You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
스스로 움직이는 사용자 에이전트
사람과의 상호작용 없이 연속된 웹 트랜잭션을 자동으로 수행하는 소프트웨어 프로그램
- 크롤러, 스파이더, 웜, 봇 등 으로 불림
주식그래프 로봇 : 주식시장 서버에 매 분 HTTP GET 요청을 보내 주가 추이 그래프를 생성
웹 통계 조사 로봇 : 웹을 떠돌며 페이지 개수를 세고 페이지의 크기, 언어, 미디어타입을 기록하며 웹 통계정보 수집
검색엔진 로봇
가격 비교 로봇 : 상품에 대한 가격 데이터베이스를 만들기 위해 온라인 쇼핑몰의 카탈로그에서 웹페이지를 수집
1. 크롤러와 크롤링
웹 크롤러는 웹 페이지를 한 개 가져오고, 그 다음 그 페이지가 가리키는 모든 웹 페이지를 가져오면서
"재귀적으로 반복하는 방식으로 웹을 순회하는 로봇"이다.
`크롤러`, `스파이디` 라고 부름 ( crawl : 기어다니기 )
1-1. 어디에서 시작하는가 : 루트 집합
크롤러가 방문을 시작하는 URL들의 초기 집합 : 루트 집합(root set)
모든 링크를 크롤링하면 결과적으로 웹페이지들의 대부분을 가져오게 될 수 있도록 충분히 다른 장소에서 URL들을 선택해야한다.
루트집합에 너무 많은 페이지가 있을 필요는 없다.
그림의 예시로는 A, G, S면 충분
일반적으로 좋은 루트집합은 크고 인기있는 웹사이트, 새로 생성된 페이지 목록, 자주 링크되지 않는 페이지들의 목록으로 구성
1-2. 링크 추출과 상대 링크 정상화
크롤러는 웹을 돌아다니며 꾸준히 HTML 문서를 검색하고 검색한 페이지 안에 있는 URL 링크를 파싱해서 크롤링할 페이지 목록에 추가한다.
이 때 파싱한 상대 링크를 절대 링크로 변환할 필요가 있다.
1-3. 순환 피하기
로봇이 웹을 크롤링 할 때, **루프나 순환에 빠지지 않도록 매우 조심해야한다.**
예시 (A->B->C->A)
로봇들은 순환을 피하기 위해 반드시 그들이 어디를 방문했는지 알아야한다. 순환은 로봇을 함정에 빠뜨려서 멈추거나 느려지게한다.
1-4. 루프와 중복
루프로 인한 낭비 (loops)
순환으로 크롤러를 루프에 빠뜨리면 크롤러는 빙빙 돌게되고, 같은 페이지를 반복해서 가져와 모든 시간을 낭비한다.
또한 네트워크 대역폭을 다 차지해 다른 페이지를 가져올 수 없게 되어버린다.
웹 서버의 부담
크롤러가 같은 페이지를 빠르게 반복해서 요청하면 웹 서버의 부담이 된다.
다른 실제 사용자가 사이트에 접근할 수 없도록 막아버리게 될 수 있다.
중복된 페이지 (dups)
루프 자체가 문제가 되지 않더라도, 중복페이지로 쓸모없는 중복 컨텐츠가 넘쳐날 수 있다.
1-5. 빵 부스러기의 흔적
헨젤과 그레텔인가 ..? 제목 이름 뭐지
어떤 URL을 방문했는지 빠르게 판단하기 위해서 **복잡한 자료구조(검색 트리, 해시 테이블 등)을 **사용할 필요가 있다. 이 자료구조는 속도와 메모리 사용 면에서 효과적이어야한다.
단순 예시로도 평균 URL이 40바이트이고 5억개를 크롤링했다면 URL 유지에 20GB 메모리가 필요함
트리(검색 트리)와 해시테이블
URL을 훨씬 빨리 찾아볼 수 있게 해주는 소프트웨어 자료구조
느슨한 존재 비트맵
공간 사용을 최소화 하기 위해 **존재 비트 배열(presence bit array)**와 같은 느슨한 자료구조를 사용
각 URL은 해시 함수에 의해 고정된 크기의 숫자로 변환되고 배열 안에 대응하는 **존재 비트(presence bit)**를 가져 존재비트가 이미 존재한다면 이미 크롤링되었다고 간주한다.
