diff --git a/.gitignore b/.gitignore
index 2296323..cc8be8e 100755
--- a/.gitignore
+++ b/.gitignore
@@ -16,6 +16,9 @@ ldm_ae*
data/*
*.pth
.gradio/
+*.bin
+*.safetensors
+*.pkl
# Byte-compiled / optimized / DLL files
__pycache__/
diff --git a/asset/docs/sana_lora_dreambooth.md b/asset/docs/sana_lora_dreambooth.md
index c9cec39..e433dbf 100644
--- a/asset/docs/sana_lora_dreambooth.md
+++ b/asset/docs/sana_lora_dreambooth.md
@@ -53,7 +53,7 @@ Let's first download it locally:
```python
from huggingface_hub import snapshot_download
-local_dir = "./dog"
+local_dir = "data/dreambooth/dog"
snapshot_download(
"diffusers/dog-example",
local_dir=local_dir, repo_type="dataset",
@@ -74,9 +74,7 @@ bash train_scripts/train_lora.sh
or you can run it locally:
```bash
-huggingface-cli download diffusers/dog-example --local-dir data/dreambooth/dog --repo-type dataset
-
-export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_diffusers"
+export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers"
export INSTANCE_DIR="data/dreambooth/dog"
export OUTPUT_DIR="trained-sana-lora"
@@ -87,7 +85,6 @@ accelerate launch --num_processes 8 --main_process_port 29500 --gpu_ids 0,1,2,3
--output_dir=$OUTPUT_DIR \
--mixed_precision="bf16" \
--instance_prompt="a photo of sks dog" \
- --mixed_precision="fp16" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
@@ -97,7 +94,7 @@ accelerate launch --num_processes 8 --main_process_port 29500 --gpu_ids 0,1,2,3
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
- --validation_prompt="A photo of sks dog in a bucket" \
+ --validation_prompt="A photo of sks dog in a pond, yarn art style" \
--validation_epochs=25 \
--seed="0" \
--push_to_hub
@@ -129,3 +126,19 @@ We provide several options for optimizing memory optimization:
- `--use_8bit_adam`: When enabled, we will use the 8bit version of AdamW provided by the `bitsandbytes` library.
Refer to the [official documentation](https://huggingface.co/docs/diffusers/main/en/api/pipelines/sana) of the `SanaPipeline` to know more about the models available under the SANA family and their preferred dtypes during inference.
+
+## Samples
+
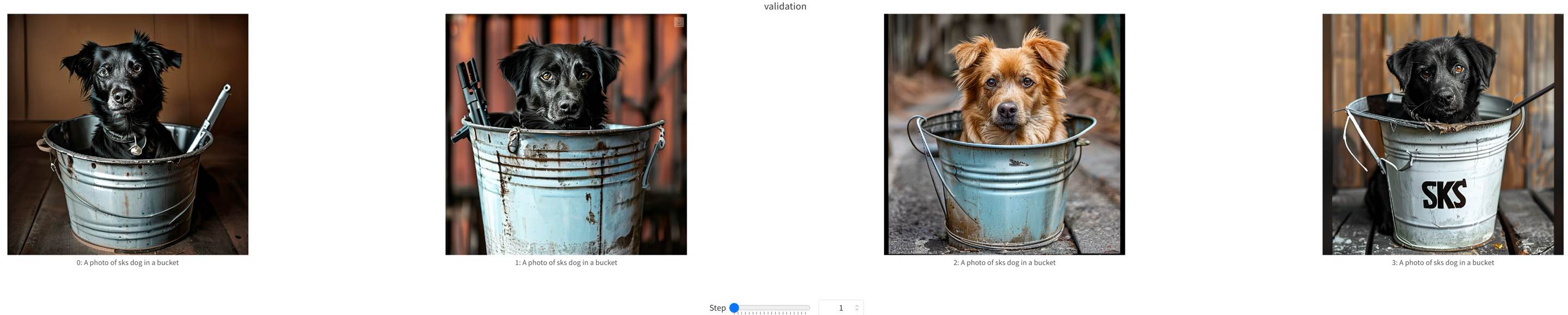
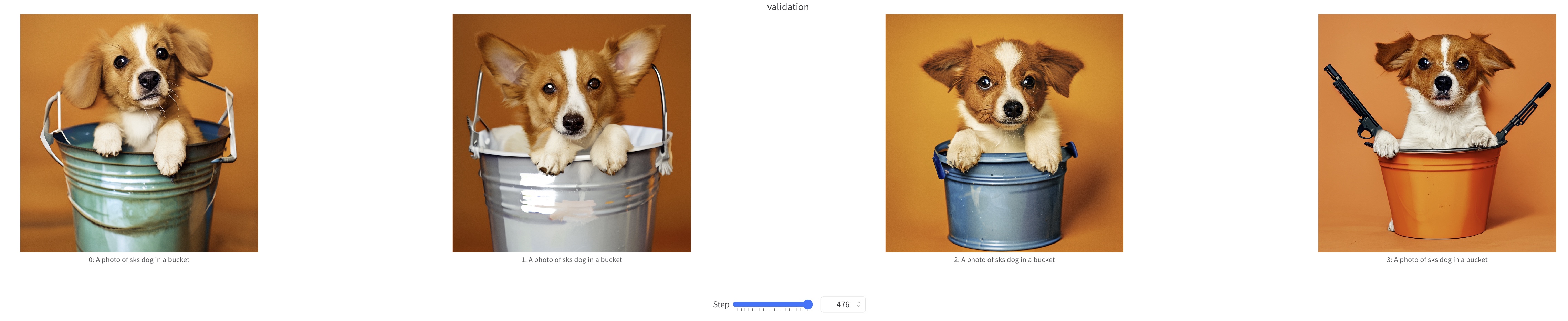
+We show some samples during Sana-LoRA fine-tuning process below.
