数据准备
本节介绍Euler的图数据模型以及如何准备一份Euler可以读取的图数据。
Euler支持带权异构属性图。在Euler中,一张图的基本元素是顶点(node)和边(edge)。其中顶点和边都具有类型(type)和权重(weight)。边是有向的,一条边由:起点、终点、类型三者标识,即相同的两点之间可以同时具有多条不同类型的边。
同时,顶点和边都可以拥有属性(feature),Euler将属性分为三种:float、uint64、binary。在算法包中,这三类属性会分别被识别为稠密特征、稀疏特征,和二进制特征。下面是一个简单的例子:
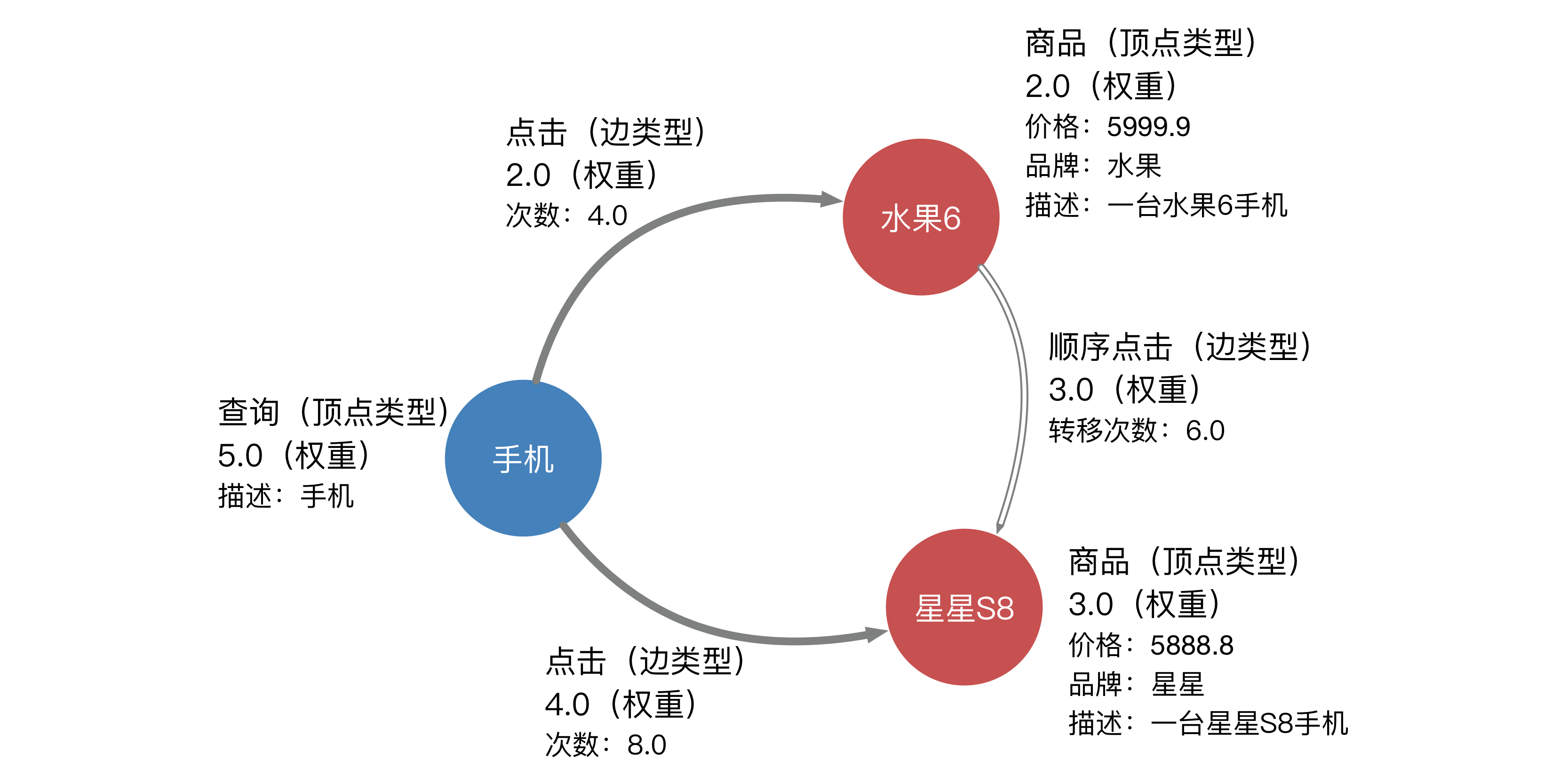
Euler中的顶点以uint64标识,顶点类型、边类型,以及点边上的三种属性均独自从0开始以连续的非负整数命名。对于例子中的图,我们需要将点边及其类型和属性归类编号,得到一张Euler可以识别的图:
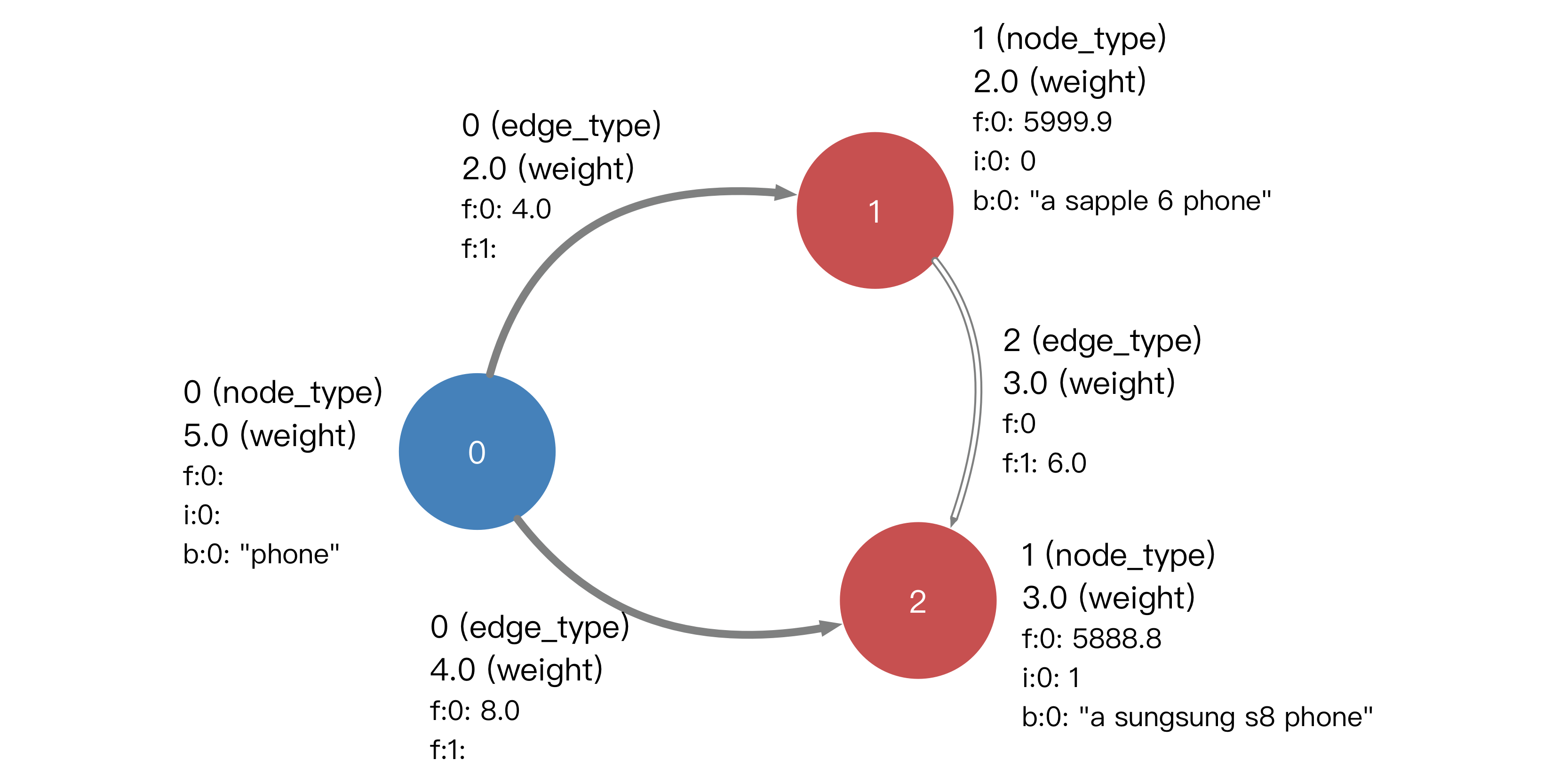
Euler中的图数据格式有两种:明文格式和二进制格式。明文格式基于JSON,一般用于预处理准备和调试阅读,其中包括图数据以及元信息。二进制格式是经过优化的紧凑存储,用于在启动图引擎时快速加载图数据。在使用图引擎之前,明文格式的图数据需要先被转换成二进制格式。
为了高效的加载与查询图中每个顶点相关的边,Euler在图数据和引擎中都以邻接表的方式存储图,即一个顶点与其出边存储在一起,称为一个Block。在明文格式中,一个Block是一个有固定结构的合法的JSON,语法如下:
{
"node_id": "顶点编号,int",
"node_type": "顶点类型,int",
"node_weight": "顶点权重,float",
"neighbor": {"边类型": {"邻居id": "权重", "...": "..."}, "...": "..."},
"uint64_feature": {"属性编号": ["int", "..."], "...": "..."},
"float_feature": {"属性编号": ["float", "..."], "...": "..."},
"binary_feature": {"属性编号": "string", "...": "..."},
"edge":[{
"src_id": "起点id, int",
"dst_id": "终点id, int",
"edge_type": "边类型, int",
"weight": "边权重, float",
"uint64_feature": {"属性编号": ["int", "..."], "...": ["int", "..."]},
"float_feature": {"属性编号": ["float", "..."], "...": ["float", "..."]},
"binary_feature": {"属性编号": "string", "...": "..."}
}, "..."]
