- Lab 1
- Access cluster
- Install Knox
- Security w/o kerberos
- Lab 2
- Review use case
- AD overview
- Configure Name Resolution & AD Certificate
- Setup Access to Active Directory Server
- Lab 3: Ambari Server Security
- Enable Active Directory Authentication for Ambari
- Ambari server as non-root
- Ambari Encrypt Database and LDAP Passwords
- SSL For Ambari server
- Lab 4: Kerberos
- Kerborize cluster
- Setup AD/Operating System Integration using SSSD - AD KDC
- Kerberos for Ambari Views
- SPNEGO
- Lab 5
- Ranger install pre-reqs
- Ranger install
- Lab 6a
- Ranger KMS install
- Add a KMS on another node
- Lab 6b
- HDFS encryption exercises
- Move Hive warehouse to EZ
- Lab 7a
- Secured Hadoop exercises
- HDFS
- Hive
- HBase
- Sqoop
- Drop Encrypted Hive table
- Secured Hadoop exercises
- Lab 7b - Do Not Use
- Tag-Based Policies (Atlas+Ranger Integration)
- Tag-Based Access Control
- Attribute-Based Access Control
- Tag-Based Masking
- Location-Based Access Control
- Time-Based Policies
- Policy Evaluation and Precedence
- Tag-Based Policies (Atlas+Ranger Integration)
- Lab 8
- Configure Knox to authenticate via AD
- Utilize Knox to Connect to Hadoop Cluster Services
- WebHDFS
- Hive
Credentials will be provided for these services by the instructor:
- SSH
- Ambari
-
Right click to download this ppk key > Save link as > save to Downloads folder
-
Use putty to connect to your node using the ppk key:
- Connection > SSH > Auth > Private key for authentication > Browse... > Select training-keypair.ppk
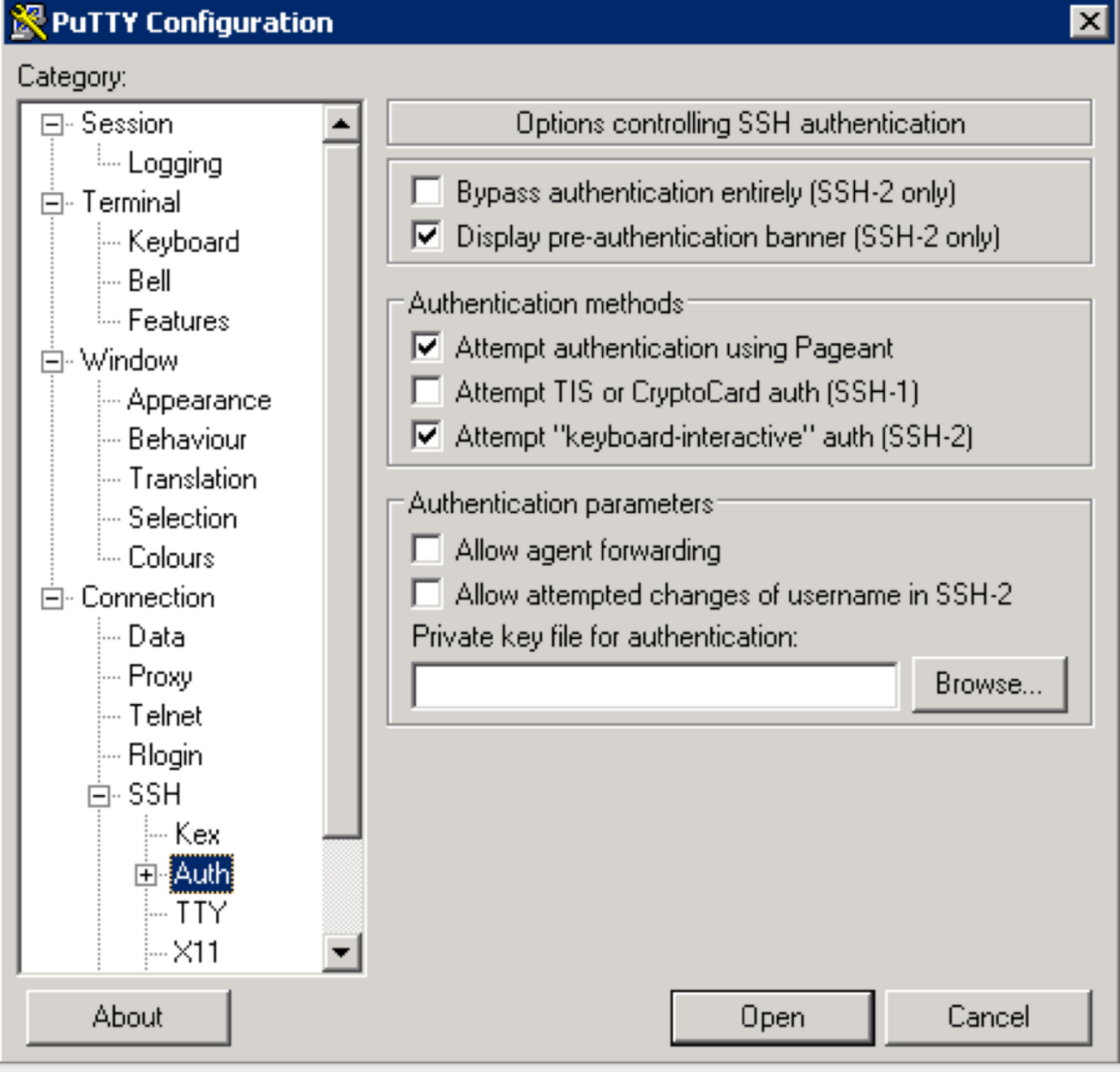
- Connection > SSH > Auth > Private key for authentication > Browse... > Select training-keypair.ppk
-
Make sure to click "Save" on the session page before logging in
-
When connecting, it will prompt you for username. Enter
centos
- SSH into Ambari node of your cluster using below steps:
- Right click to download this pem key > Save link as > save to Downloads folder
- Copy pem key to ~/.ssh dir and correct permissions
cp ~/Downloads/training-keypair.pem ~/.ssh/ chmod 400 ~/.ssh/training-keypair.pem - Login to the Ambari node of the cluster you have been assigned by replacing IP_ADDRESS_OF_AMBARI_NODE below with Ambari node IP Address (your instructor will provide this)
ssh -i ~/.ssh/training-keypair.pem centos@IP_ADDRESS_OF_AMBARI_NODE
- To change user to root you can:
sudo su -
-
Similarly login via SSH to each of the other nodes in your cluster as you will need to run commands on each node in a future lab
-
Tip: Since in the next labs you will be required to run the same set of commands on each of the cluster hosts, now would be a good time to setup your favorite tool to do so: examples here
- On OSX, an easy way to do this is to use iTerm: open multiple tabs/splits and then use 'Broadcast input' feature (under Shell -> Broadcast input)
- If you are not already familiar with such a tool, you can also just run the commands on the cluster, one host at a time
-
Login to Ambari web UI by opening http://AMBARI_PUBLIC_IP:8080 and log in with admin/BadPass#1
-
You will see a list of Hadoop components running on your cluster on the left side of the page
- They should all show green (ie started) status. If not, start them by Ambari via 'Service Actions' menu for that service
-
Following are useful techniques you can use in future labs to find your cluster specific details:
- From SSH terminal, how can I find the cluster name?
#run on ambari node to fetch cluster name via Ambari API PASSWORD=BadPass#1 output=`curl -u admin:$PASSWORD -i -H 'X-Requested-By: ambari' http://localhost:8080/api/v1/clusters` cluster=`echo $output | sed -n 's/.*"cluster_name" : "\([^\"]*\)".*/\1/p'` echo $cluster- From SSH terminal, how can I find internal hostname (aka FQDN) of the node I'm logged into?
$ hostname -f ip-172-30-0-186.us-west-2.compute.internal- From SSH terminal, how can I to find external hostname of the node I'm logged into?
$ curl icanhazptr.com ec2-52-33-248-70.us-west-2.compute.amazonaws.com- From SSH terminal, how can I to find external (public) IP of the node I'm logged into?
$ curl icanhazip.com 54.68.246.157-
From Ambari how do I check the cluster name?
- It is displayed on the top left of the Ambari dashboard, next to the Ambari logo. If the name appears truncated, you can hover over it to produce a helptext dialog with the full name

