diff --git a/.pre-commit-config.yaml b/.pre-commit-config.yaml
index 039139b95..feb6c766e 100644
--- a/.pre-commit-config.yaml
+++ b/.pre-commit-config.yaml
@@ -1,6 +1,6 @@
repos:
- repo: https://github.com/astral-sh/ruff-pre-commit
- rev: v0.1.15
+ rev: v0.2.0
hooks:
- id: ruff
args:
diff --git a/README.md b/README.md
index 61dede8c1..43eadf5a3 100644
--- a/README.md
+++ b/README.md
@@ -1,195 +1,17 @@
-# bitsandbytes
+# `bitsandbytes`
-The bitsandbytes is a lightweight wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication (LLM.int8()), and quantization functions.
+The `bitsandbytes` library is a lightweight Python wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication (LLM.int8()), and 8 & 4-bit quantization functions.
+The library includes quantization primitives for 8-bit & 4-bit operations, through `bitsandbytes.nn.Linear8bitLt` and `bitsandbytes.nn.Linear4bit` and 8-bit optimizers through `bitsandbytes.optim` module.
+There are ongoing efforts to support further hardware backends, i.e. Intel CPU + GPU, AMD GPU, Apple Silicon. Windows support is quite far along and is on its way as well.
-Resources:
-- [8-bit Optimizer Paper](https://arxiv.org/abs/2110.02861) -- [Video](https://www.youtube.com/watch?v=IxrlHAJtqKE) -- [Docs](https://bitsandbytes.readthedocs.io/en/latest/)
+**Please head to the official documentation page:**
-- [LLM.int8() Paper](https://arxiv.org/abs/2208.07339) -- [LLM.int8() Software Blog Post](https://huggingface.co/blog/hf-bitsandbytes-integration) -- [LLM.int8() Emergent Features Blog Post](https://timdettmers.com/2022/08/17/llm-int8-and-emergent-features/)
-
-## TL;DR
-**Requirements**
-Python >=3.8. Linux distribution (Ubuntu, MacOS, etc.) + CUDA > 10.0.
-
-(Deprecated: CUDA 10.0 is deprecated and only CUDA >= 11.0) will be supported with release 0.39.0)
-
-**Installation**:
-
-``pip install bitsandbytes``
-
-In some cases it can happen that you need to compile from source. If this happens please consider submitting a bug report with `python -m bitsandbytes` information. What now follows is some short instructions which might work out of the box if `nvcc` is installed. If these do not work see further below.
-
-Compilation quickstart:
-```bash
-git clone https://github.com/timdettmers/bitsandbytes.git
-cd bitsandbytes
-
-# CUDA_VERSIONS in {110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122}
-# make argument in {cuda110, cuda11x, cuda12x}
-# if you do not know what CUDA you have, try looking at the output of: python -m bitsandbytes
-CUDA_VERSION=117 make cuda11x
-python setup.py install
-```
-
-**Using Int8 inference with HuggingFace Transformers**
-
-```python
-from transformers import AutoModelForCausalLM
-model = AutoModelForCausalLM.from_pretrained(
- 'decapoda-research/llama-7b-hf',
- device_map='auto',
- load_in_8bit=True,
- max_memory={
- i: f'{int(torch.cuda.mem_get_info(i)[0]/1024**3)-2}GB'
- for i in range(torch.cuda.device_count())
- }
-)
-```
-
-A more detailed example, can be found in [examples/int8_inference_huggingface.py](examples/int8_inference_huggingface.py).
-
-**Using 8-bit optimizer**:
-1. Comment out optimizer: ``#torch.optim.Adam(....)``
-2. Add 8-bit optimizer of your choice ``bnb.optim.Adam8bit(....)`` (arguments stay the same)
-3. Replace embedding layer if necessary: ``torch.nn.Embedding(..) -> bnb.nn.Embedding(..)``
-
-
-**Using 8-bit Inference**:
-1. Comment out torch.nn.Linear: ``#linear = torch.nn.Linear(...)``
-2. Add bnb 8-bit linear light module: ``linear = bnb.nn.Linear8bitLt(...)`` (base arguments stay the same)
-3. There are two modes:
- - Mixed 8-bit training with 16-bit main weights. Pass the argument ``has_fp16_weights=True`` (default)
- - Int8 inference. Pass the argument ``has_fp16_weights=False``
-4. To use the full LLM.int8() method, use the ``threshold=k`` argument. We recommend ``k=6.0``.
-```python
-# LLM.int8()
-linear = bnb.nn.Linear8bitLt(dim1, dim2, bias=True, has_fp16_weights=False, threshold=6.0)
-# inputs need to be fp16
-out = linear(x.to(torch.float16))
-```
-
-
-## Features
-- 8-bit Matrix multiplication with mixed precision decomposition
-- LLM.int8() inference
-- 8-bit Optimizers: Adam, AdamW, RMSProp, LARS, LAMB, Lion (saves 75% memory)
-- Stable Embedding Layer: Improved stability through better initialization, and normalization
-- 8-bit quantization: Quantile, Linear, and Dynamic quantization
-- Fast quantile estimation: Up to 100x faster than other algorithms
-
-## Requirements & Installation
-
-Requirements: anaconda, cudatoolkit, pytorch
-
-Hardware requirements:
- - LLM.int8(): NVIDIA Turing (RTX 20xx; T4) or Ampere GPU (RTX 30xx; A4-A100); (a GPU from 2018 or newer).
- - 8-bit optimizers and quantization: NVIDIA Kepler GPU or newer (>=GTX 78X).
-
-Supported CUDA versions: 10.2 - 12.2
-
-The bitsandbytes library is currently only supported on Linux distributions. Windows is not supported at the moment.
-
-The requirements can best be fulfilled by installing pytorch via anaconda. You can install PyTorch by following the ["Get Started"](https://pytorch.org/get-started/locally/) instructions on the official website.
-
-To install run:
-
-``pip install bitsandbytes``
-
-## Using bitsandbytes
-
-### Using Int8 Matrix Multiplication
-
-For straight Int8 matrix multiplication with mixed precision decomposition you can use ``bnb.matmul(...)``. To enable mixed precision decomposition, use the threshold parameter:
-```python
-bnb.matmul(..., threshold=6.0)
-```
-
-For instructions how to use LLM.int8() inference layers in your own code, see the TL;DR above or for extended instruction see [this blog post](https://huggingface.co/blog/hf-bitsandbytes-integration).