}在明文格式中,图数据文件的每一行会被解析成一个Block。例子中图可以编写成如下的明文格式:
{"node_id":0,"node_type":0,"node_weight":5.0,"neighbor":{"0":{"1":2.0,"2":4.0},"1":{}},"uint64_feature":{"0":[]},"float_feature":{"0":[]},"binary_feature":{"0":"phone"},"edge":[{"src_id":0,"dst_id":1,"edge_type":0,"weight":2.0,"uint64_feature":{},"float_feature":{"0":[4.0],"1":[]},"binary_feature":{}},{"src_id":0,"dst_id":2,"edge_type":0,"weight":4.0,"uint64_feature":{},"float_feature":{"0":[8.0],"1":[]},"binary_feature":{}}]}
{"node_id":1,"node_type":1,"node_weight":2.0,"neighbor":{"0":{},"1":{"2":3.0}},"uint64_feature":{"0":[0]},"float_feature":{"0":[5999.9]},"binary_feature":{"0":"a sapple 6 phone"},"edge":[{"src_id":1,"dst_id":2,"edge_type":1,"weight":3.0,"uint64_feature":{},"float_feature":{"0":[],"1":[6.0]},"binary_feature":{}}]}
{"node_id":2,"node_type":1,"node_weight":3.0,"neighbor":{"0":{},"1":{}},"uint64_feature":{"0":[1]},"float_feature":{"0":[5888.8]},"binary_feature":{"0":"a sungsung s8 phone"},"edge":[]}元信息文件描述图中点边类型的个数与点边各自三种属性的个数。例子中的图的元信息可以描述为:
{
"node_type_num": 2,
"edge_type_num": 2,
"node_uint64_feature_num": 1,
"node_float_feature_num": 1,
"node_binary_feature_num": 1,
"edge_uint64_feature_num": 0,
"edge_float_feature_num": 2,
"edge_binary_feature_num": 0
}Euler中提供了相关工具可以将一个明文图数据文件转换为一个二进制图数据文件。
当用户数据量比较少的时候,可以直接使用euler中包含的转换工具将明文图数据转化为二进制数据。
python -m euler.tools -c simple_meta.json -i simple_graph.json -o simple_graph.dat其中simple_meta.json为元信息文件,simple_graph.json为图数据文件,输出的二进制文件为simple_graph.dat。在启动图引擎时,用户需要指定一个图数据目录,目录中的所有以*.dat*为后缀的文件都会被当作图数据文件加载。
当用户有大量的明文图数据需要转换为二进制存储时,可以使用map reduce来完成。我们提供了相关的Java类来帮助这部分用户进行开发。类的源代码在Euler/tools/graph_data_parser下面,主要可以使用其中的BLockParser.java来将一个Block明文字符串转化为byte[]。主要步骤如下:
- 用FastJson库转换meta JSON字符串为meta对象
Meta meta = JSON.parseObject(metaJSONString, Meta.class);- 用FastJson库转换block JSON字符串为block对象
Block block = JSON.parseObject(blockJSONString, Block.class);- 将block对象转化为byte[]数组
byte[] bytes = new BlockParser(meta).BlockJsonToBytes(block)当进行分布式训练时,用户需要将图数据分片(partition)到多个文件中,每个图引擎的实例只会加载一部分的文件。用户需要隐式地指定一个分片数(num_partitions)。分片数需要大于或等于图引擎实例的个数,一般会设置为100以上的值。
具体地,图数据目录中的文件需要以xxx_<par_idx>.dat的形式命名。其中*<par_idx>为分片索引,目录中最大的<par_idx>* + 1为该份图数据的分片数。同一个分片索引可以对应于多个图数据文件,即所有以相同*<par_idx>.dat为后缀的文件组成一个分片。每个分片只包含node_id % num_partitions = par_idx*的顶点。
如果我们将例子中的图分片到两个分片中,则图数据的形式可为:
# simple_graph_0.dat
{"node_id":0,"...":"..."}
{"node_id":2,"...":"..."}
# simple_graph_1.dat
{"node_id":1,"...":"..."}