- Built with ❤️ by{" "}
- ![]() {" "}
+ Built with ❤️ by
{" "}
+ Built with ❤️ by ![]() {" "}
Acryl Data
{" "}
- and
{" "}
Acryl Data
{" "}
- and ![]() LinkedIn.
+ and
LinkedIn.
+ and ![]() LinkedIn.
LinkedIn.
Run the following command to get started with DataHub.
-Run the following command to get started with DataHub.
+

@@ -198,12 +198,12 @@ Once your assertion has run, you will begin to see Success or Failure status for
-## Stopping a Custom Assertion +## Stopping a Custom SQL Assertion -In order to temporarily stop the evaluation of a Custom Assertion: +In order to temporarily stop the evaluation of a Custom SQL Assertion: 1. Navigate to the **Validations** tab of the Table with the assertion -2. Click **Custom** to open the Custom Assertions list +2. Click **Custom** to open the Custom SQL Assertions list 3. Click the three-dot menu on the right side of the assertion you want to disable 4. Click **Stop** @@ -211,16 +211,16 @@ In order to temporarily stop the evaluation of a Custom Assertion: -To resume the Custom Assertion, simply click **Turn On**.
+To resume the Custom SQL Assertion, simply click **Turn On**.
-To resume the Custom Assertion, simply click **Turn On**.
+To resume the Custom SQL Assertion, simply click **Turn On**.

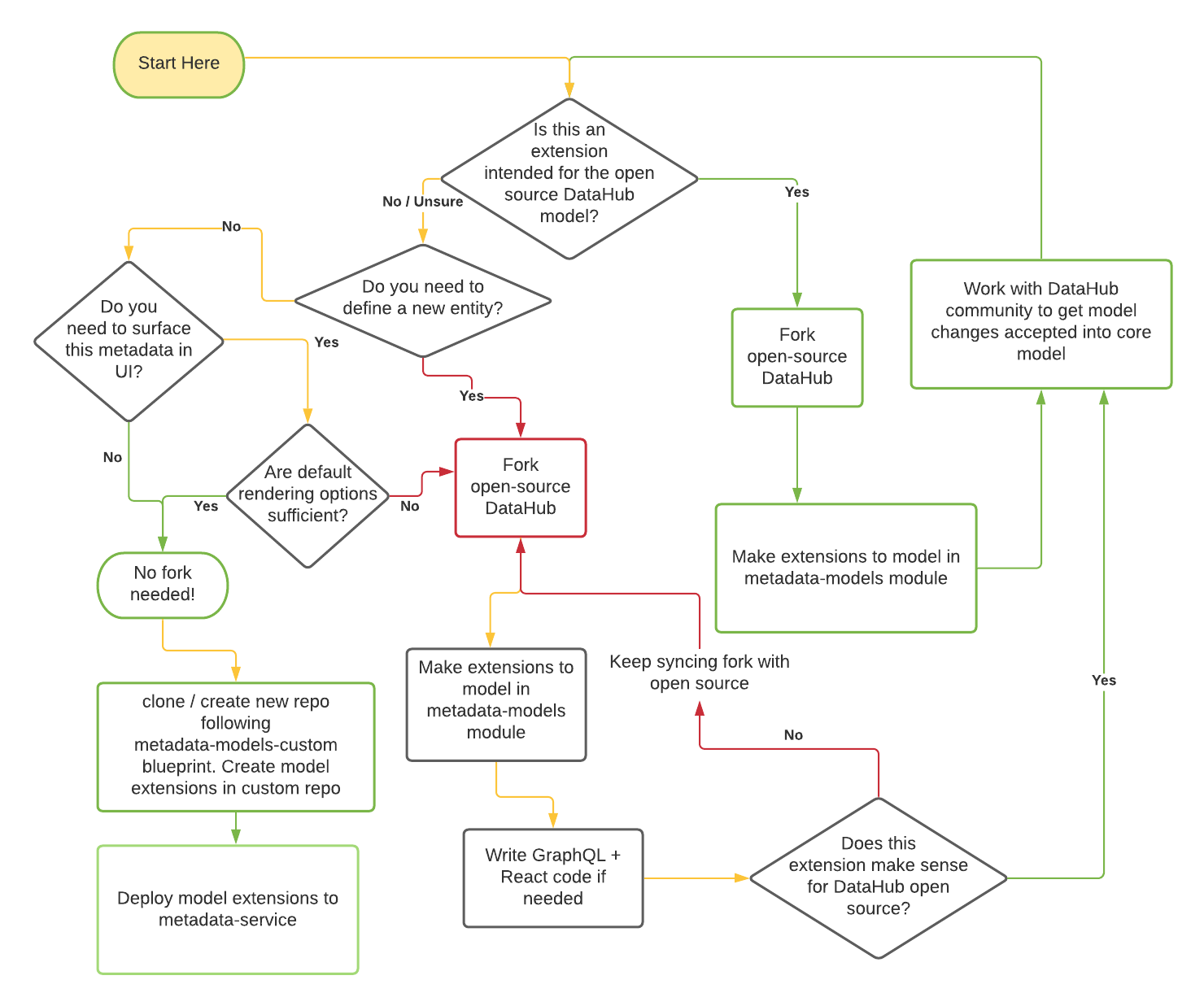 -
The green lines represent pathways that will lead to lesser friction for you to maintain your code long term. The red lines represent higher risk of conflicts in the future. We are working hard to move the majority of model extension use-cases to no-code / low-code pathways to ensure that you can extend the core metadata model without having to maintain a custom fork of DataHub.
We will refer to the two options as the **open-source fork** and **custom repository** approaches in the rest of the document below.
@@ -92,10 +91,11 @@ the annotation model.
Define the entity within an `entity-registry.yml` file. Depending on your approach, the location of this file may vary. More on that in steps [4](#step-4-choose-a-place-to-store-your-model-extension) and [5](#step-5-attaching-your-non-key-aspects-to-the-entity).
Example:
+
```yaml
- - name: dashboard
