Advanced Programming with C++¶
Estimated time to read: 9 minutes
Recapitulation¶
Before we start, let's recapitulate what we have learned in the previous course. Use the links below to refresh your memory. Or go straigth to the Introduction to Programming Course.
Structs¶
Structs in C++ are a way to represent a collection of data packed sequentially into a single data structure.
The code above defines a type named as Enemy. This type has members(fields) named health, score with different types, and x, y and z with the same type.
struct Enemy
+{
+ double health; // 8 bytes
+ float x, y, z; // 4 bytes each. 12 bytes total
+ int score; // 4 bytes
+};
+The memory usage of a struct is defined roughly by the sum of the memory usage of its members. Assuming the default sizing of common data types in C++, in the example above, the struct will use 8 bytes for the double, 3 times 4 bytes for the floats and 4 bytes for the int. The total memory usage for the struct will be 20 bytes.
Data Alignment¶
The memory usage of a struct is not always exactly the sum of the memory usage of its members. The compiler may add padding bytes between the members of a struct to align the data in memory. This is done to improve the performance of the program. If you are programming in a multi-platform, cross-platform or even using different compilers, the size of the struct may vary even if it is the same.
The struct above stores a total of 8 bytes of data, but the compiler allocates more. It will add 3 padding bytes between the int and the last char to align the data with biggest field in the struct. In this case, the total memory usage of the struct will be 12 bytes instead of the expected 8.
struct InneficientMemoryLayoutExample
+{
+ char a; // 1 byte
+ // compiler will add 3 padding bytes here
+ int b; // 4 bytes
+ char c; // 1 byte
+ char d; // 1 bytes
+ char e; // 1 byte
+ // compiler will add 1 padding byte here
+}; // total of 12 bytes allocated for this layout
+You might think C++ compilers are smart and reorder the fields for us, but in order to maintain compatibility to C, the standard forbids it. So if you want to pack more data you will have to reorder the layout manually to something like this:
struct EfficientMemoryLayoutExample
+{
+ int b; // 4 bytes
+ char a; // 1 byte
+ char c; // 1 byte
+ char d; // 1 bytes
+ char e; // 1 byte
+}; // total of 8 bytes allocated for this layout
+Alternatively you can use the #pragma pack directive to tell the compiler to pack the data in memory without padding bytes. But be aware that it will force the compiler to do more memory operations to get the data, thus it will slow your software. Besides that, pragma pack may not work in all compilers.
#pragma pack(push, 1) // push current alignment to stack and set alignment to 1 byte boundary
+struct EfficientMemoryLayoutExample
+{
+ char a; // 1 byte
+ int b; // 4 bytes
+ char c; // 1 byte
+ char d; // 1 bytes
+ char e; // 1 byte
+};
+#pragma pack(pop)
+Bitfields¶
If you really want to specify the layout location for each field and want to be sure that in will work on every compiler/platform, you will have to specify the number of bits each field will be able to use. This is called bitfields. But if you follow this path, you will have to be aware of the endianness of the platform you are working on.
struct BitfieldExample
+{
+ char a : 8; // 8 bits = 1 byte
+ int b : 32; // 32 bits = 4 bytes
+ char c : 8; // 8 bits = 1 byte
+ char d : 8; // 8 bits = 1 byte
+ char e : 8; // 8 bits = 1 byte
+}; // total of 8 bytes allocated for this layout
+Another nice application of bitfields is when you do not want to use the full range of a data type. For example, if you want to store a number between 0 and 7, as in a chess game or other board games, you can use a char and waste 5 bits or you can use a bitfield and use only 3 bits.
Advanced Programming¶
Estimated time to read: 11 minutes
Table of Contents¶
Safe and welcoming space¶
TLDR: Be nice to each other, and don't copy code from the internet.
Some assignments can be hard, and you may feel tempted to copy code from the internet. Don't do it. You will only hurt yourself. You will learn nothing, and you will be caught. Once you get caught, you will be reported to the Dean of Students for academic dishonesty.
If you are struggling with an assignment, please contact me in my office-hours, or via discord. I am really slow at answering emails, so do it so only if something needs to be official. Quick questions are better asked in discord by me or your peers.
Privacy and FERPA Compliance¶
FERPA WAIVER
If you are willing to share your final project publicly, you MUST SIGN this FERPA waiver.
This class will use github extensively, in order to keep you safe, we will use private repositories. This means that only you and me will be able to see your code. In your final project, you must share it with your pair partner, and with me.
Activities¶
TLDR: there is no TLDR, read the whole thing.
Setup Github repository¶
Gitkraken
Optionally you might want to use GitKraken as your git user interface. Once you open it for the first time, signup using your github account with student pack associated. Install Gitkraken
- Signup on github and apply for Github Student Pack. Apply for Student Pack
- Send me your github username in class, so I will share the assignment repository with you;
- Create a private repository by clicking "use as template" the repository InfiniBrains/csi240 or Create CSI240 repository
- Share your repository with me. Click on settings, then collaborators, and add me as a collaborator. My username: @tolstenko
- Clone your repository to your computer. You can use the command line, or any Git GUI tool. I recommend GitKraken
Setup your IDE¶
Other IDEs
Optionally you might want to use any other IDE, such as Visual Studio, VSCode, XCode, NeoVim or any other, but I will not be able to help you with that.
I will use CLion in class, and I recommend you to use it as well so you can follow the same steps as me. It is free for students. And it works on Windows, Mac and Linux.
- Apply for student license for JetBrains or Apply Form
- You can install CLion only or install CLion via their Install Toolbox
- Open CLion for the first time, and login with your JetBrains account you created earlier;
Setup your Assignments project¶
Common problems
Your machine might not have git on your path. If so, install it from git-scm.com and make sure you tick the option to add git to your PATH.
- Open your IDE, and click on "Open Project";
- Select the folder where you cloned your repository;
- Click on "Open as Project" or "Open as CMake Project";
- Wait for CMake to finish generating the project;
- On the top right corner, select the target you want to run/debug;
Check Github Actions¶
Github Actions
Github Actions is a CI/CD tool that will run your tests automatically when you push your code to github. It will also run your tests when you create a pull request. It is a great tool to make sure your code is always working.
You might want to explore the folder .github/workflows to see how it works, but you don't need to change anything there.

Every commit you push to your repository will be automatically tested through Github Actions. You can see the results of the tests by clicking on the "Actions" tab on your repository.
- Go to your repository on github;
- Click on the "Actions" tab;
- Click on the "Build and Test" action;
- Click on the latest commit;
- On the jobs panel, Click on the assignment you want to see the results;
- Read the logs to see if your tests passed or failed;
- It is your job to read the README.md from every assignment and fulfill the requirements;
- You can run/debug the tests locally by targeting the assignmentXX_tests;
Homework¶
- Read the Syllabus fully. Pay attention to the schedule, outcomes and grading;
- Do all assignments on Canvas, specially the git training;
Introduction to Object-Oriented Programming¶
Estimated time to read: 14 minutes
C++ in a language that keeps evolving and adding new features. The language is now a multi-paradigm language, which means that it supports different programming styles, and we are going to cover the Object-Oriented Programming (OOP) paradigm in this course.

What is OOP?¶
Object-Oriented Programming is a paradigm that encapsulate data and their interactions into a single entity called object. The object is an instance of a class, which is a blueprint for the object. The class defines the data and the operations that can be performed on the data.
Class declaration¶
Here goes a simple declaration of a class Greeter:
Greeter.h
#include <string>
+class Greeter {
+ std::string name; // this is a private attribute
+public:
+ Greeter(std::string username) {
+ name = username;
+ }
+ void Greet(){
+ std::cout << "Hello, " << name << "!" << std::endl;
+ }
+};
+If you run this code, the output will be:
Here goes a rework of the previous example using more robust concepts and multiple files:
Greeter.h
#include <string>
+class Greeter {
+ // class members are private by default
+ std::string name;
+public:
+ // public constructor
+ // explicit to avoid implicit conversions
+ // const to avoid modification
+ // ref to avoid copying
+ explicit Greeter(const std::string& name);
+ ~Greeter(); // public destructor
+ void Greet(); // public method
+};
+Greeter.cpp
#include "Greeter.h"
+#include <iostream>
+// :: is the scope resolution operator
+Greeter::Greeter(const std::string& name): name(name) {
+ std::cout << "I exist and I received " << name << std::endl;
+}
+Greeter::~Greeter() {
+ std::cout << "Goodbye, " << name << "!" << std::endl;
+}
+void Greeter::Greet() {
+ std::cout << "Hello, " << name << "!" << std::endl;
+}
+main.cpp
#include "Greeter.h"
+int main() {
+ Greeter greeter("Stranger");
+ greeter.Greet();
+ // cannot use greeter.name because it is private
+}
+Advantages of OOP¶

Modularity¶
Classes can be used it in different parts of your code. You can even create libraries and share it with other people.
Encapsulation¶
Classes can hide their implementation details from the developer. The developer only needs the header file to use the class which acts as an interface.
Inheritance¶
Classes can inherit from other classes. This allows you to reuse code and extend the functionality of existing classes expanding the original behavior.
We will cover details about inheritance in another moment.
Polymorphism¶
By its roots, the word polymorphism means "many forms". It can be applied to classes in many different aspects:
- Function overload: Class can have multiple definitions of the same member function, and the compiler will choose the correct one based on the type of the object.
- Casting: Classes can be casted to other classes. This allows you to treat an object of a derived class as an object of its base class, or more complex behaviors;
We will cover details about polymorphism in another moment.
Class internals¶

Constructors¶
Constructors are special methods, they are called when an object is created, and don't return anything. They are used to initialize the object. If you don't define a constructor, the compiler will generate a default constructor for you.
class Greeter {
+ std::string name;
+public:
+ Greeter(const std::string& name) {
+ this->name = name;
+ }
+};
+Default constructor¶
A default constructor should be one of the following: - A constructor that can be called with no arguments; - A constructor that can be called with default arguments;
class Greeter {
+ std::string name;
+public:
+ // Default constructor
+ Greeter() {
+ this->name = "Stranger";
+ }
+};
+or
class Greeter {
+ std::string name;
+public:
+ Greeter(const std::string& name = "Stranger") {
+ this->name = name;
+ }
+};
+If no constructor is defined, the compiler will generate a default constructor for you.
Copy constructor¶
A copy constructor is a constructor that takes a reference to an object of the same type as the class. It is used to initialize an object with another object of the same type.
class Greeter {
+ std::string name;
+public:
+ Greeter(const Greeter& other) {
+ this->name = other.name;
+ }
+};
+Move constructor¶
A move constructor is a constructor that takes a reference to an object of the same type as the class. It is used to initialize an object with another object of the same type. The difference between a copy constructor and a move constructor is that the move constructor takes ownership of the data from the other object, while the copy constructor copies the data from the other object.
class Greeter {
+ std::string name;
+public:
+ Greeter(Greeter&& other) {
+ this->name = std::move(other.name);
+ }
+};
+Explicit constructor¶
A constructor that can be called with only one argument is called an explicit constructor. This means that the compiler will not allow implicit conversions to happen.
Explicit constructors are useful to avoid unexpected behavior when calling the constructor.
class Greeter {
+ std::string name;
+public:
+ explicit Greeter(const std::string& name) {
+ this->name = name;
+ }
+};
+Destructors¶
Destructors are special methods, they are called when an object is destroyed.
Following the single responsibility principle, the destructor should be responsible for cleaning up the dynamically allocated data the object is holding.
If no destructor is defined, the compiler will generate a default destructor for you that might not be enough to clean up the data.
class IntContainer {
+ int* data;
+ // other members / methods
+public:
+ // other members / methods
+ ~IntContainer() {
+ // deallocate data
+ delete[] data;
+ }
+};
+Private and Public¶
By default, all members of a class are private. This means that they can only be accessed by the class itself. If you want to expose a member to the outside world, you have to declare it as public.
class Greeter {
+ std::string name; // private by default
+public:
+ Greeter(const std::string& name) {
+ this->name = name;
+ }
+};
+Dealing with private members¶
If your data is private, but you need to provide access or modify it, you can create public methods to do that.
- Accessors: are the type of public methods that provides readability of the specific content;
- Mutators: are the type of public methods that provides writability of the specific content;
class User {
+ std::string name; // private by default
+public:
+ explicit User(const std::string& name) {
+ this->name = name;
+ }
+ // Accessor that returns a copy
+ // const at the end means that this function does not modify the object
+ std::string GetName() const {
+ return name;
+ }
+
+ // Accessor that returns a const reference
+ // returning ref does not use extra memory
+ // returning const the caller cannot modify the object
+ const std::string& GetNameRef() const {
+ return name;
+ }
+
+ // Mutator
+ void SetName(const std::string& name) {
+ this->name = name;
+ }
+};
+Operator "." and "->"¶
When you have an object, you can access its members using the dot operator .. If you have a pointer to an object, you can access its members using the arrow operator ->.
int main(){
+ Greeter greeter("Stranger");
+ greeter.Greet(); // dot operator
+ Greeter* greeterPtr = &greeter;
+ greeterPtr->Greet(); // arrow operator
+}
+Scope resolution operator "::"¶
It can be used to access members of a class that are not part of an object. It can also be used to access members of a namespace.
namespace MyNamespace {
+ int myInt = 0;
+ class MyClass {
+ public:
+ // static vars are allocated in the data segment instead of the stack
+ static inline const int myInt = 1;
+ int myOtherInt = 2;
+ };
+ void MyFunction() {
+ int myInt = 3;
+ std::cout << myInt << std::endl; // 3
+ std::cout << MyNamespace::myInt << std::endl; // 0
+ std::cout << MyNamespace::MyClass::myInt << std::endl; // 1
+ std::cout << MyClass::myInt << std::endl; // 1
+ std::cout << MyNamespace::MyClass().myOtherInt << std::endl; // 2
+ }
+}
+Differences between class and struct¶
In C++, the only difference between a class and a struct is the default access level. In a class, the default access level is private, while in a struct, the default access level is public.
class MyClass {
+ int myInt; // private by default
+public:
+ MyClass(int myInt) {
+ this->myInt = myInt;
+ }
+ int GetMyInt() const {
+ return myInt;
+ }
+};
+
+struct MyStruct {
+ // to achieve the same behavior as the class above
+private:
+ int myInt;
+public:
+ MyStruct(int myInt) {
+ this->myInt = myInt;
+ }
+ int GetMyInt() const {
+ return myInt;
+ }
+};
+Pointers¶
Estimated time to read: 15 minutes
Pointer arithmetic¶
Pointer arithmetic is the arithmetic of pointers. You can call operators +, -, ++, --, +=, and -= on pointers passing an integer as the right operand.
#include <iostream>
+
+int main() {
+ int arr[] = {1, 2, 3, 4, 5};
+ int* ptr = arr; // ptr points to the first element of the array
+ std::cout << *ptr << std::endl; // prints 1
+ ptr++; // ptr points to the second element of the array
+ std::cout << *ptr << std::endl; // prints 2
+ ptr += 2; // ptr points to the fourth element of the array
+ std::cout << *ptr << std::endl; // prints 4
+ ptr--; // ptr points to the third element of the array
+ std::cout << *ptr << std::endl; // prints 3
+ std::cout << *(ptr + 1) << std::endl; // prints 4
+ std::cout << *(arr + 1) << std::endl; // prints 2
+ return 0;
+}
+Dynamic arrays¶
Dynamic arrays are arrays that can be allocated and deallocated at runtime. They are useful when the size of the array is not known at compile time.
#include <iostream>
+
+int main() {
+ int n;
+ std::cin >> n; // read the size of the array
+ int* arr = new int[n]; // dynamic arry allocation
+ for (int i = 0; i < n; i++) {
+ arr[i] = i; // fill the array with values
+ }
+ for (int i = 0; i < n; i++) {
+ std::cout << arr[i] << " ";
+ }
+ std::cout << std::endl;
+ delete[] arr; // return the memory to the system
+ return 0;
+}
+In the example above, we read the size of the array from the standard input, allocate the array, fill it with values, print the values, and then deallocate the array.
Array decay¶
When an array is passed to a function, it decays into a pointer to its first element. This means that the size of the array is lost, and the function cannot know the size of the array.
#include <iostream>
+
+// another possible declaration: void print_array(int* arr, int n) {
+void print_array(int arr[], int n) {
+ for (int i = 0; i < n; i++) {
+ std::cout << arr[i] << " ";
+ }
+ std::cout << std::endl;
+}
+
+int main() {
+ int arr[] = {1, 2, 3, 4, 5};
+ print_array(arr, 5);
+ return 0;
+}
+So every time you pass an array to a function, you should also pass the size of the array.
Matrix¶
A matrix is a two-dimensional array. It can be represented as an array of arrays;
#include <iostream>
+
+int main() {
+ int n, m;
+ std::cin >> n >> m; // read the size of the matrix
+ int** matrix = new int*[n]; // allocate the rows
+ // allocate the columns
+ for (int i = 0; i < n; i++) {
+ matrix[i] = new int[m];
+ }
+ // fill the matrix with values
+ for (int i = 0; i < n; i++) {
+ for (int j = 0; j < m; j++) {
+ matrix[i][j] = i * m + j;
+ }
+ }
+ // print the matrix
+ for (int i = 0; i < n; i++) {
+ for (int j = 0; j < m; j++) {
+ std::cout << matrix[i][j] << " ";
+ }
+ std::cout << std::endl;
+ }
+ for (int i = 0; i < n; i++) {
+ delete[] matrix[i]; // deallocate the columns
+ }
+ delete[] matrix; // deallocate the rows
+ return 0;
+}
+In the example above, we read the size of the matrix from the standard input, allocate the rows, allocate the columns, fill the matrix with values, print the matrix, and then deallocate the matrix.
You can extend the concept of a matrix to a three-dimensional array, and so on.
Matrix linearization¶
A matrix can be linearized into a one-dimensional array. This is useful when you want to be cache friendly.
#include <iostream>
+
+int main() {
+ int n, m;
+ std::cin >> n >> m; // read the size of the matrix
+ int* matrix = new int[n * m]; // allocate the matrix
+ // fill the matrix with values
+ for (int i = 0; i < n; i++) {
+ for (int j = 0; j < m; j++) {
+ matrix[i * m + j] = i * m + j;
+ }
+ }
+ // print the matrix
+ for (int i = 0; i < n; i++) {
+ for (int j = 0; j < m; j++) {
+ std::cout << matrix[i * m + j] << " ";
+ }
+ std::cout << std::endl;
+ }
+ delete[] matrix; // deallocate the matrix
+ return 0;
+}
+Passing parameters¶
The common way of passing parameter is a copy of the value. This is not efficient for large objects ex.: the contents of a huge text file.
#include <iostream>
+
+void printAndIncrease(int x) { // x is a copy of the value
+ std::cout << x << std::endl;
+ x++; // the copy is increased but the outer variable is not
+}
+
+int main() {
+ int x = 42;
+ printAndIncrease(x); // prints 42
+ printAndIncrease(x); // prints 42
+ return 0;
+}
+You can pass a reference to the variable, so the function can modify the outer variable.
#include <iostream>
+
+void swap(int& a, int& b) { // a and b are references to the variables
+ int temp = a;
+ a = b;
+ b = temp;
+}
+
+int main() {
+ int x = 42, y = 24;
+ swap(x, y);
+ std::cout << x << " " << y << std::endl; // prints 24 42
+ return 0;
+}
+You can also pass a pointer to the variable, so the function can modify the outer variable.
#include <iostream>
+
+void swap(int* a, int* b) { // a and b are pointers to the variables
+ int temp = *a;
+ *a = *b;
+ *b = temp;
+}
+
+int main() {
+ int x = 42, y = 24;
+ swap(&x, &y);
+ std::cout << x << " " << y << std::endl; // prints 24 42
+ return 0;
+}
+As you can see passing as reference is more readable and less error-prone than passing as pointer. But both are valid, and you should be aware of both.
Smart pointers¶
Smart pointers are wrappers to raw pointers that manage the memory automatically. They are useful to avoid memory leaks and dangling pointers.
You can implement a naive smart pointer using a struct that will deallocate when it goes out of scope.
#include <iostream>
+
+template <typename T>
+struct SmartPointer {
+ T* ptr;
+ SmartPointer(T* ptr) : ptr(ptr) {}
+ ~SmartPointer() {
+ delete ptr;
+ }
+};
+
+int main() {
+ SmartPointer<int> sp(new int(42));
+ std::cout << *sp.ptr << std::endl; // prints 42
+ return 0;
+} // when sp goes out of scope, the destructor is called and the memory is deallocated
+Note
The Standard Library implements 3 types of smart pointers: std::unique_ptr, std::shared_ptr, and std::weak_ptr.
std::unique_ptr¶
The std::unique_ptr is a smart pointer that owns the object exclusively. It is useful when you want to transfer the ownership of the object to another smart pointer.
#include <iostream>
+#include <memory>
+
+int main() {
+ // make_unique is a C++14 feature
+ std::unique_ptr<int> up = std::make_unique<int>(42);
+ // or you can just use:
+ // std::unique_ptr<int> up(new int(42));
+ std::cout << *up << std::endl; // prints 42
+ return 0;
+} // when up goes out of scope, the destructor is called and the memory is deallocated
+std::shared_ptr¶
The std::shared_ptr is a smart pointer that owns the object with shared ownership. It is useful when you want to share the ownership of the object with another smart pointer. It is deallocated when the last std::shared_ptr goes out of scope.
#include <iostream>
+#include <memory>
+
+int main() {
+ std::shared_ptr<int> sp1 = std::make_shared<int>(42);
+ std::shared_ptr<int> sp2 = sp1;
+ std::cout << *sp1 << " " << *sp2 << std::endl; // prints 42 42
+ return 0;
+} // when sp1 and sp2 goes out of scope, the destructor is called and the memory is deallocated
+std::weak_ptr¶
The std::weak_ptr is a smart pointer that owns the object with weak ownership. It is useful when you want to observe the object without owning it. It is deallocated when the last std::shared_ptr goes out of scope.
Note
std::weak_ptr will help solve the circular reference problem.
#include <iostream>
+#include <memory>
+
+int main() {
+ std::shared_ptr<int> sp1 = std::make_shared<int>(42);
+ std::weak_ptr<int> wp = sp1;
+ // in order to use a weak pointer, you have to lock it to tell others that you are using it
+ std::cout << *sp1 << " " << *wp.lock() << std::endl; // prints 42 42
+ return 0;
+} // when sp1 goes out of scope, the destructor is called and the memory is deallocated
+Exaple of a circular reference:
#include <iostream>
+#include <memory>
+
+struct A;
+struct B;
+
+struct A {
+ std::shared_ptr<B> b;
+ ~A() {
+ std::cout << "A destructor" << std::endl;
+ }
+};
+
+struct B {
+ std::shared_ptr<A> a;
+ ~B() {
+ std::cout << "B destructor" << std::endl;
+ }
+};
+
+int main() {
+ std::shared_ptr<A> a = std::make_shared<A>();
+ std::shared_ptr<B> b = std::make_shared<B>();
+ a->b = b;
+ b->a = a;
+ return 0;
+} // memory is leaked: the destructors are not called, and the memory is not deallocated
+You can solve the circular reference problem using std::weak_ptr.
#include <iostream>
+#include <memory>
+
+struct A;
+struct B;
+
+struct A {
+ std::shared_ptr<B> b;
+ ~A() {
+ std::cout << "A destructor" << std::endl;
+ }
+};
+
+struct B {
+ std::weak_ptr<A> a;
+ ~B() {
+ std::cout << "B destructor" << std::endl;
+ }
+};
+
+int main() {
+ std::shared_ptr<A> a = std::make_shared<A>();
+ std::shared_ptr<B> b = std::make_shared<B>();
+ a->b = b;
+ b->a = a;
+ return 0;
+} // when a and b goes out of scope, the destructors are called and the memory is deallocated
+C++ custom Operators¶
Estimated time to read: 7 minutes
In C++ you can define custom operators for your class using operator overloading. This allows you to define the behavior of operators when applied to objects of your class.
You might want to implement some of the following operators for your class:
- arithmetic operators:
+,-,*,/,% - comparison operators:
==,!=,<,>,<=,>= - spaceship operator:
<=>(C++20) - unary operators:
+,-,*,&,!,~,++,-- - compound assignment operators:
+=,-=,*=,/=,%=,<<=,>>=,&=,|=,^= - prefix increment and decrement operators:
++,-- - postfix increment and decrement operators:
++,-- - subscript operator:
[] - stream insertion and extraction operators:
<<,>>
#include <iostream>
+
+struct Vector2i {
+ int x, y;
+ Vector2i() : x(0), y(0) {}
+ Vector2i(int x, int y) : x(x), y(y) {}
+ // arithmetic operators
+ Vector2i operator+(const Vector2i& other) const {
+ return {x + other.x, y + other.y};
+ }
+ Vector2i operator-(const Vector2i& other) const {
+ return {x - other.x, y - other.y};
+ }
+ Vector2i operator*(int scalar) const {
+ return {x * scalar, y * scalar};
+ }
+ Vector2i operator/(int scalar) const {
+ return {x / scalar, y / scalar};
+ }
+ Vector2i operator*(const Vector2i& other) const {
+ return {x * other.x, y * other.y};
+ }
+ Vector2i operator/(const Vector2i& other) const {
+ return {x / other.x, y / other.y};
+ }
+ // comparison operators
+ bool operator==(const Vector2i& other) const {
+ return x == other.x && y == other.y;
+ }
+ bool operator!=(const Vector2i& other) const {
+ return !(*this == other);
+ }
+ // spaceship operator C++20
+ // useful when you want to compare two objects or
+ // use it in std::map or std::set
+ auto operator<=>(const Vector2i& other) const {
+ if (x < other.x && y < other.y) return -1;
+ if (x == other.x && y == other.y) return 0;
+ return 1;
+ }
+
+ // unary operators
+ Vector2i operator-() const {
+ return Vector2i(-x, -y);
+ }
+ // compound assignment operators
+ Vector2i& operator+=(const Vector2i& other) {
+ x += other.x;
+ y += other.y;
+ return *this;
+ }
+ Vector2i& operator-=(const Vector2i& other) {
+ x -= other.x;
+ y -= other.y;
+ return *this;
+ }
+ Vector2i& operator*=(int scalar) {
+ x *= scalar;
+ y *= scalar;
+ return *this;
+ }
+ Vector2i& operator/=(int scalar) {
+ x /= scalar;
+ y /= scalar;
+ return *this;
+ }
+ // prefix increment and decrement operators
+ Vector2i& operator++() {
+ x++;
+ y++;
+ return *this;
+ }
+ Vector2i& operator--() {
+ x--;
+ y--;
+ return *this;
+ }
+ // postfix increment and decrement operators
+ Vector2i operator++(int) {
+ Vector2i temp = *this;
+ ++*this;
+ return temp;
+ }
+ Vector2i operator--(int) {
+ Vector2i temp = *this;
+ --*this;
+ return temp;
+ }
+ // subscript operator
+ int& operator[](int index) {
+ return index == 0 ? x : y;
+ }
+ // stream insertion operator
+ friend std::ostream& operator<<(std::ostream& stream, const Vector2i& vector) {
+ return stream << vector.x << ", " << vector.y;
+ }
+ // stream extraction operator
+ friend std::istream& operator>>(std::istream& stream, Vector2i& vector) {
+ return stream >> vector.x >> vector.y;
+ }
+};
+
Special operators¶
You can create special operators for your class such as:
()operator: function call operator->operator: member access operator- 'new' and 'delete' operators: memory allocation and deallocation operators
A nice usecase for function call operator is to create a functor, a class that acts like a function.
#include <iostream>
+
+struct Adder {
+ int operator()(int a, int b) const {
+ return a + b;
+ }
+};
+
+int main() {
+ Adder adder;
+ std::cout << adder(1, 2) << std::endl; // 3
+ return 0;
+}
+The -> operator is used to overload the member access operator. It is used to define the behavior of the arrow operator -> when applied to objects of your class.
#include <iostream>
+
+struct Pointer {
+ int value;
+ int* operator->() {
+ return &value;
+ }
+};
+
+int main() {
+ Pointer pointer;
+ pointer.value = 42;
+ std::cout << *pointer << std::endl; // 42
+ return 0;
+}
+You might want to overload the new and delete operators to define the behavior of memory allocation and deallocation for your class. Specially to track memory usage or to implement a custom memory pool. Or even overload it globally to track memory usage for the whole program.
#include <iostream>
+#include <cstdlib>
+
+// declare the alloc counter
+int alloc_counter = 0;
+
+void* operator new(std::size_t size) {
+ alloc_counter ++;
+ return std::malloc(size);
+}
+
+void operator delete(void* ptr) noexcept {
+ std::free(ptr);
+ alloc_counter--;
+}
+
+int main() {
+ int* ptr = new int;
+ std::cout << "alloc_counter: " << alloc_counter << std::endl; // 1
+ delete ptr;
+ std::cout << "alloc_counter: " << alloc_counter << std::endl; // 0
+ return 0;
+}
+Advanced Programming¶
Estimated time to read: 9 minutes
This course builds on the content from Introduction to Programming. Students study the Object Oriented Programming (OOP) Paradigm with topics such as objects, classes, encapsulation, abstraction, modularity, inheritance, and polymorphism. Students examine and use structures such as arrays, structs, classes, and linked lists to model complex information. Pointers and dynamic memory allocation are covered, as well as principles such as overloading and overriding. Students work to solve problems by selecting implementation options from competing alternatives.
Requirements¶
Textbook¶
- C++ Early Objects, 10th Edition, Gaddis, Walters, Muganda, Pearson, 2019. ISBN 978-0135235003
Student-centered Learning Outcomes¶
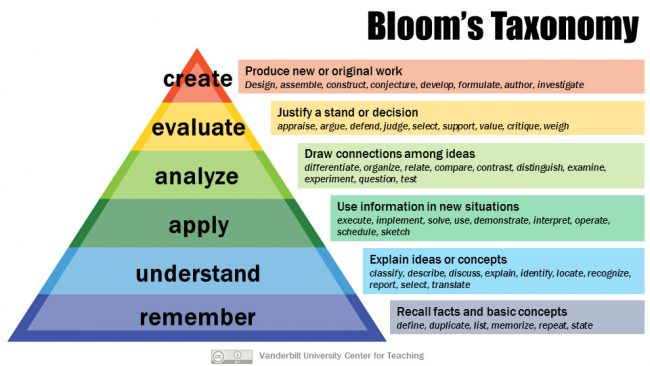
Upon completion of the Advanced Programming course in C++, students should be able to:
- Articulate key concepts of Object-Oriented Programming (OOP), including objects, classes, encapsulation, abstraction, modularity, inheritance, and polymorphism.
- Exhibit a comprehensive understanding of the OOP paradigm and its fundamental principles.
- Differentiate between various structures (arrays, structs, classes, and linked lists) and proficiently apply them in modeling complex information.
- Apply OOP principles effectively to design and implement solutions for real-world problems.
- Utilize Pointers and Dynamic Memory Allocation.
- Effectively employ pointers and dynamic memory allocation in C++ programming.
- Analyze and evaluate competing alternatives for implementation options when solving programming problems. Break down complex problems into manageable components using OOP concepts.
- Evaluate the effectiveness of different implementation strategies in addressing programming challenges.
- Critically assess the advantages and disadvantages of using structures like arrays, structs, classes, and linked lists in specific scenarios.
- Develop solutions for programming challenges by integrating and synthesizing various OOP principles.
- Implement advanced programming concepts, such as overloading and overriding, to enhance code functionality.
Schedule¶
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use the github repo as the source of truth for the schedule and materials. The materials provided in canvas are just a copy for archiving purposes and might be outdated.
College dates for the Spring 2024 semester:
| Date | Event |
|---|---|
| Jan 16 | Classes Begin |
| Jan 16 - 22 | Add/Drop |
| Feb 26 - March 1 | Midterms |
| March 11 - March 15 | Spring Break |
| March 25 - April 5 | Registration for Fall Classes |
| April 5 | Last Day to Withdraw |
| April 8 - 19 | Idea Evaluation |
| April 12 | No Classes - College remains open |
| April 26 | Last Day of Classes |
| April 29 - May 3 | Finals |
| May 11 | Commencement |
-
 Review¶
Review¶
-
 Introduction to OOP¶
Introduction to OOP¶
- Week 2. 2024/01/22
- Topic: Introduction to OOP Objects, classes, member functions, constructors, destructors
-
More about OOP¶
- Week 3. 2024/01/29
- Topic: Private member functions, object passing, object composition, structs and unions
-
Pointers¶
- Week 4. 2024/02/05
- Topic: Address operator, pointer variables, arrays and pointers, pointer math, pointers as function parameters and return types, dynamic memory allocation
-
Pointers continued¶
- Week 5. 2024/02/12
- Topic: this pointer, constant member functions, static members, friends, member-wise assignment, copy constructors
-
 Operators and more¶
Operators and more¶
- Week 6. 2024/02/19
- Topic: Operator overloading, type conversion operators, convert constructors, aggregation and composition, namespaces
-
 Midterms¶
Midterms¶
- Week 7. 2024/02/26
- Topic: Midterms
-
Vectors, Arrays & Linked Lists_¶
- Week 8. 2024/03/04
- Topic: Vectors and arrays of objects: Linked lists, linked list operations
-
Break¶
- Week 09. 2024/03/11
- Topic: Spring BREAK. No classes this week.
-
Inheritance¶
- Week 10. 2024/03/18
- Topic: inheritance, protected members, constructors/destructors
-
Override¶
- Week 11. 2024/03/25
- Topic: inheritance, overriding base class functions
-
Polymorphism¶
- Week 12. 2024/04/01
- Topic: inheritance hierarchies, polymorphism and virtual member functions, abstract base classes and pure virtual functions
-
Exceptions, Templates and STL¶
- Week 13. 2024/04/08
- Topic: Exceptions, function and class templates, STL and STL containers, iterators
-
Stack and queue¶
- Week 14. 2024/04/15
- Topic: Stack and queue
-
 Project Presentation¶
Project Presentation¶
- Week 15. 2024/04/22
- Topic: Work sessions for final project
- Finals¶
- Week 16. 2024/04/29
- Topic: Finals Week
Data-Structures & Algorithms¶
Estimated time to read: 11 minutes
Table of Contents¶
Safe and welcoming space¶
TLDR: Be nice to each other, and don't copy code from the internet.
Some assignments can be hard, and you may feel tempted to copy code from the internet. Don't do it. You will only hurt yourself. You will learn nothing, and you will be caught. Once you get caught, you will be reported to the Dean of Students for academic dishonesty.
If you are struggling with an assignment, please contact me in my office-hours, or via discord. I am really slow at answering emails, so do it so only if something needs to be official. Quick questions are better asked in discord by me or your peers.
Privacy and FERPA Compliance¶
FERPA WAIVER
If you are willing to share your final project publicly, you MUST SIGN this FERPA waiver.
This class will use github extensively, in order to keep you safe, we will use private repositories. This means that only you and me will be able to see your code. In your final project, you must share it with your pair partner, and with me.
Activities¶
TLDR: there is no TLDR, read the whole thing.
Setup Github repository¶
Gitkraken
Optionally you might want to use GitKraken as your git user interface. Once you open it for the first time, signup using your github account with student pack associated. Install Gitkraken
- Signup on github and apply for Github Student Pack. Apply for Student Pack
- Send me your github username in class, so I will share the assignment repository with you;
- Create a private repository by clicking "use as template" the repository InfiniBrains/csi281 or Create CSI281 repository
- Share your repository with me. Click on settings, then collaborators, and add me as a collaborator. My username: @tolstenko
- Clone your repository to your computer. You can use the command line, or any Git GUI tool. I recommend GitKraken
Setup your IDE¶
Other IDEs
Optionally you might want to use any other IDE, such as Visual Studio, VSCode, XCode, NeoVim or any other, but I will not be able to help you with that.
I will use CLion in class, and I recommend you to use it as well so you can follow the same steps as me. It is free for students. And it works on Windows, Mac and Linux.
- Apply for student license for JetBrains or Apply Form
- You can install CLion only or install CLion via their Install Toolbox
- Open CLion for the first time, and login with your JetBrains account you created earlier;
Setup your Assignments project¶
Common problems
Your machine might not have git on your path. If so, install it from git-scm.com and make sure you tick the option to add git to your PATH.
- Open your IDE, and click on "Open Project";
- Select the folder where you cloned your repository;
- Click on "Open as Project" or "Open as CMake Project";
- Wait for CMake to finish generating the project;
- On the top right corner, select the target you want to run/debug;
Check Github Actions¶
Github Actions
Github Actions is a CI/CD tool that will run your tests automatically when you push your code to github. It will also run your tests when you create a pull request. It is a great tool to make sure your code is always working.
You might want to explore the folder .github/workflows to see how it works, but you don't need to change anything there.
Every commit you push to your repository will be automatically tested through Github Actions. You can see the results of the tests by clicking on the "Actions" tab on your repository.
- Go to your repository on github;
- Click on the "Actions" tab;
- Click on the "Build and Test" action;
- Click on the latest commit;
- On the jobs panel, Click on the assignment you want to see the results;
- Read the logs to see if your tests passed or failed;
- It is your job to read the README.md from every assignment and fulfill the requirements;
- You can run/debug the tests locally by targeting the assignmentXX_tests;
Homework¶
- Read the Syllabus fully. Pay attention to the schedule, outcomes and grading;
- Do all assignments on Canvas, specially the git training;
Algorthm Analysis¶
Estimated time to read: 8 minutes
Before starting, lets thin about 3 problems:
For an array of size \(N\), dont overthink. Just answer:
- How many iterations a loop run to find a specific number inside an array? (naively)
- How many comparisons should I make to find two numbers in an array that sum a specific target? (naively)
- List all different shuffled arrays we can make? (naively) ex for n==3 123, 132, 213, 231, 312, 321
How to measure an algorithm mathematically?¶
find a number in a vector
find two numbers sum in an array
vector<int> findsum2(vector<int> v, int target) {
+ // how many outer loop iterations?
+ for (int i = 0; i < v.size(); i++) {
+ // how many inner loop iterations?
+ for (int j = i+1; j < v.size(); j++) {
+ // how many comparisons?
+ if (v[i] + v[j] == target) {
+ return {i, j};
+ }
+ }
+ }
+ return {-1, -1};
+}
+Print all pormutations of an array
void generatePermutations(std::vector<int>& vec, int index) {
+ if (index == vec.size() - 1) {
+ // Print the current permutation
+ for (int num : vec) {
+ std::cout << num << " ";
+ }
+ std::cout << std::endl;
+ return;
+ }
+
+ // how many swaps for every recursive call?
+ for (int i = index; i < vec.size(); ++i) {
+ // Swap the elements at indices index and i
+ std::swap(vec[index], vec[i]);
+
+ // Recursively generate permutations for the rest of the vector
+ // How deep this can go?
+ generatePermutations(vec, index + 1);
+
+ // Backtrack: undo the swap to explore other possibilities
+ std::swap(vec[index], vec[i]);
+ }
+}
+Trying to be mathematicaly correct, the number of instructions the first one should be a function similar to this:
- \(f(n) = a*n + b\) : Where \(b\) is the cost of what runs before and after the main loop and \(a\) is the cost of the loop.
- \(f(n) = a*n^2 + b*n + c\) : Where \(c\) is the cost of what runs before and after the oter loop; \(b\) is the cost of the outer loop; and \(a\) is the cost of the inner loop;
- \(f(n) = a*n!\) : Where \(a\) is the cost of what runs before and after the outer loop;
To simplify, we remove the constants and the lower order terms:
- \(f(n) = n\)
- \(f(n) = n^2\)
- \(f(n) = n!\)
Difference between Big O vs Big Theta Θ vs Big Omega Ω Notations¶
Big O¶
- Most used notation;
- Upper bound;
- "never worse than";
- A real case cannot be faster than it;
- \(0 <= func <= O\)
Big Theta Θ¶
- Wrongly stated as average;
- Theta is two-sided;
- Tight bound between 2 constants of the same function
- \(k1*Θ <= func <= k2*Θ\)
- When \(N\) goes to infinite, it cannot be faster or slower than it;
Honorable mentions¶
- Big Omega Ω: roughly the oposite of Big O;
- Little o and Little Omega (ω). The same concept from the big, but exclude the exact bound;
Common Big Os¶
Logarithm
In computer science, when we say log, assume base 2, unless expressely stated;
| Big O | Name | Example |
|---|---|---|
| O(1) | Constant | sum two numbers |
| O(lg(n)) | Logarithmic | binary search |
| O(n) | Linear | search in an array |
| O(n*lg(n)) | Linearithmic | Merge Sort |
| O(n^c) | Polinomial | match 2 sum |
| O(c^n) | Exponential | brute force password of size n |
| O(n!) | factorial | list all combinations |
What is logarithm?¶
Log is the inverse of exponentiation. It is the number of times you have to multiply a number by itself to get another number.
\[ log_b(b^x) = x \]
What is binary search?¶
In a binary search, we commonly divide the array in half (base 2), and check if the target is in the left or right half. Then we repeat the process until we find the target or we run out of elements.

Common data structures and algorithms¶

Common Issues and misconceptions¶
- Big O and Theta are commonly mixed;
- Hashtables: it is commonly assumed that queries on
<map>or<set>beingO(1); std::<map>and<set>are not the ideal implementation! Watch this CppCon video for some deep level insights;
Dynamic data¶
Estimated time to read: 7 minutes
In C++'s Standard Library, we have a bunch of data structures already implemented for us. But you need to understand what is inside it in order do ponder the best tool for your job. In this week we are going to cover Dynamic Arrays (equivalent of std::vector) and Linked Lists(equivalent of std::list) .
Dynamic Arrays¶
A dynamic array is a random access, variable-size list data structure that allows elements to be added or removed. It is supplied with standard libraries in many modern mainstream programming languages. Let's try to implement one here for the sake of teaching purposes;
template<typename T>
+struct Vector {
+private:
+ size_t _size;
+ size_t _capacity;
+ T* _data;
+public:
+ // constructors
+ Vector() : _size(0), _capacity(1), _data(new T[1]) {}
+ explicit Vector(size_t size) : _size(size), _capacity(size), _data(new T[size]) {}
+
+ // destructor
+ ~Vector() { delete[] _data;}
+
+ // accessors
+ size_t size() const { return _size; }
+ size_t capacity() const { return _capacity;}
+
+ // push_back takes care of resizing the array if necessary
+ // this insertion will amortize the cost of resizing
+ void push_back(const T& value) {
+ if (_size == _capacity) {
+ // growth factor of 2
+ _capacity = _capacity == 0 ? 1 : _capacity * 2;
+ // allocate new memory
+ T* new_data = new T[_capacity];
+ // copy the old data into the new memory
+ for (size_t i = 0; i < _size; ++i)
+ new_data[i] = _data[i];
+ // release the old memory
+ delete[] _data;
+ // update the data pointer
+ _data = new_data;
+ }
+ _data[_size++] = value;
+ }
+
+ // operator[] for read-write access
+ T& operator[](size_t index) { return _data[index]; }
+
+ // other functions
+ // ...
+};
+With this boilerplate you should be able to implement the rest of the functions for the Vector class.
Linked Lists¶
A linked list is a linear access, variable-size list data structure that allows elements to be added or removed without the need of resizing. It is supplied with standard libraries in many modern mainstream programming languages. Let's try to build one here for the sake of teaching purposes;
// linkedlist
+template <typename T>
+struct LinkedList {
+private:
+ // linkedlist node
+ struct LinkedListNode {
+ T data;
+ LinkedListNode *next;
+ LinkedListNode(T data) : data(data), next(nullptr) {}
+ };
+
+ LinkedListNode *_head;
+ size_t _size;
+public:
+ LinkedList() : _head(nullptr), _size(0) {}
+
+ // delete all nodes in the linkedlist
+ ~LinkedList() {
+ while (_head) {
+ LinkedListNode *temp = _head;
+ _head = _head->next;
+ delete temp;
+ }
+ }
+
+ // _size
+ size_t size() const { return _size; }
+
+ // is it possible to make it O(1) instead of O(n)?
+ void push_back(T data) {
+ if (!_head) {
+ _head = new LinkedListNode(data);
+ _size++;
+ return;
+ }
+ auto* temp = _head;
+ while (temp->next)
+ temp = temp->next;
+ temp->next = new LinkedListNode(data);
+ _size++;
+ }
+
+ // operator[] for read-write access
+ T &operator[](size_t index) {
+ auto* temp = _head;
+ for (size_t i = 0; i < index; i++)
+ temp = temp->next;
+ return temp->data;
+ };
+
+ // other functions
+};
+Homework¶
For both, implement the following functions:
T* find(const T& value): returns a pointer to the first occurrence of the value in the collection, or nullptr if the value is not found.bool contains(const T& value): returns true if the value is found in the collection, false otherwise.T& at(size_t index): returns a reference to the element at the specified index. If the index is out of bounds, throw anstd::out_of_rangeexception.void push_front(const T& value): adds a new element to the beginning of the collection.- improve push_back of the linkedlist to be O(1) instead of O(n);
void insert_at(size_t index, const T& value): inserts a new element at the specified index. If the index is out of bounds, throw anstd::out_of_rangeexception.void pop_front(): removes the first element of the collection.void pop_back(): removes the last element of the collection. Is it possible to make it O(1) instead of O(n)?void remove_all(const T& value): removes all occurrences of the value from the collection.void remove_at(size_t index): removes the element at the specified index. If the index is out of bounds, throw anstd::out_of_rangeexception.
Now compare the complexity of linked list and dynamic array for each of the functions you implemented and create a table. What is the best data structure for each use case? Why?
Sorting algorithms¶
Estimated time to read: 6 minutes
Swap function¶
Bubble sort¶
void bubble_sort(int arr[], int n) {
+ for (int i = 0; i < n; i++) { // n passes
+ for (int j = 0; j < n - 1; j++) { // linear pass
+ if (arr[j] > arr[j + 1]) { // swap if the element is greater than the next
+ swap(arr[j], arr[j + 1]);
+ }
+ }
+ }
+}
+Is it possible to optimize the bubble sort algorithm? - The example above always pass from the beginning to the end of the array, but it is possible to stop the inner loop earlier if the right side of the array is already sorted. - You can count how many swaps you did in the inner loop, and if you did 0 swaps, you can stop the outer loop.
Questions:¶
- What is the best case scenario for the bubble sort?
- What is the worst case scenario for the bubble sort?
- How many writes does the bubble sort do?
- How many reads does the bubble sort do?
- What is the time complexity of the bubble sort?
- What is the space complexity of the bubble sort?
Selection sort¶
void selection_sort(int arr[], int n) {
+ for (int i = 0; i < n - 1; i++) { // n - 1 passes
+ int min_index = i; // the minimum element in the unsorted part of the array
+ for (int j = i + 1; j < n; j++) { // linear search
+ if (arr[j] < arr[min_index]) { // find the minimum element
+ min_index = j;
+ }
+ }
+ swap(arr[i], arr[min_index]); // swap the minimum element with the first element of the unsorted part
+ }
+}
+Questions:¶
- What is the best case scenario for the selection sort?
- What is the worst case scenario for the selection sort?
- How many writes does the selection sort do?
- How many reads does the selection sort do?
- What is the time complexity of the selection sort?
- What is the space complexity of the selection sort?
- What is the difference between the bubble sort and the selection sort?
Insertion sort¶
void insertion_sort(int arr[], int n) {
+ for (int i = 1; i < n; i++) { // n - 1 passes
+ int key = arr[i]; // the key element to be inserted in the sorted part of the array
+ int j = i - 1; // the last element of the sorted part of the array
+ while (j >= 0 && arr[j] > key) { // shift the elements to the right to make space for the key
+ arr[j + 1] = arr[j];
+ j--;
+ }
+ arr[j + 1] = key; // insert the key in the right position
+ }
+}
+Questions:¶
- What is the best case scenario for the insertion sort?
- What is the worst case scenario for the insertion sort?
- How many writes does the insertion sort do?
- How many reads does the insertion sort do?
- What is the time complexity of the insertion sort?
- What is the space complexity of the insertion sort?
- What is the difference between the bubble sort, the selection sort, and the insertion sort?
Discussion¶
- Why is sorting typically taught towards the beginning of an algorithms course?
- Why do we study algorithms like bubble sort that are almost never used in practice?
- Can you describe a non-comparative sorting algorithm?
- Which of these sorting algorithms is the best: bubble sort, selection sort, or insertion sort?
Table of differences between the sorting algorithms:
| Algorithm | Best case | Worst case | Time complexity | Space complexity | Swaps |
|---|---|---|---|---|---|
| Bubble | O(n) | O(n^2) | O(N^2) | O(1) | O(n^2) |
| Selection | O(n^2) | O(n^2) | O(N^2) | O(1) | O(n) |
| Insertion | O(n) | O(n^2) | O(N^2) | O(1) | O(n^2) |
Mergesort and QuickSort¶
Estimated time to read: 16 minutes
Both algorithms are based on recursion and divide-and-conquer strategy. Both are efficient for large datasets, but they have different performance characteristics.
Recursion¶
Recursion is a programming technique where a function calls itself. It is a powerful tool to solve problems that can be divided into smaller problems of the same type.
The recursion has two main parts:
- Base case: the condition that stops the recursion;
- Recursive case: the condition that calls the function again.
Let's see an example of a recursive function to calculate the factorial of a number:
#include <iostream>
+
+int factorial(int n) {
+ if (n == 0) {
+ return 1;
+ }
+ return n * factorial(n - 1);
+}
+Mergesort¶
Mergesort divides the input array into two halves, calls itself for the two halves, and then merges the two sorted halves.
You can split the algorithm into two main parts:
- Mergesort: the function that calls itself for the two halves;
- Merge: the function that merges the two sorted halves.

The algorthims will keep dividing the array (in red) until it reaches the base case, where the array has only one element(in gray). Then it will merge the two sorted subarrays (in green).

Mergesort time complexity¶
- Mergesort is time
O(n*lg(n))in the worst case scenario. It is the best time complexity for a comparison-based sorting algorithm. - The algorithm is stable. It maintain the relative order of elements with the same keys during the sorting process.
Mergesort implementation¶
#include <iostream>
+#include <vector>
+#include <queue>
+
+// inplace merge without extra space
+template <typename T>
+requires std::is_arithmetic<T>::value // C++20
+void mergeInplace(std::vector<T>& arr, const size_t start, size_t mid, const size_t end) {
+ size_t left = start;
+ size_t right = mid + 1;
+
+ while (left <= mid && right <= end) {
+ if (arr[left] <= arr[right]) {
+ left++;
+ } else {
+ T temp = arr[right];
+ for (size_t i = right; i > left; i--) {
+ arr[i] = arr[i - 1];
+ }
+ arr[left] = temp;
+ left++;
+ mid++;
+ right++;
+ }
+ }
+}
+
+// Merge two sorted halves
+template <typename T>
+requires std::is_arithmetic<T>::value // C++20
+void merge(std::vector<T>& arr, const size_t start, const size_t mid, const size_t end) {
+ // create a temporary array to store the merged array
+ std::vector<T> temp(end - start + 1);
+
+ // indexes for the subarrays:
+ const size_t leftStart = start;
+ const size_t leftEnd = mid;
+ const size_t rightStart = mid + 1;
+ const size_t rightEnd = end;
+
+ // indexes for
+ size_t tempIdx = 0;
+ size_t leftIdx = leftStart;
+ size_t rightIdx = rightStart;
+
+ // merge the subarrays
+ while (leftIdx <= leftEnd && rightIdx <= rightEnd) {
+ if (arr[leftIdx] < arr[rightIdx])
+ temp[tempIdx++] = arr[leftIdx++];
+ else
+ temp[tempIdx++] = arr[rightIdx++];
+ }
+
+ // copy the remaining elements of the left subarray
+ while (leftIdx <= leftEnd)
+ temp[tempIdx++] = arr[leftIdx++];
+
+ // copy the remaining elements of the right subarray
+ while (rightIdx <= rightEnd)
+ temp[tempIdx++] = arr[rightIdx++];
+
+ // copy the merged array back to the original array
+ std::copy(temp.begin(), temp.end(), arr.begin() + start);
+}
+
+// recursive mergesort
+template <typename T>
+requires std::is_arithmetic<T>::value // C++20
+void mergesortRecursive(std::vector<T>& arr,
+ size_t left,
+ size_t right) {
+ if (right - left > 0) {
+ size_t mid = (left + right) / 2;
+ mergesortRecursive(arr, left, mid);
+ mergesortRecursive(arr, mid+1, right);
+ merge(arr, left, mid, right);
+ // if the memory is limited, use the inplace merge at the cost of performance
+ // mergeInplace(arr, left, mid - 1, right - 1);
+ }
+}
+
+// interactive mergesort
+template <typename T>
+requires std::is_arithmetic<T>::value // C++20
+void mergesortInteractive(std::vector<T>& arr) {
+ for(size_t width = 1; width < arr.size(); width *= 2) {
+ for(size_t left = 0; left < arr.size(); left += 2 * width) {
+ size_t mid = std::min(left + width, arr.size());
+ size_t right = std::min(left + 2 * width, arr.size());
+ merge(arr, left, mid - 1, right - 1);
+ // if the memory is limited, use the inplace merge at the cost of performance
+ // mergeInplace(arr, left, mid - 1, right - 1);
+ }
+ }
+}
+
+
+int main() {
+ std::vector<int> arr1;
+ for(int i = 1000; i > 0; i--)
+ arr1.push_back(rand()%1000);
+ std::vector<int> arr2 = arr1;
+
+ for(auto i: arr1) std::cout << i << " ";
+ std::cout << std::endl;
+
+ mergesortRecursive(arr1, 0, arr1.size() - 1);
+ for(auto i: arr1) std::cout << i << " ";
+ std::cout << std::endl;
+
+ mergesortInteractive(arr2);
+ for(auto i: arr2) std::cout << i << " ";
+ std::cout << std::endl;
+
+ return 0;
+}
+Mergesort space complexity¶
You can implement Mergesort in two ways:
- Recursive: the function calls itself for the two halves;
- Iterative: the function uses a loop to merge the two sorted halves.
The interactive version is more efficient than the recursive version, but it is more complex to understand. But both uses the same core algorithm to merge the two sorted halves.
The main issue with Mergesort is that it requires extra space O(n) to merge the subarrays, which can be problem for large datasets.
- The recursive version will increase the call stack by
O(lg(n)and can potentially cause a stack overflow; - The iterative version does not add pressure to the stack;
QuickSort¶
Quicksort is prtetty similar to mergesort, but it solves the extra memory allocation at expense of stability. So quicksort is an in-place and unstable sorting algorithm.
One of the core strategy of quicksort is pivoting. It will be selected and the array will be partitioned in two subarrays: one with elements smaller than the pivot (left) and the other with elements greater than the pivot (right).
The partitioning process consists of the following steps:
- Select a pivotIndex (left, right, random or median);
- Swap the pivot with the leftmost element (this can be delayed to the end of the step);
- Set the pivot to the leftmost element (assuming you swapped);
- Set the left and right indexes;
- While the left index is less than or equal to the right index:
- If the left element is less than or equal to the pivot, increment the left index;
- If the right element is greater than the pivot, decrement the right index;
- If the left element is greater than the pivot and the right element is less than or equal to the pivot, swap the left and right elements;

Quicksort time complexity¶
The main issue with quicksort is that it can degrade to O(n^2) in an already sorted array. To solve this issue, we can select a random pivot, or the median of the first, middle and last element of the array. This can increase the stability of the algorithm at the expense of performance. The best case scenario is O(n*lg(n)) and the average case is O(n*lg(n)).
QuickSort implementation¶
#include <iostream>
+#include <vector>
+#include <utility>
+#include <stack>
+#include <random>
+
+using std::stack;
+using std::swap;
+using std::pair;
+using std::vector;
+using std::cout;
+
+// Function to generate a random pivot index within the range [left, right]
+template<typename T>
+requires std::integral<T> // c++20
+T randomRange(T left, T right) {
+ static std::random_device rd;
+ static std::mt19937 gen(rd());
+ std::uniform_int_distribution<T> dist(left, right);
+ return dist(gen);
+}
+
+// partition
+template<typename T>
+requires std::is_arithmetic_v<T>
+size_t partition(std::vector<T>& arr, size_t left, size_t right) {
+ // random pivot to increase stability at the cost of performance by random call
+ size_t pivotIndex = randomRange(left, right);
+ swap(arr[left], arr[pivotIndex]);
+
+ size_t pivot = left;
+ size_t l = left + 1;
+ size_t r = right;
+
+ while (l <= r) {
+ if (arr[l] <= arr[pivot]) l++;
+ else if (arr[r] > arr[pivot]) r--;
+ else swap(arr[l], arr[r]);
+ }
+ swap(arr[pivot], arr[r]);
+ return r;
+}
+
+// quicksort recursive
+template<typename T>
+requires std::is_arithmetic_v<T>
+void quicksortRecursive(std::vector<T>& arr, size_t left, size_t right) {
+ if (left < right) {
+ // partition the array
+ size_t pivot = partition(arr, left, right);
+ // recursive call to left and right subarray
+ quicksortRecursive(arr, left, pivot - 1);
+ quicksortRecursive(arr, pivot + 1, right);
+ }
+}
+
+// quicksort interactive
+template<typename T>
+requires std::is_arithmetic_v<T>
+void quicksortInteractive(std::vector<T>& arr, size_t left, size_t right) {
+ // simulate recursive call and avoid potential stack overflow
+ // std::stack allocate memory to hold data content on heap.
+ stack<pair<size_t, size_t>> stack;
+ // produce the initial state
+ stack.emplace(left, right);
+ // iterate
+ while (!stack.empty()) {
+ // consume
+ auto [left, right] = stack.top(); // C++17
+ stack.pop();
+ if (left < right) {
+ auto pivot = partition(arr, left, right);
+ // produce
+ stack.emplace(left, pivot - 1);
+ stack.emplace(pivot + 1, right);
+ }
+ }
+}
+
+int main() {
+ std::vector<int> arr1;
+ for (int i = 0; i < 100; i++) arr1.push_back(rand() % 100);
+ vector<int> arr2 = arr1;
+
+ for (auto& i : arr1) cout << i << " ";
+ cout << std::endl;
+
+ quicksortRecursive(arr1, 0, arr1.size() - 1);
+ for (auto& i : arr1) cout << i << " ";
+ cout << std::endl;
+
+ quicksortInteractive(arr2, 0, arr2.size() - 1);
+ for (auto& i : arr2) cout << i << " ";
+ cout << std::endl;
+
+ return 0;
+}
+Quicksort space consumption¶
- The recursive version of quicksort can increase the function call stack by
O(lg(n))on average, but it can degrade toO(n)in the worst case scenario. Potentially causing a stack overflow; - The interactive version of quicksort avoids the function call stack issue, avoiding stack overflow. But the memory required for the replacement is still
O(lg(n))on average andO(n)for the indexes in the worst case scenario.
Hastables¶
Estimated time to read: 24 minutes
Hashtables ane associative datastructures that stores key-value pairs. It uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
The core of the generic associative container is to implement ways to get and set values by keys such as:
void insert(K key, V value): Add a new key-value pair to the hashtable. If the key already exists, update the value.V at(K key): Get the value of a given key. If the key does not exist, return a default value.void remove(K key): Remove a key-value pair from the hashtable.bool contains(K key): Check if a key exists in the hashtable.int size(): Get the number of key-value pairs in the hashtable.bool isEmpty(): Check if the hashtable is empty.void clear(): Remove all key-value pairs from the hashtable.V& operator[](K key): Get the value of a given key. If the key does not exist, insert a new key-value pair with a default value.
Key-value pairs¶
In C++ you could use std::pair from the utility library to store key-value pairs.
#include <utility>
+#include <iostream>
+
+int main() {
+ std::pair<int, int> pair = std::make_pair(1, 2);
+ std::cout << pair.first << " " << pair.second << std::endl;
+ // prints 1 2
+ return 0;
+}
+Or you could create your own key-value pair class.
#include <iostream>
+
+template <typename K, typename V>
+struct KeyValuePair {
+ K key;
+ V value;
+ KeyValuePair(K key, V value) : key(key), value(value) {}
+};
+
+int main() {
+ KeyValuePair<int, int> pair(1, 2);
+ std::cout << pair.key << " " << pair.value << std::endl;
+ // prints 1 2
+ return 0;
+}
+Hash function¶
The hash function will process the key data and return an index. Usually in C++, the index is of type size_t which is biggest unsigned integer the platform can handle.
The hash function should be fast and should distribute the keys uniformly across the array of buckets. The hash function should be deterministic, meaning that the same key should always produce the same hash.
If the size of your key is less than the size_t you could just use the key casted to size_t as the hash function. If it is not, you will have to implement your own hash function. You probably should use bitwise operations to do so.
struct MyCustomDataWith128Bits {
+ uint32_t a;
+ uint32_t b;
+ uint32_t c;
+ uint32_t d;
+ size_t hash() const {
+ return (a << 32) ^ (b << 24) ^ (c << 16) ^ d;
+ }
+};
+Think a bit and try to come up with a nice answer: what is the ideal hash function for a given type? What are the requirements for a good hash function?
Special case: String or arrays¶
In order to use strings as keys, you will have to create a way to convert the string's underlying data structure into a size_t. You could use the std::hash function from the functional library. Or create your own hash function.
#include <iostream>
+#include <functional>
+
+size_t hash(const std::string& key) {
+ size_t hash=0; // accumulator pattern
+ // the cost of this operation is O(n)
+ for (char c : key)
+ hash = (hash << 5) ^ c;
+ return hash;
+}
+
+int main() {
+ std::hash<std::string> hash;
+ std::string key = "hello";
+ std::cout << hash(key) << std::endl;
+ // prints number
+ return 0;
+}
+You can hide and amortize the cost of the hash function by cashing it. There are plenty of ideas for that. Try to come up with your own.
Hash tables¶
Now that you have the hash function for you type and the key-value data structure, you can implement the hash table.
There are plenty of algorithms to do so, and even the std::unordered_map is not the best, please watch those videos to understand the trade-offs and the best way to implement a hash table.
For the sake of simplicity I will use the operator modulo to convert the hash into an index array. This is not the best way to do so, but it is the easiest way to implement a hash table.
Collision resolution¶
Linked lists¶
Assuming that your hash function is not perfect, you will have to deal with collisions. Two or more different keys could produce the same hash. There are plenty of ways to deal with that, but the easiest way is to use a linked list to store the key-value pairs that have the same hash.
Try to come up with your own strategy to deal with collisions.
Key restrictions¶
In order for the hash table to work, the key should be:
- not modifiable
- implement a hash function
- implement the
==operator
In C++20 you can use the concept feature to enforce those restrictions.
// concept for a hash table
+template <typename T>
+concept HasHashFunction =
+requires(T t, T u) {
+ { t.hash() } -> std::convertible_to<std::size_t>;
+ { t == u } -> std::convertible_to<bool>;
+ std::is_const_v<T>;
+} || requires(T t, T u) {
+ { std::hash<T>{}(t) } -> std::convertible_to<std::size_t>;
+ { t == u } -> std::convertible_to<bool>;
+};
+
+
+int main() {
+ struct MyHashableType {
+ int value;
+ size_t hash() const {
+ return value;
+ }
+ bool operator==(const MyHashableType& other) const {
+ return value == other.value;
+ }
+ };
+ static_assert(HasHashFunction<const MyHashableType>);
+ static_assert(HasHashFunction<int>);
+ return 0;
+}
+But you can require more from the key if you are going to implement a more complex collision resolution strategy.
Hash table implementation with linked lists (chaining)¶

This implementation is naive and not efficient. It is just to give you an idea of how to implement a hash table.
#include <iostream>
+
+// key should not be modifiable
+// implements hash function and implements == operator
+template <typename T>
+concept HasHashFunction =
+requires(T t, T u) {
+ { t.hash() } -> std::convertible_to<std::size_t>;
+ { t == u } -> std::convertible_to<bool>;
+ std::is_const_v<T>;
+} || requires(T t, T u) {
+ { std::hash<T>{}(t) } -> std::convertible_to<std::size_t>;
+ { t == u } -> std::convertible_to<bool>;
+};
+
+// hash table
+template <HasHashFunction K, typename V>
+struct Hashtable {
+private:
+ // key pair
+ struct KeyValuePair {
+ K key;
+ V value;
+ KeyValuePair(K key, V value) : key(key), value(value) {}
+ };
+
+ // node of the linked list
+ struct HashtableNode {
+ KeyValuePair data;
+ HashtableNode* next;
+ HashtableNode(K key, V value) : data(key, value), next(nullptr) {}
+ };
+
+ // array of linked lists
+ HashtableNode** table;
+ int size;
+public:
+ // the hashtable will start with a constant size. You can resize it if you want or use any other strategy
+ // a good size is something similar to the number of elements you are going to store
+ explicit Hashtable(size_t size) {
+ // you colud make it automatically resize and increase the complexity of the implementation
+ // for the sake of simplicity I will not do that
+ this->size = size;
+ table = new HashtableNode*[size];
+ for (size_t i = 0; i < size; i++) {
+ table[i] = nullptr;
+ }
+ }
+private:
+ inline size_t convertKeyToIndex(K t) {
+ return t.hash() % size;
+ }
+public:
+ // inserts a new key value pair
+ void insert(K key, V value) {
+ // you can optionally resize the table and rearrange the elements if the table is too full
+ size_t index = convertKeyToIndex(key);
+ auto* node = new HashtableNode(key, value);
+ if (table[index] == nullptr) {
+ table[index] = node;
+ } else {
+ HashtableNode* current = table[index];
+ while (current->next != nullptr)
+ current = current->next;
+ current->next = node;
+ }
+ }
+
+ // contains the key
+ bool contains(K key) {
+ size_t index = convertKeyToIndex(key);
+ HashtableNode* current = table[index];
+ while (current != nullptr) {
+ if (current->data.key == key) {
+ return true;
+ }
+ current = current->next;
+ }
+ return false;
+ }
+
+ // subscript operator
+ // creates a new element if the key does not exist
+ // fails if the key is not found
+ V& operator[](K key) {
+ size_t index = convertKeyToIndex(key);
+ HashtableNode* current = table[index];
+ while (current != nullptr) {
+ if (current->data.key == key) {
+ return current->data.value;
+ }
+ current = current->next;
+ }
+ throw std::out_of_range("Key not found");
+ }
+
+ // deletes the key
+ // fails if the key is not found
+ void remove(K key) {
+ size_t index = convertKeyToIndex(key);
+ HashtableNode* current = table[index];
+ HashtableNode* previous = nullptr;
+ while (current != nullptr) {
+ if (current->data.key == key) {
+ if (previous == nullptr) {
+ table[index] = current->next;
+ } else {
+ previous->next = current->next;
+ }
+ delete current;
+ return;
+ }
+ previous = current;
+ current = current->next;
+ }
+ throw std::out_of_range("Key not found");
+ }
+
+ ~Hashtable() {
+ for (size_t i = 0; i < size; i++) {
+ HashtableNode* current = table[i];
+ while (current != nullptr) {
+ HashtableNode* next = current->next;
+ delete current;
+ current = next;
+ }
+ }
+ }
+};
+
+struct MyHashableType {
+ int value;
+ size_t hash() const {
+ return value;
+ }
+ bool operator==(const MyHashableType& other) const {
+ return value == other.value;
+ }
+};
+
+int main() {
+ // keys shouldn't be modifiable, implement hash function and == operator
+ Hashtable<const MyHashableType, int> hashtable(5);
+ hashtable.insert(MyHashableType{1}, 1);
+ hashtable.insert(MyHashableType{2}, 2);
+ hashtable.insert(MyHashableType{3}, 3);
+ hashtable.insert(MyHashableType{6}, 6); // should add to the same index as 1
+
+ std::cout << hashtable[MyHashableType{1}] << std::endl;
+ std::cout << hashtable[MyHashableType{2}] << std::endl;
+ std::cout << hashtable[MyHashableType{3}] << std::endl;
+ std::cout << hashtable[MyHashableType{6}] << std::endl;
+ return 0;
+}
+Open addressing with linear probing¶
Open addressing is a method of collision resolution in hash tables. In this approach, each cell is not a pointer to the linked list of contents of that bucket, but instead contains a single key-value pair. In linear probing, when a collision occurs, the next cell is checked. If it is occupied, the next cell is checked, and so on, until an empty cell is found.

The main advantage of open addressing is cache-friendliness. The main disadvantage is that it is more complex to implement, and it is not as efficient as linked lists when the table is too full. That's why we have to resize the table earlier, usually at 50% full, but at least 70% full.
In this implementation below, I have implemented a strategy to resize the table when it is half full. This is a common strategy to mitigate the O(n) search time when we have a lot of collisions. But on each resize, we have to rehash all elements: O(n) when it grows. This growth will occur rarely so this O(n) is amortized.
Implementation with open addressing and linear probing¶
#include <iostream>
+
+// key should not be modifiable
+// implements hash function and implements == operator
+template <typename T>
+concept HasHashFunction =
+requires(T t, T u) {
+ { t.hash() } -> std::convertible_to<std::size_t>;
+ { t == u } -> std::convertible_to<bool>;
+ std::is_const_v<T>;
+} || requires(T t, T u) {
+ { std::hash<T>{}(t) } -> std::convertible_to<std::size_t>;
+ { t == u } -> std::convertible_to<bool>;
+};
+
+// hash table
+template <HasHashFunction K, typename V>
+struct Hashtable {
+private:
+ // key pair
+ struct KeyValuePair {
+ K key;
+ V value;
+ KeyValuePair(K key, V value) : key(key), value(value) {}
+ };
+
+ // array of linked lists
+ KeyValuePair** table;
+ int size;
+ int capacity;
+public:
+ // a good size is something 2x bigger than the number of elements you are going to store
+ explicit Hashtable(size_t capacity=1) {
+ if(capacity == 0)
+ throw std::invalid_argument("Capacity must be greater than 0");
+ // you could make it automatically resize and increase the complexity of the implementation
+ // for the sake of simplicity I will not do that
+ this->size = 0;
+ this->capacity = capacity;
+ table = new KeyValuePair*[capacity];
+ for (size_t i = 0; i < capacity; i++)
+ table[i] = nullptr;
+ }
+private:
+ inline size_t convertKeyToIndex(K t) {
+ return t.hash() % capacity;
+ }
+public:
+ // inserts a new key value pair
+ // this implementation uses open addressing and resize the table when it is half full
+ void insert(K key, V value) {
+ size_t index = convertKeyToIndex(key);
+ // resize if necessary
+ // in open addressing, it is common to resize when the table is half full
+ // this help mitigate O(n) search time when we have a lot of collisions
+ // but on each resize, we have to rehash all elements: O(n)
+ if (size >= capacity/2) {
+ auto oldTable = table;
+ table = new KeyValuePair*[capacity*2];
+ capacity *= 2;
+ for (size_t i = 0; i < capacity; i++)
+ table[i] = nullptr;
+ size_t oldSize = size;
+ size = 0;
+ // insert all elements again
+ for (size_t i = 0; i < oldSize; i++) {
+ if (oldTable[i] != nullptr) {
+ insert(oldTable[i]->key, oldTable[i]->value);
+ delete oldTable[i];
+ }
+ }
+ delete[] oldTable;
+ }
+ // insert the new element
+ KeyValuePair* newElement = new KeyValuePair(key, value);
+ while (table[index] != nullptr) // find the next open index
+ index = (index + 1) % capacity;
+ table[index] = newElement;
+ size++;
+ }
+
+ // contains the key
+ bool contains(K key) {
+ size_t index = convertKeyToIndex(key);
+ KeyValuePair* current = table[index];
+ while (current != nullptr) {
+ if (current->key == key) {
+ return true;
+ }
+ index = (index + 1) % capacity;
+ current = table[index];
+ }
+
+ return false;
+ }
+
+ // subscript operator
+ // fails if the key is not found
+ V& operator[](K key) {
+ size_t index = convertKeyToIndex(key);
+ KeyValuePair* current = table[index];
+ while (current != nullptr) {
+ if (current->key == key) {
+ return current->value;
+ }
+ index = (index + 1) % capacity;
+ current = table[index];
+ }
+ throw std::out_of_range("Key not found");
+ }
+
+ // deletes the key
+ // fails if the key is not found
+ void remove(K key) {
+ // ideal index
+ const size_t idealIndex = convertKeyToIndex(key);
+ size_t currentIndex = idealIndex;
+ // store the last index with the same hash so we move it to the position of the removed element
+ size_t lastIndexWithSameIdealIndex = idealIndex;
+ size_t indexOfTheRemovedElement = idealIndex;
+ // iterate until we find the element, or we find an empty slot
+ while (table[currentIndex] != nullptr) {
+ if (table[currentIndex]->key == key)
+ indexOfTheRemovedElement = currentIndex;
+ if (convertKeyToIndex(table[currentIndex]->key) == idealIndex)
+ lastIndexWithSameIdealIndex = currentIndex;
+ currentIndex = (currentIndex + 1) % capacity;
+ }
+ if(table[indexOfTheRemovedElement] == nullptr || table[indexOfTheRemovedElement]->key != key)
+ throw std::out_of_range("Key not found");
+ // mave the last element with the same key to the position of the removed element
+ delete table[indexOfTheRemovedElement];
+ table[indexOfTheRemovedElement] = table[lastIndexWithSameIdealIndex];
+ table[lastIndexWithSameIdealIndex] = nullptr;
+
+ // todo: shrink the table if it is too empty
+ }
+
+ ~Hashtable() {
+ for (size_t i = 0; i < capacity; i++) {
+ if (table[i] != nullptr)
+ delete table[i];
+ }
+ delete[] table;
+ }
+};
+
+struct MyHashableType {
+ int value;
+ size_t hash() const {
+ return value;
+ }
+ bool operator==(const MyHashableType& other) const {
+ return value == other.value;
+ }
+};
+
+int main() {
+ // keys shouldn't be modifiable, implement hash function and == operator
+ Hashtable<const MyHashableType, int> hashtable(5);
+ hashtable.insert(MyHashableType{0}, 0);
+ hashtable.insert(MyHashableType{1}, 1);
+ hashtable.insert(MyHashableType{2}, 2); // triggers resize
+ hashtable.insert(MyHashableType{10}, 10); // should be inserted in the same index as 1
+
+ std::cout << hashtable[MyHashableType{0}] << std::endl;
+ std::cout << hashtable[MyHashableType{1}] << std::endl;
+ std::cout << hashtable[MyHashableType{2}] << std::endl;
+ std::cout << hashtable[MyHashableType{10}] << std::endl; // should trigger linear search
+
+ hashtable.remove(MyHashableType{0}); // should trigger swap
+
+ std::cout << hashtable[MyHashableType{10}] << std::endl; // shauld not trigger linear search
+ return 0;
+}
+Stack and queue¶
Estimated time to read: 7 minutes
Warning
This section is a continuation of the Dynamic Data section. Please make sure to read it before continuing.
Stack¶
Stacks are a type of dynamic data where the last element added is the first one to be removed. This is known as LIFO (Last In First Out) or FILO (First In Last Out). Stacks are used in many algorithms and data structures, such as the depth-first search algorithm, back-track and the call stack.
Stack Basic Operations¶
push- Add an element to the top of the stack.pop- Remove the top element from the stack.top- Return the top element of the stack.

Stack Implementation¶
You can either implement it using a dynamic array or a linked list. But the dynamic array implementation is more efficient in terms of memory and speed. So let's use it.
#include <iostream>
+
+// stack
+template <typename T>
+class Stack {
+ T* data; // dynamic array
+ size_t size; // number of elements in the stack
+ size_t capacity; // capacity of the stack
+public:
+ Stack() : data(nullptr), size(0), capacity(0) {}
+ ~Stack() {
+ delete[] data;
+ }
+ void push(const T& value) {
+ // if it needs to be resized
+ // amortized cost of push is O(1)
+ if (size == capacity) {
+ capacity = capacity == 0 ? 1 : capacity * 2;
+ T* new_data = new T[capacity];
+ std::copy(data, data + size, new_data);
+ delete[] data;
+ data = new_data;
+ }
+ // stores the value and then increments the size
+ data[size++] = value;
+ }
+ T pop() {
+ if (size == 0)
+ throw std::out_of_range("Stack is empty");
+
+ // shrink the array if necessary
+ // ammortized cost of pop is O(1)
+ if (size <= capacity / 4) {
+ capacity /= 2;
+ T* new_data = new T[capacity];
+ std::copy(data, data + size, new_data);
+ delete[] data;
+ data = new_data;
+ }
+ return data[--size];
+ }
+ T& top() const {
+ if (size == 0)
+ throw std::out_of_range("Stack is empty");
+ // cost of top is O(1)
+ return data[size - 1];
+ }
+ size_t get_size() const {
+ return size;
+ }
+ bool is_empty() const {
+ return size == 0;
+ }
+};
+Queue¶

A queue is a type of dynamic data where the first element added is the first one to be removed. This is known as FIFO (First In First Out). Queues are used in many algorithms and data structures, such as the breadth-first search algorithm. Usually it is implemented as a linked list, in order to provide O(1) time complexity for the enqueue and dequeue operations. But it can be implemented using a dynamic array as well and amortize the cost for resizing. The dynamic array implementation is more efficient in terms of memory and speed(if not resized frequently).
Queue Basic Operations¶
enqueue- Add an element to the end of the queue.dequeue- Remove the first element from the queue.front- Return the first element of the queue.

Queue Implementation¶
// queue
+template <typename T>
+class Queue {
+ // dynamic array approach instead of linked list
+ T* data;
+ size_t front; // index of the first valid element
+ size_t back; // index of the next free slot
+ size_t capacity; // current capacity of the array
+ size_t size; // number of elements in the queue
+
+ explicit Queue() : data(nullptr), front(0), back(0), capacity(capacity), size(0) {};
+
+ void enqueue(T value) {
+ // resize if necessary
+ // amortized O(1) time complexity
+ if (size == capacity) {
+ auto old_capacity = capacity;
+ capacity = capacity ? capacity * 2 : 1;
+ T* new_data = new T[capacity];
+ for (size_t i = 0; i < size; i++)
+ new_data[i] = data[(front + i) % old_capacity];
+ delete[] data;
+ data = new_data;
+ front = 0;
+ back = size;
+ }
+ data[back] = value;
+ back = (back + 1) % capacity;
+ size++;
+ }
+
+ void dequeue() {
+ if (size) {
+ front = (front + 1) % capacity;
+ size--;
+ }
+ // shrink if necessary
+ if(size <= capacity / 4) {
+ auto old_capacity = capacity;
+ capacity /= 2;
+ T* new_data = new T[capacity];
+ for (size_t i = 0; i < size; i++)
+ new_data[i] = data[(front + i) % old_capacity];
+ delete[] data;
+ data = new_data;
+ front = 0;
+ back = size;
+ }
+ }
+
+ T& head() {
+ return data[front];
+ }
+};
+Graph¶
Estimated time to read: 15 minutes
Graphs are a type of data structures that interconnects nodes (or vertices) with edges. They are used to model relationships between objects. This is the basics for most AI algorithms, such as pathfinding, decision making, neuron networks, and others.
Basic Definitions¶
- Nodes or vertices are the basic entities in a graph and hold the data.
- Edges are the connections and relation between the nodes. The relationship can be enriched in multiple ways such as direction, weight, and others.
- Neighbours are the nodes that are connected to a specific node.
- Path is the sequence of edges and nodes that allows you to go from one node to another.
- Degree of a node is the number of edges connected to it.
Representation¶
A graph is composed by a set of vertices(nodes) and edges. There are multiple ways to represent a graph, and every style has its own advantages and disadvantages.
Adjacency matrix¶
Assuming every node is labeled with a number from 0 to n-1, an adjacency matrix is a 2D array of size n x n. The entry a[i][j] is 1 if there is an edge from node i to node j, and 0 otherwise. The adjacency matrix for a graph is always a square matrix.
// adjacency matrix
+// NUMBER_OF_NODES is the number of nodes
+// bool marks if there is an edge between the nodes.
+// switch bool to float if you want to store the weight of the edge.
+// switch bool to a data structure if you want to store more information about the edge.
+bool adj_matrix[NUMBER_OF_NODES][NUMBER_OF_NODES];
+vector<Node> nodes;
+- Pros: it is simple and easy to implement and blazing fast for checking if there is an edge between two nodes.
- Cons: it consumes a lot of space, especially for sparse graphs.
Adjacency list¶
It can be implemented in multiple ways, but a common one is to use an array of lists(or vectors). The index(key) of the array is the node id, and the value is a list of nodes that are connected to the key node.
// adjacency list
+// NUMBER_OF_NODES is the number of nodes
+// vector for storing the connected nodes ids as integers
+// switch vector<int> to map<int, float> if you want to store the weight of the edge.
+// switch map<int, float> to map<int, data_structure> if you want to store more information about the edge.
+vector<int> adj_list[NUMBER_OF_NODES];
+vector<Node> nodes;
+- Pros: it is more memory efficient for sparse graphs.
- Cons: it can be slower to check if there is an edge between two nodes.
Edge list¶
It is a collection of edges, where each egge can be represented as a pair of nodes, a pair of node ids, or a pair of references to nodes.
- Pros: it is the most memory efficient representation for sparse graphs.
- Cons: it can be slower to check if there is an edge between two nodes.
Graph Types¶
- Null graph: A graph with no edges.
- Trivial graph: A graph with only one vertex.
- Directed graph: A graph where the edges have direction.
- Weighted graph: A graph where the edges have a weight.
- Undirected graph: A graph where the edges have no direction or are bidirectional. If weighted, the weights are the same in both directions.
- Connected graph: A graph where all nodes can be reached from any other node.
- Disconnected graph: A graph where some nodes cannot be reached from other nodes.
- Cyclic graph: A graph that has at least one cycle, a path that starts and ends at the same node.
- Acyclic graph: A graph that has no cycles.
- Complete graph: A graph where every pair of nodes is connected by a unique edge.
- Regular graph: A graph where every node has the same degree.
Graph Algorithms¶
Depth-First Search (DFS)¶
DFS is a graph traversal algorithm based on a stack data structure. Basically, the algorithm starts at a node and explores as far as possible along each branch before backtracking. It is used to find connected components, determine the connectivity of the graph, and solve many other problems.
#include <iostream>
+#include <vector>
+#include <unordered_set>
+#include <unordered_map>
+#include <string>
+
+// graph is represented as an adjacency list
+std::unordered_map<std::string, std::unordered_set<std::string>> graph;
+std::unordered_set<std::string> visited;
+
+// dfs recursive version
+// it exploits the call stack to store the nodes to visit
+// you might want to use the iterative version if you have a large graph
+// for that, use std::stack data structure and producer-consumer pattern
+void dfs(const std::string& node) {
+ std::cout << node << std::endl;
+ visited.insert(node);
+ for (const auto& neighbor : graph[node])
+ if (!visited.contains(neighbor))
+ dfs(neighbor);
+}
+
+void dfs_interactive(const std::string& node) {
+ std::stack<std::string> stack;
+ // produce the first node
+ stack.push(node);
+ while (!stack.empty()) {
+ // consume the node
+ std::string current = stack.top();
+ stack.pop();
+ // avoid visiting the same node twice
+ if (visited.contains(current))
+ continue;
+ // mark as visited
+ visited.insert(current);
+
+ // visit the node
+ std::cout << current << std::endl;
+
+ // produce the next node to visit
+ for (const auto& neighbor : graph[current]) {
+ if (!visited.contains(neighbor)) {
+ stack.push(neighbor);
+ break; // is this break necessary?
+ }
+ }
+ }
+}
+
+int main() {
+ std::cout << "Write one node string per line. When you are done, add an empty line." << std::endl;
+ std::string node;
+ while (std::getline(std::cin, node) && !node.empty())
+ graph[node] = {};
+ std::cout << "Write the edges as 'node1;node2'. When you are done, add an empty line." << std::endl;
+ std::string edge;
+ while (std::getline(std::cin, edge) && !edge.empty()) {
+ auto pos = edge.find(';');
+ // Bidirectional
+ std::string source = edge.substr(0, pos);
+ std::string destination = edge.substr(pos + 1);
+ graph[source].insert(destination);
+ graph[destination].insert(source);
+ }
+ std::cout << "Write the starting node." << std::endl;
+ std::string start;
+ std::cin >> start;
+ dfs(start);
+ return 0;
+}
+Breadth-First Search (BFS)¶
BFS is a graph traversal algorithm based on a queue data structure. It starts at a node and explores all of its neighbours before moving on to the next level of neighbours by enqueing them. It is used to find the shortest path, determine the connectivity of the graph, and others.
#include <iostream>
+#include <vector>
+#include <unordered_set>
+#include <unordered_map>
+#include <string>
+#include <queue>
+
+// graph is represented as an adjacency list
+std::unordered_map<std::string, std::unordered_set<std::string>> graph;
+std::unordered_set<std::string> visited;
+
+// bfs
+void bfs(const std::string& node) {
+ std::queue<std::string> queue;
+ // produce the first node
+ queue.push(node);
+ while (!queue.empty()) {
+ // consume the node
+ std::string current = queue.front();
+ queue.pop();
+ // avoid visiting the same node twice
+ if (visited.contains(current))
+ continue;
+ // mark as visited
+ visited.insert(current);
+
+ // visit the node
+ std::cout << current << std::endl;
+
+ // produce the next node to visit
+ for (const auto& neighbor : graph[current]) {
+ if (!visited.contains(neighbor))
+ queue.push(neighbor);
+ }
+ }
+}
+
+void dfs_interactive(const std::string& node) {
+ std::stack<std::string> stack;
+ // produce the first node
+ stack.push(node);
+ while (!stack.empty()) {
+ // consume the node
+ std::string current = stack.top();
+ stack.pop();
+ // avoid visiting the same node twice
+ if (visited.contains(current))
+ continue;
+ // mark as visited
+ visited.insert(current);
+
+ // visit the node
+ std::cout << current << std::endl;
+
+ // produce the next node to visit
+ for (const auto& neighbor : graph[current]) {
+ if (!visited.contains(neighbor)) {
+ stack.push(neighbor);
+ break; // is this break necessary?
+ }
+ }
+ }
+}
+
+int main() {
+ std::cout << "Write one node string per line. When you are done, add an empty line." << std::endl;
+ std::string node;
+ while (std::getline(std::cin, node) && !node.empty())
+ graph[node] = {};
+ std::cout << "Write the edges as 'node1;node2'. When you are done, add an empty line." << std::endl;
+ std::string edge;
+ while (std::getline(std::cin, edge) && !edge.empty()) {
+ auto pos = edge.find(';');
+ // Bidirectional
+ std::string source = edge.substr(0, pos);
+ std::string destination = edge.substr(pos + 1);
+ graph[source].insert(destination);
+ graph[destination].insert(source);
+ }
+ std::cout << "Write the starting node." << std::endl;
+ std::string start;
+ std::cin >> start;
+ // dfs(start);
+ dfs_interactive(start);
+ return 0;
+}
+https://www.redblobgames.com/pathfinding/grids/graphs.html
https://www.redblobgames.com/pathfinding/a-star/introduction.html
Djikstra's algorithm¶
Estimated time to read: 9 minutes
Dijkstra's algorithm is a graph traversal algorithm similar to BFS, but it takes into account the weight of the edges. It uses a priority list to visit the nodes with the smallest cost first and a set to keep track of the visited nodes. A came_from map can be used to store the parent node of each node to create a pathfinding algorithm.
It uses the producer-consumer pattern, where the producer is the algorithm that adds the nodes to the priority queue and the consumer is the algorithm that removes the nodes from the priority queue and do the work.
The algorithm is greedy and works well with positive weights. It is not optimal for negative weights, for that you should use the Bellman-Ford algorithm.
Data Structure¶
For the graph, we will use an adjacency list:
// node registry
+// K is the key type for indexing the nodes, usually it can be a string or an integer
+// Node is the Node type to store node related data
+unordered_map<K, N> nodes;
+
+// K is the key type of the index
+// W is the weight type of the edge, usually it can be an integer or a float
+// W can be more robust and become a struct, for example, to store the weight and the edge name
+// if W is a struct, remember no implement the < operator for the priority queue work
+// unordered_map is used to exploit the O(1) access time and be tolerant to sparse keys
+unordered_map<K, unordered_map<K, W>> edges;
+
+// usage
+// the cost from node A to node B is 5
+edges["A"]["B"] = 5;
+// if you want to make it bidirectional set the opposite edge too
+// edges["B"]["A"] = 5;
+For the algoritm to work we will need a priority queue to store the nodes to be visited:
// priority queue to store the nodes to be visited
+// C is the W type and stores the accumulated cost to reach the node
+// K is the key type of the index of the node
+priority_queue<pair<C, K>> frontier;
+For the visited nodes we will use a set:
// set to store the visited nodes
+// K is the key type of the index of the node
+unordered_set<K> visited;
+Algorithm¶
List of visualizations:
- https://www.cs.usfca.edu/~galles/visualization/Dijkstra.html
- https://visualgo.net/en/sssp
- https://qiao.github.io/PathFinding.js/visual/
Example of Dijkstra's algorithm in C++ to build a path from the start node to the end node:
#include <iostream>
+#include <unordered_map>
+#include <unordered_set>
+#include <string>
+#include <queue>
+using namespace std;
+
+// Dijikstra
+struct Node {
+ // add your custom data here
+ string name;
+};
+
+// nodes indexed by id
+unordered_map<uint64_t, Node> nodes;
+// edges indexed by source id and destination id, the value is the
+unordered_map<uint64_t, unordered_map<uint64_t, double>> edges;
+// priority queue for the frontier
+// this could be declared inside the Dijkstra function
+priority_queue<pair<double, uint64_t>> frontier;
+
+// optionally, in order to create a pathfinding, use came_from map to store the parent node
+unordered_map<uint64_t, uint64_t> came_from;
+// cost to reach the node so far
+unordered_map<uint64_t, double> cost_so_far;
+
+void Visit(Node* node){
+ // add your custom code here
+ cout << node->name << endl;
+}
+
+void Dijkstra(uint64_t start_id) {
+ cout << "Visiting nodes:" << endl;
+ // clear the costs so far
+ cost_so_far.clear();
+ // boostrap the frontier
+ // 0 means the cost to reach the start node is 0
+ frontier.emplace(0, start_id);
+ cost_so_far[start_id] = 0;
+ // while there are nodes to visit
+ while (!frontier.empty()) {
+ // get the node with the lowest cost
+ auto [cost, current_id] = frontier.top();
+ frontier.pop();
+ // get the node
+ Node* current = &nodes[current_id];
+ // visit the node
+ Visit(current);
+ // for each neighbor
+ for (const auto& [neighbor_id, edge_cost] : edges[current_id]) {
+ // calculate the new cost to reach the neighbor
+ double new_cost = cost_so_far[current_id] + edge_cost;
+ // if the neighbor is not visited yet or the new cost is less than the previous cost
+ if (!cost_so_far.contains(neighbor_id) || new_cost < cost_so_far[neighbor_id]) {
+ // update the cost
+ cost_so_far[neighbor_id] = new_cost;
+ // add the neighbor to the frontier
+ frontier.emplace(new_cost, neighbor_id);
+ // update the parent node
+ came_from[neighbor_id] = current_id;
+ }
+ }
+ }
+}
+
+int main() {
+ // build the graph
+ nodes[0] = {"A"}; // this will be our start
+ nodes[1] = {"B"};
+ nodes[2] = {"C"};
+ nodes[3] = {"D"}; // this will be our end
+ // store the edges costs
+ edges[0][1] = 1;
+ edges[0][2] = 2;
+ edges[0][3] = 100; // this is a very expensive edge
+ edges[1][3] = 3;
+ edges[2][3] = 1;
+ // the path from 0 to 3 is A -> C -> D even though the edge A -> D have less steps
+ Dijkstra(0);
+ // print the path from the end to the start
+ cout << "Path:" << endl;
+ uint64_t index = 3;
+ // prevents infinite loop if the end is unreachable
+ if(!came_from.contains(index)) {
+ cout << "No path found" << endl;
+ return 0;
+ }
+ while (index != 0) {
+ cout << nodes[index].name << endl;
+ index = came_from[index];
+ }
+ cout << nodes[0].name << endl;
+ return 0;
+}
+Minimum Spanning Tree¶
Estimated time to read: 20 minutes
Jarnik's(and Prim's) developed the Minimum Spanning Tree, it is an algorithm to find a tree in a graph that connects all the vertices with the minimum possible accumulated weight.
The output of the algorithm is a set of edges that the sum of the weighs is the minimum possible and connects all reachable vertices.
Minimum Spanning Tree Algorithm¶
- Add a vertex to the minimum spanning tree;
- While all nodes are not in the minimum spanning tree:
- Find the edge with the minimum weight that connects a vertex in the MST to a vertex not in the MST;
- Add the vertex from that edge to the MST;
Example¶
Let's consider the following graph:
graph LR
+v0((0))
+v1((1))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7((7))
+v8((8))
+v3 <-. 3 .-> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-. 4 .-> v3
+v2 <-. 6 .-> v5
+v6 <-. 1 .-> v5
+v2 <-. 8 .-> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-. 6 .-> v8
+v7 <-. 11 .-> v6
+v1 <-. 2 .-> v7
+v0 <-. 4 .-> v7
+v0 <-. 8 .-> v1In order to bootstrap the algorithm we need to:
- Select a random vertex;
- let's choose the vertex 0;
- Add the vertex 0 to minimum spanning tree;
- Add all edges that connect the vertex 0 to the priority queue, we add 1 with the weight of 8 and 7 with the weight of 4;
Current state of data:
- Minimum Spanning Tree: {0}
graph LR
+v0(((0)))
+v1((1))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7((7))
+v8((8))
+v3 <-. 3 .-> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-. 4 .-> v3
+v2 <-. 6 .-> v5
+v6 <-. 1 .-> v5
+v2 <-. 8 .-> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-. 6 .-> v8
+v7 <-. 11 .-> v6
+v1 <-. 2 .-> v7
+v0 <-. 4 .-> v7
+v0 <-. 8 .-> v1After the initial setup, we will start running the producer-consumer loop:
- List all edges from all vertices in the minimum spanning tree where the other vertex is not in the minimum spanning tree;
- The edges are:
- {0, 1} with the weight of 8;
- {0, 7} with the weight of 4;
- The edges are:
graph LR
+v0(((0)))
+v1((1))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7((7))
+v8((8))
+v3 ~~~ v4
+v5 ~~~ v4
+v3 ~~~ v5
+v2 ~~~ v3
+v2 ~~~ v5
+v6 ~~~ v5
+v2 ~~~ v8
+v8 ~~~ v6
+v1 ~~~ v2
+v7 ~~~ v8
+v7 ~~~ v6
+v1 ~~~ v7
+v0 <-. 4 .-> v7
+v0 <-. 8 .-> v1- Select the edge with the minimum weight;
- The edge {0, 7} with the weight of 4;
graph LR
+v0(((0)))
+v1((1))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7((7))
+v8((8))
+v3 ~~~ v4
+v5 ~~~ v4
+v3 ~~~ v5
+v2 ~~~ v3
+v2 ~~~ v5
+v6 ~~~ v5
+v2 ~~~ v8
+v8 ~~~ v6
+v1 ~~~ v2
+v7 ~~~ v8
+v7 ~~~ v6
+v1 ~~~ v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1- From the selected edge, add the other vertex to the minimum spanning tree
- Add the vertex 7 to the minimum spanning tree;
The current state of the minimum spanning three is [{0, 7}].;
graph LR
+v0(((0)))
+v1((1))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7(((7)))
+v8((8))
+v3 ~~~ v4
+v5 ~~~ v4
+v3 ~~~ v5
+v2 ~~~ v3
+v2 ~~~ v5
+v6 ~~~ v5
+v2 ~~~ v8
+v8 ~~~ v6
+v1 ~~~ v2
+v7 ~~~ v8
+v7 ~~~ v6
+v1 ~~~ v7
+v0 <-- 4 --> v7
+v0 ~~~ v1Let's repeat the process once more to illustrate the algorithm:
graph LR
+v0(((0)))
+v1((1))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7(((7)))
+v8((8))
+v3 <-. 3 .-> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-. 4 .-> v3
+v2 <-. 6 .-> v5
+v6 <-. 1 .-> v5
+v2 <-. 8 .-> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-. 6 .-> v8
+v7 <-. 11 .-> v6
+v1 <-. 2 .-> v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1- List all edges from all vertices in the minimum spanning tree where the other vertex is not in the minimum spanning tree;
- The edges are:
- {0, 1} with the weight of 8;
- {7, 1} with the weight of 2;
- {7, 8} with the weight of 6;
- {7, 6} with the weight of 11;
- The edges are:
graph LR
+v0(((0)))
+v1((1))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7(((7)))
+v8((8))
+v3 ~~~ v4
+v5 ~~~ v4
+v3 ~~~ v5
+v2 ~~~ v3
+v2 ~~~ v5
+v6 ~~~ v5
+v2 ~~~ v8
+v8 ~~~ v6
+v1 ~~~ v2
+v7 <-. 6 .-> v8
+v7 <-. 11 .-> v6
+v1 <-. 2 .-> v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1- Select the edge with the minimum weight;
- The edge {7, 1} with the weight of 2;
- From the selected edge, add the other vertex to the minimum spanning tree
- Add the vertex 1 to the minimum spanning tree;
The current state of the minimum spanning three is [{0, 7}, {1, 7}].
graph LR
+v0(((0)))
+v1(((1)))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7(((7)))
+v8((8))
+v3 ~~~ v4
+v5 ~~~ v4
+v3 ~~~ v5
+v2 ~~~ v3
+v2 ~~~ v5
+v6 ~~~ v5
+v2 ~~~ v8
+v8 ~~~ v6
+v1 ~~~ v2
+v7 ~~~ v8
+v7 ~~~ v6
+v1 <-- 2 --> v7
+v0 <-- 4 --> v7
+v0 ~~~ v1Now the current exploration state is:
graph LR
+v0(((0)))
+v1(((1)))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7(((7)))
+v8((8))
+v3 <-. 3 .-> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-. 4 .-> v3
+v2 <-. 6 .-> v5
+v6 <-. 1 .-> v5
+v2 <-. 8 .-> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-. 6 .-> v8
+v7 <-. 11 .-> v6
+v1 <-- 2 --> v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1The edges candidates are:
- {0, 1}: 12;
- {7, 8}: 6;
- {7, 6}: 11;
The edge with the minimum weight is {7, 8}: 6. So we will add 8 to the minimum spanning tree.
The current state of the minimum spanning three is [{0, 7}, {1, 7}, {8, 7}].
graph LR
+v0(((0)))
+v1(((1)))
+v2((2))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7(((7)))
+v8(((8)))
+v3 <-. 3 .-> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-. 4 .-> v3
+v2 <-. 6 .-> v5
+v6 <-. 1 .-> v5
+v2 <-. 8 .-> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-- 6 --> v8
+v7 <-. 11 .-> v6
+v1 <-- 2 --> v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1The edges candidates are:
- {1, 2}: 12;
- {8, 2}: 8;
- {8, 6}: 10;
- {7, 6}: 11;
The edge with the minimum weight is {8, 2}: 8. So we will add 2 to the minimum spanning tree.
The current state of the minimum spanning three is [{0, 7}, {1, 7}, {8, 7}, {2, 8}].
graph LR
+v0(((0)))
+v1(((1)))
+v2(((2)))
+v3((3))
+v4((4))
+v5((5))
+v6((6))
+v7(((7)))
+v8(((8)))
+v3 <-. 3 .-> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-. 4 .-> v3
+v2 <-. 6 .-> v5
+v6 <-. 1 .-> v5
+v2 <-- 8 --> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-- 6 --> v8
+v7 <-. 11 .-> v6
+v1 <-- 2 --> v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1The edges candidates are:
- {2, 3}: 4;
- {2, 5}: 6;
- {8, 6}: 10;
- {7, 6}: 11;
We will add the edge {2, 3}: 4 to the minimum spanning tree.
The minimum spanning three is [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}].
graph LR
+v0(((0)))
+v1(((1)))
+v2(((2)))
+v3(((3)))
+v4((4))
+v5((5))
+v6((6))
+v7(((7)))
+v8(((8)))
+v3 <-. 3 .-> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-- 4 --> v3
+v2 <-. 6 .-> v5
+v6 <-. 1 .-> v5
+v2 <-- 8 --> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-- 6 --> v8
+v7 <-. 11 .-> v6
+v1 <-- 2 --> v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1Candidates:
- {3, 4}: 3;
- {3, 5}: 12;
- {2, 5}: 6;
- {8, 6}: 10;
- {7, 6}: 11;
The edge with the minimum weight is {3, 4}: 3. So we will add 4 to the minimum spanning tree.
The minimum spanning three is now [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}].
graph LR
+v0(((0)))
+v1(((1)))
+v2(((2)))
+v3(((3)))
+v4(((4)))
+v5((5))
+v6((6))
+v7(((7)))
+v8(((8)))
+v3 <-- 3 --> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-- 4 --> v3
+v2 <-. 6 .-> v5
+v6 <-. 1 .-> v5
+v2 <-- 8 --> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-- 6 --> v8
+v7 <-. 11 .-> v6
+v1 <-- 2 --> v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1The egdes candidates are:
- {3, 5}: 12;
- {2, 5}: 6;
- {4, 5}: 15;
- {8, 6}: 10;
- {7, 6}: 11;
Select {2, 5}: 6; Add 5 to MST. [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}, {5, 2}].
graph LR
+v0(((0)))
+v1(((1)))
+v2(((2)))
+v3(((3)))
+v4(((4)))
+v5(((5)))
+v6((6))
+v7(((7)))
+v8(((8)))
+v3 <-- 3 --> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-- 4 --> v3
+v2 <-- 6 --> v5
+v6 <-. 1 .-> v5
+v2 <-- 8 --> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-- 6 --> v8
+v7 <-. 11 .-> v6
+v1 <-- 2 --> v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1Candidates are:
- {5, 6}: 1;
- {8, 6}: 10;
- {7, 6}: 11;
Select {5, 6}: 1; Add 6 to MST. [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}, {5, 2}, {6, 5}].
graph LR
+v0(((0)))
+v1(((1)))
+v2(((2)))
+v3(((3)))
+v4(((4)))
+v5(((5)))
+v6(((6)))
+v7(((7)))
+v8(((8)))
+v3 <-- 3 --> v4
+v5 <-. 15 .-> v4
+v3 <-. 12 .-> v5
+v2 <-- 4 --> v3
+v2 <-- 6 --> v5
+v6 <-- 1 --> v5
+v2 <-- 8 --> v8
+v8 <-. 10 .-> v6
+v1 <-. 12 .-> v2
+v7 <-- 6 --> v8
+v7 <-. 11 .-> v6
+v1 <-- 2 --> v7
+v0 <-- 4 --> v7
+v0 <-. 8 .-> v1Now, our current MST does not any candidates to explore, so the algorithm is finished. The minimum spanning tree is [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}, {5, 2}, {6, 5}].
graph LR
+v0(((0)))
+v1(((1)))
+v2(((2)))
+v3(((3)))
+v4(((4)))
+v5(((5)))
+v6(((6)))
+v7(((7)))
+v8(((8)))
+v3 <-- 3 --> v4
+v5 ~~~ v4
+v3 ~~~ v5
+v2 <-- 4 --> v3
+v2 <-- 6 --> v5
+v6 <-- 1 --> v5
+v2 <-- 8 --> v8
+v8 ~~~ v6
+v1 ~~~ v2
+v7 <-- 6 --> v8
+v7 ~~~ v6
+v1 <-- 2 --> v7
+v0 <-- 4 --> v7
+v0 ~~~ v1The total weight of the minimum spanning tree from {0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}, {5, 2}, {6, 5} is 4 + 2 + 6 + 8 + 4 + 3 + 6 + 1 = 34.
Implementation¶
There are many implementations for the Minimum Spanning Tree algorithm, here goes one possible implementation int as key, int as value and int as weight:
#include <iostream>
+#include <unordered_set>
+#include <unordered_map>
+#include <optional>
+#include <tuple>
+#include <vector>
+#include <utility>
+using namespace std;
+
+// rename optional<tuple<int, int, int>> to edge
+typedef optional<tuple<int, int, int>> Edge;
+
+// rename unordered_map<int, unordered_map<int, int>> to Graph
+typedef unordered_map<int, unordered_map<int, int>> Graph;
+
+// source, destination, weight
+Edge findMinEdge(const Graph& graph, const Graph& mst){
+ if(graph.empty())
+ return nullopt;
+ if(mst.empty()){
+ // select a random node to start, we will get the first vertex
+ int source = graph.begin()->first;
+ // candidates to be destination
+ auto candidates = graph.at(source);
+ // iterator
+ auto it = candidates.begin();
+ // best destination and weight
+ int bestDestination = it->first;
+ int bestWeight = it->second;
+ // iterate over the candidates
+ for(; it != candidates.end(); it++){
+ if(it->second < bestWeight){
+ bestDestination = it->first;
+ bestWeight = it->second;
+ }
+ }
+ return make_tuple(source, bestDestination, bestWeight);
+ }
+ // list all vertices from the minimum spanning tree
+ std::unordered_set<int> mstVertices;
+ for(auto& [source, destinations] : mst){
+ mstVertices.insert(source);
+ for(auto& [destination, weight] : destinations){
+ mstVertices.insert(destination);
+ }
+ }
+ // iterate over the vertices from the minimum spanning tree to find the minimum edge
+ int bestWeight = INT_MAX;
+ int bestSource = -1;
+ int bestDestination = -1;
+ for(auto& source : mstVertices){
+ for(auto& [destination, weight] : graph.at(source)){
+ if(!mstVertices.contains(destination) && weight < bestWeight){
+ bestSource = source;
+ bestDestination = destination;
+ bestWeight = weight;
+ }
+ }
+ }
+ if(bestSource == -1)
+ return nullopt;
+ return make_tuple(bestSource, bestDestination, bestWeight);
+}
+
+// returns the accumulated weight of the minimum spanning tree
+// the graph is represented as [source, destination] -> weight
+int MSP(const Graph& graph){
+ Graph mst;
+ int accumulatedWeight = 0;
+ while(true){
+ auto edge = findMinEdge(graph, mst);
+ if(!edge.has_value())
+ break;
+ auto [source, destination, weight] = edge.value();
+ mst[source][destination] = weight;
+ mst[destination][source] = weight;
+ accumulatedWeight += weight;
+ }
+ return accumulatedWeight;
+}
+Trees¶
Estimated time to read: 2 minutes
- It is a connected graph what have no cycles;
- Has a single path between any two vertices;
- A tree with N vertices has N-1 edges;
Traversing a Binary Tree¶
There are mostly three ways to explore a binary search tree, they generate different outputs:
- In-order: Left, Root, Right;
- Pre-order: Root, Left, Right;
- Post-order: Left, Right, Root;
Binary Search Trees¶
A binary search tree is a binary tree:
- Each node has at most two children;
- The left child is less than the parent;
- The right child is greater than the parent;
- The left and right subtrees are also binary search trees;
In a binary search tree, the search complexity is O(log(n)) in a balanced tree. But it can be O(n) if not balanced.
Check the animations on https://visualgo.net/en/bst.
AVL Trees¶
WiP.
Data Structures and Algorithms¶
Estimated time to read: 8 minutes
Students compare and contrast a variety of data structures. Students compare algorithms for tasks such as searching and sorting, while articulating efficiency in terms of time complexity. Students implement data structures and algorithms to support solution designs. Course Catalog
Requirements¶
Textbook¶
- Grokking Algorithms, Aditya Bhargava, Manning Publications, 2016. ISBN 978-1617292231
Student-centered Learning Outcomes¶
Upon completion of the Data Structures and Algorithms course in C++, students should be able to:
Objective Outcomes¶
- Analyze and contrast diverse data structures
- Evaluate algorithmic efficiency using time complexity analysis
- Implement, create and apply data structures and algorithms
- Critically assess sorting algorithms
- Analyze and contrast search algorithms
Assessment Outcomes¶
- Demonstrate the ability to evaluate and differentiate between various data structures, including arrays, linked lists, stacks, queues, trees, and graphs, based on their characteristics and use cases.
- Evaluate algorithms by analyzing their time complexity, enabling the comparison of different algorithms and making informed decisions about their suitability for specific problem-solving scenarios.
- Develop and implement solutions using appropriate data structures and algorithms to address real-world problems, demonstrating proficiency in translating solution designs into C++ code.
- Investigate and compare the merits and drawbacks of brute-force and divide-and-conquer sorting algorithms, including quicksort, mergesort, and insertion sort, in order to make informed choices when selecting sorting techniques for specific scenarios.
- Examine and compare the characteristics, advantages, and limitations of sequential, binary, depth-first, and breadth-first search algorithms, demonstrating the ability to choose the most suitable search strategy based on problem requirements.
Schedule¶
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use this github repo as the source of truth for the materials and Canvas for the assignment deadlines.
College dates for the Spring 2024 semester:
| Date | Event |
|---|---|
| Jan 16 | Classes Begin |
| Jan 16 - 22 | Add/Drop |
| Feb 26 - March 1 | Midterms |
| March 11 - March 15 | Spring Break |
| March 25 - April 5 | Registration for Fall Classes |
| April 5 | Last Day to Withdraw |
| April 8 - 19 | Idea Evaluation |
| April 12 | No Classes - College remains open |
| April 26 | Last Day of Classes |
| April 29 - May 3 | Finals |
| May 11 | Commencement |
- Introduction¶
- Week 1. 2024/01/15
- Topic: Introduction to Data Structures and Algorithms
- Activities:
- Introduction
- Read all materials shared on Canvas;
- Do all assignments on Canvas;
- Algorithm Analysis¶
- Week 2. 2024/01/22
- Topic: Algorithm Analysis
-
Dynamic Data¶
- Week 3. 2024/01/29
- Topic: Array, Linked Lists, Dynamic Arrays
-
Sorting¶
- Week 4. Date: 2024/02/05
- Topic: Bubble Sort, Selection Sort and Insertion Sort
-
Divide & Conquer¶
- Week 5. 2024/02/12
- Topic: Merge Sort and Quick Sort
- Hashtables¶
- Week 6. 2024/02/19
- Topic: Hashtables
- Midterms¶
- Week 7. Date: 2024/02/26
- Topic: Midterms
-
Stacks & Queues¶
- Week 8. 2024/03/04
- Topic: Stacks and Queues
-
Break¶
- Week 09. 2024/03/11
- Topic: Spring BREAK. No classes this week.
-
Graphs¶
- Week 10. 2024/03/18
- Topic: Graphs
-
Dijkstra¶
- Week 11. 2024/03/25
- Topic: Dijkstra
-
Prim & Jarnik¶
- Week 12. 2024/04/01
- Topic: Prim's and Jarnik's Algorithm
-
BST¶
- Week 13. 2024/04/01
- Topic: Binary Search Trees
-
Heap and Priority queue¶
- Week 14. 2024/04/08
- Topic: Heap and Priority Queues
- Project Presentation¶
- Week 15. 2024/04/15
- Topic: Work sessions for final project
- Finals¶
- Week 16. 2024/04/22
- Topic: Finals Week
Introduction to AI¶
Estimated time to read: 4 minutes
Note
Please refer to this repository in order follow the previous assignments for the first course of AI. https://github.com/InfiniBrains/mobagen
Topics suggested in the survey, and some of my considerations.
- Procedural Content Generation. Advanced terrain generation - It was previously covered in the last class, I am going to focus other topics
- AI applied to improve 3D Animation Movement. Follow this https://github.com/sebastianstarke/AI4Animation
- Topics relating to an AI Fighting game - Mostly Agents, State Machines and latency simulation (reflex)
- Tactical AI - Linear programming, Restriction and Satisfiability problem
- Neuron networks / Machine learning - This can be real hard to cover all topics in this class
- Genetic algorithms and Reinforced learning - Find the best parameters for agent behaviors
- Chess AI - In a broader sense it is a table game, and it is mostly heuristics and state exploration, chess is awesome to learn optimization techniques to reduce memory usage, space exploration, branch and cut, minmax, planning and satisfaction
- Prediction algorithms for multiplayer - We can cover some techniques to extrapolate data to compensate lag instead of just mathematically extrapolate position, this is mostly an application of agent theory.
- Stable diffusion/chatbot - This is a hot topic, I didn't went too deep on that, but I can help you at least surf this wave to create fun stuff for games, such as dialog creation.
- Procedural audio generation - Most of them use convolutional networks mixed with recurrent neuron network. It can be real hard, so if we cover that, we are just goint to understand the overall idea, and learn how to use pre-determined models available for free.
- Behavior trees - I have to be honest this is a topic that I don't like, but it is a good tool to have in your toolbox, so I can cover it.
- ChatGPT and its siblings to generate text - I can cover at least how to modify small scoped model and use for your own intent.
- Stable Diffusion and its siblings to generate images - I can cover at least how to modify small scoped model and use for your own intent.
- AI subsystems and how to debug it.
- Spatial quantization optimized for AI queries - I really enjoy this, but it can be hard to understand, because it uses lots of data structures
Note for myself: game worldbox
Procedural Content Generation¶
Estimated time to read: 10 minutes
PCG is a technique to algorithmically generate game content and assets, such as levels, textures, sound, enemies, quests, and more. The goal of PCG is to create unique and varied content without the need for manual labor. This can save time and money during development, and also allow for a more dynamic and replayable experience for the player. There are many different algorithms and techniques used in PCG, such as random generation, evolutionary algorithms, and rule-based systems.
PCG can also be used in other areas of game development such as textures, terrain, narrative, quests, and sound effects. With PCG, the possibilities are endless. It's important to note that PCG is not a replacement for human creativity, but rather a tool that can help create new and unique content. It is often used in conjunction with manual design and artistic direction.
Procedural Scenario Generation¶
Procedural scenario generation is a specific application of procedural content generation that is used to create unique and varied scenarios or missions in a game. These scenarios can include objectives, enemies, and environmental elements such as terrain and buildings.
Two common techniques are rule and noise based algorithms, and you can combine both. But first let's cover Pseudo Random Number Generation.
Random Number Generation¶
There are a plethora of algorithms to generate random numbers. The expected interface for a random number function is to just call it, (i.e. random()) and receive, ideally, a high quality and non-deterministic random number.
In the best scenario, some systems possess a random device (i.e. an antenna capturing electrical noise from the environment), and the random function will be a system call to it. Natural noise are stateless and subject only to the environmental influence that are (arguably) impossible to tamper. It is an awesome source of noise, but the problem is that device call is slow and not portable. So we need to use pseudo random number generators.
Pseudo Random Number Generation¶
In this field, the main challenge is to create a function capable to generate a sequence of numbers that are statistically random or, at least, can pass some tests of randomness at some degree of quality. The function must be fast, portable and deterministic, so it can be reproduced in different machines and platforms The function must be able to generate the same sequence of numbers given the same seed.
A common PRNG is XORShift. It is fast, portable and deterministic, but do not deliver a high quality of randomness. It is a good choice for games, but not for cryptography.
uint32_t xorshift32()
+{
+ // seed and state 'x' must be non-zero
+ // you should implement the state initialization differently
+ static uint32_t x = 123456789;
+ // XOR the state with itself shifted by 13, 17 and 5.
+ // you can use other shifts, but these are the most common
+ x ^= x << 13;
+ x ^= x >> 17;
+ x ^= x << 5;
+ return x;
+}
+As you might notice, the function is not stateless, so you have to initialize the state with a seed. It uses the previous state to generate the next one. A common practice is to use the system time as seed, or a random device call, but you can use any number you want. The seed is the only way to reproduce the sequence of numbers.
Another one is the Mersenne Twister. It is a high quality PRNG, but it is a bit slower.
Noise Generation¶
Noise based Procedural Terrain Generation¶
Wave function collapse¶
Homework¶
You can either use your favorite game engine or use this repository as an entry point. 1. Use a noise function to generate a heightmap. Optional: Use octaves and fractals to make it feels nicer; 2. Implement islands reference or any other meaningful way to make hydraulically erosion apparent; 3. Implement Hydraulic Erosion to make the scenario feels more realistic. See the section 'HYDRAULIC EROSION' from book AI for Games Third ed. IanMillington; 4. Render the heightmap with biomes colors to make more understandable(ocean, sand, forest, mountains, snow...). Optionally use gradient / ramp functions instead of conditionals.
References¶
Procedural content generation is a broad topic, and we need to narrow down some applications and algorithms to cover. I carefully covered Maze generation and Scenario Generation here https://github.com/InfiniBrains/mobagen and I invite you to check the examples named maze and scenario. Besides that, Amit Patel have a really nice website focused in many game algorithms, check it out and support his work https://www.redblobgames.com/
Please refer to the book below. We are going to follow the contents mostly from it.
Book: https://amzn.to/3kvtNDS

