diff --git a/datahub-frontend/app/auth/AuthModule.java b/datahub-frontend/app/auth/AuthModule.java
index d0d17fda26392..7bb2547890701 100644
--- a/datahub-frontend/app/auth/AuthModule.java
+++ b/datahub-frontend/app/auth/AuthModule.java
@@ -21,6 +21,7 @@
import com.linkedin.util.Configuration;
import config.ConfigurationProvider;
import controllers.SsoCallbackController;
+import io.datahubproject.metadata.context.ValidationContext;
import java.nio.charset.StandardCharsets;
import java.util.Collections;
@@ -187,6 +188,7 @@ protected OperationContext provideOperationContext(
.authorizationContext(AuthorizationContext.builder().authorizer(Authorizer.EMPTY).build())
.searchContext(SearchContext.EMPTY)
.entityRegistryContext(EntityRegistryContext.builder().build(EmptyEntityRegistry.EMPTY))
+ .validationContext(ValidationContext.builder().alternateValidation(false).build())
.build(systemAuthentication);
}
diff --git a/datahub-upgrade/src/main/java/com/linkedin/datahub/upgrade/config/SystemUpdateConfig.java b/datahub-upgrade/src/main/java/com/linkedin/datahub/upgrade/config/SystemUpdateConfig.java
index f3a4c47c59f0b..661717c6309cf 100644
--- a/datahub-upgrade/src/main/java/com/linkedin/datahub/upgrade/config/SystemUpdateConfig.java
+++ b/datahub-upgrade/src/main/java/com/linkedin/datahub/upgrade/config/SystemUpdateConfig.java
@@ -29,6 +29,7 @@
import io.datahubproject.metadata.context.OperationContextConfig;
import io.datahubproject.metadata.context.RetrieverContext;
import io.datahubproject.metadata.context.ServicesRegistryContext;
+import io.datahubproject.metadata.context.ValidationContext;
import io.datahubproject.metadata.services.RestrictedService;
import java.util.List;
import javax.annotation.Nonnull;
@@ -161,7 +162,8 @@ protected OperationContext javaSystemOperationContext(
@Nonnull final GraphService graphService,
@Nonnull final SearchService searchService,
@Qualifier("baseElasticSearchComponents")
- BaseElasticSearchComponentsFactory.BaseElasticSearchComponents components) {
+ BaseElasticSearchComponentsFactory.BaseElasticSearchComponents components,
+ @Nonnull final ConfigurationProvider configurationProvider) {
EntityServiceAspectRetriever entityServiceAspectRetriever =
EntityServiceAspectRetriever.builder()
@@ -186,6 +188,10 @@ protected OperationContext javaSystemOperationContext(
.aspectRetriever(entityServiceAspectRetriever)
.graphRetriever(systemGraphRetriever)
.searchRetriever(searchServiceSearchRetriever)
+ .build(),
+ ValidationContext.builder()
+ .alternateValidation(
+ configurationProvider.getFeatureFlags().isAlternateMCPValidation())
.build());
entityServiceAspectRetriever.setSystemOperationContext(systemOperationContext);
diff --git a/docker/kafka-setup/Dockerfile b/docker/kafka-setup/Dockerfile
index dd88060cd7165..a11f823f5efa5 100644
--- a/docker/kafka-setup/Dockerfile
+++ b/docker/kafka-setup/Dockerfile
@@ -1,4 +1,4 @@
-ARG KAFKA_DOCKER_VERSION=7.4.6
+ARG KAFKA_DOCKER_VERSION=7.7.1
# Defining custom repo urls for use in enterprise environments. Re-used between stages below.
ARG ALPINE_REPO_URL=http://dl-cdn.alpinelinux.org/alpine
diff --git a/docker/profiles/docker-compose.gms.yml b/docker/profiles/docker-compose.gms.yml
index 2683734c2d5e5..147bbd35ff646 100644
--- a/docker/profiles/docker-compose.gms.yml
+++ b/docker/profiles/docker-compose.gms.yml
@@ -101,6 +101,7 @@ x-datahub-gms-service: &datahub-gms-service
environment: &datahub-gms-env
<<: [*primary-datastore-mysql-env, *graph-datastore-search-env, *search-datastore-env, *datahub-quickstart-telemetry-env, *kafka-env]
ELASTICSEARCH_QUERY_CUSTOM_CONFIG_FILE: ${ELASTICSEARCH_QUERY_CUSTOM_CONFIG_FILE:-search_config.yaml}
+ ALTERNATE_MCP_VALIDATION: ${ALTERNATE_MCP_VALIDATION:-true}
healthcheck:
test: curl -sS --fail http://datahub-gms:${DATAHUB_GMS_PORT:-8080}/health
start_period: 90s
@@ -182,6 +183,7 @@ x-datahub-mce-consumer-service: &datahub-mce-consumer-service
- ${DATAHUB_LOCAL_MCE_ENV:-empty2.env}
environment: &datahub-mce-consumer-env
<<: [*primary-datastore-mysql-env, *graph-datastore-search-env, *search-datastore-env, *datahub-quickstart-telemetry-env, *kafka-env]
+ ALTERNATE_MCP_VALIDATION: ${ALTERNATE_MCP_VALIDATION:-true}
x-datahub-mce-consumer-service-dev: &datahub-mce-consumer-service-dev
<<: *datahub-mce-consumer-service
diff --git a/docs-website/docusaurus.config.js b/docs-website/docusaurus.config.js
index cc421748557be..a3315ee071339 100644
--- a/docs-website/docusaurus.config.js
+++ b/docs-website/docusaurus.config.js
@@ -68,7 +68,7 @@ module.exports = {
announcementBar: {
id: "announcement-2",
content:
- 'NEW
Join us at Metadata & AI Summit, Oct. 29 & 30!
Register →NEW
Join us at Metadata & AI Summit, Oct. 29 & 30!
Register →
`bigquery.taxonomies.update` |
+| Assign/remove policy tags from columns | `bigquery.tables.updateTag` |
+| Edit table description | `bigquery.tables.update` |
+| Edit column description | `bigquery.tables.update` |
+| Assign/remove labels from tables | `bigquery.tables.update` |
+
+## Enabling BigQuery Sync Automation
+
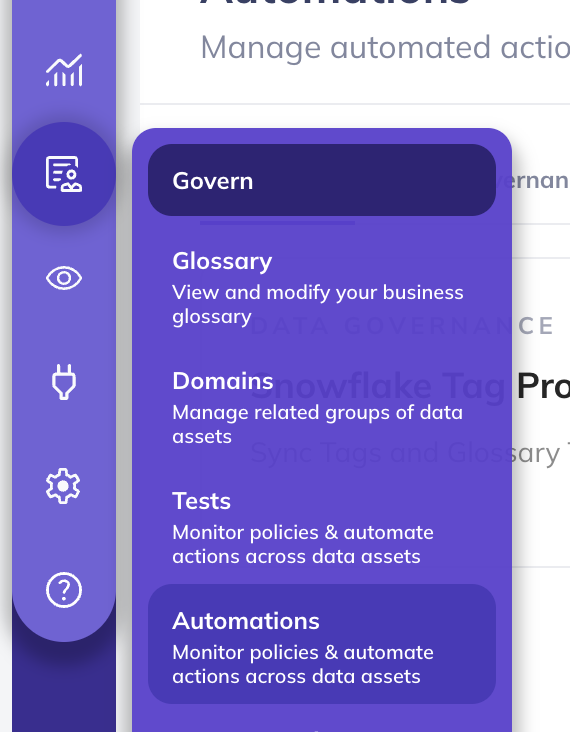
+1. **Navigate to Automations**: Click on 'Govern' > 'Automations' in the navigation bar.
+
+
+  +
+
+
+2. **Create An Automation**: Click on 'Create' and select 'BigQuery Tag Propagation'.
+
+
+  +
+
+
+3. **Configure Automation**:
+
+ 1. **Select a Propagation Action**
+
+
+  +
+
+
+ | Propagation Type | DataHub Entity | BigQuery Entity | Note |
+ | -------- | ------- | ------- | ------- |
+ | Table Tags as Labels | [Table Tag](https://datahubproject.io/docs/tags/) | [BigQuery Label](https://cloud.google.com/bigquery/docs/labels-intro) | - |
+ | Column Glossary Terms as Policy Tags | [Glossary Term on Table Column](https://datahubproject.io/docs/0.14.0/glossary/business-glossary/) | [Policy Tag](https://cloud.google.com/bigquery/docs/best-practices-policy-tags) | - Assigned Policy tags are created under DataHub taxonomy.
- Only the latest assigned glossary term set as policy tag. BigQuery only supports one assigned policy tag.
- Policy Tags are not synced to DataHub as glossary term from BigQuery.
+ | Table Descriptions | [Table Description](https://datahubproject.io/docs/api/tutorials/descriptions/) | Table Description | - |
+ | Column Descriptions | [Column Description](https://datahubproject.io/docs/api/tutorials/descriptions/) | Column Description | - |
+
+ :::note
+
+ You can limit propagation based on specific Tags and Glossary Terms. If none are selected, ALL Tags or Glossary Terms will be automatically propagated to BigQuery tables and columns. (The recommended approach is to not specify a filter to avoid inconsistent states.)
+
+ :::
+
+ :::note
+
+ - BigQuery supports only one Policy Tag per table field. Consequently, the most recently assigned Glossary Term will be set as the Policy Tag for that field.
+ - Policy Tags cannot be applied to fields in External tables. Therefore, if a Glossary Term is assigned to a field in an External table, it will not be applied.
+
+ :::
+
+ 2. **Fill in the required fields to connect to BigQuery, along with the name, description, and category**
+
+
+  +
+
+
+ 3. **Finally, click 'Save and Run' to start the automation**
+
+## Propagating for Existing Assets
+
+To ensure that all existing table Tags and Column Glossary Terms are propagated to BigQuery, you can back-fill historical data for existing assets. Note that the initial back-filling process may take some time, depending on the number of BigQuery assets you have.
+
+To do so, follow these steps:
+
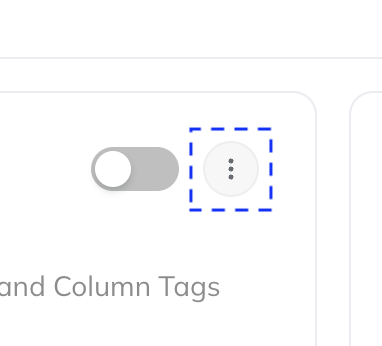
+1. Navigate to the Automation you created in Step 3 above
+2. Click the 3-dot "More" menu
+
+
+  +
+
+
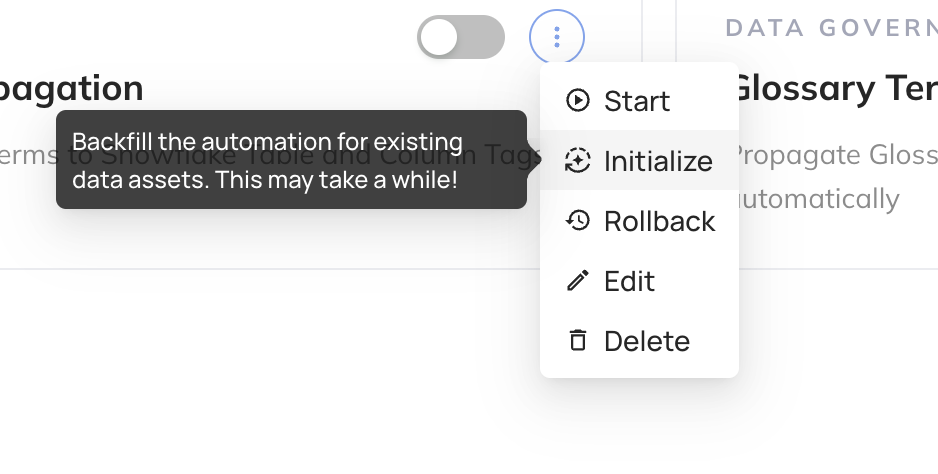
+3. Click "Initialize"
+
+
+  +
+
+
+This one-time step will kick off the back-filling process for existing descriptions. If you only want to begin propagating descriptions going forward, you can skip this step.
+
+## Viewing Propagated Tags
+
+You can view propagated Tags inside the BigQuery UI to confirm the automation is working as expected.
+
+
+  +
+
+
+## Troubleshooting BigQuery Propagation
+
+### Q: What metadata elements support bi-directional syncing between DataHub and BigQuery?
+
+A: The following metadata elements support bi-directional syncing:
+
+- Tags (via BigQuery Labels): Changes made in either DataHub Table Tags or BigQuery Table Labels will be reflected in the other system.
+- Descriptions: Both table and column descriptions are synced bi-directionally.
+
+### Q: Are Policy Tags bi-directionally synced?
+
+A: No, BigQuery Policy Tags are only propagated from DataHub to BigQuery, not vice versa. This means that Policy Tags should be mastered in DataHub using the [Business Glossary](https://datahubproject.io/docs/glossary/business-glossary/).
+
+It is recommended to avoid enabling `extract_policy_tags_from_catalog` during
+ingestion, as this will ingest policy tags as BigQuery labels. Our sync process
+propagates Glossary Term assignments to BigQuery as Policy Tags.
+
+In a future release, we plan to remove this restriction to support full bi-directional syncing.
+
+### Q: What metadata is synced from BigQuery to DataHub during ingestion?
+
+A: During ingestion from BigQuery:
+
+- Tags and descriptions from BigQuery will be ingested into DataHub.
+- Existing Policy Tags in BigQuery will not overwrite or create Business Glossary Terms in DataHub. It only syncs assigned column Glossary Terms from DataHub to BigQuery.
+
+### Q: Where should I manage my Business Glossary?
+
+A: The expectation is that you author and manage the glossary in DataHub. Policy tags in BigQuery should be treated as a reflection of the DataHub glossary, not as the primary source of truth.
+
+### Q: Are there any limitations with Policy Tags in BigQuery?
+
+A: Yes, BigQuery only supports one Policy Tag per column. If multiple glossary
+terms are assigned to a column in DataHub, only the most recently assigned term
+will be set as the policy tag in BigQuery. To reduce the scope of conflicts, you
+can set up filters in the BigQuery Metadata Sync to only synchronize terms from
+a specific area of the Business Glossary.
+
+### Q: How frequently are changes synced between DataHub and BigQuery?
+
+A: From DataHub to BigQuery, the sync happens instantly (within a few seconds)
+when the change occurs in DataHub.
+
+From BigQuery to DataHub, changes are synced when ingestion occurs, and the frequency depends on your custom ingestion schedule. (Visible on the **Integrations** page)
+
+### Q: What happens if there's a conflict between DataHub and BigQuery metadata?
+
+A: In case of conflicts (e.g., a tag is modified in both systems between syncs), the DataHub version will typically take precedence. However, it's best to make changes in one system consistently to avoid potential conflicts.
+
+### Q: What permissions are required for bi-directional syncing?
+
+A: Ensure that the service account used for the automation has the necessary permissions in both DataHub and BigQuery to read and write metadata. See the required BigQuery permissions at the top of the page.
+
+## Related Documentation
+
+- [DataHub Tags Documentation](https://datahubproject.io/docs/tags/)
+- [DataHub Glossary Documentation](https://datahubproject.io/docs/glossary/business-glossary/)
+- [BigQuery Labels Documentation](https://cloud.google.com/bigquery/docs/labels-intro)
+- [BigQuery Policy Tags Documentation](https://cloud.google.com/bigquery/docs/best-practices-policy-tags)
diff --git a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java
index f99dd18d3c9c1..54ccd3877395f 100644
--- a/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java
+++ b/entity-registry/src/main/java/com/linkedin/metadata/aspect/plugins/PluginSpec.java
@@ -12,7 +12,7 @@
@AllArgsConstructor
@EqualsAndHashCode
public abstract class PluginSpec {
- protected static String ENTITY_WILDCARD = "*";
+ protected static String WILDCARD = "*";
@Nonnull
public abstract AspectPluginConfig getConfig();
@@ -50,7 +50,7 @@ protected boolean isEntityAspectSupported(
return (getConfig().getSupportedEntityAspectNames().stream()
.anyMatch(
supported ->
- ENTITY_WILDCARD.equals(supported.getEntityName())
+ WILDCARD.equals(supported.getEntityName())
|| supported.getEntityName().equals(entityName)))
&& isAspectSupported(aspectName);
}
@@ -59,13 +59,16 @@ protected boolean isAspectSupported(@Nonnull String aspectName) {
return getConfig().getSupportedEntityAspectNames().stream()
.anyMatch(
supported ->
- ENTITY_WILDCARD.equals(supported.getAspectName())
+ WILDCARD.equals(supported.getAspectName())
|| supported.getAspectName().equals(aspectName));
}
protected boolean isChangeTypeSupported(@Nullable ChangeType changeType) {
return (changeType == null && getConfig().getSupportedOperations().isEmpty())
|| getConfig().getSupportedOperations().stream()
- .anyMatch(supported -> supported.equalsIgnoreCase(String.valueOf(changeType)));
+ .anyMatch(
+ supported ->
+ WILDCARD.equals(supported)
+ || supported.equalsIgnoreCase(String.valueOf(changeType)));
}
}
diff --git a/metadata-ingestion-modules/dagster-plugin/setup.py b/metadata-ingestion-modules/dagster-plugin/setup.py
index 50450ddd5917a..660dbb2981c51 100644
--- a/metadata-ingestion-modules/dagster-plugin/setup.py
+++ b/metadata-ingestion-modules/dagster-plugin/setup.py
@@ -13,14 +13,6 @@ def get_long_description():
return pathlib.Path(os.path.join(root, "README.md")).read_text()
-rest_common = {"requests", "requests_file"}
-
-sqlglot_lib = {
- # Using an Acryl fork of sqlglot.
- # https://github.com/tobymao/sqlglot/compare/main...hsheth2:sqlglot:main?expand=1
- "acryl-sqlglot[rs]==24.0.1.dev7",
-}
-
_version: str = package_metadata["__version__"]
_self_pin = (
f"=={_version}"
@@ -32,11 +24,7 @@ def get_long_description():
# Actual dependencies.
"dagster >= 1.3.3",
"dagit >= 1.3.3",
- *rest_common,
- # Ignoring the dependency below because it causes issues with the vercel built wheel install
- # f"acryl-datahub[datahub-rest]{_self_pin}",
- "acryl-datahub[datahub-rest]",
- *sqlglot_lib,
+ f"acryl-datahub[datahub-rest,sql-parser]{_self_pin}",
}
mypy_stubs = {
diff --git a/metadata-ingestion-modules/prefect-plugin/src/prefect_datahub/datahub_emitter.py b/metadata-ingestion-modules/prefect-plugin/src/prefect_datahub/datahub_emitter.py
index 5991503416aec..8617381cf1613 100644
--- a/metadata-ingestion-modules/prefect-plugin/src/prefect_datahub/datahub_emitter.py
+++ b/metadata-ingestion-modules/prefect-plugin/src/prefect_datahub/datahub_emitter.py
@@ -155,12 +155,11 @@ async def _get_flow_run_graph(self, flow_run_id: str) -> Optional[List[Dict]]:
The flow run graph in json format.
"""
try:
- response = orchestration.get_client()._client.get(
+ response_coroutine = orchestration.get_client()._client.get(
f"/flow_runs/{flow_run_id}/graph"
)
- if asyncio.iscoroutine(response):
- response = await response
+ response = await response_coroutine
if hasattr(response, "json"):
response_json = response.json()
@@ -410,10 +409,9 @@ async def get_flow_run(flow_run_id: UUID) -> FlowRun:
if not hasattr(client, "read_flow_run"):
raise ValueError("Client does not support async read_flow_run method")
- response = client.read_flow_run(flow_run_id=flow_run_id)
+ response_coroutine = client.read_flow_run(flow_run_id=flow_run_id)
- if asyncio.iscoroutine(response):
- response = await response
+ response = await response_coroutine
return FlowRun.parse_obj(response)
@@ -477,10 +475,9 @@ async def get_task_run(task_run_id: UUID) -> TaskRun:
if not hasattr(client, "read_task_run"):
raise ValueError("Client does not support async read_task_run method")
- response = client.read_task_run(task_run_id=task_run_id)
+ response_coroutine = client.read_task_run(task_run_id=task_run_id)
- if asyncio.iscoroutine(response):
- response = await response
+ response = await response_coroutine
return TaskRun.parse_obj(response)
diff --git a/metadata-ingestion/pyproject.toml b/metadata-ingestion/pyproject.toml
index 2b6c87926c6c4..94e06fd53a70e 100644
--- a/metadata-ingestion/pyproject.toml
+++ b/metadata-ingestion/pyproject.toml
@@ -14,7 +14,7 @@ target-version = ['py37', 'py38', 'py39', 'py310']
[tool.isort]
combine_as_imports = true
indent = ' '
-known_future_library = ['__future__', 'datahub.utilities._markupsafe_compat', 'datahub_provider._airflow_compat']
+known_future_library = ['__future__', 'datahub.utilities._markupsafe_compat', 'datahub.sql_parsing._sqlglot_patch']
profile = 'black'
sections = 'FUTURE,STDLIB,THIRDPARTY,FIRSTPARTY,LOCALFOLDER'
skip_glob = 'src/datahub/metadata'
diff --git a/metadata-ingestion/scripts/avro_codegen.py b/metadata-ingestion/scripts/avro_codegen.py
index 5be8b6ed4cc21..e2dd515143992 100644
--- a/metadata-ingestion/scripts/avro_codegen.py
+++ b/metadata-ingestion/scripts/avro_codegen.py
@@ -361,9 +361,6 @@ def write_urn_classes(key_aspects: List[dict], urn_dir: Path) -> None:
for aspect in key_aspects:
entity_type = aspect["Aspect"]["keyForEntity"]
- if aspect["Aspect"]["entityCategory"] == "internal":
- continue
-
code += generate_urn_class(entity_type, aspect)
(urn_dir / "urn_defs.py").write_text(code)
diff --git a/metadata-ingestion/setup.py b/metadata-ingestion/setup.py
index 365da21208ecc..35dbff5cc2c71 100644
--- a/metadata-ingestion/setup.py
+++ b/metadata-ingestion/setup.py
@@ -99,9 +99,11 @@
}
sqlglot_lib = {
- # Using an Acryl fork of sqlglot.