- It is displayed on the top left of the Ambari dashboard, next to the Ambari logo. If the name appears truncated, you can hover over it to produce a helptext dialog with the full name
-
From Ambari how can I find external hostname of node where a component (e.g. Resource Manager or Hive) is installed?
- Click the parent service (e.g. YARN) and hover over the name of the component. The external hostname will appear.
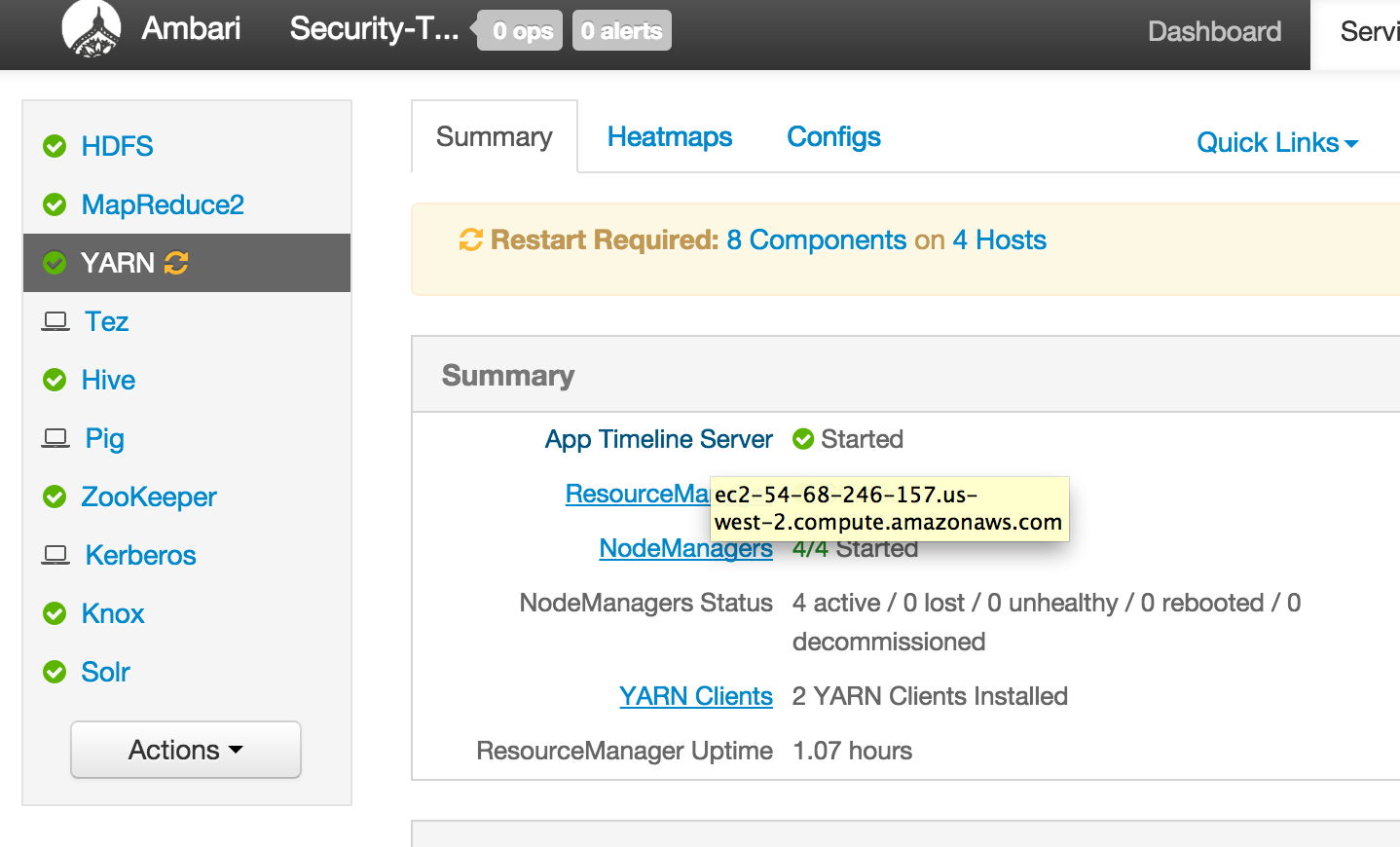
- Click the parent service (e.g. YARN) and hover over the name of the component. The external hostname will appear.
-
From Ambari how can I find internal hostname of node where a component (e.g. Resource Manager or Hive) is installed?
- Click the parent service (e.g. YARN) and click on the name of the component. It will take you to hosts page of that node and display the internal hostname on the top.
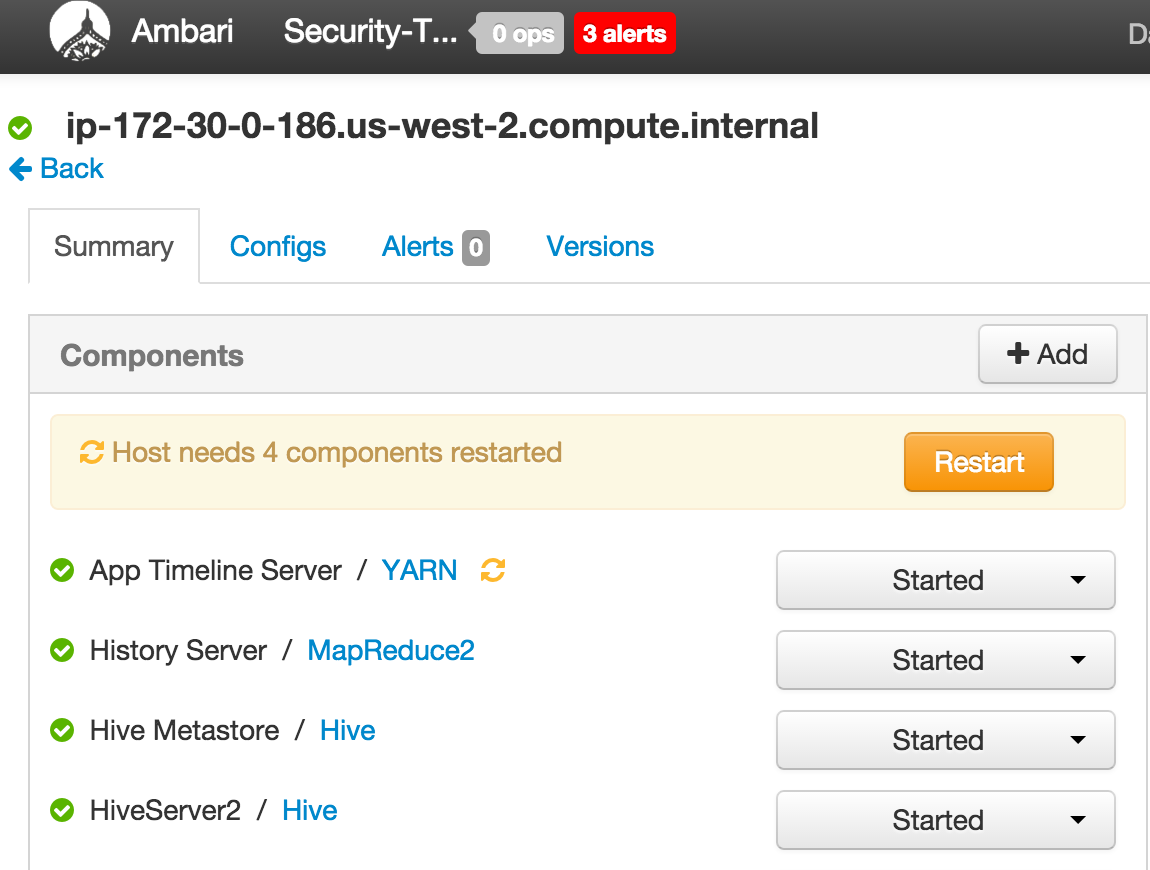
- Click the parent service (e.g. YARN) and click on the name of the component. It will take you to hosts page of that node and display the internal hostname on the top.
-
In future labs you may need to provide private or public hostname of nodes running a particular component (e.g. YARN RM or Mysql or HiveServer)
-
Run below on the node where HiveServer2 is installed to download data and import it into a Hive table for later labs
- You can either find the node using Ambari as outlined in Lab 1
- Download and import data
cd /tmp wget https://raw.githubusercontent.com/HortonworksUniversity/Security_Labs/master/labdata/sample_07.csv wget https://raw.githubusercontent.com/HortonworksUniversity/Security_Labs/master/labdata/sample_08.csv- Create user dir for admin, sales1 and hr1
sudo -u hdfs hdfs dfs -mkdir /user/admin sudo -u hdfs hdfs dfs -chown admin:hadoop /user/admin sudo -u hdfs hdfs dfs -mkdir /user/sales1 sudo -u hdfs hdfs dfs -chown sales1:hadoop /user/sales1 sudo -u hdfs hdfs dfs -mkdir /user/hr1 sudo -u hdfs hdfs dfs -chown hr1:hadoop /user/hr1- Now create Hive table in default database by
- Start beeline shell from the node where Hive is installed:
beeline -n admin -u "jdbc:hive2://localhost:10000/default"
- At beeline prompt, run below:
CREATE TABLE `sample_07` (
`code` string ,
`description` string ,
`total_emp` int ,
`salary` int )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TextFile;
load data local inpath '/tmp/sample_07.csv' into table sample_07;
CREATE TABLE `sample_08` (
`code` string ,
`description` string ,
`total_emp` int ,
`salary` int )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TextFile;
load data local inpath '/tmp/sample_08.csv' into table sample_08;
-
Notice that in the JDBC connect string for connecting to an unsecured Hive while its running in default (ie binary) transport mode :
- port is 10000
- no kerberos principal was needed
-
This will change after we:
- enable kerberos
- configure Hive for http transport mode (to go through Knox)
- On your unsecured cluster try to access a restricted dir in HDFS
hdfs dfs -ls /tmp/hive
## this should fail with Permission Denied
- Now try again after setting HADOOP_USER_NAME env var
export HADOOP_USER_NAME=hdfs
hdfs dfs -ls /tmp/hive
## this shows the file listing!
- Unset the env var and it will fail again
unset HADOOP_USER_NAME
hdfs dfs -ls /tmp/hive
- From node running NameNode, make a WebHDFS request using below command:
curl -sk -L "http://$(hostname -f):50070/webhdfs/v1/user/?op=LISTSTATUS"
- In the absence of Knox, notice it goes over HTTP (not HTTPS) on port 50070 and no credentials were needed
-
From Ambari notice you can open the WebUIs without any authentication
- HDFS > Quicklinks > NameNode UI
- Mapreduce > Quicklinks > JobHistory UI
- YARN > Quicklinks > ResourceManager UI
-
This should tell you why kerberos (and other security) is needed on Hadoop :)
-
Login to Ambari web UI by opening http://AMBARI_PUBLIC_IP:8080 and log in with admin/BadPass#1
-
Use the 'Add Service' Wizard (under 'Actions' dropdown, near bottom left of page) to install Knox on a node other than the one running Ambari
- Make sure not to install Knox on same node as Ambari (or if you must, change its port from 8443)
- Reason: in a later lab after we enable SSL for Ambari, it will run on port 8443
- When prompted for the
Knox Master Secret, set it toknox - Do not use password with special characters (like #, $ etc) here as seems beeline may have problem with it
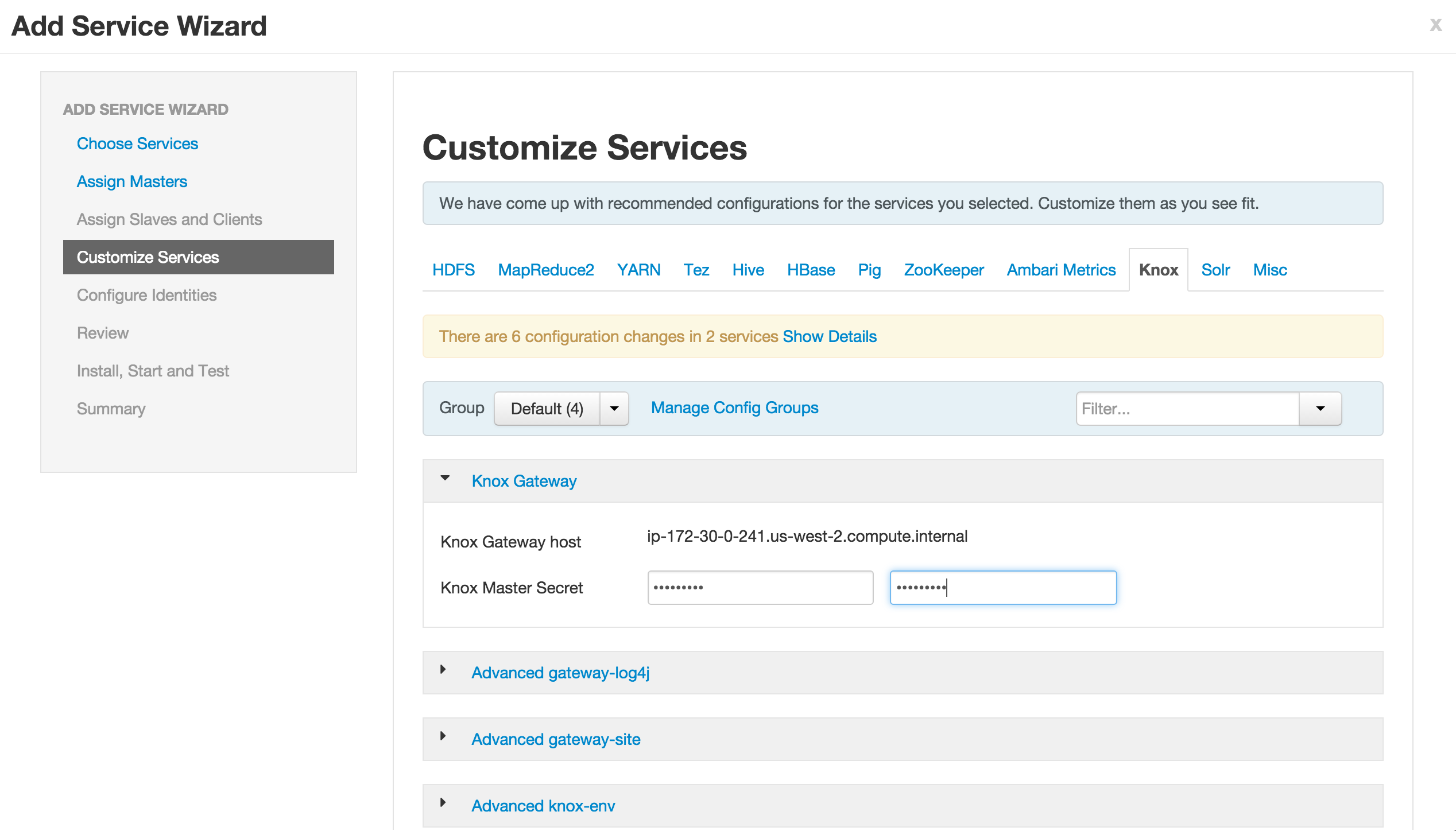
- Click Next > Proceed Anyway > Deploy to accept all defaults
- Make sure not to install Knox on same node as Ambari (or if you must, change its port from 8443)
-
We will use Knox further in a later exercise.
-
After the install completed, Ambari will show that a number of services need to be restarted. Ignore this for now, we will restart them at a later stage.
- Ensure Tez is installed on all nodes where Pig clients are installed. This is done to ensure Pig service checks do not fail later on.
- Ambari > Pig > click the 'Pig clients' link
- This tell us which nodes have Pig clients installed
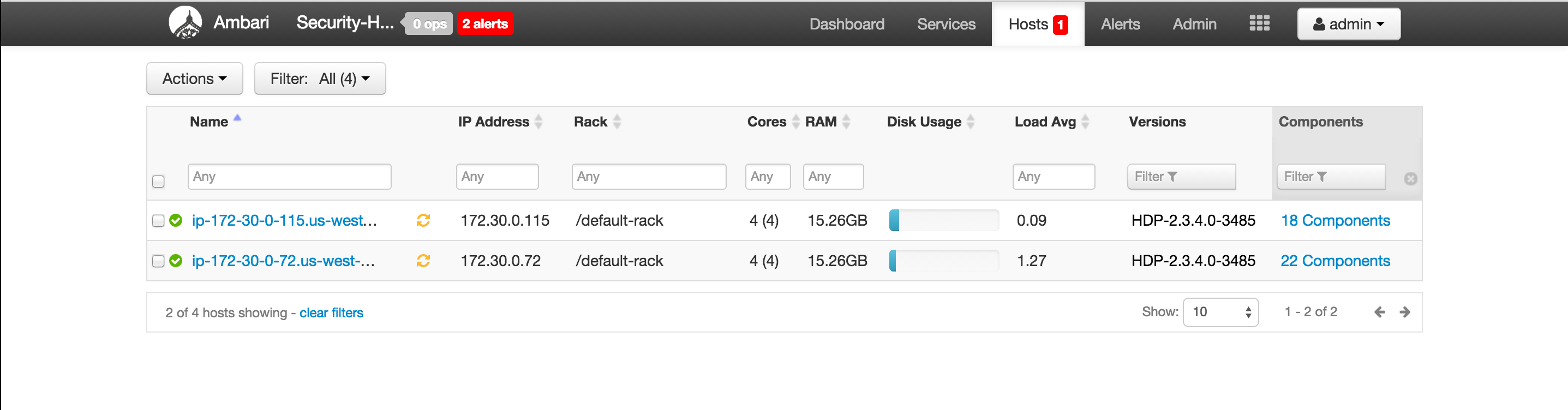
- For each node that has Pig installed:
- Click on the hyperlink of the node name to view that shows all the services running on that particular node
- Click '+Add' and select 'Tez client' > Confirm add
- If 'Tez client'does not appear in the list, it is already installed on this host, so you can skip this host
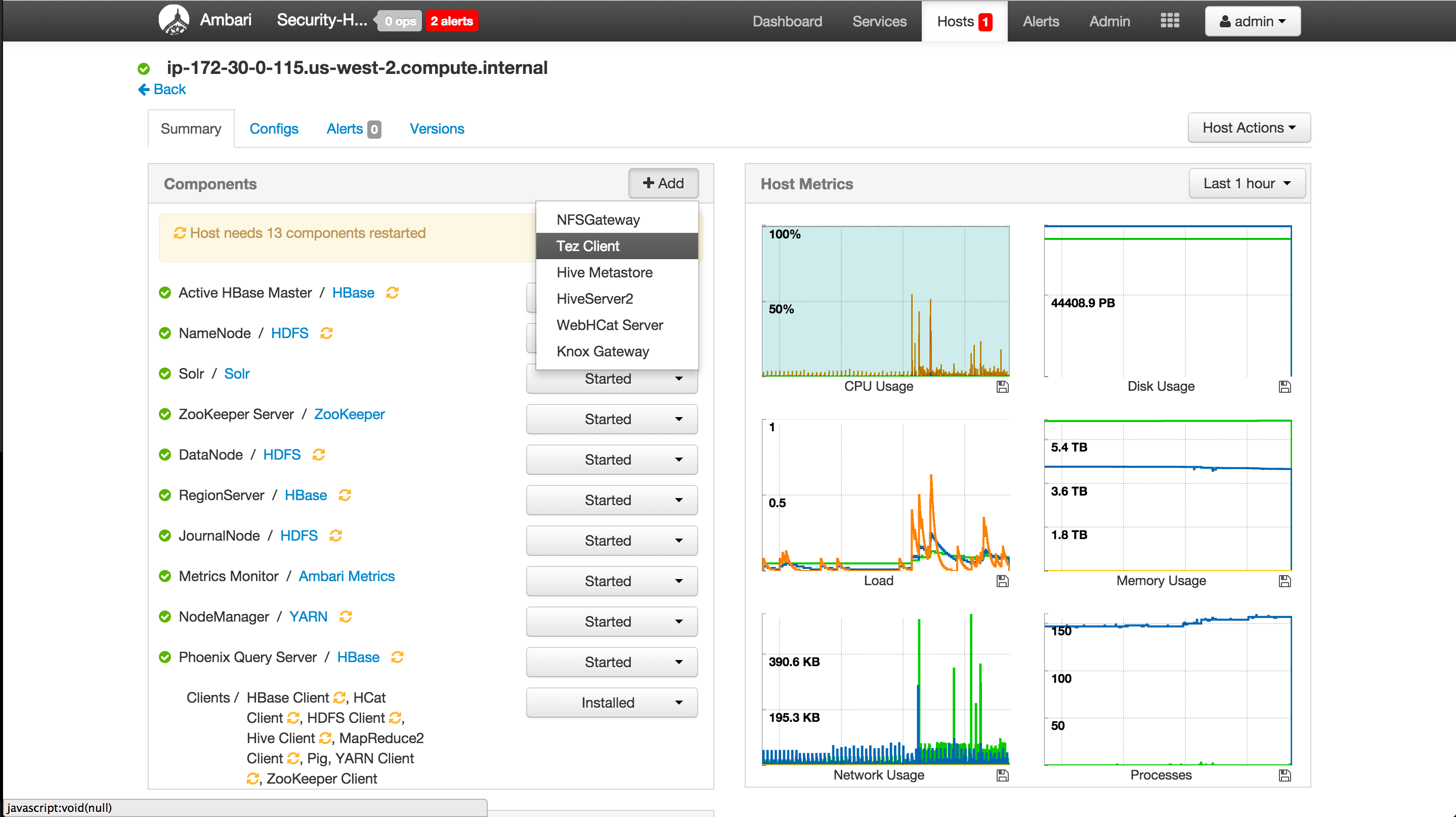
- If 'Tez client'does not appear in the list, it is already installed on this host, so you can skip this host
Use case: Customer has an existing cluster which they would like you to secure for them
-
Current setup:
- The customer has multiple organizational groups (i.e. sales, hr, legal) which contain business users (sales1, hr1, legal1 etc) and hadoopadmin
- These groups and users are defined in Active Directory (AD) under its own Organizational Unit (OU) called CorpUsers
- There are empty OUs created in AD to store hadoop principals/hadoop nodes (HadoopServices, HadoopNodes)
- Hadoopadmin user has administrative credentials with delegated control of "Create, delete, and manage user accounts" on above OUs
- Hadoop cluster running HDP has already been setup using Ambari (including HDFS, YARN, Hive, Hbase, Solr, Zookeeper)
-
Goals:
- Integrate Ambari with AD - so that hadoopadmin can administer the cluster
- Integrate Hadoop nodes OS with AD - so business users are recognized and can submit Hadoop jobs
- Enable kerberos using KDC - to secured the cluster and enable authentication
- Install Ranger and enable Hadoop plugins - to allow admin to setup authorization policies and review audits across Hadoop components
- Install Ranger KMS and enable HDFS encryption - to be able to create encryption zones
- Encrypt Hive backing dirs - to protect hive tables
- Configure Ranger policies to:
- Protect /sales HDFS dir - so only sales group has access to it
- Protect sales hive table - so only sales group has access to it
- Protect sales HBase table - so only sales group has access to it
- Install Knox and integrate with AD - for perimeter security and give clients access to APIs w/o dealing with kerberos
- Enable Ambari views to work on secured cluster
We will run through a series of labs and step by step, achieve all of the above goals
-
Active Directory will already be setup by the instructor. A basic structure of OrganizationalUnits will have been pre-created to look something like the below:
-
CorpUsers OU, which contains:
- business users and groups (e.g. it1, hr1, legal1) and
- hadoopadmin: Admin user (for AD, Ambari, ...)
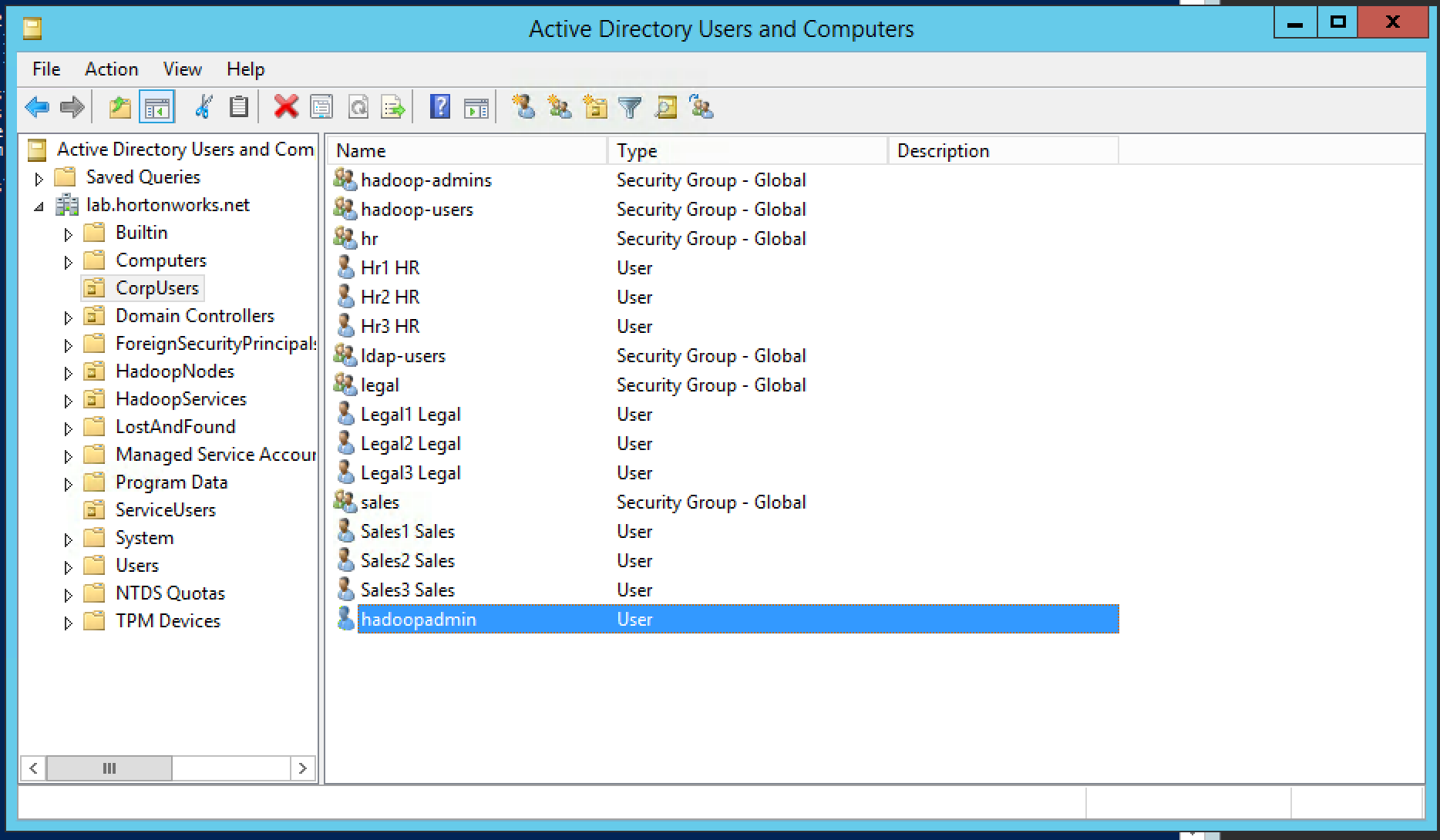
-
ServiceUsers OU: service users - that would not be created by Ambari (e.g. rangeradmin, ambari etc)
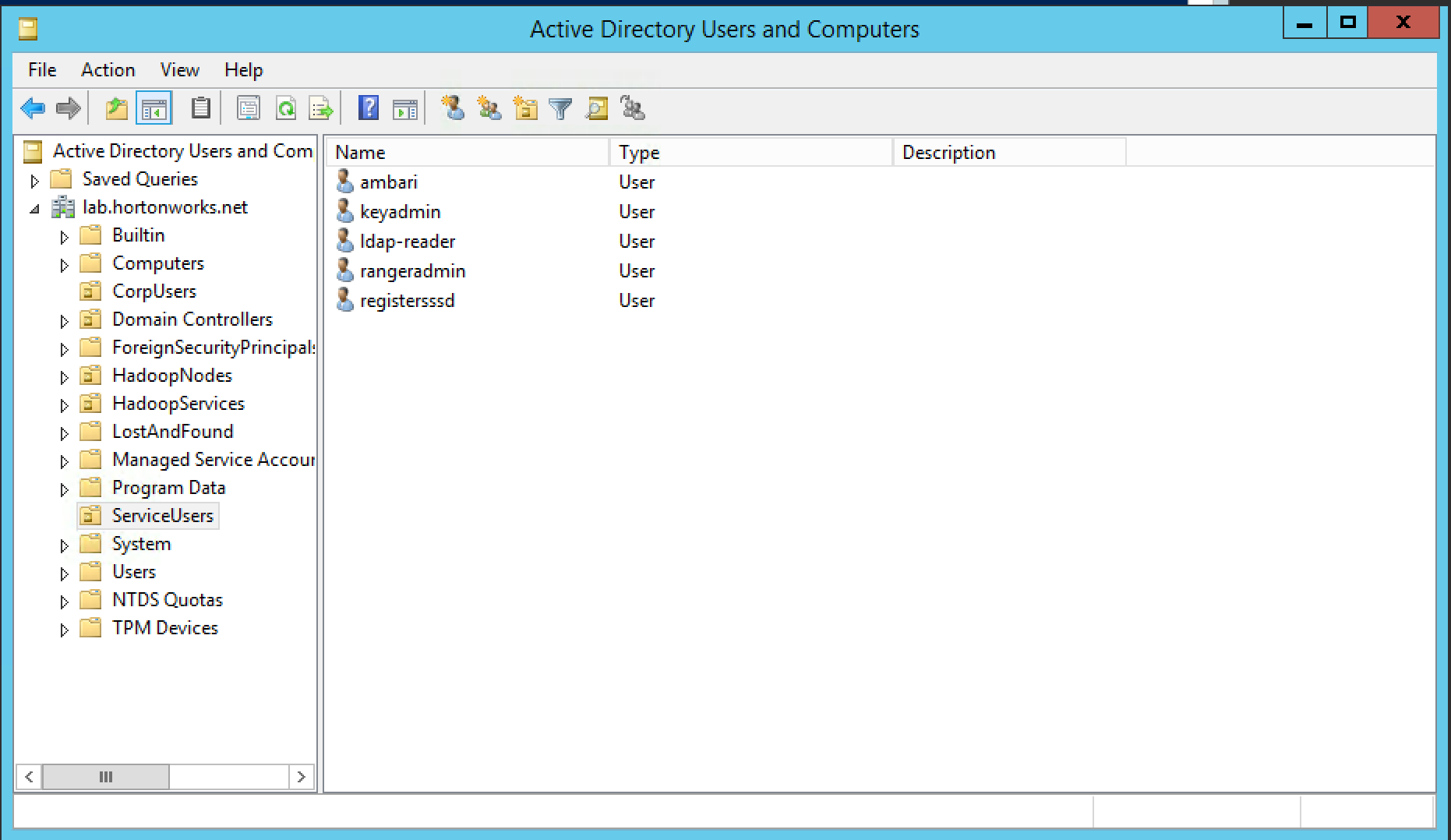
-
HadoopNodes OU: list of nodes registered with AD
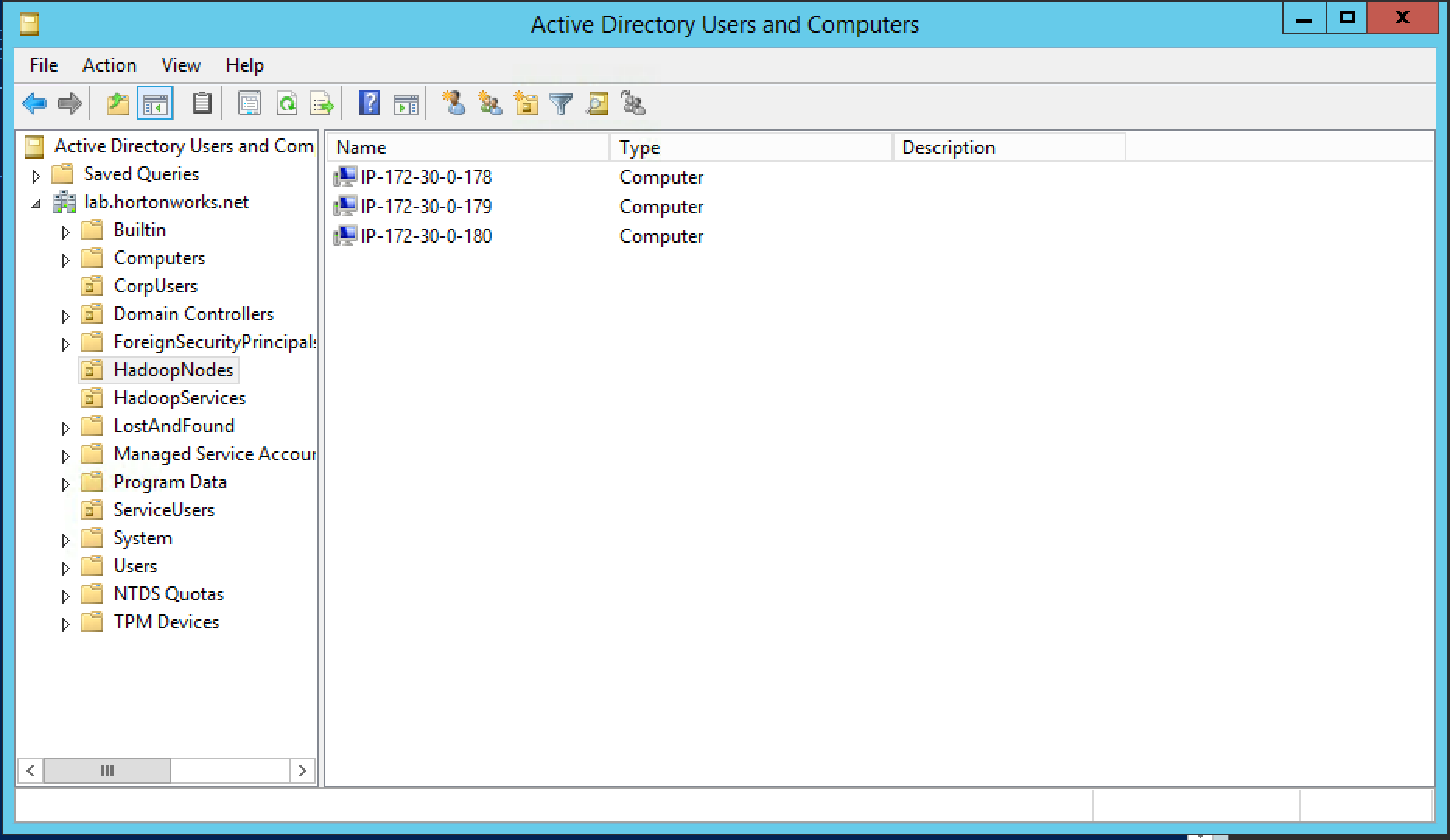
-
HadoopServices will be created in Ambari in KDC (not AD)
-
-
In addition, the below steps would have been completed in advance per doc:
- Ambari Server and cluster hosts have network access to, and be able to resolve the DNS names of, the MIT KDC and AD Domain Controllers.
-
For general info on Active Directory refer to Microsoft website here
-
MIT KDC will already be setup by the instructor using the steps in the documentation here
- Here is a screenshot of what the /etc/krb5.conf on the MIT KDC
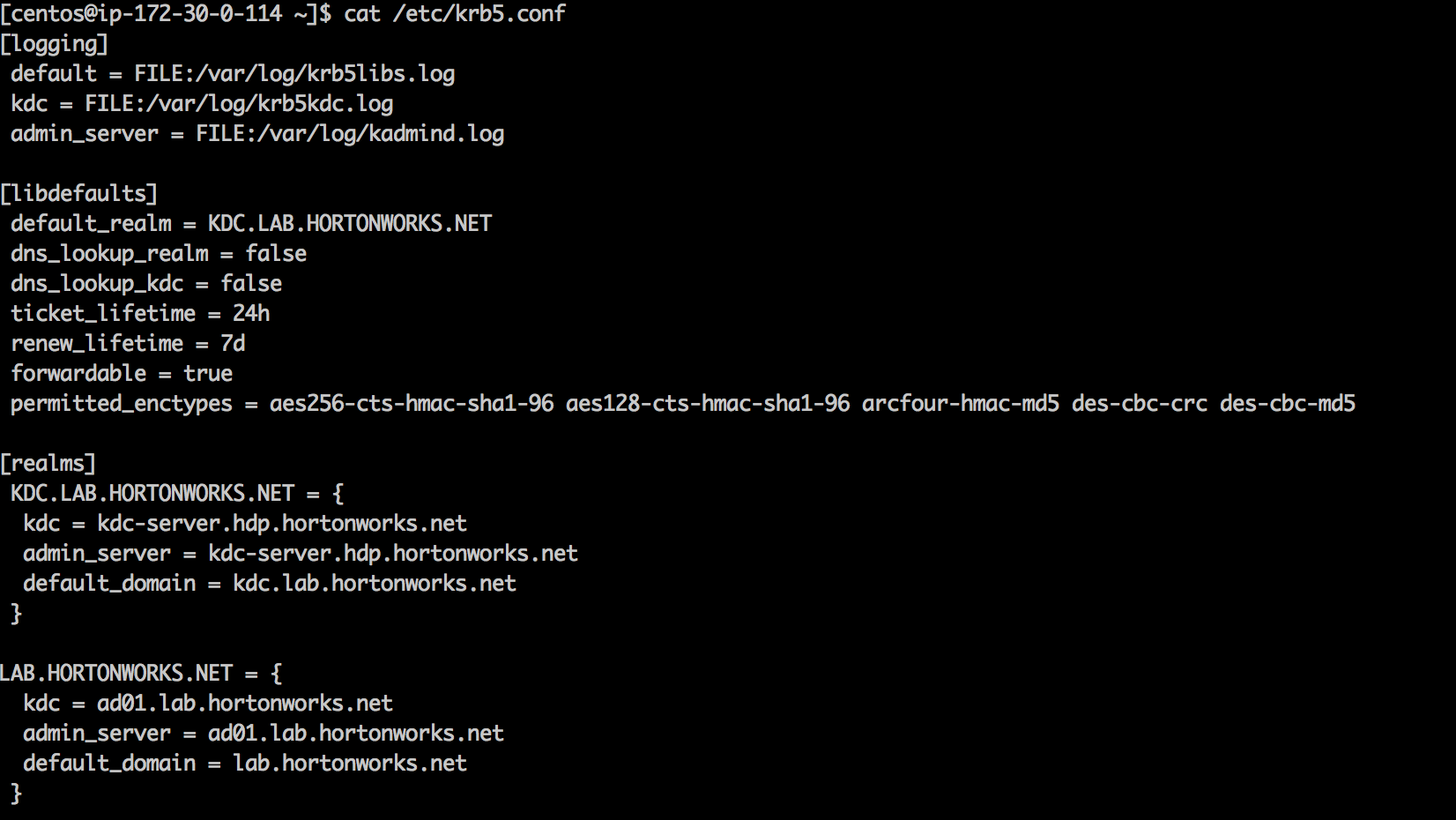
- Here is a screenshot of what the /etc/krb5.conf on the MIT KDC
-
A one way trust between KDC realm and Active Directory domain has already been created by the administrator. You can review the steps here
-
For general info on Kerberos, KDC, Principals, Keytabs, Realms etc see doc here
Run below on all nodes
- Add your Active Directory's internal IP to /etc/hosts (if not in DNS). Make sure you replace the IP address of your AD from your instructor below.
- Change the IP to match your ADs internal IP
ad_ip=GET_THE_AD_IP_FROM_YOUR_INSTRUCTOR
echo "${ad_ip} ad01.lab.hortonworks.net ad01" | sudo tee -a /etc/hosts
- Add your KDC's internal IP to /etc/hosts (if not in DNS). Make sure you replace the IP address of your KDC from your instructor below.
- Change the IP to match your KDCs internal IP
kdc_ip=GET_THE_KDC_IP_FROM_YOUR_INSTRUCTOR
echo "${kdc_ip} kdc-server.hdp.hortonworks.net kdc-server" | sudo tee -a /etc/hosts
Make sure to repeat the above steps on all nodes
Further documentation here
- Create a user for the Ambari Server if it does not exists
useradd -d /var/lib/ambari-server -G hadoop -M -r -s /sbin/nologin ambari
- Otherwise - Update the Ambari Server with the following
usermod -d /var/lib/ambari-server -G hadoop -s /sbin/nologin ambari
- Grant the user 'sudoers' rights. This is required for Ambari Server to create it's Kerberos keytabs. You can remove this after kerberizing the cluster
echo 'ambari ALL=(ALL) NOPASSWD:SETENV: /bin/mkdir, /bin/cp, /bin/chmod, /bin/rm, /bin/chown' > /etc/sudoers.d/ambari-server
-
Also confirm your sudoers file has correct defaults, as per https://docs.hortonworks.com/HDPDocuments/Ambari-2.5.0.3/bk_ambari-security/content/sudo_defaults_server.html
-
To setup Ambari server as non-root run below on Ambari-server node:
ambari-server setup
-
Then enter the below at the prompts:
- OK to continue? y
- Customize user account for ambari-server daemon? y
- Enter user account for ambari-server daemon (root):ambari
- Do you want to change Oracle JDK [y/n] (n)? n
- Enter advanced database configuration [y/n] (n)? n
-
Sample output:
# ambari-server setup
Using python /usr/bin/python2
Setup ambari-server
Checking SELinux...
SELinux status is 'enabled'
SELinux mode is 'permissive'
WARNING: SELinux is set to 'permissive' mode and temporarily disabled.
OK to continue [y/n] (y)? y
Customize user account for ambari-server daemon [y/n] (n)? y
Enter user account for ambari-server daemon (root):ambari
Adjusting ambari-server permissions and ownership...
Checking firewall status...
Redirecting to /bin/systemctl status iptables.service
Checking JDK...
Do you want to change Oracle JDK [y/n] (n)? n
Completing setup...
Configuring database...
Enter advanced database configuration [y/n] (n)? n
Configuring database...
Default properties detected. Using built-in database.
Configuring ambari database...
Checking PostgreSQL...
Configuring local database...
Connecting to local database...done.
Configuring PostgreSQL...
Backup for pg_hba found, reconfiguration not required
Extracting system views...
.......
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup' completed successfully.
- For now we will skip configuring Ambari Agents for Non-Root
-
Needed to allow Ambari to cache the admin password. Run below on Ambari-server node:
-
To encrypt password, run below
ambari-server stop
ambari-server setup-security
-
Then enter the below at the prompts:
- enter choice: 2
- provide master key: BadPass#1
- re-enter master key: BadPass#1
- do you want to persist? y
-
Then start ambari
ambari-server start
- Sample output
# ambari-server setup-security
Using python /usr/bin/python2
Security setup options...
===========================================================================
Choose one of the following options:
[1] Enable HTTPS for Ambari server.
[2] Encrypt passwords stored in ambari.properties file.
[3] Setup Ambari kerberos JAAS configuration.
[4] Setup truststore.
[5] Import certificate to truststore.
===========================================================================
Enter choice, (1-5): 2
Please provide master key for locking the credential store:
Re-enter master key:
Do you want to persist master key. If you choose not to persist, you need to provide the Master Key while starting the ambari server as an env variable named AMBARI_SECURITY_MASTER_KEY or the start will prompt for the master key. Persist [y/n] (y)? y
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup-security' completed successfully.
- Enables Ambari WebUI to run on HTTPS instead of HTTP
-
For this lab we will be generating a self-signed certificate. In production environments you would want to use a signed certificate (either from a public authority or your own CA).
-
Generate the certificate & key
openssl req -x509 -newkey rsa:4096 -keyout ambari.key -out ambari.crt -days 1000 -nodes -subj "/CN=$(curl icanhazptr.com)"
- Move & secure the certificate & key
chown ambari ambari.crt ambari.key
chmod 0400 ambari.crt ambari.key
mv ambari.crt /etc/pki/tls/certs/
mv ambari.key /etc/pki/tls/private/
- Stop Ambari server
ambari-server stop
- Setup HTTPS for Ambari
ambari-server setup-security
Using python /usr/bin/python2
Security setup options...
===========================================================================
Choose one of the following options:
[1] Enable HTTPS for Ambari server.
[2] Encrypt passwords stored in ambari.properties file.
[3] Setup Ambari kerberos JAAS configuration.
[4] Setup truststore.
[5] Import certificate to truststore.
===========================================================================
Enter choice, (1-5): 1
Do you want to configure HTTPS [y/n] (y)? y
SSL port [8443] ? 8443
Enter path to Certificate: /etc/pki/tls/certs/ambari.crt
Enter path to Private Key: /etc/pki/tls/private/ambari.key
Please enter password for Private Key: BadPass#1
Importing and saving Certificate...done.
Adjusting ambari-server permissions and ownership...
- Start Ambari
ambari-server start
-
Now you can access Ambari on HTTPS on port 8443 e.g. https://ec2-52-32-113-77.us-west-2.compute.amazonaws.com:8443
- If you were not able to access the Ambari UI, make sure you are trying to access https not http
-
Note that the browser will not trust the new self signed ambari certificate. You will need to trust that cert first.
- If Firefox, you can do this by clicking on 'i understand the risk' > 'Add Exception...'
- If Chome, you can do this by clicking on 'Advanced' > 'Proceed to xxxxxx'
- If Firefox, you can do this by clicking on 'i understand the risk' > 'Add Exception...'
Run below on only Ambari node:
- Trust the ambari certificate on Ambari host
sudo keytool -import -trustcacerts -keystore /etc/pki/java/cacerts -storepass changeit -noprompt -alias ambari -file /etc/pki/tls/certs/ambari.crt
-
Recently Redhat changed default behaviour for checking SSL certificates (see here for more details). To get around this there are 2 options:
- Option 1: Modify the
SERVER_API_HOST = '127.0.0.1'line in Ambari's serverUtils.py toSERVER_API_HOST = 'yourpublichost.domain.com'. The hostname should match the CN entry used when the Ambari crt was generated a few steps ago
- Option 1: Modify the
vi /usr/lib/python2.6/site-packages/ambari_server/serverUtils.py
- Option 2: Set below to just disable python HTTPS verification before running LDAP sync
export PYTHONHTTPSVERIFY=0
- This puts our AD-specific settings into variables for use in the following command
ad_host="ad01.lab.hortonworks.net"
ad_root="ou=CorpUsers,dc=lab,dc=hortonworks,dc=net"
ad_user="cn=ldap-reader,ou=ServiceUsers,dc=lab,dc=hortonworks,dc=net"
-
Execute the following to configure Ambari to sync with LDAP.
-
Use the default password used throughout this course.
ambari-server setup-ldap \ --ldap-url=${ad_host}:389 \ --ldap-secondary-url= \ --ldap-ssl=false \ --ldap-base-dn=${ad_root} \ --ldap-manager-dn=${ad_user} \ --ldap-bind-anonym=false \ --ldap-dn=distinguishedName \ --ldap-member-attr=member \ --ldap-group-attr=cn \ --ldap-group-class=group \ --ldap-user-class=user \ --ldap-user-attr=sAMAccountName \ --ldap-save-settings \ --ldap-bind-anonym=false \ --ldap-referral=
-
Restart Ambari server
ambari-server restart -
Run LDAPsync to sync only the groups we want
- When prompted for user/password, use the local Ambari admin credentials (i.e. admin/BadPass#1)
echo hadoop-users,hr,sales,legal,hadoop-admins > groups.txt ambari-server sync-ldap --groups groups.txt- This should show a summary of what objects were created

-
Give 'hadoop-admin' admin permissions in Ambari to allow the user to manage the cluster
- Login to Ambari as your local 'admin' user (i.e. admin/BadPass#1)
- Grant 'hadoopadmin' user permissions to manage the cluster:
- Click the dropdown on top right of Ambari UI
- Click 'Manage Ambari'
- Under 'Users', select 'hadoopadmin'
- Change 'Ambari Admin' to Yes
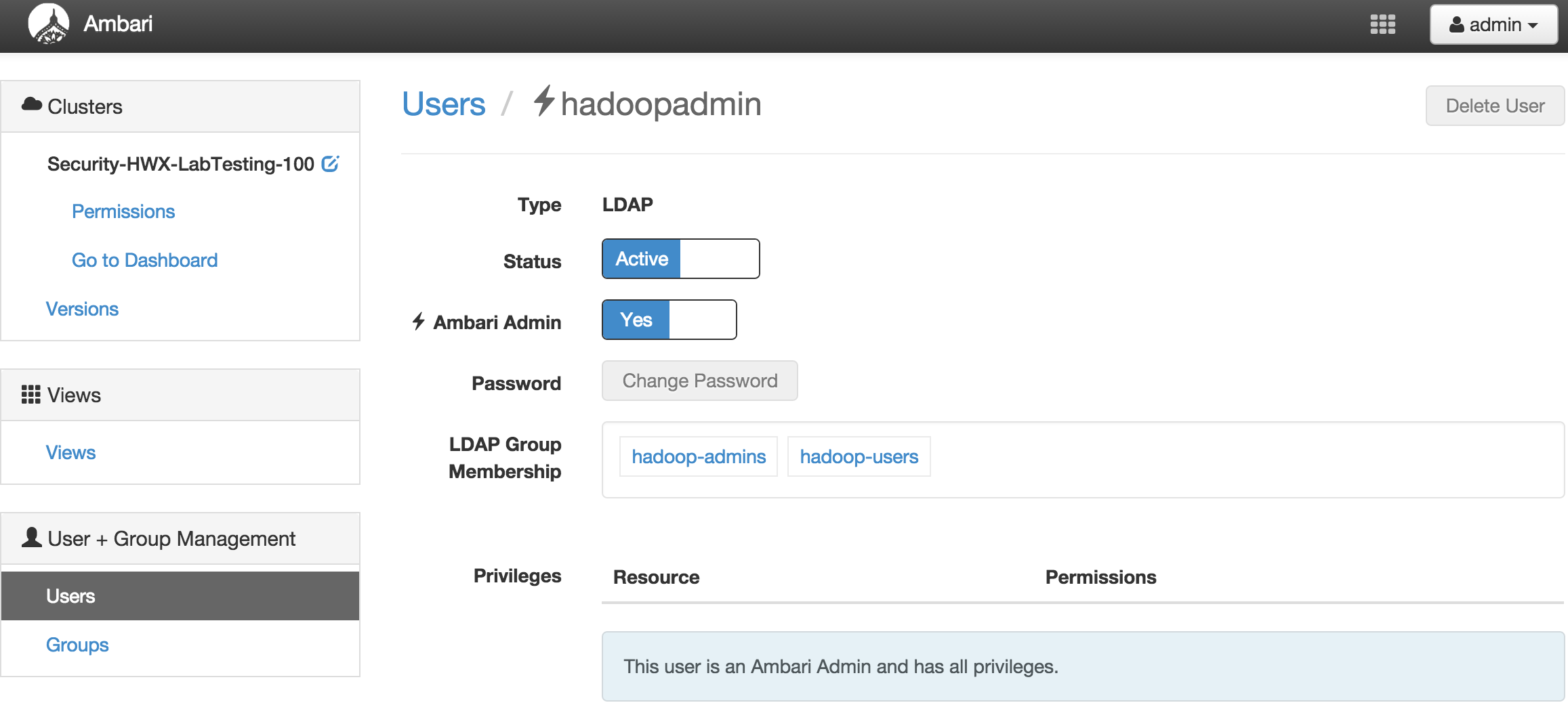
-
Sign out and then log back into Ambari, this time as 'hadoopadmin' and verify the user has rights to monitor/manage the cluster
-
(optional) Disable local 'admin' user using the same 'Manage Ambari' menu