배열 사이즈에 따라 충돌이 일어날 수 있다.
체크포인트
로봇프로그램의 갑작스런 중단에 대비해 방문한 URL의 목록이 디스크에 저장되어있는지 확인
파티셔닝
한 대의 컴퓨터로는 충분하지 못할 수 있으므로 분리된 한 대의 컴퓨터인 로봇들이 동시에 일하고 있는 **농장(farm)**을 이용해 특정 한 부분이 할당되어 서로 도와주거나 크롤링
개별 로봇들은 URL을 넘겨주거나 오동작하는 동료를 도와주거나 커뮤니케이션을 한다.
1-6. 별칭과 로봇 순환
URL이 별칭을 가질 수 있어서 이전에 방문한 페이지를 파악하지 못할 수 있다.
포트번호 80 생략
이스케이핑된 문자
# 태그
대소문자
기본페이지 (index.html)
도메인과 IP주소
1-7. URL 정규화 하기
URL을 표준형식으로 정규화하여 같은 리소스를 미리 제거하려 시도한다.
포트번호 생략 -> 80을 추가
%xx 이스케이핑 문자 -> 대응 문자로 변환
# 태그 제거
다음은 서버에 따라 설정이 달라서 정규화하기 어려운 것도 있다.
대소문자를 구분하는지
서버의 색인 페이지 설정
도메인과 IP주소 얻어오기, 가상호스팅 설정
1-8. 파일 시스템 링크 순환
실수 혹은 악의적
/subdir이 /로 링크되어 순환되는데 로봇은 눈치채지 못해 루프로 빠질 수 있다.
1-9. 동적 가상 웹 공간
악의적으로 순진한 로봇을 함정으로 빠뜨리기 위해 의도적으로 복잡한 크롤러 루프를 만들 수 있다.
같은 서버에 있는 가상의 URL링크를 HTML에 만들어냄 (url 1씩 증가,,)
혹은 악의가 없더라도 달력을 무한히 넘겨본다던지 자신도 모르게 심볼릭 링크나 동적 콘텐츠를 통해 함정을 만들 수도 있다.
1-10. 루프와 중복 피하기
순환을 피하기 위해 휴리스틱집합을 필요로한다.
단점은 약간의 손실을 유발할 수 있다, 의심스러워 보이지만 실제로 유효한 콘텐츠일 수 있음
URL 정규화
URL을 표준 형태로 변환함으로써 같은 리소스를 가리키는 중복된 URL이 생기는 것을 일부 회피
너비 우선 크롤링
너비우선으로 스케쥴링하면 순환의 영향을 최소화할 수 있다. DFS 방식은 무한히 빠져나올 수 없게 될수도 있다.
스로틀링
일정 시간 동안 가져올 수 있는 페이지의 숫자를 제한한다.
URL크기 제한
일정길이의 URL은 크롤링을 거부
주의할 점 : 가져오지 못하는 콘텐츠가 생김
URL이 특정 크기에 도달할 때 에러 로그를 남김으로써 특정 사이트에서 어떤 일이 벌어지는지 감시하는 사용자에게는 훌륭한 신호가 될 것
URL/사이트 블랙리스트
문제를 일으키는 사이트를 블랙리스트에 추가
패턴 발견
순환과 오설정들은 일정 패턴을 따르는 경향이 있으므로 몇가지 다른 주기의 패턴을 감지
콘텐츠 지문(fingerprint)
페이지의 콘텐츠에서 몇 바이트 얻어내어 체크섬(checksum) 계산해서 이전에 크롤링한 페이지인지 확인
체크섬함수는 어떤 두 페이지가 서로 다름에도 체크섬이 똑같을 확률이 적은 것을 사용해야한다. - `MD5와 같은 메시지 요약 함수
웹 서버들은 페이지를 동적으로 생성하기 때문에 체크섬 감지에 어려울 수 있다.