-
-### Using the 8-bit Optimizers
-
-With bitsandbytes 8-bit optimizers can be used by changing a single line of code in your codebase. For NLP models we recommend also to use the StableEmbedding layers (see below) which improves results and helps with stable 8-bit optimization. To get started with 8-bit optimizers, it is sufficient to replace your old optimizer with the 8-bit optimizer in the following way:
-```python
-import bitsandbytes as bnb
-
-# adam = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # comment out old optimizer
-adam = bnb.optim.Adam8bit(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # add bnb optimizer
-adam = bnb.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995), optim_bits=8) # equivalent
-
-
-torch.nn.Embedding(...) -> bnb.nn.StableEmbedding(...) # recommended for NLP models
-```
-
-Note that by default all parameter tensors with less than 4096 elements are kept at 32-bit even if you initialize those parameters with 8-bit optimizers. This is done since such small tensors do not save much memory and often contain highly variable parameters (biases) or parameters that require high precision (batch norm, layer norm). You can change this behavior like so:
-```python
-# parameter tensors with less than 16384 values are optimized in 32-bit
-# it is recommended to use multiplies of 4096
-adam = bnb.optim.Adam8bit(model.parameters(), min_8bit_size=16384)
-```
-
-### Change Bits and other Hyperparameters for Individual Parameters
-
-If you want to optimize some unstable parameters with 32-bit Adam and others with 8-bit Adam, you can use the `GlobalOptimManager`. With this, we can also configure specific hyperparameters for particular layers, such as embedding layers. To do that, we need two things: (1) register the parameter while they are still on the CPU, (2) override the config with the new desired hyperparameters (anytime, anywhere). See our [guide](howto_config_override.md) for more details
-
-### Fairseq Users
-
-To use the Stable Embedding Layer, override the respective `build_embedding(...)` function of your model. Make sure to also use the `--no-scale-embedding` flag to disable scaling of the word embedding layer (nor replaced with layer norm). You can use the optimizers by replacing the optimizer in the respective file (`adam.py` etc.).
-
-## Release and Feature History
-
-For upcoming features and changes and full history see [Patch Notes](CHANGELOG.md).
-
-## Errors
-
-1. RuntimeError: CUDA error: no kernel image is available for execution on the device. [Solution](errors_and_solutions.md#No-kernel-image-available)
-2. __fatbinwrap_.. [Solution](errors_and_solutions.md#fatbinwrap_)
-
-## Compile from source
-To compile from source, you need an installation of CUDA. If `nvcc` is not installed, you can install the CUDA Toolkit with nvcc through the following commands.
-
-```bash
-wget https://raw.githubusercontent.com/TimDettmers/bitsandbytes/main/install_cuda.sh
-# Syntax cuda_install CUDA_VERSION INSTALL_PREFIX EXPORT_TO_BASH
-# CUDA_VERSION in {110, 111, 112, 113, 114, 115, 116, 117, 118, 120, 121, 122}
-# EXPORT_TO_BASH in {0, 1} with 0=False and 1=True
-
-# For example, the following installs CUDA 11.7 to ~/local/cuda-11.7 and exports the path to your .bashrc
-bash install_cuda.sh 117 ~/local 1
-```
-
-To use a specific CUDA version just for a single compile run, you can set the variable `CUDA_HOME`, for example the following command compiles `libbitsandbytes_cuda117.so` using compiler flags for cuda11x with the cuda version at `~/local/cuda-11.7`:
-
-``CUDA_HOME=~/local/cuda-11.7 CUDA_VERSION=117 make cuda11x``
-
-For more detailed instruction, please follow the [compile_from_source.md](compile_from_source.md) instructions.
+**[https://huggingface.co/docs/bitsandbytes/main](https://huggingface.co/docs/bitsandbytes/main)**
## License
-The majority of bitsandbytes is licensed under MIT, however portions of the project are available under separate license terms: Pytorch is licensed under the BSD license.
+The majority of bitsandbytes is licensed under MIT, however small portions of the project are available under separate license terms, as the parts adapted from Pytorch are licensed under the BSD license.
We thank Fabio Cannizzo for his work on [FastBinarySearch](https://github.com/fabiocannizzo/FastBinarySearch) which we use for CPU quantization.
-
-## How to cite us
-If you found this library and found LLM.int8() useful, please consider citing our work:
-
-```bibtex
-@article{dettmers2022llmint8,
- title={LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale},
- author={Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke},
- journal={arXiv preprint arXiv:2208.07339},
- year={2022}
-}
-```
-
-For 8-bit optimizers or quantization routines, please consider citing the following work:
-
-```bibtex
-@article{dettmers2022optimizers,
- title={8-bit Optimizers via Block-wise Quantization},
- author={Dettmers, Tim and Lewis, Mike and Shleifer, Sam and Zettlemoyer, Luke},
- journal={9th International Conference on Learning Representations, ICLR},
- year={2022}
-}
-```
diff --git a/bitsandbytes/nn/modules.py b/bitsandbytes/nn/modules.py
index 922feae15..6eeecc273 100644
--- a/bitsandbytes/nn/modules.py
+++ b/bitsandbytes/nn/modules.py
@@ -19,6 +19,42 @@
class StableEmbedding(torch.nn.Embedding):
+ """
+ Custom embedding layer designed for stable training in NLP tasks. The stable
+ embedding layer improves stability during optimization for models with word
+ embeddings, addressing issues related to the non-uniform distribution of input
+ tokens.
+
+ This stable embedding layer is initialized with Xavier uniform initialization,
+ followed by layer normalization. It is designed to support aggressive quantization,
+ addressing extreme gradient variations in non-uniform input distributions. The
+ stability of training is enhanced by using 32-bit optimizer states specifically
+ for this layer.
+
+ Example:
+
+ ```
+ # Initialize StableEmbedding layer with vocabulary size 1000, embedding dimension 300
+ embedding_layer = StableEmbedding(num_embeddings=1000, embedding_dim=300)
+
+ # Reset embedding parameters
+ embedding_layer.reset_parameters()
+
+ # Perform a forward pass with input tensor
+ input_tensor = torch.tensor([1, 2, 3])
+ output_embedding = embedding_layer(input_tensor)
+ ```
+
+ Attributes:
+ norm (torch.nn.LayerNorm): Layer normalization applied after the embedding.
+
+ Methods:
+ reset_parameters(): Reset embedding parameters using Xavier uniform initialization.
+ forward(input: Tensor) -> Tensor: Forward pass through the stable embedding layer.
+
+ Reference:
+ - [8-bit optimizer paper](https://arxiv.org/pdf/2110.02861.pdf)
+ """
def __init__(
self,
num_embeddings: int,
@@ -32,6 +68,17 @@ def __init__(
device=None,
dtype=None,
) -> None:
+ """
+ Args:
+ num_embeddings (`int`): The number of unique embeddings (vocabulary size).
+ embedding_dim (`int`): The dimensionality of the embedding.
+ padding_idx (`Optional[int]`): If specified, pads the output with zeros at the given index.
+ max_norm (`Optional[float]`): If given, renormalizes embeddings to have a maximum L2 norm.
+ norm_type (`float`, defaults to `2.0`): The p-norm to compute for the max_norm option.
+ scale_grad_by_freq (`bool`): Scale gradient by frequency during backpropagation.
+ sparse (`bool`): If True, computes sparse gradients; False, computes dense gradients.
+ _weight (`Optional[Tensor]`): Pre-trained embeddings.
+ """
super().__init__(
num_embeddings,
embedding_dim,
@@ -222,8 +269,49 @@ def to(self, *args, **kwargs):
class Linear4bit(nn.Linear):
+ """
+ This class is the base module for the 4-bit quantization algorithm presented in [QLoRA](https://arxiv.org/abs/2305.14314).
+ QLoRA 4-bit linear layers uses blockwise k-bit quantization under the hood, with the possibility of selecting various
+ compute datatypes such as FP4 and NF4.
+
+ In order to quantize a linear layer one should first load the original fp16 / bf16 weights into
+ the Linear8bitLt module, then call `quantized_module.to("cuda")` to quantize the fp16 / bf16 weights.
+
+ Example:
+
+ ```python
+ import torch
+ import torch.nn as nn
+
+ import bitsandbytes as bnb
+ from bnb.nn import Linear4bit
+ fp16_model = nn.Sequential(
+ nn.Linear(64, 64),
+ nn.Linear(64, 64)
+ )
+
+ quantized_model = nn.Sequential(
+ Linear4bit(64, 64),
+ Linear4bit(64, 64)
+ )
+
+ quantized_model.load_state_dict(fp16_model.state_dict())
+ quantized_model = quantized_model.to(0) # Quantization happens here
+ ```
+ """
def __init__(self, input_features, output_features, bias=True, compute_dtype=None, compress_statistics=True, quant_type='fp4', quant_storage=torch.uint8, device=None):
+ """
+ Initialize Linear4bit class.
+
+ Args:
+ input_features (`str`):
+ Number of input features of the linear layer.
+ output_features (`str`):
+ Number of output features of the linear layer.
+ bias (`bool`, defaults to `True`):
+ Whether the linear class uses the bias term as well.
+ """
super().__init__(input_features, output_features, bias, device)
self.weight = Params4bit(self.weight.data, requires_grad=False, compress_statistics=compress_statistics, quant_type=quant_type, quant_storage=quant_storage, module=self)
# self.persistent_buffers = [] # TODO consider as way to save quant state
@@ -397,8 +485,49 @@ def maybe_rearrange_weight(state_dict, prefix, local_metadata, strict, missing_k
class Linear8bitLt(nn.Linear):
+ """
+ This class is the base module for the [LLM.int8()](https://arxiv.org/abs/2208.07339) algorithm.
+ To read more about it, have a look at the paper.
+
+ In order to quantize a linear layer one should first load the original fp16 / bf16 weights into
+ the Linear8bitLt module, then call `int8_module.to("cuda")` to quantize the fp16 weights.
+
+ Example:
+
+ ```python
+ import torch
+ import torch.nn as nn
+
+ import bitsandbytes as bnb
+ from bnb.nn import Linear8bitLt
+
+ fp16_model = nn.Sequential(
+ nn.Linear(64, 64),
+ nn.Linear(64, 64)
+ )
+
+ int8_model = nn.Sequential(
+ Linear8bitLt(64, 64, has_fp16_weights=False),
+ Linear8bitLt(64, 64, has_fp16_weights=False)
+ )
+
+ int8_model.load_state_dict(fp16_model.state_dict())
+ int8_model = int8_model.to(0) # Quantization happens here
+ ```
+ """
def __init__(self, input_features, output_features, bias=True, has_fp16_weights=True,
memory_efficient_backward=False, threshold=0.0, index=None, device=None):
+ """
+ Initialize Linear8bitLt class.
+
+ Args:
+ input_features (`str`):
+ Number of input features of the linear layer.
+ output_features (`str`):
+ Number of output features of the linear layer.
+ bias (`bool`, defaults to `True`):
+ Whether the linear class uses the bias term as well.
+ """
super().__init__(input_features, output_features, bias, device)
assert not memory_efficient_backward, "memory_efficient_backward is no longer required and the argument is deprecated in 0.37.0 and will be removed in 0.39.0"
self.state = bnb.MatmulLtState()
diff --git a/compile_from_source.md b/compile_from_source.md
deleted file mode 100644
index 6310fd6c6..000000000
--- a/compile_from_source.md
+++ /dev/null
@@ -1,39 +0,0 @@
-# Compiling from source
-
-Basic steps.
-1. `CUDA_VERSION=XXX make [target]` where `[target]` is among `cuda92, cuda10x, cuda110, cuda11x, cuda12x, cpuonly`
-2. `python setup.py install`
-
-To run these steps you will need to have the nvcc compiler installed that comes with a CUDA installation. If you use anaconda (recommended) then you can figure out which version of CUDA you are using with PyTorch via the command `conda list | grep cudatoolkit`. Then you can install the nvcc compiler by downloading and installing the same CUDA version from the [CUDA toolkit archive](https://developer.nvidia.com/cuda-toolkit-archive).
-
-You can install CUDA locally without sudo by following the following steps:
-
-```bash
-wget https://raw.githubusercontent.com/TimDettmers/bitsandbytes/main/install_cuda.sh
-# Syntax cuda_install CUDA_VERSION INSTALL_PREFIX EXPORT_TO_BASH
-# CUDA_VERSION in {110, 111, 112, 113, 114, 115, 116, 117, 118, 120, 121, 122}
-# EXPORT_TO_BASH in {0, 1} with 0=False and 1=True
-
-# For example, the following installs CUDA 11.7 to ~/local/cuda-11.7 and exports the path to your .bashrc
-bash install_cuda.sh 117 ~/local 1
-```
-
-By default, the Makefile will look at your `CUDA_HOME` environmental variable to find your CUDA version for compiling the library. If this path is not set it is inferred from the path of your `nvcc` compiler.
-
-Either `nvcc` needs to be in path for the `CUDA_HOME` variable needs to be set to the CUDA directory root (e.g. `/usr/local/cuda`) in order for compilation to succeed
-
-If you type `nvcc` and it cannot be found, you might need to add to your path or set the CUDA_HOME variable. You can run `python -m bitsandbytes` to find the path to CUDA. For example if `python -m bitsandbytes` shows you the following:
-```
-++++++++++++++++++ /usr/local CUDA PATHS +++++++++++++++++++
-/usr/local/cuda-11.7/targets/x86_64-linux/lib/libcudart.so
-```
-You can set `CUDA_HOME` to `/usr/local/cuda-11.7`. For example, you might be able to compile like this.
-
-``CUDA_HOME=~/local/cuda-11.7 CUDA_VERSION=117 make cuda11x``
-
-
-If you have problems compiling the library with these instructions from source, please open an issue.