Ambari views setup on secure cluster will be covered in later lab so we will skip this for now (here)
-
Enable kerberos using Ambari security wizard (under 'Admin' tab > Kerberos > Enable kerberos > proceed).
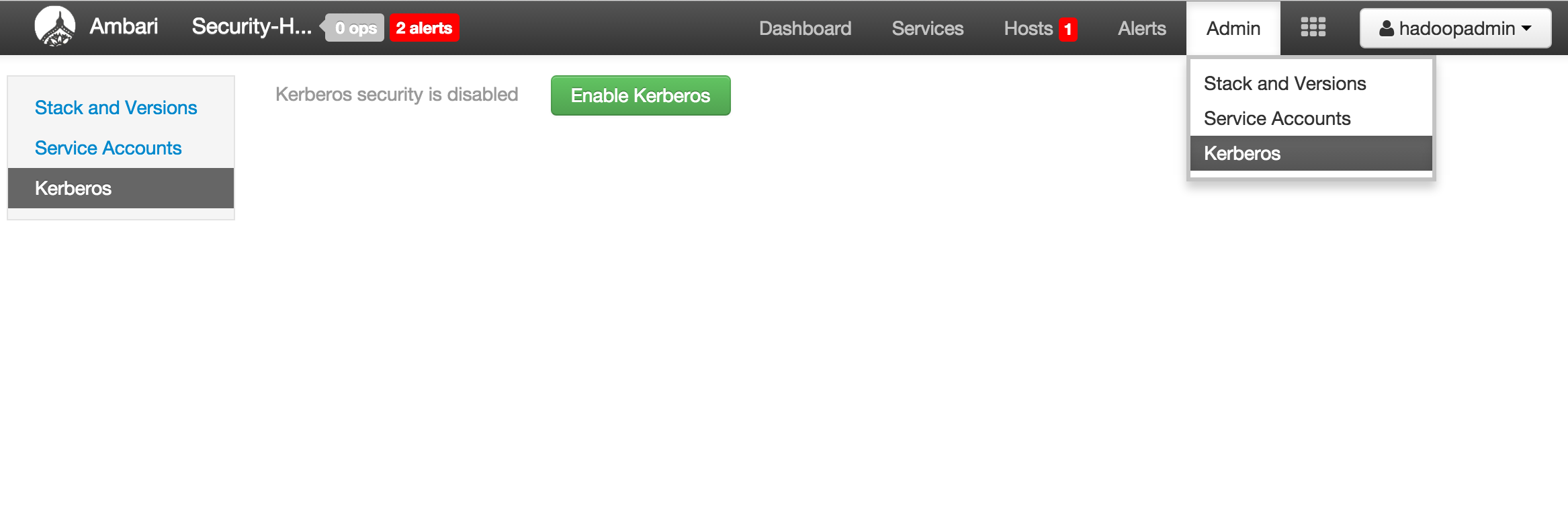
-
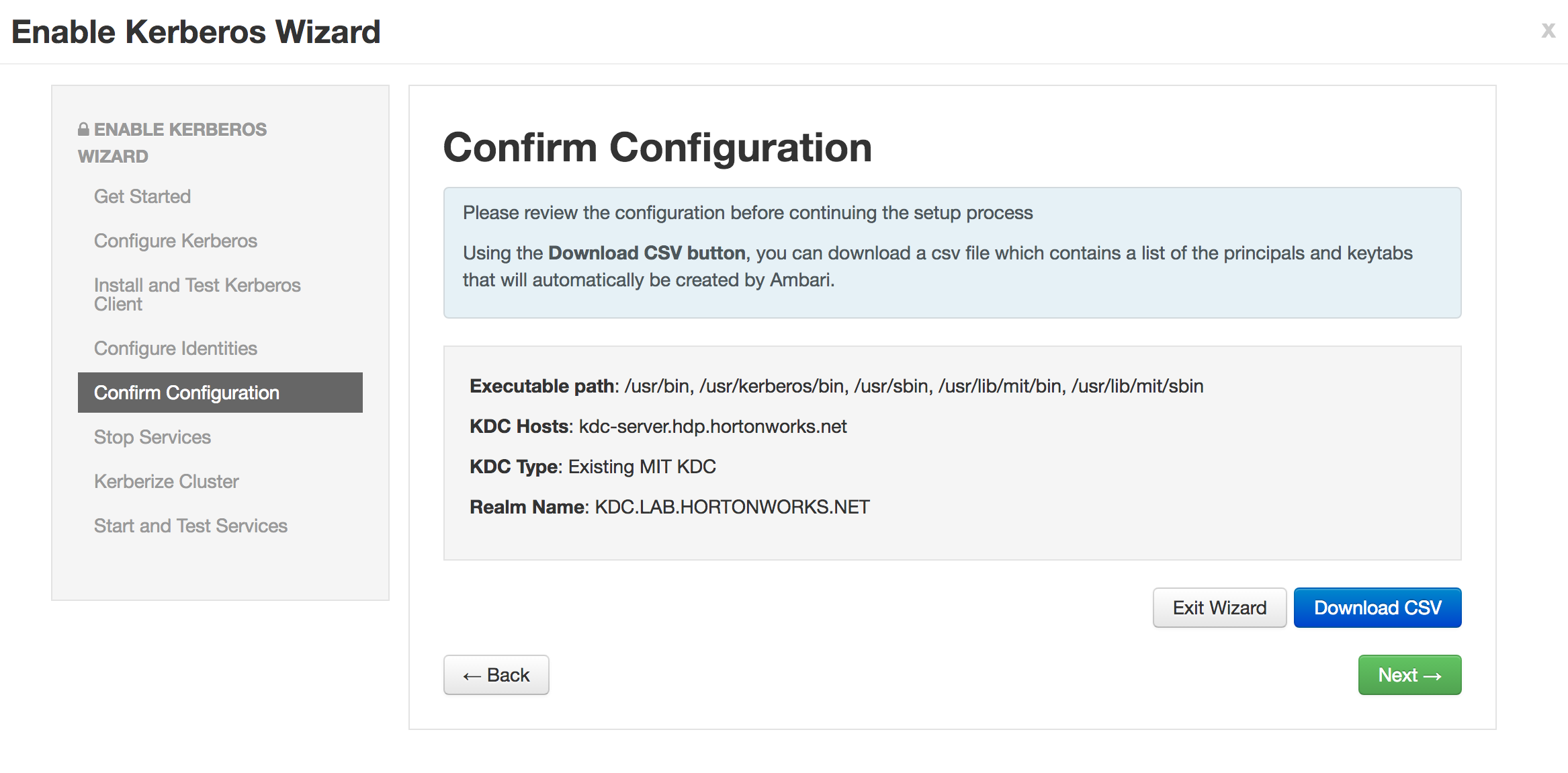
Select "Existing MIT KDC" and check all the boxes
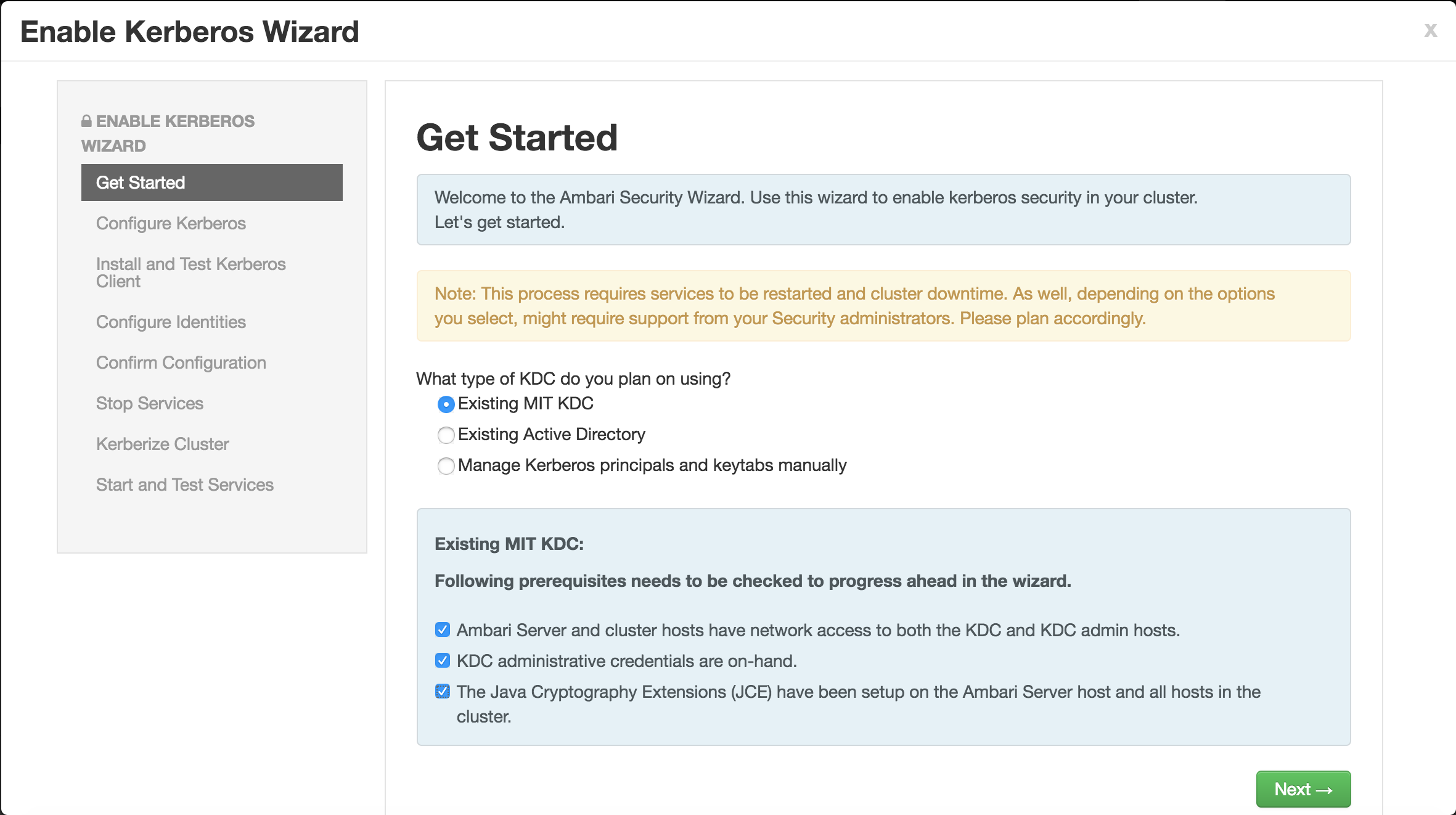
-
Enter the below details:
-
KDC:
- KDC hosts:
kdc-server.hdp.hortonworks.net - Realm name:
KDC.LAB.HORTONWORKS.NET - Domains:
us-west-2.compute.internal,.us-west-2.compute.internal
- KDC hosts:
-
Kadmin:
- Kadmin host:
kdc-server.hdp.hortonworks.net - Admin principal:
admin/[email protected] - Admin password:
BadPass#1
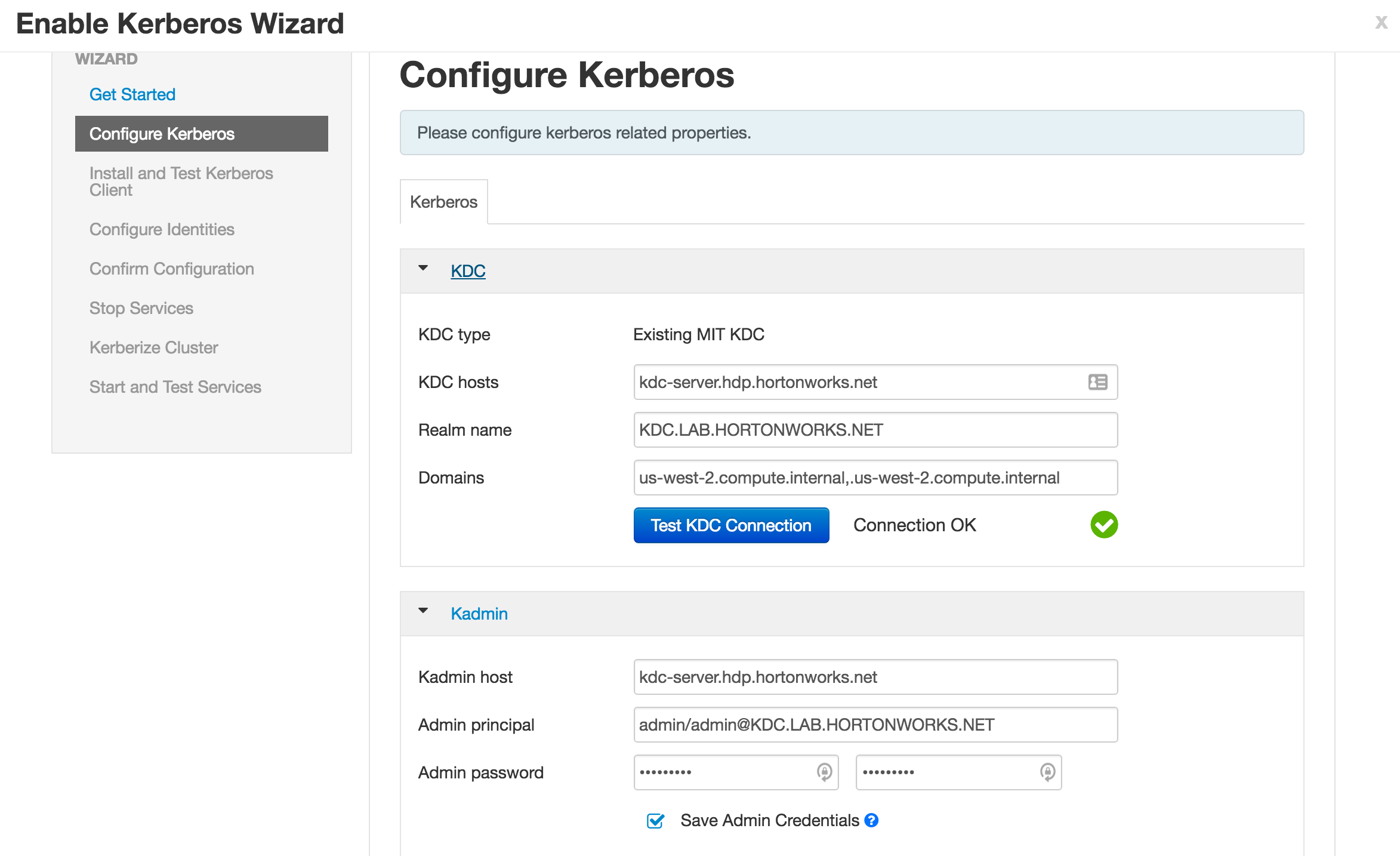
- Notice that the "Save admin credentials" checkbox is available, clicking the check box will save the "admin principal".
- Sometimes the "Test Connection" button may fail (usually related to AWS issues), but if you previously ran the "Configure name resolution & certificate to Active Directory" steps on all nodes, you can proceed.
- Kadmin host:
-
As part of the security wizard, Ambari will also create krb5.conf files on all cluster hosts. Since we are doing one way trust with AD, we need to update the krb5.conf template to include the AD domain entry show below
LAB.HORTONWORKS.NET = {
kdc = ad01.lab.hortonworks.net
admin_server = ad01.lab.hortonworks.net
default_domain = lab.hortonworks.net
}
-
Scroll down to 'Advanced krb5-conf template' and scroll down to bottom of the text box. Then paste the entry for the Active Dirctory
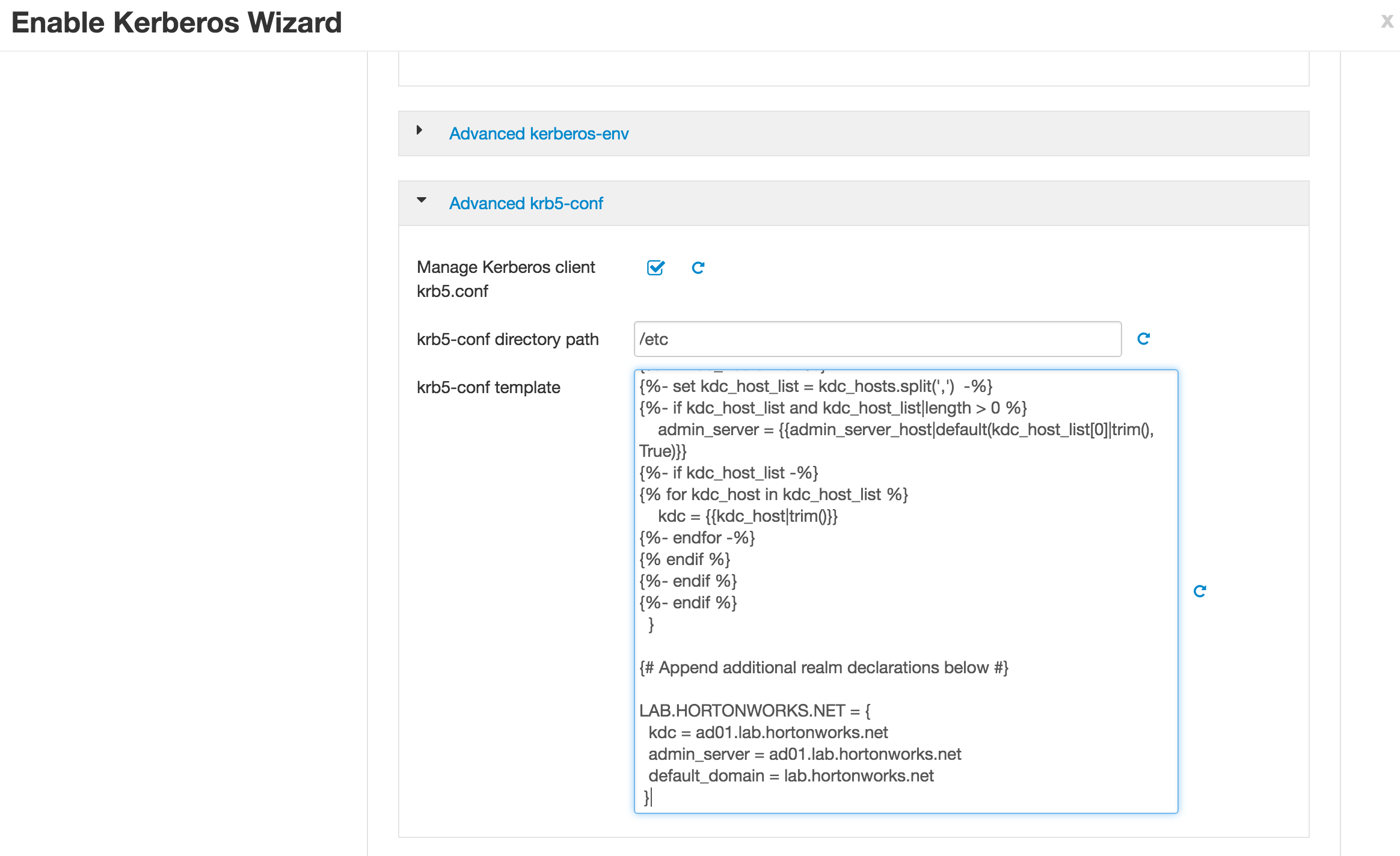
-
Now click Next on all the following screens to proceed with all the default values
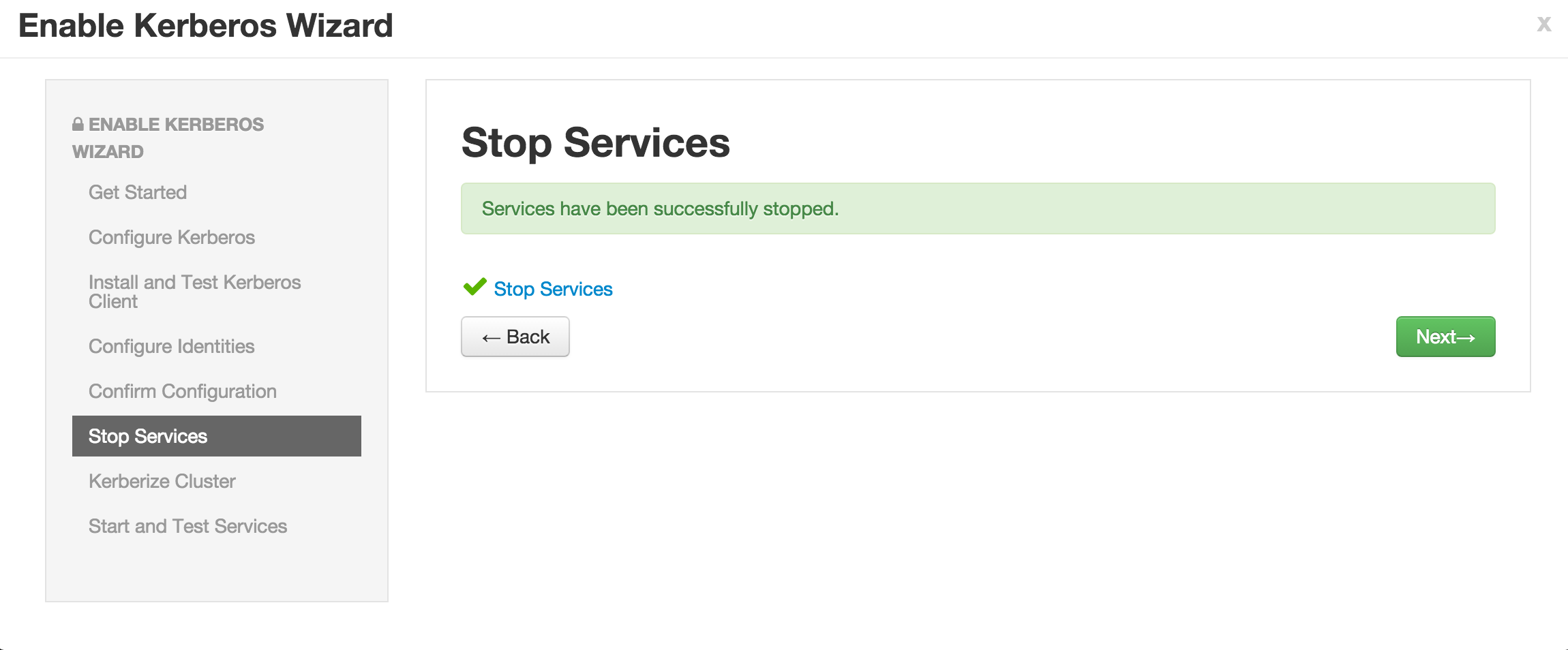
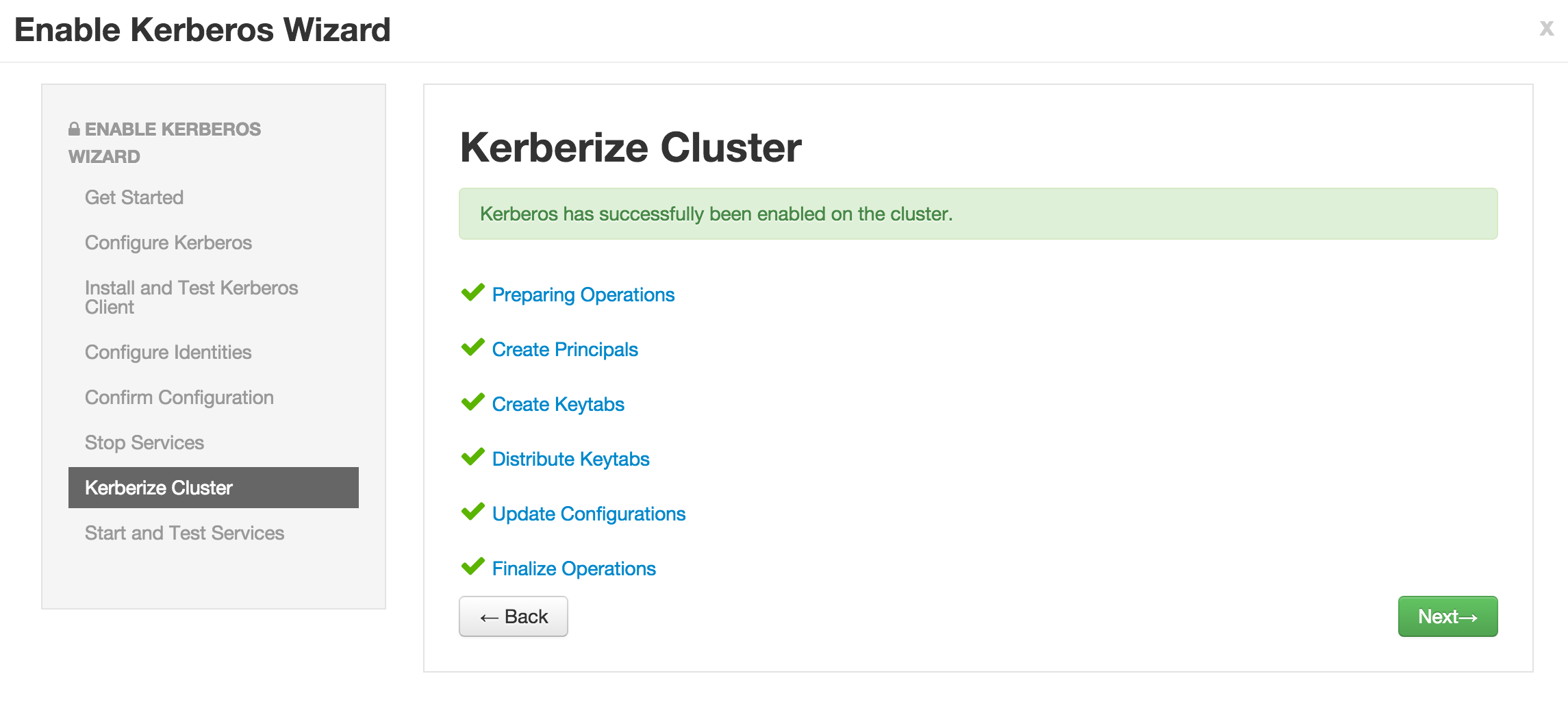
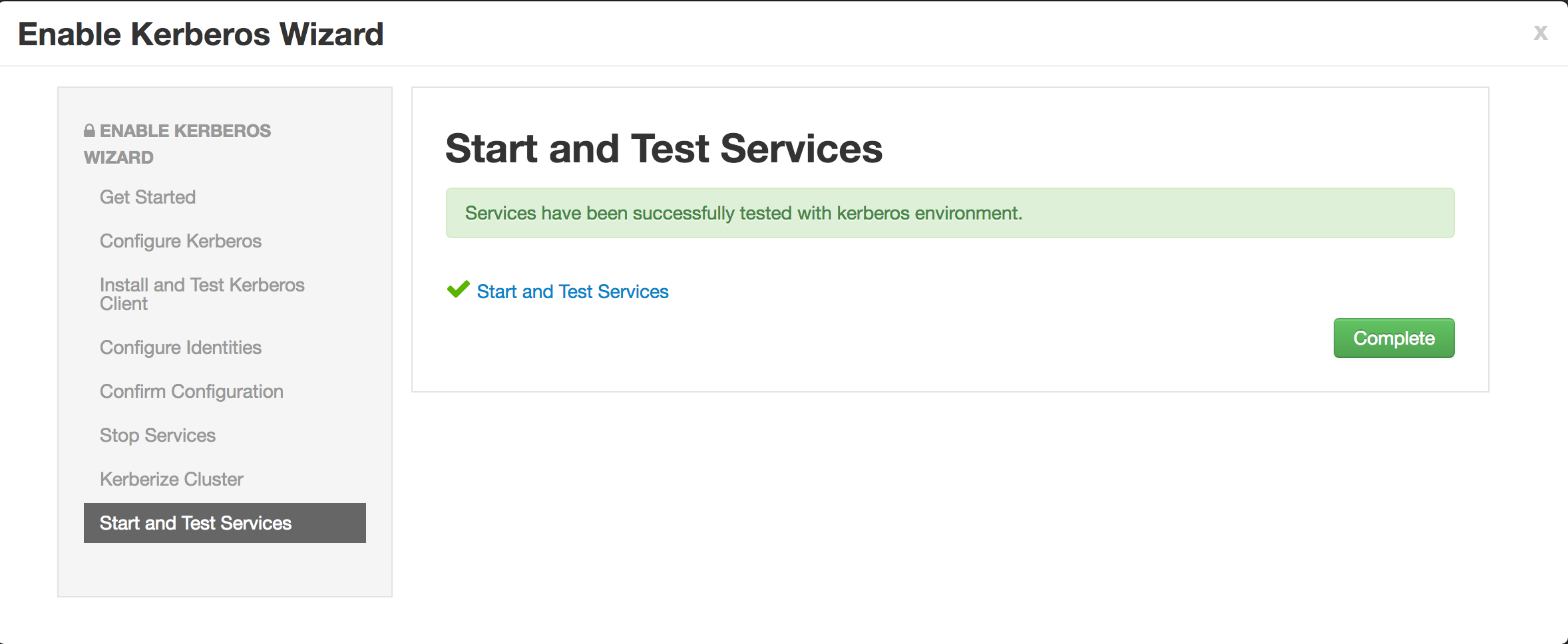
- Note if the wizard fails after completing more than 90% of "Start and test services" phase, you can just click "Complete" and manually start any unstarted services (e.g. WebHCat or HBase master)
-
Check the keytabs directory and notice that keytabs have been generated here:
ls -la /etc/security/keytabs/
- Run a
klist -ektone of the service keytab files to see the principal name it is for. Sample output below (executed on host running Namenode):
$ sudo klist -ekt /etc/security/keytabs/nn.service.keytab
Keytab name: FILE:/etc/security/keytabs/nn.service.keytab
KVNO Timestamp Principal
---- ------------------- ------------------------------------------------------
0 10/03/2016 22:20:12 nn/[email protected] (des3-cbc-sha1)
0 10/03/2016 22:20:12 nn/[email protected] (arcfour-hmac)
0 10/03/2016 22:20:12 nn/[email protected] (des-cbc-md5)
0 10/03/2016 22:20:12 nn/[email protected] (aes128-cts-hmac-sha1-96)
0 10/03/2016 22:20:12 nn/[email protected] (aes256-cts-hmac-sha1-96)
- Notice how the service keytabs are divided into the below 3 parts. The instance here is the FQDN of the node so these keytabs are host specific.
{name of entity}/{instance}@{REALM}.
- Run a
klist -kton one of the headless keytab files to see the principal name it is for. Sample output below (executed on host running Namenode):
$ sudo klist -ekt /etc/security/keytabs/hdfs.headless.keytab
Keytab name: FILE:/etc/security/keytabs/hdfs.headless.keytab
KVNO Timestamp Principal
---- ------------------- ------------------------------------------------------
0 10/03/2016 22:20:12 [email protected] (des3-cbc-sha1)
0 10/03/2016 22:20:12 [email protected] (arcfour-hmac)
0 10/03/2016 22:20:12 [email protected] (des-cbc-md5)
0 10/03/2016 22:20:12 [email protected] (aes128-cts-hmac-sha1-96)
0 10/03/2016 22:20:12 [email protected] (aes256-cts-hmac-sha1-96)
- Notice how the headless keytabs are divided into the below 3 parts. These keytabs are cluster specific (i.e one per cluster)
{name of entity}-{cluster}@{REALM}.
- Notice we can now successfully kinit as the KDC admin
kinit admin/admin
klist
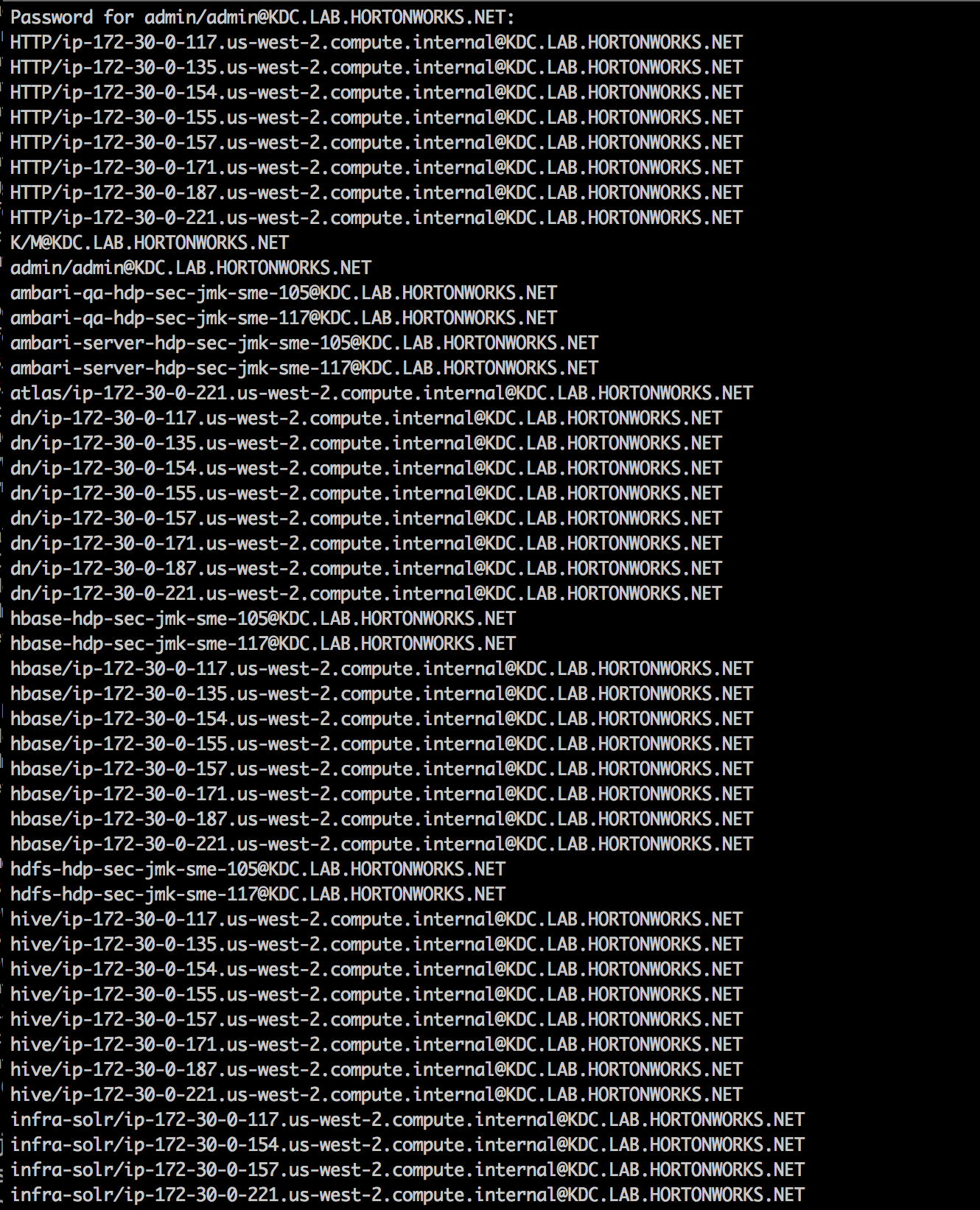
- To view the principals created in KDC, run below to run listprincs query to the remote KDC (passwords are BadPass#1)
kadmin -q listprincs
-
Sample output:
-
Also notice you can also successfully kinit as a user defined in the Active Directory
- This is enabled by the one way trust that was setup between KDC and AD
kinit [email protected]
klist
- For general info on Kerberos, KDC, Principals, Keytabs, Realms etc see doc here
-
Why?
- This is needed for Hadoop to recognize users defined in AD i.e. it maps [email protected] to hadoopadmin, so we can later set policies in Ranger using just the userid, without including the full domain.
-
How?
- In Ambari, click HDFS > Configs > Advanced and filter for 'auth' to expose the hadoop.security.auth_to_local property and expand the text field size so its easier to read
- Find the line that reads
RULE:[1:$1@$0](.*@KDC.LAB.HORTONWORKS.NET)s/@.*// - Above that line, paste a line that reads:
RULE:[1:$1@$0](.*@LAB.HORTONWORKS.NET)s/@.*//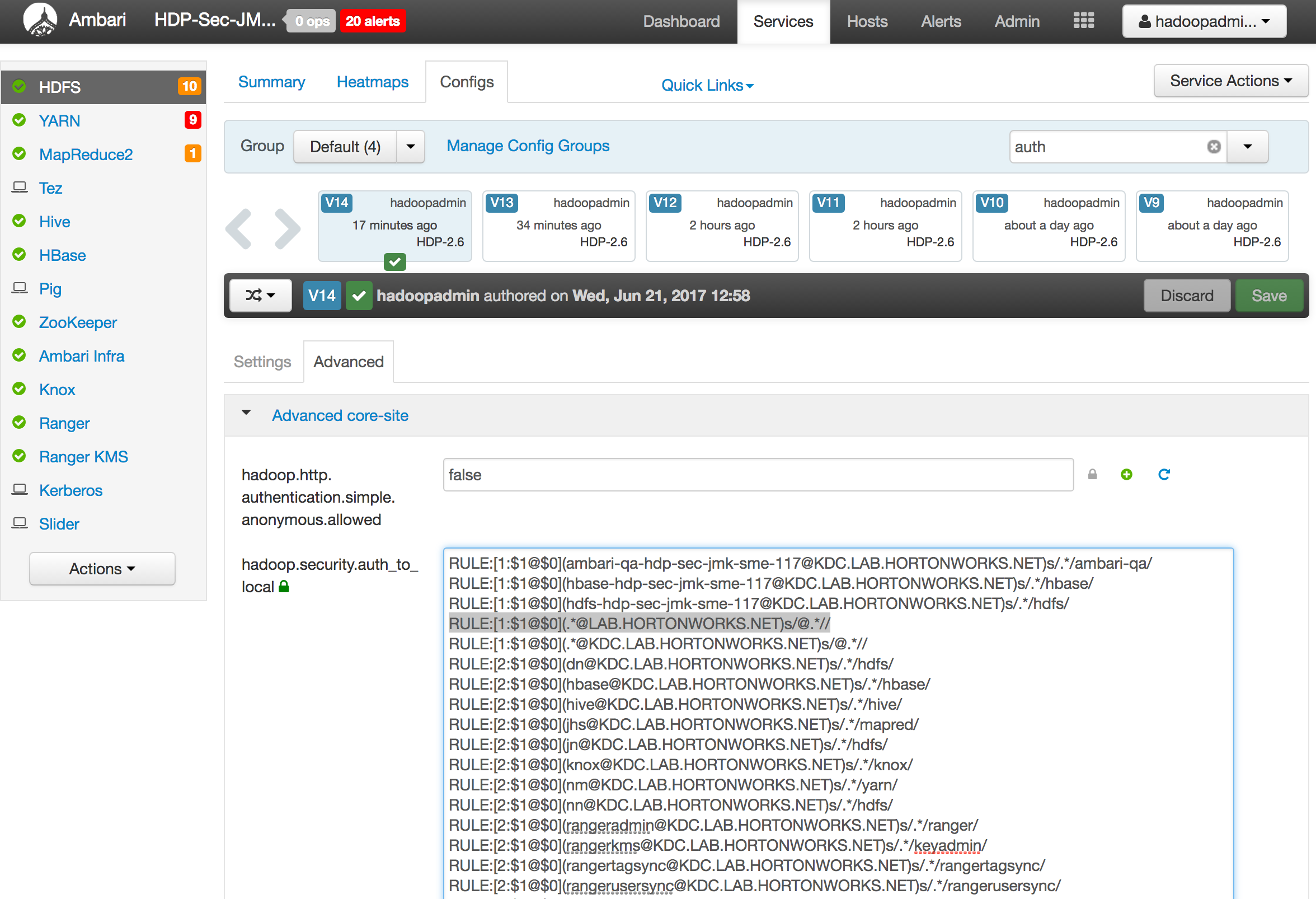
- Save but do not restart HDFS yet (we will do this in next section)
-
For more details on auth_to_local see here
-
Why?
- Currently your hadoop nodes do not recognize users/groups defined in AD.
- You can check this by running below:
id it1 groups it1 hdfs groups it1 ## groups: it1: no such user -
Pre-req for below steps: Your AD admin/instructor should have given 'registersssd' user permissions to add the workstation to OU=HadoopNodes (needed to run 'adcli join' successfully)
-
Note: the below is just a sample way of using SSSD. It will vary completely by environment and needs tuning and testing for your environment.
-
Run the steps in this section on each node
ad_user="registersssd"
ad_domain="lab.hortonworks.net"
ad_dc="ad01.lab.hortonworks.net"
ad_root="dc=lab,dc=hortonworks,dc=net"
ad_ou="ou=HadoopNodes,${ad_root}"
ad_realm=${ad_domain^^}
sudo kinit ${ad_user}@${ad_realm}
## enter BadPass#1 for password
sudo yum makecache fast
##sudo yum -y -q install epel-release ## epel is required for adcli --Erik Maxwell - epel not required in RHEL 7 for adcli
sudo yum -y -q install sssd oddjob-mkhomedir authconfig sssd-krb5 sssd-ad sssd-tools
sudo yum -y -q install adcli
#paste all the lines in this block together, in one shot
sudo adcli join -v \
--domain-controller=${ad_dc} \
--domain-ou="${ad_ou}" \
--login-ccache="/tmp/krb5cc_0" \
--login-user="${ad_user}" \
-v \
--show-details
## This will output a lot of text. In the middle you should see something like below:
## ! Couldn't find a computer container in the ou, creating computer account directly in: ou=HadoopNodes,dc=lab,dc=hortonworks,dc=net
## * Calculated computer account: CN=IP-172-30-0-206,ou=HadoopNodes,dc=lab,dc=hortonworks,dc=net
## * Created computer account: CN=IP-172-30-0-206,ou=HadoopNodes,dc=lab,dc=hortonworks,dc=net
#paste all the lines in this block together, in one shot - to create the sssd.conf file