사람의 모니터링
어쨌든 해결할 수 없는 문제는 사람의 모니터링에 의존할 수 밖에 없다.
2. 로봇의 HTTP
웹 로봇도 HTTP 명세 규칙을 지켜야한다.
많은 로봇들이 콘텐츠를 요청하기 위해 필요한 HTTP를 최소한으로 구현하려고 한다.
결과적으로 많은 로봇들이 `HTTP/1.0`요청을 보낸다 (1.0이 요구사항이 적기 때문)
2-1. 요청 헤더 식별하기
신원 식별 헤더 (특히 User-Agent)를 구현하고 전송
잘못된 크롤러의 소유자를 찾아낼 때와 로봇이 어떤 종류의 콘텐츠를 다룰 수 있는지에 대한 약간의 정보를 주려할 때 유용한 정보가 된다.
User-Agent
서버에게 요청을 만든 로봇의 이름을 말해준다.
From
로봇의 사용자/관리자의 이메일 주소를 제공한다.
Accept
어떤 미디어 타입을 보내도 되는지 말해준다. 로봇이 관심있는 유형의 콘텐츠만 받게될 것임을 확신하는데 도움을 준다.
Referer
현재의 요청URL을 포함한 문서의 URL을 제공한다. - 어떻게 로봇이 그들 사이트를 발견했는지 알수 있음
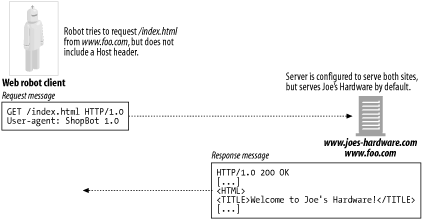
2-2. 가상 호스팅
로봇 구현자들은 Host 헤더를 지원할 필요가 있다.
요청에 Host헤더를 포함하지 않으면 로봇이 어떤 URL에 대해 잘못된 콘텐츠를 찾게 만든다.
두개의 사이트를 운영하는 서버에 요청을 보낼 때 원하는 곳이 아닌 다른 사이트에서 콘텐츠를 받아오게 될 수도 있음
2-3. 조건부 요청
변경되었을 때만, 자신이 받아간 이후에 업데이트된 것이 있는지 조건부 요청을 구현하여 받아옴.
캐시와 비슷
2-4. 응답 다루기
대다수 로봇들은 GET으로 콘텐츠를 요청해서 가져오는것이라 응답을 다루지 않지만,
조건부 요청과 같은 몇몇 기능을 사용하는 로봇이나 서버와의 상호작용을 더 잘해보려는 로봇은 여러 종류의 HTTP응답을 다룰 줄 알 필요가 있다.
상태 코드
일반적으로 200 OK, 404 NOT FOUND와 같은 상태 코드를 이해해야 한다.
모든 서버가 언제나 적절한 에러코드를 반환하지 않는다는 것도 알아둬야한다.
엔터티
HTTP 헤더에 임베딩된 정보를 따라 엔터티 자체의 정보를 찾을 수 있다.
메타 http-equiv태그와 같은 메타 HTML 태그는 리소스에 대해 콘텐츠 저자가 포함시킨 정보다.
http-equiv 태그 자체는 콘텐츠 저자가 콘텐츠를 다루는 서버가 제공할 수도 있는 헤더를 덮어쓰기 위한 수단이다.
<metahttp-equiv="Referesh" content="1; URL=index.html"><!-- 수신자가 문서를 마치 HTTP 응답값이 1; URL=index.html인 referesh 헤더를 포함하고 있는 것 처럼 다루게 한다. Refresh HTTP 헤더는 리다이렉트용으로 사용되는데 이건 1초 후에 index.html로 리다이렉트 하라는 의미-->
2-5. User-Agent Targeting
많은 웹사이트들이 브라우저 종류를 감지하여 콘텐츠를 최적화함으로써 로봇에게 콘텐츠 대신 에러페이지를 제공하기도 한다.