-
-## Compilation with Kepler
-
-Since 0.39.1 bitsandbytes installed via pip no longer provides Kepler binaries and these need to be compiled from source. Follow the steps above and instead of `cuda11x_nomatmul` etc use `cuda11x_nomatmul_kepler`
diff --git a/docs/source/_toctree.yml b/docs/source/_toctree.yml
index 043597177..ede41bb6c 100644
--- a/docs/source/_toctree.yml
+++ b/docs/source/_toctree.yml
@@ -1,8 +1,34 @@
-- sections:
+- title: Get started
+ sections:
- local: index
- title: Bits & Bytes
+ title: Index
- local: quickstart
title: Quickstart
- local: installation
title: Installation
- title: Get started
+- title: Features & Integrations
+ sections:
+ - local: quantization
+ title: Quantization
+ - local: optimizers
+ title: Optimizers
+ - local: integrations
+ title: Integrations
+ - local: algorithms
+ title: Algorithms
+- title: Support & Learning
+ sections:
+ - local: resources
+ title: Papers, resources & how to cite
+ - local: errors
+ title: Errors & Solutions
+ - local: nonpytorchcuda
+ title: Non-PyTorch CUDA
+ - local: compiling
+ title: Compilation from Source (extended)
+ - local: faqs
+ title: FAQs (Frequently Asked Questions)
+- title: Contributors Guidelines
+ sections:
+ - local: contributing
+ title: Contributing
diff --git a/docs/source/algorithms.mdx b/docs/source/algorithms.mdx
new file mode 100644
index 000000000..d9db5cb04
--- /dev/null
+++ b/docs/source/algorithms.mdx
@@ -0,0 +1,12 @@
+# Other algorithms
+_WIP: Still incomplete... Community contributions would be greatly welcome!_
+
+This is an overview of the `bnb.functional` API in `bitsandbytes` that we think would also be useful as standalone entities.
+
+## Using Int8 Matrix Multiplication
+
+For straight Int8 matrix multiplication with mixed precision decomposition you can use ``bnb.matmul(...)``. To enable mixed precision decomposition, use the threshold parameter:
+
+```py
+bnb.matmul(..., threshold=6.0)
+```
diff --git a/docs/source/compiling.mdx b/docs/source/compiling.mdx
new file mode 100644
index 000000000..fc8c58769
--- /dev/null
+++ b/docs/source/compiling.mdx
@@ -0,0 +1,41 @@
+# Compiling from Source[[compiling]]
+
+To compile from source, the CUDA Toolkit is required. Ensure `nvcc` is installed; if not, follow these steps to install it along with the CUDA Toolkit:
+
+```bash
+wget https://raw.githubusercontent.com/TimDettmers/bitsandbytes/main/install_cuda.sh
+# Use the following syntax: cuda_install CUDA_VERSION INSTALL_PREFIX EXPORT_TO_BASH
+# CUDA_VERSION options include 110 to 122
+# EXPORT_TO_BASH: 0 for False, 1 for True
+
+# Example for installing CUDA 11.7 at ~/local/cuda-11.7 and exporting the path to .bashrc:
+bash install_cuda.sh 117 ~/local 1
+```
+
+For a single compile run with a specific CUDA version, set `CUDA_HOME` to point to your CUDA installation directory. For instance, to compile using CUDA 11.7 located at `~/local/cuda-11.7`, use:
+
+```
+CUDA_HOME=~/local/cuda-11.7 CUDA_VERSION=117 make cuda11x
+```
+
+## General Compilation Steps
+
+1. Use `CUDA_VERSION=XXX make [target]` to compile, where `[target]` includes options like `cuda92`, `cuda10x`, `cuda11x`, and others.
+2. Install with `python setup.py install`.
+
+Ensure `nvcc` is available in your system. If using Anaconda, determine your CUDA version with PyTorch using `conda list | grep cudatoolkit` and match it by downloading the corresponding version from the [CUDA Toolkit Archive](https://developer.nvidia.com/cuda-toolkit-archive).
+
+To install CUDA locally without administrative rights:
+
+```bash
+wget https://raw.githubusercontent.com/TimDettmers/bitsandbytes/main/install_cuda.sh
+# Follow the same syntax and example as mentioned earlier
+```
+
+The compilation process relies on the `CUDA_HOME` environment variable to locate CUDA. If `CUDA_HOME` is unset, it will attempt to infer the location from `nvcc`. If `nvcc` is not in your path, you may need to add it or set `CUDA_HOME` manually. For example, if `python -m bitsandbytes` indicates your CUDA path as `/usr/local/cuda-11.7`, you can set `CUDA_HOME` to this path.
+
+If compilation issues arise, please report them.
+
+## Compilation for Kepler Architecture
+
+From version 0.39.1, bitsandbytes no longer includes Kepler binaries in pip installations, requiring manual compilation. Follow the general steps and use `cuda11x_nomatmul_kepler` for Kepler-targeted compilation.
diff --git a/docs/source/contributing.mdx b/docs/source/contributing.mdx
new file mode 100644
index 000000000..b28e91936
--- /dev/null
+++ b/docs/source/contributing.mdx
@@ -0,0 +1,20 @@
+# Contributors guidelines
+... stil under construction ... (feel free to propose materials, `bitsandbytes` is a community project)
+
+## Setup pre-commit hooks
+- Install pre-commit hooks with `pip install pre-commit`.
+- Run `pre-commit autoupdate` once to configure the hooks.
+- Re-run `pre-commit autoupdate` every time a new hook got added.
+
+Now all the pre-commit hooks will be automatically run when you try to commit and if they introduce some changes, you need to re-add the changed files before being able to commit and push.
+
+## Doc-string syntax
+
+We're following NumPy doc-string conventions with the only notable difference being that we use Markdown instead of Rich text format (RTF) for markup within the doc-strings.
+
+Please see the existing documentation to see how to generate autodocs.
+
+## Documentation
+- [guideline for documentation syntax](https://github.com/huggingface/doc-builder#readme)
+- images shall be uploaded via PR in the `bitsandbytes/` directory [here](https://huggingface.co/datasets/huggingface/documentation-images)
+- find the documentation builds for each PR in a link posted to the PR, such as https://moon-ci-docs.huggingface.co/docs/bitsandbytes/pr_1012/en/introduction
diff --git a/errors_and_solutions.md b/docs/source/errors.mdx
similarity index 68%
rename from errors_and_solutions.md
rename to docs/source/errors.mdx
index 5b8cbcdd5..293017173 100644
--- a/errors_and_solutions.md
+++ b/docs/source/errors.mdx
@@ -1,21 +1,22 @@
-# No kernel image available
+# Errors & Solutions
-This problem arises with the cuda version loaded by bitsandbytes is not supported by your GPU, or if you pytorch CUDA version mismatches. To solve this problem you need to debug ``$LD_LIBRARY_PATH``, ``$CUDA_HOME``, ``$PATH``. You can print these via ``echo $PATH``. You should look for multiple paths to different CUDA versions. This can include versions in your anaconda path, for example ``$HOME/anaconda3/lib``. You can check those versions via ``ls -l $HOME/anaconda3/lib/*cuda*`` or equivalent paths. Look at the CUDA versions of files in these paths. Does it match with ``nvidia-smi``?
+## No kernel image available
-If you are feeling lucky, you can also try to compile the library from source. This can be still problematic if your PATH variables have multiple cuda versions. As such, it is recommended to figure out path conflicts before you proceed with compilation.
+This problem arises with the cuda version loaded by bitsandbytes is not supported by your GPU, or if you pytorch CUDA version mismatches.
+To solve this problem you need to debug ``$LD_LIBRARY_PATH``, ``$CUDA_HOME`` as well as ``$PATH``. You can print these via ``echo $PATH``. You should look for multiple paths to different CUDA versions. This can include versions in your anaconda path, for example ``$HOME/anaconda3/lib``. You can check those versions via ``ls -l $HOME/anaconda3/lib/*cuda*`` or equivalent paths. Look at the CUDA versions of files in these paths. Does it match with ``nvidia-smi``?