sudo tee /etc/sssd/sssd.conf > /dev/null <<EOF
[sssd]
## master & data nodes only require nss. Edge nodes require pam.
services = nss, pam, ssh, autofs, pac
config_file_version = 2
domains = ${ad_realm}
override_space = _
[domain/${ad_realm}]
id_provider = ad
ad_server = ${ad_dc}
#ad_server = ad01, ad02, ad03
#ad_backup_server = ad-backup01, 02, 03
auth_provider = ad
chpass_provider = ad
access_provider = ad
enumerate = False
krb5_realm = ${ad_realm}
ldap_schema = ad
ldap_id_mapping = True
cache_credentials = True
ldap_access_order = expire
ldap_account_expire_policy = ad
ldap_force_upper_case_realm = true
fallback_homedir = /home/%d/%u
default_shell = /bin/false
ldap_referrals = false
[nss]
memcache_timeout = 3600
override_shell = /bin/bash
EOF
sudo chmod 0600 /etc/sssd/sssd.conf
sudo service sssd restart
sudo authconfig --enablesssd --enablesssdauth --enablemkhomedir --enablelocauthorize --update
sudo chkconfig oddjobd on
sudo service oddjobd restart
sudo chkconfig sssd on
sudo service sssd restart
sudo kdestroy
- Confirm that your nodes OS can now recognize AD users
id sales1
groups sales1
-
Once the above is completed on all nodes you need to refresh the user group mappings in HDFS & YARN by running the below commands
-
Restart HDFS service via Ambari. This is needed for Hadoop to recognize the group mappings (else the
hdfs groupscommand will not work) -
Once HDFS has been restarted, execute the following on the Ambari node:
export PASSWORD=BadPass#1
#detect name of cluster
output=`curl -k -u hadoopadmin:$PASSWORD -i -H 'X-Requested-By: ambari' https://localhost:8443/api/v1/clusters`
cluster=`echo $output | sed -n 's/.*"cluster_name" : "\([^\"]*\)".*/\1/p'`
#refresh user and group mappings
sudo sudo -u hdfs kinit -kt /etc/security/keytabs/hdfs.headless.keytab hdfs-"${cluster,,}"
sudo sudo -u hdfs hdfs dfsadmin -refreshUserToGroupsMappings
- Execute the following on the node where the YARN ResourceManager is installed:
sudo sudo -u yarn kinit -kt /etc/security/keytabs/yarn.service.keytab yarn/$(hostname -f)@KDC.LAB.HORTONWORKS.NET
sudo sudo -u yarn yarn rmadmin -refreshUserToGroupsMappings
- kinit as an end user (password is BadPass#1)
kinit [email protected]
- check the group mappings
hdfs groups
sudo sudo -u yarn yarn rmadmin -getGroups hr1
- output should look like below, indicating both OS-level and hadoop-level group mappings :
$ hdfs groups
[email protected] : domain_users hr hadoop-users
$ sudo sudo -u yarn kinit -kt /etc/security/keytabs/yarn.service.keytab yarn/$(hostname -f)@KDC.LAB.HORTONWORKS.NET
$ sudo sudo -u yarn yarn rmadmin -getGroups hr1
hr1 : domain_users hr hadoop-users
- remove kerberos ticket
kdestroy
- Login as sales1 user and try to access the same /tmp/hive HDFS dir
sudo su - sales1
hdfs dfs -ls /tmp/hive
## since we did not authenticate, this fails with GSSException: No valid credentials provided
#authenticate
kinit [email protected]
##enter BadPass#1
klist
## shows the principal for sales1
hdfs dfs -ls /tmp/hive
## fails with Permission denied
#Now try to get around security by setting the same env variable
export HADOOP_USER_NAME=hdfs
hdfs dfs -ls /tmp/hive
unset HADOOP_USER_NAME
#log out as sales1
logout
- Notice that now that the cluster is kerberized, we were not able to circumvent security by setting the env var
For Ambari Views to access the cluster, Ambari must be configured to use Kerberos to access the cluster. The Kerberos wizard handles this configuration for you (as of Ambari 2.4).
For those configurations to take affect, execute the following on the Ambari Server:
sudo ambari-server restart
-
Needed to secure the Hadoop components webUIs (e.g. Namenode UI, JobHistory UI, Yarn ResourceManager UI etc...)
-
Run steps on ambari server node
-
Create Secret Key Used for Signing Authentication Tokens
sudo dd if=/dev/urandom of=/etc/security/http_secret bs=1024 count=1
sudo chown hdfs:hadoop /etc/security/http_secret
sudo chmod 440 /etc/security/http_secret
- Place the file in Ambari resources dir so it gets pushed to all nodes
sudo cp /etc/security/http_secret /var/lib/ambari-server/resources/host_scripts/
sudo ambari-server restart
-
Wait 30 seconds for the http_secret file to get pushed to all nodes under /var/lib/ambari-agent/cache/host_scripts
-
On non-Ambari nodes, once the above file is available, run below to put it in right dir and correct its permissions
sudo cp /var/lib/ambari-agent/cache/host_scripts/http_secret /etc/security/
sudo chown hdfs:hadoop /etc/security/http_secret
sudo chmod 440 /etc/security/http_secret
-
In Ambari > HDFS > Configs, set the below
-
Under Advanced core-site:
- hadoop.http.authentication.simple.anonymous.allowed=false
-
Under Custom core-site, add the below properties (using bulk add tab):
hadoop.http.authentication.signature.secret.file=/etc/security/http_secret hadoop.http.authentication.type=kerberos hadoop.http.authentication.kerberos.keytab=/etc/security/keytabs/spnego.service.keytab hadoop.http.authentication.kerberos.principal=HTTP/[email protected] hadoop.http.authentication.cookie.domain=lab.hortonworks.net hadoop.http.filter.initializers=org.apache.hadoop.security.AuthenticationFilterInitializer -
-
Save configs
-
Restart all services that require restart (HDFS, Mapreduce, YARN, HBase). You can use the 'Actions' > 'Restart All Required' button to restart all the services in one shot
- Now when you try to open any of the web UIs like below you will get
401: Authentication required- HDFS: Namenode UI
- Mapreduce: Job history UI
- YARN: Resource Manager UI
Goal: In this lab we will install Apache Ranger via Ambari and setup Ranger plugins for Hadoop components: HDFS, Hive, Hbase, YARN, Knox. We will also enable Ranger audits to Solr and HDFS
Prepare MySQL DB for Ranger use.
-
Run these steps on the node where MySQL/Hive is located. To find this, you can either:
- use Ambari UI or
- Just run
mysqlon each node: if it returnsmysql: command not found, move onto next node
-
sudo mysql -
Execute following in the MySQL shell. Change the password to your preference.
CREATE USER 'root'@'%';
GRANT ALL PRIVILEGES ON *.* to 'root'@'%' WITH GRANT OPTION;
SET PASSWORD FOR 'root'@'%' = PASSWORD('BadPass#1');
SET PASSWORD = PASSWORD('BadPass#1');
FLUSH PRIVILEGES;
exit- Confirm MySQL user:
mysql -u root -h $(hostname -f) -p -e "select count(user) from mysql.user;"- Output should be a simple count. Check the last step if there are errors.
- Run this on Ambari node
- Add MySQL JAR to Ambari:
sudo ambari-server setup --jdbc-db=mysql --jdbc-driver=/usr/share/java/mysql-connector-java.jar- If the file is not present, it is available on RHEL/CentOS with:
sudo yum -y install mysql-connector-java
- If the file is not present, it is available on RHEL/CentOS with:
This should already be installed on your cluster. If not, refer to appendix here
- Starting HDP 2.5, if you have deployed Ambari Infra services, you can just use the embedded Solr for Ranger audits.
- Just make sure Ambari Infra service is installed/started and proceed
- TODO: add steps to install/configure Banana dashboard for Ranger Audits
-
Start the Ambari 'Add Service' wizard and select Ranger
-
When prompted for where to install it, choose any node you like
-
On the Ranger Requirements popup windows, you can check the box and continue as we have already completed the pre-requisite steps
-
On the 'Customize Services' page of the wizard there are a number of tabs that need to be configured as below
-
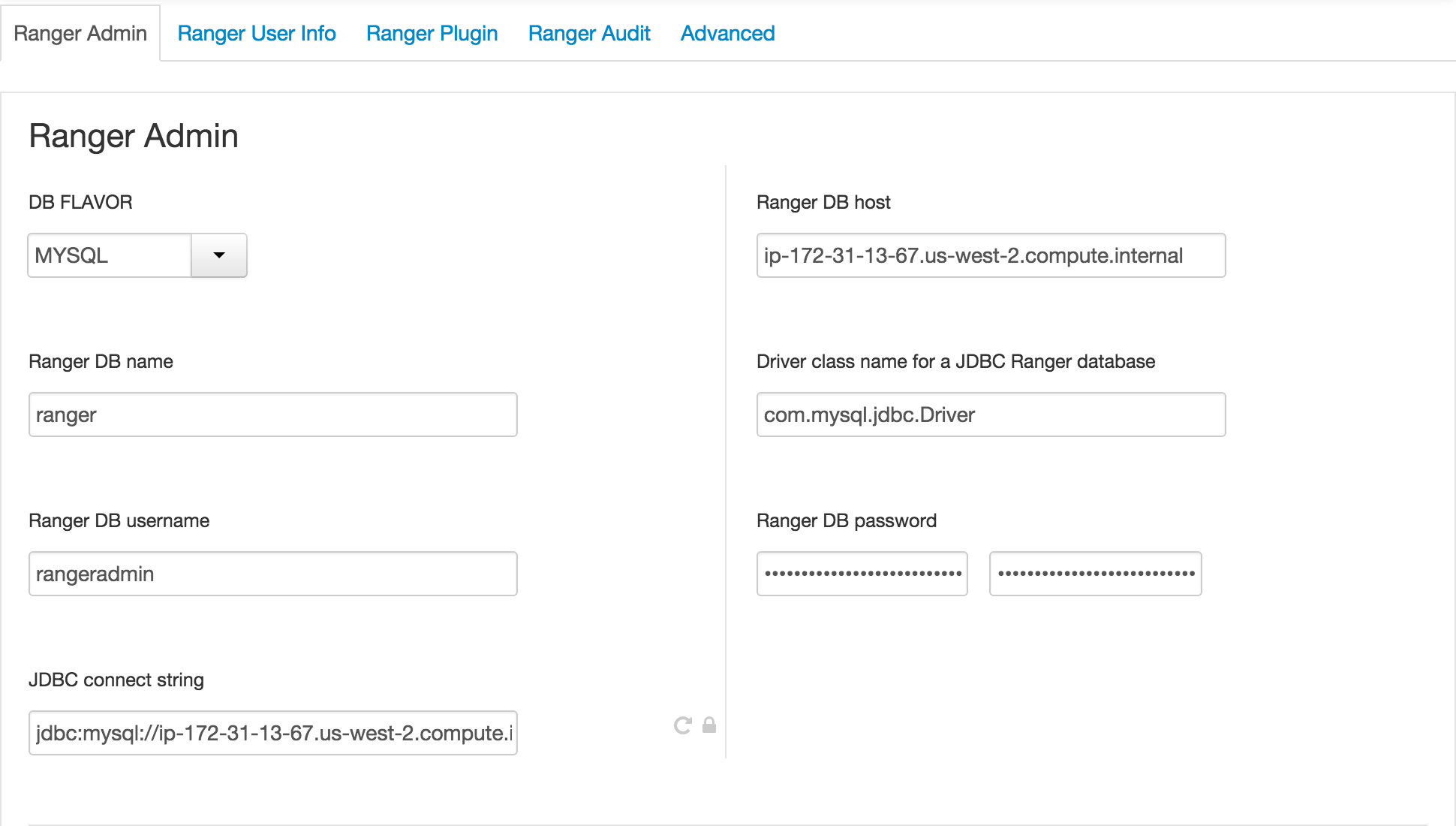
Go through each Ranger config tab, making below changes:
- Ranger Admin tab:
- Ranger DB Host = FQDN of host where Mysql is running (e.g. ip-172-30-0-242.us-west-2.compute.internal)
- Enter passwords: BadPass#1
- Click 'Test Connection' button
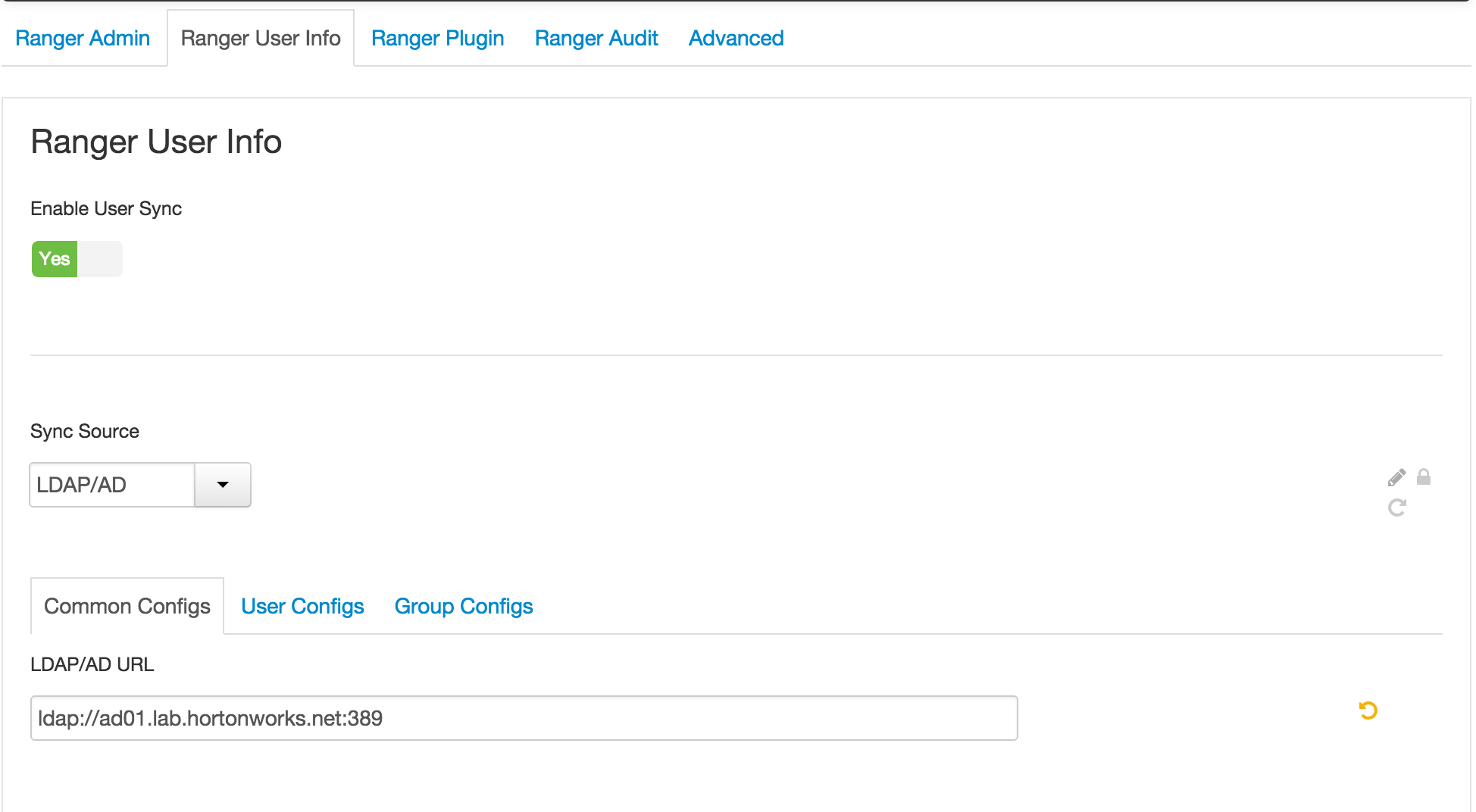
- Ranger User info tab
- 'Sync Source' = LDAP/AD
- Common configs subtab
- Enter password: BadPass#1
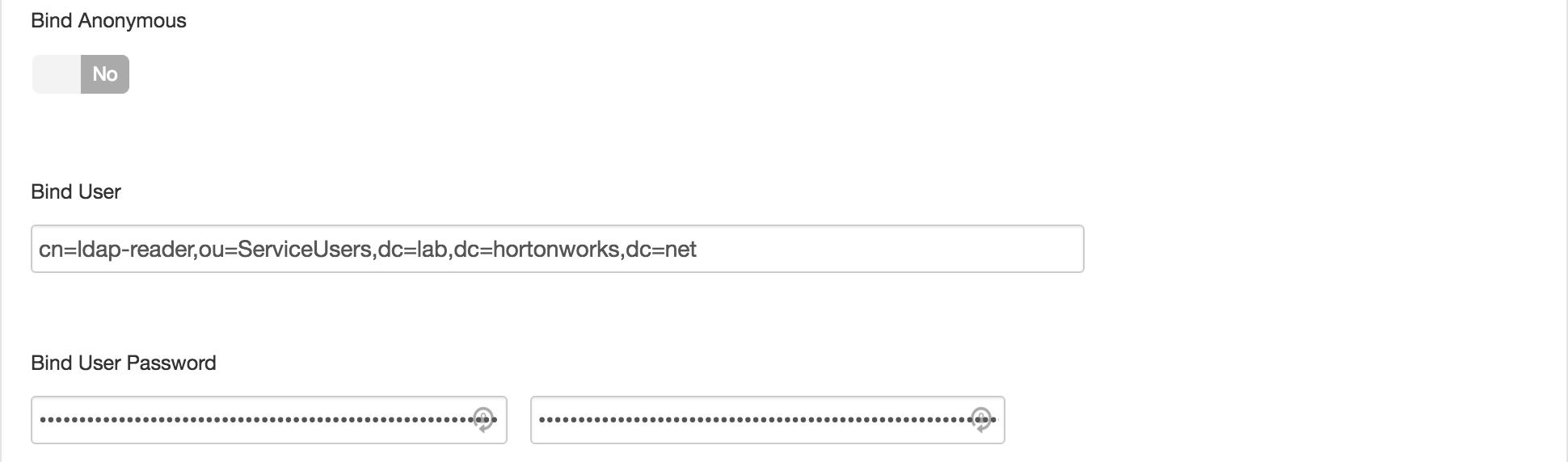
- Enter password: BadPass#1
- Ranger User info tab
- User configs subtab
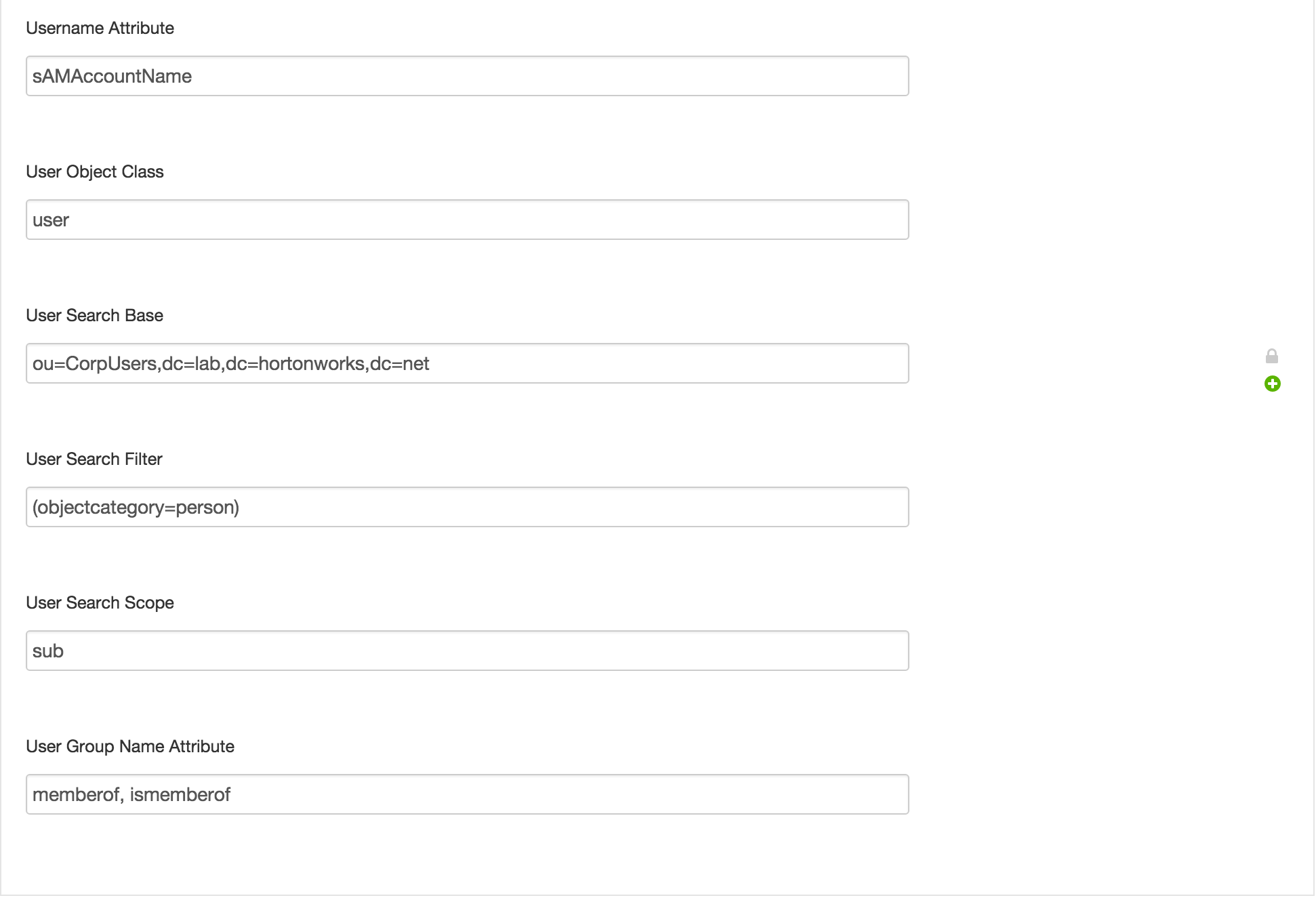
- User Search Base =
ou=CorpUsers,dc=lab,dc=hortonworks,dc=net - User Search Filter =
(objectcategory=person)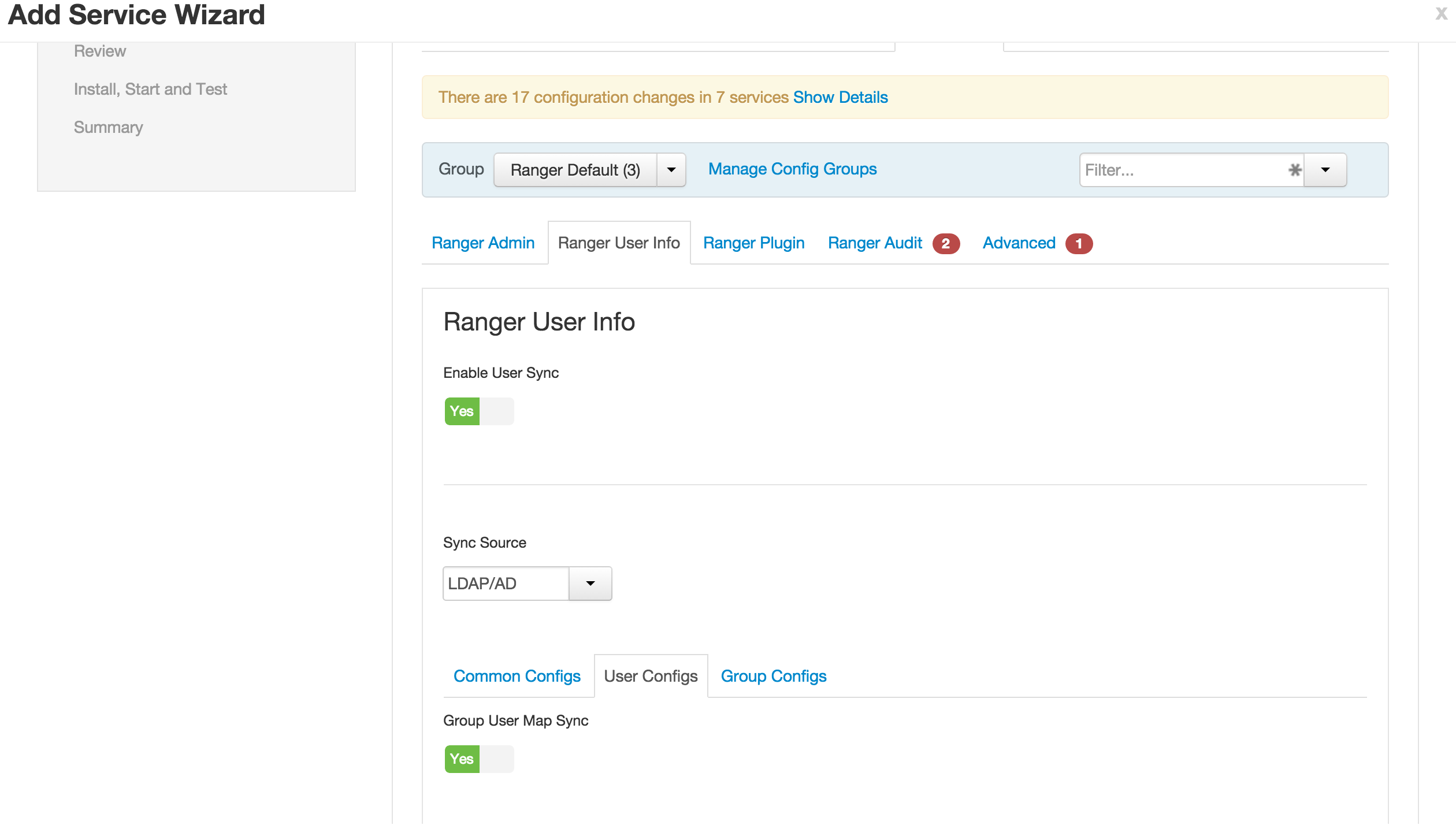
- User Search Base =
- Ranger User info tab
- Group configs subtab
- Disable Group sync
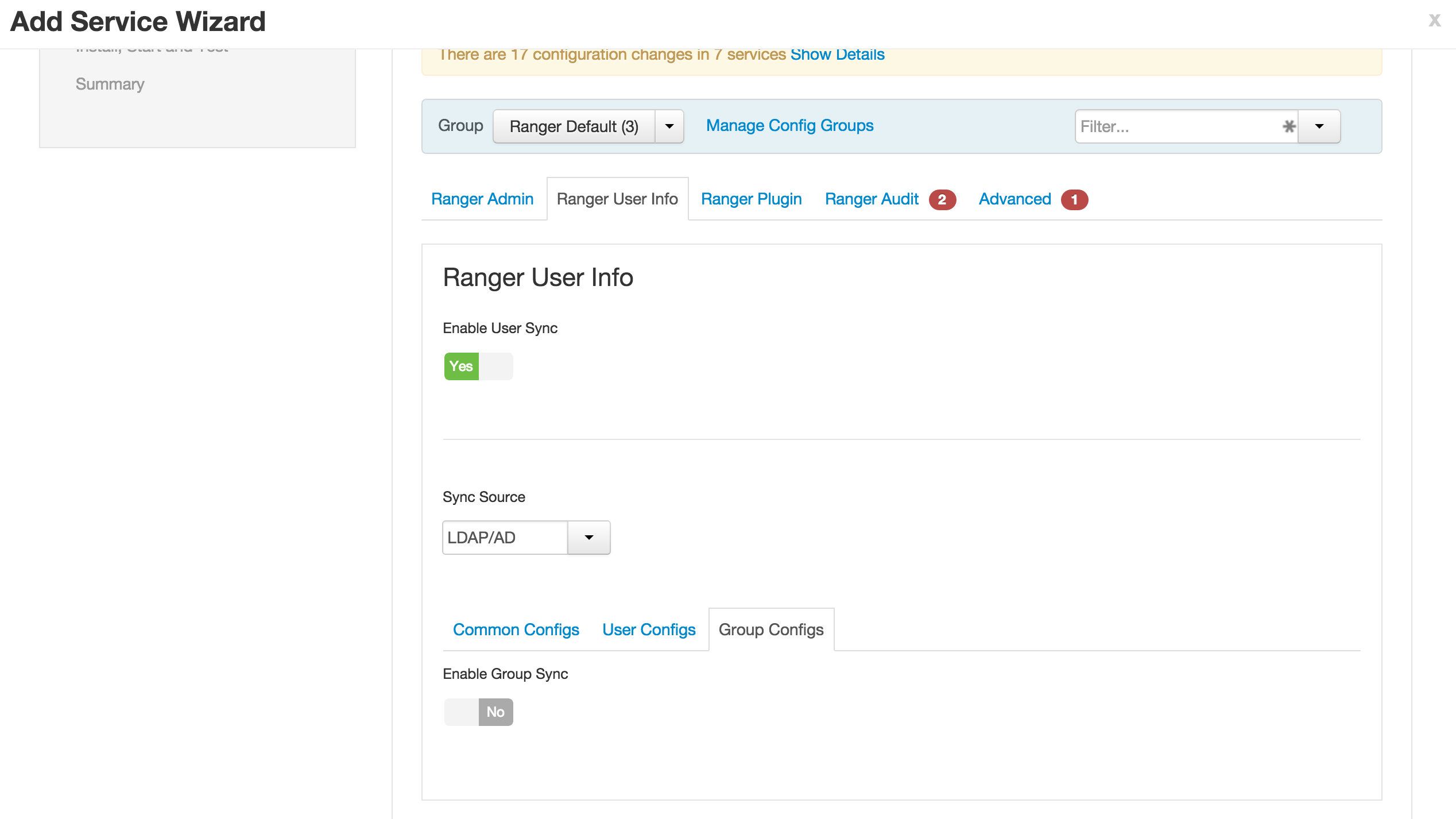
- Disable Group sync
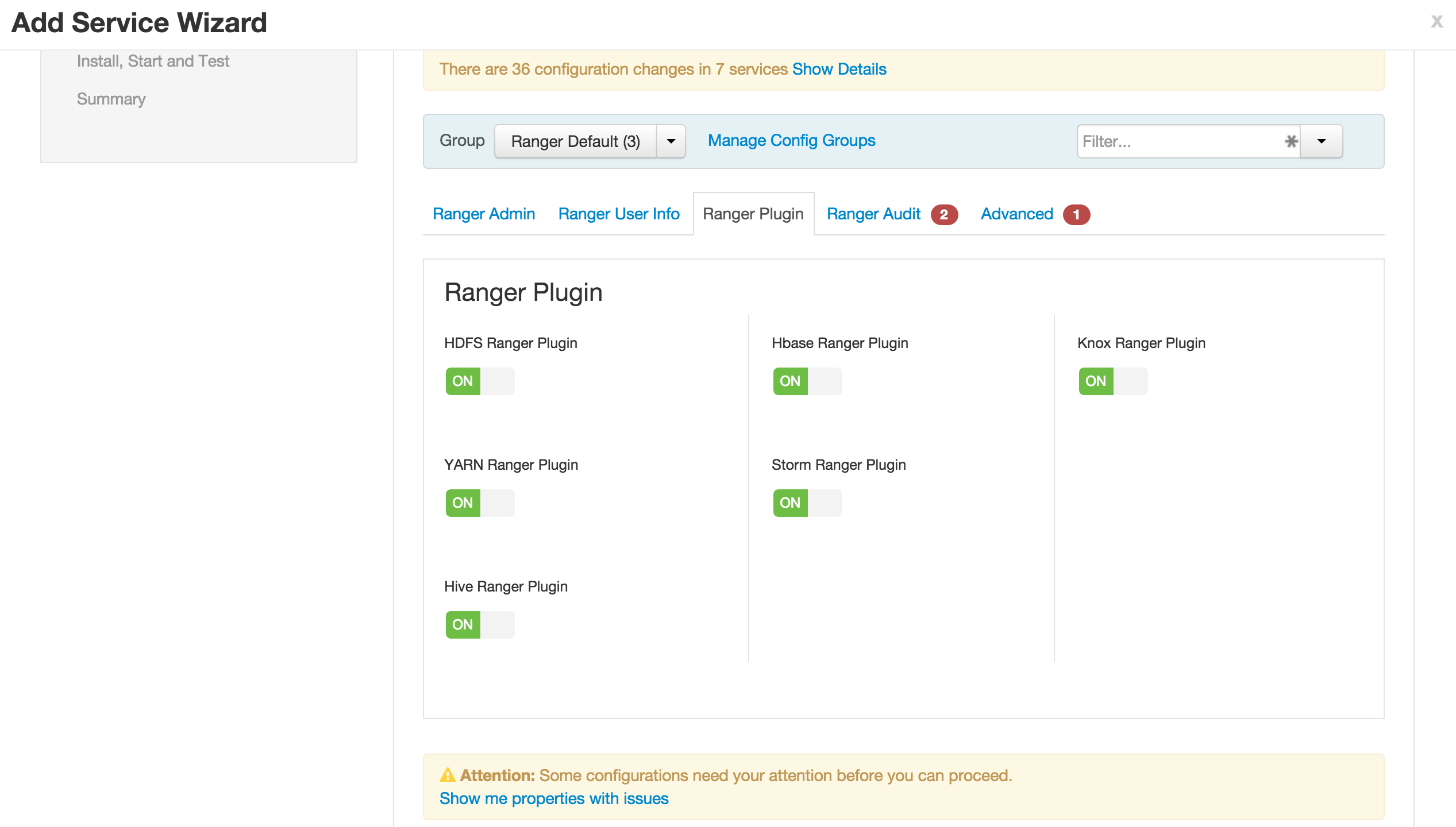
- Ranger plugins tab
- Enable all plugins
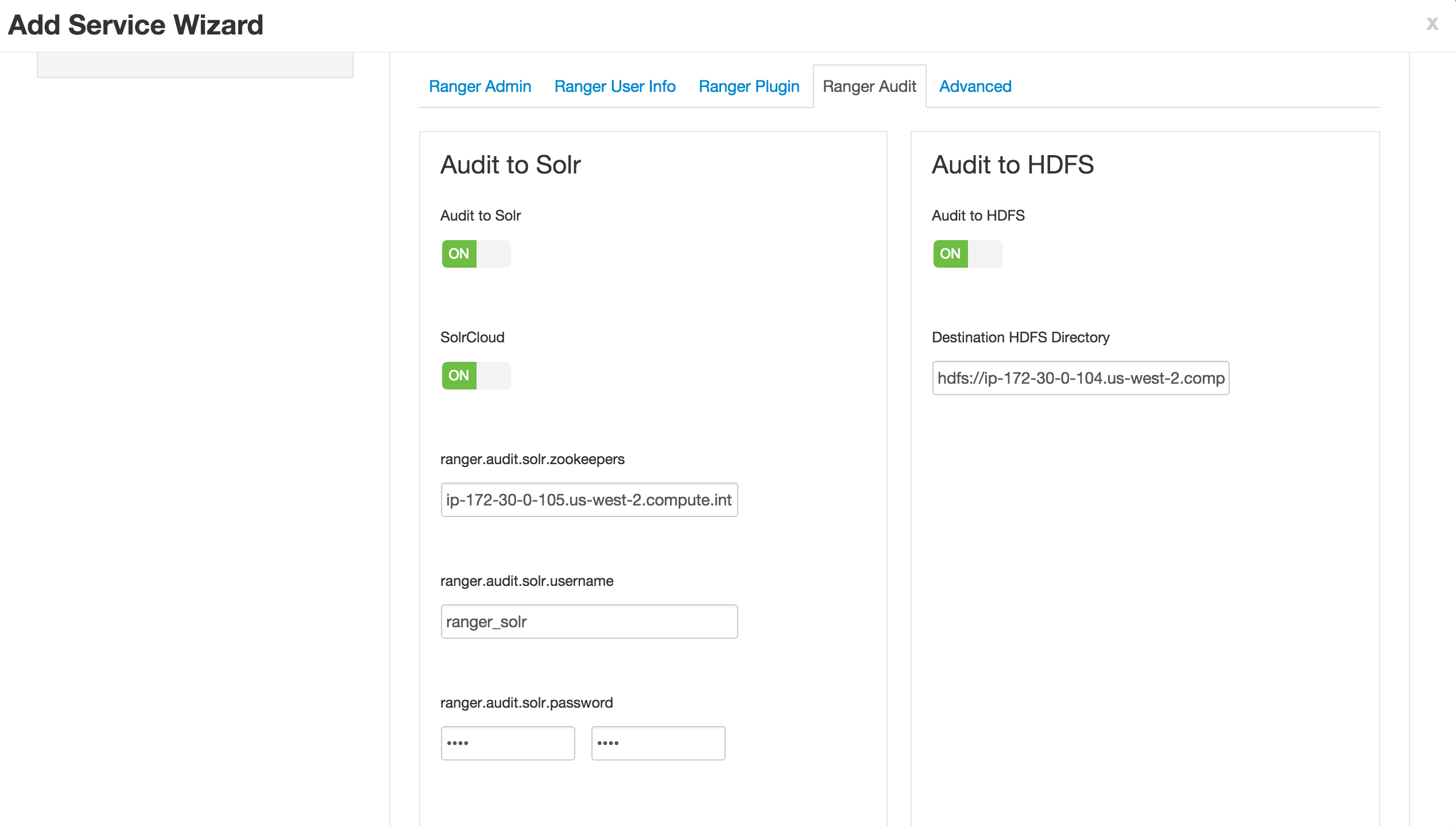
- Ranger Audits tab
- SolrCloud = ON
7.Advanced tab
-
No changes needed (skipping configuring Ranger authentication against AD for now)
-
Click Next > Proceed Anyway to proceed
-
If prompted, on Configure Identities page, you may have to enter your AD admin credentials:
- Admin principal:
admin/[email protected] - Admin password: BadPass#1
- Notice that you can now save the admin credentials. Check this box too
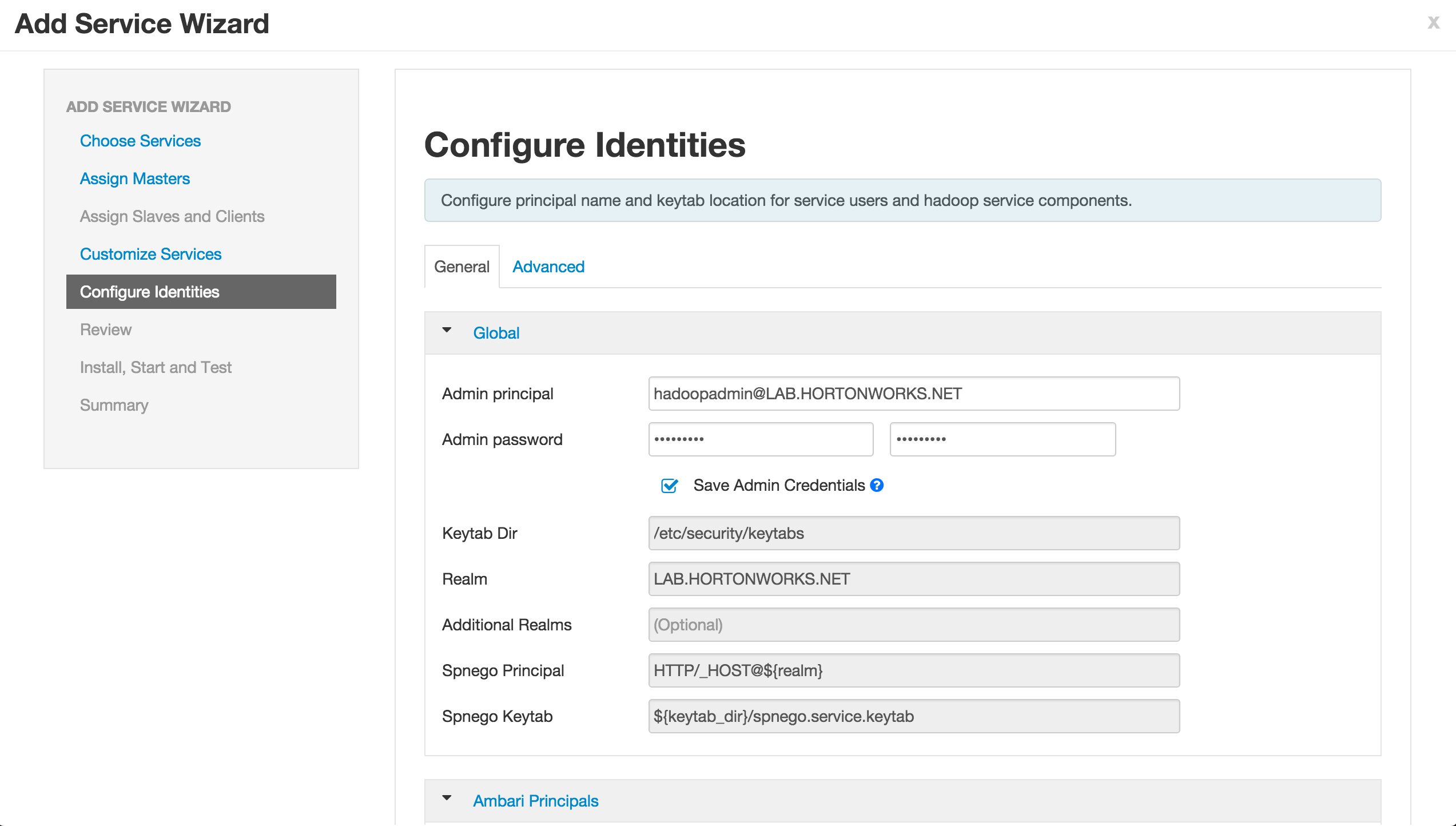
- Admin principal:
-
Click Next > Deploy to install Ranger
-
Once installed, restart components that require restart (e.g. HDFS, YARN, Hive etc)
-
(Optional) In case of failure (usually caused by incorrectly entering the Mysql nodes FQDN in the config above), delete Ranger service from Ambari and retry.
8 - (Optional) Enable Deny Conditions in Ranger
The deny condition in policies is optional by default and must be enabled for use.
-
From Ambari>Ranger>Configs>Advanced>Custom ranger-admin-site, add :
ranger.servicedef.enableDenyAndExceptionsInPolicies=true -
Restart Ranger
-
Open Ranger UI at http://RANGERHOST_PUBLIC_IP:6080 using admin/admin
-
Confirm that repos for HDFS, YARN, Hive, HBase, Knox appear under 'Access Manager tab'
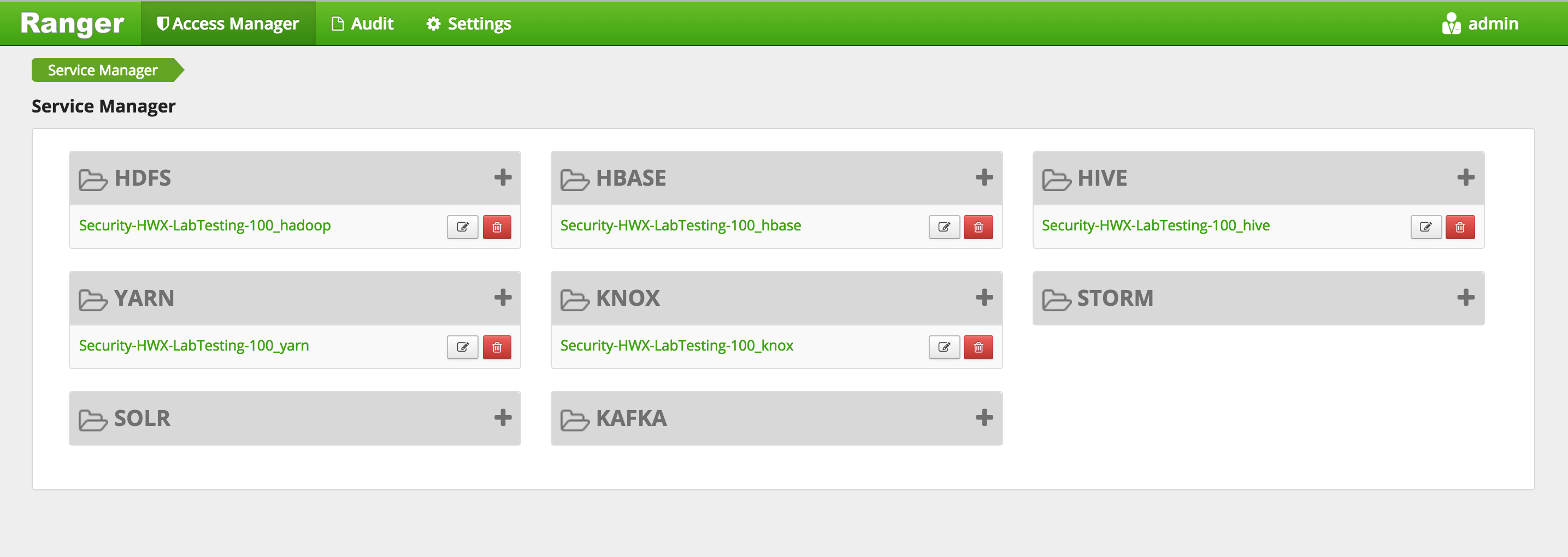
-
Confirm that audits appear under 'Audit' > 'Access' tab
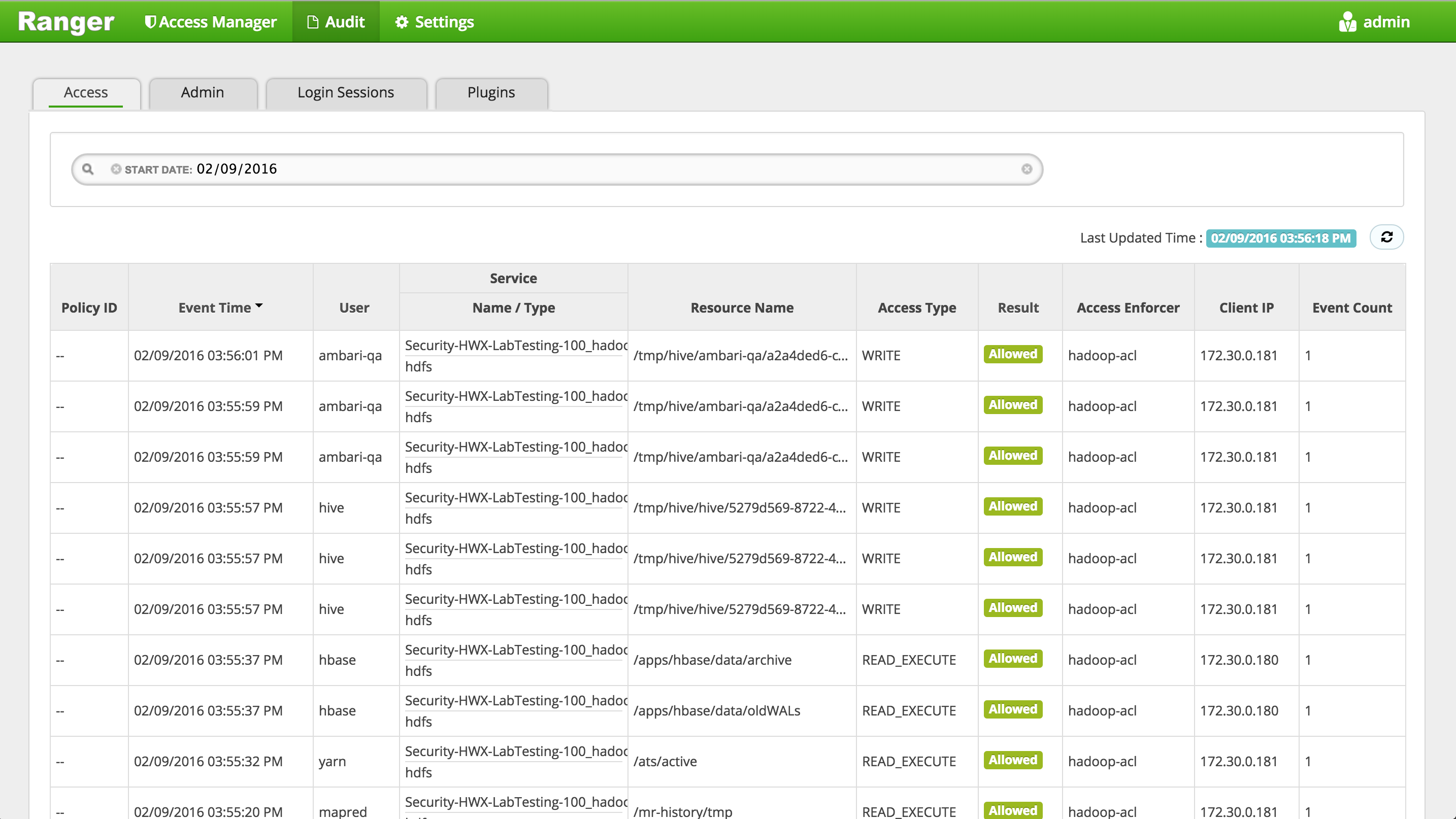
- If audits do not show up here, you may need to restart 'Ambari Infra' from Ambari
-
Confirm that plugins for HDFS, YARN, Hive etc appear under 'Audit' > 'Plugins' tab
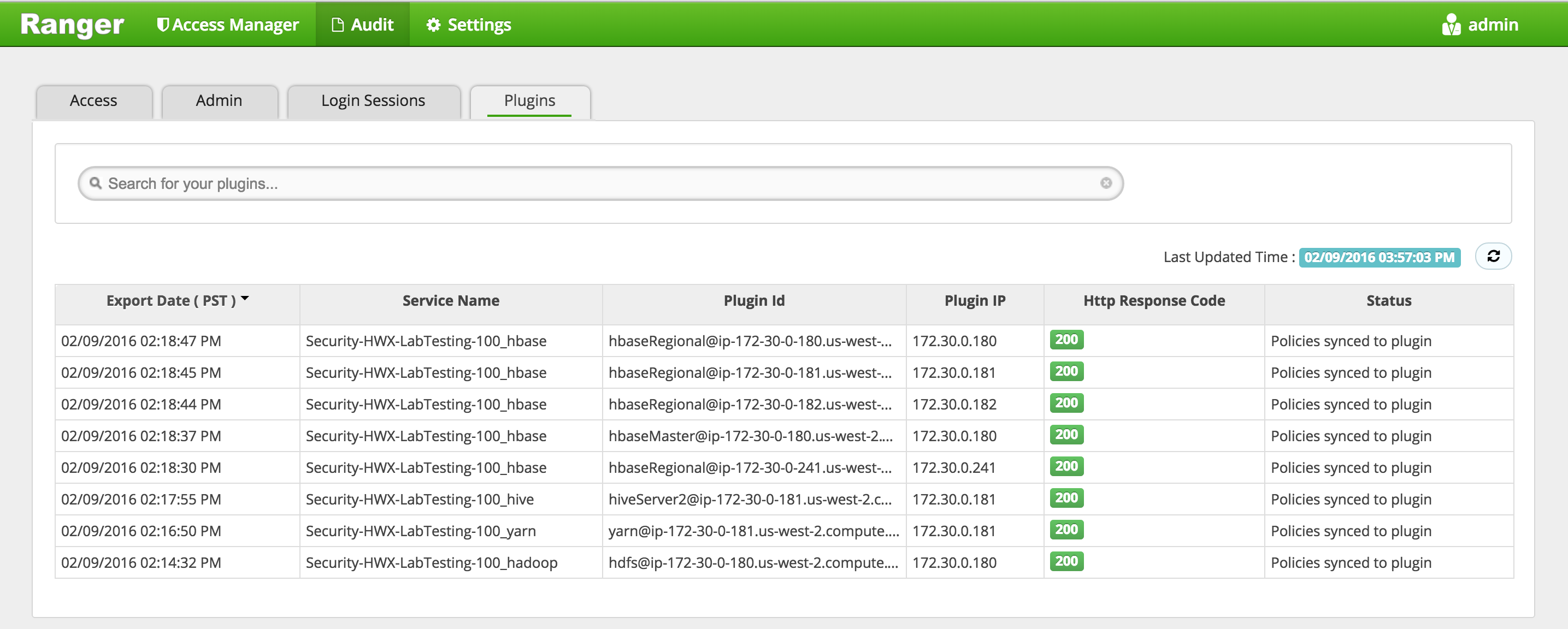
-
Confirm users/group sync from AD into Ranger are working by clicking 'Settings' > 'Users/Groups tab' in Ranger UI and noticing AD users/groups are present
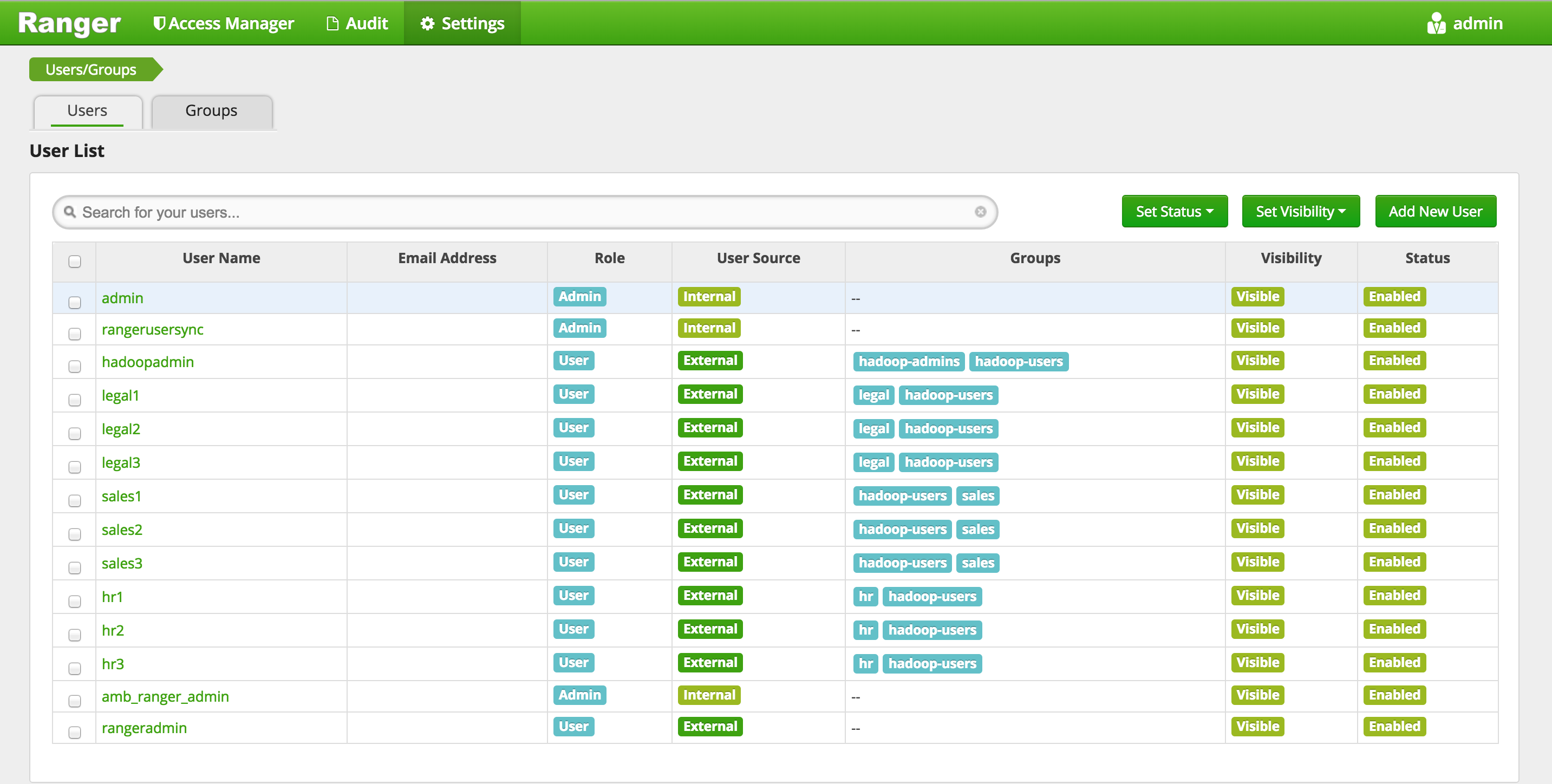
-
Confirm HDFS audits working by querying the audits dir in HDFS:
sudo -u hdfs hdfs dfs -cat /ranger/audit/hdfs/*/*
-
Goal: In this lab we will install Ranger KMS via Ambari. Next we will create some encryption keys and use them to create encryption zones (EZs) and copy files into them. Reference: docs
-
In this section we will have to setup proxyusers. This is done to enable impersonation whereby a superuser can submit jobs or access hdfs on behalf of another user (e.g. because superuser has kerberos credentials but user joe doesn’t have any)
- For more details on this, refer to the doc
-
Before starting KMS install, find and note down the below piece of information. These will be used during KMS install
- Find the internal hostname of host running Mysql and note it down
- From Ambari > Hive > Mysql > click the 'Mysql Server' hyperlink. The internal hostname should appear in upper left of the page.
- Find the internal hostname of host running Mysql and note it down
-
Open Ambari > start 'Add service' wizard > select 'Ranger KMS'.
-
Pick any node to install on
-
Keep the default configs except for
-
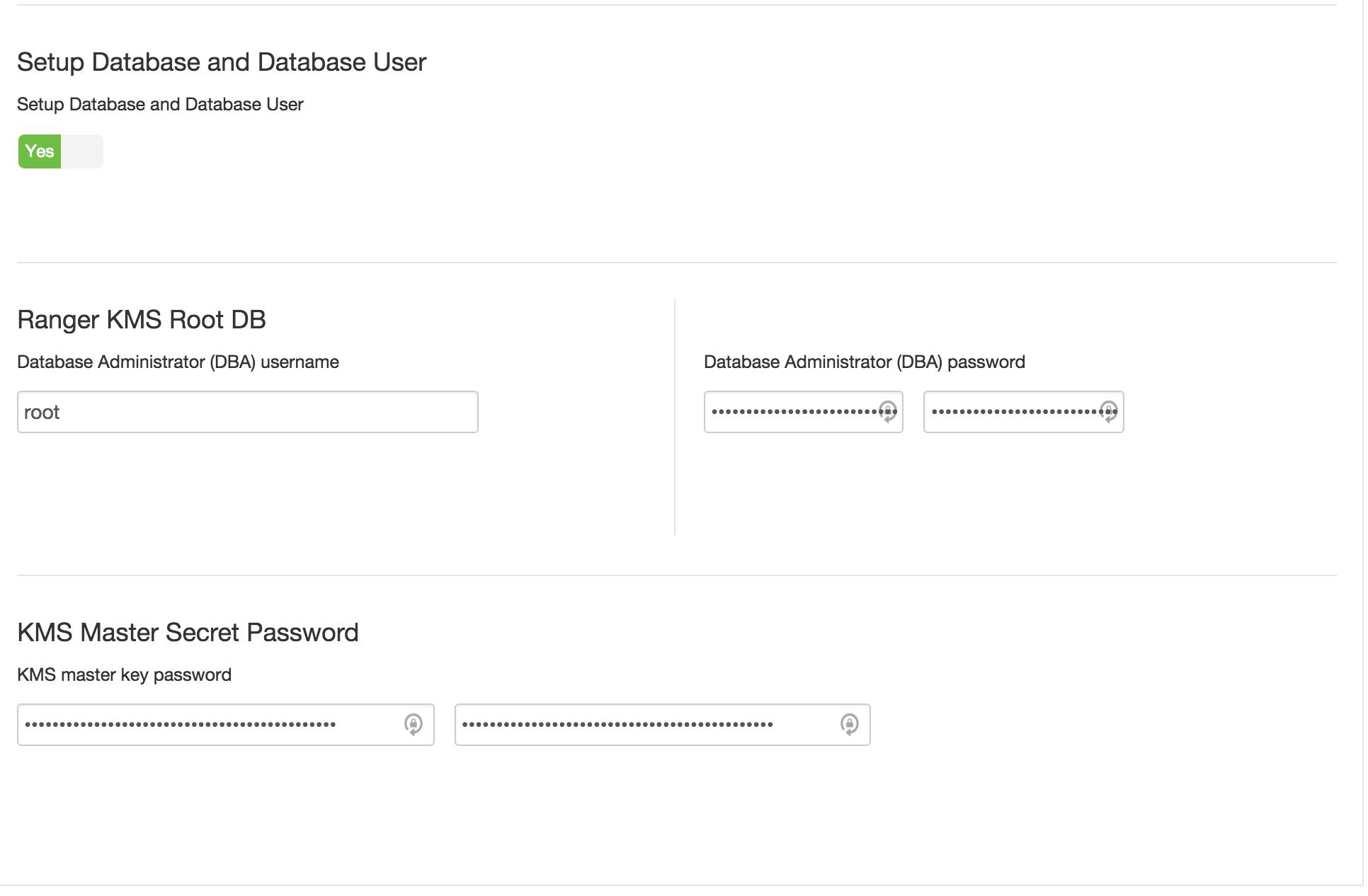
under Ambari > Ranger KMS > Settings tab :
- Ranger KMS DB host:
- Ranger KMS DB password:
BadPass#1 - DBA password:
BadPass#1 - KMS master secret password:
BadPass#1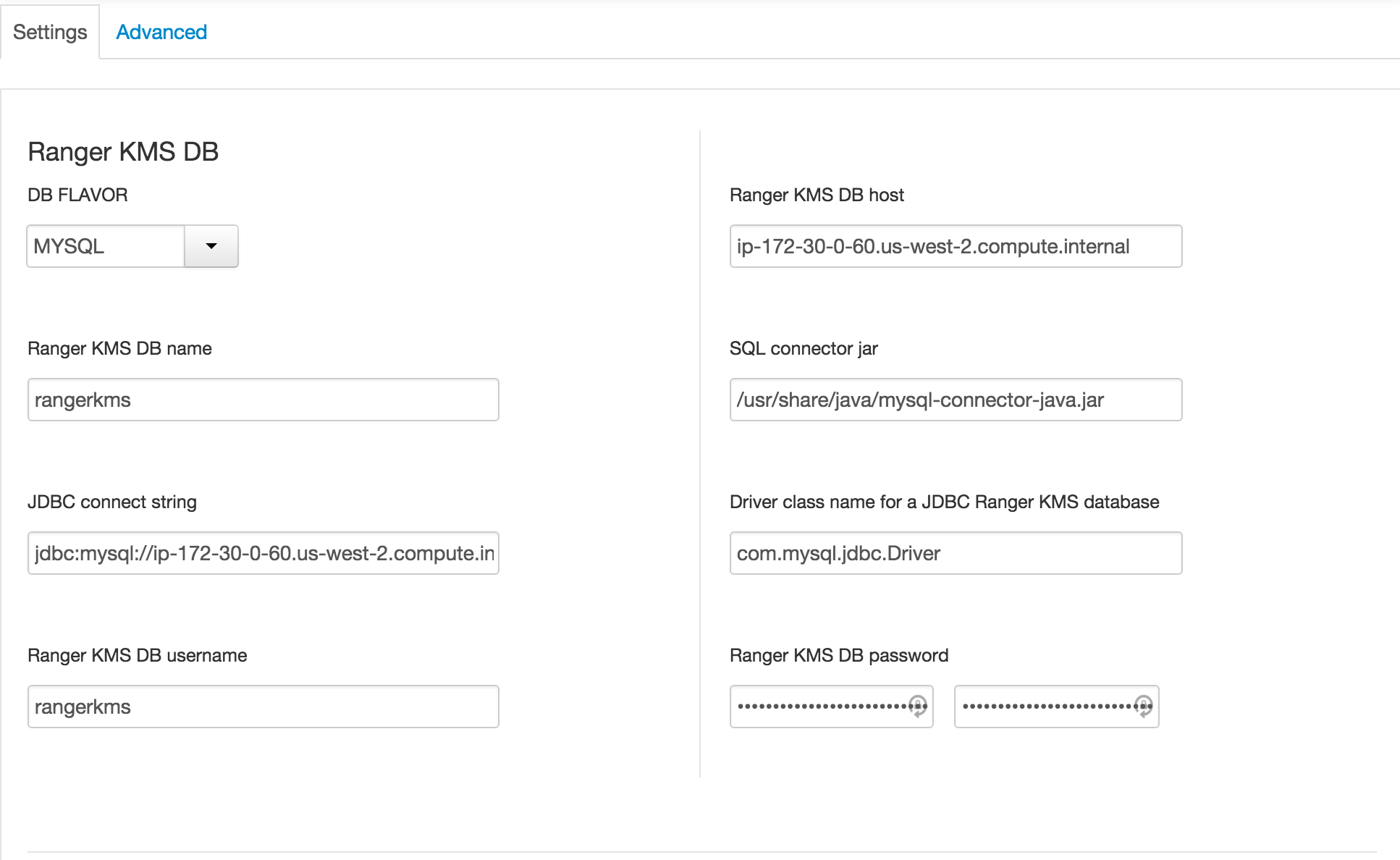
-
Custom kms-site (to avoid adding one at a time, you can use 'bulk add' mode):
- hadoop.kms.proxyuser.ambari.users=*
- hadoop.kms.proxyuser.ambari.hosts=*
- hadoop.kms.proxyuser.keyadmin.groups=*
- hadoop.kms.proxyuser.keyadmin.hosts=*
- hadoop.kms.proxyuser.keyadmin.users=*
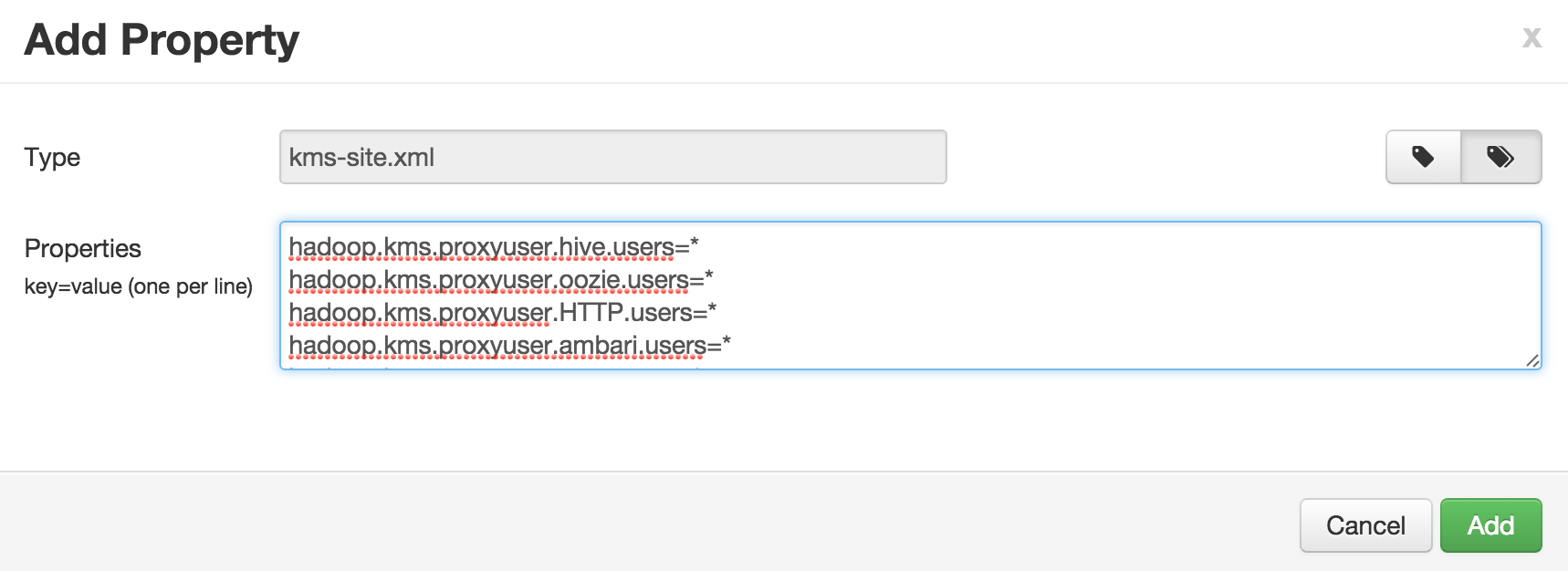
-
-
Click Next > Proceed Anyway to proceed with the wizard
-
If prompted, on Configure Identities page, you may have to enter your AD admin credentials:
- Admin principal:
admin/[email protected] - Admin password: BadPass#1
- Check the "Save admin credentials" checkbox
- Admin principal:
-
Click Next > Deploy to install RangerKMS
-
Confirm these properties got populated to kms://http@(kmshostname):9292/kms
- HDFS > Configs > Advanced core-site:
- hadoop.security.key.provider.path
- HDFS > Configs > Advanced hdfs-site:
- dfs.encryption.key.provider.uri
- HDFS > Configs > Advanced core-site:
-
Restart the services that require it e.g. HDFS, Mapreduce, YARN via Actions > Restart All Required
-
Make sire the auth_to_local value we added before was propogated to RangerKMS
- Under RangerKMS > Configs > Advanced >Advanced kms-site, check for below entry:
RULE:[1:$1@$0](.*@LAB.HORTONWORKS.NET)s/@.*//
- Under RangerKMS > Configs > Advanced >Advanced kms-site, check for below entry:
-
Restart Ranger and RangerKMS services.
-
(Optional) Add another KMS:
-
Ambari > Ranger KMS > Service Actions > Add Ranger KMS Server > Pick any host
-
After it is installed, you can start it by:
- Ambari > Ranger KMS > Service Actions > Start
-
Once started you will see multiple KMS Servers running in Ambari:
-
-
Before we can start exercising HDFS encryption, we will need to set:
-
policy for hadoopadmin access to HDFS
-
policy for hadoopadmin access to Hive
-
policy for hadoopadmin access to the KMS keys we created
-
Add the user hadoopadmin to the Ranger HDFS global policies.
- Access Manager > HDFS > (clustername)_hdfs
- This will open the list of HDFS policies

