
- hive shell、JDBC/ODBC(java访问hive)、WEBUI
- 表名、表所属数据库、表的拥有者、列/分区字段、表的类型、表的数据所在目录
- 在 Hive 中,表名、表结构、字段名、字段类型、表的分隔符等统一被称为元数据。所有的元数据默认存储在 Hive 内置的 derby 数据库中,但由于 derby 只能有一个实例,也就是说不能有多个命令行客户端同时访问,所以在实际生产环境中,通常使用 MySQL 代替 derby。
- Hive 进行的是统一的元数据管理,就是说你在 Hive 上创建了一张表,然后在 presto/impala/sparksql 中都是可以直接使用的,它们会从 Metastore 中获取统一的元数据信息,同样的你在 presto/impala/sparksql 中创建一张表,在 Hive 中也可以直接使用。
- 解析器:将SQL字符串转换成抽象语法树AST,一般使用antlr对AST进行语法分析,比如表是否存在等
- 编译器:将AST编译生成执行计划
- 优化器:对逻辑执行计划进行优化
- 执行器:基于MR/Spark做计算
- 语法解析:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象 语法树 AST Tree;
- 语义解析:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
- 生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
- 优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并不必要的
ReduceSinkOperator,减少 shuffle 数据量; - 生成物理执行计划:遍历 OperatorTree,翻译为 MapReduce 任务;
- 优化物理执行计划:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
| 大类 | 类型 |
|---|---|
| Integers(整型) | TINYINT—1 字节的有符号整数 SMALLINT—2 字节的有符号整数 INT—4 字节的有符号整数 BIGINT—8 字节的有符号整数 |
| Boolean(布尔型) | BOOLEAN—TRUE/FALSE |
| Floating point numbers(浮点型) | FLOAT— 单精度浮点型 DOUBLE—双精度浮点型 |
| Fixed point numbers(定点数) | DECIMAL—用户自定义精度定点数,比如 DECIMAL(7,2) |
| String types(字符串) | STRING—指定字符集的字符序列 VARCHAR—具有最大长度限制的字符序列 CHAR—固定长度的字符序列 |
| Date and time types(日期时间类型) | TIMESTAMP — 时间戳 TIMESTAMP WITH LOCAL TIME ZONE — 时间戳,纳秒精度 DATE—日期类型 |
| Binary types(二进制类型) | BINARY—字节序列 |
Hive 中基本数据类型遵循以下的层次结构,按照这个层次结构,子类型到祖先类型允许隐式转换。例如 INT 类型的数据允许隐式转换为 BIGINT 类型。额外注意的是:按照类型层次结构允许将 STRING 类型隐式转换为 DOUBLE 类型。

| 类型 | 描述 | 示例 |
|---|---|---|
| STRUCT | 类似于对象,是字段的集合,字段的类型可以不同,可以使用 名称.字段名 方式进行访问 |
STRUCT ('xiaoming', 12 , '2018-12-12') |
| MAP | 键值对的集合,可以使用 名称[key] 的方式访问对应的值 |
map('a', 1, 'b', 2) |
| ARRAY | 数组是一组具有相同类型和名称的变量的集合,可以使用 名称[index] 访问对应的值 |
ARRAY('a', 'b', 'c', 'd') |
CREATE TABLE students(
name STRING, -- 姓名
age INT, -- 年龄
subject ARRAY<STRING>, --学科
score MAP<STRING,FLOAT>, --各个学科考试成绩
address STRUCT<houseNumber:int, street:STRING, city:STRING, province:STRING> --家庭居住地址
) ROW FORMAT DELIMITED FIELDS TERMINATED BY "\t";# 配置Hadoop Home
HADOOP_HOME=/Users/babywang/Documents/reserch/studySummary/module/hadoop-2.8.5
# 配置HIVE_CONF_DIR
export HIVE_CONF_DIR=/Users/babywang/Documents/reserch/studySummary/module/hive/apache-hive-2.3.6-bin/conf# hdfs上创建tmp和/user/hive/warehouse目录
hdfs dfs -mkdir /tmp
hdfs dfs -mkdir -p /user/hive/warehouse
# 添加组权限
hdfs dfs -chmod g+w /tmp
