You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
constgraph={};graph.you=['alice','bob','claire'];graph.bob=['anuj','peggy'];graph.alice=['peggy'];graph.claire=['thom','jonny'];graph.anuj=[];graph.peggy=[];graph.thom=[];constisSeller=name=>name[name.length-1]==='m';constsearch=(name,graph)=>{constiter=(waited,visited)=>{if(waited.length===0){returnfalse;}const[current, ...rest]=waited;if(visited.has(current)){returniter(rest,visited);}if(isSeller(current)){console.log(`${current} is a mango seller!`);returntrue;}visited.add(current);constpersonFriends=graph[current];returniter([...rest, ...personFriends],visited);};returniter(graph[name],newSet());};search('you');
// the graphconstgraph={};graph.start={};graph.start.a=6;graph.start.b=2;graph.a={};graph.a.fin=1;graph.b={};graph.b.a=3;graph.b.fin=5;graph.fin={};// The costs tableconstcosts={};costs.a=6;costs.b=2;costs.fin=Infinity;// the parents tableconstparents={};parents.a='start';parents.b='start';parents.fin=null;letprocessed=[];constfindLowestCostNode=(itCosts)=>{letlowestCost=Infinity;letlowestCostNode=null;Object.keys(itCosts).forEach((node)=>{constcost=itCosts[node];// If it's the lowest cost so far and hasn't been processed yet...if(cost<lowestCost&&(processed.indexOf(node)===-1)){// ... set it as the new lowest-cost node.lowestCost=cost;lowestCostNode=node;}});returnlowestCostNode;};letnode=findLowestCostNode(costs);while(node!==null){constcost=costs[node];// Go through all the neighbors of this nodeconstneighbors=graph[node];Object.keys(neighbors).forEach((n)=>{constnewCost=cost+neighbors[n];// If it's cheaper to get to this neighbor by going through this nodeif(costs[n]>newCost){// ... update the cost for this nodecosts[n]=newCost;// This node becomes the new parent for this neighbor.parents[n]=node;}});// Mark the node as processedprocessed=processed.concat(node);// Find the next node to process, and loopnode=findLowestCostNode(costs);}console.log('Cost from the start to each node:');console.log(costs);// { a: 5, b: 2, fin: 6 }
「算法」二字听来高深,常常让人望而却步,而《算法图解》是一本对算法初学者友好的书,此书图文并茂,循序渐进的帮我们理清算法中一些基础概念,还介绍了一些有意思的算法及其用途,以提升读者的兴趣,帮助我们步入算法的大门。本书也许不仅仅是一本讲述概念的书,作者还在潜移默化中培养我们的算法思维,从计算机的角度来看待问题。
原书中的示例使用 Python 编写,不过考虑到目前我日常工作中使用最多的还是
JavaScript,为了加深自己对相关概念的理解,笔记中我又用 JS 重写了一些示例。何为算法
算法为何重要
关于这点,我们来看一个实际的例子。
问题:
从 1 ~ 100 个数中猜出某个我现在想到的数字,我只会告诉你「大了」,「小了」,「对了」,最快需要几次猜到?