웹 관리자도 로봇의 요청을 다루기 위한 전략을 세워야한다.
3. 부적절하게 동작하는 로봇들
폭주하는 로봇
빠르게 HTTP요청을 만드는 로봇들이 순환에 빠지거나 에러를 가지고 있으면 서버에 과부하를 유발하여 다른 서비스 제공을 방해한다.
오래된 URL
몇몇 로봇이 방문한 URL이 오래되어 존재하지 않는 URL에 대한 요청을 많이 보낼 수 있다.
이런 접근 요청으로 에러 페이지를 제공하는 부하로 인해 웹 서버에 요청에 대한 수용 능력이 감소할 수도 있다.
길고 잘못된 URL
URL이 충분히 길어 웹 서버 처리능력에 영향을 주고, 로그를 어지럽게 채울 수 있다.
호기심이 지나친 로봇
데이터의 소유자가 웹페이지가 알려지는것을 원치 않았을 때도 검색엔진이나 애플리케이션을 통해 접근하게 만들어버릴 수도 있다.
민감한 데이터를 로봇이 검색할 수 있다는 것에 주의해야한다.
동적 게이트웨이 접근
로봇은 게이트웨이 어플리케이션의 콘텐츠에 대한 URL로 요청을 할 수도있다.
특수 목적을 위한 처리비용이 많이 드는 요청을 로봇이 하는것을 웹 사이트 관리자는 좋아하지 않는다.
4. 로봇 차단하기
로봇의 접근을 제어하는 정보를 저장하는 파일 "robots.txt"
서버의 문서 루트에 robots.txt 파일을 선택적으로 제공하여 어떤 로봇이 서버에 어떤 부분에 접근할 수 있는지 정보를 제공한다.
표준 방법
v0.0 : robots.txt
v1.0 : allow 지시자 지원 추가
v2.0 : 정규식, 타이밍 정보 추가 - 널리 쓰이진 않음
4-2. 웹 사이트와 robots.txt 파일들
웹 사이트의 어떤 URL을 방문하기 전에, 그 웹 사이트에 robots.txt파일이 존재한다면 로봇은 반드시 그 파일을 가져와서 처리해야한다.
사이트 전체에 대한 robots.txt파일은 단 하나만 존재한다.
가상 호스팅 된다면 가상 docroot마다 여러개 존재할 수 있다.
robots.txt 가져오기
보통 HTTP GET 메서드를 이용해 가져온다.
존재한다면 서버는 text/plain으로 반환
404 NOT FOUND라면 로봇 접근을 제한하지 않는것으로 간주
로봇이 보낼 수 있는 HTTP 크롤링 요청의 예
GET /robots.txt HTTP/1.0Host: www.joes-hardware.comUser-Agent: Slurp/2.0Date: Wed Oct 3 20:22:48 EST 2001
응답 코드에 따른 처리
성공응답 (2xx)
응답 콘텐츠를 파싱하여 차단 규칙을 얻고 규칙에 따라야한다.
리소스 존재하지 않음(404)
차단 규칙 존재하지 않는다고 가정하고 제약 없이 사이트에 접근
접근 제한(401,403)
접근이 완전 제한되어있다고 판단
요청 시도 실패(503)
검색 시도를 미뤄야한다.
리다이렉션(3xx)
리소스가 발견될 때 까지 리다이렉트를 따라가야함
4-3. robots.txt 파일 포맷
robots.txt파일은 매우 단순한 줄 기반 문법을 갖는다.
[종류]
빈 줄, 주석 줄, 규칙 줄
규칙 줄 - HTTP 헤더처럼 필드:값 형식
예
# robots.txt 파일은 Slurp과 Webralwer가 공개된 영역을 크롤링하는것을 허락하지만 다른 로봇은 안됨
User-Agent: slurp
User-Agent: webcrawler
Disallow: /private
User-Agent: *
Disallow:
줄들은 레코드로 구분되어 특정 로봇들의 집합에 대한 차단 규칙 집합을 기술
레코드는 빈 줄이나 파일 끝 문자로 끝남
User-Agent로 시작해 Allow, Disallow가 뒤따라 온다.
