总结一下四月份参加的华为软挑赛,距离现在已经结束了四个多月,终于有时间抽空写写总结了(小作文),我们是粤港澳赛区的620&619-F3队,第一次参加这次比赛,本想尝试一下,但没想到也挤进了复赛,而且还拿到粤港澳赛区复赛第八的成绩。BTW,我们实验室就有三队进复赛了,另外两队分别是少吃零食多睡觉队和对队,两队都是大佬级人物orz,对队还进了总决赛(膜.
这个比赛无非就是三个优化点,①购买策略②迁移策略③部署策略
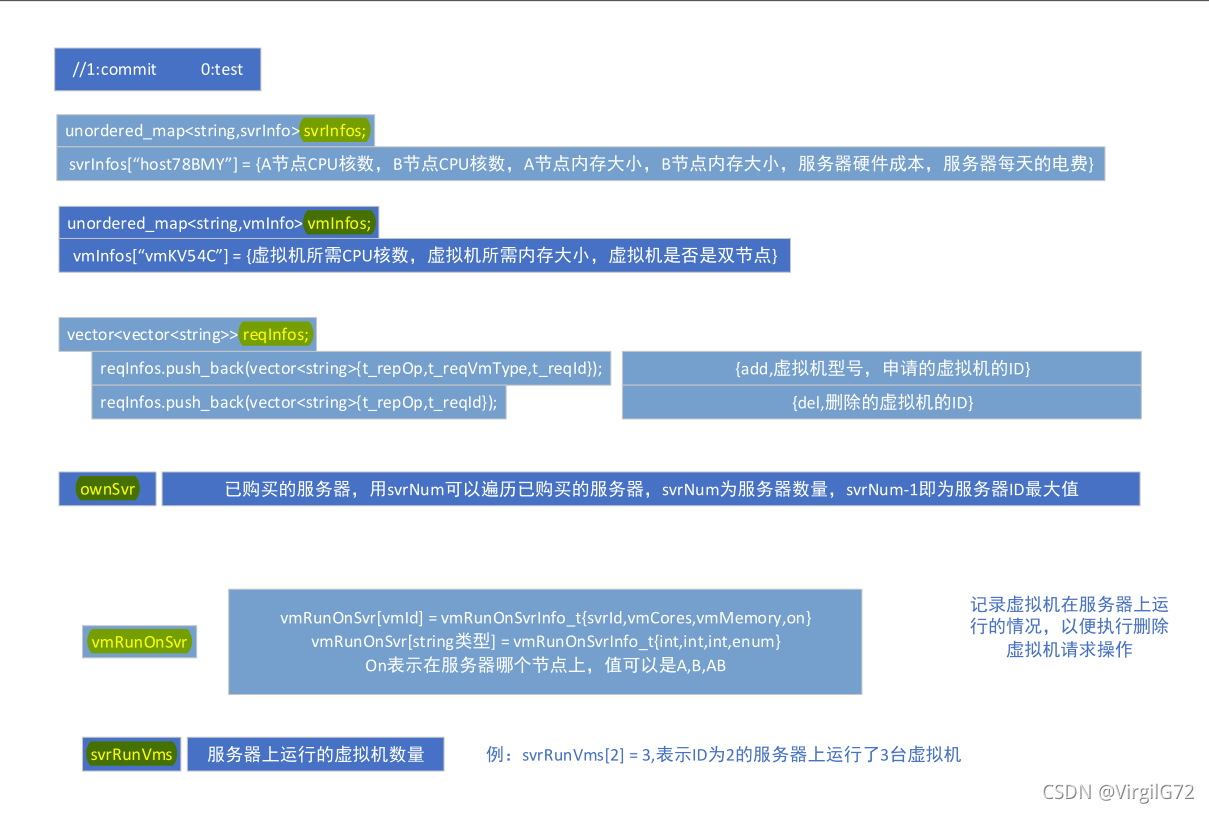
我们算法的具体流程如下:

一开始的思路是使用贪心算法,这个也是大多数队伍想到的idea。具体做法是:对服务器的硬件成本从小到大排序,然后在部署服务器的时候,若发现没有服务器能放进虚拟机的情况下,去购买最便宜的服务器。这使得我们的成本从14e直降到11.8e。但是采取此策略后,当我们输出服务器的型号,发现几乎都是价格最便宜的前三台,其他服务器没有用过。这也是成本一直降不下的原因,因为没有合理的把其他服务器也利用上。
既然购买策略是贪心算法,那么部署策略也很自然的想到用贪心算法,具体做法是:对服务器每天的占用情况从大到小排序,所以在部署虚拟机到服务器的时候,优先把虚拟机布置在占用情况最大的服务器,目的是优先填满服务器的资源,充分利用服务器资源。
版本1暂不考虑迁移策略,我们的想法是先把购买和部署策略做的最优或者较优的情况下才考虑迁移策略。
我们围绕购买策略进行了更深一步的思考,我们想到如下排序的策略: ①服务器每日的耗能成本从小到大排序 ②服务器的硬件成本/(cpu+内存)即考虑服务器的性价比从高到低 ③服务器的CPU*0.75+服务器的内存*0.25(传说中的魔法数字)从小到大 ,但很可惜,这些策略都没有我们以前的策略成本低,即对硬件成本简单粗暴的从小到大排,然后买最便宜的服务器。遂考虑怎么进一步优化部署策略
依然是围绕贪心算法去优化排序函数,这里使用了上述的策略3,也就是传说中的魔法数字,服务器的CPU*0.75+服务器的内存*0.25。有奇效!!也就是在部署虚拟机到服务器的时候,优先把虚拟机布置在策略3从小到大排序后的服务器中。这使得我们的成本下降了,从11.8e降到11.5e。 这里提一个坑:我们每次在布置虚拟机的时候,都对服务器进行排序sort,发现我们的时间一直会显示超时或者接近超时,后面经过进一步优化,我们尝试过把“每一条虚拟机请求后排序服务器” 改成 “每一天处理所有虚拟机请求前排序服务器”,但是这么做之后,时间的确减少了,但是成本提高了呀,我去...权衡再三,还是成本优先。到最后,我们采取了另一种方法:遍历服务器,也就是每次部署虚拟机到服务器的时候,我们不对服务器进行排序。而是遍历一遍当前存在的全部服务器,去找到占用资源最大的服务器,这个策略使得运行时间大大减小,这也使得我们算法能在迁移策略腾点时间,因为迁移策略真的太耗时了。
