diff --git a/docs/eks/gpu-monitoring.md b/docs/eks/gpu-monitoring.md
index bfc12c87..8514654d 100644
--- a/docs/eks/gpu-monitoring.md
+++ b/docs/eks/gpu-monitoring.md
@@ -36,6 +36,3 @@ EOF
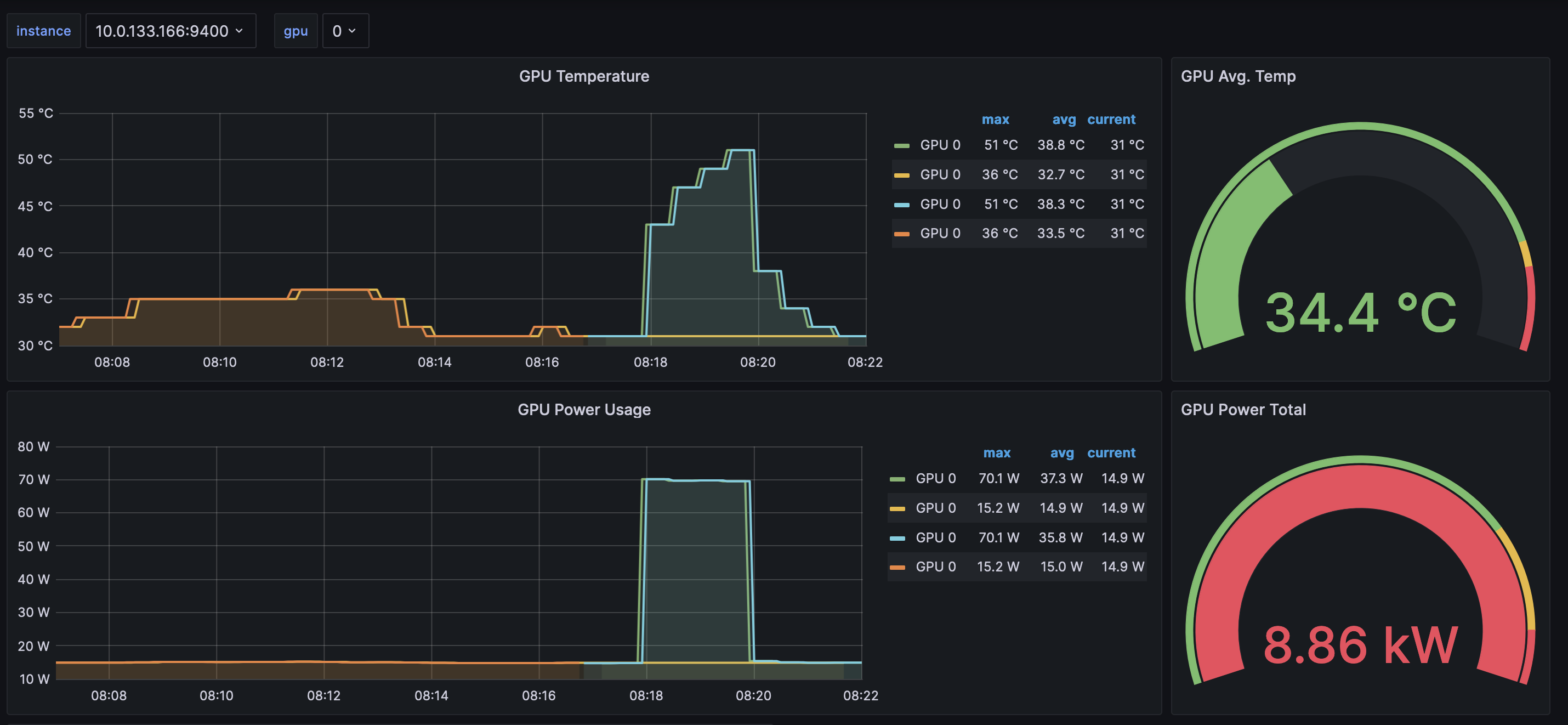
After producing the metrics they should populate the DCGM exporter dashboard:
-
-
-
diff --git a/modules/eks-monitoring/README.md b/modules/eks-monitoring/README.md
index 5116546d..2899667e 100644
--- a/modules/eks-monitoring/README.md
+++ b/modules/eks-monitoring/README.md
@@ -61,6 +61,7 @@ See examples using this Terraform modules in the **Amazon EKS** section of [this
| [kubectl_manifest.flux_gitrepository](https://registry.terraform.io/providers/alekc/kubectl/latest/docs/resources/manifest) | resource |
| [kubectl_manifest.flux_kustomization](https://registry.terraform.io/providers/alekc/kubectl/latest/docs/resources/manifest) | resource |
| [kubectl_manifest.kubeproxy_monitoring_dashboard](https://registry.terraform.io/providers/alekc/kubectl/latest/docs/resources/manifest) | resource |
+| [kubectl_manifest.nvidia_monitoring_dashboards](https://registry.terraform.io/providers/alekc/kubectl/latest/docs/resources/manifest) | resource |
| [aws_caller_identity.current](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/caller_identity) | data source |
| [aws_eks_cluster.eks_cluster](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/eks_cluster) | data source |
| [aws_partition.current](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/partition) | data source |
@@ -93,6 +94,7 @@ See examples using this Terraform modules in the **Amazon EKS** section of [this
| [enable\_managed\_prometheus](#input\_enable\_managed\_prometheus) | Creates a new Amazon Managed Service for Prometheus Workspace | `bool` | `true` | no |
| [enable\_nginx](#input\_enable\_nginx) | Enable NGINX workloads monitoring, alerting and default dashboards | `bool` | `false` | no |
| [enable\_node\_exporter](#input\_enable\_node\_exporter) | Enables or disables Node exporter. Disabling this might affect some data in the dashboards | `bool` | `true` | no |
+| [enable\_nvidia\_monitoring](#input\_enable\_nvidia\_monitoring) | Enables monitoring of nvidia metrics | `bool` | `true` | no |
| [enable\_recording\_rules](#input\_enable\_recording\_rules) | Enables or disables Managed Prometheus recording rules | `bool` | `true` | no |
| [enable\_tracing](#input\_enable\_tracing) | Enables tracing with OTLP traces receiver to X-Ray | `bool` | `true` | no |
| [flux\_config](#input\_flux\_config) | FluxCD configuration | object({
create_namespace = bool
k8s_namespace = string
helm_chart_name = string
helm_chart_version = string
helm_release_name = string
helm_repo_url = string
helm_settings = map(string)
helm_values = map(any)
}) | {
"create_namespace": true,
"helm_chart_name": "flux2",
"helm_chart_version": "2.12.2",
"helm_release_name": "observability-fluxcd-addon",
"helm_repo_url": "https://fluxcd-community.github.io/helm-charts",
"helm_settings": {},
"helm_values": {},
"k8s_namespace": "flux-system"
} | no |
@@ -127,6 +129,7 @@ See examples using this Terraform modules in the **Amazon EKS** section of [this
| [managed\_prometheus\_workspace\_region](#input\_managed\_prometheus\_workspace\_region) | Amazon Managed Prometheus Workspace's Region | `string` | `null` | no |
| [ne\_config](#input\_ne\_config) | Node exporter configuration | object({
create_namespace = bool
k8s_namespace = string
helm_chart_name = string
helm_chart_version = string
helm_release_name = string
helm_repo_url = string
helm_settings = map(string)
helm_values = map(any)
scrape_interval = string
scrape_timeout = string
}) | {
"create_namespace": true,
"helm_chart_name": "prometheus-node-exporter",
"helm_chart_version": "4.24.0",
"helm_release_name": "prometheus-node-exporter",
"helm_repo_url": "https://prometheus-community.github.io/helm-charts",
"helm_settings": {},
"helm_values": {},
"k8s_namespace": "prometheus-node-exporter",
"scrape_interval": "60s",
"scrape_timeout": "60s"
} | no |
| [nginx\_config](#input\_nginx\_config) | Configuration object for NGINX monitoring | object({
enable_alerting_rules = bool
enable_recording_rules = bool
enable_dashboards = bool
scrape_sample_limit = number
flux_gitrepository_name = string
flux_gitrepository_url = string
flux_gitrepository_branch = string
flux_kustomization_name = string
flux_kustomization_path = string
grafana_dashboard_url = string
prometheus_metrics_endpoint = string
}) | `null` | no |
+| [nvidia\_monitoring\_config](#input\_nvidia\_monitoring\_config) | Config object for nvidia monitoring | object({
flux_gitrepository_name = string
flux_gitrepository_url = string
flux_gitrepository_branch = string
flux_kustomization_name = string
flux_kustomization_path = string
}) | `null` | no |
| [prometheus\_config](#input\_prometheus\_config) | Controls default values such as scrape interval, timeouts and ports globally | object({
global_scrape_interval = string
global_scrape_timeout = string
}) | {
"global_scrape_interval": "120s",
"global_scrape_timeout": "15s"
} | no |
| [tags](#input\_tags) | Additional tags (e.g. `map('BusinessUnit`,`XYZ`) | `map(string)` | `{}` | no |
| [target\_secret\_name](#input\_target\_secret\_name) | Target secret in Kubernetes to store the Grafana API Key Secret | `string` | `"grafana-admin-credentials"` | no |