+ # We heavily monkeypatch sqlglot.
+ # Prior to the patching, we originally maintained an acryl-sqlglot fork:
# https://github.com/tobymao/sqlglot/compare/main...hsheth2:sqlglot:main?expand=1
- "acryl-sqlglot[rs]==25.25.2.dev9",
+ "sqlglot[rs]==25.26.0",
+ "patchy==2.8.0",
}
classification_lib = {
@@ -122,6 +124,10 @@
"more_itertools",
}
+cachetools_lib = {
+ "cachetools",
+}
+
sql_common = (
{
# Required for all SQL sources.
@@ -138,6 +144,7 @@
# https://github.com/ipython/traitlets/issues/741
"traitlets<5.2.2",
"greenlet",
+ *cachetools_lib,
}
| usage_common
| sqlglot_lib
@@ -213,7 +220,7 @@
"pandas",
"cryptography",
"msal",
- "cachetools",
+ *cachetools_lib,
} | classification_lib
trino = {
@@ -457,7 +464,7 @@
| sqlglot_lib
| classification_lib
| {"db-dtypes"} # Pandas extension data types
- | {"cachetools"},
+ | cachetools_lib,
"s3": {*s3_base, *data_lake_profiling},
"gcs": {*s3_base, *data_lake_profiling},
"abs": {*abs_base, *data_lake_profiling},
diff --git a/metadata-ingestion/src/datahub/api/entities/platformresource/platform_resource.py b/metadata-ingestion/src/datahub/api/entities/platformresource/platform_resource.py
index 0f7b10a067053..0ba43d7b101e5 100644
--- a/metadata-ingestion/src/datahub/api/entities/platformresource/platform_resource.py
+++ b/metadata-ingestion/src/datahub/api/entities/platformresource/platform_resource.py
@@ -14,7 +14,12 @@
from datahub.emitter.mcp import MetadataChangeProposalWrapper
from datahub.emitter.mcp_builder import DatahubKey
from datahub.ingestion.graph.client import DataHubGraph
-from datahub.metadata.urns import DataPlatformUrn, PlatformResourceUrn, Urn
+from datahub.metadata.urns import (
+ DataPlatformInstanceUrn,
+ DataPlatformUrn,
+ PlatformResourceUrn,
+ Urn,
+)
from datahub.utilities.openapi_utils import OpenAPIGraphClient
from datahub.utilities.search_utils import (
ElasticDocumentQuery,
@@ -76,21 +81,6 @@ def to_resource_info(self) -> models.PlatformResourceInfoClass:
)
-class DataPlatformInstanceUrn:
- """
- A simple implementation of a URN class for DataPlatformInstance.
- Since this is not present in the URN registry, we need to implement it here.
- """
-
- @staticmethod
- def create_from_id(platform_instance_urn: str) -> Urn:
- if platform_instance_urn.startswith("urn:li:platformInstance:"):
- string_urn = platform_instance_urn
- else:
- string_urn = f"urn:li:platformInstance:{platform_instance_urn}"
- return Urn.from_string(string_urn)
-
-
class UrnSearchField(SearchField):
"""
A search field that supports URN values.
@@ -130,7 +120,7 @@ class PlatformResourceSearchFields:
PLATFORM_INSTANCE = PlatformResourceSearchField.from_search_field(
UrnSearchField(
field_name="platformInstance.keyword",
- urn_value_extractor=DataPlatformInstanceUrn.create_from_id,
+ urn_value_extractor=DataPlatformInstanceUrn.from_string,
)
)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py
index 1235f638f68ff..f53642d1fead2 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/bigquery_v2/bigquery_schema_gen.py
@@ -310,7 +310,7 @@ def gen_dataset_containers(
logger.warning(
f"Failed to generate platform resource for label {k}:{v}: {e}"
)
- tags_joined.append(tag_urn.urn())
+ tags_joined.append(tag_urn.name)
database_container_key = self.gen_project_id_key(database=project_id)
diff --git a/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py b/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py
index 3ead59eed2d39..7d82d99412ffe 100644
--- a/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py
+++ b/metadata-ingestion/src/datahub/ingestion/source/sql/sql_config.py
@@ -2,6 +2,8 @@
from abc import abstractmethod
from typing import Any, Dict, Optional
+import cachetools
+import cachetools.keys
import pydantic
from pydantic import Field
from sqlalchemy.engine import URL
@@ -27,6 +29,7 @@
StatefulIngestionConfigBase,
)
from datahub.ingestion.source_config.operation_config import is_profiling_enabled
+from datahub.utilities.cachetools_keys import self_methodkey
logger: logging.Logger = logging.getLogger(__name__)
@@ -115,6 +118,13 @@ class SQLCommonConfig(
# Custom Stateful Ingestion settings
stateful_ingestion: Optional[StatefulStaleMetadataRemovalConfig] = None
+ # TRICKY: The operation_config is time-dependent. Because we don't want to change
+ # whether or not we're running profiling mid-ingestion, we cache the result of this method.
+ # TODO: This decorator should be moved to the is_profiling_enabled(operation_config) method.
+ @cachetools.cached(
+ cache=cachetools.LRUCache(maxsize=1),
+ key=self_methodkey,
+ )
def is_profiling_enabled(self) -> bool:
return self.profiling.enabled and is_profiling_enabled(
self.profiling.operation_config
diff --git a/metadata-ingestion/src/datahub/sql_parsing/_sqlglot_patch.py b/metadata-ingestion/src/datahub/sql_parsing/_sqlglot_patch.py
new file mode 100644
index 0000000000000..fc3f877ede629
--- /dev/null
+++ b/metadata-ingestion/src/datahub/sql_parsing/_sqlglot_patch.py
@@ -0,0 +1,215 @@
+import dataclasses
+import difflib
+import logging
+
+import patchy.api
+import sqlglot
+import sqlglot.expressions
+import sqlglot.lineage
+import sqlglot.optimizer.scope
+import sqlglot.optimizer.unnest_subqueries
+
+from datahub.utilities.is_pytest import is_pytest_running
+from datahub.utilities.unified_diff import apply_diff
+
+# This injects a few patches into sqlglot to add features and mitigate
+# some bugs and performance issues.
+# The diffs in this file should match the diffs declared in our fork.
+# https://github.com/tobymao/sqlglot/compare/main...hsheth2:sqlglot:main
+# For a diff-formatted view, see:
+# https://github.com/tobymao/sqlglot/compare/main...hsheth2:sqlglot:main.diff
+
+_DEBUG_PATCHER = is_pytest_running() or True
+logger = logging.getLogger(__name__)
+
+_apply_diff_subprocess = patchy.api._apply_patch
+
+
+def _new_apply_patch(source: str, patch_text: str, forwards: bool, name: str) -> str:
+ assert forwards, "Only forward patches are supported"
+
+ result = apply_diff(source, patch_text)
+
+ # TODO: When in testing mode, still run the subprocess and check that the
+ # results line up.
+ if _DEBUG_PATCHER:
+ result_subprocess = _apply_diff_subprocess(source, patch_text, forwards, name)
+ if result_subprocess != result:
+ logger.info("Results from subprocess and _apply_diff do not match")
+ logger.debug(f"Subprocess result:\n{result_subprocess}")
+ logger.debug(f"Our result:\n{result}")
+ diff = difflib.unified_diff(
+ result_subprocess.splitlines(), result.splitlines()
+ )
+ logger.debug("Diff:\n" + "\n".join(diff))
+ raise ValueError("Results from subprocess and _apply_diff do not match")
+
+ return result
+
+
+patchy.api._apply_patch = _new_apply_patch
+
+
+def _patch_deepcopy() -> None:
+ patchy.patch(
+ sqlglot.expressions.Expression.__deepcopy__,
+ """\
+@@ -1,4 +1,7 @@ def meta(self) -> t.Dict[str, t.Any]:
+ def __deepcopy__(self, memo):
++ import datahub.utilities.cooperative_timeout
++ datahub.utilities.cooperative_timeout.cooperate()
++
+ root = self.__class__()
+ stack = [(self, root)]
+""",
+ )
+
+
+def _patch_scope_traverse() -> None:
+ # Circular scope dependencies can happen in somewhat specific circumstances
+ # due to our usage of sqlglot.
+ # See https://github.com/tobymao/sqlglot/pull/4244
+ patchy.patch(
+ sqlglot.optimizer.scope.Scope.traverse,
+ """\
+@@ -5,9 +5,16 @@ def traverse(self):
+ Scope: scope instances in depth-first-search post-order
+ \"""
+ stack = [self]
++ seen_scopes = set()
+ result = []
+ while stack:
+ scope = stack.pop()
++
++ # Scopes aren't hashable, so we use id(scope) instead.
++ if id(scope) in seen_scopes:
++ raise OptimizeError(f"Scope {scope} has a circular scope dependency")
++ seen_scopes.add(id(scope))
++
+ result.append(scope)
+ stack.extend(
+ itertools.chain(
+""",
+ )
+
+
+def _patch_unnest_subqueries() -> None:
+ patchy.patch(
+ sqlglot.optimizer.unnest_subqueries.decorrelate,
+ """\
+@@ -261,16 +261,19 @@ def remove_aggs(node):
+ if key in group_by:
+ key.replace(nested)
+ elif isinstance(predicate, exp.EQ):
+- parent_predicate = _replace(
+- parent_predicate,
+- f"({parent_predicate} AND ARRAY_CONTAINS({nested}, {column}))",
+- )
++ if parent_predicate:
++ parent_predicate = _replace(
++ parent_predicate,
++ f"({parent_predicate} AND ARRAY_CONTAINS({nested}, {column}))",
++ )
+ else:
+ key.replace(exp.to_identifier("_x"))
+- parent_predicate = _replace(
+- parent_predicate,
+- f"({parent_predicate} AND ARRAY_ANY({nested}, _x -> {predicate}))",
+- )
++
++ if parent_predicate:
++ parent_predicate = _replace(
++ parent_predicate,
++ f"({parent_predicate} AND ARRAY_ANY({nested}, _x -> {predicate}))",
++ )
+""",
+ )
+
+
+def _patch_lineage() -> None:
+ # Add the "subfield" attribute to sqlglot.lineage.Node.
+ # With dataclasses, the easiest way to do this is with inheritance.
+ # Unfortunately, mypy won't pick up on the new field, so we need to
+ # use type ignores everywhere we use subfield.
+ @dataclasses.dataclass(frozen=True)
+ class Node(sqlglot.lineage.Node):
+ subfield: str = ""
+
+ sqlglot.lineage.Node = Node # type: ignore
+
+ patchy.patch(
+ sqlglot.lineage.lineage,
+ """\
+@@ -12,7 +12,8 @@ def lineage(
+ \"""
+
+ expression = maybe_parse(sql, dialect=dialect)
+- column = normalize_identifiers.normalize_identifiers(column, dialect=dialect).name
++ # column = normalize_identifiers.normalize_identifiers(column, dialect=dialect).name
++ assert isinstance(column, str)
+
+ if sources:
+ expression = exp.expand(
+""",
+ )
+
+ patchy.patch(
+ sqlglot.lineage.to_node,
+ """\
+@@ -235,11 +237,12 @@ def to_node(
+ )
+
+ # Find all columns that went into creating this one to list their lineage nodes.
+- source_columns = set(find_all_in_scope(select, exp.Column))
++ source_columns = list(find_all_in_scope(select, exp.Column))
+
+- # If the source is a UDTF find columns used in the UTDF to generate the table
++ # If the source is a UDTF find columns used in the UDTF to generate the table
++ source = scope.expression
+ if isinstance(source, exp.UDTF):
+- source_columns |= set(source.find_all(exp.Column))
++ source_columns += list(source.find_all(exp.Column))
+ derived_tables = [
+ source.expression.parent
+ for source in scope.sources.values()
+@@ -254,6 +257,7 @@ def to_node(
+ if dt.comments and dt.comments[0].startswith("source: ")
+ }
+
++ c: exp.Column
+ for c in source_columns:
+ table = c.table
+ source = scope.sources.get(table)
+@@ -281,8 +285,21 @@ def to_node(
+ # it means this column's lineage is unknown. This can happen if the definition of a source used in a query
+ # is not passed into the `sources` map.
+ source = source or exp.Placeholder()
++
++ subfields = []
++ field: exp.Expression = c
++ while isinstance(field.parent, exp.Dot):
++ field = field.parent
++ subfields.append(field.name)
++ subfield = ".".join(subfields)
++
+ node.downstream.append(
+- Node(name=c.sql(comments=False), source=source, expression=source)
++ Node(
++ name=c.sql(comments=False),
++ source=source,
++ expression=source,
++ subfield=subfield,
++ )
+ )
+
+ return node
+""",
+ )
+
+
+_patch_deepcopy()
+_patch_scope_traverse()
+_patch_unnest_subqueries()
+_patch_lineage()
+
+SQLGLOT_PATCHED = True
diff --git a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py
index 6a7ff5be6d1ea..b635f8cb47b6d 100644
--- a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py
+++ b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_lineage.py
@@ -1,3 +1,5 @@
+from datahub.sql_parsing._sqlglot_patch import SQLGLOT_PATCHED
+
import dataclasses
import functools
import logging
@@ -53,6 +55,8 @@
cooperative_timeout,
)
+assert SQLGLOT_PATCHED
+
logger = logging.getLogger(__name__)
Urn = str
diff --git a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_utils.py b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_utils.py
index 71245353101f6..c62312c9004cd 100644
--- a/metadata-ingestion/src/datahub/sql_parsing/sqlglot_utils.py
+++ b/metadata-ingestion/src/datahub/sql_parsing/sqlglot_utils.py
@@ -1,3 +1,5 @@
+from datahub.sql_parsing._sqlglot_patch import SQLGLOT_PATCHED
+
import functools
import hashlib
import logging
@@ -8,6 +10,8 @@
import sqlglot.errors
import sqlglot.optimizer.eliminate_ctes
+assert SQLGLOT_PATCHED
+
logger = logging.getLogger(__name__)
DialectOrStr = Union[sqlglot.Dialect, str]
SQL_PARSE_CACHE_SIZE = 1000
diff --git a/metadata-ingestion/src/datahub/utilities/cachetools_keys.py b/metadata-ingestion/src/datahub/utilities/cachetools_keys.py
new file mode 100644
index 0000000000000..e3c7d67c81cd3
--- /dev/null
+++ b/metadata-ingestion/src/datahub/utilities/cachetools_keys.py
@@ -0,0 +1,8 @@
+from typing import Any
+
+import cachetools.keys
+
+
+def self_methodkey(self: Any, *args: Any, **kwargs: Any) -> Any:
+ # Keeps the id of self around
+ return cachetools.keys.hashkey(id(self), *args, **kwargs)
diff --git a/metadata-ingestion/src/datahub/utilities/is_pytest.py b/metadata-ingestion/src/datahub/utilities/is_pytest.py
new file mode 100644
index 0000000000000..68bb1b285a50e
--- /dev/null
+++ b/metadata-ingestion/src/datahub/utilities/is_pytest.py
@@ -0,0 +1,5 @@
+import sys
+
+
+def is_pytest_running() -> bool:
+ return "pytest" in sys.modules
diff --git a/metadata-ingestion/src/datahub/utilities/unified_diff.py b/metadata-ingestion/src/datahub/utilities/unified_diff.py
new file mode 100644
index 0000000000000..c896fd4df4d8f
--- /dev/null
+++ b/metadata-ingestion/src/datahub/utilities/unified_diff.py
@@ -0,0 +1,236 @@
+import logging
+from dataclasses import dataclass
+from typing import List, Tuple
+
+logger = logging.getLogger(__name__)
+logger.setLevel(logging.INFO)
+
+_LOOKAROUND_LINES = 300
+
+# The Python difflib library can generate unified diffs, but it cannot apply them.
+# There weren't any well-maintained and easy-to-use libraries for applying
+# unified diffs, so I wrote my own.
+#
+# My implementation is focused on ensuring correctness, and will throw
+# an exception whenever it detects an issue.
+#
+# Alternatives considered:
+# - diff-match-patch: This was the most promising since it's from Google.
+# Unfortunately, they deprecated the library in Aug 2024. That may not have
+# been a dealbreaker, since a somewhat greenfield community fork exists:
+# https://github.com/dmsnell/diff-match-patch
+# However, there's also a long-standing bug in the library around the
+# handling of line breaks when parsing diffs. See:
+# https://github.com/google/diff-match-patch/issues/157
+# - python-patch: Seems abandoned.
+# - patch-ng: Fork of python-patch, but mainly targeted at applying patches to trees.
+# It did not have simple "apply patch to string" abstractions.
+# - unidiff: Parses diffs, but cannot apply them.
+
+
+class InvalidDiffError(Exception):
+ pass
+
+
+class DiffApplyError(Exception):
+ pass
+
+
+@dataclass
+class Hunk:
+ source_start: int
+ source_lines: int
+ target_start: int
+ target_lines: int
+ lines: List[Tuple[str, str]]
+
+
+def parse_patch(patch_text: str) -> List[Hunk]:
+ """
+ Parses a unified diff patch into a list of Hunk objects.
+
+ Args:
+ patch_text: Unified diff format patch text
+
+ Returns:
+ List of parsed Hunk objects
+
+ Raises:
+ InvalidDiffError: If the patch is in an invalid format
+ """
+ hunks = []
+ patch_lines = patch_text.splitlines()
+ i = 0
+
+ while i < len(patch_lines):
+ line = patch_lines[i]
+
+ if line.startswith("@@"):
+ try:
+ header_parts = line.split()
+ if len(header_parts) < 3:
+ raise ValueError(f"Invalid hunk header format: {line}")
+
+ source_changes, target_changes = header_parts[1:3]
+ source_start, source_lines = map(int, source_changes[1:].split(","))
+ target_start, target_lines = map(int, target_changes[1:].split(","))
+
+ hunk = Hunk(source_start, source_lines, target_start, target_lines, [])
+ i += 1
+
+ while i < len(patch_lines) and not patch_lines[i].startswith("@@"):
+ hunk_line = patch_lines[i]
+ if hunk_line:
+ hunk.lines.append((hunk_line[0], hunk_line[1:]))
+ else:
+ # Fully empty lines usually means an empty context line that was
+ # trimmed by trailing whitespace removal.
+ hunk.lines.append((" ", ""))
+ i += 1
+
+ hunks.append(hunk)
+ except (IndexError, ValueError) as e:
+ raise InvalidDiffError(f"Failed to parse hunk: {str(e)}") from e
+ else:
+ raise InvalidDiffError(f"Invalid line format: {line}")
+
+ return hunks
+
+
+def find_hunk_start(source_lines: List[str], hunk: Hunk) -> int:
+ """
+ Finds the actual starting line of a hunk in the source lines.
+
+ Args:
+ source_lines: The original source lines
+ hunk: The hunk to locate
+
+ Returns:
+ The actual line number where the hunk starts
+
+ Raises:
+ DiffApplyError: If the hunk's context cannot be found in the source lines
+ """
+
+ # Extract context lines from the hunk, stopping at the first non-context line
+ context_lines = []
+ for prefix, line in hunk.lines:
+ if prefix == " ":
+ context_lines.append(line)
+ else:
+ break
+
+ if not context_lines:
+ logger.debug("No context lines found in hunk.")
+ return hunk.source_start - 1 # Default to the original start if no context
+
+ logger.debug(
+ f"Searching for {len(context_lines)} context lines, starting with {context_lines[0]}"
+ )
+
+ # Define the range to search for the context lines
+ search_start = max(0, hunk.source_start - _LOOKAROUND_LINES)
+ search_end = min(len(source_lines), hunk.source_start + _LOOKAROUND_LINES)
+
+ # Iterate over the possible starting positions in the source lines
+ for i in range(search_start, search_end):
+ # Check if the context lines match the source lines starting at position i
+ match = True
+ for j, context_line in enumerate(context_lines):
+ if (i + j >= len(source_lines)) or source_lines[i + j] != context_line:
+ match = False
+ break
+ if match:
+ # logger.debug(f"Context match found at line: {i}")
+ return i
+
+ logger.debug(f"Could not find match for hunk context lines: {context_lines}")
+ raise DiffApplyError("Could not find match for hunk context.")
+
+
+def apply_hunk(result_lines: List[str], hunk: Hunk, hunk_index: int) -> None:
+ """
+ Applies a single hunk to the result lines.
+
+ Args:
+ result_lines: The current state of the patched file
+ hunk: The hunk to apply
+ hunk_index: The index of the hunk (for logging purposes)
+
+ Raises:
+ DiffApplyError: If the hunk cannot be applied correctly
+ """
+ current_line = find_hunk_start(result_lines, hunk)
+ logger.debug(f"Hunk {hunk_index + 1} start line: {current_line}")
+
+ for line_index, (prefix, content) in enumerate(hunk.lines):
+ # logger.debug(f"Processing line {line_index + 1} of hunk {hunk_index + 1}")
+ # logger.debug(f"Current line: {current_line}, Total lines: {len(result_lines)}")
+ # logger.debug(f"Prefix: {prefix}, Content: {content}")
+
+ if current_line >= len(result_lines):
+ logger.debug(f"Reached end of file while applying hunk {hunk_index + 1}")
+ while line_index < len(hunk.lines) and hunk.lines[line_index][0] == "+":
+ result_lines.append(hunk.lines[line_index][1])
+ line_index += 1
+
+ # If there's context or deletions past the end of the file, that's an error.