+
+
+  +
+
+ training samples at step=0
+
+
+
+  +
+
+ training samples at step=500
+
diff --git a/train_scripts/train_dreambooth_lora_sana.py b/train_scripts/train_dreambooth_lora_sana.py
index 4baa9f1..42b2e38 100644
--- a/train_scripts/train_dreambooth_lora_sana.py
+++ b/train_scripts/train_dreambooth_lora_sana.py
@@ -1,5 +1,4 @@
#!/usr/bin/env python
-# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
@@ -24,6 +23,7 @@
import warnings
from pathlib import Path
+import diffusers
import numpy as np
import torch
import torch.utils.checkpoint
@@ -31,6 +31,17 @@
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import DistributedDataParallelKwargs, ProjectConfiguration, set_seed
+from diffusers import AutoencoderDC, FlowMatchEulerDiscreteScheduler, SanaPipeline, SanaTransformer2DModel
+from diffusers.optimization import get_scheduler
+from diffusers.training_utils import (
+ cast_training_params,
+ compute_density_for_timestep_sampling,
+ compute_loss_weighting_for_sd3,
+ free_memory,
+)
+from diffusers.utils import check_min_version, convert_unet_state_dict_to_peft, is_wandb_available
+from diffusers.utils.hub_utils import load_or_create_model_card, populate_model_card
+from diffusers.utils.torch_utils import is_compiled_module
from huggingface_hub import create_repo, upload_folder
from huggingface_hub.utils import insecure_hashlib
from peft import LoraConfig, set_peft_model_state_dict
@@ -43,29 +54,6 @@
from tqdm.auto import tqdm
from transformers import AutoTokenizer, Gemma2Model
-import diffusers
-from diffusers import (
- AutoencoderDC,
- FlowMatchEulerDiscreteScheduler,
- SanaPipeline,
- SanaTransformer2DModel,
-)
-from diffusers.optimization import get_scheduler
-from diffusers.training_utils import (
- cast_training_params,
- compute_density_for_timestep_sampling,
- compute_loss_weighting_for_sd3,
- free_memory,
-)
-from diffusers.utils import (
- check_min_version,
- convert_unet_state_dict_to_peft,
- is_wandb_available,
-)
-from diffusers.utils.hub_utils import load_or_create_model_card, populate_model_card
-from diffusers.utils.torch_utils import is_compiled_module
-
-
if is_wandb_available():
import wandb
@@ -365,9 +353,7 @@ def parse_args(input_args=None):
parser.add_argument(
"--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
)
- parser.add_argument(
- "--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
- )
+ parser.add_argument("--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images.")
parser.add_argument("--num_train_epochs", type=int, default=1)
parser.add_argument(
"--max_train_steps",
@@ -932,6 +918,7 @@ def main(args):
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name,
exist_ok=True,
+ private=True,
).repo_id
# Load the tokenizer
@@ -1219,9 +1206,7 @@ def compute_text_embeddings(prompt, text_encoding_pipeline):
vae = vae.to("cuda")
for batch in tqdm(train_dataloader, desc="Caching latents"):
with torch.no_grad():
- batch["pixel_values"] = batch["pixel_values"].to(
- accelerator.device, non_blocking=True, dtype=vae.dtype
- )
+ batch["pixel_values"] = batch["pixel_values"].to(accelerator.device, non_blocking=True, dtype=vae.dtype)
latents_cache.append(vae.encode(batch["pixel_values"]).latent)
if args.validation_prompt is None:
diff --git a/train_scripts/train_lora.sh b/train_scripts/train_lora.sh
index cad8f75..3ed034b 100644
--- a/train_scripts/train_lora.sh
+++ b/train_scripts/train_lora.sh
@@ -1,19 +1,16 @@
#! /bin/bash
-huggingface-cli download diffusers/dog-example --local-dir data/dreambooth/dog --repo-type dataset
-
-export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_diffusers"
+export MODEL_NAME="Efficient-Large-Model/Sana_1600M_1024px_BF16_diffusers"
export INSTANCE_DIR="data/dreambooth/dog"
export OUTPUT_DIR="trained-sana-lora"
-accelerate launch --num_processes 8 --main_process_port 29500 --gpu_ids 0,1,2,3 \
+accelerate launch --num_processes 4 --main_process_port 29500 --gpu_ids 0,1,2,3 \
train_scripts/train_dreambooth_lora_sana.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--mixed_precision="bf16" \
--instance_prompt="a photo of sks dog" \
- --mixed_precision="fp16" \
--resolution=1024 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
@@ -23,7 +20,7 @@ accelerate launch --num_processes 8 --main_process_port 29500 --gpu_ids 0,1,2,3
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=500 \
- --validation_prompt="A photo of sks dog in a bucket" \
+ --validation_prompt="A photo of sks dog in a pond, yarn art style" \
--validation_epochs=25 \
--seed="0" \
--push_to_hub