Here I'll try to explain some algorithm and implementation details about this work in layman's terms.
Let's say a language model is ...
a) Trained by a lot of corpus.
b) It could predict the probability of next word given foregoing words.
=> It's just conditional probability, P(next_word | foregoing_words)
c) Since we could predict next word:
=> then predict even next, according to words just been generated
=> continuously, we could produce sentences, even paragraph.
We could easily achieve this by simple LSTM model.
Again we quote this seq2seq architecture from [Google's blogpost]
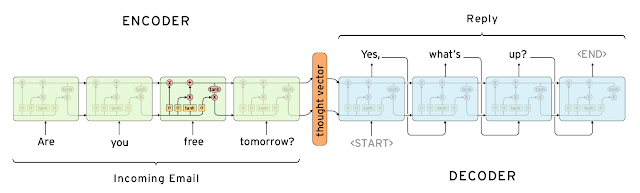
It's composed of two language model: encoder and decoder. Both of them could be LSTM model we just mentioned.
The encoder part accept input tokens and transform the whole input sentence into an embedding "thought vector", which express the meaning of input sentence in our language model domain.
Then the decoder is just a language model, like we just said, a language model could generate new sentence according to foregoing corpus. Here we use this "thought vector" as kick-off and receive the corresponding mapping, and decode it into the response.
Now you might wonder:
a) Considering this architecture, wil the "thought vector" be dominated by later stages of encoder?
b) Is that enough to represent the meaning of whole input sentence into just a vector?
For (a) actually, one of the implement detail we didn't mention before: the input sentence will be reversed before input to the encoder. Thus we shorten the distance between head of input sentence and head of response sentence. Empirically, it achieves better results. (This trick is not shown in the architecture figure above, for easy to understanding)
For (b), another methods to disclose more information to decoder is the attention mechanism. The idea is simple: allowing each stage in decoder to peep any encoder stages, if they found useful in training phase. So decoder could understand the input sentence more and automagically peep suitable positions while generating response.
A naive implementation of language model is: suppose we are training english language model, which a dictionary size of 80,000 is roughly enough. As we one-hot coding each word in our dictionary, our LSTM cell should have 80,000 outputs and we will do the softmax to choose for words with best probability...
... even if you have lots of computing resource, you don't need to waste like that. Especially if you are dealing with some other languages with more words like Chinese, which 200,000 words is barely enough.
Practically, we could reduce this 80,000 one-hot coding dictionary into embedding spaces, we could use like 64, 128 or 256 dimention to embed our 80,000 words dictionary, and train our model with only by this lower dimention. Then finally when we are generating the response, we project the embedding back into one-hot coding space for dictionary lookup.
The original implementation of tensorflow decode response sentence greedily. Empirically this trapped result in local optimum, and result in dump response which do have maximum probability in first couple of words.
So we do the beam search, keep best N candidates and move-forward, thus we could avoid local optimum and find more longer, interesting responses more closer to global optimum result.
In this paper, Google Brain team found that beam search didn't benefit a lot in machine translation, I guess that's why they didn't implement beam search. But in my experience, chatbot do benefit a lot from beam search.
As the seq2seq model is trained by MLE (maximum likelyhood estimation), the model do follow this object function by finding the "most possible" response well. But in human dialogue, a response with high probability like "thank you", "I don't know", "I love you" is not informative at all.
As currently we haven't find a good enough object function to replace MLE, there are some works to suppress this "generic response problem".
The work of Li. et al from Stanford and Microsoft Research try to suppress generic response by lower the probability of generic response from candidates while doing the beam search.
The idea is somewhat like Tf-Idf: if this response is suitable for all kinds of foregoing sentence, which means it's not specific answer for current sentence, then we discard it.
According my own experiment result, this helps a lot! Although the cost is that we will choose something grammatically not so correct, but most of time the effect is acceptable. It does generate more interesting, informative response.
Reinforcement learning is a promising domain now (in 2016). It's promising because it solve the delayed reward problem, and that's a huge merit for chatbot training. Since we could judge a continuous dialogue includeing several sentences, rather than one single sentence at a time. We could design more sophiscated metrics to reward the model and make it learn more abstract ideas.
The magic of tensorflow is that it construct a graph, which all the computing in graph could be dispatched automagically to CPU, GPU, or even distributed system (more CPU/GPU).
So far tensorflow have no native supporting operations for the delayed rewarding, so we have to do some work-around. We will calculate the gradients in graph, and accumulate and do post-processing to them out-of-graph, finally inject them back to do the apply_gradient(). You could find a minimum example in this ipython notebook.