+ if line_index < len(hunk.lines):
+ raise DiffApplyError(
+ f"Found context or deletions after end of file in hunk {hunk_index + 1}"
+ )
+ break
+
+ if prefix == "-":
+ if result_lines[current_line].strip() != content.strip():
+ raise DiffApplyError(
+ f"Removing line that doesn't exactly match. Expected: '{content.strip()}', Found: '{result_lines[current_line].strip()}'"
+ )
+ result_lines.pop(current_line)
+ elif prefix == "+":
+ result_lines.insert(current_line, content)
+ current_line += 1
+ elif prefix == " ":
+ if result_lines[current_line].strip() != content.strip():
+ raise DiffApplyError(
+ f"Context line doesn't exactly match. Expected: '{content.strip()}', Found: '{result_lines[current_line].strip()}'"
+ )
+ current_line += 1
+ else:
+ raise DiffApplyError(
+ f"Invalid line prefix '{prefix}' in hunk {hunk_index + 1}, line {line_index + 1}"
+ )
+
+
+def apply_diff(source: str, patch_text: str) -> str:
+ """
+ Applies a unified diff patch to source text and returns the patched result.
+
+ Args:
+ source: Original source text to be patched
+ patch_text: Unified diff format patch text (with @@ markers and hunks)
+
+ Returns:
+ The patched text result
+
+ Raises:
+ InvalidDiffError: If the patch is in an invalid format
+ DiffApplyError: If the patch cannot be applied correctly
+ """
+
+ # logger.debug(f"Original source:\n{source}")
+ # logger.debug(f"Patch text:\n{patch_text}")
+
+ hunks = parse_patch(patch_text)
+ logger.debug(f"Parsed into {len(hunks)} hunks")
+
+ source_lines = source.splitlines()
+ result_lines = source_lines.copy()
+
+ for hunk_index, hunk in enumerate(hunks):
+ logger.debug(f"Processing hunk {hunk_index + 1}")
+ apply_hunk(result_lines, hunk, hunk_index)
+
+ result = "\n".join(result_lines) + "\n"
+ # logger.debug(f"Patched result:\n{result}")
+ return result
diff --git a/metadata-ingestion/tests/integration/bigquery_v2/bigquery_mcp_golden.json b/metadata-ingestion/tests/integration/bigquery_v2/bigquery_mcp_golden.json
index 640ee1bf436b0..5e091596cc0f7 100644
--- a/metadata-ingestion/tests/integration/bigquery_v2/bigquery_mcp_golden.json
+++ b/metadata-ingestion/tests/integration/bigquery_v2/bigquery_mcp_golden.json
@@ -112,6 +112,26 @@
"lastRunId": "no-run-id-provided"
}
},
+{
+ "entityType": "container",
+ "entityUrn": "urn:li:container:8df46c5e3ded05a3122b0015822c0ef0",
+ "changeType": "UPSERT",
+ "aspectName": "globalTags",
+ "aspect": {
+ "json": {
+ "tags": [
+ {
+ "tag": "urn:li:tag:priority:medium:test"
+ }
+ ]
+ }
+ },
+ "systemMetadata": {
+ "lastObserved": 1643871600000,
+ "runId": "bigquery-2022_02_03-07_00_00",
+ "lastRunId": "no-run-id-provided"
+ }
+},
{
"entityType": "container",
"entityUrn": "urn:li:container:8df46c5e3ded05a3122b0015822c0ef0",
@@ -257,6 +277,64 @@
"lastRunId": "no-run-id-provided"
}
},
+{
+ "entityType": "platformResource",
+ "entityUrn": "urn:li:platformResource:7fbbf79fb726422dc2434222a8e30630",
+ "changeType": "UPSERT",
+ "aspectName": "platformResourceInfo",
+ "aspect": {
+ "json": {
+ "resourceType": "BigQueryLabelInfo",
+ "primaryKey": "priority/medium:test",
+ "secondaryKeys": [
+ "urn:li:tag:priority:medium:test"
+ ],
+ "value": {
+ "blob": "{\"datahub_urn\": \"urn:li:tag:priority:medium:test\", \"managed_by_datahub\": false, \"key\": \"priority\", \"value\": \"medium:test\"}",
+ "contentType": "JSON",
+ "schemaType": "JSON",
+ "schemaRef": "BigQueryLabelInfo"
+ }
+ }
+ },
+ "systemMetadata": {
+ "lastObserved": 1643871600000,
+ "runId": "bigquery-2022_02_03-07_00_00-2j2qqv",
+ "lastRunId": "no-run-id-provided"
+ }
+},
+{
+ "entityType": "platformResource",
+ "entityUrn": "urn:li:platformResource:7fbbf79fb726422dc2434222a8e30630",
+ "changeType": "UPSERT",
+ "aspectName": "dataPlatformInstance",
+ "aspect": {
+ "json": {
+ "platform": "urn:li:dataPlatform:bigquery"
+ }
+ },
+ "systemMetadata": {
+ "lastObserved": 1643871600000,
+ "runId": "bigquery-2022_02_03-07_00_00-2j2qqv",
+ "lastRunId": "no-run-id-provided"
+ }
+},
+{
+ "entityType": "platformResource",
+ "entityUrn": "urn:li:platformResource:7fbbf79fb726422dc2434222a8e30630",
+ "changeType": "UPSERT",
+ "aspectName": "status",
+ "aspect": {
+ "json": {
+ "removed": false
+ }
+ },
+ "systemMetadata": {
+ "lastObserved": 1643871600000,
+ "runId": "bigquery-2022_02_03-07_00_00-2j2qqv",
+ "lastRunId": "no-run-id-provided"
+ }
+},
{
"entityType": "platformResource",
"entityUrn": "urn:li:platformResource:99b34051bd90d28d922b0e107277a916",
@@ -1241,6 +1319,22 @@
"lastRunId": "no-run-id-provided"
}
},
+{
+ "entityType": "tag",
+ "entityUrn": "urn:li:tag:priority:medium:test",
+ "changeType": "UPSERT",
+ "aspectName": "tagKey",
+ "aspect": {
+ "json": {
+ "name": "priority:medium:test"
+ }
+ },
+ "systemMetadata": {
+ "lastObserved": 1643871600000,
+ "runId": "bigquery-2022_02_03-07_00_00",
+ "lastRunId": "no-run-id-provided"
+ }
+},
{
"entityType": "tag",
"entityUrn": "urn:li:tag:purchase",
diff --git a/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py b/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py
index 39cefcb42f360..1f14688636161 100644
--- a/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py
+++ b/metadata-ingestion/tests/integration/bigquery_v2/test_bigquery.py
@@ -70,6 +70,7 @@ def recipe(mcp_output_path: str, source_config_override: dict = {}) -> dict:
"include_table_lineage": True,
"include_data_platform_instance": True,
"capture_table_label_as_tag": True,
+ "capture_dataset_label_as_tag": True,
"classification": ClassificationConfig(
enabled=True,
classifiers=[
@@ -141,7 +142,10 @@ def side_effect(*args: Any) -> Optional[PlatformResource]:
get_platform_resource.side_effect = side_effect
get_datasets_for_project_id.return_value = [
- BigqueryDataset(name=dataset_name, location="US")
+ # BigqueryDataset(name=dataset_name, location="US")
+ BigqueryDataset(
+ name=dataset_name, location="US", labels={"priority": "medium:test"}
+ )
]
table_list_item = TableListItem(
diff --git a/metadata-ingestion/tests/unit/sql_parsing/test_sqlglot_patch.py b/metadata-ingestion/tests/unit/sql_parsing/test_sqlglot_patch.py
new file mode 100644
index 0000000000000..dee6d9630c12e
--- /dev/null
+++ b/metadata-ingestion/tests/unit/sql_parsing/test_sqlglot_patch.py
@@ -0,0 +1,48 @@
+from datahub.sql_parsing._sqlglot_patch import SQLGLOT_PATCHED
+
+import time
+
+import pytest
+import sqlglot
+import sqlglot.errors
+import sqlglot.lineage
+import sqlglot.optimizer
+
+from datahub.utilities.cooperative_timeout import (
+ CooperativeTimeoutError,
+ cooperative_timeout,
+)
+from datahub.utilities.perf_timer import PerfTimer
+
+assert SQLGLOT_PATCHED
+
+
+def test_cooperative_timeout_sql() -> None:
+ statement = sqlglot.parse_one("SELECT pg_sleep(3)", dialect="postgres")
+ with pytest.raises(
+ CooperativeTimeoutError
+ ), PerfTimer() as timer, cooperative_timeout(timeout=0.6):
+ while True:
+ # sql() implicitly calls copy(), which is where we check for the timeout.
+ assert statement.sql() is not None
+ time.sleep(0.0001)
+ assert 0.6 <= timer.elapsed_seconds() <= 1.0
+
+
+def test_scope_circular_dependency() -> None:
+ scope = sqlglot.optimizer.build_scope(
+ sqlglot.parse_one("WITH w AS (SELECT * FROM q) SELECT * FROM w")
+ )
+ assert scope is not None
+
+ cte_scope = scope.cte_scopes[0]
+ cte_scope.cte_scopes.append(cte_scope)
+
+ with pytest.raises(sqlglot.errors.OptimizeError, match="circular scope dependency"):
+ list(scope.traverse())
+
+
+def test_lineage_node_subfield() -> None:
+ expression = sqlglot.parse_one("SELECT 1 AS test")
+ node = sqlglot.lineage.Node("test", expression, expression, subfield="subfield") # type: ignore
+ assert node.subfield == "subfield" # type: ignore
diff --git a/metadata-ingestion/tests/unit/utilities/test_unified_diff.py b/metadata-ingestion/tests/unit/utilities/test_unified_diff.py
new file mode 100644
index 0000000000000..05277ec3fa0ab
--- /dev/null
+++ b/metadata-ingestion/tests/unit/utilities/test_unified_diff.py
@@ -0,0 +1,191 @@
+import pytest
+
+from datahub.utilities.unified_diff import (
+ DiffApplyError,
+ Hunk,
+ InvalidDiffError,
+ apply_diff,
+ apply_hunk,
+ find_hunk_start,
+ parse_patch,
+)
+
+
+def test_parse_patch():
+ patch_text = """@@ -1,3 +1,4 @@
+ Line 1
+-Line 2
++Line 2 modified
++Line 2.5
+ Line 3"""
+ hunks = parse_patch(patch_text)
+ assert len(hunks) == 1
+ assert hunks[0].source_start == 1
+ assert hunks[0].source_lines == 3
+ assert hunks[0].target_start == 1
+ assert hunks[0].target_lines == 4
+ assert hunks[0].lines == [
+ (" ", "Line 1"),
+ ("-", "Line 2"),
+ ("+", "Line 2 modified"),
+ ("+", "Line 2.5"),
+ (" ", "Line 3"),
+ ]
+
+
+def test_parse_patch_invalid():
+ with pytest.raises(InvalidDiffError):
+ parse_patch("Invalid patch")
+
+
+def test_parse_patch_bad_header():
+ # A patch with a malformed header
+ bad_patch_text = """@@ -1,3
+ Line 1
+-Line 2
++Line 2 modified
+ Line 3"""
+ with pytest.raises(InvalidDiffError):
+ parse_patch(bad_patch_text)
+
+
+def test_find_hunk_start():
+ source_lines = ["Line 1", "Line 2", "Line 3", "Line 4"]
+ hunk = Hunk(2, 2, 2, 2, [(" ", "Line 2"), (" ", "Line 3")])
+ assert find_hunk_start(source_lines, hunk) == 1
+
+
+def test_find_hunk_start_not_found():
+ source_lines = ["Line 1", "Line 2", "Line 3", "Line 4"]
+ hunk = Hunk(2, 2, 2, 2, [(" ", "Line X"), (" ", "Line Y")])
+ with pytest.raises(DiffApplyError, match="Could not find match for hunk context."):
+ find_hunk_start(source_lines, hunk)
+
+
+def test_apply_hunk_success():
+ result_lines = ["Line 1", "Line 2", "Line 3"]
+ hunk = Hunk(
+ 2,
+ 2,
+ 2,
+ 3,
+ [(" ", "Line 2"), ("-", "Line 3"), ("+", "Line 3 modified"), ("+", "Line 3.5")],
+ )
+ apply_hunk(result_lines, hunk, 0)
+ assert result_lines == ["Line 1", "Line 2", "Line 3 modified", "Line 3.5"]
+
+
+def test_apply_hunk_mismatch():
+ result_lines = ["Line 1", "Line 2", "Line X"]
+ hunk = Hunk(
+ 2, 2, 2, 2, [(" ", "Line 2"), ("-", "Line 3"), ("+", "Line 3 modified")]
+ )
+ with pytest.raises(
+ DiffApplyError, match="Removing line that doesn't exactly match"
+ ):
+ apply_hunk(result_lines, hunk, 0)
+
+
+def test_apply_hunk_context_mismatch():
+ result_lines = ["Line 1", "Line 3"]
+ hunk = Hunk(2, 2, 2, 2, [(" ", "Line 1"), ("+", "Line 2"), (" ", "Line 4")])
+ with pytest.raises(DiffApplyError, match="Context line doesn't exactly match"):
+ apply_hunk(result_lines, hunk, 0)
+
+
+def test_apply_hunk_invalid_prefix():
+ result_lines = ["Line 1", "Line 2", "Line 3"]
+ hunk = Hunk(
+ 2, 2, 2, 2, [(" ", "Line 2"), ("*", "Line 3"), ("+", "Line 3 modified")]
+ )
+ with pytest.raises(DiffApplyError, match="Invalid line prefix"):
+ apply_hunk(result_lines, hunk, 0)
+
+
+def test_apply_hunk_end_of_file():
+ result_lines = ["Line 1", "Line 2"]
+ hunk = Hunk(
+ 2, 2, 2, 3, [(" ", "Line 2"), ("-", "Line 3"), ("+", "Line 3 modified")]
+ )
+ with pytest.raises(
+ DiffApplyError, match="Found context or deletions after end of file"
+ ):
+ apply_hunk(result_lines, hunk, 0)
+
+
+def test_apply_hunk_context_beyond_end_of_file():
+ result_lines = ["Line 1", "Line 3"]
+ hunk = Hunk(
+ 2, 2, 2, 3, [(" ", "Line 1"), ("+", "Line 2"), (" ", "Line 3"), (" ", "Line 4")]
+ )
+ with pytest.raises(
+ DiffApplyError, match="Found context or deletions after end of file"
+ ):
+ apply_hunk(result_lines, hunk, 0)
+
+
+def test_apply_hunk_remove_non_existent_line():
+ result_lines = ["Line 1", "Line 2", "Line 4"]
+ hunk = Hunk(
+ 2, 2, 2, 3, [(" ", "Line 2"), ("-", "Line 3"), ("+", "Line 3 modified")]
+ )
+ with pytest.raises(
+ DiffApplyError, match="Removing line that doesn't exactly match"
+ ):
+ apply_hunk(result_lines, hunk, 0)
+
+
+def test_apply_hunk_addition_beyond_end_of_file():
+ result_lines = ["Line 1", "Line 2"]
+ hunk = Hunk(
+ 2, 2, 2, 3, [(" ", "Line 2"), ("+", "Line 3 modified"), ("+", "Line 4")]
+ )
+ apply_hunk(result_lines, hunk, 0)
+ assert result_lines == ["Line 1", "Line 2", "Line 3 modified", "Line 4"]
+
+
+def test_apply_diff():
+ source = """Line 1
+Line 2
+Line 3
+Line 4"""
+ patch = """@@ -1,4 +1,5 @@
+ Line 1
+-Line 2
++Line 2 modified
++Line 2.5
+ Line 3
+ Line 4"""
+ result = apply_diff(source, patch)
+ expected = """Line 1
+Line 2 modified
+Line 2.5
+Line 3
+Line 4
+"""
+ assert result == expected
+
+
+def test_apply_diff_invalid_patch():
+ source = "Line 1\nLine 2\n"
+ patch = "Invalid patch"
+ with pytest.raises(InvalidDiffError):
+ apply_diff(source, patch)
+
+
+def test_apply_diff_unapplicable_patch():
+ source = "Line 1\nLine 2\n"
+ patch = "@@ -1,2 +1,2 @@\n Line 1\n-Line X\n+Line 2 modified\n"
+ with pytest.raises(DiffApplyError):
+ apply_diff(source, patch)
+
+
+def test_apply_diff_add_to_empty_file():
+ source = ""
+ patch = """\
+@@ -1,0 +1,1 @@
++Line 1
++Line 2
+"""
+ result = apply_diff(source, patch)
+ assert result == "Line 1\nLine 2\n"
diff --git a/metadata-ingestion/tests/unit/utilities/test_utilities.py b/metadata-ingestion/tests/unit/utilities/test_utilities.py
index fc2aa27f70b43..68da1bc1c01be 100644
--- a/metadata-ingestion/tests/unit/utilities/test_utilities.py
+++ b/metadata-ingestion/tests/unit/utilities/test_utilities.py
@@ -1,6 +1,7 @@
import doctest
from datahub.utilities.delayed_iter import delayed_iter
+from datahub.utilities.is_pytest import is_pytest_running
from datahub.utilities.sql_parser import SqlLineageSQLParser
@@ -295,3 +296,7 @@ def test_logging_name_extraction():
).attempted
> 0
)
+
+
+def test_is_pytest_running() -> None:
+ assert is_pytest_running()
diff --git a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/EntityAspect.java b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/EntityAspect.java
index cba770d841b94..976db4133c004 100644
--- a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/EntityAspect.java
+++ b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/EntityAspect.java
@@ -9,6 +9,7 @@
import com.linkedin.metadata.aspect.SystemAspect;
import com.linkedin.metadata.models.AspectSpec;
import com.linkedin.metadata.models.EntitySpec;
+import com.linkedin.mxe.GenericAspect;
import com.linkedin.mxe.SystemMetadata;
import java.sql.Timestamp;
import javax.annotation.Nonnull;
@@ -65,7 +66,7 @@ public static class EntitySystemAspect implements SystemAspect {
@Nullable private final RecordTemplate recordTemplate;
@Nonnull private final EntitySpec entitySpec;
- @Nonnull private final AspectSpec aspectSpec;
+ @Nullable private final AspectSpec aspectSpec;
@Nonnull
public String getUrnRaw() {
@@ -151,7 +152,7 @@ private EntityAspect.EntitySystemAspect build() {
public EntityAspect.EntitySystemAspect build(
@Nonnull EntitySpec entitySpec,
- @Nonnull AspectSpec aspectSpec,
+ @Nullable AspectSpec aspectSpec,
@Nonnull EntityAspect entityAspect) {
this.entityAspect = entityAspect;
this.urn = UrnUtils.getUrn(entityAspect.getUrn());
@@ -159,7 +160,11 @@ public EntityAspect.EntitySystemAspect build(
if (entityAspect.getMetadata() != null) {
this.recordTemplate =
RecordUtils.toRecordTemplate(
- aspectSpec.getDataTemplateClass(), entityAspect.getMetadata());
+ (Class)
+ (aspectSpec == null
+ ? GenericAspect.class
+ : aspectSpec.getDataTemplateClass()),
+ entityAspect.getMetadata());
}
return new EntitySystemAspect(entityAspect, urn, recordTemplate, entitySpec, aspectSpec);
diff --git a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java
index 1fba842631720..7f56abe64f9a7 100644
--- a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java
+++ b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/AspectsBatchImpl.java
@@ -3,6 +3,7 @@
import com.linkedin.common.AuditStamp;
import com.linkedin.data.template.RecordTemplate;
import com.linkedin.events.metadata.ChangeType;
+import com.linkedin.metadata.aspect.AspectRetriever;
import com.linkedin.metadata.aspect.RetrieverContext;
import com.linkedin.metadata.aspect.SystemAspect;
import com.linkedin.metadata.aspect.batch.AspectsBatch;
@@ -11,6 +12,7 @@
import com.linkedin.metadata.aspect.batch.MCPItem;
import com.linkedin.metadata.aspect.plugins.hooks.MutationHook;
import com.linkedin.metadata.aspect.plugins.validation.ValidationExceptionCollection;
+import com.linkedin.metadata.models.EntitySpec;
import com.linkedin.mxe.MetadataChangeProposal;
import com.linkedin.util.Pair;
import java.util.Collection;
@@ -114,19 +116,7 @@ private Stream proposedItemsToChangeItemStream(List {
- if (ChangeType.PATCH.equals(mcpItem.getChangeType())) {
- return PatchItemImpl.PatchItemImplBuilder.build(
- mcpItem.getMetadataChangeProposal(),
- mcpItem.getAuditStamp(),
- retrieverContext.getAspectRetriever().getEntityRegistry());
- }
- return ChangeItemImpl.ChangeItemImplBuilder.build(
- mcpItem.getMetadataChangeProposal(),
- mcpItem.getAuditStamp(),
- retrieverContext.getAspectRetriever());
- });
+ .map(mcpItem -> patchDiscriminator(mcpItem, retrieverContext.getAspectRetriever()));
List mutatedItems =
applyProposalMutationHooks(proposedItems, retrieverContext).collect(Collectors.toList());
Stream proposedItemsToChangeItems =
@@ -134,12 +124,7 @@ private Stream proposedItemsToChangeItemStream(List mcpItem.getMetadataChangeProposal() != null)
// Filter on proposed items again to avoid applying builder to Patch Item side effects
.filter(mcpItem -> mcpItem instanceof ProposedItem)
- .map(
- mcpItem ->
- ChangeItemImpl.ChangeItemImplBuilder.build(
- mcpItem.getMetadataChangeProposal(),
- mcpItem.getAuditStamp(),
- retrieverContext.getAspectRetriever()));
+ .map(mcpItem -> patchDiscriminator(mcpItem, retrieverContext.getAspectRetriever()));
Stream sideEffectItems =
mutatedItems.stream().filter(mcpItem -> !(mcpItem instanceof ProposedItem));
Stream combinedChangeItems =