State machines¶
Estimated time to read: 1 minute
Some raw thoughts: - Probably a game of life is a good game to implement to showcase automata, state machines and decision making
Board Games¶
Estimated time to read: 1 minute
Here we are going to cover - Space exploration; - Memory optimization; - MinMax; - Branch and cut; - Rule and goal based decision-making
The game we are going to cover here can be chess, rubbik cube or any card game.
Spatial Hashing¶
Estimated time to read: 20 minutes
A Spatial Hashing is a common technique to speed up queries in a multidimensional space. It is a data structure that allows you to quickly find all objects within a certain area of space. It is commonly used in games and simulations to speed up, artificial intelligence world queries, collision detection, visibility testing and other spatial queries.
Advantages of the spatial hashing:
- simple to implement;
- very fast: as fast as your key hashing function;
- easy to parallelize;
- a good choice for big worlds;
Problem with spatial hashing:
- it is not precise;
- it is not good for small worlds;
- needs fine tune to find the right cell size;
- have to update the bucket when the object moves;
- find the nearest objects is not trivial, you will have to query the adjacent cells;
Buckets¶
The core of the spatial hashing is the bucket. It is a container that holds all the objects that are within a certain area of space contained in the cell area or volume. The terms cell and bucket can be interchangeable in this context.
In order to find buckets, you will have to create ways to quantize the world space into a grid of cells. It is hard to define the best cell size, but it is a good practice to make it be a couple of times bigger than the biggest object you have in the world. The cell size will define the precision of the spatial hashing, and the bigger it is, the less precise it will be.
Spatial quantization¶
The spatial quantization is the process of converting a continuous space into a discrete space. This is the core process of finding the right bucket for an object. Let's assume that we have a 2D space, and we want to find the bucket for a given object.
// assuming Vector2f is a 2D vector with float components;
+// and Vector2i is a 2D vector with integer components;
+// the quantizations function will be:
+Vector2<int32_t> quantized(float_t cellSize=1.0f) const {
+ return Vector2<int32_t>{
+ static_cast<int32_t>(std::floor(x + cellSize/2) / cellSize),
+ static_cast<int32_t>(std::floor(y + cellSize/2) / cellSize)
+ };
+}
+Data structures¶
Data structure for the bucket¶
First, we have to decide the data structure your bucket will use to store the objects. The common choices are:
vector<GameObject*>- a vector of pointers to game objects;set<GameObject*>- a set of pointers to game objects;-
unordered_set<GameObject*>- an unordered_set of pointers to game objects; -
The problem of using a
vectoris that it is not efficient to remove, and find an object in it:O(n); but it is efficient to add (amortizedO(1)) and iterate over it (random access isO(1)). - The underlying data structure of a
setandmapis a binary search tree, so it is efficient to find, add and remove objects:O(lg(n)), but it is not efficient to iterate over it. - Now, the
unordered_setandunordered_mapis a hash table, so it is efficient to find, add and remove objects:O(1), and it is efficient to iterate over it. The overhead of using a hash table is the memory usage and the hashing function. It will be as fast as your hashing function.
In our use case, we will frequently list all elements in a bucket, we will add and remove elements from it, while they move in the world. So, the best choice is to use an unordered_set of pointers to game objects.
So lets define the bucket:
Data structure for indexing buckets¶
Ideally, we are looking for a data structure that will give us a bucket for a given position. We have some candidates for this job:
bucket_t[width][height]- a 2D array of buckets;vector<vector<bucket_t>>- a 2D vector of buckets;map<Vector2i, bucket_t>- a map of buckets;-
unordered_map<Vector2i, bucket_t>- a map of buckets; -
arrays andvectors are the fastest data structures to use, but they are not good choices if you have a sparse world; mapis a binary search tree;unordered_mapis a hash table.
The unordered_map is the best choice for this use case.
Iterating over the whole world at once¶
Sometimes we just want to iterate over all objects in the world, add and remove elements. In this case, we can use a unordered_set to store all game objects.
Neighbor cells¶
When you need to query the neighbors of an object, most of the time you will need to check the current cell and the adjacent cells. You can create a function for that or include the content of it in your logic.
// neighbor buckets. not memory intensive
+// returns the reference to the 9 buckets surrounding the given bucket, including itself
+// but on the usage, you will have to check
+vector<go_bucket_t*> neighborBuckets(const Vector2i& bucket) {
+ vector<go_bucket_t*> neighbors;
+ neighbors.reserve(9); // to avoid reallocations
+ for (int i = -1; i <= 1; i++)
+ for (int j = -1; j <= 1; j++){
+ neighbors.push_back(&world()[Vector2i{bucket.x + i, bucket.y + j}]);
+ }
+ return neighbors;
+}
+
+// neighbors objects inside the 9 buckets surroundings the given bucket
+// memory intensive.
+go_bucket_t neighborObjects(const Vector2i& bucket) {
+ go_bucket_t neighbors;
+ for (auto& b: neighborBuckets(bucket))
+ neighbors.insert(b->begin(), b->end());
+ return neighbors;
+}
+Implementation¶
This sample bellow a bit complex, but I added a bunch of support code to make it more complete, feel free to simplify it to your needs and split into multiple files.
#include <iostream> // for cout
+#include <unordered_map> // for unordered_map
+#include <unordered_set> // for unordered_set
+#include <random> // for random_device and default_random_engine
+#include <cmath> // for floor
+#include <cstdint> // for int32_t
+#include <vector> // for vector
+
+// to allow derivated structs to be used as keys in sorted containers and binary search algorithms
+template<typename T>
+struct IComparable { virtual bool operator<(const T& other) const = 0; };
+// to allow derivated structs to be used as keys in hash based containers and linear search algorithms
+template<typename T>
+struct IEquatable { virtual bool operator==(const T& other) const = 0; };
+
+// generic Vector2
+// requires that T is a int32_t or float_t
+template<typename T>
+#ifdef __cpp_concepts
+requires std::is_same_v<T, int32_t> || std::is_same_v<T, float_t>
+#endif
+struct Vector2:
+ public IComparable<Vector2<T>>,
+ public IEquatable<Vector2<T>> {
+ T x, y;
+ Vector2(): x(0), y(0) {}
+ Vector2(T x, T y): x(x), y(y) {}
+ // operator equals
+ bool operator==(const Vector2& other) const override {
+ return this == &other || (x == other.x && y == other.y);
+ }
+ // operator < for being able to use it as a key in a map or set
+ bool operator<(const Vector2& other) const override {
+ return x < other.x || (x == other.x && y < other.y);
+ }
+
+ // quantize the vector to a 2d index
+ // to nearest integer
+ Vector2<int32_t> quantized(float_t cellSize=1.0f) const {
+ return Vector2<int32_t>{
+ static_cast<int32_t>(std::floor(x + cellSize/2) / cellSize),
+ static_cast<int32_t>(std::floor(y + cellSize/2) / cellSize)
+ };
+ }
+};
+
+// specialized Vector2 for int and float
+using Vector2i = Vector2<int32_t>;
+// float32_t is only available in c++23, so we use float_t instead
+using Vector2f = Vector2<float_t>;
+
+// helper struct to generate unique id for game objects
+// mostly debug purposes
+struct uid_type {
+private:
+ static inline size_t nextId = 0; // to be used as a counter
+ size_t uid; // to be used as a unique identifier
+public:
+ // not thread safe, but it is not a problem for this example
+ uid_type(): uid(nextId++) {}
+ inline size_t getUid() const { return uid; }
+};
+
+// generic game object implementation
+// replace this with your own data that you want to store in the world
+class GameObject: public uid_type {
+ Vector2f position;
+public:
+ GameObject();
+ GameObject(const GameObject& other);
+ // todo: add your other custom data here
+ // when the it moves, it should check if it needs to update its bucket in the world
+ void setPosition(const Vector2f& newPosition);
+ Vector2f getPosition() const { return position; }
+};
+
+// hashing
+namespace std {
+ // Hash specialization for Vector2i
+ template<>
+ struct hash<Vector2i> {
+ size_t operator()(const Vector2i& v) const {
+ // shift and xor operator the other to get a unique hash
+ // the problem of this approach is that it will generate neighboring cells with similar hashes
+ // to fix that, you might want to use a more complex hashing function from std::hash<T>
+ // copy to avoid const cast
+ auto x = v.x, y = v.y;
+ return (*reinterpret_cast<size_t*>(&x) << 32) ^ (*reinterpret_cast<size_t*>(&y));
+ }
+ };
+}
+
+// game object pointer
+using GameObjectPtr = GameObject*;
+// alias for the game object bucket
+using go_bucket_t = std::unordered_set<GameObjectPtr>;
+// alias for the world type
+using world_t = std::unordered_map<Vector2i, go_bucket_t>;
+
+// singletons here are being used to avoid global variables and to allow the world to be used in a visible scope
+// you should use a better wrappers and abstractions in a real project
+// singleton world
+world_t& world() {
+ static world_t world;
+ return world;
+}
+// singleton world objects
+go_bucket_t& worldObjects(){
+ static go_bucket_t worldObjects;
+ return worldObjects;
+}
+
+// Constructor
+GameObject::GameObject(): uid_type(), position({0,0}) {
+ // insert in the world
+ worldObjects().insert(this);
+ world()[position.quantized()].insert(this);
+}
+
+// Copy constructor
+GameObject::GameObject(const GameObject& other): uid_type(other), position(other.position) {
+ // insert in the world
+ worldObjects().insert(this);
+ world()[position.quantized()].insert(this);
+}
+
+// this function requires the world to be in a visible scope like this or change it to access through a singleton
+// if in the movement, it changes its quantized position, we should remove it from the old bucket and insert it in the new one
+void GameObject::setPosition(const Vector2f& newPosition) {
+ world_t& w = world();
+ // bucket ids
+ auto oldId = position.quantized();
+ auto newId = newPosition.quantized();
+ // update position
+ position = newPosition;
+ // check if it needs to update its bucket in the world
+ if (newId == oldId)
+ return;
+ // remove from the old bucket
+ w[oldId].erase(this);
+ if(w[oldId].empty()) [[unlikely]] // c++20
+ w.erase(oldId);
+ // insert in the new bucket
+ w[newId].insert(this);
+}
+
+// random vector2f
+Vector2f randomVector2f(float_t min, float_t max) {
+ static std::random_device rd;
+ static std::default_random_engine re(rd());
+ static std::uniform_real_distribution<float_t> dist(min, max);
+ return Vector2f{dist(re), dist(re)};
+}
+
+// neighbor buckets. not memory intensive
+// returns potentially all 9 buckets surroundings the given bucket, including itself
+std::vector<go_bucket_t*> neighborBuckets(const Vector2i& bucket) {
+ std::vector<go_bucket_t*> neighbors;
+ for (int i = -1; i <= 1; i++){
+ for (int j = -1; j <= 1; j++){
+ auto id = Vector2i{bucket.x + i, bucket.y + j};
+ if(world().contains(id) && !world()[id].empty()) // contains is c++20
+ neighbors.push_back(&world()[id]);
+ }
+ }
+ return neighbors;
+}
+
+// neighbors objects inside the 9 buckets surroundings the given bucket
+// memory intensive. use with caution
+go_bucket_t neighborObjects(const Vector2i& bucket) {
+ go_bucket_t neighbors;
+ for (auto& b: neighborBuckets(bucket))
+ neighbors.insert(b->begin(), b->end());
+ return neighbors;
+}
+
+// dump world
+void dumpWorld() {
+ for (auto& bucket: world()) {
+ std::cout << "bucket: [" << bucket.first.x << "," << bucket.first.y << "]:" << std::endl;
+ for (auto& obj: bucket.second)
+ std::cout <<" - "<< obj->getUid() << ": at (" << obj->getPosition().x << ", " << obj->getPosition().y << ")" << std::endl;
+ }
+ std::cout << std::endl;
+}
+
+int main() {
+ // fill the world with some game objects
+ for (int i = 0; i < 121; i++) {
+ // the constructor will insert it in the world
+ auto obj = new GameObject();
+ // randomly move the game objects
+ // this will update their position and their bucket in the world
+ obj -> setPosition(randomVector2f(-5, 5));
+ }
+
+ // dump the world
+ dumpWorld();
+
+ // remove all game objects
+ for (auto& obj: worldObjects())
+ delete obj;
+
+ // clear refs
+ worldObjects().clear();
+ world().clear();
+
+ return 0;
+}
+Homework¶
- Implement a spatial hashing for a 3D world;
- Implement another space partition technique, such as a quadtree/octree/kdtree and compare:
- the performance of both in scenarios of moving objects, searching for objects and adding / removing objects;
- memory consumption;
- which one will be slow down faster the bigger the world becomes;
KD-Trees¶
Estimated time to read: 16 minutes
KD-Trees are a special type of binary trees that are used to partition a k-dimensional space. They are used to solve the problem of finding the nearest neighbor of a point in a k-dimensional space. The name KD-Tree comes from the method of partitioning the space, the K stands for the number of dimensions in the space.
KD-tree are costly to mantain and balance. So use it only if you have a lot of queries to do, and the space is not changing. If you have a lot of queries, but the space is changing a lot, you should use a different data structure, such as a quadtree or a hash table.
Methodology¶
- On the binary tree KD-Tree, each node represents a k-dimensional point;
- The tree is constructed by recursively partitioning the space into two half-spaces.
- The partitioning is done by selecting a dimension and a value, and then splitting the space into two half-spaces.
- The dimension and value are selected in such a way that the space is divided into two equal parts.
- The left child of a node contains all the points for that dimension that are less than the value, and the right child contains all the points that are greater than or equal to the value.
Example¶
Let's consider the following 2D points:
The first step is to define the root. For that we need do define two things: the dimension and the value:
- For the dimension we need to select the one that has the largest range.
- For the value we need to select the median of that dimension.
So if we sort the points by the axis, we will have:
SortedByX = (1, 9), (3, 1), (2, 14), (7, 15), (12, 17), (16, 2), (19, 13)
+SortedByY = (3, 1), (16, 2), (1, 9), (19, 13), (7, 15), (3, 15), (12, 17)
+The largest range is on the X axis, so we will select the median of the X axis as the root. The median of the X axis is (7, 15), and the starting dimension will be X.
For the next level, the left side candidates will be the ones with X less than (7, 15), and the right side, the ones that are greater or equal to (7, 15). But now this level will be governed sorted by Y:
Graph showing the first split on X at (7, 15):
The median for the left side is (1, 9), and for the right side is (19, 13).
The current state of the tree is:
Now we apply the same rules for the children of the left and right nodes.
graph TD
+ Root(07,15)
+ Left(01,09)
+ Right(19,13)
+ LeftLeft(03,01)
+ LeftRight(02,14)
+ RightLeft(16,02)
+ RightRight(12,17)
+ Root --> |x<7| Left
+ Root --> |x>7| Right
+ Left --> |y<9| LeftLeft
+ Left --> |y>9| LeftRight
+ Right --> |y<13| RightLeft
+ Right --> |y>13| RightRightThe tree will be:
And lastly, we will have:
Implementation¶
#include <iostream>
+#include <vector>
+#include <algorithm>
+
+// vector
+struct Vector2f {
+ float x, y;
+ Vector2f(float x, float y) : x(x), y(y) {}
+ // subscript operator to be used in the KDTree
+ float& operator[](size_t index) {
+ return index%2 == 0 ? x : y;
+ }
+ // distanceSqrd between two vectors
+ float distanceSqrd(const Vector2f& other) const {
+ return (x - other.x)*(x - other.x) + (y - other.y)*(y - other.y);
+ }
+};
+
+// your object data structure
+class GameObject {
+ // your other data
+public:
+ Vector2f position;
+ explicit GameObject(Vector2f position={0,0}) : position(position) {}
+};
+
+// KDNode
+struct KDNode {
+ GameObject* object;
+ KDNode* left;
+ KDNode* right;
+ KDNode(GameObject* object, KDNode* left = nullptr, KDNode* right= nullptr) :
+ object(object),
+ left(left),
+ right(right)
+ {}
+};
+
+// KDTree manager
+class KDTree {
+public:
+ KDNode* root;
+ KDTree() : root(nullptr) {}
+
+ ~KDTree() {
+ // interactively delete the nodes
+ std::vector<KDNode*> nodes;
+ nodes.push_back(root);
+ while (!nodes.empty()) {
+ KDNode* current = nodes.back();
+ nodes.pop_back();
+ if (current->left != nullptr) nodes.push_back(current->left);
+ if (current->right != nullptr) nodes.push_back(current->right);
+ delete current;
+ }
+ }
+
+ void insert(GameObject* object) {
+ if (root == nullptr) {
+ root = new KDNode(object);
+ } else {
+ KDNode* current = root;
+ size_t dimensionId = 0;
+ while (true) {
+ if (object->position[dimensionId] < current->object->position[dimensionId]) {
+ if (current->left == nullptr) {
+ current->left = new KDNode(object);
+ break;
+ } else {
+ current = current->left;
+ }
+ } else {
+ if (current->right == nullptr) {
+ current->right = new KDNode(object);
+ break;
+ } else {
+ current = current->right;
+ }
+ }
+ dimensionId++;
+ }
+ }
+ }
+
+ void insert(std::vector<GameObject*> objects, int dimensionId=0 ) {
+ if(objects.empty()) return;
+ if(objects.size() == 1) {
+ insert(objects[0]);
+ return;
+ }
+ // find the median for the current dimension
+ std::sort(objects.begin(), objects.end(), [dimensionId](GameObject* a, GameObject* b) {
+ return a->position[dimensionId] < b->position[dimensionId];
+ });
+ // insert the median
+ auto medianIndex = objects.size() / 2;
+ insert(objects[medianIndex]);
+
+ // insert the left and right exluding the median
+ insert(std::vector<GameObject*>(objects.begin(), objects.begin() + medianIndex), (dimensionId + 1) % 2);
+ insert(std::vector<GameObject*>(objects.begin() + medianIndex + 1, objects.end()), (dimensionId + 1) % 2);
+ }
+
+ // get the nearest neighbor
+ GameObject* nearestNeighbor(Vector2f position) {
+ return NearestNeighbor(root, position, root->object, root->object->position.distanceSqrd(position), 0);
+ }
+
+ GameObject* NearestNeighbor(KDNode* node, Vector2f position, GameObject* best, float bestDistance, int dimensionId) {
+ // create your own Nearest Neighbor algorithm. That's not hard, just follow the rules
+ // 1. If the current node is null, return the best
+ // 2. If the current node is closer to the position, update the best
+ // 3. If the current node is closer to the position than the best, search the children
+ // 4. If the current node is not closer to the position than the best, search the children
+ // 5. Return the best
+ }
+
+ // draw the tree
+ void draw() {
+ std::vector<KDNode*> nodes;
+ // uses space to shaw the level of the node
+ std::vector<std::string> spaces;
+ nodes.push_back(root);
+ spaces.push_back("");
+ while (!nodes.empty()) {
+ KDNode* current = nodes.back();
+ std::string space = spaces.back();
+ nodes.pop_back();
+ spaces.pop_back();
+ if (current->right != nullptr) {
+ nodes.push_back(current->right);
+ spaces.push_back(space + " ");
+ }
+ std::cout << space << ":> " << current->object->position.x << ", " << current->object->position.y << std::endl;
+ if (current->left != nullptr) {
+ nodes.push_back(current->left);
+ spaces.push_back(space + " ");
+ }
+ }
+ }
+};
+
+int main(){
+ // nodes: (3, 1), (7, 15), (2, 14), (16, 2), (19, 13), (12, 17), (1, 9)
+ KDTree tree;
+ std::vector<GameObject*> objects = {
+ new GameObject(Vector2f(3, 1)),
+ new GameObject(Vector2f(7, 15)),
+ new GameObject(Vector2f(2, 14)),
+ new GameObject(Vector2f(16, 2)),
+ new GameObject(Vector2f(19, 13)),
+ new GameObject(Vector2f(12, 17)),
+ new GameObject(Vector2f(1, 9))
+ };
+ // insert the objects
+ tree.insert(objects);
+ // draw the tree
+ tree.draw();
+ // get the nearest neighbor to (10, 10)
+ GameObject* nearest = tree.nearestNeighbor(Vector2f(3, 15));
+ std::cout << "Nearest neighbor to (3, 15): " << nearest->position.x << ", " << nearest->position.y << std::endl;
+ // will print 2, 14
+ return 0;
+}
+Homework¶
- Implement the KDTree in your favorite language;
- Improve the KDTree to support 3D;
- Implement more methods to make it dynamic: insert, remove, update;
- Modify the KDTree to be balanced on insertion;
Pathfinding on a 2D grid¶
Estimated time to read: 15 minutes
Data structures¶
In order to build an A-star pathfinding algorithm, we need to define some data structures. We need:
- Index for the quantized map;
- Position for the game objects;
- Bucket to query in O(1) if the elements are there;
- Map from Index to Buckets;
- Priority Queue to store the frontier of visitable buckets;
- Vector of Indexes to store the path;
Index and Position¶
In order to A-star to work in a continuous space, we should quantize the space position into indexes.
// generic vector2 struct to work with floats and ints
+template <typename T>
+// requires T to be int32_t or float_t
+requires std::is_same<T, int32_t>::value || std::is_same<T, float_t>::value // C++20
+struct Vector2 {
+ // data
+ T x, y;
+ // constructors
+ Vector2() : x(0), y(0) {}
+ Vector2(T x, T y) : x(x), y(y) {}
+ // copy constructor
+ Vector2(const Vector2& v) : x(v.x), y(v.y) {}
+ // assignment operator
+ Vector2& operator=(const Vector2& v) {
+ x = v.x;
+ y = v.y;
+ return *this;
+ }
+ // operators
+ Vector2 operator+(const Vector2& v) const {
+ return Vector2(x + v.x, y + v.y);
+ }
+ Vector2 operator-(const Vector2& v) const {
+ return Vector2(x - v.x, y - v.y);
+ }
+ // distance
+ float distance(const Vector2& v) const {
+ return sqrt((x - v.x) * (x - v.x) + (y - v.y) * (y - v.y));
+ }
+ // distance squared
+ float distanceSquared(const Vector2& v) const {
+ return (x - v.x) * (x - v.x) + (y - v.y) * (y - v.y);
+ }
+ // quantize to index2
+ Vector2<int32_t> quantized(float scale=1) const {
+ return {(int32_t)std::round(x / scale), (int32_t)std::round(y / scale)};
+ }
+ // operator < for std::map
+ bool operator<(const Vector2& v) const {
+ return x < v.x || (x == v.x && y < v.y);
+ }
+ // operator == for std::map
+ bool operator==(const Vector2& v) const {
+ return x == v.x && y == v.y;
+ }
+};
+- The operators
<and==are required to use the Vector2 as a key in a std::map. - The
quantizedmethod is used to convert a position into an index. - The
distanceanddistanceSquaredmethods are used to calculate the distance between two positions. Is used on A-star to calculate the cost to reach a neighbor or the distance to the goal.
I am going to use Index2 to store the quantized index in the grid and Position2 to store the continuous position.
// hash function for std::unordered_map
+template <>
+struct std::hash<Index2> {
+ size_t operator()(const Index2 &v) const {
+ return (((size_t)v.x) << 32) ^ (size_t)v.y;
+ }
+};
+This hash function is for the std::unordered_map and std::unordered_set to work with Index2.
Bucket¶
In order to have an easy way to query if a game object is in a bucket, we need to use an std::unordered_set of pointers to the game objects. In order to index them, we will use an std::unordered_map from Index2 to std::unordered_set.
Costs¶
Your scenario might have different costs to reach a bucket. You can use an std::unordered_map to store the cost of each bucket.
Walls¶
You might want to avoid some buckets. You can use an std::unordered_map to store the walls.
Priority Queue¶
In order to store the frontier of visitable buckets, we need to use a std::priority_queue of pairs of float and Index2.
Implementation¶
/**
+In order to build an A-star pathfinding algorithm, we need to define some data structures. We need:
+- Index for the quantized map;
+- Position2 for the game objects;
+- Bucket to query in O(1) if the elements are there;
+- Map from Index to Buckets;
+- Priority Queue to store the frontier of visitable buckets;
+- Vector of Indexes to store the path;
+*/
+
+#include <iostream>
+#include <unordered_map>
+#include <unordered_set>
+#include <cmath>
+#include <vector>
+#include <queue>
+
+using std::pair;
+
+template<typename K, typename V>
+using umap = std::unordered_map<K, V>;
+
+template<typename T>
+using uset = std::unordered_set<T>;
+
+template<typename T>
+using pqueue = std::priority_queue<T>;
+
+// generic vector2 struct to work with floats and ints
+template <typename T>
+// requires T to be int32_t or float_t
+requires std::is_same<T, int32_t>::value || std::is_same<T, float_t>::value // C++20
+struct Vector2 {
+ // data
+ T x, y;
+ // constructors
+ Vector2() : x(0), y(0) {}
+ Vector2(T x, T y) : x(x), y(y) {}
+ // copy constructor
+ Vector2(const Vector2& v) : x(v.x), y(v.y) {}
+ // assignment operator
+ Vector2& operator=(const Vector2& v) {
+ x = v.x;
+ y = v.y;
+ return *this;
+ }
+ // operators
+ Vector2 operator+(const Vector2& v) const {
+ return Vector2(x + v.x, y + v.y);
+ }
+ Vector2 operator-(const Vector2& v) const {
+ return Vector2(x - v.x, y - v.y);
+ }
+ // distance
+ float distance(const Vector2& v) const {
+ return sqrt((x - v.x) * (x - v.x) + (y - v.y) * (y - v.y));
+ }
+ // distance squared
+ float distanceSquared(const Vector2& v) const {
+ return (float)(x - v.x) * (x - v.x) + (float)(y - v.y) * (y - v.y);
+ }
+ // quantize to index2
+ Vector2<int32_t> quantized(float scale=1) const {
+ return {(int32_t)std::round(x / scale), (int32_t)std::round(y / scale)};
+ }
+ // operator < for std::map
+ bool operator<(const Vector2& v) const {
+ return x < v.x || (x == v.x && y < v.y);
+ }
+ // operator == for std::map
+ bool operator==(const Vector2& v) const {
+ return x == v.x && y == v.y;
+ }
+};
+
+using Index2 = Vector2<int32_t>;
+using Position2 = Vector2<float_t>;
+
+// implement this struct to store game objects by yourself
+struct GameObject {
+ Position2 position;
+ // add here your other data
+
+ GameObject(const Position2& position) : position(position) {}
+ GameObject() : position(Position2()) {}
+};
+
+// hash function for std::unordered_map
+template <>
+struct std::hash<Index2> {
+ size_t operator()(const Index2 &v) const {
+ return (((size_t)v.x) << 32) | (size_t)v.y;
+ }
+};
+
+// The game objects organized into buckets
+umap<Index2, uset<GameObject*>> quantizedMap;
+// all game objects
+uset<GameObject*> gameObjects;
+// The cost of each bucket
+umap<Index2, float> costMap;
+// The walls
+umap<Index2, bool> isWall;
+
+// Pathfinding algorithm from position A to position B
+std::vector<Index2> findPath(const Position2& startPos, const Position2& endPos) {
+ // quantize
+ Index2 start = startPos.quantized();
+ Index2 end = endPos.quantized();
+
+ // datastructures
+ pqueue<pair<float, Index2>> frontier; // to store the frontier of visitable buckets
+ umap<Index2, float> accumulatedCosts; // to store the cost to reach a bucket
+
+ // initialize
+ accumulatedCosts[start] = 0;
+ frontier.emplace(0, start);
+
+ // main loop
+ while (!frontier.empty()) {
+ // consume first element from the frontier
+ auto current = frontier.top().second;
+ frontier.pop();
+
+ // quit early
+ if (current == end)
+ break;
+
+ // iterate over neighbors
+ auto candidates = {
+ current + Index2(1, 0),
+ current + Index2(-1, 0),
+ current + Index2(0, 1),
+ current + Index2(0, -1)
+ };
+ for (const auto& next : candidates) {
+ // skip walls
+ if(isWall.contains(current))
+ continue;
+ // if the neighbor has not been visited and is not on frontier
+ // calculate the cost to reach the neighbor
+ float newCost =
+ accumulatedCosts[current] + // cost so far
+ current.distance(next) + // cost to reach the neighbor
+ (costMap.contains(next) ? costMap[next] : 0); // cost of the neighbor
+ // if the cost is lower than the previous cost
+ if (!accumulatedCosts.contains(next) || newCost < accumulatedCosts[next]) {
+ // update the cost
+ accumulatedCosts[next] = newCost;
+ // calculate the priority
+ float priority = newCost + next.distance(end);
+ // push the neighbor to the frontier
+ frontier.emplace(-priority, next);
+ }
+ }
+ }
+
+ // reconstruct path
+ std::vector<Index2> path;
+ Index2 current = end;
+ while (current != start) {
+ path.push_back(current);
+ auto candidates = {
+ current + Index2(1, 0),
+ current + Index2(-1, 0),
+ current + Index2(0, 1),
+ current + Index2(0, -1)
+ };
+ for (const auto& next : candidates) {
+ if (accumulatedCosts.contains(next) && accumulatedCosts[next] < accumulatedCosts[current]) {
+ current = next;
+ break;
+ }
+ }
+ }
+ path.push_back(start);
+ std::reverse(path.begin(), path.end());
+ return path;
+}
+
+int main() {
+/*
+map. numbers are bucket cost, letters are objects, x is wall
+A 0 5 0 0 0
+0 X X 0 0 0
+5 X 0 0 5 0
+0 0 0 5 B 5
+0 0 0 0 5 0
+ */
+
+ // Create 2 Game Objects
+ GameObject a(Position2(0.1, 0.1));
+ GameObject b(Position2(3.9, 4.1));
+
+ // place walls
+ isWall[Index2(1, 1)] = true;
+ isWall[Index2(1, 2)] = true;
+ isWall[Index2(2, 1)] = true;
+
+ // add cost to some buckets
+ // should avoid these:
+ costMap[Index2(2, 0)] = 5;
+ costMap[Index2(0, 2)] = 5;
+ // should pass-through these:
+ costMap[Index2(5, 4)] = 5;
+ costMap[Index2(3, 4)] = 5;
+ costMap[Index2(4, 3)] = 5;
+ costMap[Index2(4, 5)] = 5;
+
+ // add game objects to the set
+ gameObjects.insert(&a);
+ gameObjects.insert(&b);
+
+ // add game objects to the quantized map
+ for (auto& g : gameObjects)
+ quantizedMap[g->position.quantized()].insert(g);
+
+ // find path
+ auto path = findPath(a.position, b.position);
+
+ // todo: smooth the path between the points
+
+ // print path
+ for (auto& p : path)
+ std::cout << "(" << p.x << ", " << p.y << ") ";
+ std::cout << std::endl;
+ // will print (0, 0) (1, 0) (1, -1) (2, -1) (3, -1) (3, 0) (3, 1) (3, 2) (3, 3) (4, 3) (4, 4)
+
+ return 0;
+}
+AI as a testing tool¶
Estimated time to read: 10 minutes
There are several ways to use AI as a testing tool.
- Analytics
- Predicting behavior;
- A/B Testing;
- Game Environment Automated Testing via AI agents;
- Test Case Generation;
- Anti-cheat systems;
Analytics¶
Analytics is the most common way to use AI as a testing tool. You can use AI to track the user behavior and use the data to improve the game. But with that you can only analyze the past.
You might want to track all user interactions, and use AI to analyze the data and give you insights on how to improve the game. This will be the core of many other AI testing tools.
The common ways to track the user interactions are:
- Send events to a server;
- Use a third-party service to track the user interactions;
- Progression funnels;
- Heatmaps;
- User paths;
- Map all deaths / kills / wins / losses;
- Store the replay of the user interactions;
Predicting behavior¶
You can train an AI model to predict the behavior of the user to abandon the game, and intervene before it happens.
In order to achieve this, you can track the user interactions and the consequences of those interactions. You can use a supervised learning algorithm to predict the behavior of the user. Once you discover the pattern, you can intervene and try to change the user behavior.
Example: If the player is loosing too much, you can give him a boost to keep him playing. Or automatically change the difficulty of the game. Another good example is when you predict the user is going to abandon the game, you can give him a reward to keep him playing, or allow him to ask for more lives on social media friends.
Forcing the user to take a break¶
Sometimes you want to avoid the user to get burned out and force him to take a break. This is a common practice in mobile games.
If your game gives rewards for plaing every day, or every session. You can use AI to predict when the user is going to play again and send him a notification to play again.
This can be a bit shady, but, another use case is to force the game to get harder if the user is playing too much. And when it loses, add a timer to unlock the game again. You can even use this moment to show ads, or ask for money to unlock the game again. Can you think in a game like this?
A/B Testing¶
A/B testing is a way to compare two versions of a configuration setting or a feature to determine which one is better. It relies on remote configuration and the statistical analysis to determine which one is better.
The process is simple:
- A developer create 2 scenarios to test. Ex.: the color of a button to buy a product (Red or Blue);
- The system will randomly select one of the scenarios to show to the user;
- The system will collect data from the user interaction;
- The system will compare the data from the two scenarios and determine which one is better;
- The system will select the best scenario to be the default one;
Game Environment Automated Testing via AI agents¶
This can be really hard to implement, but in summary is to create AIs that can play as humans and test the game. This can be used to test the game balance, the game difficulty, the game mechanics and the game performance.
If you are just trying to test game rules, or economy, you might wanna try to use a genetic algorithm to evolve the best strategy for a given game.
If you are looking for creating a bot to find hardlocks where the player might fall and not recover, or detect bugs, you might try to use a reinforcement learning algorithm.
This field is so vast that is hard to cover in a single section. I will use this in class just to see how it works.
Test Case Generation¶
You can use AI to generate test cases for your game. There are plenty of LLMs online that can can read your code and generate test cases for you.
Anti-cheat systems¶
You can detect cheaters using AI. But you will have to be careful to not ban innocent players. You can use AI to detect patterns of cheating and intervene before it happens.
Possible patterns to detect: Speed hacks; Aim bots; Wall hacks, ESP hacks, Macros; Auto-clickers; Memory hacks. and much more.
Shadow banning¶
It is a common technique to ban cheaters. You can shadow-ban a cheater by making him play with other cheaters only. This way, the cheater will not know he is banned, but he will only play with other cheaters. This can be done using AI to detect the cheaters and put them in the same match.
Serious Sam 3: BFE (Serious Digital Edition):¶
The protagonist encounters an invincible, extremely fast and screaming scorpion-like enemy, making the game nearly impossible to progress.
Game Dev Tycoon:¶
In the pirated versions, players find themselves struggling to make a profit as their virtual game studio is plagued by piracy.
Batman: Arkham Asylum:¶
Batman's cape doesn't work properly, leading to a rather comical and dysfunctional experience.
Mirror's Edge:¶
Faith is unable to progress past a certain point due to an inability to grab a ledge, hindering the player's ability to complete the level.
Earthbound (Mother 2):¶
In pirated copies, the game triggers a constant stream of inescapable enemy encounters.
Can you think in other examples?
Min-Max Algorithm¶
Estimated time to read: 2 minutes
Commonly while you build a tree of options, (say path, decisions, states or anything else), you will have to make a decision at each node of the tree to deepen the search. The min-max algorithm is a nice and easy approach to solve this problem. It might be used in games, decision making, and other fields.
Use cases¶
Min-Max algorithms shines in places where you will have to maximize the gain and minimize the loss.
Algorithm¶
Alpha beta prunning¶
Alpha¶
- Alpha is the best value that the maximizer currently can guarantee at that level or above.
- It is the lower bound that a MAX node can be assigned.
- MAX node will only update the value of alpha if it finds a value greater than alpha.
- Starts at -∞.
Beta¶
- Beta is the best value that the minimizer currently can guarantee at that level or above.
- It is the upper bound that a MIN node can be assigned.
- MIN node will only update the value of beta if it finds a value less than beta.
- Starts at +∞.
Deep learning¶
Estimated time to read: 1 minute
https://www.youtube.com/watch?v=14tNq-fqTmQ
Flocking agents behavior assignment¶
Estimated time to read: 17 minutes
You are in charge of implementing some functions to make some AI agents flock together in a game. After finishing it, you will be one step further to render it in a game engine, and start making reactive NPCs and enemies. You will learn all the basic concepts needed to code and customize your own AI behaviors.
What is flocking?¶
Flocking is a behavior that is observed in birds, fish and other animals that move in groups. It is a very simple behavior that can be implemented with a few lines of code. The idea is that each agent will try to move towards the center of mass of the group (cohesion), and will try to align its velocity with the average velocity of the group (AKA alignment). In addition, each agent will try to avoid collisions with other agents (AKA avoidance).
Formal Notation Review
- \( \vec{F} \) means a vector \( F \) that has components. In a 2 dimensional vector it will hold \( F_x \) and \( F_y \). For example, if \( F_x = 1 \) and \( F_y = 3 \), then \( \vec{F} = (1,3) \)
- Simple math operations between vectors are done component-wise. For example, if \( \vec{F} = (1,1) \) and \( \vec{G} = (2,2) \), then \( \vec{F} + \vec{G} = (3,3) \)
- The notation \( \overrightarrow{P_{1}P_{2}} \) means the vector that goes from \( P_1 \) to \( P_2 \). It is the same as \( P_2-P_1 \)
- The modulus notation means the length (magnitude) of the vector. \( |\vec{F}| = \sqrt{F_x^2+F_y^2} \) For example, if \( \vec{F} = (1,1) \), then \( |\vec{F}| = \sqrt{2} \)
- The hat ^ notation means the normalized vector(magnitude is 1) of the vector. \( \hat{F} = \frac{\vec{F}}{|\vec{F}|} \) For example, if \( \vec{F} = (1,1) \), then \( \hat{F} = (\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}}) \)
- The hat notation over 2 points means the normalized vector that goes from the first point to the second point. \( \widehat{P_1P_2} = \frac{\overrightarrow{P_1P_2}}{|\overrightarrow{P_1P_2}|} \) For example, if \( P_1 = (0,0) \) and \( P_2 = (1,1) \), then \( \widehat{P_1P_2} = (\frac{1}{\sqrt{2}},\frac{1}{\sqrt{2}}) \)
- The sum \( \sum \) notation means the sum of all elements in the list going from
0ton-1. Ex. \( \sum_{i=0}^{n-1} \vec{V_i} = \vec{V_0} + \vec{V_1} + \vec{V_2} + ... + \vec{V_{n-1}} \)
It is your job to implement those 3 behaviors following the ruleset below:
Cohesion¶
Apply a force towards the center of mass of the group.
- The \( n \) neighbors of an agent are all the other agents that are within a certain radius \( r_c \)(
<operation ) of the agent. It doesn't include the agent itself; - Compute the location of the center of mass of the group (\( P_{CM} \));
- Compute the force that will move the agent towards the center of mass(\( \overrightarrow{F_c} \)); The farther the agent is from the center of mass, the force increases linearly up to the limit of the cohesion radius \( r_c \).

\[ P_{CM} = \frac{\sum_{i=0}^{n-1} P_i}{n} \]
\[ \overrightarrow{F_{c}} = \begin{cases} \frac{ \overrightarrow{P_{agent}P_{CM}} }{r_c} & \text{if } |\overrightarrow{P_{agent}P_{CM}}| \leq r_c \\ 0 & \text{if } |\overrightarrow{P_{agent}P_{CM}}| > r_c \end{cases} \]
Tip
Note that the maximum magnitude of \( \overrightarrow{F_c} \) is 1. Inclusive. This value can be multiplied by a constant \( K_c \) to increase or decrease the cohesion force to looks more appealing.
Cohesion Example

Separation¶
It will move the agent away from other agents when they get too close.
- The \( n \) neighbors of an agent are all the other agents that are within the separation radius \( r_s \) of the agent;
- If the distance to a neighbor is less than the separation radius, then the agent will move away from it inversely proportionally to the distance between them.
- Accumulate the forces that will move the agent away from each neighbor (\( \overrightarrow{F_{s}} \)). And then, clamp the force to a maximum value of \( F_{Smax} \).

\[ \overrightarrow{F_s} = \sum_{i=0}^{n-1} \begin{cases} \frac{\widehat{P_aP_i}}{|\overrightarrow{P_aP_i}|} & \text{if } 0 < |\overrightarrow{P_aP_i}| \leq r_s \\ 0 & \text{if } |\overrightarrow{P_aP_i}| = 0 \lor |\overrightarrow{P_aP_i}| > r_s \end{cases} \]
Tip
Here you can see that if we have more than one neighbor and one of them is way too close, the force will be very high and make the influence of the other neighbors irrelevant. This is the expected behavior.
The force will go near infinite when the distance between the agent and the \( n \) neighbor is 0. To avoid this, after accumulating all the influences from every neighbor, the force will be clamped to a maximum magnitude of \( F_{Smax} \).
\[ \overrightarrow{F_{s}} = \begin{cases} \overrightarrow{F_s} & \text{if } |\overrightarrow{F_s}| \leq F_{Smax} \\ \widehat{F_s} \cdot F_{Smax} & \text{if } |\overrightarrow{F_s}| > F_{Smax} \end{cases} \]
Tip
- You can implement those two math together, but it is better to isolate in two steps to make it easier to understand and debug.
- This is not an averaged force like the cohesion force, it is a sum of forces. So, the maximum magnitude of the force can be higher than 1.
Separation Example

Alignment¶
It is the force that will align the velocity of the agent with the average velocity of the group.
- The \( n \) neighbors of an agent are all the agents that are within the alignment radius \( r_a \) of the agent, including itself;
- Compute the average velocity of the group (\( \overrightarrow{V_{avg}} \));
- Compute the force that will move the agent towards the average velocity (\( \overrightarrow{F_{a}} \));

\[ \overrightarrow{V_{avg}} = \frac{\sum_{i=0}^{n-1} \vec{V_i}}{n} \]
Alignment Example

Behavior composition¶
The force composition is made by a weighted sum of the influences of those 3 behaviors. This is the way we are going to work, this is not the only way to do it, nor the more correct. It is just a way to do it.
- \( \vec{F} = K_c \cdot \overrightarrow{F_c} + K_s \cdot \overrightarrow{F_s} + K_a \cdot \overrightarrow{F_a} \)
This is a weighted sum! - \( \overrightarrow{V_{new}} = \overrightarrow{V_{cur}} + \vec{F} \cdot \Delta t \)
This is a simplification! - \( P_{new} = P_{cur}+\overrightarrow{V_{new}} \cdot \Delta t \)
This is an approximation!
Warning
A more precise way for representing the new position would be to use full equations of motion. But given timestep is usually very small and it even squared, it is acceptable to ignore it. But here they are anyway, just dont use them in this assignment:
- \( \overrightarrow{V_{new}} = \overrightarrow{V_{cur}}+\frac{\overrightarrow{F}}{m} \cdot \Delta t \)
- \( P_{new} = P_{cur}+\overrightarrow{V_{cur}} \cdot \Delta t + \frac{\vec{F}}{m} \cdot \frac{\Delta t^2}{2} \)
Where:
- \( \overrightarrow{F} \) is the force applied to the agent;
- \( \overrightarrow{V} \) is the velocity of the agent;
- \( P \) is the position of the agent;
- \( m \) is the mass of the agent, here it is always 1;
- \( \Delta t \) is the time frame (1/FPS);
- \( cur \) is the current value of the variable;
- \( new \) is the new value of the variable to be used in the next frame.
The \( \overrightarrow{V_{new}} \) and \( P_{new} \) are the ones that will be used in the next frame and you will have to print to the console at the end of every single frame.
Note
- For simplicity, we are going to assume that the mass of all agents is 1.
- In a real game simulation, it would be nice to apply some friction to the velocity of the agent to make it stop eventually or just clamp it to prevent the velocity get too high. But, for simplicity, we are going to ignore it.
Combined behavior examples
Alignment + Cohesion:

Separation + Cohesion:

Separation + Alignment:

All 3:

Input¶
The input consists in a list of parameters followed by a list of agents. The parameters are:
- \( r_c \) - Cohesion radius
- \( r_s \) - Separation radius
- \( F_{Smax} \) - Maximum separation force
- \( r_a \) - Alignment radius
- \( K_c \) - Cohesion constant
- \( K_s \) - Separation constant
- \( K_a \) - Alignment constant
- \( N \) - Number of agents
Every agent is represented by 4 values in the same line, separated by a space:
- \( x \) - X coordinate
- \( y \) - Y coordinate
- \( vx \) - X velocity
- \( vy \) - Y velocity
After reading the agent's data, the program should read the time frame (\( \Delta t \)), simulate the agents and then output the new position of the agents in the same sequence and format it was read. The program should keep reading the time frame and simulating the agents until the end of the input.
Data Types
All values are double precision floating point numbers to improve consistency between different languages.
Input Example¶
In this example we are going to test only the cohesion behavior. The input is composed by the parameters and 2 agents.
1.000 0.000 0.000 0.000 1.000 0.000 0.000 2
+0.000 0.500 0.000 0.000
+0.000 -0.500 0.000 0.000
+0.125
+Output¶
The expected output is the position and velocity for each agent after the simulation step using the time frame. After printing each simulation step, the program should wait for the next time frame and then simulate the next step. All values should have exactly 3 decimal places and should be rounded to the nearest.
Grading¶
10 points total:
- 3 Points – by following standards;
- 2 Points – properly submitted in Canvas;
- 5 Points – passed on test cases;
Stable Diffusion¶
Estimated time to read: 6 minutes
Introduction¶
The steps to understand GenAI are as follows:
- Artificial Neurons, types of neurons, and activation functions
- Networks of Neurons, topology, and training
- Stable Diffusion
TLDR;¶
- Install the latest Python. Add it to the environment PATH. [Windows:] Install directly to C drive and select the 3.10.6 version of python, install for all users;
- Download latest release from Automatic1111 or clone the repository. Clone/Download it to a subfolder on C drive. Dont use your personal folder.;
- Unzip the release. Run the
webuibash file [Windows:]webui.bat; - Select a bunch of the images that you are willing to train the network with;
- Go to
traintab and create a tag for your embeddings; - Use your tag to generate a new image;
Extras:
- Go to Hugging face and download 2 Stable Diffusion models. They should be compatible (ex. both should be v2.1 or 1.5).;
- Go to checkpoin merger, and merge two or more models.
Artificial Neurons¶
graph LR
+ I1[Input1] --> |Weight1| N[Neuron]
+ I2[Input2] --> |Weight2| N[Neuron]
+ N --> |Activation| O[Output]Artificial neurons are the basic building blocks of neural networks and all the other Generative AI algorithms. Neuron networks are composed by:
- Inputs: The inputs are the data that the network will process. They are the data that the network will use to make decisions. In the case of the neural networks, the inputs are the data that will be processed by the neurons.
- Weights: The weights are the parameters that the network will learn. They are the parameters that the network will use to make decisions. In the case of the neural networks, the weights are the parameters that will be learned by the neurons.
- Functions: summing, activation and bias.
- Summing: The summing function is the function that will sum the inputs and the weights.
- Activation: The activation function is the function that will decide if the neuron will fire or not or how it will fire or propagate.
- Bias: The bias is a weight that will be added to the summing function.
- Output: The output is the result of the neuron. It can be used to feed another neuron or to be the final result of the network.
Depending on how the neuron activates, which math operator it uses to sum the inputs and the weights, and how it propagates the output, the neuron can be classified as: Linear, Binary, Sigmoid, Tanh, and many others that follow math functions to combine data and propagate the output.
Topologies¶
Generative AI¶
Generative AI is the new trend in AI. It is the field of AI that is focused on creating new data from existing data using neural networks and other algorithms. Here we will focus on the Stable Diffusion ones.
Stable diffusion pipeline:
graph TD
+ Start --> GausiannNoise
+ Start --> prompt
+ subgraph CLIP
+ direction LR
+ tokenizer --> TokenToEmbedding[Token to Embeddings]
+ end
+ prompt[Prompt] --> CLIP
+ CLIP --> embeddings[Text Embeddings]
+ embeddings --> unet[Text Conditioned 'U-Net']
+ Latents --> |Loop N times| unet
+ unet --> CoditionedLatents[Conditioned Latents]
+ CoditionedLatents --> Scheduler[Scheduler 'Reconstruct'\nto add noise]
+ Scheduler --> Latents
+ GausiannNoise[Gaussian Noise] --> Latents
+ CoditionedLatents --> VAE[Variational\nAutoencoder\nDecoder]
+ VAE --> |Image|OutputSetup the repos¶
Estimated time to read: 10 minutes
- Read about Privacy and FERPA compliance here
- This one, for in class coding assignments. https://github.com/InfiniBrains/Awesome-GameDev-Resources
- MoBaGEn, for interactive assignments. https://github.com/InfiniBrains/mobagen
- Install
CLion(hasCMakeembedded) or see #development-tools - Those repositories are updated constantly. Pay attention to syncing your repo frequently.
Types of coding assignments¶
There are two types of coding assignments:
- Algorithm: Beecrowd - This is an automatic grading system, and I am still creating assignments for it. I will try my best to make it work through it. If it does not work, you could just submit the code on canvas and I will grade it manually. Those should solved using C++ ;
-
Interactive: For the interactive assignments you can choose whatever Game Engine you like, but I recommend you to use the framework I created for you: MoBaGEn. If you use a Game Engine or custom solution for that, you will have to create all debug interfaces to showcase and debug AI wich includes, but it is not limited to:
- Draw vectors to show forces applied by the AI;
- Menus to change AI parameters;
Danger
Under no circunstaces, you should make your algorithm solutions public. Be aware that I spend so much time creating them and it is hard to me to always create new assignments.
Code assignments¶
Warning
If you are a enrolled in a class that uses this material, you SHOULD use the institutional and internal git server to be FERPA compliant. If you want to use part of this assignments to build your portfolio I recommend you to use github and make only the interactive assignment public. If you are just worried about privacy concerns, you can use a private repo on github.
- Create an account on github.com or any
githosting on your preference; -
Fork repos or duplicate the target repo on your account;
-
Add my user to your repo to it with
readrole. My userid istolstenko(or your professor) on github, for other options, talk with me in class. Follow this; - Send me a message on canvas with the link to your repo;
Recordings¶
In all interactive assignmets, you will have to record a 5 minute video explaing your code. Use OBS or any software you prefer to record your screen while you explain your code. But for this one, just send me the video showing the repo and the repo invites sent to me.
Development tools¶
I will be using CMake for the classes, but you can use whatever you want. Please read this to understand the C++ toolset.
In this class, I am going to use CLion as the IDE, because it has nice support for CMake and automated tests.
If you want to use Visual Studio , be assured that you have the C++ Desktop Development workload installed, more info this. And then go to Individual Components and install CMake Tools for Windows .
Note
If you use Visual Studio , you won't be able to use the automated testing system that comes with the assignments.
[OPINION]: If you want to use a lightweight environment, don't use VS Code for C++ development. Period. It is not a good IDE for that. It is preferred to code via sublime, notepad, vim, or any other text editor and then compile your code via terminal, and debug via gdb, than using VS Code for C++ development.
Openning the Repos¶
- (Fork and) clone the repos;
- Open
CLionor yor preferredIDEwithCMakesupport; - Open the
CMakeLists.txtas project from the root of the repo; - Wait for the setup to finish (it will download the dependencies automatically, such as
SDL);
For the interactive assignments, use this repo and the assignments are located in the examples folder.
For the algorithmic assignments, use this repo and the assignments are located in the courses/artificialintelligence/assignments folder. I created some automated tests to help you debug your code and ensure 100% of correctness. To run them, follow the steps (only available though CLion or terminal, not Visual Studio ):
- Go to the executable drop down selection (top right, near the green
runordebugbutton) and select the assignment you want to run. It will be something likeai-XXXwhereXXXis the name of the assignment; - If you want to test your assignment against the automated inputs/outputs, select the
ai-XXX-testbuild target. Here you should use thebuildbutton, not therunordebugbutton. It will run the tests and show the results in theConsoletab;
Game of Life¶
Estimated time to read: 3 minutes
You are applying for an internship position at Valvule Corp, and they want to test your abilities to manage states. You were tasked to code the Conway's Game of Life.
The game consists in a C x L matrix of cells (Columns and Lines), where each cell can be either alive or dead. The game is played in turns, where each turn the state of the cells are updated according to the following rules:
- Any live cell with fewer than two live neighbours dies, as if by underpopulation.
- Any live cell with two or three live neighbours lives on to the next generation.
- Any live cell with more than three live neighbours dies, as if by overpopulation.
- Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.

The map is continuous on every direction, so the cells on the edges have the cells on the opposite edge as neighbors. It is effectively a toroidal surface.

Input¶
The first line of the input are three numbers, C, L and T, the number of columns, lines and turns, respectively. The next L lines are the initial state of the cells, where each line has C characters, either . for dead cells or # for alive cells.
Output¶
The output should be the state of the cells after T turns, in the same format as the input.
References¶
Maze generation via Depth First Search¶
Estimated time to read: 11 minutes
You are in charge of implementing a new maze generator for a procedurally generated game. The game is a 2D top-down game, where every level is composed by squared rooms blocked by walls. The rooms are generated by a maze generator, and the walls can be removed to create paths.
There are many ways to implement a maze generation and one of the most common is the Depth First Search algorithm combined with a Random Walk. The algorithm is simple and can be implemented in a recursive or interactive way. The suggested algorithm is as follows:
- All walls are up;
- Add the top left cell to the stack;
- While the stack is not empty:
- If the stack top cell has visitable neighbor(s):
- Mark the top cell as visited;
- List visitable neighbors;
- Choose a neighbor (see below);
- Remove the wall between the cell and the neighbor;
- Add the neighbor to the stack;
- Else:
- Remove the top cell from the stack, backtracking;
- If the stack top cell has visitable neighbor(s):
Simulation
If you simulate the algorithm visually, the result would be something similar to the following

Random Number Generation¶
In order to be consistent with all languages and random functions the pseudo random number generation should follow the following sequence of 100 numbers:
[72, 99, 56, 34, 43, 62, 31, 4, 70, 22, 6, 65, 96, 71, 29, 9, 98, 41, 90, 7, 30, 3, 97, 49, 63, 88, 47, 82, 91, 54, 74, 2, 86, 14, 58, 35, 89, 11, 10, 60, 28, 21, 52, 50, 55, 69, 76, 94, 23, 66, 15, 57, 44, 18, 67, 5, 24, 33, 77, 53, 51, 59, 20, 42, 80, 61, 1, 0, 38, 64, 45, 92, 46, 79, 93, 95, 37, 40, 83, 13, 12, 78, 75, 73, 84, 81, 8, 32, 27, 19, 87, 85, 16, 25, 17, 68, 26, 39, 48, 36];
+Every call to the random function should return the current number the index is pointing to, and then increment the index. If the index is greater than 99, it should be reset to 0.
Direction decision making¶
In order to give consistency on how to decide the direction of the next cell, the following procedure should be followed:
- List all visitable neighbors of the current cell;
- Sort the list of visitable neighbors by clockwise order, starting from the top neighbor: UP, RIGHT, DOWN, LEFT;
- If there is one visitable, do not call random, just return the first neighbor found;
- If there are two or more visitable neighbors, call random and return the neighbor at the index of the random number modulo the number of visitable neighbors.
vec[i]%visitableCount
Input¶
The input is a single line with three 32 bits unsigned integer numbers, C, L and I, where C and L are the number of columns and lines of the maze, respectively, and I is the index of the first random number to be used> I can varies from 0 to 99.
In this case, our map will have 2 columns, 2 lines and the first random number to be used is the first one, 72 because it is pointed by the index 0.
Output¶
Every line is a combination of underscore _, pipe | and empty characters. The _ character represents a horizontal wall and the | character represents a vertical wall.
The initial state of the 2 x 2 map is:
In order to interactively solve this, we will add (0,0) to the queue.
The neighbors of the current top (0,0) are RIGHT and DOWN, (0,1) and (1,0) respectively.
Following the clockwise order, the sorted neighbor list will be [(0,1), (1,0)].
We have more than one neighbor, so we call random. The current random index is 0, so the random number is 72 and we increment the index.
The random number is 72 and the number of neighbors is 2, so the index of the neighbor to be chosen is 72 % 2 = 0, so we choose the neighbor (0,1), the RIGHT one.
The wall between (0,0) and (0,1) is removed, and (0,1) is added to the queue. Now it holds [(0,0), (0,1)]. The map is now:
Now the only neighbor of (0,1) is DOWN, (1,1). So no need to call random, we just choose the only neighbor.
The wall between (0,1) and (1,1) is removed, and (1,1) is added to the queue. Now it holds [(0,0), (0,1), (1,1)]. The map is now:
Now the only neighbor of (1,1) is LEFT, (1,0). So no need to call random, we just choose the only neighbor.
The wall between (1,1) and (1,0) is removed, and (1,0) is added to the queue. Now it holds [(0,0), (0,1), (1,1), (1,0)]. The map is now:
Now, the current top of the queue is (1,0) and there isn't any neighbor to be visited, so we remove the current top (1,0) from the queue and backtrack. The queue is now [(0,0), (0,1), (1,1)].
The current top is (1,1) and there isn't any neighbor to be visited, so we remove (1,1) from the queue and backtrack. The queue is now [(0,0), (0,1)].
The current top is (0,1) and there isn't any neighbor to be visited, so we remove (0,1) from the queue and backtrack. The queue is now [(0,0)].
The current top is (0,0) and there isn't any neighbor to be visited, so we remove (0,0) from the queue and backtrack. The queue is now empty and we finish priting the map state. The final map is:
And this the only one that should be printed. No intermediary maps should be printed.
Example 1¶
Input 1¶
Output 1¶
Example 2¶
Input 2¶
Output2¶
Pseudo Random Number Generation¶
Estimated time to read: 7 minutes
You are a game developer in charge to create a fast an reliable random number generator for a procedural content generation system. The requirements are:
- Do not rely on external libraries;
- Dont need to be cryptographically secure;
- Be blazing fast;
- Fully reproducible via automated tests if used the same seed;
- Use exactly 32 bits as seed;
- Be able to generate a number between a given range, both inclusive.
So you remembered a strange professor talking about the xorshift algorithm and decided it is good enough for your use case. And with some small research, you found the Marsaglia "Xorshift RNGs". You decided to implement it and test it.
XorShift¶
The xorshift is a family of pseudo random number generators created by George Marsaglia. The xorshift is a very simple algorithm that is very fast and have a good statistical quality. It is a very good choice for games and simulations.
xorshift is the process of shifting the binary value of a number and then xor'ing that binary to the original value to create a new value.
value = value xor (value shift by number)
The shift operators can be to the left << or to the right >>. When shifted to the left, it is the same thing as multiplying by 2 at the power of the number. When shifted to the right, it is the same thing as dividing.
Note
The value of a << b is the unique value congruent to \(a * 2^{b}\) modulo \( 2^{N} \) where \( N \) is the number of bits in the return type (that is, bitwise left shift is performed and the bits that get shifted out of the destination type are discarded).
The value of \( a >> b \) is \( a/2^{b} \) rounded down (in other words, right shift on signed a is arithmetic right shift).
The xorshift algorithm from Marsaglia is a combination of 3 xorshifts, the first one is the seed (or the last random number generated), and the next ones are the result of the previous xorshift. The steps are:
xorshiftthe value by13bits to the left;xorshiftthe value by17bits to the right;xorshiftthe value by5bits to the left;
At the end of this 3 xorshifts, the current state of the value is your current random number.
In order to clamp a random number the value between two numbers (max and min), you should follow this idea:
value = min + (random % (max - min + 1))
Input¶
Receives the seed S, the number N of random numbers to be generated and the range R1 and R2 of the numbers should be in, there is no guarantee the range numbers are in order. The range numbers are both inclusive. S and N are both 32 bits unsigned integers and R1 and R2 are both 32 bits signed integers.
Output¶
The list of numbers to be generated, one per line. In this case, it would be only one and the random number should be clamped to be between 0 and 99.
seed in decimal: 1
+seed in binary: 0b00000000000000000000000000000001
+
+seed: 0b00000000000000000000000000000001
+seed << 13: 0b00000000000000000010000000000000
+seed xor (seed << 13): 0b00000000000000000010000000000001
+
+seed: 0b00000000000000000010000000000001
+seed >> 17: 0b00000000000000000000000000000000
+seed xor (seed >> 17): 0b00000000000000000010000000000001
+
+seed: 0b00000000000000000010000000000001
+seed << 5: 0b00000000000001000000000000100000
+seed xor (seed << 5): 0b00000000000001000010000000100001
+
+The final result is 0b00000000000001000010000000100001 which is 270369 in decimal.
+Now in order to clamp it to be between 0 and 99, we do:
value = min + (random % (max - min + 1))
+value = 0 + (270369 % (99 - 0 + 1))
+value = 0 + (270369 % 100)
+value = 0 + 69
+value = 69
+So this output would be:
Advanced Artificial Intelligence¶
Estimated time to read: 12 minutes
Students with a firm foundation in the basic techniques of artificial intelligence for games will apply their skills to program advanced pathfinding algorithms, artificial opponents, scripting tools and other real-time drivers for non-playable agents. The goal of the course is to provide finely-tuned artificial competition for players using all the rules followed by a human.
Requirements¶
- Artificial Intelligence for Games
Texbook¶
- AI for Games, Third Edition: 9781138483972: Millington, Ian
Student-centered Learning Outcomes¶
Upon completion of the Advanced AI for Games, students should be able to:
Objective Outcomes¶
- Recall fundamental AI techniques for games;
- Identify key components of advanced AI, including pathfinding algorithms and scripting tools
- Demonstrate a deep understanding of advanced AI principles in gaming;
- Apply knowledge to program advanced AI components for finely-tuned competition;
- Evaluate the effectiveness and ethical considerations of advanced AI in game design;
- Design and implement innovative AI-driven features for enhanced gameplay;
- Integrate advanced AI seamlessly into game systems for cohesive environments;
- Consider societal impact and consequences of AI applications in gaming;
Schedule for Spring 2024¶
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use the github repo as the source of truth for the schedule and materials. The materials provided in canvas are just a copy for archiving purposes and might be outdated.
College dates for the Spring 2024 semester:
| Date | Event |
|---|---|
| Jan 16 | Classes Begin |
| Jan 16 - 22 | Add/Drop |
| Feb 26 - March 1 | Midterms |
| March 11 - March 15 | Spring Break |
| March 25 - April 5 | Registration for Fall Classes |
| April 5 | Last Day to Withdraw |
| April 8 - 19 | Idea Evaluation |
| April 12 | No Classes - College remains open |
| April 26 | Last Day of Classes |
| April 29 - May 3 | Finals |
| May 11 | Commencement |
- Introduction¶
- Week 1. 2024/01/15
- Topic: AI for games, review of basic AI techniques
- Activities:
- Read all materials shared on Canvas;
- Do all assignments on Canvas;
- Wave Function Collapse¶
- Week 2. 2024/01/22
- Topic: Wave Function Collapse
-
Applying A* into continuous space¶
- Week 3. 2024/01/29
- Topic: Applying A* into continuous spaces
-
Applying A* into continuous spaces¶
- Week 4. Date: 2024/02/05
- Topic: Applying A* into continuous spaces
-
Testing your AI Agent and rules¶
- Week 5. 2024/02/12
- Topic: Testing your AI Agent, building meaningful tests, metrics, evaluation and machinations
- Testing your AI Agent¶
- Week 6. 2024/02/19
- Topic: Testing your AI Agent, building meaningful tests, metrics, evaluation and machinations
- Midterms¶
- Week 7. Date: 2024/02/26
- Topic: Work sessions
-
Min max¶
- Week 8. 2024/03/04
- Topic: Min Max
-
Break¶
- Week 09. 2024/03/11
- Topic: Spring BREAK. No classes this week.
-
Monte Carlo Tree Search¶
- Week 10. 2024/03/18
- Topic: Monte Carlo Tree Search
-
Chess¶
- Week 11. 2024/03/25
- Topic: Chess
-
Chess¶
- Week 12. 2024/04/01
- Topic: Chess
-
Chess¶
- Week 13. 2024/04/08
- Topic: Chess
-
Chess¶
- Week 14. 2024/04/15
- Topic: Chess
- Chess¶
- Week 15. 2024/04/22
- Topic: Work sessions for chess
- Finals¶
- Week 16. 2024/04/26
- Topic: Finals Week / competition
Old schedule for reference
Schedule for Fall 2023¶
Relevant dates for the Fall 2023 semester:
- 09-10 Oct 2023 - Midterms Week
- 20-24 Nov 2023 - Thanksgiving Break
- 11-15 Dec 2023 - Finals Week
- Introduction¶
- Week 1. 2023/08/28
- Topic: Introduction
- Formal Assignment: Flocking at Beecrowd
- Interactive Assignment: Flocking at MoBaGEn
-
 Behavioral Agents¶
Behavioral Agents¶
- Week 2. 2023/09/04
- Topic: Flocking
- Formal Assignment: Flocking at Beecrowd
- Interactive Assignment: Flocking at MoBaGEn
-
Finite Automata¶
- Week 3. 2023/09/11
- Topic: Automata Finite and 2D Grids
- Formal Assignment: Game of Life at Beecrowd
- Interactive Assignment: Game of Life at MoBaGEn
-
Random Numbers¶
- Week 4. Date: 2023/09/18
- Topic: Pseudo Random Number Generation
- Formal Assignment: PRNG at Beecrowd
-
DFS¶
- Week 5. 2023/09/25
- Topic: Depth First Search, Random walk, Maze Generation
- Formal Assignment: Maze at Beecrowd
- Interactive Assignment: Maze at Mobagen
-
Path finding¶
- Week 6. 2023/10/02
- Topic: Breadth First Search and Path Finding A*
- Interactive Assignment: Catch the Cat
- Midterms¶
- Week 7. Date: 2023/10/09
- Topic: Catch the Cat Challenge and Competition
- Catch the Cat
-
Spatial Quantization¶
- Week 8. 2023/10/16
- Topic: Spatial Quantization and Partitioning
- Readings: Spatial Quantization
- Formal Assignment: Hide and Seek
-
Spatial Quantization¶
- Week 9. 2023/10/23
- Topic: Spatial Quantization and Partitioning
- Readings: Spatial Quantization
- Formal Assignment: Hide and Seek
-
Noise Functions¶
- Week 10. 2023/10/30
- Topic: Noise functions
- Formal Assignment:
- Interactive Assignment: Scenario Generation
-
 Procedural Generation¶
Procedural Generation¶
- Week 11. 2023/11/06
- Topic: Procedural Content Generation - Scenario
- Formal Assignment:
- Interactive Assignment: Scenario Generation
- Procedural Generation¶
- Week 12. 2023/11/13
- Topic: Procedural Content Generation - Scenario
- Formal Assignment:
- Interactive Assignment: Scenario Generation
-
Break¶
- Week 13. 2023/11/20
- Topic: BREAK. No classes
- Work sessions¶
- Week 14. 2023/11/27
- Topic: Work sessions for final project
- Work sessions¶
- Week 15. 2023/12/04
- Topic: Work sessions for final project
-
Finals¶
- Week 16. 2023/12/11
- Topic: Final Presentations
slide test: test
LangChain
Space quantization¶
Estimated time to read: 22 minutes
Space quantization is a way to sample continuous space, and it can to be used in in many fields, such as Artificial Intelligence, Physics, Rendering, and more. Here we are going to focus primarily Spatial Quantization for AI, because it is the base for pathfinding, line of sight, field of view, and many other techniques.
Some of the most common techniques for space quantization are: grids, voxels, graphs, quadtrees, octrees, KD-trees, BSP, Spatial Hashing and more. Another notable techniques are line of sight(or field of view), map flooding, caching, and movement zones.
Grids¶
Grids are the most common technique for space quantization. It is a very simple technique, but it is very powerful. It consists in dividing the space in a grid of cells, and then we can use the cell coordinates to represent the space. The most common grid is the square grid, but we can use hexagonal and triangular grids, you might find some irregular shapes useful to exploit the space conformation better.
Square Grid¶
The square grid is a regular grid, where the cells are squares. It is very simple to implement and understand.
There are some ways to store data for squared grids. Arguably you could 2D arrays, arrays of arrays or vector of vectors, but depending on the way you implement it, it can hurt the performance. Example: if you use an array of arrays or vector of vectors, where every entry from de outer array is a pointer to the inner array, you will have a lot of cache misses, because the inner arrays are not contiguous in memory.
Notes on cache locality¶
So in order do increase data locality for squared grids, you can use a single array, and then use the following formula to calculate the index of the cell. We call this strategy matrix flattening.
int arrray[width * height]; // 1D array with the total size of the grid
+int index = x + y * width; // index of the cell at x,y
+There is a catch here, given we usually represent points as X and Y coordinates, we need to be careful with the order of the coordinates. While you are iterating over all the matrix, you need to iterate over the Y coordinate first, and then the X coordinate. This is because the Y coordinate is the one that changes the most, so it is better to have it in the inner loop. By doing that, you will have better cache locality and effectively the index will be sequential.
vector<YourStructure> data; // data is filled with some data elsewhere
+for(int y = 0; y < height; y++) {
+ for(int x = 0; x < width; x++) {
+ // do something with the cell at index x,y
+ data[y * width + x] = yourstrucure;
+ // it is the same as: data[y][x] = yourstructure;
+ }
+}
+Quantization and dequantization of square grids¶
If your world is based on floats, you can use the square by using the floor function or just cast to integer type, because the default behavior of casting from float to integer is to floor it. Example: In the case of a quantization resolution of size of 1.0f, everything between 0 and 1 will be in the cell (0,0), everything between 1 and 2 will be in the cell (1,0), and so on.
Vector2int quantize(Vector2f position, float resolution) {
+ return Vector2int((int)floor(position.x/resolution), (int)floor(position.y/resolution));
+}
+If you need to get the center of the cell in the world coordinates following the quantization resolution, you can use the following code.
Vector2f dequantize(Vector2int index, float resolution) {
+ return Vector2f((float)index.x * resolution + resolution/2.0f, (float)index.y * resolution + resolution/2.0f);
+}
+If you need to get the corners of the cell following the quantization resolution, you can use the following code.
Rectangle2f cell_bounds(Vector2int index, float resolution) {
+ return {index.x * resolution, index.y * resolution, (index.x+1) * resolution, (index.y+1) * resolution};
+}
+If you need to get the neighbors of a cell, you can use the following code.
std::vector<Vector2int> get_neighbors(Vector2int index) {
+ return {{index.x-1, index.y}, {index.x, index.y-1},
+ {index.x+1, index.y}, {index.x, index.y+1}};
+}
+We already understood the idea of matrix flattening to improve efficiency, we can use it to represent a maze. But in a maze, we have walls to
Imagine that you are willing to be as memory efficient and more cache friendly as possible. You can use a single array to store the maze, and you can use the following formula to convert from matrix indexes to the index of the cell in the array.
## Hexagonal Grid
+
+Hexagonal grid is an extension of a square grid, but the cells are hexagons. It feels nicer to human eyes because we have more equally distant neighbors. If used as subtract for pathfinding, it can be more efficient because the path can be more straight.
+
+It can be implemented as single dimension array, but you need to be careful with shift that happens in different odd or even indexes. You can use the following formula to calculate the index of the cell. In this world quantization can be in 4 conformations, depending on the rotation of the hexagon and the alignment of the first cell.
+
+1. Point pointy top hexagon with first line aligned to the left:
+``` text
+ / \ / \ / \
+ | A | B | C |
+ \ / \ / \ / \
+ | D | E | F |
+ / \ / \ / \ /
+ | G | H | I |
+ \ / \ / \ /
+- Point pointy top hexagon with first line aligned to the right
- Flat top hexagon with first column aligned to the top:
- Flat top hexagon with first column aligned to the bottom:
Quantization and dequantization of hexagonal grids¶
For simplicity, we are going to use the first conformation, where the first line is aligned to the left, and the hexagons are pointy top. The quantization is done by using the following formula.
// I am assuming that the hexagon is pointy top, and the first line is aligned to the left
+// I am also assuming that the hexagon is centered in the cell, and the top left corner is at (0,0),
+// y axis is pointing down and x axis is pointing right
+// this dont work for all the cases, but it is a good approximation for locations near the center of the hexagon
+/*
+ / \ / \ / \
+ | A | B | C |
+ \ / \ / \ / \
+ | D | E | F |
+ / \ / \ / \ /
+ | G | H | I |
+ \ / \ / \ /
+ */
+Vector2int quantize(Vector2f position, float hexagonSide) {
+ int y = (position.y - hexagonSide)/(hexagonSide * 2);
+ int x = y%2==0 ?
+ (position.x - hexagonSide * sqrt3over2) / (hexagonSide * sqrt3over2 * 2) : // even lines
+ (position.x - hexagonSide * sqrt3over2 * 2)/(hexagonSide * sqrt3over2 * 2) // odd lines
+ return Vector2int(x, y);
+}
+Vector2f dequantize(Vector2int index, float hexagonSide) {
+ return Vector2f(index.y%2==0 ?
+ hexagonSide * sqrt3over2 + index.x * hexagonSide * sqrt3over2 * 2 : // even lines
+ hexagonSide * sqrt3over2 * 2 + index.x * hexagonSide * sqrt3over2 * 2, // odd lines
+ hexagonSide + index.y * hexagonSide * 2);
+}
+You will have to figure out the formula for the other conformations. Or send a merge request to this repository adding more information.
Voxels and Grid 3D¶
Grids in 3D works the same way as in 2D, but you need to use 3D vectors/arrays or voxel volumes. Most concepts applies here. If you want to expand this section, send a merge request.
Quadtree¶
Quadtree is a tree data structure where each node has 4 children. It is used to partition a space in 2D. It is used to optimize collision detection, pathfinding, and other algorithms that need to iterate over a space. It is also used to optimize rendering, because you can render only the visible part of the space.
Quadtree implementation¶
Quadtree is a recursive data structure, so you can implement it using a recursive data structure. The following code is a simple implementation of a quadtree.
// this code is not tested, but it should work. It is just an example and send a merge request if you find any errors.
+// node
+template<class T>
+struct DataAtPosition {
+ Vector2f center;
+ T data;
+};
+
+template<class T>
+struct QuadtreeNode {
+ Rectangle2f bounds;
+ std::vector<DataAtPosition<T>> data;
+ std::vector<QuadtreeNode<T>> children;
+};
+
+// insert
+template<class T>
+void insert(QuadtreeNode<T>& root, DataAtPosition<T> data) {
+ if (root.children.empty()) {
+ root.data.push_back(data);
+ if (root.data.size() > 4) {
+ root.children.resize(4);
+ for (int i = 0; i < 4; ++i) {
+ root.children[i].bounds = root.bounds;
+ }
+ root.children[0].bounds.max.x = root.bounds.center().x; // top left
+ root.children[0].bounds.max.y = root.bounds.center().y; // top left
+ root.children[1].bounds.min.x = root.bounds.center().x; // top right
+ root.children[1].bounds.max.y = root.bounds.center().y; // top right
+ root.children[2].bounds.min.x = root.bounds.center().x; // bottom right
+ root.children[2].bounds.min.y = root.bounds.center().y; // bottom right
+ root.children[3].bounds.max.x = root.bounds.center().x; // bottom left
+ root.children[3].bounds.min.y = root.bounds.center().y; // bottom left
+ for (auto& data : root.data) {
+ insert(root, data);
+ }
+ root.data.clear();
+ }
+ } else {
+ for (auto& child : root.children) {
+ if (child.bounds.contains(data.center)) {
+ insert(child, data);
+ break;
+ }
+ }
+ }
+}
+
+// query
+template<class T>
+void query(QuadtreeNode<T>& root, Rectangle2f bounds, std::vector<DataAtPosition<T>>& result) {
+ if (root.bounds.intersects(bounds)) {
+ for (auto& data : root.data) {
+ if (bounds.contains(data.center)) {
+ result.push_back(data);
+ }
+ }
+ for (auto& child : root.children) {
+ query(child, bounds, result);
+ }
+ }
+}
+Quadtree optimization¶
The quadtree is a recursive data structure, so it is not cache friendly. You can optimize it by using a flat array instead of a recursive data structure.
Octree¶
Section WiP. Send a merge request if you want to contribute.
KD-Tree¶
KD-Trees are a tree data structure that are used to partition a spaces in any dimension (2D, 3D, 4D, etc). They are used to optimize collision detection(Physics), pathfinding(AI), and other algorithms that need to iterate over a space. Also they are also used to optimize rendering, because you can render only the visible part of the space. Pay attention that KD-Trees are not the same as Quadtree and Octrees, even if they are similar.
In KD-trees, every node defines an orthogonal partition plan that alternate every deepening level of the tree. The partition plan is defined by a dimension, a value. The dimension is the axis that is used to partition the space, and the value is the position of the partition plan. The partition plan is orthogonal to the axis, so it is a line in 2D, a plane in 3D, and a hyperplane in 4D.
BSP Tree¶
BSP inherits almost all characteristics of KD-Trees, but it is not a tree data structure, it is a graph data structure. The main difference is to instead of being orthogonal you define the plane of the section. The plane is defined by a point and a normal. The normal is the direction of the plane, and the point is a point in the plane.
Spatial Hashing¶
Spatial hashing is a data structure that is used to partition a space. It consists in a hash table where the keys are the positions of the elements, and the values are the elements in buckets. It is very fast to insert and query elements. But it is not good for iteration, because it is not cache friendly.
Usually when you want to use a spatial hashing, you create hash functions for the bucket keys, there is no limit on how you do that, but you have to keep in mind that the hash functions have to be fast and have to be good for the distribution of the elements. Here is a good example of a hashing function for 2D vectors.
namespace std {
+ template<>
+ struct hash<Vector2f> {
+ // I am assuming size_t is 64 bits and the float is 32 bits
+ size_t operator()(const Vector2f& v) const {
+ // get the bits of the float in a integer
+ uint64_t x = *(uint64_t*)&v.x;
+ uint64_t y = *(uint64_t*)&v.y;
+ // mix the bits of the floats
+ uint64_t hash = x | (y << 32);
+ return hash;
+ }
+ };
+}
+Pay attention that the hashing function above generates collisions, so you have to use a data structure that can handle collisions. You will use datastructures like unordered_map<Vector2D, unordered_set<DATATYPE>> or unordered_map<Vector2D, vector<DATATYPE>>. The first one is better for insertion and query, but it is not cache friendly.
To avoid having one bucket per every possible position, you have to setup properly the dimension of the bucket, a good sugestion is to alwoys floor the position and have buckets dimension of 1.0f. That would be good enough for most cases.
'.concat(d,"
"))),k(d))){"none"==d.style.display&&(d.style.display="block");var c=document.createElement("div");c.className="ginlined-content",c.appendChild(d),s=c}if(r){var u=document.getElementById(r);if(!u)return!1;var g=u.cloneNode(!0);g.style.height=t.height,g.style.maxWidth=t.width,h(g,"ginlined-content"),s=g}if(!s)return console.error("Unable to append inline slide content",t),!1;o.style.height=t.height,o.style.width=t.width,o.appendChild(s),this.events["inlineclose"+r]=a("click",{onElement:o.querySelectorAll(".gtrigger-close"),withCallback:function(e){e.preventDefault(),l.close()}}),T(n)&&n()}function Z(e,t,i,n){var s=e.querySelector(".gslide-media"),l=function(e){var t=e.url,i=e.allow,n=e.callback,s=e.appendTo,l=document.createElement("iframe");return l.className="vimeo-video gvideo",l.src=t,l.style.width="100%",l.style.height="100%",i&&l.setAttribute("allow",i),l.onload=function(){h(l,"node-ready"),T(n)&&n()},s&&s.appendChild(l),l}({url:t.href,callback:n});s.parentNode.style.maxWidth=t.width,s.parentNode.style.height=t.height,s.appendChild(l)}var $=function(){function e(){var i=arguments.length>0&&void 0!==arguments[0]?arguments[0]:{};t(this,e),this.defaults={href:"",sizes:"",srcset:"",title:"",type:"",description:"",alt:"",descPosition:"bottom",effect:"",width:"",height:"",content:!1,zoomable:!0,draggable:!0},L(i)&&(this.defaults=l(this.defaults,i))}return n(e,[{key:"sourceType",value:function(e){var t=e;if(null!==(e=e.toLowerCase()).match(/\.(jpeg|jpg|jpe|gif|png|apn|webp|avif|svg)/))return"image";if(e.match(/(youtube\.com|youtube-nocookie\.com)\/watch\?v=([a-zA-Z0-9\-_]+)/)||e.match(/youtu\.be\/([a-zA-Z0-9\-_]+)/)||e.match(/(youtube\.com|youtube-nocookie\.com)\/embed\/([a-zA-Z0-9\-_]+)/))return"video";if(e.match(/vimeo\.com\/([0-9]*)/))return"video";if(null!==e.match(/\.(mp4|ogg|webm|mov)/))return"video";if(null!==e.match(/\.(mp3|wav|wma|aac|ogg)/))return"audio";if(e.indexOf("#")>-1&&""!==t.split("#").pop().trim())return"inline";return e.indexOf("goajax=true")>-1?"ajax":"external"}},{key:"parseConfig",value:function(e,t){var i=this,n=l({descPosition:t.descPosition},this.defaults);if(L(e)&&!k(e)){O(e,"type")||(O(e,"content")&&e.content?e.type="inline":O(e,"href")&&(e.type=this.sourceType(e.href)));var s=l(n,e);return this.setSize(s,t),s}var r="",a=e.getAttribute("data-glightbox"),h=e.nodeName.toLowerCase();if("a"===h&&(r=e.href),"img"===h&&(r=e.src,n.alt=e.alt),n.href=r,o(n,(function(s,l){O(t,l)&&"width"!==l&&(n[l]=t[l]);var o=e.dataset[l];I(o)||(n[l]=i.sanitizeValue(o))})),n.content&&(n.type="inline"),!n.type&&r&&(n.type=this.sourceType(r)),I(a)){if(!n.title&&"a"==h){var d=e.title;I(d)||""===d||(n.title=d)}if(!n.title&&"img"==h){var c=e.alt;I(c)||""===c||(n.title=c)}}else{var u=[];o(n,(function(e,t){u.push(";\\s?"+t)})),u=u.join("\\s?:|"),""!==a.trim()&&o(n,(function(e,t){var s=a,l=new RegExp("s?"+t+"s?:s?(.*?)("+u+"s?:|$)"),o=s.match(l);if(o&&o.length&&o[1]){var r=o[1].trim().replace(/;\s*$/,"");n[t]=i.sanitizeValue(r)}}))}if(n.description&&"."===n.description.substring(0,1)){var g;try{g=document.querySelector(n.description).innerHTML}catch(e){if(!(e instanceof DOMException))throw e}g&&(n.description=g)}if(!n.description){var v=e.querySelector(".glightbox-desc");v&&(n.description=v.innerHTML)}return this.setSize(n,t,e),this.slideConfig=n,n}},{key:"setSize",value:function(e,t){var i=arguments.length>2&&void 0!==arguments[2]?arguments[2]:null,n="video"==e.type?this.checkSize(t.videosWidth):this.checkSize(t.width),s=this.checkSize(t.height);return e.width=O(e,"width")&&""!==e.width?this.checkSize(e.width):n,e.height=O(e,"height")&&""!==e.height?this.checkSize(e.height):s,i&&"image"==e.type&&(e._hasCustomWidth=!!i.dataset.width,e._hasCustomHeight=!!i.dataset.height),e}},{key:"checkSize",value:function(e){return M(e)?"".concat(e,"px"):e}},{key:"sanitizeValue",value:function(e){return"true"!==e&&"false"!==e?e:"true"===e}}]),e}(),U=function(){function e(i,n,s){t(this,e),this.element=i,this.instance=n,this.index=s}return n(e,[{key:"setContent",value:function(){var e=this,t=arguments.length>0&&void 0!==arguments[0]?arguments[0]:null,i=arguments.length>1&&void 0!==arguments[1]&&arguments[1];if(c(t,"loaded"))return!1;var n=this.instance.settings,s=this.slideConfig,l=w();T(n.beforeSlideLoad)&&n.beforeSlideLoad({index:this.index,slide:t,player:!1});var o=s.type,r=s.descPosition,a=t.querySelector(".gslide-media"),d=t.querySelector(".gslide-title"),u=t.querySelector(".gslide-desc"),g=t.querySelector(".gdesc-inner"),v=i,f="gSlideTitle_"+this.index,p="gSlideDesc_"+this.index;if(T(n.afterSlideLoad)&&(v=function(){T(i)&&i(),n.afterSlideLoad({index:e.index,slide:t,player:e.instance.getSlidePlayerInstance(e.index)})}),""==s.title&&""==s.description?g&&g.parentNode.parentNode.removeChild(g.parentNode):(d&&""!==s.title?(d.id=f,d.innerHTML=s.title):d.parentNode.removeChild(d),u&&""!==s.description?(u.id=p,l&&n.moreLength>0?(s.smallDescription=this.slideShortDesc(s.description,n.moreLength,n.moreText),u.innerHTML=s.smallDescription,this.descriptionEvents(u,s)):u.innerHTML=s.description):u.parentNode.removeChild(u),h(a.parentNode,"desc-".concat(r)),h(g.parentNode,"description-".concat(r))),h(a,"gslide-".concat(o)),h(t,"loaded"),"video"!==o){if("external"!==o)return"inline"===o?(G.apply(this.instance,[t,s,this.index,v]),void(s.draggable&&new V({dragEl:t.querySelector(".gslide-inline"),toleranceX:n.dragToleranceX,toleranceY:n.dragToleranceY,slide:t,instance:this.instance}))):void("image"!==o?T(v)&&v():j(t,s,this.index,(function(){var i=t.querySelector("img");s.draggable&&new V({dragEl:i,toleranceX:n.dragToleranceX,toleranceY:n.dragToleranceY,slide:t,instance:e.instance}),s.zoomable&&i.naturalWidth>i.offsetWidth&&(h(i,"zoomable"),new H(i,t,(function(){e.instance.resize()}))),T(v)&&v()})));Z.apply(this,[t,s,this.index,v])}else F.apply(this.instance,[t,s,this.index,v])}},{key:"slideShortDesc",value:function(e){var t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:50,i=arguments.length>2&&void 0!==arguments[2]&&arguments[2],n=document.createElement("div");n.innerHTML=e;var s=n.innerText,l=i;if((e=s.trim()).length<=t)return e;var o=e.substr(0,t-1);return l?(n=null,o+'... '+i+""):o}},{key:"descriptionEvents",value:function(e,t){var i=this,n=e.querySelector(".desc-more");if(!n)return!1;a("click",{onElement:n,withCallback:function(e,n){e.preventDefault();var s=document.body,l=u(n,".gslide-desc");if(!l)return!1;l.innerHTML=t.description,h(s,"gdesc-open");var o=a("click",{onElement:[s,u(l,".gslide-description")],withCallback:function(e,n){"a"!==e.target.nodeName.toLowerCase()&&(d(s,"gdesc-open"),h(s,"gdesc-closed"),l.innerHTML=t.smallDescription,i.descriptionEvents(l,t),setTimeout((function(){d(s,"gdesc-closed")}),400),o.destroy())}})}})}},{key:"create",value:function(){return m(this.instance.settings.slideHTML)}},{key:"getConfig",value:function(){k(this.element)||this.element.hasOwnProperty("draggable")||(this.element.draggable=this.instance.settings.draggable);var e=new $(this.instance.settings.slideExtraAttributes);return this.slideConfig=e.parseConfig(this.element,this.instance.settings),this.slideConfig}}]),e}(),J=w(),K=null!==w()||void 0!==document.createTouch||"ontouchstart"in window||"onmsgesturechange"in window||navigator.msMaxTouchPoints,Q=document.getElementsByTagName("html")[0],ee={selector:".glightbox",elements:null,skin:"clean",theme:"clean",closeButton:!0,startAt:null,autoplayVideos:!0,autofocusVideos:!0,descPosition:"bottom",width:"900px",height:"506px",videosWidth:"960px",beforeSlideChange:null,afterSlideChange:null,beforeSlideLoad:null,afterSlideLoad:null,slideInserted:null,slideRemoved:null,slideExtraAttributes:null,onOpen:null,onClose:null,loop:!1,zoomable:!0,draggable:!0,dragAutoSnap:!1,dragToleranceX:40,dragToleranceY:65,preload:!0,oneSlidePerOpen:!1,touchNavigation:!0,touchFollowAxis:!0,keyboardNavigation:!0,closeOnOutsideClick:!0,plugins:!1,plyr:{css:"https://cdn.plyr.io/3.6.8/plyr.css",js:"https://cdn.plyr.io/3.6.8/plyr.js",config:{ratio:"16:9",fullscreen:{enabled:!0,iosNative:!0},youtube:{noCookie:!0,rel:0,showinfo:0,iv_load_policy:3},vimeo:{byline:!1,portrait:!1,title:!1,transparent:!1}}},openEffect:"zoom",closeEffect:"zoom",slideEffect:"slide",moreText:"See more",moreLength:60,cssEfects:{fade:{in:"fadeIn",out:"fadeOut"},zoom:{in:"zoomIn",out:"zoomOut"},slide:{in:"slideInRight",out:"slideOutLeft"},slideBack:{in:"slideInLeft",out:"slideOutRight"},none:{in:"none",out:"none"}},svg:{close:'',next:'',prev:''},slideHTML:'',lightboxHTML:'\n \n \n
'},te=function(){function e(){var i=arguments.length>0&&void 0!==arguments[0]?arguments[0]:{};t(this,e),this.customOptions=i,this.settings=l(ee,i),this.effectsClasses=this.getAnimationClasses(),this.videoPlayers={},this.apiEvents=[],this.fullElementsList=!1}return n(e,[{key:"init",value:function(){var e=this,t=this.getSelector();t&&(this.baseEvents=a("click",{onElement:t,withCallback:function(t,i){t.preventDefault(),e.open(i)}})),this.elements=this.getElements()}},{key:"open",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:null,t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:null;if(0==this.elements.length)return!1;this.activeSlide=null,this.prevActiveSlideIndex=null,this.prevActiveSlide=null;var i=M(t)?t:this.settings.startAt;if(k(e)){var n=e.getAttribute("data-gallery");n&&(this.fullElementsList=this.elements,this.elements=this.getGalleryElements(this.elements,n)),I(i)&&(i=this.getElementIndex(e))<0&&(i=0)}M(i)||(i=0),this.build(),g(this.overlay,"none"==this.settings.openEffect?"none":this.settings.cssEfects.fade.in);var s=document.body,l=window.innerWidth-document.documentElement.clientWidth;if(l>0){var o=document.createElement("style");o.type="text/css",o.className="gcss-styles",o.innerText=".gscrollbar-fixer {margin-right: ".concat(l,"px}"),document.head.appendChild(o),h(s,"gscrollbar-fixer")}h(s,"glightbox-open"),h(Q,"glightbox-open"),J&&(h(document.body,"glightbox-mobile"),this.settings.slideEffect="slide"),this.showSlide(i,!0),1==this.elements.length?(h(this.prevButton,"glightbox-button-hidden"),h(this.nextButton,"glightbox-button-hidden")):(d(this.prevButton,"glightbox-button-hidden"),d(this.nextButton,"glightbox-button-hidden")),this.lightboxOpen=!0,this.trigger("open"),T(this.settings.onOpen)&&this.settings.onOpen(),K&&this.settings.touchNavigation&&B(this),this.settings.keyboardNavigation&&X(this)}},{key:"openAt",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:0;this.open(null,e)}},{key:"showSlide",value:function(){var e=this,t=arguments.length>0&&void 0!==arguments[0]?arguments[0]:0,i=arguments.length>1&&void 0!==arguments[1]&&arguments[1];f(this.loader),this.index=parseInt(t);var n=this.slidesContainer.querySelector(".current");n&&d(n,"current"),this.slideAnimateOut();var s=this.slidesContainer.querySelectorAll(".gslide")[t];if(c(s,"loaded"))this.slideAnimateIn(s,i),p(this.loader);else{f(this.loader);var l=this.elements[t],o={index:this.index,slide:s,slideNode:s,slideConfig:l.slideConfig,slideIndex:this.index,trigger:l.node,player:null};this.trigger("slide_before_load",o),l.instance.setContent(s,(function(){p(e.loader),e.resize(),e.slideAnimateIn(s,i),e.trigger("slide_after_load",o)}))}this.slideDescription=s.querySelector(".gslide-description"),this.slideDescriptionContained=this.slideDescription&&c(this.slideDescription.parentNode,"gslide-media"),this.settings.preload&&(this.preloadSlide(t+1),this.preloadSlide(t-1)),this.updateNavigationClasses(),this.activeSlide=s}},{key:"preloadSlide",value:function(e){var t=this;if(e<0||e>this.elements.length-1)return!1;if(I(this.elements[e]))return!1;var i=this.slidesContainer.querySelectorAll(".gslide")[e];if(c(i,"loaded"))return!1;var n=this.elements[e],s=n.type,l={index:e,slide:i,slideNode:i,slideConfig:n.slideConfig,slideIndex:e,trigger:n.node,player:null};this.trigger("slide_before_load",l),"video"==s||"external"==s?setTimeout((function(){n.instance.setContent(i,(function(){t.trigger("slide_after_load",l)}))}),200):n.instance.setContent(i,(function(){t.trigger("slide_after_load",l)}))}},{key:"prevSlide",value:function(){this.goToSlide(this.index-1)}},{key:"nextSlide",value:function(){this.goToSlide(this.index+1)}},{key:"goToSlide",value:function(){var e=arguments.length>0&&void 0!==arguments[0]&&arguments[0];if(this.prevActiveSlide=this.activeSlide,this.prevActiveSlideIndex=this.index,!this.loop()&&(e<0||e>this.elements.length-1))return!1;e<0?e=this.elements.length-1:e>=this.elements.length&&(e=0),this.showSlide(e)}},{key:"insertSlide",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:{},t=arguments.length>1&&void 0!==arguments[1]?arguments[1]:-1;t<0&&(t=this.elements.length);var i=new U(e,this,t),n=i.getConfig(),s=l({},n),o=i.create(),r=this.elements.length-1;s.index=t,s.node=!1,s.instance=i,s.slideConfig=n,this.elements.splice(t,0,s);var a=null,h=null;if(this.slidesContainer){if(t>r)this.slidesContainer.appendChild(o);else{var d=this.slidesContainer.querySelectorAll(".gslide")[t];this.slidesContainer.insertBefore(o,d)}(this.settings.preload&&0==this.index&&0==t||this.index-1==t||this.index+1==t)&&this.preloadSlide(t),0==this.index&&0==t&&(this.index=1),this.updateNavigationClasses(),a=this.slidesContainer.querySelectorAll(".gslide")[t],h=this.getSlidePlayerInstance(t),s.slideNode=a}this.trigger("slide_inserted",{index:t,slide:a,slideNode:a,slideConfig:n,slideIndex:t,trigger:null,player:h}),T(this.settings.slideInserted)&&this.settings.slideInserted({index:t,slide:a,player:h})}},{key:"removeSlide",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:-1;if(e<0||e>this.elements.length-1)return!1;var t=this.slidesContainer&&this.slidesContainer.querySelectorAll(".gslide")[e];t&&(this.getActiveSlideIndex()==e&&(e==this.elements.length-1?this.prevSlide():this.nextSlide()),t.parentNode.removeChild(t)),this.elements.splice(e,1),this.trigger("slide_removed",e),T(this.settings.slideRemoved)&&this.settings.slideRemoved(e)}},{key:"slideAnimateIn",value:function(e,t){var i=this,n=e.querySelector(".gslide-media"),s=e.querySelector(".gslide-description"),l={index:this.prevActiveSlideIndex,slide:this.prevActiveSlide,slideNode:this.prevActiveSlide,slideIndex:this.prevActiveSlide,slideConfig:I(this.prevActiveSlideIndex)?null:this.elements[this.prevActiveSlideIndex].slideConfig,trigger:I(this.prevActiveSlideIndex)?null:this.elements[this.prevActiveSlideIndex].node,player:this.getSlidePlayerInstance(this.prevActiveSlideIndex)},o={index:this.index,slide:this.activeSlide,slideNode:this.activeSlide,slideConfig:this.elements[this.index].slideConfig,slideIndex:this.index,trigger:this.elements[this.index].node,player:this.getSlidePlayerInstance(this.index)};if(n.offsetWidth>0&&s&&(p(s),s.style.display=""),d(e,this.effectsClasses),t)g(e,this.settings.cssEfects[this.settings.openEffect].in,(function(){i.settings.autoplayVideos&&i.slidePlayerPlay(e),i.trigger("slide_changed",{prev:l,current:o}),T(i.settings.afterSlideChange)&&i.settings.afterSlideChange.apply(i,[l,o])}));else{var r=this.settings.slideEffect,a="none"!==r?this.settings.cssEfects[r].in:r;this.prevActiveSlideIndex>this.index&&"slide"==this.settings.slideEffect&&(a=this.settings.cssEfects.slideBack.in),g(e,a,(function(){i.settings.autoplayVideos&&i.slidePlayerPlay(e),i.trigger("slide_changed",{prev:l,current:o}),T(i.settings.afterSlideChange)&&i.settings.afterSlideChange.apply(i,[l,o])}))}setTimeout((function(){i.resize(e)}),100),h(e,"current")}},{key:"slideAnimateOut",value:function(){if(!this.prevActiveSlide)return!1;var e=this.prevActiveSlide;d(e,this.effectsClasses),h(e,"prev");var t=this.settings.slideEffect,i="none"!==t?this.settings.cssEfects[t].out:t;this.slidePlayerPause(e),this.trigger("slide_before_change",{prev:{index:this.prevActiveSlideIndex,slide:this.prevActiveSlide,slideNode:this.prevActiveSlide,slideIndex:this.prevActiveSlideIndex,slideConfig:I(this.prevActiveSlideIndex)?null:this.elements[this.prevActiveSlideIndex].slideConfig,trigger:I(this.prevActiveSlideIndex)?null:this.elements[this.prevActiveSlideIndex].node,player:this.getSlidePlayerInstance(this.prevActiveSlideIndex)},current:{index:this.index,slide:this.activeSlide,slideNode:this.activeSlide,slideIndex:this.index,slideConfig:this.elements[this.index].slideConfig,trigger:this.elements[this.index].node,player:this.getSlidePlayerInstance(this.index)}}),T(this.settings.beforeSlideChange)&&this.settings.beforeSlideChange.apply(this,[{index:this.prevActiveSlideIndex,slide:this.prevActiveSlide,player:this.getSlidePlayerInstance(this.prevActiveSlideIndex)},{index:this.index,slide:this.activeSlide,player:this.getSlidePlayerInstance(this.index)}]),this.prevActiveSlideIndex>this.index&&"slide"==this.settings.slideEffect&&(i=this.settings.cssEfects.slideBack.out),g(e,i,(function(){var t=e.querySelector(".ginner-container"),i=e.querySelector(".gslide-media"),n=e.querySelector(".gslide-description");t.style.transform="",i.style.transform="",d(i,"greset"),i.style.opacity="",n&&(n.style.opacity=""),d(e,"prev")}))}},{key:"getAllPlayers",value:function(){return this.videoPlayers}},{key:"getSlidePlayerInstance",value:function(e){var t="gvideo"+e,i=this.getAllPlayers();return!(!O(i,t)||!i[t])&&i[t]}},{key:"stopSlideVideo",value:function(e){if(k(e)){var t=e.querySelector(".gvideo-wrapper");t&&(e=t.getAttribute("data-index"))}console.log("stopSlideVideo is deprecated, use slidePlayerPause");var i=this.getSlidePlayerInstance(e);i&&i.playing&&i.pause()}},{key:"slidePlayerPause",value:function(e){if(k(e)){var t=e.querySelector(".gvideo-wrapper");t&&(e=t.getAttribute("data-index"))}var i=this.getSlidePlayerInstance(e);i&&i.playing&&i.pause()}},{key:"playSlideVideo",value:function(e){if(k(e)){var t=e.querySelector(".gvideo-wrapper");t&&(e=t.getAttribute("data-index"))}console.log("playSlideVideo is deprecated, use slidePlayerPlay");var i=this.getSlidePlayerInstance(e);i&&!i.playing&&i.play()}},{key:"slidePlayerPlay",value:function(e){if(k(e)){var t=e.querySelector(".gvideo-wrapper");t&&(e=t.getAttribute("data-index"))}var i=this.getSlidePlayerInstance(e);i&&!i.playing&&(i.play(),this.settings.autofocusVideos&&i.elements.container.focus())}},{key:"setElements",value:function(e){var t=this;this.settings.elements=!1;var i=[];e&&e.length&&o(e,(function(e,n){var s=new U(e,t,n),o=s.getConfig(),r=l({},o);r.slideConfig=o,r.instance=s,r.index=n,i.push(r)})),this.elements=i,this.lightboxOpen&&(this.slidesContainer.innerHTML="",this.elements.length&&(o(this.elements,(function(){var e=m(t.settings.slideHTML);t.slidesContainer.appendChild(e)})),this.showSlide(0,!0)))}},{key:"getElementIndex",value:function(e){var t=!1;return o(this.elements,(function(i,n){if(O(i,"node")&&i.node==e)return t=n,!0})),t}},{key:"getElements",value:function(){var e=this,t=[];this.elements=this.elements?this.elements:[],!I(this.settings.elements)&&E(this.settings.elements)&&this.settings.elements.length&&o(this.settings.elements,(function(i,n){var s=new U(i,e,n),o=s.getConfig(),r=l({},o);r.node=!1,r.index=n,r.instance=s,r.slideConfig=o,t.push(r)}));var i=!1;return this.getSelector()&&(i=document.querySelectorAll(this.getSelector())),i?(o(i,(function(i,n){var s=new U(i,e,n),o=s.getConfig(),r=l({},o);r.node=i,r.index=n,r.instance=s,r.slideConfig=o,r.gallery=i.getAttribute("data-gallery"),t.push(r)})),t):t}},{key:"getGalleryElements",value:function(e,t){return e.filter((function(e){return e.gallery==t}))}},{key:"getSelector",value:function(){return!this.settings.elements&&(this.settings.selector&&"data-"==this.settings.selector.substring(0,5)?"*[".concat(this.settings.selector,"]"):this.settings.selector)}},{key:"getActiveSlide",value:function(){return this.slidesContainer.querySelectorAll(".gslide")[this.index]}},{key:"getActiveSlideIndex",value:function(){return this.index}},{key:"getAnimationClasses",value:function(){var e=[];for(var t in this.settings.cssEfects)if(this.settings.cssEfects.hasOwnProperty(t)){var i=this.settings.cssEfects[t];e.push("g".concat(i.in)),e.push("g".concat(i.out))}return e.join(" ")}},{key:"build",value:function(){var e=this;if(this.built)return!1;var t=document.body.childNodes,i=[];o(t,(function(e){e.parentNode==document.body&&"#"!==e.nodeName.charAt(0)&&e.hasAttribute&&!e.hasAttribute("aria-hidden")&&(i.push(e),e.setAttribute("aria-hidden","true"))}));var n=O(this.settings.svg,"next")?this.settings.svg.next:"",s=O(this.settings.svg,"prev")?this.settings.svg.prev:"",l=O(this.settings.svg,"close")?this.settings.svg.close:"",r=this.settings.lightboxHTML;r=m(r=(r=(r=r.replace(/{nextSVG}/g,n)).replace(/{prevSVG}/g,s)).replace(/{closeSVG}/g,l)),document.body.appendChild(r);var d=document.getElementById("glightbox-body");this.modal=d;var g=d.querySelector(".gclose");this.prevButton=d.querySelector(".gprev"),this.nextButton=d.querySelector(".gnext"),this.overlay=d.querySelector(".goverlay"),this.loader=d.querySelector(".gloader"),this.slidesContainer=document.getElementById("glightbox-slider"),this.bodyHiddenChildElms=i,this.events={},h(this.modal,"glightbox-"+this.settings.skin),this.settings.closeButton&&g&&(this.events.close=a("click",{onElement:g,withCallback:function(t,i){t.preventDefault(),e.close()}})),g&&!this.settings.closeButton&&g.parentNode.removeChild(g),this.nextButton&&(this.events.next=a("click",{onElement:this.nextButton,withCallback:function(t,i){t.preventDefault(),e.nextSlide()}})),this.prevButton&&(this.events.prev=a("click",{onElement:this.prevButton,withCallback:function(t,i){t.preventDefault(),e.prevSlide()}})),this.settings.closeOnOutsideClick&&(this.events.outClose=a("click",{onElement:d,withCallback:function(t,i){e.preventOutsideClick||c(document.body,"glightbox-mobile")||u(t.target,".ginner-container")||u(t.target,".gbtn")||c(t.target,"gnext")||c(t.target,"gprev")||e.close()}})),o(this.elements,(function(t,i){e.slidesContainer.appendChild(t.instance.create()),t.slideNode=e.slidesContainer.querySelectorAll(".gslide")[i]})),K&&h(document.body,"glightbox-touch"),this.events.resize=a("resize",{onElement:window,withCallback:function(){e.resize()}}),this.built=!0}},{key:"resize",value:function(){var e=arguments.length>0&&void 0!==arguments[0]?arguments[0]:null;if((e=e||this.activeSlide)&&!c(e,"zoomed")){var t=y(),i=e.querySelector(".gvideo-wrapper"),n=e.querySelector(".gslide-image"),s=this.slideDescription,l=t.width,o=t.height;if(l<=768?h(document.body,"glightbox-mobile"):d(document.body,"glightbox-mobile"),i||n){var r=!1;if(s&&(c(s,"description-bottom")||c(s,"description-top"))&&!c(s,"gabsolute")&&(r=!0),n)if(l<=768)n.querySelector("img");else if(r){var a=s.offsetHeight,u=n.querySelector("img");u.setAttribute("style","max-height: calc(100vh - ".concat(a,"px)")),s.setAttribute("style","max-width: ".concat(u.offsetWidth,"px;"))}if(i){var g=O(this.settings.plyr.config,"ratio")?this.settings.plyr.config.ratio:"";if(!g){var v=i.clientWidth,f=i.clientHeight,p=v/f;g="".concat(v/p,":").concat(f/p)}var m=g.split(":"),x=this.settings.videosWidth,b=this.settings.videosWidth,S=(b=M(x)||-1!==x.indexOf("px")?parseInt(x):-1!==x.indexOf("vw")?l*parseInt(x)/100:-1!==x.indexOf("vh")?o*parseInt(x)/100:-1!==x.indexOf("%")?l*parseInt(x)/100:parseInt(i.clientWidth))/(parseInt(m[0])/parseInt(m[1]));if(S=Math.floor(S),r&&(o-=s.offsetHeight),b>l||S>o||o\n \n \n \n \n
\nThe problem with AI Trolley dilemma¶
Estimated time to read: 5 minutes