-__If you encounter any other error not listed here please create an issue. This will help resolve your problem and will help out others in the future.
+If you are feeling lucky, you can also try to compile the library from source. This can be still problematic if your PATH variables have multiple cuda versions. As such, it is recommended to figure out path conflicts before you proceed with compilation.
+## `fatbinwrap`
-# fatbinwrap
+This error occurs if there is a mismatch between CUDA versions in the C++ library and the CUDA part. Make sure you have right CUDA in your `$PATH` and `$LD_LIBRARY_PATH` variable. In the conda base environment you can find the library under:
-This error occurs if there is a mismatch between CUDA versions in the C++ library and the CUDA part. Make sure you have right CUDA in your $PATH and $LD_LIBRARY_PATH variable. In the conda base environment you can find the library under:
```bash
ls $CONDA_PREFIX/lib/*cudart*
```
Make sure this path is appended to the `LD_LIBRARY_PATH` so bnb can find the CUDA runtime environment library (cudart).
-If this does not fix the issue, please try [compilation from source](compile_from_source.md) next.
+If this does not fix the issue, please try compilation from source next.
If this does not work, please open an issue and paste the printed environment if you call `make` and the associated error when running bnb.
diff --git a/docs/source/faqs.mdx b/docs/source/faqs.mdx
new file mode 100644
index 000000000..b9549e9d8
--- /dev/null
+++ b/docs/source/faqs.mdx
@@ -0,0 +1,7 @@
+# FAQs
+
+Please submit your questions in [this Github Discussion thread](https://github.com/TimDettmers/bitsandbytes/discussions/1013) if you feel that they will likely affect a lot of other users and that they haven't been sufficiently covered in the documentation.
+
+We'll pick the most generally applicable ones and post the QAs here or integrate them into the general documentation (also feel free to submit doc PRs, please).
+
+# ... under construction ...
diff --git a/docs/source/index.mdx b/docs/source/index.mdx
index 67c928309..0b033c3a9 100644
--- a/docs/source/index.mdx
+++ b/docs/source/index.mdx
@@ -1,191 +1,19 @@
-# bitsandbytes
+# `bitsandbytes`
-The bitsandbytes is a lightweight wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication (LLM.int8()), and quantization functions.
+The `bitsandbytes` library is a lightweight Python wrapper around CUDA custom functions, in particular 8-bit optimizers, matrix multiplication (LLM.int8()), and 8 + 4-bit quantization functions.
+The library includes quantization primitives for 8-bit & 4-bit operations, through `bitsandbytes.nn.Linear8bitLt` and `bitsandbytes.nn.Linear4bit` and 8bit optimizers through `bitsandbytes.optim` module.
+There are ongoing efforts to support further hardware backends, i.e. Intel CPU + GPU, AMD GPU, Apple Silicon. Windows support is on its way as well.
-Resources:
-- [8-bit Optimizer Paper](https://arxiv.org/abs/2110.02861) -- [Video](https://www.youtube.com/watch?v=IxrlHAJtqKE) -- [Docs](https://bitsandbytes.readthedocs.io/en/latest/)
+## API documentation
-- [LLM.int8() Paper](https://arxiv.org/abs/2208.07339) -- [LLM.int8() Software Blog Post](https://huggingface.co/blog/hf-bitsandbytes-integration) -- [LLM.int8() Emergent Features Blog Post](https://timdettmers.com/2022/08/17/llm-int8-and-emergent-features/)
+- [Linear4bit](quantizaton#linear4bit)
+- [Linear8bit](quantizaton#linear8bit)
+- [StableEmbedding](optimizers#stableembedding)
-## TL;DR
-**Requirements**
-Python >=3.8. Linux distribution (Ubuntu, MacOS, etc.) + CUDA > 10.0.
+# License
-(Deprecated: CUDA 10.0 is deprecated and only CUDA >= 11.0) will be supported with release 0.39.0)
-
-**Installation**:
-
-``pip install bitsandbytes``
-
-In some cases it can happen that you need to compile from source. If this happens please consider submitting a bug report with `python -m bitsandbytes` information. What now follows is some short instructions which might work out of the box if `nvcc` is installed. If these do not work see further below.
-
-Compilation quickstart:
-```bash
-git clone https://github.com/timdettmers/bitsandbytes.git
-cd bitsandbytes
-
-# CUDA_VERSIONS in {110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 120}
-# make argument in {cuda110, cuda11x, cuda12x}
-# if you do not know what CUDA you have, try looking at the output of: python -m bitsandbytes
-CUDA_VERSION=117 make cuda11x
-python setup.py install
-```
-
-**Using Int8 inference with HuggingFace Transformers**
-
-```python
-from transformers import AutoModelForCausalLM
-model = AutoModelForCausalLM.from_pretrained(
- 'decapoda-research/llama-7b-hf',
- device_map='auto',
- load_in_8bit=True,
- max_memory=f'{int(torch.cuda.mem_get_info()[0]/1024**3)-2}GB')
-```
-
-A more detailed example, can be found in [examples/int8_inference_huggingface.py](examples/int8_inference_huggingface.py).
-
-**Using 8-bit optimizer**:
-1. Comment out optimizer: ``#torch.optim.Adam(....)``
-2. Add 8-bit optimizer of your choice ``bnb.optim.Adam8bit(....)`` (arguments stay the same)
-3. Replace embedding layer if necessary: ``torch.nn.Embedding(..) -> bnb.nn.Embedding(..)``
-
-
-**Using 8-bit Inference**:
-1. Comment out torch.nn.Linear: ``#linear = torch.nn.Linear(...)``
-2. Add bnb 8-bit linear light module: ``linear = bnb.nn.Linear8bitLt(...)`` (base arguments stay the same)
-3. There are two modes:
- - Mixed 8-bit training with 16-bit main weights. Pass the argument ``has_fp16_weights=True`` (default)
- - Int8 inference. Pass the argument ``has_fp16_weights=False``
-4. To use the full LLM.int8() method, use the ``threshold=k`` argument. We recommend ``k=6.0``.
-```python
-# LLM.int8()
-linear = bnb.nn.Linear8bitLt(dim1, dim2, bias=True, has_fp16_weights=False, threshold=6.0)
-# inputs need to be fp16
-out = linear(x.to(torch.float16))
-```
-
-
-## Features
-- 8-bit Matrix multiplication with mixed precision decomposition
-- LLM.int8() inference
-- 8-bit Optimizers: Adam, AdamW, RMSProp, LARS, LAMB, Lion (saves 75% memory)
-- Stable Embedding Layer: Improved stability through better initialization, and normalization
-- 8-bit quantization: Quantile, Linear, and Dynamic quantization
-- Fast quantile estimation: Up to 100x faster than other algorithms
-
-## Requirements & Installation
-
-Requirements: anaconda, cudatoolkit, pytorch
-
-Hardware requirements:
- - LLM.int8(): NVIDIA Turing (RTX 20xx; T4) or Ampere GPU (RTX 30xx; A4-A100); (a GPU from 2018 or newer).