@@ -147,6 +132,17 @@ private Stream proposedItemsToChangeItemStream(List mcps,
AuditStamp auditStamp,
RetrieverContext retrieverContext) {
+ return mcps(mcps, auditStamp, retrieverContext, false);
+ }
+
+ public AspectsBatchImplBuilder mcps(
+ Collection mcps,
+ AuditStamp auditStamp,
+ RetrieverContext retrieverContext,
+ boolean alternateMCPValidation) {
retrieverContext(retrieverContext);
items(
@@ -171,6 +175,18 @@ public AspectsBatchImplBuilder mcps(
.map(
mcp -> {
try {
+ if (alternateMCPValidation) {
+ EntitySpec entitySpec =
+ retrieverContext
+ .getAspectRetriever()
+ .getEntityRegistry()
+ .getEntitySpec(mcp.getEntityType());
+ return ProposedItem.builder()
+ .metadataChangeProposal(mcp)
+ .entitySpec(entitySpec)
+ .auditStamp(auditStamp)
+ .build();
+ }
if (mcp.getChangeType().equals(ChangeType.PATCH)) {
return PatchItemImpl.PatchItemImplBuilder.build(
mcp,
diff --git a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/PatchItemImpl.java b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/PatchItemImpl.java
index 43a7d00248a22..ec0a8422e3c4a 100644
--- a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/PatchItemImpl.java
+++ b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/PatchItemImpl.java
@@ -203,7 +203,7 @@ public static PatchItemImpl build(
.build(entityRegistry);
}
- private static JsonPatch convertToJsonPatch(MetadataChangeProposal mcp) {
+ public static JsonPatch convertToJsonPatch(MetadataChangeProposal mcp) {
JsonNode json;
try {
return Json.createPatch(
diff --git a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java
index 132a731d278af..88187ef159f23 100644
--- a/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java
+++ b/metadata-io/metadata-io-api/src/main/java/com/linkedin/metadata/entity/ebean/batch/ProposedItem.java
@@ -9,8 +9,10 @@
import com.linkedin.metadata.models.EntitySpec;
import com.linkedin.metadata.utils.EntityKeyUtils;
import com.linkedin.metadata.utils.GenericRecordUtils;
+import com.linkedin.metadata.utils.SystemMetadataUtils;
import com.linkedin.mxe.MetadataChangeProposal;
import com.linkedin.mxe.SystemMetadata;
+import java.util.Objects;
import javax.annotation.Nonnull;
import javax.annotation.Nullable;
import lombok.Builder;
@@ -83,4 +85,18 @@ public SystemMetadata getSystemMetadata() {
public ChangeType getChangeType() {
return metadataChangeProposal.getChangeType();
}
+
+ public static class ProposedItemBuilder {
+ public ProposedItem build() {
+ // Ensure systemMetadata
+ return new ProposedItem(
+ Objects.requireNonNull(this.metadataChangeProposal)
+ .setSystemMetadata(
+ SystemMetadataUtils.generateSystemMetadataIfEmpty(
+ this.metadataChangeProposal.getSystemMetadata())),
+ this.auditStamp,
+ this.entitySpec,
+ this.aspectSpec);
+ }
+ }
}
diff --git a/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java b/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java
index 8d6bdffceacb9..f5cc421042e36 100644
--- a/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java
+++ b/metadata-io/src/main/java/com/linkedin/metadata/aspect/hooks/IgnoreUnknownMutator.java
@@ -1,8 +1,14 @@
package com.linkedin.metadata.aspect.hooks;
+import static com.linkedin.events.metadata.ChangeType.CREATE;
+import static com.linkedin.events.metadata.ChangeType.CREATE_ENTITY;
+import static com.linkedin.events.metadata.ChangeType.UPDATE;
+import static com.linkedin.events.metadata.ChangeType.UPSERT;
+
import com.datahub.util.exception.ModelConversionException;
import com.linkedin.data.template.RecordTemplate;
import com.linkedin.data.transform.filter.request.MaskTree;
+import com.linkedin.events.metadata.ChangeType;
import com.linkedin.metadata.aspect.RetrieverContext;
import com.linkedin.metadata.aspect.batch.MCPItem;
import com.linkedin.metadata.aspect.plugins.config.AspectPluginConfig;
@@ -14,6 +20,7 @@
import com.linkedin.mxe.GenericAspect;
import com.linkedin.restli.internal.server.util.RestUtils;
import java.util.Collection;
+import java.util.Set;
import java.util.stream.Stream;
import javax.annotation.Nonnull;
import lombok.Getter;
@@ -27,6 +34,11 @@
@Getter
@Accessors(chain = true)
public class IgnoreUnknownMutator extends MutationHook {
+ private static final Set SUPPORTED_MIME_TYPES =
+ Set.of("application/json", "application/json-patch+json");
+ private static final Set MUTATION_TYPES =
+ Set.of(CREATE, CREATE_ENTITY, UPSERT, UPDATE);
+
@Nonnull private AspectPluginConfig config;
@Override
@@ -42,8 +54,8 @@ protected Stream proposalMutation(
item.getAspectSpec().getName());
return false;
}
- if (!"application/json"
- .equals(item.getMetadataChangeProposal().getAspect().getContentType())) {
+ if (!SUPPORTED_MIME_TYPES.contains(
+ item.getMetadataChangeProposal().getAspect().getContentType())) {
log.warn(
"Dropping unknown content type {} for aspect {} on entity {}",
item.getMetadataChangeProposal().getAspect().getContentType(),
@@ -55,25 +67,27 @@ protected Stream proposalMutation(
})
.peek(
item -> {
- try {
- AspectSpec aspectSpec = item.getEntitySpec().getAspectSpec(item.getAspectName());
- GenericAspect aspect = item.getMetadataChangeProposal().getAspect();
- RecordTemplate recordTemplate =
- GenericRecordUtils.deserializeAspect(
- aspect.getValue(), aspect.getContentType(), aspectSpec);
+ if (MUTATION_TYPES.contains(item.getChangeType())) {
try {
- ValidationApiUtils.validateOrThrow(recordTemplate);
- } catch (ValidationException | ModelConversionException e) {
- log.warn(
- "Failed to validate aspect. Coercing aspect {} on entity {}",
- item.getAspectName(),
- item.getEntitySpec().getName());
- RestUtils.trimRecordTemplate(recordTemplate, new MaskTree(), false);
- item.getMetadataChangeProposal()
- .setAspect(GenericRecordUtils.serializeAspect(recordTemplate));
+ AspectSpec aspectSpec = item.getEntitySpec().getAspectSpec(item.getAspectName());
+ GenericAspect aspect = item.getMetadataChangeProposal().getAspect();
+ RecordTemplate recordTemplate =
+ GenericRecordUtils.deserializeAspect(
+ aspect.getValue(), aspect.getContentType(), aspectSpec);
+ try {
+ ValidationApiUtils.validateOrThrow(recordTemplate);
+ } catch (ValidationException | ModelConversionException e) {
+ log.warn(
+ "Failed to validate aspect. Coercing aspect {} on entity {}",
+ item.getAspectName(),
+ item.getEntitySpec().getName());
+ RestUtils.trimRecordTemplate(recordTemplate, new MaskTree(), false);
+ item.getMetadataChangeProposal()
+ .setAspect(GenericRecordUtils.serializeAspect(recordTemplate));
+ }
+ } catch (Exception e) {
+ throw new RuntimeException(e);
}
- } catch (Exception e) {
- throw new RuntimeException(e);
}
});
}
diff --git a/metadata-io/src/main/java/com/linkedin/metadata/client/JavaEntityClient.java b/metadata-io/src/main/java/com/linkedin/metadata/client/JavaEntityClient.java
index 60a991c19ae8b..8b625b3ae2289 100644
--- a/metadata-io/src/main/java/com/linkedin/metadata/client/JavaEntityClient.java
+++ b/metadata-io/src/main/java/com/linkedin/metadata/client/JavaEntityClient.java
@@ -23,7 +23,6 @@
import com.linkedin.metadata.aspect.EnvelopedAspectArray;
import com.linkedin.metadata.aspect.VersionedAspect;
import com.linkedin.metadata.aspect.batch.AspectsBatch;
-import com.linkedin.metadata.aspect.batch.BatchItem;
import com.linkedin.metadata.browse.BrowseResult;
import com.linkedin.metadata.browse.BrowseResultV2;
import com.linkedin.metadata.entity.DeleteEntityService;
@@ -56,6 +55,7 @@
import com.linkedin.parseq.retry.backoff.BackoffPolicy;
import com.linkedin.parseq.retry.backoff.ExponentialBackoff;
import com.linkedin.r2.RemoteInvocationException;
+import com.linkedin.util.Pair;
import io.datahubproject.metadata.context.OperationContext;
import io.opentelemetry.extension.annotations.WithSpan;
import java.net.URISyntaxException;
@@ -762,38 +762,41 @@ public List batchIngestProposals(
AspectsBatch batch =
AspectsBatchImpl.builder()
- .mcps(metadataChangeProposals, auditStamp, opContext.getRetrieverContext().get())
+ .mcps(
+ metadataChangeProposals,
+ auditStamp,
+ opContext.getRetrieverContext().get(),
+ opContext.getValidationContext().isAlternateValidation())
.build();
- Map> resultMap =
+ Map, List> resultMap =
entityService.ingestProposal(opContext, batch, async).stream()
- .collect(Collectors.groupingBy(IngestResult::getRequest));
-
- // Update runIds
- batch.getItems().stream()
- .filter(resultMap::containsKey)
- .forEach(
- requestItem -> {
- List results = resultMap.get(requestItem);
- Optional resultUrn =
- results.stream().map(IngestResult::getUrn).filter(Objects::nonNull).findFirst();
- resultUrn.ifPresent(
- urn -> tryIndexRunId(opContext, urn, requestItem.getSystemMetadata()));
- });
+ .collect(
+ Collectors.groupingBy(
+ result ->
+ Pair.of(
+ result.getRequest().getUrn(), result.getRequest().getAspectName())));
// Preserve ordering
return batch.getItems().stream()
.map(
requestItem -> {
- if (resultMap.containsKey(requestItem)) {
- List results = resultMap.get(requestItem);
- return results.stream()
- .filter(r -> r.getUrn() != null)
- .findFirst()
- .map(r -> r.getUrn().toString())
- .orElse(null);
- }
- return null;
+ // Urns generated
+ List urnsForRequest =
+ resultMap
+ .getOrDefault(
+ Pair.of(requestItem.getUrn(), requestItem.getAspectName()), List.of())
+ .stream()
+ .map(IngestResult::getUrn)
+ .filter(Objects::nonNull)
+ .distinct()
+ .collect(Collectors.toList());
+
+ // Update runIds
+ urnsForRequest.forEach(
+ urn -> tryIndexRunId(opContext, urn, requestItem.getSystemMetadata()));
+
+ return urnsForRequest.isEmpty() ? null : urnsForRequest.get(0).toString();
})
.collect(Collectors.toList());
}
diff --git a/metadata-io/src/main/java/com/linkedin/metadata/entity/EntityServiceImpl.java b/metadata-io/src/main/java/com/linkedin/metadata/entity/EntityServiceImpl.java
index 00feb547ca330..9f608be4f3d18 100644
--- a/metadata-io/src/main/java/com/linkedin/metadata/entity/EntityServiceImpl.java
+++ b/metadata-io/src/main/java/com/linkedin/metadata/entity/EntityServiceImpl.java
@@ -1173,15 +1173,15 @@ public IngestResult ingestProposal(
* @return an {@link IngestResult} containing the results
*/
@Override
- public Set ingestProposal(
+ public List ingestProposal(
@Nonnull OperationContext opContext, AspectsBatch aspectsBatch, final boolean async) {
Stream timeseriesIngestResults =
ingestTimeseriesProposal(opContext, aspectsBatch, async);
Stream nonTimeseriesIngestResults =
async ? ingestProposalAsync(aspectsBatch) : ingestProposalSync(opContext, aspectsBatch);
- return Stream.concat(timeseriesIngestResults, nonTimeseriesIngestResults)
- .collect(Collectors.toSet());
+ return Stream.concat(nonTimeseriesIngestResults, timeseriesIngestResults)
+ .collect(Collectors.toList());
}
/**
@@ -1192,11 +1192,13 @@ public Set ingestProposal(
*/
private Stream ingestTimeseriesProposal(
@Nonnull OperationContext opContext, AspectsBatch aspectsBatch, final boolean async) {
+
List unsupported =
aspectsBatch.getItems().stream()
.filter(
item ->
- item.getAspectSpec().isTimeseries()
+ item.getAspectSpec() != null
+ && item.getAspectSpec().isTimeseries()
&& item.getChangeType() != ChangeType.UPSERT)
.collect(Collectors.toList());
if (!unsupported.isEmpty()) {
@@ -1212,7 +1214,7 @@ private Stream ingestTimeseriesProposal(
// Create default non-timeseries aspects for timeseries aspects
List timeseriesKeyAspects =
aspectsBatch.getMCPItems().stream()
- .filter(item -> item.getAspectSpec().isTimeseries())
+ .filter(item -> item.getAspectSpec() != null && item.getAspectSpec().isTimeseries())
.map(
item ->
ChangeItemImpl.builder()
@@ -1238,10 +1240,10 @@ private Stream ingestTimeseriesProposal(
}
// Emit timeseries MCLs
- List, Boolean>>>> timeseriesResults =
+ List, Boolean>>>> timeseriesResults =
aspectsBatch.getItems().stream()
- .filter(item -> item.getAspectSpec().isTimeseries())
- .map(item -> (ChangeItemImpl) item)
+ .filter(item -> item.getAspectSpec() != null && item.getAspectSpec().isTimeseries())
+ .map(item -> (MCPItem) item)
.map(
item ->
Pair.of(
@@ -1272,7 +1274,7 @@ private Stream ingestTimeseriesProposal(
}
});
- ChangeItemImpl request = result.getFirst();
+ MCPItem request = result.getFirst();
return IngestResult.builder()
.urn(request.getUrn())
.request(request)
@@ -1292,7 +1294,7 @@ private Stream ingestTimeseriesProposal(
private Stream ingestProposalAsync(AspectsBatch aspectsBatch) {
List nonTimeseries =
aspectsBatch.getMCPItems().stream()
- .filter(item -> !item.getAspectSpec().isTimeseries())
+ .filter(item -> item.getAspectSpec() == null || !item.getAspectSpec().isTimeseries())
.collect(Collectors.toList());
List> futures =
@@ -1328,6 +1330,7 @@ private Stream ingestProposalAsync(AspectsBatch aspectsBatch) {
private Stream ingestProposalSync(
@Nonnull OperationContext opContext, AspectsBatch aspectsBatch) {
+
AspectsBatchImpl nonTimeseries =
AspectsBatchImpl.builder()
.retrieverContext(aspectsBatch.getRetrieverContext())
diff --git a/metadata-io/src/main/java/com/linkedin/metadata/search/elasticsearch/query/filter/BaseQueryFilterRewriter.java b/metadata-io/src/main/java/com/linkedin/metadata/search/elasticsearch/query/filter/BaseQueryFilterRewriter.java
index d545f60a1ee8f..367705d369c7c 100644
--- a/metadata-io/src/main/java/com/linkedin/metadata/search/elasticsearch/query/filter/BaseQueryFilterRewriter.java
+++ b/metadata-io/src/main/java/com/linkedin/metadata/search/elasticsearch/query/filter/BaseQueryFilterRewriter.java
@@ -110,12 +110,9 @@ private BoolQueryBuilder handleNestedFilters(
mustNotQueryBuilders.forEach(expandedQueryBuilder::mustNot);
expandedQueryBuilder.queryName(boolQueryBuilder.queryName());
expandedQueryBuilder.adjustPureNegative(boolQueryBuilder.adjustPureNegative());
+ expandedQueryBuilder.minimumShouldMatch(boolQueryBuilder.minimumShouldMatch());
expandedQueryBuilder.boost(boolQueryBuilder.boost());
- if (!expandedQueryBuilder.should().isEmpty()) {
- expandedQueryBuilder.minimumShouldMatch(1);
- }
-
return expandedQueryBuilder;
}
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/client/JavaEntityClientTest.java b/metadata-io/src/test/java/com/linkedin/metadata/client/JavaEntityClientTest.java
index 2ca966b104e03..7b1fccafbb9e6 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/client/JavaEntityClientTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/client/JavaEntityClientTest.java
@@ -5,9 +5,22 @@
import static org.testng.Assert.assertThrows;
import com.codahale.metrics.Counter;
+import com.linkedin.common.AuditStamp;
+import com.linkedin.common.Status;
+import com.linkedin.common.UrnArray;
+import com.linkedin.common.urn.Urn;
+import com.linkedin.common.urn.UrnUtils;
import com.linkedin.data.template.RequiredFieldNotPresentException;
+import com.linkedin.domain.Domains;
+import com.linkedin.events.metadata.ChangeType;
+import com.linkedin.metadata.Constants;
+import com.linkedin.metadata.aspect.batch.AspectsBatch;
import com.linkedin.metadata.entity.DeleteEntityService;
import com.linkedin.metadata.entity.EntityService;
+import com.linkedin.metadata.entity.IngestResult;
+import com.linkedin.metadata.entity.UpdateAspectResult;
+import com.linkedin.metadata.entity.ebean.batch.ChangeItemImpl;
+import com.linkedin.metadata.entity.ebean.batch.ProposedItem;
import com.linkedin.metadata.event.EventProducer;
import com.linkedin.metadata.search.EntitySearchService;
import com.linkedin.metadata.search.LineageSearchService;
@@ -15,8 +28,14 @@
import com.linkedin.metadata.search.client.CachingEntitySearchService;
import com.linkedin.metadata.service.RollbackService;
import com.linkedin.metadata.timeseries.TimeseriesAspectService;
+import com.linkedin.metadata.utils.AuditStampUtils;
+import com.linkedin.metadata.utils.GenericRecordUtils;
import com.linkedin.metadata.utils.metrics.MetricUtils;
+import com.linkedin.mxe.MetadataChangeProposal;
+import com.linkedin.r2.RemoteInvocationException;
import io.datahubproject.metadata.context.OperationContext;
+import io.datahubproject.test.metadata.context.TestOperationContexts;
+import java.util.List;
import java.util.function.Supplier;
import org.mockito.MockedStatic;
import org.testng.annotations.AfterMethod;
@@ -25,7 +44,7 @@
public class JavaEntityClientTest {
- private EntityService _entityService;
+ private EntityService _entityService;
private DeleteEntityService _deleteEntityService;
private EntitySearchService _entitySearchService;
private CachingEntitySearchService _cachingEntitySearchService;
@@ -52,7 +71,7 @@ public void setupTest() {
_metricUtils = mockStatic(MetricUtils.class);
_counter = mock(Counter.class);
when(MetricUtils.counter(any(), any())).thenReturn(_counter);
- opContext = mock(OperationContext.class);
+ opContext = TestOperationContexts.systemContextNoSearchAuthorization();
}
@AfterMethod
@@ -131,4 +150,97 @@ void testThrowAfterNonRetryableException() {
() -> MetricUtils.counter(client.getClass(), "exception_" + e.getClass().getName()),
times(1));
}
+
+ @Test
+ void tesIngestOrderingWithProposedItem() throws RemoteInvocationException {
+ JavaEntityClient client = getJavaEntityClient();
+ Urn testUrn = UrnUtils.getUrn("urn:li:container:orderingTest");
+ AuditStamp auditStamp = AuditStampUtils.createDefaultAuditStamp();
+ MetadataChangeProposal mcp =
+ new MetadataChangeProposal()
+ .setEntityUrn(testUrn)
+ .setAspectName("status")
+ .setEntityType("container")
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(GenericRecordUtils.serializeAspect(new Status().setRemoved(true)));
+
+ when(_entityService.ingestProposal(
+ any(OperationContext.class), any(AspectsBatch.class), eq(false)))
+ .thenReturn(
+ List.of(
+ // Misc - unrelated urn
+ IngestResult.builder()
+ .urn(UrnUtils.getUrn("urn:li:container:domains"))
+ .request(
+ ChangeItemImpl.builder()
+ .entitySpec(
+ opContext
+ .getEntityRegistry()
+ .getEntitySpec(Constants.CONTAINER_ENTITY_NAME))
+ .aspectSpec(
+ opContext
+ .getEntityRegistry()
+ .getEntitySpec(Constants.CONTAINER_ENTITY_NAME)
+ .getAspectSpec(Constants.DOMAINS_ASPECT_NAME))
+ .changeType(ChangeType.UPSERT)
+ .urn(UrnUtils.getUrn("urn:li:container:domains"))
+ .aspectName("domains")
+ .recordTemplate(new Domains().setDomains(new UrnArray()))
+ .auditStamp(auditStamp)
+ .build(opContext.getAspectRetriever()))
+ .isUpdate(true)
+ .publishedMCL(true)
+ .sqlCommitted(true)
+ .build(),
+ // Side effect - unrelated urn
+ IngestResult.builder()
+ .urn(UrnUtils.getUrn("urn:li:container:sideEffect"))
+ .request(
+ ChangeItemImpl.builder()
+ .entitySpec(
+ opContext
+ .getEntityRegistry()
+ .getEntitySpec(Constants.CONTAINER_ENTITY_NAME))
+ .aspectSpec(
+ opContext
+ .getEntityRegistry()
+ .getEntitySpec(Constants.CONTAINER_ENTITY_NAME)
+ .getAspectSpec(Constants.STATUS_ASPECT_NAME))
+ .changeType(ChangeType.UPSERT)
+ .urn(UrnUtils.getUrn("urn:li:container:sideEffect"))
+ .aspectName("status")
+ .recordTemplate(new Status().setRemoved(false))
+ .auditStamp(auditStamp)
+ .build(opContext.getAspectRetriever()))
+ .isUpdate(true)
+ .publishedMCL(true)
+ .sqlCommitted(true)
+ .build(),
+ // Expected response
+ IngestResult.builder()
+ .urn(testUrn)
+ .request(
+ ProposedItem.builder()
+ .metadataChangeProposal(mcp)
+ .entitySpec(
+ opContext
+ .getEntityRegistry()
+ .getEntitySpec(Constants.CONTAINER_ENTITY_NAME))
+ .aspectSpec(
+ opContext
+ .getEntityRegistry()
+ .getEntitySpec(Constants.CONTAINER_ENTITY_NAME)
+ .getAspectSpec(Constants.STATUS_ASPECT_NAME))
+ .auditStamp(auditStamp)
+ .build())
+ .result(UpdateAspectResult.builder().mcp(mcp).urn(testUrn).build())
+ .isUpdate(true)
+ .publishedMCL(true)
+ .sqlCommitted(true)
+ .build()));
+
+ String urnStr = client.ingestProposal(opContext, mcp, false);
+
+ assertEquals(urnStr, "urn:li:container:orderingTest");
+ }
}
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/entity/EbeanEntityServiceTest.java b/metadata-io/src/test/java/com/linkedin/metadata/entity/EbeanEntityServiceTest.java
index e8d3c654f6f63..04c9297b1ed7a 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/entity/EbeanEntityServiceTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/entity/EbeanEntityServiceTest.java
@@ -104,7 +104,8 @@ public void setupTest() {
null,
opContext ->
((EntityServiceAspectRetriever) opContext.getAspectRetrieverOpt().get())
- .setSystemOperationContext(opContext));
+ .setSystemOperationContext(opContext),
+ null);
}
/**
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/entity/cassandra/CassandraEntityServiceTest.java b/metadata-io/src/test/java/com/linkedin/metadata/entity/cassandra/CassandraEntityServiceTest.java
index 5535866f87c99..550f55e6bfd0b 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/entity/cassandra/CassandraEntityServiceTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/entity/cassandra/CassandraEntityServiceTest.java
@@ -99,7 +99,8 @@ private void configureComponents() {
null,
opContext ->
((EntityServiceAspectRetriever) opContext.getAspectRetrieverOpt().get())
- .setSystemOperationContext(opContext));
+ .setSystemOperationContext(opContext),
+ null);
}
/**
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/BaseQueryFilterRewriterTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/BaseQueryFilterRewriterTest.java
new file mode 100644
index 0000000000000..6293d96fa35b8
--- /dev/null
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/BaseQueryFilterRewriterTest.java
@@ -0,0 +1,75 @@
+package com.linkedin.metadata.search.query.filter;
+
+import static org.mockito.Mockito.mock;
+import static org.testng.Assert.assertEquals;
+
+import com.linkedin.metadata.query.filter.Condition;
+import com.linkedin.metadata.search.elasticsearch.query.filter.BaseQueryFilterRewriter;
+import com.linkedin.metadata.search.elasticsearch.query.filter.QueryFilterRewriteChain;
+import com.linkedin.metadata.search.elasticsearch.query.filter.QueryFilterRewriterContext;
+import com.linkedin.metadata.search.elasticsearch.query.filter.QueryFilterRewriterSearchType;
+import io.datahubproject.metadata.context.OperationContext;
+import org.opensearch.index.query.BoolQueryBuilder;
+import org.opensearch.index.query.QueryBuilders;
+import org.testng.annotations.Test;
+
+public abstract class BaseQueryFilterRewriterTest {
+
+ abstract OperationContext getOpContext();
+
+ abstract T getTestRewriter();
+
+ abstract String getTargetField();
+
+ abstract String getTargetFieldValue();
+
+ abstract Condition getTargetCondition();
+
+ @Test
+ public void testPreservedMinimumMatchRewrite() {
+ BaseQueryFilterRewriter test = getTestRewriter();
+
+ // Setup nested container
+ BoolQueryBuilder testQuery = QueryBuilders.boolQuery().minimumShouldMatch(99);
+ testQuery.filter(
+ QueryBuilders.boolQuery()
+ .filter(
+ QueryBuilders.boolQuery()
+ .filter(QueryBuilders.termsQuery(getTargetField(), getTargetFieldValue()))));
+ testQuery.filter(QueryBuilders.existsQuery("someField"));
+ testQuery.should(
+ QueryBuilders.boolQuery()
+ .minimumShouldMatch(100)
+ .should(
+ QueryBuilders.boolQuery()
+ .minimumShouldMatch(101)
+ .should(QueryBuilders.termsQuery(getTargetField(), getTargetFieldValue()))));
+
+ BoolQueryBuilder expectedRewrite = QueryBuilders.boolQuery().minimumShouldMatch(99);
+ expectedRewrite.filter(
+ QueryBuilders.boolQuery()
+ .filter(
+ QueryBuilders.boolQuery()
+ .filter(QueryBuilders.termsQuery(getTargetField(), getTargetFieldValue()))));
+ expectedRewrite.filter(QueryBuilders.existsQuery("someField"));
+ expectedRewrite.should(
+ QueryBuilders.boolQuery()
+ .minimumShouldMatch(100)
+ .should(
+ QueryBuilders.boolQuery()
+ .minimumShouldMatch(101)
+ .should(QueryBuilders.termsQuery(getTargetField(), getTargetFieldValue()))));
+
+ assertEquals(
+ test.rewrite(
+ getOpContext(),
+ QueryFilterRewriterContext.builder()
+ .condition(getTargetCondition())
+ .searchType(QueryFilterRewriterSearchType.FULLTEXT_SEARCH)
+ .queryFilterRewriteChain(mock(QueryFilterRewriteChain.class))
+ .build(false),
+ testQuery),
+ expectedRewrite,
+ "Expected preservation of minimumShouldMatch");
+ }
+}
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/ContainerExpansionRewriterTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/ContainerExpansionRewriterTest.java
index 5246e4dbe5bf9..fd768424e13c1 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/ContainerExpansionRewriterTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/ContainerExpansionRewriterTest.java
@@ -39,7 +39,8 @@
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Test;
-public class ContainerExpansionRewriterTest {
+public class ContainerExpansionRewriterTest
+ extends BaseQueryFilterRewriterTest {
private static final String FIELD_NAME = "container.keyword";
private final String grandParentUrn = "urn:li:container:grand";
private final String parentUrn = "urn:li:container:foo";
@@ -74,15 +75,40 @@ public void init() {
.searchRetriever(TestOperationContexts.emptySearchRetriever)
.build(),
null,
+ null,
null);
}
+ @Override
+ OperationContext getOpContext() {
+ return opContext;
+ }
+
+ @Override
+ ContainerExpansionRewriter getTestRewriter() {
+ return ContainerExpansionRewriter.builder()
+ .config(QueryFilterRewriterConfiguration.ExpansionRewriterConfiguration.DEFAULT)
+ .build();
+ }
+
+ @Override
+ String getTargetField() {
+ return FIELD_NAME;
+ }
+
+ @Override
+ String getTargetFieldValue() {
+ return childUrn;
+ }
+
+ @Override
+ Condition getTargetCondition() {
+ return Condition.ANCESTORS_INCL;
+ }
+
@Test
public void testTermsQueryRewrite() {
- ContainerExpansionRewriter test =
- ContainerExpansionRewriter.builder()
- .config(QueryFilterRewriterConfiguration.ExpansionRewriterConfiguration.DEFAULT)
- .build();
+ ContainerExpansionRewriter test = getTestRewriter();
TermsQueryBuilder notTheFieldQuery = QueryBuilders.termsQuery("notTheField", childUrn);
assertEquals(
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/DomainExpansionRewriterTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/DomainExpansionRewriterTest.java
index edc6449438581..8741e24b1bca5 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/DomainExpansionRewriterTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/query/filter/DomainExpansionRewriterTest.java
@@ -39,7 +39,8 @@
import org.testng.annotations.BeforeMethod;
import org.testng.annotations.Test;
-public class DomainExpansionRewriterTest {
+public class DomainExpansionRewriterTest
+ extends BaseQueryFilterRewriterTest {
private static final String FIELD_NAME = "domains.keyword";
private final String grandParentUrn = "urn:li:domain:grand";
private final String parentUrn = "urn:li:domain:foo";
@@ -74,15 +75,40 @@ public void init() {
.searchRetriever(TestOperationContexts.emptySearchRetriever)
.build(),
null,
+ null,
null);
}
+ @Override
+ OperationContext getOpContext() {
+ return opContext;
+ }
+
+ @Override
+ DomainExpansionRewriter getTestRewriter() {
+ return DomainExpansionRewriter.builder()
+ .config(QueryFilterRewriterConfiguration.ExpansionRewriterConfiguration.DEFAULT)
+ .build();
+ }
+
+ @Override
+ String getTargetField() {
+ return FIELD_NAME;
+ }
+
+ @Override
+ String getTargetFieldValue() {
+ return parentUrn;
+ }
+
+ @Override
+ Condition getTargetCondition() {
+ return Condition.DESCENDANTS_INCL;
+ }
+
@Test
public void testTermsQueryRewrite() {
- DomainExpansionRewriter test =
- DomainExpansionRewriter.builder()
- .config(QueryFilterRewriterConfiguration.ExpansionRewriterConfiguration.DEFAULT)
- .build();
+ DomainExpansionRewriter test = getTestRewriter();
TermsQueryBuilder notTheFieldQuery = QueryBuilders.termsQuery("notTheField", parentUrn);
assertEquals(
diff --git a/metadata-io/src/test/java/com/linkedin/metadata/search/utils/ESAccessControlUtilTest.java b/metadata-io/src/test/java/com/linkedin/metadata/search/utils/ESAccessControlUtilTest.java
index b3dcaf174ed38..12eb468fcc61a 100644
--- a/metadata-io/src/test/java/com/linkedin/metadata/search/utils/ESAccessControlUtilTest.java
+++ b/metadata-io/src/test/java/com/linkedin/metadata/search/utils/ESAccessControlUtilTest.java
@@ -97,6 +97,7 @@ public class ESAccessControlUtilTest {
null,
null,
null,
+ null,
null);
private static final String VIEW_PRIVILEGE = "VIEW_ENTITY_PAGE";
@@ -106,6 +107,18 @@ public class ESAccessControlUtilTest {
private static final Urn RESTRICTED_RESULT_URN =
UrnUtils.getUrn("urn:li:restricted:(urn:li:dataPlatform:hive,SampleHiveDataset,PROD)");
+ private static final String PREFIX_MATCH =
+ "urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.human";
+ private static final Urn PREFIX_MATCH_URN =
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.humans,PROD)");
+ private static final Urn PREFIX_NO_MATCH_URN =
+ UrnUtils.getUrn(
+ "urn:li:dataset:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.meta_humans,PROD)");
+ private static final Urn RESTRICTED_PREFIX_NO_MATCH_URN =
+ UrnUtils.getUrn(
+ "urn:li:restricted:(urn:li:dataPlatform:snowflake,long_tail_companions.adoption.meta_humans,PROD)");
+
/** Comprehensive list of policy variations */
private static final Map TEST_POLICIES =
ImmutableMap.builder()
@@ -251,6 +264,30 @@ public class ESAccessControlUtilTest {
.setValues(
new StringArray(
List.of(DOMAIN_A.toString())))))))))
+ .put(
+ "urnPrefixAllUsers",
+ new DataHubPolicyInfo()
+ .setDisplayName("")
+ .setState(PoliciesConfig.ACTIVE_POLICY_STATE)
+ .setType(PoliciesConfig.METADATA_POLICY_TYPE)
+ .setActors(
+ new DataHubActorFilter()
+ .setAllUsers(true)
+ .setGroups(new UrnArray())
+ .setUsers(new UrnArray()))
+ .setPrivileges(new StringArray(List.of(VIEW_PRIVILEGE)))
+ .setResources(
+ new DataHubResourceFilter()
+ .setFilter(
+ new PolicyMatchFilter()
+ .setCriteria(
+ new PolicyMatchCriterionArray(
+ List.of(
+ new PolicyMatchCriterion()
+ .setField("URN")
+ .setCondition(PolicyMatchCondition.STARTS_WITH)
+ .setValues(
+ new StringArray(List.of(PREFIX_MATCH)))))))))
.build();
/** User A is a technical owner of the result User B has no ownership */
@@ -264,7 +301,7 @@ public void testAllUsersRestrictions() throws RemoteInvocationException, URISynt
// USER A
OperationContext userAContext =
- sessionWithUserAGroupAandC(Set.of(TEST_POLICIES.get("allUsers")));
+ sessionWithUserAGroupAandC(List.of(TEST_POLICIES.get("allUsers")));
SearchResult result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -272,20 +309,18 @@ public void testAllUsersRestrictions() throws RemoteInvocationException, URISynt
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
result = mockSearchResult();
- ESAccessControlUtil.restrictSearchResult(
- userAContext.withSearchFlags(flags -> flags.setIncludeRestricted(false)), result);
+ ESAccessControlUtil.restrictSearchResult(userAContext, result);
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
// USER B
- OperationContext userBContext = sessionWithUserBNoGroup(Set.of(TEST_POLICIES.get("allUsers")));
+ OperationContext userBContext = sessionWithUserBNoGroup(List.of(TEST_POLICIES.get("allUsers")));
result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
userBContext.withSearchFlags(flags -> flags.setIncludeRestricted(true)), result);
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
result = mockSearchResult();
- ESAccessControlUtil.restrictSearchResult(
- userBContext.withSearchFlags(flags -> flags.setIncludeRestricted(false)), result);
+ ESAccessControlUtil.restrictSearchResult(userBContext, result);
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
}
@@ -293,7 +328,7 @@ public void testAllUsersRestrictions() throws RemoteInvocationException, URISynt
public void testSingeUserRestrictions() throws RemoteInvocationException, URISyntaxException {
// USER A
- OperationContext userAContext = sessionWithUserAGroupAandC(Set.of(TEST_POLICIES.get("userA")));
+ OperationContext userAContext = sessionWithUserAGroupAandC(List.of(TEST_POLICIES.get("userA")));
SearchResult result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -301,12 +336,11 @@ public void testSingeUserRestrictions() throws RemoteInvocationException, URISyn
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
result = mockSearchResult();
- ESAccessControlUtil.restrictSearchResult(
- userAContext.withSearchFlags(flags -> flags.setIncludeRestricted(false)), result);
+ ESAccessControlUtil.restrictSearchResult(userAContext, result);
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
// USER B
- OperationContext userBContext = sessionWithUserBNoGroup(Set.of(TEST_POLICIES.get("userA")));
+ OperationContext userBContext = sessionWithUserBNoGroup(List.of(TEST_POLICIES.get("userA")));
result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -322,7 +356,7 @@ public void testAllGroupsRestrictions() throws RemoteInvocationException, URISyn
// USER A
OperationContext userAContext =
- sessionWithUserAGroupAandC(Set.of(TEST_POLICIES.get("allGroups")));
+ sessionWithUserAGroupAandC(List.of(TEST_POLICIES.get("allGroups")));
SearchResult result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -330,12 +364,12 @@ public void testAllGroupsRestrictions() throws RemoteInvocationException, URISyn
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
result = mockSearchResult();
- ESAccessControlUtil.restrictSearchResult(
- userAContext.withSearchFlags(flags -> flags.setIncludeRestricted(false)), result);
+ ESAccessControlUtil.restrictSearchResult(userAContext, result);
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
// USER B (No Groups!)
- OperationContext userBContext = sessionWithUserBNoGroup(Set.of(TEST_POLICIES.get("allGroups")));
+ OperationContext userBContext =
+ sessionWithUserBNoGroup(List.of(TEST_POLICIES.get("allGroups")));
result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -352,7 +386,7 @@ public void testSingleGroupRestrictions() throws RemoteInvocationException, URIS
// GROUP B Policy
// USER A
final OperationContext userAContext =
- sessionWithUserAGroupAandC(Set.of(TEST_POLICIES.get("groupB")));
+ sessionWithUserAGroupAandC(List.of(TEST_POLICIES.get("groupB")));
SearchResult result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -364,7 +398,7 @@ public void testSingleGroupRestrictions() throws RemoteInvocationException, URIS
// USER B (No Groups!)
final OperationContext userBContext =
- sessionWithUserBNoGroup(Set.of(TEST_POLICIES.get("groupB")));
+ sessionWithUserBNoGroup(List.of(TEST_POLICIES.get("groupB")));
result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -377,7 +411,7 @@ public void testSingleGroupRestrictions() throws RemoteInvocationException, URIS
// Group C Policy
// USER A
final OperationContext userAGroupCContext =
- sessionWithUserAGroupAandC(Set.of(TEST_POLICIES.get("groupC")));
+ sessionWithUserAGroupAandC(List.of(TEST_POLICIES.get("groupC")));
result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -385,13 +419,12 @@ public void testSingleGroupRestrictions() throws RemoteInvocationException, URIS
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
result = mockSearchResult();
- ESAccessControlUtil.restrictSearchResult(
- userAGroupCContext.withSearchFlags(flags -> flags.setIncludeRestricted(false)), result);
+ ESAccessControlUtil.restrictSearchResult(userAGroupCContext, result);
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
// USER B (No Groups!)
final OperationContext userBgroupCContext =
- sessionWithUserBNoGroup(Set.of(TEST_POLICIES.get("groupC")));
+ sessionWithUserBNoGroup(List.of(TEST_POLICIES.get("groupC")));
result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -407,7 +440,7 @@ public void testAnyOwnerRestrictions() throws RemoteInvocationException, URISynt
// USER A
OperationContext userAContext =
- sessionWithUserAGroupAandC(Set.of(TEST_POLICIES.get("anyOwner")));
+ sessionWithUserAGroupAandC(List.of(TEST_POLICIES.get("anyOwner")));
SearchResult result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -415,12 +448,11 @@ public void testAnyOwnerRestrictions() throws RemoteInvocationException, URISynt
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
result = mockSearchResult();
- ESAccessControlUtil.restrictSearchResult(
- userAContext.withSearchFlags(flags -> flags.setIncludeRestricted(false)), result);
+ ESAccessControlUtil.restrictSearchResult(userAContext, result);
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
// USER B (not an owner)
- OperationContext userBContext = sessionWithUserBNoGroup(Set.of(TEST_POLICIES.get("anyOwner")));
+ OperationContext userBContext = sessionWithUserBNoGroup(List.of(TEST_POLICIES.get("anyOwner")));
result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -436,7 +468,7 @@ public void testBusinessOwnerRestrictions() throws RemoteInvocationException, UR
// USER A
final OperationContext userAContext =
- sessionWithUserAGroupAandC(Set.of(TEST_POLICIES.get("businessOwner")));
+ sessionWithUserAGroupAandC(List.of(TEST_POLICIES.get("businessOwner")));
SearchResult result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -448,7 +480,7 @@ public void testBusinessOwnerRestrictions() throws RemoteInvocationException, UR
// USER B
final OperationContext userBContext =
- sessionWithUserBNoGroup(Set.of(TEST_POLICIES.get("businessOwner")));
+ sessionWithUserBNoGroup(List.of(TEST_POLICIES.get("businessOwner")));
result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -464,7 +496,7 @@ public void testDomainRestrictions() throws RemoteInvocationException, URISyntax
// USER A
OperationContext userAContext =
- sessionWithUserAGroupAandC(Set.of(TEST_POLICIES.get("domainA")));
+ sessionWithUserAGroupAandC(List.of(TEST_POLICIES.get("domainA")));
SearchResult result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
@@ -477,7 +509,7 @@ public void testDomainRestrictions() throws RemoteInvocationException, URISyntax
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
// USER B
- OperationContext userBContext = sessionWithUserBNoGroup(Set.of(TEST_POLICIES.get("domainA")));
+ OperationContext userBContext = sessionWithUserBNoGroup(List.of(TEST_POLICIES.get("domainA")));
result = mockSearchResult();
ESAccessControlUtil.restrictSearchResult(
userBContext.withSearchFlags(flags -> flags.setIncludeRestricted(true)), result);
@@ -489,6 +521,28 @@ public void testDomainRestrictions() throws RemoteInvocationException, URISyntax
assertEquals(result.getEntities().get(0).getEntity(), UNRESTRICTED_RESULT_URN);
}
+ @Test
+ public void testPrefixRestrictions() throws RemoteInvocationException, URISyntaxException {
+
+ // USER A
+ OperationContext userAContext =
+ sessionWithUserAGroupAandC(List.of(TEST_POLICIES.get("urnPrefixAllUsers")));
+
+ SearchResult result = mockPrefixSearchResult();
+ ESAccessControlUtil.restrictSearchResult(
+ userAContext.withSearchFlags(flags -> flags.setIncludeRestricted(true)), result);
+ assertEquals(result.getEntities().size(), 2);
+ assertEquals(result.getEntities().get(0).getEntity(), PREFIX_MATCH_URN);
+ assertEquals(result.getEntities().get(1).getEntity(), RESTRICTED_PREFIX_NO_MATCH_URN);
+
+ result = mockPrefixSearchResult();
+ ESAccessControlUtil.restrictSearchResult(
+ userAContext.withSearchFlags(flags -> flags.setIncludeRestricted(false)), result);
+ assertEquals(result.getEntities().size(), 2);
+ assertEquals(result.getEntities().get(0).getEntity(), PREFIX_MATCH_URN);
+ assertEquals(result.getEntities().get(1).getEntity(), PREFIX_NO_MATCH_URN);
+ }
+
private static RestrictedService mockRestrictedService() {
RestrictedService mockRestrictedService = mock(RestrictedService.class);
when(mockRestrictedService.encryptRestrictedUrn(any()))
@@ -500,6 +554,23 @@ private static RestrictedService mockRestrictedService() {
return mockRestrictedService;
}
+ private static SearchResult mockPrefixSearchResult() {
+ SearchResult result = new SearchResult();
+ result.setFrom(0);
+ result.setPageSize(10);
+ result.setNumEntities(1);
+ result.setEntities(
+ new SearchEntityArray(
+ new SearchEntity()
+ .setEntity(PREFIX_MATCH_URN)
+ .setMatchedFields(new MatchedFieldArray()),
+ new SearchEntity()
+ .setEntity(PREFIX_NO_MATCH_URN)
+ .setMatchedFields(new MatchedFieldArray())));
+ result.setMetadata(mock(SearchResultMetadata.class));
+ return result;
+ }
+
private static SearchResult mockSearchResult() {
SearchResult result = new SearchResult();
result.setFrom(0);
@@ -514,18 +585,18 @@ private static SearchResult mockSearchResult() {
return result;
}
- private static OperationContext sessionWithUserAGroupAandC(Set policies)
+ private static OperationContext sessionWithUserAGroupAandC(List policies)
throws RemoteInvocationException, URISyntaxException {
return sessionWithUserGroups(USER_A_AUTH, policies, List.of(TEST_GROUP_A, TEST_GROUP_C));
}
- private static OperationContext sessionWithUserBNoGroup(Set policies)
+ private static OperationContext sessionWithUserBNoGroup(List policies)
throws RemoteInvocationException, URISyntaxException {
return sessionWithUserGroups(USER_B_AUTH, policies, List.of());
}
private static OperationContext sessionWithUserGroups(
- Authentication auth, Set policies, List groups)
+ Authentication auth, List policies, List groups)
throws RemoteInvocationException, URISyntaxException {
Urn actorUrn = UrnUtils.getUrn(auth.getActor().toUrnStr());
Authorizer dataHubAuthorizer =
@@ -538,7 +609,7 @@ public static class TestDataHubAuthorizer extends DataHubAuthorizer {
public TestDataHubAuthorizer(
@Nonnull OperationContext opContext,
- @Nonnull Set policies,
+ @Nonnull List policies,
@Nonnull Map> userGroups,
@Nonnull Map>> resourceOwnerTypes)
throws RemoteInvocationException, URISyntaxException {
@@ -569,6 +640,7 @@ public TestDataHubAuthorizer(
Collectors.groupingBy(
Pair::getKey, Collectors.mapping(Pair::getValue, Collectors.toList())));
policyCache.putAll(byPrivilegeName);
+ policyCache.put(ALL, policies);
} finally {
readWriteLock.writeLock().unlock();
}
diff --git a/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java b/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java
index b34bb5bd0e0a8..c5f08fa8dcc8b 100644
--- a/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java
+++ b/metadata-jobs/mae-consumer/src/test/java/com/linkedin/metadata/kafka/hook/spring/MCLSpringCommonTestConfiguration.java
@@ -21,6 +21,7 @@
import io.datahubproject.metadata.context.OperationContextConfig;
import io.datahubproject.metadata.context.RetrieverContext;
import io.datahubproject.metadata.context.ServicesRegistryContext;
+import io.datahubproject.metadata.context.ValidationContext;
import io.datahubproject.test.metadata.context.TestOperationContexts;
import org.apache.avro.generic.GenericRecord;
import org.springframework.beans.factory.annotation.Qualifier;
@@ -88,7 +89,8 @@ public OperationContext operationContext(
entityRegistry,
mock(ServicesRegistryContext.class),
indexConvention,
- mock(RetrieverContext.class));
+ mock(RetrieverContext.class),
+ mock(ValidationContext.class));
}
@MockBean SpringStandardPluginConfiguration springStandardPluginConfiguration;
diff --git a/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/OperationContext.java b/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/OperationContext.java
index 61bf40f54817e..9a058c526647c 100644
--- a/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/OperationContext.java
+++ b/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/OperationContext.java
@@ -71,6 +71,7 @@ public static OperationContext asSession(
.build())
.authorizationContext(AuthorizationContext.builder().authorizer(authorizer).build())
.requestContext(requestContext)
+ .validationContext(systemOperationContext.getValidationContext())
.build(sessionAuthentication);
}
@@ -122,7 +123,8 @@ public static OperationContext asSystem(
@Nonnull EntityRegistry entityRegistry,
@Nullable ServicesRegistryContext servicesRegistryContext,
@Nullable IndexConvention indexConvention,
- @Nullable RetrieverContext retrieverContext) {
+ @Nullable RetrieverContext retrieverContext,
+ @Nonnull ValidationContext validationContext) {
return asSystem(
config,
systemAuthentication,
@@ -130,6 +132,7 @@ public static OperationContext asSystem(
servicesRegistryContext,
indexConvention,
retrieverContext,
+ validationContext,
ObjectMapperContext.DEFAULT);
}
@@ -140,6 +143,7 @@ public static OperationContext asSystem(
@Nullable ServicesRegistryContext servicesRegistryContext,
@Nullable IndexConvention indexConvention,
@Nullable RetrieverContext retrieverContext,
+ @Nonnull ValidationContext validationContext,
@Nonnull ObjectMapperContext objectMapperContext) {
ActorContext systemActorContext =
@@ -161,6 +165,7 @@ public static OperationContext asSystem(
.authorizationContext(AuthorizationContext.builder().authorizer(Authorizer.EMPTY).build())
.retrieverContext(retrieverContext)
.objectMapperContext(objectMapperContext)
+ .validationContext(validationContext)
.build(systemAuthentication);
}
@@ -174,6 +179,7 @@ public static OperationContext asSystem(
@Nullable private final RequestContext requestContext;
@Nullable private final RetrieverContext retrieverContext;
@Nonnull private final ObjectMapperContext objectMapperContext;
+ @Nonnull private final ValidationContext validationContext;
public OperationContext withSearchFlags(
@Nonnull Function flagDefaults) {
@@ -460,9 +466,8 @@ public OperationContext build(@Nonnull ActorContext sessionActor) {
this.servicesRegistryContext,
this.requestContext,
this.retrieverContext,
- this.objectMapperContext != null
- ? this.objectMapperContext
- : ObjectMapperContext.DEFAULT);
+ this.objectMapperContext != null ? this.objectMapperContext : ObjectMapperContext.DEFAULT,
+ this.validationContext);
}
private OperationContext build() {
diff --git a/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/ValidationContext.java b/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/ValidationContext.java
new file mode 100644
index 0000000000000..76560f087f22d
--- /dev/null
+++ b/metadata-operation-context/src/main/java/io/datahubproject/metadata/context/ValidationContext.java
@@ -0,0 +1,18 @@
+package io.datahubproject.metadata.context;
+
+import java.util.Optional;
+import lombok.Builder;
+import lombok.Getter;
+
+/** Context holder for environment variables relevant to operations */
+@Builder
+@Getter
+public class ValidationContext implements ContextInterface {
+ // Uses alternate validation flow for MCP ingestion
+ private final boolean alternateValidation;
+
+ @Override
+ public Optional getCacheKeyComponent() {
+ return Optional.of(alternateValidation ? 1 : 0);
+ }
+}
diff --git a/metadata-operation-context/src/main/java/io/datahubproject/test/metadata/context/TestOperationContexts.java b/metadata-operation-context/src/main/java/io/datahubproject/test/metadata/context/TestOperationContexts.java
index cdcbb540eeda4..42de6b7398c61 100644
--- a/metadata-operation-context/src/main/java/io/datahubproject/test/metadata/context/TestOperationContexts.java
+++ b/metadata-operation-context/src/main/java/io/datahubproject/test/metadata/context/TestOperationContexts.java
@@ -31,6 +31,7 @@
import io.datahubproject.metadata.context.RequestContext;
import io.datahubproject.metadata.context.RetrieverContext;
import io.datahubproject.metadata.context.ServicesRegistryContext;
+import io.datahubproject.metadata.context.ValidationContext;
import java.util.List;
import java.util.Map;
import java.util.Optional;
@@ -58,6 +59,8 @@ public class TestOperationContexts {
.build();
private static EntityRegistry defaultEntityRegistryInstance;
+ private static ValidationContext defaultValidationContext =
+ ValidationContext.builder().alternateValidation(false).build();
public static EntityRegistry defaultEntityRegistry() {
if (defaultEntityRegistryInstance == null) {
@@ -114,6 +117,11 @@ public static OperationContext systemContextNoSearchAuthorization() {
return systemContextNoSearchAuthorization(null, null, null);
}
+ public static OperationContext systemContextNoValidate() {
+ return systemContextNoSearchAuthorization(
+ null, null, null, () -> ValidationContext.builder().alternateValidation(true).build());
+ }
+
public static OperationContext systemContextNoSearchAuthorization(
@Nullable EntityRegistry entityRegistry, @Nullable IndexConvention indexConvention) {
return systemContextNoSearchAuthorization(() -> entityRegistry, null, () -> indexConvention);
@@ -160,9 +168,27 @@ public static OperationContext systemContextNoSearchAuthorization(
entityRegistrySupplier,
retrieverContextSupplier,
indexConventionSupplier,
+ null,
null);
}
+ public static OperationContext systemContextNoSearchAuthorization(
+ @Nullable Supplier entityRegistrySupplier,
+ @Nullable Supplier retrieverContextSupplier,
+ @Nullable Supplier indexConventionSupplier,
+ @Nullable Supplier environmentContextSupplier) {
+
+ return systemContext(
+ null,
+ null,
+ null,
+ entityRegistrySupplier,
+ retrieverContextSupplier,
+ indexConventionSupplier,
+ null,
+ environmentContextSupplier);
+ }
+
public static OperationContext systemContext(
@Nullable Supplier configSupplier,
@Nullable Supplier systemAuthSupplier,
@@ -170,7 +196,8 @@ public static OperationContext systemContext(
@Nullable Supplier entityRegistrySupplier,
@Nullable Supplier retrieverContextSupplier,
@Nullable Supplier indexConventionSupplier,
- @Nullable Consumer postConstruct) {
+ @Nullable Consumer postConstruct,
+ @Nullable Supplier environmentContextSupplier) {
OperationContextConfig config =
Optional.ofNullable(configSupplier).map(Supplier::get).orElse(DEFAULT_OPCONTEXT_CONFIG);
@@ -196,6 +223,11 @@ public static OperationContext systemContext(
ServicesRegistryContext servicesRegistryContext =
Optional.ofNullable(servicesRegistrySupplier).orElse(() -> null).get();
+ ValidationContext validationContext =
+ Optional.ofNullable(environmentContextSupplier)
+ .map(Supplier::get)
+ .orElse(defaultValidationContext);
+
OperationContext operationContext =
OperationContext.asSystem(
config,
@@ -203,7 +235,8 @@ public static OperationContext systemContext(
entityRegistry,
servicesRegistryContext,
indexConvention,
- retrieverContext);
+ retrieverContext,
+ validationContext);
if (postConstruct != null) {
postConstruct.accept(operationContext);
diff --git a/metadata-operation-context/src/test/java/io/datahubproject/metadata/context/OperationContextTest.java b/metadata-operation-context/src/test/java/io/datahubproject/metadata/context/OperationContextTest.java
index 6a5e9e04f7dda..3e092e20127ee 100644
--- a/metadata-operation-context/src/test/java/io/datahubproject/metadata/context/OperationContextTest.java
+++ b/metadata-operation-context/src/test/java/io/datahubproject/metadata/context/OperationContextTest.java
@@ -25,7 +25,8 @@ public void testSystemPrivilegeEscalation() {
mock(EntityRegistry.class),
mock(ServicesRegistryContext.class),
null,
- mock(RetrieverContext.class));
+ mock(RetrieverContext.class),
+ mock(ValidationContext.class));
OperationContext opContext =
systemOpContext.asSession(RequestContext.TEST, Authorizer.EMPTY, userAuth);
diff --git a/metadata-service/auth-impl/src/test/java/com/datahub/authorization/DataHubAuthorizerTest.java b/metadata-service/auth-impl/src/test/java/com/datahub/authorization/DataHubAuthorizerTest.java
index 985cfe48f6bcf..4437682bfeb0a 100644
--- a/metadata-service/auth-impl/src/test/java/com/datahub/authorization/DataHubAuthorizerTest.java
+++ b/metadata-service/auth-impl/src/test/java/com/datahub/authorization/DataHubAuthorizerTest.java
@@ -54,6 +54,7 @@
import io.datahubproject.metadata.context.OperationContextConfig;
import io.datahubproject.metadata.context.RetrieverContext;
import io.datahubproject.metadata.context.ServicesRegistryContext;
+import io.datahubproject.metadata.context.ValidationContext;
import java.util.Collections;
import java.util.HashMap;
import java.util.HashSet;
@@ -318,7 +319,8 @@ public void setupTest() throws Exception {
mock(EntityRegistry.class),
mock(ServicesRegistryContext.class),
mock(IndexConvention.class),
- mock(RetrieverContext.class));
+ mock(RetrieverContext.class),
+ mock(ValidationContext.class));
_dataHubAuthorizer =
new DataHubAuthorizer(
@@ -598,7 +600,6 @@ private DataHubPolicyInfo createDataHubPolicyInfoFor(
dataHubPolicyInfo.setDisplayName("My Test Display");
dataHubPolicyInfo.setDescription("My test display!");
dataHubPolicyInfo.setEditable(true);
-
dataHubPolicyInfo.setActors(actorFilter);
final DataHubResourceFilter resourceFilter = new DataHubResourceFilter();
diff --git a/metadata-service/configuration/src/main/java/com/linkedin/datahub/graphql/featureflags/FeatureFlags.java b/metadata-service/configuration/src/main/java/com/linkedin/datahub/graphql/featureflags/FeatureFlags.java
index 167515a13c4da..0c62bdc196326 100644
--- a/metadata-service/configuration/src/main/java/com/linkedin/datahub/graphql/featureflags/FeatureFlags.java
+++ b/metadata-service/configuration/src/main/java/com/linkedin/datahub/graphql/featureflags/FeatureFlags.java
@@ -23,4 +23,5 @@ public class FeatureFlags {
private boolean dataContractsEnabled = false;
private boolean editableDatasetNameEnabled = false;
private boolean showSeparateSiblings = false;
+ private boolean alternateMCPValidation = false;
}
diff --git a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/MCPValidationConfig.java b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/MCPValidationConfig.java
new file mode 100644
index 0000000000000..622dbb010a576
--- /dev/null
+++ b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/MCPValidationConfig.java
@@ -0,0 +1,9 @@
+package com.linkedin.metadata.config;
+
+import com.linkedin.metadata.config.structuredProperties.extensions.ModelExtensionValidationConfiguration;
+import lombok.Data;
+
+@Data
+public class MCPValidationConfig {
+ private ModelExtensionValidationConfiguration extensions;
+}
diff --git a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/MetadataChangeProposalConfig.java b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/MetadataChangeProposalConfig.java
index 4e8c18912c40e..86b4a1b8562b7 100644
--- a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/MetadataChangeProposalConfig.java
+++ b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/MetadataChangeProposalConfig.java
@@ -8,6 +8,7 @@
public class MetadataChangeProposalConfig {
ThrottlesConfig throttle;
+ MCPValidationConfig validation;
SideEffectsConfig sideEffects;
@Data
diff --git a/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/structuredProperties/extensions/ModelExtensionValidationConfiguration.java b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/structuredProperties/extensions/ModelExtensionValidationConfiguration.java
new file mode 100644
index 0000000000000..71db309154038
--- /dev/null
+++ b/metadata-service/configuration/src/main/java/com/linkedin/metadata/config/structuredProperties/extensions/ModelExtensionValidationConfiguration.java
@@ -0,0 +1,10 @@
+package com.linkedin.metadata.config.structuredProperties.extensions;
+
+import lombok.Data;
+import lombok.extern.slf4j.Slf4j;
+
+@Data
+@Slf4j
+public class ModelExtensionValidationConfiguration {
+ private boolean enabled;
+}
diff --git a/metadata-service/configuration/src/main/resources/application.yaml b/metadata-service/configuration/src/main/resources/application.yaml
index ef3ae76d81fae..50170410cd635 100644
--- a/metadata-service/configuration/src/main/resources/application.yaml
+++ b/metadata-service/configuration/src/main/resources/application.yaml
@@ -435,6 +435,7 @@ featureFlags:
schemaFieldEntityFetchEnabled: ${SCHEMA_FIELD_ENTITY_FETCH_ENABLED:true} # Enables fetching for schema field entities from the database when we hydrate them on schema fields
businessAttributeEntityEnabled: ${BUSINESS_ATTRIBUTE_ENTITY_ENABLED:false} # Enables business attribute entity which can be associated with field of dataset
dataContractsEnabled: ${DATA_CONTRACTS_ENABLED:true} # Enables the Data Contracts feature (Tab) in the UI
+ alternateMCPValidation: ${ALTERNATE_MCP_VALIDATION:false} # Enables alternate MCP validation flow
showSeparateSiblings: ${SHOW_SEPARATE_SIBLINGS:false} # If turned on, all siblings will be separated with no way to get to a "combined" sibling view
editableDatasetNameEnabled: ${EDITABLE_DATASET_NAME_ENABLED:false} # Enables the ability to edit the dataset name in the UI
@@ -539,6 +540,8 @@ businessAttribute:
metadataChangeProposal:
validation:
ignoreUnknown: ${MCP_VALIDATION_IGNORE_UNKNOWN:true}
+ extensions:
+ enabled: ${MCP_VALIDATION_EXTENSIONS_ENABLED:false}
sideEffects:
schemaField:
enabled: ${MCP_SIDE_EFFECTS_SCHEMA_FIELD_ENABLED:false}
diff --git a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/common/CacheConfig.java b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/common/CacheConfig.java
index 383716a80cc60..545f8e087838d 100644
--- a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/common/CacheConfig.java
+++ b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/common/CacheConfig.java
@@ -48,7 +48,7 @@ private Caffeine caffeineCacheBuilder() {
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(cacheMaxSize)
- .expireAfterAccess(cacheTtlSeconds, TimeUnit.SECONDS)
+ .expireAfterWrite(cacheTtlSeconds, TimeUnit.SECONDS)
.recordStats();
}
@@ -86,10 +86,7 @@ public CacheManager hazelcastCacheManager(
@Bean
@ConditionalOnProperty(name = "searchService.cacheImplementation", havingValue = "hazelcast")
public MapConfig defaultMapConfig() {
- // TODO: This setting is equivalent to expireAfterAccess, refreshes timer after a get, put,
- // containsKey etc.
- // is this behavior what we actually desire? Should we change it now?
- MapConfig mapConfig = new MapConfig().setMaxIdleSeconds(cacheTtlSeconds);
+ MapConfig mapConfig = new MapConfig().setTimeToLiveSeconds(cacheTtlSeconds);
EvictionConfig evictionConfig =
new EvictionConfig()
diff --git a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/context/SystemOperationContextFactory.java b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/context/SystemOperationContextFactory.java
index b8c4796dd4312..f5235dc3682fc 100644
--- a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/context/SystemOperationContextFactory.java
+++ b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/context/SystemOperationContextFactory.java
@@ -16,6 +16,7 @@
import io.datahubproject.metadata.context.OperationContextConfig;
import io.datahubproject.metadata.context.RetrieverContext;
import io.datahubproject.metadata.context.ServicesRegistryContext;
+import io.datahubproject.metadata.context.ValidationContext;
import io.datahubproject.metadata.services.RestrictedService;
import javax.annotation.Nonnull;
import org.springframework.beans.factory.annotation.Qualifier;
@@ -43,7 +44,8 @@ protected OperationContext javaSystemOperationContext(
@Nonnull final GraphService graphService,
@Nonnull final SearchService searchService,
@Qualifier("baseElasticSearchComponents")
- BaseElasticSearchComponentsFactory.BaseElasticSearchComponents components) {
+ BaseElasticSearchComponentsFactory.BaseElasticSearchComponents components,
+ @Nonnull final ConfigurationProvider configurationProvider) {
EntityServiceAspectRetriever entityServiceAspectRetriever =
EntityServiceAspectRetriever.builder()
@@ -68,6 +70,10 @@ protected OperationContext javaSystemOperationContext(
.aspectRetriever(entityServiceAspectRetriever)
.graphRetriever(systemGraphRetriever)
.searchRetriever(searchServiceSearchRetriever)
+ .build(),
+ ValidationContext.builder()
+ .alternateValidation(
+ configurationProvider.getFeatureFlags().isAlternateMCPValidation())
.build());
entityServiceAspectRetriever.setSystemOperationContext(systemOperationContext);
@@ -95,7 +101,8 @@ protected OperationContext restliSystemOperationContext(
@Nonnull final GraphService graphService,
@Nonnull final SearchService searchService,
@Qualifier("baseElasticSearchComponents")
- BaseElasticSearchComponentsFactory.BaseElasticSearchComponents components) {
+ BaseElasticSearchComponentsFactory.BaseElasticSearchComponents components,
+ @Nonnull final ConfigurationProvider configurationProvider) {
EntityClientAspectRetriever entityServiceAspectRetriever =
EntityClientAspectRetriever.builder().entityClient(systemEntityClient).build();
@@ -117,6 +124,10 @@ protected OperationContext restliSystemOperationContext(
.aspectRetriever(entityServiceAspectRetriever)
.graphRetriever(systemGraphRetriever)
.searchRetriever(searchServiceSearchRetriever)
+ .build(),
+ ValidationContext.builder()
+ .alternateValidation(
+ configurationProvider.getFeatureFlags().isAlternateMCPValidation())
.build());
entityServiceAspectRetriever.setSystemOperationContext(systemOperationContext);
diff --git a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java
index 943b1c7184a60..b2db0857a6a5c 100644
--- a/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java
+++ b/metadata-service/factories/src/main/java/com/linkedin/gms/factory/plugins/SpringStandardPluginConfiguration.java
@@ -45,7 +45,7 @@ public MutationHook ignoreUnknownMutator() {
AspectPluginConfig.builder()
.className(IgnoreUnknownMutator.class.getName())
.enabled(ignoreUnknownEnabled && !extensionsEnabled)
- .supportedOperations(List.of("CREATE", "CREATE_ENTITY", "UPSERT"))
+ .supportedOperations(List.of("*"))
.supportedEntityAspectNames(
List.of(
AspectPluginConfig.EntityAspectName.builder()
diff --git a/metadata-service/openapi-servlet/models/src/main/java/io/datahubproject/openapi/v2/models/GenericEntityV2.java b/metadata-service/openapi-servlet/models/src/main/java/io/datahubproject/openapi/v2/models/GenericEntityV2.java
index 83c23f3552409..e281a39f764e5 100644
--- a/metadata-service/openapi-servlet/models/src/main/java/io/datahubproject/openapi/v2/models/GenericEntityV2.java
+++ b/metadata-service/openapi-servlet/models/src/main/java/io/datahubproject/openapi/v2/models/GenericEntityV2.java
@@ -3,6 +3,7 @@
import com.datahub.util.RecordUtils;
import com.fasterxml.jackson.annotation.JsonInclude;
import com.fasterxml.jackson.annotation.JsonProperty;
+import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.linkedin.data.template.RecordTemplate;
import com.linkedin.mxe.SystemMetadata;
@@ -37,29 +38,42 @@ public static class GenericEntityV2Builder {
public GenericEntityV2 build(
ObjectMapper objectMapper, Map> aspects) {
+ return build(objectMapper, aspects, false);
+ }
+
+ public GenericEntityV2 build(
+ ObjectMapper objectMapper,
+ Map> aspects,
+ boolean isAsyncAlternateValidation) {
Map jsonObjectMap =
aspects.entrySet().stream()
.map(
e -> {
try {
- Map valueMap =
+ Map valueMap =
Map.of(
"value",
objectMapper.readTree(
RecordUtils.toJsonString(e.getValue().getFirst())
.getBytes(StandardCharsets.UTF_8)));
+ Object aspectValue =
+ isAsyncAlternateValidation
+ ? valueMap.get("value").get("value")
+ : valueMap.get("value");
+
if (e.getValue().getSecond() != null) {
return Map.entry(
e.getKey(),
new GenericAspectV2(
Map.of(
- "systemMetadata", e.getValue().getSecond(),
- "value", valueMap.get("value"))));
+ "systemMetadata",
+ e.getValue().getSecond(),
+ "value",
+ aspectValue)));
} else {
return Map.entry(
- e.getKey(),
- new GenericAspectV2(Map.of("value", valueMap.get("value"))));
+ e.getKey(), new GenericAspectV2(Map.of("value", aspectValue)));
}
} catch (IOException ex) {
throw new RuntimeException(ex);
diff --git a/metadata-service/openapi-servlet/models/src/main/java/io/datahubproject/openapi/v3/models/GenericEntityV3.java b/metadata-service/openapi-servlet/models/src/main/java/io/datahubproject/openapi/v3/models/GenericEntityV3.java
index 54d6ac2c1736f..dbbfc117a8ab3 100644
--- a/metadata-service/openapi-servlet/models/src/main/java/io/datahubproject/openapi/v3/models/GenericEntityV3.java
+++ b/metadata-service/openapi-servlet/models/src/main/java/io/datahubproject/openapi/v3/models/GenericEntityV3.java
@@ -29,6 +29,10 @@ public GenericEntityV3(Map m) {
super(m);
}
+ public String getUrn() {
+ return (String) get("urn");
+ }
+
@Override
public Map getAspects() {
return this.entrySet().stream()
@@ -40,17 +44,31 @@ public static class GenericEntityV3Builder {
public GenericEntityV3 build(
ObjectMapper objectMapper, @Nonnull Urn urn, Map aspects) {
+ return build(objectMapper, urn, aspects, false);
+ }
+
+ public GenericEntityV3 build(
+ ObjectMapper objectMapper,
+ @Nonnull Urn urn,
+ Map aspects,
+ boolean isAsyncAlternateValidation) {
Map jsonObjectMap =
aspects.entrySet().stream()
.map(
entry -> {
try {
String aspectName = entry.getKey();
- Map aspectValue =
+ Map aspectValueMap =
objectMapper.readValue(
RecordUtils.toJsonString(entry.getValue().getAspect())
.getBytes(StandardCharsets.UTF_8),
new TypeReference<>() {});
+
+ Map aspectValue =
+ isAsyncAlternateValidation
+ ? (Map) aspectValueMap.get("value")
+ : aspectValueMap;
+
Map systemMetadata =
entry.getValue().getSystemMetadata() != null
? objectMapper.convertValue(
diff --git a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/controller/GenericEntitiesController.java b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/controller/GenericEntitiesController.java
index 7427f293c848f..ee23cced7f468 100644
--- a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/controller/GenericEntitiesController.java
+++ b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/controller/GenericEntitiesController.java
@@ -163,7 +163,9 @@ protected abstract List buildEntityVersionedAspectList(
throws URISyntaxException;
protected abstract List buildEntityList(
- Set ingestResults, boolean withSystemMetadata);
+ Collection ingestResults,
+ boolean withSystemMetadata,
+ boolean isAsyncAlternateValidation);
protected abstract E buildGenericEntity(
@Nonnull String aspectName,
@@ -510,12 +512,14 @@ public ResponseEntity> createEntity(
}
AspectsBatch batch = toMCPBatch(opContext, jsonEntityList, authentication.getActor());
- Set results = entityService.ingestProposal(opContext, batch, async);
+ List results = entityService.ingestProposal(opContext, batch, async);
if (!async) {
- return ResponseEntity.ok(buildEntityList(results, withSystemMetadata));
+ return ResponseEntity.ok(buildEntityList(results, withSystemMetadata, false));
} else {
- return ResponseEntity.accepted().body(buildEntityList(results, withSystemMetadata));
+ boolean isAsyncAlternateValidation = opContext.getValidationContext().isAlternateValidation();
+ return ResponseEntity.accepted()
+ .body(buildEntityList(results, withSystemMetadata, isAsyncAlternateValidation));
}
}
@@ -602,7 +606,7 @@ public ResponseEntity createAspect(
jsonAspect,
authentication.getActor());
- Set results =
+ List results =
entityService.ingestProposal(
opContext,
AspectsBatchImpl.builder()
diff --git a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v2/controller/EntityController.java b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v2/controller/EntityController.java
index 7bec052a9fd5d..d55f2fd1c2a04 100644
--- a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v2/controller/EntityController.java
+++ b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v2/controller/EntityController.java
@@ -23,11 +23,14 @@
import com.linkedin.metadata.entity.UpdateAspectResult;
import com.linkedin.metadata.entity.ebean.batch.AspectsBatchImpl;
import com.linkedin.metadata.entity.ebean.batch.ChangeItemImpl;
+import com.linkedin.metadata.entity.ebean.batch.ProposedItem;
import com.linkedin.metadata.models.AspectSpec;
import com.linkedin.metadata.search.SearchEntity;
import com.linkedin.metadata.search.SearchEntityArray;
import com.linkedin.metadata.utils.AuditStampUtils;
import com.linkedin.metadata.utils.GenericRecordUtils;
+import com.linkedin.metadata.utils.SystemMetadataUtils;
+import com.linkedin.mxe.MetadataChangeProposal;
import com.linkedin.mxe.SystemMetadata;
import com.linkedin.util.Pair;
import io.datahubproject.metadata.context.OperationContext;
@@ -161,7 +164,25 @@ protected AspectsBatch toMCPBatch(
AspectSpec aspectSpec = lookupAspectSpec(entityUrn, aspect.getKey()).get();
- if (aspectSpec != null) {
+ if (opContext.getValidationContext().isAlternateValidation()) {
+ ProposedItem.ProposedItemBuilder builder =
+ ProposedItem.builder()
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(entityUrn)
+ .setAspectName(aspect.getKey())
+ .setEntityType(entityUrn.getEntityType())
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(GenericRecordUtils.serializeAspect(aspect.getValue()))
+ .setSystemMetadata(SystemMetadataUtils.createDefaultSystemMetadata()))
+ .auditStamp(AuditStampUtils.createAuditStamp(actor.toUrnStr()))
+ .entitySpec(
+ opContext
+ .getAspectRetriever()
+ .getEntityRegistry()
+ .getEntitySpec(entityUrn.getEntityType()));
+ items.add(builder.build());
+ } else if (aspectSpec != null) {
ChangeItemImpl.ChangeItemImplBuilder builder =
ChangeItemImpl.builder()
.urn(entityUrn)
@@ -181,7 +202,7 @@ protected AspectsBatch toMCPBatch(
objectMapper.writeValueAsString(aspect.getValue().get("systemMetadata"))));
}
- items.add(builder.build(opContext.getRetrieverContext().get().getAspectRetriever()));
+ items.add(builder.build(opContext.getAspectRetrieverOpt().get()));
}
}
}
@@ -263,7 +284,9 @@ private List toRecordTemplates(
@Override
protected List buildEntityList(
- Set ingestResults, boolean withSystemMetadata) {
+ Collection ingestResults,
+ boolean withSystemMetadata,
+ boolean isAsyncAlternateValidation) {
List responseList = new LinkedList<>();
Map> entityMap =
@@ -282,7 +305,7 @@ protected List buildEntityList(
responseList.add(
GenericEntityV2.builder()
.urn(urnAspects.getKey().toString())
- .build(objectMapper, aspectsMap));
+ .build(objectMapper, aspectsMap, isAsyncAlternateValidation));
}
return responseList;
}
diff --git a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/controller/EntityController.java b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/controller/EntityController.java
index 55cf310be3438..64046b23db7be 100644
--- a/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/controller/EntityController.java
+++ b/metadata-service/openapi-servlet/src/main/java/io/datahubproject/openapi/v3/controller/EntityController.java
@@ -13,6 +13,8 @@
import com.fasterxml.jackson.databind.node.ObjectNode;
import com.linkedin.common.urn.Urn;
import com.linkedin.data.ByteString;
+import com.linkedin.data.template.SetMode;
+import com.linkedin.data.template.StringMap;
import com.linkedin.entity.EnvelopedAspect;
import com.linkedin.events.metadata.ChangeType;
import com.linkedin.metadata.aspect.AspectRetriever;
@@ -24,6 +26,7 @@
import com.linkedin.metadata.entity.UpdateAspectResult;
import com.linkedin.metadata.entity.ebean.batch.AspectsBatchImpl;
import com.linkedin.metadata.entity.ebean.batch.ChangeItemImpl;
+import com.linkedin.metadata.entity.ebean.batch.ProposedItem;
import com.linkedin.metadata.models.AspectSpec;
import com.linkedin.metadata.models.EntitySpec;
import com.linkedin.metadata.query.filter.SortCriterion;
@@ -34,6 +37,7 @@
import com.linkedin.metadata.utils.AuditStampUtils;
import com.linkedin.metadata.utils.GenericRecordUtils;
import com.linkedin.metadata.utils.SearchUtil;
+import com.linkedin.mxe.MetadataChangeProposal;
import com.linkedin.mxe.SystemMetadata;
import io.datahubproject.metadata.context.OperationContext;
import io.datahubproject.metadata.context.RequestContext;
@@ -281,7 +285,9 @@ private Map toAspectItemMap(
@Override
protected List buildEntityList(
- Set ingestResults, boolean withSystemMetadata) {
+ Collection ingestResults,
+ boolean withSystemMetadata,
+ boolean isAsyncAlternateValidation) {
List responseList = new LinkedList<>();
Map> entityMap =
@@ -304,7 +310,8 @@ protected List buildEntityList(
.build()))
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue));
responseList.add(
- GenericEntityV3.builder().build(objectMapper, urnAspects.getKey(), aspectsMap));
+ GenericEntityV3.builder()
+ .build(objectMapper, urnAspects.getKey(), aspectsMap, isAsyncAlternateValidation));
}
return responseList;
}
@@ -442,23 +449,42 @@ protected AspectsBatch toMCPBatch(
}
AspectSpec aspectSpec = lookupAspectSpec(entityUrn, aspect.getKey()).orElse(null);
+ SystemMetadata systemMetadata = null;
+ if (aspect.getValue().has("systemMetadata")) {
+ systemMetadata =
+ EntityApiUtils.parseSystemMetadata(
+ objectMapper.writeValueAsString(aspect.getValue().get("systemMetadata")));
+ ((ObjectNode) aspect.getValue()).remove("systemMetadata");
+ }
+ Map headers = null;
+ if (aspect.getValue().has("headers")) {
+ headers =
+ objectMapper.convertValue(
+ aspect.getValue().get("headers"), new TypeReference<>() {});
+ }
- if (aspectSpec != null) {
-
- SystemMetadata systemMetadata = null;
- if (aspect.getValue().has("systemMetadata")) {
- systemMetadata =
- EntityApiUtils.parseSystemMetadata(
- objectMapper.writeValueAsString(aspect.getValue().get("systemMetadata")));
- ((ObjectNode) aspect.getValue()).remove("systemMetadata");
- }
- Map headers = null;
- if (aspect.getValue().has("headers")) {
- headers =
- objectMapper.convertValue(
- aspect.getValue().get("headers"), new TypeReference<>() {});
- }
-
+ if (opContext.getValidationContext().isAlternateValidation()) {
+ ProposedItem.ProposedItemBuilder builder =
+ ProposedItem.builder()
+ .metadataChangeProposal(
+ new MetadataChangeProposal()
+ .setEntityUrn(entityUrn)
+ .setAspectName(aspect.getKey())
+ .setEntityType(entityUrn.getEntityType())
+ .setChangeType(ChangeType.UPSERT)
+ .setAspect(GenericRecordUtils.serializeAspect(aspect.getValue()))
+ .setHeaders(
+ headers != null ? new StringMap(headers) : null,
+ SetMode.IGNORE_NULL)
+ .setSystemMetadata(systemMetadata, SetMode.IGNORE_NULL))
+ .auditStamp(AuditStampUtils.createAuditStamp(actor.toUrnStr()))
+ .entitySpec(
+ opContext
+ .getAspectRetriever()
+ .getEntityRegistry()
+ .getEntitySpec(entityUrn.getEntityType()));
+ items.add(builder.build());
+ } else if (aspectSpec != null) {
ChangeItemImpl.ChangeItemImplBuilder builder =
ChangeItemImpl.builder()
.urn(entityUrn)
diff --git a/metadata-service/restli-client-api/src/main/java/com/linkedin/entity/client/EntityClient.java b/metadata-service/restli-client-api/src/main/java/com/linkedin/entity/client/EntityClient.java
index 5f086e79a387a..cf6e571cb8cbe 100644
--- a/metadata-service/restli-client-api/src/main/java/com/linkedin/entity/client/EntityClient.java
+++ b/metadata-service/restli-client-api/src/main/java/com/linkedin/entity/client/EntityClient.java
@@ -36,6 +36,7 @@
import java.util.Collection;
import java.util.List;
import java.util.Map;
+import java.util.Objects;
import java.util.Optional;
import java.util.Set;
import javax.annotation.Nonnull;
@@ -523,12 +524,16 @@ default String ingestProposal(
*
* @return the urn string ingested
*/
+ @Nullable
default String ingestProposal(
@Nonnull OperationContext opContext,
@Nonnull final MetadataChangeProposal metadataChangeProposal,
final boolean async)
throws RemoteInvocationException {
- return batchIngestProposals(opContext, List.of(metadataChangeProposal), async).get(0);
+ return batchIngestProposals(opContext, List.of(metadataChangeProposal), async).stream()
+ .filter(Objects::nonNull)
+ .findFirst()
+ .orElse(null);
}
@Deprecated
diff --git a/metadata-service/restli-servlet-impl/src/main/java/com/linkedin/metadata/resources/entity/AspectResource.java b/metadata-service/restli-servlet-impl/src/main/java/com/linkedin/metadata/resources/entity/AspectResource.java
index 12422044bc8ef..634e8d32cc722 100644
--- a/metadata-service/restli-servlet-impl/src/main/java/com/linkedin/metadata/resources/entity/AspectResource.java
+++ b/metadata-service/restli-servlet-impl/src/main/java/com/linkedin/metadata/resources/entity/AspectResource.java
@@ -33,6 +33,7 @@
import com.linkedin.metadata.resources.restli.RestliUtils;
import com.linkedin.metadata.search.EntitySearchService;
import com.linkedin.metadata.timeseries.TimeseriesAspectService;
+import com.linkedin.mxe.GenericAspect;
import com.linkedin.mxe.MetadataChangeProposal;
import com.linkedin.mxe.SystemMetadata;
import com.linkedin.parseq.Task;
@@ -51,6 +52,7 @@
import io.datahubproject.metadata.context.RequestContext;
import io.opentelemetry.extension.annotations.WithSpan;
import java.net.URISyntaxException;
+import java.nio.charset.StandardCharsets;
import java.time.Clock;
import java.util.Arrays;
import java.util.List;
@@ -61,6 +63,7 @@
import javax.inject.Inject;
import javax.inject.Named;
import lombok.extern.slf4j.Slf4j;
+import org.apache.commons.lang3.StringUtils;
/** Single unified resource for fetching, updating, searching, & browsing DataHub entities */
@Slf4j
@@ -85,6 +88,8 @@ public class AspectResource extends CollectionResourceTaskTemplate _entityService;
@@ -238,16 +243,20 @@ public Task ingestProposal(
@ActionParam(PARAM_PROPOSAL) @Nonnull MetadataChangeProposal metadataChangeProposal,
@ActionParam(PARAM_ASYNC) @Optional(UNSET) String async)
throws URISyntaxException {
- log.info("INGEST PROPOSAL proposal: {}", metadataChangeProposal);
-
- final boolean asyncBool;
- if (UNSET.equals(async)) {
- asyncBool = Boolean.parseBoolean(System.getenv(ASYNC_INGEST_DEFAULT_NAME));
- } else {
- asyncBool = Boolean.parseBoolean(async);
- }
- return ingestProposals(List.of(metadataChangeProposal), asyncBool);
+ String urn = metadataChangeProposal.getEntityUrn() != null ? metadataChangeProposal.getEntityUrn().toString() :
+ java.util.Optional.ofNullable(metadataChangeProposal.getEntityKeyAspect()).orElse(new GenericAspect())
+ .getValue().asString(StandardCharsets.UTF_8);
+ String proposedValue = java.util.Optional.ofNullable(metadataChangeProposal.getAspect()).orElse(new GenericAspect())
+ .getValue().asString(StandardCharsets.UTF_8);
+
+ final boolean asyncBool;
+ if (UNSET.equals(async)) {
+ asyncBool = Boolean.parseBoolean(System.getenv(ASYNC_INGEST_DEFAULT_NAME));
+ } else {
+ asyncBool = Boolean.parseBoolean(async);
+ }
+ return ingestProposals(List.of(metadataChangeProposal), asyncBool);
}
@Action(name = ACTION_INGEST_PROPOSAL_BATCH)
@@ -303,10 +312,21 @@ private Task ingestProposals(
log.debug("Proposals: {}", metadataChangeProposals);
try {
final AspectsBatch batch = AspectsBatchImpl.builder()
- .mcps(metadataChangeProposals, auditStamp, opContext.getRetrieverContext().get())
+ .mcps(metadataChangeProposals, auditStamp, opContext.getRetrieverContext().get(),
+ opContext.getValidationContext().isAlternateValidation())
.build();
- Set results =
+ batch.getMCPItems().forEach(item ->
+ log.info(
+ "INGEST PROPOSAL content: urn: {}, async: {}, value: {}",
+ item.getUrn(),
+ asyncBool,
+ StringUtils.abbreviate(java.util.Optional.ofNullable(item.getMetadataChangeProposal())
+ .map(MetadataChangeProposal::getAspect)
+ .orElse(new GenericAspect())
+ .getValue().asString(StandardCharsets.UTF_8), MAX_LOG_WIDTH)));
+
+ List results =
_entityService.ingestProposal(opContext, batch, asyncBool);
for (IngestResult result : results) {
diff --git a/metadata-service/restli-servlet-impl/src/main/java/com/linkedin/metadata/resources/entity/EntityResource.java b/metadata-service/restli-servlet-impl/src/main/java/com/linkedin/metadata/resources/entity/EntityResource.java
index 9755a76848adf..30aa3ffa578c1 100644
--- a/metadata-service/restli-servlet-impl/src/main/java/com/linkedin/metadata/resources/entity/EntityResource.java
+++ b/metadata-service/restli-servlet-impl/src/main/java/com/linkedin/metadata/resources/entity/EntityResource.java
@@ -927,7 +927,7 @@ public Task deleteEntity(
opContext.getEntityRegistry(), urn.getEntityType());
if (aspectName != null && !timeseriesAspectNames.contains(aspectName)) {
throw new UnsupportedOperationException(
- String.format("Not supported for non-timeseries aspect '{}'.", aspectName));
+ String.format("Not supported for non-timeseries aspect %s.", aspectName));
}
List timeseriesAspectsToDelete =
(aspectName == null) ? timeseriesAspectNames : ImmutableList.of(aspectName);
diff --git a/metadata-service/restli-servlet-impl/src/test/java/com/linkedin/metadata/resources/entity/AspectResourceTest.java b/metadata-service/restli-servlet-impl/src/test/java/com/linkedin/metadata/resources/entity/AspectResourceTest.java
index 9872f45648d7b..82db3d88b9e12 100644
--- a/metadata-service/restli-servlet-impl/src/test/java/com/linkedin/metadata/resources/entity/AspectResourceTest.java
+++ b/metadata-service/restli-servlet-impl/src/test/java/com/linkedin/metadata/resources/entity/AspectResourceTest.java
@@ -27,6 +27,7 @@
import com.linkedin.metadata.models.registry.EntityRegistry;
import com.linkedin.metadata.service.UpdateIndicesService;
import com.linkedin.metadata.utils.GenericRecordUtils;
+import com.linkedin.mxe.GenericAspect;
import com.linkedin.mxe.MetadataChangeLog;
import com.linkedin.mxe.MetadataChangeProposal;
import java.net.URISyntaxException;
@@ -136,4 +137,31 @@ public void testAsyncDefaultAspects() throws URISyntaxException {
.produceMetadataChangeLog(eq(urn), any(AspectSpec.class), any(MetadataChangeLog.class));
verifyNoMoreInteractions(producer);
}
+
+ @Test
+ public void testNoValidateAsync() throws URISyntaxException {
+ OperationContext noValidateOpContext = TestOperationContexts.systemContextNoValidate();
+ aspectResource.setSystemOperationContext(noValidateOpContext);
+ reset(producer, aspectDao);
+ MetadataChangeProposal mcp = new MetadataChangeProposal();
+ mcp.setEntityType(DATASET_ENTITY_NAME);
+ Urn urn = new DatasetUrn(new DataPlatformUrn("platform"), "name", FabricType.PROD);
+ mcp.setEntityUrn(urn);
+ GenericAspect properties = GenericRecordUtils.serializeAspect(new DatasetProperties().setName("name"));
+ mcp.setAspect(GenericRecordUtils.serializeAspect(properties));
+ mcp.setAspectName("notAnAspect");
+ mcp.setChangeType(ChangeType.UPSERT);
+ mcp.setSystemMetadata(new SystemMetadata());
+
+ Authentication mockAuthentication = mock(Authentication.class);
+ AuthenticationContext.setAuthentication(mockAuthentication);
+ Actor actor = new Actor(ActorType.USER, "user");
+ when(mockAuthentication.getActor()).thenReturn(actor);
+ aspectResource.ingestProposal(mcp, "true");
+ verify(producer, times(1)).produceMetadataChangeProposal(urn, mcp);
+ verifyNoMoreInteractions(producer);
+ verifyNoMoreInteractions(aspectDao);
+ reset(producer, aspectDao);
+ aspectResource.setSystemOperationContext(opContext);
+ }
}
diff --git a/metadata-service/services/src/main/java/com/linkedin/metadata/entity/EntityService.java b/metadata-service/services/src/main/java/com/linkedin/metadata/entity/EntityService.java
index 66f7ff50a3624..beb8bd3d090a5 100644
--- a/metadata-service/services/src/main/java/com/linkedin/metadata/entity/EntityService.java
+++ b/metadata-service/services/src/main/java/com/linkedin/metadata/entity/EntityService.java
@@ -487,7 +487,7 @@ RollbackRunResult rollbackWithConditions(
Map conditions,
boolean hardDelete);
- Set ingestProposal(
+ List ingestProposal(
@Nonnull OperationContext opContext, AspectsBatch aspectsBatch, final boolean async);
/**
diff --git a/metadata-utils/src/main/java/com/linkedin/metadata/utils/GenericRecordUtils.java b/metadata-utils/src/main/java/com/linkedin/metadata/utils/GenericRecordUtils.java
index 6638481c1d279..fafca9b113973 100644
--- a/metadata-utils/src/main/java/com/linkedin/metadata/utils/GenericRecordUtils.java
+++ b/metadata-utils/src/main/java/com/linkedin/metadata/utils/GenericRecordUtils.java
@@ -1,6 +1,7 @@
package com.linkedin.metadata.utils;
import com.datahub.util.RecordUtils;
+import com.fasterxml.jackson.databind.JsonNode;
import com.linkedin.common.urn.Urn;
import com.linkedin.data.ByteString;
import com.linkedin.data.template.RecordTemplate;
@@ -70,6 +71,14 @@ public static GenericAspect serializeAspect(@Nonnull String str) {
return genericAspect;
}
+ @Nonnull
+ public static GenericAspect serializeAspect(@Nonnull JsonNode json) {
+ GenericAspect genericAspect = new GenericAspect();
+ genericAspect.setValue(ByteString.unsafeWrap(json.toString().getBytes(StandardCharsets.UTF_8)));
+ genericAspect.setContentType(GenericRecordUtils.JSON);
+ return genericAspect;
+ }
+
@Nonnull
public static GenericPayload serializePayload(@Nonnull RecordTemplate payload) {
GenericPayload genericPayload = new GenericPayload();
diff --git a/smoke-test/conftest.py b/smoke-test/conftest.py
index 69a58cd766182..6d148db9886a4 100644
--- a/smoke-test/conftest.py
+++ b/smoke-test/conftest.py
@@ -15,16 +15,19 @@
os.environ["DATAHUB_TELEMETRY_ENABLED"] = "false"
+def build_auth_session():
+ wait_for_healthcheck_util(requests)
+ return TestSessionWrapper(get_frontend_session())
+
+
@pytest.fixture(scope="session")
def auth_session():
- wait_for_healthcheck_util(requests)
- auth_session = TestSessionWrapper(get_frontend_session())
+ auth_session = build_auth_session()
yield auth_session
auth_session.destroy()
-@pytest.fixture(scope="session")
-def graph_client(auth_session) -> DataHubGraph:
+def build_graph_client(auth_session):
print(auth_session.cookies)
graph: DataHubGraph = DataHubGraph(
config=DatahubClientConfig(
@@ -34,6 +37,11 @@ def graph_client(auth_session) -> DataHubGraph:
return graph
+@pytest.fixture(scope="session")
+def graph_client(auth_session) -> DataHubGraph:
+ return build_graph_client(auth_session)
+
+
def pytest_sessionfinish(session, exitstatus):
"""whole test run finishes."""
send_message(exitstatus)
diff --git a/smoke-test/cypress-dev.sh b/smoke-test/cypress-dev.sh
index 3db81b11c67fa..bb9b287cb654e 100755
--- a/smoke-test/cypress-dev.sh
+++ b/smoke-test/cypress-dev.sh
@@ -16,7 +16,16 @@ set -x
# set environment variables for the test
source ./set-test-env-vars.sh
-python -c 'from tests.cypress.integration_test import ingest_data; ingest_data()'
+LOAD_DATA=$(cat < None:
)
else:
# we want to sleep for an additional period of time for Elastic writes buffer to clear
- time.sleep(_ELASTIC_BUFFER_WRITES_TIME_IN_SEC)
+ time.sleep(ELASTICSEARCH_REFRESH_INTERVAL_SECONDS)
diff --git a/smoke-test/tests/lineage/test_lineage.py b/smoke-test/tests/lineage/test_lineage.py
index 8757741d1cb23..4a43fd591ae2e 100644
--- a/smoke-test/tests/lineage/test_lineage.py
+++ b/smoke-test/tests/lineage/test_lineage.py
@@ -796,7 +796,7 @@ def test_expectation(self, graph: DataHubGraph) -> bool:
expectation.impacted_entities[impacted_entity]
), f"Expected impacted entity paths to be {expectation.impacted_entities[impacted_entity]}, found {impacted_entity_paths}"
except Exception:
- breakpoint()
+ # breakpoint()
raise
# for i in range(len(impacted_entity_paths)):
# assert impacted_entity_paths[i].path == expectation.impacted_entities[impacted_entity][i].path, f"Expected impacted entity paths to be {expectation.impacted_entities[impacted_entity][i].path}, found {impacted_entity_paths[i].path}"
diff --git a/smoke-test/tests/platform_resources/test_platform_resource.py b/smoke-test/tests/platform_resources/test_platform_resource.py
index 39d15f2e8dea6..23a147bda695b 100644
--- a/smoke-test/tests/platform_resources/test_platform_resource.py
+++ b/smoke-test/tests/platform_resources/test_platform_resource.py
@@ -11,17 +11,11 @@
PlatformResourceSearchFields,
)
-from tests.utils import wait_for_healthcheck_util, wait_for_writes_to_sync
+from tests.utils import wait_for_writes_to_sync
logger = logging.getLogger(__name__)
-@pytest.fixture(scope="module")
-def wait_for_healthchecks(auth_session):
- wait_for_healthcheck_util(auth_session)
- yield
-
-
def generate_random_id(length=8):
return "".join(random.choices(string.ascii_lowercase + string.digits, k=length))
diff --git a/smoke-test/tests/restli/__init__.py b/smoke-test/tests/restli/__init__.py
new file mode 100644
index 0000000000000..e69de29bb2d1d
diff --git a/smoke-test/tests/restli/restli_test.py b/smoke-test/tests/restli/restli_test.py
new file mode 100644
index 0000000000000..7e9cf6aa76235
--- /dev/null
+++ b/smoke-test/tests/restli/restli_test.py
@@ -0,0 +1,98 @@
+import dataclasses
+import json
+import time
+from typing import List
+
+import pytest
+from datahub.emitter.aspect import JSON_CONTENT_TYPE
+from datahub.emitter.mce_builder import make_dashboard_urn
+from datahub.emitter.mcp import MetadataChangeProposalWrapper
+from datahub.emitter.serialization_helper import pre_json_transform
+from datahub.metadata.schema_classes import (
+ AuditStampClass,
+ ChangeAuditStampsClass,
+ DashboardInfoClass,
+ GenericAspectClass,
+ MetadataChangeProposalClass,
+)
+from datahub.utilities.urns.urn import guess_entity_type
+
+from tests.utils import delete_urns
+
+generated_urns: List[str] = []
+
+
+@dataclasses.dataclass
+class MetadataChangeProposalInvalidWrapper(MetadataChangeProposalWrapper):
+ @staticmethod
+ def _make_generic_aspect(dict) -> GenericAspectClass:
+ serialized = json.dumps(pre_json_transform(dict))
+ return GenericAspectClass(
+ value=serialized.encode(),
+ contentType=JSON_CONTENT_TYPE,
+ )
+
+ def __init__(self, *args, **kwargs):
+ super().__init__(*args, **kwargs)
+
+ def __post_init__(self) -> None:
+ if self.entityUrn:
+ self.entityType = guess_entity_type(self.entityUrn)
+
+ def make_mcp(self) -> MetadataChangeProposalClass:
+ serializedAspect = None
+ if self.aspect is not None:
+ serializedAspect = (
+ MetadataChangeProposalInvalidWrapper._make_generic_aspect(self.aspect)
+ )
+
+ mcp = self._make_mcp_without_aspects()
+ mcp.aspect = serializedAspect
+ return mcp
+
+
+@pytest.fixture(scope="module")
+def ingest_cleanup_data(auth_session, graph_client, request):
+ yield
+ delete_urns(graph_client, generated_urns)
+
+
+def test_gms_ignore_unknown_dashboard_info(graph_client):
+ dashboard_urn = make_dashboard_urn(platform="looker", name="test-ignore-unknown")
+ generated_urns.extend([dashboard_urn])
+
+ audit_stamp = pre_json_transform(
+ ChangeAuditStampsClass(
+ created=AuditStampClass(
+ time=int(time.time() * 1000),
+ actor="urn:li:corpuser:datahub",
+ )
+ ).to_obj()
+ )
+
+ invalid_dashboard_info = {
+ "title": "Ignore Unknown Title",
+ "description": "Ignore Unknown Description",
+ "lastModified": audit_stamp,
+ "notAValidField": "invalid field value",
+ }
+ mcpw = MetadataChangeProposalInvalidWrapper(
+ entityUrn=dashboard_urn,
+ aspectName="dashboardInfo",
+ aspect=invalid_dashboard_info,
+ )
+
+ mcp = mcpw.make_mcp()
+ assert "notAValidField" in str(mcp)
+ assert "invalid field value" in str(mcp)
+
+ graph_client.emit_mcp(mcpw, async_flag=False)
+
+ dashboard_info = graph_client.get_aspect(
+ entity_urn=dashboard_urn,
+ aspect_type=DashboardInfoClass,
+ )
+
+ assert dashboard_info
+ assert dashboard_info.title == invalid_dashboard_info["title"]
+ assert dashboard_info.description == invalid_dashboard_info["description"]
diff --git a/smoke-test/tests/tests/data.json b/smoke-test/tests/tests/data.json
index b91c9d9f0ec3b..7dccc70457e71 100644
--- a/smoke-test/tests/tests/data.json
+++ b/smoke-test/tests/tests/data.json
@@ -148,7 +148,7 @@
"changeType": "UPSERT",
"aspectName": "testInfo",
"aspect": {
- "value": "{\"name\": \"Sample Test 1\", \"category\": \"Examples\", \"description\": \"An example of Metadata Test\", \"definition\": { \"type\": \"JSON\", \"json\": \"{\\\"on\\\":{\\\"dataset\\\":[{\\\"query\\\":\\\"dataPlatformInstance.platform\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:dataPlatform:bigQuery\\\"]}]},\\\"rules\\\":{\\\"or\\\":[{\\\"query\\\":\\\"glossaryTerms.terms.glossaryTermInfo.parentNode\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:glossaryNode:Category\\\"]},{\\\"query\\\":\\\"container.container.glossaryTerms.terms.glossaryTermInfo.parentNode\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:glossaryNode:Category\\\"]}]}}\"} }",
+ "value": "{\"name\": \"Sample Test 1\", \"category\": \"Examples\", \"description\": \"An example of Metadata Test\", \"definition\": { \"type\": \"JSON\", \"json\": \"{\\\"on\\\":{\\\"types\\\":[\\\"dataset\\\"],\\\"dataset\\\":[{\\\"query\\\":\\\"dataPlatformInstance.platform\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:dataPlatform:bigQuery\\\"]}]},\\\"rules\\\":{\\\"or\\\":[{\\\"query\\\":\\\"glossaryTerms.terms.glossaryTermInfo.parentNode\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:glossaryNode:Category\\\"]},{\\\"query\\\":\\\"container.container.glossaryTerms.terms.glossaryTermInfo.parentNode\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:glossaryNode:Category\\\"]}]}}\"} }",
"contentType": "application/json"
},
"systemMetadata": null
@@ -161,7 +161,7 @@
"changeType": "UPSERT",
"aspectName": "testInfo",
"aspect": {
- "value": "{\"name\": \"Sample Test 2\", \"category\": \"Examples\", \"description\": \"An example of another Metadata Test\", \"definition\": { \"type\": \"JSON\", \"json\": \"{\\\"on\\\":{\\\"dataset\\\":[{\\\"query\\\":\\\"dataPlatformInstance.platform\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:dataPlatform:bigQuery\\\"]}]},\\\"rules\\\":{\\\"or\\\":[{\\\"query\\\":\\\"glossaryTerms.terms.glossaryTermInfo.parentNode\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:glossaryNode:Category\\\"]},{\\\"query\\\":\\\"container.container.glossaryTerms.terms.glossaryTermInfo.parentNode\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:glossaryNode:Category\\\"]}]}}\"} }",
+ "value": "{\"name\": \"Sample Test 2\", \"category\": \"Examples\", \"description\": \"An example of another Metadata Test\", \"definition\": { \"type\": \"JSON\", \"json\": \"{\\\"on\\\":{\\\"types\\\":[\\\"dataset\\\"],\\\"dataset\\\":[{\\\"query\\\":\\\"dataPlatformInstance.platform\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:dataPlatform:bigQuery\\\"]}]},\\\"rules\\\":{\\\"or\\\":[{\\\"query\\\":\\\"glossaryTerms.terms.glossaryTermInfo.parentNode\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:glossaryNode:Category\\\"]},{\\\"query\\\":\\\"container.container.glossaryTerms.terms.glossaryTermInfo.parentNode\\\",\\\"condition\\\":\\\"EQUALS\\\",\\\"values\\\":[\\\"urn:li:glossaryNode:Category\\\"]}]}}\"} }",
"contentType": "application/json"
},
"systemMetadata": null
diff --git a/smoke-test/tests/tests/tests_test.py b/smoke-test/tests/tests/tests_test.py
index bc9ebe46c5279..8e6af2f3f5bf4 100644
--- a/smoke-test/tests/tests/tests_test.py
+++ b/smoke-test/tests/tests/tests_test.py
@@ -1,10 +1,20 @@
+import time
+from typing import List
+
import pytest
import tenacity
-from tests.utils import delete_urns_from_file, get_sleep_info, ingest_file_via_rest
+from tests.utils import (
+ delete_urns,
+ delete_urns_from_file,
+ get_sleep_info,
+ ingest_file_via_rest,
+)
sleep_sec, sleep_times = get_sleep_info()
+TEST_URNS: List[str] = []
+
@pytest.fixture(scope="module", autouse=True)
def ingest_cleanup_data(auth_session, graph_client, request):
@@ -12,17 +22,20 @@ def ingest_cleanup_data(auth_session, graph_client, request):
ingest_file_via_rest(auth_session, "tests/tests/data.json")
yield
print("removing test data")
+ delete_urns(graph_client, TEST_URNS)
delete_urns_from_file(graph_client, "tests/tests/data.json")
-test_id = "test id"
test_name = "test name"
test_category = "test category"
test_description = "test description"
test_description = "test description"
-def create_test(auth_session):
+def create_test(auth_session, test_id="test id"):
+ test_id = f"{test_id}_{int(time.time())}"
+ TEST_URNS.extend([f"urn:li:test:{test_id}"])
+
# Create new Test
create_test_json = {
"query": """mutation createTest($input: CreateTestInput!) {\n
@@ -53,21 +66,50 @@ def create_test(auth_session):
return res_data["data"]["createTest"]
-def delete_test(auth_session, test_urn):
- delete_test_json = {
- "query": """mutation deleteTest($urn: String!) {\n
- deleteTest(urn: $urn)
+@pytest.mark.dependency()
+def test_get_test_results(auth_session):
+ urn = (
+ "urn:li:dataset:(urn:li:dataPlatform:kafka,test-tests-sample,PROD)" # Test urn
+ )
+ json = {
+ "query": """query getDataset($urn: String!) {\n
+ dataset(urn: $urn) {\n
+ urn\n
+ testResults {\n
+ failing {\n
+ test {\n
+ urn\n
+ }\n
+ type
+ }\n
+ passing {\n
+ test {\n
+ urn\n
+ }\n
+ type
+ }\n
+ }\n
+ }\n
}""",
- "variables": {"urn": test_urn},
+ "variables": {"urn": urn},
}
-
response = auth_session.post(
- f"{auth_session.frontend_url()}/api/v2/graphql", json=delete_test_json
+ f"{auth_session.frontend_url()}/api/v2/graphql", json=json
)
response.raise_for_status()
+ res_data = response.json()
+ assert res_data
+ assert res_data["data"]
+ assert res_data["data"]["dataset"]
+ assert res_data["data"]["dataset"]["urn"] == urn
+ assert res_data["data"]["dataset"]["testResults"] == {
+ "failing": [{"test": {"urn": "urn:li:test:test-1"}, "type": "FAILURE"}],
+ "passing": [{"test": {"urn": "urn:li:test:test-2"}, "type": "SUCCESS"}],
+ }
-@pytest.mark.dependency()
+
+@pytest.mark.dependency(depends=["test_get_test_results"])
def test_create_test(auth_session):
test_urn = create_test(auth_session)
@@ -105,17 +147,14 @@ def test_create_test(auth_session):
}
assert "errors" not in res_data
- # Delete test
- delete_test(auth_session, test_urn)
-
- # Ensure the test no longer exists
+ # Ensure that soft-deleted tests
response = auth_session.post(
f"{auth_session.frontend_url()}/api/v2/graphql", json=get_test_json
)
response.raise_for_status()
res_data = response.json()
- assert res_data["data"]["test"] is None
+ assert res_data["data"]["test"] is not None
assert "errors" not in res_data
@@ -125,7 +164,6 @@ def test_update_test(auth_session):
test_name = "new name"
test_category = "new category"
test_description = "new description"
- test_description = "new description"
# Update Test
update_test_json = {
@@ -188,8 +226,6 @@ def test_update_test(auth_session):
}
assert "errors" not in res_data
- delete_test(auth_session, test_urn)
-
@tenacity.retry(
stop=tenacity.stop_after_attempt(sleep_times), wait=tenacity.wait_fixed(sleep_sec)
@@ -225,45 +261,3 @@ def test_list_tests_retries(auth_session):
@pytest.mark.dependency(depends=["test_update_test"])
def test_list_tests(auth_session):
test_list_tests_retries(auth_session)
-
-
-def test_get_test_results(auth_session):
- urn = (
- "urn:li:dataset:(urn:li:dataPlatform:kafka,test-tests-sample,PROD)" # Test urn
- )
- json = {
- "query": """query getDataset($urn: String!) {\n
- dataset(urn: $urn) {\n
- urn\n
- testResults {\n
- failing {\n
- test {\n
- urn\n
- }\n
- type
- }\n
- passing {\n
- test {\n
- urn\n
- }\n
- type
- }\n
- }\n
- }\n
- }""",
- "variables": {"urn": urn},
- }
- response = auth_session.post(
- f"{auth_session.frontend_url()}/api/v2/graphql", json=json
- )
- response.raise_for_status()
- res_data = response.json()
-
- assert res_data
- assert res_data["data"]
- assert res_data["data"]["dataset"]
- assert res_data["data"]["dataset"]["urn"] == urn
- assert res_data["data"]["dataset"]["testResults"] == {
- "failing": [{"test": {"urn": "urn:li:test:test-1"}, "type": "FAILURE"}],
- "passing": [{"test": {"urn": "urn:li:test:test-2"}, "type": "SUCCESS"}],
- }
diff --git a/smoke-test/tests/tokens/revokable_access_token_test.py b/smoke-test/tests/tokens/revokable_access_token_test.py
index 0ae18c32662c5..af29437c051e1 100644
--- a/smoke-test/tests/tokens/revokable_access_token_test.py
+++ b/smoke-test/tests/tokens/revokable_access_token_test.py
@@ -17,11 +17,6 @@
(admin_user, admin_pass) = get_admin_credentials()
-@pytest.fixture(autouse=True)
-def setup(auth_session):
- wait_for_writes_to_sync()
-
-
@pytest.fixture()
def auth_exclude_filter():
return {