The premise about the AI trolley dilemma is invalid. So the whole discussion about who should the car kill in a fatal situation. Let me explain why.
Yesterday I attended a conference about Ethics and AI, and the speaker mentioned the trolley dilemma. The question asked was "What should the self-driving car do?" and kind of forced us to take sides on the matter.
- Kill the passengers;
- Kill the pedestrians;
This is the same as the trolley problem but one difference. AI don't have morals, it will follow what is programmed without any hesitation. So the question is not what the AI should do, but what the programmer codes it to do.
Well, the whole premise on asking what should do "kill this, or that" is totally wrong. As a programmer myself, and knowing the limits of the system, I would never code a system to make such a decision. If the car is in a situation that it cannot break in time with the current limited vision, it should go slower. So no decision ever has to be made.
Let's do some math for you to see how this could be easily solved.
The math¶
Let's use the standard formula for the distance needed to stop a car.
\[S = v*t + \frac{v^2}{2*u*g}\]
Where:
- \(S\) is the distance needed to stop;
- \(v\) is the speed of the car;
- \(t\) is the reaction time;
- \(v*t\) is the distance traveled during the reaction time;
- \(u\) is the tire friction factor;
- \(g\) is the gravity acceleration;
- \(\frac{v^2}{2*u*g}\) is the distance traveled during the breaking time;
If the car is going at \(100 km/h\) (\(27.7 m/s\), \(62.14 mi/h\)) and the reaction time of the AI is relatively fast, let's say \(0.2 s\), so the distance traveled to a complete sage stop would be:
\[S = 27.7 * 0.2 + \frac{27.7^2}{2*0.2*9.8} = 5.54 + 38.5 = 44.04 m\]
Which means that the car would need \(44.04 m\) to stop. So if the car cannot clearly see a distance greater than that, it should slow down. And this is the reason the self-driving AIs are said to be slow drivers.
Let's talk about Virtual Reality¶
Estimated time to read: 17 minutes
The goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
History¶
graph TB
+ Start[Start]
+ -- 1838 --> Stereoscope[Stereoscope]
+ -- 1935 --> multisensory[Multi Sensory Machines]
+ -- 1960 --> hmd[Head Mounted Devices\nVR Goggles]
+ -- 1965 --> military[Military Research\nTraining\nHelmets]
+ -- 1970 --> artificialreality[Artificial Reality\nComputer Simulations]
+ -- 1980 --> gloves[Stereo Vision Glasses\nGloves for VR]
+ -- 1989 --> nasa[NASA Training\nComputer Simulated Teleoperation]
+ -- 1990 --> game[VR Gaming\nVR Arcades]
+ -- 1997 --> serious[PTSD Treatment]
+ -- 2007 --> datavis[Google Street View\nStereoscopic 3D]
+ -- 2010 -->oculus[Oculus VR\nOculus Kickstarter\nFacebook acquisition]
+ -- 2015 -->general[General Audience\nMultiple VR products]
+ -- 2016 -->ar[AR\nPokemon Go\nHololens]
+ -- 2017 -->ARKIT[AR\nApple ARKit]
+ -- 2018 -->oculusquest[Oculus Quest\nStandalone VR]
+ -- 2021 -->metaverse[Metaverse\nFacebook rebrands to Meta]
+ -- 2023 -->apple[Apple Vision]As you can see the history of VR is quite long and full of interesting surprising developments, but it is only in the last 10 years that it has become a reality for the general audience.
Terms Disambiguation¶
Before we go any further, let's disambiguate some terms that are often used interchangeably. Nowadays we have a spectrum of immersive technologies that goes from the real world to the virtual world.
graph LR
+ real[Real World]-->mixed
+
+ subgraph mixed[Mixed Reality]
+ augmentedreality[Augmented Reality]
+ augmentedvirtuality[Augmented Virtuality]
+ end
+
+ mixed --> virtual[Virtual Reality]Virtual Reality¶
Virtual Reality (VR) is the most pervasive and ambiguous term. It is sometimes used as an umbrella for all immersive technologies, but it is more commonly used to refer to the process of simulating a virtual world that is completely isolated the user from the real world. This is usually done by using a Head Mounted Display (HMD) that blocks the user's view of the real world and replaces it with a simulation in front of the user's eyes; and headphones to replace the real sounds with virtual. The user can also use controllers to interact in it.
This term gained lots of attention with the modern VR boom that started in 2010 with the Oculus Kickstarter campaign followed by its acquisition by Facebook in 2014. After that, many other companies started to develop their own VR products, such as the HTC Vive, the Playstation VR, and the Samsung Gear VR.
Augmented Reality¶
Augmented Reality is another ambiguous term, but its meaning is more settled. It refers to the process of adding computer generated elements to the real world. It can be done by using a Head Mounted Display (HMD) that allows the user to see the real world and the virtual elements at the same time such as Google Glass or the Microsoft Hololens. It can also be done by using a smartphone or tablet that uses the camera to capture the real world and then adds virtual elements to it. This is the case of the Snapchat filters and the popular game Pokemon Go launched in 2016.
Augmented Virtuality¶
This term usually is not misused and more specifically refers to the process of adding real world elements to a virtual world. It can appears in many forms, for example, the use of a treadmill to simulate walking in the virtual world or the use of a camera to capture the user's face and add it to the virtual world. Stereocameras or depth sensors are also used to capture the user's hands and add them to the virtual world as well.
Most of the time Augmented Virtuality (AV) is seen as an enhancement to the already existing immersive experience. It can be used to add another level of realism to the virtual world, to make the user feel more immersed in it, reduce nausea, or discomfort by adding real world anchors to the virtual world.
Challenges¶
In order to make immersive gadgets a reality, we need to overcome some challenges. The most important ones are:
- Motion Sickness: the feeling of nausea and discomfort caused by the mismatch between the user's movements and the virtual world. It is mostly caused by:
- Latency: the time it takes for the system to react to the user's actions. The system needs to process the inputs, accelerometers, gyroscopes, and other sensors, and then render the new image to the user. This process takes time and if it is too long the user will feel unresponsiveness and will get sick;
- Field of View: the area that the user can see at any given time doesnt match the area that the user can see in the real world;
- Resolution: the number of pixels that the user can see at any given time. Ex. The Oculus Rift DK1 had a resolution of 640x800 per eye that was zoomed to cover the user's entire field of view, and on top of that, the spacing between pixels makes the image looks like a grid of squared dots; you can see why it received so many complaints;
- Tracking: the ability of the system to track the user's movements properly. The sensors usually do not refresh at the same rate as the display, so the system needs to interpolate the user's movements between the sensor readings. This can cause the user to feel like the virtual world is lagging behind the real world and be out of sync with the user's movements;
- Comfort: the feeling of comfort that the user has while using the system. If the device needs to be worn for a long period of time, right weight distribution, padding, and ventilation are important to make the user feel comfortable;
- Cost: the cost of the system. The machinery and technology used to create the system can be very expensive to be accessible to the general audience;
- Portability: the ability of the system to be used in different places. If the system is too heavy or too big it will be hard to carry;
- Social Acceptance: the acceptance of the system by the society. If the system is too intrusive or too weird it will be hard to use in public places. It could be seen as a threat to privacy or as a threat to the user's safety;
- Battery Life: the amount of time that the system can be used without being plugged in. If the system needs to be plugged in all the time it will be hard to use in public places;
- Software Development Kits: the tools that developers use to create applications for the system. If the SDK is too hard to use or too limited it will be hard to create applications for the system;
I will add to this list a personal experience that I don't see many people talking about: bad smell, oily foams, and connectors corrosion. The root of those problems is the proximity with the user's face. The user's face is a very oily place and the foam that is used to make the device comfortable is an exceptional place for bacteria to grow. The connectors are also exposed to the user's sweat and can corrode over time and brick your device.
Applications¶
There are virtually infinite applications for immersive technologies, but I will focus on the ones that I think are the most important ones in my opinion:
- Entertainment: Games in general, but also movies, etc.;
- Data Visualization: the ability to visualize data in a 3D space can be very useful to understand complex data;
- Education: Training, virtual classrooms, virtual museums, virtual tours, etc.;
- Social: Virtual meetings, parties, dating, etc.;
- Psychological Treatment: Virtual exposure therapy(Ex.: PTSD, phobias), virtual reality therapy, etc.;
- Medical: Surgery planning, surgery simulation, etc.;
- Design: Architecture, interior design, etc.;
Future¶
In my past, I have created a startup to help surgeons plan their surgeries and ported it to VR - DocDo. I created some small scoped projects to psychological treatment via progressive exposition, some for data visualization and others for education. I am not in position to have a strong opinion about the future of VR, but I can share my thoughts about it.
At the beginning of the metaverse boom, I was very skeptical about it, and I am still. I felt it was a just a new interpretation of a product previously tested on Second Life and proved to be a niche product, focused in being fun, but forcing the use of device with many issues. Another problem was the lack of a real application besides the fun factor.
As a developer, I am in love with Apple's new Vision OS emulator and SDK. It is surprisingly easy to use, filled with useful functions, although it is buggy and crashes randomly in beta channel that I am using now. I think it is an exceptional example of how to create a nice SDK for a new platform. I am not sure if it will be a success, but I am sure that it will empower many developers to create new or port existing applications to their platform. They have created a simply way to bring a desktop experience to a VR gadget that just work. You can "easily" port your app to it and it will work. It is portable, easy to code, powerful hardware, nice battery life, and a nice SDK. I think it is a nice recipe for success. My only concern is related to the cost and social acceptance.
Notes on Submissions¶
Estimated time to read: 7 minutes

Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
Policy on Limited use of AI-assisted tools¶
Note
"During our classes, we may use AI writing tools such as ChatGPT in certain specific cases. You will be informed as to when, where, and how these tools are permitted to be used, along with guidance for attribution. Any use outside of these specific cases constitutes a violation of Academic Honesty Policy." Source.
The learner has to produce original content. You can use tools like ChatGPT to help you learn by prompting your own questions, but not to solve the problems, assignments, or quizzes.
The rationale is that the student has to learn the concepts and ideas rather than just copying and pasting the answers.
What is acceptable:¶
- On writing, coding assignments, or interactive assignments, you can ask AI questions about concepts, ideas, syntaxes, etc;
- You can ask AI assistants what is wrong with your code, but you cannot use the answer 1 to 1 copy to your final submission. You have to modify it;
- If your submission contains part of an AI-assisted tool, you have to cite it. Ex.: "I prompted ____ in ChatGPT, and the answer was ____." and as a professor, I will deduct points from your submission with fairness instead of giving you zero points;
What is not acceptable¶
- You cannot copy the question and prompt AI to answer it and then use the answer as your own;
- You cannot ask AI to code a solution for you;
- You cannot use any AI while coding(e.g. GitHub Copilot), but I do recommend you to use any IDE instead;
- You cannot use AI assistance to solve quizzes or exams in any circumstances.
- Even in accepted cases, using AI assistance and not citing it will be considered plagiarism and will be reported to higher instances and zero-ed;
How do I detect Plagiarism and AI-assisted tools abuse¶
- I use some automated tools such as Turnitin(canvas), moss(Beecrowd), and others;
- I use my own experience to detect plagiarism;
- If two students use the same AI assistant, chances are high that they will produce the same answer, and I will detect it;
Grading Timings¶
I usually take up to 1 week to grade assignments, but I will grade them as soon as possible. The worst-case scenario is two weeks.
Late Submissions Policy¶
If you submit an assignment late, you will receive a flat 20% deduction on your grade.
If you have accommodations, message me, and I will try accommodating you. But always send a message on every submission stating that. Canvas is a nice tool, but it needs to cover accommodations better.
If you fall under special conditions, such as sickness, death of a relative, or any other condition that you cannot submit the assignment on time, please send me a message through Canvas, and I will try to accommodate you.
Plagiarism¶
Plagiarism is a serious offense and will be reported to the higher instances. I will not tolerate any plagiarism as I define:
- Searching for answers on the internet and copy and paste it as your own;
- Copying answers from other students;
- Using AI-assisted tools to produce full answers;
- Using AI-assisted tools to produce partial answers without citing it;
Welcoming environment¶
I am here to teach you the best I can and guide you through your learning process. You can count on me as a friend and a teacher, and I will help you as much as possible. I am willing to make exceptions for the ones that need it.
FERPA Consent¶
Estimated time to read: 6 minutes
FERPA (The Family Educational Rights and Privacy Act) is a federal law protecting the confidentiality of student records. It restricts others from accessing or discussing your educational records without your consent. Here we are going to discuss how it applies to the courses I teach and what are the benefits on sharing your work publicly if you want.
Read more about the reasoning and rationale below.
Note
This a modified version from this original.
In a typical class, your homework (and other information delineating your academic performance) would not be visible to the public. Indeed, the FERPA law requires that you have the right to privacy in this regard. This is one of the main reasons for the existence of so many "walled gardens" for courseware, such as Autolab, Blackboard, CanvasLMS and Piazza, which keep all student work hidden behind passwords.
An essential component of the educational experience in new media arts, however, is learning how to participate in the "Grand Conversation" all around us, by becoming more effective culture operators. We cannot do this in the safe space of a Canvas module. Our work is strengthened and sharpened in the forge of public scrutiny: in this case, the agora of the Internet.
Sometimes students are afraid to publish something because it is of poor quality. They think that they will receive embarrassing, negative critiques. In fact, negative critique is quite rare. The most common thing that happens when one creates an artwork of poor quality, is that it is simply ignored. Being ignored - this, not being shunned or derided - this is the fate of mediocre work.
On the other hand, if something is truly great is published - and great projects can happen, and have happened, even in an introductory class like this one - there is the chance that it may be circulated widely on the Internet. Every year that I have taught, a handful of the students' projects get blogged and receive as many as 50000 views in a week. It cannot be emphasized that this can be an absolutely transformative experience for students, that cannot be obtained without taking the risk to work publicly. Students get jobs and build careers on the basis of such success.
That said, there are also plenty of reasons why you may wish to work anonymously, when you work online. Perhaps you are concerned about stalkers or harassment. Perhaps you wish to address themes in your work which might not meet with the approval of your parents or future employers. These are valid considerations, in which case, we advise using an anonymous identity on Github. On our course repository, your work will be indexed by a public-facing name, generally your first name. If you would prefer something else, please inform the professor.
Ferpa Consent Form¶
Fill this form if you want to share your work publicly. If you don't fill this form, your work should be private:
Setup SDL with CMake and CPM¶
Estimated time to read: 14 minutes
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
-
CLion - Cross-platform C++ IDE with embedded CMake support
- Apply for a student license;
- Download and install it;
- For Macs, you will need extra tools:
XCodeand the command line tools. You can install them by runningxcode-select --installon the terminal;
-
(Required for Windows and if you don't use CLion) Git - Version control system
- Download only if you are on Windows and don't forget to tick the option to add it to your environment path (CMake will be calling it). On Mac and Linux, you can install via your package manager (ex. brew on Mac e apt on Ubuntu).
After installing the tool(s) above, you can follow the steps below to create a new project:
CLion project¶
- Open CLion and select
New Project:

- Create a new project and select
C++ ExecutableandC++XXas the language standard, whereXXis the latest one available for you. Use the default compiler and toolchain:

- Start coding:

You might note the existence of a CMakeLists.txt file on the left side of the IDE on the Project tab. This file is used by CMake to generate the build files for your project. Now, we are going to set up everything you need to use SDL3. If you open the CMakeLists.txt file, you will see something similar to the following:
# cmake_minimum_required(VERSION <specify CMake version here>)
+cmake_minimum_required(VERSION 3.26)
+# project(<name> [<language-name>...])
+project(MyGame)
+# set(CMAKE_CXX_STANDARD <specify C++ standard here>)
+set(CMAKE_CXX_STANDARD 17)
+# add_executable(<name> file.cpp file2.cpp ...)
+add_executable(MyGame main.cpp)
+CPM - C++ Package Manager¶
CPM is a setup-free C++ package manager. It is a single CMake script that you can add to your project and use to download and install packages from GitHub. It is a great tool to manage dependencies and many C++ projects use it.
You can make this as simple as adding the following lines to your CMakeLists.txt file (after the project command):
set(CPM_DOWNLOAD_VERSION 0.38.2)
+
+if(CPM_SOURCE_CACHE)
+ set(CPM_DOWNLOAD_LOCATION "${CPM_SOURCE_CACHE}/cpm/CPM_${CPM_DOWNLOAD_VERSION}.cmake")
+elseif(DEFINED ENV{CPM_SOURCE_CACHE})
+ set(CPM_DOWNLOAD_LOCATION "$ENV{CPM_SOURCE_CACHE}/cpm/CPM_${CPM_DOWNLOAD_VERSION}.cmake")
+else()
+ set(CPM_DOWNLOAD_LOCATION "${CMAKE_BINARY_DIR}/cmake/CPM_${CPM_DOWNLOAD_VERSION}.cmake")
+endif()
+
+# Expand relative path. This is important if the provided path contains a tilde (~)
+get_filename_component(CPM_DOWNLOAD_LOCATION ${CPM_DOWNLOAD_LOCATION} ABSOLUTE)
+
+function(download_cpm)
+ message(STATUS "Downloading CPM.cmake to ${CPM_DOWNLOAD_LOCATION}")
+ file(DOWNLOAD
+ https://github.com/cpm-cmake/CPM.cmake/releases/download/v${CPM_DOWNLOAD_VERSION}/CPM.cmake
+ ${CPM_DOWNLOAD_LOCATION}
+ )
+endfunction()
+
+if(NOT (EXISTS ${CPM_DOWNLOAD_LOCATION}))
+ download_cpm()
+else()
+ # resume download if it previously failed
+ file(READ ${CPM_DOWNLOAD_LOCATION} check)
+ if("${check}" STREQUAL "")
+ download_cpm()
+ endif()
+ unset(check)
+endif()
+
+include(${CPM_DOWNLOAD_LOCATION})
+This will download the CPM.cmake file to your project, and you can use it to download and install packages from GitHub.
To check if CPM is being automatically downloaded, you can go to CLion and click on CMake icon on the left side of the Project. It is the first one on the bottom. And then click the Reload CMake Project button:

Now that you have CPM, you can start adding packages to your project. Here are some ways of doing that:
# A git package from a given uri with a version
+CPMAddPackage("uri@version")
+# A git package from a given uri with a git tag or commit hash
+CPMAddPackage("uri#tag")
+# A git package with both version and tag provided
+CPMAddPackage("uri@version#tag")
+# examples:
+# CPMAddPackage("gh:fmtlib/fmt#7.1.3")
+# CPMAddPackage("gh:nlohmann/json@3.10.5")
+# CPMAddPackage("gh:catchorg/Catch2@3.2.1")
+# An archive package from a given url. The version is inferred
+# CPMAddPackage("https://example.com/my-package-1.2.3.zip")
+# An archive package from a given url with an MD5 hash provided
+# CPMAddPackage("https://example.com/my-package-1.2.3.zip#MD5=68e20f674a48be38d60e129f600faf7d")
+# An archive package from a given url. The version is explicitly given
+# CPMAddPackage("https://example.com/my-package.zip@1.2.3")
+
+# A complex package with options:
+CPMAddPackage(
+ NAME # The unique name of the dependency (should be the exported target's name)
+ VERSION # The minimum version of the dependency (optional, defaults to 0)
+ OPTIONS # Configuration options passed to the dependency (optional)
+ DOWNLOAD_ONLY # If set, the project is downloaded, but not configured (optional)
+ GITHUB_REPOSITORY # The GitHub repository (owner/repo) to download from (optional)
+ GIT_TAG # The git tag or commit hash to download (optional)
+ [...] # Origin parameters forwarded to FetchContent_Declare
+)
+SDL¶
In order to generate SDL libraries and link them corretly in our executable, we have to state the lib should be in the same folder as the executable, so you have to add this to your CMakeLists.txt file:
# Set all outputs to be at the same location
+set(CMAKE_ARCHIVE_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR})
+set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR})
+set(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR})
+link_directories(${CMAKE_BINARY_DIR})
+Now that we have CPM set up, we can use it to download and install SDL. If you want to try the stable version v2, add the following lines to your CMakeLists.txt file and refresh CMake:
CPMAddPackage(
+ NAME SDL2
+ GITHUB_REPOSITORY libsdl-org/SDL
+ GIT_TAG release-2.28.3
+ VERSION 2.28.3
+)
+If you don't have git installed on your machine, you might want to use the ZIP version(it is even faster to download but slower to switch versions). In this case, you can use the following lines and refresh CMake:
CPMAddPackage(
+ NAME SDL2
+ URL "https://github.com/libsdl-org/SDL/archive/refs/tags/release-2.28.3.zip"
+ VERSION 2.28.3
+)
+If you want to try the bleeding edge version v3, add the following lines to your CMakeLists.txt file at your own risk:
Now that we have SDL set up, we should link it to our project. In order to do that, we can add the following lines after the line add_executable to our CMakeLists.txt file and refresh CMake:
target_link_libraries(MyGame SDL2::SDL2)
+# change SDL2 to SDL3 if you are using the bleeding edge version
+#target_link_libraries(MyGame SDL2::SDL2)
+And this will make SDL available to our project. Now we can start coding. Let's create a simple window:
#define SDL_MAIN_HANDLED true
+#include <SDL.h>
+
+int main(int argc, char** argv) {
+ SDL_Init(SDL_INIT_VIDEO);
+
+ SDL_Window* window = SDL_CreateWindow(
+ "SDL2Test",
+ SDL_WINDOWPOS_UNDEFINED,
+ SDL_WINDOWPOS_UNDEFINED,
+ 640,
+ 480,
+ 0
+ );
+
+ SDL_Renderer* renderer = SDL_CreateRenderer(window, -1, SDL_RENDERER_ACCELERATED);
+
+ SDL_Event e;
+ bool quit = false;
+ while (!quit){
+ while (SDL_PollEvent(&e)){
+ if (e.type == SDL_QUIT){
+ quit = true;
+ }
+ }
+
+ SDL_SetRenderDrawColor(renderer, 255, 0, 0, 255);
+ SDL_RenderClear(renderer);
+ SDL_RenderPresent(renderer);
+ SDL_Delay(0);
+ }
+
+ SDL_DestroyWindow(window);
+ SDL_Quit();
+
+ return 0;
+}
+If you feel that you want to test the bleeding-edge version, you can use this code instead:
#define SDL_MAIN_HANDLED true
+#include <SDL.h>
+
+int main(int argc, char* argv[]) {
+ SDL_Init(SDL_INIT_VIDEO);
+
+ SDL_Window *window = SDL_CreateWindow(
+ "MyGame",
+ 640,
+ 480,
+ 0
+ );
+
+ SDL_Renderer* renderer = SDL_CreateRenderer(window, nullptr, SDL_RENDERER_ACCELERATED);
+ SDL_Event e;
+ bool quit = false;
+
+ while (!quit) {
+ while (SDL_PollEvent(&e)) {
+ if (e.type == SDL_EVENT_QUIT) {
+ quit = true;
+ }
+ }
+ SDL_SetRenderDrawColor(renderer, 255, 0, 0, 255);
+ SDL_RenderClear(renderer);
+ SDL_RenderPresent(renderer);
+ SDL_Delay(0);
+ }
+
+ SDL_DestroyWindow(window);
+ SDL_Quit();
+
+ return 0;
+}
+Now you have a way to code games with SDL in a way that is cross-platform, and easy to setup.
If you hit Run or Debug on CLion, you will see a window like this:

and then:

I hope it works for you. If you have any problems, please let me know on Discord or via GitHub issues.
Memory-efficient Data Structure for Procedural Maze Generation¶
Estimated time to read: 13 minutes
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Problem statement: You need to generate mazes dynamicly, and you need to break or add walls between rooms. Ex.: How can we store data for a simple 3x3 maze like this:
The naive approach is to create a data structure like this:
class Node {
+ Node* top, right, bottom, left;
+ bool top_wall, right_wall, bottom_wall, left_wall;
+};
+This one above will work, but it is:
- Cache unfriendly;
- Random access to any element will be slow;
- Memory inefficient;
- Huge memory consumption;
- Redundant data usage;
Cache Unfriendly: The cache locality is hurt by extensive usage of dynamic allocation (4 pointer per node), and not reserving contigous memory for every new object created.
Random Access: To access the room {x,y} will have to iterate over node by node from the origin. The access of a room will have the algorithmic complexity of O(rows+columns) or simply O(n). For small mazes it is not a problem, but for big mazes it will be.
Memory inefficiency: The memory allocation for each room is 4 pointers and 4 booleans. If the size of the pointer is 8 bytes and each boolean is 1 byte, we might think it will have 36 bytes per room, right? Wrong! The compiler will add padding to the struct, so it will have 40 bytes per room. If we have a 1000x1000 maze, we will have 40MB of memory allocated for the maze. It is a lot of memory for a simple maze.
Data redundancy: The wall data is stored in two neighbors. If we break a wall, we have to break the wall in two places. It is not a big deal, but it is a waste of memory.
Optimization¶
Well, let's try to optimize it. The first step is to use a single array of data. And then we need to reduce the duplicity of data.
By removing all the pointers, and store the wall data in a single array following matrix linearization, we will drop the memory consumption to 4 bytes per room (10x improvement). It is a huge improvement, but we can do better. Now we can create an array of WallData as follows:
struct WallData {
+ bool top, right, bottom, left;
+};
+vector<WallData> data;
+WallData get_wall(int x, int y) {
+ return data[y * width + x];
+}
+The size of the WallData is 4 bytes. But we can reduce it if we use data layout optimization:
In this version, WallData will use 1 byte per room(40x improvement). But we will be using only 4 bits of the byte. Another way of optmizing it is to use vector of bools for every type of wall. Let's group them into vectors.
For vector, depending on the implementation, it needs to store the size of it, the capacity, and the pointer to the data, which will use 24 bytes per vector. If can reach 32 if it stores the reference count to it as a smart pointer.
So what we are going to do next? Reduce the number of vectors used to reduce overhead. If you want to go deeper, you can use only one vector
Can we do it better? Yes! As you might have noticed, every wall data is being stored in two nodes redundantly. So we will jump from 40 bytes(320 bits) to 2 bits per room (approximately 160x improvement). But in order to achieve that, you have to follow a strict set of rules andodifications.
- Every even bit is a top wall, and every odd bit is a right wall relative to an intersection;
- Every dimension of the maze will be increased by one unity in order to properly address the borders.
- We need to create accessors via matrix index and flaten with linearization technique.
This 3x2 maze will be represented by a 4x3 linearized matrix. It is easier to understand if you look at the walls as edges and the wall intersections as nodes. So for a 3x2 maze, we need 4 vertical walls and 3 horizontal walls. So in this specific case, if we follow the pattern of 1 if the wall is present and 0 if it is not there, and do this only for top and right walls of a node(intersection), we will have:
This fully blocked 3x2 maze
+ _ _ _
+|_|_|_|
+|_|_|_|
+
+Will give us 4x3 pairs of bits:
+01 01 01 00
+11 11 11 10
+11 11 11 10
+
+Linearized as:
+010101001111111011111110
+Just to recaptulate: we went from 40 Bytes (320 bits) per room to approximately 2 bits per room. A maze map with 128x128 would go from 128*128*320/8 = 640KB to 129*129*2/8 = 4161 bytes. It is 157.5 times densely packed. It is a huge improvement.
Notes about vectors:¶
- vector of bools is a bitfield, so it will pack 8 bools per byte, it will do the shift and masking for us.
- vector of bools is arguably an antipattern because it doesn't behave like a commom vector by not following the rule of zero cost abstraction from C++. It adds a cost for the densely packed bitfield.
- For our intent, this is exactly what we want, so we can use it, just check if your compiler implements it as a bitfield.
Here goes a simple implementation of a data structure to hold the maze data:
struct Maze {
+private:
+ vector<bool> walls;
+ vector<bool> visited;
+ int width, height;
+public:
+ Maze(int width, int height): width(width), height(height) {
+ walls.resize((width+1)*(height+1)*2, true);
+ for(int i = 0; i <= width; i++) // clear verticals on the top
+ SetNorthWall(i, 0, false);
+ for(int i = 0; i <= height; i++) // clear horizontals on the right
+ SetEastWall(width, i, false);
+ visited.resize(width*height, false); // no room is visited yet
+ }
+
+ bool GetVisited(int x, int y) const { return visited[y*width + x]; }
+ void SetVisited(int x, int y, bool val) { visited[y*width + x] = val; }
+
+ bool GetNorthWall(int x, int y) const { return walls[(y*(width+1) + x)*2 + 1]; }
+ bool GetSouthWall(int x, int y) const { return walls[((y+1)*(width+1) + x)*2 + 1];}
+ bool GetEastWall(int x, int y) const { return walls[((y+1)*(width+1) + x+1)*2];}
+ bool GetWestWall(int x, int y) const { return walls[((y+1)*(width+1) + x)*2];}
+
+ void SetNorthWall(int x, int y, bool val) { walls[(y*(width+1) + x)*2 + 1] = val; }
+ void SetSouthWall(int x, int y, bool val) { walls[((y+1)*(width+1) + x)*2 + 1] = val;}
+ void SetEastWall(int x, int y, bool val) { walls[((y+1)*(width+1) + x+1)*2] = val;}
+ void SetWestWall(int x, int y, bool val) { walls[((y+1)*(width+1) + x)*2] = val;}
+}
+Further ideas¶
- Is it possible to explore even more the structure?
- Is it possible to do the same for hexagonal grids? Every node will have 3 walls instead of 4 in the squared grid.
Differences between map vs unordered_map¶
Estimated time to read: 9 minutes
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.

Underlying Data Structure:¶
std::map: Implements a balanced binary search tree:- Usually a red-black tree, but it is defined by the STL implementation provided by your compiler;
- Ensures that elements are always sorted, which allows for efficient range queries and ordered traversal;
-
std::unordered_map: Implements a hash table.- The elements are not sorted and are stored in buckets based on the hash value of the keys.
-
On a
map, if the tree become too deep, it can have performance issues, because it is O(lg(N)) for almost all functions. The jumps between nodes pointers might not be cache friendly. - On an
unordered_map, the keys are stored as hashes and might have collisions, if it does collide to be stored on the same bucket, the search inside it is linear. Given the size of the bucket is usually small, this search is usually fast.
Complexity:¶
On a map, when you query, you will pay the price for navigating a tree until you find the element you are searching for. While on a unordered_map you pay the price for the hashing function you use and when it have colision, and pay the price to find an element in a vector that is the bucket.
map: query(key) -> navigate tree(might be not cache friendly) -> your value;unordered_map: query(key) -> hash the key(can be costly) -> find the bucket -> linear search in all elements inside the bucket(cache friendly)
Algorithm analysis:¶
Evaluate the cost of:
map:- How many node hops;
- How many key comparisons;
- Tree indexing can fit in the cache the whole time;
unordered_map:- How many CPU cycles the hashing function uses;
- How frequent collisions happens;
- How many elements you will have in the bucket on average?
Example:
Assume you have \(1024\) elements, a balanced tree can potentially reach 10 levels deep. \(\log_{2}(1024) = 10\) .
In a tree search we will fetch content of pointers 10 times and make 10 key comparisons until we reach the leaves;
If the key is just a pair of int32_t, you can easily implement a hash function that concatenates the bits of one into the another and have a uint64_t value as the key. This shift operation followed by xor is really cheap, but still have a constant cost. If your key is anything more complex, you might face a performance penalty. In this case, the cost here will be 2 basic CPU operations;
After paying the cost of hashing your key, you will have to fetch the content of pointer 1 time to receive the address of an array of elements which is the bucket. Hopefully you just have one element inside it, if not, you will have to iterate inside the bucket array.
In a hashing-bucket approach you pay the cost of hashing funtion, 1 fetch content, and then the linear search inside the bucket array.
So what is better?
a. Jump between memory locations in tree nodes; b. pay the price for a hashing function and then potentially a search inside an array?
Insertion, Query, and Deletion Complexity:¶
std::map:- Insertion/Deletion:
O(log n) - Query:
O(log n)
- Insertion/Deletion:
std::unordered_map:- Average-case complexity (amortized):
- Insertion/Deletion:
O(1) - Query:
O(1)
- Insertion/Deletion:
- Worst-case complexity (when dealing with hash collisions):
- Insertion/Deletion:
O(n)in the worst case - Query:
O(n)in the worst case
- Insertion/Deletion:
- Average-case complexity (amortized):
Ordered vs. Unordered:¶
std::mapmaintains order based on the keys, allowing for efficient range queries and ordered traversal of elements.std::unordered_mapdoes not guarantee any specific order of elements.
Memory Overhead:¶
std::map typically has a higher memory overhead due to the additional structure needed for the balanced binary search tree.
std::unordered_map may have a lower memory overhead, but it can be affected by the load factor and hash collisions.
Use Cases:¶
Use std::map when you need ordered traversal or range queries and can tolerate slightly slower insertion and deletion. Use std::unordered_map when you need fast average-case constant-time complexity for insertion, deletion, and queries, and the order of elements is not important.
Closing¶
In summary, the choice between std::map and std::unordered_map depends on the specific requirements of your application. If you need ordered elements and can tolerate slightly slower operations, std::map might be a better choice. If you prioritize fast average-case constant-time operations and the order of elements is not important, std::unordered_map may be more suitable.
I challenge you to implement your own associative container following what you learned here. It is a great exercise to learn how to implement a hash table and a binary search tree. Talk with me via discord if you want to discuss your implementation.
2023¶
Estimated time to read: 1 minute
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Setup SDL with CMake and CPM
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
FERPA Consent
FERPA (The Family Educational Rights and Privacy Act) is a federal law protecting the confidentiality of student records. It restricts others from accessing or discussing your educational records without your consent. Here we are going to discuss how it applies to the courses I teach and what are the benefits on sharing your work publicly if you want.
Notes on Submissions

Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
Let's talk about Virtual Reality
The goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
The problem with AI Trolley dilemma

The premise about the AI trolley dilemma is invalid. So the whole discussion about who should the car kill in a fatal situation. Let me explain why.
2024¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.

Academic Honesty¶
Estimated time to read: 1 minute
Notes on Submissions
Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
AI¶
Estimated time to read: 1 minute
Notes on Submissions
Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
The problem with AI Trolley dilemma
The premise about the AI trolley dilemma is invalid. So the whole discussion about who should the car kill in a fatal situation. Let me explain why.
Algorithms¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
Augmented Reality¶
Estimated time to read: 1 minute
Let's talk about Virtual Reality
The goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
Augmented Virtuality¶
Estimated time to read: 1 minute
Let's talk about Virtual Reality
The goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
Bitfield¶
Estimated time to read: 1 minute
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
C++¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Setup SDL with CMake and CPM
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
Cache¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Canvas¶
Estimated time to read: 1 minute
Notes on Submissions
Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
ChatGPT¶
Estimated time to read: 1 minute
Notes on Submissions
Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
CLion¶
Estimated time to read: 1 minute
Setup SDL with CMake and CPM
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
CMake¶
Estimated time to read: 1 minute
Setup SDL with CMake and CPM
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
CPM¶
Estimated time to read: 1 minute
Setup SDL with CMake and CPM
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
Data Structures¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
FERPA¶
Estimated time to read: 1 minute
FERPA Consent
FERPA (The Family Educational Rights and Privacy Act) is a federal law protecting the confidentiality of student records. It restricts others from accessing or discussing your educational records without your consent. Here we are going to discuss how it applies to the courses I teach and what are the benefits on sharing your work publicly if you want.
GameDev¶
Estimated time to read: 1 minute
Setup SDL with CMake and CPM
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
Github Copilot¶
Estimated time to read: 1 minute
Notes on Submissions
Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
map¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
Maze Generation¶
Estimated time to read: 1 minute
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Maze¶
Estimated time to read: 1 minute
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Memory¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Mixed Reality¶
Estimated time to read: 1 minute
Let's talk about Virtual Reality
The goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
Moss¶
Estimated time to read: 1 minute
Notes on Submissions
Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
Optimization¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Philosophy¶
Estimated time to read: 1 minute
The problem with AI Trolley dilemma
The premise about the AI trolley dilemma is invalid. So the whole discussion about who should the car kill in a fatal situation. Let me explain why.
Plagiarism¶
Estimated time to read: 1 minute
Notes on Submissions
Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
Privacy¶
Estimated time to read: 1 minute
FERPA Consent
FERPA (The Family Educational Rights and Privacy Act) is a federal law protecting the confidentiality of student records. It restricts others from accessing or discussing your educational records without your consent. Here we are going to discuss how it applies to the courses I teach and what are the benefits on sharing your work publicly if you want.
SDL2¶
Estimated time to read: 1 minute
Setup SDL with CMake and CPM
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
SDL3¶
Estimated time to read: 1 minute
Setup SDL with CMake and CPM
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
Teaching¶
Estimated time to read: 1 minute
Notes on Submissions
Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
Turnitin¶
Estimated time to read: 1 minute
Notes on Submissions
Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
unordered_map¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
Vector¶
Estimated time to read: 1 minute
Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Virtual Reality¶
Estimated time to read: 1 minute
Let's talk about Virtual Reality
The goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
Blog¶
Estimated time to read: 1 minute
Differences between map vs unordered_map
Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.

Memory-efficient Data Structure for Procedural Maze Generation
In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Setup SDL with CMake and CPM
In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
FERPA Consent
FERPA (The Family Educational Rights and Privacy Act) is a federal law protecting the confidentiality of student records. It restricts others from accessing or discussing your educational records without your consent. Here we are going to discuss how it applies to the courses I teach and what are the benefits on sharing your work publicly if you want.
Notes on Submissions

Here are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
Let's talk about Virtual Reality
The goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
The problem with AI Trolley dilemma

The premise about the AI trolley dilemma is invalid. So the whole discussion about who should the car kill in a fatal situation. Let me explain why.
Full Cycle Cross-platform Game Development with SDL, CMAKE and GitHub¶
Estimated time to read: 10 minutes
This Dojo is focused in training professionals on setting up a full cycle project using SDL, CMAKE and GitHub actions.
Agenda:¶
- Introduction (5 minutes): The facilitator introduces the coding dojo and the goal of the session, which is to create a CMake build system for an SDL project using GitHub Actions.
- Warm-up exercise (10 minutes): A brief exercise is conducted to get participants warmed up and familiar with SDL and CMake.
- Setting up the project (30 minutes): Participants work in pairs or small groups to clone the SDL project from GitHub and create a CMake build system for it.
- Adding GitHub Actions (30 minutes): Participants continue to work on their CMake build systems and add GitHub Actions to automate the build and test process.
- Review and discussion (10 minutes): Participants share their solutions and discuss the various approaches taken to create the CMake build system and implement GitHub Actions.
- Retrospective (5 minutes): Participants reflect on the session and provide feedback on what went well and what could be improved for future sessions.
- Closing (5 minutes): The facilitator concludes the session and thanks the participants for their contributions.
Introduction¶
Warm-up¶
- Write down what do you expect from this Dojo here;
Setup¶
You can either fork Modern CPP Starter Repo (and star it) or create your own from scratch.
Ensure that you have the following software installed in your machine:
- C++ Compiler. Ex.: GCC(build-essential, and cmake) on Linux, MS Visual Studio on Windows(select C++ and in additional tools, select cmake), Command Line Tools for OSX.
- Git. Ex.: Gitkraken(free for students);
- IDE. Ex.: Clion(free for students);
- CMake. Ex.: cmake-gui, but clion already bundle it for you.
Action¶
1. Clone.¶
Clone your repository you created or forked in the last step (Modern CPP Starter Repo);
2. CMake Glob¶
Edit your CMakeLists.txt to glob your files (naive and powerful approach). Example:
Minimum CMake:
cmake_minimum_required(VERSION 3.25)
+project(MY_PROJECT)
+set(CMAKE_CXX_STANDARD 17)
+add_executable(mygamename main.cpp)
+file(GLOB MY_INCLUDES # Rename this variable
+ CONFIGURE_DEPENDS
+ ${CMAKE_CURRENT_SOURCE_DIR}/*.h
+ ${CMAKE_CURRENT_SOURCE_DIR}/*.hpp
+ )
+
+file(GLOB MY_SOURCE # Rename this variable
+ CONFIGURE_DEPENDS
+ ${CMAKE_CURRENT_SOURCE_DIR}/*.cpp
+ ${CMAKE_CURRENT_SOURCE_DIR}/*.c
+ )
+3. CPM¶
Add code for the package manager CPM.
Read their example and how do you download it. Optionally, you can download it dynamically, this is the way I prefer.;
4. SDL dependency¶
Use CPM to download your dependencies. Please refer to this issue comment for an example. If you want to see something already done, check this one;
5. Linking¶
Link your executable to SDL;
You can see it in action here. In this example, we include the external cmake file manage that. It is a good practice to do that.6. Optional: ImGUI¶
ImGui for debugging interface purposes;
Use CPM to download ImGUI and link it to your library. Example - You can optionally remove the static link if you want. https://github.com/InfiniBrains/SDL2-CPM-CMake-Example/blob/main/main.cpp
Link your executable to IMGUI
7. It is GAME time!¶
Copy this example here to your main.cpp if you are going do use ImGUI or just use something like this:
#include <stdio.h>
+
+#include "SDL.h"
+
+int main()
+{
+ if(SDL_Init(SDL_INIT_VIDEO) != 0) {
+ fprintf(stderr, "Could not init SDL: %s\n", SDL_GetError());
+ return 1;
+ }
+ SDL_Window *screen = SDL_CreateWindow("My application",
+ SDL_WINDOWPOS_UNDEFINED,
+ SDL_WINDOWPOS_UNDEFINED,
+ 640, 480,
+ 0);
+ if(!screen) {
+ fprintf(stderr, "Could not create window\n");
+ return 1;
+ }
+ SDL_Renderer *renderer = SDL_CreateRenderer(screen, -1, SDL_RENDERER_SOFTWARE);
+ if(!renderer) {
+ fprintf(stderr, "Could not create renderer\n");
+ return 1;
+ }
+
+ SDL_SetRenderDrawColor(renderer, 0, 0, 0, 255);
+ SDL_RenderClear(renderer);
+ SDL_RenderPresent(renderer);
+ SDL_Delay(3000);
+
+ SDL_DestroyWindow(screen);
+ SDL_Quit();
+ return 0;
+}
+8. Github Actions.¶
Create folder .github and inside it another one workflows. Inside it create a .yml file.
Here you will code declaratively how your build should proceed. The basic steps are usually: Clone, Cache, Install dependencies, Configure, Build, Test and Release conditionally to branch.
Check and try to reproduce the same thing you see here.
If you are following the Modern CPP Starter Repo, you can explore automated tests. Be my guest and try it.
Review¶
How far you went? Share your repos here.
Retrospective¶
Please give me feedbacks in what we did today. If you like or have something to improve, say something in here. Ah! you can always fork this repo, improve it and send a pull request back to this repo.
Closing¶
Give stars to all repos you saw here as a way to contribute to the continuity of the project. ![]()
Propose a new Dojo and be in touch.
The most asked interview question¶
Estimated time to read: 5 minutes
Arguably, the most asked question in coding interviews is the Two Number Sum. It is used by many Bigtechs and AAA Game Studios. You can see this question in many youtube videos, coding websites such as hackerank, leetcode, algoexpert ...
Agenda: Two Number Sum Coding Dojo¶
Introduction (5 minutes)¶
- Welcome participants to the dojo
- Introduce the Two Number Sum question as a common coding interview question
- Discuss the importance of problem-solving skills in coding interviews
- Briefly explain the rules and structure of the dojo
- Problem Explanation (10 minutes)
Provide a brief overview of the Two Number Sum question¶
- Define the problem and its requirements
- Discuss potential edge cases and constraints
- Review sample inputs and expected outputs
- Coding Session (50 minutes)
Problem restrictions and characterization¶
Write a function that will receive an array/vector/list of integers and a target number. Find two numbers inside the array that summed will match the target. You have to return both in a array/vector/list ordered.
Implement the solution in 3 different ways. Open the details only after you try. First approach:
1. Naive solution. O(N^2) time and O(1) space; - required to know this;
Can you make it faster?
2. Fastest solution. O(N) time and O(N) space; - this will make you
Can you make it not use much memory, but still be fast?
3. Fastest without mem allocation. O(N*log(N)) time and O(1) space;
Participants work on solving the Two Number Sum problem in pairs or small groups¶
- Emphasize the importance of communication and collaboration during the coding session
- Encourage participants to use a whiteboard or paper to sketch out their solutions
- Provide guidance and support as needed
- Code Review (20 minutes)
Participants share their solutions with the group¶
- Facilitate a discussion about each solution, highlighting strengths and areas for improvement
- Encourage participants to ask questions and provide feedback to their peers
- Discuss potential optimizations and alternative approaches to the problem
- Wrap-Up (5 minutes)
Recap the main takeaways from the dojo¶
- Encourage participants to continue practicing problem-solving skills on their own
- Thank participants for attending the dojo and provide any additional resources or support as needed.
- Note: The time allocation can be adjusted based on the group's needs and pace.
Coding Dojo Definition¶
Estimated time to read: 3 minutes
A coding dojo is a programming practice that involves a group of developers coming together to collaborate on solving coding challenges. It is a learning and collaborative environment where developers can improve their coding skills and work on real-world coding problems.
The term "dojo" comes from the Japanese term for place of the way, which is a traditional place of training for martial arts. In a coding dojo, participants practice the skills they have learned, exchange knowledge and experience, and work together to solve programming challenges.
During a coding dojo session, participants work in pairs or small groups to solve programming challenges, using techniques such as pair programming and test-driven development. They work through the problem step by step, discussing and sharing their ideas and approaches along the way. The goal of a coding dojo is to improve individual and team coding skills, and to learn from each other's experiences.
Timeline Structure¶
- Introduction (5 minutes): The facilitator introduces the coding dojo and the coding challenge for the session.
- Warm-up exercise (10 minutes): A brief exercise is conducted to get participants warmed up and ready for the coding challenge.
- Coding challenge (60 minutes): Participants work in pairs or small groups to solve the coding challenge using techniques such as pair programming and test-driven development.
- Review and discussion (15 minutes): Participants share their solutions and discuss the various approaches taken to solve the challenge.
- Retrospective (10 minutes): Participants reflect on the session and provide feedback on what went well and what could be improved for future sessions.
- Closing (5 minutes): The facilitator concludes the session and thanks the participants for their contributions.
Differences between map vs unordered_map
\nBoth std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.

Memory-efficient Data Structure for Procedural Maze Generation
\nIn this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
", "image": null, "date_published": "2023-10-02T23:00:00+00:00", "authors": [{"name": "tolstenko"}], "tags": ["Bitfield", "C++", "Cache", "Data Structures", "Maze", "Maze Generation", "Memory", "Optimization", "Vector"]}, {"id": "https://courses.tolstenko.net/blog/2023/09/09/setup-sdl-with-cmake-and-cpm/", "url": "https://courses.tolstenko.net/blog/2023/09/09/setup-sdl-with-cmake-and-cpm/", "title": "Setup SDL with CMake and CPM", "content_html": "Setup SDL with CMake and CPM
\nIn my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
", "image": null, "date_published": "2023-09-09T03:11:08.658000+00:00", "authors": [{"name": "tolstenko"}], "tags": ["C++", "CLion", "CMake", "CPM", "GameDev", "SDL2", "SDL3"]}, {"id": "https://courses.tolstenko.net/blog/2023/08/30/ferpa-consent/", "url": "https://courses.tolstenko.net/blog/2023/08/30/ferpa-consent/", "title": "FERPA Consent", "content_html": "FERPA Consent
\nFERPA (The Family Educational Rights and Privacy Act) is a federal law protecting the confidentiality of student records. It restricts others from accessing or discussing your educational records without your consent. Here we are going to discuss how it applies to the courses I teach and what are the benefits on sharing your work publicly if you want.
\n", "image": null, "date_published": "2023-08-30T18:00:00+00:00", "authors": [{"name": "tolstenko"}], "tags": ["FERPA", "Privacy"]}, {"id": "https://courses.tolstenko.net/blog/2023/08/24/notes-on-submissions/", "url": "https://courses.tolstenko.net/blog/2023/08/24/notes-on-submissions/", "title": "Notes on Submissions", "content_html": "Notes on Submissions
\nHere are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
", "image": null, "date_published": "2023-08-24T16:40:00+00:00", "authors": [{"name": "tolstenko"}], "tags": ["AI", "Academic Honesty", "Canvas", "ChatGPT", "Github Copilot", "Moss", "Plagiarism", "Teaching", "Turnitin"]}, {"id": "https://courses.tolstenko.net/blog/2023/08/09/lets-talk-about-virtual-reality/", "url": "https://courses.tolstenko.net/blog/2023/08/09/lets-talk-about-virtual-reality/", "title": "Let's talk about Virtual Reality", "content_html": "Let's talk about Virtual Reality
\nThe goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
", "image": null, "date_published": "2023-08-09T16:00:00+00:00", "authors": [{"name": "tolstenko"}], "tags": ["Augmented Reality", "Augmented Virtuality", "Mixed Reality", "Virtual Reality"]}, {"id": "https://courses.tolstenko.net/blog/2023/07/28/the-problem-with-ai-trolley-dilemma/", "url": "https://courses.tolstenko.net/blog/2023/07/28/the-problem-with-ai-trolley-dilemma/", "title": "The problem with AI Trolley dilemma", "content_html": "The problem with AI Trolley dilemma
\n
The premise about the AI trolley dilemma is invalid. So the whole discussion about who should the car kill in a fatal situation. Let me explain why.
", "image": null, "date_published": "2023-07-28T18:42:39+00:00", "authors": [{"name": "tolstenko"}], "tags": ["AI", "Philosophy"]}]} \ No newline at end of file diff --git a/feed_json_updated.json b/feed_json_updated.json new file mode 100644 index 000000000..b05d1c028 --- /dev/null +++ b/feed_json_updated.json @@ -0,0 +1 @@ +{"version": "https://jsonfeed.org/version/1", "title": "Awesome GameDev Resources", "home_page_url": "https://courses.tolstenko.net/", "feed_url": "https://courses.tolstenko.net/feed_json_updated.json", "description": "Awesome GameDev Resources for learning how to make games", "icon": null, "authors": [{"name": "See contributors and authors at https://github.com/InfiniBrains/Awesome-GameDev-Resources/graphs/contributors"}], "language": "en", "items": [{"id": "https://courses.tolstenko.net/blog/2024/01/29/differences-between-map-vs-unordered_map/", "url": "https://courses.tolstenko.net/blog/2024/01/29/differences-between-map-vs-unordered_map/", "title": "Differences between map vs unordered_map", "content_html": "Differences between map vs unordered_map
\nBoth std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
The problem with AI Trolley dilemma
\n
The premise about the AI trolley dilemma is invalid. So the whole discussion about who should the car kill in a fatal situation. Let me explain why.
", "image": null, "date_modified": "2024-02-07T16:04:23+00:00", "authors": [{"name": "tolstenko"}], "tags": ["AI", "Philosophy"]}, {"id": "https://courses.tolstenko.net/blog/2023/09/09/setup-sdl-with-cmake-and-cpm/", "url": "https://courses.tolstenko.net/blog/2023/09/09/setup-sdl-with-cmake-and-cpm/", "title": "Setup SDL with CMake and CPM", "content_html": "Setup SDL with CMake and CPM
\nIn my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
", "image": null, "date_modified": "2024-02-07T16:04:23+00:00", "authors": [{"name": "tolstenko"}], "tags": ["C++", "CLion", "CMake", "CPM", "GameDev", "SDL2", "SDL3"]}, {"id": "https://courses.tolstenko.net/blog/2023/08/30/ferpa-consent/", "url": "https://courses.tolstenko.net/blog/2023/08/30/ferpa-consent/", "title": "FERPA Consent", "content_html": "FERPA Consent
\nFERPA (The Family Educational Rights and Privacy Act) is a federal law protecting the confidentiality of student records. It restricts others from accessing or discussing your educational records without your consent. Here we are going to discuss how it applies to the courses I teach and what are the benefits on sharing your work publicly if you want.
\n", "image": null, "date_modified": "2024-02-07T16:04:23+00:00", "authors": [{"name": "tolstenko"}], "tags": ["FERPA", "Privacy"]}, {"id": "https://courses.tolstenko.net/blog/2023/10/02/memory-efficient-data-structure-for-procedural-maze-generation/", "url": "https://courses.tolstenko.net/blog/2023/10/02/memory-efficient-data-structure-for-procedural-maze-generation/", "title": "Memory-efficient Data Structure for Procedural Maze Generation", "content_html": "Memory-efficient Data Structure for Procedural Maze Generation
\nIn this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
", "image": null, "date_modified": "2024-02-07T16:04:23+00:00", "authors": [{"name": "tolstenko"}], "tags": ["Bitfield", "C++", "Cache", "Data Structures", "Maze", "Maze Generation", "Memory", "Optimization", "Vector"]}, {"id": "https://courses.tolstenko.net/blog/2023/08/09/lets-talk-about-virtual-reality/", "url": "https://courses.tolstenko.net/blog/2023/08/09/lets-talk-about-virtual-reality/", "title": "Let's talk about Virtual Reality", "content_html": "Let's talk about Virtual Reality
\nThe goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
", "image": null, "date_modified": "2024-02-07T16:04:23+00:00", "authors": [{"name": "tolstenko"}], "tags": ["Augmented Reality", "Augmented Virtuality", "Mixed Reality", "Virtual Reality"]}, {"id": "https://courses.tolstenko.net/blog/2023/08/24/notes-on-submissions/", "url": "https://courses.tolstenko.net/blog/2023/08/24/notes-on-submissions/", "title": "Notes on Submissions", "content_html": "Notes on Submissions
\nHere are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
", "image": null, "date_modified": "2024-02-07T16:04:23+00:00", "authors": [{"name": "tolstenko"}], "tags": ["AI", "Academic Honesty", "Canvas", "ChatGPT", "Github Copilot", "Moss", "Plagiarism", "Teaching", "Turnitin"]}]} \ No newline at end of file diff --git a/feed_rss_created.xml b/feed_rss_created.xml new file mode 100644 index 000000000..1ea23ef9e --- /dev/null +++ b/feed_rss_created.xml @@ -0,0 +1 @@ +Awesome GameDev Resources¶
Estimated time to read: 15 minutes
Join is on Discord!
How to use this repo: Read the topics, and if you're unsure if you understand the topics covered here it is a good time for you to revisit them.
Ways of reading:
- Website: read through your browser the interactive examples and animations will work better in this version;
- Github: You read through the github repo;
- PDF: download the latest
- Amazon Kindle: You can buy the book in Amazon and read it in your kindle device;
- Contribute!: If you want to go deep and propose changes to repo, use the github repo.

Badges¶
CI: ![]()
Join us: ![]()


Metrics:






{kind=link}
Code of conduct: ![]()
Topics¶
Philosophy¶
This repository aims to be practical, and it will be updated as we test the methodology. Frame it as a guidebook, not a manual. Most of the time, we are constrained by the time, so in order to move fast, we won't cover deeply some topics, but the basics that allows you to explore by yourself or point the directions for you to study in other places acting as a self-taught student, so you really should look for more information elsewhere if you feels so. I use lots of references and highly incentive you to look for other too and propose changes in this repo. Sometimes, it will mostly presented in a chaotic way, which implies that you will need to explore the concepts by yourself or read the manual/books. Every student should follow your own path to learning, it is impossible to cover every learning style, so it is up to you to build your own path and discover the best way to learn. What worked for me or what works for a given student probably won't work for you, so dont compare yourself to others too much, but be assured that we're here to help you to succeed. If you need help, just send private messages, or use public forums such as github issues and discussions.
Reflections on teaching and learning processes¶
Philosophies¶
I would like to categorize the classes into philosophies. so I can address them properly: - Advanced classes: are more focused on work and deliveries than theory, they are tailored toward the student goals more than the closed boxes and fixed expected results. It comprehends AI and Adv. AI; - Introduction classes: are focused on theory and practice. In those classes, they have more focus on structural knowledge and basic content. It comprehends classes such as Introduction to Programming. - Guidance: are more focused on how can we bring the student to the highest standard and get ready to be hired. It comprehends classes such as Capstone, Portfolio classes, and Mentoring activities.
Learning Styles¶
- Visual: You prefer using pictures, images, and spatial understanding;
- For this style I recently acquired a pen-tablet monitor, so I will be adding this type of content more often.
- I also use lots of diagrams via code2flow, sequence diagram and others
- I assume my handwriting is not the best, but I compensate it with lots of diagrams and pictures, and always project what I write in the computer.
- Aural: You prefer using sound and music;
- I always link to youtube videos and podcasts, so they can follow up with extra content and material;
- Verbal: You prefer using words, both in speech and writing;
- I setup my machine to record specific topics that might be hard to undestand in just one go, and I did some experimental recordings, but I am still struggling with video editing. I will be adding more videos in the future.
- My main issue here is that I am not a native english speaker, so I am still struggling with the language, but I am trying to improve it.
- Other issue that I can name is eye-to-eye contact. It feels overburned to me to keep eye-to-eye contact, that I usually look away.
- Physical: You prefer using your body, hands and sense of touch;
- Given my cultural origin, I am usually over expressive in this field, and I need more fine tuning my proxemic. Brazilians commonly talk and walk closer to each other than americans.
- While lecture I really enjoy to use my hands to express myself, and I am trying to use more body language to express myself.
- Logical: You prefer using logic, reasoning and systems;
- I always craft and test teaching experiences to push them to think and reason about the topics.
- I always use tools such as beecrowd to let them code and test their ability to solve problems.
- Social: You prefer to learn in groups or with other people;
- I incentive them to do in-class assignments in pairs, and do group assignments. But I recognize this might be a problem for some students, so I am trying to find a way to make it more inclusive.
- Strangelly for me, some students prefer to socialize with me by booking office hours more than working together. Probably next semester I will reserve a time to do a type of co-working time when I can be available to help them in their assignments.
- Solitary: You prefer to work alone and use self-study.
- Sometimes and some topics you really need to study by yourself, and it can be the best way for some. But I warn them about the effects of loneliness and impostor syndrome.
- This is usually the most common way to learn, and I always keep an eye on the ones that are struggling to keep up with the class. I always try to reach them and help them to keep up with the class.
- To compensate this solitude I incentive them to present their work to the class no they can experience having attention even when the lack social skills.
Teaching Styles¶
For every type of style, I try to give a bit of insights:
- Authoritative: control the classroom and maintain discipline;
- I create a set of rules that should be followed in order to guarantee the student's success;
- Delegator: give students control of their learning;
- For the intro classes I follow more this strategy;
- Facilitator: guide students and help them learn by themselves;
- I usually follow this strategy on advanced classes;
- Demonstrator: explain and show things to students;
- I usully provide a stream of references or even create my own content to show them how to do things;
Credits¶
Give us stars! Click ->
Reasons why you should learn how to program with C++¶
Estimated time to read: 26 minutes
Before we start, this repository aims to be practical, and I highly incentive you to look for other references. I want to add this another awesome repository it holds an awesome compilation of modern C++ concepts.
Another relevant reference for what we are going to cover is the updated core guidelines that explain why some syntax or style is bad and what you should be doing instead.
Why?¶
The first thing when you think of becoming a programmer is HOW DO I START? Well, C++ is one of the best programming languages to give you insights into how a computer works. Through the process of learning how to code C++, you will learn not only how to use this language as a tool to solve your problems, but the farther you go, the more you will start uncovering and exploring exciting computer concepts.
C++ gives you the simplicity of C and adds a lot of steroids. It delivers lots of quality-of-life stuff, increasing the developer experience. Let’s compare C with C++, shall we?
- The iconic book "The C Programming Language" by Brian W. Kernighan and Dennis M. Ritchie has only 263 pages. Pretty simple, huh?
- The book "C++ How to Program" by Harvey and Paul Deitel It holds around 1000 pages, and the pages are way bigger than the other one.

So, don’t worry, you just need to learn the basics first, and all the rest are somehow advanced concepts. I will do my best to keep you focused on what is relevant to each moment of your learning journey.
Without further ado. Get in the car!

Speed Matters¶
A LOT. Period. C++ is one of the closest intelligible programming languages before reaching the level of machine code, as known as Assembly Language. If you code in machine code, you obviously will code precisely what you want the machine to do, but this task is too painful to be the de-facto standard of coding. So we need something more straightforward and more human-readable. So C++ lies in this exact area of being close to assembly language and still able to be "easily" understandable. Note the quotes, they are there because it might not be that easy when you compare its syntax to other languages, C++ has to obey some constraints to keep the generated binary fast as a mad horse while trying to be easier than assembly. Remember, it can always get worse.

The main philosophy that guides C++ is the "Zero-cost abstractions", and it is the main reason why C++ is so fast. It means that the language does not add any overhead to assembly. So, if someone proposes a new core feature as a Technical specification, it should pass through this filter. And it is a very high bar to pass. I am looking at you, ts reflection, everyone I know that want to make games, ask for this feature, but it is not there yet.

Why does speed matter?¶
Mainly because we don’t want to waste time. Right? But it has more impactful consequences. Let’s think a bit more, you probably have a smartphone, and it lives only while it has enough energy on its battery. So, if you are a lazy mobile developer and do not want to learn how to do code efficiently, you will make your app drain more energy from the battery just by making the user wait for the task to be finished or by doing lots of unnecessary calculations! You will be the reason the user has not enough power to use their phones up to the end of the day. In fact, you will be punishing your user by using your app. You don’t want that, right? So let’s learn how to code appropriately. For the sake of the argument, worse than that, a lazy blockchain smart contract developer will make their users pay more for extra gas fee usage for the extra inefficient CPU cycles.

Language benchmarks¶
I don’t want to point fingers at languages, but, hey, excuse me, python, are you listening to me, python? Python? Please answer! reference cpp vs python. Nevermind. It is still trying to figure things out. Ah! Hey ruby, don’t be shy, I know you look gorgeous, and I admire you a lot, but can you dress up faster and be ready to run anytime soon?
You don’t need makeup to run fast. That’s the idea. If the language does lots of fancy stuff, it won’t be extracting the juicy power of the CPU.
So let’s first clarify some concepts for a fair comparison. Some languages do not generate binaries that run in your CPU. Some of them run on top of a virtual machine. The Virtual Machine(VM) is a piece of software that, in runtime, translates the bytecode or even compiles source code to something the CPU can understand. It’s like an old car; some of them will make you wait for the ignition or even get warm enough to run fast. I am looking at you Java and JavaScript. It is a funny concept, I admit, but you can see here that the ones that run on top of a translation device would never run as fast as a compiled binary ready to run on the CPU.
So let’s bring some ideas from my own experience, and I invite you to test by yourself. Just search for "programming languages benchmark" on your preferred search engine or go here.

I don’t want to start a flame-war. Those numbers might be wrong, but the overall idea is correct. Assuming C++ does not add much overhead to your native binary, let’s set the speed to run as 1x. Java would be around 1.4x slower, and JavaScript is 1.6x, python 40x, and ruby 100x. The only good competitor in the house is Rust because its compiled code runs straight on the CPU efficiently with lots of quality-of-life additions. Rust gives almost similar results if you do not play around with memory-intensive problems. Another honorable mention is WASM - Web Assembly, although it is a bytecode for a virtual machine, many programming languages are able to target it(compile for it), it is becoming blazing fast and it is getting traction nowadays, keep tuned.

Who should learn C++¶

YOU! Yes, seriously, I don’t know you, but I am pretty sure you should know how to code in any language. C++ can be challenging, it is a fact, but if you dare to challenge yourself to learn it, your life will be somewhat better.
Let’s cut to the bullets:
- The ones who seek to build efficient modules for mobile apps, such as the video/image processing unit;
- Game developers. Even the gameplay developers that usually only script things should know how to ride a horse(CPU) fast;
- Researchers looking to not waste time by coding inefficient code and wait hours, even days, to see the result of their calculations. They should reduce the costs of renting CPU clusters;
- Computer scientists are those who should know how a computer works. After all, C++ is one of the preferred programming languages that unlocks all the power of the CPU;
- Engineers, in general, should know how to simulate things efficiently;
How do machines run code?¶
The first thing is: the CPU does not understand any programming language, only binary instructions. So you have to convert your code into something the machine can understand. This is the job of the compiler. A compiler is a piece of software that reads a text file written following the rules of a programming language and essentially converts it into binary instructions that the CPU can execute. There are many strategies and many ways of doing it. So, given its nature of being near assembly, with C++, you will control precisely what instructions the CPU will run.
But, there is a catch here: for each CPU, you will need a compiler for that instruction set. Ex.: the compiler GCC can generate an executable program for ARM processors, and the generated program won’t work on x86 processors; In the same way, an x64 executable won’t work on an x86; you need to match the binary instructions generated by the compiler with the same instruction set available on the target CPU you want to run it. Some compilers can cross-compile: the compiler runs in your machine on your CPU with its instruction set, but the binary generated only runs on a target machine with its own instruction set.
graph TD
+ START((Start))-->
+ |Source Code|PreProcessor-->
+ |Pre-processed Code|Compiler-->
+ |Target Assembly Code|Assembler-->
+ |Relacable Machine Code|Linker-->
+ |Executable Machine Code|Loader-->
+ |Operation System|Memory-->
+ |CPU|RUN((Run))Program Life Cycle¶
Software development is complex and there is lots of styles, philosophies and standard, but the overall structure looks like this:
- Analysis, Specification, Problem definition
- Design of the Software (pseudocode/algorithm, flowchart), Problem analysis
- Implementation / Coding
- Testing and Debugging - In TDD(Test Driven Development) we write the tests first.
- Maintenance - Analytics and Improvements
- End of Life
Pseudocode¶
Pseudocode is a way of expressing algorithms using a combination of natural language and programming constructs. It is not a programming language and cannot be compiled or executed, but it provides a clear and concise way to describe the steps of an algorithm. Here is an example of pseudocode that describes the process of finding the maximum value in a list of numbers:
set maxValue to 0 +for each number in the list of numbers + if number is greater than maxValue + set maxValue to number +output maxValue +Pseudocode is often used as a planning tool for programmers and can help to clarify the logic of a program before it is written in a specific programming language. It can also be used to communicate algorithms to people who are not familiar with a particular programming language. Reference
Flowcharts¶
A flowchart is a graphical representation of a process or system that shows the steps or events in a sequential order. It is a useful tool for demonstrating how a process works, identifying potential bottlenecks or inefficiencies in a process, and for communicating the steps involved in a process to others.
Flowcharts are typically composed of a series of boxes or shapes, connected by arrows, that represent the steps in a process. Each box or shape usually contains a brief description of the step or event it represents. The arrows show the flow or movement from one step to the next.
Flowcharts can be used in a variety of settings, including business, engineering, and software development. They are particularly useful for demonstrating how a process works, identifying potential issues or bottlenecks in the process, and for communicating the steps involved in a process to others.
There are many symbols and notations that can be used to create flowcharts, and different organizations and industries may have their own standards or conventions for using these symbols. Some common symbols and notations used in flowcharts include:
- Start and end symbols: These are used to indicate the beginning and end of a process.
- Process symbols: These are used to represent the various steps or events in a process.
- Decision symbols: These are used to represent a decision point in a process, where the flow of the process depends on the outcome of a decision.
- Connector symbols: These are used to connect the various symbols in a flowchart, showing the flow or movement from one step to the next.
- Annotation symbols: These are used to add additional information or notes to a flowchart.
By using a combination of these symbols and notations, you can create a clear and concise flowchart that effectively communicates the steps involved in a process or system. Reference
I suggest using the tool Code2Flow to write pseudocode and see the flowchart drawn in real time. But you can draw them on Diagrams. If you are into sequence diagrams, I suggest using sequencediagram.org.
Practice¶
Try to think ahead the problem definition by questioning yourself before expressing the algorithm as pseudocode or flowchart: - What are the inputs? - What is a valid input? - How to compute the math? - What is the output? - How many decimals is needed to express the result?
Use diagrams to draw a flowchart or use Code2Flow to write a working pseudocode to: 1. Compute the weighted average of two numbers. The first number has weight of 1 and the second has weight of 3; 2. Area of a circle; 3. Compute GPA; 4. Factorial number;
Glossary¶
It is expected for you to know superficially these terms and concepts. Research about them. It is not strictly required, because we are going to cover them in class.
- CPU
- GPU
- ALU
- Main Memory
- Secondary Memory
- Programming Language
- Compiler
- Linker
- Assembler
- Pseudocode
- Algorithms
- Flowchart
Activities¶
- Sign up on beecrowd. If you are a enrolled student, look for the key in canvas to be assigned to the coding assignments.
- https://blockly.games/maze - test your ability to solve small problems via block programming
- https://codecombat.com/ - very interesting game
- https://scratch.mit.edu/ - start a project and make it say hello when you click on it
Troubleshooting¶
If you have problems here, start a discussion this is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me.
Tools for C++ development¶
Estimated time to read: 45 minutes
Opinion
This list is a mix of standard tools and personal choice. It is a good starting point, but in the future you will be impacted by other options, just keep your mind open to new choices.
Every programing language use different set of tools in order to effectively code. In C++ you will need to learn how to use a bunch of them to solve problems and develop software.
Version Control ¶
Version control are tools that help you to keep track of your code changes. It is a must have tool for any developer. You can keep track the state of your code, and if you mess up something, you can go back to a previous state. It is also a great tool to collaborate with other developers. You can work on the same codebase without messing up each other work.
GIT ¶
Optional
Git is a version control system that is used to track changes to files, including source code, documents, and other types of files. It allows multiple people to work on the same files concurrently, and it keeps track of all changes made to the files, making it easy to go back to previous versions or merge changes made by different people. Git is widely used by developers for managing source code, but it can be used to track changes to any type of file. It is particularly useful for coordinating work on projects that involve multiple people, as it allows everyone to see and track changes made by others.
Github ¶
Action
Github is a web-based platform for version control and collaboration on software projects. It is a popular platform for developers to share and collaborate on code, as well as to track and manage software development projects. GitHub provides version control using Git, a version control system that allows developers to track changes to their codebase and collaborate with other developers on the same codebase. It also includes a range of features such as bug tracking, project management, and team communication tools. In addition to being a platform for software development, GitHub is also a community of developers and a marketplace for buying and selling software development services.
In this course we are going to extensively use GITHUB functionalities. So create an account now with your personal account. Use a meaningful username. Avoid names that hard to associate with you. If you have a educational email or student id, apply for the Github Student Pack, so you will have access to lots of free tools.
It is nice to have git in your machine, but it is not required, because we are going to use gui via gui tools. See GitKraken below.
GitKraken ¶
Action
GitKraken is a Git client for Windows, Mac, and Linux that provides a graphical interface for working with Git repositories. It allows users to manage Git repositories, create and review changes to code, and collaborate with other developers. Some features of GitKraken include a visual representation of the repository's commit history, the ability to stage and discard changes, and support for popular version control systems like GitHub and GitLab. GitKraken is designed to be user-friendly and to make it easier for developers to work with Git, particularly for those who may be new to version control systems.
Gitkraken is a paid software, and it is free for public repositories, but you can have all enterprise and premium functionalities enabled for free with the student pack and described before.
Install Gitkraken. If you login into gitkraken using GitHub with student pack it will unlock all pro features.
Compiler¶
A compiler is a type of computer program that translates source code into machine instructions that can be run or the CPU or interpreted in a Virtual Machine.
graph TD
+ SRC[Source Code] --> |Assembly| OBJ[Machine Code];
+ OBJ --> EXE[Executable];
+ OBJ --> LIB[Library];Source Codein C++, is associated to two different type of textual file extensions:.cppfor sources and.hfor header files. It is what the developer writes.Assemblyis a human readable representation of theMachine Code. It is not theMachine Codeitself, but it is a representation of it. It is a way to make theMachine Codehuman readable.Machine Codeis what theCPUcan run and understand. It is a sequence of0and1that theCPUcan understand and execute. It is not human readable.Executableis the result of the compilation process. It is a file that can be executed by theOperating System.Libraryis a collection ofMachine Codethat can be used by other programs.ExecutableandLibraryAre binary file that contains theMachine Codeinstructions that theCPUcan execute.
Note
In compiled languages, the end user only receives the executables and libraries. The source code is not distributed.
Here you can see briefly a small function to square a number in C++ compiled via GCC into a x86-64 assembly. The left side is the Source Code and the right side is the code compiled into a human-readble Assembly. This code still needs links to the Operation System in order to be executed.
Notes on Virtual Machines (VM)¶
Tip
The knowledge of this section is not required for this course, but it is good to know.
Some languages such as Java, C# and others, compile the Source Code into bytecode that runs on top of an abstraction layer called Virtual Machine (VM). The VM is a software that runs on top of the Operating System and it is responsible to translate the bytecode into Machine Code that the CPU can understand. This is a way to make the Source Code portable across different Operating Systems and CPU architectures - cross-platform. But this abstraction layer has it cost and it is not as efficient as the Machine Code itself.
To speed up the execution, some VM can Just In Time (JIT) compile the bytecode into Machine Code at runtime when the VM detects parts of Source Code is running a lot(Hotspots), to speed up the execution. When this optmization step is happening, the machine is warming up.
graph TD
+ SRC[Source Code] --> |Compiles| BYT[Bytecode];
+ BYT --> |JIT Compiler| CPU[Machine Code];Note
In languages that uses VMs, the end user receives the bytecode. The source code is not distributed.
Notes on Interpreters¶
Tip
The knowledge of this section is not required for this course, but it is good to know.
Some languages such as Python, Javascript and others, do not compile the Source Code, instead, they run on top a program called Interpreter that reads the Source Code and executes it line by line.
graph TD
+ SRC[Source Code] --> |read line| INT[Interpreter];
+ INT --> |translates| CPU[Machine Code];Some Interpreters are Ahead Of Time (AOT) and they compile the Source Code into Machine Code before the Source Code is executed.
graph TD
+ SRC[Source Code] --> |AoT compile| INT[Bytecode / Machine Code];
+ INT --> CPU;Note
In intrepreted languages, the end user receives the source code. Sometimes the source code is obfuscated, but it is still readable.
Platform specific¶
This where things get tricky, C++ compiles the code into a binary that runs directly on the processor and interacts with the operating system. So we can have multiple combinations here. Most compilers are cross-platform, but there is exceptions. And to worsen it, some Compilers are tightly coupled with some IDEs(see below, next item).
I personally prefer to use CLang to be my target because it is the one that is most reliable cross-platform compiler. Which means the code will work as expected in most of the scenarios, the feature support table is the same across all platforms. But GCC is the more bleeding edge, which means usually it is the first to support all new fancy features C++ introduces.
No need to download anything here. We are going to use the CLion IDE. See below topics.
CMake¶
CMake CMake is a cross-platform free and open-source software tool for managing the build process of software using a compiler-independent method. It is designed to support directory hierarchies and applications that depend on multiple libraries. It is used to control the software compilation process using simple platform and compiler independent configuration files, and generate native makefiles and workspaces that can be used in the compiler environment of your choice.
Note
If you use a good IDE(see next topic), you won't need to download anything here.
CMake is typically used in conjunction with native build environments such as Make, Ninja, or Visual Studio. It can also generate project files for IDEs such as Xcode and Visual Studio. You can see a full list of supported generators here.
Here is a simple example of a CMakeLists.txt file that can be used to build a program called "myproject" that consists of a single source file called "main.cpp":
# Set minimum version of CMake that can be used
+cmake_minimum_required(VERSION 3.10)
+# Set the project name
+project(myproject)
+# Add executable named "myproject" to be built from the source "main.cpp"
+add_executable(myproject main.cpp)
+Warning
Every executable can only cave one main function. Each file with a main function describes a new executable program. If you want to have multiple executables in the same project, in other words, you want to manage multiple executables in the same place, you can change the cmake descriptor to match that as follows, and use your IDE to switch between them:
Tip
If you are using a nice IDE, you won't need to run this on the command line. So go to next topic.
If you want to build via command line this project, you would first generate a build directory, and then run CMake to build the files using the detected compiler or IDE:
This will create a Makefile or a Visual Studio solution file in the build directory, depending on your platform and compiler. You can then use the native build tools to build the project by running "make" or opening the solution file in Visual Studio.
CMake provides many options and variables that can be used to customize the build process, such as setting compiler flags, specifying dependencies, and configuring installation targets. You can learn more about CMake by reading the documentation at https://cmake.org/.
IDE¶
An integrated development environment (IDE) is a software application that provides comprehensive facilities to computer programmers for software development. An IDE typically integrates a source code editor, build automation tools, and a debugger. Some IDEs also include additional tools, such as a version control system, a class browser, and a support for literate programming. IDEs are designed to maximize programmer productivity by providing tight-knit components with similar user interfaces. This can be achieved through features such as auto-complete, syntax highlighting, and code refactoring. Many IDEs also provide a code debugger, which allows the programmer to step through code execution and find and fix errors. Some examples of popular IDEs include Eclipse, NetBeans, Visual Studio, and Xcode. Each of these IDEs has its own set of features and capabilities, and developers may choose one based on their specific needs and preferences.
In this course, it is strongly suggested to use an IDE in order to achieve higher quality of deliveries, a good IDE effectively flatten the C++ learning curve. You can opt out and use everything by hand, of course, and it will deepen your knowledge on how things work but be assured it can slow down your learning process. Given this course is result oriented, it is not recommended to not use an IDE here. So use one.
OPINION: The most pervasive C++ IDE is CLion and this the one I am going to use. If you use it too, it would be easier to follow my recorded videos. It works on all platforms Windows, Linux and Mac. I recommend downloading it via Jetbrains Toolbox. If you are a student, apply for student pack for free here. On Windows, CLion embeds a GCC compiler or optionally can use visual studio, while on Macs it requires the xcode command line tools, and on Linux, uses GCC from the system installation.
The other options I suggest are:
On all platforms¶
REPLIT - an online and real-time multiplayer IDE. It is slow and lack many functionalities, but can be used for small scoped activities or work with a friend.
VSCode - a small and highly modularized code editor, it have lots of extensions, but it can be complex to set up everything needed: git, cmake, compiler and other stuff.
On Windows:¶
Visual Studio - mostly for Windows. When installing, mark C++ development AND search and install additional tools "CMake". Otherwise, this repo won't work smoothly for you.
DevC++ - an outdated and small IDE. Lacks lots of functionalities, but if you don't have HD space or use an old machine, this can be your option. In long term, this choice would be bad for you for the lack of functionalities. It is better to use REPLIT than this tool, in my opinion.
On OSX¶
XCode - for OSX and Apple devices. It is required at least to have the Command Line Tools. CLion on Macs depends on that.
Xcode Command Line Tools is a small suite of software development tools that are installed on your Mac along with Xcode. These tools include the GCC compiler, which is used to compile C and C++ programs, as well as other tools such as Make and GDB, which are used for debugging and development. The Xcode Command Line Tools are necessary for working with projects from the command line, as well as for using certain software development tools such as Homebrew.
To install the Xcode Command Line Tools, you need to have Xcode installed on your Mac. To check if Xcode is already installed, open a Terminal window and type:
xcode-select -p
If Xcode is already installed, this command will print the path to the Xcode developer directory. If Xcode is not installed, you will see a message saying "xcode-select: error: command line tools are not installed, use xcode-select --install to install."
To install the Xcode Command Line Tools, open a Terminal window and type:
xcode-select --install
This will open a window that prompts you to install the Xcode Command Line Tools. Follow the prompts to complete the installation.
Once the Xcode Command Line Tools are installed, you can use them from the command line by typing commands such as gcc, make, and gdb. You can also use them to install and manage software packages with tools like Homebrew.
On Linux¶
If you are using Linux, you know the drill. No need for further explanations here, you are ahead of the others.
If you are using an Ubuntu distro, you can try this to install most of the tools you will need here:
sudo apt-get update && sudo apt-get install -y build-essential git cmake lcov xcb libx11-dev libx11-xcb-dev libxcb-randr0-dev
+In order to compile:
Where g++ is the compiler frontend program to compile your C++ source code; inputFile.cpp is the filename you want to compile, you can pass multiple files here separated by spaces ex.: inputFile1.cpp inputFile2.cpp; -o means the next text will be the output program name where the executable will be built, (for windows, the name should end with .exe ex.: program.exe).
You will have a plethora of editors and IDEs. The one I can suggest is the VSCode, Code::Blocks or KDevelop. But I really prefer CLion.
CLion project workflow with CMake¶
When you create a new project, select New C++ Executable, set the C++ Standard to the newest one, C++20 is enough, and place in a folder location where you prefer.
CLion automatically generate 2 files for you. - CMakeLists.txt is the CMake multiplatform project descriptor, with that, you can share your project with colleagues that are using different platforms than you. - main.cpp is the entry point for your code.
It is not the moment to talk about multiple file projects, but if you want to get ready for it, you will have to edit the CMakeLists.txt file and add them in the add_executable function.
Hello World¶
// this a single line comment and it is not compiled. comments are used to explain the code.
+// you can do single line comment by adding // in front of the line or
+// you can do multi line comments by wrapping your comment in /* and */ such as: /* insert comment here */
+/* this is
+ * a multi line
+ * comment
+ */
+#include <iostream> // this includes an external library used to deal with console input and output
+
+using namespace std; // we declare that we are going to use the namespace std of the library we just included
+
+// "int" means it should return an integer number in the end of its execution to communicate if it finished properly
+// "main()" function where the operating system will look for starting the code.
+// "()" empty parameters. this main function here needs no parameter to execute
+// anynthing between { and } is considered a scope.
+// everything stack allocated in this scope will be deallocated in the end of the scope. ex.: local variables.
+int main() {
+ /* "cout" means console output. Print to the console the content of what is passed after the
+ * "<<" stream operator. Streams what in the wright side of it to the cout object
+ * "endl" means end line. Append a new line to the stream, in the case, console output.
+ */
+ cout << "Hello World" << endl;
+
+ /* tells the operating system the program finished without errors. Any number different from that is considered
+ * a error code or error number.
+ */
+ return 0;
+}
+Hello Username¶
#include <iostream>
+#include <string> // structure to deal with a char sequence, it is called string
+using namespace std;
+int main(){
+ // invites the user to write something
+ cout << "Type your name: " << endl;
+
+ /* * string means the type of the variable, this definition came from the string include
+ * username means the name of the variable, the container to hold and store the data
+ */
+ string username;
+ /*
+ * cin mean console input. It captures data from the console.
+ * note the opposite direction of the stream operator. it streams what come from the cin object to the variable.
+ */
+ cin >> username;
+ // example of how to stream and concatenate texts to the console output;
+ cout << "Hello " << username << endl;
+}
+Common Bugs¶

1. Syntax error¶
Syntax errors in C++ are usually caused by mistakes in the source code that prevent the compiler from being able to understand it. Some common causes of syntax errors include: 1. Omitting a required component of a statement, such as a semicolon at the end of a line or a closing curly brace. 2. Using incorrect capitalization or spelling in a keyword or identifier. 3. Using the wrong punctuation, such as using a comma instead of a semicolon. 4. Mixing up the order of operations, such as using an operator that expects two operands before the operands have been provided.
To fix a syntax error, you will need to locate the source of the error and correct it in the code. This can often be a challenging task, as syntax errors can be caused by a variety of factors, and it is not always immediately clear what the problem is. However, there are a few tools that can help you locate and fix syntax errors in your C++ code: 1. A compiler error message: When you try to compile your code, the compiler will often provide an error message that can help you locate the source of the syntax error. These error messages can be somewhat cryptic, but they usually include the line number and a brief description of the problem. 2. A text editor with syntax highlighting: Many text editors, such as Visual Studio or Eclipse, include syntax highlighting, which can help you identify syntax errors by coloring different parts of the code differently. For example, keywords may be highlighted in blue, while variables may be highlighted in green. 3. A debugger: A debugger is a tool that allows you to step through your code line by line, examining the values of variables and the state of the program at each step. This can be a very useful tool for tracking down syntax errors, as it allows you to see exactly where the error occurs and what caused it.
2. Logic Error¶
A logic error in C++ is an error that occurs when the code produces unintended results or behaves in unexpected ways due to a mistake in the logic of the program. This type of error is usually caused by a coding mistake, such as using the wrong operator, omitting a necessary statement, or using the wrong variable. Here are some common causes of logic errors in C++:
- Incorrect use of conditional statements (e.g., using the wrong comparison operator or forgetting to include a necessary else clause)
- Mistakenly using the assignment operator (=) instead of the equality operator (==) in a conditional statement
- Omitting a necessary loop iteration or failing to terminate a loop at the appropriate time
- Using the wrong variable or array index
- Incorrectly calling a function or passing the wrong arguments to a function
To fix a logic error in C++, you will need to carefully examine your code and identify the mistake. It may be helpful to use a debugger to step through your code and see how it is executing, or to add print statements to help you understand what is happening at each step.
3. Run-time error¶
A runtime error in C++ means that there is an error in your program that is causing it to behave unexpectedly or crash during runtime, i.e., after you have compiled and run the program. There are many possible causes of runtime errors in C++, including:
- Dereferencing a null pointer
- Accessing an array out of bounds
- Using an uninitialized variable
- Trying to divide by zero
- Attempting to use an object that has been deleted or has gone out of scope
To troubleshoot a runtime error, you'll need to identify the source of the error by examining the error message and the code that is causing the error. Some common tools and techniques you can use to troubleshoot runtime errors include:
- Using a debugger to step through your code line by line
- Printing out the values of variables to see where the error might be occurring
- Adding additional debug statements or logging to your code to help identify the source of the error
It's also a good idea to ensure that you have compiled your code with debugging symbols enabled, as this will allow you to use the debugger to get a better understanding of what is happening in your code. will cause the program to crash during run-time
Exercises:¶
- Research and read about other notable errors: segmentation fault, stack overflow, buffer overflow.
- Hello World - just print
hello world.
Homework¶
- Setup your environment for your needs following the choices given above. If you are unsure, use CLion and you will be mostly safe.
- Fork this repo privately. You will have to do your assignments there. Go to the home repo and hit fork.
- Clone this repo to your machine. gitkraken + github gitkraken clone gitkraken big tutorial
- Make sure the CMake option "ENABLE_INTRO" is set as ON in CMakeLists.txt file in the root directory in order to see and enable all activities.
- (enrolled students) If you are enrolled in a class with me, share your repo with me, so I can track your evolution. And do the activities described there.
- (optional) star this repo :-)
Troubleshooting¶
If you have problems here, start a discussion this is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me.
Variables, Data Types, Expressions, Assignment, Formatting¶
Estimated time to read: 51 minutes
Variables¶
Variables are containers to store information and facilitates data manipulation. They are named and typed. Detailed Reference
Container sizes are measured in Bytes. Bytes are the smallest addressable unit in a computer. Each byte is composed by 8 bits. Each bit can be 1 or 0 (true or false). If one byte have 8 bits and each bit one can hold 2 different values, the combination of all possible cases that a byte can be is 2^8 which is 256, so one byte can hold up to 256 different states or possibilities.
Data Types¶
There are several types of variables in C++, including:
- Primitive data types: These are the most basic data types in C++ and include integer, floating-point, character, and boolean types.
- Derived data types: These data types are derived from the primitive data types and include arrays, pointers, and references.
- User-defined data types: These data types are defined by the programmer and include structures, classes, and enumerations.
Numeric types¶
There are some basic integer container types with different sizes. It can have some type modifiers to change the default behavior or the type.
The common size of the integer containers are 1(char), 2(short int), 4(int) or 8(long long) bytes. For a more detailed coverage read this.
Note
But the only guarantee the C++ imposes is: 1 == sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long) and it can result in compiler defined behaviours where a char can have 8 bytes and a long long can be 1 byte.
Note
If you care about being cross-platform conformant, you have to always specify the sign modifier or use a more descriptive type such as listed here.
For floating pointing numbers, the container size can be 4(float), 8(double), 10(deprecated) or 16(long double) bytes.
The sign modifiers can be signed and unsigned and are applicable only for integer types.
The default behavior of the types in a x86 cpu are as signed numbers and the first bit of the container is the signal. If the first bit is 0, it means it is positive. If the first bit is 1, it means it is negative. More details.
Which means that if the container follow two complement and is the size of 1 byte(8 bits), it have 1 bit for the signal and 7 bit for the content. So this number goes from -128 up to 127, this container is typically a signed char. The positive size has 1 less quantity in absolute than the negative because 0 is represented in positive side. There are 256 numbers between -128 and 127 inclusive.
Char¶
A standard char type uses 1 byte to store data and follows complement of 1. Going -127 to 127, so tipically represents 255 numbers.
A signed char follows complement of 2 and it can represent 2^8 or 256 different numbers. By default, in x86 machine char is signed and the represented numbers can go from -2^7 or -128 up to 2^7 - 1 or 127.
An unsigned char
Chars can be used to represent letters following the ascii table where each value means a specific letter, digit or symbol.
Note
A char can have different sizes to represent different character coding for different languages. If you are using hebrew, chinese, or others, you probably will need more than 1 byte to represent the chars. Use char8_t (UTF8), char16_t(UTF16) or char36_t(UTF32), to cover your character encoding for the language you are using.
ASCII table¶
ASCII - American Standard Code for Information Interchange - maps a number to a character. It is used to represent letters, digits and symbols. It is a standard that is used by most of the computers in the world.
It is a 7 bit table, so it can represent 2^7 or 128 different characters. The first 32 characters are control characters and the rest are printable characters. Reference. There are other tables that extend the ASCII table to 8 bits, or even 16 bits.
The printable chacacters starts at number 32 and goes up to 126. The first 32 characters are control characters and the rest are printable.

