OpenStack framework currently meets high availability requirements for its own infrastructure services like MySQL backend database, RabbitMQ messaging server, Neutron services, Nova services, Cinder services, etc. However, OpenStack does not guarantee high availability for individual guest instances. This section reports some common methods of implementing highly available systems, with an emphasis on the core OpenStack services and other open source services that are closely aligned with the OpenStack framework.
In an High Availability system, preventing single points of failure can depend on whether or not a service is stateless.
-
Stateless service: a service that provides a response after the request and then requires no further attention. To make a stateless service highly available, you need to provide redundant instances and load balance them. Examples of OpenStack services that are stateless are: nova-api, nova-conductor, glance-api, keystone-api, neutron-api and nova-scheduler.
-
Stateful service: a service where subsequent requests to the service depend on the results of the first request. Stateful services are more difficult to manage because a single action typically involves more than one request, so simply providing redundant instances and load balancing does not solve the problem. Examples of OpenStack services that are stateful include the OpenStack MySQL database and RabbitMQ message queue server.
Two components drive High Availability for all core and non-core OpenStack services:
-
Cluster Manager: the cluster manager is responsible for the startup and recovery of an inter-related services across a set of appropriate responses from the cluster manager to ensure service availability and data integrity. OpenStack uses Pacemaker as Cluster Manager. By configuring virtual IP addresses, services, and other features as resources in a cluster, Pacemaker makes sure that a set of OpenStack resources are running and available. When a service or entire node in a cluster fails, Pacemaker can restart the service, take the node out of the cluster, or reboot the node.
-
Proxy Server: the Proxy Server acts as load balancer between different instances of a service running on different nodes of the cluster. OpenStack uses the HAProxy as Proxy Server.
By combining the Cluster Manager and the Proxy Server capabilities, the OpenStack platform is able to provide High Availability of both its own stateless and stateful services. Depending of nature of resources, i.e. stateless or stateful, the services in an High Availability OpenStack run in one of two modes:
- active/active: in this mode, the same service is running on multiple controller nodes with Pacemaker, then traffic can either be distributed across the nodes running the requested service by HAProxy or directed to a particular controller via a single IP address. In some cases, HAProxy distributes traffic to active/active services in a round robin fashion.
- active/passive: services that are not capable of or reliable enough to run in active/active mode are run in active/passive mode. This means that only one instance of the service is active at a time.
In OpenStack, the Pacemaker application is used as Cluster Manager for all the HA functions. In general, an HA deployment of OpenStack uses three Controller nodes as result of TripleO installation.
Pacemaker relies on the Corosync messaging layer for reliable cluster communications. Corosync implements the Totem single-ring ordering and membership protocol. Pacemaker does not understand the applications it manages. Instead, it relies on resource agents, scripts that encapsulate the knowledge of how to start, stop, and check the health of each application managed by the cluster. These agents must conform to the OCF or systemd standards. Pacemaker ships with a large set of Open Cluster Format and systemd agents.
From one of the Controller nodes, check the status of the cluster
$ sudo pcs status cluster
Cluster Status:
Last updated: Thu Aug 18 10:11:51 2016
Last change: Thu Aug 18 08:33:45 2016 by hacluster via crmd on overcloud-controller-1
Stack: corosync
Current DC: overcloud-controller-2 (version 1.1.13-10.el7_2.2-44eb2dd) - partition with quorum
3 nodes and 112 resources configured
Online: [ overcloud-controller-0 overcloud-controller-1 overcloud-controller-2 ]
PCSD Status:
overcloud-controller-0: Online
overcloud-controller-1: Online
overcloud-controller-2: Online
There are three nodes on-line: overcloud-controller-0, overcloud-controller-1 and overcloud-controller-2. Cluster nodes should not be halted as other standard nodes. It's always a best practice to shutdown the cluster first and then shutdown the system.
To stop the cluster on a signle node
$ sudo pcs cluster stop
Stopping Cluster (pacemaker)... Stopping Cluster (corosync)...
$ sudo pcs cluster status
Error: cluster is not currently running on this node
Or on all nodes of the cluster
$ sudo pcs cluster stop --all
overcloud-controller-0: Stopping Cluster (pacemaker)...
overcloud-controller-1: Stopping Cluster (pacemaker)...
overcloud-controller-2: Stopping Cluster (pacemaker)...
overcloud-controller-0: Stopping Cluster (corosync)...
overcloud-controller-1: Stopping Cluster (corosync)...
overcloud-controller-2: Stopping Cluster (corosync)...
Start on all nodes
$ sudo pcs cluster start --all
Check the resources:
$ sudo pcs status resources
ip-10.10.10.101 (ocf::heartbeat:IPaddr2): Started overcloud-controller-2
ip-172.19.1.10 (ocf::heartbeat:IPaddr2): Started overcloud-controller-2
ip-172.20.1.10 (ocf::heartbeat:IPaddr2): Started overcloud-controller-1
ip-172.18.1.10 (ocf::heartbeat:IPaddr2): Started overcloud-controller-2
ip-172.20.1.11 (ocf::heartbeat:IPaddr2): Started overcloud-controller-0
ip-192.0.2.15 (ocf::heartbeat:IPaddr2): Started overcloud-controller-2
Master/Slave Set: redis-master [redis]
Masters: [ overcloud-controller-2 ]
Slaves: [ overcloud-controller-0 overcloud-controller-1 ]
Master/Slave Set: galera-master [galera]
Masters: [ overcloud-controller-0 overcloud-controller-1 overcloud-controller-2 ]
Clone Set: haproxy-clone [haproxy]
Started: [ overcloud-controller-0 overcloud-controller-1 overcloud-controller-2 ]
Clone Set: mongod-clone [mongod]
Started: [ overcloud-controller-0 overcloud-controller-1 overcloud-controller-2 ]
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ overcloud-controller-0 overcloud-controller-1 overcloud-controller-2 ]
Clone Set: memcached-clone [memcached]
Started: [ overcloud-controller-0 overcloud-controller-1 overcloud-controller-2 ]
Clone Set: openstack-nova-scheduler-clone [openstack-nova-scheduler]
Started: [ overcloud-controller-0 overcloud-controller-1 overcloud-controller-2 ]
...
There are:
- IP Address resources
- Master/Slave resources
- Clone Set resources
An IP Address resource sets a virtual IP address that clients use to request access to a service. If the Controller Node assigned to that IP address goes down, the IP address gets reassigned to a different controller. Note that each IP address is initially attached to a particular controller. However, if that controller goes down, its virtual IP address will be reassigned by Pacemaker to other controllers in the cluster. For example, the virtual IP address 10.10.10.101 is assigned to the controller overcloud-controller-2.
Login to that controller and check the IP address and which services are listening on
$ ip addr show br-ex
13: br-ex: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN
link/ether 00:0c:29:1e:e0:a3 brd ff:ff:ff:ff:ff:ff
inet 10.10.10.104/24 brd 10.10.10.255 scope global br-ex
valid_lft forever preferred_lft forever
inet 10.10.10.101/32 brd 10.10.10.255 scope global br-ex
valid_lft forever preferred_lft forever
$ sudo netstat -tupln | grep 10.10.10.101
tcp 0 0 10.10.10.101:5000 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:8776 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:8777 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:9292 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:8080 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:80 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:35357 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:6080 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:9696 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:8000 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:8003 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:8004 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:8773 0.0.0.0:* LISTEN 4338/haproxy
tcp 0 0 10.10.10.101:8774 0.0.0.0:* LISTEN 4338/haproxy
We have HAProxy listening on all the service ports. The port numbers shown in the netstat output helps to identify the service HAProxy is listening for. Check the /etc/haproxy/haproxy.cfg file to see what services those port numbers represent. Here are just a few examples:
TCP port 5000: keystone
TCP port 9696: neutron
TCP port 8776: cinder
TCP port 9292: glance-api
TCP port 80: horizon
All these services are listening specifically on virtual IP 10.10.10.101 on all three controllers. However, only overcloud-controller-2 is actually listening externally on it.
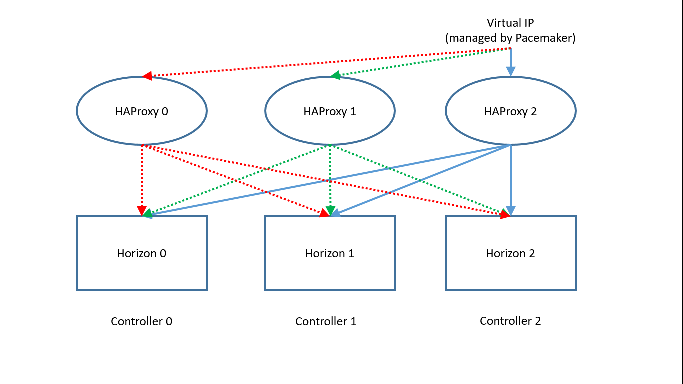
If the controller owning the virtual IP address goes down, Pacemaker only needs to reassign the virtual IP to another controller where all the services are already running. For this reaseon, most services are configured as Clone Set resources, where they are started on each controller and set to always run on each controller. Services are cloned if they need to be active on multiple nodes.
...
Clone Set: openstack-nova-scheduler-clone [openstack-nova-scheduler]
Started: [ overcloud-controller-0 overcloud-controller-1 ]
Stopped: [ overcloud-controller-2 ]
...
For the Clone Set resource, we can see:
- The name Pacemaker assigns to the service:
openstack-nova-scheduler-clone - The actual service name:
openstack-nova-scheduler - The set of controllers on which the services are started:
[overcloud-controller-0 overcloud-controller-1] - The set of controllers on which the services are stopped:
[overcloud-controller-2]
The HAProxy load balancing feature distribute the client requests toward all the controllers for better performances. Howewer, not all Cloned Set resources use the HAProxy. Some services as RabbitMQ, memcached and MongoDB do not use HAProxy. Instead, clients of these services use a full list of the controller running the services.
Here is the list of OpenStack services managed by HAProxy on the controller nodes:
- ceilometer
- cinder
- glance_api
- glance_registry
- heat_api
- heat_cfn
- heat_cloudwatch
- horizon
- keystone_admin
- keystone_public
- mysql
- neutron
- nova_ec2
- nova_metadata
- nova_novncproxy
- nova_osapi
- redis
- swift_proxy
The MariaDB Galera and Redis services are run as Master/Slave resources
Master/Slave Set: redis-master [redis]
Masters: [ overcloud-controller-2 ]
Slaves: [ overcloud-controller-0 overcloud-controller-1 ]
Master/Slave Set: galera-master [galera]
Masters: [ overcloud-controller-0 overcloud-controller-1 overcloud-controller-2 ]
For the MariaDB Galera resource, all three controllers are running as masters. For the Redis resource, overcloud-controller-2 is running as the master, while the other two controllers are running as slaves. This means the MariaDB Galera service is running under one set of constraints on all three controllers, while Redis may be subject to different constraints on the master and slave controllers.