User-Agent
User-Agent: <robot-name>
부분 문자열과 맞춰보므로 의도치 않게 맞는 경우에 주의해야한다.
Disallow, Allow
User-Agent바로 다음에 오고 어떤 URL경로가 명시적으로 금지, 허용되는지 기술한다. robots.txt URL은 금지되어서는 안된다.
prefix, 이스케이핑등 처리
별표는 모든 문자의 의미를 갖지는 않고 모든 문자는 빈 문자로 사용한다.
아직 어떤 경로냐에 상관 없이 특정 이름을 제한하는 표현수단은 제공하지 않는다.
4-4. 그 외 알아둘 점
robots.txt를 파싱할 때 지켜야할 규칙
파일 명세가 발전함에 따라 다른게 추가될 수 있다. 로봇은 자신이 이해하지 못하는 필드는 무시해야한다.
하위 호환성을 위해 한 줄을 여러줄로 나누어 적는것은 허용하지 않는다.
주석은 어디서든 허용된다.
0.0 버전은 allow 줄을 지원하지 않는다.
4-5. robots.txt의 캐싱과 만료
로봇은 주기적으로 robots.txt를 가져와서 그 결과를 캐시해야한다.
캐시 제어 메커니즘 - Cache-Control, Expires 헤더 이용
단 크롤러 제품들이 HTTP/1.1 클라이언트가 아니라서 robots.txt에 적용되는 캐시 지시자를 이해하지 못할 수도 있다.
4-6. 로봇 차단 펄 코드
생략
4-7. HTML 로봇 제어 META 태그
robots.txt파일은 사이트 관리자가 로봇을 웹 사이트 일부 혹은 전체에 접근할 수 없게 한다.
HTML 페이지 저자는 로봇이 개별 페이지에 접근하는 것을 제한하는 좀 더 직접적인 방법을 가지고 있다.
<METANAME="ROBOTS" CONTENT=directive-list> 와 같은 형식으로 구현
HTML HEAD에 나타내야한다. 대소문자는 구분하지 않는다.
NOINDEX, NOFOLLOW, NONE
크롤링 못하도록, 혹은 무시하도록
INDEX, FOLLOW, ALL
허용
NOARCHIVE
사본 저장 X
검색엔진 META 태그
name = DESCRIPTION content=텍스트 : 웹페이지에 대한 짧은 요약 정의
name=keywords content=쉼표 목록 키워드 검색을 돕기 위함
name=REVISIT-AFTER content=숫자 : 다시 방문할 날짜 지정
5. 로봇 에티켓
웹 로봇을 위한 가이드라인 제공
1. 로봇의 신원을 밝혀라 - User-Agent, Form, 등
2. 긴장, 대비, 감시, 로그, 조정
3. 스스로 제한 (필터링), robots.txt에 따르라
4. 루프와 중복 견뎌내기 - 응답 코드 다루기, URL 정규화, 순환 피하기, 함정 감시, 블랙리스트 관리
5. 확장성 - 공간 이해, 대역폭 이해, 시간 이해, 분할 정복
6. 신뢰성 - 테스트, 체크포인트, 실패에 대한 유연성
7. 소통 - 준비, 이해, 즉각 대응
6. 검색 엔진
웹 로봇을 가장 광범위하게 사용하는 것은 인터넷 검색엔진이다.
인터넷 검색 엔진은 사용자가 전세계의 어떤 주제에 대한 문서라도 찾을 수 있게 해준다.
웹 크롤러들은 검색엔진에게 웹에 존재하는 문서를 가져다주어서 검색 엔진이 색인을 생성할 수 있도록 한다.
