile + 1
- if ntar <= 1:
- self.block_checkcall('tar czfh %s %s' % (of, " ".join(files)))
- else:
- of_tar = self.job_uuid + '.tar'
- for ii in range(ntar):
- ff = files[per_nfile * ii : per_nfile * (ii+1)]
- if ii == 0:
- # tar cf for the first time
- self.block_checkcall('tar cfh %s %s' % (of_tar, " ".join(ff)))
- else:
- # append using tar rf
- # -r, --append append files to the end of an archive
- self.block_checkcall('tar rfh %s %s' % (of_tar, " ".join(ff)))
- # compress the tar file using gzip, and will get a tar.gz file
- # overwrite considering dpgen may stop and restart
- # -f, --force force overwrite of output file and compress links
- self.block_checkcall('gzip -f %s' % of_tar)
- # trans
- from_f = os.path.join(self.remote_root, of)
- to_f = os.path.join(self.local_root, of)
- if os.path.isfile(to_f) :
- os.remove(to_f)
- self.sftp.get(from_f, to_f)
- # extract
- cwd = os.getcwd()
- os.chdir(self.local_root)
- with tarfile.open(of, "r:gz") as tar:
- def is_within_directory(directory, target):
-
- abs_directory = os.path.abspath(directory)
- abs_target = os.path.abspath(target)
-
- prefix = os.path.commonprefix([abs_directory, abs_target])
-
- return prefix == abs_directory
-
- def safe_extract(tar, path=".", members=None, *, numeric_owner=False):
-
- for member in tar.getmembers():
- member_path = os.path.join(path, member.name)
- if not is_within_directory(path, member_path):
- raise Exception("Attempted Path Traversal in Tar File")
-
- tar.extractall(path, members, numeric_owner=numeric_owner)
-
-
- safe_extract(tar)
- os.chdir(cwd)
- # cleanup
- os.remove(to_f)
- self.sftp.remove(from_f)
diff --git a/dpgen/dispatcher/Shell.py b/dpgen/dispatcher/Shell.py
deleted file mode 100644
index 35a82018d..000000000
--- a/dpgen/dispatcher/Shell.py
+++ /dev/null
@@ -1,112 +0,0 @@
-import os,getpass,time
-from dpgen.dispatcher.Batch import Batch
-from dpgen.dispatcher.JobStatus import JobStatus
-import datetime
-
-def _default_item(resources, key, value) :
- if key not in resources :
- resources[key] = value
-
-
-class Shell(Batch) :
-
- def check_status(self) :
- if self.check_finish_tag():
- return JobStatus.finished
- elif self.check_running():
- return JobStatus.running
- else:
- return JobStatus.terminated
- ## warn: cannont distinguish terminated from unsubmitted.
-
- def do_submit(self,
- job_dirs,
- cmd,
- args = None,
- res = None,
- outlog = 'log',
- errlog = 'err'):
- if res == None:
- res = {}
- script_str = self.sub_script(job_dirs, cmd, args=args, res=res, outlog=outlog, errlog=errlog)
- self.context.write_file(self.sub_script_name, script_str)
- self.proc = self.context.call('cd %s && exec bash %s' % (self.context.remote_root, self.sub_script_name))
-
- def check_running(self):
- uuid_names = self.context.job_uuid
- ## Check if the uuid.sub is running on remote machine
- cnt = 0
- ret, stdin, stdout, stderr = self.context.block_call("ps aux | grep %s"%uuid_names)
- response_list = stdout.read().decode('utf-8').split("\n")
- for response in response_list:
- if uuid_names + ".sub" in response:
- return True
- return False
-
- def default_resources(self, res_) :
- if res_ == None :
- res = {}
- else:
- res = res_
- _default_item(res, 'task_per_node', 1)
- _default_item(res, 'module_list', [])
- _default_item(res, 'module_unload_list', [])
- _default_item(res, 'source_list', [])
- _default_item(res, 'envs', {})
- _default_item(res, 'with_mpi', False)
- _default_item(res, 'cuda_multi_tasks', False)
- _default_item(res, 'allow_failure', False)
- _default_item(res, 'cvasp', False)
- return res
-
- def sub_script_head(self, resources) :
- envs = resources['envs']
- module_list = resources['module_list']
- module_unload_list = resources['module_unload_list']
- task_per_node = resources['task_per_node']
- source_list = resources['source_list']
-
- ret = ''
- ret += ('#!/bin/bash\n\n')
- # fp.write('set -euo pipefail\n')
- for key in envs.keys() :
- ret += ('export %s=%s\n' % (key, envs[key]))
- ret += ('\n')
- for ii in module_unload_list :
- ret += ('module unload %s\n' % ii)
- ret += ('\n')
- for ii in module_list :
- ret += ('module load %s\n' % ii)
- ret += ('\n')
- for ii in source_list :
- ret += ('source %s\n' % ii)
- ret += ('\n')
- return ret
-
-
- def sub_script_cmd(self,
- cmd,
- arg,
- res) :
- try:
- cvasp=res['cvasp']
- fp_max_errors = 3
- try:
- fp_max_errors = res['fp_max_errors']
- except Exception:
- pass
- except Exception:
- cvasp=False
-
- _cmd = cmd.split('1>')[0].strip()
- if cvasp :
- if res['with_mpi']:
- _cmd = 'python cvasp.py "mpirun -n %d %s %s" %s' % (res['task_per_node'], _cmd, arg, fp_max_errors)
- else :
- _cmd = 'python cvasp.py "%s %s" %s' % (_cmd, arg, fp_max_errors)
- else :
- if res['with_mpi']:
- _cmd = 'mpirun -n %d %s %s' % (res['task_per_node'], _cmd, arg)
- else :
- _cmd = '%s %s' % (_cmd, arg)
- return _cmd
diff --git a/dpgen/dispatcher/Slurm.py b/dpgen/dispatcher/Slurm.py
deleted file mode 100644
index e1d3550e2..000000000
--- a/dpgen/dispatcher/Slurm.py
+++ /dev/null
@@ -1,209 +0,0 @@
-import os,getpass,time
-from dpgen.dispatcher.Batch import Batch
-from dpgen.dispatcher.JobStatus import JobStatus
-
-def _default_item(resources, key, value) :
- if key not in resources :
- resources[key] = value
-
-class Slurm(Batch) :
-
- def check_status(self) :
- """
- check the status of a job
- """
- job_id = self._get_job_id()
- if job_id == '' :
- return JobStatus.unsubmitted
- while True:
- stat = self._check_status_inner(job_id)
- if stat != JobStatus.completing:
- return stat
- else:
- time.sleep(5)
-
- def do_submit(self,
- job_dirs,
- cmd,
- args = None,
- res = None,
- outlog = 'log',
- errlog = 'err'):
- if res == None:
- res = self.default_resources(res)
- if 'task_max' in res and res['task_max'] > 0:
- while self._check_sub_limit(task_max=res['task_max']):
- time.sleep(60)
- script_str = self.sub_script(job_dirs, cmd, args=args, res=res, outlog=outlog, errlog=errlog)
- self.context.write_file(self.sub_script_name, script_str)
- stdin, stdout, stderr = self.context.block_checkcall('cd %s && %s %s' % (self.context.remote_root, 'sbatch', self.sub_script_name))
- subret = (stdout.readlines())
- job_id = subret[0].split()[-1]
- self.context.write_file(self.job_id_name, job_id)
-
- def default_resources(self, res_) :
- """
- set default value if a key in res_ is not fhound
- """
- if res_ == None :
- res = {}
- else:
- res = res_
- _default_item(res, 'numb_node', 1)
- _default_item(res, 'task_per_node', 1)
- _default_item(res, 'cpus_per_task', -1)
- _default_item(res, 'numb_gpu', 0)
- _default_item(res, 'time_limit', '1:0:0')
- _default_item(res, 'mem_limit', -1)
- _default_item(res, 'partition', '')
- _default_item(res, 'account', '')
- _default_item(res, 'qos', '')
- _default_item(res, 'constraint_list', [])
- _default_item(res, 'license_list', [])
- _default_item(res, 'exclude_list', [])
- _default_item(res, 'module_unload_list', [])
- _default_item(res, 'module_list', [])
- _default_item(res, 'source_list', [])
- _default_item(res, 'envs', None)
- _default_item(res, 'with_mpi', False)
- _default_item(res, 'cuda_multi_tasks', False)
- _default_item(res, 'allow_failure', False)
- _default_item(res, 'cvasp', False)
- return res
-
- def sub_script_head(self, res):
- ret = ''
- ret += "#!/bin/bash -l\n"
- ret += "#SBATCH -N %d\n" % res['numb_node']
- ret += "#SBATCH --ntasks-per-node=%d\n" % res['task_per_node']
- if res['cpus_per_task'] > 0 :
- ret += "#SBATCH --cpus-per-task=%d\n" % res['cpus_per_task']
- ret += "#SBATCH -t %s\n" % res['time_limit']
- if res['mem_limit'] > 0 :
- ret += "#SBATCH --mem=%dG \n" % res['mem_limit']
- if 'job_name' in res:
- if len(res['job_name']) > 0:
- ret += '#SBATCH --job-name=%s\n' % res['job_name']
- if len(res['account']) > 0 :
- ret += "#SBATCH --account=%s \n" % res['account']
- if len(res['partition']) > 0 :
- ret += "#SBATCH --partition=%s \n" % res['partition']
- if len(res['qos']) > 0 :
- ret += "#SBATCH --qos=%s \n" % res['qos']
- if res['numb_gpu'] > 0 :
- ret += "#SBATCH --gres=gpu:%d\n" % res['numb_gpu']
- for ii in res['constraint_list'] :
- ret += '#SBATCH -C %s \n' % ii
- for ii in res['license_list'] :
- ret += '#SBATCH -L %s \n' % ii
- if len(res['exclude_list']) >0:
- temp_exclude = ""
- for ii in res['exclude_list'] :
- temp_exclude += ii
- temp_exclude += ","
- temp_exclude = temp_exclude[:-1]
- ret += '#SBATCH --exclude=%s \n' % temp_exclude
- for flag in res.get('custom_flags', []):
- ret += '#SBATCH %s \n' % flag
- ret += "\n"
- for ii in res['module_unload_list'] :
- ret += "module unload %s\n" % ii
- for ii in res['module_list'] :
- ret += "module load %s\n" % ii
- ret += "\n"
- for ii in res['source_list'] :
- ret += "source %s\n" %ii
- ret += "\n"
- envs = res['envs']
- if envs != None :
- for key in envs.keys() :
- ret += 'export %s=%s\n' % (key, envs[key])
- ret += '\n'
- return ret
-
- def sub_script_cmd(self,
- cmd,
- arg,
- res) :
- try:
- cvasp=res['cvasp']
- fp_max_errors = 3
- try:
- fp_max_errors = res['fp_max_errors']
- except Exception:
- pass
- except Exception:
- cvasp=False
-
- _cmd = cmd.split('1>')[0].strip()
- if cvasp :
- if res['with_mpi']:
- _cmd = 'python cvasp.py "srun %s %s" %s' % (_cmd, arg, fp_max_errors)
- else :
- _cmd = 'python cvasp.py "%s %s" %s' % (_cmd, arg, fp_max_errors)
- else :
- if res['with_mpi']:
- _cmd = 'srun %s %s' % (_cmd, arg)
- else :
- _cmd = '%s %s' % (_cmd, arg)
- return _cmd
-
- def _get_job_id(self) :
- if self.context.check_file_exists(self.job_id_name) :
- return self.context.read_file(self.job_id_name)
- else:
- return ""
-
- def _check_status_inner(self, job_id, retry=0):
- ret, stdin, stdout, stderr\
- = self.context.block_call ('squeue -o "%.18i %.2t" -j ' + job_id)
- if (ret != 0) :
- err_str = stderr.read().decode('utf-8')
- if str("Invalid job id specified") in err_str :
- if self.check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- # retry 3 times
- if retry < 3:
- # rest 60s
- time.sleep(60)
- return self._check_status_inner(job_id, retry=retry+1)
- raise RuntimeError\
- ("status command squeue fails to execute\nerror message:%s\nreturn code %d\n" % (err_str, ret))
- status_line = stdout.read().decode('utf-8').split ('\n')[-2]
- status_word = status_line.split ()[-1]
- if not (len(status_line.split()) == 2 and status_word.isupper()):
- raise RuntimeError("Error in getting job status, " +
- f"status_line = {status_line}, " +
- f"parsed status_word = {status_word}")
- if status_word in ["PD","CF","S"] :
- return JobStatus.waiting
- elif status_word in ["R"] :
- return JobStatus.running
- elif status_word in ["CG"] :
- return JobStatus.completing
- elif status_word in ["C","E","K","BF","CA","CD","F","NF","PR","SE","ST","TO"] :
- if self.check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- return JobStatus.unknown
-
-
- def _check_sub_limit(self, task_max, **kwarg) :
- if task_max <= 0:
- return True
- username = getpass.getuser()
- stdin, stdout, stderr = self.context.block_checkcall('squeue -u %s -h' % username)
- nj = len(stdout.readlines())
- return nj >= task_max
-
- def _make_squeue(self,mdata1, res):
- ret = ''
- ret += 'squeue -u %s ' % mdata1['username']
- ret += '-p %s ' % res['partition']
- ret += '| grep PD'
- return ret
diff --git a/dpgen/generator/arginfo.py b/dpgen/generator/arginfo.py
index 40c9b19a5..45c148d0d 100644
--- a/dpgen/generator/arginfo.py
+++ b/dpgen/generator/arginfo.py
@@ -1,4 +1,5 @@
from typing import Dict, List
+
from dargs import Argument, Variant
from dpgen.arginfo import general_mdata_arginfo
@@ -6,7 +7,7 @@
def run_mdata_arginfo() -> Argument:
"""Generate arginfo for dpgen run mdata.
-
+
Returns
-------
Argument
@@ -14,141 +15,217 @@ def run_mdata_arginfo() -> Argument:
"""
return general_mdata_arginfo("run_mdata", ("train", "model_devi", "fp"))
+
# basics
def basic_args() -> List[Argument]:
- doc_type_map = 'Atom types. Reminder: The elements in param.json, type.raw and data.lmp(when using lammps) should be in the same order.'
+ doc_type_map = "Atom types. Reminder: The elements in param.json, type.raw and data.lmp(when using lammps) should be in the same order."
doc_mass_map = 'Standard atomic weights (default: "auto"). if one want to use isotopes, or non-standard element names, chemical symbols, or atomic number in the type_map list, please customize the mass_map list instead of using "auto".'
- doc_use_ele_temp = 'Currently only support fp_style vasp. \n\n\
+ doc_use_ele_temp = "Currently only support fp_style vasp. \n\n\
- 0: no electron temperature. \n\n\
- 1: eletron temperature as frame parameter. \n\n\
-- 2: electron temperature as atom parameter.'
+- 2: electron temperature as atom parameter."
return [
Argument("type_map", list, optional=False, doc=doc_type_map),
- Argument("mass_map", [list, str], optional=True, default="auto", doc=doc_mass_map),
- Argument("use_ele_temp", int, optional=True,
- default=0, doc=doc_use_ele_temp),
+ Argument(
+ "mass_map", [list, str], optional=True, default="auto", doc=doc_mass_map
+ ),
+ Argument("use_ele_temp", int, optional=True, default=0, doc=doc_use_ele_temp),
]
def data_args() -> List[Argument]:
- doc_init_data_prefix = 'Prefix of initial data directories.'
- doc_init_data_sys = 'Paths of initial data. The path can be either a system diretory containing NumPy files or an HDF5 file. You may use either absolute or relative path here. Systems will be detected recursively in the directories or the HDF5 file.'
- doc_sys_format = 'Format of sys_configs.'
- doc_init_batch_size = 'Each number is the batch_size of corresponding system for training in init_data_sys. One recommended rule for setting the sys_batch_size and init_batch_size is that batch_size mutiply number of atoms ot the stucture should be larger than 32. If set to auto, batch size will be 32 divided by number of atoms.'
- doc_sys_configs_prefix = 'Prefix of sys_configs.'
- doc_sys_configs = 'Containing directories of structures to be explored in iterations.Wildcard characters are supported here.'
- doc_sys_batch_size = 'Each number is the batch_size for training of corresponding system in sys_configs. If set to auto, batch size will be 32 divided by number of atoms.'
+ doc_init_data_prefix = "Prefix of initial data directories."
+ doc_init_data_sys = "Paths of initial data. The path can be either a system diretory containing NumPy files or an HDF5 file. You may use either absolute or relative path here. Systems will be detected recursively in the directories or the HDF5 file."
+ doc_sys_format = "Format of sys_configs."
+ doc_init_batch_size = "Each number is the batch_size of corresponding system for training in init_data_sys. One recommended rule for setting the sys_batch_size and init_batch_size is that batch_size mutiply number of atoms ot the stucture should be larger than 32. If set to auto, batch size will be 32 divided by number of atoms."
+ doc_sys_configs_prefix = "Prefix of sys_configs."
+ doc_sys_configs = "Containing directories of structures to be explored in iterations.Wildcard characters are supported here."
+ doc_sys_batch_size = "Each number is the batch_size for training of corresponding system in sys_configs. If set to auto, batch size will be 32 divided by number of atoms."
return [
- Argument("init_data_prefix", str, optional=True,
- doc=doc_init_data_prefix),
- Argument("init_data_sys", list,
- optional=False, doc=doc_init_data_sys),
- Argument("sys_format", str, optional=True, default='vasp/poscar', doc=doc_sys_format),
- Argument("init_batch_size", [list, str], optional=True,
- doc=doc_init_batch_size),
- Argument("sys_configs_prefix", str, optional=True,
- doc=doc_sys_configs_prefix),
+ Argument("init_data_prefix", str, optional=True, doc=doc_init_data_prefix),
+ Argument("init_data_sys", list, optional=False, doc=doc_init_data_sys),
+ Argument(
+ "sys_format", str, optional=True, default="vasp/poscar", doc=doc_sys_format
+ ),
+ Argument(
+ "init_batch_size", [list, str], optional=True, doc=doc_init_batch_size
+ ),
+ Argument("sys_configs_prefix", str, optional=True, doc=doc_sys_configs_prefix),
Argument("sys_configs", list, optional=False, doc=doc_sys_configs),
- Argument("sys_batch_size", list, optional=True,
- doc=doc_sys_batch_size),
+ Argument("sys_batch_size", list, optional=True, doc=doc_sys_batch_size),
]
+
# Training
def training_args() -> List[Argument]:
"""Traning arguments.
-
+
Returns
-------
list[dargs.Argument]
List of training arguments.
"""
- doc_numb_models = 'Number of models to be trained in 00.train. 4 is recommend.'
- doc_training_iter0_model_path = 'The model used to init the first iter training. Number of element should be equal to numb_models.'
- doc_training_init_model = 'Iteration > 0, the model parameters will be initilized from the model trained at the previous iteration. Iteration == 0, the model parameters will be initialized from training_iter0_model_path.'
- doc_default_training_param = 'Training parameters for deepmd-kit in 00.train. You can find instructions from here: (https://github.com/deepmodeling/deepmd-kit).'
- doc_dp_compress = 'Use dp compress to compress the model.'
+ doc_numb_models = "Number of models to be trained in 00.train. 4 is recommend."
+ doc_training_iter0_model_path = "The model used to init the first iter training. Number of element should be equal to numb_models."
+ doc_training_init_model = "Iteration > 0, the model parameters will be initilized from the model trained at the previous iteration. Iteration == 0, the model parameters will be initialized from training_iter0_model_path."
+ doc_default_training_param = "Training parameters for deepmd-kit in 00.train. You can find instructions from here: (https://github.com/deepmodeling/deepmd-kit)."
+ doc_dp_compress = "Use dp compress to compress the model."
doc_training_reuse_iter = "The minimal index of iteration that continues training models from old models of last iteration."
doc_reusing = " This option is only adopted when continuing training models from old models. This option will override default parameters."
- doc_training_reuse_old_ratio = "The probability proportion of old data during training." + doc_reusing
+ doc_training_reuse_old_ratio = (
+ "The probability proportion of old data during training." + doc_reusing
+ )
doc_training_reuse_numb_steps = "Number of training batch." + doc_reusing
- doc_training_reuse_start_lr = "The learning rate the start of the training." + doc_reusing
- doc_training_reuse_start_pref_e = "The prefactor of energy loss at the start of the training." + doc_reusing
- doc_training_reuse_start_pref_f = "The prefactor of force loss at the start of the training." + doc_reusing
+ doc_training_reuse_start_lr = (
+ "The learning rate the start of the training." + doc_reusing
+ )
+ doc_training_reuse_start_pref_e = (
+ "The prefactor of energy loss at the start of the training." + doc_reusing
+ )
+ doc_training_reuse_start_pref_f = (
+ "The prefactor of force loss at the start of the training." + doc_reusing
+ )
doc_model_devi_activation_func = "The activation function in the model. The shape of list should be (N_models, 2), where 2 represents the embedding and fitting network. This option will override default parameters."
+ doc_srtab_file_path = "The path of the table for the short-range pairwise interaction which is needed when using DP-ZBL potential"
+ doc_one_h5 = (
+ "Before training, all of the training data will be merged into one HDF5 file."
+ )
return [
Argument("numb_models", int, optional=False, doc=doc_numb_models),
- Argument("training_iter0_model_path", list, optional=True,
- doc=doc_training_iter0_model_path),
- Argument("training_init_model", bool, optional=True,
- doc=doc_training_init_model),
- Argument("default_training_param", dict, optional=False,
- doc=doc_default_training_param),
- Argument("dp_compress", bool, optional=True,
- default=False, doc=doc_dp_compress),
- Argument("training_reuse_iter", [None, int], optional=True, doc=doc_training_reuse_iter),
- Argument("training_reuse_old_ratio", [None, float], optional=True, doc=doc_training_reuse_old_ratio),
- Argument("training_reuse_numb_steps", [None, int], alias=["training_reuse_stop_batch"], optional=True, default=400000, doc=doc_training_reuse_numb_steps),
- Argument("training_reuse_start_lr", [None, float], optional=True, default=1e-4, doc=doc_training_reuse_start_lr),
- Argument("training_reuse_start_pref_e", [None, float, int], optional=True, default=0.1, doc=doc_training_reuse_start_pref_e),
- Argument("training_reuse_start_pref_f", [None, float, int], optional=True, default=100, doc=doc_training_reuse_start_pref_f),
- Argument("model_devi_activation_func", [None, list], optional=True, doc=doc_model_devi_activation_func),
+ Argument(
+ "training_iter0_model_path",
+ list,
+ optional=True,
+ doc=doc_training_iter0_model_path,
+ ),
+ Argument(
+ "training_init_model", bool, optional=True, doc=doc_training_init_model
+ ),
+ Argument(
+ "default_training_param",
+ dict,
+ optional=False,
+ doc=doc_default_training_param,
+ ),
+ Argument(
+ "dp_compress", bool, optional=True, default=False, doc=doc_dp_compress
+ ),
+ Argument(
+ "training_reuse_iter",
+ [None, int],
+ optional=True,
+ doc=doc_training_reuse_iter,
+ ),
+ Argument(
+ "training_reuse_old_ratio",
+ [None, float],
+ optional=True,
+ doc=doc_training_reuse_old_ratio,
+ ),
+ Argument(
+ "training_reuse_numb_steps",
+ [None, int],
+ alias=["training_reuse_stop_batch"],
+ optional=True,
+ default=400000,
+ doc=doc_training_reuse_numb_steps,
+ ),
+ Argument(
+ "training_reuse_start_lr",
+ [None, float],
+ optional=True,
+ default=1e-4,
+ doc=doc_training_reuse_start_lr,
+ ),
+ Argument(
+ "training_reuse_start_pref_e",
+ [None, float, int],
+ optional=True,
+ default=0.1,
+ doc=doc_training_reuse_start_pref_e,
+ ),
+ Argument(
+ "training_reuse_start_pref_f",
+ [None, float, int],
+ optional=True,
+ default=100,
+ doc=doc_training_reuse_start_pref_f,
+ ),
+ Argument(
+ "model_devi_activation_func",
+ [None, list],
+ optional=True,
+ doc=doc_model_devi_activation_func,
+ ),
+ Argument("srtab_file_path", str, optional=True, doc=doc_srtab_file_path),
+ Argument("one_h5", bool, optional=True, default=False, doc=doc_one_h5),
]
# Exploration
def model_devi_jobs_template_args() -> Argument:
- doc_template = ('Give an input file template for the supported engine software adopted in 01.model_devi. '
- 'Through user-defined template, any freedom (function) that is permitted by the engine '
- 'software could be inherited (invoked) in the workflow.')
- doc_template_lmp = 'The path to input.lammps template'
- doc_template_plm = 'The path to input.plumed template'
+ doc_template = (
+ "Give an input file template for the supported engine software adopted in 01.model_devi. "
+ "Through user-defined template, any freedom (function) that is permitted by the engine "
+ "software could be inherited (invoked) in the workflow."
+ )
+ doc_template_lmp = "The path to input.lammps template"
+ doc_template_plm = "The path to input.plumed template"
args = [
Argument("lmp", str, optional=True, doc=doc_template_lmp),
Argument("plm", str, optional=True, doc=doc_template_plm),
]
- return Argument("template", list, args, [], optional=True, repeat=False, doc=doc_template)
+ return Argument(
+ "template", list, args, [], optional=True, repeat=False, doc=doc_template
+ )
def model_devi_jobs_rev_mat_args() -> Argument:
- doc_rev_mat = ('revise matrix for revising variable(s) defined in the template into the specific values (iteration-resolved).'
- ' Values will be broadcasted for all tasks within the iteration invoking this key.')
- doc_rev_mat_lmp = 'revise matrix for revising variable(s) defined in the lammps template into the specific values (iteration-resolved).'
- doc_rev_mat_plm = 'revise matrix for revising variable(s) defined in the plumed template into specific values(iteration-resolved)'
+ doc_rev_mat = (
+ "revise matrix for revising variable(s) defined in the template into the specific values (iteration-resolved)."
+ " Values will be broadcasted for all tasks within the iteration invoking this key."
+ )
+ doc_rev_mat_lmp = "revise matrix for revising variable(s) defined in the lammps template into the specific values (iteration-resolved)."
+ doc_rev_mat_plm = "revise matrix for revising variable(s) defined in the plumed template into specific values(iteration-resolved)"
args = [
Argument("lmp", dict, optional=True, doc=doc_rev_mat_lmp),
Argument("plm", dict, optional=True, doc=doc_rev_mat_plm),
]
- return Argument("rev_mat", list, args, [], optional=True, repeat=False, doc=doc_rev_mat)
+ return Argument(
+ "rev_mat", list, args, [], optional=True, repeat=False, doc=doc_rev_mat
+ )
def model_devi_jobs_args() -> List[Argument]:
# this may be not correct
- doc_sys_rev_mat = ('system-resolved revise matrix for revising variable(s) defined in the template into specific values. '
- 'Values should be individually assigned to each system adopted by this iteration, through a dictionary '
- 'where first-level keys are values of sys_idx of this iteration.')
- doc_sys_idx = 'Systems to be selected as the initial structure of MD and be explored. The index corresponds exactly to the sys_configs.'
- doc_temps = 'Temperature (K) in MD.'
- doc_press = 'Pressure (Bar) in MD. Required when ensemble is npt.'
- doc_trj_freq = 'Frequecy of trajectory saved in MD.'
- doc_nsteps = 'Running steps of MD. It is not optional when not using a template.'
- doc_ensemble = 'Determining which ensemble used in MD, options include “npt” and “nvt”. It is not optional when not using a template.'
- doc_neidelay = 'delay building until this many steps since last build.'
- doc_taut = 'Coupling time of thermostat (ps).'
- doc_taup = 'Coupling time of barostat (ps).'
- doc_model_devi_f_trust_lo = 'Lower bound of forces for the selection. If dict, should be set for each index in sys_idx, respectively.'
- doc_model_devi_f_trust_hi = 'Upper bound of forces for the selection. If dict, should be set for each index in sys_idx, respectively.'
- doc_model_devi_v_trust_lo = 'Lower bound of virial for the selection. If dict, should be set for each index in sys_idx, respectively. Should be used with DeePMD-kit v2.x.'
- doc_model_devi_v_trust_hi = 'Upper bound of virial for the selection. If dict, should be set for each index in sys_idx, respectively. Should be used with DeePMD-kit v2.x.'
+ doc_sys_rev_mat = (
+ "system-resolved revise matrix for revising variable(s) defined in the template into specific values. "
+ "Values should be individually assigned to each system adopted by this iteration, through a dictionary "
+ "where first-level keys are values of sys_idx of this iteration."
+ )
+ doc_sys_idx = "Systems to be selected as the initial structure of MD and be explored. The index corresponds exactly to the sys_configs."
+ doc_temps = "Temperature (K) in MD."
+ doc_press = "Pressure (Bar) in MD. Required when ensemble is npt."
+ doc_trj_freq = "Frequecy of trajectory saved in MD."
+ doc_nsteps = "Running steps of MD. It is not optional when not using a template."
+ doc_ensemble = "Determining which ensemble used in MD, options include “npt” and “nvt”. It is not optional when not using a template."
+ doc_neidelay = "delay building until this many steps since last build."
+ doc_taut = "Coupling time of thermostat (ps)."
+ doc_taup = "Coupling time of barostat (ps)."
+ doc_model_devi_f_trust_lo = "Lower bound of forces for the selection. If dict, should be set for each index in sys_idx, respectively."
+ doc_model_devi_f_trust_hi = "Upper bound of forces for the selection. If dict, should be set for each index in sys_idx, respectively."
+ doc_model_devi_v_trust_lo = "Lower bound of virial for the selection. If dict, should be set for each index in sys_idx, respectively. Should be used with DeePMD-kit v2.x."
+ doc_model_devi_v_trust_hi = "Upper bound of virial for the selection. If dict, should be set for each index in sys_idx, respectively. Should be used with DeePMD-kit v2.x."
args = [
- model_devi_jobs_template_args(),
+ model_devi_jobs_template_args(),
model_devi_jobs_rev_mat_args(),
Argument("sys_rev_mat", dict, optional=True, doc=doc_sys_rev_mat),
Argument("sys_idx", list, optional=False, doc=doc_sys_idx),
@@ -160,132 +237,246 @@ def model_devi_jobs_args() -> List[Argument]:
Argument("neidelay", int, optional=True, doc=doc_neidelay),
Argument("taut", float, optional=True, doc=doc_taut),
Argument("taup", float, optional=True, doc=doc_taup),
- Argument("model_devi_f_trust_lo", [
- float, dict], optional=True, doc=doc_model_devi_f_trust_lo),
- Argument("model_devi_f_trust_hi", [
- float, dict], optional=True, doc=doc_model_devi_f_trust_hi),
- Argument("model_devi_v_trust_lo", [
- float, dict], optional=True, doc=doc_model_devi_v_trust_lo),
- Argument("model_devi_v_trust_hi", [
- float, dict], optional=True, doc=doc_model_devi_v_trust_hi),
+ Argument(
+ "model_devi_f_trust_lo",
+ [float, dict],
+ optional=True,
+ doc=doc_model_devi_f_trust_lo,
+ ),
+ Argument(
+ "model_devi_f_trust_hi",
+ [float, dict],
+ optional=True,
+ doc=doc_model_devi_f_trust_hi,
+ ),
+ Argument(
+ "model_devi_v_trust_lo",
+ [float, dict],
+ optional=True,
+ doc=doc_model_devi_v_trust_lo,
+ ),
+ Argument(
+ "model_devi_v_trust_hi",
+ [float, dict],
+ optional=True,
+ doc=doc_model_devi_v_trust_hi,
+ ),
]
- doc_model_devi_jobs = 'Settings for exploration in 01.model_devi. Each dict in the list corresponds to one iteration. The index of model_devi_jobs exactly accord with index of iterations'
- return Argument("model_devi_jobs", list, args, [], repeat=True, doc=doc_model_devi_jobs)
+ doc_model_devi_jobs = "Settings for exploration in 01.model_devi. Each dict in the list corresponds to one iteration. The index of model_devi_jobs exactly accord with index of iterations"
+ return Argument(
+ "model_devi_jobs", list, args, [], repeat=True, doc=doc_model_devi_jobs
+ )
def model_devi_lmp_args() -> List[Argument]:
- doc_model_devi_dt = 'Timestep for MD. 0.002 is recommend.'
- doc_model_devi_skip = 'Number of structures skipped for fp in each MD.'
- doc_model_devi_f_trust_lo = 'Lower bound of forces for the selection. If list or dict, should be set for each index in sys_configs, respectively.'
- doc_model_devi_f_trust_hi = 'Upper bound of forces for the selection. If list or dict, should be set for each index in sys_configs, respectively.'
- doc_model_devi_v_trust_lo = 'Lower bound of virial for the selection. If list or dict, should be set for each index in sys_configs, respectively. Should be used with DeePMD-kit v2.x.'
- doc_model_devi_v_trust_hi = 'Upper bound of virial for the selection. If list or dict, should be set for each index in sys_configs, respectively. Should be used with DeePMD-kit v2.x.'
- doc_model_devi_adapt_trust_lo = 'Adaptively determines the lower trust levels of force and virial. This option should be used together with model_devi_numb_candi_f, model_devi_numb_candi_v and optionally with model_devi_perc_candi_f and model_devi_perc_candi_v. dpgen will make two sets:\n\n\
+ doc_model_devi_dt = "Timestep for MD. 0.002 is recommend."
+ doc_model_devi_skip = "Number of structures skipped for fp in each MD."
+ doc_model_devi_f_trust_lo = "Lower bound of forces for the selection. If list or dict, should be set for each index in sys_configs, respectively."
+ doc_model_devi_f_trust_hi = "Upper bound of forces for the selection. If list or dict, should be set for each index in sys_configs, respectively."
+ doc_model_devi_v_trust_lo = "Lower bound of virial for the selection. If list or dict, should be set for each index in sys_configs, respectively. Should be used with DeePMD-kit v2.x."
+ doc_model_devi_v_trust_hi = "Upper bound of virial for the selection. If list or dict, should be set for each index in sys_configs, respectively. Should be used with DeePMD-kit v2.x."
+ doc_model_devi_adapt_trust_lo = "Adaptively determines the lower trust levels of force and virial. This option should be used together with model_devi_numb_candi_f, model_devi_numb_candi_v and optionally with model_devi_perc_candi_f and model_devi_perc_candi_v. dpgen will make two sets:\n\n\
- 1. From the frames with force model deviation lower than model_devi_f_trust_hi, select max(model_devi_numb_candi_f, model_devi_perc_candi_f*n_frames) frames with largest force model deviation. \n\n\
- 2. From the frames with virial model deviation lower than model_devi_v_trust_hi, select max(model_devi_numb_candi_v, model_devi_perc_candi_v*n_frames) frames with largest virial model deviation. \n\n\
-The union of the two sets is made as candidate dataset.'
- doc_model_devi_numb_candi_f = 'See model_devi_adapt_trust_lo.'
- doc_model_devi_numb_candi_v = 'See model_devi_adapt_trust_lo.'
- doc_model_devi_perc_candi_f = 'See model_devi_adapt_trust_lo.'
- doc_model_devi_perc_candi_v = 'See model_devi_adapt_trust_lo.'
- doc_model_devi_f_avg_relative = 'Normalized the force model deviations by the RMS force magnitude along the trajectory. This key should not be used with use_relative.'
- doc_model_devi_clean_traj = 'If type of model_devi_clean_traj is bool type then it denote whether to clean traj folders in MD since they are too large. If it is Int type, then the most recent n iterations of traj folders will be retained, others will be removed.'
- doc_model_devi_merge_traj = 'If model_devi_merge_traj is set as True, only all.lammpstrj will be generated, instead of lots of small traj files.'
- doc_model_devi_nopbc = 'Assume open boundary condition in MD simulations.'
- doc_model_devi_plumed = '' # looking forward to update
- doc_model_devi_plumed_path = '' # looking forward to update
- doc_shuffle_poscar = 'Shuffle atoms of each frame before running simulations. The purpose is to sample the element occupation of alloys.'
- doc_use_relative = 'Calculate relative force model deviation.'
- doc_epsilon = 'The level parameter for computing the relative force model deviation.'
- doc_use_relative_v = 'Calculate relative virial model deviation.'
- doc_epsilon_v = 'The level parameter for computing the relative virial model deviation.'
+The union of the two sets is made as candidate dataset."
+ doc_model_devi_numb_candi_f = "See model_devi_adapt_trust_lo."
+ doc_model_devi_numb_candi_v = "See model_devi_adapt_trust_lo."
+ doc_model_devi_perc_candi_f = "See model_devi_adapt_trust_lo."
+ doc_model_devi_perc_candi_v = "See model_devi_adapt_trust_lo."
+ doc_model_devi_f_avg_relative = "Normalized the force model deviations by the RMS force magnitude along the trajectory. This key should not be used with use_relative."
+ doc_model_devi_clean_traj = "If type of model_devi_clean_traj is bool type then it denote whether to clean traj folders in MD since they are too large. If it is Int type, then the most recent n iterations of traj folders will be retained, others will be removed."
+ doc_model_devi_merge_traj = "If model_devi_merge_traj is set as True, only all.lammpstrj will be generated, instead of lots of small traj files."
+ doc_model_devi_nopbc = "Assume open boundary condition in MD simulations."
+ doc_model_devi_plumed = "" # looking forward to update
+ doc_model_devi_plumed_path = "" # looking forward to update
+ doc_shuffle_poscar = "Shuffle atoms of each frame before running simulations. The purpose is to sample the element occupation of alloys."
+ doc_use_relative = "Calculate relative force model deviation."
+ doc_epsilon = (
+ "The level parameter for computing the relative force model deviation."
+ )
+ doc_use_relative_v = "Calculate relative virial model deviation."
+ doc_epsilon_v = (
+ "The level parameter for computing the relative virial model deviation."
+ )
return [
model_devi_jobs_args(),
- Argument("model_devi_dt", float,
- optional=False, doc=doc_model_devi_dt),
- Argument("model_devi_skip", int, optional=False,
- doc=doc_model_devi_skip),
- Argument("model_devi_f_trust_lo", [
- float, list, dict], optional=False, doc=doc_model_devi_f_trust_lo),
- Argument("model_devi_f_trust_hi", [
- float, list, dict], optional=False, doc=doc_model_devi_f_trust_hi),
- Argument("model_devi_v_trust_lo", [
- float, list, dict], optional=True, default=1e10, doc=doc_model_devi_v_trust_lo),
- Argument("model_devi_v_trust_hi", [
- float, list, dict], optional=True, default=1e10, doc=doc_model_devi_v_trust_hi),
- Argument("model_devi_adapt_trust_lo", bool, optional=True,
- doc=doc_model_devi_adapt_trust_lo),
- Argument("model_devi_numb_candi_f", int, optional=True,
- doc=doc_model_devi_numb_candi_f),
- Argument("model_devi_numb_candi_v", int, optional=True,
- doc=doc_model_devi_numb_candi_v),
- Argument("model_devi_perc_candi_f", float,
- optional=True, doc=doc_model_devi_perc_candi_f),
- Argument("model_devi_perc_candi_v", float,
- optional=True, doc=doc_model_devi_perc_candi_v),
- Argument("model_devi_f_avg_relative", bool, optional=True,
- doc=doc_model_devi_f_avg_relative),
- Argument("model_devi_clean_traj", [
- bool, int], optional=True, default=True , doc=doc_model_devi_clean_traj),
- Argument("model_devi_merge_traj",
- bool, optional=True, default=False , doc=doc_model_devi_merge_traj),
- Argument("model_devi_nopbc", bool, optional=True, default=False,
- doc=doc_model_devi_nopbc),
- Argument("model_devi_plumed",
- bool, optional=True, default=False , doc=doc_model_devi_plumed),
- Argument("model_devi_plumed_path",
- bool, optional=True, default=False , doc=doc_model_devi_plumed_path),
- Argument("shuffle_poscar", bool, optional=True, default=False, doc=doc_shuffle_poscar),
- Argument("use_relative", bool, optional=True, default=False, doc=doc_use_relative),
+ Argument("model_devi_dt", float, optional=False, doc=doc_model_devi_dt),
+ Argument("model_devi_skip", int, optional=False, doc=doc_model_devi_skip),
+ Argument(
+ "model_devi_f_trust_lo",
+ [float, list, dict],
+ optional=False,
+ doc=doc_model_devi_f_trust_lo,
+ ),
+ Argument(
+ "model_devi_f_trust_hi",
+ [float, list, dict],
+ optional=False,
+ doc=doc_model_devi_f_trust_hi,
+ ),
+ Argument(
+ "model_devi_v_trust_lo",
+ [float, list, dict],
+ optional=True,
+ default=1e10,
+ doc=doc_model_devi_v_trust_lo,
+ ),
+ Argument(
+ "model_devi_v_trust_hi",
+ [float, list, dict],
+ optional=True,
+ default=1e10,
+ doc=doc_model_devi_v_trust_hi,
+ ),
+ Argument(
+ "model_devi_adapt_trust_lo",
+ bool,
+ optional=True,
+ doc=doc_model_devi_adapt_trust_lo,
+ ),
+ Argument(
+ "model_devi_numb_candi_f",
+ int,
+ optional=True,
+ doc=doc_model_devi_numb_candi_f,
+ ),
+ Argument(
+ "model_devi_numb_candi_v",
+ int,
+ optional=True,
+ doc=doc_model_devi_numb_candi_v,
+ ),
+ Argument(
+ "model_devi_perc_candi_f",
+ float,
+ optional=True,
+ doc=doc_model_devi_perc_candi_f,
+ ),
+ Argument(
+ "model_devi_perc_candi_v",
+ float,
+ optional=True,
+ doc=doc_model_devi_perc_candi_v,
+ ),
+ Argument(
+ "model_devi_f_avg_relative",
+ bool,
+ optional=True,
+ doc=doc_model_devi_f_avg_relative,
+ ),
+ Argument(
+ "model_devi_clean_traj",
+ [bool, int],
+ optional=True,
+ default=True,
+ doc=doc_model_devi_clean_traj,
+ ),
+ Argument(
+ "model_devi_merge_traj",
+ bool,
+ optional=True,
+ default=False,
+ doc=doc_model_devi_merge_traj,
+ ),
+ Argument(
+ "model_devi_nopbc",
+ bool,
+ optional=True,
+ default=False,
+ doc=doc_model_devi_nopbc,
+ ),
+ Argument(
+ "model_devi_plumed",
+ bool,
+ optional=True,
+ default=False,
+ doc=doc_model_devi_plumed,
+ ),
+ Argument(
+ "model_devi_plumed_path",
+ bool,
+ optional=True,
+ default=False,
+ doc=doc_model_devi_plumed_path,
+ ),
+ Argument(
+ "shuffle_poscar", bool, optional=True, default=False, doc=doc_shuffle_poscar
+ ),
+ Argument(
+ "use_relative", bool, optional=True, default=False, doc=doc_use_relative
+ ),
Argument("epsilon", float, optional=True, doc=doc_epsilon),
- Argument("use_relative_v", bool, optional=True, default=False, doc=doc_use_relative_v),
+ Argument(
+ "use_relative_v", bool, optional=True, default=False, doc=doc_use_relative_v
+ ),
Argument("epsilon_v", float, optional=True, doc=doc_epsilon_v),
]
def model_devi_amber_args() -> List[Argument]:
"""Amber engine arguments."""
- doc_model_devi_jobs = "List of dicts. The list including the dict for information of each cycle."
+ doc_model_devi_jobs = (
+ "List of dicts. The list including the dict for information of each cycle."
+ )
doc_sys_idx = "List of ints. List of systems to run."
doc_trj_freq = "Frequency to dump trajectory."
- doc_low_level = "Low level method. The value will be filled into mdin file as @qm_theory@."
+ doc_low_level = (
+ "Low level method. The value will be filled into mdin file as @qm_theory@."
+ )
doc_cutoff = "Cutoff radius for the DPRc model."
doc_parm7_prefix = "The path prefix to AMBER PARM7 files."
doc_parm7 = "List of paths to AMBER PARM7 files. Each file maps to a system."
doc_mdin_prefix = "The path prefix to AMBER mdin template files."
- doc_mdin = ("List of paths to AMBER mdin template files. Each files maps to a system. "
- "In the template, the following keywords will be replaced by the actual value: "
- "`@freq@`: freq to dump trajectory; "
- "`@nstlim@`: total time step to run; "
- "`@qm_region@`: AMBER mask of the QM region; "
- "`@qm_theory@`: The low level QM theory, such as DFTB2; "
- "`@qm_charge@`: The total charge of the QM theory, such as -2; "
- "`@rcut@`: cutoff radius of the DPRc model; "
- "`@GRAPH_FILE0@`, `@GRAPH_FILE1@`, ... : graph files."
- )
- doc_qm_region = "List of strings. AMBER mask of the QM region. Each mask maps to a system."
- doc_qm_charge = "List of ints. Charge of the QM region. Each charge maps to a system."
- doc_nsteps = "List of ints. The number of steps to run. Each number maps to a system."
- doc_r = ("3D or 4D list of floats. Constrict values for the enhanced sampling. "
- "The first dimension maps to systems. "
- "The second dimension maps to confs in each system. The third dimension is the "
- "constrict value. It can be a single float for 1D or list of floats for nD.")
+ doc_mdin = (
+ "List of paths to AMBER mdin template files. Each files maps to a system. "
+ "In the template, the following keywords will be replaced by the actual value: "
+ "`@freq@`: freq to dump trajectory; "
+ "`@nstlim@`: total time step to run; "
+ "`@qm_region@`: AMBER mask of the QM region; "
+ "`@qm_theory@`: The low level QM theory, such as DFTB2; "
+ "`@qm_charge@`: The total charge of the QM theory, such as -2; "
+ "`@rcut@`: cutoff radius of the DPRc model; "
+ "`@GRAPH_FILE0@`, `@GRAPH_FILE1@`, ... : graph files."
+ )
+ doc_qm_region = (
+ "List of strings. AMBER mask of the QM region. Each mask maps to a system."
+ )
+ doc_qm_charge = (
+ "List of ints. Charge of the QM region. Each charge maps to a system."
+ )
+ doc_nsteps = (
+ "List of ints. The number of steps to run. Each number maps to a system."
+ )
+ doc_r = (
+ "3D or 4D list of floats. Constrict values for the enhanced sampling. "
+ "The first dimension maps to systems. "
+ "The second dimension maps to confs in each system. The third dimension is the "
+ "constrict value. It can be a single float for 1D or list of floats for nD."
+ )
doc_disang_prefix = "The path prefix to disang prefix."
- doc_disang = ("List of paths to AMBER disang files. Each file maps to a sytem. "
- "The keyword RVAL will be replaced by the constrict values, or RVAL1, RVAL2, ... "
- "for an nD system.")
- doc_model_devi_f_trust_lo = 'Lower bound of forces for the selection. If dict, should be set for each index in sys_idx, respectively.'
- doc_model_devi_f_trust_hi = 'Upper bound of forces for the selection. If dict, should be set for each index in sys_idx, respectively.'
+ doc_disang = (
+ "List of paths to AMBER disang files. Each file maps to a sytem. "
+ "The keyword RVAL will be replaced by the constrict values, or RVAL1, RVAL2, ... "
+ "for an nD system."
+ )
+ doc_model_devi_f_trust_lo = "Lower bound of forces for the selection. If dict, should be set for each index in sys_idx, respectively."
+ doc_model_devi_f_trust_hi = "Upper bound of forces for the selection. If dict, should be set for each index in sys_idx, respectively."
-
return [
# make model devi args
- Argument("model_devi_jobs", list, optional=False, repeat=True, doc=doc_model_devi_jobs, sub_fields=[
- Argument("sys_idx", list, optional=False, doc=doc_sys_idx),
- Argument("trj_freq", int, optional=False, doc=doc_trj_freq),
- ]),
+ Argument(
+ "model_devi_jobs",
+ list,
+ optional=False,
+ repeat=True,
+ doc=doc_model_devi_jobs,
+ sub_fields=[
+ Argument("sys_idx", list, optional=False, doc=doc_sys_idx),
+ Argument("trj_freq", int, optional=False, doc=doc_trj_freq),
+ ],
+ ),
Argument("low_level", str, optional=False, doc=doc_low_level),
Argument("cutoff", float, optional=False, doc=doc_cutoff),
Argument("parm7_prefix", str, optional=True, doc=doc_parm7_prefix),
@@ -299,56 +490,78 @@ def model_devi_amber_args() -> List[Argument]:
Argument("disang_prefix", str, optional=True, doc=doc_disang_prefix),
Argument("disang", list, optional=False, doc=doc_disang),
# post model devi args
- Argument("model_devi_f_trust_lo", [
- float, list, dict], optional=False, doc=doc_model_devi_f_trust_lo),
- Argument("model_devi_f_trust_hi", [
- float, list, dict], optional=False, doc=doc_model_devi_f_trust_hi),
+ Argument(
+ "model_devi_f_trust_lo",
+ [float, list, dict],
+ optional=False,
+ doc=doc_model_devi_f_trust_lo,
+ ),
+ Argument(
+ "model_devi_f_trust_hi",
+ [float, list, dict],
+ optional=False,
+ doc=doc_model_devi_f_trust_hi,
+ ),
]
def model_devi_args() -> List[Variant]:
doc_model_devi_engine = "Engine for the model deviation task."
doc_amber = "Amber DPRc engine. The command argument in the machine file should be path to sander."
- return [Variant("model_devi_engine", [
- Argument("lammps", dict, model_devi_lmp_args(), doc="LAMMPS"),
- Argument("amber", dict, model_devi_amber_args(), doc=doc_amber),
- ], default_tag="lammps", optional=True, doc=doc_model_devi_engine)]
+ return [
+ Variant(
+ "model_devi_engine",
+ [
+ Argument("lammps", dict, model_devi_lmp_args(), doc="LAMMPS"),
+ Argument("amber", dict, model_devi_amber_args(), doc=doc_amber),
+ Argument("calypso", dict, [], doc="TODO: add doc"),
+ Argument("gromacs", dict, [], doc="TODO: add doc"),
+ ],
+ default_tag="lammps",
+ optional=True,
+ doc=doc_model_devi_engine,
+ )
+ ]
# Labeling
# vasp
def fp_style_vasp_args() -> List[Argument]:
- doc_fp_pp_path = 'Directory of psuedo-potential file to be used for 02.fp exists.'
- doc_fp_pp_files = 'Psuedo-potential file to be used for 02.fp. Note that the order of elements should correspond to the order in type_map.'
- doc_fp_incar = 'Input file for VASP. INCAR must specify KSPACING and KGAMMA.'
- doc_fp_aniso_kspacing = 'Set anisotropic kspacing. Usually useful for 1-D or 2-D materials. Only support VASP. If it is setting the KSPACING key in INCAR will be ignored.'
- doc_cvasp = 'If cvasp is true, DP-GEN will use Custodian to help control VASP calculation.'
- doc_ratio_failed = 'Check the ratio of unsuccessfully terminated jobs. If too many FP tasks are not converged, RuntimeError will be raised.'
- doc_fp_skip_bad_box = 'Skip the configurations that are obviously unreasonable before 02.fp'
+ doc_fp_pp_path = "Directory of psuedo-potential file to be used for 02.fp exists."
+ doc_fp_pp_files = "Psuedo-potential file to be used for 02.fp. Note that the order of elements should correspond to the order in type_map."
+ doc_fp_incar = "Input file for VASP. INCAR must specify KSPACING and KGAMMA."
+ doc_fp_aniso_kspacing = "Set anisotropic kspacing. Usually useful for 1-D or 2-D materials. Only support VASP. If it is setting the KSPACING key in INCAR will be ignored."
+ doc_cvasp = (
+ "If cvasp is true, DP-GEN will use Custodian to help control VASP calculation."
+ )
+ doc_ratio_failed = "Check the ratio of unsuccessfully terminated jobs. If too many FP tasks are not converged, RuntimeError will be raised."
+ doc_fp_skip_bad_box = (
+ "Skip the configurations that are obviously unreasonable before 02.fp"
+ )
return [
Argument("fp_pp_path", str, optional=False, doc=doc_fp_pp_path),
Argument("fp_pp_files", list, optional=False, doc=doc_fp_pp_files),
Argument("fp_incar", str, optional=False, doc=doc_fp_incar),
- Argument("fp_aniso_kspacing", list, optional=True,
- doc=doc_fp_aniso_kspacing),
+ Argument("fp_aniso_kspacing", list, optional=True, doc=doc_fp_aniso_kspacing),
Argument("cvasp", bool, optional=True, doc=doc_cvasp),
- Argument("ratio_failed", float, optional=True,
- doc=doc_ratio_failed),
- Argument("fp_skip_bad_box", str, optional=True,
- doc=doc_fp_skip_bad_box),
+ Argument("ratio_failed", float, optional=True, doc=doc_ratio_failed),
+ Argument("fp_skip_bad_box", str, optional=True, doc=doc_fp_skip_bad_box),
]
+
# abacus
def fp_style_abacus_args() -> List[Argument]:
- doc_fp_pp_path = 'Directory of psuedo-potential or numerical orbital files to be used for 02.fp exists.'
- doc_fp_pp_files = 'Psuedo-potential file to be used for 02.fp. Note that the order of elements should correspond to the order in type_map.'
- doc_fp_orb_files = 'numerical orbital file to be used for 02.fp when using LCAO basis. Note that the order of elements should correspond to the order in type_map.'
- doc_fp_incar = 'Input file for ABACUS. This is optinal but priority over user_fp_params, one can also setting the key and value of INPUT in user_fp_params.'
- doc_fp_kpt_file = 'KPT file for ABACUS.'
- doc_fp_dpks_descriptor = 'DeePKS descriptor file name. The file should be in pseudopotential directory.'
- doc_user_fp_params = 'Set the key and value of INPUT.'
- doc_k_points = 'Monkhorst-Pack k-grids setting for generating KPT file of ABACUS'
+ doc_fp_pp_path = "Directory of psuedo-potential or numerical orbital files to be used for 02.fp exists."
+ doc_fp_pp_files = "Psuedo-potential file to be used for 02.fp. Note that the order of elements should correspond to the order in type_map."
+ doc_fp_orb_files = "numerical orbital file to be used for 02.fp when using LCAO basis. Note that the order of elements should correspond to the order in type_map."
+ doc_fp_incar = "Input file for ABACUS. This is optinal but the priority is lower than user_fp_params, and you should not set user_fp_params if you want to use fp_incar."
+ doc_fp_kpt_file = 'KPT file for ABACUS.If the "kspacing" or "gamma_only=1" is defined in INPUT or "k_points" is defined, fp_kpt_file will be ignored.'
+ doc_fp_dpks_descriptor = (
+ "DeePKS descriptor file name. The file should be in pseudopotential directory."
+ )
+ doc_user_fp_params = "Set the key and value of INPUT."
+ doc_k_points = 'Monkhorst-Pack k-grids setting for generating KPT file of ABACUS, such as: [1,1,1,0,0,0]. NB: if "kspacing" or "gamma_only=1" is defined in INPUT, k_points will be ignored.'
return [
Argument("fp_pp_path", str, optional=False, doc=doc_fp_pp_path),
@@ -362,76 +575,106 @@ def fp_style_abacus_args() -> List[Argument]:
]
-
# gaussian
def fp_style_gaussian_args() -> List[Argument]:
"""Gaussian fp style arguments.
-
+
Returns
-------
list[dargs.Argument]
list of Gaussian fp style arguments
"""
- doc_keywords = 'Keywords for Gaussian input, e.g. force b3lyp/6-31g**. If a list, run multiple steps.'
- doc_multiplicity = ('Spin multiplicity for Gaussian input. If `auto`, multiplicity will be detected automatically, '
- 'with the following rules: when fragment_guesses=True, multiplicity will +1 for each radical, '
- 'and +2 for each oxygen molecule; when fragment_guesses=False, multiplicity will be 1 or 2, '
- 'but +2 for each oxygen molecule.')
- doc_nproc = 'The number of processors for Gaussian input.'
- doc_charge = 'Molecule charge. Only used when charge is not provided by the system.'
- doc_fragment_guesses = 'Initial guess generated from fragment guesses. If True, `multiplicity` should be `auto`.'
- doc_basis_set = 'Custom basis set.'
- doc_keywords_high_multiplicity = ('Keywords for points with multiple raicals. `multiplicity` should be `auto`. '
- 'If not set, fallback to normal keywords.')
-
+ doc_keywords = "Keywords for Gaussian input, e.g. force b3lyp/6-31g**. If a list, run multiple steps."
+ doc_multiplicity = (
+ "Spin multiplicity for Gaussian input. If `auto`, multiplicity will be detected automatically, "
+ "with the following rules: when fragment_guesses=True, multiplicity will +1 for each radical, "
+ "and +2 for each oxygen molecule; when fragment_guesses=False, multiplicity will be 1 or 2, "
+ "but +2 for each oxygen molecule."
+ )
+ doc_nproc = "The number of processors for Gaussian input."
+ doc_charge = "Molecule charge. Only used when charge is not provided by the system."
+ doc_fragment_guesses = "Initial guess generated from fragment guesses. If True, `multiplicity` should be `auto`."
+ doc_basis_set = "Custom basis set."
+ doc_keywords_high_multiplicity = (
+ "Keywords for points with multiple raicals. `multiplicity` should be `auto`. "
+ "If not set, fallback to normal keywords."
+ )
args = [
- Argument("keywords", [str, list],
- optional=False, doc=doc_keywords),
- Argument("multiplicity", [int, str],
- optional=True, default="auto", doc=doc_multiplicity),
+ Argument("keywords", [str, list], optional=False, doc=doc_keywords),
+ Argument(
+ "multiplicity",
+ [int, str],
+ optional=True,
+ default="auto",
+ doc=doc_multiplicity,
+ ),
Argument("nproc", int, optional=False, doc=doc_nproc),
Argument("charge", int, optional=True, default=0, doc=doc_charge),
- Argument("fragment_guesses", bool, optional=True, default=False, doc=doc_fragment_guesses),
+ Argument(
+ "fragment_guesses",
+ bool,
+ optional=True,
+ default=False,
+ doc=doc_fragment_guesses,
+ ),
Argument("basis_set", str, optional=True, doc=doc_basis_set),
- Argument("keywords_high_multiplicity", str, optional=True, doc=doc_keywords_high_multiplicity),
+ Argument(
+ "keywords_high_multiplicity",
+ str,
+ optional=True,
+ doc=doc_keywords_high_multiplicity,
+ ),
]
- doc_use_clusters = 'If set to true, clusters will be taken instead of the whole system.'
- doc_cluster_cutoff = ('The soft cutoff radius of clusters if `use_clusters` is set to true. Molecules will be taken '
- 'as whole even if part of atoms is out of the cluster. Use `cluster_cutoff_hard` to only '
- 'take atoms within the hard cutoff radius.')
- doc_cluster_cutoff_hard = ('The hard cutoff radius of clusters if `use_clusters` is set to true. Outside the hard cutoff radius, '
- 'atoms will not be taken even if they are in a molecule where some atoms are within the cutoff radius.')
- doc_cluster_minify = ('If enabled, when an atom within the soft cutoff radius connects a single bond with '
- 'a non-hydrogen atom out of the soft cutoff radius, the outer atom will be replaced by a '
- 'hydrogen atom. When the outer atom is a hydrogen atom, the outer atom will be '
- 'kept. In this case, other atoms out of the soft cutoff radius will be removed.')
- doc_fp_params_gaussian = 'Parameters for Gaussian calculation.'
- doc_ratio_failed = 'Check the ratio of unsuccessfully terminated jobs. If too many FP tasks are not converged, RuntimeError will be raised.'
+ doc_use_clusters = (
+ "If set to true, clusters will be taken instead of the whole system."
+ )
+ doc_cluster_cutoff = (
+ "The soft cutoff radius of clusters if `use_clusters` is set to true. Molecules will be taken "
+ "as whole even if part of atoms is out of the cluster. Use `cluster_cutoff_hard` to only "
+ "take atoms within the hard cutoff radius."
+ )
+ doc_cluster_cutoff_hard = (
+ "The hard cutoff radius of clusters if `use_clusters` is set to true. Outside the hard cutoff radius, "
+ "atoms will not be taken even if they are in a molecule where some atoms are within the cutoff radius."
+ )
+ doc_cluster_minify = (
+ "If enabled, when an atom within the soft cutoff radius connects a single bond with "
+ "a non-hydrogen atom out of the soft cutoff radius, the outer atom will be replaced by a "
+ "hydrogen atom. When the outer atom is a hydrogen atom, the outer atom will be "
+ "kept. In this case, other atoms out of the soft cutoff radius will be removed."
+ )
+ doc_fp_params_gaussian = "Parameters for Gaussian calculation."
+ doc_ratio_failed = "Check the ratio of unsuccessfully terminated jobs. If too many FP tasks are not converged, RuntimeError will be raised."
return [
- Argument("use_clusters", bool, optional=True, default=False, doc=doc_use_clusters),
- Argument("cluster_cutoff", float,
- optional=True, doc=doc_cluster_cutoff),
- Argument("cluster_cutoff_hard", float, optional=True, doc=doc_cluster_cutoff_hard),
- Argument("cluster_minify", bool, optional=True, default=False, doc=doc_cluster_minify),
- Argument("fp_params", dict, args, [],
- optional=False, doc=doc_fp_params_gaussian),
- Argument("ratio_failed", float, optional=True,
- doc=doc_ratio_failed),
+ Argument(
+ "use_clusters", bool, optional=True, default=False, doc=doc_use_clusters
+ ),
+ Argument("cluster_cutoff", float, optional=True, doc=doc_cluster_cutoff),
+ Argument(
+ "cluster_cutoff_hard", float, optional=True, doc=doc_cluster_cutoff_hard
+ ),
+ Argument(
+ "cluster_minify", bool, optional=True, default=False, doc=doc_cluster_minify
+ ),
+ Argument(
+ "fp_params", dict, args, [], optional=False, doc=doc_fp_params_gaussian
+ ),
+ Argument("ratio_failed", float, optional=True, doc=doc_ratio_failed),
]
# siesta
def fp_style_siesta_args() -> List[Argument]:
- doc_ecut = 'Define the plane wave cutoff for grid.'
- doc_ediff = 'Tolerance of Density Matrix.'
- doc_kspacing = 'Sample factor in Brillouin zones.'
- doc_mixingweight = 'Proportion a of output Density Matrix to be used for the input Density Matrix of next SCF cycle (linear mixing).'
- doc_NumberPulay = 'Controls the Pulay convergence accelerator.'
- doc_fp_pp_path = 'Directory of psuedo-potential or numerical orbital files to be used for 02.fp exists.'
- doc_fp_pp_files = 'Psuedo-potential file to be used for 02.fp. Note that the order of elements should correspond to the order in type_map.'
+ doc_ecut = "Define the plane wave cutoff for grid."
+ doc_ediff = "Tolerance of Density Matrix."
+ doc_kspacing = "Sample factor in Brillouin zones."
+ doc_mixingweight = "Proportion a of output Density Matrix to be used for the input Density Matrix of next SCF cycle (linear mixing)."
+ doc_NumberPulay = "Controls the Pulay convergence accelerator."
+ doc_fp_pp_path = "Directory of psuedo-potential or numerical orbital files to be used for 02.fp exists."
+ doc_fp_pp_files = "Psuedo-potential file to be used for 02.fp. Note that the order of elements should correspond to the order in type_map."
args = [
Argument("ecut", int, optional=False, doc=doc_ecut),
@@ -441,35 +684,39 @@ def fp_style_siesta_args() -> List[Argument]:
Argument("NumberPulay", int, optional=False, doc=doc_NumberPulay),
]
- doc_use_clusters = 'If set to true, clusters will be taken instead of the whole system. This option does not work with DeePMD-kit 0.x.'
- doc_cluster_cutoff = 'The cutoff radius of clusters if use_clusters is set to true.'
- doc_fp_params_siesta = 'Parameters for siesta calculation.'
+ doc_use_clusters = "If set to true, clusters will be taken instead of the whole system. This option does not work with DeePMD-kit 0.x."
+ doc_cluster_cutoff = "The cutoff radius of clusters if use_clusters is set to true."
+ doc_fp_params_siesta = "Parameters for siesta calculation."
return [
Argument("use_clusters", bool, optional=True, doc=doc_use_clusters),
- Argument("cluster_cutoff", float,
- optional=True, doc=doc_cluster_cutoff),
- Argument("fp_params", dict, args, [],
- optional=False, doc=doc_fp_params_siesta),
+ Argument("cluster_cutoff", float, optional=True, doc=doc_cluster_cutoff),
+ Argument("fp_params", dict, args, [], optional=False, doc=doc_fp_params_siesta),
Argument("fp_pp_path", str, optional=False, doc=doc_fp_pp_path),
Argument("fp_pp_files", list, optional=False, doc=doc_fp_pp_files),
]
+
# cp2k
def fp_style_cp2k_args() -> List[Argument]:
- doc_user_fp_params = 'Parameters for cp2k calculation. find detail in manual.cp2k.org. only the kind section must be set before use. we assume that you have basic knowledge for cp2k input.'
- doc_external_input_path = 'Conflict with key:user_fp_params, use the template input provided by user, some rules should be followed, read the following text in detail.'
- doc_ratio_failed = 'Check the ratio of unsuccessfully terminated jobs. If too many FP tasks are not converged, RuntimeError will be raised.'
+ doc_user_fp_params = "Parameters for cp2k calculation. find detail in manual.cp2k.org. only the kind section must be set before use. we assume that you have basic knowledge for cp2k input."
+ doc_external_input_path = "Conflict with key:user_fp_params, use the template input provided by user, some rules should be followed, read the following text in detail."
+ doc_ratio_failed = "Check the ratio of unsuccessfully terminated jobs. If too many FP tasks are not converged, RuntimeError will be raised."
return [
- Argument("user_fp_params", dict, optional=True,
- doc=doc_user_fp_params, alias=["fp_params"]),
- Argument("external_input_path", str, optional=True,
- doc=doc_external_input_path),
- Argument("ratio_failed", float, optional=True,
- doc=doc_ratio_failed),
+ Argument(
+ "user_fp_params",
+ dict,
+ optional=True,
+ doc=doc_user_fp_params,
+ alias=["fp_params"],
+ ),
+ Argument(
+ "external_input_path", str, optional=True, doc=doc_external_input_path
+ ),
+ Argument("ratio_failed", float, optional=True, doc=doc_ratio_failed),
]
@@ -481,76 +728,110 @@ def fp_style_amber_diff_args() -> List[Argument]:
list[dargs.Argument]
list of Gaussian fp style arguments
"""
- doc_fp_params_gaussian = 'Parameters for FP calculation.'
- doc_high_level = "High level method. The value will be filled into mdin template as @qm_theory@."
- doc_high_level_mdin = ("Path to high-level AMBER mdin template file. %qm_theory%, %qm_region%, "
- "and %qm_charge% will be replaced.")
- doc_low_level_mdin = ("Path to low-level AMBER mdin template file. %qm_theory%, %qm_region%, "
- "and %qm_charge% will be replaced.")
+ doc_fp_params_gaussian = "Parameters for FP calculation."
+ doc_high_level = (
+ "High level method. The value will be filled into mdin template as @qm_theory@."
+ )
+ doc_high_level_mdin = (
+ "Path to high-level AMBER mdin template file. %qm_theory%, %qm_region%, "
+ "and %qm_charge% will be replaced."
+ )
+ doc_low_level_mdin = (
+ "Path to low-level AMBER mdin template file. %qm_theory%, %qm_region%, "
+ "and %qm_charge% will be replaced."
+ )
return [
Argument("high_level", str, optional=False, doc=doc_high_level),
- Argument("fp_params", dict,
- optional=False, doc=doc_fp_params_gaussian,
- sub_fields=[
- Argument("high_level_mdin", str, optional=False, doc=doc_high_level_mdin),
- Argument("low_level_mdin", str, optional=False, doc=doc_low_level_mdin),
- ]),
+ Argument(
+ "fp_params",
+ dict,
+ optional=False,
+ doc=doc_fp_params_gaussian,
+ sub_fields=[
+ Argument(
+ "high_level_mdin", str, optional=False, doc=doc_high_level_mdin
+ ),
+ Argument("low_level_mdin", str, optional=False, doc=doc_low_level_mdin),
+ ],
+ ),
]
def fp_style_variant_type_args() -> Variant:
- doc_fp_style = 'Software for First Principles.'
- doc_amber_diff = ('Amber/diff style for DPRc models. Note: this fp style '
- 'only supports to be used with model_devi_engine `amber`, '
- 'where some arguments are reused. '
- 'The command argument in the machine file should be path to sander. '
- 'One should also install dpamber and make it visible in the PATH.')
-
- return Variant("fp_style", [Argument("vasp", dict, fp_style_vasp_args()),
- Argument("gaussian", dict,
- fp_style_gaussian_args()),
- Argument("siesta", dict,
- fp_style_siesta_args()),
- Argument("cp2k", dict, fp_style_cp2k_args()),
- Argument("abacus", dict, fp_style_abacus_args()),
- Argument("amber/diff", dict, fp_style_amber_diff_args(), doc=doc_amber_diff),
- ],
- optional=False,
- doc=doc_fp_style)
+ doc_fp_style = "Software for First Principles."
+ doc_amber_diff = (
+ "Amber/diff style for DPRc models. Note: this fp style "
+ "only supports to be used with model_devi_engine `amber`, "
+ "where some arguments are reused. "
+ "The command argument in the machine file should be path to sander. "
+ "One should also install dpamber and make it visible in the PATH."
+ )
+
+ return Variant(
+ "fp_style",
+ [
+ Argument("vasp", dict, fp_style_vasp_args()),
+ Argument("gaussian", dict, fp_style_gaussian_args()),
+ Argument("siesta", dict, fp_style_siesta_args()),
+ Argument("cp2k", dict, fp_style_cp2k_args()),
+ Argument("abacus", dict, fp_style_abacus_args()),
+ Argument(
+ "amber/diff", dict, fp_style_amber_diff_args(), doc=doc_amber_diff
+ ),
+ Argument("pwmat", dict, [], doc="TODO: add doc"),
+ Argument("pwscf", dict, [], doc="TODO: add doc"),
+ ],
+ optional=False,
+ doc=doc_fp_style,
+ )
def fp_args() -> List[Argument]:
- doc_fp_task_max = 'Maximum number of structures to be calculated in each system in 02.fp of each iteration.'
- doc_fp_task_min = 'Minimum number of structures to be calculated in each system in 02.fp of each iteration.'
- doc_fp_accurate_threshold = 'If the accurate ratio is larger than this number, no fp calculation will be performed, i.e. fp_task_max = 0.'
- doc_fp_accurate_soft_threshold = 'If the accurate ratio is between this number and fp_accurate_threshold, the fp_task_max linearly decays to zero.'
- doc_fp_cluster_vacuum = 'If the vacuum size is smaller than this value, this cluster will not be choosen for labeling.'
- doc_detailed_report_make_fp = 'If set to true, detailed report will be generated for each iteration.'
+ doc_fp_task_max = "Maximum number of structures to be calculated in each system in 02.fp of each iteration."
+ doc_fp_task_min = "Minimum number of structures to be calculated in each system in 02.fp of each iteration."
+ doc_fp_accurate_threshold = "If the accurate ratio is larger than this number, no fp calculation will be performed, i.e. fp_task_max = 0."
+ doc_fp_accurate_soft_threshold = "If the accurate ratio is between this number and fp_accurate_threshold, the fp_task_max linearly decays to zero."
+ doc_fp_cluster_vacuum = "If the vacuum size is smaller than this value, this cluster will not be choosen for labeling."
+ doc_detailed_report_make_fp = (
+ "If set to true, detailed report will be generated for each iteration."
+ )
return [
Argument("fp_task_max", int, optional=False, doc=doc_fp_task_max),
Argument("fp_task_min", int, optional=False, doc=doc_fp_task_min),
- Argument("fp_accurate_threshold", float,
- optional=True, doc=doc_fp_accurate_threshold),
- Argument("fp_accurate_soft_threshold", float,
- optional=True, doc=doc_fp_accurate_soft_threshold),
- Argument("fp_cluster_vacuum", float,
- optional=True, doc=doc_fp_cluster_vacuum),
- Argument("detailed_report_make_fp", bool, optional=True, default=True, doc=doc_detailed_report_make_fp),
+ Argument(
+ "fp_accurate_threshold", float, optional=True, doc=doc_fp_accurate_threshold
+ ),
+ Argument(
+ "fp_accurate_soft_threshold",
+ float,
+ optional=True,
+ doc=doc_fp_accurate_soft_threshold,
+ ),
+ Argument("fp_cluster_vacuum", float, optional=True, doc=doc_fp_cluster_vacuum),
+ Argument(
+ "detailed_report_make_fp",
+ bool,
+ optional=True,
+ default=True,
+ doc=doc_detailed_report_make_fp,
+ ),
]
def run_jdata_arginfo() -> Argument:
"""Argument information for dpgen run mdata.
-
+
Returns
-------
Argument
argument information
"""
doc_run_jdata = "param.json file"
- return Argument("run_jdata",
- dict,
- sub_fields=basic_args() + data_args() + training_args() + fp_args(),
- sub_variants=model_devi_args() + [fp_style_variant_type_args()],
- doc=doc_run_jdata)
+ return Argument(
+ "run_jdata",
+ dict,
+ sub_fields=basic_args() + data_args() + training_args() + fp_args(),
+ sub_variants=model_devi_args() + [fp_style_variant_type_args()],
+ doc=doc_run_jdata,
+ )
diff --git a/dpgen/generator/lib/abacus_scf.py b/dpgen/generator/lib/abacus_scf.py
index 3c255b867..c307c0ad5 100644
--- a/dpgen/generator/lib/abacus_scf.py
+++ b/dpgen/generator/lib/abacus_scf.py
@@ -1,8 +1,13 @@
+import os
+
import numpy as np
-from dpdata.abacus.scf import get_cell, get_coords
+from dpdata.abacus.scf import get_cell, get_coords, get_nele_from_stru
+
from dpgen.auto_test.lib import vasp
-import os
+
bohr2ang = 0.52917721067
+
+
def make_abacus_scf_kpt(fp_params):
# Make KPT file for abacus pw scf calculation.
# KPT file is the file containing k points infomation in ABACUS scf calculation.
@@ -10,101 +15,155 @@ def make_abacus_scf_kpt(fp_params):
if "k_points" in fp_params:
k_points = fp_params["k_points"]
if len(k_points) != 6:
- raise RuntimeError("k_points has to be a list containig 6 integers specifying MP k points generation.")
+ raise RuntimeError(
+ "k_points has to be a list containig 6 integers specifying MP k points generation."
+ )
ret = "K_POINTS\n0\nGamma\n"
for i in range(6):
ret += str(k_points[i]) + " "
return ret
+
def make_abacus_scf_input(fp_params):
# Make INPUT file for abacus pw scf calculation.
ret = "INPUT_PARAMETERS\n"
ret += "calculation scf\n"
for key in fp_params:
- if key == "ntype":
- fp_params["ntype"] = int(fp_params["ntype"])
- assert(fp_params['ntype'] >= 0 and type(fp_params["ntype"]) == int), "'ntype' should be a positive integer."
- ret += "ntype %d\n" % fp_params['ntype']
- #ret += "pseudo_dir ./\n"
- elif key == "ecutwfc":
+ if key == "ecutwfc":
fp_params["ecutwfc"] = float(fp_params["ecutwfc"])
- assert(fp_params["ecutwfc"] >= 0) , "'ntype' should be non-negative."
+ assert fp_params["ecutwfc"] >= 0, "'ecutwfc' should be non-negative."
ret += "ecutwfc %f\n" % fp_params["ecutwfc"]
elif key == "kspacing":
fp_params["kspacing"] = float(fp_params["kspacing"])
- assert(fp_params["kspacing"] >= 0) , "'ntype' should be non-negative."
+ assert fp_params["kspacing"] >= 0, "'kspacing' should be non-negative."
ret += "kspacing %f\n" % fp_params["kspacing"]
elif key == "scf_thr":
fp_params["scf_thr"] = float(fp_params["scf_thr"])
ret += "scf_thr %e\n" % fp_params["scf_thr"]
elif key == "scf_nmax":
fp_params["scf_nmax"] = int(fp_params["scf_nmax"])
- assert(fp_params['scf_nmax'] >= 0 and type(fp_params["scf_nmax"])== int), "'scf_nmax' should be a positive integer."
+ assert (
+ fp_params["scf_nmax"] >= 0 and type(fp_params["scf_nmax"]) == int
+ ), "'scf_nmax' should be a positive integer."
ret += "scf_nmax %d\n" % fp_params["scf_nmax"]
elif key == "basis_type":
- assert(fp_params["basis_type"] in ["pw", "lcao", "lcao_in_pw"]) , "'basis_type' must in 'pw', 'lcao' or 'lcao_in_pw'."
- ret+= "basis_type %s\n" % fp_params["basis_type"]
+ assert fp_params["basis_type"] in [
+ "pw",
+ "lcao",
+ "lcao_in_pw",
+ ], "'basis_type' must in 'pw', 'lcao' or 'lcao_in_pw'."
+ ret += "basis_type %s\n" % fp_params["basis_type"]
elif key == "dft_functional":
ret += "dft_functional %s\n" % fp_params["dft_functional"]
elif key == "gamma_only":
- if type(fp_params["gamma_only"])==str:
+ if type(fp_params["gamma_only"]) == str:
fp_params["gamma_only"] = int(eval(fp_params["gamma_only"]))
- assert(fp_params["gamma_only"] == 0 or fp_params["gamma_only"] == 1), "'gamma_only' should be either 0 or 1."
- ret+= "gamma_only %d\n" % fp_params["gamma_only"]
+ assert (
+ fp_params["gamma_only"] == 0 or fp_params["gamma_only"] == 1
+ ), "'gamma_only' should be either 0 or 1."
+ ret += "gamma_only %d\n" % fp_params["gamma_only"]
elif key == "mixing_type":
- assert(fp_params["mixing_type"] in ["plain", "kerker", "pulay", "pulay-kerker", "broyden"])
+ assert fp_params["mixing_type"] in [
+ "plain",
+ "kerker",
+ "pulay",
+ "pulay-kerker",
+ "broyden",
+ ]
ret += "mixing_type %s\n" % fp_params["mixing_type"]
elif key == "mixing_beta":
fp_params["mixing_beta"] = float(fp_params["mixing_beta"])
- assert(fp_params["mixing_beta"] >= 0 and fp_params["mixing_beta"] < 1), "'mixing_beta' should between 0 and 1."
+ assert (
+ fp_params["mixing_beta"] >= 0 and fp_params["mixing_beta"] < 1
+ ), "'mixing_beta' should between 0 and 1."
ret += "mixing_beta %f\n" % fp_params["mixing_beta"]
elif key == "symmetry":
- if type(fp_params["symmetry"])==str:
+ if type(fp_params["symmetry"]) == str:
fp_params["symmetry"] = int(eval(fp_params["symmetry"]))
- assert(fp_params["symmetry"] == 0 or fp_params["symmetry"] == 1), "'symmetry' should be either 0 or 1."
+ assert (
+ fp_params["symmetry"] == 0 or fp_params["symmetry"] == 1
+ ), "'symmetry' should be either 0 or 1."
ret += "symmetry %d\n" % fp_params["symmetry"]
elif key == "nbands":
fp_params["nbands"] = int(fp_params["nbands"])
- assert(fp_params["nbands"] > 0 and type(fp_params["nbands"]) == int), "'nbands' should be a positive integer."
+ assert (
+ fp_params["nbands"] > 0 and type(fp_params["nbands"]) == int
+ ), "'nbands' should be a positive integer."
ret += "nbands %d\n" % fp_params["nbands"]
elif key == "nspin":
fp_params["nspin"] = int(fp_params["nspin"])
- assert(fp_params["nspin"] == 1 or fp_params["nspin"] == 2 or fp_params["nspin"] == 4), "'nspin' can anly take 1, 2 or 4"
+ assert (
+ fp_params["nspin"] == 1
+ or fp_params["nspin"] == 2
+ or fp_params["nspin"] == 4
+ ), "'nspin' can anly take 1, 2 or 4"
ret += "nspin %d\n" % fp_params["nspin"]
elif key == "ks_solver":
- assert(fp_params["ks_solver"] in ["cg", "dav", "lapack", "genelpa", "hpseps", "scalapack_gvx"]), "'ks_sover' should in 'cgx', 'dav', 'lapack', 'genelpa', 'hpseps', 'scalapack_gvx'."
+ assert fp_params["ks_solver"] in [
+ "cg",
+ "dav",
+ "lapack",
+ "genelpa",
+ "hpseps",
+ "scalapack_gvx",
+ ], "'ks_sover' should in 'cgx', 'dav', 'lapack', 'genelpa', 'hpseps', 'scalapack_gvx'."
ret += "ks_solver %s\n" % fp_params["ks_solver"]
elif key == "smearing_method":
- assert(fp_params["smearing_method"] in ["gauss","gaussian", "fd", "fixed", "mp", "mp2", "mv"]), "'smearing_method' should in 'gauss', 'gaussian', 'fd', 'fixed', 'mp', 'mp2', 'mv'. "
+ assert fp_params["smearing_method"] in [
+ "gauss",
+ "gaussian",
+ "fd",
+ "fixed",
+ "mp",
+ "mp2",
+ "mv",
+ ], "'smearing_method' should in 'gauss', 'gaussian', 'fd', 'fixed', 'mp', 'mp2', 'mv'. "
ret += "smearing_method %s\n" % fp_params["smearing_method"]
elif key == "smearing_sigma":
fp_params["smearing_sigma"] = float(fp_params["smearing_sigma"])
- assert(fp_params["smearing_sigma"] >= 0), "'smearing_sigma' should be non-negative."
+ assert (
+ fp_params["smearing_sigma"] >= 0
+ ), "'smearing_sigma' should be non-negative."
ret += "smearing_sigma %f\n" % fp_params["smearing_sigma"]
elif key == "cal_force":
- if type(fp_params["cal_force"])==str:
+ if type(fp_params["cal_force"]) == str:
fp_params["cal_force"] = int(eval(fp_params["cal_force"]))
- assert(fp_params["cal_force"] == 0 or fp_params["cal_force"] == 1), "'cal_force' should be either 0 or 1."
+ assert (
+ fp_params["cal_force"] == 0 or fp_params["cal_force"] == 1
+ ), "'cal_force' should be either 0 or 1."
ret += "cal_force %d\n" % fp_params["cal_force"]
elif key == "cal_stress":
- if type(fp_params["cal_stress"])==str:
+ if type(fp_params["cal_stress"]) == str:
fp_params["cal_stress"] = int(eval(fp_params["cal_stress"]))
- assert(fp_params["cal_stress"] == 0 or fp_params["cal_stress"] == 1), "'cal_stress' should be either 0 or 1."
+ assert (
+ fp_params["cal_stress"] == 0 or fp_params["cal_stress"] == 1
+ ), "'cal_stress' should be either 0 or 1."
ret += "cal_stress %d\n" % fp_params["cal_stress"]
- #paras for deepks
+ # paras for deepks
elif key == "deepks_out_labels":
- if type(fp_params["deepks_out_labels"])==str:
- fp_params["deepks_out_labels"] = int(eval(fp_params["deepks_out_labels"]))
- assert(fp_params["deepks_out_labels"] == 0 or fp_params["deepks_out_labels"] == 1), "'deepks_out_labels' should be either 0 or 1."
+ if type(fp_params["deepks_out_labels"]) == str:
+ fp_params["deepks_out_labels"] = int(
+ eval(fp_params["deepks_out_labels"])
+ )
+ assert (
+ fp_params["deepks_out_labels"] == 0
+ or fp_params["deepks_out_labels"] == 1
+ ), "'deepks_out_labels' should be either 0 or 1."
ret += "deepks_out_labels %d\n" % fp_params["deepks_out_labels"]
elif key == "deepks_descriptor_lmax":
- fp_params["deepks_descriptor_lmax"] = int(fp_params["deepks_descriptor_lmax"])
- assert(fp_params["deepks_descriptor_lmax"] >= 0), "'deepks_descriptor_lmax' should be a positive integer."
+ fp_params["deepks_descriptor_lmax"] = int(
+ fp_params["deepks_descriptor_lmax"]
+ )
+ assert (
+ fp_params["deepks_descriptor_lmax"] >= 0
+ ), "'deepks_descriptor_lmax' should be a positive integer."
ret += "deepks_descriptor_lmax %d\n" % fp_params["deepks_descriptor_lmax"]
elif key == "deepks_scf":
- if type(fp_params["deepks_scf"])==str:
+ if type(fp_params["deepks_scf"]) == str:
fp_params["deepks_scf"] = int(eval(fp_params["deepks_scf"]))
- assert(fp_params["deepks_scf"] == 0 or fp_params["deepks_scf"] == 1), "'deepks_scf' should be either 0 or 1."
+ assert (
+ fp_params["deepks_scf"] == 0 or fp_params["deepks_scf"] == 1
+ ), "'deepks_scf' should be either 0 or 1."
ret += "deepks_scf %d\n" % fp_params["deepks_scf"]
elif key == "deepks_model":
ret += "deepks_model %s\n" % fp_params["deepks_model"]
@@ -116,29 +175,50 @@ def make_abacus_scf_input(fp_params):
ret += "%s %s\n" % (key, str(fp_params[key]))
return ret
-def make_abacus_scf_stru(sys_data, fp_pp_files, fp_orb_files = None, fp_dpks_descriptor = None, fp_params = None):
- atom_names = sys_data['atom_names']
- atom_numbs = sys_data['atom_numbs']
- assert(len(atom_names) == len(fp_pp_files)), "the number of pp_files must be equal to the number of atom types. "
- assert(len(atom_names) == len(atom_numbs)), "Please check the name of atoms. "
+
+def make_abacus_scf_stru(
+ sys_data,
+ fp_pp_files,
+ fp_orb_files=None,
+ fp_dpks_descriptor=None,
+ fp_params=None,
+ type_map=None,
+):
+ atom_names = sys_data["atom_names"]
+ atom_numbs = sys_data["atom_numbs"]
+ if type_map == None:
+ type_map = atom_names
+
+ assert len(atom_names) == len(atom_numbs), "Please check the name of atoms. "
cell = sys_data["cells"].reshape([3, 3])
- coord = sys_data['coords'].reshape([sum(atom_numbs), 3])
- #volume = np.linalg.det(cell)
- #lattice_const = np.power(volume, 1/3)
+ coord = sys_data["coords"].reshape([sum(atom_numbs), 3])
+ # volume = np.linalg.det(cell)
+ # lattice_const = np.power(volume, 1/3)
ret = "ATOMIC_SPECIES\n"
for iatom in range(len(atom_names)):
- if 'atom_masses' not in sys_data:
- ret += atom_names[iatom] + " 1.00 " + fp_pp_files[iatom] + "\n"
+ assert atom_names[iatom] in type_map, (
+ "element %s is not defined in type_map" % atom_names[iatom]
+ )
+ idx = type_map.index(atom_names[iatom])
+ if "atom_masses" not in sys_data:
+ ret += atom_names[iatom] + " 1.00 " + fp_pp_files[idx] + "\n"
else:
- ret += atom_names[iatom] + " %.3f "%sys_data['atom_masses'][iatom] + fp_pp_files[iatom] + "\n"
+ ret += (
+ atom_names[iatom]
+ + " %.3f " % sys_data["atom_masses"][iatom]
+ + fp_pp_files[idx]
+ + "\n"
+ )
if fp_params is not None and "lattice_constant" in fp_params:
ret += "\nLATTICE_CONSTANT\n"
- ret += str(fp_params["lattice_constant"]) + "\n\n" # in Bohr, in this way coord and cell are in Angstrom
+ ret += (
+ str(fp_params["lattice_constant"]) + "\n\n"
+ ) # in Bohr, in this way coord and cell are in Angstrom
else:
ret += "\nLATTICE_CONSTANT\n"
- ret += str(1/bohr2ang) + "\n\n"
+ ret += str(1 / bohr2ang) + "\n\n"
ret += "LATTICE_VECTORS\n"
for ix in range(3):
@@ -149,35 +229,44 @@ def make_abacus_scf_stru(sys_data, fp_pp_files, fp_orb_files = None, fp_dpks_des
ret += "ATOMIC_POSITIONS\n"
ret += "Cartesian # Cartesian(Unit is LATTICE_CONSTANT)\n"
- #ret += "\n"
+ # ret += "\n"
natom_tot = 0
for iele in range(len(atom_names)):
ret += atom_names[iele] + "\n"
ret += "0.0\n"
ret += str(atom_numbs[iele]) + "\n"
for iatom in range(atom_numbs[iele]):
- ret += "%.12f %.12f %.12f %d %d %d\n" % (coord[natom_tot, 0], coord[natom_tot, 1], coord[natom_tot, 2], 1, 1, 1)
+ ret += "%.12f %.12f %.12f %d %d %d\n" % (
+ coord[natom_tot, 0],
+ coord[natom_tot, 1],
+ coord[natom_tot, 2],
+ 1,
+ 1,
+ 1,
+ )
natom_tot += 1
- assert(natom_tot == sum(atom_numbs))
+ assert natom_tot == sum(atom_numbs)
if fp_orb_files is not None:
- ret +="\nNUMERICAL_ORBITAL\n"
- assert(len(fp_orb_files)==len(atom_names))
+ ret += "\nNUMERICAL_ORBITAL\n"
+ assert len(fp_orb_files) == len(type_map)
for iatom in range(len(atom_names)):
- ret += fp_orb_files[iatom] +"\n"
+ idx = type_map.index(atom_names[iatom])
+ ret += fp_orb_files[idx] + "\n"
if fp_dpks_descriptor is not None:
- ret +="\nNUMERICAL_DESCRIPTOR\n"
- ret +="%s\n"%fp_dpks_descriptor
+ ret += "\nNUMERICAL_DESCRIPTOR\n"
+ ret += "%s\n" % fp_dpks_descriptor
return ret
+
def get_abacus_input_parameters(INPUT):
with open(INPUT) as fp:
inlines = fp.read().split("\n")
input_parameters = {}
for line in inlines:
- if line.split() == [] or len(line.split()) < 2 or line[0] in ['#']:
+ if line.split() == [] or len(line.split()) < 2 or line[0] in ["#"]:
continue
parameter_name = line.split()[0]
parameter_value = line.split()[1]
@@ -185,38 +274,45 @@ def get_abacus_input_parameters(INPUT):
fp.close()
return input_parameters
-def get_mass_from_STRU(geometry_inlines, inlines, atom_names):
- nele = None
- for line in inlines:
- if line.split() == []:
- continue
- if "ntype" in line and "ntype" == line.split()[0]:
- nele = int(line.split()[1])
- assert(nele is not None)
+
+def get_mass_from_STRU(geometry_inlines, atom_names):
+ nele = get_nele_from_stru(geometry_inlines)
+ assert nele > 0
mass_list = [0 for i in atom_names]
pp_file_list = [i for i in atom_names]
for iline, line in enumerate(geometry_inlines):
if line.split() == []:
continue
if "ATOMIC_SPECIES" == line.split()[0]:
- for iele1 in range(1, 1+nele):
+ for iele1 in range(1, 1 + nele):
for iele2 in range(nele):
- if geometry_inlines[iline+iele1].split()[0] == atom_names[iele2]:
- mass_list[iele2] = float(geometry_inlines[iline+iele1].split()[1])
- pp_file_list[iele2] = geometry_inlines[iline+iele1].split()[2]
+ if geometry_inlines[iline + iele1].split()[0] == atom_names[iele2]:
+ mass_list[iele2] = float(
+ geometry_inlines[iline + iele1].split()[1]
+ )
+ pp_file_list[iele2] = geometry_inlines[iline + iele1].split()[2]
for iele in range(len(mass_list)):
- assert(mass_list[iele] > 0)
+ assert mass_list[iele] > 0
return mass_list, pp_file_list
+
def get_natoms_from_stru(geometry_inlines):
- key_words_list = ["ATOMIC_SPECIES", "NUMERICAL_ORBITAL", "LATTICE_CONSTANT", "LATTICE_VECTORS", "ATOMIC_POSITIONS","NUMERICAL_DESCRIPTOR"]
+ key_words_list = [
+ "ATOMIC_SPECIES",
+ "NUMERICAL_ORBITAL",
+ "LATTICE_CONSTANT",
+ "LATTICE_VECTORS",
+ "ATOMIC_POSITIONS",
+ "NUMERICAL_DESCRIPTOR",
+ ]
keyword_sequence = []
keyword_line_index = []
atom_names = []
atom_numbs = []
tmp_line = []
for i in geometry_inlines:
- if i.strip() != '': tmp_line.append(i)
+ if i.strip() != "":
+ tmp_line.append(i)
for iline, line in enumerate(tmp_line):
if line.split() == []:
continue
@@ -225,18 +321,19 @@ def get_natoms_from_stru(geometry_inlines):
if keyword in line and keyword == line.split()[0]:
keyword_sequence.append(keyword)
keyword_line_index.append(iline)
- assert(len(keyword_line_index) == len(keyword_sequence))
- assert(len(keyword_sequence) > 0)
+ assert len(keyword_line_index) == len(keyword_sequence)
+ assert len(keyword_sequence) > 0
keyword_line_index.append(len(tmp_line))
for idx, keyword in enumerate(keyword_sequence):
if keyword == "ATOMIC_POSITIONS":
- iline = keyword_line_index[idx]+2
- while iline < keyword_line_index[idx+1]-1:
+ iline = keyword_line_index[idx] + 2
+ while iline < keyword_line_index[idx + 1] - 1:
atom_names.append(tmp_line[iline].split()[0])
- atom_numbs.append(int(tmp_line[iline+2].split()[0]))
- iline += 3+atom_numbs[-1]
+ atom_numbs.append(int(tmp_line[iline + 2].split()[0]))
+ iline += 3 + atom_numbs[-1]
return atom_names, atom_numbs
+
def get_additional_from_STRU(geometry_inlines, nele):
dpks_descriptor_kw = "NUMERICAL_DESCRIPTOR"
orb_file_kw = "NUMERICAL_ORBITAL"
@@ -247,75 +344,82 @@ def get_additional_from_STRU(geometry_inlines, nele):
if orb_file_kw == geometry_inlines[iline].split()[0]:
orb_file = []
for iele in range(nele):
- orb_file.append(geometry_inlines[iline + iele + 1].rstrip())
+ orb_file.append(geometry_inlines[iline + iele + 1].strip())
if dpks_descriptor_kw == geometry_inlines[iline].split()[0]:
- dpks_descriptor = geometry_inlines[iline + 1].rstrip()
+ dpks_descriptor = geometry_inlines[iline + 1].strip()
return orb_file, dpks_descriptor
-def get_abacus_STRU(STRU, INPUT = None, n_ele = None):
+
+def get_abacus_STRU(STRU, INPUT=None, n_ele=None):
# read in geometry from STRU file. n_ele is the number of elements.
# Either n_ele or INPUT should be provided.
- with open(STRU, 'r') as fp:
- geometry_inlines = fp.read().split('\n')
+ with open(STRU, "r") as fp:
+ geometry_inlines = fp.read().split("\n")
for iline, line in enumerate(geometry_inlines):
if line.split() == [] or len(line) == 0:
del geometry_inlines[iline]
geometry_inlines.append("")
- celldm, cell = get_cell(geometry_inlines)
- if n_ele is None and INPUT is not None:
- assert(os.path.isfile(INPUT)), "file %s should exists" % INPUT
- with open(INPUT, 'r') as fp:
- inlines = fp.read().split('\n')
- atom_names, natoms, types, coords = get_coords(celldm, cell, geometry_inlines, inlines)
- elif n_ele is not None and INPUT is None:
- assert(n_ele > 0)
- inlines = ["ntype %d" %n_ele]
- atom_names, natoms, types, coords = get_coords(celldm, cell, geometry_inlines, inlines)
- else:
- atom_names, atom_numbs = get_natoms_from_stru(geometry_inlines)
- inlines = ["ntype %d" %len(atom_numbs)]
- atom_names, natoms, types, coords = get_coords(celldm, cell, geometry_inlines, inlines)
- masses, pp_files = get_mass_from_STRU(geometry_inlines, inlines, atom_names)
+ celldm, cell = get_cell(geometry_inlines)
+ atom_names, natoms, types, coords = get_coords(celldm, cell, geometry_inlines)
+ masses, pp_files = get_mass_from_STRU(geometry_inlines, atom_names)
orb_files, dpks_descriptor = get_additional_from_STRU(geometry_inlines, len(masses))
data = {}
- data['atom_names'] = atom_names
- data['atom_numbs'] = natoms
- data['atom_types'] = types
- data['cells'] = cell
- data['coords'] = coords
- data['atom_masses'] = masses # Notice that this key is not defined in dpdata system.
- data['pp_files'] = pp_files
- data['orb_files'] = orb_files
- data['dpks_descriptor'] = dpks_descriptor
+ data["atom_names"] = atom_names
+ data["atom_numbs"] = natoms
+ data["atom_types"] = types
+ data["cells"] = cell
+ data["coords"] = coords
+ data[
+ "atom_masses"
+ ] = masses # Notice that this key is not defined in dpdata system.
+ data["pp_files"] = pp_files
+ data["orb_files"] = orb_files
+ data["dpks_descriptor"] = dpks_descriptor
return data
+
def make_supercell_abacus(from_struct, super_cell):
if "types" in from_struct:
- from_struct["types"] = from_struct["types"] * super_cell[0] * super_cell[1] * super_cell[2]
+ from_struct["types"] = (
+ from_struct["types"] * super_cell[0] * super_cell[1] * super_cell[2]
+ )
for ix in range(super_cell[0]):
for iy in range(super_cell[1]):
for iz in range(super_cell[2]):
if ix == 0 and iy == 0 and iz == 0:
continue
for ia in range(sum(from_struct["atom_numbs"])):
- coord = from_struct['coords'][ia] + from_struct['cells'][0]*ix + from_struct['cells'][1]*iy + from_struct['cells'][2]*iz
- from_struct['coords'] = np.vstack([from_struct['coords'], coord])
- from_struct["atom_numbs"] = [i * super_cell[0] * super_cell[1] * super_cell[2] for i in from_struct["atom_numbs"]]
- from_struct['cells'][0] *= super_cell[0]
- from_struct['cells'][1] *= super_cell[1]
- from_struct['cells'][2] *= super_cell[2]
+ coord = (
+ from_struct["coords"][ia]
+ + from_struct["cells"][0] * ix
+ + from_struct["cells"][1] * iy
+ + from_struct["cells"][2] * iz
+ )
+ from_struct["coords"] = np.vstack([from_struct["coords"], coord])
+ from_struct["atom_numbs"] = [
+ i * super_cell[0] * super_cell[1] * super_cell[2]
+ for i in from_struct["atom_numbs"]
+ ]
+ from_struct["cells"][0] *= super_cell[0]
+ from_struct["cells"][1] *= super_cell[1]
+ from_struct["cells"][2] *= super_cell[2]
return from_struct
-def make_kspacing_kpoints_stru(stru, kspacing) :
+
+def make_kspacing_kpoints_stru(stru, kspacing):
# adapted from dpgen.autotest.lib.vasp.make_kspacing_kpoints
if type(kspacing) is not list:
kspacing = [kspacing, kspacing, kspacing]
- box = stru['cells']
+ box = stru["cells"]
rbox = vasp.reciprocal_box(box)
- kpoints = [max(1,(np.ceil(2 * np.pi * np.linalg.norm(ii) / ks).astype(int))) for ii,ks in zip(rbox,kspacing)]
+ kpoints = [
+ max(1, (np.ceil(2 * np.pi * np.linalg.norm(ii) / ks).astype(int)))
+ for ii, ks in zip(rbox, kspacing)
+ ]
kpoints += [0, 0, 0]
return kpoints
+
if __name__ == "__main__":
fp_params = {"k_points": [1, 1, 1, 0, 0, 0]}
ret = make_abacus_scf_kpt(fp_params)
diff --git a/dpgen/generator/lib/calypso_check_outcar.py b/dpgen/generator/lib/calypso_check_outcar.py
index 5e9b8490b..148e3a5af 100644
--- a/dpgen/generator/lib/calypso_check_outcar.py
+++ b/dpgen/generator/lib/calypso_check_outcar.py
@@ -1,104 +1,129 @@
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
+import glob
+import os
+import sys
+import time
+
import numpy as np
-import os,sys,glob,time
+from ase.io import read
from deepmd.calculator import DP
-from ase.io import read
-'''
+"""
check if structure optimization worked well
if not, this script will generate a fake outcar
-'''
+"""
+
def Get_Element_Num(elements):
- '''Using the Atoms.symples to Know Element&Num'''
+ """Using the Atoms.symples to Know Element&Num"""
element = []
ele = {}
element.append(elements[0])
for x in elements:
- if x not in element :
+ if x not in element:
element.append(x)
for x in element:
ele[x] = elements.count(x)
return element, ele
+
def Write_Contcar(element, ele, lat, pos):
- '''Write CONTCAR'''
- f = open('CONTCAR','w')
- f.write('ASE-DPKit-FAILED-nan\n')
- f.write('1.0\n')
- for i in range(3):
- f.write('%15.10f %15.10f %15.10f\n' % tuple(lat[i]))
- for x in element:
- f.write(x + ' ')
- f.write('\n')
+ """Write CONTCAR"""
+ f = open("CONTCAR", "w")
+ f.write("ASE-DPKit-FAILED-nan\n")
+ f.write("1.0\n")
+ for i in range(3):
+ f.write("%15.10f %15.10f %15.10f\n" % tuple(lat[i]))
for x in element:
- f.write(str(ele[x]) + ' ')
- f.write('\n')
- f.write('Direct\n')
+ f.write(x + " ")
+ f.write("\n")
+ for x in element:
+ f.write(str(ele[x]) + " ")
+ f.write("\n")
+ f.write("Direct\n")
na = sum(ele.values())
- dpos = np.dot(pos,np.linalg.inv(lat))
+ dpos = np.dot(pos, np.linalg.inv(lat))
for i in range(na):
- f.write('%15.10f %15.10f %15.10f\n' % tuple(dpos[i]))
-
-def Write_Outcar(element, ele, volume, lat, pos, ene, force, stress,pstress):
- '''Write OUTCAR'''
- f = open('OUTCAR','w')
- for x in element:
- f.write('VRHFIN =' + str(x) + '\n')
- f.write('ions per type =')
+ f.write("%15.10f %15.10f %15.10f\n" % tuple(dpos[i]))
+
+
+def Write_Outcar(element, ele, volume, lat, pos, ene, force, stress, pstress):
+ """Write OUTCAR"""
+ f = open("OUTCAR", "w")
+ for x in element:
+ f.write("VRHFIN =" + str(x) + "\n")
+ f.write("ions per type =")
for x in element:
- f.write('%5d' % ele[x])
- f.write('\nDirection XX YY ZZ XY YZ ZX\n')
- f.write('in kB')
- f.write('%15.6f' % stress[0])
- f.write('%15.6f' % stress[1])
- f.write('%15.6f' % stress[2])
- f.write('%15.6f' % stress[3])
- f.write('%15.6f' % stress[4])
- f.write('%15.6f' % stress[5])
- f.write('\n')
- ext_pressure = np.sum(stress[0] + stress[1] + stress[2])/3.0 - pstress
- f.write('external pressure = %20.6f kB Pullay stress = %20.6f kB\n'% (ext_pressure, pstress))
- f.write('volume of cell : %20.6f\n' % volume)
- f.write('direct lattice vectors\n')
+ f.write("%5d" % ele[x])
+ f.write(
+ "\nDirection XX YY ZZ XY YZ ZX\n"
+ )
+ f.write("in kB")
+ f.write("%15.6f" % stress[0])
+ f.write("%15.6f" % stress[1])
+ f.write("%15.6f" % stress[2])
+ f.write("%15.6f" % stress[3])
+ f.write("%15.6f" % stress[4])
+ f.write("%15.6f" % stress[5])
+ f.write("\n")
+ ext_pressure = np.sum(stress[0] + stress[1] + stress[2]) / 3.0 - pstress
+ f.write(
+ "external pressure = %20.6f kB Pullay stress = %20.6f kB\n"
+ % (ext_pressure, pstress)
+ )
+ f.write("volume of cell : %20.6f\n" % volume)
+ f.write("direct lattice vectors\n")
for i in range(3):
- f.write('%10.6f %10.6f %10.6f\n' % tuple(lat[i]))
- f.write('POSITION TOTAL-FORCE(eV/Angst)\n')
- f.write('-------------------------------------------------------------------\n')
+ f.write("%10.6f %10.6f %10.6f\n" % tuple(lat[i]))
+ f.write("POSITION TOTAL-FORCE(eV/Angst)\n")
+ f.write("-------------------------------------------------------------------\n")
na = sum(ele.values())
- for i in range(na):
- f.write('%15.6f %15.6f %15.6f' % tuple(pos[i]))
- f.write('%15.6f %15.6f %15.6f\n' % tuple(force[i]))
- f.write('-------------------------------------------------------------------\n')
- f.write('energy without entropy= %20.6f %20.6f\n' % (ene, ene))
- enthalpy = ene + pstress * volume / 1602.17733
- f.write('enthalpy is TOTEN = %20.6f %20.6f\n' % (enthalpy, enthalpy))
+ for i in range(na):
+ f.write("%15.6f %15.6f %15.6f" % tuple(pos[i]))
+ f.write("%15.6f %15.6f %15.6f\n" % tuple(force[i]))
+ f.write("-------------------------------------------------------------------\n")
+ f.write("energy without entropy= %20.6f %20.6f\n" % (ene, ene))
+ enthalpy = ene + pstress * volume / 1602.17733
+ f.write("enthalpy is TOTEN = %20.6f %20.6f\n" % (enthalpy, enthalpy))
+
def check():
- from deepmd.calculator import DP
from ase.io import read
- calc = DP(model='../graph.000.pb') # init the model before iteration
+ from deepmd.calculator import DP
- to_be_opti = read('POSCAR')
- to_be_opti.calc = calc
+ calc = DP(model="../graph.000.pb") # init the model before iteration
+
+ to_be_opti = read("POSCAR")
+ to_be_opti.calc = calc
# ---------------------------------
- # for failed outcar
+ # for failed outcar
atoms_symbols_f = to_be_opti.get_chemical_symbols()
element_f, ele_f = Get_Element_Num(atoms_symbols_f)
- atoms_vol_f = to_be_opti.get_volume()
+ atoms_vol_f = to_be_opti.get_volume()
atoms_stress_f = to_be_opti.get_stress()
- atoms_stress_f = atoms_stress_f/(0.01*0.6242)
- atoms_lat_f = to_be_opti.cell
+ atoms_stress_f = atoms_stress_f / (0.01 * 0.6242)
+ atoms_lat_f = to_be_opti.cell
atoms_pos_f = to_be_opti.positions
atoms_force_f = to_be_opti.get_forces()
- atoms_ene_f = 610612509
- # ---------------------------------
+ atoms_ene_f = 610612509
+ # ---------------------------------
Write_Contcar(element_f, ele_f, atoms_lat_f, atoms_pos_f)
- Write_Outcar(element_f, ele_f, atoms_vol_f, atoms_lat_f, atoms_pos_f,atoms_ene_f, atoms_force_f, atoms_stress_f * -10.0, 0)
-
+ Write_Outcar(
+ element_f,
+ ele_f,
+ atoms_vol_f,
+ atoms_lat_f,
+ atoms_pos_f,
+ atoms_ene_f,
+ atoms_force_f,
+ atoms_stress_f * -10.0,
+ 0,
+ )
+
+
cwd = os.getcwd()
-if not os.path.exists(os.path.join(cwd,'OUTCAR')):
+if not os.path.exists(os.path.join(cwd, "OUTCAR")):
check()
diff --git a/dpgen/generator/lib/calypso_run_model_devi.py b/dpgen/generator/lib/calypso_run_model_devi.py
index 95f7e7d37..f3ed62a36 100644
--- a/dpgen/generator/lib/calypso_run_model_devi.py
+++ b/dpgen/generator/lib/calypso_run_model_devi.py
@@ -1,56 +1,62 @@
import argparse
import copy
-import dpdata
import glob
import math
-import numpy as np
import os
-import sys
import shutil
-from deepmd.infer import calc_model_devi
+import sys
+
+import dpdata
+import numpy as np
from deepmd.infer import DeepPot as DP
+from deepmd.infer import calc_model_devi
def write_model_devi_out(devi, fname):
assert devi.shape[1] == 8
- #assert devi.shape[1] == 7
- header = '%5s' % 'step'
- for item in 'vf':
- header += '%16s%16s%16s' % (f'max_devi_{item}', f'min_devi_{item}',f'avg_devi_{item}')
- header += '%16s'%str('min_dis')
- np.savetxt(fname,
- devi,
- fmt=['%5d'] + ['%17.6e' for _ in range(7)],
- delimiter='',
- header=header)
+ # assert devi.shape[1] == 7
+ header = "%5s" % "step"
+ for item in "vf":
+ header += "%16s%16s%16s" % (
+ f"max_devi_{item}",
+ f"min_devi_{item}",
+ f"avg_devi_{item}",
+ )
+ header += "%16s" % str("min_dis")
+ np.savetxt(
+ fname,
+ devi,
+ fmt=["%5d"] + ["%17.6e" for _ in range(7)],
+ delimiter="",
+ header=header,
+ )
return devi
-def Modd(all_models,type_map):
+def Modd(all_models, type_map):
- # Model Devi
+ # Model Devi
cwd = os.getcwd()
graphs = [DP(model) for model in all_models]
Devis = []
pcount = 0
- strus_lists = glob.glob(os.path.join(cwd,'*.structures'))
+ strus_lists = glob.glob(os.path.join(cwd, "*.structures"))
for num, strus_path in enumerate(strus_lists):
- structures_data = dpdata.System(strus_path,'deepmd/npy',type_map=type_map)
+ structures_data = dpdata.System(strus_path, "deepmd/npy", type_map=type_map)
# every 500 confs in one task dir
- nnum = structures_data.get_nframes()
+ nnum = structures_data.get_nframes()
if nnum == 0:
continue
else:
- num_per_task = math.ceil(nnum/500)
-
+ num_per_task = math.ceil(nnum / 500)
for temp in range(num_per_task):
- task_name = os.path.join(cwd,'task.%03d.%03d'%(num,temp))
- put_poscar = os.path.join(task_name,'traj')
+ task_name = os.path.join(cwd, "task.%03d.%03d" % (num, temp))
+ put_poscar = os.path.join(task_name, "traj")
if not os.path.exists(task_name):
os.mkdir(task_name)
os.mkdir(put_poscar)
@@ -59,30 +65,30 @@ def Modd(all_models,type_map):
os.mkdir(task_name)
os.mkdir(put_poscar)
devis = []
- if (nnum - (temp+1)*500) >= 0:
- temp_sl = range(temp*500,(temp+1)*500)
+ if (nnum - (temp + 1) * 500) >= 0:
+ temp_sl = range(temp * 500, (temp + 1) * 500)
else:
- temp_sl = range(temp*500,nnum)
-
+ temp_sl = range(temp * 500, nnum)
+
new_index = 0
- for index,frameid in enumerate(temp_sl):
+ for index, frameid in enumerate(temp_sl):
pdata = structures_data[frameid]
- pdata.to_vasp_poscar(os.path.join(put_poscar,'%s.poscar'%str(index)))
+ pdata.to_vasp_poscar(os.path.join(put_poscar, "%s.poscar" % str(index)))
nopbc = pdata.nopbc
- coord = pdata.data['coords']
- cell = pdata.data['cells'] if not nopbc else None
- atom_types = pdata.data['atom_types']
+ coord = pdata.data["coords"]
+ cell = pdata.data["cells"] if not nopbc else None
+ atom_types = pdata.data["atom_types"]
try:
- devi = calc_model_devi(coord,cell,atom_types,graphs,nopbc=nopbc)
+ devi = calc_model_devi(coord, cell, atom_types, graphs, nopbc=nopbc)
except TypeError:
- devi = calc_model_devi(coord,cell,atom_types,graphs)
+ devi = calc_model_devi(coord, cell, atom_types, graphs)
# ------------------------------------------------------------------------------------
# append min-distance in devi list
dis = pdata.to_ase_structure()[0].get_all_distances(mic=True)
- row,col = np.diag_indices_from(dis)
- dis[row,col] = 10000
+ row, col = np.diag_indices_from(dis)
+ dis[row, col] = 10000
min_dis = np.nanmin(dis)
- devi = np.append(devi[0],min_dis)
+ devi = np.append(devi[0], min_dis)
t = [devi]
devi = np.array(t)
# ------------------------------------------------------------------------------------
@@ -90,38 +96,46 @@ def Modd(all_models,type_map):
temp_D = copy.deepcopy(devi)
devis.append(temp_d)
Devis.append(temp_D)
- devis[index][0][0] = np.array(index)
+ devis[index][0][0] = np.array(index)
Devis[pcount][0][0] = np.array(pcount)
pcount += 1
new_index += 1
devis = np.vstack(devis)
- write_model_devi_out(devis,os.path.join(task_name, 'model_devi.out'))
+ write_model_devi_out(devis, os.path.join(task_name, "model_devi.out"))
Devis = np.vstack(Devis)
- write_model_devi_out(Devis,os.path.join(cwd,'Model_Devi.out'))
+ write_model_devi_out(Devis, os.path.join(cwd, "Model_Devi.out"))
- f = open(os.path.join(os.path.abspath(os.path.join(cwd,os.pardir)),'record.calypso'),'a+')
- f.write('4')
+ f = open(
+ os.path.join(os.path.abspath(os.path.join(cwd, os.pardir)), "record.calypso"),
+ "a+",
+ )
+ f.write("4")
f.close()
-if __name__ == '__main__':
+
+if __name__ == "__main__":
cwd = os.getcwd()
- model_path = os.path.join(os.path.abspath(os.path.join(cwd,os.pardir)),'gen_stru_analy')
- parser = argparse.ArgumentParser(description='calc model-devi by `all_models` and `type_map`')
+ model_path = os.path.join(
+ os.path.abspath(os.path.join(cwd, os.pardir)), "gen_stru_analy"
+ )
+ parser = argparse.ArgumentParser(
+ description="calc model-devi by `all_models` and `type_map`"
+ )
parser.add_argument(
- '--all_models',
+ "--all_models",
type=str,
- nargs='+',
+ nargs="+",
default=model_path,
- help='the path of models which will be used to do model-deviation',
+ help="the path of models which will be used to do model-deviation",
)
parser.add_argument(
- '--type_map',
- nargs='+',
- help='the type map of models which will be used to do model-deviation',
+ "--type_map",
+ nargs="+",
+ help="the type map of models which will be used to do model-deviation",
)
args = parser.parse_args()
- #print(vars(args))
- Modd(args.all_models,args.type_map)
- #Modd(sys.argv[1],sys.argv[2])
+ # print(vars(args))
+ Modd(args.all_models, args.type_map)
+ # Modd(sys.argv[1],sys.argv[2])
diff --git a/dpgen/generator/lib/calypso_run_opt.py b/dpgen/generator/lib/calypso_run_opt.py
index dc84864fd..99c0fec80 100644
--- a/dpgen/generator/lib/calypso_run_opt.py
+++ b/dpgen/generator/lib/calypso_run_opt.py
@@ -1,148 +1,177 @@
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
-import os,sys,glob,time
+import glob
+import os
+import sys
+import time
+
import numpy as np
-from ase.io import read
-from ase.optimize import BFGS,QuasiNewton,LBFGS
-from ase.constraints import UnitCellFilter, ExpCellFilter
-from deepmd.calculator import DP
-'''
+from ase.constraints import ExpCellFilter, UnitCellFilter
+from ase.io import read
+from ase.optimize import BFGS, LBFGS, QuasiNewton
+from deepmd.calculator import DP
+
+"""
structure optimization with DP model and ASE
PSTRESS and fmax should exist in input.dat
-'''
+"""
+
def Get_Element_Num(elements):
- '''Using the Atoms.symples to Know Element&Num'''
+ """Using the Atoms.symples to Know Element&Num"""
element = []
ele = {}
element.append(elements[0])
- for x in elements:
- if x not in element :
+ for x in elements:
+ if x not in element:
element.append(x)
- for x in element:
+ for x in element:
ele[x] = elements.count(x)
- return element, ele
-
+ return element, ele
+
+
def Write_Contcar(element, ele, lat, pos):
- '''Write CONTCAR'''
- f = open('CONTCAR','w')
- f.write('ASE-DPKit-Optimization\n')
- f.write('1.0\n')
+ """Write CONTCAR"""
+ f = open("CONTCAR", "w")
+ f.write("ASE-DPKit-Optimization\n")
+ f.write("1.0\n")
for i in range(3):
- f.write('%15.10f %15.10f %15.10f\n' % tuple(lat[i]))
- for x in element:
- f.write(x + ' ')
- f.write('\n')
+ f.write("%15.10f %15.10f %15.10f\n" % tuple(lat[i]))
for x in element:
- f.write(str(ele[x]) + ' ')
- f.write('\n')
- f.write('Direct\n')
+ f.write(x + " ")
+ f.write("\n")
+ for x in element:
+ f.write(str(ele[x]) + " ")
+ f.write("\n")
+ f.write("Direct\n")
na = sum(ele.values())
- dpos = np.dot(pos,np.linalg.inv(lat))
- for i in range(na):
- f.write('%15.10f %15.10f %15.10f\n' % tuple(dpos[i]))
-
-def Write_Outcar(element, ele, volume, lat, pos, ene, force, stress,pstress):
- '''Write OUTCAR'''
- f = open('OUTCAR','w')
- for x in element:
- f.write('VRHFIN =' + str(x) + '\n')
- f.write('ions per type =')
+ dpos = np.dot(pos, np.linalg.inv(lat))
+ for i in range(na):
+ f.write("%15.10f %15.10f %15.10f\n" % tuple(dpos[i]))
+
+
+def Write_Outcar(element, ele, volume, lat, pos, ene, force, stress, pstress):
+ """Write OUTCAR"""
+ f = open("OUTCAR", "w")
for x in element:
- f.write('%5d' % ele[x])
- f.write('\nDirection XX YY ZZ XY YZ ZX\n')
- f.write('in kB')
- f.write('%15.6f' % stress[0])
- f.write('%15.6f' % stress[1])
- f.write('%15.6f' % stress[2])
- f.write('%15.6f' % stress[3])
- f.write('%15.6f' % stress[4])
- f.write('%15.6f' % stress[5])
- f.write('\n')
- ext_pressure = np.sum(stress[0] + stress[1] + stress[2])/3.0 - pstress
- f.write('external pressure = %20.6f kB Pullay stress = %20.6f kB\n'% (ext_pressure, pstress))
- f.write('volume of cell : %20.6f\n' % volume)
- f.write('direct lattice vectors\n')
+ f.write("VRHFIN =" + str(x) + "\n")
+ f.write("ions per type =")
+ for x in element:
+ f.write("%5d" % ele[x])
+ f.write(
+ "\nDirection XX YY ZZ XY YZ ZX\n"
+ )
+ f.write("in kB")
+ f.write("%15.6f" % stress[0])
+ f.write("%15.6f" % stress[1])
+ f.write("%15.6f" % stress[2])
+ f.write("%15.6f" % stress[3])
+ f.write("%15.6f" % stress[4])
+ f.write("%15.6f" % stress[5])
+ f.write("\n")
+ ext_pressure = np.sum(stress[0] + stress[1] + stress[2]) / 3.0 - pstress
+ f.write(
+ "external pressure = %20.6f kB Pullay stress = %20.6f kB\n"
+ % (ext_pressure, pstress)
+ )
+ f.write("volume of cell : %20.6f\n" % volume)
+ f.write("direct lattice vectors\n")
for i in range(3):
- f.write('%10.6f %10.6f %10.6f\n' % tuple(lat[i]))
- f.write('POSITION TOTAL-FORCE(eV/Angst)\n')
- f.write('-------------------------------------------------------------------\n')
- na = sum(ele.values())
- for i in range(na):
- f.write('%15.6f %15.6f %15.6f' % tuple(pos[i]))
- f.write('%15.6f %15.6f %15.6f\n' % tuple(force[i]))
- f.write('-------------------------------------------------------------------\n')
- f.write('energy without entropy= %20.6f %20.6f\n' % (ene, ene/na))
- enthalpy = ene + pstress * volume / 1602.17733
- f.write('enthalpy is TOTEN = %20.6f %20.6f\n' % (enthalpy, enthalpy/na))
-
+ f.write("%10.6f %10.6f %10.6f\n" % tuple(lat[i]))
+ f.write("POSITION TOTAL-FORCE(eV/Angst)\n")
+ f.write("-------------------------------------------------------------------\n")
+ na = sum(ele.values())
+ for i in range(na):
+ f.write("%15.6f %15.6f %15.6f" % tuple(pos[i]))
+ f.write("%15.6f %15.6f %15.6f\n" % tuple(force[i]))
+ f.write("-------------------------------------------------------------------\n")
+ f.write("energy without entropy= %20.6f %20.6f\n" % (ene, ene / na))
+ enthalpy = ene + pstress * volume / 1602.17733
+ f.write("enthalpy is TOTEN = %20.6f %20.6f\n" % (enthalpy, enthalpy / na))
+
+
def read_stress_fmax():
pstress = 0
fmax = 0.01
- #assert os.path.exists('./input.dat'), 'input.dat does not exist!'
+ # assert os.path.exists('./input.dat'), 'input.dat does not exist!'
try:
- f = open('input.dat','r')
+ f = open("input.dat", "r")
except:
- assert os.path.exists('../input.dat'),' now we are in %s, do not find ../input.dat'%(os.getcwd())
- f = open('../input.dat','r')
+ assert os.path.exists(
+ "../input.dat"
+ ), " now we are in %s, do not find ../input.dat" % (os.getcwd())
+ f = open("../input.dat", "r")
lines = f.readlines()
f.close()
for line in lines:
- if line[0] == '#':
+ if line[0] == "#":
continue
- if 'PSTRESS' in line or 'pstress' in line:
- pstress = float(line.split('=')[1])
- if 'fmax' in line:
- fmax = float(line.split('=')[1])
- return fmax,pstress
-
-def run_opt(fmax,stress):
- '''Using the ASE&DP to Optimize Configures'''
-
- calc = DP(model='../graph.000.pb') # init the model before iteration
- os.system('mv OUTCAR OUTCAR-last')
-
- print('Start to Optimize Structures by DP----------')
-
- Opt_Step = 1000
- start = time.time()
+ if "PSTRESS" in line or "pstress" in line:
+ pstress = float(line.split("=")[1])
+ if "fmax" in line:
+ fmax = float(line.split("=")[1])
+ return fmax, pstress
+
+
+def run_opt(fmax, stress):
+ """Using the ASE&DP to Optimize Configures"""
+
+ calc = DP(model="../graph.000.pb") # init the model before iteration
+ os.system("mv OUTCAR OUTCAR-last")
+
+ print("Start to Optimize Structures by DP----------")
+
+ Opt_Step = 1000
+ start = time.time()
# pstress kbar
pstress = stress
# kBar to eV/A^3
# 1 eV/A^3 = 160.21766028 GPa
# 1 / 160.21766028 ~ 0.006242
- aim_stress = 1.0 * pstress* 0.01 * 0.6242 / 10.0
- to_be_opti = read('POSCAR')
- to_be_opti.calc = calc
+ aim_stress = 1.0 * pstress * 0.01 * 0.6242 / 10.0
+ to_be_opti = read("POSCAR")
+ to_be_opti.calc = calc
ucf = UnitCellFilter(to_be_opti, scalar_pressure=aim_stress)
- atoms_vol_2 = to_be_opti.get_volume()
+ atoms_vol_2 = to_be_opti.get_volume()
# opt
- opt = LBFGS(ucf,trajectory='traj.traj')
- opt.run(fmax=fmax,steps=Opt_Step)
-
- atoms_lat = to_be_opti.cell
+ opt = LBFGS(ucf, trajectory="traj.traj")
+ opt.run(fmax=fmax, steps=Opt_Step)
+
+ atoms_lat = to_be_opti.cell
atoms_pos = to_be_opti.positions
- atoms_force = to_be_opti.get_forces()
- atoms_stress = to_be_opti.get_stress()
+ atoms_force = to_be_opti.get_forces()
+ atoms_stress = to_be_opti.get_stress()
# eV/A^3 to GPa
- atoms_stress = atoms_stress/(0.01*0.6242)
- atoms_symbols = to_be_opti.get_chemical_symbols()
- atoms_ene = to_be_opti.get_potential_energy()
- atoms_vol = to_be_opti.get_volume()
- element, ele = Get_Element_Num(atoms_symbols)
+ atoms_stress = atoms_stress / (0.01 * 0.6242)
+ atoms_symbols = to_be_opti.get_chemical_symbols()
+ atoms_ene = to_be_opti.get_potential_energy()
+ atoms_vol = to_be_opti.get_volume()
+ element, ele = Get_Element_Num(atoms_symbols)
Write_Contcar(element, ele, atoms_lat, atoms_pos)
- Write_Outcar(element, ele, atoms_vol, atoms_lat, atoms_pos,atoms_ene, atoms_force, atoms_stress * -10.0, pstress)
+ Write_Outcar(
+ element,
+ ele,
+ atoms_vol,
+ atoms_lat,
+ atoms_pos,
+ atoms_ene,
+ atoms_force,
+ atoms_stress * -10.0,
+ pstress,
+ )
stop = time.time()
_cwd = os.getcwd()
_cwd = os.path.basename(_cwd)
- print('%s is done, time: %s' % (_cwd,stop-start))
+ print("%s is done, time: %s" % (_cwd, stop - start))
+
def run():
fmax, stress = read_stress_fmax()
run_opt(fmax, stress)
-if __name__=='__main__':
+
+if __name__ == "__main__":
run()
diff --git a/dpgen/generator/lib/cp2k.py b/dpgen/generator/lib/cp2k.py
index 4c598a817..2bfede252 100644
--- a/dpgen/generator/lib/cp2k.py
+++ b/dpgen/generator/lib/cp2k.py
@@ -1,63 +1,36 @@
import dpdata
import numpy as np
-default_config={
- "GLOBAL": {
- "PROJECT": "DPGEN"
- },
- "FORCE_EVAL": {
- "METHOD": "QS",
- "STRESS_TENSOR": "ANALYTICAL",
- "DFT": {
- "BASIS_SET_FILE_NAME": "./cp2k_basis_pp_file/BASIS_MOLOPT",
- "POTENTIAL_FILE_NAME": "./cp2k_basis_pp_file/GTH_POTENTIALS",
- "CHARGE": 0,
- "UKS": "F",
- "MULTIPLICITY": 1,
- "MGRID": {
- "CUTOFF": 400,
- "REL_CUTOFF": 50,
- "NGRIDS": 4
- },
- "QS": {
- "EPS_DEFAULT": "1.0E-12"
- },
- "SCF": {
- "SCF_GUESS": "ATOMIC",
- "EPS_SCF": "1.0E-6",
- "MAX_SCF": 50
- },
- "XC": {
- "XC_FUNCTIONAL": {
- "_": "PBE"
- }
-
- }
- },
- "SUBSYS": {
- "CELL":{
- "A": "10 .0 .0",
- "B": ".0 10 .0",
- "C": ".0 .0 10"
+default_config = {
+ "GLOBAL": {"PROJECT": "DPGEN"},
+ "FORCE_EVAL": {
+ "METHOD": "QS",
+ "STRESS_TENSOR": "ANALYTICAL",
+ "DFT": {
+ "BASIS_SET_FILE_NAME": "./cp2k_basis_pp_file/BASIS_MOLOPT",
+ "POTENTIAL_FILE_NAME": "./cp2k_basis_pp_file/GTH_POTENTIALS",
+ "CHARGE": 0,
+ "UKS": "F",
+ "MULTIPLICITY": 1,
+ "MGRID": {"CUTOFF": 400, "REL_CUTOFF": 50, "NGRIDS": 4},
+ "QS": {"EPS_DEFAULT": "1.0E-12"},
+ "SCF": {"SCF_GUESS": "ATOMIC", "EPS_SCF": "1.0E-6", "MAX_SCF": 50},
+ "XC": {"XC_FUNCTIONAL": {"_": "PBE"}},
+ },
+ "SUBSYS": {
+ "CELL": {"A": "10 .0 .0", "B": ".0 10 .0", "C": ".0 .0 10"},
+ "COORD": {"@include": "coord.xyz"},
+ "KIND": {
+ "_": ["H", "C", "N"],
+ "POTENTIAL": ["GTH-PBE-q1", "GTH-PBE-q4", "GTH-PBE-q5"],
+ "BASIS_SET": ["DZVP-MOLOPT-GTH", "DZVP-MOLOPT-GTH", "DZVP-MOLOPT-GTH"],
},
- "COORD": {"@include": "coord.xyz"},
- "KIND": {
- "_": ["H","C","N"],
- "POTENTIAL": ["GTH-PBE-q1","GTH-PBE-q4", "GTH-PBE-q5"],
- "BASIS_SET": ["DZVP-MOLOPT-GTH","DZVP-MOLOPT-GTH","DZVP-MOLOPT-GTH"]
- }
- },
- "PRINT": {
- "FORCES": {
- "_": "ON"
+ },
+ "PRINT": {"FORCES": {"_": "ON"}, "STRESS_TENSOR": {"_": "ON"}},
},
- "STRESS_TENSOR":{
- "_": "ON"
- }
- }
-}
}
+
def update_dict(old_d, update_d):
"""
a method to recursive update dict
@@ -65,12 +38,18 @@ def update_dict(old_d, update_d):
:update_d: some update value written in dictionary form
"""
import collections.abc
+
for k, v in update_d.items():
- if (k in old_d and isinstance(old_d[k], dict) and isinstance(update_d[k], collections.abc.Mapping)):
+ if (
+ k in old_d
+ and isinstance(old_d[k], dict)
+ and isinstance(update_d[k], collections.abc.Mapping)
+ ):
update_dict(old_d[k], update_d[k])
else:
old_d[k] = update_d[k]
+
def iterdict(d, out_list, flag=None):
"""
:doc: a recursive expansion of dictionary into cp2k input
@@ -80,26 +59,26 @@ def iterdict(d, out_list, flag=None):
:flag: used to record dictionary state. if flag is None,
it means we are in top level dict. flag is a string.
"""
- for k,v in d.items():
- k=str(k) # cast key into string
- #if value is dictionary
+ for k, v in d.items():
+ k = str(k) # cast key into string
+ # if value is dictionary
if isinstance(v, dict):
# flag == None, it is now in top level section of cp2k
- if flag==None :
- out_list.append("&"+k)
- out_list.append("&END "+k)
+ if flag == None:
+ out_list.append("&" + k)
+ out_list.append("&END " + k)
iterdict(v, out_list, k)
# flag is not None, now it has name of section
else:
index = out_list.index("&END " + flag)
- out_list.insert(index, "&"+k)
- out_list.insert(index+1,"&END "+k )
+ out_list.insert(index, "&" + k)
+ out_list.insert(index + 1, "&END " + k)
iterdict(v, out_list, k)
elif isinstance(v, list):
-# print("we have encountered the repeat section!")
- index = out_list.index("&"+flag)
+ # print("we have encountered the repeat section!")
+ index = out_list.index("&" + flag)
# delete the current constructed repeat section
- del out_list[index:index+2]
+ del out_list[index : index + 2]
# do a loop over key and corresponding list
k_tmp_list = []
v_list_tmp_list = []
@@ -107,90 +86,80 @@ def iterdict(d, out_list, flag=None):
k_tmp_list.append(str(k_tmp))
v_list_tmp_list.append(v_tmp)
for repeat_keyword in zip(*v_list_tmp_list):
- out_list.insert(index,"&" + flag)
- out_list.insert(index+1, "&END " + flag)
+ out_list.insert(index, "&" + flag)
+ out_list.insert(index + 1, "&END " + flag)
for idx, k_tmp in enumerate(k_tmp_list):
if k_tmp == "_":
out_list[index] = "&" + flag + " " + repeat_keyword[idx]
else:
- out_list.insert(index+1, k_tmp+" "+repeat_keyword[idx])
+ out_list.insert(index + 1, k_tmp + " " + repeat_keyword[idx])
break
else:
- v=str(v)
- if flag==None :
- out_list.append(k+" "+v)
- print (k,":",v)
+ v = str(v)
+ if flag == None:
+ out_list.append(k + " " + v)
+ print(k, ":", v)
else:
if k == "_":
index = out_list.index("&" + flag)
- out_list[index] = ("&" + flag + " " + v)
+ out_list[index] = "&" + flag + " " + v
else:
- index = out_list.index("&END "+flag)
- out_list.insert(index, k+" "+v)
+ index = out_list.index("&END " + flag)
+ out_list.insert(index, k + " " + v)
def make_cp2k_input(sys_data, fp_params):
- #covert cell to cell string
- cell = sys_data['cells'][0]
- cell = np.reshape(cell, [3,3])
- cell_a = np.array2string(cell[0,:])
+ # covert cell to cell string
+ cell = sys_data["cells"][0]
+ cell = np.reshape(cell, [3, 3])
+ cell_a = np.array2string(cell[0, :])
cell_a = cell_a[1:-1]
- cell_b = np.array2string(cell[1,:])
+ cell_b = np.array2string(cell[1, :])
cell_b = cell_b[1:-1]
- cell_c = np.array2string(cell[2,:])
+ cell_c = np.array2string(cell[2, :])
cell_c = cell_c[1:-1]
- #get update from user
- user_config=fp_params
- #get update from cell
- cell_config={"FORCE_EVAL":{
- "SUBSYS":{
- "CELL":{
- "A": cell_a,
- "B": cell_b,
- "C": cell_c
- }
- }
- }
- }
+ # get update from user
+ user_config = fp_params
+ # get update from cell
+ cell_config = {
+ "FORCE_EVAL": {"SUBSYS": {"CELL": {"A": cell_a, "B": cell_b, "C": cell_c}}}
+ }
update_dict(default_config, user_config)
update_dict(default_config, cell_config)
- #output list
+ # output list
input_str = []
iterdict(default_config, input_str)
- string="\n".join(input_str)
+ string = "\n".join(input_str)
return string
-
-
def make_cp2k_xyz(sys_data):
- #get structral information
- atom_names = sys_data['atom_names']
- atom_types = sys_data['atom_types']
+ # get structral information
+ atom_names = sys_data["atom_names"]
+ atom_types = sys_data["atom_types"]
- #write coordinate to xyz file used by cp2k input
- coord_list = sys_data['coords'][0]
+ # write coordinate to xyz file used by cp2k input
+ coord_list = sys_data["coords"][0]
u = np.array(atom_names)
atom_list = u[atom_types]
- x = '\n'
- for kind, coord in zip(atom_list, coord_list) :
- x += str(kind) + ' ' + str(coord[:])[1:-1] + '\n'
+ x = "\n"
+ for kind, coord in zip(atom_list, coord_list):
+ x += str(kind) + " " + str(coord[:])[1:-1] + "\n"
return x
-
def make_cp2k_input_from_external(sys_data, exinput_path):
# read the input content as string
- with open(exinput_path, 'r') as f:
+ with open(exinput_path, "r") as f:
exinput = f.readlines()
# find the ABC cell string
for line_idx, line in enumerate(exinput):
- if 'ABC' in line:
+ if "ABC" in line:
delete_cell_idx = line_idx
delete_cell_line = line
@@ -199,19 +168,17 @@ def make_cp2k_input_from_external(sys_data, exinput_path):
# insert the cell information
# covert cell to cell string
- cell = sys_data['cells'][0]
- cell = np.reshape(cell, [3,3])
- cell_a = np.array2string(cell[0,:])
+ cell = sys_data["cells"][0]
+ cell = np.reshape(cell, [3, 3])
+ cell_a = np.array2string(cell[0, :])
cell_a = cell_a[1:-1]
- cell_b = np.array2string(cell[1,:])
+ cell_b = np.array2string(cell[1, :])
cell_b = cell_b[1:-1]
- cell_c = np.array2string(cell[2,:])
+ cell_c = np.array2string(cell[2, :])
cell_c = cell_c[1:-1]
- exinput.insert(delete_cell_idx, 'A ' + cell_a + '\n')
- exinput.insert(delete_cell_idx+1, 'B ' + cell_b + '\n')
- exinput.insert(delete_cell_idx+2, 'C ' + cell_c + '\n')
-
- return ''.join(exinput)
-
+ exinput.insert(delete_cell_idx, "A " + cell_a + "\n")
+ exinput.insert(delete_cell_idx + 1, "B " + cell_b + "\n")
+ exinput.insert(delete_cell_idx + 2, "C " + cell_c + "\n")
+ return "".join(exinput)
diff --git a/dpgen/generator/lib/cvasp.py b/dpgen/generator/lib/cvasp.py
index 43faf6790..d98d549d4 100644
--- a/dpgen/generator/lib/cvasp.py
+++ b/dpgen/generator/lib/cvasp.py
@@ -1,45 +1,80 @@
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
-from custodian.vasp.jobs import VaspJob as cvj
-from custodian.vasp.validators import VaspFilesValidator,VasprunXMLValidator
-from custodian.vasp.handlers import VaspErrorHandler,UnconvergedErrorHandler, \
- NonConvergingErrorHandler,FrozenJobErrorHandler,StdErrHandler,\
- WalltimeHandler,PositiveEnergyErrorHandler
-from custodian import Custodian
import argparse
-handlers=[VaspErrorHandler(),FrozenJobErrorHandler(),StdErrHandler(),NonConvergingErrorHandler(),
- WalltimeHandler(),PositiveEnergyErrorHandler(),UnconvergedErrorHandler()]
-validators=[VaspFilesValidator(),VasprunXMLValidator()]
+from custodian import Custodian
+from custodian.vasp.handlers import (
+ FrozenJobErrorHandler,
+ NonConvergingErrorHandler,
+ PositiveEnergyErrorHandler,
+ StdErrHandler,
+ UnconvergedErrorHandler,
+ VaspErrorHandler,
+ WalltimeHandler,
+)
+from custodian.vasp.jobs import VaspJob as cvj
+from custodian.vasp.validators import VaspFilesValidator, VasprunXMLValidator
+
+handlers = [
+ VaspErrorHandler(),
+ FrozenJobErrorHandler(),
+ StdErrHandler(),
+ NonConvergingErrorHandler(),
+ WalltimeHandler(),
+ PositiveEnergyErrorHandler(),
+ UnconvergedErrorHandler(),
+]
+validators = [VaspFilesValidator(), VasprunXMLValidator()]
-def runvasp(cmd,opt=False,max_errors=3,backup=False,auto_gamma=False,auto_npar=False,ediffg=-.05):
+
+def runvasp(
+ cmd,
+ opt=False,
+ max_errors=3,
+ backup=False,
+ auto_gamma=False,
+ auto_npar=False,
+ ediffg=-0.05,
+):
"""
cmd example:
cmd=['mpirun', '-np', '32' , '-machinefile', 'hosts','vasp_std']
"""
if opt:
- jobs = cvj.full_opt_run(cmd, auto_npar=auto_npar, ediffg=ediffg, backup=backup, auto_gamma=auto_gamma )
+ jobs = cvj.full_opt_run(
+ cmd,
+ auto_npar=auto_npar,
+ ediffg=ediffg,
+ backup=backup,
+ auto_gamma=auto_gamma,
+ )
else:
- jobs = [cvj(cmd, auto_npar=auto_npar, backup=backup, auto_gamma=auto_gamma)]
- c = Custodian(handlers, jobs, validators=validators,max_errors=max_errors)
+ jobs = [cvj(cmd, auto_npar=auto_npar, backup=backup, auto_gamma=auto_gamma)]
+ c = Custodian(handlers, jobs, validators=validators, max_errors=max_errors)
c.run()
+
def __main():
parser = argparse.ArgumentParser()
- parser.add_argument("CMD", type=str,
- help="""The command for runing vasp, e.g.,
+ parser.add_argument(
+ "CMD",
+ type=str,
+ help="""The command for runing vasp, e.g.,
'mpirun -np 32 /path/vasp_std' or
'srun /path/vasp_std'
- """)
- parser.add_argument("MAXERR", type=int,
- help="The maximum error time for runing vasp")
+ """,
+ )
+ parser.add_argument(
+ "MAXERR", type=int, help="The maximum error time for runing vasp"
+ )
args = parser.parse_args()
- cmd=args.CMD.split()
- runvasp(cmd=cmd,max_errors=args.MAXERR)
-
-if __name__=='__main__':
- __main()
- #vasp="/sharedext4/vasp/vasp.5.4.4/bin/vasp_std"
- #runvasp(cmd=['srun', vasp],max_errors=3,backup=True)
- #runvasp(cmd=['mpirun', '-np', ncpu, fp_cmd],max_errors=max_errors)
+ cmd = args.CMD.split()
+ runvasp(cmd=cmd, max_errors=args.MAXERR)
+
+
+if __name__ == "__main__":
+ __main()
+ # vasp="/sharedext4/vasp/vasp.5.4.4/bin/vasp_std"
+ # runvasp(cmd=['srun', vasp],max_errors=3,backup=True)
+ # runvasp(cmd=['mpirun', '-np', ncpu, fp_cmd],max_errors=max_errors)
diff --git a/dpgen/generator/lib/ele_temp.py b/dpgen/generator/lib/ele_temp.py
index 90372e1a1..e2396b6fe 100644
--- a/dpgen/generator/lib/ele_temp.py
+++ b/dpgen/generator/lib/ele_temp.py
@@ -1,12 +1,14 @@
-import os,dpdata,json
+import json
+import os
+
+import dpdata
import numpy as np
import scipy.constants as pc
from pymatgen.io.vasp.inputs import Incar
class NBandsEsti(object):
- def __init__ (self,
- test_list):
+ def __init__(self, test_list):
if type(test_list) is list:
ele_t = []
vol = []
@@ -14,15 +16,15 @@ def __init__ (self,
nbd = []
for ii in test_list:
res = NBandsEsti._get_res(ii)
- ele_t.append(res['ele_temp'])
- vol.append(res['vol'])
+ ele_t.append(res["ele_temp"])
+ vol.append(res["vol"])
d_nbd.append(NBandsEsti._get_default_nbands(res))
- nbd.append(res['nbands'])
+ nbd.append(res["nbands"])
ele_t = np.array(ele_t)
vol = np.array(vol)
d_nbd = np.array(d_nbd)
nbd = np.array(nbd)
- alpha = (nbd - d_nbd) / vol / ele_t**1.5
+ alpha = (nbd - d_nbd) / vol / ele_t**1.5
self.err = np.std(alpha)
self.pref = np.average(alpha)
# print(np.average(alpha), np.std(alpha), self.err/self.pref)
@@ -32,61 +34,63 @@ def __init__ (self,
self.pref = float(fp.readline())
self.err = float(fp.readline())
else:
- raise RuntimeError('unknown input type ' + type(test_list))
+ raise RuntimeError("unknown input type " + type(test_list))
def save(self, fname):
- with open(fname, 'w') as fp:
- fp.write(str(self.pref) + '\n')
- fp.write(str(self.err) + '\n')
+ with open(fname, "w") as fp:
+ fp.write(str(self.pref) + "\n")
+ fp.write(str(self.err) + "\n")
- def predict(self,
- target_dir,
- tolerance = 0.5):
+ def predict(self, target_dir, tolerance=0.5):
res = NBandsEsti._get_res(target_dir)
- ele_t=(res['ele_temp'])
- vol=(res['vol'])
- d_nbd=(NBandsEsti._get_default_nbands(res))
- nbd=(res['nbands'])
- esti = (self.pref + tolerance*self.err) * ele_t**1.5 * vol + d_nbd
- return int(esti)+1
+ ele_t = res["ele_temp"]
+ vol = res["vol"]
+ d_nbd = NBandsEsti._get_default_nbands(res)
+ nbd = res["nbands"]
+ esti = (self.pref + tolerance * self.err) * ele_t**1.5 * vol + d_nbd
+ return int(esti) + 1
@classmethod
def _get_res(self, res_dir):
res = {}
- sys = dpdata.System(os.path.join(res_dir, 'POSCAR'))
- res['natoms'] = (sys['atom_numbs'])
- res['vol'] = np.linalg.det(sys['cells'][0])
- res['nvalence'] = (self._get_potcar_nvalence(os.path.join(res_dir, 'POTCAR')))
- res['ele_temp'] = self._get_incar_ele_temp(os.path.join(res_dir, 'INCAR')) * pc.electron_volt / pc.Boltzmann
- res['nbands'] = self._get_incar_nbands(os.path.join(res_dir, 'INCAR'))
+ sys = dpdata.System(os.path.join(res_dir, "POSCAR"))
+ res["natoms"] = sys["atom_numbs"]
+ res["vol"] = np.linalg.det(sys["cells"][0])
+ res["nvalence"] = self._get_potcar_nvalence(os.path.join(res_dir, "POTCAR"))
+ res["ele_temp"] = (
+ self._get_incar_ele_temp(os.path.join(res_dir, "INCAR"))
+ * pc.electron_volt
+ / pc.Boltzmann
+ )
+ res["nbands"] = self._get_incar_nbands(os.path.join(res_dir, "INCAR"))
return res
@classmethod
def _get_default_nbands(self, res):
ret = 0
- for ii,jj in zip(res['natoms'], res['nvalence']):
+ for ii, jj in zip(res["natoms"], res["nvalence"]):
ret += ii * jj // 2 + ii // 2 + 2
return ret
@classmethod
def _get_potcar_nvalence(self, fname):
with open(fname) as fp:
- pot_str = fp.read().split('\n')
+ pot_str = fp.read().split("\n")
head_idx = []
- for idx,ii in enumerate(pot_str):
- if ('PAW_' in ii) and ('TITEL' not in ii):
+ for idx, ii in enumerate(pot_str):
+ if ("PAW_" in ii) and ("TITEL" not in ii):
head_idx.append(idx)
res = []
for ii in head_idx:
- res.append(float(pot_str[ii+1]))
+ res.append(float(pot_str[ii + 1]))
return res
@classmethod
def _get_incar_ele_temp(self, fname):
incar = Incar.from_file(fname)
- return incar['SIGMA']
+ return incar["SIGMA"]
@classmethod
def _get_incar_nbands(self, fname):
incar = Incar.from_file(fname)
- return incar.get('NBANDS')
+ return incar.get("NBANDS")
diff --git a/dpgen/generator/lib/gaussian.py b/dpgen/generator/lib/gaussian.py
index fe04d2974..eb4c919f2 100644
--- a/dpgen/generator/lib/gaussian.py
+++ b/dpgen/generator/lib/gaussian.py
@@ -1,20 +1,22 @@
#!/usr/bin/python3
-import uuid
import itertools
+import uuid
import warnings
-import numpy as np
+
import dpdata
+import numpy as np
from scipy.sparse import csr_matrix
from scipy.sparse.csgraph import connected_components
+
try:
# expect openbabel >= 3.1.0
from openbabel import openbabel
except ImportError:
pass
try:
- from ase import Atoms, Atom
+ from ase import Atom, Atoms
from ase.data import atomic_numbers
except ImportError:
pass
@@ -22,11 +24,13 @@
def _crd2frag(symbols, crds, pbc=False, cell=None, return_bonds=False):
atomnumber = len(symbols)
- all_atoms = Atoms(symbols = symbols, positions = crds, pbc=pbc, cell=cell)
+ all_atoms = Atoms(symbols=symbols, positions=crds, pbc=pbc, cell=cell)
# Use openbabel to connect atoms
mol = openbabel.OBMol()
mol.BeginModify()
- for idx, (num, position) in enumerate(zip(all_atoms.get_atomic_numbers(), all_atoms.positions)):
+ for idx, (num, position) in enumerate(
+ zip(all_atoms.get_atomic_numbers(), all_atoms.positions)
+ ):
atom = mol.NewAtom(idx)
atom.SetAtomicNum(int(num))
atom.SetVector(*position)
@@ -53,7 +57,8 @@ def _crd2frag(symbols, crds, pbc=False, cell=None, return_bonds=False):
bonds.extend([[a, b, bo], [b, a, bo]])
bonds = np.array(bonds, ndmin=2).reshape((-1, 3))
graph = csr_matrix(
- (bonds[:, 2], (bonds[:, 0], bonds[:, 1])), shape=(atomnumber, atomnumber))
+ (bonds[:, 2], (bonds[:, 0], bonds[:, 1])), shape=(atomnumber, atomnumber)
+ )
frag_numb, frag_index = connected_components(graph, 0)
if return_bonds:
return frag_numb, frag_index, graph
@@ -62,16 +67,24 @@ def _crd2frag(symbols, crds, pbc=False, cell=None, return_bonds=False):
def _crd2mul(symbols, crds):
atomnumber = len(symbols)
- xyzstring = ''.join((f"{atomnumber}\nDPGEN\n", "\n".join(
- ['{:2s} {:22.15f} {:22.15f} {:22.15f}'.format(s, x, y, z)
- for s, (x, y, z) in zip(symbols, crds)])))
+ xyzstring = "".join(
+ (
+ f"{atomnumber}\nDPGEN\n",
+ "\n".join(
+ [
+ "{:2s} {:22.15f} {:22.15f} {:22.15f}".format(s, x, y, z)
+ for s, (x, y, z) in zip(symbols, crds)
+ ]
+ ),
+ )
+ )
conv = openbabel.OBConversion()
- conv.SetInAndOutFormats('xyz', 'gjf')
+ conv.SetInAndOutFormats("xyz", "gjf")
mol = openbabel.OBMol()
conv.ReadString(mol, xyzstring)
gjfstring = conv.WriteString(mol)
- mul = int(gjfstring.split('\n')[5].split()[1])
- return mul
+ mul = int(gjfstring.split("\n")[5].split()[1])
+ return mul
def detect_multiplicity(symbols):
@@ -85,19 +98,22 @@ def detect_multiplicity(symbols):
def make_gaussian_input(sys_data, fp_params):
- coordinates = sys_data['coords'][0]
- atom_names = sys_data['atom_names']
- #atom_numbs = sys_data['atom_numbs']
- atom_types = sys_data['atom_types']
+ coordinates = sys_data["coords"][0]
+ atom_names = sys_data["atom_names"]
+ # atom_numbs = sys_data['atom_numbs']
+ atom_types = sys_data["atom_types"]
# get atom symbols list
symbols = [atom_names[atom_type] for atom_type in atom_types]
- nproc = fp_params['nproc']
+ nproc = fp_params["nproc"]
- if 'keywords_high_multiplicity' in fp_params and _crd2mul(symbols, coordinates)>=3:
+ if (
+ "keywords_high_multiplicity" in fp_params
+ and _crd2mul(symbols, coordinates) >= 3
+ ):
# multiplicity >= 3, meaning at least 2 radicals
- keywords = fp_params['keywords_high_multiplicity']
+ keywords = fp_params["keywords_high_multiplicity"]
else:
- keywords = fp_params['keywords']
+ keywords = fp_params["keywords"]
if type(keywords) == str:
keywords = [keywords]
@@ -105,17 +121,17 @@ def make_gaussian_input(sys_data, fp_params):
keywords = keywords.copy()
# assume default charge is zero and default spin multiplicity is 1
- if 'charge' in sys_data.keys():
- charge = sys_data['charge']
+ if "charge" in sys_data.keys():
+ charge = sys_data["charge"]
else:
- charge = fp_params.get('charge', 0)
-
+ charge = fp_params.get("charge", 0)
+
use_fragment_guesses = False
- multiplicity = fp_params.get('multiplicity', 'auto')
+ multiplicity = fp_params.get("multiplicity", "auto")
if type(multiplicity) == int:
- multiplicity = fp_params['multiplicity']
+ multiplicity = fp_params["multiplicity"]
mult_auto = False
- elif multiplicity == 'auto':
+ elif multiplicity == "auto":
mult_auto = True
else:
raise RuntimeError('The keyword "multiplicity" is illegal.')