As you can imagine, this table is not enough to represent all the characters in the world(latin, chinese, japanese, etc). So there are other tables that extend the ASCII table to 8 bits, or even 16 bits.
Integer¶
Note
Most of the information that I am covering here might be not precise, but the overall idea is correct. If you want a deep dive, read this.
A standard int type uses 4 bytes to store data. It is signed by default.
It can represent 2^32 or 4294967296 different numbers. As a signed type, it can represent numbers from -2^31 or -2147483648 up to 2^31 - 1 or 2147483647.
The type int can accept sign modifiers as signed or unsigned to change the behavior of the first bit to act as a sign or not.
The type int can accept size modifiers as short (2 bytes) or long long (8 bytes) to change the size and representation capacity of the container. Type declaration short and short int result in the same container size of 2 bytes. In the same way a long long or long long int reserves the same size of 8 bytes for the container.
The type long or long int usually gives the same size of int as 4 bytes. Historical fact or myth: This abnormality, comes from the evolution of the definition of int: in the past, 2 bytes were enough for the majority of the scenarios in the 16 bits processors, but it frequently reached the limits of the container and it overflowed. So they changed the standard definition of a integer from being 2 bytes to 4 bytes, and created the short modifier. In this scenario the long int lost the reason to exist.
Here goes a list of valid integer types and its probable size(it depends on the implementation, cpu architecture and operation system): - Size of 2 bytes: short int, short, signed short int, signed short, unsigned short int, unsigned short, - Size of 4 bytes: signed, unsigned, int, signed int, unsigned int, long int, long, signed long int, signed long, unsigned long int, unsigned long, - Size of 8 bytes: long long int, long long, signed long long int, signed long long, unsigned long long int, unsigned long long.
OPINION: I highly recommend the usage of these types instead, to ensure determinism and consistency between compilers, operating systems and cpu architectures.
Float pointing¶
There are 3 basic types of floating point containers: float(4 bytes) and double(8 bytes) and long double(16 bytes) to represent fractional numeric types.
The standard IEEE754 specifies how a floating point number is stored in the form of bits inside the container. The container holds 3 basic information to simulate the behavior of a fractional type inside a binary type: signal, exponent and fraction.
Note
This standard was very open to implementation definition in the past, and this is one of the root causes of non-determinism physics simulation. This is the main problem you cannot guarantee the same operation with the same pair of numbers will consistently give the same result across different types of processors and compilers, thus making the physics of a multiplayer game consistency hardly achievable. Many deterministic physics engines tend to not use this standard at all, and implement those behaviors via software on top of integers instead. There are 2 approaches to solve the floating-point determinism: softfloat that implement all the IEEE754 specifications via software, or implement some kind of fixed-point arithmetic on top of integers.
Booleans¶
bool is a special type that has the container size of 1 byte but the compiler can optimize and pack up to 8 bools in one byte if they are declared in sequence.
Enums¶
An enumeration is a type that consists of a set of named integral constants. It can be defined using the enum keyword:
This defines a new type called Color, which has three possible values: Red, Green, and Blue. By default, the values of these constants are 0, 1, and 2, respectively. However, you can specify your own values:
You can then use the enumeration type just like any other type:
Enumerations can also have their underlying type explicitly specified:
Here, the underlying type of the enumeration is char, so the constants Red, Green, and Blue will be stored as characters(1 byte size). The enum class syntax is known as a "scoped" enumeration, and it is recommended over the traditional enum syntax because it helps prevent naming conflicts. See the CppCoreGuidelines to understand better why you should prefer using this.
// You can make the value of the constants
+// explicit to make your debugging easier:
+enum class Color : char {
+ Red = 'r',
+ Green = 'g',
+ Blue = 'b'
+};
+Special derived type: string¶
string is a derived type and in order to use it, string should be included in the beginning of the file or in the header. char are the basic unit of a string and is used to store words as a sequence of chars.
In C++, a string is a sequence of characters that is stored in an object of the std::string class. The std::string class is part of the C++ Standard Library and provides a variety of functions and operators for manipulating strings.
void type¶
When void type specifier is used in functions, it indicates that a function does not return a value.
It can also be used as a placeholder for a pointer to a memory location to indicate that the pointer is "universal" and can point to data of any type, but this can be arguably a bad pattern, and should be used exceptionally when interchanging types with c-style API.
We are going to cover this again when covering pointers and functions.
Variable Naming¶
Variable names are called identifiers. In C++, you can use any combination of letters, digits, and underscores to name a variable, it should follow some rules:
- Variables can have numbers, en any position, except the first character, so the name does not begin with a digit. Ex.
point2andvector2dare allowed, but9lifeisn't; - Variable names are case-sensitive, so "myVar" and "myvar" are considered to be different variables;
- Can have
_in any position of the identifier. Ex._mynameanduser_nameare allowed; - It is not a reserved keyword;
Keep in mind that it is a good practice to choose descriptive and meaningful names for your variables, as this can make your code easier to read and understand. Avoid using abbreviations or acronyms that may not be familiar to others who may read your code.
It is also important to note that C++ has some naming conventions that are commonly followed by programmers. For example, it is common to use camelCase or snake_case to separate words in a variable name, and to use all lowercase letters for variables that are local to a function and all uppercase letters for constants.
Variable declaration¶
Variable declaration in C++ follows this pattern.
TYPENAME can be the name of any predefined type. See Variable Types for the types. VARIABLENAME can be anything as long it follow the naming rules. See Variable Naming for the naming rules. Note
A given variable name can only be declared once in the same context / scope. If you try to redeclare the same variable, the compiler will accuse an error.
Note
You can redeclare the same variable name in different scopes. If one scope is parent of the other, the current will be used and will shadow the content of the one from outer scope. We are going to cover this more when we are covering multi-file projects and functions.
Examples:
int a; // integer variable
+float pi; // floating-point variable
+char c; // character variable
+bool d; // boolean variable
+string name; // string variable
+Note
We are going to cover later in this course other complex types in other modules such as arrays, pointers and references.
Variable assignment¶
= operator means that whatever the container have will be overwritten by the result of the right side statement. You should read it not as equal but as receives to avoid misunderstanding. Reference
int a = 10; // integer variable
+float pi = 3.14; // floating-point variable
+char c = 'A'; // character variable
+bool d = true; // boolean variable
+string name = "John Doe"; // string variable
+Every variable, by default, is not initialized. It means that you have to set the content of it after declaring. If the variable is read before the assignment, its content is garbage, it will read whatever is set in the memory stack for the given container location. So the best approach is to always set a value when a variable is declared or be assured that every variable is never read before an assigment.
A char variable can be assigned by integer numbers or any characters between single quotes.
char c;
+c = 'A'; // the content is 65 and the representation is A. see ascii table.
+c = 98; // the content is 98 and the representation is b. see ascii table.
+A bool is by default either true or false, but it can be assigned by numeric value following this rule: - if the value is 0, then the value stored by the variable is false (0); - if the value is anything different than 0, the value stored is true (1);
To convert a string to a int, you have to use a function stoi(for int), stol(for long) or stoll(for long long) because both types are not compatibles.
To convert a string to a float, you have to use a function stof(for float), stod(for double), or stold(for long double) because both types are not compatibles.
Literals¶
Literals are values that are expressed freely in the code. Every numeric type can be appended with suffixes to specify explicitly the type to avoid undefined behaviors or compiler defined behaviors such as implicit cast or container size.
Integer literals¶
There are 4 types of integer literals. - decimal-literal: never starts with digit 0 and followed by any decimal digit; - octal-literal: starts with 0 digit and followed by any octal digit; - hex-literal: starts with 0x or 0X and followed by any hexadecimal digit; - binary-literal: starts with 0b or 0B and followed by any binary digit;
// all of these variables holds the same value, 42, but using different bases.
+// the right side of the = are literals
+int deci = 42;
+int octa = 052;
+int hexa = 0x2a;
+int bina = 0b101010;
+Suffixes:
no suffixprovided: it will use the first smallest signed integer container that can hold the data starting fromint;uorU: it will use the first smallest unsigned integer container that can hold the data starting fromunsigned int;lorL: it will use the first smallest signed integer container that can hold the data starting fromlong;luorLU: it will use the first smallest unsigned integer container that can hold the data starting fromunsigned long;llorLL: it will use the long long signed integer containerlong long;lluorLLU: it will use the long long unsigned integer containerunsigned long long;
Float point literals¶
There are 3 suffixes in floating point decimals.
no suffixmeans the container is a double;fsuffix means it is a float container;lsuffix means it is a long double container;
A floating point literal can be defined by 3 ways:
- digit-sequence decimal-exponent suffix(optional).
1e2means its adoublewith the value of1*10^2or100;1e-2fmeans its afloatwith the value of1*10^-2or0.01;
- digit-sequence . decimal-exponent(optional) suffix(optional).
2.means it is adoublewith value of2;2.fmeans it is afloatwith value of2;2.1lmeans it is along doublewith value of2.1;
- digit-sequence(optional) . digit-sequence decimal-exponent(optional) suffix(optional)
3.1415fmeans it is afloatwith value of3.1415;.1means it is adoublewith value of0.1;0.1e1Lmeans it is along doublewith value of1;
Arithmetic Operations¶
In C++, you can perform common arithmetic operations is statements using the following operators Reference:
- Addition:
+ - Subtraction:
- - Multiplication:
* - Division:
/ - Modulus (remainder):
%
There are two special cases called unary increment / decrement operators that may occur in before(prefixed) or after(postfixed) the variable name reference. If prefixed it is executed first and then return the result, if postfixed, it returns the current value and then execute the operation:
- Increment:
++; - Decrement:
--;
There are shorthand assignment operators reference that reassign the value of the variable after executing the arithmetic operation with the right side of the operator with the old value of the variable:
- Addition:
+= - Subtraction:
-= - Multiplication:
*= - Division:
/= - Modulus (remainder):
%=
Here is an example of how to use these operators in a C++ program:
#include <iostream>
+
+int main() {
+ int a = 5;
+ int b = 2;
+
+ std::cout << a + b << std::endl; // Outputs 7
+ std::cout << a - b << std::endl; // Outputs 3
+ std::cout << a * b << std::endl; // Outputs 10
+ std::cout << a / b << std::endl; // Outputs 2
+ std::cout << a % b << std::endl; // Outputs 1
+ a++;
+ std::cout << a << std::endl; // Outputs 6
+ a--;
+ std::cout << a << std::endl; // Outputs 5
+
+ std::cout << a++ << std::endl; // Outputs 5 because it first returns the current value and then increments.
+ std::cout << a << std::endl; // Outputs 6
+
+ std::cout << --a << std::endl; // Outputs 5 because it first decrements the value and then return it already changed;
+ std::cout << a << std::endl; // Outputs 5
+
+ b *= 2; // it is a short version of b = b * 2;
+ std::cout << b << std::endl; // Outputs 4
+
+ b /= 2; // it is a short version of b = b / 2;
+ std::cout << b << std::endl; // Outputs 2
+
+ return 0;
+}
+Note that the division operator (/) performs integer division if both operands are integers. If either operand is a floating-point type, the division will be performed as floating-point division. So 5/2 is 2 because both are integers, se we use integer division, but 5/2. is 2.5 because the second one is a double literal.
Also, the modulus operator (%) returns the remainder of an integer division. For example, 7 % 3 is equal to 1, because 3 goes into 7 two times with a remainder of 1.
Implicit cast¶
Implicit casting, also known as type coercion, is the process of converting a value of one data type to another data type without the need for an explicit cast operator. In C++, this can occur when an expression involves operands of different data types and the compiler automatically converts one of the operands to the data type of the other in order to perform the operation.
For example:
int a = 1;
+double b = 1.5;
+
+int c = a + b; // c is automatically converted to a double before the addition
+b is a double, while the value of a is an int. When the addition operator is used, the compiler will automatically convert a to a double before performing the addition. The result of the expression is a double, so c is also automatically converted to a double before being assigned the result of the expression. Implicit casting can also occur when assigning a value to a variable of a different data type. For example:
In this case, the value of a is an int, but it is being assigned to a double variable. The compiler will automatically convert the value of a to a double before making the assignment.
It's important to be aware of implicit casting, because it can sometimes lead to unexpected results or loss of precision if not handled properly. In some cases, it may be necessary to use an explicit cast operator to explicitly convert a value to a specific data type.
Explicit cast¶
In C++, you can use an explicit cast operator to explicitly convert a value of one data type to another. The general syntax for an explicit cast are:
// ref: https://en.wikibooks.org/wiki/C%2B%2B_Programming/Programming_Languages/C%2B%2B/Code/Statements/Variables/Type_Casting
+(TYPENAME) value; // regular c-style. do not use this extensively
+static_cast<TYPENAME>(value); // c++ style conversion, arguably it is the preferred style. use this if you know what you are doing.
+TYPENAME(value); // functional initialization, slower but safer. might not work for every case. Use this if you are unsure or want to be safe.
+TYPENAME{value}; // initialization style, faster, convenient, concise and arguably safer because it triggers warnings. use this for the general case.
+For example:
In this example, the value of a is an int, but it is being explicitly converted to a double using the explicit cast operator. The result of the cast is then assigned to the double variable b.
Explicit casts can be useful in situations where you want to ensure that a value is converted to a specific data type, regardless of the data types of the operands in an expression. However, it's important to be aware that explicit casts can also lead to unexpected results or loss of precision if not used carefully. This behaviour is called narrowing.
C-style:
In this case, the value of a is an int, but it is being explicitly converted to a char using the explicit cast operator. However, the range of values that can be represented by a char is much smaller than the range of values that can be represented by an int, so the value of a is outside the range that can be represented by a char. As a result, b is assigned the ASCII value for the character 1, which is not the same as the original value of a. The value ! is 33 in ASCII table, and 33 is the result of the 20001 % 256 where 256 is the number of elements the char can represent. In this case, what happened was a bug that is hard to track called int overflow.
auto keyword¶
auto keyword is mostly a syntax sugar to automatically infer the data type. It is used to avoid writing the full declaration of complex types when it is easily inferred. auto is not a dynamic type, once it is inferred, it cannot be changed later like in other dynamic typed languages such as javascript.
auto i = 0; // automatically inferred as an integer type;
+auto f = 0.0f; // automatically inferred as a float type;
+
+i = "word"; // this won't work, because it was already inferred as an integer and integer container cannot hold string
+Formatting¶
There are many functions to help you format the output in the way it is expected, here goes a selection of the most useful ones I can think. Yon can find more functions and manipulators here and here.
To set a fixed precision for floating point numbers in C++, you can use the std::setprecision manipulator from the iomanip header, along with the std::fixed manipulator.
Here's an example of how to use these manipulators to output a floating point number with a fixed precision of 3 decimal places:
#include <iostream>
+#include <iomanip>
+
+int main() {
+ double num = 3.14159265;
+
+ std::cout << std::fixed << std::setprecision(3) << num << std::endl;
+ // Output: 3.142
+ return 0;
+}
+You can also use the std::setw manipulator to set the minimum field width for the output, which can be useful for aligning the decimal points in a table of numbers.
For example:
#include <iostream>
+#include <iomanip>
+
+int main() {
+ double num1 = 3.14159265;
+ double num2 = 123.456789;
+
+ std::cout << std::fixed << std::setprecision(3) << std::setw(8) << num1 << std::endl;
+ std::cout << std::fixed << std::setprecision(3) << std::setw(8) << num2 << std::endl;
+ // Output:
+ // 3.142
+ // 123.457
+ return 0;
+}
+Note that these manipulators only affect the output stream, and do not modify the values of the floating point variables themselves. If you want to store the numbers with a fixed precision, you will need to use a different method such as rounding or truncating the numbers.
To align text to the right or left in C++, you can use the setw manipulator in the iomanip header and the right or left flag. More details here
Here is an example:
#include <iostream>
+#include <iomanip>
+
+int main() {
+ std::cout << std::right << std::setw(10) << "Apple" << std::endl;
+ std::cout << std::left << std::setw(10) << "Banana" << std::endl;
+ return 0;
+}
+Both will print inside a virtual column with the size of 10 chars. This will output the following:
Optional Exercises¶
Do all exercises up to this topic here.
In order to get into coding, the easiest way to learn is by solving coding challenges. It is like learning any new language, you have to be exposed and involved. Do not do only the homeworks, otherwise you are going to fail. Another metaphor is: the homework is the like a competition that you have to run to prove that you are trained, but in order to train, you have to do small runs and do small steps first, so you have to train yourself ot least 2x per week.
The best way to train yourself in coding and solving problems in my opinion is this:
- Sort Beecrowd questions from the most solved to the least solved questions here is the link of the list already filtered.
- Start solving the questions from the top to the bottom. Chose one from de the beginning, it would be one of the easiest;
- If you are feeling comfortable and being able to solve more than 3 per hour, you are allowed to skip some of the questions. It is just like in a gym, when you get used with the load, you increase it. Otherwise continue training slowly.
Homework¶
banknotes and coins - Here you will use formatting, modulus, casting, arithmetic operations, compound assignment. You don't need to use if-else.
Hint. Follow this only if dont find your way of solving it. You can read the number as a double, multiply by 100 and then do a sequence of modulus and division operations.
double input; // declare the container to store the input
+cin >> input; // read the input
+
+long long cents = static_cast<long long>(input * 100); // number of cents. Note: if you just use float, you will face issues.
+
+long long notes100 = cents/10000; // get the number of notes of 100 dollar (100 units of 100 cents)
+cents %= 10000; // remove the amount of 100 dollars
+Another good way of solving it avoiding casting is reading the number as string and removing the point. Never use float for money
string input; // declare the container to store the input
+cin >> input; // read the input
+
+// given every input will have the dot, we should remove it. remove the dot `.`
+input = input.erase(str.find('.'), 1);
+
+// not it is safe to use int, because no bit is lost in floating casting and nobody have more than MAX_INT cents.
+int cents = stoll(input); // number of cents.
+
+long long notes100 = cents/10000; // get the number of notes of 100 dollar (100 units of 100 cents)
+cents %= 10000; // update the remaining cents by removing the amount of 100 dollars in cents units
+Troubleshooting¶
If you have problems here, start a discussion. Nhis is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me. Or visit the tutoring service.
Conditionals, Switch, Boolean Operations¶
Estimated time to read: 26 minutes
Boolean Operations¶
In C++, the boolean operators are used to perform logical operations on boolean values (values that can only be true or false).
AND¶
And operators can be represented by &&(most common syntax) or and(C++20 and up - alternative operator representation). This operator represents the logical AND operation. It returns true if both operands are true, and false otherwise. - It needs only if one false element to make the result be false; - It needs all elements to be true in order the result be true;
p | q | p and q |
|---|---|---|
true | true | true |
true | false | false |
false | true | false |
false | folse | false |
For example:
OR¶
Or operators can be represented by ||(most common syntax) or or(C++20 and up - - alternative operator representation). This operator represents the logical OR operation. It returns true if one operands are true, and false if all are false. - It needs only if one true element to make the result be true; - It needs all elements to be false in order the result be false;
p | q | p or q |
|---|---|---|
true | true | true |
true | false | true |
false | true | true |
false | folse | false |
For example:
NOT¶
Not operator can be represented by !(most common syntax) or not(C++20 and up - alternative operator representation). This operator represents the logical NOT operation. It returns true if operand after it is false, and true otherwise._
p | not p |
|---|---|
true | false |
false | true |
For example:
Bitwise operations¶
In C++, the bitwise operators are used to perform operations on the individual bits of an integer value.
AND¶
Bitwise and can be represented by & or bitand(C++20 and up - alternative operator representation: This operator performs the bitwise AND operation. It compares each bit of the first operand to the corresponding bit of the second operand, and if both bits are 1, the corresponding result bit is set to 1. Otherwise, the corresponding result bit is set to 0. For example:
int x = 5; // binary representation is 0101
+int y = 3; // binary representation is 0011
+int z = x & y; // z is assigned the value 1, which is binary 0001
+OR¶
Bitwise or can be represented by | or bitor(C++20 and up - alternative operator representation: This operator performs the bitwise OR operation. It compares each bit of the first operand to the corresponding bit of the second operand, and if either bit is 1, the corresponding result bit is set to 1. Otherwise, the corresponding result bit is set to 0. For example:
int x = 5; // binary representation is 0101
+int y = 3; // binary representation is 0011
+int z = x | y; // z is assigned the value 7, which is binary 0111
+XOR¶
Bitwise xor can be represented by ^ or bitxor(C++20 and up - alternative operator representation: This operator performs the bitwise XOR (exclusive OR) operation. It compares each bit of the first operand to the corresponding bit of the second operand, and if the bits are different, the corresponding result bit is set to 1. Otherwise, the corresponding result bit is set to 0.
int x = 5; // binary representation is 0101
+int y = 3; // binary representation is 0011
+int z = x ^ y; // z is assigned the value 6, which is binary 0110
+Bitwise xor is a type of binary sum without carry bit.
NOT¶
Bitwise not can be represented by ~ or bitnot(C++20 and up - alternative operator representation: This operator performs the bitwise NOT (negation) operation. It inverts each bit of the operand (changes 1 to 0 and 0 to 1). For example:
int x = 5; // binary representation is 0101
+int y = ~x; // y is assigned the value -6, which is binary 11111010. See complement of two for more details.
+SHIFT¶
In C++, the shift operators are used to shift the bits of a binary number to the left or right. Pay attention to not mix with the same ones used to strings, in that case they are called stream operators. There are two shift operators:
<<: This operator shifts the bits of the left operand to the left by the number of positions specified by the right operand. For example:
int x = 2; // binary representation is 10
+x = x << 1; // shifts the bits of x one position to the left and assigns the result to x
+// x now contains 4, which is binary 100
+>>: This operator shifts the bits of the left operand to the right by the number of positions specified by the right operand. For example:
int x = 4; // binary representation is 100
+x = x >> 1; // shifts the bits of x one position to the right and assigns the result to x
+// x now contains 2, which is binary 10
+The shift operators are often used to perform operations more efficiently than can be done with other operators. They can also be used to extract or insert specific bits from or into a value.
Conditionals¶
Conditionals are used to branch and execute different blocks of code based on whether a certain condition is true or false. There are several types of conditionals, including:
if clause¶
if statements: These execute a block of code if a certain condition is true. If statements usually uses comparison operators or any result that can be transformed as boolean - any number different than 0 is considered true, only 0 is considered false.
Comparison operator is used to compare the value of two operands. The operands can be variables, expressions, or constants. The comparison operator returns a Boolean value of true or false, depending on the result of the comparison. There are several comparison operators available:
==: returnstrueif the operands are equal;!=: returnstrueif the operands are not equal;>: returnstrueif the left operand is greater than the right operand;<: returnstrueif the left operand is less than the right operand;>=: returnstrueif the left operand is greater than or equal to the right operand;<=: returnstrueif the left operand is less than or equal to the right operand;
For example:
If it appears without scope {}, the condition will applied only to the next statement. For example
if (x > y)
+ doSomething(); // only happens if x > y is evaluated as true
+otherThing(); // this will always occur.
+A common source of error is adding a ; after the condition. In this case, the compiler will understand that it is an empty statement and always execute the next statement.
if (x > y); // note the inline empty statement here finished with a `;`
+ doSomething(); // this will always happen
+Note
It is preferred to always create scopes with {}, but there is no need to have them if you have only one statement that will happen for that condition.
if-else clause¶
All the explanations from if applies here but now we have a fallback case.
if-else statements: These execute a block of code if a certain condition is true, and a different block of code if the condition is false. For example:
if (x > y) {
+ // code to execute if x is greater than y
+} else {
+ // code to execute if x is not greater than y
+}
+All the explanations about scope on the if clause described before, can be applied to the else.
Ternary Operator¶
The ternary operator is also known as the conditional operator. It is used to evaluate a condition and return one value if the condition is true and another value if the condition is false. The syntax for the ternary operator is:
For example:
int a = 5;
+int b = 10;
+int min = (a < b) ? a : b; // min will be assigned the value of a, since a is less than b
+Here, the condition a < b is evaluated to be true, so the value of a is returned. If the condition had been false, the value of b would have been returned instead.
The ternary operator can be used as a shorthand for an if-else statement. For example, the code above could be written as:
Switch¶
switch statement allows you to execute a block of code based on the value of a variable or expression. The switch statement is often used as an alternative to a series of if statements, as it can make the code more concise and easier to read. Here is the basic syntax for a switch statement in C++:
switch (expression) {
+ case value1:
+ // code to be executed if expression == value1
+ break;
+ case value2:
+ // code to be executed if expression == value2
+ break;
+ // ...
+ default:
+ // code to be executed if expression is not equal to any of the values
+}
+The expression is evaluated once, and the value is compared to the values in each case statement. If a match is found, the code associated with that case is executed. The break statement is used to exit the switch statement and prevent the code in subsequent cases from being executed. The default case is optional, and is executed if none of the other cases match the value of the expression.
Here is an example of a switch statement that checks the value of a variable x and executes different code depending on the value of x:
int x = 2;
+
+switch (x) {
+ case 1:
+ cout << "x is 1" << endl;
+ break;
+ case 2:
+ cout << "x is 2" << endl;
+ break;
+ case 3:
+ cout << "x is 3" << endl;
+ break;
+ default:
+ cout << "x is not 1, 2, or 3" << endl;
+}
+In this example, the output would be "x is 2", as the value of x is 2.
Note
It's important to note that C++ uses strict type checking, so you need to be careful about the types of variables you use in your conditionals. For example, you can't compare a string to an integer using the == operator.
Switch fallthrough¶
In C++, the break statement is used to exit a switch statement and prevent the code in subsequent cases from being executed. However, sometimes you may want to allow the code in multiple cases to be executed if certain conditions are met. This is known as a "fallthrough" in C++.
To allow a switch statement to fall through to the next case, you can omit the break statement at the end of the case's code block. The code in the next case will then be executed, and the switch statement will continue to execute until a break statement is encountered or the end of the switch is reached.
Here is an example of a switch statement with a fallthrough:
int x = 2;
+
+switch (x) {
+ case 1:
+ cout << "x is 1" << endl;
+ case 2:
+ cout << "x is 2" << endl;
+ case 3:
+ cout << "x is 3" << endl;
+ default:
+ cout << "x is not 1, 2, or 3" << endl;
+}
+In this example, the output would be "x is 2", "x is 3" and "x is not 1, 2, or 3", as the break statement is omitted in the case 2 block and the code in the case 3 block is executed as a result.
It is generally considered good practice to include a break statement at the end of each case in a switch statement to avoid unintended fallthrough. However, there may be cases where a fallthrough is desired behavior. In such cases, it is important to document the intended fallthrough in the code to make it clear to other programmers.
Issues with switch and enums¶
A nice usecase for switches is to be used to select between possible choices and enums are one of the best ways of expressing choices. So it seems natural to combine both, right? Well, not so fast. There are some issues with this combination that you might be aware of.
The main issue with this approach relies on the switch's default behavior. If you use deafult on swiches in conjunction with stringly typed enums (enum class or enum struct), the compiler won't be able to warn you about missing cases. This is because the default case will be triggered for any value that is not explicitly handled by the switch. This is a problem because it is very easy to forget to add a new case when a new value is added to the enum and the compiler won't warn you about it. Example:
UseCaseX.cpp
// this code goes inside some function that uses Color c
+switch(c){
+ case Color::Red:
+ // do something
+ break;
+ default: // covers Color::Green and any other value
+ // do something else
+ break;
+}
+But you just remembered that now you should cover the Blue state. So you add it to the enum:
But you might forget to add the coverage for the new case to the switch, it will fall into the default case without warnings.
So the best combination is to use switches with enum classes and do not use default cases. This way, the compiler will warn you about missing cases. So if you add a new enum value had this code instead, you will be warned about missing cases.
UseCaseX.cpp
// this code goes inside some function that uses Color c
+switch(c){
+ case Color::Red:
+ // do something
+ break;
+ case Color::Green:
+ // do something else
+ break;
+}
+// this code will throw a warning if you forget to add a case for the new enum value
+Homework¶
-
Do all exercises up to this topic here.
-
Coordinates of a Point. In this activity, you will have to code a way to find the quadrant of a given coordinate.
Outcomes¶
It is expected for you to be able to solve all questions before this one 1041 on beecrowd. Sort Beecrowd questions from the most solved to the least solved questions here in the link. If you don't, see Troubleshooting. Don`t let your study pile up, this homework is just a small test, it is expected from you to do other questions on Beecrowd or any other tool such as leetcode.
Troubleshooting¶
If you have problems here, start a discussion. Nhis is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me. Or visit the tutoring service.
Loops, for, while and goto¶
Estimated time to read: 16 minutes
A loop is a control flow statement that allows you to repeat a block of code.
while loop¶
This loop is used when you want to execute a block of code an unknown number of times, as long as a certain condition is true. It has the following syntax:
Syntax:
Example:If the block is only one statement, it can be expressed without {}s.
Syntax:
Example:do-while loop¶
This is similar to the while loop, but it is guaranteed to execute at least once.
Syntax:
Example:
If the block is only one statement, it can be expressed without {}s.
Syntax:
Example:for loop¶
This loop is used when you know in advance how many times you want to execute a block of code.
- The initialization part is executed only once, at the beginning of the loop. It is used to initialize any loop variables.
- The condition is evaluated at the beginning of each iteration of the loop. If the condition is true, the code block inside the loop is executed. If the condition is false, the loop is terminated.
- The increment part is executed at the end of each iteration of the loop. It is used to update the loop variables.
Syntax:
Example:
If the block is only one statement, it can be expressed without {}s.
Syntax:
Example:range based loops¶
A range-based loop is a loop that iterates over a range of elements. The declaration type should follow the same type of the elements in the range.
Syntax:
orTo avoid explaining arrays and vectors now, assume v as an iterable container that can hold multiple elements. I am going to use auto here to avoid explaining this topic any further.
auto v = {1, 2, 3, 4, 5}; // an automatically inferred iterable container with multiple elements
+for (int x : v) {
+ cout << x << " ";
+}
+It is possible to automatically generate ranges
#include <ranges>
+#include <iostream>
+using namespace std;
+int main() {
+ // goes from 0 to 9. in iota, the first element is inclusive and the last one is exclusive.
+ for (int i : views::iota(0, 10))
+ cout << i << ' ';
+}
+Loop Control Statements¶
break¶
break keyword defines a way to break the current loop and end it immediately.
// check if it is prime
+int num;
+cin >> num; // read the number to be checked if is prime or not
+bool isPrime = true;
+for(int i=2; i<num; i++){
+ if(num%i==0){ // check if i divides num
+ isPrime = false;
+ break; // this will break the loop and prevent further precessing
+ }
+}
+continue¶
continue keyword is used to skip the following statements of the loop and move to the next iteration.
// print all even numbers
+for (int i = 1; i <= 10; i++) {
+ if (i % 2 == 1)
+ continue;
+ cout << i << " "; // this statement is skipped if odd numbers
+}
+goto¶
You should avoid goto keyword. PERIOD. The only acceptable usage is to break multiple nested loops at the same time. But even in this case, is better to use return statement and functions that you're going to see later in this course.
The goto keyword allows you to transfer control to a labeled statement elsewhere in your code.
Example on how to create a loop using labels and goto. You can create a loop just using labels(anchors) and goto keywords. But this syntax is hard to debug and read. Avoid it at all costs:
#include <iostream>
+using namespace std;
+int main() {
+ int i=0;
+ start: // this a label named as start.
+ cout << i << endl;
+ i++;
+ if(i<10)
+ goto start; // jump back to start
+ else
+ goto finish; // jump to finish
+ finish: // this a label named as finish.
+ return 0;
+}
+Example on how to jump over and skip statements:
#include <iostream>
+
+int main() {
+ int x = 10;
+
+ goto jump_over_this; // control jumps to the label below
+
+ x = 20; // this line of code is skipped
+
+ jump_over_this: // label for goto statement
+ std::cout << x << std::endl; // outputs 10
+
+ return 0;
+}
+Example of an arguably acceptable use of goto. Here you can see the usage of a way to break both loops at the same time. If you use break, you will only break the inner loop. In this situation it is better to break your code into functions to reduce complexity and nesting.
for (int i = 0; i < imax; ++i)
+ for (int j = 0; j < jmax; ++j) {
+ if (i + j > elem_max) goto finished;
+ // ...
+ }
+finished:
+// ...
+Loop nesting¶
You can nest loops by placing one loop inside another. The inner loop will be executed completely for each iteration of the outer loop. Here is an example of nesting a for loop inside another for loop:
for (int i = 0; i < 10; i++) {
+ for (int j = 0; j < 5; j++) {
+ cout << "i: " << i << " j: " << j << endl;
+ }
+}
+Infinite loops¶
A infinite loop is when the code loops indefinitely without having a way out. Here goes some examples:
int i = 0;
+while(i<10); // note the ';' here, it will run indefinitely an empty statement because it won't reach the scope.
+{
+ cout << i << endl;
+ i++;
+}
+Accumulator Pattern¶
The accumulator pattern is a way to accumulate values in a loop. Here is an example of how to use it:
int fact = 1; // accumulator variable
+for(int i=2; i<5; i++){
+ fact *= i; // multiply the accumulator by the current value of i
+}
+// fact = 1*1*2*3*4 = 24
+cout << fact << endl;
+Search pattern¶
The search pattern is a way to search for a value in a loop, the most common implementation is a boolean flag. Here is an example of how to use it:
int num;
+cin >> num; // read the number to be checked if is prime or not
+bool isPrime = true; // flag to indicate if the number is prime or not
+for(int i=2; i<num; i++){
+ if(num%i==0){ // check if i divides num
+ isPrime = false;
+ break; // this will break the loop and prevent further precessing
+ }
+}
+cout << num << " is " << (isPrime ? "" : "not ") << "prime" << endl;
+// (isPrime ? "" : "not ") is the ternary operator, it is a shorthand for if-else
+Debugging¶
Debugging is the act of instrumentalize your code in order to track problems and fix them.
The most naive way of doing it is by printing variables random texts to find the problem. Don't do it. Use debugger tools instead. Each IDE has his its ows set of tools, if you are using CLion, use this tutorial.
Automated tests¶
There are lots of methodologies to guarantee your code is correct and solve the problem it is supposed to solve. The one that stand out is Automated tests.
When you are using beecrowd, leetcode, hackerrank or any other tool to solve problems to learn how to code, a problem is posted to be solved and they test your code solution against a set of expected outputs. This is automated testing. You can generate custom automated tests for your code and cover all cases that you can imagine before you start coding the solution. This is a good practice and is documented in the industry as Test Driven Development.
Homework¶
Do all exercises up to this topic here.
In this activity, you will have to solve Fibonacci sequence. You should implement using loops, and variables. Do not use arrays nor closed-form formulas.
Optional Readings on Fibonacci Sequence;
Hint: Create two variables, one to store the current value and the previous value. For each iteration step, calculate the sum of both and store and put into a temp variable. Copy the current into the previous and set the current with the temporary you calculated before.
Outcomes¶
It is expected for you to be able to solve all questions before this one 1151 on beecrowd. Sort Beecrowd questions from the most solved to the least solved questions here in the link. If you don't, see Troubleshooting. Don`t let your study pile up, this homework is just a small test, it is expected from you to do other questions on Beecrowd or any other tool such as leetcode.
Troubleshooting¶
If you have problems here, start a discussion. Nhis is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me. Or visit the tutoring service.
Base Conversion, Functions, Pointers, Parameter Passing¶
Estimated time to read: 33 minutes
Base conversion¶
Data containers use binary coding to store data where every digit can be 0 or 1, this is called base 2, but there are different types of binary encodings and representation, the most common integer representation is Complement of two for representing positive and negative numbers and for floats is IEEE754. Given that, it is relevant to learn how to convert the most used common bases in computer science in order to code more efficiently.
Most common bases are: - Base 2 - Binary. Digits can go from 0 to 1. {0, 1}; - Base 8 - Octal. Digits can go from 0 to 7. {0, 1, 2, 3, 4, 5, 6, 7}; - Base 10 - Decimal. Digits can go from 0 to 9. {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; - Base 16 - Hexadecimal. Digits can go from 0 to 9 and then from A to F. {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F};
Converting from Decimal to any base¶
There are several methods for performing base conversion, but one common method is to use the repeated division and remainder method. To convert a number from base 10 to another base b, you can divide the number by b and record the remainder. Repeat this process with the quotient obtained from the previous division until the quotient becomes zero. The remainders obtained during the process will be the digits of the result in the new base, with the last remainder being the least significant digit.
For example, to convert the decimal number 75 to base 2 (binary), we can follow these steps:
75 ÷ 2 = 37 remainder 1
+37 ÷ 2 = 18 remainder 1
+18 ÷ 2 = 9 remainder 0
+9 ÷ 2 = 4 remainder 1
+4 ÷ 2 = 2 remainder 0
+2 ÷ 2 = 1 remainder 0
+1 ÷ 2 = 0 remainder 1
+The remainders obtained during the process (1, 1, 0, 1, 0, 0, 1) are the digits of the result in base 2, with the last remainder (1) being the least significant digit. Therefore, the number 75 in base 10 is equal to 1001011 in base 2.
Converting from any base to decimal¶
The most common way to convert from any base to decimal is to follow the formula:
dn-1*bn-1 + dn-2*bn-2 + ... + d1*b1 + d0*b0
Where dx represents the digit at the corresponding position x in the number, n is the number of digits in the number, and b is the base of the number.
For example, to convert the number 1001011 (base 2) to base 10, we can use the following formula:
(1 * 2^6) + (0 * 2^5) + (0 * 2^4) + (1 * 2^3) + (0 * 2^2) + (1 * 2^1) + (1 * 2^0) = 75
Therefore, the number 1001011 in base 2 is equal to 75 in base 10.
Functions¶
A function is a block of code that performs a specific task. It is mostly used to isolate specific reusable functionality from the rest of the code. It has a name, a return type, and a list of parameters. Functions can be called from other parts of the program to execute the task. Here is an example of a simple C++ function that takes two integers as input and returns their sum.
To call the function, you would use its name followed by the arguments in parentheses:
Functions can also be declared before they are defined, in which case they are called "prototypes." This allows you to use the function before it is defined, which can be useful if you want to define the function after it is used. For example:
int add(int x, int y);
+
+int main() {
+ int a = 2, b = 3;
+ int c = add(a, b);
+ return 0;
+}
+
+int add(int x, int y) {
+ int sum = x + y;
+ return sum;
+}
+Reference Declaration¶
Note
This content only covers an introduction to the topic.
The & is used to refer memory address of the variable. When used in the declaration, it is the Lvalue reference declarator. It is an alias to an already-existing, variable, object or function. Read more here.
When used as an prefix operator before the name of a variable, it will return the memory address where the variable is allocated.
Example:
string s;
+
+// the variable r has the same memory address of s
+// the declaration requires initialization
+string& r = s;
+
+s = "Hello";
+
+cout << &s << endl; // prints the variable memory address location. in my machine: "0x7ffc53631cd0"
+cout << &r << endl; // prints the same variable memory address location. in my machine: "0x7ffc53631cd0"
+
+cout << s << endl; // prints "Hello"
+cout << r << endl; // prints "Hello"
+
+// update the content
+r += " world!";
+
+cout << s << endl; // prints "Hello world!"
+cout << r << endl; // prints "Hello world!"
+Pointer Declaration¶
Note
This content only covers an introduction to the topic.
The * is used to declare a variable that holds the address of a memory position. A pointer is an integer number that points to a memory location of a container of a given type. Read more here.
string* r = nullptr; // it is not required do initialize, but it is a good practice to always initialize a pointer pointing to null address (0).
+string s = "Hello";
+r = &s; // the variable r stores the memory address of s
+
+cout << s << endl; // prints the content of the variable s. "Hello"
+cout << &s << endl; // prints the address of the variable s. in my machine "0x7fffdda021b0"
+
+cout << r << endl; // prints the numeric value of the address the pointer points, in this case it is "0x7fffdda021b0".
+cout << &r << endl; // prints the address of the variable r. it is a different address than s, in my machine "0x7fffdda021d0".
+cout << *r << endl; // prints the content of the container that is pointing, it prints "Hello".
+
+string other = "world";
+r = &s; // r now points to another variable
+
+cout << *r << endl; // prints the content of the container that is pointing, it prints "world"
+void type¶
We covered briefly the void type when we covered data types. There are 2 main usages of void
void is used to specify that some function dont return anything to the caller.
voidFunction.cpp
// this function does not need to return anything
+// optionally you can use an empty `return` keyword without variable to break the flow early
+void doSomething() {
+ // function body goes here
+ return; // this line is optional, it can be used inside conditional do break early the function flow
+}
+void* is used as a placeholder to store a pointer to anything in memory. Use this with extreme caution, because you can easily mess with it and lose track of the type or the conversion. The most common use are: - Access the raw content of a variable in memory; - Low-level raw memory allocation; - Placeholder to act as a pointer to anything;
rawpointer.cpp
#include <iostream>
+#include <iomanip>
+#include <bitset>
+using namespace std;
+int main()
+{
+ // declare our data
+ float f = 2.0f;
+ // point without type that points to the memory location of `f`
+ void* p = &f;
+ // (int*) casts the void* to int*, so it can be understandable
+ // * in front means that we want to fetch the content of what is pointing
+ int i = *(int*)(p);
+ cout << hex << i << endl; // prints 40000000
+ std::bitset<32> bits(i);
+ cout << bits << endl; // prints 01000000000000000000000000000000
+ return 0;
+}
+Passing parameter to a function by value¶
Pass-by-value is when the parameter declaration follows the traditional variable declaration without &. A copy of the value is made and passed to the function. Any changes made to the parameter inside the function have don't change on the original value outside the function.
Passing parameter to a function by reference¶
Pass-by-reference occurs when the function parameter uses the & in the parameter declaration. It will allow the function to modify the value of the parameter directly in the other scope, rather than making a copy of the value as it does with pass-by-value. The mechanism behind the variable passed is that it is an alias to the outer variable because it uses the same memory position.
Passing parameter to a function by pointer¶
Pass-by-pointer occurs when the function parameter uses the * in the parameter declaration. It will allow the function to modify the value of the parameter in the other scope via memory pointer, rather than making a copy of the value as it does with pass-by-value. The mechanism behind it is to pass the memory location of the outer variable as a parameter to the function.
Function overload¶
A function with a specific name can be overload with different not implicitly convertible parameters.
#include <iostream>
+using namespace std;
+
+float average(float a, float b){
+ return (a + b)/2;
+}
+
+float average(float a, float b, float c){
+ return (a + b + c)/3;
+}
+
+int main(){
+ cout << average(1, 2) << endl; // print 1.5
+ cout << average(1, 2, 3) << endl; // print 2
+ return 0;
+}
+Default parameter¶
Functions can have default parameters that should be used if the parameter is not provided, making it optional.
defaultparam.cpp
#include <iostream>
+using namespace std;
+
+void greet(string username = "user") {
+ cout << "Hello " << mes << endl;
+}
+
+int main() {
+ // Prints "Hello user"
+ greet(); // the default parameter user is used here
+
+ // Prints "Hello John"
+ greet("John");
+
+ return 0;
+}
+Scopes¶
Scope is a region of the code where a identifier is accessible. A scope usually is specified by what is inside { and }. The global scope is the one that do not is inside any {}.
scope.cpp
#include <iostream>
+#include <string>
+using namespace std;
+string h = "Hello"; // this variable is in the global scope
+int main() {
+ string w = " world"; // this variable belongs to the scope of the main function
+ cout << h << w << endl; // both variables are visible and accessible
+ return 0;
+}
+Multiple identifiers with same name can not be created in the same scope. But in a nested scope it is possible to shadow the outer one when declared in the inner scope.
variableShadowing.cpp
#include <iostream>
+#include <string>
+using namespace std;
+string h = "Hello"; // this variable is in the global scope
+int main() {
+ cout << h; // will print "Hello"
+ string h = " world"; // this will shadow the global variable with the same name h
+ cout << h; // will print " world"
+ return 0;
+}
+Lambda functions¶
In C++, an anonymous function is a function without a name. Anonymous functions are often referred to as lambda functions or just lambdas. They are useful for situations where you only need to use a function in one place, or when you don't want to give a name to a function for some other reason.
auto lambda = [](int x, int y) { return x + y; };
+// auto lambda = [] (int x, int y) -> int { return x + y; }; // or you can specify the return type
+int z = lambda(1, 2); // z is now 3
+In this case the only variables accessible by the lambda function scope are the ones passed as parameter x and y, and works just like a normal function, but it can be declared inside at any scope.
If you want to make a variable available to the lambda, you can pass it via captures, and it can be by-value or by-reference. To capture a variable by value, just pass the variable name inside the []. To capture a variable by reference, you use the & operator followed by the variable name inside the []. Here is an example of capturing a variable by value:
The value of x is copied into the lambda function, and any changes to x inside the lambda function have no effect on the original variable.
Here is an example of capturing a variable by reference:
The lambda function has direct access to the original variable, and any changes to x inside the lambda function are reflected in the original variable.
You can also capture multiple variables by separating them with a comma. For example:
This defines a lambda function that captures x by-value and y by-reference. The lambda function can modify y but not x.
Lambda captures are a useful feature of C++ that allow you to write more concise and expressive code. They can be especially useful when working with algorithms from the Standard Template Library (STL), where you often need to pass a function as an argument.
In order to capture everything automatically you can either capture by copy [=] or by reference [&].
// capture everything via copy
+int x = 1, y = 2;
+auto lambda = [=] {
+ // x += 1; // cannot be changed because it is read-only
+ // y += 1; // cannot be changed because it is read-only
+ return x + y;
+};
+int c = lambda(); // c will be 5, but x and y wont change their values
+// capture everything via reference
+int x = 1, y = 2;
+auto lambda = [&] { x += 1; y += 1; return x + y; };
+int c = lambda(); // c will be 5, x will be 2, and y will be 3.
+For a more in depth understanding, go to Manual Reference or check this tutorial.
Multiple files¶
In bigger projects, it is useful to split your code in multiple files isolating intention and organizing your code. To do so, you can create a header file with the extension .h and a source file with the extension .cpp. The header file will contain the declarations of the functions and the source file will contain the definitions of the functions. The header file will be included in the source file and the source file will be compiled together with the main file.
main.cpp
#include <iostream>
+#include "functions.h"
+using namespace std;
+
+int main() {
+ cout << sum(1, 2) << endl;
+ return 0;
+}
+functions.h
// Preprocessor directive (macro) to ensure that this header file is only included once
+#ifndef FUNCTIONS_H
+#define FUNCTIONS_H
+
+// Function declaration without body
+int sum(int a, int b);
+
+#endif
+Alternatively, you can use #pragma once instead of #ifndef, #define end #endif to ensure that the header file is only included once. This is a non-standard preprocessor directive, but it is supported by most compilers. Ex.:
functions.h
// Preprocessor directive (macro) to ensure that this header file is only included once
+#pragma once
+
+// Function declaration without body
+int sum(int a, int b);
+functions.cpp
// include the header file that contains the function declaration
+#include "functions.h"
+
+// function definition with body
+int sum(int a, int b) {
+ return a + b;
+}
+Preprocessor directives and macros¶
In C++, the preprocessor is a text substitution tool. It runs before compiling the code. It scans a program for special commands called preprocessor directives, which begin with a # symbol. When it finds a preprocessor directive, it performs the specified text substitutions before the program is compiled.
The most common preprocessor directive is #include, which tells the preprocessor to include the contents of another file in the current file. The included file is called a header file, and commonly has a .h extension. For example:
Another extensively used macro is #define, which defines a macro. A macro is a symbolic name for a constant value or a small piece of code. For example:
It will replace all occurrences of PI with 3.14159 before compiling the code. But pay attention that is not recommended to use macros for constants, because they are not type safe and can cause unexpected behavior. It is recommended to declare const variable instead.
See more about some cases against macros here:
- https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#enum1-prefer-enumerations-over-macros
- https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#es30-dont-use-macros-for-program-text-manipulation
- https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#es31-dont-use-macros-for-constants-or-functions
Nowadays the best use case for macros are for conditional compilation or platform specification. For example:
#define DEBUG 1
+
+int main() {
+ #if DEBUG
+ std::cout << "Debug mode" << std::endl;
+ #else
+ std::cout << "Release mode" << std::endl;
+ #endif
+}
+Another example is to define the operating system:
#ifdef _WIN32
+ #define OS "Windows"
+#elif __APPLE__
+ #define OS "MacOS"
+#elif __linux__
+ #define OS "Linux"
+#else
+ #define OS "Unknown"
+#endif
+
+int main() {
+ std::cout << "OS: " << OS << std::endl;
+}
+Homework¶
- Do all exercises up to this topic here.
- Hexadecimal converter. In this activity, you will have to code a way to find the convert to hexadecimal without using any std library to do it for you. DON'T USE
std::hex.
Outcomes¶
It is expected for you to be able to solve all questions before this one 1957 on beecrowd. Sort Beecrowd questions from the most solved to the least solved questions here in the link. If you don't, see Troubleshooting. Don`t let your study pile up, this homework is just a small test, it is expected from you to do other questions on Beecrowd or any other tool such as leetcode.
Troubleshooting¶
If you have problems here, start a discussion. Nhis is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me. Or visit the tutoring service.
Streams and File IO¶
Estimated time to read: 12 minutes
At this point, you already are familiar with the iostream header. But we never discussed what it is properly. It is a basic stream and it has two static variable we already use: cin for reading variables from the console input and cout to output things to console, see details here. It is possible to interact with all streams via the >> and << operators.
But C++ have 2 other relevant streams that we need to cover: fstream and sstream.
File streams¶
File streams are streams that target files instead of the terminal console. The fstream header describes the file streams and the ways you can interact with it.
The main differences between console and file streams are: - You have to target the filesystem path for files because we can manage different files at the same, but for console, you only have one, so you dont need to target which console we are streaming. In order to not mess each target, you have to declare a different variable to store the target and state. - Files are persistent, so if you write something to them, and try to read from it again, the that will be there saved.
Files are a kind of resource managed by the operation system. So every time you request something to be read or write, behind the scenes you are requesting something to the operating system, and it can be slow or subject by lock control. When you open a file to be read or write, the OS locks it to avoid problems. You can open a file to be read multiple times simultaneously, but you cannot write more than once. So to avoid problems, after reading or writing the file, you should close the file.
#include <fstream>
+#include <iostream>
+#include <string>
+
+using namespace std;
+
+int main() {
+ // Open the file
+ // this file path is relative to the executable, so be assured it exists in the same folder the executable is placed
+ // fin is the variablename and it is function initialized via a file path to target, but it can be any valid identifier
+ // I am using fin as variable to follow the same metaphor `fin` as `file input` as we have with console input `cin`,
+ ifstream fin("file.txt");
+
+ // Check if the file is open
+ // it is a good practice to check if the file is really there before doing anything
+ if (!fin.is_open()) {
+ cerr << "Error opening file" << endl;
+ return 1; // quits the program with an error code
+ }
+
+ // Read the contents of the file line by line
+ string line;
+ // getline can target streams in general, so you can pass the file stream as a target
+ while (getline(fin, line)) { // while the file have lines, read and store the content inside the line variable
+ cout << line << endl; // output each string into the console
+ }
+
+ // Close the file
+ fin.close();
+
+ return 0;
+}
+String Stream¶
The sstream header describes string stream, which is a type of memory stream and is very useful to do string manipulation. For our intent, we aro going to focus 3 types of memory streams.
ostringstream: works just likecoutbut the content will printed to a memory region.- it is more efficient to build a complex string in this way than
couting multiple times; istringstream: works just likecinbut it will read from a memory area.- it is safer to read from a closed memory area than, and you ran reset the reading pointer to re-read previous elements easier than with
cin.
#include <iostream>
+#include <sstream>
+using namespace std;
+int main() {
+ ostringstream oss; // declare the output stream
+ // print numbers from 0 to 100
+ for(int i=0; i<=100; i++)
+ oss << i << ' '; // store the data into memory
+ cout << oss.str(); // convert the stream into a string to be printed all at once
+}
+#include <iostream>
+#include <sstream>
+using namespace std;
+int main() {
+ // read input
+ string input;
+ getline(cin, input);
+
+ // initialize string stream with the content from a console line
+ istringstream ss(input); // declare the stream to read from
+
+ // extract input
+ string name;
+ string course;
+ string grade;
+
+ iss >> name >> course >> grade;
+}
+You can combine string stream and file stream to read a whole file and store into a single string.
#include <fstream>
+#include <iostream>
+#include <sstream>
+#include <string>
+
+using namespace std;
+
+int main() {
+ // Open the file
+ ifstream file("file.txt");
+
+ // Check if the file is open
+ if (!file.is_open()) {
+ cerr << "Error opening file" << endl;
+ return 1;
+ }
+
+ // Read the contents of the file into a stringstream
+ stringstream ss;
+ ss << file.rdbuf(); // read the whole file buffer and stores it into a string stream
+
+ // Close the file
+ file.close();
+
+ // Convert the stringstream into a string
+ string contents = ss.str();
+
+ cout << contents << endl; // prints the whole file at once
+
+ return 0;
+}
+Homework¶
You have the job of creating a small program to read a file image in the format PGMA and inverse the colors as a negative image.
You can test your code with different images if you want. You can download more images here. But here goes 2 examples:
- Sample input easy: baboon.ascii.pgm - max intensity is not 255 and don't have comments.
- Sample input harder: lena.ascii.pgm - have comments, and the max intensity is different than 255.
You can test if your output file is correct using this tool. You can open this file via any text reader, use the online viewer, or use any app that reads pnm images.
Attention:¶
- To create the inverse image, you should read the file header and search for the maximum intensity. You should use this number as a base to inverse. In the Lena case, it is 245.
- You should pay attention that every line shouldn't be bigger than 70 chars;
- Pay attention that the line 2 might exists or not. And any comment found in the file should be skipped.
The user should input the filename to be read. So you should store it into a string variable. The output filename should be the same as the input but with '.inverse' concatenated in the end. Ex.: lena.pgm becomes lena.inverse.pgm; If you find this too complicated, just concatenate with .inverse.pgm would be acceptable. ex.: lena.pgm becomes lena.pgm.inverse.pgm
In order for your program to find the file to be read, you should provide the fullpath to the file or simply put the file in the same folder your executable is.
HINT: In order to find comments and ignore them do something like that:
Arrays¶
Estimated time to read: 23 minutes
An array is a collection of similar data items, stored in contiguous memory locations. The items in an array can be of any built-in data type such as int, float, char, etc. An array is defined using a syntax similar to declaring a variable, but with square brackets indicating the size of the array.
Here's an example of declaring an array of integers with a size of 5:
The above declaration creates an array named arr of size 5, which means it can store 5 integers. The array elements are stored in contiguous memory locations, which means the next element is stored at the immediate next memory location. The first element of the array is stored at the 0th index, the second element at the 1st index, and so on up to 4. Between 0 an 4 all inclusive we have 5 elements.
This creates an array called "myArray" that can hold 5 integers. The first element of the array is accessed using the index 0, and the last element is accessed using the index 4. You can initialize the array elements during declaration by providing a comma-separated list of values enclosed in braces:
In this case, the first element of the array will be 10, the second element will be 20, and so on.
You can also use loops to iterate over the elements of an array and perform operations on them. For example:
This loop multiplies each element of the "myArray" by 2.
Arrays are a useful data structure in C++ because they allow you to store and manipulate collections of data in a structured way. However, they have some limitations, such as a fixed size that cannot be changed at runtime, and the potential for buffer overflow if you try to access elements beyond the end of the array.
Buffer overflow¶
A buffer overflow occurs when a program attempts to write more data to a fixed-size buffer than it can hold. This can happen when a program attempts to write more data to a buffer than the buffer can hold, or when a program attempts to read more data from a buffer than the buffer contains. This can happen when a program attempts to write more data to a buffer than the buffer can hold, or when a program attempts to read more data from a buffer than the buffer contains.
A buffer overflow can be caused by a number of different factors, including:
- A program that attempts to write more data to a buffer than the buffer can hold
- A program that attempts to read more data from a buffer than the buffer contains
Buffer overflow vulnerabilities are a common type of security vulnerability, as they can be exploited by malicious attackers to execute arbitrary code or gain unauthorized access to a system. To prevent buffer overflow vulnerabilities, it's important to carefully manage memory allocation and use bounds checking functions or techniques such as using safe C++ library functions like std::vector or std::array, and ensuring that input data is properly validated and sanitized.
Multi-dimensional arrays¶
A multi-dimensional array is an array of arrays. For example, a 2-dimensional array is an array of arrays, where each element of the array is itself an array. A 3-dimensional array is an array of 2-dimensional arrays, where each element of the array is itself a 2-dimensional array. And so on.
For example, to declare a two-dimensional array with 3 rows and 4 columns of integers, you would use the following code:
You can access elements in a multidimensional array using multiple sets of square brackets. For example, to access the element at row 2 and column 3 of myArray, you would use the following code:
In C++, you can have arrays with any number of dimensions, but keep in mind that as the number of dimensions increases, it becomes more difficult to manage and visualize the data.
Array dynamic allocation¶
In some cases, you dont know the size of the array at compile time. In this case, you can use dynamic memory allocation to allocate the array at runtime. This is done using the new operator, which allocates a block of memory on the heap and returns a pointer to the beginning of the block. For example, to allocate an array of 5 integers on the heap, you would use the following code:
The above code allocates a block of memory on the heap that is large enough to hold 5 integers. The new operator returns a pointer to the beginning of the block, which is assigned to the pointer variable arr. You can then use the pointer to access the elements of the array. You can access individual elements of the array using the array subscript notation:
When you are done using the array, you should free the memory using the delete operator. For example, to free the memory allocated to the array in the previous example, you would use the following code:
delete[] arr; // Free the memory by telling the operation system you are done with it
+arr = nullptr; // Reset the pointer to null to avoid dangling pointers and other bugs
+The delete operator takes a pointer to the beginning of the block of memory to free. The [] operator is used to indicate that the block of memory contains an array, and that the delete operator should free the entire array.
Dynamic allocation of multi-dimensional arrays¶
In the case of dynamically allocate memory for a multidimensional array, first you have to understand that in the same way you can have an array of arrays, you can have a pointer to a pointer. This is called a double pointer. So, if you want to allocate a 2-dimensional array dynamically, you can do it like this:
int lines, columns;
+cin >> lines >> columns;
+int **arr = new int*[lines]; // Allocate an array of pointers to pointers
+for (int i = 0; i < lines; i++) {
+ arr[i] = new int[columns]; // Allocate an array of integers for each pointer
+}
+// do stuff with the array
+for (int i = 0; i < lines; i++) {
+ delete[] arr[i]; // Free the memory for each array of integers
+}
+delete[] arr; // Free the memory for the array of pointers
+Smart pointers to rescue¶
You probably noticed the number of bugs and vulnerabilities that can be caused by improper memory management. To help address that, C++ introduced smart pointers. The general purpose smart contract you will be mostly using is shared_ptr that in the end of the scope and when all references to it become 0 will automatically free the memory. The other smart pointers are unique_ptr and weak_ptr that are used in more advanced scenarios. But for now, we will focus on shared_ptr.
In C++11, smart pointers were introduced to help manage memory allocation and deallocation. Smart pointers are classes that wrap a pointer to a dynamically allocated object and provide additional features such as automatic memory management. The most commonly used smart pointers are std::unique_ptr and std::shared_ptr. The std::unique_ptr class is a smart pointer that owns and manages another object through a pointer and disposes of that object when the std::unique_ptr goes out of scope. The std::shared_ptr class is a smart pointer that retains shared ownership of an object through a pointer. Several std::shared_ptr objects may own the same object. The object is destroyed and its memory deallocated when either of the following happens:
- the last remaining
std::shared_ptrowning the object is:- destroyed
- is assigned another pointer via
operator=orreset() - is reset or released
- moved from
- is swapped with another
std::shared_ptrusingswap() - the function
std::shared_ptr::swap()is called with the last remainingstd::shared_ptrowning the object as an argument
- the object is no longer reachable from the program (for example, when the program terminates)
- the program:
- throws an exception that is not caught within the same thread
- calls terminating calls such as
std::terminate(),std::abort(),std::exit(), orstd::quick_exit()
To create a dynamic array of int using shared pointers, you can use the std::shared_ptr class template. Here's an example:
This creates a shared pointer to an array of 5 integers. The new int[5] expression dynamically allocates memory for the array on the heap, and the shared pointer takes ownership of the memory. When the shared pointer goes out of scope, the memory is automatically freed.
You can access individual elements of the array using the array subscript notation, just like with a regular C-style array:
To deallocate the memory, you don't need to call delete[] explicitly, because the shared pointer takes care of it automatically. When the last shared pointer that points to the array goes out of scope or is explicitly reset, the memory is deallocated automatically:
arr.reset(); // deallocates the memory and reset the shared pointer to null to avoid dangling pointers and other bugs
+Shared pointers provide a convenient and safe way to manage dynamic memory in C++, because they automatically handle memory allocation and deallocation, and help prevent memory leaks and dangling pointers.
Smart pointers are no silver bullet. They are not a replacement for proper memory management, but they can help you avoid common memory management bugs and vulnerabilities. For example, smart pointers can help you avoid memory leaks, dangling pointers, and double frees. They can also help you avoid buffer overflow vulnerabilities by providing bounds checking functions.
Passing arrays to functions¶
You can pass arrays to functions in C++ in the same way that you pass any other variable to a function. For example, to pass an array to a function, you would use the following code:
void printArray(int arr[], int size) // Pass the array by reference to avoid copying the entire array
+{
+ for (int i = 0; i < size; ++i)
+ std::cout << arr[i] << ' ';
+ std::cout << '\n';
+}
+Alternativelly you can pass the array as a pointer:
void printArray(int *arr, int size)
+{
+ for (int i = 0; i < size; ++i)
+ std::cout << arr[i] << ' ';
+ std::cout << '\n';
+}
+If you want to pass a two dimension array, you can do it in multiple ways:
This approach is problematic as you can see it in depth here. It does not check for types and it is not safe. You can also pass the array as a pointer to an array:
void printArray(int rows, int arr[][10]); // if you know the number of columns and it is fixed, in this case 10
+void printArray(int rows, int (*arr)[10]); // if you know the number of columns and it is fixed, in this case 10
+void printArray(int arr[10][10]); // if you know the number of rows and columns and they are fixed, in this case both 10
+There is others ways to pass arrays to functions, such as templates but they are more advanced and we will not cover them now.
EXTRA: Standard Template Library (STL)¶
Those are the most common data structures that you will be using in C++. But it is outside the scope of this course to cover them in depth. So we will only give entry-points for you to learn more about them.
Arrays¶
If you are using fixed sized arrays, and want to be safe to avoid problems related to out of bounds, you should use the STL arrays. It is a template class that encapsulates fixed size arrays and adds protections for it. It is a safer alternative to C-style arrays. Read more about it here.
Vectors¶
Vectors are the safest way to deal with dynamic arrays in C++, the cpp core guideline even states that you should use it whenever you can. Vector is implemented in the standard template library and provide a lot of useful functions. Read more about them here.
Extra curiosities¶
Context on common bugs and vulnerabilities:
Recursion¶
Estimated time to read: 7 minutes
Recursion is a method of solving problems where the solution depends on solutions to smaller instances of the same problem. It is a common technique used in computer science, and is one of the central ideas of functional programming. Let's explore recursion by looking at some examples.
You have to be aware that recursion isn't always the best solution for a problem. Sometimes it can be more efficient to use a loop and a producer-consumer strategy instead of recursion. But, in some cases, recursion is the more elegant solution.
When you call functions inside functions, the compiler will store the return point, value and variables on the stack, and it has limited size. Each time you call a function, it is added to the top of the stack. When the function returns, it is removed from the top of the stack. The last function to be called is the first to be returned. This is called the call stack. A common source of problems in programming is when the call stack gets too big. This is called a stack overflow. This is why you should be careful when using recursion.
Fibonacci numbers¶
The Fibonacci numbers are a sequence of numbers where each number is the sum of the two numbers before it. The constraints are: the first number is 0, the second number is 1, it only run on integers and it is not negative. The sequence looks like this:
int fibonacci(int n) {
+ // base case
+ if (n == 0 || n == 1)
+ return n;
+ else // recursive case
+ return fibonacci(n - 1) + fibonacci(n - 2);
+}
+Factorial numbers¶
The factorial of a number is the product of all the numbers from 1 to that number. It only works for positive numbers greater than 1.
int factorial(int n) {
+ // base case
+ if (n <= 1)
+ return 1;
+ else // recursive case
+ return n * factorial(n - 1);
+}
+Divide and Conquer¶
Divide and conquer is a method of solving problems by breaking them down into smaller subproblems. It is extensively used to reduce the complexity of some algorithms and increase readability.
Binary search¶
Imagine that you already have a sorted array of numbers and you want to find the location of a specific number in that array. You can use a binary search to find it. The binary search works by dividing the array in half and checking if the number you are looking for is in the first half or the second half. If it is in the first half, you repeat the process with the first half of the array. If it is in the second half, you repeat the process with the second half of the array. You keep doing this until you find the number or you know that it is not in the array.
// recursive binary search on a sorted array to return the position of a number
+int binarySearch(int arr[], int start, int end, int number) {
+ // base case
+ if (start > end)
+ return -1; // number not found
+ else {
+ // recursive case
+ int mid = (start + end) / 2;
+ // return the middle if wi find the number
+ if (arr[mid] == number)
+ return mid;
+ // if the number is smaller than the middle, search in left side
+ else if (arr[mid] > number)
+ return binarySearch(arr, start, mid - 1, number);
+ // if the number is bigger than the middle, search in right side
+ else
+ return binarySearch(arr, mid + 1, end, number);
+ }
+}
+Binary search plays a fundamental role in Newton's method, which is a method to find and approximate the result of complex mathematical functions such as the square root of a number. Binary-sort is extensively used in sorting algorithms such as quick sort and merge sort.
Merge sort¶
Please refer to the Merge sort section in the sorting chapter.
Sorting algorithms¶
Estimated time to read: 23 minutes
TODO: Note for my furune self: add complete example of how to use those algorithms
Sorting are algorithms that put elements of a list in a certain order. It is cruxial to understand the basics of sorting in order to start understanding more complex algorithms and why you have to pay attention to efficiency.
Before going deep, please watch this video:
SEIZURE WARNING!! 
and this one:
Explore the concepts interactively at visualgo.net.
Try to answer the following questions, before continuing:
- What are the slowest sorting algorithms?
- What are the fastest sorting algorithms?
- Con you infer the difference between a stable and unstable sorting algorithm?
- What is the difference between a comparison and a non-comparison sorting algorithm?
- What would be an in-place and a non-in-place sorting algorithm?
- What is the difference between a recursive and a non-recursive sorting algorithm?
The basics¶
Many of the algorithms will have to swap elements from the array, vector or list. In order to do that, we will need to create a function that swaps two elements. Here is the function:
// A function to swap two elements
+void swap(int *xp, int *yp) {
+ int temp = *xp;
+ *xp = *yp;
+ *yp = temp;
+}
+The * operator used in the function signature means that the function will receive a pointer to an integer. So it will efectivelly change the content in another scope. The * operator is used to dereference a pointer, which means that it will return the value stored in the memory address pointed by the pointer. Given the declaration is int *xp, the *xp will return the value stored in the memory address pointed by xp.
Alternatively you could use the & operator to pass the reference to that variable in the similar fashion, but the usage wont be requiring the * before the variable name as follows:
// A function to swap two elements
+void swap(int &xp, int &yp) {
+ int temp = xp;
+ xp = yp;
+ yp = temp;
+}
+The result is the same, but the usage is different. The first one is more common in C++, while the second one is more common in C.
Bubble sort¶
Bubble sort is the simplest sorting algorithm that works by repeatedly swapping the adjacent elements if they are in wrong order.
// A function to implement bubble sort
+void bubbleSort(int arr[], int n) {
+ // if the array has only one element, it is already sorted
+ if(n<=1)
+ return;
+
+ int i, j;
+ for (i = 0; i < n-1; i++)
+ // Last i elements are already in place
+ for (j = 0; j < n-i-1; j++)
+ if (arr[j] > arr[j+1])
+ swap(&arr[j], &arr[j+1]);
+}
+As you can see, the algorithm is very simple, but it is not very efficient. It has a time complexity of O(n^2) and a space complexity of O(1).
One of the drawbacks of this algorithm is the sheer amount of swaps. In the worst scenario, it does n^2 swaps, which is a lot. If your machine have slow writes, it will be very slow.
Insertion sort¶
Insertion sort is a simple sorting algorithm that works the way we sort playing cards in our hands. You pick one card and insert it in the correct position in the sorted part of the list. You repeat this process until you have sorted the whole list. Here is the code:
// A function to implement insertion sort
+void insertionSort(int arr[], int n) {
+ // if the array has only one element, it is already sorted
+ if(n<=1)
+ return;
+
+ int i, key, j;
+ for (i = 1; i < n; i++) {
+ key = arr[i];
+ j = i - 1;
+
+ /* Move elements of arr[0..i-1], that are
+ greater than key, to one position ahead
+ of their current position */
+ while (j >= 0 && arr[j] > key) {
+ arr[j + 1] = arr[j];
+ j = j - 1;
+ }
+ arr[j + 1] = key;
+ }
+}
+It falls in the same category of algorithms that are very simple, but not very efficient. It has a time complexity of O(n^2) and a space complexity of O(1).
Although it have the same complexity as bubble sort, it is a little bit more efficient. It does less swaps than bubble sort, but it is still not very efficient. It will swap all numbers to the left of the current number, which is a lot of swaps.
Selection sort¶
Selection sort is a simple sorting algorithm. This sorting algorithm is an in-place comparison-based algorithm in which the list is divided into two parts, the sorted part at the left end and the unsorted part at the right end. Initially, the sorted part is empty and the unsorted part is the entire list. The smallest element is selected from the unsorted array and swapped with the leftmost element, and that element becomes a part of the sorted array. This process continues moving unsorted array boundary by one element to the right. Here is the code:
// A function to implement selection sort
+void selectionSort(int arr[], int n) {
+ // if the array has only one element, it is already sorted
+ if(n<=1)
+ return;
+
+ int i, j, min_idx;
+
+ // One by one move boundary of unsorted subarray
+ for (i = 0; i < n-1; i++) {
+ // Find the minimum element in unsorted array
+ min_idx = i;
+ for (j = i+1; j < n; j++)
+ if (arr[j] < arr[min_idx])
+ min_idx = j;
+
+ // Swap the found minimum element with the first element
+ swap(&arr[min_idx], &arr[i]);
+ }
+}
+It is also a simple algorithm, but it is a little bit more efficient than the previous two. It has a time complexity of O(n^2) and a space complexity of O(1).
It does less swaps than the previous two algorithms, potentially n swaps, but it is still not very efficient. It selects for the current position, the smallest number to the right of it and swaps it with the current number. It does this for every number in the list, which fatally a lot of swaps.
Merge sort¶
Merge sort is a divide and conquer algorithm. It divides input array in two halves, calls itself for the two halves and then merges the two sorted halves. Here is the code:
// recursive merge sort
+void mergeSort(int arr[], int l, int r) {
+ if (l < r) {
+ // Same as (l+r)/2, but avoids overflow for
+ // large l and h
+ int m = l+(r-l)/2;
+
+ // Sort first and second halves
+ mergeSort(arr, l, m);
+ mergeSort(arr, m+1, r);
+
+ merge(arr, l, m, r);
+ }
+}
+
+// merge function
+void merge(int arr[], int l, int m, int r) {
+ int i, j, k;
+ int n1 = m - l + 1;
+ int n2 = r - m;
+
+ // allocate memory for the sub arrays
+ int *L = new int[n1];
+ int *R = new int[n2];
+
+ /* Copy data to temp arrays L[] and R[] */
+ for (i = 0; i < n1; i++)
+ L[i] = arr[l + i];
+ for (j = 0; j < n2; j++)
+ R[j] = arr[m + 1+ j];
+
+ /* Merge the temp arrays back into arr[l..r]*/
+ i = 0; // Initial index of first subarray
+ j = 0; // Initial index of second subarray
+ k = l; // Initial index of merged subarray
+ while (i < n1 && j < n2) {
+ if (L[i] <= R[j]) {
+ arr[k] = L[i];
+ i++;
+ }
+ else {
+ arr[k] = R[j];
+ j++;
+ }
+ k++;
+ }
+
+ /* Copy the remaining elements of L[], if there are any */
+ while (i < n1) {
+ arr[k] = L[i];
+ i++;
+ k++;
+ }
+
+ /* Copy the remaining elements of R[], if there
+ are any */
+ while (j < n2) {
+ arr[k] = R[j];
+ j++;
+ k++;
+ }
+
+ // deallocate memory
+ delete[] L;
+ delete[] R;
+}
+It is a very efficient algorithm that needs extra memory to work. It has a time complexity of O(n*log(n)) and a space complexity of O(n). It is a very efficient algorithm, but it is not very simple. It is quite more complex than the previous algorithms. It is a divide and conquer algorithm, which means that it divides the problem in smaller problems and solves them. It divides the list in two halves, sorts them and then merges them. It does this recursively until it has a list of size 1, which is sorted. Then it merges the lists and returns the sorted list.
Quick sort¶
Quick sort is a divide and conquer algorithm. It picks an element as pivot and partitions the given array around the picked pivot. Here is the code:
// recursive quick sort
+void quickSort(int arr[], int low, int high) {
+ if (low < high) {
+ /* pi is partitioning index, arr[p] is now
+ at right place */
+ int pi = partition(arr, low, high);
+
+ // Separately sort elements before
+ // partition and after partition
+ quickSort(arr, low, pi - 1);
+ quickSort(arr, pi + 1, high);
+ }
+}
+
+// partition function
+int partition (int arr[], int low, int high) {
+ int pivot = arr[high]; // pivot
+ int i = (low - 1); // Index of smaller element
+
+ for (int j = low; j <= high- 1; j++) {
+ // If current element is smaller than or
+ // equal to pivot
+ if (arr[j] <= pivot) {
+ i++; // increment index of smaller element
+ swap(&arr[i], &arr[j]);
+ }
+ }
+ swap(&arr[i + 1], &arr[high]);
+ return (i + 1);
+}
+It is a very efficient algorithm that don't needs extra memory, which means it is in-place. In average, it can be as fast as mergesort with time complexity of O(n*log(n)), but in the worst case it can be as slow as O(n^2). But it is a better choice if you are not allowed to use extra memory. It is a divide and conquer algorithm, which means that it divides the problem in smaller problems and solves them. It selects a pivot and partitions the list around the pivot. It does this recursively until it has a list of size 1, which is sorted. Then it merges the lists and returns the sorted list.
Counting sort¶
Counting sort is a specialized algorithm for sorting numbers. It only works well if you have a small range of numbers. It counts the number of occurrences of each number and then uses the count to place the numbers in the right position. Here is the code:
// counting sort
+void countingSort(int arr[], int n) {
+ // if the array has only one element, it is already sorted
+ if(n<=1)
+ return;
+
+ int max=arr[0];
+ int min[0];
+
+ // find the max and min number
+ for(int i=0; i<n; i++) {
+ if(arr[i]>max) {
+ max=arr[i];
+ }
+ if(arr[i]<min) {
+ min=arr[i];
+ }
+ }
+
+ // allocate memory for the count array
+ int *count = new int[max-min+1];
+
+ // initialize the count array
+ for(int i=0; i<max-min+1; i++) {
+ count[i]=0;
+ }
+
+ // count the number of occurrences of each number
+ for(int i=0; i<n; i++) {
+ count[arr[i]-min]++;
+ }
+
+ // place the numbers in the right position
+ int j=0;
+ for(int i=0; i<max-min+1; i++) {
+ while(count[i]>0) {
+ arr[j]=i+min;
+ j++;
+ count[i]--;
+ }
+ }
+
+ // deallocate memory
+ delete[] count;
+}
+Counting sort is a very efficient sorting algorithm which do not rely on comparisons. It has a time complexity of O(n+k) where k is the range of numbers. Space complexity is O(k) which means it is not an in-place sorting algorithm. It is a very efficient algorithm, but it is not very simple. It counts the number of occurrences of each number and then uses the count to place the numbers in the right position.
Radix sort¶
Radix sort is a specialized algorithm for sorting numbers. It only works well if you have a small range of numbers. It sorts the numbers by their digits. Here is the code:
// Radix sort
+void radixSort(int arr[], int n) {
+ // if the array has only one element, return
+ if(n<=1)
+ return;
+
+ // initialize the max number as the first number.
+ int max=arr[0];
+
+ // find the max number
+ for(int i=0; i<n; i++) {
+ if(arr[i]>max) {
+ max=arr[i];
+ }
+ }
+
+ // allocate memory for the count array
+ int *count = new int[10]; // 10 digits
+
+ // allocate memory for the output array
+ int *output = new int[n];
+
+ // do counting sort for every digit
+ for(int exp=1; max/exp>0; exp*=10) {
+ // initialize the count array
+ for(int i=0; i<10; i++) {
+ count[i]=0;
+ }
+
+ // count the number of occurrences of each number
+ for(int i=0; i<n; i++) {
+ count[(arr[i]/exp)%10]++;
+ }
+
+ // change count[i] so that count[i] now contains actual position of this digit in output[]
+ for(int i=1; i<10; i++) {
+ count[i]+=count[i-1];
+ }
+
+ // build the output array
+ for(int i=n-1; i>=0; i--) {
+ output[count[(arr[i]/exp)%10]-1]=arr[i];
+ count[(arr[i]/exp)%10]--;
+ }
+
+ // copy the output array to the input array
+ for(int i=0; i<n; i++) {
+ arr[i]=output[i];
+ }
+ }
+}
+Radix sort is just a counting sort that is applied to every digit. It has a time complexity of O(n*k) where k is the number of digits.
Conclusion¶
This is the first time we will talk about efficiency, and for now on, you will start evaluating and taking care about your algorithms' efficiency. You will learn more about efficiency in the next semester and course when we cover data structures.
Structs¶
Estimated time to read: 1 minute
wip
Intro to Programming¶
Estimated time to read: 7 minutes
Learning Objectives¶
- Understand the fundamental concepts of programming and computer science;
- Practice how to solve problems programatically using C++;
- Use tools to write and compile C++ programs;
- Code, document, test, and implement a well-structured, robust computer program using the C++ programming language.
- Write reusable modules (collections of functions).
- Use version control to manage your code;
- Use the debugger to find and fix bugs in your code;
- Understand the basics of file input/output;
- Work in groups to solve problems;
Learning Outcomes¶
- Be able to understand computer science concepts and terminology;
- To describe the basic components of a computer system and their functions;
- Differentiate between the various types of programming languages;
- To describe and use software tools in the programming process;
- Use modern concepts and principles of C++ programming language;
- To design, code, test, and debug a computer program using the C++ programming language;
- To demonstrate an understanding of primitive data types, values, operators and expressions in C/C++;
- Manage and manipulate files in C++;
- Deliver a full working project collaboratively;
Schedule¶
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use the github repo as the source of truth for the schedule and materials. The materials provided in canvas are just a copy for archiving purposes and might be outdated.
Relevant dates for the Fall 2023 semester:
- 09-13 Oct 2023 - Midterms Week
- 20-24 Nov 2023 - Thanksgiving Break
- 11-15 Dec 2023 - Finals Week
| Week | Date | Topic |
|---|---|---|
| 1 | 2023/08/28 | 1. Introduction, 2. Tools for first Program |
| 2 | 2023/09/04 | Data Types, Arithmetic Operations, Type conversion |
| 3 | 2023/09/11 | Conditionals, Boolean and Bitwise Operations |
| 4 | 2023/09/18 | Loops, for, while, goto and debugging |
| 5 | 2023/09/25 | Functions, Base Conversion, Pointers, Reference |
| 6 | 2023/10/02 | Streams, File IO |
| 7 | 2023/10/09 | Midterm |
| 8 | 2023/10/16 | Arrays, Vectors, String |
| 9 | 2023/10/23 | Recursion |
| 10 | 2023/10/30 | Sorting |
| 11 | 2023/11/06 | Structs, Unions, Enumerations |
| 12 | 2023/11/13 | Work sessions |
| 13 | 2023/11/20 | Thanks giving week |
| 14 | 2023/11/27 | Work sessions / Review |
| 15 | 2023/12/04 | Review / Presentations |
| 16 | 2023/12/11 | Finals |
References¶
10th edition Gaddis, T. (2020) Starting out with C++. Early objects / Tony Gaddis, Judy Walters, Godfrey Muganda. Pearson Education, Inc. Available at: https://research-ebsco-com.cobalt.champlain.edu/linkprocessor/plink?id=047f7203-3c9c-399b-834f-42cdaac4c1da
9th edition Gaddis, T. (2017) Starting out with C++. Early objects / Tony Gaddis, Judy Walters, Godfrey Muganda. Pearson. Available at: https://discovery-ebsco-com.cobalt.champlain.edu/linkprocessor/plink?id=502e29d6-3b46-38ff-9dc2-65e79c81c29b
- C++ early objects. Amazon (Champlain: 9th 10th)
- Modern C++ Programming
- learncpp
- cpluslus
- cprogramming
- programming-books
- google style guide
- riptutorial
- cpp manual
- cpp core guidelines
- rooksguide
- cpp best practices
Introduction¶
Estimated time to read: 14 minutes
A game developer portfolio is a collection of materials that showcase a game developer's skills, experience, and accomplishments. It is typically used by game developers to demonstrate their abilities to potential employers, clients, or partners, and may include a variety of materials such as:
- A resume or CV: This should highlight your education, work experience, and skills relevant to game development.
- Examples of your work: This can include demos, prototypes, or completed games that you have developed or contributed to. It's a good idea to include links to any online versions of your work, as well as screenshots or video trailers.
- A portfolio website: Many game developers choose to create a website specifically for their portfolio, which can include additional information about their skills and experience, as well as links to their work.
- Blogs, articles, or other writing: If you have written about game development or related topics, you may want to include these in your portfolio to show your knowledge and expertise.
- Testimonials or references: Including positive feedback from clients or colleagues can help to demonstrate the quality of your work.
Overall, a game developer portfolio should be designed to demonstrate your abilities and accomplishments in a clear and concise way, and should be tailored to the specific needs and goals of the person or organization you are presenting it to.
Building a portfolio is not only about you, it is about making the life easier of the ones interested on you by giving insights if they should hire you, follow you or anything else. In order to make people understand you, you have to know yourself better.

Who are you, what you excel and what do you enjoy doing?¶
In your portfolio, you will have to express yourself in a way that others can understand who you are, and it can be challenging for some. In order do help you discover who you are, what you excel, and what do you really enjoy doing. I will be briefly vague here to point some emotional support and reasoning to help you answer the question. If you are clear about that, please skip this entire section. Here goes a small amount of advices I wish I have heard when I was young.