6-1. 넓게 생각해라
초창기 웹 : 웹상 문서 위치 알아내는 데이터베이스
지금 : 수백만명의 사용자가 수십억개의 웹페이지에서 정보를 찾고 있음. `병렬처리` 필수
6-2. 현대적인 검색 엔진의 아키텍처
오늘날의 검색 엔진은 웹페이지들에 대해 `풀 텍스트 색인` 데이터베이스를 생성한다.
검색엔진 크롤러들은 웹페이지들을 수집해서 이 풀 텍스트 색인에 추가하고, 사용자들은 웹 검색 게이트웨이를 통해 색인에 대한 질의를 보낸다.
6-3 풀 텍스트 색인
풀 텍스트 색인은 단어 하나를 입력받아 그 단어를 포함하고 있는 문서를 즉각 알려줄 수 있는 데이터베이스이다.
단어 a는 문서 A,B에 들어있다
단어 drill은 문서 A,B에 들어있다.
6-4. 질의 보내기
사용자가 질의를 검색엔진 게이트웨이로 보내는 방법은 HTML폼을 사용자가 채워 넣고 브라우저가 그 폼을 HTTP GET이나 POST요청을 이용해서 게이트웨이로 보내는 식이다.
게이트 웨이 프로그램은 검색 질의를 추출하고 웹 UI질의를 풀 텍스트 색인을 검색할 때 사용되는 표현식으로 변환한다.
6-5. 검색 결과를 정렬하여 보여주기
관련도 랭킹 등,,
6-6. 스푸핑
사용자들은 자신이 찾는 내용이 검색 결과의 최상위 몇줄에서 보이지 않는다면 대게 불만족스러워 하므로 웹 사이트를 찾을 때 검색결과의 순서는 중요하다.
많은 웹 마스터가 수많은 키워드들을 나열한 가짜 페이지를 만들거나, 검색 엔진의 관련도 알고리즘을 속일 수 있는 게이트웨이 어플리케이션을 만들어 사용하기도 한다.
웹 로봇
1. 크롤러와 크롤링
1-1. 어디에서 시작하는가 : 루트 집합
크롤러가 방문을 시작하는 URL들의 초기 집합 :
루트 집합(root set)모든 링크를 크롤링하면 결과적으로 웹페이지들의 대부분을 가져오게 될 수 있도록 충분히 다른 장소에서 URL들을 선택해야한다.
일반적으로 좋은 루트집합은 크고 인기있는 웹사이트, 새로 생성된 페이지 목록, 자주 링크되지 않는 페이지들의 목록으로 구성
1-2. 링크 추출과 상대 링크 정상화
크롤러는 웹을 돌아다니며 꾸준히 HTML 문서를 검색하고 검색한 페이지 안에 있는 URL 링크를 파싱해서 크롤링할 페이지 목록에 추가한다.
이 때 파싱한 상대 링크를 절대 링크로 변환할 필요가 있다.
1-3. 순환 피하기
로봇들은 순환을 피하기 위해 반드시 그들이 어디를 방문했는지 알아야한다. 순환은 로봇을 함정에 빠뜨려서 멈추거나 느려지게한다.
1-4. 루프와 중복
1-5. 빵 부스러기의 흔적
헨젤과 그레텔인가 ..? 제목 이름 뭐지
트리(검색 트리)와 해시테이블
URL을 훨씬 빨리 찾아볼 수 있게 해주는 소프트웨어 자료구조
느슨한 존재 비트맵
공간 사용을 최소화 하기 위해 **존재 비트 배열(presence bit array)**와 같은 느슨한 자료구조를 사용
각 URL은 해시 함수에 의해 고정된 크기의 숫자로 변환되고 배열 안에 대응하는 **존재 비트(presence bit)**를 가져 존재비트가 이미 존재한다면 이미 크롤링되었다고 간주한다.
배열 사이즈에 따라 충돌이 일어날 수 있다.
체크포인트
로봇프로그램의 갑작스런 중단에 대비해 방문한 URL의 목록이 디스크에 저장되어있는지 확인
파티셔닝
한 대의 컴퓨터로는 충분하지 못할 수 있으므로 분리된 한 대의 컴퓨터인 로봇들이 동시에 일하고 있는 **농장(farm)**을 이용해 특정 한 부분이 할당되어 서로 도와주거나 크롤링
개별 로봇들은 URL을 넘겨주거나 오동작하는 동료를 도와주거나 커뮤니케이션을 한다.
