
阅读本文的其他语言版本:English。
在次 Code Pattern 中,我们将使用 Node.js 和 Watson Conversation 来创建一个聊天机器人。通过使用 Natural Language Understanding 来识别实体并使用 Tone Analyzer 来检测客户情绪,从而改进 Conversation 流程。要获取 FAQ,请调用 Discovery 服务,使用段落检索从文档集合中提取答案。
读者完成本 Code Pattern 后,将会掌握如何:
- 使用 Watson Conversation 和 Node.js,创建通过 Web UI 对话的聊天机器人
- 使用 Watson Discovery 和段落检索在 FAQ 文档中查找答案
- 使用 Watson Tone Analyzer 来检测对话中的情绪
- 使用 Watson Natural Language Understanding 来识别实体

1.将 FAQ 文档添加到 Discovery 集合中。
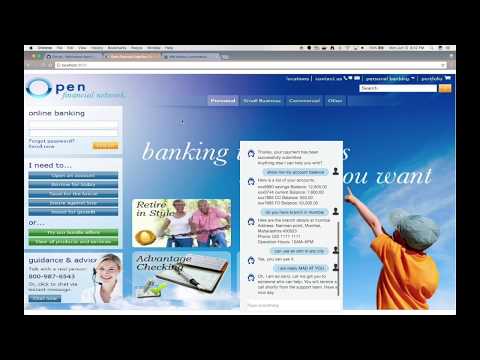
2.用户通过应用程序 UI 与聊天机器人进行交互。
3.使用 Tone Analyzer 来处理用户输入,以检测愤怒情绪。在上下文中添加愤怒评分。
4.使用 Natural Language Understanding (NLU) 来处理用户输入。使用 NLU 检测到的实体和关键字(例如,地点)来充实上下文。
5.将输入和经过充实的上下文发送到 Conversation。Conversation 识别意图、实体和对话路径。它使用回复和/或操作予以响应。
6.(可选)由应用程序执行的请求操作。这可能包含以下操作之一:
- 从银行服务中查找其他信息以附加到回复中
- 使用 Discovery 以利用来自 FAQ 文档的答案作出回复
想要进一步改进您的 Watson 应用程序?正在考虑使用 Watson 品牌资产?加入 With Watson 计划,此计划提供独家品牌、营销和技术资源,帮助增强和加速您的 Watson 嵌入式商业解决方案。
- IBM Watson Conversation:跨多种移动设备、消息传递平台甚至是物理机器人来构建、测试和部署机器人或虚拟代理。
- IBM Watson Discovery:一个认知搜索和内容分析引擎,供应用程序用来识别模式、趋势和可行洞察。
- IBM Watson Natural Language Understanding:使用 Natural Language Understanding 来分析文本,从内容中提取元数据,比如概念、实体、关键词、类别、情绪、情感、关系和语义角色。
- IBM Watson Tone Analyzer:使用语言分析来检测书面文本中的交流语气。
- Node.js:异步事件驱动的 JavaScript 运行时,旨在构建可扩展的应用程序。
使用 Deploy to IBM Cloud 按钮或在本地创建服务并运行。

1.按上面的 Deploy to IBM Cloud 按钮,然后单击 Deploy。
2.在 Toolchains 中,单击 Delivery Pipeline 以观看应用程序部署流程。完成部署后,可通过单击 View app 来查看该应用程序。

3.要查看为本 Code Pattern 创建和配置的应用程序和服务,可以使用 IBM Cloud 仪表板。此应用程序命名为 watson-banking-chatbot(含有独特后缀)。可使用 wbc- 前缀来创建并轻松识别以下服务:
* wbc-conversation-service
* wbc-discovery-service
* wbc-natural-language-understanding-service
* wbc-tone-analyzer-service
注:只有在本地运行(而不是使用
Deploy to IBM Cloud按钮)时,才需要执行这些步骤。
1.克隆存储库
5.配置凭证
6.运行应用程序
在本地克隆 watson-banking-chatbot。在终端中,运行:
$ git clone https://github.com/IBM/watson-banking-chatbot
我们将使用文件 data/conversation/workspaces/banking.json 和文件夹
data/conversation/workspaces/
创建以下服务:
启动 Watson Conversation 工具。使用右侧的 import 图标按钮

找到 data/conversation/workspaces/banking.json 的本地版本,并选择
Import。单击新工作空间的上下文菜单并选择 View details
来查找 Workspace ID。保存此 ID 以供稍后使用。

(可选)如果你要查看对话框,请选中工作空间,然后选择 Dialog 选项卡,以下是对话片段:

启动 Watson Discovery 工具。创建新数据集合 并为该数据集合提供一个唯一的名称。

保存 environment_id 和 collection_id,以供下一步中的
.env文件使用。
在 Add data to this collection 下,使用 Drag and drop your documents here or browse from computer 挑选 data/discovery/docs 中五个文档的内容作为种子数据。
通过选择每一项服务的“Service Credentials”选项,
可在 IBM Cloud 中的 Services 菜单中找到
IBM Cloud 服务(Conversation、Discovery、Tone Analyzer 和 Natural Language Understanding)的凭证。
在前面的步骤(DISCOVERY_COLLECTION_ID、DISCOVERY_ENVIRONMENT_ID 和
WORKSPACE_ID)中收集了Conversation 和 Discovery 的其他设置。
将 env.sample 复制到 .env。
$ cp env.sample .env
使用必要的设置来编辑 .env 文件。
# Replace the credentials here with your own.
# Rename this file to .env before starting the app.
# Watson Conversation
CONVERSATION_USERNAME=<add_conversation_username>
CONVERSATION_PASSWORD=<add_conversation_password>
WORKSPACE_ID=<add_conversation_workspace>
# Watson Discovery
DISCOVERY_USERNAME=<add_discovery_username>
DISCOVERY_PASSWORD=<add_discovery_password>
DISCOVERY_ENVIRONMENT_ID=<add_discovery_environment>
DISCOVERY_COLLECTION_ID=<add_discovery_collection>
# Watson Natural Language Understanding
NATURAL_LANGUAGE_UNDERSTANDING_USERNAME=<add_nlu_username>
NATURAL_LANGUAGE_UNDERSTANDING_PASSWORD=<add_nlu_password>
# Watson Tone Analyzer
TONE_ANALYZER_USERNAME=<add_tone_analyzer_username>
TONE_ANALYZER_PASSWORD=<add_tone_analyzer_password>
# Run locally on a non-default port (default is 3000)
# PORT=3000
1.安装 Node.js 运行时或 NPM。
2.通过运行 npm install 然后运行 npm start,以启动应用程序。
3.使用位于 localhost:3000 的聊天机器人。
注:可根据需要在 server.js 中更改服务器主机,可在
.env中设置PORT。

-
错误:环境 {GUID} 尚未处于激活状态,请在状态激活后重试
这是首次运行期间常见的错误。应用程序尝试在完全创建 Discovery 环境之前启动。请稍等一两分钟。此环境重新启动后 应可供使用。如果使用了
Deploy to IBM Cloud,那么应该会自动重新启动。 -
错误:每个组织仅允许使用一个免费环境
要使用免费试用版,请创建一个小型的免费 Discovery 环境。如果您已拥有 Discovery 环境,此操作将失败。如果您尚未使用 Discovery,请查找 旧服务,可能需要将其删除。否则,请使用 .env DISCOVERY_ENVIRONMENT_ID 来告知 该应用程序要使用的环境。将在此环境中使用默认配置 创建一个集合。
如果使用 Deploy to IBM Cloud 按钮,那么会跟踪某些指标,并将以下
信息发送到每个部署上的 Deployment Tracker 和
Metrics collector 服务:
- Node.js 程序包版本
- Node.js 存储库 URL
- 应用程序名称 (
application_name) - 应用程序 GUID (
application_id) - 应用程序实例索引编号 (
instance_index) - 空间 ID (
space_id) - 应用程序版本 (
application_version) - 应用程序 URI (
application_uris) - Cloud Foundry API (
cf_api) - 绑定服务的标签
- 每个绑定服务的实例数量和相关计划信息
- repository.yaml 文件中的元数据
这些数据收集自样本应用程序中的 package.json 和 repository.yaml 文件,以及 IBM Cloud 和其他 Cloud Foundry 平台中的 VCAP_APPLICATION 和 VCAP_SERVICES 环境变量。IBM 将使用这些数据来跟踪与样本应用程序在 IBM Cloud 上的部署相关的指标,方便我们度量示例的实用性,以便持续改进所提供的内容。仅有那些包含代码以对 Deployment Tracker 服务执行 ping 操作的样本应用程序的部署过程才会被跟踪。
要禁用跟踪,只需从顶级目录中的 app.js 文件中移除 require("cf-deployment-tracker-client").track(); 和 require('metrics-tracker-client').track(); 即可。