- - 8-bit optimizers and quantization: NVIDIA Kepler GPU or newer (>=GTX 78X).
-
-Supported CUDA versions: 10.2 - 12.0
-
-The bitsandbytes library is currently only supported on Linux distributions. Windows is not supported at the moment.
-
-The requirements can best be fulfilled by installing pytorch via anaconda. You can install PyTorch by following the ["Get Started"](https://pytorch.org/get-started/locally/) instructions on the official website.
-
-To install run:
-
-``pip install bitsandbytes``
-
-## Using bitsandbytes
-
-### Using Int8 Matrix Multiplication
-
-For straight Int8 matrix multiplication with mixed precision decomposition you can use ``bnb.matmul(...)``. To enable mixed precision decomposition, use the threshold parameter:
-```python
-bnb.matmul(..., threshold=6.0)
-```
-
-For instructions how to use LLM.int8() inference layers in your own code, see the TL;DR above or for extended instruction see [this blog post](https://huggingface.co/blog/hf-bitsandbytes-integration).
-
-### Using the 8-bit Optimizers
-
-With bitsandbytes 8-bit optimizers can be used by changing a single line of code in your codebase. For NLP models we recommend also to use the StableEmbedding layers (see below) which improves results and helps with stable 8-bit optimization. To get started with 8-bit optimizers, it is sufficient to replace your old optimizer with the 8-bit optimizer in the following way:
-```python
-import bitsandbytes as bnb
-
-# adam = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # comment out old optimizer
-adam = bnb.optim.Adam8bit(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # add bnb optimizer
-adam = bnb.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995), optim_bits=8) # equivalent
-
-
-torch.nn.Embedding(...) -> bnb.nn.StableEmbedding(...) # recommended for NLP models
-```
-
-Note that by default all parameter tensors with less than 4096 elements are kept at 32-bit even if you initialize those parameters with 8-bit optimizers. This is done since such small tensors do not save much memory and often contain highly variable parameters (biases) or parameters that require high precision (batch norm, layer norm). You can change this behavior like so:
-```python
-# parameter tensors with less than 16384 values are optimized in 32-bit
-# it is recommended to use multiplies of 4096
-adam = bnb.optim.Adam8bit(model.parameters(), min_8bit_size=16384)
-```
-
-### Change Bits and other Hyperparameters for Individual Parameters
-
-If you want to optimize some unstable parameters with 32-bit Adam and others with 8-bit Adam, you can use the `GlobalOptimManager`. With this, we can also configure specific hyperparameters for particular layers, such as embedding layers. To do that, we need two things: (1) register the parameter while they are still on the CPU, (2) override the config with the new desired hyperparameters (anytime, anywhere). See our [guide](howto_config_override.md) for more details
-
-### Fairseq Users
-
-To use the Stable Embedding Layer, override the respective `build_embedding(...)` function of your model. Make sure to also use the `--no-scale-embedding` flag to disable scaling of the word embedding layer (nor replaced with layer norm). You can use the optimizers by replacing the optimizer in the respective file (`adam.py` etc.).
-
-## Release and Feature History
-
-For upcoming features and changes and full history see [Patch Notes](CHANGELOG.md).
-
-## Errors
-
-1. RuntimeError: CUDA error: no kernel image is available for execution on the device. [Solution](errors_and_solutions.md#No-kernel-image-available)
-2. __fatbinwrap_.. [Solution](errors_and_solutions.md#fatbinwrap_)
-
-## Compile from source
-To compile from source, you need an installation of CUDA. If `nvcc` is not installed, you can install the CUDA Toolkit with nvcc through the following commands.
-
-```bash
-wget https://raw.githubusercontent.com/TimDettmers/bitsandbytes/main/install_cuda.sh
-# Syntax cuda_install CUDA_VERSION INSTALL_PREFIX EXPORT_TO_BASH
-# CUDA_VERSION in {110, 111, 112, 113, 114, 115, 116, 117, 118, 120, 121, 122}
-# EXPORT_TO_BASH in {0, 1} with 0=False and 1=True
-
-# For example, the following installs CUDA 11.7 to ~/local/cuda-11.7 and exports the path to your .bashrc
-bash install_cuda.sh 117 ~/local 1
-```
-
-To use a specific CUDA version just for a single compile run, you can set the variable `CUDA_HOME`, for example the following command compiles `libbitsandbytes_cuda117.so` using compiler flags for cuda11x with the cuda version at `~/local/cuda-11.7`:
-
-``CUDA_HOME=~/local/cuda-11.7 CUDA_VERSION=117 make cuda11x``
-
-For more detailed instruction, please follow the [compile_from_source.md](compile_from_source.md) instructions.
-
-## License
-
-The majority of bitsandbytes is licensed under MIT, however portions of the project are available under separate license terms: Pytorch is licensed under the BSD license.
+The majority of bitsandbytes is licensed under MIT, however portions of the project are available under separate license terms, as the parts adapted from Pytorch are licensed under the BSD license.
We thank Fabio Cannizzo for his work on [FastBinarySearch](https://github.com/fabiocannizzo/FastBinarySearch) which we use for CPU quantization.
-
-## How to cite us
-If you found this library and found LLM.int8() useful, please consider citing our work:
-
-```bibtex
-@article{dettmers2022llmint8,
- title={LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale},
- author={Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke},
- journal={arXiv preprint arXiv:2208.07339},
- year={2022}
-}
-```
-
-For 8-bit optimizers or quantization routines, please consider citing the following work:
-
-```bibtex
-@article{dettmers2022optimizers,
- title={8-bit Optimizers via Block-wise Quantization},
- author={Dettmers, Tim and Lewis, Mike and Shleifer, Sam and Zettlemoyer, Luke},
- journal={9th International Conference on Learning Representations, ICLR},
- year={2022}
-}
-```
diff --git a/docs/source/installation.mdx b/docs/source/installation.mdx
index 50031acf7..ecdcdeb28 100644
--- a/docs/source/installation.mdx
+++ b/docs/source/installation.mdx
@@ -5,6 +5,12 @@ Note currently `bitsandbytes` is only supported on CUDA GPU hardwares, support f
+## Hardware requirements:
+ - LLM.int8(): NVIDIA Turing (RTX 20xx; T4) or Ampere GPU (RTX 30xx; A4-A100); (a GPU from 2018 or newer).
+ - 8-bit optimizers and quantization: NVIDIA Kepler GPU or newer (>=GTX 78X).
+
+Supported CUDA versions: 10.2 - 12.0 #TODO: check currently supported versions
+
## Linux
### From Pypi
@@ -21,14 +27,16 @@ CUDA_VERSION=XXX make cuda12x
python setup.py install
```
-with `XXX` being your CUDA version, for <12.0 call `make cuda 11x`
+with `XXX` being your CUDA version, for <12.0 call `make cuda 11x`. Note support for non-CUDA GPUs (e.g. AMD, Intel), is also coming soon.