hdfs dfs -chmod g+w /user/hive/warehouse<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://db1.mydomain.pvt/hive_db?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>database_user</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>database_pass</value>
</property>
</configuration> - 将mysql驱动放入hive的lib目录下
- $HIVE_HOME/scripts/metastore/upgrade/mysql找到对应版本的scheme.sql
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property> # 查询显示列名
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
# 查询显示当前数据库
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property> 1.Hive的log默认存放在/tmp/atguigu/hive.log目录下(当前用户名下)
2.修改hive的log存放日志到/opt/module/hive/logs
(1)修改/opt/module/hive/conf/hive-log4j.properties.template文件名称为
hive-log4j.properties
[atguigu@hadoop102 conf]$ pwd
/opt/module/hive/conf
mv hive-log4j.properties.template hive-log4j.properties
(2)在hive-log4j.properties文件中修改log存放位置
hive.log.dir=/opt/module/hive/logs- 修改hive-site.xml
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>- Hive底层MR引擎
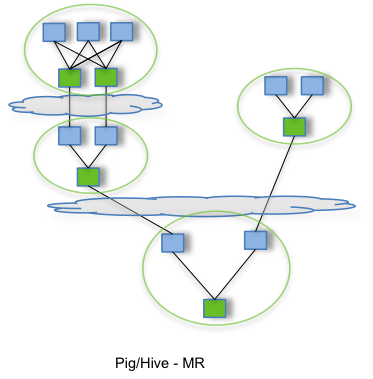
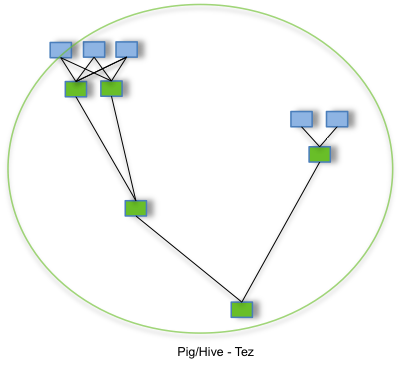
- Tez引擎
用Hive直接编写MR程序,假设有四个有依赖关系的MR作业,上图中,绿色是Reduce Task,云状表示写屏蔽,需要将中间结果持久化写到HDFS。
Tez可以将多个有依赖的作业转换为一个作业,这样只需写一次HDFS,且中间节点较少,从而大大提升作业的计算性能。# 下载tez
curl https://mirrors.tuna.tsinghua.edu.cn/apache/tez/0.9.2/export TEZ_HOME=/Users/babywang/Documents/reserch/studySummary/module/tez-0.9.2
export TEZ_JARS=""
# 将jar包放入TEZ_JARS变量中
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
# 将lib下的jar放入TEZ_JARS中
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done
# 放入到hive lib下
export HIVE_AUX_JARS_PATH=/Users/babywang/Documents/reserch/studySummary/module/hive/apache-hive-2.3.6-bin/lib$TEZ_JARS<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property><?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>tez.lib.uris</name>
<value>${fs.defaultFS}/tez/tez-0.9.2,${fs.defaultFS}/tez/tez-0.9.2/lib</value>
</property>
<property>
<name>tez.lib.uris.classpath</name>
<value>${fs.defaultFS}/tez/tez-0.9.2,${fs.defaultFS}/tez/tez-0.9.2/lib</value>
</property>
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<property>
<name>tez.history.logging.service.class</name>
<value>org.apache.tez.dag.history.logging.ats.ATSHistoryLoggingService</value>
</property>
</configuration># 创建tez目录
hdfs dfs -mkdir /tez
# 上传tez
hdfs dfs -put tez-0.9.2/ /tez
- Hive提供类SQL的语言,HQL。
- Hive存在在Hadoop的HDFS或者其他分布式文件系统中,数据库存放在数据库中
- Hive适合读多写少的,Hive不建议对数据进行改写,所有数据都在加载确定好的,数据库则适合传统的curd。
- Hive在加载数据的过程中不会对数据做任何处理,甚至不会对数据进行扫描,因此也没有对数据的某些key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个目录的数据。但是Hive可以基于Spark、MR做并行访问数据,因此可以支持大量数据访问。Hive支持BitMap和Compact索引。