Note
The above image links to a very good reference to understand the drives that you should be aware while taking decisions on your future career. Visit it.
You are a complex being and hard to define. I know. It is hard to put yourself in a frame or box, but this process is relevant to make the life of the others to evaluate if they want more you or not. If for some reason a person is reading your portfolio, it means that you are ahead of the others, so you must respect their time and goals while they are reading your content.
What you do, do not define what you are, you can even work with something you dont love as long it is part of a bigger plan. Given that, you have to know how to differentiate yourself from your work while respecting your feelings. The sweet spot is when you mix who you are with what you do, and you have nice feelings about it. But this can be hard to achieve and require maturity to mix things. If you dont have a clear understand of those aspects of yourself, you will be subjected to be exploited by bad companies and managers.
It is totally fine try to excel some job you are not passionate. You just have to find means to make your time doing it as enjoyable as possible. In the end of the journey it will slowly become something you can be proud of, and you will become a different person than the one you are now. Understanding this kind of mentality will help you endure more and be more resilient to problems.
Keep track of your progress towards your goal. First of all, have a clear goal, so you can build a path to it. Otherwise, any path would sound just like any other apathetic path. Having a clear goal will make your path shine and easy to choose. It will help you in difficult moments where you feel uncomfortable by being just a small piece of a machinery. You will be able to act as part of machine while you need to achieve your goal as a necessary step.
Focus on always keep track on your evolution on your journey to excellence. Don't compare too much yourself to the others, everyone is facing a different journey and everyone took different paths in their career that probably you didn't have the option to chose in the past. But you cannot be uncritical either, you have to analyse your progress and check if your current path is making you life good, you have to take a decision to change the plan or even the goal with the new information you learned through the current path you are pursuing.
In other point of view, you wont start your career as senior developer, so you have to build your own path. Making mistakes is part of the process, and that is the reason you will be gradually exposed to big things. You should accept yourself, don't push too hard, and do some basic stuff. Just accept the challenges of doing something not fancy, but relevant to build your career.
Define and state your mission and goal¶
- Are you a generalist or a specialist type?
- What position you are looking for?
- What kind of person you want to become?
Gather information¶
In order to build a good portfolio, you will need to gather information about yourself and your work. In the process you will discover yourself. It will feels like looking to a mirror for the first time.
If you didnt published yot your projects on itchio, github, or any other platform, now it is a good moment for doing it. Pay attention that if you are going to share your code publicly, you have to avoid sharing content that do not belong to you. In other words, avoid copyright infringements.
Proof of your accomplishments¶
It is a good practice to always take screenshots, use web archive or any means to prove what you are stating. Some games got lost in time, they die or become unavailable in the long term.
Personal advice
In my case, we developed a very successful game in the past, and because of some problems with investors and judicial dispute, we had to shut down the game. But it was one of the most successful games in that year, it was nominated to Unity Awards and it was the most downloaded racing game. The only things that I can showcase now are print-screens, recorded videos and web-archive pages. So it is something that can make you survive the questions.
Videos, photos, or lightweight web builds¶
A good way to express your work is to show it in a form of videos, or photos. If your game is small enough to be embedded, or you can strip the most relevant part of it and built for web(webgl, wasm etc), try to publish the relevant part of it online, but do not over-do it, because it will take too much time to craft a good interaction.
Homework¶
Index¶
Estimated time to read: 2 minutes
Assessment 1¶
Summary¶
- The date the evaluation happened
- The portfolio evaluated
- Briefing
Strength¶
What things you judge as good and you are aiming to follow and target. Add images as reference using print-screens uploaded to image hosting services such as imgur or others;
Improvements¶
- What things you judge that needs attention or should be improved?
- What questions you would ask this person?
Best fit¶
- Why you would hire the owner of the portfolio?
- For what kind of task?
- What position?
- How do you see this person interacting with others?
General considerations¶
- Just add some final consideration for the portfolio owner;
- If possible, send a message to one of its communication channels informing your assessment;
Assessment 2¶
The other student willing to do multiple assessment for the same portfolio, just create an entry in the index following the same structure and same the assessment differently in this case, we put number 2. And use the same structure on the 1.
Case Study¶
Estimated time to read: 9 minutes
Index¶
This class will be focused in planning, portfolio evaluation, github processes, ci/cd and in-class activities.
Activity 1¶
Start setting up your Github pages. We are going to use github pages mostly for two intentions: Webpage hosting for your portfolio and Demo project hosting.
Webpage¶
For your webpage, you can develop something from ground up using your preferred web framework and we are going to show you how to do it, but the fastest way is to just follow any template. Here goes a bunch of open sourced developer portfolios you can fork and modify for your intent. https://github.com/topics/developer-portfolio?l=html . Try to take a look on them and check if you want to fork any of them. So in this activity you will have to fork and try to run a clone of a portfolio you like just to got into some action and discover how things work.
- Find a developer portfolio on github
- Fork it
- Clone in your machine
- Make some changes
- Build it
- Deploy it to gh-pages either via automated ci/cd or via publishing a build from a empty branch or the main one
Demo reels¶
For project demo, game, or whatever interaction you want to allow the user to do, I built some boilerplates for you. Later on, you will be able to embed those webgl/html5 builds into your portfolio, so it is a good moment for you to start doing it now. As extras, optionally you can add badges for your repo from here: https://shields.io/
SDL2¶
In order to showcase your ability to build something from ground up, this repo holds a boilerplate with C++, SDL2, IMGUI, SDL2IMAGE, SDL2TTF, SDL2MIXER, CI/CD automation for automatic deployment: https://github.com/InfiniBrains/SDL2-CPM-CMake-Example
- fork it
- go to the repo settings, actions, general, in the bottom, enable workflow permission, read and write, save
- run github action at least once
- enable actions and automatic page deployment from a branch gh-pages
AI + SDL2¶
If you enjoy AI programming and want to test yourself, you can try forking this repo and implement what is inside the examples folder https://github.com/InfiniBrains/mobagen
- fork it
- run github action at least once
- enable actions and automatic page deployment from a branch gh-pages
Unity¶
If you want to showcase your ability with Untiy, you can follow this boilerplate to have an automatic build set up. https://github.com/InfiniBrains/UnityBoilerplate
- Fork it
- run github action for getting an unit licence at least once
- grab the generated file, and upload it to https://license.unity3d.com/manual
- get the signed licence and copy the text content to your clipboard
- go to your repo settings, security, secrets and variables, actions and setup a new repository secret with the name 'UNITY_LICENSE' and the content from your clipboard
- go to the repo settings, actions, general, in the bottom, enable workflow permission, read and write, save
- run the main action
- enable actions and automatic page deployment from a branch gh-pages
- edit webgl template with your logo or image
Activity 2¶
This class is totally up to you. Here goes what you should do in class and finish at home. The idea is for you to feel a whole process on how to create merge and pull requests to a public repo.
- Search a good portfolio published online
- use Twitter, LinkedIn, Google to search for good game developer portfolios;
- another good query on google would be "awesome developer portfolio", or "curated list of developer portfolios" try it!. Example: https://github.com/emmabostian/developer-portfolios
- You can use this time to search a good and open sourced portfolio to fork and start your own based on other. https://github.com/topics/developer-portfolio
- Fork this repo
- Create a markdown file in this folder with a meaningful name about the benchmarked repository.
- Follow this example
- The file name should be the website domain name followed by .md
- If another student is aiming to evaluate the same portfolio, just edit the file adding your evaluation to the text.
- Your file should contain:
- A summary
- The portfolio evaluated
- The date the evaluation happened
- Print-screens uploaded to image hosting services such as imgur or others
- What things you judge as good and you are aiming to follow and target
- What things you judge that needs attention and should be improved
- Why you would hire the owner of the portfolio
- General considerations
- Edit this file on github to link your work here if you want to showcase it here.
- Be Kind and constructive
- Send a push request
Considerations¶
- The portfolios evaluated here are just opinions
Evaluated Portfolios¶
Game Developer Portfolio Structure¶
Estimated time to read: 10 minutes
Create a single page app containing most of these features listed here.
Head / Summary¶
Chose carefully what to you use as a head of your page. It is the first thing a person reads. It can be an impactful message, a headline, personal statement, background video or very limited interactive section.
Note
Avoid bravado. You can be bold without being naive. Let the bravado statements for when you become a senior. If you write bravados right in the begining of your portifolio and you are still a junior, you are just communicating that you will be hard to work with. A senior developer reading your portfolio is more interested in developers eager to learn, humble, and looking for guidance so they will have a easier life hiring you.
About¶
This is a summary obout yourself, be brief and achievement oriented. What and who you are. Contact info via social medias. State your working status and target. If you are a narrative centred person, you can create something fancy here, but dont over-do, less is more!
Showcase¶
- Projects
- Ability and versatility
- Community Contributions
You can showcase your personal work, a job you make for a client(if authorized).
Projects
It is a good practice to showcase only the best works you made. You might find interesting to add more than 5, but there are chances of your reader clicking exactly on the worst one and have a bad first impression of you. In your showcase section, avoid showcasing bad work. Invite some of your friends to help you select the best ones to showcase.
Ability
Avoid using percentage graphs to showcase your proficiency on specific tech stack or tool. The main reason is: how do you grade of your ability as 80%, 100% or 30%? Worse than that, how can the reader be sure of that? If you want to do that, it is better to apply for certificates, there are plenty on linkedin or specialized sites.
Achievements¶
- List key achievements and skills. Dont use any kind of grading
- Education
- Testimonials or anything to prove your skills and capacity
Project Details¶
- You should create a way to explain more about what is showcased. Ex.: redirect the user to the project description page, or open a modal
Blog¶
- Featured posts/content and call to action to read your ongoing content production
- Explain your process in designing a game or piece of software
- Explain some interesting details you learn or describe your knowledge explorations.
Contact¶
Explicitly state what people should expect if they contact you and what they can expect from your return. Ex.: If you aim to be a freelance, state your offer and ask for them to briefly state the job activity, time frame and the rate they are willing to pay. If you are looking for a full-time position, the most common way is to just share your email, so they can contact you.
Another option is to list all of your social medias, but dont overuse this. Nowadays we have a bunch of them, so if you list all of them, there is chances, you are not active there and the link will guide the reader to a empty and haunted house and they will not engage.
General tips¶
- Keep the Target Audience in Mind
- Take Advantage of Your Homepage
- Make Your Portfolio Scannable
- Minimize Clicks
- Remember UX and UI
- Go Mobile or Go Home
- Optimize Website Performance
- Remember Accessibility
- Showcase Your Best Work and Skills
- Share Your Code and Live Projects
- OR Provide Code Samples and GIFs
- Boast Freelance and Personal Projects
- BUT Be Selective
- Prove that You Are on The Same Page
- Show Your Personality
- Use Custom Domain
- Make Use of Introductory Statement
- Use Your Tone of Voice
- Share Your Motivation (Optional)
- Maintain Personal Brand
- Keep Portfolio Up-to-Date
- Include Testimonials
- Encourage Communication
- Call-to-action button or link to contact
Homework¶
- [Optional]Create a wireframe draft of what you are going to do on figma, miro or any other tool you find relevant. If you already have a Portfolio page already set, try to think on how do you make it be responsive on mobile devices.
- Scaffold your project in github. Describe in the README.md what you are going to do in your demo. You might try to convince a colleague to work with you. You can do more than one demo if you want. Some examples:
- Raytrace demo for cloud and Human body. ref https://www.youtube.com/watch?v=Qj_tK_mdRcA
- Networking game using the phone as a controller and your portfolio demo as the viewer. https://blockrage.pgs-soft.com/
- Catch the cat demo for AI. https://llerrah.com/cattrap.htm
- Create unity editor plugin to dynamically generate meshes via splines based on sample locations. https://www.youtube.com/watch?v=f5Q7Z2KxILE is a game with 50million downloads that used this technique to generate scenarios. Here you can watch a better explanation. https://www.youtube.com/watch?v=saAQNRSYU9k
- Embed a shader toy behind your portfolio page. https://shadertoyunofficial.wordpress.com/2018/02/17/embedding-shadertoys-in-website/
- A nice collection of fun ideas to code for your portfolio https://mrdoob.com/
- Board game simulation. Ex: chess https://www.chessprogramming.org/ or https://github.com/JuUnland/Chess/ or this https://www.youtube.com/watch?v=WKs685H6uOQ
- [Optional] Simulate a real test by creating a console based space invader in 48h.
- Efficiently draw (print on console)
- Efficient collision check
Communication¶
Estimated time to read: 12 minutes
Having a well-written and organized portfolio is important for any game developer, as it can help them stand out from the competition and demonstrate their skills and experience to potential employers. A good portfolio should clearly communicate the developer's strengths and accomplishments, and should be tailored to the specific needs and expectations of the audience.
Effective communication is crucial in building a strong game developer portfolio, as it allows the developer to clearly convey their skills and experiences to potential employers. A portfolio that is well-written and easy to understand will be more effective at convincing an employer to hire the developer, while a poorly written or poorly organized portfolio may have the opposite effect.
Audience¶
In general your portfolio will be read by:
Human Resources¶
If you are applying for a big tech company, chances are your submission won't be read by a tech person the first human triage. So in order to pass this first filter, you have to be generic and precise. They are often very busy evaluating multiple applications, and probably they will spend 30-60 seconds before making the decision about moving forward in the process or not. Your portfolio will need to catch their attention and communicate clearly your fit, passion and ability in a short time frame.
Software Developer Managers¶
In contrast with HR, developer managers probably will not be shocked with any fancy stuff(such as full page pre-loaders) you add to your portfolio, so be concise and straight to the point, because most of them already know all the contents. From all of your portfolio readers, they are one of the most critique of your job.
In another hand, usually developers do not look for programming language fit, frameworks or tools you use. They are more interested if you will be able to learn and execute the job in a meaningful time. So try to express yourself in a way that showcase your ability to solve problems, no matter what problem is, they are mostly curious on how to solve complex problem by framing the problem in another way or how to be innovative.
What they look for¶
The following metrics can be evaluated by reading your portfolio, interviews or tests. The most common evaluation metrics they made are:
- Position Fit
- They are going to search if your portfolio showcase experience in the same area of what they are looking for the specific position they received. Usually they will look for specific keywords for the requirements list;
- Company fit
- They take count on your expressed ideas, stated goals, tone, alignment and supporting projects to evaluate your future evolution inside the company; ex. https://wa.aws.amazon.com/wat.pillars.wa-pillars.en.html
- Passion
- Passionate developers tend to express projects they are proud of. The description of the projects are mostly achievement-based. Ex.: more than X million downloads. This example showcases that you were part of something huge, and it is easily understandable.
- There is a high correlation on high performant people that they usually shine in side-projects or even hobbies. So they look for it. Ex.: Google encourages employees to devote 20% of their time to hobbies or skill-building.
- Competence
- They need to evaluate if you are really able to solve the problem properly, in a meaningful time, and in a team. You have to describe which tools, tech stack and how you glue everything in order to solve the problem. Be assured you are correctly expressing yourself here, because it is one of the central part that is not taken superficially.
- Innovation and Curiosity
- Innovative developers solve problems out of the box. It doesn't matter how complex the problem is, but if you solve in a innovative way, reframe it or do any magic to solve it, chances are to have good points here;
- Good companies incentives research and test new stuff. So they usually like to see your deliverables with new bleeding-edge technology tools.
- Proactiveness
- Usually the more proactive developers tend to have more leadership positions. So if you want to give the readers a glimpse of your ability in this area, a good place to showcase that is in project description section. Express problems that arise and how do you manage that before it become a real problem.
- Learner
- It is good to be always tuned with the current evolution of the technology, so try to keep the education section always updated with some courses or publish blog posts about some new tech.
- Thinking big / Thoughtfulness / Risk management
- They are going to look for your ability to think big, and how you manage risks. So if you have a project that you had to manage risks, or think big, it is a good place to showcase that.
- Expose cases where you had to manage risks, or think big, and how you manage that. What you learned in the process trying to achieve bigger goals.
In class activities¶
1. Self-Reflection on the audience¶
Try to look at your portfolio from the perspective of the audience. What are the strengths and weaknesses of your portfolio? What are the areas that you need to improve in order to better communicate your skills and experiences to potential employers?
2. Mock interviews¶
Pair up with a colleague and find some common questions that company usually asks. You can find some of them here. Then, take turns interviewing each other and providing feedback on how well you communicated your skills and experiences.
Homework¶
- Write the content for each one of your projects and all other sections of your portfolio.
- 1st round of Portfolio Feedbacks.
- Research in a game company you like the resources on their hiring process. Take notes on how they hire and which positions you want to apply. Here goes some examples on how to get ready for interviews:
- Epic: https://www.epicgames.com/site/en-US/earlycareers/career-paths
- AWS: https://aws.amazon.com/careers/how-we-hire/
- General interview questions https://www.mockquestions.com/
- Top interview questions https://leetcode.com/problem-list/top-interview-questions/. Some examples:
- https://leetcode.com/problems/two-sum/ - the most asked question
- https://leetcode.com/problems/kth-largest-element-in-an-array/ - heap
- https://leetcode.com/problems/median-of-two-sorted-arrays/
- https://leetcode.com/problems/minimum-space-wasted-from-packaging/ - bin packing, try to solve for 2d image pack for textures
- Watch this video https://www.youtube.com/watch?v=Kte-t1pQQ3I and start contributing into an open source project or community
Strategies to get hired¶
Estimated time to read: 13 minutes
Strategies for your portfolio¶
Ask some questions for ChatGPT. Here goes a sample extracted from this prompt:
- Develop the right skills: The first step to getting hired in a AAA game studio is to develop the right skills for the job. Start by researching the job positions in the studio and look for the required skills, experience, and qualifications. Then, focus on building those skills through relevant education, training, and projects. You can also take courses, attend workshops or conferences, and create a portfolio of your work to showcase your abilities.
- Network with industry professionals: Networking with industry professionals can help you gain exposure and insights into the game development industry. Attend industry events, join online forums, participate in game development communities, and reach out to professionals in the field to build relationships. You can also consider working on collaborative projects with other game developers to expand your network.
- Stay up-to-date with industry trends: Keeping up with the latest trends and news in the gaming industry can help you stay ahead of the game and impress your potential employers. Read industry blogs, participate in online discussions, follow industry influencers on social media, and stay up-to-date with the latest game releases to show that you are knowledgeable and passionate about the industry.
- Research the game studio: Before applying for a job, research the game studio to learn about their culture, values, and work environment. Look for information about their current projects, the team structure, and the company's mission statement. This will help you tailor your resume and cover letter to match the company's requirements and demonstrate that you are a good fit for the team.
- Apply for internships: Consider applying for internships in a AAA game studio. This is an excellent opportunity to gain industry experience and build your skills. Even if the internship is unpaid, the experience and contacts you gain could be invaluable for your future career.
- Prepare for the interview: Once you get an interview, make sure to prepare thoroughly. Research common interview questions and practice your responses. Be ready to talk about your experience, skills, and passion for game development. Also, prepare questions to ask the interviewer about the company and the job position to show your interest and enthusiasm.
- Develop a strong portfolio: Your portfolio is your calling card, so it needs to showcase your programming skills, creativity, and technical abilities. Create a portfolio that showcases your best work, including your personal game development projects, demos, and samples of your code. Highlight your experience with programming languages, software, tools, and engines that are commonly used in the indie game development industry.
- Research indie game studios: Do your research on the indie game studios that interest you. Find out what kind of games they make, the size of the studio, the company culture, and their current job openings. Look for studios that align with your interests, values, and career goals.
- Build a network: Building a network of like-minded professionals in the game development industry can be invaluable. Attend industry events, join online forums and communities, and engage with indie game developers on social media. This will help you stay up-to-date on the latest trends, technologies, and job openings.
- Gain experience: Gain experience by creating your own games, participating in game jams, contributing to open-source projects, or volunteering for a non-profit game development organization. This will help you gain valuable experience and demonstrate your passion and commitment to game development.
- Apply for internships: Many indie game studios offer internships or junior positions for game programmers. This is an excellent opportunity to gain hands-on experience, build your skills, and make contacts in the industry. Even if the internship is unpaid, the experience and contacts you gain could be invaluable for your future career.
- Tailor your resume and cover letter: Tailor your resume and cover letter to showcase your programming skills, experience, and passion for game development. Highlight your technical skills, programming languages, software, and engines that you are proficient in. Be sure to mention any experience you have working in a team and collaborating with other game developers.
- Prepare for the interview: Once you get an interview, make sure to prepare thoroughly. Research the indie game studio, their current projects, and their company culture. Be ready to talk about your experience, skills, and passion for game development. Also, prepare questions to ask the interviewer about the company and the job position to show your interest and enthusiasm.
Analytics¶
- Analytics. Recommendation: Google Analytics or Firebase Analytics;
- Heatmaps. Recommendation: smartlook;
Generate traffic¶
For more details see promoting section;
Strategies for interviews¶
Train yourself in coding interviews with some materials: - Crack the Coding Interview - Interviews on AWS - Interview on Google - Course on get ready for an AWS interview
Coding resources¶
Curated videos on most common programming interview questions¶
Strategies for Social Networks¶
All social networks uses some type of relevance algorithm to promote your content or profile. So you have to find means to increase your relevance. Most of the algorithms measure your relevance by number of reactions(likes, follows, comments, replies...), so every time you post something, you should try to incentive the content consumers to do that.
Google¶
If your aim is to be relevant on Google, try to check the trending words people are searching now via Google trends.
If you follow this path, the main strategy is the common SEO optimization techniques. Here goes some guides to help you nail that.
- https://searchengineland.com/guide/what-is-seo
- https://www.wordstream.com/seo
- https://searchengineland.com/yandex-leak-learnings-392393
If you are a prolific writer and really into it. You can try to make wikipedia refer you and raise your rate on google algorithm. You can query google site:wikipedia.org [your niche keyword] + "dead link" and check the pages that are missing references to your content, then edit the wikipedia page to refer your website or blog post to give sources for something missing.
Linkedin¶
- Consistency is the key. You have to post frequently. Period.
- Follow other professionals in your field and check what they are posting to try replicate their behavior.
- Follow companies you want to work
- Connect with the hiring personal from the companies you want to work for, so when they search for people, you will be on the top suggestions.
Activity¶
WiP
Portfolio Reels¶
Estimated time to read: 34 minutes
Demo Reels Structure¶
Game demo reels should showcase the best features and gameplay of a game to potential players and investors. Here are some important elements that a game demo reel should include:
- Captivating Intro: The game demo reel should start with a captivating intro that hooks the audience and captures their attention.
- Gameplay Footage: The demo reel should showcase the actual gameplay footage of the game. This should include a variety of gameplay scenarios, showcasing the game mechanics and the different features of the game.
- Visuals: The game demo reel should showcase the visual quality of the game. This should include graphics, animations, lighting, and special effects.
- Audio: The game demo reel should include the game's audio elements, such as sound effects, music, and voice acting.
- User Interface: The demo reel should showcase the user interface of the game, including the menus, HUD, and other interactive elements.
- Story and Characters: If the game has a story or characters, the demo reel should include footage that showcases these elements.
- Game Modes: If the game has different game modes, the demo reel should showcase the different modes and gameplay styles.
- Multiplayer: If the game has a multiplayer mode, the demo reel should showcase the multiplayer gameplay and the features that make it unique.
- Call-to-Action: The demo reel should end with a clear call-to-action, such as a link to the game's website or social media page, or instructions on how to download the demo.
Overall, the game demo reel should be well-paced, engaging, and give a good sense of what the game is all about.
Captivating Intro¶
A captivating intro is an essential part of a game demo reel, as it sets the tone and captures the viewer's attention from the start. There are several ways to create a captivating intro, depending on the type of game and the intended audience. Here are a few ideas:
- Show a brief teaser: Start the demo reel with a brief teaser that highlights the game's most exciting features, such as a stunning visual effect or a heart-pumping action sequence.
- Use a dramatic voiceover: Use a dramatic voiceover to introduce the game and create a sense of anticipation. The voiceover can provide a brief overview of the game's story or setting, or simply hype up the viewer with promises of intense gameplay and unforgettable experiences.
- Introduce the developer: If the game is developed by a well-known studio or an indie developer with a strong following, introduce them in the intro. Share their mission and goals for creating the game and convey their passion and expertise in the field.
- Set the mood with music: Use music to set the mood for the demo reel. Choose a track that complements the game's theme or genre and builds up the excitement for the upcoming gameplay footage.
- Use a creative animation: Use a creative animation that visually represents the game's core concept or theme. This can help to grab the viewer's attention and give them a taste of what the game is all about.
Whatever approach is taken, the intro should be brief and impactful, providing a sense of the game's style and tone while leaving the viewer eager to see more.
Gameplay Footage¶
Gameplay footage is the heart of any game demo reel, as it showcases the actual gameplay experience that the game offers. This section of the demo reel should be carefully crafted to highlight the most exciting and impressive features of the game. Here are some tips for creating engaging gameplay footage:
- Variety of gameplay scenarios: The gameplay footage should showcase a variety of gameplay scenarios to give viewers a well-rounded idea of what the game is all about. This can include different levels or environments, various weapons or abilities, and different characters or modes.
- Highlight unique features: Highlight the game's unique features and mechanics, such as special abilities, game modes, or multiplayer options. This can help to differentiate the game from other titles in the same genre.
- Showcase player choices: If the game allows players to make choices that affect the story or gameplay, showcase these choices in the demo reel. This can help to create a sense of player agency and show how the game responds to different playstyles.
- Show off impressive visuals: The gameplay footage should also showcase the game's impressive visuals, such as high-quality textures, realistic lighting and shadow effects, or dynamic particle effects. These elements can help to create a more immersive and engaging gameplay experience.
- Keep it concise: The gameplay footage should be concise and to the point, showcasing the most exciting and impressive elements of the game without becoming overly long or repetitive.
- Use high-quality footage: The footage should be high-quality and well-shot, with clear visuals and smooth frame rates. This can help to create a professional and polished demo reel that shows off the game in the best possible light.
Overall, the gameplay footage should provide a clear and exciting look at what the game has to offer, highlighting its unique features and impressive visuals while keeping the viewer engaged and interested.
Visuals¶
Visuals are a critical component of any game demo reel, as they are often the first thing that potential players and investors will notice. The visuals of a game should be showcased prominently in the demo reel, demonstrating the game's graphical capabilities and the level of detail and polish that has gone into its development. Here are some key elements of visuals to consider when creating a game demo reel:
- Graphics quality: The graphics quality of the game should be highlighted in the demo reel. This can include high-quality textures, realistic lighting and shadows, dynamic particle effects, and other visual elements that make the game stand out.
- Art style: The art style of the game is also an important visual element to showcase. Whether the game has a realistic or stylized art style, it should be highlighted in the demo reel to give viewers a sense of the game's aesthetic.
- Animations: The animations of the game are an important part of the overall visual experience. The demo reel should showcase the game's character animations, object interactions, and any other animations that add to the game's visual appeal.
- Camera work: The camera work used in the demo reel can also be used to highlight the game's visual elements. Different camera angles, zooms, and cuts can be used to showcase the game's graphics and make them stand out.
- User interface: The user interface (UI) of the game is also an important visual element that should be showcased in the demo reel. The demo reel should highlight the UI design and any interactive elements, such as buttons or menus.
- Environment design: The game's environment design is another important visual element to showcase in the demo reel. Whether the game takes place in a realistic or fantastical setting, the environment design should be highlighted to give viewers a sense of the game's atmosphere.
Overall, visuals play a crucial role in creating an immersive and engaging gameplay experience, and they should be showcased prominently in a game demo reel. By highlighting the game's graphics quality, art style, animations, camera work, user interface, and environment design, the demo reel can give viewers a clear and exciting look at what the game has to offer.
Audio¶
Audio is an often overlooked but crucial component of any game demo reel. It can enhance the overall gameplay experience, create an immersive atmosphere, and contribute to the game's overall appeal. Here are some key elements of audio to consider when creating a game demo reel:
- Sound effects: Sound effects are an important component of any game's audio design. The demo reel should showcase the game's sound effects, such as weapon sounds, environmental effects, and character vocalizations.
- Music: The music used in the game can also be an important part of the overall audio experience. The demo reel should highlight the game's soundtrack, showcasing any memorable themes or musical cues that contribute to the game's atmosphere.
- Voice acting: If the game features voice acting, it should be highlighted in the demo reel. The demo reel should showcase any memorable voice performances and give viewers a sense of the quality of the voice acting.
- Sound design: The overall sound design of the game is another important element of the game's audio. The demo reel should showcase how the game's audio elements work together to create an immersive atmosphere, such as the use of ambient sounds or dynamic music that changes based on the player's actions.
- Audio quality: The quality of the game's audio should also be highlighted in the demo reel. The sound effects, music, and voice acting should be clear and well-produced, with high-quality mixing and mastering that enhances the overall experience.
Overall, audio is a critical component of any game demo reel. By showcasing the game's sound effects, music, voice acting, sound design, and audio quality, the demo reel can give viewers a clear and engaging look at the game's overall audio experience.
User Interface¶
The user interface (UI) is a critical component of any game, and it should be showcased prominently in a game demo reel. The UI is the primary way that players interact with the game, and it can greatly impact the overall gameplay experience. Here are some key elements of UI to consider when creating a game demo reel:
- Design: The design of the UI is an important aspect to showcase in the demo reel. The UI design should be visually appealing, easy to navigate, and intuitive for players to use. The demo reel should showcase any unique design elements, such as custom icons or animations, that contribute to the overall look and feel of the game.
- Functionality: The functionality of the UI is also an important element to showcase in the demo reel. The UI should be designed to help players easily access important information, such as health, inventory, or map data. The demo reel should showcase how the UI functions during gameplay and how it supports the overall game mechanics.
- Customizability: Some games offer customizable UI options, such as changing the size or placement of UI elements. If the game has this feature, it should be highlighted in the demo reel to showcase the flexibility of the UI design.
- Responsiveness: The responsiveness of the UI is another important aspect to showcase in the demo reel. The UI should respond quickly and smoothly to player input, and any interactive elements should have clear feedback to help players understand their actions.
- Accessibility: Finally, the accessibility of the UI is an important consideration. The demo reel should showcase how the UI supports players with different needs, such as colorblind options or font size adjustments.
Overall, the UI is a critical component of any game, and it should be showcased prominently in a demo reel. By highlighting the design, functionality, customizability, responsiveness, and accessibility of the UI, the demo reel can give viewers a clear and engaging look at how players interact with the game and how the UI supports the overall gameplay experience.
Story and Characters¶
The story and characters are important elements of many games, and they can greatly impact the overall experience. When creating a game demo reel, it is important to showcase the game's story and characters in a way that is engaging and gives viewers a clear sense of what to expect from the game. Here are some key elements of story and characters to consider when creating a game demo reel:
- Story: The demo reel should give viewers a sense of the game's story, including the setting, premise, and major plot points. The story should be presented in a way that is engaging and makes viewers want to learn more about the game's world and characters.
- Characters: The demo reel should also showcase the game's characters, including their personalities, motivations, and relationships with each other. Characters should be presented in a way that is relatable and makes viewers care about their journeys throughout the game.
- Dialogue: If the game features dialogue, it should be highlighted in the demo reel. The dialogue should showcase the quality of the writing and voice acting, and give viewers a sense of the characters' personalities and relationships.
- Cutscenes: Cutscenes are a great way to showcase the game's story and characters in a visually compelling way. The demo reel should include any memorable or important cutscenes that help to advance the story or develop the characters.
- Worldbuilding: Finally, the demo reel should showcase the game's worldbuilding, including any lore or backstory that helps to flesh out the game's world and characters. This can include things like environmental storytelling, item descriptions, or other worldbuilding details.
Overall, the story and characters are important elements of many games, and they should be showcased prominently in a game demo reel. By highlighting the story, characters, dialogue, cutscenes, and worldbuilding, the demo reel can give viewers a clear and engaging look at what to expect from the game's narrative and characters.
Game Modes¶
Game modes are an important aspect of many games, particularly in multiplayer titles, and they can greatly impact the overall experience. When creating a game demo reel, it is important to showcase the different game modes in a way that is engaging and gives viewers a clear sense of what to expect from each mode. Here are some key elements of game modes to consider when creating a game demo reel:
- Variety: The demo reel should showcase a variety of different game modes, particularly if the game has several unique modes to choose from. This will give viewers a sense of the game's overall variety and replayability, and help them understand how each mode contributes to the overall experience.
- Objectives: Each game mode should have clear objectives that are highlighted in the demo reel. This can include things like capturing objectives, defeating enemies, or completing tasks within a certain timeframe. The objectives should be presented in a way that is clear and easy to understand for viewers.
- Mechanics: The demo reel should showcase the different mechanics and gameplay elements that are unique to each game mode. This can include things like different weapons or abilities, unique maps or terrain, or different objectives and win conditions. By highlighting these unique mechanics, viewers can get a sense of how each mode feels and plays.
- Multiplayer: If the game has multiplayer modes, it is important to showcase how players can interact with each other within each mode. This can include things like team play, player versus player combat, or cooperative objectives.
- Replayability: Finally, the demo reel should showcase how each game mode contributes to the game's overall replayability. This can include things like unlockable rewards, leaderboards, or other features that encourage players to come back and play the game multiple times.
Overall, game modes are an important aspect of many games, particularly in multiplayer titles, and they should be showcased prominently in a game demo reel. By highlighting the variety, objectives, mechanics, multiplayer elements, and replayability of each mode, the demo reel can give viewers a clear and engaging look at what to expect from each game mode and how it contributes to the overall experience.
Multiplayer¶
Multiplayer is an important aspect of many games, particularly in online multiplayer games, and it can greatly impact the overall experience. When creating a game demo reel, it is important to showcase the multiplayer aspects in a way that is engaging and gives viewers a clear sense of what to expect from the multiplayer modes. Here are some key elements of multiplayer to consider when creating a game demo reel:
- Modes: The demo reel should showcase the different multiplayer modes that are available in the game. This can include things like team-based modes, objective-based modes, and free-for-all modes. The demo reel should highlight how each mode plays and what the objectives are.
- Player Count: The demo reel should also showcase the player count for each mode. This can include things like 1v1, 2v2, 4v4, or larger player counts for massive multiplayer games. The player count is an important factor in determining the pacing and flow of the game, and should be highlighted in the demo reel.
- Matchmaking: If the game features matchmaking, it is important to showcase how the matchmaking system works and how players are paired with opponents of similar skill levels. This can include things like player ranking systems or other matchmaking algorithms that help to ensure fair matches.
- Progression: The demo reel should also highlight any progression systems that are available in the multiplayer modes. This can include things like unlocking new weapons or abilities as players progress through the game, or other rewards for completing objectives or winning matches.
- Social Features: Finally, the demo reel should showcase any social features that are available in the multiplayer modes. This can include things like chat systems, friend lists, or the ability to form clans or teams with other players.
Overall, multiplayer is an important aspect of many games, particularly in online multiplayer games, and it should be showcased prominently in a game demo reel. By highlighting the different modes, player count, matchmaking, progression, and social features of the game's multiplayer modes, the demo reel can give viewers a clear and engaging look at what to expect from the multiplayer experience.
Call to Action¶
The Call-to-Action (CTA) is an important element of any game demo reel because it prompts viewers to take action after watching the video. The CTA can be in the form of a request or suggestion that encourages viewers to do something related to the game, such as signing up for a mailing list, pre-ordering the game, or visiting the game's website. Here are some key elements to consider when including a Call-to-Action in a game demo reel:
- Clarity: The CTA should be clear and specific, so that viewers know exactly what action they are being asked to take. This can include things like "pre-order now" or "sign up for updates", and should be prominently displayed at the end of the video.
- Relevance: The CTA should be relevant to the content of the video, and should relate directly to the game being showcased. For example, if the demo reel is showcasing a new game trailer, the CTA could be to pre-order the game.
- Timing: The CTA should be timed appropriately within the video, so that it appears at the end and is not too distracting during the main content of the video.
- Design: The design of the CTA should be visually appealing and eye-catching, using bold fonts and contrasting colors to draw attention to it.
- Placement: The CTA should be placed in a prominent location within the video, such as at the end or in a lower third graphic.
Overall, the Call-to-Action is an important element of any game demo reel because it prompts viewers to take action after watching the video. By including a clear, relevant, and well-designed CTA at the end of the video, game developers can encourage viewers to take action and engage with the game in meaningful ways.
Specifications¶
Specifications for the Demo Reels:
Video Specifications:
- Size: 1920x1080 (16:9)
- Format: saved as
.mp4 - Length:
- Game Art = 90 seconds.
- Game Design, Game Production Management, Game Programming, Game Sound Design = 60 seconds.
- No audio with lyrics
- No X-rated content
- Use audio that won't get removed from Vimeo (where we store the files) because of copyright infringement.
Homework¶
Watch some videos from Sample Portfolio Reels and create a script detailing what you are going to present yourself. Start creating the timeline of feelings and you are going to present at each time.
Tell a story where you are (or your work is) the protagonist.
Hosting¶
Estimated time to read: 9 minutes
There are many hosting options and solutions to match each need. Lets cover some options here.
Options low code¶
- Google sites - My preference
Other notable options: - Godaddy - Wordpress - Wix - Squarespace
The problem with those are they require payments to be fully functional, so if you want to go deep and have mor freedom, we are going to cover other options.
Static HTML with Static Data¶
If what you want to serve is static hosting, your content is only frontend and do not require backend, you can use github pages, google firebase, S3 bucket hosting or many others. This is the easiest approach. - In this scenario you will be able to store only pre-generated html and static files; - This is useful even if you use blogs that changes rarely, you would have to redeploy your page for every change.
Static HTML with Dynamic Data¶
If your html is static and need backend services that are rarely called, you can go with cloud functions, my suggestions here are google cloud run and aws amplify or even firebase functions. If you use nextjs website, check vercel or netlify hosting services. - The deploys are easy; - It can be very expensive if you hit high traffic, but it will remain free if you dont hit the free tiers; - You will have to pay attention to your database management;
Dynamic HTML with Dynamic Data¶
If your website generate content dynamically such as Wordpress blogs or any custom made combination with next or anything. - There is many "cheap hosting" solutions that are mostly bad performant(it can reach more than 10s to answer a request). You have to avoid them to make your user enjoy the visit; - Management can go as hard as possible, but the results can be awesome; - It can be really expensive;
CDN and DNS Management¶
I highly recommend you to use Cloudflare as you DNS nameserver, so you can cache your website results for faster loading. But you can use your own nameserver provider by your domain name registrar.
DNS stands for Domain Name System, which is a system that translates domain names into IP addresses. When you type a domain name into your web browser, such as "www.example.com," your computer sends a request to a DNS server to resolve the domain name into an IP address, such as "192.0.2.1." The IP address is then used to establish a connection with the web server that hosts the website you are trying to access.
DNS plays a crucial role in hosting because it enables users to access websites using domain names instead of IP addresses. This makes it easier for users to remember and find websites. DNS also allows websites to change servers or IP addresses without affecting the user experience, as long as the DNS records are updated properly.
In hosting, DNS is important because it determines which server is responsible for hosting a particular website. DNS records can be configured to point to different servers depending on factors such as geographic location, server load, and failover. Hosting providers typically offer DNS management tools to help users configure and manage their DNS records.
Homework¶
The goal is to have as website up and running for your portfolio.
Here goes my preferable way for hosting anything. With that you can host microservices, game services, serve API, static and dynamic websites and much more. It can be tricky but lets setup it now.
- Oracle cloud - Free forever - Virtual Machine with 4vCPU, 24GB ram, 200GB storage. https://www.youtube.com/watch?v=NKc3k7xceT8 watch up to 5:38 time
- Coolify - Your private Software as a Service (SAAS) manager - https://youtu.be/Jg6SWqyvYys?t=125 starts from minute 2:00
- CI/CD - to your remote machine https://www.youtube.com/watch?v=Uj7F3hdgmEo
- Cloudflare DNS - set your domain to point to your DNS - https://www.youtube.com/watch?v=XQKkb84EjNQ
- Install Wordpress via coolify interface(new resource, new service) and use your own DNS. Or host your page statically https://www.youtube.com/watch?v=CfdPyASUSkI&
Talk with me if you dont have a domain and want to use my infrastructure temporarily.
I am assuming you wont have a huge traffic, but you have a complex combination of services. In the complex cases and if you want to make your life easier and cheaper,my suggestion for hosting would be oracle cloud with arm cpu. They offer for free a virtual machine with 200gb storage, 4vcpus, 24gb ram for free at this date of 2022/12 tutorial. In this scenario, I recommend using https://coolify.io/ as your deployment management system, just pay attention that this machine is running in an arm cpu. With this combination, you can manage everything easily in one place for free. This is not ideal, because you wont have backups, but it is good enough for most scenarios.
If you have plenty of money or your website have high traffic, I recommend you to use Kubernetes to orchestrate every microservice.
Content Management System¶
Estimated time to read: 2 minutes
Play with chatgpt¶
In order to train yourself for a game position try some prompts similar to this one.
Act as technical recruiter for a AAA game studio. You are going to interview me by asking me questions relevant for an entry level position as "unreal gameplay developer". Skills required are: Unreal Egine, Data structures, Algorithms, VR and Rendering pipelines.
+You are going to ask me a question when I prompt "ask".
+My answer to your question will start with "response".
+On each response I give to your question, you will provide me 5 bullets: SCORE: from 0 to 100 points to evaluate if I answered it well or not; EXPLANATION: why you gave me that score; RATIONALE: explain what a typical recruiter is measuring with the question previously asked; ADVISE: to improve for answer to score 100 answer; NEXT: question.
+Do you understand? Dont ask anything now.
+Common interview questions¶
Estimated time to read: 1 minute
Resources: - https://debbie.codes/blog/interviewing-with-the-big-tech-companies/
Final project¶
Estimated time to read: 4 minutes
Your portfolio should be a hosted webpage and a open repository on github.
You should follow a portfolio structure, to build a website and host it publicly. It should have a nice style, a good communication is the key to execute and analyse your strategy in order to capture insights. You can optionally increment your portfolio via dynamic content such as blogs or whatever you find relevant. Another extra step would be to create a generic cover letter to express your intentions and goals more personally. Note that some game companies still require CVs To boost your visualization, you can promote.
Minimum steps: 1. Have a domain or at least a meaningful github username/organization; 2. Create a github repository; 3. Push your frontend to the repo; 4. Enable github pages; 5. Create a CI/CD to build and deploy to gh pages; 6. Point your domain to gh-pages if you have one;
It is expected to have something to showcase, so it is expected to have at least 3 projects to showcase. It is preferable to showcase something that could be testable(webgl builds) or watchable in a lightweight manner.
If you are willing to showcase your ability in Unity, I recommend you to try GameCI and github pages. If you want to showcase your game engine abilities with C++, I recommend you using CMake, SDL2 and emscripten to build and deploy for github pages.
If you want to start something from scratch you can use this repo to start have a SDL2 project with all libraries already set. It builds and publish a Github page via Github actions automatically, you can check it running here. It features CMake tooling, IMGUI for debug interfaces, SDL2, SDL2_ttf, SDL_image, SDL_mixer,
2023¶
Here goes a list of portfolios
Frontend for your portfolio¶
Estimated time to read: 3 minutes
Here goes a curated templates for a quick start: - https://github.com/techfolios/template - the easiest one - https://github.com/rammcodes/Dopefolio - straight to the point developer portfolio - https://github.com/ashutosh1919/masterPortfolio - animated with a strong opening - https://smaranjitghose.github.io/awesome-portfolio-websites a good compilation on how to build and deploy your portfolio with a good pre-made template
But for this class, we are going to follow this template, sofork this boilerplate if you want a more robust webapp experience.
Frontend frameworks¶
There are many frontend frameworks floating around, but in order to speed up your learning curve on how to deploy a fully customized webpage, I am going to use this combination of technologies:
- React for building website;
- Vite for tooling;
- Tailwindcss for styling;
Some examples with this stack:
- https://reactjsexample.com/a-portfolio-page-using-react-js-and-tailwind-css/
- https://github.com/InfiniBrains/reactjs-vite-tailwindcss-boilerplate
Watch this video to get a fast entry to this stack Here goes an introductory video about this combination.
How to promote yourself and your work¶
Estimated time to read: 13 minutes
For most of us, game developers, the most important thing is to make games. But, in order to make games, we need to promote ourselves and our work. In this section, we will learn how to do that.
Defining the target to be promoted¶
Before we start promoting, we need to define what we want to promote. The main difference between promoting ourselves or our work is the tone, the message and the medium being promoted. So we can build a successful strategy.
In ether path you chose, consider the following questions:
- What is the target audience?
- What is the target platform?
- What is the target medium?
- What is the target message and content?
- What is the target call to action?
- What is the target result?
- How to measure the success?
- How to improve the promotion?
Defining the Audience¶
Before creating and running a promotion campaigns, we need to define the audience. The audience is the group of people we want to reach with our promotion and it can defined by the following:
- Recruiters, HR, and hiring managers;
- Other game developers, especially those who are in the same field as you;
- Game players;
- Journalists, writers and critics;
- Investors;
- Communities;
About Platforms¶
To reach specific audiences, we need to be in the same platform they are. For example: - Game players: Steam, Twitch, YouTube, itchio, GameJolt, Discord; - Journalists: Twitter, LinkedIn; - Investors: AngelList, Ycombinator, LinkedIn, Crunchbase; - Communities: Reddit, Discord, Facebook, Twitter; - Recruiters: mostly Linkedin.
Social media is a great way to promote yourself as a game developer. You can use it to share your work, your thoughts, your ideas, and your opinions. You can also use it to connect with other developers and learn from them.
Here goes my opinion about the most important platforms:
- Twitter: it is the best and easy way to communicate with anyone in the world. The distance between to reach anyone is zero. And it has an awesome tagging structure. It is a great way to share your thoughts and ideas and ask for feedbacks. It is a great way to connect with other developers and learn from them. You can also use it to share your work and promote your games.
- LinkedIn: It is a great way to connect with recruiters and hiring managers. Usually you will see other developers publishing their thoughts and ideas, so try to post relevant comments on their publications to get noticed and improve your visibility.
- Facebook: It is mostly a general purpose social media. You can use it to connect with your friends and family, and collect feedbacks for your content. It is a great way to promote your finished games.
- Instagram and Tiktok: Are more focused in fast, small and visual content. You can use it to promote your games and your work, but it is not the best way to share your thoughts and ideas.
- Reddit: This one is the best for collecting feedbacks from other developers about your content, but the reach is limited.
- Discord: The best tool be in touch with communities, you can build your own community for your game and be in direct contact with yours consumers. Another good use is to be in direct contact with other developers and learn from them.
- YouTube and Twitch: The best way to share your work and promote your games.
- Medium and Blogs in general: The best way to share your thoughts and ideas and ask for feedbacks. You can use it in conjunction with other platforms to catch the general attention and bring them to your content.
Mediums¶
The mediums are: Social media posts, Blog posts, Email, Podcasts, Videos, Events, Conferences, Meetups, Workshops, Webinars, Webcasts, and more.
For each type of medium, we need to plan the content, the frequency, and the duration. We have very nice tools to help us with that, like Buffer, Hootsuite and many others.
Message and tone¶
The message is the main idea we want to communicate. The tone is the way we want to communicate it. You have to match the tone with the message in the given platform to reach the right audience. So plan ahead how you want to communicate your message and what tone you want to use.
When planning the message, it is good to plan the emotions we want to trigger in the audience. For example, if we want to promote our game, we can use the following emotions: Excitement, Joy, Curiosity, and Fun. If we want to promote yourself by doing something interesting, you can use the following emotions: Curiosity, Fun, Surprise and Pride.
Call to action¶
The call to action is the action we want your audience to take. It can be: Download the game, Read my Resume, be part of by community, Take a look on my Repository, Buy the game, Play the game, Follow me, Subscribe, Share, Like, Comment, and more.
Results¶
Whatever is your goal, you need to define the results you want to achieve so you should track and measure your progress. You can use tools like Google Analytics mostly for web content, Google Firebase for apps and games and many other.
Here some ideas of results you can track: Number of downloads, page views, number of people reaching you, number of followers, number of subscribers, number of likes, number of comments, number of shares, number of retweets, number of reposts and more.
Improving the promotion¶
If you really want to go deep in this rabbit hole, I highly recommend you to create performance measurements such as KPI dashboard to track your progress and improve your promotion. You can use tools like Google Data Studio or Tableau. With the KPI dashboard, you can track your progress and improve your promotion. You can also use it to track your competitors and learn from them.
Another good strategy is to A/B test your promotion. You can use tools like Google Optimize to create different versions of your promotion and test which one is the best. You can also use it to test different messages, tones, and call to actions. I cannot stress enough how important it is to test your promotion, the most successful companies in the world do it. Zynga even quoted once "We are not in the business of making games, we are in the business of testing games" and "We are a data warehouse maskerated as a game company". So being data-driven and customer-centric is the key to success.
Homework¶
- Create a promotion strategy for yourself and your work.
- What would be your first content and medium to promote?
- What is the message and the tone?
- Define your call to action.
- How do you measure your results?
- How would you plan to improve your promotion?
Conclusion¶
I hope you enjoyed this content. If you have any questions, please create an issue in this repository. If you want to contribute, please create a pull request. If you want to support me, please share this content with your friends and colleagues. If you want to support me financially, please consider buying me a coffee or a very fancy wine.
How to write an Awesome Cover Letter¶
Estimated time to read: 13 minutes
What is a cover letter?¶
A cover letter is a document that is sent together with your resume. It is a way to introduce yourself to the company, explain why you're applying for the job, and why you're a good fit for the position. You should also explain why you're interested in the company, and why you want to work for them.
Nowadays writing a Cover Letter seems to be a lost art. Most of the time, people just send their resume and that's it. But, if you want to stand out from the crowd, you should write a cover letter.
In a cover letter you can be more personal to sell yourself more effectively. The core of it is to link your skills and history to what they do and need. Now lets see how to write a cover letter.
Strategies to write a cover letter¶
There are many strategies to write a cover letter. But the main idea is to be personal and try to sell yourself more effectively. Here are some strategies to write a cover letter:
- Be clear, concise and specific. You should try to be clear and try to sell yourself more effectively. Don't waste their time with long and boring paragraphs. You can do that by linking your skills and history to what they do and need. You can also try to show your personality and your passion for the job;
- Be personal, enthusiastic and professional: You should try to be personal setting the best tone that matches your style and the company, just don't exaggerate. You can also try to show your personality and your passion for the job. But, you should also be professional and try to be polite and respectful. If you're unsure about the company culture, you can do that by using a formal language and a professional tone;
Knowing your audience¶
Usually, game companies are interested in people who are passionate about games. But there are some core differences between what profiles AAA game studios and Indie Studios seek for. AAA usually follow the path of the specialist, while Indie Studios usually, the generalist. So try to match this style of writing in your cover letter.
Another relevant aspect is the company culture. You should try to match the tone of your cover letter to the company culture. If you're unsure about the company culture, you can do that by using a formal language and a professional tone. Or try to connect with some employees of the company and ask them about the company culture.
Research about the company. Try to find out what they do, what they are looking for, and what they are interested in. You can do that by reading their website, their blog, and their social media. They tend to prefer people that have culture, passion and goals aligned with theirs. So try to show that you are passionate about their products and their goals.
Play their games, and use their products. An awesome icebreaker can be yourself telling about some funny bug or how you enjoyed the game connecting it to your life. It would be awesome if you can show that you are a fan of their products to the point to even create mods or fan art.
Write interesting content¶
You should try to write memorable sentences to maintain your reader engaged. One strategy is to start the paragraphs with a short and powerful sentence that summarizes the the topic you are about to write. Arguably, you can also try to use a powerful quote to start your cover letter.
Your first sentence plays a huge role in your cover letter, it should be meaningful to you and to the reader. Chances are, they wont be reading the whole cover letter, so you should try to make the first sentence as interesting as possible. Try to be catchy and try to make them want to read more, but take care not to exaggerate.
Sometimes your content is really relevant to you but it might not be that relevant to the company or the job. Sometimes we get too excited and we want to tell everything about ourselves and how passionate we are, by try telling all the things you ever did. But you should try to be clear and concise. Just add some breadcrumbs for the reader ask you in the interview about the things you didn't mention in the cover letter.
Strengths¶
You should try to highlight your strengths. You can do that by using a list of your skills and achievements. They will try to extrapolate the value you brought to the previous companies you worked for to themselves. So try show that you are a good fit for the job by giving success stories about your acchievents. Some examples:
- AAA centred: I published a game on Steam with 100k downloads while a student. I acted as the main developer and tech lead, responsible for creating tools for level designers and AI system for the game. Besides that, I played a fundamental role to cut the scope of the game to make it possible to be released on time and consequently the sanity of the team;
- Indie: I am fearless. I am not afraid to fail or take risks. This behavior pressures me to have a good plan and to be prepared for the worst. Once we tried a very ambitious feature that we thought would be awesome, we tracked the adoption of it, just to discover that nobody used it. We learned from it and we tried again with a smaller scope and it worked. We released the game on time and we were happy with the result;
Pay attention that some companies might not like to see that you are a risk taker. So try to be careful with that, and ask some employees of the company and ask them about the company culture.
Closure¶
You should try to close your cover letter with summary, thank them for their consideration and time, and add a call to action. You can also try to add a call to action to connect with you on social media or to visit your website, or just say that you are in hopes to talk with them in person soon.
Create a Template¶
You should try to create a template for your cover letter. A way of doing it is to add replaceable tags for the company name, the job title, and the date. Try to mark those tags in some colorful way, so you can easily find them and replace them. You can also try to add some comments to help you remember what to write in each tag.
Another strategy to templating your cover letter is to create one template for every type of company. For example, you can create a template for AAA game studios, another for Indie game studios, and another for game companies. You can also create a template for each type of job. For example, you can create a template for a game designer, another for a gameplay developer, and another for a UI/frontend developer.
But if you pursue this path, you have to pay attention to the examples and products/games that you use in your cover letter. You will have to change them to match the company you are applying for.
Homework¶
Write a Cover Letter for a game company.
Game Developer's Portfolio¶
Estimated time to read: 9 minutes
Creating and maintaining a portfolio is a crucial part in any game developer's job search and career.? Portfolios are especially challenging for programmers, since the work presented is not inherently visual, yet it must still effectively demonstrate the individual's prowess and skills in their discipline.? This course provides Game Programmers a formal opportunity to sum up their experience in the major and produce a portfolio worthy of presentation at the Senior Show.? In this course, students discuss and implement pertinent portfolio materials for programmers, such as websites, repositories and demo reels.? Students will have an opportunity to spearhead an entirely solo project to add as a centerpiece to their materials. Source
Requirements¶
- 90 Credits
Student-centered Learning Outcomes¶
Upon completion of the Game Developer's Portfolio course, students should be able to:
Objective Outcomes¶
- Demonstrate Proficiency in Programming Languages:
- Showcase competence in relevant programming languages commonly used in game development.
- Implement and explain code snippets that highlight problem-solving skills and efficiency.
- Develop an Individual Project:
- Spearhead a solo game development project to showcase the ability to conceive, plan, and execute a complete game;
- Demonstrate a deep understanding of programming concepts through the development of a unique and challenging project.
- Create a Professional Portfolio Website:
- Design and develop a visually appealing and user-friendly portfolio website to showcase programming projects.
- Utilize web development tools and frameworks to enhance the presentation of coding projects.
- Build a Source Code Repository:
- Establish and maintain a version-controlled repository (e.g., GitHub) containing well-documented code samples.
- Demonstrate proficiency in using version control tools and collaborative development practices.
- Develop a Demo Reel:
- Create a compelling demo reel that effectively communicates programming skills and contributions to game projects.
- Edit and present code snippets in a clear and concise manner within the demo reel.
- Articulate Programming Contributions:
- Clearly communicate the role and impact of programming contributions in game development projects.
- Develop the ability to discuss technical aspects of projects in a non-technical manner for diverse audiences.
- Understand Industry Standards and Best Practices:
- Adhere to industry standards and best practices in game programming.
- Apply knowledge of optimization, performance, and coding conventions commonly used in the game development industry.
- Prepare for the Job Search and Senior Show:
- Develop skills in resume writing, cover letter creation, and interview preparation specific to game programming roles.
- Prepare and present the portfolio effectively at the Senior Show or similar events to potential employers and industry professionals.
- Receive and Provide Constructive Feedback:
- Participate in peer reviews and constructive critiques to enhance the quality of portfolio materials.
- Provide thoughtful feedback to peers on both the technical and presentation aspects of their portfolios.
- Reflect on Learning and Career Goals:
- Reflect on personal learning experiences and identify areas for continuous improvement in game programming skills.
- Develop a clear understanding of career goals and create a plan for ongoing professional development in the game development industry.
Schedule for Spring 2024¶
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use the github repo as the source of truth for the schedule and materials. The materials provided in canvas are just a copy for archiving purposes and might be outdated.
College dates for the Spring 2024 semester:
| Date | Event |
|---|---|
| Jan 16 | Classes Begin |
| Jan 16 - 22 | Add/Drop |
| Feb 26 - March 1 | Midterms |
| March 11 - March 15 | Spring Break |
| March 25 - April 5 | Registration for Fall Classes |
| April 5 | Last Day to Withdraw |
| April 8 - 19 | Idea Evaluation |
| April 12 | No Classes - College remains open |
| April 26 | Last Day of Classes |
| April 29 - May 3 | Finals |
| May 11 | Commencement |
| Week | Date | Topic |
|---|---|---|
| 1 | 2024/01/15 | Introduction |
| 2 | 2024/01/22 | Case Studies |
| 3 | 2024/01/29 | Game Developer Portfolio Structure |
| 4 | 2024/02/05 | Communication & Audience |
| 5 | 2024/02/12 | Strategy & Analytics |
| 6 | 2024/02/19 | Demo Reels |
| 7 | 2024/02/26 | Frontend |
| 8 | 2024/03/04 | Content Management System |
| 9 | 2024/03/11 | BREAK |
| 10 | 2024/03/18 | Final Project & Coding Interviews |
| 11 | 2024/03/25 | Hosting and Domain |
| 12 | 2023/04/01 | Dynamic Content & Blogs |
| 13 | 2023/04/08 | Promoting |
| 14 | 2023/04/15 | Cover Letters |
| 15 | 2023/04/22 | Traditional CVs |
| 16 | 2023/04/26 | FINALS |
Join is on Discord!
How to use this repo: Read the topics, and if you're unsure if you understand the topics covered here it is a good time for you to revisit them.
Ways of reading:
- Website: read through your browser the interactive examples and animations will work better in this version;
- Github: You read through the github repo;
- PDF: download the latest
- Amazon Kindle: You can buy the book in Amazon and read it in your kindle device;
- Contribute!: If you want to go deep and propose changes to repo, use the github repo.
CI:
Join us: .
Metrics:
Code of conduct:
"},{"location":"#topics","title":"Topics","text":"- Intro to Programming
- Advanced Programming
- Artificial Intelligence
- Developer Portfolio
This repository aims to be practical, and it will be updated as we test the methodology. Frame it as a guidebook, not a manual. Most of the time, we are constrained by the time, so in order to move fast, we won't cover deeply some topics, but the basics that allows you to explore by yourself or point the directions for you to study in other places acting as a self-taught student, so you really should look for more information elsewhere if you feels so. I use lots of references and highly incentive you to look for other too and propose changes in this repo. Sometimes, it will mostly presented in a chaotic way, which implies that you will need to explore the concepts by yourself or read the manual/books. Every student should follow your own path to learning, it is impossible to cover every learning style, so it is up to you to build your own path and discover the best way to learn. What worked for me or what works for a given student probably won't work for you, so dont compare yourself to others too much, but be assured that we're here to help you to succeed. If you need help, just send private messages, or use public forums such as github issues and discussions.
"},{"location":"#reflections-on-teaching-and-learning-processes","title":"Reflections on teaching and learning processes","text":""},{"location":"#philosophies","title":"Philosophies","text":"I would like to categorize the classes into philosophies. so I can address them properly: - Advanced classes: are more focused on work and deliveries than theory, they are tailored toward the student goals more than the closed boxes and fixed expected results. It comprehends AI and Adv. AI; - Introduction classes: are focused on theory and practice. In those classes, they have more focus on structural knowledge and basic content. It comprehends classes such as Introduction to Programming. - Guidance: are more focused on how can we bring the student to the highest standard and get ready to be hired. It comprehends classes such as Capstone, Portfolio classes, and Mentoring activities.
"},{"location":"#learning-styles","title":"Learning Styles","text":"- Visual: You prefer using pictures, images, and spatial understanding;
- For this style I recently acquired a pen-tablet monitor, so I will be adding this type of content more often.
- I also use lots of diagrams via code2flow, sequence diagram and others
- I assume my handwriting is not the best, but I compensate it with lots of diagrams and pictures, and always project what I write in the computer.
- Aural: You prefer using sound and music;
- I always link to youtube videos and podcasts, so they can follow up with extra content and material;
- Verbal: You prefer using words, both in speech and writing;
- I setup my machine to record specific topics that might be hard to undestand in just one go, and I did some experimental recordings, but I am still struggling with video editing. I will be adding more videos in the future.
- My main issue here is that I am not a native english speaker, so I am still struggling with the language, but I am trying to improve it.
- Other issue that I can name is eye-to-eye contact. It feels overburned to me to keep eye-to-eye contact, that I usually look away.
- Physical: You prefer using your body, hands and sense of touch;
- Given my cultural origin, I am usually over expressive in this field, and I need more fine tuning my proxemic. Brazilians commonly talk and walk closer to each other than americans.
- While lecture I really enjoy to use my hands to express myself, and I am trying to use more body language to express myself.
- Logical: You prefer using logic, reasoning and systems;
- I always craft and test teaching experiences to push them to think and reason about the topics.
- I always use tools such as beecrowd to let them code and test their ability to solve problems.
- Social: You prefer to learn in groups or with other people;
- I incentive them to do in-class assignments in pairs, and do group assignments. But I recognize this might be a problem for some students, so I am trying to find a way to make it more inclusive.
- Strangelly for me, some students prefer to socialize with me by booking office hours more than working together. Probably next semester I will reserve a time to do a type of co-working time when I can be available to help them in their assignments.
- Solitary: You prefer to work alone and use self-study.
- Sometimes and some topics you really need to study by yourself, and it can be the best way for some. But I warn them about the effects of loneliness and impostor syndrome.
- This is usually the most common way to learn, and I always keep an eye on the ones that are struggling to keep up with the class. I always try to reach them and help them to keep up with the class.
- To compensate this solitude I incentive them to present their work to the class no they can experience having attention even when the lack social skills.
For every type of style, I try to give a bit of insights:
- Authoritative: control the classroom and maintain discipline;
- I create a set of rules that should be followed in order to guarantee the student's success;
- Delegator: give students control of their learning;
- For the intro classes I follow more this strategy;
- Facilitator: guide students and help them learn by themselves;
- I usually follow this strategy on advanced classes;
- Demonstrator: explain and show things to students;
- I usully provide a stream of references or even create my own content to show them how to do things;
Give us stars! Click ->
"},{"location":"advanced/","title":"Advanced Programming","text":"This course builds on the content from Introduction to Programming. Students study the Object Oriented Programming (OOP) Paradigm with topics such as objects, classes, encapsulation, abstraction, modularity, inheritance, and polymorphism. Students examine and use structures such as arrays, structs, classes, and linked lists to model complex information. Pointers and dynamic memory allocation are covered, as well as principles such as overloading and overriding. Students work to solve problems by selecting implementation options from competing alternatives.
"},{"location":"advanced/#requirements","title":"Requirements","text":"- Introduction to Programming
- Advanced Programming
- C++ Early Objects, 10th Edition, Gaddis, Walters, Muganda, Pearson, 2019. ISBN 978-0135235003
Upon completion of the Advanced Programming course in C++, students should be able to:
- Articulate key concepts of Object-Oriented Programming (OOP), including objects, classes, encapsulation, abstraction, modularity, inheritance, and polymorphism.
- Exhibit a comprehensive understanding of the OOP paradigm and its fundamental principles.
- Differentiate between various structures (arrays, structs, classes, and linked lists) and proficiently apply them in modeling complex information.
- Apply OOP principles effectively to design and implement solutions for real-world problems.
- Utilize Pointers and Dynamic Memory Allocation.
- Effectively employ pointers and dynamic memory allocation in C++ programming.
- Analyze and evaluate competing alternatives for implementation options when solving programming problems. Break down complex problems into manageable components using OOP concepts.
- Evaluate the effectiveness of different implementation strategies in addressing programming challenges.
- Critically assess the advantages and disadvantages of using structures like arrays, structs, classes, and linked lists in specific scenarios.
- Develop solutions for programming challenges by integrating and synthesizing various OOP principles.
- Implement advanced programming concepts, such as overloading and overriding, to enhance code functionality.
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use the github repo as the source of truth for the schedule and materials. The materials provided in canvas are just a copy for archiving purposes and might be outdated.
College dates for the Spring 2024 semester:
Date Event Jan 16 Classes Begin Jan 16 - 22 Add/Drop Feb 26 - March 1 Midterms March 11 - March 15 Spring Break March 25 - April 5 Registration for Fall Classes April 5 Last Day to Withdraw April 8 - 19 Idea Evaluation April 12 No Classes - College remains open April 26 Last Day of Classes April 29 - May 3 Finals May 11 Commencement"},{"location":"advanced/#review","title":"Review","text":"- Week 1. 2024/01/15
- Topic:
- Review: variables, decision making, iteration, functions, strings, and arrays. Structs and 2D arrays
- Setup: Github, CLion, Github Actions
- Week 2. 2024/01/22
- Topic: Introduction to OOP Objects, classes, member functions, constructors, destructors
- Week 3. 2024/01/29
- Topic: Private member functions, object passing, object composition, structs and unions
- Week 4. 2024/02/05
- Topic: Address operator, pointer variables, arrays and pointers, pointer math, pointers as function parameters and return types, dynamic memory allocation
- Week 5. 2024/02/12
- Topic: this pointer, constant member functions, static members, friends, member-wise assignment, copy constructors
- Week 6. 2024/02/19
- Topic: Operator overloading, type conversion operators, convert constructors, aggregation and composition, namespaces
- Week 7. 2024/02/26
- Topic: Midterms
- Week 8. 2024/03/04
- Topic: Vectors and arrays of objects: Linked lists, linked list operations
- Week 09. 2024/03/11
- Topic: Spring BREAK. No classes this week.
- Week 10. 2024/03/18
- Topic: inheritance, protected members, constructors/destructors
- Week 11. 2024/03/25
- Topic: inheritance, overriding base class functions
- Week 12. 2024/04/01
- Topic: inheritance hierarchies, polymorphism and virtual member functions, abstract base classes and pure virtual functions
- Week 13. 2024/04/08
- Topic: Exceptions, function and class templates, STL and STL containers, iterators
- Week 14. 2024/04/15
- Topic: Stack and queue
- Week 15. 2024/04/22
- Topic: Work sessions for final project
- Week 16. 2024/04/29
- Topic: Finals Week
Before we start, let's recapitulate what we have learned in the previous course. Use the links below to refresh your memory. Or go straigth to the Introduction to Programming Course.
- Variables
- Decision-making
- Loops;
- Functions;
- Strings;
- Arrays;
- Multidimensional arrays;
Structs in C++ are a way to represent a collection of data packed sequentially into a single data structure.
struct Enemy\n{\n double health; \n float x, y, z;\n int score;\n};\nThe code above defines a type named as Enemy. This type has members(fields) named health, score with different types, and x, y and z with the same type.
struct Enemy\n{\n double health; // 8 bytes\n float x, y, z; // 4 bytes each. 12 bytes total\n int score; // 4 bytes\n};\nThe memory usage of a struct is defined roughly by the sum of the memory usage of its members. Assuming the default sizing of common data types in C++, in the example above, the struct will use 8 bytes for the double, 3 times 4 bytes for the floats and 4 bytes for the int. The total memory usage for the struct will be 20 bytes.
The memory usage of a struct is not always exactly the sum of the memory usage of its members. The compiler may add padding bytes between the members of a struct to align the data in memory. This is done to improve the performance of the program. If you are programming in a multi-platform, cross-platform or even using different compilers, the size of the struct may vary even if it is the same.
struct InneficientMemoryLayoutExample\n{\n char a;\n int b;\n char c;\n char d;\n char e;\n};\nThe struct above stores a total of 8 bytes of data, but the compiler allocates more. It will add 3 padding bytes between the int and the last char to align the data with biggest field in the struct. In this case, the total memory usage of the struct will be 12 bytes instead of the expected 8.
struct InneficientMemoryLayoutExample\n{\n char a; // 1 byte\n // compiler will add 3 padding bytes here\n int b; // 4 bytes\n char c; // 1 byte\n char d; // 1 bytes\n char e; // 1 byte\n // compiler will add 1 padding byte here\n}; // total of 12 bytes allocated for this layout\nYou might think C++ compilers are smart and reorder the fields for us, but in order to maintain compatibility to C, the standard forbids it. So if you want to pack more data you will have to reorder the layout manually to something like this:
struct EfficientMemoryLayoutExample\n{\n int b; // 4 bytes\n char a; // 1 byte\n char c; // 1 byte\n char d; // 1 bytes\n char e; // 1 byte\n}; // total of 8 bytes allocated for this layout\nAlternatively you can use the #pragma pack directive to tell the compiler to pack the data in memory without padding bytes. But be aware that it will force the compiler to do more memory operations to get the data, thus it will slow your software. Besides that, pragma pack may not work in all compilers.
#pragma pack(push, 1) // push current alignment to stack and set alignment to 1 byte boundary\nstruct EfficientMemoryLayoutExample\n{\n char a; // 1 byte\n int b; // 4 bytes\n char c; // 1 byte\n char d; // 1 bytes\n char e; // 1 byte\n};\n#pragma pack(pop)\nIf you really want to specify the layout location for each field and want to be sure that in will work on every compiler/platform, you will have to specify the number of bits each field will be able to use. This is called bitfields. But if you follow this path, you will have to be aware of the endianness of the platform you are working on.
struct BitfieldExample\n{\n char a : 8; // 8 bits = 1 byte\n int b : 32; // 32 bits = 4 bytes\n char c : 8; // 8 bits = 1 byte\n char d : 8; // 8 bits = 1 byte\n char e : 8; // 8 bits = 1 byte\n}; // total of 8 bytes allocated for this layout\nAnother nice application of bitfields is when you do not want to use the full range of a data type. For example, if you want to store a number between 0 and 7, as in a chess game or other board games, you can use a char and waste 5 bits or you can use a bitfield and use only 3 bits.
struct BitfieldExample\n{\n char row : 3; // 3 bits\n char column : 3; // 3 bits\n unsigned int state : 2; // 2 bit. will store 0, 1, 2 or 3\n}; // total of 1 byte allocated for this layout\n- Syllabus
- Safe and welcoming space
- Privacy and FERPA Compliance
- Activities
- Setup Github repository
- Setup your IDE
- Setup your Assignments project
- Check Github Actions
- Homework
TLDR: Be nice to each other, and don't copy code from the internet.
- Code of Conduct
- Notes on Submissions and Plagiarism
Some assignments can be hard, and you may feel tempted to copy code from the internet. Don't do it. You will only hurt yourself. You will learn nothing, and you will be caught. Once you get caught, you will be reported to the Dean of Students for academic dishonesty.
If you are struggling with an assignment, please contact me in my office-hours, or via discord. I am really slow at answering emails, so do it so only if something needs to be official. Quick questions are better asked in discord by me or your peers.
"},{"location":"advanced/01-introduction/setup/#privacy-and-ferpa-compliance","title":"Privacy and FERPA Compliance","text":"FERPA WAIVER
If you are willing to share your final project publicly, you MUST SIGN this FERPA waiver.
via GIPHY
This class will use github extensively, in order to keep you safe, we will use private repositories. This means that only you and me will be able to see your code. In your final project, you must share it with your pair partner, and with me.
"},{"location":"advanced/01-introduction/setup/#activities","title":"Activities","text":"TLDR: there is no TLDR, read the whole thing.
via GIPHY
"},{"location":"advanced/01-introduction/setup/#setup-github-repository","title":"Setup Github repository","text":"Gitkraken
Optionally you might want to use GitKraken as your git user interface. Once you open it for the first time, signup using your github account with student pack associated. Install Gitkraken
- Signup on github and apply for Github Student Pack. Apply for Student Pack
- Send me your github username in class, so I will share the assignment repository with you;
- Create a private repository by clicking \"use as template\" the repository InfiniBrains/csi240 or Create CSI240 repository
- Share your repository with me. Click on settings, then collaborators, and add me as a collaborator. My username: @tolstenko
- Clone your repository to your computer. You can use the command line, or any Git GUI tool. I recommend GitKraken
Other IDEs
Optionally you might want to use any other IDE, such as Visual Studio, VSCode, XCode, NeoVim or any other, but I will not be able to help you with that.
I will use CLion in class, and I recommend you to use it as well so you can follow the same steps as me. It is free for students. And it works on Windows, Mac and Linux.
- Apply for student license for JetBrains or Apply Form
- You can install CLion only or install CLion via their Install Toolbox
- Open CLion for the first time, and login with your JetBrains account you created earlier;
Common problems
Your machine might not have git on your path. If so, install it from git-scm.com and make sure you tick the option to add git to your PATH.
- Open your IDE, and click on \"Open Project\";
- Select the folder where you cloned your repository;
- Click on \"Open as Project\" or \"Open as CMake Project\";
- Wait for CMake to finish generating the project;
- On the top right corner, select the target you want to run/debug;
Github Actions
Github Actions is a CI/CD tool that will run your tests automatically when you push your code to github. It will also run your tests when you create a pull request. It is a great tool to make sure your code is always working.
You might want to explore the folder .github/workflows to see how it works, but you don't need to change anything there.
Every commit you push to your repository will be automatically tested through Github Actions. You can see the results of the tests by clicking on the \"Actions\" tab on your repository.
- Go to your repository on github;
- Click on the \"Actions\" tab;
- Click on the \"Build and Test\" action;
- Click on the latest commit;
- On the jobs panel, Click on the assignment you want to see the results;
- Read the logs to see if your tests passed or failed;
- It is your job to read the README.md from every assignment and fulfill the requirements;
- You can run/debug the tests locally by targeting the assignmentXX_tests;
via GIPHY
- Read the Syllabus fully. Pay attention to the schedule, outcomes and grading;
- Do all assignments on Canvas, specially the git training;
C++ in a language that keeps evolving and adding new features. The language is now a multi-paradigm language, which means that it supports different programming styles, and we are going to cover the Object-Oriented Programming (OOP) paradigm in this course.
"},{"location":"advanced/02-oop/#what-is-oop","title":"What is OOP?","text":"Object-Oriented Programming is a paradigm that encapsulate data and their interactions into a single entity called object. The object is an instance of a class, which is a blueprint for the object. The class defines the data and the operations that can be performed on the data.
"},{"location":"advanced/02-oop/#class-declaration","title":"Class declaration","text":"Here goes a simple declaration of a class Greeter:
Greeter.h#include <string>\nclass Greeter {\n std::string name; // this is a private attribute\npublic:\n Greeter(std::string username) {\n name = username;\n }\n void Greet(){\n std::cout << \"Hello, \" << name << \"!\" << std::endl;\n }\n};\n#include \"Greeter.h\"\nint main() {\n Greeter greeter(\"Stranger\");\n greeter.Greet();\n}\nIf you run this code, the output will be:
Hello, Stranger!\nHere goes a rework of the previous example using more robust concepts and multiple files:
Greeter.h#include <string>\nclass Greeter {\n // class members are private by default\n std::string name;\npublic:\n // public constructor\n // explicit to avoid implicit conversions\n // const to avoid modification\n // ref to avoid copying\n explicit Greeter(const std::string& name);\n ~Greeter(); // public destructor\n void Greet(); // public method\n};\n#include \"Greeter.h\"\n#include <iostream>\n// :: is the scope resolution operator\nGreeter::Greeter(const std::string& name): name(name) {\n std::cout << \"I exist and I received \" << name << std::endl;\n}\nGreeter::~Greeter() {\n std::cout << \"Goodbye, \" << name << \"!\" << std::endl;\n}\nvoid Greeter::Greet() {\n std::cout << \"Hello, \" << name << \"!\" << std::endl;\n}\n#include \"Greeter.h\"\nint main() {\n Greeter greeter(\"Stranger\");\n greeter.Greet();\n // cannot use greeter.name because it is private\n}\nClasses can be used it in different parts of your code. You can even create libraries and share it with other people.
"},{"location":"advanced/02-oop/#encapsulation","title":"Encapsulation","text":"Classes can hide their implementation details from the developer. The developer only needs the header file to use the class which acts as an interface.
"},{"location":"advanced/02-oop/#inheritance","title":"Inheritance","text":"Classes can inherit from other classes. This allows you to reuse code and extend the functionality of existing classes expanding the original behavior.
We will cover details about inheritance in another moment.
"},{"location":"advanced/02-oop/#polymorphism","title":"Polymorphism","text":"By its roots, the word polymorphism means \"many forms\". It can be applied to classes in many different aspects:
- Function overload: Class can have multiple definitions of the same member function, and the compiler will choose the correct one based on the type of the object.
- Casting: Classes can be casted to other classes. This allows you to treat an object of a derived class as an object of its base class, or more complex behaviors;
We will cover details about polymorphism in another moment.
"},{"location":"advanced/02-oop/#class-internals","title":"Class internals","text":""},{"location":"advanced/02-oop/#constructors","title":"Constructors","text":"Constructors are special methods, they are called when an object is created, and don't return anything. They are used to initialize the object. If you don't define a constructor, the compiler will generate a default constructor for you.
class Greeter {\n std::string name;\npublic:\n Greeter(const std::string& name) {\n this->name = name;\n }\n};\nA default constructor should be one of the following: - A constructor that can be called with no arguments; - A constructor that can be called with default arguments;
class Greeter {\n std::string name;\npublic:\n // Default constructor\n Greeter() {\n this->name = \"Stranger\";\n }\n};\nor
class Greeter {\n std::string name;\npublic:\n Greeter(const std::string& name = \"Stranger\") {\n this->name = name;\n }\n};\nIf no constructor is defined, the compiler will generate a default constructor for you.
"},{"location":"advanced/02-oop/#copy-constructor","title":"Copy constructor","text":"A copy constructor is a constructor that takes a reference to an object of the same type as the class. It is used to initialize an object with another object of the same type.
class Greeter {\n std::string name;\npublic:\n Greeter(const Greeter& other) {\n this->name = other.name;\n }\n};\nA move constructor is a constructor that takes a reference to an object of the same type as the class. It is used to initialize an object with another object of the same type. The difference between a copy constructor and a move constructor is that the move constructor takes ownership of the data from the other object, while the copy constructor copies the data from the other object.
class Greeter {\n std::string name;\npublic:\n Greeter(Greeter&& other) {\n this->name = std::move(other.name);\n }\n};\nA constructor that can be called with only one argument is called an explicit constructor. This means that the compiler will not allow implicit conversions to happen.
Explicit constructors are useful to avoid unexpected behavior when calling the constructor.
class Greeter {\n std::string name;\npublic:\n explicit Greeter(const std::string& name) {\n this->name = name;\n }\n};\nDestructors are special methods, they are called when an object is destroyed.
Following the single responsibility principle, the destructor should be responsible for cleaning up the dynamically allocated data the object is holding.
If no destructor is defined, the compiler will generate a default destructor for you that might not be enough to clean up the data.
class IntContainer {\n int* data;\n // other members / methods\npublic:\n // other members / methods\n ~IntContainer() {\n // deallocate data\n delete[] data;\n }\n};\nBy default, all members of a class are private. This means that they can only be accessed by the class itself. If you want to expose a member to the outside world, you have to declare it as public.
class Greeter {\n std::string name; // private by default\npublic:\n Greeter(const std::string& name) {\n this->name = name;\n }\n};\nIf your data is private, but you need to provide access or modify it, you can create public methods to do that.
- Accessors: are the type of public methods that provides readability of the specific content;
- Mutators: are the type of public methods that provides writability of the specific content;
class User {\n std::string name; // private by default\npublic:\n explicit User(const std::string& name) {\n this->name = name;\n }\n // Accessor that returns a copy\n // const at the end means that this function does not modify the object\n std::string GetName() const {\n return name;\n }\n\n // Accessor that returns a const reference\n // returning ref does not use extra memory\n // returning const the caller cannot modify the object\n const std::string& GetNameRef() const {\n return name;\n }\n\n // Mutator\n void SetName(const std::string& name) {\n this->name = name;\n }\n};\nWhen you have an object, you can access its members using the dot operator .. If you have a pointer to an object, you can access its members using the arrow operator ->.
int main(){\n Greeter greeter(\"Stranger\");\n greeter.Greet(); // dot operator\n Greeter* greeterPtr = &greeter;\n greeterPtr->Greet(); // arrow operator\n}\nIt can be used to access members of a class that are not part of an object. It can also be used to access members of a namespace.
namespace MyNamespace {\n int myInt = 0;\n class MyClass {\n public:\n // static vars are allocated in the data segment instead of the stack\n static inline const int myInt = 1;\n int myOtherInt = 2;\n };\n void MyFunction() {\n int myInt = 3;\n std::cout << myInt << std::endl; // 3\n std::cout << MyNamespace::myInt << std::endl; // 0\n std::cout << MyNamespace::MyClass::myInt << std::endl; // 1\n std::cout << MyClass::myInt << std::endl; // 1\n std::cout << MyNamespace::MyClass().myOtherInt << std::endl; // 2\n }\n}\nIn C++, the only difference between a class and a struct is the default access level. In a class, the default access level is private, while in a struct, the default access level is public.
class MyClass {\n int myInt; // private by default\npublic:\n MyClass(int myInt) {\n this->myInt = myInt;\n }\n int GetMyInt() const {\n return myInt;\n }\n};\n\nstruct MyStruct {\n // to achieve the same behavior as the class above\nprivate:\n int myInt; \npublic:\n MyStruct(int myInt) {\n this->myInt = myInt;\n }\n int GetMyInt() const {\n return myInt;\n }\n};\nPointer arithmetic is the arithmetic of pointers. You can call operators +, -, ++, --, +=, and -= on pointers passing an integer as the right operand.
#include <iostream>\n\nint main() {\n int arr[] = {1, 2, 3, 4, 5};\n int* ptr = arr; // ptr points to the first element of the array\n std::cout << *ptr << std::endl; // prints 1\n ptr++; // ptr points to the second element of the array\n std::cout << *ptr << std::endl; // prints 2\n ptr += 2; // ptr points to the fourth element of the array\n std::cout << *ptr << std::endl; // prints 4\n ptr--; // ptr points to the third element of the array\n std::cout << *ptr << std::endl; // prints 3\n std::cout << *(ptr + 1) << std::endl; // prints 4\n std::cout << *(arr + 1) << std::endl; // prints 2\n return 0;\n}\nDynamic arrays are arrays that can be allocated and deallocated at runtime. They are useful when the size of the array is not known at compile time.
#include <iostream>\n\nint main() {\n int n;\n std::cin >> n; // read the size of the array\n int* arr = new int[n]; // dynamic arry allocation\n for (int i = 0; i < n; i++) {\n arr[i] = i; // fill the array with values\n }\n for (int i = 0; i < n; i++) {\n std::cout << arr[i] << \" \";\n }\n std::cout << std::endl;\n delete[] arr; // return the memory to the system\n return 0;\n}\nIn the example above, we read the size of the array from the standard input, allocate the array, fill it with values, print the values, and then deallocate the array.
"},{"location":"advanced/03-pointers/#array-decay","title":"Array decay","text":"When an array is passed to a function, it decays into a pointer to its first element. This means that the size of the array is lost, and the function cannot know the size of the array.
#include <iostream>\n\n// another possible declaration: void print_array(int* arr, int n) {\nvoid print_array(int arr[], int n) {\n for (int i = 0; i < n; i++) {\n std::cout << arr[i] << \" \";\n }\n std::cout << std::endl;\n}\n\nint main() {\n int arr[] = {1, 2, 3, 4, 5};\n print_array(arr, 5);\n return 0;\n}\nSo every time you pass an array to a function, you should also pass the size of the array.
"},{"location":"advanced/03-pointers/#matrix","title":"Matrix","text":"A matrix is a two-dimensional array. It can be represented as an array of arrays;
#include <iostream>\n\nint main() {\n int n, m;\n std::cin >> n >> m; // read the size of the matrix\n int** matrix = new int*[n]; // allocate the rows\n // allocate the columns\n for (int i = 0; i < n; i++) {\n matrix[i] = new int[m]; \n }\n // fill the matrix with values\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n matrix[i][j] = i * m + j; \n }\n }\n // print the matrix\n for (int i = 0; i < n; i++) { \n for (int j = 0; j < m; j++) {\n std::cout << matrix[i][j] << \" \";\n }\n std::cout << std::endl;\n }\n for (int i = 0; i < n; i++) {\n delete[] matrix[i]; // deallocate the columns\n }\n delete[] matrix; // deallocate the rows\n return 0;\n}\nIn the example above, we read the size of the matrix from the standard input, allocate the rows, allocate the columns, fill the matrix with values, print the matrix, and then deallocate the matrix.
You can extend the concept of a matrix to a three-dimensional array, and so on.
"},{"location":"advanced/03-pointers/#matrix-linearization","title":"Matrix linearization","text":"A matrix can be linearized into a one-dimensional array. This is useful when you want to be cache friendly.
#include <iostream>\n\nint main() {\n int n, m;\n std::cin >> n >> m; // read the size of the matrix\n int* matrix = new int[n * m]; // allocate the matrix\n // fill the matrix with values\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n matrix[i * m + j] = i * m + j; \n }\n }\n // print the matrix\n for (int i = 0; i < n; i++) {\n for (int j = 0; j < m; j++) {\n std::cout << matrix[i * m + j] << \" \";\n }\n std::cout << std::endl;\n }\n delete[] matrix; // deallocate the matrix\n return 0;\n}\nThe common way of passing parameter is a copy of the value. This is not efficient for large objects ex.: the contents of a huge text file.
#include <iostream>\n\nvoid printAndIncrease(int x) { // x is a copy of the value\n std::cout << x << std::endl; \n x++; // the copy is increased but the outer variable is not\n}\n\nint main() {\n int x = 42;\n printAndIncrease(x); // prints 42\n printAndIncrease(x); // prints 42\n return 0;\n}\nYou can pass a reference to the variable, so the function can modify the outer variable.
#include <iostream>\n\nvoid swap(int& a, int& b) { // a and b are references to the variables\n int temp = a;\n a = b;\n b = temp;\n}\n\nint main() {\n int x = 42, y = 24;\n swap(x, y);\n std::cout << x << \" \" << y << std::endl; // prints 24 42\n return 0;\n}\nYou can also pass a pointer to the variable, so the function can modify the outer variable.
#include <iostream>\n\nvoid swap(int* a, int* b) { // a and b are pointers to the variables\n int temp = *a;\n *a = *b;\n *b = temp;\n}\n\nint main() {\n int x = 42, y = 24;\n swap(&x, &y);\n std::cout << x << \" \" << y << std::endl; // prints 24 42\n return 0;\n}\nAs you can see passing as reference is more readable and less error-prone than passing as pointer. But both are valid, and you should be aware of both.
"},{"location":"advanced/03-pointers/#smart-pointers","title":"Smart pointers","text":"Smart pointers are wrappers to raw pointers that manage the memory automatically. They are useful to avoid memory leaks and dangling pointers.
You can implement a naive smart pointer using a struct that will deallocate when it goes out of scope.
#include <iostream>\n\ntemplate <typename T>\nstruct SmartPointer {\n T* ptr;\n SmartPointer(T* ptr) : ptr(ptr) {}\n ~SmartPointer() {\n delete ptr;\n }\n};\n\nint main() {\n SmartPointer<int> sp(new int(42));\n std::cout << *sp.ptr << std::endl; // prints 42\n return 0;\n} // when sp goes out of scope, the destructor is called and the memory is deallocated\nNote
The Standard Library implements 3 types of smart pointers: std::unique_ptr, std::shared_ptr, and std::weak_ptr.
std::unique_ptr","text":"The std::unique_ptr is a smart pointer that owns the object exclusively. It is useful when you want to transfer the ownership of the object to another smart pointer.
#include <iostream>\n#include <memory>\n\nint main() {\n // make_unique is a C++14 feature\n std::unique_ptr<int> up = std::make_unique<int>(42);\n // or you can just use:\n // std::unique_ptr<int> up(new int(42));\n std::cout << *up << std::endl; // prints 42\n return 0;\n} // when up goes out of scope, the destructor is called and the memory is deallocated\nstd::shared_ptr","text":"The std::shared_ptr is a smart pointer that owns the object with shared ownership. It is useful when you want to share the ownership of the object with another smart pointer. It is deallocated when the last std::shared_ptr goes out of scope.
#include <iostream>\n#include <memory>\n\nint main() {\n std::shared_ptr<int> sp1 = std::make_shared<int>(42);\n std::shared_ptr<int> sp2 = sp1;\n std::cout << *sp1 << \" \" << *sp2 << std::endl; // prints 42 42\n return 0;\n} // when sp1 and sp2 goes out of scope, the destructor is called and the memory is deallocated\nstd::weak_ptr","text":"The std::weak_ptr is a smart pointer that owns the object with weak ownership. It is useful when you want to observe the object without owning it. It is deallocated when the last std::shared_ptr goes out of scope.
Note
std::weak_ptr will help solve the circular reference problem.
#include <iostream>\n#include <memory>\n\nint main() {\n std::shared_ptr<int> sp1 = std::make_shared<int>(42);\n std::weak_ptr<int> wp = sp1;\n // in order to use a weak pointer, you have to lock it to tell others that you are using it\n std::cout << *sp1 << \" \" << *wp.lock() << std::endl; // prints 42 42\n return 0;\n} // when sp1 goes out of scope, the destructor is called and the memory is deallocated\nExaple of a circular reference:
#include <iostream>\n#include <memory>\n\nstruct A;\nstruct B;\n\nstruct A {\n std::shared_ptr<B> b;\n ~A() {\n std::cout << \"A destructor\" << std::endl;\n }\n};\n\nstruct B {\n std::shared_ptr<A> a;\n ~B() {\n std::cout << \"B destructor\" << std::endl;\n }\n};\n\nint main() {\n std::shared_ptr<A> a = std::make_shared<A>();\n std::shared_ptr<B> b = std::make_shared<B>();\n a->b = b;\n b->a = a;\n return 0;\n} // memory is leaked: the destructors are not called, and the memory is not deallocated\nYou can solve the circular reference problem using std::weak_ptr.
#include <iostream>\n#include <memory>\n\nstruct A;\nstruct B;\n\nstruct A {\n std::shared_ptr<B> b;\n ~A() {\n std::cout << \"A destructor\" << std::endl;\n }\n};\n\nstruct B {\n std::weak_ptr<A> a;\n ~B() {\n std::cout << \"B destructor\" << std::endl;\n }\n};\n\nint main() {\n std::shared_ptr<A> a = std::make_shared<A>();\n std::shared_ptr<B> b = std::make_shared<B>();\n a->b = b;\n b->a = a;\n return 0;\n} // when a and b goes out of scope, the destructors are called and the memory is deallocated\nIn C++ you can define custom operators for your class using operator overloading. This allows you to define the behavior of operators when applied to objects of your class.
You might want to implement some of the following operators for your class:
- arithmetic operators:
+,-,*,/,% - comparison operators:
==,!=,<,>,<=,>= - spaceship operator:
<=>(C++20) - unary operators:
+,-,*,&,!,~,++,-- - compound assignment operators:
+=,-=,*=,/=,%=,<<=,>>=,&=,|=,^= - prefix increment and decrement operators:
++,-- - postfix increment and decrement operators:
++,-- - subscript operator:
[] - stream insertion and extraction operators:
<<,>>
#include <iostream>\n\nstruct Vector2i {\n int x, y;\n Vector2i() : x(0), y(0) {}\n Vector2i(int x, int y) : x(x), y(y) {}\n // arithmetic operators\n Vector2i operator+(const Vector2i& other) const {\n return {x + other.x, y + other.y};\n }\n Vector2i operator-(const Vector2i& other) const {\n return {x - other.x, y - other.y};\n }\n Vector2i operator*(int scalar) const {\n return {x * scalar, y * scalar};\n }\n Vector2i operator/(int scalar) const {\n return {x / scalar, y / scalar};\n }\n Vector2i operator*(const Vector2i& other) const {\n return {x * other.x, y * other.y};\n }\n Vector2i operator/(const Vector2i& other) const {\n return {x / other.x, y / other.y};\n }\n // comparison operators\n bool operator==(const Vector2i& other) const {\n return x == other.x && y == other.y;\n }\n bool operator!=(const Vector2i& other) const {\n return !(*this == other);\n }\n // spaceship operator C++20\n // useful when you want to compare two objects or\n // use it in std::map or std::set\n auto operator<=>(const Vector2i& other) const {\n if (x < other.x && y < other.y) return -1;\n if (x == other.x && y == other.y) return 0;\n return 1;\n }\n\n // unary operators\n Vector2i operator-() const {\n return Vector2i(-x, -y);\n }\n // compound assignment operators\n Vector2i& operator+=(const Vector2i& other) {\n x += other.x;\n y += other.y;\n return *this;\n }\n Vector2i& operator-=(const Vector2i& other) {\n x -= other.x;\n y -= other.y;\n return *this;\n }\n Vector2i& operator*=(int scalar) {\n x *= scalar;\n y *= scalar;\n return *this;\n }\n Vector2i& operator/=(int scalar) {\n x /= scalar;\n y /= scalar;\n return *this;\n }\n // prefix increment and decrement operators\n Vector2i& operator++() {\n x++;\n y++;\n return *this;\n }\n Vector2i& operator--() {\n x--;\n y--;\n return *this;\n }\n // postfix increment and decrement operators\n Vector2i operator++(int) {\n Vector2i temp = *this;\n ++*this;\n return temp;\n }\n Vector2i operator--(int) {\n Vector2i temp = *this;\n --*this;\n return temp;\n }\n // subscript operator\n int& operator[](int index) {\n return index == 0 ? x : y;\n }\n // stream insertion operator\n friend std::ostream& operator<<(std::ostream& stream, const Vector2i& vector) {\n return stream << vector.x << \", \" << vector.y;\n }\n // stream extraction operator\n friend std::istream& operator>>(std::istream& stream, Vector2i& vector) {\n return stream >> vector.x >> vector.y;\n }\n};\nYou can create special operators for your class such as:
()operator: function call operator->operator: member access operator- 'new' and 'delete' operators: memory allocation and deallocation operators
A nice usecase for function call operator is to create a functor, a class that acts like a function.
#include <iostream>\n\nstruct Adder {\n int operator()(int a, int b) const {\n return a + b;\n }\n};\n\nint main() {\n Adder adder;\n std::cout << adder(1, 2) << std::endl; // 3\n return 0;\n}\nThe -> operator is used to overload the member access operator. It is used to define the behavior of the arrow operator -> when applied to objects of your class.
#include <iostream>\n\nstruct Pointer {\n int value;\n int* operator->() {\n return &value;\n }\n};\n\nint main() {\n Pointer pointer;\n pointer.value = 42;\n std::cout << *pointer << std::endl; // 42\n return 0;\n}\nYou might want to overload the new and delete operators to define the behavior of memory allocation and deallocation for your class. Specially to track memory usage or to implement a custom memory pool. Or even overload it globally to track memory usage for the whole program.
#include <iostream>\n#include <cstdlib>\n\n// declare the alloc counter\nint alloc_counter = 0;\n\nvoid* operator new(std::size_t size) {\n alloc_counter ++;\n return std::malloc(size);\n}\n\nvoid operator delete(void* ptr) noexcept {\n std::free(ptr);\n alloc_counter--;\n}\n\nint main() {\n int* ptr = new int;\n std::cout << \"alloc_counter: \" << alloc_counter << std::endl; // 1\n delete ptr;\n std::cout << \"alloc_counter: \" << alloc_counter << std::endl; // 0\n return 0;\n}\nStudents compare and contrast a variety of data structures. Students compare algorithms for tasks such as searching and sorting, while articulating efficiency in terms of time complexity. Students implement data structures and algorithms to support solution designs. Course Catalog
"},{"location":"algorithms/#requirements","title":"Requirements","text":"- Introduction to Programming
- Advanced Programming
- Grokking Algorithms, Aditya Bhargava, Manning Publications, 2016. ISBN 978-1617292231
Upon completion of the Data Structures and Algorithms course in C++, students should be able to:
"},{"location":"algorithms/#objective-outcomes","title":"Objective Outcomes","text":"- Analyze and contrast diverse data structures
- Evaluate algorithmic efficiency using time complexity analysis
- Implement, create and apply data structures and algorithms
- Critically assess sorting algorithms
- Analyze and contrast search algorithms
- Demonstrate the ability to evaluate and differentiate between various data structures, including arrays, linked lists, stacks, queues, trees, and graphs, based on their characteristics and use cases.
- Evaluate algorithms by analyzing their time complexity, enabling the comparison of different algorithms and making informed decisions about their suitability for specific problem-solving scenarios.
- Develop and implement solutions using appropriate data structures and algorithms to address real-world problems, demonstrating proficiency in translating solution designs into C++ code.
- Investigate and compare the merits and drawbacks of brute-force and divide-and-conquer sorting algorithms, including quicksort, mergesort, and insertion sort, in order to make informed choices when selecting sorting techniques for specific scenarios.
- Examine and compare the characteristics, advantages, and limitations of sequential, binary, depth-first, and breadth-first search algorithms, demonstrating the ability to choose the most suitable search strategy based on problem requirements.
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use this github repo as the source of truth for the materials and Canvas for the assignment deadlines.
College dates for the Spring 2024 semester:
Date Event Jan 16 Classes Begin Jan 16 - 22 Add/Drop Feb 26 - March 1 Midterms March 11 - March 15 Spring Break March 25 - April 5 Registration for Fall Classes April 5 Last Day to Withdraw April 8 - 19 Idea Evaluation April 12 No Classes - College remains open April 26 Last Day of Classes April 29 - May 3 Finals May 11 Commencement"},{"location":"algorithms/#introduction","title":"Introduction","text":"- Week 1. 2024/01/15
- Topic: Introduction to Data Structures and Algorithms
- Activities:
- Introduction
- Read all materials shared on Canvas;
- Do all assignments on Canvas;
- Week 2. 2024/01/22
- Topic: Algorithm Analysis
- Week 3. 2024/01/29
- Topic: Array, Linked Lists, Dynamic Arrays
- Week 4. Date: 2024/02/05
- Topic: Bubble Sort, Selection Sort and Insertion Sort
- Week 5. 2024/02/12
- Topic: Merge Sort and Quick Sort
- Week 6. 2024/02/19
- Topic: Hashtables
- Week 7. Date: 2024/02/26
- Topic: Midterms
- Week 8. 2024/03/04
- Topic: Stacks and Queues
- Week 09. 2024/03/11
- Topic: Spring BREAK. No classes this week.
- Week 10. 2024/03/18
- Topic: Graphs
- Week 11. 2024/03/25
- Topic: Dijkstra
- Week 12. 2024/04/01
- Topic: Prim's and Jarnik's Algorithm
- Week 13. 2024/04/01
- Topic: Binary Search Trees
- Week 14. 2024/04/08
- Topic: Heap and Priority Queues
- Week 15. 2024/04/15
- Topic: Work sessions for final project
- Week 16. 2024/04/22
- Topic: Finals Week
- Syllabus
- Safe and welcoming space
- Privacy and FERPA Compliance
- Activities
- Setup Github repository
- Setup your IDE
- Setup your Assignments project
- Check Github Actions
- Homework
TLDR: Be nice to each other, and don't copy code from the internet.
- Code of Conduct
- Notes on Submissions and Plagiarism
Some assignments can be hard, and you may feel tempted to copy code from the internet. Don't do it. You will only hurt yourself. You will learn nothing, and you will be caught. Once you get caught, you will be reported to the Dean of Students for academic dishonesty.
If you are struggling with an assignment, please contact me in my office-hours, or via discord. I am really slow at answering emails, so do it so only if something needs to be official. Quick questions are better asked in discord by me or your peers.
"},{"location":"algorithms/01-introduction/#privacy-and-ferpa-compliance","title":"Privacy and FERPA Compliance","text":"FERPA WAIVER
If you are willing to share your final project publicly, you MUST SIGN this FERPA waiver.
via GIPHY
This class will use github extensively, in order to keep you safe, we will use private repositories. This means that only you and me will be able to see your code. In your final project, you must share it with your pair partner, and with me.
"},{"location":"algorithms/01-introduction/#activities","title":"Activities","text":"TLDR: there is no TLDR, read the whole thing.
via GIPHY
"},{"location":"algorithms/01-introduction/#setup-github-repository","title":"Setup Github repository","text":"Gitkraken
Optionally you might want to use GitKraken as your git user interface. Once you open it for the first time, signup using your github account with student pack associated. Install Gitkraken
- Signup on github and apply for Github Student Pack. Apply for Student Pack
- Send me your github username in class, so I will share the assignment repository with you;
- Create a private repository by clicking \"use as template\" the repository InfiniBrains/csi281 or Create CSI281 repository
- Share your repository with me. Click on settings, then collaborators, and add me as a collaborator. My username: @tolstenko
- Clone your repository to your computer. You can use the command line, or any Git GUI tool. I recommend GitKraken
Other IDEs
Optionally you might want to use any other IDE, such as Visual Studio, VSCode, XCode, NeoVim or any other, but I will not be able to help you with that.
I will use CLion in class, and I recommend you to use it as well so you can follow the same steps as me. It is free for students. And it works on Windows, Mac and Linux.
- Apply for student license for JetBrains or Apply Form
- You can install CLion only or install CLion via their Install Toolbox
- Open CLion for the first time, and login with your JetBrains account you created earlier;
Common problems
Your machine might not have git on your path. If so, install it from git-scm.com and make sure you tick the option to add git to your PATH.
- Open your IDE, and click on \"Open Project\";
- Select the folder where you cloned your repository;
- Click on \"Open as Project\" or \"Open as CMake Project\";
- Wait for CMake to finish generating the project;
- On the top right corner, select the target you want to run/debug;
Github Actions
Github Actions is a CI/CD tool that will run your tests automatically when you push your code to github. It will also run your tests when you create a pull request. It is a great tool to make sure your code is always working.
You might want to explore the folder .github/workflows to see how it works, but you don't need to change anything there.
Every commit you push to your repository will be automatically tested through Github Actions. You can see the results of the tests by clicking on the \"Actions\" tab on your repository.
- Go to your repository on github;
- Click on the \"Actions\" tab;
- Click on the \"Build and Test\" action;
- Click on the latest commit;
- On the jobs panel, Click on the assignment you want to see the results;
- Read the logs to see if your tests passed or failed;
- It is your job to read the README.md from every assignment and fulfill the requirements;
- You can run/debug the tests locally by targeting the assignmentXX_tests;
via GIPHY
- Read the Syllabus fully. Pay attention to the schedule, outcomes and grading;
- Do all assignments on Canvas, specially the git training;
Before starting, lets thin about 3 problems:
For an array of size \\(N\\), dont overthink. Just answer:
- How many iterations a loop run to find a specific number inside an array? (naively)
- How many comparisons should I make to find two numbers in an array that sum a specific target? (naively)
- List all different shuffled arrays we can make? (naively) ex for n==3 123, 132, 213, 231, 312, 321
int find(vector<int> v, int target) {\n // how many iterations?\n for (int i = 0; i < v.size(); i++) {\n // how many comparisons?\n if (v[i] == target) { \n return i;\n }\n }\n return -1;\n}\nvector<int> findsum2(vector<int> v, int target) {\n // how many outer loop iterations?\n for (int i = 0; i < v.size(); i++) {\n // how many inner loop iterations?\n for (int j = i+1; j < v.size(); j++) {\n // how many comparisons?\n if (v[i] + v[j] == target) {\n return {i, j};\n }\n }\n }\n return {-1, -1};\n}\nvoid generatePermutations(std::vector<int>& vec, int index) {\n if (index == vec.size() - 1) {\n // Print the current permutation\n for (int num : vec) {\n std::cout << num << \" \";\n }\n std::cout << std::endl;\n return;\n }\n\n // how many swaps for every recursive call?\n for (int i = index; i < vec.size(); ++i) { \n // Swap the elements at indices index and i\n std::swap(vec[index], vec[i]);\n\n // Recursively generate permutations for the rest of the vector\n // How deep this can go?\n generatePermutations(vec, index + 1);\n\n // Backtrack: undo the swap to explore other possibilities\n std::swap(vec[index], vec[i]);\n }\n}\nTrying to be mathematicaly correct, the number of instructions the first one should be a function similar to this:
- \\(f(n) = a*n + b\\) : Where \\(b\\) is the cost of what runs before and after the main loop and \\(a\\) is the cost of the loop.
- \\(f(n) = a*n^2 + b*n + c\\) : Where \\(c\\) is the cost of what runs before and after the oter loop; \\(b\\) is the cost of the outer loop; and \\(a\\) is the cost of the inner loop;
- \\(f(n) = a*n!\\) : Where \\(a\\) is the cost of what runs before and after the outer loop;
To simplify, we remove the constants and the lower order terms:
- \\(f(n) = n\\)
- \\(f(n) = n^2\\)
- \\(f(n) = n!\\)
- Most used notation;
- Upper bound;
- \"never worse than\";
- A real case cannot be faster than it;
- \\(0 <= func <= O\\)
- Wrongly stated as average;
- Theta is two-sided;
- Tight bound between 2 constants of the same function
- \\(k1*\u0398 <= func <= k2*\u0398\\)
- When \\(N\\) goes to infinite, it cannot be faster or slower than it;
- Big Omega \u03a9: roughly the oposite of Big O;
- Little o and Little Omega (\u03c9). The same concept from the big, but exclude the exact bound;
Logarithm
In computer science, when we say log, assume base 2, unless expressely stated;
Big O Name Example O(1) Constant sum two numbers O(lg(n)) Logarithmic binary search O(n) Linear search in an array O(n*lg(n)) Linearithmic Merge Sort O(n^c) Polinomial match 2 sum O(c^n) Exponential brute force password of size n O(n!) factorial list all combinations"},{"location":"algorithms/02-analysis/#what-is-logarithm","title":"What is logarithm?","text":"Log is the inverse of exponentiation. It is the number of times you have to multiply a number by itself to get another number.
\\[ log_b(b^x) = x \\]"},{"location":"algorithms/02-analysis/#what-is-binary-search","title":"What is binary search?","text":"In a binary search, we commonly divide the array in half (base 2), and check if the target is in the left or right half. Then we repeat the process until we find the target or we run out of elements.
Source: mathwarehouse.com"},{"location":"algorithms/02-analysis/#common-data-structures-and-algorithms","title":"Common data structures and algorithms","text":"Source: bigocheatsheet.com Source: bigocheatsheet.com"},{"location":"algorithms/02-analysis/#common-issues-and-misconceptions","title":"Common Issues and misconceptions","text":"
- Big O and Theta are commonly mixed;
- Hashtables: it is commonly assumed that queries on
<map>or<set>beingO(1); std::<map>and<set>are not the ideal implementation! Watch this CppCon video for some deep level insights;
In C++'s Standard Library, we have a bunch of data structures already implemented for us. But you need to understand what is inside it in order do ponder the best tool for your job. In this week we are going to cover Dynamic Arrays (equivalent of std::vector) and Linked Lists(equivalent of std::list) .
"},{"location":"algorithms/03-dynamic-data/#dynamic-arrays","title":"Dynamic Arrays","text":"A dynamic array is a random access, variable-size list data structure that allows elements to be added or removed. It is supplied with standard libraries in many modern mainstream programming languages. Let's try to implement one here for the sake of teaching purposes;
template<typename T>\nstruct Vector {\nprivate:\n size_t _size;\n size_t _capacity;\n T* _data;\npublic:\n // constructors\n Vector() : _size(0), _capacity(1), _data(new T[1]) {}\n explicit Vector(size_t size) : _size(size), _capacity(size), _data(new T[size]) {}\n\n // destructor\n ~Vector() { delete[] _data;}\n\n // accessors\n size_t size() const { return _size; }\n size_t capacity() const { return _capacity;}\n\n // push_back takes care of resizing the array if necessary\n // this insertion will amortize the cost of resizing\n void push_back(const T& value) {\n if (_size == _capacity) {\n // growth factor of 2\n _capacity = _capacity == 0 ? 1 : _capacity * 2;\n // allocate new memory\n T* new_data = new T[_capacity];\n // copy the old data into the new memory\n for (size_t i = 0; i < _size; ++i)\n new_data[i] = _data[i];\n // release the old memory\n delete[] _data;\n // update the data pointer\n _data = new_data;\n }\n _data[_size++] = value;\n }\n\n // operator[] for read-write access\n T& operator[](size_t index) { return _data[index]; }\n\n // other functions\n // ...\n};\nWith this boilerplate you should be able to implement the rest of the functions for the Vector class.
"},{"location":"algorithms/03-dynamic-data/#linked-lists","title":"Linked Lists","text":"A linked list is a linear access, variable-size list data structure that allows elements to be added or removed without the need of resizing. It is supplied with standard libraries in many modern mainstream programming languages. Let's try to build one here for the sake of teaching purposes;
// linkedlist\ntemplate <typename T>\nstruct LinkedList {\nprivate:\n // linkedlist node\n struct LinkedListNode {\n T data;\n LinkedListNode *next;\n LinkedListNode(T data) : data(data), next(nullptr) {}\n };\n\n LinkedListNode *_head;\n size_t _size;\npublic:\n LinkedList() : _head(nullptr), _size(0) {}\n\n // delete all nodes in the linkedlist\n ~LinkedList() {\n while (_head) {\n LinkedListNode *temp = _head;\n _head = _head->next;\n delete temp;\n }\n }\n\n // _size\n size_t size() const { return _size; }\n\n // is it possible to make it O(1) instead of O(n)?\n void push_back(T data) {\n if (!_head) {\n _head = new LinkedListNode(data);\n _size++;\n return;\n }\n auto* temp = _head;\n while (temp->next)\n temp = temp->next;\n temp->next = new LinkedListNode(data);\n _size++;\n }\n\n // operator[] for read-write access\n T &operator[](size_t index) {\n auto* temp = _head;\n for (size_t i = 0; i < index; i++)\n temp = temp->next;\n return temp->data;\n };\n\n // other functions\n};\nFor both, implement the following functions:
T* find(const T& value): returns a pointer to the first occurrence of the value in the collection, or nullptr if the value is not found.bool contains(const T& value): returns true if the value is found in the collection, false otherwise.T& at(size_t index): returns a reference to the element at the specified index. If the index is out of bounds, throw anstd::out_of_rangeexception.void push_front(const T& value): adds a new element to the beginning of the collection.- improve push_back of the linkedlist to be O(1) instead of O(n);
void insert_at(size_t index, const T& value): inserts a new element at the specified index. If the index is out of bounds, throw anstd::out_of_rangeexception.void pop_front(): removes the first element of the collection.void pop_back(): removes the last element of the collection. Is it possible to make it O(1) instead of O(n)?void remove_all(const T& value): removes all occurrences of the value from the collection.void remove_at(size_t index): removes the element at the specified index. If the index is out of bounds, throw anstd::out_of_rangeexception.
Now compare the complexity of linked list and dynamic array for each of the functions you implemented and create a table. What is the best data structure for each use case? Why?
"},{"location":"algorithms/04-sorting/","title":"Sorting algorithms","text":""},{"location":"algorithms/04-sorting/#swap-function","title":"Swap function","text":"void swap(int &a, int &b) {\n int temp = a;\n a = b;\n b = temp;\n}\nvoid bubble_sort(int arr[], int n) {\n for (int i = 0; i < n; i++) { // n passes\n for (int j = 0; j < n - 1; j++) { // linear pass\n if (arr[j] > arr[j + 1]) { // swap if the element is greater than the next\n swap(arr[j], arr[j + 1]);\n }\n }\n }\n}\nIs it possible to optimize the bubble sort algorithm? - The example above always pass from the beginning to the end of the array, but it is possible to stop the inner loop earlier if the right side of the array is already sorted. - You can count how many swaps you did in the inner loop, and if you did 0 swaps, you can stop the outer loop.
"},{"location":"algorithms/04-sorting/#questions","title":"Questions:","text":"- What is the best case scenario for the bubble sort?
- What is the worst case scenario for the bubble sort?
- How many writes does the bubble sort do?
- How many reads does the bubble sort do?
- What is the time complexity of the bubble sort?
- What is the space complexity of the bubble sort?
void selection_sort(int arr[], int n) {\n for (int i = 0; i < n - 1; i++) { // n - 1 passes\n int min_index = i; // the minimum element in the unsorted part of the array\n for (int j = i + 1; j < n; j++) { // linear search\n if (arr[j] < arr[min_index]) { // find the minimum element\n min_index = j;\n }\n }\n swap(arr[i], arr[min_index]); // swap the minimum element with the first element of the unsorted part\n }\n}\n- What is the best case scenario for the selection sort?
- What is the worst case scenario for the selection sort?
- How many writes does the selection sort do?
- How many reads does the selection sort do?
- What is the time complexity of the selection sort?
- What is the space complexity of the selection sort?
- What is the difference between the bubble sort and the selection sort?
void insertion_sort(int arr[], int n) {\n for (int i = 1; i < n; i++) { // n - 1 passes\n int key = arr[i]; // the key element to be inserted in the sorted part of the array\n int j = i - 1; // the last element of the sorted part of the array\n while (j >= 0 && arr[j] > key) { // shift the elements to the right to make space for the key\n arr[j + 1] = arr[j];\n j--;\n }\n arr[j + 1] = key; // insert the key in the right position\n }\n}\n- What is the best case scenario for the insertion sort?
- What is the worst case scenario for the insertion sort?
- How many writes does the insertion sort do?
- How many reads does the insertion sort do?
- What is the time complexity of the insertion sort?
- What is the space complexity of the insertion sort?
- What is the difference between the bubble sort, the selection sort, and the insertion sort?
- Why is sorting typically taught towards the beginning of an algorithms course?
- Why do we study algorithms like bubble sort that are almost never used in practice?
- Can you describe a non-comparative sorting algorithm?
- Which of these sorting algorithms is the best: bubble sort, selection sort, or insertion sort?
Table of differences between the sorting algorithms:
Algorithm Best case Worst case Time complexity Space complexity Swaps Bubble O(n) O(n^2) O(N^2) O(1) O(n^2) Selection O(n^2) O(n^2) O(N^2) O(1) O(n) Insertion O(n) O(n^2) O(N^2) O(1) O(n^2)"},{"location":"algorithms/05-divide-and-conquer/","title":"Mergesort and QuickSort","text":"Both algorithms are based on recursion and divide-and-conquer strategy. Both are efficient for large datasets, but they have different performance characteristics.
"},{"location":"algorithms/05-divide-and-conquer/#recursion","title":"Recursion","text":"Recursion is a programming technique where a function calls itself. It is a powerful tool to solve problems that can be divided into smaller problems of the same type.
The recursion has two main parts:
- Base case: the condition that stops the recursion;
- Recursive case: the condition that calls the function again.
Let's see an example of a recursive function to calculate the factorial of a number:
#include <iostream>\n\nint factorial(int n) {\n if (n == 0) {\n return 1;\n }\n return n * factorial(n - 1);\n}\nMergesort divides the input array into two halves, calls itself for the two halves, and then merges the two sorted halves.
You can split the algorithm into two main parts:
- Mergesort: the function that calls itself for the two halves;
- Merge: the function that merges the two sorted halves.
image source
The algorthims will keep dividing the array (in red) until it reaches the base case, where the array has only one element(in gray). Then it will merge the two sorted subarrays (in green).
image source
"},{"location":"algorithms/05-divide-and-conquer/#mergesort-time-complexity","title":"Mergesort time complexity","text":"- Mergesort is time
O(n*lg(n))in the worst case scenario. It is the best time complexity for a comparison-based sorting algorithm. - The algorithm is stable. It maintain the relative order of elements with the same keys during the sorting process.
#include <iostream>\n#include <vector>\n#include <queue>\n\n// inplace merge without extra space\ntemplate <typename T>\nrequires std::is_arithmetic<T>::value // C++20\nvoid mergeInplace(std::vector<T>& arr, const size_t start, size_t mid, const size_t end) {\n size_t left = start;\n size_t right = mid + 1;\n\n while (left <= mid && right <= end) {\n if (arr[left] <= arr[right]) {\n left++;\n } else {\n T temp = arr[right];\n for (size_t i = right; i > left; i--) {\n arr[i] = arr[i - 1];\n }\n arr[left] = temp;\n left++;\n mid++;\n right++;\n }\n }\n}\n\n// Merge two sorted halves\ntemplate <typename T>\nrequires std::is_arithmetic<T>::value // C++20\nvoid merge(std::vector<T>& arr, const size_t start, const size_t mid, const size_t end) {\n // create a temporary array to store the merged array\n std::vector<T> temp(end - start + 1);\n\n // indexes for the subarrays:\n const size_t leftStart = start;\n const size_t leftEnd = mid;\n const size_t rightStart = mid + 1;\n const size_t rightEnd = end;\n\n // indexes for\n size_t tempIdx = 0;\n size_t leftIdx = leftStart;\n size_t rightIdx = rightStart;\n\n // merge the subarrays\n while (leftIdx <= leftEnd && rightIdx <= rightEnd) {\n if (arr[leftIdx] < arr[rightIdx])\n temp[tempIdx++] = arr[leftIdx++];\n else\n temp[tempIdx++] = arr[rightIdx++];\n }\n\n // copy the remaining elements of the left subarray\n while (leftIdx <= leftEnd)\n temp[tempIdx++] = arr[leftIdx++];\n\n // copy the remaining elements of the right subarray\n while (rightIdx <= rightEnd)\n temp[tempIdx++] = arr[rightIdx++];\n\n // copy the merged array back to the original array\n std::copy(temp.begin(), temp.end(), arr.begin() + start);\n}\n\n// recursive mergesort\ntemplate <typename T>\nrequires std::is_arithmetic<T>::value // C++20\nvoid mergesortRecursive(std::vector<T>& arr,\n size_t left,\n size_t right) {\n if (right - left > 0) {\n size_t mid = (left + right) / 2;\n mergesortRecursive(arr, left, mid);\n mergesortRecursive(arr, mid+1, right);\n merge(arr, left, mid, right);\n // if the memory is limited, use the inplace merge at the cost of performance\n // mergeInplace(arr, left, mid - 1, right - 1);\n }\n}\n\n// interactive mergesort\ntemplate <typename T>\nrequires std::is_arithmetic<T>::value // C++20\nvoid mergesortInteractive(std::vector<T>& arr) {\n for(size_t width = 1; width < arr.size(); width *= 2) {\n for(size_t left = 0; left < arr.size(); left += 2 * width) {\n size_t mid = std::min(left + width, arr.size());\n size_t right = std::min(left + 2 * width, arr.size());\n merge(arr, left, mid - 1, right - 1);\n // if the memory is limited, use the inplace merge at the cost of performance\n // mergeInplace(arr, left, mid - 1, right - 1);\n }\n }\n}\n\n\nint main() {\n std::vector<int> arr1;\n for(int i = 1000; i > 0; i--)\n arr1.push_back(rand()%1000);\n std::vector<int> arr2 = arr1;\n\n for(auto i: arr1) std::cout << i << \" \";\n std::cout << std::endl;\n\n mergesortRecursive(arr1, 0, arr1.size() - 1);\n for(auto i: arr1) std::cout << i << \" \";\n std::cout << std::endl;\n\n mergesortInteractive(arr2);\n for(auto i: arr2) std::cout << i << \" \";\n std::cout << std::endl;\n\n return 0;\n}\nYou can implement Mergesort in two ways:
- Recursive: the function calls itself for the two halves;
- Iterative: the function uses a loop to merge the two sorted halves.
The interactive version is more efficient than the recursive version, but it is more complex to understand. But both uses the same core algorithm to merge the two sorted halves.
The main issue with Mergesort is that it requires extra space O(n) to merge the subarrays, which can be problem for large datasets.
- The recursive version will increase the call stack by
O(lg(n)and can potentially cause a stack overflow; - The iterative version does not add pressure to the stack;
Quicksort is prtetty similar to mergesort, but it solves the extra memory allocation at expense of stability. So quicksort is an in-place and unstable sorting algorithm.
One of the core strategy of quicksort is pivoting. It will be selected and the array will be partitioned in two subarrays: one with elements smaller than the pivot (left) and the other with elements greater than the pivot (right).
The partitioning process consists of the following steps:
- Select a pivotIndex (left, right, random or median);
- Swap the pivot with the leftmost element (this can be delayed to the end of the step);
- Set the pivot to the leftmost element (assuming you swapped);
- Set the left and right indexes;
- While the left index is less than or equal to the right index:
- If the left element is less than or equal to the pivot, increment the left index;
- If the right element is greater than the pivot, decrement the right index;
- If the left element is greater than the pivot and the right element is less than or equal to the pivot, swap the left and right elements;
source
"},{"location":"algorithms/05-divide-and-conquer/#quicksort-time-complexity","title":"Quicksort time complexity","text":"The main issue with quicksort is that it can degrade to O(n^2) in an already sorted array. To solve this issue, we can select a random pivot, or the median of the first, middle and last element of the array. This can increase the stability of the algorithm at the expense of performance. The best case scenario is O(n*lg(n)) and the average case is O(n*lg(n)).
#include <iostream>\n#include <vector>\n#include <utility>\n#include <stack>\n#include <random>\n\nusing std::stack;\nusing std::swap;\nusing std::pair;\nusing std::vector;\nusing std::cout;\n\n// Function to generate a random pivot index within the range [left, right]\ntemplate<typename T>\nrequires std::integral<T> // c++20\nT randomRange(T left, T right) {\n static std::random_device rd;\n static std::mt19937 gen(rd());\n std::uniform_int_distribution<T> dist(left, right);\n return dist(gen);\n}\n\n// partition\ntemplate<typename T>\nrequires std::is_arithmetic_v<T>\nsize_t partition(std::vector<T>& arr, size_t left, size_t right) {\n // random pivot to increase stability at the cost of performance by random call\n size_t pivotIndex = randomRange(left, right);\n swap(arr[left], arr[pivotIndex]);\n\n size_t pivot = left;\n size_t l = left + 1;\n size_t r = right;\n\n while (l <= r) {\n if (arr[l] <= arr[pivot]) l++;\n else if (arr[r] > arr[pivot]) r--;\n else swap(arr[l], arr[r]);\n }\n swap(arr[pivot], arr[r]);\n return r;\n}\n\n// quicksort recursive\ntemplate<typename T>\nrequires std::is_arithmetic_v<T>\nvoid quicksortRecursive(std::vector<T>& arr, size_t left, size_t right) {\n if (left < right) {\n // partition the array\n size_t pivot = partition(arr, left, right);\n // recursive call to left and right subarray\n quicksortRecursive(arr, left, pivot - 1);\n quicksortRecursive(arr, pivot + 1, right);\n }\n}\n\n// quicksort interactive\ntemplate<typename T>\nrequires std::is_arithmetic_v<T>\nvoid quicksortInteractive(std::vector<T>& arr, size_t left, size_t right) {\n // simulate recursive call and avoid potential stack overflow\n // std::stack allocate memory to hold data content on heap.\n stack<pair<size_t, size_t>> stack;\n // produce the initial state\n stack.emplace(left, right);\n // iterate\n while (!stack.empty()) {\n // consume\n auto [left, right] = stack.top(); // C++17\n stack.pop();\n if (left < right) {\n auto pivot = partition(arr, left, right);\n // produce\n stack.emplace(left, pivot - 1);\n stack.emplace(pivot + 1, right);\n }\n }\n}\n\nint main() {\n std::vector<int> arr1;\n for (int i = 0; i < 100; i++) arr1.push_back(rand() % 100);\n vector<int> arr2 = arr1;\n\n for (auto& i : arr1) cout << i << \" \";\n cout << std::endl;\n\n quicksortRecursive(arr1, 0, arr1.size() - 1);\n for (auto& i : arr1) cout << i << \" \";\n cout << std::endl;\n\n quicksortInteractive(arr2, 0, arr2.size() - 1);\n for (auto& i : arr2) cout << i << \" \";\n cout << std::endl;\n\n return 0;\n}\n- The recursive version of quicksort can increase the function call stack by
O(lg(n))on average, but it can degrade toO(n)in the worst case scenario. Potentially causing a stack overflow; - The interactive version of quicksort avoids the function call stack issue, avoiding stack overflow. But the memory required for the replacement is still
O(lg(n))on average andO(n)for the indexes in the worst case scenario.
Hashtables ane associative datastructures that stores key-value pairs. It uses a hash function to compute an index into an array of buckets or slots, from which the desired value can be found.
The core of the generic associative container is to implement ways to get and set values by keys such as:
void insert(K key, V value): Add a new key-value pair to the hashtable. If the key already exists, update the value.V at(K key): Get the value of a given key. If the key does not exist, return a default value.void remove(K key): Remove a key-value pair from the hashtable.bool contains(K key): Check if a key exists in the hashtable.int size(): Get the number of key-value pairs in the hashtable.bool isEmpty(): Check if the hashtable is empty.void clear(): Remove all key-value pairs from the hashtable.V& operator[](K key): Get the value of a given key. If the key does not exist, insert a new key-value pair with a default value.
In C++ you could use std::pair from the utility library to store key-value pairs.
#include <utility>\n#include <iostream>\n\nint main() {\n std::pair<int, int> pair = std::make_pair(1, 2);\n std::cout << pair.first << \" \" << pair.second << std::endl;\n // prints 1 2\n return 0;\n}\nOr you could create your own key-value pair class.
#include <iostream>\n\ntemplate <typename K, typename V>\nstruct KeyValuePair {\n K key;\n V value;\n KeyValuePair(K key, V value) : key(key), value(value) {}\n};\n\nint main() {\n KeyValuePair<int, int> pair(1, 2);\n std::cout << pair.key << \" \" << pair.value << std::endl;\n // prints 1 2\n return 0;\n}\nThe hash function will process the key data and return an index. Usually in C++, the index is of type size_t which is biggest unsigned integer the platform can handle.
The hash function should be fast and should distribute the keys uniformly across the array of buckets. The hash function should be deterministic, meaning that the same key should always produce the same hash.
If the size of your key is less than the size_t you could just use the key casted to size_t as the hash function. If it is not, you will have to implement your own hash function. You probably should use bitwise operations to do so.
struct MyCustomDataWith128Bits {\n uint32_t a;\n uint32_t b;\n uint32_t c;\n uint32_t d;\n size_t hash() const {\n return (a << 32) ^ (b << 24) ^ (c << 16) ^ d;\n }\n};\nThink a bit and try to come up with a nice answer: what is the ideal hash function for a given type? What are the requirements for a good hash function?
"},{"location":"algorithms/06-hashtables/#special-case-string-or-arrays","title":"Special case: String or arrays","text":"In order to use strings as keys, you will have to create a way to convert the string's underlying data structure into a size_t. You could use the std::hash function from the functional library. Or create your own hash function.
#include <iostream>\n#include <functional>\n\nsize_t hash(const std::string& key) {\n size_t hash=0; // accumulator pattern\n // the cost of this operation is O(n)\n for (char c : key)\n hash = (hash << 5) ^ c;\n return hash;\n}\n\nint main() {\n std::hash<std::string> hash;\n std::string key = \"hello\";\n std::cout << hash(key) << std::endl;\n // prints number\n return 0;\n}\nYou can hide and amortize the cost of the hash function by cashing it. There are plenty of ideas for that. Try to come up with your own.
"},{"location":"algorithms/06-hashtables/#hash-tables","title":"Hash tables","text":"Now that you have the hash function for you type and the key-value data structure, you can implement the hash table.
There are plenty of algorithms to do so, and even the std::unordered_map is not the best, please watch those videos to understand the trade-offs and the best way to implement a hash table.
- CppCon 2017: Matt Kulukundis \u201cDesigning a Fast, Efficient, Cache-friendly Hash Table, Step by Step\u201d
For the sake of simplicity I will use the operator modulo to convert the hash into an index array. This is not the best way to do so, but it is the easiest way to implement a hash table.
"},{"location":"algorithms/06-hashtables/#collision-resolution","title":"Collision resolution","text":""},{"location":"algorithms/06-hashtables/#linked-lists","title":"Linked lists","text":"Assuming that your hash function is not perfect, you will have to deal with collisions. Two or more different keys could produce the same hash. There are plenty of ways to deal with that, but the easiest way is to use a linked list to store the key-value pairs that have the same hash.
Try to come up with your own strategy to deal with collisions.
source
"},{"location":"algorithms/06-hashtables/#key-restrictions","title":"Key restrictions","text":"In order for the hash table to work, the key should be:
- not modifiable
- implement a hash function
- implement the
==operator
In C++20 you can use the concept feature to enforce those restrictions.
// concept for a hash table\ntemplate <typename T>\nconcept HasHashFunction =\nrequires(T t, T u) {\n { t.hash() } -> std::convertible_to<std::size_t>;\n { t == u } -> std::convertible_to<bool>;\n std::is_const_v<T>;\n} || requires(T t, T u) {\n { std::hash<T>{}(t) } -> std::convertible_to<std::size_t>;\n { t == u } -> std::convertible_to<bool>;\n};\n\n\nint main() {\n struct MyHashableType {\n int value;\n size_t hash() const {\n return value;\n }\n bool operator==(const MyHashableType& other) const {\n return value == other.value;\n }\n };\n static_assert(HasHashFunction<const MyHashableType>);\n static_assert(HasHashFunction<int>);\n return 0;\n}\nBut you can require more from the key if you are going to implement a more complex collision resolution strategy.
"},{"location":"algorithms/06-hashtables/#hash-table-implementation-with-linked-lists-chaining","title":"Hash table implementation with linked lists (chaining)","text":"This implementation is naive and not efficient. It is just to give you an idea of how to implement a hash table.
#include <iostream>\n\n// key should not be modifiable\n// implements hash function and implements == operator\ntemplate <typename T>\nconcept HasHashFunction =\nrequires(T t, T u) {\n { t.hash() } -> std::convertible_to<std::size_t>;\n { t == u } -> std::convertible_to<bool>;\n std::is_const_v<T>;\n} || requires(T t, T u) {\n { std::hash<T>{}(t) } -> std::convertible_to<std::size_t>;\n { t == u } -> std::convertible_to<bool>;\n};\n\n// hash table\ntemplate <HasHashFunction K, typename V>\nstruct Hashtable {\nprivate:\n // key pair\n struct KeyValuePair {\n K key;\n V value;\n KeyValuePair(K key, V value) : key(key), value(value) {}\n };\n\n // node of the linked list\n struct HashtableNode {\n KeyValuePair data;\n HashtableNode* next;\n HashtableNode(K key, V value) : data(key, value), next(nullptr) {}\n };\n\n // array of linked lists\n HashtableNode** table;\n int size;\npublic:\n // the hashtable will start with a constant size. You can resize it if you want or use any other strategy\n // a good size is something similar to the number of elements you are going to store\n explicit Hashtable(size_t size) {\n // you colud make it automatically resize and increase the complexity of the implementation \n // for the sake of simplicity I will not do that\n this->size = size;\n table = new HashtableNode*[size];\n for (size_t i = 0; i < size; i++) {\n table[i] = nullptr;\n }\n }\nprivate:\n inline size_t convertKeyToIndex(K t) {\n return t.hash() % size;\n }\npublic:\n // inserts a new key value pair\n void insert(K key, V value) {\n // you can optionally resize the table and rearrange the elements if the table is too full\n size_t index = convertKeyToIndex(key);\n auto* node = new HashtableNode(key, value);\n if (table[index] == nullptr) {\n table[index] = node;\n } else {\n HashtableNode* current = table[index];\n while (current->next != nullptr)\n current = current->next;\n current->next = node;\n }\n }\n\n // contains the key\n bool contains(K key) {\n size_t index = convertKeyToIndex(key);\n HashtableNode* current = table[index];\n while (current != nullptr) {\n if (current->data.key == key) {\n return true;\n }\n current = current->next;\n }\n return false;\n }\n\n // subscript operator\n // creates a new element if the key does not exist\n // fails if the key is not found\n V& operator[](K key) {\n size_t index = convertKeyToIndex(key);\n HashtableNode* current = table[index];\n while (current != nullptr) {\n if (current->data.key == key) {\n return current->data.value;\n }\n current = current->next;\n }\n throw std::out_of_range(\"Key not found\");\n }\n\n // deletes the key\n // fails if the key is not found\n void remove(K key) {\n size_t index = convertKeyToIndex(key);\n HashtableNode* current = table[index];\n HashtableNode* previous = nullptr;\n while (current != nullptr) {\n if (current->data.key == key) {\n if (previous == nullptr) {\n table[index] = current->next;\n } else {\n previous->next = current->next;\n }\n delete current;\n return;\n }\n previous = current;\n current = current->next;\n }\n throw std::out_of_range(\"Key not found\");\n }\n\n ~Hashtable() {\n for (size_t i = 0; i < size; i++) {\n HashtableNode* current = table[i];\n while (current != nullptr) {\n HashtableNode* next = current->next;\n delete current;\n current = next;\n }\n }\n }\n};\n\nstruct MyHashableType {\n int value;\n size_t hash() const {\n return value;\n }\n bool operator==(const MyHashableType& other) const {\n return value == other.value;\n }\n};\n\nint main() {\n // keys shouldn't be modifiable, implement hash function and == operator\n Hashtable<const MyHashableType, int> hashtable(5);\n hashtable.insert(MyHashableType{1}, 1);\n hashtable.insert(MyHashableType{2}, 2);\n hashtable.insert(MyHashableType{3}, 3);\n hashtable.insert(MyHashableType{6}, 6); // should add to the same index as 1\n\n std::cout << hashtable[MyHashableType{1}] << std::endl;\n std::cout << hashtable[MyHashableType{2}] << std::endl;\n std::cout << hashtable[MyHashableType{3}] << std::endl;\n std::cout << hashtable[MyHashableType{6}] << std::endl;\n return 0;\n}\nOpen addressing is a method of collision resolution in hash tables. In this approach, each cell is not a pointer to the linked list of contents of that bucket, but instead contains a single key-value pair. In linear probing, when a collision occurs, the next cell is checked. If it is occupied, the next cell is checked, and so on, until an empty cell is found.
source
The main advantage of open addressing is cache-friendliness. The main disadvantage is that it is more complex to implement, and it is not as efficient as linked lists when the table is too full. That's why we have to resize the table earlier, usually at 50% full, but at least 70% full.
source
In this implementation below, I have implemented a strategy to resize the table when it is half full. This is a common strategy to mitigate the O(n) search time when we have a lot of collisions. But on each resize, we have to rehash all elements: O(n) when it grows. This growth will occur rarely so this O(n) is amortized.
"},{"location":"algorithms/06-hashtables/#implementation-with-open-addressing-and-linear-probing","title":"Implementation with open addressing and linear probing","text":"#include <iostream>\n\n// key should not be modifiable\n// implements hash function and implements == operator\ntemplate <typename T>\nconcept HasHashFunction =\nrequires(T t, T u) {\n { t.hash() } -> std::convertible_to<std::size_t>;\n { t == u } -> std::convertible_to<bool>;\n std::is_const_v<T>;\n} || requires(T t, T u) {\n { std::hash<T>{}(t) } -> std::convertible_to<std::size_t>;\n { t == u } -> std::convertible_to<bool>;\n};\n\n// hash table\ntemplate <HasHashFunction K, typename V>\nstruct Hashtable {\nprivate:\n // key pair\n struct KeyValuePair {\n K key;\n V value;\n KeyValuePair(K key, V value) : key(key), value(value) {}\n };\n\n // array of linked lists\n KeyValuePair** table;\n int size;\n int capacity;\npublic:\n // a good size is something 2x bigger than the number of elements you are going to store\n explicit Hashtable(size_t capacity=1) {\n if(capacity == 0)\n throw std::invalid_argument(\"Capacity must be greater than 0\");\n // you could make it automatically resize and increase the complexity of the implementation\n // for the sake of simplicity I will not do that\n this->size = 0;\n this->capacity = capacity;\n table = new KeyValuePair*[capacity];\n for (size_t i = 0; i < capacity; i++)\n table[i] = nullptr;\n }\nprivate:\n inline size_t convertKeyToIndex(K t) {\n return t.hash() % capacity;\n }\npublic:\n // inserts a new key value pair\n // this implementation uses open addressing and resize the table when it is half full\n void insert(K key, V value) {\n size_t index = convertKeyToIndex(key);\n // resize if necessary\n // in open addressing, it is common to resize when the table is half full\n // this help mitigate O(n) search time when we have a lot of collisions\n // but on each resize, we have to rehash all elements: O(n)\n if (size >= capacity/2) {\n auto oldTable = table;\n table = new KeyValuePair*[capacity*2];\n capacity *= 2;\n for (size_t i = 0; i < capacity; i++)\n table[i] = nullptr;\n size_t oldSize = size;\n size = 0;\n // insert all elements again\n for (size_t i = 0; i < oldSize; i++) {\n if (oldTable[i] != nullptr) {\n insert(oldTable[i]->key, oldTable[i]->value);\n delete oldTable[i];\n }\n }\n delete[] oldTable;\n }\n // insert the new element\n KeyValuePair* newElement = new KeyValuePair(key, value);\n while (table[index] != nullptr) // find the next open index\n index = (index + 1) % capacity;\n table[index] = newElement;\n size++;\n }\n\n // contains the key\n bool contains(K key) {\n size_t index = convertKeyToIndex(key);\n KeyValuePair* current = table[index];\n while (current != nullptr) {\n if (current->key == key) {\n return true;\n }\n index = (index + 1) % capacity;\n current = table[index];\n }\n\n return false;\n }\n\n // subscript operator\n // fails if the key is not found\n V& operator[](K key) {\n size_t index = convertKeyToIndex(key);\n KeyValuePair* current = table[index];\n while (current != nullptr) {\n if (current->key == key) {\n return current->value;\n }\n index = (index + 1) % capacity;\n current = table[index];\n }\n throw std::out_of_range(\"Key not found\");\n }\n\n // deletes the key\n // fails if the key is not found\n void remove(K key) {\n // ideal index\n const size_t idealIndex = convertKeyToIndex(key);\n size_t currentIndex = idealIndex;\n // store the last index with the same hash so we move it to the position of the removed element\n size_t lastIndexWithSameIdealIndex = idealIndex;\n size_t indexOfTheRemovedElement = idealIndex;\n // iterate until we find the element, or we find an empty slot\n while (table[currentIndex] != nullptr) {\n if (table[currentIndex]->key == key)\n indexOfTheRemovedElement = currentIndex;\n if (convertKeyToIndex(table[currentIndex]->key) == idealIndex)\n lastIndexWithSameIdealIndex = currentIndex;\n currentIndex = (currentIndex + 1) % capacity;\n }\n if(table[indexOfTheRemovedElement] == nullptr || table[indexOfTheRemovedElement]->key != key)\n throw std::out_of_range(\"Key not found\");\n // mave the last element with the same key to the position of the removed element\n delete table[indexOfTheRemovedElement];\n table[indexOfTheRemovedElement] = table[lastIndexWithSameIdealIndex];\n table[lastIndexWithSameIdealIndex] = nullptr;\n\n // todo: shrink the table if it is too empty\n }\n\n ~Hashtable() {\n for (size_t i = 0; i < capacity; i++) {\n if (table[i] != nullptr)\n delete table[i];\n }\n delete[] table;\n }\n};\n\nstruct MyHashableType {\n int value;\n size_t hash() const {\n return value;\n }\n bool operator==(const MyHashableType& other) const {\n return value == other.value;\n }\n};\n\nint main() {\n // keys shouldn't be modifiable, implement hash function and == operator\n Hashtable<const MyHashableType, int> hashtable(5);\n hashtable.insert(MyHashableType{0}, 0);\n hashtable.insert(MyHashableType{1}, 1);\n hashtable.insert(MyHashableType{2}, 2); // triggers resize\n hashtable.insert(MyHashableType{10}, 10); // should be inserted in the same index as 1\n\n std::cout << hashtable[MyHashableType{0}] << std::endl;\n std::cout << hashtable[MyHashableType{1}] << std::endl;\n std::cout << hashtable[MyHashableType{2}] << std::endl;\n std::cout << hashtable[MyHashableType{10}] << std::endl; // should trigger linear search\n\n hashtable.remove(MyHashableType{0}); // should trigger swap\n\n std::cout << hashtable[MyHashableType{10}] << std::endl; // shauld not trigger linear search\n return 0;\n}\nWarning
This section is a continuation of the Dynamic Data section. Please make sure to read it before continuing.
"},{"location":"algorithms/08-stack-and-queue/#stack","title":"Stack","text":"source
Stacks are a type of dynamic data where the last element added is the first one to be removed. This is known as LIFO (Last In First Out) or FILO (First In Last Out). Stacks are used in many algorithms and data structures, such as the depth-first search algorithm, back-track and the call stack.
"},{"location":"algorithms/08-stack-and-queue/#stack-basic-operations","title":"Stack Basic Operations","text":"push- Add an element to the top of the stack.pop- Remove the top element from the stack.top- Return the top element of the stack.
source
"},{"location":"algorithms/08-stack-and-queue/#stack-implementation","title":"Stack Implementation","text":"You can either implement it using a dynamic array or a linked list. But the dynamic array implementation is more efficient in terms of memory and speed. So let's use it.
#include <iostream>\n\n// stack\ntemplate <typename T>\nclass Stack {\n T* data; // dynamic array\n size_t size; // number of elements in the stack\n size_t capacity; // capacity of the stack\npublic:\n Stack() : data(nullptr), size(0), capacity(0) {}\n ~Stack() {\n delete[] data;\n }\n void push(const T& value) {\n // if it needs to be resized\n // amortized cost of push is O(1)\n if (size == capacity) {\n capacity = capacity == 0 ? 1 : capacity * 2;\n T* new_data = new T[capacity];\n std::copy(data, data + size, new_data);\n delete[] data;\n data = new_data;\n }\n // stores the value and then increments the size\n data[size++] = value; \n }\n T pop() {\n if (size == 0)\n throw std::out_of_range(\"Stack is empty\");\n\n // shrink the array if necessary\n // ammortized cost of pop is O(1)\n if (size <= capacity / 4) {\n capacity /= 2;\n T* new_data = new T[capacity];\n std::copy(data, data + size, new_data);\n delete[] data;\n data = new_data;\n }\n return data[--size];\n }\n T& top() const {\n if (size == 0)\n throw std::out_of_range(\"Stack is empty\");\n // cost of top is O(1)\n return data[size - 1];\n }\n size_t get_size() const {\n return size;\n }\n bool is_empty() const {\n return size == 0;\n }\n};\nsource
A queue is a type of dynamic data where the first element added is the first one to be removed. This is known as FIFO (First In First Out). Queues are used in many algorithms and data structures, such as the breadth-first search algorithm. Usually it is implemented as a linked list, in order to provide O(1) time complexity for the enqueue and dequeue operations. But it can be implemented using a dynamic array as well and amortize the cost for resizing. The dynamic array implementation is more efficient in terms of memory and speed(if not resized frequently).
enqueue- Add an element to the end of the queue.dequeue- Remove the first element from the queue.front- Return the first element of the queue.
source
"},{"location":"algorithms/08-stack-and-queue/#queue-implementation","title":"Queue Implementation","text":"// queue\ntemplate <typename T>\nclass Queue {\n // dynamic array approach instead of linked list\n T* data;\n size_t front; // index of the first valid element\n size_t back; // index of the next free slot\n size_t capacity; // current capacity of the array\n size_t size; // number of elements in the queue\n\n explicit Queue() : data(nullptr), front(0), back(0), capacity(capacity), size(0) {};\n\n void enqueue(T value) {\n // resize if necessary\n // amortized O(1) time complexity\n if (size == capacity) {\n auto old_capacity = capacity;\n capacity = capacity ? capacity * 2 : 1;\n T* new_data = new T[capacity];\n for (size_t i = 0; i < size; i++)\n new_data[i] = data[(front + i) % old_capacity];\n delete[] data;\n data = new_data;\n front = 0;\n back = size;\n }\n data[back] = value;\n back = (back + 1) % capacity;\n size++;\n }\n\n void dequeue() {\n if (size) {\n front = (front + 1) % capacity;\n size--;\n }\n // shrink if necessary\n if(size <= capacity / 4) {\n auto old_capacity = capacity;\n capacity /= 2;\n T* new_data = new T[capacity];\n for (size_t i = 0; i < size; i++)\n new_data[i] = data[(front + i) % old_capacity];\n delete[] data;\n data = new_data;\n front = 0;\n back = size;\n }\n }\n\n T& head() {\n return data[front];\n }\n};\nGraphs are a type of data structures that interconnects nodes (or vertices) with edges. They are used to model relationships between objects. This is the basics for most AI algorithms, such as pathfinding, decision making, neuron networks, and others.
"},{"location":"algorithms/10-graphs/#basic-definitions","title":"Basic Definitions","text":"- Nodes or vertices are the basic entities in a graph and hold the data.
- Edges are the connections and relation between the nodes. The relationship can be enriched in multiple ways such as direction, weight, and others.
- Neighbours are the nodes that are connected to a specific node.
- Path is the sequence of edges and nodes that allows you to go from one node to another.
- Degree of a node is the number of edges connected to it.
A graph is composed by a set of vertices(nodes) and edges. There are multiple ways to represent a graph, and every style has its own advantages and disadvantages.
"},{"location":"algorithms/10-graphs/#adjacency-matrix","title":"Adjacency matrix","text":"Assuming every node is labeled with a number from 0 to n-1, an adjacency matrix is a 2D array of size n x n. The entry a[i][j] is 1 if there is an edge from node i to node j, and 0 otherwise. The adjacency matrix for a graph is always a square matrix.
// adjacency matrix\n// NUMBER_OF_NODES is the number of nodes\n// bool marks if there is an edge between the nodes.\n// switch bool to float if you want to store the weight of the edge.\n// switch bool to a data structure if you want to store more information about the edge.\nbool adj_matrix[NUMBER_OF_NODES][NUMBER_OF_NODES];\nvector<Node> nodes;\n- Pros: it is simple and easy to implement and blazing fast for checking if there is an edge between two nodes.
- Cons: it consumes a lot of space, especially for sparse graphs.
It can be implemented in multiple ways, but a common one is to use an array of lists(or vectors). The index(key) of the array is the node id, and the value is a list of nodes that are connected to the key node.
// adjacency list\n// NUMBER_OF_NODES is the number of nodes\n// vector for storing the connected nodes ids as integers\n// switch vector<int> to map<int, float> if you want to store the weight of the edge.\n// switch map<int, float> to map<int, data_structure> if you want to store more information about the edge.\nvector<int> adj_list[NUMBER_OF_NODES];\nvector<Node> nodes;\n- Pros: it is more memory efficient for sparse graphs.
- Cons: it can be slower to check if there is an edge between two nodes.
It is a collection of edges, where each egge can be represented as a pair of nodes, a pair of node ids, or a pair of references to nodes.
// edge list\nvector<pair<int, int>> edges;\nvector<Node> nodes;\n- Pros: it is the most memory efficient representation for sparse graphs.
- Cons: it can be slower to check if there is an edge between two nodes.
- Null graph: A graph with no edges.
- Trivial graph: A graph with only one vertex.
- Directed graph: A graph where the edges have direction.
- Weighted graph: A graph where the edges have a weight.
- Undirected graph: A graph where the edges have no direction or are bidirectional. If weighted, the weights are the same in both directions.
- Connected graph: A graph where all nodes can be reached from any other node.
- Disconnected graph: A graph where some nodes cannot be reached from other nodes.
- Cyclic graph: A graph that has at least one cycle, a path that starts and ends at the same node.
- Acyclic graph: A graph that has no cycles.
- Complete graph: A graph where every pair of nodes is connected by a unique edge.
- Regular graph: A graph where every node has the same degree.
DFS is a graph traversal algorithm based on a stack data structure. Basically, the algorithm starts at a node and explores as far as possible along each branch before backtracking. It is used to find connected components, determine the connectivity of the graph, and solve many other problems.
DFS visualization
#include <iostream>\n#include <vector>\n#include <unordered_set>\n#include <unordered_map>\n#include <string>\n\n// graph is represented as an adjacency list\nstd::unordered_map<std::string, std::unordered_set<std::string>> graph;\nstd::unordered_set<std::string> visited;\n\n// dfs recursive version\n// it exploits the call stack to store the nodes to visit\n// you might want to use the iterative version if you have a large graph\n// for that, use std::stack data structure and producer-consumer pattern\nvoid dfs(const std::string& node) {\n std::cout << node << std::endl;\n visited.insert(node);\n for (const auto& neighbor : graph[node])\n if (!visited.contains(neighbor))\n dfs(neighbor);\n}\n\nvoid dfs_interactive(const std::string& node) {\n std::stack<std::string> stack;\n // produce the first node\n stack.push(node);\n while (!stack.empty()) {\n // consume the node\n std::string current = stack.top();\n stack.pop();\n // avoid visiting the same node twice\n if (visited.contains(current))\n continue;\n // mark as visited\n visited.insert(current);\n\n // visit the node\n std::cout << current << std::endl;\n\n // produce the next node to visit\n for (const auto& neighbor : graph[current]) {\n if (!visited.contains(neighbor)) {\n stack.push(neighbor);\n break; // is this break necessary?\n }\n }\n }\n}\n\nint main() {\n std::cout << \"Write one node string per line. When you are done, add an empty line.\" << std::endl;\n std::string node;\n while (std::getline(std::cin, node) && !node.empty())\n graph[node] = {};\n std::cout << \"Write the edges as 'node1;node2'. When you are done, add an empty line.\" << std::endl;\n std::string edge;\n while (std::getline(std::cin, edge) && !edge.empty()) {\n auto pos = edge.find(';');\n // Bidirectional\n std::string source = edge.substr(0, pos);\n std::string destination = edge.substr(pos + 1);\n graph[source].insert(destination);\n graph[destination].insert(source);\n }\n std::cout << \"Write the starting node.\" << std::endl;\n std::string start;\n std::cin >> start;\n dfs(start);\n return 0;\n}\nBFS is a graph traversal algorithm based on a queue data structure. It starts at a node and explores all of its neighbours before moving on to the next level of neighbours by enqueing them. It is used to find the shortest path, determine the connectivity of the graph, and others.
BFS visualization
#include <iostream>\n#include <vector>\n#include <unordered_set>\n#include <unordered_map>\n#include <string>\n#include <queue>\n\n// graph is represented as an adjacency list\nstd::unordered_map<std::string, std::unordered_set<std::string>> graph;\nstd::unordered_set<std::string> visited;\n\n// bfs\nvoid bfs(const std::string& node) {\n std::queue<std::string> queue;\n // produce the first node\n queue.push(node);\n while (!queue.empty()) {\n // consume the node\n std::string current = queue.front();\n queue.pop();\n // avoid visiting the same node twice\n if (visited.contains(current))\n continue;\n // mark as visited\n visited.insert(current);\n\n // visit the node\n std::cout << current << std::endl;\n\n // produce the next node to visit\n for (const auto& neighbor : graph[current]) {\n if (!visited.contains(neighbor))\n queue.push(neighbor);\n }\n }\n}\n\nvoid dfs_interactive(const std::string& node) {\n std::stack<std::string> stack;\n // produce the first node\n stack.push(node);\n while (!stack.empty()) {\n // consume the node\n std::string current = stack.top();\n stack.pop();\n // avoid visiting the same node twice\n if (visited.contains(current))\n continue;\n // mark as visited\n visited.insert(current);\n\n // visit the node\n std::cout << current << std::endl;\n\n // produce the next node to visit\n for (const auto& neighbor : graph[current]) {\n if (!visited.contains(neighbor)) {\n stack.push(neighbor);\n break; // is this break necessary?\n }\n }\n }\n}\n\nint main() {\n std::cout << \"Write one node string per line. When you are done, add an empty line.\" << std::endl;\n std::string node;\n while (std::getline(std::cin, node) && !node.empty())\n graph[node] = {};\n std::cout << \"Write the edges as 'node1;node2'. When you are done, add an empty line.\" << std::endl;\n std::string edge;\n while (std::getline(std::cin, edge) && !edge.empty()) {\n auto pos = edge.find(';');\n // Bidirectional\n std::string source = edge.substr(0, pos);\n std::string destination = edge.substr(pos + 1);\n graph[source].insert(destination);\n graph[destination].insert(source);\n }\n std::cout << \"Write the starting node.\" << std::endl;\n std::string start;\n std::cin >> start;\n // dfs(start);\n dfs_interactive(start);\n return 0;\n}\nsource
https://www.redblobgames.com/pathfinding/grids/graphs.html
https://www.redblobgames.com/pathfinding/a-star/introduction.html
https://qiao.github.io/PathFinding.js/visual/
"},{"location":"algorithms/11-dijkstra/","title":"Djikstra's algorithm","text":"source
Dijkstra's algorithm is a graph traversal algorithm similar to BFS, but it takes into account the weight of the edges. It uses a priority list to visit the nodes with the smallest cost first and a set to keep track of the visited nodes. A came_from map can be used to store the parent node of each node to create a pathfinding algorithm.
It uses the producer-consumer pattern, where the producer is the algorithm that adds the nodes to the priority queue and the consumer is the algorithm that removes the nodes from the priority queue and do the work.
The algorithm is greedy and works well with positive weights. It is not optimal for negative weights, for that you should use the Bellman-Ford algorithm.
"},{"location":"algorithms/11-dijkstra/#data-structure","title":"Data Structure","text":"For the graph, we will use an adjacency list:
// node registry\n// K is the key type for indexing the nodes, usually it can be a string or an integer\n// Node is the Node type to store node related data \nunordered_map<K, N> nodes;\n\n// K is the key type of the index\n// W is the weight type of the edge, usually it can be an integer or a float\n// W can be more robust and become a struct, for example, to store the weight and the edge name\n// if W is a struct, remember no implement the < operator for the priority queue work\n// unordered_map is used to exploit the O(1) access time and be tolerant to sparse keys\nunordered_map<K, unordered_map<K, W>> edges;\n\n// usage\n// the cost from node A to node B is 5\nedges[\"A\"][\"B\"] = 5;\n// if you want to make it bidirectional set the opposite edge too\n// edges[\"B\"][\"A\"] = 5;\nFor the algoritm to work we will need a priority queue to store the nodes to be visited:
// priority queue to store the nodes to be visited\n// C is the W type and stores the accumulated cost to reach the node\n// K is the key type of the index of the node\npriority_queue<pair<C, K>> frontier;\nFor the visited nodes we will use a set:
// set to store the visited nodes\n// K is the key type of the index of the node\nunordered_set<K> visited;\nList of visualizations:
- https://www.cs.usfca.edu/~galles/visualization/Dijkstra.html
- https://visualgo.net/en/sssp
- https://qiao.github.io/PathFinding.js/visual/
Example of Dijkstra's algorithm in C++ to build a path from the start node to the end node:
#include <iostream>\n#include <unordered_map>\n#include <unordered_set>\n#include <string>\n#include <queue>\nusing namespace std;\n\n// Dijikstra\nstruct Node {\n // add your custom data here\n string name;\n};\n\n// nodes indexed by id\nunordered_map<uint64_t, Node> nodes;\n// edges indexed by source id and destination id, the value is the\nunordered_map<uint64_t, unordered_map<uint64_t, double>> edges;\n// priority queue for the frontier\n// this could be declared inside the Dijkstra function\npriority_queue<pair<double, uint64_t>> frontier;\n\n// optionally, in order to create a pathfinding, use came_from map to store the parent node\nunordered_map<uint64_t, uint64_t> came_from;\n// cost to reach the node so far\nunordered_map<uint64_t, double> cost_so_far;\n\nvoid Visit(Node* node){\n // add your custom code here\n cout << node->name << endl;\n}\n\nvoid Dijkstra(uint64_t start_id) {\n cout << \"Visiting nodes:\" << endl;\n // clear the costs so far\n cost_so_far.clear();\n // boostrap the frontier\n // 0 means the cost to reach the start node is 0\n frontier.emplace(0, start_id);\n cost_so_far[start_id] = 0;\n // while there are nodes to visit\n while (!frontier.empty()) {\n // get the node with the lowest cost\n auto [cost, current_id] = frontier.top();\n frontier.pop();\n // get the node\n Node* current = &nodes[current_id];\n // visit the node\n Visit(current);\n // for each neighbor\n for (const auto& [neighbor_id, edge_cost] : edges[current_id]) {\n // calculate the new cost to reach the neighbor\n double new_cost = cost_so_far[current_id] + edge_cost;\n // if the neighbor is not visited yet or the new cost is less than the previous cost\n if (!cost_so_far.contains(neighbor_id) || new_cost < cost_so_far[neighbor_id]) {\n // update the cost\n cost_so_far[neighbor_id] = new_cost;\n // add the neighbor to the frontier\n frontier.emplace(new_cost, neighbor_id);\n // update the parent node\n came_from[neighbor_id] = current_id;\n }\n }\n }\n}\n\nint main() {\n // build the graph\n nodes[0] = {\"A\"}; // this will be our start\n nodes[1] = {\"B\"};\n nodes[2] = {\"C\"};\n nodes[3] = {\"D\"}; // this will be our end\n // store the edges costs\n edges[0][1] = 1;\n edges[0][2] = 2;\n edges[0][3] = 100; // this is a very expensive edge\n edges[1][3] = 3;\n edges[2][3] = 1;\n // the path from 0 to 3 is A -> C -> D even though the edge A -> D have less steps\n Dijkstra(0);\n // print the path from the end to the start\n cout << \"Path:\" << endl;\n uint64_t index = 3;\n // prevents infinite loop if the end is unreachable\n if(!came_from.contains(index)) {\n cout << \"No path found\" << endl;\n return 0;\n }\n while (index != 0) {\n cout << nodes[index].name << endl;\n index = came_from[index];\n }\n cout << nodes[0].name << endl;\n return 0;\n}\nJarnik's(and Prim's) developed the Minimum Spanning Tree, it is an algorithm to find a tree in a graph that connects all the vertices with the minimum possible accumulated weight.
The output of the algorithm is a set of edges that the sum of the weighs is the minimum possible and connects all reachable vertices.
"},{"location":"algorithms/12-mst/#minimum-spanning-tree-algorithm","title":"Minimum Spanning Tree Algorithm","text":"- Add a vertex to the minimum spanning tree;
- While all nodes are not in the minimum spanning tree:
- Find the edge with the minimum weight that connects a vertex in the MST to a vertex not in the MST;
- Add the vertex from that edge to the MST;
Let's consider the following graph:
graph LR\nv0((0))\nv1((1))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7((7))\nv8((8))\nv3 <-. 3 .-> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-. 4 .-> v3\nv2 <-. 6 .-> v5\nv6 <-. 1 .-> v5\nv2 <-. 8 .-> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-. 6 .-> v8\nv7 <-. 11 .-> v6\nv1 <-. 2 .-> v7\nv0 <-. 4 .-> v7\nv0 <-. 8 .-> v1In order to bootstrap the algorithm we need to:
- Select a random vertex;
- let's choose the vertex 0;
- Add the vertex 0 to minimum spanning tree;
- Add all edges that connect the vertex 0 to the priority queue, we add 1 with the weight of 8 and 7 with the weight of 4;
Current state of data:
- Minimum Spanning Tree: {0}
graph LR\nv0(((0)))\nv1((1))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7((7))\nv8((8))\nv3 <-. 3 .-> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-. 4 .-> v3\nv2 <-. 6 .-> v5\nv6 <-. 1 .-> v5\nv2 <-. 8 .-> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-. 6 .-> v8\nv7 <-. 11 .-> v6\nv1 <-. 2 .-> v7\nv0 <-. 4 .-> v7\nv0 <-. 8 .-> v1After the initial setup, we will start running the producer-consumer loop:
- List all edges from all vertices in the minimum spanning tree where the other vertex is not in the minimum spanning tree;
- The edges are:
- {0, 1} with the weight of 8;
- {0, 7} with the weight of 4;
- The edges are:
graph LR\nv0(((0)))\nv1((1))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7((7))\nv8((8))\nv3 ~~~ v4\nv5 ~~~ v4\nv3 ~~~ v5\nv2 ~~~ v3\nv2 ~~~ v5\nv6 ~~~ v5\nv2 ~~~ v8\nv8 ~~~ v6\nv1 ~~~ v2\nv7 ~~~ v8\nv7 ~~~ v6\nv1 ~~~ v7\nv0 <-. 4 .-> v7\nv0 <-. 8 .-> v1- Select the edge with the minimum weight;
- The edge {0, 7} with the weight of 4;
graph LR\nv0(((0)))\nv1((1))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7((7))\nv8((8))\nv3 ~~~ v4\nv5 ~~~ v4\nv3 ~~~ v5\nv2 ~~~ v3\nv2 ~~~ v5\nv6 ~~~ v5\nv2 ~~~ v8\nv8 ~~~ v6\nv1 ~~~ v2\nv7 ~~~ v8\nv7 ~~~ v6\nv1 ~~~ v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1- From the selected edge, add the other vertex to the minimum spanning tree
- Add the vertex 7 to the minimum spanning tree;
The current state of the minimum spanning three is [{0, 7}].;
graph LR\nv0(((0)))\nv1((1))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7(((7)))\nv8((8))\nv3 ~~~ v4\nv5 ~~~ v4\nv3 ~~~ v5\nv2 ~~~ v3\nv2 ~~~ v5\nv6 ~~~ v5\nv2 ~~~ v8\nv8 ~~~ v6\nv1 ~~~ v2\nv7 ~~~ v8\nv7 ~~~ v6\nv1 ~~~ v7\nv0 <-- 4 --> v7\nv0 ~~~ v1Let's repeat the process once more to illustrate the algorithm:
graph LR\nv0(((0)))\nv1((1))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7(((7)))\nv8((8))\nv3 <-. 3 .-> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-. 4 .-> v3\nv2 <-. 6 .-> v5\nv6 <-. 1 .-> v5\nv2 <-. 8 .-> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-. 6 .-> v8\nv7 <-. 11 .-> v6\nv1 <-. 2 .-> v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1- List all edges from all vertices in the minimum spanning tree where the other vertex is not in the minimum spanning tree;
- The edges are:
- {0, 1} with the weight of 8;
- {7, 1} with the weight of 2;
- {7, 8} with the weight of 6;
- {7, 6} with the weight of 11;
- The edges are:
graph LR\nv0(((0)))\nv1((1))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7(((7)))\nv8((8))\nv3 ~~~ v4\nv5 ~~~ v4\nv3 ~~~ v5\nv2 ~~~ v3\nv2 ~~~ v5\nv6 ~~~ v5\nv2 ~~~ v8\nv8 ~~~ v6\nv1 ~~~ v2\nv7 <-. 6 .-> v8\nv7 <-. 11 .-> v6\nv1 <-. 2 .-> v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1- Select the edge with the minimum weight;
- The edge {7, 1} with the weight of 2;
- From the selected edge, add the other vertex to the minimum spanning tree
- Add the vertex 1 to the minimum spanning tree;
The current state of the minimum spanning three is [{0, 7}, {1, 7}].
graph LR\nv0(((0)))\nv1(((1)))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7(((7)))\nv8((8))\nv3 ~~~ v4\nv5 ~~~ v4\nv3 ~~~ v5\nv2 ~~~ v3\nv2 ~~~ v5\nv6 ~~~ v5\nv2 ~~~ v8\nv8 ~~~ v6\nv1 ~~~ v2\nv7 ~~~ v8\nv7 ~~~ v6\nv1 <-- 2 --> v7\nv0 <-- 4 --> v7\nv0 ~~~ v1Now the current exploration state is:
graph LR\nv0(((0)))\nv1(((1)))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7(((7)))\nv8((8))\nv3 <-. 3 .-> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-. 4 .-> v3\nv2 <-. 6 .-> v5\nv6 <-. 1 .-> v5\nv2 <-. 8 .-> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-. 6 .-> v8\nv7 <-. 11 .-> v6\nv1 <-- 2 --> v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1The edges candidates are:
- {0, 1}: 12;
- {7, 8}: 6;
- {7, 6}: 11;
The edge with the minimum weight is {7, 8}: 6. So we will add 8 to the minimum spanning tree.
The current state of the minimum spanning three is [{0, 7}, {1, 7}, {8, 7}].
graph LR\nv0(((0)))\nv1(((1)))\nv2((2))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7(((7)))\nv8(((8)))\nv3 <-. 3 .-> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-. 4 .-> v3\nv2 <-. 6 .-> v5\nv6 <-. 1 .-> v5\nv2 <-. 8 .-> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-- 6 --> v8\nv7 <-. 11 .-> v6\nv1 <-- 2 --> v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1The edges candidates are:
- {1, 2}: 12;
- {8, 2}: 8;
- {8, 6}: 10;
- {7, 6}: 11;
The edge with the minimum weight is {8, 2}: 8. So we will add 2 to the minimum spanning tree.
The current state of the minimum spanning three is [{0, 7}, {1, 7}, {8, 7}, {2, 8}].
graph LR\nv0(((0)))\nv1(((1)))\nv2(((2)))\nv3((3))\nv4((4))\nv5((5))\nv6((6))\nv7(((7)))\nv8(((8)))\nv3 <-. 3 .-> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-. 4 .-> v3\nv2 <-. 6 .-> v5\nv6 <-. 1 .-> v5\nv2 <-- 8 --> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-- 6 --> v8\nv7 <-. 11 .-> v6\nv1 <-- 2 --> v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1The edges candidates are:
- {2, 3}: 4;
- {2, 5}: 6;
- {8, 6}: 10;
- {7, 6}: 11;
We will add the edge {2, 3}: 4 to the minimum spanning tree.
The minimum spanning three is [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}].
graph LR\nv0(((0)))\nv1(((1)))\nv2(((2)))\nv3(((3)))\nv4((4))\nv5((5))\nv6((6))\nv7(((7)))\nv8(((8)))\nv3 <-. 3 .-> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-- 4 --> v3\nv2 <-. 6 .-> v5\nv6 <-. 1 .-> v5\nv2 <-- 8 --> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-- 6 --> v8\nv7 <-. 11 .-> v6\nv1 <-- 2 --> v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1Candidates:
- {3, 4}: 3;
- {3, 5}: 12;
- {2, 5}: 6;
- {8, 6}: 10;
- {7, 6}: 11;
The edge with the minimum weight is {3, 4}: 3. So we will add 4 to the minimum spanning tree.
The minimum spanning three is now [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}].
graph LR\nv0(((0)))\nv1(((1)))\nv2(((2)))\nv3(((3)))\nv4(((4)))\nv5((5))\nv6((6))\nv7(((7)))\nv8(((8)))\nv3 <-- 3 --> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-- 4 --> v3\nv2 <-. 6 .-> v5\nv6 <-. 1 .-> v5\nv2 <-- 8 --> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-- 6 --> v8\nv7 <-. 11 .-> v6\nv1 <-- 2 --> v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1The egdes candidates are:
- {3, 5}: 12;
- {2, 5}: 6;
- {4, 5}: 15;
- {8, 6}: 10;
- {7, 6}: 11;
Select {2, 5}: 6; Add 5 to MST. [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}, {5, 2}].
graph LR\nv0(((0)))\nv1(((1)))\nv2(((2)))\nv3(((3)))\nv4(((4)))\nv5(((5)))\nv6((6))\nv7(((7)))\nv8(((8)))\nv3 <-- 3 --> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-- 4 --> v3\nv2 <-- 6 --> v5\nv6 <-. 1 .-> v5\nv2 <-- 8 --> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-- 6 --> v8\nv7 <-. 11 .-> v6\nv1 <-- 2 --> v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1Candidates are:
- {5, 6}: 1;
- {8, 6}: 10;
- {7, 6}: 11;
Select {5, 6}: 1; Add 6 to MST. [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}, {5, 2}, {6, 5}].