+
+For a more detailed compilation guide, head to the [dedicated page on the topic](./compiling)
## Windows
-Currently for Windows users, you need to build bitsandbytes from source
+Currently for Windows users, you need to build bitsandbytes from source:
```bash
git clone https://github.com/TimDettmers/bitsandbytes.git && cd bitsandbytes/
@@ -39,5 +47,15 @@ python -m build --wheel
Big thanks to [wkpark](https://github.com/wkpark), [Jamezo97](https://github.com/Jamezo97), [rickardp](https://github.com/rickardp), [akx](https://github.com/akx) for their amazing contributions to make bitsandbytes compatible with Windows.
+For a more detailed compilation guide, head to the [dedicated page on the topic](./compiling)
+
+
+
+## MacOS
+
+Mac support is still a work in progress. Please make sure to check out the [Apple Silicon implementation coordination issue](https://github.com/TimDettmers/bitsandbytes/issues/1020) to get notified about the discussions and progress with respect to MacOS integration.
+
+
+
diff --git a/docs/source/integrations.mdx b/docs/source/integrations.mdx
new file mode 100644
index 000000000..7857abf4c
--- /dev/null
+++ b/docs/source/integrations.mdx
@@ -0,0 +1,42 @@
+# Transformers
+
+With Transformers it's very easy to load any model in 4 or 8-bit, quantizing them on the fly with bitsandbytes primitives.
+
+Please review the [bitsandbytes section in the Accelerate docs](https://huggingface.co/docs/transformers/v4.37.2/en/quantization#bitsandbytes).
+
+Details about the BitsAndBytesConfig can be found here](https://huggingface.co/docs/transformers/v4.37.2/en/main_classes/quantization#transformers.BitsAndBytesConfig).
+
+## Beware: bf16 is optional compute data type
+If your hardware supports it, `bf16` is the optimal compute dtype. The default is `float32` for backward compatibility and numerical stability. `float16` often leads to numerical instabilities, but `bfloat16` provides the benefits of both worlds: numerical stability and significant computation speedup. Therefore, be sure to check if your hardware supports `bf16` and configure it using the `bnb_4bit_compute_dtype` parameter in BitsAndBytesConfig:
+
+```py
+import torch
+from transformers import BitsAndBytesConfig
+
+quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16)
+```
+
+# PEFT
+With `PEFT`, you can use QLoRA out of the box with `LoraConfig` and a 4-bit base model.
+
+Please review the [bitsandbytes section in the Accelerate docs](https://huggingface.co/docs/peft/developer_guides/quantization#quantize-a-model).
+
+# Accelerate
+
+Bitsandbytes is also easily usable from within Accelerate.
+
+Please review the [bitsandbytes section in the Accelerate docs](https://huggingface.co/docs/accelerate/en/usage_guides/quantization).
+
+# Trainer for the optimizers
+
+You can use any of the 8-bit and/or paged optimizers by simple passing them to the `transformers.Trainer` class on intialization.All bnb optimizers are supported by passing the correct string in `TrainingArguments`'s `optim` attribute - e.g. (`paged_adamw_32bit`).
+
+See the [official API docs for reference](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.Trainer).
+
+Here we point out to relevant doc sections in transformers / peft / Trainer + very briefly explain how these are integrated:
+e.g. for transformers state that you can load any model in 8-bit / 4-bit precision, for PEFT, you can use QLoRA out of the box with `LoraConfig` + 4-bit base model, for Trainer: all bnb optimizers are supported by passing the correct string in `TrainingArguments`'s `optim` attribute - e.g. (`paged_adamw_32bit`):
+
+# Blog posts
+
+- [Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA](https://huggingface.co/blog/4bit-transformers-bitsandbytes)
+- [A Gentle Introduction to 8-bit Matrix Multiplication for transformers at scale using Hugging Face Transformers, Accelerate and bitsandbytes](https://huggingface.co/blog/hf-bitsandbytes-integration)
diff --git a/how_to_use_nonpytorch_cuda.md b/docs/source/nonpytorchcuda.mdx
similarity index 76%
rename from how_to_use_nonpytorch_cuda.md
rename to docs/source/nonpytorchcuda.mdx
index 566b0170e..099a6961b 100644
--- a/how_to_use_nonpytorch_cuda.md
+++ b/docs/source/nonpytorchcuda.mdx
@@ -1,6 +1,6 @@
-## How to use a CUDA version that is different from PyTorch
+# How to use a CUDA version that is different from PyTorch
-Some features of bitsandbytes may need a newer CUDA version than regularly supported by PyTorch binaries from conda / pip. In that case you can use the following instructions to load a precompiled bitsandbytes binary that works for you.
+Some features of `bitsandbytes` may need a newer CUDA version than regularly supported by PyTorch binaries from conda / pip. In that case you can use the following instructions to load a precompiled `bitsandbytes` binary that works for you.
## Installing or determining the CUDA installation
@@ -12,7 +12,7 @@ Determine the path of the CUDA version that you want to use. Common paths paths
where XX.X is the CUDA version number.
-You can also install CUDA version that you need locally with a script provided by bitsandbytes as follows:
+You can also install CUDA version that you need locally with a script provided by `bitsandbytes` as follows:
```bash
wget https://raw.githubusercontent.com/TimDettmers/bitsandbytes/main/install_cuda.sh
@@ -25,7 +25,7 @@ wget https://raw.githubusercontent.com/TimDettmers/bitsandbytes/main/install_cud
bash cuda_install.sh 117 ~/local 1
```
-## Setting the environmental variables BNB_CUDA_VERSION, and LD_LIBRARY_PATH
+## Setting the environmental variables `BNB_CUDA_VERSION`, and `LD_LIBRARY_PATH`
To manually override the PyTorch installed CUDA version you need to set to variable, like so:
diff --git a/docs/source/optimizers.mdx b/docs/source/optimizers.mdx
new file mode 100644
index 000000000..18d20de1d
--- /dev/null
+++ b/docs/source/optimizers.mdx
@@ -0,0 +1,190 @@
+# Introduction: 8-bit optimizers
+
+With 8-bit optimizers, larger models can be finetuned with the same GPU memory compared to standard 32-bit optimizer training. 8-bit optimizers are a drop-in replacement for regular optimizers, with the following properties:
+
+- Faster (e.g. 4x faster than regular Adam)
+- 75% less memory, same performance
+- No hyperparameter tuning needed
+
+8-bit optimizers are mostly useful to finetune large models that did not fit into memory before. They also make it easier to pretrain larger models and have great synergy with sharded data parallelism. 8-bit Adam, for example, is already used across multiple teams in Facebook. This optimizer saves a ton of memory at no accuracy hit.
+
+Generally, our 8-bit optimizers have three components:
+1. **block-wise quantization** isolates outliers and distributes the error more equally over all bits,
+2. **dynamic quantization** quantizes both small and large values with high precision,
+3. a **stable embedding layer** improves stability during optimization for models with word embeddings.
+
+With these components, performing an optimizer update with 8-bit states is straightforward and for GPUs, this makes 8-bit optimizers way faster than regular 32-bit optimizers. [Further details below](#research-background)
+
+We feature 8-bit `Adagrad`, `Adam`, `AdamW`, `LAMB`, `LARS`, `Lion`, `RMSprop` and `SGD` (momentum).