1-6. 별칭과 로봇 순환
#태그1-7. URL 정규화 하기
#태그 제거1-8. 파일 시스템 링크 순환
/subdir이 /로 링크되어 순환되는데 로봇은 눈치채지 못해 루프로 빠질 수 있다.
1-9. 동적 가상 웹 공간
1-10. 루프와 중복 피하기
URL 정규화
URL을 표준 형태로 변환함으로써 같은 리소스를 가리키는 중복된 URL이 생기는 것을 일부 회피
너비 우선 크롤링
너비우선으로 스케쥴링하면 순환의 영향을 최소화할 수 있다. DFS 방식은 무한히 빠져나올 수 없게 될수도 있다.
스로틀링
일정 시간 동안 가져올 수 있는 페이지의 숫자를 제한한다.
URL크기 제한
일정길이의 URL은 크롤링을 거부
URL/사이트 블랙리스트
문제를 일으키는 사이트를 블랙리스트에 추가
패턴 발견
순환과 오설정들은 일정 패턴을 따르는 경향이 있으므로 몇가지 다른 주기의 패턴을 감지
콘텐츠 지문(fingerprint)
페이지의 콘텐츠에서 몇 바이트 얻어내어 체크섬(checksum) 계산해서 이전에 크롤링한 페이지인지 확인
체크섬함수는 어떤 두 페이지가 서로 다름에도 체크섬이 똑같을 확률이 적은 것을 사용해야한다. - `MD5와 같은 메시지 요약 함수
웹 서버들은 페이지를 동적으로 생성하기 때문에 체크섬 감지에 어려울 수 있다.
사람의 모니터링
어쨌든 해결할 수 없는 문제는 사람의 모니터링에 의존할 수 밖에 없다.
2. 로봇의 HTTP
웹 로봇도 HTTP 명세 규칙을 지켜야한다. 많은 로봇들이 콘텐츠를 요청하기 위해 필요한 HTTP를 최소한으로 구현하려고 한다. 결과적으로 많은 로봇들이 `HTTP/1.0`요청을 보낸다 (1.0이 요구사항이 적기 때문)2-1. 요청 헤더 식별하기
User-Agent
서버에게 요청을 만든 로봇의 이름을 말해준다.
From
로봇의 사용자/관리자의 이메일 주소를 제공한다.
Accept
어떤 미디어 타입을 보내도 되는지 말해준다. 로봇이 관심있는 유형의 콘텐츠만 받게될 것임을 확신하는데 도움을 준다.
Referer
현재의 요청URL을 포함한 문서의 URL을 제공한다. - 어떻게 로봇이 그들 사이트를 발견했는지 알수 있음
2-2. 가상 호스팅
두개의 사이트를 운영하는 서버에 요청을 보낼 때 원하는 곳이 아닌 다른 사이트에서 콘텐츠를 받아오게 될 수도 있음
2-3. 조건부 요청
2-4. 응답 다루기
상태 코드
일반적으로
200 OK,404 NOT FOUND와 같은 상태 코드를 이해해야 한다.모든 서버가 언제나 적절한 에러코드를 반환하지 않는다는 것도 알아둬야한다.
엔터티
HTTP 헤더에 임베딩된 정보를 따라 엔터티 자체의 정보를 찾을 수 있다.
메타
http-equiv태그와 같은 메타 HTML 태그는 리소스에 대해 콘텐츠 저자가 포함시킨 정보다.http-equiv 태그 자체는 콘텐츠 저자가 콘텐츠를 다루는 서버가 제공할 수도 있는 헤더를 덮어쓰기 위한 수단이다.
2-5. User-Agent Targeting
3. 부적절하게 동작하는 로봇들
폭주하는 로봇
빠르게 HTTP요청을 만드는 로봇들이 순환에 빠지거나 에러를 가지고 있으면 서버에 과부하를 유발하여 다른 서비스 제공을 방해한다.