这个版本开始考虑迁移策略,很自然的,跟大多数的队伍想法一样,我们也是优先把虚拟机迁移到占用资源大的服务器,即尽可能的使服务器的剩余资源小,由于前面版本没有加迁移,所以加了迁移策略,成本理所当然的也下降了,从11.5e降到11.249e,虽然成本降了,但是运行时间增长的异常夸张,直接激增到100多秒甚至超时(大赛限制在180s)。原因是我们在迁移策略写了一个五层循环!注意是五层循环!注意是五层循环!重要的事情说三遍!后期优化到了三层循环,时间才降低了,但还是逼近超时。
迁移策略我们队长想到了一个特别骚的套路,前无古人后无来者,因为我们之前的迁移策略,包括很多队伍的策略都是纯暴力,也就是不断去遍历服务器,导致时间大幅增加。于是我们想起了大学算法分析课上的二分查找(就记得这个了hhh),即在迁移时,用二分查找方法找到第一个能放入该虚拟机的服务器,然后在该虚拟机附近进行一个小范围的暴力搜索,也就是大大减小了暴力搜索耗费的时间,且成本也进一步下降了!
这里补充一点:我们在处理每天的请求时,先把当天的连续虚拟机add请求(遇到del请求前)全部push进一个vector,然后当遇到del请求后,对刚才的vector进行排序,按照scores(虚拟机的CPU+内存)从大到小排序,然后先处理scores大的虚拟机add请求,再处理scores小的虚拟机add请求;依次类推,继续下一个新的add请求vector组,遇到del请求后,开始处理add请求vector组.....,使用此方法,成本也有显著的下降。
这里补充一个小插曲: 在初赛前几天,我们排名还在24,而32强才能进复赛,所以我们还是不能松懈。因为后面一堆老卷王,指不定在初赛的最后这几天,把我们一举反超了,所以我们一点都不敢掉以轻心。事实证明,我们当时居安思危是十分正确的,因为我们在最后一刻排到了33名(电影都不敢这么拍),然后我们那天心灰意冷的去吃了学校外面的鸡公煲,路上一直在叹息,觉得遇到了人生的大挫折,特别咽不下那口气。但是戏剧性的一幕来了,比赛结束后的第二天下午,主办方公布名单的时候,我们队伍居然也挤进去初赛了(电影都不敢这么拍)。然后仔细询问主办方为何我们排名还靠前了(当时是从33名升到了28名),主办方说因为前排有不少人的代码被查重系统拦截了,所以取消成绩。哇...得知这个消息后,欣喜若狂....感觉经历了人生的一个大起大落!
直接交我们的初赛baseline,成本为21e,由此可见,复赛的数据集比初赛复杂,且数据规模更大。从这个版本开始,我们的购买策略变动较大,我们添加了滑动窗口,并综合考虑了如下因素:
①服务器的CPU/内存尽量接近虚拟机的CPU/内存
②服务器的CPU/内存尽量接近滑动窗口当天所需要的CPU/内存
③服务器自身CPU尽量接近内存
④服务器的硬件成本尽量接近当前的平均硬件成本
⑤服务器的每日耗费成本尽量接近当前的平均耗费成本
且④⑤点引入了日期的概念,即前期选择服务器硬件成本大的、能源成本小的;后期选择服务器硬件成本小的、能源成本大的。
具体代码如下:
for (auto it = svrInfos.begin(); it != svrInfos.end(); it++)
{
if (overLoad(createVmInfo, it->second) == 1)//如果超出负载,则跳过
continue;
double totalCpu = it->second.cpuCores_A * 2;//服务器的CPU核数
double totalMemory = it->second.memorySize_A * 2;//服务器的内存数
double svrRate = totalCpu / totalMemory;//若大于1,则代表服务器的CPU>Memory;若小于1,则代表服务器的CPU<Memory
double cpuMemoryBalance = abs(totalCpu - totalMemory) / (totalCpu + totalMemory) / 2;//尽可能使服务器的CPU与Memory相近
double svrCostRate = it->second.serverCost / AvgSvrCost;//使svrCost尽可能接近1
double svrPowerCostRate = it->second.powerCost / AvgPowerCost;//使powerCost尽可能接近1
if (slideWindowInfo.needCpu > 0 && slideWindowInfo.needMemory > 0 && slideWindowInfo.totalVmsNum > 0)//当天del数小于add数的情况
{
double windowRate = slideWindowInfo.needCpu * 1.0 / slideWindowInfo.needMemory;//若大于1,则代表滑动窗口的CPU>Memory;若小于1,则代表滑动窗口的CPU<Memory
double nodeRate = slideWindowInfo.twoNodesNum * 1.0 / slideWindowInfo.totalVmsNum;//代表双结点数
loss = abs(svrRate - vmRate) * svrRate_vmRate_coef +//尽可能使虚拟机的Rate与服务器的Rate相近
abs(windowRate - svrRate) * windowRate_svrRate_coef +//尽可能使当天的Rate与服务器的Rate相近
cpuMemoryBalance * nodeRate * cpuMemoryBalance_coef +//若双结点比较多,则cpuMemoryBalance的值要求小;若单结点比较多,则cpuMemoryBalance的值可大可小
svrCostRate * start / TotalDay * svrCost_coef +//前期选择服务器硬件成本大的,后期选择服务器硬件成本小的
svrPowerCostRate * (TotalDay - start) / TotalDay * svrPowerCost_coef;//前期选择服务器能源成本小的,后期选择服务器能源成本大的
}
}我们的部署策略为每次部署虚拟机在服务器时,遍历所有服务器,计算loss,loss的定义为若分配此虚拟机后服务器的剩余CPU*0.75+内存*0.25;然后找出当中最小loss的服务器,然后部署虚拟机在服务器上。核心思想也是尽可能让服务器的剩余资源小。
与初赛version1一样,暂不考虑迁移策略。
这里补充一点:也就是我们上面提到的滑动窗口,因为复赛要求从初赛的给出全部T天的数据变更为只给出前K天的数据,当你的程序完整输出了第一天的决策信息后,你将会读取到第 K+1 天的请求序列数据。然后你需要输出第二天的决策信息,并且读取第 K+2 天的请求序列,以此类推。因此,我们考虑到使用滑动窗口,也就是在一开始统计前K天的虚拟机所需的全部CPU和内存(当中如果有虚拟机释放的话,则对应的CPU和内存也要减去),然后给出第K+1、K+2.....天后,依次计算对应的滑动窗口大小。
在计算原来的loss基础上,添加了一个负载均衡的判断,若部署该虚拟机到服务器时,A/B结点的剩余资源出现一个特别大或者一个特别小的情况时,loss+=1e5,也就是loss会特别大,即算法会尽量不满足这种极端情况的出现。
我们发现迁移策略的思想可以从部署策略中借鉴,也就是同样都是计算loss,遍历所有服务器,loss的定义为若分配此虚拟机后服务器的剩余CPU*0.75+内存*0.25;然后找出当中最小loss的服务器;然后迁移虚拟机到最小loss的服务器上。核心思想也是与部署策略一样,尽可能让服务器的剩余资源小。这里有个细节就是,我们添加了一个参数:使用率rate,由于比赛有限制运行时间,所以我们规定,使用率<0.93的服务器才进行迁移。这里再补充一个trick:我们原本的运行时间是达到了150秒左右,但是使用了C++的引用特性后(也就是在函数形参前加&引用),即从值传递变为引用传递,大大减少了函数的拷贝成本,运行时间直降100秒,于是我们才能把腾出之后的时间全部用于迁移策略,所以使用率rate才能设置到0.93这么高。
主办方在复赛当天变更了需求,如下:

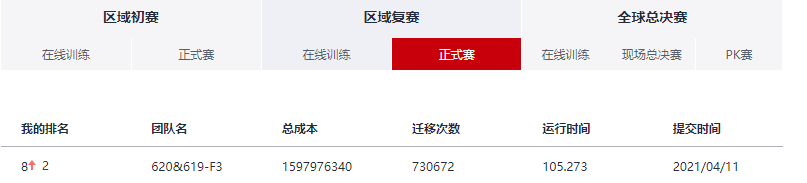
从初赛的第33名到复赛的第8名,用了一个多月的准备时间,这是最有收获的一次比赛!一路走来,有经历过深夜改bug改到头秃的绝望,也有体会到排行榜名次上升的喜悦。不过不管结果怎么样,享受的是整个比赛的过程!特别幸运能在比赛中结识到各位大佬!
发一下当天复赛的图来纪念一下哈哈哈:

Github开源地址:https://github.com/VirgilG72/CodeCraft-2021