+
+## Caveats
+
+8-bit optimizers reduce the memory footprint and accelerate optimization on a wide range of tasks. However, since 8-bit optimizers reduce only the memory footprint proportional to the number of parameters, **models that use large amounts of activation memory, such as convolutional networks, have few benefits from using 8-bit optimizers**. Thus, 8-bit optimizers are most beneficial for training or finetuning models with many parameters on highly memory-constrained GPUs.
+
+## Usage
+
+It only requires a two-line code change to get started.
+```diff
+import bitsandbytes as bnb
+
+- adam = torch.optim.Adam(...)
++ adam = bnb.optim.Adam8bit(...)
+
+# recommended for NLP models
+- before: torch.nn.Embedding(...)
++ bnb.nn.StableEmbedding(...)
+```
+
+The arguments passed are the same as standard Adam. For NLP models we recommend to also use the StableEmbedding layers which improves results and helps with stable 8-bit optimization.
+
+Note that by default all parameter tensors with less than 4096 elements are kept at 32-bit even if you initialize those parameters with 8-bit optimizers. This is done since such small tensors do not save much memory and often contain highly variable parameters (biases) or parameters that require high precision (batch norm, layer norm). You can change this behavior like so:
+
+```py
+# For parameter tensors with less than 16384 values are optimized in 32-bit
+# it is recommended to use multiplies of 4096:
+adam = bnb.optim.Adam8bit(model.parameters(), min_8bit_size=16384)
+```
+
+Some more examples of how you can replace your old optimizer with the 8-bit optimizer:
+
+```diff
+import bitsandbytes as bnb
+
+- adam = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # comment out old optimizer
++ adam = bnb.optim.Adam8bit(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # add bnb optimizer
+
+# use 32-bit Adam with 5th percentile clipping
++ adam = bnb.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995), optim_bits=32, percentile_clipping=5)
+- adam = torch.optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.995)) # comment out old optimizer
+```
+
+## Overview of supported 8-bit optimizers
+
+Currently, `bitsandbytes` supports the following optimizers:
+
+- `Adagrad`, `Adagrad8bit`, `Adagrad32bit`
+- `Adam`, `Adam8bit`, `Adam32bit`, `PagedAdam`, `PagedAdam8bit`, `PagedAdam32bit`
+- `AdamW`, `AdamW8bit`, `AdamW32bit`, `PagedAdamW`, `PagedAdamW8bit`, `PagedAdamW32bit`
+- `LAMB`, `LAMB8bit`, `LAMB32bit`
+- `LARS`, `LARS8bit`, `LARS32bit`, `PytorchLARS`
+- `Lion`, `Lion8bit`, `Lion32bit`, `PagedLion`, `PagedLion8bit`, `PagedLion32bit`
+- `RMSprop`, `RMSprop8bit`, `RMSprop32bit`
+- `SGD`, `SGD8bit`, `SGD32bit`
+
+Additionally, for cases in which you want to optimize some unstable parameters with 32-bit Adam and others with 8-bit Adam, you can use the `GlobalOptimManager`, [as explained in greater detail below](#optim_manager).
+
+Find the API docs [here](#optim_api_docs) (still under construction).
+
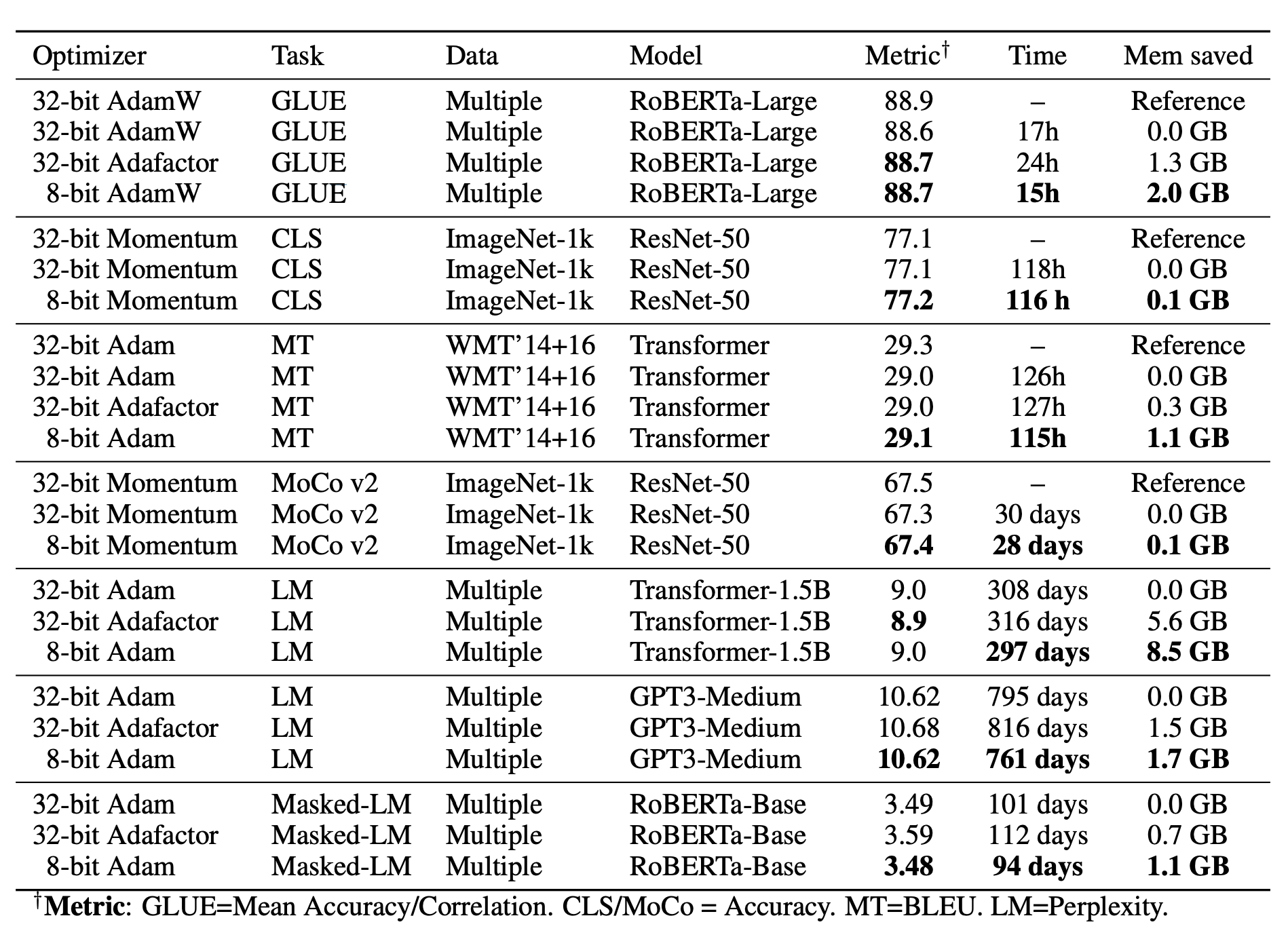
+## Overview of expected gains
+
+
+
+
+

+