오래된 URL
몇몇 로봇이 방문한 URL이 오래되어 존재하지 않는 URL에 대한 요청을 많이 보낼 수 있다.
이런 접근 요청으로 에러 페이지를 제공하는 부하로 인해 웹 서버에 요청에 대한 수용 능력이 감소할 수도 있다.
길고 잘못된 URL
URL이 충분히 길어 웹 서버 처리능력에 영향을 주고, 로그를 어지럽게 채울 수 있다.
호기심이 지나친 로봇
데이터의 소유자가 웹페이지가 알려지는것을 원치 않았을 때도 검색엔진이나 애플리케이션을 통해 접근하게 만들어버릴 수도 있다.
민감한 데이터를 로봇이 검색할 수 있다는 것에 주의해야한다.
동적 게이트웨이 접근
로봇은 게이트웨이 어플리케이션의 콘텐츠에 대한 URL로 요청을 할 수도있다.
특수 목적을 위한 처리비용이 많이 드는 요청을 로봇이 하는것을 웹 사이트 관리자는 좋아하지 않는다.
4. 로봇 차단하기
로봇의 접근을 제어하는 정보를 저장하는 파일 "robots.txt" 서버의 문서 루트에 robots.txt 파일을 선택적으로 제공하여 어떤 로봇이 서버에 어떤 부분에 접근할 수 있는지 정보를 제공한다.표준 방법
4-2. 웹 사이트와 robots.txt 파일들
robots.txt 가져오기
보통
HTTP GET메서드를 이용해 가져온다.로봇이 보낼 수 있는 HTTP 크롤링 요청의 예
응답 코드에 따른 처리
4-3. robots.txt 파일 포맷
예
User-Agent
부분 문자열과 맞춰보므로 의도치 않게 맞는 경우에 주의해야한다.
Disallow, Allow
User-Agent바로 다음에 오고 어떤 URL경로가 명시적으로 금지, 허용되는지 기술한다.
robots.txt URL은 금지되어서는 안된다.
4-4. 그 외 알아둘 점
4-5. robots.txt의 캐싱과 만료
4-6. 로봇 차단 펄 코드
생략
4-7. HTML 로봇 제어 META 태그
검색엔진 META 태그
name = DESCRIPTION content=텍스트: 웹페이지에 대한 짧은 요약 정의name=keywords content=쉼표 목록키워드 검색을 돕기 위함name=REVISIT-AFTER content=숫자: 다시 방문할 날짜 지정5. 로봇 에티켓
6. 검색 엔진
6-1. 넓게 생각해라
6-2. 현대적인 검색 엔진의 아키텍처
6-3 풀 텍스트 색인
풀 텍스트 색인은 단어 하나를 입력받아 그 단어를 포함하고 있는 문서를 즉각 알려줄 수 있는 데이터베이스이다.
6-4. 질의 보내기
사용자가 질의를 검색엔진 게이트웨이로 보내는 방법은 HTML폼을 사용자가 채워 넣고 브라우저가 그 폼을 HTTP GET이나 POST요청을 이용해서 게이트웨이로 보내는 식이다.
게이트 웨이 프로그램은 검색 질의를 추출하고 웹 UI질의를 풀 텍스트 색인을 검색할 때 사용되는 표현식으로 변환한다.
6-5. 검색 결과를 정렬하여 보여주기
관련도 랭킹 등,,
6-6. 스푸핑
사용자들은 자신이 찾는 내용이 검색 결과의 최상위 몇줄에서 보이지 않는다면 대게 불만족스러워 하므로 웹 사이트를 찾을 때 검색결과의 순서는 중요하다.
많은 웹 마스터가 수많은 키워드들을 나열한 가짜 페이지를 만들거나, 검색 엔진의 관련도 알고리즘을 속일 수 있는 게이트웨이 어플리케이션을 만들어 사용하기도 한다.
The text was updated successfully, but these errors were encountered: