-
一种美妙的函数处理方式
-
以哈诺塔为例子:
- 声明函数HANOI(检查处理几个饼,int X;从1柱子,char A;经过2柱子,char B;到3柱子,char C)
- HANOI=(A→B,x=1;or 递归 )
- 递归中:X-1个饼A到B (HANOI),A到C,X-1个饼B到C
-
先调用,后返回(记住了调用的地址,能够准确返回)
-
编译器可能会将其优化,变成循环的逻辑(伪递归)
- add 将值排到队列最后
- pop 将队列头调出
- pop 将队列尾调出
- 用先进后出的模式
- if(strcmp(button,"+")==0) 判断键入是否是符号
- button需要是一个字符串类型
- 主义char【】格式默认尾巴有个0
- 长度赋予2
- atoi 函数: aoti(char a), 会将a中数字提取出,返回一个int类型的整数
- 逆波兰原理:来数字扔到队伍最后,来符号处理队伍最后两个数字,来等于号输出队列第一个数字
结构体指针:指向结构体的具体地址
节点:用结构体实现:
struct node{ int data; //数据 struct node* next; //指向下一个节点的指针(在结构体中引用指向自身类型结构的结构指针) };
节点的推进:
while(p->next!=NULL){ p=p->next; }
//会令过渡指针p指向链表中的最后一个节点
节点的创建(以在末节点为例)
p->next = intput;//p已经指向原来的末节点;让intpu和前者连上 intput->next= NULL;//让intput指向后者
基本原理无非如此。
*神经网络
15*15:每一格用两位代表状态
给每一种选择打分:四连极高,三连很高,边际降为0
C程序由以下要素组成(底层原理):
- 预处理器指令:#include<stdio.h>
- 函数:int main()[主函数],void add(int a, int b),printf……
- 变量:int a,char b,int*a
- 语句 & 表达式:函数与变量的组合
- 注释://…… /* …… */
无非就这些吗?
C 程序由各种令牌组成,令牌可以是关键字、标识符、常量、字符串值,或者是一个符号。
-
分号:在 C 程序中,分号是语句结束符。也就是说,每个语句必须以分号结束。它表明一个逻辑实体的结束
-
注释:C 标识符是用来标识变量、函数,或任何其他用户自定义项目的名称。
- 一个标识符以字母 A-Z 或 a-z 或下划线 _ 开始,后跟零个或多个字母、下划线和数字(0-9)。
- C 标识符内不允许出现标点字符,比如 @、$ 和 %。
- C 是区分大小写的编程语言。
-
关键字:关键字不能作为常量名、变量名或其他标识符名称。
-
C 中的空格:只包含空格的行,被称为空白行,可能带有注释,C 编译器会完全忽略它。
- 在 C 中,空格用于描述空白符、制表符、换行符和注释。
- 空格分隔语句的各个部分,让编译器能识别语句中的某个元素(比如 int)在哪里结束,下一个元素在哪里开始。
- 为了增强可读性,可以根据需要适当增加一些空格。
- **基本类型:**它们是算术类型,包括两种类型:整数类型和浮点类型
- **枚举类型:**它们也是算术类型,被用来定义在程序中只能赋予其一定的离散整数值的变量。(常量)
- **void 类型:**类型说明符 void 表明没有可用的值。
- **派生类型:**它们包括:指针类型、数组类型、结构类型、共用体类型和函数类型。
| 类型 | 存储大小 | 值范围 |
|---|---|---|
| char | 1 字节 | -128 到 127 或 0 到 255 |
| unsigned char | 1 字节 | 0 到 255 |
| signed char | 1 字节 | -128 到 127 |
| int | 2 或 4 字节 | -32,768 到 32,767 或 -2,147,483,648 到 2,147,483,647 |
| unsigned int | 2 或 4 字节 | 0 到 65,535 或 0 到 4,294,967,295 |
| short | 2 字节 | -32,768 到 32,767 |
| unsigned short | 2 字节 | 0 到 65,535 |
| long | 4 字节 | -2,147,483,648 到 2,147,483,647 |
| unsigned long | 4 字节 | 0 到 4,294,967,295 |
- 为了得到某个类型或某个变量在特定平台上的准确大小,可以使用 sizeof 运算符。
- ⭐表达式 sizeof(type) 得到对象或类型的存储字节大小。
下表列出了关于标准浮点类型的存储大小、值范围和精度的细节:
| 类型 | 存储大小 | 值范围 | 精度 |
|---|---|---|---|
| float | 4 字节 | 1.2E-38 到 3.4E+38 | 6 位小数 |
| double | 8 字节 | 2.3E-308 到 1.7E+308 | 15 位小数 |
| long double | 16 字节 | 3.4E-4932 到 1.1E+4932 | 19 位小数 |
void 类型指定没有可用的值。它通常用于以下三种情况下:
| 序号 | 类型与描述 |
|---|---|
| 1 | 函数返回为空 C 中有各种函数都不返回值,或者您可以说它们返回空。不返回值的函数的返回类型为空。例如 void exit (int status); |
| 2 | 函数参数为空 C 中有各种函数不接受任何参数。不带参数的函数可以接受一个 void。例如 int rand(void); |
| 3 | 指针指向 void 类型为 void * 的指针代表对象的地址,而不是类型。例如,内存分配函数 void *malloc( size_t size ); 返回指向 void 的指针,可以转换为任何数据类型。 |
- ⭐如果现在您还是无法完全理解 void 类型,不用太担心,在后续的章节中我们将会详细讲解这些概念。
-
⭐ **变量其实只不过是程序可操作的存储区的名称。**存储区域!存储区域!存储区域!
- C 中每个变量都有特定的类型,类型决定了变量存储的大小和布局,该范围内的值都可以存储在内存中。
- 运算符可应用于变量上。
-
变量的名称可以由字母、数字和下划线字符组成。它必须以字母或下划线开头。
| 类型 | 描述 |
|---|---|
| char | 通常是一个字节(八位), 这是一个整数类型。 |
| int | 整型,4 个字节,取值范围 -2147483648 到 2147483647。 |
| float | 单精度浮点值。单精度是这样的格式,1位符号,8位指数,23位小数。 |
| double | 双精度浮点值。双精度是1位符号,11位指数,52位小数。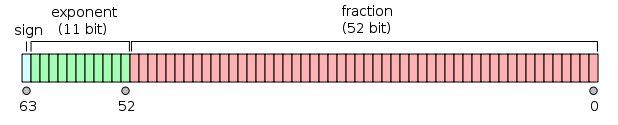 |
| void | 表示类型的缺失。 |
- 不带初始化的定义:带有静态存储持续时间的变量会被隐式初始化为 NULL(所有字节的值都是 0),其他所有变量的初始值是未定义的。
变量声明向编译器保证变量(”声明“的作用)以指定的类型和名称存在,这样编译器在不需要知道变量完整细节的情况下也能继续进一步的编译。变量声明只在编译时有它的意义,在程序连接时编译器需要实际的变量声明。
变量的声明有两种情况:
- 1、一种是需要建立存储空间的。例如:int a 在声明的时候就已经建立了存储空间。
- 2、另一种是不需要建立存储空间的,通过使用extern关键字声明变量名而不定义它。 例如:extern int a 其中变量 a 可以在别的文件中定义的。
- 除非有extern关键字,否则都是变量的定义。
C 中有两种类型的表达式:
-
**左值(lvalue):**指向内存位置的表达式被称为左值(lvalue)表达式。左值可以出现在赋值号的左边或右边。
-
**右值(rvalue):**术语右值(rvalue)指的是存储在内存中某些地址的数值。右值是不能对其进行赋值的表达式,也就是说,右值可以出现在赋值号的右边,但不能出现在赋值号的左边。
常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量。
常量可以是任何的基本数据类型,比如整数常量、浮点常量、字符常量,或字符串字面值,也有枚举常量。
常量就像是常规的变量,只不过常量的值在定义后不能进行修改。
整数常量可以是十进制、八进制或十六进制的常量。前缀指定基数:
- 0x 或 0X 表示十六进制
- 0 表示八进制
- 不带前缀则默认表示十进制。
整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。
浮点常量由整数部分、小数点、小数部分和指数部分组成。可以使用小数形式或者指数形式来表示浮点常量。
当使用小数形式表示时,必须包含整数部分、小数部分,或同时包含两者。
当使用指数形式表示时, 必须包含小数点、指数,或同时包含两者。带符号的指数是用 e 或 E 引入的。
字符常量是括在单引号中,例如,'x' 可以存储在 char 类型的简单变量中。
字符常量可以是一个普通的字符(例如 'x')、一个转义序列(例如 '\t'),或一个通用的字符(例如 '\u02C0')。
⭐在 C 中,有一些特定的字符,当它们前面有反斜杠时,它们就具有特殊的含义
| 转义序列 | 含义 |
|---|---|
| \ | \ 字符 |
| ' | ' 字符 |
| " | " 字符 |
| ? | ? 字符 |
| \a | 警报铃声 |
| \b | 退格键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ooo | 一到三位的八进制数 |
| \xhh . . . | 一个或多个数字的十六进制数 |
字符串字面值或常量是括在双引号 "" 中的。
一个字符串包含类似于字符常量的字符:普通的字符、转义序列和通用的字符。
您可以使用空格做分隔符,把一个很长的字符串常量进行分行。
在 C 中,有两种简单的定义常量的方式:
- 使用 #define 预处理器。define identifier value;
- 使用 const 关键字。const type variable = value;
存储类定义 C 程序中变量/函数的范围(可见性)和生命周期。这些说明符放置在它们所修饰的类型之前。下面列出 C 程序中可用的存储类:
- 所有局部变量默认的存储类
- 存储在寄存器中而不是 RAM 中的局部变量。这意味着变量的最大尺寸等于寄存器的大小(通常是一个词),且不能对它应用一元的 '&' 运算符(因为它没有内存位置)。
- 寄存器只用于需要快速访问的变量,比如计数器。还应注意的是,定义 'register' 并不意味着变量将被存储在寄存器中,它意味着变量可能存储在寄存器中,这取决于硬件和实现的限制。
-
static 存储类指示编译器在程序的生命周期内保持局部变量的存在,而不需要在每次它进入和离开作用域时进行创建和销毁。因此,使用 static 修饰局部变量可以在函数调用之间保持局部变量的值。
-
void func1(void) {
static int thingy=5;
thingy++;
}
-
在上述例子中,thingy只会初始化一次,也就是说每次thingy++后的thingy++值都会被保留,不会因为函数再次被调用而被初始化
- extern 存储类用于提供一个全局变量的引用,全局变量对所有的程序文件都是可见的。对于无法初始化的变量,会把变量名指向一个之前定义过的存储位置。
- 可以在其他文件中使用 extern 来得到已定义的变量或函数的引用。可以这么理解,extern 是用来在另一个文件中声明一个全局变量或函数。
运算符是一种告诉编译器执行特定的数学或逻辑操作的符号。C 语言内提供了以下类型的运算符:
假设A=10,B=20
| / | 分子除以分母 | B / A 将得到 2 |
|---|---|---|
| % | 取模运算符,整除后的余数 | B % A 将得到 0 |
| ++ | 自增运算符,整数值增加 1 | A++ 将得到 11 |
| -- | 自减运算符,整数值减少 1 | A-- 将得到 9 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 检查两个操作数的值是否相等,如果相等则条件为真。 | (A == B) 为假。 |
| != | 检查两个操作数的值是否相等,如果不相等则条件为真。 | (A != B) 为真。 |
| > | 检查左操作数的值是否大于右操作数的值,如果是则条件为真。 | (A > B) 为假。 |
| < | 检查左操作数的值是否小于右操作数的值,如果是则条件为真。 | (A < B) 为真。 |
| >= | 检查左操作数的值是否大于或等于右操作数的值,如果是则条件为真。 | (A >= B) 为假。 |
| <= | 检查左操作数的值是否小于或等于右操作数的值,如果是则条件为真。 | (A <= B) 为真。 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 称为逻辑与运算符。如果两个操作数都非零,则条件为真。 | (1&& 0) 为假。 |
| || | 称为逻辑或运算符。如果两个操作数中有任意一个非零,则条件为真。 | (1 || 0) 为真。 |
| ! | 称为逻辑非运算符。用来逆转操作数的逻辑状态。如果条件为真则逻辑非运算符将使其为假。 | !(1 && 0) 为真。 |
位运算符作用于位,并逐位执行操作。&、 | 和 ^ 的真值表如下所示:
| p | q | p & q | p | q | p ^ q |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 |
| 1 | 0 | 0 | 1 | 1 |
| ~ | 取反运算符,按二进制位进行"取反"运算。运算规则:~1=-2; ~0=1; |
(~A ) 将得到 -61,即为 1100 0011,一个有符号二进制数的补码形式。 |
|---|---|---|
| << | 二进制左移运算符。将一个运算对象的各二进制位全部左移若干位(左边的二进制位丢弃,右边补0)。 | A << 2 将得到 240,即为 1111 0000 |
| >> | 二进制右移运算符。将一个数的各二进制位全部右移若干位,正数左补0,负数左补1,右边丢弃。 | A >> 2 将得到 15,即为 0000 1111 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,把右边操作数的值赋给左边操作数 | C = A + B 将把 A + B 的值赋给 C |
| += | 加且赋值运算符,把右边操作数加上左边操作数的结果赋值给左边操作数 | C += A 相当于 C = C + A |
| -= | 减且赋值运算符,把左边操作数减去右边操作数的结果赋值给左边操作数 | C -= A 相当于 C = C - A |
| *= | 乘且赋值运算符,把右边操作数乘以左边操作数的结果赋值给左边操作数 | C *= A 相当于 C = C * A |
| /= | 除且赋值运算符,把左边操作数除以右边操作数的结果赋值给左边操作数 | C /= A 相当于 C = C / A |
| %= | 求模且赋值运算符,求两个操作数的模赋值给左边操作数 | C %= A 相当于 C = C % A |
| <<= | 左移且赋值运算符 | C <<= 2 等同于 C = C << 2 |
| >>= | 右移且赋值运算符 | C >>= 2 等同于 C = C >> 2 |
| &= | 按位与且赋值运算符 | C &= 2 等同于 C = C & 2 |
| ^= | 按位异或且赋值运算符 | C ^= 2 等同于 C = C ^ 2 |
| |= | 按位或且赋值运算符 | C |= 2 等同于 C = C | 2 |
| 运算符 | 描述 | 实例 |
|---|---|---|
| sizeof() | 返回变量的大小。 | sizeof(a) 将返回 4,其中 a 是整数。 |
| & | 返回变量的地址。 | &a; 将给出变量的实际地址。 |
| * | 指向一个变量。 | *a; 将指向一个变量。 |
| ? : | 条件表达式 | 如果条件为真 ? 则值为 X : 否则值为 Y |
- 我们已经在前面的章节中讲解了 条件运算符 ? :,可以用来替代 if...else 语句。它的一般形式如下:
Exp1 ? Exp2 : Exp3;
-
其中,Exp1、Exp2 和 Exp3 是表达式。请注意,冒号的使用和位置。
-
? 表达式的值是由 Exp1 决定的。
-
如果 Exp1 为真,则计算 Exp2 的值,结果即为整个表达式的值。如果 Exp1 为假,则计算 Exp3 的值,结果即为整个表达式的值。
switch(表达式)
{
case 常量表达式1:语句1;//若不加break,则会继续运行case 2
case 常量表达式2:语句2;
...
default:语句n+1;
}
与 if 语句的不同:if 语句中若判断为真则只执行这个判断后的语句,执行完就跳出 if 语句,不会执行其他 if 语句;而 switch 语句不会在执行判断为真后的语句之后跳出循环,而是继续执行后面所有 case 语句。在每一 case 语句之后增加 break 语句,使每一次执行之后均可跳出 switch 语句,从而避免输出不应有的结果。
-
内敛函数
-
将函数拷贝到位置使用
-
逻辑与普通函数一致
-
加在函数声明前
- 上帝编程:先想一个函数干嘛的,取名字,再编写内部逻辑
- 取名清楚,代码清晰,编写轻松
int * p
-
一个指针,指向p的地址
-
=&x 初始化符号,令其指向x
-
*p: 简引用,取他指向的东西
-
p++:让指针指的东西指向下一个(改变p,改变指向的地址)
-
不允许指针+指针(没有意义)
-
指针减指针:有点意义,意味着他们隔多少
-
p1 == p2: 指向同一个东西
-
p1 = p2:令他们指向一个东西
-
数组↔指针
-
动态分配:int * a = (int *) malloc (100 * sizeof(int) );
- 借了要还:free(a)
- 记得重看网课
-
野指针:很危险 free完的指针
- 在free后接一个a = NULL
-
scope / lifetime
-
变量在哪些函数中作用/变量在那些时间中作用
-
全局变量:数据段
-
编译器的工作原理
-
预处理阶段
-
词法与语法分析阶段
-
编译阶段
首先编译成纯汇编语句,再将之汇编成跟CPU相关的二进制码,生成各个目标文件 (.obj文件)
- 连接阶段
将各个目标文件中的各段代码进行绝对地址定位,生成跟特定平台相关的可执行文件,当然,最后还可以用objcopy生成纯二进制码,也就是去掉了文件格式信息。(生成.exe文件)
-
-
编译器在编译时是以C文件为单位进行的
-
连接器是以目标文件为单位,它将一个或多个目标文件进行函数与变量的重定位,生成最终的可执行文件,在PC上的程序开发,一般都有一个main函数,这是各个编译器的约定
(main .c文件 目标文件 可执行文件)
#include <stdio.h>
#include "mytest.h"
int main(int argc,char **argv)
{
test = 25;
printf("test.................%d\n",test);
}
mytest.h头文件内容如下:
int test;
-
预处理阶段:编译器以C文件作为一个单元,首先读这个C文件,发现第一句与第二句是包含一个头文件,就会在所有搜索路径中寻找这两个文件,找到之后,就会将相应头文件中再去处理宏,变量,函数声明,嵌套的头文件包含等,检测依赖关系,进行宏替换,看是否有重复定义与声明的情况发生,最后将那些文件中所有的东东全部扫描。
-
2.编译阶段,在上一步中相当于将那个头文件中的test变量扫描进了一个中间C文件,那么test变量就变成了这个文件中的一个全局变量,此时就将所有这个中间C文件的所有变量,函数分配空间,将各个函数编译成二进制码,按照特定目标文件格式生成目标文件,在这种格式的目标文件中进行各个全局变量,函数的符号描述,将这些二进制码按照一定的标准组织成一个目标文件
-
连接阶段,将上一步成生的各个目标文件,根据一些参数,连接生成最终的可执行文件,主要的工作就是重定位各个目标文件的函数,变量等,相当于将个目标文件中的二进制码按一定的规范合到一个文件中再回到C文件与头文件各写什么内容的话题上:理论上来说C文件与头文件里的内容,只要是C语言所支持的,无论写什么都可以的,比如你在头文件中写函数体,只要在任何一个C文件包含此头文件就可以将这个函数编译成目标文件的一部分(编译是以C文件为单位的,如果不在任何C文件中包含此头文件的话,这段代码就形同虚设),你可以在C文件中进行函数声明,变量声明,结构体声明,这也不成问题!!!那为何一定要分成头文件与C文件呢?又为何一般都在头件中进行函数,变量声明,宏声明,结构体声明呢?而在C文件中去进行变量定义,函数实现呢??原因如下:
- 如果在头文件中实现一个函数体,那么如果在多个C文件中引用它,而且又同时编译多个C文件,将其生成的目标文件连接成一个可执行文件,在每个引用此头文件的C文件所生成的目标文件中,都有一份这个函数的代码,如果这段函数又没有定义成局部函数,那么在连接时,就会发现多个相同的函数,就会报错
- 如果在头文件中定义全局变量,并且将此全局变量赋初值,那么在多个引用此头文件的C文件中同样存在相同变量名的拷贝,关键是此变量被赋了初值,所以编译器就会将此变量放入DATA段,最终在连接阶段,会在DATA段中存在多个相同的变量,它无法将这些变量统一成一个变量,也就是仅为此变量分配一个空间,而不是多份空间,假定这个变量在头文件没有赋初值,编译器就会将之放入 BSS段,连接器会对BSS段的多个同名变量仅分配一个存储空间
- 如果在C文件中声明宏,结构体,函数等,那么我要在另一个C文件中引用相应的宏,结构体,就必须再做一次重复的工作,如果我改了一个C文件中的一个声明,那么又忘了改其它C文件中的声明,这不就出了大问题了,程序的逻辑就变成了你不可想象的了,如果把这些公共的东东放在一个头文件中,想用它的C文件就只需要引用一个就OK了!!!这样岂不方便,要改某个声明的时候,只需要动一下头文件就行了(实际情况下我们会自包含)
- 在头文件中声明结构体,函数等,当你需要将你的代码封装成一个库,让别人来用你的代码,你又不想公布源码,那么人家如何利用你的库呢?也就是如何利用你的库中的各个函数呢??一种方法是公布源码,别人想怎么用就怎么用,另一种是提供头文件,别人从头文件中看你的函数原型,这样人家才知道如何调用你写的函数,就如同你调用printf函数一样,里面的参数是怎样的??你是怎么知道的??还不是看人家的头文件中的相关声明啊!!!当然这些东东都成了C标准,就算不看人家的头文件,你一样可以知道怎么使用
-
.h文件是头文件,内含函数声明、宏定义、结构体定义等内容
-
c文件是程序文件,内含函数实现,变量定义等内容
-
main函数为标准C/C++的程序入口,编译器会先找到该函数所在的文件。
-
include的过程完全可以"看成"是一个文件拼接的过程,将声明和实现分别写在头文件及C文件中,或者将二者同时写在头文件中,理论上没有本质的区别。
对于静态方式,基本所有的C/C++编译器都支持一种链接方式被称为Static Link,即所谓静态链接。
在这种方式下,我们所要做的,就是写出包含函数,类等等声明的头文件(a.h,b.h,...),以及他们对应的实现文件(a.cpp,b.cpp,...),编译程序会将其编译为静态的库文件(a.lib,b.lib,...)。在随后的代码重用过程中,我们只需要提供相应的头文件(.h)和相应的库文件(.lib),就可以使用过去的代码了。
相对动态方式而言,静态方式的好处是实现代码的隐蔽性,即C++中提倡的"接口对外,实现代码不可见"。有利于库文件的转发.