- doc: A container of related data assets.
- keyAspect: dashboardKey
+- name: dashboard
+ doc: A container of related data assets.
+ keyAspect: dashboardKey
```
- name: The entity name/type, this will be present as a part of the Urn.
@@ -196,8 +196,8 @@ The Aspect has four key components: its properties, the @Aspect annotation, the
can be defined as PDL primitives, enums, records, or collections (
see [pdl schema documentation](https://linkedin.github.io/rest.li/pdl_schema))
references to other entities, of type Urn or optionally `
-
The green lines represent pathways that will lead to lesser friction for you to maintain your code long term. The red lines represent higher risk of conflicts in the future. We are working hard to move the majority of model extension use-cases to no-code / low-code pathways to ensure that you can extend the core metadata model without having to maintain a custom fork of DataHub.
We will refer to the two options as the **open-source fork** and **custom repository** approaches in the rest of the document below.
@@ -92,10 +91,11 @@ the annotation model.
Define the entity within an `entity-registry.yml` file. Depending on your approach, the location of this file may vary. More on that in steps [4](#step-4-choose-a-place-to-store-your-model-extension) and [5](#step-5-attaching-your-non-key-aspects-to-the-entity).
Example:
+
```yaml
- - name: dashboard
- doc: A container of related data assets.
- keyAspect: dashboardKey
+- name: dashboard
+ doc: A container of related data assets.
+ keyAspect: dashboardKey
```
- name: The entity name/type, this will be present as a part of the Urn.
@@ -196,8 +196,8 @@ The Aspect has four key components: its properties, the @Aspect annotation, the
can be defined as PDL primitives, enums, records, or collections (
see [pdl schema documentation](https://linkedin.github.io/rest.li/pdl_schema))
references to other entities, of type Urn or optionally `
-  +
+ 
-  +
+ 
-  +
+ 
-  +
+ 
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+
+
+  +
+
+  +
+
+
+
+
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+  +
+
+ +
+
+ +
+
+  +
+
+  +
+
+  +
+
+ +
+
+ +
+
+ +
+
+ +
+
+ +
+