graph LR\nv0(((0)))\nv1(((1)))\nv2(((2)))\nv3(((3)))\nv4(((4)))\nv5(((5)))\nv6(((6)))\nv7(((7)))\nv8(((8)))\nv3 <-- 3 --> v4\nv5 <-. 15 .-> v4\nv3 <-. 12 .-> v5\nv2 <-- 4 --> v3\nv2 <-- 6 --> v5\nv6 <-- 1 --> v5\nv2 <-- 8 --> v8\nv8 <-. 10 .-> v6\nv1 <-. 12 .-> v2\nv7 <-- 6 --> v8\nv7 <-. 11 .-> v6\nv1 <-- 2 --> v7\nv0 <-- 4 --> v7\nv0 <-. 8 .-> v1Now, our current MST does not any candidates to explore, so the algorithm is finished. The minimum spanning tree is [{0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}, {5, 2}, {6, 5}].
graph LR\nv0(((0)))\nv1(((1)))\nv2(((2)))\nv3(((3)))\nv4(((4)))\nv5(((5)))\nv6(((6)))\nv7(((7)))\nv8(((8)))\nv3 <-- 3 --> v4\nv5 ~~~ v4\nv3 ~~~ v5\nv2 <-- 4 --> v3\nv2 <-- 6 --> v5\nv6 <-- 1 --> v5\nv2 <-- 8 --> v8\nv8 ~~~ v6\nv1 ~~~ v2\nv7 <-- 6 --> v8\nv7 ~~~ v6\nv1 <-- 2 --> v7\nv0 <-- 4 --> v7\nv0 ~~~ v1The total weight of the minimum spanning tree from {0, 7}, {1, 7}, {8, 7}, {2, 8}, {3, 2}, {4, 3}, {5, 2}, {6, 5} is 4 + 2 + 6 + 8 + 4 + 3 + 6 + 1 = 34.
There are many implementations for the Minimum Spanning Tree algorithm, here goes one possible implementation int as key, int as value and int as weight:
#include <iostream>\n#include <unordered_set>\n#include <unordered_map>\n#include <optional>\n#include <tuple>\n#include <vector>\n#include <utility>\nusing namespace std;\n\n// rename optional<tuple<int, int, int>> to edge\ntypedef optional<tuple<int, int, int>> Edge;\n\n// rename unordered_map<int, unordered_map<int, int>> to Graph\ntypedef unordered_map<int, unordered_map<int, int>> Graph;\n\n// source, destination, weight\nEdge findMinEdge(const Graph& graph, const Graph& mst){\n if(graph.empty())\n return nullopt;\n if(mst.empty()){\n // select a random node to start, we will get the first vertex\n int source = graph.begin()->first;\n // candidates to be destination\n auto candidates = graph.at(source);\n // iterator\n auto it = candidates.begin();\n // best destination and weight\n int bestDestination = it->first;\n int bestWeight = it->second;\n // iterate over the candidates\n for(; it != candidates.end(); it++){\n if(it->second < bestWeight){\n bestDestination = it->first;\n bestWeight = it->second;\n }\n }\n return make_tuple(source, bestDestination, bestWeight);\n }\n // list all vertices from the minimum spanning tree\n std::unordered_set<int> mstVertices;\n for(auto& [source, destinations] : mst){\n mstVertices.insert(source);\n for(auto& [destination, weight] : destinations){\n mstVertices.insert(destination);\n }\n }\n // iterate over the vertices from the minimum spanning tree to find the minimum edge\n int bestWeight = INT_MAX;\n int bestSource = -1;\n int bestDestination = -1;\n for(auto& source : mstVertices){\n for(auto& [destination, weight] : graph.at(source)){\n if(!mstVertices.contains(destination) && weight < bestWeight){\n bestSource = source;\n bestDestination = destination;\n bestWeight = weight;\n }\n }\n }\n if(bestSource == -1)\n return nullopt;\n return make_tuple(bestSource, bestDestination, bestWeight);\n}\n\n// returns the accumulated weight of the minimum spanning tree\n// the graph is represented as [source, destination] -> weight\nint MSP(const Graph& graph){\n Graph mst;\n int accumulatedWeight = 0;\n while(true){\n auto edge = findMinEdge(graph, mst);\n if(!edge.has_value())\n break;\n auto [source, destination, weight] = edge.value();\n mst[source][destination] = weight;\n mst[destination][source] = weight;\n accumulatedWeight += weight;\n }\n return accumulatedWeight;\n}\n- It is a connected graph what have no cycles;
- Has a single path between any two vertices;
- A tree with N vertices has N-1 edges;
There are mostly three ways to explore a binary search tree, they generate different outputs:
- In-order: Left, Root, Right;
- Pre-order: Root, Left, Right;
- Post-order: Left, Right, Root;
A binary search tree is a binary tree:
- Each node has at most two children;
- The left child is less than the parent;
- The right child is greater than the parent;
- The left and right subtrees are also binary search trees;
In a binary search tree, the search complexity is O(log(n)) in a balanced tree. But it can be O(n) if not balanced.
Check the animations on https://visualgo.net/en/bst.
"},{"location":"algorithms/13-bst/#avl-trees","title":"AVL Trees","text":"WiP.
"},{"location":"artificialintelligence/","title":"Advanced Artificial Intelligence","text":"Students with a firm foundation in the basic techniques of artificial intelligence for games will apply their skills to program advanced pathfinding algorithms, artificial opponents, scripting tools and other real-time drivers for non-playable agents. The goal of the course is to provide finely-tuned artificial competition for players using all the rules followed by a human.
"},{"location":"artificialintelligence/#requirements","title":"Requirements","text":"- Artificial Intelligence for Games
- AI for Games, Third Edition: 9781138483972: Millington, Ian
Upon completion of the Advanced AI for Games, students should be able to:
"},{"location":"artificialintelligence/#objective-outcomes","title":"Objective Outcomes","text":"- Recall fundamental AI techniques for games;
- Identify key components of advanced AI, including pathfinding algorithms and scripting tools
- Demonstrate a deep understanding of advanced AI principles in gaming;
- Apply knowledge to program advanced AI components for finely-tuned competition;
- Evaluate the effectiveness and ethical considerations of advanced AI in game design;
- Design and implement innovative AI-driven features for enhanced gameplay;
- Integrate advanced AI seamlessly into game systems for cohesive environments;
- Consider societal impact and consequences of AI applications in gaming;
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use the github repo as the source of truth for the schedule and materials. The materials provided in canvas are just a copy for archiving purposes and might be outdated.
College dates for the Spring 2024 semester:
Date Event Jan 16 Classes Begin Jan 16 - 22 Add/Drop Feb 26 - March 1 Midterms March 11 - March 15 Spring Break March 25 - April 5 Registration for Fall Classes April 5 Last Day to Withdraw April 8 - 19 Idea Evaluation April 12 No Classes - College remains open April 26 Last Day of Classes April 29 - May 3 Finals May 11 CommencementOld schedule for reference
"},{"location":"artificialintelligence/#introduction","title":"Introduction","text":"- Week 1. 2024/01/15
- Topic: AI for games, review of basic AI techniques
- Activities:
- Read all materials shared on Canvas;
- Do all assignments on Canvas;
- Week 2. 2024/01/22
- Topic: Wave Function Collapse
- Week 3. 2024/01/29
- Topic: Applying A* into continuous spaces
- Week 4. Date: 2024/02/05
- Topic: Applying A* into continuous spaces
- Week 5. 2024/02/12
- Topic: Testing your AI Agent, building meaningful tests, metrics, evaluation and machinations
- Week 6. 2024/02/19
- Topic: Testing your AI Agent, building meaningful tests, metrics, evaluation and machinations
- Week 7. Date: 2024/02/26
- Topic: Work sessions
- Week 8. 2024/03/04
- Topic: Min Max
- Week 09. 2024/03/11
- Topic: Spring BREAK. No classes this week.
- Week 10. 2024/03/18
- Topic: Monte Carlo Tree Search
- Week 11. 2024/03/25
- Topic: Chess
- Week 12. 2024/04/01
- Topic: Chess
- Week 13. 2024/04/08
- Topic: Chess
- Week 14. 2024/04/15
- Topic: Chess
- Week 15. 2024/04/22
- Topic: Work sessions for chess
- Week 16. 2024/04/26
- Topic: Finals Week / competition
Relevant dates for the Fall 2023 semester:
- 09-10 Oct 2023 - Midterms Week
- 20-24 Nov 2023 - Thanksgiving Break
- 11-15 Dec 2023 - Finals Week
slide test: test
LangChain
"},{"location":"artificialintelligence/#introduction_1","title":"Introduction","text":"- Week 1. 2023/08/28
- Topic: Introduction
- Formal Assignment: Flocking at Beecrowd
- Interactive Assignment: Flocking at MoBaGEn
- Week 2. 2023/09/04
- Topic: Flocking
- Formal Assignment: Flocking at Beecrowd
- Interactive Assignment: Flocking at MoBaGEn
- Week 3. 2023/09/11
- Topic: Automata Finite and 2D Grids
- Formal Assignment: Game of Life at Beecrowd
- Interactive Assignment: Game of Life at MoBaGEn
- Week 4. Date: 2023/09/18
- Topic: Pseudo Random Number Generation
- Formal Assignment: PRNG at Beecrowd
- Week 5. 2023/09/25
- Topic: Depth First Search, Random walk, Maze Generation
- Formal Assignment: Maze at Beecrowd
- Interactive Assignment: Maze at Mobagen
- Week 6. 2023/10/02
- Topic: Breadth First Search and Path Finding A*
- Interactive Assignment: Catch the Cat
- Week 7. Date: 2023/10/09
- Topic: Catch the Cat Challenge and Competition
- Catch the Cat
- Week 8. 2023/10/16
- Topic: Spatial Quantization and Partitioning
- Readings: Spatial Quantization
- Formal Assignment: Hide and Seek
- Week 9. 2023/10/23
- Topic: Spatial Quantization and Partitioning
- Readings: Spatial Quantization
- Formal Assignment: Hide and Seek
- Week 10. 2023/10/30
- Topic: Noise functions
- Formal Assignment:
- Interactive Assignment: Scenario Generation
- Week 11. 2023/11/06
- Topic: Procedural Content Generation - Scenario
- Formal Assignment:
- Interactive Assignment: Scenario Generation
- Week 12. 2023/11/13
- Topic: Procedural Content Generation - Scenario
- Formal Assignment:
- Interactive Assignment: Scenario Generation
- Week 13. 2023/11/20
- Topic: BREAK. No classes
- Week 14. 2023/11/27
- Topic: Work sessions for final project
- Week 15. 2023/12/04
- Topic: Work sessions for final project
- Week 16. 2023/12/11
- Topic: Final Presentations
Note
Please refer to this repository in order follow the previous assignments for the first course of AI. https://github.com/InfiniBrains/mobagen
Topics suggested in the survey, and some of my considerations.
- Procedural Content Generation. Advanced terrain generation - It was previously covered in the last class, I am going to focus other topics
- AI applied to improve 3D Animation Movement. Follow this https://github.com/sebastianstarke/AI4Animation
- Topics relating to an AI Fighting game - Mostly Agents, State Machines and latency simulation (reflex)
- Tactical AI - Linear programming, Restriction and Satisfiability problem
- Neuron networks / Machine learning - This can be real hard to cover all topics in this class
- Genetic algorithms and Reinforced learning - Find the best parameters for agent behaviors
- Chess AI - In a broader sense it is a table game, and it is mostly heuristics and state exploration, chess is awesome to learn optimization techniques to reduce memory usage, space exploration, branch and cut, minmax, planning and satisfaction
- Prediction algorithms for multiplayer - We can cover some techniques to extrapolate data to compensate lag instead of just mathematically extrapolate position, this is mostly an application of agent theory.
- Stable diffusion/chatbot - This is a hot topic, I didn't went too deep on that, but I can help you at least surf this wave to create fun stuff for games, such as dialog creation.
- Procedural audio generation - Most of them use convolutional networks mixed with recurrent neuron network. It can be real hard, so if we cover that, we are just goint to understand the overall idea, and learn how to use pre-determined models available for free.
- Behavior trees - I have to be honest this is a topic that I don't like, but it is a good tool to have in your toolbox, so I can cover it.
- ChatGPT and its siblings to generate text - I can cover at least how to modify small scoped model and use for your own intent.
- Stable Diffusion and its siblings to generate images - I can cover at least how to modify small scoped model and use for your own intent.
- AI subsystems and how to debug it.
- Spatial quantization optimized for AI queries - I really enjoy this, but it can be hard to understand, because it uses lots of data structures
Note for myself: game worldbox
"},{"location":"artificialintelligence/01-pcg/","title":"Procedural Content Generation","text":"PCG is a technique to algorithmically generate game content and assets, such as levels, textures, sound, enemies, quests, and more. The goal of PCG is to create unique and varied content without the need for manual labor. This can save time and money during development, and also allow for a more dynamic and replayable experience for the player. There are many different algorithms and techniques used in PCG, such as random generation, evolutionary algorithms, and rule-based systems.
PCG can also be used in other areas of game development such as textures, terrain, narrative, quests, and sound effects. With PCG, the possibilities are endless. It's important to note that PCG is not a replacement for human creativity, but rather a tool that can help create new and unique content. It is often used in conjunction with manual design and artistic direction.
"},{"location":"artificialintelligence/01-pcg/#procedural-scenario-generation","title":"Procedural Scenario Generation","text":"Procedural scenario generation is a specific application of procedural content generation that is used to create unique and varied scenarios or missions in a game. These scenarios can include objectives, enemies, and environmental elements such as terrain and buildings.
Two common techniques are rule and noise based algorithms, and you can combine both. But first let's cover Pseudo Random Number Generation.
"},{"location":"artificialintelligence/01-pcg/#random-number-generation","title":"Random Number Generation","text":"There are a plethora of algorithms to generate random numbers. The expected interface for a random number function is to just call it, (i.e. random()) and receive, ideally, a high quality and non-deterministic random number.
In the best scenario, some systems possess a random device (i.e. an antenna capturing electrical noise from the environment), and the random function will be a system call to it. Natural noise are stateless and subject only to the environmental influence that are (arguably) impossible to tamper. It is an awesome source of noise, but the problem is that device call is slow and not portable. So we need to use pseudo random number generators.
"},{"location":"artificialintelligence/01-pcg/#pseudo-random-number-generation","title":"Pseudo Random Number Generation","text":"In this field, the main challenge is to create a function capable to generate a sequence of numbers that are statistically random or, at least, can pass some tests of randomness at some degree of quality. The function must be fast, portable and deterministic, so it can be reproduced in different machines and platforms The function must be able to generate the same sequence of numbers given the same seed.
A common PRNG is XORShift. It is fast, portable and deterministic, but do not deliver a high quality of randomness. It is a good choice for games, but not for cryptography.
uint32_t xorshift32()\n{\n // seed and state 'x' must be non-zero\n // you should implement the state initialization differently\n static uint32_t x = 123456789;\n // XOR the state with itself shifted by 13, 17 and 5.\n // you can use other shifts, but these are the most common\n x ^= x << 13;\n x ^= x >> 17;\n x ^= x << 5;\n return x;\n}\nAs you might notice, the function is not stateless, so you have to initialize the state with a seed. It uses the previous state to generate the next one. A common practice is to use the system time as seed, or a random device call, but you can use any number you want. The seed is the only way to reproduce the sequence of numbers.
Another one is the Mersenne Twister. It is a high quality PRNG, but it is a bit slower.
"},{"location":"artificialintelligence/01-pcg/#noise-generation","title":"Noise Generation","text":""},{"location":"artificialintelligence/01-pcg/#noise-based-procedural-terrain-generation","title":"Noise based Procedural Terrain Generation","text":""},{"location":"artificialintelligence/01-pcg/#wave-function-collapse","title":"Wave function collapse","text":""},{"location":"artificialintelligence/01-pcg/#homework","title":"Homework","text":"You can either use your favorite game engine or use this repository as an entry point. 1. Use a noise function to generate a heightmap. Optional: Use octaves and fractals to make it feels nicer; 2. Implement islands reference or any other meaningful way to make hydraulically erosion apparent; 3. Implement Hydraulic Erosion to make the scenario feels more realistic. See the section 'HYDRAULIC EROSION' from book AI for Games Third ed. IanMillington; 4. Render the heightmap with biomes colors to make more understandable(ocean, sand, forest, mountains, snow...). Optionally use gradient / ramp functions instead of conditionals.
"},{"location":"artificialintelligence/01-pcg/#references","title":"References","text":"Procedural content generation is a broad topic, and we need to narrow down some applications and algorithms to cover. I carefully covered Maze generation and Scenario Generation here https://github.com/InfiniBrains/mobagen and I invite you to check the examples named maze and scenario. Besides that, Amit Patel have a really nice website focused in many game algorithms, check it out and support his work https://www.redblobgames.com/
Please refer to the book below. We are going to follow the contents mostly from it.
Book: https://amzn.to/3kvtNDS
"},{"location":"artificialintelligence/02-sm/","title":"State machines","text":"Some raw thoughts: - Probably a game of life is a good game to implement to showcase automata, state machines and decision making
"},{"location":"artificialintelligence/03-boardgames/","title":"Board Games","text":"Here we are going to cover - Space exploration; - Memory optimization; - MinMax; - Branch and cut; - Rule and goal based decision-making
The game we are going to cover here can be chess, rubbik cube or any card game.
"},{"location":"artificialintelligence/04-spatialhashing/","title":"Spatial Hashing","text":"A Spatial Hashing is a common technique to speed up queries in a multidimensional space. It is a data structure that allows you to quickly find all objects within a certain area of space. It is commonly used in games and simulations to speed up, artificial intelligence world queries, collision detection, visibility testing and other spatial queries.
Advantages of the spatial hashing:
- simple to implement;
- very fast: as fast as your key hashing function;
- easy to parallelize;
- a good choice for big worlds;
Problem with spatial hashing:
- it is not precise;
- it is not good for small worlds;
- needs fine tune to find the right cell size;
- have to update the bucket when the object moves;
- find the nearest objects is not trivial, you will have to query the adjacent cells;
The core of the spatial hashing is the bucket. It is a container that holds all the objects that are within a certain area of space contained in the cell area or volume. The terms cell and bucket can be interchangeable in this context.
In order to find buckets, you will have to create ways to quantize the world space into a grid of cells. It is hard to define the best cell size, but it is a good practice to make it be a couple of times bigger than the biggest object you have in the world. The cell size will define the precision of the spatial hashing, and the bigger it is, the less precise it will be.
"},{"location":"artificialintelligence/04-spatialhashing/#spatial-quantization","title":"Spatial quantization","text":"The spatial quantization is the process of converting a continuous space into a discrete space. This is the core process of finding the right bucket for an object. Let's assume that we have a 2D space, and we want to find the bucket for a given object.
// assuming Vector2f is a 2D vector with float components;\n// and Vector2i is a 2D vector with integer components;\n// the quantizations function will be:\nVector2<int32_t> quantized(float_t cellSize=1.0f) const {\n return Vector2<int32_t>{\n static_cast<int32_t>(std::floor(x + cellSize/2) / cellSize),\n static_cast<int32_t>(std::floor(y + cellSize/2) / cellSize)\n };\n}\nFirst, we have to decide the data structure your bucket will use to store the objects. The common choices are:
vector<GameObject*>- a vector of pointers to game objects;set<GameObject*>- a set of pointers to game objects;-
unordered_set<GameObject*>- an unordered_set of pointers to game objects; -
The problem of using a
vectoris that it is not efficient to remove, and find an object in it:O(n); but it is efficient to add (amortizedO(1)) and iterate over it (random access isO(1)). - The underlying data structure of a
setandmapis a binary search tree, so it is efficient to find, add and remove objects:O(lg(n)), but it is not efficient to iterate over it. - Now, the
unordered_setandunordered_mapis a hash table, so it is efficient to find, add and remove objects:O(1), and it is efficient to iterate over it. The overhead of using a hash table is the memory usage and the hashing function. It will be as fast as your hashing function.
In our use case, we will frequently list all elements in a bucket, we will add and remove elements from it, while they move in the world. So, the best choice is to use an unordered_set of pointers to game objects.
So lets define the bucket:
using std::unordered_set<GameObject*> = bucket_t;\nIdeally, we are looking for a data structure that will give us a bucket for a given position. We have some candidates for this job:
bucket_t[width][height]- a 2D array of buckets;vector<vector<bucket_t>>- a 2D vector of buckets;map<Vector2i, bucket_t>- a map of buckets;-
unordered_map<Vector2i, bucket_t>- a map of buckets; -
arrays andvectors are the fastest data structures to use, but they are not good choices if you have a sparse world; mapis a binary search tree;unordered_mapis a hash table.
The unordered_map is the best choice for this use case.
// quantized world\nunordered_map<Vector2i, go_bucket_t> world;\nSometimes we just want to iterate over all objects in the world, add and remove elements. In this case, we can use a unordered_set to store all game objects.
// all game objects for faster global world iteration and cleanup\ngo_bucket_t worldObjects;\nWhen you need to query the neighbors of an object, most of the time you will need to check the current cell and the adjacent cells. You can create a function for that or include the content of it in your logic.
// neighbor buckets. not memory intensive\n// returns the reference to the 9 buckets surrounding the given bucket, including itself\n// but on the usage, you will have to check \nvector<go_bucket_t*> neighborBuckets(const Vector2i& bucket) {\n vector<go_bucket_t*> neighbors;\n neighbors.reserve(9); // to avoid reallocations\n for (int i = -1; i <= 1; i++)\n for (int j = -1; j <= 1; j++){\n neighbors.push_back(&world()[Vector2i{bucket.x + i, bucket.y + j}]);\n }\n return neighbors;\n}\n\n// neighbors objects inside the 9 buckets surroundings the given bucket\n// memory intensive.\ngo_bucket_t neighborObjects(const Vector2i& bucket) {\n go_bucket_t neighbors;\n for (auto& b: neighborBuckets(bucket))\n neighbors.insert(b->begin(), b->end());\n return neighbors;\n}\nThis sample bellow a bit complex, but I added a bunch of support code to make it more complete, feel free to simplify it to your needs and split into multiple files.
#include <iostream> // for cout\n#include <unordered_map> // for unordered_map\n#include <unordered_set> // for unordered_set\n#include <random> // for random_device and default_random_engine\n#include <cmath> // for floor\n#include <cstdint> // for int32_t\n#include <vector> // for vector\n\n// to allow derivated structs to be used as keys in sorted containers and binary search algorithms\ntemplate<typename T>\nstruct IComparable { virtual bool operator<(const T& other) const = 0; };\n// to allow derivated structs to be used as keys in hash based containers and linear search algorithms\ntemplate<typename T>\nstruct IEquatable { virtual bool operator==(const T& other) const = 0; };\n\n// generic Vector2\n// requires that T is a int32_t or float_t\ntemplate<typename T>\n#ifdef __cpp_concepts\nrequires std::is_same_v<T, int32_t> || std::is_same_v<T, float_t>\n#endif\nstruct Vector2:\n public IComparable<Vector2<T>>,\n public IEquatable<Vector2<T>> {\n T x, y;\n Vector2(): x(0), y(0) {}\n Vector2(T x, T y): x(x), y(y) {}\n // operator equals\n bool operator==(const Vector2& other) const override {\n return this == &other || (x == other.x && y == other.y);\n }\n // operator < for being able to use it as a key in a map or set\n bool operator<(const Vector2& other) const override {\n return x < other.x || (x == other.x && y < other.y);\n }\n\n // quantize the vector to a 2d index\n // to nearest integer\n Vector2<int32_t> quantized(float_t cellSize=1.0f) const {\n return Vector2<int32_t>{\n static_cast<int32_t>(std::floor(x + cellSize/2) / cellSize),\n static_cast<int32_t>(std::floor(y + cellSize/2) / cellSize)\n };\n }\n};\n\n// specialized Vector2 for int and float\nusing Vector2i = Vector2<int32_t>;\n// float32_t is only available in c++23, so we use float_t instead\nusing Vector2f = Vector2<float_t>;\n\n// helper struct to generate unique id for game objects\n// mostly debug purposes\nstruct uid_type {\nprivate:\n static inline size_t nextId = 0; // to be used as a counter\n size_t uid; // to be used as a unique identifier\npublic:\n // not thread safe, but it is not a problem for this example\n uid_type(): uid(nextId++) {}\n inline size_t getUid() const { return uid; }\n};\n\n// generic game object implementation\n// replace this with your own data that you want to store in the world\nclass GameObject: public uid_type {\n Vector2f position;\npublic:\n GameObject();\n GameObject(const GameObject& other);\n // todo: add your other custom data here\n // when the it moves, it should check if it needs to update its bucket in the world\n void setPosition(const Vector2f& newPosition);\n Vector2f getPosition() const { return position; }\n};\n\n// hashing\nnamespace std {\n // Hash specialization for Vector2i\n template<>\n struct hash<Vector2i> {\n size_t operator()(const Vector2i& v) const {\n // shift and xor operator the other to get a unique hash\n // the problem of this approach is that it will generate neighboring cells with similar hashes\n // to fix that, you might want to use a more complex hashing function from std::hash<T>\n // copy to avoid const cast\n auto x = v.x, y = v.y;\n return (*reinterpret_cast<size_t*>(&x) << 32) ^ (*reinterpret_cast<size_t*>(&y));\n }\n };\n}\n\n// game object pointer\nusing GameObjectPtr = GameObject*;\n// alias for the game object bucket\nusing go_bucket_t = std::unordered_set<GameObjectPtr>;\n// alias for the world type\nusing world_t = std::unordered_map<Vector2i, go_bucket_t>;\n\n// singletons here are being used to avoid global variables and to allow the world to be used in a visible scope\n// you should use a better wrappers and abstractions in a real project\n// singleton world\nworld_t& world() {\n static world_t world;\n return world;\n}\n// singleton world objects\ngo_bucket_t& worldObjects(){\n static go_bucket_t worldObjects;\n return worldObjects;\n}\n\n// Constructor\nGameObject::GameObject(): uid_type(), position({0,0}) {\n // insert in the world\n worldObjects().insert(this);\n world()[position.quantized()].insert(this);\n}\n\n// Copy constructor\nGameObject::GameObject(const GameObject& other): uid_type(other), position(other.position) {\n // insert in the world\n worldObjects().insert(this);\n world()[position.quantized()].insert(this);\n}\n\n// this function requires the world to be in a visible scope like this or change it to access through a singleton\n// if in the movement, it changes its quantized position, we should remove it from the old bucket and insert it in the new one\nvoid GameObject::setPosition(const Vector2f& newPosition) {\n world_t& w = world();\n // bucket ids\n auto oldId = position.quantized();\n auto newId = newPosition.quantized();\n // update position\n position = newPosition;\n // check if it needs to update its bucket in the world\n if (newId == oldId)\n return;\n // remove from the old bucket\n w[oldId].erase(this);\n if(w[oldId].empty()) [[unlikely]] // c++20\n w.erase(oldId);\n // insert in the new bucket\n w[newId].insert(this);\n}\n\n// random vector2f\nVector2f randomVector2f(float_t min, float_t max) {\n static std::random_device rd;\n static std::default_random_engine re(rd());\n static std::uniform_real_distribution<float_t> dist(min, max);\n return Vector2f{dist(re), dist(re)};\n}\n\n// neighbor buckets. not memory intensive\n// returns potentially all 9 buckets surroundings the given bucket, including itself\nstd::vector<go_bucket_t*> neighborBuckets(const Vector2i& bucket) {\n std::vector<go_bucket_t*> neighbors;\n for (int i = -1; i <= 1; i++){\n for (int j = -1; j <= 1; j++){\n auto id = Vector2i{bucket.x + i, bucket.y + j};\n if(world().contains(id) && !world()[id].empty()) // contains is c++20\n neighbors.push_back(&world()[id]);\n }\n }\n return neighbors;\n}\n\n// neighbors objects inside the 9 buckets surroundings the given bucket\n// memory intensive. use with caution\ngo_bucket_t neighborObjects(const Vector2i& bucket) {\n go_bucket_t neighbors;\n for (auto& b: neighborBuckets(bucket))\n neighbors.insert(b->begin(), b->end());\n return neighbors;\n}\n\n// dump world\nvoid dumpWorld() {\n for (auto& bucket: world()) {\n std::cout << \"bucket: [\" << bucket.first.x << \",\" << bucket.first.y << \"]:\" << std::endl;\n for (auto& obj: bucket.second)\n std::cout <<\" - \"<< obj->getUid() << \": at (\" << obj->getPosition().x << \", \" << obj->getPosition().y << \")\" << std::endl;\n }\n std::cout << std::endl;\n}\n\nint main() {\n // fill the world with some game objects\n for (int i = 0; i < 121; i++) {\n // the constructor will insert it in the world\n auto obj = new GameObject();\n // randomly move the game objects\n // this will update their position and their bucket in the world\n obj -> setPosition(randomVector2f(-5, 5));\n }\n\n // dump the world\n dumpWorld();\n\n // remove all game objects\n for (auto& obj: worldObjects())\n delete obj;\n\n // clear refs\n worldObjects().clear();\n world().clear();\n\n return 0;\n}\n- Implement a spatial hashing for a 3D world;
- Implement another space partition technique, such as a quadtree/octree/kdtree and compare:
- the performance of both in scenarios of moving objects, searching for objects and adding / removing objects;
- memory consumption;
- which one will be slow down faster the bigger the world becomes;
KD-Trees are a special type of binary trees that are used to partition a k-dimensional space. They are used to solve the problem of finding the nearest neighbor of a point in a k-dimensional space. The name KD-Tree comes from the method of partitioning the space, the K stands for the number of dimensions in the space.
KD-tree are costly to mantain and balance. So use it only if you have a lot of queries to do, and the space is not changing. If you have a lot of queries, but the space is changing a lot, you should use a different data structure, such as a quadtree or a hash table.
"},{"location":"artificialintelligence/05-kdtree/#methodology","title":"Methodology","text":"- On the binary tree KD-Tree, each node represents a k-dimensional point;
- The tree is constructed by recursively partitioning the space into two half-spaces.
- The partitioning is done by selecting a dimension and a value, and then splitting the space into two half-spaces.
- The dimension and value are selected in such a way that the space is divided into two equal parts.
- The left child of a node contains all the points for that dimension that are less than the value, and the right child contains all the points that are greater than or equal to the value.
Let's consider the following 2D points:
(3, 1), (7, 15), (2, 14), (16, 2), (19, 13), (12, 17), (1, 9)\n{ \"$schema\": \"https://vega.github.io/schema/vega-lite/v4.json\", \"description\": \"A scatter plot of the points\", \"data\": { \"values\": [ {\"x\": 3, \"y\": 1}, {\"x\": 7, \"y\": 15}, {\"x\": 2, \"y\": 14}, {\"x\": 16, \"y\": 2}, {\"x\": 19, \"y\": 13}, {\"x\": 12, \"y\": 17}, {\"x\": 1, \"y\": 9} ] }, \"mark\": \"point\", \"encoding\": { \"x\": {\"field\": \"x\", \"type\": \"quantitative\"}, \"y\": {\"field\": \"y\", \"type\": \"quantitative\"} } }
The first step is to define the root. For that we need do define two things: the dimension and the value:
- For the dimension we need to select the one that has the largest range.
- For the value we need to select the median of that dimension.
So if we sort the points by the axis, we will have:
SortedByX = (1, 9), (3, 1), (2, 14), (7, 15), (12, 17), (16, 2), (19, 13)\nSortedByY = (3, 1), (16, 2), (1, 9), (19, 13), (7, 15), (3, 15), (12, 17)\nThe largest range is on the X axis, so we will select the median of the X axis as the root. The median of the X axis is (7, 15), and the starting dimension will be X.
For the next level, the left side candidates will be the ones with X less than (7, 15), and the right side, the ones that are greater or equal to (7, 15). But now this level will be governed sorted by Y:
LeftSortedByY = (3, 1), (1, 9), (2, 14)\nRightSortedByY = (16, 2), (19, 13), (12, 17)\nGraph showing the first split on X at (7, 15):
The median for the left side is (1, 9), and for the right side is (19, 13).
The current state of the tree is:
{ \"$schema\": \"https://vega.github.io/schema/vega-lite/v4.json\", \"description\": \"A scatter plot of the points\", \"encoding\": { \"x\": {\"field\": \"x\", \"type\": \"quantitative\"}, \"y\": {\"field\": \"y\", \"type\": \"quantitative\"} }, \"layer\": [ { \"data\": { \"values\": [ {\"x\": 3, \"y\": 1}, {\"x\": 7, \"y\": 15}, {\"x\": 2, \"y\": 14}, {\"x\": 16, \"y\": 2}, {\"x\": 19, \"y\": 13}, {\"x\": 12, \"y\": 17}, {\"x\": 1, \"y\": 9} ] }, \"mark\": \"point\" }, { \"data\": { \"values\": [ {\"x\": 7, \"y\": 0}, {\"x\": 7, \"y\": 20} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#DB745B\" } } } ] }
Now we apply the same rules for the children of the left and right nodes.
graph TD\n Root(07,15)\n Left(01,09)\n Right(19,13)\n LeftLeft(03,01)\n LeftRight(02,14)\n RightLeft(16,02)\n RightRight(12,17)\n Root --> |x<7| Left\n Root --> |x>7| Right\n Left --> |y<9| LeftLeft\n Left --> |y>9| LeftRight\n Right --> |y<13| RightLeft\n Right --> |y>13| RightRightThe tree will be:
{ \"$schema\": \"https://vega.github.io/schema/vega-lite/v4.json\", \"description\": \"A scatter plot of the points\", \"encoding\": { \"x\": {\"field\": \"x\", \"type\": \"quantitative\"}, \"y\": {\"field\": \"y\", \"type\": \"quantitative\"} }, \"layer\": [ { \"data\": { \"values\": [ {\"x\": 3, \"y\": 1}, {\"x\": 7, \"y\": 15}, {\"x\": 2, \"y\": 14}, {\"x\": 16, \"y\": 2}, {\"x\": 19, \"y\": 13}, {\"x\": 12, \"y\": 17}, {\"x\": 1, \"y\": 9} ] }, \"mark\": \"point\" }, { \"data\": { \"values\": [ {\"x\": 7, \"y\": 0}, {\"x\": 7, \"y\": 20} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#DB745B\" } } }, { \"data\": { \"values\": [ {\"x\": 0, \"y\": 9}, {\"x\": 7, \"y\": 9} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#4F72DB\" } } }, { \"data\": { \"values\": [ {\"x\": 7, \"y\": 13}, {\"x\": 20, \"y\": 13} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#4F72DB\" } } } ] }
And lastly, we will have:
{ \"$schema\": \"https://vega.github.io/schema/vega-lite/v4.json\", \"description\": \"A scatter plot of the points\", \"encoding\": { \"x\": {\"field\": \"x\", \"type\": \"quantitative\"}, \"y\": {\"field\": \"y\", \"type\": \"quantitative\"} }, \"layer\": [ { \"data\": { \"values\": [ {\"x\": 3, \"y\": 1}, {\"x\": 7, \"y\": 15}, {\"x\": 2, \"y\": 14}, {\"x\": 16, \"y\": 2}, {\"x\": 19, \"y\": 13}, {\"x\": 12, \"y\": 17}, {\"x\": 1, \"y\": 9} ] }, \"mark\": \"point\" }, { \"data\": { \"values\": [ {\"x\": 7, \"y\": 0}, {\"x\": 7, \"y\": 20} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#DB745B\" } } }, { \"data\": { \"values\": [ {\"x\": 0, \"y\": 9}, {\"x\": 7, \"y\": 9} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#4F72DB\" } } }, { \"data\": { \"values\": [ {\"x\": 7, \"y\": 13}, {\"x\": 20, \"y\": 13} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#4F72DB\" } } }, { \"data\": { \"values\": [ {\"x\": 3, \"y\": 0}, {\"x\": 3, \"y\": 9} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#93DB35\" } } }, { \"data\": { \"values\": [ {\"x\": 2, \"y\": 9}, {\"x\": 2, \"y\": 20} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#93DB35\" } } }, { \"data\": { \"values\": [ {\"x\": 12, \"y\": 13}, {\"x\": 12, \"y\": 20} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#93DB35\" } } }, { \"data\": { \"values\": [ {\"x\": 16, \"y\": 13}, {\"x\": 16, \"y\": 0} ] }, \"mark\": \"line\", \"encoding\": { \"color\": { \"value\": \"#93DB35\" } } } ] }
"},{"location":"artificialintelligence/05-kdtree/#implementation","title":"Implementation","text":"#include <iostream>\n#include <vector>\n#include <algorithm>\n\n// vector\nstruct Vector2f {\n float x, y;\n Vector2f(float x, float y) : x(x), y(y) {}\n // subscript operator to be used in the KDTree\n float& operator[](size_t index) {\n return index%2 == 0 ? x : y;\n }\n // distanceSqrd between two vectors\n float distanceSqrd(const Vector2f& other) const {\n return (x - other.x)*(x - other.x) + (y - other.y)*(y - other.y);\n }\n};\n\n// your object data structure\nclass GameObject {\n // your other data\npublic:\n Vector2f position;\n explicit GameObject(Vector2f position={0,0}) : position(position) {}\n};\n\n// KDNode\nstruct KDNode {\n GameObject* object;\n KDNode* left;\n KDNode* right;\n KDNode(GameObject* object, KDNode* left = nullptr, KDNode* right= nullptr) :\n object(object),\n left(left),\n right(right)\n {}\n};\n\n// KDTree manager\nclass KDTree {\npublic:\n KDNode* root;\n KDTree() : root(nullptr) {}\n\n ~KDTree() {\n // interactively delete the nodes\n std::vector<KDNode*> nodes;\n nodes.push_back(root);\n while (!nodes.empty()) {\n KDNode* current = nodes.back();\n nodes.pop_back();\n if (current->left != nullptr) nodes.push_back(current->left);\n if (current->right != nullptr) nodes.push_back(current->right);\n delete current;\n }\n }\n\n void insert(GameObject* object) {\n if (root == nullptr) {\n root = new KDNode(object);\n } else {\n KDNode* current = root;\n size_t dimensionId = 0;\n while (true) {\n if (object->position[dimensionId] < current->object->position[dimensionId]) {\n if (current->left == nullptr) {\n current->left = new KDNode(object);\n break;\n } else {\n current = current->left;\n }\n } else {\n if (current->right == nullptr) {\n current->right = new KDNode(object);\n break;\n } else {\n current = current->right;\n }\n }\n dimensionId++;\n }\n }\n }\n\n void insert(std::vector<GameObject*> objects, int dimensionId=0 ) {\n if(objects.empty()) return;\n if(objects.size() == 1) {\n insert(objects[0]);\n return;\n }\n // find the median for the current dimension\n std::sort(objects.begin(), objects.end(), [dimensionId](GameObject* a, GameObject* b) {\n return a->position[dimensionId] < b->position[dimensionId];\n });\n // insert the median\n auto medianIndex = objects.size() / 2;\n insert(objects[medianIndex]);\n\n // insert the left and right exluding the median\n insert(std::vector<GameObject*>(objects.begin(), objects.begin() + medianIndex), (dimensionId + 1) % 2);\n insert(std::vector<GameObject*>(objects.begin() + medianIndex + 1, objects.end()), (dimensionId + 1) % 2);\n }\n\n // get the nearest neighbor\n GameObject* nearestNeighbor(Vector2f position) {\n return NearestNeighbor(root, position, root->object, root->object->position.distanceSqrd(position), 0);\n }\n\n GameObject* NearestNeighbor(KDNode* node, Vector2f position, GameObject* best, float bestDistance, int dimensionId) {\n // create your own Nearest Neighbor algorithm. That's not hard, just follow the rules\n // 1. If the current node is null, return the best\n // 2. If the current node is closer to the position, update the best\n // 3. If the current node is closer to the position than the best, search the children\n // 4. If the current node is not closer to the position than the best, search the children\n // 5. Return the best\n }\n\n // draw the tree\n void draw() {\n std::vector<KDNode*> nodes;\n // uses space to shaw the level of the node\n std::vector<std::string> spaces;\n nodes.push_back(root);\n spaces.push_back(\"\");\n while (!nodes.empty()) {\n KDNode* current = nodes.back();\n std::string space = spaces.back();\n nodes.pop_back();\n spaces.pop_back();\n if (current->right != nullptr) {\n nodes.push_back(current->right);\n spaces.push_back(space + \" \");\n }\n std::cout << space << \":> \" << current->object->position.x << \", \" << current->object->position.y << std::endl;\n if (current->left != nullptr) {\n nodes.push_back(current->left);\n spaces.push_back(space + \" \");\n }\n }\n }\n};\n\nint main(){\n // nodes: (3, 1), (7, 15), (2, 14), (16, 2), (19, 13), (12, 17), (1, 9)\n KDTree tree;\n std::vector<GameObject*> objects = {\n new GameObject(Vector2f(3, 1)),\n new GameObject(Vector2f(7, 15)),\n new GameObject(Vector2f(2, 14)),\n new GameObject(Vector2f(16, 2)),\n new GameObject(Vector2f(19, 13)),\n new GameObject(Vector2f(12, 17)),\n new GameObject(Vector2f(1, 9))\n };\n // insert the objects\n tree.insert(objects);\n // draw the tree\n tree.draw();\n // get the nearest neighbor to (10, 10)\n GameObject* nearest = tree.nearestNeighbor(Vector2f(3, 15));\n std::cout << \"Nearest neighbor to (3, 15): \" << nearest->position.x << \", \" << nearest->position.y << std::endl;\n // will print 2, 14\n return 0;\n}\n- Implement the KDTree in your favorite language;
- Improve the KDTree to support 3D;
- Implement more methods to make it dynamic: insert, remove, update;
- Modify the KDTree to be balanced on insertion;
In order to build an A-star pathfinding algorithm, we need to define some data structures. We need:
- Index for the quantized map;
- Position for the game objects;
- Bucket to query in O(1) if the elements are there;
- Map from Index to Buckets;
- Priority Queue to store the frontier of visitable buckets;
- Vector of Indexes to store the path;
In order to A-star to work in a continuous space, we should quantize the space position into indexes.
// generic vector2 struct to work with floats and ints\ntemplate <typename T>\n// requires T to be int32_t or float_t\nrequires std::is_same<T, int32_t>::value || std::is_same<T, float_t>::value // C++20\nstruct Vector2 {\n // data\n T x, y;\n // constructors\n Vector2() : x(0), y(0) {}\n Vector2(T x, T y) : x(x), y(y) {}\n // copy constructor\n Vector2(const Vector2& v) : x(v.x), y(v.y) {}\n // assignment operator\n Vector2& operator=(const Vector2& v) {\n x = v.x;\n y = v.y;\n return *this;\n }\n // operators\n Vector2 operator+(const Vector2& v) const {\n return Vector2(x + v.x, y + v.y);\n }\n Vector2 operator-(const Vector2& v) const {\n return Vector2(x - v.x, y - v.y);\n }\n // distance\n float distance(const Vector2& v) const {\n return sqrt((x - v.x) * (x - v.x) + (y - v.y) * (y - v.y));\n }\n // distance squared\n float distanceSquared(const Vector2& v) const {\n return (x - v.x) * (x - v.x) + (y - v.y) * (y - v.y);\n }\n // quantize to index2\n Vector2<int32_t> quantized(float scale=1) const {\n return {(int32_t)std::round(x / scale), (int32_t)std::round(y / scale)};\n }\n // operator < for std::map\n bool operator<(const Vector2& v) const {\n return x < v.x || (x == v.x && y < v.y);\n }\n // operator == for std::map\n bool operator==(const Vector2& v) const {\n return x == v.x && y == v.y;\n }\n};\n- The operators
<and==are required to use the Vector2 as a key in a std::map. - The
quantizedmethod is used to convert a position into an index. - The
distanceanddistanceSquaredmethods are used to calculate the distance between two positions. Is used on A-star to calculate the cost to reach a neighbor or the distance to the goal.
using Index2 = Vector2<int32_t>;\nusing Position2 = Vector2<float_t>;\nI am going to use Index2 to store the quantized index in the grid and Position2 to store the continuous position.
// hash function for std::unordered_map\ntemplate <>\nstruct std::hash<Index2> {\n size_t operator()(const Index2 &v) const {\n return (((size_t)v.x) << 32) ^ (size_t)v.y;\n }\n};\nThis hash function is for the std::unordered_map and std::unordered_set to work with Index2.
In order to have an easy way to query if a game object is in a bucket, we need to use an std::unordered_set of pointers to the game objects. In order to index them, we will use an std::unordered_map from Index2 to std::unordered_set.
std::unordered_map<Index2, std::unordered_set<GameObject*>> quantizedMap;\nYour scenario might have different costs to reach a bucket. You can use an std::unordered_map to store the cost of each bucket.
std::unordered_map<Index2, float> costMap;\nYou might want to avoid some buckets. You can use an std::unordered_map to store the walls.
std::unordered_map<Index2, bool> isWall;\nIn order to store the frontier of visitable buckets, we need to use a std::priority_queue of pairs of float and Index2.
std::priority_queue<std::pair<float, Index2>> frontier;\n/**\nIn order to build an A-star pathfinding algorithm, we need to define some data structures. We need:\n- Index for the quantized map;\n- Position2 for the game objects;\n- Bucket to query in O(1) if the elements are there;\n- Map from Index to Buckets;\n- Priority Queue to store the frontier of visitable buckets;\n- Vector of Indexes to store the path;\n*/\n\n#include <iostream>\n#include <unordered_map>\n#include <unordered_set>\n#include <cmath>\n#include <vector>\n#include <queue>\n\nusing std::pair;\n\ntemplate<typename K, typename V>\nusing umap = std::unordered_map<K, V>;\n\ntemplate<typename T>\nusing uset = std::unordered_set<T>;\n\ntemplate<typename T>\nusing pqueue = std::priority_queue<T>;\n\n// generic vector2 struct to work with floats and ints\ntemplate <typename T>\n// requires T to be int32_t or float_t\nrequires std::is_same<T, int32_t>::value || std::is_same<T, float_t>::value // C++20\nstruct Vector2 {\n // data\n T x, y;\n // constructors\n Vector2() : x(0), y(0) {}\n Vector2(T x, T y) : x(x), y(y) {}\n // copy constructor\n Vector2(const Vector2& v) : x(v.x), y(v.y) {}\n // assignment operator\n Vector2& operator=(const Vector2& v) {\n x = v.x;\n y = v.y;\n return *this;\n }\n // operators\n Vector2 operator+(const Vector2& v) const {\n return Vector2(x + v.x, y + v.y);\n }\n Vector2 operator-(const Vector2& v) const {\n return Vector2(x - v.x, y - v.y);\n }\n // distance\n float distance(const Vector2& v) const {\n return sqrt((x - v.x) * (x - v.x) + (y - v.y) * (y - v.y));\n }\n // distance squared\n float distanceSquared(const Vector2& v) const {\n return (float)(x - v.x) * (x - v.x) + (float)(y - v.y) * (y - v.y);\n }\n // quantize to index2\n Vector2<int32_t> quantized(float scale=1) const {\n return {(int32_t)std::round(x / scale), (int32_t)std::round(y / scale)};\n }\n // operator < for std::map\n bool operator<(const Vector2& v) const {\n return x < v.x || (x == v.x && y < v.y);\n }\n // operator == for std::map\n bool operator==(const Vector2& v) const {\n return x == v.x && y == v.y;\n }\n};\n\nusing Index2 = Vector2<int32_t>;\nusing Position2 = Vector2<float_t>;\n\n// implement this struct to store game objects by yourself\nstruct GameObject {\n Position2 position;\n // add here your other data\n\n GameObject(const Position2& position) : position(position) {}\n GameObject() : position(Position2()) {}\n};\n\n// hash function for std::unordered_map\ntemplate <>\nstruct std::hash<Index2> {\n size_t operator()(const Index2 &v) const {\n return (((size_t)v.x) << 32) | (size_t)v.y;\n }\n};\n\n// The game objects organized into buckets\numap<Index2, uset<GameObject*>> quantizedMap;\n// all game objects\nuset<GameObject*> gameObjects;\n// The cost of each bucket\numap<Index2, float> costMap;\n// The walls\numap<Index2, bool> isWall;\n\n// Pathfinding algorithm from position A to position B\nstd::vector<Index2> findPath(const Position2& startPos, const Position2& endPos) {\n // quantize\n Index2 start = startPos.quantized();\n Index2 end = endPos.quantized();\n\n // datastructures\n pqueue<pair<float, Index2>> frontier; // to store the frontier of visitable buckets\n umap<Index2, float> accumulatedCosts; // to store the cost to reach a bucket\n\n // initialize\n accumulatedCosts[start] = 0;\n frontier.emplace(0, start);\n\n // main loop\n while (!frontier.empty()) {\n // consume first element from the frontier\n auto current = frontier.top().second;\n frontier.pop();\n\n // quit early\n if (current == end)\n break;\n\n // iterate over neighbors\n auto candidates = {\n current + Index2(1, 0),\n current + Index2(-1, 0),\n current + Index2(0, 1),\n current + Index2(0, -1)\n };\n for (const auto& next : candidates) {\n // skip walls\n if(isWall.contains(current))\n continue;\n // if the neighbor has not been visited and is not on frontier\n // calculate the cost to reach the neighbor\n float newCost =\n accumulatedCosts[current] + // cost so far\n current.distance(next) + // cost to reach the neighbor\n (costMap.contains(next) ? costMap[next] : 0); // cost of the neighbor\n // if the cost is lower than the previous cost\n if (!accumulatedCosts.contains(next) || newCost < accumulatedCosts[next]) {\n // update the cost\n accumulatedCosts[next] = newCost;\n // calculate the priority\n float priority = newCost + next.distance(end);\n // push the neighbor to the frontier\n frontier.emplace(-priority, next);\n }\n }\n }\n\n // reconstruct path\n std::vector<Index2> path;\n Index2 current = end;\n while (current != start) {\n path.push_back(current);\n auto candidates = {\n current + Index2(1, 0),\n current + Index2(-1, 0),\n current + Index2(0, 1),\n current + Index2(0, -1)\n };\n for (const auto& next : candidates) {\n if (accumulatedCosts.contains(next) && accumulatedCosts[next] < accumulatedCosts[current]) {\n current = next;\n break;\n }\n }\n }\n path.push_back(start);\n std::reverse(path.begin(), path.end());\n return path;\n}\n\nint main() {\n/*\nmap. numbers are bucket cost, letters are objects, x is wall\nA 0 5 0 0 0\n0 X X 0 0 0\n5 X 0 0 5 0\n0 0 0 5 B 5\n0 0 0 0 5 0\n */\n\n // Create 2 Game Objects\n GameObject a(Position2(0.1, 0.1));\n GameObject b(Position2(3.9, 4.1));\n\n // place walls\n isWall[Index2(1, 1)] = true;\n isWall[Index2(1, 2)] = true;\n isWall[Index2(2, 1)] = true;\n\n // add cost to some buckets\n // should avoid these:\n costMap[Index2(2, 0)] = 5;\n costMap[Index2(0, 2)] = 5;\n // should pass-through these:\n costMap[Index2(5, 4)] = 5;\n costMap[Index2(3, 4)] = 5;\n costMap[Index2(4, 3)] = 5;\n costMap[Index2(4, 5)] = 5;\n\n // add game objects to the set\n gameObjects.insert(&a);\n gameObjects.insert(&b);\n\n // add game objects to the quantized map\n for (auto& g : gameObjects)\n quantizedMap[g->position.quantized()].insert(g);\n\n // find path\n auto path = findPath(a.position, b.position);\n\n // todo: smooth the path between the points\n\n // print path\n for (auto& p : path)\n std::cout << \"(\" << p.x << \", \" << p.y << \") \";\n std::cout << std::endl;\n // will print (0, 0) (1, 0) (1, -1) (2, -1) (3, -1) (3, 0) (3, 1) (3, 2) (3, 3) (4, 3) (4, 4)\n\n return 0;\n}\nThere are several ways to use AI as a testing tool.
- Analytics
- Predicting behavior;
- A/B Testing;
- Game Environment Automated Testing via AI agents;
- Test Case Generation;
- Anti-cheat systems;
Analytics is the most common way to use AI as a testing tool. You can use AI to track the user behavior and use the data to improve the game. But with that you can only analyze the past.
You might want to track all user interactions, and use AI to analyze the data and give you insights on how to improve the game. This will be the core of many other AI testing tools.
The common ways to track the user interactions are:
- Send events to a server;
- Use a third-party service to track the user interactions;
- Progression funnels;
- Heatmaps;
- User paths;
- Map all deaths / kills / wins / losses;
- Store the replay of the user interactions;
You can train an AI model to predict the behavior of the user to abandon the game, and intervene before it happens.
In order to achieve this, you can track the user interactions and the consequences of those interactions. You can use a supervised learning algorithm to predict the behavior of the user. Once you discover the pattern, you can intervene and try to change the user behavior.
Example: If the player is loosing too much, you can give him a boost to keep him playing. Or automatically change the difficulty of the game. Another good example is when you predict the user is going to abandon the game, you can give him a reward to keep him playing, or allow him to ask for more lives on social media friends.
"},{"location":"artificialintelligence/07-automatedtesting/#forcing-the-user-to-take-a-break","title":"Forcing the user to take a break","text":"Sometimes you want to avoid the user to get burned out and force him to take a break. This is a common practice in mobile games.
If your game gives rewards for plaing every day, or every session. You can use AI to predict when the user is going to play again and send him a notification to play again.
This can be a bit shady, but, another use case is to force the game to get harder if the user is playing too much. And when it loses, add a timer to unlock the game again. You can even use this moment to show ads, or ask for money to unlock the game again. Can you think in a game like this?
"},{"location":"artificialintelligence/07-automatedtesting/#ab-testing","title":"A/B Testing","text":"A/B testing is a way to compare two versions of a configuration setting or a feature to determine which one is better. It relies on remote configuration and the statistical analysis to determine which one is better.
The process is simple:
- A developer create 2 scenarios to test. Ex.: the color of a button to buy a product (Red or Blue);
- The system will randomly select one of the scenarios to show to the user;
- The system will collect data from the user interaction;
- The system will compare the data from the two scenarios and determine which one is better;
- The system will select the best scenario to be the default one;
This can be really hard to implement, but in summary is to create AIs that can play as humans and test the game. This can be used to test the game balance, the game difficulty, the game mechanics and the game performance.
If you are just trying to test game rules, or economy, you might wanna try to use a genetic algorithm to evolve the best strategy for a given game.
If you are looking for creating a bot to find hardlocks where the player might fall and not recover, or detect bugs, you might try to use a reinforcement learning algorithm.
This field is so vast that is hard to cover in a single section. I will use this in class just to see how it works.
"},{"location":"artificialintelligence/07-automatedtesting/#test-case-generation","title":"Test Case Generation","text":"You can use AI to generate test cases for your game. There are plenty of LLMs online that can can read your code and generate test cases for you.
"},{"location":"artificialintelligence/07-automatedtesting/#anti-cheat-systems","title":"Anti-cheat systems","text":"You can detect cheaters using AI. But you will have to be careful to not ban innocent players. You can use AI to detect patterns of cheating and intervene before it happens.
Possible patterns to detect: Speed hacks; Aim bots; Wall hacks, ESP hacks, Macros; Auto-clickers; Memory hacks. and much more.
"},{"location":"artificialintelligence/07-automatedtesting/#shadow-banning","title":"Shadow banning","text":"It is a common technique to ban cheaters. You can shadow-ban a cheater by making him play with other cheaters only. This way, the cheater will not know he is banned, but he will only play with other cheaters. This can be done using AI to detect the cheaters and put them in the same match.
"},{"location":"artificialintelligence/07-automatedtesting/#serious-sam-3-bfe-serious-digital-edition","title":"Serious Sam 3: BFE (Serious Digital Edition):","text":"The protagonist encounters an invincible, extremely fast and screaming scorpion-like enemy, making the game nearly impossible to progress.
"},{"location":"artificialintelligence/07-automatedtesting/#game-dev-tycoon","title":"Game Dev Tycoon:","text":"In the pirated versions, players find themselves struggling to make a profit as their virtual game studio is plagued by piracy.
"},{"location":"artificialintelligence/07-automatedtesting/#batman-arkham-asylum","title":"Batman: Arkham Asylum:","text":"Batman's cape doesn't work properly, leading to a rather comical and dysfunctional experience.
"},{"location":"artificialintelligence/07-automatedtesting/#mirrors-edge","title":"Mirror's Edge:","text":"Faith is unable to progress past a certain point due to an inability to grab a ledge, hindering the player's ability to complete the level.
"},{"location":"artificialintelligence/07-automatedtesting/#earthbound-mother-2","title":"Earthbound (Mother 2):","text":"In pirated copies, the game triggers a constant stream of inescapable enemy encounters.
Can you think in other examples?
"},{"location":"artificialintelligence/09-minmax/","title":"Min-Max Algorithm","text":"Commonly while you build a tree of options, (say path, decisions, states or anything else), you will have to make a decision at each node of the tree to deepen the search. The min-max algorithm is a nice and easy approach to solve this problem. It might be used in games, decision making, and other fields.
"},{"location":"artificialintelligence/09-minmax/#use-cases","title":"Use cases","text":"Min-Max algorithms shines in places where you will have to maximize the gain and minimize the loss.
"},{"location":"artificialintelligence/09-minmax/#algorithm","title":"Algorithm","text":""},{"location":"artificialintelligence/09-minmax/#alpha-beta-prunning","title":"Alpha beta prunning","text":""},{"location":"artificialintelligence/09-minmax/#alpha","title":"Alpha","text":"- Alpha is the best value that the maximizer currently can guarantee at that level or above.
- It is the lower bound that a MAX node can be assigned.
- MAX node will only update the value of alpha if it finds a value greater than alpha.
- Starts at -\u221e.
- Beta is the best value that the minimizer currently can guarantee at that level or above.
- It is the upper bound that a MIN node can be assigned.
- MIN node will only update the value of beta if it finds a value less than beta.
- Starts at +\u221e.
https://cascadeur.com/
https://www.youtube.com/watch?v=14tNq-fqTmQ
https://www.youtube.com/watch?v=wAbLsRymXe4
https://github.com/sebastianstarke/AI4Animation
"},{"location":"artificialintelligence/assignments/","title":"Setup the repos","text":"- Read about Privacy and FERPA compliance here
- This one, for in class coding assignments. https://github.com/InfiniBrains/Awesome-GameDev-Resources
- MoBaGEn, for interactive assignments. https://github.com/InfiniBrains/mobagen
- Install
CLion(hasCMakeembedded) or see #development-tools - Those repositories are updated constantly. Pay attention to syncing your repo frequently.
There are two types of coding assignments:
- Algorithm: Beecrowd - This is an automatic grading system, and I am still creating assignments for it. I will try my best to make it work through it. If it does not work, you could just submit the code on canvas and I will grade it manually. Those should solved using C++ ;
-
Interactive: For the interactive assignments you can choose whatever Game Engine you like, but I recommend you to use the framework I created for you: MoBaGEn. If you use a Game Engine or custom solution for that, you will have to create all debug interfaces to showcase and debug AI wich includes, but it is not limited to:
- Draw vectors to show forces applied by the AI;
- Menus to change AI parameters;
Danger
Under no circunstaces, you should make your algorithm solutions public. Be aware that I spend so much time creating them and it is hard to me to always create new assignments.
"},{"location":"artificialintelligence/assignments/#code-assignments","title":"Code assignments","text":"Warning
If you are a enrolled in a class that uses this material, you SHOULD use the institutional and internal git server to be FERPA compliant. If you want to use part of this assignments to build your portfolio I recommend you to use github and make only the interactive assignment public. If you are just worried about privacy concerns, you can use a private repo on github.
- Create an account on github.com or any
githosting on your preference; -
Fork repos or duplicate the target repo on your account;
- If you want to make it count as part of your portfolio, fork the repo follow this;
- If you want to keep it private or be FERPA compliant, duplicate the repo following this;
-
Add my user to your repo to it with
readrole. My userid istolstenko(or your professor) on github, for other options, talk with me in class. Follow this; - Send me a message on canvas with the link to your repo;
In all interactive assignmets, you will have to record a 5 minute video explaing your code. Use OBS or any software you prefer to record your screen while you explain your code. But for this one, just send me the video showing the repo and the repo invites sent to me.
"},{"location":"artificialintelligence/assignments/#development-tools","title":"Development tools","text":"I will be using CMake for the classes, but you can use whatever you want. Please read this to understand the C++ toolset.
In this class, I am going to use CLion as the IDE, because it has nice support for CMake and automated tests.
- Download it here.
- If you are a student, you can get a free license here.
If you want to use Visual Studio , be assured that you have the C++ Desktop Development workload installed, more info this. And then go to Individual Components and install CMake Tools for Windows .
Note
If you use Visual Studio , you won't be able to use the automated testing system that comes with the assignments.
[OPINION]: If you want to use a lightweight environment, don't use VS Code for C++ development. Period. It is not a good IDE for that. It is preferred to code via sublime, notepad, vim, or any other text editor and then compile your code via terminal, and debug via gdb, than using VS Code for C++ development.
"},{"location":"artificialintelligence/assignments/#openning-the-repos","title":"Openning the Repos","text":"- (Fork and) clone the repos;
- Open
CLionor yor preferredIDEwithCMakesupport; - Open the
CMakeLists.txtas project from the root of the repo; - Wait for the setup to finish (it will download the dependencies automatically, such as
SDL);
For the interactive assignments, use this repo and the assignments are located in the examples folder.
For the algorithmic assignments, use this repo and the assignments are located in the courses/artificialintelligence/assignments folder. I created some automated tests to help you debug your code and ensure 100% of correctness. To run them, follow the steps (only available though CLion or terminal, not Visual Studio ):
- Go to the executable drop down selection (top right, near the green
runordebugbutton) and select the assignment you want to run. It will be something likeai-XXXwhereXXXis the name of the assignment; - If you want to test your assignment against the automated inputs/outputs, select the
ai-XXX-testbuild target. Here you should use thebuildbutton, not therunordebugbutton. It will run the tests and show the results in theConsoletab;
You are in charge of implementing some functions to make some AI agents flock together in a game. After finishing it, you will be one step further to render it in a game engine, and start making reactive NPCs and enemies. You will learn all the basic concepts needed to code and customize your own AI behaviors.
"},{"location":"artificialintelligence/assignments/flocking/#what-is-flocking","title":"What is flocking?","text":"Flocking is a behavior that is observed in birds, fish and other animals that move in groups. It is a very simple behavior that can be implemented with a few lines of code. The idea is that each agent will try to move towards the center of mass of the group (cohesion), and will try to align its velocity with the average velocity of the group (AKA alignment). In addition, each agent will try to avoid collisions with other agents (AKA avoidance).
Formal Notation Review
- \\( \\vec{F} \\) means a vector \\( F \\) that has components. In a 2 dimensional vector it will hold \\( F_x \\) and \\( F_y \\). For example, if \\( F_x = 1 \\) and \\( F_y = 3 \\), then \\( \\vec{F} = (1,3) \\)
- Simple math operations between vectors are done component-wise. For example, if \\( \\vec{F} = (1,1) \\) and \\( \\vec{G} = (2,2) \\), then \\( \\vec{F} + \\vec{G} = (3,3) \\)
- The notation \\( \\overrightarrow{P_{1}P_{2}} \\) means the vector that goes from \\( P_1 \\) to \\( P_2 \\). It is the same as \\( P_2-P_1 \\)
- The modulus notation means the length (magnitude) of the vector. \\( |\\vec{F}| = \\sqrt{F_x^2+F_y^2} \\) For example, if \\( \\vec{F} = (1,1) \\), then \\( |\\vec{F}| = \\sqrt{2} \\)
- The hat ^ notation means the normalized vector(magnitude is 1) of the vector. \\( \\hat{F} = \\frac{\\vec{F}}{|\\vec{F}|} \\) For example, if \\( \\vec{F} = (1,1) \\), then \\( \\hat{F} = (\\frac{1}{\\sqrt{2}},\\frac{1}{\\sqrt{2}}) \\)
- The hat notation over 2 points means the normalized vector that goes from the first point to the second point. \\( \\widehat{P_1P_2} = \\frac{\\overrightarrow{P_1P_2}}{|\\overrightarrow{P_1P_2}|} \\) For example, if \\( P_1 = (0,0) \\) and \\( P_2 = (1,1) \\), then \\( \\widehat{P_1P_2} = (\\frac{1}{\\sqrt{2}},\\frac{1}{\\sqrt{2}}) \\)
- The sum \\( \\sum \\) notation means the sum of all elements in the list going from
0ton-1. Ex. \\( \\sum_{i=0}^{n-1} \\vec{V_i} = \\vec{V_0} + \\vec{V_1} + \\vec{V_2} + ... + \\vec{V_{n-1}} \\)
It is your job to implement those 3 behaviors following the ruleset below:
"},{"location":"artificialintelligence/assignments/flocking/#cohesion","title":"Cohesion","text":"Apply a force towards the center of mass of the group.
- The \\( n \\) neighbors of an agent are all the other agents that are within a certain radius \\( r_c \\)(
<operation ) of the agent. It doesn't include the agent itself; - Compute the location of the center of mass of the group (\\( P_{CM} \\));
- Compute the force that will move the agent towards the center of mass(\\( \\overrightarrow{F_c} \\)); The farther the agent is from the center of mass, the force increases linearly up to the limit of the cohesion radius \\( r_c \\).
Tip
Note that the maximum magnitude of \\( \\overrightarrow{F_c} \\) is 1. Inclusive. This value can be multiplied by a constant \\( K_c \\) to increase or decrease the cohesion force to looks more appealing.
Cohesion Example "},{"location":"artificialintelligence/assignments/flocking/#separation","title":"Separation","text":"It will move the agent away from other agents when they get too close.
- The \\( n \\) neighbors of an agent are all the other agents that are within the separation radius \\( r_s \\) of the agent;
- If the distance to a neighbor is less than the separation radius, then the agent will move away from it inversely proportionally to the distance between them.
- Accumulate the forces that will move the agent away from each neighbor (\\( \\overrightarrow{F_{s}} \\)). And then, clamp the force to a maximum value of \\( F_{Smax} \\).
\\[ \\overrightarrow{F_s} = \\sum_{i=0}^{n-1} \\begin{cases} \\frac{\\widehat{P_aP_i}}{|\\overrightarrow{P_aP_i}|} & \\text{if } 0 < |\\overrightarrow{P_aP_i}| \\leq r_s \\\\ 0 & \\text{if } |\\overrightarrow{P_aP_i}| = 0 \\lor |\\overrightarrow{P_aP_i}| > r_s \\end{cases} \\]
Tip
Here you can see that if we have more than one neighbor and one of them is way too close, the force will be very high and make the influence of the other neighbors irrelevant. This is the expected behavior.
The force will go near infinite when the distance between the agent and the \\( n \\) neighbor is 0. To avoid this, after accumulating all the influences from every neighbor, the force will be clamped to a maximum magnitude of \\( F_{Smax} \\).
\\[ \\overrightarrow{F_{s}} = \\begin{cases} \\overrightarrow{F_s} & \\text{if } |\\overrightarrow{F_s}| \\leq F_{Smax} \\\\ \\widehat{F_s} \\cdot F_{Smax} & \\text{if } |\\overrightarrow{F_s}| > F_{Smax} \\end{cases} \\]Tip
- You can implement those two math together, but it is better to isolate in two steps to make it easier to understand and debug.
- This is not an averaged force like the cohesion force, it is a sum of forces. So, the maximum magnitude of the force can be higher than 1.
It is the force that will align the velocity of the agent with the average velocity of the group.
- The \\( n \\) neighbors of an agent are all the agents that are within the alignment radius \\( r_a \\) of the agent, including itself;
- Compute the average velocity of the group (\\( \\overrightarrow{V_{avg}} \\));
- Compute the force that will move the agent towards the average velocity (\\( \\overrightarrow{F_{a}} \\));
The force composition is made by a weighted sum of the influences of those 3 behaviors. This is the way we are going to work, this is not the only way to do it, nor the more correct. It is just a way to do it.
- \\( \\vec{F} = K_c \\cdot \\overrightarrow{F_c} + K_s \\cdot \\overrightarrow{F_s} + K_a \\cdot \\overrightarrow{F_a} \\)
This is a weighted sum! - \\( \\overrightarrow{V_{new}} = \\overrightarrow{V_{cur}} + \\vec{F} \\cdot \\Delta t \\)
This is a simplification! - \\( P_{new} = P_{cur}+\\overrightarrow{V_{new}} \\cdot \\Delta t \\)
This is an approximation!
Warning
A more precise way for representing the new position would be to use full equations of motion. But given timestep is usually very small and it even squared, it is acceptable to ignore it. But here they are anyway, just dont use them in this assignment:
- \\( \\overrightarrow{V_{new}} = \\overrightarrow{V_{cur}}+\\frac{\\overrightarrow{F}}{m} \\cdot \\Delta t \\)
- \\( P_{new} = P_{cur}+\\overrightarrow{V_{cur}} \\cdot \\Delta t + \\frac{\\vec{F}}{m} \\cdot \\frac{\\Delta t^2}{2} \\)
Where:
- \\( \\overrightarrow{F} \\) is the force applied to the agent;
- \\( \\overrightarrow{V} \\) is the velocity of the agent;
- \\( P \\) is the position of the agent;
- \\( m \\) is the mass of the agent, here it is always 1;
- \\( \\Delta t \\) is the time frame (1/FPS);
- \\( cur \\) is the current value of the variable;
- \\( new \\) is the new value of the variable to be used in the next frame.
The \\( \\overrightarrow{V_{new}} \\) and \\( P_{new} \\) are the ones that will be used in the next frame and you will have to print to the console at the end of every single frame.
Note
- For simplicity, we are going to assume that the mass of all agents is 1.
- In a real game simulation, it would be nice to apply some friction to the velocity of the agent to make it stop eventually or just clamp it to prevent the velocity get too high. But, for simplicity, we are going to ignore it.
Alignment + Cohesion:
Separation + Cohesion:
Separation + Alignment:
All 3:
"},{"location":"artificialintelligence/assignments/flocking/#input","title":"Input","text":"The input consists in a list of parameters followed by a list of agents. The parameters are:
- \\( r_c \\) - Cohesion radius
- \\( r_s \\) - Separation radius
- \\( F_{Smax} \\) - Maximum separation force
- \\( r_a \\) - Alignment radius
- \\( K_c \\) - Cohesion constant
- \\( K_s \\) - Separation constant
- \\( K_a \\) - Alignment constant
- \\( N \\) - Number of agents
Every agent is represented by 4 values in the same line, separated by a space:
- \\( x \\) - X coordinate
- \\( y \\) - Y coordinate
- \\( vx \\) - X velocity
- \\( vy \\) - Y velocity
After reading the agent's data, the program should read the time frame (\\( \\Delta t \\)), simulate the agents and then output the new position of the agents in the same sequence and format it was read. The program should keep reading the time frame and simulating the agents until the end of the input.
Data Types
All values are double precision floating point numbers to improve consistency between different languages.
"},{"location":"artificialintelligence/assignments/flocking/#input-example","title":"Input Example","text":"In this example we are going to test only the cohesion behavior. The input is composed by the parameters and 2 agents.
1.000 0.000 0.000 0.000 1.000 0.000 0.000 2\n0.000 0.500 0.000 0.000\n0.000 -0.500 0.000 0.000\n0.125\nThe expected output is the position and velocity for each agent after the simulation step using the time frame. After printing each simulation step, the program should wait for the next time frame and then simulate the next step. All values should have exactly 3 decimal places and should be rounded to the nearest.
0.000 0.484 0.000 -0.125\n0.000 -0.484 0.000 0.125\n10 points total:
- 3 Points \u2013 by following standards;
- 2 Points \u2013 properly submitted in Canvas;
- 5 Points \u2013 passed on test cases;
The steps to understand GenAI are as follows:
- Artificial Neurons, types of neurons, and activation functions
- Networks of Neurons, topology, and training
- Stable Diffusion
- Install the latest Python. Add it to the environment PATH. [Windows:] Install directly to C drive and select the 3.10.6 version of python, install for all users;
- Download latest release from Automatic1111 or clone the repository. Clone/Download it to a subfolder on C drive. Dont use your personal folder.;
- Unzip the release. Run the
webuibash file [Windows:]webui.bat; - Select a bunch of the images that you are willing to train the network with;
- Go to
traintab and create a tag for your embeddings; - Use your tag to generate a new image;
Extras:
- Go to Hugging face and download 2 Stable Diffusion models. They should be compatible (ex. both should be v2.1 or 1.5).;
- Go to checkpoin merger, and merge two or more models.
graph LR\n I1[Input1] --> |Weight1| N[Neuron]\n I2[Input2] --> |Weight2| N[Neuron]\n N --> |Activation| O[Output]Artificial neurons are the basic building blocks of neural networks and all the other Generative AI algorithms. Neuron networks are composed by:
- Inputs: The inputs are the data that the network will process. They are the data that the network will use to make decisions. In the case of the neural networks, the inputs are the data that will be processed by the neurons.
- Weights: The weights are the parameters that the network will learn. They are the parameters that the network will use to make decisions. In the case of the neural networks, the weights are the parameters that will be learned by the neurons.
- Functions: summing, activation and bias.
- Summing: The summing function is the function that will sum the inputs and the weights.
- Activation: The activation function is the function that will decide if the neuron will fire or not or how it will fire or propagate.
- Bias: The bias is a weight that will be added to the summing function.
- Output: The output is the result of the neuron. It can be used to feed another neuron or to be the final result of the network.
Depending on how the neuron activates, which math operator it uses to sum the inputs and the weights, and how it propagates the output, the neuron can be classified as: Linear, Binary, Sigmoid, Tanh, and many others that follow math functions to combine data and propagate the output.
"},{"location":"artificialintelligence/assignments/genai/#topologies","title":"Topologies","text":"Material
"},{"location":"artificialintelligence/assignments/genai/#generative-ai","title":"Generative AI","text":"Generative AI is the new trend in AI. It is the field of AI that is focused on creating new data from existing data using neural networks and other algorithms. Here we will focus on the Stable Diffusion ones.
Stable diffusion pipeline:
graph TD\n Start --> GausiannNoise\n Start --> prompt\n subgraph CLIP\n direction LR\n tokenizer --> TokenToEmbedding[Token to Embeddings]\n end\n prompt[Prompt] --> CLIP\n CLIP --> embeddings[Text Embeddings]\n embeddings --> unet[Text Conditioned 'U-Net']\n Latents --> |Loop N times| unet\n unet --> CoditionedLatents[Conditioned Latents]\n CoditionedLatents --> Scheduler[Scheduler 'Reconstruct'\\nto add noise]\n Scheduler --> Latents\n GausiannNoise[Gaussian Noise] --> Latents\n CoditionedLatents --> VAE[Variational\\nAutoencoder\\nDecoder]\n VAE --> |Image|OutputYou are applying for an internship position at Valvule Corp, and they want to test your abilities to manage states. You were tasked to code the Conway's Game of Life.
The game consists in a C x L matrix of cells (Columns and Lines), where each cell can be either alive or dead. The game is played in turns, where each turn the state of the cells are updated according to the following rules:
- Any live cell with fewer than two live neighbours dies, as if by underpopulation.
- Any live cell with two or three live neighbours lives on to the next generation.
- Any live cell with more than three live neighbours dies, as if by overpopulation.
- Any dead cell with exactly three live neighbours becomes a live cell, as if by reproduction.
The map is continuous on every direction, so the cells on the edges have the cells on the opposite edge as neighbors. It is effectively a toroidal surface.
"},{"location":"artificialintelligence/assignments/life/#input","title":"Input","text":"The first line of the input are three numbers, C, L and T, the number of columns, lines and turns, respectively. The next L lines are the initial state of the cells, where each line has C characters, either . for dead cells or # for alive cells.
5 5 4\n.#...\n..#..\n###..\n.....\n.....\nThe output should be the state of the cells after T turns, in the same format as the input.
.....\n..#..\n...#.\n.###.\n.....\n- Animated Example
- Conway's Game of Life Wiki
- Wikipedia
You are in charge of implementing a new maze generator for a procedurally generated game. The game is a 2D top-down game, where every level is composed by squared rooms blocked by walls. The rooms are generated by a maze generator, and the walls can be removed to create paths.
There are many ways to implement a maze generation and one of the most common is the Depth First Search algorithm combined with a Random Walk. The algorithm is simple and can be implemented in a recursive or interactive way. The suggested algorithm is as follows:
- All walls are up;
- Add the top left cell to the stack;
- While the stack is not empty:
- If the stack top cell has visitable neighbor(s):
- Mark the top cell as visited;
- List visitable neighbors;
- Choose a neighbor (see below);
- Remove the wall between the cell and the neighbor;
- Add the neighbor to the stack;
- Else:
- Remove the top cell from the stack, backtracking;
- If the stack top cell has visitable neighbor(s):
If you simulate the algorithm visually, the result would be something similar to the following
"},{"location":"artificialintelligence/assignments/maze/#random-number-generation","title":"Random Number Generation","text":"In order to be consistent with all languages and random functions the pseudo random number generation should follow the following sequence of 100 numbers:
[72, 99, 56, 34, 43, 62, 31, 4, 70, 22, 6, 65, 96, 71, 29, 9, 98, 41, 90, 7, 30, 3, 97, 49, 63, 88, 47, 82, 91, 54, 74, 2, 86, 14, 58, 35, 89, 11, 10, 60, 28, 21, 52, 50, 55, 69, 76, 94, 23, 66, 15, 57, 44, 18, 67, 5, 24, 33, 77, 53, 51, 59, 20, 42, 80, 61, 1, 0, 38, 64, 45, 92, 46, 79, 93, 95, 37, 40, 83, 13, 12, 78, 75, 73, 84, 81, 8, 32, 27, 19, 87, 85, 16, 25, 17, 68, 26, 39, 48, 36];\nEvery call to the random function should return the current number the index is pointing to, and then increment the index. If the index is greater than 99, it should be reset to 0.
"},{"location":"artificialintelligence/assignments/maze/#direction-decision-making","title":"Direction decision making","text":"In order to give consistency on how to decide the direction of the next cell, the following procedure should be followed:
- List all visitable neighbors of the current cell;
- Sort the list of visitable neighbors by clockwise order, starting from the top neighbor: UP, RIGHT, DOWN, LEFT;
- If there is one visitable, do not call random, just return the first neighbor found;
- If there are two or more visitable neighbors, call random and return the neighbor at the index of the random number modulo the number of visitable neighbors.
vec[i]%visitableCount
The input is a single line with three 32 bits unsigned integer numbers, C, L and I, where C and L are the number of columns and lines of the maze, respectively, and I is the index of the first random number to be used> I can varies from 0 to 99.
2 2 0\nIn this case, our map will have 2 columns, 2 lines and the first random number to be used is the first one, 72 because it is pointed by the index 0.
Every line is a combination of underscore _, pipe | and empty characters. The _ character represents a horizontal wall and the | character represents a vertical wall.
The initial state of the 2 x 2 map is:
_ _ \n|_|_| \n|_|_| \nIn order to interactively solve this, we will add (0,0) to the queue.
The neighbors of the current top (0,0) are RIGHT and DOWN, (0,1) and (1,0) respectively.
Following the clockwise order, the sorted neighbor list will be [(0,1), (1,0)].
We have more than one neighbor, so we call random. The current random index is 0, so the random number is 72 and we increment the index.
The random number is 72 and the number of neighbors is 2, so the index of the neighbor to be chosen is 72 % 2 = 0, so we choose the neighbor (0,1), the RIGHT one.
The wall between (0,0) and (0,1) is removed, and (0,1) is added to the queue. Now it holds [(0,0), (0,1)]. The map is now:
_ _ \n|_ _| \n|_|_| \nNow the only neighbor of (0,1) is DOWN, (1,1). So no need to call random, we just choose the only neighbor.
The wall between (0,1) and (1,1) is removed, and (1,1) is added to the queue. Now it holds [(0,0), (0,1), (1,1)]. The map is now:
_ _ \n|_ | \n|_|_| \nNow the only neighbor of (1,1) is LEFT, (1,0). So no need to call random, we just choose the only neighbor.
The wall between (1,1) and (1,0) is removed, and (1,0) is added to the queue. Now it holds [(0,0), (0,1), (1,1), (1,0)]. The map is now:
_ _ \n|_ | \n|_ _| \nNow, the current top of the queue is (1,0) and there isn't any neighbor to be visited, so we remove the current top (1,0) from the queue and backtrack. The queue is now [(0,0), (0,1), (1,1)].
The current top is (1,1) and there isn't any neighbor to be visited, so we remove (1,1) from the queue and backtrack. The queue is now [(0,0), (0,1)].
The current top is (0,1) and there isn't any neighbor to be visited, so we remove (0,1) from the queue and backtrack. The queue is now [(0,0)].
The current top is (0,0) and there isn't any neighbor to be visited, so we remove (0,0) from the queue and backtrack. The queue is now empty and we finish priting the map state. The final map is:
_ _ \n|_ | \n|_ _| \nAnd this the only one that should be printed. No intermediary maps should be printed.
"},{"location":"artificialintelligence/assignments/maze/#example-1","title":"Example 1","text":""},{"location":"artificialintelligence/assignments/maze/#input-1","title":"Input 1","text":"3 3 0\n _ _ _ \n|_ | | \n| _| | \n|_ _ _| \n3 3 1\n _ _ _ \n| |_ | \n|_ _ | \n|_ _ _| \nYou are a game developer in charge to create a fast an reliable random number generator for a procedural content generation system. The requirements are:
- Do not rely on external libraries;
- Dont need to be cryptographically secure;
- Be blazing fast;
- Fully reproducible via automated tests if used the same seed;
- Use exactly 32 bits as seed;
- Be able to generate a number between a given range, both inclusive.
So you remembered a strange professor talking about the xorshift algorithm and decided it is good enough for your use case. And with some small research, you found the Marsaglia \"Xorshift RNGs\". You decided to implement it and test it.
"},{"location":"artificialintelligence/assignments/rng/#xorshift","title":"XorShift","text":"The xorshift is a family of pseudo random number generators created by George Marsaglia. The xorshift is a very simple algorithm that is very fast and have a good statistical quality. It is a very good choice for games and simulations.
xorshift is the process of shifting the binary value of a number and then xor'ing that binary to the original value to create a new value.
value = value xor (value shift by number)
The shift operators can be to the left << or to the right >>. When shifted to the left, it is the same thing as multiplying by 2 at the power of the number. When shifted to the right, it is the same thing as dividing.
Note
The value of a << b is the unique value congruent to \\(a * 2^{b}\\) modulo \\( 2^{N} \\) where \\( N \\) is the number of bits in the return type (that is, bitwise left shift is performed and the bits that get shifted out of the destination type are discarded).
The value of \\( a >> b \\) is \\( a/2^{b} \\) rounded down (in other words, right shift on signed a is arithmetic right shift).
The xorshift algorithm from Marsaglia is a combination of 3 xorshifts, the first one is the seed (or the last random number generated), and the next ones are the result of the previous xorshift. The steps are:
xorshiftthe value by13bits to the left;xorshiftthe value by17bits to the right;xorshiftthe value by5bits to the left;
At the end of this 3 xorshifts, the current state of the value is your current random number.
In order to clamp a random number the value between two numbers (max and min), you should follow this idea:
value = min + (random % (max - min + 1))
Receives the seed S, the number N of random numbers to be generated and the range R1 and R2 of the numbers should be in, there is no guarantee the range numbers are in order. The range numbers are both inclusive. S and N are both 32 bits unsigned integers and R1 and R2 are both 32 bits signed integers.
1 1 0 99\nThe list of numbers to be generated, one per line. In this case, it would be only one and the random number should be clamped to be between 0 and 99.
seed in decimal: 1\nseed in binary: 0b00000000000000000000000000000001 \n\nseed: 0b00000000000000000000000000000001\nseed << 13: 0b00000000000000000010000000000000\nseed xor (seed << 13): 0b00000000000000000010000000000001\n\nseed: 0b00000000000000000010000000000001\nseed >> 17: 0b00000000000000000000000000000000\nseed xor (seed >> 17): 0b00000000000000000010000000000001\n\nseed: 0b00000000000000000010000000000001\nseed << 5: 0b00000000000001000000000000100000\nseed xor (seed << 5): 0b00000000000001000010000000100001\n\nThe final result is 0b00000000000001000010000000100001 which is 270369 in decimal.\nNow in order to clamp it to be between 0 and 99, we do:
value = min + (random % (max - min + 1))\nvalue = 0 + (270369 % (99 - 0 + 1))\nvalue = 0 + (270369 % 100)\nvalue = 0 + 69\nvalue = 69\nSo this output would be:
69\nSpace quantization is a way to sample continuous space, and it can to be used in in many fields, such as Artificial Intelligence, Physics, Rendering, and more. Here we are going to focus primarily Spatial Quantization for AI, because it is the base for pathfinding, line of sight, field of view, and many other techniques.
Some of the most common techniques for space quantization are: grids, voxels, graphs, quadtrees, octrees, KD-trees, BSP, Spatial Hashing and more. Another notable techniques are line of sight(or field of view), map flooding, caching, and movement zones.
"},{"location":"artificialintelligence/readings/spatial-quantization/#grids","title":"Grids","text":"Grids are the most common technique for space quantization. It is a very simple technique, but it is very powerful. It consists in dividing the space in a grid of cells, and then we can use the cell coordinates to represent the space. The most common grid is the square grid, but we can use hexagonal and triangular grids, you might find some irregular shapes useful to exploit the space conformation better.
"},{"location":"artificialintelligence/readings/spatial-quantization/#square-grid","title":"Square Grid","text":"The square grid is a regular grid, where the cells are squares. It is very simple to implement and understand.
There are some ways to store data for squared grids. Arguably you could 2D arrays, arrays of arrays or vector of vectors, but depending on the way you implement it, it can hurt the performance. Example: if you use an array of arrays or vector of vectors, where every entry from de outer array is a pointer to the inner array, you will have a lot of cache misses, because the inner arrays are not contiguous in memory.
"},{"location":"artificialintelligence/readings/spatial-quantization/#notes-on-cache-locality","title":"Notes on cache locality","text":"So in order do increase data locality for squared grids, you can use a single array, and then use the following formula to calculate the index of the cell. We call this strategy matrix flattening.
int arrray[width * height]; // 1D array with the total size of the grid\nint index = x + y * width; // index of the cell at x,y\nThere is a catch here, given we usually represent points as X and Y coordinates, we need to be careful with the order of the coordinates. While you are iterating over all the matrix, you need to iterate over the Y coordinate first, and then the X coordinate. This is because the Y coordinate is the one that changes the most, so it is better to have it in the inner loop. By doing that, you will have better cache locality and effectively the index will be sequential.
vector<YourStructure> data; // data is filled with some data elsewhere\nfor(int y = 0; y < height; y++) {\n for(int x = 0; x < width; x++) {\n // do something with the cell at index x,y\n data[y * width + x] = yourstrucure;\n // it is the same as: data[y][x] = yourstructure;\n }\n}\nIf your world is based on floats, you can use the square by using the floor function or just cast to integer type, because the default behavior of casting from float to integer is to floor it. Example: In the case of a quantization resolution of size of 1.0f, everything between 0 and 1 will be in the cell (0,0), everything between 1 and 2 will be in the cell (1,0), and so on.
Vector2int quantize(Vector2f position, float resolution) {\n return Vector2int((int)floor(position.x/resolution), (int)floor(position.y/resolution));\n}\nIf you need to get the center of the cell in the world coordinates following the quantization resolution, you can use the following code.
Vector2f dequantize(Vector2int index, float resolution) {\n return Vector2f((float)index.x * resolution + resolution/2.0f, (float)index.y * resolution + resolution/2.0f);\n}\nIf you need to get the corners of the cell following the quantization resolution, you can use the following code.
Rectangle2f cell_bounds(Vector2int index, float resolution) {\n return {index.x * resolution, index.y * resolution, (index.x+1) * resolution, (index.y+1) * resolution};\n}\nIf you need to get the neighbors of a cell, you can use the following code.
std::vector<Vector2int> get_neighbors(Vector2int index) {\n return {{index.x-1, index.y}, {index.x, index.y-1},\n {index.x+1, index.y}, {index.x, index.y+1}};\n}\nWe already understood the idea of matrix flattening to improve efficiency, we can use it to represent a maze. But in a maze, we have walls to
Imagine that you are willing to be as memory efficient and more cache friendly as possible. You can use a single array to store the maze, and you can use the following formula to convert from matrix indexes to the index of the cell in the array.
## Hexagonal Grid\n\nHexagonal grid is an extension of a square grid, but the cells are hexagons. It feels nicer to human eyes because we have more equally distant neighbors. If used as subtract for pathfinding, it can be more efficient because the path can be more straight.\n\nIt can be implemented as single dimension array, but you need to be careful with shift that happens in different odd or even indexes. You can use the following formula to calculate the index of the cell. In this world quantization can be in 4 conformations, depending on the rotation of the hexagon and the alignment of the first cell.\n\n1. Point pointy top hexagon with first line aligned to the left:\n``` text\n / \\ / \\ / \\ \n | A | B | C |\n \\ / \\ / \\ / \\\n | D | E | F |\n / \\ / \\ / \\ /\n | G | H | I |\n \\ / \\ / \\ / \n- Point pointy top hexagon with first line aligned to the right
/ \\ / \\ / \\\n | A | B | C |\n / \\ / \\ / \\ / \n | D | E | F |\n \\ / \\ / \\ / \\\n | G | H | I |\n \\ / \\ / \\ /\n - Flat top hexagon with first column aligned to the top:
__ __\n/A \\__/C \\\n\\__/B \\__/\n/D \\__/F \\\n\\__/E \\__/\n/G \\__/I \\\n\\__/H \\__/\n \\__/\n - Flat top hexagon with first column aligned to the bottom:
__\n __/B \\__ \n /A \\__/C \\\n \\__/E \\__/\n /D \\__/F \\\n \\__/H \\__/\n /G \\__/I \\\n \\__/ \\__/\n
For simplicity, we are going to use the first conformation, where the first line is aligned to the left, and the hexagons are pointy top. The quantization is done by using the following formula.
// I am assuming that the hexagon is pointy top, and the first line is aligned to the left\n// I am also assuming that the hexagon is centered in the cell, and the top left corner is at (0,0), \n// y axis is pointing down and x axis is pointing right\n// this dont work for all the cases, but it is a good approximation for locations near the center of the hexagon\n/*\n / \\ / \\ / \\ \n | A | B | C |\n \\ / \\ / \\ / \\\n | D | E | F |\n / \\ / \\ / \\ /\n | G | H | I |\n \\ / \\ / \\ /\n */\nVector2int quantize(Vector2f position, float hexagonSide) {\n int y = (position.y - hexagonSide)/(hexagonSide * 2);\n int x = y%2==0 ?\n (position.x - hexagonSide * sqrt3over2) / (hexagonSide * sqrt3over2 * 2) : // even lines\n (position.x - hexagonSide * sqrt3over2 * 2)/(hexagonSide * sqrt3over2 * 2) // odd lines\n return Vector2int(x, y);\n}\nVector2f dequantize(Vector2int index, float hexagonSide) {\n return Vector2f(index.y%2==0 ? \n hexagonSide * sqrt3over2 + index.x * hexagonSide * sqrt3over2 * 2 : // even lines\n hexagonSide * sqrt3over2 * 2 + index.x * hexagonSide * sqrt3over2 * 2, // odd lines\n hexagonSide + index.y * hexagonSide * 2);\n}\nYou will have to figure out the formula for the other conformations. Or send a merge request to this repository adding more information.
"},{"location":"artificialintelligence/readings/spatial-quantization/#voxels-and-grid-3d","title":"Voxels and Grid 3D","text":"Grids in 3D works the same way as in 2D, but you need to use 3D vectors/arrays or voxel volumes. Most concepts applies here. If you want to expand this section, send a merge request.
"},{"location":"artificialintelligence/readings/spatial-quantization/#quadtree","title":"Quadtree","text":"Quadtree is a tree data structure where each node has 4 children. It is used to partition a space in 2D. It is used to optimize collision detection, pathfinding, and other algorithms that need to iterate over a space. It is also used to optimize rendering, because you can render only the visible part of the space.
"},{"location":"artificialintelligence/readings/spatial-quantization/#quadtree-implementation","title":"Quadtree implementation","text":"Quadtree is a recursive data structure, so you can implement it using a recursive data structure. The following code is a simple implementation of a quadtree.
// this code is not tested, but it should work. It is just an example and send a merge request if you find any errors.\n// node\ntemplate<class T>\nstruct DataAtPosition {\n Vector2f center;\n T data;\n};\n\ntemplate<class T>\nstruct QuadtreeNode {\n Rectangle2f bounds;\n std::vector<DataAtPosition<T>> data;\n std::vector<QuadtreeNode<T>> children;\n};\n\n// insert\ntemplate<class T>\nvoid insert(QuadtreeNode<T>& root, DataAtPosition<T> data) {\n if (root.children.empty()) {\n root.data.push_back(data);\n if (root.data.size() > 4) {\n root.children.resize(4);\n for (int i = 0; i < 4; ++i) {\n root.children[i].bounds = root.bounds;\n }\n root.children[0].bounds.max.x = root.bounds.center().x; // top left\n root.children[0].bounds.max.y = root.bounds.center().y; // top left\n root.children[1].bounds.min.x = root.bounds.center().x; // top right\n root.children[1].bounds.max.y = root.bounds.center().y; // top right\n root.children[2].bounds.min.x = root.bounds.center().x; // bottom right\n root.children[2].bounds.min.y = root.bounds.center().y; // bottom right\n root.children[3].bounds.max.x = root.bounds.center().x; // bottom left\n root.children[3].bounds.min.y = root.bounds.center().y; // bottom left\n for (auto& data : root.data) {\n insert(root, data);\n }\n root.data.clear();\n }\n } else {\n for (auto& child : root.children) {\n if (child.bounds.contains(data.center)) {\n insert(child, data);\n break;\n }\n }\n }\n}\n\n// query\ntemplate<class T>\nvoid query(QuadtreeNode<T>& root, Rectangle2f bounds, std::vector<DataAtPosition<T>>& result) {\n if (root.bounds.intersects(bounds)) {\n for (auto& data : root.data) {\n if (bounds.contains(data.center)) {\n result.push_back(data);\n }\n }\n for (auto& child : root.children) {\n query(child, bounds, result);\n }\n }\n}\nThe quadtree is a recursive data structure, so it is not cache friendly. You can optimize it by using a flat array instead of a recursive data structure.
"},{"location":"artificialintelligence/readings/spatial-quantization/#octree","title":"Octree","text":"Section WiP. Send a merge request if you want to contribute.
"},{"location":"artificialintelligence/readings/spatial-quantization/#kd-tree","title":"KD-Tree","text":"KD-Trees are a tree data structure that are used to partition a spaces in any dimension (2D, 3D, 4D, etc). They are used to optimize collision detection(Physics), pathfinding(AI), and other algorithms that need to iterate over a space. Also they are also used to optimize rendering, because you can render only the visible part of the space. Pay attention that KD-Trees are not the same as Quadtree and Octrees, even if they are similar.
In KD-trees, every node defines an orthogonal partition plan that alternate every deepening level of the tree. The partition plan is defined by a dimension, a value. The dimension is the axis that is used to partition the space, and the value is the position of the partition plan. The partition plan is orthogonal to the axis, so it is a line in 2D, a plane in 3D, and a hyperplane in 4D.
"},{"location":"artificialintelligence/readings/spatial-quantization/#bsp-tree","title":"BSP Tree","text":"BSP inherits almost all characteristics of KD-Trees, but it is not a tree data structure, it is a graph data structure. The main difference is to instead of being orthogonal you define the plane of the section. The plane is defined by a point and a normal. The normal is the direction of the plane, and the point is a point in the plane.
"},{"location":"artificialintelligence/readings/spatial-quantization/#spatial-hashing","title":"Spatial Hashing","text":"Spatial hashing is a data structure that is used to partition a space. It consists in a hash table where the keys are the positions of the elements, and the values are the elements in buckets. It is very fast to insert and query elements. But it is not good for iteration, because it is not cache friendly.
Usually when you want to use a spatial hashing, you create hash functions for the bucket keys, there is no limit on how you do that, but you have to keep in mind that the hash functions have to be fast and have to be good for the distribution of the elements. Here is a good example of a hashing function for 2D vectors.
namespace std {\n template<>\n struct hash<Vector2f> {\n // I am assuming size_t is 64 bits and the float is 32 bits\n size_t operator()(const Vector2f& v) const {\n // get the bits of the float in a integer\n uint64_t x = *(uint64_t*)&v.x;\n uint64_t y = *(uint64_t*)&v.y;\n // mix the bits of the floats\n uint64_t hash = x | (y << 32);\n return hash;\n }\n };\n}\nPay attention that the hashing function above generates collisions, so you have to use a data structure that can handle collisions. You will use datastructures like unordered_map<Vector2D, unordered_set<DATATYPE>> or unordered_map<Vector2D, vector<DATATYPE>>. The first one is better for insertion and query, but it is not cache friendly.
To avoid having one bucket per every possible position, you have to setup properly the dimension of the bucket, a good sugestion is to alwoys floor the position and have buckets dimension of 1.0f. That would be good enough for most cases.
"},{"location":"blog/","title":"Blog","text":""},{"location":"blog/2023/07/28/the-problem-with-ai-trolley-dilemma/","title":"The problem with AI Trolley dilemma","text":"The premise about the AI trolley dilemma is invalid. So the whole discussion about who should the car kill in a fatal situation. Let me explain why.
Yesterday I attended a conference about Ethics and AI, and the speaker mentioned the trolley dilemma. The question asked was \"What should the self-driving car do?\" and kind of forced us to take sides on the matter.
- Kill the passengers;
- Kill the pedestrians;
This is the same as the trolley problem but one difference. AI don't have morals, it will follow what is programmed without any hesitation. So the question is not what the AI should do, but what the programmer codes it to do.
Well, the whole premise on asking what should do \"kill this, or that\" is totally wrong. As a programmer myself, and knowing the limits of the system, I would never code a system to make such a decision. If the car is in a situation that it cannot break in time with the current limited vision, it should go slower. So no decision ever has to be made.
Let's do some math for you to see how this could be easily solved.
"},{"location":"blog/2023/07/28/the-problem-with-ai-trolley-dilemma/#the-math","title":"The math","text":"Let's use the standard formula for the distance needed to stop a car.
\\[S = v*t + \\frac{v^2}{2*u*g}\\]Where:
- \\(S\\) is the distance needed to stop;
- \\(v\\) is the speed of the car;
- \\(t\\) is the reaction time;
- \\(v*t\\) is the distance traveled during the reaction time;
- \\(u\\) is the tire friction factor;
- \\(g\\) is the gravity acceleration;
- \\(\\frac{v^2}{2*u*g}\\) is the distance traveled during the breaking time;
If the car is going at \\(100 km/h\\) (\\(27.7 m/s\\), \\(62.14 mi/h\\)) and the reaction time of the AI is relatively fast, let's say \\(0.2 s\\), so the distance traveled to a complete sage stop would be:
\\[S = 27.7 * 0.2 + \\frac{27.7^2}{2*0.2*9.8} = 5.54 + 38.5 = 44.04 m\\]Which means that the car would need \\(44.04 m\\) to stop. So if the car cannot clearly see a distance greater than that, it should slow down. And this is the reason the self-driving AIs are said to be slow drivers.
"},{"location":"blog/2023/09/09/setup-sdl-with-cmake-and-cpm/","title":"Setup SDL with CMake and CPM","text":"In my opinion, the minimum toolset needed to give you the ability to start creating games cross-platform from scratch is the combination of the following tools:
-
CLion - Cross-platform C++ IDE with embedded CMake support
- Apply for a student license;
- Download and install it;
- For Macs, you will need extra tools:
XCodeand the command line tools. You can install them by runningxcode-select --installon the terminal;
-
(Required for Windows and if you don't use CLion) Git - Version control system
- Download only if you are on Windows and don't forget to tick the option to add it to your environment path (CMake will be calling it). On Mac and Linux, you can install via your package manager (ex. brew on Mac e apt on Ubuntu).
After installing the tool(s) above, you can follow the steps below to create a new project:
"},{"location":"blog/2023/09/09/setup-sdl-with-cmake-and-cpm/#clion-project","title":"CLion project","text":"- Open CLion and select
New Project:
- Create a new project and select
C++ ExecutableandC++XXas the language standard, whereXXis the latest one available for you. Use the default compiler and toolchain:
- Start coding:
You might note the existence of a CMakeLists.txt file on the left side of the IDE on the Project tab. This file is used by CMake to generate the build files for your project. Now, we are going to set up everything you need to use SDL3. If you open the CMakeLists.txt file, you will see something similar to the following:
# cmake_minimum_required(VERSION <specify CMake version here>)\ncmake_minimum_required(VERSION 3.26)\n# project(<name> [<language-name>...])\nproject(MyGame)\n# set(CMAKE_CXX_STANDARD <specify C++ standard here>)\nset(CMAKE_CXX_STANDARD 17)\n# add_executable(<name> file.cpp file2.cpp ...)\nadd_executable(MyGame main.cpp)\nCPM is a setup-free C++ package manager. It is a single CMake script that you can add to your project and use to download and install packages from GitHub. It is a great tool to manage dependencies and many C++ projects use it.
You can make this as simple as adding the following lines to your CMakeLists.txt file (after the project command):
set(CPM_DOWNLOAD_VERSION 0.38.2)\n\nif(CPM_SOURCE_CACHE)\n set(CPM_DOWNLOAD_LOCATION \"${CPM_SOURCE_CACHE}/cpm/CPM_${CPM_DOWNLOAD_VERSION}.cmake\")\nelseif(DEFINED ENV{CPM_SOURCE_CACHE})\n set(CPM_DOWNLOAD_LOCATION \"$ENV{CPM_SOURCE_CACHE}/cpm/CPM_${CPM_DOWNLOAD_VERSION}.cmake\")\nelse()\n set(CPM_DOWNLOAD_LOCATION \"${CMAKE_BINARY_DIR}/cmake/CPM_${CPM_DOWNLOAD_VERSION}.cmake\")\nendif()\n\n# Expand relative path. This is important if the provided path contains a tilde (~)\nget_filename_component(CPM_DOWNLOAD_LOCATION ${CPM_DOWNLOAD_LOCATION} ABSOLUTE)\n\nfunction(download_cpm)\n message(STATUS \"Downloading CPM.cmake to ${CPM_DOWNLOAD_LOCATION}\")\n file(DOWNLOAD\n https://github.com/cpm-cmake/CPM.cmake/releases/download/v${CPM_DOWNLOAD_VERSION}/CPM.cmake\n ${CPM_DOWNLOAD_LOCATION}\n )\nendfunction()\n\nif(NOT (EXISTS ${CPM_DOWNLOAD_LOCATION}))\n download_cpm()\nelse()\n # resume download if it previously failed\n file(READ ${CPM_DOWNLOAD_LOCATION} check)\n if(\"${check}\" STREQUAL \"\")\n download_cpm()\n endif()\n unset(check)\nendif()\n\ninclude(${CPM_DOWNLOAD_LOCATION})\nThis will download the CPM.cmake file to your project, and you can use it to download and install packages from GitHub.
To check if CPM is being automatically downloaded, you can go to CLion and click on CMake icon on the left side of the Project. It is the first one on the bottom. And then click the Reload CMake Project button:
Now that you have CPM, you can start adding packages to your project. Here are some ways of doing that:
# A git package from a given uri with a version\nCPMAddPackage(\"uri@version\")\n# A git package from a given uri with a git tag or commit hash\nCPMAddPackage(\"uri#tag\")\n# A git package with both version and tag provided\nCPMAddPackage(\"uri@version#tag\")\n# examples:\n# CPMAddPackage(\"gh:fmtlib/fmt#7.1.3\")\n# CPMAddPackage(\"gh:nlohmann/json@3.10.5\")\n# CPMAddPackage(\"gh:catchorg/Catch2@3.2.1\")\n# An archive package from a given url. The version is inferred\n# CPMAddPackage(\"https://example.com/my-package-1.2.3.zip\")\n# An archive package from a given url with an MD5 hash provided\n# CPMAddPackage(\"https://example.com/my-package-1.2.3.zip#MD5=68e20f674a48be38d60e129f600faf7d\")\n# An archive package from a given url. The version is explicitly given\n# CPMAddPackage(\"https://example.com/my-package.zip@1.2.3\")\n\n# A complex package with options:\nCPMAddPackage(\n NAME # The unique name of the dependency (should be the exported target's name)\n VERSION # The minimum version of the dependency (optional, defaults to 0)\n OPTIONS # Configuration options passed to the dependency (optional)\n DOWNLOAD_ONLY # If set, the project is downloaded, but not configured (optional)\n GITHUB_REPOSITORY # The GitHub repository (owner/repo) to download from (optional)\n GIT_TAG # The git tag or commit hash to download (optional)\n [...] # Origin parameters forwarded to FetchContent_Declare\n)\nIn order to generate SDL libraries and link them corretly in our executable, we have to state the lib should be in the same folder as the executable, so you have to add this to your CMakeLists.txt file:
# Set all outputs to be at the same location\nset(CMAKE_ARCHIVE_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR})\nset(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR})\nset(CMAKE_RUNTIME_OUTPUT_DIRECTORY ${CMAKE_BINARY_DIR})\nlink_directories(${CMAKE_BINARY_DIR})\nNow that we have CPM set up, we can use it to download and install SDL. If you want to try the stable version v2, add the following lines to your CMakeLists.txt file and refresh CMake:
CPMAddPackage(\n NAME SDL2\n GITHUB_REPOSITORY libsdl-org/SDL\n GIT_TAG release-2.28.3 \n VERSION 2.28.3\n)\nIf you don't have git installed on your machine, you might want to use the ZIP version(it is even faster to download but slower to switch versions). In this case, you can use the following lines and refresh CMake:
CPMAddPackage(\n NAME SDL2\n URL \"https://github.com/libsdl-org/SDL/archive/refs/tags/release-2.28.3.zip\"\n VERSION 2.28.3\n)\nIf you want to try the bleeding edge version v3, add the following lines to your CMakeLists.txt file at your own risk:
CPMAddPackage(\n NAME SDL3\n GITHUB_REPOSITORY libsdl-org/SDL\n GIT_TAG main\n)\nNow that we have SDL set up, we should link it to our project. In order to do that, we can add the following lines after the line add_executable to our CMakeLists.txt file and refresh CMake:
target_link_libraries(MyGame SDL2::SDL2)\n# change SDL2 to SDL3 if you are using the bleeding edge version\n#target_link_libraries(MyGame SDL2::SDL2)\nAnd this will make SDL available to our project. Now we can start coding. Let's create a simple window:
#define SDL_MAIN_HANDLED true\n#include <SDL.h>\n\nint main(int argc, char** argv) {\n SDL_Init(SDL_INIT_VIDEO);\n\n SDL_Window* window = SDL_CreateWindow(\n \"SDL2Test\",\n SDL_WINDOWPOS_UNDEFINED,\n SDL_WINDOWPOS_UNDEFINED,\n 640,\n 480,\n 0\n );\n\n SDL_Renderer* renderer = SDL_CreateRenderer(window, -1, SDL_RENDERER_ACCELERATED);\n\n SDL_Event e;\n bool quit = false;\n while (!quit){\n while (SDL_PollEvent(&e)){\n if (e.type == SDL_QUIT){\n quit = true;\n }\n }\n\n SDL_SetRenderDrawColor(renderer, 255, 0, 0, 255);\n SDL_RenderClear(renderer);\n SDL_RenderPresent(renderer);\n SDL_Delay(0);\n }\n\n SDL_DestroyWindow(window);\n SDL_Quit();\n\n return 0;\n}\nIf you feel that you want to test the bleeding-edge version, you can use this code instead:
#define SDL_MAIN_HANDLED true\n#include <SDL.h>\n\nint main(int argc, char* argv[]) {\n SDL_Init(SDL_INIT_VIDEO);\n\n SDL_Window *window = SDL_CreateWindow(\n \"MyGame\",\n 640,\n 480,\n 0\n );\n\n SDL_Renderer* renderer = SDL_CreateRenderer(window, nullptr, SDL_RENDERER_ACCELERATED);\n SDL_Event e;\n bool quit = false;\n\n while (!quit) {\n while (SDL_PollEvent(&e)) {\n if (e.type == SDL_EVENT_QUIT) {\n quit = true;\n }\n }\n SDL_SetRenderDrawColor(renderer, 255, 0, 0, 255);\n SDL_RenderClear(renderer);\n SDL_RenderPresent(renderer);\n SDL_Delay(0);\n }\n\n SDL_DestroyWindow(window);\n SDL_Quit();\n\n return 0;\n}\nNow you have a way to code games with SDL in a way that is cross-platform, and easy to setup.
If you hit Run or Debug on CLion, you will see a window like this:
and then:
I hope it works for you. If you have any problems, please let me know on Discord or via GitHub issues.
"},{"location":"blog/2023/08/30/ferpa-consent/","title":"FERPA Consent","text":"FERPA (The Family Educational Rights and Privacy Act) is a federal law protecting the confidentiality of student records. It restricts others from accessing or discussing your educational records without your consent. Here we are going to discuss how it applies to the courses I teach and what are the benefits on sharing your work publicly if you want.
FERPA consent form
Read more about the reasoning and rationale below.
Note
This a modified version from this original.
In a typical class, your homework (and other information delineating your academic performance) would not be visible to the public. Indeed, the FERPA law requires that you have the right to privacy in this regard. This is one of the main reasons for the existence of so many \"walled gardens\" for courseware, such as Autolab, Blackboard, CanvasLMS and Piazza, which keep all student work hidden behind passwords.
An essential component of the educational experience in new media arts, however, is learning how to participate in the \"Grand Conversation\" all around us, by becoming more effective culture operators. We cannot do this in the safe space of a Canvas module. Our work is strengthened and sharpened in the forge of public scrutiny: in this case, the agora of the Internet.
Sometimes students are afraid to publish something because it is of poor quality. They think that they will receive embarrassing, negative critiques. In fact, negative critique is quite rare. The most common thing that happens when one creates an artwork of poor quality, is that it is simply ignored. Being ignored - this, not being shunned or derided - this is the fate of mediocre work.
On the other hand, if something is truly great is published - and great projects can happen, and have happened, even in an introductory class like this one - there is the chance that it may be circulated widely on the Internet. Every year that I have taught, a handful of the students' projects get blogged and receive as many as 50000 views in a week. It cannot be emphasized that this can be an absolutely transformative experience for students, that cannot be obtained without taking the risk to work publicly. Students get jobs and build careers on the basis of such success.
That said, there are also plenty of reasons why you may wish to work anonymously, when you work online. Perhaps you are concerned about stalkers or harassment. Perhaps you wish to address themes in your work which might not meet with the approval of your parents or future employers. These are valid considerations, in which case, we advise using an anonymous identity on Github. On our course repository, your work will be indexed by a public-facing name, generally your first name. If you would prefer something else, please inform the professor.
"},{"location":"blog/2023/08/30/ferpa-consent/#ferpa-consent-form","title":"Ferpa Consent Form","text":"Fill this form if you want to share your work publicly. If you don't fill this form, your work should be private:
FERPA consent form
"},{"location":"blog/2024/01/29/differences-between-map-vs-unordered_map/","title":"Differences between map vs unordered_map","text":"Both std::map and std::unordered_map are associative containers that store key-value pairs, let's have a deep dive into the differences between them.
std::map: Implements a balanced binary search tree:- Usually a red-black tree, but it is defined by the STL implementation provided by your compiler;
- Ensures that elements are always sorted, which allows for efficient range queries and ordered traversal;
-
std::unordered_map: Implements a hash table.- The elements are not sorted and are stored in buckets based on the hash value of the keys.
-
On a
map, if the tree become too deep, it can have performance issues, because it is O(lg(N)) for almost all functions. The jumps between nodes pointers might not be cache friendly. - On an
unordered_map, the keys are stored as hashes and might have collisions, if it does collide to be stored on the same bucket, the search inside it is linear. Given the size of the bucket is usually small, this search is usually fast.
On a map, when you query, you will pay the price for navigating a tree until you find the element you are searching for. While on a unordered_map you pay the price for the hashing function you use and when it have colision, and pay the price to find an element in a vector that is the bucket.
map: query(key) -> navigate tree(might be not cache friendly) -> your value;unordered_map: query(key) -> hash the key(can be costly) -> find the bucket -> linear search in all elements inside the bucket(cache friendly)
Evaluate the cost of:
map:- How many node hops;
- How many key comparisons;
- Tree indexing can fit in the cache the whole time;
unordered_map:- How many CPU cycles the hashing function uses;
- How frequent collisions happens;
- How many elements you will have in the bucket on average?
Example:
Assume you have \\(1024\\) elements, a balanced tree can potentially reach 10 levels deep. \\(\\log_{2}(1024) = 10\\) .
In a tree search we will fetch content of pointers 10 times and make 10 key comparisons until we reach the leaves;
If the key is just a pair of int32_t, you can easily implement a hash function that concatenates the bits of one into the another and have a uint64_t value as the key. This shift operation followed by xor is really cheap, but still have a constant cost. If your key is anything more complex, you might face a performance penalty. In this case, the cost here will be 2 basic CPU operations;
After paying the cost of hashing your key, you will have to fetch the content of pointer 1 time to receive the address of an array of elements which is the bucket. Hopefully you just have one element inside it, if not, you will have to iterate inside the bucket array.
In a hashing-bucket approach you pay the cost of hashing funtion, 1 fetch content, and then the linear search inside the bucket array.
So what is better?
a. Jump between memory locations in tree nodes; b. pay the price for a hashing function and then potentially a search inside an array?
"},{"location":"blog/2024/01/29/differences-between-map-vs-unordered_map/#insertion-query-and-deletion-complexity","title":"Insertion, Query, and Deletion Complexity:","text":"std::map:- Insertion/Deletion:
O(log n) - Query:
O(log n)
- Insertion/Deletion:
std::unordered_map:- Average-case complexity (amortized):
- Insertion/Deletion:
O(1) - Query:
O(1)
- Insertion/Deletion:
- Worst-case complexity (when dealing with hash collisions):
- Insertion/Deletion:
O(n)in the worst case - Query:
O(n)in the worst case
- Insertion/Deletion:
- Average-case complexity (amortized):
std::mapmaintains order based on the keys, allowing for efficient range queries and ordered traversal of elements.std::unordered_mapdoes not guarantee any specific order of elements.
std::map typically has a higher memory overhead due to the additional structure needed for the balanced binary search tree.
std::unordered_map may have a lower memory overhead, but it can be affected by the load factor and hash collisions.
Use std::map when you need ordered traversal or range queries and can tolerate slightly slower insertion and deletion. Use std::unordered_map when you need fast average-case constant-time complexity for insertion, deletion, and queries, and the order of elements is not important.
In summary, the choice between std::map and std::unordered_map depends on the specific requirements of your application. If you need ordered elements and can tolerate slightly slower operations, std::map might be a better choice. If you prioritize fast average-case constant-time operations and the order of elements is not important, std::unordered_map may be more suitable.
I challenge you to implement your own associative container following what you learned here. It is a great exercise to learn how to implement a hash table and a binary search tree. Talk with me via discord if you want to discuss your implementation.
"},{"location":"blog/2023/10/02/memory-efficient-data-structure-for-procedural-maze-generation/","title":"Memory-efficient Data Structure for Procedural Maze Generation","text":"In this post, you will learn how to create a memory-efficient data structure for maze generation. We will jump from a 320 bits data structure to just 2! It is achieved by taking a bunch of clever decisions, changing the referential and doing some math. Be warned, this not for the fainted hearts. Are you brave enough?
Problem statement: You need to generate mazes dynamicly, and you need to break or add walls between rooms. Ex.: How can we store data for a simple 3x3 maze like this:
_ _ _ \n| | |\n| | | |\n|_ _|_|\nThe naive approach is to create a data structure like this:
class Node {\n Node* top, right, bottom, left;\n bool top_wall, right_wall, bottom_wall, left_wall;\n};\nThis one above will work, but it is:
- Cache unfriendly;
- Random access to any element will be slow;
- Memory inefficient;
- Huge memory consumption;
- Redundant data usage;
Cache Unfriendly: The cache locality is hurt by extensive usage of dynamic allocation (4 pointer per node), and not reserving contigous memory for every new object created.
Random Access: To access the room {x,y} will have to iterate over node by node from the origin. The access of a room will have the algorithmic complexity of O(rows+columns) or simply O(n). For small mazes it is not a problem, but for big mazes it will be.
Memory inefficiency: The memory allocation for each room is 4 pointers and 4 booleans. If the size of the pointer is 8 bytes and each boolean is 1 byte, we might think it will have 36 bytes per room, right? Wrong! The compiler will add padding to the struct, so it will have 40 bytes per room. If we have a 1000x1000 maze, we will have 40MB of memory allocated for the maze. It is a lot of memory for a simple maze.
Data redundancy: The wall data is stored in two neighbors. If we break a wall, we have to break the wall in two places. It is not a big deal, but it is a waste of memory.
"},{"location":"blog/2023/10/02/memory-efficient-data-structure-for-procedural-maze-generation/#optimization","title":"Optimization","text":"Well, let's try to optimize it. The first step is to use a single array of data. And then we need to reduce the duplicity of data.
By removing all the pointers, and store the wall data in a single array following matrix linearization, we will drop the memory consumption to 4 bytes per room (10x improvement). It is a huge improvement, but we can do better. Now we can create an array of WallData as follows:
struct WallData {\n bool top, right, bottom, left;\n};\nvector<WallData> data;\nWallData get_wall(int x, int y) {\n return data[y * width + x];\n}\nThe size of the WallData is 4 bytes. But we can reduce it if we use data layout optimization:
struct WallData {\n bool top:1, right:1, bottom:1, left:1;\n};\nIn this version, WallData will use 1 byte per room(40x improvement). But we will be using only 4 bits of the byte. Another way of optmizing it is to use vector of bools for every type of wall. Let's group them into vectors.
vector<bool> topWalls, rightWals, bottomWalls, leftWalls;\nFor vector, depending on the implementation, it needs to store the size of it, the capacity, and the pointer to the data, which will use 24 bytes per vector. If can reach 32 if it stores the reference count to it as a smart pointer.
So what we are going to do next? Reduce the number of vectors used to reduce overhead. If you want to go deeper, you can use only one vector where every bit is a wall. So we will have only 4 bits per room and do some math to get the right bit(80x improvement).
vector<bool> walls;\nCan we do it better? Yes! As you might have noticed, every wall data is being stored in two nodes redundantly. So we will jump from 40 bytes(320 bits) to 2 bits per room (approximately 160x improvement). But in order to achieve that, you have to follow a strict set of rules andodifications.
- Every even bit is a top wall, and every odd bit is a right wall relative to an intersection;
- Every dimension of the maze will be increased by one unity in order to properly address the borders.
- We need to create accessors via matrix index and flaten with linearization technique.
_ _ _\n|_|_|_|\n|_|_|_|\nThis 3x2 maze will be represented by a 4x3 linearized matrix. It is easier to understand if you look at the walls as edges and the wall intersections as nodes. So for a 3x2 maze, we need 4 vertical walls and 3 horizontal walls. So in this specific case, if we follow the pattern of 1 if the wall is present and 0 if it is not there, and do this only for top and right walls of a node(intersection), we will have:
This fully blocked 3x2 maze\n _ _ _\n|_|_|_|\n|_|_|_|\n\nWill give us 4x3 pairs of bits:\n01 01 01 00\n11 11 11 10\n11 11 11 10\n\nLinearized as:\n010101001111111011111110\nJust to recaptulate: we went from 40 Bytes (320 bits) per room to approximately 2 bits per room. A maze map with 128x128 would go from 128*128*320/8 = 640KB to 129*129*2/8 = 4161 bytes. It is 157.5 times densely packed. It is a huge improvement.
"},{"location":"blog/2023/10/02/memory-efficient-data-structure-for-procedural-maze-generation/#notes-about-vectors","title":"Notes about vectors:","text":"- vector of bools is a bitfield, so it will pack 8 bools per byte, it will do the shift and masking for us.
- vector of bools is arguably an antipattern because it doesn't behave like a commom vector by not following the rule of zero cost abstraction from C++. It adds a cost for the densely packed bitfield.
- For our intent, this is exactly what we want, so we can use it, just check if your compiler implements it as a bitfield.
Here goes a simple implementation of a data structure to hold the maze data:
struct Maze {\nprivate:\n vector<bool> walls;\n vector<bool> visited;\n int width, height;\npublic:\n Maze(int width, int height): width(width), height(height) {\n walls.resize((width+1)*(height+1)*2, true);\n for(int i = 0; i <= width; i++) // clear verticals on the top\n SetNorthWall(i, 0, false);\n for(int i = 0; i <= height; i++) // clear horizontals on the right\n SetEastWall(width, i, false);\n visited.resize(width*height, false); // no room is visited yet\n }\n\n bool GetVisited(int x, int y) const { return visited[y*width + x]; }\n void SetVisited(int x, int y, bool val) { visited[y*width + x] = val; }\n\n bool GetNorthWall(int x, int y) const { return walls[(y*(width+1) + x)*2 + 1]; }\n bool GetSouthWall(int x, int y) const { return walls[((y+1)*(width+1) + x)*2 + 1];}\n bool GetEastWall(int x, int y) const { return walls[((y+1)*(width+1) + x+1)*2];}\n bool GetWestWall(int x, int y) const { return walls[((y+1)*(width+1) + x)*2];}\n\n void SetNorthWall(int x, int y, bool val) { walls[(y*(width+1) + x)*2 + 1] = val; }\n void SetSouthWall(int x, int y, bool val) { walls[((y+1)*(width+1) + x)*2 + 1] = val;}\n void SetEastWall(int x, int y, bool val) { walls[((y+1)*(width+1) + x+1)*2] = val;}\n void SetWestWall(int x, int y, bool val) { walls[((y+1)*(width+1) + x)*2] = val;}\n}\n- Is it possible to explore even more the structure?
- Is it possible to do the same for hexagonal grids? Every node will have 3 walls instead of 4 in the squared grid.
The goal of this article is not be a comprehensive guide about Virtual Reality, but to give you a general sense of what it is and how it works. I will also give you some examples of how it is being used today and what we can expect for the future.
"},{"location":"blog/2023/08/09/lets-talk-about-virtual-reality/#history","title":"History","text":"graph TB\n Start[Start] \n -- 1838 --> Stereoscope[Stereoscope] \n -- 1935 --> multisensory[Multi Sensory Machines]\n -- 1960 --> hmd[Head Mounted Devices\\nVR Goggles]\n -- 1965 --> military[Military Research\\nTraining\\nHelmets]\n -- 1970 --> artificialreality[Artificial Reality\\nComputer Simulations]\n -- 1980 --> gloves[Stereo Vision Glasses\\nGloves for VR]\n -- 1989 --> nasa[NASA Training\\nComputer Simulated Teleoperation]\n -- 1990 --> game[VR Gaming\\nVR Arcades]\n -- 1997 --> serious[PTSD Treatment]\n -- 2007 --> datavis[Google Street View\\nStereoscopic 3D]\n -- 2010 -->oculus[Oculus VR\\nOculus Kickstarter\\nFacebook acquisition]\n -- 2015 -->general[General Audience\\nMultiple VR products]\n -- 2016 -->ar[AR\\nPokemon Go\\nHololens] \n -- 2017 -->ARKIT[AR\\nApple ARKit] \n -- 2018 -->oculusquest[Oculus Quest\\nStandalone VR]\n -- 2021 -->metaverse[Metaverse\\nFacebook rebrands to Meta]\n -- 2023 -->apple[Apple Vision]As you can see the history of VR is quite long and full of interesting surprising developments, but it is only in the last 10 years that it has become a reality for the general audience.
"},{"location":"blog/2023/08/09/lets-talk-about-virtual-reality/#terms-disambiguation","title":"Terms Disambiguation","text":"Before we go any further, let's disambiguate some terms that are often used interchangeably. Nowadays we have a spectrum of immersive technologies that goes from the real world to the virtual world.
graph LR\n real[Real World]-->mixed\n\n subgraph mixed[Mixed Reality]\n augmentedreality[Augmented Reality]\n augmentedvirtuality[Augmented Virtuality]\n end\n\n mixed --> virtual[Virtual Reality]Virtual Reality (VR) is the most pervasive and ambiguous term. It is sometimes used as an umbrella for all immersive technologies, but it is more commonly used to refer to the process of simulating a virtual world that is completely isolated the user from the real world. This is usually done by using a Head Mounted Display (HMD) that blocks the user's view of the real world and replaces it with a simulation in front of the user's eyes; and headphones to replace the real sounds with virtual. The user can also use controllers to interact in it.
This term gained lots of attention with the modern VR boom that started in 2010 with the Oculus Kickstarter campaign followed by its acquisition by Facebook in 2014. After that, many other companies started to develop their own VR products, such as the HTC Vive, the Playstation VR, and the Samsung Gear VR.
"},{"location":"blog/2023/08/09/lets-talk-about-virtual-reality/#augmented-reality","title":"Augmented Reality","text":"Augmented Reality is another ambiguous term, but its meaning is more settled. It refers to the process of adding computer generated elements to the real world. It can be done by using a Head Mounted Display (HMD) that allows the user to see the real world and the virtual elements at the same time such as Google Glass or the Microsoft Hololens. It can also be done by using a smartphone or tablet that uses the camera to capture the real world and then adds virtual elements to it. This is the case of the Snapchat filters and the popular game Pokemon Go launched in 2016.
"},{"location":"blog/2023/08/09/lets-talk-about-virtual-reality/#augmented-virtuality","title":"Augmented Virtuality","text":"This term usually is not misused and more specifically refers to the process of adding real world elements to a virtual world. It can appears in many forms, for example, the use of a treadmill to simulate walking in the virtual world or the use of a camera to capture the user's face and add it to the virtual world. Stereocameras or depth sensors are also used to capture the user's hands and add them to the virtual world as well.
Most of the time Augmented Virtuality (AV) is seen as an enhancement to the already existing immersive experience. It can be used to add another level of realism to the virtual world, to make the user feel more immersed in it, reduce nausea, or discomfort by adding real world anchors to the virtual world.
"},{"location":"blog/2023/08/09/lets-talk-about-virtual-reality/#challenges","title":"Challenges","text":"In order to make immersive gadgets a reality, we need to overcome some challenges. The most important ones are:
- Motion Sickness: the feeling of nausea and discomfort caused by the mismatch between the user's movements and the virtual world. It is mostly caused by:
- Latency: the time it takes for the system to react to the user's actions. The system needs to process the inputs, accelerometers, gyroscopes, and other sensors, and then render the new image to the user. This process takes time and if it is too long the user will feel unresponsiveness and will get sick;
- Field of View: the area that the user can see at any given time doesnt match the area that the user can see in the real world;
- Resolution: the number of pixels that the user can see at any given time. Ex. The Oculus Rift DK1 had a resolution of 640x800 per eye that was zoomed to cover the user's entire field of view, and on top of that, the spacing between pixels makes the image looks like a grid of squared dots; you can see why it received so many complaints;
- Tracking: the ability of the system to track the user's movements properly. The sensors usually do not refresh at the same rate as the display, so the system needs to interpolate the user's movements between the sensor readings. This can cause the user to feel like the virtual world is lagging behind the real world and be out of sync with the user's movements;
- Comfort: the feeling of comfort that the user has while using the system. If the device needs to be worn for a long period of time, right weight distribution, padding, and ventilation are important to make the user feel comfortable;
- Cost: the cost of the system. The machinery and technology used to create the system can be very expensive to be accessible to the general audience;
- Portability: the ability of the system to be used in different places. If the system is too heavy or too big it will be hard to carry;
- Social Acceptance: the acceptance of the system by the society. If the system is too intrusive or too weird it will be hard to use in public places. It could be seen as a threat to privacy or as a threat to the user's safety;
- Battery Life: the amount of time that the system can be used without being plugged in. If the system needs to be plugged in all the time it will be hard to use in public places;
- Software Development Kits: the tools that developers use to create applications for the system. If the SDK is too hard to use or too limited it will be hard to create applications for the system;
I will add to this list a personal experience that I don't see many people talking about: bad smell, oily foams, and connectors corrosion. The root of those problems is the proximity with the user's face. The user's face is a very oily place and the foam that is used to make the device comfortable is an exceptional place for bacteria to grow. The connectors are also exposed to the user's sweat and can corrode over time and brick your device.
"},{"location":"blog/2023/08/09/lets-talk-about-virtual-reality/#applications","title":"Applications","text":"There are virtually infinite applications for immersive technologies, but I will focus on the ones that I think are the most important ones in my opinion:
- Entertainment: Games in general, but also movies, etc.;
- Data Visualization: the ability to visualize data in a 3D space can be very useful to understand complex data;
- Education: Training, virtual classrooms, virtual museums, virtual tours, etc.;
- Social: Virtual meetings, parties, dating, etc.;
- Psychological Treatment: Virtual exposure therapy(Ex.: PTSD, phobias), virtual reality therapy, etc.;
- Medical: Surgery planning, surgery simulation, etc.;
- Design: Architecture, interior design, etc.;
In my past, I have created a startup to help surgeons plan their surgeries and ported it to VR - DocDo. I created some small scoped projects to psychological treatment via progressive exposition, some for data visualization and others for education. I am not in position to have a strong opinion about the future of VR, but I can share my thoughts about it.
At the beginning of the metaverse boom, I was very skeptical about it, and I am still. I felt it was a just a new interpretation of a product previously tested on Second Life and proved to be a niche product, focused in being fun, but forcing the use of device with many issues. Another problem was the lack of a real application besides the fun factor.
As a developer, I am in love with Apple's new Vision OS emulator and SDK. It is surprisingly easy to use, filled with useful functions, although it is buggy and crashes randomly in beta channel that I am using now. I think it is an exceptional example of how to create a nice SDK for a new platform. I am not sure if it will be a success, but I am sure that it will empower many developers to create new or port existing applications to their platform. They have created a simply way to bring a desktop experience to a VR gadget that just work. You can \"easily\" port your app to it and it will work. It is portable, easy to code, powerful hardware, nice battery life, and a nice SDK. I think it is a nice recipe for success. My only concern is related to the cost and social acceptance.
"},{"location":"blog/2023/08/24/notes-on-submissions/","title":"Notes on Submissions","text":"Source: ideogramHere are my personal opinions, rules and processes that I follow about submissions. I will cover gradings, deadlines, tolerances, and AI-assistant tools usage.
"},{"location":"blog/2023/08/24/notes-on-submissions/#policy-on-limited-use-of-ai-assisted-tools","title":"Policy on Limited use of AI-assisted tools","text":"Note
\"During our classes, we may use AI writing tools such as ChatGPT in certain specific cases. You will be informed as to when, where, and how these tools are permitted to be used, along with guidance for attribution. Any use outside of these specific cases constitutes a violation of Academic Honesty Policy.\" Source.
The learner has to produce original content. You can use tools like ChatGPT to help you learn by prompting your own questions, but not to solve the problems, assignments, or quizzes.
The rationale is that the student has to learn the concepts and ideas rather than just copying and pasting the answers.
"},{"location":"blog/2023/08/24/notes-on-submissions/#what-is-acceptable","title":"What is acceptable:","text":"- On writing, coding assignments, or interactive assignments, you can ask AI questions about concepts, ideas, syntaxes, etc;
- You can ask AI assistants what is wrong with your code, but you cannot use the answer 1 to 1 copy to your final submission. You have to modify it;
- If your submission contains part of an AI-assisted tool, you have to cite it. Ex.: \"I prompted ____ in ChatGPT, and the answer was ____.\" and as a professor, I will deduct points from your submission with fairness instead of giving you zero points;
- You cannot copy the question and prompt AI to answer it and then use the answer as your own;
- You cannot ask AI to code a solution for you;
- You cannot use any AI while coding(e.g. GitHub Copilot), but I do recommend you to use any IDE instead;
- You cannot use AI assistance to solve quizzes or exams in any circumstances.
- Even in accepted cases, using AI assistance and not citing it will be considered plagiarism and will be reported to higher instances and zero-ed;
- I use some automated tools such as Turnitin(canvas), moss(Beecrowd), and others;
- I use my own experience to detect plagiarism;
- If two students use the same AI assistant, chances are high that they will produce the same answer, and I will detect it;
I usually take up to 1 week to grade assignments, but I will grade them as soon as possible. The worst-case scenario is two weeks.
"},{"location":"blog/2023/08/24/notes-on-submissions/#late-submissions-policy","title":"Late Submissions Policy","text":"If you submit an assignment late, you will receive a flat 20% deduction on your grade.
If you have accommodations, message me, and I will try accommodating you. But always send a message on every submission stating that. Canvas is a nice tool, but it needs to cover accommodations better.
If you fall under special conditions, such as sickness, death of a relative, or any other condition that you cannot submit the assignment on time, please send me a message through Canvas, and I will try to accommodate you.
"},{"location":"blog/2023/08/24/notes-on-submissions/#plagiarism","title":"Plagiarism","text":"Plagiarism is a serious offense and will be reported to the higher instances. I will not tolerate any plagiarism as I define:
- Searching for answers on the internet and copy and paste it as your own;
- Copying answers from other students;
- Using AI-assisted tools to produce full answers;
- Using AI-assisted tools to produce partial answers without citing it;
I am here to teach you the best I can and guide you through your learning process. You can count on me as a friend and a teacher, and I will help you as much as possible. I am willing to make exceptions for the ones that need it.
"},{"location":"dojo/","title":"Coding Dojo Definition","text":"A coding dojo is a programming practice that involves a group of developers coming together to collaborate on solving coding challenges. It is a learning and collaborative environment where developers can improve their coding skills and work on real-world coding problems.
The term \"dojo\" comes from the Japanese term for place of the way, which is a traditional place of training for martial arts. In a coding dojo, participants practice the skills they have learned, exchange knowledge and experience, and work together to solve programming challenges.
During a coding dojo session, participants work in pairs or small groups to solve programming challenges, using techniques such as pair programming and test-driven development. They work through the problem step by step, discussing and sharing their ideas and approaches along the way. The goal of a coding dojo is to improve individual and team coding skills, and to learn from each other's experiences.
"},{"location":"dojo/#timeline-structure","title":"Timeline Structure","text":"- Introduction (5 minutes): The facilitator introduces the coding dojo and the coding challenge for the session.
- Warm-up exercise (10 minutes): A brief exercise is conducted to get participants warmed up and ready for the coding challenge.
- Coding challenge (60 minutes): Participants work in pairs or small groups to solve the coding challenge using techniques such as pair programming and test-driven development.
- Review and discussion (15 minutes): Participants share their solutions and discuss the various approaches taken to solve the challenge.
- Retrospective (10 minutes): Participants reflect on the session and provide feedback on what went well and what could be improved for future sessions.
- Closing (5 minutes): The facilitator concludes the session and thanks the participants for their contributions.
This Dojo is focused in training professionals on setting up a full cycle project using SDL, CMAKE and GitHub actions.
"},{"location":"dojo/Full-Cycle-SDL-Development/#agenda","title":"Agenda:","text":"- Introduction (5 minutes): The facilitator introduces the coding dojo and the goal of the session, which is to create a CMake build system for an SDL project using GitHub Actions.
- Warm-up exercise (10 minutes): A brief exercise is conducted to get participants warmed up and familiar with SDL and CMake.
- Setting up the project (30 minutes): Participants work in pairs or small groups to clone the SDL project from GitHub and create a CMake build system for it.
- Adding GitHub Actions (30 minutes): Participants continue to work on their CMake build systems and add GitHub Actions to automate the build and test process.
- Review and discussion (10 minutes): Participants share their solutions and discuss the various approaches taken to create the CMake build system and implement GitHub Actions.
- Retrospective (5 minutes): Participants reflect on the session and provide feedback on what went well and what could be improved for future sessions.
- Closing (5 minutes): The facilitator concludes the session and thanks the participants for their contributions.
- Write down what do you expect from this Dojo here;
You can either fork Modern CPP Starter Repo (and star it) or create your own from scratch.
Ensure that you have the following software installed in your machine:
- C++ Compiler. Ex.: GCC(build-essential, and cmake) on Linux, MS Visual Studio on Windows(select C++ and in additional tools, select cmake), Command Line Tools for OSX.
- Git. Ex.: Gitkraken(free for students);
- IDE. Ex.: Clion(free for students);
- CMake. Ex.: cmake-gui, but clion already bundle it for you.
Clone your repository you created or forked in the last step (Modern CPP Starter Repo);
"},{"location":"dojo/Full-Cycle-SDL-Development/#2-cmake-glob","title":"2. CMake Glob","text":"Edit your CMakeLists.txt to glob your files (naive and powerful approach). Example:
Minimum CMake:
cmake_minimum_required(VERSION 3.25)\nproject(MY_PROJECT)\nset(CMAKE_CXX_STANDARD 17)\nadd_executable(mygamename main.cpp)\nfile(GLOB MY_INCLUDES # Rename this variable\n CONFIGURE_DEPENDS\n ${CMAKE_CURRENT_SOURCE_DIR}/*.h\n ${CMAKE_CURRENT_SOURCE_DIR}/*.hpp\n )\n\nfile(GLOB MY_SOURCE # Rename this variable\n CONFIGURE_DEPENDS\n ${CMAKE_CURRENT_SOURCE_DIR}/*.cpp\n ${CMAKE_CURRENT_SOURCE_DIR}/*.c\n )\nadd_executable(mygamename ${MY_SOURCE} ${MY_INCLUDE})\nAdd code for the package manager CPM.
Read their example and how do you download it. Optionally, you can download it dynamically, this is the way I prefer.;
"},{"location":"dojo/Full-Cycle-SDL-Development/#4-sdl-dependency","title":"4. SDL dependency","text":"Use CPM to download your dependencies. Please refer to this issue comment for an example. If you want to see something already done, check this one;
"},{"location":"dojo/Full-Cycle-SDL-Development/#5-linking","title":"5. Linking","text":"Link your executable to SDL;
target_link_libraries(mygamename PUBLIC SDL2)\nImGui for debugging interface purposes;
Use CPM to download ImGUI and link it to your library. Example - You can optionally remove the static link if you want. https://github.com/InfiniBrains/SDL2-CPM-CMake-Example/blob/main/main.cpp
Link your executable to IMGUI
target_link_libraries(mygamename PUBLIC SDL2 IMGUI)\nCopy this example here to your main.cpp if you are going do use ImGUI or just use something like this:
#include <stdio.h>\n\n#include \"SDL.h\"\n\nint main()\n{\n if(SDL_Init(SDL_INIT_VIDEO) != 0) {\n fprintf(stderr, \"Could not init SDL: %s\\n\", SDL_GetError());\n return 1;\n }\n SDL_Window *screen = SDL_CreateWindow(\"My application\",\n SDL_WINDOWPOS_UNDEFINED,\n SDL_WINDOWPOS_UNDEFINED,\n 640, 480,\n 0);\n if(!screen) {\n fprintf(stderr, \"Could not create window\\n\");\n return 1;\n }\n SDL_Renderer *renderer = SDL_CreateRenderer(screen, -1, SDL_RENDERER_SOFTWARE);\n if(!renderer) {\n fprintf(stderr, \"Could not create renderer\\n\");\n return 1;\n }\n\n SDL_SetRenderDrawColor(renderer, 0, 0, 0, 255);\n SDL_RenderClear(renderer);\n SDL_RenderPresent(renderer);\n SDL_Delay(3000);\n\n SDL_DestroyWindow(screen);\n SDL_Quit();\n return 0;\n}\nCreate folder .github and inside it another one workflows. Inside it create a .yml file.
Here you will code declaratively how your build should proceed. The basic steps are usually: Clone, Cache, Install dependencies, Configure, Build, Test and Release conditionally to branch.
Check and try to reproduce the same thing you see here.
If you are following the Modern CPP Starter Repo, you can explore automated tests. Be my guest and try it.
"},{"location":"dojo/Full-Cycle-SDL-Development/#review","title":"Review","text":"How far you went? Share your repos here.
"},{"location":"dojo/Full-Cycle-SDL-Development/#retrospective","title":"Retrospective","text":"Please give me feedbacks in what we did today. If you like or have something to improve, say something in here. Ah! you can always fork this repo, improve it and send a pull request back to this repo.
"},{"location":"dojo/Full-Cycle-SDL-Development/#closing","title":"Closing","text":"Give stars to all repos you saw here as a way to contribute to the continuity of the project.
Propose a new Dojo and be in touch.
"},{"location":"dojo/The-most-asked-interview-question/","title":"The most asked interview question","text":"Arguably, the most asked question in coding interviews is the Two Number Sum. It is used by many Bigtechs and AAA Game Studios. You can see this question in many youtube videos, coding websites such as hackerank, leetcode, algoexpert ...
"},{"location":"dojo/The-most-asked-interview-question/#agenda-two-number-sum-coding-dojo","title":"Agenda: Two Number Sum Coding Dojo","text":""},{"location":"dojo/The-most-asked-interview-question/#introduction-5-minutes","title":"Introduction (5 minutes)","text":"- Welcome participants to the dojo
- Introduce the Two Number Sum question as a common coding interview question
- Discuss the importance of problem-solving skills in coding interviews
- Briefly explain the rules and structure of the dojo
- Problem Explanation (10 minutes)
- Define the problem and its requirements
- Discuss potential edge cases and constraints
- Review sample inputs and expected outputs
- Coding Session (50 minutes)
Write a function that will receive an array/vector/list of integers and a target number. Find two numbers inside the array that summed will match the target. You have to return both in a array/vector/list ordered.
Implement the solution in 3 different ways. Open the details only after you try. First approach:
1. Naive solution. O(N^2) time and O(1) space; - required to know this;Can you make it faster?
2. Fastest solution. O(N) time and O(N) space; - this will make youCan you make it not use much memory, but still be fast?
3. Fastest without mem allocation. O(N*log(N)) time and O(1) space;"},{"location":"dojo/The-most-asked-interview-question/#participants-work-on-solving-the-two-number-sum-problem-in-pairs-or-small-groups","title":"Participants work on solving the Two Number Sum problem in pairs or small groups","text":"- Emphasize the importance of communication and collaboration during the coding session
- Encourage participants to use a whiteboard or paper to sketch out their solutions
- Provide guidance and support as needed
- Code Review (20 minutes)
- Facilitate a discussion about each solution, highlighting strengths and areas for improvement
- Encourage participants to ask questions and provide feedback to their peers
- Discuss potential optimizations and alternative approaches to the problem
- Wrap-Up (5 minutes)
- Encourage participants to continue practicing problem-solving skills on their own
- Thank participants for attending the dojo and provide any additional resources or support as needed.
- Note: The time allocation can be adjusted based on the group's needs and pace.
- Understand the fundamental concepts of programming and computer science;
- Practice how to solve problems programatically using C++;
- Use tools to write and compile C++ programs;
- Code, document, test, and implement a well-structured, robust computer program using the C++ programming language.
- Write reusable modules (collections of functions).
- Use version control to manage your code;
- Use the debugger to find and fix bugs in your code;
- Understand the basics of file input/output;
- Work in groups to solve problems;
- Be able to understand computer science concepts and terminology;
- To describe the basic components of a computer system and their functions;
- Differentiate between the various types of programming languages;
- To describe and use software tools in the programming process;
- Use modern concepts and principles of C++ programming language;
- To design, code, test, and debug a computer program using the C++ programming language;
- To demonstrate an understanding of primitive data types, values, operators and expressions in C/C++;
- Manage and manipulate files in C++;
- Deliver a full working project collaboratively;
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use the github repo as the source of truth for the schedule and materials. The materials provided in canvas are just a copy for archiving purposes and might be outdated.
Relevant dates for the Fall 2023 semester:
- 09-13 Oct 2023 - Midterms Week
- 20-24 Nov 2023 - Thanksgiving Break
- 11-15 Dec 2023 - Finals Week
10th edition Gaddis, T. (2020) Starting out with C++. Early objects / Tony Gaddis, Judy Walters, Godfrey Muganda. Pearson Education, Inc. Available at: https://research-ebsco-com.cobalt.champlain.edu/linkprocessor/plink?id=047f7203-3c9c-399b-834f-42cdaac4c1da
9th edition Gaddis, T. (2017) Starting out with C++. Early objects / Tony Gaddis, Judy Walters, Godfrey Muganda. Pearson. Available at: https://discovery-ebsco-com.cobalt.champlain.edu/linkprocessor/plink?id=502e29d6-3b46-38ff-9dc2-65e79c81c29b
- C++ early objects. Amazon (Champlain: 9th 10th)
- Modern C++ Programming
- learncpp
- cpluslus
- cprogramming
- programming-books
- google style guide
- riptutorial
- cpp manual
- cpp core guidelines
- rooksguide
- cpp best practices
Before we start, this repository aims to be practical, and I highly incentive you to look for other references. I want to add this another awesome repository it holds an awesome compilation of modern C++ concepts.
Another relevant reference for what we are going to cover is the updated core guidelines that explain why some syntax or style is bad and what you should be doing instead.
"},{"location":"intro/01-introduction/#why","title":"Why?","text":"The first thing when you think of becoming a programmer is HOW DO I START? Well, C++ is one of the best programming languages to give you insights into how a computer works. Through the process of learning how to code C++, you will learn not only how to use this language as a tool to solve your problems, but the farther you go, the more you will start uncovering and exploring exciting computer concepts.
C++ gives you the simplicity of C and adds a lot of steroids. It delivers lots of quality-of-life stuff, increasing the developer experience. Let\u2019s compare C with C++, shall we?
- The iconic book \"The C Programming Language\" by Brian W. Kernighan and Dennis M. Ritchie has only 263 pages. Pretty simple, huh?
- The book \"C++ How to Program\" by Harvey and Paul Deitel It holds around 1000 pages, and the pages are way bigger than the other one.
So, don\u2019t worry, you just need to learn the basics first, and all the rest are somehow advanced concepts. I will do my best to keep you focused on what is relevant to each moment of your learning journey.
Without further ado. Get in the car!
"},{"location":"intro/01-introduction/#speed-matters","title":"Speed Matters","text":"A LOT. Period. C++ is one of the closest intelligible programming languages before reaching the level of machine code, as known as Assembly Language. If you code in machine code, you obviously will code precisely what you want the machine to do, but this task is too painful to be the de-facto standard of coding. So we need something more straightforward and more human-readable. So C++ lies in this exact area of being close to assembly language and still able to be \"easily\" understandable. Note the quotes, they are there because it might not be that easy when you compare its syntax to other languages, C++ has to obey some constraints to keep the generated binary fast as a mad horse while trying to be easier than assembly. Remember, it can always get worse.
The main philosophy that guides C++ is the \"Zero-cost abstractions\", and it is the main reason why C++ is so fast. It means that the language does not add any overhead to assembly. So, if someone proposes a new core feature as a Technical specification, it should pass through this filter. And it is a very high bar to pass. I am looking at you, ts reflection, everyone I know that want to make games, ask for this feature, but it is not there yet.
"},{"location":"intro/01-introduction/#why-does-speed-matter","title":"Why does speed matter?","text":"Mainly because we don\u2019t want to waste time. Right? But it has more impactful consequences. Let\u2019s think a bit more, you probably have a smartphone, and it lives only while it has enough energy on its battery. So, if you are a lazy mobile developer and do not want to learn how to do code efficiently, you will make your app drain more energy from the battery just by making the user wait for the task to be finished or by doing lots of unnecessary calculations! You will be the reason the user has not enough power to use their phones up to the end of the day. In fact, you will be punishing your user by using your app. You don\u2019t want that, right? So let\u2019s learn how to code appropriately. For the sake of the argument, worse than that, a lazy blockchain smart contract developer will make their users pay more for extra gas fee usage for the extra inefficient CPU cycles.
"},{"location":"intro/01-introduction/#language-benchmarks","title":"Language benchmarks","text":"I don\u2019t want to point fingers at languages, but, hey, excuse me, python, are you listening to me, python? Python? Please answer! reference cpp vs python. Nevermind. It is still trying to figure things out. Ah! Hey ruby, don\u2019t be shy, I know you look gorgeous, and I admire you a lot, but can you dress up faster and be ready to run anytime soon?
You don\u2019t need makeup to run fast. That\u2019s the idea. If the language does lots of fancy stuff, it won\u2019t be extracting the juicy power of the CPU.
So let\u2019s first clarify some concepts for a fair comparison. Some languages do not generate binaries that run in your CPU. Some of them run on top of a virtual machine. The Virtual Machine(VM) is a piece of software that, in runtime, translates the bytecode or even compiles source code to something the CPU can understand. It\u2019s like an old car; some of them will make you wait for the ignition or even get warm enough to run fast. I am looking at you Java and JavaScript. It is a funny concept, I admit, but you can see here that the ones that run on top of a translation device would never run as fast as a compiled binary ready to run on the CPU.
So let\u2019s bring some ideas from my own experience, and I invite you to test by yourself. Just search for \"programming languages benchmark\" on your preferred search engine or go here.
I don\u2019t want to start a flame-war. Those numbers might be wrong, but the overall idea is correct. Assuming C++ does not add much overhead to your native binary, let\u2019s set the speed to run as 1x. Java would be around 1.4x slower, and JavaScript is 1.6x, python 40x, and ruby 100x. The only good competitor in the house is Rust because its compiled code runs straight on the CPU efficiently with lots of quality-of-life additions. Rust gives almost similar results if you do not play around with memory-intensive problems. Another honorable mention is WASM - Web Assembly, although it is a bytecode for a virtual machine, many programming languages are able to target it(compile for it), it is becoming blazing fast and it is getting traction nowadays, keep tuned.
"},{"location":"intro/01-introduction/#who-should-learn-c","title":"Who should learn C++","text":"YOU! Yes, seriously, I don\u2019t know you, but I am pretty sure you should know how to code in any language. C++ can be challenging, it is a fact, but if you dare to challenge yourself to learn it, your life will be somewhat better.
Let\u2019s cut to the bullets:
- The ones who seek to build efficient modules for mobile apps, such as the video/image processing unit;
- Game developers. Even the gameplay developers that usually only script things should know how to ride a horse(CPU) fast;
- Researchers looking to not waste time by coding inefficient code and wait hours, even days, to see the result of their calculations. They should reduce the costs of renting CPU clusters;
- Computer scientists are those who should know how a computer works. After all, C++ is one of the preferred programming languages that unlocks all the power of the CPU;
- Engineers, in general, should know how to simulate things efficiently;
The first thing is: the CPU does not understand any programming language, only binary instructions. So you have to convert your code into something the machine can understand. This is the job of the compiler. A compiler is a piece of software that reads a text file written following the rules of a programming language and essentially converts it into binary instructions that the CPU can execute. There are many strategies and many ways of doing it. So, given its nature of being near assembly, with C++, you will control precisely what instructions the CPU will run.
But, there is a catch here: for each CPU, you will need a compiler for that instruction set. Ex.: the compiler GCC can generate an executable program for ARM processors, and the generated program won\u2019t work on x86 processors; In the same way, an x64 executable won\u2019t work on an x86; you need to match the binary instructions generated by the compiler with the same instruction set available on the target CPU you want to run it. Some compilers can cross-compile: the compiler runs in your machine on your CPU with its instruction set, but the binary generated only runs on a target machine with its own instruction set.
graph TD\n START((Start))-->\n |Source Code|PreProcessor-->\n |Pre-processed Code|Compiler-->\n |Target Assembly Code|Assembler-->\n |Relacable Machine Code|Linker-->\n |Executable Machine Code|Loader-->\n |Operation System|Memory-->\n |CPU|RUN((Run))Software development is complex and there is lots of styles, philosophies and standard, but the overall structure looks like this:
- Analysis, Specification, Problem definition
- Design of the Software (pseudocode/algorithm, flowchart), Problem analysis
- Implementation / Coding
- Testing and Debugging - In TDD(Test Driven Development) we write the tests first.
- Maintenance - Analytics and Improvements
- End of Life
Pseudocode is a way of expressing algorithms using a combination of natural language and programming constructs. It is not a programming language and cannot be compiled or executed, but it provides a clear and concise way to describe the steps of an algorithm. Here is an example of pseudocode that describes the process of finding the maximum value in a list of numbers:
set maxValue to 0\nfor each number in the list of numbers\n if number is greater than maxValue\n set maxValue to number\noutput maxValue\nPseudocode is often used as a planning tool for programmers and can help to clarify the logic of a program before it is written in a specific programming language. It can also be used to communicate algorithms to people who are not familiar with a particular programming language. Reference
"},{"location":"intro/01-introduction/#flowcharts","title":"Flowcharts","text":"A flowchart is a graphical representation of a process or system that shows the steps or events in a sequential order. It is a useful tool for demonstrating how a process works, identifying potential bottlenecks or inefficiencies in a process, and for communicating the steps involved in a process to others.
Flowcharts are typically composed of a series of boxes or shapes, connected by arrows, that represent the steps in a process. Each box or shape usually contains a brief description of the step or event it represents. The arrows show the flow or movement from one step to the next.
Flowcharts can be used in a variety of settings, including business, engineering, and software development. They are particularly useful for demonstrating how a process works, identifying potential issues or bottlenecks in the process, and for communicating the steps involved in a process to others.
There are many symbols and notations that can be used to create flowcharts, and different organizations and industries may have their own standards or conventions for using these symbols. Some common symbols and notations used in flowcharts include:
- Start and end symbols: These are used to indicate the beginning and end of a process.
- Process symbols: These are used to represent the various steps or events in a process.
- Decision symbols: These are used to represent a decision point in a process, where the flow of the process depends on the outcome of a decision.
- Connector symbols: These are used to connect the various symbols in a flowchart, showing the flow or movement from one step to the next.
- Annotation symbols: These are used to add additional information or notes to a flowchart.
By using a combination of these symbols and notations, you can create a clear and concise flowchart that effectively communicates the steps involved in a process or system. Reference
I suggest using the tool Code2Flow to write pseudocode and see the flowchart drawn in real time. But you can draw them on Diagrams. If you are into sequence diagrams, I suggest using sequencediagram.org.
"},{"location":"intro/01-introduction/#practice","title":"Practice","text":"Try to think ahead the problem definition by questioning yourself before expressing the algorithm as pseudocode or flowchart: - What are the inputs? - What is a valid input? - How to compute the math? - What is the output? - How many decimals is needed to express the result?
Use diagrams to draw a flowchart or use Code2Flow to write a working pseudocode to: 1. Compute the weighted average of two numbers. The first number has weight of 1 and the second has weight of 3; 2. Area of a circle; 3. Compute GPA; 4. Factorial number;
"},{"location":"intro/01-introduction/#glossary","title":"Glossary","text":"It is expected for you to know superficially these terms and concepts. Research about them. It is not strictly required, because we are going to cover them in class.
- CPU
- GPU
- ALU
- Main Memory
- Secondary Memory
- Programming Language
- Compiler
- Linker
- Assembler
- Pseudocode
- Algorithms
- Flowchart
- Sign up on beecrowd. If you are a enrolled student, look for the key in canvas to be assigned to the coding assignments.
- https://blockly.games/maze - test your ability to solve small problems via block programming
- https://codecombat.com/ - very interesting game
- https://scratch.mit.edu/ - start a project and make it say hello when you click on it
If you have problems here, start a discussion this is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me.
"},{"location":"intro/02-tooling/","title":"Tools for C++ development","text":"Opinion
This list is a mix of standard tools and personal choice. It is a good starting point, but in the future you will be impacted by other options, just keep your mind open to new choices.
- Version Control
- GIT
- Github
- GitKraken
- Compiler
- CMake
Every programing language use different set of tools in order to effectively code. In C++ you will need to learn how to use a bunch of them to solve problems and develop software.
"},{"location":"intro/02-tooling/#version-control","title":"Version Control","text":"Version control are tools that help you to keep track of your code changes. It is a must have tool for any developer. You can keep track the state of your code, and if you mess up something, you can go back to a previous state. It is also a great tool to collaborate with other developers. You can work on the same codebase without messing up each other work.
"},{"location":"intro/02-tooling/#git","title":"GIT","text":"Optional
Install Git
Git is a version control system that is used to track changes to files, including source code, documents, and other types of files. It allows multiple people to work on the same files concurrently, and it keeps track of all changes made to the files, making it easy to go back to previous versions or merge changes made by different people. Git is widely used by developers for managing source code, but it can be used to track changes to any type of file. It is particularly useful for coordinating work on projects that involve multiple people, as it allows everyone to see and track changes made by others.
"},{"location":"intro/02-tooling/#github","title":"Github","text":"Action
Github Student Pack
Github is a web-based platform for version control and collaboration on software projects. It is a popular platform for developers to share and collaborate on code, as well as to track and manage software development projects. GitHub provides version control using Git, a version control system that allows developers to track changes to their codebase and collaborate with other developers on the same codebase. It also includes a range of features such as bug tracking, project management, and team communication tools. In addition to being a platform for software development, GitHub is also a community of developers and a marketplace for buying and selling software development services.
In this course we are going to extensively use GITHUB functionalities. So create an account now with your personal account. Use a meaningful username. Avoid names that hard to associate with you. If you have a educational email or student id, apply for the Github Student Pack, so you will have access to lots of free tools.
It is nice to have git in your machine, but it is not required, because we are going to use gui via gui tools. See GitKraken below.
Action
Install Gitkraken
GitKraken is a Git client for Windows, Mac, and Linux that provides a graphical interface for working with Git repositories. It allows users to manage Git repositories, create and review changes to code, and collaborate with other developers. Some features of GitKraken include a visual representation of the repository's commit history, the ability to stage and discard changes, and support for popular version control systems like GitHub and GitLab. GitKraken is designed to be user-friendly and to make it easier for developers to work with Git, particularly for those who may be new to version control systems.
Gitkraken is a paid software, and it is free for public repositories, but you can have all enterprise and premium functionalities enabled for free with the student pack and described before.
Install Gitkraken. If you login into gitkraken using GitHub with student pack it will unlock all pro features.
"},{"location":"intro/02-tooling/#compiler","title":"Compiler","text":"A compiler is a type of computer program that translates source code into machine instructions that can be run or the CPU or interpreted in a Virtual Machine.
graph TD\n SRC[Source Code] --> |Assembly| OBJ[Machine Code];\n OBJ --> EXE[Executable];\n OBJ --> LIB[Library];Source Codein C++, is associated to two different type of textual file extensions:.cppfor sources and.hfor header files. It is what the developer writes.Assemblyis a human readable representation of theMachine Code. It is not theMachine Codeitself, but it is a representation of it. It is a way to make theMachine Codehuman readable.Machine Codeis what theCPUcan run and understand. It is a sequence of0and1that theCPUcan understand and execute. It is not human readable.Executableis the result of the compilation process. It is a file that can be executed by theOperating System.Libraryis a collection ofMachine Codethat can be used by other programs.ExecutableandLibraryAre binary file that contains theMachine Codeinstructions that theCPUcan execute.
Note
In compiled languages, the end user only receives the executables and libraries. The source code is not distributed.
Here you can see briefly a small function to square a number in C++ compiled via GCC into a x86-64 assembly. The left side is the Source Code and the right side is the code compiled into a human-readble Assembly. This code still needs links to the Operation System in order to be executed.
Tip
The knowledge of this section is not required for this course, but it is good to know.
Some languages such as Java, C# and others, compile the Source Code into bytecode that runs on top of an abstraction layer called Virtual Machine (VM). The VM is a software that runs on top of the Operating System and it is responsible to translate the bytecode into Machine Code that the CPU can understand. This is a way to make the Source Code portable across different Operating Systems and CPU architectures - cross-platform. But this abstraction layer has it cost and it is not as efficient as the Machine Code itself.
To speed up the execution, some VM can Just In Time (JIT) compile the bytecode into Machine Code at runtime when the VM detects parts of Source Code is running a lot(Hotspots), to speed up the execution. When this optmization step is happening, the machine is warming up.
graph TD\n SRC[Source Code] --> |Compiles| BYT[Bytecode];\n BYT --> |JIT Compiler| CPU[Machine Code];Note
In languages that uses VMs, the end user receives the bytecode. The source code is not distributed.
"},{"location":"intro/02-tooling/#notes-on-interpreters","title":"Notes on Interpreters","text":"Tip
The knowledge of this section is not required for this course, but it is good to know.
Some languages such as Python, Javascript and others, do not compile the Source Code, instead, they run on top a program called Interpreter that reads the Source Code and executes it line by line.
graph TD\n SRC[Source Code] --> |read line| INT[Interpreter];\n INT --> |translates| CPU[Machine Code];Some Interpreters are Ahead Of Time (AOT) and they compile the Source Code into Machine Code before the Source Code is executed.
graph TD\n SRC[Source Code] --> |AoT compile| INT[Bytecode / Machine Code];\n INT --> CPU;Note
In intrepreted languages, the end user receives the source code. Sometimes the source code is obfuscated, but it is still readable.
"},{"location":"intro/02-tooling/#platform-specific","title":"Platform specific","text":"This where things get tricky, C++ compiles the code into a binary that runs directly on the processor and interacts with the operating system. So we can have multiple combinations here. Most compilers are cross-platform, but there is exceptions. And to worsen it, some Compilers are tightly coupled with some IDEs(see below, next item).
I personally prefer to use CLang to be my target because it is the one that is most reliable cross-platform compiler. Which means the code will work as expected in most of the scenarios, the feature support table is the same across all platforms. But GCC is the more bleeding edge, which means usually it is the first to support all new fancy features C++ introduces.
No need to download anything here. We are going to use the CLion IDE. See below topics.
"},{"location":"intro/02-tooling/#cmake","title":"CMake","text":"CMake CMake is a cross-platform free and open-source software tool for managing the build process of software using a compiler-independent method. It is designed to support directory hierarchies and applications that depend on multiple libraries. It is used to control the software compilation process using simple platform and compiler independent configuration files, and generate native makefiles and workspaces that can be used in the compiler environment of your choice.
Note
If you use a good IDE(see next topic), you won't need to download anything here.
CMake is typically used in conjunction with native build environments such as Make, Ninja, or Visual Studio. It can also generate project files for IDEs such as Xcode and Visual Studio. You can see a full list of supported generators here.
Here is a simple example of a CMakeLists.txt file that can be used to build a program called \"myproject\" that consists of a single source file called \"main.cpp\":
# Set minimum version of CMake that can be used\ncmake_minimum_required(VERSION 3.10)\n# Set the project name\nproject(myproject)\n# Add executable named \"myproject\" to be built from the source \"main.cpp\"\nadd_executable(myproject main.cpp)\nWarning
Every executable can only cave one main function. Each file with a main function describes a new executable program. If you want to have multiple executables in the same project, in other words, you want to manage multiple executables in the same place, you can change the cmake descriptor to match that as follows, and use your IDE to switch between them:
cmake_minimum_required(VERSION 3.10)\nproject(myproject)\nadd_executable(myexecutable1 main1.cpp)\nadd_executable(myexecutable2 main2.cpp)\nTip
If you are using a nice IDE, you won't need to run this on the command line. So go to next topic.
If you want to build via command line this project, you would first generate a build directory, and then run CMake to build the files using the detected compiler or IDE:
cmake -S. -Bbuild\ncmake --build build -j20\nThis will create a Makefile or a Visual Studio solution file in the build directory, depending on your platform and compiler. You can then use the native build tools to build the project by running \"make\" or opening the solution file in Visual Studio.
CMake provides many options and variables that can be used to customize the build process, such as setting compiler flags, specifying dependencies, and configuring installation targets. You can learn more about CMake by reading the documentation at https://cmake.org/.
"},{"location":"intro/02-tooling/#ide","title":"IDE","text":"An integrated development environment (IDE) is a software application that provides comprehensive facilities to computer programmers for software development. An IDE typically integrates a source code editor, build automation tools, and a debugger. Some IDEs also include additional tools, such as a version control system, a class browser, and a support for literate programming. IDEs are designed to maximize programmer productivity by providing tight-knit components with similar user interfaces. This can be achieved through features such as auto-complete, syntax highlighting, and code refactoring. Many IDEs also provide a code debugger, which allows the programmer to step through code execution and find and fix errors. Some examples of popular IDEs include Eclipse, NetBeans, Visual Studio, and Xcode. Each of these IDEs has its own set of features and capabilities, and developers may choose one based on their specific needs and preferences.
In this course, it is strongly suggested to use an IDE in order to achieve higher quality of deliveries, a good IDE effectively flatten the C++ learning curve. You can opt out and use everything by hand, of course, and it will deepen your knowledge on how things work but be assured it can slow down your learning process. Given this course is result oriented, it is not recommended to not use an IDE here. So use one.
OPINION: The most pervasive C++ IDE is CLion and this the one I am going to use. If you use it too, it would be easier to follow my recorded videos. It works on all platforms Windows, Linux and Mac. I recommend downloading it via Jetbrains Toolbox. If you are a student, apply for student pack for free here. On Windows, CLion embeds a GCC compiler or optionally can use visual studio, while on Macs it requires the xcode command line tools, and on Linux, uses GCC from the system installation.
The other options I suggest are:
"},{"location":"intro/02-tooling/#on-all-platforms","title":"On all platforms","text":"REPLIT - an online and real-time multiplayer IDE. It is slow and lack many functionalities, but can be used for small scoped activities or work with a friend.
VSCode - a small and highly modularized code editor, it have lots of extensions, but it can be complex to set up everything needed: git, cmake, compiler and other stuff.
"},{"location":"intro/02-tooling/#on-windows","title":"On Windows:","text":"Visual Studio - mostly for Windows. When installing, mark C++ development AND search and install additional tools \"CMake\". Otherwise, this repo won't work smoothly for you.
DevC++ - an outdated and small IDE. Lacks lots of functionalities, but if you don't have HD space or use an old machine, this can be your option. In long term, this choice would be bad for you for the lack of functionalities. It is better to use REPLIT than this tool, in my opinion.
"},{"location":"intro/02-tooling/#on-osx","title":"On OSX","text":"XCode - for OSX and Apple devices. It is required at least to have the Command Line Tools. CLion on Macs depends on that.
Xcode Command Line Tools is a small suite of software development tools that are installed on your Mac along with Xcode. These tools include the GCC compiler, which is used to compile C and C++ programs, as well as other tools such as Make and GDB, which are used for debugging and development. The Xcode Command Line Tools are necessary for working with projects from the command line, as well as for using certain software development tools such as Homebrew.
To install the Xcode Command Line Tools, you need to have Xcode installed on your Mac. To check if Xcode is already installed, open a Terminal window and type:
xcode-select -p
If Xcode is already installed, this command will print the path to the Xcode developer directory. If Xcode is not installed, you will see a message saying \"xcode-select: error: command line tools are not installed, use xcode-select --install to install.\"
To install the Xcode Command Line Tools, open a Terminal window and type:
xcode-select --install
This will open a window that prompts you to install the Xcode Command Line Tools. Follow the prompts to complete the installation.
Once the Xcode Command Line Tools are installed, you can use them from the command line by typing commands such as gcc, make, and gdb. You can also use them to install and manage software packages with tools like Homebrew.
"},{"location":"intro/02-tooling/#on-linux","title":"On Linux","text":"If you are using Linux, you know the drill. No need for further explanations here, you are ahead of the others.
If you are using an Ubuntu distro, you can try this to install most of the tools you will need here:
sudo apt-get update && sudo apt-get install -y build-essential git cmake lcov xcb libx11-dev libx11-xcb-dev libxcb-randr0-dev\nIn order to compile:
g++ inputFile.cpp -o executableName\nWhere g++ is the compiler frontend program to compile your C++ source code; inputFile.cpp is the filename you want to compile, you can pass multiple files here separated by spaces ex.: inputFile1.cpp inputFile2.cpp; -o means the next text will be the output program name where the executable will be built, (for windows, the name should end with .exe ex.: program.exe).
You will have a plethora of editors and IDEs. The one I can suggest is the VSCode, Code::Blocks or KDevelop. But I really prefer CLion.
"},{"location":"intro/02-tooling/#clion-project-workflow-with-cmake","title":"CLion project workflow with CMake","text":"When you create a new project, select New C++ Executable, set the C++ Standard to the newest one, C++20 is enough, and place in a folder location where you prefer.
CLion automatically generate 2 files for you. - CMakeLists.txt is the CMake multiplatform project descriptor, with that, you can share your project with colleagues that are using different platforms than you. - main.cpp is the entry point for your code.
It is not the moment to talk about multiple file projects, but if you want to get ready for it, you will have to edit the CMakeLists.txt file and add them in the add_executable function.
Hello World
// this a single line comment and it is not compiled. comments are used to explain the code.\n// you can do single line comment by adding // in front of the line or\n// you can do multi line comments by wrapping your comment in /* and */ such as: /* insert comment here */\n/* this is\n * a multi line\n * comment\n */\n#include <iostream> // this includes an external library used to deal with console input and output\n\nusing namespace std; // we declare that we are going to use the namespace std of the library we just included \n\n// \"int\" means it should return an integer number in the end of its execution to communicate if it finished properly\n// \"main()\" function where the operating system will look for starting the code.\n// \"()\" empty parameters. this main function here needs no parameter to execute\n// anynthing between { and } is considered a scope. \n// everything stack allocated in this scope will be deallocated in the end of the scope. ex.: local variables. \nint main() {\n /* \"cout\" means console output. Print to the console the content of what is passed after the \n * \"<<\" stream operator. Streams what in the wright side of it to the cout object\n * \"endl\" means end line. Append a new line to the stream, in the case, console output.\n */\n cout << \"Hello World\" << endl;\n\n /* tells the operating system the program finished without errors. Any number different from that is considered \n * a error code or error number.\n */\n return 0; \n}\n#include <iostream>\n#include <string> // structure to deal with a char sequence, it is called string\nusing namespace std;\nint main(){\n // invites the user to write something\n cout << \"Type your name: \" << endl;\n\n /* * string means the type of the variable, this definition came from the string include\n * username means the name of the variable, the container to hold and store the data\n */\n string username;\n /*\n * cin mean console input. It captures data from the console.\n * note the opposite direction of the stream operator. it streams what come from the cin object to the variable.\n */\n cin >> username;\n // example of how to stream and concatenate texts to the console output;\n cout << \"Hello \" << username << endl;\n}\nSyntax errors in C++ are usually caused by mistakes in the source code that prevent the compiler from being able to understand it. Some common causes of syntax errors include: 1. Omitting a required component of a statement, such as a semicolon at the end of a line or a closing curly brace. 2. Using incorrect capitalization or spelling in a keyword or identifier. 3. Using the wrong punctuation, such as using a comma instead of a semicolon. 4. Mixing up the order of operations, such as using an operator that expects two operands before the operands have been provided.
To fix a syntax error, you will need to locate the source of the error and correct it in the code. This can often be a challenging task, as syntax errors can be caused by a variety of factors, and it is not always immediately clear what the problem is. However, there are a few tools that can help you locate and fix syntax errors in your C++ code: 1. A compiler error message: When you try to compile your code, the compiler will often provide an error message that can help you locate the source of the syntax error. These error messages can be somewhat cryptic, but they usually include the line number and a brief description of the problem. 2. A text editor with syntax highlighting: Many text editors, such as Visual Studio or Eclipse, include syntax highlighting, which can help you identify syntax errors by coloring different parts of the code differently. For example, keywords may be highlighted in blue, while variables may be highlighted in green. 3. A debugger: A debugger is a tool that allows you to step through your code line by line, examining the values of variables and the state of the program at each step. This can be a very useful tool for tracking down syntax errors, as it allows you to see exactly where the error occurs and what caused it.
Reference
"},{"location":"intro/02-tooling/#2-logic-error","title":"2. Logic Error","text":"A logic error in C++ is an error that occurs when the code produces unintended results or behaves in unexpected ways due to a mistake in the logic of the program. This type of error is usually caused by a coding mistake, such as using the wrong operator, omitting a necessary statement, or using the wrong variable. Here are some common causes of logic errors in C++:
- Incorrect use of conditional statements (e.g., using the wrong comparison operator or forgetting to include a necessary else clause)
- Mistakenly using the assignment operator (=) instead of the equality operator (==) in a conditional statement
- Omitting a necessary loop iteration or failing to terminate a loop at the appropriate time
- Using the wrong variable or array index
- Incorrectly calling a function or passing the wrong arguments to a function
To fix a logic error in C++, you will need to carefully examine your code and identify the mistake. It may be helpful to use a debugger to step through your code and see how it is executing, or to add print statements to help you understand what is happening at each step.
Reference
"},{"location":"intro/02-tooling/#3-run-time-error","title":"3. Run-time error","text":"A runtime error in C++ means that there is an error in your program that is causing it to behave unexpectedly or crash during runtime, i.e., after you have compiled and run the program. There are many possible causes of runtime errors in C++, including:
- Dereferencing a null pointer
- Accessing an array out of bounds
- Using an uninitialized variable
- Trying to divide by zero
- Attempting to use an object that has been deleted or has gone out of scope
To troubleshoot a runtime error, you'll need to identify the source of the error by examining the error message and the code that is causing the error. Some common tools and techniques you can use to troubleshoot runtime errors include:
- Using a debugger to step through your code line by line
- Printing out the values of variables to see where the error might be occurring
- Adding additional debug statements or logging to your code to help identify the source of the error
It's also a good idea to ensure that you have compiled your code with debugging symbols enabled, as this will allow you to use the debugger to get a better understanding of what is happening in your code. will cause the program to crash during run-time
Reference
"},{"location":"intro/02-tooling/#exercises","title":"Exercises:","text":"- Research and read about other notable errors: segmentation fault, stack overflow, buffer overflow.
- Hello World - just print
hello world.
- Setup your environment for your needs following the choices given above. If you are unsure, use CLion and you will be mostly safe.
- Fork this repo privately. You will have to do your assignments there. Go to the home repo and hit fork.
- Clone this repo to your machine. gitkraken + github gitkraken clone gitkraken big tutorial
- Make sure the CMake option \"ENABLE_INTRO\" is set as ON in CMakeLists.txt file in the root directory in order to see and enable all activities.
- (enrolled students) If you are enrolled in a class with me, share your repo with me, so I can track your evolution. And do the activities described there.
- (optional) star this repo :-)
If you have problems here, start a discussion this is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me.
"},{"location":"intro/03-datatypes/","title":"Variables, Data Types, Expressions, Assignment, Formatting","text":""},{"location":"intro/03-datatypes/#variables","title":"Variables","text":"Variables are containers to store information and facilitates data manipulation. They are named and typed. Detailed Reference
Container sizes are measured in Bytes. Bytes are the smallest addressable unit in a computer. Each byte is composed by 8 bits. Each bit can be 1 or 0 (true or false). If one byte have 8 bits and each bit one can hold 2 different values, the combination of all possible cases that a byte can be is 2^8 which is 256, so one byte can hold up to 256 different states or possibilities.
There are several types of variables in C++, including:
- Primitive data types: These are the most basic data types in C++ and include integer, floating-point, character, and boolean types.
- Derived data types: These data types are derived from the primitive data types and include arrays, pointers, and references.
- User-defined data types: These data types are defined by the programmer and include structures, classes, and enumerations.
Detailed Reference
"},{"location":"intro/03-datatypes/#numeric-types","title":"Numeric types","text":"There are some basic integer container types with different sizes. It can have some type modifiers to change the default behavior or the type.
The common size of the integer containers are 1(char), 2(short int), 4(int) or 8(long long) bytes. For a more detailed coverage read this.
Note
But the only guarantee the C++ imposes is: 1 == sizeof(char) <= sizeof(short) <= sizeof(int) <= sizeof(long) <= sizeof(long long) and it can result in compiler defined behaviours where a char can have 8 bytes and a long long can be 1 byte.
Note