解决这个问题有多种方案,如果你运气好,也许1次就猜对了,运气差也许会需要100次。有一种叫做「二分查找」的算法非常适合解决这类问题。
二分查找
定义:
二分查找是一种算法,其输入是一个有序的元素列表,如果元素包含在列表中,二分查找返回其位置,否则返回
null.分析:
简单查找模式:从1开始往上猜,又称「傻找」,最多会需要99次猜测。
二分查找:每次猜最大,最小数字的中间值,由此每次可排除一般的可能性,最多只需要7次就可猜对。
代码实现
上面提到简单查找模式最多需要 99 次猜测, 而用二分查找最多需要 ㏒ n步,这其实引出了另外一个算法初学者还不算熟悉但很重要的概念 — 运行时间。
算法速度的表征方式 —— 大O表示法
我们都想选用效率最高的算法,以最大限度的减少运行时间或占用空间,换句话说我们想要选用时间复杂度低的算法,大O表示法是一种指明算法的速度有多快的特殊表示法,常常用它来表示时间复杂度。我们继续以上面的例子来说明
比如说我们 1ms 能查看一个元素,下表表现了不同元素个数简单查找和二分查找找到某个元素的时间
不要误解,大O表示法并非指的是以秒为单位的速度,而是告诉我们运行时间会以何种方式随着运算量的增加而增长,换句话说它指出了算法运行时间的的增速。
例如,假设列表包含 n 个元素。简单查找需要检查每个元素,因此需要执行 n 次操作。使用大O表示法, 这个运行时间为
O(n)。O 是Operation的简写。还需要注意的是大O表示法指出的是最糟糕的情况下的运行时间,这种运行时间是一个保证。
一些常见的时间复杂度
算法的时间复杂度往往是以下几种中的一种或者组合,虽然还没有介绍到具体的算法,不过我们可以先就各种时间复杂度留下一个印象。
O(log n):也叫对数时间,这样的算法包括二分查找;O(n):也叫线性时间,这样的算法包括简单查找;O(n * log n): 这种算法包括快速排序 —— 一种速度较快的排序算法;O(n²):这样的算法包括选择排序 —— 一种速度较慢的排序算法;O(n!): 这样的算法包括难以解决的旅行商问题 —— 一种非常慢的算法。算法常常和数据结构挂钩。在介绍数据结构之前,我们需要先理解内存的工作原理,这样有助于我们理解数据结构。
常见的数据结构 — 数组和链表
内存的工作原理
我们可以把计算机的内存想象成有很多抽屉的柜子,每个柜子都有其编号。
当需要将数据存储到内存时,我们会请求计算机提供存储空间,计算机会分配一个柜子给我们(存储地址),一个柜子只能存放一样东西,当需要存储多项连续的数据时,我们需要以一种特殊的方法来请求存储空间,这就涉及到两种基本的数据结构—数组和链表。
数组和链表的区别
数组
「数组」这个概念我们很熟悉,在我们的平日的开发过程中会经常用到,不过暂时忘记 JavaScript 中的 Array 吧。我们来看看数组的本质。
使用数组意味着所有的存储事项在内存中都是相连的。
这样做的优点是,如果我们知道某个存储事项的索引,我们只需要一步就能找到其对应的内容。
但是缺点也显而易见,如果计算机开始为我们的数组分配的是一块只能容纳三项的空间,当需要存储第四项的时候,会需要把所有内容整体移动到新的分配区域。如果新的区域再满了,则需要再整体移动到另外一个更大的空区域。因此有时候在数组中添加新元素是很麻烦的一件事情。针对这个问题常见的解决方案时预留空间,不过预留空间也有两个问题:
* 可能浪费空间;
* 预留的空间可能依旧不够用;
链表
链表中的元素可以存储在任何地方,链表的每个元素都存储了下一个元素的地址,从而使得一系列的内存地址串在一起。
考虑到链表的这些性质,链表在「插入元素」方便颇具优势,存储后只需要修改相关元素的指向内存地址即可。当然伴随而来也有劣势,那就是在需要读取链表的最后一个元素时,必须从第一个元素开始查找直至找到最后一个元素。
链表的劣势恰恰是数组的优势,当需要随机读取元素时,数组的效率很高。(数组中的元素存储的内存地址相邻,可容易计算出任意位置的元素的存储位置)。
链表和数组各种操作的时间复杂度对比
O(1)O(n)O(n)O(1)O(n)O(1)前面介绍的「二分查找」的前提是查找的内容是有序的,在熟悉了数组和链表后,我们来学习第一种排序算法—选择排序。
选择排序
定义
遍历一个列表,每次找出其中最大的那个值,存入一个新的列表,并从原来的列表中去除该值,直到排完。