@@ -138,59 +154,82 @@ def make_gaussian_input(sys_data, fp_params):
mult_frags.append(detect_multiplicity(np.array(symbols)[idx]))
if use_fragment_guesses:
multiplicity = sum(mult_frags) - frag_numb + 1
- chargekeywords_frag = "%d %d" % (charge, multiplicity) + \
- ''.join([' %d %d' % (charge, mult_frag)
- for mult_frag in mult_frags])
+ chargekeywords_frag = "%d %d" % (charge, multiplicity) + "".join(
+ [" %d %d" % (charge, mult_frag) for mult_frag in mult_frags]
+ )
else:
multi_frags = np.array(mult_frags)
- multiplicity = 1 + \
- np.count_nonzero(multi_frags == 2) % 2 + \
- np.count_nonzero(multi_frags == 3) * 2
+ multiplicity = (
+ 1
+ + np.count_nonzero(multi_frags == 2) % 2
+ + np.count_nonzero(multi_frags == 3) * 2
+ )
buff = []
# keywords, e.g., force b3lyp/6-31g**
if use_fragment_guesses:
- keywords[0] = '{} guess=fragment={}'.format(
- keywords[0], frag_numb)
+ keywords[0] = "{} guess=fragment={}".format(keywords[0], frag_numb)
chkkeywords = []
- if len(keywords)>1:
- chkkeywords.append('%chk={}.chk'.format(str(uuid.uuid1())))
+ if len(keywords) > 1:
+ chkkeywords.append("%chk={}.chk".format(str(uuid.uuid1())))
- nprockeywords = '%nproc={:d}'.format(nproc)
- titlekeywords = 'DPGEN'
- chargekeywords = '{} {}'.format(charge, multiplicity)
+ nprockeywords = "%nproc={:d}".format(nproc)
+ titlekeywords = "DPGEN"
+ chargekeywords = "{} {}".format(charge, multiplicity)
- buff = [*chkkeywords, nprockeywords, '#{}'.format(
- keywords[0]), '', titlekeywords, '', (chargekeywords_frag if use_fragment_guesses else chargekeywords)]
+ buff = [
+ *chkkeywords,
+ nprockeywords,
+ "#{}".format(keywords[0]),
+ "",
+ titlekeywords,
+ "",
+ (chargekeywords_frag if use_fragment_guesses else chargekeywords),
+ ]
for ii, (symbol, coordinate) in enumerate(zip(symbols, coordinates)):
if use_fragment_guesses:
- buff.append("%s(Fragment=%d) %f %f %f" %
- (symbol, frag_index[ii] + 1, *coordinate))
+ buff.append(
+ "%s(Fragment=%d) %f %f %f" % (symbol, frag_index[ii] + 1, *coordinate)
+ )
else:
buff.append("%s %f %f %f" % (symbol, *coordinate))
- if 'basis_set' in fp_params:
+ if "basis_set" in fp_params:
# custom basis set
- buff.extend(['', fp_params['basis_set'], ''])
+ buff.extend(["", fp_params["basis_set"], ""])
for kw in itertools.islice(keywords, 1, None):
- buff.extend(['\n--link1--', *chkkeywords, nprockeywords,
- '#{}'.format(kw), '', titlekeywords, '', chargekeywords, ''])
- buff.append('\n')
- return '\n'.join(buff)
+ buff.extend(
+ [
+ "\n--link1--",
+ *chkkeywords,
+ nprockeywords,
+ "#{}".format(kw),
+ "",
+ titlekeywords,
+ "",
+ chargekeywords,
+ "",
+ ]
+ )
+ buff.append("\n")
+ return "\n".join(buff)
+
def take_cluster(old_conf_name, type_map, idx, jdata):
- cutoff = jdata['cluster_cutoff']
- cutoff_hard = jdata.get('cluster_cutoff_hard', None)
- sys = dpdata.System(old_conf_name, fmt = 'lammps/dump', type_map = type_map)
- atom_names = sys['atom_names']
- atom_types = sys['atom_types']
- cell = sys['cells'][0]
- coords = sys['coords'][0]
+ cutoff = jdata["cluster_cutoff"]
+ cutoff_hard = jdata.get("cluster_cutoff_hard", None)
+ sys = dpdata.System(old_conf_name, fmt="lammps/dump", type_map=type_map)
+ atom_names = sys["atom_names"]
+ atom_types = sys["atom_types"]
+ cell = sys["cells"][0]
+ coords = sys["coords"][0]
symbols = [atom_names[atom_type] for atom_type in atom_types]
- # detect fragment
- frag_numb, frag_index, graph = _crd2frag(symbols, coords, True, cell, return_bonds=True)
+ # detect fragment
+ frag_numb, frag_index, graph = _crd2frag(
+ symbols, coords, True, cell, return_bonds=True
+ )
# get_distances
- all_atoms = Atoms(symbols = symbols, positions = coords, pbc=True, cell=cell)
+ all_atoms = Atoms(symbols=symbols, positions=coords, pbc=True, cell=cell)
all_atoms[idx].tag = 1
distances = all_atoms.get_distances(idx, range(len(all_atoms)), mic=True)
distancescutoff = distances < cutoff
@@ -207,31 +246,43 @@ def take_cluster(old_conf_name, type_map, idx, jdata):
# drop atoms out of the hard cutoff anyway
frag_atoms_idx = np.intersect1d(frag_atoms_idx, cutoff_atoms_idx_hard)
if np.any(np.isin(frag_atoms_idx, cutoff_atoms_idx)):
- if 'cluster_minify' in jdata and jdata['cluster_minify']:
+ if "cluster_minify" in jdata and jdata["cluster_minify"]:
# support for organic species
- take_frag_idx=[]
+ take_frag_idx = []
for aa in frag_atoms_idx:
if np.any(np.isin(aa, cutoff_atoms_idx)):
# atom is in the soft cutoff
# pick up anyway
take_frag_idx.append(aa)
- elif np.count_nonzero(np.logical_and(distancescutoff, graph.toarray()[aa]==1)):
+ elif np.count_nonzero(
+ np.logical_and(distancescutoff, graph.toarray()[aa] == 1)
+ ):
# atom is between the hard cutoff and the soft cutoff
# and has a single bond with the atom inside
- if all_atoms[aa].symbol == 'H':
+ if all_atoms[aa].symbol == "H":
# for atom H: just add it
take_frag_idx.append(aa)
else:
# for other atoms (C, O, etc.): replace it with a ghost H atom
- near_atom_idx = np.nonzero(np.logical_and(distancescutoff, graph.toarray()[aa]>0))[0][0]
- vector = all_atoms[aa].position - all_atoms[near_atom_idx].position
- new_position = all_atoms[near_atom_idx].position + vector / np.linalg.norm(vector) * 1.09
- added.append(Atom('H', new_position))
- elif np.count_nonzero(np.logical_and(distancescutoff, graph.toarray()[aa]>1)):
+ near_atom_idx = np.nonzero(
+ np.logical_and(distancescutoff, graph.toarray()[aa] > 0)
+ )[0][0]
+ vector = (
+ all_atoms[aa].position
+ - all_atoms[near_atom_idx].position
+ )
+ new_position = (
+ all_atoms[near_atom_idx].position
+ + vector / np.linalg.norm(vector) * 1.09
+ )
+ added.append(Atom("H", new_position))
+ elif np.count_nonzero(
+ np.logical_and(distancescutoff, graph.toarray()[aa] > 1)
+ ):
# if that atom has a double bond with the atom inside
# just pick up the whole fragment (within the hard cutoff)
# TODO: use a more fantastic method
- take_frag_idx=frag_atoms_idx
+ take_frag_idx = frag_atoms_idx
break
else:
take_frag_idx = frag_atoms_idx
@@ -240,13 +291,14 @@ def take_cluster(old_conf_name, type_map, idx, jdata):
# wrap
cutoff_atoms = sum(added, all_atoms[all_taken_atoms_idx])
cutoff_atoms.wrap(
- center=coords[idx] /
- cutoff_atoms.get_cell_lengths_and_angles()[0: 3],
- pbc=True)
+ center=coords[idx] / cutoff_atoms.get_cell_lengths_and_angles()[0:3], pbc=True
+ )
coords = cutoff_atoms.get_positions()
- sys.data['coords'] = np.array([coords])
- sys.data['atom_types'] = np.array(list(atom_types[all_taken_atoms_idx]) + [atom_names.index('H')]*len(added))
- sys.data['atom_pref'] = np.array([cutoff_atoms.get_tags()])
+ sys.data["coords"] = np.array([coords])
+ sys.data["atom_types"] = np.array(
+ list(atom_types[all_taken_atoms_idx]) + [atom_names.index("H")] * len(added)
+ )
+ sys.data["atom_pref"] = np.array([cutoff_atoms.get_tags()])
for ii, _ in enumerate(atom_names):
- sys.data['atom_numbs'][ii] = np.count_nonzero(sys.data['atom_types']==ii)
+ sys.data["atom_numbs"][ii] = np.count_nonzero(sys.data["atom_types"] == ii)
return sys
diff --git a/dpgen/generator/lib/lammps.py b/dpgen/generator/lib/lammps.py
index 62cdbe291..e03ed7def 100644
--- a/dpgen/generator/lib/lammps.py
+++ b/dpgen/generator/lib/lammps.py
@@ -1,213 +1,248 @@
#!/usr/bin/env python3
-import random, os, sys, dpdata
-import numpy as np
+import os
+import random
import subprocess as sp
+import sys
+
+import dpdata
+import numpy as np
import scipy.constants as pc
-from distutils.version import LooseVersion
+from packaging.version import Version
+
-def _sample_sphere() :
+def _sample_sphere():
while True:
vv = np.array([np.random.normal(), np.random.normal(), np.random.normal()])
vn = np.linalg.norm(vv)
- if vn < 0.2 :
+ if vn < 0.2:
continue
return vv / vn
-def make_lammps_input(ensemble,
- conf_file,
- graphs,
- nsteps,
- dt,
- neidelay,
- trj_freq,
- mass_map,
- temp,
- jdata,
- tau_t = 0.1,
- pres = None,
- tau_p = 0.5,
- pka_e = None,
- ele_temp_f = None,
- ele_temp_a = None,
- max_seed = 1000000,
- nopbc = False,
- deepmd_version = '0.1') :
- if (ele_temp_f is not None or ele_temp_a is not None) and LooseVersion(deepmd_version) < LooseVersion('1'):
- raise RuntimeError('the electron temperature is only supported by deepmd-kit >= 1.0.0, please upgrade your deepmd-kit')
+
+def make_lammps_input(
+ ensemble,
+ conf_file,
+ graphs,
+ nsteps,
+ dt,
+ neidelay,
+ trj_freq,
+ mass_map,
+ temp,
+ jdata,
+ tau_t=0.1,
+ pres=None,
+ tau_p=0.5,
+ pka_e=None,
+ ele_temp_f=None,
+ ele_temp_a=None,
+ max_seed=1000000,
+ nopbc=False,
+ deepmd_version="0.1",
+):
+ if (ele_temp_f is not None or ele_temp_a is not None) and Version(
+ deepmd_version
+ ) < Version("1"):
+ raise RuntimeError(
+ "the electron temperature is only supported by deepmd-kit >= 1.0.0, please upgrade your deepmd-kit"
+ )
if ele_temp_f is not None and ele_temp_a is not None:
- raise RuntimeError('the frame style ele_temp and atom style ele_temp should not be set at the same time')
+ raise RuntimeError(
+ "the frame style ele_temp and atom style ele_temp should not be set at the same time"
+ )
ret = "variable NSTEPS equal %d\n" % nsteps
- ret+= "variable THERMO_FREQ equal %d\n" % trj_freq
- ret+= "variable DUMP_FREQ equal %d\n" % trj_freq
- ret+= "variable TEMP equal %f\n" % temp
+ ret += "variable THERMO_FREQ equal %d\n" % trj_freq
+ ret += "variable DUMP_FREQ equal %d\n" % trj_freq
+ ret += "variable TEMP equal %f\n" % temp
if ele_temp_f is not None:
- ret+= "variable ELE_TEMP equal %f\n" % ele_temp_f
+ ret += "variable ELE_TEMP equal %f\n" % ele_temp_f
if ele_temp_a is not None:
- ret+= "variable ELE_TEMP equal %f\n" % ele_temp_a
- ret+= "variable PRES equal %f\n" % pres
- ret+= "variable TAU_T equal %f\n" % tau_t
- ret+= "variable TAU_P equal %f\n" % tau_p
- ret+= "\n"
- ret+= "units metal\n"
+ ret += "variable ELE_TEMP equal %f\n" % ele_temp_a
+ ret += "variable PRES equal %f\n" % pres
+ ret += "variable TAU_T equal %f\n" % tau_t
+ ret += "variable TAU_P equal %f\n" % tau_p
+ ret += "\n"
+ ret += "units metal\n"
if nopbc:
- ret+= "boundary f f f\n"
+ ret += "boundary f f f\n"
else:
- ret+= "boundary p p p\n"
- ret+= "atom_style atomic\n"
- ret+= "\n"
- ret+= "neighbor 1.0 bin\n"
- if neidelay is not None :
- ret+= "neigh_modify delay %d\n" % neidelay
- ret+= "\n"
- ret+= "box tilt large\n"
- ret+= "if \"${restart} > 0\" then \"read_restart dpgen.restart.*\" else \"read_data %s\"\n" % conf_file
- ret+= "change_box all triclinic\n"
- for jj in range(len(mass_map)) :
- ret+= "mass %d %f\n" %(jj+1, mass_map[jj])
+ ret += "boundary p p p\n"
+ ret += "atom_style atomic\n"
+ ret += "\n"
+ ret += "neighbor 1.0 bin\n"
+ if neidelay is not None:
+ ret += "neigh_modify delay %d\n" % neidelay
+ ret += "\n"
+ ret += "box tilt large\n"
+ ret += (
+ 'if "${restart} > 0" then "read_restart dpgen.restart.*" else "read_data %s"\n'
+ % conf_file
+ )
+ ret += "change_box all triclinic\n"
+ for jj in range(len(mass_map)):
+ ret += "mass %d %f\n" % (jj + 1, mass_map[jj])
graph_list = ""
- for ii in graphs :
+ for ii in graphs:
graph_list += ii + " "
- if LooseVersion(deepmd_version) < LooseVersion('1'):
+ if Version(deepmd_version) < Version("1"):
# 0.x
- ret+= "pair_style deepmd %s ${THERMO_FREQ} model_devi.out\n" % graph_list
+ ret += "pair_style deepmd %s ${THERMO_FREQ} model_devi.out\n" % graph_list
else:
# 1.x
keywords = ""
- if jdata.get('use_clusters', False):
+ if jdata.get("use_clusters", False):
keywords += "atomic "
- if jdata.get('use_relative', False):
- keywords += "relative %s " % jdata['epsilon']
- if jdata.get('use_relative_v', False):
- keywords += "relative_v %s " % jdata['epsilon_v']
+ if jdata.get("use_relative", False):
+ keywords += "relative %s " % jdata["epsilon"]
+ if jdata.get("use_relative_v", False):
+ keywords += "relative_v %s " % jdata["epsilon_v"]
if ele_temp_f is not None:
keywords += "fparam ${ELE_TEMP}"
if ele_temp_a is not None:
keywords += "aparam ${ELE_TEMP}"
- ret+= "pair_style deepmd %s out_freq ${THERMO_FREQ} out_file model_devi.out %s\n" % (graph_list, keywords)
- ret+= "pair_coeff * *\n"
- ret+= "\n"
- ret+= "thermo_style custom step temp pe ke etotal press vol lx ly lz xy xz yz\n"
- ret+= "thermo ${THERMO_FREQ}\n"
- model_devi_merge_traj = jdata.get('model_devi_merge_traj', False)
- if(model_devi_merge_traj is True):
- ret+= "dump 1 all custom ${DUMP_FREQ} all.lammpstrj id type x y z fx fy fz\n"
+ ret += (
+ "pair_style deepmd %s out_freq ${THERMO_FREQ} out_file model_devi.out %s\n"
+ % (graph_list, keywords)
+ )
+ ret += "pair_coeff * *\n"
+ ret += "\n"
+ ret += "thermo_style custom step temp pe ke etotal press vol lx ly lz xy xz yz\n"
+ ret += "thermo ${THERMO_FREQ}\n"
+ model_devi_merge_traj = jdata.get("model_devi_merge_traj", False)
+ if model_devi_merge_traj is True:
+ ret += "dump 1 all custom ${DUMP_FREQ} all.lammpstrj id type x y z fx fy fz\n"
+ ret += 'if "${restart} > 0" then "dump_modify 1 append yes"\n'
+ else:
+ ret += "dump 1 all custom ${DUMP_FREQ} traj/*.lammpstrj id type x y z fx fy fz\n"
+ ret += "restart 10000 dpgen.restart\n"
+ ret += "\n"
+ if pka_e is None:
+ ret += 'if "${restart} == 0" then "velocity all create ${TEMP} %d"' % (
+ random.randrange(max_seed - 1) + 1
+ )
else:
- ret+= "dump 1 all custom ${DUMP_FREQ} traj/*.lammpstrj id type x y z fx fy fz\n"
- ret+= "restart 10000 dpgen.restart\n"
- ret+= "\n"
- if pka_e is None :
- ret+= "if \"${restart} == 0\" then \"velocity all create ${TEMP} %d\"" % (random.randrange(max_seed-1)+1)
- else :
- sys = dpdata.System(conf_file, fmt = 'lammps/lmp')
+ sys = dpdata.System(conf_file, fmt="lammps/lmp")
sys_data = sys.data
- pka_mass = mass_map[sys_data['atom_types'][0] - 1]
- pka_vn = pka_e * pc.electron_volt / \
- (0.5 * pka_mass * 1e-3 / pc.Avogadro * (pc.angstrom / pc.pico) ** 2)
+ pka_mass = mass_map[sys_data["atom_types"][0] - 1]
+ pka_vn = (
+ pka_e
+ * pc.electron_volt
+ / (0.5 * pka_mass * 1e-3 / pc.Avogadro * (pc.angstrom / pc.pico) ** 2)
+ )
pka_vn = np.sqrt(pka_vn)
print(pka_vn)
pka_vec = _sample_sphere()
pka_vec *= pka_vn
- ret+= 'group first id 1\n'
- ret+= 'if \"${restart} == 0\" then \"velocity first set %f %f %f\"\n' % (pka_vec[0], pka_vec[1], pka_vec[2])
- ret+= 'fix 2 all momentum 1 linear 1 1 1\n'
- ret+= "\n"
- if ensemble.split('-')[0] == 'npt' :
- assert (pres is not None)
+ ret += "group first id 1\n"
+ ret += 'if "${restart} == 0" then "velocity first set %f %f %f"\n' % (
+ pka_vec[0],
+ pka_vec[1],
+ pka_vec[2],
+ )
+ ret += "fix 2 all momentum 1 linear 1 1 1\n"
+ ret += "\n"
+ if ensemble.split("-")[0] == "npt":
+ assert pres is not None
if nopbc:
- raise RuntimeError('ensemble %s is conflicting with nopbc' % ensemble)
- if ensemble == "npt" or ensemble == "npt-i" or ensemble == "npt-iso" :
- ret+= "fix 1 all npt temp ${TEMP} ${TEMP} ${TAU_T} iso ${PRES} ${PRES} ${TAU_P}\n"
- elif ensemble == 'npt-a' or ensemble == 'npt-aniso' :
- ret+= "fix 1 all npt temp ${TEMP} ${TEMP} ${TAU_T} aniso ${PRES} ${PRES} ${TAU_P}\n"
- elif ensemble == 'npt-t' or ensemble == 'npt-tri' :
- ret+= "fix 1 all npt temp ${TEMP} ${TEMP} ${TAU_T} tri ${PRES} ${PRES} ${TAU_P}\n"
- elif ensemble == "nvt" :
- ret+= "fix 1 all nvt temp ${TEMP} ${TEMP} ${TAU_T}\n"
- elif ensemble == 'nve' :
- ret+= "fix 1 all nve\n"
- else :
+ raise RuntimeError("ensemble %s is conflicting with nopbc" % ensemble)
+ if ensemble == "npt" or ensemble == "npt-i" or ensemble == "npt-iso":
+ ret += "fix 1 all npt temp ${TEMP} ${TEMP} ${TAU_T} iso ${PRES} ${PRES} ${TAU_P}\n"
+ elif ensemble == "npt-a" or ensemble == "npt-aniso":
+ ret += "fix 1 all npt temp ${TEMP} ${TEMP} ${TAU_T} aniso ${PRES} ${PRES} ${TAU_P}\n"
+ elif ensemble == "npt-t" or ensemble == "npt-tri":
+ ret += "fix 1 all npt temp ${TEMP} ${TEMP} ${TAU_T} tri ${PRES} ${PRES} ${TAU_P}\n"
+ elif ensemble == "nvt":
+ ret += "fix 1 all nvt temp ${TEMP} ${TEMP} ${TAU_T}\n"
+ elif ensemble == "nve":
+ ret += "fix 1 all nve\n"
+ else:
raise RuntimeError("unknown emsemble " + ensemble)
if nopbc:
- ret+= "velocity all zero linear\n"
- ret+= "fix fm all momentum 1 linear 1 1 1\n"
- ret+= "\n"
- ret+= "timestep %f\n" % dt
- ret+= "run ${NSTEPS} upto\n"
+ ret += "velocity all zero linear\n"
+ ret += "fix fm all momentum 1 linear 1 1 1\n"
+ ret += "\n"
+ ret += "timestep %f\n" % dt
+ ret += "run ${NSTEPS} upto\n"
return ret
-
+
+
# ret = make_lammps_input ("npt", "al.lmp", ['graph.000.pb', 'graph.001.pb'], 20000, 20, [27], 1000, pres = 1.0)
# print (ret)
# cvt_lammps_conf('POSCAR', 'tmp.lmp')
-def get_dumped_forces(
- file_name):
- with open(file_name) as fp:
- lines = fp.read().split('\n')
+def get_dumped_forces(file_name):
+ with open(file_name) as fp:
+ lines = fp.read().split("\n")
natoms = None
- for idx,ii in enumerate(lines):
- if 'ITEM: NUMBER OF ATOMS' in ii:
- natoms = int(lines[idx+1])
+ for idx, ii in enumerate(lines):
+ if "ITEM: NUMBER OF ATOMS" in ii:
+ natoms = int(lines[idx + 1])
break
if natoms is None:
- raise RuntimeError('wrong dump file format, cannot find number of atoms', file_name)
+ raise RuntimeError(
+ "wrong dump file format, cannot find number of atoms", file_name
+ )
idfx = None
- for idx,ii in enumerate(lines):
- if 'ITEM: ATOMS' in ii:
+ for idx, ii in enumerate(lines):
+ if "ITEM: ATOMS" in ii:
keys = ii
- keys = keys.replace('ITEM: ATOMS', '')
+ keys = keys.replace("ITEM: ATOMS", "")
keys = keys.split()
- idfx = keys.index('fx')
- idfy = keys.index('fy')
- idfz = keys.index('fz')
+ idfx = keys.index("fx")
+ idfy = keys.index("fy")
+ idfz = keys.index("fz")
break
if idfx is None:
- raise RuntimeError('wrong dump file format, cannot find dump keys', file_name)
+ raise RuntimeError("wrong dump file format, cannot find dump keys", file_name)
ret = []
- for ii in range(idx+1, idx+natoms+1):
+ for ii in range(idx + 1, idx + natoms + 1):
words = lines[ii].split()
- ret.append([ float(words[ii]) for ii in [idfx, idfy, idfz] ])
+ ret.append([float(words[ii]) for ii in [idfx, idfy, idfz]])
ret = np.array(ret)
return ret
-def get_all_dumped_forces(
- file_name):
- with open(file_name) as fp:
- lines = fp.read().split('\n')
+
+def get_all_dumped_forces(file_name):
+ with open(file_name) as fp:
+ lines = fp.read().split("\n")
ret = []
exist_natoms = False
exist_atoms = False
- for idx,ii in enumerate(lines):
+ for idx, ii in enumerate(lines):
- if 'ITEM: NUMBER OF ATOMS' in ii:
- natoms = int(lines[idx+1])
+ if "ITEM: NUMBER OF ATOMS" in ii:
+ natoms = int(lines[idx + 1])
exist_natoms = True
- if 'ITEM: ATOMS' in ii:
+ if "ITEM: ATOMS" in ii:
keys = ii
- keys = keys.replace('ITEM: ATOMS', '')
+ keys = keys.replace("ITEM: ATOMS", "")
keys = keys.split()
- idfx = keys.index('fx')
- idfy = keys.index('fy')
- idfz = keys.index('fz')
+ idfx = keys.index("fx")
+ idfy = keys.index("fy")
+ idfz = keys.index("fz")
exist_atoms = True
-
+
single_traj = []
- for jj in range(idx+1, idx+natoms+1):
+ for jj in range(idx + 1, idx + natoms + 1):
words = lines[jj].split()
- single_traj.append([ float(words[jj]) for jj in [idfx, idfy, idfz] ])
+ single_traj.append([float(words[jj]) for jj in [idfx, idfy, idfz]])
single_traj = np.array(single_traj)
ret.append(single_traj)
-
+
if exist_natoms is False:
- raise RuntimeError('wrong dump file format, cannot find number of atoms', file_name)
+ raise RuntimeError(
+ "wrong dump file format, cannot find number of atoms", file_name
+ )
if exist_atoms is False:
- raise RuntimeError('wrong dump file format, cannot find dump keys', file_name)
+ raise RuntimeError("wrong dump file format, cannot find dump keys", file_name)
return ret
-if __name__ == '__main__':
- ret = get_dumped_forces('40.lammpstrj')
+
+if __name__ == "__main__":
+ ret = get_dumped_forces("40.lammpstrj")
print(ret)
diff --git a/dpgen/generator/lib/make_calypso.py b/dpgen/generator/lib/make_calypso.py
index bb2db0af8..00c1412de 100644
--- a/dpgen/generator/lib/make_calypso.py
+++ b/dpgen/generator/lib/make_calypso.py
@@ -1,154 +1,190 @@
#!/usr/bin/env python3
+import glob
+import json
import os
import shutil
-import json
-import glob
+
import numpy as np
+
from dpgen.generator.lib.utils import create_path
-def make_calypso_input(nameofatoms,numberofatoms,
- numberofformula,volume,
- distanceofion,psoratio,popsize,
- maxstep,icode,split,vsc,
- maxnumatom,ctrlrange,pstress,fmax):
+
+def make_calypso_input(
+ nameofatoms,
+ numberofatoms,
+ numberofformula,
+ volume,
+ distanceofion,
+ psoratio,
+ popsize,
+ maxstep,
+ icode,
+ split,
+ vsc,
+ maxnumatom,
+ ctrlrange,
+ pstress,
+ fmax,
+):
ret = "################################ The Basic Parameters of CALYPSO ################################\n"
- ret+= "# A string of one or several words contain a descriptive name of the system (max. 40 characters).\n"
+ ret += "# A string of one or several words contain a descriptive name of the system (max. 40 characters).\n"
assert nameofatoms is not None
- ret+= "SystemName = %s\n"%(''.join(nameofatoms))
- ret+= "# Number of different atomic species in the simulation.\n"
- ret+= "NumberOfSpecies = %d\n"%(len(nameofatoms))
- ret+= "# Element symbols of the different chemical species.\n"
- ret+= "NameOfAtoms = %s\n"%(' '.join(nameofatoms))
- ret+= "# Number of atoms for each chemical species in one formula unit. \n"
+ ret += "SystemName = %s\n" % ("".join(nameofatoms))
+ ret += "# Number of different atomic species in the simulation.\n"
+ ret += "NumberOfSpecies = %d\n" % (len(nameofatoms))
+ ret += "# Element symbols of the different chemical species.\n"
+ ret += "NameOfAtoms = %s\n" % (" ".join(nameofatoms))
+ ret += "# Number of atoms for each chemical species in one formula unit. \n"
assert numberofatoms is not None and len(numberofatoms) == len(nameofatoms)
- ret+= "NumberOfAtoms = %s\n"%(' '.join(list(map(str,numberofatoms))))
- ret+= "# The range of formula unit per cell in your simulation. \n"
- assert numberofformula is not None and len(numberofformula) == 2 and type(numberofformula) is list
- ret+= "NumberOfFormula = %s\n"%(' '.join(list(map(str,numberofformula))))
- ret+= "# The volume per formula unit. Unit is in angstrom^3.\n"
+ ret += "NumberOfAtoms = %s\n" % (" ".join(list(map(str, numberofatoms))))
+ ret += "# The range of formula unit per cell in your simulation. \n"
+ assert (
+ numberofformula is not None
+ and len(numberofformula) == 2
+ and type(numberofformula) is list
+ )
+ ret += "NumberOfFormula = %s\n" % (" ".join(list(map(str, numberofformula))))
+ ret += "# The volume per formula unit. Unit is in angstrom^3.\n"
if volume is None:
- ret+= "# volume not found, CALYPSO will set one!\n"
+ ret += "# volume not found, CALYPSO will set one!\n"
else:
- ret+= "Volume = %s\n"%(volume)
- ret+= "# Minimal distance between atoms of each chemical species. Unit is in angstrom.\n"
- assert len(distanceofion) == len(nameofatoms) #"check distance of ions and the number of atoms"
+ ret += "Volume = %s\n" % (volume)
+ ret += "# Minimal distance between atoms of each chemical species. Unit is in angstrom.\n"
+ assert len(distanceofion) == len(
+ nameofatoms
+ ) # "check distance of ions and the number of atoms"
assert len(distanceofion[0]) == len(nameofatoms)
- ret+= "@DistanceOfIon \n"
+ ret += "@DistanceOfIon \n"
for temp in distanceofion:
- ret+="%4s \n"%(' '.join(list(map(str,temp))))
- ret+= "@End\n"
- ret+= "# It determines which algorithm should be adopted in the simulation.\n"
- ret+= "Ialgo = 2\n"
- ret+= "# Ialgo = 1 for Global PSO\n"
- ret+= "# Ialgo = 2 for Local PSO (default value)\n"
- ret+= "# The proportion of the structures generated by PSO.\n"
- assert (0 <= psoratio <= 1 )
- ret+= "PsoRatio = %s\n"%(psoratio)
- ret+= "# The population size. Normally, it has a larger number for larger systems.\n"
+ ret += "%4s \n" % (" ".join(list(map(str, temp))))
+ ret += "@End\n"
+ ret += "# It determines which algorithm should be adopted in the simulation.\n"
+ ret += "Ialgo = 2\n"
+ ret += "# Ialgo = 1 for Global PSO\n"
+ ret += "# Ialgo = 2 for Local PSO (default value)\n"
+ ret += "# The proportion of the structures generated by PSO.\n"
+ assert 0 <= psoratio <= 1
+ ret += "PsoRatio = %s\n" % (psoratio)
+ ret += (
+ "# The population size. Normally, it has a larger number for larger systems.\n"
+ )
assert popsize is not None and type(popsize) is int
- ret+= "PopSize = %d\n"%(popsize)
+ ret += "PopSize = %d\n" % (popsize)
assert maxstep is not None and type(maxstep) is int
- ret+= "# The Max step for iteration\n"
- ret+= "MaxStep = %d\n"%(maxstep)
- ret+= "#It determines which method should be adopted in generation the random structure. \n"
- ret+= "GenType= 1 \n"
- ret+= "# 1 under symmetric constraints\n"
- ret+= "# 2 grid method for large system\n"
- ret+= "# 3 and 4 core grow method \n"
- ret+= "# 0 combination of all method\n"
- ret+= "# If GenType=3 or 4, it determined the small unit to grow the whole structure\n"
- ret+= "# It determines which local optimization method should be interfaced in the simulation.\n"
+ ret += "# The Max step for iteration\n"
+ ret += "MaxStep = %d\n" % (maxstep)
+ ret += "#It determines which method should be adopted in generation the random structure. \n"
+ ret += "GenType= 1 \n"
+ ret += "# 1 under symmetric constraints\n"
+ ret += "# 2 grid method for large system\n"
+ ret += "# 3 and 4 core grow method \n"
+ ret += "# 0 combination of all method\n"
+ ret += "# If GenType=3 or 4, it determined the small unit to grow the whole structure\n"
+ ret += "# It determines which local optimization method should be interfaced in the simulation.\n"
assert icode is not None and type(icode) is int
- ret+= "ICode= %d\n"%(icode)
- ret+= "# ICode= 1 interfaced with VASP\n"
- ret+= "# ICode= 2 interfaced with SIESTA\n"
- ret+= "# ICode= 3 interfaced with GULP\n"
- ret+= "# The number of lbest for local PSO\n"
- ret+= "NumberOfLbest=4\n"
- ret+= "# The Number of local optimization for each structure.\n"
- ret+= "NumberOfLocalOptim= 3\n"
- ret+= "# The command to perform local optimiztion calculation (e.g., VASP, SIESTA) on your computer.\n"
- ret+= "Command = sh submit.sh\n"
- ret+= "MaxTime = 9000 \n"
- ret+= "# If True, a previous calculation will be continued.\n"
- ret+= "PickUp = F\n"
- ret+= "# At which step will the previous calculation be picked up.\n"
- ret+= "PickStep = 1\n"
- ret+= "# If True, the local optimizations performed by parallel\n"
- ret+= "Parallel = F\n"
- ret+= "# The number node for parallel \n"
- ret+= "NumberOfParallel = 4\n"
- assert split is not None
- ret+= "Split = %s\n"%(split)
+ ret += "ICode= %d\n" % (icode)
+ ret += "# ICode= 1 interfaced with VASP\n"
+ ret += "# ICode= 2 interfaced with SIESTA\n"
+ ret += "# ICode= 3 interfaced with GULP\n"
+ ret += "# The number of lbest for local PSO\n"
+ ret += "NumberOfLbest=4\n"
+ ret += "# The Number of local optimization for each structure.\n"
+ ret += "NumberOfLocalOptim= 3\n"
+ ret += "# The command to perform local optimiztion calculation (e.g., VASP, SIESTA) on your computer.\n"
+ ret += "Command = sh submit.sh\n"
+ ret += "MaxTime = 9000 \n"
+ ret += "# If True, a previous calculation will be continued.\n"
+ ret += "PickUp = F\n"
+ ret += "# At which step will the previous calculation be picked up.\n"
+ ret += "PickStep = 1\n"
+ ret += "# If True, the local optimizations performed by parallel\n"
+ ret += "Parallel = F\n"
+ ret += "# The number node for parallel \n"
+ ret += "NumberOfParallel = 4\n"
+ assert split is not None
+ ret += "Split = %s\n" % (split)
assert pstress is not None and (type(pstress) is int or type(pstress) is float)
- ret+= "PSTRESS = %f\n"%(pstress)
+ ret += "PSTRESS = %f\n" % (pstress)
assert fmax is not None or type(fmax) is float
- ret+= "fmax = %f\n"%(fmax)
- ret+= "################################ End of The Basic Parameters of CALYPSO #######################\n"
- if vsc == 'T':
- assert len(ctrlrange) == len(nameofatoms) #'check distance of ions and the number of atoms'
- ret+= "##### The Parameters For Variational Stoichiometry ##############\n"
- ret+= "## If True, Variational Stoichiometry structure prediction is performed\n"
- ret+= "VSC = %s\n"%(vsc)
- ret+= "# The Max Number of Atoms in unit cell\n"
- ret+= "MaxNumAtom = %s\n"%(maxnumatom)
- ret+= "# The Variation Range for each type atom \n"
- ret+= "@CtrlRange\n"
+ ret += "fmax = %f\n" % (fmax)
+ ret += "################################ End of The Basic Parameters of CALYPSO #######################\n"
+ if vsc == "T":
+ assert len(ctrlrange) == len(
+ nameofatoms
+ ) #'check distance of ions and the number of atoms'
+ ret += "##### The Parameters For Variational Stoichiometry ##############\n"
+ ret += (
+ "## If True, Variational Stoichiometry structure prediction is performed\n"
+ )
+ ret += "VSC = %s\n" % (vsc)
+ ret += "# The Max Number of Atoms in unit cell\n"
+ ret += "MaxNumAtom = %s\n" % (maxnumatom)
+ ret += "# The Variation Range for each type atom \n"
+ ret += "@CtrlRange\n"
for ttemp in ctrlrange:
- ret+="%4s \n"%(' '.join(list(map(str,ttemp))))
- ret+= "@end\n"
- ret+= "###################End Parameters for VSC ##########################\n"
+ ret += "%4s \n" % (" ".join(list(map(str, ttemp))))
+ ret += "@end\n"
+ ret += "###################End Parameters for VSC ##########################\n"
return ret
-def _make_model_devi_buffet(jdata,calypso_run_opt_path):
- calypso_input_path = jdata.get('calypso_input_path')
- if jdata.get('vsc', False):
+def _make_model_devi_buffet(jdata, calypso_run_opt_path):
+
+ calypso_input_path = jdata.get("calypso_input_path")
+ if jdata.get("vsc", False):
# [input.dat.Li.250, input.dat.Li.300]
one_ele_inputdat_list = list(
- set(glob.glob(
+ set(
+ glob.glob(
f"{jdata.get('calypso_input_path')}/input.dat.{jdata.get('type_map')[0]}.*"
- ))
)
+ )
+ )
# [input.dat.La, input.dat.H, input.dat.LaH,] only one pressure
if len(one_ele_inputdat_list) == 0:
os.system(f"cp {calypso_input_path}/input.dat.* {calypso_run_opt_path[0]}")
# different pressure, 250GPa and 300GPa
# [input.dat.La.250, input.dat.H.250, input.dat.LaH.250, input.dat.La.300, input.dat.H.300, input.dat.LaH.300,]
- else:
- pressures_list = [temp.split('.')[-1] for temp in one_ele_inputdat_list]
+ else:
+ pressures_list = [temp.split(".")[-1] for temp in one_ele_inputdat_list]
pressures_list = list(map(int, pressures_list))
# calypso_run_opt_path = ['gen_struc_analy.000','gen_struc_analy.001']
for press_idx, temp_calypso_run_opt_path in enumerate(calypso_run_opt_path):
cur_press = pressures_list[press_idx]
- os.system(f"cp {calypso_input_path}/input.dat.*.{cur_press} {temp_calypso_run_opt_path}")
- elif not jdata.get('vsc', False):
- shutil.copyfile(os.path.join(calypso_input_path,'input.dat'),os.path.join(calypso_run_opt_path[0], 'input.dat'))
- if not os.path.exists(os.path.join(calypso_run_opt_path[0], 'input.dat')):
- raise FileNotFoundError('input.dat')
+ os.system(
+ f"cp {calypso_input_path}/input.dat.*.{cur_press} {temp_calypso_run_opt_path}"
+ )
+ elif not jdata.get("vsc", False):
+ shutil.copyfile(
+ os.path.join(calypso_input_path, "input.dat"),
+ os.path.join(calypso_run_opt_path[0], "input.dat"),
+ )
+ if not os.path.exists(os.path.join(calypso_run_opt_path[0], "input.dat")):
+ raise FileNotFoundError("input.dat")
-def _make_model_devi_native_calypso(iter_index,model_devi_jobs, calypso_run_opt_path):
+
+def _make_model_devi_native_calypso(iter_index, model_devi_jobs, calypso_run_opt_path):
for iiidx, jobbs in enumerate(model_devi_jobs):
- if iter_index in jobbs.get('times'):
+ if iter_index in jobbs.get("times"):
cur_job = model_devi_jobs[iiidx]
work_path = os.path.dirname(calypso_run_opt_path[0])
# cur_job.json
- with open(os.path.join(work_path, 'cur_job.json'), 'w') as outfile:
- json.dump(cur_job, outfile, indent = 4)
+ with open(os.path.join(work_path, "cur_job.json"), "w") as outfile:
+ json.dump(cur_job, outfile, indent=4)
# Crystal Parameters
- nameofatoms = cur_job.get('NameOfAtoms')
- numberofatoms = cur_job.get('NumberOfAtoms')
- numberofformula = cur_job.get('NumberOfFormula',[1,1])
- volume = cur_job.get('Volume')
- distanceofion = cur_job.get('DistanceOfIon')
- psoratio = cur_job.get('PsoRatio', 0.6)
- popsize = cur_job.get('PopSize', 30)
- maxstep = cur_job.get('MaxStep', 5)
- icode = cur_job.get('ICode',1)
- split = cur_job.get('Split','T')
+ nameofatoms = cur_job.get("NameOfAtoms")
+ numberofatoms = cur_job.get("NumberOfAtoms")
+ numberofformula = cur_job.get("NumberOfFormula", [1, 1])
+ volume = cur_job.get("Volume")
+ distanceofion = cur_job.get("DistanceOfIon")
+ psoratio = cur_job.get("PsoRatio", 0.6)
+ popsize = cur_job.get("PopSize", 30)
+ maxstep = cur_job.get("MaxStep", 5)
+ icode = cur_job.get("ICode", 1)
+ split = cur_job.get("Split", "T")
# Cluster
# 2D
@@ -156,37 +192,55 @@ def _make_model_devi_native_calypso(iter_index,model_devi_jobs, calypso_run_opt_
# VSC Control
maxnumatom = None
ctrlrange = None
- vsc = cur_job.get('VSC','F')
- if vsc == 'T':
- maxnumatom = cur_job.get('MaxNumAtom')
- ctrlrange = cur_job.get('CtrlRange')
+ vsc = cur_job.get("VSC", "F")
+ if vsc == "T":
+ maxnumatom = cur_job.get("MaxNumAtom")
+ ctrlrange = cur_job.get("CtrlRange")
# Optimization
- fmax = cur_job.get('fmax',0.01)
+ fmax = cur_job.get("fmax", 0.01)
# pstress is a List which contains the target stress
- pstress = cur_job.get('PSTRESS',[0.001])
+ pstress = cur_job.get("PSTRESS", [0.001])
# pressures
for press_idx, temp_calypso_run_opt_path in enumerate(calypso_run_opt_path):
# cur_press
cur_press = pstress[press_idx]
- file_c = make_calypso_input(nameofatoms,numberofatoms,
- numberofformula,volume,
- distanceofion,psoratio,popsize,
- maxstep,icode,split,vsc,
- maxnumatom,ctrlrange,cur_press,fmax)
- with open(os.path.join(temp_calypso_run_opt_path, 'input.dat'), 'w') as cin :
+ file_c = make_calypso_input(
+ nameofatoms,
+ numberofatoms,
+ numberofformula,
+ volume,
+ distanceofion,
+ psoratio,
+ popsize,
+ maxstep,
+ icode,
+ split,
+ vsc,
+ maxnumatom,
+ ctrlrange,
+ cur_press,
+ fmax,
+ )
+ with open(os.path.join(temp_calypso_run_opt_path, "input.dat"), "w") as cin:
cin.write(file_c)
+
def write_model_devi_out(devi, fname):
assert devi.shape[1] == 8
- #assert devi.shape[1] == 7
- header = '%5s' % 'step'
- for item in 'vf':
- header += '%16s%16s%16s' % (f'max_devi_{item}', f'min_devi_{item}',f'avg_devi_{item}')
- header += '%16s'%str('min_dis')
- np.savetxt(fname,
- devi,
- fmt=['%5d'] + ['%17.6e' for _ in range(7)],
- delimiter='',
- header=header)
+ # assert devi.shape[1] == 7
+ header = "%5s" % "step"
+ for item in "vf":
+ header += "%16s%16s%16s" % (
+ f"max_devi_{item}",
+ f"min_devi_{item}",
+ f"avg_devi_{item}",
+ )
+ header += "%16s" % str("min_dis")
+ np.savetxt(
+ fname,
+ devi,
+ fmt=["%5d"] + ["%17.6e" for _ in range(7)],
+ delimiter="",
+ header=header,
+ )
return devi
-
diff --git a/dpgen/generator/lib/parse_calypso.py b/dpgen/generator/lib/parse_calypso.py
index df842c789..7bd3d7d50 100644
--- a/dpgen/generator/lib/parse_calypso.py
+++ b/dpgen/generator/lib/parse_calypso.py
@@ -1,38 +1,41 @@
-import numpy as np
import os
-def _parse_calypso_input(var,input_path):
-
- if os.path.basename(input_path) != 'input.dat':
- input_path = os.path.join(input_path,'input.dat')
- if not os.path.exists(input_path):
- raise FileNotFoundError(input_path)
-
- f = open(input_path,'r')
- lines = f.readlines()
- f.close()
-
- for line in lines:
- if var in line:
- variable = line.split('=')[1].strip()
- return variable
-
-def _parse_calypso_dis_mtx(numberofspecies,input_path):
- try:
- f = open(input_path,'r')
- except:
- f = open(os.path.join(input_path,'input.dat'),'r')
- while True:
- line = f.readline()
- if len(line) == 0:
- break
- if '@DistanceOfIon' in line:
- dis = []
- for i in range(int(numberofspecies)):
- line = f.readline()
- dis.append(line.split())
- f.close()
- break
- dis = np.array(dis)
- dis = dis.reshape((1,int(numberofspecies)**2))
- return dis[0][np.argmin(dis)]
+import numpy as np
+
+
+def _parse_calypso_input(var, input_path):
+
+ if os.path.basename(input_path) != "input.dat":
+ input_path = os.path.join(input_path, "input.dat")
+ if not os.path.exists(input_path):
+ raise FileNotFoundError(input_path)
+
+ f = open(input_path, "r")
+ lines = f.readlines()
+ f.close()
+
+ for line in lines:
+ if var in line:
+ variable = line.split("=")[1].strip()
+ return variable
+
+
+def _parse_calypso_dis_mtx(numberofspecies, input_path):
+ try:
+ f = open(input_path, "r")
+ except:
+ f = open(os.path.join(input_path, "input.dat"), "r")
+ while True:
+ line = f.readline()
+ if len(line) == 0:
+ break
+ if "@DistanceOfIon" in line:
+ dis = []
+ for i in range(int(numberofspecies)):
+ line = f.readline()
+ dis.append(line.split())
+ f.close()
+ break
+ dis = np.array(dis)
+ dis = dis.reshape((1, int(numberofspecies) ** 2))
+ return dis[0][np.argmin(dis)]
diff --git a/dpgen/generator/lib/pwmat.py b/dpgen/generator/lib/pwmat.py
index 4011b82c7..06ef0ddf3 100644
--- a/dpgen/generator/lib/pwmat.py
+++ b/dpgen/generator/lib/pwmat.py
@@ -1,60 +1,78 @@
-#!/usr/bin/python3
+#!/usr/bin/python3
import os
+
import numpy as np
-def _reciprocal_box(box) :
+
+def _reciprocal_box(box):
rbox = np.linalg.inv(box)
rbox = rbox.T
return rbox
-def _make_pwmat_kp_mp(kpoints) :
+
+def _make_pwmat_kp_mp(kpoints):
ret = ""
ret += "%d %d %d 0 0 0 " % (kpoints[0], kpoints[1], kpoints[2])
return ret
-def _make_kspacing_kpoints(config, kspacing) :
- with open(config, 'r') as fp:
- lines = fp.read().split('\n')
+
+def _make_kspacing_kpoints(config, kspacing):
+ with open(config, "r") as fp:
+ lines = fp.read().split("\n")
box = []
for idx, ii in enumerate(lines):
- if 'lattice' in ii or 'Lattice' in ii or 'LATTICE' in ii:
- for kk in range(idx+1,idx+1+3):
- vector=[float(jj) for jj in lines[kk].split()[0:3]]
+ if "lattice" in ii or "Lattice" in ii or "LATTICE" in ii:
+ for kk in range(idx + 1, idx + 1 + 3):
+ vector = [float(jj) for jj in lines[kk].split()[0:3]]
box.append(vector)
box = np.array(box)
rbox = _reciprocal_box(box)
- kpoints = [(np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int)) for ii in rbox]
+ kpoints = [
+ (np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int)) for ii in rbox
+ ]
ret = _make_pwmat_kp_mp(kpoints)
return ret
-def make_pwmat_input_dict (node1, node2, atom_config, ecut, e_error,
- rho_error, icmix = None, smearing = None,
- sigma = None,kspacing = 0.5, flag_symm = None) :
+def make_pwmat_input_dict(
+ node1,
+ node2,
+ atom_config,
+ ecut,
+ e_error,
+ rho_error,
+ icmix=None,
+ smearing=None,
+ sigma=None,
+ kspacing=0.5,
+ flag_symm=None,
+):
input_dict = {}
- input_dict['node1'] = node1
- input_dict['node2'] = node2
- input_dict['in.atom'] = atom_config
- input_dict['ecut'] = ecut
- input_dict['e_error'] = e_error
- input_dict['rho_error'] = rho_error
+ input_dict["node1"] = node1
+ input_dict["node2"] = node2
+ input_dict["in.atom"] = atom_config
+ input_dict["ecut"] = ecut
+ input_dict["e_error"] = e_error
+ input_dict["rho_error"] = rho_error
if icmix is not None:
if sigma is not None:
if smearing is not None:
SCF_ITER0_1 = "6 4 3 0.0000 " + str(sigma) + " " + str(smearing)
- SCF_ITER0_2 = "94 4 3 " + str(icmix) + " " + str(sigma) + " " + str(smearing)
+ SCF_ITER0_2 = (
+ "94 4 3 " + str(icmix) + " " + str(sigma) + " " + str(smearing)
+ )
else:
- SCF_ITER0_1 = "6 4 3 0.0000 " + str(simga) + " 2"
- SCF_ITER0_2 = "94 4 3 " + str(icmix) + " " + str(simga) + " 2"
+ SCF_ITER0_1 = "6 4 3 0.0000 " + str(simga) + " 2"
+ SCF_ITER0_2 = "94 4 3 " + str(icmix) + " " + str(simga) + " 2"
else:
if smearing is not None:
SCF_ITER0_1 = "6 4 3 0.0000 0.025 " + str(smearing)
SCF_ITER0_2 = "94 4 3 " + str(icmix) + " 0.025 " + str(smearing)
else:
- SCF_ITER0_1 = "6 4 3 0.0000 0.025 2"
- SCF_ITER0_2 = "94 4 3 " + str(icmix) + " 0.025 2"
+ SCF_ITER0_1 = "6 4 3 0.0000 0.025 2"
+ SCF_ITER0_2 = "94 4 3 " + str(icmix) + " 0.025 2"
else:
if sigma is not None:
if smearing is not None:
@@ -70,51 +88,53 @@ def make_pwmat_input_dict (node1, node2, atom_config, ecut, e_error,
else:
SCF_ITER0_1 = "6 4 3 0.0000 0.025 2"
SCF_ITER0_2 = "94 4 3 1.0000 0.025 2"
- input_dict['scf_iter0_1'] = SCF_ITER0_1
- input_dict['scf_iter0_2'] = SCF_ITER0_2
- if flag_symm is not None :
+ input_dict["scf_iter0_1"] = SCF_ITER0_1
+ input_dict["scf_iter0_2"] = SCF_ITER0_2
+ if flag_symm is not None:
MP_N123 = _make_kspacing_kpoints(atom_config, kspacing)
MP_N123 += str(flag_symm)
else:
MP_N123 = _make_kspacing_kpoints(atom_config, kspacing)
- input_dict['mp_n123'] = MP_N123
- input_dict['out.wg'] = 'F'
- input_dict['out.rho'] = 'F'
- input_dict['out.mlmd'] = 'T\n'
+ input_dict["mp_n123"] = MP_N123
+ input_dict["out.wg"] = "F"
+ input_dict["out.rho"] = "F"
+ input_dict["out.mlmd"] = "T\n"
return input_dict
-def _update_input_dict(input_dict_, user_dict) :
+
+def _update_input_dict(input_dict_, user_dict):
if user_dict is None:
return input_dict_
input_dict = input_dict_
- for ii in user_dict :
+ for ii in user_dict:
input_dict[ci] = user_dict[ii]
return input_dict
-def write_input_dict(input_dict) :
+
+def write_input_dict(input_dict):
lines = []
for key in input_dict:
- if (type(input_dict[key]) == bool):
+ if type(input_dict[key]) == bool:
if input_dict[key]:
- rs = 'T'
- else :
- rs = 'F'
- else :
+ rs = "T"
+ else:
+ rs = "F"
+ else:
rs = str(input_dict[key])
- lines.append('%s=%s' % (key, rs))
- return '\n'.join(lines)
+ lines.append("%s=%s" % (key, rs))
+ return "\n".join(lines)
-def _make_smearing(fp_params) :
+def _make_smearing(fp_params):
icmix = None
smearing = None
sigma = None
- if 'icmix' in fp_params :
- icmix = fp_params['icmix']
- if 'smearing' in fp_params :
- smearing = fp_params['smearing']
- if 'sigma' in fp_params :
- sigma = fp_params['sigma']
+ if "icmix" in fp_params:
+ icmix = fp_params["icmix"]
+ if "smearing" in fp_params:
+ smearing = fp_params["smearing"]
+ if "sigma" in fp_params:
+ sigma = fp_params["sigma"]
if icmix == None:
if smearing == None:
if sigma == None:
@@ -137,41 +157,53 @@ def _make_smearing(fp_params) :
return icmix, smearing, None
else:
return icmix, smearing, sigma
-def _make_flag_symm(fp_params) :
+
+
+def _make_flag_symm(fp_params):
flag_symm = None
- if 'flag_symm' in fp_params :
- flag_symm = fp_params['flag_symm']
- if flag_symm == 'NONE' :
+ if "flag_symm" in fp_params:
+ flag_symm = fp_params["flag_symm"]
+ if flag_symm == "NONE":
flag_symm = None
- elif str(flag_symm) not in [None, '0', '1', '2', '3'] :
- raise RuntimeError ("unknow flag_symm type " + str(flag_symm))
+ elif str(flag_symm) not in [None, "0", "1", "2", "3"]:
+ raise RuntimeError("unknow flag_symm type " + str(flag_symm))
return flag_symm
-def make_pwmat_input_user_dict(fp_params) :
- node1 = fp_params['node1']
- node2 = fp_params['node2']
- atom_config = fp_params['in.atom']
- ecut = fp_params['ecut']
- e_error = fp_params['e_error']
- rho_error = fp_params['rho_error']
- kspacing = fp_params['kspacing']
- if 'user_pwmat_params' in fp_params :
- user_dict = fp_params['user_pwmat_params']
- else :
+
+def make_pwmat_input_user_dict(fp_params):
+ node1 = fp_params["node1"]
+ node2 = fp_params["node2"]
+ atom_config = fp_params["in.atom"]
+ ecut = fp_params["ecut"]
+ e_error = fp_params["e_error"]
+ rho_error = fp_params["rho_error"]
+ kspacing = fp_params["kspacing"]
+ if "user_pwmat_params" in fp_params:
+ user_dict = fp_params["user_pwmat_params"]
+ else:
user_dict = None
icmix, smearing, sigma = _make_smearing(fp_params)
flag_symm = _make_flag_symm(fp_params)
- input_dict = make_pwmat_input_dict(node1, node2, atom_config, ecut, e_error,
- rho_error, icmix = icmix, smearing = smearing,
- sigma = sigma, kspacing = kspacing,
- flag_symm = flag_symm
+ input_dict = make_pwmat_input_dict(
+ node1,
+ node2,
+ atom_config,
+ ecut,
+ e_error,
+ rho_error,
+ icmix=icmix,
+ smearing=smearing,
+ sigma=sigma,
+ kspacing=kspacing,
+ flag_symm=flag_symm,
)
input_dict = _update_input_dict(input_dict, user_dict)
input = write_input_dict(input_dict)
return input
-
+
+
def input_upper(dinput):
- standard_input={}
- for key,val in dinput.items():
- standard_input[key.upper()]=val
+ standard_input = {}
+ for key, val in dinput.items():
+ standard_input[key.upper()] = val
return Input(standard_input)
diff --git a/dpgen/generator/lib/pwscf.py b/dpgen/generator/lib/pwscf.py
index 94a454698..bc3c6bab3 100644
--- a/dpgen/generator/lib/pwscf.py
+++ b/dpgen/generator/lib/pwscf.py
@@ -1,51 +1,53 @@
-#!/usr/bin/python3
+#!/usr/bin/python3
import numpy as np
+
# from lib.vasp import system_from_poscar
-def _convert_dict(idict) :
+
+def _convert_dict(idict):
lines = []
- for key in idict.keys() :
+ for key in idict.keys():
if type(idict[key]) == bool:
- if idict[key] :
- ws = '.TRUE.'
+ if idict[key]:
+ ws = ".TRUE."
else:
- ws = '.FALSE.'
+ ws = ".FALSE."
elif type(idict[key]) == str:
- ws = '\'' + idict[key] + '\''
- else :
+ ws = "'" + idict[key] + "'"
+ else:
ws = str(idict[key])
- lines.append('%s=%s,' % (key, ws))
+ lines.append("%s=%s," % (key, ws))
return lines
-def make_pwscf_01_runctrl_dict(sys_data, idict) :
- tot_natoms = sum(sys_data['atom_numbs'])
- ntypes = len(sys_data['atom_names'])
+def make_pwscf_01_runctrl_dict(sys_data, idict):
+ tot_natoms = sum(sys_data["atom_numbs"])
+ ntypes = len(sys_data["atom_names"])
lines = []
- lines.append('&control')
- lines += _convert_dict(idict['control'])
- lines.append('pseudo_dir=\'./\',')
- lines.append('/')
- lines.append('&system')
- lines += _convert_dict(idict['system'])
- lines.append('ibrav=0,')
- lines.append('nat=%d,' % tot_natoms)
- lines.append('ntyp=%d,' % ntypes)
- lines.append('/')
- if 'electrons' in idict :
- lines.append('&electrons')
- lines += _convert_dict(idict['electrons'])
- lines.append('/')
- lines.append('')
- return '\n'.join(lines)
-
-
-def _make_pwscf_01_runctrl(sys_data, ecut, ediff, smearing, degauss) :
- tot_natoms = sum(sys_data['atom_numbs'])
- ntypes = len(sys_data['atom_names'])
+ lines.append("&control")
+ lines += _convert_dict(idict["control"])
+ lines.append("pseudo_dir='./',")
+ lines.append("/")
+ lines.append("&system")
+ lines += _convert_dict(idict["system"])
+ lines.append("ibrav=0,")
+ lines.append("nat=%d," % tot_natoms)
+ lines.append("ntyp=%d," % ntypes)
+ lines.append("/")
+ if "electrons" in idict:
+ lines.append("&electrons")
+ lines += _convert_dict(idict["electrons"])
+ lines.append("/")
+ lines.append("")
+ return "\n".join(lines)
+
+
+def _make_pwscf_01_runctrl(sys_data, ecut, ediff, smearing, degauss):
+ tot_natoms = sum(sys_data["atom_numbs"])
+ ntypes = len(sys_data["atom_names"])
ret = ""
- ret += '&control\n'
+ ret += "&control\n"
ret += "calculation='scf',\n"
ret += "restart_mode='from_scratch',\n"
ret += "outdir='./OUT',\n"
@@ -62,38 +64,40 @@ def _make_pwscf_01_runctrl(sys_data, ecut, ediff, smearing, degauss) :
ret += "ibrav=0,\n"
ret += "nat=%d,\n" % tot_natoms
ret += "ntyp=%d,\n" % ntypes
- if degauss is not None :
- ret += 'degauss=%f,\n' % degauss
- if smearing is not None :
- ret += 'smearing=\'%s\',\n' % (smearing.lower())
+ if degauss is not None:
+ ret += "degauss=%f,\n" % degauss
+ if smearing is not None:
+ ret += "smearing='%s',\n" % (smearing.lower())
ret += "/\n"
ret += "&electrons\n"
ret += "conv_thr=%s,\n" % str(ediff)
ret += "/\n"
return ret
-def _make_pwscf_02_species(sys_data, pps) :
- atom_names = (sys_data['atom_names'])
- if 'atom_masses' in sys_data:
- atom_masses = (sys_data['atom_masses'])
- else :
+
+def _make_pwscf_02_species(sys_data, pps):
+ atom_names = sys_data["atom_names"]
+ if "atom_masses" in sys_data:
+ atom_masses = sys_data["atom_masses"]
+ else:
atom_masses = [1 for ii in atom_names]
ret = ""
ret += "ATOMIC_SPECIES\n"
ntypes = len(atom_names)
- assert(ntypes == len(atom_names))
- assert(ntypes == len(atom_masses))
- assert(ntypes == len(pps))
- for ii in range(ntypes) :
+ assert ntypes == len(atom_names)
+ assert ntypes == len(atom_masses)
+ assert ntypes == len(pps)
+ for ii in range(ntypes):
ret += "%s %d %s\n" % (atom_names[ii], atom_masses[ii], pps[ii])
return ret
-
-def _make_pwscf_03_config(sys_data) :
- cell = sys_data['cells'][0]
- cell = np.reshape(cell, [3,3])
- coordinates = sys_data['coords'][0]
- atom_names = (sys_data['atom_names'])
- atom_numbs = (sys_data['atom_numbs'])
+
+
+def _make_pwscf_03_config(sys_data):
+ cell = sys_data["cells"][0]
+ cell = np.reshape(cell, [3, 3])
+ coordinates = sys_data["coords"][0]
+ atom_names = sys_data["atom_names"]
+ atom_numbs = sys_data["atom_numbs"]
ntypes = len(atom_names)
ret = ""
ret += "CELL_PARAMETERS { angstrom }\n"
@@ -105,62 +109,69 @@ def _make_pwscf_03_config(sys_data) :
ret += "ATOMIC_POSITIONS { angstrom }\n"
cc = 0
for ii in range(ntypes):
- for jj in range(atom_numbs[ii]):
- ret += "%s %f %f %f\n" % (atom_names[ii],
- coordinates[cc][0],
- coordinates[cc][1],
- coordinates[cc][2])
+ for jj in range(atom_numbs[ii]):
+ ret += "%s %f %f %f\n" % (
+ atom_names[ii],
+ coordinates[cc][0],
+ coordinates[cc][1],
+ coordinates[cc][2],
+ )
cc += 1
return ret
-def _kshift(nkpt) :
- if (nkpt//2) * 2 == nkpt :
+
+def _kshift(nkpt):
+ if (nkpt // 2) * 2 == nkpt:
return 1
- else :
+ else:
return 0
-
+
+
def _make_pwscf_04_kpoints(sys_data, kspacing):
- cell = sys_data['cells'][0]
- cell = np.reshape(cell, [3,3])
+ cell = sys_data["cells"][0]
+ cell = np.reshape(cell, [3, 3])
rcell = np.linalg.inv(cell)
rcell = rcell.T
- kpoints = [(np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int))
- for ii in rcell]
+ kpoints = [
+ (np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int)) for ii in rcell
+ ]
ret = ""
- if kpoints == [1,1,1]:
+ if kpoints == [1, 1, 1]:
ret += "K_POINTS gamma"
else:
ret += "K_POINTS { automatic }\n"
- for ii in range(3) :
+ for ii in range(3):
ret += "%d " % kpoints[ii]
- for ii in range(3) :
+ for ii in range(3):
ret += "%d " % _kshift(kpoints[ii])
ret += "\n"
return ret
-def _make_smearing(fp_params) :
+
+def _make_smearing(fp_params):
smearing = None
- degauss = None
- if 'smearing' in fp_params :
- smearing = (fp_params['smearing']).lower()
- if 'sigma' in fp_params :
- degauss = fp_params['sigma']
- if (smearing is not None) and (smearing.split(':')[0] == 'mp') :
- smearing = 'mp'
- if not (smearing in [None, 'gauss', 'mp', 'fd']) :
+ degauss = None
+ if "smearing" in fp_params:
+ smearing = (fp_params["smearing"]).lower()
+ if "sigma" in fp_params:
+ degauss = fp_params["sigma"]
+ if (smearing is not None) and (smearing.split(":")[0] == "mp"):
+ smearing = "mp"
+ if not (smearing in [None, "gauss", "mp", "fd"]):
raise RuntimeError("unknow smearing method " + smearing)
return smearing, degauss
-def make_pwscf_input(sys_data, fp_pp_files, fp_params, user_input = True) :
- if not user_input :
- ecut = fp_params['ecut']
- ediff = fp_params['ediff']
+
+def make_pwscf_input(sys_data, fp_pp_files, fp_params, user_input=True):
+ if not user_input:
+ ecut = fp_params["ecut"]
+ ediff = fp_params["ediff"]
smearing, degauss = _make_smearing(fp_params)
- kspacing = fp_params['kspacing']
+ kspacing = fp_params["kspacing"]
ret = ""
if not user_input:
ret += _make_pwscf_01_runctrl(sys_data, ecut, ediff, smearing, degauss)
- else :
+ else:
ret += make_pwscf_01_runctrl_dict(sys_data, fp_params)
ret += "\n"
ret += _make_pwscf_02_species(sys_data, fp_pp_files)
@@ -171,14 +182,16 @@ def make_pwscf_input(sys_data, fp_pp_files, fp_params, user_input = True) :
ret += "\n"
return ret
+
ry2ev = 13.605693009
bohr2ang = 0.52917721067
kbar2evperang3 = 1
-def get_block (lines, keyword, skip = 0) :
+
+def get_block(lines, keyword, skip=0):
ret = []
- for idx,ii in enumerate(lines) :
- if keyword in ii :
+ for idx, ii in enumerate(lines):
+ if keyword in ii:
blk_idx = idx + 1 + skip
while len(lines[blk_idx]) != 0 and blk_idx != len(lines):
ret.append(lines[blk_idx])
@@ -186,97 +199,104 @@ def get_block (lines, keyword, skip = 0) :
break
return ret
-def get_types (lines) :
+
+def get_types(lines):
ret = []
- blk = get_block(lines, 'ATOMIC_SPECIES')
+ blk = get_block(lines, "ATOMIC_SPECIES")
for ii in blk:
ret.append(ii.split()[0])
return ret
-def get_cell (lines) :
+
+def get_cell(lines):
ret = []
- blk = get_block(lines, 'CELL_PARAMETERS')
+ blk = get_block(lines, "CELL_PARAMETERS")
for ii in blk:
ret.append([float(jj) for jj in ii.split()[0:3]])
ret = np.array([ret])
return ret
-def get_coords (lines) :
+
+def get_coords(lines):
ret = []
- blk = get_block(lines, 'ATOMIC_POSITIONS')
+ blk = get_block(lines, "ATOMIC_POSITIONS")
for ii in blk:
ret.append([float(jj) for jj in ii.split()[1:4]])
ret = np.array([ret])
return ret
-def get_natoms (lines) :
- types = get_types (lines)
+
+def get_natoms(lines):
+ types = get_types(lines)
names = []
- blk = get_block(lines, 'ATOMIC_POSITIONS')
+ blk = get_block(lines, "ATOMIC_POSITIONS")
for ii in blk:
names.append(ii.split()[0])
natoms = []
- for ii in types :
+ for ii in types:
natoms.append(names.count(ii))
# return np.array(natoms, dtype = int)
return natoms
-def get_atom_types(lines) :
- types = get_types (lines)
+
+def get_atom_types(lines):
+ types = get_types(lines)
names = []
- blk = get_block(lines, 'ATOMIC_POSITIONS')
+ blk = get_block(lines, "ATOMIC_POSITIONS")
for ii in blk:
names.append(ii.split()[0])
ret = []
for ii in names:
ret.append(types.index(ii))
- return np.array(ret, dtype = int)
+ return np.array(ret, dtype=int)
-def get_energy (lines) :
- for ii in lines :
- if '! total energy' in ii :
- return np.array([ry2ev * float(ii.split('=')[1].split()[0])])
+
+def get_energy(lines):
+ for ii in lines:
+ if "! total energy" in ii:
+ return np.array([ry2ev * float(ii.split("=")[1].split()[0])])
return None
-def get_force (lines) :
- blk = get_block(lines, 'Forces acting on atoms', skip = 1)
+
+def get_force(lines):
+ blk = get_block(lines, "Forces acting on atoms", skip=1)
ret = []
for ii in blk:
- ret.append([float(jj) for jj in ii.split('=')[1].split()])
+ ret.append([float(jj) for jj in ii.split("=")[1].split()])
ret = np.array([ret])
- ret *= (ry2ev / bohr2ang)
+ ret *= ry2ev / bohr2ang
return ret
-def get_stress (lines, cells) :
+
+def get_stress(lines, cells):
vols = []
for ii in cells:
- vols.append(np.linalg.det(ii.reshape([3,3])))
- blk = get_block(lines, 'total stress')
+ vols.append(np.linalg.det(ii.reshape([3, 3])))
+ blk = get_block(lines, "total stress")
ret = []
for ii in blk:
ret.append([float(jj) for jj in ii.split()[3:6]])
ret = np.array([ret])
- for idx,ii in enumerate(ret):
+ for idx, ii in enumerate(ret):
ii *= vols[idx] * 1e3 / 1.602176621e6
return ret
-
-def cvt_1frame (fin, fout):
+
+def cvt_1frame(fin, fout):
with open(fout) as fp:
- outlines = fp.read().split('\n')
+ outlines = fp.read().split("\n")
with open(fin) as fp:
- inlines = fp.read().split('\n')
+ inlines = fp.read().split("\n")
# outlines = open(fout, 'r').read().split('\n')
# inlines = open(fin, 'r').read().split('\n')
data = {}
- data['orig'] = np.array([0,0,0])
- data['atom_names'] = (get_types (inlines))
- data['atom_numbs'] = (get_natoms(inlines))
- data['atom_types'] = (get_atom_types(inlines))
- data['coords'] = (get_coords(inlines))
- data['cells'] = (get_cell (inlines))
- data['energies'] = (get_energy(outlines))
- data['forces'] = (get_force (outlines))
- data['virials'] = (get_stress(outlines, data['cells']))
+ data["orig"] = np.array([0, 0, 0])
+ data["atom_names"] = get_types(inlines)
+ data["atom_numbs"] = get_natoms(inlines)
+ data["atom_types"] = get_atom_types(inlines)
+ data["coords"] = get_coords(inlines)
+ data["cells"] = get_cell(inlines)
+ data["energies"] = get_energy(outlines)
+ data["forces"] = get_force(outlines)
+ data["virials"] = get_stress(outlines, data["cells"])
return data
-
diff --git a/dpgen/generator/lib/run_calypso.py b/dpgen/generator/lib/run_calypso.py
index f43af2e31..289f63266 100644
--- a/dpgen/generator/lib/run_calypso.py
+++ b/dpgen/generator/lib/run_calypso.py
@@ -6,58 +6,63 @@
"""
import copy
-import dpdata
+import glob
import math
-import numpy as np
import os
import random
import re
-import glob
import shutil
import sys
-from ase.io.vasp import write_vasp
-from ase.io.trajectory import Trajectory
-from pathlib import Path
from itertools import combinations
-from distutils.version import LooseVersion
+from pathlib import Path
+
+import dpdata
+import numpy as np
+from ase.io.trajectory import Trajectory
+from ase.io.vasp import write_vasp
+from packaging.version import Version
+
from dpgen import dlog
-from dpgen.generator.lib.utils import create_path
-from dpgen.generator.lib.utils import make_iter_name
+from dpgen.dispatcher.Dispatcher import make_submission
from dpgen.generator.lib.parse_calypso import _parse_calypso_input
-from dpgen.dispatcher.Dispatcher import make_dispatcher, make_submission
+from dpgen.generator.lib.utils import create_path, make_iter_name
+
+train_name = "00.train"
+model_devi_name = "01.model_devi"
+fp_name = "02.fp"
+calypso_run_opt_name = "gen_stru_analy"
+calypso_model_devi_name = "model_devi_results"
-train_name = '00.train'
-model_devi_name = '01.model_devi'
-fp_name = '02.fp'
-calypso_run_opt_name = 'gen_stru_analy'
-calypso_model_devi_name = 'model_devi_results'
-def gen_structures(iter_index, jdata, mdata, caly_run_path, current_idx, length_of_caly_runopt_list):
+def gen_structures(
+ iter_index, jdata, mdata, caly_run_path, current_idx, length_of_caly_runopt_list
+):
# run calypso
# vsc means generate elemental, binary and ternary at the same time
- vsc = jdata.get('vsc',False) # take CALYPSO as confs generator
-
- model_devi_group_size = mdata['model_devi_group_size']
- model_devi_resources = mdata['model_devi_resources']
- api_version = mdata.get('api_version', '0.9')
+ vsc = jdata.get("vsc", False) # take CALYPSO as confs generator
+ model_devi_group_size = mdata["model_devi_group_size"]
+ model_devi_resources = mdata["model_devi_resources"]
+ api_version = mdata.get("api_version", "1.0")
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, model_devi_name)
- assert(os.path.isdir(work_path))
+ assert os.path.isdir(work_path)
calypso_run_opt_path = caly_run_path
- calypso_model_devi_path = os.path.join(work_path,calypso_model_devi_name)
+ calypso_model_devi_path = os.path.join(work_path, calypso_model_devi_name)
+
+ calypso_path = mdata.get("model_devi_calypso_path")
+ # calypso_input_path = jdata.get('calypso_input_path')
- calypso_path = mdata.get('model_devi_calypso_path')
- #calypso_input_path = jdata.get('calypso_input_path')
-
- all_models = glob.glob(os.path.join(calypso_run_opt_path, 'graph*pb'))
+ all_models = glob.glob(os.path.join(calypso_run_opt_path, "graph*pb"))
model_names = [os.path.basename(ii) for ii in all_models]
- deepmdkit_python = mdata.get('model_devi_deepmdkit_python')
- command = "%s calypso_run_opt.py 1>> model_devi.log 2>> model_devi.log" % (deepmdkit_python)
+ deepmdkit_python = mdata.get("model_devi_deepmdkit_python")
+ command = "%s calypso_run_opt.py 1>> model_devi.log 2>> model_devi.log" % (
+ deepmdkit_python
+ )
# command = "%s calypso_run_opt.py %s 1>> model_devi.log 2>> model_devi.log" % (deepmdkit_python,os.path.abspath(calypso_run_opt_path))
# command += " || %s check_outcar.py %s " % (deepmdkit_python,os.path.abspath(calypso_run_opt_path))
command += " || %s check_outcar.py " % (deepmdkit_python)
@@ -66,81 +71,83 @@ def gen_structures(iter_index, jdata, mdata, caly_run_path, current_idx, length_
cwd = os.getcwd()
os.chdir(calypso_run_opt_path)
- forward_files = ['POSCAR', 'calypso_run_opt.py','check_outcar.py','input.dat']
- backward_files = ['OUTCAR','CONTCAR','traj.traj','model_devi.log']
+ forward_files = ["POSCAR", "calypso_run_opt.py", "check_outcar.py", "input.dat"]
+ backward_files = ["OUTCAR", "CONTCAR", "traj.traj", "model_devi.log"]
- run_calypso = calypso_path+'/calypso.x | tee log'
+ run_calypso = calypso_path + "/calypso.x | tee log"
if not vsc:
- Lpickup = _parse_calypso_input('PickUp','.')
- PickUpStep = _parse_calypso_input('PickStep','.')
- if os.path.exists('tag_pickup_%s'%(str(PickUpStep))):
- dlog.info('caution! tag_pickup_%s exists!'%str(PickUpStep))
- Lpickup = 'F'
- if Lpickup == 'T':
- ftag = open('tag_pickup_%s'%(str(PickUpStep)),'w')
+ Lpickup = _parse_calypso_input("PickUp", ".")
+ PickUpStep = _parse_calypso_input("PickStep", ".")
+ if os.path.exists("tag_pickup_%s" % (str(PickUpStep))):
+ dlog.info("caution! tag_pickup_%s exists!" % str(PickUpStep))
+ Lpickup = "F"
+ if Lpickup == "T":
+ ftag = open("tag_pickup_%s" % (str(PickUpStep)), "w")
ftag.close()
- os.remove('step')
- fstep = open('step','w')
- fstep.write('%12s'%str(PickUpStep))
+ os.remove("step")
+ fstep = open("step", "w")
+ fstep.write("%12s" % str(PickUpStep))
fstep.close()
else:
PickUpStep = 1
try:
- os.mkdir('opt')
+ os.mkdir("opt")
except:
pass
- popsize = int(_parse_calypso_input('PopSize', '.'))
- maxstep = int(_parse_calypso_input('MaxStep', '.'))
+ popsize = int(_parse_calypso_input("PopSize", "."))
+ maxstep = int(_parse_calypso_input("MaxStep", "."))
- for ii in range(int(PickUpStep)-1,maxstep+1):
- dlog.info('CALYPSO step %s'%ii)
- if ii == maxstep :
- os.system('%s'%run_calypso)
+ for ii in range(int(PickUpStep) - 1, maxstep + 1):
+ dlog.info("CALYPSO step %s" % ii)
+ if ii == maxstep:
+ os.system("%s" % run_calypso)
break
# run calypso
- os.system('%s'%(run_calypso))
-
- for pop in range(ii*int(popsize),(ii+1)*int(popsize)):
+ os.system("%s" % (run_calypso))
+
+ for pop in range(ii * int(popsize), (ii + 1) * int(popsize)):
try:
- os.mkdir('task.%03d'%pop)
+ os.mkdir("task.%03d" % pop)
except:
- shutil.rmtree('task.%03d'%pop)
- os.mkdir('task.%03d'%pop)
- shutil.copyfile('calypso_run_opt.py',os.path.join('task.%03d'%pop,'calypso_run_opt.py'))
- shutil.copyfile('check_outcar.py',os.path.join('task.%03d'%pop,'check_outcar.py'))
- shutil.copyfile('POSCAR_%s'%str(pop-ii*int(popsize)+1),os.path.join('task.%03d'%(pop),'POSCAR'))
- shutil.copyfile('input.dat',os.path.join('task.%03d'%pop,'input.dat'))
- #for iii in range(1,popsize+1):
+ shutil.rmtree("task.%03d" % pop)
+ os.mkdir("task.%03d" % pop)
+ shutil.copyfile(
+ "calypso_run_opt.py",
+ os.path.join("task.%03d" % pop, "calypso_run_opt.py"),
+ )
+ shutil.copyfile(
+ "check_outcar.py",
+ os.path.join("task.%03d" % pop, "check_outcar.py"),
+ )
+ shutil.copyfile(
+ "POSCAR_%s" % str(pop - ii * int(popsize) + 1),
+ os.path.join("task.%03d" % (pop), "POSCAR"),
+ )
+ shutil.copyfile(
+ "input.dat", os.path.join("task.%03d" % pop, "input.dat")
+ )
+ # for iii in range(1,popsize+1):
# shutil.copyfile('POSCAR_%s'%str(iii),os.path.join('task.%03d'%(iii-1),'POSCAR'))
- all_task = glob.glob( "task.*")
+ all_task = glob.glob("task.*")
all_task.sort()
run_tasks_ = all_task
run_tasks = [os.path.basename(ii) for ii in run_tasks_]
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher=make_dispatcher(mdata['model_devi_machine'],mdata['model_devi_resources'],'./', run_tasks, model_devi_group_size)
- dispatcher.run_jobs(mdata['model_devi_resources'],
- commands,
- './',
- run_tasks,
- model_devi_group_size,
- model_names,
- forward_files,
- backward_files,
- outlog = 'model_devi.log',
- errlog = 'model_devi.log')
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0."
+ % api_version
+ )
+ elif Version(api_version) >= Version("1.0"):
os.chdir(cwd)
submission = make_submission(
- mdata['model_devi_machine'],
- mdata['model_devi_resources'],
+ mdata["model_devi_machine"],
+ mdata["model_devi_resources"],
commands=commands,
work_path=calypso_run_opt_path,
run_tasks=run_tasks,
@@ -148,80 +155,111 @@ def gen_structures(iter_index, jdata, mdata, caly_run_path, current_idx, length_
forward_common_files=model_names,
forward_files=forward_files,
backward_files=backward_files,
- outlog = 'model_devi.log',
- errlog = 'model_devi.log')
+ outlog="model_devi.log",
+ errlog="model_devi.log",
+ )
submission.run_submission()
os.chdir(calypso_run_opt_path)
-
- sstep = os.path.join('opt',str(ii))
+
+ sstep = os.path.join("opt", str(ii))
os.mkdir(sstep)
- if not os.path.exists('traj'):
- os.mkdir('traj')
+ if not os.path.exists("traj"):
+ os.mkdir("traj")
- for jjj in range(ii*int(popsize),(ii+1)*int(popsize)):
+ for jjj in range(ii * int(popsize), (ii + 1) * int(popsize)):
# to opt directory
- shutil.copyfile('POSCAR_%s'%str(jjj+1-ii*int(popsize)),os.path.join(sstep,'POSCAR_%s'%str(jjj+1-ii*int(popsize))),)
- shutil.copyfile(os.path.join('task.%03d'%(jjj),'OUTCAR'),os.path.join(sstep,'OUTCAR_%s'%str(jjj+1-ii*int(popsize))),)
- shutil.copyfile(os.path.join('task.%03d'%(jjj),'CONTCAR'),os.path.join(sstep,'CONTCAR_%s'%str(jjj+1-ii*int(popsize))),)
+ shutil.copyfile(
+ "POSCAR_%s" % str(jjj + 1 - ii * int(popsize)),
+ os.path.join(sstep, "POSCAR_%s" % str(jjj + 1 - ii * int(popsize))),
+ )
+ shutil.copyfile(
+ os.path.join("task.%03d" % (jjj), "OUTCAR"),
+ os.path.join(sstep, "OUTCAR_%s" % str(jjj + 1 - ii * int(popsize))),
+ )
+ shutil.copyfile(
+ os.path.join("task.%03d" % (jjj), "CONTCAR"),
+ os.path.join(
+ sstep, "CONTCAR_%s" % str(jjj + 1 - ii * int(popsize))
+ ),
+ )
# to run calypso directory
- shutil.copyfile(os.path.join('task.%03d'%(jjj),'OUTCAR'),'OUTCAR_%s'%str(jjj+1-ii*int(popsize)),)
- shutil.copyfile(os.path.join('task.%03d'%(jjj),'CONTCAR'),'CONTCAR_%s'%str(jjj+1-ii*int(popsize)),)
+ shutil.copyfile(
+ os.path.join("task.%03d" % (jjj), "OUTCAR"),
+ "OUTCAR_%s" % str(jjj + 1 - ii * int(popsize)),
+ )
+ shutil.copyfile(
+ os.path.join("task.%03d" % (jjj), "CONTCAR"),
+ "CONTCAR_%s" % str(jjj + 1 - ii * int(popsize)),
+ )
# to traj
- shutil.copyfile(os.path.join('task.%03d'%(jjj),'traj.traj'),os.path.join('traj','%s.traj'%str(jjj+1)),)
-
- if LooseVersion(api_version) < LooseVersion('1.0'):
- os.rename('jr.json','jr_%s.json'%(str(ii)))
+ shutil.copyfile(
+ os.path.join("task.%03d" % (jjj), "traj.traj"),
+ os.path.join("traj", "%s.traj" % str(jjj + 1)),
+ )
- tlist = glob.glob('task.*')
+ tlist = glob.glob("task.*")
for t in tlist:
shutil.rmtree(t)
else:
# --------------------------------------------------------------
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
how_many_spec = len(type_map)
if how_many_spec == 1:
- dlog.info('vsc mode can not work in one-element situation' )
+ dlog.info("vsc mode can not work in one-element situation")
sys.exit()
- comp_temp = list(map(list,list(combinations(type_map,1))))
- for hms in range(2,how_many_spec+1):
+ comp_temp = list(map(list, list(combinations(type_map, 1))))
+ for hms in range(2, how_many_spec + 1):
# comp_temp = [['Mg'],['Al'],['Cu'],['Mg','Al'],['Mg','Cu'],['Al','Cu'],['Mg','Al','Cu']]
- comp_temp.extend(list(map(list,list(combinations(type_map,hms)))))
-
+ comp_temp.extend(list(map(list, list(combinations(type_map, hms)))))
+
component = []
for comp_temp_ in comp_temp:
- component.append(''.join(comp_temp_)) # component = ['Mg','Al','Cu','MgAl','MgCu','AlCu','MgAlCu']
+ component.append(
+ "".join(comp_temp_)
+ ) # component = ['Mg','Al','Cu','MgAl','MgCu','AlCu','MgAlCu']
dlog.info(component)
# calypso_input_path = jdata.get('calypso_input_path')
-
+
pwd = os.getcwd()
- if len(glob.glob(f'input.dat.{component[0]}.*')) != 0:
- os.system('for i in input.dat.*;do mv $i ${i%.*};done')
+ if len(glob.glob(f"input.dat.{component[0]}.*")) != 0:
+ os.system("for i in input.dat.*;do mv $i ${i%.*};done")
for idx, com in enumerate(component):
if not os.path.exists(com):
os.mkdir(com)
- #shutil.copyfile(os.path.join(calypso_input_path,'input.dat.%s'%com),os.path.join(com,'input.dat'))
- shutil.copyfile('input.dat.%s'%com ,os.path.join(com,'input.dat'))
+ # shutil.copyfile(os.path.join(calypso_input_path,'input.dat.%s'%com),os.path.join(com,'input.dat'))
+ shutil.copyfile("input.dat.%s" % com, os.path.join(com, "input.dat"))
os.chdir(com)
os.system(run_calypso)
os.chdir(pwd)
- shutil.copyfile('input.dat.%s'%component[-1], 'input.dat')
+ shutil.copyfile("input.dat.%s" % component[-1], "input.dat")
- name_list = Path('.').glob('*/POSCAR_*')
- for idx,name in enumerate(name_list):
- shutil.copyfile(name,'POSCAR_%s'%(idx+1))
+ name_list = Path(".").glob("*/POSCAR_*")
+ for idx, name in enumerate(name_list):
+ shutil.copyfile(name, "POSCAR_%s" % (idx + 1))
try:
- os.mkdir('task.%04d'%(idx+1))
+ os.mkdir("task.%04d" % (idx + 1))
except:
- shutil.rmtree('task.%04d'%(idx+1))
- os.mkdir('task.%04d'%(idx+1))
- shutil.copyfile('calypso_run_opt.py',os.path.join('task.%04d'%(idx+1),'calypso_run_opt.py'))
- shutil.copyfile('check_outcar.py',os.path.join('task.%04d'%(idx+1),'check_outcar.py'))
- shutil.copyfile('POSCAR_%s'%str(idx+1),os.path.join('task.%04d'%(idx+1),'POSCAR'))
- shutil.copyfile('input.dat',os.path.join('task.%04d'%(idx+1),'input.dat'))
+ shutil.rmtree("task.%04d" % (idx + 1))
+ os.mkdir("task.%04d" % (idx + 1))
+ shutil.copyfile(
+ "calypso_run_opt.py",
+ os.path.join("task.%04d" % (idx + 1), "calypso_run_opt.py"),
+ )
+ shutil.copyfile(
+ "check_outcar.py",
+ os.path.join("task.%04d" % (idx + 1), "check_outcar.py"),
+ )
+ shutil.copyfile(
+ "POSCAR_%s" % str(idx + 1),
+ os.path.join("task.%04d" % (idx + 1), "POSCAR"),
+ )
+ shutil.copyfile(
+ "input.dat", os.path.join("task.%04d" % (idx + 1), "input.dat")
+ )
# sys.exit()
@@ -232,25 +270,15 @@ def gen_structures(iter_index, jdata, mdata, caly_run_path, current_idx, length_
run_tasks = [os.path.basename(ii) for ii in run_tasks_]
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher=make_dispatcher(mdata['model_devi_machine'],mdata['model_devi_resources'],'./', run_tasks, model_devi_group_size)
- dispatcher.run_jobs(mdata['model_devi_resources'],
- commands,
- './',
- run_tasks,
- model_devi_group_size,
- model_names,
- forward_files,
- backward_files,
- outlog = 'model_devi.log',
- errlog = 'model_devi.log')
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+ elif Version(api_version) >= Version("1.0"):
os.chdir(cwd)
submission = make_submission(
- mdata['model_devi_machine'],
- mdata['model_devi_resources'],
+ mdata["model_devi_machine"],
+ mdata["model_devi_resources"],
commands=commands,
work_path=calypso_run_opt_path,
run_tasks=run_tasks,
@@ -258,69 +286,95 @@ def gen_structures(iter_index, jdata, mdata, caly_run_path, current_idx, length_
forward_common_files=model_names,
forward_files=forward_files,
backward_files=backward_files,
- outlog = 'model_devi.log',
- errlog = 'model_devi.log')
+ outlog="model_devi.log",
+ errlog="model_devi.log",
+ )
submission.run_submission()
os.chdir(calypso_run_opt_path)
-
- os.mkdir('opt')
- if not os.path.exists('traj'):
- os.mkdir('traj')
+
+ os.mkdir("opt")
+ if not os.path.exists("traj"):
+ os.mkdir("traj")
for jjj in range(len(all_task)):
# to opt directory
- shutil.copyfile('POSCAR_%s'%str(jjj+1),os.path.join('opt','POSCAR_%s'%str(jjj+1)),)
- shutil.copyfile(os.path.join('task.%04d'%(jjj+1),'OUTCAR'),os.path.join('opt','OUTCAR_%s'%str(jjj+1)),)
- shutil.copyfile(os.path.join('task.%04d'%(jjj+1),'CONTCAR'),os.path.join('opt','CONTCAR_%s'%str(jjj+1)),)
+ shutil.copyfile(
+ "POSCAR_%s" % str(jjj + 1),
+ os.path.join("opt", "POSCAR_%s" % str(jjj + 1)),
+ )
+ shutil.copyfile(
+ os.path.join("task.%04d" % (jjj + 1), "OUTCAR"),
+ os.path.join("opt", "OUTCAR_%s" % str(jjj + 1)),
+ )
+ shutil.copyfile(
+ os.path.join("task.%04d" % (jjj + 1), "CONTCAR"),
+ os.path.join("opt", "CONTCAR_%s" % str(jjj + 1)),
+ )
# to run calypso directory
- shutil.copyfile(os.path.join('task.%04d'%(jjj+1),'OUTCAR'),'OUTCAR_%s'%str(jjj+1),)
- shutil.copyfile(os.path.join('task.%04d'%(jjj+1),'CONTCAR'),'CONTCAR_%s'%str(jjj+1),)
+ shutil.copyfile(
+ os.path.join("task.%04d" % (jjj + 1), "OUTCAR"),
+ "OUTCAR_%s" % str(jjj + 1),
+ )
+ shutil.copyfile(
+ os.path.join("task.%04d" % (jjj + 1), "CONTCAR"),
+ "CONTCAR_%s" % str(jjj + 1),
+ )
# to traj
- shutil.copyfile(os.path.join('task.%04d'%(jjj+1),'traj.traj'),os.path.join('traj','%s.traj'%str(jjj+1)),)
+ shutil.copyfile(
+ os.path.join("task.%04d" % (jjj + 1), "traj.traj"),
+ os.path.join("traj", "%s.traj" % str(jjj + 1)),
+ )
- tlist = glob.glob('task.*')
+ tlist = glob.glob("task.*")
for t in tlist:
shutil.rmtree(t)
# --------------------------------------------------------------
if current_idx < length_of_caly_runopt_list - 1:
- tobewrite = '1 %s\n'%(str(current_idx + 1))
- elif current_idx == length_of_caly_runopt_list - 1 :
- tobewrite = '2\n'
+ tobewrite = "1 %s\n" % (str(current_idx + 1))
+ elif current_idx == length_of_caly_runopt_list - 1:
+ tobewrite = "2\n"
os.chdir(cwd)
os.chdir(work_path)
- f = open('record.calypso','a+')
+ f = open("record.calypso", "a+")
f.write(tobewrite)
f.close()
os.chdir(cwd)
+
def gen_main(iter_index, jdata, mdata, caly_run_opt_list, gen_idx):
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, model_devi_name)
- current_gen_path = os.path.join(work_path, '%s.%03d'%(calypso_run_opt_name, int(gen_idx)))
+ current_gen_path = os.path.join(
+ work_path, "%s.%03d" % (calypso_run_opt_name, int(gen_idx))
+ )
if current_gen_path not in caly_run_opt_list:
- dlog.info(f"current gen path {current_gen_path} not in caly run opt list {caly_run_opt_list}")
+ dlog.info(
+ f"current gen path {current_gen_path} not in caly run opt list {caly_run_opt_list}"
+ )
sys.exit()
indice = caly_run_opt_list.index(current_gen_path)
for iidx, temp_path in enumerate(caly_run_opt_list):
if iidx >= indice:
- gen_structures(iter_index, jdata, mdata, temp_path, iidx, len(caly_run_opt_list))
+ gen_structures(
+ iter_index, jdata, mdata, temp_path, iidx, len(caly_run_opt_list)
+ )
def analysis(iter_index, jdata, calypso_model_devi_path):
# Analysis
- ms = dpdata.MultiSystems(type_map=jdata['type_map'])
+ ms = dpdata.MultiSystems(type_map=jdata["type_map"])
cwd = os.getcwd()
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, model_devi_name)
- deepmd_data_path = os.path.join(work_path,'confs', 'deepmd')
- traj_pos_path = os.path.join(work_path,'confs', 'traj_confs')
+ deepmd_data_path = os.path.join(work_path, "confs", "deepmd")
+ traj_pos_path = os.path.join(work_path, "confs", "traj_confs")
create_path(deepmd_data_path)
create_path(traj_pos_path)
@@ -328,128 +382,142 @@ def analysis(iter_index, jdata, calypso_model_devi_path):
# traj_path = os.path.join(calypso_run_opt_path,'traj')
# traj_list = glob.glob(traj_path+'/*.traj')
# 'gen_struc_analy.000/traj/*.traj' 'gen_struc_analy.001/traj/*.traj' 'gen_struc_analy.002/traj/*.traj'
- traj_list = glob.glob(f'{work_path}/*/traj/*.traj')
+ traj_list = glob.glob(f"{work_path}/*/traj/*.traj")
# read poscar from traj file in confs/traj/*.traj
record_traj_num = 0
for traj_name in traj_list:
- traj_num = os.path.basename(traj_name).split('.')[0]
- press_num = traj_name.split('/')[-3].split('.')[-1]
+ traj_num = os.path.basename(traj_name).split(".")[0]
+ press_num = traj_name.split("/")[-3].split(".")[-1]
trajs_origin = Trajectory(traj_name)
record_traj_num += len(trajs_origin)
- if len(trajs_origin) >= 20 :
- trajs = [trajs_origin[iii] for iii in [4,9,-10,-5,-1]]
- elif 5<=len(trajs_origin)<20:
- trajs = [trajs_origin[random.randint(1,len(trajs_origin)-1)] for iii in range(4)]
- trajs.append(trajs[-1])
- elif 3<= len(trajs_origin) <5:
- trajs = [trajs_origin[round((len(trajs_origin)-1)/2)] ]
- trajs.append(trajs[-1])
+ if len(trajs_origin) >= 20:
+ trajs = [trajs_origin[iii] for iii in [4, 9, -10, -5, -1]]
+ elif 5 <= len(trajs_origin) < 20:
+ trajs = [
+ trajs_origin[random.randint(1, len(trajs_origin) - 1)]
+ for iii in range(4)
+ ]
+ trajs.append(trajs[-1])
+ elif 3 <= len(trajs_origin) < 5:
+ trajs = [trajs_origin[round((len(trajs_origin) - 1) / 2)]]
+ trajs.append(trajs[-1])
elif len(trajs_origin) == 2:
- trajs = [trajs_origin[0],trajs_origin[-1] ]
+ trajs = [trajs_origin[0], trajs_origin[-1]]
elif len(trajs_origin) == 1:
- trajs = [trajs_origin[0] ]
+ trajs = [trajs_origin[0]]
else:
- pass
-
+ pass
+
for idx, traj in enumerate(trajs):
- write_vasp(os.path.join(
- traj_pos_path,'%d.%03d.%03d.poscar' % (
- int(press_num), int(traj_num), int(idx)
- )
+ write_vasp(
+ os.path.join(
+ traj_pos_path,
+ "%d.%03d.%03d.poscar" % (int(press_num), int(traj_num), int(idx)),
),
- traj)
-
- traj_pos_list = glob.glob(traj_pos_path+'/*.poscar')
+ traj,
+ )
+
+ traj_pos_list = glob.glob(traj_pos_path + "/*.poscar")
for npos in traj_pos_list:
try:
- ms.append(dpdata.System(npos, type_map = jdata['type_map']))
+ ms.append(dpdata.System(npos, type_map=jdata["type_map"]))
except Exception as e:
- dlog.info(npos,'failed : ',e)
+ dlog.info(npos, "failed : ", e)
if len(ms) == 0:
- dlog.info('too little confs, ')
- raise RuntimeError('no confs found in Analysis part and this should not happen!')
+ dlog.info("too little confs, ")
+ raise RuntimeError(
+ "no confs found in Analysis part and this should not happen!"
+ )
if os.path.exists(deepmd_data_path):
shutil.rmtree(deepmd_data_path)
ms.to_deepmd_raw(deepmd_data_path)
ms.to_deepmd_npy(deepmd_data_path)
- split_lists = glob.glob(os.path.join(deepmd_data_path,'*'))
- for i,split_list in enumerate(split_lists):
- strus_path = os.path.join(calypso_model_devi_path,'%03d.structures'%i)
+ split_lists = glob.glob(os.path.join(deepmd_data_path, "*"))
+ for i, split_list in enumerate(split_lists):
+ strus_path = os.path.join(calypso_model_devi_path, "%03d.structures" % i)
if not os.path.exists(strus_path):
- shutil.copytree(split_list,strus_path)
+ shutil.copytree(split_list, strus_path)
else:
shutil.rmtree(strus_path)
- shutil.copytree(split_list,strus_path)
+ shutil.copytree(split_list, strus_path)
os.chdir(cwd)
os.chdir(work_path)
- f = open('record.calypso','a+')
- f.write('3\n')
+ f = open("record.calypso", "a+")
+ f.write("3\n")
f.close()
os.chdir(cwd)
-def run_calypso_model_devi (iter_index,
- jdata,
- mdata) :
+def run_calypso_model_devi(iter_index, jdata, mdata):
- dlog.info('start running CALYPSO')
+ dlog.info("start running CALYPSO")
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, model_devi_name)
- assert(os.path.isdir(work_path))
+ assert os.path.isdir(work_path)
- calypso_model_devi_path = os.path.join(work_path,calypso_model_devi_name)
+ calypso_model_devi_path = os.path.join(work_path, calypso_model_devi_name)
- _caly_run_opt_list = glob.glob(os.path.join(work_path,'%s.*'%(str(calypso_run_opt_name))))
+ _caly_run_opt_list = glob.glob(
+ os.path.join(work_path, "%s.*" % (str(calypso_run_opt_name)))
+ )
caly_run_opt_list = _caly_run_opt_list.copy()
# check if gen_struc_analy.000.bk000 in caly_run_opt_list
for temp_value in _caly_run_opt_list:
- if 'bk' in temp_value:
+ if "bk" in temp_value:
caly_run_opt_list.remove(temp_value)
caly_run_opt_list.sort()
cwd = os.getcwd()
- record_calypso_path = os.path.join(work_path,'record.calypso')
+ record_calypso_path = os.path.join(work_path, "record.calypso")
while True:
if not os.path.exists(record_calypso_path):
- f = open(record_calypso_path,'w')
- f.write('1 0\n')
- lines = ['1 0\n']
+ f = open(record_calypso_path, "w")
+ f.write("1 0\n")
+ lines = ["1 0\n"]
f.close()
else:
- f = open(record_calypso_path,'r')
+ f = open(record_calypso_path, "r")
lines = f.readlines()
f.close()
- if lines[-1].strip().strip('\n').split()[0] == '1':
+ if lines[-1].strip().strip("\n").split()[0] == "1":
# Gen Structures
- gen_index = lines[-1].strip().strip('\n').split()[1]
+ gen_index = lines[-1].strip().strip("\n").split()[1]
gen_main(iter_index, jdata, mdata, caly_run_opt_list, gen_index)
- elif lines[-1].strip().strip('\n') == '2':
+ elif lines[-1].strip().strip("\n") == "2":
# Analysis & to deepmd/raw
analysis(iter_index, jdata, calypso_model_devi_path)
- elif lines[-1].strip().strip('\n') == '3':
+ elif lines[-1].strip().strip("\n") == "3":
# Model Devi
_calypso_run_opt_path = os.path.abspath(caly_run_opt_list[0])
- all_models = glob.glob(os.path.join(_calypso_run_opt_path, 'graph*pb'))
+ all_models = glob.glob(os.path.join(_calypso_run_opt_path, "graph*pb"))
cwd = os.getcwd()
os.chdir(calypso_model_devi_path)
- args = ' '.join(['calypso_run_model_devi.py', '--all_models',' '.join(all_models),'--type_map',' '.join(jdata.get('type_map'))])
- deepmdkit_python = mdata.get('model_devi_deepmdkit_python')
- os.system(f'{deepmdkit_python} {args} ')
- #Modd(iter_index,calypso_model_devi_path,all_models,jdata)
+ args = " ".join(
+ [
+ "calypso_run_model_devi.py",
+ "--all_models",
+ " ".join(all_models),
+ "--type_map",
+ " ".join(jdata.get("type_map")),
+ ]
+ )
+ deepmdkit_python = mdata.get("model_devi_deepmdkit_python")
+ os.system(f"{deepmdkit_python} {args} ")
+ # Modd(iter_index,calypso_model_devi_path,all_models,jdata)
os.chdir(cwd)
- elif lines[-1].strip().strip('\n') == '4':
- dlog.info('Model Devi is done.')
+ elif lines[-1].strip().strip("\n") == "4":
+ dlog.info("Model Devi is done.")
# return
break
diff --git a/dpgen/generator/lib/siesta.py b/dpgen/generator/lib/siesta.py
index 4a2787e7b..0c7faabc9 100644
--- a/dpgen/generator/lib/siesta.py
+++ b/dpgen/generator/lib/siesta.py
@@ -1,94 +1,107 @@
import numpy as np
from dpdata.periodic_table import Element
+
def _make_siesta_01_common(sys_data, fp_params):
- tot_natoms = sum(sys_data['atom_numbs'])
- ntypes = len(sys_data['atom_names'])
+ tot_natoms = sum(sys_data["atom_numbs"])
+ ntypes = len(sys_data["atom_names"])
ret = ""
- ret += 'SystemName system\n'
- ret += 'SystemLabel system\n'
- ret += 'NumberOfAtoms %d\n' % tot_natoms
- ret += 'NumberOfSpecies %d\n' % ntypes
- ret += '\n'
- ret += 'WriteForces T\n'
- ret += 'WriteCoorStep T\n'
- ret += 'WriteCoorXmol T\n'
- ret += 'WriteMDXmol T\n'
- ret += 'WriteMDHistory T\n\n'
-
- if 'ecut' in fp_params.keys():
- ecut = fp_params['ecut']
- ret += 'MeshCutoff %s' % str(ecut)
- ret += ' Ry\n'
- if 'ediff' in fp_params.keys():
- ediff = fp_params['ediff']
- ret += 'DM.Tolerance %e\n' % ediff
- if 'mixWeight' in fp_params.keys():
- mixingWeight = fp_params['mixingWeight']
- ret += 'DM.MixingWeight %f\n' % mixingWeight
- if 'NumberPulay' in fp_params.keys():
- NumberPulay = fp_params['NumberPulay']
- ret += 'DM.NumberPulay %d\n' % NumberPulay
- ret += 'DM.UseSaveDM true\n'
- ret += 'XC.functional GGA\n'
- ret += 'XC.authors PBE\n'
- ret += 'MD.UseSaveXV T\n\n'
- ret += 'DM.UseSaveDM F\n'
- ret += 'WriteDM F\n'
- ret += 'WriteDM.NetCDF F\n'
- ret += 'WriteDMHS.NetCDF F\n'
+ ret += "SystemName system\n"
+ ret += "SystemLabel system\n"
+ ret += "NumberOfAtoms %d\n" % tot_natoms
+ ret += "NumberOfSpecies %d\n" % ntypes
+ ret += "\n"
+ ret += "WriteForces T\n"
+ ret += "WriteCoorStep T\n"
+ ret += "WriteCoorXmol T\n"
+ ret += "WriteMDXmol T\n"
+ ret += "WriteMDHistory T\n\n"
+
+ if "ecut" in fp_params.keys():
+ ecut = fp_params["ecut"]
+ ret += "MeshCutoff %s" % str(ecut)
+ ret += " Ry\n"
+ if "ediff" in fp_params.keys():
+ ediff = fp_params["ediff"]
+ ret += "DM.Tolerance %e\n" % ediff
+ if "mixWeight" in fp_params.keys():
+ mixingWeight = fp_params["mixingWeight"]
+ ret += "DM.MixingWeight %f\n" % mixingWeight
+ if "NumberPulay" in fp_params.keys():
+ NumberPulay = fp_params["NumberPulay"]
+ ret += "DM.NumberPulay %d\n" % NumberPulay
+ ret += "DM.UseSaveDM true\n"
+ ret += "XC.functional GGA\n"
+ ret += "XC.authors PBE\n"
+ ret += "MD.UseSaveXV T\n\n"
+ ret += "DM.UseSaveDM F\n"
+ ret += "WriteDM F\n"
+ ret += "WriteDM.NetCDF F\n"
+ ret += "WriteDMHS.NetCDF F\n"
return ret
+
def _make_siesta_02_species(sys_data, pps):
- atom_nums = sys_data['atom_numbs']
- atom_names = sys_data['atom_names']
+ atom_nums = sys_data["atom_numbs"]
+ atom_names = sys_data["atom_names"]
ntypes = len(atom_nums)
- assert (ntypes == len(atom_names))
- assert (ntypes == len(pps))
- ret = ''
- ret += '%block Chemical_Species_label\n'
+ assert ntypes == len(atom_names)
+ assert ntypes == len(pps)
+ ret = ""
+ ret += "%block Chemical_Species_label\n"
for i in range(0, len(atom_names)):
- ret += str(i + 1) + '\t' + str(Element(atom_names[i]).Z) + '\t' + atom_names[i] + '\n'
- ret += '%endblock Chemical_Species_label\n'
+ ret += (
+ str(i + 1)
+ + "\t"
+ + str(Element(atom_names[i]).Z)
+ + "\t"
+ + atom_names[i]
+ + "\n"
+ )
+ ret += "%endblock Chemical_Species_label\n"
return ret
+
# ## kpoints !!!
def _make_siesta_03_kpoint(sys_data, fp_param):
- if 'kspacing' in fp_param.keys():
- kspacing = fp_param['kspacing']
- cell = sys_data['cells'][0]
+ if "kspacing" in fp_param.keys():
+ kspacing = fp_param["kspacing"]
+ cell = sys_data["cells"][0]
cell = np.reshape(cell, [3, 3])
rcell = np.linalg.inv(cell)
rcell = rcell.T
- kpoints = [(np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int))
- for ii in rcell]
+ kpoints = [
+ (np.ceil(2 * np.pi * np.linalg.norm(ii) / kspacing).astype(int))
+ for ii in rcell
+ ]
ret = ""
- ret += '%block kgrid_Monkhorst_Pack\n'
- ret += '%d' % kpoints[0]
- ret += '\t0\t0\t0.0\n'
+ ret += "%block kgrid_Monkhorst_Pack\n"
+ ret += "%d" % kpoints[0]
+ ret += "\t0\t0\t0.0\n"
- ret += '0\t'
- ret += '%d' % kpoints[1]
- ret += '\t0\t0.0\n'
+ ret += "0\t"
+ ret += "%d" % kpoints[1]
+ ret += "\t0\t0.0\n"
- ret += '0\t0\t'
- ret += '%d' % kpoints[2]
- ret += '\t0.0\n'
+ ret += "0\t0\t"
+ ret += "%d" % kpoints[2]
+ ret += "\t0.0\n"
- ret += '%endblock kgrid_Monkhorst_Pack\n'
+ ret += "%endblock kgrid_Monkhorst_Pack\n"
return ret
else:
- return ''
+ return ""
+
### coordinate
def _make_siesta_04_ucVectorCoord(sys_data):
- cell = sys_data['cells'][0]
+ cell = sys_data["cells"][0]
cell = np.reshape(cell, [3, 3])
- coordinates = sys_data['coords'][0]
- atom_names = (sys_data['atom_names'])
- atom_numbs = (sys_data['atom_numbs'])
+ coordinates = sys_data["coords"][0]
+ atom_names = sys_data["atom_names"]
+ atom_numbs = sys_data["atom_numbs"]
ntypes = len(atom_names)
ret = ""
ret += "LatticeConstant 1.00 Ang\n"
@@ -105,15 +118,18 @@ def _make_siesta_04_ucVectorCoord(sys_data):
cc = 0
for ii in range(ntypes):
for jj in range(atom_numbs[ii]):
- ret += "%f %f %f %d %s\n" % (coordinates[cc][0],
- coordinates[cc][1],
- coordinates[cc][2],
- ii + 1,
- atom_names[ii])
+ ret += "%f %f %f %d %s\n" % (
+ coordinates[cc][0],
+ coordinates[cc][1],
+ coordinates[cc][2],
+ ii + 1,
+ atom_names[ii],
+ )
cc += 1
ret += "%endblock AtomicCoordinatesAndAtomicSpecies"
return ret
+
def make_siesta_input(sys_data, fp_pp_files, fp_params):
ret = ""
ret += _make_siesta_01_common(sys_data, fp_params)
@@ -125,4 +141,3 @@ def make_siesta_input(sys_data, fp_pp_files, fp_params):
ret += _make_siesta_04_ucVectorCoord(sys_data)
ret += "\n"
return ret
-
diff --git a/dpgen/generator/lib/utils.py b/dpgen/generator/lib/utils.py
index 772d379ce..10c1ae360 100644
--- a/dpgen/generator/lib/utils.py
+++ b/dpgen/generator/lib/utils.py
@@ -1,73 +1,85 @@
#!/usr/bin/env python3
-import os, re, shutil, logging
import glob
+import logging
+import os
+import re
+import shutil
iter_format = "%06d"
task_format = "%02d"
log_iter_head = "iter " + iter_format + " task " + task_format + ": "
-def make_iter_name (iter_index) :
+
+def make_iter_name(iter_index):
return "iter." + (iter_format % iter_index)
-def create_path (path) :
- path += '/'
- if os.path.isdir(path) :
- dirname = os.path.dirname(path)
+
+def create_path(path):
+ path += "/"
+ if os.path.isdir(path):
+ dirname = os.path.dirname(path)
counter = 0
- while True :
+ while True:
bk_dirname = dirname + ".bk%03d" % counter
- if not os.path.isdir(bk_dirname) :
- shutil.move (dirname, bk_dirname)
+ if not os.path.isdir(bk_dirname):
+ shutil.move(dirname, bk_dirname)
break
counter += 1
- os.makedirs (path)
-
-def replace (file_name, pattern, subst) :
- file_handel = open (file_name, 'r')
- file_string = file_handel.read ()
- file_handel.close ()
- file_string = ( re.sub (pattern, subst, file_string) )
- file_handel = open (file_name, 'w')
- file_handel.write (file_string)
- file_handel.close ()
-
-def copy_file_list (file_list, from_path, to_path) :
- for jj in file_list :
- if os.path.isfile(os.path.join(from_path, jj)) :
- shutil.copy (os.path.join(from_path, jj), to_path)
- elif os.path.isdir(os.path.join(from_path, jj)) :
- shutil.copytree (os.path.join(from_path, jj), os.path.join(to_path, jj))
-
-def cmd_append_log (cmd,
- log_file) :
+ os.makedirs(path)
+
+
+def replace(file_name, pattern, subst):
+ file_handel = open(file_name, "r")
+ file_string = file_handel.read()
+ file_handel.close()
+ file_string = re.sub(pattern, subst, file_string)
+ file_handel = open(file_name, "w")
+ file_handel.write(file_string)
+ file_handel.close()
+
+
+def copy_file_list(file_list, from_path, to_path):
+ for jj in file_list:
+ if os.path.isfile(os.path.join(from_path, jj)):
+ shutil.copy(os.path.join(from_path, jj), to_path)
+ elif os.path.isdir(os.path.join(from_path, jj)):
+ shutil.copytree(os.path.join(from_path, jj), os.path.join(to_path, jj))
+
+
+def cmd_append_log(cmd, log_file):
ret = cmd
ret = ret + " 1> " + log_file
ret = ret + " 2> " + log_file
return ret
-def log_iter (task, ii, jj) :
- logging.info ((log_iter_head + "%s") % (ii, jj, task))
+
+def log_iter(task, ii, jj):
+ logging.info((log_iter_head + "%s") % (ii, jj, task))
+
def repeat_to_length(string_to_expand, length):
ret = ""
- for ii in range (length) :
+ for ii in range(length):
ret += string_to_expand
return ret
-def log_task (message) :
- header = repeat_to_length (" ", len(log_iter_head % (0, 0)))
- logging.info (header + message)
-def record_iter (record, ii, jj) :
- with open (record, "a") as frec :
- frec.write ("%d %d\n" % (ii, jj))
+def log_task(message):
+ header = repeat_to_length(" ", len(log_iter_head % (0, 0)))
+ logging.info(header + message)
+
-def symlink_user_forward_files(mdata, task_type, work_path, task_format = None):
- '''
+def record_iter(record, ii, jj):
+ with open(record, "a") as frec:
+ frec.write("%d %d\n" % (ii, jj))
+
+
+def symlink_user_forward_files(mdata, task_type, work_path, task_format=None):
+ """
Symlink user-defined forward_common_files
Current path should be work_path, such as 00.train
-
+
Parameters
---------
mdata : dict
@@ -79,19 +91,20 @@ def symlink_user_forward_files(mdata, task_type, work_path, task_format = None):
Returns
-------
None
- '''
+ """
user_forward_files = mdata.get(task_type + "_" + "user_forward_files", [])
- #Angus: In the future, we may unify the task format.
+ # Angus: In the future, we may unify the task format.
if task_format is None:
- task_format = {"train" : "0*", "model_devi" : "task.*", "fp": "task.*"}
- #"init_relax" : "sys-*", "init_md" : "sys-*/scale*/00*"
+ task_format = {"train": "0*", "model_devi": "task.*", "fp": "task.*"}
+ # "init_relax" : "sys-*", "init_md" : "sys-*/scale*/00*"
for file in user_forward_files:
- assert os.path.isfile(file) ,\
- "user_forward_file %s of %s stage doesn't exist. " % (file, task_type)
+ assert os.path.isfile(
+ file
+ ), "user_forward_file %s of %s stage doesn't exist. " % (file, task_type)
tasks = glob.glob(os.path.join(work_path, task_format[task_type]))
for task in tasks:
if os.path.isfile(os.path.join(task, os.path.basename(file))):
os.remove(os.path.join(task, os.path.basename(file)))
- os.symlink(file, os.path.join(task, os.path.basename(file)))
+ abs_file = os.path.abspath(file)
+ os.symlink(abs_file, os.path.join(task, os.path.basename(file)))
return
-
\ No newline at end of file
diff --git a/dpgen/generator/lib/vasp.py b/dpgen/generator/lib/vasp.py
index b6846d19e..dcfbf0e43 100644
--- a/dpgen/generator/lib/vasp.py
+++ b/dpgen/generator/lib/vasp.py
@@ -1,121 +1,141 @@
-#!/usr/bin/python3
+#!/usr/bin/python3
import os
+
import numpy as np
from pymatgen.io.vasp import Incar
-def _make_vasp_incar_dict (ecut, ediff, npar, kpar,
- kspacing = 0.5, kgamma = True,
- smearing = None, sigma = None,
- metagga = None) :
+
+def _make_vasp_incar_dict(
+ ecut,
+ ediff,
+ npar,
+ kpar,
+ kspacing=0.5,
+ kgamma=True,
+ smearing=None,
+ sigma=None,
+ metagga=None,
+):
incar_dict = {}
- incar_dict['PREC'] = 'A'
- incar_dict['ENCUT'] = ecut
- incar_dict['ISYM'] = 0
- incar_dict['ALGO'] = 'fast'
- incar_dict['EDIFF'] = ediff
- incar_dict['LREAL'] = 'A'
- incar_dict['NPAR'] = npar
- incar_dict['KPAR'] = kpar
- incar_dict['NELMIN'] = 4
- incar_dict['ISIF'] = 2
- if smearing is not None :
- incar_dict['ISMEAR'] = smearing
- if sigma is not None :
- incar_dict['SIGMA'] = sigma
- incar_dict['IBRION'] = -1
- incar_dict['NSW'] = 0
- incar_dict['LWAVE'] = 'F'
- incar_dict['LCHARG'] = 'F'
- incar_dict['PSTRESS'] = 0
- incar_dict['KSPACING'] = kspacing
+ incar_dict["PREC"] = "A"
+ incar_dict["ENCUT"] = ecut
+ incar_dict["ISYM"] = 0
+ incar_dict["ALGO"] = "fast"
+ incar_dict["EDIFF"] = ediff
+ incar_dict["LREAL"] = "A"
+ incar_dict["NPAR"] = npar
+ incar_dict["KPAR"] = kpar
+ incar_dict["NELMIN"] = 4
+ incar_dict["ISIF"] = 2
+ if smearing is not None:
+ incar_dict["ISMEAR"] = smearing
+ if sigma is not None:
+ incar_dict["SIGMA"] = sigma
+ incar_dict["IBRION"] = -1
+ incar_dict["NSW"] = 0
+ incar_dict["LWAVE"] = "F"
+ incar_dict["LCHARG"] = "F"
+ incar_dict["PSTRESS"] = 0
+ incar_dict["KSPACING"] = kspacing
if kgamma:
- incar_dict['KGAMMA'] = 'T'
- else :
- incar_dict['KGAMMA'] = 'F'
- if metagga is not None :
- incar_dict['LASPH'] = 'T'
- incar_dict['METAGGA'] = metagga
+ incar_dict["KGAMMA"] = "T"
+ else:
+ incar_dict["KGAMMA"] = "F"
+ if metagga is not None:
+ incar_dict["LASPH"] = "T"
+ incar_dict["METAGGA"] = metagga
return incar_dict
-def _update_incar_dict(incar_dict_, user_dict) :
+
+def _update_incar_dict(incar_dict_, user_dict):
if user_dict is None:
return incar_dict_
incar_dict = incar_dict_
- for ii in user_dict :
+ for ii in user_dict:
ci = ii.upper()
incar_dict[ci] = user_dict[ii]
return incar_dict
-def write_incar_dict(incar_dict) :
+
+def write_incar_dict(incar_dict):
lines = []
for key in incar_dict:
- if (type(incar_dict[key]) == bool):
+ if type(incar_dict[key]) == bool:
if incar_dict[key]:
- rs = 'T'
- else :
- rs = 'F'
- else :
+ rs = "T"
+ else:
+ rs = "F"
+ else:
rs = str(incar_dict[key])
- lines.append('%s=%s' % (key, rs))
- return '\n'.join(lines)
+ lines.append("%s=%s" % (key, rs))
+ return "\n".join(lines)
-def _make_smearing(fp_params) :
+def _make_smearing(fp_params):
smearing = None
sigma = None
- if 'smearing' in fp_params :
- smearing = fp_params['smearing']
- if 'sigma' in fp_params :
- sigma = fp_params['sigma']
- if smearing == None :
+ if "smearing" in fp_params:
+ smearing = fp_params["smearing"]
+ if "sigma" in fp_params:
+ sigma = fp_params["sigma"]
+ if smearing == None:
return None, sigma
- smearing_method = (smearing.split(':')[0]).lower()
- if smearing_method == 'mp' :
+ smearing_method = (smearing.split(":")[0]).lower()
+ if smearing_method == "mp":
order = 1
- if len(smearing.split(':')) == 2 :
- order = int(smearing.split(':')[1])
+ if len(smearing.split(":")) == 2:
+ order = int(smearing.split(":")[1])
return order, sigma
- elif smearing_method == 'gauss' :
+ elif smearing_method == "gauss":
return 0, sigma
- elif smearing_method == 'fd' :
+ elif smearing_method == "fd":
return -1, sigma
- else :
+ else:
raise RuntimeError("unsuppported smearing method %s " % smearing_method)
-def _make_metagga(fp_params) :
+
+def _make_metagga(fp_params):
metagga = None
- if 'metagga' in fp_params :
- metagga = fp_params['metagga']
- if metagga == 'NONE':
+ if "metagga" in fp_params:
+ metagga = fp_params["metagga"]
+ if metagga == "NONE":
metagga = None
- elif metagga not in [None,'SCAN', 'TPSS', 'RTPSS', 'M06L', 'MBJ'] :
- raise RuntimeError ("unknown metagga method " + metagga)
+ elif metagga not in [None, "SCAN", "TPSS", "RTPSS", "M06L", "MBJ"]:
+ raise RuntimeError("unknown metagga method " + metagga)
return metagga
-
-def make_vasp_incar_user_dict(fp_params) :
- ecut = fp_params['ecut']
- ediff = fp_params['ediff']
- npar = fp_params['npar']
- kpar = fp_params['kpar']
- kspacing = fp_params['kspacing']
- if 'user_vasp_params' in fp_params :
- user_dict = fp_params['user_vasp_params']
- else :
+
+
+def make_vasp_incar_user_dict(fp_params):
+ ecut = fp_params["ecut"]
+ ediff = fp_params["ediff"]
+ npar = fp_params["npar"]
+ kpar = fp_params["kpar"]
+ kspacing = fp_params["kspacing"]
+ if "user_vasp_params" in fp_params:
+ user_dict = fp_params["user_vasp_params"]
+ else:
user_dict = None
smearing, sigma = _make_smearing(fp_params)
metagga = _make_metagga(fp_params)
- incar_dict = _make_vasp_incar_dict(ecut, ediff, npar, kpar,
- kspacing = kspacing, kgamma = False,
- smearing = smearing, sigma = sigma,
- metagga = metagga
+ incar_dict = _make_vasp_incar_dict(
+ ecut,
+ ediff,
+ npar,
+ kpar,
+ kspacing=kspacing,
+ kgamma=False,
+ smearing=smearing,
+ sigma=sigma,
+ metagga=metagga,
)
incar_dict = _update_incar_dict(incar_dict, user_dict)
incar = write_incar_dict(incar_dict)
return incar
-
+
+
def incar_upper(dincar):
- standard_incar={}
- for key,val in dincar.items():
- standard_incar[key.upper()]=val
+ standard_incar = {}
+ for key, val in dincar.items():
+ standard_incar[key.upper()] = val
return Incar(standard_incar)
diff --git a/dpgen/generator/run.py b/dpgen/generator/run.py
index f0b12ae4a..9984d058e 100644
--- a/dpgen/generator/run.py
+++ b/dpgen/generator/run.py
@@ -9,186 +9,231 @@
03.data
"""
-import os
-import sys
import argparse
+import copy
import glob
+import itertools
import json
-import random
import logging
import logging.handlers
+import os
import queue
-import warnings
+import random
import shutil
-import itertools
-import copy
-import dpdata
-import numpy as np
import subprocess as sp
-import scipy.constants as pc
+import sys
+import warnings
from collections import Counter
from collections.abc import Iterable
-from distutils.version import LooseVersion
from typing import List
-from numpy.linalg import norm
-from dpgen import dlog
-from dpgen import SHORT_CMD
-from dpgen.generator.lib.utils import make_iter_name
-from dpgen.generator.lib.utils import create_path
-from dpgen.generator.lib.utils import copy_file_list
-from dpgen.generator.lib.utils import replace
-from dpgen.generator.lib.utils import log_iter
-from dpgen.generator.lib.utils import record_iter
-from dpgen.generator.lib.utils import log_task
-from dpgen.generator.lib.utils import symlink_user_forward_files
-from dpgen.generator.lib.lammps import make_lammps_input, get_dumped_forces, get_all_dumped_forces
-from dpgen.generator.lib.make_calypso import _make_model_devi_native_calypso,_make_model_devi_buffet
-from dpgen.generator.lib.run_calypso import gen_structures,analysis,run_calypso_model_devi
-from dpgen.generator.lib.parse_calypso import _parse_calypso_input,_parse_calypso_dis_mtx
-from dpgen.generator.lib.vasp import write_incar_dict
-from dpgen.generator.lib.vasp import make_vasp_incar_user_dict
-from dpgen.generator.lib.vasp import incar_upper
+
+import dpdata
+import numpy as np
+import scipy.constants as pc
+from numpy.linalg import norm
+from packaging.version import Version
+from pymatgen.io.vasp import Incar, Kpoints, Potcar
+
+from dpgen import ROOT_PATH, SHORT_CMD, dlog
+from dpgen.auto_test.lib.vasp import make_kspacing_kpoints
+from dpgen.dispatcher.Dispatcher import make_submission
+from dpgen.generator.lib.abacus_scf import (
+ get_abacus_input_parameters,
+ get_abacus_STRU,
+ make_abacus_scf_input,
+ make_abacus_scf_kpt,
+ make_abacus_scf_stru,
+)
+from dpgen.generator.lib.cp2k import (
+ make_cp2k_input,
+ make_cp2k_input_from_external,
+ make_cp2k_xyz,
+)
+from dpgen.generator.lib.ele_temp import NBandsEsti
+from dpgen.generator.lib.gaussian import make_gaussian_input, take_cluster
+from dpgen.generator.lib.lammps import (
+ get_all_dumped_forces,
+ get_dumped_forces,
+ make_lammps_input,
+)
+from dpgen.generator.lib.make_calypso import (
+ _make_model_devi_buffet,
+ _make_model_devi_native_calypso,
+)
+from dpgen.generator.lib.parse_calypso import (
+ _parse_calypso_dis_mtx,
+ _parse_calypso_input,
+)
+
+# from dpgen.generator.lib.pwscf import cvt_1frame
+from dpgen.generator.lib.pwmat import (
+ input_upper,
+ make_pwmat_input_dict,
+ make_pwmat_input_user_dict,
+ write_input_dict,
+)
from dpgen.generator.lib.pwscf import make_pwscf_input
-from dpgen.generator.lib.abacus_scf import make_abacus_scf_stru, make_abacus_scf_input, make_abacus_scf_kpt
-from dpgen.generator.lib.abacus_scf import get_abacus_input_parameters
-#from dpgen.generator.lib.pwscf import cvt_1frame
-from dpgen.generator.lib.pwmat import make_pwmat_input_dict
-from dpgen.generator.lib.pwmat import write_input_dict
-from dpgen.generator.lib.pwmat import make_pwmat_input_user_dict
-from dpgen.generator.lib.pwmat import input_upper
+from dpgen.generator.lib.run_calypso import (
+ analysis,
+ gen_structures,
+ run_calypso_model_devi,
+)
from dpgen.generator.lib.siesta import make_siesta_input
-from dpgen.generator.lib.gaussian import make_gaussian_input, take_cluster
-from dpgen.generator.lib.cp2k import make_cp2k_input, make_cp2k_input_from_external, make_cp2k_xyz
-from dpgen.generator.lib.ele_temp import NBandsEsti
+from dpgen.generator.lib.utils import (
+ copy_file_list,
+ create_path,
+ log_iter,
+ log_task,
+ make_iter_name,
+ record_iter,
+ replace,
+ symlink_user_forward_files,
+)
+from dpgen.generator.lib.vasp import (
+ incar_upper,
+ make_vasp_incar_user_dict,
+ write_incar_dict,
+)
from dpgen.remote.decide_machine import convert_mdata
-from dpgen.dispatcher.Dispatcher import Dispatcher, _split_tasks, make_dispatcher, make_submission
-from dpgen.util import sepline, expand_sys_str, normalize
-from dpgen import ROOT_PATH
-from pymatgen.io.vasp import Incar,Kpoints,Potcar
-from dpgen.auto_test.lib.vasp import make_kspacing_kpoints
-from .arginfo import run_jdata_arginfo
+from dpgen.util import convert_training_data_to_hdf5, expand_sys_str, normalize, sepline
+from .arginfo import run_jdata_arginfo
-template_name = 'template'
-train_name = '00.train'
-train_task_fmt = '%03d'
+template_name = "template"
+train_name = "00.train"
+train_task_fmt = "%03d"
train_tmpl_path = os.path.join(template_name, train_name)
-default_train_input_file = 'input.json'
-data_system_fmt = '%03d'
-model_devi_name = '01.model_devi'
-model_devi_task_fmt = data_system_fmt + '.%06d'
-model_devi_conf_fmt = data_system_fmt + '.%04d'
-fp_name = '02.fp'
-fp_task_fmt = data_system_fmt + '.%06d'
-cvasp_file=os.path.join(ROOT_PATH,'generator/lib/cvasp.py')
-# for calypso
-calypso_run_opt_name = 'gen_stru_analy'
-calypso_model_devi_name = 'model_devi_results'
-calypso_run_model_devi_file = os.path.join(ROOT_PATH,'generator/lib/calypso_run_model_devi.py')
-check_outcar_file = os.path.join(ROOT_PATH,'generator/lib/calypso_check_outcar.py')
-run_opt_file = os.path.join(ROOT_PATH,'generator/lib/calypso_run_opt.py')
-
-def get_job_names(jdata) :
+default_train_input_file = "input.json"
+data_system_fmt = "%03d"
+model_devi_name = "01.model_devi"
+model_devi_task_fmt = data_system_fmt + ".%06d"
+model_devi_conf_fmt = data_system_fmt + ".%04d"
+fp_name = "02.fp"
+fp_task_fmt = data_system_fmt + ".%06d"
+cvasp_file = os.path.join(ROOT_PATH, "generator/lib/cvasp.py")
+# for calypso
+calypso_run_opt_name = "gen_stru_analy"
+calypso_model_devi_name = "model_devi_results"
+calypso_run_model_devi_file = os.path.join(
+ ROOT_PATH, "generator/lib/calypso_run_model_devi.py"
+)
+check_outcar_file = os.path.join(ROOT_PATH, "generator/lib/calypso_check_outcar.py")
+run_opt_file = os.path.join(ROOT_PATH, "generator/lib/calypso_run_opt.py")
+
+
+def get_job_names(jdata):
jobkeys = []
- for ii in jdata.keys() :
- if ii.split('_')[0] == "job" :
+ for ii in jdata.keys():
+ if ii.split("_")[0] == "job":
jobkeys.append(ii)
jobkeys.sort()
return jobkeys
-def make_model_devi_task_name (sys_idx, task_idx) :
+
+def make_model_devi_task_name(sys_idx, task_idx):
return "task." + model_devi_task_fmt % (sys_idx, task_idx)
-def make_model_devi_conf_name (sys_idx, conf_idx) :
+
+def make_model_devi_conf_name(sys_idx, conf_idx):
return model_devi_conf_fmt % (sys_idx, conf_idx)
-def make_fp_task_name(sys_idx, counter) :
- return 'task.' + fp_task_fmt % (sys_idx, counter)
-def get_sys_index(task) :
+def make_fp_task_name(sys_idx, counter):
+ return "task." + fp_task_fmt % (sys_idx, counter)
+
+
+def get_sys_index(task):
task.sort()
system_index = []
- for ii in task :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in task:
+ system_index.append(os.path.basename(ii).split(".")[1])
set_tmp = set(system_index)
system_index = list(set_tmp)
system_index.sort()
return system_index
-def _check_empty_iter(iter_index, max_v = 0) :
+
+def _check_empty_iter(iter_index, max_v=0):
fp_path = os.path.join(make_iter_name(iter_index), fp_name)
# check the number of collected data
sys_data = glob.glob(os.path.join(fp_path, "data.*"))
empty_sys = []
- for ii in sys_data :
+ for ii in sys_data:
nframe = 0
sys_paths = expand_sys_str(ii)
for single_sys in sys_paths:
- sys = dpdata.LabeledSystem(os.path.join(single_sys), fmt = 'deepmd/npy')
+ sys = dpdata.LabeledSystem(os.path.join(single_sys), fmt="deepmd/npy")
nframe += len(sys)
empty_sys.append(nframe < max_v)
return all(empty_sys)
-def copy_model(numb_model, prv_iter_index, cur_iter_index) :
- cwd=os.getcwd()
+
+def copy_model(numb_model, prv_iter_index, cur_iter_index):
+ cwd = os.getcwd()
prv_train_path = os.path.join(make_iter_name(prv_iter_index), train_name)
cur_train_path = os.path.join(make_iter_name(cur_iter_index), train_name)
prv_train_path = os.path.abspath(prv_train_path)
cur_train_path = os.path.abspath(cur_train_path)
create_path(cur_train_path)
for ii in range(numb_model):
- prv_train_task = os.path.join(prv_train_path, train_task_fmt%ii)
+ prv_train_task = os.path.join(prv_train_path, train_task_fmt % ii)
os.chdir(cur_train_path)
- os.symlink(os.path.relpath(prv_train_task), train_task_fmt%ii)
- os.symlink(os.path.join(train_task_fmt%ii, 'frozen_model.pb'), 'graph.%03d.pb' % ii)
+ os.symlink(os.path.relpath(prv_train_task), train_task_fmt % ii)
+ os.symlink(
+ os.path.join(train_task_fmt % ii, "frozen_model.pb"), "graph.%03d.pb" % ii
+ )
os.chdir(cwd)
- with open(os.path.join(cur_train_path, "copied"), 'w') as fp:
+ with open(os.path.join(cur_train_path, "copied"), "w") as fp:
None
-def poscar_natoms(lines) :
+
+def poscar_natoms(lines):
numb_atoms = 0
- for ii in lines[6].split() :
+ for ii in lines[6].split():
numb_atoms += int(ii)
return numb_atoms
-def poscar_shuffle(poscar_in, poscar_out) :
- with open(poscar_in, 'r') as fin :
+
+def poscar_shuffle(poscar_in, poscar_out):
+ with open(poscar_in, "r") as fin:
lines = list(fin)
numb_atoms = poscar_natoms(lines)
- idx = np.arange(8, 8+numb_atoms)
+ idx = np.arange(8, 8 + numb_atoms)
np.random.shuffle(idx)
out_lines = lines[0:8]
- for ii in range(numb_atoms) :
+ for ii in range(numb_atoms):
out_lines.append(lines[idx[ii]])
- with open(poscar_out, 'w') as fout:
+ with open(poscar_out, "w") as fout:
fout.write("".join(out_lines))
-def expand_idx (in_list) :
+
+def expand_idx(in_list):
ret = []
- for ii in in_list :
- if type(ii) == int :
+ for ii in in_list:
+ if type(ii) == int:
ret.append(ii)
elif type(ii) == str:
- step_str = ii.split(':')
- if len(step_str) > 1 :
+ step_str = ii.split(":")
+ if len(step_str) > 1:
step = int(step_str[1])
- else :
+ else:
step = 1
- range_str = step_str[0].split('-')
- assert(len(range_str)) == 2
+ range_str = step_str[0].split("-")
+ assert (len(range_str)) == 2
ret += range(int(range_str[0]), int(range_str[1]), step)
return ret
-def _check_skip_train(job) :
- try :
- skip = _get_param_alias(job, ['s_t', 'sk_tr', 'skip_train', 'skip_training'])
- except ValueError :
+
+def _check_skip_train(job):
+ try:
+ skip = _get_param_alias(job, ["s_t", "sk_tr", "skip_train", "skip_training"])
+ except ValueError:
skip = False
return skip
def poscar_to_conf(poscar, conf):
- sys = dpdata.System(poscar, fmt = 'vasp/poscar')
+ sys = dpdata.System(poscar, fmt="vasp/poscar")
sys.to_lammps_lmp(conf)
@@ -196,66 +241,75 @@ def poscar_to_conf(poscar, conf):
# sys = dpdata.System(dump, fmt = fmt, type_map = type_map)
# sys.to_vasp_poscar(poscar)
-def dump_to_deepmd_raw(dump, deepmd_raw, type_map, fmt='gromacs/gro', charge=None):
- system = dpdata.System(dump, fmt = fmt, type_map = type_map)
+
+def dump_to_deepmd_raw(dump, deepmd_raw, type_map, fmt="gromacs/gro", charge=None):
+ system = dpdata.System(dump, fmt=fmt, type_map=type_map)
system.to_deepmd_raw(deepmd_raw)
if charge is not None:
- with open(os.path.join(deepmd_raw, "charge"), 'w') as f:
+ with open(os.path.join(deepmd_raw, "charge"), "w") as f:
f.write(str(charge))
-def make_train (iter_index,
- jdata,
- mdata) :
+def make_train(iter_index, jdata, mdata):
# load json param
# train_param = jdata['train_param']
train_input_file = default_train_input_file
- numb_models = jdata['numb_models']
- init_data_prefix = jdata['init_data_prefix']
+ numb_models = jdata["numb_models"]
+ init_data_prefix = jdata["init_data_prefix"]
init_data_prefix = os.path.abspath(init_data_prefix)
- init_data_sys_ = jdata['init_data_sys']
- fp_task_min = jdata['fp_task_min']
- model_devi_jobs = jdata['model_devi_jobs']
- use_ele_temp = jdata.get('use_ele_temp', 0)
- training_iter0_model = jdata.get('training_iter0_model_path', [])
- training_init_model = jdata.get('training_init_model', False)
- training_reuse_iter = jdata.get('training_reuse_iter')
- training_reuse_old_ratio = jdata.get('training_reuse_old_ratio', None)
-
- if 'training_reuse_stop_batch' in jdata.keys():
- training_reuse_stop_batch = jdata['training_reuse_stop_batch']
- elif 'training_reuse_numb_steps' in jdata.keys():
- training_reuse_stop_batch = jdata['training_reuse_numb_steps']
+ init_data_sys_ = jdata["init_data_sys"]
+ fp_task_min = jdata["fp_task_min"]
+ model_devi_jobs = jdata["model_devi_jobs"]
+ use_ele_temp = jdata.get("use_ele_temp", 0)
+ training_iter0_model = jdata.get("training_iter0_model_path", [])
+ training_init_model = jdata.get("training_init_model", False)
+ training_reuse_iter = jdata.get("training_reuse_iter")
+ training_reuse_old_ratio = jdata.get("training_reuse_old_ratio", None)
+
+ # if you want to use DP-ZBL potential , you have to give the path of your energy potential file
+ if "srtab_file_path" in jdata.keys():
+ srtab_file_path = os.path.abspath(jdata.get("srtab_file_path", None))
+
+ if "training_reuse_stop_batch" in jdata.keys():
+ training_reuse_stop_batch = jdata["training_reuse_stop_batch"]
+ elif "training_reuse_numb_steps" in jdata.keys():
+ training_reuse_stop_batch = jdata["training_reuse_numb_steps"]
else:
training_reuse_stop_batch = 400000
-
- training_reuse_start_lr = jdata.get('training_reuse_start_lr', 1e-4)
- training_reuse_start_pref_e = jdata.get('training_reuse_start_pref_e', 0.1)
- training_reuse_start_pref_f = jdata.get('training_reuse_start_pref_f', 100)
- model_devi_activation_func = jdata.get('model_devi_activation_func', None)
+
+ training_reuse_start_lr = jdata.get("training_reuse_start_lr", 1e-4)
+ training_reuse_start_pref_e = jdata.get("training_reuse_start_pref_e", 0.1)
+ training_reuse_start_pref_f = jdata.get("training_reuse_start_pref_f", 100)
+ model_devi_activation_func = jdata.get("model_devi_activation_func", None)
if training_reuse_iter is not None and training_reuse_old_ratio is None:
- raise RuntimeError("training_reuse_old_ratio not found but is mandatory when using init-model (training_reuse_iter is detected in param).\n" \
- "It defines the ratio of the old-data picking probability to the all-data(old-data plus new-data) picking probability in training after training_reuse_iter.\n" \
- "Denoting the index of the current iter as N (N >= training_reuse_iter ), old-data refers to those existed before the N-1 iter, and new-data refers to that obtained by the N-1 iter.\n" \
- "A recommended strategy is making the new-to-old ratio close to 10 times of the default value, to reasonably increase the sensitivity of the model to the new-data.\n" \
- "By default, the picking probability of data from one system or one iter is proportional to the number of batches (the number of frames divided by batch_size) of that systems or iter.\n" \
- "Detailed discussion about init-model (in Chinese) please see https://mp.weixin.qq.com/s/qsKMZ0j270YhQKvwXUiFvQ")
-
- model_devi_engine = jdata.get('model_devi_engine', "lammps")
- if iter_index > 0 and _check_empty_iter(iter_index-1, fp_task_min) :
- log_task('prev data is empty, copy prev model')
- copy_model(numb_models, iter_index-1, iter_index)
+ raise RuntimeError(
+ "training_reuse_old_ratio not found but is mandatory when using init-model (training_reuse_iter is detected in param).\n"
+ "It defines the ratio of the old-data picking probability to the all-data(old-data plus new-data) picking probability in training after training_reuse_iter.\n"
+ "Denoting the index of the current iter as N (N >= training_reuse_iter ), old-data refers to those existed before the N-1 iter, and new-data refers to that obtained by the N-1 iter.\n"
+ "A recommended strategy is making the new-to-old ratio close to 10 times of the default value, to reasonably increase the sensitivity of the model to the new-data.\n"
+ "By default, the picking probability of data from one system or one iter is proportional to the number of batches (the number of frames divided by batch_size) of that systems or iter.\n"
+ "Detailed discussion about init-model (in Chinese) please see https://mp.weixin.qq.com/s/qsKMZ0j270YhQKvwXUiFvQ"
+ )
+
+ model_devi_engine = jdata.get("model_devi_engine", "lammps")
+ if iter_index > 0 and _check_empty_iter(iter_index - 1, fp_task_min):
+ log_task("prev data is empty, copy prev model")
+ copy_model(numb_models, iter_index - 1, iter_index)
return
- elif model_devi_engine != 'calypso' and iter_index > 0 and _check_skip_train(model_devi_jobs[iter_index-1]):
- log_task('skip training at step %d ' % (iter_index-1))
- copy_model(numb_models, iter_index-1, iter_index)
+ elif (
+ model_devi_engine != "calypso"
+ and iter_index > 0
+ and _check_skip_train(model_devi_jobs[iter_index - 1])
+ ):
+ log_task("skip training at step %d " % (iter_index - 1))
+ copy_model(numb_models, iter_index - 1, iter_index)
return
- else :
+ else:
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, train_name)
- copy_flag = os.path.join(work_path, 'copied')
- if os.path.isfile(copy_flag) :
+ copy_flag = os.path.join(work_path, "copied")
+ if os.path.isfile(copy_flag):
os.remove(copy_flag)
# establish work path
@@ -265,169 +319,254 @@ def make_train (iter_index,
# link init data
cwd = os.getcwd()
os.chdir(work_path)
- os.symlink(os.path.abspath(init_data_prefix), 'data.init')
+ os.symlink(os.path.abspath(init_data_prefix), "data.init")
# link iter data
- os.mkdir('data.iters')
- os.chdir('data.iters')
- for ii in range(iter_index) :
- os.symlink(os.path.relpath(os.path.join(cwd, make_iter_name(ii))), make_iter_name(ii))
+ os.mkdir("data.iters")
+ os.chdir("data.iters")
+ for ii in range(iter_index):
+ os.symlink(
+ os.path.relpath(os.path.join(cwd, make_iter_name(ii))), make_iter_name(ii)
+ )
os.chdir(cwd)
init_data_sys = []
init_batch_size = []
- if 'init_batch_size' in jdata:
- init_batch_size_ = list(jdata['init_batch_size'])
+ if "init_batch_size" in jdata:
+ init_batch_size_ = list(jdata["init_batch_size"])
if len(init_data_sys_) > len(init_batch_size_):
- warnings.warn("The batch sizes are not enough. Assume auto for those not spefified.")
- init_batch_size.extend(["auto" for aa in range(len(init_data_sys_)-len(init_batch_size))])
+ warnings.warn(
+ "The batch sizes are not enough. Assume auto for those not spefified."
+ )
+ init_batch_size.extend(
+ ["auto" for aa in range(len(init_data_sys_) - len(init_batch_size))]
+ )
else:
- init_batch_size_ = ["auto" for aa in range(len(jdata['init_data_sys']))]
- if 'sys_batch_size' in jdata:
- sys_batch_size = jdata['sys_batch_size']
+ init_batch_size_ = ["auto" for aa in range(len(jdata["init_data_sys"]))]
+ if "sys_batch_size" in jdata:
+ sys_batch_size = jdata["sys_batch_size"]
else:
- sys_batch_size = ["auto" for aa in range(len(jdata['sys_configs']))]
+ sys_batch_size = ["auto" for aa in range(len(jdata["sys_configs"]))]
# make sure all init_data_sys has the batch size -- for the following `zip`
- assert (len(init_data_sys_) <= len(init_batch_size_))
- for ii, ss in zip(init_data_sys_, init_batch_size_) :
+ assert len(init_data_sys_) <= len(init_batch_size_)
+ for ii, ss in zip(init_data_sys_, init_batch_size_):
sys_paths = expand_sys_str(os.path.join(init_data_prefix, ii))
for single_sys in sys_paths:
- init_data_sys.append(os.path.normpath(os.path.join('..', 'data.init', ii, os.path.relpath(single_sys, os.path.join(init_data_prefix, ii)))))
+ init_data_sys.append(
+ os.path.normpath(
+ os.path.join(
+ "..",
+ "data.init",
+ ii,
+ os.path.relpath(single_sys, os.path.join(init_data_prefix, ii)),
+ )
+ )
+ )
init_batch_size.append(detect_batch_size(ss, single_sys))
old_range = None
- if iter_index > 0 :
- for ii in range(iter_index) :
+ if iter_index > 0:
+ for ii in range(iter_index):
if ii == iter_index - 1:
old_range = len(init_data_sys)
fp_path = os.path.join(make_iter_name(ii), fp_name)
fp_data_sys = glob.glob(os.path.join(fp_path, "data.*"))
- if model_devi_engine == 'calypso':
- _modd_path = os.path.join(make_iter_name(ii), model_devi_name, calypso_model_devi_name)
+ if model_devi_engine == "calypso":
+ _modd_path = os.path.join(
+ make_iter_name(ii), model_devi_name, calypso_model_devi_name
+ )
sys_list = glob.glob(os.path.join(_modd_path, "*.structures"))
sys_batch_size = ["auto" for aa in range(len(sys_list))]
- for jj in fp_data_sys :
- sys_idx = int(jj.split('.')[-1])
+ for jj in fp_data_sys:
+ sys_idx = int(jj.split(".")[-1])
sys_paths = expand_sys_str(jj)
nframes = 0
for sys_single in sys_paths:
- nframes += dpdata.LabeledSystem(sys_single, fmt="deepmd/npy").get_nframes()
- if nframes < fp_task_min :
- log_task('nframes (%d) in data sys %s is too small, skip' % (nframes, jj))
+ nframes += dpdata.LabeledSystem(
+ sys_single, fmt="deepmd/npy"
+ ).get_nframes()
+ if nframes < fp_task_min:
+ log_task(
+ "nframes (%d) in data sys %s is too small, skip" % (nframes, jj)
+ )
continue
for sys_single in sys_paths:
- init_data_sys.append(os.path.normpath(os.path.join('..', 'data.iters', sys_single)))
- init_batch_size.append(detect_batch_size(sys_batch_size[sys_idx], sys_single))
+ init_data_sys.append(
+ os.path.normpath(os.path.join("..", "data.iters", sys_single))
+ )
+ init_batch_size.append(
+ detect_batch_size(sys_batch_size[sys_idx], sys_single)
+ )
# establish tasks
- jinput = jdata['default_training_param']
+ jinput = jdata["default_training_param"]
try:
mdata["deepmd_version"]
except KeyError:
mdata = set_version(mdata)
# setup data systems
- if LooseVersion(mdata["deepmd_version"]) >= LooseVersion('1') and LooseVersion(mdata["deepmd_version"]) < LooseVersion('2'):
+ if Version(mdata["deepmd_version"]) >= Version("1") and Version(
+ mdata["deepmd_version"]
+ ) < Version("2"):
# 1.x
- jinput['training']['systems'] = init_data_sys
- jinput['training']['batch_size'] = init_batch_size
- jinput['model']['type_map'] = jdata['type_map']
+ jinput["training"]["systems"] = init_data_sys
+ jinput["training"]["batch_size"] = init_batch_size
+ jinput["model"]["type_map"] = jdata["type_map"]
# electron temperature
if use_ele_temp == 0:
pass
elif use_ele_temp == 1:
- jinput['model']['fitting_net']['numb_fparam'] = 1
- jinput['model']['fitting_net'].pop('numb_aparam', None)
+ jinput["model"]["fitting_net"]["numb_fparam"] = 1
+ jinput["model"]["fitting_net"].pop("numb_aparam", None)
elif use_ele_temp == 2:
- jinput['model']['fitting_net']['numb_aparam'] = 1
- jinput['model']['fitting_net'].pop('numb_fparam', None)
+ jinput["model"]["fitting_net"]["numb_aparam"] = 1
+ jinput["model"]["fitting_net"].pop("numb_fparam", None)
else:
- raise RuntimeError('invalid setting for use_ele_temp ' + str(use_ele_temp))
- elif LooseVersion(mdata["deepmd_version"]) >= LooseVersion('2') and LooseVersion(mdata["deepmd_version"]) < LooseVersion('3'):
+ raise RuntimeError("invalid setting for use_ele_temp " + str(use_ele_temp))
+ elif Version(mdata["deepmd_version"]) >= Version("2") and Version(
+ mdata["deepmd_version"]
+ ) < Version("3"):
# 2.x
- jinput['training']['training_data'] = {}
- jinput['training']['training_data']['systems'] = init_data_sys
- jinput['training']['training_data']['batch_size'] = init_batch_size
- jinput['model']['type_map'] = jdata['type_map']
+ jinput["training"]["training_data"] = {}
+ jinput["training"]["training_data"]["systems"] = init_data_sys
+ jinput["training"]["training_data"]["batch_size"] = init_batch_size
+ jinput["model"]["type_map"] = jdata["type_map"]
# electron temperature
if use_ele_temp == 0:
pass
elif use_ele_temp == 1:
- jinput['model']['fitting_net']['numb_fparam'] = 1
- jinput['model']['fitting_net'].pop('numb_aparam', None)
+ jinput["model"]["fitting_net"]["numb_fparam"] = 1
+ jinput["model"]["fitting_net"].pop("numb_aparam", None)
elif use_ele_temp == 2:
- jinput['model']['fitting_net']['numb_aparam'] = 1
- jinput['model']['fitting_net'].pop('numb_fparam', None)
+ jinput["model"]["fitting_net"]["numb_aparam"] = 1
+ jinput["model"]["fitting_net"].pop("numb_fparam", None)
else:
- raise RuntimeError('invalid setting for use_ele_temp ' + str(use_ele_temp))
+ raise RuntimeError("invalid setting for use_ele_temp " + str(use_ele_temp))
else:
- raise RuntimeError("DP-GEN currently only supports for DeePMD-kit 1.x or 2.x version!" )
+ raise RuntimeError(
+ "DP-GEN currently only supports for DeePMD-kit 1.x or 2.x version!"
+ )
# set training reuse model
if training_reuse_iter is not None and iter_index >= training_reuse_iter:
- if LooseVersion('1') <= LooseVersion(mdata["deepmd_version"]) < LooseVersion('2'):
- jinput['training']['stop_batch'] = training_reuse_stop_batch
- jinput['training']['auto_prob_style'] \
- ="prob_sys_size; 0:%d:%f; %d:%d:%f" \
- %(old_range, training_reuse_old_ratio, old_range, len(init_data_sys), 1.-training_reuse_old_ratio)
- elif LooseVersion('2') <= LooseVersion(mdata["deepmd_version"]) < LooseVersion('3'):
- jinput['training']['numb_steps'] = training_reuse_stop_batch
- jinput['training']['training_data']['auto_prob'] \
- ="prob_sys_size; 0:%d:%f; %d:%d:%f" \
- %(old_range, training_reuse_old_ratio, old_range, len(init_data_sys), 1.-training_reuse_old_ratio)
+ if "numb_steps" in jinput["training"] and training_reuse_stop_batch is not None:
+ jinput["training"]["numb_steps"] = training_reuse_stop_batch
+ elif (
+ "stop_batch" in jinput["training"] and training_reuse_stop_batch is not None
+ ):
+ jinput["training"]["stop_batch"] = training_reuse_stop_batch
+ if Version("1") <= Version(mdata["deepmd_version"]) < Version("2"):
+ jinput["training"][
+ "auto_prob_style"
+ ] = "prob_sys_size; 0:%d:%f; %d:%d:%f" % (
+ old_range,
+ training_reuse_old_ratio,
+ old_range,
+ len(init_data_sys),
+ 1.0 - training_reuse_old_ratio,
+ )
+ elif Version("2") <= Version(mdata["deepmd_version"]) < Version("3"):
+ jinput["training"]["training_data"][
+ "auto_prob"
+ ] = "prob_sys_size; 0:%d:%f; %d:%d:%f" % (
+ old_range,
+ training_reuse_old_ratio,
+ old_range,
+ len(init_data_sys),
+ 1.0 - training_reuse_old_ratio,
+ )
else:
- raise RuntimeError("Unsupported DeePMD-kit version: %s" % mdata["deepmd_version"])
- if jinput['loss'].get('start_pref_e') is not None:
- jinput['loss']['start_pref_e'] = training_reuse_start_pref_e
- if jinput['loss'].get('start_pref_f') is not None:
- jinput['loss']['start_pref_f'] = training_reuse_start_pref_f
- jinput['learning_rate']['start_lr'] = training_reuse_start_lr
-
-
- for ii in range(numb_models) :
+ raise RuntimeError(
+ "Unsupported DeePMD-kit version: %s" % mdata["deepmd_version"]
+ )
+ if jinput["loss"].get("start_pref_e") is not None:
+ jinput["loss"]["start_pref_e"] = training_reuse_start_pref_e
+ if jinput["loss"].get("start_pref_f") is not None:
+ jinput["loss"]["start_pref_f"] = training_reuse_start_pref_f
+ jinput["learning_rate"]["start_lr"] = training_reuse_start_lr
+
+ input_files = []
+ for ii in range(numb_models):
task_path = os.path.join(work_path, train_task_fmt % ii)
create_path(task_path)
os.chdir(task_path)
- for jj in init_data_sys :
+
+ if "srtab_file_path" in jdata.keys():
+ shutil.copyfile(srtab_file_path, os.path.basename(srtab_file_path))
+
+ for jj in init_data_sys:
# HDF5 path contains #
- if not (os.path.isdir(jj) if "#" not in jj else os.path.isfile(jj.split("#")[0])):
- raise RuntimeError ("data sys %s does not exists, cwd is %s" % (jj, os.getcwd()))
+ if not (
+ os.path.isdir(jj) if "#" not in jj else os.path.isfile(jj.split("#")[0])
+ ):
+ raise RuntimeError(
+ "data sys %s does not exists, cwd is %s" % (jj, os.getcwd())
+ )
os.chdir(cwd)
# set random seed for each model
- if LooseVersion(mdata["deepmd_version"]) >= LooseVersion('1') and LooseVersion(mdata["deepmd_version"]) < LooseVersion('3'):
+ if Version(mdata["deepmd_version"]) >= Version("1") and Version(
+ mdata["deepmd_version"]
+ ) < Version("3"):
# 1.x
- if jinput['model']['descriptor']['type'] == 'hybrid':
- for desc in jinput['model']['descriptor']['list']:
- desc['seed'] = random.randrange(sys.maxsize) % (2**32)
- elif jinput['model']['descriptor']['type'] == 'loc_frame':
+ if jinput["model"]["descriptor"]["type"] == "hybrid":
+ for desc in jinput["model"]["descriptor"]["list"]:
+ desc["seed"] = random.randrange(sys.maxsize) % (2**32)
+ elif jinput["model"]["descriptor"]["type"] == "loc_frame":
pass
else:
- jinput['model']['descriptor']['seed'] = random.randrange(sys.maxsize) % (2**32)
- jinput['model']['fitting_net']['seed'] = random.randrange(sys.maxsize) % (2**32)
- if 'type_embedding' in jinput['model']:
- jinput['model']['type_embedding']['seed'] = random.randrange(sys.maxsize) % (2**32)
- jinput['training']['seed'] = random.randrange(sys.maxsize) % (2**32)
+ jinput["model"]["descriptor"]["seed"] = random.randrange(
+ sys.maxsize
+ ) % (2**32)
+ jinput["model"]["fitting_net"]["seed"] = random.randrange(sys.maxsize) % (
+ 2**32
+ )
+ if "type_embedding" in jinput["model"]:
+ jinput["model"]["type_embedding"]["seed"] = random.randrange(
+ sys.maxsize
+ ) % (2**32)
+ jinput["training"]["seed"] = random.randrange(sys.maxsize) % (2**32)
else:
- raise RuntimeError("DP-GEN currently only supports for DeePMD-kit 1.x or 2.x version!" )
+ raise RuntimeError(
+ "DP-GEN currently only supports for DeePMD-kit 1.x or 2.x version!"
+ )
# set model activation function
if model_devi_activation_func is not None:
- if LooseVersion(mdata["deepmd_version"]) < LooseVersion('1'):
- raise RuntimeError('model_devi_activation_func does not suppport deepmd version', mdata['deepmd_version'])
- assert(type(model_devi_activation_func) is list and len(model_devi_activation_func) == numb_models)
- if len(np.array(model_devi_activation_func).shape) == 2 : # 2-dim list for emd/fitting net-resolved assignment of actF
- jinput['model']['descriptor']['activation_function'] = model_devi_activation_func[ii][0]
- jinput['model']['fitting_net']['activation_function'] = model_devi_activation_func[ii][1]
- if len(np.array(model_devi_activation_func).shape) == 1 : # for backward compatibility, 1-dim list, not net-resolved
- jinput['model']['descriptor']['activation_function'] = model_devi_activation_func[ii]
- jinput['model']['fitting_net']['activation_function'] = model_devi_activation_func[ii]
+ if Version(mdata["deepmd_version"]) < Version("1"):
+ raise RuntimeError(
+ "model_devi_activation_func does not suppport deepmd version",
+ mdata["deepmd_version"],
+ )
+ assert (
+ type(model_devi_activation_func) is list
+ and len(model_devi_activation_func) == numb_models
+ )
+ if (
+ len(np.array(model_devi_activation_func).shape) == 2
+ ): # 2-dim list for emd/fitting net-resolved assignment of actF
+ jinput["model"]["descriptor"][
+ "activation_function"
+ ] = model_devi_activation_func[ii][0]
+ jinput["model"]["fitting_net"][
+ "activation_function"
+ ] = model_devi_activation_func[ii][1]
+ if (
+ len(np.array(model_devi_activation_func).shape) == 1
+ ): # for backward compatibility, 1-dim list, not net-resolved
+ jinput["model"]["descriptor"][
+ "activation_function"
+ ] = model_devi_activation_func[ii]
+ jinput["model"]["fitting_net"][
+ "activation_function"
+ ] = model_devi_activation_func[ii]
# dump the input.json
- with open(os.path.join(task_path, train_input_file), 'w') as outfile:
- json.dump(jinput, outfile, indent = 4)
+ with open(os.path.join(task_path, train_input_file), "w") as outfile:
+ json.dump(jinput, outfile, indent=4)
+ input_files.append(os.path.join(task_path, train_input_file))
# link old models
- if iter_index > 0 :
- prev_iter_name = make_iter_name(iter_index-1)
+ if iter_index > 0:
+ prev_iter_name = make_iter_name(iter_index - 1)
prev_work_path = os.path.join(prev_iter_name, train_name)
- for ii in range(numb_models) :
- prev_task_path = os.path.join(prev_work_path, train_task_fmt%ii)
- old_model_files = glob.glob(
- os.path.join(prev_task_path, "model.ckpt*"))
+ for ii in range(numb_models):
+ prev_task_path = os.path.join(prev_work_path, train_task_fmt % ii)
+ old_model_files = glob.glob(os.path.join(prev_task_path, "model.ckpt*"))
_link_old_models(work_path, old_model_files, ii)
else:
if type(training_iter0_model) == str:
@@ -438,13 +577,18 @@ def make_train (iter_index,
model_is.sort()
iter0_models += [os.path.abspath(ii) for ii in model_is]
if training_init_model:
- assert(numb_models == len(iter0_models)), "training_iter0_model should be provided, and the number of models should be equal to %d" % numb_models
+ assert numb_models == len(iter0_models), (
+ "training_iter0_model should be provided, and the number of models should be equal to %d"
+ % numb_models
+ )
for ii in range(len(iter0_models)):
- old_model_files = glob.glob(os.path.join(iter0_models[ii], 'model.ckpt*'))
+ old_model_files = glob.glob(os.path.join(iter0_models[ii], "model.ckpt*"))
_link_old_models(work_path, old_model_files, ii)
# Copy user defined forward files
symlink_user_forward_files(mdata=mdata, task_type="train", work_path=work_path)
-
+ # HDF5 format for training data
+ if jdata.get("one_h5", False):
+ convert_training_data_to_hdf5(input_files, os.path.join(work_path, "data.hdf5"))
def _link_old_models(work_path, old_model_files, ii):
@@ -453,7 +597,7 @@ def _link_old_models(work_path, old_model_files, ii):
the `ii`th training task in `work_path`
"""
task_path = os.path.join(work_path, train_task_fmt % ii)
- task_old_path = os.path.join(task_path, 'old')
+ task_old_path = os.path.join(task_path, "old")
create_path(task_old_path)
cwd = os.getcwd()
for jj in old_model_files:
@@ -470,22 +614,27 @@ def detect_batch_size(batch_size, system=None):
elif batch_size == "auto":
# automaticcaly set batch size, batch_size = 32 // atom_numb (>=1, <=fram_numb)
# check if h5 file
- format = 'deepmd/npy' if "#" not in system else 'deepmd/hdf5'
+ format = "deepmd/npy" if "#" not in system else "deepmd/hdf5"
s = dpdata.LabeledSystem(system, fmt=format)
- return int(min( np.ceil(32.0 / float(s["coords"].shape[1]) ), s["coords"].shape[0]))
+ return int(
+ min(np.ceil(32.0 / float(s["coords"].shape[1])), s["coords"].shape[0])
+ )
else:
raise RuntimeError("Unsupported batch size")
-def run_train (iter_index,
- jdata,
- mdata) :
+
+def run_train(iter_index, jdata, mdata):
# print("debug:run_train:mdata", mdata)
# load json param
- numb_models = jdata['numb_models']
+ numb_models = jdata["numb_models"]
# train_param = jdata['train_param']
train_input_file = default_train_input_file
- training_reuse_iter = jdata.get('training_reuse_iter')
- training_init_model = jdata.get('training_init_model', False)
+ training_reuse_iter = jdata.get("training_reuse_iter")
+ training_init_model = jdata.get("training_init_model", False)
+
+ if "srtab_file_path" in jdata.keys():
+ zbl_file = os.path.basename(jdata.get("srtab_file_path", None))
+
if training_reuse_iter is not None and iter_index >= training_reuse_iter:
training_init_model = True
try:
@@ -493,45 +642,54 @@ def run_train (iter_index,
except KeyError:
mdata = set_version(mdata)
-
- train_command = mdata.get('train_command', 'dp')
- train_resources = mdata['train_resources']
+ train_command = mdata.get("train_command", "dp")
+ train_resources = mdata["train_resources"]
# paths
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, train_name)
# check if is copied
- copy_flag = os.path.join(work_path, 'copied')
- if os.path.isfile(copy_flag) :
- log_task('copied model, do not train')
+ copy_flag = os.path.join(work_path, "copied")
+ if os.path.isfile(copy_flag):
+ log_task("copied model, do not train")
return
# make tasks
all_task = []
- for ii in range(numb_models) :
+ for ii in range(numb_models):
task_path = os.path.join(work_path, train_task_fmt % ii)
all_task.append(task_path)
commands = []
- if LooseVersion(mdata["deepmd_version"]) >= LooseVersion('1') and LooseVersion(mdata["deepmd_version"]) < LooseVersion('3'):
-
+ if Version(mdata["deepmd_version"]) >= Version("1") and Version(
+ mdata["deepmd_version"]
+ ) < Version("3"):
+
# 1.x
## Commands are like `dp train` and `dp freeze`
## train_command should not be None
- assert(train_command)
- command = '%s train %s' % (train_command, train_input_file)
+ assert train_command
+ command = "%s train %s" % (train_command, train_input_file)
if training_init_model:
- command = "{ if [ ! -f model.ckpt.index ]; then %s --init-model old/model.ckpt; else %s --restart model.ckpt; fi }" % (command, command)
+ command = (
+ "{ if [ ! -f model.ckpt.index ]; then %s --init-model old/model.ckpt; else %s --restart model.ckpt; fi }"
+ % (command, command)
+ )
else:
- command = "{ if [ ! -f model.ckpt.index ]; then %s; else %s --restart model.ckpt; fi }" % (command, command)
+ command = (
+ "{ if [ ! -f model.ckpt.index ]; then %s; else %s --restart model.ckpt; fi }"
+ % (command, command)
+ )
command = "/bin/sh -c '%s'" % command
commands.append(command)
- command = '%s freeze' % train_command
+ command = "%s freeze" % train_command
commands.append(command)
if jdata.get("dp_compress", False):
commands.append("%s compress" % train_command)
else:
- raise RuntimeError("DP-GEN currently only supports for DeePMD-kit 1.x or 2.x version!" )
+ raise RuntimeError(
+ "DP-GEN currently only supports for DeePMD-kit 1.x or 2.x version!"
+ )
- #_tasks = [os.path.basename(ii) for ii in all_task]
+ # _tasks = [os.path.basename(ii) for ii in all_task]
# run_tasks = []
# for ii in all_task:
# check_pb = os.path.join(ii, "frozen_model.pb")
@@ -543,66 +701,68 @@ def run_train (iter_index,
run_tasks = [os.path.basename(ii) for ii in all_task]
forward_files = [train_input_file]
+ if "srtab_file_path" in jdata.keys():
+ forward_files.append(zbl_file)
if training_init_model:
- forward_files += [os.path.join('old', 'model.ckpt.meta'),
- os.path.join('old', 'model.ckpt.index'),
- os.path.join('old', 'model.ckpt.data-00000-of-00001')
+ forward_files += [
+ os.path.join("old", "model.ckpt.meta"),
+ os.path.join("old", "model.ckpt.index"),
+ os.path.join("old", "model.ckpt.data-00000-of-00001"),
]
- backward_files = ['frozen_model.pb', 'lcurve.out', 'train.log']
- backward_files+= ['model.ckpt.meta', 'model.ckpt.index', 'model.ckpt.data-00000-of-00001', 'checkpoint']
+ backward_files = ["frozen_model.pb", "lcurve.out", "train.log"]
+ backward_files += [
+ "model.ckpt.meta",
+ "model.ckpt.index",
+ "model.ckpt.data-00000-of-00001",
+ "checkpoint",
+ ]
if jdata.get("dp_compress", False):
- backward_files.append('frozen_model_compressed.pb')
- init_data_sys_ = jdata['init_data_sys']
- init_data_sys = []
- for ii in init_data_sys_ :
- init_data_sys.append(os.path.join('data.init', ii))
- trans_comm_data = []
- cwd = os.getcwd()
- os.chdir(work_path)
- fp_data = glob.glob(os.path.join('data.iters', 'iter.*', '02.fp', 'data.*'))
- for ii in itertools.chain(init_data_sys, fp_data) :
- sys_paths = expand_sys_str(ii)
- for single_sys in sys_paths:
- if "#" not in single_sys:
- trans_comm_data += glob.glob(os.path.join(single_sys, 'set.*'))
- trans_comm_data += glob.glob(os.path.join(single_sys, 'type*.raw'))
- trans_comm_data += glob.glob(os.path.join(single_sys, 'nopbc'))
- else:
- # H5 file
- trans_comm_data.append(single_sys.split("#")[0])
+ backward_files.append("frozen_model_compressed.pb")
+ if not jdata.get("one_h5", False):
+ init_data_sys_ = jdata["init_data_sys"]
+ init_data_sys = []
+ for ii in init_data_sys_:
+ init_data_sys.append(os.path.join("data.init", ii))
+ trans_comm_data = []
+ cwd = os.getcwd()
+ os.chdir(work_path)
+ fp_data = glob.glob(os.path.join("data.iters", "iter.*", "02.fp", "data.*"))
+ for ii in itertools.chain(init_data_sys, fp_data):
+ sys_paths = expand_sys_str(ii)
+ for single_sys in sys_paths:
+ if "#" not in single_sys:
+ trans_comm_data += glob.glob(os.path.join(single_sys, "set.*"))
+ trans_comm_data += glob.glob(os.path.join(single_sys, "type*.raw"))
+ trans_comm_data += glob.glob(os.path.join(single_sys, "nopbc"))
+ else:
+ # H5 file
+ trans_comm_data.append(single_sys.split("#")[0])
+ else:
+ cwd = os.getcwd()
+ trans_comm_data = ["data.hdf5"]
# remove duplicated files
trans_comm_data = list(set(trans_comm_data))
os.chdir(cwd)
try:
- train_group_size = mdata['train_group_size']
+ train_group_size = mdata["train_group_size"]
except Exception:
train_group_size = 1
- api_version = mdata.get('api_version', '0.9')
-
+ api_version = mdata.get("api_version", "1.0")
+
user_forward_files = mdata.get("train" + "_user_forward_files", [])
forward_files += [os.path.basename(file) for file in user_forward_files]
backward_files += mdata.get("train" + "_user_backward_files", [])
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher = make_dispatcher(mdata['train_machine'], mdata['train_resources'], work_path, run_tasks, train_group_size)
- dispatcher.run_jobs(mdata['train_resources'],
- commands,
- work_path,
- run_tasks,
- train_group_size,
- trans_comm_data,
- forward_files,
- backward_files,
- outlog = 'train.log',
- errlog = 'train.log')
-
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+
+ elif Version(api_version) >= Version("1.0"):
submission = make_submission(
- mdata['train_machine'],
- mdata['train_resources'],
+ mdata["train_machine"],
+ mdata["train_resources"],
commands=commands,
work_path=work_path,
run_tasks=run_tasks,
@@ -610,226 +770,265 @@ def run_train (iter_index,
forward_common_files=trans_comm_data,
forward_files=forward_files,
backward_files=backward_files,
- outlog = 'train.log',
- errlog = 'train.log')
+ outlog="train.log",
+ errlog="train.log",
+ )
submission.run_submission()
-def post_train (iter_index,
- jdata,
- mdata) :
+
+def post_train(iter_index, jdata, mdata):
# load json param
- numb_models = jdata['numb_models']
+ numb_models = jdata["numb_models"]
# paths
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, train_name)
# check if is copied
- copy_flag = os.path.join(work_path, 'copied')
- if os.path.isfile(copy_flag) :
- log_task('copied model, do not post train')
+ copy_flag = os.path.join(work_path, "copied")
+ if os.path.isfile(copy_flag):
+ log_task("copied model, do not post train")
return
# symlink models
- for ii in range(numb_models) :
+ for ii in range(numb_models):
if not jdata.get("dp_compress", False):
- model_name = 'frozen_model.pb'
+ model_name = "frozen_model.pb"
else:
- model_name = 'frozen_model_compressed.pb'
+ model_name = "frozen_model_compressed.pb"
task_file = os.path.join(train_task_fmt % ii, model_name)
- ofile = os.path.join(work_path, 'graph.%03d.pb' % ii)
- if os.path.isfile(ofile) :
+ ofile = os.path.join(work_path, "graph.%03d.pb" % ii)
+ if os.path.isfile(ofile):
os.remove(ofile)
os.symlink(task_file, ofile)
-def _get_param_alias(jdata,
- names) :
- for ii in names :
- if ii in jdata :
+
+def _get_param_alias(jdata, names):
+ for ii in names:
+ if ii in jdata:
return jdata[ii]
- raise ValueError("one of the keys %s should be in jdata %s" % (str(names), (json.dumps(jdata, indent=4))))
+ raise ValueError(
+ "one of the keys %s should be in jdata %s"
+ % (str(names), (json.dumps(jdata, indent=4)))
+ )
+
-def parse_cur_job(cur_job) :
- ensemble = _get_param_alias(cur_job, ['ens', 'ensemble'])
+def parse_cur_job(cur_job):
+ ensemble = _get_param_alias(cur_job, ["ens", "ensemble"])
temps = [-1]
press = [-1]
- if 'npt' in ensemble :
- temps = _get_param_alias(cur_job, ['Ts','temps'])
- press = _get_param_alias(cur_job, ['Ps','press'])
- elif 'nvt' == ensemble or 'nve' == ensemble:
- temps = _get_param_alias(cur_job, ['Ts','temps'])
- nsteps = _get_param_alias(cur_job, ['nsteps'])
- trj_freq = _get_param_alias(cur_job, ['t_freq', 'trj_freq','traj_freq'])
- if 'pka_e' in cur_job :
- pka_e = _get_param_alias(cur_job, ['pka_e'])
- else :
+ if "npt" in ensemble:
+ temps = _get_param_alias(cur_job, ["Ts", "temps"])
+ press = _get_param_alias(cur_job, ["Ps", "press"])
+ elif "nvt" == ensemble or "nve" == ensemble:
+ temps = _get_param_alias(cur_job, ["Ts", "temps"])
+ nsteps = _get_param_alias(cur_job, ["nsteps"])
+ trj_freq = _get_param_alias(cur_job, ["t_freq", "trj_freq", "traj_freq"])
+ if "pka_e" in cur_job:
+ pka_e = _get_param_alias(cur_job, ["pka_e"])
+ else:
pka_e = None
- if 'dt' in cur_job :
- dt = _get_param_alias(cur_job, ['dt'])
- else :
+ if "dt" in cur_job:
+ dt = _get_param_alias(cur_job, ["dt"])
+ else:
dt = None
return ensemble, nsteps, trj_freq, temps, press, pka_e, dt
-def expand_matrix_values(target_list, cur_idx = 0):
+
+def expand_matrix_values(target_list, cur_idx=0):
nvar = len(target_list)
- if cur_idx == nvar :
+ if cur_idx == nvar:
return [[]]
- else :
+ else:
res = []
- prev = expand_matrix_values(target_list, cur_idx+1)
+ prev = expand_matrix_values(target_list, cur_idx + 1)
for ii in target_list[cur_idx]:
tmp = copy.deepcopy(prev)
for jj in tmp:
- jj.insert(0, ii)
- res.append(jj)
+ jj.insert(0, ii)
+ res.append(jj)
return res
-def parse_cur_job_revmat(cur_job, use_plm = False):
- templates = [cur_job['template']['lmp']]
- if use_plm :
- templates.append(cur_job['template']['plm'])
+
+def parse_cur_job_revmat(cur_job, use_plm=False):
+ templates = [cur_job["template"]["lmp"]]
+ if use_plm:
+ templates.append(cur_job["template"]["plm"])
revise_keys = []
revise_values = []
- if 'rev_mat' not in cur_job.keys():
- cur_job['rev_mat'] = {}
- if 'lmp' not in cur_job['rev_mat'].keys():
- cur_job['rev_mat']['lmp'] = {}
- for ii in cur_job['rev_mat']['lmp'].keys():
+ if "rev_mat" not in cur_job.keys():
+ cur_job["rev_mat"] = {}
+ if "lmp" not in cur_job["rev_mat"].keys():
+ cur_job["rev_mat"]["lmp"] = {}
+ for ii in cur_job["rev_mat"]["lmp"].keys():
revise_keys.append(ii)
- revise_values.append(cur_job['rev_mat']['lmp'][ii])
+ revise_values.append(cur_job["rev_mat"]["lmp"][ii])
n_lmp_keys = len(revise_keys)
if use_plm:
- if 'plm' not in cur_job['rev_mat'].keys():
- cur_job['rev_mat']['plm'] = {}
- for ii in cur_job['rev_mat']['plm'].keys():
+ if "plm" not in cur_job["rev_mat"].keys():
+ cur_job["rev_mat"]["plm"] = {}
+ for ii in cur_job["rev_mat"]["plm"].keys():
revise_keys.append(ii)
- revise_values.append(cur_job['rev_mat']['plm'][ii])
+ revise_values.append(cur_job["rev_mat"]["plm"][ii])
revise_matrix = expand_matrix_values(revise_values)
return revise_keys, revise_matrix, n_lmp_keys
def parse_cur_job_sys_revmat(cur_job, sys_idx, use_plm=False):
- templates = [cur_job['template']['lmp']]
+ templates = [cur_job["template"]["lmp"]]
if use_plm:
- templates.append(cur_job['template']['plm'])
+ templates.append(cur_job["template"]["plm"])
sys_revise_keys = []
sys_revise_values = []
- if 'sys_rev_mat' not in cur_job.keys():
- cur_job['sys_rev_mat'] = {}
- local_rev = cur_job['sys_rev_mat'].get(str(sys_idx), {})
- if 'lmp' not in local_rev.keys():
- local_rev['lmp'] = {}
- for ii in local_rev['lmp'].keys():
+ if "sys_rev_mat" not in cur_job.keys():
+ cur_job["sys_rev_mat"] = {}
+ local_rev = cur_job["sys_rev_mat"].get(str(sys_idx), {})
+ if "lmp" not in local_rev.keys():
+ local_rev["lmp"] = {}
+ for ii in local_rev["lmp"].keys():
sys_revise_keys.append(ii)
- sys_revise_values.append(local_rev['lmp'][ii])
+ sys_revise_values.append(local_rev["lmp"][ii])
n_sys_lmp_keys = len(sys_revise_keys)
if use_plm:
- if 'plm' not in local_rev.keys():
- local_rev['plm'] = {}
- for ii in local_rev['plm'].keys():
+ if "plm" not in local_rev.keys():
+ local_rev["plm"] = {}
+ for ii in local_rev["plm"].keys():
sys_revise_keys.append(ii)
- sys_revise_values.append(local_rev['plm'][ii])
+ sys_revise_values.append(local_rev["plm"][ii])
sys_revise_matrix = expand_matrix_values(sys_revise_values)
return sys_revise_keys, sys_revise_matrix, n_sys_lmp_keys
+
def find_only_one_key(lmp_lines, key):
found = []
for idx in range(len(lmp_lines)):
words = lmp_lines[idx].split()
nkey = len(key)
- if len(words) >= nkey and words[:nkey] == key :
+ if len(words) >= nkey and words[:nkey] == key:
found.append(idx)
if len(found) > 1:
- raise RuntimeError('found %d keywords %s' % (len(found), key))
+ raise RuntimeError("found %d keywords %s" % (len(found), key))
if len(found) == 0:
- raise RuntimeError('failed to find keyword %s' % (key))
+ raise RuntimeError("failed to find keyword %s" % (key))
return found[0]
-def revise_lmp_input_model(lmp_lines, task_model_list, trj_freq, deepmd_version = '1'):
- idx = find_only_one_key(lmp_lines, ['pair_style', 'deepmd'])
- graph_list = ' '.join(task_model_list)
- if LooseVersion(deepmd_version) < LooseVersion('1'):
- lmp_lines[idx] = "pair_style deepmd %s %d model_devi.out\n" % (graph_list, trj_freq)
+def revise_lmp_input_model(lmp_lines, task_model_list, trj_freq, deepmd_version="1"):
+ idx = find_only_one_key(lmp_lines, ["pair_style", "deepmd"])
+ graph_list = " ".join(task_model_list)
+ if Version(deepmd_version) < Version("1"):
+ lmp_lines[idx] = "pair_style deepmd %s %d model_devi.out\n" % (
+ graph_list,
+ trj_freq,
+ )
else:
- lmp_lines[idx] = "pair_style deepmd %s out_freq %d out_file model_devi.out\n" % (graph_list, trj_freq)
+ lmp_lines[
+ idx
+ ] = "pair_style deepmd %s out_freq %d out_file model_devi.out\n" % (
+ graph_list,
+ trj_freq,
+ )
return lmp_lines
-def revise_lmp_input_dump(lmp_lines, trj_freq):
- idx = find_only_one_key(lmp_lines, ['dump', 'dpgen_dump'])
- lmp_lines[idx] = "dump dpgen_dump all custom %d traj/*.lammpstrj id type x y z\n" % trj_freq
+def revise_lmp_input_dump(lmp_lines, trj_freq, model_devi_merge_traj=False):
+ idx = find_only_one_key(lmp_lines, ["dump", "dpgen_dump"])
+ if model_devi_merge_traj:
+ lmp_lines[idx] = (
+ "dump dpgen_dump all custom %d all.lammpstrj id type x y z\n"
+ % trj_freq
+ )
+ else:
+ lmp_lines[idx] = (
+ "dump dpgen_dump all custom %d traj/*.lammpstrj id type x y z\n"
+ % trj_freq
+ )
+
return lmp_lines
-def revise_lmp_input_plm(lmp_lines, in_plm, out_plm = 'output.plumed'):
- idx = find_only_one_key(lmp_lines, ['fix', 'dpgen_plm'])
- lmp_lines[idx] = "fix dpgen_plm all plumed plumedfile %s outfile %s\n" % (in_plm, out_plm)
+def revise_lmp_input_plm(lmp_lines, in_plm, out_plm="output.plumed"):
+ idx = find_only_one_key(lmp_lines, ["fix", "dpgen_plm"])
+ lmp_lines[
+ idx
+ ] = "fix dpgen_plm all plumed plumedfile %s outfile %s\n" % (
+ in_plm,
+ out_plm,
+ )
return lmp_lines
def revise_by_keys(lmp_lines, keys, values):
- for kk,vv in zip(keys, values):
+ for kk, vv in zip(keys, values):
for ii in range(len(lmp_lines)):
lmp_lines[ii] = lmp_lines[ii].replace(kk, str(vv))
return lmp_lines
-def make_model_devi (iter_index,
- jdata,
- mdata) :
+
+def make_model_devi(iter_index, jdata, mdata):
# The MD engine to perform model deviation
# Default is lammps
- model_devi_engine = jdata.get('model_devi_engine', "lammps")
+ model_devi_engine = jdata.get("model_devi_engine", "lammps")
- model_devi_jobs = jdata['model_devi_jobs']
- if model_devi_engine != 'calypso':
- if (iter_index >= len(model_devi_jobs)) :
+ model_devi_jobs = jdata["model_devi_jobs"]
+ if model_devi_engine != "calypso":
+ if iter_index >= len(model_devi_jobs):
return False
else:
# mode 1: generate structures according to the user-provided input.dat file, so calypso_input_path and model_devi_max_iter are needed
run_mode = 1
if "calypso_input_path" in jdata:
try:
- maxiter = jdata.get('model_devi_max_iter')
+ maxiter = jdata.get("model_devi_max_iter")
except KeyError:
- raise KeyError('calypso_input_path key exists so you should provide model_devi_max_iter key to control the max iter number')
+ raise KeyError(
+ "calypso_input_path key exists so you should provide model_devi_max_iter key to control the max iter number"
+ )
# mode 2: control each iteration to generate structures in specific way by providing model_devi_jobs key
else:
try:
- maxiter = max(model_devi_jobs[-1].get('times'))
+ maxiter = max(model_devi_jobs[-1].get("times"))
run_mode = 2
except KeyError:
raise KeyError('did not find model_devi_jobs["times"] key')
- if (iter_index > maxiter) :
- dlog.info(f'iter_index is {iter_index} and maxiter is {maxiter}')
+ if iter_index > maxiter:
+ dlog.info(f"iter_index is {iter_index} and maxiter is {maxiter}")
return False
if "sys_configs_prefix" in jdata:
sys_configs = []
for sys_list in jdata["sys_configs"]:
- #assert (isinstance(sys_list, list) ), "Currently only support type list for sys in 'sys_conifgs' "
- temp_sys_list = [os.path.join(jdata["sys_configs_prefix"], sys) for sys in sys_list]
+ # assert (isinstance(sys_list, list) ), "Currently only support type list for sys in 'sys_conifgs' "
+ temp_sys_list = [
+ os.path.join(jdata["sys_configs_prefix"], sys) for sys in sys_list
+ ]
sys_configs.append(temp_sys_list)
else:
- sys_configs = jdata['sys_configs']
- shuffle_poscar = jdata.get('shuffle_poscar', False)
+ sys_configs = jdata["sys_configs"]
+ shuffle_poscar = jdata.get("shuffle_poscar", False)
- if model_devi_engine != 'calypso':
+ if model_devi_engine != "calypso":
cur_job = model_devi_jobs[iter_index]
- sys_idx = expand_idx(cur_job['sys_idx'])
+ sys_idx = expand_idx(cur_job["sys_idx"])
else:
- cur_job = {'model_devi_engine':'calypso','input.dat':'user_provided'}
+ cur_job = {"model_devi_engine": "calypso", "input.dat": "user_provided"}
sys_idx = []
- if (len(sys_idx) != len(list(set(sys_idx)))) :
+ if len(sys_idx) != len(list(set(sys_idx))):
raise RuntimeError("system index should be uniq")
conf_systems = []
- for idx in sys_idx :
+ for idx in sys_idx:
cur_systems = []
ss = sys_configs[idx]
- for ii in ss :
- cur_systems += sorted(glob.glob(ii))
- # cur_systems should not be sorted, as we may add specific constrict to the similutions
- #cur_systems.sort()
+ for ii in ss:
+ ii_systems = sorted(glob.glob(ii))
+ if ii_systems == []:
+ warnings.warn(
+ "There is no system in the path %s. Please check if the path is correct."
+ % ii
+ )
+ cur_systems += ii_systems
+ # cur_systems should not be sorted, as we may add specific constrict to the similutions
+ # cur_systems.sort()
cur_systems = [os.path.abspath(ii) for ii in cur_systems]
- conf_systems.append (cur_systems)
+ conf_systems.append(cur_systems)
iter_name = make_iter_name(iter_index)
train_path = os.path.join(iter_name, train_name)
@@ -837,59 +1036,69 @@ def make_model_devi (iter_index,
models = sorted(glob.glob(os.path.join(train_path, "graph*pb")))
work_path = os.path.join(iter_name, model_devi_name)
create_path(work_path)
- if model_devi_engine == 'calypso':
- _calypso_run_opt_path = os.path.join(work_path,calypso_run_opt_name)
- calypso_model_devi_path = os.path.join(work_path,calypso_model_devi_name)
+ if model_devi_engine == "calypso":
+ _calypso_run_opt_path = os.path.join(work_path, calypso_run_opt_name)
+ calypso_model_devi_path = os.path.join(work_path, calypso_model_devi_name)
create_path(calypso_model_devi_path)
# run model devi script
- calypso_run_model_devi_script = os.path.join(calypso_model_devi_path,'calypso_run_model_devi.py')
- shutil.copyfile(calypso_run_model_devi_file,calypso_run_model_devi_script)
+ calypso_run_model_devi_script = os.path.join(
+ calypso_model_devi_path, "calypso_run_model_devi.py"
+ )
+ shutil.copyfile(calypso_run_model_devi_file, calypso_run_model_devi_script)
# Create work path list
calypso_run_opt_path = []
# mode 1: generate structures according to the user-provided input.dat file,
# so calypso_input_path and model_devi_max_iter are needed
if run_mode == 1:
- if jdata.get('vsc', False) and len(jdata.get('type_map')) > 1:
+ if jdata.get("vsc", False) and len(jdata.get("type_map")) > 1:
# [input.dat.Li.250, input.dat.Li.300]
one_ele_inputdat_list = glob.glob(
- f"{jdata.get('calypso_input_path')}/input.dat.{jdata.get('type_map')[0]}.*"
- )
+ f"{jdata.get('calypso_input_path')}/input.dat.{jdata.get('type_map')[0]}.*"
+ )
if len(one_ele_inputdat_list) == 0:
number_of_pressure = 1
- else:
+ else:
number_of_pressure = len(list(set(one_ele_inputdat_list)))
# calypso_run_opt_path = ['gen_struc_analy.000','gen_struc_analy.001']
for temp_idx in range(number_of_pressure):
- calypso_run_opt_path.append('%s.%03d'%(_calypso_run_opt_path, temp_idx))
- elif not jdata.get('vsc', False):
- calypso_run_opt_path.append('%s.%03d'%(_calypso_run_opt_path, 0))
-
- # mode 2: control each iteration to generate structures in specific way
+ calypso_run_opt_path.append(
+ "%s.%03d" % (_calypso_run_opt_path, temp_idx)
+ )
+ elif not jdata.get("vsc", False):
+ calypso_run_opt_path.append("%s.%03d" % (_calypso_run_opt_path, 0))
+
+ # mode 2: control each iteration to generate structures in specific way
# by providing model_devi_jobs key
elif run_mode == 2:
for iiidx, jobbs in enumerate(model_devi_jobs):
- if iter_index in jobbs.get('times'):
+ if iter_index in jobbs.get("times"):
cur_job = model_devi_jobs[iiidx]
-
- pressures_list = cur_job.get('PSTRESS', [0.0001])
+
+ pressures_list = cur_job.get("PSTRESS", [0.0001])
for temp_idx in range(len(pressures_list)):
- calypso_run_opt_path.append('%s.%03d'%(_calypso_run_opt_path, temp_idx))
+ calypso_run_opt_path.append(
+ "%s.%03d" % (_calypso_run_opt_path, temp_idx)
+ )
# to different directory
# calypso_run_opt_path = ['gen_struc_analy.000','gen_struc_analy.001','gen_struc_analy.002',]
for temp_calypso_run_opt_path in calypso_run_opt_path:
create_path(temp_calypso_run_opt_path)
# run confs opt script
- run_opt_script = os.path.join(temp_calypso_run_opt_path,'calypso_run_opt.py')
- shutil.copyfile(run_opt_file,run_opt_script)
+ run_opt_script = os.path.join(
+ temp_calypso_run_opt_path, "calypso_run_opt.py"
+ )
+ shutil.copyfile(run_opt_file, run_opt_script)
# check outcar script
- check_outcar_script = os.path.join(temp_calypso_run_opt_path,'check_outcar.py')
- shutil.copyfile(check_outcar_file,check_outcar_script)
+ check_outcar_script = os.path.join(
+ temp_calypso_run_opt_path, "check_outcar.py"
+ )
+ shutil.copyfile(check_outcar_file, check_outcar_script)
- for mm in models :
+ for mm in models:
model_name = os.path.basename(mm)
- if model_devi_engine != 'calypso':
+ if model_devi_engine != "calypso":
os.symlink(mm, os.path.join(work_path, model_name))
else:
for temp_calypso_run_opt_path in calypso_run_opt_path:
@@ -897,40 +1106,50 @@ def make_model_devi (iter_index,
if not os.path.exists(models_path):
os.symlink(mm, models_path)
- with open(os.path.join(work_path, 'cur_job.json'), 'w') as outfile:
- json.dump(cur_job, outfile, indent = 4)
+ with open(os.path.join(work_path, "cur_job.json"), "w") as outfile:
+ json.dump(cur_job, outfile, indent=4)
- conf_path = os.path.join(work_path, 'confs')
+ conf_path = os.path.join(work_path, "confs")
create_path(conf_path)
sys_counter = 0
for ss in conf_systems:
conf_counter = 0
- for cc in ss :
+ for cc in ss:
if model_devi_engine == "lammps":
- conf_name = make_model_devi_conf_name(sys_idx[sys_counter], conf_counter)
- orig_poscar_name = conf_name + '.orig.poscar'
- poscar_name = conf_name + '.poscar'
- lmp_name = conf_name + '.lmp'
- if shuffle_poscar :
+ conf_name = make_model_devi_conf_name(
+ sys_idx[sys_counter], conf_counter
+ )
+ orig_poscar_name = conf_name + ".orig.poscar"
+ poscar_name = conf_name + ".poscar"
+ lmp_name = conf_name + ".lmp"
+ if shuffle_poscar:
os.symlink(cc, os.path.join(conf_path, orig_poscar_name))
- poscar_shuffle(os.path.join(conf_path, orig_poscar_name),
- os.path.join(conf_path, poscar_name))
- else :
+ poscar_shuffle(
+ os.path.join(conf_path, orig_poscar_name),
+ os.path.join(conf_path, poscar_name),
+ )
+ else:
os.symlink(cc, os.path.join(conf_path, poscar_name))
- if 'sys_format' in jdata:
- fmt = jdata['sys_format']
+ if "sys_format" in jdata:
+ fmt = jdata["sys_format"]
else:
- fmt = 'vasp/poscar'
- system = dpdata.System(os.path.join(conf_path, poscar_name), fmt = fmt, type_map = jdata['type_map'])
- if jdata.get('model_devi_nopbc', False):
+ fmt = "vasp/poscar"
+ system = dpdata.System(
+ os.path.join(conf_path, poscar_name),
+ fmt=fmt,
+ type_map=jdata["type_map"],
+ )
+ if jdata.get("model_devi_nopbc", False):
system.remove_pbc()
system.to_lammps_lmp(os.path.join(conf_path, lmp_name))
elif model_devi_engine == "gromacs":
pass
elif model_devi_engine == "amber":
# Jinzhe's specific Amber version
- conf_name = make_model_devi_conf_name(sys_idx[sys_counter], conf_counter)
- rst7_name = conf_name + '.rst7'
+ conf_name = make_model_devi_conf_name(
+ sys_idx[sys_counter], conf_counter
+ )
+ rst7_name = conf_name + ".rst7"
# link restart file
os.symlink(cc, os.path.join(conf_path, rst7_name))
conf_counter += 1
@@ -941,8 +1160,8 @@ def make_model_devi (iter_index,
input_mode = "buffet"
if "template" in cur_job:
input_mode = "revise_template"
- use_plm = jdata.get('model_devi_plumed', False)
- use_plm_path = jdata.get('model_devi_plumed_path', False)
+ use_plm = jdata.get("model_devi_plumed", False)
+ use_plm_path = jdata.get("model_devi_plumed_path", False)
if input_mode == "native":
if model_devi_engine == "lammps":
_make_model_devi_native(iter_index, jdata, mdata, conf_systems)
@@ -951,40 +1170,45 @@ def make_model_devi (iter_index,
elif model_devi_engine == "amber":
_make_model_devi_amber(iter_index, jdata, mdata, conf_systems)
elif model_devi_engine == "calypso":
- _make_model_devi_native_calypso(iter_index,model_devi_jobs, calypso_run_opt_path) # generate input.dat automatic in each iter
+ _make_model_devi_native_calypso(
+ iter_index, model_devi_jobs, calypso_run_opt_path
+ ) # generate input.dat automatic in each iter
else:
raise RuntimeError("unknown model_devi engine", model_devi_engine)
elif input_mode == "revise_template":
_make_model_devi_revmat(iter_index, jdata, mdata, conf_systems)
elif input_mode == "buffet":
- _make_model_devi_buffet(jdata,calypso_run_opt_path) # generate confs according to the input.dat provided
+ _make_model_devi_buffet(
+ jdata, calypso_run_opt_path
+ ) # generate confs according to the input.dat provided
else:
- raise RuntimeError('unknown model_devi input mode', input_mode)
- #Copy user defined forward_files
+ raise RuntimeError("unknown model_devi input mode", input_mode)
+ # Copy user defined forward_files
symlink_user_forward_files(mdata=mdata, task_type="model_devi", work_path=work_path)
return True
+
def _make_model_devi_revmat(iter_index, jdata, mdata, conf_systems):
- model_devi_jobs = jdata['model_devi_jobs']
- if (iter_index >= len(model_devi_jobs)) :
+ model_devi_jobs = jdata["model_devi_jobs"]
+ if iter_index >= len(model_devi_jobs):
return False
cur_job = model_devi_jobs[iter_index]
- sys_idx = expand_idx(cur_job['sys_idx'])
- if (len(sys_idx) != len(list(set(sys_idx)))) :
+ sys_idx = expand_idx(cur_job["sys_idx"])
+ if len(sys_idx) != len(list(set(sys_idx))):
raise RuntimeError("system index should be uniq")
- mass_map = jdata['mass_map']
- use_plm = jdata.get('model_devi_plumed', False)
- use_plm_path = jdata.get('model_devi_plumed_path', False)
- trj_freq = _get_param_alias(cur_job, ['t_freq', 'trj_freq','traj_freq'])
+ mass_map = jdata["mass_map"]
+ use_plm = jdata.get("model_devi_plumed", False)
+ use_plm_path = jdata.get("model_devi_plumed_path", False)
+ trj_freq = _get_param_alias(cur_job, ["t_freq", "trj_freq", "traj_freq"])
- rev_keys, rev_mat, num_lmp = parse_cur_job_revmat(cur_job, use_plm = use_plm)
- lmp_templ = cur_job['template']['lmp']
+ rev_keys, rev_mat, num_lmp = parse_cur_job_revmat(cur_job, use_plm=use_plm)
+ lmp_templ = cur_job["template"]["lmp"]
lmp_templ = os.path.abspath(lmp_templ)
if use_plm:
- plm_templ = cur_job['template']['plm']
+ plm_templ = cur_job["template"]["plm"]
plm_templ = os.path.abspath(plm_templ)
if use_plm_path:
- plm_path_templ = cur_job['template']['plm_path']
+ plm_path_templ = cur_job["template"]["plm_path"]
plm_path_templ = os.path.abspath(plm_path_templ)
iter_name = make_iter_name(iter_index)
@@ -993,28 +1217,28 @@ def _make_model_devi_revmat(iter_index, jdata, mdata, conf_systems):
models = sorted(glob.glob(os.path.join(train_path, "graph*pb")))
task_model_list = []
for ii in models:
- task_model_list.append(os.path.join('..', os.path.basename(ii)))
+ task_model_list.append(os.path.join("..", os.path.basename(ii)))
work_path = os.path.join(iter_name, model_devi_name)
try:
mdata["deepmd_version"]
except KeyError:
mdata = set_version(mdata)
- deepmd_version = mdata['deepmd_version']
+ deepmd_version = mdata["deepmd_version"]
sys_counter = 0
for ss in conf_systems:
conf_counter = 0
task_counter = 0
- for cc in ss :
- sys_rev = cur_job.get('sys_rev_mat', None)
+ for cc in ss:
+ sys_rev = cur_job.get("sys_rev_mat", None)
total_rev_keys = rev_keys
total_rev_mat = rev_mat
total_num_lmp = num_lmp
if sys_rev is not None:
total_rev_mat = []
- sys_rev_keys, sys_rev_mat, sys_num_lmp = parse_cur_job_sys_revmat(cur_job,
- sys_idx=sys_idx[sys_counter],
- use_plm=use_plm)
+ sys_rev_keys, sys_rev_mat, sys_num_lmp = parse_cur_job_sys_revmat(
+ cur_job, sys_idx=sys_idx[sys_counter], use_plm=use_plm
+ )
_lmp_keys = rev_keys[:num_lmp] + sys_rev_keys[:sys_num_lmp]
if use_plm:
_plm_keys = rev_keys[num_lmp:] + sys_rev_keys[sys_num_lmp:]
@@ -1030,68 +1254,114 @@ def _make_model_devi_revmat(iter_index, jdata, mdata, conf_systems):
total_rev_mat.append(_lmp_mat)
for ii in range(len(total_rev_mat)):
total_rev_item = total_rev_mat[ii]
- task_name = make_model_devi_task_name(sys_idx[sys_counter], task_counter)
- conf_name = make_model_devi_conf_name(sys_idx[sys_counter], conf_counter) + '.lmp'
+ task_name = make_model_devi_task_name(
+ sys_idx[sys_counter], task_counter
+ )
+ conf_name = (
+ make_model_devi_conf_name(sys_idx[sys_counter], conf_counter)
+ + ".lmp"
+ )
task_path = os.path.join(work_path, task_name)
# create task path
create_path(task_path)
- model_devi_merge_traj = jdata.get('model_devi_merge_traj', False)
- if not model_devi_merge_traj :
- create_path(os.path.join(task_path, 'traj'))
+ model_devi_merge_traj = jdata.get("model_devi_merge_traj", False)
+ if not model_devi_merge_traj:
+ create_path(os.path.join(task_path, "traj"))
# link conf
- loc_conf_name = 'conf.lmp'
- os.symlink(os.path.join(os.path.join('..','confs'), conf_name),
- os.path.join(task_path, loc_conf_name) )
+ loc_conf_name = "conf.lmp"
+ os.symlink(
+ os.path.join(os.path.join("..", "confs"), conf_name),
+ os.path.join(task_path, loc_conf_name),
+ )
cwd_ = os.getcwd()
# chdir to task path
os.chdir(task_path)
- shutil.copyfile(lmp_templ, 'input.lammps')
+ shutil.copyfile(lmp_templ, "input.lammps")
# revise input of lammps
- with open('input.lammps') as fp:
+ with open("input.lammps") as fp:
lmp_lines = fp.readlines()
# only revise the line "pair_style deepmd" if the user has not written the full line (checked by then length of the line)
- template_has_pair_deepmd=1
- for line_idx,line_context in enumerate(lmp_lines):
- if (line_context[0] != "#") and ("pair_style" in line_context) and ("deepmd" in line_context):
- template_has_pair_deepmd=0
- template_pair_deepmd_idx=line_idx
+ template_has_pair_deepmd = 1
+ for line_idx, line_context in enumerate(lmp_lines):
+ if (
+ (line_context[0] != "#")
+ and ("pair_style" in line_context)
+ and ("deepmd" in line_context)
+ ):
+ template_has_pair_deepmd = 0
+ template_pair_deepmd_idx = line_idx
if template_has_pair_deepmd == 0:
- if LooseVersion(deepmd_version) < LooseVersion('1'):
- if len(lmp_lines[template_pair_deepmd_idx].split()) != (len(models) + len(["pair_style","deepmd","10", "model_devi.out"])):
- lmp_lines = revise_lmp_input_model(lmp_lines, task_model_list, trj_freq, deepmd_version = deepmd_version)
+ if Version(deepmd_version) < Version("1"):
+ if len(lmp_lines[template_pair_deepmd_idx].split()) != (
+ len(models)
+ + len(["pair_style", "deepmd", "10", "model_devi.out"])
+ ):
+ lmp_lines = revise_lmp_input_model(
+ lmp_lines,
+ task_model_list,
+ trj_freq,
+ deepmd_version=deepmd_version,
+ )
else:
- if len(lmp_lines[template_pair_deepmd_idx].split()) != (len(models) + len(["pair_style","deepmd","out_freq", "10", "out_file", "model_devi.out"])):
- lmp_lines = revise_lmp_input_model(lmp_lines, task_model_list, trj_freq, deepmd_version = deepmd_version)
- #use revise_lmp_input_model to raise error message if "part_style" or "deepmd" not found
+ if len(lmp_lines[template_pair_deepmd_idx].split()) != (
+ len(models)
+ + len(
+ [
+ "pair_style",
+ "deepmd",
+ "out_freq",
+ "10",
+ "out_file",
+ "model_devi.out",
+ ]
+ )
+ ):
+ lmp_lines = revise_lmp_input_model(
+ lmp_lines,
+ task_model_list,
+ trj_freq,
+ deepmd_version=deepmd_version,
+ )
+ # use revise_lmp_input_model to raise error message if "part_style" or "deepmd" not found
else:
- lmp_lines = revise_lmp_input_model(lmp_lines, task_model_list, trj_freq, deepmd_version = deepmd_version)
-
- lmp_lines = revise_lmp_input_dump(lmp_lines, trj_freq)
+ lmp_lines = revise_lmp_input_model(
+ lmp_lines,
+ task_model_list,
+ trj_freq,
+ deepmd_version=deepmd_version,
+ )
+
+ lmp_lines = revise_lmp_input_dump(
+ lmp_lines, trj_freq, model_devi_merge_traj
+ )
lmp_lines = revise_by_keys(
- lmp_lines, total_rev_keys[:total_num_lmp], total_rev_item[:total_num_lmp]
+ lmp_lines,
+ total_rev_keys[:total_num_lmp],
+ total_rev_item[:total_num_lmp],
)
# revise input of plumed
if use_plm:
- lmp_lines = revise_lmp_input_plm(lmp_lines, 'input.plumed')
- shutil.copyfile(plm_templ, 'input.plumed')
- with open('input.plumed') as fp:
+ lmp_lines = revise_lmp_input_plm(lmp_lines, "input.plumed")
+ shutil.copyfile(plm_templ, "input.plumed")
+ with open("input.plumed") as fp:
plm_lines = fp.readlines()
# allow using the same list as lmp
# user should not use the same key name for plm
plm_lines = revise_by_keys(
plm_lines, total_rev_keys, total_rev_item
)
- with open('input.plumed', 'w') as fp:
- fp.write(''.join(plm_lines))
+ with open("input.plumed", "w") as fp:
+ fp.write("".join(plm_lines))
if use_plm_path:
- shutil.copyfile(plm_path_templ, 'plmpath.pdb')
+ shutil.copyfile(plm_path_templ, "plmpath.pdb")
# dump input of lammps
- with open('input.lammps', 'w') as fp:
- fp.write(''.join(lmp_lines))
- with open('job.json', 'w') as fp:
+ with open("input.lammps", "w") as fp:
+ fp.write("".join(lmp_lines))
+ with open("job.json", "w") as fp:
job = {}
- for ii,jj in zip(total_rev_keys, total_rev_item) : job[ii] = jj
- json.dump(job, fp, indent = 4)
+ for ii, jj in zip(total_rev_keys, total_rev_item):
+ job[ii] = jj
+ json.dump(job, fp, indent=4)
os.chdir(cwd_)
task_counter += 1
conf_counter += 1
@@ -1099,30 +1369,30 @@ def _make_model_devi_revmat(iter_index, jdata, mdata, conf_systems):
def _make_model_devi_native(iter_index, jdata, mdata, conf_systems):
- model_devi_jobs = jdata['model_devi_jobs']
- if (iter_index >= len(model_devi_jobs)) :
+ model_devi_jobs = jdata["model_devi_jobs"]
+ if iter_index >= len(model_devi_jobs):
return False
cur_job = model_devi_jobs[iter_index]
ensemble, nsteps, trj_freq, temps, press, pka_e, dt = parse_cur_job(cur_job)
- if dt is not None :
+ if dt is not None:
model_devi_dt = dt
- sys_idx = expand_idx(cur_job['sys_idx'])
- if (len(sys_idx) != len(list(set(sys_idx)))) :
+ sys_idx = expand_idx(cur_job["sys_idx"])
+ if len(sys_idx) != len(list(set(sys_idx))):
raise RuntimeError("system index should be uniq")
- use_ele_temp = jdata.get('use_ele_temp', 0)
- model_devi_dt = jdata['model_devi_dt']
+ use_ele_temp = jdata.get("use_ele_temp", 0)
+ model_devi_dt = jdata["model_devi_dt"]
model_devi_neidelay = None
- if 'model_devi_neidelay' in jdata :
- model_devi_neidelay = jdata['model_devi_neidelay']
+ if "model_devi_neidelay" in jdata:
+ model_devi_neidelay = jdata["model_devi_neidelay"]
model_devi_taut = 0.1
- if 'model_devi_taut' in jdata :
- model_devi_taut = jdata['model_devi_taut']
+ if "model_devi_taut" in jdata:
+ model_devi_taut = jdata["model_devi_taut"]
model_devi_taup = 0.5
- if 'model_devi_taup' in jdata :
- model_devi_taup = jdata['model_devi_taup']
- mass_map = jdata['mass_map']
- nopbc = jdata.get('model_devi_nopbc', False)
+ if "model_devi_taup" in jdata:
+ model_devi_taup = jdata["model_devi_taup"]
+ mass_map = jdata["mass_map"]
+ nopbc = jdata.get("model_devi_nopbc", False)
iter_name = make_iter_name(iter_index)
train_path = os.path.join(iter_name, train_name)
@@ -1130,14 +1400,14 @@ def _make_model_devi_native(iter_index, jdata, mdata, conf_systems):
models = glob.glob(os.path.join(train_path, "graph*pb"))
task_model_list = []
for ii in models:
- task_model_list.append(os.path.join('..', os.path.basename(ii)))
+ task_model_list.append(os.path.join("..", os.path.basename(ii)))
work_path = os.path.join(iter_name, model_devi_name)
sys_counter = 0
for ss in conf_systems:
conf_counter = 0
task_counter = 0
- for cc in ss :
+ for cc in ss:
for tt_ in temps:
if use_ele_temp:
if type(tt_) == list:
@@ -1149,7 +1419,7 @@ def _make_model_devi_native(iter_index, jdata, mdata, conf_systems):
te_f = None
te_a = tt_[1]
else:
- assert(type(tt_) == float or type(tt_) == int)
+ assert type(tt_) == float or type(tt_) == int
tt = float(tt_)
if use_ele_temp == 1:
te_f = tt
@@ -1157,47 +1427,56 @@ def _make_model_devi_native(iter_index, jdata, mdata, conf_systems):
else:
te_f = None
te_a = tt
- else :
+ else:
tt = tt_
te_f = None
te_a = None
for pp in press:
- task_name = make_model_devi_task_name(sys_idx[sys_counter], task_counter)
- conf_name = make_model_devi_conf_name(sys_idx[sys_counter], conf_counter) + '.lmp'
+ task_name = make_model_devi_task_name(
+ sys_idx[sys_counter], task_counter
+ )
+ conf_name = (
+ make_model_devi_conf_name(sys_idx[sys_counter], conf_counter)
+ + ".lmp"
+ )
task_path = os.path.join(work_path, task_name)
# dlog.info(task_path)
create_path(task_path)
- model_devi_merge_traj = jdata.get('model_devi_merge_traj', False)
- if not model_devi_merge_traj :
- create_path(os.path.join(task_path, 'traj'))
- loc_conf_name = 'conf.lmp'
- os.symlink(os.path.join(os.path.join('..','confs'), conf_name),
- os.path.join(task_path, loc_conf_name) )
+ model_devi_merge_traj = jdata.get("model_devi_merge_traj", False)
+ if not model_devi_merge_traj:
+ create_path(os.path.join(task_path, "traj"))
+ loc_conf_name = "conf.lmp"
+ os.symlink(
+ os.path.join(os.path.join("..", "confs"), conf_name),
+ os.path.join(task_path, loc_conf_name),
+ )
cwd_ = os.getcwd()
os.chdir(task_path)
try:
mdata["deepmd_version"]
except KeyError:
mdata = set_version(mdata)
- deepmd_version = mdata['deepmd_version']
- file_c = make_lammps_input(ensemble,
- loc_conf_name,
- task_model_list,
- nsteps,
- model_devi_dt,
- model_devi_neidelay,
- trj_freq,
- mass_map,
- tt,
- jdata = jdata,
- tau_t = model_devi_taut,
- pres = pp,
- tau_p = model_devi_taup,
- pka_e = pka_e,
- ele_temp_f = te_f,
- ele_temp_a = te_a,
- nopbc = nopbc,
- deepmd_version = deepmd_version)
+ deepmd_version = mdata["deepmd_version"]
+ file_c = make_lammps_input(
+ ensemble,
+ loc_conf_name,
+ task_model_list,
+ nsteps,
+ model_devi_dt,
+ model_devi_neidelay,
+ trj_freq,
+ mass_map,
+ tt,
+ jdata=jdata,
+ tau_t=model_devi_taut,
+ pres=pp,
+ tau_p=model_devi_taup,
+ pka_e=pka_e,
+ ele_temp_f=te_f,
+ ele_temp_a=te_a,
+ nopbc=nopbc,
+ deepmd_version=deepmd_version,
+ )
job = {}
job["ensemble"] = ensemble
job["press"] = pp
@@ -1206,50 +1485,55 @@ def _make_model_devi_native(iter_index, jdata, mdata, conf_systems):
job["ele_temp"] = te_f
if te_a is not None:
job["ele_temp"] = te_a
- job["model_devi_dt"] = model_devi_dt
- with open('job.json', 'w') as _outfile:
- json.dump(job, _outfile, indent = 4)
+ job["model_devi_dt"] = model_devi_dt
+ with open("job.json", "w") as _outfile:
+ json.dump(job, _outfile, indent=4)
os.chdir(cwd_)
- with open(os.path.join(task_path, 'input.lammps'), 'w') as fp :
+ with open(os.path.join(task_path, "input.lammps"), "w") as fp:
fp.write(file_c)
task_counter += 1
conf_counter += 1
sys_counter += 1
+
def _make_model_devi_native_gromacs(iter_index, jdata, mdata, conf_systems):
try:
from gromacs.fileformats.mdp import MDP
except ImportError as e:
- raise RuntimeError("GromacsWrapper>=0.8.0 is needed for DP-GEN + Gromacs.") from e
+ raise RuntimeError(
+ "GromacsWrapper>=0.8.0 is needed for DP-GEN + Gromacs."
+ ) from e
# only support for deepmd v2.0
- if LooseVersion(mdata['deepmd_version']) < LooseVersion('2.0'):
- raise RuntimeError("Only support deepmd-kit 2.x for model_devi_engine='gromacs'")
- model_devi_jobs = jdata['model_devi_jobs']
- if (iter_index >= len(model_devi_jobs)) :
+ if Version(mdata["deepmd_version"]) < Version("2.0"):
+ raise RuntimeError(
+ "Only support deepmd-kit 2.x for model_devi_engine='gromacs'"
+ )
+ model_devi_jobs = jdata["model_devi_jobs"]
+ if iter_index >= len(model_devi_jobs):
return False
cur_job = model_devi_jobs[iter_index]
dt = cur_job.get("dt", None)
if dt is not None:
model_devi_dt = dt
else:
- model_devi_dt = jdata['model_devi_dt']
+ model_devi_dt = jdata["model_devi_dt"]
nsteps = cur_job.get("nsteps", None)
lambdas = cur_job.get("lambdas", [1.0])
temps = cur_job.get("temps", [298.0])
for ll in lambdas:
- assert (ll >= 0.0 and ll <= 1.0), "Lambda should be in [0,1]"
+ assert ll >= 0.0 and ll <= 1.0, "Lambda should be in [0,1]"
if nsteps is None:
raise RuntimeError("nsteps is None, you should set nsteps in model_devi_jobs!")
# Currently Gromacs engine is not supported for different temperatures!
# If you want to change temperatures, you should change it in mdp files.
-
- sys_idx = expand_idx(cur_job['sys_idx'])
- if (len(sys_idx) != len(list(set(sys_idx)))) :
+
+ sys_idx = expand_idx(cur_job["sys_idx"])
+ if len(sys_idx) != len(list(set(sys_idx))):
raise RuntimeError("system index should be uniq")
- mass_map = jdata['mass_map']
+ mass_map = jdata["mass_map"]
iter_name = make_iter_name(iter_index)
train_path = os.path.join(iter_name, train_name)
@@ -1257,64 +1541,76 @@ def _make_model_devi_native_gromacs(iter_index, jdata, mdata, conf_systems):
models = glob.glob(os.path.join(train_path, "graph*pb"))
task_model_list = []
for ii in models:
- task_model_list.append(os.path.join('..', os.path.basename(ii)))
+ task_model_list.append(os.path.join("..", os.path.basename(ii)))
work_path = os.path.join(iter_name, model_devi_name)
sys_counter = 0
for ss in conf_systems:
conf_counter = 0
task_counter = 0
- for cc in ss :
+ for cc in ss:
for ll in lambdas:
for tt in temps:
- task_name = make_model_devi_task_name(sys_idx[sys_counter], task_counter)
+ task_name = make_model_devi_task_name(
+ sys_idx[sys_counter], task_counter
+ )
task_path = os.path.join(work_path, task_name)
create_path(task_path)
- gromacs_settings = jdata.get("gromacs_settings" , "")
- for key,file in gromacs_settings.items():
- if key != "traj_filename" and key != "mdp_filename" and key != "group_name" and key != "maxwarn":
- os.symlink(os.path.join(cc,file), os.path.join(task_path, file))
+ gromacs_settings = jdata.get("gromacs_settings", "")
+ for key, file in gromacs_settings.items():
+ if (
+ key != "traj_filename"
+ and key != "mdp_filename"
+ and key != "group_name"
+ and key != "maxwarn"
+ ):
+ os.symlink(
+ os.path.join(cc, file), os.path.join(task_path, file)
+ )
# input.json for DP-Gromacs
with open(os.path.join(cc, "input.json")) as f:
input_json = json.load(f)
input_json["graph_file"] = models[0]
input_json["lambda"] = ll
- with open(os.path.join(task_path,'input.json'), 'w') as _outfile:
- json.dump(input_json, _outfile, indent = 4)
+ with open(os.path.join(task_path, "input.json"), "w") as _outfile:
+ json.dump(input_json, _outfile, indent=4)
# trj_freq
trj_freq = cur_job.get("trj_freq", 10)
mdp = MDP()
- mdp.read(os.path.join(cc, gromacs_settings['mdp_filename']))
- mdp['nstcomm'] = trj_freq
- mdp['nstxout'] = trj_freq
- mdp['nstlog'] = trj_freq
- mdp['nstenergy'] = trj_freq
+ mdp.read(os.path.join(cc, gromacs_settings["mdp_filename"]))
+ mdp["nstcomm"] = trj_freq
+ mdp["nstxout"] = trj_freq
+ mdp["nstlog"] = trj_freq
+ mdp["nstenergy"] = trj_freq
# dt
- mdp['dt'] = model_devi_dt
+ mdp["dt"] = model_devi_dt
# nsteps
- mdp['nsteps'] = nsteps
+ mdp["nsteps"] = nsteps
# temps
if "ref_t" in list(mdp.keys()):
mdp["ref_t"] = tt
else:
mdp["ref-t"] = tt
- mdp.write(os.path.join(task_path, gromacs_settings['mdp_filename']))
+ mdp.write(os.path.join(task_path, gromacs_settings["mdp_filename"]))
cwd_ = os.getcwd()
os.chdir(task_path)
job = {}
job["trj_freq"] = cur_job["trj_freq"]
- job["model_devi_dt"] = model_devi_dt
+ job["model_devi_dt"] = model_devi_dt
job["nsteps"] = nsteps
- with open('job.json', 'w') as _outfile:
- json.dump(job, _outfile, indent = 4)
- os.chdir(cwd_)
+ with open("job.json", "w") as _outfile:
+ json.dump(job, _outfile, indent=4)
+ os.chdir(cwd_)
task_counter += 1
conf_counter += 1
sys_counter += 1
-def _make_model_devi_amber(iter_index: int, jdata: dict, mdata: dict, conf_systems: list):
+
+def _make_model_devi_amber(
+ iter_index: int, jdata: dict, mdata: dict, conf_systems: list
+):
"""Make amber's MD inputs.
Parameters
@@ -1337,7 +1633,7 @@ def _make_model_devi_amber(iter_index: int, jdata: dict, mdata: dict, conf_syste
The path prefix to AMBER PARM7 files
parm7 : list[str]
List of paths to AMBER PARM7 files. Each file maps to a system.
- mdin_prefix : str
+ mdin_prefix : str
The path prefix to AMBER mdin files
mdin : list[str]
List of paths to AMBER mdin files. Each files maps to a system.
@@ -1373,19 +1669,19 @@ def _make_model_devi_amber(iter_index: int, jdata: dict, mdata: dict, conf_syste
References
----------
.. [1] Development of Range-Corrected Deep Learning Potentials for Fast, Accurate Quantum
- Mechanical/Molecular Mechanical Simulations of Chemical Reactions in Solution,
+ Mechanical/Molecular Mechanical Simulations of Chemical Reactions in Solution,
Jinzhe Zeng, Timothy J. Giese, Şölen Ekesan, and Darrin M. York, Journal of Chemical
- Theory and Computation 2021 17 (11), 6993-7009
+ Theory and Computation 2021 17 (11), 6993-7009
inputs: restart (coords), param, mdin, graph, disang (optional)
"""
- model_devi_jobs = jdata['model_devi_jobs']
- if (iter_index >= len(model_devi_jobs)) :
+ model_devi_jobs = jdata["model_devi_jobs"]
+ if iter_index >= len(model_devi_jobs):
return False
- cur_job = model_devi_jobs[iter_index]
- sys_idx = expand_idx(cur_job['sys_idx'])
- if (len(sys_idx) != len(list(set(sys_idx)))) :
+ cur_job = model_devi_jobs[iter_index]
+ sys_idx = expand_idx(cur_job["sys_idx"])
+ if len(sys_idx) != len(list(set(sys_idx))):
raise RuntimeError("system index should be uniq")
iter_name = make_iter_name(iter_index)
@@ -1393,49 +1689,53 @@ def _make_model_devi_amber(iter_index: int, jdata: dict, mdata: dict, conf_syste
train_path = os.path.abspath(train_path)
work_path = os.path.join(iter_name, model_devi_name)
# parm7 - list
- parm7 = jdata['parm7']
+ parm7 = jdata["parm7"]
parm7_prefix = jdata.get("parm7_prefix", "")
parm7 = [os.path.join(parm7_prefix, pp) for pp in parm7]
# link parm file
for ii, pp in enumerate(parm7):
- os.symlink(pp, os.path.join(work_path, 'qmmm%d.parm7'%ii))
+ os.symlink(pp, os.path.join(work_path, "qmmm%d.parm7" % ii))
# TODO: consider writing input in json instead of a given file
- # mdin
- mdin = jdata['mdin']
+ # mdin
+ mdin = jdata["mdin"]
mdin_prefix = jdata.get("mdin_prefix", "")
mdin = [os.path.join(mdin_prefix, pp) for pp in mdin]
- qm_region = jdata['qm_region']
- qm_charge = jdata['qm_charge']
- nsteps = jdata['nsteps']
+ qm_region = jdata["qm_region"]
+ qm_charge = jdata["qm_charge"]
+ nsteps = jdata["nsteps"]
for ii, pp in enumerate(mdin):
- with open(pp) as f, open(os.path.join(work_path, 'init%d.mdin'%ii), 'w') as fw:
+ with open(pp) as f, open(
+ os.path.join(work_path, "init%d.mdin" % ii), "w"
+ ) as fw:
mdin_str = f.read()
# freq, nstlim, qm_region, qm_theory, qm_charge, rcut, graph
- mdin_str = mdin_str.replace("@freq@", str(cur_job.get('trj_freq', 50))) \
- .replace("@nstlim@", str(nsteps[ii])) \
- .replace("@qm_region@", qm_region[ii]) \
- .replace("@qm_charge@", str(qm_charge[ii])) \
- .replace("@qm_theory@", jdata['low_level']) \
- .replace("@rcut@", str(jdata['cutoff']))
+ mdin_str = (
+ mdin_str.replace("@freq@", str(cur_job.get("trj_freq", 50)))
+ .replace("@nstlim@", str(nsteps[ii]))
+ .replace("@qm_region@", qm_region[ii])
+ .replace("@qm_charge@", str(qm_charge[ii]))
+ .replace("@qm_theory@", jdata["low_level"])
+ .replace("@rcut@", str(jdata["cutoff"]))
+ )
models = sorted(glob.glob(os.path.join(train_path, "graph.*.pb")))
task_model_list = []
for ii in models:
- task_model_list.append(os.path.join('..', os.path.basename(ii)))
+ task_model_list.append(os.path.join("..", os.path.basename(ii)))
# graph
for jj, mm in enumerate(task_model_list):
# replace graph
mdin_str = mdin_str.replace("@GRAPH_FILE%d@" % jj, mm)
fw.write(mdin_str)
# disang - list
- disang = jdata['disang']
+ disang = jdata["disang"]
disang_prefix = jdata.get("disang_prefix", "")
disang = [os.path.join(disang_prefix, pp) for pp in disang]
for sys_counter, ss in enumerate(conf_systems):
- for idx_cc, cc in enumerate(ss) :
+ for idx_cc, cc in enumerate(ss):
task_counter = idx_cc
conf_counter = idx_cc
@@ -1445,56 +1745,62 @@ def _make_model_devi_amber(iter_index: int, jdata: dict, mdata: dict, conf_syste
# create task path
create_path(task_path)
# link restart file
- loc_conf_name = 'init.rst7'
- os.symlink(os.path.join(os.path.join('..','confs'), conf_name + ".rst7"),
- os.path.join(task_path, loc_conf_name) )
+ loc_conf_name = "init.rst7"
+ os.symlink(
+ os.path.join(os.path.join("..", "confs"), conf_name + ".rst7"),
+ os.path.join(task_path, loc_conf_name),
+ )
cwd_ = os.getcwd()
# chdir to task path
os.chdir(task_path)
-
+
# reaction coordinates of umbrella sampling
# TODO: maybe consider a better name instead of `r`?
- if 'r' in jdata:
- r=jdata['r'][sys_idx[sys_counter]][conf_counter]
+ if "r" in jdata:
+ r = jdata["r"][sys_idx[sys_counter]][conf_counter]
# r can either be a float or a list of float (for 2D coordinates)
if not isinstance(r, Iterable) or isinstance(r, str):
r = [r]
# disang file should include RVAL, RVAL2, ...
- with open(disang[sys_idx[sys_counter]]) as f, open('TEMPLATE.disang', 'w') as fw:
+ with open(disang[sys_idx[sys_counter]]) as f, open(
+ "TEMPLATE.disang", "w"
+ ) as fw:
tl = f.read()
for ii, rr in enumerate(r):
if isinstance(rr, Iterable) and not isinstance(rr, str):
- raise RuntimeError("rr should not be iterable! sys: %d rr: %s r: %s" % (sys_idx[sys_counter], str(rr), str(r)))
- tl = tl.replace("RVAL"+str(ii+1), str(rr))
+ raise RuntimeError(
+ "rr should not be iterable! sys: %d rr: %s r: %s"
+ % (sys_idx[sys_counter], str(rr), str(r))
+ )
+ tl = tl.replace("RVAL" + str(ii + 1), str(rr))
if len(r) == 1:
tl = tl.replace("RVAL", str(r[0]))
fw.write(tl)
- with open('job.json', 'w') as fp:
- json.dump(cur_job, fp, indent = 4)
+ with open("job.json", "w") as fp:
+ json.dump(cur_job, fp, indent=4)
os.chdir(cwd_)
-def run_md_model_devi (iter_index,
- jdata,
- mdata) :
- #rmdlog.info("This module has been run !")
- model_devi_exec = mdata['model_devi_command']
+def run_md_model_devi(iter_index, jdata, mdata):
+
+ # rmdlog.info("This module has been run !")
+ model_devi_exec = mdata["model_devi_command"]
- model_devi_group_size = mdata['model_devi_group_size']
- model_devi_resources = mdata['model_devi_resources']
- use_plm = jdata.get('model_devi_plumed', False)
- use_plm_path = jdata.get('model_devi_plumed_path', False)
- model_devi_merge_traj = jdata.get('model_devi_merge_traj', False)
+ model_devi_group_size = mdata["model_devi_group_size"]
+ model_devi_resources = mdata["model_devi_resources"]
+ use_plm = jdata.get("model_devi_plumed", False)
+ use_plm_path = jdata.get("model_devi_plumed_path", False)
+ model_devi_merge_traj = jdata.get("model_devi_merge_traj", False)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, model_devi_name)
- assert(os.path.isdir(work_path))
+ assert os.path.isdir(work_path)
all_task = glob.glob(os.path.join(work_path, "task.*"))
all_task.sort()
- fp = open (os.path.join(work_path, 'cur_job.json'), 'r')
- cur_job = json.load (fp)
+ fp = open(os.path.join(work_path, "cur_job.json"), "r")
+ cur_job = json.load(fp)
run_tasks_ = all_task
# for ii in all_task:
@@ -1507,33 +1813,36 @@ def run_md_model_devi (iter_index,
# run_tasks_.append(ii)
run_tasks = [os.path.basename(ii) for ii in run_tasks_]
- #dlog.info("all_task is ", all_task)
- #dlog.info("run_tasks in run_model_deviation",run_tasks_)
- all_models = glob.glob(os.path.join(work_path, 'graph*pb'))
+ # dlog.info("all_task is ", all_task)
+ # dlog.info("run_tasks in run_model_deviation",run_tasks_)
+ all_models = glob.glob(os.path.join(work_path, "graph*pb"))
model_names = [os.path.basename(ii) for ii in all_models]
model_devi_engine = jdata.get("model_devi_engine", "lammps")
if model_devi_engine == "lammps":
- command = "{ if [ ! -f dpgen.restart.10000 ]; then %s -i input.lammps -v restart 0; else %s -i input.lammps -v restart 1; fi }" % (model_devi_exec, model_devi_exec)
+ command = (
+ "{ if [ ! -f dpgen.restart.10000 ]; then %s -i input.lammps -v restart 0; else %s -i input.lammps -v restart 1; fi }"
+ % (model_devi_exec, model_devi_exec)
+ )
command = "/bin/sh -c '%s'" % command
commands = [command]
-
- forward_files = ['conf.lmp', 'input.lammps']
- backward_files = ['model_devi.out', 'model_devi.log']
- if model_devi_merge_traj :
- backward_files += ['all.lammpstrj']
- else :
- forward_files += ['traj']
- backward_files += ['traj']
+
+ forward_files = ["conf.lmp", "input.lammps"]
+ backward_files = ["model_devi.out", "model_devi.log"]
+ if model_devi_merge_traj:
+ backward_files += ["all.lammpstrj"]
+ else:
+ forward_files += ["traj"]
+ backward_files += ["traj"]
if use_plm:
- forward_files += ['input.plumed']
- # backward_files += ['output.plumed']
- backward_files += ['output.plumed','COLVAR']
+ forward_files += ["input.plumed"]
+ # backward_files += ['output.plumed']
+ backward_files += ["output.plumed", "COLVAR"]
if use_plm_path:
- forward_files += ['plmpath.pdb']
+ forward_files += ["plmpath.pdb"]
elif model_devi_engine == "gromacs":
-
+
gromacs_settings = jdata.get("gromacs_settings", {})
mdp_filename = gromacs_settings.get("mdp_filename", "md.mdp")
topol_filename = gromacs_settings.get("topol_filename", "processed.top")
@@ -1550,30 +1859,68 @@ def run_md_model_devi (iter_index,
grp_name = gromacs_settings.get("group_name", "Other")
trj_freq = cur_job.get("trj_freq", 10)
- command = "%s grompp -f %s -p %s -c %s -o %s -maxwarn %d" % (model_devi_exec, mdp_filename, topol_filename, conf_filename, deffnm, maxwarn)
- command += "&& %s mdrun -deffnm %s -cpi" %(model_devi_exec, deffnm)
+ command = "%s grompp -f %s -p %s -c %s -o %s -maxwarn %d" % (
+ model_devi_exec,
+ mdp_filename,
+ topol_filename,
+ conf_filename,
+ deffnm,
+ maxwarn,
+ )
+ command += "&& %s mdrun -deffnm %s -cpi" % (model_devi_exec, deffnm)
if ndx_filename:
- command += f"&& echo -e \"{grp_name}\\n{grp_name}\\n\" | {model_devi_exec} trjconv -s {ref_filename} -f {deffnm}.trr -n {ndx_filename} -o {traj_filename} -pbc mol -ur compact -center"
+ command += f'&& echo -e "{grp_name}\\n{grp_name}\\n" | {model_devi_exec} trjconv -s {ref_filename} -f {deffnm}.trr -n {ndx_filename} -o {traj_filename} -pbc mol -ur compact -center'
else:
- command += "&& echo -e \"%s\\n%s\\n\" | %s trjconv -s %s -f %s.trr -o %s -pbc mol -ur compact -center" % (grp_name, grp_name, model_devi_exec, ref_filename, deffnm, traj_filename)
+ command += (
+ '&& echo -e "%s\\n%s\\n" | %s trjconv -s %s -f %s.trr -o %s -pbc mol -ur compact -center'
+ % (
+ grp_name,
+ grp_name,
+ model_devi_exec,
+ ref_filename,
+ deffnm,
+ traj_filename,
+ )
+ )
command += "&& if [ ! -d traj ]; then \n mkdir traj; fi\n"
command += f"python -c \"import dpdata;system = dpdata.System('{traj_filename}', fmt='gromacs/gro'); [system.to_gromacs_gro('traj/%d.gromacstrj' % (i * {trj_freq}), frame_idx=i) for i in range(system.get_nframes())]; system.to_deepmd_npy('traj_deepmd')\""
command += f"&& dp model-devi -m ../graph.000.pb ../graph.001.pb ../graph.002.pb ../graph.003.pb -s traj_deepmd -o model_devi.out -f {trj_freq}"
commands = [command]
- forward_files = [mdp_filename, topol_filename, conf_filename, index_filename, ref_filename, type_filename, "input.json", "job.json" ]
- if ndx_filename: forward_files.append(ndx_filename)
- backward_files = ["%s.tpr" % deffnm, "%s.log" %deffnm , traj_filename, 'model_devi.out', "traj", "traj_deepmd" ]
+ forward_files = [
+ mdp_filename,
+ topol_filename,
+ conf_filename,
+ index_filename,
+ ref_filename,
+ type_filename,
+ "input.json",
+ "job.json",
+ ]
+ if ndx_filename:
+ forward_files.append(ndx_filename)
+ backward_files = [
+ "%s.tpr" % deffnm,
+ "%s.log" % deffnm,
+ traj_filename,
+ "model_devi.out",
+ "traj",
+ "traj_deepmd",
+ ]
elif model_devi_engine == "amber":
- commands = [(
- "TASK=$(basename $(pwd)) && "
- "SYS1=${TASK:5:3} && "
- "SYS=$((10#$SYS1)) && "
- )+ model_devi_exec + (
- " -O -p ../qmmm$SYS.parm7 -c init.rst7 -i ../init$SYS.mdin -o rc.mdout -r rc.rst7 -x rc.nc -inf rc.mdinfo -ref init.rst7"
- )]
- forward_files = ['init.rst7', 'TEMPLATE.disang']
- backward_files = ['rc.mdout', 'rc.nc', 'rc.rst7', 'TEMPLATE.dumpave']
+ commands = [
+ (
+ "TASK=$(basename $(pwd)) && "
+ "SYS1=${TASK:5:3} && "
+ "SYS=$((10#$SYS1)) && "
+ )
+ + model_devi_exec
+ + (
+ " -O -p ../qmmm$SYS.parm7 -c init.rst7 -i ../init$SYS.mdin -o rc.mdout -r rc.rst7 -x rc.nc -inf rc.mdinfo -ref init.rst7"
+ )
+ ]
+ forward_files = ["init.rst7", "TEMPLATE.disang"]
+ backward_files = ["rc.mdout", "rc.nc", "rc.rst7", "TEMPLATE.dumpave"]
model_names.extend(["qmmm*.parm7", "init*.mdin"])
cwd = os.getcwd()
@@ -1581,28 +1928,20 @@ def run_md_model_devi (iter_index,
user_forward_files = mdata.get("model_devi" + "_user_forward_files", [])
forward_files += [os.path.basename(file) for file in user_forward_files]
backward_files += mdata.get("model_devi" + "_user_backward_files", [])
- api_version = mdata.get('api_version', '0.9')
- if(len(run_tasks) == 0):
- raise RuntimeError("run_tasks for model_devi should not be empty! Please check your files.")
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher = make_dispatcher(mdata['model_devi_machine'], mdata['model_devi_resources'], work_path, run_tasks, model_devi_group_size)
- dispatcher.run_jobs(mdata['model_devi_resources'],
- commands,
- work_path,
- run_tasks,
- model_devi_group_size,
- model_names,
- forward_files,
- backward_files,
- outlog = 'model_devi.log',
- errlog = 'model_devi.log')
-
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ api_version = mdata.get("api_version", "1.0")
+ if len(run_tasks) == 0:
+ raise RuntimeError(
+ "run_tasks for model_devi should not be empty! Please check your files."
+ )
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+
+ elif Version(api_version) >= Version("1.0"):
submission = make_submission(
- mdata['model_devi_machine'],
- mdata['model_devi_resources'],
+ mdata["model_devi_machine"],
+ mdata["model_devi_resources"],
commands=commands,
work_path=work_path,
run_tasks=run_tasks,
@@ -1610,208 +1949,237 @@ def run_md_model_devi (iter_index,
forward_common_files=model_names,
forward_files=forward_files,
backward_files=backward_files,
- outlog = 'model_devi.log',
- errlog = 'model_devi.log')
+ outlog="model_devi.log",
+ errlog="model_devi.log",
+ )
submission.run_submission()
-def run_model_devi(iter_index,jdata,mdata):
+
+def run_model_devi(iter_index, jdata, mdata):
model_devi_engine = jdata.get("model_devi_engine", "lammps")
if model_devi_engine != "calypso":
- run_md_model_devi(iter_index,jdata,mdata)
+ run_md_model_devi(iter_index, jdata, mdata)
else:
- run_calypso_model_devi(iter_index,jdata,mdata)
-
-def post_model_devi (iter_index,
- jdata,
- mdata) :
+ run_calypso_model_devi(iter_index, jdata, mdata)
+
+
+def post_model_devi(iter_index, jdata, mdata):
pass
def _to_face_dist(box_):
- box = np.reshape(box_, [3,3])
+ box = np.reshape(box_, [3, 3])
vol = np.abs(np.linalg.det(box))
dists = []
- for [ii,jj] in [[0, 1], [1, 2], [2, 0]]:
+ for [ii, jj] in [[0, 1], [1, 2], [2, 0]]:
vv = np.cross(box[ii], box[jj])
dists.append(vol / np.linalg.norm(vv))
return np.array(dists)
-def check_cluster(conf_name,
- fp_cluster_vacuum,
- fmt='lammps/dump'):
+
+def check_cluster(conf_name, fp_cluster_vacuum, fmt="lammps/dump"):
sys = dpdata.System(conf_name, fmt)
- assert(sys.get_nframes() == 1)
- cell=sys.data['cells'][0]
- coord=sys.data['coords'][0]
- xlim=max(coord[:,0])-min(coord[:,0])
- ylim=max(coord[:,1])-min(coord[:,1])
- zlim=max(coord[:,2])-min(coord[:,2])
- a,b,c=map(norm,[cell[0,:],cell[1,:],cell[2,:]])
- min_vac=min([a-xlim,b-ylim,c-zlim])
- #print([a-xlim,b-ylim,c-zlim])
- #_,r3d=miniball.get_bounding_ball(coord)
+ assert sys.get_nframes() == 1
+ cell = sys.data["cells"][0]
+ coord = sys.data["coords"][0]
+ xlim = max(coord[:, 0]) - min(coord[:, 0])
+ ylim = max(coord[:, 1]) - min(coord[:, 1])
+ zlim = max(coord[:, 2]) - min(coord[:, 2])
+ a, b, c = map(norm, [cell[0, :], cell[1, :], cell[2, :]])
+ min_vac = min([a - xlim, b - ylim, c - zlim])
+ # print([a-xlim,b-ylim,c-zlim])
+ # _,r3d=miniball.get_bounding_ball(coord)
if min_vac < fp_cluster_vacuum:
- is_bad = True
+ is_bad = True
else:
- is_bad = False
+ is_bad = False
return is_bad
-def check_bad_box(conf_name,
- criteria,
- fmt = 'lammps/dump'):
- all_c = criteria.split(';')
+
+def check_bad_box(conf_name, criteria, fmt="lammps/dump"):
+ all_c = criteria.split(";")
sys = dpdata.System(conf_name, fmt)
- assert(sys.get_nframes() == 1)
+ assert sys.get_nframes() == 1
is_bad = False
for ii in all_c:
- [key, value] = ii.split(':')
- if key == 'length_ratio':
- lengths = np.linalg.norm(sys['cells'][0], axis = 1)
+ [key, value] = ii.split(":")
+ if key == "length_ratio":
+ lengths = np.linalg.norm(sys["cells"][0], axis=1)
ratio = np.max(lengths) / np.min(lengths)
if ratio > float(value):
is_bad = True
- elif key == 'height_ratio':
- lengths = np.linalg.norm(sys['cells'][0], axis = 1)
- dists = _to_face_dist(sys['cells'][0])
+ elif key == "height_ratio":
+ lengths = np.linalg.norm(sys["cells"][0], axis=1)
+ dists = _to_face_dist(sys["cells"][0])
ratio = np.max(lengths) / np.min(dists)
if ratio > float(value):
is_bad = True
#
- elif key == 'wrap_ratio':
- ratio=[sys['cells'][0][1][0]/sys['cells'][0][0][0],sys['cells'][0][2][1]/sys['cells'][0][1][1],sys['cells'][0][2][0]/sys['cells'][0][0][0]]
+ elif key == "wrap_ratio":
+ ratio = [
+ sys["cells"][0][1][0] / sys["cells"][0][0][0],
+ sys["cells"][0][2][1] / sys["cells"][0][1][1],
+ sys["cells"][0][2][0] / sys["cells"][0][0][0],
+ ]
if np.max(np.abs(ratio)) > float(value):
is_bad = True
- elif key == 'tilt_ratio':
- ratio=[sys['cells'][0][1][0]/sys['cells'][0][1][1],sys['cells'][0][2][1]/sys['cells'][0][2][2],sys['cells'][0][2][0]/sys['cells'][0][2][2]]
+ elif key == "tilt_ratio":
+ ratio = [
+ sys["cells"][0][1][0] / sys["cells"][0][1][1],
+ sys["cells"][0][2][1] / sys["cells"][0][2][2],
+ sys["cells"][0][2][0] / sys["cells"][0][2][2],
+ ]
if np.max(np.abs(ratio)) > float(value):
- is_bad= True
+ is_bad = True
else:
- raise RuntimeError('unknow key', key)
+ raise RuntimeError("unknow key", key)
return is_bad
+
def _read_model_devi_file(
- task_path : str,
- model_devi_f_avg_relative : bool = False,
- model_devi_merge_traj : bool = False
+ task_path: str,
+ model_devi_f_avg_relative: bool = False,
+ model_devi_merge_traj: bool = False,
):
- model_devi = np.loadtxt(os.path.join(task_path, 'model_devi.out'))
- if model_devi_f_avg_relative :
- if(model_devi_merge_traj is True) :
- all_traj = os.path.join(task_path, 'all.lammpstrj')
+ model_devi = np.loadtxt(os.path.join(task_path, "model_devi.out"))
+ if model_devi_f_avg_relative:
+ if model_devi_merge_traj is True:
+ all_traj = os.path.join(task_path, "all.lammpstrj")
all_f = get_all_dumped_forces(all_traj)
- else :
- trajs = glob.glob(os.path.join(task_path, 'traj', '*.lammpstrj'))
+ else:
+ trajs = glob.glob(os.path.join(task_path, "traj", "*.lammpstrj"))
all_f = []
for ii in trajs:
- all_f.append(get_dumped_forces(ii))
+ all_f.append(get_dumped_forces(ii))
all_f = np.array(all_f)
- all_f = all_f.reshape([-1,3])
- avg_f = np.sqrt(np.average(np.sum(np.square(all_f), axis = 1)))
- model_devi[:,4:7] = model_devi[:,4:7] / avg_f
- np.savetxt(os.path.join(task_path, 'model_devi_avgf.out'), model_devi, fmt='%16.6e')
+ all_f = all_f.reshape([-1, 3])
+ avg_f = np.sqrt(np.average(np.sum(np.square(all_f), axis=1)))
+ model_devi[:, 4:7] = model_devi[:, 4:7] / avg_f
+ np.savetxt(
+ os.path.join(task_path, "model_devi_avgf.out"), model_devi, fmt="%16.6e"
+ )
return model_devi
def _select_by_model_devi_standard(
- modd_system_task: List[str],
- f_trust_lo : float,
- f_trust_hi : float,
- v_trust_lo : float,
- v_trust_hi : float,
- cluster_cutoff : float,
- model_devi_engine : str,
- model_devi_skip : int = 0,
- model_devi_f_avg_relative : bool = False,
- model_devi_merge_traj : bool = False,
- detailed_report_make_fp : bool = True,
+ modd_system_task: List[str],
+ f_trust_lo: float,
+ f_trust_hi: float,
+ v_trust_lo: float,
+ v_trust_hi: float,
+ cluster_cutoff: float,
+ model_devi_engine: str,
+ model_devi_skip: int = 0,
+ model_devi_f_avg_relative: bool = False,
+ model_devi_merge_traj: bool = False,
+ detailed_report_make_fp: bool = True,
):
- if model_devi_engine == 'calypso':
- iter_name = modd_system_task[0].split('/')[0]
+ if model_devi_engine == "calypso":
+ iter_name = modd_system_task[0].split("/")[0]
_work_path = os.path.join(iter_name, model_devi_name)
# calypso_run_opt_path = os.path.join(_work_path,calypso_run_opt_name)
- calypso_run_opt_path = glob.glob('%s/%s.*'%(_work_path, calypso_run_opt_name))[0]
- numofspecies = _parse_calypso_input('NumberOfSpecies',calypso_run_opt_path)
- min_dis = _parse_calypso_dis_mtx(numofspecies,calypso_run_opt_path)
+ calypso_run_opt_path = glob.glob(
+ "%s/%s.*" % (_work_path, calypso_run_opt_name)
+ )[0]
+ numofspecies = _parse_calypso_input("NumberOfSpecies", calypso_run_opt_path)
+ min_dis = _parse_calypso_dis_mtx(numofspecies, calypso_run_opt_path)
fp_candidate = []
if detailed_report_make_fp:
fp_rest_accurate = []
fp_rest_failed = []
cc = 0
counter = Counter()
- counter['candidate'] = 0
- counter['failed'] = 0
- counter['accurate'] = 0
- for tt in modd_system_task :
+ counter["candidate"] = 0
+ counter["failed"] = 0
+ counter["accurate"] = 0
+ for tt in modd_system_task:
with warnings.catch_warnings():
warnings.simplefilter("ignore")
- all_conf = _read_model_devi_file(tt, model_devi_f_avg_relative, model_devi_merge_traj)
+ all_conf = _read_model_devi_file(
+ tt, model_devi_f_avg_relative, model_devi_merge_traj
+ )
if all_conf.shape == (7,):
- all_conf = all_conf.reshape(1,all_conf.shape[0])
- elif model_devi_engine == 'calypso' and all_conf.shape == (8,):
- all_conf = all_conf.reshape(1,all_conf.shape[0])
- for ii in range(all_conf.shape[0]) :
- if all_conf[ii][0] < model_devi_skip :
+ all_conf = all_conf.reshape(1, all_conf.shape[0])
+ elif model_devi_engine == "calypso" and all_conf.shape == (8,):
+ all_conf = all_conf.reshape(1, all_conf.shape[0])
+ for ii in range(all_conf.shape[0]):
+ if all_conf[ii][0] < model_devi_skip:
continue
cc = int(all_conf[ii][0])
if cluster_cutoff is None:
- if model_devi_engine == 'calypso':
+ if model_devi_engine == "calypso":
if float(all_conf[ii][-1]) <= float(min_dis):
if detailed_report_make_fp:
fp_rest_failed.append([tt, cc])
- counter['failed'] += 1
+ counter["failed"] += 1
continue
- if (all_conf[ii][1] < v_trust_hi and all_conf[ii][1] >= v_trust_lo) or \
- (all_conf[ii][4] < f_trust_hi and all_conf[ii][4] >= f_trust_lo) :
+ if (
+ all_conf[ii][1] < v_trust_hi and all_conf[ii][1] >= v_trust_lo
+ ) or (
+ all_conf[ii][4] < f_trust_hi and all_conf[ii][4] >= f_trust_lo
+ ):
fp_candidate.append([tt, cc])
- counter['candidate'] += 1
- elif (all_conf[ii][1] >= v_trust_hi ) or (all_conf[ii][4] >= f_trust_hi ):
+ counter["candidate"] += 1
+ elif (all_conf[ii][1] >= v_trust_hi) or (
+ all_conf[ii][4] >= f_trust_hi
+ ):
if detailed_report_make_fp:
fp_rest_failed.append([tt, cc])
- counter['failed'] += 1
- elif (all_conf[ii][1] < v_trust_lo and all_conf[ii][4] < f_trust_lo ):
+ counter["failed"] += 1
+ elif all_conf[ii][1] < v_trust_lo and all_conf[ii][4] < f_trust_lo:
if detailed_report_make_fp:
fp_rest_accurate.append([tt, cc])
- counter['accurate'] += 1
- else :
- if model_devi_engine == 'calypso':
- dlog.info('ase opt traj %s frame %d with f devi %f does not belong to either accurate, candidiate and failed '% (tt, ii, all_conf[ii][4]))
+ counter["accurate"] += 1
+ else:
+ if model_devi_engine == "calypso":
+ dlog.info(
+ "ase opt traj %s frame %d with f devi %f does not belong to either accurate, candidiate and failed "
+ % (tt, ii, all_conf[ii][4])
+ )
else:
- raise RuntimeError('md traj %s frame %d with f devi %f does not belong to either accurate, candidiate and failed, it should not happen' % (tt, ii, all_conf[ii][4]))
+ raise RuntimeError(
+ "md traj %s frame %d with f devi %f does not belong to either accurate, candidiate and failed, it should not happen"
+ % (tt, ii, all_conf[ii][4])
+ )
else:
- idx_candidate = np.where(np.logical_and(all_conf[ii][7:] < f_trust_hi, all_conf[ii][7:] >= f_trust_lo))[0]
+ idx_candidate = np.where(
+ np.logical_and(
+ all_conf[ii][7:] < f_trust_hi,
+ all_conf[ii][7:] >= f_trust_lo,
+ )
+ )[0]
for jj in idx_candidate:
fp_candidate.append([tt, cc, jj])
- counter['candidate'] += len(idx_candidate)
+ counter["candidate"] += len(idx_candidate)
idx_rest_accurate = np.where(all_conf[ii][7:] < f_trust_lo)[0]
if detailed_report_make_fp:
for jj in idx_rest_accurate:
fp_rest_accurate.append([tt, cc, jj])
- counter['accurate'] += len(idx_rest_accurate)
+ counter["accurate"] += len(idx_rest_accurate)
idx_rest_failed = np.where(all_conf[ii][7:] >= f_trust_hi)[0]
if detailed_report_make_fp:
for jj in idx_rest_failed:
fp_rest_failed.append([tt, cc, jj])
- counter['failed'] += len(idx_rest_failed)
-
- return fp_rest_accurate, fp_candidate, fp_rest_failed, counter
+ counter["failed"] += len(idx_rest_failed)
+ return fp_rest_accurate, fp_candidate, fp_rest_failed, counter
def _select_by_model_devi_adaptive_trust_low(
- modd_system_task: List[str],
- f_trust_hi : float,
- numb_candi_f : int,
- perc_candi_f : float,
- v_trust_hi : float,
- numb_candi_v : int,
- perc_candi_v : float,
- model_devi_skip : int = 0,
- model_devi_f_avg_relative : bool = False,
- model_devi_merge_traj : bool = False,
+ modd_system_task: List[str],
+ f_trust_hi: float,
+ numb_candi_f: int,
+ perc_candi_f: float,
+ v_trust_hi: float,
+ numb_candi_v: int,
+ perc_candi_v: float,
+ model_devi_skip: int = 0,
+ model_devi_f_avg_relative: bool = False,
+ model_devi_merge_traj: bool = False,
):
"""
modd_system_task model deviation tasks belonging to one system
@@ -1822,7 +2190,7 @@ def _select_by_model_devi_adaptive_trust_low(
numb_candi_v number of candidate due to the v model deviation
perc_candi_v percentage of candidate due to the v model deviation
model_devi_skip
-
+
returns
accur the accurate set
candi the candidate set
@@ -1841,10 +2209,12 @@ def _select_by_model_devi_adaptive_trust_low(
for tt in modd_system_task:
with warnings.catch_warnings():
warnings.simplefilter("ignore")
- model_devi = np.loadtxt(os.path.join(tt, 'model_devi.out'))
- model_devi = _read_model_devi_file(tt, model_devi_f_avg_relative, model_devi_merge_traj)
- for ii in range(model_devi.shape[0]) :
- if model_devi[ii][0] < model_devi_skip :
+ model_devi = np.loadtxt(os.path.join(tt, "model_devi.out"))
+ model_devi = _read_model_devi_file(
+ tt, model_devi_f_avg_relative, model_devi_merge_traj
+ )
+ for ii in range(model_devi.shape[0]):
+ if model_devi[ii][0] < model_devi_skip:
continue
cc = int(model_devi[ii][0])
# tt: name of task folder
@@ -1862,7 +2232,7 @@ def _select_by_model_devi_adaptive_trust_low(
# sort
coll_v.sort()
coll_f.sort()
- assert(len(coll_v) == len(coll_f))
+ assert len(coll_v) == len(coll_f)
# calcuate numbers
numb_candi_v = max(numb_candi_v, int(perc_candi_v * 0.01 * len(coll_v)))
numb_candi_f = max(numb_candi_f, int(perc_candi_f * 0.01 * len(coll_f)))
@@ -1879,7 +2249,7 @@ def _select_by_model_devi_adaptive_trust_low(
if numb_candi_f == 0:
f_trust_lo = f_trust_hi
else:
- f_trust_lo = coll_f[-numb_candi_f][0]
+ f_trust_lo = coll_f[-numb_candi_f][0]
# add to candidate set
for ii in range(len(coll_v) - numb_candi_v, len(coll_v)):
candi.add(tuple(coll_v[ii][1:]))
@@ -1892,26 +2262,28 @@ def _select_by_model_devi_adaptive_trust_low(
accur = [list(ii) for ii in accur]
# counters
counter = Counter()
- counter['candidate'] = len(candi)
- counter['failed'] = len(failed)
- counter['accurate'] = len(accur)
+ counter["candidate"] = len(candi)
+ counter["failed"] = len(failed)
+ counter["accurate"] = len(accur)
return accur, candi, failed, counter, f_trust_lo, v_trust_lo
-
-
-def _make_fp_vasp_inner (iter_index,
- modd_path,
- work_path,
- model_devi_skip,
- v_trust_lo,
- v_trust_hi,
- f_trust_lo,
- f_trust_hi,
- fp_task_min,
- fp_task_max,
- fp_link_files,
- type_map,
- jdata):
+
+
+def _make_fp_vasp_inner(
+ iter_index,
+ modd_path,
+ work_path,
+ model_devi_skip,
+ v_trust_lo,
+ v_trust_hi,
+ f_trust_lo,
+ f_trust_hi,
+ fp_task_min,
+ fp_task_max,
+ fp_link_files,
+ type_map,
+ jdata,
+):
"""
iter_index int iter index
modd_path string path of model devi
@@ -1922,40 +2294,45 @@ def _make_fp_vasp_inner (iter_index,
"""
# --------------------------------------------------------------------------------------------------------------------------------------
- model_devi_engine = jdata.get('model_devi_engine', 'lammps')
- if model_devi_engine == 'calypso':
- iter_name = work_path.split('/')[0]
+ model_devi_engine = jdata.get("model_devi_engine", "lammps")
+ if model_devi_engine == "calypso":
+ iter_name = work_path.split("/")[0]
_work_path = os.path.join(iter_name, model_devi_name)
# calypso_run_opt_path = os.path.join(_work_path,calypso_run_opt_name)
- calypso_run_opt_path = glob.glob('%s/%s.*'%(_work_path, calypso_run_opt_name))[0]
- numofspecies = _parse_calypso_input('NumberOfSpecies',calypso_run_opt_path)
- min_dis = _parse_calypso_dis_mtx(numofspecies,calypso_run_opt_path)
+ calypso_run_opt_path = glob.glob(
+ "%s/%s.*" % (_work_path, calypso_run_opt_name)
+ )[0]
+ numofspecies = _parse_calypso_input("NumberOfSpecies", calypso_run_opt_path)
+ min_dis = _parse_calypso_dis_mtx(numofspecies, calypso_run_opt_path)
calypso_total_fp_num = 300
- modd_path = os.path.join(modd_path,calypso_model_devi_name)
+ modd_path = os.path.join(modd_path, calypso_model_devi_name)
model_devi_skip = -1
- with open(os.path.join(modd_path,'Model_Devi.out'),'r') as summfile:
+ with open(os.path.join(modd_path, "Model_Devi.out"), "r") as summfile:
summary = np.loadtxt(summfile)
- summaryfmax = summary[:,-4]
- dis = summary[:,-1]
- acc = np.where((summaryfmax <= f_trust_lo) & (dis > float(min_dis)))
- fail = np.where((summaryfmax > f_trust_hi) | (dis <= float(min_dis)))
+ summaryfmax = summary[:, -4]
+ dis = summary[:, -1]
+ acc = np.where((summaryfmax <= f_trust_lo) & (dis > float(min_dis)))
+ fail = np.where((summaryfmax > f_trust_hi) | (dis <= float(min_dis)))
nnan = np.where(np.isnan(summaryfmax))
- acc_num = len(acc[0])
+ acc_num = len(acc[0])
fail_num = len(fail[0])
- nan_num = len(nnan[0])
+ nan_num = len(nnan[0])
tot = len(summaryfmax) - nan_num
candi_num = tot - acc_num - fail_num
- dlog.info("summary accurate_ratio: {0:8.4f}% candidata_ratio: {1:8.4f}% failed_ratio: {2:8.4f}% in {3:d} structures".format(
- acc_num*100/tot,candi_num*100/tot,fail_num*100/tot,tot ))
+ dlog.info(
+ "summary accurate_ratio: {0:8.4f}% candidata_ratio: {1:8.4f}% failed_ratio: {2:8.4f}% in {3:d} structures".format(
+ acc_num * 100 / tot, candi_num * 100 / tot, fail_num * 100 / tot, tot
+ )
+ )
# --------------------------------------------------------------------------------------------------------------------------------------
modd_task = glob.glob(os.path.join(modd_path, "task.*"))
modd_task.sort()
system_index = []
- for ii in modd_task :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in modd_task:
+ system_index.append(os.path.basename(ii).split(".")[1])
set_tmp = set(system_index)
system_index = list(set_tmp)
@@ -1966,16 +2343,16 @@ def _make_fp_vasp_inner (iter_index,
charges_recorder = [] # record charges for each fp_task
charges_map = jdata.get("sys_charges", [])
- cluster_cutoff = jdata.get('cluster_cutoff', None)
- model_devi_adapt_trust_lo = jdata.get('model_devi_adapt_trust_lo', False)
- model_devi_f_avg_relative = jdata.get('model_devi_f_avg_relative', False)
- model_devi_merge_traj = jdata.get('model_devi_merge_traj', False)
+ cluster_cutoff = jdata.get("cluster_cutoff", None)
+ model_devi_adapt_trust_lo = jdata.get("model_devi_adapt_trust_lo", False)
+ model_devi_f_avg_relative = jdata.get("model_devi_f_avg_relative", False)
+ model_devi_merge_traj = jdata.get("model_devi_merge_traj", False)
# skip save *.out if detailed_report_make_fp is False, default is True
detailed_report_make_fp = jdata.get("detailed_report_make_fp", True)
# skip bad box criteria
- skip_bad_box = jdata.get('fp_skip_bad_box')
+ skip_bad_box = jdata.get("fp_skip_bad_box")
# skip discrete structure in cluster
- fp_cluster_vacuum = jdata.get('fp_cluster_vacuum',None)
+ fp_cluster_vacuum = jdata.get("fp_cluster_vacuum", None)
def _trust_limitation_check(sys_idx, lim):
if isinstance(lim, list):
@@ -1987,10 +2364,10 @@ def _trust_limitation_check(sys_idx, lim):
return sys_lim
for ss in system_index:
- modd_system_glob = os.path.join(modd_path, 'task.' + ss + '.*')
+ modd_system_glob = os.path.join(modd_path, "task." + ss + ".*")
modd_system_task = glob.glob(modd_system_glob)
modd_system_task.sort()
- if model_devi_engine in ('lammps', 'gromacs', 'calypso'):
+ if model_devi_engine in ("lammps", "gromacs", "calypso"):
# convert global trust limitations to local ones
f_trust_lo_sys = _trust_limitation_check(int(ss), f_trust_lo)
f_trust_hi_sys = _trust_limitation_check(int(ss), f_trust_hi)
@@ -1999,42 +2376,62 @@ def _trust_limitation_check(sys_idx, lim):
# assumed e -> v
if not model_devi_adapt_trust_lo:
- fp_rest_accurate, fp_candidate, fp_rest_failed, counter \
- = _select_by_model_devi_standard(
- modd_system_task,
- f_trust_lo_sys, f_trust_hi_sys,
- v_trust_lo_sys, v_trust_hi_sys,
- cluster_cutoff,
- model_devi_engine,
- model_devi_skip,
- model_devi_f_avg_relative = model_devi_f_avg_relative,
- model_devi_merge_traj = model_devi_merge_traj,
- detailed_report_make_fp = detailed_report_make_fp,
- )
+ (
+ fp_rest_accurate,
+ fp_candidate,
+ fp_rest_failed,
+ counter,
+ ) = _select_by_model_devi_standard(
+ modd_system_task,
+ f_trust_lo_sys,
+ f_trust_hi_sys,
+ v_trust_lo_sys,
+ v_trust_hi_sys,
+ cluster_cutoff,
+ model_devi_engine,
+ model_devi_skip,
+ model_devi_f_avg_relative=model_devi_f_avg_relative,
+ model_devi_merge_traj=model_devi_merge_traj,
+ detailed_report_make_fp=detailed_report_make_fp,
+ )
else:
- numb_candi_f = jdata.get('model_devi_numb_candi_f', 10)
- numb_candi_v = jdata.get('model_devi_numb_candi_v', 0)
- perc_candi_f = jdata.get('model_devi_perc_candi_f', 0.)
- perc_candi_v = jdata.get('model_devi_perc_candi_v', 0.)
- fp_rest_accurate, fp_candidate, fp_rest_failed, counter, f_trust_lo_ad, v_trust_lo_ad \
- = _select_by_model_devi_adaptive_trust_low(
- modd_system_task,
- f_trust_hi_sys, numb_candi_f, perc_candi_f,
- v_trust_hi_sys, numb_candi_v, perc_candi_v,
- model_devi_skip = model_devi_skip,
- model_devi_f_avg_relative = model_devi_f_avg_relative,
- model_devi_merge_traj = model_devi_merge_traj,
+ numb_candi_f = jdata.get("model_devi_numb_candi_f", 10)
+ numb_candi_v = jdata.get("model_devi_numb_candi_v", 0)
+ perc_candi_f = jdata.get("model_devi_perc_candi_f", 0.0)
+ perc_candi_v = jdata.get("model_devi_perc_candi_v", 0.0)
+ (
+ fp_rest_accurate,
+ fp_candidate,
+ fp_rest_failed,
+ counter,
+ f_trust_lo_ad,
+ v_trust_lo_ad,
+ ) = _select_by_model_devi_adaptive_trust_low(
+ modd_system_task,
+ f_trust_hi_sys,
+ numb_candi_f,
+ perc_candi_f,
+ v_trust_hi_sys,
+ numb_candi_v,
+ perc_candi_v,
+ model_devi_skip=model_devi_skip,
+ model_devi_f_avg_relative=model_devi_f_avg_relative,
+ model_devi_merge_traj=model_devi_merge_traj,
+ )
+ dlog.info(
+ "system {0:s} {1:9s} : f_trust_lo {2:6.3f} v_trust_lo {3:6.3f}".format(
+ ss, "adapted", f_trust_lo_ad, v_trust_lo_ad
)
- dlog.info("system {0:s} {1:9s} : f_trust_lo {2:6.3f} v_trust_lo {3:6.3f}".format(ss, 'adapted', f_trust_lo_ad, v_trust_lo_ad))
+ )
elif model_devi_engine == "amber":
counter = Counter()
- counter['candidate'] = 0
- counter['failed'] = 0
- counter['accurate'] = 0
+ counter["candidate"] = 0
+ counter["failed"] = 0
+ counter["accurate"] = 0
fp_rest_accurate = []
fp_candidate = []
fp_rest_failed = []
- for tt in modd_system_task :
+ for tt in modd_system_task:
cc = 0
with open(os.path.join(tt, "rc.mdout")) as f:
skip_first = False
@@ -2042,125 +2439,176 @@ def _trust_limitation_check(sys_idx, lim):
for line in f:
if line.startswith(" ntx = 1"):
skip_first = True
- if line.startswith("Active learning frame written with max. frc. std.:"):
+ if line.startswith(
+ "Active learning frame written with max. frc. std.:"
+ ):
if skip_first and first_active:
first_active = False
continue
- model_devi = float(line.split()[-2]) * dpdata.unit.EnergyConversion("kcal_mol", "eV").value()
+ model_devi = (
+ float(line.split()[-2])
+ * dpdata.unit.EnergyConversion("kcal_mol", "eV").value()
+ )
if model_devi < f_trust_lo:
# accurate
if detailed_report_make_fp:
fp_rest_accurate.append([tt, cc])
- counter['accurate'] += 1
+ counter["accurate"] += 1
elif model_devi > f_trust_hi:
# failed
if detailed_report_make_fp:
fp_rest_failed.append([tt, cc])
- counter['failed'] += 1
+ counter["failed"] += 1
else:
# candidate
fp_candidate.append([tt, cc])
- counter['candidate'] += 1
+ counter["candidate"] += 1
cc += 1
else:
- raise RuntimeError('unknown model_devi_engine', model_devi_engine)
+ raise RuntimeError("unknown model_devi_engine", model_devi_engine)
# print a report
fp_sum = sum(counter.values())
if fp_sum == 0:
- dlog.info('system {0:s} has no fp task, maybe the model devi is nan %'.format(ss))
+ dlog.info(
+ "system {0:s} has no fp task, maybe the model devi is nan %".format(ss)
+ )
continue
for cc_key, cc_value in counter.items():
- dlog.info("system {0:s} {1:9s} : {2:6d} in {3:6d} {4:6.2f} %".format(ss, cc_key, cc_value, fp_sum, cc_value/fp_sum*100))
+ dlog.info(
+ "system {0:s} {1:9s} : {2:6d} in {3:6d} {4:6.2f} %".format(
+ ss, cc_key, cc_value, fp_sum, cc_value / fp_sum * 100
+ )
+ )
random.shuffle(fp_candidate)
if detailed_report_make_fp:
random.shuffle(fp_rest_failed)
random.shuffle(fp_rest_accurate)
- with open(os.path.join(work_path,'candidate.shuffled.%s.out'%ss), 'w') as fp:
+ with open(
+ os.path.join(work_path, "candidate.shuffled.%s.out" % ss), "w"
+ ) as fp:
for ii in fp_candidate:
fp.write(" ".join([str(nn) for nn in ii]) + "\n")
- with open(os.path.join(work_path,'rest_accurate.shuffled.%s.out'%ss), 'w') as fp:
+ with open(
+ os.path.join(work_path, "rest_accurate.shuffled.%s.out" % ss), "w"
+ ) as fp:
for ii in fp_rest_accurate:
fp.write(" ".join([str(nn) for nn in ii]) + "\n")
- with open(os.path.join(work_path,'rest_failed.shuffled.%s.out'%ss), 'w') as fp:
+ with open(
+ os.path.join(work_path, "rest_failed.shuffled.%s.out" % ss), "w"
+ ) as fp:
for ii in fp_rest_failed:
fp.write(" ".join([str(nn) for nn in ii]) + "\n")
# set number of tasks
- accurate_ratio = float(counter['accurate']) / float(fp_sum)
- fp_accurate_threshold = jdata.get('fp_accurate_threshold', 1)
- fp_accurate_soft_threshold = jdata.get('fp_accurate_soft_threshold', fp_accurate_threshold)
- if accurate_ratio < fp_accurate_soft_threshold :
+ accurate_ratio = float(counter["accurate"]) / float(fp_sum)
+ fp_accurate_threshold = jdata.get("fp_accurate_threshold", 1)
+ fp_accurate_soft_threshold = jdata.get(
+ "fp_accurate_soft_threshold", fp_accurate_threshold
+ )
+ if accurate_ratio < fp_accurate_soft_threshold:
this_fp_task_max = fp_task_max
- elif accurate_ratio >= fp_accurate_soft_threshold and accurate_ratio < fp_accurate_threshold:
- this_fp_task_max = int(fp_task_max * (accurate_ratio - fp_accurate_threshold) / (fp_accurate_soft_threshold - fp_accurate_threshold))
+ elif (
+ accurate_ratio >= fp_accurate_soft_threshold
+ and accurate_ratio < fp_accurate_threshold
+ ):
+ this_fp_task_max = int(
+ fp_task_max
+ * (accurate_ratio - fp_accurate_threshold)
+ / (fp_accurate_soft_threshold - fp_accurate_threshold)
+ )
else:
this_fp_task_max = 0
# ----------------------------------------------------------------------------
- if model_devi_engine == 'calypso':
- calypso_intend_fp_num_temp = (len(fp_candidate)/candi_num)*calypso_total_fp_num
+ if model_devi_engine == "calypso":
+ calypso_intend_fp_num_temp = (
+ len(fp_candidate) / candi_num
+ ) * calypso_total_fp_num
if calypso_intend_fp_num_temp < 1:
calypso_intend_fp_num = 1
else:
calypso_intend_fp_num = int(calypso_intend_fp_num_temp)
# ----------------------------------------------------------------------------
numb_task = min(this_fp_task_max, len(fp_candidate))
- if (numb_task < fp_task_min):
+ if numb_task < fp_task_min:
numb_task = 0
- # ----------------------------------------------------------------------------
- if (model_devi_engine == 'calypso' and len(jdata.get('type_map')) == 1) or \
- (model_devi_engine == 'calypso' and len(jdata.get('type_map')) > 1 and candi_num <= calypso_total_fp_num):
+ # ----------------------------------------------------------------------------
+ if (model_devi_engine == "calypso" and len(jdata.get("type_map")) == 1) or (
+ model_devi_engine == "calypso"
+ and len(jdata.get("type_map")) > 1
+ and candi_num <= calypso_total_fp_num
+ ):
numb_task = min(this_fp_task_max, len(fp_candidate))
- if (numb_task < fp_task_min):
+ if numb_task < fp_task_min:
numb_task = 0
- elif (model_devi_engine == 'calypso' and len(jdata.get('type_map')) > 1 and candi_num > calypso_total_fp_num):
+ elif (
+ model_devi_engine == "calypso"
+ and len(jdata.get("type_map")) > 1
+ and candi_num > calypso_total_fp_num
+ ):
numb_task = calypso_intend_fp_num
- if (len(fp_candidate) < numb_task):
+ if len(fp_candidate) < numb_task:
numb_task = 0
# ----------------------------------------------------------------------------
- dlog.info("system {0:s} accurate_ratio: {1:8.4f} thresholds: {2:6.4f} and {3:6.4f} eff. task min and max {4:4d} {5:4d} number of fp tasks: {6:6d}".format(ss, accurate_ratio, fp_accurate_soft_threshold, fp_accurate_threshold, fp_task_min, this_fp_task_max, numb_task))
+ dlog.info(
+ "system {0:s} accurate_ratio: {1:8.4f} thresholds: {2:6.4f} and {3:6.4f} eff. task min and max {4:4d} {5:4d} number of fp tasks: {6:6d}".format(
+ ss,
+ accurate_ratio,
+ fp_accurate_soft_threshold,
+ fp_accurate_threshold,
+ fp_task_min,
+ this_fp_task_max,
+ numb_task,
+ )
+ )
# make fp tasks
-
+
# read all.lammpstrj, save in all_sys for each system_index
all_sys = []
trj_freq = None
- if model_devi_merge_traj :
- for ii in modd_system_task :
- all_traj = os.path.join(ii, 'all.lammpstrj')
- all_sys_per_task = dpdata.System(all_traj, fmt = 'lammps/dump', type_map = type_map)
+ if model_devi_merge_traj:
+ for ii in modd_system_task:
+ all_traj = os.path.join(ii, "all.lammpstrj")
+ all_sys_per_task = dpdata.System(
+ all_traj, fmt="lammps/dump", type_map=type_map
+ )
all_sys.append(all_sys_per_task)
- model_devi_jobs = jdata['model_devi_jobs']
+ model_devi_jobs = jdata["model_devi_jobs"]
cur_job = model_devi_jobs[iter_index]
- trj_freq = int(_get_param_alias(cur_job, ['t_freq', 'trj_freq', 'traj_freq']))
-
+ trj_freq = int(
+ _get_param_alias(cur_job, ["t_freq", "trj_freq", "traj_freq"])
+ )
+
count_bad_box = 0
count_bad_cluster = 0
fp_candidate = sorted(fp_candidate[:numb_task])
- for cc in range(numb_task) :
+ for cc in range(numb_task):
tt = fp_candidate[cc][0]
ii = fp_candidate[cc][1]
- ss = os.path.basename(tt).split('.')[1]
+ ss = os.path.basename(tt).split(".")[1]
conf_name = os.path.join(tt, "traj")
conf_sys = None
if model_devi_engine == "lammps":
- if model_devi_merge_traj :
- conf_sys = all_sys[int(os.path.basename(tt).split('.')[-1])][int(int(ii) / trj_freq)]
- else :
- conf_name = os.path.join(conf_name, str(ii) + '.lammpstrj')
- ffmt = 'lammps/dump'
+ if model_devi_merge_traj:
+ conf_sys = all_sys[int(os.path.basename(tt).split(".")[-1])][
+ int(int(ii) / trj_freq)
+ ]
+ else:
+ conf_name = os.path.join(conf_name, str(ii) + ".lammpstrj")
+ ffmt = "lammps/dump"
elif model_devi_engine == "gromacs":
- conf_name = os.path.join(conf_name, str(ii) + '.gromacstrj')
- ffmt = 'lammps/dump'
+ conf_name = os.path.join(conf_name, str(ii) + ".gromacstrj")
+ ffmt = "lammps/dump"
elif model_devi_engine == "amber":
conf_name = os.path.join(tt, "rc.nc")
rst_name = os.path.abspath(os.path.join(tt, "init.rst7"))
elif model_devi_engine == "calypso":
- conf_name = os.path.join(conf_name, str(ii) + '.poscar')
- ffmt = 'vasp/poscar'
+ conf_name = os.path.join(conf_name, str(ii) + ".poscar")
+ ffmt = "vasp/poscar"
else:
raise RuntimeError("unknown model_devi engine", model_devi_engine)
conf_name = os.path.abspath(conf_name)
@@ -2171,13 +2619,13 @@ def _trust_limitation_check(sys_idx, lim):
continue
if fp_cluster_vacuum is not None:
- assert fp_cluster_vacuum >0
+ assert fp_cluster_vacuum > 0
skip_cluster = check_cluster(conf_name, fp_cluster_vacuum)
if skip_cluster:
- count_bad_cluster +=1
+ count_bad_cluster += 1
continue
- if model_devi_engine != 'calypso':
+ if model_devi_engine != "calypso":
# link job.json
job_name = os.path.join(tt, "job.json")
job_name = os.path.abspath(job_name)
@@ -2185,7 +2633,7 @@ def _trust_limitation_check(sys_idx, lim):
if cluster_cutoff is not None:
# take clusters
jj = fp_candidate[cc][2]
- poscar_name = '{}.cluster.{}.POSCAR'.format(conf_name, jj)
+ poscar_name = "{}.cluster.{}.POSCAR".format(conf_name, jj)
new_system = take_cluster(conf_name, type_map, jj, jdata)
new_system.to_vasp_poscar(poscar_name)
fp_task_name = make_fp_task_name(int(ss), cc)
@@ -2197,19 +2645,23 @@ def _trust_limitation_check(sys_idx, lim):
cwd = os.getcwd()
os.chdir(fp_task_path)
if cluster_cutoff is None:
- if model_devi_engine == "lammps":
+ if model_devi_engine == "lammps":
if model_devi_merge_traj:
conf_sys.to("lammps/lmp", "conf.dump")
- else:
- os.symlink(os.path.relpath(conf_name), 'conf.dump')
- os.symlink(os.path.relpath(job_name), 'job.json')
+ else:
+ os.symlink(os.path.relpath(conf_name), "conf.dump")
+ os.symlink(os.path.relpath(job_name), "job.json")
elif model_devi_engine == "gromacs":
- os.symlink(os.path.relpath(conf_name), 'conf.dump')
- os.symlink(os.path.relpath(job_name), 'job.json')
+ os.symlink(os.path.relpath(conf_name), "conf.dump")
+ os.symlink(os.path.relpath(job_name), "job.json")
elif model_devi_engine == "amber":
# read and write with ase
- from ase.io.netcdftrajectory import NetCDFTrajectory, write_netcdftrajectory
- if cc > 0 and tt == fp_candidate[cc-1][0]:
+ from ase.io.netcdftrajectory import (
+ NetCDFTrajectory,
+ write_netcdftrajectory,
+ )
+
+ if cc > 0 and tt == fp_candidate[cc - 1][0]:
# same MD task, use the same file
pass
else:
@@ -2219,32 +2671,44 @@ def _trust_limitation_check(sys_idx, lim):
netcdftraj.close()
netcdftraj = NetCDFTrajectory(conf_name)
# write nc file
- write_netcdftrajectory('rc.nc', netcdftraj[ii])
+ write_netcdftrajectory("rc.nc", netcdftraj[ii])
if cc >= numb_task - 1:
netcdftraj.close()
# link restart since it's necessary to start Amber
- os.symlink(os.path.relpath(rst_name), 'init.rst7')
- os.symlink(os.path.relpath(job_name), 'job.json')
+ os.symlink(os.path.relpath(rst_name), "init.rst7")
+ os.symlink(os.path.relpath(job_name), "job.json")
elif model_devi_engine == "calypso":
- os.symlink(os.path.relpath(conf_name), 'POSCAR')
- fjob = open('job.json','w+')
+ os.symlink(os.path.relpath(conf_name), "POSCAR")
+ fjob = open("job.json", "w+")
fjob.write('{"model_devi_engine":"calypso"}')
fjob.close()
- #os.system('touch job.json')
+ # os.system('touch job.json')
else:
- raise RuntimeError('unknown model_devi_engine', model_devi_engine)
+ raise RuntimeError("unknown model_devi_engine", model_devi_engine)
else:
- os.symlink(os.path.relpath(poscar_name), 'POSCAR')
+ os.symlink(os.path.relpath(poscar_name), "POSCAR")
np.save("atom_pref", new_system.data["atom_pref"])
- for pair in fp_link_files :
+ for pair in fp_link_files:
os.symlink(pair[0], pair[1])
os.chdir(cwd)
if count_bad_box > 0:
- dlog.info("system {0:s} skipped {1:6d} confs with bad box, {2:6d} remains".format(ss, count_bad_box, numb_task - count_bad_box))
+ dlog.info(
+ "system {0:s} skipped {1:6d} confs with bad box, {2:6d} remains".format(
+ ss, count_bad_box, numb_task - count_bad_box
+ )
+ )
if count_bad_cluster > 0:
- dlog.info("system {0:s} skipped {1:6d} confs with bad cluster, {2:6d} remains".format(ss, count_bad_cluster, numb_task - count_bad_cluster))
- if model_devi_engine == 'calypso':
- dlog.info("summary accurate_ratio: {0:8.4f}% candidata_ratio: {1:8.4f}% failed_ratio: {2:8.4f}% in {3:d} structures".format( acc_num*100/tot,candi_num*100/tot,fail_num*100/tot,tot ))
+ dlog.info(
+ "system {0:s} skipped {1:6d} confs with bad cluster, {2:6d} remains".format(
+ ss, count_bad_cluster, numb_task - count_bad_cluster
+ )
+ )
+ if model_devi_engine == "calypso":
+ dlog.info(
+ "summary accurate_ratio: {0:8.4f}% candidata_ratio: {1:8.4f}% failed_ratio: {2:8.4f}% in {3:d} structures".format(
+ acc_num * 100 / tot, candi_num * 100 / tot, fail_num * 100 / tot, tot
+ )
+ )
if cluster_cutoff is None:
cwd = os.getcwd()
for idx, task in enumerate(fp_tasks):
@@ -2252,229 +2716,260 @@ def _trust_limitation_check(sys_idx, lim):
if model_devi_engine == "lammps":
sys = None
if model_devi_merge_traj:
- sys = dpdata.System('conf.dump', fmt = "lammps/lmp", type_map = type_map)
- else :
- sys = dpdata.System('conf.dump', fmt = "lammps/dump", type_map = type_map)
- sys.to_vasp_poscar('POSCAR')
- # dump to poscar
+ sys = dpdata.System(
+ "conf.dump", fmt="lammps/lmp", type_map=type_map
+ )
+ else:
+ sys = dpdata.System(
+ "conf.dump", fmt="lammps/dump", type_map=type_map
+ )
+ sys.to_vasp_poscar("POSCAR")
+ # dump to poscar
if charges_map:
- warnings.warn('"sys_charges" keyword only support for gromacs engine now.')
+ warnings.warn(
+ '"sys_charges" keyword only support for gromacs engine now.'
+ )
elif model_devi_engine == "gromacs":
# dump_to_poscar('conf.dump', 'POSCAR', type_map, fmt = "gromacs/gro")
if charges_map:
- dump_to_deepmd_raw('conf.dump', 'deepmd.raw', type_map, fmt='gromacs/gro', charge=charges_recorder[idx])
+ dump_to_deepmd_raw(
+ "conf.dump",
+ "deepmd.raw",
+ type_map,
+ fmt="gromacs/gro",
+ charge=charges_recorder[idx],
+ )
else:
- dump_to_deepmd_raw('conf.dump', 'deepmd.raw', type_map, fmt='gromacs/gro', charge=None)
- elif model_devi_engine in ("amber", 'calypso'):
+ dump_to_deepmd_raw(
+ "conf.dump",
+ "deepmd.raw",
+ type_map,
+ fmt="gromacs/gro",
+ charge=None,
+ )
+ elif model_devi_engine in ("amber", "calypso"):
pass
else:
raise RuntimeError("unknown model_devi engine", model_devi_engine)
os.chdir(cwd)
return fp_tasks
+
def make_vasp_incar(jdata, filename):
- if 'fp_incar' in jdata.keys() :
- fp_incar_path = jdata['fp_incar']
- assert(os.path.exists(fp_incar_path))
+ if "fp_incar" in jdata.keys():
+ fp_incar_path = jdata["fp_incar"]
+ assert os.path.exists(fp_incar_path)
fp_incar_path = os.path.abspath(fp_incar_path)
fr = open(fp_incar_path)
incar = fr.read()
fr.close()
- elif 'user_fp_params' in jdata.keys() :
- incar = write_incar_dict(jdata['user_fp_params'])
+ elif "user_fp_params" in jdata.keys():
+ incar = write_incar_dict(jdata["user_fp_params"])
else:
- incar = make_vasp_incar_user_dict(jdata['fp_params'])
- with open(filename, 'w') as fp:
+ incar = make_vasp_incar_user_dict(jdata["fp_params"])
+ with open(filename, "w") as fp:
fp.write(incar)
return incar
+
def make_pwmat_input(jdata, filename):
- if 'fp_incar' in jdata.keys() :
- fp_incar_path = jdata['fp_incar']
- assert(os.path.exists(fp_incar_path))
+ if "fp_incar" in jdata.keys():
+ fp_incar_path = jdata["fp_incar"]
+ assert os.path.exists(fp_incar_path)
fp_incar_path = os.path.abspath(fp_incar_path)
fr = open(fp_incar_path)
input = fr.read()
fr.close()
- elif 'user_fp_params' in jdata.keys() :
- fp_params = jdata['user_fp_params']
- node1 = fp_params['node1']
- node2 = fp_params['node2']
- atom_config = fp_params['in.atom']
- ecut = fp_params['ecut']
- e_error = fp_params['e_error']
- rho_error = fp_params['rho_error']
- kspacing = fp_params['kspacing']
- flag_symm = fp_params['flag_symm']
+ elif "user_fp_params" in jdata.keys():
+ fp_params = jdata["user_fp_params"]
+ node1 = fp_params["node1"]
+ node2 = fp_params["node2"]
+ atom_config = fp_params["in.atom"]
+ ecut = fp_params["ecut"]
+ e_error = fp_params["e_error"]
+ rho_error = fp_params["rho_error"]
+ kspacing = fp_params["kspacing"]
+ flag_symm = fp_params["flag_symm"]
os.system("command -v poscar2config.x | wc -l > 1.txt")
- fc = open('1.txt')
+ fc = open("1.txt")
flag_command = fc.read()
fc.close()
- if int(flag_command) == 1 :
- os.system('poscar2config.x < POSCAR > tmp.config')
+ if int(flag_command) == 1:
+ os.system("poscar2config.x < POSCAR > tmp.config")
else:
- os.system('cp ../../../out_data_post_fp_pwmat/02.fp/task.000.000000/poscar2config.x ./')
- os.system('./poscar2config.x < POSCAR > tmp.config')
- os.system('rm -rf tmp.config')
- input_dict = make_pwmat_input_dict(node1, node2, atom_config, ecut, e_error,
- rho_error, icmix = None, smearing = None,
- sigma = None, kspacing = kspacing,
- flag_symm = flag_symm
+ os.system(
+ "cp ../../../out_data_post_fp_pwmat/02.fp/task.000.000000/poscar2config.x ./"
+ )
+ os.system("./poscar2config.x < POSCAR > tmp.config")
+ os.system("rm -rf tmp.config")
+ input_dict = make_pwmat_input_dict(
+ node1,
+ node2,
+ atom_config,
+ ecut,
+ e_error,
+ rho_error,
+ icmix=None,
+ smearing=None,
+ sigma=None,
+ kspacing=kspacing,
+ flag_symm=flag_symm,
)
input = write_input_dict(input_dict)
else:
- input = make_pwmat_input_user_dict(jdata['fp_params'])
- if 'IN.PSP' in input or 'in.psp' in input:
- with open(filename, 'w') as fp:
+ input = make_pwmat_input_user_dict(jdata["fp_params"])
+ if "IN.PSP" in input or "in.psp" in input:
+ with open(filename, "w") as fp:
fp.write(input)
- fp.write('job=scf\n')
- if 'OUT.MLMD' in input or 'out.mlmd' in input:
+ fp.write("job=scf\n")
+ if "OUT.MLMD" in input or "out.mlmd" in input:
return input
else:
- fp.write('OUT.MLMD = T')
+ fp.write("OUT.MLMD = T")
return input
else:
- with open(filename, 'w') as fp:
+ with open(filename, "w") as fp:
fp.write(input)
- fp.write('job=scf\n')
- fp_pp_files = jdata['fp_pp_files']
- for idx, ii in enumerate(fp_pp_files) :
- fp.write('IN.PSP%d = %s\n' %(idx+1, ii))
- if 'OUT.MLMD' in input or 'out.mlmd' in input:
+ fp.write("job=scf\n")
+ fp_pp_files = jdata["fp_pp_files"]
+ for idx, ii in enumerate(fp_pp_files):
+ fp.write("IN.PSP%d = %s\n" % (idx + 1, ii))
+ if "OUT.MLMD" in input or "out.mlmd" in input:
return input
else:
- fp.write('OUT.MLMD = T')
+ fp.write("OUT.MLMD = T")
return input
-def make_vasp_incar_ele_temp(jdata, filename, ele_temp, nbands_esti = None):
+
+def make_vasp_incar_ele_temp(jdata, filename, ele_temp, nbands_esti=None):
with open(filename) as fp:
incar = fp.read()
incar = incar_upper(Incar.from_string(incar))
- incar['ISMEAR'] = -1
- incar['SIGMA'] = ele_temp * pc.Boltzmann / pc.electron_volt
- incar.write_file('INCAR')
+ incar["ISMEAR"] = -1
+ incar["SIGMA"] = ele_temp * pc.Boltzmann / pc.electron_volt
+ incar.write_file("INCAR")
if nbands_esti is not None:
- nbands = nbands_esti.predict('.')
+ nbands = nbands_esti.predict(".")
with open(filename) as fp:
incar = Incar.from_string(fp.read())
- incar['NBANDS'] = nbands
- incar.write_file('INCAR')
+ incar["NBANDS"] = nbands
+ incar.write_file("INCAR")
-def make_fp_vasp_incar (iter_index,
- jdata,
- nbands_esti = None) :
+
+def make_fp_vasp_incar(iter_index, jdata, nbands_esti=None):
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
- make_vasp_incar(jdata, 'INCAR')
- if os.path.exists('job.json'):
- with open('job.json') as fp:
+ make_vasp_incar(jdata, "INCAR")
+ if os.path.exists("job.json"):
+ with open("job.json") as fp:
job_data = json.load(fp)
- if 'ele_temp' in job_data:
- make_vasp_incar_ele_temp(jdata, 'INCAR',
- job_data['ele_temp'],
- nbands_esti = nbands_esti)
+ if "ele_temp" in job_data:
+ make_vasp_incar_ele_temp(
+ jdata, "INCAR", job_data["ele_temp"], nbands_esti=nbands_esti
+ )
os.chdir(cwd)
-def _make_fp_pwmat_input (iter_index,
- jdata) :
+
+def _make_fp_pwmat_input(iter_index, jdata):
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
- make_pwmat_input(jdata, 'etot.input')
+ make_pwmat_input(jdata, "etot.input")
os.system("sed -i '1,2c 4 1' etot.input")
os.chdir(cwd)
-def make_fp_vasp_cp_cvasp(iter_index,jdata):
+
+def make_fp_vasp_cp_cvasp(iter_index, jdata):
# Move cvasp interface to jdata
- if ('cvasp' in jdata) and (jdata['cvasp'] == True):
- pass
+ if ("cvasp" in jdata) and (jdata["cvasp"] == True):
+ pass
else:
- return
+ return
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
- #copy cvasp.py
- shutil.copyfile(cvasp_file, 'cvasp.py')
+ # copy cvasp.py
+ shutil.copyfile(cvasp_file, "cvasp.py")
os.chdir(cwd)
-def make_fp_vasp_kp (iter_index,jdata):
+
+def make_fp_vasp_kp(iter_index, jdata):
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_aniso_kspacing = jdata.get('fp_aniso_kspacing')
+ fp_aniso_kspacing = jdata.get("fp_aniso_kspacing")
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
# get kspacing and kgamma from incar
- assert(os.path.exists('INCAR'))
- with open('INCAR') as fp:
+ assert os.path.exists("INCAR")
+ with open("INCAR") as fp:
incar = fp.read()
standard_incar = incar_upper(Incar.from_string(incar))
if fp_aniso_kspacing is None:
try:
- kspacing = standard_incar['KSPACING']
+ kspacing = standard_incar["KSPACING"]
except KeyError:
- raise RuntimeError ("KSPACING must be given in INCAR")
- else :
+ raise RuntimeError("KSPACING must be given in INCAR")
+ else:
kspacing = fp_aniso_kspacing
try:
- gamma = standard_incar['KGAMMA']
- if isinstance(gamma,bool):
+ gamma = standard_incar["KGAMMA"]
+ if isinstance(gamma, bool):
pass
else:
- if gamma[0].upper()=="T":
- gamma=True
+ if gamma[0].upper() == "T":
+ gamma = True
else:
- gamma=False
+ gamma = False
except KeyError:
- raise RuntimeError ("KGAMMA must be given in INCAR")
+ raise RuntimeError("KGAMMA must be given in INCAR")
# check poscar
- assert(os.path.exists('POSCAR'))
+ assert os.path.exists("POSCAR")
# make kpoints
- ret=make_kspacing_kpoints('POSCAR', kspacing, gamma)
- kp=Kpoints.from_string(ret)
+ ret = make_kspacing_kpoints("POSCAR", kspacing, gamma)
+ kp = Kpoints.from_string(ret)
kp.write_file("KPOINTS")
os.chdir(cwd)
-def _link_fp_vasp_pp (iter_index,
- jdata) :
- fp_pp_path = jdata['fp_pp_path']
- fp_pp_files = jdata['fp_pp_files']
- assert(os.path.exists(fp_pp_path))
+def _link_fp_vasp_pp(iter_index, jdata):
+ fp_pp_path = jdata["fp_pp_path"]
+ fp_pp_files = jdata["fp_pp_files"]
+ assert os.path.exists(fp_pp_path)
fp_pp_path = os.path.abspath(fp_pp_path)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
cwd = os.getcwd()
for ii in fp_tasks:
@@ -2484,231 +2979,275 @@ def _link_fp_vasp_pp (iter_index,
os.symlink(pp_file, jj)
os.chdir(cwd)
-def sys_link_fp_vasp_pp (iter_index,
- jdata) :
- fp_pp_path = jdata['fp_pp_path']
- fp_pp_files = jdata['fp_pp_files']
+
+def sys_link_fp_vasp_pp(iter_index, jdata):
+ fp_pp_path = jdata["fp_pp_path"]
+ fp_pp_files = jdata["fp_pp_files"]
fp_pp_path = os.path.abspath(fp_pp_path)
- type_map = jdata['type_map']
- assert(os.path.exists(fp_pp_path))
- assert(len(fp_pp_files) == len(type_map)), 'size of fp_pp_files should be the same as the size of type_map'
+ type_map = jdata["type_map"]
+ assert os.path.exists(fp_pp_path)
+ assert len(fp_pp_files) == len(
+ type_map
+ ), "size of fp_pp_files should be the same as the size of type_map"
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
- system_idx_str = [os.path.basename(ii).split('.')[1] for ii in fp_tasks]
+ system_idx_str = [os.path.basename(ii).split(".")[1] for ii in fp_tasks]
system_idx_str = list(set(system_idx_str))
system_idx_str.sort()
for ii in system_idx_str:
potcars = []
- sys_tasks = glob.glob(os.path.join(work_path, 'task.%s.*' % ii))
- assert (len(sys_tasks) != 0)
- sys_poscar = os.path.join(sys_tasks[0], 'POSCAR')
- sys = dpdata.System(sys_poscar, fmt = 'vasp/poscar')
- for ele_name in sys['atom_names']:
- ele_idx = jdata['type_map'].index(ele_name)
+ sys_tasks = glob.glob(os.path.join(work_path, "task.%s.*" % ii))
+ assert len(sys_tasks) != 0
+ sys_poscar = os.path.join(sys_tasks[0], "POSCAR")
+ sys = dpdata.System(sys_poscar, fmt="vasp/poscar")
+ for ele_name in sys["atom_names"]:
+ ele_idx = jdata["type_map"].index(ele_name)
potcars.append(fp_pp_files[ele_idx])
- with open(os.path.join(work_path,'POTCAR.%s' % ii), 'w') as fp_pot:
+ with open(os.path.join(work_path, "POTCAR.%s" % ii), "w") as fp_pot:
for jj in potcars:
with open(os.path.join(fp_pp_path, jj)) as fp:
fp_pot.write(fp.read())
- sys_tasks = glob.glob(os.path.join(work_path, 'task.%s.*' % ii))
+ sys_tasks = glob.glob(os.path.join(work_path, "task.%s.*" % ii))
cwd = os.getcwd()
for jj in sys_tasks:
os.chdir(jj)
- os.symlink(os.path.join('..', 'POTCAR.%s' % ii), 'POTCAR')
+ os.symlink(os.path.join("..", "POTCAR.%s" % ii), "POTCAR")
os.chdir(cwd)
-def _link_fp_abacus_orb_descript (iter_index,
- jdata) :
- # assume lcao orbital files, numerical descrptors and model for dpks are all in fp_pp_path.
- fp_pp_path = jdata['fp_pp_path']
-
- fp_orb_files = jdata['fp_orb_files']
- assert(os.path.exists(fp_pp_path))
- fp_dpks_descriptor = None
- fp_dpks_model = None
- if "fp_dpks_descriptor" in jdata:
- fp_dpks_descriptor = jdata["fp_dpks_descriptor"]
- if "user_fp_params" in jdata:
- if "deepks_model" in jdata["user_fp_params"]:
- fp_dpks_model = jdata["user_fp_params"]["deepks_model"]
- fp_pp_path = os.path.abspath(fp_pp_path)
+def _link_fp_abacus_pporb_descript(iter_index, jdata):
+ # assume pp orbital files, numerical descrptors and model for dpks are all in fp_pp_path.
+ fp_pp_path = os.path.abspath(jdata["fp_pp_path"])
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
-
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
+
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
- for jj in fp_orb_files:
- orb_file = os.path.join(fp_pp_path, jj)
- os.symlink(orb_file, jj)
- if fp_dpks_descriptor is not None:
- descrptor = os.path.join(fp_pp_path, fp_dpks_descriptor)
- os.symlink(descrptor, fp_dpks_descriptor)
- if fp_dpks_model is not None:
- dpks_model = os.path.join(fp_pp_path, fp_dpks_model)
- os.symlink(dpks_model, fp_dpks_model)
+
+ # get value of 'deepks_model' from INPUT
+ input_param = get_abacus_input_parameters("INPUT")
+ fp_dpks_model = input_param.get("deepks_model", None)
+ if fp_dpks_model != None:
+ model_file = os.path.join(fp_pp_path, fp_dpks_model)
+ assert os.path.isfile(model_file), (
+ "Can not find the deepks model file %s, which is defined in %s/INPUT"
+ % (model_file, ii)
+ )
+ os.symlink(model_file, fp_dpks_model)
+
+ # get pp, orb, descriptor filenames from STRU
+ stru_param = get_abacus_STRU("STRU")
+ pp_files = stru_param.get("pp_files", [])
+ orb_files = stru_param.get("orb_files", [])
+ descriptor_file = stru_param.get("dpks_descriptor", None)
+ pp_files = [] if pp_files == None else pp_files
+ orb_files = [] if orb_files == None else orb_files
+
+ for jj in pp_files:
+ ifile = os.path.join(fp_pp_path, jj)
+ assert os.path.isfile(ifile), (
+ "Can not find the pseudopotential file %s, which is defined in %s/STRU"
+ % (ifile, ii)
+ )
+ os.symlink(ifile, jj)
+
+ for jj in orb_files:
+ ifile = os.path.join(fp_pp_path, jj)
+ assert os.path.isfile(
+ ifile
+ ), "Can not find the orbital file %s, which is defined in %s/STRU" % (
+ ifile,
+ ii,
+ )
+ os.symlink(ifile, jj)
+
+ if descriptor_file != None:
+ ifile = os.path.join(fp_pp_path, descriptor_file)
+ assert os.path.isfile(ifile), (
+ "Can not find the deepks descriptor file %s, which is defined in %s/STRU"
+ % (ifile, ii)
+ )
+ os.symlink(ifile, descriptor_file)
os.chdir(cwd)
-def _make_fp_vasp_configs(iter_index,
- jdata):
- fp_task_max = jdata['fp_task_max']
- model_devi_skip = jdata['model_devi_skip']
- type_map = jdata['type_map']
+
+def _make_fp_vasp_configs(iter_index, jdata):
+ fp_task_max = jdata["fp_task_max"]
+ model_devi_skip = jdata["model_devi_skip"]
+ type_map = jdata["type_map"]
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
create_path(work_path)
-
modd_path = os.path.join(iter_name, model_devi_name)
task_min = -1
- if os.path.isfile(os.path.join(modd_path, 'cur_job.json')) :
- cur_job = json.load(open(os.path.join(modd_path, 'cur_job.json'), 'r'))
- if 'task_min' in cur_job :
- task_min = cur_job['task_min']
+ if os.path.isfile(os.path.join(modd_path, "cur_job.json")):
+ cur_job = json.load(open(os.path.join(modd_path, "cur_job.json"), "r"))
+ if "task_min" in cur_job:
+ task_min = cur_job["task_min"]
else:
cur_job = {}
# support iteration dependent trust levels
- v_trust_lo = cur_job.get('model_devi_v_trust_lo', jdata.get('model_devi_v_trust_lo', 1e10))
- v_trust_hi = cur_job.get('model_devi_v_trust_hi', jdata.get('model_devi_v_trust_hi', 1e10))
- if cur_job.get('model_devi_f_trust_lo') is not None:
- f_trust_lo = cur_job.get('model_devi_f_trust_lo')
+ v_trust_lo = cur_job.get(
+ "model_devi_v_trust_lo", jdata.get("model_devi_v_trust_lo", 1e10)
+ )
+ v_trust_hi = cur_job.get(
+ "model_devi_v_trust_hi", jdata.get("model_devi_v_trust_hi", 1e10)
+ )
+ if cur_job.get("model_devi_f_trust_lo") is not None:
+ f_trust_lo = cur_job.get("model_devi_f_trust_lo")
else:
- f_trust_lo = jdata['model_devi_f_trust_lo']
- if cur_job.get('model_devi_f_trust_hi') is not None:
- f_trust_hi = cur_job.get('model_devi_f_trust_hi')
+ f_trust_lo = jdata["model_devi_f_trust_lo"]
+ if cur_job.get("model_devi_f_trust_hi") is not None:
+ f_trust_hi = cur_job.get("model_devi_f_trust_hi")
else:
- f_trust_hi = jdata['model_devi_f_trust_hi']
+ f_trust_hi = jdata["model_devi_f_trust_hi"]
# make configs
- fp_tasks = _make_fp_vasp_inner(iter_index,
- modd_path, work_path,
- model_devi_skip,
- v_trust_lo, v_trust_hi,
- f_trust_lo, f_trust_hi,
- task_min, fp_task_max,
- [],
- type_map,
- jdata)
+ fp_tasks = _make_fp_vasp_inner(
+ iter_index,
+ modd_path,
+ work_path,
+ model_devi_skip,
+ v_trust_lo,
+ v_trust_hi,
+ f_trust_lo,
+ f_trust_hi,
+ task_min,
+ fp_task_max,
+ [],
+ type_map,
+ jdata,
+ )
return fp_tasks
-def make_fp_vasp (iter_index,
- jdata) :
+
+def make_fp_vasp(iter_index, jdata):
# make config
fp_tasks = _make_fp_vasp_configs(iter_index, jdata)
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
# abs path for fp_incar if it exists
- if 'fp_incar' in jdata:
- jdata['fp_incar'] = os.path.abspath(jdata['fp_incar'])
+ if "fp_incar" in jdata:
+ jdata["fp_incar"] = os.path.abspath(jdata["fp_incar"])
# get nbands esti if it exists
- if 'fp_nbands_esti_data' in jdata:
- nbe = NBandsEsti(jdata['fp_nbands_esti_data'])
+ if "fp_nbands_esti_data" in jdata:
+ nbe = NBandsEsti(jdata["fp_nbands_esti_data"])
else:
nbe = None
# order is critical!
# 1, create potcar
sys_link_fp_vasp_pp(iter_index, jdata)
# 2, create incar
- make_fp_vasp_incar(iter_index, jdata, nbands_esti = nbe)
+ make_fp_vasp_incar(iter_index, jdata, nbands_esti=nbe)
# 3, create kpoints
make_fp_vasp_kp(iter_index, jdata)
# 4, copy cvasp
- make_fp_vasp_cp_cvasp(iter_index,jdata)
+ make_fp_vasp_cp_cvasp(iter_index, jdata)
-def make_fp_pwscf(iter_index,
- jdata) :
+def make_fp_pwscf(iter_index, jdata):
# make config
fp_tasks = _make_fp_vasp_configs(iter_index, jdata)
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
# make pwscf input
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_pp_files = jdata['fp_pp_files']
- if 'user_fp_params' in jdata.keys() :
- fp_params = jdata['user_fp_params']
+ fp_pp_files = jdata["fp_pp_files"]
+ if "user_fp_params" in jdata.keys():
+ fp_params = jdata["user_fp_params"]
user_input = True
else:
- fp_params = jdata['fp_params']
+ fp_params = jdata["fp_params"]
user_input = False
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
- sys_data = dpdata.System('POSCAR').data
- sys_data['atom_masses'] = []
+ sys_data = dpdata.System("POSCAR").data
+ sys_data["atom_masses"] = []
pps = []
- for iii in sys_data['atom_names']:
- sys_data['atom_masses'].append(jdata['mass_map'][jdata['type_map'].index(iii)])
- pps.append(fp_pp_files[jdata['type_map'].index(iii)])
- ret = make_pwscf_input(sys_data, pps, fp_params, user_input = user_input)
- with open('input', 'w') as fp:
+ for iii in sys_data["atom_names"]:
+ sys_data["atom_masses"].append(
+ jdata["mass_map"][jdata["type_map"].index(iii)]
+ )
+ pps.append(fp_pp_files[jdata["type_map"].index(iii)])
+ ret = make_pwscf_input(sys_data, pps, fp_params, user_input=user_input)
+ with open("input", "w") as fp:
fp.write(ret)
os.chdir(cwd)
# link pp files
_link_fp_vasp_pp(iter_index, jdata)
-def make_fp_abacus_scf(iter_index,
- jdata) :
+
+def make_fp_abacus_scf(iter_index, jdata):
# make config
fp_tasks = _make_fp_vasp_configs(iter_index, jdata)
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
# make abacus/pw/scf input
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_pp_files = jdata['fp_pp_files']
+ fp_pp_files = jdata["fp_pp_files"]
fp_orb_files = None
fp_dpks_descriptor = None
# get paramters for writting INPUT file
fp_params = {}
- if 'user_fp_params' in jdata.keys() :
- fp_params = jdata['user_fp_params']
- # for lcao
- if 'basis_type' in fp_params:
- if fp_params['basis_type'] == 'lcao':
- assert('fp_orb_files' in jdata and type(jdata['fp_orb_files']) == list and len(jdata['fp_orb_files']) == len(fp_pp_files))
- fp_orb_files = jdata['fp_orb_files']
- dpks_out_labels = fp_params.get('deepks_out_labels',0)
- dpks_scf = fp_params.get('deepks_scf',0)
- if dpks_out_labels or dpks_scf:
- assert('fp_dpks_descriptor' in jdata and type(jdata['fp_dpks_descriptor']) == str)
- fp_dpks_descriptor = jdata['fp_dpks_descriptor']
- #user_input = True
- ret_input = make_abacus_scf_input(fp_params)
- elif 'fp_incar' in jdata.keys():
- fp_input_path = jdata['fp_incar']
- assert(os.path.exists(fp_input_path))
+ if "user_fp_params" in jdata.keys():
+ fp_params = jdata["user_fp_params"]
+ elif "fp_incar" in jdata.keys():
+ fp_input_path = jdata["fp_incar"]
+ assert os.path.exists(fp_input_path)
fp_input_path = os.path.abspath(fp_input_path)
fp_params = get_abacus_input_parameters(fp_input_path)
- ret_input = make_abacus_scf_input(fp_params)
else:
- raise RuntimeError("Set 'user_fp_params' or 'fp_incar' in json file to make INPUT of ABACUS")
+ raise RuntimeError(
+ "Set 'user_fp_params' or 'fp_incar' in json file to make INPUT of ABACUS"
+ )
+ ret_input = make_abacus_scf_input(fp_params)
+
+ # Get orbital and deepks setting
+ if "basis_type" in fp_params:
+ if fp_params["basis_type"] == "lcao":
+ assert (
+ "fp_orb_files" in jdata
+ and type(jdata["fp_orb_files"]) == list
+ and len(jdata["fp_orb_files"]) == len(fp_pp_files)
+ )
+ fp_orb_files = jdata["fp_orb_files"]
+ dpks_out_labels = fp_params.get("deepks_out_labels", 0)
+ dpks_scf = fp_params.get("deepks_scf", 0)
+ if dpks_out_labels or dpks_scf:
+ assert (
+ "fp_dpks_descriptor" in jdata and type(jdata["fp_dpks_descriptor"]) == str
+ )
+ fp_dpks_descriptor = jdata["fp_dpks_descriptor"]
+
# get paramters for writting KPT file
- if 'kspacing' not in fp_params.keys():
- if 'gamma_only' in fp_params.keys():
- if fp_params["gamma_only"]==1:
- gamma_param = {"k_points":[1,1,1,0,0,0]}
+ if "kspacing" not in fp_params.keys():
+ if "gamma_only" in fp_params.keys():
+ if fp_params["gamma_only"] == 1:
+ gamma_param = {"k_points": [1, 1, 1, 0, 0, 0]}
ret_kpt = make_abacus_scf_kpt(gamma_param)
else:
- if 'k_points' in jdata.keys() :
+ if "k_points" in jdata.keys():
ret_kpt = make_abacus_scf_kpt(jdata)
- elif 'fp_kpt_file' in jdata.keys():
- fp_kpt_path = jdata['fp_kpt_file']
- assert(os.path.exists(fp_kpt_path))
+ elif "fp_kpt_file" in jdata.keys():
+ fp_kpt_path = jdata["fp_kpt_file"]
+ assert os.path.exists(fp_kpt_path)
fp_kpt_path = os.path.abspath(fp_kpt_path)
fk = open(fp_kpt_path)
ret_kpt = fk.read()
@@ -2716,135 +3255,139 @@ def make_fp_abacus_scf(iter_index,
else:
raise RuntimeError("Cannot find any k-points information")
else:
- if 'k_points' in jdata.keys() :
+ if "k_points" in jdata.keys():
ret_kpt = make_abacus_scf_kpt(jdata)
- elif 'fp_kpt_file' in jdata.keys():
- fp_kpt_path = jdata['fp_kpt_file']
- assert(os.path.exists(fp_kpt_path))
+ elif "fp_kpt_file" in jdata.keys():
+ fp_kpt_path = jdata["fp_kpt_file"]
+ assert os.path.exists(fp_kpt_path)
fp_kpt_path = os.path.abspath(fp_kpt_path)
fk = open(fp_kpt_path)
ret_kpt = fk.read()
fk.close()
else:
- gamma_param = {"k_points":[1,1,1,0,0,0]}
+ gamma_param = {"k_points": [1, 1, 1, 0, 0, 0]}
ret_kpt = make_abacus_scf_kpt(gamma_param)
- warnings.warn("Cannot find k-points information, gamma_only will be generated.")
+ warnings.warn(
+ "Cannot find k-points information, gamma_only will be generated."
+ )
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
- sys_data = dpdata.System('POSCAR').data
- if 'mass_map' in jdata:
- sys_data['atom_masses'] = jdata['mass_map']
- with open('INPUT', 'w') as fp:
+ sys_data = dpdata.System("POSCAR").data
+ if "mass_map" in jdata:
+ sys_data["atom_masses"] = jdata["mass_map"]
+ with open("INPUT", "w") as fp:
fp.write(ret_input)
- if 'kspacing' not in fp_params.keys():
+ if "kspacing" not in fp_params.keys():
with open("KPT", "w") as fp:
fp.write(ret_kpt)
- ret_stru = make_abacus_scf_stru(sys_data, fp_pp_files, fp_orb_files, fp_dpks_descriptor, fp_params)
+ ret_stru = make_abacus_scf_stru(
+ sys_data,
+ fp_pp_files,
+ fp_orb_files,
+ fp_dpks_descriptor,
+ fp_params,
+ type_map=jdata["type_map"],
+ )
with open("STRU", "w") as fp:
fp.write(ret_stru)
os.chdir(cwd)
- # link pp files
- _link_fp_vasp_pp(iter_index, jdata)
- if 'basis_type' in fp_params:
- if fp_params['basis_type'] == 'lcao':
- _link_fp_abacus_orb_descript(iter_index, jdata)
+ # link pp and orbital files
+ _link_fp_abacus_pporb_descript(iter_index, jdata)
-def make_fp_siesta(iter_index,
- jdata) :
+def make_fp_siesta(iter_index, jdata):
# make config
fp_tasks = _make_fp_vasp_configs(iter_index, jdata)
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
# make siesta input
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_pp_files = jdata['fp_pp_files']
- if 'user_fp_params' in jdata.keys() :
- fp_params = jdata['user_fp_params']
+ fp_pp_files = jdata["fp_pp_files"]
+ if "user_fp_params" in jdata.keys():
+ fp_params = jdata["user_fp_params"]
user_input = True
else:
- fp_params = jdata['fp_params']
+ fp_params = jdata["fp_params"]
user_input = False
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
- sys_data = dpdata.System('POSCAR').data
+ sys_data = dpdata.System("POSCAR").data
ret = make_siesta_input(sys_data, fp_pp_files, fp_params)
- with open('input', 'w') as fp:
+ with open("input", "w") as fp:
fp.write(ret)
os.chdir(cwd)
# link pp files
_link_fp_vasp_pp(iter_index, jdata)
-def make_fp_gaussian(iter_index,
- jdata):
+
+def make_fp_gaussian(iter_index, jdata):
# make config
fp_tasks = _make_fp_vasp_configs(iter_index, jdata)
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
# make gaussian gjf file
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- if 'user_fp_params' in jdata.keys() :
- fp_params = jdata['user_fp_params']
+ if "user_fp_params" in jdata.keys():
+ fp_params = jdata["user_fp_params"]
else:
- fp_params = jdata['fp_params']
+ fp_params = jdata["fp_params"]
cwd = os.getcwd()
- model_devi_engine = jdata.get('model_devi_engine', 'lammps')
+ model_devi_engine = jdata.get("model_devi_engine", "lammps")
for ii in fp_tasks:
os.chdir(ii)
if model_devi_engine == "lammps":
- sys_data = dpdata.System('POSCAR').data
+ sys_data = dpdata.System("POSCAR").data
elif model_devi_engine == "gromacs":
- sys_data = dpdata.System("deepmd.raw", fmt='deepmd/raw').data
- if os.path.isfile('deepmd.raw/charge'):
- sys_data['charge'] = int(np.loadtxt('deepmd.raw/charge', dtype=int))
+ sys_data = dpdata.System("deepmd.raw", fmt="deepmd/raw").data
+ if os.path.isfile("deepmd.raw/charge"):
+ sys_data["charge"] = int(np.loadtxt("deepmd.raw/charge", dtype=int))
ret = make_gaussian_input(sys_data, fp_params)
- with open('input', 'w') as fp:
+ with open("input", "w") as fp:
fp.write(ret)
os.chdir(cwd)
-def make_fp_cp2k (iter_index,
- jdata):
+def make_fp_cp2k(iter_index, jdata):
# make config
fp_tasks = _make_fp_vasp_configs(iter_index, jdata)
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
# make cp2k input
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- if 'user_fp_params' in jdata.keys() :
- fp_params = jdata['user_fp_params']
+ if "user_fp_params" in jdata.keys():
+ fp_params = jdata["user_fp_params"]
# some users might use own inputs
# specify the input path string
- elif 'external_input_path' in jdata.keys() :
+ elif "external_input_path" in jdata.keys():
fp_params = None
- exinput_path = os.path.abspath(jdata['external_input_path'])
+ exinput_path = os.path.abspath(jdata["external_input_path"])
else:
- fp_params = jdata['fp_params']
+ fp_params = jdata["fp_params"]
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
- sys_data = dpdata.System('POSCAR').data
+ sys_data = dpdata.System("POSCAR").data
# make input for every task
# if fp_params exits, make keys
if fp_params:
cp2k_input = make_cp2k_input(sys_data, fp_params)
else:
- # else read from user input
+ # else read from user input
cp2k_input = make_cp2k_input_from_external(sys_data, exinput_path)
- with open('input.inp', 'w') as fp:
+ with open("input.inp", "w") as fp:
fp.write(cp2k_input)
fp.close()
# make coord.xyz used by cp2k for every task
cp2k_coord = make_cp2k_xyz(sys_data)
- with open('coord.xyz', 'w') as fp:
+ with open("coord.xyz", "w") as fp:
fp.write(cp2k_coord)
fp.close()
os.chdir(cwd)
@@ -2852,21 +3395,22 @@ def make_fp_cp2k (iter_index,
# link pp files
_link_fp_vasp_pp(iter_index, jdata)
-def make_fp_pwmat (iter_index,
- jdata) :
+
+def make_fp_pwmat(iter_index, jdata):
# make config
fp_tasks = _make_fp_vasp_configs(iter_index, jdata)
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
# abs path for fp_incar if it exists
- if 'fp_incar' in jdata:
- jdata['fp_incar'] = os.path.abspath(jdata['fp_incar'])
+ if "fp_incar" in jdata:
+ jdata["fp_incar"] = os.path.abspath(jdata["fp_incar"])
# order is critical!
# 1, link pp files
_link_fp_vasp_pp(iter_index, jdata)
# 2, create pwmat input
_make_fp_pwmat_input(iter_index, jdata)
+
def make_fp_amber_diff(iter_index: int, jdata: dict):
"""Run amber twice to calculate high-level and low-level potential,
and then generate difference between them.
@@ -2882,7 +3426,7 @@ def make_fp_amber_diff(iter_index: int, jdata: dict):
iter index
jdata : dict
Run parameters. The following parameters are used in this method:
- mdin_prefix : str
+ mdin_prefix : str
The path prefix to AMBER mdin files
qm_region : list[str]
AMBER mask of the QM region. Each mask maps to a system.
@@ -2904,13 +3448,13 @@ def make_fp_amber_diff(iter_index: int, jdata: dict):
The path prefix to AMBER PARM7 files
parm7 : list[str]
List of paths to AMBER PARM7 files. Each file maps to a system.
-
+
References
----------
.. [1] Development of Range-Corrected Deep Learning Potentials for Fast, Accurate Quantum
- Mechanical/Molecular Mechanical Simulations of Chemical Reactions in Solution,
+ Mechanical/Molecular Mechanical Simulations of Chemical Reactions in Solution,
Jinzhe Zeng, Timothy J. Giese, Şölen Ekesan, and Darrin M. York, Journal of Chemical
- Theory and Computation 2021 17 (11), 6993-7009
+ Theory and Computation 2021 17 (11), 6993-7009
"""
# make config
fp_tasks = _make_fp_vasp_configs(iter_index, jdata)
@@ -2918,194 +3462,213 @@ def make_fp_amber_diff(iter_index: int, jdata: dict):
cwd = os.getcwd()
# link two mdin files and param7
os.chdir(os.path.join(fp_tasks[0], ".."))
- mdin_prefix = jdata.get('mdin_prefix', '')
- low_level_mdin = jdata['fp_params']['low_level_mdin']
+ mdin_prefix = jdata.get("mdin_prefix", "")
+ low_level_mdin = jdata["fp_params"]["low_level_mdin"]
low_level_mdin = os.path.join(mdin_prefix, low_level_mdin)
- high_level_mdin = jdata['fp_params']['high_level_mdin']
+ high_level_mdin = jdata["fp_params"]["high_level_mdin"]
high_level_mdin = os.path.join(mdin_prefix, high_level_mdin)
with open(low_level_mdin) as f:
low_level_mdin_str = f.read()
with open(high_level_mdin) as f:
high_level_mdin_str = f.read()
- qm_region = jdata['qm_region']
- high_level = jdata['high_level']
- low_level = jdata['low_level']
- qm_charge = jdata['qm_charge']
+ qm_region = jdata["qm_region"]
+ high_level = jdata["high_level"]
+ low_level = jdata["low_level"]
+ qm_charge = jdata["qm_charge"]
# qm_theory qm_region qm_charge
for ii, _ in enumerate(qm_region):
- mdin_new_str = low_level_mdin_str.replace("%qm_theory%", low_level) \
- .replace("%qm_region%", qm_region[ii]) \
- .replace("%qm_charge%", str(qm_charge[ii]))
- with open('low_level%d.mdin'%ii, 'w') as f:
+ mdin_new_str = (
+ low_level_mdin_str.replace("%qm_theory%", low_level)
+ .replace("%qm_region%", qm_region[ii])
+ .replace("%qm_charge%", str(qm_charge[ii]))
+ )
+ with open("low_level%d.mdin" % ii, "w") as f:
f.write(mdin_new_str)
- mdin_new_str = high_level_mdin_str.replace("%qm_theory%", high_level) \
- .replace("%qm_region%", qm_region[ii]) \
- .replace("%qm_charge%", str(qm_charge[ii]))
- with open('high_level%d.mdin'%ii, 'w') as f:
+ mdin_new_str = (
+ high_level_mdin_str.replace("%qm_theory%", high_level)
+ .replace("%qm_region%", qm_region[ii])
+ .replace("%qm_charge%", str(qm_charge[ii]))
+ )
+ with open("high_level%d.mdin" % ii, "w") as f:
f.write(mdin_new_str)
- parm7 = jdata['parm7']
+ parm7 = jdata["parm7"]
parm7_prefix = jdata.get("parm7_prefix", "")
parm7 = [os.path.join(parm7_prefix, pp) for pp in parm7]
for ii, pp in enumerate(parm7):
- os.symlink(pp, "qmmm%d.parm7"%ii)
-
+ os.symlink(pp, "qmmm%d.parm7" % ii)
+
rst7_prefix = jdata.get("sys_configs_prefix", "")
- for ii, ss in enumerate(jdata['sys_configs']):
- os.symlink(os.path.join(rst7_prefix, ss[0]), "init%d.rst7"%ii)
+ for ii, ss in enumerate(jdata["sys_configs"]):
+ os.symlink(os.path.join(rst7_prefix, ss[0]), "init%d.rst7" % ii)
- with open("qm_region", 'w') as f:
+ with open("qm_region", "w") as f:
f.write("\n".join(qm_region))
os.chdir(cwd)
-def make_fp (iter_index,
- jdata,
- mdata) :
- fp_style = jdata['fp_style']
- if fp_style == "vasp" :
+def make_fp(iter_index, jdata, mdata):
+ fp_style = jdata["fp_style"]
+
+ if fp_style == "vasp":
make_fp_vasp(iter_index, jdata)
- elif fp_style == "pwscf" :
+ elif fp_style == "pwscf":
make_fp_pwscf(iter_index, jdata)
- elif fp_style == "abacus" :
+ elif fp_style == "abacus":
make_fp_abacus_scf(iter_index, jdata)
- elif fp_style == "siesta" :
+ elif fp_style == "siesta":
make_fp_siesta(iter_index, jdata)
- elif fp_style == "gaussian" :
+ elif fp_style == "gaussian":
make_fp_gaussian(iter_index, jdata)
- elif fp_style == "cp2k" :
+ elif fp_style == "cp2k":
make_fp_cp2k(iter_index, jdata)
- elif fp_style == "pwmat" :
+ elif fp_style == "pwmat":
make_fp_pwmat(iter_index, jdata)
elif fp_style == "amber/diff":
make_fp_amber_diff(iter_index, jdata)
- else :
- raise RuntimeError ("unsupported fp style")
+ else:
+ raise RuntimeError("unsupported fp style")
# Copy user defined forward_files
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
symlink_user_forward_files(mdata=mdata, task_type="fp", work_path=work_path)
-def _vasp_check_fin (ii) :
- if os.path.isfile(os.path.join(ii, 'OUTCAR')) :
- with open(os.path.join(ii, 'OUTCAR'), 'r') as fp :
+
+def _vasp_check_fin(ii):
+ if os.path.isfile(os.path.join(ii, "OUTCAR")):
+ with open(os.path.join(ii, "OUTCAR"), "r") as fp:
content = fp.read()
- count = content.count('Elapse')
- if count != 1 :
+ count = content.count("Elapse")
+ if count != 1:
return False
- else :
+ else:
return False
return True
-def _qe_check_fin(ii) :
- if os.path.isfile(os.path.join(ii, 'output')) :
- with open(os.path.join(ii, 'output'), 'r') as fp :
+
+def _qe_check_fin(ii):
+ if os.path.isfile(os.path.join(ii, "output")):
+ with open(os.path.join(ii, "output"), "r") as fp:
content = fp.read()
- count = content.count('JOB DONE')
- if count != 1 :
+ count = content.count("JOB DONE")
+ if count != 1:
return False
- else :
+ else:
return False
return True
-def _abacus_scf_check_fin(ii) :
- if os.path.isfile(os.path.join(ii, 'OUT.ABACUS/running_scf.log')) :
- with open(os.path.join(ii, 'OUT.ABACUS/running_scf.log'), 'r') as fp :
+
+def _abacus_scf_check_fin(ii):
+ if os.path.isfile(os.path.join(ii, "OUT.ABACUS/running_scf.log")):
+ with open(os.path.join(ii, "OUT.ABACUS/running_scf.log"), "r") as fp:
content = fp.read()
- count = content.count('!FINAL_ETOT_IS')
- if count != 1 :
+ count = content.count("!FINAL_ETOT_IS")
+ if count != 1:
return False
- else :
+ else:
return False
return True
-def _siesta_check_fin(ii) :
- if os.path.isfile(os.path.join(ii, 'output')) :
- with open(os.path.join(ii, 'output'), 'r') as fp :
+
+def _siesta_check_fin(ii):
+ if os.path.isfile(os.path.join(ii, "output")):
+ with open(os.path.join(ii, "output"), "r") as fp:
content = fp.read()
- count = content.count('End of run')
- if count != 1 :
+ count = content.count("End of run")
+ if count != 1:
return False
- else :
+ else:
return False
return True
+
def _gaussian_check_fin(ii):
- if os.path.isfile(os.path.join(ii, 'output')) :
- with open(os.path.join(ii, 'output'), 'r') as fp :
+ if os.path.isfile(os.path.join(ii, "output")):
+ with open(os.path.join(ii, "output"), "r") as fp:
content = fp.read()
- count = content.count('termination')
- if count == 0 :
+ count = content.count("termination")
+ if count == 0:
return False
- else :
+ else:
return False
return True
+
def _cp2k_check_fin(ii):
- if os.path.isfile(os.path.join(ii, 'output')) :
- with open(os.path.join(ii, 'output'), 'r') as fp :
+ if os.path.isfile(os.path.join(ii, "output")):
+ with open(os.path.join(ii, "output"), "r") as fp:
content = fp.read()
- count = content.count('SCF run converged')
- if count == 0 :
+ count = content.count("SCF run converged")
+ if count == 0:
return False
- else :
+ else:
return False
return True
-def _pwmat_check_fin (ii) :
- if os.path.isfile(os.path.join(ii, 'REPORT')) :
- with open(os.path.join(ii, 'REPORT'), 'r') as fp :
+
+def _pwmat_check_fin(ii):
+ if os.path.isfile(os.path.join(ii, "REPORT")):
+ with open(os.path.join(ii, "REPORT"), "r") as fp:
content = fp.read()
- count = content.count('time')
- if count != 1 :
+ count = content.count("time")
+ if count != 1:
return False
- else :
+ else:
return False
return True
-def run_fp_inner (iter_index,
- jdata,
- mdata,
- forward_files,
- backward_files,
- check_fin,
- log_file = "fp.log",
- forward_common_files=[]) :
- fp_command = mdata['fp_command']
- fp_group_size = mdata['fp_group_size']
- fp_resources = mdata['fp_resources']
- mark_failure = fp_resources.get('mark_failure', False)
+
+def run_fp_inner(
+ iter_index,
+ jdata,
+ mdata,
+ forward_files,
+ backward_files,
+ check_fin,
+ log_file="fp.log",
+ forward_common_files=[],
+):
+ fp_command = mdata["fp_command"]
+ fp_group_size = mdata["fp_group_size"]
+ fp_resources = mdata["fp_resources"]
+ mark_failure = fp_resources.get("mark_failure", False)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
-
- fp_style = jdata['fp_style']
- if fp_style == 'amber/diff':
+
+ fp_style = jdata["fp_style"]
+ if fp_style == "amber/diff":
# firstly get sys_idx
fp_command = (
- "TASK=$(basename $(pwd)) && "
- "SYS1=${TASK:5:3} && "
- "SYS=$((10#$SYS1)) && "
- 'QM_REGION=$(awk "NR==$SYS+1" ../qm_region) &&'
- ) + fp_command + (
- " -O -p ../qmmm$SYS.parm7 -c ../init$SYS.rst7 -i ../low_level$SYS.mdin -o low_level.mdout -r low_level.rst7 "
- "-x low_level.nc -y rc.nc -frc low_level.mdfrc -inf low_level.mdinfo && "
- ) + fp_command + (
- " -O -p ../qmmm$SYS.parm7 -c ../init$SYS.rst7 -i ../high_level$SYS.mdin -o high_level.mdout -r high_level.rst7 "
- "-x high_level.nc -y rc.nc -frc high_level.mdfrc -inf high_level.mdinfo && "
- ) + (
- "dpamber corr --cutoff %f --parm7_file ../qmmm$SYS.parm7 --nc rc.nc --hl high_level --ll low_level --qm_region \"$QM_REGION\"") % (
- jdata['cutoff'],
+ (
+ "TASK=$(basename $(pwd)) && "
+ "SYS1=${TASK:5:3} && "
+ "SYS=$((10#$SYS1)) && "
+ 'QM_REGION=$(awk "NR==$SYS+1" ../qm_region) &&'
+ )
+ + fp_command
+ + (
+ " -O -p ../qmmm$SYS.parm7 -c ../init$SYS.rst7 -i ../low_level$SYS.mdin -o low_level.mdout -r low_level.rst7 "
+ "-x low_level.nc -y rc.nc -frc low_level.mdfrc -inf low_level.mdinfo && "
+ )
+ + fp_command
+ + (
+ " -O -p ../qmmm$SYS.parm7 -c ../init$SYS.rst7 -i ../high_level$SYS.mdin -o high_level.mdout -r high_level.rst7 "
+ "-x high_level.nc -y rc.nc -frc high_level.mdfrc -inf high_level.mdinfo && "
+ )
+ + (
+ 'dpamber corr --cutoff %f --parm7_file ../qmmm$SYS.parm7 --nc rc.nc --hl high_level --ll low_level --qm_region "$QM_REGION"'
+ )
+ % (jdata["cutoff"],)
)
-
fp_run_tasks = fp_tasks
# for ii in fp_tasks :
# if not check_fin(ii) :
@@ -3115,28 +3678,17 @@ def run_fp_inner (iter_index,
user_forward_files = mdata.get("fp" + "_user_forward_files", [])
forward_files += [os.path.basename(file) for file in user_forward_files]
backward_files += mdata.get("fp" + "_user_backward_files", [])
-
- api_version = mdata.get('api_version', '0.9')
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher = make_dispatcher(mdata['fp_machine'], mdata['fp_resources'], work_path, run_tasks, fp_group_size)
- dispatcher.run_jobs(mdata['fp_resources'],
- [fp_command],
- work_path,
- run_tasks,
- fp_group_size,
- forward_common_files,
- forward_files,
- backward_files,
- mark_failure = mark_failure,
- outlog = log_file,
- errlog = log_file)
-
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+
+ api_version = mdata.get("api_version", "1.0")
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+
+ elif Version(api_version) >= Version("1.0"):
submission = make_submission(
- mdata['fp_machine'],
- mdata['fp_resources'],
+ mdata["fp_machine"],
+ mdata["fp_resources"],
commands=[fp_command],
work_path=work_path,
run_tasks=run_tasks,
@@ -3144,47 +3696,63 @@ def run_fp_inner (iter_index,
forward_common_files=forward_common_files,
forward_files=forward_files,
backward_files=backward_files,
- outlog = log_file,
- errlog = log_file)
+ outlog=log_file,
+ errlog=log_file,
+ )
submission.run_submission()
-def run_fp (iter_index,
- jdata,
- mdata) :
- fp_style = jdata['fp_style']
- fp_pp_files = jdata.get('fp_pp_files', [])
+def run_fp(iter_index, jdata, mdata):
+ fp_style = jdata["fp_style"]
+ fp_pp_files = jdata.get("fp_pp_files", [])
- if fp_style == "vasp" :
- forward_files = ['POSCAR', 'INCAR', 'POTCAR','KPOINTS']
- backward_files = ['fp.log','OUTCAR','vasprun.xml']
+ if fp_style == "vasp":
+ forward_files = ["POSCAR", "INCAR", "POTCAR", "KPOINTS"]
+ backward_files = ["fp.log", "OUTCAR", "vasprun.xml"]
# Move cvasp interface to jdata
- if ('cvasp' in jdata) and (jdata['cvasp'] == True):
- mdata['fp_resources']['cvasp'] = True
- if ('cvasp' in mdata["fp_resources"] ) and (mdata["fp_resources"]["cvasp"]==True):
+ if ("cvasp" in jdata) and (jdata["cvasp"] == True):
+ mdata["fp_resources"]["cvasp"] = True
+ if ("cvasp" in mdata["fp_resources"]) and (
+ mdata["fp_resources"]["cvasp"] == True
+ ):
dlog.info("cvasp is on !")
- forward_files.append('cvasp.py')
- forward_common_files=[]
+ forward_files.append("cvasp.py")
+ forward_common_files = []
else:
- forward_common_files=[]
- run_fp_inner(iter_index, jdata, mdata, forward_files, backward_files, _vasp_check_fin,
- forward_common_files=forward_common_files)
- elif fp_style == "pwscf" :
- forward_files = ['input'] + fp_pp_files
- backward_files = ['output']
- run_fp_inner(iter_index, jdata, mdata, forward_files, backward_files, _qe_check_fin, log_file = 'output')
+ forward_common_files = []
+ run_fp_inner(
+ iter_index,
+ jdata,
+ mdata,
+ forward_files,
+ backward_files,
+ _vasp_check_fin,
+ forward_common_files=forward_common_files,
+ )
+ elif fp_style == "pwscf":
+ forward_files = ["input"] + fp_pp_files
+ backward_files = ["output"]
+ run_fp_inner(
+ iter_index,
+ jdata,
+ mdata,
+ forward_files,
+ backward_files,
+ _qe_check_fin,
+ log_file="output",
+ )
elif fp_style == "abacus":
fp_params = {}
- if 'user_fp_params' in jdata.keys() :
- fp_params = jdata['user_fp_params']
- elif 'fp_incar' in jdata.keys():
- fp_input_path = jdata['fp_incar']
- assert(os.path.exists(fp_input_path))
+ if "user_fp_params" in jdata.keys():
+ fp_params = jdata["user_fp_params"]
+ elif "fp_incar" in jdata.keys():
+ fp_input_path = jdata["fp_incar"]
+ assert os.path.exists(fp_input_path)
fp_input_path = os.path.abspath(fp_input_path)
fp_params = get_abacus_input_parameters(fp_input_path)
forward_files = ["INPUT", "STRU"]
- if 'kspacing' not in fp_params.keys():
- forward_files = ["INPUT","STRU","KPT"]
+ if "kspacing" not in fp_params.keys():
+ forward_files = ["INPUT", "STRU", "KPT"]
forward_files += fp_pp_files
if "fp_orb_files" in jdata:
forward_files += jdata["fp_orb_files"]
@@ -3194,47 +3762,102 @@ def run_fp (iter_index,
if "deepks_model" in jdata["user_fp_params"]:
forward_files.append(jdata["user_fp_params"]["deepks_model"])
backward_files = ["output", "OUT.ABACUS"]
- run_fp_inner(iter_index, jdata, mdata, forward_files, backward_files, _abacus_scf_check_fin, log_file = 'output')
+ run_fp_inner(
+ iter_index,
+ jdata,
+ mdata,
+ forward_files,
+ backward_files,
+ _abacus_scf_check_fin,
+ log_file="output",
+ )
elif fp_style == "siesta":
- forward_files = ['input'] + fp_pp_files
- backward_files = ['output']
- run_fp_inner(iter_index, jdata, mdata, forward_files, backward_files, _siesta_check_fin, log_file='output')
+ forward_files = ["input"] + fp_pp_files
+ backward_files = ["output"]
+ run_fp_inner(
+ iter_index,
+ jdata,
+ mdata,
+ forward_files,
+ backward_files,
+ _siesta_check_fin,
+ log_file="output",
+ )
elif fp_style == "gaussian":
- forward_files = ['input']
- backward_files = ['output']
- run_fp_inner(iter_index, jdata, mdata, forward_files, backward_files, _gaussian_check_fin, log_file = 'output')
+ forward_files = ["input"]
+ backward_files = ["output"]
+ run_fp_inner(
+ iter_index,
+ jdata,
+ mdata,
+ forward_files,
+ backward_files,
+ _gaussian_check_fin,
+ log_file="output",
+ )
elif fp_style == "cp2k":
- forward_files = ['input.inp', 'coord.xyz']
- backward_files = ['output']
- run_fp_inner(iter_index, jdata, mdata, forward_files, backward_files, _cp2k_check_fin, log_file = 'output')
- elif fp_style == "pwmat" :
- forward_files = ['atom.config', 'etot.input'] + fp_pp_files
- backward_files = ['REPORT', 'OUT.MLMD', 'output']
- run_fp_inner(iter_index, jdata, mdata, forward_files, backward_files, _pwmat_check_fin, log_file = 'output')
- elif fp_style == 'amber/diff':
- forward_files = ['rc.nc']
+ forward_files = ["input.inp", "coord.xyz"]
+ backward_files = ["output"]
+ run_fp_inner(
+ iter_index,
+ jdata,
+ mdata,
+ forward_files,
+ backward_files,
+ _cp2k_check_fin,
+ log_file="output",
+ )
+ elif fp_style == "pwmat":
+ forward_files = ["atom.config", "etot.input"] + fp_pp_files
+ backward_files = ["REPORT", "OUT.MLMD", "output"]
+ run_fp_inner(
+ iter_index,
+ jdata,
+ mdata,
+ forward_files,
+ backward_files,
+ _pwmat_check_fin,
+ log_file="output",
+ )
+ elif fp_style == "amber/diff":
+ forward_files = ["rc.nc"]
backward_files = [
- 'low_level.mdfrc', 'low_level.mdout',
- 'high_level.mdfrc', 'high_level.mdout',
- 'output', 'dataset'
+ "low_level.mdfrc",
+ "low_level.mdout",
+ "high_level.mdfrc",
+ "high_level.mdout",
+ "output",
+ "dataset",
]
- forward_common_files = ['low_level*.mdin', 'high_level*.mdin', 'qmmm*.parm7', 'qm_region', 'init*.rst7']
- run_fp_inner(iter_index, jdata, mdata, forward_files, backward_files, None, log_file = 'output',
- forward_common_files=forward_common_files)
- else :
- raise RuntimeError ("unsupported fp style")
+ forward_common_files = [
+ "low_level*.mdin",
+ "high_level*.mdin",
+ "qmmm*.parm7",
+ "qm_region",
+ "init*.rst7",
+ ]
+ run_fp_inner(
+ iter_index,
+ jdata,
+ mdata,
+ forward_files,
+ backward_files,
+ None,
+ log_file="output",
+ forward_common_files=forward_common_files,
+ )
+ else:
+ raise RuntimeError("unsupported fp style")
-def post_fp_check_fail(iter_index,
- jdata,
- rfailed = None) :
+def post_fp_check_fail(iter_index, jdata, rfailed=None):
- ratio_failed = rfailed if rfailed else jdata.get('ratio_failed',0.05)
+ ratio_failed = rfailed if rfailed else jdata.get("ratio_failed", 0.05)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
ntask = len(fp_tasks)
nfail = 0
@@ -3243,40 +3866,38 @@ def post_fp_check_fail(iter_index,
sys_data = glob.glob(os.path.join(work_path, "data.*"))
sys_data.sort()
nframe = 0
- for ii in sys_data :
+ for ii in sys_data:
sys_paths = expand_sys_str(ii)
for single_sys in sys_paths:
- sys = dpdata.LabeledSystem(os.path.join(single_sys), fmt = 'deepmd/npy')
+ sys = dpdata.LabeledSystem(os.path.join(single_sys), fmt="deepmd/npy")
nframe += len(sys)
nfail = ntask - nframe
rfail = float(nfail) / float(ntask)
- dlog.info("failed tasks: %6d in %6d %6.2f %% " % (nfail, ntask, rfail * 100.))
+ dlog.info("failed tasks: %6d in %6d %6.2f %% " % (nfail, ntask, rfail * 100.0))
if rfail > ratio_failed:
- raise RuntimeError("find too many unsuccessfully terminated jobs")
+ raise RuntimeError("find too many unsuccessfully terminated jobs")
-def post_fp_vasp (iter_index,
- jdata,
- rfailed=None):
+def post_fp_vasp(iter_index, jdata, rfailed=None):
- ratio_failed = rfailed if rfailed else jdata.get('ratio_failed',0.05)
- model_devi_engine = jdata.get('model_devi_engine', "lammps")
- if model_devi_engine != 'calypso':
- model_devi_jobs = jdata['model_devi_jobs']
- assert (iter_index < len(model_devi_jobs))
- use_ele_temp = jdata.get('use_ele_temp', 0)
+ ratio_failed = rfailed if rfailed else jdata.get("ratio_failed", 0.05)
+ model_devi_engine = jdata.get("model_devi_engine", "lammps")
+ if model_devi_engine != "calypso":
+ model_devi_jobs = jdata["model_devi_jobs"]
+ assert iter_index < len(model_devi_jobs)
+ use_ele_temp = jdata.get("use_ele_temp", 0)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
system_index = []
- for ii in fp_tasks :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in fp_tasks:
+ system_index.append(os.path.basename(ii).split(".")[1])
system_index.sort()
set_tmp = set(system_index)
system_index = list(set_tmp)
@@ -3284,271 +3905,285 @@ def post_fp_vasp (iter_index,
cwd = os.getcwd()
- tcount=0
- icount=0
- for ss in system_index :
- sys_outcars = glob.glob(os.path.join(work_path, "task.%s.*/OUTCAR"%ss))
+ tcount = 0
+ icount = 0
+ for ss in system_index:
+ sys_outcars = glob.glob(os.path.join(work_path, "task.%s.*/OUTCAR" % ss))
sys_outcars.sort()
tcount += len(sys_outcars)
all_sys = None
all_te = []
- for oo in sys_outcars :
+ for oo in sys_outcars:
try:
- _sys = dpdata.LabeledSystem(oo, type_map = jdata['type_map'])
+ _sys = dpdata.LabeledSystem(oo, type_map=jdata["type_map"])
except Exception:
- dlog.info('Try to parse from vasprun.xml')
+ dlog.info("Try to parse from vasprun.xml")
try:
- _sys = dpdata.LabeledSystem(oo.replace('OUTCAR','vasprun.xml'), type_map = jdata['type_map'])
+ _sys = dpdata.LabeledSystem(
+ oo.replace("OUTCAR", "vasprun.xml"), type_map=jdata["type_map"]
+ )
except Exception:
- _sys = dpdata.LabeledSystem()
- dlog.info('Failed fp path: %s'%oo.replace('OUTCAR',''))
+ _sys = dpdata.LabeledSystem()
+ dlog.info("Failed fp path: %s" % oo.replace("OUTCAR", ""))
if len(_sys) == 1:
if all_sys is None:
all_sys = _sys
else:
all_sys.append(_sys)
# save ele_temp, if any
- if(os.path.exists(oo.replace('OUTCAR', 'job.json')) ):
- with open(oo.replace('OUTCAR', 'job.json')) as fp:
+ if os.path.exists(oo.replace("OUTCAR", "job.json")):
+ with open(oo.replace("OUTCAR", "job.json")) as fp:
job_data = json.load(fp)
- if 'ele_temp' in job_data:
- assert(use_ele_temp)
- ele_temp = job_data['ele_temp']
+ if "ele_temp" in job_data:
+ assert use_ele_temp
+ ele_temp = job_data["ele_temp"]
all_te.append(ele_temp)
elif len(_sys) >= 2:
- raise RuntimeError("The vasp parameter NSW should be set as 1")
+ raise RuntimeError("The vasp parameter NSW should be set as 1")
else:
- icount+=1
+ icount += 1
all_te = np.array(all_te)
if all_sys is not None:
- sys_data_path = os.path.join(work_path, 'data.%s'%ss)
- all_sys.to_deepmd_raw(sys_data_path)
- all_sys.to_deepmd_npy(sys_data_path, set_size = len(sys_outcars))
- if all_te.size > 0:
- assert(len(all_sys) == all_sys.get_nframes())
- assert(len(all_sys) == all_te.size)
- all_te = np.reshape(all_te, [-1,1])
- if use_ele_temp == 0:
- raise RuntimeError('should not get ele temp at setting: use_ele_temp == 0')
- elif use_ele_temp == 1:
- np.savetxt(os.path.join(sys_data_path, 'fparam.raw'), all_te)
- np.save(os.path.join(sys_data_path, 'set.000', 'fparam.npy'), all_te)
- elif use_ele_temp == 2:
- tile_te = np.tile(all_te, [1, all_sys.get_natoms()])
- np.savetxt(os.path.join(sys_data_path, 'aparam.raw'), tile_te)
- np.save(os.path.join(sys_data_path, 'set.000', 'aparam.npy'), tile_te)
- else:
- raise RuntimeError('invalid setting of use_ele_temp ' + str(use_ele_temp))
-
- if(tcount == 0) :
+ sys_data_path = os.path.join(work_path, "data.%s" % ss)
+ all_sys.to_deepmd_raw(sys_data_path)
+ all_sys.to_deepmd_npy(sys_data_path, set_size=len(sys_outcars))
+ if all_te.size > 0:
+ assert len(all_sys) == all_sys.get_nframes()
+ assert len(all_sys) == all_te.size
+ all_te = np.reshape(all_te, [-1, 1])
+ if use_ele_temp == 0:
+ raise RuntimeError(
+ "should not get ele temp at setting: use_ele_temp == 0"
+ )
+ elif use_ele_temp == 1:
+ np.savetxt(os.path.join(sys_data_path, "fparam.raw"), all_te)
+ np.save(
+ os.path.join(sys_data_path, "set.000", "fparam.npy"), all_te
+ )
+ elif use_ele_temp == 2:
+ tile_te = np.tile(all_te, [1, all_sys.get_natoms()])
+ np.savetxt(os.path.join(sys_data_path, "aparam.raw"), tile_te)
+ np.save(
+ os.path.join(sys_data_path, "set.000", "aparam.npy"), tile_te
+ )
+ else:
+ raise RuntimeError(
+ "invalid setting of use_ele_temp " + str(use_ele_temp)
+ )
+
+ if tcount == 0:
rfail = 0.0
dlog.info("failed frame: %6d in %6d " % (icount, tcount))
- else :
- rfail=float(icount)/float(tcount)
- dlog.info("failed frame: %6d in %6d %6.2f %% " % (icount, tcount, rfail * 100.))
+ else:
+ rfail = float(icount) / float(tcount)
+ dlog.info(
+ "failed frame: %6d in %6d %6.2f %% " % (icount, tcount, rfail * 100.0)
+ )
- if rfail>ratio_failed:
- raise RuntimeError("find too many unsuccessfully terminated jobs. Too many FP tasks are not converged. Please check your input parameters (e.g. INCAR) or configuration (e.g. POSCAR) in directories \'iter.*.*/02.fp/task.*.*/.\'")
+ if rfail > ratio_failed:
+ raise RuntimeError(
+ "find too many unsuccessfully terminated jobs. Too many FP tasks are not converged. Please check your input parameters (e.g. INCAR) or configuration (e.g. POSCAR) in directories 'iter.*.*/02.fp/task.*.*/.'"
+ )
-def post_fp_pwscf (iter_index,
- jdata):
- model_devi_jobs = jdata['model_devi_jobs']
- assert (iter_index < len(model_devi_jobs))
+def post_fp_pwscf(iter_index, jdata):
+ model_devi_jobs = jdata["model_devi_jobs"]
+ assert iter_index < len(model_devi_jobs)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
system_index = []
- for ii in fp_tasks :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in fp_tasks:
+ system_index.append(os.path.basename(ii).split(".")[1])
system_index.sort()
set_tmp = set(system_index)
system_index = list(set_tmp)
system_index.sort()
cwd = os.getcwd()
- for ss in system_index :
- sys_output = glob.glob(os.path.join(work_path, "task.%s.*/output"%ss))
- sys_input = glob.glob(os.path.join(work_path, "task.%s.*/input"%ss))
+ for ss in system_index:
+ sys_output = glob.glob(os.path.join(work_path, "task.%s.*/output" % ss))
+ sys_input = glob.glob(os.path.join(work_path, "task.%s.*/input" % ss))
sys_output.sort()
sys_input.sort()
- flag=True
- for ii,oo in zip(sys_input,sys_output) :
+ flag = True
+ for ii, oo in zip(sys_input, sys_output):
if flag:
- _sys = dpdata.LabeledSystem(oo, fmt = 'qe/pw/scf', type_map = jdata['type_map'])
- if len(_sys)>0:
- all_sys=_sys
- flag=False
+ _sys = dpdata.LabeledSystem(
+ oo, fmt="qe/pw/scf", type_map=jdata["type_map"]
+ )
+ if len(_sys) > 0:
+ all_sys = _sys
+ flag = False
else:
- pass
+ pass
else:
- _sys = dpdata.LabeledSystem(oo, fmt = 'qe/pw/scf', type_map = jdata['type_map'])
- if len(_sys)>0:
- all_sys.append(_sys)
+ _sys = dpdata.LabeledSystem(
+ oo, fmt="qe/pw/scf", type_map=jdata["type_map"]
+ )
+ if len(_sys) > 0:
+ all_sys.append(_sys)
- sys_data_path = os.path.join(work_path, 'data.%s'%ss)
+ sys_data_path = os.path.join(work_path, "data.%s" % ss)
all_sys.to_deepmd_raw(sys_data_path)
- all_sys.to_deepmd_npy(sys_data_path, set_size = len(sys_output))
+ all_sys.to_deepmd_npy(sys_data_path, set_size=len(sys_output))
-def post_fp_abacus_scf (iter_index,
- jdata):
- model_devi_jobs = jdata['model_devi_jobs']
- assert (iter_index < len(model_devi_jobs))
+
+def post_fp_abacus_scf(iter_index, jdata):
+ model_devi_jobs = jdata["model_devi_jobs"]
+ assert iter_index < len(model_devi_jobs)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
system_index = []
- for ii in fp_tasks :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in fp_tasks:
+ system_index.append(os.path.basename(ii).split(".")[1])
system_index.sort()
set_tmp = set(system_index)
system_index = list(set_tmp)
system_index.sort()
cwd = os.getcwd()
- for ss in system_index :
- sys_output = glob.glob(os.path.join(work_path, "task.%s.*"%ss))
- sys_input = glob.glob(os.path.join(work_path, "task.%s.*/INPUT"%ss))
+ for ss in system_index:
+ sys_output = glob.glob(os.path.join(work_path, "task.%s.*" % ss))
+ sys_input = glob.glob(os.path.join(work_path, "task.%s.*/INPUT" % ss))
sys_output.sort()
sys_input.sort()
- flag=True
- for ii,oo in zip(sys_input,sys_output) :
- if flag:
- _sys = dpdata.LabeledSystem(oo, fmt = 'abacus/scf', type_map = jdata['type_map'])
- if len(_sys)>0:
- all_sys=_sys
- flag=False
+ all_sys = None
+ for ii, oo in zip(sys_input, sys_output):
+ _sys = dpdata.LabeledSystem(
+ oo, fmt="abacus/scf", type_map=jdata["type_map"]
+ )
+ if len(_sys) > 0:
+ if all_sys == None:
+ all_sys = _sys
else:
- pass
- else:
- _sys = dpdata.LabeledSystem(oo, fmt = 'abacus/scf', type_map = jdata['type_map'])
- if len(_sys)>0:
- all_sys.append(_sys)
+ all_sys.append(_sys)
+
+ if all_sys != None:
+ sys_data_path = os.path.join(work_path, "data.%s" % ss)
+ all_sys.to_deepmd_raw(sys_data_path)
+ all_sys.to_deepmd_npy(sys_data_path, set_size=len(sys_output))
- sys_data_path = os.path.join(work_path, 'data.%s'%ss)
- all_sys.to_deepmd_raw(sys_data_path)
- all_sys.to_deepmd_npy(sys_data_path, set_size = len(sys_output))
-def post_fp_siesta (iter_index,
- jdata):
- model_devi_jobs = jdata['model_devi_jobs']
- assert (iter_index < len(model_devi_jobs))
+def post_fp_siesta(iter_index, jdata):
+ model_devi_jobs = jdata["model_devi_jobs"]
+ assert iter_index < len(model_devi_jobs)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
system_index = []
- for ii in fp_tasks :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in fp_tasks:
+ system_index.append(os.path.basename(ii).split(".")[1])
system_index.sort()
set_tmp = set(system_index)
system_index = list(set_tmp)
system_index.sort()
cwd = os.getcwd()
- for ss in system_index :
- sys_output = glob.glob(os.path.join(work_path, "task.%s.*/output"%ss))
- sys_input = glob.glob(os.path.join(work_path, "task.%s.*/input"%ss))
+ for ss in system_index:
+ sys_output = glob.glob(os.path.join(work_path, "task.%s.*/output" % ss))
+ sys_input = glob.glob(os.path.join(work_path, "task.%s.*/input" % ss))
sys_output.sort()
sys_input.sort()
for idx, oo in enumerate(sys_output):
_sys = dpdata.LabeledSystem()
- _sys.data['atom_names'], \
- _sys.data['atom_numbs'], \
- _sys.data['atom_types'], \
- _sys.data['cells'], \
- _sys.data['coords'], \
- _sys.data['energies'], \
- _sys.data['forces'], \
- _sys.data['virials'] \
- = dpdata.siesta.output.obtain_frame(oo)
+ (
+ _sys.data["atom_names"],
+ _sys.data["atom_numbs"],
+ _sys.data["atom_types"],
+ _sys.data["cells"],
+ _sys.data["coords"],
+ _sys.data["energies"],
+ _sys.data["forces"],
+ _sys.data["virials"],
+ ) = dpdata.siesta.output.obtain_frame(oo)
if idx == 0:
all_sys = _sys
else:
all_sys.append(_sys)
- sys_data_path = os.path.join(work_path, 'data.%s'%ss)
+ sys_data_path = os.path.join(work_path, "data.%s" % ss)
all_sys.to_deepmd_raw(sys_data_path)
- all_sys.to_deepmd_npy(sys_data_path, set_size = len(sys_output))
-
+ all_sys.to_deepmd_npy(sys_data_path, set_size=len(sys_output))
-def post_fp_gaussian (iter_index,
- jdata):
- model_devi_jobs = jdata['model_devi_jobs']
- assert (iter_index < len(model_devi_jobs))
+def post_fp_gaussian(iter_index, jdata):
+ model_devi_jobs = jdata["model_devi_jobs"]
+ assert iter_index < len(model_devi_jobs)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
system_index = []
- for ii in fp_tasks :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in fp_tasks:
+ system_index.append(os.path.basename(ii).split(".")[1])
system_index.sort()
set_tmp = set(system_index)
system_index = list(set_tmp)
system_index.sort()
cwd = os.getcwd()
- for ss in system_index :
- sys_output = glob.glob(os.path.join(work_path, "task.%s.*/output"%ss))
+ for ss in system_index:
+ sys_output = glob.glob(os.path.join(work_path, "task.%s.*/output" % ss))
sys_output.sort()
- for idx,oo in enumerate(sys_output) :
- sys = dpdata.LabeledSystem(oo, fmt = 'gaussian/log')
+ for idx, oo in enumerate(sys_output):
+ sys = dpdata.LabeledSystem(oo, fmt="gaussian/log")
if len(sys) > 0:
- sys.check_type_map(type_map = jdata['type_map'])
- if jdata.get('use_atom_pref', False):
- sys.data['atom_pref'] = np.load(os.path.join(os.path.dirname(oo), "atom_pref.npy"))
+ sys.check_type_map(type_map=jdata["type_map"])
+ if jdata.get("use_atom_pref", False):
+ sys.data["atom_pref"] = np.load(
+ os.path.join(os.path.dirname(oo), "atom_pref.npy")
+ )
if idx == 0:
- if jdata.get('use_clusters', False):
- all_sys = dpdata.MultiSystems(sys, type_map = jdata['type_map'])
+ if jdata.get("use_clusters", False):
+ all_sys = dpdata.MultiSystems(sys, type_map=jdata["type_map"])
else:
all_sys = sys
else:
all_sys.append(sys)
- sys_data_path = os.path.join(work_path, 'data.%s'%ss)
+ sys_data_path = os.path.join(work_path, "data.%s" % ss)
all_sys.to_deepmd_raw(sys_data_path)
- all_sys.to_deepmd_npy(sys_data_path, set_size = len(sys_output))
+ all_sys.to_deepmd_npy(sys_data_path, set_size=len(sys_output))
+
+def post_fp_cp2k(iter_index, jdata, rfailed=None):
-def post_fp_cp2k (iter_index,
- jdata,
- rfailed=None):
-
- ratio_failed = rfailed if rfailed else jdata.get('ratio_failed',0.10)
- model_devi_jobs = jdata['model_devi_jobs']
- assert (iter_index < len(model_devi_jobs))
+ ratio_failed = rfailed if rfailed else jdata.get("ratio_failed", 0.10)
+ model_devi_jobs = jdata["model_devi_jobs"]
+ assert iter_index < len(model_devi_jobs)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
system_index = []
- for ii in fp_tasks :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in fp_tasks:
+ system_index.append(os.path.basename(ii).split(".")[1])
system_index.sort()
set_tmp = set(system_index)
system_index = list(set_tmp)
@@ -3559,55 +4194,57 @@ def post_fp_cp2k (iter_index,
tcount = 0
# icount: num of converged fp tasks
icount = 0
- for ss in system_index :
- sys_output = glob.glob(os.path.join(work_path, "task.%s.*/output"%ss))
+ for ss in system_index:
+ sys_output = glob.glob(os.path.join(work_path, "task.%s.*/output" % ss))
sys_output.sort()
tcount += len(sys_output)
all_sys = None
- for oo in sys_output :
- _sys = dpdata.LabeledSystem(oo, fmt = 'cp2k/output')
- #_sys.check_type_map(type_map = jdata['type_map'])
+ for oo in sys_output:
+ _sys = dpdata.LabeledSystem(oo, fmt="cp2k/output")
+ # _sys.check_type_map(type_map = jdata['type_map'])
if all_sys is None:
all_sys = _sys
else:
all_sys.append(_sys)
-
icount += len(all_sys)
if all_sys is not None:
- sys_data_path = os.path.join(work_path, 'data.%s'%ss)
+ sys_data_path = os.path.join(work_path, "data.%s" % ss)
all_sys.to_deepmd_raw(sys_data_path)
- all_sys.to_deepmd_npy(sys_data_path, set_size = len(sys_output))
+ all_sys.to_deepmd_npy(sys_data_path, set_size=len(sys_output))
- if(tcount == 0) :
+ if tcount == 0:
rfail = 0.0
dlog.info("failed frame: %6d in %6d " % (tcount - icount, tcount))
- else :
- rfail=float(tcount - icount)/float(tcount)
- dlog.info("failed frame: %6d in %6d %6.2f %% " % (tcount - icount, tcount, rfail * 100.))
+ else:
+ rfail = float(tcount - icount) / float(tcount)
+ dlog.info(
+ "failed frame: %6d in %6d %6.2f %% "
+ % (tcount - icount, tcount, rfail * 100.0)
+ )
- if rfail>ratio_failed:
- raise RuntimeError("find too many unsuccessfully terminated jobs. Too many FP tasks are not converged. Please check your files in directories \'iter.*.*/02.fp/task.*.*/.\'")
+ if rfail > ratio_failed:
+ raise RuntimeError(
+ "find too many unsuccessfully terminated jobs. Too many FP tasks are not converged. Please check your files in directories 'iter.*.*/02.fp/task.*.*/.'"
+ )
-def post_fp_pwmat (iter_index,
- jdata,
- rfailed=None):
+def post_fp_pwmat(iter_index, jdata, rfailed=None):
- ratio_failed = rfailed if rfailed else jdata.get('ratio_failed',0.05)
- model_devi_jobs = jdata['model_devi_jobs']
- assert (iter_index < len(model_devi_jobs))
+ ratio_failed = rfailed if rfailed else jdata.get("ratio_failed", 0.05)
+ model_devi_jobs = jdata["model_devi_jobs"]
+ assert iter_index < len(model_devi_jobs)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
system_index = []
- for ii in fp_tasks :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in fp_tasks:
+ system_index.append(os.path.basename(ii).split(".")[1])
system_index.sort()
set_tmp = set(system_index)
system_index = list(set_tmp)
@@ -3615,92 +4252,94 @@ def post_fp_pwmat (iter_index,
cwd = os.getcwd()
- tcount=0
- icount=0
- for ss in system_index :
- sys_output = glob.glob(os.path.join(work_path, "task.%s.*/OUT.MLMD"%ss))
+ tcount = 0
+ icount = 0
+ for ss in system_index:
+ sys_output = glob.glob(os.path.join(work_path, "task.%s.*/OUT.MLMD" % ss))
sys_output.sort()
tcount += len(sys_output)
all_sys = None
- for oo in sys_output :
- _sys = dpdata.LabeledSystem(oo, type_map = jdata['type_map'])
+ for oo in sys_output:
+ _sys = dpdata.LabeledSystem(oo, type_map=jdata["type_map"])
if len(_sys) == 1:
if all_sys is None:
all_sys = _sys
else:
all_sys.append(_sys)
else:
- icount+=1
+ icount += 1
if all_sys is not None:
- sys_data_path = os.path.join(work_path, 'data.%s'%ss)
- all_sys.to_deepmd_raw(sys_data_path)
- all_sys.to_deepmd_npy(sys_data_path, set_size = len(sys_output))
- dlog.info("failed frame number: %s "%icount)
- dlog.info("total frame number: %s "%tcount)
- reff=icount/tcount
- dlog.info('ratio of failed frame: {:.2%}'.format(reff))
+ sys_data_path = os.path.join(work_path, "data.%s" % ss)
+ all_sys.to_deepmd_raw(sys_data_path)
+ all_sys.to_deepmd_npy(sys_data_path, set_size=len(sys_output))
+ dlog.info("failed frame number: %s " % icount)
+ dlog.info("total frame number: %s " % tcount)
+ reff = icount / tcount
+ dlog.info("ratio of failed frame: {:.2%}".format(reff))
- if reff>ratio_failed:
- raise RuntimeError("find too many unsuccessfully terminated jobs")
+ if reff > ratio_failed:
+ raise RuntimeError("find too many unsuccessfully terminated jobs")
def post_fp_amber_diff(iter_index, jdata):
- model_devi_jobs = jdata['model_devi_jobs']
- assert (iter_index < len(model_devi_jobs))
+ model_devi_jobs = jdata["model_devi_jobs"]
+ assert iter_index < len(model_devi_jobs)
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
fp_tasks.sort()
- if len(fp_tasks) == 0 :
+ if len(fp_tasks) == 0:
return
system_index = []
- for ii in fp_tasks :
- system_index.append(os.path.basename(ii).split('.')[1])
+ for ii in fp_tasks:
+ system_index.append(os.path.basename(ii).split(".")[1])
system_index.sort()
set_tmp = set(system_index)
system_index = list(set_tmp)
system_index.sort()
- for ss in system_index :
- sys_output = glob.glob(os.path.join(work_path, "task.%s.*"%ss))
+ for ss in system_index:
+ sys_output = glob.glob(os.path.join(work_path, "task.%s.*" % ss))
sys_output.sort()
- all_sys=dpdata.MultiSystems(type_map=jdata['type_map'])
- for oo in sys_output :
- sys=dpdata.MultiSystems(type_map=jdata['type_map']).from_deepmd_npy(os.path.join(oo, 'dataset'))
+ all_sys = dpdata.MultiSystems(type_map=jdata["type_map"])
+ for oo in sys_output:
+ sys = dpdata.MultiSystems(type_map=jdata["type_map"]).from_deepmd_npy(
+ os.path.join(oo, "dataset")
+ )
all_sys.append(sys)
- sys_data_path = os.path.join(work_path, 'data.%s'%ss)
+ sys_data_path = os.path.join(work_path, "data.%s" % ss)
all_sys.to_deepmd_raw(sys_data_path)
- all_sys.to_deepmd_npy(sys_data_path, set_size = len(sys_output), prec=np.float64)
+ all_sys.to_deepmd_npy(sys_data_path, set_size=len(sys_output), prec=np.float64)
+
-def post_fp (iter_index,
- jdata) :
- fp_style = jdata['fp_style']
- if fp_style == "vasp" :
+def post_fp(iter_index, jdata):
+ fp_style = jdata["fp_style"]
+ if fp_style == "vasp":
post_fp_vasp(iter_index, jdata)
- elif fp_style == "pwscf" :
+ elif fp_style == "pwscf":
post_fp_pwscf(iter_index, jdata)
elif fp_style == "abacus":
post_fp_abacus_scf(iter_index, jdata)
elif fp_style == "siesta":
post_fp_siesta(iter_index, jdata)
- elif fp_style == 'gaussian' :
+ elif fp_style == "gaussian":
post_fp_gaussian(iter_index, jdata)
- elif fp_style == 'cp2k' :
+ elif fp_style == "cp2k":
post_fp_cp2k(iter_index, jdata)
- elif fp_style == 'pwmat' :
+ elif fp_style == "pwmat":
post_fp_pwmat(iter_index, jdata)
- elif fp_style == 'amber/diff':
+ elif fp_style == "amber/diff":
post_fp_amber_diff(iter_index, jdata)
- else :
- raise RuntimeError ("unsupported fp style")
+ else:
+ raise RuntimeError("unsupported fp style")
post_fp_check_fail(iter_index, jdata)
# clean traj
clean_traj = True
- if 'model_devi_clean_traj' in jdata :
- clean_traj = jdata['model_devi_clean_traj']
- modd_path = None
+ if "model_devi_clean_traj" in jdata:
+ clean_traj = jdata["model_devi_clean_traj"]
+ modd_path = None
if isinstance(clean_traj, bool):
iter_name = make_iter_name(iter_index)
if clean_traj:
@@ -3710,48 +4349,61 @@ def post_fp (iter_index,
if clean_index >= 0:
modd_path = os.path.join(make_iter_name(clean_index), model_devi_name)
if modd_path is not None:
- md_trajs = glob.glob(os.path.join(modd_path, 'task*/traj'))
+ md_trajs = glob.glob(os.path.join(modd_path, "task*/traj"))
for ii in md_trajs:
shutil.rmtree(ii)
-
def set_version(mdata):
-
- deepmd_version = '1'
- mdata['deepmd_version'] = deepmd_version
+
+ deepmd_version = "1"
+ mdata["deepmd_version"] = deepmd_version
return mdata
-def run_iter (param_file, machine_file) :
+
+def run_iter(param_file, machine_file):
try:
- import ruamel
- from monty.serialization import loadfn,dumpfn
- warnings.simplefilter('ignore', ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
- jdata=loadfn(param_file)
- mdata=loadfn(machine_file)
+ import ruamel
+ from monty.serialization import dumpfn, loadfn
+
+ warnings.simplefilter("ignore", ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
+ jdata = loadfn(param_file)
+ mdata = loadfn(machine_file)
except Exception:
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
jdata_arginfo = run_jdata_arginfo()
jdata = normalize(jdata_arginfo, jdata, strict_check=False)
update_mass_map(jdata)
-
- if jdata.get('pretty_print',False):
- #assert(jdata["pretty_format"] in ['json','yaml'])
- fparam=SHORT_CMD+'_'+param_file.split('.')[0]+'.'+jdata.get('pretty_format','json')
- dumpfn(jdata,fparam,indent=4)
- fmachine=SHORT_CMD+'_'+machine_file.split('.')[0]+'.'+jdata.get('pretty_format','json')
- dumpfn(mdata,fmachine,indent=4)
-
- if mdata.get('handlers', None):
- if mdata['handlers'].get('smtp', None):
+
+ if jdata.get("pretty_print", False):
+ # assert(jdata["pretty_format"] in ['json','yaml'])
+ fparam = (
+ SHORT_CMD
+ + "_"
+ + param_file.split(".")[0]
+ + "."
+ + jdata.get("pretty_format", "json")
+ )
+ dumpfn(jdata, fparam, indent=4)
+ fmachine = (
+ SHORT_CMD
+ + "_"
+ + machine_file.split(".")[0]
+ + "."
+ + jdata.get("pretty_format", "json")
+ )
+ dumpfn(mdata, fmachine, indent=4)
+
+ if mdata.get("handlers", None):
+ if mdata["handlers"].get("smtp", None):
que = queue.Queue(-1)
queue_handler = logging.handlers.QueueHandler(que)
- smtp_handler = logging.handlers.SMTPHandler(**mdata['handlers']['smtp'])
+ smtp_handler = logging.handlers.SMTPHandler(**mdata["handlers"]["smtp"])
listener = logging.handlers.QueueListener(que, smtp_handler)
dlog.addHandler(queue_handler)
listener.start()
@@ -3761,147 +4413,674 @@ def run_iter (param_file, machine_file) :
numb_task = 9
record = "record.dpgen"
iter_rec = [0, -1]
- if os.path.isfile (record) :
- with open (record) as frec :
- for line in frec :
+ if os.path.isfile(record):
+ with open(record) as frec:
+ for line in frec:
iter_rec = [int(x) for x in line.split()]
- if len(iter_rec) == 0:
+ if len(iter_rec) == 0:
raise ValueError("There should not be blank lines in record.dpgen.")
- dlog.info ("continue from iter %03d task %02d" % (iter_rec[0], iter_rec[1]))
+ dlog.info("continue from iter %03d task %02d" % (iter_rec[0], iter_rec[1]))
cont = True
ii = -1
while cont:
ii += 1
- iter_name=make_iter_name(ii)
- sepline(iter_name,'=')
- for jj in range (numb_task) :
- if ii * max_tasks + jj <= iter_rec[0] * max_tasks + iter_rec[1] :
+ iter_name = make_iter_name(ii)
+ sepline(iter_name, "=")
+ for jj in range(numb_task):
+ if ii * max_tasks + jj <= iter_rec[0] * max_tasks + iter_rec[1]:
continue
- task_name="task %02d"%jj
- sepline("{} {}".format(iter_name, task_name),'-')
- if jj == 0 :
- log_iter ("make_train", ii, jj)
- make_train (ii, jdata, mdata)
- elif jj == 1 :
- log_iter ("run_train", ii, jj)
- run_train (ii, jdata, mdata)
- elif jj == 2 :
- log_iter ("post_train", ii, jj)
- post_train (ii, jdata, mdata)
- elif jj == 3 :
- log_iter ("make_model_devi", ii, jj)
- cont = make_model_devi (ii, jdata, mdata)
- if not cont :
+ task_name = "task %02d" % jj
+ sepline("{} {}".format(iter_name, task_name), "-")
+ if jj == 0:
+ log_iter("make_train", ii, jj)
+ make_train(ii, jdata, mdata)
+ elif jj == 1:
+ log_iter("run_train", ii, jj)
+ run_train(ii, jdata, mdata)
+ elif jj == 2:
+ log_iter("post_train", ii, jj)
+ post_train(ii, jdata, mdata)
+ elif jj == 3:
+ log_iter("make_model_devi", ii, jj)
+ cont = make_model_devi(ii, jdata, mdata)
+ if not cont:
break
- elif jj == 4 :
- log_iter ("run_model_devi", ii, jj)
- run_model_devi (ii, jdata, mdata)
-
- elif jj == 5 :
- log_iter ("post_model_devi", ii, jj)
- post_model_devi (ii, jdata, mdata)
- elif jj == 6 :
- log_iter ("make_fp", ii, jj)
- make_fp (ii, jdata, mdata)
- elif jj == 7 :
- log_iter ("run_fp", ii, jj)
- run_fp (ii, jdata, mdata)
- elif jj == 8 :
- log_iter ("post_fp", ii, jj)
- post_fp (ii, jdata)
- else :
- raise RuntimeError ("unknown task %d, something wrong" % jj)
- record_iter (record, ii, jj)
+ elif jj == 4:
+ log_iter("run_model_devi", ii, jj)
+ run_model_devi(ii, jdata, mdata)
+
+ elif jj == 5:
+ log_iter("post_model_devi", ii, jj)
+ post_model_devi(ii, jdata, mdata)
+ elif jj == 6:
+ log_iter("make_fp", ii, jj)
+ make_fp(ii, jdata, mdata)
+ elif jj == 7:
+ log_iter("run_fp", ii, jj)
+ run_fp(ii, jdata, mdata)
+ elif jj == 8:
+ log_iter("post_fp", ii, jj)
+ post_fp(ii, jdata)
+ else:
+ raise RuntimeError("unknown task %d, something wrong" % jj)
+ record_iter(record, ii, jj)
def get_atomic_masses(atom):
- element_names = ['Hydrogen', 'Helium', 'Lithium', 'Beryllium', 'Boron', 'Carbon', 'Nitrogen',
- 'Oxygen', 'Fluorine', 'Neon', 'Sodium', 'Magnesium', 'Aluminium', 'Silicon',
- 'Phosphorus', 'Sulfur', 'Chlorine', 'Argon', 'Potassium', 'Calcium', 'Scandium',
- 'Titanium', 'Vanadium', 'Chromium', 'Manganese', 'Iron', 'Cobalt', 'Nickel',
- 'Copper', 'Zinc', 'Gallium', 'Germanium', 'Arsenic', 'Selenium', 'Bromine',
- 'Krypton', 'Rubidium', 'Strontium', 'Yttrium', 'Zirconium', 'Niobium',
- 'Molybdenum', 'Technetium', 'Ruthenium', 'Rhodium', 'Palladium', 'Silver',
- 'Cadmium', 'Indium', 'Tin', 'Antimony', 'Tellurium', 'Iodine', 'Xenon',
- 'Caesium', 'Barium', 'Lanthanum', 'Cerium', 'Praseodymium', 'Neodymium',
- 'Promethium', 'Samarium', 'Europium', 'Gadolinium', 'Terbium', 'Dysprosium',
- 'Holmium', 'Erbium', 'Thulium', 'Ytterbium', 'Lutetium', 'Hafnium', 'Tantalum',
- 'Tungsten', 'Rhenium', 'Osmium', 'Iridium', 'Platinum', 'Gold', 'Mercury',
- 'Thallium', 'Lead', 'Bismuth', 'Polonium', 'Astatine', 'Radon', 'Francium',
- 'Radium', 'Actinium', 'Thorium', 'Protactinium', 'Uranium', 'Neptunium',
- 'Plutonium', 'Americium', 'Curium', 'Berkelium', 'Californium', 'Einsteinium',
- 'Fermium', 'Mendelevium', 'Nobelium', 'Lawrencium', 'Rutherfordium', 'Dubnium',
- 'Seaborgium', 'Bohrium', 'Hassium', 'Meitnerium', 'Darmastadtium', 'Roentgenium',
- 'Copernicium', 'Nihonium', 'Flerovium', 'Moscovium', 'Livermorium', 'Tennessine',
- 'Oganesson']
- chemical_symbols = ['H', 'He', 'Li', 'Be', 'B', 'C', 'N', 'O', 'F', 'Ne', 'Na', 'Mg', 'Al',
- 'Si', 'P', 'S', 'Cl', 'Ar', 'K', 'Ca', 'Sc', 'Ti', 'V', 'Cr', 'Mn', 'Fe',
- 'Co', 'Ni', 'Cu', 'Zn', 'Ga', 'Ge', 'As', 'Se', 'Br', 'Kr', 'Rb', 'Sr',
- 'Y', 'Zr', 'Nb', 'Mo', 'Tc', 'Ru', 'Rh', 'Pd', 'Ag', 'Cd', 'In', 'Sn',
- 'Sb', 'Te', 'I', 'Xe', 'Cs', 'Ba', 'La', 'Ce', 'Pr', 'Nd', 'Pm', 'Sm',
- 'Eu', 'Gd', 'Tb', 'Dy', 'Ho', 'Er', 'Tm', 'Yb', 'Lu', 'Hf', 'Ta', 'W',
- 'Re', 'Os', 'Ir', 'Pt', 'Au', 'Hg', 'Tl', 'Pb', 'Bi', 'Po', 'At', 'Rn',
- 'Fr', 'Ra', 'Ac', 'Th', 'Pa', 'U', 'Np', 'Pu', 'Am', 'Cm', 'Bk', 'Cf',
- 'Es', 'Fm', 'Md', 'No', 'Lr', 'Rf', 'Db', 'Sg', 'Bh', 'Hs', 'Mt', 'Ds',
- 'Rg', 'Cn', 'Nh', 'Fl', 'Mc', 'Lv', 'Ts', 'Og']
- atomic_number = [ i+1 for i in range(len(chemical_symbols)) ]
+ element_names = [
+ "Hydrogen",
+ "Helium",
+ "Lithium",
+ "Beryllium",
+ "Boron",
+ "Carbon",
+ "Nitrogen",
+ "Oxygen",
+ "Fluorine",
+ "Neon",
+ "Sodium",
+ "Magnesium",
+ "Aluminium",
+ "Silicon",
+ "Phosphorus",
+ "Sulfur",
+ "Chlorine",
+ "Argon",
+ "Potassium",
+ "Calcium",
+ "Scandium",
+ "Titanium",
+ "Vanadium",
+ "Chromium",
+ "Manganese",
+ "Iron",
+ "Cobalt",
+ "Nickel",
+ "Copper",
+ "Zinc",
+ "Gallium",
+ "Germanium",
+ "Arsenic",
+ "Selenium",
+ "Bromine",
+ "Krypton",
+ "Rubidium",
+ "Strontium",
+ "Yttrium",
+ "Zirconium",
+ "Niobium",
+ "Molybdenum",
+ "Technetium",
+ "Ruthenium",
+ "Rhodium",
+ "Palladium",
+ "Silver",
+ "Cadmium",
+ "Indium",
+ "Tin",
+ "Antimony",
+ "Tellurium",
+ "Iodine",
+ "Xenon",
+ "Caesium",
+ "Barium",
+ "Lanthanum",
+ "Cerium",
+ "Praseodymium",
+ "Neodymium",
+ "Promethium",
+ "Samarium",
+ "Europium",
+ "Gadolinium",
+ "Terbium",
+ "Dysprosium",
+ "Holmium",
+ "Erbium",
+ "Thulium",
+ "Ytterbium",
+ "Lutetium",
+ "Hafnium",
+ "Tantalum",
+ "Tungsten",
+ "Rhenium",
+ "Osmium",
+ "Iridium",
+ "Platinum",
+ "Gold",
+ "Mercury",
+ "Thallium",
+ "Lead",
+ "Bismuth",
+ "Polonium",
+ "Astatine",
+ "Radon",
+ "Francium",
+ "Radium",
+ "Actinium",
+ "Thorium",
+ "Protactinium",
+ "Uranium",
+ "Neptunium",
+ "Plutonium",
+ "Americium",
+ "Curium",
+ "Berkelium",
+ "Californium",
+ "Einsteinium",
+ "Fermium",
+ "Mendelevium",
+ "Nobelium",
+ "Lawrencium",
+ "Rutherfordium",
+ "Dubnium",
+ "Seaborgium",
+ "Bohrium",
+ "Hassium",
+ "Meitnerium",
+ "Darmastadtium",
+ "Roentgenium",
+ "Copernicium",
+ "Nihonium",
+ "Flerovium",
+ "Moscovium",
+ "Livermorium",
+ "Tennessine",
+ "Oganesson",
+ ]
+ chemical_symbols = [
+ "H",
+ "He",
+ "Li",
+ "Be",
+ "B",
+ "C",
+ "N",
+ "O",
+ "F",
+ "Ne",
+ "Na",
+ "Mg",
+ "Al",
+ "Si",
+ "P",
+ "S",
+ "Cl",
+ "Ar",
+ "K",
+ "Ca",
+ "Sc",
+ "Ti",
+ "V",
+ "Cr",
+ "Mn",
+ "Fe",
+ "Co",
+ "Ni",
+ "Cu",
+ "Zn",
+ "Ga",
+ "Ge",
+ "As",
+ "Se",
+ "Br",
+ "Kr",
+ "Rb",
+ "Sr",
+ "Y",
+ "Zr",
+ "Nb",
+ "Mo",
+ "Tc",
+ "Ru",
+ "Rh",
+ "Pd",
+ "Ag",
+ "Cd",
+ "In",
+ "Sn",
+ "Sb",
+ "Te",
+ "I",
+ "Xe",
+ "Cs",
+ "Ba",
+ "La",
+ "Ce",
+ "Pr",
+ "Nd",
+ "Pm",
+ "Sm",
+ "Eu",
+ "Gd",
+ "Tb",
+ "Dy",
+ "Ho",
+ "Er",
+ "Tm",
+ "Yb",
+ "Lu",
+ "Hf",
+ "Ta",
+ "W",
+ "Re",
+ "Os",
+ "Ir",
+ "Pt",
+ "Au",
+ "Hg",
+ "Tl",
+ "Pb",
+ "Bi",
+ "Po",
+ "At",
+ "Rn",
+ "Fr",
+ "Ra",
+ "Ac",
+ "Th",
+ "Pa",
+ "U",
+ "Np",
+ "Pu",
+ "Am",
+ "Cm",
+ "Bk",
+ "Cf",
+ "Es",
+ "Fm",
+ "Md",
+ "No",
+ "Lr",
+ "Rf",
+ "Db",
+ "Sg",
+ "Bh",
+ "Hs",
+ "Mt",
+ "Ds",
+ "Rg",
+ "Cn",
+ "Nh",
+ "Fl",
+ "Mc",
+ "Lv",
+ "Ts",
+ "Og",
+ ]
+ atomic_number = [i + 1 for i in range(len(chemical_symbols))]
# NIST Standard Reference Database 144
# URL: https://physics.nist.gov/cgi-bin/Compositions/stand_alone.pl?ele=&ascii=ascii&isotype=all
- atomic_masses_common = [1.00782503223, 4.00260325413, 7.0160034366, 9.012183065, 11.00930536,
- 12.0, 14.00307400443, 15.99491461957, 18.99840316273, 19.9924401762,
- 22.989769282, 23.985041697, 26.98153853, 27.97692653465, 30.97376199842,
- 31.9720711744, 34.968852682, 39.9623831237, 38.9637064864, 39.962590863,
- 44.95590828, 47.94794198, 50.94395704, 51.94050623, 54.93804391,
- 55.93493633, 58.93319429, 57.93534241, 62.92959772, 63.92914201,
- 68.9255735, 73.921177761, 74.92159457, 79.9165218, 78.9183376, 83.9114977282,
- 84.9117897379, 87.9056125, 88.9058403, 89.9046977, 92.906373, 97.90540482,
- 96.9063667, 101.9043441, 102.905498, 105.9034804, 106.9050916, 113.90336509,
- 114.903878776, 119.90220163, 120.903812, 129.906222748, 126.9044719,
- 131.9041550856, 132.905451961, 137.905247, 138.9063563, 139.9054431,
- 140.9076576, 141.907729, 144.9127559, 151.9197397, 152.921238, 157.9241123,
- 158.9253547, 163.9291819, 164.9303288, 165.9302995, 168.9342179, 173.9388664,
- 174.9407752, 179.946557, 180.9479958, 183.95093092, 186.9557501, 191.961477,
- 192.9629216, 194.9647917, 196.96656879, 201.9706434, 204.9744278, 207.9766525,
- 208.9803991, 208.9824308, 209.9871479, 222.0175782, 223.019736, 226.0254103,
- 227.0277523, 232.0380558, 231.0358842, 238.0507884, 237.0481736, 244.0642053,
- 243.0613813, 247.0703541, 247.0703073, 251.0795886, 252.08298, 257.0951061,
- 258.0984315, 259.10103, 262.10961, 267.12179, 268.12567, 271.13393, 272.13826,
- 270.13429, 276.15159, 281.16451, 280.16514, 285.17712, 284.17873, 289.19042,
- 288.19274, 293.20449, 292.20746, 294.21392]
+ atomic_masses_common = [
+ 1.00782503223,
+ 4.00260325413,
+ 7.0160034366,
+ 9.012183065,
+ 11.00930536,
+ 12.0,
+ 14.00307400443,
+ 15.99491461957,
+ 18.99840316273,
+ 19.9924401762,
+ 22.989769282,
+ 23.985041697,
+ 26.98153853,
+ 27.97692653465,
+ 30.97376199842,
+ 31.9720711744,
+ 34.968852682,
+ 39.9623831237,
+ 38.9637064864,
+ 39.962590863,
+ 44.95590828,
+ 47.94794198,
+ 50.94395704,
+ 51.94050623,
+ 54.93804391,
+ 55.93493633,
+ 58.93319429,
+ 57.93534241,
+ 62.92959772,
+ 63.92914201,
+ 68.9255735,
+ 73.921177761,
+ 74.92159457,
+ 79.9165218,
+ 78.9183376,
+ 83.9114977282,
+ 84.9117897379,
+ 87.9056125,
+ 88.9058403,
+ 89.9046977,
+ 92.906373,
+ 97.90540482,
+ 96.9063667,
+ 101.9043441,
+ 102.905498,
+ 105.9034804,
+ 106.9050916,
+ 113.90336509,
+ 114.903878776,
+ 119.90220163,
+ 120.903812,
+ 129.906222748,
+ 126.9044719,
+ 131.9041550856,
+ 132.905451961,
+ 137.905247,
+ 138.9063563,
+ 139.9054431,
+ 140.9076576,
+ 141.907729,
+ 144.9127559,
+ 151.9197397,
+ 152.921238,
+ 157.9241123,
+ 158.9253547,
+ 163.9291819,
+ 164.9303288,
+ 165.9302995,
+ 168.9342179,
+ 173.9388664,
+ 174.9407752,
+ 179.946557,
+ 180.9479958,
+ 183.95093092,
+ 186.9557501,
+ 191.961477,
+ 192.9629216,
+ 194.9647917,
+ 196.96656879,
+ 201.9706434,
+ 204.9744278,
+ 207.9766525,
+ 208.9803991,
+ 208.9824308,
+ 209.9871479,
+ 222.0175782,
+ 223.019736,
+ 226.0254103,
+ 227.0277523,
+ 232.0380558,
+ 231.0358842,
+ 238.0507884,
+ 237.0481736,
+ 244.0642053,
+ 243.0613813,
+ 247.0703541,
+ 247.0703073,
+ 251.0795886,
+ 252.08298,
+ 257.0951061,
+ 258.0984315,
+ 259.10103,
+ 262.10961,
+ 267.12179,
+ 268.12567,
+ 271.13393,
+ 272.13826,
+ 270.13429,
+ 276.15159,
+ 281.16451,
+ 280.16514,
+ 285.17712,
+ 284.17873,
+ 289.19042,
+ 288.19274,
+ 293.20449,
+ 292.20746,
+ 294.21392,
+ ]
# IUPAC Technical Report
# doi:10.1515/pac-2015-0305
- atomic_masses_2013 = [1.00784, 4.002602, 6.938, 9.0121831, 10.806, 12.0096, 14.00643, 15.99903,
- 18.99840316, 20.1797, 22.98976928, 24.304, 26.9815385, 28.084, 30.973762,
- 32.059, 35.446, 39.948, 39.0983, 40.078, 44.955908, 47.867, 50.9415, 51.9961,
- 54.938044, 55.845, 58.933194, 58.6934, 63.546, 65.38, 69.723, 72.63, 74.921595,
- 78.971, 79.901, 83.798, 85.4678, 87.62, 88.90584, 91.224, 92.90637, 95.95, None,
- 101.07, 102.9055, 106.42, 107.8682, 112.414, 114.818, 118.71, 121.76, 127.6,
- 126.90447, 131.293, 132.905452, 137.327, 138.90547, 140.116, 140.90766, 144.242,
- None, 150.36, 151.964, 157.25, 158.92535, 162.5, 164.93033, 167.259, 168.93422,
- 173.054, 174.9668, 178.49, 180.94788, 183.84, 186.207, 190.23, 192.217, 195.084,
- 196.966569, 200.592, 204.382, 207.2, 208.9804, None, None, None, None, None, None,
- 232.0377, 231.03588, 238.02891, None, None, None, None, None, None, None, None,
- None, None, None, None, None, None, None, None, None, None, None, None, None,
- None, None, None, None, None]
+ atomic_masses_2013 = [
+ 1.00784,
+ 4.002602,
+ 6.938,
+ 9.0121831,
+ 10.806,
+ 12.0096,
+ 14.00643,
+ 15.99903,
+ 18.99840316,
+ 20.1797,
+ 22.98976928,
+ 24.304,
+ 26.9815385,
+ 28.084,
+ 30.973762,
+ 32.059,
+ 35.446,
+ 39.948,
+ 39.0983,
+ 40.078,
+ 44.955908,
+ 47.867,
+ 50.9415,
+ 51.9961,
+ 54.938044,
+ 55.845,
+ 58.933194,
+ 58.6934,
+ 63.546,
+ 65.38,
+ 69.723,
+ 72.63,
+ 74.921595,
+ 78.971,
+ 79.901,
+ 83.798,
+ 85.4678,
+ 87.62,
+ 88.90584,
+ 91.224,
+ 92.90637,
+ 95.95,
+ None,
+ 101.07,
+ 102.9055,
+ 106.42,
+ 107.8682,
+ 112.414,
+ 114.818,
+ 118.71,
+ 121.76,
+ 127.6,
+ 126.90447,
+ 131.293,
+ 132.905452,
+ 137.327,
+ 138.90547,
+ 140.116,
+ 140.90766,
+ 144.242,
+ None,
+ 150.36,
+ 151.964,
+ 157.25,
+ 158.92535,
+ 162.5,
+ 164.93033,
+ 167.259,
+ 168.93422,
+ 173.054,
+ 174.9668,
+ 178.49,
+ 180.94788,
+ 183.84,
+ 186.207,
+ 190.23,
+ 192.217,
+ 195.084,
+ 196.966569,
+ 200.592,
+ 204.382,
+ 207.2,
+ 208.9804,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ 232.0377,
+ 231.03588,
+ 238.02891,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ ]
# IUPAC Technical Report
# doi:10.1515/pac-2019-0603
- atomic_masses_2021 = [1.00784, 4.002602, 6.938, 9.0121831, 10.806, 12.0096, 14.00643, 15.99903,
- 18.99840316, 20.1797, 22.98976928, 24.304, 26.9815384, 28.084, 30.973762,
- 32.059, 35.446, 39.792, 39.0983, 40.078, 44.955907, 47.867, 50.9415, 51.9961,
- 54.938043, 55.845, 58.933194, 58.6934, 63.546, 65.38, 69.723, 72.63, 74.921595,
- 78.971, 79.901, 83.798, 85.4678, 87.62, 88.905838, 91.224, 92.90637, 95.95,
- None, 101.07, 102.90549, 106.42, 107.8682, 112.414, 114.818, 118.71, 121.76,
- 127.6, 126.90447, 131.293, 132.905452, 137.327, 138.90547, 140.116, 140.90766,
- 144.242, None, 150.36, 151.964, 157.25, 158.925354, 162.5, 164.930329, 167.259,
- 168.934219, 173.045, 174.9668, 178.486, 180.94788, 183.84, 186.207, 190.23,
- 192.217, 195.084, 196.96657, 200.592, 204.382, 206.14, 208.9804, None, None,
- None, None, None, None, 232.0377, 231.03588, 238.02891, None, None, None,
- None, None, None, None, None, None, None, None, None, None, None, None, None,
- None, None, None, None, None, None, None, None, None, None]
-
- atomic_masses = [atomic_masses_common[n] if i is None else i for n,i in enumerate(atomic_masses_2021)]
+ atomic_masses_2021 = [
+ 1.00784,
+ 4.002602,
+ 6.938,
+ 9.0121831,
+ 10.806,
+ 12.0096,
+ 14.00643,
+ 15.99903,
+ 18.99840316,
+ 20.1797,
+ 22.98976928,
+ 24.304,
+ 26.9815384,
+ 28.084,
+ 30.973762,
+ 32.059,
+ 35.446,
+ 39.792,
+ 39.0983,
+ 40.078,
+ 44.955907,
+ 47.867,
+ 50.9415,
+ 51.9961,
+ 54.938043,
+ 55.845,
+ 58.933194,
+ 58.6934,
+ 63.546,
+ 65.38,
+ 69.723,
+ 72.63,
+ 74.921595,
+ 78.971,
+ 79.901,
+ 83.798,
+ 85.4678,
+ 87.62,
+ 88.905838,
+ 91.224,
+ 92.90637,
+ 95.95,
+ None,
+ 101.07,
+ 102.90549,
+ 106.42,
+ 107.8682,
+ 112.414,
+ 114.818,
+ 118.71,
+ 121.76,
+ 127.6,
+ 126.90447,
+ 131.293,
+ 132.905452,
+ 137.327,
+ 138.90547,
+ 140.116,
+ 140.90766,
+ 144.242,
+ None,
+ 150.36,
+ 151.964,
+ 157.25,
+ 158.925354,
+ 162.5,
+ 164.930329,
+ 167.259,
+ 168.934219,
+ 173.045,
+ 174.9668,
+ 178.486,
+ 180.94788,
+ 183.84,
+ 186.207,
+ 190.23,
+ 192.217,
+ 195.084,
+ 196.96657,
+ 200.592,
+ 204.382,
+ 206.14,
+ 208.9804,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ 232.0377,
+ 231.03588,
+ 238.02891,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ None,
+ ]
+
+ atomic_masses = [
+ atomic_masses_common[n] if i is None else i
+ for n, i in enumerate(atomic_masses_2021)
+ ]
if atom in element_names:
return atomic_masses[element_names.index(atom)]
@@ -3910,38 +5089,43 @@ def get_atomic_masses(atom):
elif atom in atomic_number:
return atomic_masses[atomic_number.index(atom)]
else:
- raise RuntimeError('unknown atomic identifier', atom, 'if one want to use isotopes, or non-standard element names, chemical symbols, or atomic number in the type_map list, please customize the mass_map list instead of using "auto".')
+ raise RuntimeError(
+ "unknown atomic identifier",
+ atom,
+ 'if one want to use isotopes, or non-standard element names, chemical symbols, or atomic number in the type_map list, please customize the mass_map list instead of using "auto".',
+ )
def update_mass_map(jdata):
- if jdata['mass_map'] == 'auto':
- jdata['mass_map'] = [get_atomic_masses(i) for i in jdata['type_map']]
-
-
-def gen_run(args) :
+ if jdata["mass_map"] == "auto":
+ jdata["mass_map"] = [get_atomic_masses(i) for i in jdata["type_map"]]
+
+
+def gen_run(args):
if args.PARAM and args.MACHINE:
if args.debug:
dlog.setLevel(logging.DEBUG)
- dlog.info ("start running")
- run_iter (args.PARAM, args.MACHINE)
- dlog.info ("finished")
+ dlog.info("start running")
+ run_iter(args.PARAM, args.MACHINE)
+ dlog.info("finished")
-def _main () :
+def _main():
parser = argparse.ArgumentParser()
- parser.add_argument("PARAM", type=str,
- help="The parameters of the generator")
- parser.add_argument("MACHINE", type=str,
- help="The settings of the machine running the generator")
+ parser.add_argument("PARAM", type=str, help="The parameters of the generator")
+ parser.add_argument(
+ "MACHINE", type=str, help="The settings of the machine running the generator"
+ )
args = parser.parse_args()
- logging.basicConfig (level=logging.INFO, format='%(asctime)s %(message)s')
+ logging.basicConfig(level=logging.INFO, format="%(asctime)s %(message)s")
# logging.basicConfig (filename="compute_string.log", filemode="a", level=logging.INFO, format='%(asctime)s %(message)s')
logging.getLogger("paramiko").setLevel(logging.WARNING)
- logging.info ("start running")
- run_iter (args.PARAM, args.MACHINE)
- logging.info ("finished!")
+ logging.info("start running")
+ run_iter(args.PARAM, args.MACHINE)
+ logging.info("finished!")
+
-if __name__ == '__main__':
+if __name__ == "__main__":
_main()
diff --git a/dpgen/main.py b/dpgen/main.py
index 7c4dd5932..c0a94803d 100644
--- a/dpgen/main.py
+++ b/dpgen/main.py
@@ -4,21 +4,20 @@
import argparse
-import sys
import itertools
-from dpgen.generator.run import gen_run
+import sys
+
+from dpgen import __version__, info
+from dpgen.auto_test.run import gen_test
+from dpgen.collect.collect import gen_collect
from dpgen.data.gen import gen_init_bulk
-from dpgen.data.surf import gen_init_surf
from dpgen.data.reaction import gen_init_reaction
-from dpgen.collect.collect import gen_collect
-from dpgen.simplify.simplify import gen_simplify
-from dpgen.auto_test.run import gen_test
+from dpgen.data.surf import gen_init_surf
from dpgen.database.run import db_run
-from dpgen.tools.run_report import run_report
+from dpgen.generator.run import gen_run
+from dpgen.simplify.simplify import gen_simplify
from dpgen.tools.auto_gen_param import auto_gen_param
-from dpgen import info, __version__
-
-
+from dpgen.tools.run_report import run_report
"""
A master convenience script with many tools for driving dpgen.
@@ -32,133 +31,181 @@
def main_parser() -> argparse.ArgumentParser:
"""Returns parser for `dpgen` command.
-
+
Returns
-------
argparse.ArgumentParser
parser for `dpgen` command
"""
- parser = argparse.ArgumentParser(description="""
+ parser = argparse.ArgumentParser(
+ description="""
dpgen is a convenient script that uses DeepGenerator to prepare initial
data, drive DeepMDkit and analyze results. This script works based on
several sub-commands with their own options. To see the options for the
- sub-commands, type "dpgen sub-command -h".""")
+ sub-commands, type "dpgen sub-command -h"."""
+ )
subparsers = parser.add_subparsers()
# init surf model
parser_init_surf = subparsers.add_parser(
- "init_surf", help="Generating initial data for surface systems.")
- parser_init_surf.add_argument('PARAM', type=str,
- help="parameter file, json/yaml format")
- parser_init_surf.add_argument('MACHINE', type=str,default=None,nargs="?",
- help="machine file, json/yaml format")
+ "init_surf", help="Generating initial data for surface systems."
+ )
+ parser_init_surf.add_argument(
+ "PARAM", type=str, help="parameter file, json/yaml format"
+ )
+ parser_init_surf.add_argument(
+ "MACHINE",
+ type=str,
+ default=None,
+ nargs="?",
+ help="machine file, json/yaml format",
+ )
parser_init_surf.set_defaults(func=gen_init_surf)
-
+
# init bulk model
parser_init_bulk = subparsers.add_parser(
- "init_bulk", help="Generating initial data for bulk systems.")
- parser_init_bulk.add_argument('PARAM', type=str,
- help="parameter file, json/yaml format")
- parser_init_bulk.add_argument('MACHINE', type=str,default=None,nargs="?",
- help="machine file, json/yaml format")
+ "init_bulk", help="Generating initial data for bulk systems."
+ )
+ parser_init_bulk.add_argument(
+ "PARAM", type=str, help="parameter file, json/yaml format"
+ )
+ parser_init_bulk.add_argument(
+ "MACHINE",
+ type=str,
+ default=None,
+ nargs="?",
+ help="machine file, json/yaml format",
+ )
parser_init_bulk.set_defaults(func=gen_init_bulk)
parser_auto_gen_param = subparsers.add_parser(
- "auto_gen_param", help="auto gen param.json")
+ "auto_gen_param", help="auto gen param.json"
+ )
# parser_auto_gen_param.add_argument('meltpoint', type=float, help="melt point")
- parser_auto_gen_param.add_argument('PARAM', type=str,
- help="parameter file, json/yaml format")
+ parser_auto_gen_param.add_argument(
+ "PARAM", type=str, help="parameter file, json/yaml format"
+ )
parser_auto_gen_param.set_defaults(func=auto_gen_param)
# parser_init_reaction
parser_init_reaction = subparsers.add_parser(
- "init_reaction", help="Generating initial data for reactive systems.")
- parser_init_reaction.add_argument('PARAM', type=str,
- help="parameter file, json/yaml format")
- parser_init_reaction.add_argument('MACHINE', type=str,default=None,nargs="?",
- help="machine file, json/yaml format")
+ "init_reaction", help="Generating initial data for reactive systems."
+ )
+ parser_init_reaction.add_argument(
+ "PARAM", type=str, help="parameter file, json/yaml format"
+ )
+ parser_init_reaction.add_argument(
+ "MACHINE",
+ type=str,
+ default=None,
+ nargs="?",
+ help="machine file, json/yaml format",
+ )
parser_init_reaction.set_defaults(func=gen_init_reaction)
- # run
+ # run
parser_run = subparsers.add_parser(
- "run",
- help="Main process of Deep Potential Generator.")
- parser_run.add_argument('PARAM', type=str,
- help="parameter file, json/yaml format")
- parser_run.add_argument('MACHINE', type=str,
- help="machine file, json/yaml format")
- parser_run.add_argument('-d','--debug', action='store_true',
- help="log debug info")
+ "run", help="Main process of Deep Potential Generator."
+ )
+ parser_run.add_argument("PARAM", type=str, help="parameter file, json/yaml format")
+ parser_run.add_argument("MACHINE", type=str, help="machine file, json/yaml format")
+ parser_run.add_argument("-d", "--debug", action="store_true", help="log debug info")
parser_run.set_defaults(func=gen_run)
# run/report
parser_rr = subparsers.add_parser(
"run/report",
- help="Report the systems and the thermodynamic conditions of the labeled frames.")
- parser_rr.add_argument("JOB_DIR", type=str,
- help="the directory of the DP-GEN job,")
- parser_rr.add_argument('-s',"--stat-sys", action = 'store_true',
- help="count the labeled frames for each system")
- parser_rr.add_argument('-i', "--stat-iter", action= 'store_true',
- help="print the iteration candidate,failed,accurate count and fp calculation,success and fail count")
- parser_rr.add_argument('-t', "--stat-time", action= 'store_true',
- help="print the iteration time, warning!! assume model_devi parallel cores == 1")
- parser_rr.add_argument('-p',"--param", type=str, default = 'param.json',
- help="the json file provides DP-GEN paramters, should be located in JOB_DIR")
- parser_rr.add_argument('-v',"--verbose", action = 'store_true',
- help="being loud")
- parser_rr.set_defaults(func=run_report)
+ help="Report the systems and the thermodynamic conditions of the labeled frames.",
+ )
+ parser_rr.add_argument("JOB_DIR", type=str, help="the directory of the DP-GEN job,")
+ parser_rr.add_argument(
+ "-s",
+ "--stat-sys",
+ action="store_true",
+ help="count the labeled frames for each system",
+ )
+ parser_rr.add_argument(
+ "-i",
+ "--stat-iter",
+ action="store_true",
+ help="print the iteration candidate,failed,accurate count and fp calculation,success and fail count",
+ )
+ parser_rr.add_argument(
+ "-t",
+ "--stat-time",
+ action="store_true",
+ help="print the iteration time, warning!! assume model_devi parallel cores == 1",
+ )
+ parser_rr.add_argument(
+ "-p",
+ "--param",
+ type=str,
+ default="param.json",
+ help="the json file provides DP-GEN paramters, should be located in JOB_DIR",
+ )
+ parser_rr.add_argument("-v", "--verbose", action="store_true", help="being loud")
+ parser_rr.set_defaults(func=run_report)
# collect
- parser_coll = subparsers.add_parser(
- "collect",
- help="Collect data.")
- parser_coll.add_argument("JOB_DIR", type=str,
- help="the directory of the DP-GEN job")
- parser_coll.add_argument("OUTPUT", type=str,
- help="the output directory of data")
- parser_coll.add_argument('-p',"--parameter", type=str, default = 'param.json',
- help="the json file provides DP-GEN paramters, should be located in JOB_DIR")
- parser_coll.add_argument('-v',"--verbose", action = 'store_true',
- help="print number of data in each system")
- parser_coll.add_argument('-m',"--merge", action = 'store_true',
- help="merge the systems with the same chemical formula")
- parser_coll.add_argument('-s',"--shuffle", action = 'store_true',
- help="shuffle the data systems")
+ parser_coll = subparsers.add_parser("collect", help="Collect data.")
+ parser_coll.add_argument(
+ "JOB_DIR", type=str, help="the directory of the DP-GEN job"
+ )
+ parser_coll.add_argument("OUTPUT", type=str, help="the output directory of data")
+ parser_coll.add_argument(
+ "-p",
+ "--parameter",
+ type=str,
+ default="param.json",
+ help="the json file provides DP-GEN paramters, should be located in JOB_DIR",
+ )
+ parser_coll.add_argument(
+ "-v",
+ "--verbose",
+ action="store_true",
+ help="print number of data in each system",
+ )
+ parser_coll.add_argument(
+ "-m",
+ "--merge",
+ action="store_true",
+ help="merge the systems with the same chemical formula",
+ )
+ parser_coll.add_argument(
+ "-s", "--shuffle", action="store_true", help="shuffle the data systems"
+ )
parser_coll.set_defaults(func=gen_collect)
# simplify
- parser_run = subparsers.add_parser(
- "simplify",
- help="Simplify data.")
- parser_run.add_argument('PARAM', type=str,
- help="parameter file, json/yaml format")
- parser_run.add_argument('MACHINE', type=str,
- help="machine file, json/yaml format")
- parser_run.add_argument('-d','--debug', action='store_true',
- help="log debug info")
+ parser_run = subparsers.add_parser("simplify", help="Simplify data.")
+ parser_run.add_argument("PARAM", type=str, help="parameter file, json/yaml format")
+ parser_run.add_argument("MACHINE", type=str, help="machine file, json/yaml format")
+ parser_run.add_argument("-d", "--debug", action="store_true", help="log debug info")
parser_run.set_defaults(func=gen_simplify)
- # test
- parser_test = subparsers.add_parser("autotest", help="Auto-test for Deep Potential.")
- parser_test.add_argument('TASK', type=str,
- help="task can be make, run or post")
- parser_test.add_argument('PARAM', type=str,
- help="parameter file, json/yaml format")
- parser_test.add_argument('MACHINE', type=str,default=None,nargs="?",
- help="machine file, json/yaml format")
- parser_test.add_argument('-d','--debug', action='store_true',
- help="log debug info")
- parser_test.set_defaults(func=gen_test)
-
- # db
- parser_db = subparsers.add_parser(
- "db",
- help="Collecting data from DP-GEN.")
-
- parser_db.add_argument('PARAM', type=str,
- help="parameter file, json format")
+ # test
+ parser_test = subparsers.add_parser(
+ "autotest", help="Auto-test for Deep Potential."
+ )
+ parser_test.add_argument("TASK", type=str, help="task can be make, run or post")
+ parser_test.add_argument("PARAM", type=str, help="parameter file, json/yaml format")
+ parser_test.add_argument(
+ "MACHINE",
+ type=str,
+ default=None,
+ nargs="?",
+ help="machine file, json/yaml format",
+ )
+ parser_test.add_argument(
+ "-d", "--debug", action="store_true", help="log debug info"
+ )
+ parser_test.set_defaults(func=gen_test)
+
+ # db
+ parser_db = subparsers.add_parser("db", help="Collecting data from DP-GEN.")
+
+ parser_db.add_argument("PARAM", type=str, help="parameter file, json format")
parser_db.set_defaults(func=db_run)
return parser
@@ -170,6 +217,7 @@ def main():
parser = main_parser()
try:
import argcomplete
+
argcomplete.autocomplete(parser)
except ImportError:
# argcomplete not present.
diff --git a/dpgen/remote/RemoteJob.py b/dpgen/remote/RemoteJob.py
deleted file mode 100644
index 992fb82f4..000000000
--- a/dpgen/remote/RemoteJob.py
+++ /dev/null
@@ -1,949 +0,0 @@
-#!/usr/bin/env python
-# coding: utf-8
-
-import os, sys, paramiko, json, uuid, tarfile, time, stat, shutil
-from glob import glob
-from enum import Enum
-from dpgen import dlog
-
-
-class JobStatus (Enum) :
- unsubmitted = 1
- waiting = 2
- running = 3
- terminated = 4
- finished = 5
- unknown = 100
-
-class awsMachineJob(object):
- def __init__ (self,
- remote_root,
- work_path,
- job_uuid=None,
- ) :
- self.remote_root=os.path.join(remote_root,work_path)
- self.local_root = os.path.abspath(work_path)
- if job_uuid:
- self.job_uuid=job_uuid
- else:
- self.job_uuid = str(uuid.uuid4())
-
- dlog.info("local_root is %s"% self.local_root)
- dlog.info("remote_root is %s"% self.remote_root)
-
- def upload(self,
- job_dir,
- local_up_files,
- dereference = True) :
- cwd = os.getcwd()
- print('cwd=',cwd)
- os.chdir(self.local_root)
- for ii in local_up_files :
- print('self.local_root=',self.local_root,'remote_root=',self.remote_root,'job_dir=',job_dir,'ii=',ii)
- if os.path.isfile(os.path.join(job_dir,ii)):
- if not os.path.exists(os.path.join(self.remote_root,job_dir)):
- os.makedirs(os.path.join(self.remote_root,job_dir))
- shutil.copyfile(os.path.join(job_dir,ii),os.path.join(self.remote_root,job_dir,ii))
- elif os.path.isdir(os.path.join(job_dir,ii)):
- shutil.copytree(os.path.join(job_dir,ii),os.path.join(self.remote_root,job_dir,ii))
- else:
- print('unknownfile','local_root=',self.local_root,'job_dir=',job_dir,'filename=',ii)
- os.chdir(cwd)
- def download(self,
- job_dir,
- remote_down_files,
- dereference = True) :
- for ii in remote_down_files:
- # print('self.local_root=',self.local_root,'remote_root=',self.remote_root,'job_dir=',job_dir,'ii=',ii)
- file_succ_copy_flag=False
- while not file_succ_copy_flag:
- if os.path.isfile(os.path.join(self.remote_root,job_dir,ii)):
- shutil.copyfile(os.path.join(self.remote_root,job_dir,ii),os.path.join(self.local_root,job_dir,ii))
- file_succ_copy_flag=True
- elif os.path.isdir(os.path.join(self.remote_root,job_dir,ii)):
- try:
- os.rmdir(os.path.join(self.local_root,job_dir,ii))
- except Exception:
- print('dir is not empty '+str(os.path.join(self.local_root,job_dir,ii)))
- else:
- shutil.copytree(os.path.join(self.remote_root,job_dir,ii),os.path.join(self.local_root,job_dir,ii))
- file_succ_copy_flag=True
- else:
- print('unknownfile,maybe need for waiting for a while','local_root=',self.local_root,'job_dir=',job_dir,'filename=',ii)
- time.sleep(5)
-
-def _default_item(resources, key, value) :
- if key not in resources :
- resources[key] = value
-
-def _set_default_resource(res) :
- if res == None :
- res = {}
- _default_item(res, 'numb_node', 1)
- _default_item(res, 'task_per_node', 1)
- _default_item(res, 'numb_gpu', 0)
- _default_item(res, 'time_limit', '1:0:0')
- _default_item(res, 'mem_limit', -1)
- _default_item(res, 'partition', '')
- _default_item(res, 'account', '')
- _default_item(res, 'qos', '')
- _default_item(res, 'constraint_list', [])
- _default_item(res, 'license_list', [])
- _default_item(res, 'exclude_list', [])
- _default_item(res, 'module_unload_list', [])
- _default_item(res, 'module_list', [])
- _default_item(res, 'source_list', [])
- _default_item(res, 'envs', None)
- _default_item(res, 'with_mpi', False)
-
-
-class SSHSession (object) :
- def __init__ (self, jdata) :
- self.remote_profile = jdata
- # with open(remote_profile) as fp :
- # self.remote_profile = json.load(fp)
- self.remote_host = self.remote_profile['hostname']
- self.remote_port = self.remote_profile['port']
- self.remote_uname = self.remote_profile['username']
- self.remote_password = None
- if 'password' in self.remote_profile :
- self.remote_password = self.remote_profile['password']
- self.local_key_filename = None
- if 'key_filename' in self.remote_profile:
- self.local_key_filename = self.remote_profile['key_filename']
- self.remote_timeout = None
- if 'timeout' in self.remote_profile:
- self.remote_timeout = self.remote_profile['timeout']
- self.local_key_passphrase = None
- if 'passphrase' in self.remote_profile:
- self.local_key_passphrase = self.remote_profile['passphrase']
- self.remote_workpath = self.remote_profile['work_path']
- self.ssh = self._setup_ssh(hostname=self.remote_host,
- port=self.remote_port,
- username=self.remote_uname,
- password=self.remote_password,
- key_filename=self.local_key_filename,
- timeout=self.remote_timeout,
- passphrase=self.local_key_passphrase)
-
- def _setup_ssh(self,
- hostname,
- port=22,
- username=None,
- password=None,
- key_filename=None,
- timeout=None,
- passphrase=None
- ):
- ssh_client = paramiko.SSHClient()
- ssh_client.load_system_host_keys()
- ssh_client.set_missing_host_key_policy(paramiko.WarningPolicy)
- ssh_client.connect(hostname, port, username, password,
- key_filename, timeout, passphrase)
- assert(ssh_client.get_transport().is_active())
- return ssh_client
-
- def get_ssh_client(self) :
- return self.ssh
-
- def get_session_root(self) :
- return self.remote_workpath
-
- def close(self) :
- self.ssh.close()
-
-
-class RemoteJob (object):
- def __init__ (self,
- ssh_session,
- local_root,
- job_uuid=None,
- ) :
- self.local_root = os.path.abspath(local_root)
- if job_uuid:
- self.job_uuid=job_uuid
- else:
- self.job_uuid = str(uuid.uuid4())
-
- self.remote_root = os.path.join(ssh_session.get_session_root(), self.job_uuid)
- dlog.info("local_root is %s"% local_root)
- dlog.info("remote_root is %s"% self.remote_root)
- self.ssh = ssh_session.get_ssh_client()
- # keep ssh alive
- transport = self.ssh.get_transport()
- transport.set_keepalive(60)
- try:
- sftp = self.ssh.open_sftp()
- sftp.mkdir(self.remote_root)
- sftp.close()
- except Exception:
- pass
- # open('job_uuid', 'w').write(self.job_uuid)
-
- def get_job_root(self) :
- return self.remote_root
-
- def upload(self,
- job_dirs,
- local_up_files,
- dereference = True) :
- cwd = os.getcwd()
- os.chdir(self.local_root)
- file_list = []
- for ii in job_dirs :
- for jj in local_up_files :
- file_list.append(os.path.join(ii,jj))
- self._put_files(file_list, dereference = dereference)
- os.chdir(cwd)
-
- def download(self,
- job_dirs,
- remote_down_files,
- back_error=False) :
- cwd = os.getcwd()
- os.chdir(self.local_root)
- file_list = []
- for ii in job_dirs :
- for jj in remote_down_files :
- file_list.append(os.path.join(ii,jj))
- if back_error:
- errors=glob(os.path.join(ii,'error*'))
- file_list.extend(errors)
- self._get_files(file_list)
- os.chdir(cwd)
-
- def block_checkcall(self,
- cmd) :
- stdin, stdout, stderr = self.ssh.exec_command(('cd %s ;' % self.remote_root) + cmd)
- exit_status = stdout.channel.recv_exit_status()
- if exit_status != 0:
- dlog.info("Error info: %s "%(stderr.readlines()[0]))
- raise RuntimeError("Get error code %d in calling %s through ssh with job: %s "% (exit_status, cmd, self.job_uuid))
- return stdin, stdout, stderr
-
- def block_call(self,
- cmd) :
- stdin, stdout, stderr = self.ssh.exec_command(('cd %s ;' % self.remote_root) + cmd)
- exit_status = stdout.channel.recv_exit_status()
- return exit_status, stdin, stdout, stderr
-
- def clean(self) :
- sftp = self.ssh.open_sftp()
- self._rmtree(sftp, self.remote_root)
- sftp.close()
-
- def _rmtree(self, sftp, remotepath, level=0, verbose = False):
- for f in sftp.listdir_attr(remotepath):
- rpath = os.path.join(remotepath, f.filename)
- if stat.S_ISDIR(f.st_mode):
- self._rmtree(sftp, rpath, level=(level + 1))
- else:
- rpath = os.path.join(remotepath, f.filename)
- if verbose: dlog.info('removing %s%s' % (' ' * level, rpath))
- sftp.remove(rpath)
- if verbose: dlog.info('removing %s%s' % (' ' * level, remotepath))
- sftp.rmdir(remotepath)
-
- def _put_files(self,
- files,
- dereference = True) :
- of = self.job_uuid + '.tgz'
- # local tar
- cwd = os.getcwd()
- os.chdir(self.local_root)
- if os.path.isfile(of) :
- os.remove(of)
- with tarfile.open(of, "w:gz", dereference = dereference) as tar:
- for ii in files :
- tar.add(ii)
- os.chdir(cwd)
- # trans
- from_f = os.path.join(self.local_root, of)
- to_f = os.path.join(self.remote_root, of)
- sftp = self.ssh.open_sftp()
- sftp.put(from_f, to_f)
- # remote extract
- self.block_checkcall('tar xf %s' % of)
- # clean up
- os.remove(from_f)
- sftp.remove(to_f)
- sftp.close()
-
- def _get_files(self,
- files) :
- of = self.job_uuid + '.tgz'
- flist = ""
- for ii in files :
- flist += " " + ii
- # remote tar
- self.block_checkcall('tar czf %s %s' % (of, flist))
- # trans
- from_f = os.path.join(self.remote_root, of)
- to_f = os.path.join(self.local_root, of)
- if os.path.isfile(to_f) :
- os.remove(to_f)
- sftp = self.ssh.open_sftp()
- sftp.get(from_f, to_f)
- # extract
- cwd = os.getcwd()
- os.chdir(self.local_root)
- with tarfile.open(of, "r:gz") as tar:
- def is_within_directory(directory, target):
-
- abs_directory = os.path.abspath(directory)
- abs_target = os.path.abspath(target)
-
- prefix = os.path.commonprefix([abs_directory, abs_target])
-
- return prefix == abs_directory
-
- def safe_extract(tar, path=".", members=None, *, numeric_owner=False):
-
- for member in tar.getmembers():
- member_path = os.path.join(path, member.name)
- if not is_within_directory(path, member_path):
- raise Exception("Attempted Path Traversal in Tar File")
-
- tar.extractall(path, members, numeric_owner=numeric_owner)
-
-
- safe_extract(tar)
- os.chdir(cwd)
- # cleanup
- os.remove(to_f)
- sftp.remove(from_f)
-
-class CloudMachineJob (RemoteJob) :
- def submit(self,
- job_dirs,
- cmd,
- args = None,
- resources = None) :
-
- #dlog.info("Current path is",os.getcwd())
-
- #for ii in job_dirs :
- # if not os.path.isdir(ii) :
- # raise RuntimeError("cannot find dir %s" % ii)
- # dlog.info(self.remote_root)
- script_name = self._make_script(job_dirs, cmd, args, resources)
- self.stdin, self.stdout, self.stderr = self.ssh.exec_command(('cd %s; bash %s' % (self.remote_root, script_name)))
- # dlog.info(self.stderr.read().decode('utf-8'))
- # dlog.info(self.stdout.read().decode('utf-8'))
-
- def check_status(self) :
- if not self._check_finish(self.stdout) :
- return JobStatus.running
- elif self._get_exit_status(self.stdout) == 0 :
- return JobStatus.finished
- else :
- return JobStatus.terminated
-
- def _check_finish(self, stdout) :
- return stdout.channel.exit_status_ready()
-
- def _get_exit_status(self, stdout) :
- return stdout.channel.recv_exit_status()
-
- def _make_script(self,
- job_dirs,
- cmd,
- args = None,
- resources = None) :
- _set_default_resource(resources)
- envs = resources['envs']
- module_list = resources['module_list']
- module_unload_list = resources['module_unload_list']
- task_per_node = resources['task_per_node']
-
- script_name = 'run.sh'
- if args == None :
- args = []
- for ii in job_dirs:
- args.append('')
- script = os.path.join(self.remote_root, script_name)
- sftp = self.ssh.open_sftp()
- with sftp.open(script, 'w') as fp :
- fp.write('#!/bin/bash\n\n')
- # fp.write('set -euo pipefail\n')
- if envs != None :
- for key in envs.keys() :
- fp.write('export %s=%s\n' % (key, envs[key]))
- fp.write('\n')
- if module_unload_list is not None :
- for ii in module_unload_list :
- fp.write('module unload %s\n' % ii)
- fp.write('\n')
- if module_list is not None :
- for ii in module_list :
- fp.write('module load %s\n' % ii)
- fp.write('\n')
- for ii,jj in zip(job_dirs, args) :
- fp.write('cd %s\n' % ii)
- fp.write('test $? -ne 0 && exit\n')
- if resources['with_mpi'] == True :
- fp.write('mpirun -n %d %s %s\n'
- % (task_per_node, cmd, jj))
- else :
- fp.write('%s %s\n' % (cmd, jj))
- if 'allow_failure' not in resources or resources['allow_failure'] is False:
- fp.write('test $? -ne 0 && exit\n')
- fp.write('cd %s\n' % self.remote_root)
- fp.write('test $? -ne 0 && exit\n')
- fp.write('\ntouch tag_finished\n')
- sftp.close()
- return script_name
-
-
-class SlurmJob (RemoteJob) :
- def submit(self,
- job_dirs,
- cmd,
- args = None,
- resources = None,
- restart=False) :
-
- def _submit():
- script_name = self._make_script(job_dirs, cmd, args, res = resources)
- stdin, stdout, stderr = self.block_checkcall(('cd %s; sbatch %s' % (self.remote_root, script_name)))
- subret = (stdout.readlines())
- job_id = subret[0].split()[-1]
- sftp = self.ssh.open_sftp()
-
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'w') as fp:
- fp.write(job_id)
- sftp.close()
-
- dlog.debug(restart)
- if restart:
- try:
- status = self.check_status()
- dlog.debug(status)
- if status in [ JobStatus.unsubmitted, JobStatus.unknown, JobStatus.terminated ]:
- dlog.debug('task restart point !!!')
- _submit()
- elif status==JobStatus.waiting:
- dlog.debug('task is waiting')
- elif status==JobStatus.running:
- dlog.debug('task is running')
- else:
- dlog.debug('task is finished')
-
- except Exception:
- dlog.debug('no job_id file')
- dlog.debug('task restart point !!!')
- _submit()
- else:
- dlog.debug('new task!!!')
- _submit()
-
- def check_status(self) :
- job_id = self._get_job_id()
- if job_id == "" :
- raise RuntimeError("job %s has not been submitted" % self.remote_root)
- ret, stdin, stdout, stderr\
- = self.block_call ("squeue --job " + job_id)
- err_str = stderr.read().decode('utf-8')
- if (ret != 0) :
- if str("Invalid job id specified") in err_str :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- raise RuntimeError\
- ("status command squeue fails to execute\nerror message:%s\nreturn code %d\n" % (err_str, ret))
- status_line = stdout.read().decode('utf-8').split ('\n')[-2]
- status_word = status_line.split ()[-4]
- if status_word in ["PD","CF","S"] :
- return JobStatus.waiting
- elif status_word in ["R","CG"] :
- return JobStatus.running
- elif status_word in ["C","E","K","BF","CA","CD","F","NF","PR","SE","ST","TO"] :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- return JobStatus.unknown
-
- def _get_job_id(self) :
- sftp = self.ssh.open_sftp()
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'r') as fp:
- ret = fp.read().decode('utf-8')
- sftp.close()
- return ret
-
- def _check_finish_tag(self) :
- sftp = self.ssh.open_sftp()
- try:
- sftp.stat(os.path.join(self.remote_root, 'tag_finished'))
- ret = True
- except IOError:
- ret = False
- sftp.close()
- return ret
-
- def _make_squeue(self,mdata1, res):
- ret = ''
- ret += 'squeue -u %s ' % mdata1['username']
- ret += '-p %s ' % res['partition']
- ret += '| grep PD'
- return ret
-
- def _make_script(self,
- job_dirs,
- cmd,
- args = None,
- res = None) :
- _set_default_resource(res)
- ret = ''
- ret += "#!/bin/bash -l\n"
- ret += "#SBATCH -N %d\n" % res['numb_node']
- ret += "#SBATCH --ntasks-per-node %d\n" % res['task_per_node']
- ret += "#SBATCH -t %s\n" % res['time_limit']
- if res['mem_limit'] > 0 :
- ret += "#SBATCH --mem %dG \n" % res['mem_limit']
- if len(res['account']) > 0 :
- ret += "#SBATCH --account %s \n" % res['account']
- if len(res['partition']) > 0 :
- ret += "#SBATCH --partition %s \n" % res['partition']
- if len(res['qos']) > 0 :
- ret += "#SBATCH --qos %s \n" % res['qos']
- if res['numb_gpu'] > 0 :
- ret += "#SBATCH --gres=gpu:%d\n" % res['numb_gpu']
- for ii in res['constraint_list'] :
- ret += '#SBATCH -C %s \n' % ii
- for ii in res['license_list'] :
- ret += '#SBATCH -L %s \n' % ii
- if len(res['exclude_list']) >0:
- temp_exclude = ""
- for ii in res['exclude_list'] :
- temp_exclude += ii
- temp_exclude += ","
- temp_exclude = temp_exclude[:-1]
- ret += '#SBATCH --exclude %s \n' % temp_exclude
- ret += "\n"
- # ret += 'set -euo pipefail\n\n'
- for ii in res['module_unload_list'] :
- ret += "module unload %s\n" % ii
- for ii in res['module_list'] :
- ret += "module load %s\n" % ii
- ret += "\n"
- for ii in res['source_list'] :
- ret += "source %s\n" %ii
- ret += "\n"
- envs = res['envs']
- if envs != None :
- for key in envs.keys() :
- ret += 'export %s=%s\n' % (key, envs[key])
- ret += '\n'
-
- if args == None :
- args = []
- for ii in job_dirs:
- args.append('')
-
- try:
- cvasp=res['cvasp']
- try:
- fp_max_errors = res['fp_max_errors']
- except Exception:
- fp_max_errors = 3
- except Exception:
- cvasp=False
-
- for ii,jj in zip(job_dirs, args) :
- ret += 'cd %s\n' % ii
- ret += 'test $? -ne 0 && exit\n\n'
-
- if cvasp:
- cmd=cmd.split('1>')[0].strip()
- if res['with_mpi'] :
- ret += 'if [ -f tag_finished ] ;then\n'
- ret += ' echo gogogo \n'
- ret += 'else\n'
- ret += ' python ../cvasp.py "srun %s" %s %s 1>log 2>log\n' % (cmd, fp_max_errors, jj)
- ret += ' if test $? -ne 0 \n'
- ret += ' then\n'
- ret += ' exit\n'
- ret += ' else\n'
- ret += ' touch tag_finished\n'
- ret += ' fi\n'
- ret += 'fi\n\n'
- else :
- ret += 'if [ -f tag_finished ] ;then\n'
- ret += ' echo gogogo \n'
- ret += 'else\n'
- ret += ' python ../cvasp.py "%s" %s %s 1>log 2>log\n' % (cmd, fp_max_errors, jj)
- ret += ' if test $? -ne 0 \n'
- ret += ' then\n'
- ret += ' exit\n'
- ret += ' else\n'
- ret += ' touch tag_finished\n'
- ret += ' fi\n'
- ret += 'fi\n\n'
- else:
- if res['with_mpi'] :
- ret += 'if [ -f tag_finished ] ;then\n'
- ret += ' echo gogogo \n'
- ret += 'else\n'
- ret += ' srun %s %s\n' % (cmd, jj)
- ret += ' if test $? -ne 0 \n'
- ret += ' then\n'
- ret += ' exit\n'
- ret += ' else\n'
- ret += ' touch tag_finished\n'
- ret += ' fi\n'
- ret += 'fi\n\n'
- else :
- ret += 'if [ -f tag_finished ] ;then\n'
- ret += ' echo gogogo \n'
- ret += 'else\n'
- ret += ' %s %s\n' % (cmd, jj)
- ret += ' if test $? -ne 0 \n'
- ret += ' then\n'
- ret += ' exit\n'
- ret += ' else\n'
- ret += ' touch tag_finished\n'
- ret += ' fi\n'
- ret += 'fi\n\n'
- if 'allow_failure' not in res or res['allow_failure'] is False:
- ret += 'test $? -ne 0 && exit\n'
- ret += 'cd %s\n' % self.remote_root
- ret += 'test $? -ne 0 && exit\n'
- ret += '\ntouch tag_finished\n'
-
- script_name = 'run.sub'
- script = os.path.join(self.remote_root, script_name)
- sftp = self.ssh.open_sftp()
- with sftp.open(script, 'w') as fp :
- fp.write(ret)
- sftp.close()
-
- return script_name
-
-
-class PBSJob (RemoteJob) :
- def submit(self,
- job_dirs,
- cmd,
- args = None,
- resources = None) :
- script_name = self._make_script(job_dirs, cmd, args, res = resources)
- stdin, stdout, stderr = self.block_checkcall(('cd %s; qsub %s' % (self.remote_root, script_name)))
- subret = (stdout.readlines())
- job_id = subret[0].split()[0]
- sftp = self.ssh.open_sftp()
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'w') as fp:
- fp.write(job_id)
- sftp.close()
-
- def check_status(self) :
- job_id = self._get_job_id()
- if job_id == "" :
- raise RuntimeError("job %s is has not been submitted" % self.remote_root)
- ret, stdin, stdout, stderr\
- = self.block_call ("qstat " + job_id)
- err_str = stderr.read().decode('utf-8')
- if (ret != 0) :
- if str("qstat: Unknown Job Id") in err_str :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- raise RuntimeError ("status command qstat fails to execute. erro info: %s return code %d"
- % (err_str, ret))
- status_line = stdout.read().decode('utf-8').split ('\n')[-2]
- status_word = status_line.split ()[-2]
- # dlog.info (status_word)
- if status_word in ["Q","H"] :
- return JobStatus.waiting
- elif status_word in ["R"] :
- return JobStatus.running
- elif status_word in ["C","E","K"] :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- return JobStatus.unknown
-
- def _get_job_id(self) :
- sftp = self.ssh.open_sftp()
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'r') as fp:
- ret = fp.read().decode('utf-8')
- sftp.close()
- return ret
-
- def _check_finish_tag(self) :
- sftp = self.ssh.open_sftp()
- try:
- sftp.stat(os.path.join(self.remote_root, 'tag_finished'))
- ret = True
- except IOError:
- ret = False
- sftp.close()
- return ret
-
- def _make_script(self,
- job_dirs,
- cmd,
- args = None,
- res = None) :
- _set_default_resource(res)
- ret = ''
- ret += "#!/bin/bash -l\n"
- if res['numb_gpu'] == 0:
- ret += '#PBS -l nodes=%d:ppn=%d\n' % (res['numb_node'], res['task_per_node'])
- else :
- ret += '#PBS -l nodes=%d:ppn=%d:gpus=%d\n' % (res['numb_node'], res['task_per_node'], res['numb_gpu'])
- ret += '#PBS -l walltime=%s\n' % (res['time_limit'])
- if res['mem_limit'] > 0 :
- ret += "#PBS -l mem=%dG \n" % res['mem_limit']
- ret += '#PBS -j oe\n'
- if len(res['partition']) > 0 :
- ret += '#PBS -q %s\n' % res['partition']
- ret += "\n"
- for ii in res['module_unload_list'] :
- ret += "module unload %s\n" % ii
- for ii in res['module_list'] :
- ret += "module load %s\n" % ii
- ret += "\n"
- for ii in res['source_list'] :
- ret += "source %s\n" %ii
- ret += "\n"
- envs = res['envs']
- if envs != None :
- for key in envs.keys() :
- ret += 'export %s=%s\n' % (key, envs[key])
- ret += '\n'
- ret += 'cd $PBS_O_WORKDIR\n\n'
-
- if args == None :
- args = []
- for ii in job_dirs:
- args.append('')
- for ii,jj in zip(job_dirs, args) :
- ret += 'cd %s\n' % ii
- ret += 'test $? -ne 0 && exit\n'
- if res['with_mpi'] :
- ret += 'mpirun -machinefile $PBS_NODEFILE -n %d %s %s\n' % (res['numb_node'] * res['task_per_node'], cmd, jj)
- else :
- ret += '%s %s\n' % (cmd, jj)
- if 'allow_failure' not in res or res['allow_failure'] is False:
- ret += 'test $? -ne 0 && exit\n'
- ret += 'cd %s\n' % self.remote_root
- ret += 'test $? -ne 0 && exit\n'
- ret += '\ntouch tag_finished\n'
-
- script_name = 'run.sub'
- script = os.path.join(self.remote_root, script_name)
- sftp = self.ssh.open_sftp()
- with sftp.open(script, 'w') as fp :
- fp.write(ret)
- sftp.close()
-
- return script_name
-
-
-# ssh_session = SSHSession('localhost.json')
-# rjob = CloudMachineJob(ssh_session, '.')
-# # can upload dirs and normal files
-# rjob.upload(['job0', 'job1'], ['batch_exec.py', 'test'])
-# rjob.submit(['job0', 'job1'], 'touch a; sleep 2')
-# while rjob.check_status() == JobStatus.running :
-# dlog.info('checked')
-# time.sleep(2)
-# dlog.info(rjob.check_status())
-# # can download dirs and normal files
-# rjob.download(['job0', 'job1'], ['a'])
-# # rjob.clean()
-
-
-class LSFJob (RemoteJob) :
- def submit(self,
- job_dirs,
- cmd,
- args = None,
- resources = None,
- restart = False):
- dlog.debug(restart)
- if restart:
- status = self.check_status()
- if status in [ JobStatus.unsubmitted, JobStatus.unknown, JobStatus.terminated ]:
- dlog.debug('task restart point !!!')
- if 'task_max' in resources and resources['task_max'] > 0:
- while self.check_limit(task_max=resources['task_max']):
- time.sleep(60)
- self._submit(job_dirs, cmd, args, resources)
- elif status==JobStatus.waiting:
- dlog.debug('task is waiting')
- elif status==JobStatus.running:
- dlog.debug('task is running')
- else:
- dlog.debug('task is finished')
- #except Exception:
- #dlog.debug('no job_id file')
- #dlog.debug('task restart point !!!')
- #self._submit(job_dirs, cmd, args, resources)
- else:
- dlog.debug('new task!!!')
- if 'task_max' in resources and resources['task_max'] > 0:
- while self.check_limit(task_max=resources['task_max']):
- time.sleep(60)
- self._submit(job_dirs, cmd, args, resources)
- if resources.get('wait_time', False):
- time.sleep(resources['wait_time']) # For preventing the crash of the tasks while submitting.
-
- def _submit(self,
- job_dirs,
- cmd,
- args = None,
- resources = None) :
- script_name = self._make_script(job_dirs, cmd, args, res = resources)
- stdin, stdout, stderr = self.block_checkcall(('cd %s; bsub < %s' % (self.remote_root, script_name)))
- subret = (stdout.readlines())
- job_id = subret[0].split()[1][1:-1]
- sftp = self.ssh.open_sftp()
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'w') as fp:
- fp.write(job_id)
- sftp.close()
-
- def check_limit(self, task_max):
- stdin_run, stdout_run, stderr_run = self.block_checkcall("bjobs | grep RUN | wc -l")
- njobs_run = int(stdout_run.read().decode('utf-8').split ('\n')[0])
- stdin_pend, stdout_pend, stderr_pend = self.block_checkcall("bjobs | grep PEND | wc -l")
- njobs_pend = int(stdout_pend.read().decode('utf-8').split ('\n')[0])
- if (njobs_pend + njobs_run) < task_max:
- return False
- else:
- return True
-
- def check_status(self) :
- try:
- job_id = self._get_job_id()
- except Exception:
- return JobStatus.terminated
- if job_id == "" :
- raise RuntimeError("job %s is has not been submitted" % self.remote_root)
- ret, stdin, stdout, stderr\
- = self.block_call ("bjobs " + job_id)
- err_str = stderr.read().decode('utf-8')
- if ("Job <%s> is not found" % job_id) in err_str :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- elif ret != 0 :
- raise RuntimeError ("status command bjobs fails to execute. erro info: %s return code %d"
- % (err_str, ret))
- status_out = stdout.read().decode('utf-8').split('\n')
- if len(status_out) < 2:
- return JobStatus.unknown
- else:
- status_line = status_out[1]
- status_word = status_line.split()[2]
-
- # ref: https://www.ibm.com/support/knowledgecenter/en/SSETD4_9.1.2/lsf_command_ref/bjobs.1.html
- if status_word in ["PEND", "WAIT", "PSUSP"] :
- return JobStatus.waiting
- elif status_word in ["RUN", "USUSP"] :
- return JobStatus.running
- elif status_word in ["DONE","EXIT"] :
- if self._check_finish_tag() :
- return JobStatus.finished
- else :
- return JobStatus.terminated
- else :
- return JobStatus.unknown
-
- def _get_job_id(self) :
- sftp = self.ssh.open_sftp()
- with sftp.open(os.path.join(self.remote_root, 'job_id'), 'r') as fp:
- ret = fp.read().decode('utf-8')
- sftp.close()
- return ret
-
- def _check_finish_tag(self) :
- sftp = self.ssh.open_sftp()
- try:
- sftp.stat(os.path.join(self.remote_root, 'tag_finished'))
- ret = True
- except IOError:
- ret = False
- sftp.close()
- return ret
-
- def _make_script(self,
- job_dirs,
- cmd,
- args = None,
- res = None) :
- _set_default_resource(res)
- ret = ''
- ret += "#!/bin/bash -l\n#BSUB -e %J.err\n#BSUB -o %J.out\n"
- if res['numb_gpu'] == 0:
- ret += '#BSUB -n %d\n#BSUB -R span[ptile=%d]\n' % (
- res['numb_node'] * res['task_per_node'], res['node_cpu'])
- else:
- if res['node_cpu']:
- ret += '#BSUB -R span[ptile=%d]\n' % res['node_cpu']
- if 'new_lsf_gpu' in res and res['new_lsf_gpu'] == True:
- # supportted in LSF >= 10.1.0 SP6
- # ref: https://www.ibm.com/support/knowledgecenter/en/SSWRJV_10.1.0/lsf_resource_sharing/use_gpu_res_reqs.html
- ret += '#BSUB -n %d\n#BSUB -gpu "num=%d:mode=shared:j_exclusive=yes"\n' % (
- res['numb_gpu'], res['task_per_node'])
- else:
- ret += '#BSUB -n %d\n#BSUB -R "select[ngpus >0] rusage[ngpus_excl_p=%d]"\n' % (
- res['numb_gpu'], res['task_per_node'])
- if res['time_limit']:
- ret += '#BSUB -W %s\n' % (res['time_limit'].split(':')[
- 0] + ':' + res['time_limit'].split(':')[1])
- if res['mem_limit'] > 0 :
- ret += "#BSUB -M %d \n" % (res['mem_limit'])
- ret += '#BSUB -J %s\n' % (res['job_name'] if 'job_name' in res else 'dpgen')
- if len(res['partition']) > 0 :
- ret += '#BSUB -q %s\n' % res['partition']
- ret += "\n"
- for ii in res['module_unload_list'] :
- ret += "module unload %s\n" % ii
- for ii in res['module_list'] :
- ret += "module load %s\n" % ii
- ret += "\n"
- for ii in res['source_list'] :
- ret += "source %s\n" %ii
- ret += "\n"
- envs = res['envs']
- if envs != None :
- for key in envs.keys() :
- ret += 'export %s=%s\n' % (key, envs[key])
- ret += '\n'
-
- if args == None :
- args = []
- for ii in job_dirs:
- args.append('')
- for ii,jj in zip(job_dirs, args) :
- ret += 'cd %s\n' % ii
- ret += 'test $? -ne 0 && exit\n'
- if res['with_mpi']:
- ret += 'mpirun -machinefile $LSB_DJOB_HOSTFILE -n %d %s %s\n' % (
- res['numb_node'] * res['task_per_node'], cmd, jj)
- else :
- ret += '%s %s\n' % (cmd, jj)
- if 'allow_failure' not in res or res['allow_failure'] is False:
- ret += 'test $? -ne 0 && exit\n'
- ret += 'cd %s\n' % self.remote_root
- ret += 'test $? -ne 0 && exit\n'
- ret += '\ntouch tag_finished\n'
-
- script_name = 'run.sub'
- script = os.path.join(self.remote_root, script_name)
- sftp = self.ssh.open_sftp()
- with sftp.open(script, 'w') as fp :
- fp.write(ret)
- sftp.close()
-
- return script_name
diff --git a/dpgen/remote/decide_machine.py b/dpgen/remote/decide_machine.py
index c551be44b..ced049ef0 100644
--- a/dpgen/remote/decide_machine.py
+++ b/dpgen/remote/decide_machine.py
@@ -1,19 +1,9 @@
#!/usr/bin/env python
# coding: utf-8
-from dpgen.dispatcher.SSHContext import SSHSession
-from dpgen.dispatcher.SSHContext import SSHContext
-from dpgen.dispatcher.Slurm import Slurm
-from dpgen.dispatcher.LSF import LSF
-from dpgen import dlog
-import os
-import json
-import numpy as np
-from distutils.version import LooseVersion
-
def convert_mdata(mdata, task_types=["train", "model_devi", "fp"]):
- '''
+ """
Convert mdata for DP-GEN main process.
New convension is like mdata["fp"]["machine"],
DP-GEN needs mdata["fp_machine"]
@@ -33,7 +23,7 @@ def convert_mdata(mdata, task_types=["train", "model_devi", "fp"]):
-------
dict
mdata converted
- '''
+ """
for task_type in task_types:
if task_type in mdata:
if isinstance(mdata[task_type], dict):
@@ -50,281 +40,3 @@ def convert_mdata(mdata, task_types=["train", "model_devi", "fp"]):
group_size = task_data.get("group_size", 1)
mdata[task_type + "_" + "group_size"] = group_size
return mdata
-
-
-
-# def decide_train_machine(mdata):
-# if LooseVersion(mdata.get('api_version', '0.9')) >= LooseVersion('1.0'):
-# mdata['train_group_size'] = mdata['train'][0]['resources']['group_size']
-# if 'train' in mdata:
-# continue_flag = False
-# if 'record.machine' in os.listdir():
-# try:
-# with open('record.machine', 'r') as _infile:
-# profile = json.load(_infile)
-# if profile['purpose'] == 'train':
-# mdata['train_machine'] = profile['machine']
-# mdata['train_resources'] = profile['resources']
-#
-# if 'python_path' in profile:
-# mdata['python_path'] = profile['python_path']
-# if "group_size" in profile:
-# mdata["train_group_size"] = profile["group_size"]
-# if 'deepmd_version' in profile:
-# mdata["deepmd_version"] = profile['deepmd_version']
-# if 'command' in profile:
-# mdata['train_command'] = profile["command"]
-# continue_flag = True
-# except Exception:
-# pass
-# if ("hostname" not in mdata["train"][0]["machine"]) or (len(mdata["train"]) == 1):
-# mdata["train_machine"] = mdata["train"][0]["machine"]
-# mdata["train_resources"] = mdata["train"][0]["resources"]
-#
-# if 'python_path' in mdata["train"][0]:
-# mdata["python_path"] = mdata["train"][0]["python_path"]
-# if "group_size" in mdata["train"][0]:
-# mdata["train_group_size"] = mdata["train"][0]["group_size"]
-# if 'deepmd_version' in mdata["train"][0]:
-# mdata["deepmd_version"] = mdata["train"][0]["deepmd_version"]
-# if 'command' in mdata["train"][0]:
-# mdata["train_command"] = mdata["train"][0]["command"]
-# continue_flag = True
-#
-# pd_flag = False
-# pd_count_list =[]
-# # pd for pending job in slurm
-# # if we need to launch new machine_idxines
-# if not continue_flag:
-#
-# #assert isinstance(mdata['train']['machine'], list)
-# #assert isinstance(mdata['train']['resources'], list)
-# #assert len(mdata['train']['machine']) == len(mdata['train']['resources'])
-# # mdata['train'] is a list
-# for machine_idx in range(len(mdata['train'])):
-# temp_machine = mdata['train'][machine_idx]['machine']
-# temp_resources = mdata['train'][machine_idx]['resources']
-# temp_ssh_sess = SSHSession(temp_machine)
-# cwd = os.getcwd()
-# temp_context = SSHContext(cwd, temp_ssh_sess)
-# if temp_machine['machine_type'] == 'lsf':
-# temp_batch = LSF(temp_context)
-# else:
-# temp_batch = Slurm(temp_context)
-# # For other type of machines, please add them using 'elif'.
-# # Here slurm is selected as the final choice in convinience.
-# command = temp_batch._make_squeue(temp_machine, temp_resources)
-# ret, stdin, stdout, stderr = temp_batch.context.block_call(command)
-# pd_response = stdout.read().decode('utf-8').split("\n")
-# pd_count = len(pd_response)
-# temp_context.clean()
-# ## If there is no need to waiting for allocation
-# if pd_count ==1:
-# mdata['train_machine'] = temp_machine
-# mdata['train_resources'] = temp_resources
-#
-# if 'python_path' in mdata['train'][machine_idx]:
-# mdata['python_path'] = mdata['train'][machine_idx]['python_path']
-# if 'group_size' in mdata['train'][machine_idx]:
-# mdata['train_group_size'] = mdata['train'][machine_idx]['group_size']
-# if 'deepmd_version' in mdata['train'][machine_idx]:
-# mdata['deepmd_version'] = mdata['train'][machine_idx]['deepmd_version']
-# if 'command' in mdata['train'][machine_idx]:
-# mdata['train_command'] = mdata['train'][machine_idx]['command']
-#
-# ## No need to wait
-# pd_flag = True
-# break
-# else:
-# pd_count_list.append(pd_count)
-# if not pd_flag:
-# ## All machines need waiting, then compare waiting jobs
-# ## Select a machine which has fewest waiting jobs
-# min_machine_idx = np.argsort(pd_count_list)[0]
-# mdata['train_machine'] = mdata['train'][min_machine_idx]['machine']
-# mdata['train_resources'] = mdata['train'][min_machine_idx]['resources']
-#
-# if 'python_path' in mdata['train'][min_machine_idx]:
-# mdata['python_path'] = mdata['train'][min_machine_idx]['python_path']
-# if "group_size" in mdata['train'][min_machine_idx]:
-# mdata["train_group_size"] = mdata['train'][min_machine_idx]["group_size"]
-# if 'deepmd_version' in mdata['train'][min_machine_idx]:
-# mdata['deepmd_version'] = mdata['train'][min_machine_idx]["deepmd_version"]
-# if 'command' in mdata['train'][min_machine_idx]:
-# mdata['train_command'] = mdata['train'][min_machine_idx]['command']
-#
-# ## Record which machine is selected
-# with open("record.machine","w") as _outfile:
-# profile = {}
-# profile['purpose'] = 'train'
-# profile['machine'] = mdata['train_machine']
-# profile['resources'] = mdata['train_resources']
-#
-# if 'python_path' in mdata:
-# profile['python_path'] = mdata['python_path']
-# if "train_group_size" in mdata:
-# profile["group_size"] = mdata["train_group_size"]
-# if 'deepmd_version' in mdata:
-# profile['deepmd_version'] = mdata['deepmd_version']
-# if 'train_command' in mdata:
-# profile['command'] = mdata['train_command']
-#
-# json.dump(profile, _outfile, indent = 4)
-# return mdata
-#
-# def decide_model_devi_machine(mdata):
-# if LooseVersion(mdata.get('api_version', '0.9')) >= LooseVersion('1.0'):
-# mdata['model_devi_group_size'] = mdata['model_devi'][0]['resources']['group_size']
-# if 'model_devi' in mdata:
-# continue_flag = False
-# if 'record.machine' in os.listdir():
-# try:
-# with open('record.machine', 'r') as _infile:
-# profile = json.load(_infile)
-# if profile['purpose'] == 'model_devi':
-# mdata['model_devi_machine'] = profile['machine']
-# mdata['model_devi_resources'] = profile['resources']
-# mdata['model_devi_command'] = profile['command']
-# mdata['model_devi_group_size'] = profile['group_size']
-# continue_flag = True
-# except Exception:
-# pass
-# if ("hostname" not in mdata["model_devi"][0]["machine"]) or (len(mdata["model_devi"]) == 1):
-# mdata["model_devi_machine"] = mdata["model_devi"][0]["machine"]
-# mdata["model_devi_resources"] = mdata["model_devi"][0]["resources"]
-# mdata["model_devi_command"] = mdata["model_devi"][0]["command"]
-# #if "group_size" in mdata["train"][0]:
-# mdata["model_devi_group_size"] = mdata["model_devi"][0].get("group_size", 1)
-# continue_flag = True
-#
-# pd_count_list =[]
-# pd_flag = False
-# if not continue_flag:
-#
-# #assert isinstance(mdata['model_devi']['machine'], list)
-# #ssert isinstance(mdata['model_devi']['resources'], list)
-# #assert len(mdata['model_devi']['machine']) == len(mdata['model_devi']['resources'])
-#
-# for machine_idx in range(len(mdata['model_devi'])):
-# temp_machine = mdata['model_devi'][machine_idx]['machine']
-# temp_resources = mdata['model_devi'][machine_idx]['resources']
-# #assert isinstance(temp_machine, dict), "unsupported type of model_devi machine [%d]!" %machine_idx
-# #assert isinstance(temp_resources, dict), "unsupported type of model_devi resources [%d]!"%machine_idx
-# #assert temp_machine['machine_type'] == 'slurm', "Currently only support for Slurm!"
-# temp_ssh_sess = SSHSession(temp_machine)
-# cwd = os.getcwd()
-# temp_context = SSHContext(cwd, temp_ssh_sess)
-# if temp_machine['machine_type'] == 'lsf':
-# temp_batch = LSF(temp_context)
-# else:
-# temp_batch = Slurm(temp_context)
-# # For other type of machines, please add them using 'elif'.
-# # Here slurm is selected as the final choice in convinience.
-# command = temp_batch._make_squeue(temp_machine, temp_resources)
-# ret, stdin, stdout, stderr = temp_batch.context.block_call(command)
-# pd_response = stdout.read().decode('utf-8').split("\n")
-# pd_count = len(pd_response)
-# temp_context.clean()
-# if pd_count ==0:
-# mdata['model_devi_machine'] = temp_machine
-# mdata['model_devi_resources'] = temp_resources
-# mdata['model_devi_command'] = mdata['model_devi'][machine_idx]['command']
-# mdata['model_devi_group_size'] = mdata['model_devi'][machine_idx].get('group_size', 1)
-# pd_flag = True
-# break
-# else:
-# pd_count_list.append(pd_count)
-# if not pd_flag:
-# min_machine_idx = np.argsort(pd_count_list)[0]
-# mdata['model_devi_machine'] = mdata['model_devi'][min_machine_idx]['machine']
-# mdata['model_devi_resources'] = mdata['model_devi'][min_machine_idx]['resources']
-# mdata['model_devi_command'] = mdata['model_devi'][min_machine_idx]['command']
-# mdata['model_devi_group_size'] = mdata['model_devi'][min_machine_idx].get('group_size', 1)
-# with open("record.machine","w") as _outfile:
-# profile = {}
-# profile['purpose'] = 'model_devi'
-# profile['machine'] = mdata['model_devi_machine']
-# profile['resources'] = mdata['model_devi_resources']
-# profile['group_size'] = mdata['model_devi_group_size']
-# profile['command'] = mdata['model_devi_command']
-#
-# json.dump(profile, _outfile, indent = 4)
-# return mdata
-# def decide_fp_machine(mdata):
-# if LooseVersion(mdata.get('api_version', '0.9')) >= LooseVersion('1.0'):
-# mdata['fp_group_size'] = mdata['fp'][0]['resources']['group_size']
-# if 'fp' in mdata:
-# #ssert isinstance(mdata['fp']['machine'], list)
-# #assert isinstance(mdata['fp']['resources'], list)
-# #assert len(mdata['fp']['machine']) == len(mdata['fp']['resources'])
-# continue_flag = False
-# ## decide whether to use an existing machine
-# if 'record.machine' in os.listdir():
-# try:
-# with open('record.machine', 'r') as _infile:
-# profile = json.load(_infile)
-# if profile['purpose'] == 'fp':
-# mdata['fp_machine'] = profile['machine']
-# mdata['fp_resources'] = profile['resources']
-# mdata['fp_command'] = profile['command']
-# mdata['fp_group_size'] = profile['group_size']
-#
-# continue_flag = True
-# except Exception:
-# pass
-# if ("hostname" not in mdata["fp"][0]["machine"]) or (len(mdata["fp"]) == 1):
-# mdata["fp_machine"] = mdata["fp"][0]["machine"]
-# mdata["fp_resources"] = mdata["fp"][0]["resources"]
-# mdata["fp_command"] = mdata["fp"][0]["command"]
-# #if "group_size" in mdata["train"][0]:
-# mdata["fp_group_size"] = mdata["fp"][0].get("group_size", 1)
-# continue_flag = True
-#
-#
-# pd_count_list =[]
-# pd_flag = False
-# if not continue_flag:
-# for machine_idx in range(len(mdata['fp'])):
-# temp_machine = mdata['fp'][machine_idx]['machine']
-# temp_resources = mdata['fp'][machine_idx]['resources']
-# temp_ssh_sess = SSHSession(temp_machine)
-# cwd = os.getcwd()
-# temp_context = SSHContext(cwd, temp_ssh_sess)
-# if temp_machine['machine_type'] == 'lsf':
-# temp_batch = LSF(temp_context)
-# else:
-# temp_batch = Slurm(temp_context)
-# # For other type of machines, please add them using 'elif'.
-# # Here slurm is selected as the final choice in convinience.
-# command = temp_batch._make_squeue(temp_machine, temp_resources)
-# ret, stdin, stdout, stderr = temp_batch.context.block_call(command)
-# pd_response = stdout.read().decode('utf-8').split("\n")
-# pd_count = len(pd_response)
-# temp_context.clean()
-# #dlog.info(temp_machine["username"] + " " + temp_machine["hostname"] + " " + str(pd_count))
-# if pd_count ==0:
-# mdata['fp_machine'] = temp_machine
-# mdata['fp_resources'] = temp_resources
-# mdata['fp_command'] = mdata['fp'][machine_idx]['command']
-# mdata['fp_group_size'] = mdata['fp'][machine_idx].get('group_size', 1)
-# pd_flag = True
-# break
-# else:
-# pd_count_list.append(pd_count)
-# if not pd_flag:
-# min_machine_idx = np.argsort(pd_count_list)[0]
-# mdata['fp_machine'] = mdata['fp'][min_machine_idx]['machine']
-# mdata['fp_resources'] = mdata['fp'][min_machine_idx]['resources']
-# mdata['fp_command'] = mdata['fp'][min_machine_idx]['command']
-# mdata['fp_group_size'] = mdata['fp'][min_machine_idx].get('group_size',1)
-#
-# with open("record.machine","w") as _outfile:
-# profile = {}
-# profile['purpose'] = 'fp'
-# profile['machine'] = mdata['fp_machine']
-# profile['resources'] = mdata['fp_resources']
-# profile['group_size'] = mdata['fp_group_size']
-# profile['command'] = mdata['fp_command']
-# json.dump(profile, _outfile, indent = 4)
-# return mdata
-
diff --git a/dpgen/remote/group_jobs.py b/dpgen/remote/group_jobs.py
deleted file mode 100644
index 588bcfbed..000000000
--- a/dpgen/remote/group_jobs.py
+++ /dev/null
@@ -1,430 +0,0 @@
-#!/usr/bin/env python
-# coding: utf-8
-
-import os,sys,glob,time
-import numpy as np
-import subprocess as sp
-from monty.serialization import dumpfn,loadfn
-from dpgen.remote.RemoteJob import SlurmJob, PBSJob, CloudMachineJob, JobStatus, awsMachineJob,SSHSession
-from dpgen import dlog
-
-import requests
-from hashlib import sha1
-
-def _verfy_ac(private_key, params):
- items= sorted(params.items())
-
- params_data = ""
- for key, value in items:
- params_data = params_data + str(key) + str(value)
- params_data = params_data + private_key
- sign = sha1()
- sign.update(params_data.encode())
- signature = sign.hexdigest()
- return signature
-
-def aws_submit_jobs(machine,
- resources,
- command,
- work_path,
- tasks,
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference = True):
- import boto3
- task_chunks = [
- [os.path.basename(j) for j in tasks[i:i + group_size]] \
- for i in range(0, len(tasks), group_size)
- ]
- task_chunks = (str(task_chunks).translate((str.maketrans('','',' \'"[]'))).split(','))
- # flatten the task_chunks
- print('task_chunks=',task_chunks)
- njob = len(task_chunks)
- print('njob=',njob)
- continue_status = False
- ecs=boto3.client('ecs')
- ec2=boto3.client('ec2')
- status_list=[]
- containerInstanceArns=ecs.list_container_instances(cluster="tensorflow")
- if containerInstanceArns['containerInstanceArns']:
- containerInstances=ecs.describe_container_instances(cluster="tensorflow", \
- containerInstances=containerInstanceArns['containerInstanceArns'])['containerInstances']
- status_list=[container['status'] for container in containerInstances]
-
- need_apply_num=group_size-len(status_list)
- print('need_apply_num=',need_apply_num)
- if need_apply_num>0:
- for ii in range(need_apply_num) : #apply for machines,
- ec2.run_instances(**machine['run_instances'])
- machine_fin = False
- status_list=[]
- while not len(status_list)>=group_size:
- containerInstanceArns=ecs.list_container_instances(cluster="tensorflow")
- if containerInstanceArns['containerInstanceArns']:
- containerInstances=ecs.describe_container_instances(cluster="tensorflow", \
- containerInstances=containerInstanceArns['containerInstanceArns'])['containerInstances']
- status_list=[container['status'] for container in containerInstances]
- if len(status_list)>=group_size:
- break
- else:
- time.sleep(20)
- print('current available containers status_list=',status_list)
- print('remote_root=',machine['remote_root'])
- rjob = awsMachineJob(machine['remote_root'],work_path)
- taskARNs=[]
- taskstatus=[]
- running_job_num=0
- rjob.upload('.', forward_common_files)
- for ijob in range(njob) : #uplaod && submit job
- containerInstanceArns=ecs.list_container_instances(cluster="tensorflow")
- containerInstances=ecs.describe_container_instances(cluster="tensorflow", \
- containerInstances=containerInstanceArns['containerInstanceArns'])['containerInstances']
- status_list=[container['status'] for container in containerInstances]
- print('current available containers status_list=',status_list)
- while running_job_num>=group_size:
- taskstatus=[task['lastStatus'] for task in ecs.describe_tasks(cluster='tensorflow',tasks=taskARNs)['tasks']]
- running_job_num=len(list(filter(lambda str:(str=='PENDING' or str =='RUNNING'),taskstatus)))
- print('waiting for running job finished, taskstatus=',taskstatus,'running_job_num=',running_job_num)
- time.sleep(10)
- chunk = str(task_chunks[ijob])
- print('current task chunk=',chunk)
- task_definition=command['task_definition']
- concrete_command=(command['concrete_command'] %(work_path,chunk))
- command_override=command['command_override']
- command_override['containerOverrides'][0]['command'][0]=concrete_command
- print('concrete_command=',concrete_command)
- rjob.upload(chunk, forward_task_files,
- dereference = forward_task_deference)
- taskres=ecs.run_task(cluster='tensorflow',\
- taskDefinition=task_definition,overrides=command_override)
- while not taskres['tasks'][0]:
- print('task submit failed,taskres=',taskres,'trying to re-submit'+str(chunk),)
- time.sleep(10)
- taskres=ecs.run_task(cluster='tensorflow',\
- taskDefinition=task_definition,overrides=command_override)
-
- taskARNs.append(taskres['tasks'][0]['taskArn'])
- taskstatus=[task['lastStatus'] for task in ecs.describe_tasks(cluster='tensorflow',tasks=taskARNs)['tasks']]
- running_job_num=len(list(filter(lambda str:(str=='PENDING' or str =='RUNNING'),taskstatus)))
- print('have submitted %s/%s,taskstatus=' %(work_path,chunk) ,taskstatus,'running_job_num=',running_job_num )
- task_fin_flag=False
- while not task_fin_flag:
- taskstatus=[task['lastStatus'] for task in ecs.describe_tasks(cluster='tensorflow',tasks=taskARNs)['tasks']]
- task_fin_flag=all([status=='STOPPED' for status in taskstatus])
- if task_fin_flag:
- print('task finished,next step:copy files to local && taskstatus=',taskstatus)
- else:
- print('all tasks submitted,task running && taskstatus=',taskstatus)
- time.sleep(20)
- for ii in range(njob):
- chunk = task_chunks[ii]
- print('downloading '+str(chunk),backward_task_files)
- rjob.download(chunk,backward_task_files)
-
-def _ucloud_remove_machine(machine, UHostId):
- ucloud_url = machine['url']
- ucloud_stop_param = {}
- ucloud_stop_param['Action'] = "StopUHostInstance"
- ucloud_stop_param['Region'] = machine['ucloud_param']['Region']
- ucloud_stop_param['UHostId'] = UHostId
- ucloud_stop_param['PublicKey'] = machine['ucloud_param']['PublicKey']
- ucloud_stop_param['Signature'] = _verfy_ac(machine['Private'], ucloud_stop_param)
-
-
- req = requests.get(ucloud_url, ucloud_stop_param)
- if req.json()['RetCode'] != 0 :
- raise RuntimeError ("failed to stop ucloud machine")
-
- terminate_fin = False
- try_time = 0
- while not terminate_fin:
- ucloud_delete_param = {}
- ucloud_delete_param['Action'] = "TerminateUHostInstance"
- ucloud_delete_param['Region'] = machine['ucloud_param']['Region']
- ucloud_delete_param['UHostId'] = UHostId
- ucloud_delete_param['PublicKey'] = machine['ucloud_param']['PublicKey']
- ucloud_delete_param['Signature'] = _verfy_ac(machine['Private'], ucloud_delete_param)
- req = requests.get(ucloud_url, ucloud_delete_param)
- if req.json()['RetCode'] == 0 :
- terminate_fin = True
- try_time = try_time + 1
- if try_time >= 200:
- raise RuntimeError ("failed to terminate ucloud machine")
- time.sleep(10)
- print("Machine ",UHostId,"has been successfully terminated!")
-
-def ucloud_submit_jobs(machine,
- resources,
- command,
- work_path,
- tasks,
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference = True) :
- task_chunks = [
- [os.path.basename(j) for j in tasks[i:i + group_size]] \
- for i in range(0, len(tasks), group_size)
- ]
- njob = len(task_chunks)
- continue_status = False
- if os.path.isfile("record.machine"):
- with open ("record.machine", "r") as fr:
- record_machine = json.load(fr)
- if record_machine["purpose"] == machine["purpose"] and record_machine["njob"] == njob:
- continue_status = True
- ucloud_machines = record_machine["ucloud_machines"]
- ucloud_hostids = record_machine["ucloud_hostids"]
- fr.close()
- ucloud_url = machine['url']
- if continue_status == False:
- assert machine['machine_type'] == 'ucloud'
- ucloud_start_param = machine['ucloud_param']
- ucloud_start_param['Action'] = "CreateUHostInstance"
- ucloud_start_param['Name'] = "train"
- ucloud_start_param['Signature'] = _verfy_ac(machine['Private'], ucloud_start_param)
-
-
- ucloud_machines = []
- ucloud_hostids = []
- for ii in range(njob) :
- req = requests.get(ucloud_url, ucloud_start_param)
- if req.json()['RetCode'] != 0 :
- print(json.dumps(req.json(),indent=2, sort_keys=True))
- raise RuntimeError ("failed to start ucloud machine")
- ucloud_machines.append(str(req.json()["IPs"][0]))
- ucloud_hostids.append(str(req.json()["UHostIds"][0]))
-
- new_record_machine = {}
- new_record_machine["purpose"] = machine["purpose"]
- new_record_machine["njob"] = njob
- new_record_machine["ucloud_machines"] = ucloud_machines
- new_record_machine["ucloud_hostids"] = ucloud_hostids
- with open ("record.machine", "w") as fw:
- json.dump(new_record_machine, fw)
- fw.close()
-
- machine_fin = [False for ii in ucloud_machines]
- total_machine_num = len(ucloud_machines)
- fin_machine_num = 0
- while not all(machine_fin):
- for idx,mac in enumerate(ucloud_machines):
- if not machine_fin[idx]:
- ucloud_check_param = {}
- ucloud_check_param['Action'] = "GetUHostInstanceVncInfo"
- ucloud_check_param['Region'] = machine['ucloud_param']['Region']
- ucloud_check_param['UHostId'] = ucloud_hostids[idx]
- ucloud_check_param['PublicKey'] = machine['ucloud_param']['PublicKey']
- ucloud_check_param['Signature'] = _verfy_ac(machine['Private'], ucloud_check_param)
- req = requests.get(ucloud_url, ucloud_check_param)
- print("the UHostId is", ucloud_hostids[idx])
- print(json.dumps(req.json(),indent=2, sort_keys=True))
- if req.json()['RetCode'] == 0 :
- machine_fin[idx] = True
- fin_machine_num = fin_machine_num + 1
- print("Current finish",fin_machine_num,"/", total_machine_num)
-
-
- ucloud_check_param1 = {}
- ucloud_check_param1['Action'] = "DescribeUHostInstance"
- ucloud_check_param1['Region'] = machine['ucloud_param']['Region']
- ucloud_check_param1["Limit"] = 100
- ucloud_check_param1['PublicKey'] = machine['ucloud_param']['PublicKey']
- ucloud_check_param1['Signature'] = _verfy_ac(machine['Private'], ucloud_check_param1)
- req1 = requests.get(ucloud_url, ucloud_check_param1).json()
-
- machine_all_fin = True
- for idx1 in range(int(req1["TotalCount"])):
- if req1["UHostSet"][idx1]["State"] != "Running":
- machine_all_fin = False
- break
- if machine_all_fin == True:
- machine_fin = [True for i in machine_fin]
- time.sleep(10)
- ssh_sess = []
- ssh_param = {}
- ssh_param['port'] = 22
- ssh_param['username'] = 'root'
- ssh_param['work_path'] = machine['work_path']
- for ii in ucloud_machines :
- ssh_param['hostname'] = ii
- ssh_sess.append(SSHSession(ssh_param))
-
- job_list = []
- for ii in range(njob) :
- chunk = task_chunks[ii]
- print("Current machine is", ucloud_machines[ii])
- rjob = CloudMachineJob(ssh_sess[ii], work_path)
- rjob.upload('.', forward_common_files)
- rjob.upload(chunk, forward_task_files,
- dereference = forward_task_deference)
- rjob.submit(chunk, command, resources = resources)
- job_list.append(rjob)
-
- job_fin = [False for ii in job_list]
- while not all(job_fin) :
- for idx,rjob in enumerate(job_list) :
- if not job_fin[idx] :
- status = rjob.check_status()
- if status == JobStatus.terminated :
- raise RuntimeError("find unsuccessfully terminated job on machine" % ucloud_machines[idx])
- elif status == JobStatus.finished :
- rjob.download(task_chunks[idx], backward_task_files)
- rjob.clean()
- _ucloud_remove_machine(machine, ucloud_hostids[idx])
- job_fin[idx] = True
- time.sleep(10)
- os.remove("record.machine")
-
-
-def group_slurm_jobs(ssh_sess,
- resources,
- command,
- work_path,
- tasks,
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- remote_job = SlurmJob,
- forward_task_deference = True) :
-
- task_chunks = [
- [os.path.basename(j) for j in tasks[i:i + group_size]] \
- for i in range(0, len(tasks), group_size)
- ]
- cwd=os.getcwd()
- _pmap=PMap(cwd)
- path_map=_pmap.load()
- dlog.debug("work_path: %s"% work_path)
- dlog.debug("curr_path: %s"% cwd)
-
- job_list = []
- task_chunks_=['+'.join(ii) for ii in task_chunks]
- for ii in task_chunks_:
- dlog.debug("task_chunk %s" % ii)
-
- #dlog.debug(path_map)
- for ii,chunk in enumerate(task_chunks) :
-
- # map chunk info. to uniq id
- chunk_uni=task_chunks_[ii].encode('utf-8')
- chunk_sha1=sha1(chunk_uni).hexdigest()
-
- if chunk_sha1 in path_map:
- job_uuid=path_map[chunk_sha1][1].split('/')[-1]
- dlog.debug("load uuid %s" % job_uuid)
- else:
- job_uuid=None
-
- rjob = remote_job(ssh_sess, work_path, job_uuid)
- dlog.debug('uuid %s'%job_uuid)
- rjob.upload('.', forward_common_files)
- rjob.upload(chunk, forward_task_files,
- dereference = forward_task_deference)
- if job_uuid:
- rjob.submit(chunk, command, resources = resources,restart=True)
- else:
- rjob.submit(chunk, command, resources = resources)
- job_list.append(rjob)
- path_map[chunk_sha1]=[rjob.local_root,rjob.remote_root]
- _pmap.dump(path_map)
-
- job_fin = [False for ii in job_list]
- lcount=[0]*len(job_list)
- count_fail = 0
- while not all(job_fin) :
- for idx,rjob in enumerate(job_list) :
- if not job_fin[idx] :
- try:
- status = rjob.check_status()
- except Exception:
- ssh_sess = SSHSession(ssh_sess.remote_profile)
- for _idx,_rjob in enumerate(job_list):
- job_list[_idx] = SlurmJob(ssh_sess, work_path, _rjob.job_uuid)
- count_fail = count_fail +1
- dlog.info("ssh_sess failed for %d times"%count_fail)
- break
- if status == JobStatus.terminated :
- lcount[idx]+=1
- _job_uuid=rjob.remote_root.split('/')[-1]
- dlog.info('Job at %s terminated, submit again'% _job_uuid)
- dlog.debug('try %s times for %s'% (lcount[idx], _job_uuid))
- rjob.submit(task_chunks[idx], command, resources = resources,restart=True)
- if lcount[idx]>3:
- dlog.info('Too many errors for ! %s ' % _job_uuid)
- rjob.download(task_chunks[idx], backward_task_files,back_error=True)
- rjob.clean()
- job_fin[idx] = True
- elif status == JobStatus.finished :
- rjob.download(task_chunks[idx], backward_task_files)
- rjob.clean()
- job_fin[idx] = True
- time.sleep(10)
- dlog.debug('error count')
- dlog.debug(lcount)
- # delete path map file when job finish
- _pmap.delete()
-
-def group_local_jobs(ssh_sess,
- resources,
- command,
- work_path,
- tasks,
- group_size,
- forward_common_files,
- forward_task_files,
- backward_task_files,
- forward_task_deference = True) :
- task_chunks = [
- [os.path.basename(j) for j in tasks[i:i + group_size]] \
- for i in range(0, len(tasks), group_size)
- ]
- job_list = []
- for chunk in task_chunks :
- rjob = CloudMachineJob(ssh_sess, work_path)
- rjob.upload('.', forward_common_files)
- rjob.upload(chunk, forward_task_files,
- dereference = forward_task_deference)
- rjob.submit(chunk, command, resources = resources)
- job_list.append(rjob)
- job_fin = False
- while not job_fin :
- status = rjob.check_status()
- if status == JobStatus.terminated :
- raise RuntimeError("find unsuccessfully terminated job in %s" % rjob.get_job_root())
- elif status == JobStatus.finished :
- rjob.download(chunk, backward_task_files)
- rjob.clean()
- job_fin = True
- time.sleep(10)
-
-class PMap(object):
- '''
- Path map class to operate {read,write,delte} the pmap.json file
- '''
-
- def __init__(self,path,fname="pmap.json"):
- self.f_path_map=os.path.join(path,fname)
-
- def load(self):
- f_path_map=self.f_path_map
- if os.path.isfile(f_path_map):
- path_map=loadfn(f_path_map)
- else:
- path_map={}
- return path_map
-
- def dump(self,pmap,indent=4):
- f_path_map=self.f_path_map
- dumpfn(pmap,f_path_map,indent=indent)
-
- def delete(self):
- f_path_map=self.f_path_map
- try:
- os.remove(f_path_map)
- except Exception:
- pass
diff --git a/dpgen/remote/localhost.json b/dpgen/remote/localhost.json
deleted file mode 100644
index f2feaed5d..000000000
--- a/dpgen/remote/localhost.json
+++ /dev/null
@@ -1,7 +0,0 @@
-{
- "hostname" : "localhost",
- "port" : 22,
- "username": "wanghan",
- "work_path" : "/home/wanghan/tmp",
- "_comment" : "that's all"
-}
diff --git a/dpgen/simplify/arginfo.py b/dpgen/simplify/arginfo.py
index 7f89826ae..5b0d7175b 100644
--- a/dpgen/simplify/arginfo.py
+++ b/dpgen/simplify/arginfo.py
@@ -1,13 +1,14 @@
from typing import List
+
from dargs import Argument, Variant
from dpgen.arginfo import general_mdata_arginfo
from dpgen.generator.arginfo import (
basic_args,
data_args,
- training_args,
- fp_style_vasp_args,
fp_style_gaussian_args,
+ fp_style_vasp_args,
+ training_args,
)
@@ -23,42 +24,60 @@ def general_simplify_arginfo() -> Argument:
doc_pick_data = "(List of) Path to the directory with the pick data with the deepmd/npy or the HDF5 file with deepmd/hdf5 format. Systems are detected recursively."
doc_init_pick_number = "The number of initial pick data."
doc_iter_pick_number = "The number of pick data in each iteration."
- doc_model_devi_f_trust_lo = "The lower bound of forces for the selection for the model deviation."
- doc_model_devi_f_trust_hi = "The higher bound of forces for the selection for the model deviation."
+ doc_model_devi_f_trust_lo = (
+ "The lower bound of forces for the selection for the model deviation."
+ )
+ doc_model_devi_f_trust_hi = (
+ "The higher bound of forces for the selection for the model deviation."
+ )
return [
Argument("labeled", bool, optional=True, default=False, doc=doc_labeled),
Argument("pick_data", [str, list], doc=doc_pick_data),
Argument("init_pick_number", int, doc=doc_init_pick_number),
Argument("iter_pick_number", int, doc=doc_iter_pick_number),
- Argument("model_devi_f_trust_lo", float, optional=False, doc=doc_model_devi_f_trust_lo),
- Argument("model_devi_f_trust_hi", float, optional=False, doc=doc_model_devi_f_trust_hi),
+ Argument(
+ "model_devi_f_trust_lo",
+ float,
+ optional=False,
+ doc=doc_model_devi_f_trust_lo,
+ ),
+ Argument(
+ "model_devi_f_trust_hi",
+ float,
+ optional=False,
+ doc=doc_model_devi_f_trust_hi,
+ ),
]
def fp_style_variant_type_args() -> Variant:
"""Generate variant for fp style variant type.
-
+
Returns
-------
Variant
variant for fp style
"""
- doc_fp_style = 'Software for First Principles, if `labeled` is false. Options include “vasp”, “gaussian” up to now.'
- doc_fp_style_none = 'No fp.'
- doc_fp_style_vasp = 'VASP.'
- doc_fp_style_gaussian = 'Gaussian. The command should be set as `g16 < input`.'
-
- return Variant("fp_style", [
- Argument("none", dict, doc=doc_fp_style_none),
- # simplify use the same fp method as run
- Argument("vasp", dict, fp_style_vasp_args(), doc=doc_fp_style_vasp),
- Argument("gaussian", dict, fp_style_gaussian_args(),
- doc=doc_fp_style_gaussian),
- ],
+ doc_fp_style = "Software for First Principles, if `labeled` is false. Options include “vasp”, “gaussian” up to now."
+ doc_fp_style_none = "No fp."
+ doc_fp_style_vasp = "VASP."
+ doc_fp_style_gaussian = "Gaussian. The command should be set as `g16 < input`."
+
+ return Variant(
+ "fp_style",
+ [
+ Argument("none", dict, doc=doc_fp_style_none),
+ # simplify use the same fp method as run
+ Argument("vasp", dict, fp_style_vasp_args(), doc=doc_fp_style_vasp),
+ Argument(
+ "gaussian", dict, fp_style_gaussian_args(), doc=doc_fp_style_gaussian
+ ),
+ ],
optional=True,
default_tag="none",
- doc=doc_fp_style)
+ doc=doc_fp_style,
+ )
def fp_args() -> List[Argument]:
@@ -69,18 +88,27 @@ def fp_args() -> List[Argument]:
List[Argument]
arginfo
"""
- doc_fp_task_max = 'Maximum of structures to be calculated in 02.fp of each iteration.'
- doc_fp_task_min = 'Minimum of structures to be calculated in 02.fp of each iteration.'
- doc_fp_accurate_threshold = 'If the accurate ratio is larger than this number, no fp calculation will be performed, i.e. fp_task_max = 0.'
- doc_fp_accurate_soft_threshold = 'If the accurate ratio is between this number and fp_accurate_threshold, the fp_task_max linearly decays to zero.'
+ doc_fp_task_max = (
+ "Maximum of structures to be calculated in 02.fp of each iteration."
+ )
+ doc_fp_task_min = (
+ "Minimum of structures to be calculated in 02.fp of each iteration."
+ )
+ doc_fp_accurate_threshold = "If the accurate ratio is larger than this number, no fp calculation will be performed, i.e. fp_task_max = 0."
+ doc_fp_accurate_soft_threshold = "If the accurate ratio is between this number and fp_accurate_threshold, the fp_task_max linearly decays to zero."
return [
Argument("fp_task_max", int, optional=True, doc=doc_fp_task_max),
Argument("fp_task_min", int, optional=True, doc=doc_fp_task_min),
- Argument("fp_accurate_threshold", float,
- optional=True, doc=doc_fp_accurate_threshold),
- Argument("fp_accurate_soft_threshold", float,
- optional=True, doc=doc_fp_accurate_soft_threshold),
+ Argument(
+ "fp_accurate_threshold", float, optional=True, doc=doc_fp_accurate_threshold
+ ),
+ Argument(
+ "fp_accurate_soft_threshold",
+ float,
+ optional=True,
+ doc=doc_fp_accurate_soft_threshold,
+ ),
]
@@ -92,23 +120,26 @@ def simplify_jdata_arginfo() -> Argument:
Argument
arginfo
"""
- doc_run_jdata = "Parameters for simplify.json, the first argument of `dpgen simplify`."
- return Argument("simplify_jdata",
- dict,
- sub_fields=[
- *basic_args(),
- # TODO: we may remove sys_configs; it is required in train method
- *data_args(),
- *general_simplify_arginfo(),
- # simplify use the same training method as run
- *training_args(),
- *fp_args(),
- ],
- sub_variants=[
- fp_style_variant_type_args(),
- ],
- doc=doc_run_jdata,
- )
+ doc_run_jdata = (
+ "Parameters for simplify.json, the first argument of `dpgen simplify`."
+ )
+ return Argument(
+ "simplify_jdata",
+ dict,
+ sub_fields=[
+ *basic_args(),
+ # TODO: we may remove sys_configs; it is required in train method
+ *data_args(),
+ *general_simplify_arginfo(),
+ # simplify use the same training method as run
+ *training_args(),
+ *fp_args(),
+ ],
+ sub_variants=[
+ fp_style_variant_type_args(),
+ ],
+ doc=doc_run_jdata,
+ )
def simplify_mdata_arginfo() -> Argument:
diff --git a/dpgen/simplify/simplify.py b/dpgen/simplify/simplify.py
index 1aeabe14c..46374c6f1 100644
--- a/dpgen/simplify/simplify.py
+++ b/dpgen/simplify/simplify.py
@@ -5,41 +5,62 @@
Iter:
00: train models (same as generator)
-01: calculate model deviations of the rest dataset, pick up data with proper model deviaiton
+01: calculate model deviations of the rest dataset, pick up data with proper model deviaiton
02: fp (optional, if the original dataset do not have fp data, same as generator)
"""
+import glob
+import json
import logging
-import warnings
-import queue
import os
-import json
-import argparse
-import pickle
-import glob
-import fnmatch
+import queue
+import warnings
+from typing import List, Union
+
import dpdata
import numpy as np
-from typing import Union, List
+from packaging.version import Version
from dpgen import dlog
-from dpgen import SHORT_CMD
-from dpgen.util import sepline, expand_sys_str, normalize
-from distutils.version import LooseVersion
-from dpgen.dispatcher.Dispatcher import Dispatcher, _split_tasks, make_dispatcher, make_submission
-from dpgen.generator.run import make_train, run_train, post_train, run_fp, post_fp, fp_name, model_devi_name, train_name, train_task_fmt, sys_link_fp_vasp_pp, make_fp_vasp_incar, make_fp_vasp_kp, make_fp_vasp_cp_cvasp, data_system_fmt, model_devi_task_fmt, fp_task_fmt
-# TODO: maybe the following functions can be moved to dpgen.util
-from dpgen.generator.lib.utils import log_iter, make_iter_name, create_path, record_iter
+from dpgen.dispatcher.Dispatcher import make_submission
from dpgen.generator.lib.gaussian import make_gaussian_input
-from dpgen.remote.decide_machine import convert_mdata
-from .arginfo import simplify_jdata_arginfo
+# TODO: maybe the following functions can be moved to dpgen.util
+from dpgen.generator.lib.utils import (
+ create_path,
+ log_iter,
+ make_iter_name,
+ record_iter,
+ symlink_user_forward_files,
+)
+from dpgen.generator.run import (
+ data_system_fmt,
+ fp_name,
+ fp_task_fmt,
+ make_fp_vasp_cp_cvasp,
+ make_fp_vasp_incar,
+ make_fp_vasp_kp,
+ make_train,
+ model_devi_name,
+ model_devi_task_fmt,
+ post_fp,
+ post_train,
+ run_fp,
+ run_train,
+ sys_link_fp_vasp_pp,
+ train_name,
+ train_task_fmt,
+)
+from dpgen.remote.decide_machine import convert_mdata
+from dpgen.util import expand_sys_str, normalize, sepline
+
+from .arginfo import simplify_jdata_arginfo
picked_data_name = "data.picked"
rest_data_name = "data.rest"
accurate_data_name = "data.accurate"
detail_file_name_prefix = "details"
-sys_name_fmt = 'sys.' + data_system_fmt
-sys_name_pattern = 'sys.[0-9]*[0-9]'
+sys_name_fmt = "sys." + data_system_fmt
+sys_name_pattern = "sys.[0-9]*[0-9]"
def get_system_cls(jdata):
@@ -56,7 +77,7 @@ def get_multi_system(path: Union[str, List[str]], jdata: dict) -> dpdata.MultiSy
If `labeled` in jdata is True, returns MultiSystems with LabeledSystem.
Otherwise, returns MultiSystems with System.
-
+
Parameters
----------
path : str or list of str
@@ -76,26 +97,32 @@ def get_multi_system(path: Union[str, List[str]], jdata: dict) -> dpdata.MultiSy
for pp in path:
system_paths.extend(expand_sys_str(pp))
systems = dpdata.MultiSystems(
- *[system(s, fmt=('deepmd/npy' if "#" not in s else 'deepmd/hdf5')) for s in system_paths],
- type_map=jdata['type_map'],
+ *[
+ system(s, fmt=("deepmd/npy" if "#" not in s else "deepmd/hdf5"))
+ for s in system_paths
+ ],
+ type_map=jdata["type_map"],
)
return systems
def init_model(iter_index, jdata, mdata):
- training_init_model = jdata.get('training_init_model', False)
+ training_init_model = jdata.get("training_init_model", False)
if not training_init_model:
return
iter0_models = []
- training_iter0_model = jdata.get('training_iter0_model_path', [])
+ training_iter0_model = jdata.get("training_iter0_model_path", [])
if type(training_iter0_model) == str:
training_iter0_model = [training_iter0_model]
- for ii in training_iter0_model:
+ for ii in training_iter0_model:
model_is = glob.glob(ii)
model_is.sort()
iter0_models += [os.path.abspath(ii) for ii in model_is]
- numb_models = jdata['numb_models']
- assert(numb_models == len(iter0_models)), "training_iter0_model_path should be provided, and the number of models should be equal to %d" % numb_models
+ numb_models = jdata["numb_models"]
+ assert numb_models == len(iter0_models), (
+ "training_iter0_model_path should be provided, and the number of models should be equal to %d"
+ % numb_models
+ )
work_path = os.path.join(make_iter_name(iter_index), train_name)
create_path(work_path)
cwd = os.getcwd()
@@ -103,7 +130,7 @@ def init_model(iter_index, jdata, mdata):
train_path = os.path.join(work_path, train_task_fmt % ii)
create_path(train_path)
os.chdir(train_path)
- ckpt_files = glob.glob(os.path.join(iter0_models[ii], 'model.ckpt*'))
+ ckpt_files = glob.glob(os.path.join(iter0_models[ii], "model.ckpt*"))
for jj in ckpt_files:
os.symlink(jj, os.path.basename(jj))
os.chdir(cwd)
@@ -111,8 +138,8 @@ def init_model(iter_index, jdata, mdata):
def init_pick(iter_index, jdata, mdata):
"""pick up init data from dataset randomly"""
- pick_data = jdata['pick_data']
- init_pick_number = jdata['init_pick_number']
+ pick_data = jdata["pick_data"]
+ init_pick_number = jdata["init_pick_number"]
# use MultiSystems with System
# TODO: support System and LabeledSystem
# TODO: support other format
@@ -142,7 +169,7 @@ def init_pick(iter_index, jdata, mdata):
def _init_dump_selected_frames(systems, labels, selc_idx, sys_data_path, jdata):
- selc_systems = dpdata.MultiSystems(type_map=jdata['type_map'])
+ selc_systems = dpdata.MultiSystems(type_map=jdata["type_map"])
for j in selc_idx:
sys_name, sys_id = labels[j]
selc_systems.append(systems[sys_name][sys_id])
@@ -152,7 +179,7 @@ def _init_dump_selected_frames(systems, labels, selc_idx, sys_data_path, jdata):
def make_model_devi(iter_index, jdata, mdata):
"""calculate the model deviation of the rest idx"""
- pick_data = jdata['pick_data']
+ pick_data = jdata["pick_data"]
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, model_devi_name)
create_path(work_path)
@@ -164,11 +191,14 @@ def make_model_devi(iter_index, jdata, mdata):
model_name = os.path.basename(mm)
os.symlink(mm, os.path.join(work_path, model_name))
# link the last rest data
- last_iter_name = make_iter_name(iter_index-1)
+ last_iter_name = make_iter_name(iter_index - 1)
rest_data_path = os.path.join(last_iter_name, model_devi_name, rest_data_name)
if not os.path.exists(rest_data_path):
return False
- os.symlink(os.path.abspath(rest_data_path), os.path.join(work_path, rest_data_name + ".old"))
+ os.symlink(
+ os.path.abspath(rest_data_path),
+ os.path.join(work_path, rest_data_name + ".old"),
+ )
return True
@@ -184,43 +214,33 @@ def run_model_devi(iter_index, jdata, mdata):
model_names = [os.path.basename(ii) for ii in models]
task_model_list = []
for ii in model_names:
- task_model_list.append(os.path.join('.', ii))
+ task_model_list.append(os.path.join(".", ii))
# models
commands = []
detail_file_name = detail_file_name_prefix
command = "{dp} model-devi -m {model} -s {system} -o {detail_file}".format(
- dp=mdata.get('model_devi_command', 'dp'),
+ dp=mdata.get("model_devi_command", "dp"),
model=" ".join(task_model_list),
system=rest_data_name + ".old",
detail_file=detail_file_name,
)
commands = [command]
# submit
- model_devi_group_size = mdata.get('model_devi_group_size', 1)
+ model_devi_group_size = mdata.get("model_devi_group_size", 1)
forward_files = [rest_data_name + ".old"]
backward_files = [detail_file_name]
- api_version = mdata.get('api_version', '0.9')
- if LooseVersion(api_version) < LooseVersion('1.0'):
- warnings.warn(f"the dpdispatcher will be updated to new version."
- f"And the interface may be changed. Please check the documents for more details")
- dispatcher = make_dispatcher(mdata['model_devi_machine'], mdata['model_devi_resources'], work_path, run_tasks, model_devi_group_size)
- dispatcher.run_jobs(mdata['model_devi_resources'],
- commands,
- work_path,
- run_tasks,
- model_devi_group_size,
- model_names,
- forward_files,
- backward_files,
- outlog = 'model_devi.log',
- errlog = 'model_devi.log')
-
- elif LooseVersion(api_version) >= LooseVersion('1.0'):
+ api_version = mdata.get("api_version", "1.0")
+ if Version(api_version) < Version("1.0"):
+ raise RuntimeError(
+ "API version %s has been removed. Please upgrade to 1.0." % api_version
+ )
+
+ elif Version(api_version) >= Version("1.0"):
submission = make_submission(
- mdata['model_devi_machine'],
- mdata['model_devi_resources'],
+ mdata["model_devi_machine"],
+ mdata["model_devi_resources"],
commands=commands,
work_path=work_path,
run_tasks=run_tasks,
@@ -228,8 +248,9 @@ def run_model_devi(iter_index, jdata, mdata):
forward_common_files=model_names,
forward_files=forward_files,
backward_files=backward_files,
- outlog = 'model_devi.log',
- errlog = 'model_devi.log')
+ outlog="model_devi.log",
+ errlog="model_devi.log",
+ )
submission.run_submission()
@@ -238,17 +259,19 @@ def post_model_devi(iter_index, jdata, mdata):
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, model_devi_name)
- f_trust_lo = jdata['model_devi_f_trust_lo']
- f_trust_hi = jdata['model_devi_f_trust_hi']
+ f_trust_lo = jdata["model_devi_f_trust_lo"]
+ f_trust_hi = jdata["model_devi_f_trust_hi"]
type_map = jdata.get("type_map", [])
sys_accurate = dpdata.MultiSystems(type_map=type_map)
sys_candinate = dpdata.MultiSystems(type_map=type_map)
sys_failed = dpdata.MultiSystems(type_map=type_map)
-
+
labeled = jdata.get("labeled", False)
- sys_entire = dpdata.MultiSystems(type_map = type_map).from_deepmd_npy(os.path.join(work_path, rest_data_name + ".old"), labeled=labeled)
-
+ sys_entire = dpdata.MultiSystems(type_map=type_map).from_deepmd_npy(
+ os.path.join(work_path, rest_data_name + ".old"), labeled=labeled
+ )
+
detail_file_name = detail_file_name_prefix
with open(os.path.join(work_path, detail_file_name)) as f:
for line in f:
@@ -267,15 +290,25 @@ def post_model_devi(iter_index, jdata, mdata):
elif f_devi < f_trust_lo:
sys_accurate.append(subsys)
else:
- raise RuntimeError('reach a place that should NOT be reached...')
+ raise RuntimeError("reach a place that should NOT be reached...")
- counter = {"candidate": sys_candinate.get_nframes(), "accurate": sys_accurate.get_nframes(), "failed": sys_failed.get_nframes()}
+ counter = {
+ "candidate": sys_candinate.get_nframes(),
+ "accurate": sys_accurate.get_nframes(),
+ "failed": sys_failed.get_nframes(),
+ }
fp_sum = sum(counter.values())
for cc_key, cc_value in counter.items():
- dlog.info("{0:9s} : {1:6d} in {2:6d} {3:6.2f} %".format(cc_key, cc_value, fp_sum, cc_value/fp_sum*100))
-
- if counter['candidate'] == 0 and counter['failed'] > 0:
- raise RuntimeError('no candidate but still have failed cases, stop. You may want to refine the training or to increase the trust level hi')
+ dlog.info(
+ "{0:9s} : {1:6d} in {2:6d} {3:6.2f} %".format(
+ cc_key, cc_value, fp_sum, cc_value / fp_sum * 100
+ )
+ )
+
+ if counter["candidate"] == 0 and counter["failed"] > 0:
+ raise RuntimeError(
+ "no candidate but still have failed cases, stop. You may want to refine the training or to increase the trust level hi"
+ )
# label the candidate system
labels = []
@@ -284,20 +317,27 @@ def post_model_devi(iter_index, jdata, mdata):
for key, system in items:
labels.extend([(key, j) for j in range(len(system))])
# candinate: pick up randomly
- iter_pick_number = jdata['iter_pick_number']
- idx = np.arange(counter['candidate'])
- assert(len(idx) == len(labels))
+ iter_pick_number = jdata["iter_pick_number"]
+ idx = np.arange(counter["candidate"])
+ assert len(idx) == len(labels)
np.random.shuffle(idx)
pick_idx = idx[:iter_pick_number]
rest_idx = idx[iter_pick_number:]
- if(counter['candidate'] == 0) :
+ if counter["candidate"] == 0:
dlog.info("no candidate")
- else :
- dlog.info("total candidate {0:6d} picked {1:6d} ({2:6.2f} %) rest {3:6d} ({4:6.2f} % )".format\
- (counter['candidate'], len(pick_idx), float(len(pick_idx))/counter['candidate']*100., len(rest_idx), float(len(rest_idx))/counter['candidate']*100.))
+ else:
+ dlog.info(
+ "total candidate {0:6d} picked {1:6d} ({2:6.2f} %) rest {3:6d} ({4:6.2f} % )".format(
+ counter["candidate"],
+ len(pick_idx),
+ float(len(pick_idx)) / counter["candidate"] * 100.0,
+ len(rest_idx),
+ float(len(rest_idx)) / counter["candidate"] * 100.0,
+ )
+ )
# dump the picked candinate data
- picked_systems = dpdata.MultiSystems(type_map = type_map)
+ picked_systems = dpdata.MultiSystems(type_map=type_map)
for j in pick_idx:
sys_name, sys_id = labels[j]
picked_systems.append(sys_candinate[sys_name][sys_id])
@@ -305,18 +345,15 @@ def post_model_devi(iter_index, jdata, mdata):
picked_systems.to_deepmd_raw(sys_data_path)
picked_systems.to_deepmd_npy(sys_data_path, set_size=iter_pick_number)
-
# dump the rest data (not picked candinate data and failed data)
- rest_systems = dpdata.MultiSystems(type_map = type_map)
+ rest_systems = dpdata.MultiSystems(type_map=type_map)
for j in rest_idx:
sys_name, sys_id = labels[j]
rest_systems.append(sys_candinate[sys_name][sys_id])
rest_systems += sys_failed
sys_data_path = os.path.join(work_path, rest_data_name)
rest_systems.to_deepmd_raw(sys_data_path)
- if rest_idx.size:
- rest_systems.to_deepmd_npy(sys_data_path, set_size=rest_idx.size)
-
+ rest_systems.to_deepmd_npy(sys_data_path, set_size=rest_systems.get_nframes())
# dump the accurate data -- to another directory
sys_data_path = os.path.join(work_path, accurate_data_name)
@@ -324,21 +361,25 @@ def post_model_devi(iter_index, jdata, mdata):
sys_accurate.to_deepmd_npy(sys_data_path, set_size=sys_accurate.get_nframes())
-def make_fp_labeled(iter_index, jdata):
+def make_fp_labeled(iter_index, jdata):
dlog.info("already labeled, skip make_fp and link data directly")
- pick_data = jdata['pick_data']
+ pick_data = jdata["pick_data"]
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
create_path(work_path)
picked_data_path = os.path.join(iter_name, model_devi_name, picked_data_name)
- os.symlink(os.path.abspath(picked_data_path), os.path.abspath(
- os.path.join(work_path, "task." + data_system_fmt % 0)))
- os.symlink(os.path.abspath(picked_data_path), os.path.abspath(
- os.path.join(work_path, "data." + data_system_fmt % 0)))
+ os.symlink(
+ os.path.abspath(picked_data_path),
+ os.path.abspath(os.path.join(work_path, "task." + fp_task_fmt % (0, 0))),
+ )
+ os.symlink(
+ os.path.abspath(picked_data_path),
+ os.path.abspath(os.path.join(work_path, "data." + data_system_fmt % 0)),
+ )
def make_fp_configs(iter_index, jdata):
- pick_data = jdata['pick_data']
+ pick_data = jdata["pick_data"]
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
create_path(work_path)
@@ -351,57 +392,57 @@ def make_fp_configs(iter_index, jdata):
task_name = "task." + fp_task_fmt % (ii, jj)
task_path = os.path.join(work_path, task_name)
create_path(task_path)
- subsys.to('vasp/poscar', os.path.join(task_path, 'POSCAR'))
+ subsys.to("vasp/poscar", os.path.join(task_path, "POSCAR"))
jj += 1
ii += 1
def make_fp_gaussian(iter_index, jdata):
work_path = os.path.join(make_iter_name(iter_index), fp_name)
- fp_tasks = glob.glob(os.path.join(work_path, 'task.*'))
+ fp_tasks = glob.glob(os.path.join(work_path, "task.*"))
cwd = os.getcwd()
- if 'user_fp_params' in jdata.keys() :
- fp_params = jdata['user_fp_params']
+ if "user_fp_params" in jdata.keys():
+ fp_params = jdata["user_fp_params"]
else:
- fp_params = jdata['fp_params']
+ fp_params = jdata["fp_params"]
cwd = os.getcwd()
for ii in fp_tasks:
os.chdir(ii)
- sys_data = dpdata.System('POSCAR').data
+ sys_data = dpdata.System("POSCAR").data
ret = make_gaussian_input(sys_data, fp_params)
- with open('input', 'w') as fp:
+ with open("input", "w") as fp:
fp.write(ret)
os.chdir(cwd)
def make_fp_vasp(iter_index, jdata):
# abs path for fp_incar if it exists
- if 'fp_incar' in jdata:
- jdata['fp_incar'] = os.path.abspath(jdata['fp_incar'])
+ if "fp_incar" in jdata:
+ jdata["fp_incar"] = os.path.abspath(jdata["fp_incar"])
# get nbands esti if it exists
- if 'fp_nbands_esti_data' in jdata:
- nbe = NBandsEsti(jdata['fp_nbands_esti_data'])
+ if "fp_nbands_esti_data" in jdata:
+ nbe = NBandsEsti(jdata["fp_nbands_esti_data"])
else:
nbe = None
# order is critical!
# 1, create potcar
sys_link_fp_vasp_pp(iter_index, jdata)
# 2, create incar
- make_fp_vasp_incar(iter_index, jdata, nbands_esti = nbe)
+ make_fp_vasp_incar(iter_index, jdata, nbands_esti=nbe)
# 3, create kpoints
make_fp_vasp_kp(iter_index, jdata)
# 4, copy cvasp
- make_fp_vasp_cp_cvasp(iter_index,jdata)
+ make_fp_vasp_cp_cvasp(iter_index, jdata)
def make_fp_calculation(iter_index, jdata):
- fp_style = jdata['fp_style']
- if fp_style == 'vasp':
+ fp_style = jdata["fp_style"]
+ if fp_style == "vasp":
make_fp_vasp(iter_index, jdata)
- elif fp_style == 'gaussian':
+ elif fp_style == "gaussian":
make_fp_gaussian(iter_index, jdata)
- else :
- raise RuntimeError('unsupported fp_style ' + fp_style)
+ else:
+ raise RuntimeError("unsupported fp_style " + fp_style)
def make_fp(iter_index, jdata, mdata):
@@ -411,10 +452,14 @@ def make_fp(iter_index, jdata, mdata):
else:
make_fp_configs(iter_index, jdata)
make_fp_calculation(iter_index, jdata)
+ # Copy user defined forward_files
+ iter_name = make_iter_name(iter_index)
+ work_path = os.path.join(iter_name, fp_name)
+ symlink_user_forward_files(mdata=mdata, task_type="fp", work_path=work_path)
def run_iter(param_file, machine_file):
- """ init (iter 0): init_pick
+ """init (iter 0): init_pick
tasks (iter > 0):
00 make_train (same as generator)
@@ -430,30 +475,29 @@ def run_iter(param_file, machine_file):
# TODO: function of handling input json should be combined as one function
try:
import ruamel
- from monty.serialization import loadfn, dumpfn
- warnings.simplefilter(
- 'ignore', ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
+ from monty.serialization import dumpfn, loadfn
+
+ warnings.simplefilter("ignore", ruamel.yaml.error.MantissaNoDotYAML1_1Warning)
jdata = loadfn(param_file)
mdata = loadfn(machine_file)
except Exception:
- with open(param_file, 'r') as fp:
+ with open(param_file, "r") as fp:
jdata = json.load(fp)
- with open(machine_file, 'r') as fp:
+ with open(machine_file, "r") as fp:
mdata = json.load(fp)
jdata_arginfo = simplify_jdata_arginfo()
jdata = normalize(jdata_arginfo, jdata)
- if mdata.get('handlers', None):
- if mdata['handlers'].get('smtp', None):
+ if mdata.get("handlers", None):
+ if mdata["handlers"].get("smtp", None):
que = queue.Queue(-1)
queue_handler = logging.handlers.QueueHandler(que)
- smtp_handler = logging.handlers.SMTPHandler(
- **mdata['handlers']['smtp'])
+ smtp_handler = logging.handlers.SMTPHandler(**mdata["handlers"]["smtp"])
listener = logging.handlers.QueueListener(que, smtp_handler)
dlog.addHandler(queue_handler)
listener.start()
-
+
mdata = convert_mdata(mdata)
max_tasks = 10000
numb_task = 9
@@ -463,21 +507,20 @@ def run_iter(param_file, machine_file):
with open(record) as frec:
for line in frec:
iter_rec = [int(x) for x in line.split()]
- dlog.info("continue from iter %03d task %02d" %
- (iter_rec[0], iter_rec[1]))
+ dlog.info("continue from iter %03d task %02d" % (iter_rec[0], iter_rec[1]))
cont = True
ii = -1
while cont:
ii += 1
iter_name = make_iter_name(ii)
- sepline(iter_name, '=')
+ sepline(iter_name, "=")
for jj in range(numb_task):
if ii * max_tasks + jj <= iter_rec[0] * max_tasks + iter_rec[1]:
continue
task_name = "task %02d" % jj
- sepline("{} {}".format(iter_name, task_name), '-')
- jdata['model_devi_jobs'] = [{} for _ in range(ii+1)]
+ sepline("{} {}".format(iter_name, task_name), "-")
+ jdata["model_devi_jobs"] = [{} for _ in range(ii + 1)]
if ii == 0 and jj < 6:
if jj == 0:
log_iter("init_pick", ii, jj)
@@ -489,7 +532,7 @@ def run_iter(param_file, machine_file):
make_train(ii, jdata, mdata)
elif jj == 1:
log_iter("run_train", ii, jj)
- #disp = make_dispatcher(mdata['train_machine'])
+ # disp = make_dispatcher(mdata['train_machine'])
run_train(ii, jdata, mdata)
elif jj == 2:
log_iter("post_train", ii, jj)
@@ -497,11 +540,11 @@ def run_iter(param_file, machine_file):
elif jj == 3:
log_iter("make_model_devi", ii, jj)
cont = make_model_devi(ii, jdata, mdata)
- if not cont or ii >= jdata.get("stop_iter", ii+1):
+ if not cont or ii >= jdata.get("stop_iter", ii + 1):
break
elif jj == 4:
log_iter("run_model_devi", ii, jj)
- #disp = make_dispatcher(mdata['model_devi_machine'])
+ # disp = make_dispatcher(mdata['model_devi_machine'])
run_model_devi(ii, jdata, mdata)
elif jj == 5:
log_iter("post_model_devi", ii, jj)
@@ -514,7 +557,7 @@ def run_iter(param_file, machine_file):
if jdata.get("labeled", False):
dlog.info("already have labeled data, skip run_fp")
else:
- #disp = make_dispatcher(mdata['fp_machine'])
+ # disp = make_dispatcher(mdata['fp_machine'])
run_fp(ii, jdata, mdata)
elif jj == 8:
log_iter("post_fp", ii, jj)
diff --git a/dpgen/tools/auto_gen_param.py b/dpgen/tools/auto_gen_param.py
index cd6252d3d..9b6340b20 100755
--- a/dpgen/tools/auto_gen_param.py
+++ b/dpgen/tools/auto_gen_param.py
@@ -1,10 +1,11 @@
#%%
-import os
import argparse
import json
+import os
from collections import defaultdict
from itertools import tee
+
class System(object):
current_num_of_system = 0
current_num_of_sub_systems = 0
@@ -14,76 +15,80 @@ def index_system(self):
return self._index_system
@index_system.setter
- def index_system(self,value):
+ def index_system(self, value):
self._index_system = value
-
+
@classmethod
def register_system(cls):
- cls.current_num_of_system+=1
- return cls.current_num_of_system-1
-
+ cls.current_num_of_system += 1
+ return cls.current_num_of_system - 1
+
@classmethod
def register_sub_system(cls):
- cls.current_num_of_sub_systems+=1
- return cls.current_num_of_sub_systems-1
+ cls.current_num_of_sub_systems += 1
+ return cls.current_num_of_sub_systems - 1
def __init__(self, system_prefix=""):
# print(files_list)
# if sum(map_relations)>len(files_list):
# raise RuntimeError(
- # "files_list not enough;sum(map_relations):%s>len(files_list):%s, %s"
+ # "files_list not enough;sum(map_relations):%s>len(files_list):%s, %s"
# % (sum(map_relations),len(files_list),files_list,))
self.index_system = self.register_system()
self.sub_system_list = []
self.system_prefix = system_prefix
self.current_idx2 = 0
-
- def add_sub_system(self,idx2, files_list):
+
+ def add_sub_system(self, idx2, files_list):
idx1 = self.register_sub_system()
- idx2 = self.current_idx2
+ idx2 = self.current_idx2
self.sub_system_list.append((idx1, self.index_system, idx2, files_list))
self.current_idx2 += 1
-
+
def get_sub_system(self):
return self.sub_system_list
-
+
class Iteration(object):
current_num_of_itearation = 0
current_num_of_sub_itearation = 0
-
+
@property
def index_iteration(self):
- return self._index_iteration # pylint: disable=no-member
-
+ return self._index_iteration # pylint: disable=no-member
+
@index_iteration.setter
def index_iteration(self, value):
self._index_sub_iteration = value
-
+
@classmethod
def register_iteration(cls):
- cls.current_num_of_itearation+=1
- return cls.current_num_of_itearation-1
-
+ cls.current_num_of_itearation += 1
+ return cls.current_num_of_itearation - 1
+
@classmethod
def register_sub_iteartion(cls):
- cls.current_num_of_sub_itearation +=1
- return cls.current_num_of_sub_itearation-1
-
- def __init__(self,
- temps,
- nsteps_list=[500, 500, 1000, 1000, 3000, 3000, 6000, 6000],
- sub_iteration_num=8,
- ensemble='npt',
- press=[1.0, 10.0, 100.0, 1000.0, 5000.0, 10000.0, 20000.0, 50000.0],
- trj_freq=10):
+ cls.current_num_of_sub_itearation += 1
+ return cls.current_num_of_sub_itearation - 1
+
+ def __init__(
+ self,
+ temps,
+ nsteps_list=[500, 500, 1000, 1000, 3000, 3000, 6000, 6000],
+ sub_iteration_num=8,
+ ensemble="npt",
+ press=[1.0, 10.0, 100.0, 1000.0, 5000.0, 10000.0, 20000.0, 50000.0],
+ trj_freq=10,
+ ):
if len(nsteps_list) != sub_iteration_num:
- raise RuntimeError(f'{nsteps_list}, {sub_iteration_num}; length does not match')
+ raise RuntimeError(
+ f"{nsteps_list}, {sub_iteration_num}; length does not match"
+ )
self.temps = temps
self.index_iteration = self.register_iteration()
- self.nsteps_list=nsteps_list
- self.sub_iteration_num=sub_iteration_num
- self.ensemble=ensemble
+ self.nsteps_list = nsteps_list
+ self.sub_iteration_num = sub_iteration_num
+ self.ensemble = ensemble
self.press = press
self.trj_freq = trj_freq
@@ -91,62 +96,75 @@ def gen_sub_iter(self, system_list):
sub_iter_list = []
for idx2 in range(self.sub_iteration_num):
iter_dict = {}
- iter_dict['_idx'] = self.register_sub_iteartion()
- iter_dict['ensemble'] = self.ensemble
- iter_dict['nsteps'] = self.nsteps_list[idx2]
- iter_dict['press'] = self.press
- iter_dict['sys_idx'] = [ii[0] for ii in system_list if ii[2]==idx2]
- iter_dict['temps'] = self.temps
- iter_dict['trj_freq'] = self.trj_freq
+ iter_dict["_idx"] = self.register_sub_iteartion()
+ iter_dict["ensemble"] = self.ensemble
+ iter_dict["nsteps"] = self.nsteps_list[idx2]
+ iter_dict["press"] = self.press
+ iter_dict["sys_idx"] = [ii[0] for ii in system_list if ii[2] == idx2]
+ iter_dict["temps"] = self.temps
+ iter_dict["trj_freq"] = self.trj_freq
sub_iter_list.append(iter_dict)
return sub_iter_list
-def default_map_generator(map_list=[1,1,2,2,2,4,4,4], data_list=None):
+
+def default_map_generator(map_list=[1, 1, 2, 2, 2, 4, 4, 4], data_list=None):
num = 0
# if len(data_list) < sum(map_list):
# raise RuntimeError(f'{data_list} < {map_list};not enough structure to expore, data_list_too_short!')
- if (data_list is None) and ( all(el%10==0 for el in map_list) ):
+ if (data_list is None) and (all(el % 10 == 0 for el in map_list)):
for ii in map_list:
- yield [f"{jj:0<5}?" for jj in range(num, num+ii//10)]
- num+=(ii//10)
+ yield [f"{jj:0<5}?" for jj in range(num, num + ii // 10)]
+ num += ii // 10
elif data_list:
for ii in map_list:
- yield [data_list[jj] for jj in range(num, num+ii)]
+ yield [data_list[jj] for jj in range(num, num + ii)]
num += ii
raise RuntimeError(f"{map_list} length is not enough")
# while True:
- # yield [data_list[jj] for jj in range(num, num+ii)]
- # num += ii
+ # yield [data_list[jj] for jj in range(num, num+ii)]
+ # num += ii
+
-def get_system_list(system_dict,
- map_list=[1,1,2,2,2,4,4,4],
- meta_iter_num=4,
- sub_iteration_num=8,
+def get_system_list(
+ system_dict,
+ map_list=[1, 1, 2, 2, 2, 4, 4, 4],
+ meta_iter_num=4,
+ sub_iteration_num=8,
map_iterator=None,
- file_name="POSCAR"):
+ file_name="POSCAR",
+):
"""
:type map_iterator: Iterable use to generate sys_configs
:Exmaple [['000000', '000001',], ['00000[2-9]',], ['00001?', '000020',],]
"""
if sub_iteration_num != len(map_list):
- raise RuntimeError(f"{sub_iteration_num},{map_list};sub_iteration_num does not match the length of map_list")
-
+ raise RuntimeError(
+ f"{sub_iteration_num},{map_list};sub_iteration_num does not match the length of map_list"
+ )
+
system_list = []
- for system_prefix,data_list in system_dict.items():
+ for system_prefix, data_list in system_dict.items():
if map_iterator is None:
- print('12', data_list)
- new_map_iterator = default_map_generator(map_list=map_list, data_list=data_list)
+ print("12", data_list)
+ new_map_iterator = default_map_generator(
+ map_list=map_list, data_list=data_list
+ )
else:
- origin_one, new_map_iterator = tee(map_iterator) # pylint: disable=unused-variable
- # tee means copy;new_map_generator will become a copy of map_iterator
+ origin_one, new_map_iterator = tee(
+ map_iterator
+ ) # pylint: disable=unused-variable
+ # tee means copy;new_map_generator will become a copy of map_iterator
system = System(system_prefix)
for idx2 in range(sub_iteration_num):
- files_list = [os.path.join(system_prefix, jj) for jj in next(new_map_iterator)]
+ files_list = [
+ os.path.join(system_prefix, jj) for jj in next(new_map_iterator)
+ ]
system.add_sub_system(idx2=idx2, files_list=files_list)
system_list.extend(system.get_sub_system())
return system_list
-def scan_files(scan_dir="./" ,file_name="POSCAR", min_allow_files_num=20):
+
+def scan_files(scan_dir="./", file_name="POSCAR", min_allow_files_num=20):
# will return
# files_list=[]
system_dict = defaultdict(list)
@@ -155,81 +173,94 @@ def scan_files(scan_dir="./" ,file_name="POSCAR", min_allow_files_num=20):
system_prefix = os.path.dirname(ii[0])
system_suffix = os.path.basename(ii[0])
system_dict[system_prefix].append(os.path.join(system_suffix, file_name))
- for k,v in list(system_dict.items()):
+ for k, v in list(system_dict.items()):
if len(v) < min_allow_files_num:
del system_dict[k]
return system_dict
+
# def gen_
-
+
+
def default_temps_generator(melt_point, temps_intervel=0.1, num_temps=5):
- temps = [50, ]
- last_temp = 0
- for ii in range(num_temps-1): # pylint: disable=unused-variable
- last_temp = last_temp + temps_intervel*melt_point
+ temps = [
+ 50,
+ ]
+ last_temp = 0
+ for ii in range(num_temps - 1): # pylint: disable=unused-variable
+ last_temp = last_temp + temps_intervel * melt_point
temps.append(last_temp)
yield temps
while True:
temps = []
for ii in range(num_temps):
- last_temp = last_temp + temps_intervel*melt_point
+ last_temp = last_temp + temps_intervel * melt_point
temps.append(last_temp)
yield temps
-def get_model_devi_jobs(melt_point,
+
+def get_model_devi_jobs(
+ melt_point,
system_list,
nsteps_list=[500, 500, 1000, 1000, 3000, 3000, 6000, 6000],
press=[1.0, 10.0, 100.0, 1000.0, 5000.0, 10000.0, 20000.0, 50000.0],
- meta_iter_num=4,
+ meta_iter_num=4,
sub_iteration_num=8,
temps_iterator=None,
ensemble="npt",
trj_freq=10,
temps_intervel=0.1,
- num_temps=5):
+ num_temps=5,
+):
if temps_iterator is None:
- temps_iterator = default_temps_generator(melt_point=melt_point,
- temps_intervel=temps_intervel, num_temps=num_temps)
+ temps_iterator = default_temps_generator(
+ melt_point=melt_point, temps_intervel=temps_intervel, num_temps=num_temps
+ )
if len(nsteps_list) != sub_iteration_num:
raise RuntimeError(f"{nsteps_list}, {sub_iteration_num};length do not match!")
- model_devi_jobs =[]
- for ii in range(meta_iter_num): # pylint: disable=unused-variable
+ model_devi_jobs = []
+ for ii in range(meta_iter_num): # pylint: disable=unused-variable
temps = next(temps_iterator)
- meta_iter = Iteration(temps=temps,
+ meta_iter = Iteration(
+ temps=temps,
nsteps_list=nsteps_list,
sub_iteration_num=sub_iteration_num,
ensemble=ensemble,
press=press,
- trj_freq=trj_freq)
+ trj_freq=trj_freq,
+ )
model_devi_jobs.extend(meta_iter.gen_sub_iter(system_list))
return model_devi_jobs
+
def get_sys_configs(system_list):
- sys_configs=[[] for ii in system_list]
+ sys_configs = [[] for ii in system_list]
for t in system_list:
- sys_configs[t[0]]=t[3]
+ sys_configs[t[0]] = t[3]
return sys_configs
-def get_init_data_sys(scan_dir='./', init_file_name='type.raw'):
+
+def get_init_data_sys(scan_dir="./", init_file_name="type.raw"):
init_data_sys = []
for t in os.walk(scan_dir):
if init_file_name in t[2]:
init_data_sys.append(t[0])
- else:
+ else:
pass
return init_data_sys
-def get_basic_param_json(melt_point,
- out_param_filename='param_basic.json',
- scan_dir="./",
- file_name='POSCAR',
- init_file_name='type.raw',
+def get_basic_param_json(
+ melt_point,
+ out_param_filename="param_basic.json",
+ scan_dir="./",
+ file_name="POSCAR",
+ init_file_name="type.raw",
min_allow_files_num=16,
- map_list=[1,1,2,2,2,4,4,4],
+ map_list=[1, 1, 2, 2, 2, 4, 4, 4],
meta_iter_num=4,
sub_iteration_num=8,
map_iterator=None,
@@ -239,58 +270,70 @@ def get_basic_param_json(melt_point,
ensemble="npt",
trj_freq=10,
temps_intervel=0.1,
- num_temps=5,):
+ num_temps=5,
+):
init_data_sys = get_init_data_sys(scan_dir=scan_dir, init_file_name=init_file_name)
print(f"length of init_data_sys: {len(init_data_sys)} {init_data_sys}")
system_dict = scan_files(scan_dir, file_name, min_allow_files_num)
print(f"num of different systems: {len(system_dict)}")
- system_list =get_system_list(system_dict,
- map_list=map_list,
- meta_iter_num=meta_iter_num,
- sub_iteration_num=sub_iteration_num,
+ system_list = get_system_list(
+ system_dict,
+ map_list=map_list,
+ meta_iter_num=meta_iter_num,
+ sub_iteration_num=sub_iteration_num,
map_iterator=map_iterator,
- file_name=file_name)
+ file_name=file_name,
+ )
sys_configs = get_sys_configs(system_list)
print(f"length of sys_configs: {len(sys_configs)}")
- model_devi_jobs = get_model_devi_jobs(melt_point=melt_point,
+ model_devi_jobs = get_model_devi_jobs(
+ melt_point=melt_point,
system_list=system_list,
nsteps_list=nsteps_list,
press=press,
- meta_iter_num=meta_iter_num,
- sub_iteration_num=sub_iteration_num,
+ meta_iter_num=meta_iter_num,
+ sub_iteration_num=sub_iteration_num,
temps_iterator=temps_iterator,
ensemble=ensemble,
trj_freq=trj_freq,
temps_intervel=temps_intervel,
- num_temps=num_temps)
- param_dict={
- 'init_data_sys': init_data_sys,
- 'sys_configs':sys_configs,
- 'model_devi_jobs':model_devi_jobs
+ num_temps=num_temps,
+ )
+ param_dict = {
+ "init_data_sys": init_data_sys,
+ "sys_configs": sys_configs,
+ "model_devi_jobs": model_devi_jobs,
}
- with open(out_param_filename, 'w') as p:
+ with open(out_param_filename, "w") as p:
json.dump(param_dict, p, indent=4)
- return param_dict
+ return param_dict
+
+
def _main():
- parser = argparse.ArgumentParser(description='Collect data from inputs and generate basic param.json')
+ parser = argparse.ArgumentParser(
+ description="Collect data from inputs and generate basic param.json"
+ )
parser.add_argument("melt_point", type=float, help="melt_point")
# parser.addparser.add_argument("JOB_DIR", type=str, help="the directory of the DP-GEN job")
args = parser.parse_args()
get_basic_param_json(melt_point=args.melt_point)
-
-if __name__=='__main__':
+
+
+if __name__ == "__main__":
_main()
+
def auto_gen_param(args):
if args.PARAM:
with open(args.PARAM) as p:
j = json.load(p)
- melt_point = j['melt_point']
- print('param_basic.json', get_basic_param_json(melt_point=melt_point))
+ melt_point = j["melt_point"]
+ print("param_basic.json", get_basic_param_json(melt_point=melt_point))
else:
- raise RuntimeError('must provide melt point or PARAM')
+ raise RuntimeError("must provide melt point or PARAM")
+
#%%
diff --git a/dpgen/tools/collect_data.py b/dpgen/tools/collect_data.py
index b1d2d59ac..2a270a47e 100755
--- a/dpgen/tools/collect_data.py
+++ b/dpgen/tools/collect_data.py
@@ -1,8 +1,14 @@
#!/usr/bin/env python3
-import os,sys,json,glob,argparse
-import numpy as np
+import argparse
+import glob
+import json
+import os
import subprocess as sp
+import sys
+
+import numpy as np
+
def file_len(fname):
with open(fname) as f:
@@ -10,94 +16,105 @@ def file_len(fname):
pass
return i + 1
-def collect_data(target_folder, param_file, output, verbose = True) :
+
+def collect_data(target_folder, param_file, output, verbose=True):
target_folder = os.path.abspath(target_folder)
output = os.path.abspath(output)
- tool_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'template')
- command_cvt_2_raw = os.path.join(tool_path, 'tools.vasp', 'convert2raw.py')
- command_cvt_2_raw += ' data.configs'
- command_shuffle_raw = os.path.join(tool_path, 'tools.raw', 'shuffle_raw.py')
- command_raw_2_set = os.path.join(tool_path, 'tools.raw', 'raw_to_set.sh')
- # goto input
+ tool_path = os.path.join(
+ os.path.dirname(os.path.realpath(__file__)), "..", "template"
+ )
+ command_cvt_2_raw = os.path.join(tool_path, "tools.vasp", "convert2raw.py")
+ command_cvt_2_raw += " data.configs"
+ command_shuffle_raw = os.path.join(tool_path, "tools.raw", "shuffle_raw.py")
+ command_raw_2_set = os.path.join(tool_path, "tools.raw", "raw_to_set.sh")
+ # goto input
cwd = os.getcwd()
os.chdir(target_folder)
jdata = json.load(open(param_file))
- sys = jdata['sys_configs']
- if verbose :
+ sys = jdata["sys_configs"]
+ if verbose:
max_str_len = max([len(str(ii)) for ii in sys])
- ptr_fmt = '%%%ds %%6d' % (max_str_len+5)
+ ptr_fmt = "%%%ds %%6d" % (max_str_len + 5)
# collect systems from iter dirs
- coll_sys = [[] for ii in sys]
+ coll_sys = [[] for ii in sys]
numb_sys = len(sys)
- iters = glob.glob('iter.[0-9]*[0-9]')
- iters.sort()
- for ii in iters :
- iter_data = glob.glob(os.path.join(ii, '02.fp', 'data.[0-9]*[0-9]'))
+ iters = glob.glob("iter.[0-9]*[0-9]")
+ iters.sort()
+ for ii in iters:
+ iter_data = glob.glob(os.path.join(ii, "02.fp", "data.[0-9]*[0-9]"))
iter_data.sort()
- for jj in iter_data :
- sys_idx = int(os.path.basename(jj).split('.')[-1])
+ for jj in iter_data:
+ sys_idx = int(os.path.basename(jj).split(".")[-1])
coll_sys[sys_idx].append(jj)
# create output dir
- os.makedirs(output, exist_ok = True)
+ os.makedirs(output, exist_ok=True)
# loop over systems
- for idx,ii in enumerate(coll_sys) :
- if len(ii) == 0 :
+ for idx, ii in enumerate(coll_sys):
+ if len(ii) == 0:
continue
# link iter data dirs
- out_sys_path = os.path.join(output, 'system.%03d' % idx)
+ out_sys_path = os.path.join(output, "system.%03d" % idx)
os.makedirs(out_sys_path, exist_ok=True)
cwd_ = os.getcwd()
os.chdir(out_sys_path)
- for jj in ii :
+ for jj in ii:
in_sys_path = os.path.join(target_folder, jj)
- in_iter = in_sys_path.split('/')[-3]
- in_base = in_sys_path.split('/')[-1]
- out_file = in_iter + '.' + in_base
- if os.path.exists(out_file) :
+ in_iter = in_sys_path.split("/")[-3]
+ in_base = in_sys_path.split("/")[-1]
+ out_file = in_iter + "." + in_base
+ if os.path.exists(out_file):
os.remove(out_file)
os.symlink(in_sys_path, out_file)
# cat data.configs
- data_configs = glob.glob(os.path.join('iter.[0-9]*[0-9].data.[0-9]*[0-9]', 'orig', 'data.configs'))
+ data_configs = glob.glob(
+ os.path.join("iter.[0-9]*[0-9].data.[0-9]*[0-9]", "orig", "data.configs")
+ )
data_configs.sort()
- os.makedirs('orig', exist_ok = True)
- with open(os.path.join('orig', 'data.configs'), 'w') as outfile:
+ os.makedirs("orig", exist_ok=True)
+ with open(os.path.join("orig", "data.configs"), "w") as outfile:
for fname in data_configs:
with open(fname) as infile:
- outfile.write(infile.read())
+ outfile.write(infile.read())
# convert to raw
- os.chdir('orig')
- sp.check_call(command_cvt_2_raw, shell = True)
- os.chdir('..')
+ os.chdir("orig")
+ sp.check_call(command_cvt_2_raw, shell=True)
+ os.chdir("..")
# shuffle raw
- sp.check_call(command_shuffle_raw + ' orig ' + ' . > /dev/null', shell = True)
- if os.path.exists('type.raw') :
- os.remove('type.raw')
- os.symlink(os.path.join('orig', 'type.raw'), 'type.raw')
+ sp.check_call(command_shuffle_raw + " orig " + " . > /dev/null", shell=True)
+ if os.path.exists("type.raw"):
+ os.remove("type.raw")
+ os.symlink(os.path.join("orig", "type.raw"), "type.raw")
# raw to sets
- sp.check_call(command_raw_2_set + ' > /dev/null', shell = True)
+ sp.check_call(command_raw_2_set + " > /dev/null", shell=True)
# print summary
- if verbose :
- ndata = file_len('box.raw')
+ if verbose:
+ ndata = file_len("box.raw")
print(ptr_fmt % (str(sys[idx]), ndata))
# ch dir
os.chdir(cwd_)
-def _main() :
- parser = argparse.ArgumentParser(description='Collect data from DP-GEN iterations')
- parser.add_argument("JOB_DIR", type=str,
- help="the directory of the DP-GEN job")
- parser.add_argument("OUTPUT", type=str,
- help="the output directory of data")
- parser.add_argument('-p',"--parameter", type=str, default = 'param.json',
- help="the json file provides DP-GEN paramters, should be located in JOB_DIR")
- parser.add_argument('-v',"--verbose", action = 'store_true',
- help="print number of data in each system")
+def _main():
+ parser = argparse.ArgumentParser(description="Collect data from DP-GEN iterations")
+ parser.add_argument("JOB_DIR", type=str, help="the directory of the DP-GEN job")
+ parser.add_argument("OUTPUT", type=str, help="the output directory of data")
+ parser.add_argument(
+ "-p",
+ "--parameter",
+ type=str,
+ default="param.json",
+ help="the json file provides DP-GEN paramters, should be located in JOB_DIR",
+ )
+ parser.add_argument(
+ "-v",
+ "--verbose",
+ action="store_true",
+ help="print number of data in each system",
+ )
args = parser.parse_args()
-
- collect_data(args.JOB_DIR, args.parameter, args.OUTPUT, args.verbose)
-if __name__ == '__main__':
- _main()
+ collect_data(args.JOB_DIR, args.parameter, args.OUTPUT, args.verbose)
-
+
+if __name__ == "__main__":
+ _main()
diff --git a/dpgen/tools/relabel.py b/dpgen/tools/relabel.py
index 21dd0bf8e..ac5196eaa 100755
--- a/dpgen/tools/relabel.py
+++ b/dpgen/tools/relabel.py
@@ -1,158 +1,181 @@
#!/usr/bin/env python3
-import os,sys,json,glob,argparse,shutil
-import numpy as np
+import argparse
+import glob
+import json
+import os
+import shutil
import subprocess as sp
-sys.path.insert(0, os.path.join(os.path.dirname(os.path.realpath(__file__)), '..'))
+import sys
+
+import numpy as np
+
+sys.path.insert(0, os.path.join(os.path.dirname(os.path.realpath(__file__)), ".."))
+import dpdata
+
from dpgen.generator.lib.pwscf import make_pwscf_input
from dpgen.generator.lib.siesta import make_siesta_input
from dpgen.generator.run import make_vasp_incar, update_mass_map
-import dpdata
-def get_lmp_info(input_file) :
+
+def get_lmp_info(input_file):
with open(input_file) as fp:
- lines = [line.rstrip('\n') for line in fp]
- for ii in lines :
+ lines = [line.rstrip("\n") for line in fp]
+ for ii in lines:
words = ii.split()
- if len(words) >= 4 and words[0] == 'variable' :
- if words[1] == 'TEMP' :
+ if len(words) >= 4 and words[0] == "variable":
+ if words[1] == "TEMP":
temp = float(words[3])
- elif words[1] == 'PRES' :
+ elif words[1] == "PRES":
pres = float(words[3])
- if len(words) >= 4 and words[0] == 'fix' :
- if words[3] == 'nvt' :
- ens = 'nvt'
- elif words[3] == 'npt' :
- ens = 'npt'
+ if len(words) >= 4 and words[0] == "fix":
+ if words[3] == "nvt":
+ ens = "nvt"
+ elif words[3] == "npt":
+ ens = "npt"
return ens, temp, pres
-def link_pp_files(tdir, fp_pp_path, fp_pp_files) :
+def link_pp_files(tdir, fp_pp_path, fp_pp_files):
cwd = os.getcwd()
os.chdir(tdir)
- for ii in fp_pp_files :
- if os.path.lexists(ii) :
+ for ii in fp_pp_files:
+ if os.path.lexists(ii):
os.remove(ii)
- os.symlink(os.path.join(fp_pp_path, ii), ii)
+ os.symlink(os.path.join(fp_pp_path, ii), ii)
os.chdir(cwd)
-def copy_pp_files(tdir, fp_pp_path, fp_pp_files) :
+def copy_pp_files(tdir, fp_pp_path, fp_pp_files):
cwd = os.getcwd()
os.chdir(tdir)
- for ii in fp_pp_files :
- if os.path.lexists(ii) :
+ for ii in fp_pp_files:
+ if os.path.lexists(ii):
os.remove(ii)
- if os.path.exists(ii) :
+ if os.path.exists(ii):
os.remove(ii)
- shutil.copyfile(os.path.join(fp_pp_path, ii), ii)
+ shutil.copyfile(os.path.join(fp_pp_path, ii), ii)
os.chdir(cwd)
-
-
-def make_vasp(tdir, fp_params) :
+
+
+def make_vasp(tdir, fp_params):
cwd = os.getcwd()
os.chdir(tdir)
incar = make_vasp_incar(fp_params)
- with open('INCAR', 'w') as fp:
+ with open("INCAR", "w") as fp:
fp.write(incar)
os.chdir(cwd)
-
-def make_vasp_incar(tdir, fp_incar) :
+
+
+def make_vasp_incar(tdir, fp_incar):
cwd = os.getcwd()
os.chdir(tdir)
- shutil.copyfile(fp_incar, 'INCAR')
- os.chdir(cwd)
+ shutil.copyfile(fp_incar, "INCAR")
+ os.chdir(cwd)
-def make_pwscf(tdir, fp_params, mass_map, fp_pp_path, fp_pp_files, user_input) :
+
+def make_pwscf(tdir, fp_params, mass_map, fp_pp_path, fp_pp_files, user_input):
cwd = os.getcwd()
os.chdir(tdir)
- sys_data = dpdata.System('POSCAR').data
- sys_data['atom_masses'] = mass_map
+ sys_data = dpdata.System("POSCAR").data
+ sys_data["atom_masses"] = mass_map
ret = make_pwscf_input(sys_data, fp_pp_files, fp_params)
- open('input', 'w').write(ret)
+ open("input", "w").write(ret)
os.chdir(cwd)
-def make_siesta(tdir, fp_params, fp_pp_path, fp_pp_files) :
+
+def make_siesta(tdir, fp_params, fp_pp_path, fp_pp_files):
cwd = os.getcwd()
os.chdir(tdir)
- sys_data = dpdata.System('POSCAR').data
+ sys_data = dpdata.System("POSCAR").data
ret = make_siesta_input(sys_data, fp_pp_files, fp_params)
- open('input', 'w').write(ret)
+ open("input", "w").write(ret)
os.chdir(cwd)
-def create_init_tasks(target_folder, param_file, output, fp_json, verbose = True) :
+
+def create_init_tasks(target_folder, param_file, output, fp_json, verbose=True):
target_folder = os.path.abspath(target_folder)
output = os.path.abspath(output)
- tool_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'template')
+ tool_path = os.path.join(
+ os.path.dirname(os.path.realpath(__file__)), "..", "template"
+ )
jdata = json.load(open(os.path.join(target_folder, param_file)))
update_mass_map(jdata)
fp_jdata = json.load(open(fp_json))
# fp settings
- mass_map = jdata['mass_map']
- type_map = jdata['type_map']
- fp_style = fp_jdata['fp_style']
- fp_pp_path = fp_jdata['fp_pp_path']
- fp_pp_files = fp_jdata['fp_pp_files']
+ mass_map = jdata["mass_map"]
+ type_map = jdata["type_map"]
+ fp_style = fp_jdata["fp_style"]
+ fp_pp_path = fp_jdata["fp_pp_path"]
+ fp_pp_files = fp_jdata["fp_pp_files"]
cwd_ = os.getcwd()
os.chdir(target_folder)
fp_pp_path = os.path.abspath(fp_pp_path)
os.chdir(cwd_)
# init data sys
- init_data_prefix = jdata['init_data_prefix']
- init_data_sys = jdata['init_data_sys']
- for idx,ii in enumerate(init_data_sys):
- sys = dpdata.LabeledSystem(os.path.join(init_data_prefix, ii), fmt = 'deepmd/npy', type_map = type_map)
+ init_data_prefix = jdata["init_data_prefix"]
+ init_data_sys = jdata["init_data_sys"]
+ for idx, ii in enumerate(init_data_sys):
+ sys = dpdata.LabeledSystem(
+ os.path.join(init_data_prefix, ii), fmt="deepmd/npy", type_map=type_map
+ )
nframes = sys.get_nframes()
- sys_dir = os.path.join(output, 'init_system.%03d' % idx)
- os.makedirs(sys_dir, exist_ok = True)
- if verbose :
- print('# working on ' + sys_dir)
- with open(os.path.join(sys_dir,'record'), 'w') as fp:
- fp.write(os.path.join(init_data_prefix, ii) + '\n')
- for ff in range(nframes) :
- task_dir = os.path.join(sys_dir, 'task.%06d' % ff)
- os.makedirs(task_dir, exist_ok = True)
- sys.to_vasp_poscar(os.path.join(task_dir, 'POSCAR'), frame_idx=ff)
+ sys_dir = os.path.join(output, "init_system.%03d" % idx)
+ os.makedirs(sys_dir, exist_ok=True)
+ if verbose:
+ print("# working on " + sys_dir)
+ with open(os.path.join(sys_dir, "record"), "w") as fp:
+ fp.write(os.path.join(init_data_prefix, ii) + "\n")
+ for ff in range(nframes):
+ task_dir = os.path.join(sys_dir, "task.%06d" % ff)
+ os.makedirs(task_dir, exist_ok=True)
+ sys.to_vasp_poscar(os.path.join(task_dir, "POSCAR"), frame_idx=ff)
# make fp
cwd_ = os.getcwd()
os.chdir(task_dir)
- for pp in fp_pp_files :
- if os.path.lexists(pp) :
+ for pp in fp_pp_files:
+ if os.path.lexists(pp):
os.remove(pp)
os.symlink(os.path.relpath(os.path.join(output, pp)), pp)
- if fp_style == 'vasp':
- if os.path.lexists('INCAR') :
- os.remove('INCAR')
- os.symlink(os.path.relpath(os.path.join(output, 'INCAR')), 'INCAR')
- elif fp_style == 'pwscf':
- try:
- fp_params = fp_jdata['user_fp_params']
+ if fp_style == "vasp":
+ if os.path.lexists("INCAR"):
+ os.remove("INCAR")
+ os.symlink(os.path.relpath(os.path.join(output, "INCAR")), "INCAR")
+ elif fp_style == "pwscf":
+ try:
+ fp_params = fp_jdata["user_fp_params"]
user_input = True
except Exception:
- fp_params = fp_jdata['fp_params']
+ fp_params = fp_jdata["fp_params"]
user_input = False
- make_pwscf('.', fp_params, mass_map, fp_pp_files, fp_pp_files, user_input)
- elif fp_style == 'siesta':
- make_siesta('.', fp_params, fp_pp_files, fp_pp_files)
- os.chdir(cwd_)
-
+ make_pwscf(
+ ".", fp_params, mass_map, fp_pp_files, fp_pp_files, user_input
+ )
+ elif fp_style == "siesta":
+ make_siesta(".", fp_params, fp_pp_files, fp_pp_files)
+ os.chdir(cwd_)
+
-def create_tasks(target_folder, param_file, output, fp_json, verbose = True, numb_iter = -1) :
+def create_tasks(
+ target_folder, param_file, output, fp_json, verbose=True, numb_iter=-1
+):
target_folder = os.path.abspath(target_folder)
output = os.path.abspath(output)
- tool_path = os.path.join(os.path.dirname(os.path.realpath(__file__)), '..', 'template')
+ tool_path = os.path.join(
+ os.path.dirname(os.path.realpath(__file__)), "..", "template"
+ )
jdata = json.load(open(os.path.join(target_folder, param_file)))
update_mass_map(jdata)
fp_jdata = json.load(open(fp_json))
- # goto input
+ # goto input
cwd = os.getcwd()
os.chdir(target_folder)
- sys = jdata['sys_configs']
+ sys = jdata["sys_configs"]
# fp settings
- mass_map = jdata['mass_map']
- fp_style = fp_jdata['fp_style']
- fp_pp_path = fp_jdata['fp_pp_path']
- fp_pp_files = fp_jdata['fp_pp_files']
+ mass_map = jdata["mass_map"]
+ fp_style = fp_jdata["fp_style"]
+ fp_pp_path = fp_jdata["fp_pp_path"]
+ fp_pp_files = fp_jdata["fp_pp_files"]
cwd_ = os.getcwd()
os.chdir(target_folder)
fp_pp_path = os.path.abspath(fp_pp_path)
@@ -163,114 +186,152 @@ def create_tasks(target_folder, param_file, output, fp_json, verbose = True, num
sys_tasks_record = [[] for ii in sys]
sys_tasks_cc = [0 for ii in sys]
numb_sys = len(sys)
- iters = glob.glob('iter.[0-9]*[0-9]')
+ iters = glob.glob("iter.[0-9]*[0-9]")
iters.sort()
# iters = iters[:2]
- for ii in iters[:numb_iter] :
- iter_tasks = glob.glob(os.path.join(ii, '02.fp', 'task.[0-9]*[0-9].[0-9]*[0-9]'))
+ for ii in iters[:numb_iter]:
+ iter_tasks = glob.glob(
+ os.path.join(ii, "02.fp", "task.[0-9]*[0-9].[0-9]*[0-9]")
+ )
iter_tasks.sort()
- if verbose :
- print('# check iter ' + ii + ' with %6d tasks' % len(iter_tasks))
- for jj in iter_tasks :
- sys_idx = int(os.path.basename(jj).split('.')[-2])
+ if verbose:
+ print("# check iter " + ii + " with %6d tasks" % len(iter_tasks))
+ for jj in iter_tasks:
+ sys_idx = int(os.path.basename(jj).split(".")[-2])
sys_tasks[sys_idx].append(jj)
- if os.path.islink(os.path.join(jj, 'conf.lmp')):
- linked_file = os.path.realpath(os.path.join(jj, 'conf.lmp'))
- elif os.path.islink(os.path.join(jj, 'conf.dump')):
- linked_file = os.path.realpath(os.path.join(jj, 'conf.dump'))
+ if os.path.islink(os.path.join(jj, "conf.lmp")):
+ linked_file = os.path.realpath(os.path.join(jj, "conf.lmp"))
+ elif os.path.islink(os.path.join(jj, "conf.dump")):
+ linked_file = os.path.realpath(os.path.join(jj, "conf.dump"))
else:
- raise RuntimeError('cannot file linked conf file')
- linked_keys = linked_file.split('/')
- task_record = linked_keys[-5] + '.' + linked_keys[-3] + '.' + linked_keys[-1].split('.')[0]
- task_record_keys = task_record.split('.')
- ens, temp, pres = get_lmp_info(os.path.join(ii, '01.model_devi', linked_keys[-3], 'input.lammps'))
- human_record = 'iter: %s system: %s model_devi_task: %s frame: %6d fp_task: %s ens: %s temp: %10.2f pres: %10.2f' \
- % (task_record_keys[1],
- task_record_keys[3],
- linked_keys[-3],
- int(task_record_keys[-1]),
- os.path.basename(jj),
- ens, temp, pres
- )
+ raise RuntimeError("cannot file linked conf file")
+ linked_keys = linked_file.split("/")
+ task_record = (
+ linked_keys[-5]
+ + "."
+ + linked_keys[-3]
+ + "."
+ + linked_keys[-1].split(".")[0]
+ )
+ task_record_keys = task_record.split(".")
+ ens, temp, pres = get_lmp_info(
+ os.path.join(ii, "01.model_devi", linked_keys[-3], "input.lammps")
+ )
+ human_record = (
+ "iter: %s system: %s model_devi_task: %s frame: %6d fp_task: %s ens: %s temp: %10.2f pres: %10.2f"
+ % (
+ task_record_keys[1],
+ task_record_keys[3],
+ linked_keys[-3],
+ int(task_record_keys[-1]),
+ os.path.basename(jj),
+ ens,
+ temp,
+ pres,
+ )
+ )
# print(human_record)
- sys_tasks_record[sys_idx].append(human_record)
+ sys_tasks_record[sys_idx].append(human_record)
# for ii in range(numb_sys) :
# for jj in range(len(sys_tasks[ii])) :
# print(sys_tasks[ii][jj], sys_tasks_record[ii][jj])
# mk output
- os.makedirs(output, exist_ok = True)
- if fp_style == 'vasp':
+ os.makedirs(output, exist_ok=True)
+ if fp_style == "vasp":
copy_pp_files(output, fp_pp_path, fp_pp_files)
make_vasp_incar(fp_params, output)
- if fp_style == 'pwscf' :
+ if fp_style == "pwscf":
copy_pp_files(output, fp_pp_path, fp_pp_files)
- if fp_style == 'siesta' :
+ if fp_style == "siesta":
copy_pp_files(output, fp_pp_path, fp_pp_files)
- for si in range(numb_sys) :
- sys_dir = os.path.join(output, 'system.%03d' % si)
- if verbose :
- print('# working on ' + sys_dir)
- for tt,rr in zip(sys_tasks[si], sys_tasks_record[si]) :
+ for si in range(numb_sys):
+ sys_dir = os.path.join(output, "system.%03d" % si)
+ if verbose:
+ print("# working on " + sys_dir)
+ for tt, rr in zip(sys_tasks[si], sys_tasks_record[si]):
# copy poscar
- source_path = os.path.join(('iter.%s/02.fp' % rr.split()[1]), rr.split()[9])
- source_file = os.path.join(source_path, 'POSCAR')
- target_path = os.path.join(sys_dir, 'task.%06d'%sys_tasks_cc[si])
+ source_path = os.path.join(("iter.%s/02.fp" % rr.split()[1]), rr.split()[9])
+ source_file = os.path.join(source_path, "POSCAR")
+ target_path = os.path.join(sys_dir, "task.%06d" % sys_tasks_cc[si])
sys_tasks_cc[si] += 1
- os.makedirs(target_path, exist_ok = True)
- target_file = os.path.join(target_path, 'POSCAR')
- target_recd = os.path.join(target_path, 'record')
- if os.path.exists(target_file) :
+ os.makedirs(target_path, exist_ok=True)
+ target_file = os.path.join(target_path, "POSCAR")
+ target_recd = os.path.join(target_path, "record")
+ if os.path.exists(target_file):
os.remove(target_file)
- if os.path.exists(target_recd) :
+ if os.path.exists(target_recd):
os.remove(target_recd)
shutil.copyfile(source_file, target_file)
- with open(target_recd, 'w') as fp:
- fp.write('\n'.join([target_folder, rr, '']))
+ with open(target_recd, "w") as fp:
+ fp.write("\n".join([target_folder, rr, ""]))
# make fp
cwd_ = os.getcwd()
os.chdir(target_path)
- for pp in fp_pp_files :
- if os.path.lexists(pp) :
+ for pp in fp_pp_files:
+ if os.path.lexists(pp):
os.remove(pp)
os.symlink(os.path.relpath(os.path.join(output, pp)), pp)
- if fp_style == 'vasp':
- if os.path.lexists('INCAR') :
- os.remove('INCAR')
- os.symlink(os.path.relpath(os.path.join(output, 'INCAR')), 'INCAR')
- elif fp_style == 'pwscf':
- try:
- fp_params = fp_jdata['user_fp_params']
+ if fp_style == "vasp":
+ if os.path.lexists("INCAR"):
+ os.remove("INCAR")
+ os.symlink(os.path.relpath(os.path.join(output, "INCAR")), "INCAR")
+ elif fp_style == "pwscf":
+ try:
+ fp_params = fp_jdata["user_fp_params"]
user_input = True
except Exception:
- fp_params = fp_jdata['fp_params']
+ fp_params = fp_jdata["fp_params"]
user_input = False
- make_pwscf('.', fp_params, mass_map, fp_pp_files, fp_pp_files, user_input)
- elif fp_style == 'siesta':
- make_siesta('.', fp_params, mass_map, fp_pp_files, fp_pp_files)
+ make_pwscf(
+ ".", fp_params, mass_map, fp_pp_files, fp_pp_files, user_input
+ )
+ elif fp_style == "siesta":
+ make_siesta(".", fp_params, mass_map, fp_pp_files, fp_pp_files)
os.chdir(cwd_)
os.chdir(cwd)
-def _main() :
- parser = argparse.ArgumentParser(description='Create tasks for relabeling from a DP-GEN job')
- parser.add_argument("JOB_DIR", type=str,
- help="the directory of the DP-GEN job")
- parser.add_argument("PARAM", type=str, default = 'fp.json',
- help="the json file defines vasp tasks")
- parser.add_argument("OUTPUT", type=str,
- help="the output directory of relabel tasks")
- parser.add_argument('-p',"--parameter", type=str, default = 'param.json',
- help="the json file provides DP-GEN paramters, should be located in JOB_DIR")
- parser.add_argument('-n',"--numb-iter", type=int, default = -1,
- help="number of iterations to relabel")
- parser.add_argument('-v',"--verbose", action = 'store_true',
- help="being loud")
+def _main():
+ parser = argparse.ArgumentParser(
+ description="Create tasks for relabeling from a DP-GEN job"
+ )
+ parser.add_argument("JOB_DIR", type=str, help="the directory of the DP-GEN job")
+ parser.add_argument(
+ "PARAM", type=str, default="fp.json", help="the json file defines vasp tasks"
+ )
+ parser.add_argument(
+ "OUTPUT", type=str, help="the output directory of relabel tasks"
+ )
+ parser.add_argument(
+ "-p",
+ "--parameter",
+ type=str,
+ default="param.json",
+ help="the json file provides DP-GEN paramters, should be located in JOB_DIR",
+ )
+ parser.add_argument(
+ "-n",
+ "--numb-iter",
+ type=int,
+ default=-1,
+ help="number of iterations to relabel",
+ )
+ parser.add_argument("-v", "--verbose", action="store_true", help="being loud")
args = parser.parse_args()
-
- create_tasks(args.JOB_DIR, args.parameter, args.OUTPUT, args.PARAM, numb_iter = args.numb_iter, verbose = args.verbose)
- create_init_tasks(args.JOB_DIR, args.parameter, args.OUTPUT, args.PARAM, verbose = args.verbose)
-if __name__ == '__main__':
+ create_tasks(
+ args.JOB_DIR,
+ args.parameter,
+ args.OUTPUT,
+ args.PARAM,
+ numb_iter=args.numb_iter,
+ verbose=args.verbose,
+ )
+ create_init_tasks(
+ args.JOB_DIR, args.parameter, args.OUTPUT, args.PARAM, verbose=args.verbose
+ )
+
+
+if __name__ == "__main__":
_main()
-
diff --git a/dpgen/tools/run_report.py b/dpgen/tools/run_report.py
index 17751c9c7..88b3a4b06 100755
--- a/dpgen/tools/run_report.py
+++ b/dpgen/tools/run_report.py
@@ -1,16 +1,24 @@
#!/usr/bin/env python3
-import os,sys,json,glob,argparse,shutil
-import numpy as np
+import argparse
+import glob
+import json
+import os
+import shutil
import subprocess as sp
+import sys
+
+import numpy as np
+
+from dpgen.tools.stat_iter import stat_iter
from dpgen.tools.stat_sys import stat_sys
-from dpgen.tools.stat_iter import stat_iter
from dpgen.tools.stat_time import stat_time
+
def run_report(args):
report_count = 0
if args.stat_sys:
- stat_sys(args.JOB_DIR, args.param, args.verbose)
+ stat_sys(args.JOB_DIR, args.param, args.verbose)
report_count += 1
# other stats added in the following
if args.stat_iter:
@@ -20,6 +28,6 @@ def run_report(args):
stat_time(args.JOB_DIR, args.param, args.verbose)
report_count += 1
if report_count == 0:
- print('nothing to report, rerun with -h for help')
+ print("nothing to report, rerun with -h for help")
return report_count
diff --git a/dpgen/tools/stat_iter.py b/dpgen/tools/stat_iter.py
index 531868c51..5a3eb8932 100644
--- a/dpgen/tools/stat_iter.py
+++ b/dpgen/tools/stat_iter.py
@@ -1,69 +1,94 @@
#!/usr/bin/env python3
-import os,sys,json
+import json
+import os
import subprocess
+import sys
from collections import defaultdict
import dpdata
-def stat_iter(target_folder,
- param_file = 'param.json',
- verbose = True,
- mute = False):
- jdata={}
+
+def stat_iter(target_folder, param_file="param.json", verbose=True, mute=False):
+ jdata = {}
with open(f"{target_folder}/{param_file}") as param_file:
jdata = json.load(param_file)
iter_dict = defaultdict(lambda: defaultdict(int))
- output = subprocess.run([f"wc -l {target_folder}/iter.??????/02.fp/*out", ],
- shell=True,stdout=subprocess.PIPE).stdout
- data = output.decode() # split(b'\n')
- for line in data.split('\n'):
- if 'out' in line:
- num, relative_path_doc = line.strip().split(' ')
+ output = subprocess.run(
+ [
+ f"wc -l {target_folder}/iter.??????/02.fp/*out",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ ).stdout
+ data = output.decode() # split(b'\n')
+ for line in data.split("\n"):
+ if "out" in line:
+ num, relative_path_doc = line.strip().split(" ")
path_doc = os.path.abspath(relative_path_doc)
num = int(num)
- prefix, iter_dirname, stage, out_filename = path_doc.rsplit('/',3) # pylint: disable=unused-variable
- pk_id, out_filename = path_doc.rsplit('/', 1)
- iter = int(iter_dirname.split('.')[-1]) # pylint: disable=unused-variable
- out_id = int(out_filename.strip().split('.')[-2]) # pylint: disable=unused-variable
- out_type = out_filename.strip().split('.')[0]
+ prefix, iter_dirname, stage, out_filename = path_doc.rsplit(
+ "/", 3
+ ) # pylint: disable=unused-variable
+ pk_id, out_filename = path_doc.rsplit("/", 1)
+ iter = int(iter_dirname.split(".")[-1]) # pylint: disable=unused-variable
+ out_id = int(
+ out_filename.strip().split(".")[-2]
+ ) # pylint: disable=unused-variable
+ out_type = out_filename.strip().split(".")[0]
iter_dict[pk_id][out_type] += num
- # for ii in
- output2 = subprocess.run([f"ls -d -1 {target_folder}/iter.??????/02.fp/task.*/OUTCAR", ],
- shell=True,stdout=subprocess.PIPE).stdout
+ # for ii in
+ output2 = subprocess.run(
+ [
+ f"ls -d -1 {target_folder}/iter.??????/02.fp/task.*/OUTCAR",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ ).stdout
data2 = output2.decode()
if verbose:
# print('find OUTCAR', data2)
- print("use param_jsonfile jdata['type_map']", jdata['type_map'])
- for line in data2.split('\n'):
+ print("use param_jsonfile jdata['type_map']", jdata["type_map"])
+ for line in data2.split("\n"):
if line:
# [/home/felix/workplace/SiC/iter.000002/02.fp/task.018.000040/OUTCAR]
path_doc = os.path.abspath(line)
- pk_id, task_dirname, OUTCAR_filename=path_doc.rsplit('/', 2) # pylint: disable=unused-variable
+ pk_id, task_dirname, OUTCAR_filename = path_doc.rsplit(
+ "/", 2
+ ) # pylint: disable=unused-variable
try:
- _sys = dpdata.LabeledSystem(path_doc, type_map = jdata['type_map'] )
+ _sys = dpdata.LabeledSystem(path_doc, type_map=jdata["type_map"])
except Exception:
try:
- _sys = dpdata.LabeledSystem(path_doc.replace('OUTCAR','vasprun.xml'), type_map = jdata['type_map'])
+ _sys = dpdata.LabeledSystem(
+ path_doc.replace("OUTCAR", "vasprun.xml"),
+ type_map=jdata["type_map"],
+ )
except Exception:
_sys = dpdata.LabeledSystem()
if len(_sys) == 1:
pass
else:
if verbose:
- print('OUTCAR not label by dpdata, not convergence or unfinshed', path_doc)
- iter_dict[pk_id]['OUTCAR_not_convergence'] +=1
- iter_dict[pk_id]['OUTCAR_total_count'] +=1
+ print(
+ "OUTCAR not label by dpdata, not convergence or unfinshed",
+ path_doc,
+ )
+ iter_dict[pk_id]["OUTCAR_not_convergence"] += 1
+ iter_dict[pk_id]["OUTCAR_total_count"] += 1
for pk_id in {**iter_dict}:
- if iter_dict[pk_id]['OUTCAR_total_count']:
- iter_dict[pk_id]['reff']=round(iter_dict[pk_id]['OUTCAR_not_convergence']/iter_dict[pk_id]['OUTCAR_total_count'],5)
+ if iter_dict[pk_id]["OUTCAR_total_count"]:
+ iter_dict[pk_id]["reff"] = round(
+ iter_dict[pk_id]["OUTCAR_not_convergence"]
+ / iter_dict[pk_id]["OUTCAR_total_count"],
+ 5,
+ )
for pk_id, value in iter_dict.items():
- print(f"{pk_id}:candidate:{value['candidate']}"
- f":rest_failed:{value['rest_failed']}"
- f":rest_accurate:{value['rest_accurate']}"
- f":OUTCAR_total_count:{value['OUTCAR_total_count']}"
- f":OUTCAR_not_convergence:{value['OUTCAR_not_convergence']}"
- f":reff:{value['reff']}")
-
-
-
+ print(
+ f"{pk_id}:candidate:{value['candidate']}"
+ f":rest_failed:{value['rest_failed']}"
+ f":rest_accurate:{value['rest_accurate']}"
+ f":OUTCAR_total_count:{value['OUTCAR_total_count']}"
+ f":OUTCAR_not_convergence:{value['OUTCAR_not_convergence']}"
+ f":reff:{value['reff']}"
+ )
diff --git a/dpgen/tools/stat_sys.py b/dpgen/tools/stat_sys.py
index 83ddf75ad..5a0cb6471 100644
--- a/dpgen/tools/stat_sys.py
+++ b/dpgen/tools/stat_sys.py
@@ -1,86 +1,106 @@
#!/usr/bin/env python3
-import os,sys,json,glob,argparse,shutil
-import numpy as np
+import argparse
+import glob
+import json
+import os
+import shutil
import subprocess as sp
-sys.path.append(os.path.join(os.path.dirname(os.path.realpath(__file__)), '..'))
+import sys
+
+import numpy as np
+
+sys.path.append(os.path.join(os.path.dirname(os.path.realpath(__file__)), ".."))
from dpgen.tools.relabel import get_lmp_info
-def ascii_hist(count) :
- np = (count-1) // 5 + 1
+
+def ascii_hist(count):
+ np = (count - 1) // 5 + 1
ret = " |"
for ii in range(np):
- ret += '='
- return ret
+ ret += "="
+ return ret
-def stat_sys(target_folder,
- param_file = 'param.json',
- verbose = True,
- mute = False) :
+
+def stat_sys(target_folder, param_file="param.json", verbose=True, mute=False):
target_folder = os.path.abspath(target_folder)
with open(os.path.join(target_folder, param_file)) as fp:
jdata = json.load(fp)
- # goto input
+ # goto input
cwd = os.getcwd()
os.chdir(target_folder)
- sys = jdata['sys_configs']
+ sys = jdata["sys_configs"]
numb_sys = len(sys)
sys_tasks_count = [0 for ii in sys]
sys_tasks_trait = [[] for ii in sys]
sys_tasks_trait_count = [[] for ii in sys]
# collect tasks from iter dirs
- iters = glob.glob('iter.[0-9]*[0-9]')
+ iters = glob.glob("iter.[0-9]*[0-9]")
iters.sort()
# iters = iters[:2]
- for ii in iters :
- iter_tasks = glob.glob(os.path.join(ii, '02.fp', 'task.[0-9]*[0-9].[0-9]*[0-9]'))
+ for ii in iters:
+ iter_tasks = glob.glob(
+ os.path.join(ii, "02.fp", "task.[0-9]*[0-9].[0-9]*[0-9]")
+ )
iter_tasks.sort()
- if verbose :
- print('# check iter ' + ii + ' with %6d tasks' % len(iter_tasks))
- for jj in iter_tasks :
- sys_idx = int(os.path.basename(jj).split('.')[-2])
+ if verbose:
+ print("# check iter " + ii + " with %6d tasks" % len(iter_tasks))
+ for jj in iter_tasks:
+ sys_idx = int(os.path.basename(jj).split(".")[-2])
sys_tasks_count[sys_idx] += 1
- linked_file = os.path.realpath(os.path.join(jj, 'conf.dump'))
- linked_keys = linked_file.split('/')
- task_record = linked_keys[-5] + '.' + linked_keys[-3] + '.' + linked_keys[-1].split('.')[0]
- task_record_keys = task_record.split('.')
- ens, temp, pres = get_lmp_info(os.path.join(ii, '01.model_devi', linked_keys[-3], 'input.lammps'))
+ linked_file = os.path.realpath(os.path.join(jj, "conf.dump"))
+ linked_keys = linked_file.split("/")
+ task_record = (
+ linked_keys[-5]
+ + "."
+ + linked_keys[-3]
+ + "."
+ + linked_keys[-1].split(".")[0]
+ )
+ task_record_keys = task_record.split(".")
+ ens, temp, pres = get_lmp_info(
+ os.path.join(ii, "01.model_devi", linked_keys[-3], "input.lammps")
+ )
trait = [ens, temp, pres]
- if not trait in sys_tasks_trait[sys_idx] :
+ if not trait in sys_tasks_trait[sys_idx]:
sys_tasks_trait[sys_idx].append(trait)
sys_tasks_trait_count[sys_idx].append(0)
t_idx = sys_tasks_trait[sys_idx].index(trait)
sys_tasks_trait_count[sys_idx][t_idx] += 1
sys_tasks_all = []
- for ii in range(numb_sys) :
+ for ii in range(numb_sys):
# print(sys[ii], sys_tasks_count[ii])
tmp_all = []
- for jj in range(len(sys_tasks_trait[ii])) :
+ for jj in range(len(sys_tasks_trait[ii])):
tmp_all.append(sys_tasks_trait[ii][jj] + [sys_tasks_trait_count[ii][jj]])
sys_tasks_all.append(tmp_all)
for ii in sys_tasks_all:
ii.sort()
max_str_len = max([len(str(ii)) for ii in sys])
- sys_fmt = '%%%ds %%6d' % (max_str_len+1)
+ sys_fmt = "%%%ds %%6d" % (max_str_len + 1)
blank = max_str_len - 50
str_blk = ""
for ii in range(blank):
str_blk += " "
- trait_fmt = str_blk + 'ens: %s T: %10.2f P: %12.2f count: %6d'
+ trait_fmt = str_blk + "ens: %s T: %10.2f P: %12.2f count: %6d"
for ii in range(numb_sys):
if not mute:
print(sys_fmt % (str(sys[ii]), sys_tasks_count[ii]))
for jj in range(len(sys_tasks_all[ii])):
hist_str = ascii_hist(sys_tasks_all[ii][jj][3])
if not mute:
- print((trait_fmt + hist_str) % (sys_tasks_all[ii][jj][0],
- sys_tasks_all[ii][jj][1],
- sys_tasks_all[ii][jj][2],
- sys_tasks_all[ii][jj][3]))
+ print(
+ (trait_fmt + hist_str)
+ % (
+ sys_tasks_all[ii][jj][0],
+ sys_tasks_all[ii][jj][1],
+ sys_tasks_all[ii][jj][2],
+ sys_tasks_all[ii][jj][3],
+ )
+ )
os.chdir(cwd)
return sys, sys_tasks_count, sys_tasks_all
-def run_report(args):
- stat_tasks(args.JOB_DIR, args.param, args.verbose)
-
+def run_report(args):
+ stat_tasks(args.JOB_DIR, args.param, args.verbose)
diff --git a/dpgen/tools/stat_time.py b/dpgen/tools/stat_time.py
index 8e3a286fc..5a2e129ac 100755
--- a/dpgen/tools/stat_time.py
+++ b/dpgen/tools/stat_time.py
@@ -1,105 +1,211 @@
-import subprocess
import os
-def stat_time(target_folder,
- param_file = 'param.json',
- verbose = True,
- mute = False):
- train_dirs = subprocess.run([f"ls -d -1 {target_folder}/iter.??????/00.train/", ],
- shell=True,stdout=subprocess.PIPE).stdout.decode().strip().split('\n')
+import subprocess
+
+
+def stat_time(target_folder, param_file="param.json", verbose=True, mute=False):
+ train_dirs = (
+ subprocess.run(
+ [
+ f"ls -d -1 {target_folder}/iter.??????/00.train/",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip()
+ .split("\n")
+ )
for dir in train_dirs:
abs_dir = os.path.abspath(dir)
stage = os.path.basename(os.path.dirname(dir))
- train_time_logs = subprocess.run([f"grep -H --text 'wall time' {dir}/???/train.log", ],
- shell=True,stdout=subprocess.PIPE).stdout.decode().strip().split('\n')
- upload_task_dir_num = subprocess.run([f"ls -1 -d {dir}/??? |wc -l", ],
- shell=True, stdout=subprocess.PIPE).stdout.decode().strip('\n')
+ train_time_logs = (
+ subprocess.run(
+ [
+ f"grep -H --text 'wall time' {dir}/???/train.log",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip()
+ .split("\n")
+ )
+ upload_task_dir_num = (
+ subprocess.run(
+ [
+ f"ls -1 -d {dir}/??? |wc -l",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip("\n")
+ )
total_core_sec = float(0)
-
+
# assume training on single GPU
paral_cores = 1
finished_task_file_num = len(train_time_logs)
# gpu_type_set = set([])
for log in train_time_logs:
- # log example :
+ # log example :
# .//iter.000000/00.train//003/train.log:# DEEPMD: wall time: 7960.265 s
# print(log.split(':'))
- file_path, text1, text2, wall_time = log.split(':') # pylint: disable=unused-variable
+ file_path, text1, text2, wall_time = log.split(
+ ":"
+ ) # pylint: disable=unused-variable
abs_file_path = os.path.abspath(file_path)
# stage=='00.train'
-
- wall_time_sec = float(wall_time.strip('s').strip(' '))
+
+ wall_time_sec = float(wall_time.strip("s").strip(" "))
total_core_sec += wall_time_sec * paral_cores
# r'd\nja\1lgje' leading 'r' means dont treat '\' as Escape character
# gpu_type = subprocess.run([fr"grep -e 'physical GPU' {abs_file_path} |sed -n -E -e 's|^.*name: (.*), pci.*|\1|p'", ],
# shell=True,stdout=subprocess.PIPE).stdout.decode().strip().split('\n').pop()
# gpu_type_set.add(gpu_type)
-
- total_core_hour = total_core_sec * paral_cores / 3600
- print(f"{stage}:{abs_dir}"
+
+ total_core_hour = total_core_sec * paral_cores / 3600
+ print(
+ f"{stage}:{abs_dir}"
f"paral_cores:{paral_cores}"
f":upload_task_dir_num:{upload_task_dir_num}"
f":finished_task_file_num:{finished_task_file_num}"
- f":total_core_hour:{total_core_hour:.3f}")
-
- model_devi_dirs = subprocess.run([f"ls -d -1 {target_folder}/iter.??????/01.model_devi/", ],
- shell=True,stdout=subprocess.PIPE).stdout.decode().strip().split('\n')
+ f":total_core_hour:{total_core_hour:.3f}"
+ )
+
+ model_devi_dirs = (
+ subprocess.run(
+ [
+ f"ls -d -1 {target_folder}/iter.??????/01.model_devi/",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip()
+ .split("\n")
+ )
# print(model_devi_dirs)
for dir in model_devi_dirs:
abs_dir = os.path.abspath(dir)
stage = os.path.basename(os.path.dirname(dir))
# print(dir)
- model_devi_time_logs = subprocess.run([f"grep -H --text 'wall time' {dir}/task.*/log.lammps", ],
- shell=True,stdout=subprocess.PIPE).stdout.decode().strip().split('\n')
- upload_task_dir_num = subprocess.run([f"ls -1 -d {dir}/task.* |wc -l", ],
- shell=True, stdout=subprocess.PIPE).stdout.decode().strip('\n')
+ model_devi_time_logs = (
+ subprocess.run(
+ [
+ f"grep -H --text 'wall time' {dir}/task.*/log.lammps",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip()
+ .split("\n")
+ )
+ upload_task_dir_num = (
+ subprocess.run(
+ [
+ f"ls -1 -d {dir}/task.* |wc -l",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip("\n")
+ )
total_core_sec = float(0)
finished_task_file_num = len(model_devi_time_logs)
# assume model_devi lammps job running on GPUs , set paral_cores==1
- paral_cores = 1
+ paral_cores = 1
for log in model_devi_time_logs:
# log example:
# .//iter.000002/01.model_devi//task.018.000075/log.lammps:Total wall time: 0:00:39
# print(log)
- file_path, text1, hour, min, sec = log.split(':') # pylint: disable=unused-variable
- abs_file_path = os.path.abspath(file_path)
- wall_time_sec = 3600*int(hour) + 60*int(min) + 1*int(sec)
+ file_path, text1, hour, min, sec = log.split(
+ ":"
+ ) # pylint: disable=unused-variable
+ abs_file_path = os.path.abspath(file_path)
+ wall_time_sec = 3600 * int(hour) + 60 * int(min) + 1 * int(sec)
total_core_sec += wall_time_sec * paral_cores
total_core_hour = total_core_sec / 3600
- print(f"{stage}:{abs_dir}"
+ print(
+ f"{stage}:{abs_dir}"
f":paral_cores:{paral_cores}"
f":upload_task_dir_num:{upload_task_dir_num}"
f":finished_task_file_num:{finished_task_file_num}"
- f":total_core_hour:{total_core_hour:.3f}")
+ f":total_core_hour:{total_core_hour:.3f}"
+ )
- fp_dirs = subprocess.run([f"ls -d -1 {target_folder}/iter.??????/02.fp/", ],
- shell=True,stdout=subprocess.PIPE).stdout.decode().strip().split('\n')
+ fp_dirs = (
+ subprocess.run(
+ [
+ f"ls -d -1 {target_folder}/iter.??????/02.fp/",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip()
+ .split("\n")
+ )
for dir in fp_dirs:
abs_dir = os.path.abspath(dir)
stage = os.path.basename(os.path.dirname(dir))
- fp_time_logs = subprocess.run([f"grep -H --text 'CPU time' {dir}/task.*/OUTCAR", ],
- shell=True,stdout=subprocess.PIPE).stdout.decode().strip().split('\n')
- upload_task_dir_num = subprocess.run([f"ls -1 -d {dir}/task.* |wc -l", ],
- shell=True, stdout=subprocess.PIPE).stdout.decode().strip('\n')
+ fp_time_logs = (
+ subprocess.run(
+ [
+ f"grep -H --text 'CPU time' {dir}/task.*/OUTCAR",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip()
+ .split("\n")
+ )
+ upload_task_dir_num = (
+ subprocess.run(
+ [
+ f"ls -1 -d {dir}/task.* |wc -l",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip("\n")
+ )
total_core_sec = float(0)
finished_task_file_num = len(fp_time_logs)
for log in fp_time_logs:
# log example:
# .//iter.000002/02.fp//task.018.000048/OUTCAR: Total CPU time used (sec): 288.395
- file_path, text1, sec = log.split(':')
+ file_path, text1, sec = log.split(":")
abs_file_path = os.path.abspath(file_path)
wall_time_sec = float(sec)
- paral_cores = subprocess.run([fr"head -n 1000 {abs_file_path} | grep 'running on' | sed -n -E -e 's|running on\s+([0-9]+)+\s.*|\1|p' ", ],
- shell=True,stdout=subprocess.PIPE).stdout.decode().strip()
+ paral_cores = (
+ subprocess.run(
+ [
+ rf"head -n 1000 {abs_file_path} | grep 'running on' | sed -n -E -e 's|running on\s+([0-9]+)+\s.*|\1|p' ",
+ ],
+ shell=True,
+ stdout=subprocess.PIPE,
+ )
+ .stdout.decode()
+ .strip()
+ )
total_core_sec += wall_time_sec * int(paral_cores)
- total_core_hour = total_core_sec /3600
+ total_core_hour = total_core_sec / 3600
- print(f"{stage}:{abs_dir}"
+ print(
+ f"{stage}:{abs_dir}"
f":paral_cores:{paral_cores}"
f":upload_task_dir_num:{upload_task_dir_num}"
f":finished_task_file_num:{finished_task_file_num}"
- f":total_core_hour:{total_core_hour:.3f}")
+ f":total_core_hour:{total_core_hour:.3f}"
+ )
+
-if __name__=='__main__':
- stat_time(target_folder="./")
\ No newline at end of file
+if __name__ == "__main__":
+ stat_time(target_folder="./")
diff --git a/dpgen/util.py b/dpgen/util.py
index ef3c96de2..b4ec68010 100644
--- a/dpgen/util.py
+++ b/dpgen/util.py
@@ -1,8 +1,11 @@
#!/usr/bin/env python
# coding: utf-8
-from typing import Union, List
+import json
+import os
from pathlib import Path
+from typing import List, Union
+import dpdata
import h5py
from dargs import Argument
@@ -13,23 +16,25 @@
"""
# constants define
-MaxLength=70
+MaxLength = 70
-def sepline(ch='-',sp='-',screen=False):
- r'''
+
+def sepline(ch="-", sp="-", screen=False):
+ r"""
seperate the output by '-'
- '''
+ """
if screen:
- print(ch.center(MaxLength,sp))
+ print(ch.center(MaxLength, sp))
else:
- dlog.info(ch.center(MaxLength,sp))
+ dlog.info(ch.center(MaxLength, sp))
-def box_center(ch='',fill=' ',sp="|"):
- r'''
+
+def box_center(ch="", fill=" ", sp="|"):
+ r"""
put the string at the center of | |
- '''
- strs=ch.center(Len,fill)
- dlog.info(sp+strs[1:len(strs)-1:]+sp)
+ """
+ strs = ch.center(Len, fill)
+ dlog.info(sp + strs[1 : len(strs) - 1 :] + sp)
def expand_sys_str(root_dir: Union[str, Path]) -> List[str]:
@@ -54,15 +59,20 @@ def expand_sys_str(root_dir: Union[str, Path]) -> List[str]:
matches.append(str(root_dir))
elif root_dir.is_file():
# HDF5 file
- with h5py.File(root_dir, 'r') as f:
+ with h5py.File(root_dir, "r") as f:
# list of keys in the h5 file
f_keys = ["/"]
f.visit(lambda x: f_keys.append("/" + x))
- matches = ["%s#%s"%(root_dir, d) for d in f_keys if str(Path(d) / "type.raw") in f_keys]
+ matches = [
+ "%s#%s" % (root_dir, d)
+ for d in f_keys
+ if str(Path(d) / "type.raw") in f_keys
+ ]
else:
raise OSError(f"{root_dir} does not exist.")
return matches
+
def normalize(arginfo: Argument, data: dict, strict_check: bool = True) -> dict:
"""Normalize and check input data.
@@ -83,3 +93,62 @@ def normalize(arginfo: Argument, data: dict, strict_check: bool = True) -> dict:
data = arginfo.normalize_value(data, trim_pattern="_*")
arginfo.check_value(data, strict=strict_check)
return data
+
+
+def convert_training_data_to_hdf5(input_files: List[str], h5_file: str):
+ """Convert training data to HDF5 format and update the input files.
+
+ Parameters
+ ----------
+ input_files : list of str
+ DeePMD-kit input file names
+ h5_file : str
+ HDF5 file name
+ """
+ systems = []
+ h5_dir = Path(h5_file).parent.absolute()
+ cwd = Path.cwd().absolute()
+ for ii in input_files:
+ ii = Path(ii)
+ dd = ii.parent.absolute()
+ with open(ii, "r+") as f:
+ jinput = json.load(f)
+ if "training_data" in jinput["training"]:
+ # v2.0
+ p_sys = jinput["training"]["training_data"]["systems"]
+ else:
+ # v1.x
+ p_sys = jinput["training"]["systems"]
+ for ii, pp in enumerate(p_sys):
+ if "#" in pp:
+ # HDF5 file
+ p1, p2 = pp.split("#")
+ ff = os.path.normpath(str((dd / p1).absolute().relative_to(cwd)))
+ pp = ff + "#" + p2
+ new_pp = os.path.normpath(os.path.relpath(ff, h5_dir)) + "/" + p2
+ else:
+ pp = os.path.normpath(str((dd / pp).absolute().relative_to(cwd)))
+ new_pp = os.path.normpath(os.path.relpath(pp, h5_dir))
+ p_sys[ii] = (
+ os.path.normpath(os.path.relpath(h5_file, dd)) + "#/" + str(new_pp)
+ )
+ systems.append(pp)
+ f.seek(0)
+ json.dump(jinput, f, indent=4)
+ systems = list(set(systems))
+
+ dlog.info("Combining %d training systems to %s...", len(systems), h5_file)
+
+ with h5py.File(h5_file, "w") as f:
+ for ii in systems:
+ if "#" in ii:
+ p1, p2 = ii.split("#")
+ p1 = os.path.normpath(os.path.relpath(p1, h5_dir))
+ group = f.create_group(str(p1) + "/" + p2)
+ s = dpdata.LabeledSystem(ii, fmt="deepmd/hdf5")
+ s.to("deepmd/hdf5", group)
+ else:
+ pp = os.path.normpath(os.path.relpath(ii, h5_dir))
+ group = f.create_group(str(pp))
+ s = dpdata.LabeledSystem(ii, fmt="deepmd/npy")
+ s.to("deepmd/hdf5", group)
diff --git a/examples/CH4-lebesgue/CH4.POSCAR b/examples/CH4-lebesgue/CH4.POSCAR
index 2f9def780..5bc4a91c2 100644
--- a/examples/CH4-lebesgue/CH4.POSCAR
+++ b/examples/CH4-lebesgue/CH4.POSCAR
@@ -1 +1 @@
-../init/CH4.POSCAR
\ No newline at end of file
+../init/CH4.POSCAR
diff --git a/examples/CH4-lebesgue/INCAR_methane b/examples/CH4-lebesgue/INCAR_methane
index b946fb7e5..e5e21d9f9 100644
--- a/examples/CH4-lebesgue/INCAR_methane
+++ b/examples/CH4-lebesgue/INCAR_methane
@@ -1 +1 @@
-../run/dp1.x-lammps-vasp/CH4/INCAR_methane
\ No newline at end of file
+../run/dp1.x-lammps-vasp/CH4/INCAR_methane
diff --git a/examples/CH4-lebesgue/INCAR_methane.md b/examples/CH4-lebesgue/INCAR_methane.md
index 4c48cdd86..342cf9984 100644
--- a/examples/CH4-lebesgue/INCAR_methane.md
+++ b/examples/CH4-lebesgue/INCAR_methane.md
@@ -1 +1 @@
-../init/INCAR_methane.md
\ No newline at end of file
+../init/INCAR_methane.md
diff --git a/examples/CH4-lebesgue/INCAR_methane.rlx b/examples/CH4-lebesgue/INCAR_methane.rlx
index e44202f43..53ffea28a 100644
--- a/examples/CH4-lebesgue/INCAR_methane.rlx
+++ b/examples/CH4-lebesgue/INCAR_methane.rlx
@@ -1 +1 @@
-../init/INCAR_methane.rlx
\ No newline at end of file
+../init/INCAR_methane.rlx
diff --git a/examples/CH4-lebesgue/README.md b/examples/CH4-lebesgue/README.md
index d550d16f0..b4c565442 100644
--- a/examples/CH4-lebesgue/README.md
+++ b/examples/CH4-lebesgue/README.md
@@ -1 +1 @@
-../machine/DeePMD-kit-2.x/lebesgue_v2_machine_README.md
\ No newline at end of file
+../machine/DeePMD-kit-2.x/lebesgue_v2_machine_README.md
diff --git a/examples/CH4-lebesgue/init.json b/examples/CH4-lebesgue/init.json
index 72cc77ef5..f4dd430a2 100644
--- a/examples/CH4-lebesgue/init.json
+++ b/examples/CH4-lebesgue/init.json
@@ -1 +1 @@
-../init/ch4.json
\ No newline at end of file
+../init/ch4.json
diff --git a/examples/CH4-lebesgue/lebesgue_v2_machine.json b/examples/CH4-lebesgue/lebesgue_v2_machine.json
index 02f838b49..b53503005 100644
--- a/examples/CH4-lebesgue/lebesgue_v2_machine.json
+++ b/examples/CH4-lebesgue/lebesgue_v2_machine.json
@@ -1 +1 @@
-../machine/DeePMD-kit-2.x/lebesgue_v2_machine.json
\ No newline at end of file
+../machine/DeePMD-kit-2.x/lebesgue_v2_machine.json
diff --git a/examples/CH4-lebesgue/param_CH4_deepmd-kit-2.0.1.json b/examples/CH4-lebesgue/param_CH4_deepmd-kit-2.0.1.json
index 1b19d3d66..1acefee06 100644
--- a/examples/CH4-lebesgue/param_CH4_deepmd-kit-2.0.1.json
+++ b/examples/CH4-lebesgue/param_CH4_deepmd-kit-2.0.1.json
@@ -1 +1 @@
-../run/dp2.x-lammps-vasp/param_CH4_deepmd-kit-2.0.1.json
\ No newline at end of file
+../run/dp2.x-lammps-vasp/param_CH4_deepmd-kit-2.0.1.json
diff --git a/examples/database/param_Ti.json b/examples/database/param_Ti.json
index 5b222f30a..be78af113 100644
--- a/examples/database/param_Ti.json
+++ b/examples/database/param_Ti.json
@@ -1,7 +1,7 @@
{
"path" : "/path/to/Ti",
"calculator" : "vasp",
- "_comment" : "Current only support VASP",
+ "_comment" : "Current only support VASP",
"output" : "./db_Ti.json",
"id_prefix" : "",
"config_info_dict" : {
diff --git a/examples/init/abacus/fcc-Al-lcao/Al.STRU b/examples/init/abacus/fcc-Al-lcao/Al.STRU
index 6c8b504c6..caa7923df 100644
--- a/examples/init/abacus/fcc-Al-lcao/Al.STRU
+++ b/examples/init/abacus/fcc-Al-lcao/Al.STRU
@@ -8,8 +8,8 @@ LATTICE_CONSTANT
1.8897261254578281
LATTICE_VECTORS
-4.04 0.0 0.0
-0.0 4.04 0.0
+4.04 0.0 0.0
+0.0 4.04 0.0
0.0 0.0 4.04
ATOMIC_POSITIONS
diff --git a/examples/init/abacus/fcc-Al-lcao/Al_ONCV_PBE-1.0.upf b/examples/init/abacus/fcc-Al-lcao/Al_ONCV_PBE-1.0.upf
index 51a1e8dba..7f3c9e3d8 100644
--- a/examples/init/abacus/fcc-Al-lcao/Al_ONCV_PBE-1.0.upf
+++ b/examples/init/abacus/fcc-Al-lcao/Al_ONCV_PBE-1.0.upf
@@ -15,22 +15,22 @@
Copyright 2015 The Regents of the University of California
-
- This work is licensed under the Creative Commons Attribution-ShareAlike
- 4.0 International License. To view a copy of this license, visit
- http://creativecommons.org/licenses/by-sa/4.0/ or send a letter to
+
+ This work is licensed under the Creative Commons Attribution-ShareAlike
+ 4.0 International License. To view a copy of this license, visit
+ http://creativecommons.org/licenses/by-sa/4.0/ or send a letter to
Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
-
- This pseudopotential is part of the Schlipf-Gygi norm-conserving
- pseudopotential library. Its construction parameters were tuned to
- reproduce materials of a training set with very high accuracy and
- should be suitable as a general purpose pseudopotential to treat a
- variety of different compounds. For details of the construction and
+
+ This pseudopotential is part of the Schlipf-Gygi norm-conserving
+ pseudopotential library. Its construction parameters were tuned to
+ reproduce materials of a training set with very high accuracy and
+ should be suitable as a general purpose pseudopotential to treat a
+ variety of different compounds. For details of the construction and
testing of the pseudopotential please refer to:
-
+
[insert reference to paper here]
-
- We kindly ask that you include this reference in all publications
+
+ We kindly ask that you include this reference in all publications
associated to this pseudopotential.
diff --git a/examples/init/abacus/fcc-Al-lcao/Al_gga_9au_100Ry_4s4p1d.orb b/examples/init/abacus/fcc-Al-lcao/Al_gga_9au_100Ry_4s4p1d.orb
index 2dc09782f..6313b3ffe 100644
--- a/examples/init/abacus/fcc-Al-lcao/Al_gga_9au_100Ry_4s4p1d.orb
+++ b/examples/init/abacus/fcc-Al-lcao/Al_gga_9au_100Ry_4s4p1d.orb
@@ -2062,4 +2062,4 @@ dr 0.01
1.743108846350e-03 1.435508098330e-03 1.147407005317e-03 8.852535528600e-04
6.544321470349e-04 4.588642296619e-04 3.006765031383e-04 1.799705705548e-04
9.472133372655e-05 4.082158294282e-05 1.227773636824e-05 1.547916295765e-06
- 0.000000000000e+00
\ No newline at end of file
+ 0.000000000000e+00
diff --git a/examples/init/abacus/fcc-Al-lcao/init.json b/examples/init/abacus/fcc-Al-lcao/init.json
index baedb830f..fccb79da7 100644
--- a/examples/init/abacus/fcc-Al-lcao/init.json
+++ b/examples/init/abacus/fcc-Al-lcao/init.json
@@ -6,7 +6,7 @@
"elements": ["Al"],
"from_poscar": true,
"from_poscar_path": "./Al.STRU",
- "potcars": ["Al_ONCV_PBE-1.0.upf"],
+ "potcars": ["Al_ONCV_PBE-1.0.upf"],
"orb_files": ["Al_gga_9au_100Ry_4s4p1d.orb"],
"relax_incar": "./INPUT.rlx",
"md_incar" : "./INPUT.md",
diff --git a/examples/init/abacus/fcc-Al-pw/Al.STRU b/examples/init/abacus/fcc-Al-pw/Al.STRU
index 0c5249a4b..f2ce85c2a 100644
--- a/examples/init/abacus/fcc-Al-pw/Al.STRU
+++ b/examples/init/abacus/fcc-Al-pw/Al.STRU
@@ -5,8 +5,8 @@ LATTICE_CONSTANT
1.8897261254578281
LATTICE_VECTORS
-4.04 0.0 0.0
-0.0 4.04 0.0
+4.04 0.0 0.0
+0.0 4.04 0.0
0.0 0.0 4.04
ATOMIC_POSITIONS
diff --git a/examples/init/abacus/fcc-Al-pw/Al_ONCV_PBE-1.0.upf b/examples/init/abacus/fcc-Al-pw/Al_ONCV_PBE-1.0.upf
index 51a1e8dba..7f3c9e3d8 100644
--- a/examples/init/abacus/fcc-Al-pw/Al_ONCV_PBE-1.0.upf
+++ b/examples/init/abacus/fcc-Al-pw/Al_ONCV_PBE-1.0.upf
@@ -15,22 +15,22 @@
Copyright 2015 The Regents of the University of California
-
- This work is licensed under the Creative Commons Attribution-ShareAlike
- 4.0 International License. To view a copy of this license, visit
- http://creativecommons.org/licenses/by-sa/4.0/ or send a letter to
+
+ This work is licensed under the Creative Commons Attribution-ShareAlike
+ 4.0 International License. To view a copy of this license, visit
+ http://creativecommons.org/licenses/by-sa/4.0/ or send a letter to
Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
-
- This pseudopotential is part of the Schlipf-Gygi norm-conserving
- pseudopotential library. Its construction parameters were tuned to
- reproduce materials of a training set with very high accuracy and
- should be suitable as a general purpose pseudopotential to treat a
- variety of different compounds. For details of the construction and
+
+ This pseudopotential is part of the Schlipf-Gygi norm-conserving
+ pseudopotential library. Its construction parameters were tuned to
+ reproduce materials of a training set with very high accuracy and
+ should be suitable as a general purpose pseudopotential to treat a
+ variety of different compounds. For details of the construction and
testing of the pseudopotential please refer to:
-
+
[insert reference to paper here]
-
- We kindly ask that you include this reference in all publications
+
+ We kindly ask that you include this reference in all publications
associated to this pseudopotential.
diff --git a/examples/init/abacus/fcc-Al-pw/INPUT.md b/examples/init/abacus/fcc-Al-pw/INPUT.md
index cd4a9ddc1..d70a6e5bf 100644
--- a/examples/init/abacus/fcc-Al-pw/INPUT.md
+++ b/examples/init/abacus/fcc-Al-pw/INPUT.md
@@ -21,7 +21,7 @@ smearing_method gauss
smearing_sigma 0.002
#Parameters (5.Mixing)
-mixing_type broyden
+mixing_type broyden
mixing_beta 0.7
cal_stress 1
diff --git a/examples/init/abacus/fcc-Al-pw/INPUT.rlx b/examples/init/abacus/fcc-Al-pw/INPUT.rlx
index 66e41eb09..65b8ec1ed 100644
--- a/examples/init/abacus/fcc-Al-pw/INPUT.rlx
+++ b/examples/init/abacus/fcc-Al-pw/INPUT.rlx
@@ -21,7 +21,7 @@ smearing_method gauss
smearing_sigma 0.002
#Parameters (5.Mixing)
-mixing_type broyden
+mixing_type broyden
mixing_beta 0.7
kspacing 200
diff --git a/examples/init/al.POSCAR b/examples/init/al.POSCAR
index 5dfe2cec3..846267d9e 100644
--- a/examples/init/al.POSCAR
+++ b/examples/init/al.POSCAR
@@ -4,7 +4,7 @@ AL
0.0 4.04 0.0
0.0 0.0 4.04
Al
-4
+4
Cartesian
0.0 0.0 0.0
2.02 2.02 0.0
diff --git a/examples/init/al.json b/examples/init/al.json
index 8e264a9b8..41e365cad 100644
--- a/examples/init/al.json
+++ b/examples/init/al.json
@@ -29,4 +29,4 @@
"Al"
],
"_comment": "that's all"
-}
\ No newline at end of file
+}
diff --git a/examples/init/al.yaml b/examples/init/al.yaml
index c1d9c5fa2..3869912d2 100644
--- a/examples/init/al.yaml
+++ b/examples/init/al.yaml
@@ -21,4 +21,3 @@ pert_box: 0.03
pert_atom: 0.01
coll_ndata: 10
_comment: that's all
-
diff --git a/examples/init/ch4.yaml b/examples/init/ch4.yaml
index 4bc7b43dc..778f3d455 100644
--- a/examples/init/ch4.yaml
+++ b/examples/init/ch4.yaml
@@ -23,4 +23,3 @@ pert_atom: 0.01
deepgen_templ: "../generator/template/"
coll_ndata: 5000
_comment: that's all
-
diff --git a/examples/init/reaction.json b/examples/init/reaction.json
index 12322333c..8bf070726 100644
--- a/examples/init/reaction.json
+++ b/examples/init/reaction.json
@@ -16,4 +16,4 @@
"cutoff": 3.5,
"dataset_size": 100,
"qmkeywords": "b3lyp/6-31g** force Geom=PrintInputOrient"
-}
\ No newline at end of file
+}
diff --git a/examples/init/surf.yaml b/examples/init/surf.yaml
index a78b11433..e598872a8 100644
--- a/examples/init/surf.yaml
+++ b/examples/init/surf.yaml
@@ -40,4 +40,3 @@ pert_box: 0.03
pert_atom: 0.01
coll_ndata: 5000
_comment: that's all
-
diff --git a/examples/machine/DeePMD-kit-1.x/machine-ali.json b/examples/machine/DeePMD-kit-1.x/machine-ali.json
deleted file mode 100644
index e78fc9dd4..000000000
--- a/examples/machine/DeePMD-kit-1.x/machine-ali.json
+++ /dev/null
@@ -1,112 +0,0 @@
-{
- "train":
- {
- "machine": {
- "batch": "shell",
- "hostname": "",
- "password": "PASSWORD",
- "port": 22,
- "username": "root",
- "work_path": "/root/dpgen_work",
- "ali_auth": {
- "AccessKey_ID":"",
- "AccessKey_Secret":"",
- "regionID": "cn-shenzhen",
- "img_name": "kit",
- "machine_type_price": [
- {"machine_type": "ecs.gn6v-c8g1.2xlarge", "price_limit": 20.00, "numb": 1, "priority": 0},
- {"machine_type": "ecs.gn5-c4g1.xlarge", "price_limit": 20.00, "numb": 1, "priority": 1}
- ],
- "instance_name": "CH4",
- "pay_strategy": "spot"
- }
- },
- "resources": {
- "numb_gpu": 1,
- "numb_node": 1,
- "task_per_node": 12,
- "partition": "gpu",
- "exclude_list": [],
- "mem_limit": 32,
- "source_list": [],
- "module_list": [],
- "time_limit": "23:0:0"
- },
- "command": "/root/deepmd-kit/bin/dp",
- "group_size": 2
- },
-
- "model_devi":
- {
- "machine": {
- "batch": "shell",
- "hostname": "",
- "password": "PASSWORD",
- "port": 22,
- "username": "root",
- "work_path": "/root/dpgen_work",
- "ali_auth": {
- "AccessKey_ID":"",
- "AccessKey_Secret":"",
- "regionID": "cn-shenzhen",
- "img_name": "kit",
- "machine_type_price": [
- {"machine_type": "ecs.gn6v-c8g1.2xlarge", "price_limit": 20.00, "numb": 1, "priority": 0},
- {"machine_type": "ecs.gn5-c4g1.xlarge", "price_limit": 20.00, "numb": 1, "priority": 1}
- ],
- "instance_name": "CH4",
- "pay_strategy": "spot"
- }
- },
- "resources": {
- "numb_gpu": 1,
- "task_per_node": 4,
- "partition": "gpu",
- "exclude_list": [],
- "mem_limit": 11,
- "source_list": [],
- "module_list": [],
- "time_limit": "23:0:0"
- },
- "command": "/root/deepmd-kit/bin/lmp",
- "group_size": 2
- },
-
- "fp":
- {
- "machine": {
- "batch": "shell",
- "hostname": "",
- "password": "PASSWORD",
- "port": 22,
- "username": "root",
- "work_path": "/root/dpgen_work",
- "ali_auth": {
- "AccessKey_ID":"",
- "AccessKey_Secret":"",
- "regionID": "cn-shenzhen",
- "img_name": "vasp",
- "machine_type_price": [
- {"machine_type": "ecs.c6.4xlarge", "price_limit": 0.2, "numb": 16, "priority": 0},
- {"machine_type": "ecs.g6.4xlarge", "price_limit": 0.2, "numb": 16, "priority": 1}
- ],
- "instance_name": "CH4",
- "pay_strategy": "spot"
- }
- },
- "resources": {
- "numb_gpu": 0,
- "task_per_node": 16,
- "with_mpi": "false",
- "source_list": ["/opt/intel/parallel_studio_xe_2018/psxevars.sh"],
- "module_list": [],
- "partition": "cpu",
- "envs" : {"PATH" : "/root/deepmd-pkg/vasp.5.4.4/bin:$PATH"}
- },
- "command": "mpirun -n 16 /root/deepmd-pkg/vasp.5.4.4/bin/vasp_std",
- "group_size": 1
- }
-}
-
-
-
diff --git a/examples/machine/DeePMD-kit-1.x/machine-local.json b/examples/machine/DeePMD-kit-1.x/machine-local.json
index c8134d750..2eb999743 100644
--- a/examples/machine/DeePMD-kit-1.x/machine-local.json
+++ b/examples/machine/DeePMD-kit-1.x/machine-local.json
@@ -62,4 +62,4 @@
},
"command": "mpirun -n 4 /home/wanghan/local/bin/vasp_std"
}
-}
\ No newline at end of file
+}
diff --git a/examples/machine/DeePMD-kit-1.x/machine-lsf-slurm-cp2k.json b/examples/machine/DeePMD-kit-1.x/machine-lsf-slurm-cp2k.json
index 348609c1e..0fab6e8b9 100644
--- a/examples/machine/DeePMD-kit-1.x/machine-lsf-slurm-cp2k.json
+++ b/examples/machine/DeePMD-kit-1.x/machine-lsf-slurm-cp2k.json
@@ -95,4 +95,4 @@
"command": "mpirun -n 32 cp2k.popt -i input.inp"
},
"api_version": "1.0"
-}
\ No newline at end of file
+}
diff --git a/examples/machine/DeePMD-kit-1.x/machine-pbs-gaussian.json b/examples/machine/DeePMD-kit-1.x/machine-pbs-gaussian.json
index daa743dcc..cc8eca816 100644
--- a/examples/machine/DeePMD-kit-1.x/machine-pbs-gaussian.json
+++ b/examples/machine/DeePMD-kit-1.x/machine-pbs-gaussian.json
@@ -85,4 +85,4 @@
},
"command": "/public/home/tzhu/g16/g16 < input || :"
}
-}
\ No newline at end of file
+}
diff --git a/examples/machine/DeePMD-kit-1.x/machine-slurm-qe.json b/examples/machine/DeePMD-kit-1.x/machine-slurm-qe.json
index 2ff5b4a4b..6f96d397d 100644
--- a/examples/machine/DeePMD-kit-1.x/machine-slurm-qe.json
+++ b/examples/machine/DeePMD-kit-1.x/machine-slurm-qe.json
@@ -33,7 +33,7 @@
"number_node": 1,
"_comment" : "The number of CPUs. #SBATCH -n 4",
"cpu_per_node": 4,
- "_comment" : "The number of GPU cards. #SBATCH --gres=gpu:1",
+ "_comment" : "The number of GPU cards. #SBATCH --gres=gpu:1",
"gpu_per_node": 1,
"queue_name": "all",
"custom_flags": [
@@ -109,4 +109,4 @@
"command": "mpirun -n 8 /gpfs/share/home/1600017784/yuzhi/soft/QE-mpi/PW/src/pw.x < input"
},
"api_version": "1.0"
-}
\ No newline at end of file
+}
diff --git a/examples/machine/DeePMD-kit-2.x/lebesgue_v2_machine.json b/examples/machine/DeePMD-kit-2.x/lebesgue_v2_machine.json
index 0ecba4fa6..ae6ac31ab 100644
--- a/examples/machine/DeePMD-kit-2.x/lebesgue_v2_machine.json
+++ b/examples/machine/DeePMD-kit-2.x/lebesgue_v2_machine.json
@@ -27,8 +27,8 @@
}
},
"resources": {
+ "batch_type": "DpCloudServer",
"number_node": 1,
- "local_root":"./",
"cpu_per_node": 4,
"gpu_per_node": 1,
"queue_name": "GPU",
@@ -61,8 +61,8 @@
}
},
"resources": {
+ "batch_type": "DpCloudServer",
"number_node": 1,
- "local_root":"./",
"cpu_per_node": 4,
"gpu_per_node": 1,
"queue_name": "GPU",
@@ -95,12 +95,12 @@
}
},
"resources": {
+ "batch_type": "DpCloudServer",
"number_node": 1,
"cpu_per_node": 32,
"gpu_per_node": 0,
"queue_name": "CPU",
"group_size": 5,
- "local_root":"./",
"source_list": ["/opt/intel/oneapi/setvars.sh"]
}
}
diff --git a/examples/machine/DeePMD-kit-2.x/lebesgue_v2_machine_README.md b/examples/machine/DeePMD-kit-2.x/lebesgue_v2_machine_README.md
index 3c81f5d04..b91527386 100644
--- a/examples/machine/DeePMD-kit-2.x/lebesgue_v2_machine_README.md
+++ b/examples/machine/DeePMD-kit-2.x/lebesgue_v2_machine_README.md
@@ -1,6 +1,6 @@
# Config machine.json file in order to submit task to lebesgue platform.
-You can login to lebesgue official website http://lebesgue.dp.tech/ . Then click [Function]-[DPGEN]-[manual]\(On the top left corner of the function panel\) from left navigator bar http://lebesgue.dp.tech/#/jobs/dpgen.
+You can login to lebesgue official website http://lebesgue.dp.tech/ . Then click [Function]-[DPGEN]-[manual]\(On the top left corner of the function panel\) from left navigator bar http://lebesgue.dp.tech/#/jobs/dpgen.
Below is the description of each json fields, please visit official documentation for more information and update.
@@ -21,4 +21,4 @@ Below is the description of each json fields, please visit official documentatio
| scass_type | false | string | machine configuration, about scass_type, you can find them on [lebesgue official website] - [Finance]-[Price calculator] to select disire machine configuration. invalid when instance_group_id is present |
| instance_group_id | true | int | group of scass type |
| platform | false | string | avaliable platform: "aws" "ali" "sugon" |
-| grouped | false | bool | weather group same task in to one job group. |
\ No newline at end of file
+| grouped | false | bool | weather group same task in to one job group. |
diff --git a/examples/machine/deprecated/DeePMD-kit-0.12/machine-aws.json b/examples/machine/deprecated/DeePMD-kit-0.12/machine-aws.json
deleted file mode 100644
index 7d050b548..000000000
--- a/examples/machine/deprecated/DeePMD-kit-0.12/machine-aws.json
+++ /dev/null
@@ -1,164 +0,0 @@
-{
- "machine_type":"aws",
- "train_machine":{
- "machine_type":"aws",
- "remote_root":"/home/ec2-user/efs",
- "run_instances":{
- "BlockDeviceMappings":[
- {
- "DeviceName": "/dev/xvda",
- "Ebs": {
- "DeleteOnTermination": true,
- "VolumeSize": 40,
- "VolumeType": "gp2"
- }
- }
- ],
- "ImageId":"ami-0329a1fdc914b0c55",
- "InstanceType":"t2.small",
- "KeyName":"yfb",
- "IamInstanceProfile":{
- "Name": "ecsInstanceRole"},
- "MaxCount":1,
- "MinCount":1,
- "Monitoring":{
- "Enabled": false
- },
- "SecurityGroupIds":[
- "sg-0c3e6637acfb70200"
- ],
- "UserData":"#!/bin/bash\ncloud-init-per once yum_update yum update -y\ncloud-init-per once install_nfs_utils yum install -y nfs-utils\ncloud-init-per once mkdir_efs mkdir /efs\ncloud-init-per once mount_efs echo -e 'fs-96b3e4ef.efs.us-east-2.amazonaws.com:/ /efs nfs4 nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 0 0' >> /etc/fstab\nmount -a\necho \"ECS_CLUSTER=tensorflow\" >> /etc/ecs/ecs.config"
- }
- },
- "model_devi_group_size":5,
- "model_devi_machine":{
- "machine_type":"aws",
- "remote_root":"/home/ec2-user/efs",
- "run_instances":{
- "BlockDeviceMappings":[
- {
- "DeviceName": "/dev/xvda",
- "Ebs": {
- "DeleteOnTermination": true,
- "VolumeSize": 40,
- "VolumeType": "gp2"
- }
- }
- ],
- "ImageId":"ami-0329a1fdc914b0c55",
- "InstanceType":"t2.small",
- "KeyName":"yfb",
- "IamInstanceProfile":{
- "Name": "ecsInstanceRole"},
- "MaxCount":1,
- "MinCount":1,
- "Monitoring":{
- "Enabled": false
- },
- "SecurityGroupIds":[
- "sg-0c3e6637acfb70200"
- ],
- "UserData":"#!/bin/bash\ncloud-init-per once yum_update yum update -y\ncloud-init-per once install_nfs_utils yum install -y nfs-utils\ncloud-init-per once mkdir_efs mkdir /efs\ncloud-init-per once mount_efs echo -e 'fs-96b3e4ef.efs.us-east-2.amazonaws.com:/ /efs nfs4 nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 0 0' >> /etc/fstab\nmount -a\necho \"ECS_CLUSTER=tensorflow\" >> /etc/ecs/ecs.config"
- }
- },
- "fp_machine":{
- "machine_type":"aws",
- "remote_root":"/home/ec2-user/efs",
- "run_instances":{
- "BlockDeviceMappings":[
- {
- "DeviceName": "/dev/xvda",
- "Ebs": {
- "DeleteOnTermination": true,
- "VolumeSize": 40,
- "VolumeType": "gp2"
- }
- }
- ],
- "ImageId":"ami-0329a1fdc914b0c55",
- "InstanceType":"t2.small",
- "KeyName":"yfb",
- "IamInstanceProfile":{
- "Name": "ecsInstanceRole"},
- "MaxCount":1,
- "MinCount":1,
- "Monitoring":{
- "Enabled":false
- },
- "SecurityGroupIds":[
- "sg-0c3e6637acfb70200"
- ],
- "UserData":"#!/bin/bash\ncloud-init-per once yum_update yum update -y\ncloud-init-per once install_nfs_utils yum install -y nfs-utils\ncloud-init-per once mkdir_efs mkdir /efs\ncloud-init-per once mount_efs echo -e 'fs-96b3e4ef.efs.us-east-2.amazonaws.com:/ /efs nfs4 nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2 0 0' >> /etc/fstab\nmount -a\necho \"ECS_CLUSTER=tensorflow\" >> /etc/ecs/ecs.config"
- }
- },
- "fp_group_size":5,
- "fp_resources":{
- "with_mpi":true
- },
- "deepmd_path": "/deepmd_root/",
- "model_devi_command":"/usr/bin/lmp_mpi",
- "fp_command":"/usr/bin/vasp_std",
-
- "train_resources": {},
- "model_devi_resources":{},
-
- "task_definition":{
- "requiresCompatibilities": [
- "EC2"
- ],
- "containerDefinitions": [{
- "command": [
- "ls /home/ec2-user/efs && cd /deepmd-kit/examples/train && dp_train water_smth_test.json | tee /home/ec2-user/efs/dp_train.log"
- ],
- "entryPoint": [
- "sh",
- "-c"
- ],
- "name": "deepmd-training-container",
- "mountPoints": [{
- "sourceVolume": "efs",
- "containerPath": "/home/ec2-user"}
- ],
- "image": "787517567283.dkr.ecr.us-east-2.amazonaws.com/deepmd:squashed",
- "memory": 1800,
- "cpu": 1000,
- "essential": true,
- "portMappings": [{
- "containerPort": 80,
- "protocol": "tcp"
- }],
- "logConfiguration": {
- "logDriver": "awslogs",
- "options": {
- "awslogs-group": "awslogs-tf-ecs",
- "awslogs-region": "us-east-2",
- "awslogs-stream-prefix": "tf",
- "awslogs-create-group": "true"
- }
- }
- }],
- "volumes": [{
- "host": {
- "sourcePath": "/" },
- "name": "efs"
- }
- ],
- "networkMode": "bridge",
- "placementConstraints": [],
- "family": "deepmd"},
- "run_train_task_definition":{
- "command_override":{"containerOverrides":[{"name":"deepmd-training-container","command":["concrete_command"]}]},
- "task_definition":"arn:aws:ecs:us-east-2:787517567283:task-definition/run_train:1",
- "concrete_command":"cd /home/ec2-user/efs/%s/%s && dp_train input.json && dp_frz"
- },
- "model_devi_task_definition":{
- "command_override":{"containerOverrides":[{"name":"deepmd-training-container","command":["concrete_command"]}]},
- "task_definition":"arn:aws:ecs:us-east-2:787517567283:task-definition/run_train:2",
- "concrete_command":"cd /home/ec2-user/efs/%s/%s && /usr/bin/lmp_mpi -i input.lammps | tee model_devi.log"
- },
- "fp_task_definition":{
- "command_override":{"containerOverrides":[{"name":"deepmd-training-container","command":["concrete_command"]}]},
- "task_definition":"arn:aws:ecs:us-east-2:787517567283:task-definition/run_fp:2",
- "concrete_command":"cd /home/ec2-user/efs/%s/%s && mpirun -n 2 --allow-run-as-root /usr/bin/vasp_std | tee fp.log"
- }
-}
diff --git a/examples/machine/deprecated/DeePMD-kit-0.12/machine-local.json b/examples/machine/deprecated/DeePMD-kit-0.12/machine-local.json
deleted file mode 100644
index b8e15a625..000000000
--- a/examples/machine/deprecated/DeePMD-kit-0.12/machine-local.json
+++ /dev/null
@@ -1,43 +0,0 @@
-{
- "_comment": "training on localhost ",
- "_comment" : "This is for DeePMD-kit 0.12.4",
- "deepmd_path": "/home/wanghan/local/deepmd/0.12.4/",
- "train_machine": {
- "batch": "shell",
- "work_path" : "/home/wanghan/tmp/subs/"
- },
- "train_resources": {
- "envs": {
- "PYTHONPATH" : "/home/wanghan/local/tensorflow/1.8.py/lib/python3.6/site-packages/"
- }
- },
-
-
- "_comment": "model_devi on localhost ",
- "model_devi_command": "/home/wanghan/local/bin/lmp_mpi_010",
- "model_devi_group_size": 5,
- "model_devi_machine": {
- "batch": "shell",
- "_comment" : "If lazy_local is true, calculations are done directly in current folders.",
- "lazy_local" : true
- },
- "model_devi_resources": {
- },
-
- "_comment": "fp on localhost ",
- "fp_command": "/home/wanghan/local/bin/vasp_std",
- "fp_group_size": 2,
- "fp_machine": {
- "batch": "local",
- "work_path" : "/home/wanghan/tmp/subs/",
- "_comment" : "that's all"
- },
- "fp_resources": {
- "module_list": ["mpi"],
- "task_per_node":4,
- "with_mpi": true,
- "_comment": "that's all"
- },
-
- "_comment": " that's all "
-}
diff --git a/examples/machine/deprecated/DeePMD-kit-0.12/machine-lsf.json b/examples/machine/deprecated/DeePMD-kit-0.12/machine-lsf.json
deleted file mode 100644
index d8ebd61ed..000000000
--- a/examples/machine/deprecated/DeePMD-kit-0.12/machine-lsf.json
+++ /dev/null
@@ -1,93 +0,0 @@
-{
- "train": [
- {
- "machine": {
- "batch": "lsf",
- "hostname": "localhost",
- "port": 22,
- "username": "ypliu",
- "work_path": "/data/home/ypliu/test/deepmd-tutorial/cp2k_dpgen/dpmd"
- },
- "resources": {
- "_comment": "this part should be modified if GPU resources could be called directly by LSF",
- "node_cpu": 4,
- "numb_node": 1,
- "task_per_node": 4,
- "partition": "gpu",
- "exclude_list": [],
- "mem_limit": 11,
- "source_list": [
- "/data/home/ypliu/test/deepmd-tutorial/cp2k_dpgen/source_env.sh",
- "/data/home/ypliu/test/deepmd-tutorial/cp2k_dpgen/test_gpu_sub.sh"
- ],
- "module_list": [
- "vasp/5.4.4",
- "cuda"
- ],
- "time_limit": "23:0:0"
- },
- "deepmd_path": "/data/home/ypliu/deepmd/deepmd_root"
- }
- ],
- "model_devi": [
- {
- "machine": {
- "batch": "lsf",
- "hostname": "localhost",
- "port": 22,
- "username": "ypliu",
- "work_path": "/data/home/ypliu/test/deepmd-tutorial/cp2k_dpgen/lammps"
- },
- "resources": {
- "_comment": "this part should be modified if GPU resources could be called directly by LSF",
- "node_cpu": 4,
- "numb_node": 1,
- "task_per_node": 4,
- "partition": "gpu",
- "exclude_list": [],
- "mem_limit": 11,
- "source_list": [
- "/data/home/ypliu/test/deepmd-tutorial/cp2k_dpgen/source_env.sh",
- "/data/home/ypliu/test/deepmd-tutorial/cp2k_dpgen/test_gpu_sub.sh"
- ],
- "module_list": [
- "vasp/5.4.4",
- "cuda",
- "gcc/4.9.4"
- ],
- "time_limit": "23:0:0"
- },
- "command": "/data/home/ypliu/lammps/lammps-7Aug19/src/lmp_mpi",
- "group_size": 10
- }
- ],
- "fp": [
- {
- "machine": {
- "batch": "lsf",
- "hostname": "localhost",
- "port": 22,
- "username": "ypliu",
- "work_path": "/data/home/ypliu/test/deepmd-tutorial/cp2k_dpgen/cp2k"
- },
- "resources": {
- "cvasp": false,
- "task_per_node": 28,
- "node_cpu": 28,
- "exclude_list": [],
- "mem_limit": 128,
- "with_mpi": true,
- "source_list": [],
- "module_list": [
- "intel/17.0.1",
- "mpi/intel/2017.1.132"
- ],
- "time_limit": "96:0:0",
- "partition": "q2680v4m128",
- "_comment": "that's Bel"
- },
- "command": "/share/apps/cp2k-5.0/Linux-x86-64-intel-host/cp2k.popt -i input.inp",
- "group_size": 5
- }
- ]
-}
\ No newline at end of file
diff --git a/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-multi.json b/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-multi.json
deleted file mode 100644
index e24838077..000000000
--- a/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-multi.json
+++ /dev/null
@@ -1,241 +0,0 @@
-{
- "train": [
- {
- "machine": {
- "batch": "slurm",
- "hostname": "localhost",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node": 4,
- "partition": "GPU",
- "exclude_list": [],
- "source_list": [
- "/gpfs/share/home/1600017784/env/train_tf112_float.env"
- ],
- "module_list": [],
- "time_limit": "23:0:0",
- "qos": "bigdata"
- },
- "deepmd_path": "/gpfs/share/software/deepmd-kit/0.12.4/gpu/gcc/4.9.0/tf1120-lowprec"
- },
- {
- "machine": {
- "batch": "slurm",
- "hostname": "localhost",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node": 4,
- "partition": "AdminGPU",
- "exclude_list": [],
- "source_list": [
- "/gpfs/share/home/1600017784/env/train_tf112_float.env"
- ],
- "module_list": [],
- "time_limit": "23:0:0",
- "qos": "bigdata"
- },
- "deepmd_path": "/gpfs/share/software/deepmd-kit/0.12.4/gpu/gcc/4.9.0/tf1120-lowprec"
- },
- {
- "deepmd_path": "/data2/publicsoft/deepmd-kit/0.12.4-s/",
- "machine": {
- "batch": "slurm",
- "hostname": "115.27.161.2",
- "port": 22,
- "username": "anguse",
- "work_path": "/data1/anguse/generator/Cu/work/",
- "_comment": "that's all"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node": 4,
- "partition": "all",
- "mem_limit": 16,
- "exclude_list": [
- "gpu06",
- "gpu07"
- ],
- "source_list": [
- "/data1/anguse/env/train.env"
- ],
- "module_list": [],
- "time_limit": "23:0:0",
- "_comment": "that's all"
- }
- }
- ],
- "model_devi": [
- {
- "machine": {
- "batch": "slurm",
- "hostname": "localhost",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node": 2,
- "partition": "GPU",
- "exclude_list": [],
- "source_list": [
- "/gpfs/share/home/1600017784/env/lmp_tf112_float.env"
- ],
- "module_list": [],
- "time_limit": "23:0:0",
- "qos": "bigdata"
- },
- "command": "lmp_serial",
- "group_size": 10
- },
- {
- "machine": {
- "batch": "slurm",
- "hostname": "localhost",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node": 2,
- "partition": "AdminGPU",
- "exclude_list": [],
- "source_list": [
- "/gpfs/share/home/1600017784/env/lmp_tf112_float.env"
- ],
- "module_list": [],
- "time_limit": "23:0:0",
- "qos": "bigdata"
- },
- "command": "lmp_serial",
- "group_size": 10
- },
- {
- "machine": {
- "batch": "slurm",
- "hostname": "115.27.161.2",
- "port": 22,
- "username": "anguse",
- "work_path": "/data1/anguse/generator/Cu/work/",
- "_comment": "that's all"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node": 4,
- "partition": "all",
- "mem_limit": 16,
- "exclude_list": [
- "gpu12"
- ],
- "source_list": [
- "/data1/anguse/env/lmp.env"
- ],
- "module_list": [],
- "time_limit": "23:0:0",
- "_comment": "that's all"
- },
- "command": "lmp_serial",
- "group_size": 20
- }
- ],
- "fp": [
- {
- "machine": {
- "batch": "slurm",
- "hostname": "localhost",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "cvasp": true,
- "task_per_node": 28,
- "numb_gpu": 0,
- "exclude_list": [],
- "with_mpi": true,
- "source_list": [],
- "module_list": [
- "intel/2017.1",
- "vasp/5.4.4-intel-2017.1"
- ],
- "time_limit": "120:0:0",
- "partition": "C028M256G",
- "qos": "bigdata",
- "_comment": "that's Bel"
- },
- "command": "vasp_std",
- "group_size": 5
- },
- {
- "machine": {
- "batch": "slurm",
- "hostname": "162.105.133.134",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "cvasp": true,
- "task_per_node": 16,
- "numb_gpu": 0,
- "exclude_list": [],
- "with_mpi": false,
- "source_list": [
- "activate dppy"
- ],
- "module_list": [
- "mpich/3.2.1-intel-2017.1",
- "vasp/5.4.4-intel-2017.1"
- ],
- "time_limit": "120:0:0",
- "partition": "C032M0128G",
- "_comment": "that's Bel"
- },
- "command": "mpirun -n 16 vasp_std",
- "group_size": 5
- },
- {
- "machine": {
- "batch": "slurm",
- "hostname": "162.105.133.134",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "cvasp": true,
- "task_per_node": 16,
- "numb_gpu": 0,
- "exclude_list": [],
- "with_mpi": false,
- "source_list": [
- "activate dppy"
- ],
- "module_list": [
- "mpich/3.2.1-intel-2017.1",
- "vasp/5.4.4-intel-2017.1"
- ],
- "time_limit": "120:0:0",
- "partition": "C032M0256G",
- "_comment": "that's all"
- },
- "command": "mpirun -n 16 vasp_std",
- "group_size": 5
- }
- ]
-}
\ No newline at end of file
diff --git a/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-multi.yaml b/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-multi.yaml
deleted file mode 100644
index 5bd30d186..000000000
--- a/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-multi.yaml
+++ /dev/null
@@ -1,189 +0,0 @@
----
-train:
-- machine:
- batch: slurm
- hostname: localhost
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- numb_node: 1
- numb_gpu: 1
- task_per_node: 4
- partition: GPU
- exclude_list: []
- source_list:
- - "/gpfs/share/home/1600017784/env/train_tf112_float.env"
- module_list: []
- time_limit: '23:0:0'
- qos: bigdata
- deepmd_path: "/gpfs/share/software/deepmd-kit/0.12.4/gpu/gcc/4.9.0/tf1120-lowprec"
-- machine:
- batch: slurm
- hostname: localhost
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- numb_node: 1
- numb_gpu: 1
- task_per_node: 4
- partition: AdminGPU
- exclude_list: []
- source_list:
- - "/gpfs/share/home/1600017784/env/train_tf112_float.env"
- module_list: []
- time_limit: '23:0:0'
- qos: bigdata
- deepmd_path: "/gpfs/share/software/deepmd-kit/0.12.4/gpu/gcc/4.9.0/tf1120-lowprec"
-- deepmd_path: "/data2/publicsoft/deepmd-kit/0.12.4-s/"
- machine:
- batch: slurm
- hostname: 115.27.161.2
- port: 22
- username: anguse
- work_path: "/data1/anguse/generator/Cu/work/"
- _comment: that's all
- resources:
- numb_node: 1
- numb_gpu: 1
- task_per_node: 4
- partition: all
- mem_limit: 16
- exclude_list:
- - gpu06
- - gpu07
- source_list:
- - "/data1/anguse/env/train.env"
- module_list: []
- time_limit: '23:0:0'
- _comment: that's all
-model_devi:
-- machine:
- batch: slurm
- hostname: localhost
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- numb_node: 1
- numb_gpu: 1
- task_per_node: 2
- partition: GPU
- exclude_list: []
- source_list:
- - "/gpfs/share/home/1600017784/env/lmp_tf112_float.env"
- module_list: []
- time_limit: '23:0:0'
- qos: bigdata
- command: lmp_serial
- group_size: 10
-- machine:
- batch: slurm
- hostname: localhost
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- numb_node: 1
- numb_gpu: 1
- task_per_node: 2
- partition: AdminGPU
- exclude_list: []
- source_list:
- - "/gpfs/share/home/1600017784/env/lmp_tf112_float.env"
- module_list: []
- time_limit: '23:0:0'
- qos: bigdata
- command: lmp_serial
- group_size: 10
-- machine:
- batch: slurm
- hostname: 115.27.161.2
- port: 22
- username: anguse
- work_path: "/data1/anguse/generator/Cu/work/"
- _comment: that's all
- resources:
- numb_node: 1
- numb_gpu: 1
- task_per_node: 4
- partition: all
- mem_limit: 16
- exclude_list:
- - gpu12
- source_list:
- - "/data1/anguse/env/lmp.env"
- module_list: []
- time_limit: '23:0:0'
- _comment: that's all
- command: lmp_serial
- group_size: 20
-fp:
-- machine:
- batch: slurm
- hostname: localhost
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- cvasp: true
- task_per_node: 28
- numb_gpu: 0
- exclude_list: []
- with_mpi: true
- source_list: []
- module_list:
- - intel/2017.1
- - vasp/5.4.4-intel-2017.1
- time_limit: '120:0:0'
- partition: C028M256G
- qos: bigdata
- _comment: that's Bel
- command: vasp_std
- group_size: 5
-- machine:
- batch: slurm
- hostname: 162.105.133.134
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- cvasp: true
- task_per_node: 16
- numb_gpu: 0
- exclude_list: []
- with_mpi: false
- source_list:
- - activate dppy
- module_list:
- - mpich/3.2.1-intel-2017.1
- - vasp/5.4.4-intel-2017.1
- time_limit: '120:0:0'
- partition: C032M0128G
- _comment: that's Bel
- command: mpirun -n 16 vasp_std
- group_size: 5
-- machine:
- batch: slurm
- hostname: 162.105.133.134
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- cvasp: true
- task_per_node: 16
- numb_gpu: 0
- exclude_list: []
- with_mpi: false
- source_list:
- - activate dppy
- module_list:
- - mpich/3.2.1-intel-2017.1
- - vasp/5.4.4-intel-2017.1
- time_limit: '120:0:0'
- partition: C032M0256G
- _comment: that's all
- command: mpirun -n 16 vasp_std
- group_size: 5
-
diff --git a/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-single.json b/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-single.json
deleted file mode 100644
index 2dbdafd5e..000000000
--- a/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-single.json
+++ /dev/null
@@ -1,82 +0,0 @@
-{
- "train": [
- {
- "machine": {
- "batch": "slurm",
- "hostname": "localhost",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node": 4,
- "partition": "GPU",
- "exclude_list": [],
- "source_list": [
- "/gpfs/share/home/1600017784/env/train_tf112_float.env"
- ],
- "module_list": [],
- "time_limit": "23:0:0",
- "qos": "bigdata"
- },
- "deepmd_path": "/gpfs/share/software/deepmd-kit/0.12.4/gpu/gcc/4.9.0/tf1120-lowprec"
- }
- ],
- "model_devi": [
- {
- "machine": {
- "batch": "slurm",
- "hostname": "localhost",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node": 2,
- "partition": "GPU",
- "exclude_list": [],
- "source_list": [
- "/gpfs/share/home/1600017784/env/lmp_tf112_float.env"
- ],
- "module_list": [],
- "time_limit": "23:0:0",
- "qos": "bigdata"
- },
- "command": "lmp_serial",
- "group_size": 10
- }
- ],
- "fp": [
- {
- "machine": {
- "batch": "slurm",
- "hostname": "localhost",
- "port": 22,
- "username": "1600017784",
- "work_path": "/gpfs/share/home/1600017784/generator/Cu/work"
- },
- "resources": {
- "cvasp": true,
- "task_per_node": 4,
- "numb_gpu": 1,
- "exclude_list": [],
- "with_mpi": false,
- "source_list": [],
- "module_list": [
- "mpich/3.2.1-intel-2017.1",
- "vasp/5.4.4-intel-2017.1",
- "cuda/10.1"
- ],
- "time_limit": "120:0:0",
- "partition": "GPU",
- "_comment": "that's All"
- },
- "command": "vasp_gpu",
- "group_size": 5
- }
- ]
-}
\ No newline at end of file
diff --git a/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-single.yaml b/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-single.yaml
deleted file mode 100644
index 3b52e52ce..000000000
--- a/examples/machine/deprecated/DeePMD-kit-0.12/machine-slurm-vasp-single.yaml
+++ /dev/null
@@ -1,64 +0,0 @@
----
-train:
-- machine:
- batch: slurm
- hostname: localhost
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- numb_node: 1
- numb_gpu: 1
- task_per_node: 4
- partition: GPU
- exclude_list: []
- source_list:
- - "/gpfs/share/home/1600017784/env/train_tf112_float.env"
- module_list: []
- time_limit: '23:0:0'
- qos: bigdata
- deepmd_path: "/gpfs/share/software/deepmd-kit/0.12.4/gpu/gcc/4.9.0/tf1120-lowprec"
-model_devi:
-- machine:
- batch: slurm
- hostname: localhost
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- numb_node: 1
- numb_gpu: 1
- task_per_node: 2
- partition: GPU
- exclude_list: []
- source_list:
- - "/gpfs/share/home/1600017784/env/lmp_tf112_float.env"
- module_list: []
- time_limit: '23:0:0'
- qos: bigdata
- command: lmp_serial
- group_size: 10
-fp:
-- machine:
- batch: slurm
- hostname: localhost
- port: 22
- username: '1600017784'
- work_path: "/gpfs/share/home/1600017784/generator/Cu/work"
- resources:
- cvasp: true
- task_per_node: 4
- numb_gpu: 1
- exclude_list: []
- with_mpi: false
- source_list: []
- module_list:
- - mpich/3.2.1-intel-2017.1
- - vasp/5.4.4-intel-2017.1
- - cuda/10.1
- time_limit: '120:0:0'
- partition: GPU
- _comment: that's All
- command: vasp_gpu
- group_size: 5
-
diff --git a/examples/machine/deprecated/machine-hnu.json b/examples/machine/deprecated/machine-hnu.json
deleted file mode 100644
index eb9cb91f2..000000000
--- a/examples/machine/deprecated/machine-hnu.json
+++ /dev/null
@@ -1,71 +0,0 @@
-{
- "deepmd_path": "/home/llang/dp_v2/local/0.12.0/",
- "train_machine": {
- "machine_type": "pbs",
- "hostname" : "localhost",
- "port" : 22,
- "username": "llang",
- "work_path" : "/home/llang/dp_v2/wanghan/tmp/",
- "_comment" : "that's all"
- },
- "train_resources": {
- "numb_node": 1,
- "numb_gpu": 0,
- "task_per_node":20,
- "source_list": [ "/opt/rh/devtoolset-4/enable" ],
- "module_list": [ ],
- "envs": {
- "OMP_NUM_THREADS": 1
- },
- "time_limit": "12:0:0",
- "_comment": "that's all"
- },
-
- "model_devi_command": "/home/llang/dp_v2/local/bin/lmp_mpi_0_12_0",
- "model_devi_group_size": 10,
- "_comment": "model_devi on localhost ",
- "model_devi_machine": {
- "machine_type": "pbs",
- "hostname" : "localhost",
- "port" : 22,
- "username": "llang",
- "work_path" : "/home/llang/dp_v2/wanghan/tmp/",
- "_comment" : "that's all"
- },
- "_comment": " if numb_nodes(nn) = 1 multi-threading rather than mpi is assumed",
- "model_devi_resources": {
- "numb_node": 1,
- "numb_gpu": 0,
- "task_per_node":1,
- "with_mpi": true,
- "source_list": [ "/opt/rh/devtoolset-4/enable" ],
- "module_list": [ ],
- "time_limit": "2:0:0",
- "_comment": "that's all"
- },
-
-
- "_comment": "fp on localhost ",
- "fp_command": "/opt/software/vasp.5.4.4/bin/vasp_std",
- "fp_group_size": 5,
- "fp_machine": {
- "machine_type": "pbs",
- "hostname" : "localhost",
- "port" : 22,
- "username": "llang",
- "work_path" : "/home/llang/dp_v2/wanghan/tmp/",
- "_comment" : "that's all"
- },
- "fp_resources": {
- "numb_node": 1,
- "task_per_node":10,
- "numb_gpu": 0,
- "with_mpi": true,
- "source_list": [ "/opt/rh/devtoolset-4/enable" ],
- "module_list": [ ],
- "time_limit": "2:0:0",
- "_comment": "that's all"
- },
-
- "_comment": " that's all "
-}
diff --git a/examples/machine/deprecated/machine-tiger-pwscf-della.json b/examples/machine/deprecated/machine-tiger-pwscf-della.json
deleted file mode 100644
index 44911f487..000000000
--- a/examples/machine/deprecated/machine-tiger-pwscf-della.json
+++ /dev/null
@@ -1,70 +0,0 @@
-{
- "deepmd_path": "/home/linfengz/SCR/wanghan/local/deeppot/0.11.0-gpu/",
- "train_machine": {
- "machine_type": "slurm",
- "hostname" : "localhost",
- "port" : 22,
- "username": "linfengz",
- "work_path" : "/home/linfengz/SCR/tmp/",
- "_comment" : "that's all"
- },
- "train_resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node":7,
- "source_list": [ "/home/linfengz/SCR/softwares/tensorflow.gpu.1.6/bin/activate" ],
- "module_list": [ "cudatoolkit/9.2", "cudnn/cuda-9.2/7.1.4"],
- "time_limit": "6:0:0",
- "mem_limit": 32,
- "_comment": "that's all"
- },
-
- "model_devi_command": "/home/linfengz/SCR/wanghan/local/bin/lmp_serial_0110_gpu",
- "model_devi_group_size": 20,
- "_comment": "model_devi on localhost ",
- "model_devi_machine": {
- "machine_type": "slurm",
- "hostname" : "localhost",
- "port" : 22,
- "username": "linfengz",
- "work_path" : "/home/linfengz/SCR/tmp/",
- "_comment" : "that's all"
- },
- "_comment": " if use GPU, numb_nodes(nn) should always be 1 ",
- "_comment": " if numb_nodes(nn) = 1 multi-threading rather than mpi is assumed",
- "model_devi_resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node":7,
- "source_list": [ ],
- "module_list": [ "cudatoolkit/9.2", "cudnn/cuda-9.2/7.1.4"],
- "time_limit": "2:0:0",
- "mem_limit": 32,
- "_comment": "that's all"
- },
-
-
- "_comment": "fp on localhost ",
- "fp_command": "/home/linfengz/local/bin/pw.x < input",
- "fp_group_size": 2,
- "fp_machine": {
- "machine_type": "slurm",
- "hostname" : "della.princeton.edu",
- "port" : 22,
- "username": "linfengz",
- "work_path" : "/home/linfengz/data.gpfs/remote.subs",
- "_comment" : "that's all"
- },
- "fp_resources": {
- "numb_node": 1,
- "task_per_node":4,
- "with_mpi": true,
- "source_list": [ ],
- "module_list": [ "fftw", "intel", "openmpi" ],
- "time_limit": "5:0:0",
- "mem_limit": 32,
- "_comment": "that's all"
- },
-
- "_comment": " that's all "
-}
diff --git a/examples/machine/deprecated/machine-tiger-vasp-della.json b/examples/machine/deprecated/machine-tiger-vasp-della.json
deleted file mode 100644
index fa1fdf6e9..000000000
--- a/examples/machine/deprecated/machine-tiger-vasp-della.json
+++ /dev/null
@@ -1,69 +0,0 @@
-{
- "deepmd_path": "/home/linfengz/SCR/wanghan/local/deeppot/0.11.0-gpu/",
- "train_machine": {
- "machine_type": "slurm",
- "hostname" : "localhost",
- "port" : 22,
- "username": "yixiaoc",
- "work_path" : "/home/yixiaoc/SCR/tmp/",
- "_comment" : "that's all"
- },
- "train_resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node":7,
- "source_list": [ "/home/linfengz/SCR/softwares/tensorflow.gpu.1.6/bin/activate" ],
- "module_list": [ "cudatoolkit/9.2", "cudnn/cuda-9.2/7.1.4"],
- "time_limit": "12:0:0",
- "mem_limit": 32,
- "_comment": "that's all"
- },
-
- "model_devi_command": "/home/linfengz/SCR/wanghan/local/bin/lmp_serial_0110_gpu",
- "model_devi_group_size": 10,
- "_comment": "model_devi on localhost ",
- "model_devi_machine": {
- "machine_type": "slurm",
- "hostname" : "localhost",
- "port" : 22,
- "username": "yixiaoc",
- "work_path" : "/home/yixiaoc/SCR/tmp/",
- "_comment" : "that's all"
- },
- "_comment": " if use GPU, numb_nodes(nn) should always be 1 ",
- "_comment": " if numb_nodes(nn) = 1 multi-threading rather than mpi is assumed",
- "model_devi_resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node":7,
- "source_list": [ ],
- "module_list": [ "cudatoolkit/9.2", "cudnn/cuda-9.2/7.1.4"],
- "time_limit": "4:0:0",
- "mem_limit": 32,
- "_comment": "that's all"
- },
-
-
- "_comment": "fp on localhost ",
- "fp_command": "/home/linfengz/local/bin/vasp_cpu_kpt_ptch",
- "fp_group_size": 1,
- "fp_machine": {
- "machine_type": "slurm",
- "hostname" : "della.princeton.edu",
- "port" : 22,
- "username": "linfengz",
- "work_path" : "/home/linfengz/data.gpfs/remote.subs",
- "_comment" : "that's all"
- },
- "fp_resources": {
- "numb_node": 1,
- "task_per_node":16,
- "with_mpi": true,
- "source_list": [ ],
- "module_list": [ "intel/17.0/64/17.0.5.239", "intel-mpi/intel/2017.5/64", "intel-mkl/2017.4/5/64" ],
- "time_limit": "6:0:0",
- "_comment": "that's all"
- },
-
- "_comment": " that's all "
-}
diff --git a/examples/machine/deprecated/machine-tiger.json b/examples/machine/deprecated/machine-tiger.json
deleted file mode 100644
index ccc1b573f..000000000
--- a/examples/machine/deprecated/machine-tiger.json
+++ /dev/null
@@ -1,69 +0,0 @@
-{
- "deepmd_path": "/home/linfengz/SCR/wanghan/local/deeppot/0.11.0-gpu/",
- "train_machine": {
- "machine_type": "slurm",
- "hostname" : "localhost",
- "port" : 22,
- "username": "linfengz",
- "work_path" : "/home/linfengz/SCR/tmp/",
- "_comment" : "that's all"
- },
- "train_resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node":7,
- "source_list": [ "/home/linfengz/SCR/softwares/tensorflow.gpu.1.6/bin/activate" ],
- "module_list": [ "cudatoolkit/9.2", "cudnn/cuda-9.2/7.1.4"],
- "time_limit": "6:0:0",
- "mem_limit": 32,
- "_comment": "that's all"
- },
-
- "model_devi_command": "/home/linfengz/SCR/wanghan/local/bin/lmp_serial_0110_gpu",
- "model_devi_group_size": 20,
- "_comment": "model_devi on localhost ",
- "model_devi_machine": {
- "machine_type": "slurm",
- "hostname" : "localhost",
- "port" : 22,
- "username": "linfengz",
- "work_path" : "/home/linfengz/SCR/tmp/",
- "_comment" : "that's all"
- },
- "_comment": " if use GPU, numb_nodes(nn) should always be 1 ",
- "_comment": " if numb_nodes(nn) = 1 multi-threading rather than mpi is assumed",
- "model_devi_resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "task_per_node":7,
- "source_list": [ ],
- "module_list": [ "cudatoolkit/9.2", "cudnn/cuda-9.2/7.1.4"],
- "time_limit": "2:0:0",
- "mem_limit": 32,
- "_comment": "that's all"
- },
-
-
- "_comment": "fp on localhost ",
- "fp_command": "/home/linfengz/SCR/wanghan/local/bin/vasp",
- "fp_group_size": 5,
- "fp_machine": {
- "machine_type": "slurm",
- "hostname" : "localhost",
- "port" : 22,
- "username": "linfengz",
- "work_path" : "/home/linfengz/SCR/tmp/",
- "_comment" : "that's all"
- },
- "fp_resources": {
- "numb_node": 1,
- "task_per_node":1,
- "numb_gpu": 1,
- "source_list": [ ],
- "module_list": ["cudatoolkit/9.2", "cudnn/cuda-9.2/7.1.4", "intel-mkl/2017.4/5/64", "intel/17.0/64/17.0.5.239"],
- "time_limit": "2:0:0",
- "_comment": "that's all"
- },
-
- "_comment": " that's all "
-}
diff --git a/examples/machine/deprecated/machine-ucloud.json b/examples/machine/deprecated/machine-ucloud.json
deleted file mode 100644
index 52e9040c1..000000000
--- a/examples/machine/deprecated/machine-ucloud.json
+++ /dev/null
@@ -1,92 +0,0 @@
-{
- "deepmd_path": "/home/ubuntu/software/deepmd_float/",
- "_comment": "training on ucloud ",
- "train_machine": {
- "machine_type": "ucloud",
- "url": "http://api.ucloud.cn",
- "work_path" : "/root/",
- "Private": "g5GGyzJM3TdVPK338tkXhcUZ4GuyChs2VONcug9kcYohwLAaWWQAWYMwYtMHrPm2",
- "ucloud_param": {
- "Region" : "cn-bj2",
- "Zone" : "cn-bj2-04",
- "ImageId" : "uimage-z2tlg4",
- "ChargeType": "Month",
- "GPU" : "1",
- "Name" : "train",
- "UHostType" : "G2",
- "PublicKey" : "71RUR4l/3cFVntcHsMaoQk8qZo6uWDflDI7EAwdWqvdev0KvJek//w==" ,
- "LoginMode" : "Password",
- "Password": "YW5ndXNlMTk5OA=="
- },
- "purpose" : "train" ,
- "_comment" : "that's all"
- },
- "train_resources": {
- "envs": {
- "PATH" : "/usr/local/cuda-9.0/bin:$PATH",
- "LD_LIBRARY_PATH" : "/usr/local/cuda-9.0/lib64:$LD_LIBRARY_PATH"
- },
- "_comment": "that's all"
- },
-
-
- "model_devi_command": "/usr/bin/lmp_mpi",
- "model_devi_group_size": 20,
- "model_devi_machine": {
- "machine_type": "ucloud",
- "url": "http://api.ucloud.cn",
- "work_path" : "/root/",
- "Private": "g5GGyzJM3TdVPK338tkXhcUZ4GuyChs2VONcug9kcYohwLAaWWQAWYMwYtMHrPm2",
- "ucloud_param": {
- "Region" : "cn-bj2",
- "Zone" : "cn-bj2-05",
- "ImageId": "uimage-tnj2gb",
- "ChargeType" : "Month",
- "Name" : "model",
- "PublicKey" : "71RUR4l/3cFVntcHsMaoQk8qZo6uWDflDI7EAwdWqvdev0KvJek//w==" ,
- "LoginMode" : "Password",
- "Password": "YW5ndXNlMTk5OA=="
- },
- "purpose" : "model" ,
- "_comment" : "that's all"
- },
- "model_devi_resources": {
- "envs": {
- "LD_LIBRARY_PATH" : "/home/ubuntu/software/deepmd_float/lib:$LD_LIBRARY_PATH"
- },
- "_comment": "that's all"
- },
-
-
- "_comment": "fp on localhost ",
- "fp_command": "/usr/bin/vasp_std",
- "fp_group_size": 5,
- "fp_machine": {
- "machine_type": "ucloud",
- "url": "http://api.ucloud.cn",
- "work_path" : "/root/",
- "Private": "g5GGyzJM3TdVPK338tkXhcUZ4GuyChs2VONcug9kcYohwLAaWWQAWYMwYtMHrPm2",
- "ucloud_param": {
- "Region" : "cn-bj2",
- "Zone" : "cn-bj2-05",
- "Name": "fp",
- "ImageId": "uimage-tnj2gb",
- "ChargeType" : "Month",
- "PublicKey" : "71RUR4l/3cFVntcHsMaoQk8qZo6uWDflDI7EAwdWqvdev0KvJek//w==" ,
- "LoginMode" : "Password",
- "Password": "YW5ndXNlMTk5OA=="
- },
- "purpose" : "fp" ,
- "_comment" : "that's all"
- },
- "fp_resources": {
- "task_per_node":8,
- "with_mpi": true,
- "envs": {
- "LD_LIBRARY_PATH" : "/home/ubuntu/software/deepmd_float/lib:$LD_LIBRARY_PATH"
- },
- "_comment": "that's all"
- },
-
- "_comment": " that's all "
-}
diff --git a/examples/run/deprecated/dp0.12-lammps-cp2k/CH4/param_CH4.json b/examples/run/deprecated/dp0.12-lammps-cp2k/CH4/param_CH4.json
index b7da49de3..b8163e785 100644
--- a/examples/run/deprecated/dp0.12-lammps-cp2k/CH4/param_CH4.json
+++ b/examples/run/deprecated/dp0.12-lammps-cp2k/CH4/param_CH4.json
@@ -1,125 +1,125 @@
{
"type_map": [
- "H",
+ "H",
"C"
- ],
+ ],
"mass_map": [
- 1,
+ 1,
12
- ],
- "init_data_prefix": "/public/data/deepmd-tutorial/data/",
+ ],
+ "init_data_prefix": "/public/data/deepmd-tutorial/data/",
"init_data_sys": [
"deepmd"
- ],
+ ],
"init_batch_size": [
8
- ],
+ ],
"sys_configs": [
[
"/public/data/deepmd-tutorial/data/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000*/POSCAR"
- ],
+ ],
[
"/public/data/deepmd-tutorial/data/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00001*/POSCAR"
]
- ],
+ ],
"sys_batch_size": [
- 8,
- 8,
- 8,
+ 8,
+ 8,
+ 8,
8
- ],
- "_comment": " that's all ",
- "numb_models": 4,
+ ],
+ "_comment": " that's all ",
+ "numb_models": 4,
"default_training_param": {
- "_comment": "that's all",
- "use_smooth": true,
+ "_comment": "that's all",
+ "use_smooth": true,
"sel_a": [
- 16,
+ 16,
4
- ],
- "rcut_smth": 0.5,
- "rcut": 5,
+ ],
+ "rcut_smth": 0.5,
+ "rcut": 5,
"filter_neuron": [
- 10,
- 20,
+ 10,
+ 20,
40
- ],
- "filter_resnet_dt": false,
- "n_axis_neuron": 12,
+ ],
+ "filter_resnet_dt": false,
+ "n_axis_neuron": 12,
"n_neuron": [
- 120,
- 120,
+ 120,
+ 120,
120
- ],
- "resnet_dt": true,
- "coord_norm": true,
- "type_fitting_net": false,
- "systems": [ ],
- "set_prefix": "set",
- "stop_batch": 40000,
- "batch_size": 1,
- "start_lr": 0.001,
- "decay_steps": 200,
- "decay_rate": 0.95,
- "seed": 0,
- "start_pref_e": 0.02,
- "limit_pref_e": 2,
- "start_pref_f": 1000,
- "limit_pref_f": 1,
- "start_pref_v": 0,
- "limit_pref_v": 0,
- "disp_file": "lcurve.out",
- "disp_freq": 1000,
- "numb_test": 4,
- "save_freq": 1000,
- "save_ckpt": "model.ckpt",
- "load_ckpt": "model.ckpt",
- "disp_training": true,
- "time_training": true,
- "profiling": false,
+ ],
+ "resnet_dt": true,
+ "coord_norm": true,
+ "type_fitting_net": false,
+ "systems": [ ],
+ "set_prefix": "set",
+ "stop_batch": 40000,
+ "batch_size": 1,
+ "start_lr": 0.001,
+ "decay_steps": 200,
+ "decay_rate": 0.95,
+ "seed": 0,
+ "start_pref_e": 0.02,
+ "limit_pref_e": 2,
+ "start_pref_f": 1000,
+ "limit_pref_f": 1,
+ "start_pref_v": 0,
+ "limit_pref_v": 0,
+ "disp_file": "lcurve.out",
+ "disp_freq": 1000,
+ "numb_test": 4,
+ "save_freq": 1000,
+ "save_ckpt": "model.ckpt",
+ "load_ckpt": "model.ckpt",
+ "disp_training": true,
+ "time_training": true,
+ "profiling": false,
"profiling_file": "timeline.json"
- },
- "model_devi_dt": 0.002,
- "model_devi_skip": 0,
- "model_devi_f_trust_lo": 0.05,
- "model_devi_f_trust_hi": 0.15,
- "model_devi_clean_traj": true,
+ },
+ "model_devi_dt": 0.002,
+ "model_devi_skip": 0,
+ "model_devi_f_trust_lo": 0.05,
+ "model_devi_f_trust_hi": 0.15,
+ "model_devi_clean_traj": true,
"model_devi_jobs": [
{
"sys_idx": [
0
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 1000,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 1000,
+ "ensemble": "nvt",
"_idx": "00"
- },
+ },
{
"sys_idx": [
1
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 5000,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 5000,
+ "ensemble": "nvt",
"_idx": "01"
}
- ],
- "fp_style": "cp2k",
- "shuffle_poscar": false,
- "fp_task_max": 20,
- "fp_task_min": 5,
+ ],
+ "fp_style": "cp2k",
+ "shuffle_poscar": false,
+ "fp_task_max": 20,
+ "fp_task_min": 5,
"fp_params": {
"cutoff": "400",
"rel_cutoff": "50",
diff --git a/examples/run/deprecated/dp0.12-lammps-pwmat/param_CH4.json b/examples/run/deprecated/dp0.12-lammps-pwmat/param_CH4.json
index f75398f4c..b1b3756ad 100644
--- a/examples/run/deprecated/dp0.12-lammps-pwmat/param_CH4.json
+++ b/examples/run/deprecated/dp0.12-lammps-pwmat/param_CH4.json
@@ -16,7 +16,7 @@
["/home/test/software/dpgen/examples/run/dp-lammps-pwmat/scale-1.000/00000*/POSCAR"],
["/home/test/software/dpgen/examples/run/dp-lammps-pwmat/scale-1.000/00001*/POSCAR"]
],
-
+
"sys_batch_size": [
8, 8, 8, 8
],
@@ -92,6 +92,6 @@
"fp_task_min": 8,
"fp_pp_path": ".",
"fp_pp_files": ["C.SG15.PBE.UPF", "H.SG15.PBE.UPF"],
- "fp_incar" : "etot.input",
+ "fp_incar" : "etot.input",
"_comment": " that's all "
}
diff --git a/examples/run/deprecated/dp0.12-lammps-siesta/dp-lammps-siesta/CH4/param_CH4.json b/examples/run/deprecated/dp0.12-lammps-siesta/dp-lammps-siesta/CH4/param_CH4.json
index a7fb9a501..44ebced0e 100644
--- a/examples/run/deprecated/dp0.12-lammps-siesta/dp-lammps-siesta/CH4/param_CH4.json
+++ b/examples/run/deprecated/dp0.12-lammps-siesta/dp-lammps-siesta/CH4/param_CH4.json
@@ -1,133 +1,133 @@
{
"type_map": [
- "H",
+ "H",
"C"
- ],
+ ],
"mass_map": [
- 1,
+ 1,
12
- ],
- "init_data_prefix": "/public/data/deepmd-tutorial/data/",
+ ],
+ "init_data_prefix": "/public/data/deepmd-tutorial/data/",
"init_data_sys": [
"deepmd"
- ],
+ ],
"init_batch_size": [
8
- ],
+ ],
"sys_configs": [
[
"/public/data/deepmd-tutorial/data/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000*/POSCAR"
- ],
+ ],
[
"/public/data/deepmd-tutorial/data/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00001*/POSCAR"
]
- ],
+ ],
"sys_batch_size": [
- 8,
- 8,
- 8,
+ 8,
+ 8,
+ 8,
8
- ],
- "_comment": " that's all ",
- "numb_models": 4,
+ ],
+ "_comment": " that's all ",
+ "numb_models": 4,
"default_training_param": {
- "_comment": "that's all",
- "use_smooth": true,
+ "_comment": "that's all",
+ "use_smooth": true,
"sel_a": [
- 16,
+ 16,
4
- ],
- "rcut_smth": 0.5,
- "rcut": 5,
+ ],
+ "rcut_smth": 0.5,
+ "rcut": 5,
"filter_neuron": [
- 10,
- 20,
+ 10,
+ 20,
40
- ],
- "filter_resnet_dt": false,
- "n_axis_neuron": 12,
+ ],
+ "filter_resnet_dt": false,
+ "n_axis_neuron": 12,
"n_neuron": [
- 120,
- 120,
+ 120,
+ 120,
120
- ],
- "resnet_dt": true,
- "coord_norm": true,
- "type_fitting_net": false,
- "systems": [ ],
- "set_prefix": "set",
- "stop_batch": 40000,
- "batch_size": 1,
- "start_lr": 0.001,
- "decay_steps": 200,
- "decay_rate": 0.95,
- "seed": 0,
- "start_pref_e": 0.02,
- "limit_pref_e": 2,
- "start_pref_f": 1000,
- "limit_pref_f": 1,
- "start_pref_v": 0,
- "limit_pref_v": 0,
- "disp_file": "lcurve.out",
- "disp_freq": 1000,
- "numb_test": 4,
- "save_freq": 1000,
- "save_ckpt": "model.ckpt",
- "load_ckpt": "model.ckpt",
- "disp_training": true,
- "time_training": true,
- "profiling": false,
+ ],
+ "resnet_dt": true,
+ "coord_norm": true,
+ "type_fitting_net": false,
+ "systems": [ ],
+ "set_prefix": "set",
+ "stop_batch": 40000,
+ "batch_size": 1,
+ "start_lr": 0.001,
+ "decay_steps": 200,
+ "decay_rate": 0.95,
+ "seed": 0,
+ "start_pref_e": 0.02,
+ "limit_pref_e": 2,
+ "start_pref_f": 1000,
+ "limit_pref_f": 1,
+ "start_pref_v": 0,
+ "limit_pref_v": 0,
+ "disp_file": "lcurve.out",
+ "disp_freq": 1000,
+ "numb_test": 4,
+ "save_freq": 1000,
+ "save_ckpt": "model.ckpt",
+ "load_ckpt": "model.ckpt",
+ "disp_training": true,
+ "time_training": true,
+ "profiling": false,
"profiling_file": "timeline.json"
- },
- "model_devi_dt": 0.002,
- "model_devi_skip": 0,
- "model_devi_f_trust_lo": 0.05,
- "model_devi_f_trust_hi": 0.15,
- "model_devi_clean_traj": true,
+ },
+ "model_devi_dt": 0.002,
+ "model_devi_skip": 0,
+ "model_devi_f_trust_lo": 0.05,
+ "model_devi_f_trust_hi": 0.15,
+ "model_devi_clean_traj": true,
"model_devi_jobs": [
{
"sys_idx": [
0
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 1000,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 1000,
+ "ensemble": "nvt",
"_idx": "00"
- },
+ },
{
"sys_idx": [
1
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 5000,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 5000,
+ "ensemble": "nvt",
"_idx": "01"
}
- ],
- "fp_style": "siesta",
- "shuffle_poscar": false,
- "fp_task_max": 20,
- "fp_task_min": 5,
- "fp_pp_path": ".",
+ ],
+ "fp_style": "siesta",
+ "shuffle_poscar": false,
+ "fp_task_max": 20,
+ "fp_task_min": 5,
+ "fp_pp_path": ".",
"fp_pp_files": ["C.psf", "H.psf"],
"fp_params": {
"ecut": 300,
"ediff": 1e-4,
"kspacing": 1.0,
- "mixingWeight": 0.05,
- "NumberPulay": 5,
+ "mixingWeight": 0.05,
+ "NumberPulay": 5,
"_comment": " that's all "
},
"_comment": " that's all "
diff --git a/examples/run/deprecated/dp0.12-lammps-siesta/dp-lammps-siesta/CH4/param_CH4.yaml b/examples/run/deprecated/dp0.12-lammps-siesta/dp-lammps-siesta/CH4/param_CH4.yaml
index 5b4f0cdfb..6a3ae9598 100644
--- a/examples/run/deprecated/dp0.12-lammps-siesta/dp-lammps-siesta/CH4/param_CH4.yaml
+++ b/examples/run/deprecated/dp0.12-lammps-siesta/dp-lammps-siesta/CH4/param_CH4.yaml
@@ -1,4 +1,3 @@
----
type_map:
- H
- C
@@ -97,10 +96,10 @@ shuffle_poscar: false
fp_task_max: 20
fp_task_min: 5
fp_pp_path: "."
-fp_pp_files: ["C.psf", "H.psf"],
+fp_pp_files: ["C.psf", "H.psf"]
fp_params:
ecut: 300
ediff: 1e-4
- kspacing: 1
- mixingWeight: 0.05
+ kspacing: 1
+ mixingWeight: 0.05
NumberPulay": 5
diff --git a/examples/run/deprecated/dp0.12-lammps-vasp/Al/param_al_all_gpu.json b/examples/run/deprecated/dp0.12-lammps-vasp/Al/param_al_all_gpu.json
index f5f6c9934..f8950dca1 100644
--- a/examples/run/deprecated/dp0.12-lammps-vasp/Al/param_al_all_gpu.json
+++ b/examples/run/deprecated/dp0.12-lammps-vasp/Al/param_al_all_gpu.json
@@ -22,9 +22,9 @@
["/gpfs/share/home/1600017784/generator/Al/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00002*/POSCAR"],
["/gpfs/share/home/1600017784/generator/Al/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00003*/POSCAR"],
["/gpfs/share/home/1600017784/generator/Al/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00004*/POSCAR"],
- ["/gpfs/share/home/1600017784/generator/Al/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00005*/POSCAR",
+ ["/gpfs/share/home/1600017784/generator/Al/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00005*/POSCAR",
"/gpfs/share/home/1600017784/generator/Al/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00006*/POSCAR"],
- ["/gpfs/share/home/1600017784/generator/Al/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00007*/POSCAR",
+ ["/gpfs/share/home/1600017784/generator/Al/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00007*/POSCAR",
"/gpfs/share/home/1600017784/generator/Al/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00008*/POSCAR"],
["/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00000[0-4]/POSCAR"],
@@ -33,9 +33,9 @@
["/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00002*/POSCAR"],
["/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00003*/POSCAR"],
["/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00004*/POSCAR"],
- ["/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00005*/POSCAR",
+ ["/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00005*/POSCAR",
"/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00006*/POSCAR"],
- ["/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00007*/POSCAR",
+ ["/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00007*/POSCAR",
"/gpfs/share/home/1600017784/generator/Al/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00008*/POSCAR"],
["/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00000[0-4]/POSCAR"],
@@ -44,9 +44,9 @@
["/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00002*/POSCAR"],
["/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00003*/POSCAR"],
["/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00004*/POSCAR"],
- ["/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00005*/POSCAR",
+ ["/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00005*/POSCAR",
"/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00006*/POSCAR"],
- ["/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00007*/POSCAR",
+ ["/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00007*/POSCAR",
"/gpfs/share/home/1600017784/generator/Al/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00008*/POSCAR"]
],
"sys_batch_size": [
@@ -132,7 +132,7 @@
"model_devi_f_trust_lo": 0.05,
"model_devi_f_trust_hi": 0.20,
"model_devi_clean_traj": false,
- "model_devi_jobs":
+ "model_devi_jobs":
[
{
"_idx": 0,
@@ -391,4 +391,3 @@
"fp_incar": "/gpfs/share/home/1600017784/start/pku_input_set/INCAR_metal_scf_gpu",
"_comment": " that's all "
}
-
diff --git a/examples/run/deprecated/dp0.12-lammps-vasp/Al/param_al_all_gpu.yaml b/examples/run/deprecated/dp0.12-lammps-vasp/Al/param_al_all_gpu.yaml
index f06404494..37409d69a 100644
--- a/examples/run/deprecated/dp0.12-lammps-vasp/Al/param_al_all_gpu.yaml
+++ b/examples/run/deprecated/dp0.12-lammps-vasp/Al/param_al_all_gpu.yaml
@@ -329,4 +329,3 @@ fp_pp_path: "/gpfs/share/home/1600017784/start/data/POTCAR/Al/"
fp_pp_files:
- POTCAR
fp_incar: "/gpfs/share/home/1600017784/start/pku_input_set/INCAR_metal_scf_gpu"
-
diff --git a/examples/run/deprecated/dp0.12-lammps-vasp/CH4/param_CH4.json b/examples/run/deprecated/dp0.12-lammps-vasp/CH4/param_CH4.json
index c6c7befea..6af7ed649 100644
--- a/examples/run/deprecated/dp0.12-lammps-vasp/CH4/param_CH4.json
+++ b/examples/run/deprecated/dp0.12-lammps-vasp/CH4/param_CH4.json
@@ -16,7 +16,7 @@
["CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale*/00000*/POSCAR"],
["CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale*/00001*/POSCAR"]
],
-
+
"sys_batch_size": [
8, 8, 8, 8
],
@@ -93,6 +93,6 @@
"fp_task_min": 5,
"fp_pp_path": "/gpfs/share/home/1600017784/yuzhi/methane/",
"fp_pp_files": ["POT_H","POT_C"],
-"fp_incar" : "/gpfs/share/home/1600017784/yuzhi/methane/INCAR_methane",
+"fp_incar" : "/gpfs/share/home/1600017784/yuzhi/methane/INCAR_methane",
"_comment": " that's all "
}
diff --git a/examples/run/deprecated/dp0.12-lammps-vasp/CH4/param_CH4.yaml b/examples/run/deprecated/dp0.12-lammps-vasp/CH4/param_CH4.yaml
index d16bb1edc..2a77eddef 100644
--- a/examples/run/deprecated/dp0.12-lammps-vasp/CH4/param_CH4.yaml
+++ b/examples/run/deprecated/dp0.12-lammps-vasp/CH4/param_CH4.yaml
@@ -102,4 +102,3 @@ fp_pp_path: "/gpfs/share/home/1600017784/yuzhi/methane/"
fp_pp_files:
- POTCAR
fp_incar: "/gpfs/share/home/1600017784/yuzhi/methane/INCAR_methane"
-
diff --git a/examples/run/deprecated/param-h2oscan-vasp.json b/examples/run/deprecated/param-h2oscan-vasp.json
index 9d35a309c..1ccc592b7 100644
--- a/examples/run/deprecated/param-h2oscan-vasp.json
+++ b/examples/run/deprecated/param-h2oscan-vasp.json
@@ -1,4 +1,4 @@
-{
+{
"type_map": ["O", "H"],
"mass_map": [16, 2],
@@ -99,7 +99,7 @@
"_comment": "48 ....................................... 63",
"_comment": "64 65 66 67",
"sys_batch_size": [1, 1, 1, 1, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3,
- 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 2, 2, 2, 2,
+ 1, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 2, 2, 2, 2,
4, 4, 4, 4, 3, 3, 3, 3, 2, 2, 2, 2, 2, 2, 2, 2,
3, 3, 3, 3, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3, 3, 3,
1, 1, 1, 1
@@ -123,7 +123,7 @@
"_comment": " traing controls",
"systems": [],
- "set_prefix": "set",
+ "set_prefix": "set",
"stop_batch": 1000000,
"batch_size": 1,
"start_lr": 0.002,
@@ -167,7 +167,7 @@
"model_devi_jobs": [
{"sys_idx":[ 0, 4, 8, 12, 16, 20, 24, 36, 44, 48, 52, 56, 60, 64], "s_t": true,
"Ts": [ 50], "Ps": [1e-1,5e-1,1e0,5e0,1e1,5e1,1e2,5e2,1e3,5e3,1e4,5e4], "t_freq": 20, "nsteps": 1000, "ens": "npt", "_idx": "00"},
- {"sys_idx":[ 28,32,40],
+ {"sys_idx":[ 28,32,40],
"Ts": [ 50], "Ps": [1e1,5e1,1e2,5e2,1e3,5e3,1e4,5e4,1e5,5e5], "t_freq": 20, "nsteps": 1000, "ens": "npt", "_idx": "01"},
{"sys_idx":[ 1, 5, 9, 13, 17, 21, 25, 37, 45, 49, 53, 57, 61, 65], "s_t": true,
"Ts": [ 50], "Ps": [1e-1,5e-1,1e0,5e0,1e1,5e1,1e2,5e2,1e3,5e3,1e4,5e4], "t_freq": 20, "nsteps": 5000, "ens": "npt", "_idx": "02"},
diff --git a/examples/run/deprecated/param-mg-vasp-ucloud.json b/examples/run/deprecated/param-mg-vasp-ucloud.json
index 63b634f81..507e79396 100644
--- a/examples/run/deprecated/param-mg-vasp-ucloud.json
+++ b/examples/run/deprecated/param-mg-vasp-ucloud.json
@@ -1,4 +1,4 @@
-{
+{
"type_map": ["Mg"],
"mass_map": [24],
@@ -71,7 +71,7 @@
"_comment": " traing controls",
"systems": [],
- "set_prefix": "set",
+ "set_prefix": "set",
"stop_batch": 400000,
"batch_size": 1,
"start_lr": 0.002,
diff --git a/examples/run/deprecated/param-mg-vasp.json b/examples/run/deprecated/param-mg-vasp.json
index df13dec8d..126f63cc1 100644
--- a/examples/run/deprecated/param-mg-vasp.json
+++ b/examples/run/deprecated/param-mg-vasp.json
@@ -1,4 +1,4 @@
-{
+{
"type_map": ["Mg"],
"mass_map": [24],
@@ -71,7 +71,7 @@
"_comment": " traing controls",
"systems": [],
- "set_prefix": "set",
+ "set_prefix": "set",
"stop_batch": 400000,
"batch_size": 1,
"start_lr": 0.002,
diff --git a/examples/run/deprecated/param-pyridine-pwscf.json b/examples/run/deprecated/param-pyridine-pwscf.json
index c1044ae3b..f7348c583 100644
--- a/examples/run/deprecated/param-pyridine-pwscf.json
+++ b/examples/run/deprecated/param-pyridine-pwscf.json
@@ -1,7 +1,7 @@
-{
+{
"type_map": ["C", "H", "N"],
"mass_map": [16, 2, 14],
-
+
"init_data_prefix": "/home/linfengz/SCR/wanghan/deepgen.pyridine/init",
"init_data_sys": ["Pyridine-I",
"Pyridine-II"
@@ -41,7 +41,7 @@
"_comment": " traing controls",
"systems": [],
- "set_prefix": "set",
+ "set_prefix": "set",
"stop_batch": 400000,
"batch_size": 1,
"start_lr": 0.002,
diff --git a/examples/run/dp-calypso-vasp/param.json b/examples/run/dp-calypso-vasp/param.json
index 1818a12fb..96f566938 100644
--- a/examples/run/dp-calypso-vasp/param.json
+++ b/examples/run/dp-calypso-vasp/param.json
@@ -79,7 +79,7 @@
"start_pref_f": 100,
"limit_pref_f": 1,
"start_pref_v": 0,
- "limit_pref_v": 0
+ "limit_pref_v": 0
},
"training": {
"stop_batch": 6000,
diff --git a/examples/run/dp-lammps-enhance_sampling/lmp/input.lammps b/examples/run/dp-lammps-enhance_sampling/lmp/input.lammps
index e498fa0f9..19ca3b3fe 100644
--- a/examples/run/dp-lammps-enhance_sampling/lmp/input.lammps
+++ b/examples/run/dp-lammps-enhance_sampling/lmp/input.lammps
@@ -19,7 +19,7 @@ mass 2 1.008
#Interatomic potentials - DeepMD
-pair_style deepmd
+pair_style deepmd
pair_coeff * *
@@ -38,4 +38,3 @@ thermo ${THERMO_FREQ} #Ouputing thermodynamic properties
dump dpgen_dump
#dump 2 all custom 100 vel.xyz id type vx vy vz
run ${NSTEPS} #25 ps
-
diff --git a/examples/run/dp1.x-lammps-ABACUS-lcao-dpks/methane/machine.json b/examples/run/dp1.x-lammps-ABACUS-lcao-dpks/methane/machine.json
index ee4d2f305..0bc72e8b2 100644
--- a/examples/run/dp1.x-lammps-ABACUS-lcao-dpks/methane/machine.json
+++ b/examples/run/dp1.x-lammps-ABACUS-lcao-dpks/methane/machine.json
@@ -72,4 +72,4 @@
}
}
]
- }
\ No newline at end of file
+ }
diff --git a/examples/run/dp1.x-lammps-ABACUS-lcao-dpks/methane/param.json b/examples/run/dp1.x-lammps-ABACUS-lcao-dpks/methane/param.json
index a0909cd28..1af3ae951 100644
--- a/examples/run/dp1.x-lammps-ABACUS-lcao-dpks/methane/param.json
+++ b/examples/run/dp1.x-lammps-ABACUS-lcao-dpks/methane/param.json
@@ -17,7 +17,7 @@
[
"CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/000000/POSCAR",
"CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/000001/POSCAR",
- "CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000[2-9]/POSCAR"
+ "CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000[2-9]/POSCAR"
],
[
"CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00001*/POSCAR"
@@ -34,7 +34,7 @@
"default_training_param": {
"model": {
"type_map": ["H","C"],
- "descriptor": {
+ "descriptor": {
"type": "se_a",
"sel": [16,4],
"rcut_smth": 0.5,
@@ -138,7 +138,7 @@
"deepks_model": "model.ptg",
"deepks_out_labels": 1,
"basis_type": "lcao",
- "gamma_only": 1,
+ "gamma_only": 1,
"ecutwfc": 80,
"mixing_type": "pulay",
"mixing_beta": 0.4,
diff --git a/examples/run/dp1.x-lammps-ABACUS-pw/methane/machine.json b/examples/run/dp1.x-lammps-ABACUS-pw/methane/machine.json
index ee4d2f305..0bc72e8b2 100644
--- a/examples/run/dp1.x-lammps-ABACUS-pw/methane/machine.json
+++ b/examples/run/dp1.x-lammps-ABACUS-pw/methane/machine.json
@@ -72,4 +72,4 @@
}
}
]
- }
\ No newline at end of file
+ }
diff --git a/examples/run/dp1.x-lammps-ABACUS-pw/methane/param.json b/examples/run/dp1.x-lammps-ABACUS-pw/methane/param.json
index e9cf9b5e9..a6cf0eb30 100644
--- a/examples/run/dp1.x-lammps-ABACUS-pw/methane/param.json
+++ b/examples/run/dp1.x-lammps-ABACUS-pw/methane/param.json
@@ -17,7 +17,7 @@
[
"CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/000000/POSCAR",
"CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/000001/POSCAR",
- "CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000[2-9]/POSCAR"
+ "CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000[2-9]/POSCAR"
],
[
"CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00001*/POSCAR"
@@ -34,7 +34,7 @@
"default_training_param": {
"model": {
"type_map": ["H","C"],
- "descriptor": {
+ "descriptor": {
"type": "se_a",
"sel": [16,4],
"rcut_smth": 0.5,
diff --git a/examples/run/dp1.x-lammps-cp2k/methane/param-ch4.json b/examples/run/dp1.x-lammps-cp2k/methane/param-ch4.json
index f4f19b761..bab722abf 100644
--- a/examples/run/dp1.x-lammps-cp2k/methane/param-ch4.json
+++ b/examples/run/dp1.x-lammps-cp2k/methane/param-ch4.json
@@ -1,134 +1,134 @@
{
"type_map": [
- "H",
+ "H",
"C"
- ],
+ ],
"mass_map": [
- 1,
+ 1,
12
- ],
- "init_data_prefix": "/data/ybzhuang/methane-dpgen/dpgen-tutorial-2020-08-23/dpgen-tutorial-mathane/data",
+ ],
+ "init_data_prefix": "/data/ybzhuang/methane-dpgen/dpgen-tutorial-2020-08-23/dpgen-tutorial-mathane/data",
"init_data_sys": [
"deepmd"
- ],
+ ],
"init_batch_size": [
8
- ],
+ ],
"sys_configs": [
["/data/ybzhuang/methane-dpgen/dpgen-tutorial-2020-08-23/dpgen-tutorial-mathane/data/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000*/POSCAR"],
["/data/ybzhuang/methane-dpgen/dpgen-tutorial-2020-08-23/dpgen-tutorial-mathane/data/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000*/POSCAR"]
- ],
+ ],
"sys_batch_size": [
- 8,
- 8,
- 8,
+ 8,
+ 8,
+ 8,
8
- ],
- "_comment": " that's all ",
- "numb_models": 4,
+ ],
+ "_comment": " that's all ",
+ "numb_models": 4,
"default_training_param": {
"model": {
"descriptor": {
"type": "se_a",
"sel": [
- 16,
+ 16,
4
- ],
- "rcut_smth": 0.5,
+ ],
+ "rcut_smth": 0.5,
"rcut": 5.0,
- "_comment": "modify according your system",
+ "_comment": "modify according your system",
"neuron": [
- 10,
- 20,
+ 10,
+ 20,
40
- ],
- "resnet_dt": false,
+ ],
+ "resnet_dt": false,
"axis_neuron": 12,
"seed": 1
},
"fitting_net": {
"neuron": [
- 120,
- 120,
+ 120,
+ 120,
120
- ],
- "resnet_dt": true,
+ ],
+ "resnet_dt": true,
"seed": 1
}},
"learning_rate": {
"type": "exp",
- "start_lr": 0.001,
+ "start_lr": 0.001,
"decay_steps": 100,
- "_comment": "nope",
+ "_comment": "nope",
"decay_rate": 0.95
},
"loss": {
- "start_pref_e": 0.02,
- "limit_pref_e": 2,
- "start_pref_f": 1000,
- "limit_pref_f": 1,
- "start_pref_v": 0.0,
+ "start_pref_e": 0.02,
+ "limit_pref_e": 2,
+ "start_pref_f": 1000,
+ "limit_pref_f": 1,
+ "start_pref_v": 0.0,
"limit_pref_v": 0.0
},
"training": {
- "systems": [ ],
- "set_prefix": "set",
- "stop_batch": 2000,
- "batch_size": 1,
+ "systems": [ ],
+ "set_prefix": "set",
+ "stop_batch": 2000,
+ "batch_size": 1,
"seed": 1,
- "disp_file": "lcurve.out",
- "disp_freq": 1000,
- "numb_test": 4,
- "save_freq": 1000,
- "save_ckpt": "model.ckpt",
- "load_ckpt": "model.ckpt",
- "disp_training": true,
- "time_training": true,
- "profiling": false,
+ "disp_file": "lcurve.out",
+ "disp_freq": 1000,
+ "numb_test": 4,
+ "save_freq": 1000,
+ "save_ckpt": "model.ckpt",
+ "load_ckpt": "model.ckpt",
+ "disp_training": true,
+ "time_training": true,
+ "profiling": false,
"profiling_file": "timeline.json"
}
- },
- "model_devi_dt": 0.002,
- "model_devi_skip": 0,
- "model_devi_f_trust_lo": 0.05,
- "model_devi_f_trust_hi": 0.15,
- "model_devi_clean_traj": true,
+ },
+ "model_devi_dt": 0.002,
+ "model_devi_skip": 0,
+ "model_devi_f_trust_lo": 0.05,
+ "model_devi_f_trust_hi": 0.15,
+ "model_devi_clean_traj": true,
"model_devi_jobs": [
{
"sys_idx": [
0
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 300,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 300,
+ "ensemble": "nvt",
"_idx": "00"
- },
+ },
{
"sys_idx": [
1
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 3000,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 3000,
+ "ensemble": "nvt",
"_idx": "01"
}
- ],
- "fp_style": "cp2k",
- "shuffle_poscar": false,
- "fp_task_max": 20,
- "fp_task_min": 5,
+ ],
+ "fp_style": "cp2k",
+ "shuffle_poscar": false,
+ "fp_task_max": 20,
+ "fp_task_min": 5,
"external_input_path": "/data/ybzhuang/methane-dpgen/dpgen-tutorial-2020-08-23/dpgen-tutorial-mathane/cp2k_dpgen/template.inp"
}
diff --git a/examples/run/dp1.x-lammps-cp2k/methane/template.inp b/examples/run/dp1.x-lammps-cp2k/methane/template.inp
index d89b3aee2..47fb5c715 100755
--- a/examples/run/dp1.x-lammps-cp2k/methane/template.inp
+++ b/examples/run/dp1.x-lammps-cp2k/methane/template.inp
@@ -19,7 +19,7 @@
STRESS_TENSOR ANALYTICAL
&PRINT
&FORCES ON
- &END FORCES
+ &END FORCES
&STRESS_TENSOR ON
&END STRESS_TENSOR
&END PRINT
@@ -28,36 +28,36 @@
BASIS_SET_FILE_NAME BASIS_MOLOPT
POTENTIAL_FILE_NAME GTH_POTENTIALS
&MGRID
- CUTOFF ${CUTOFF}
+ CUTOFF ${CUTOFF}
REL_CUTOFF 60
&END MGRID
&QS
EPS_DEFAULT 1.0E-13
&END QS
&SCF
- SCF_GUESS RESTART
+ SCF_GUESS RESTART
EPS_SCF 3.0E-7
MAX_SCF 50
- &OUTER_SCF
+ &OUTER_SCF
EPS_SCF 3.0E-7
- MAX_SCF 15
+ MAX_SCF 15
&END OUTER_SCF
- &OT
+ &OT
MINIMIZER DIIS
PRECONDITIONER FULL_SINGLE_INVERSE
&END OT
&END SCF
&XC
-########## This part is PBE ##########
+########## This part is PBE ##########
&XC_FUNCTIONAL PBE
&END XC_FUNCTIONAL
########## This part is PBE ##########
&END XC
########## This part controls the print information ##########
&END DFT
- &SUBSYS
+ &SUBSYS
&CELL
- ABC [angstrom] ${CELL_A}*${SCALE_FACTOR} ${CELL_B}*${SCALE_FACTOR} ${CELL_C}*${SCALE_FACTOR}
+ ABC [angstrom] ${CELL_A}*${SCALE_FACTOR} ${CELL_B}*${SCALE_FACTOR} ${CELL_C}*${SCALE_FACTOR}
ALPHA_BETA_GAMMA ${ANGLE_A} ${ANGLE_B} ${ANGLE_C}
MULTIPLE_UNIT_CELL ${NREPA} ${NREPB} ${NREPC}
&END CELL
diff --git a/examples/run/dp1.x-lammps-vasp-et/param_elet.json b/examples/run/dp1.x-lammps-vasp-et/param_elet.json
index 27a225fe7..cc0f4a962 100644
--- a/examples/run/dp1.x-lammps-vasp-et/param_elet.json
+++ b/examples/run/dp1.x-lammps-vasp-et/param_elet.json
@@ -97,4 +97,3 @@
"fp_incar": "/home/wanghan/study/deep.md/dpgen/almg/vasp/INCAR",
"_comment": " that's all "
}
-
diff --git a/examples/run/dp1.x-lammps-vasp/Al/param_al_all_gpu-deepmd-kit-1.1.0.json b/examples/run/dp1.x-lammps-vasp/Al/param_al_all_gpu-deepmd-kit-1.1.0.json
index 1032a4e0b..4b4d92ba2 100644
--- a/examples/run/dp1.x-lammps-vasp/Al/param_al_all_gpu-deepmd-kit-1.1.0.json
+++ b/examples/run/dp1.x-lammps-vasp/Al/param_al_all_gpu-deepmd-kit-1.1.0.json
@@ -17,9 +17,9 @@
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00002*/POSCAR"],
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00003*/POSCAR"],
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00004*/POSCAR"],
- ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00005*/POSCAR",
+ ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00005*/POSCAR",
"/data1/yfb222333/2_dpgen_gpu_multi/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00006*/POSCAR"],
- ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00007*/POSCAR",
+ ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00007*/POSCAR",
"/data1/yfb222333/2_dpgen_gpu_multi/init/al.fcc.02x02x02/01.scale_pert/sys-0032/scale-1.000/00008*/POSCAR"],
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00000[0-4]/POSCAR"],
@@ -28,9 +28,9 @@
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00002*/POSCAR"],
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00003*/POSCAR"],
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00004*/POSCAR"],
- ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00005*/POSCAR",
+ ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00005*/POSCAR",
"/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00006*/POSCAR"],
- ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00007*/POSCAR",
+ ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00007*/POSCAR",
"/data1/yfb222333/2_dpgen_gpu_multi/init/al.hcp.02x02x02/01.scale_pert/sys-0016/scale-1.000/00008*/POSCAR"],
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00000[0-4]/POSCAR"],
@@ -39,9 +39,9 @@
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00002*/POSCAR"],
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00003*/POSCAR"],
["/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00004*/POSCAR"],
- ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00005*/POSCAR",
+ ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00005*/POSCAR",
"/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00006*/POSCAR"],
- ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00007*/POSCAR",
+ ["/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00007*/POSCAR",
"/data1/yfb222333/2_dpgen_gpu_multi/init/al.bcc.02x02x02/01.scale_pert/sys-0016/scale-1.000/00008*/POSCAR"]
],
"_comment": " 00.train ",
@@ -110,7 +110,7 @@
"model_devi_f_trust_lo": 0.05,
"model_devi_f_trust_hi": 0.20,
"model_devi_clean_traj": false,
- "model_devi_jobs":
+ "model_devi_jobs":
[
{
"_idx": 0,
@@ -369,4 +369,3 @@
"fp_incar": "/data1/yfb222333/2_dpgen_gpu_multi/INCAR_metal_scf_gpu",
"_comment": " that's all "
}
-
diff --git a/examples/run/dp1.x-lammps-vasp/CH4/POT_H b/examples/run/dp1.x-lammps-vasp/CH4/POT_H
index 81ae32edd..4c6399dc0 100644
--- a/examples/run/dp1.x-lammps-vasp/CH4/POT_H
+++ b/examples/run/dp1.x-lammps-vasp/CH4/POT_H
@@ -1 +1 @@
-# We can only provide empty files in public, you should provide valid POTCARS yourself when running DP-GEN.
\ No newline at end of file
+# We can only provide empty files in public, you should provide valid POTCARS yourself when running DP-GEN.
diff --git a/examples/run/dp1.x_lammps_gaussian/dodecane/dodecane.json b/examples/run/dp1.x_lammps_gaussian/dodecane/dodecane.json
index 0260a5c16..b6f80d142 100644
--- a/examples/run/dp1.x_lammps_gaussian/dodecane/dodecane.json
+++ b/examples/run/dp1.x_lammps_gaussian/dodecane/dodecane.json
@@ -1,4 +1,4 @@
-{
+{
"type_map": ["C", "H"],
"mass_map": [12.011, 1.008],
"init_data_prefix": "/home/jzzeng/0719dodecane/gen/",
@@ -42,7 +42,7 @@
"limit_pref_pf": 0
},
"training":{
- "set_prefix": "set",
+ "set_prefix": "set",
"stop_batch": 400000,
"disp_file": "lcurve.out",
"disp_freq": 1000,
diff --git a/examples/run/dp2.x-gromacs-gaussian/machine.json b/examples/run/dp2.x-gromacs-gaussian/machine.json
deleted file mode 100644
index 0f73b2277..000000000
--- a/examples/run/dp2.x-gromacs-gaussian/machine.json
+++ /dev/null
@@ -1,69 +0,0 @@
-{
- "deepmd_version" : "2.0",
- "train": [
- {
- "machine": {
- "batch": "slurm",
- "work_path": "/work/path"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "partition": "all",
- "time_limit": "120:0:0",
- "task_per_node": 8,
- "exclude_list": [],
- "module_list": [],
- "source_list": ["/path/to/dp-2.0.env"]
- },
- "command": "dp"
- }
- ],
- "model_devi": [
- {
- "machine": {
- "batch": "slurm",
- "work_path": "/work/path"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 1,
- "partition": "all",
- "time_limit": "120:0:0",
- "task_per_node": 8,
- "source_list": [
- "/path/to/gromacs-dp/env"
- ],
- "module_list": [],
- "exclude_list": [],
- "envs": {
- "GMX_DEEPMD_INPUT_JSON": "input.json"
- }
- },
- "command": "gmx_mpi",
- "group_size": 1
- }
- ],
- "fp": [
- {
- "machine": {
- "batch": "slurm",
- "work_path": "/work/path"
- },
- "resources": {
- "numb_node": 1,
- "numb_gpu": 0,
- "time_limit": "120:0:0",
- "task_per_node": 28,
- "partition": "cpu",
- "exclude_list": [],
- "source_list": [
- "/path/to/gaussian/bashrc"
- ],
- "module_list": []
- },
- "command": "g16 < input",
- "group_size": 20
- }
- ]
-}
diff --git a/examples/run/dp2.x-lammps-ABACUS-pw/fcc-al/INPUT.run b/examples/run/dp2.x-lammps-ABACUS-pw/fcc-al/INPUT.run
index 1535634ed..7370e0a0e 100644
--- a/examples/run/dp2.x-lammps-ABACUS-pw/fcc-al/INPUT.run
+++ b/examples/run/dp2.x-lammps-ABACUS-pw/fcc-al/INPUT.run
@@ -1,13 +1,12 @@
ntype 1
ecutwfc 40
-mixing_type pulay
+mixing_type pulay
mixing_beta 0.8
symmetry 1
nspin 1
-ks_solver cg
-smearing_method fixed
+ks_solver cg
+smearing_method fixed
smearing_sigma 0.001
scf_thr 1e-8
cal_force 1
kspacing 200
-
diff --git a/examples/run/dp2.x-lammps-cp2k/param_CH4_deepmd-kit-2.0.1.json b/examples/run/dp2.x-lammps-cp2k/param_CH4_deepmd-kit-2.0.1.json
index 254496728..df596a6d1 100644
--- a/examples/run/dp2.x-lammps-cp2k/param_CH4_deepmd-kit-2.0.1.json
+++ b/examples/run/dp2.x-lammps-cp2k/param_CH4_deepmd-kit-2.0.1.json
@@ -1,26 +1,26 @@
{
"type_map": [
- "H",
+ "H",
"C"
- ],
+ ],
"mass_map": [
- 1,
+ 1,
12
- ],
- "init_data_prefix": "./data",
+ ],
+ "init_data_prefix": "./data",
"init_data_sys": [
"deepmd"
- ],
+ ],
"sys_configs": [
[
"./data/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00000*/POSCAR"
- ],
+ ],
[
"./data/CH4.POSCAR.01x01x01/01.scale_pert/sys-0004-0001/scale-1.000/00001*/POSCAR"
]
- ],
- "_comment": " that's all ",
- "numb_models": 4,
+ ],
+ "_comment": " that's all ",
+ "numb_models": 4,
"default_training_param": {
"model": {
"type_map": [
@@ -83,49 +83,49 @@
"_comment": "that's all"
}
},
- "model_devi_dt": 0.002,
- "model_devi_skip": 0,
- "model_devi_f_trust_lo": 0.02,
- "model_devi_f_trust_hi": 0.15,
- "model_devi_clean_traj": true,
+ "model_devi_dt": 0.002,
+ "model_devi_skip": 0,
+ "model_devi_f_trust_lo": 0.02,
+ "model_devi_f_trust_hi": 0.15,
+ "model_devi_clean_traj": true,
"model_devi_jobs": [
{
"sys_idx": [
0
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 2000,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 2000,
+ "ensemble": "nvt",
"_idx": "00"
- },
+ },
{
"sys_idx": [
1
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 5000,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 5000,
+ "ensemble": "nvt",
"_idx": "01"
}
- ],
- "ratio_failed": 0.20,
- "fp_style": "cp2k",
- "shuffle_poscar": false,
- "fp_task_max": 30,
- "fp_task_min": 1,
+ ],
+ "ratio_failed": 0.20,
+ "fp_style": "cp2k",
+ "shuffle_poscar": false,
+ "fp_task_max": 30,
+ "fp_task_min": 1,
"user_fp_params": {
"FORCE_EVAL":{
"DFT":{
diff --git a/examples/run/dp2.x-lammps-gaussian/machine.json b/examples/run/dp2.x-lammps-gaussian/machine.json
index d6bb88c38..f9f19c37a 100644
--- a/examples/run/dp2.x-lammps-gaussian/machine.json
+++ b/examples/run/dp2.x-lammps-gaussian/machine.json
@@ -107,4 +107,3 @@
}
}
}
-
diff --git a/examples/run/dp2.x-lammps-gaussian/param_C4H16N4_deepmd-kit-2.0.1.json b/examples/run/dp2.x-lammps-gaussian/param_C4H16N4_deepmd-kit-2.0.1.json
index a7bfd05dc..4f422fe73 100644
--- a/examples/run/dp2.x-lammps-gaussian/param_C4H16N4_deepmd-kit-2.0.1.json
+++ b/examples/run/dp2.x-lammps-gaussian/param_C4H16N4_deepmd-kit-2.0.1.json
@@ -1,15 +1,15 @@
{
"type_map": [
- "H",
+ "H",
"C",
"N"
- ],
+ ],
"mass_map": [
- 1,
+ 1,
12,
14
- ],
- "init_data_prefix": "./data/deepmd/",
+ ],
+ "init_data_prefix": "./data/deepmd/",
"init_data_sys": [
"data.000","data.001","data.002","data.003","data.004","data.005"
],
@@ -18,10 +18,10 @@
[
"./data/md_sys/data.ch4n2"
]
- ],
- "_comment": " that's all ",
+ ],
+ "_comment": " that's all ",
"numb_models": 4,
- "sys_format":"lammps/lmp",
+ "sys_format":"lammps/lmp",
"default_training_param": {
"model": {
"type_map": [
@@ -84,50 +84,50 @@
"_comment": "that's all"
}
},
- "model_devi_dt": 0.002,
- "model_devi_skip": 0,
- "model_devi_f_trust_lo": 0.02,
- "model_devi_f_trust_hi": 1.95,
- "model_devi_clean_traj": true,
+ "model_devi_dt": 0.002,
+ "model_devi_skip": 0,
+ "model_devi_f_trust_lo": 0.02,
+ "model_devi_f_trust_hi": 1.95,
+ "model_devi_clean_traj": true,
"model_devi_jobs": [
{
"sys_idx": [
0
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 2000,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 2000,
+ "ensemble": "nvt",
"_idx": "00"
- },
+ },
{
"sys_idx": [
0
- ],
+ ],
"temps": [
100
- ],
+ ],
"press": [
1
- ],
- "trj_freq": 10,
- "nsteps": 5000,
- "ensemble": "nvt",
+ ],
+ "trj_freq": 10,
+ "nsteps": 5000,
+ "ensemble": "nvt",
"_idx": "01"
}
- ],
+ ],
"use_clusters": true,
"cluster_cutoff": 5.0,
"cluster_minify": true,
"use_relative": true,
"epsilon": 1.0,
- "ratio_failed": 0.20,
+ "ratio_failed": 0.20,
"fp_style": "gaussian",
"shuffle_poscar": false,
"fp_task_max": 20,
diff --git a/examples/run/dprc/generator.json b/examples/run/dprc/generator.json
index c3e668378..44fe4e851 100644
--- a/examples/run/dprc/generator.json
+++ b/examples/run/dprc/generator.json
@@ -367,4 +367,4 @@
"model_devi_engine": "amber",
"fp_style": "amber/diff",
"detailed_report_make_fp": true
-}
\ No newline at end of file
+}
diff --git a/examples/run/dprc/generator.yaml b/examples/run/dprc/generator.yaml
index b52635be6..3202777e3 100644
--- a/examples/run/dprc/generator.yaml
+++ b/examples/run/dprc/generator.yaml
@@ -158,37 +158,37 @@ training_reuse_iter: 2
nsteps:
- 10000
model_devi_jobs:
- - sys_idx: [0]
+ - sys_idx: [0]
trj_freq: 40
- #1
- - sys_idx: [0]
+ #1
+ - sys_idx: [0]
trj_freq: 40
- #2
- - sys_idx: [0]
+ #2
+ - sys_idx: [0]
trj_freq: 40
#3
- - sys_idx: [0]
+ - sys_idx: [0]
trj_freq: 40
- #4
- - sys_idx: [0]
+ #4
+ - sys_idx: [0]
trj_freq: 40
- #5
- - sys_idx: [0]
+ #5
+ - sys_idx: [0]
trj_freq: 40
- #6
- - sys_idx: [0]
+ #6
+ - sys_idx: [0]
trj_freq: 40
- #7
- - sys_idx: [0]
+ #7
+ - sys_idx: [0]
trj_freq: 40
- #8
- - sys_idx: [0]
+ #8
+ - sys_idx: [0]
trj_freq: 40
#9
- - sys_idx: [0]
+ - sys_idx: [0]
trj_freq: 40
#10
- - sys_idx: [0]
+ - sys_idx: [0]
trj_freq: 40
# fp_task_max: the maximum fp tasks to calculate
diff --git a/examples/simplify-MAPbI3-scan-lebesgue/README.md b/examples/simplify-MAPbI3-scan-lebesgue/README.md
index c1bb39025..4045674eb 100644
--- a/examples/simplify-MAPbI3-scan-lebesgue/README.md
+++ b/examples/simplify-MAPbI3-scan-lebesgue/README.md
@@ -1,7 +1,7 @@
-This is an example for `dpgen simplify`. `data` contains a simplistic data set based on MAPbI3-scan case. Since it has been greatly reduced, do not take it seriously. It is just a demo.
-`simplify_example` is the work path, which contains `INCAR` and templates for `simplify.json` and `machine.json`. You can use the command `nohup dpgen simplify simplify.json machine.json 1>log 2>err &` here to test if `dpgen simplify` can run normally.
+This is an example for `dpgen simplify`. `data` contains a simplistic data set based on MAPbI3-scan case. Since it has been greatly reduced, do not take it seriously. It is just a demo.
+`simplify_example` is the work path, which contains `INCAR` and templates for `simplify.json` and `machine.json`. You can use the command `nohup dpgen simplify simplify.json machine.json 1>log 2>err &` here to test if `dpgen simplify` can run normally.
-Kindly reminder:
+Kindly reminder:
1. `machine.json` is supported by `dpdispatcher 0.4.15`, please check https://docs.deepmodeling.com/projects/dpdispatcher/en/latest/ to update the parameters according to your `dpdispatcher` version.
-2. `POTCAR` should be prepared by the user.
-3. Please check the path and files name and make sure they are correct.
\ No newline at end of file
+2. `POTCAR` should be prepared by the user.
+3. Please check the path and files name and make sure they are correct.
diff --git a/examples/simplify-MAPbI3-scan-lebesgue/simplify_example/machine.json b/examples/simplify-MAPbI3-scan-lebesgue/simplify_example/machine.json
index 80e6f49a9..ae25aa061 100644
--- a/examples/simplify-MAPbI3-scan-lebesgue/simplify_example/machine.json
+++ b/examples/simplify-MAPbI3-scan-lebesgue/simplify_example/machine.json
@@ -111,4 +111,3 @@
}
}
}
-
diff --git a/examples/simplify-MAPbI3-scan-lebesgue/simplify_example/simplify.json b/examples/simplify-MAPbI3-scan-lebesgue/simplify_example/simplify.json
index b26434657..cb5420910 100644
--- a/examples/simplify-MAPbI3-scan-lebesgue/simplify_example/simplify.json
+++ b/examples/simplify-MAPbI3-scan-lebesgue/simplify_example/simplify.json
@@ -2,22 +2,22 @@
"type_map": ["I","Pb","C","N","H"],
"mass_map": [126.90447, 207.2, 12.0108, 14.0067, 1.00795],
- "pick_data": "../data",
+ "pick_data": "../data",
"init_data_prefix": "",
"init_data_sys": [],
"sys_configs": [null],
- "sys_batch_size": [1],
+ "sys_batch_size": [1],
"_comment": " 00.train ",
"numb_models": 4,
"model_devi_activation_func":[["tanh","tanh"],["tanh","gelu"],["gelu","gelu"],["gelu","tanh"]],
-
+
"default_training_param": {
"model": {
"type_map": ["I","Pb","C","N","H"],
- "descriptor": {
+ "descriptor": {
"type": "se_e2_a",
- "sel":
+ "sel":
[
20,
8,
@@ -65,7 +65,7 @@
"disp_freq": 1000,
"numb_test": 4,
"save_freq": 10000,
- "save_ckpt": "model.ckpt",
+ "save_ckpt": "model.ckpt",
"disp_training": true,
"time_training": true,
"profiling": false,
@@ -89,6 +89,6 @@
"init_pick_number":5,
"iter_pick_number":5,
"model_devi_f_trust_lo":0.30,
- "model_devi_f_trust_hi":100.00,
+ "model_devi_f_trust_hi":100.00,
"cvasp": false
}
diff --git a/examples/test/deepmd_param.json b/examples/test/deepmd_param.json
index 68e8eab30..ae920184d 100644
--- a/examples/test/deepmd_param.json
+++ b/examples/test/deepmd_param.json
@@ -7,7 +7,7 @@
"key_id": "key id of Material project",
"task_type": "deepmd",
"task": "all",
-
+
"vasp_params": {
"ecut": 650,
"ediff": 1e-6,
diff --git a/examples/test/meam_param.json b/examples/test/meam_param.json
index 1a5c50a7e..1790bb2a9 100644
--- a/examples/test/meam_param.json
+++ b/examples/test/meam_param.json
@@ -7,7 +7,7 @@
"key_id": "key id of Material project",
"task_type": "meam",
"task": "all",
-
+
"vasp_params": {
"ecut": 650,
"ediff": 1e-6,
diff --git a/examples/test/vasp_param.json b/examples/test/vasp_param.json
index be9d07648..d1dfb9a1d 100644
--- a/examples/test/vasp_param.json
+++ b/examples/test/vasp_param.json
@@ -7,7 +7,7 @@
"key_id": "key id of Material project",
"task_type": "vasp",
"task": "all",
-
+
"vasp_params": {
"ecut": 650,
"ediff": 1e-6,
diff --git a/pyproject.toml b/pyproject.toml
index babeac8c2..c893bddd1 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -21,7 +21,7 @@ classifiers = [
dependencies = [
'numpy>=1.14.3',
'dpdata>=0.2.6,!=0.2.11',
- 'pymatgen>=2022.7.19',
+ 'pymatgen>=2022.11.1',
'ase',
'monty>2.0.0',
'paramiko',
@@ -33,6 +33,7 @@ dependencies = [
'h5py',
'pymatgen-analysis-defects',
'openbabel-wheel',
+ 'packaging',
]
requires-python = ">=3.8"
readme = "README.md"
@@ -51,3 +52,12 @@ include = ["dpgen*"]
[tool.setuptools_scm]
write_to = "dpgen/_version.py"
+
+[tool.isort]
+profile = "black"
+
+[tool.ruff]
+target-version = "py37"
+select = [
+ "I", # isort
+]
diff --git a/tests/auto_test/abacus_input/INPUT b/tests/auto_test/abacus_input/INPUT
index 97bfa0065..ad900f61a 100644
--- a/tests/auto_test/abacus_input/INPUT
+++ b/tests/auto_test/abacus_input/INPUT
@@ -2,7 +2,6 @@ INPUT_PARAMETERS
#Parameters (1.General)
suffix ABACUS
calculation relax
-ntype 1
symmetry 1
pseudo_type upf201
diff --git a/tests/auto_test/context.py b/tests/auto_test/context.py
index 1ff54188a..454820555 100644
--- a/tests/auto_test/context.py
+++ b/tests/auto_test/context.py
@@ -1,6 +1,9 @@
-import sys,os
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
+import os
+import sys
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
from dpgen.auto_test.lib.vasp import *
+
def setUpModule():
os.chdir(os.path.abspath(os.path.dirname(__file__)))
diff --git a/tests/auto_test/data.vasp.kp.gf/make_kp_test.py b/tests/auto_test/data.vasp.kp.gf/make_kp_test.py
index 4deddecd4..dddf45840 100644
--- a/tests/auto_test/data.vasp.kp.gf/make_kp_test.py
+++ b/tests/auto_test/data.vasp.kp.gf/make_kp_test.py
@@ -1,24 +1,26 @@
#!/usr/bin/env python3
-import numpy as np
+import os
+
+import ase
import dpdata
-import ase,os
+import numpy as np
-def make_one(out_dir) :
+def make_one(out_dir):
# [0.5, 1)
- [aa,bb,cc] = np.random.random(3) * 0.5 + 0.5
+ [aa, bb, cc] = np.random.random(3) * 0.5 + 0.5
# [1, 179)
- [alpha,beta,gamma] = np.random.random(3) * (178 / 180) + 1
+ [alpha, beta, gamma] = np.random.random(3) * (178 / 180) + 1
# make cell
- cell = ase.geometry.cellpar_to_cell([aa,bb,cc,alpha,beta,gamma])
- sys = dpdata.System('POSCAR')
- sys['cells'][0] = cell
+ cell = ase.geometry.cellpar_to_cell([aa, bb, cc, alpha, beta, gamma])
+ sys = dpdata.System("POSCAR")
+ sys["cells"][0] = cell
os.makedirs(out_dir, exist_ok=True)
- sys.to_vasp_poscar(os.path.join(out_dir, 'POSCAR'))
-
+ sys.to_vasp_poscar(os.path.join(out_dir, "POSCAR"))
+
ntest = 30
-for ii in range(ntest) :
- out_dir = 'test.%03d' % ii
- make_one(out_dir)
+for ii in range(ntest):
+ out_dir = "test.%03d" % ii
+ make_one(out_dir)
diff --git a/tests/auto_test/equi/abacus/INPUT b/tests/auto_test/equi/abacus/INPUT
index ba426a193..26a01ddb2 100644
--- a/tests/auto_test/equi/abacus/INPUT
+++ b/tests/auto_test/equi/abacus/INPUT
@@ -2,7 +2,6 @@ INPUT_PARAMETERS
#Parameters (5.Mixing)
suffix ABACUS
calculation cell-relax
-ntype 1
symmetry 1
pseudo_type upf201
ecutwfc 60
diff --git a/tests/auto_test/output/gamma_00/POSCAR b/tests/auto_test/output/gamma_00/POSCAR
deleted file mode 120000
index 75eec9b68..000000000
--- a/tests/auto_test/output/gamma_00/POSCAR
+++ /dev/null
@@ -1 +0,0 @@
-../relaxation/relax_task/CONTCAR
\ No newline at end of file
diff --git a/tests/auto_test/test_abacus.py b/tests/auto_test/test_abacus.py
index d0e35a67a..0bf09dced 100644
--- a/tests/auto_test/test_abacus.py
+++ b/tests/auto_test/test_abacus.py
@@ -1,17 +1,21 @@
-import os, sys, shutil
-import numpy as np
+import os
+import shutil
+import sys
import unittest
+
+import numpy as np
from monty.serialization import loadfn
+
+from dpgen.auto_test.ABACUS import ABACUS
+from dpgen.auto_test.lib import abacus
from dpgen.generator.lib import abacus_scf
-from dpgen.auto_test.lib import abacus
-from dpgen.auto_test.ABACUS import ABACUS
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from .context import setUpModule
-class TestABACUS(unittest.TestCase):
+class TestABACUS(unittest.TestCase):
def setUp(self):
self.jdata = {
"structures": ["confs/fcc-Al"],
@@ -20,143 +24,211 @@ def setUp(self):
"incar": "abacus_input/INPUT",
"potcar_prefix": "abacus_input",
"potcars": {"Al": "Al_ONCV_PBE-1.0.upf"},
- "orb_files": {"Al":"Al_gga_9au_100Ry_4s4p1d.orb"}
+ "orb_files": {"Al": "Al_gga_9au_100Ry_4s4p1d.orb"},
},
"relaxation": {
- "cal_type": "relaxation",
- "cal_setting": {"relax_pos":True,
- "relax_shape":True,
- "relax_vol":True}
- }
+ "cal_type": "relaxation",
+ "cal_setting": {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": True,
+ },
+ },
}
- self.conf_path = 'confs/fcc-Al'
- self.equi_path = 'confs/fcc-Al/relaxation/relax_task'
- self.source_path = 'equi/abacus'
+ self.conf_path = "confs/fcc-Al"
+ self.equi_path = "confs/fcc-Al/relaxation/relax_task"
+ self.source_path = "equi/abacus"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
self.confs = self.jdata["structures"]
inter_param = self.jdata["interaction"]
self.task_param = self.jdata["relaxation"]
- self.ABACUS = ABACUS(inter_param, os.path.join(self.conf_path, 'STRU'))
+ self.ABACUS = ABACUS(inter_param, os.path.join(self.conf_path, "STRU"))
def tearDown(self):
- if os.path.exists('confs/fcc-Al/relaxation'):
- shutil.rmtree('confs/fcc-Al/relaxation')
+ if os.path.exists("confs/fcc-Al/relaxation"):
+ shutil.rmtree("confs/fcc-Al/relaxation")
def test_make_potential_files(self):
- if not os.path.exists(os.path.join(self.equi_path, 'STRU')):
+ if not os.path.exists(os.path.join(self.equi_path, "STRU")):
with self.assertRaises(FileNotFoundError):
- self.ABACUS.make_potential_files(self.equi_path)
- shutil.copy(os.path.join(self.conf_path, 'STRU'), os.path.join(self.equi_path, 'STRU'))
+ self.ABACUS.make_potential_files(self.equi_path)
+ shutil.copy(
+ os.path.join(self.conf_path, "STRU"), os.path.join(self.equi_path, "STRU")
+ )
self.ABACUS.make_potential_files(self.equi_path)
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "pp_orb/Al_ONCV_PBE-1.0.upf")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "pp_orb/Al_gga_9au_100Ry_4s4p1d.orb")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, 'inter.json')))
+ self.assertTrue(
+ os.path.isfile(os.path.join(self.equi_path, "pp_orb/Al_ONCV_PBE-1.0.upf"))
+ )
+ self.assertTrue(
+ os.path.isfile(
+ os.path.join(self.equi_path, "pp_orb/Al_gga_9au_100Ry_4s4p1d.orb")
+ )
+ )
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "inter.json")))
def test_make_input_file_1(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":True,
- "relax_shape":True,
- "relax_vol":False}
- shutil.copy(os.path.join(self.conf_path, 'STRU'), os.path.join(self.equi_path, 'STRU'))
- self.ABACUS.make_input_file(self.equi_path,'relaxation',param)
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": False,
+ }
+ shutil.copy(
+ os.path.join(self.conf_path, "STRU"), os.path.join(self.equi_path, "STRU")
+ )
+ self.ABACUS.make_input_file(self.equi_path, "relaxation", param)
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "INPUT")))
- abacus_input = abacus_scf.get_abacus_input_parameters(os.path.join(self.equi_path, "INPUT"))
- self.assertEqual(abacus_input['calculation'].lower(),"cell-relax")
- self.assertEqual(abacus_input['fixed_axes'].lower(),"volume")
- self.assertTrue(abacus.check_stru_fixed(os.path.join(self.equi_path, 'STRU'),fixed=False))
+ abacus_input = abacus_scf.get_abacus_input_parameters(
+ os.path.join(self.equi_path, "INPUT")
+ )
+ self.assertEqual(abacus_input["calculation"].lower(), "cell-relax")
+ self.assertEqual(abacus_input["fixed_axes"].lower(), "volume")
+ self.assertTrue(
+ abacus.check_stru_fixed(os.path.join(self.equi_path, "STRU"), fixed=False)
+ )
def test_make_input_file_2(self):
- shutil.copy(os.path.join(self.conf_path, 'STRU'), os.path.join(self.equi_path, 'STRU'))
- self.ABACUS.make_input_file(self.equi_path,'relaxation',self.task_param)
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
+ shutil.copy(
+ os.path.join(self.conf_path, "STRU"), os.path.join(self.equi_path, "STRU")
+ )
+ self.ABACUS.make_input_file(self.equi_path, "relaxation", self.task_param)
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "INPUT")))
- abacus_input = abacus_scf.get_abacus_input_parameters(os.path.join(self.equi_path, "INPUT"))
- self.assertEqual(abacus_input['calculation'].lower(),"cell-relax")
- self.assertTrue('fixed_axes' not in abacus_input or abacus_input['fixed_axes'] == 'None')
- self.assertTrue(abacus.check_stru_fixed(os.path.join(self.equi_path, 'STRU'),fixed=False))
+ abacus_input = abacus_scf.get_abacus_input_parameters(
+ os.path.join(self.equi_path, "INPUT")
+ )
+ self.assertEqual(abacus_input["calculation"].lower(), "cell-relax")
+ self.assertTrue(
+ "fixed_axes" not in abacus_input or abacus_input["fixed_axes"] == "None"
+ )
+ self.assertTrue(
+ abacus.check_stru_fixed(os.path.join(self.equi_path, "STRU"), fixed=False)
+ )
def test_make_input_file_3(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":True,
- "relax_shape":False,
- "relax_vol":False}
- shutil.copy(os.path.join(self.conf_path, 'STRU'), os.path.join(self.equi_path, 'STRU'))
- self.ABACUS.make_input_file(self.equi_path,'relaxation',param)
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": True,
+ "relax_shape": False,
+ "relax_vol": False,
+ }
+ shutil.copy(
+ os.path.join(self.conf_path, "STRU"), os.path.join(self.equi_path, "STRU")
+ )
+ self.ABACUS.make_input_file(self.equi_path, "relaxation", param)
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "INPUT")))
- abacus_input = abacus_scf.get_abacus_input_parameters(os.path.join(self.equi_path, "INPUT"))
- self.assertEqual(abacus_input['calculation'].lower(),"relax")
- self.assertTrue('fixed_axes' not in abacus_input or abacus_input['fixed_axes'] == 'None')
- self.assertTrue(abacus.check_stru_fixed(os.path.join(self.equi_path, 'STRU'),fixed=False))
+ abacus_input = abacus_scf.get_abacus_input_parameters(
+ os.path.join(self.equi_path, "INPUT")
+ )
+ self.assertEqual(abacus_input["calculation"].lower(), "relax")
+ self.assertTrue(
+ "fixed_axes" not in abacus_input or abacus_input["fixed_axes"] == "None"
+ )
+ self.assertTrue(
+ abacus.check_stru_fixed(os.path.join(self.equi_path, "STRU"), fixed=False)
+ )
def test_make_input_file_4(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":False,
- "relax_shape":True,
- "relax_vol":False}
- shutil.copy(os.path.join(self.conf_path, 'STRU'), os.path.join(self.equi_path, 'STRU'))
- self.ABACUS.make_input_file(self.equi_path,'relaxation',param)
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": False,
+ "relax_shape": True,
+ "relax_vol": False,
+ }
+ shutil.copy(
+ os.path.join(self.conf_path, "STRU"), os.path.join(self.equi_path, "STRU")
+ )
+ self.ABACUS.make_input_file(self.equi_path, "relaxation", param)
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "INPUT")))
- abacus_input = abacus_scf.get_abacus_input_parameters(os.path.join(self.equi_path, "INPUT"))
- self.assertEqual(abacus_input['calculation'].lower(),"cell-relax")
- self.assertEqual(abacus_input['fixed_axes'].lower(),"volume")
- self.assertTrue(abacus.check_stru_fixed(os.path.join(self.equi_path, 'STRU'),fixed=True))
+ abacus_input = abacus_scf.get_abacus_input_parameters(
+ os.path.join(self.equi_path, "INPUT")
+ )
+ self.assertEqual(abacus_input["calculation"].lower(), "cell-relax")
+ self.assertEqual(abacus_input["fixed_axes"].lower(), "volume")
+ self.assertTrue(
+ abacus.check_stru_fixed(os.path.join(self.equi_path, "STRU"), fixed=True)
+ )
def test_make_input_file_5(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":False,
- "relax_shape":True,
- "relax_vol":True}
- shutil.copy(os.path.join(self.conf_path, 'STRU'), os.path.join(self.equi_path, 'STRU'))
- self.ABACUS.make_input_file(self.equi_path,'relaxation',param)
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": False,
+ "relax_shape": True,
+ "relax_vol": True,
+ }
+ shutil.copy(
+ os.path.join(self.conf_path, "STRU"), os.path.join(self.equi_path, "STRU")
+ )
+ self.ABACUS.make_input_file(self.equi_path, "relaxation", param)
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPT")))
self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "INPUT")))
- abacus_input = abacus_scf.get_abacus_input_parameters(os.path.join(self.equi_path, "INPUT"))
- self.assertEqual(abacus_input['calculation'].lower(),"cell-relax")
- self.assertTrue('fixed_axes' not in abacus_input or abacus_input['fixed_axes'] == 'None')
- self.assertTrue(abacus.check_stru_fixed(os.path.join(self.equi_path, 'STRU'),fixed=True))
+ abacus_input = abacus_scf.get_abacus_input_parameters(
+ os.path.join(self.equi_path, "INPUT")
+ )
+ self.assertEqual(abacus_input["calculation"].lower(), "cell-relax")
+ self.assertTrue(
+ "fixed_axes" not in abacus_input or abacus_input["fixed_axes"] == "None"
+ )
+ self.assertTrue(
+ abacus.check_stru_fixed(os.path.join(self.equi_path, "STRU"), fixed=True)
+ )
def test_make_input_file_kspacing(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":False,
- "relax_shape":True,
- "relax_vol":True,
- "kspacing":0.1}
- shutil.copy(os.path.join(self.conf_path, 'STRU'), os.path.join(self.equi_path, 'STRU'))
- self.ABACUS.make_input_file(self.equi_path,'relaxation',param)
- with open(os.path.join(self.equi_path, "KPT")) as f1: kpt = f1.read().strip().split('\n')[-1].split()
- self.assertEqual(kpt,['9','9','9','0','0','0'])
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": False,
+ "relax_shape": True,
+ "relax_vol": True,
+ "kspacing": 0.1,
+ }
+ shutil.copy(
+ os.path.join(self.conf_path, "STRU"), os.path.join(self.equi_path, "STRU")
+ )
+ self.ABACUS.make_input_file(self.equi_path, "relaxation", param)
+ with open(os.path.join(self.equi_path, "KPT")) as f1:
+ kpt = f1.read().strip().split("\n")[-1].split()
+ self.assertEqual(kpt, ["9", "9", "9", "0", "0", "0"])
def test_compuate(self):
- ret=self.ABACUS.compute(os.path.join(self.equi_path))
+ ret = self.ABACUS.compute(os.path.join(self.equi_path))
self.assertIsNone(ret)
- shutil.copy(os.path.join(self.source_path, 'INPUT'), os.path.join(self.equi_path, 'INPUT'))
- shutil.copy(os.path.join(self.conf_path, 'STRU'), os.path.join(self.equi_path, 'STRU'))
- os.mkdir(os.path.join(self.equi_path, 'OUT.ABACUS'))
- shutil.copy(os.path.join(self.source_path, 'running_cell-relax.log'), os.path.join(self.equi_path, 'OUT.ABACUS','running_cell-relax.log'))
- ret=self.ABACUS.compute(self.equi_path)
- ret_ref=loadfn(os.path.join(self.source_path, 'cell-relax.json'))
-
- def compare_dict(dict1,dict2):
- self.assertEqual(dict1.keys(),dict2.keys())
+ shutil.copy(
+ os.path.join(self.source_path, "INPUT"),
+ os.path.join(self.equi_path, "INPUT"),
+ )
+ shutil.copy(
+ os.path.join(self.conf_path, "STRU"), os.path.join(self.equi_path, "STRU")
+ )
+ os.mkdir(os.path.join(self.equi_path, "OUT.ABACUS"))
+ shutil.copy(
+ os.path.join(self.source_path, "running_cell-relax.log"),
+ os.path.join(self.equi_path, "OUT.ABACUS", "running_cell-relax.log"),
+ )
+ ret = self.ABACUS.compute(self.equi_path)
+ ret_ref = loadfn(os.path.join(self.source_path, "cell-relax.json"))
+
+ def compare_dict(dict1, dict2):
+ self.assertEqual(dict1.keys(), dict2.keys())
for key in dict1:
if type(dict1[key]) is dict:
- compare_dict(dict1[key],dict2[key])
+ compare_dict(dict1[key], dict2[key])
else:
if type(dict1[key]) is np.ndarray:
- np.testing.assert_almost_equal(dict1[key], dict2[key],decimal=5)
+ np.testing.assert_almost_equal(
+ dict1[key], dict2[key], decimal=5
+ )
else:
self.assertTrue(dict1[key] == dict2[key])
- compare_dict(ret,ret_ref.as_dict())
-
+ compare_dict(ret, ret_ref.as_dict())
diff --git a/tests/auto_test/test_abacus_equi.py b/tests/auto_test/test_abacus_equi.py
index f8aa8f678..372e5eb0e 100644
--- a/tests/auto_test/test_abacus_equi.py
+++ b/tests/auto_test/test_abacus_equi.py
@@ -1,13 +1,20 @@
-import os, sys, json, glob, shutil
-from monty.serialization import loadfn
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-from dpgen.generator.lib import abacus_scf
+
+from monty.serialization import loadfn
+
from dpgen.auto_test.common_equi import make_equi, post_equi
+from dpgen.generator.lib import abacus_scf
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from .context import setUpModule
+
class TestEqui(unittest.TestCase):
jdata = {
"structures": ["confs/fcc-Al"],
@@ -16,17 +23,17 @@ class TestEqui(unittest.TestCase):
"incar": "abacus_input/INPUT",
"potcar_prefix": "abacus_input",
"potcars": {"Al": "Al_ONCV_PBE-1.0.upf"},
- "orb_files": {"Al":"Al_gga_9au_100Ry_4s4p1d.orb"}
+ "orb_files": {"Al": "Al_gga_9au_100Ry_4s4p1d.orb"},
},
"relaxation": {
"cal_type": "relaxation",
- "cal_setting":{"input_prop": "abacus_input/INPUT"}
- }
+ "cal_setting": {"input_prop": "abacus_input/INPUT"},
+ },
}
def tearDown(self):
- if os.path.exists('confs/fcc-Al/relaxation'):
- shutil.rmtree('confs/fcc-Al/relaxation')
+ if os.path.exists("confs/fcc-Al/relaxation"):
+ shutil.rmtree("confs/fcc-Al/relaxation")
def test_make_equi(self):
confs = self.jdata["structures"]
@@ -34,51 +41,64 @@ def test_make_equi(self):
relax_param = self.jdata["relaxation"]
make_equi(confs, inter_param, relax_param)
- target_path = 'confs/fcc-Al/relaxation/relax_task'
+ target_path = "confs/fcc-Al/relaxation/relax_task"
- incar0 = abacus_scf.get_abacus_input_parameters(os.path.join('abacus_input', 'INPUT'))
- incar1 = abacus_scf.get_abacus_input_parameters(os.path.join(target_path, 'INPUT'))
+ incar0 = abacus_scf.get_abacus_input_parameters(
+ os.path.join("abacus_input", "INPUT")
+ )
+ incar1 = abacus_scf.get_abacus_input_parameters(
+ os.path.join(target_path, "INPUT")
+ )
self.assertTrue(incar0 == incar1)
- with open(os.path.join('abacus_input', 'Al_ONCV_PBE-1.0.upf')) as fp:
+ with open(os.path.join("abacus_input", "Al_ONCV_PBE-1.0.upf")) as fp:
pot0 = fp.read()
- with open(os.path.join(target_path,'pp_orb', 'Al_ONCV_PBE-1.0.upf')) as fp:
+ with open(os.path.join(target_path, "pp_orb", "Al_ONCV_PBE-1.0.upf")) as fp:
pot1 = fp.read()
self.assertEqual(pot0, pot1)
- with open(os.path.join('abacus_input', 'Al_gga_9au_100Ry_4s4p1d.orb')) as fp:
+ with open(os.path.join("abacus_input", "Al_gga_9au_100Ry_4s4p1d.orb")) as fp:
pot0 = fp.read()
- with open(os.path.join(target_path,'pp_orb', 'Al_gga_9au_100Ry_4s4p1d.orb')) as fp:
+ with open(
+ os.path.join(target_path, "pp_orb", "Al_gga_9au_100Ry_4s4p1d.orb")
+ ) as fp:
pot1 = fp.read()
self.assertEqual(pot0, pot1)
- self.assertTrue(os.path.isfile(os.path.join(target_path, 'KPT')))
+ self.assertTrue(os.path.isfile(os.path.join(target_path, "KPT")))
- task_json_file = os.path.join(target_path, 'task.json')
+ task_json_file = os.path.join(target_path, "task.json")
self.assertTrue(os.path.isfile(task_json_file))
task_json = loadfn(task_json_file)
self.assertEqual(task_json, relax_param)
- inter_json_file = os.path.join(target_path, 'inter.json')
+ inter_json_file = os.path.join(target_path, "inter.json")
self.assertTrue(os.path.isfile(inter_json_file))
inter_json = loadfn(inter_json_file)
self.assertEqual(inter_json, inter_param)
- self.assertTrue(os.path.islink(os.path.join(target_path, 'STRU')))
+ self.assertTrue(os.path.islink(os.path.join(target_path, "STRU")))
def test_post_equi(self):
- confs = self.jdata["structures"]
- inter_param = self.jdata["interaction"]
- relax_param = self.jdata["relaxation"]
- target_path = 'confs/fcc-Al/relaxation/relax_task'
- source_path = 'equi/abacus'
-
- make_equi(confs, inter_param, relax_param)
- os.mkdir(os.path.join(target_path, 'OUT.ABACUS'))
- shutil.copy(os.path.join(source_path, 'INPUT'), os.path.join(target_path, 'INPUT'))
- shutil.copy(os.path.join(source_path, 'STRU'), os.path.join(target_path, 'STRU'))
- shutil.copy(os.path.join(source_path, 'running_cell-relax.log'), os.path.join(target_path, 'OUT.ABACUS','running_cell-relax.log'))
- post_equi(confs, inter_param)
-
- result_json_file = os.path.join(target_path, 'result.json')
- self.assertTrue(os.path.isfile(result_json_file))
+ confs = self.jdata["structures"]
+ inter_param = self.jdata["interaction"]
+ relax_param = self.jdata["relaxation"]
+ target_path = "confs/fcc-Al/relaxation/relax_task"
+ source_path = "equi/abacus"
+
+ make_equi(confs, inter_param, relax_param)
+ os.mkdir(os.path.join(target_path, "OUT.ABACUS"))
+ shutil.copy(
+ os.path.join(source_path, "INPUT"), os.path.join(target_path, "INPUT")
+ )
+ shutil.copy(
+ os.path.join(source_path, "STRU"), os.path.join(target_path, "STRU")
+ )
+ shutil.copy(
+ os.path.join(source_path, "running_cell-relax.log"),
+ os.path.join(target_path, "OUT.ABACUS", "running_cell-relax.log"),
+ )
+ post_equi(confs, inter_param)
+
+ result_json_file = os.path.join(target_path, "result.json")
+ self.assertTrue(os.path.isfile(result_json_file))
diff --git a/tests/auto_test/test_abacus_property.py b/tests/auto_test/test_abacus_property.py
index bfd1ed0ec..41e25382c 100644
--- a/tests/auto_test/test_abacus_property.py
+++ b/tests/auto_test/test_abacus_property.py
@@ -1,24 +1,29 @@
-import os, sys, shutil, glob
-import numpy as np
+import glob
+import os
+import shutil
+import sys
import unittest
+
+import numpy as np
from monty.serialization import loadfn
-from dpgen.generator.lib import abacus_scf
-from dpgen.auto_test.ABACUS import ABACUS
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-from .context import setUpModule
+from dpgen.auto_test.ABACUS import ABACUS
+from dpgen.generator.lib import abacus_scf
-from dpgen.auto_test.EOS import EOS
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
+from dpgen.auto_test.common_prop import make_property
from dpgen.auto_test.Elastic import Elastic
-from dpgen.auto_test.Vacancy import Vacancy
+from dpgen.auto_test.EOS import EOS
+from dpgen.auto_test.Gamma import Gamma
from dpgen.auto_test.Interstitial import Interstitial
from dpgen.auto_test.Surface import Surface
-from dpgen.auto_test.Gamma import Gamma
-from dpgen.auto_test.common_prop import make_property
+from dpgen.auto_test.Vacancy import Vacancy
-class TestABACUS(unittest.TestCase):
+from .context import setUpModule
+
+class TestABACUS(unittest.TestCase):
def setUp(self):
self.jdata = {
"structures": ["confs/fcc-Al"],
@@ -27,236 +32,269 @@ def setUp(self):
"incar": "abacus_input/INPUT",
"potcar_prefix": "abacus_input",
"potcars": {"Al": "Al_ONCV_PBE-1.0.upf"},
- "orb_files": {"Al":"Al_gga_9au_100Ry_4s4p1d.orb"}
- }
+ "orb_files": {"Al": "Al_gga_9au_100Ry_4s4p1d.orb"},
+ },
}
- self.conf_path = 'confs/fcc-Al'
- self.equi_path = 'confs/fcc-Al/relaxation/relax_task'
- self.source_path = 'equi/abacus'
+ self.conf_path = "confs/fcc-Al"
+ self.equi_path = "confs/fcc-Al/relaxation/relax_task"
+ self.source_path = "equi/abacus"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
- if not os.path.exists(os.path.join(self.equi_path,'OUT.ABACUS')):
- os.makedirs(os.path.join(self.equi_path,'OUT.ABACUS'))
- for ifile in ['INPUT','STRU']:
- if not os.path.exists(os.path.join(self.equi_path,ifile)):
- shutil.copy(os.path.join(self.source_path,ifile),os.path.join(self.equi_path,ifile))
- for ifile in ['running_cell-relax.log','STRU_ION_D']:
- if not os.path.exists(os.path.join(self.equi_path,'OUT.ABACUS',ifile)):
- shutil.copy(os.path.join(self.source_path,ifile),os.path.join(self.equi_path,'OUT.ABACUS',ifile))
- shutil.copy(os.path.join(self.source_path,'cell-relax.json'),os.path.join(self.equi_path,'result.json'))
+ if not os.path.exists(os.path.join(self.equi_path, "OUT.ABACUS")):
+ os.makedirs(os.path.join(self.equi_path, "OUT.ABACUS"))
+ for ifile in ["INPUT", "STRU"]:
+ if not os.path.exists(os.path.join(self.equi_path, ifile)):
+ shutil.copy(
+ os.path.join(self.source_path, ifile),
+ os.path.join(self.equi_path, ifile),
+ )
+ for ifile in ["running_cell-relax.log", "STRU_ION_D"]:
+ if not os.path.exists(os.path.join(self.equi_path, "OUT.ABACUS", ifile)):
+ shutil.copy(
+ os.path.join(self.source_path, ifile),
+ os.path.join(self.equi_path, "OUT.ABACUS", ifile),
+ )
+ shutil.copy(
+ os.path.join(self.source_path, "cell-relax.json"),
+ os.path.join(self.equi_path, "result.json"),
+ )
self.confs = self.jdata["structures"]
self.inter_param = self.jdata["interaction"]
- self.ABACUS = ABACUS(self.inter_param, os.path.join(self.conf_path, 'STRU'))
+ self.ABACUS = ABACUS(self.inter_param, os.path.join(self.conf_path, "STRU"))
def tearDown(self):
- if os.path.exists('confs/fcc-Al/relaxation'):
- shutil.rmtree('confs/fcc-Al/relaxation')
- if os.path.exists('confs/fcc-Al/eos_00'):
- shutil.rmtree('confs/fcc-Al/eos_00')
- if os.path.exists('confs/fcc-Al/eos_02'):
- shutil.rmtree('confs/fcc-Al/eos_02')
- if os.path.exists('confs/fcc-Al/elastic_00'):
- shutil.rmtree('confs/fcc-Al/elastic_00')
- if os.path.exists('confs/fcc-Al/vacancy_00'):
- shutil.rmtree('confs/fcc-Al/vacancy_00')
- if os.path.exists('confs/fcc-Al/interstitial_00'):
- shutil.rmtree('confs/fcc-Al/interstitial_00')
- if os.path.exists('confs/fcc-Al/surface_00'):
- shutil.rmtree('confs/fcc-Al/surface_00')
+ if os.path.exists("confs/fcc-Al/relaxation"):
+ shutil.rmtree("confs/fcc-Al/relaxation")
+ if os.path.exists("confs/fcc-Al/eos_00"):
+ shutil.rmtree("confs/fcc-Al/eos_00")
+ if os.path.exists("confs/fcc-Al/eos_02"):
+ shutil.rmtree("confs/fcc-Al/eos_02")
+ if os.path.exists("confs/fcc-Al/elastic_00"):
+ shutil.rmtree("confs/fcc-Al/elastic_00")
+ if os.path.exists("confs/fcc-Al/vacancy_00"):
+ shutil.rmtree("confs/fcc-Al/vacancy_00")
+ if os.path.exists("confs/fcc-Al/interstitial_00"):
+ shutil.rmtree("confs/fcc-Al/interstitial_00")
+ if os.path.exists("confs/fcc-Al/surface_00"):
+ shutil.rmtree("confs/fcc-Al/surface_00")
def test_make_property(self):
- property = {"type": "eos",
- "vol_start": 0.85,
- "vol_end": 1.15,
- "vol_step": 0.01
- }
+ property = {"type": "eos", "vol_start": 0.85, "vol_end": 1.15, "vol_step": 0.01}
make_property(self.jdata["structures"], self.jdata["interaction"], [property])
- self.assertTrue(os.path.exists(os.path.join(self.conf_path,"eos_00")))
- self.assertTrue(os.path.exists(os.path.join(self.conf_path,"eos_00","INPUT")))
- for ii in glob.glob(os.path.join(self.conf_path,"eos_00", 'task.*')):
- self.assertTrue(os.path.exists(os.path.join(ii,"INPUT")))
- self.assertTrue(os.path.exists(os.path.join(ii,"pp_orb")))
- self.assertTrue(os.path.exists(os.path.join(ii,"KPT")))
- self.assertTrue(os.path.exists(os.path.join(ii,"STRU")))
- self.assertEqual(os.path.realpath(os.path.join(ii, 'pp_orb', 'Al_ONCV_PBE-1.0.upf')),
- os.path.realpath(os.path.join(self.jdata['interaction']['potcar_prefix'], 'Al_ONCV_PBE-1.0.upf')))
+ self.assertTrue(os.path.exists(os.path.join(self.conf_path, "eos_00")))
+ self.assertTrue(os.path.exists(os.path.join(self.conf_path, "eos_00", "INPUT")))
+ for ii in glob.glob(os.path.join(self.conf_path, "eos_00", "task.*")):
+ self.assertTrue(os.path.exists(os.path.join(ii, "INPUT")))
+ self.assertTrue(os.path.exists(os.path.join(ii, "pp_orb")))
+ self.assertTrue(os.path.exists(os.path.join(ii, "KPT")))
+ self.assertTrue(os.path.exists(os.path.join(ii, "STRU")))
+ self.assertEqual(
+ os.path.realpath(os.path.join(ii, "pp_orb", "Al_ONCV_PBE-1.0.upf")),
+ os.path.realpath(
+ os.path.join(
+ self.jdata["interaction"]["potcar_prefix"],
+ "Al_ONCV_PBE-1.0.upf",
+ )
+ ),
+ )
def test_make_property_eos(self):
- property = {"type": "eos",
- "vol_start": 0.85,
- "vol_end": 1.15,
- "vol_step": 0.01
- }
- work_path = os.path.join(self.conf_path,"eos_00")
- eos = EOS(property,self.inter_param)
+ property = {"type": "eos", "vol_start": 0.85, "vol_end": 1.15, "vol_step": 0.01}
+ work_path = os.path.join(self.conf_path, "eos_00")
+ eos = EOS(property, self.inter_param)
eos.make_confs(work_path, self.equi_path, refine=False)
- for ii in glob.glob(os.path.join(work_path, 'task.*')):
- self.assertTrue(os.path.isfile(os.path.join(ii, 'STRU')))
- self.assertTrue(os.path.isfile(os.path.join(ii, 'eos.json')))
- self.assertEqual(os.path.realpath(os.path.join(ii, 'STRU.orig')),
- os.path.realpath(os.path.join(self.equi_path, 'OUT.ABACUS', 'STRU_ION_D')))
+ for ii in glob.glob(os.path.join(work_path, "task.*")):
+ self.assertTrue(os.path.isfile(os.path.join(ii, "STRU")))
+ self.assertTrue(os.path.isfile(os.path.join(ii, "eos.json")))
+ self.assertEqual(
+ os.path.realpath(os.path.join(ii, "STRU.orig")),
+ os.path.realpath(
+ os.path.join(self.equi_path, "OUT.ABACUS", "STRU_ION_D")
+ ),
+ )
- eos_json = loadfn(os.path.join(ii, 'eos.json'))
- stru_data = abacus_scf.get_abacus_STRU(os.path.realpath(os.path.join(ii, 'STRU')))
- vol_per_atom = abs(np.linalg.det(stru_data['cells'])) / np.array(stru_data['atom_numbs']).sum()
- self.assertAlmostEqual(eos_json['volume'], vol_per_atom)
+ eos_json = loadfn(os.path.join(ii, "eos.json"))
+ stru_data = abacus_scf.get_abacus_STRU(
+ os.path.realpath(os.path.join(ii, "STRU"))
+ )
+ vol_per_atom = (
+ abs(np.linalg.det(stru_data["cells"]))
+ / np.array(stru_data["atom_numbs"]).sum()
+ )
+ self.assertAlmostEqual(eos_json["volume"], vol_per_atom)
def test_make_property_elastic(self):
- property = {"type": "elastic",
- "norm_deform": 1e-2,
- "shear_deform": 1e-2
- }
- work_path = os.path.join(self.conf_path,"elastic_00")
- elastic = Elastic(property,self.inter_param)
+ property = {"type": "elastic", "norm_deform": 1e-2, "shear_deform": 1e-2}
+ work_path = os.path.join(self.conf_path, "elastic_00")
+ elastic = Elastic(property, self.inter_param)
elastic.make_confs(work_path, self.equi_path, refine=False)
- self.assertEqual(os.path.realpath(os.path.join(work_path, 'STRU')),
- os.path.realpath(os.path.join(self.equi_path, 'OUT.ABACUS', 'STRU_ION_D')))
- for ii in glob.glob(os.path.join(work_path, 'task.*')):
- self.assertTrue(os.path.isfile(os.path.join(ii, 'STRU')))
- self.assertTrue(os.path.isfile(os.path.join(ii, 'strain.json')))
+ self.assertEqual(
+ os.path.realpath(os.path.join(work_path, "STRU")),
+ os.path.realpath(os.path.join(self.equi_path, "OUT.ABACUS", "STRU_ION_D")),
+ )
+ for ii in glob.glob(os.path.join(work_path, "task.*")):
+ self.assertTrue(os.path.isfile(os.path.join(ii, "STRU")))
+ self.assertTrue(os.path.isfile(os.path.join(ii, "strain.json")))
- os.remove(os.path.realpath(os.path.join(self.equi_path, 'OUT.ABACUS', 'STRU_ION_D')))
+ os.remove(
+ os.path.realpath(os.path.join(self.equi_path, "OUT.ABACUS", "STRU_ION_D"))
+ )
with self.assertRaises(RuntimeError):
elastic.make_confs(work_path, self.equi_path, refine=False)
def test_make_property_elastic_post_process(self):
- property = {"type": "elastic",
- "norm_deform": 1e-2,
- "shear_deform": 1e-2
- }
+ property = {"type": "elastic", "norm_deform": 1e-2, "shear_deform": 1e-2}
make_property(self.jdata["structures"], self.jdata["interaction"], [property])
- work_path = os.path.join(self.conf_path,"elastic_00")
+ work_path = os.path.join(self.conf_path, "elastic_00")
+
+ self.assertTrue(os.path.exists(os.path.join(work_path, "INPUT")))
+ self.assertTrue(os.path.exists(os.path.join(work_path, "KPT")))
- self.assertTrue(os.path.exists(os.path.join(work_path,"INPUT")))
- self.assertTrue(os.path.exists(os.path.join(work_path,"KPT")))
+ for ii in glob.glob(os.path.join(work_path, "task.*")):
+ self.assertEqual(
+ os.path.realpath(os.path.join(work_path, "KPT")),
+ os.path.realpath(os.path.join(ii, "KPT")),
+ )
+ self.assertEqual(
+ os.path.realpath(os.path.join(work_path, "INPUT")),
+ os.path.realpath(os.path.join(ii, "INPUT")),
+ )
- for ii in glob.glob(os.path.join(work_path, 'task.*')):
- self.assertEqual(os.path.realpath(os.path.join(work_path, 'KPT')),
- os.path.realpath(os.path.join(ii, 'KPT')))
- self.assertEqual(os.path.realpath(os.path.join(work_path, 'INPUT')),
- os.path.realpath(os.path.join(ii, 'INPUT')))
-
def test_make_property_vacancy(self):
- property = {"type": "vacancy",
- "supercell": [1, 1, 1]
- }
- work_path = os.path.join(self.conf_path,"vacancy_00")
- vacancy = Vacancy(property,self.inter_param)
+ property = {"type": "vacancy", "supercell": [1, 1, 1]}
+ work_path = os.path.join(self.conf_path, "vacancy_00")
+ vacancy = Vacancy(property, self.inter_param)
vacancy.make_confs(work_path, self.equi_path, refine=False)
- self.assertEqual(os.path.realpath(os.path.join(work_path, 'STRU')),
- os.path.realpath(os.path.join(self.equi_path, 'OUT.ABACUS', 'STRU_ION_D')))
+ self.assertEqual(
+ os.path.realpath(os.path.join(work_path, "STRU")),
+ os.path.realpath(os.path.join(self.equi_path, "OUT.ABACUS", "STRU_ION_D")),
+ )
- stru_data = abacus_scf.get_abacus_STRU(os.path.realpath(os.path.join(work_path, 'STRU')))
- natom1 = np.array(stru_data['atom_numbs']).sum()
- for ii in glob.glob(os.path.join(work_path, 'task.*')):
- self.assertTrue(os.path.isfile(os.path.join(ii, 'STRU')))
- stru_data = abacus_scf.get_abacus_STRU(os.path.realpath(os.path.join(ii, 'STRU')))
- natom2 = np.array(stru_data['atom_numbs']).sum()
- self.assertTrue(natom1==natom2+1)
+ stru_data = abacus_scf.get_abacus_STRU(
+ os.path.realpath(os.path.join(work_path, "STRU"))
+ )
+ natom1 = np.array(stru_data["atom_numbs"]).sum()
+ for ii in glob.glob(os.path.join(work_path, "task.*")):
+ self.assertTrue(os.path.isfile(os.path.join(ii, "STRU")))
+ stru_data = abacus_scf.get_abacus_STRU(
+ os.path.realpath(os.path.join(ii, "STRU"))
+ )
+ natom2 = np.array(stru_data["atom_numbs"]).sum()
+ self.assertTrue(natom1 == natom2 + 1)
def test_make_property_interstitial(self):
- property = {"type": "interstitial",
- "supercell": [1, 1, 1],
- "insert_ele": ["H"]
- }
- self.inter_param['potcars']['H'] = 'H_ONCV_PBE-1.0.upf'
- self.inter_param['orb_files']['H'] = 'H_gga_8au_100Ry_2s1p.orb'
-
- work_path = os.path.join(self.conf_path,"interstitial_00")
+ property = {"type": "interstitial", "supercell": [1, 1, 1], "insert_ele": ["H"]}
+ self.inter_param["potcars"]["H"] = "H_ONCV_PBE-1.0.upf"
+ self.inter_param["orb_files"]["H"] = "H_gga_8au_100Ry_2s1p.orb"
+
+ work_path = os.path.join(self.conf_path, "interstitial_00")
if os.path.exists(work_path):
- shutil.rmtree(work_path)
+ shutil.rmtree(work_path)
os.makedirs(work_path)
- interstitial = Interstitial(property,self.inter_param)
- interstitial.make_confs(work_path, self.equi_path, refine=False)
-
- self.assertEqual(os.path.realpath(os.path.join(work_path, 'STRU')),
- os.path.realpath(os.path.join(self.equi_path, 'OUT.ABACUS', 'STRU_ION_D')))
- stru_data = abacus_scf.get_abacus_STRU(os.path.realpath(os.path.join(work_path, 'STRU')))
- natom1 = np.array(stru_data['atom_numbs']).sum()
- for ii in glob.glob(os.path.join(work_path, 'task.*')):
- self.assertTrue(os.path.isfile(os.path.join(ii, 'STRU')))
- stru_data = abacus_scf.get_abacus_STRU(os.path.realpath(os.path.join(ii, 'STRU')))
- self.assertTrue('H' in stru_data['atom_names'])
- natom2 = np.array(stru_data['atom_numbs']).sum()
- self.assertTrue(natom1==natom2-1)
+ interstitial = Interstitial(property, self.inter_param)
+ interstitial.make_confs(work_path, self.equi_path, refine=False)
+
+ self.assertEqual(
+ os.path.realpath(os.path.join(work_path, "STRU")),
+ os.path.realpath(os.path.join(self.equi_path, "OUT.ABACUS", "STRU_ION_D")),
+ )
+ stru_data = abacus_scf.get_abacus_STRU(
+ os.path.realpath(os.path.join(work_path, "STRU"))
+ )
+ natom1 = np.array(stru_data["atom_numbs"]).sum()
+ for ii in glob.glob(os.path.join(work_path, "task.*")):
+ self.assertTrue(os.path.isfile(os.path.join(ii, "STRU")))
+ stru_data = abacus_scf.get_abacus_STRU(
+ os.path.realpath(os.path.join(ii, "STRU"))
+ )
+ self.assertTrue("H" in stru_data["atom_names"])
+ natom2 = np.array(stru_data["atom_numbs"]).sum()
+ self.assertTrue(natom1 == natom2 - 1)
def test_make_property_surface(self):
- property = {"type": "surface",
- "min_slab_size": 15,
- "min_vacuum_size":11,
- "pert_xz": 0.01,
- "max_miller": 2,
- "cal_type": "static"
- }
- work_path = os.path.join(self.conf_path,"surface_00")
- surface = Surface(property,self.inter_param)
+ property = {
+ "type": "surface",
+ "min_slab_size": 15,
+ "min_vacuum_size": 11,
+ "pert_xz": 0.01,
+ "max_miller": 2,
+ "cal_type": "static",
+ }
+ work_path = os.path.join(self.conf_path, "surface_00")
+ surface = Surface(property, self.inter_param)
surface.make_confs(work_path, self.equi_path, refine=False)
- self.assertEqual(os.path.realpath(os.path.join(work_path, 'STRU')),
- os.path.realpath(os.path.join(self.equi_path, 'OUT.ABACUS', 'STRU_ION_D')))
- for ii in glob.glob(os.path.join(work_path, 'task.*')):
- self.assertTrue(os.path.isfile(os.path.join(ii, 'STRU')))
- self.assertTrue(os.path.isfile(os.path.join(ii, 'miller.json')))
+ self.assertEqual(
+ os.path.realpath(os.path.join(work_path, "STRU")),
+ os.path.realpath(os.path.join(self.equi_path, "OUT.ABACUS", "STRU_ION_D")),
+ )
+ for ii in glob.glob(os.path.join(work_path, "task.*")):
+ self.assertTrue(os.path.isfile(os.path.join(ii, "STRU")))
+ self.assertTrue(os.path.isfile(os.path.join(ii, "miller.json")))
def test_make_property_gamma(self):
- property = {"type": "gamma",
- "lattice_type": "fcc",
- "miller_index": [1, 1, 1],
- "displace_direction": [1, 1, 0],
- "supercell_size": [1, 1, 10],
- "min_vacuum_size": 10,
- "add_fix": ["true", "true", "false"],
- "n_steps": 20
- }
- work_path = os.path.join(self.conf_path,"gamma_00")
- gamma = Gamma(property,self.inter_param)
+ property = {
+ "type": "gamma",
+ "lattice_type": "fcc",
+ "miller_index": [1, 1, 1],
+ "displace_direction": [1, 1, 0],
+ "supercell_size": [1, 1, 10],
+ "min_vacuum_size": 10,
+ "add_fix": ["true", "true", "false"],
+ "n_steps": 20,
+ }
+ work_path = os.path.join(self.conf_path, "gamma_00")
+ gamma = Gamma(property, self.inter_param)
gamma.make_confs(work_path, self.equi_path, refine=False)
- dfm_dirs = glob.glob(os.path.join(work_path, 'task.*'))
- self.assertEqual(len(dfm_dirs), gamma.n_steps+1)
+ dfm_dirs = glob.glob(os.path.join(work_path, "task.*"))
+ self.assertEqual(len(dfm_dirs), gamma.n_steps + 1)
- self.assertEqual(os.path.realpath(os.path.join(work_path, 'STRU')),
- os.path.realpath(os.path.join(self.equi_path, 'OUT.ABACUS', 'STRU_ION_D')))
- for ii in glob.glob(os.path.join(work_path, 'task.*')):
- self.assertTrue(os.path.isfile(os.path.join(ii, 'STRU')))
- self.assertTrue(os.path.isfile(os.path.join(ii, 'miller.json')))
+ self.assertEqual(
+ os.path.realpath(os.path.join(work_path, "STRU")),
+ os.path.realpath(os.path.join(self.equi_path, "OUT.ABACUS", "STRU_ION_D")),
+ )
+ for ii in glob.glob(os.path.join(work_path, "task.*")):
+ self.assertTrue(os.path.isfile(os.path.join(ii, "STRU")))
+ self.assertTrue(os.path.isfile(os.path.join(ii, "miller.json")))
def test_make_property_refine(self):
- property = {"type": "eos",
- "vol_start": 0.85,
- "vol_end": 1.15,
- "vol_step": 0.01
- }
- pwd=os.getcwd()
- target_path_0 = 'confs/fcc-Al/eos_00'
- target_path_2 = 'confs/fcc-Al/eos_02'
+ property = {"type": "eos", "vol_start": 0.85, "vol_end": 1.15, "vol_step": 0.01}
+ pwd = os.getcwd()
+ target_path_0 = "confs/fcc-Al/eos_00"
+ target_path_2 = "confs/fcc-Al/eos_02"
path_to_work = os.path.abspath(target_path_0)
make_property(self.jdata["structures"], self.jdata["interaction"], [property])
- dfm_dirs_0 = glob.glob(os.path.join(target_path_0, 'task.*'))
+ dfm_dirs_0 = glob.glob(os.path.join(target_path_0, "task.*"))
for ii in dfm_dirs_0:
- self.assertTrue(os.path.isfile(os.path.join(ii, 'STRU')))
- os.makedirs(os.path.join(ii,'OUT.ABACUS'))
- shutil.copy(os.path.join(ii, 'STRU'),os.path.join(ii, 'OUT.ABACUS', 'STRU_ION_D'))
-
- new_prop_list=[
- {
- "type": "eos",
- "init_from_suffix": "00",
- "output_suffix": "02",
- "cal_setting": {
- "relax_pos": True,
- "relax_shape": True,
- "relax_vol": False}
- }
+ self.assertTrue(os.path.isfile(os.path.join(ii, "STRU")))
+ os.makedirs(os.path.join(ii, "OUT.ABACUS"))
+ shutil.copy(
+ os.path.join(ii, "STRU"), os.path.join(ii, "OUT.ABACUS", "STRU_ION_D")
+ )
+
+ new_prop_list = [
+ {
+ "type": "eos",
+ "init_from_suffix": "00",
+ "output_suffix": "02",
+ "cal_setting": {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": False,
+ },
+ }
]
- make_property(self.jdata["structures"], self.jdata["interaction"], new_prop_list)
- self.assertTrue(os.path.isdir(path_to_work.replace('00','02')))
+ make_property(
+ self.jdata["structures"], self.jdata["interaction"], new_prop_list
+ )
+ self.assertTrue(os.path.isdir(path_to_work.replace("00", "02")))
os.chdir(pwd)
- dfm_dirs_2 = glob.glob(os.path.join(target_path_2, 'task.*'))
- self.assertEqual(len(dfm_dirs_2),len(dfm_dirs_0))
\ No newline at end of file
+ dfm_dirs_2 = glob.glob(os.path.join(target_path_2, "task.*"))
+ self.assertEqual(len(dfm_dirs_2), len(dfm_dirs_0))
diff --git a/tests/auto_test/test_elastic.py b/tests/auto_test/test_elastic.py
index 5750e5d48..c611a4f8a 100644
--- a/tests/auto_test/test_elastic.py
+++ b/tests/auto_test/test_elastic.py
@@ -1,24 +1,26 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
+
import dpdata
-from monty.serialization import loadfn, dumpfn
-from pymatgen.analysis.elasticity.strain import Strain, Deformation
+import numpy as np
+from monty.serialization import dumpfn, loadfn
+from pymatgen.analysis.elasticity.strain import Deformation, Strain
from pymatgen.core import Structure
from pymatgen.io.vasp import Incar
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from dpgen.auto_test.Elastic import Elastic
+from .context import make_kspacing_kpoints, setUpModule
-class TestElastic(unittest.TestCase):
+class TestElastic(unittest.TestCase):
def setUp(self):
_jdata = {
"structures": ["confs/std-fcc"],
@@ -26,32 +28,32 @@ def setUp(self):
"type": "vasp",
"incar": "vasp_input/INCAR.rlx",
"potcar_prefix": ".",
- "potcars": {"Al": "vasp_input/POT_Al"}
+ "potcars": {"Al": "vasp_input/POT_Al"},
},
"properties": [
{
- "skip":False,
+ "skip": False,
"type": "elastic",
"norm_deform": 2e-2,
- "shear_deform": 5e-2
+ "shear_deform": 5e-2,
}
- ]
+ ],
}
- self.equi_path = 'confs/std-fcc/relaxation/task_relax'
- self.source_path = 'equi/vasp'
- self.target_path = 'confs/std-fcc/elastic_00'
+ self.equi_path = "confs/std-fcc/relaxation/task_relax"
+ self.source_path = "equi/vasp"
+ self.target_path = "confs/std-fcc/elastic_00"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
self.confs = _jdata["structures"]
self.inter_param = _jdata["interaction"]
- self.prop_param = _jdata['properties']
+ self.prop_param = _jdata["properties"]
- self.elastic = Elastic(_jdata['properties'][0])
+ self.elastic = Elastic(_jdata["properties"][0])
def tearDown(self):
- if os.path.exists(os.path.join(self.equi_path,'..')):
+ if os.path.exists(os.path.join(self.equi_path, "..")):
shutil.rmtree(self.equi_path)
if os.path.exists(self.equi_path):
shutil.rmtree(self.equi_path)
@@ -59,30 +61,38 @@ def tearDown(self):
shutil.rmtree(self.target_path)
def test_task_type(self):
- self.assertEqual('elastic', self.elastic.task_type())
+ self.assertEqual("elastic", self.elastic.task_type())
def test_task_param(self):
self.assertEqual(self.prop_param[0], self.elastic.task_param())
def test_make_confs(self):
- shutil.copy(os.path.join(self.source_path, 'Al-fcc.json'), os.path.join(self.equi_path, 'result.json'))
- if not os.path.exists(os.path.join(self.equi_path, 'CONTCAR')):
+ shutil.copy(
+ os.path.join(self.source_path, "Al-fcc.json"),
+ os.path.join(self.equi_path, "result.json"),
+ )
+ if not os.path.exists(os.path.join(self.equi_path, "CONTCAR")):
with self.assertRaises(RuntimeError):
self.elastic.make_confs(self.target_path, self.equi_path)
- shutil.copy(os.path.join(self.source_path, 'CONTCAR_Al_fcc'), os.path.join(self.equi_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(self.source_path, "CONTCAR_Al_fcc"),
+ os.path.join(self.equi_path, "CONTCAR"),
+ )
task_list = self.elastic.make_confs(self.target_path, self.equi_path)
- dfm_dirs = glob.glob(os.path.join(self.target_path, 'task.*'))
+ dfm_dirs = glob.glob(os.path.join(self.target_path, "task.*"))
- incar0 = Incar.from_file(os.path.join('vasp_input', 'INCAR.rlx'))
- incar0['ISIF'] = 4
+ incar0 = Incar.from_file(os.path.join("vasp_input", "INCAR.rlx"))
+ incar0["ISIF"] = 4
- self.assertEqual(os.path.realpath(os.path.join(self.equi_path, 'CONTCAR')),
- os.path.realpath(os.path.join(self.target_path, 'POSCAR')))
- ref_st = Structure.from_file(os.path.join(self.target_path, 'POSCAR'))
+ self.assertEqual(
+ os.path.realpath(os.path.join(self.equi_path, "CONTCAR")),
+ os.path.realpath(os.path.join(self.target_path, "POSCAR")),
+ )
+ ref_st = Structure.from_file(os.path.join(self.target_path, "POSCAR"))
dfm_dirs.sort()
for ii in dfm_dirs:
- st_file = os.path.join(ii, 'POSCAR')
+ st_file = os.path.join(ii, "POSCAR")
self.assertTrue(os.path.isfile(st_file))
- strain_json_file = os.path.join(ii, 'strain.json')
+ strain_json_file = os.path.join(ii, "strain.json")
self.assertTrue(os.path.isfile(strain_json_file))
diff --git a/tests/auto_test/test_eos.py b/tests/auto_test/test_eos.py
index 6dfb31f6e..6c5f90ad1 100644
--- a/tests/auto_test/test_eos.py
+++ b/tests/auto_test/test_eos.py
@@ -1,22 +1,24 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
+
import dpdata
-from monty.serialization import loadfn, dumpfn
+import numpy as np
+from monty.serialization import dumpfn, loadfn
from pymatgen.io.vasp import Incar
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from dpgen.auto_test.EOS import EOS
+from .context import make_kspacing_kpoints, setUpModule
-class TestEOS(unittest.TestCase):
+class TestEOS(unittest.TestCase):
def setUp(self):
_jdata = {
"structures": ["confs/std-fcc"],
@@ -24,40 +26,40 @@ def setUp(self):
"type": "vasp",
"incar": "vasp_input/INCAR.rlx",
"potcar_prefix": ".",
- "potcars": {"Li": "vasp_input/POTCAR"}
+ "potcars": {"Li": "vasp_input/POTCAR"},
},
"properties": [
- {
- "type": "eos",
- "skip": False,
- "vol_start": 0.8,
- "vol_end": 1.2,
- "vol_step": 0.01,
- "cal_setting": {
- "relax_pos": True,
- "relax_shape": True,
- "relax_vol": False,
- "overwrite_interaction":{
- "type": "deepmd",
- "model": "lammps_input/frozen_model.pb",
- "type_map":{"Al": 0}
- }
- }
- }
- ]
+ {
+ "type": "eos",
+ "skip": False,
+ "vol_start": 0.8,
+ "vol_end": 1.2,
+ "vol_step": 0.01,
+ "cal_setting": {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": False,
+ "overwrite_interaction": {
+ "type": "deepmd",
+ "model": "lammps_input/frozen_model.pb",
+ "type_map": {"Al": 0},
+ },
+ },
+ }
+ ],
}
- self.equi_path = 'confs/std-fcc/relaxation/relax_task'
- self.source_path = 'equi/vasp'
- self.target_path = 'confs/std-fcc/eos_00'
+ self.equi_path = "confs/std-fcc/relaxation/relax_task"
+ self.source_path = "equi/vasp"
+ self.target_path = "confs/std-fcc/eos_00"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
self.confs = _jdata["structures"]
self.inter_param = _jdata["interaction"]
- self.prop_param = _jdata['properties']
+ self.prop_param = _jdata["properties"]
- self.eos = EOS(_jdata['properties'][0])
+ self.eos = EOS(_jdata["properties"][0])
def tearDown(self):
if os.path.exists(self.equi_path):
@@ -66,36 +68,46 @@ def tearDown(self):
shutil.rmtree(self.target_path)
def test_task_type(self):
- self.assertEqual('eos', self.eos.task_type())
+ self.assertEqual("eos", self.eos.task_type())
def test_task_param(self):
self.assertEqual(self.prop_param[0], self.eos.task_param())
def test_make_confs_0(self):
- if not os.path.exists(os.path.join(self.equi_path, 'CONTCAR')):
+ if not os.path.exists(os.path.join(self.equi_path, "CONTCAR")):
with self.assertRaises(RuntimeError):
self.eos.make_confs(self.target_path, self.equi_path)
- shutil.copy(os.path.join(self.source_path, 'CONTCAR'), os.path.join(self.equi_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(self.source_path, "CONTCAR"),
+ os.path.join(self.equi_path, "CONTCAR"),
+ )
task_list = self.eos.make_confs(self.target_path, self.equi_path)
- dfm_dirs = glob.glob(os.path.join(self.target_path, 'task.*'))
+ dfm_dirs = glob.glob(os.path.join(self.target_path, "task.*"))
- incar0 = Incar.from_file(os.path.join('vasp_input', 'INCAR.rlx'))
- incar0['ISIF'] = 4
+ incar0 = Incar.from_file(os.path.join("vasp_input", "INCAR.rlx"))
+ incar0["ISIF"] = 4
for ii in dfm_dirs:
- self.assertTrue(os.path.isfile(os.path.join(ii, 'POSCAR')))
- eos_json_file = os.path.join(ii, 'eos.json')
+ self.assertTrue(os.path.isfile(os.path.join(ii, "POSCAR")))
+ eos_json_file = os.path.join(ii, "eos.json")
self.assertTrue(os.path.isfile(eos_json_file))
eos_json = loadfn(eos_json_file)
- self.assertEqual(os.path.realpath(os.path.join(ii, 'POSCAR.orig')),
- os.path.realpath(os.path.join(self.equi_path, 'CONTCAR')))
- sys = dpdata.System(os.path.join(ii, 'POSCAR'))
+ self.assertEqual(
+ os.path.realpath(os.path.join(ii, "POSCAR.orig")),
+ os.path.realpath(os.path.join(self.equi_path, "CONTCAR")),
+ )
+ sys = dpdata.System(os.path.join(ii, "POSCAR"))
natoms = sys.get_natoms()
- self.assertAlmostEqual(eos_json['volume'], np.linalg.det(sys['cells'][0]) / natoms)
+ self.assertAlmostEqual(
+ eos_json["volume"], np.linalg.det(sys["cells"][0]) / natoms
+ )
def test_make_confs_1(self):
self.eos.reprod = True
- shutil.copy(os.path.join(self.source_path, 'CONTCAR'), os.path.join(self.equi_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(self.source_path, "CONTCAR"),
+ os.path.join(self.equi_path, "CONTCAR"),
+ )
with self.assertRaises(RuntimeError):
self.eos.make_confs(self.target_path, self.equi_path)
diff --git a/tests/auto_test/test_gamma.py b/tests/auto_test/test_gamma.py
index 2f7a57f28..7cdd97371 100644
--- a/tests/auto_test/test_gamma.py
+++ b/tests/auto_test/test_gamma.py
@@ -1,43 +1,44 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-import dpdata
-from monty.serialization import loadfn, dumpfn
-from pymatgen.core.structure import Structure
-from pymatgen.core.surface import SlabGenerator
-from pymatgen.io.vasp import Incar
-from pymatgen.io.ase import AseAtomsAdaptor
+import dpdata
+import numpy as np
from ase.lattice.cubic import BodyCenteredCubic as bcc
from ase.lattice.cubic import FaceCenteredCubic as fcc
from ase.lattice.hexagonal import HexagonalClosedPacked as hcp
+from monty.serialization import dumpfn, loadfn
+from pymatgen.core.structure import Structure
+from pymatgen.core.surface import SlabGenerator
+from pymatgen.io.ase import AseAtomsAdaptor
+from pymatgen.io.vasp import Incar
import dpgen.auto_test.lib.vasp as vasp
from dpgen import dlog
from dpgen.auto_test.Property import Property
from dpgen.auto_test.refine import make_refine
-from dpgen.auto_test.reproduce import make_repro
-from dpgen.auto_test.reproduce import post_repro
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
+from dpgen.auto_test.reproduce import make_repro, post_repro
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from dpgen.auto_test.Gamma import Gamma
-class TestGamma(unittest.TestCase):
+from .context import make_kspacing_kpoints, setUpModule
+
+class TestGamma(unittest.TestCase):
def setUp(self):
_jdata = {
- "structures": ["confs/std-fcc"],
+ "structures": ["confs/std-fcc"],
"interaction": {
- "type": "vasp",
- "incar": "vasp_input/INCAR_Mo",
+ "type": "vasp",
+ "incar": "vasp_input/INCAR_Mo",
"potcar_prefix": "vasp_input",
- "potcars": {"Mo": "POTCAR_Mo"}
+ "potcars": {"Mo": "POTCAR_Mo"},
},
"properties": [
{
@@ -48,16 +49,16 @@ def setUp(self):
"supercell_size": [1, 1, 10],
"min_vacuum_size": 10,
"add_fix": ["true", "true", "false"],
- "n_steps": 20
+ "n_steps": 20,
}
- ]
+ ],
}
- self.equi_path = 'confs/hp-Mo/relaxation/relax_task'
- self.source_path = 'equi/vasp'
- self.target_path = 'confs/hp-Mo/gamma_00'
- self.res_data = 'output/gamma_00/result.json'
- self.ptr_data = 'output/gamma_00/result.out'
+ self.equi_path = "confs/hp-Mo/relaxation/relax_task"
+ self.source_path = "equi/vasp"
+ self.target_path = "confs/hp-Mo/gamma_00"
+ self.res_data = "output/gamma_00/result.json"
+ self.ptr_data = "output/gamma_00/result.out"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
@@ -66,9 +67,9 @@ def setUp(self):
self.confs = _jdata["structures"]
self.inter_param = _jdata["interaction"]
- self.prop_param = _jdata['properties']
+ self.prop_param = _jdata["properties"]
- self.gamma = Gamma(_jdata['properties'][0])
+ self.gamma = Gamma(_jdata["properties"][0])
def tearDown(self):
if os.path.exists(self.equi_path):
@@ -81,49 +82,51 @@ def tearDown(self):
os.remove(self.ptr_data)
def test_task_type(self):
- self.assertEqual('gamma', self.gamma.task_type())
+ self.assertEqual("gamma", self.gamma.task_type())
def test_task_param(self):
self.assertEqual(self.prop_param[0], self.gamma.task_param())
def test_make_confs_bcc(self):
- if not os.path.exists(os.path.join(self.equi_path, 'CONTCAR')):
+ if not os.path.exists(os.path.join(self.equi_path, "CONTCAR")):
with self.assertRaises(RuntimeError):
self.gamma.make_confs(self.target_path, self.equi_path)
- shutil.copy(os.path.join(self.source_path, 'CONTCAR_Mo_bcc'), os.path.join(self.equi_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(self.source_path, "CONTCAR_Mo_bcc"),
+ os.path.join(self.equi_path, "CONTCAR"),
+ )
task_list = self.gamma.make_confs(self.target_path, self.equi_path)
- dfm_dirs = glob.glob(os.path.join(self.target_path, 'task.*'))
- self.assertEqual(len(dfm_dirs), self.gamma.n_steps+1)
+ dfm_dirs = glob.glob(os.path.join(self.target_path, "task.*"))
+ self.assertEqual(len(dfm_dirs), self.gamma.n_steps + 1)
- incar0 = Incar.from_file(os.path.join('vasp_input', 'INCAR.rlx'))
- incar0['ISIF'] = 4
+ incar0 = Incar.from_file(os.path.join("vasp_input", "INCAR.rlx"))
+ incar0["ISIF"] = 4
- self.assertEqual(os.path.realpath(os.path.join(self.equi_path, 'CONTCAR')),
- os.path.realpath(os.path.join(self.target_path, 'POSCAR')))
- ref_st = Structure.from_file(os.path.join(self.target_path, 'POSCAR'))
+ self.assertEqual(
+ os.path.realpath(os.path.join(self.equi_path, "CONTCAR")),
+ os.path.realpath(os.path.join(self.target_path, "POSCAR")),
+ )
+ ref_st = Structure.from_file(os.path.join(self.target_path, "POSCAR"))
dfm_dirs.sort()
for ii in dfm_dirs:
- st_file = os.path.join(ii, 'POSCAR')
+ st_file = os.path.join(ii, "POSCAR")
self.assertTrue(os.path.isfile(st_file))
st0 = Structure.from_file(st_file)
- st1_file = os.path.join(ii, 'POSCAR.tmp')
+ st1_file = os.path.join(ii, "POSCAR.tmp")
self.assertTrue(os.path.isfile(st1_file))
st1 = Structure.from_file(st1_file)
- with open(st1_file, mode='r') as f:
+ with open(st1_file, mode="r") as f:
z_coord_str = f.readlines()[-1].split()[-2]
z_coord = float(z_coord_str)
self.assertTrue(z_coord <= 1)
def test_compute_lower(self):
cwd = os.getcwd()
- output_file = os.path.join(cwd, 'output/gamma_00/result.json')
- all_tasks = glob.glob('output/gamma_00/task.*')
+ output_file = os.path.join(cwd, "output/gamma_00/result.json")
+ all_tasks = glob.glob("output/gamma_00/task.*")
all_tasks.sort()
- all_res = [os.path.join(task, 'result_task.json') for task in all_tasks]
+ all_res = [os.path.join(task, "result_task.json") for task in all_tasks]
- self.gamma._compute_lower(output_file,
- all_tasks,
- all_res)
+ self.gamma._compute_lower(output_file, all_tasks, all_res)
self.assertTrue(os.path.isfile(self.res_data))
-
diff --git a/tests/auto_test/test_interstitial.py b/tests/auto_test/test_interstitial.py
index 6d646e3de..ce22631bb 100644
--- a/tests/auto_test/test_interstitial.py
+++ b/tests/auto_test/test_interstitial.py
@@ -1,25 +1,27 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
+
import dpdata
-from monty.serialization import loadfn, dumpfn
+import numpy as np
+from monty.serialization import dumpfn, loadfn
+from pymatgen.analysis.defects.core import Interstitial as pmg_Interstitial
from pymatgen.core import Structure
from pymatgen.io.vasp import Incar
from pymatgen.symmetry.analyzer import SpacegroupAnalyzer
-from pymatgen.analysis.defects.core import Interstitial as pmg_Interstitial
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from dpgen.auto_test.Interstitial import Interstitial
+from .context import make_kspacing_kpoints, setUpModule
-class TestInterstitial(unittest.TestCase):
+class TestInterstitial(unittest.TestCase):
def setUp(self):
_jdata = {
"structures": ["confs/std-bcc"],
@@ -27,21 +29,21 @@ def setUp(self):
"type": "vasp",
"incar": "vasp_input/INCAR.rlx",
"potcar_prefix": "vasp_input",
- "potcars": {"V": "POTCAR"}
+ "potcars": {"V": "POTCAR"},
},
"properties": [
{
"type": "interstitial",
"supercell": [1, 1, 1],
"insert_ele": ["V"],
- "bcc_self": True
+ "bcc_self": True,
}
- ]
+ ],
}
- self.equi_path = 'confs/std-bcc/relaxation/relax_task'
- self.source_path = 'equi/vasp'
- self.target_path = 'confs/std-bcc/interstitial_00'
+ self.equi_path = "confs/std-bcc/relaxation/relax_task"
+ self.source_path = "equi/vasp"
+ self.target_path = "confs/std-bcc/interstitial_00"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
if not os.path.exists(self.target_path):
@@ -49,9 +51,9 @@ def setUp(self):
self.confs = _jdata["structures"]
self.inter_param = _jdata["interaction"]
- self.prop_param = _jdata['properties']
+ self.prop_param = _jdata["properties"]
- self.interstitial = Interstitial(_jdata['properties'][0])
+ self.interstitial = Interstitial(_jdata["properties"][0])
def tearDown(self):
if os.path.exists(self.equi_path):
@@ -60,38 +62,45 @@ def tearDown(self):
shutil.rmtree(self.target_path)
def test_task_type(self):
- self.assertEqual('interstitial', self.interstitial.task_type())
+ self.assertEqual("interstitial", self.interstitial.task_type())
def test_task_param(self):
self.assertEqual(self.prop_param[0], self.interstitial.task_param())
def test_make_confs_bcc(self):
- if not os.path.exists(os.path.join(self.equi_path, 'CONTCAR')):
+ if not os.path.exists(os.path.join(self.equi_path, "CONTCAR")):
with self.assertRaises(RuntimeError):
self.interstitial.make_confs(self.target_path, self.equi_path)
- shutil.copy(os.path.join(self.source_path, 'CONTCAR_V_bcc'), os.path.join(self.equi_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(self.source_path, "CONTCAR_V_bcc"),
+ os.path.join(self.equi_path, "CONTCAR"),
+ )
task_list = self.interstitial.make_confs(self.target_path, self.equi_path)
- dfm_dirs = glob.glob(os.path.join(self.target_path, 'task.*'))
+ dfm_dirs = glob.glob(os.path.join(self.target_path, "task.*"))
self.assertEqual(len(dfm_dirs), 7)
- incar0 = Incar.from_file(os.path.join('vasp_input', 'INCAR.rlx'))
- incar0['ISIF'] = 3
+ incar0 = Incar.from_file(os.path.join("vasp_input", "INCAR.rlx"))
+ incar0["ISIF"] = 3
- self.assertEqual(os.path.realpath(os.path.join(self.equi_path, 'CONTCAR')),
- os.path.realpath(os.path.join(self.target_path, 'POSCAR')))
- ref_st = Structure.from_file(os.path.join(self.target_path, 'POSCAR'))
+ self.assertEqual(
+ os.path.realpath(os.path.join(self.equi_path, "CONTCAR")),
+ os.path.realpath(os.path.join(self.target_path, "POSCAR")),
+ )
+ ref_st = Structure.from_file(os.path.join(self.target_path, "POSCAR"))
dfm_dirs.sort()
for ii in dfm_dirs[:4]:
- st_file = os.path.join(ii, 'POSCAR')
+ st_file = os.path.join(ii, "POSCAR")
self.assertTrue(os.path.isfile(st_file))
st0 = Structure.from_file(st_file)
inter_site = st0[0]
inter = pmg_Interstitial(ref_st, inter_site)
- st1 = inter.get_supercell_structure(sc_mat=np.eye(3)*self.prop_param[0]['supercell'])
+ st1 = inter.get_supercell_structure(
+ sc_mat=np.eye(3) * self.prop_param[0]["supercell"]
+ )
self.assertEqual(st0, st1)
for ii in dfm_dirs[4:]:
- st_file = os.path.join(ii, 'POSCAR')
+ st_file = os.path.join(ii, "POSCAR")
self.assertTrue(os.path.isfile(st_file))
st0 = Structure.from_file(st_file)
inter_site1 = st0.pop(0)
diff --git a/tests/auto_test/test_lammps.py b/tests/auto_test/test_lammps.py
index 517757e13..a13f5c6a8 100644
--- a/tests/auto_test/test_lammps.py
+++ b/tests/auto_test/test_lammps.py
@@ -1,21 +1,24 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-from monty.serialization import loadfn, dumpfn
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
+import dpdata
+import numpy as np
+from monty.serialization import dumpfn, loadfn
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
-from dpgen.auto_test.lib.lammps import inter_deepmd
from dpgen.auto_test.Lammps import Lammps
+from dpgen.auto_test.lib.lammps import inter_deepmd
+from .context import make_kspacing_kpoints, setUpModule
-class TestLammps(unittest.TestCase):
+class TestLammps(unittest.TestCase):
def setUp(self):
self.jdata = {
"structures": ["confs/std-fcc"],
@@ -23,34 +26,40 @@ def setUp(self):
"type": "deepmd",
"model": "lammps_input/frozen_model.pb",
"deepmd_version": "1.1.0",
- "type_map": {"Al": 0}
+ "type_map": {"Al": 0},
},
"relaxation": {
"cal_type": "relaxation",
- "cal_setting": {"relax_pos": True,
- "relax_shape": True,
- "relax_vol": True}
- }
+ "cal_setting": {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": True,
+ },
+ },
}
- self.equi_path = 'confs/std-fcc/relaxation/relax_task'
- self.source_path = 'equi/lammps'
+ self.equi_path = "confs/std-fcc/relaxation/relax_task"
+ self.source_path = "equi/lammps"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
- if not os.path.isfile(os.path.join(self.equi_path,'POSCAR')):
- shutil.copy(os.path.join(self.source_path, 'Al-fcc.vasp'), os.path.join('confs/std-fcc','POSCAR'))
-
+ if not os.path.isfile(os.path.join(self.equi_path, "POSCAR")):
+ shutil.copy(
+ os.path.join(self.source_path, "Al-fcc.vasp"),
+ os.path.join("confs/std-fcc", "POSCAR"),
+ )
self.confs = self.jdata["structures"]
self.inter_param = self.jdata["interaction"]
self.relax_param = self.jdata["relaxation"]
- self.Lammps = Lammps(self.inter_param, os.path.join(self.source_path, 'Al-fcc.vasp'))
+ self.Lammps = Lammps(
+ self.inter_param, os.path.join(self.source_path, "Al-fcc.vasp")
+ )
def tearDown(self):
- if os.path.exists('confs/std-fcc/relaxation'):
- shutil.rmtree('confs/std-fcc/relaxation')
+ if os.path.exists("confs/std-fcc/relaxation"):
+ shutil.rmtree("confs/std-fcc/relaxation")
def test_set_inter_type_func(self):
self.Lammps.set_inter_type_func()
@@ -58,34 +67,39 @@ def test_set_inter_type_func(self):
def test_set_model_param(self):
self.Lammps.set_model_param()
- model_param = {'model_name': ['frozen_model.pb'],
- 'param_type': {"Al": 0},
- 'deepmd_version': '1.1.0'}
+ model_param = {
+ "model_name": ["frozen_model.pb"],
+ "param_type": {"Al": 0},
+ "deepmd_version": "1.1.0",
+ }
self.assertEqual(model_param, self.Lammps.model_param)
def test_make_potential_files(self):
- cwd=os.getcwd()
- abs_equi_path=os.path.abspath(self.equi_path)
+ cwd = os.getcwd()
+ abs_equi_path = os.path.abspath(self.equi_path)
self.Lammps.make_potential_files(abs_equi_path)
self.assertTrue(os.path.islink(os.path.join(self.equi_path, "frozen_model.pb")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, 'inter.json')))
- ret=loadfn(os.path.join(self.equi_path, 'inter.json'))
- self.assertTrue(self.inter_param,ret)
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "inter.json")))
+ ret = loadfn(os.path.join(self.equi_path, "inter.json"))
+ self.assertTrue(self.inter_param, ret)
os.chdir(cwd)
def test_make_input_file(self):
- cwd=os.getcwd()
- abs_equi_path=os.path.abspath('confs/std-fcc/relaxation/relax_task')
- shutil.copy(os.path.join('confs/std-fcc','POSCAR'), os.path.join(self.equi_path, 'POSCAR'))
- self.Lammps.make_input_file(abs_equi_path,'relaxation', self.relax_param)
+ cwd = os.getcwd()
+ abs_equi_path = os.path.abspath("confs/std-fcc/relaxation/relax_task")
+ shutil.copy(
+ os.path.join("confs/std-fcc", "POSCAR"),
+ os.path.join(self.equi_path, "POSCAR"),
+ )
+ self.Lammps.make_input_file(abs_equi_path, "relaxation", self.relax_param)
self.assertTrue(os.path.isfile(os.path.join(abs_equi_path, "conf.lmp")))
self.assertTrue(os.path.islink(os.path.join(abs_equi_path, "in.lammps")))
self.assertTrue(os.path.isfile(os.path.join(abs_equi_path, "task.json")))
def test_forward_common_files(self):
- fc_files = ['in.lammps', 'frozen_model.pb']
+ fc_files = ["in.lammps", "frozen_model.pb"]
self.assertEqual(self.Lammps.forward_common_files(), fc_files)
def test_backward_files(self):
- backward_files = ['log.lammps', 'outlog', 'dump.relax']
+ backward_files = ["log.lammps", "outlog", "dump.relax"]
self.assertEqual(self.Lammps.backward_files(), backward_files)
diff --git a/tests/auto_test/test_make_prop.py b/tests/auto_test/test_make_prop.py
index ed733236d..2c63b5845 100644
--- a/tests/auto_test/test_make_prop.py
+++ b/tests/auto_test/test_make_prop.py
@@ -1,18 +1,23 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-from monty.serialization import loadfn, dumpfn
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
+import dpdata
+import numpy as np
+from monty.serialization import dumpfn, loadfn
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from pymatgen.io.vasp import Incar
+
from dpgen.auto_test.common_prop import make_property
+from .context import make_kspacing_kpoints, setUpModule
+
class TestMakeProperty(unittest.TestCase):
jdata = {
@@ -21,72 +26,77 @@ class TestMakeProperty(unittest.TestCase):
"type": "vasp",
"incar": "vasp_input/INCAR.rlx",
"potcar_prefix": "vasp_input",
- "potcars": {"Al": "POT_Al"}
+ "potcars": {"Al": "POT_Al"},
},
"properties": [
- {
- "type": "eos",
- "skip": False,
- "vol_start": 0.8,
- "vol_end": 1.2,
- "vol_step": 0.01,
- "cal_setting": {
- "relax_pos": True,
- "relax_shape": True,
- "relax_vol": False,
- "overwrite_interaction":{
- "type": "vasp",
- "incar": "vasp_input/INCAR.rlx",
- "potcar_prefix":"vasp_input",
- "potcars": {"Al": "POT_Al"}
- }
- }
- }
- ]
+ {
+ "type": "eos",
+ "skip": False,
+ "vol_start": 0.8,
+ "vol_end": 1.2,
+ "vol_step": 0.01,
+ "cal_setting": {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": False,
+ "overwrite_interaction": {
+ "type": "vasp",
+ "incar": "vasp_input/INCAR.rlx",
+ "potcar_prefix": "vasp_input",
+ "potcars": {"Al": "POT_Al"},
+ },
+ },
+ }
+ ],
}
def tearDown(self):
- if os.path.exists('confs/std-fcc/eos_00'):
- shutil.rmtree('confs/std-fcc/eos_00')
- if os.path.exists('confs/std-fcc/relaxation'):
- shutil.rmtree('confs/std-fcc/relaxation')
+ if os.path.exists("confs/std-fcc/eos_00"):
+ shutil.rmtree("confs/std-fcc/eos_00")
+ if os.path.exists("confs/std-fcc/relaxation"):
+ shutil.rmtree("confs/std-fcc/relaxation")
def test_make_eos(self):
confs = self.jdata["structures"]
inter_param = self.jdata["interaction"]
property_list = self.jdata["properties"]
- target_path = 'confs/std-fcc/eos_00'
- equi_path = 'confs/std-fcc/relaxation/relax_task'
- source_path = 'equi/vasp'
+ target_path = "confs/std-fcc/eos_00"
+ equi_path = "confs/std-fcc/relaxation/relax_task"
+ source_path = "equi/vasp"
if not os.path.exists(equi_path):
os.makedirs(equi_path)
- shutil.copy(os.path.join(source_path, 'CONTCAR_Al_fcc'), os.path.join(equi_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(source_path, "CONTCAR_Al_fcc"),
+ os.path.join(equi_path, "CONTCAR"),
+ )
make_property(confs, inter_param, property_list)
- dfm_dirs = glob.glob(os.path.join(target_path, 'task.*'))
+ dfm_dirs = glob.glob(os.path.join(target_path, "task.*"))
- incar0 = Incar.from_file(os.path.join('vasp_input', 'INCAR.rlx'))
- incar0['ISIF'] = 4
+ incar0 = Incar.from_file(os.path.join("vasp_input", "INCAR.rlx"))
+ incar0["ISIF"] = 4
- with open(os.path.join('vasp_input', 'POT_Al')) as fp:
+ with open(os.path.join("vasp_input", "POT_Al")) as fp:
pot0 = fp.read()
for ii in dfm_dirs:
- self.assertTrue(os.path.isfile(os.path.join(ii, 'KPOINTS')))
- incar1 = Incar.from_file(os.path.join(ii, 'INCAR'))
+ self.assertTrue(os.path.isfile(os.path.join(ii, "KPOINTS")))
+ incar1 = Incar.from_file(os.path.join(ii, "INCAR"))
self.assertTrue(incar0 == incar1)
- self.assertTrue(os.path.isfile(os.path.join(ii, 'INCAR')))
- self.assertTrue(os.path.isfile(os.path.join(ii, 'POSCAR')))
- self.assertTrue(os.path.isfile(os.path.join(ii, 'POTCAR')))
- self.assertTrue(os.path.isfile(os.path.join(ii, 'task.json')))
- inter_json_file = os.path.join(ii, 'inter.json')
+ self.assertTrue(os.path.isfile(os.path.join(ii, "INCAR")))
+ self.assertTrue(os.path.isfile(os.path.join(ii, "POSCAR")))
+ self.assertTrue(os.path.isfile(os.path.join(ii, "POTCAR")))
+ self.assertTrue(os.path.isfile(os.path.join(ii, "task.json")))
+ inter_json_file = os.path.join(ii, "inter.json")
self.assertTrue(os.path.isfile(inter_json_file))
inter_json = loadfn(inter_json_file)
self.assertEqual(inter_json, inter_param)
- self.assertEqual(os.path.realpath(os.path.join(ii, 'POSCAR.orig')),
- os.path.realpath(os.path.join(equi_path, 'CONTCAR')))
- with open(os.path.join(ii, 'POTCAR')) as fp:
+ self.assertEqual(
+ os.path.realpath(os.path.join(ii, "POSCAR.orig")),
+ os.path.realpath(os.path.join(equi_path, "CONTCAR")),
+ )
+ with open(os.path.join(ii, "POTCAR")) as fp:
poti = fp.read()
self.assertEqual(pot0, poti)
diff --git a/tests/auto_test/test_mpdb.py b/tests/auto_test/test_mpdb.py
index 7299d28da..055240908 100644
--- a/tests/auto_test/test_mpdb.py
+++ b/tests/auto_test/test_mpdb.py
@@ -1,47 +1,47 @@
import os
import sys
import unittest
-from pymatgen.core import Structure
-from pymatgen.analysis.structure_matcher import StructureMatcher
-from monty.serialization import loadfn,dumpfn
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+from monty.serialization import dumpfn, loadfn
+from pymatgen.analysis.structure_matcher import StructureMatcher
+from pymatgen.core import Structure
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from dpgen.auto_test.mpdb import get_structure
+
+from .context import make_kspacing_kpoints, setUpModule
+
try:
- os.environ['MAPI_KEY']
- exist_key=True
+ os.environ["MAPI_KEY"]
+ exist_key = True
except Exception:
- exist_key=False
+ exist_key = False
-def fit(struct0,struct1) :
- m = StructureMatcher()
- if m.fit(struct0, struct1) :
- return True
+def fit(struct0, struct1):
+ m = StructureMatcher()
+ if m.fit(struct0, struct1):
+ return True
return False
-@unittest.skipIf(not exist_key,"skip mpdb")
-class TestMpdb(unittest.TestCase):
+@unittest.skipIf(not exist_key, "skip mpdb")
+class TestMpdb(unittest.TestCase):
def setUp(self):
- if 'MAPI_KEY' in os.environ:
- self.key=os.environ['MAPI_KEY']
+ if "MAPI_KEY" in os.environ:
+ self.key = os.environ["MAPI_KEY"]
else:
- self.key=None
- self.mpid='mp-141'
- self.st_file=self.mpid+'.vasp'
- self.st0_file=os.path.join('confs/',self.mpid,self.mpid+'.cif')
-
+ self.key = None
+ self.mpid = "mp-141"
+ self.st_file = self.mpid + ".vasp"
+ self.st0_file = os.path.join("confs/", self.mpid, self.mpid + ".cif")
def tearDown(self):
if os.path.exists(self.st_file):
- os.remove(self.st_file)
+ os.remove(self.st_file)
- def test_get_structure (self):
- st1=get_structure(self.mpid)
- st0=Structure.from_file(self.st0_file)
- self.assertTrue(fit(st0,st1))
+ def test_get_structure(self):
+ st1 = get_structure(self.mpid)
+ st0 = Structure.from_file(self.st0_file)
+ self.assertTrue(fit(st0, st1))
diff --git a/tests/auto_test/test_refine.py b/tests/auto_test/test_refine.py
index e758ca7ba..b380ead2d 100644
--- a/tests/auto_test/test_refine.py
+++ b/tests/auto_test/test_refine.py
@@ -1,19 +1,23 @@
-import os, sys, json, glob, shutil
+import glob
+import json
+import os
+import shutil
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-from monty.serialization import loadfn, dumpfn
+from monty.serialization import dumpfn, loadfn
from pymatgen.io.vasp import Incar
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from dpgen.auto_test.common_prop import make_property
from dpgen.auto_test.refine import make_refine
+from .context import make_kspacing_kpoints, setUpModule
+
class TestMakeProperty(unittest.TestCase):
jdata = {
@@ -22,79 +26,83 @@ class TestMakeProperty(unittest.TestCase):
"type": "vasp",
"incar": "vasp_input/INCAR.rlx",
"potcar_prefix": "vasp_input",
- "potcars": {"Al": "POT_Al"}
+ "potcars": {"Al": "POT_Al"},
},
"properties": [
- {
- "type": "eos",
- "skip": False,
- "vol_start": 0.8,
- "vol_end": 1.2,
- "vol_step": 0.01,
- "cal_setting": {
- "relax_pos": True,
- "relax_shape": True,
- "relax_vol": False,
- "overwrite_interaction":{
- "type": "vasp",
- "incar": "vasp_input/INCAR.rlx",
- "potcar_prefix":"vasp_input",
- "potcars": {"Al": "POT_Al"}
- }
- }
- }
- ]
+ {
+ "type": "eos",
+ "skip": False,
+ "vol_start": 0.8,
+ "vol_end": 1.2,
+ "vol_step": 0.01,
+ "cal_setting": {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": False,
+ "overwrite_interaction": {
+ "type": "vasp",
+ "incar": "vasp_input/INCAR.rlx",
+ "potcar_prefix": "vasp_input",
+ "potcars": {"Al": "POT_Al"},
+ },
+ },
+ }
+ ],
}
def tearDown(self):
- if os.path.exists('confs/std-fcc/eos_00'):
- shutil.rmtree('confs/std-fcc/eos_00')
- if os.path.exists('confs/std-fcc/eos_02'):
- shutil.rmtree('confs/std-fcc/eos_02')
- if os.path.exists('confs/std-fcc/relaxation'):
- shutil.rmtree('confs/std-fcc/relaxation')
+ if os.path.exists("confs/std-fcc/eos_00"):
+ shutil.rmtree("confs/std-fcc/eos_00")
+ if os.path.exists("confs/std-fcc/eos_02"):
+ shutil.rmtree("confs/std-fcc/eos_02")
+ if os.path.exists("confs/std-fcc/relaxation"):
+ shutil.rmtree("confs/std-fcc/relaxation")
def test_make_eos(self):
- pwd=os.getcwd()
+ pwd = os.getcwd()
confs = self.jdata["structures"]
inter_param = self.jdata["interaction"]
property_list = self.jdata["properties"]
- target_path_0 = 'confs/std-fcc/eos_00'
- target_path_2 = 'confs/std-fcc/eos_02'
- equi_path = 'confs/std-fcc/relaxation/relax_task'
- source_path = 'equi/vasp'
+ target_path_0 = "confs/std-fcc/eos_00"
+ target_path_2 = "confs/std-fcc/eos_02"
+ equi_path = "confs/std-fcc/relaxation/relax_task"
+ source_path = "equi/vasp"
if not os.path.exists(equi_path):
os.makedirs(equi_path)
- shutil.copy(os.path.join(source_path, 'CONTCAR_Al_fcc'), os.path.join(equi_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(source_path, "CONTCAR_Al_fcc"),
+ os.path.join(equi_path, "CONTCAR"),
+ )
make_property(confs, inter_param, property_list)
- dfm_dirs_0 = glob.glob(os.path.join(target_path_0, 'task.*'))
+ dfm_dirs_0 = glob.glob(os.path.join(target_path_0, "task.*"))
for ii in dfm_dirs_0:
- self.assertTrue(os.path.isfile(os.path.join(ii, 'POSCAR')))
- shutil.copy(os.path.join(ii, 'POSCAR'),os.path.join(ii, 'CONTCAR'))
+ self.assertTrue(os.path.isfile(os.path.join(ii, "POSCAR")))
+ shutil.copy(os.path.join(ii, "POSCAR"), os.path.join(ii, "CONTCAR"))
path_to_work = os.path.abspath(target_path_0)
- new_prop_list=[
- {
- "type": "eos",
- "init_from_suffix": "00",
- "output_suffix": "02",
- "cal_setting": {
- "relax_pos": True,
- "relax_shape": True,
- "relax_vol": False,
- "input_prop": "lammps_input/lammps_high"}
- }
+ new_prop_list = [
+ {
+ "type": "eos",
+ "init_from_suffix": "00",
+ "output_suffix": "02",
+ "cal_setting": {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": False,
+ "input_prop": "lammps_input/lammps_high",
+ },
+ }
]
- #ret=make_refine('00', '02', path_to_work)
- #self.assertEqual(len(ret),len(dfm_dirs_0))
+ # ret=make_refine('00', '02', path_to_work)
+ # self.assertEqual(len(ret),len(dfm_dirs_0))
make_property(confs, inter_param, new_prop_list)
- self.assertTrue(os.path.isdir(path_to_work.replace('00','02')))
+ self.assertTrue(os.path.isdir(path_to_work.replace("00", "02")))
os.chdir(pwd)
- dfm_dirs_2 = glob.glob(os.path.join(target_path_2, 'task.*'))
- self.assertEqual(len(dfm_dirs_2),len(dfm_dirs_0))
+ dfm_dirs_2 = glob.glob(os.path.join(target_path_2, "task.*"))
+ self.assertEqual(len(dfm_dirs_2), len(dfm_dirs_0))
diff --git a/tests/auto_test/test_surface.py b/tests/auto_test/test_surface.py
index 12f72f608..b6abdfa26 100644
--- a/tests/auto_test/test_surface.py
+++ b/tests/auto_test/test_surface.py
@@ -1,24 +1,26 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
+
import dpdata
-from monty.serialization import loadfn, dumpfn
+import numpy as np
+from monty.serialization import dumpfn, loadfn
from pymatgen.core import Structure
-from pymatgen.io.vasp import Incar
from pymatgen.core.surface import SlabGenerator
+from pymatgen.io.vasp import Incar
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from dpgen.auto_test.Surface import Surface
+from .context import make_kspacing_kpoints, setUpModule
-class TestSurface(unittest.TestCase):
+class TestSurface(unittest.TestCase):
def setUp(self):
_jdata = {
"structures": ["confs/mp-141"],
@@ -26,7 +28,7 @@ def setUp(self):
"type": "vasp",
"incar": "vasp_input/INCAR.rlx",
"potcar_prefix": ".",
- "potcars": {"Yb": "vasp_input/POTCAR"}
+ "potcars": {"Yb": "vasp_input/POTCAR"},
},
"properties": [
{
@@ -35,67 +37,74 @@ def setUp(self):
"min_vacuum_size": 11,
"pert_xz": 0.01,
"max_miller": 1,
- "cal_type": "relaxation"
+ "cal_type": "relaxation",
}
- ]
+ ],
}
- self.equi_path = 'confs/mp-141/relaxation/relax_task'
- self.source_path = 'equi/vasp'
- self.target_path = 'confs/mp-141/surface_00'
+ self.equi_path = "confs/mp-141/relaxation/relax_task"
+ self.source_path = "equi/vasp"
+ self.target_path = "confs/mp-141/surface_00"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
self.confs = _jdata["structures"]
self.inter_param = _jdata["interaction"]
- self.prop_param = _jdata['properties']
+ self.prop_param = _jdata["properties"]
- self.surface = Surface(_jdata['properties'][0])
+ self.surface = Surface(_jdata["properties"][0])
def tearDown(self):
- if os.path.exists(os.path.abspath(os.path.join(self.equi_path,'..'))):
- shutil.rmtree(os.path.abspath(os.path.join(self.equi_path,'..')))
+ if os.path.exists(os.path.abspath(os.path.join(self.equi_path, ".."))):
+ shutil.rmtree(os.path.abspath(os.path.join(self.equi_path, "..")))
if os.path.exists(self.equi_path):
shutil.rmtree(self.equi_path)
if os.path.exists(self.target_path):
shutil.rmtree(self.target_path)
def test_task_type(self):
- self.assertEqual('surface', self.surface.task_type())
+ self.assertEqual("surface", self.surface.task_type())
def test_task_param(self):
self.assertEqual(self.prop_param[0], self.surface.task_param())
def test_make_confs_0(self):
- if not os.path.exists(os.path.join(self.equi_path, 'CONTCAR')):
+ if not os.path.exists(os.path.join(self.equi_path, "CONTCAR")):
with self.assertRaises(RuntimeError):
self.surface.make_confs(self.target_path, self.equi_path)
- shutil.copy(os.path.join(self.source_path, 'mp-141.vasp'), os.path.join(self.equi_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(self.source_path, "mp-141.vasp"),
+ os.path.join(self.equi_path, "CONTCAR"),
+ )
task_list = self.surface.make_confs(self.target_path, self.equi_path)
self.assertEqual(len(task_list), 7)
- dfm_dirs = glob.glob(os.path.join(self.target_path, 'task.*'))
+ dfm_dirs = glob.glob(os.path.join(self.target_path, "task.*"))
- incar0 = Incar.from_file(os.path.join('vasp_input', 'INCAR.rlx'))
- incar0['ISIF'] = 4
+ incar0 = Incar.from_file(os.path.join("vasp_input", "INCAR.rlx"))
+ incar0["ISIF"] = 4
- self.assertEqual(os.path.realpath(os.path.join(self.equi_path, 'CONTCAR')),
- os.path.realpath(os.path.join(self.target_path, 'POSCAR')))
- ref_st = Structure.from_file(os.path.join(self.target_path, 'POSCAR'))
+ self.assertEqual(
+ os.path.realpath(os.path.join(self.equi_path, "CONTCAR")),
+ os.path.realpath(os.path.join(self.target_path, "POSCAR")),
+ )
+ ref_st = Structure.from_file(os.path.join(self.target_path, "POSCAR"))
dfm_dirs.sort()
for ii in dfm_dirs:
- st_file = os.path.join(ii, 'POSCAR')
+ st_file = os.path.join(ii, "POSCAR")
self.assertTrue(os.path.isfile(st_file))
st0 = Structure.from_file(st_file)
- st1_file = os.path.join(ii, 'POSCAR.tmp')
+ st1_file = os.path.join(ii, "POSCAR.tmp")
self.assertTrue(os.path.isfile(st1_file))
st1 = Structure.from_file(st1_file)
- miller_json_file = os.path.join(ii, 'miller.json')
+ miller_json_file = os.path.join(ii, "miller.json")
self.assertTrue(os.path.isfile(miller_json_file))
miller_json = loadfn(miller_json_file)
- sl = SlabGenerator(ref_st,
- miller_json,
- self.prop_param[0]["min_slab_size"],
- self.prop_param[0]["min_vacuum_size"])
+ sl = SlabGenerator(
+ ref_st,
+ miller_json,
+ self.prop_param[0]["min_slab_size"],
+ self.prop_param[0]["min_vacuum_size"],
+ )
slb = sl.get_slab()
st2 = Structure(slb.lattice, slb.species, slb.frac_coords)
self.assertEqual(len(st1), len(st2))
diff --git a/tests/auto_test/test_vacancy.py b/tests/auto_test/test_vacancy.py
index f76626f88..b2e348573 100644
--- a/tests/auto_test/test_vacancy.py
+++ b/tests/auto_test/test_vacancy.py
@@ -1,25 +1,27 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
+
import dpdata
-from monty.serialization import loadfn, dumpfn
+import numpy as np
+from monty.serialization import dumpfn, loadfn
+from pymatgen.analysis.defects.core import Vacancy as pmg_Vacancy
from pymatgen.core import Structure
from pymatgen.io.vasp import Incar
from pymatgen.symmetry.analyzer import SpacegroupAnalyzer
-from pymatgen.analysis.defects.core import Vacancy as pmg_Vacancy
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from dpgen.auto_test.Vacancy import Vacancy
+from .context import make_kspacing_kpoints, setUpModule
-class TestVacancy(unittest.TestCase):
+class TestVacancy(unittest.TestCase):
def setUp(self):
_jdata = {
"structures": ["confs/hp-Li"],
@@ -27,27 +29,22 @@ def setUp(self):
"type": "vasp",
"incar": "vasp_input/INCAR.rlx",
"potcar_prefix": ".",
- "potcars": {"Yb": "vasp_input/POTCAR"}
+ "potcars": {"Yb": "vasp_input/POTCAR"},
},
- "properties": [
- {
- "type": "vacancy",
- "supercell": [1, 1, 1]
- }
- ]
+ "properties": [{"type": "vacancy", "supercell": [1, 1, 1]}],
}
- self.equi_path = 'confs/hp-Li/relaxation/relax_task'
- self.source_path = 'equi/vasp'
- self.target_path = 'confs/hp-Li/vacancy_00'
+ self.equi_path = "confs/hp-Li/relaxation/relax_task"
+ self.source_path = "equi/vasp"
+ self.target_path = "confs/hp-Li/vacancy_00"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
self.confs = _jdata["structures"]
self.inter_param = _jdata["interaction"]
- self.prop_param = _jdata['properties']
+ self.prop_param = _jdata["properties"]
- self.vacancy = Vacancy(_jdata['properties'][0])
+ self.vacancy = Vacancy(_jdata["properties"][0])
def tearDown(self):
if os.path.exists(self.equi_path):
@@ -56,35 +53,42 @@ def tearDown(self):
shutil.rmtree(self.target_path)
def test_task_type(self):
- self.assertEqual('vacancy', self.vacancy.task_type())
+ self.assertEqual("vacancy", self.vacancy.task_type())
def test_task_param(self):
self.assertEqual(self.prop_param[0], self.vacancy.task_param())
def test_make_confs_0(self):
- if not os.path.exists(os.path.join(self.equi_path, 'CONTCAR')):
+ if not os.path.exists(os.path.join(self.equi_path, "CONTCAR")):
with self.assertRaises(RuntimeError):
self.vacancy.make_confs(self.target_path, self.equi_path)
- shutil.copy(os.path.join(self.source_path, 'CONTCAR'), os.path.join(self.equi_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(self.source_path, "CONTCAR"),
+ os.path.join(self.equi_path, "CONTCAR"),
+ )
task_list = self.vacancy.make_confs(self.target_path, self.equi_path)
- dfm_dirs = glob.glob(os.path.join(self.target_path, 'task.*'))
+ dfm_dirs = glob.glob(os.path.join(self.target_path, "task.*"))
self.assertEqual(len(dfm_dirs), 5)
- incar0 = Incar.from_file(os.path.join('vasp_input', 'INCAR.rlx'))
- incar0['ISIF'] = 4
+ incar0 = Incar.from_file(os.path.join("vasp_input", "INCAR.rlx"))
+ incar0["ISIF"] = 4
- self.assertEqual(os.path.realpath(os.path.join(self.equi_path, 'CONTCAR')),
- os.path.realpath(os.path.join(self.target_path, 'POSCAR')))
- ref_st = Structure.from_file(os.path.join(self.target_path, 'POSCAR'))
+ self.assertEqual(
+ os.path.realpath(os.path.join(self.equi_path, "CONTCAR")),
+ os.path.realpath(os.path.join(self.target_path, "POSCAR")),
+ )
+ ref_st = Structure.from_file(os.path.join(self.target_path, "POSCAR"))
sga = SpacegroupAnalyzer(ref_st)
sym_st = sga.get_symmetrized_structure()
equiv_site_seq = list(sym_st.equivalent_sites)
dfm_dirs.sort()
for ii in dfm_dirs:
- st_file = os.path.join(ii, 'POSCAR')
+ st_file = os.path.join(ii, "POSCAR")
self.assertTrue(os.path.isfile(st_file))
st0 = Structure.from_file(st_file)
vac_site = equiv_site_seq.pop(0)
vac = pmg_Vacancy(ref_st, vac_site[0])
- st1 = vac.get_supercell_structure(sc_mat=np.eye(3)*self.prop_param[0]['supercell'])
+ st1 = vac.get_supercell_structure(
+ sc_mat=np.eye(3) * self.prop_param[0]["supercell"]
+ )
self.assertEqual(st0, st1)
diff --git a/tests/auto_test/test_vasp.py b/tests/auto_test/test_vasp.py
index 2f74055ec..e994c8906 100644
--- a/tests/auto_test/test_vasp.py
+++ b/tests/auto_test/test_vasp.py
@@ -1,23 +1,26 @@
-import os, sys, json, glob, shutil
+import glob
+import json
+import os
+import shutil
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
from dpdata import LabeledSystem
+from monty.serialization import dumpfn, loadfn
from pymatgen.io.vasp import Incar
-from monty.serialization import loadfn, dumpfn
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
-from dpgen.auto_test.VASP import VASP
+from dpgen.auto_test.VASP import VASP
from dpgen.generator.lib.vasp import incar_upper
+from .context import make_kspacing_kpoints, setUpModule
-class TestVASP(unittest.TestCase):
+class TestVASP(unittest.TestCase):
def setUp(self):
self.jdata = {
"structures": ["confs/hp-*"],
@@ -25,122 +28,139 @@ def setUp(self):
"type": "vasp",
"incar": "vasp_input/INCAR",
"potcar_prefix": ".",
- "potcars": {"Li": "vasp_input/POTCAR"}
+ "potcars": {"Li": "vasp_input/POTCAR"},
},
"relaxation": {
- "cal_type": "relaxation",
- "cal_setting": {"relax_pos":True,
- "relax_shape":True,
- "relax_vol":True}
- }
+ "cal_type": "relaxation",
+ "cal_setting": {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": True,
+ },
+ },
}
- self.conf_path = 'confs/hp-Li'
- self.equi_path = 'confs/hp-Li/relaxation/relax_task'
- self.source_path = 'equi/vasp'
+ self.conf_path = "confs/hp-Li"
+ self.equi_path = "confs/hp-Li/relaxation/relax_task"
+ self.source_path = "equi/vasp"
if not os.path.exists(self.equi_path):
os.makedirs(self.equi_path)
self.confs = self.jdata["structures"]
inter_param = self.jdata["interaction"]
self.task_param = self.jdata["relaxation"]
- self.VASP = VASP(inter_param, os.path.join(self.conf_path, 'POSCAR'))
+ self.VASP = VASP(inter_param, os.path.join(self.conf_path, "POSCAR"))
def tearDown(self):
- if os.path.exists('confs/hp-Li/relaxation'):
- shutil.rmtree('confs/hp-Li/relaxation')
- if os.path.exists('inter.json'):
- os.remove('inter.json')
- if os.path.exists('POTCAR'):
- os.remove('POTCAR')
+ if os.path.exists("confs/hp-Li/relaxation"):
+ shutil.rmtree("confs/hp-Li/relaxation")
+ if os.path.exists("inter.json"):
+ os.remove("inter.json")
+ if os.path.exists("POTCAR"):
+ os.remove("POTCAR")
def test_make_potential_files(self):
- if not os.path.exists(os.path.join(self.equi_path, 'POSCAR')):
+ if not os.path.exists(os.path.join(self.equi_path, "POSCAR")):
with self.assertRaises(FileNotFoundError):
- self.VASP.make_potential_files(self.equi_path)
- shutil.copy(os.path.join(self.conf_path, 'POSCAR'), os.path.join(self.equi_path, 'POSCAR'))
+ self.VASP.make_potential_files(self.equi_path)
+ shutil.copy(
+ os.path.join(self.conf_path, "POSCAR"),
+ os.path.join(self.equi_path, "POSCAR"),
+ )
self.VASP.make_potential_files(self.equi_path)
self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "POTCAR")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, 'inter.json')))
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "inter.json")))
def test_make_input_file_1(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":True,
- "relax_shape":True,
- "relax_vol":False}
- self.VASP.make_input_file(self.equi_path,'relaxation',param)
- incar=incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
- self.assertEqual(incar['ISIF'],4)
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": True,
+ "relax_shape": True,
+ "relax_vol": False,
+ }
+ self.VASP.make_input_file(self.equi_path, "relaxation", param)
+ incar = incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
+ self.assertEqual(incar["ISIF"], 4)
def test_make_input_file_2(self):
- self.VASP.make_input_file(self.equi_path,'relaxation',self.task_param)
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPOINTS")))
- self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "INCAR")))
- incar=incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
- self.assertEqual(incar['ISIF'],3)
+ self.VASP.make_input_file(self.equi_path, "relaxation", self.task_param)
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "task.json")))
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "KPOINTS")))
+ self.assertTrue(os.path.isfile(os.path.join(self.equi_path, "INCAR")))
+ incar = incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
+ self.assertEqual(incar["ISIF"], 3)
def test_make_input_file_3(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":True,
- "relax_shape":False,
- "relax_vol":False}
- self.VASP.make_input_file(self.equi_path,'relaxation',param)
- incar=incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
- self.assertEqual(incar['ISIF'],2)
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": True,
+ "relax_shape": False,
+ "relax_vol": False,
+ }
+ self.VASP.make_input_file(self.equi_path, "relaxation", param)
+ incar = incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
+ self.assertEqual(incar["ISIF"], 2)
def test_make_input_file_4(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":False,
- "relax_shape":True,
- "relax_vol":False}
- self.VASP.make_input_file(self.equi_path,'relaxation',param)
- incar=incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
- self.assertEqual(incar['ISIF'],5)
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": False,
+ "relax_shape": True,
+ "relax_vol": False,
+ }
+ self.VASP.make_input_file(self.equi_path, "relaxation", param)
+ incar = incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
+ self.assertEqual(incar["ISIF"], 5)
def test_make_input_file_5(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":False,
- "relax_shape":True,
- "relax_vol":True}
- self.VASP.make_input_file(self.equi_path,'relaxation',param)
- incar=incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
- self.assertEqual(incar['ISIF'],6)
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": False,
+ "relax_shape": True,
+ "relax_vol": True,
+ }
+ self.VASP.make_input_file(self.equi_path, "relaxation", param)
+ incar = incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
+ self.assertEqual(incar["ISIF"], 6)
def test_make_input_file_5(self):
- param=self.task_param.copy()
- param["cal_setting"]= {"relax_pos":False,
- "relax_shape":True,
- "relax_vol":True,
- "kspacing":0.01}
- self.VASP.make_input_file(self.equi_path,'relaxation',param)
- incar=incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
- self.assertEqual(incar['ISIF'],6)
- self.assertEqual(incar['KSPACING'],0.01)
+ param = self.task_param.copy()
+ param["cal_setting"] = {
+ "relax_pos": False,
+ "relax_shape": True,
+ "relax_vol": True,
+ "kspacing": 0.01,
+ }
+ self.VASP.make_input_file(self.equi_path, "relaxation", param)
+ incar = incar_upper(Incar.from_file(os.path.join(self.equi_path, "INCAR")))
+ self.assertEqual(incar["ISIF"], 6)
+ self.assertEqual(incar["KSPACING"], 0.01)
def test_compuate(self):
- ret=self.VASP.compute(os.path.join(self.conf_path,'relaxation'))
+ ret = self.VASP.compute(os.path.join(self.conf_path, "relaxation"))
self.assertIsNone(ret)
- shutil.copy(os.path.join(self.source_path, 'OUTCAR'), os.path.join(self.equi_path, 'OUTCAR'))
- ret=self.VASP.compute(self.equi_path)
- ret_ref=loadfn(os.path.join(self.source_path, 'outcar.json'))
-
- def compare_dict(dict1,dict2):
- self.assertEqual(dict1.keys(),dict2.keys())
+ shutil.copy(
+ os.path.join(self.source_path, "OUTCAR"),
+ os.path.join(self.equi_path, "OUTCAR"),
+ )
+ ret = self.VASP.compute(self.equi_path)
+ ret_ref = loadfn(os.path.join(self.source_path, "outcar.json"))
+
+ def compare_dict(dict1, dict2):
+ self.assertEqual(dict1.keys(), dict2.keys())
for key in dict1:
- if key == 'stress':
- self.assertTrue((np.array(dict1[key]['data']) == dict2[key]).all())
+ if key == "stress":
+ self.assertTrue((np.array(dict1[key]["data"]) == dict2[key]).all())
elif type(dict1[key]) is dict:
- compare_dict(dict1[key],dict2[key])
+ compare_dict(dict1[key], dict2[key])
else:
if type(dict1[key]) is np.ndarray:
self.assertTrue((dict1[key] == dict2[key]).all())
else:
self.assertTrue(dict1[key] == dict2[key])
- compare_dict(ret,ret_ref.as_dict())
-
-
+ compare_dict(ret, ret_ref.as_dict())
+
def test_backward_files(self):
- backward_files = ['OUTCAR', 'outlog', 'CONTCAR', 'OSZICAR', 'XDATCAR']
+ backward_files = ["OUTCAR", "outlog", "CONTCAR", "OSZICAR", "XDATCAR"]
self.assertEqual(self.VASP.backward_files(), backward_files)
diff --git a/tests/auto_test/test_vasp_equi.py b/tests/auto_test/test_vasp_equi.py
index 59b78c2f1..37c7f6c60 100644
--- a/tests/auto_test/test_vasp_equi.py
+++ b/tests/auto_test/test_vasp_equi.py
@@ -1,18 +1,23 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
-from monty.serialization import loadfn, dumpfn
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
+import dpdata
+import numpy as np
+from monty.serialization import dumpfn, loadfn
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from pymatgen.io.vasp import Incar
-from dpgen.auto_test.common_equi import make_equi, post_equi
+
from dpgen.auto_test.calculator import make_calculator
+from dpgen.auto_test.common_equi import make_equi, post_equi
+
+from .context import make_kspacing_kpoints, setUpModule
class TestEqui(unittest.TestCase):
@@ -22,17 +27,17 @@ class TestEqui(unittest.TestCase):
"type": "vasp",
"incar": "vasp_input/INCAR.rlx",
"potcar_prefix": ".",
- "potcars": {"Li": "vasp_input/POTCAR"}
+ "potcars": {"Li": "vasp_input/POTCAR"},
},
"relaxation": {
"cal_type": "relaxation",
- "cal_setting":{"input_prop": "vasp_input/INCAR"}
- }
+ "cal_setting": {"input_prop": "vasp_input/INCAR"},
+ },
}
def tearDown(self):
- if os.path.exists('confs/hp-Li/relaxation'):
- shutil.rmtree('confs/hp-Li/relaxation')
+ if os.path.exists("confs/hp-Li/relaxation"):
+ shutil.rmtree("confs/hp-Li/relaxation")
def test_make_equi(self):
confs = self.jdata["structures"]
@@ -40,46 +45,50 @@ def test_make_equi(self):
relax_param = self.jdata["relaxation"]
make_equi(confs, inter_param, relax_param)
- target_path = 'confs/hp-Li/relaxation/relax_task'
- source_path = 'vasp_input'
+ target_path = "confs/hp-Li/relaxation/relax_task"
+ source_path = "vasp_input"
- incar0 = Incar.from_file(os.path.join('vasp_input', 'INCAR'))
- incar1 = Incar.from_file(os.path.join(target_path, 'INCAR'))
+ incar0 = Incar.from_file(os.path.join("vasp_input", "INCAR"))
+ incar1 = Incar.from_file(os.path.join(target_path, "INCAR"))
self.assertTrue(incar0 == incar1)
- with open(os.path.join('vasp_input', 'POTCAR')) as fp:
+ with open(os.path.join("vasp_input", "POTCAR")) as fp:
pot0 = fp.read()
- with open(os.path.join(target_path, 'POTCAR')) as fp:
+ with open(os.path.join(target_path, "POTCAR")) as fp:
pot1 = fp.read()
self.assertEqual(pot0, pot1)
- self.assertTrue(os.path.isfile(os.path.join(target_path, 'KPOINTS')))
+ self.assertTrue(os.path.isfile(os.path.join(target_path, "KPOINTS")))
- task_json_file = os.path.join(target_path, 'task.json')
+ task_json_file = os.path.join(target_path, "task.json")
self.assertTrue(os.path.isfile(task_json_file))
task_json = loadfn(task_json_file)
self.assertEqual(task_json, relax_param)
- inter_json_file = os.path.join(target_path, 'inter.json')
+ inter_json_file = os.path.join(target_path, "inter.json")
self.assertTrue(os.path.isfile(inter_json_file))
inter_json = loadfn(inter_json_file)
self.assertEqual(inter_json, inter_param)
- self.assertTrue(os.path.islink(os.path.join(target_path, 'POSCAR')))
+ self.assertTrue(os.path.islink(os.path.join(target_path, "POSCAR")))
def test_post_equi(self):
confs = self.jdata["structures"]
inter_param = self.jdata["interaction"]
relax_param = self.jdata["relaxation"]
- target_path = 'confs/hp-Li/relaxation/relax_task'
- source_path = 'equi/vasp'
+ target_path = "confs/hp-Li/relaxation/relax_task"
+ source_path = "equi/vasp"
- poscar = os.path.join(source_path, 'POSCAR')
+ poscar = os.path.join(source_path, "POSCAR")
make_equi(confs, inter_param, relax_param)
- shutil.copy(os.path.join(source_path, 'OUTCAR'), os.path.join(target_path, 'OUTCAR'))
- shutil.copy(os.path.join(source_path, 'CONTCAR'), os.path.join(target_path, 'CONTCAR'))
+ shutil.copy(
+ os.path.join(source_path, "OUTCAR"), os.path.join(target_path, "OUTCAR")
+ )
+ shutil.copy(
+ os.path.join(source_path, "CONTCAR"), os.path.join(target_path, "CONTCAR")
+ )
post_equi(confs, inter_param)
- result_json_file = os.path.join(target_path, 'result.json')
+ result_json_file = os.path.join(target_path, "result.json")
result_json = loadfn(result_json_file)
self.assertTrue(os.path.isfile(result_json_file))
diff --git a/tests/auto_test/test_vasp_equi_std.py b/tests/auto_test/test_vasp_equi_std.py
index 34f44a9b0..5f513dbaa 100644
--- a/tests/auto_test/test_vasp_equi_std.py
+++ b/tests/auto_test/test_vasp_equi_std.py
@@ -1,18 +1,23 @@
-import os, sys, json, glob, shutil
-import dpdata
-import numpy as np
-from monty.serialization import loadfn, dumpfn
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
+import dpdata
+import numpy as np
+from monty.serialization import dumpfn, loadfn
-from .context import make_kspacing_kpoints
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
from pymatgen.io.vasp import Incar
-from dpgen.auto_test.common_equi import make_equi, post_equi
+
from dpgen.auto_test.calculator import make_calculator
+from dpgen.auto_test.common_equi import make_equi, post_equi
+
+from .context import make_kspacing_kpoints, setUpModule
class TestEqui(unittest.TestCase):
@@ -22,19 +27,19 @@ class TestEqui(unittest.TestCase):
"type": "vasp",
"incar": "vasp_input/INCAR.rlx",
"potcar_prefix": ".",
- "potcars": {"Al": "vasp_input/POT_Al"}
+ "potcars": {"Al": "vasp_input/POT_Al"},
},
"relaxation": {
"cal_type": "relaxation",
- "cal_setting":{"input_prop": "vasp_input/INCAR"}
- }
+ "cal_setting": {"input_prop": "vasp_input/INCAR"},
+ },
}
def tearDown(self):
- if os.path.isfile('confs/std-fcc/POSCAR'):
- os.remove('confs/std-fcc/POSCAR')
- if os.path.exists('confs/std-fcc/relaxation'):
- shutil.rmtree('confs/std-fcc/relaxation')
+ if os.path.isfile("confs/std-fcc/POSCAR"):
+ os.remove("confs/std-fcc/POSCAR")
+ if os.path.exists("confs/std-fcc/relaxation"):
+ shutil.rmtree("confs/std-fcc/relaxation")
def test_make_equi(self):
confs = self.jdata["structures"]
@@ -44,30 +49,29 @@ def test_make_equi(self):
self.assertTrue(os.path.isfile("confs/std-fcc/POSCAR"))
- target_path = 'confs/std-fcc/relaxation/relax_task'
- source_path = 'vasp_input'
+ target_path = "confs/std-fcc/relaxation/relax_task"
+ source_path = "vasp_input"
- incar0 = Incar.from_file(os.path.join('vasp_input', 'INCAR'))
- incar1 = Incar.from_file(os.path.join(target_path, 'INCAR'))
+ incar0 = Incar.from_file(os.path.join("vasp_input", "INCAR"))
+ incar1 = Incar.from_file(os.path.join(target_path, "INCAR"))
self.assertTrue(incar0 == incar1)
- with open(os.path.join('vasp_input', 'POT_Al')) as fp:
+ with open(os.path.join("vasp_input", "POT_Al")) as fp:
pot0 = fp.read()
- with open(os.path.join(target_path, 'POTCAR')) as fp:
+ with open(os.path.join(target_path, "POTCAR")) as fp:
pot1 = fp.read()
self.assertEqual(pot0, pot1)
- self.assertTrue(os.path.isfile(os.path.join(target_path, 'KPOINTS')))
+ self.assertTrue(os.path.isfile(os.path.join(target_path, "KPOINTS")))
- task_json_file = os.path.join(target_path, 'task.json')
+ task_json_file = os.path.join(target_path, "task.json")
self.assertTrue(os.path.isfile(task_json_file))
task_json = loadfn(task_json_file)
self.assertEqual(task_json, relax_param)
- inter_json_file = os.path.join(target_path, 'inter.json')
+ inter_json_file = os.path.join(target_path, "inter.json")
self.assertTrue(os.path.isfile(inter_json_file))
inter_json = loadfn(inter_json_file)
self.assertEqual(inter_json, inter_param)
- self.assertTrue(os.path.islink(os.path.join(target_path, 'POSCAR')))
-
+ self.assertTrue(os.path.islink(os.path.join(target_path, "POSCAR")))
diff --git a/tests/auto_test/test_vasp_kspacing.py b/tests/auto_test/test_vasp_kspacing.py
index f427d4f23..cac726a8a 100644
--- a/tests/auto_test/test_vasp_kspacing.py
+++ b/tests/auto_test/test_vasp_kspacing.py
@@ -1,22 +1,27 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'auto_test'
-from .context import make_kspacing_kpoints
-from .context import setUpModule
-from pymatgen.io.vasp import Kpoints,Incar
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "auto_test"
+from pymatgen.io.vasp import Incar, Kpoints
+
+from .context import make_kspacing_kpoints, setUpModule
+
class TestVASPMakeKpoint(unittest.TestCase):
- def test_gf_all (self):
+ def test_gf_all(self):
kspacing = 0.16
gamma = False
- all_test = glob.glob(os.path.join('data.vasp.kp.gf', 'test.*'))
- for ii in all_test :
- ret=make_kspacing_kpoints(os.path.join(ii, 'POSCAR'), kspacing, gamma)
- kp = [int(jj) for jj in (ret.split('\n')[3].split())]
- kp_ref = list(np.loadtxt(os.path.join(ii, 'kp.ref'), dtype = int))
+ all_test = glob.glob(os.path.join("data.vasp.kp.gf", "test.*"))
+ for ii in all_test:
+ ret = make_kspacing_kpoints(os.path.join(ii, "POSCAR"), kspacing, gamma)
+ kp = [int(jj) for jj in (ret.split("\n")[3].split())]
+ kp_ref = list(np.loadtxt(os.path.join(ii, "kp.ref"), dtype=int))
self.assertTrue(kp == kp_ref)
-
diff --git a/tests/data/Cu.STRU b/tests/data/Cu.STRU
new file mode 100644
index 000000000..98512ee0d
--- /dev/null
+++ b/tests/data/Cu.STRU
@@ -0,0 +1,17 @@
+ATOMIC_SPECIES
+Cu 63.550 Cu_ONCV_PBE-1.0.upf
+
+LATTICE_CONSTANT
+1.8897261254578281
+
+LATTICE_VECTORS
+3.76 0.0 0.0
+0.0 3.76 0.0
+0.0 0.0 3.76
+
+ATOMIC_POSITIONS
+Cartesian # Cartesian(Unit is LATTICE_CONSTANT)
+Cu
+0.0
+1
+1.880000000000 0.000000000000 1.880000000000 1 1 1
diff --git a/tests/data/context.py b/tests/data/context.py
index d99d19c1f..4c65e8fd7 100644
--- a/tests/data/context.py
+++ b/tests/data/context.py
@@ -1,9 +1,13 @@
-import sys,os
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
+import os
+import sys
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
from dpgen.data.gen import *
-param_file = 'al.json'
-abacus_param_file = 'ch4.json'
-abacus_stru_file = 'STRU.hcp'
+param_file = "al.json"
+abacus_param_file = "ch4.json"
+abacus_stru_file = "STRU.hcp"
+
+
def setUpModule():
os.chdir(os.path.abspath(os.path.dirname(__file__)))
diff --git a/tests/data/context_bulk.py b/tests/data/context_bulk.py
index 1a46b37bd..9602a2e12 100644
--- a/tests/data/context_bulk.py
+++ b/tests/data/context_bulk.py
@@ -1,6 +1,8 @@
-import sys,os
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
+import os
+import sys
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
from dpgen.data.gen import *
-param_file = 'alloy.json'
-abacus_param_file = 'CuW.json'
+param_file = "alloy.json"
+abacus_param_file = "CuW.json"
diff --git a/tests/data/context_surf.py b/tests/data/context_surf.py
index b3797e6ad..e4ad3516a 100644
--- a/tests/data/context_surf.py
+++ b/tests/data/context_surf.py
@@ -1,6 +1,7 @@
-import sys,os
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
-from dpgen.data.surf import *
+import os
+import sys
-param_file = 'surf.json'
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
+from dpgen.data.surf import *
+param_file = "surf.json"
diff --git a/tests/data/context_surf_poscar.py b/tests/data/context_surf_poscar.py
index 89bc492cc..11d15717f 100644
--- a/tests/data/context_surf_poscar.py
+++ b/tests/data/context_surf_poscar.py
@@ -1,6 +1,7 @@
-import sys,os
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
-from dpgen.data.surf import *
+import os
+import sys
-param_file = 'surf_poscar.json'
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
+from dpgen.data.surf import *
+param_file = "surf_poscar.json"
diff --git a/tests/data/test_coll_abacus.py b/tests/data/test_coll_abacus.py
index feabec88d..c5f11f526 100644
--- a/tests/data/test_coll_abacus.py
+++ b/tests/data/test_coll_abacus.py
@@ -1,63 +1,80 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'data'
-from .context import coll_abacus_md
-from .context import out_dir_name
-from .context import abacus_param_file
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "data"
+from .context import abacus_param_file, coll_abacus_md, out_dir_name, setUpModule
+
class TestCollAbacus(unittest.TestCase):
def setUp(self):
- with open (abacus_param_file, 'r') as fp :
- jdata = json.load (fp)
+ with open(abacus_param_file, "r") as fp:
+ jdata = json.load(fp)
self.odir = out_dir_name(jdata)
- assert os.path.isdir('out_data_02_md_abacus'), 'out data for post fp vasp should exist'
- if os.path.isdir(self.odir) :
+ assert os.path.isdir(
+ "out_data_02_md_abacus"
+ ), "out data for post fp vasp should exist"
+ if os.path.isdir(self.odir):
shutil.rmtree(self.odir)
- shutil.copytree('out_data_02_md_abacus', self.odir)
+ shutil.copytree("out_data_02_md_abacus", self.odir)
self.ref_coord = np.reshape(np.genfromtxt("abacus.out/coord.raw"), [8, 5, 3])
self.ref_cell = np.reshape(np.genfromtxt("abacus.out/box.raw"), [8, 3, 3])
- self.ref_e = np.reshape(np.genfromtxt("abacus.out/energy.raw"), [8, ])
+ self.ref_e = np.reshape(
+ np.genfromtxt("abacus.out/energy.raw"),
+ [
+ 8,
+ ],
+ )
self.ref_f = np.reshape(np.genfromtxt("abacus.out/force.raw"), [8, 5, 3])
self.ref_v = np.reshape(np.genfromtxt("abacus.out/virial.raw"), [8, 3, 3])
+
def tearDown(self):
- #print("escape.")
+ # print("escape.")
shutil.rmtree(self.odir)
def test_coll(self):
- with open (abacus_param_file, 'r') as fp :
- jdata = json.load (fp)
- jdata['out_dir'] = self.odir
+ with open(abacus_param_file, "r") as fp:
+ jdata = json.load(fp)
+ jdata["out_dir"] = self.odir
print(os.getcwd())
coll_abacus_md(jdata)
-
- sys = dpdata.LabeledSystem(self.odir + '/02.md/sys-0004-0001/deepmd//', fmt = 'deepmd/raw')
+
+ sys = dpdata.LabeledSystem(
+ self.odir + "/02.md/sys-0004-0001/deepmd//", fmt="deepmd/raw"
+ )
self.assertEqual(sys.get_nframes(), 8)
-
- for ff in range(8) :
- self.assertAlmostEqual(self.ref_e[ff], sys.data['energies'][ff])
- for ff in range(8) :
- for ii in range(5) :
- for dd in range(3) :
- self.assertAlmostEqual(self.ref_coord[ff][ii][dd],
- sys.data['coords'][ff][ii][dd])
- self.assertAlmostEqual(self.ref_f[ff][ii][dd],
- sys.data['forces'][ff][ii][dd])
+
for ff in range(8):
- for ii in range(3) :
- for jj in range(3) :
- self.assertAlmostEqual(self.ref_v[ff][ii][jj],
- sys.data['virials'][ff][ii][jj], places = 5)
- self.assertAlmostEqual(self.ref_cell[ff][ii][jj],
- sys.data['cells'][ff][ii][jj])
-
-if __name__ == '__main__':
- unittest.main()
-
+ self.assertAlmostEqual(self.ref_e[ff], sys.data["energies"][ff])
+ for ff in range(8):
+ for ii in range(5):
+ for dd in range(3):
+ self.assertAlmostEqual(
+ self.ref_coord[ff][ii][dd], sys.data["coords"][ff][ii][dd]
+ )
+ self.assertAlmostEqual(
+ self.ref_f[ff][ii][dd], sys.data["forces"][ff][ii][dd]
+ )
+ for ff in range(8):
+ for ii in range(3):
+ for jj in range(3):
+ self.assertAlmostEqual(
+ self.ref_v[ff][ii][jj],
+ sys.data["virials"][ff][ii][jj],
+ places=5,
+ )
+ self.assertAlmostEqual(
+ self.ref_cell[ff][ii][jj], sys.data["cells"][ff][ii][jj]
+ )
+
-
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tests/data/test_coll_vasp.py b/tests/data/test_coll_vasp.py
index b13f99403..e5b282698 100644
--- a/tests/data/test_coll_vasp.py
+++ b/tests/data/test_coll_vasp.py
@@ -1,42 +1,46 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'data'
-from .context import coll_vasp_md
-from .context import out_dir_name
-from .context import param_file
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "data"
+from .context import coll_vasp_md, out_dir_name, param_file, setUpModule
+
class TestCollVasp(unittest.TestCase):
def setUp(self):
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
self.odir = out_dir_name(jdata)
- assert os.path.isdir('out_data_02_md'), 'out data for post fp vasp should exist'
- if os.path.isdir(self.odir) :
+ assert os.path.isdir("out_data_02_md"), "out data for post fp vasp should exist"
+ if os.path.isdir(self.odir):
shutil.rmtree(self.odir)
- shutil.copytree('out_data_02_md', self.odir)
- self.ref_coord = [[[0, 0, 0], [2.3, 2.3, 2.3]],
- [[0, 0, 0], [2.2, 2.3, 2.4]]]
+ shutil.copytree("out_data_02_md", self.odir)
+ self.ref_coord = [[[0, 0, 0], [2.3, 2.3, 2.3]], [[0, 0, 0], [2.2, 2.3, 2.4]]]
self.ref_cell = [4.6 * np.eye(3), 4.6 * np.eye(3)]
self.ref_at = [1, 1]
self.ref_e = [-1.90811235, -1.89718546]
- self.ref_f = [[[ 0. , 0. , 0. ], \
- [-0. , -0. , -0. ]],\
- [[-0.110216, 0. , 0.110216], \
- [ 0.110216, -0. , -0.110216]]]
- self.ref_v = [[[ 1.50816698, 0. , -0. ], \
- [ 0. , 1.50816698, 0. ], \
- [-0. , 0. , 1.50816795]],\
- [[ 1.45208913, 0. , 0.03036584], \
- [ 0. , 1.67640928, 0. ], \
- [ 0.03036584, 0. , 1.45208913]]]
+ self.ref_f = [
+ [[0.0, 0.0, 0.0], [-0.0, -0.0, -0.0]],
+ [[-0.110216, 0.0, 0.110216], [0.110216, -0.0, -0.110216]],
+ ]
+ self.ref_v = [
+ [[1.50816698, 0.0, -0.0], [0.0, 1.50816698, 0.0], [-0.0, 0.0, 1.50816795]],
+ [
+ [1.45208913, 0.0, 0.03036584],
+ [0.0, 1.67640928, 0.0],
+ [0.03036584, 0.0, 1.45208913],
+ ],
+ ]
self.ref_coord = np.array(self.ref_coord)
self.ref_cell = np.array(self.ref_cell)
- self.ref_at = np.array(self.ref_at, dtype = int)
+ self.ref_at = np.array(self.ref_at, dtype=int)
self.ref_e = np.array(self.ref_e)
self.ref_f = np.array(self.ref_f)
self.ref_v = np.array(self.ref_v)
@@ -46,17 +50,19 @@ def tearDown(self):
def test_coll(self):
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- jdata['out_dir'] = self.odir
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ jdata["out_dir"] = self.odir
coll_vasp_md(jdata)
-
- sys = dpdata.LabeledSystem(self.odir + '/02.md/sys-004/deepmd//', fmt = 'deepmd/raw')
+
+ sys = dpdata.LabeledSystem(
+ self.odir + "/02.md/sys-004/deepmd//", fmt="deepmd/raw"
+ )
self.assertEqual(sys.get_nframes(), 2)
-
- if sys.data['coords'][0][1][0] < sys.data['coords'][1][1][0]:
+
+ if sys.data["coords"][0][1][0] < sys.data["coords"][1][1][0]:
idx = [1, 0]
- else :
+ else:
idx = [0, 1]
ref_coord = self.ref_coord[idx]
ref_cell = self.ref_cell[idx]
@@ -64,28 +70,30 @@ def test_coll(self):
ref_f = self.ref_f[idx]
ref_v = self.ref_v[idx]
ref_at = self.ref_at
-
- for ff in range(2) :
- self.assertAlmostEqual(ref_e[ff], sys.data['energies'][ff])
- for ii in range(2) :
- self.assertEqual(ref_at[ff], sys.data['atom_types'][ff])
- for ff in range(2) :
- for ii in range(2) :
- for dd in range(3) :
- self.assertAlmostEqual(ref_coord[ff][ii][dd],
- sys.data['coords'][ff][ii][dd])
- self.assertAlmostEqual(ref_f[ff][ii][dd],
- sys.data['forces'][ff][ii][dd])
+
+ for ff in range(2):
+ self.assertAlmostEqual(ref_e[ff], sys.data["energies"][ff])
+ for ii in range(2):
+ self.assertEqual(ref_at[ff], sys.data["atom_types"][ff])
+ for ff in range(2):
+ for ii in range(2):
+ for dd in range(3):
+ self.assertAlmostEqual(
+ ref_coord[ff][ii][dd], sys.data["coords"][ff][ii][dd]
+ )
+ self.assertAlmostEqual(
+ ref_f[ff][ii][dd], sys.data["forces"][ff][ii][dd]
+ )
for ff in range(2):
- for ii in range(3) :
- for jj in range(3) :
- self.assertAlmostEqual(ref_v[ff][ii][jj],
- sys.data['virials'][ff][ii][jj], places = 5)
- self.assertAlmostEqual(ref_cell[ff][ii][jj],
- sys.data['cells'][ff][ii][jj])
+ for ii in range(3):
+ for jj in range(3):
+ self.assertAlmostEqual(
+ ref_v[ff][ii][jj], sys.data["virials"][ff][ii][jj], places=5
+ )
+ self.assertAlmostEqual(
+ ref_cell[ff][ii][jj], sys.data["cells"][ff][ii][jj]
+ )
-if __name__ == '__main__':
- unittest.main()
-
-
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tests/data/test_disturb_abacus.py b/tests/data/test_disturb_abacus.py
index eca24bc2d..f64d8554c 100644
--- a/tests/data/test_disturb_abacus.py
+++ b/tests/data/test_disturb_abacus.py
@@ -1,50 +1,76 @@
-import sys, os
+import os
+import sys
import unittest
+
import numpy as np
+
from dpgen.data.tools.create_random_disturb import create_disturbs_abacus_dev
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'data'
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "data"
from .context import *
+
class TestPertAbacus(unittest.TestCase):
def setUp(self):
- create_disturbs_abacus_dev(abacus_stru_file,1)
+ create_disturbs_abacus_dev(abacus_stru_file, 1)
+
def tearDown(self):
- if os.path.isfile('STRU.hcp1.abacus'):
- os.remove('STRU.hcp1.abacus')
+ if os.path.isfile("STRU.hcp1.abacus"):
+ os.remove("STRU.hcp1.abacus")
+
def test_stru(self):
- if os.path.isfile('STRU.hcp1.abacus'):
- stru1 = get_abacus_STRU('STRU.hcp1.abacus')
+ if os.path.isfile("STRU.hcp1.abacus"):
+ stru1 = get_abacus_STRU("STRU.hcp1.abacus")
stru0 = get_abacus_STRU(abacus_stru_file)
- self.assertEqual(stru0['atom_names'],stru1['atom_names'])
- self.assertEqual(stru0['atom_numbs'],stru1['atom_numbs'])
- self.assertEqual(stru0['atom_masses'],stru1['atom_masses'])
- coords = stru1['coords']
- cells = stru1['cells']
+ self.assertEqual(stru0["atom_names"], stru1["atom_names"])
+ self.assertEqual(stru0["atom_numbs"], stru1["atom_numbs"])
+ self.assertEqual(stru0["atom_masses"], stru1["atom_masses"])
+ coords = stru1["coords"]
+ cells = stru1["cells"]
mindis = 100
minm = minn = mini = minj = mink = 0
maxdis = 0
volume = np.linalg.det(np.array(cells))
for m in range(len(coords)):
- x1,y1,z1 = coords[m]
-
- for n in range(m,len(coords)):
- for i in range(-1,2):
- for j in range(-1,2):
- for k in range(-1,2):
- if m==n and i==0 and j==0 and k==0:continue
- x2 = coords[n][0] + i * cells[0][0] + j * cells[1][0] + k * cells[2][0]
- y2 = coords[n][1] + i * cells[0][1] + j * cells[1][1] + k * cells[2][1]
- z2 = coords[n][2] + i * cells[0][2] + j * cells[1][2] + k * cells[2][2]
-
- distance = ((x1-x2)**2 + (y1-y2)**2 + (z1-z2)**2)**0.5
+ x1, y1, z1 = coords[m]
+
+ for n in range(m, len(coords)):
+ for i in range(-1, 2):
+ for j in range(-1, 2):
+ for k in range(-1, 2):
+ if m == n and i == 0 and j == 0 and k == 0:
+ continue
+ x2 = (
+ coords[n][0]
+ + i * cells[0][0]
+ + j * cells[1][0]
+ + k * cells[2][0]
+ )
+ y2 = (
+ coords[n][1]
+ + i * cells[0][1]
+ + j * cells[1][1]
+ + k * cells[2][1]
+ )
+ z2 = (
+ coords[n][2]
+ + i * cells[0][2]
+ + j * cells[1][2]
+ + k * cells[2][2]
+ )
+
+ distance = (
+ (x1 - x2) ** 2 + (y1 - y2) ** 2 + (z1 - z2) ** 2
+ ) ** 0.5
if distance < mindis:
mindis = distance
- self.assertTrue(volume>0.0)
- self.assertTrue(mindis>0.01)
+ self.assertTrue(volume > 0.0)
+ self.assertTrue(mindis > 0.01)
def test_FileExist(self):
- self.assertTrue(os.path.isfile('STRU.hcp1.abacus'))
+ self.assertTrue(os.path.isfile("STRU.hcp1.abacus"))
+
-if __name__ == '__main__':
+if __name__ == "__main__":
unittest.main()
diff --git a/tests/data/test_gen_bulk.py b/tests/data/test_gen_bulk.py
index 54a9cfd61..a8eefad87 100644
--- a/tests/data/test_gen_bulk.py
+++ b/tests/data/test_gen_bulk.py
@@ -1,31 +1,37 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-from pymatgen.core import Structure, Composition
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'data'
+from pymatgen.core import Composition, Structure
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "data"
from .context import setUpModule
from .context_bulk import *
+
class TestGenBulk(unittest.TestCase):
def setUp(self):
- self.alloy=[]
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
+ self.alloy = []
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
if "init_fp_style" not in jdata:
jdata["init_fp_style"] = "VASP"
out_dir = out_dir_name(jdata)
- self.out_dir= out_dir
- jdata['out_dir'] = out_dir
- self.elements=jdata["elements"]
- self.scale_numb=len(jdata["scale"])
- self.pert_numb=jdata["pert_numb"]
- self.root_dir= out_dir
+ self.out_dir = out_dir
+ jdata["out_dir"] = out_dir
+ self.elements = jdata["elements"]
+ self.scale_numb = len(jdata["scale"])
+ self.pert_numb = jdata["pert_numb"]
+ self.root_dir = out_dir
create_path(out_dir)
make_unit_cell(jdata)
make_super_cell(jdata)
place_element(jdata)
- make_vasp_relax(jdata,{"fp_resources":{}})
+ make_vasp_relax(jdata, {"fp_resources": {}})
make_scale(jdata)
pert_scaled(jdata)
@@ -33,28 +39,28 @@ def tearDown(self):
shutil.rmtree(self.root_dir)
def test(self):
- path=self.out_dir+"/00.place_ele"
- struct0=Structure.from_file(os.path.join(path,"POSCAR"))
- alloys=glob.glob(os.path.join(path,"sys-*"))
- self.assertEqual(len(alloys),len(struct0)-1)
+ path = self.out_dir + "/00.place_ele"
+ struct0 = Structure.from_file(os.path.join(path, "POSCAR"))
+ alloys = glob.glob(os.path.join(path, "sys-*"))
+ self.assertEqual(len(alloys), len(struct0) - 1)
for ii in alloys:
- elem_numb=[int(i) for i in ii.split('/')[-1].split('-')[1:]]
- comp=''
- for num, el in zip(elem_numb,self.elements):
- comp+=el+str(num)
- comp=Composition(comp)
- struct=Structure.from_file(os.path.join(ii,"POSCAR"))
- self.assertEqual(struct.composition,comp)
- path=self.out_dir+"/01.scale_pert"
- alloys=glob.glob(os.path.join(path,"sys-*"))
- self.assertEqual(len(alloys),len(struct0)-1)
+ elem_numb = [int(i) for i in ii.split("/")[-1].split("-")[1:]]
+ comp = ""
+ for num, el in zip(elem_numb, self.elements):
+ comp += el + str(num)
+ comp = Composition(comp)
+ struct = Structure.from_file(os.path.join(ii, "POSCAR"))
+ self.assertEqual(struct.composition, comp)
+ path = self.out_dir + "/01.scale_pert"
+ alloys = glob.glob(os.path.join(path, "sys-*"))
+ self.assertEqual(len(alloys), len(struct0) - 1)
for ii in alloys:
- scales=glob.glob(os.path.join(ii,"scale-*"))
- self.assertEqual(len(scales),self.scale_numb)
+ scales = glob.glob(os.path.join(ii, "scale-*"))
+ self.assertEqual(len(scales), self.scale_numb)
for scale in scales:
- perts=glob.glob(os.path.join(scale,"[0-9]*"))
- self.assertEqual(len(perts),self.pert_numb+1)
+ perts = glob.glob(os.path.join(scale, "[0-9]*"))
+ self.assertEqual(len(perts), self.pert_numb + 1)
-if __name__ == '__main__':
- unittest.main()
\ No newline at end of file
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tests/data/test_gen_bulk_abacus.py b/tests/data/test_gen_bulk_abacus.py
index 4ac7ef39f..7223db6cf 100644
--- a/tests/data/test_gen_bulk_abacus.py
+++ b/tests/data/test_gen_bulk_abacus.py
@@ -1,55 +1,88 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'data'
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "data"
from .context import setUpModule
from .context_bulk import *
+
class TestGenBulkABACUS(unittest.TestCase):
def setUp(self):
- self.alloy=[]
- with open (abacus_param_file, 'r') as fp :
- jdata = json.load (fp)
+ self.alloy = []
+ with open(abacus_param_file, "r") as fp:
+ jdata = json.load(fp)
out_dir = out_dir_name(jdata)
- self.out_dir= out_dir
- jdata['out_dir'] = out_dir
- self.elements=jdata["elements"]
- self.scale_numb=len(jdata["scale"])
- self.pert_numb=jdata["pert_numb"]
- self.root_dir= out_dir
+ self.out_dir = out_dir
+ jdata["out_dir"] = out_dir
+ self.elements = jdata["elements"]
+ self.scale_numb = len(jdata["scale"])
+ self.pert_numb = jdata["pert_numb"]
+ self.root_dir = out_dir
+ self.jdata = jdata
create_path(out_dir)
- stru_data = make_unit_cell_ABACUS(jdata)
- supercell_stru = make_super_cell_ABACUS(jdata, stru_data)
- place_element_ABACUS(jdata, supercell_stru)
- make_abacus_relax(jdata, {"fp_resources":{}})
- make_scale_ABACUS(jdata)
- pert_scaled(jdata)
def tearDown(self):
shutil.rmtree(self.root_dir)
def test(self):
- path=self.out_dir+"/00.place_ele"
- #struct0=Structure.from_file(os.path.join(path,"STRU"))
- alloys=glob.glob(os.path.join(path,"sys-*"))
+ jdata = self.jdata
+ stru_data = make_unit_cell_ABACUS(jdata)
+ supercell_stru = make_super_cell_ABACUS(jdata, stru_data)
+ place_element_ABACUS(jdata, supercell_stru)
+ make_abacus_relax(jdata, {"fp_resources": {}})
+ make_scale_ABACUS(jdata)
+ pert_scaled(jdata)
+ path = self.out_dir + "/00.place_ele"
+ # struct0=Structure.from_file(os.path.join(path,"STRU"))
+ alloys = glob.glob(os.path.join(path, "sys-*"))
+ stru0 = get_abacus_STRU(os.path.join(alloys[0], "STRU"))
+ self.assertEqual(len(alloys), stru0["coords"].shape[0] - 1)
+ for ii in alloys:
+ elem_numb = [int(i) for i in ii.split("/")[-1].split("-")[1:]]
+ struct = get_abacus_STRU(os.path.join(ii, "STRU"))
+ self.assertEqual(struct["atom_names"], self.elements)
+ self.assertEqual(struct["atom_numbs"], elem_numb)
+ path = self.out_dir + "/01.scale_pert"
+ alloys = glob.glob(os.path.join(path, "sys-*"))
+ self.assertEqual(len(alloys), stru0["coords"].shape[0] - 1)
+ for ii in alloys:
+ scales = glob.glob(os.path.join(ii, "scale-*"))
+ self.assertEqual(len(scales), self.scale_numb)
+ for scale in scales:
+ perts = glob.glob(os.path.join(scale, "[0-9]*"))
+ self.assertEqual(len(perts), self.pert_numb + 1)
+
+ def testSTRU(self):
+ jdata = self.jdata
+ jdata["from_poscar_path"] = "./Cu.STRU"
+ make_super_cell_STRU(jdata)
+ make_abacus_relax(jdata, {"fp_resources": {}})
+ make_scale_ABACUS(jdata)
+ pert_scaled(jdata)
+ path = self.out_dir + "/00.place_ele"
+ # struct0=Structure.from_file(os.path.join(path,"STRU"))
+ alloys = glob.glob(os.path.join(path, "sys-*"))
stru0 = get_abacus_STRU(os.path.join(alloys[0], "STRU"))
- self.assertEqual(len(alloys),stru0['coords'].shape[0]-1)
+ self.assertEqual(len(alloys), stru0["coords"].shape[0])
for ii in alloys:
- elem_numb=[int(i) for i in ii.split('/')[-1].split('-')[1:]]
- struct=get_abacus_STRU(os.path.join(ii,"STRU"))
- self.assertEqual(struct["atom_names"],self.elements)
+ elem_numb = [int(i) for i in ii.split("/")[-1].split("-")[1:]]
+ struct = get_abacus_STRU(os.path.join(ii, "STRU"))
self.assertEqual(struct["atom_numbs"], elem_numb)
- path=self.out_dir+"/01.scale_pert"
- alloys=glob.glob(os.path.join(path,"sys-*"))
- self.assertEqual(len(alloys), stru0['coords'].shape[0]-1)
+ path = self.out_dir + "/01.scale_pert"
+ alloys = glob.glob(os.path.join(path, "sys-*"))
+ self.assertEqual(len(alloys), stru0["coords"].shape[0])
for ii in alloys:
- scales=glob.glob(os.path.join(ii,"scale-*"))
- self.assertEqual(len(scales),self.scale_numb)
+ scales = glob.glob(os.path.join(ii, "scale-*"))
+ self.assertEqual(len(scales), self.scale_numb)
for scale in scales:
- perts=glob.glob(os.path.join(scale,"[0-9]*"))
- self.assertEqual(len(perts),self.pert_numb+1)
+ perts = glob.glob(os.path.join(scale, "[0-9]*"))
+ self.assertEqual(len(perts), self.pert_numb + 1)
-if __name__ == '__main__':
- unittest.main()
\ No newline at end of file
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tests/data/test_gen_surf.py b/tests/data/test_gen_surf.py
index d40f6e1ab..e1a484d9b 100644
--- a/tests/data/test_gen_surf.py
+++ b/tests/data/test_gen_surf.py
@@ -1,50 +1,68 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-from pymatgen.core import Structure, Element
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'data'
+from pymatgen.core import Element, Structure
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "data"
from .context import setUpModule
from .context_surf import *
+
class TestGenSurf(unittest.TestCase):
def setUp(self):
- self.surfs=["surf-100"]
- self.elongs=["elong-0.500", "elong-1.000", "elong-1.500", "elong-2.000", "elong-2.500",\
- "elong-3.000", "elong-3.500", "elong-4.000", "elong-5.000", "elong-6.000",\
- "elong-7.000", "elong-8.000" ]
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
+ self.surfs = ["surf-100"]
+ self.elongs = [
+ "elong-0.500",
+ "elong-1.000",
+ "elong-1.500",
+ "elong-2.000",
+ "elong-2.500",
+ "elong-3.000",
+ "elong-3.500",
+ "elong-4.000",
+ "elong-5.000",
+ "elong-6.000",
+ "elong-7.000",
+ "elong-8.000",
+ ]
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
out_dir = out_dir_name(jdata)
- jdata['out_dir'] = out_dir
- self.root_dir= out_dir
+ jdata["out_dir"] = out_dir
+ self.root_dir = out_dir
create_path(out_dir)
make_super_cell_pymatgen(jdata)
place_element(jdata)
make_vasp_relax(jdata)
make_scale(jdata)
pert_scaled(jdata)
- self.jdata=jdata
+ self.jdata = jdata
def tearDown(self):
shutil.rmtree(self.root_dir)
def test(self):
- surfs=glob.glob("surf.al.fcc.01x01x01/00.place_ele/surf*")
- surfs=[ii.split('/')[-1] for ii in surfs]
+ surfs = glob.glob("surf.al.fcc.01x01x01/00.place_ele/surf*")
+ surfs = [ii.split("/")[-1] for ii in surfs]
surfs.sort()
- self.assertEqual(surfs,self.surfs)
- poscars=glob.glob("surf.al.fcc.01x01x01/00.place_ele/surf*/sys*/POSCAR")
+ self.assertEqual(surfs, self.surfs)
+ poscars = glob.glob("surf.al.fcc.01x01x01/00.place_ele/surf*/sys*/POSCAR")
for poscar in poscars:
- surf=poscar.split('/')[-3]
- st1=Structure.from_file(surf+'.POSCAR')
- st2=Structure.from_file(poscar)
- vacuum_size=float(Element(self.jdata['elements'][0]).atomic_radius*2)
- self.assertTrue(st1.lattice.c+vacuum_size-st2.lattice.c<0.01)
-
+ surf = poscar.split("/")[-3]
+ st1 = Structure.from_file(surf + ".POSCAR")
+ st2 = Structure.from_file(poscar)
+ vacuum_size = float(Element(self.jdata["elements"][0]).atomic_radius * 2)
+ self.assertTrue(st1.lattice.c + vacuum_size - st2.lattice.c < 0.01)
+
for surf in self.surfs:
- elongs=glob.glob("surf.al.fcc.01x01x01/01.scale_pert/"+surf+"/sys-*/scale-1.000/el*")
- elongs=[ii.split('/')[-1] for ii in elongs]
+ elongs = glob.glob(
+ "surf.al.fcc.01x01x01/01.scale_pert/" + surf + "/sys-*/scale-1.000/el*"
+ )
+ elongs = [ii.split("/")[-1] for ii in elongs]
elongs.sort()
- self.assertEqual(elongs,self.elongs)
-
+ self.assertEqual(elongs, self.elongs)
diff --git a/tests/data/test_gen_surf_poscar.py b/tests/data/test_gen_surf_poscar.py
index b47cb308b..89ebfc33c 100644
--- a/tests/data/test_gen_surf_poscar.py
+++ b/tests/data/test_gen_surf_poscar.py
@@ -1,50 +1,61 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-from pymatgen.core import Structure, Element
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'data'
+from pymatgen.core import Element, Structure
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "data"
from .context import setUpModule
from .context_surf_poscar import *
+
class TestGenSurfPOSCAR(unittest.TestCase):
def setUp(self):
- self.surfs=["surf-100"]
- self.elongs=["elong-0.500", "elong-1.000", "elong-1.500",
- "elong-2.000", "elong-4.000"]
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
+ self.surfs = ["surf-100"]
+ self.elongs = [
+ "elong-0.500",
+ "elong-1.000",
+ "elong-1.500",
+ "elong-2.000",
+ "elong-4.000",
+ ]
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
out_dir = out_dir_name(jdata)
- jdata['out_dir'] = out_dir
- self.root_dir= out_dir
+ jdata["out_dir"] = out_dir
+ self.root_dir = out_dir
create_path(out_dir)
make_super_cell_pymatgen(jdata)
place_element(jdata)
make_vasp_relax(jdata)
make_scale(jdata)
pert_scaled(jdata)
- self.jdata=jdata
+ self.jdata = jdata
def tearDown(self):
shutil.rmtree(self.root_dir)
def test(self):
- surfs=glob.glob("POSCAR.01x01x01/01.scale_pert/surf*")
- surfs=[ii.split('/')[-1] for ii in surfs]
+ surfs = glob.glob("POSCAR.01x01x01/01.scale_pert/surf*")
+ surfs = [ii.split("/")[-1] for ii in surfs]
surfs.sort()
- self.assertEqual(surfs,self.surfs)
- poscars=glob.glob("POSCAR.01x01x01/00.place_ele/surf*/sys*/POSCAR")
+ self.assertEqual(surfs, self.surfs)
+ poscars = glob.glob("POSCAR.01x01x01/00.place_ele/surf*/sys*/POSCAR")
for poscar in poscars:
- surf=poscar.split('/')[-3]
- st1=Structure.from_file(surf+'.POSCAR')
- st2=Structure.from_file(poscar)
- vacuum_size=float(Element(self.jdata['elements'][0]).atomic_radius*2)
- self.assertTrue(st1.lattice.c+vacuum_size-st2.lattice.c<0.01)
+ surf = poscar.split("/")[-3]
+ st1 = Structure.from_file(surf + ".POSCAR")
+ st2 = Structure.from_file(poscar)
+ vacuum_size = float(Element(self.jdata["elements"][0]).atomic_radius * 2)
+ self.assertTrue(st1.lattice.c + vacuum_size - st2.lattice.c < 0.01)
-
for surf in self.surfs:
- elongs=glob.glob("POSCAR.01x01x01/01.scale_pert/"+surf+"/sys-*/scale-1.000/el*")
- elongs=[ii.split('/')[-1] for ii in elongs]
+ elongs = glob.glob(
+ "POSCAR.01x01x01/01.scale_pert/" + surf + "/sys-*/scale-1.000/el*"
+ )
+ elongs = [ii.split("/")[-1] for ii in elongs]
elongs.sort()
- self.assertEqual(elongs,self.elongs)
-
+ self.assertEqual(elongs, self.elongs)
diff --git a/tests/database/context.py b/tests/database/context.py
index 6454ada0a..fbe0aa186 100644
--- a/tests/database/context.py
+++ b/tests/database/context.py
@@ -1,9 +1,12 @@
-import sys,os
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..','..')))
+import os
+import sys
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
import dpgen
from dpgen.database.entry import Entry
from dpgen.database.run import parsing_vasp
-from dpgen.database.vasp import VaspInput,DPPotcar
+from dpgen.database.vasp import DPPotcar, VaspInput
+
def setUpModule():
os.chdir(os.path.abspath(os.path.dirname(__file__)))
diff --git a/tests/database/test_db_vasp.py b/tests/database/test_db_vasp.py
index 9e5251880..17fe7f0fd 100644
--- a/tests/database/test_db_vasp.py
+++ b/tests/database/test_db_vasp.py
@@ -1,156 +1,162 @@
-import os,sys,shutil
-import unittest
import json
-import numpy as np
+import os
+import shutil
+import sys
import tarfile
+import unittest
from glob import glob
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'database'
-from .context import dpgen
-from .context import Entry
-from .context import VaspInput,DPPotcar
-from .context import parsing_vasp
-from dpdata import System,LabeledSystem
-from monty.shutil import remove
-from monty.serialization import loadfn,dumpfn
-from pymatgen.io.vasp import Potcar,Poscar,Incar,Kpoints
-from .context import setUpModule
-
-iter_pat="02.fp/task.007.00000*"
-init_pat="al.bcc.02x02x02/02.md/sys-0016/scale-1.000/00000*"
-
-def tar_file(path,outdir='.'):
+import numpy as np
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "database"
+from dpdata import LabeledSystem, System
+from monty.serialization import dumpfn, loadfn
+from monty.shutil import remove
+from pymatgen.io.vasp import Incar, Kpoints, Poscar, Potcar
+
+from .context import DPPotcar, Entry, VaspInput, dpgen, parsing_vasp, setUpModule
+
+iter_pat = "02.fp/task.007.00000*"
+init_pat = "al.bcc.02x02x02/02.md/sys-0016/scale-1.000/00000*"
+
+
+def tar_file(path, outdir="."):
tar = tarfile.open(path)
names = tar.getnames()
for name in names:
- tar.extract(name,path=outdir)
+ tar.extract(name, path=outdir)
tar.close()
class Test(unittest.TestCase):
def setUp(self):
- self.cwd=os.getcwd()
- self.r_init_path=os.path.join(self.cwd,'init')
- self.data=os.path.join(self.cwd,'data')
- self.r_iter_path=os.path.join(self.cwd,'iter.000000')
- for path in [self.r_init_path, self.r_iter_path]+[self.data]:
- if os.path.isdir(path) :
- shutil.rmtree(path)
- tar_file(path+'.tar.gz')
- assert os.path.isdir(path)
- self.ref_init_input=loadfn(os.path.join(self.cwd,'data/init_input.json'))
- self.ref_entries=loadfn(os.path.join(self.cwd,'data/entries.json'))
- self.init_path=sorted(glob(os.path.join(self.r_init_path,init_pat)))
- self.iter_path=sorted(glob(os.path.join(self.r_iter_path,iter_pat)))
+ self.cwd = os.getcwd()
+ self.r_init_path = os.path.join(self.cwd, "init")
+ self.data = os.path.join(self.cwd, "data")
+ self.r_iter_path = os.path.join(self.cwd, "iter.000000")
+ for path in [self.r_init_path, self.r_iter_path] + [self.data]:
+ if os.path.isdir(path):
+ shutil.rmtree(path)
+ tar_file(path + ".tar.gz")
+ assert os.path.isdir(path)
+ self.ref_init_input = loadfn(os.path.join(self.cwd, "data/init_input.json"))
+ self.ref_entries = loadfn(os.path.join(self.cwd, "data/entries.json"))
+ self.init_path = sorted(glob(os.path.join(self.r_init_path, init_pat)))
+ self.iter_path = sorted(glob(os.path.join(self.r_iter_path, iter_pat)))
with open("param_Al.json", "r") as fr:
- jdata = json.load(fr)
+ jdata = json.load(fr)
self.config_info_dict = jdata["config_info_dict"]
self.skip_init = jdata["skip_init"]
self.output = jdata["output"]
def testDPPotcar(self):
-
- refd={'@module': 'dpgen.database.vasp',
- '@class': 'DPPotcar',
- 'symbols': ['Al'],
- 'elements': ['Al'],
- 'hashs': '',
- 'functional': 'PBE'}
+
+ refd = {
+ "@module": "dpgen.database.vasp",
+ "@class": "DPPotcar",
+ "symbols": ["Al"],
+ "elements": ["Al"],
+ "hashs": "",
+ "functional": "PBE",
+ }
try:
- Potcar(['Al'])
- #ps TITEL = PAW_PBE Al 04Jan2001
- refd.update({'hashs':['9aafba2c552fad8414179cae2e888e67']})
+ Potcar(["Al"])
+ # ps TITEL = PAW_PBE Al 04Jan2001
+ refd.update({"hashs": ["9aafba2c552fad8414179cae2e888e67"]})
except Exception:
- pass
-
- for f in self.init_path+self.iter_path:
- fpp=os.path.join(f,'POTCAR')
- pp=DPPotcar.from_file(fpp)
- self.assertEqual( pp.elements, refd['elements'])
- self.assertEqual( pp.symbols, refd['symbols'])
- self.assertEqual( pp.hashs, refd['hashs'])
- self.assertEqual( pp.functional, refd['functional'])
- self.assertEqual( pp.as_dict(), refd)
-
+ pass
+
+ for f in self.init_path + self.iter_path:
+ fpp = os.path.join(f, "POTCAR")
+ pp = DPPotcar.from_file(fpp)
+ self.assertEqual(pp.elements, refd["elements"])
+ self.assertEqual(pp.symbols, refd["symbols"])
+ self.assertEqual(pp.hashs, refd["hashs"])
+ self.assertEqual(pp.functional, refd["functional"])
+ self.assertEqual(pp.as_dict(), refd)
+
def testVaspInput(self):
for f in self.init_path:
- vi=VaspInput.from_directory(f)
- self.assertEqual(vi['INCAR'],self.ref_init_input['INCAR'])
- self.assertEqual(str(vi['POTCAR']),str(self.ref_init_input['POTCAR']))
- self.assertEqual(vi['POSCAR'].structure,self.ref_init_input['POSCAR'].structure)
+ vi = VaspInput.from_directory(f)
+ self.assertEqual(vi["INCAR"], self.ref_init_input["INCAR"])
+ self.assertEqual(str(vi["POTCAR"]), str(self.ref_init_input["POTCAR"]))
+ self.assertEqual(
+ vi["POSCAR"].structure, self.ref_init_input["POSCAR"].structure
+ )
def testEntry(self):
- entries=[]
- for i,f in enumerate(self.iter_path):
- vi=VaspInput.from_directory(f)
- ls=LabeledSystem(os.path.join(f,'OUTCAR'))
- attrib=loadfn(os.path.join(f,'job.json'))
- comp=vi['POSCAR'].structure.composition
- entry=Entry(comp,
- 'vasp',
- vi.as_dict(),
- ls.as_dict(),
- entry_id='pku-'+str(i),
- attribute=attrib)
+ entries = []
+ for i, f in enumerate(self.iter_path):
+ vi = VaspInput.from_directory(f)
+ ls = LabeledSystem(os.path.join(f, "OUTCAR"))
+ attrib = loadfn(os.path.join(f, "job.json"))
+ comp = vi["POSCAR"].structure.composition
+ entry = Entry(
+ comp,
+ "vasp",
+ vi.as_dict(),
+ ls.as_dict(),
+ entry_id="pku-" + str(i),
+ attribute=attrib,
+ )
entries.append(entry)
- self.assertEqual( len(entries), len(self.ref_entries))
- ret0=entries[0]
- r0=self.ref_entries[0]
+ self.assertEqual(len(entries), len(self.ref_entries))
+ ret0 = entries[0]
+ r0 = self.ref_entries[0]
self.assertEqual(
- Incar.from_dict(ret0.inputs['INCAR']),
- Incar.from_dict(r0.inputs['INCAR'])
- )
+ Incar.from_dict(ret0.inputs["INCAR"]), Incar.from_dict(r0.inputs["INCAR"])
+ )
self.assertEqual(
- str(r0.inputs['KPOINTS']),
- str(Kpoints.from_dict(ret0.inputs['KPOINTS']))
- )
+ str(r0.inputs["KPOINTS"]), str(Kpoints.from_dict(ret0.inputs["KPOINTS"]))
+ )
+ self.assertEqual(ret0.inputs["POTCAR"], r0.inputs["POTCAR"].as_dict())
self.assertEqual(
- ret0.inputs['POTCAR'],
- r0.inputs['POTCAR'].as_dict()
- )
- self.assertEqual(
- Poscar.from_dict(ret0.inputs['POSCAR']).structure,
- r0.inputs['POSCAR'].structure
- )
- self.assertEqual(ret0.entry_id,'pku-0')
+ Poscar.from_dict(ret0.inputs["POSCAR"]).structure,
+ r0.inputs["POSCAR"].structure,
+ )
+ self.assertEqual(ret0.entry_id, "pku-0")
def testParsingVasp(self):
- parsing_vasp(self.cwd, self.config_info_dict, self.skip_init,self.output, id_prefix=dpgen.SHORT_CMD )
- #try:
+ parsing_vasp(
+ self.cwd,
+ self.config_info_dict,
+ self.skip_init,
+ self.output,
+ id_prefix=dpgen.SHORT_CMD,
+ )
+ # try:
# Potcar(['Al'])
# ref=os.path.join(self.cwd,'data/all_data_pp.json')
- #except Exception:
+ # except Exception:
# ref=os.path.join(self.cwd,'data/all_data.json')
- #Potcar(['Al'])
- ref=os.path.join(self.cwd,'data/all_data_pp.json')
-
- ret=os.path.join(self.cwd,'dpgen_db.json')
-
- retd=loadfn(ret)
- retd=sorted(retd,key= lambda x: int(x.entry_id.split('_')[-1]))
-
- refd=loadfn(ref)
- refd=sorted(refd,key= lambda x: int(x.entry_id.split('_')[-1]))
- self.assertEqual(len(retd),len(refd))
- for i,j in zip(retd,refd):
- self.assertEqual(i.entry_id,j.entry_id)
- self.assertEqual(i.calculator,j.calculator)
- self.assertEqual(len(i.data),len(j.data))
- self.assertEqual(i.number_element , j.number_element )
- self.assertEqual(i.entry_id , j.entry_id )
- self.assertEqual(len(i.composition),len(j.composition))
- self.assertEqual(len(i.attribute),len(j.attribute))
- os.remove(os.path.join(self.cwd,'dpgen_db.json'))
-
+ # Potcar(['Al'])
+ ref = os.path.join(self.cwd, "data/all_data_pp.json")
+
+ ret = os.path.join(self.cwd, "dpgen_db.json")
+
+ retd = loadfn(ret)
+ retd = sorted(retd, key=lambda x: int(x.entry_id.split("_")[-1]))
+
+ refd = loadfn(ref)
+ refd = sorted(refd, key=lambda x: int(x.entry_id.split("_")[-1]))
+ self.assertEqual(len(retd), len(refd))
+ for i, j in zip(retd, refd):
+ self.assertEqual(i.entry_id, j.entry_id)
+ self.assertEqual(i.calculator, j.calculator)
+ self.assertEqual(len(i.data), len(j.data))
+ self.assertEqual(i.number_element, j.number_element)
+ self.assertEqual(i.entry_id, j.entry_id)
+ self.assertEqual(len(i.composition), len(j.composition))
+ self.assertEqual(len(i.attribute), len(j.attribute))
+ os.remove(os.path.join(self.cwd, "dpgen_db.json"))
def tearDown(self):
for path in [self.r_init_path, self.r_iter_path, self.data]:
- if os.path.isdir(path) :
- shutil.rmtree(path)
+ if os.path.isdir(path):
+ shutil.rmtree(path)
if os.path.isfile("dpgen.log"):
- os.remove("dpgen.log")
+ os.remove("dpgen.log")
if os.path.isfile("record.database"):
- os.remove("record.database")
-
+ os.remove("record.database")
diff --git a/tests/dispatcher/context.py b/tests/dispatcher/context.py
deleted file mode 100644
index 1ab29dc9a..000000000
--- a/tests/dispatcher/context.py
+++ /dev/null
@@ -1,16 +0,0 @@
-import sys,os
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
-
-from dpgen.dispatcher.LocalContext import LocalSession
-from dpgen.dispatcher.LocalContext import LocalContext
-from dpgen.dispatcher.LazyLocalContext import LazyLocalContext
-from dpgen.dispatcher.SSHContext import SSHSession
-from dpgen.dispatcher.SSHContext import SSHContext
-# from dpgen.dispatcher.Dispatcher import FinRecord
-from dpgen.dispatcher.Dispatcher import _split_tasks
-
-from dpgen.dispatcher.LocalContext import _identical_files
-
-def setUpModule():
- os.chdir(os.path.abspath(os.path.dirname(__file__)))
diff --git a/tests/dispatcher/loc/task0/dir0/test2 b/tests/dispatcher/loc/task0/dir0/test2
deleted file mode 100644
index 48e9eaa49..000000000
--- a/tests/dispatcher/loc/task0/dir0/test2
+++ /dev/null
@@ -1 +0,0 @@
-140c75e5-993c-4644-b877-cd3ceb2b254a
\ No newline at end of file
diff --git a/tests/dispatcher/loc/task0/test0 b/tests/dispatcher/loc/task0/test0
deleted file mode 100644
index 2271a069f..000000000
--- a/tests/dispatcher/loc/task0/test0
+++ /dev/null
@@ -1 +0,0 @@
-dfea7618-49df-42ac-b723-f7c04e349203
\ No newline at end of file
diff --git a/tests/dispatcher/loc/task0/test1 b/tests/dispatcher/loc/task0/test1
deleted file mode 100644
index 8b014a575..000000000
--- a/tests/dispatcher/loc/task0/test1
+++ /dev/null
@@ -1 +0,0 @@
-99cee2e2-0de4-43ba-a296-805f4e551ace
\ No newline at end of file
diff --git a/tests/dispatcher/loc/task1/dir0/test2 b/tests/dispatcher/loc/task1/dir0/test2
deleted file mode 100644
index abb717f2c..000000000
--- a/tests/dispatcher/loc/task1/dir0/test2
+++ /dev/null
@@ -1 +0,0 @@
-0d7eaf5f-0a04-492a-b9ae-c7d77781c928
\ No newline at end of file
diff --git a/tests/dispatcher/loc/task1/test0 b/tests/dispatcher/loc/task1/test0
deleted file mode 100644
index c44e41aff..000000000
--- a/tests/dispatcher/loc/task1/test0
+++ /dev/null
@@ -1 +0,0 @@
-b96519be-c495-4150-b634-39b61b54ffd9
\ No newline at end of file
diff --git a/tests/dispatcher/loc/task1/test1 b/tests/dispatcher/loc/task1/test1
deleted file mode 100644
index 514520d9d..000000000
--- a/tests/dispatcher/loc/task1/test1
+++ /dev/null
@@ -1 +0,0 @@
-00bc5947-dfb6-47e4-909e-3c647b551c82
\ No newline at end of file
diff --git a/tests/dispatcher/lsf/context.py b/tests/dispatcher/lsf/context.py
deleted file mode 100644
index bddf23c43..000000000
--- a/tests/dispatcher/lsf/context.py
+++ /dev/null
@@ -1,19 +0,0 @@
-import sys,os
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..', '..')))
-
-from dpgen.dispatcher.LocalContext import LocalSession
-from dpgen.dispatcher.SSHContext import SSHSession
-from dpgen.dispatcher.LocalContext import LocalContext
-from dpgen.dispatcher.SSHContext import SSHContext
-from dpgen.dispatcher.LSF import LSF
-from dpgen.dispatcher.Dispatcher import Dispatcher
-from dpgen.dispatcher.JobStatus import JobStatus
-
-def my_file_cmp(test, f0, f1):
- with open(f0) as fp0 :
- with open(f1) as fp1:
- test.assertTrue(fp0.read() == fp1.read())
-
-def setUpModule():
- os.chdir(os.path.abspath(os.path.dirname(__file__)))
diff --git a/tests/dispatcher/lsf/test_dispatcher.py b/tests/dispatcher/lsf/test_dispatcher.py
deleted file mode 100644
index 7f0cff086..000000000
--- a/tests/dispatcher/lsf/test_dispatcher.py
+++ /dev/null
@@ -1,46 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'lsf'
-from .context import LocalSession
-from .context import LocalContext
-from .context import LSF
-from .context import JobStatus
-from .context import Dispatcher
-from .context import my_file_cmp
-from .context import setUpModule
-
-class TestDispatcher(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- os.makedirs('loc/task2', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1', 'loc/task2']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write('this is test0 from ' + ii + '\n')
- work_profile = {'work_path':'rmt'}
- self.disp = Dispatcher(work_profile, 'local', 'lsf')
-
- @unittest.skipIf(not shutil.which("bsub"), "requires LSF")
- def test_sub_success(self):
- tasks = ['task0', 'task1', 'task2']
- self.disp.run_jobs(None,
- 'cp test0 test1',
- 'loc',
- tasks,
- 2,
- [],
- ['test0'],
- ['test1', 'hereout.log', 'hereerr.log'],
- outlog = 'hereout.log',
- errlog = 'hereerr.log')
- for ii in tasks:
- my_file_cmp(self,
- os.path.join('loc', ii, 'test0'),
- os.path.join('loc', ii, 'test1'))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereout.log')))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereerr.log')))
-
diff --git a/tests/dispatcher/lsf/test_lsf_local.py b/tests/dispatcher/lsf/test_lsf_local.py
deleted file mode 100644
index e036042b4..000000000
--- a/tests/dispatcher/lsf/test_lsf_local.py
+++ /dev/null
@@ -1,106 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'lsf'
-from .context import LocalSession
-from .context import LocalContext
-from .context import LSF
-from .context import JobStatus
-from .context import setUpModule
-
-class TestLSF(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- work_profile = LocalSession({'work_path':'rmt'})
- self.ctx = LocalContext('loc', work_profile)
- self.lsf = LSF(self.ctx)
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
- if os.path.exists('dpgen.log'):
- os.remove('dpgen.log')
-
- def test_gen_sub_script(self):
- job_dirs = ['task0', 'task1']
- self.lsf.context.upload(job_dirs, ['test0'])
- ret = self.lsf.sub_script(job_dirs, ['touch test1', 'touch test2'])
- self.lsf.context.write_file('run.sub', ret)
- with open('run.sub', 'w') as fp:
- fp.write(ret)
-
- @unittest.skipIf(not shutil.which("bsub"), "requires LSF")
- def test_sub_success(self) :
- job_dirs = ['task0', 'task1']
- self.lsf.context.upload(job_dirs, ['test0'])
- self.lsf.submit(job_dirs, ['touch test1', 'touch test2'])
- while True:
- ret = self.lsf.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'tag_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/test2')))
-
- @unittest.skipIf(not shutil.which("bsub"), "requires LSF")
- def test_sub_bkill(self) :
- job_dirs = ['task0', 'task1']
- self.lsf.context.upload(job_dirs, ['test0'])
- # sub
- self.lsf.submit(job_dirs, ['touch test1', 'sleep 10'])
- while True:
- ret = self.lsf.check_status()
- if ret == JobStatus.finished :
- raise RuntimeError('should not finished')
- if ret == JobStatus.running :
- # wait for file writing
- time.sleep(2)
- job_id = self.lsf._get_job_id()
- os.system('bkill ' + job_id)
- break
- time.sleep(1)
- while True:
- ret = self.lsf.check_status()
- if ret == JobStatus.terminated :
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/tag_1_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'tag_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/test1')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/test2')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/test2')))
- # sub restart
- self.lsf.submit(job_dirs, ['rm test1', 'touch test2'], restart = True)
- while True:
- ret = self.lsf.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'tag_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.lsf.context.remote_root, 'task1/test2')))
-
diff --git a/tests/dispatcher/pbs/context.py b/tests/dispatcher/pbs/context.py
deleted file mode 100644
index b9b96469e..000000000
--- a/tests/dispatcher/pbs/context.py
+++ /dev/null
@@ -1,19 +0,0 @@
-import sys,os
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..', '..')))
-
-from dpgen.dispatcher.LocalContext import LocalSession
-from dpgen.dispatcher.SSHContext import SSHSession
-from dpgen.dispatcher.LocalContext import LocalContext
-from dpgen.dispatcher.SSHContext import SSHContext
-from dpgen.dispatcher.PBS import PBS
-from dpgen.dispatcher.Dispatcher import Dispatcher
-from dpgen.dispatcher.JobStatus import JobStatus
-
-def my_file_cmp(test, f0, f1):
- with open(f0) as fp0 :
- with open(f1) as fp1:
- test.assertTrue(fp0.read() == fp1.read())
-
-def setUpModule():
- os.chdir(os.path.abspath(os.path.dirname(__file__)))
diff --git a/tests/dispatcher/pbs/test_dispatcher.py b/tests/dispatcher/pbs/test_dispatcher.py
deleted file mode 100644
index 94832d24a..000000000
--- a/tests/dispatcher/pbs/test_dispatcher.py
+++ /dev/null
@@ -1,46 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'pbs'
-from .context import LocalSession
-from .context import LocalContext
-from .context import PBS
-from .context import JobStatus
-from .context import Dispatcher
-from .context import my_file_cmp
-from .context import setUpModule
-
-@unittest.skipIf(not shutil.which("qsub"), "requires PBS")
-class TestDispatcher(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- os.makedirs('loc/task2', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1', 'loc/task2']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write('this is test0 from ' + ii + '\n')
- work_profile = {'work_path':'rmt'}
- self.disp = Dispatcher(work_profile, 'local', 'pbs')
-
- def test_sub_success(self):
- tasks = ['task0', 'task1', 'task2']
- self.disp.run_jobs(None,
- 'cp test0 test1',
- 'loc',
- tasks,
- 2,
- [],
- ['test0'],
- ['test1', 'hereout.log', 'hereerr.log'],
- outlog = 'hereout.log',
- errlog = 'hereerr.log')
- for ii in tasks:
- my_file_cmp(self,
- os.path.join('loc', ii, 'test0'),
- os.path.join('loc', ii, 'test1'))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereout.log')))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereerr.log')))
-
diff --git a/tests/dispatcher/pbs/test_pbs_local.py b/tests/dispatcher/pbs/test_pbs_local.py
deleted file mode 100644
index 9ffc68c47..000000000
--- a/tests/dispatcher/pbs/test_pbs_local.py
+++ /dev/null
@@ -1,100 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'pbs'
-from .context import LocalSession
-from .context import LocalContext
-from .context import PBS
-from .context import JobStatus
-from .context import setUpModule
-
-@unittest.skipIf(not shutil.which("qsub"), "requires PBS")
-class TestPBS(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- work_profile = LocalSession({'work_path':'rmt'})
- self.ctx = LocalContext('loc', work_profile)
- self.pbs = PBS(self.ctx)
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
- if os.path.exists('dpgen.log'):
- os.remove('dpgen.log')
-
- def test_gen_sub_script(self):
- job_dirs = ['task0', 'task1']
- self.pbs.context.upload(job_dirs, ['test0'])
- ret = self.pbs.sub_script(job_dirs, ['touch test1', 'touch test2'])
- self.pbs.context.write_file('run.sub', ret)
- with open('run.sub', 'w') as fp:
- fp.write(ret)
-
- # def test_sub_success(self) :
- # job_dirs = ['task0', 'task1']
- # self.pbs.context.upload(job_dirs, ['test0'])
- # self.pbs.submit(job_dirs, ['touch test1', 'touch test2'])
- # while True:
- # ret = self.pbs.check_status()
- # if ret == JobStatus.finished :
- # break
- # time.sleep(1)
- # self.assertTrue(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/tag_0_finished')))
- # self.assertTrue(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/tag_1_finished')))
- # self.assertTrue(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/tag_0_finished')))
- # self.assertTrue(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/tag_1_finished')))
- # self.assertTrue(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'tag_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/test1')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/test1')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/test2')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/test2')))
-
- # def test_sub_scancel(self) :
- # job_dirs = ['task0', 'task1']
- # self.pbs.context.upload(job_dirs, ['test0'])
- # # sub
- # self.pbs.submit(job_dirs, ['touch test1', 'sleep 10'])
- # while True:
- # ret = self.pbs.check_status()
- # if ret == JobStatus.finished :
- # raise RuntimeError('should not finished')
- # if ret == JobStatus.running :
- # # wait for file writing
- # time.sleep(2)
- # job_id = self.pbs._get_job_id()
- # os.system('scancel ' + job_id)
- # break
- # time.sleep(1)
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/tag_0_finished')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/tag_1_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/tag_0_finished')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/tag_1_finished')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'tag_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/test1')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/test1')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/test2')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/test2')))
- # # sub restart
- # self.pbs.submit(job_dirs, ['rm test1', 'touch test2'], restart = True)
- # while True:
- # ret = self.pbs.check_status()
- # if ret == JobStatus.finished :
- # break
- # time.sleep(1)
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/tag_0_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/tag_1_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/tag_0_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/tag_1_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'tag_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/test1')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/test1')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task0/test2')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.pbs.context.remote_root, 'task1/test2')))
-
diff --git a/tests/dispatcher/shell/context.py b/tests/dispatcher/shell/context.py
deleted file mode 100644
index f9ceec793..000000000
--- a/tests/dispatcher/shell/context.py
+++ /dev/null
@@ -1,20 +0,0 @@
-import sys,os
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..', '..')))
-
-from dpgen.dispatcher.SSHContext import SSHSession
-from dpgen.dispatcher.SSHContext import SSHContext
-from dpgen.dispatcher.LocalContext import LocalSession
-from dpgen.dispatcher.LocalContext import LocalContext
-from dpgen.dispatcher.Shell import Shell
-from dpgen.dispatcher.JobStatus import JobStatus
-from dpgen.dispatcher.Dispatcher import Dispatcher
-
-def my_file_cmp(test, f0, f1):
- with open(f0) as fp0 :
- with open(f1) as fp1:
- test.assertTrue(fp0.read() == fp1.read())
-
-def setUpModule():
- os.chdir(os.path.abspath(os.path.dirname(__file__)))
-
diff --git a/tests/dispatcher/shell/test_dispatcher.py b/tests/dispatcher/shell/test_dispatcher.py
deleted file mode 100644
index 6d7b642ab..000000000
--- a/tests/dispatcher/shell/test_dispatcher.py
+++ /dev/null
@@ -1,45 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'shell'
-from .context import LocalSession
-from .context import LocalContext
-from .context import Shell
-from .context import JobStatus
-from .context import Dispatcher
-from .context import my_file_cmp
-from .context import setUpModule
-
-class TestDispatcher(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- os.makedirs('loc/task2', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1', 'loc/task2']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write('this is test0 from ' + ii + '\n')
- work_profile = {'work_path':'rmt'}
- self.disp = Dispatcher(work_profile, context_type = 'local', batch_type = 'shell')
-
- def test_sub_success(self):
- tasks = ['task0', 'task1', 'task2']
- self.disp.run_jobs(None,
- 'cp test0 test1',
- 'loc',
- tasks,
- 2,
- [],
- ['test0'],
- ['test1', 'hereout.log', 'hereerr.log'],
- outlog = 'hereout.log',
- errlog = 'hereerr.log')
- for ii in tasks:
- my_file_cmp(self,
- os.path.join('loc', ii, 'test0'),
- os.path.join('loc', ii, 'test1'))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereout.log')))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereerr.log')))
-
diff --git a/tests/dispatcher/shell/test_shell_local.py b/tests/dispatcher/shell/test_shell_local.py
deleted file mode 100644
index 4c47136c1..000000000
--- a/tests/dispatcher/shell/test_shell_local.py
+++ /dev/null
@@ -1,125 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'shell'
-from .context import LocalSession
-from .context import LocalContext
-from .context import Shell
-from .context import JobStatus
-from .context import my_file_cmp
-from .context import setUpModule
-
-class TestShell(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- work_profile = LocalSession({'work_path':'rmt'})
- self.ctx = LocalContext('loc', work_profile)
- self.shell = Shell(self.ctx)
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
- if os.path.exists('dpgen.log'):
- os.remove('dpgen.log')
- if os.path.exists('run.sub'):
- os.remove('run.sub')
- if os.path.exists('run.sub.1'):
- os.remove('run.sub.1')
-
- def test_manual_cuda_devices(self):
- job_dirs = ['task0', 'task1']
- res = {'manual_cuda_devices': 3}
- ret = self.shell.sub_script(job_dirs, ['touch test1', 'touch test2'], res = res)
- with open('run.sub.gpu', 'w') as fp:
- fp.write(ret)
-
- def test_manual_cuda_multiplicity(self):
- job_dirs = ['task0', 'task1', 'task2', 'task3']
- res = {'manual_cuda_devices': 2, 'manual_cuda_multiplicity': 2}
- ret = self.shell.sub_script(job_dirs, ['touch test1', 'touch test2'], res = res)
- with open('run.sub.gpu.multi', 'w') as fp:
- fp.write(ret)
-
- def test_gen_sub_script(self):
- job_dirs = ['task0', 'task1']
- self.shell.context.upload(job_dirs, ['test0'])
- ret = self.shell.sub_script(job_dirs, ['touch test1', 'touch test2'])
- with open('run.sub', 'w') as fp:
- fp.write(ret)
- ret1 = self.shell.sub_script(job_dirs, ['touch', 'touch'], args = [['test1 ', 'test1 '], ['test2 ', 'test2 ']])
- with open('run.sub.1', 'w') as fp:
- fp.write(ret1)
- time.sleep(1)
- my_file_cmp(self, 'run.sub.1', 'run.sub')
- # with open('run.sub', 'w') as fp:
- # fp.write(ret)
-
- def test_sub_success(self) :
- job_dirs = ['task0', 'task1']
- self.shell.context.upload(job_dirs, ['test0'])
- self.shell.submit(job_dirs, ['touch test1', 'touch test2'])
- while True:
- ret = self.shell.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, '%s_tag_finished' % self.shell.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test2')))
-
-
- def test_sub_scancel(self) :
- job_dirs = ['task0', 'task1']
- self.shell.context.upload(job_dirs, ['test0'])
- # sub
- self.shell.submit(job_dirs, ['touch test1', 'sleep 10'])
- while True:
- ret = self.shell.check_status()
- if ret == JobStatus.finished :
- raise RuntimeError('should not finished')
- if ret == JobStatus.running :
- # wait for file writing
- time.sleep(2)
- # kill job
- self.shell.context.kill(self.shell.proc)
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_1_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, '%s_tag_finished' % self.shell.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test1')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test2')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test2')))
- # sub restart
- self.shell.submit(job_dirs, ['rm test1', 'touch test2'], restart = True)
- while True:
- ret = self.shell.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, '%s_tag_finished' % self.shell.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test2')))
-
diff --git a/tests/dispatcher/shell/test_shell_ssh.py b/tests/dispatcher/shell/test_shell_ssh.py
deleted file mode 100644
index 7b9f0773b..000000000
--- a/tests/dispatcher/shell/test_shell_ssh.py
+++ /dev/null
@@ -1,113 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time,getpass
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'shell'
-from .context import SSHSession
-from .context import SSHContext
-from .context import Shell
-from .context import JobStatus
-from .context import setUpModule
-
-class TestShell(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- port = 22
- try :
- ssh_session = SSHSession({'hostname' : 'localhost',
- 'port': port,
- 'username' : getpass.getuser(),
- 'work_path' : os.path.join(os.getcwd(), 'rmt')})
- except Exception:
- ssh_session = SSHSession({'hostname' : 'localhost',
- 'port': 5566,
- 'username' : getpass.getuser(),
- 'work_path' : os.path.join(os.getcwd(), 'rmt')})
- self.ctx = SSHContext('loc', ssh_session)
- self.shell = Shell(self.ctx)
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
- if os.path.exists('dpgen.log'):
- os.remove('dpgen.log')
-
- def test_gen_sub_script(self):
- job_dirs = ['task0', 'task1']
- self.shell.context.upload(job_dirs, ['test0'])
- ret = self.shell.sub_script(job_dirs, ['touch test1', 'touch test2'])
- self.shell.context.write_file('run.sub', ret)
- # with open('run.sub', 'w') as fp:
- # fp.write(ret)
-
- def test_sub_success(self) :
- job_dirs = ['task0', 'task1']
- self.shell.context.upload(job_dirs, ['test0'])
- self.shell.submit(job_dirs, ['touch test1', 'touch test2'])
- while True:
- ret = self.shell.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, '%s_tag_finished' % self.shell.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test2')))
-
-
- # def test_sub_scancel(self) :
- # job_dirs = ['task0', 'task1']
- # self.shell.context.upload(job_dirs, ['test0'])
- # # sub
- # self.shell.submit(job_dirs, ['touch test1', 'sleep 10'])
- # while True:
- # ret = self.shell.check_status()
- # if ret == JobStatus.finished :
- # raise RuntimeError('should not finished')
- # if ret == JobStatus.running :
- # # wait for file writing
- # time.sleep(2)
- # # kill job
- # ##################################################
- # # problematic killing remotly
- # ##################################################
- # self.shell.context.kill(self.shell.proc)
- # break
- # time.sleep(1)
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_0_finished')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_1_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_0_finished')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_1_finished')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'tag_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test1')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test1')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test2')))
- # self.assertFalse(os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test2')))
- # # sub restart
- # self.shell.submit(job_dirs, ['rm test1', 'touch test2'], restart = True)
- # while True:
- # ret = self.shell.check_status()
- # if ret == JobStatus.finished :
- # break
- # time.sleep(1)
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_0_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/tag_1_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_0_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/tag_1_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'tag_finished')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test1')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test1')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task0/test2')))
- # self.assertTrue (os.path.isfile(os.path.join('rmt', self.shell.context.remote_root, 'task1/test2')))
-
diff --git a/tests/dispatcher/slurm/context.py b/tests/dispatcher/slurm/context.py
deleted file mode 100644
index e608d2a7a..000000000
--- a/tests/dispatcher/slurm/context.py
+++ /dev/null
@@ -1,20 +0,0 @@
-import sys,os
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..', '..')))
-
-from dpgen.dispatcher.LocalContext import LocalSession
-from dpgen.dispatcher.SSHContext import SSHSession
-from dpgen.dispatcher.LocalContext import LocalContext
-from dpgen.dispatcher.LazyLocalContext import LazyLocalContext
-from dpgen.dispatcher.SSHContext import SSHContext
-from dpgen.dispatcher.Slurm import Slurm
-from dpgen.dispatcher.Dispatcher import Dispatcher
-from dpgen.dispatcher.JobStatus import JobStatus
-
-def my_file_cmp(test, f0, f1):
- with open(f0) as fp0 :
- with open(f1) as fp1:
- test.assertTrue(fp0.read() == fp1.read())
-
-def setUpModule():
- os.chdir(os.path.abspath(os.path.dirname(__file__)))
diff --git a/tests/dispatcher/slurm/test_dispatcher.py b/tests/dispatcher/slurm/test_dispatcher.py
deleted file mode 100644
index 3009eed8b..000000000
--- a/tests/dispatcher/slurm/test_dispatcher.py
+++ /dev/null
@@ -1,52 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'slurm'
-from .context import LocalSession
-from .context import LocalContext
-from .context import Slurm
-from .context import JobStatus
-from .context import Dispatcher
-from .context import my_file_cmp
-from .context import setUpModule
-
-@unittest.skipIf(not shutil.which("sbatch"), "requires Slurm")
-class TestDispatcher(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- os.makedirs('loc/task2', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1', 'loc/task2']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write('this is test0 from ' + ii + '\n')
- work_profile = {'work_path':'rmt'}
- self.disp = Dispatcher(work_profile, 'local', 'slurm')
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
- if os.path.exists('dpgen.log'):
- os.remove('dpgen.log')
-
- def test_sub_success(self):
- tasks = ['task0', 'task1', 'task2']
- self.disp.run_jobs(None,
- 'cp test0 test1',
- 'loc',
- tasks,
- 2,
- [],
- ['test0'],
- ['test1', 'hereout.log', 'hereerr.log'],
- outlog = 'hereout.log',
- errlog = 'hereerr.log')
- for ii in tasks:
- my_file_cmp(self,
- os.path.join('loc', ii, 'test0'),
- os.path.join('loc', ii, 'test1'))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereout.log')))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereerr.log')))
-
diff --git a/tests/dispatcher/slurm/test_dispatcher_lazy_local.py b/tests/dispatcher/slurm/test_dispatcher_lazy_local.py
deleted file mode 100644
index 89fd9b9a4..000000000
--- a/tests/dispatcher/slurm/test_dispatcher_lazy_local.py
+++ /dev/null
@@ -1,52 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'slurm'
-from .context import LocalSession
-from .context import LocalContext
-from .context import Slurm
-from .context import JobStatus
-from .context import Dispatcher
-from .context import my_file_cmp
-from .context import setUpModule
-
-@unittest.skipIf(not shutil.which("sbatch"), "requires Slurm")
-class TestDispatcher(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- os.makedirs('loc/task2', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1', 'loc/task2']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write('this is test0 from ' + ii + '\n')
- work_profile = {}
- self.disp = Dispatcher(work_profile, 'lazy-local', 'slurm')
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
- if os.path.exists('dpgen.log'):
- os.remove('dpgen.log')
-
- def test_sub_success(self):
- tasks = ['task0', 'task1', 'task2']
- self.disp.run_jobs(None,
- 'cp test0 test1',
- 'loc',
- tasks,
- 2,
- [],
- ['test0'],
- ['test1', 'hereout.log', 'hereerr.log'],
- outlog = 'hereout.log',
- errlog = 'hereerr.log')
- for ii in tasks:
- my_file_cmp(self,
- os.path.join('loc', ii, 'test0'),
- os.path.join('loc', ii, 'test1'))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereout.log')))
- self.assertTrue(os.path.isfile(os.path.join('loc', ii, 'hereerr.log')))
-
diff --git a/tests/dispatcher/slurm/test_slurm_lazy_local.py b/tests/dispatcher/slurm/test_slurm_lazy_local.py
deleted file mode 100644
index ac44886a3..000000000
--- a/tests/dispatcher/slurm/test_slurm_lazy_local.py
+++ /dev/null
@@ -1,106 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'slurm'
-from .context import LazyLocalContext
-from .context import Slurm
-from .context import JobStatus
-from .context import setUpModule
-
-@unittest.skipIf(not shutil.which("sbatch"), "requires Slurm")
-class TestSlurm(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- self.ctx = LazyLocalContext('loc')
- self.slurm = Slurm(self.ctx, uuid_names = True)
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
- if os.path.exists('dpgen.log'):
- os.remove('dpgen.log')
-
- def test_gen_sub_script(self):
- job_dirs = ['task0', 'task1']
- self.slurm.context.upload(job_dirs, ['test0'])
- ret = self.slurm.sub_script(job_dirs, ['touch test1', 'touch test2'])
- self.slurm.context.write_file('run.sub', ret)
- with open('run.sub', 'w') as fp:
- fp.write(ret)
-
- def test_sub_success(self) :
- job_dirs = ['task0', 'task1']
- self.slurm.context.upload(job_dirs, ['test0'])
- self.slurm.submit(job_dirs, ['touch test1', 'touch test2'])
- job_uuid = self.slurm.context.job_uuid
- with open(os.path.join('rmt', self.slurm.context.remote_root, '%s_job_id' % job_uuid)) as fp:
- tmp_id = fp.read()
- self.assertEqual(self.slurm._get_job_id(), tmp_id)
- while True:
- ret = self.slurm.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, '%s_tag_finished' % job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test2')))
-
- def test_sub_scancel(self) :
- job_dirs = ['task0', 'task1']
- self.slurm.context.upload(job_dirs, ['test0'])
- # sub
- self.slurm.submit(job_dirs, ['touch test1', 'sleep 10'])
- while True:
- ret = self.slurm.check_status()
- if ret == JobStatus.finished :
- raise RuntimeError('should not finished')
- if ret == JobStatus.running :
- # wait for file writing
- time.sleep(2)
- job_id = self.slurm._get_job_id()
- job_uuid = self.slurm.context.job_uuid
- with open(os.path.join('rmt', self.slurm.context.remote_root, '%s_job_id' % job_uuid)) as fp:
- tmp_id = fp.read()
- self.assertEqual(job_id, tmp_id)
- os.system('scancel ' + job_id)
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_1_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, '%s_tag_finished' % job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test1')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test2')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test2')))
- # sub restart
- self.slurm.submit(job_dirs, ['rm test1', 'touch test2'], restart = True)
- while True:
- ret = self.slurm.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, '%s_tag_finished' % job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test2')))
-
diff --git a/tests/dispatcher/slurm/test_slurm_local.py b/tests/dispatcher/slurm/test_slurm_local.py
deleted file mode 100644
index 0aeca1f75..000000000
--- a/tests/dispatcher/slurm/test_slurm_local.py
+++ /dev/null
@@ -1,100 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'slurm'
-from .context import LocalSession
-from .context import LocalContext
-from .context import Slurm
-from .context import JobStatus
-from .context import setUpModule
-
-@unittest.skipIf(not shutil.which("sbatch"), "requires Slurm")
-class TestSlurm(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- work_profile = LocalSession({'work_path':'rmt'})
- self.ctx = LocalContext('loc', work_profile)
- self.slurm = Slurm(self.ctx)
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
- if os.path.exists('dpgen.log'):
- os.remove('dpgen.log')
-
- def test_gen_sub_script(self):
- job_dirs = ['task0', 'task1']
- self.slurm.context.upload(job_dirs, ['test0'])
- ret = self.slurm.sub_script(job_dirs, ['touch test1', 'touch test2'])
- self.slurm.context.write_file('run.sub', ret)
- with open('run.sub', 'w') as fp:
- fp.write(ret)
-
- def test_sub_success(self) :
- job_dirs = ['task0', 'task1']
- self.slurm.context.upload(job_dirs, ['test0'])
- self.slurm.submit(job_dirs, ['touch test1', 'touch test2'])
- while True:
- ret = self.slurm.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, '%s_tag_finished' % self.slurm.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test2')))
-
- def test_sub_scancel(self) :
- job_dirs = ['task0', 'task1']
- self.slurm.context.upload(job_dirs, ['test0'])
- # sub
- self.slurm.submit(job_dirs, ['touch test1', 'sleep 10'])
- while True:
- ret = self.slurm.check_status()
- if ret == JobStatus.finished :
- raise RuntimeError('should not finished')
- if ret == JobStatus.running :
- # wait for file writing
- time.sleep(2)
- job_id = self.slurm._get_job_id()
- os.system('scancel ' + job_id)
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_1_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, '%s_tag_finished' % self.slurm.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test1')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test2')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test2')))
- # sub restart
- self.slurm.submit(job_dirs, ['rm test1', 'touch test2'], restart = True)
- while True:
- ret = self.slurm.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, '%s_tag_finished' % self.slurm.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test2')))
-
diff --git a/tests/dispatcher/slurm/test_slurm_ssh.py b/tests/dispatcher/slurm/test_slurm_ssh.py
deleted file mode 100644
index 774650110..000000000
--- a/tests/dispatcher/slurm/test_slurm_ssh.py
+++ /dev/null
@@ -1,105 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'slurm'
-from .context import LocalSession
-from .context import LocalContext
-from .context import Slurm
-from .context import JobStatus
-from .context import my_file_cmp
-from .context import setUpModule
-
-@unittest.skipIf(not shutil.which("sbatch"), "requires Slurm")
-class TestSlurm(unittest.TestCase) :
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('rmt', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- work_profile = LocalSession({'work_path':'rmt'})
- self.ctx = LocalContext('loc', work_profile)
- self.slurm = Slurm(self.ctx)
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
- if os.path.exists('dpgen.log'):
- os.remove('dpgen.log')
-
- def test_gen_sub_script(self):
- job_dirs = ['task0', 'task1']
- self.slurm.context.upload(job_dirs, ['test0'])
- ret = self.slurm.sub_script(job_dirs, ['touch test1', 'touch test2'])
- self.slurm.context.write_file('run.sub', ret)
- with open('run.sub', 'w') as fp:
- fp.write(ret)
- ret1 = self.slurm.sub_script(job_dirs, ['touch', 'touch'], [['test1 ', 'test1 '], ['test2 ', 'test2 ']])
- with open('run.sub.1', 'w') as fp:
- fp.write(ret1)
- my_file_cmp(self, 'run.sub.1', 'run.sub')
-
- def test_sub_success(self) :
- job_dirs = ['task0', 'task1']
- self.slurm.context.upload(job_dirs, ['test0'])
- self.slurm.submit(job_dirs, ['touch test1', 'touch test2'])
- while True:
- ret = self.slurm.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, '%s_tag_finished' % self.slurm.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test2')))
-
- def test_sub_scancel(self) :
- job_dirs = ['task0', 'task1']
- self.slurm.context.upload(job_dirs, ['test0'])
- # sub
- self.slurm.submit(job_dirs, ['touch test1', 'sleep 10'])
- while True:
- ret = self.slurm.check_status()
- if ret == JobStatus.finished :
- raise RuntimeError('should not finished')
- if ret == JobStatus.running :
- # wait for file writing
- time.sleep(2)
- job_id = self.slurm._get_job_id()
- os.system('scancel ' + job_id)
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_0_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_1_finished')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, '%s_tag_finished' % self.slurm.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test1')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test2')))
- self.assertFalse(os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test2')))
- # sub restart
- self.slurm.submit(job_dirs, ['rm test1', 'touch test2'], restart = True)
- while True:
- ret = self.slurm.check_status()
- if ret == JobStatus.finished :
- break
- time.sleep(1)
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_0_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/tag_1_finished')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, '%s_tag_finished' % self.slurm.context.job_uuid)))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test1')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task0/test2')))
- self.assertTrue (os.path.isfile(os.path.join('rmt', self.slurm.context.remote_root, 'task1/test2')))
-
diff --git a/tests/dispatcher/test_dispatcher_utils.py b/tests/dispatcher/test_dispatcher_utils.py
deleted file mode 100644
index 01f0e0a1f..000000000
--- a/tests/dispatcher/test_dispatcher_utils.py
+++ /dev/null
@@ -1,41 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'dispatcher'
-# from .context import FinRecord
-from .context import _split_tasks
-from .context import setUpModule
-
-# class TestFinRecord(unittest.TestCase):
-# def setUp(self):
-# self.njobs = 10
-# self.fr = FinRecord('.', self.njobs)
-
-# def tearDown(self):
-# if os.path.isfile('fin.record'):
-# os.remove('fin.record')
-
-# def test_all_false(self) :
-# recd = self.fr.get_record()
-# self.assertEqual(recd, [False]*self.njobs)
-
-# def test_write_read(self) :
-# recd = self.fr.get_record()
-# recd[self.njobs//3] = True
-# self.fr.write_record(recd)
-# recd1 = self.fr.get_record()
-# self.assertEqual(recd, recd1)
-
-class TestDispatchSplit(unittest.TestCase):
- def test_split(self):
- tasks = [ii for ii in range(10)]
- chunks = _split_tasks(tasks, 5)
- self.assertEqual(chunks, [[0,2,4,6,8],[1,3,5,7,9]])
-
- def test_split_1(self):
- tasks = [ii for ii in range(13)]
- chunks = _split_tasks(tasks, 5)
- self.assertEqual(chunks, [[0,3,6,9,12],[1,4,7,10],[2,5,8,11]])
-
-
diff --git a/tests/dispatcher/test_lazy_local_context.py b/tests/dispatcher/test_lazy_local_context.py
deleted file mode 100644
index 87270d836..000000000
--- a/tests/dispatcher/test_lazy_local_context.py
+++ /dev/null
@@ -1,174 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-from pathlib import Path
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'dispatcher'
-from .context import LazyLocalContext
-from .context import setUpModule
-
-class TestLazyLocalContext(unittest.TestCase):
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- with open(os.path.join(ii, 'test1'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- with open(os.path.join(ii, 'test2'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- os.makedirs(os.path.join(ii, 'dir0'), exist_ok = True)
-
- def tearDown(self):
- shutil.rmtree('loc')
-
- def test_upload(self) :
- self.job = LazyLocalContext('loc', None)
- self.job1 = LazyLocalContext('loc', None, job_uuid = self.job.job_uuid)
- tasks = ['task0', 'task1']
- files = ['test0', 'test1']
- self.job.upload(tasks, files)
- self.job1.upload(tasks, files)
-
- def test_download(self):
- # upload files
- self.job = LazyLocalContext('loc', None)
- tasks = ['task0', 'task1']
- self.job.upload(tasks, ['test0', 'dir0'])
- self.job.download(tasks, ['test0', 'dir0'])
-
- def test_download_check_mark(self):
- # upload files
- self.job = LazyLocalContext('loc', None)
- tasks = ['task0', 'task1']
- self.job.upload(tasks, ['test0', 'dir0'])
- record_uuid = []
- # generate extra donwload files
- for ii in tasks :
- for jj in ['test6', 'test7'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6'):
- continue
- with open(os.path.join('loc',ii,jj), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- self.job.download(tasks, ['test6', 'test7', 'dir1'], check_exists = True, mark_failure = True)
- # check dlded
- cc = 0
- for ii in tasks :
- for jj in ['test6', 'test7'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6') :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)),
- msg = 'found ' + os.path.join('loc', ii, jj))
- self.assertTrue(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)),
- msg = 'failed to find ' + os.path.join('loc', ii, 'tag_failure_download_%s' % jj))
- continue
- with open(os.path.join('loc',ii,jj), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
- for ii in tasks :
- for jj in ['dir1'] :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)))
- self.assertTrue(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)))
-
-
- def test_download_check_nomark(self):
- # upload files
- self.job = LazyLocalContext('loc', None)
- tasks = ['task0', 'task1']
- self.job.upload(tasks, ['test0', 'dir0'])
- record_uuid = []
- # generate extra donwload files
- for ii in tasks :
- for jj in ['test6', 'test7'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6'):
- continue
- with open(os.path.join('loc',ii,jj), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- self.job.download(tasks, ['test6', 'test7', 'dir1'], check_exists = True, mark_failure = False)
- # check dlded
- cc = 0
- for ii in tasks :
- for jj in ['test6', 'test7'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6') :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)),
- msg = 'found ' + os.path.join('loc', ii, jj))
- self.assertFalse(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)),
- msg = 'found ' + os.path.join('loc', ii, 'tag_failure_download_%s' % jj))
- continue
- with open(os.path.join('loc',ii,jj), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
- for ii in tasks :
- for jj in ['dir1'] :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)))
- self.assertFalse(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)))
-
-
-
- def test_block_call(self) :
- self.job = LazyLocalContext('loc', None)
- tasks = ['task0', 'task1']
- files = ['test0', 'test1']
- self.job.upload(tasks, files)
- # ls
- code, stdin, stdout, stderr = self.job.block_call('ls')
- self.assertEqual(stdout.read().decode('utf-8'), 'task0\ntask1\n')
- self.assertEqual(stdout.readlines(), ['task0\n','task1\n'])
- self.assertEqual(code, 0)
- code, stdin, stdout, stderr = self.job.block_call('ls a')
- self.assertEqual(code, 2)
- # self.assertEqual(stderr.read().decode('utf-8'), 'ls: cannot access a: No such file or directory\n')
- err_msg = stderr.read().decode('utf-8')
- self.assertTrue('ls: cannot access' in err_msg)
- self.assertTrue('No such file or directory\n' in err_msg)
-
- def test_block_checkcall(self) :
- self.job = LazyLocalContext('loc', None)
- tasks = ['task0', 'task1']
- files = ['test0', 'test1']
- self.job.upload(tasks, files)
- # ls
- stdin, stdout, stderr = self.job.block_checkcall('ls')
- self.assertEqual(stdout.read().decode('utf-8'), 'task0\ntask1\n')
- self.assertEqual(stdout.readlines(), ['task0\n','task1\n'])
- with self.assertRaises(RuntimeError):
- stdin, stdout, stderr = self.job.block_checkcall('ls a')
-
- def test_file(self) :
- self.job = LazyLocalContext('loc', None)
- self.assertFalse(self.job.check_file_exists('aaa'))
- tmp = str(uuid.uuid4())
- self.job.write_file('aaa', tmp)
- self.assertTrue(self.job.check_file_exists('aaa'))
- tmp1 = self.job.read_file('aaa')
- self.assertEqual(tmp, tmp1)
-
-
- def test_call(self) :
- self.job = LazyLocalContext('loc', None)
- proc = self.job.call('sleep 1.5')
- self.assertFalse(self.job.check_finish(proc))
- time.sleep(1)
- self.assertFalse(self.job.check_finish(proc))
- time.sleep(2.5)
- self.assertTrue(self.job.check_finish(proc))
- r,o,e=self.job.get_return(proc)
- self.assertEqual(r, 0)
- self.assertEqual(o.read(), b'')
- self.assertEqual(e.read(), b'')
- # r,o,e=self.job.get_return(proc)
- # self.assertEqual(r, 0)
- # self.assertEqual(o, None)
- # self.assertEqual(e, None)
-
diff --git a/tests/dispatcher/test_local_context.py b/tests/dispatcher/test_local_context.py
deleted file mode 100644
index c5b046485..000000000
--- a/tests/dispatcher/test_local_context.py
+++ /dev/null
@@ -1,363 +0,0 @@
-import os,sys,json,glob,shutil,uuid,time
-import unittest
-from pathlib import Path
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'dispatcher'
-from .context import LocalContext, LocalSession
-from .context import setUpModule
-from .context import _identical_files
-
-class TestIdFile(unittest.TestCase) :
- def test_id(self) :
- with open('f0', 'w') as fp:
- fp.write('foo')
- with open('f1', 'w') as fp:
- fp.write('foo')
- self.assertTrue(_identical_files('f0', 'f1'))
- os.remove('f0')
- os.remove('f1')
-
- def test_diff(self) :
- with open('f0', 'w') as fp:
- fp.write('foo')
- with open('f1', 'w') as fp:
- fp.write('bar')
- self.assertFalse(_identical_files('f0', 'f1'))
- os.remove('f0')
- os.remove('f1')
-
-
-class TestLocalContext(unittest.TestCase):
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- with open(os.path.join(ii, 'test1'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- with open(os.path.join(ii, 'test2'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- os.makedirs(os.path.join(ii, 'dir0'), exist_ok = True)
- os.makedirs(os.path.join(ii, 'dir2'), exist_ok = True)
- with open(os.path.join(ii, 'dir2', 'dtest0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- os.makedirs('rmt', exist_ok = True)
-
- def tearDown(self):
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
-
- def test_upload_non_exist(self) :
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- tasks = ['task0', 'task1']
- # test uploading non-existing file
- with self.assertRaises(OSError):
- self.job.upload(tasks, ['foo'])
-
- def test_upload(self) :
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- self.job1 = LocalContext('loc', work_profile, job_uuid = self.job.job_uuid)
- tasks = ['task0', 'task1']
- files = ['test0', 'test1', 'dir2/dtest0']
- self.job.upload(tasks, files)
- for ii in tasks :
- for jj in files :
- locf = os.path.join('loc', ii, jj)
- rmtf = os.path.join('rmt', self.job.job_uuid, ii, jj)
- with open(locf) as fp:
- locs = fp.read()
- with open(rmtf) as fp:
- rmts = fp.read()
- self.assertEqual(locs, rmts)
- self.job.upload(tasks, ['dir0'])
- for ii in tasks :
- for jj in ['dir0'] :
- locf = os.path.join('loc', ii, jj)
- rmtf = os.path.join('rmt', self.job.job_uuid, ii, jj)
- self.assertEqual(os.path.realpath(locf),
- os.path.realpath(rmtf))
- self.job1.upload(tasks, files)
- for ii in tasks :
- for jj in files :
- locf = os.path.join('loc', ii, jj)
- rmtf = os.path.join('rmt', self.job.job_uuid, ii, jj)
- with open(locf) as fp:
- locs = fp.read()
- with open(rmtf) as fp:
- rmts = fp.read()
- self.assertEqual(locs, rmts)
-
- def test_dl_f_f(self):
- # no local, no remote
- self.test_download_non_exist()
-
- def test_dl_t_f(self) :
- # has local, no remote
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- tasks = ['task0', 'task1']
- record_uuid = []
- for ii in tasks :
- for jj in ['dir1'] :
- os.makedirs(os.path.join('loc',ii,jj), exist_ok=False)
- for kk in ['test6', 'test7']:
- with open(os.path.join('loc',ii,jj,kk), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- files = ['dir1']
- self.job.download(tasks, files)
- cc = 0
- for ii in tasks :
- for jj in ['dir1'] :
- for kk in ['test6', 'test7']:
- with open(os.path.join('loc',ii,jj,kk), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
-
- def test_dl_t_t(self) :
- # has local, has remote
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- tasks = ['task0', 'task1']
- for ii in tasks :
- for jj in ['dir1'] :
- os.makedirs(os.path.join('loc',ii,jj), exist_ok=False)
- for kk in ['test6', 'test7']:
- with open(os.path.join('loc',ii,jj,kk), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid = []
- for ii in tasks :
- for jj in ['dir1'] :
- os.makedirs(os.path.join('rmt', self.job.job_uuid,ii,jj), exist_ok=False)
- for kk in ['test6', 'test7']:
- with open(os.path.join('rmt', self.job.job_uuid,ii,jj,kk), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- files = ['dir1']
- self.job.download(tasks, files)
- cc = 0
- for ii in tasks :
- for jj in ['dir1'] :
- for kk in ['test6', 'test7']:
- with open(os.path.join('loc',ii,jj,kk), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
-
-
- def test_download_non_exist(self):
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- tasks = ['task0', 'task1']
- # down load non-existing file
- with self.assertRaises(RuntimeError):
- self.job.download(tasks, ['foo'])
-
- def test_download(self):
- # upload files
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- tasks = ['task0', 'task1']
- self.job.upload(tasks, ['test0', 'dir0'])
- # generate extra donwload files
- record_uuid = []
- for ii in tasks :
- for jj in ['test4', 'test5'] :
- with open(os.path.join('rmt',self.job.job_uuid,ii,jj), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- # generate extra donwload dirs and files
- for ii in tasks :
- for jj in ['dir1'] :
- os.makedirs(os.path.join('rmt',self.job.job_uuid,ii,jj), exist_ok=False)
- for kk in ['test6']:
- with open(os.path.join('rmt',self.job.job_uuid,ii,jj,kk), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- # donwload
- files = ['test0', 'dir0', 'test4', 'test5', 'dir1']
- self.job.download(tasks, files)
- # check dlded
- cc = 0
- for ii in tasks :
- for jj in ['test4', 'test5'] :
- with open(os.path.join('loc',ii,jj), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
- for ii in tasks :
- for jj in ['dir1'] :
- for kk in ['test6']:
- with open(os.path.join('loc',ii,jj,kk), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
- # check links preserved
- for ii in tasks :
- for jj in ['test0'] :
- locf = os.path.join('loc', ii, jj)
- rmtf = os.path.join('rmt', self.job.job_uuid, ii, jj)
- self.assertEqual(os.path.realpath(locf),
- os.path.realpath(rmtf))
- for ii in tasks :
- for jj in ['dir0'] :
- for kk in ['test6'] :
- locf = os.path.join('loc', ii, jj, kk)
- rmtf = os.path.join('rmt', self.job.job_uuid, ii, jj, kk)
- self.assertEqual(os.path.realpath(locf),
- os.path.realpath(rmtf))
-
- def test_download_check_mark(self):
- # upload files
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- tasks = ['task0', 'task1']
- self.job.upload(tasks, ['test0', 'dir0'])
- # generate extra donwload files
- record_uuid = []
- for ii in tasks :
- for jj in ['test7', 'test8'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6') :
- continue
- with open(os.path.join('rmt',self.job.job_uuid,ii,jj), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- # donwload
- files = ['test7', 'test8', 'dir1']
- self.job.download(tasks, files, check_exists = True, mark_failure = True)
- # check dlded
- cc = 0
- for ii in tasks :
- for jj in ['test7', 'test8'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6') :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)),
- msg = 'found ' + os.path.join('loc', ii, jj))
- self.assertTrue(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)),
- msg = 'failed to find ' + os.path.join('loc', ii, 'tag_failure_download_%s' % jj))
- continue
- with open(os.path.join('loc',ii,jj), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
- for ii in tasks :
- for jj in ['dir1'] :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)))
- self.assertTrue(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)))
-
-
- def test_download_check_nomark(self):
- # upload files
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- tasks = ['task0', 'task1']
- self.job.upload(tasks, ['test0', 'dir0'])
- # generate extra donwload files
- record_uuid = []
- for ii in tasks :
- for jj in ['test7', 'test8'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6') :
- continue
- with open(os.path.join('rmt',self.job.job_uuid,ii,jj), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- # donwload
- files = ['test7', 'test8', 'dir1']
- self.job.download(tasks, files, check_exists = True, mark_failure = False)
- # check dlded
- cc = 0
- for ii in tasks :
- for jj in ['test7', 'test8'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6') :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)),
- msg = 'found ' + os.path.join('loc', ii, jj))
- self.assertFalse(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)),
- msg = 'found ' + os.path.join('loc', ii, 'tag_failure_download_%s' % jj))
- continue
- with open(os.path.join('loc',ii,jj), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
- for ii in tasks :
- for jj in ['dir1'] :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)))
- self.assertFalse(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)))
-
-
- def test_block_call(self) :
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- tasks = ['task0', 'task1']
- files = ['test0', 'test1']
- self.job.upload(tasks, files)
- # ls
- code, stdin, stdout, stderr = self.job.block_call('ls')
- self.assertEqual(stdout.read().decode('utf-8'), 'task0\ntask1\n')
- self.assertEqual(stdout.readlines(), ['task0\n','task1\n'])
- self.assertEqual(code, 0)
- code, stdin, stdout, stderr = self.job.block_call('ls a')
- self.assertEqual(code, 2)
- # self.assertEqual(stderr.read().decode('utf-8'), 'ls: cannot access a: No such file or directory\n')
- err_msg = stderr.read().decode('utf-8')
- self.assertTrue('ls: cannot access' in err_msg)
- self.assertTrue('No such file or directory\n' in err_msg)
-
-
- def test_block_checkcall(self) :
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- tasks = ['task0', 'task1']
- files = ['test0', 'test1']
- self.job.upload(tasks, files)
- # ls
- stdin, stdout, stderr = self.job.block_checkcall('ls')
- self.assertEqual(stdout.read().decode('utf-8'), 'task0\ntask1\n')
- self.assertEqual(stdout.readlines(), ['task0\n','task1\n'])
- with self.assertRaises(RuntimeError):
- stdin, stdout, stderr = self.job.block_checkcall('ls a')
-
- def test_file(self) :
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- self.assertFalse(self.job.check_file_exists('aaa'))
- tmp = str(uuid.uuid4())
- self.job.write_file('aaa', tmp)
- self.assertTrue(self.job.check_file_exists('aaa'))
- tmp1 = self.job.read_file('aaa')
- self.assertEqual(tmp, tmp1)
-
-
- def test_call(self) :
- work_profile = LocalSession({'work_path':'rmt'})
- self.job = LocalContext('loc', work_profile)
- proc = self.job.call('sleep 1.5')
- self.assertFalse(self.job.check_finish(proc))
- time.sleep(1)
- self.assertFalse(self.job.check_finish(proc))
- time.sleep(2.5)
- self.assertTrue(self.job.check_finish(proc))
- r,o,e=self.job.get_return(proc)
- self.assertEqual(r, 0)
- self.assertEqual(o.read(), b'')
- self.assertEqual(e.read(), b'')
- # r,o,e=self.job.get_return(proc)
- # self.assertEqual(r, 0)
- # self.assertEqual(o, None)
- # self.assertEqual(e, None)
-
diff --git a/tests/dispatcher/test_local_session.py b/tests/dispatcher/test_local_session.py
deleted file mode 100644
index 6712e639f..000000000
--- a/tests/dispatcher/test_local_session.py
+++ /dev/null
@@ -1,16 +0,0 @@
-import os,sys,json,glob,shutil
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'dispatcher'
-from .context import LocalSession
-from .context import setUpModule
-
-class TestLocalSession(unittest.TestCase):
- def test_work_path(self):
- cwd = os.getcwd()
- wp = LocalSession({'work_path' : cwd})
- self.assertTrue(os.path.abspath(cwd), wp.get_work_root())
-
-
-
diff --git a/tests/dispatcher/test_ssh_context.py b/tests/dispatcher/test_ssh_context.py
deleted file mode 100644
index a24e2d653..000000000
--- a/tests/dispatcher/test_ssh_context.py
+++ /dev/null
@@ -1,231 +0,0 @@
-import os,sys,json,glob,shutil,uuid,getpass
-import unittest
-from pathlib import Path
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'dispatcher'
-from .context import SSHContext, SSHSession
-from .context import setUpModule
-
-class TestSSHContext(unittest.TestCase):
- def setUp(self) :
- os.makedirs('loc', exist_ok = True)
- os.makedirs('loc/task0', exist_ok = True)
- os.makedirs('loc/task1', exist_ok = True)
- for ii in ['loc/task0', 'loc/task1']:
- with open(os.path.join(ii, 'test0'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- with open(os.path.join(ii, 'test1'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- os.makedirs(os.path.join(ii, 'dir0'), exist_ok = True)
- with open(os.path.join(ii, 'dir0', 'test2'),'w') as fp:
- fp.write(str(uuid.uuid4()))
- os.makedirs('rmt', exist_ok = True)
- try :
- self.ssh_session = SSHSession({'hostname' : 'localhost',
- 'port': 22,
- 'username' : getpass.getuser(),
- 'work_path' : os.path.join(os.getcwd(), 'rmt')})
- except Exception:
- # for tianhe-2
- try:
- self.ssh_session = SSHSession({'hostname' : 'localhost',
- 'port': 5566,
- 'username' : getpass.getuser(),
- 'work_path' : os.path.join(os.getcwd(), 'rmt')})
- except Exception:
- self.skipTest("Network error")
- self.job = SSHContext('loc', self.ssh_session)
- self.job1 = SSHContext('loc', self.ssh_session, job_uuid = self.job.job_uuid)
-
- def tearDown(self):
- self.job.close()
- self.job1.close()
- shutil.rmtree('loc')
- shutil.rmtree('rmt')
-
- def test_upload(self) :
- tasks = ['task0', 'task1']
- files = ['test0', 'test1']
- self.job.upload(tasks, files)
- for ii in tasks :
- for jj in files :
- locf = os.path.join('loc', ii, jj)
- rmtf = os.path.join('rmt', self.job.job_uuid, ii, jj)
- with open(locf) as fp:
- locs = fp.read()
- with open(rmtf) as fp:
- rmts = fp.read()
- self.assertEqual(locs, rmts)
- self.job.upload(tasks, ['dir0'])
- for ii in tasks :
- for jj in ['dir0'] :
- for kk in ['test2'] :
- locf = os.path.join('loc', ii, jj, kk)
- rmtf = os.path.join('rmt', self.job.job_uuid, ii, jj, kk)
- with open(locf) as fp:
- locs = fp.read()
- with open(rmtf) as fp:
- rmts = fp.read()
- self.assertEqual(locs, rmts)
-
-
- def test_donwload(self):
- tasks = ['task0', 'task1']
- self.job.upload(tasks, ['test0', 'dir0'])
- # generate extra donwload files
- record_uuid = []
- for ii in tasks :
- for jj in ['test4', 'test5'] :
- with open(os.path.join('rmt',self.job.job_uuid,ii,jj), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- # generate extra donwload dirs and files
- for ii in tasks :
- for jj in ['dir1'] :
- os.makedirs(os.path.join('rmt',self.job.job_uuid,ii,jj), exist_ok=False)
- for kk in ['test6']:
- with open(os.path.join('rmt',self.job.job_uuid,ii,jj,kk), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- # donwload
- files = ['test4', 'test5', 'dir1']
- self.job.download(tasks, files)
- # check dlded
- cc = 0
- for ii in tasks :
- for jj in ['test4', 'test5'] :
- with open(os.path.join('loc',ii,jj), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
- for ii in tasks :
- for jj in ['dir1'] :
- for kk in ['test6']:
- with open(os.path.join('loc',ii,jj,kk), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
-
-
- def test_donwload_check_mark(self):
- tasks = ['task0', 'task1']
- self.job.upload(tasks, ['test0', 'dir0'])
- # generate extra donwload files
- record_uuid = []
- for ii in tasks :
- for jj in ['test6', 'test7'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6'):
- continue
- with open(os.path.join('rmt',self.job.job_uuid,ii,jj), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- # donwload
- files = ['test6', 'test7', 'dir1']
- self.job.download(tasks, files, check_exists = True, mark_failure = True)
- # check dlded
- cc = 0
- for ii in tasks :
- for jj in ['test6', 'test7'] :
- if (ii == 'task1' and jj == 'test7') or \
- (ii == 'task0' and jj == 'test6') :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)),
- msg = 'found ' + os.path.join('loc', ii, jj))
- self.assertTrue(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)),
- msg = 'failed to find ' + os.path.join('loc', ii, 'tag_failure_download_%s' % jj))
- continue
- with open(os.path.join('loc',ii,jj), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
- for ii in tasks :
- for jj in ['dir1'] :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)))
- self.assertTrue(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)))
-
-
- def test_donwload_check_nomark(self):
- tasks = ['task0', 'task1']
- self.job.upload(tasks, ['test0', 'dir0'])
- # generate extra donwload files
- record_uuid = []
- for ii in tasks :
- for jj in ['test6', 'test7'] :
- if ii == 'task1' and jj == 'test7' :
- continue
- if ii == 'task0' and jj == 'test6' :
- continue
- with open(os.path.join('rmt',self.job.job_uuid,ii,jj), 'w') as fp:
- tmp = str(uuid.uuid4())
- fp.write(tmp)
- record_uuid.append(tmp)
- # donwload
- files = ['test6', 'test7', 'dir1']
- self.job.download(tasks, files, check_exists = True, mark_failure = False)
- # check dlded
- cc = 0
- for ii in tasks :
- for jj in ['test6', 'test7'] :
- if ii == 'task1' and jj == 'test7' :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)),
- msg = 'found ' + os.path.join('loc', ii, jj))
- self.assertFalse(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)),
- msg = 'found ' + os.path.join('loc', ii, 'tag_failure_download_%s' % jj))
- continue
- if ii == 'task0' and jj == 'test6' :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)),
- msg = 'found ' + os.path.join('loc', ii, jj))
- self.assertFalse(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)),
- msg = 'found ' + os.path.join('loc', ii, 'tag_failure_download_%s' % jj))
- continue
- with open(os.path.join('loc',ii,jj), 'r') as fp:
- tmp = fp.read()
- self.assertEqual(tmp, record_uuid[cc])
- cc += 1
- for ii in tasks :
- for jj in ['dir1'] :
- self.assertFalse(os.path.exists(os.path.join('loc', ii, jj)))
- self.assertFalse(os.path.exists(os.path.join('loc', ii, 'tag_failure_download_%s' % jj)))
-
- def test_block_call(self) :
- tasks = ['task0', 'task1']
- files = ['test0', 'test1']
- self.job.upload(tasks, files)
- # ls
- code, stdin, stdout, stderr = self.job.block_call('ls')
- self.assertEqual(stdout.read(), b'task0\ntask1\n')
- self.assertEqual(code, 0)
- code, stdin, stdout, stderr = self.job.block_call('ls')
- self.assertEqual(stdout.readlines(), ['task0\n','task1\n'])
- code, stdin, stdout, stderr = self.job.block_call('ls a')
- self.assertEqual(code, 2)
- # self.assertEqual(stderr.read().decode('utf-8'), 'ls: cannot access a: No such file or directory\n')
- err_msg = stderr.read().decode('utf-8')
- self.assertTrue('ls: cannot access' in err_msg)
- self.assertTrue('No such file or directory\n' in err_msg)
-
- def test_block_checkcall(self) :
- tasks = ['task0', 'task1']
- files = ['test0', 'test1']
- self.job.upload(tasks, files)
- # ls
- stdin, stdout, stderr = self.job.block_checkcall('ls')
- self.assertEqual(stdout.read(), b'task0\ntask1\n')
- stdin, stdout, stderr = self.job.block_checkcall('ls')
- self.assertEqual(stdout.readlines(), ['task0\n','task1\n'])
- with self.assertRaises(RuntimeError):
- stdin, stdout, stderr = self.job.block_checkcall('ls a')
-
- def test_file(self) :
- self.assertFalse(self.job.check_file_exists('aaa'))
- tmp = str(uuid.uuid4())
- self.job.write_file('aaa', tmp)
- self.assertTrue(self.job.check_file_exists('aaa'))
- tmp1 = self.job.read_file('aaa')
- self.assertEqual(tmp, tmp1)
-
-
diff --git a/tests/generator/__init__.py b/tests/generator/__init__.py
index b3992b148..159956f19 100644
--- a/tests/generator/__init__.py
+++ b/tests/generator/__init__.py
@@ -1,3 +1,4 @@
# disable logging
import logging
-logging.disable(logging.CRITICAL)
\ No newline at end of file
+
+logging.disable(logging.CRITICAL)
diff --git a/tests/generator/abacus/INPUT.diy b/tests/generator/abacus/INPUT.diy
index c3018db6a..3366d835e 100644
--- a/tests/generator/abacus/INPUT.diy
+++ b/tests/generator/abacus/INPUT.diy
@@ -1,4 +1,3 @@
-ntype 2
ecutwfc 80
scf_thr 1e-7
scf_nmax 50
diff --git a/tests/generator/comp_sys.py b/tests/generator/comp_sys.py
index 10705d81a..8806ddb5e 100644
--- a/tests/generator/comp_sys.py
+++ b/tests/generator/comp_sys.py
@@ -1,125 +1,137 @@
import numpy as np
+
def test_atom_names(testCase, system_1, system_2):
- testCase.assertEqual(system_1.data['atom_names'],
- system_2.data['atom_names'])
+ testCase.assertEqual(system_1.data["atom_names"], system_2.data["atom_names"])
+
def test_atom_types(testCase, system_1, system_2):
- testCase.assertEqual(system_1.data['atom_types'][0],
- system_2.data['atom_types'][0])
- testCase.assertEqual(system_1.data['atom_types'][1],
- system_2.data['atom_types'][1])
-
-def test_cell(testCase, system_1, system_2, places = 5):
- testCase.assertEqual(system_1.get_nframes(),
- system_2.get_nframes())
- for ff in range(system_1.get_nframes()) :
- for ii in range(3) :
- for jj in range(3) :
- testCase.assertAlmostEqual(system_1.data['cells'][ff][ii][jj],
- system_2.data['cells'][ff][ii][jj],
- places = places,
- msg = 'cell[%d][%d][%d] failed' % (ff,ii,jj))
-
-def test_coord(testCase, system_1, system_2, places = 5):
- testCase.assertEqual(system_1.get_nframes(),
- system_2.get_nframes())
+ testCase.assertEqual(system_1.data["atom_types"][0], system_2.data["atom_types"][0])
+ testCase.assertEqual(system_1.data["atom_types"][1], system_2.data["atom_types"][1])
+
+
+def test_cell(testCase, system_1, system_2, places=5):
+ testCase.assertEqual(system_1.get_nframes(), system_2.get_nframes())
+ for ff in range(system_1.get_nframes()):
+ for ii in range(3):
+ for jj in range(3):
+ testCase.assertAlmostEqual(
+ system_1.data["cells"][ff][ii][jj],
+ system_2.data["cells"][ff][ii][jj],
+ places=places,
+ msg="cell[%d][%d][%d] failed" % (ff, ii, jj),
+ )
+
+
+def test_coord(testCase, system_1, system_2, places=5):
+ testCase.assertEqual(system_1.get_nframes(), system_2.get_nframes())
# think about direct coord
- tmp_cell = system_1.data['cells']
+ tmp_cell = system_1.data["cells"]
tmp_cell = np.reshape(tmp_cell, [-1, 3])
- tmp_cell_norm = np.reshape(np.linalg.norm(tmp_cell, axis = 1), [-1, 3])
- for ff in range(system_1.get_nframes()) :
- for ii in range(sum(system_1.data['atom_numbs'])) :
- for jj in range(3) :
- testCase.assertAlmostEqual(system_1.data['coords'][ff][ii][jj] / tmp_cell_norm[ff][jj],
- system_2.data['coords'][ff][ii][jj] / tmp_cell_norm[ff][jj],
- places = places,
- msg = 'coord[%d][%d][%d] failed' % (ff,ii,jj))
+ tmp_cell_norm = np.reshape(np.linalg.norm(tmp_cell, axis=1), [-1, 3])
+ for ff in range(system_1.get_nframes()):
+ for ii in range(sum(system_1.data["atom_numbs"])):
+ for jj in range(3):
+ testCase.assertAlmostEqual(
+ system_1.data["coords"][ff][ii][jj] / tmp_cell_norm[ff][jj],
+ system_2.data["coords"][ff][ii][jj] / tmp_cell_norm[ff][jj],
+ places=places,
+ msg="coord[%d][%d][%d] failed" % (ff, ii, jj),
+ )
-class CompSys :
+class CompSys:
def test_atom_numbs(self):
- self.assertEqual(self.system_1.data['atom_numbs'],
- self.system_2.data['atom_numbs'])
+ self.assertEqual(
+ self.system_1.data["atom_numbs"], self.system_2.data["atom_numbs"]
+ )
def test_atom_names(self):
- self.assertEqual(self.system_1.data['atom_names'],
- self.system_2.data['atom_names'])
+ self.assertEqual(
+ self.system_1.data["atom_names"], self.system_2.data["atom_names"]
+ )
def test_atom_types(self):
- self.assertEqual(self.system_1.data['atom_types'][0],
- self.system_2.data['atom_types'][0])
- self.assertEqual(self.system_1.data['atom_types'][1],
- self.system_2.data['atom_types'][1])
+ self.assertEqual(
+ self.system_1.data["atom_types"][0], self.system_2.data["atom_types"][0]
+ )
+ self.assertEqual(
+ self.system_1.data["atom_types"][1], self.system_2.data["atom_types"][1]
+ )
def test_orig(self):
- for d0 in range(3) :
- self.assertEqual(self.system_1.data['orig'][d0],
- self.system_2.data['orig'][d0])
+ for d0 in range(3):
+ self.assertEqual(
+ self.system_1.data["orig"][d0], self.system_2.data["orig"][d0]
+ )
def test_nframs(self):
- self.assertEqual(self.system_1.get_nframes(),
- self.system_2.get_nframes())
+ self.assertEqual(self.system_1.get_nframes(), self.system_2.get_nframes())
def test_cell(self):
- self.assertEqual(self.system_1.get_nframes(),
- self.system_2.get_nframes())
- for ff in range(self.system_1.get_nframes()) :
- for ii in range(3) :
- for jj in range(3) :
- self.assertAlmostEqual(self.system_1.data['cells'][ff][ii][jj],
- self.system_2.data['cells'][ff][ii][jj],
- places = self.places,
- msg = 'cell[%d][%d][%d] failed' % (ff,ii,jj))
-
- def test_coord(self):
- self.assertEqual(self.system_1.get_nframes(),
- self.system_2.get_nframes())
+ self.assertEqual(self.system_1.get_nframes(), self.system_2.get_nframes())
+ for ff in range(self.system_1.get_nframes()):
+ for ii in range(3):
+ for jj in range(3):
+ self.assertAlmostEqual(
+ self.system_1.data["cells"][ff][ii][jj],
+ self.system_2.data["cells"][ff][ii][jj],
+ places=self.places,
+ msg="cell[%d][%d][%d] failed" % (ff, ii, jj),
+ )
+
+ def test_coord(self):
+ self.assertEqual(self.system_1.get_nframes(), self.system_2.get_nframes())
# think about direct coord
- tmp_cell = self.system_1.data['cells']
+ tmp_cell = self.system_1.data["cells"]
tmp_cell = np.reshape(tmp_cell, [-1, 3])
- tmp_cell_norm = np.reshape(np.linalg.norm(tmp_cell, axis = 1), [-1, 3])
- for ff in range(self.system_1.get_nframes()) :
- for ii in range(sum(self.system_1.data['atom_numbs'])) :
- for jj in range(3) :
- self.assertAlmostEqual(self.system_1.data['coords'][ff][ii][jj] / tmp_cell_norm[ff][jj],
- self.system_2.data['coords'][ff][ii][jj] / tmp_cell_norm[ff][jj],
- places = self.places,
- msg = 'coord[%d][%d][%d] failed' % (ff,ii,jj))
-
-
-class CompLabeledSys (CompSys) :
- def test_energy(self) :
- self.assertEqual(self.system_1.get_nframes(),
- self.system_2.get_nframes())
- for ff in range(self.system_1.get_nframes()) :
- self.assertAlmostEqual(self.system_1.data['energies'][ff],
- self.system_2.data['energies'][ff],
- places = self.e_places,
- msg = 'energies[%d] failed' % (ff))
-
- def test_force(self) :
- self.assertEqual(self.system_1.get_nframes(),
- self.system_2.get_nframes())
- for ff in range(self.system_1.get_nframes()) :
- for ii in range(self.system_1.data['forces'].shape[1]) :
- for jj in range(3) :
- self.assertAlmostEqual(self.system_1.data['forces'][ff][ii][jj],
- self.system_2.data['forces'][ff][ii][jj],
- places = self.f_places,
- msg = 'forces[%d][%d][%d] failed' % (ff,ii,jj))
-
- def test_virial(self) :
- self.assertEqual(self.system_1.get_nframes(),
- self.system_2.get_nframes())
+ tmp_cell_norm = np.reshape(np.linalg.norm(tmp_cell, axis=1), [-1, 3])
+ for ff in range(self.system_1.get_nframes()):
+ for ii in range(sum(self.system_1.data["atom_numbs"])):
+ for jj in range(3):
+ self.assertAlmostEqual(
+ self.system_1.data["coords"][ff][ii][jj]
+ / tmp_cell_norm[ff][jj],
+ self.system_2.data["coords"][ff][ii][jj]
+ / tmp_cell_norm[ff][jj],
+ places=self.places,
+ msg="coord[%d][%d][%d] failed" % (ff, ii, jj),
+ )
+
+
+class CompLabeledSys(CompSys):
+ def test_energy(self):
+ self.assertEqual(self.system_1.get_nframes(), self.system_2.get_nframes())
+ for ff in range(self.system_1.get_nframes()):
+ self.assertAlmostEqual(
+ self.system_1.data["energies"][ff],
+ self.system_2.data["energies"][ff],
+ places=self.e_places,
+ msg="energies[%d] failed" % (ff),
+ )
+
+ def test_force(self):
+ self.assertEqual(self.system_1.get_nframes(), self.system_2.get_nframes())
+ for ff in range(self.system_1.get_nframes()):
+ for ii in range(self.system_1.data["forces"].shape[1]):
+ for jj in range(3):
+ self.assertAlmostEqual(
+ self.system_1.data["forces"][ff][ii][jj],
+ self.system_2.data["forces"][ff][ii][jj],
+ places=self.f_places,
+ msg="forces[%d][%d][%d] failed" % (ff, ii, jj),
+ )
+
+ def test_virial(self):
+ self.assertEqual(self.system_1.get_nframes(), self.system_2.get_nframes())
if not self.system_1.has_virial():
return
- for ff in range(self.system_1.get_nframes()) :
- for ii in range(3) :
- for jj in range(3) :
- self.assertAlmostEqual(self.system_1['virials'][ff][ii][jj],
- self.system_2['virials'][ff][ii][jj],
- places = self.v_places,
- msg = 'virials[%d][%d][%d] failed' % (ff,ii,jj))
-
-
+ for ff in range(self.system_1.get_nframes()):
+ for ii in range(3):
+ for jj in range(3):
+ self.assertAlmostEqual(
+ self.system_1["virials"][ff][ii][jj],
+ self.system_2["virials"][ff][ii][jj],
+ places=self.v_places,
+ msg="virials[%d][%d][%d] failed" % (ff, ii, jj),
+ )
diff --git a/tests/generator/context.py b/tests/generator/context.py
index 7e7113a93..033f4cb50 100644
--- a/tests/generator/context.py
+++ b/tests/generator/context.py
@@ -1,41 +1,46 @@
-import sys,os
+import os
+import sys
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
-from dpgen.generator.run import *
-from dpgen.generator.lib.gaussian import detect_multiplicity, _crd2frag
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
from dpgen.generator.lib.ele_temp import NBandsEsti
-from dpgen.generator.lib.lammps import get_dumped_forces
-from dpgen.generator.lib.lammps import get_all_dumped_forces
-from dpgen.generator.lib.make_calypso import make_calypso_input,write_model_devi_out
-from dpgen.generator.lib.parse_calypso import _parse_calypso_input,_parse_calypso_dis_mtx
+from dpgen.generator.lib.gaussian import _crd2frag, detect_multiplicity
+from dpgen.generator.lib.lammps import get_all_dumped_forces, get_dumped_forces
+from dpgen.generator.lib.make_calypso import make_calypso_input, write_model_devi_out
+from dpgen.generator.lib.parse_calypso import (
+ _parse_calypso_dis_mtx,
+ _parse_calypso_input,
+)
+from dpgen.generator.run import *
-param_file = 'param-mg-vasp.json'
-param_file_merge_traj = 'param-mg-vasp_merge_traj.json'
-param_file_v1 = 'param-mg-vasp-v1.json'
-param_file_v1_et = 'param-mg-vasp-v1-et.json'
-param_old_file = 'param-mg-vasp-old.json'
-param_pwscf_file = 'param-pyridine-pwscf.json'
-param_pwscf_old_file = 'param-pyridine-pwscf-old.json'
-param_gaussian_file = 'param-pyridine-gaussian.json'
-param_siesta_file = 'param-pyridine-siesta.json'
-param_cp2k_file = 'param-pyridine-cp2k.json'
-param_cp2k_file_exinput = 'param-mgo-cp2k-exinput.json'
-ref_cp2k_file_input = 'cp2k_test_ref.inp'
-ref_cp2k_file_exinput = 'cp2k_test_exref.inp'
-machine_file = 'machine-local.json'
-machine_file_v1 = 'machine-local-v1.json'
-param_diy_file = 'param-mg-vasp-diy.json'
-param_pwmat_file = 'param-pyridine-pwmat.json'
-param_abacus_file = 'param-pyridine-abacus.json'
-param_abacus_post_file = 'param-methane-abacus.json'
-param_diy_abacus_post_file = 'param-methane-abacus-diy.json'
+param_file = "param-mg-vasp.json"
+param_file_merge_traj = "param-mg-vasp_merge_traj.json"
+param_file_v1 = "param-mg-vasp-v1.json"
+param_file_v1_et = "param-mg-vasp-v1-et.json"
+param_old_file = "param-mg-vasp-old.json"
+param_pwscf_file = "param-pyridine-pwscf.json"
+param_pwscf_old_file = "param-pyridine-pwscf-old.json"
+param_gaussian_file = "param-pyridine-gaussian.json"
+param_siesta_file = "param-pyridine-siesta.json"
+param_cp2k_file = "param-pyridine-cp2k.json"
+param_cp2k_file_exinput = "param-mgo-cp2k-exinput.json"
+ref_cp2k_file_input = "cp2k_test_ref.inp"
+ref_cp2k_file_exinput = "cp2k_test_exref.inp"
+machine_file = "machine-local.json"
+machine_file_v1 = "machine-local-v1.json"
+param_diy_file = "param-mg-vasp-diy.json"
+param_pwmat_file = "param-pyridine-pwmat.json"
+param_abacus_file = "param-pyridine-abacus.json"
+param_abacus_post_file = "param-methane-abacus.json"
+param_diy_abacus_post_file = "param-methane-abacus-diy.json"
param_amber_file = "param-amber.json"
-param_multiple_trust_file = 'param-mg-vasp-multi-trust.json'
+param_multiple_trust_file = "param-mg-vasp-multi-trust.json"
+
def my_file_cmp(test, f0, f1):
- with open(f0) as fp0 :
+ with open(f0) as fp0:
with open(f1) as fp1:
test.assertTrue(fp0.read() == fp1.read())
+
def setUpModule():
os.chdir(os.path.abspath(os.path.dirname(__file__)))
diff --git a/tests/generator/gromacs/model_devi_case/model_devi.py b/tests/generator/gromacs/model_devi_case/model_devi.py
index 0c7e245cf..6c0b81568 100755
--- a/tests/generator/gromacs/model_devi_case/model_devi.py
+++ b/tests/generator/gromacs/model_devi_case/model_devi.py
@@ -1,44 +1,52 @@
#!/data1/anguse/zijian/deepmd-kit-devel/virtual_tf_2/bin/python
+import json
+import os
+import sys
+
import deepmd.DeepPot as DP
import dpdata
import numpy as np
-import os, sys
-import json
+
+
def calc_model_devi_f(fs):
- '''
- fs : numpy.ndarray, size of `n_models x n_frames x n_atoms x 3`
- '''
+ """
+ fs : numpy.ndarray, size of `n_models x n_frames x n_atoms x 3`
+ """
fs_mean = np.mean(fs, axis=0)
# print(fs_mean.shape)
fs_err = np.sum((fs - fs_mean) ** 2, axis=-1)
# print(fs_err.shape)
fs_devi = np.mean(fs_err, axis=0) ** 0.5
- # print(fs_devi.shape)
+ # print(fs_devi.shape)
max_devi_f = np.max(fs_devi, axis=1)
# min_devi_f = np.min(fs_devi, axis=1)
# avg_devi_f = np.mean(fs_devi, axis=1)
return max_devi_f
-def write_model_devi_out(system, models, fname=None, trj_freq = 10):
+
+def write_model_devi_out(system, models, fname=None, trj_freq=10):
forces = []
for model in models:
labeled = system.predict(model)
- forces.append(labeled['forces'])
+ forces.append(labeled["forces"])
forces = np.array(forces)
max_devi_f = calc_model_devi_f(forces)
model_devi_out = np.zeros((system.get_nframes(), 7))
model_devi_out[:, 0] += np.arange(system.get_nframes()) * trj_freq
model_devi_out[:, 4] += max_devi_f
if fname is not None:
- np.savetxt(fname,
- model_devi_out,
- fmt=['%d'] + ['%.8e' for _ in range(6)],
- delimiter='\t',
- header='step\tmax_devi_e\tmin_devi_e\tavg_devi_e\tmax_devi_f\tmin_devi_f\tavg_devi_f')
+ np.savetxt(
+ fname,
+ model_devi_out,
+ fmt=["%d"] + ["%.8e" for _ in range(6)],
+ delimiter="\t",
+ header="step\tmax_devi_e\tmin_devi_e\tavg_devi_e\tmax_devi_f\tmin_devi_f\tavg_devi_f",
+ )
return model_devi_out
+
if __name__ == "__main__":
- system = dpdata.System(sys.argv[1], fmt='gromacs/gro')
+ system = dpdata.System(sys.argv[1], fmt="gromacs/gro")
if os.path.isfile("job.json"):
trj_freq = json.load(open("job.json")).get("trj_freq", 10)
else:
@@ -46,6 +54,6 @@ def write_model_devi_out(system, models, fname=None, trj_freq = 10):
if not os.path.isdir("traj"):
os.mkdir("traj")
for i in range(system.get_nframes()):
- system[i].to_gromacs_gro("traj/%d.gromacstrj" % (trj_freq * i) )
+ system[i].to_gromacs_gro("traj/%d.gromacstrj" % (trj_freq * i))
models = [DP(f"../graph.{ii:03}.pb") for ii in range(4)]
write_model_devi_out(system, models, "model_devi.out", trj_freq)
diff --git a/tests/dispatcher/__init__.py b/tests/generator/model.ptg
similarity index 100%
rename from tests/dispatcher/__init__.py
rename to tests/generator/model.ptg
diff --git a/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/INPUT b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/INPUT
new file mode 100644
index 000000000..2b76680e7
--- /dev/null
+++ b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/INPUT
@@ -0,0 +1,14 @@
+INPUT_PARAMETERS
+ntype 2
+pseudo_dir ./
+ecutwfc 80.000000
+mixing_type pulay
+mixing_beta 0.400000
+symmetry 1
+nbands 5.000000
+nspin 1
+ks_solver cg
+smearing fixed
+sigma 0.001000
+force 1
+stress 1
diff --git a/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/KPT b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/KPT
new file mode 100644
index 000000000..5ab6cd6d4
--- /dev/null
+++ b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/KPT
@@ -0,0 +1,4 @@
+K_POINTS
+0
+Gamma
+1 1 1 0 0 0
\ No newline at end of file
diff --git a/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/OUT.ABACUS/running_scf.log b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/OUT.ABACUS/running_scf.log
new file mode 100644
index 000000000..4a481d6eb
--- /dev/null
+++ b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/OUT.ABACUS/running_scf.log
@@ -0,0 +1,198 @@
+
+ ABACUS v3.1
+
+ Atomic-orbital Based Ab-initio Computation at UStc
+
+ Website: http://abacus.ustc.edu.cn/
+ Documentation: https://abacus.deepmodeling.com/
+ Repository: https://github.com/abacusmodeling/abacus-develop
+ https://github.com/deepmodeling/abacus-develop
+
+ Start Time is Wed Mar 15 18:24:30 2023
+
+ ------------------------------------------------------------------------------------
+
+ READING GENERAL INFORMATION
+ global_out_dir = OUT.ABACUS/
+ global_in_card = INPUT
+ pseudo_dir =
+ orbital_dir =
+ DRANK = 1
+ DSIZE = 8
+ DCOLOR = 1
+ GRANK = 1
+ GSIZE = 1
+ The esolver type has been set to : ksdft_lcao
+
+
+
+
+ >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
+ | |
+ | Reading atom information in unitcell: |
+ | From the input file and the structure file we know the number of |
+ | different elments in this unitcell, then we list the detail |
+ | information for each element, especially the zeta and polar atomic |
+ | orbital number for each element. The total atom number is counted. |
+ | We calculate the nearest atom distance for each atom and show the |
+ | Cartesian and Direct coordinates for each atom. We list the file |
+ | address for atomic orbitals. The volume and the lattice vectors |
+ | in real and reciprocal space is also shown. |
+ | |
+ <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
+
+
+
+
+ READING UNITCELL INFORMATION
+ ntype = 2
+ atom label for species 1 = H
+ atom label for species 2 = O
+ lattice constant (Bohr) = 1.88973
+ lattice constant (Angstrom) = 1
+
+ READING ATOM TYPE 1
+ atom label = H
+ L=0, number of zeta = 2
+ L=1, number of zeta = 1
+ number of atom for this type = 2
+ start magnetization = FALSE
+ start magnetization = FALSE
+
+ READING ATOM TYPE 2
+ atom label = O
+ L=0, number of zeta = 2
+ L=1, number of zeta = 2
+ L=2, number of zeta = 1
+ number of atom for this type = 1
+ start magnetization = FALSE
+
+ TOTAL ATOM NUMBER = 3
+
+ CARTESIAN COORDINATES ( UNIT = 1.88973 Bohr ).
+ atom x y z mag vx vy vz
+ tauc_H1 10.1236 0.358121000009 2.96728000001 0 0 0 0
+ tauc_H2 10.097 0.457652000002 1.52015 0 0 0 0
+ tauc_O1 10.263 0.407492999997 3.07706999999 0 0 0 0
+
+
+ READING ORBITAL FILE NAMES FOR LCAO
+ orbital file: H_gga_6au_60Ry_2s1p.orb
+ orbital file: O_gga_6au_60Ry_2s2p1d.orb
+
+ Volume (Bohr^3) = 22712.4312372
+ Volume (A^3) = 3365.6310456
+
+ Lattice vectors: (Cartesian coordinate: in unit of a_0)
+ +14.9758141613 +0 +0
+ -0.1998739632 +14.9158454229 +0
+ +0.0479160432 +0.2573204003 +15.0670665885
+ Reciprocal vectors: (Cartesian coordinate: in unit of 2 pi/a_0)
+ +0.066774332883 +0.000894783378008 -0.00022763607076
+ -0 +0.0670427972165 -0.00114497930408
+ +0 -0 +0.066369919727
+
+
+
+
+ >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
+ | |
+ | Reading pseudopotentials files: |
+ | The pseudopotential file is in UPF format. The 'NC' indicates that |
+ | the type of pseudopotential is 'norm conserving'. Functional of |
+ | exchange and correlation is decided by 4 given parameters in UPF |
+ | file. We also read in the 'core correction' if there exists. |
+ | Also we can read the valence electrons number and the maximal |
+ | angular momentum used in this pseudopotential. We also read in the |
+ | trail wave function, trail atomic density and local-pseudopotential|
+ | on logrithmic grid. The non-local pseudopotential projector is also|
+ | read in if there is any. |
+ | |
+ <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
+
+
+
+
+ PAO radial cut off (Bohr) = 15
+
+ Read in pseudopotential file is H_ONCV_PBE-1.0.upf
+ pseudopotential type = NC
+ exchange-correlation functional = PBE
+ nonlocal core correction = 0
+ valence electrons = 1
+ lmax = 0
+ number of zeta = 0
+ number of projectors = 2
+ L of projector = 0
+ L of projector = 0
+
+ In Pseudopot_upf::read_pseudo_header : dft_functional from INPUT does not match that in pseudopot file
+ Please make sure this is what you need
+ XC functional updated to : lda
+ exchange-correlation functional = LDA
+ PAO radial cut off (Bohr) = 15
+
+ Read in pseudopotential file is O_ONCV_PBE-1.0.upf
+ pseudopotential type = NC
+ exchange-correlation functional = PBE
+ nonlocal core correction = 0
+ valence electrons = 6
+ lmax = 1
+ number of zeta = 0
+ number of projectors = 4
+ L of projector = 0
+ L of projector = 0
+ L of projector = 1
+ L of projector = 1
+
+ In Pseudopot_upf::read_pseudo_header : dft_functional from INPUT does not match that in pseudopot file
+ Please make sure this is what you need
+ XC functional updated to : lda
+ exchange-correlation functional = LDA
+
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+!!! WARNING: Some atoms are too close!!!
+!!! Please check the nearest-neighbor list in log file.
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+!!! WARNING: Some atoms are too close!!!
+!!! Please check the nearest-neighbor list in log file.
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+!!! WARNING: Some atoms are too close!!!
+!!! Please check the nearest-neighbor list in log file.
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+ 1-th H, 1-th O (cell: 0 0 0), distance= 0.348 Bohr (0.184 Angstrom)
+If this structure is what you want, you can set 'min_dist_coef'
+as a smaller value (the current value is 0.2) in INPUT file.
+ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
+ NOTICE
+ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
+
+ The structure is unreasonable!
+ CHECK IN FILE : OUT.ABACUS/warning.log
+
+ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
+ NOTICE
+ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
+ Check in file : OUT.ABACUS/warning.log
+
+
+
+
+ |CLASS_NAME---------|NAME---------------|TIME(Sec)-----|CALLS----|AVG------|PER%-------
+ ----------------------------------------------------------------------------------------
diff --git a/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/POSCAR b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/POSCAR
new file mode 100644
index 000000000..94357dd48
--- /dev/null
+++ b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/POSCAR
@@ -0,0 +1,13 @@
+H4 C1
+1.0
+1.0256560185400000e+01 0.0000000000000000e+00 0.0000000000000000e+00
+-2.4531774970000000e-01 9.8128484190999998e+00 0.0000000000000000e+00
+-2.5710315189999999e-01 -3.0129123369999999e-01 9.8293471193999995e+00
+H C
+4 1
+Cartesian
+ 5.3475200000 4.1329900000 3.4240900000
+ 4.0099600000 5.0100700000 4.1737100000
+ 5.5891800000 5.0824200000 4.8661200000
+ 4.7052500000 3.5190100000 4.8860700000
+ 4.9222700000 4.4726500000 4.3767300000
diff --git a/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/STRU b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/STRU
new file mode 100644
index 000000000..4fb0bec50
--- /dev/null
+++ b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/STRU
@@ -0,0 +1,25 @@
+ATOMIC_SPECIES
+H 1.00 H_ONCV_PBE-1.0.upf
+C 1.00 C_ONCV_PBE-1.0.upf
+
+LATTICE_CONSTANT
+1.8897261254578281
+
+LATTICE_VECTORS
+10.2565601854 0.0 0.0
+-0.2453177497 9.8128484191 0.0
+-0.2571031519 -0.3012912337 9.8293471194
+
+ATOMIC_POSITIONS
+Cartesian # Cartesian(Unit is LATTICE_CONSTANT)
+H
+0.0
+4
+5.347520000000 4.132990000000 3.424090000000 0 0 0
+4.009960000000 5.010070000000 4.173710000000 0 0 0
+5.589180000000 5.082420000000 4.866120000000 0 0 0
+4.705250000000 3.519010000000 4.886070000000 0 0 0
+C
+0.0
+1
+4.922270000000 4.472650000000 4.376730000000 0 0 0
diff --git a/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/output b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/output
new file mode 100644
index 000000000..ad700205d
--- /dev/null
+++ b/tests/generator/out_data_post_fp_abacus/02.fp/task.001.000002/output
@@ -0,0 +1,67 @@
+WARNING: Total thread number on this node mismatches with hardware availability. This may cause poor performance.
+Info: Local MPI proc number: 8,OpenMP thread number: 1,Total thread number: 8,Local thread limit: 16
+
+ ABACUS v3.1
+
+ Atomic-orbital Based Ab-initio Computation at UStc
+
+ Website: http://abacus.ustc.edu.cn/
+ Documentation: https://abacus.deepmodeling.com/
+ Repository: https://github.com/abacusmodeling/abacus-develop
+ https://github.com/deepmodeling/abacus-develop
+
+ Wed Mar 15 18:24:30 2023
+ MAKE THE DIR : OUT.ABACUS/
+ dft_functional readin is: lda
+ dft_functional in pseudopot file is: PBE
+In Pseudopot_upf::read_pseudo_header : dft_functional from INPUT does not match that in pseudopot file
+Please make sure this is what you need
+ dft_functional readin is: lda
+ dft_functional in pseudopot file is: PBE
+In Pseudopot_upf::read_pseudo_header : dft_functional from INPUT does not match that in pseudopot file
+Please make sure this is what you need
+
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+!!! WARNING: Some atoms are too close!!!
+!!! Please check the nearest-neighbor list in log file.
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+!!! WARNING: Some atoms are too close!!!
+!!! Please check the nearest-neighbor list in log file.
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+!!! WARNING: Some atoms are too close!!!
+!!! Please check the nearest-neighbor list in log file.
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+%%%%%% WARNING WARNING WARNING WARNING WARNING %%%%%%
+%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
+
+If this structure is what you want, you can set 'min_dist_coef'
+as a smaller value (the current value is 0.2) in INPUT file.
+
+ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
+ NOTICE
+ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
+
+ The structure is unreasonable!
+ CHECK IN FILE : OUT.ABACUS/warning.log
+
+ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
+ NOTICE
+ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
+
+ |CLASS_NAME---------|NAME---------------|TIME(Sec)-----|CALLS----|AVG------|PER%-------
+ ----------------------------------------------------------------------------------------
+ See output information in : OUT.ABACUS/
diff --git a/tests/generator/param-methane-abacus.json b/tests/generator/param-methane-abacus.json
index 0b2ab547a..2f9ff1b96 100644
--- a/tests/generator/param-methane-abacus.json
+++ b/tests/generator/param-methane-abacus.json
@@ -135,7 +135,6 @@
"_fp_kpt_file": "./abacus/KPT",
"_k_points": [3,3,3,0,0,0],
"user_fp_params":{
- "ntype": 2,
"ecutwfc": 80,
"scf_thr": 1e-7,
"scf_nmax": 50,
diff --git a/tests/generator/test_calypso.py b/tests/generator/test_calypso.py
index 958b9e40e..cb4546bca 100644
--- a/tests/generator/test_calypso.py
+++ b/tests/generator/test_calypso.py
@@ -1,34 +1,88 @@
-import os,sys,json,glob,shutil,textwrap
-import dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
+import textwrap
import unittest
from pathlib import Path
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
+import dpdata
+import numpy as np
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
-from .context import make_calypso_input
-from .context import write_model_devi_out
-from .context import _parse_calypso_input
-from .context import _parse_calypso_dis_mtx
+from .context import (
+ _parse_calypso_dis_mtx,
+ _parse_calypso_input,
+ make_calypso_input,
+ write_model_devi_out,
+)
# temp dir
-test_path = Path('.').joinpath('calypso_test_path')
-test_path.mkdir(parents=True,exist_ok=True)
-os.system('rm calypso_test_path/*')
+test_path = Path(".").joinpath("calypso_test_path")
+test_path.mkdir(parents=True, exist_ok=True)
+os.system("rm calypso_test_path/*")
fmax = 0.01
cwd = os.getcwd()
-model_devi = np.array([[0.000000e+00, 2.328491e-02, 5.476687e-09, 1.009454e-02,
- 3.279617e-02, 4.053224e-03, 1.869795e-02, 2.184905e+00],
- [1.000000e+00, 3.668334e-02, 8.200870e-09, 1.706517e-02,
- 2.844074e-02, 7.093109e-03, 1.623275e-02, 2.424708e+00],
- [2.000000e+00, 2.832296e-02, 4.828951e-08, 1.573961e-02,
- 2.443331e-02, 2.871548e-03, 1.489787e-02, 2.564113e+00]])
+model_devi = np.array(
+ [
+ [
+ 0.000000e00,
+ 2.328491e-02,
+ 5.476687e-09,
+ 1.009454e-02,
+ 3.279617e-02,
+ 4.053224e-03,
+ 1.869795e-02,
+ 2.184905e00,
+ ],
+ [
+ 1.000000e00,
+ 3.668334e-02,
+ 8.200870e-09,
+ 1.706517e-02,
+ 2.844074e-02,
+ 7.093109e-03,
+ 1.623275e-02,
+ 2.424708e00,
+ ],
+ [
+ 2.000000e00,
+ 2.832296e-02,
+ 4.828951e-08,
+ 1.573961e-02,
+ 2.443331e-02,
+ 2.871548e-03,
+ 1.489787e-02,
+ 2.564113e00,
+ ],
+ ]
+)
+
+model_devi_jobs = {
+ "model_devi_jobs": {
+ "times": [4],
+ "NameOfAtoms": ["Mg", "Al", "Cu"],
+ "NumberOfAtoms": [1, 1, 1],
+ "NumberOfFormula": [1, 4],
+ "Volume": [30],
+ "DistanceOfIon": [[1.48, 1.44, 1.59], [1.44, 1.41, 1.56], [1.59, 1.56, 1.70]],
+ "PsoRatio": [0.6],
+ "PopSize": [5],
+ "MaxStep": [3],
+ "ICode": [13],
+ "Split": "T",
+ "VSC": "T",
+ "MaxNumAtom": [31],
+ "CtrlRange": [[1, 10], [1, 10], [1, 10]],
+ "PSTRESS": [0],
+ "fmax": [0.01],
+ }
+}
-model_devi_jobs = {"model_devi_jobs": {"times":[4],"NameOfAtoms":["Mg","Al","Cu"],"NumberOfAtoms":[1,1,1],"NumberOfFormula":[1,4],"Volume":[30],"DistanceOfIon":[[1.48,1.44,1.59],[1.44,1.41,1.56],[1.59,1.56,1.70]],"PsoRatio":[0.6],"PopSize":[5],"MaxStep":[3],"ICode":[13],"Split":"T","VSC":"T","MaxNumAtom":[31],
- "CtrlRange":[[1,10],[1,10],[1,10]],"PSTRESS":[0],"fmax":[0.01]}}
-
class TestCALYPSOScript(unittest.TestCase):
def setUp(self):
@@ -38,57 +92,92 @@ def tearDown(self):
pass
def test_write_model_devi_out(self):
- #devi = write_model_devi_out(model_devi, 'calypso_test_path/model_devi.out')
- #ndevi = np.loadtxt('calypso_test_path/model_devi.out')
- devi = write_model_devi_out(model_devi, 'model_devi.out')
- ndevi = np.loadtxt('model_devi.out')
- self.assertEqual(ndevi[2,4],model_devi[2,4])
- os.remove('model_devi.out')
+ # devi = write_model_devi_out(model_devi, 'calypso_test_path/model_devi.out')
+ # ndevi = np.loadtxt('calypso_test_path/model_devi.out')
+ devi = write_model_devi_out(model_devi, "model_devi.out")
+ ndevi = np.loadtxt("model_devi.out")
+ self.assertEqual(ndevi[2, 4], model_devi[2, 4])
+ os.remove("model_devi.out")
def test_make_calypso_input(self):
- ret = make_calypso_input(["Mg","Al","Cu"],[1,1,1],[1,4],30,[
- [1.48,1.44,1.59],[1.44,1.41,1.56],[1.59,1.56,1.70]
- ],0.6,5,3,13,"T","T",31,[[1,10],[1,10],[1,10]],0,0.01)
- #with open('calypso_test_path/input.dat','w') as fin:
- with open('input.dat','w') as fin:
+ ret = make_calypso_input(
+ ["Mg", "Al", "Cu"],
+ [1, 1, 1],
+ [1, 4],
+ 30,
+ [[1.48, 1.44, 1.59], [1.44, 1.41, 1.56], [1.59, 1.56, 1.70]],
+ 0.6,
+ 5,
+ 3,
+ 13,
+ "T",
+ "T",
+ 31,
+ [[1, 10], [1, 10], [1, 10]],
+ 0,
+ 0.01,
+ )
+ # with open('calypso_test_path/input.dat','w') as fin:
+ with open("input.dat", "w") as fin:
fin.write(ret)
- f = open('input.dat')
- #f = open('calypso_test_path/input.dat')
+ f = open("input.dat")
+ # f = open('calypso_test_path/input.dat')
lines = f.readlines()
f.close()
- for line in lines :
- if line[0] == '#':
+ for line in lines:
+ if line[0] == "#":
continue
- if 'PopSize' in line:
- temp_1 = line.split('=')[1].strip()
- self.assertEqual(int(temp_1),5)
- if 'MaxStep' in line:
- temp_2 = line.split('=')[1].strip()
- self.assertEqual(int(temp_2),3)
- os.remove('input.dat')
+ if "PopSize" in line:
+ temp_1 = line.split("=")[1].strip()
+ self.assertEqual(int(temp_1), 5)
+ if "MaxStep" in line:
+ temp_2 = line.split("=")[1].strip()
+ self.assertEqual(int(temp_2), 3)
+ os.remove("input.dat")
break
def test_parse_calypso_input(self):
- ret = make_calypso_input(["Mg","Al","Cu"],[1,1,1],[1,4],30,[
- [1.48,1.44,1.59],[1.44,1.41,1.56],[1.59,1.56,1.70]
- ],0.6,5,3,13,"T","T",31,[[1,10],[1,10],[1,10]],0,0.01)
- #with open('calypso_test_path/input.dat','w') as fin:
- with open('input.dat','w') as fin:
+ ret = make_calypso_input(
+ ["Mg", "Al", "Cu"],
+ [1, 1, 1],
+ [1, 4],
+ 30,
+ [[1.48, 1.44, 1.59], [1.44, 1.41, 1.56], [1.59, 1.56, 1.70]],
+ 0.6,
+ 5,
+ 3,
+ 13,
+ "T",
+ "T",
+ 31,
+ [[1, 10], [1, 10], [1, 10]],
+ 0,
+ 0.01,
+ )
+ # with open('calypso_test_path/input.dat','w') as fin:
+ with open("input.dat", "w") as fin:
fin.write(ret)
- formula = _parse_calypso_input('NumberOfFormula','input.dat').split()
- #formula = _parse_calypso_input('NumberOfFormula',calypso_data).split()
- formula = list(map(int,formula))
- self.assertEqual(formula,model_devi_jobs.get('model_devi_jobs').get('NumberOfFormula'))
-
- nameofatoms = _parse_calypso_input('NameOfAtoms','input.dat').split()
- #nameofatoms = _parse_calypso_input('NameOfAtoms',calypso_data).split()
- self.assertEqual(nameofatoms,model_devi_jobs.get('model_devi_jobs').get('NameOfAtoms'))
-
- min_dis = _parse_calypso_dis_mtx(len(nameofatoms),'input.dat')
- #min_dis = _parse_calypso_dis_mtx(len(nameofatoms),calypso_data)
- self.assertEqual(float(min_dis),np.nanmin(model_devi_jobs.get('model_devi_jobs').get('DistanceOfIon')))
- os.remove('input.dat')
-
-
-if __name__ == '__main__':
+ formula = _parse_calypso_input("NumberOfFormula", "input.dat").split()
+ # formula = _parse_calypso_input('NumberOfFormula',calypso_data).split()
+ formula = list(map(int, formula))
+ self.assertEqual(
+ formula, model_devi_jobs.get("model_devi_jobs").get("NumberOfFormula")
+ )
+
+ nameofatoms = _parse_calypso_input("NameOfAtoms", "input.dat").split()
+ # nameofatoms = _parse_calypso_input('NameOfAtoms',calypso_data).split()
+ self.assertEqual(
+ nameofatoms, model_devi_jobs.get("model_devi_jobs").get("NameOfAtoms")
+ )
+
+ min_dis = _parse_calypso_dis_mtx(len(nameofatoms), "input.dat")
+ # min_dis = _parse_calypso_dis_mtx(len(nameofatoms),calypso_data)
+ self.assertEqual(
+ float(min_dis),
+ np.nanmin(model_devi_jobs.get("model_devi_jobs").get("DistanceOfIon")),
+ )
+ os.remove("input.dat")
+
+
+if __name__ == "__main__":
unittest.main(verbosity=2)
diff --git a/tests/generator/test_check_bad_box.py b/tests/generator/test_check_bad_box.py
index ba210128e..e40b42853 100644
--- a/tests/generator/test_check_bad_box.py
+++ b/tests/generator/test_check_bad_box.py
@@ -1,22 +1,28 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
from .context import check_bad_box
+
class TestCheckBadBox(unittest.TestCase):
def test_length_ratio(self):
dirname = os.path.dirname(__file__)
- conf_bad = os.path.join(dirname, 'check_bad_box', 'bad.length.lammpstrj')
- conf_good = os.path.join(dirname, 'check_bad_box', 'good.lammpstrj')
- self.assertTrue(check_bad_box(conf_bad, 'length_ratio:5'))
- self.assertFalse(check_bad_box(conf_good, 'length_ratio:5'))
+ conf_bad = os.path.join(dirname, "check_bad_box", "bad.length.lammpstrj")
+ conf_good = os.path.join(dirname, "check_bad_box", "good.lammpstrj")
+ self.assertTrue(check_bad_box(conf_bad, "length_ratio:5"))
+ self.assertFalse(check_bad_box(conf_good, "length_ratio:5"))
def test_height_ratio(self):
dirname = os.path.dirname(__file__)
- conf_bad = os.path.join(dirname, 'check_bad_box', 'bad.height.POSCAR')
- self.assertTrue(check_bad_box(conf_bad, 'height_ratio:5', fmt = 'vasp/POSCAR'))
- self.assertFalse(check_bad_box(conf_bad, 'length_ratio:5', fmt = 'vasp/POSCAR'))
+ conf_bad = os.path.join(dirname, "check_bad_box", "bad.height.POSCAR")
+ self.assertTrue(check_bad_box(conf_bad, "height_ratio:5", fmt="vasp/POSCAR"))
+ self.assertFalse(check_bad_box(conf_bad, "length_ratio:5", fmt="vasp/POSCAR"))
diff --git a/tests/generator/test_check_cluster.py b/tests/generator/test_check_cluster.py
index 47fa9569e..fb969e047 100644
--- a/tests/generator/test_check_cluster.py
+++ b/tests/generator/test_check_cluster.py
@@ -1,28 +1,27 @@
-import os,sys
+import importlib
+import os
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-import importlib
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
-from .context import check_cluster
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
+from .context import check_cluster, setUpModule
class Test_check_cluster(unittest.TestCase):
- def test (self) :
- conf_name='POSCAR_Au_cluster'
- fmt='POSCAR'
+ def test(self):
+ conf_name = "POSCAR_Au_cluster"
+ fmt = "POSCAR"
ret = check_cluster(conf_name, fp_cluster_vacuum=15, fmt=fmt)
- #bad cluster
+ # bad cluster
self.assertTrue(ret)
- #good cluster
+ # good cluster
ret = check_cluster(conf_name, fp_cluster_vacuum=10, fmt=fmt)
self.assertFalse(ret)
-if __name__ == '__main__':
- unittest.main()
-
-
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tests/generator/test_cluster.py b/tests/generator/test_cluster.py
index 4fcdeb551..87151b4ef 100644
--- a/tests/generator/test_cluster.py
+++ b/tests/generator/test_cluster.py
@@ -1,56 +1,54 @@
-import os,sys
+import importlib
+import os
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-import importlib
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
-from .context import take_cluster, _crd2frag
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
from .comp_sys import CompSys
+from .context import _crd2frag, setUpModule, take_cluster
@unittest.skipIf(importlib.util.find_spec("openbabel") is None, "requires openbabel")
class Test_take_cluster(unittest.TestCase, CompSys):
- def setUp (self) :
- type_map = ['C', 'H']
- jdata={
- "cluster_cutoff": 3.5
- }
+ def setUp(self):
+ type_map = ["C", "H"]
+ jdata = {"cluster_cutoff": 3.5}
self.system_1 = take_cluster("cluster/14400.lammpstrj", type_map, 1125, jdata)
self.system_2 = dpdata.System.load("cluster/cluster1.json")
- self.places=0
+ self.places = 0
@unittest.skipIf(importlib.util.find_spec("openbabel") is None, "requires openbabel")
class Test_take_cluster_minify(unittest.TestCase, CompSys):
- def setUp (self) :
- type_map = ['C', 'H']
- jdata={
- "cluster_cutoff": 3.5,
- "cluster_minify": True
- }
+ def setUp(self):
+ type_map = ["C", "H"]
+ jdata = {"cluster_cutoff": 3.5, "cluster_minify": True}
self.system_1 = take_cluster("cluster/14400.lammpstrj", type_map, 1125, jdata)
- self.system_2 = dpdata.LabeledSystem("cluster/input0_new.gaussianlog", fmt="gaussian/log")
- self.system_2.data['cells'] = self.system_1['cells']
- self.places=0
+ self.system_2 = dpdata.LabeledSystem(
+ "cluster/input0_new.gaussianlog", fmt="gaussian/log"
+ )
+ self.system_2.data["cells"] = self.system_1["cells"]
+ self.places = 0
class TestCrd2Frag(unittest.TestCase):
def test_crd2frag_pbc(self):
- crds = np.array([[0., 0., 0.], [19., 19., 19.]])
+ crds = np.array([[0.0, 0.0, 0.0], [19.0, 19.0, 19.0]])
symbols = ["O", "O"]
- cell = np.diag([20., 20., 20.])
+ cell = np.diag([20.0, 20.0, 20.0])
frag_numb, _ = _crd2frag(symbols, crds, pbc=True, cell=cell)
self.assertEqual(frag_numb, 1)
-
+
def test_crd2frag_nopbc(self):
- crds = np.array([[0., 0., 0.], [19., 19., 19.]])
+ crds = np.array([[0.0, 0.0, 0.0], [19.0, 19.0, 19.0]])
symbols = ["O", "O"]
frag_numb, _ = _crd2frag(symbols, crds, pbc=False)
self.assertEqual(frag_numb, 2)
-if __name__ == '__main__':
+if __name__ == "__main__":
unittest.main()
diff --git a/tests/generator/test_concat_fp_vasp_pp.py b/tests/generator/test_concat_fp_vasp_pp.py
index c36168a7e..989a09bd2 100644
--- a/tests/generator/test_concat_fp_vasp_pp.py
+++ b/tests/generator/test_concat_fp_vasp_pp.py
@@ -1,14 +1,17 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
-from .context import sys_link_fp_vasp_pp
-from .context import make_iter_name
-from .context import fp_name
-from .context import setUpModule
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
+from .context import fp_name, make_iter_name, setUpModule, sys_link_fp_vasp_pp
+
class TestConcatVASPPP(unittest.TestCase):
def test(self):
@@ -16,46 +19,55 @@ def test(self):
iter_name = make_iter_name(iter_index)
work_path = os.path.join(iter_name, fp_name)
- if os.path.isdir(iter_name) :
+ if os.path.isdir(iter_name):
shutil.rmtree(iter_name)
- os.makedirs(iter_name, exist_ok = False)
- os.makedirs(work_path, exist_ok = False)
- os.makedirs(os.path.join(work_path, 'task.000.000000'), exist_ok = False)
- os.makedirs(os.path.join(work_path, 'task.000.000001'), exist_ok = False)
- os.makedirs(os.path.join(work_path, 'task.001.000000'), exist_ok = False)
- os.makedirs(os.path.join(work_path, 'task.001.000001'), exist_ok = False)
- shutil.copyfile(os.path.join('vasp', 'POSCAR.oh'),
- os.path.join(work_path, 'task.000.000000', 'POSCAR'))
- shutil.copyfile(os.path.join('vasp', 'POSCAR.oh'),
- os.path.join(work_path, 'task.000.000001', 'POSCAR'))
- shutil.copyfile(os.path.join('vasp', 'POSCAR.ch4'),
- os.path.join(work_path, 'task.001.000000', 'POSCAR'))
- shutil.copyfile(os.path.join('vasp', 'POSCAR.ch4'),
- os.path.join(work_path, 'task.001.000001', 'POSCAR'))
- sys_link_fp_vasp_pp(0, {'type_map' : ['H', 'C', 'O'],
- 'fp_pp_path': os.path.join('vasp', 'potcars'),
- 'fp_pp_files': ['POTCAR.H', 'POTCAR.C', 'POTCAR.O'],
- })
- self.assertTrue(os.path.isfile(os.path.join(work_path, 'POTCAR.000')))
- self.assertTrue(os.path.isfile(os.path.join(work_path, 'POTCAR.001')))
- with open((os.path.join(work_path, 'POTCAR.000'))) as fp:
+ os.makedirs(iter_name, exist_ok=False)
+ os.makedirs(work_path, exist_ok=False)
+ os.makedirs(os.path.join(work_path, "task.000.000000"), exist_ok=False)
+ os.makedirs(os.path.join(work_path, "task.000.000001"), exist_ok=False)
+ os.makedirs(os.path.join(work_path, "task.001.000000"), exist_ok=False)
+ os.makedirs(os.path.join(work_path, "task.001.000001"), exist_ok=False)
+ shutil.copyfile(
+ os.path.join("vasp", "POSCAR.oh"),
+ os.path.join(work_path, "task.000.000000", "POSCAR"),
+ )
+ shutil.copyfile(
+ os.path.join("vasp", "POSCAR.oh"),
+ os.path.join(work_path, "task.000.000001", "POSCAR"),
+ )
+ shutil.copyfile(
+ os.path.join("vasp", "POSCAR.ch4"),
+ os.path.join(work_path, "task.001.000000", "POSCAR"),
+ )
+ shutil.copyfile(
+ os.path.join("vasp", "POSCAR.ch4"),
+ os.path.join(work_path, "task.001.000001", "POSCAR"),
+ )
+ sys_link_fp_vasp_pp(
+ 0,
+ {
+ "type_map": ["H", "C", "O"],
+ "fp_pp_path": os.path.join("vasp", "potcars"),
+ "fp_pp_files": ["POTCAR.H", "POTCAR.C", "POTCAR.O"],
+ },
+ )
+ self.assertTrue(os.path.isfile(os.path.join(work_path, "POTCAR.000")))
+ self.assertTrue(os.path.isfile(os.path.join(work_path, "POTCAR.001")))
+ with open((os.path.join(work_path, "POTCAR.000"))) as fp:
pot = fp.read()
- self.assertEqual(pot, 'O\nH\n')
- with open((os.path.join(work_path, 'POTCAR.001'))) as fp:
+ self.assertEqual(pot, "O\nH\n")
+ with open((os.path.join(work_path, "POTCAR.001"))) as fp:
pot = fp.read()
- self.assertEqual(pot, 'H\nC\n')
- for ii in ['task.000.000000', 'task.000.000001'] :
- with open(os.path.join(work_path, ii, 'POTCAR')) as fp:
+ self.assertEqual(pot, "H\nC\n")
+ for ii in ["task.000.000000", "task.000.000001"]:
+ with open(os.path.join(work_path, ii, "POTCAR")) as fp:
pot = fp.read()
- self.assertEqual(pot, 'O\nH\n')
- for ii in ['task.001.000000', 'task.001.000001'] :
- with open(os.path.join(work_path, ii, 'POTCAR')) as fp:
+ self.assertEqual(pot, "O\nH\n")
+ for ii in ["task.001.000000", "task.001.000001"]:
+ with open(os.path.join(work_path, ii, "POTCAR")) as fp:
pot = fp.read()
- self.assertEqual(pot, 'H\nC\n')
-
+ self.assertEqual(pot, "H\nC\n")
-if __name__ == '__main__':
+if __name__ == "__main__":
unittest.main()
-
-
diff --git a/tests/generator/test_gromacs_engine.py b/tests/generator/test_gromacs_engine.py
index b8b01a84b..20c8d6e25 100644
--- a/tests/generator/test_gromacs_engine.py
+++ b/tests/generator/test_gromacs_engine.py
@@ -1,23 +1,28 @@
-import os, sys, glob, shutil
-import unittest
+import glob
+import importlib
import json
+import os
+import shutil
+import sys
+import unittest
+
import numpy as np
-import importlib
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
dirname = os.path.join(os.path.abspath(os.path.dirname(__file__)), "gromacs")
-from .context import make_model_devi
-from .context import make_fp_gaussian
+from .context import make_fp_gaussian, make_model_devi
+
def _make_fake_graphs(train_path):
if not os.path.exists(train_path):
os.mkdir(train_path)
for ii in range(4):
- with open(os.path.join(train_path, f"graph.{ii:03}.pb"), 'w+') as f:
+ with open(os.path.join(train_path, f"graph.{ii:03}.pb"), "w+") as f:
f.write("Fake Model")
+
class TestGromacsModelDeviEngine(unittest.TestCase):
def setUp(self):
self.dirname = dirname
@@ -29,27 +34,22 @@ def setUp(self):
"sys_format": "gromacs/gro",
"model_devi_engine": "gromacs",
"gromacs_settings": {
- "mdp_filename": "md.mdp",
- "topol_filename": "processed.top",
- "conf_filename": "npt.gro",
- "index_filename": "index.raw",
- "ref_filename": "em.tpr",
+ "mdp_filename": "md.mdp",
+ "topol_filename": "processed.top",
+ "conf_filename": "npt.gro",
+ "index_filename": "index.raw",
+ "ref_filename": "em.tpr",
"model_devi_script": "model_devi.py",
- "traj_filename": "deepmd_traj.gro"
+ "traj_filename": "deepmd_traj.gro",
},
- "model_devi_dt": 0.001,
+ "model_devi_dt": 0.001,
"model_devi_f_trust_lo": 0.05,
"model_devi_f_trust_hi": 0.10,
"model_devi_clean_traj": False,
- "model_devi_skip": 0,
- "model_devi_nopbc": True,
+ "model_devi_skip": 0,
+ "model_devi_nopbc": True,
"model_devi_jobs": [
- {
- "ensemble": "nvt",
- "nsteps": 5000,
- "sys_idx": [0],
- "trj_freq": 10
- }
+ {"ensemble": "nvt", "nsteps": 5000, "sys_idx": [0], "trj_freq": 10}
],
"shuffle_poscar": False,
"fp_style": "gaussian",
@@ -61,58 +61,86 @@ def setUp(self):
"fp_params": {
"keywords": "force m062x/6-31g(d) nosymm",
"nproc": 16,
- "multiplicity": "auto"
- }
+ "multiplicity": "auto",
+ },
}
- self.iter_path = os.path.join(os.path.abspath(os.path.dirname(__file__)), "iter.000000")
+ self.iter_path = os.path.join(
+ os.path.abspath(os.path.dirname(__file__)), "iter.000000"
+ )
if not os.path.exists(self.iter_path):
os.mkdir(self.iter_path)
self.train_path = os.path.join(self.iter_path, "00.train")
self.model_devi_path = os.path.join(self.iter_path, "01.model_devi")
- self.model_devi_task_path = os.path.join(self.model_devi_path, "task.000.000000")
+ self.model_devi_task_path = os.path.join(
+ self.model_devi_path, "task.000.000000"
+ )
self.fp_path = os.path.join(self.iter_path, "02.fp")
_make_fake_graphs(self.train_path)
-
+
def _check_dir(self, wdir, post=True):
- for key in self.jdata['gromacs_settings'].keys():
+ for key in self.jdata["gromacs_settings"].keys():
if key != "traj_filename":
- self.assertTrue(os.path.exists(os.path.join(wdir, self.jdata['gromacs_settings'][key])))
+ self.assertTrue(
+ os.path.exists(
+ os.path.join(wdir, self.jdata["gromacs_settings"][key])
+ )
+ )
else:
if post:
- self.assertTrue(os.path.exists(os.path.join(wdir, self.jdata['gromacs_settings'][key])))
-
+ self.assertTrue(
+ os.path.exists(
+ os.path.join(wdir, self.jdata["gromacs_settings"][key])
+ )
+ )
+
def _copy_outputs(self, path_1, path_2):
- shutil.copy(os.path.join(path_1, "deepmd_traj.gro"), os.path.join(path_2, "deepmd_traj.gro"))
- shutil.copy(os.path.join(path_1, "model_devi.out"), os.path.join(path_2, "model_devi.out"))
+ shutil.copy(
+ os.path.join(path_1, "deepmd_traj.gro"),
+ os.path.join(path_2, "deepmd_traj.gro"),
+ )
+ shutil.copy(
+ os.path.join(path_1, "model_devi.out"),
+ os.path.join(path_2, "model_devi.out"),
+ )
shutil.copytree(os.path.join(path_1, "traj"), os.path.join(path_2, "traj"))
-
- @unittest.skipIf(importlib.util.find_spec("openbabel") != None, "when openbabel is found, this test will be skipped. ")
+ @unittest.skipIf(
+ importlib.util.find_spec("openbabel") != None,
+ "when openbabel is found, this test will be skipped. ",
+ )
def test_make_model_devi_gromacs_without_openbabel(self):
- flag = make_model_devi(iter_index=0,
- jdata=self.jdata,
- mdata={"deepmd_version": "2.0"})
+ flag = make_model_devi(
+ iter_index=0, jdata=self.jdata, mdata={"deepmd_version": "2.0"}
+ )
self.assertTrue(flag)
self.assertTrue(os.path.exists(self.model_devi_path))
self.assertTrue(os.path.exists(self.model_devi_task_path))
self._check_dir(self.model_devi_task_path, post=False)
- self._copy_outputs(os.path.join(self.dirname, "outputs"), self.model_devi_task_path)
+ self._copy_outputs(
+ os.path.join(self.dirname, "outputs"), self.model_devi_task_path
+ )
self._check_dir(self.model_devi_task_path, post=True)
-
- @unittest.skipIf(importlib.util.find_spec("openbabel") is None, "requires openbabel")
+
+ @unittest.skipIf(
+ importlib.util.find_spec("openbabel") is None, "requires openbabel"
+ )
def test_make_model_devi_gromacs_with_openbabel(self):
- flag = make_model_devi(iter_index=0,
- jdata=self.jdata,
- mdata={"deepmd_version": "2.0"})
- self._copy_outputs(os.path.join(self.dirname, "outputs"), self.model_devi_task_path)
+ flag = make_model_devi(
+ iter_index=0, jdata=self.jdata, mdata={"deepmd_version": "2.0"}
+ )
+ self._copy_outputs(
+ os.path.join(self.dirname, "outputs"), self.model_devi_task_path
+ )
make_fp_gaussian(iter_index=0, jdata=self.jdata)
- candi = np.loadtxt(os.path.join(self.fp_path, "candidate.shuffled.000.out"), dtype=np.str)
- self.assertEqual(sorted([int(i) for i in candi[:,1]]), [0,10,20,30,50])
-
-
+ candi = np.loadtxt(
+ os.path.join(self.fp_path, "candidate.shuffled.000.out"), dtype=str
+ )
+ self.assertEqual(sorted([int(i) for i in candi[:, 1]]), [0, 10, 20, 30, 50])
+
def tearDown(self):
# pass
shutil.rmtree(self.iter_path)
-if __name__ == '__main__':
- unittest.main()
+
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tests/generator/test_lammps.py b/tests/generator/test_lammps.py
index f1205162c..2fbf011ca 100644
--- a/tests/generator/test_lammps.py
+++ b/tests/generator/test_lammps.py
@@ -1,16 +1,23 @@
-import os,sys,json,glob,shutil,textwrap
+import glob
+import json
+import os
+import shutil
+import sys
+import textwrap
+import unittest
+
import dpdata
import numpy as np
-import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
-from .context import get_dumped_forces
-from .context import get_all_dumped_forces
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
+from .context import get_all_dumped_forces, get_dumped_forces
+
class TestGetDumpForce(unittest.TestCase):
def setUp(self):
- file_content = textwrap.dedent("""\
+ file_content = textwrap.dedent(
+ """\
ITEM: TIMESTEP
40
ITEM: NUMBER OF ATOMS
@@ -22,25 +29,35 @@ def setUp(self):
ITEM: ATOMS id type x y z fx fy fz
1 1 2.09532 8.19528 2.00538 -0.00569269 -0.0200373 -0.0342394
2 1 -0.0727384 4.01773 4.05582 -0.0297083 0.0817184 0.0722508
-""")
- with open('tmp.dump', 'w') as fp:
+"""
+ )
+ with open("tmp.dump", "w") as fp:
fp.write(file_content)
- self.expected_f = [ -0.00569269, -0.0200373, -0.0342394, -0.0297083, 0.0817184, 0.0722508]
+ self.expected_f = [
+ -0.00569269,
+ -0.0200373,
+ -0.0342394,
+ -0.0297083,
+ 0.0817184,
+ 0.0722508,
+ ]
def tearDown(self):
- if os.path.isfile('tmp.dump'):
- os.remove('tmp.dump')
+ if os.path.isfile("tmp.dump"):
+ os.remove("tmp.dump")
def test_read_dump(self):
- ff = get_dumped_forces('tmp.dump')
+ ff = get_dumped_forces("tmp.dump")
self.assertEqual(ff.shape, (2, 3))
ff = ff.reshape([-1])
for ii in range(6):
self.assertAlmostEqual(ff[ii], self.expected_f[ii])
+
class TestGetDumpForce(unittest.TestCase):
def setUp(self):
- file_content = textwrap.dedent("""\
+ file_content = textwrap.dedent(
+ """\
ITEM: TIMESTEP
0
ITEM: NUMBER OF ATOMS
@@ -63,18 +80,33 @@ def setUp(self):
ITEM: ATOMS id type x y z fx fy fz
1 1 5.35629 3.93297 3.70556 -0.125424 0.0481604 -0.0833015
2 2 3.93654 4.79972 4.48179 0.134843 -0.0444238 -0.143111
-""")
- with open('tmp.dump', 'w') as fp:
+"""
+ )
+ with open("tmp.dump", "w") as fp:
fp.write(file_content)
- self.expected_f = [ 0.000868817 , -0.00100822 , -0.000960258 , 0.000503458 , -0.000374043 , -9.15676e-05 , -0.125424 , 0.0481604 , -0.0833015 , 0.134843 , -0.0444238 , -0.143111]
+ self.expected_f = [
+ 0.000868817,
+ -0.00100822,
+ -0.000960258,
+ 0.000503458,
+ -0.000374043,
+ -9.15676e-05,
+ -0.125424,
+ 0.0481604,
+ -0.0833015,
+ 0.134843,
+ -0.0444238,
+ -0.143111,
+ ]
+
def tearDown(self):
- if os.path.isfile('tmp.dump'):
- os.remove('tmp.dump')
+ if os.path.isfile("tmp.dump"):
+ os.remove("tmp.dump")
def test_read_all_dump(self):
- ff = get_all_dumped_forces('tmp.dump')
+ ff = get_all_dumped_forces("tmp.dump")
ff = np.array(ff)
- self.assertEqual(ff.shape, (2,2,3))
+ self.assertEqual(ff.shape, (2, 2, 3))
ff = ff.reshape([-1])
for ii in range(12):
self.assertAlmostEqual(ff[ii], self.expected_f[ii])
diff --git a/tests/generator/test_make_dispatcher.py b/tests/generator/test_make_dispatcher.py
deleted file mode 100644
index 998ed39f9..000000000
--- a/tests/generator/test_make_dispatcher.py
+++ /dev/null
@@ -1,44 +0,0 @@
-import os,sys,sys
-import unittest
-
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
-from .context import make_dispatcher
-
-class TestDispatcher(unittest.TestCase):
- # def test_ssh_slurm(self):
- # dis = make_dispatcher({
- # 'batch': 'slurm',
- # 'hostname': 'localhost',
- # 'username': 'wanghan',
- # 'port': 22,
- # 'work_path': '.',
- # })
- # self.assertEqual(dis.context.__name__, 'SSHContext')
- # self.assertEqual(dis.batch.__name__, 'Slurm')
-
- def test_local_slurm(self):
- dis = make_dispatcher({
- 'batch': 'slurm',
- 'work_path': '.',
- })
- self.assertEqual(dis.context.__name__, 'LocalContext')
- self.assertEqual(dis.batch.__name__, 'Slurm')
-
- def test_lazy_local_slurm(self):
- dis = make_dispatcher({
- 'batch': 'slurm',
- 'lazy_local': True,
- 'work_path': '.',
- })
- self.assertEqual(dis.context.__name__, 'LazyLocalContext')
- self.assertEqual(dis.batch.__name__, 'Slurm')
-
- def test_dep_lazy_local_slurm(self):
- dis = make_dispatcher({
- 'machine_type': 'slurm',
- 'lazy_local': True,
- 'work_path': '.',
- })
- self.assertEqual(dis.context.__name__, 'LazyLocalContext')
- self.assertEqual(dis.batch.__name__, 'Slurm')
diff --git a/tests/generator/test_make_fp.py b/tests/generator/test_make_fp.py
index ae8e9d9a6..c39b2323e 100644
--- a/tests/generator/test_make_fp.py
+++ b/tests/generator/test_make_fp.py
@@ -1,41 +1,46 @@
-import os,sys,json,glob,shutil
+import glob
+import importlib
+import json
+import os
+import shutil
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-import importlib
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
-from .context import make_fp
-from .context import detect_multiplicity
-from .context import parse_cur_job
-from .context import param_file
-from .context import param_file_merge_traj
-from .context import param_old_file
-from .context import param_pwscf_file
-from .context import param_pwscf_old_file
-from .context import param_abacus_post_file
-from .context import param_diy_abacus_post_file
-from .context import param_siesta_file
-from .context import param_gaussian_file
-from .context import param_cp2k_file
-from .context import param_cp2k_file_exinput
-from .context import param_amber_file
-from .context import ref_cp2k_file_input
-from .context import ref_cp2k_file_exinput
-from .context import machine_file
-from .context import param_diy_file
-from .context import param_multiple_trust_file
-from .context import make_kspacing_kpoints
-from .context import my_file_cmp
-from .context import setUpModule
-from .comp_sys import test_atom_names
-from .comp_sys import test_atom_types
-from .comp_sys import test_coord
-from .comp_sys import test_cell
-from pymatgen.io.vasp import Kpoints,Incar
-from .context import param_pwmat_file
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
import scipy.constants as pc
+from pymatgen.io.vasp import Incar, Kpoints
+
+from .comp_sys import test_atom_names, test_atom_types, test_cell, test_coord
+from .context import (
+ detect_multiplicity,
+ machine_file,
+ make_fp,
+ make_kspacing_kpoints,
+ my_file_cmp,
+ param_abacus_post_file,
+ param_amber_file,
+ param_cp2k_file,
+ param_cp2k_file_exinput,
+ param_diy_abacus_post_file,
+ param_diy_file,
+ param_file,
+ param_file_merge_traj,
+ param_gaussian_file,
+ param_multiple_trust_file,
+ param_old_file,
+ param_pwmat_file,
+ param_pwscf_file,
+ param_pwscf_old_file,
+ param_siesta_file,
+ parse_cur_job,
+ ref_cp2k_file_exinput,
+ ref_cp2k_file_input,
+ setUpModule,
+)
vasp_incar_ref = "PREC=A\n\
ENCUT=600\n\
@@ -55,7 +60,7 @@
LCHARG=F\n\
PSTRESS=0\n\
KSPACING=0.16\n\
-KGAMMA=F\n";
+KGAMMA=F\n"
vasp_incar_ele_temp_ref = "PREC=A\n\
ENCUT=600\n\
@@ -75,9 +80,9 @@
LCHARG=F\n\
PSTRESS=0\n\
KSPACING=0.16\n\
-KGAMMA=F\n";
+KGAMMA=F\n"
-pwscf_input_ref="&control\n\
+pwscf_input_ref = "&control\n\
calculation='scf',\n\
restart_mode='from_scratch',\n\
outdir='./OUT',\n\
@@ -99,7 +104,7 @@
conv_thr=1e-08,\n\
/\n"
-siesta_input_ref="\
+siesta_input_ref = "\
SystemName system\n\
SystemLabel system\n\
NumberOfAtoms 6\n\
@@ -130,7 +135,7 @@
3 7 N\n"
-gaussian_input_ref="""%nproc=14
+gaussian_input_ref = """%nproc=14
#force b3lyp/6-31g*
DPGEN
@@ -151,11 +156,10 @@
job=scf\n\
IN.PSP1 = C.SG15.PBE.UPF\n\
IN.PSP2 = H.SG15.PBE.UPF\n\
-IN.PSP3 = N.SG15.PBE.UPF\n";
+IN.PSP3 = N.SG15.PBE.UPF\n"
abacus_input_ref = "INPUT_PARAMETERS\n\
calculation scf\n\
-ntype 2\n\
ecutwfc 80.000000\n\
scf_thr 1.000000e-07\n\
scf_nmax 50\n\
@@ -183,9 +187,9 @@
1 1 1 0 0 0\n"
-def _box2lmpbox(orig, box) :
- lohi = np.zeros([3,2])
- for dd in range(3) :
+def _box2lmpbox(orig, box):
+ lohi = np.zeros([3, 2])
+ for dd in range(3):
lohi[dd][0] = orig[dd]
tilt = np.zeros(3)
tilt[0] = box[1][0]
@@ -195,45 +199,49 @@ def _box2lmpbox(orig, box) :
lens[0] = box[0][0]
lens[1] = box[1][1]
lens[2] = box[2][2]
- for dd in range(3) :
+ for dd in range(3):
lohi[dd][1] = lohi[dd][0] + lens[dd]
return lohi, tilt
-def _box2dumpbox(orig, box) :
+
+def _box2dumpbox(orig, box):
lohi, tilt = _box2lmpbox(orig, box)
xy = tilt[0]
xz = tilt[1]
yz = tilt[2]
- bounds = np.zeros([3,2])
- bounds[0][0] = lohi[0][0] + min(0.0,xy,xz,xy+xz)
- bounds[0][1] = lohi[0][1] + max(0.0,xy,xz,xy+xz)
- bounds[1][0] = lohi[1][0] + min(0.0,yz)
- bounds[1][1] = lohi[1][1] + max(0.0,yz)
+ bounds = np.zeros([3, 2])
+ bounds[0][0] = lohi[0][0] + min(0.0, xy, xz, xy + xz)
+ bounds[0][1] = lohi[0][1] + max(0.0, xy, xz, xy + xz)
+ bounds[1][0] = lohi[1][0] + min(0.0, yz)
+ bounds[1][1] = lohi[1][1] + max(0.0, yz)
bounds[2][0] = lohi[2][0]
bounds[2][1] = lohi[2][1]
return bounds, tilt
-def _write_lammps_dump(sys, dump_file, f_idx = 0) :
- cell = sys['cells'][f_idx].reshape([3,3])
- coord = sys['coords'][f_idx].reshape([-1,3])
+def _write_lammps_dump(sys, dump_file, f_idx=0):
+ cell = sys["cells"][f_idx].reshape([3, 3])
+ coord = sys["coords"][f_idx].reshape([-1, 3])
bd, tilt = _box2dumpbox(np.zeros(3), cell)
- atype = sys['atom_types']
- natoms = len(sys['atom_types'])
- with open(dump_file, 'a') as fp:
- fp.write('ITEM: TIMESTEP\n')
- fp.write('0\n')
- fp.write('ITEM: NUMBER OF ATOMS\n')
- fp.write(str(natoms) + '\n')
- fp.write('ITEM: BOX BOUNDS xy xz yz pp pp pp\n')
+ atype = sys["atom_types"]
+ natoms = len(sys["atom_types"])
+ with open(dump_file, "a") as fp:
+ fp.write("ITEM: TIMESTEP\n")
+ fp.write("0\n")
+ fp.write("ITEM: NUMBER OF ATOMS\n")
+ fp.write(str(natoms) + "\n")
+ fp.write("ITEM: BOX BOUNDS xy xz yz pp pp pp\n")
for ii in range(3):
- fp.write('%f %f %f\n' % (bd[ii][0], bd[ii][1], tilt[ii]))
- fp.write('ITEM: ATOMS id type x y z\n')
- for ii in range(natoms) :
- fp.write('%d %d %f %f %f\n' % (ii+1, atype[ii]+1, coord[ii][0], coord[ii][1], coord[ii][2]))
+ fp.write("%f %f %f\n" % (bd[ii][0], bd[ii][1], tilt[ii]))
+ fp.write("ITEM: ATOMS id type x y z\n")
+ for ii in range(natoms):
+ fp.write(
+ "%d %d %f %f %f\n"
+ % (ii + 1, atype[ii] + 1, coord[ii][0], coord[ii][1], coord[ii][2])
+ )
-def _make_fake_md(idx, md_descript, atom_types, type_map, ele_temp = None) :
+def _make_fake_md(idx, md_descript, atom_types, type_map, ele_temp=None):
"""
md_descript: list of dimension
[n_sys][n_MD][n_frame]
@@ -242,37 +250,37 @@ def _make_fake_md(idx, md_descript, atom_types, type_map, ele_temp = None) :
"""
natoms = len(atom_types)
ntypes = len(type_map)
- atom_types = np.array(atom_types, dtype = int)
+ atom_types = np.array(atom_types, dtype=int)
atom_numbs = [np.sum(atom_types == ii) for ii in range(ntypes)]
sys = dpdata.System()
- sys.data['atom_names'] = type_map
- sys.data['atom_numbs'] = atom_numbs
- sys.data['atom_types'] = atom_types
- for sidx,ss in enumerate(md_descript) :
- for midx,mm in enumerate(ss) :
+ sys.data["atom_names"] = type_map
+ sys.data["atom_numbs"] = atom_numbs
+ sys.data["atom_types"] = atom_types
+ for sidx, ss in enumerate(md_descript):
+ for midx, mm in enumerate(ss):
nframes = len(mm)
- cells = np.random.random([nframes,3,3])
- coords = np.random.random([nframes,natoms,3])
- sys.data['coords'] = coords
- sys.data['cells'] = cells
- task_dir = os.path.join('iter.%06d' % idx,
- '01.model_devi',
- 'task.%03d.%06d' % (sidx, midx))
- os.makedirs(os.path.join(task_dir, 'traj'), exist_ok = True)
- for ii in range(nframes) :
- _write_lammps_dump(sys,
- os.path.join(task_dir,
- 'traj',
- '%d.lammpstrj' % ii))
+ cells = np.random.random([nframes, 3, 3])
+ coords = np.random.random([nframes, natoms, 3])
+ sys.data["coords"] = coords
+ sys.data["cells"] = cells
+ task_dir = os.path.join(
+ "iter.%06d" % idx, "01.model_devi", "task.%03d.%06d" % (sidx, midx)
+ )
+ os.makedirs(os.path.join(task_dir, "traj"), exist_ok=True)
+ for ii in range(nframes):
+ _write_lammps_dump(
+ sys, os.path.join(task_dir, "traj", "%d.lammpstrj" % ii)
+ )
md_out = np.zeros([nframes, 7])
- md_out[:,0] = np.arange(nframes)
- md_out[:,4] = mm
- np.savetxt(os.path.join(task_dir, 'model_devi.out'), md_out)
+ md_out[:, 0] = np.arange(nframes)
+ md_out[:, 4] = mm
+ np.savetxt(os.path.join(task_dir, "model_devi.out"), md_out)
if ele_temp is not None:
- with open(os.path.join(task_dir, 'job.json'), 'w') as fp:
+ with open(os.path.join(task_dir, "job.json"), "w") as fp:
json.dump({"ele_temp": ele_temp[sidx][midx]}, fp)
-def _make_fake_md_merge_traj(idx, md_descript, atom_types, type_map, ele_temp = None) :
+
+def _make_fake_md_merge_traj(idx, md_descript, atom_types, type_map, ele_temp=None):
"""
md_descript: list of dimension
[n_sys][n_MD][n_frame]
@@ -281,26 +289,26 @@ def _make_fake_md_merge_traj(idx, md_descript, atom_types, type_map, ele_temp =
"""
natoms = len(atom_types)
ntypes = len(type_map)
- atom_types = np.array(atom_types, dtype = int)
+ atom_types = np.array(atom_types, dtype=int)
atom_numbs = [np.sum(atom_types == ii) for ii in range(ntypes)]
sys = dpdata.System()
- sys.data['atom_names'] = type_map
- sys.data['atom_numbs'] = atom_numbs
- sys.data['atom_types'] = atom_types
- for sidx,ss in enumerate(md_descript) :
- for midx,mm in enumerate(ss) :
+ sys.data["atom_names"] = type_map
+ sys.data["atom_numbs"] = atom_numbs
+ sys.data["atom_types"] = atom_types
+ for sidx, ss in enumerate(md_descript):
+ for midx, mm in enumerate(ss):
nframes = len(mm)
- cells = np.random.random([nframes,3,3])
- coords = np.random.random([nframes,natoms,3])
- sys.data['coords'] = coords
- sys.data['cells'] = cells
- task_dir = os.path.join('iter.%06d' % idx,
- '01.model_devi',
- 'task.%03d.%06d' % (sidx, midx))
+ cells = np.random.random([nframes, 3, 3])
+ coords = np.random.random([nframes, natoms, 3])
+ sys.data["coords"] = coords
+ sys.data["cells"] = cells
+ task_dir = os.path.join(
+ "iter.%06d" % idx, "01.model_devi", "task.%03d.%06d" % (sidx, midx)
+ )
cwd = os.getcwd()
- os.makedirs(task_dir,exist_ok = True)
+ os.makedirs(task_dir, exist_ok=True)
for ii in range(nframes):
- _write_lammps_dump(sys,os.path.join(task_dir,'all.lammpstrj'),ii)
+ _write_lammps_dump(sys, os.path.join(task_dir, "all.lammpstrj"), ii)
file_content = """\
0.000000000000000000e+01 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00
1.000000000000000000e+01 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 2.899999999999999800e-02 0.000000000000000000e+00 0.000000000000000000e+00
@@ -313,47 +321,49 @@ def _make_fake_md_merge_traj(idx, md_descript, atom_types, type_map, ele_temp =
8.000000000000000000e+01 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 2.319999999999999840e-01 0.000000000000000000e+00 0.000000000000000000e+00
9.000000000000000000e+01 0.000000000000000000e+00 0.000000000000000000e+00 0.000000000000000000e+00 2.610000000000000098e-01 0.000000000000000000e+00 0.000000000000000000e+00
"""
- with open(os.path.join(task_dir, 'model_devi.out') , 'w') as fp:
+ with open(os.path.join(task_dir, "model_devi.out"), "w") as fp:
fp.write(file_content)
if ele_temp is not None:
- with open(os.path.join(task_dir, 'job.json'), 'w') as fp:
+ with open(os.path.join(task_dir, "job.json"), "w") as fp:
json.dump({"ele_temp": ele_temp[sidx][midx]}, fp)
-def _check_poscars(testCase, idx, fp_task_max, type_map) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- candi_files = glob.glob(os.path.join(fp_path, 'candidate.shuffled.*.out'))
+
+def _check_poscars(testCase, idx, fp_task_max, type_map):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ candi_files = glob.glob(os.path.join(fp_path, "candidate.shuffled.*.out"))
candi_files.sort()
- sys_idx = [str(os.path.basename(ii).split('.')[2]) for ii in candi_files]
- for sidx,ii in zip(sys_idx, candi_files) :
+ sys_idx = [str(os.path.basename(ii).split(".")[2]) for ii in candi_files]
+ for sidx, ii in zip(sys_idx, candi_files):
md_task = []
f_idx = []
with open(ii) as fp:
- for ii in fp :
+ for ii in fp:
md_task.append(ii.split()[0])
f_idx.append(ii.split()[1])
md_task = md_task[:fp_task_max]
f_idx = f_idx[:fp_task_max]
cc = 0
- for tt,ff in zip(md_task, f_idx) :
- traj_file = os.path.join(tt, 'traj', '%d.lammpstrj' % int(ff))
- poscar_file = os.path.join(fp_path,
- 'task.%03d.%06d' % (int(sidx), cc),
- 'POSCAR')
+ for tt, ff in zip(md_task, f_idx):
+ traj_file = os.path.join(tt, "traj", "%d.lammpstrj" % int(ff))
+ poscar_file = os.path.join(
+ fp_path, "task.%03d.%06d" % (int(sidx), cc), "POSCAR"
+ )
cc += 1
- sys0 = dpdata.System(traj_file, fmt = 'lammps/dump', type_map = type_map)
- sys1 = dpdata.System(poscar_file, fmt = 'vasp/poscar')
+ sys0 = dpdata.System(traj_file, fmt="lammps/dump", type_map=type_map)
+ sys1 = dpdata.System(poscar_file, fmt="vasp/poscar")
test_atom_names(testCase, sys0, sys1)
-def _check_poscars_merge_traj(testCase, idx, fp_task_max, type_map ) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- candi_files = glob.glob(os.path.join(fp_path, 'candidate.shuffled.*.out'))
+
+def _check_poscars_merge_traj(testCase, idx, fp_task_max, type_map):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ candi_files = glob.glob(os.path.join(fp_path, "candidate.shuffled.*.out"))
candi_files.sort()
- sys_idx = [str(os.path.basename(ii).split('.')[2]) for ii in candi_files]
- for sidx,ii in zip(sys_idx, candi_files) :
+ sys_idx = [str(os.path.basename(ii).split(".")[2]) for ii in candi_files]
+ for sidx, ii in zip(sys_idx, candi_files):
md_task = []
f_idx = []
with open(ii) as fp:
- for ii in fp :
+ for ii in fp:
md_task.append(ii.split()[0])
f_idx.append(ii.split()[1])
md_task = md_task[:fp_task_max]
@@ -362,73 +372,78 @@ def _check_poscars_merge_traj(testCase, idx, fp_task_max, type_map ) :
label_0 = 0
label_1 = 0
- for tt,ff in zip(md_task, f_idx) :
- traj_file = os.path.join(tt, 'all.lammpstrj')
- poscar_file = os.path.join(fp_path,
- 'task.%03d.%06d' % (int(sidx), cc),
- 'POSCAR')
+ for tt, ff in zip(md_task, f_idx):
+ traj_file = os.path.join(tt, "all.lammpstrj")
+ poscar_file = os.path.join(
+ fp_path, "task.%03d.%06d" % (int(sidx), cc), "POSCAR"
+ )
cc += 1
- sys0 = dpdata.System(traj_file, fmt = 'lammps/dump', type_map = type_map)
- sys1 = dpdata.System(poscar_file, fmt = 'vasp/poscar')
+ sys0 = dpdata.System(traj_file, fmt="lammps/dump", type_map=type_map)
+ sys1 = dpdata.System(poscar_file, fmt="vasp/poscar")
new_coords_0 = float(sys1["coords"][0][0][0])
new_coords_1 = float(sys1["coords"][0][1][0])
- if (label_0 == new_coords_0 and label_1 == new_coords_1):
- raise RuntimeError("The exact same POSCAR is generated under different first-principles calculation catalogs")
+ if label_0 == new_coords_0 and label_1 == new_coords_1:
+ raise RuntimeError(
+ "The exact same POSCAR is generated under different first-principles calculation catalogs"
+ )
label_0 = new_coords_0
label_1 = new_coords_1
- test_atom_names(testCase, sys0[int(int(ff)/10)], sys1)
-
-def _check_kpoints_exists(testCase, idx) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
- testCase.assertTrue(os.path.isfile(os.path.join(ii, 'KPOINTS')))
-
-def _check_kpoints(testCase, idx) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
- kpoints=Kpoints.from_file(os.path.join(os.path.join(ii, 'KPOINTS')))
- incar=Incar.from_file(os.path.join(os.path.join(ii, 'INCAR')))
- kspacing = incar['KSPACING']
- gamma = incar['KGAMMA']
- if isinstance(gamma,bool):
- pass
+ test_atom_names(testCase, sys0[int(int(ff) / 10)], sys1)
+
+
+def _check_kpoints_exists(testCase, idx):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
+ testCase.assertTrue(os.path.isfile(os.path.join(ii, "KPOINTS")))
+
+
+def _check_kpoints(testCase, idx):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
+ kpoints = Kpoints.from_file(os.path.join(os.path.join(ii, "KPOINTS")))
+ incar = Incar.from_file(os.path.join(os.path.join(ii, "INCAR")))
+ kspacing = incar["KSPACING"]
+ gamma = incar["KGAMMA"]
+ if isinstance(gamma, bool):
+ pass
else:
- if gamma[0].upper()=="T":
- gamma=True
- else:
- gamma=False
- ret=make_kspacing_kpoints(os.path.join(os.path.join(ii, 'POSCAR')), kspacing, gamma)
- kpoints_ref=Kpoints.from_string(ret)
+ if gamma[0].upper() == "T":
+ gamma = True
+ else:
+ gamma = False
+ ret = make_kspacing_kpoints(
+ os.path.join(os.path.join(ii, "POSCAR")), kspacing, gamma
+ )
+ kpoints_ref = Kpoints.from_string(ret)
testCase.assertEqual(repr(kpoints), repr(kpoints_ref))
-def _check_incar_exists(testCase, idx) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
+def _check_incar_exists(testCase, idx):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
# testCase.assertTrue(os.path.isfile(os.path.join(fp_path, 'INCAR')))
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
- my_file_cmp(testCase,
- os.path.join(fp_path, 'INCAR'),
- os.path.join(ii, 'INCAR'))
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
+ my_file_cmp(testCase, os.path.join(fp_path, "INCAR"), os.path.join(ii, "INCAR"))
-def _check_potcar(testCase, idx, fp_pp_path, fp_pp_files) :
+def _check_potcar(testCase, idx, fp_pp_path, fp_pp_files):
nfile = len(fp_pp_files)
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
for ii in range(nfile):
testCase.assertTrue(os.path.isfile(os.path.join(fp_pp_path, fp_pp_files[ii])))
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
for jj in range(nfile):
- my_file_cmp(testCase,
- os.path.join(fp_pp_path, fp_pp_files[jj]),
- os.path.join(ii, fp_pp_files[jj]))
+ my_file_cmp(
+ testCase,
+ os.path.join(fp_pp_path, fp_pp_files[jj]),
+ os.path.join(ii, fp_pp_files[jj]),
+ )
def _check_sel(testCase, idx, fp_task_max, flo, fhi):
-
def _trust_limitation_check(sys_idx, lim):
if isinstance(lim, list):
sys_lim = lim[sys_idx]
@@ -437,589 +452,681 @@ def _trust_limitation_check(sys_idx, lim):
else:
sys_lim = lim
return sys_lim
-
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- candi_files = glob.glob(os.path.join(fp_path, 'candidate.shuffled.*.out'))
+
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ candi_files = glob.glob(os.path.join(fp_path, "candidate.shuffled.*.out"))
candi_files.sort()
- sys_idx = [str(os.path.basename(ii).split('.')[2]) for ii in candi_files]
- for sidx,ii in zip(sys_idx, candi_files) :
+ sys_idx = [str(os.path.basename(ii).split(".")[2]) for ii in candi_files]
+ for sidx, ii in zip(sys_idx, candi_files):
md_task = []
f_idx = []
with open(ii) as fp:
- for ii in fp :
+ for ii in fp:
md_task.append(ii.split()[0])
f_idx.append(ii.split()[1])
md_task = md_task[:fp_task_max]
f_idx = f_idx[:fp_task_max]
flo = _trust_limitation_check(int(sidx), flo)
fhi = _trust_limitation_check(int(sidx), fhi)
- for tt,ff in zip(md_task, f_idx):
- md_value = np.loadtxt(os.path.join(tt, 'model_devi.out'))
+ for tt, ff in zip(md_task, f_idx):
+ md_value = np.loadtxt(os.path.join(tt, "model_devi.out"))
fvalue = md_value[int(ff)][4]
testCase.assertTrue(fvalue >= flo)
- testCase.assertTrue(fvalue < fhi)
+ testCase.assertTrue(fvalue < fhi)
def _check_incar(testCase, idx):
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
cwd = os.getcwd()
- for ii in tasks :
+ for ii in tasks:
os.chdir(ii)
- with open('INCAR') as fp:
+ with open("INCAR") as fp:
incar = fp.read()
testCase.assertEqual(incar.strip(), vasp_incar_ref.strip())
os.chdir(cwd)
+
def _check_incar_ele_temp(testCase, idx, ele_temp):
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
cwd = os.getcwd()
- for ii in tasks :
+ for ii in tasks:
os.chdir(ii)
bname = os.path.basename(ii)
- sidx = int(bname.split('.')[1])
- tidx = int(bname.split('.')[2])
- with open('INCAR') as fp:
+ sidx = int(bname.split(".")[1])
+ tidx = int(bname.split(".")[2])
+ with open("INCAR") as fp:
incar = fp.read()
incar0 = Incar.from_string(incar)
# make_fake_md: the frames in a system shares the same ele_temp
- incar1 = Incar.from_string(vasp_incar_ele_temp_ref%(ele_temp[sidx][0] * pc.Boltzmann / pc.electron_volt))
+ incar1 = Incar.from_string(
+ vasp_incar_ele_temp_ref
+ % (ele_temp[sidx][0] * pc.Boltzmann / pc.electron_volt)
+ )
for ii in incar0.keys():
# skip checking nbands...
- if ii == 'NBANDS':
+ if ii == "NBANDS":
continue
- testCase.assertAlmostEqual(incar0[ii], incar1[ii], msg = 'key %s differ' % (ii), places = 5)
+ testCase.assertAlmostEqual(
+ incar0[ii], incar1[ii], msg="key %s differ" % (ii), places=5
+ )
os.chdir(cwd)
-def _check_pwscf_input_head(testCase, idx) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
- ifile = os.path.join(ii, 'input')
+
+def _check_pwscf_input_head(testCase, idx):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
+ ifile = os.path.join(ii, "input")
testCase.assertTrue(os.path.isfile(ifile))
with open(ifile) as fp:
- lines = fp.read().split('\n')
- for idx, jj in enumerate(lines) :
- if 'ATOMIC_SPECIES' in jj :
+ lines = fp.read().split("\n")
+ for idx, jj in enumerate(lines):
+ if "ATOMIC_SPECIES" in jj:
break
lines = lines[:idx]
- testCase.assertEqual(('\n'.join(lines)).strip(), pwscf_input_ref.strip())
+ testCase.assertEqual(("\n".join(lines)).strip(), pwscf_input_ref.strip())
-def _check_abacus_input(testCase, idx) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
- ifile = os.path.join(ii, 'INPUT')
+
+def _check_abacus_input(testCase, idx):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
+ ifile = os.path.join(ii, "INPUT")
testCase.assertTrue(os.path.isfile(ifile))
with open(ifile) as fp:
- lines = fp.read().split('\n')
- testCase.assertEqual(('\n'.join(lines)).strip(), abacus_input_ref.strip())
-
-def _check_abacus_kpt(testCase, idx) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
- ifile = os.path.join(ii, 'KPT')
+ lines = fp.read().split("\n")
+ testCase.assertEqual(("\n".join(lines)).strip(), abacus_input_ref.strip())
+
+
+def _check_abacus_kpt(testCase, idx):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
+ ifile = os.path.join(ii, "KPT")
testCase.assertTrue(os.path.isfile(ifile))
with open(ifile) as fp:
- lines = fp.read().split('\n')
- testCase.assertEqual(('\n'.join(lines)).strip(), abacus_kpt_ref.strip())
-
-def _check_siesta_input_head(testCase, idx) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
- ifile = os.path.join(ii, 'input')
+ lines = fp.read().split("\n")
+ testCase.assertEqual(("\n".join(lines)).strip(), abacus_kpt_ref.strip())
+
+
+def _check_siesta_input_head(testCase, idx):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
+ ifile = os.path.join(ii, "input")
testCase.assertTrue(os.path.isfile(ifile))
with open(ifile) as fp:
- lines = fp.read().split('\n')
- for idx, jj in enumerate(lines) :
- if '%endblock Chemical_Species_label' in jj :
+ lines = fp.read().split("\n")
+ for idx, jj in enumerate(lines):
+ if "%endblock Chemical_Species_label" in jj:
break
lines = lines[:idx]
- testCase.assertEqual(('\n'.join(lines)).strip(), siesta_input_ref.strip())
+ testCase.assertEqual(("\n".join(lines)).strip(), siesta_input_ref.strip())
-def _check_gaussian_input_head(testCase, idx) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
- ifile = os.path.join(ii, 'input')
+def _check_gaussian_input_head(testCase, idx):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
+ ifile = os.path.join(ii, "input")
testCase.assertTrue(os.path.isfile(ifile))
with open(ifile) as fp:
- lines = fp.read().split('\n')
- for idx, jj in enumerate(lines) :
- if '0 1' in jj :
+ lines = fp.read().split("\n")
+ for idx, jj in enumerate(lines):
+ if "0 1" in jj:
break
lines = lines[:idx]
- testCase.assertEqual(('\n'.join(lines)).strip(), gaussian_input_ref.strip())
+ testCase.assertEqual(("\n".join(lines)).strip(), gaussian_input_ref.strip())
-def _check_cp2k_input_head(testCase, idx, ref_out) :
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
- for ii in tasks :
- ifile = os.path.join(ii, 'input.inp')
+def _check_cp2k_input_head(testCase, idx, ref_out):
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
+ for ii in tasks:
+ ifile = os.path.join(ii, "input.inp")
testCase.assertTrue(os.path.isfile(ifile))
with open(ifile) as fp:
- lines = fp.read().split('\n')
- for idx, jj in enumerate(lines) :
- if '&CELL' in jj :
+ lines = fp.read().split("\n")
+ for idx, jj in enumerate(lines):
+ if "&CELL" in jj:
cell_start_idx = idx
- if '&END CELL' in jj :
+ if "&END CELL" in jj:
cell_end_idx = idx
- lines_check = lines[:cell_start_idx+1] + lines[cell_end_idx:]
- testCase.assertEqual(('\n'.join(lines_check)).strip(), ref_out.strip())
-
+ lines_check = lines[: cell_start_idx + 1] + lines[cell_end_idx:]
+ testCase.assertEqual(("\n".join(lines_check)).strip(), ref_out.strip())
def _check_pwmat_input(testCase, idx):
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
cwd = os.getcwd()
- for ii in tasks :
+ for ii in tasks:
os.chdir(ii)
os.system("sed -i '8c mp_n123=147 57 39 0 0 0 2' etot.input")
- with open('etot.input') as fp:
+ with open("etot.input") as fp:
lines = fp.read()
testCase.assertEqual(lines.strip(), pwmat_input_ref.strip())
os.chdir(cwd)
+
def _check_symlink_user_forward_files(testCase, idx, file):
- fp_path = os.path.join('iter.%06d' % idx, '02.fp')
- tasks = glob.glob(os.path.join(fp_path, 'task.*'))
+ fp_path = os.path.join("iter.%06d" % idx, "02.fp")
+ tasks = glob.glob(os.path.join(fp_path, "task.*"))
cwd = os.getcwd()
for ii in tasks:
os.chdir(ii)
testCase.assertEqual(os.path.isfile("vdw_kernel.bindat"), True)
os.chdir(cwd)
+
class TestMakeFPPwscf(unittest.TestCase):
def test_make_fp_pwscf(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_pwscf_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_pwscf_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 2, 2, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
_check_pwscf_input_head(self, 0)
- _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ _check_potcar(self, 0, jdata["fp_pp_path"], jdata["fp_pp_files"])
+ shutil.rmtree("iter.000000")
def test_make_fp_pwscf_old(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_pwscf_old_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_pwscf_old_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 2, 2, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
_check_pwscf_input_head(self, 0)
- _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ _check_potcar(self, 0, jdata["fp_pp_path"], jdata["fp_pp_files"])
+ shutil.rmtree("iter.000000")
+
class TestMakeFPABACUS(unittest.TestCase):
def test_make_fp_abacus(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_abacus_post_file, 'r') as fp :
- jdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_abacus_post_file, "r") as fp:
+ jdata = json.load(fp)
fp.close()
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
fp.close()
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 0, 0, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
_check_abacus_input(self, 0)
_check_abacus_kpt(self, 0)
- _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ _check_potcar(self, 0, jdata["fp_pp_path"], jdata["fp_pp_files"])
+ shutil.rmtree("iter.000000")
def test_make_fp_abacus_from_input(self):
## Verify if user chooses to diy ABACUS INPUT totally.
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_diy_abacus_post_file, 'r') as fp :
- jdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_diy_abacus_post_file, "r") as fp:
+ jdata = json.load(fp)
fp.close()
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
fp.close()
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
_check_abacus_input(self, 0)
_check_abacus_kpt(self, 0)
- _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ _check_potcar(self, 0, jdata["fp_pp_path"], jdata["fp_pp_files"])
+ shutil.rmtree("iter.000000")
+
class TestMakeFPAMBERDiff(unittest.TestCase):
def test_make_fp_amber_diff(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open(param_amber_file, 'r') as fp:
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_amber_file, "r") as fp:
jdata = json.load(fp)
- jdata['mdin_prefix'] = os.path.abspath(jdata['mdin_prefix'])
- task_dir = os.path.join('iter.%06d' % 0,
- '01.model_devi',
- 'task.%03d.%06d' % (0, 0))
- os.makedirs(task_dir, exist_ok = True)
- with open(os.path.join(task_dir, "rc.mdout"), 'w') as f:
- f.write("Active learning frame written with max. frc. std.: 3.29037 kcal/mol/A")
+ jdata["mdin_prefix"] = os.path.abspath(jdata["mdin_prefix"])
+ task_dir = os.path.join(
+ "iter.%06d" % 0, "01.model_devi", "task.%03d.%06d" % (0, 0)
+ )
+ os.makedirs(task_dir, exist_ok=True)
+ with open(os.path.join(task_dir, "rc.mdout"), "w") as f:
+ f.write(
+ "Active learning frame written with max. frc. std.: 3.29037 kcal/mol/A"
+ )
import ase
from ase.io.netcdftrajectory import write_netcdftrajectory
- write_netcdftrajectory(os.path.join(task_dir, 'rc.nc'), ase.Atoms("C", positions=np.zeros((1, 3))))
+
+ write_netcdftrajectory(
+ os.path.join(task_dir, "rc.nc"), ase.Atoms("C", positions=np.zeros((1, 3)))
+ )
make_fp(0, jdata, {})
class TestMakeFPSIESTA(unittest.TestCase):
def test_make_fp_siesta(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_siesta_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_siesta_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 2, 2, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
_check_siesta_input_head(self, 0)
- _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ _check_potcar(self, 0, jdata["fp_pp_path"], jdata["fp_pp_files"])
+ shutil.rmtree("iter.000000")
+
class TestMakeFPVasp(unittest.TestCase):
def test_make_fp_vasp(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
- make_fp(0, jdata, {"fp_user_forward_files" : ["vdw_kernel.bindat"] })
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ make_fp(0, jdata, {"fp_user_forward_files": ["vdw_kernel.bindat"]})
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
# _check_incar_exists(self, 0)
_check_incar(self, 0)
_check_kpoints_exists(self, 0)
- _check_kpoints(self,0)
+ _check_kpoints(self, 0)
# checked elsewhere
# _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
-
+ shutil.rmtree("iter.000000")
+
def test_make_fp_vasp_merge_traj(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_file_merge_traj, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_file_merge_traj, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md_merge_traj(0, md_descript, atom_types, type_map)
- make_fp(0, jdata, {"fp_user_forward_files" : ["vdw_kernel.bindat"] })
- _check_poscars_merge_traj(self, 0, jdata['fp_task_max'], jdata['type_map'])
- #_check_incar_exists(self, 0)
+ make_fp(0, jdata, {"fp_user_forward_files": ["vdw_kernel.bindat"]})
+ _check_poscars_merge_traj(self, 0, jdata["fp_task_max"], jdata["type_map"])
+ # _check_incar_exists(self, 0)
_check_incar(self, 0)
_check_kpoints_exists(self, 0)
- _check_kpoints(self,0)
+ _check_kpoints(self, 0)
# checked elsewhere
# _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ shutil.rmtree("iter.000000")
def test_make_fp_vasp_old(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_old_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_old_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
# _check_incar_exists(self, 0)
_check_incar(self, 0)
_check_kpoints_exists(self, 0)
- _check_kpoints(self,0)
+ _check_kpoints(self, 0)
# checked elsewhere
# _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ shutil.rmtree("iter.000000")
def test_make_fp_vasp_less_sel(self):
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 1
nmd = 1
n_frame = 8
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
# _check_incar_exists(self, 0)
_check_incar(self, 0)
_check_kpoints_exists(self, 0)
- _check_kpoints(self,0)
+ _check_kpoints(self, 0)
# checked elsewhere
# _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
-
+ shutil.rmtree("iter.000000")
def test_make_fp_vasp_from_incar(self):
## Verify if user chooses to diy VASP INCAR totally.
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_diy_file, 'r') as fp :
- jdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_diy_file, "r") as fp:
+ jdata = json.load(fp)
fp.close()
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
fp.close()
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
# _check_incar_exists(self, 0)
_check_incar(self, 0)
_check_kpoints_exists(self, 0)
- _check_kpoints(self,0)
+ _check_kpoints(self, 0)
# checked elsewhere
# _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ shutil.rmtree("iter.000000")
def test_make_fp_vasp_ele_temp(self):
## Verify if user chooses to diy VASP INCAR totally.
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_diy_file, 'r') as fp :
- jdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_diy_file, "r") as fp:
+ jdata = json.load(fp)
fp.close()
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
fp.close()
md_descript = []
ele_temp = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
ele_temp.append([np.random.random() * 100000] * nmd)
atom_types = [0, 1, 0, 1]
- type_map = jdata['type_map']
- _make_fake_md(0, md_descript, atom_types, type_map, ele_temp = ele_temp)
+ type_map = jdata["type_map"]
+ _make_fake_md(0, md_descript, atom_types, type_map, ele_temp=ele_temp)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
_check_incar_ele_temp(self, 0, ele_temp)
_check_kpoints_exists(self, 0)
- _check_kpoints(self,0)
+ _check_kpoints(self, 0)
# checked elsewhere
# _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ shutil.rmtree("iter.000000")
def test_make_fp_vasp_multiple_trust_level(self):
# Verify if sys_idx dependent trust level could be read.
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_multiple_trust_file, 'r') as fp :
- jdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_multiple_trust_file, "r") as fp:
+ jdata = json.load(fp)
fp.close()
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
fp.close()
md_descript = []
ele_temp = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
ele_temp.append([np.random.random() * 100000] * nmd)
atom_types = [0, 1, 0, 1]
- type_map = jdata['type_map']
- _make_fake_md(0, md_descript, atom_types, type_map, ele_temp = ele_temp)
+ type_map = jdata["type_map"]
+ _make_fake_md(0, md_descript, atom_types, type_map, ele_temp=ele_temp)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
_check_incar_ele_temp(self, 0, ele_temp)
_check_kpoints_exists(self, 0)
- _check_kpoints(self,0)
+ _check_kpoints(self, 0)
# checked elsewhere
# _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
-
+ shutil.rmtree("iter.000000")
+
class TestMakeFPGaussian(unittest.TestCase):
def make_fp_gaussian(self, multiplicity="auto"):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_gaussian_file, 'r') as fp :
- jdata = json.load (fp)
- jdata['user_fp_params']['multiplicity'] = multiplicity
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_gaussian_file, "r") as fp:
+ jdata = json.load(fp)
+ jdata["user_fp_params"]["multiplicity"] = multiplicity
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 2, 2, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
_check_gaussian_input_head(self, 0)
- _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ _check_potcar(self, 0, jdata["fp_pp_path"], jdata["fp_pp_files"])
+ shutil.rmtree("iter.000000")
- @unittest.skipIf(importlib.util.find_spec("openbabel") is None, "requires openbabel")
+ @unittest.skipIf(
+ importlib.util.find_spec("openbabel") is None, "requires openbabel"
+ )
def test_make_fp_gaussian(self):
self.make_fp_gaussian()
@@ -1028,109 +1135,127 @@ def test_make_fp_gaussian_multiplicity_one(self):
def test_detect_multiplicity(self):
# oxygen O2 3
- self._check_multiplicity(['O', 'O'], 3)
+ self._check_multiplicity(["O", "O"], 3)
# methane CH4 1
- self._check_multiplicity(['C', 'H', 'H', 'H', 'H'], 1)
+ self._check_multiplicity(["C", "H", "H", "H", "H"], 1)
# CH3 2
- self._check_multiplicity(['C', 'H', 'H', 'H'], 2)
+ self._check_multiplicity(["C", "H", "H", "H"], 2)
# CH2 1
- self._check_multiplicity(['C', 'H', 'H'], 1)
+ self._check_multiplicity(["C", "H", "H"], 1)
# CH 2
- self._check_multiplicity(['C', 'H'], 2)
+ self._check_multiplicity(["C", "H"], 2)
def _check_multiplicity(self, symbols, multiplicity):
self.assertEqual(detect_multiplicity(np.array(symbols)), multiplicity)
+
class TestMakeFPCP2K(unittest.TestCase):
def test_make_fp_cp2k(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_cp2k_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_cp2k_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 2, 2, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
- with open(ref_cp2k_file_input, 'r') as f:
- cp2k_input_ref = ''.join(f.readlines())
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
+ with open(ref_cp2k_file_input, "r") as f:
+ cp2k_input_ref = "".join(f.readlines())
_check_cp2k_input_head(self, 0, cp2k_input_ref)
- _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
+ _check_potcar(self, 0, jdata["fp_pp_path"], jdata["fp_pp_files"])
+ shutil.rmtree("iter.000000")
+
def test_make_fp_cp2k_exinput(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_cp2k_file_exinput, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_cp2k_file_exinput, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 2, 2, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
- with open(ref_cp2k_file_exinput, 'r') as f:
- cp2k_exinput_ref = ''.join(f.readlines())
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
+ with open(ref_cp2k_file_exinput, "r") as f:
+ cp2k_exinput_ref = "".join(f.readlines())
_check_cp2k_input_head(self, 0, cp2k_exinput_ref)
- _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- shutil.rmtree('iter.000000')
-
+ _check_potcar(self, 0, jdata["fp_pp_path"], jdata["fp_pp_files"])
+ shutil.rmtree("iter.000000")
class TestMakeFPPWmat(unittest.TestCase):
def test_make_fp_pwmat(self):
setUpModule()
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_pwmat_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_pwmat_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
md_descript = []
nsys = 2
nmd = 3
n_frame = 10
- for ii in range(nsys) :
+ for ii in range(nsys):
tmp = []
- for jj in range(nmd) :
- tmp.append(np.arange(0, 0.29, 0.29/10))
+ for jj in range(nmd):
+ tmp.append(np.arange(0, 0.29, 0.29 / 10))
md_descript.append(tmp)
atom_types = [0, 1, 2, 2, 0, 1]
- type_map = jdata['type_map']
+ type_map = jdata["type_map"]
_make_fake_md(0, md_descript, atom_types, type_map)
make_fp(0, jdata, {})
- _check_sel(self, 0, jdata['fp_task_max'], jdata['model_devi_f_trust_lo'], jdata['model_devi_f_trust_hi'])
- _check_poscars(self, 0, jdata['fp_task_max'], jdata['type_map'])
+ _check_sel(
+ self,
+ 0,
+ jdata["fp_task_max"],
+ jdata["model_devi_f_trust_lo"],
+ jdata["model_devi_f_trust_hi"],
+ )
+ _check_poscars(self, 0, jdata["fp_task_max"], jdata["type_map"])
_check_pwmat_input(self, 0)
- _check_potcar(self, 0, jdata['fp_pp_path'], jdata['fp_pp_files'])
- os.system('rm -r iter.000000')
- #shutil.rmtree('iter.000000')
-
-if __name__ == '__main__':
- unittest.main()
+ _check_potcar(self, 0, jdata["fp_pp_path"], jdata["fp_pp_files"])
+ os.system("rm -r iter.000000")
+ # shutil.rmtree('iter.000000')
+if __name__ == "__main__":
+ unittest.main()
diff --git a/tests/generator/test_make_md.py b/tests/generator/test_make_md.py
index 1f756f29b..f22bb4236 100644
--- a/tests/generator/test_make_md.py
+++ b/tests/generator/test_make_md.py
@@ -1,179 +1,184 @@
-import os,sys,json,glob,shutil,copy
-import dpdata
-import numpy as np
+import copy
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
from pathlib import Path
+import dpdata
+import numpy as np
+
from dpgen.generator.run import parse_cur_job_sys_revmat
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
-from .context import make_model_devi
-from .context import parse_cur_job
-from .context import parse_cur_job_revmat
-from .context import param_file, param_amber_file
-from .context import machine_file
-from .context import my_file_cmp
-from .context import setUpModule
-from .context import find_only_one_key
-from .context import revise_lmp_input_model
-from .context import revise_lmp_input_dump
-from .context import revise_lmp_input_plm
-from .context import revise_by_keys
-from .comp_sys import test_atom_names
-from .comp_sys import test_atom_types
-from .comp_sys import test_coord
-from .comp_sys import test_cell
-
-def _make_fake_models(idx, numb_models) :
- train_dir = os.path.join('iter.%06d' % idx,
- '00.train')
- os.makedirs(train_dir, exist_ok = True)
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
+from .comp_sys import test_atom_names, test_atom_types, test_cell, test_coord
+from .context import (
+ find_only_one_key,
+ machine_file,
+ make_model_devi,
+ my_file_cmp,
+ param_amber_file,
+ param_file,
+ parse_cur_job,
+ parse_cur_job_revmat,
+ revise_by_keys,
+ revise_lmp_input_dump,
+ revise_lmp_input_model,
+ revise_lmp_input_plm,
+ setUpModule,
+)
+
+
+def _make_fake_models(idx, numb_models):
+ train_dir = os.path.join("iter.%06d" % idx, "00.train")
+ os.makedirs(train_dir, exist_ok=True)
pwd = os.getcwd()
os.chdir(train_dir)
- for ii in range(numb_models) :
- os.makedirs('%03d' % ii, exist_ok = True)
- with open(os.path.join('%03d' % ii, 'forzen_model.pb'), 'w') as fp:
+ for ii in range(numb_models):
+ os.makedirs("%03d" % ii, exist_ok=True)
+ with open(os.path.join("%03d" % ii, "forzen_model.pb"), "w") as fp:
fp.write(str(ii))
- if not os.path.isfile('graph.%03d.pb' % ii) :
- os.symlink(os.path.join('%03d' % ii, 'forzen_model.pb'),
- 'graph.%03d.pb' % ii)
+ if not os.path.isfile("graph.%03d.pb" % ii):
+ os.symlink(
+ os.path.join("%03d" % ii, "forzen_model.pb"), "graph.%03d.pb" % ii
+ )
os.chdir(pwd)
-def _check_confs(testCase, idx, jdata) :
- md_dir = os.path.join('iter.%06d' % idx,
- '01.model_devi')
- tasks = glob.glob(os.path.join(md_dir, 'task.*'))
+def _check_confs(testCase, idx, jdata):
+ md_dir = os.path.join("iter.%06d" % idx, "01.model_devi")
+ tasks = glob.glob(os.path.join(md_dir, "task.*"))
tasks.sort()
- cur_job = jdata['model_devi_jobs'][idx]
- sys_idx = cur_job['sys_idx']
- sys_configs = jdata['sys_configs']
+ cur_job = jdata["model_devi_jobs"][idx]
+ sys_idx = cur_job["sys_idx"]
+ sys_configs = jdata["sys_configs"]
poscars = []
- for ii in sys_idx :
+ for ii in sys_idx:
sys_poscars = []
for ss in sys_configs[ii]:
tmp_poscars = sorted(glob.glob(ss))
sys_poscars += tmp_poscars
poscars.append(sys_poscars)
- for ii in tasks :
- conf_file = os.path.join(ii, 'conf.lmp')
+ for ii in tasks:
+ conf_file = os.path.join(ii, "conf.lmp")
l_conf_file = os.path.basename(os.readlink(conf_file))
- poscar_file = poscars[int(l_conf_file.split('.')[0])][int(l_conf_file.split('.')[1])]
- sys_0 = dpdata.System(conf_file, type_map = jdata['type_map'])
- sys_1 = dpdata.System(poscar_file, type_map = jdata['type_map'])
+ poscar_file = poscars[int(l_conf_file.split(".")[0])][
+ int(l_conf_file.split(".")[1])
+ ]
+ sys_0 = dpdata.System(conf_file, type_map=jdata["type_map"])
+ sys_1 = dpdata.System(poscar_file, type_map=jdata["type_map"])
test_atom_names(testCase, sys_0, sys_1)
test_atom_types(testCase, sys_0, sys_1)
test_cell(testCase, sys_0, sys_1)
test_coord(testCase, sys_0, sys_1)
-
-
-def _check_pb(testCase, idx) :
- md_dir = os.path.join('iter.%06d' % idx,
- '01.model_devi')
- tr_dir = os.path.join('iter.%06d' % idx,
- '00.train')
- md_pb = glob.glob(os.path.join(md_dir, 'grapb*pb'))
- tr_pb = glob.glob(os.path.join(tr_dir, 'grapb*pb'))
+
+
+def _check_pb(testCase, idx):
+ md_dir = os.path.join("iter.%06d" % idx, "01.model_devi")
+ tr_dir = os.path.join("iter.%06d" % idx, "00.train")
+ md_pb = glob.glob(os.path.join(md_dir, "grapb*pb"))
+ tr_pb = glob.glob(os.path.join(tr_dir, "grapb*pb"))
md_pb.sort()
tr_pb.sort()
- for ii,jj in zip(md_pb, tr_pb) :
- my_file_cmp(testCase,ii,jj)
-
-
-def _check_traj_dir(testCase, idx) :
- md_dir = os.path.join('iter.%06d' % idx,
- '01.model_devi')
- tasks = glob.glob(os.path.join(md_dir, 'task.*'))
+ for ii, jj in zip(md_pb, tr_pb):
+ my_file_cmp(testCase, ii, jj)
+
+
+def _check_traj_dir(testCase, idx):
+ md_dir = os.path.join("iter.%06d" % idx, "01.model_devi")
+ tasks = glob.glob(os.path.join(md_dir, "task.*"))
tasks.sort()
for ii in tasks:
- testCase.assertTrue(os.path.isdir(os.path.join(ii, 'traj')))
+ testCase.assertTrue(os.path.isdir(os.path.join(ii, "traj")))
-def _get_lammps_pt(lmp_input) :
- with open(lmp_input) as fp:
+def _get_lammps_pt(lmp_input):
+ with open(lmp_input) as fp:
for ii in fp:
- if 'variable' in ii and 'TEMP' in ii :
+ if "variable" in ii and "TEMP" in ii:
lt = float(ii.split()[3])
- if 'variable' in ii and 'PRES' in ii :
+ if "variable" in ii and "PRES" in ii:
lp = float(ii.split()[3])
- return lt,lp
+ return lt, lp
-def _check_pt(testCase, idx, jdata) :
- md_dir = os.path.join('iter.%06d' % idx,
- '01.model_devi')
- tasks = glob.glob(os.path.join(md_dir, 'task.*'))
+
+def _check_pt(testCase, idx, jdata):
+ md_dir = os.path.join("iter.%06d" % idx, "01.model_devi")
+ tasks = glob.glob(os.path.join(md_dir, "task.*"))
tasks.sort()
- cur_job = jdata['model_devi_jobs'][idx]
+ cur_job = jdata["model_devi_jobs"][idx]
ensemble, nsteps, trj_freq, temps, press, pka_e, dt = parse_cur_job(cur_job)
- testCase.assertTrue(ensemble, 'npt')
+ testCase.assertTrue(ensemble, "npt")
# get poscars
- sys_idx = cur_job['sys_idx']
- sys_configs = jdata['sys_configs']
+ sys_idx = cur_job["sys_idx"]
+ sys_configs = jdata["sys_configs"]
poscars = []
- for ii in sys_idx :
+ for ii in sys_idx:
sys_poscars = []
for ss in sys_configs[ii]:
tmp_poscars = glob.glob(ss)
sys_poscars += tmp_poscars
sys_poscars.sort()
poscars.append(sys_poscars)
- for sidx,ii in enumerate(poscars) :
+ for sidx, ii in enumerate(poscars):
count = 0
for ss in ii:
for tt in temps:
for pp in press:
- task_dir = os.path.join(md_dir, 'task.%03d.%06d' % (sidx, count))
- lt, lp = _get_lammps_pt(os.path.join(task_dir, 'input.lammps'))
+ task_dir = os.path.join(md_dir, "task.%03d.%06d" % (sidx, count))
+ lt, lp = _get_lammps_pt(os.path.join(task_dir, "input.lammps"))
testCase.assertAlmostEqual(lt, tt)
testCase.assertAlmostEqual(lp, pp)
count += 1
-
+
class TestMakeModelDevi(unittest.TestCase):
def tearDown(self):
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
-
- def test_make_model_devi (self) :
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
- _make_fake_models(0, jdata['numb_models'])
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+
+ def test_make_model_devi(self):
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
+ _make_fake_models(0, jdata["numb_models"])
make_model_devi(0, jdata, mdata)
_check_pb(self, 0)
_check_confs(self, 0, jdata)
_check_traj_dir(self, 0)
_check_pt(self, 0, jdata)
- #shutil.rmtree('iter.000000')
-
- def test_make_model_devi_nopbc_npt (self) :
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- jdata['model_devi_nopbc'] = True
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
- _make_fake_models(0, jdata['numb_models'])
+ # shutil.rmtree('iter.000000')
+
+ def test_make_model_devi_nopbc_npt(self):
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ jdata["model_devi_nopbc"] = True
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
+ _make_fake_models(0, jdata["numb_models"])
cwd = os.getcwd()
- with self.assertRaises(RuntimeError) :
- make_model_devi(0, jdata, mdata)
+ with self.assertRaises(RuntimeError):
+ make_model_devi(0, jdata, mdata)
os.chdir(cwd)
- def test_make_model_devi_nopbc_nvt (self) :
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- jdata['model_devi_nopbc'] = True
- jdata['model_devi_jobs'][0]['ensemble'] = 'nvt'
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
- _make_fake_models(0, jdata['numb_models'])
+ def test_make_model_devi_nopbc_nvt(self):
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ jdata["model_devi_nopbc"] = True
+ jdata["model_devi_jobs"][0]["ensemble"] = "nvt"
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
+ _make_fake_models(0, jdata["numb_models"])
make_model_devi(0, jdata, mdata)
_check_pb(self, 0)
# _check_confs(self, 0, jdata)
@@ -184,95 +189,117 @@ def test_make_model_devi_nopbc_nvt (self) :
class TestMakeModelDeviRevMat(unittest.TestCase):
def tearDown(self):
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
- def test_make_model_devi (self) :
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
+ def test_make_model_devi(self):
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
jdata = {
- "type_map": ["Mg", "Al"],
- "mass_map": [24, 27],
- "init_data_prefix": "data",
- "init_data_sys": ["deepmd"],
- "init_batch_size": [16],
+ "type_map": ["Mg", "Al"],
+ "mass_map": [24, 27],
+ "init_data_prefix": "data",
+ "init_data_sys": ["deepmd"],
+ "init_batch_size": [16],
"sys_configs_prefix": os.getcwd(),
- "sys_configs": [
- ["data/al.fcc.02x02x02/01.scale_pert/sys-0032/scale*/000001/POSCAR"],
- ["data/al.fcc.02x02x02/01.scale_pert/sys-0032/scale*/000000/POSCAR"]
+ "sys_configs": [
+ ["data/al.fcc.02x02x02/01.scale_pert/sys-0032/scale*/000001/POSCAR"],
+ ["data/al.fcc.02x02x02/01.scale_pert/sys-0032/scale*/000000/POSCAR"],
+ ],
+ "numb_models": 4,
+ "shuffle_poscar": False,
+ "model_devi_f_trust_lo": 0.050,
+ "model_devi_f_trust_hi": 0.150,
+ "model_devi_plumed": True,
+ "model_devi_jobs": [
+ {
+ "sys_idx": [0, 1],
+ "traj_freq": 10,
+ "template": {"lmp": "lmp/input.lammps", "plm": "lmp/input.plumed"},
+ "rev_mat": {
+ "lmp": {"V_NSTEPS": [1000], "V_TEMP": [50, 100]},
+ "plm": {"V_DIST0": [3, 4]},
+ },
+ "sys_rev_mat": {
+ "0": {"lmp": {"V_PRES": [1, 10]}, "plm": {"V_DIST1": [5, 6]}},
+ "1": {
+ "lmp": {"V_PRES": [1, 5, 10]},
+ "plm": {"V_DIST1": [5, 6, 7]},
+ },
+ },
+ }
],
- "numb_models": 4,
- "shuffle_poscar": False,
- "model_devi_f_trust_lo": 0.050,
- "model_devi_f_trust_hi": 0.150,
- "model_devi_plumed": True,
- "model_devi_jobs": [
- {"sys_idx": [0, 1], 'traj_freq': 10, "template": {"lmp": "lmp/input.lammps", "plm": "lmp/input.plumed"},
- "rev_mat": {
- "lmp": {"V_NSTEPS": [1000], "V_TEMP": [50, 100]}, "plm": {"V_DIST0": [3, 4]}
- },
- "sys_rev_mat": {
- "0": {
- "lmp": {"V_PRES": [1, 10]}, "plm": {"V_DIST1": [5, 6]}
- },
- "1": {
- "lmp": {"V_PRES": [1, 5, 10]}, "plm": {"V_DIST1": [5, 6, 7]}
- }
- }
- }
- ]
}
- mdata = {'deepmd_version': '1'}
- _make_fake_models(0, jdata['numb_models'])
+ mdata = {"deepmd_version": "1"}
+ _make_fake_models(0, jdata["numb_models"])
make_model_devi(0, jdata, mdata)
_check_pb(self, 0)
_check_confs(self, 0, jdata)
_check_traj_dir(self, 0)
# check the first task
- md_dir = os.path.join('iter.%06d' % 0, '01.model_devi')
- tasks = glob.glob(os.path.join(md_dir, 'task.*'))
+ md_dir = os.path.join("iter.%06d" % 0, "01.model_devi")
+ tasks = glob.glob(os.path.join(md_dir, "task.*"))
tasks.sort()
# each system contains 2 frames
- self.assertEqual(len(tasks), (len(jdata['model_devi_jobs'][0]['rev_mat']['lmp']['V_NSTEPS']) *
- len(jdata['model_devi_jobs'][0]['rev_mat']['lmp']['V_TEMP']) *
- len(jdata['model_devi_jobs'][0]['rev_mat']['plm']['V_DIST0']) *
- (len(jdata['model_devi_jobs'][0]['sys_rev_mat']['0']['lmp']['V_PRES']) *
- len(jdata['model_devi_jobs'][0]['sys_rev_mat']['0']['plm']['V_DIST1']) +
- len(jdata['model_devi_jobs'][0]['sys_rev_mat']['1']['lmp']['V_PRES']) *
- len(jdata['model_devi_jobs'][0]['sys_rev_mat']['1']['plm']['V_DIST1'])) *
- 2))
-
- cur_job = jdata['model_devi_jobs'][0]
- rev_keys = ['V_NSTEPS', 'V_TEMP', 'V_PRES', 'V_DIST0', 'V_DIST1']
+ self.assertEqual(
+ len(tasks),
+ (
+ len(jdata["model_devi_jobs"][0]["rev_mat"]["lmp"]["V_NSTEPS"])
+ * len(jdata["model_devi_jobs"][0]["rev_mat"]["lmp"]["V_TEMP"])
+ * len(jdata["model_devi_jobs"][0]["rev_mat"]["plm"]["V_DIST0"])
+ * (
+ len(
+ jdata["model_devi_jobs"][0]["sys_rev_mat"]["0"]["lmp"]["V_PRES"]
+ )
+ * len(
+ jdata["model_devi_jobs"][0]["sys_rev_mat"]["0"]["plm"][
+ "V_DIST1"
+ ]
+ )
+ + len(
+ jdata["model_devi_jobs"][0]["sys_rev_mat"]["1"]["lmp"]["V_PRES"]
+ )
+ * len(
+ jdata["model_devi_jobs"][0]["sys_rev_mat"]["1"]["plm"][
+ "V_DIST1"
+ ]
+ )
+ )
+ * 2
+ ),
+ )
+
+ cur_job = jdata["model_devi_jobs"][0]
+ rev_keys = ["V_NSTEPS", "V_TEMP", "V_PRES", "V_DIST0", "V_DIST1"]
rev_matrix = []
# 2 systems with each 2 frames
- for i0 in cur_job['rev_mat']['lmp']['V_NSTEPS']:
- for i1 in cur_job['rev_mat']['lmp']['V_TEMP']:
- for i3 in cur_job['rev_mat']['plm']['V_DIST0']:
- for i2 in cur_job['sys_rev_mat']['0']['lmp']['V_PRES']:
- for i4 in cur_job['sys_rev_mat']['0']['plm']['V_DIST1']:
+ for i0 in cur_job["rev_mat"]["lmp"]["V_NSTEPS"]:
+ for i1 in cur_job["rev_mat"]["lmp"]["V_TEMP"]:
+ for i3 in cur_job["rev_mat"]["plm"]["V_DIST0"]:
+ for i2 in cur_job["sys_rev_mat"]["0"]["lmp"]["V_PRES"]:
+ for i4 in cur_job["sys_rev_mat"]["0"]["plm"]["V_DIST1"]:
rev_matrix.append([i0, i1, i2, i3, i4])
- for i0 in cur_job['rev_mat']['lmp']['V_NSTEPS']:
- for i1 in cur_job['rev_mat']['lmp']['V_TEMP']:
- for i3 in cur_job['rev_mat']['plm']['V_DIST0']:
- for i2 in cur_job['sys_rev_mat']['0']['lmp']['V_PRES']:
- for i4 in cur_job['sys_rev_mat']['0']['plm']['V_DIST1']:
+ for i0 in cur_job["rev_mat"]["lmp"]["V_NSTEPS"]:
+ for i1 in cur_job["rev_mat"]["lmp"]["V_TEMP"]:
+ for i3 in cur_job["rev_mat"]["plm"]["V_DIST0"]:
+ for i2 in cur_job["sys_rev_mat"]["0"]["lmp"]["V_PRES"]:
+ for i4 in cur_job["sys_rev_mat"]["0"]["plm"]["V_DIST1"]:
rev_matrix.append([i0, i1, i2, i3, i4])
- for i0 in cur_job['rev_mat']['lmp']['V_NSTEPS']:
- for i1 in cur_job['rev_mat']['lmp']['V_TEMP']:
- for i3 in cur_job['rev_mat']['plm']['V_DIST0']:
- for i2 in cur_job['sys_rev_mat']['1']['lmp']['V_PRES']:
- for i4 in cur_job['sys_rev_mat']['1']['plm']['V_DIST1']:
+ for i0 in cur_job["rev_mat"]["lmp"]["V_NSTEPS"]:
+ for i1 in cur_job["rev_mat"]["lmp"]["V_TEMP"]:
+ for i3 in cur_job["rev_mat"]["plm"]["V_DIST0"]:
+ for i2 in cur_job["sys_rev_mat"]["1"]["lmp"]["V_PRES"]:
+ for i4 in cur_job["sys_rev_mat"]["1"]["plm"]["V_DIST1"]:
rev_matrix.append([i0, i1, i2, i3, i4])
- for i0 in cur_job['rev_mat']['lmp']['V_NSTEPS']:
- for i1 in cur_job['rev_mat']['lmp']['V_TEMP']:
- for i3 in cur_job['rev_mat']['plm']['V_DIST0']:
- for i2 in cur_job['sys_rev_mat']['1']['lmp']['V_PRES']:
- for i4 in cur_job['sys_rev_mat']['1']['plm']['V_DIST1']:
+ for i0 in cur_job["rev_mat"]["lmp"]["V_NSTEPS"]:
+ for i1 in cur_job["rev_mat"]["lmp"]["V_TEMP"]:
+ for i3 in cur_job["rev_mat"]["plm"]["V_DIST0"]:
+ for i2 in cur_job["sys_rev_mat"]["1"]["lmp"]["V_PRES"]:
+ for i4 in cur_job["sys_rev_mat"]["1"]["plm"]["V_DIST1"]:
rev_matrix.append([i0, i1, i2, i3, i4])
numb_rev = len(rev_matrix)
for ii in range(len(tasks)):
- with open(os.path.join(tasks[ii], 'job.json')) as fp:
+ with open(os.path.join(tasks[ii], "job.json")) as fp:
rev_values = rev_matrix[ii % numb_rev]
job_recd = json.load(fp)
for kk in job_recd.keys():
@@ -281,109 +308,110 @@ def test_make_model_devi (self) :
cwd_ = os.getcwd()
os.chdir(tasks[0])
- with open('input.lammps') as fp:
+ with open("input.lammps") as fp:
lines = fp.readlines()
for ii in lines:
- if 'variable' in ii and 'TEMP' in ii:
- self.assertEqual('variable TEMP equal 50',
- ' '.join(ii.split()))
- if 'variable' in ii and 'PRES' in ii:
- self.assertEqual('variable PRES equal 1',
- ' '.join(ii.split()))
- if 'variable' in ii and 'NSTEPS' in ii:
- self.assertEqual('variable NSTEPS equal 1000',
- ' '.join(ii.split()))
- with open('input.plumed') as fp:
+ if "variable" in ii and "TEMP" in ii:
+ self.assertEqual("variable TEMP equal 50", " ".join(ii.split()))
+ if "variable" in ii and "PRES" in ii:
+ self.assertEqual("variable PRES equal 1", " ".join(ii.split()))
+ if "variable" in ii and "NSTEPS" in ii:
+ self.assertEqual("variable NSTEPS equal 1000", " ".join(ii.split()))
+ with open("input.plumed") as fp:
lines = fp.readlines()
for ii in lines:
- if 'RESTRAINT' in ii:
- self.assertEqual('RESTRAINT ARG=d1,d2 AT=3,5 KAPPA=150.0,150.0 LABEL=restraint',
- ' '.join(ii.split()))
+ if "RESTRAINT" in ii:
+ self.assertEqual(
+ "RESTRAINT ARG=d1,d2 AT=3,5 KAPPA=150.0,150.0 LABEL=restraint",
+ " ".join(ii.split()),
+ )
os.chdir(cwd_)
-
- def test_make_model_devi_null (self) :
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
+ def test_make_model_devi_null(self):
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
jdata = {
- "type_map": ["Mg", "Al"],
- "mass_map": [24, 27],
- "init_data_prefix": "data",
- "init_data_sys": ["deepmd"],
- "init_batch_size": [16],
+ "type_map": ["Mg", "Al"],
+ "mass_map": [24, 27],
+ "init_data_prefix": "data",
+ "init_data_sys": ["deepmd"],
+ "init_batch_size": [16],
"sys_configs_prefix": os.getcwd(),
- "sys_configs": [
- ["data/al.fcc.02x02x02/01.scale_pert/sys-0032/scale*/000001/POSCAR"],
- ["data/al.fcc.02x02x02/01.scale_pert/sys-0032/scale*/000000/POSCAR"]
+ "sys_configs": [
+ ["data/al.fcc.02x02x02/01.scale_pert/sys-0032/scale*/000001/POSCAR"],
+ ["data/al.fcc.02x02x02/01.scale_pert/sys-0032/scale*/000000/POSCAR"],
],
- "numb_models": 4,
- "shuffle_poscar": False,
- "model_devi_f_trust_lo": 0.050,
- "model_devi_f_trust_hi": 0.150,
- "model_devi_plumed": True,
- "model_devi_jobs": [
- {"sys_idx": [0, 1], 'traj_freq': 10, "template":{"lmp": "lmp/input.lammps", "plm": "lmp/input.plumed"},
+ "numb_models": 4,
+ "shuffle_poscar": False,
+ "model_devi_f_trust_lo": 0.050,
+ "model_devi_f_trust_hi": 0.150,
+ "model_devi_plumed": True,
+ "model_devi_jobs": [
+ {
+ "sys_idx": [0, 1],
+ "traj_freq": 10,
+ "template": {"lmp": "lmp/input.lammps", "plm": "lmp/input.plumed"},
}
- ]
+ ],
}
- mdata = {'deepmd_version': '1'}
- _make_fake_models(0, jdata['numb_models'])
+ mdata = {"deepmd_version": "1"}
+ _make_fake_models(0, jdata["numb_models"])
make_model_devi(0, jdata, mdata)
_check_pb(self, 0)
_check_confs(self, 0, jdata)
_check_traj_dir(self, 0)
# check the first task
- md_dir = os.path.join('iter.%06d' % 0, '01.model_devi')
- tasks = glob.glob(os.path.join(md_dir, 'task.*'))
+ md_dir = os.path.join("iter.%06d" % 0, "01.model_devi")
+ tasks = glob.glob(os.path.join(md_dir, "task.*"))
# 4 accounts for 2 systems each with 2 frames
self.assertEqual(len(tasks), (4))
tasks.sort()
cwd_ = os.getcwd()
os.chdir(tasks[0])
- with open('input.lammps') as fp:
+ with open("input.lammps") as fp:
lines = fp.readlines()
for ii in lines:
- if 'variable' in ii and 'TEMP' in ii:
- self.assertEqual('variable TEMP equal V_TEMP',
- ' '.join(ii.split()))
- if 'variable' in ii and 'PRES' in ii:
- self.assertEqual('variable PRES equal V_PRES',
- ' '.join(ii.split()))
- if 'variable' in ii and 'NSTEPS' in ii:
- self.assertEqual('variable NSTEPS equal V_NSTEPS',
- ' '.join(ii.split()))
- with open('input.plumed') as fp:
+ if "variable" in ii and "TEMP" in ii:
+ self.assertEqual("variable TEMP equal V_TEMP", " ".join(ii.split()))
+ if "variable" in ii and "PRES" in ii:
+ self.assertEqual("variable PRES equal V_PRES", " ".join(ii.split()))
+ if "variable" in ii and "NSTEPS" in ii:
+ self.assertEqual(
+ "variable NSTEPS equal V_NSTEPS", " ".join(ii.split())
+ )
+ with open("input.plumed") as fp:
lines = fp.readlines()
for ii in lines:
- if 'RESTRAINT' in ii:
- self.assertEqual('RESTRAINT ARG=d1,d2 AT=V_DIST0,V_DIST1 KAPPA=150.0,150.0 LABEL=restraint',
- ' '.join(ii.split()))
+ if "RESTRAINT" in ii:
+ self.assertEqual(
+ "RESTRAINT ARG=d1,d2 AT=V_DIST0,V_DIST1 KAPPA=150.0,150.0 LABEL=restraint",
+ " ".join(ii.split()),
+ )
os.chdir(cwd_)
-
-
class TestParseCurJobRevMat(unittest.TestCase):
def setUp(self):
self.cur_job = {
"sys_idx": [0, 1],
- "template":{"lmp": "lmp/input.lammps", "plm": "lmp/input.plumed"},
- "rev_mat":{
- "lmp": {"V_NSTEPS": [1000], "V_TEMP": [50, 100], "V_PRES": [1, 10]}, "plm": {"V_DIST0": [3,4], "V_DIST1": [5, 6]}
- }
+ "template": {"lmp": "lmp/input.lammps", "plm": "lmp/input.plumed"},
+ "rev_mat": {
+ "lmp": {"V_NSTEPS": [1000], "V_TEMP": [50, 100], "V_PRES": [1, 10]},
+ "plm": {"V_DIST0": [3, 4], "V_DIST1": [5, 6]},
+ },
}
self.ref_matrix = []
- for i0 in self.cur_job['rev_mat']['lmp']['V_NSTEPS']:
- for i1 in self.cur_job['rev_mat']['lmp']['V_TEMP']:
- for i2 in self.cur_job['rev_mat']['lmp']['V_PRES']:
- for i3 in self.cur_job['rev_mat']['plm']['V_DIST0']:
- for i4 in self.cur_job['rev_mat']['plm']['V_DIST1']:
+ for i0 in self.cur_job["rev_mat"]["lmp"]["V_NSTEPS"]:
+ for i1 in self.cur_job["rev_mat"]["lmp"]["V_TEMP"]:
+ for i2 in self.cur_job["rev_mat"]["lmp"]["V_PRES"]:
+ for i3 in self.cur_job["rev_mat"]["plm"]["V_DIST0"]:
+ for i4 in self.cur_job["rev_mat"]["plm"]["V_DIST1"]:
self.ref_matrix.append([i0, i1, i2, i3, i4])
- self.ref_keys = ['V_NSTEPS', 'V_TEMP', 'V_PRES', 'V_DIST0', 'V_DIST1']
+ self.ref_keys = ["V_NSTEPS", "V_TEMP", "V_PRES", "V_DIST0", "V_DIST1"]
self.ref_nlmp = 3
def test_parse_cur_job(self):
- rk, rm, nl = parse_cur_job_revmat(self.cur_job, use_plm = True)
+ rk, rm, nl = parse_cur_job_revmat(self.cur_job, use_plm=True)
self.assertEqual(rk, self.ref_keys)
self.assertEqual(nl, self.ref_nlmp)
self.assertEqual(rm, self.ref_matrix)
@@ -393,29 +421,24 @@ class TestParseCurJobSysRevMat(unittest.TestCase):
def setUp(self):
self.cur_job = {
"sys_idx": [0, 1],
- "template":{"lmp": "lmp/input.lammps", "plm": "lmp/input.plumed"},
- "rev_mat":{
- "lmp": {"V_NSTEPS": [1000], "V_TEMP": [50, 100]}, "plm": {"V_DIST0": [3, 4]}
+ "template": {"lmp": "lmp/input.lammps", "plm": "lmp/input.plumed"},
+ "rev_mat": {
+ "lmp": {"V_NSTEPS": [1000], "V_TEMP": [50, 100]},
+ "plm": {"V_DIST0": [3, 4]},
},
"sys_rev_mat": {
- "0": {
- "lmp": {"V_PRES": [1, 10]},
- "plm": {"V_DIST1": [5, 6]}
- },
- "1": {
- "lmp": {"V_PRES": [1, 10, 20]},
- "plm": {"V_DIST1": [5, 6, 7]}
- }
- }
+ "0": {"lmp": {"V_PRES": [1, 10]}, "plm": {"V_DIST1": [5, 6]}},
+ "1": {"lmp": {"V_PRES": [1, 10, 20]}, "plm": {"V_DIST1": [5, 6, 7]}},
+ },
}
self.sys_ref_matrix = [[], []]
- for i0 in self.cur_job['sys_rev_mat']['0']['lmp']['V_PRES']:
- for i1 in self.cur_job['sys_rev_mat']['0']['plm']['V_DIST1']:
+ for i0 in self.cur_job["sys_rev_mat"]["0"]["lmp"]["V_PRES"]:
+ for i1 in self.cur_job["sys_rev_mat"]["0"]["plm"]["V_DIST1"]:
self.sys_ref_matrix[0].append([i0, i1])
- for i0 in self.cur_job['sys_rev_mat']['1']['lmp']['V_PRES']:
- for i1 in self.cur_job['sys_rev_mat']['1']['plm']['V_DIST1']:
+ for i0 in self.cur_job["sys_rev_mat"]["1"]["lmp"]["V_PRES"]:
+ for i1 in self.cur_job["sys_rev_mat"]["1"]["plm"]["V_DIST1"]:
self.sys_ref_matrix[1].append([i0, i1])
- self.sys_ref_keys = ['V_PRES', 'V_DIST1']
+ self.sys_ref_keys = ["V_PRES", "V_DIST1"]
self.sys_ref_nlmp_0 = 1
self.sys_ref_nlmp_1 = 1
@@ -428,91 +451,98 @@ def test_parse_cur_job(self):
self.assertEqual(rk1, self.sys_ref_keys)
self.assertEqual(nl1, self.sys_ref_nlmp_1)
self.assertEqual(rm1, self.sys_ref_matrix[1])
-
+
class MakeModelDeviByReviseMatrix(unittest.TestCase):
def test_find_only_one_key_1(self):
- lines = ['aaa bbb ccc\n', 'bbb ccc\n', 'ccc bbb ccc\n']
- idx = find_only_one_key(lines, ['bbb', 'ccc'])
+ lines = ["aaa bbb ccc\n", "bbb ccc\n", "ccc bbb ccc\n"]
+ idx = find_only_one_key(lines, ["bbb", "ccc"])
self.assertEqual(idx, 1)
- def test_find_only_one_key_0(self):
- lines = ['aaa bbb\n', 'bbb aaa\n', 'ccc ddd\n']
+ def test_find_only_one_key_0(self):
+ lines = ["aaa bbb\n", "bbb aaa\n", "ccc ddd\n"]
with self.assertRaises(RuntimeError):
- idx = find_only_one_key(lines, ['ccc','eee'])
+ idx = find_only_one_key(lines, ["ccc", "eee"])
- def test_find_only_one_key_2(self):
- lines = ['aaa bbb\n', 'bbb ccc\n', 'bbb ccc\n', 'fff eee\n']
+ def test_find_only_one_key_2(self):
+ lines = ["aaa bbb\n", "bbb ccc\n", "bbb ccc\n", "fff eee\n"]
with self.assertRaises(RuntimeError):
- idx = find_only_one_key(lines, ['bbb','ccc'])
+ idx = find_only_one_key(lines, ["bbb", "ccc"])
def test_revise_lmp_input_model_0(self):
- lines = ['foo\n', 'pair_style deepmd aaa ccc fff\n', 'bar\n', '\n']
+ lines = ["foo\n", "pair_style deepmd aaa ccc fff\n", "bar\n", "\n"]
ref_lines = copy.deepcopy(lines)
- lines = revise_lmp_input_model(lines, ['model0', 'model1'], 10, '0.1')
- for ii in [0, 2, 3] :
+ lines = revise_lmp_input_model(lines, ["model0", "model1"], 10, "0.1")
+ for ii in [0, 2, 3]:
self.assertEqual(lines[ii], ref_lines[ii])
tmp = " ".join(lines[1].split())
self.assertEqual(tmp, "pair_style deepmd model0 model1 10 model_devi.out")
-
+
def test_revise_lmp_input_model_1(self):
- lines = ['foo\n', 'pair_style deepmd aaa ccc fff\n', 'bar\n', '\n']
+ lines = ["foo\n", "pair_style deepmd aaa ccc fff\n", "bar\n", "\n"]
ref_lines = copy.deepcopy(lines)
- lines = revise_lmp_input_model(lines, ['model0', 'model1'], 10, '1')
- for ii in [0, 2, 3] :
+ lines = revise_lmp_input_model(lines, ["model0", "model1"], 10, "1")
+ for ii in [0, 2, 3]:
self.assertEqual(lines[ii], ref_lines[ii])
tmp = " ".join(lines[1].split())
- self.assertEqual(tmp, "pair_style deepmd model0 model1 out_freq 10 out_file model_devi.out")
-
+ self.assertEqual(
+ tmp, "pair_style deepmd model0 model1 out_freq 10 out_file model_devi.out"
+ )
+
def test_revise_lmp_input_dump(self):
- lines = ['foo\n', 'dump dpgen_dump ccc fff\n', 'bar\n', '\n']
+ lines = ["foo\n", "dump dpgen_dump ccc fff\n", "bar\n", "\n"]
ref_lines = copy.deepcopy(lines)
lines = revise_lmp_input_dump(lines, 10)
- for ii in [0, 2, 3] :
+ for ii in [0, 2, 3]:
self.assertEqual(lines[ii], ref_lines[ii])
tmp = " ".join(lines[1].split())
- self.assertEqual(tmp, "dump dpgen_dump all custom 10 traj/*.lammpstrj id type x y z")
-
+ self.assertEqual(
+ tmp, "dump dpgen_dump all custom 10 traj/*.lammpstrj id type x y z"
+ )
+
def test_revise_lmp_input_plm(self):
- lines = ['foo\n', 'fix dpgen_plm ccc fff\n', 'bar\n', '\n']
+ lines = ["foo\n", "fix dpgen_plm ccc fff\n", "bar\n", "\n"]
ref_lines = copy.deepcopy(lines)
- lines = revise_lmp_input_plm(lines, 'input.plumed')
- for ii in [0, 2, 3] :
+ lines = revise_lmp_input_plm(lines, "input.plumed")
+ for ii in [0, 2, 3]:
self.assertEqual(lines[ii], ref_lines[ii])
tmp = " ".join(lines[1].split())
- self.assertEqual(tmp, "fix dpgen_plm all plumed plumedfile input.plumed outfile output.plumed")
-
+ self.assertEqual(
+ tmp,
+ "fix dpgen_plm all plumed plumedfile input.plumed outfile output.plumed",
+ )
+
def test_revise_by_key(self):
- lines = ['foo\n', 'aaa\n', 'bar\n', 'bbb\n', '\n']
+ lines = ["foo\n", "aaa\n", "bar\n", "bbb\n", "\n"]
ref_lines = copy.deepcopy(lines)
- lines = revise_by_keys(lines, ['aaa', 'bbb'], ['ccc','ddd'])
- for ii in [0, 2, 4] :
+ lines = revise_by_keys(lines, ["aaa", "bbb"], ["ccc", "ddd"])
+ for ii in [0, 2, 4]:
self.assertEqual(lines[ii], ref_lines[ii])
tmp = " ".join(lines[1].split())
self.assertEqual(tmp, "ccc")
tmp = " ".join(lines[3].split())
self.assertEqual(tmp, "ddd")
-
+
class TestMakeMDAMBER(unittest.TestCase):
def tearDown(self):
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
-
- def test_make_model_devi (self) :
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- with open (param_amber_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
- jdata['sys_prefix'] = os.path.abspath(jdata['sys_prefix'])
- _make_fake_models(0, jdata['numb_models'])
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+
+ def test_make_model_devi(self):
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ with open(param_amber_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
+ jdata["sys_prefix"] = os.path.abspath(jdata["sys_prefix"])
+ _make_fake_models(0, jdata["numb_models"])
make_model_devi(0, jdata, mdata)
_check_pb(self, 0)
_check_confs(self, 0, jdata)
_check_traj_dir(self, 0)
-if __name__ == '__main__':
+if __name__ == "__main__":
unittest.main()
diff --git a/tests/generator/test_make_train.py b/tests/generator/test_make_train.py
index 12fbd9cf7..bb368391b 100644
--- a/tests/generator/test_make_train.py
+++ b/tests/generator/test_make_train.py
@@ -1,367 +1,528 @@
#!/usr/bin/env python3
-import os,sys,json,glob,shutil,dpdata
-import numpy as np
+import glob
+import json
+import os
+import shutil
+import sys
import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
+import dpdata
+import numpy as np
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
import tempfile
-from .context import make_train, run_train
-from .context import param_file
-from .context import param_file_v1
-from .context import param_file_v1_et
-from .context import machine_file
-from .context import machine_file_v1
-from .context import setUpModule
-
-def _comp_sys_files (sys0, sys1) :
+
+from .context import (
+ machine_file,
+ machine_file_v1,
+ make_train,
+ param_file,
+ param_file_v1,
+ param_file_v1_et,
+ run_train,
+ setUpModule,
+)
+
+
+def _comp_sys_files(sys0, sys1):
pwd = os.getcwd()
- os.chdir(sys0)
- files = glob.glob('*.raw')
- set_files = glob.glob('set.*/*npy')
+ os.chdir(sys0)
+ files = glob.glob("*.raw")
+ set_files = glob.glob("set.*/*npy")
# files += set_files
os.chdir(pwd)
- for ii in files :
- with open(os.path.join(sys0, ii)) as fp0 :
+ for ii in files:
+ with open(os.path.join(sys0, ii)) as fp0:
with open(os.path.join(sys1, ii)) as fp1:
- if fp0.read() != fp1.read() :
+ if fp0.read() != fp1.read():
return False
for ii in set_files:
t0 = np.load(os.path.join(sys0, ii))
t1 = np.load(os.path.join(sys1, ii))
- if np.linalg.norm(t0-t1) > 1e-12 :
+ if np.linalg.norm(t0 - t1) > 1e-12:
return False
return True
-def _comp_init_data(testCase, iter_idx, init_data_prefix, init_data_sys) :
- for ii in init_data_sys :
- sys0 = os.path.join(init_data_prefix, ii)
- sys1 = os.path.join('iter.%06d' % iter_idx,
- '00.train',
- 'data.init',
- ii)
- testCase.assertTrue(_comp_sys_files(sys0, sys1),
- 'systems %s %s are not identical' % (sys0, sys1))
-
-def _check_numb_models(testCase, iter_idx, numb_models) :
- models = glob.glob(os.path.join('iter.%06d' % iter_idx,
- '00.train',
- '[0-9][0-9][0-9]'))
+
+def _comp_init_data(testCase, iter_idx, init_data_prefix, init_data_sys):
+ for ii in init_data_sys:
+ sys0 = os.path.join(init_data_prefix, ii)
+ sys1 = os.path.join("iter.%06d" % iter_idx, "00.train", "data.init", ii)
+ testCase.assertTrue(
+ _comp_sys_files(sys0, sys1),
+ "systems %s %s are not identical" % (sys0, sys1),
+ )
+
+
+def _check_numb_models(testCase, iter_idx, numb_models):
+ models = glob.glob(
+ os.path.join("iter.%06d" % iter_idx, "00.train", "[0-9][0-9][0-9]")
+ )
testCase.assertTrue(len(models), numb_models)
-def _check_model_inputs(testCase, iter_idx, jdata) :
- train_param = jdata.get('train_param', 'input.json')
- numb_models = jdata['numb_models']
- default_training_param = jdata['default_training_param']
- init_data_sys = [os.path.join('..', 'data.init', ii) for ii in jdata['init_data_sys']]
- init_batch_size = jdata['init_batch_size']
- sys_batch_size = jdata['sys_batch_size']
- if iter_idx > 0 :
- systems = glob.glob(os.path.join('iter.*', '02.fp', 'data.*'))
- for ii in systems :
- init_data_sys.append(os.path.join('..', 'data.iters', ii))
- sys_idx = int(os.path.basename(ii).split('.')[1])
+def _check_model_inputs(testCase, iter_idx, jdata):
+ train_param = jdata.get("train_param", "input.json")
+ numb_models = jdata["numb_models"]
+ default_training_param = jdata["default_training_param"]
+ init_data_sys = [
+ os.path.join("..", "data.init", ii) for ii in jdata["init_data_sys"]
+ ]
+ init_batch_size = jdata["init_batch_size"]
+ sys_batch_size = jdata["sys_batch_size"]
+ if iter_idx > 0:
+ systems = glob.glob(os.path.join("iter.*", "02.fp", "data.*"))
+ for ii in systems:
+ init_data_sys.append(os.path.join("..", "data.iters", ii))
+ sys_idx = int(os.path.basename(ii).split(".")[1])
init_batch_size.append(sys_batch_size[sys_idx])
- for kk in range(numb_models) :
- with open(os.path.join('iter.%06d' % iter_idx,
- '00.train',
- '%03d' % kk,
- train_param)) as fp :
+ for kk in range(numb_models):
+ with open(
+ os.path.join("iter.%06d" % iter_idx, "00.train", "%03d" % kk, train_param)
+ ) as fp:
jdata0 = json.load(fp)
# keys except 'systems', 'batch_size', 'seed' should be identical
- for ii in jdata0.keys() :
- if ii == 'systems' :
- for jj,kk in zip(jdata0[ii], init_data_sys):
+ for ii in jdata0.keys():
+ if ii == "systems":
+ for jj, kk in zip(jdata0[ii], init_data_sys):
testCase.assertEqual(jj, kk)
- elif ii == 'batch_size' :
- for jj, kk in zip(jdata0[ii], init_batch_size) :
+ elif ii == "batch_size":
+ for jj, kk in zip(jdata0[ii], init_batch_size):
testCase.assertEqual(jj, kk)
- elif ii == 'seed':
+ elif ii == "seed":
pass
- else :
+ else:
testCase.assertEqual(jdata0[ii], default_training_param[ii])
-def _check_model_input_dict(testCase, input_dict, init_data_sys, init_batch_size, default_training_param):
- for ii in input_dict.keys() :
- if ii == 'systems' :
- for jj,kk in zip(input_dict[ii], init_data_sys):
+
+def _check_model_input_dict(
+ testCase, input_dict, init_data_sys, init_batch_size, default_training_param
+):
+ for ii in input_dict.keys():
+ if ii == "systems":
+ for jj, kk in zip(input_dict[ii], init_data_sys):
testCase.assertEqual(jj, kk)
- elif ii == 'batch_size' :
- for jj, kk in zip(input_dict[ii], init_batch_size) :
+ elif ii == "batch_size":
+ for jj, kk in zip(input_dict[ii], init_batch_size):
testCase.assertEqual(jj, kk)
- elif ii == 'seed':
+ elif ii == "seed":
# can be anything
pass
- elif ii == 'numb_fparam':
+ elif ii == "numb_fparam":
testCase.assertEqual(input_dict[ii], 1)
- elif ii == 'numb_aparam':
+ elif ii == "numb_aparam":
testCase.assertEqual(input_dict[ii], 1)
- else :
+ else:
testCase.assertEqual(input_dict[ii], default_training_param[ii])
-def _check_model_inputs_v1(testCase, iter_idx, jdata, reuse = False) :
- train_param = jdata.get('train_param', 'input.json')
- numb_models = jdata['numb_models']
- use_ele_temp = jdata.get('use_ele_temp', 0)
- default_training_param = jdata['default_training_param']
- init_data_sys = [os.path.join('..', 'data.init', ii) for ii in jdata['init_data_sys']]
- init_batch_size = jdata['init_batch_size']
- sys_batch_size = jdata['sys_batch_size']
- if iter_idx > 0 :
- systems = glob.glob(os.path.join('iter.*', '02.fp', 'data.*'))
- for ii in systems :
- init_data_sys.append(os.path.join('..', 'data.iters', ii))
- sys_idx = int(os.path.basename(ii).split('.')[1])
+def _check_model_inputs_v1(testCase, iter_idx, jdata, reuse=False):
+ train_param = jdata.get("train_param", "input.json")
+ numb_models = jdata["numb_models"]
+ use_ele_temp = jdata.get("use_ele_temp", 0)
+ default_training_param = jdata["default_training_param"]
+ init_data_sys = [
+ os.path.join("..", "data.init", ii) for ii in jdata["init_data_sys"]
+ ]
+ init_batch_size = jdata["init_batch_size"]
+ sys_batch_size = jdata["sys_batch_size"]
+ if iter_idx > 0:
+ systems = glob.glob(os.path.join("iter.*", "02.fp", "data.*"))
+ for ii in systems:
+ init_data_sys.append(os.path.join("..", "data.iters", ii))
+ sys_idx = int(os.path.basename(ii).split(".")[1])
init_batch_size.append(sys_batch_size[sys_idx])
- for kk in range(numb_models) :
- with open(os.path.join('iter.%06d' % iter_idx,
- '00.train',
- '%03d' % kk,
- train_param)) as fp :
+ for kk in range(numb_models):
+ with open(
+ os.path.join("iter.%06d" % iter_idx, "00.train", "%03d" % kk, train_param)
+ ) as fp:
jdata0 = json.load(fp)
# keys except 'systems', 'batch_size', 'seed' should be identical
if use_ele_temp == 1:
- testCase.assertTrue('numb_fparam' in jdata0['model']['fitting_net'])
- testCase.assertFalse('numb_aparam' in jdata0['model']['fitting_net'])
+ testCase.assertTrue("numb_fparam" in jdata0["model"]["fitting_net"])
+ testCase.assertFalse("numb_aparam" in jdata0["model"]["fitting_net"])
if use_ele_temp == 2:
- testCase.assertTrue('numb_aparam' in jdata0['model']['fitting_net'])
- testCase.assertFalse('numb_fparam' in jdata0['model']['fitting_net'])
- _check_model_input_dict(testCase, jdata0['model']['descriptor'], init_data_sys, init_batch_size, default_training_param['model']['descriptor'])
- _check_model_input_dict(testCase, jdata0['model']['fitting_net'], init_data_sys, init_batch_size, default_training_param['model']['fitting_net'])
- _check_model_input_dict(testCase, jdata0['loss'], init_data_sys, init_batch_size, default_training_param['loss'])
- _check_model_input_dict(testCase, jdata0['learning_rate'], init_data_sys, init_batch_size, default_training_param['learning_rate'])
- _check_model_input_dict(testCase, jdata0['training'], init_data_sys, init_batch_size, default_training_param['training'])
+ testCase.assertTrue("numb_aparam" in jdata0["model"]["fitting_net"])
+ testCase.assertFalse("numb_fparam" in jdata0["model"]["fitting_net"])
+ _check_model_input_dict(
+ testCase,
+ jdata0["model"]["descriptor"],
+ init_data_sys,
+ init_batch_size,
+ default_training_param["model"]["descriptor"],
+ )
+ _check_model_input_dict(
+ testCase,
+ jdata0["model"]["fitting_net"],
+ init_data_sys,
+ init_batch_size,
+ default_training_param["model"]["fitting_net"],
+ )
+ _check_model_input_dict(
+ testCase,
+ jdata0["loss"],
+ init_data_sys,
+ init_batch_size,
+ default_training_param["loss"],
+ )
+ _check_model_input_dict(
+ testCase,
+ jdata0["learning_rate"],
+ init_data_sys,
+ init_batch_size,
+ default_training_param["learning_rate"],
+ )
+ _check_model_input_dict(
+ testCase,
+ jdata0["training"],
+ init_data_sys,
+ init_batch_size,
+ default_training_param["training"],
+ )
if reuse:
- testCase.assertEqual(jdata['training_reuse_stop_batch'],
- jdata0['training']['stop_batch'])
- testCase.assertEqual(jdata['training_reuse_start_lr'],
- jdata0['learning_rate']['start_lr'])
- testCase.assertEqual(jdata['training_reuse_start_pref_e'],
- jdata0['loss']['start_pref_e'])
- testCase.assertEqual(jdata['training_reuse_start_pref_f'],
- jdata0['loss']['start_pref_f'])
- old_ratio = jdata['training_reuse_old_ratio']
- testCase.assertEqual(jdata0['training']['auto_prob_style'],
- "prob_sys_size; 0:1:%f; 1:2:%f" % (old_ratio, 1-old_ratio))
+ testCase.assertEqual(
+ jdata["training_reuse_stop_batch"], jdata0["training"]["stop_batch"]
+ )
+ testCase.assertEqual(
+ jdata["training_reuse_start_lr"], jdata0["learning_rate"]["start_lr"]
+ )
+ testCase.assertEqual(
+ jdata["training_reuse_start_pref_e"], jdata0["loss"]["start_pref_e"]
+ )
+ testCase.assertEqual(
+ jdata["training_reuse_start_pref_f"], jdata0["loss"]["start_pref_f"]
+ )
+ old_ratio = jdata["training_reuse_old_ratio"]
+ testCase.assertEqual(
+ jdata0["training"]["auto_prob_style"],
+ "prob_sys_size; 0:1:%f; 1:2:%f" % (old_ratio, 1 - old_ratio),
+ )
def _make_fake_fp(iter_idx, sys_idx, nframes):
- for ii in range(nframes) :
- dirname = os.path.join('iter.%06d' % iter_idx,
- '02.fp',
- 'task.%03d.%06d' % (sys_idx, ii))
- os.makedirs(dirname, exist_ok = True)
- dirname = os.path.join('iter.%06d' % iter_idx,
- '02.fp',
- 'data.%03d' % sys_idx)
- os.makedirs(dirname, exist_ok = True)
- tmp_sys = dpdata.LabeledSystem('out_data_post_fp_vasp/02.fp/task.000.000000/OUTCAR')
+ for ii in range(nframes):
+ dirname = os.path.join(
+ "iter.%06d" % iter_idx, "02.fp", "task.%03d.%06d" % (sys_idx, ii)
+ )
+ os.makedirs(dirname, exist_ok=True)
+ dirname = os.path.join("iter.%06d" % iter_idx, "02.fp", "data.%03d" % sys_idx)
+ os.makedirs(dirname, exist_ok=True)
+ tmp_sys = dpdata.LabeledSystem("out_data_post_fp_vasp/02.fp/task.000.000000/OUTCAR")
tmp_sys1 = tmp_sys.sub_system([0])
tmp_sys2 = tmp_sys1
for ii in range(1, nframes):
tmp_sys2.append(tmp_sys1)
- tmp_sys2.to('deepmd/npy', dirname)
+ tmp_sys2.to("deepmd/npy", dirname)
-def _check_pb_link(testCase, iter_idx, numb_models) :
+def _check_pb_link(testCase, iter_idx, numb_models):
pwd = os.getcwd()
- os.chdir(os.path.join('iter.%06d' % iter_idx,
- '00.train'))
- for ii in range(numb_models) :
- lnk = os.readlink('graph.%03d.pb' % ii)
- testCase.assertEqual(lnk, os.path.join('%03d' % ii, 'frozen_model.pb'))
+ os.chdir(os.path.join("iter.%06d" % iter_idx, "00.train"))
+ for ii in range(numb_models):
+ lnk = os.readlink("graph.%03d.pb" % ii)
+ testCase.assertEqual(lnk, os.path.join("%03d" % ii, "frozen_model.pb"))
os.chdir(pwd)
-class TestMakeTrain(unittest.TestCase):
- def test_0 (self) :
- # No longer support for DeePMD-kit-0.x version.
- return
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
- fp_task_min = jdata['fp_task_min']
+class TestMakeTrain(unittest.TestCase):
+ def test_0(self):
+ # No longer support for DeePMD-kit-0.x version.
+ return
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
+ fp_task_min = jdata["fp_task_min"]
make_train(0, jdata, mdata)
# comp init data
- init_data_prefix = jdata['init_data_prefix']
- init_data_sys = jdata['init_data_sys']
+ init_data_prefix = jdata["init_data_prefix"]
+ init_data_sys = jdata["init_data_sys"]
_comp_init_data(self, 0, init_data_prefix, init_data_sys)
# check number of models
- _check_numb_models(self, 0, jdata['numb_models'])
+ _check_numb_models(self, 0, jdata["numb_models"])
# check models inputs
_check_model_inputs(self, 0, jdata)
# remove iter
- shutil.rmtree('iter.000000')
+ shutil.rmtree("iter.000000")
- def test_1_data(self) :
- # No longer support for DeePMD-kit-0.x version.
+ def test_1_data(self):
+ # No longer support for DeePMD-kit-0.x version.
return
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
make_train(0, jdata, mdata)
# make fake fp results #data == fp_task_min
- _make_fake_fp(0, 0, jdata['fp_task_min'])
+ _make_fake_fp(0, 0, jdata["fp_task_min"])
# make iter1 train
make_train(1, jdata, mdata)
# check data is linked
- self.assertTrue(os.path.isdir(os.path.join('iter.000001', '00.train', 'data.iters', 'iter.000000', '02.fp')))
+ self.assertTrue(
+ os.path.isdir(
+ os.path.join(
+ "iter.000001", "00.train", "data.iters", "iter.000000", "02.fp"
+ )
+ )
+ )
# check models inputs
_check_model_inputs(self, 1, jdata)
# remove testing dirs
- shutil.rmtree('iter.000001')
- shutil.rmtree('iter.000000')
-
+ shutil.rmtree("iter.000001")
+ shutil.rmtree("iter.000000")
def test_1_skip(self):
- # No longer support for DeePMD-kit-0.x version.
+ # No longer support for DeePMD-kit-0.x version.
return
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file, 'r') as fp:
- mdata = json.load (fp)
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file, "r") as fp:
+ mdata = json.load(fp)
make_train(0, jdata, mdata)
# make fake fp results #data == fp_task_min - 1
- _make_fake_fp(0, 0, jdata['fp_task_min'] - 1)
+ _make_fake_fp(0, 0, jdata["fp_task_min"] - 1)
# make iter1 train
make_train(1, jdata, mdata)
- self.assertTrue(os.path.isfile(os.path.join('iter.000001', '00.train', 'copied')))
+ self.assertTrue(
+ os.path.isfile(os.path.join("iter.000001", "00.train", "copied"))
+ )
# check pb file linked
- _check_pb_link(self, 1, jdata['numb_models'])
+ _check_pb_link(self, 1, jdata["numb_models"])
# remove testing dirs
- shutil.rmtree('iter.000001')
- shutil.rmtree('iter.000000')
-
+ shutil.rmtree("iter.000001")
+ shutil.rmtree("iter.000000")
- def test_1_data_v1(self) :
- with open (param_file_v1, 'r') as fp :
- jdata = json.load (fp)
- jdata.pop('use_ele_temp', None)
- with open (machine_file_v1, 'r') as fp:
- mdata = json.load (fp)
+ def test_1_data_v1(self):
+ with open(param_file_v1, "r") as fp:
+ jdata = json.load(fp)
+ jdata.pop("use_ele_temp", None)
+ with open(machine_file_v1, "r") as fp:
+ mdata = json.load(fp)
make_train(0, jdata, mdata)
# make fake fp results #data == fp_task_min
- _make_fake_fp(0, 0, jdata['fp_task_min'])
+ _make_fake_fp(0, 0, jdata["fp_task_min"])
# make iter1 train
make_train(1, jdata, mdata)
# check data is linked
- self.assertTrue(os.path.isdir(os.path.join('iter.000001', '00.train', 'data.iters', 'iter.000000', '02.fp')))
+ self.assertTrue(
+ os.path.isdir(
+ os.path.join(
+ "iter.000001", "00.train", "data.iters", "iter.000000", "02.fp"
+ )
+ )
+ )
# check models inputs
_check_model_inputs_v1(self, 1, jdata)
# remove testing dirs
- shutil.rmtree('iter.000001')
- shutil.rmtree('iter.000000')
-
-
- def test_1_data_reuse_v1(self) :
- with open (param_file_v1, 'r') as fp :
- jdata = json.load (fp)
- jdata.pop('use_ele_temp', None)
- jdata['training_reuse_iter'] = 1
- jdata['training_reuse_old_ratio'] = 0.8
- jdata['training_reuse_stop_batch'] = 400000
- jdata['training_reuse_start_lr'] = 1e-4
- jdata['training_reuse_start_pref_e'] = 0.1
- jdata['training_reuse_start_pref_f'] = 100
- with open (machine_file_v1, 'r') as fp:
- mdata = json.load (fp)
+ shutil.rmtree("iter.000001")
+ shutil.rmtree("iter.000000")
+
+ def test_1_data_reuse_v1(self):
+ with open(param_file_v1, "r") as fp:
+ jdata = json.load(fp)
+ jdata.pop("use_ele_temp", None)
+ jdata["training_reuse_iter"] = 1
+ jdata["training_reuse_old_ratio"] = 0.8
+ jdata["training_reuse_stop_batch"] = 400000
+ jdata["training_reuse_start_lr"] = 1e-4
+ jdata["training_reuse_start_pref_e"] = 0.1
+ jdata["training_reuse_start_pref_f"] = 100
+ with open(machine_file_v1, "r") as fp:
+ mdata = json.load(fp)
make_train(0, jdata, mdata)
# make fake fp results #data == fp_task_min
- _make_fake_fp(0, 0, jdata['fp_task_min'])
+ _make_fake_fp(0, 0, jdata["fp_task_min"])
# make iter1 train
make_train(1, jdata, mdata)
# check data is linked
- self.assertTrue(os.path.isdir(os.path.join('iter.000001', '00.train', 'data.iters', 'iter.000000', '02.fp')))
+ self.assertTrue(
+ os.path.isdir(
+ os.path.join(
+ "iter.000001", "00.train", "data.iters", "iter.000000", "02.fp"
+ )
+ )
+ )
# check old models are linked
- self.assertTrue(os.path.isdir(os.path.join('iter.000001', '00.train', '000', 'old')))
- self.assertTrue(os.path.isdir(os.path.join('iter.000001', '00.train', '001', 'old')))
- self.assertTrue(os.path.isdir(os.path.join('iter.000001', '00.train', '002', 'old')))
- self.assertTrue(os.path.isdir(os.path.join('iter.000001', '00.train', '003', 'old')))
+ self.assertTrue(
+ os.path.isdir(os.path.join("iter.000001", "00.train", "000", "old"))
+ )
+ self.assertTrue(
+ os.path.isdir(os.path.join("iter.000001", "00.train", "001", "old"))
+ )
+ self.assertTrue(
+ os.path.isdir(os.path.join("iter.000001", "00.train", "002", "old"))
+ )
+ self.assertTrue(
+ os.path.isdir(os.path.join("iter.000001", "00.train", "003", "old"))
+ )
# check models inputs
- _check_model_inputs_v1(self, 1, jdata, reuse = True)
+ _check_model_inputs_v1(self, 1, jdata, reuse=True)
# remove testing dirs
- shutil.rmtree('iter.000001')
- shutil.rmtree('iter.000000')
-
-
- def test_1_data_v1_eletron_temp(self) :
- with open (param_file_v1_et, 'r') as fp :
- jdata = json.load (fp)
- with open (machine_file_v1, 'r') as fp:
- mdata = json.load (fp)
+ shutil.rmtree("iter.000001")
+ shutil.rmtree("iter.000000")
+
+ def test_1_data_v1_eletron_temp(self):
+ with open(param_file_v1_et, "r") as fp:
+ jdata = json.load(fp)
+ with open(machine_file_v1, "r") as fp:
+ mdata = json.load(fp)
make_train(0, jdata, mdata)
# make fake fp results #data == fp_task_min
- _make_fake_fp(0, 0, jdata['fp_task_min'])
+ _make_fake_fp(0, 0, jdata["fp_task_min"])
# make iter1 train
make_train(1, jdata, mdata)
# check data is linked
- self.assertTrue(os.path.isdir(os.path.join('iter.000001', '00.train', 'data.iters', 'iter.000000', '02.fp')))
+ self.assertTrue(
+ os.path.isdir(
+ os.path.join(
+ "iter.000001", "00.train", "data.iters", "iter.000000", "02.fp"
+ )
+ )
+ )
# check models inputs
_check_model_inputs_v1(self, 1, jdata)
# remove testing dirs
- shutil.rmtree('iter.000001')
- shutil.rmtree('iter.000000')
-
- def test_1_data_v1_h5(self) :
+ shutil.rmtree("iter.000001")
+ shutil.rmtree("iter.000000")
+
+ def test_1_data_v1_h5(self):
"""Test HDF5 file as input data."""
- dpdata.LabeledSystem("data/deepmd", fmt='deepmd/npy').to_deepmd_hdf5('data/deepmd.hdf5')
- with open (param_file_v1, 'r') as fp :
- jdata = json.load (fp)
- jdata.pop('use_ele_temp', None)
- jdata['init_data_sys'].append('deepmd.hdf5')
- jdata['init_batch_size'].append('auto')
- with open (machine_file_v1, 'r') as fp:
- mdata = json.load (fp)
+ dpdata.LabeledSystem("data/deepmd", fmt="deepmd/npy").to_deepmd_hdf5(
+ "data/deepmd.hdf5"
+ )
+ with open(param_file_v1, "r") as fp:
+ jdata = json.load(fp)
+ jdata.pop("use_ele_temp", None)
+ jdata["init_data_sys"].append("deepmd.hdf5")
+ jdata["init_batch_size"].append("auto")
+ with open(machine_file_v1, "r") as fp:
+ mdata = json.load(fp)
make_train(0, jdata, mdata)
# make fake fp results #data == fp_task_min
- _make_fake_fp(0, 0, jdata['fp_task_min'])
+ _make_fake_fp(0, 0, jdata["fp_task_min"])
# make iter1 train
make_train(1, jdata, mdata)
# check data is linked
- self.assertTrue(os.path.isdir(os.path.join('iter.000001', '00.train', 'data.iters', 'iter.000000', '02.fp')))
+ self.assertTrue(
+ os.path.isdir(
+ os.path.join(
+ "iter.000001", "00.train", "data.iters", "iter.000000", "02.fp"
+ )
+ )
+ )
# check models inputs
- with open(os.path.join('iter.%06d' % 1,
- '00.train',
- '%03d' % 0,
- "input.json")) as fp:
+ with open(
+ os.path.join("iter.%06d" % 1, "00.train", "%03d" % 0, "input.json")
+ ) as fp:
jdata0 = json.load(fp)
- self.assertEqual(jdata0['training']['systems'], [
- '../data.init/deepmd',
- '../data.init/deepmd.hdf5#',
- '../data.iters/iter.000000/02.fp/data.000',
- ])
+ self.assertEqual(
+ jdata0["training"]["systems"],
+ [
+ "../data.init/deepmd",
+ "../data.init/deepmd.hdf5#",
+ "../data.iters/iter.000000/02.fp/data.000",
+ ],
+ )
# test run_train -- confirm transferred files are correct
with tempfile.TemporaryDirectory() as remote_root:
- run_train(1, jdata, {
- "api_version": "1.0",
- "train_command": (
- "test -d ../data.init/deepmd"
- "&& test -f ../data.init/deepmd.hdf5"
- "&& test -d ../data.iters/iter.000000/02.fp/data.000"
- "&& touch frozen_model.pb lcurve.out model.ckpt.meta model.ckpt.index model.ckpt.data-00000-of-00001 checkpoint"
- "&& echo dp"
- ),
- "train_machine": {
- "batch_type": "shell",
- "local_root": "./",
- "remote_root": remote_root,
- "context_type": "local",
+ run_train(
+ 1,
+ jdata,
+ {
+ "api_version": "1.0",
+ "train_command": (
+ "test -d ../data.init/deepmd"
+ "&& test -f ../data.init/deepmd.hdf5"
+ "&& test -d ../data.iters/iter.000000/02.fp/data.000"
+ "&& touch frozen_model.pb lcurve.out model.ckpt.meta model.ckpt.index model.ckpt.data-00000-of-00001 checkpoint"
+ "&& echo dp"
+ ),
+ "train_machine": {
+ "batch_type": "shell",
+ "local_root": "./",
+ "remote_root": remote_root,
+ "context_type": "local",
+ },
+ "train_resources": {
+ "group_size": 1,
+ },
},
- "train_resources": {
- "group_size": 1,
+ )
+
+ # remove testing dirs
+ shutil.rmtree("iter.000001")
+ shutil.rmtree("iter.000000")
+ os.remove("data/deepmd.hdf5")
+
+ def test_1_data_v1_one_h5(self):
+ """Test `one_h5` option."""
+ dpdata.LabeledSystem("data/deepmd", fmt="deepmd/npy").to_deepmd_hdf5(
+ "data/deepmd.hdf5"
+ )
+ with open(param_file_v1, "r") as fp:
+ jdata = json.load(fp)
+ jdata.pop("use_ele_temp", None)
+ jdata["init_data_sys"].append("deepmd.hdf5")
+ jdata["init_batch_size"].append("auto")
+ jdata["one_h5"] = True
+ with open(machine_file_v1, "r") as fp:
+ mdata = json.load(fp)
+ make_train(0, jdata, mdata)
+ # make fake fp results #data == fp_task_min
+ _make_fake_fp(0, 0, jdata["fp_task_min"])
+ # make iter1 train
+ make_train(1, jdata, mdata)
+ # check data is linked
+ self.assertTrue(
+ os.path.isdir(
+ os.path.join(
+ "iter.000001", "00.train", "data.iters", "iter.000000", "02.fp"
+ )
+ )
+ )
+ # check models inputs
+ with open(
+ os.path.join("iter.%06d" % 1, "00.train", "%03d" % 0, "input.json")
+ ) as fp:
+ jdata0 = json.load(fp)
+ self.assertEqual(
+ jdata0["training"]["systems"],
+ [
+ "../data.hdf5#/data.init/deepmd",
+ "../data.hdf5#/data.init/deepmd.hdf5/",
+ "../data.hdf5#/data.iters/iter.000000/02.fp/data.000",
+ ],
+ )
+ # test run_train -- confirm transferred files are correct
+ with tempfile.TemporaryDirectory() as remote_root:
+ run_train(
+ 1,
+ jdata,
+ {
+ "api_version": "1.0",
+ "train_command": (
+ "test -f ../data.hdf5"
+ "&& touch frozen_model.pb lcurve.out model.ckpt.meta model.ckpt.index model.ckpt.data-00000-of-00001 checkpoint"
+ "&& echo dp"
+ ),
+ "train_machine": {
+ "batch_type": "shell",
+ "local_root": "./",
+ "remote_root": remote_root,
+ "context_type": "local",
+ },
+ "train_resources": {
+ "group_size": 1,
+ },
},
- })
+ )
# remove testing dirs
- shutil.rmtree('iter.000001')
- shutil.rmtree('iter.000000')
- os.remove('data/deepmd.hdf5')
+ shutil.rmtree("iter.000001")
+ shutil.rmtree("iter.000000")
-if __name__ == '__main__':
+if __name__ == "__main__":
unittest.main()
diff --git a/tests/generator/test_nbands_esti.py b/tests/generator/test_nbands_esti.py
index b5edf447b..c5d9bcdb5 100644
--- a/tests/generator/test_nbands_esti.py
+++ b/tests/generator/test_nbands_esti.py
@@ -1,79 +1,88 @@
-import os,sys
+import importlib
+import os
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-import importlib
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
from .context import NBandsEsti
-class TestNBandsEsti(unittest.TestCase):
+
+class TestNBandsEsti(unittest.TestCase):
def test_predict(self):
- self.nbe = NBandsEsti(['out_data_nbands_esti/md.010000K',
- 'out_data_nbands_esti/md.020000K',
- 'out_data_nbands_esti/md.040000K',
- 'out_data_nbands_esti/md.080000K',
- 'out_data_nbands_esti/md.160000K',
- ])
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.010000K'), 72)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.020000K'), 83)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.040000K'), 112)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.080000K'), 195)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.160000K'), 429)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.240000K'), 732)
+ self.nbe = NBandsEsti(
+ [
+ "out_data_nbands_esti/md.010000K",
+ "out_data_nbands_esti/md.020000K",
+ "out_data_nbands_esti/md.040000K",
+ "out_data_nbands_esti/md.080000K",
+ "out_data_nbands_esti/md.160000K",
+ ]
+ )
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.010000K"), 72)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.020000K"), 83)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.040000K"), 112)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.080000K"), 195)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.160000K"), 429)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.240000K"), 732)
def test_save_load(self):
- self.nbe2 = NBandsEsti(['out_data_nbands_esti/md.010000K',
- 'out_data_nbands_esti/md.020000K',
- 'out_data_nbands_esti/md.040000K',
- 'out_data_nbands_esti/md.080000K',
- 'out_data_nbands_esti/md.160000K',
- ])
- self.nbe2.save('tmp.log')
- self.nbe = NBandsEsti('tmp.log')
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.010000K'), 72)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.020000K'), 83)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.040000K'), 112)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.080000K'), 195)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.160000K'), 429)
- self.assertEqual(self.nbe.predict('out_data_nbands_esti/md.240000K'), 732)
- os.remove('tmp.log')
+ self.nbe2 = NBandsEsti(
+ [
+ "out_data_nbands_esti/md.010000K",
+ "out_data_nbands_esti/md.020000K",
+ "out_data_nbands_esti/md.040000K",
+ "out_data_nbands_esti/md.080000K",
+ "out_data_nbands_esti/md.160000K",
+ ]
+ )
+ self.nbe2.save("tmp.log")
+ self.nbe = NBandsEsti("tmp.log")
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.010000K"), 72)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.020000K"), 83)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.040000K"), 112)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.080000K"), 195)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.160000K"), 429)
+ self.assertEqual(self.nbe.predict("out_data_nbands_esti/md.240000K"), 732)
+ os.remove("tmp.log")
def test_get_default_nbands(self):
- res = NBandsEsti._get_res('out_data_nbands_esti/md.020000K/')
+ res = NBandsEsti._get_res("out_data_nbands_esti/md.020000K/")
nb = NBandsEsti._get_default_nbands(res)
self.assertEqual(nb, 66)
def test_get_default_nbands(self):
- res = NBandsEsti._get_res('out_data_nbands_esti/mgal/')
+ res = NBandsEsti._get_res("out_data_nbands_esti/mgal/")
nb = NBandsEsti._get_default_nbands(res)
self.assertEqual(nb, 124)
- def test_potcar_nvalence (self) :
- res = NBandsEsti._get_potcar_nvalence('out_data_nbands_esti/POTCAR.dbl')
- self.assertEqual(res, [10., 3.])
+ def test_potcar_nvalence(self):
+ res = NBandsEsti._get_potcar_nvalence("out_data_nbands_esti/POTCAR.dbl")
+ self.assertEqual(res, [10.0, 3.0])
- def test_incar_ele_temp (self) :
- res = NBandsEsti._get_incar_ele_temp('out_data_nbands_esti/md.000300K/INCAR')
+ def test_incar_ele_temp(self):
+ res = NBandsEsti._get_incar_ele_temp("out_data_nbands_esti/md.000300K/INCAR")
self.assertAlmostEqual(res, 0.025851991011651636)
- def test_incar_nbands (self) :
- res = NBandsEsti._get_incar_nbands('out_data_nbands_esti/md.020000K/INCAR')
+ def test_incar_nbands(self):
+ res = NBandsEsti._get_incar_nbands("out_data_nbands_esti/md.020000K/INCAR")
self.assertEqual(res, 81)
def test_get_res(self):
- res = NBandsEsti._get_res('out_data_nbands_esti/md.020000K/')
+ res = NBandsEsti._get_res("out_data_nbands_esti/md.020000K/")
ref = {
- 'natoms': [32],
- 'vol': 138.55418502346618,
- 'nvalence': [3.],
- 'ele_temp': 20000.0,
- 'nbands': 81
+ "natoms": [32],
+ "vol": 138.55418502346618,
+ "nvalence": [3.0],
+ "ele_temp": 20000.0,
+ "nbands": 81,
}
- self.assertEqual(res['natoms'], ref['natoms'])
- self.assertAlmostEqual(res['vol'], ref['vol'])
- self.assertAlmostEqual(res['nvalence'][0], ref['nvalence'][0])
- self.assertEqual(len(res['nvalence']), len(ref['nvalence']))
- self.assertAlmostEqual(res['ele_temp'], ref['ele_temp'], places = 1)
- self.assertEqual(res['nbands'], ref['nbands'])
+ self.assertEqual(res["natoms"], ref["natoms"])
+ self.assertAlmostEqual(res["vol"], ref["vol"])
+ self.assertAlmostEqual(res["nvalence"][0], ref["nvalence"][0])
+ self.assertEqual(len(res["nvalence"]), len(ref["nvalence"]))
+ self.assertAlmostEqual(res["ele_temp"], ref["ele_temp"], places=1)
+ self.assertEqual(res["nbands"], ref["nbands"])
diff --git a/tests/generator/test_parse_cur_job.py b/tests/generator/test_parse_cur_job.py
index 7941e01c8..e03c920ea 100644
--- a/tests/generator/test_parse_cur_job.py
+++ b/tests/generator/test_parse_cur_job.py
@@ -1,68 +1,67 @@
-import os,sys
-import numpy as np
+import os
+import sys
import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
-from .context import parse_cur_job
-from .context import param_file
-from .context import machine_file
-from .context import setUpModule
+import numpy as np
+
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
+from .context import machine_file, param_file, parse_cur_job, setUpModule
+
class TestParseCurJob(unittest.TestCase):
- def test_npt (self) :
- ens = 'npt'
- ts = [100,200]
- ps = [1e5,1e6,1e7]
+ def test_npt(self):
+ ens = "npt"
+ ts = [100, 200]
+ ps = [1e5, 1e6, 1e7]
ns = 1000
tf = 10
cur_job = {}
- cur_job['ens'] = ens
- cur_job['Ts'] = ts
- cur_job['Ps'] = ps
- cur_job['nsteps'] = ns
- cur_job['t_freq'] = tf
+ cur_job["ens"] = ens
+ cur_job["Ts"] = ts
+ cur_job["Ps"] = ps
+ cur_job["nsteps"] = ns
+ cur_job["t_freq"] = tf
res = parse_cur_job(cur_job)
- for ii,jj in zip(res, [ens, ns, tf, ts, ps, None, None]) :
- self.assertEqual(ii,jj)
+ for ii, jj in zip(res, [ens, ns, tf, ts, ps, None, None]):
+ self.assertEqual(ii, jj)
- def test_nvt (self) :
- ens = 'nvt'
- ts = [100,200]
- ps = [1e5,1e6,1e7]
+ def test_nvt(self):
+ ens = "nvt"
+ ts = [100, 200]
+ ps = [1e5, 1e6, 1e7]
ns = 1000
tf = 10
cur_job = {}
- cur_job['ens'] = ens
- cur_job['Ts'] = ts
- cur_job['Ps'] = ps
- cur_job['nsteps'] = ns
- cur_job['t_freq'] = tf
+ cur_job["ens"] = ens
+ cur_job["Ts"] = ts
+ cur_job["Ps"] = ps
+ cur_job["nsteps"] = ns
+ cur_job["t_freq"] = tf
res = parse_cur_job(cur_job)
- for ii,jj in zip(res, [ens, ns, tf, ts, [-1], None, None]) :
- self.assertEqual(ii,jj)
+ for ii, jj in zip(res, [ens, ns, tf, ts, [-1], None, None]):
+ self.assertEqual(ii, jj)
- def test_pka (self) :
- ens = 'nvt'
- ts = [100,200]
- ps = [1e5,1e6,1e7]
+ def test_pka(self):
+ ens = "nvt"
+ ts = [100, 200]
+ ps = [1e5, 1e6, 1e7]
ns = 1000
tf = 10
pka = [10, 20, 30]
dt = 0.001
cur_job = {}
- cur_job['ens'] = ens
- cur_job['Ts'] = ts
- cur_job['Ps'] = ps
- cur_job['nsteps'] = ns
- cur_job['t_freq'] = tf
- cur_job['pka_e'] = pka
- cur_job['dt'] = dt
+ cur_job["ens"] = ens
+ cur_job["Ts"] = ts
+ cur_job["Ps"] = ps
+ cur_job["nsteps"] = ns
+ cur_job["t_freq"] = tf
+ cur_job["pka_e"] = pka
+ cur_job["dt"] = dt
res = parse_cur_job(cur_job)
- for ii,jj in zip(res, [ens, ns, tf, ts, [-1], pka, dt]) :
- self.assertEqual(ii,jj)
+ for ii, jj in zip(res, [ens, ns, tf, ts, [-1], pka, dt]):
+ self.assertEqual(ii, jj)
-if __name__ == '__main__':
+if __name__ == "__main__":
unittest.main()
-
diff --git a/tests/generator/test_post_fp.py b/tests/generator/test_post_fp.py
index ffa65652b..132819964 100644
--- a/tests/generator/test_post_fp.py
+++ b/tests/generator/test_post_fp.py
@@ -1,81 +1,93 @@
-import os,sys,json,glob,shutil
+import glob
+import json
+import os
+import shutil
+import sys
+import unittest
+
import dpdata
import numpy as np
-import unittest
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
-__package__ = 'generator'
-from .context import post_fp
-from .context import post_fp_pwscf
-from .context import post_fp_abacus_scf
-from .context import post_fp_siesta
-from .context import post_fp_vasp
-from .context import post_fp_gaussian
-from .context import post_fp_cp2k
-from .context import param_file
-from .context import param_old_file
-from .context import param_pwscf_file
-from .context import param_pwscf_old_file
-from .context import param_abacus_post_file
-from .context import param_siesta_file
-from .context import param_gaussian_file
-from .context import param_cp2k_file
-from .context import param_amber_file
-from .context import machine_file
-from .context import setUpModule
-from .comp_sys import test_atom_names
-from .comp_sys import test_atom_types
-from .comp_sys import test_coord
-from .comp_sys import test_cell
-from .comp_sys import CompLabeledSys
-from .context import param_pwmat_file
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
+__package__ = "generator"
+from .comp_sys import (
+ CompLabeledSys,
+ test_atom_names,
+ test_atom_types,
+ test_cell,
+ test_coord,
+)
+from .context import (
+ machine_file,
+ param_abacus_post_file,
+ param_amber_file,
+ param_cp2k_file,
+ param_file,
+ param_gaussian_file,
+ param_old_file,
+ param_pwmat_file,
+ param_pwscf_file,
+ param_pwscf_old_file,
+ param_siesta_file,
+ post_fp,
+ post_fp_abacus_scf,
+ post_fp_cp2k,
+ post_fp_gaussian,
+ post_fp_pwscf,
+ post_fp_siesta,
+ post_fp_vasp,
+ setUpModule,
+)
class TestPostFPVasp(unittest.TestCase):
def setUp(self):
- assert os.path.isdir('out_data_post_fp_vasp'), 'out data for post fp vasp should exist'
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- shutil.copytree('out_data_post_fp_vasp', 'iter.000000')
- self.ref_coord = [[[0, 0, 0], [2.3, 2.3, 2.3]],
- [[0, 0, 0], [2.2, 2.3, 2.4]]]
+ assert os.path.isdir(
+ "out_data_post_fp_vasp"
+ ), "out data for post fp vasp should exist"
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ shutil.copytree("out_data_post_fp_vasp", "iter.000000")
+ self.ref_coord = [[[0, 0, 0], [2.3, 2.3, 2.3]], [[0, 0, 0], [2.2, 2.3, 2.4]]]
self.ref_cell = [4.6 * np.eye(3), 4.6 * np.eye(3)]
# type_map = ["Mg", "Al"], Al OUTCAR provided
self.ref_at = [1, 1]
self.ref_e = [-1.90811235, -1.89718546]
- self.ref_f = [[[ 0. , 0. , 0. ], \
- [-0. , -0. , -0. ]],\
- [[-0.110216, 0. , 0.110216], \
- [ 0.110216, -0. , -0.110216]]]
- self.ref_v = [[[ 1.50816698, 0. , -0. ], \
- [ 0. , 1.50816698, 0. ], \
- [-0. , 0. , 1.50816795]],\
- [[ 1.45208913, 0. , 0.03036584], \
- [ 0. , 1.67640928, 0. ], \
- [ 0.03036584, 0. , 1.45208913]]]
+ self.ref_f = [
+ [[0.0, 0.0, 0.0], [-0.0, -0.0, -0.0]],
+ [[-0.110216, 0.0, 0.110216], [0.110216, -0.0, -0.110216]],
+ ]
+ self.ref_v = [
+ [[1.50816698, 0.0, -0.0], [0.0, 1.50816698, 0.0], [-0.0, 0.0, 1.50816795]],
+ [
+ [1.45208913, 0.0, 0.03036584],
+ [0.0, 1.67640928, 0.0],
+ [0.03036584, 0.0, 1.45208913],
+ ],
+ ]
self.ref_coord = np.array(self.ref_coord)
self.ref_cell = np.array(self.ref_cell)
- self.ref_at = np.array(self.ref_at, dtype = int)
+ self.ref_at = np.array(self.ref_at, dtype=int)
self.ref_e = np.array(self.ref_e)
self.ref_f = np.array(self.ref_f)
self.ref_v = np.array(self.ref_v)
def tearDown(self):
- shutil.rmtree('iter.000000')
+ shutil.rmtree("iter.000000")
def test_post_fp_vasp_0(self):
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- jdata['use_ele_temp'] = 2
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ jdata["use_ele_temp"] = 2
post_fp_vasp(0, jdata, rfailed=0.3)
- sys = dpdata.LabeledSystem('iter.000000/02.fp/data.000/', fmt = 'deepmd/raw')
+ sys = dpdata.LabeledSystem("iter.000000/02.fp/data.000/", fmt="deepmd/raw")
self.assertEqual(sys.get_nframes(), 2)
- if sys.data['coords'][0][1][0] < sys.data['coords'][1][1][0]:
+ if sys.data["coords"][0][1][0] < sys.data["coords"][1][1][0]:
idx = [1, 0]
- else :
+ else:
idx = [0, 1]
ref_coord = self.ref_coord[idx]
ref_cell = self.ref_cell[idx]
@@ -84,41 +96,44 @@ def test_post_fp_vasp_0(self):
ref_v = self.ref_v[idx]
ref_at = self.ref_at
- for ff in range(2) :
- self.assertAlmostEqual(ref_e[ff], sys.data['energies'][ff])
- for ii in range(2) :
- self.assertEqual(ref_at[ff], sys.data['atom_types'][ff])
- for ff in range(2) :
- for ii in range(2) :
- for dd in range(3) :
- self.assertAlmostEqual(ref_coord[ff][ii][dd],
- sys.data['coords'][ff][ii][dd])
- self.assertAlmostEqual(ref_f[ff][ii][dd],
- sys.data['forces'][ff][ii][dd])
for ff in range(2):
- for ii in range(3) :
- for jj in range(3) :
- self.assertAlmostEqual(ref_v[ff][ii][jj],
- sys.data['virials'][ff][ii][jj], places = 5)
- self.assertAlmostEqual(ref_cell[ff][ii][jj],
- sys.data['cells'][ff][ii][jj])
-
- self.assertTrue(os.path.isfile('iter.000000/02.fp/data.000/set.000/aparam.npy'))
- aparam = np.load('iter.000000/02.fp/data.000/set.000/aparam.npy')
+ self.assertAlmostEqual(ref_e[ff], sys.data["energies"][ff])
+ for ii in range(2):
+ self.assertEqual(ref_at[ff], sys.data["atom_types"][ff])
+ for ff in range(2):
+ for ii in range(2):
+ for dd in range(3):
+ self.assertAlmostEqual(
+ ref_coord[ff][ii][dd], sys.data["coords"][ff][ii][dd]
+ )
+ self.assertAlmostEqual(
+ ref_f[ff][ii][dd], sys.data["forces"][ff][ii][dd]
+ )
+ for ff in range(2):
+ for ii in range(3):
+ for jj in range(3):
+ self.assertAlmostEqual(
+ ref_v[ff][ii][jj], sys.data["virials"][ff][ii][jj], places=5
+ )
+ self.assertAlmostEqual(
+ ref_cell[ff][ii][jj], sys.data["cells"][ff][ii][jj]
+ )
+
+ self.assertTrue(os.path.isfile("iter.000000/02.fp/data.000/set.000/aparam.npy"))
+ aparam = np.load("iter.000000/02.fp/data.000/set.000/aparam.npy")
natoms = sys.get_natoms()
self.assertEqual(natoms, 2)
- self.assertEqual(list(list(aparam)[0]), [0,0])
- self.assertEqual(list(list(aparam)[1]), [1,1])
-
+ self.assertEqual(list(list(aparam)[0]), [0, 0])
+ self.assertEqual(list(list(aparam)[1]), [1, 1])
def test_post_fp_vasp_1(self):
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- jdata['use_ele_temp'] = 1
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ jdata["use_ele_temp"] = 1
post_fp_vasp(0, jdata, rfailed=0.3)
- sys = dpdata.LabeledSystem('iter.000000/02.fp/data.001/', fmt = 'deepmd/raw')
+ sys = dpdata.LabeledSystem("iter.000000/02.fp/data.001/", fmt="deepmd/raw")
self.assertEqual(sys.get_nframes(), 1)
# if sys.data['coords'][0][1][0] < sys.data['coords'][1][1][0]:
@@ -132,34 +147,37 @@ def test_post_fp_vasp_1(self):
ref_v = self.ref_v[idx]
ref_at = self.ref_at
- for ff in range(1) :
- self.assertAlmostEqual(ref_e[ff], sys.data['energies'][ff])
- for ii in range(2) :
- self.assertEqual(ref_at[ff], sys.data['atom_types'][ff])
- for ff in range(1) :
- for ii in range(2) :
- for dd in range(3) :
- self.assertAlmostEqual(ref_coord[ff][ii][dd],
- sys.data['coords'][ff][ii][dd])
- self.assertAlmostEqual(ref_f[ff][ii][dd],
- sys.data['forces'][ff][ii][dd])
for ff in range(1):
- for ii in range(3) :
- for jj in range(3) :
- self.assertAlmostEqual(ref_v[ff][ii][jj],
- sys.data['virials'][ff][ii][jj], places = 5)
- self.assertAlmostEqual(ref_cell[ff][ii][jj],
- sys.data['cells'][ff][ii][jj])
-
- fparam = np.load('iter.000000/02.fp/data.001/set.000/fparam.npy')
+ self.assertAlmostEqual(ref_e[ff], sys.data["energies"][ff])
+ for ii in range(2):
+ self.assertEqual(ref_at[ff], sys.data["atom_types"][ff])
+ for ff in range(1):
+ for ii in range(2):
+ for dd in range(3):
+ self.assertAlmostEqual(
+ ref_coord[ff][ii][dd], sys.data["coords"][ff][ii][dd]
+ )
+ self.assertAlmostEqual(
+ ref_f[ff][ii][dd], sys.data["forces"][ff][ii][dd]
+ )
+ for ff in range(1):
+ for ii in range(3):
+ for jj in range(3):
+ self.assertAlmostEqual(
+ ref_v[ff][ii][jj], sys.data["virials"][ff][ii][jj], places=5
+ )
+ self.assertAlmostEqual(
+ ref_cell[ff][ii][jj], sys.data["cells"][ff][ii][jj]
+ )
+
+ fparam = np.load("iter.000000/02.fp/data.001/set.000/fparam.npy")
self.assertEqual(fparam.shape[0], 1)
self.assertEqual(list(fparam), [100000])
-
def test_post_fp_vasp_2(self):
- with open (param_file, 'r') as fp :
- jdata = json.load (fp)
- jdata['use_ele_temp'] = 1
+ with open(param_file, "r") as fp:
+ jdata = json.load(fp)
+ jdata["use_ele_temp"] = 1
with self.assertRaises(RuntimeError):
post_fp_vasp(0, jdata)
@@ -170,15 +188,20 @@ def setUp(self):
self.e_places = 5
self.f_places = 5
self.v_places = 2
- assert os.path.isdir('out_data_post_fp_pwscf'), 'out data for post fp pwscf should exist'
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- shutil.copytree('out_data_post_fp_pwscf', 'iter.000000')
- with open (param_pwscf_file, 'r') as fp :
- jdata = json.load (fp)
+ assert os.path.isdir(
+ "out_data_post_fp_pwscf"
+ ), "out data for post fp pwscf should exist"
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ shutil.copytree("out_data_post_fp_pwscf", "iter.000000")
+ with open(param_pwscf_file, "r") as fp:
+ jdata = json.load(fp)
post_fp(0, jdata)
- self.system_1 = dpdata.LabeledSystem('iter.000000/orig', fmt = 'deepmd/raw')
- self.system_2 = dpdata.LabeledSystem('iter.000000/02.fp/data.000', fmt = 'deepmd/raw')
+ self.system_1 = dpdata.LabeledSystem("iter.000000/orig", fmt="deepmd/raw")
+ self.system_2 = dpdata.LabeledSystem(
+ "iter.000000/02.fp/data.000", fmt="deepmd/raw"
+ )
+
class TestPostFPABACUS(unittest.TestCase, CompLabeledSys):
def setUp(self):
@@ -186,15 +209,23 @@ def setUp(self):
self.e_places = 5
self.f_places = 5
self.v_places = 2
- assert os.path.isdir('out_data_post_fp_abacus'), 'out data for post fp pwscf should exist'
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- shutil.copytree('out_data_post_fp_abacus', 'iter.000000')
- with open (param_abacus_post_file, 'r') as fp :
- jdata = json.load (fp)
+ assert os.path.isdir(
+ "out_data_post_fp_abacus"
+ ), "out data for post fp pwscf should exist"
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ shutil.copytree("out_data_post_fp_abacus", "iter.000000")
+ with open(param_abacus_post_file, "r") as fp:
+ jdata = json.load(fp)
post_fp(0, jdata)
- self.system_1 = dpdata.LabeledSystem('iter.000000/orig', fmt = 'deepmd/raw')
- self.system_2 = dpdata.LabeledSystem('iter.000000/02.fp/data.000', fmt = 'deepmd/raw')
+ self.system_1 = dpdata.LabeledSystem("iter.000000/orig", fmt="deepmd/raw")
+ self.system_2 = dpdata.LabeledSystem(
+ "iter.000000/02.fp/data.000", fmt="deepmd/raw"
+ )
+
+ def test_nframs_with_failed_job(self):
+ self.assertEqual(self.system_2.get_nframes(), 2)
+
class TestPostFPSIESTA(unittest.TestCase, CompLabeledSys):
def setUp(self):
@@ -202,15 +233,20 @@ def setUp(self):
self.e_places = 5
self.f_places = 5
self.v_places = 5
- assert os.path.isdir('out_data_post_fp_siesta'), 'out data for post fp siesta should exist'
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- shutil.copytree('out_data_post_fp_siesta', 'iter.000000')
- with open (param_siesta_file, 'r') as fp :
- jdata = json.load (fp)
+ assert os.path.isdir(
+ "out_data_post_fp_siesta"
+ ), "out data for post fp siesta should exist"
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ shutil.copytree("out_data_post_fp_siesta", "iter.000000")
+ with open(param_siesta_file, "r") as fp:
+ jdata = json.load(fp)
post_fp(0, jdata)
- self.system_1 = dpdata.LabeledSystem('iter.000000/orig', fmt = 'deepmd/raw')
- self.system_2 = dpdata.LabeledSystem('iter.000000/02.fp/data.000', fmt = 'deepmd/raw')
+ self.system_1 = dpdata.LabeledSystem("iter.000000/orig", fmt="deepmd/raw")
+ self.system_2 = dpdata.LabeledSystem(
+ "iter.000000/02.fp/data.000", fmt="deepmd/raw"
+ )
+
class TestPostGaussian(unittest.TestCase, CompLabeledSys):
def setUp(self):
@@ -218,15 +254,20 @@ def setUp(self):
self.e_places = 5
self.f_places = 5
self.v_places = 5
- assert os.path.isdir('out_data_post_fp_gaussian'), 'out data for post fp gaussian should exist'
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- shutil.copytree('out_data_post_fp_gaussian', 'iter.000000')
- with open (param_gaussian_file, 'r') as fp :
- jdata = json.load (fp)
+ assert os.path.isdir(
+ "out_data_post_fp_gaussian"
+ ), "out data for post fp gaussian should exist"
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ shutil.copytree("out_data_post_fp_gaussian", "iter.000000")
+ with open(param_gaussian_file, "r") as fp:
+ jdata = json.load(fp)
post_fp(0, jdata)
- self.system_1 = dpdata.LabeledSystem('iter.000000/orig', fmt = 'deepmd/raw')
- self.system_2 = dpdata.LabeledSystem('iter.000000/02.fp/data.000', fmt = 'deepmd/raw')
+ self.system_1 = dpdata.LabeledSystem("iter.000000/orig", fmt="deepmd/raw")
+ self.system_2 = dpdata.LabeledSystem(
+ "iter.000000/02.fp/data.000", fmt="deepmd/raw"
+ )
+
class TestPostCP2K(unittest.TestCase, CompLabeledSys):
def setUp(self):
@@ -234,15 +275,19 @@ def setUp(self):
self.e_places = 5
self.f_places = 5
self.v_places = 5
- assert os.path.isdir('out_data_post_fp_cp2k'), 'out data for post fp gaussian should exist'
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- shutil.copytree('out_data_post_fp_cp2k', 'iter.000000')
- with open (param_cp2k_file, 'r') as fp :
- jdata = json.load (fp)
+ assert os.path.isdir(
+ "out_data_post_fp_cp2k"
+ ), "out data for post fp gaussian should exist"
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ shutil.copytree("out_data_post_fp_cp2k", "iter.000000")
+ with open(param_cp2k_file, "r") as fp:
+ jdata = json.load(fp)
post_fp(0, jdata)
- self.system_1 = dpdata.LabeledSystem('iter.000000/orig', fmt = 'deepmd/raw')
- self.system_2 = dpdata.LabeledSystem('iter.000000/02.fp/data.000', fmt = 'deepmd/raw')
+ self.system_1 = dpdata.LabeledSystem("iter.000000/orig", fmt="deepmd/raw")
+ self.system_2 = dpdata.LabeledSystem(
+ "iter.000000/02.fp/data.000", fmt="deepmd/raw"
+ )
class TestPostFPPWmat(unittest.TestCase, CompLabeledSys):
@@ -251,15 +296,19 @@ def setUp(self):
self.e_places = 5
self.f_places = 5
self.v_places = 2
- assert os.path.isdir('out_data_post_fp_pwmat'), 'out data for post fp pwmat should exist'
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- shutil.copytree('out_data_post_fp_pwmat', 'iter.000000')
- with open (param_pwmat_file, 'r') as fp :
- jdata = json.load (fp)
+ assert os.path.isdir(
+ "out_data_post_fp_pwmat"
+ ), "out data for post fp pwmat should exist"
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ shutil.copytree("out_data_post_fp_pwmat", "iter.000000")
+ with open(param_pwmat_file, "r") as fp:
+ jdata = json.load(fp)
post_fp(0, jdata)
- self.system_1 = dpdata.LabeledSystem('iter.000000/orig', fmt = 'deepmd/raw')
- self.system_2 = dpdata.LabeledSystem('iter.000000/02.fp/data.000', fmt = 'deepmd/raw')
+ self.system_1 = dpdata.LabeledSystem("iter.000000/orig", fmt="deepmd/raw")
+ self.system_2 = dpdata.LabeledSystem(
+ "iter.000000/02.fp/data.000", fmt="deepmd/raw"
+ )
class TestPostAmberDiff(unittest.TestCase, CompLabeledSys):
@@ -269,17 +318,25 @@ def setUp(self):
self.f_places = 5
self.v_places = 5
- if os.path.isdir('iter.000000') :
- shutil.rmtree('iter.000000')
- ms = dpdata.MultiSystems(dpdata.LabeledSystem(os.path.join('data', 'deepmd'), fmt="deepmd/raw"))
- ms.to_deepmd_npy(os.path.join('iter.000000', '02.fp', 'task.000.000000', 'dataset'))
+ if os.path.isdir("iter.000000"):
+ shutil.rmtree("iter.000000")
+ ms = dpdata.MultiSystems(
+ dpdata.LabeledSystem(os.path.join("data", "deepmd"), fmt="deepmd/raw")
+ )
+ ms.to_deepmd_npy(
+ os.path.join("iter.000000", "02.fp", "task.000.000000", "dataset")
+ )
self.system_1 = list(ms.systems.values())[0]
- with open (param_amber_file, 'r') as fp :
- jdata = json.load (fp)
- jdata['type_map'] = self.system_1.get_atom_names()
+ with open(param_amber_file, "r") as fp:
+ jdata = json.load(fp)
+ jdata["type_map"] = self.system_1.get_atom_names()
post_fp(0, jdata)
- self.system_2 = list(dpdata.MultiSystems(type_map = jdata['type_map']).from_deepmd_raw('iter.000000/02.fp/data.000').systems.values())[0]
+ self.system_2 = list(
+ dpdata.MultiSystems(type_map=jdata["type_map"])
+ .from_deepmd_raw("iter.000000/02.fp/data.000")
+ .systems.values()
+ )[0]
-if __name__ == '__main__':
+if __name__ == "__main__":
unittest.main()
diff --git a/tests/simplify/context.py b/tests/simplify/context.py
index 3e7d3fc0b..88f06f91b 100644
--- a/tests/simplify/context.py
+++ b/tests/simplify/context.py
@@ -1,6 +1,6 @@
-import sys
import os
+import sys
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
-import dpgen.simplify.simplify
\ No newline at end of file
+import dpgen.simplify.simplify
diff --git a/tests/simplify/test_get_multi_system.py b/tests/simplify/test_get_multi_system.py
index 31cadb963..641e0e80c 100644
--- a/tests/simplify/test_get_multi_system.py
+++ b/tests/simplify/test_get_multi_system.py
@@ -1,26 +1,27 @@
-import unittest
import os
import shutil
+import unittest
-import numpy as np
import dpdata
-
+import numpy as np
from context import dpgen
class TestGetMultiSystem(unittest.TestCase):
def setUp(self) -> None:
- system = dpdata.System(data={
- "atom_names": ["H"],
- "atom_numbs": [1],
- "atom_types": np.zeros((1,), dtype=int),
- "coords": np.zeros((1, 1, 3), dtype=np.float32),
- "cells": np.zeros((1, 3, 3), dtype=np.float32),
- "orig": np.zeros(3, dtype=np.float32),
- "nopbc": True,
- "energies": np.zeros((1,), dtype=np.float32),
- "forces": np.zeros((1, 1, 3), dtype=np.float32),
- })
+ system = dpdata.System(
+ data={
+ "atom_names": ["H"],
+ "atom_numbs": [1],
+ "atom_types": np.zeros((1,), dtype=int),
+ "coords": np.zeros((1, 1, 3), dtype=np.float32),
+ "cells": np.zeros((1, 3, 3), dtype=np.float32),
+ "orig": np.zeros(3, dtype=np.float32),
+ "nopbc": True,
+ "energies": np.zeros((1,), dtype=np.float32),
+ "forces": np.zeros((1, 1, 3), dtype=np.float32),
+ }
+ )
system.to_deepmd_npy("data0")
system.to_deepmd_npy("data1")
system.to_deepmd_hdf5("data2.hdf5")
@@ -47,5 +48,7 @@ def test_get_multi_system(self):
)
assert isinstance(ms, dpdata.MultiSystems)
for ss in ms.systems.values():
- assert isinstance(ss, dpdata.LabeledSystem if labeled else dpdata.System)
+ assert isinstance(
+ ss, dpdata.LabeledSystem if labeled else dpdata.System
+ )
assert ms.get_nframes() == len(self.data) if list_data else 1
diff --git a/tests/test_check_examples.py b/tests/test_check_examples.py
index a8029c644..976980b15 100644
--- a/tests/test_check_examples.py
+++ b/tests/test_check_examples.py
@@ -1,24 +1,18 @@
"""This module ensures input in the examples directory
could pass the argument checking.
"""
-import unittest
import json
+import unittest
from pathlib import Path
-from dpgen.util import normalize
from dpgen.data.arginfo import (
init_bulk_jdata_arginfo,
- init_surf_jdata_arginfo,
init_reaction_jdata_arginfo,
+ init_surf_jdata_arginfo,
)
-from dpgen.simplify.arginfo import (
- simplify_jdata_arginfo,
- simplify_mdata_arginfo,
-)
-from dpgen.generator.arginfo import (
- run_jdata_arginfo,
- run_mdata_arginfo,
-)
+from dpgen.generator.arginfo import run_jdata_arginfo, run_mdata_arginfo
+from dpgen.simplify.arginfo import simplify_jdata_arginfo, simplify_mdata_arginfo
+from dpgen.util import normalize
init_bulk_jdata = init_bulk_jdata_arginfo()
init_surf_jdata = init_surf_jdata_arginfo()
@@ -40,51 +34,145 @@
# (init_surf_jdata, p_examples / "init" / "cu.surf.hcp.111.json"),
(init_reaction_jdata, p_examples / "init" / "reaction.json"),
(simplify_jdata, p_examples / "simplify" / "qm7.json"),
- (simplify_jdata, p_examples / "simplify-MAPbI3-scan-lebesgue" / "simplify_example" / "simplify.json"),
- (run_jdata, p_examples / "run" / "dp2.x-lammps-vasp" / "param_CH4_deepmd-kit-2.0.1.json"),
- (run_jdata, p_examples / "run" / "dp2.x-lammps-cp2k" / "param_CH4_deepmd-kit-2.0.1.json"),
- #(run_jdata, p_examples / "run" / "dp2.x-gromacs-gaussian" / "param.json"),
- (run_jdata, p_examples / "run" / "dp1.x-lammps-vasp" / "CH4" / "param_CH4_deepmd-kit-1.1.0.json"),
- (run_jdata, p_examples / "run" / "dp1.x-lammps-vasp" / "Al" / "param_al_all_gpu-deepmd-kit-1.1.0.json"),
+ (
+ simplify_jdata,
+ p_examples
+ / "simplify-MAPbI3-scan-lebesgue"
+ / "simplify_example"
+ / "simplify.json",
+ ),
+ (
+ run_jdata,
+ p_examples / "run" / "dp2.x-lammps-vasp" / "param_CH4_deepmd-kit-2.0.1.json",
+ ),
+ (
+ run_jdata,
+ p_examples / "run" / "dp2.x-lammps-cp2k" / "param_CH4_deepmd-kit-2.0.1.json",
+ ),
+ # (run_jdata, p_examples / "run" / "dp2.x-gromacs-gaussian" / "param.json"),
+ (
+ run_jdata,
+ p_examples
+ / "run"
+ / "dp1.x-lammps-vasp"
+ / "CH4"
+ / "param_CH4_deepmd-kit-1.1.0.json",
+ ),
+ (
+ run_jdata,
+ p_examples
+ / "run"
+ / "dp1.x-lammps-vasp"
+ / "Al"
+ / "param_al_all_gpu-deepmd-kit-1.1.0.json",
+ ),
(run_jdata, p_examples / "run" / "dp1.x-lammps-vasp-et" / "param_elet.json"),
- (run_jdata, p_examples / "run" / "dp2.x-lammps-ABACUS-lcao" / "fcc-al" / "run_param.json"),
- (run_jdata, p_examples / "run" / "dp2.x-lammps-ABACUS-pw" / "fcc-al" / "run_param.json"),
- (run_jdata, p_examples / "run" / "dp1.x-lammps-cp2k" / "methane" / "param-ch4.json"),
- (run_jdata, p_examples / "run" / "dp1.x-lammps-ABACUS-pw" / "methane" / "param.json"),
- (run_jdata, p_examples / "run" / "dp1.x-lammps-ABACUS-lcao-dpks" / "methane" / "param.json"),
- (run_jdata, p_examples / "run" / "dp1.x_lammps_gaussian" / "dodecane" / "dodecane.json"),
+ (
+ run_jdata,
+ p_examples / "run" / "dp2.x-lammps-ABACUS-lcao" / "fcc-al" / "run_param.json",
+ ),
+ (
+ run_jdata,
+ p_examples / "run" / "dp2.x-lammps-ABACUS-pw" / "fcc-al" / "run_param.json",
+ ),
+ (
+ run_jdata,
+ p_examples / "run" / "dp1.x-lammps-cp2k" / "methane" / "param-ch4.json",
+ ),
+ (
+ run_jdata,
+ p_examples / "run" / "dp1.x-lammps-ABACUS-pw" / "methane" / "param.json",
+ ),
+ (
+ run_jdata,
+ p_examples / "run" / "dp1.x-lammps-ABACUS-lcao-dpks" / "methane" / "param.json",
+ ),
+ (
+ run_jdata,
+ p_examples / "run" / "dp1.x_lammps_gaussian" / "dodecane" / "dodecane.json",
+ ),
(run_jdata, p_examples / "run" / "dp-lammps-enhance_sampling" / "param.json"),
- #(run_jdata, p_examples / "run" / "deprecated" / "param-mg-vasp.json"),
- #(run_jdata, p_examples / "run" / "deprecated" / "param-mg-vasp-ucloud.json"),
- #(run_jdata, p_examples / "run" / "deprecated" / "param-pyridine-pwscf.json"),
- #(run_jdata, p_examples / "run" / "deprecated" / "param-h2oscan-vasp.json"),
- (run_jdata, p_examples / "run" / "deprecated" / "dp0.12-lammps-cp2k" / "CH4" / "param_CH4.json"),
- #(run_jdata, p_examples / "run" / "deprecated" / "dp0.12-lammps-pwmat" / "param_CH4.json"),
- (run_jdata, p_examples / "run" / "deprecated" / "dp0.12-lammps-siesta" / "dp-lammps-siesta" / "CH4" / "param_CH4.json"),
- (run_jdata, p_examples / "run" / "deprecated" / "dp0.12-lammps-vasp" / "Al" / "param_al_all_gpu.json"),
- (run_jdata, p_examples / "run" / "deprecated" / "dp0.12-lammps-vasp" / "CH4" / "param_CH4.json"),
- (run_jdata, p_examples / "run" / "dp2.x-lammps-gaussian" / "param_C4H16N4_deepmd-kit-2.0.1.json"),
+ # (run_jdata, p_examples / "run" / "deprecated" / "param-mg-vasp.json"),
+ # (run_jdata, p_examples / "run" / "deprecated" / "param-mg-vasp-ucloud.json"),
+ # (run_jdata, p_examples / "run" / "deprecated" / "param-pyridine-pwscf.json"),
+ # (run_jdata, p_examples / "run" / "deprecated" / "param-h2oscan-vasp.json"),
+ (
+ run_jdata,
+ p_examples
+ / "run"
+ / "deprecated"
+ / "dp0.12-lammps-cp2k"
+ / "CH4"
+ / "param_CH4.json",
+ ),
+ # (run_jdata, p_examples / "run" / "deprecated" / "dp0.12-lammps-pwmat" / "param_CH4.json"),
+ (
+ run_jdata,
+ p_examples
+ / "run"
+ / "deprecated"
+ / "dp0.12-lammps-siesta"
+ / "dp-lammps-siesta"
+ / "CH4"
+ / "param_CH4.json",
+ ),
+ (
+ run_jdata,
+ p_examples
+ / "run"
+ / "deprecated"
+ / "dp0.12-lammps-vasp"
+ / "Al"
+ / "param_al_all_gpu.json",
+ ),
+ (
+ run_jdata,
+ p_examples
+ / "run"
+ / "deprecated"
+ / "dp0.12-lammps-vasp"
+ / "CH4"
+ / "param_CH4.json",
+ ),
+ (
+ run_jdata,
+ p_examples
+ / "run"
+ / "dp2.x-lammps-gaussian"
+ / "param_C4H16N4_deepmd-kit-2.0.1.json",
+ ),
(run_jdata, p_examples / "run" / "dprc" / "generator.json"),
# machines
- #(run_mdata, p_examples / "machine" / "DeePMD-kit-2.x" / "lebesgue_v2_machine.json"),
- #(run_mdata, p_examples / "machine" / "DeePMD-kit-1.x" / "machine-ali.json"),
+ (run_mdata, p_examples / "machine" / "DeePMD-kit-2.x" / "lebesgue_v2_machine.json"),
(run_mdata, p_examples / "machine" / "DeePMD-kit-1.x" / "machine-local.json"),
- (run_mdata, p_examples / "machine" / "DeePMD-kit-1.x" / "machine-lsf-slurm-cp2k.json"),
- (run_mdata, p_examples / "machine" / "DeePMD-kit-1.x" / "machine-pbs-gaussian.json"),
+ (
+ run_mdata,
+ p_examples / "machine" / "DeePMD-kit-1.x" / "machine-lsf-slurm-cp2k.json",
+ ),
+ (
+ run_mdata,
+ p_examples / "machine" / "DeePMD-kit-1.x" / "machine-pbs-gaussian.json",
+ ),
(run_mdata, p_examples / "machine" / "DeePMD-kit-1.x" / "machine-slurm-qe.json"),
(run_mdata, p_examples / "machine" / "DeePMD-kit-1.0" / "machine-local-4GPU.json"),
- #(run_mdata, p_examples / "machine" / "deprecated" / "machine-hnu.json"),
- #(run_mdata, p_examples / "machine" / "deprecated" / "machine-tiger-pwscf-della.json"),
- #(run_mdata, p_examples / "machine" / "deprecated" / "machine-tiger-vasp-della.json"),
- #(run_mdata, p_examples / "machine" / "deprecated" / "machine-tiger.json"),
- #(run_mdata, p_examples / "machine" / "deprecated" / "machine-ucloud.json"),
(run_mdata, p_examples / "CH4-refact-dpdispatcher" / "machine-ali-ehpc.json"),
(run_mdata, p_examples / "CH4-refact-dpdispatcher" / "machine-dpcloudserver.json"),
- (run_mdata, p_examples / "run" / "dp2.x-lammps-ABACUS-lcao" / "fcc-al" / "machine.json"),
- (run_mdata, p_examples / "run" / "dp2.x-lammps-ABACUS-pw" / "fcc-al" / "machine.json"),
+ (
+ run_mdata,
+ p_examples / "run" / "dp2.x-lammps-ABACUS-lcao" / "fcc-al" / "machine.json",
+ ),
+ (
+ run_mdata,
+ p_examples / "run" / "dp2.x-lammps-ABACUS-pw" / "fcc-al" / "machine.json",
+ ),
(run_mdata, p_examples / "run" / "dp2.x-lammps-gaussian" / "machine.json"),
- #(run_mdata, p_examples / "run" / "dp2.x-gromacs-gaussian" / "machine.json"),
- (simplify_mdata, p_examples / "simplify-MAPbI3-scan-lebesgue" / "simplify_example" / "machine.json"),
+ (
+ simplify_mdata,
+ p_examples
+ / "simplify-MAPbI3-scan-lebesgue"
+ / "simplify_example"
+ / "machine.json",
+ ),
)
diff --git a/tests/test_cli.py b/tests/test_cli.py
index 0174c838c..cd2a4a7a3 100644
--- a/tests/test_cli.py
+++ b/tests/test_cli.py
@@ -1,10 +1,17 @@
+import subprocess as sp
import sys
import unittest
-import subprocess as sp
class TestCLI(unittest.TestCase):
def test_cli(self):
sp.check_output(["dpgen", "-h"])
- for subcommand in ('run', 'simplify', 'init_surf', 'init_bulk', 'init_reaction', 'autotest'):
+ for subcommand in (
+ "run",
+ "simplify",
+ "init_surf",
+ "init_bulk",
+ "init_reaction",
+ "autotest",
+ ):
sp.check_output(["dpgen", subcommand, "-h"])
diff --git a/tests/tools/context.py b/tests/tools/context.py
index 1d3510786..3f1ab8fbb 100644
--- a/tests/tools/context.py
+++ b/tests/tools/context.py
@@ -1,12 +1,15 @@
-import sys,os
+import os
+import sys
-sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
+sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..", "..")))
from dpgen.tools.run_report import *
+
def my_file_cmp(test, f0, f1):
- with open(f0) as fp0 :
+ with open(f0) as fp0:
with open(f1) as fp1:
test.assertTrue(fp0.read() == fp1.read())
+
def setUpModule():
os.chdir(os.path.abspath(os.path.dirname(__file__)))
diff --git a/tests/tools/test_convert_mdata.py b/tests/tools/test_convert_mdata.py
index 5dc1b944e..1f0c020c8 100644
--- a/tests/tools/test_convert_mdata.py
+++ b/tests/tools/test_convert_mdata.py
@@ -1,16 +1,20 @@
-import os,sys,json
+import json
+import os
+import sys
import unittest
test_dir = os.path.abspath(os.path.join(os.path.dirname(__file__)))
-sys.path.insert(0, os.path.join(test_dir, '..'))
-__package__ = 'tools'
+sys.path.insert(0, os.path.join(test_dir, ".."))
+__package__ = "tools"
from dpgen.remote.decide_machine import convert_mdata
+
from .context import setUpModule
+
class TestConvertMdata(unittest.TestCase):
- machine_file = 'machine_fp_single.json'
+ machine_file = "machine_fp_single.json"
- def test_convert_mdata (self):
+ def test_convert_mdata(self):
mdata = json.load(open(self.machine_file))
mdata = convert_mdata(mdata, ["fp"])
self.assertEqual(mdata["fp_command"], "vasp_std")
@@ -20,4 +24,4 @@ def test_convert_mdata (self):
class TestConvertMdata2(TestConvertMdata):
- machine_file = 'machine_fp_single2.json'
+ machine_file = "machine_fp_single2.json"
diff --git a/tests/tools/test_run_report.py b/tests/tools/test_run_report.py
index e31ac3a56..0553d99f0 100644
--- a/tests/tools/test_run_report.py
+++ b/tests/tools/test_run_report.py
@@ -1,18 +1,31 @@
-import os,sys,json
+import json
+import os
+import sys
import unittest
test_dir = os.path.abspath(os.path.join(os.path.dirname(__file__)))
-sys.path.insert(0, os.path.join(test_dir, '..'))
-__package__ = 'tools'
+sys.path.insert(0, os.path.join(test_dir, ".."))
+__package__ = "tools"
from .context import stat_sys
+
class TestRunReport(unittest.TestCase):
- def test_stat_sys (self):
- folder = 'run_report_test_output'
- sys, sys_count, sys_all = stat_sys(os.path.join(test_dir,folder), verbose = False, mute = True)
- with open(os.path.join(test_dir, folder, 'param.json')) as fp:
+ def test_stat_sys(self):
+ folder = "run_report_test_output"
+ sys, sys_count, sys_all = stat_sys(
+ os.path.join(test_dir, folder), verbose=False, mute=True
+ )
+ with open(os.path.join(test_dir, folder, "param.json")) as fp:
jdata = json.load(fp)
- self.assertEqual(sys, jdata['sys_configs'])
- self.assertEqual(sys_count, [jdata['fp_task_max'], jdata['fp_task_max']])
- ref_all = [[['npt', 50.0, 1.0, 4], ['npt', 50.0, 2.0, 1], ['npt', 100.0, 1.0, 2], ['npt', 100.0, 2.0, 1]], [['npt', 50.0, 1.0, 2], ['npt', 50.0, 2.0, 4], ['npt', 100.0, 1.0, 2]]]
+ self.assertEqual(sys, jdata["sys_configs"])
+ self.assertEqual(sys_count, [jdata["fp_task_max"], jdata["fp_task_max"]])
+ ref_all = [
+ [
+ ["npt", 50.0, 1.0, 4],
+ ["npt", 50.0, 2.0, 1],
+ ["npt", 100.0, 1.0, 2],
+ ["npt", 100.0, 2.0, 1],
+ ],
+ [["npt", 50.0, 1.0, 2], ["npt", 50.0, 2.0, 4], ["npt", 100.0, 1.0, 2]],
+ ]
self.assertEqual(sys_all, ref_all)