If you care about being cross-platform conformant, you have to always specify the sign modifier or use a more descriptive type such as listed here.
For floating pointing numbers, the container size can be 4(float), 8(double), 10(deprecated) or 16(long double) bytes.
The sign modifiers can be signed and unsigned and are applicable only for integer types.
The default behavior of the types in a x86 cpu are as signed numbers and the first bit of the container is the signal. If the first bit is 0, it means it is positive. If the first bit is 1, it means it is negative. More details.
Which means that if the container follow two complement and is the size of 1 byte(8 bits), it have 1 bit for the signal and 7 bit for the content. So this number goes from -128 up to 127, this container is typically a signed char. The positive size has 1 less quantity in absolute than the negative because 0 is represented in positive side. There are 256 numbers between -128 and 127 inclusive.
A standard char type uses 1 byte to store data and follows complement of 1. Going -127 to 127, so tipically represents 255 numbers.
A signed char follows complement of 2 and it can represent 2^8 or 256 different numbers. By default, in x86 machine char is signed and the represented numbers can go from -2^7 or -128 up to 2^7 - 1 or 127.
An unsigned char
Chars can be used to represent letters following the ascii table where each value means a specific letter, digit or symbol.
Note
A char can have different sizes to represent different character coding for different languages. If you are using hebrew, chinese, or others, you probably will need more than 1 byte to represent the chars. Use char8_t (UTF8), char16_t(UTF16) or char36_t(UTF32), to cover your character encoding for the language you are using.
ASCII - American Standard Code for Information Interchange - maps a number to a character. It is used to represent letters, digits and symbols. It is a standard that is used by most of the computers in the world.
It is a 7 bit table, so it can represent 2^7 or 128 different characters. The first 32 characters are control characters and the rest are printable characters. Reference. There are other tables that extend the ASCII table to 8 bits, or even 16 bits.
The printable chacacters starts at number 32 and goes up to 126. The first 32 characters are control characters and the rest are printable.
ASCII Table
As you can imagine, this table is not enough to represent all the characters in the world(latin, chinese, japanese, etc). So there are other tables that extend the ASCII table to 8 bits, or even 16 bits.
"},{"location":"intro/03-datatypes/#integer","title":"Integer","text":"Note
Most of the information that I am covering here might be not precise, but the overall idea is correct. If you want a deep dive, read this.
A standard int type uses 4 bytes to store data. It is signed by default.
It can represent 2^32 or 4294967296 different numbers. As a signed type, it can represent numbers from -2^31 or -2147483648 up to 2^31 - 1 or 2147483647.
The type int can accept sign modifiers as signed or unsigned to change the behavior of the first bit to act as a sign or not.
The type int can accept size modifiers as short (2 bytes) or long long (8 bytes) to change the size and representation capacity of the container. Type declaration short and short int result in the same container size of 2 bytes. In the same way a long long or long long int reserves the same size of 8 bytes for the container.
The type long or long int usually gives the same size of int as 4 bytes. Historical fact or myth: This abnormality, comes from the evolution of the definition of int: in the past, 2 bytes were enough for the majority of the scenarios in the 16 bits processors, but it frequently reached the limits of the container and it overflowed. So they changed the standard definition of a integer from being 2 bytes to 4 bytes, and created the short modifier. In this scenario the long int lost the reason to exist.
Here goes a list of valid integer types and its probable size(it depends on the implementation, cpu architecture and operation system): - Size of 2 bytes: short int, short, signed short int, signed short, unsigned short int, unsigned short, - Size of 4 bytes: signed, unsigned, int, signed int, unsigned int, long int, long, signed long int, signed long, unsigned long int, unsigned long, - Size of 8 bytes: long long int, long long, signed long long int, signed long long, unsigned long long int, unsigned long long.
OPINION: I highly recommend the usage of these types instead, to ensure determinism and consistency between compilers, operating systems and cpu architectures.
"},{"location":"intro/03-datatypes/#float-pointing","title":"Float pointing","text":"There are 3 basic types of floating point containers: float(4 bytes) and double(8 bytes) and long double(16 bytes) to represent fractional numeric types.
The standard IEEE754 specifies how a floating point number is stored in the form of bits inside the container. The container holds 3 basic information to simulate the behavior of a fractional type inside a binary type: signal, exponent and fraction.
Note
This standard was very open to implementation definition in the past, and this is one of the root causes of non-determinism physics simulation. This is the main problem you cannot guarantee the same operation with the same pair of numbers will consistently give the same result across different types of processors and compilers, thus making the physics of a multiplayer game consistency hardly achievable. Many deterministic physics engines tend to not use this standard at all, and implement those behaviors via software on top of integers instead. There are 2 approaches to solve the floating-point determinism: softfloat that implement all the IEEE754 specifications via software, or implement some kind of fixed-point arithmetic on top of integers.
"},{"location":"intro/03-datatypes/#booleans","title":"Booleans","text":"bool is a special type that has the container size of 1 byte but the compiler can optimize and pack up to 8 bools in one byte if they are declared in sequence.
An enumeration is a type that consists of a set of named integral constants. It can be defined using the enum keyword:
enum Color {\n Red,\n Green,\n Blue\n};\nThis defines a new type called Color, which has three possible values: Red, Green, and Blue. By default, the values of these constants are 0, 1, and 2, respectively. However, you can specify your own values:
enum Color {\n Red = 5,\n Green, // 6\n Blue // 7\n};\nYou can then use the enumeration type just like any other type:
Color favoriteColor = Red;\nEnumerations can also have their underlying type explicitly specified:
enum class Color : char {\n Red, \n Green,\n Blue\n};\nHere, the underlying type of the enumeration is char, so the constants Red, Green, and Blue will be stored as characters(1 byte size). The enum class syntax is known as a \"scoped\" enumeration, and it is recommended over the traditional enum syntax because it helps prevent naming conflicts. See the CppCoreGuidelines to understand better why you should prefer using this.
// You can make the value of the constants\n// explicit to make your debugging easier:\nenum class Color : char {\n Red = 'r',\n Green = 'g',\n Blue = 'b'\n};\nstring is a derived type and in order to use it, string should be included in the beginning of the file or in the header. char are the basic unit of a string and is used to store words as a sequence of chars.
In C++, a string is a sequence of characters that is stored in an object of the std::string class. The std::string class is part of the C++ Standard Library and provides a variety of functions and operators for manipulating strings.
void type","text":"When void type specifier is used in functions, it indicates that a function does not return a value.
It can also be used as a placeholder for a pointer to a memory location to indicate that the pointer is \"universal\" and can point to data of any type, but this can be arguably a bad pattern, and should be used exceptionally when interchanging types with c-style API.
We are going to cover this again when covering pointers and functions.
"},{"location":"intro/03-datatypes/#variable-naming","title":"Variable Naming","text":"Variable names are called identifiers. In C++, you can use any combination of letters, digits, and underscores to name a variable, it should follow some rules:
- Variables can have numbers, en any position, except the first character, so the name does not begin with a digit. Ex.
point2andvector2dare allowed, but9lifeisn't; - Variable names are case-sensitive, so \"myVar\" and \"myvar\" are considered to be different variables;
- Can have
_in any position of the identifier. Ex._mynameanduser_nameare allowed; - It is not a reserved keyword;
Keep in mind that it is a good practice to choose descriptive and meaningful names for your variables, as this can make your code easier to read and understand. Avoid using abbreviations or acronyms that may not be familiar to others who may read your code.
It is also important to note that C++ has some naming conventions that are commonly followed by programmers. For example, it is common to use camelCase or snake_case to separate words in a variable name, and to use all lowercase letters for variables that are local to a function and all uppercase letters for constants.
"},{"location":"intro/03-datatypes/#variable-declaration","title":"Variable declaration","text":"Variable declaration in C++ follows this pattern.
TYPENAME VARIABLENAME;\nTYPENAME can be the name of any predefined type. See Variable Types for the types. VARIABLENAME can be anything as long it follow the naming rules. See Variable Naming for the naming rules. Note
A given variable name can only be declared once in the same context / scope. If you try to redeclare the same variable, the compiler will accuse an error.
Note
You can redeclare the same variable name in different scopes. If one scope is parent of the other, the current will be used and will shadow the content of the one from outer scope. We are going to cover this more when we are covering multi-file projects and functions.
Examples:
int a; // integer variable\nfloat pi; // floating-point variable\nchar c; // character variable\nbool d; // boolean variable\nstring name; // string variable \nNote
We are going to cover later in this course other complex types in other modules such as arrays, pointers and references.
"},{"location":"intro/03-datatypes/#variable-assignment","title":"Variable assignment","text":"= operator means that whatever the container have will be overwritten by the result of the right side statement. You should read it not as equal but as receives to avoid misunderstanding. Reference
int a = 10; // integer variable\nfloat pi = 3.14; // floating-point variable\nchar c = 'A'; // character variable\nbool d = true; // boolean variable\nstring name = \"John Doe\"; // string variable \nEvery variable, by default, is not initialized. It means that you have to set the content of it after declaring. If the variable is read before the assignment, its content is garbage, it will read whatever is set in the memory stack for the given container location. So the best approach is to always set a value when a variable is declared or be assured that every variable is never read before an assigment.
A char variable can be assigned by integer numbers or any characters between single quotes.
char c;\nc = 'A'; // the content is 65 and the representation is A. see ascii table.\nc = 98; // the content is 98 and the representation is b. see ascii table.\nA bool is by default either true or false, but it can be assigned by numeric value following this rule: - if the value is 0, then the value stored by the variable is false (0); - if the value is anything different than 0, the value stored is true (1);
To convert a string to a int, you have to use a function stoi(for int), stol(for long) or stoll(for long long) because both types are not compatibles.
To convert a string to a float, you have to use a function stof(for float), stod(for double), or stold(for long double) because both types are not compatibles.
Literals are values that are expressed freely in the code. Every numeric type can be appended with suffixes to specify explicitly the type to avoid undefined behaviors or compiler defined behaviors such as implicit cast or container size.
"},{"location":"intro/03-datatypes/#integer-literals","title":"Integer literals","text":"There are 4 types of integer literals. - decimal-literal: never starts with digit 0 and followed by any decimal digit; - octal-literal: starts with 0 digit and followed by any octal digit; - hex-literal: starts with 0x or 0X and followed by any hexadecimal digit; - binary-literal: starts with 0b or 0B and followed by any binary digit;
// all of these variables holds the same value, 42, but using different bases.\n// the right side of the = are literals\nint deci = 42; \nint octa = 052; \nint hexa = 0x2a; \nint bina = 0b101010;\nSuffixes:
no suffixprovided: it will use the first smallest signed integer container that can hold the data starting fromint;uorU: it will use the first smallest unsigned integer container that can hold the data starting fromunsigned int;lorL: it will use the first smallest signed integer container that can hold the data starting fromlong;luorLU: it will use the first smallest unsigned integer container that can hold the data starting fromunsigned long;llorLL: it will use the long long signed integer containerlong long;lluorLLU: it will use the long long unsigned integer containerunsigned long long;
unsigned long long l1 = 15731685574866854135ull;\nReference
"},{"location":"intro/03-datatypes/#float-point-literals","title":"Float point literals","text":"There are 3 suffixes in floating point decimals.
no suffixmeans the container is a double;fsuffix means it is a float container;lsuffix means it is a long double container;
A floating point literal can be defined by 3 ways:
- digit-sequence decimal-exponent suffix(optional).
1e2means its adoublewith the value of1*10^2or100;1e-2fmeans its afloatwith the value of1*10^-2or0.01;
- digit-sequence . decimal-exponent(optional) suffix(optional).
2.means it is adoublewith value of2;2.fmeans it is afloatwith value of2;2.1lmeans it is along doublewith value of2.1;
- digit-sequence(optional) . digit-sequence decimal-exponent(optional) suffix(optional)
3.1415fmeans it is afloatwith value of3.1415;.1means it is adoublewith value of0.1;0.1e1Lmeans it is along doublewith value of1;
Reference
"},{"location":"intro/03-datatypes/#arithmetic-operations","title":"Arithmetic Operations","text":"In C++, you can perform common arithmetic operations is statements using the following operators Reference:
- Addition:
+ - Subtraction:
- - Multiplication:
* - Division:
/ - Modulus (remainder):
%
There are two special cases called unary increment / decrement operators that may occur in before(prefixed) or after(postfixed) the variable name reference. If prefixed it is executed first and then return the result, if postfixed, it returns the current value and then execute the operation:
- Increment:
++; - Decrement:
--;
There are shorthand assignment operators reference that reassign the value of the variable after executing the arithmetic operation with the right side of the operator with the old value of the variable:
- Addition:
+= - Subtraction:
-= - Multiplication:
*= - Division:
/= - Modulus (remainder):
%=
Here is an example of how to use these operators in a C++ program:
#include <iostream>\n\nint main() {\n int a = 5;\n int b = 2;\n\n std::cout << a + b << std::endl; // Outputs 7\n std::cout << a - b << std::endl; // Outputs 3\n std::cout << a * b << std::endl; // Outputs 10\n std::cout << a / b << std::endl; // Outputs 2\n std::cout << a % b << std::endl; // Outputs 1\n a++;\n std::cout << a << std::endl; // Outputs 6\n a--;\n std::cout << a << std::endl; // Outputs 5\n\n std::cout << a++ << std::endl; // Outputs 5 because it first returns the current value and then increments.\n std::cout << a << std::endl; // Outputs 6\n\n std::cout << --a << std::endl; // Outputs 5 because it first decrements the value and then return it already changed;\n std::cout << a << std::endl; // Outputs 5\n\n b *= 2; // it is a short version of b = b * 2; \n std::cout << b << std::endl; // Outputs 4\n\n b /= 2; // it is a short version of b = b / 2; \n std::cout << b << std::endl; // Outputs 2\n\n return 0;\n}\nNote that the division operator (/) performs integer division if both operands are integers. If either operand is a floating-point type, the division will be performed as floating-point division. So 5/2 is 2 because both are integers, se we use integer division, but 5/2. is 2.5 because the second one is a double literal.
Also, the modulus operator (%) returns the remainder of an integer division. For example, 7 % 3 is equal to 1, because 3 goes into 7 two times with a remainder of 1.
Implicit casting, also known as type coercion, is the process of converting a value of one data type to another data type without the need for an explicit cast operator. In C++, this can occur when an expression involves operands of different data types and the compiler automatically converts one of the operands to the data type of the other in order to perform the operation.
For example:
int a = 1;\ndouble b = 1.5;\n\nint c = a + b; // c is automatically converted to a double before the addition\nb is a double, while the value of a is an int. When the addition operator is used, the compiler will automatically convert a to a double before performing the addition. The result of the expression is a double, so c is also automatically converted to a double before being assigned the result of the expression. Implicit casting can also occur when assigning a value to a variable of a different data type. For example:
int a = 2;\ndouble b = a; // a is automatically converted to a double before the assignment\nIn this case, the value of a is an int, but it is being assigned to a double variable. The compiler will automatically convert the value of a to a double before making the assignment.
It's important to be aware of implicit casting, because it can sometimes lead to unexpected results or loss of precision if not handled properly. In some cases, it may be necessary to use an explicit cast operator to explicitly convert a value to a specific data type.
"},{"location":"intro/03-datatypes/#explicit-cast","title":"Explicit cast","text":"In C++, you can use an explicit cast operator to explicitly convert a value of one data type to another. The general syntax for an explicit cast are:
// ref: https://en.wikibooks.org/wiki/C%2B%2B_Programming/Programming_Languages/C%2B%2B/Code/Statements/Variables/Type_Casting\n(TYPENAME) value; // regular c-style. do not use this extensively\nstatic_cast<TYPENAME>(value); // c++ style conversion, arguably it is the preferred style. use this if you know what you are doing.\nTYPENAME(value); // functional initialization, slower but safer. might not work for every case. Use this if you are unsure or want to be safe.\nTYPENAME{value}; // initialization style, faster, convenient, concise and arguably safer because it triggers warnings. use this for the general case. \nFor example:
int a = 7;\ndouble b = (double) a; // a is explicitly converted to a double\nIn this example, the value of a is an int, but it is being explicitly converted to a double using the explicit cast operator. The result of the cast is then assigned to the double variable b.
Explicit casts can be useful in situations where you want to ensure that a value is converted to a specific data type, regardless of the data types of the operands in an expression. However, it's important to be aware that explicit casts can also lead to unexpected results or loss of precision if not used carefully. This behaviour is called narrowing.
C-style:
int a = 20001;\nchar b = (char) a; // b is assigned the ASCII value for the character '!'\nIn this case, the value of a is an int, but it is being explicitly converted to a char using the explicit cast operator. However, the range of values that can be represented by a char is much smaller than the range of values that can be represented by an int, so the value of a is outside the range that can be represented by a char. As a result, b is assigned the ASCII value for the character 1, which is not the same as the original value of a. The value ! is 33 in ASCII table, and 33 is the result of the 20001 % 256 where 256 is the number of elements the char can represent. In this case, what happened was a bug that is hard to track called int overflow.
auto keyword","text":"auto keyword is mostly a syntax sugar to automatically infer the data type. It is used to avoid writing the full declaration of complex types when it is easily inferred. auto is not a dynamic type, once it is inferred, it cannot be changed later like in other dynamic typed languages such as javascript.
auto i = 0; // automatically inferred as an integer type;\nauto f = 0.0f; // automatically inferred as a float type;\n\ni = \"word\"; // this won't work, because it was already inferred as an integer and integer container cannot hold string\nThere are many functions to help you format the output in the way it is expected, here goes a selection of the most useful ones I can think. Yon can find more functions and manipulators here and here.
To set a fixed precision for floating point numbers in C++, you can use the std::setprecision manipulator from the iomanip header, along with the std::fixed manipulator.
Here's an example of how to use these manipulators to output a floating point number with a fixed precision of 3 decimal places:
#include <iostream>\n#include <iomanip>\n\nint main() {\n double num = 3.14159265;\n\n std::cout << std::fixed << std::setprecision(3) << num << std::endl;\n // Output: 3.142\n return 0;\n}\nYou can also use the std::setw manipulator to set the minimum field width for the output, which can be useful for aligning the decimal points in a table of numbers.
For example:
#include <iostream>\n#include <iomanip>\n\nint main() {\n double num1 = 3.14159265;\n double num2 = 123.456789;\n\n std::cout << std::fixed << std::setprecision(3) << std::setw(8) << num1 << std::endl;\n std::cout << std::fixed << std::setprecision(3) << std::setw(8) << num2 << std::endl;\n // Output:\n // 3.142\n // 123.457\n return 0;\n}\nNote that these manipulators only affect the output stream, and do not modify the values of the floating point variables themselves. If you want to store the numbers with a fixed precision, you will need to use a different method such as rounding or truncating the numbers.
To align text to the right or left in C++, you can use the setw manipulator in the iomanip header and the right or left flag. More details here
Here is an example:
#include <iostream>\n#include <iomanip>\n\nint main() {\n std::cout << std::right << std::setw(10) << \"Apple\" << std::endl;\n std::cout << std::left << std::setw(10) << \"Banana\" << std::endl;\n return 0;\n}\nBoth will print inside a virtual column with the size of 10 chars. This will output the following:
Apple\nBanana \nDo all exercises up to this topic here.
In order to get into coding, the easiest way to learn is by solving coding challenges. It is like learning any new language, you have to be exposed and involved. Do not do only the homeworks, otherwise you are going to fail. Another metaphor is: the homework is the like a competition that you have to run to prove that you are trained, but in order to train, you have to do small runs and do small steps first, so you have to train yourself ot least 2x per week.
The best way to train yourself in coding and solving problems in my opinion is this:
- Sort Beecrowd questions from the most solved to the least solved questions here is the link of the list already filtered.
- Start solving the questions from the top to the bottom. Chose one from de the beginning, it would be one of the easiest;
- If you are feeling comfortable and being able to solve more than 3 per hour, you are allowed to skip some of the questions. It is just like in a gym, when you get used with the load, you increase it. Otherwise continue training slowly.
banknotes and coins - Here you will use formatting, modulus, casting, arithmetic operations, compound assignment. You don't need to use if-else.
Hint. Follow this only if dont find your way of solving it. You can read the number as a double, multiply by 100 and then do a sequence of modulus and division operations.
double input; // declare the container to store the input\ncin >> input; // read the input\n\nlong long cents = static_cast<long long>(input * 100); // number of cents. Note: if you just use float, you will face issues. \n\nlong long notes100 = cents/10000; // get the number of notes of 100 dollar (100 units of 100 cents) \ncents %= 10000; // remove the amount of 100 dollars\nAnother good way of solving it avoiding casting is reading the number as string and removing the point. Never use float for money
string input; // declare the container to store the input\ncin >> input; // read the input\n\n// given every input will have the dot, we should remove it. remove the dot `.`\ninput = input.erase(str.find('.'), 1);\n\n// not it is safe to use int, because no bit is lost in floating casting and nobody have more than MAX_INT cents. \nint cents = stoll(input); // number of cents. \n\nlong long notes100 = cents/10000; // get the number of notes of 100 dollar (100 units of 100 cents) \ncents %= 10000; // update the remaining cents by removing the amount of 100 dollars in cents units\nIf you have problems here, start a discussion. Nhis is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me. Or visit the tutoring service.
"},{"location":"intro/04-conditionals/","title":"Conditionals, Switch, Boolean Operations","text":"- Boolean Operations
- Bitwise Operations
- Conditionals
- Switch
In C++, the boolean operators are used to perform logical operations on boolean values (values that can only be true or false).
"},{"location":"intro/04-conditionals/#and","title":"AND","text":"And operators can be represented by &&(most common syntax) or and(C++20 and up - alternative operator representation). This operator represents the logical AND operation. It returns true if both operands are true, and false otherwise. - It needs only if one false element to make the result be false; - It needs all elements to be true in order the result be true;
p q p and q true true true true false false false true false false folse false For example:
bool x = true;\nbool y = false;\nbool z = x && y; // z is assigned the value false\nOr operators can be represented by ||(most common syntax) or or(C++20 and up - - alternative operator representation). This operator represents the logical OR operation. It returns true if one operands are true, and false if all are false. - It needs only if one true element to make the result be true; - It needs all elements to be false in order the result be false;
p q p or q true true true true false true false true true false folse false For example:
bool x = true;\nbool y = false;\nbool z = x || y; // z is assigned the value true\nNot operator can be represented by !(most common syntax) or not(C++20 and up - alternative operator representation). This operator represents the logical NOT operation. It returns true if operand after it is false, and true otherwise._
p not p true false false true For example:
bool x = true;\nbool y = !x; // y is assigned the value false\nIn C++, the bitwise operators are used to perform operations on the individual bits of an integer value.
"},{"location":"intro/04-conditionals/#and_1","title":"AND","text":"Bitwise and can be represented by & or bitand(C++20 and up - alternative operator representation: This operator performs the bitwise AND operation. It compares each bit of the first operand to the corresponding bit of the second operand, and if both bits are 1, the corresponding result bit is set to 1. Otherwise, the corresponding result bit is set to 0. For example:
int x = 5; // binary representation is 0101\nint y = 3; // binary representation is 0011\nint z = x & y; // z is assigned the value 1, which is binary 0001\nBitwise or can be represented by | or bitor(C++20 and up - alternative operator representation: This operator performs the bitwise OR operation. It compares each bit of the first operand to the corresponding bit of the second operand, and if either bit is 1, the corresponding result bit is set to 1. Otherwise, the corresponding result bit is set to 0. For example:
int x = 5; // binary representation is 0101\nint y = 3; // binary representation is 0011\nint z = x | y; // z is assigned the value 7, which is binary 0111\nBitwise xor can be represented by ^ or bitxor(C++20 and up - alternative operator representation: This operator performs the bitwise XOR (exclusive OR) operation. It compares each bit of the first operand to the corresponding bit of the second operand, and if the bits are different, the corresponding result bit is set to 1. Otherwise, the corresponding result bit is set to 0.
int x = 5; // binary representation is 0101\nint y = 3; // binary representation is 0011\nint z = x ^ y; // z is assigned the value 6, which is binary 0110\nBitwise xor is a type of binary sum without carry bit.
"},{"location":"intro/04-conditionals/#not_1","title":"NOT","text":"Bitwise not can be represented by ~ or bitnot(C++20 and up - alternative operator representation: This operator performs the bitwise NOT (negation) operation. It inverts each bit of the operand (changes 1 to 0 and 0 to 1). For example:
int x = 5; // binary representation is 0101\nint y = ~x; // y is assigned the value -6, which is binary 11111010. See complement of two for more details.\nIn C++, the shift operators are used to shift the bits of a binary number to the left or right. Pay attention to not mix with the same ones used to strings, in that case they are called stream operators. There are two shift operators:
<<: This operator shifts the bits of the left operand to the left by the number of positions specified by the right operand. For example:
int x = 2; // binary representation is 10\nx = x << 1; // shifts the bits of x one position to the left and assigns the result to x\n// x now contains 4, which is binary 100\n>>: This operator shifts the bits of the left operand to the right by the number of positions specified by the right operand. For example:
int x = 4; // binary representation is 100\nx = x >> 1; // shifts the bits of x one position to the right and assigns the result to x\n// x now contains 2, which is binary 10\nThe shift operators are often used to perform operations more efficiently than can be done with other operators. They can also be used to extract or insert specific bits from or into a value.
"},{"location":"intro/04-conditionals/#conditionals","title":"Conditionals","text":"Conditionals are used to branch and execute different blocks of code based on whether a certain condition is true or false. There are several types of conditionals, including:
"},{"location":"intro/04-conditionals/#if-clause","title":"if clause","text":"if statements: These execute a block of code if a certain condition is true. If statements usually uses comparison operators or any result that can be transformed as boolean - any number different than 0 is considered true, only 0 is considered false.
Comparison operator is used to compare the value of two operands. The operands can be variables, expressions, or constants. The comparison operator returns a Boolean value of true or false, depending on the result of the comparison. There are several comparison operators available:
==: returnstrueif the operands are equal;!=: returnstrueif the operands are not equal;>: returnstrueif the left operand is greater than the right operand;<: returnstrueif the left operand is less than the right operand;>=: returnstrueif the left operand is greater than or equal to the right operand;<=: returnstrueif the left operand is less than or equal to the right operand;
For example:
if (x > y) {\n // code to execute if x is greater than y\n}\nIf it appears without scope {}, the condition will applied only to the next statement. For example
if (x > y) \n doSomething(); // only happens if x > y is evaluated as true\notherThing(); // this will always occur. \nif (x > y) doSomething(); // only happens if x > y is evaluated as true\nif (x > y) {doSomething();} // only happens if x > y is evaluated as true\nA common source of error is adding a ; after the condition. In this case, the compiler will understand that it is an empty statement and always execute the next statement.
if (x > y); // note the inline empty statement here finished with a `;`\n doSomething(); // this will always happen\nNote
It is preferred to always create scopes with {}, but there is no need to have them if you have only one statement that will happen for that condition.
All the explanations from if applies here but now we have a fallback case.
if-else statements: These execute a block of code if a certain condition is true, and a different block of code if the condition is false. For example:
if (x > y) {\n // code to execute if x is greater than y\n} else {\n // code to execute if x is not greater than y\n}\nAll the explanations about scope on the if clause described before, can be applied to the else.
The ternary operator is also known as the conditional operator. It is used to evaluate a condition and return one value if the condition is true and another value if the condition is false. The syntax for the ternary operator is:
condition ? value_if_true : value_if_false\nFor example:
int a = 5;\nint b = 10;\nint min = (a < b) ? a : b; // min will be assigned the value of a, since a is less than b\nHere, the condition a < b is evaluated to be true, so the value of a is returned. If the condition had been false, the value of b would have been returned instead.
The ternary operator can be used as a shorthand for an if-else statement. For example, the code above could be written as:
int a = 5;\nint b = 10;\nint min;\nif (a < b) {\n min = a;\n} else {\n min = b;\n}\nswitch statement allows you to execute a block of code based on the value of a variable or expression. The switch statement is often used as an alternative to a series of if statements, as it can make the code more concise and easier to read. Here is the basic syntax for a switch statement in C++:
switch (expression) {\n case value1:\n // code to be executed if expression == value1\n break;\n case value2:\n // code to be executed if expression == value2\n break;\n // ...\n default:\n // code to be executed if expression is not equal to any of the values\n}\nThe expression is evaluated once, and the value is compared to the values in each case statement. If a match is found, the code associated with that case is executed. The break statement is used to exit the switch statement and prevent the code in subsequent cases from being executed. The default case is optional, and is executed if none of the other cases match the value of the expression.
Here is an example of a switch statement that checks the value of a variable x and executes different code depending on the value of x:
int x = 2;\n\nswitch (x) {\n case 1:\n cout << \"x is 1\" << endl;\n break;\n case 2:\n cout << \"x is 2\" << endl;\n break;\n case 3:\n cout << \"x is 3\" << endl;\n break;\n default:\n cout << \"x is not 1, 2, or 3\" << endl;\n}\nIn this example, the output would be \"x is 2\", as the value of x is 2.
Note
It's important to note that C++ uses strict type checking, so you need to be careful about the types of variables you use in your conditionals. For example, you can't compare a string to an integer using the == operator.
In C++, the break statement is used to exit a switch statement and prevent the code in subsequent cases from being executed. However, sometimes you may want to allow the code in multiple cases to be executed if certain conditions are met. This is known as a \"fallthrough\" in C++.
To allow a switch statement to fall through to the next case, you can omit the break statement at the end of the case's code block. The code in the next case will then be executed, and the switch statement will continue to execute until a break statement is encountered or the end of the switch is reached.
Here is an example of a switch statement with a fallthrough:
int x = 2;\n\nswitch (x) {\n case 1:\n cout << \"x is 1\" << endl;\n case 2:\n cout << \"x is 2\" << endl;\n case 3:\n cout << \"x is 3\" << endl;\n default:\n cout << \"x is not 1, 2, or 3\" << endl;\n}\nIn this example, the output would be \"x is 2\", \"x is 3\" and \"x is not 1, 2, or 3\", as the break statement is omitted in the case 2 block and the code in the case 3 block is executed as a result.
It is generally considered good practice to include a break statement at the end of each case in a switch statement to avoid unintended fallthrough. However, there may be cases where a fallthrough is desired behavior. In such cases, it is important to document the intended fallthrough in the code to make it clear to other programmers.
A nice usecase for switches is to be used to select between possible choices and enums are one of the best ways of expressing choices. So it seems natural to combine both, right? Well, not so fast. There are some issues with this combination that you might be aware of.
The main issue with this approach relies on the switch's default behavior. If you use deafult on swiches in conjunction with stringly typed enums (enum class or enum struct), the compiler won't be able to warn you about missing cases. This is because the default case will be triggered for any value that is not explicitly handled by the switch. This is a problem because it is very easy to forget to add a new case when a new value is added to the enum and the compiler won't warn you about it. Example:
enum class Color { Red, Green };\n// this code goes inside some function that uses Color c\nswitch(c){\n case Color::Red:\n // do something\n break;\n default: // covers Color::Green and any other value\n // do something else\n break;\n}\nBut you just remembered that now you should cover the Blue state. So you add it to the enum:
enum class Color { Red, Green, Blue };\nBut you might forget to add the coverage for the new case to the switch, it will fall into the default case without warnings.
So the best combination is to use switches with enum classes and do not use default cases. This way, the compiler will warn you about missing cases. So if you add a new enum value had this code instead, you will be warned about missing cases.
// this code goes inside some function that uses Color c\nswitch(c){\n case Color::Red:\n // do something\n break;\n case Color::Green:\n // do something else\n break;\n}\n// this code will throw a warning if you forget to add a case for the new enum value\n-
Do all exercises up to this topic here.
-
Coordinates of a Point. In this activity, you will have to code a way to find the quadrant of a given coordinate.
It is expected for you to be able to solve all questions before this one 1041 on beecrowd. Sort Beecrowd questions from the most solved to the least solved questions here in the link. If you don't, see Troubleshooting. Don`t let your study pile up, this homework is just a small test, it is expected from you to do other questions on Beecrowd or any other tool such as leetcode.
If you have problems here, start a discussion. Nhis is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me. Or visit the tutoring service.
"},{"location":"intro/05-loops/","title":"Loops, for, while and goto","text":"A loop is a control flow statement that allows you to repeat a block of code.
"},{"location":"intro/05-loops/#while-loop","title":"while loop","text":"This loop is used when you want to execute a block of code an unknown number of times, as long as a certain condition is true. It has the following syntax:
Syntax:
while (condition) {\n // code block to be executed\n}\nint nums = 10;\nwhile (nums>=0) {\n cout << nums << endl;\n nums--;\n}\nIf the block is only one statement, it can be expressed without {}s.
Syntax:
while (condition) \n // statement goes here\nint nums = 10;\nwhile (nums>=0) \n cout << nums-- << endl;\nThis is similar to the while loop, but it is guaranteed to execute at least once.
Syntax:
do {\n // code block to be executed\n} while (condition);\nExample:
int x = 0;\ndo{\n cout << x << endl;\n x++;\n} while(x<10);\nIf the block is only one statement, it can be expressed without {}s.
Syntax:
do\n // single statement goes here\nwhile (condition); \nint x = 0;\ndo \n cout << x++ << endl;\nwhile (x<=10);\nThis loop is used when you know in advance how many times you want to execute a block of code.
- The initialization part is executed only once, at the beginning of the loop. It is used to initialize any loop variables.
- The condition is evaluated at the beginning of each iteration of the loop. If the condition is true, the code block inside the loop is executed. If the condition is false, the loop is terminated.
- The increment part is executed at the end of each iteration of the loop. It is used to update the loop variables.
Syntax:
for (initialization; condition; step_iteration) {\n // code block to be executed\n}\nExample:
for(int i=10; i<=0; i--){\n cout << i << endl; \n}\nIf the block is only one statement, it can be expressed without {}s.
Syntax:
for (initialization; condition; step_iteration)\n // single statement goes here\nfor(int i=10; i<=0; i--)\n cout << i << endl;\nA range-based loop is a loop that iterates over a range of elements. The declaration type should follow the same type of the elements in the range.
Syntax:
for (declaration : range) {\n // code block to be executed\n}\nfor (declaration : range)\n // single statement\nTo avoid explaining arrays and vectors now, assume v as an iterable container that can hold multiple elements. I am going to use auto here to avoid explaining this topic any further.
auto v = {1, 2, 3, 4, 5}; // an automatically inferred iterable container with multiple elements\nfor (int x : v) {\n cout << x << \" \";\n}\nIt is possible to automatically generate ranges
#include <ranges>\n#include <iostream>\nusing namespace std;\nint main() { \n // goes from 0 to 9. in iota, the first element is inclusive and the last one is exclusive.\n for (int i : views::iota(0, 10)) \n cout << i << ' ';\n}\nbreak","text":"break keyword defines a way to break the current loop and end it immediately.
// check if it is prime\nint num; \ncin >> num; // read the number to be checked if is prime or not\nbool isPrime = true;\nfor(int i=2; i<num; i++){\n if(num%i==0){ // check if i divides num\n isPrime = false;\n break; // this will break the loop and prevent further precessing\n }\n}\ncontinue","text":"continue keyword is used to skip the following statements of the loop and move to the next iteration.
// print all even numbers\nfor (int i = 1; i <= 10; i++) {\n if (i % 2 == 1)\n continue;\n cout << i << \" \"; // this statement is skipped if odd numbers\n}\ngoto","text":"You should avoid goto keyword. PERIOD. The only acceptable usage is to break multiple nested loops at the same time. But even in this case, is better to use return statement and functions that you're going to see later in this course.
The goto keyword allows you to transfer control to a labeled statement elsewhere in your code.
Example on how to create a loop using labels and goto. You can create a loop just using labels(anchors) and goto keywords. But this syntax is hard to debug and read. Avoid it at all costs:
#include <iostream>\nusing namespace std;\nint main() {\n int i=0;\n start: // this a label named as start.\n cout << i << endl;\n i++;\n if(i<10)\n goto start; // jump back to start\n else\n goto finish; // jump to finish\n finish: // this a label named as finish.\n return 0;\n}\nExample on how to jump over and skip statements:
#include <iostream>\n\nint main() {\n int x = 10;\n\n goto jump_over_this; // control jumps to the label below\n\n x = 20; // this line of code is skipped\n\n jump_over_this: // label for goto statement\n std::cout << x << std::endl; // outputs 10\n\n return 0;\n}\nExample of an arguably acceptable use of goto. Here you can see the usage of a way to break both loops at the same time. If you use break, you will only break the inner loop. In this situation it is better to break your code into functions to reduce complexity and nesting.
for (int i = 0; i < imax; ++i)\n for (int j = 0; j < jmax; ++j) {\n if (i + j > elem_max) goto finished;\n // ...\n }\nfinished:\n// ...\nYou can nest loops by placing one loop inside another. The inner loop will be executed completely for each iteration of the outer loop. Here is an example of nesting a for loop inside another for loop:
for (int i = 0; i < 10; i++) {\n for (int j = 0; j < 5; j++) {\n cout << \"i: \" << i << \" j: \" << j << endl;\n }\n}\nA infinite loop is when the code loops indefinitely without having a way out. Here goes some examples:
while(true)\n cout << \"Hello World!\" << endl; \nfor(;;)\n cout << \"Hello World!\" << endl; \nint i = 0;\nwhile(i<10); // note the ';' here, it will run indefinitely an empty statement because it won't reach the scope.\n{\n cout << i << endl;\n i++;\n}\nThe accumulator pattern is a way to accumulate values in a loop. Here is an example of how to use it:
int fact = 1; // accumulator variable\nfor(int i=2; i<5; i++){\n fact *= i; // multiply the accumulator by the current value of i\n}\n// fact = 1*1*2*3*4 = 24\ncout << fact << endl;\nThe search pattern is a way to search for a value in a loop, the most common implementation is a boolean flag. Here is an example of how to use it:
int num;\ncin >> num; // read the number to be checked if is prime or not\nbool isPrime = true; // flag to indicate if the number is prime or not\nfor(int i=2; i<num; i++){\n if(num%i==0){ // check if i divides num\n isPrime = false;\n break; // this will break the loop and prevent further precessing\n }\n}\ncout << num << \" is \" << (isPrime ? \"\" : \"not \") << \"prime\" << endl;\n// (isPrime ? \"\" : \"not \") is the ternary operator, it is a shorthand for if-else\nDebugging is the act of instrumentalize your code in order to track problems and fix them.
The most naive way of doing it is by printing variables random texts to find the problem. Don't do it. Use debugger tools instead. Each IDE has his its ows set of tools, if you are using CLion, use this tutorial.
"},{"location":"intro/05-loops/#automated-tests","title":"Automated tests","text":"There are lots of methodologies to guarantee your code is correct and solve the problem it is supposed to solve. The one that stand out is Automated tests.
When you are using beecrowd, leetcode, hackerrank or any other tool to solve problems to learn how to code, a problem is posted to be solved and they test your code solution against a set of expected outputs. This is automated testing. You can generate custom automated tests for your code and cover all cases that you can imagine before you start coding the solution. This is a good practice and is documented in the industry as Test Driven Development.
"},{"location":"intro/05-loops/#homework","title":"Homework","text":"Do all exercises up to this topic here.
In this activity, you will have to solve Fibonacci sequence. You should implement using loops, and variables. Do not use arrays nor closed-form formulas.
- Easy Fibonacci
Optional Readings on Fibonacci Sequence;
Hint: Create two variables, one to store the current value and the previous value. For each iteration step, calculate the sum of both and store and put into a temp variable. Copy the current into the previous and set the current with the temporary you calculated before.
"},{"location":"intro/05-loops/#outcomes","title":"Outcomes","text":"It is expected for you to be able to solve all questions before this one 1151 on beecrowd. Sort Beecrowd questions from the most solved to the least solved questions here in the link. If you don't, see Troubleshooting. Don`t let your study pile up, this homework is just a small test, it is expected from you to do other questions on Beecrowd or any other tool such as leetcode.
If you have problems here, start a discussion. Nhis is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me. Or visit the tutoring service.
"},{"location":"intro/06-functions/","title":"Base Conversion, Functions, Pointers, Parameter Passing","text":""},{"location":"intro/06-functions/#base-conversion","title":"Base conversion","text":"Data containers use binary coding to store data where every digit can be 0 or 1, this is called base 2, but there are different types of binary encodings and representation, the most common integer representation is Complement of two for representing positive and negative numbers and for floats is IEEE754. Given that, it is relevant to learn how to convert the most used common bases in computer science in order to code more efficiently.
Most common bases are: - Base 2 - Binary. Digits can go from 0 to 1. {0, 1}; - Base 8 - Octal. Digits can go from 0 to 7. {0, 1, 2, 3, 4, 5, 6, 7}; - Base 10 - Decimal. Digits can go from 0 to 9. {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}; - Base 16 - Hexadecimal. Digits can go from 0 to 9 and then from A to F. {0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F};
There are several methods for performing base conversion, but one common method is to use the repeated division and remainder method. To convert a number from base 10 to another base b, you can divide the number by b and record the remainder. Repeat this process with the quotient obtained from the previous division until the quotient becomes zero. The remainders obtained during the process will be the digits of the result in the new base, with the last remainder being the least significant digit.
For example, to convert the decimal number 75 to base 2 (binary), we can follow these steps:
75 \u00f7 2 = 37 remainder 1\n37 \u00f7 2 = 18 remainder 1\n18 \u00f7 2 = 9 remainder 0\n9 \u00f7 2 = 4 remainder 1\n4 \u00f7 2 = 2 remainder 0\n2 \u00f7 2 = 1 remainder 0\n1 \u00f7 2 = 0 remainder 1\nThe remainders obtained during the process (1, 1, 0, 1, 0, 0, 1) are the digits of the result in base 2, with the last remainder (1) being the least significant digit. Therefore, the number 75 in base 10 is equal to 1001011 in base 2.
"},{"location":"intro/06-functions/#converting-from-any-base-to-decimal","title":"Converting from any base to decimal","text":"The most common way to convert from any base to decimal is to follow the formula:
dn-1*bn-1 + dn-2*bn-2 + ... + d1*b1 + d0*b0
Where dx represents the digit at the corresponding position x in the number, n is the number of digits in the number, and b is the base of the number.
For example, to convert the number 1001011 (base 2) to base 10, we can use the following formula:
(1 * 2^6) + (0 * 2^5) + (0 * 2^4) + (1 * 2^3) + (0 * 2^2) + (1 * 2^1) + (1 * 2^0) = 75
Therefore, the number 1001011 in base 2 is equal to 75 in base 10.
"},{"location":"intro/06-functions/#functions","title":"Functions","text":"A function is a block of code that performs a specific task. It is mostly used to isolate specific reusable functionality from the rest of the code. It has a name, a return type, and a list of parameters. Functions can be called from other parts of the program to execute the task. Here is an example of a simple C++ function that takes two integers as input and returns their sum.
int add(int x, int y) {\n int sum = x + y;\n return sum;\n}\nTo call the function, you would use its name followed by the arguments in parentheses:
int a = 2, b = 3;\nint c = add(a, b); // c will be equal to 5\nFunctions can also be declared before they are defined, in which case they are called \"prototypes.\" This allows you to use the function before it is defined, which can be useful if you want to define the function after it is used. For example:
int add(int x, int y);\n\nint main() {\n int a = 2, b = 3;\n int c = add(a, b);\n return 0;\n}\n\nint add(int x, int y) {\n int sum = x + y;\n return sum;\n}\nThis content only covers an introduction to the topic.
The & is used to refer memory address of the variable. When used in the declaration, it is the Lvalue reference declarator. It is an alias to an already-existing, variable, object or function. Read more here.
When used as an prefix operator before the name of a variable, it will return the memory address where the variable is allocated.
Example:
string s;\n\n// the variable r has the same memory address of s\n// the declaration requires initialization\nstring& r = s; \n\ns = \"Hello\";\n\ncout << &s << endl; // prints the variable memory address location. in my machine: \"0x7ffc53631cd0\"\ncout << &r << endl; // prints the same variable memory address location. in my machine: \"0x7ffc53631cd0\"\n\ncout << s << endl; // prints \"Hello\"\ncout << r << endl; // prints \"Hello\"\n\n// update the content\nr += \" world!\";\n\ncout << s << endl; // prints \"Hello world!\"\ncout << r << endl; // prints \"Hello world!\"\nThis content only covers an introduction to the topic.
The * is used to declare a variable that holds the address of a memory position. A pointer is an integer number that points to a memory location of a container of a given type. Read more here.
string* r = nullptr; // it is not required do initialize, but it is a good practice to always initialize a pointer pointing to null address (0). \nstring s = \"Hello\";\nr = &s; // the variable r stores the memory address of s\n\ncout << s << endl; // prints the content of the variable s. \"Hello\"\ncout << &s << endl; // prints the address of the variable s. in my machine \"0x7fffdda021b0\"\n\ncout << r << endl; // prints the numeric value of the address the pointer points, in this case it is \"0x7fffdda021b0\".\ncout << &r << endl; // prints the address of the variable r. it is a different address than s, in my machine \"0x7fffdda021d0\".\ncout << *r << endl; // prints the content of the container that is pointing, it prints \"Hello\".\n\nstring other = \"world\";\nr = &s; // r now points to another variable\n\ncout << *r << endl; // prints the content of the container that is pointing, it prints \"world\"\nvoid type","text":"We covered briefly the void type when we covered data types. There are 2 main usages of void
void is used to specify that some function dont return anything to the caller.
// this function does not need to return anything\n// optionally you can use an empty `return` keyword without variable to break the flow early\nvoid doSomething() {\n // function body goes here\n return; // this line is optional, it can be used inside conditional do break early the function flow\n}\nvoid* is used as a placeholder to store a pointer to anything in memory. Use this with extreme caution, because you can easily mess with it and lose track of the type or the conversion. The most common use are: - Access the raw content of a variable in memory; - Low-level raw memory allocation; - Placeholder to act as a pointer to anything;
#include <iostream>\n#include <iomanip>\n#include <bitset>\nusing namespace std;\nint main()\n{\n // declare our data\n float f = 2.0f;\n // point without type that points to the memory location of `f`\n void* p = &f; \n // (int*) casts the void* to int*, so it can be understandable\n // * in front means that we want to fetch the content of what is pointing\n int i = *(int*)(p); \n cout << hex << i << endl; // prints 40000000\n std::bitset<32> bits(i);\n cout << bits << endl; // prints 01000000000000000000000000000000\n return 0;\n}\nPass-by-value is when the parameter declaration follows the traditional variable declaration without &. A copy of the value is made and passed to the function. Any changes made to the parameter inside the function have don't change on the original value outside the function.
#include <iostream>\nusing namespace std;\nvoid times2(int x) {\n x = x * 2;\n // the value x here is doubled. but it dont change the value outside the scope\n}\n\nint main()\n{\n int y = 2;\n times2(y); // this dont change the value, it passes a copy to the function\n cout << y << endl; // output: 2\n return 0;\n}\nPass-by-reference occurs when the function parameter uses the & in the parameter declaration. It will allow the function to modify the value of the parameter directly in the other scope, rather than making a copy of the value as it does with pass-by-value. The mechanism behind the variable passed is that it is an alias to the outer variable because it uses the same memory position.
#include <iostream>\nusing namespace std;\nvoid times2(int &x) { // by using &, x has the same address the variable passed where the function is called \n x*=2; // it will change the variable in caller scope\n}\n\nint main() {\n int y = 2;\n times2(y);\n cout << y << endl; // Outputs 4\n return 0;\n}\nPass-by-pointer occurs when the function parameter uses the * in the parameter declaration. It will allow the function to modify the value of the parameter in the other scope via memory pointer, rather than making a copy of the value as it does with pass-by-value. The mechanism behind it is to pass the memory location of the outer variable as a parameter to the function.
#include <iostream>\nusing namespace std;\nvoid times2(int *x) { // by using *, x has the same address the variable passed where the function is called\n // x holds the address of the outer variable\n // *x is the content of what x points.\n *x *= 2; // it will change the variable in caller scope\n}\n\nint main() {\n int y = 2;\n times2(&y); // the function expects a pointer, given pointer is an address, we pass the address of the variable here\n cout << y << endl; // Outputs 4\n return 0;\n}\nA function with a specific name can be overload with different not implicitly convertible parameters.
#include <iostream>\nusing namespace std;\n\nfloat average(float a, float b){\n return (a + b)/2;\n}\n\nfloat average(float a, float b, float c){\n return (a + b + c)/3;\n}\n\nint main(){\n cout << average(1, 2) << endl; // print 1.5\n cout << average(1, 2, 3) << endl; // print 2\n return 0;\n}\nFunctions can have default parameters that should be used if the parameter is not provided, making it optional.
defaultparam.cpp#include <iostream>\nusing namespace std;\n\nvoid greet(string username = \"user\") {\n cout << \"Hello \" << mes << endl;\n}\n\nint main() {\n // Prints \"Hello user\"\n greet(); // the default parameter user is used here\n\n // Prints \"Hello John\"\n greet(\"John\");\n\n return 0;\n}\nScope is a region of the code where a identifier is accessible. A scope usually is specified by what is inside { and }. The global scope is the one that do not is inside any {}.
#include <iostream>\n#include <string>\nusing namespace std;\nstring h = \"Hello\"; // this variable is in the global scope\nint main() {\n string w = \" world\"; // this variable belongs to the scope of the main function\n cout << h << w << endl; // both variables are visible and accessible\n return 0;\n}\nMultiple identifiers with same name can not be created in the same scope. But in a nested scope it is possible to shadow the outer one when declared in the inner scope.
variableShadowing.cpp#include <iostream>\n#include <string>\nusing namespace std;\nstring h = \"Hello\"; // this variable is in the global scope\nint main() {\n cout << h; // will print \"Hello\"\n string h = \" world\"; // this will shadow the global variable with the same name h\n cout << h; // will print \" world\"\n return 0;\n}\nIn C++, an anonymous function is a function without a name. Anonymous functions are often referred to as lambda functions or just lambdas. They are useful for situations where you only need to use a function in one place, or when you don't want to give a name to a function for some other reason.
auto lambda = [](int x, int y) { return x + y; };\n// auto lambda = [] (int x, int y) -> int { return x + y; }; // or you can specify the return type\nint z = lambda(1, 2); // z is now 3\nIn this case the only variables accessible by the lambda function scope are the ones passed as parameter x and y, and works just like a normal function, but it can be declared inside at any scope.
If you want to make a variable available to the lambda, you can pass it via captures, and it can be by-value or by-reference. To capture a variable by value, just pass the variable name inside the []. To capture a variable by reference, you use the & operator followed by the variable name inside the []. Here is an example of capturing a variable by value:
int x = 1;\nauto lambda = [x] { return x + 1; };\nThe value of x is copied into the lambda function, and any changes to x inside the lambda function have no effect on the original variable.
Here is an example of capturing a variable by reference:
int x = 1;\nauto lambda = [&x] { return x + 1; };\nThe lambda function has direct access to the original variable, and any changes to x inside the lambda function are reflected in the original variable.
You can also capture multiple variables by separating them with a comma. For example:
int x = 1, y = 2;\nauto lambda = [x, &y] { x += 1; y += 1; return x + y; };\nThis defines a lambda function that captures x by-value and y by-reference. The lambda function can modify y but not x.
Lambda captures are a useful feature of C++ that allow you to write more concise and expressive code. They can be especially useful when working with algorithms from the Standard Template Library (STL), where you often need to pass a function as an argument.
In order to capture everything automatically you can either capture by copy [=] or by reference [&].
// capture everything via copy\nint x = 1, y = 2;\nauto lambda = [=] { \n // x += 1; // cannot be changed because it is read-only \n // y += 1; // cannot be changed because it is read-only\n return x + y; \n};\nint c = lambda(); // c will be 5, but x and y wont change their values\n// capture everything via reference\nint x = 1, y = 2;\nauto lambda = [&] { x += 1; y += 1; return x + y; };\nint c = lambda(); // c will be 5, x will be 2, and y will be 3.\nFor a more in depth understanding, go to Manual Reference or check this tutorial.
"},{"location":"intro/06-functions/#multiple-files","title":"Multiple files","text":"In bigger projects, it is useful to split your code in multiple files isolating intention and organizing your code. To do so, you can create a header file with the extension .h and a source file with the extension .cpp. The header file will contain the declarations of the functions and the source file will contain the definitions of the functions. The header file will be included in the source file and the source file will be compiled together with the main file.
#include <iostream>\n#include \"functions.h\"\nusing namespace std;\n\nint main() {\n cout << sum(1, 2) << endl;\n return 0;\n}\n// Preprocessor directive (macro) to ensure that this header file is only included once\n#ifndef FUNCTIONS_H\n#define FUNCTIONS_H\n\n// Function declaration without body\nint sum(int a, int b);\n\n#endif\nAlternatively, you can use #pragma once instead of #ifndef, #define end #endif to ensure that the header file is only included once. This is a non-standard preprocessor directive, but it is supported by most compilers. Ex.:
// Preprocessor directive (macro) to ensure that this header file is only included once\n#pragma once\n\n// Function declaration without body\nint sum(int a, int b);\n// include the header file that contains the function declaration\n#include \"functions.h\"\n\n// function definition with body \nint sum(int a, int b) {\n return a + b;\n}\nIn C++, the preprocessor is a text substitution tool. It runs before compiling the code. It scans a program for special commands called preprocessor directives, which begin with a # symbol. When it finds a preprocessor directive, it performs the specified text substitutions before the program is compiled.
The most common preprocessor directive is #include, which tells the preprocessor to include the contents of another file in the current file. The included file is called a header file, and commonly has a .h extension. For example:
#include <iostream>\nAnother extensively used macro is #define, which defines a macro. A macro is a symbolic name for a constant value or a small piece of code. For example:
#define PI 3.14159\nIt will replace all occurrences of PI with 3.14159 before compiling the code. But pay attention that is not recommended to use macros for constants, because they are not type safe and can cause unexpected behavior. It is recommended to declare const variable instead.
See more about some cases against macros here:
- https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#enum1-prefer-enumerations-over-macros
- https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#es30-dont-use-macros-for-program-text-manipulation
- https://isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines#es31-dont-use-macros-for-constants-or-functions
Nowadays the best use case for macros are for conditional compilation or platform specification. For example:
#define DEBUG 1\n\nint main() {\n #if DEBUG\n std::cout << \"Debug mode\" << std::endl;\n #else\n std::cout << \"Release mode\" << std::endl;\n #endif\n}\nAnother example is to define the operating system:
#ifdef _WIN32\n #define OS \"Windows\"\n#elif __APPLE__\n #define OS \"MacOS\"\n#elif __linux__\n #define OS \"Linux\"\n#else\n #define OS \"Unknown\"\n#endif\n\nint main() {\n std::cout << \"OS: \" << OS << std::endl;\n}\n- Do all exercises up to this topic here.
- Hexadecimal converter. In this activity, you will have to code a way to find the convert to hexadecimal without using any std library to do it for you. DON'T USE
std::hex.
It is expected for you to be able to solve all questions before this one 1957 on beecrowd. Sort Beecrowd questions from the most solved to the least solved questions here in the link. If you don't, see Troubleshooting. Don`t let your study pile up, this homework is just a small test, it is expected from you to do other questions on Beecrowd or any other tool such as leetcode.
If you have problems here, start a discussion. Nhis is publicly visible and not FERPA compliant. Use discussions in Canvas if you are enrolled in a class with me. Or visit the tutoring service.
"},{"location":"intro/07-streams/","title":"Streams and File IO","text":"At this point, you already are familiar with the iostream header. But we never discussed what it is properly. It is a basic stream and it has two static variable we already use: cin for reading variables from the console input and cout to output things to console, see details here. It is possible to interact with all streams via the >> and << operators.
But C++ have 2 other relevant streams that we need to cover: fstream and sstream.
File streams are streams that target files instead of the terminal console. The fstream header describes the file streams and the ways you can interact with it.
The main differences between console and file streams are: - You have to target the filesystem path for files because we can manage different files at the same, but for console, you only have one, so you dont need to target which console we are streaming. In order to not mess each target, you have to declare a different variable to store the target and state. - Files are persistent, so if you write something to them, and try to read from it again, the that will be there saved.
Files are a kind of resource managed by the operation system. So every time you request something to be read or write, behind the scenes you are requesting something to the operating system, and it can be slow or subject by lock control. When you open a file to be read or write, the OS locks it to avoid problems. You can open a file to be read multiple times simultaneously, but you cannot write more than once. So to avoid problems, after reading or writing the file, you should close the file.
#include <fstream>\n#include <iostream>\n#include <string>\n\nusing namespace std;\n\nint main() {\n // Open the file\n // this file path is relative to the executable, so be assured it exists in the same folder the executable is placed\n // fin is the variablename and it is function initialized via a file path to target, but it can be any valid identifier\n // I am using fin as variable to follow the same metaphor `fin` as `file input` as we have with console input `cin`, \n ifstream fin(\"file.txt\"); \n\n // Check if the file is open\n // it is a good practice to check if the file is really there before doing anything\n if (!fin.is_open()) {\n cerr << \"Error opening file\" << endl;\n return 1; // quits the program with an error code\n }\n\n // Read the contents of the file line by line\n string line;\n // getline can target streams in general, so you can pass the file stream as a target\n while (getline(fin, line)) { // while the file have lines, read and store the content inside the line variable\n cout << line << endl; // output each string into the console\n }\n\n // Close the file\n fin.close();\n\n return 0;\n}\nThe sstream header describes string stream, which is a type of memory stream and is very useful to do string manipulation. For our intent, we aro going to focus 3 types of memory streams.
ostringstream: works just likecoutbut the content will printed to a memory region.- it is more efficient to build a complex string in this way than
couting multiple times; istringstream: works just likecinbut it will read from a memory area.- it is safer to read from a closed memory area than, and you ran reset the reading pointer to re-read previous elements easier than with
cin.
#include <iostream>\n#include <sstream>\nusing namespace std;\nint main() {\n ostringstream oss; // declare the output stream\n // print numbers from 0 to 100\n for(int i=0; i<=100; i++)\n oss << i << ' '; // store the data into memory\n cout << oss.str(); // convert the stream into a string to be printed all at once\n}\n#include <iostream>\n#include <sstream>\nusing namespace std;\nint main() {\n // read input\n string input;\n getline(cin, input);\n\n // initialize string stream with the content from a console line\n istringstream ss(input); // declare the stream to read from\n\n // extract input\n string name;\n string course;\n string grade;\n\n iss >> name >> course >> grade;\n}\nYou can combine string stream and file stream to read a whole file and store into a single string.
#include <fstream>\n#include <iostream>\n#include <sstream>\n#include <string>\n\nusing namespace std;\n\nint main() {\n // Open the file\n ifstream file(\"file.txt\");\n\n // Check if the file is open\n if (!file.is_open()) {\n cerr << \"Error opening file\" << endl;\n return 1;\n }\n\n // Read the contents of the file into a stringstream\n stringstream ss;\n ss << file.rdbuf(); // read the whole file buffer and stores it into a string stream\n\n // Close the file\n file.close();\n\n // Convert the stringstream into a string\n string contents = ss.str();\n\n cout << contents << endl; // prints the whole file at once\n\n return 0;\n}\nYou have the job of creating a small program to read a file image in the format PGMA and inverse the colors as a negative image.
You can test your code with different images if you want. You can download more images here. But here goes 2 examples:
- Sample input easy: baboon.ascii.pgm - max intensity is not 255 and don't have comments.
- Sample input harder: lena.ascii.pgm - have comments, and the max intensity is different than 255.
You can test if your output file is correct using this tool. You can open this file via any text reader, use the online viewer, or use any app that reads pnm images.
"},{"location":"intro/07-streams/#attention","title":"Attention:","text":"- To create the inverse image, you should read the file header and search for the maximum intensity. You should use this number as a base to inverse. In the Lena case, it is 245.
- You should pay attention that every line shouldn't be bigger than 70 chars;
- Pay attention that the line 2 might exists or not. And any comment found in the file should be skipped.
The user should input the filename to be read. So you should store it into a string variable. The output filename should be the same as the input but with '.inverse' concatenated in the end. Ex.: lena.pgm becomes lena.inverse.pgm; If you find this too complicated, just concatenate with .inverse.pgm would be acceptable. ex.: lena.pgm becomes lena.pgm.inverse.pgm
In order for your program to find the file to be read, you should provide the fullpath to the file or simply put the file in the same folder your executable is.
HINT: In order to find comments and ignore them do something like that:
string widthstr;\nint width;\nfin >> widthstr;\nif(widthstr.at(0)=='#')\n getline(fin, widthstr); // ignore line\nelse\n width = stoi(widthstr); // covert string to integer\nAn array is a collection of similar data items, stored in contiguous memory locations. The items in an array can be of any built-in data type such as int, float, char, etc. An array is defined using a syntax similar to declaring a variable, but with square brackets indicating the size of the array.
Here's an example of declaring an array of integers with a size of 5:
int arr[5]; // declare an array of size 5 at the stack\nThe above declaration creates an array named arr of size 5, which means it can store 5 integers. The array elements are stored in contiguous memory locations, which means the next element is stored at the immediate next memory location. The first element of the array is stored at the 0th index, the second element at the 1st index, and so on up to 4. Between 0 an 4 all inclusive we have 5 elements.
This creates an array called \"myArray\" that can hold 5 integers. The first element of the array is accessed using the index 0, and the last element is accessed using the index 4. You can initialize the array elements during declaration by providing a comma-separated list of values enclosed in braces:
int myArr[5] = {10, 20, 30, 40, 50}; // initialize the array with 5 elements\nIn this case, the first element of the array will be 10, the second element will be 20, and so on.
You can also use loops to iterate over the elements of an array and perform operations on them. For example:
for (int i = 0; i < 5; i++) { \n myArray[i] *= 2;\n}\nThis loop multiplies each element of the \"myArray\" by 2.
Arrays are a useful data structure in C++ because they allow you to store and manipulate collections of data in a structured way. However, they have some limitations, such as a fixed size that cannot be changed at runtime, and the potential for buffer overflow if you try to access elements beyond the end of the array.
"},{"location":"intro/08-arrays/#buffer-overflow","title":"Buffer overflow","text":"A buffer overflow occurs when a program attempts to write more data to a fixed-size buffer than it can hold. This can happen when a program attempts to write more data to a buffer than the buffer can hold, or when a program attempts to read more data from a buffer than the buffer contains. This can happen when a program attempts to write more data to a buffer than the buffer can hold, or when a program attempts to read more data from a buffer than the buffer contains.
A buffer overflow can be caused by a number of different factors, including:
- A program that attempts to write more data to a buffer than the buffer can hold
- A program that attempts to read more data from a buffer than the buffer contains
Buffer overflow vulnerabilities are a common type of security vulnerability, as they can be exploited by malicious attackers to execute arbitrary code or gain unauthorized access to a system. To prevent buffer overflow vulnerabilities, it's important to carefully manage memory allocation and use bounds checking functions or techniques such as using safe C++ library functions like std::vector or std::array, and ensuring that input data is properly validated and sanitized.
A multi-dimensional array is an array of arrays. For example, a 2-dimensional array is an array of arrays, where each element of the array is itself an array. A 3-dimensional array is an array of 2-dimensional arrays, where each element of the array is itself a 2-dimensional array. And so on.
For example, to declare a two-dimensional array with 3 rows and 4 columns of integers, you would use the following code:
int arr[3][4]; // Declare a 2-dimensional array with 3 rows and 4 columns at the stack\nYou can access elements in a multidimensional array using multiple sets of square brackets. For example, to access the element at row 2 and column 3 of myArray, you would use the following code:
int element = myArray[1][2]; // Access the element at row 2 and column 3\nIn C++, you can have arrays with any number of dimensions, but keep in mind that as the number of dimensions increases, it becomes more difficult to manage and visualize the data.
"},{"location":"intro/08-arrays/#array-dynamic-allocation","title":"Array dynamic allocation","text":"In some cases, you dont know the size of the array at compile time. In this case, you can use dynamic memory allocation to allocate the array at runtime. This is done using the new operator, which allocates a block of memory on the heap and returns a pointer to the beginning of the block. For example, to allocate an array of 5 integers on the heap, you would use the following code:
int *arr = new int[5]; // Allocate a block of memory on the heap\nThe above code allocates a block of memory on the heap that is large enough to hold 5 integers. The new operator returns a pointer to the beginning of the block, which is assigned to the pointer variable arr. You can then use the pointer to access the elements of the array. You can access individual elements of the array using the array subscript notation:
arr[0] = 10;\narr[1] = 20;\narr[2] = 30;\narr[3] = 40;\narr[4] = 50;\nWhen you are done using the array, you should free the memory using the delete operator. For example, to free the memory allocated to the array in the previous example, you would use the following code:
delete[] arr; // Free the memory by telling the operation system you are done with it\narr = nullptr; // Reset the pointer to null to avoid dangling pointers and other bugs\nThe delete operator takes a pointer to the beginning of the block of memory to free. The [] operator is used to indicate that the block of memory contains an array, and that the delete operator should free the entire array.
In the case of dynamically allocate memory for a multidimensional array, first you have to understand that in the same way you can have an array of arrays, you can have a pointer to a pointer. This is called a double pointer. So, if you want to allocate a 2-dimensional array dynamically, you can do it like this:
int lines, columns;\ncin >> lines >> columns;\nint **arr = new int*[lines]; // Allocate an array of pointers to pointers\nfor (int i = 0; i < lines; i++) {\n arr[i] = new int[columns]; // Allocate an array of integers for each pointer\n}\n// do stuff with the array\nfor (int i = 0; i < lines; i++) {\n delete[] arr[i]; // Free the memory for each array of integers\n}\ndelete[] arr; // Free the memory for the array of pointers\nYou probably noticed the number of bugs and vulnerabilities that can be caused by improper memory management. To help address that, C++ introduced smart pointers. The general purpose smart contract you will be mostly using is shared_ptr that in the end of the scope and when all references to it become 0 will automatically free the memory. The other smart pointers are unique_ptr and weak_ptr that are used in more advanced scenarios. But for now, we will focus on shared_ptr.
In C++11, smart pointers were introduced to help manage memory allocation and deallocation. Smart pointers are classes that wrap a pointer to a dynamically allocated object and provide additional features such as automatic memory management. The most commonly used smart pointers are std::unique_ptr and std::shared_ptr. The std::unique_ptr class is a smart pointer that owns and manages another object through a pointer and disposes of that object when the std::unique_ptr goes out of scope. The std::shared_ptr class is a smart pointer that retains shared ownership of an object through a pointer. Several std::shared_ptr objects may own the same object. The object is destroyed and its memory deallocated when either of the following happens:
- the last remaining
std::shared_ptrowning the object is:- destroyed
- is assigned another pointer via
operator=orreset() - is reset or released
- moved from
- is swapped with another
std::shared_ptrusingswap() - the function
std::shared_ptr::swap()is called with the last remainingstd::shared_ptrowning the object as an argument
- the object is no longer reachable from the program (for example, when the program terminates)
- the program:
- throws an exception that is not caught within the same thread
- calls terminating calls such as
std::terminate(),std::abort(),std::exit(), orstd::quick_exit()
To create a dynamic array of int using shared pointers, you can use the std::shared_ptr class template. Here's an example:
#include <memory> // for std::shared_ptr\nstd::shared_ptr<int[]> arr(new int[5]);\nThis creates a shared pointer to an array of 5 integers. The new int[5] expression dynamically allocates memory for the array on the heap, and the shared pointer takes ownership of the memory. When the shared pointer goes out of scope, the memory is automatically freed.
You can access individual elements of the array using the array subscript notation, just like with a regular C-style array:
arr[0] = 10;\narr[1] = 20;\narr[2] = 30;\narr[3] = 40;\narr[4] = 50;\nTo deallocate the memory, you don't need to call delete[] explicitly, because the shared pointer takes care of it automatically. When the last shared pointer that points to the array goes out of scope or is explicitly reset, the memory is deallocated automatically:
arr.reset(); // deallocates the memory and reset the shared pointer to null to avoid dangling pointers and other bugs\nShared pointers provide a convenient and safe way to manage dynamic memory in C++, because they automatically handle memory allocation and deallocation, and help prevent memory leaks and dangling pointers.
Smart pointers are no silver bullet. They are not a replacement for proper memory management, but they can help you avoid common memory management bugs and vulnerabilities. For example, smart pointers can help you avoid memory leaks, dangling pointers, and double frees. They can also help you avoid buffer overflow vulnerabilities by providing bounds checking functions.
"},{"location":"intro/08-arrays/#passing-arrays-to-functions","title":"Passing arrays to functions","text":"You can pass arrays to functions in C++ in the same way that you pass any other variable to a function. For example, to pass an array to a function, you would use the following code:
void printArray(int arr[], int size) // Pass the array by reference to avoid copying the entire array\n{\n for (int i = 0; i < size; ++i)\n std::cout << arr[i] << ' ';\n std::cout << '\\n';\n}\nAlternativelly you can pass the array as a pointer:
void printArray(int *arr, int size)\n{\n for (int i = 0; i < size; ++i)\n std::cout << arr[i] << ' ';\n std::cout << '\\n';\n}\nIf you want to pass a two dimension array, you can do it in multiple ways:
void printArray(int rows, int columns, int **arr); // Pass the array as a pointer of pointers\nThis approach is problematic as you can see it in depth here. It does not check for types and it is not safe. You can also pass the array as a pointer to an array:
void printArray(int rows, int arr[][10]); // if you know the number of columns and it is fixed, in this case 10 \nvoid printArray(int rows, int (*arr)[10]); // if you know the number of columns and it is fixed, in this case 10 \nvoid printArray(int arr[10][10]); // if you know the number of rows and columns and they are fixed, in this case both 10\nThere is others ways to pass arrays to functions, such as templates but they are more advanced and we will not cover them now.
"},{"location":"intro/08-arrays/#extra-standard-template-library-stl","title":"EXTRA: Standard Template Library (STL)","text":"Those are the most common data structures that you will be using in C++. But it is outside the scope of this course to cover them in depth. So we will only give entry-points for you to learn more about them.
"},{"location":"intro/08-arrays/#arrays_1","title":"Arrays","text":"If you are using fixed sized arrays, and want to be safe to avoid problems related to out of bounds, you should use the STL arrays. It is a template class that encapsulates fixed size arrays and adds protections for it. It is a safer alternative to C-style arrays. Read more about it here.
"},{"location":"intro/08-arrays/#vectors","title":"Vectors","text":"Vectors are the safest way to deal with dynamic arrays in C++, the cpp core guideline even states that you should use it whenever you can. Vector is implemented in the standard template library and provide a lot of useful functions. Read more about them here.
"},{"location":"intro/08-arrays/#extra-curiosities","title":"Extra curiosities","text":"Context on common bugs and vulnerabilities:
- Weaknesses in the 2022 CWE Top 25 Most Dangerous Software Weaknesses
- US Government enforces cyber security requirements
- https://en.cppreference.com/w/cpp/language/array
Recursion is a method of solving problems where the solution depends on solutions to smaller instances of the same problem. It is a common technique used in computer science, and is one of the central ideas of functional programming. Let's explore recursion by looking at some examples.
You have to be aware that recursion isn't always the best solution for a problem. Sometimes it can be more efficient to use a loop and a producer-consumer strategy instead of recursion. But, in some cases, recursion is the more elegant solution.
When you call functions inside functions, the compiler will store the return point, value and variables on the stack, and it has limited size. Each time you call a function, it is added to the top of the stack. When the function returns, it is removed from the top of the stack. The last function to be called is the first to be returned. This is called the call stack. A common source of problems in programming is when the call stack gets too big. This is called a stack overflow. This is why you should be careful when using recursion.
"},{"location":"intro/09-recursion/#fibonacci-numbers","title":"Fibonacci numbers","text":"The Fibonacci numbers are a sequence of numbers where each number is the sum of the two numbers before it. The constraints are: the first number is 0, the second number is 1, it only run on integers and it is not negative. The sequence looks like this:
int fibonacci(int n) {\n // base case\n if (n == 0 || n == 1)\n return n;\n else // recursive case\n return fibonacci(n - 1) + fibonacci(n - 2);\n}\nThe factorial of a number is the product of all the numbers from 1 to that number. It only works for positive numbers greater than 1.
int factorial(int n) {\n // base case\n if (n <= 1)\n return 1;\n else // recursive case\n return n * factorial(n - 1);\n}\nDivide and conquer is a method of solving problems by breaking them down into smaller subproblems. It is extensively used to reduce the complexity of some algorithms and increase readability.
"},{"location":"intro/09-recursion/#binary-search","title":"Binary search","text":"Imagine that you already have a sorted array of numbers and you want to find the location of a specific number in that array. You can use a binary search to find it. The binary search works by dividing the array in half and checking if the number you are looking for is in the first half or the second half. If it is in the first half, you repeat the process with the first half of the array. If it is in the second half, you repeat the process with the second half of the array. You keep doing this until you find the number or you know that it is not in the array.
// recursive binary search on a sorted array to return the position of a number\nint binarySearch(int arr[], int start, int end, int number) {\n // base case\n if (start > end)\n return -1; // number not found\n else {\n // recursive case\n int mid = (start + end) / 2;\n // return the middle if wi find the number\n if (arr[mid] == number)\n return mid;\n // if the number is smaller than the middle, search in left side\n else if (arr[mid] > number)\n return binarySearch(arr, start, mid - 1, number);\n // if the number is bigger than the middle, search in right side\n else\n return binarySearch(arr, mid + 1, end, number);\n }\n}\nBinary search plays a fundamental role in Newton's method, which is a method to find and approximate the result of complex mathematical functions such as the square root of a number. Binary-sort is extensively used in sorting algorithms such as quick sort and merge sort.
"},{"location":"intro/09-recursion/#merge-sort","title":"Merge sort","text":"Please refer to the Merge sort section in the sorting chapter.
"},{"location":"intro/10-sorting/","title":"Sorting algorithms","text":"TODO: Note for my furune self: add complete example of how to use those algorithms
Sorting are algorithms that put elements of a list in a certain order. It is cruxial to understand the basics of sorting in order to start understanding more complex algorithms and why you have to pay attention to efficiency.
Before going deep, please watch this video:
SEIZURE WARNING!!
and this one:
Explore the concepts interactively at visualgo.net.
Try to answer the following questions, before continuing:
- What are the slowest sorting algorithms?
- What are the fastest sorting algorithms?
- Con you infer the difference between a stable and unstable sorting algorithm?
- What is the difference between a comparison and a non-comparison sorting algorithm?
- What would be an in-place and a non-in-place sorting algorithm?
- What is the difference between a recursive and a non-recursive sorting algorithm?
Many of the algorithms will have to swap elements from the array, vector or list. In order to do that, we will need to create a function that swaps two elements. Here is the function:
// A function to swap two elements\nvoid swap(int *xp, int *yp) { \n int temp = *xp; \n *xp = *yp; \n *yp = temp; \n} \nThe * operator used in the function signature means that the function will receive a pointer to an integer. So it will efectivelly change the content in another scope. The * operator is used to dereference a pointer, which means that it will return the value stored in the memory address pointed by the pointer. Given the declaration is int *xp, the *xp will return the value stored in the memory address pointed by xp.
Alternatively you could use the & operator to pass the reference to that variable in the similar fashion, but the usage wont be requiring the * before the variable name as follows:
// A function to swap two elements\nvoid swap(int &xp, int &yp) { \n int temp = xp; \n xp = yp; \n yp = temp; \n} \nThe result is the same, but the usage is different. The first one is more common in C++, while the second one is more common in C.
"},{"location":"intro/10-sorting/#bubble-sort","title":"Bubble sort","text":"Bubble sort is the simplest sorting algorithm that works by repeatedly swapping the adjacent elements if they are in wrong order.
// A function to implement bubble sort\nvoid bubbleSort(int arr[], int n) { \n // if the array has only one element, it is already sorted\n if(n<=1)\n return;\n\n int i, j; \n for (i = 0; i < n-1; i++)\n // Last i elements are already in place \n for (j = 0; j < n-i-1; j++) \n if (arr[j] > arr[j+1]) \n swap(&arr[j], &arr[j+1]); \n} \nAs you can see, the algorithm is very simple, but it is not very efficient. It has a time complexity of O(n^2) and a space complexity of O(1).
One of the drawbacks of this algorithm is the sheer amount of swaps. In the worst scenario, it does n^2 swaps, which is a lot. If your machine have slow writes, it will be very slow.
"},{"location":"intro/10-sorting/#insertion-sort","title":"Insertion sort","text":"Insertion sort is a simple sorting algorithm that works the way we sort playing cards in our hands. You pick one card and insert it in the correct position in the sorted part of the list. You repeat this process until you have sorted the whole list. Here is the code:
// A function to implement insertion sort\nvoid insertionSort(int arr[], int n) { \n // if the array has only one element, it is already sorted\n if(n<=1)\n return;\n\n int i, key, j; \n for (i = 1; i < n; i++) { \n key = arr[i]; \n j = i - 1; \n\n /* Move elements of arr[0..i-1], that are \n greater than key, to one position ahead \n of their current position */\n while (j >= 0 && arr[j] > key) { \n arr[j + 1] = arr[j]; \n j = j - 1; \n } \n arr[j + 1] = key; \n } \n} \nIt falls in the same category of algorithms that are very simple, but not very efficient. It has a time complexity of O(n^2) and a space complexity of O(1).
Although it have the same complexity as bubble sort, it is a little bit more efficient. It does less swaps than bubble sort, but it is still not very efficient. It will swap all numbers to the left of the current number, which is a lot of swaps.
"},{"location":"intro/10-sorting/#selection-sort","title":"Selection sort","text":"Selection sort is a simple sorting algorithm. This sorting algorithm is an in-place comparison-based algorithm in which the list is divided into two parts, the sorted part at the left end and the unsorted part at the right end. Initially, the sorted part is empty and the unsorted part is the entire list. The smallest element is selected from the unsorted array and swapped with the leftmost element, and that element becomes a part of the sorted array. This process continues moving unsorted array boundary by one element to the right. Here is the code:
// A function to implement selection sort\nvoid selectionSort(int arr[], int n) {\n // if the array has only one element, it is already sorted\n if(n<=1)\n return;\n\n int i, j, min_idx; \n\n // One by one move boundary of unsorted subarray \n for (i = 0; i < n-1; i++) { \n // Find the minimum element in unsorted array \n min_idx = i; \n for (j = i+1; j < n; j++) \n if (arr[j] < arr[min_idx]) \n min_idx = j; \n\n // Swap the found minimum element with the first element \n swap(&arr[min_idx], &arr[i]); \n } \n} \nIt is also a simple algorithm, but it is a little bit more efficient than the previous two. It has a time complexity of O(n^2) and a space complexity of O(1).
It does less swaps than the previous two algorithms, potentially n swaps, but it is still not very efficient. It selects for the current position, the smallest number to the right of it and swaps it with the current number. It does this for every number in the list, which fatally a lot of swaps.
"},{"location":"intro/10-sorting/#merge-sort","title":"Merge sort","text":"Merge sort is a divide and conquer algorithm. It divides input array in two halves, calls itself for the two halves and then merges the two sorted halves. Here is the code:
// recursive merge sort\nvoid mergeSort(int arr[], int l, int r) { \n if (l < r) { \n // Same as (l+r)/2, but avoids overflow for \n // large l and h \n int m = l+(r-l)/2; \n\n // Sort first and second halves \n mergeSort(arr, l, m); \n mergeSort(arr, m+1, r); \n\n merge(arr, l, m, r); \n } \n} \n\n// merge function\nvoid merge(int arr[], int l, int m, int r) { \n int i, j, k; \n int n1 = m - l + 1; \n int n2 = r - m; \n\n // allocate memory for the sub arrays\n int *L = new int[n1];\n int *R = new int[n2];\n\n /* Copy data to temp arrays L[] and R[] */\n for (i = 0; i < n1; i++) \n L[i] = arr[l + i]; \n for (j = 0; j < n2; j++) \n R[j] = arr[m + 1+ j]; \n\n /* Merge the temp arrays back into arr[l..r]*/\n i = 0; // Initial index of first subarray \n j = 0; // Initial index of second subarray \n k = l; // Initial index of merged subarray \n while (i < n1 && j < n2) { \n if (L[i] <= R[j]) { \n arr[k] = L[i]; \n i++; \n } \n else { \n arr[k] = R[j]; \n j++; \n } \n k++; \n } \n\n /* Copy the remaining elements of L[], if there are any */\n while (i < n1) { \n arr[k] = L[i]; \n i++; \n k++; \n } \n\n /* Copy the remaining elements of R[], if there \n are any */\n while (j < n2) { \n arr[k] = R[j]; \n j++; \n k++; \n }\n\n // deallocate memory\n delete[] L;\n delete[] R;\n} \nIt is a very efficient algorithm that needs extra memory to work. It has a time complexity of O(n*log(n)) and a space complexity of O(n). It is a very efficient algorithm, but it is not very simple. It is quite more complex than the previous algorithms. It is a divide and conquer algorithm, which means that it divides the problem in smaller problems and solves them. It divides the list in two halves, sorts them and then merges them. It does this recursively until it has a list of size 1, which is sorted. Then it merges the lists and returns the sorted list.
"},{"location":"intro/10-sorting/#quick-sort","title":"Quick sort","text":"Quick sort is a divide and conquer algorithm. It picks an element as pivot and partitions the given array around the picked pivot. Here is the code:
// recursive quick sort\nvoid quickSort(int arr[], int low, int high) { \n if (low < high) { \n /* pi is partitioning index, arr[p] is now \n at right place */\n int pi = partition(arr, low, high); \n\n // Separately sort elements before \n // partition and after partition \n quickSort(arr, low, pi - 1); \n quickSort(arr, pi + 1, high); \n } \n}\n\n// partition function\nint partition (int arr[], int low, int high) { \n int pivot = arr[high]; // pivot \n int i = (low - 1); // Index of smaller element \n\n for (int j = low; j <= high- 1; j++) { \n // If current element is smaller than or \n // equal to pivot \n if (arr[j] <= pivot) { \n i++; // increment index of smaller element \n swap(&arr[i], &arr[j]); \n } \n } \n swap(&arr[i + 1], &arr[high]); \n return (i + 1); \n} \nIt is a very efficient algorithm that don't needs extra memory, which means it is in-place. In average, it can be as fast as mergesort with time complexity of O(n*log(n)), but in the worst case it can be as slow as O(n^2). But it is a better choice if you are not allowed to use extra memory. It is a divide and conquer algorithm, which means that it divides the problem in smaller problems and solves them. It selects a pivot and partitions the list around the pivot. It does this recursively until it has a list of size 1, which is sorted. Then it merges the lists and returns the sorted list.
"},{"location":"intro/10-sorting/#counting-sort","title":"Counting sort","text":"Counting sort is a specialized algorithm for sorting numbers. It only works well if you have a small range of numbers. It counts the number of occurrences of each number and then uses the count to place the numbers in the right position. Here is the code:
// counting sort\nvoid countingSort(int arr[], int n) { \n // if the array has only one element, it is already sorted\n if(n<=1)\n return;\n\n int max=arr[0];\n int min[0];\n\n // find the max and min number\n for(int i=0; i<n; i++) {\n if(arr[i]>max) {\n max=arr[i];\n }\n if(arr[i]<min) {\n min=arr[i];\n }\n }\n\n // allocate memory for the count array\n int *count = new int[max-min+1];\n\n // initialize the count array\n for(int i=0; i<max-min+1; i++) {\n count[i]=0;\n }\n\n // count the number of occurrences of each number\n for(int i=0; i<n; i++) {\n count[arr[i]-min]++;\n }\n\n // place the numbers in the right position\n int j=0;\n for(int i=0; i<max-min+1; i++) {\n while(count[i]>0) {\n arr[j]=i+min;\n j++;\n count[i]--;\n }\n }\n\n // deallocate memory\n delete[] count;\n}\nCounting sort is a very efficient sorting algorithm which do not rely on comparisons. It has a time complexity of O(n+k) where k is the range of numbers. Space complexity is O(k) which means it is not an in-place sorting algorithm. It is a very efficient algorithm, but it is not very simple. It counts the number of occurrences of each number and then uses the count to place the numbers in the right position.
"},{"location":"intro/10-sorting/#radix-sort","title":"Radix sort","text":"Radix sort is a specialized algorithm for sorting numbers. It only works well if you have a small range of numbers. It sorts the numbers by their digits. Here is the code:
// Radix sort\nvoid radixSort(int arr[], int n) {\n // if the array has only one element, return\n if(n<=1)\n return;\n\n // initialize the max number as the first number. \n int max=arr[0];\n\n // find the max number\n for(int i=0; i<n; i++) {\n if(arr[i]>max) {\n max=arr[i];\n }\n }\n\n // allocate memory for the count array\n int *count = new int[10]; // 10 digits\n\n // allocate memory for the output array\n int *output = new int[n];\n\n // do counting sort for every digit\n for(int exp=1; max/exp>0; exp*=10) {\n // initialize the count array\n for(int i=0; i<10; i++) {\n count[i]=0;\n }\n\n // count the number of occurrences of each number\n for(int i=0; i<n; i++) {\n count[(arr[i]/exp)%10]++;\n }\n\n // change count[i] so that count[i] now contains actual position of this digit in output[]\n for(int i=1; i<10; i++) {\n count[i]+=count[i-1];\n }\n\n // build the output array\n for(int i=n-1; i>=0; i--) {\n output[count[(arr[i]/exp)%10]-1]=arr[i];\n count[(arr[i]/exp)%10]--;\n }\n\n // copy the output array to the input array\n for(int i=0; i<n; i++) {\n arr[i]=output[i];\n }\n }\n}\nRadix sort is just a counting sort that is applied to every digit. It has a time complexity of O(n*k) where k is the number of digits.
"},{"location":"intro/10-sorting/#conclusion","title":"Conclusion","text":"This is the first time we will talk about efficiency, and for now on, you will start evaluating and taking care about your algorithms' efficiency. You will learn more about efficiency in the next semester and course when we cover data structures.
"},{"location":"intro/11-structs/","title":"Structs","text":"wip
"},{"location":"portfolio/","title":"Game Developer's Portfolio","text":"Creating and maintaining a portfolio is a crucial part in any game developer's job search and career.? Portfolios are especially challenging for programmers, since the work presented is not inherently visual, yet it must still effectively demonstrate the individual's prowess and skills in their discipline.? This course provides Game Programmers a formal opportunity to sum up their experience in the major and produce a portfolio worthy of presentation at the Senior Show.? In this course, students discuss and implement pertinent portfolio materials for programmers, such as websites, repositories and demo reels.? Students will have an opportunity to spearhead an entirely solo project to add as a centerpiece to their materials. Source
"},{"location":"portfolio/#requirements","title":"Requirements","text":"- 90 Credits
Upon completion of the Game Developer's Portfolio course, students should be able to:
"},{"location":"portfolio/#objective-outcomes","title":"Objective Outcomes","text":"- Demonstrate Proficiency in Programming Languages:
- Showcase competence in relevant programming languages commonly used in game development.
- Implement and explain code snippets that highlight problem-solving skills and efficiency.
- Develop an Individual Project:
- Spearhead a solo game development project to showcase the ability to conceive, plan, and execute a complete game;
- Demonstrate a deep understanding of programming concepts through the development of a unique and challenging project.
- Create a Professional Portfolio Website:
- Design and develop a visually appealing and user-friendly portfolio website to showcase programming projects.
- Utilize web development tools and frameworks to enhance the presentation of coding projects.
- Build a Source Code Repository:
- Establish and maintain a version-controlled repository (e.g., GitHub) containing well-documented code samples.
- Demonstrate proficiency in using version control tools and collaborative development practices.
- Develop a Demo Reel:
- Create a compelling demo reel that effectively communicates programming skills and contributions to game projects.
- Edit and present code snippets in a clear and concise manner within the demo reel.
- Articulate Programming Contributions:
- Clearly communicate the role and impact of programming contributions in game development projects.
- Develop the ability to discuss technical aspects of projects in a non-technical manner for diverse audiences.
- Understand Industry Standards and Best Practices:
- Adhere to industry standards and best practices in game programming.
- Apply knowledge of optimization, performance, and coding conventions commonly used in the game development industry.
- Prepare for the Job Search and Senior Show:
- Develop skills in resume writing, cover letter creation, and interview preparation specific to game programming roles.
- Prepare and present the portfolio effectively at the Senior Show or similar events to potential employers and industry professionals.
- Receive and Provide Constructive Feedback:
- Participate in peer reviews and constructive critiques to enhance the quality of portfolio materials.
- Provide thoughtful feedback to peers on both the technical and presentation aspects of their portfolios.
- Reflect on Learning and Career Goals:
- Reflect on personal learning experiences and identify areas for continuous improvement in game programming skills.
- Develop a clear understanding of career goals and create a plan for ongoing professional development in the game development industry.
Warning
This is a work in progress, and the schedule is subject to change. Every change will be communicated in class. Use the github repo as the source of truth for the schedule and materials. The materials provided in canvas are just a copy for archiving purposes and might be outdated.
College dates for the Spring 2024 semester:
Date Event Jan 16 Classes Begin Jan 16 - 22 Add/Drop Feb 26 - March 1 Midterms March 11 - March 15 Spring Break March 25 - April 5 Registration for Fall Classes April 5 Last Day to Withdraw April 8 - 19 Idea Evaluation April 12 No Classes - College remains open April 26 Last Day of Classes April 29 - May 3 Finals May 11 Commencement Week Date Topic 1 2024/01/15 Introduction 2 2024/01/22 Case Studies 3 2024/01/29 Game Developer Portfolio Structure 4 2024/02/05 Communication & Audience 5 2024/02/12 Strategy & Analytics 6 2024/02/19 Demo Reels 7 2024/02/26 Frontend 8 2024/03/04 Content Management System 9 2024/03/11 BREAK 10 2024/03/18 Final Project & Coding Interviews 11 2024/03/25 Hosting and Domain 12 2023/04/01 Dynamic Content & Blogs 13 2023/04/08 Promoting 14 2023/04/15 Cover Letters 15 2023/04/22 Traditional CVs 16 2023/04/26 FINALS"},{"location":"portfolio/01-introduction/","title":"Introduction","text":"A game developer portfolio is a collection of materials that showcase a game developer's skills, experience, and accomplishments. It is typically used by game developers to demonstrate their abilities to potential employers, clients, or partners, and may include a variety of materials such as:
- A resume or CV: This should highlight your education, work experience, and skills relevant to game development.
- Examples of your work: This can include demos, prototypes, or completed games that you have developed or contributed to. It's a good idea to include links to any online versions of your work, as well as screenshots or video trailers.
- A portfolio website: Many game developers choose to create a website specifically for their portfolio, which can include additional information about their skills and experience, as well as links to their work.
- Blogs, articles, or other writing: If you have written about game development or related topics, you may want to include these in your portfolio to show your knowledge and expertise.
- Testimonials or references: Including positive feedback from clients or colleagues can help to demonstrate the quality of your work.
Overall, a game developer portfolio should be designed to demonstrate your abilities and accomplishments in a clear and concise way, and should be tailored to the specific needs and goals of the person or organization you are presenting it to.
Building a portfolio is not only about you, it is about making the life easier of the ones interested on you by giving insights if they should hire you, follow you or anything else. In order to make people understand you, you have to know yourself better.
"},{"location":"portfolio/01-introduction/#who-are-you-what-you-excel-and-what-do-you-enjoy-doing","title":"Who are you, what you excel and what do you enjoy doing?","text":"In your portfolio, you will have to express yourself in a way that others can understand who you are, and it can be challenging for some. In order do help you discover who you are, what you excel, and what do you really enjoy doing. I will be briefly vague here to point some emotional support and reasoning to help you answer the question. If you are clear about that, please skip this entire section. Here goes a small amount of advices I wish I have heard when I was young.
Ikigai Note
The above image links to a very good reference to understand the drives that you should be aware while taking decisions on your future career. Visit it.
You are a complex being and hard to define. I know. It is hard to put yourself in a frame or box, but this process is relevant to make the life of the others to evaluate if they want more you or not. If for some reason a person is reading your portfolio, it means that you are ahead of the others, so you must respect their time and goals while they are reading your content.
What you do, do not define what you are, you can even work with something you dont love as long it is part of a bigger plan. Given that, you have to know how to differentiate yourself from your work while respecting your feelings. The sweet spot is when you mix who you are with what you do, and you have nice feelings about it. But this can be hard to achieve and require maturity to mix things. If you dont have a clear understand of those aspects of yourself, you will be subjected to be exploited by bad companies and managers.
It is totally fine try to excel some job you are not passionate. You just have to find means to make your time doing it as enjoyable as possible. In the end of the journey it will slowly become something you can be proud of, and you will become a different person than the one you are now. Understanding this kind of mentality will help you endure more and be more resilient to problems.
Keep track of your progress towards your goal. First of all, have a clear goal, so you can build a path to it. Otherwise, any path would sound just like any other apathetic path. Having a clear goal will make your path shine and easy to choose. It will help you in difficult moments where you feel uncomfortable by being just a small piece of a machinery. You will be able to act as part of machine while you need to achieve your goal as a necessary step.
Focus on always keep track on your evolution on your journey to excellence. Don't compare too much yourself to the others, everyone is facing a different journey and everyone took different paths in their career that probably you didn't have the option to chose in the past. But you cannot be uncritical either, you have to analyse your progress and check if your current path is making you life good, you have to take a decision to change the plan or even the goal with the new information you learned through the current path you are pursuing.
In other point of view, you wont start your career as senior developer, so you have to build your own path. Making mistakes is part of the process, and that is the reason you will be gradually exposed to big things. You should accept yourself, don't push too hard, and do some basic stuff. Just accept the challenges of doing something not fancy, but relevant to build your career.
"},{"location":"portfolio/01-introduction/#define-and-state-your-mission-and-goal","title":"Define and state your mission and goal","text":"- Are you a generalist or a specialist type?
- What position you are looking for?
- What kind of person you want to become?
In order to build a good portfolio, you will need to gather information about yourself and your work. In the process you will discover yourself. It will feels like looking to a mirror for the first time.
If you didnt published yot your projects on itchio, github, or any other platform, now it is a good moment for doing it. Pay attention that if you are going to share your code publicly, you have to avoid sharing content that do not belong to you. In other words, avoid copyright infringements.
"},{"location":"portfolio/01-introduction/#proof-of-your-accomplishments","title":"Proof of your accomplishments","text":"It is a good practice to always take screenshots, use web archive or any means to prove what you are stating. Some games got lost in time, they die or become unavailable in the long term.
Personal adviceIn my case, we developed a very successful game in the past, and because of some problems with investors and judicial dispute, we had to shut down the game. But it was one of the most successful games in that year, it was nominated to Unity Awards and it was the most downloaded racing game. The only things that I can showcase now are print-screens, recorded videos and web-archive pages. So it is something that can make you survive the questions.
"},{"location":"portfolio/01-introduction/#videos-photos-or-lightweight-web-builds","title":"Videos, photos, or lightweight web builds","text":"A good way to express your work is to show it in a form of videos, or photos. If your game is small enough to be embedded, or you can strip the most relevant part of it and built for web(webgl, wasm etc), try to publish the relevant part of it online, but do not over-do it, because it will take too much time to craft a good interaction.
"},{"location":"portfolio/01-introduction/#homework","title":"Homework","text":"- Define your domain name;
- I usually search domains here and buy on wherever is cheaper, usually here
- Find a good portfolio to follow;
- Design the scaffold / wireframe of what you want to show;
- Gather the data you want to show;
- Think on catchphrases and call to actions.
- Activity 1
- Activity 2
- Considerations
- Evaluated Portfolios
This class will be focused in planning, portfolio evaluation, github processes, ci/cd and in-class activities.
"},{"location":"portfolio/02-cases/#activity-1","title":"Activity 1","text":"Start setting up your Github pages. We are going to use github pages mostly for two intentions: Webpage hosting for your portfolio and Demo project hosting.
"},{"location":"portfolio/02-cases/#webpage","title":"Webpage","text":"For your webpage, you can develop something from ground up using your preferred web framework and we are going to show you how to do it, but the fastest way is to just follow any template. Here goes a bunch of open sourced developer portfolios you can fork and modify for your intent. https://github.com/topics/developer-portfolio?l=html . Try to take a look on them and check if you want to fork any of them. So in this activity you will have to fork and try to run a clone of a portfolio you like just to got into some action and discover how things work.
- Find a developer portfolio on github
- Fork it
- Clone in your machine
- Make some changes
- Build it
- Deploy it to gh-pages either via automated ci/cd or via publishing a build from a empty branch or the main one
For project demo, game, or whatever interaction you want to allow the user to do, I built some boilerplates for you. Later on, you will be able to embed those webgl/html5 builds into your portfolio, so it is a good moment for you to start doing it now. As extras, optionally you can add badges for your repo from here: https://shields.io/
"},{"location":"portfolio/02-cases/#sdl2","title":"SDL2","text":"In order to showcase your ability to build something from ground up, this repo holds a boilerplate with C++, SDL2, IMGUI, SDL2IMAGE, SDL2TTF, SDL2MIXER, CI/CD automation for automatic deployment: https://github.com/InfiniBrains/SDL2-CPM-CMake-Example
- fork it
- go to the repo settings, actions, general, in the bottom, enable workflow permission, read and write, save
- run github action at least once
- enable actions and automatic page deployment from a branch gh-pages
If you enjoy AI programming and want to test yourself, you can try forking this repo and implement what is inside the examples folder https://github.com/InfiniBrains/mobagen
- fork it
- run github action at least once
- enable actions and automatic page deployment from a branch gh-pages
If you want to showcase your ability with Untiy, you can follow this boilerplate to have an automatic build set up. https://github.com/InfiniBrains/UnityBoilerplate
- Fork it
- run github action for getting an unit licence at least once
- grab the generated file, and upload it to https://license.unity3d.com/manual
- get the signed licence and copy the text content to your clipboard
- go to your repo settings, security, secrets and variables, actions and setup a new repository secret with the name 'UNITY_LICENSE' and the content from your clipboard
- go to the repo settings, actions, general, in the bottom, enable workflow permission, read and write, save
- run the main action
- enable actions and automatic page deployment from a branch gh-pages
- edit webgl template with your logo or image
This class is totally up to you. Here goes what you should do in class and finish at home. The idea is for you to feel a whole process on how to create merge and pull requests to a public repo.
- Search a good portfolio published online
- use Twitter, LinkedIn, Google to search for good game developer portfolios;
- another good query on google would be \"awesome developer portfolio\", or \"curated list of developer portfolios\" try it!. Example: https://github.com/emmabostian/developer-portfolios
- You can use this time to search a good and open sourced portfolio to fork and start your own based on other. https://github.com/topics/developer-portfolio
- Fork this repo
- Create a markdown file in this folder with a meaningful name about the benchmarked repository.
- Follow this example
- The file name should be the website domain name followed by .md
- If another student is aiming to evaluate the same portfolio, just edit the file adding your evaluation to the text.
- Your file should contain:
- A summary
- The portfolio evaluated
- The date the evaluation happened
- Print-screens uploaded to image hosting services such as imgur or others
- What things you judge as good and you are aiming to follow and target
- What things you judge that needs attention and should be improved
- Why you would hire the owner of the portfolio
- General considerations
- Edit this file on github to link your work here if you want to showcase it here.
- Be Kind and constructive
- Send a push request
- The portfolios evaluated here are just opinions
- Example
- Assessment 1
- Assessment 2
- The date the evaluation happened
- The portfolio evaluated
- Briefing
What things you judge as good and you are aiming to follow and target. Add images as reference using print-screens uploaded to image hosting services such as imgur or others;
"},{"location":"portfolio/02-cases/example.com/#improvements","title":"Improvements","text":"- What things you judge that needs attention or should be improved?
- What questions you would ask this person?
- Why you would hire the owner of the portfolio?
- For what kind of task?
- What position?
- How do you see this person interacting with others?
- Just add some final consideration for the portfolio owner;
- If possible, send a message to one of its communication channels informing your assessment;
The other student willing to do multiple assessment for the same portfolio, just create an entry in the index following the same structure and same the assessment differently in this case, we put number 2. And use the same structure on the 1.
"},{"location":"portfolio/03-structure/","title":"Game Developer Portfolio Structure","text":"Create a single page app containing most of these features listed here.
"},{"location":"portfolio/03-structure/#head-summary","title":"Head / Summary","text":"Chose carefully what to you use as a head of your page. It is the first thing a person reads. It can be an impactful message, a headline, personal statement, background video or very limited interactive section.
Note
Avoid bravado. You can be bold without being naive. Let the bravado statements for when you become a senior. If you write bravados right in the begining of your portifolio and you are still a junior, you are just communicating that you will be hard to work with. A senior developer reading your portfolio is more interested in developers eager to learn, humble, and looking for guidance so they will have a easier life hiring you.
"},{"location":"portfolio/03-structure/#about","title":"About","text":"This is a summary obout yourself, be brief and achievement oriented. What and who you are. Contact info via social medias. State your working status and target. If you are a narrative centred person, you can create something fancy here, but dont over-do, less is more!
"},{"location":"portfolio/03-structure/#showcase","title":"Showcase","text":"- Projects
- Ability and versatility
- Community Contributions
You can showcase your personal work, a job you make for a client(if authorized).
Projects
It is a good practice to showcase only the best works you made. You might find interesting to add more than 5, but there are chances of your reader clicking exactly on the worst one and have a bad first impression of you. In your showcase section, avoid showcasing bad work. Invite some of your friends to help you select the best ones to showcase.
Ability
Avoid using percentage graphs to showcase your proficiency on specific tech stack or tool. The main reason is: how do you grade of your ability as 80%, 100% or 30%? Worse than that, how can the reader be sure of that? If you want to do that, it is better to apply for certificates, there are plenty on linkedin or specialized sites.
"},{"location":"portfolio/03-structure/#achievements","title":"Achievements","text":"- List key achievements and skills. Dont use any kind of grading
- Education
- Testimonials or anything to prove your skills and capacity
- You should create a way to explain more about what is showcased. Ex.: redirect the user to the project description page, or open a modal
- Featured posts/content and call to action to read your ongoing content production
- Explain your process in designing a game or piece of software
- Explain some interesting details you learn or describe your knowledge explorations.
Explicitly state what people should expect if they contact you and what they can expect from your return. Ex.: If you aim to be a freelance, state your offer and ask for them to briefly state the job activity, time frame and the rate they are willing to pay. If you are looking for a full-time position, the most common way is to just share your email, so they can contact you.
Another option is to list all of your social medias, but dont overuse this. Nowadays we have a bunch of them, so if you list all of them, there is chances, you are not active there and the link will guide the reader to a empty and haunted house and they will not engage.
"},{"location":"portfolio/03-structure/#general-tips","title":"General tips","text":"- Keep the Target Audience in Mind
- Take Advantage of Your Homepage
- Make Your Portfolio Scannable
- Minimize Clicks
- Remember UX and UI
- Go Mobile or Go Home
- Optimize Website Performance
- Remember Accessibility
- Showcase Your Best Work and Skills
- Share Your Code and Live Projects
- OR Provide Code Samples and GIFs
- Boast Freelance and Personal Projects
- BUT Be Selective
- Prove that You Are on The Same Page
- Show Your Personality
- Use Custom Domain
- Make Use of Introductory Statement
- Use Your Tone of Voice
- Share Your Motivation (Optional)
- Maintain Personal Brand
- Keep Portfolio Up-to-Date
- Include Testimonials
- Encourage Communication
- Call-to-action button or link to contact
reference
"},{"location":"portfolio/03-structure/#homework","title":"Homework","text":"- [Optional]Create a wireframe draft of what you are going to do on figma, miro or any other tool you find relevant. If you already have a Portfolio page already set, try to think on how do you make it be responsive on mobile devices.
- Scaffold your project in github. Describe in the README.md what you are going to do in your demo. You might try to convince a colleague to work with you. You can do more than one demo if you want. Some examples:
- Raytrace demo for cloud and Human body. ref https://www.youtube.com/watch?v=Qj_tK_mdRcA
- Networking game using the phone as a controller and your portfolio demo as the viewer. https://blockrage.pgs-soft.com/
- Catch the cat demo for AI. https://llerrah.com/cattrap.htm
- Create unity editor plugin to dynamically generate meshes via splines based on sample locations. https://www.youtube.com/watch?v=f5Q7Z2KxILE is a game with 50million downloads that used this technique to generate scenarios. Here you can watch a better explanation. https://www.youtube.com/watch?v=saAQNRSYU9k
- Embed a shader toy behind your portfolio page. https://shadertoyunofficial.wordpress.com/2018/02/17/embedding-shadertoys-in-website/
- A nice collection of fun ideas to code for your portfolio https://mrdoob.com/
- Board game simulation. Ex: chess https://www.chessprogramming.org/ or https://github.com/JuUnland/Chess/ or this https://www.youtube.com/watch?v=WKs685H6uOQ
- [Optional] Simulate a real test by creating a console based space invader in 48h.
- Efficiently draw (print on console)
- Efficient collision check
Having a well-written and organized portfolio is important for any game developer, as it can help them stand out from the competition and demonstrate their skills and experience to potential employers. A good portfolio should clearly communicate the developer's strengths and accomplishments, and should be tailored to the specific needs and expectations of the audience.
Effective communication is crucial in building a strong game developer portfolio, as it allows the developer to clearly convey their skills and experiences to potential employers. A portfolio that is well-written and easy to understand will be more effective at convincing an employer to hire the developer, while a poorly written or poorly organized portfolio may have the opposite effect.
"},{"location":"portfolio/04-communication/#audience","title":"Audience","text":"In general your portfolio will be read by:
- Human Resources
- Software Developers
If you are applying for a big tech company, chances are your submission won't be read by a tech person the first human triage. So in order to pass this first filter, you have to be generic and precise. They are often very busy evaluating multiple applications, and probably they will spend 30-60 seconds before making the decision about moving forward in the process or not. Your portfolio will need to catch their attention and communicate clearly your fit, passion and ability in a short time frame.
"},{"location":"portfolio/04-communication/#software-developer-managers","title":"Software Developer Managers","text":"In contrast with HR, developer managers probably will not be shocked with any fancy stuff(such as full page pre-loaders) you add to your portfolio, so be concise and straight to the point, because most of them already know all the contents. From all of your portfolio readers, they are one of the most critique of your job.
In another hand, usually developers do not look for programming language fit, frameworks or tools you use. They are more interested if you will be able to learn and execute the job in a meaningful time. So try to express yourself in a way that showcase your ability to solve problems, no matter what problem is, they are mostly curious on how to solve complex problem by framing the problem in another way or how to be innovative.
"},{"location":"portfolio/04-communication/#what-they-look-for","title":"What they look for","text":"The following metrics can be evaluated by reading your portfolio, interviews or tests. The most common evaluation metrics they made are:
- Position Fit
- They are going to search if your portfolio showcase experience in the same area of what they are looking for the specific position they received. Usually they will look for specific keywords for the requirements list;
- Company fit
- They take count on your expressed ideas, stated goals, tone, alignment and supporting projects to evaluate your future evolution inside the company; ex. https://wa.aws.amazon.com/wat.pillars.wa-pillars.en.html
- Passion
- Passionate developers tend to express projects they are proud of. The description of the projects are mostly achievement-based. Ex.: more than X million downloads. This example showcases that you were part of something huge, and it is easily understandable.
- There is a high correlation on high performant people that they usually shine in side-projects or even hobbies. So they look for it. Ex.: Google encourages employees to devote 20% of their time to hobbies or skill-building.
- Competence
- They need to evaluate if you are really able to solve the problem properly, in a meaningful time, and in a team. You have to describe which tools, tech stack and how you glue everything in order to solve the problem. Be assured you are correctly expressing yourself here, because it is one of the central part that is not taken superficially.
- Innovation and Curiosity
- Innovative developers solve problems out of the box. It doesn't matter how complex the problem is, but if you solve in a innovative way, reframe it or do any magic to solve it, chances are to have good points here;
- Good companies incentives research and test new stuff. So they usually like to see your deliverables with new bleeding-edge technology tools.
- Proactiveness
- Usually the more proactive developers tend to have more leadership positions. So if you want to give the readers a glimpse of your ability in this area, a good place to showcase that is in project description section. Express problems that arise and how do you manage that before it become a real problem.
- Learner
- It is good to be always tuned with the current evolution of the technology, so try to keep the education section always updated with some courses or publish blog posts about some new tech.
- Thinking big / Thoughtfulness / Risk management
- They are going to look for your ability to think big, and how you manage risks. So if you have a project that you had to manage risks, or think big, it is a good place to showcase that.
- Expose cases where you had to manage risks, or think big, and how you manage that. What you learned in the process trying to achieve bigger goals.
Try to look at your portfolio from the perspective of the audience. What are the strengths and weaknesses of your portfolio? What are the areas that you need to improve in order to better communicate your skills and experiences to potential employers?
"},{"location":"portfolio/04-communication/#2-mock-interviews","title":"2. Mock interviews","text":"Pair up with a colleague and find some common questions that company usually asks. You can find some of them here. Then, take turns interviewing each other and providing feedback on how well you communicated your skills and experiences.
"},{"location":"portfolio/04-communication/#homework","title":"Homework","text":"- Write the content for each one of your projects and all other sections of your portfolio.
- 1st round of Portfolio Feedbacks.
- Research in a game company you like the resources on their hiring process. Take notes on how they hire and which positions you want to apply. Here goes some examples on how to get ready for interviews:
- Epic: https://www.epicgames.com/site/en-US/earlycareers/career-paths
- AWS: https://aws.amazon.com/careers/how-we-hire/
- General interview questions https://www.mockquestions.com/
- Top interview questions https://leetcode.com/problem-list/top-interview-questions/. Some examples:
- https://leetcode.com/problems/two-sum/ - the most asked question
- https://leetcode.com/problems/kth-largest-element-in-an-array/ - heap
- https://leetcode.com/problems/median-of-two-sorted-arrays/
- https://leetcode.com/problems/minimum-space-wasted-from-packaging/ - bin packing, try to solve for 2d image pack for textures
- Watch this video https://www.youtube.com/watch?v=Kte-t1pQQ3I and start contributing into an open source project or community
- Portfolio
- Interviews
- Social Network
Ask some questions for ChatGPT. Here goes a sample extracted from this prompt:
Create a strategy to get hired on a AAA game studio like COMPANY_NAME as a POSITION_NAME\n- Develop the right skills: The first step to getting hired in a AAA game studio is to develop the right skills for the job. Start by researching the job positions in the studio and look for the required skills, experience, and qualifications. Then, focus on building those skills through relevant education, training, and projects. You can also take courses, attend workshops or conferences, and create a portfolio of your work to showcase your abilities.
- Network with industry professionals: Networking with industry professionals can help you gain exposure and insights into the game development industry. Attend industry events, join online forums, participate in game development communities, and reach out to professionals in the field to build relationships. You can also consider working on collaborative projects with other game developers to expand your network.
- Stay up-to-date with industry trends: Keeping up with the latest trends and news in the gaming industry can help you stay ahead of the game and impress your potential employers. Read industry blogs, participate in online discussions, follow industry influencers on social media, and stay up-to-date with the latest game releases to show that you are knowledgeable and passionate about the industry.
- Research the game studio: Before applying for a job, research the game studio to learn about their culture, values, and work environment. Look for information about their current projects, the team structure, and the company's mission statement. This will help you tailor your resume and cover letter to match the company's requirements and demonstrate that you are a good fit for the team.
- Apply for internships: Consider applying for internships in a AAA game studio. This is an excellent opportunity to gain industry experience and build your skills. Even if the internship is unpaid, the experience and contacts you gain could be invaluable for your future career.
- Prepare for the interview: Once you get an interview, make sure to prepare thoroughly. Research common interview questions and practice your responses. Be ready to talk about your experience, skills, and passion for game development. Also, prepare questions to ask the interviewer about the company and the job position to show your interest and enthusiasm.
Write a strategy to get hired as a Game Programmer in a Indie Game Studio\n- Develop a strong portfolio: Your portfolio is your calling card, so it needs to showcase your programming skills, creativity, and technical abilities. Create a portfolio that showcases your best work, including your personal game development projects, demos, and samples of your code. Highlight your experience with programming languages, software, tools, and engines that are commonly used in the indie game development industry.
- Research indie game studios: Do your research on the indie game studios that interest you. Find out what kind of games they make, the size of the studio, the company culture, and their current job openings. Look for studios that align with your interests, values, and career goals.
- Build a network: Building a network of like-minded professionals in the game development industry can be invaluable. Attend industry events, join online forums and communities, and engage with indie game developers on social media. This will help you stay up-to-date on the latest trends, technologies, and job openings.
- Gain experience: Gain experience by creating your own games, participating in game jams, contributing to open-source projects, or volunteering for a non-profit game development organization. This will help you gain valuable experience and demonstrate your passion and commitment to game development.
- Apply for internships: Many indie game studios offer internships or junior positions for game programmers. This is an excellent opportunity to gain hands-on experience, build your skills, and make contacts in the industry. Even if the internship is unpaid, the experience and contacts you gain could be invaluable for your future career.
- Tailor your resume and cover letter: Tailor your resume and cover letter to showcase your programming skills, experience, and passion for game development. Highlight your technical skills, programming languages, software, and engines that you are proficient in. Be sure to mention any experience you have working in a team and collaborating with other game developers.
- Prepare for the interview: Once you get an interview, make sure to prepare thoroughly. Research the indie game studio, their current projects, and their company culture. Be ready to talk about your experience, skills, and passion for game development. Also, prepare questions to ask the interviewer about the company and the job position to show your interest and enthusiasm.
- Analytics. Recommendation: Google Analytics or Firebase Analytics;
- Heatmaps. Recommendation: smartlook;
For more details see promoting section;
"},{"location":"portfolio/05-strategy/#strategies-for-interviews","title":"Strategies for interviews","text":"Train yourself in coding interviews with some materials: - Crack the Coding Interview - Interviews on AWS - Interview on Google - Course on get ready for an AWS interview
"},{"location":"portfolio/05-strategy/#coding-resources","title":"Coding resources","text":"- Leetcode
- Hackerrank
- Geeksforgeeks
- Interview Questions
- Review on algorithms
- Practice code interviews
- AlgoExpert
All social networks uses some type of relevance algorithm to promote your content or profile. So you have to find means to increase your relevance. Most of the algorithms measure your relevance by number of reactions(likes, follows, comments, replies...), so every time you post something, you should try to incentive the content consumers to do that.
"},{"location":"portfolio/05-strategy/#google","title":"Google","text":"If your aim is to be relevant on Google, try to check the trending words people are searching now via Google trends.
If you follow this path, the main strategy is the common SEO optimization techniques. Here goes some guides to help you nail that.
- https://searchengineland.com/guide/what-is-seo
- https://www.wordstream.com/seo
- https://searchengineland.com/yandex-leak-learnings-392393
If you are a prolific writer and really into it. You can try to make wikipedia refer you and raise your rate on google algorithm. You can query google site:wikipedia.org [your niche keyword] + \"dead link\" and check the pages that are missing references to your content, then edit the wikipedia page to refer your website or blog post to give sources for something missing.
- Consistency is the key. You have to post frequently. Period.
- Follow other professionals in your field and check what they are posting to try replicate their behavior.
- Follow companies you want to work
- Connect with the hiring personal from the companies you want to work for, so when they search for people, you will be on the top suggestions.
WiP
"},{"location":"portfolio/06-reels/","title":"Portfolio Reels","text":"Sample Portfolio Reels
"},{"location":"portfolio/06-reels/#demo-reels-structure","title":"Demo Reels Structure","text":"Game demo reels should showcase the best features and gameplay of a game to potential players and investors. Here are some important elements that a game demo reel should include:
- Captivating Intro: The game demo reel should start with a captivating intro that hooks the audience and captures their attention.
- Gameplay Footage: The demo reel should showcase the actual gameplay footage of the game. This should include a variety of gameplay scenarios, showcasing the game mechanics and the different features of the game.
- Visuals: The game demo reel should showcase the visual quality of the game. This should include graphics, animations, lighting, and special effects.
- Audio: The game demo reel should include the game's audio elements, such as sound effects, music, and voice acting.
- User Interface: The demo reel should showcase the user interface of the game, including the menus, HUD, and other interactive elements.
- Story and Characters: If the game has a story or characters, the demo reel should include footage that showcases these elements.
- Game Modes: If the game has different game modes, the demo reel should showcase the different modes and gameplay styles.
- Multiplayer: If the game has a multiplayer mode, the demo reel should showcase the multiplayer gameplay and the features that make it unique.
- Call-to-Action: The demo reel should end with a clear call-to-action, such as a link to the game's website or social media page, or instructions on how to download the demo.
Overall, the game demo reel should be well-paced, engaging, and give a good sense of what the game is all about.
"},{"location":"portfolio/06-reels/#captivating-intro","title":"Captivating Intro","text":"A captivating intro is an essential part of a game demo reel, as it sets the tone and captures the viewer's attention from the start. There are several ways to create a captivating intro, depending on the type of game and the intended audience. Here are a few ideas:
- Show a brief teaser: Start the demo reel with a brief teaser that highlights the game's most exciting features, such as a stunning visual effect or a heart-pumping action sequence.
- Use a dramatic voiceover: Use a dramatic voiceover to introduce the game and create a sense of anticipation. The voiceover can provide a brief overview of the game's story or setting, or simply hype up the viewer with promises of intense gameplay and unforgettable experiences.
- Introduce the developer: If the game is developed by a well-known studio or an indie developer with a strong following, introduce them in the intro. Share their mission and goals for creating the game and convey their passion and expertise in the field.
- Set the mood with music: Use music to set the mood for the demo reel. Choose a track that complements the game's theme or genre and builds up the excitement for the upcoming gameplay footage.
- Use a creative animation: Use a creative animation that visually represents the game's core concept or theme. This can help to grab the viewer's attention and give them a taste of what the game is all about.
Whatever approach is taken, the intro should be brief and impactful, providing a sense of the game's style and tone while leaving the viewer eager to see more.
"},{"location":"portfolio/06-reels/#gameplay-footage","title":"Gameplay Footage","text":"Gameplay footage is the heart of any game demo reel, as it showcases the actual gameplay experience that the game offers. This section of the demo reel should be carefully crafted to highlight the most exciting and impressive features of the game. Here are some tips for creating engaging gameplay footage:
- Variety of gameplay scenarios: The gameplay footage should showcase a variety of gameplay scenarios to give viewers a well-rounded idea of what the game is all about. This can include different levels or environments, various weapons or abilities, and different characters or modes.
- Highlight unique features: Highlight the game's unique features and mechanics, such as special abilities, game modes, or multiplayer options. This can help to differentiate the game from other titles in the same genre.
- Showcase player choices: If the game allows players to make choices that affect the story or gameplay, showcase these choices in the demo reel. This can help to create a sense of player agency and show how the game responds to different playstyles.
- Show off impressive visuals: The gameplay footage should also showcase the game's impressive visuals, such as high-quality textures, realistic lighting and shadow effects, or dynamic particle effects. These elements can help to create a more immersive and engaging gameplay experience.
- Keep it concise: The gameplay footage should be concise and to the point, showcasing the most exciting and impressive elements of the game without becoming overly long or repetitive.
- Use high-quality footage: The footage should be high-quality and well-shot, with clear visuals and smooth frame rates. This can help to create a professional and polished demo reel that shows off the game in the best possible light.
Overall, the gameplay footage should provide a clear and exciting look at what the game has to offer, highlighting its unique features and impressive visuals while keeping the viewer engaged and interested.
"},{"location":"portfolio/06-reels/#visuals","title":"Visuals","text":"Visuals are a critical component of any game demo reel, as they are often the first thing that potential players and investors will notice. The visuals of a game should be showcased prominently in the demo reel, demonstrating the game's graphical capabilities and the level of detail and polish that has gone into its development. Here are some key elements of visuals to consider when creating a game demo reel:
- Graphics quality: The graphics quality of the game should be highlighted in the demo reel. This can include high-quality textures, realistic lighting and shadows, dynamic particle effects, and other visual elements that make the game stand out.
- Art style: The art style of the game is also an important visual element to showcase. Whether the game has a realistic or stylized art style, it should be highlighted in the demo reel to give viewers a sense of the game's aesthetic.
- Animations: The animations of the game are an important part of the overall visual experience. The demo reel should showcase the game's character animations, object interactions, and any other animations that add to the game's visual appeal.
- Camera work: The camera work used in the demo reel can also be used to highlight the game's visual elements. Different camera angles, zooms, and cuts can be used to showcase the game's graphics and make them stand out.
- User interface: The user interface (UI) of the game is also an important visual element that should be showcased in the demo reel. The demo reel should highlight the UI design and any interactive elements, such as buttons or menus.
- Environment design: The game's environment design is another important visual element to showcase in the demo reel. Whether the game takes place in a realistic or fantastical setting, the environment design should be highlighted to give viewers a sense of the game's atmosphere.
Overall, visuals play a crucial role in creating an immersive and engaging gameplay experience, and they should be showcased prominently in a game demo reel. By highlighting the game's graphics quality, art style, animations, camera work, user interface, and environment design, the demo reel can give viewers a clear and exciting look at what the game has to offer.
"},{"location":"portfolio/06-reels/#audio","title":"Audio","text":"Audio is an often overlooked but crucial component of any game demo reel. It can enhance the overall gameplay experience, create an immersive atmosphere, and contribute to the game's overall appeal. Here are some key elements of audio to consider when creating a game demo reel:
- Sound effects: Sound effects are an important component of any game's audio design. The demo reel should showcase the game's sound effects, such as weapon sounds, environmental effects, and character vocalizations.
- Music: The music used in the game can also be an important part of the overall audio experience. The demo reel should highlight the game's soundtrack, showcasing any memorable themes or musical cues that contribute to the game's atmosphere.
- Voice acting: If the game features voice acting, it should be highlighted in the demo reel. The demo reel should showcase any memorable voice performances and give viewers a sense of the quality of the voice acting.
- Sound design: The overall sound design of the game is another important element of the game's audio. The demo reel should showcase how the game's audio elements work together to create an immersive atmosphere, such as the use of ambient sounds or dynamic music that changes based on the player's actions.
- Audio quality: The quality of the game's audio should also be highlighted in the demo reel. The sound effects, music, and voice acting should be clear and well-produced, with high-quality mixing and mastering that enhances the overall experience.
Overall, audio is a critical component of any game demo reel. By showcasing the game's sound effects, music, voice acting, sound design, and audio quality, the demo reel can give viewers a clear and engaging look at the game's overall audio experience.
"},{"location":"portfolio/06-reels/#user-interface","title":"User Interface","text":"The user interface (UI) is a critical component of any game, and it should be showcased prominently in a game demo reel. The UI is the primary way that players interact with the game, and it can greatly impact the overall gameplay experience. Here are some key elements of UI to consider when creating a game demo reel:
- Design: The design of the UI is an important aspect to showcase in the demo reel. The UI design should be visually appealing, easy to navigate, and intuitive for players to use. The demo reel should showcase any unique design elements, such as custom icons or animations, that contribute to the overall look and feel of the game.
- Functionality: The functionality of the UI is also an important element to showcase in the demo reel. The UI should be designed to help players easily access important information, such as health, inventory, or map data. The demo reel should showcase how the UI functions during gameplay and how it supports the overall game mechanics.
- Customizability: Some games offer customizable UI options, such as changing the size or placement of UI elements. If the game has this feature, it should be highlighted in the demo reel to showcase the flexibility of the UI design.
- Responsiveness: The responsiveness of the UI is another important aspect to showcase in the demo reel. The UI should respond quickly and smoothly to player input, and any interactive elements should have clear feedback to help players understand their actions.
- Accessibility: Finally, the accessibility of the UI is an important consideration. The demo reel should showcase how the UI supports players with different needs, such as colorblind options or font size adjustments.
Overall, the UI is a critical component of any game, and it should be showcased prominently in a demo reel. By highlighting the design, functionality, customizability, responsiveness, and accessibility of the UI, the demo reel can give viewers a clear and engaging look at how players interact with the game and how the UI supports the overall gameplay experience.
"},{"location":"portfolio/06-reels/#story-and-characters","title":"Story and Characters","text":"The story and characters are important elements of many games, and they can greatly impact the overall experience. When creating a game demo reel, it is important to showcase the game's story and characters in a way that is engaging and gives viewers a clear sense of what to expect from the game. Here are some key elements of story and characters to consider when creating a game demo reel:
- Story: The demo reel should give viewers a sense of the game's story, including the setting, premise, and major plot points. The story should be presented in a way that is engaging and makes viewers want to learn more about the game's world and characters.
- Characters: The demo reel should also showcase the game's characters, including their personalities, motivations, and relationships with each other. Characters should be presented in a way that is relatable and makes viewers care about their journeys throughout the game.
- Dialogue: If the game features dialogue, it should be highlighted in the demo reel. The dialogue should showcase the quality of the writing and voice acting, and give viewers a sense of the characters' personalities and relationships.
- Cutscenes: Cutscenes are a great way to showcase the game's story and characters in a visually compelling way. The demo reel should include any memorable or important cutscenes that help to advance the story or develop the characters.
- Worldbuilding: Finally, the demo reel should showcase the game's worldbuilding, including any lore or backstory that helps to flesh out the game's world and characters. This can include things like environmental storytelling, item descriptions, or other worldbuilding details.
Overall, the story and characters are important elements of many games, and they should be showcased prominently in a game demo reel. By highlighting the story, characters, dialogue, cutscenes, and worldbuilding, the demo reel can give viewers a clear and engaging look at what to expect from the game's narrative and characters.
"},{"location":"portfolio/06-reels/#game-modes","title":"Game Modes","text":"Game modes are an important aspect of many games, particularly in multiplayer titles, and they can greatly impact the overall experience. When creating a game demo reel, it is important to showcase the different game modes in a way that is engaging and gives viewers a clear sense of what to expect from each mode. Here are some key elements of game modes to consider when creating a game demo reel:
- Variety: The demo reel should showcase a variety of different game modes, particularly if the game has several unique modes to choose from. This will give viewers a sense of the game's overall variety and replayability, and help them understand how each mode contributes to the overall experience.
- Objectives: Each game mode should have clear objectives that are highlighted in the demo reel. This can include things like capturing objectives, defeating enemies, or completing tasks within a certain timeframe. The objectives should be presented in a way that is clear and easy to understand for viewers.
- Mechanics: The demo reel should showcase the different mechanics and gameplay elements that are unique to each game mode. This can include things like different weapons or abilities, unique maps or terrain, or different objectives and win conditions. By highlighting these unique mechanics, viewers can get a sense of how each mode feels and plays.
- Multiplayer: If the game has multiplayer modes, it is important to showcase how players can interact with each other within each mode. This can include things like team play, player versus player combat, or cooperative objectives.
- Replayability: Finally, the demo reel should showcase how each game mode contributes to the game's overall replayability. This can include things like unlockable rewards, leaderboards, or other features that encourage players to come back and play the game multiple times.
Overall, game modes are an important aspect of many games, particularly in multiplayer titles, and they should be showcased prominently in a game demo reel. By highlighting the variety, objectives, mechanics, multiplayer elements, and replayability of each mode, the demo reel can give viewers a clear and engaging look at what to expect from each game mode and how it contributes to the overall experience.
"},{"location":"portfolio/06-reels/#multiplayer","title":"Multiplayer","text":"Multiplayer is an important aspect of many games, particularly in online multiplayer games, and it can greatly impact the overall experience. When creating a game demo reel, it is important to showcase the multiplayer aspects in a way that is engaging and gives viewers a clear sense of what to expect from the multiplayer modes. Here are some key elements of multiplayer to consider when creating a game demo reel:
- Modes: The demo reel should showcase the different multiplayer modes that are available in the game. This can include things like team-based modes, objective-based modes, and free-for-all modes. The demo reel should highlight how each mode plays and what the objectives are.
- Player Count: The demo reel should also showcase the player count for each mode. This can include things like 1v1, 2v2, 4v4, or larger player counts for massive multiplayer games. The player count is an important factor in determining the pacing and flow of the game, and should be highlighted in the demo reel.
- Matchmaking: If the game features matchmaking, it is important to showcase how the matchmaking system works and how players are paired with opponents of similar skill levels. This can include things like player ranking systems or other matchmaking algorithms that help to ensure fair matches.
- Progression: The demo reel should also highlight any progression systems that are available in the multiplayer modes. This can include things like unlocking new weapons or abilities as players progress through the game, or other rewards for completing objectives or winning matches.
- Social Features: Finally, the demo reel should showcase any social features that are available in the multiplayer modes. This can include things like chat systems, friend lists, or the ability to form clans or teams with other players.
Overall, multiplayer is an important aspect of many games, particularly in online multiplayer games, and it should be showcased prominently in a game demo reel. By highlighting the different modes, player count, matchmaking, progression, and social features of the game's multiplayer modes, the demo reel can give viewers a clear and engaging look at what to expect from the multiplayer experience.
"},{"location":"portfolio/06-reels/#call-to-action","title":"Call to Action","text":"The Call-to-Action (CTA) is an important element of any game demo reel because it prompts viewers to take action after watching the video. The CTA can be in the form of a request or suggestion that encourages viewers to do something related to the game, such as signing up for a mailing list, pre-ordering the game, or visiting the game's website. Here are some key elements to consider when including a Call-to-Action in a game demo reel:
- Clarity: The CTA should be clear and specific, so that viewers know exactly what action they are being asked to take. This can include things like \"pre-order now\" or \"sign up for updates\", and should be prominently displayed at the end of the video.
- Relevance: The CTA should be relevant to the content of the video, and should relate directly to the game being showcased. For example, if the demo reel is showcasing a new game trailer, the CTA could be to pre-order the game.
- Timing: The CTA should be timed appropriately within the video, so that it appears at the end and is not too distracting during the main content of the video.
- Design: The design of the CTA should be visually appealing and eye-catching, using bold fonts and contrasting colors to draw attention to it.
- Placement: The CTA should be placed in a prominent location within the video, such as at the end or in a lower third graphic.
Overall, the Call-to-Action is an important element of any game demo reel because it prompts viewers to take action after watching the video. By including a clear, relevant, and well-designed CTA at the end of the video, game developers can encourage viewers to take action and engage with the game in meaningful ways.
"},{"location":"portfolio/06-reels/#specifications","title":"Specifications","text":"Specifications for the Demo Reels:
Video Specifications:
- Size: 1920x1080 (16:9)
- Format: saved as
.mp4 - Length:
- Game Art = 90 seconds.
- Game Design, Game Production Management, Game Programming, Game Sound Design = 60 seconds.
- No audio with lyrics
- No X-rated content
- Use audio that won't get removed from Vimeo (where we store the files) because of copyright infringement.
Watch some videos from Sample Portfolio Reels and create a script detailing what you are going to present yourself. Start creating the timeline of feelings and you are going to present at each time.
Tell a story where you are (or your work is) the protagonist.
"},{"location":"portfolio/07-hosting/","title":"Hosting","text":"There are many hosting options and solutions to match each need. Lets cover some options here.
"},{"location":"portfolio/07-hosting/#options-low-code","title":"Options low code","text":"- Google sites - My preference
Other notable options: - Godaddy - Wordpress - Wix - Squarespace
The problem with those are they require payments to be fully functional, so if you want to go deep and have mor freedom, we are going to cover other options.
"},{"location":"portfolio/07-hosting/#static-html-with-static-data","title":"Static HTML with Static Data","text":"If what you want to serve is static hosting, your content is only frontend and do not require backend, you can use github pages, google firebase, S3 bucket hosting or many others. This is the easiest approach. - In this scenario you will be able to store only pre-generated html and static files; - This is useful even if you use blogs that changes rarely, you would have to redeploy your page for every change.
"},{"location":"portfolio/07-hosting/#static-html-with-dynamic-data","title":"Static HTML with Dynamic Data","text":"If your html is static and need backend services that are rarely called, you can go with cloud functions, my suggestions here are google cloud run and aws amplify or even firebase functions. If you use nextjs website, check vercel or netlify hosting services. - The deploys are easy; - It can be very expensive if you hit high traffic, but it will remain free if you dont hit the free tiers; - You will have to pay attention to your database management;
"},{"location":"portfolio/07-hosting/#dynamic-html-with-dynamic-data","title":"Dynamic HTML with Dynamic Data","text":"If your website generate content dynamically such as Wordpress blogs or any custom made combination with next or anything. - There is many \"cheap hosting\" solutions that are mostly bad performant(it can reach more than 10s to answer a request). You have to avoid them to make your user enjoy the visit; - Management can go as hard as possible, but the results can be awesome; - It can be really expensive;
"},{"location":"portfolio/07-hosting/#cdn-and-dns-management","title":"CDN and DNS Management","text":"I highly recommend you to use Cloudflare as you DNS nameserver, so you can cache your website results for faster loading. But you can use your own nameserver provider by your domain name registrar.
DNS stands for Domain Name System, which is a system that translates domain names into IP addresses. When you type a domain name into your web browser, such as \"www.example.com,\" your computer sends a request to a DNS server to resolve the domain name into an IP address, such as \"192.0.2.1.\" The IP address is then used to establish a connection with the web server that hosts the website you are trying to access.
DNS plays a crucial role in hosting because it enables users to access websites using domain names instead of IP addresses. This makes it easier for users to remember and find websites. DNS also allows websites to change servers or IP addresses without affecting the user experience, as long as the DNS records are updated properly.
In hosting, DNS is important because it determines which server is responsible for hosting a particular website. DNS records can be configured to point to different servers depending on factors such as geographic location, server load, and failover. Hosting providers typically offer DNS management tools to help users configure and manage their DNS records.
"},{"location":"portfolio/07-hosting/#homework","title":"Homework","text":"The goal is to have as website up and running for your portfolio.
Here goes my preferable way for hosting anything. With that you can host microservices, game services, serve API, static and dynamic websites and much more. It can be tricky but lets setup it now.
- Oracle cloud - Free forever - Virtual Machine with 4vCPU, 24GB ram, 200GB storage. https://www.youtube.com/watch?v=NKc3k7xceT8 watch up to 5:38 time
- Coolify - Your private Software as a Service (SAAS) manager - https://youtu.be/Jg6SWqyvYys?t=125 starts from minute 2:00
- CI/CD - to your remote machine https://www.youtube.com/watch?v=Uj7F3hdgmEo
- Cloudflare DNS - set your domain to point to your DNS - https://www.youtube.com/watch?v=XQKkb84EjNQ
- Install Wordpress via coolify interface(new resource, new service) and use your own DNS. Or host your page statically https://www.youtube.com/watch?v=CfdPyASUSkI&
Talk with me if you dont have a domain and want to use my infrastructure temporarily.
I am assuming you wont have a huge traffic, but you have a complex combination of services. In the complex cases and if you want to make your life easier and cheaper,my suggestion for hosting would be oracle cloud with arm cpu. They offer for free a virtual machine with 200gb storage, 4vcpus, 24gb ram for free at this date of 2022/12 tutorial. In this scenario, I recommend using https://coolify.io/ as your deployment management system, just pay attention that this machine is running in an arm cpu. With this combination, you can manage everything easily in one place for free. This is not ideal, because you wont have backups, but it is good enough for most scenarios.
If you have plenty of money or your website have high traffic, I recommend you to use Kubernetes to orchestrate every microservice.
"},{"location":"portfolio/08-cms/","title":"Content Management System","text":""},{"location":"portfolio/08-cms/#play-with-chatgpt","title":"Play with chatgpt","text":"In order to train yourself for a game position try some prompts similar to this one.
Act as technical recruiter for a AAA game studio. You are going to interview me by asking me questions relevant for an entry level position as \"unreal gameplay developer\". Skills required are: Unreal Egine, Data structures, Algorithms, VR and Rendering pipelines. \nYou are going to ask me a question when I prompt \"ask\".\nMy answer to your question will start with \"response\".\nOn each response I give to your question, you will provide me 5 bullets: SCORE: from 0 to 100 points to evaluate if I answered it well or not; EXPLANATION: why you gave me that score; RATIONALE: explain what a typical recruiter is measuring with the question previously asked; ADVISE: to improve for answer to score 100 answer; NEXT: question. \nDo you understand? Dont ask anything now.\nYour portfolio should be a hosted webpage and a open repository on github.
You should follow a portfolio structure, to build a website and host it publicly. It should have a nice style, a good communication is the key to execute and analyse your strategy in order to capture insights. You can optionally increment your portfolio via dynamic content such as blogs or whatever you find relevant. Another extra step would be to create a generic cover letter to express your intentions and goals more personally. Note that some game companies still require CVs To boost your visualization, you can promote.
Minimum steps: 1. Have a domain or at least a meaningful github username/organization; 2. Create a github repository; 3. Push your frontend to the repo; 4. Enable github pages; 5. Create a CI/CD to build and deploy to gh pages; 6. Point your domain to gh-pages if you have one;
It is expected to have something to showcase, so it is expected to have at least 3 projects to showcase. It is preferable to showcase something that could be testable(webgl builds) or watchable in a lightweight manner.
If you are willing to showcase your ability in Unity, I recommend you to try GameCI and github pages. If you want to showcase your game engine abilities with C++, I recommend you using CMake, SDL2 and emscripten to build and deploy for github pages.
If you want to start something from scratch you can use this repo to start have a SDL2 project with all libraries already set. It builds and publish a Github page via Github actions automatically, you can check it running here. It features CMake tooling, IMGUI for debug interfaces, SDL2, SDL2_ttf, SDL_image, SDL_mixer,
"},{"location":"portfolio/09-get-ready/#2023","title":"2023","text":"Here goes a list of portfolios
"},{"location":"portfolio/09-get-ready/common-intenterview-questions/","title":"Common interview questions","text":"Resources: - https://debbie.codes/blog/interviewing-with-the-big-tech-companies/
"},{"location":"portfolio/10-frontend/","title":"Frontend for your portfolio","text":"Here goes a curated templates for a quick start: - https://github.com/techfolios/template - the easiest one - https://github.com/rammcodes/Dopefolio - straight to the point developer portfolio - https://github.com/ashutosh1919/masterPortfolio - animated with a strong opening - https://smaranjitghose.github.io/awesome-portfolio-websites a good compilation on how to build and deploy your portfolio with a good pre-made template
But for this class, we are going to follow this template, sofork this boilerplate if you want a more robust webapp experience.
"},{"location":"portfolio/10-frontend/#frontend-frameworks","title":"Frontend frameworks","text":"There are many frontend frameworks floating around, but in order to speed up your learning curve on how to deploy a fully customized webpage, I am going to use this combination of technologies:
- React for building website;
- Vite for tooling;
- Tailwindcss for styling;
Some examples with this stack:
- https://reactjsexample.com/a-portfolio-page-using-react-js-and-tailwind-css/
- https://github.com/InfiniBrains/reactjs-vite-tailwindcss-boilerplate
Watch this video to get a fast entry to this stack Here goes an introductory video about this combination.
"},{"location":"portfolio/12-promoting/","title":"How to promote yourself and your work","text":"For most of us, game developers, the most important thing is to make games. But, in order to make games, we need to promote ourselves and our work. In this section, we will learn how to do that.
"},{"location":"portfolio/12-promoting/#defining-the-target-to-be-promoted","title":"Defining the target to be promoted","text":"Before we start promoting, we need to define what we want to promote. The main difference between promoting ourselves or our work is the tone, the message and the medium being promoted. So we can build a successful strategy.
In ether path you chose, consider the following questions:
- What is the target audience?
- What is the target platform?
- What is the target medium?
- What is the target message and content?
- What is the target call to action?
- What is the target result?
- How to measure the success?
- How to improve the promotion?
Before creating and running a promotion campaigns, we need to define the audience. The audience is the group of people we want to reach with our promotion and it can defined by the following:
- Recruiters, HR, and hiring managers;
- Other game developers, especially those who are in the same field as you;
- Game players;
- Journalists, writers and critics;
- Investors;
- Communities;
To reach specific audiences, we need to be in the same platform they are. For example: - Game players: Steam, Twitch, YouTube, itchio, GameJolt, Discord; - Journalists: Twitter, LinkedIn; - Investors: AngelList, Ycombinator, LinkedIn, Crunchbase; - Communities: Reddit, Discord, Facebook, Twitter; - Recruiters: mostly Linkedin.
Social media is a great way to promote yourself as a game developer. You can use it to share your work, your thoughts, your ideas, and your opinions. You can also use it to connect with other developers and learn from them.
Here goes my opinion about the most important platforms:
- Twitter: it is the best and easy way to communicate with anyone in the world. The distance between to reach anyone is zero. And it has an awesome tagging structure. It is a great way to share your thoughts and ideas and ask for feedbacks. It is a great way to connect with other developers and learn from them. You can also use it to share your work and promote your games.
- LinkedIn: It is a great way to connect with recruiters and hiring managers. Usually you will see other developers publishing their thoughts and ideas, so try to post relevant comments on their publications to get noticed and improve your visibility.
- Facebook: It is mostly a general purpose social media. You can use it to connect with your friends and family, and collect feedbacks for your content. It is a great way to promote your finished games.
- Instagram and Tiktok: Are more focused in fast, small and visual content. You can use it to promote your games and your work, but it is not the best way to share your thoughts and ideas.
- Reddit: This one is the best for collecting feedbacks from other developers about your content, but the reach is limited.
- Discord: The best tool be in touch with communities, you can build your own community for your game and be in direct contact with yours consumers. Another good use is to be in direct contact with other developers and learn from them.
- YouTube and Twitch: The best way to share your work and promote your games.
- Medium and Blogs in general: The best way to share your thoughts and ideas and ask for feedbacks. You can use it in conjunction with other platforms to catch the general attention and bring them to your content.
The mediums are: Social media posts, Blog posts, Email, Podcasts, Videos, Events, Conferences, Meetups, Workshops, Webinars, Webcasts, and more.
For each type of medium, we need to plan the content, the frequency, and the duration. We have very nice tools to help us with that, like Buffer, Hootsuite and many others.
"},{"location":"portfolio/12-promoting/#message-and-tone","title":"Message and tone","text":"The message is the main idea we want to communicate. The tone is the way we want to communicate it. You have to match the tone with the message in the given platform to reach the right audience. So plan ahead how you want to communicate your message and what tone you want to use.
When planning the message, it is good to plan the emotions we want to trigger in the audience. For example, if we want to promote our game, we can use the following emotions: Excitement, Joy, Curiosity, and Fun. If we want to promote yourself by doing something interesting, you can use the following emotions: Curiosity, Fun, Surprise and Pride.
"},{"location":"portfolio/12-promoting/#call-to-action","title":"Call to action","text":"The call to action is the action we want your audience to take. It can be: Download the game, Read my Resume, be part of by community, Take a look on my Repository, Buy the game, Play the game, Follow me, Subscribe, Share, Like, Comment, and more.
"},{"location":"portfolio/12-promoting/#results","title":"Results","text":"Whatever is your goal, you need to define the results you want to achieve so you should track and measure your progress. You can use tools like Google Analytics mostly for web content, Google Firebase for apps and games and many other.
Here some ideas of results you can track: Number of downloads, page views, number of people reaching you, number of followers, number of subscribers, number of likes, number of comments, number of shares, number of retweets, number of reposts and more.
"},{"location":"portfolio/12-promoting/#improving-the-promotion","title":"Improving the promotion","text":"If you really want to go deep in this rabbit hole, I highly recommend you to create performance measurements such as KPI dashboard to track your progress and improve your promotion. You can use tools like Google Data Studio or Tableau. With the KPI dashboard, you can track your progress and improve your promotion. You can also use it to track your competitors and learn from them.
Another good strategy is to A/B test your promotion. You can use tools like Google Optimize to create different versions of your promotion and test which one is the best. You can also use it to test different messages, tones, and call to actions. I cannot stress enough how important it is to test your promotion, the most successful companies in the world do it. Zynga even quoted once \"We are not in the business of making games, we are in the business of testing games\" and \"We are a data warehouse maskerated as a game company\". So being data-driven and customer-centric is the key to success.
"},{"location":"portfolio/12-promoting/#homework","title":"Homework","text":"- Create a promotion strategy for yourself and your work.
- What would be your first content and medium to promote?
- What is the message and the tone?
- Define your call to action.
- How do you measure your results?
- How would you plan to improve your promotion?
I hope you enjoyed this content. If you have any questions, please create an issue in this repository. If you want to contribute, please create a pull request. If you want to support me, please share this content with your friends and colleagues. If you want to support me financially, please consider buying me a coffee or a very fancy wine.
"},{"location":"portfolio/13-cover-letter/","title":"How to write an Awesome Cover Letter","text":""},{"location":"portfolio/13-cover-letter/#what-is-a-cover-letter","title":"What is a cover letter?","text":"A cover letter is a document that is sent together with your resume. It is a way to introduce yourself to the company, explain why you're applying for the job, and why you're a good fit for the position. You should also explain why you're interested in the company, and why you want to work for them.
Nowadays writing a Cover Letter seems to be a lost art. Most of the time, people just send their resume and that's it. But, if you want to stand out from the crowd, you should write a cover letter.
In a cover letter you can be more personal to sell yourself more effectively. The core of it is to link your skills and history to what they do and need. Now lets see how to write a cover letter.
"},{"location":"portfolio/13-cover-letter/#strategies-to-write-a-cover-letter","title":"Strategies to write a cover letter","text":"There are many strategies to write a cover letter. But the main idea is to be personal and try to sell yourself more effectively. Here are some strategies to write a cover letter:
- Be clear, concise and specific. You should try to be clear and try to sell yourself more effectively. Don't waste their time with long and boring paragraphs. You can do that by linking your skills and history to what they do and need. You can also try to show your personality and your passion for the job;
- Be personal, enthusiastic and professional: You should try to be personal setting the best tone that matches your style and the company, just don't exaggerate. You can also try to show your personality and your passion for the job. But, you should also be professional and try to be polite and respectful. If you're unsure about the company culture, you can do that by using a formal language and a professional tone;
Usually, game companies are interested in people who are passionate about games. But there are some core differences between what profiles AAA game studios and Indie Studios seek for. AAA usually follow the path of the specialist, while Indie Studios usually, the generalist. So try to match this style of writing in your cover letter.
Another relevant aspect is the company culture. You should try to match the tone of your cover letter to the company culture. If you're unsure about the company culture, you can do that by using a formal language and a professional tone. Or try to connect with some employees of the company and ask them about the company culture.
Research about the company. Try to find out what they do, what they are looking for, and what they are interested in. You can do that by reading their website, their blog, and their social media. They tend to prefer people that have culture, passion and goals aligned with theirs. So try to show that you are passionate about their products and their goals.
Play their games, and use their products. An awesome icebreaker can be yourself telling about some funny bug or how you enjoyed the game connecting it to your life. It would be awesome if you can show that you are a fan of their products to the point to even create mods or fan art.
"},{"location":"portfolio/13-cover-letter/#write-interesting-content","title":"Write interesting content","text":"You should try to write memorable sentences to maintain your reader engaged. One strategy is to start the paragraphs with a short and powerful sentence that summarizes the the topic you are about to write. Arguably, you can also try to use a powerful quote to start your cover letter.
Your first sentence plays a huge role in your cover letter, it should be meaningful to you and to the reader. Chances are, they wont be reading the whole cover letter, so you should try to make the first sentence as interesting as possible. Try to be catchy and try to make them want to read more, but take care not to exaggerate.
Sometimes your content is really relevant to you but it might not be that relevant to the company or the job. Sometimes we get too excited and we want to tell everything about ourselves and how passionate we are, by try telling all the things you ever did. But you should try to be clear and concise. Just add some breadcrumbs for the reader ask you in the interview about the things you didn't mention in the cover letter.
"},{"location":"portfolio/13-cover-letter/#strengths","title":"Strengths","text":"You should try to highlight your strengths. You can do that by using a list of your skills and achievements. They will try to extrapolate the value you brought to the previous companies you worked for to themselves. So try show that you are a good fit for the job by giving success stories about your acchievents. Some examples:
- AAA centred: I published a game on Steam with 100k downloads while a student. I acted as the main developer and tech lead, responsible for creating tools for level designers and AI system for the game. Besides that, I played a fundamental role to cut the scope of the game to make it possible to be released on time and consequently the sanity of the team;
- Indie: I am fearless. I am not afraid to fail or take risks. This behavior pressures me to have a good plan and to be prepared for the worst. Once we tried a very ambitious feature that we thought would be awesome, we tracked the adoption of it, just to discover that nobody used it. We learned from it and we tried again with a smaller scope and it worked. We released the game on time and we were happy with the result;
Pay attention that some companies might not like to see that you are a risk taker. So try to be careful with that, and ask some employees of the company and ask them about the company culture.
"},{"location":"portfolio/13-cover-letter/#closure","title":"Closure","text":"You should try to close your cover letter with summary, thank them for their consideration and time, and add a call to action. You can also try to add a call to action to connect with you on social media or to visit your website, or just say that you are in hopes to talk with them in person soon.
"},{"location":"portfolio/13-cover-letter/#create-a-template","title":"Create a Template","text":"You should try to create a template for your cover letter. A way of doing it is to add replaceable tags for the company name, the job title, and the date. Try to mark those tags in some colorful way, so you can easily find them and replace them. You can also try to add some comments to help you remember what to write in each tag.
Another strategy to templating your cover letter is to create one template for every type of company. For example, you can create a template for AAA game studios, another for Indie game studios, and another for game companies. You can also create a template for each type of job. For example, you can create a template for a game designer, another for a gameplay developer, and another for a UI/frontend developer.
But if you pursue this path, you have to pay attention to the examples and products/games that you use in your cover letter. You will have to change them to match the company you are applying for.
"},{"location":"portfolio/13-cover-letter/#homework","title":"Homework","text":"Write a Cover Letter for a game company.
"},{"location":"tools/git/","title":"Try Git","text":"This document started as a copy from this Source
Here is a helpful three-part tutorial:
- Read About Version Control & the excellent Intro to Git
- Install Git for the command line. See the information below.
- Do the Try Git interactive tutorial. It basically runs you through using Git on the command line and with Github.
This information below contains recommended resources for learning Git and Github, which we will use this semester to store, manage and share our projects.
GitHub is a web-based hosting service for software development projects that use the Git revision control system. GitHub offers free accounts for open source projects. As of May 2011, GitHub was the most popular open source code repository site. The site provides social networking functionality such as feeds, followers and the network graph to display how developers work on their versions of a repository. [Wikipedia]
Installing GitMac OSX
- Git can be installed in Xcode via installing the Command Line Tools at Preferences->Downloads->Components
- You can also install Git via the download from the git website or through package management tools such as Homebrew and Macports
Windows
- Install Git for Windows which includes a Unix-like Bash terminal environment that matches the commands in the Try Git tutorial.
- If you're familiar with the Win/DOS Command shell but are new to Bash, check out this DOS - Bash command comparison
Linux
- Install git through your distro's package management system
Configure Git
- Set you username and email address (only need to do this once).
-
$ git config --global user.name \"YOUR_FULL_NAME\"\n$ git config --global user.email \"YOUR_EMAIL_ADDRESS\" - Turn on git colors with makes reading status and diffs much easier (only need to do this once). You shouldn't need to do this if you're using the Git Bash installed by Git for Windows.
-
$ git config --global color.ui true
The following are pulled form the excellent Introduction to Git. Bash/Shell A small list of the bread and butter Bash/Shell/Terminal commands. Some of these commands respond to the\"-h\" or \"--help\" options which print out a small usage reference. Many of the simple commands (ls, cp, mv) don't respond to \"--help\" but will simply print out a usage line when they don't understand the given arguments.
$ ls --helpAlso, most have manual pages which can be reached by using the \"man\" command and then the program name. Here's how to open the manual page for ls:
$ man lsUse the UP & DOWN arrow keys to scroll and 'q' to quit.
- ls - list contents of the current dir
- cd - change directory; ~/ refers to your home dir, . refers to the current dir, ../ refers to one directory up, ../../ refers to 2 dirs up, etc
- pwd - prints full path to the current dir (where we are)
- mkdir - make a new dir
- touch - create an empty file or update the timestamp on an existing file
- mv - move a file or dir
- cp - copy a file or folder; the -R option copies files & folders recursively (need to copy the entire contents of a given folder if it als contains folders)
Git This is just a small list of git commands. See the references below for more detailed info. All of the git commands respond to \"--help\".
- git init - initialize a dir for git source control management
- git clone - clone a git repository from another location (another git controlled folder, somewhere online, GIthub, etc)
- git checkout - switch to a branch, commit, or tag; the base location is the master branch
- git status - print status of the staging area (modified files, current branch, etc)
- git add - add a file or folder to the staging area, responds to wildcards like *.txt and . which refers to all modified files (careful with this one!)
- git rm - remove a file or folder form the staging area, removing a modfied file may require the -f argument to force it, -r adds files recursively (useful within folders).
- git mv - move or rename files or folders, only works for files currently managed by git (aka added previously)
- git commit -m \"some message\" - commit the current staging area (adds, modifications, removals); the -m option specifies the log message
- git branch some_branch - creates a branch called \"some_branch\"; don;t forget to switch to it using git checkout!
- git merge some_branch - merge a branch into the current branch, in this case merge \"some_branch\" with \"master\"
Books & Tutorials
- Try Git online course by Code School + Github. (thx @codeSchool)
- Pro Git book by Scott Chacon (free PDF). (thx @hilarymason)
- Interactive Tutorial by Code School. (thx @maxhawkins, @raunaqgupta)
Client Apps:
- SourceTree (thx @smallfly)
- Tower app for Mac OSX ($30 for students). (thx @pitaru)
- Github for Mac
- Git-Friendly shell scripts by Jamie Wilkinson. (thx @jamiew)
Videos:
- Github Learning Series Video Tutorials. (thx @julianoliver)
- Github's official YouTube channel. (thx @matthewmccull)
- Getting Git video by Scott Chacon. (thx @richbate)
- Mastering Git Basics by Tom Preston-Werner. (thx @maxhawkins)
- Code Journal Part 1 by James Paterson. (thx @joshuadavis)
- GitCasts. (thx @bgstaal)
Web Sites/Pages:
- Official Git Reference.
- Github Official Teaching Materials. (thx @matthewmccull)
- Github Setup Bootcamp.
- Getting Started with Git by Git-SCM. (thx @julianoliver)
- Introduction to Git & Git Workflow for Beginners by Steve Klise. (thx @atduskgreg)
- A Visual Git Reference by Mark Lodato. (thx @moskovich)
- The openFrameworks Git Workflow by the OF community. (thx @zachlieberman)
- Git - The Simple Guide by Roger Dudler. (thx @lennyjpg)
- How to Learn Git (Link Roundup) by Kevin Suttle. (thx @kevinSuttle)
- A Successful Git Branching Model by @nvie. (thx @smallfly)
Cheat Sheets:
- Zach Lieberman's Cheatsheet. (thx @zachlieberman)
- Git Cheatsheet by Andrew Peterson/NDP Software. (thx @julienbayle)
- Git Developer Cheatsheet (PDF) by Salesforce.com. (thx @julienbayle)
Try Git¶
Estimated time to read: 21 minutes
This document started as a copy from this Source
Here is a helpful three-part tutorial:
- Read About Version Control & the excellent Intro to Git
- Install Git for the command line. See the information below.
- Do the Try Git interactive tutorial. It basically runs you through using Git on the command line and with Github.
This information below contains recommended resources for learning Git and Github, which we will use this semester to store, manage and share our projects.

GitHub is a web-based hosting service for software development projects that use the Git revision control system. GitHub offers free accounts for open source projects. As of May 2011, GitHub was the most popular open source code repository site. The site provides social networking functionality such as feeds, followers and the network graph to display how developers work on their versions of a repository. [Wikipedia]
Installing Git
Mac OSX
- Git can be installed in Xcode via installing the Command Line Tools at Preferences->Downloads->Components
- You can also install Git via the download from the git website or through package management tools such as Homebrew and Macports
Windows
- Install Git for Windows which includes a Unix-like Bash terminal environment that matches the commands in the Try Git tutorial.
- If you're familiar with the Win/DOS Command shell but are new to Bash, check out this DOS - Bash command comparison
Linux
- Install git through your distro's package management system
Configure Git
- Set you username and email address (only need to do this once).
-
$ git config --global user.name "YOUR_FULL_NAME" +$ git config --global user.email "YOUR_EMAIL_ADDRESS" - Turn on git colors with makes reading status and diffs much easier (only need to do this once). You shouldn't need to do this if you're using the Git Bash installed by Git for Windows.
-
$ git config --global color.ui true
Useful Command Line Commands
The following are pulled form the excellent Introduction to Git. Bash/Shell A small list of the bread and butter Bash/Shell/Terminal commands. Some of these commands respond to the"-h" or "--help" options which print out a small usage reference. Many of the simple commands (ls, cp, mv) don't respond to "--help" but will simply print out a usage line when they don't understand the given arguments.
$ ls --helpAlso, most have manual pages which can be reached by using the "man" command and then the program name. Here's how to open the manual page for ls:
$ man lsUse the UP & DOWN arrow keys to scroll and 'q' to quit.
- ls - list contents of the current dir
- cd - change directory; ~/ refers to your home dir, . refers to the current dir, ../ refers to one directory up, ../../ refers to 2 dirs up, etc
- pwd - prints full path to the current dir (where we are)
- mkdir - make a new dir
- touch - create an empty file or update the timestamp on an existing file
- mv - move a file or dir
- cp - copy a file or folder; the -R option copies files & folders recursively (need to copy the entire contents of a given folder if it als contains folders)
Git This is just a small list of git commands. See the references below for more detailed info. All of the git commands respond to "--help".
- git init - initialize a dir for git source control management
- git clone - clone a git repository from another location (another git controlled folder, somewhere online, GIthub, etc)
- git checkout - switch to a branch, commit, or tag; the base location is the master branch
- git status - print status of the staging area (modified files, current branch, etc)
- git add - add a file or folder to the staging area, responds to wildcards like *.txt and . which refers to all modified files (careful with this one!)
- git rm - remove a file or folder form the staging area, removing a modfied file may require the -f argument to force it, -r adds files recursively (useful within folders).
- git mv - move or rename files or folders, only works for files currently managed by git (aka added previously)
- git commit -m "some message" - commit the current staging area (adds, modifications, removals); the -m option specifies the log message
- git branch some_branch - creates a branch called "some_branch"; don;t forget to switch to it using git checkout!
- git merge some_branch - merge a branch into the current branch, in this case merge "some_branch" with "master"
References
Books & Tutorials
- Try Git online course by Code School + Github. (thx @codeSchool)
- Pro Git book by Scott Chacon (free PDF). (thx @hilarymason)
- Interactive Tutorial by Code School. (thx @maxhawkins, @raunaqgupta)
Client Apps:
- SourceTree (thx @smallfly)
- Tower app for Mac OSX ($30 for students). (thx @pitaru)
- Github for Mac
- Git-Friendly shell scripts by Jamie Wilkinson. (thx @jamiew)
Videos:
- Github Learning Series Video Tutorials. (thx @julianoliver)
- Github's official YouTube channel. (thx @matthewmccull)
- Getting Git video by Scott Chacon. (thx @richbate)
- Mastering Git Basics by Tom Preston-Werner. (thx @maxhawkins)
- Code Journal Part 1 by James Paterson. (thx @joshuadavis)
- GitCasts. (thx @bgstaal)
Web Sites/Pages:
- Official Git Reference.
- Github Official Teaching Materials. (thx @matthewmccull)
- Github Setup Bootcamp.
- Getting Started with Git by Git-SCM. (thx @julianoliver)
- Introduction to Git & Git Workflow for Beginners by Steve Klise. (thx @atduskgreg)
- A Visual Git Reference by Mark Lodato. (thx @moskovich)
- The openFrameworks Git Workflow by the OF community. (thx @zachlieberman)
- Git - The Simple Guide by Roger Dudler. (thx @lennyjpg)
- How to Learn Git (Link Roundup) by Kevin Suttle. (thx @kevinSuttle)
- A Successful Git Branching Model by @nvie. (thx @smallfly)
Cheat Sheets:
- Zach Lieberman's Cheatsheet. (thx @zachlieberman)
- Git Cheatsheet by Andrew Peterson/NDP Software. (thx @julienbayle)
- Git Developer Cheatsheet (PDF) by Salesforce.com. (thx @julienbayle)