时间复杂度
每次遍历的时间复杂度为
O(n),需要执行n次,因此总时间为O(n²)。示例代码
上面的选择排序用到了循环,递归是很多算法都使用的一种编程方法,甚至不夸张的讲,递归是一种计算机思维。
递归
递归是一种优雅的问题解决方法。其优雅体现在它让解决方案更为清晰,虽然在性能上,有些情况下递归不如循环。
递归的组成
递归由两部分组成:
上面提到,递归可能存在性能问题,想要理解这一点,需要先理解什么是「调用栈」。
「栈」是一种先入后出(FILO)简单的数据结构。「调用栈」是计算机在内部使用的栈。当调用一个函数时,计算机会把函数调用所涉及到的所有变量都存在内存中。如果函数中继续调用函数,计算机会为第二个函数页分配内存并存在第一个函数上方。当第二个函数执行完时,会再回到第一个函数的内存处。
我们再看看「递归调用栈」:
使用递归很方便,但是也要̶出代价:存储详尽的信息需要占用大量的内存。递归中函数会嵌套执行多层函数,每个函数调用都要占用一定的内存,如果栈很高,计算机就需要存储大量函数调用的信息,这就是为什么有的语言会限制递归最多的层数。
上面提到的 「选择排序」还是太慢,接下来我们基于递归介绍一种业界通用的排序方法 —— 快速排序。
在正式讲解「快速排序」之前,我们先介绍一下「分而治之」这种方法。
「分而治之 」(divide and conquer D&C )是一种著名的递归式问题解决方法。只能解决一种问题的算法毕竟作用有限,D&C 可能帮我们找到解决问题的思路。
分而治之
运用 D & C 解决问题的过程包括两个步骤:
我们以快速排序为例来看看,如何运用分而治之的思维。
快速排序
代码实现
在最糟情况下,栈长为
O(n),而在最佳情况下,栈长为O(log n)。快速排序的平均时间复杂度为
nlog(n),比选择排序快多了O(n²)。常见的数据结构 —— 散列表
在编程语言中,存在另外一种和数组不同的复杂数据结构,比如JavaScript中的对象,或 Python 中的 字典。对应到计算机的存储上,它们可能可以对应为 散列表。
要理解散列表,我们需要先看看散列函数。
散列函数
散列函数是一种将输入映射到数字,且满足以下条件的函数:
散列函数准确的指出了数据的存储位置,能做到这个是因为:
我们可以把散列表定义为::使用散列函数和数组创建了一种数据结构。::
散列表也被称为 「散列映射」,「映射」,「字典」和「关联数组」。
但是就像上面提到的,需要连续内存位置的数组存储空间毕竟有限,散列表中如果两个键映射到了同一个位置,一般做法是在这个位置上存储一个链表。
散列表的用途
由于散列函数的存在,散列表中数据的查找变得非常快,散列函数值唯一,本身就是一种映射,基于这些,散列表可用作以下用途:
使用散列表页存在一些注意事项:
散列表的时间复杂度
理想情况下 散列表的操作为
O(1),但是最糟情况下,所有操作的运行时间为O(n)在平均情况下,散列表的查找速度和数组一样快,而插入和删除速度和链表一样快,因此它兼具二者的优点。但是在最糟的情况下,散列表的各项操作速度都很慢。
要想让散列表尽可能的快,需要避免冲突。
想要避免冲突,需要满足以下两个条件:
填装因子 = 散列表包含的元素总数 / 位置总数
如果填装因子大于1 意味着商品数量超过数组的位置数。一旦填装因子开始增大,就需要在散列表中添加位置,这被称为调整长度。
一个不错的经验是,当填装因子大于 0.7 的时候,就调整散列表的长度。
良好的散列函数
良好的散列函数让数组中的值呈均匀分布,不过我们不用担心该如何才能构造好的散列函数,著名的
SHA函数,就可用作散列函数。在大多数编程语言中,散列表都有内置的实现。下面我们看看散列表的用途。
广度优先搜索
广度优先算法是图算法的一种,可用来找出两样东西之间的最短距离。在介绍这种算法之前,我们先看看什么叫图。
什么是图
图由节点(node)和边(edge)组成,它模拟一组连接。一个节点可能与众多节点直接相连,这些节点被称为邻居。有向图指的是节点之间单向连接,无向图指的是节点直接双向连接。
在编程语言中,我们可以用散列表来抽象表示图
广度优先搜索解决的问题
广度优先搜索用以回答两类问题:
我们还是举例来说明该如何运用 广度优先搜索。
芒果销售商问题
如果你想从你的朋友或者有朋友的朋友中找到一位芒果销售商,涉及关系最短的路径是什么呢?
编码实现
上面的编码中涉及到了一种新的数据结构 —— 队列。
队列
队列的工作原理和现实生活中的队列完全相同,可类比为在公交车前排队,队列只支持两种操作:入队 和 出队。
队列是一种先进先出的(FIFO)数据结构。
散列表模拟图
散列表是一种用来模拟图的数据结构
广度优先算法的时间复杂度
广度优先算法的时间复杂度为
O(V+E)其中V为顶点数,E为边数。树
提到图就不得不说一种特殊的图 —— 树。
树其实可以看做是所有的边都只能往下指的图。树的用途非常广,还有很多种分支,更多信息可参考
狄克斯特拉算法
广度优先搜索只能找出最短的路径,但是它却并不一定是最快的路径,想要得到最快的路径需要用到狄克斯特拉算法(Dijkstra’s algorithm)
在狄克斯特拉算法算法中,每段路径存在权重,狄克斯特拉算法算法的作用是找出的是总权重最小的路径。
平时我们使用地图软件导航到某个我们不熟悉的地点时,地图软件往往会给我们指出多条路线。直达但是绕圈的公交并不一定会比需要换乘的地铁快。
狄克斯特拉算法的使用步骤如下:
狄克斯特拉算法涉及到的这种拥有权重的图被称为 「加权图」
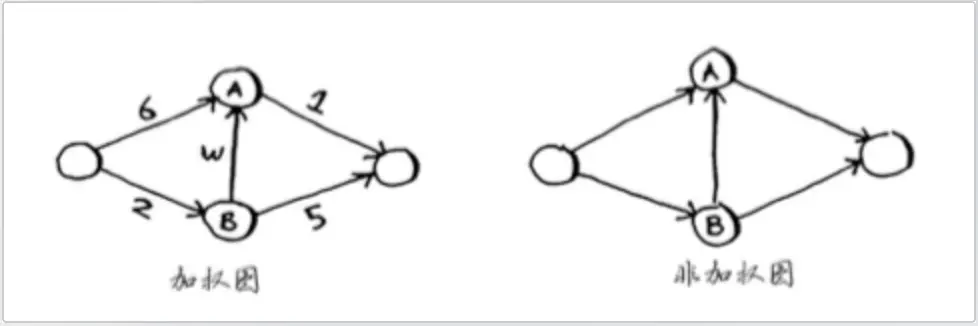
不存在权限的图被称为「非加权图」。
狄克斯特拉算法算法只适用于有向无环图。
不能将狄克斯特拉算法算法用于负权边的情况。
编码实现
并非所有问题都存在最优解
有些时候,我们很难找出最优解,这时候我们可以采用另外一种计算机思维来解决问题 —— 贪婪算法。
贪婪算法指的是每步都采取最优的做法,每步都选择局部最优解,最终的结果一定不会太差。
判断近似算法优劣的标准如下:
有的问题也许不存在所谓的最优解决方案,这类问题被称为「NP完全问题」。这类问题以难解著称,如旅行商问题和集合覆盖问题。很多非常聪明的人都认为,根本不可能编写出可快速解决这些问题的算法。对这类问题采用近似算法是很好的方案,能合理的识别NP完全问题,可以帮我们不再无结果的问题上浪费太多时间。
如何识别NP完全问题
以下是NP完成问题的一些特点,可以帮我我们识别NP完全问题:
动态规划
还有一种被称作「动态规划」的思维方式可以帮我们解决问题
这种思维方式的核心在于,先解决子问题,再逐步解决大问题。这也导致「动态规划」思想适用于子问题都是离散的,即不依赖其他子问题的问题。
动态规划使用小贴士:
K最近邻算法
本书对 KNN 也做了简单的介绍,KNN的合并观点如下
进一步的学习建议
读完本书,对算法总算有了一个入门的理解,当然算法还有很多值得深入学习的地方,以下是作者推荐的一些方向。
书读完了
《算法图解》确实是一本比较好的算法入门书,不枯燥,又能让人有收获就能激励出人的学习欲望,学习算法单阅读本书肯定还是不够的,
Coursera | Online Courses From Top Universities. Join for Free是一门非常好的算法课,如果感兴趣可以一起学学。
The text was updated successfully, but these errors were encountered: