![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
This example demonstrates how Jina can be used to search a repository of PDF files. The example employs a multimodal search architecture, allowing a user to query the data by providing text, or an image, or both simultaneously.
What's included in this example:
-
Search text, image, PDF all in one Flow or in separate Flows
-
Leverage Jina Recursive Document Representation to segment and encode text
-
Speed up indexing time with parallel Peas
-
Use customized executors to better fit your needs
-
Provide detailed docstrings for YAML files to help you understand the example
How to clone this repo❓
Because this repo contains many more example projects, if you want to clone only this example, you can do this as following
git clone --depth 1 --filter=blob:none --sparse https://github.com/jina-ai/examples
cd examples
git sparse-checkout set multimodal-search-pdfWe have included several PDF blogs as toy data in toy_data. This data is ready to use straight away. You can replace this toy data with your own by simply adding new files to the toy_data folder. Be careful to check that the files are supported by pdfplumber.
pip install -r requirements.txt| Command | Description |
|---|---|
python app.py -t index |
To index files/data |
python app.py -t query |
To run a query Flow for searching text, image, and PDF |
python app.py -t query_text |
To run a query Flow for searching text |
python app.py -t query_image |
To run a query Flow for searching image |
python app.py -t query_pdf |
To run a query Flow for searching PDF |
python app.py -t query_restful |
To expose the restful API of the query Flow for searching text, image, and PDF |
python app.py -t query_restfulWhen the REST gateway is enabled, Jina uses the data URI scheme to represent multimedia data. Simply organize your picture(s) into this scheme and send a POST request to http://0.0.0.0:45670/api/search, e.g.:
curl --request POST -d '{"top_k": 10, "mode": "search", "data": ["jina hello multimodal"]}' -H 'Content-Type: application/json' 'http://0.0.0.0:45670/api/search'The results will be like:
{
"requestId":"b5813834-5f42-4f6c-a313-0f397ef5cf12",
"search":{
"docs":[
{
"id":"2cd45334-98dd-11eb-85a3-38f9d3eb0f3c",
"weight":1.0,
"matches":[
{
"id":"f61571fc-9706-11eb-ba29-38f9d3eb0f3c",
"uri":"toy_data/blog1.pdf",
"mimeType":"application/pdf",
"score":{
"value":1.0,
"opName":"SimpleAggregateRanker",
"refId":"2cd45334-98dd-11eb-85a3-38f9d3eb0f3c"
},
"adjacency":1,
"contentHash":"3b46f0781f207674"
},
{
"id":"f618041c-9706-11eb-ba29-38f9d3eb0f3c",
"uri":"toy_data/blog3.pdf",
"mimeType":"application/pdf",
"score":{
"value":0.83538496,
"opName":"SimpleAggregateRanker",
"refId":"2cd45334-98dd-11eb-85a3-38f9d3eb0f3c"
},
"adjacency":1,
"contentHash":"89a45525161ec448"
},
{
"id":"f617ec70-9706-11eb-ba29-38f9d3eb0f3c",
"uri":"toy_data/blog2.pdf",
"mimeType":"application/pdf",
"score":{
"value":0.71500874,
"opName":"SimpleAggregateRanker",
"refId":"2cd45334-98dd-11eb-85a3-38f9d3eb0f3c"
},
"adjacency":1,
"contentHash":"debde7ffbb210b46"
}
],
"mimeType":"text/plain",
"text":"jina hello multimodal",
"contentHash":"f7beb6d4b839aa06"
}
]
}This example shows you how to feed data into Jina via REST gateway. By default, Jina uses a gRPC gateway, which has much higher performance and rich features. If you are interested in that, go ahead and check out our other examples and read our documentation on Jina IO.
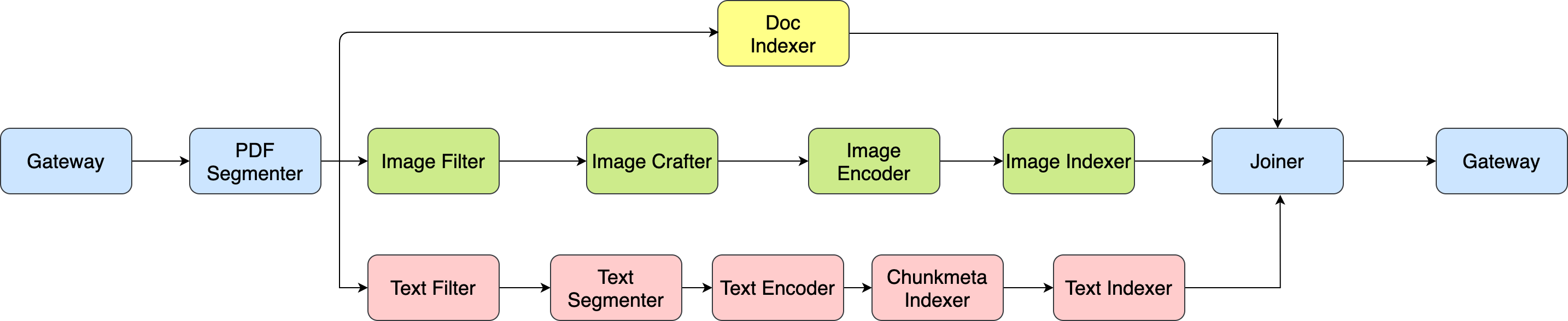
The following image shows the structure of index Flow, the text and image will be extracted from PDF files as chunks. Then we will use three paths to process and store the data.
- For the first path, the DocIndexer will store the Document ID and Document data on disk
- For the second path, the pods will filter the image chunks, and do the processing. It will also store chunk ID and chunk data on disk
- For the third path, the pods will filter the text chunks, and further segment text into smaller chunks. The ChunkMeta indexer is used to store data at chunks level and text indexer is used to store data for chunks of chunks. The joiner will wait until three paths are finished.
The following image shows the structure of query Flow. For query, we can send text, image and PDF files to one Flow and get the results. We use two parallel paths to process the query data and get results.
- For the first path, we will get embedding of the image data and use image indexer to get the most similar matches at chunks level.
- For the second path, we will get embedding of the text data at chunks of chunks level in the text encoder. Then we use CCtoC ranker to get the matches from chunks of chunks (CC) level to chunks (C) level. The chunkmeta indexer can help to append meta data for matches of chunks. The ChunktoRoot Ranker is used to get the matches at root level and then we can use the matches ID to get the documents data.

You can run the perf-script.sh in order to run all of the examples on your machine. Make sure this is done in a separate python virtualenv.
This measures QPS for indexing and querying.
This will store the results in performance.txt.
| Item | Index | Query |
|---|---|---|
| Number of Docs | 30 | 3 |
| Time | 350.74s | 5.33s |

The best way to learn Jina in depth is to read our documentation. Documentation is built on every push, merge, and release event of the master branch. You can find more details about the following topics in our documentation.
- Jina command line interface arguments explained
- Jina Python API interface
- Jina YAML syntax for executor, driver and flow
- Jina Protobuf schema
- Environment variables used in Jina
- ... and more
- Slack channel - a communication platform for developers to discuss Jina
- Community newsletter - subscribe to the latest update, release and event news of Jina
- LinkedIn - get to know Jina AI as a company and find job opportunities
- follow us and interact with us using hashtag
#JinaSearch- Company - know more about our company, we are fully committed to open-source!

Copyright (c) 2021 Jina AI Limited. All rights reserved.
Jina is licensed under the Apache License, Version 2.0. See LICENSE for the full license text.