- Edit the 'all - path' global policy (the first one) and add hadoopadmin to global HDFS policy and Save

- Your policy now includes hadoopadmin

-
Add the user hadoopadmin to the Ranger Hive global policies. (Hive has two global policies: one on Hive tables, and one on Hive UDFs)
- Access Manager > HIVE > (clustername)_hive
- This will open the list of HIVE policies Image
- Edit the 'all - database, table, column' global policy (the first one) and add hadoopadmin to global HIVE policy and Save

- Edit the 'all - database, udf' global policy (the second one) and add hadoopadmin to global HIVE policy and Save

- Your policies now includes hadoopadmin

-
Add policy for keyadmin to be able to access /ranger/audit/kms
- First Create the hdfs directory for Ranger KMS Audit
#run below on Ambari node export PASSWORD=BadPass#1 #detect name of cluster output=`curl -u hadoopadmin:$PASSWORD -k -i -H 'X-Requested-By: ambari' https://localhost:8443/api/v1/clusters` cluster=`echo $output | sed -n 's/.*"cluster_name" : "\([^\"]*\)".*/\1/p'` echo $cluster ## this should show the name of your cluster ## if not you can manully set this as below ## cluster=Security-HWX-LabTesting-XXXX #then kinit as hdfs using the headless keytab and the principal name sudo -u hdfs kinit -kt /etc/security/keytabs/hdfs.headless.keytab "hdfs-${cluster,,}" #Create the Ranger KMS Audit Directory sudo -u hdfs hdfs dfs -mkdir -p /ranger/audit/kms sudo -u hdfs hdfs dfs -chown -R kms:hdfs /ranger/audit/kms sudo -u hdfs hdfs dfs -chmod 700 /ranger/audit/kms sudo -u hdfs hdfs dfs -ls /ranger/audit/kms- Access Manager > HDFS > (clustername)_hdfs
- This will open the list of HDFS policies
- Create a new policy for keyadmin to be able to access /ranger/audit/kms and Save

- Your policy has been added
-
Give keyadmin permission to view Audits screen in Ranger:
- Settings tab > Permissions

- Click 'Audit' to change users who have access to Audit screen
- Under 'Select User', add 'keyadmin' user

- Save
- Settings tab > Permissions
-
-
Logout of Ranger
- Top right > admin > Logout
-
Login to Ranger as keyadmin/keyadmin
-
Confirm the KMS repo was setup correctly
- Under Service Manager > KMS > Click the Edit icon (next to the trash icon) to edit the KMS repo

- Click 'Test connection' and confirm it works
- Under Service Manager > KMS > Click the Edit icon (next to the trash icon) to edit the KMS repo
-
Create a key called testkey - for reference: see doc
- Select Encryption > Key Management
- Select KMS service > pick your kms > Add new Key
- if an error is thrown, go back and test connection as described in previous step
- Create a key called
testkey> Save
-
Similarly, create another key called
testkey2- Select Encryption > Key Management
- Select KMS service > pick your kms > Add new Key
- Create a key called
testkey2> Save
-
Add user
hadoopadminto default KMS key policy-
Click Access Manager tab
-
Click Service Manager > KMS > (clustername)_kms link
-
Edit the default policy

-
Under 'Select User', Add
hadoopadminuser and click Save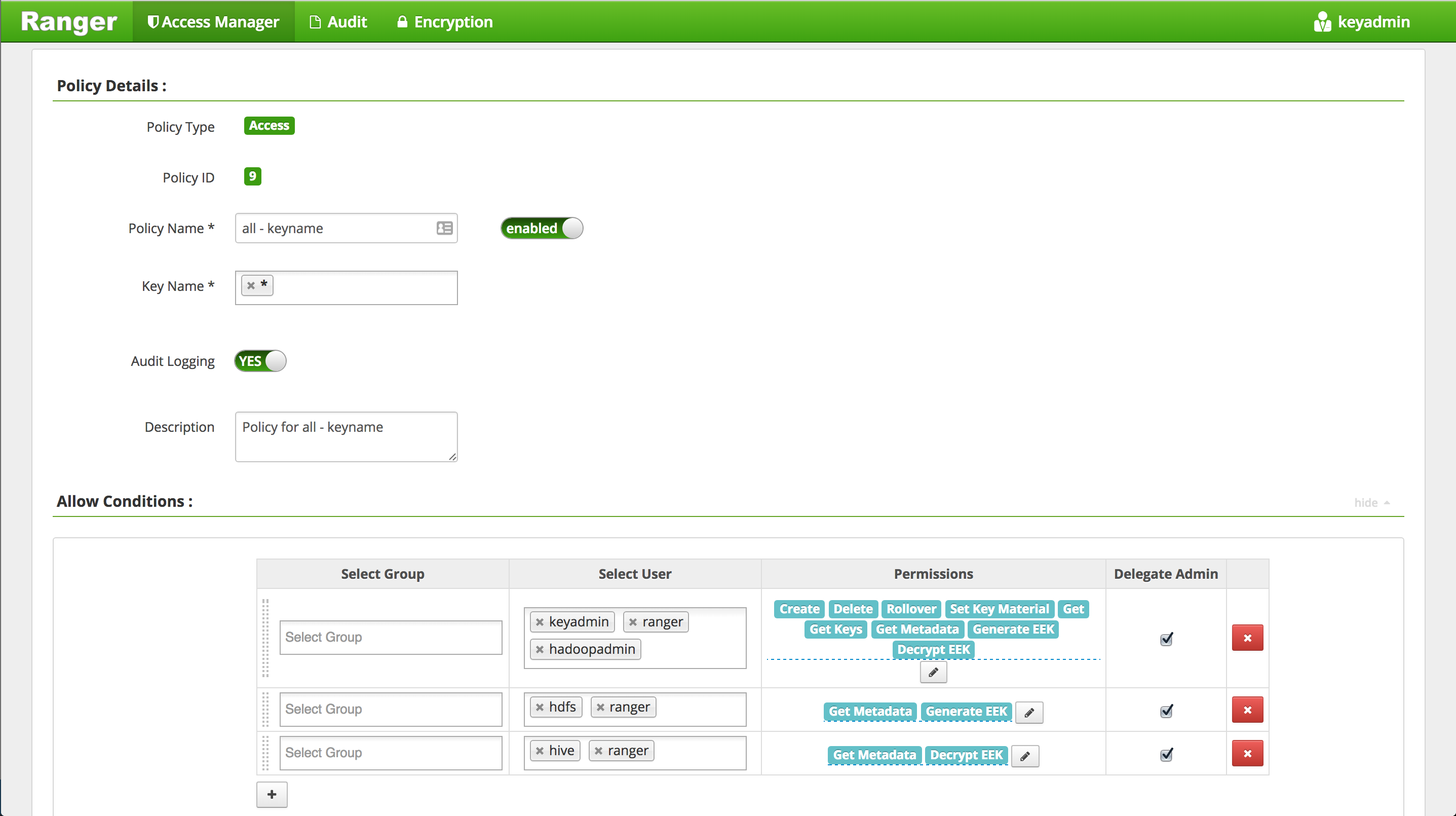
- Note that:
hdfsuser needsGetMetaDataandGenerateEEKprivilege - HDP 2.5nnuser needsGetMetaDataandGenerateEEKprivilege - HDP 2.4hiveuser needsGetMetaDataandDecryptEEKprivilege
- Note that:
-
-
Run below to create a zone using the key and perform basic key and encryption zone (EZ) exercises
- Create EZs using keys
- Copy file to EZs
- Delete file from EZ
- View contents for raw file
- Prevent access to raw file
- Copy file across EZs
- move hive warehouse dir to EZ











#run below on Ambari node
export PASSWORD=BadPass#1
#detect name of cluster
output=`curl -u hadoopadmin:$PASSWORD -k -i -H 'X-Requested-By: ambari' https://localhost:8443/api/v1/clusters`
cluster=`echo $output | sed -n 's/.*"cluster_name" : "\([^\"]*\)".*/\1/p'`
echo $cluster
## this should show the name of your cluster
## if not you can manully set this as below
## cluster=Security-HWX-LabTesting-XXXX
#first we will run login 3 different users: hdfs, hadoopadmin, sales1
#kinit as hadoopadmin and sales using BadPass#1
sudo -u hadoopadmin kinit [email protected]
## enter BadPass#1
sudo -u sales1 kinit [email protected]
## enter BadPass#1
#then kinit as hdfs using the headless keytab and the principal name
sudo -u hdfs kinit -kt /etc/security/keytabs/hdfs.headless.keytab "hdfs-${cluster,,}"
#as hadoopadmin list the keys and their metadata
sudo -u hadoopadmin hadoop key list -metadata
#as hadoopadmin create dirs for EZs
sudo -u hadoopadmin hdfs dfs -mkdir /zone_encr
sudo -u hadoopadmin hdfs dfs -mkdir /zone_encr2
#as hdfs create 2 EZs using the 2 keys
sudo -u hdfs hdfs crypto -createZone -keyName testkey -path /zone_encr
sudo -u hdfs hdfs crypto -createZone -keyName testkey2 -path /zone_encr2
# if you get 'RemoteException' error it means you have not given namenode user permissions on testkey by creating a policy for KMS in Ranger
#check EZs got created
sudo -u hdfs hdfs crypto -listZones
#create test files
sudo -u hadoopadmin echo "My test file1" > /tmp/test1.log
sudo -u hadoopadmin echo "My test file2" > /tmp/test2.log
#copy files to EZs
sudo -u hadoopadmin hdfs dfs -copyFromLocal /tmp/test1.log /zone_encr
sudo -u hadoopadmin hdfs dfs -copyFromLocal /tmp/test2.log /zone_encr
sudo -u hadoopadmin hdfs dfs -copyFromLocal /tmp/test2.log /zone_encr2
#Notice that hadoopadmin allowed to decrypt EEK but not sales user (since there is no Ranger policy allowing this)
sudo -u hadoopadmin hdfs dfs -cat /zone_encr/test1.log
sudo -u hadoopadmin hdfs dfs -cat /zone_encr2/test2.log
#this should work
sudo -u sales1 hdfs dfs -cat /zone_encr/test1.log
## this should give you below error
## cat: User:sales1 not allowed to do 'DECRYPT_EEK' on 'testkey'
-
Check the Ranger > Audit page and notice that the request from hadoopadmin was allowed but the request from sales1 was denied
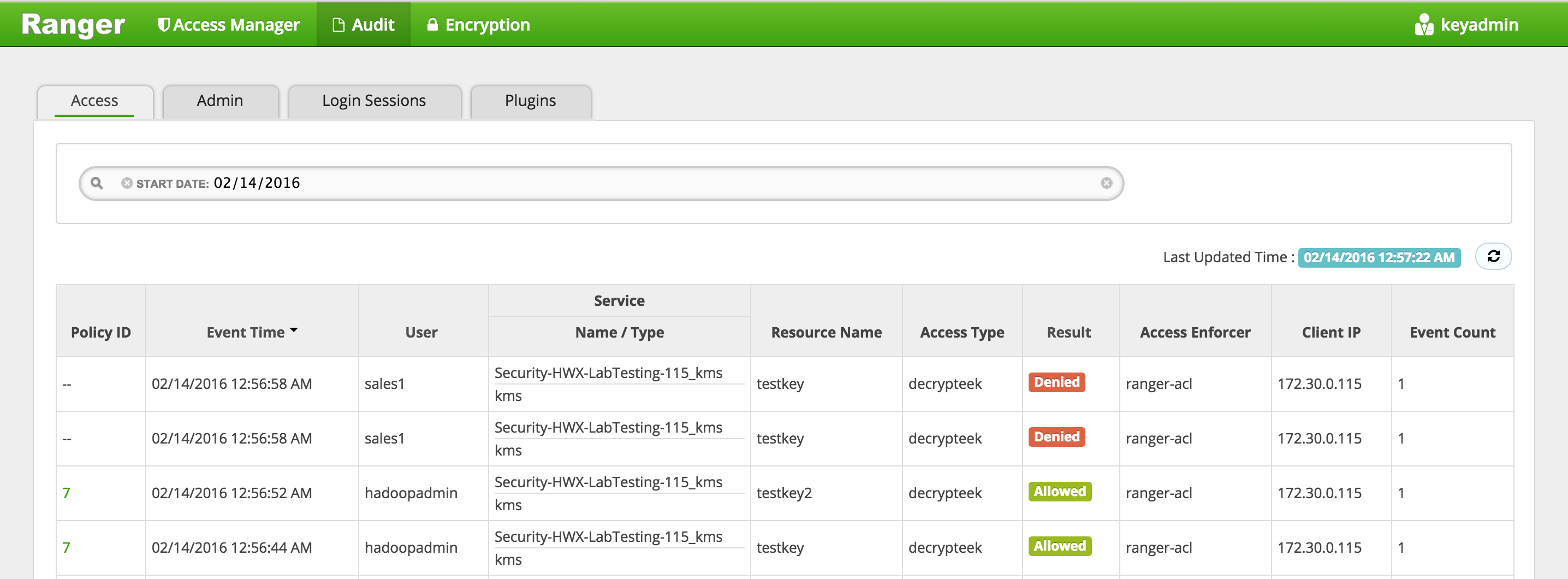
-
Now lets test deleting and copying files between EZs - (Reference doc)
#Notice that removing file from EZ using usual -rm command woks (note: Prior to HDP2.4.3, you would need to pass the -skipTrash option)
sudo -u hadoopadmin hdfs dfs -rm /zone_encr/test2.log
#confirm that test2.log was deleted and that zone_encr only contains test1.log
sudo -u hadoopadmin hdfs dfs -ls /zone_encr/
#copy a file between EZs using distcp with -skipcrccheck option
sudo -u hadoopadmin hadoop distcp -skipcrccheck -update /zone_encr2/test2.log /zone_encr/
- Lets now look at the contents of the raw file
#View contents of raw file in encrypted zone as hdfs super user. This should show some encrypted characters
sudo -u hdfs hdfs dfs -cat /.reserved/raw/zone_encr/test1.log
#Prevent user hdfs from reading the file by setting security.hdfs.unreadable.by.superuser attribute. Note that this attribute can only be set on files and can never be removed.
sudo -u hdfs hdfs dfs -setfattr -n security.hdfs.unreadable.by.superuser /.reserved/raw/zone_encr/test1.log
# Now as hdfs super user, try to read the files or the contents of the raw file
sudo -u hdfs hdfs dfs -cat /.reserved/raw/zone_encr/test1.log
## You should get below error
##cat: Access is denied for hdfs since the superuser is not allowed to perform this operation.
- Configure Hive for HDFS Encryption using testkey. Reference
sudo -u hadoopadmin hdfs dfs -mv /apps/hive /apps/hive-old
sudo -u hadoopadmin hdfs dfs -mkdir /apps/hive
sudo -u hdfs hdfs crypto -createZone -keyName testkey -path /apps/hive
sudo -u hadoopadmin hadoop distcp -skipcrccheck -update /apps/hive-old/warehouse /apps/hive/warehouse
-
To configure the Hive scratch directory (hive.exec.scratchdir) so that it resides inside the encryption zone:
- Ambari > Hive > Configs > Advanced
- hive.exec.scratchdir = /apps/hive/tmp
- Restart Hive
- Ambari > Hive > Configs > Advanced
-
Make sure that the permissions for /apps/hive/tmp are set to 1777
sudo -u hdfs hdfs dfs -chmod -R 1777 /apps/hive/tmp
- Confirm permissions by accessing the scratch dir as sales1
sudo -u sales1 hdfs dfs -ls /apps/hive/tmp
## this should provide listing
- Destroy ticket for sales1
sudo -u sales1 kdestroy
- Logout of Ranger as keyadmin user
In this lab we will see how to interact with Hadoop components (HDFS, Hive, Hbase, Sqoop) running on a kerborized cluster and create Ranger appropriate authorization policies for access.
- We will Configure Ranger policies to:
- Protect /sales HDFS dir - so only sales group has access to it
- Protect sales hive table - so only sales group has access to it
- Protect sales HBase table - so only sales group has access to it
-
Goal: Create a /sales dir in HDFS and ensure only users belonging to sales group (and admins) have access
-
Login to Ranger (using admin/admin) and confirm the HDFS repo was setup correctly in Ranger
-
Create /sales dir in HDFS as hadoopadmin
#authenticate
sudo -u hadoopadmin kinit
# enter password: BadPass#1
#create dir and set permissions to 000
sudo -u hadoopadmin hdfs dfs -mkdir /sales
sudo -u hadoopadmin hdfs dfs -chmod 000 /sales
- Now login as sales1 and notice it obtained a ticket for you under the covers
su - sales1
klist
## Default principal: [email protected]
-
If you did not have a valid ticket, this would have failed with
GSSException: No valid credentials providedbecause the cluster is kerberized and we have not authenticated yet -
Now try accessing the dir again as sales1 before adding any Ranger HDFS policy
hdfs dfs -ls /sales
-
Notice fails with authorization error:
Permission denied: user=sales1, access=READ_EXECUTE, inode="/sales":hadoopadmin:hdfs:d---------
-
Login into Ranger UI e.g. at http://RANGER_HOST_PUBLIC_IP:6080/index.html as admin/admin
-
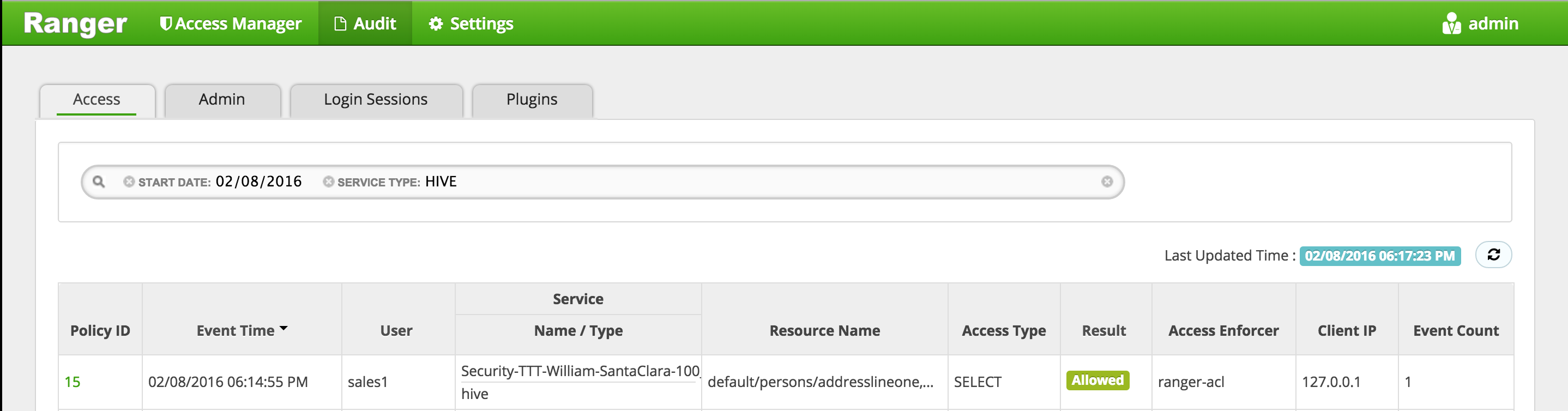
In Ranger, click on 'Audit' to open the Audits page and filter by below.
- Service Type:
HDFS - User:
sales1
- Service Type:
-
Notice that Ranger captured the access attempt and since there is currently no policy to allow the access, it was "Denied"
-
To create an HDFS Policy in Ranger, follow below steps:
- On the 'Access Manager' tab click HDFS > (clustername)_hadoop
- This will open the list of HDFS policies

- Click 'Add New Policy' button to create a new one allowing
salesgroup users access to/salesdir:- Policy Name:
sales dir - Resource Path:
/sales - Group:
sales - Permissions :
Execute Read Write - Add
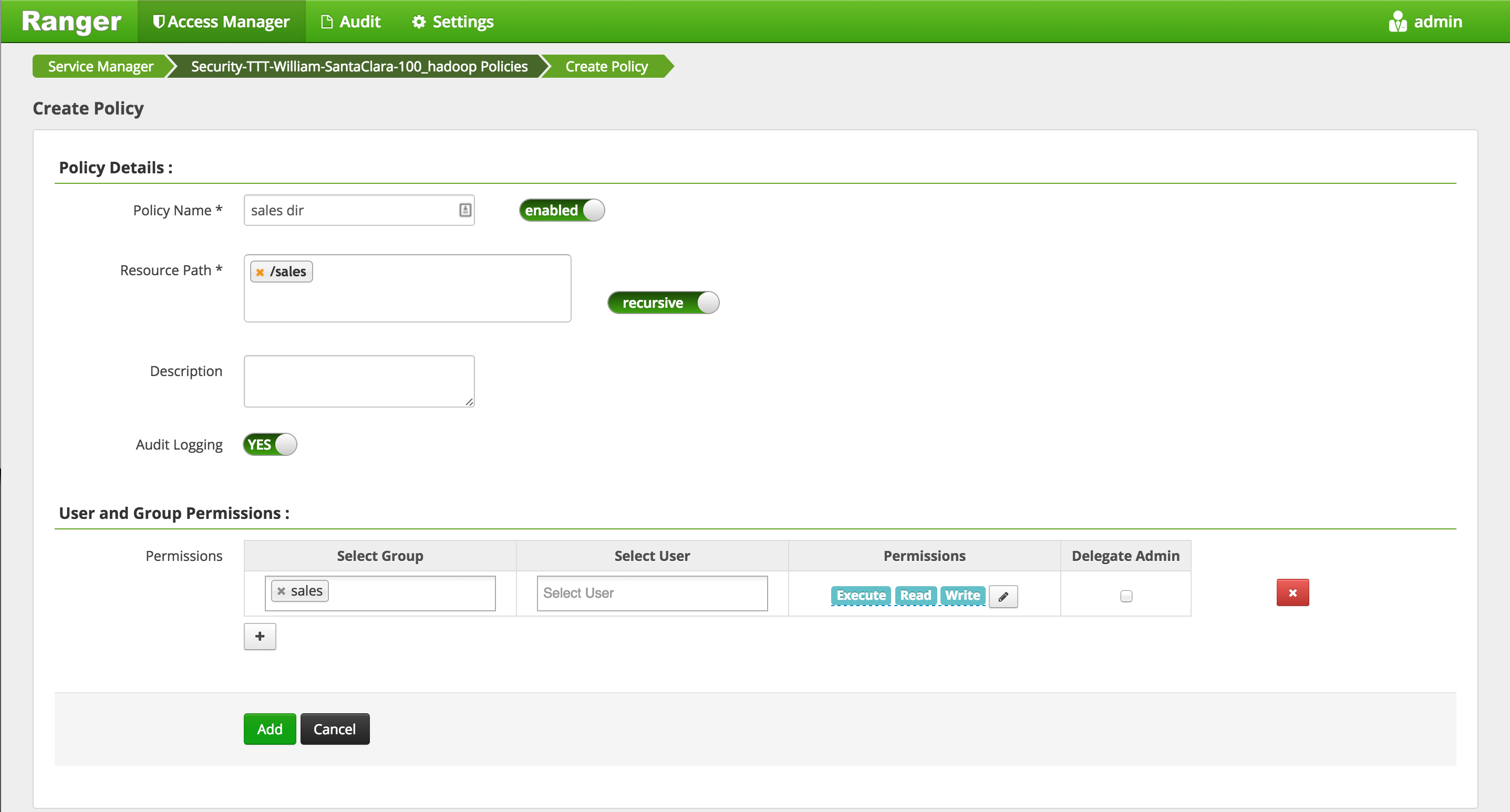
- Policy Name:
- On the 'Access Manager' tab click HDFS > (clustername)_hadoop
-
Wait 30s for policy to take effect
-
Now try accessing the dir again as sales1 and now there is no error seen
hdfs dfs -ls /sales
-
In Ranger, click on 'Audit' to open the Audits page and filter by below:
- Service Type: HDFS
- User: sales1
-
Notice that Ranger captured the access attempt and since this time there is a policy to allow the access, it was
Allowed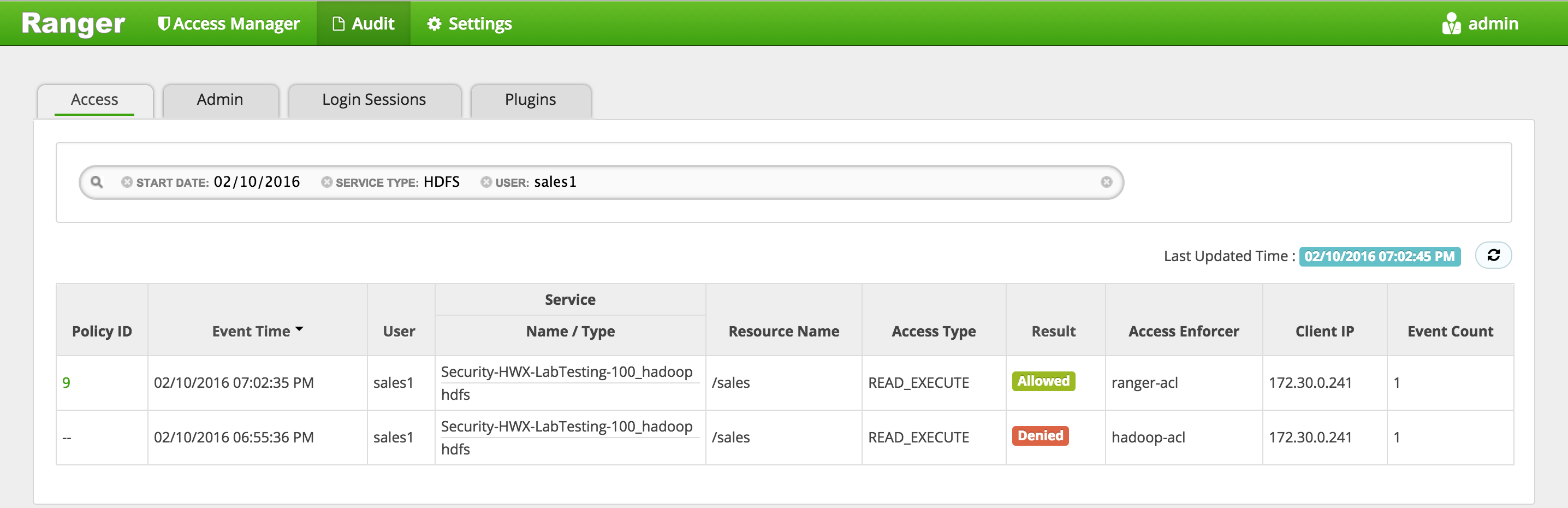
- You can also see the details that were captured for each request:
- Policy that allowed the access
- Time
- Requesting user
- Service type (e.g. hdfs, hive, hbase etc)
- Resource name
- Access type (e.g. read, write, execute)
- Result (e.g. allowed or denied)
- Access enforcer (i.e. whether native acl or ranger acls were used)
- Client IP
- Event count
- You can also see the details that were captured for each request:
-
For any allowed requests, notice that you can quickly check the details of the policy that allowed the access by clicking on the policy number in the 'Policy ID' column
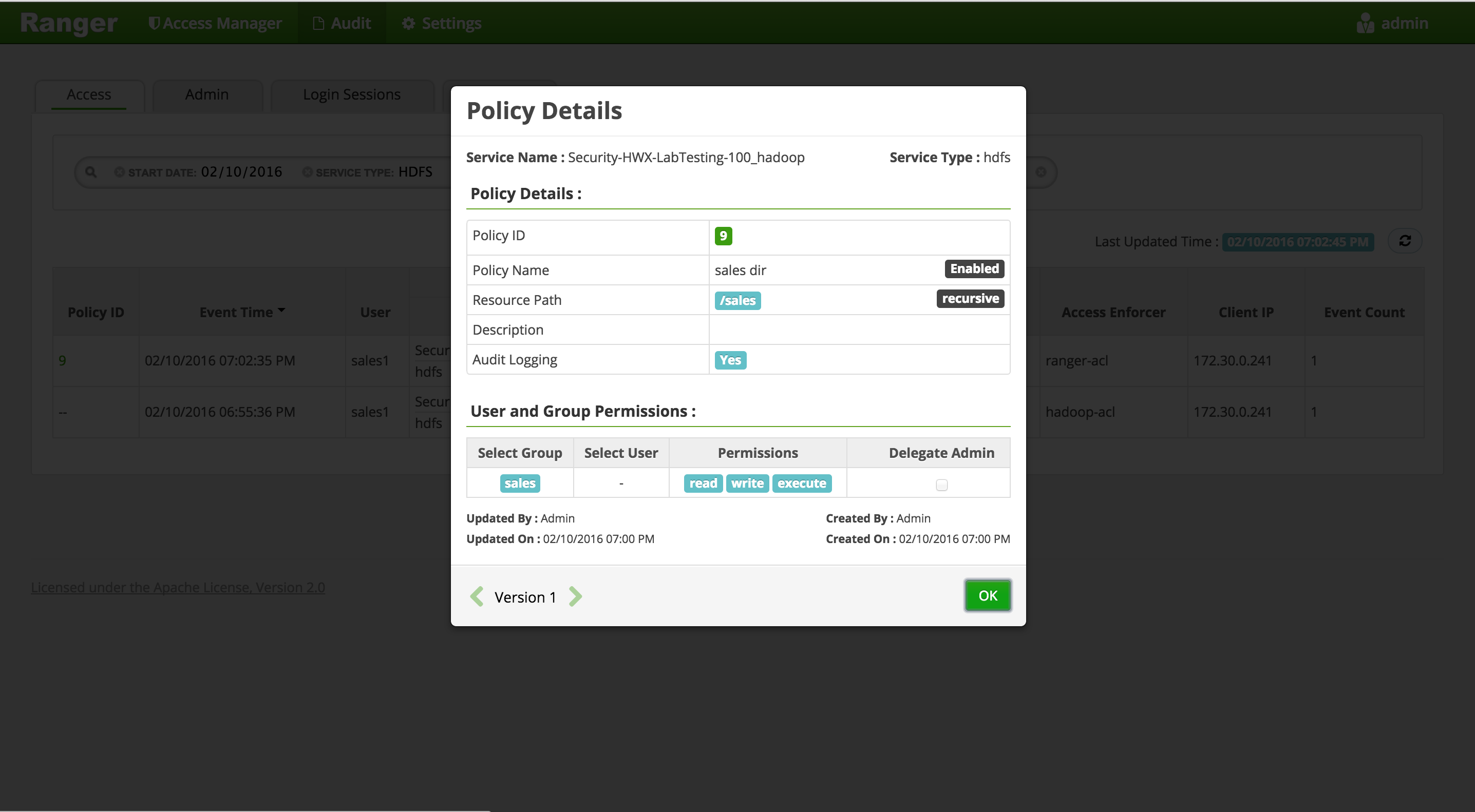
-
Now let's check whether non-sales users can access the directory
-
Logout as sales1 and log back in as hr1
#logout as sales1
logout
#login as hr1 and authenticate using password BadPass#1
su - hr1
klist
## Default principal: [email protected]
- Try to access the same dir as hr1 and notice it fails
hdfs dfs -ls /sales
## ls: Permission denied: user=hr1, access=READ_EXECUTE, inode="/sales":hadoopadmin:hdfs:d---------
-
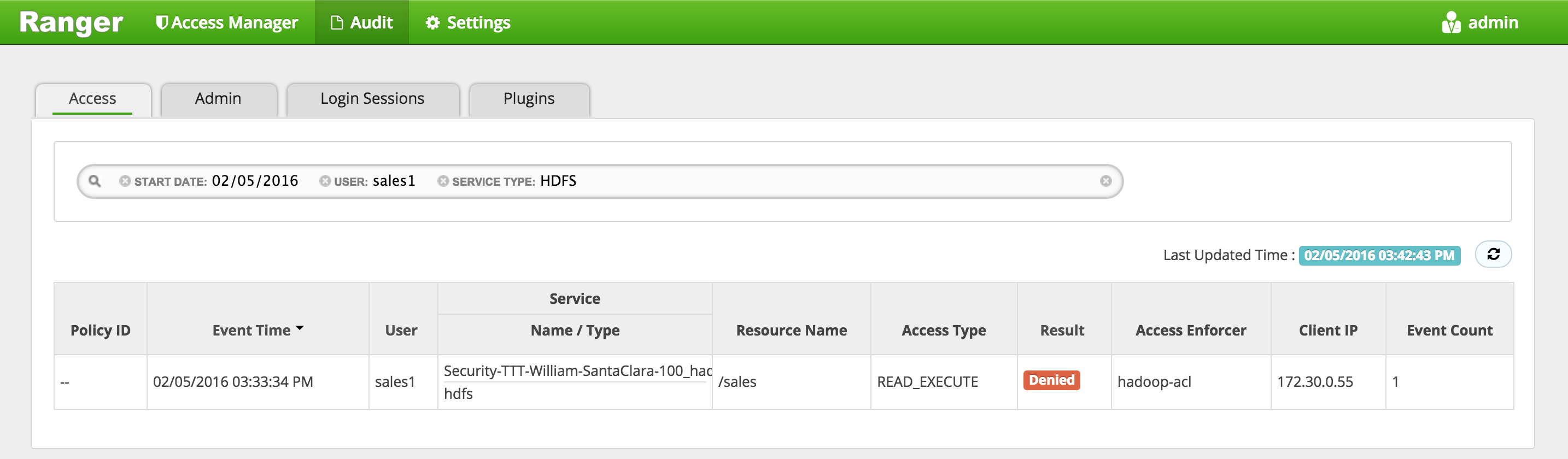
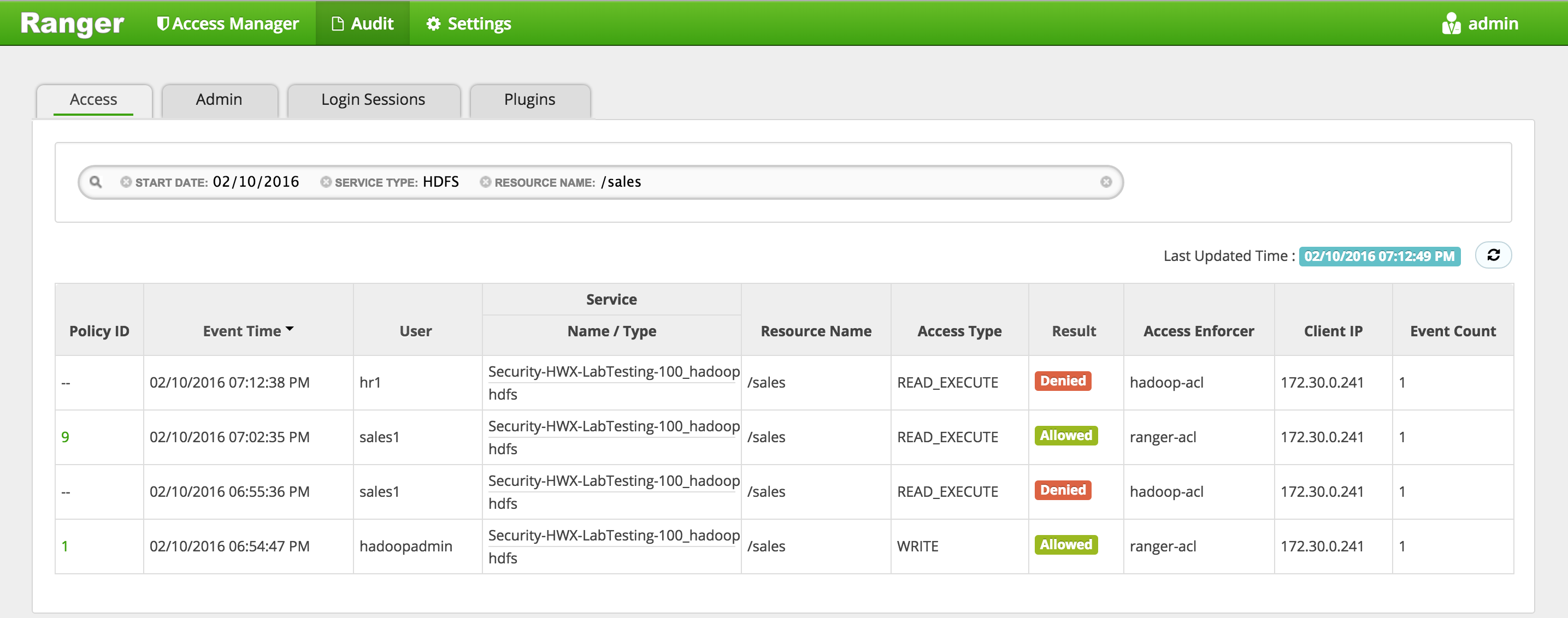
In Ranger, click on 'Audit' to open the Audits page and this time filter by 'Resource Name'
- Service Type:
HDFS - Resource Name:
/sales
- Service Type:
-
Notice you can see the history/details of all the requests made for /sales directory:
- created by hadoopadmin
- initial request by sales1 user was denied
- subsequent request by sales1 user was allowed (once the policy was created)
- request by hr1 user was denied
-
Logout as hr1
logout
- We have successfully setup an HDFS dir which is only accessible by sales group (and admins)
-
Goal: Setup Hive authorization policies to ensure sales users only have access to code, description columns in default.sample_07
-
Run these steps from node where Hive (or client) is installed
-
Login as sales1 and attempt to connect to default database in Hive via beeline and access sample_07 table
-
Notice that in the JDBC connect string for connecting to an secured Hive while its running in default (ie binary) transport mode :
- port remains 10000
- now a kerberos principal needs to be passed in
-
Login as sales1 and notice it automatically provided a kerberos ticket:
su - sales1
klist
## Default principal: [email protected]
- Now try connect to Hive via beeline as sales1
beeline -u "jdbc:hive2://localhost:10000/default;principal=hive/$(hostname -f)@LAB.HORTONWORKS.NET"
-
If you did not have a valid ticket, it would have thrown a
GSS initiate failedbecause the cluster is kerberized and we have not authenticated yet -
If you get the below error, it is because you did not add hive to the global KMS policy in an earlier step (along with nn, hadoopadmin). Go back and add it in.
org.apache.hadoop.security.authorize.AuthorizationException: User:hive not allowed to do 'GET_METADATA' on 'testkey'
- Now try to run a query
beeline> select code, description from sample_07;
-
Now it fails with authorization error:
HiveAccessControlException Permission denied: user [sales1] does not have [SELECT] privilege on [default/sample_07]
-
Login into Ranger UI e.g. at http://RANGER_HOST_PUBLIC_IP:6080/index.html as admin/admin
-
In Ranger, click on 'Audit' to open the Audits page and filter by below.
- Service Type:
Hive - User:
sales1
- Service Type:
-
Notice that Ranger captured the access attempt and since there is currently no policy to allow the access, it was
Denied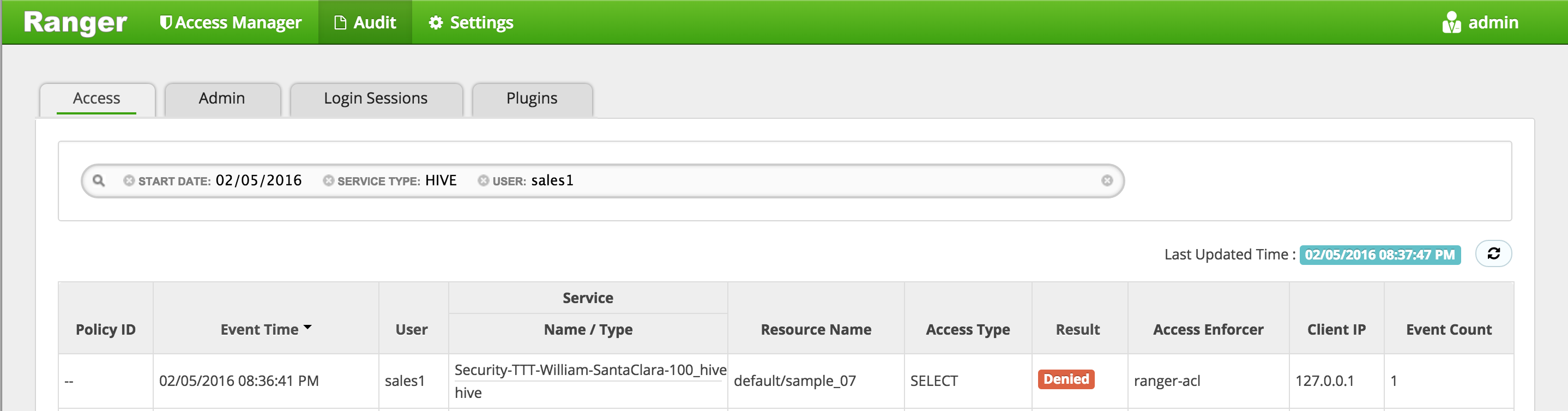
-
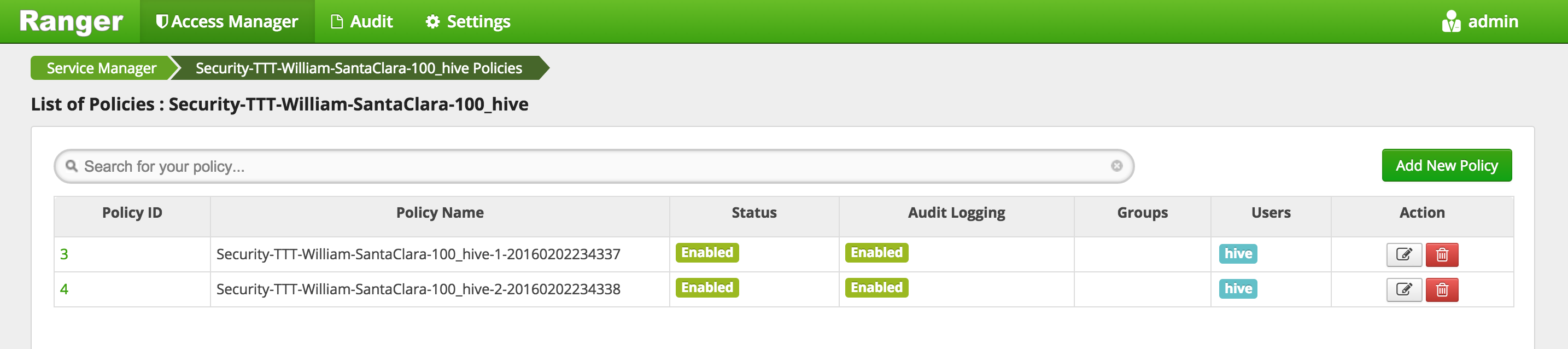
To create an HIVE Policy in Ranger, follow below steps:
- On the 'Access Manager' tab click HIVE > (clustername)_hive
- This will open the list of HIVE policies
- Click 'Add New Policy' button to create a new one allowing
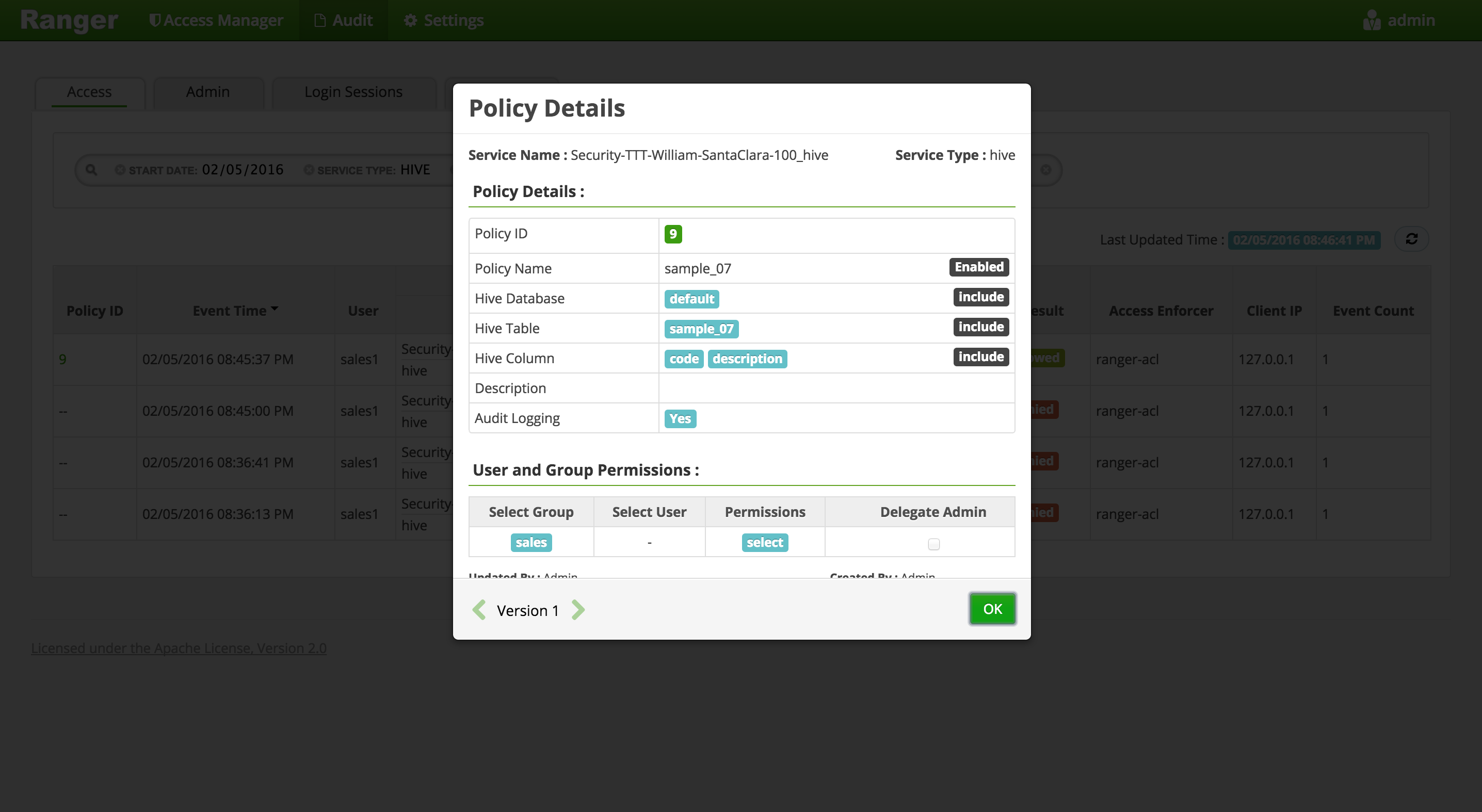
salesgroup users access tocodeanddescriptioncolumns insample_07dir:- Policy Name:
sample_07 - Hive Database:
default - table:
sample_07 - Hive Column:
codedescriptiontotal_emp - Group:
sales - Permissions :
select - Add
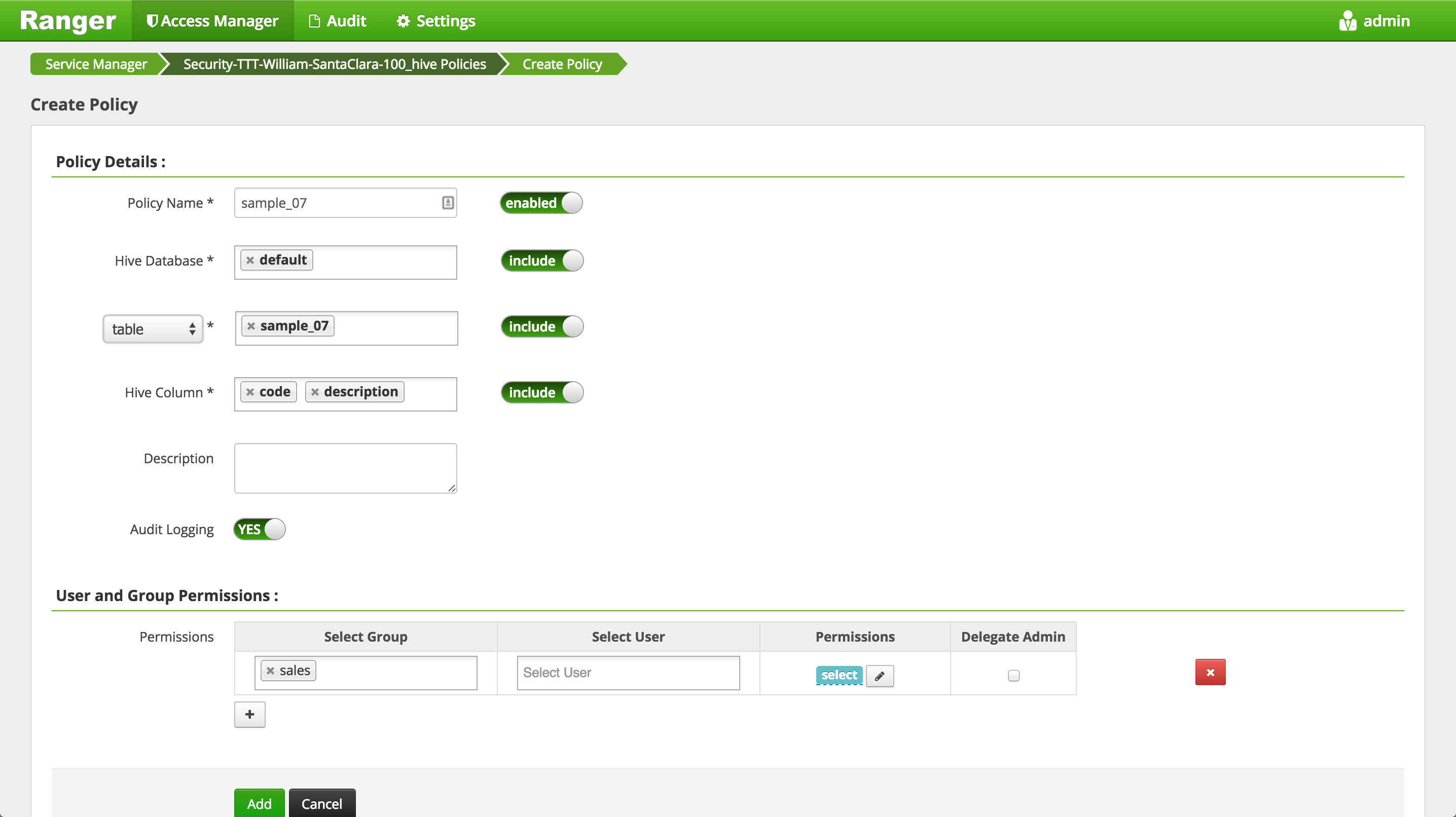
- Policy Name:
- On the 'Access Manager' tab click HIVE > (clustername)_hive
-
Notice that as you typed the name of the DB and table, Ranger was able to look these up and autocomplete them
- This was done using the rangerlookup principal
- Note in HDP 2.6.1.0, there is a bug where the lookup for Hive does not work
-
Also, notice that permissions are only configurable for allowing access, and you are not able to explicitly deny a user/group access to a resource unless you have enabled Deny Conditions during your Ranger install (step 8).
-
Wait 30s for the new policy to be picked up
-
Now try accessing the columns again and now the query works
beeline> select code, description, total_emp from sample_07;
-
Note though, that if instead you try to describe the table or query all columns, it will be denied - because we only gave sales users access to two columns in the table
beeline> desc sample_07;beeline> select * from sample_07;
-
In Ranger, click on 'Audit' to open the Audits page and filter by below:
- Service Type: HIVE
- User: sales1
-
Notice that Ranger captured the access attempt and since this time there is a policy to allow the access, it was
Allowed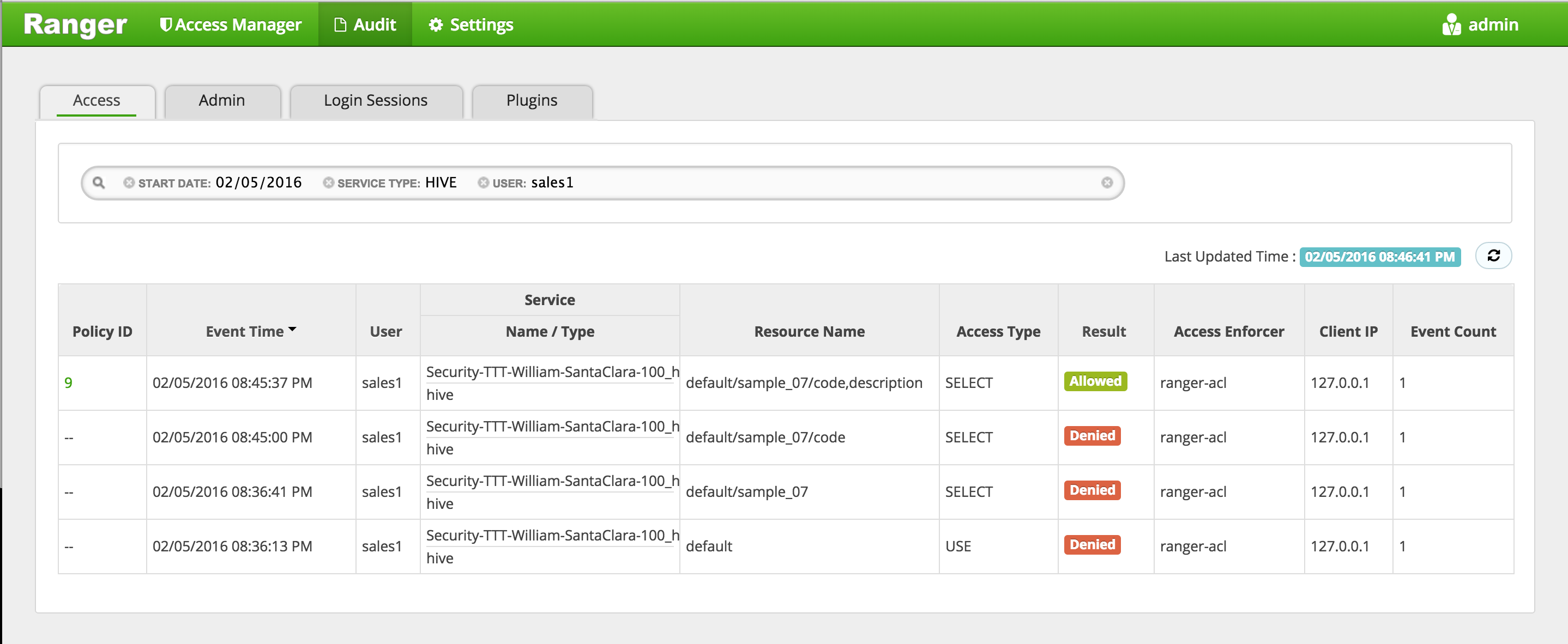
- You can also see the details that were captured for each request:
- Policy that allowed the access
- Time
- Requesting user
- Service type (e.g. hdfs, hive, hbase etc)
- Resource name
- Access type (e.g. read, write, execute)
- Result (e.g. allowed or denied)
- Access enforcer (i.e. whether native acl or ranger acls were used)
- Client IP
- Event count
- You can also see the details that were captured for each request:
-
For any allowed requests, notice that you can quickly check the details of the policy that allowed the access by clicking on the policy number in the 'Policy ID' column
-
We are able to limit sales1's access to only subset of data by using row-level filter. Suppose we only want to allow the sales group access to data where
total_empis less than 5000. -
On the Hive Policies page, select the 'Row Level Filter' tab and click on 'Add New Policy'

- Please note that in order to apply a row level filter policy the user/group must already have 'select' permissions on the table.
-
Create a policy restricting access to only rows where
total_empis less than 5000:- Policy Name:
sample_07_filter_total_emp - Hive Database:
default - table:
sample_07 - Group:
sales - Permissions :
select - Row Level Filter :
total_emp<5000- The filter syntax is similar to what you would write after a 'WHERE' clause in a SQL query
- Add

- Policy Name:
-
Wait 30s for the new policy to be picked up
-
Now try accessing the columns again and notice how only rows that match the filter criteria are shown


beeline> select code, description, total_emp from sample_07;
-
Go back to the Ranger Audits page and notice how the filter policy was applied to the query
-
Suppose we would now like to mask
total_empcolumn from sales1. This is different from denying/dis-allowing access in that the user can query the column but cannot see the actual data -
On the Hive Policies page, select the 'Masking' tab and click on 'Add New Policy'

- Please note that in order to mask a column, the user/group must already have 'select' permissions to that column. Creating a masking policy on a column that a user does not have access to will deny the user access
-
Create a policy masking the
total_empcolumn forsalesgroup users:- Policy Name:
sample_07_total_emp - Hive Database:
default - table:
sample_07 - Hive Column:
total_emp - Group:
sales - Permissions :
select - Masking Option :
redact- Notice the different masking options available
- The 'Custom' masking option can use any Hive UDF as long as it returns the same data type as that of the column
- Add

- Policy Name:
-
Wait 30s for the new policy to be picked up
-
Now try accessing the columns again and notice how the results for the
total_empcolumn is masked


beeline> select code, description, total_emp from sample_07;
-
Go back to the Ranger Audits page and notice how the masking policy was applied to the query.
-
Exit beeline
!q
-
Now let's check whether non-sales users can access the table
-
Logout as sales1 and log back in as hr1
#logout as sales1
logout
#login as hr1 and authenticate using password: BadPass#1
su - hr1
klist
## Default principal: [email protected]
- Try to access the same table as hr1 and notice it fails
beeline -u "jdbc:hive2://localhost:10000/default;principal=hive/$(hostname -f)@LAB.HORTONWORKS.NET"
beeline> select code, description from sample_07;
-
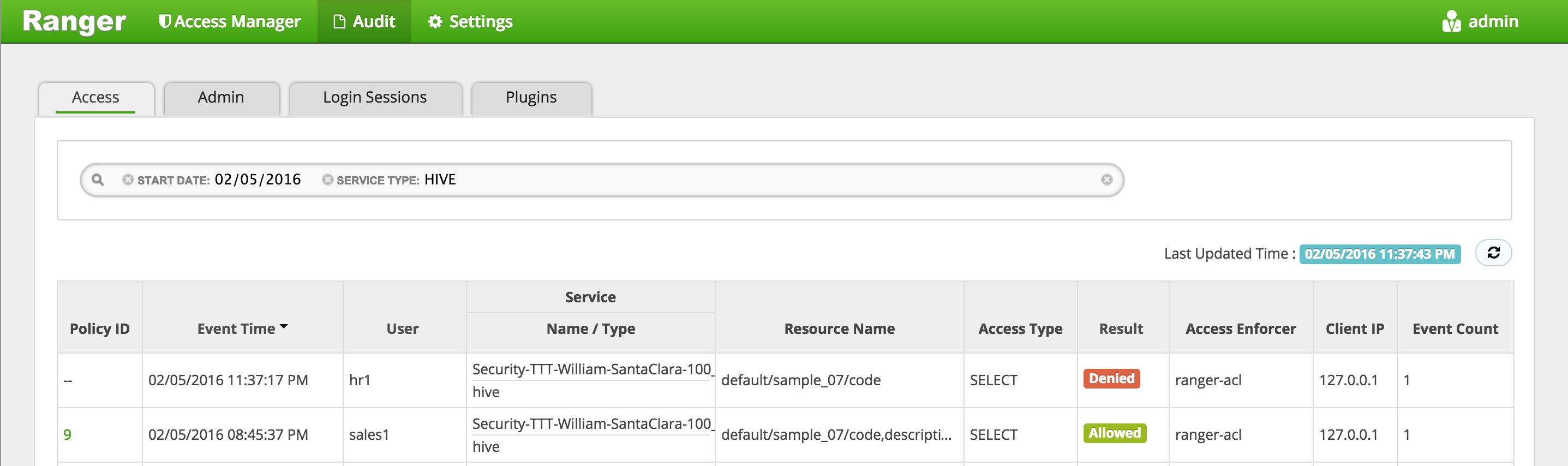
In Ranger, click on 'Audit' to open the Audits page and filter by 'Service Type' = 'Hive'
- Service Type:
HIVE
- Service Type:
-
Here you can see the request by sales1 was allowed but hr1 was denied
- Exit beeline
!q
- Logoff as hr1
logout
- We have setup Hive authorization policies to ensure only sales users have access to code, description columns in default.sample_07
-
Goal: Create a table called 'sales' in HBase and setup authorization policies to ensure only sales users have access to the table
-
Run these steps from any node where Hbase Master or RegionServer services are installed
-
Login as sales1
su - sales1
- Start the hbase shell
hbase shell
klist
## Default principal: [email protected]
- Now try connect to Hbase shell and list tables as sales1. Should return an empty list.
hbase shell
hbase> list 'default'
-
If you did not have a valid ticket, it would have failed with
GSSException: No valid credentials providedbecause the cluster is kerberized and we have not authenticated yet -
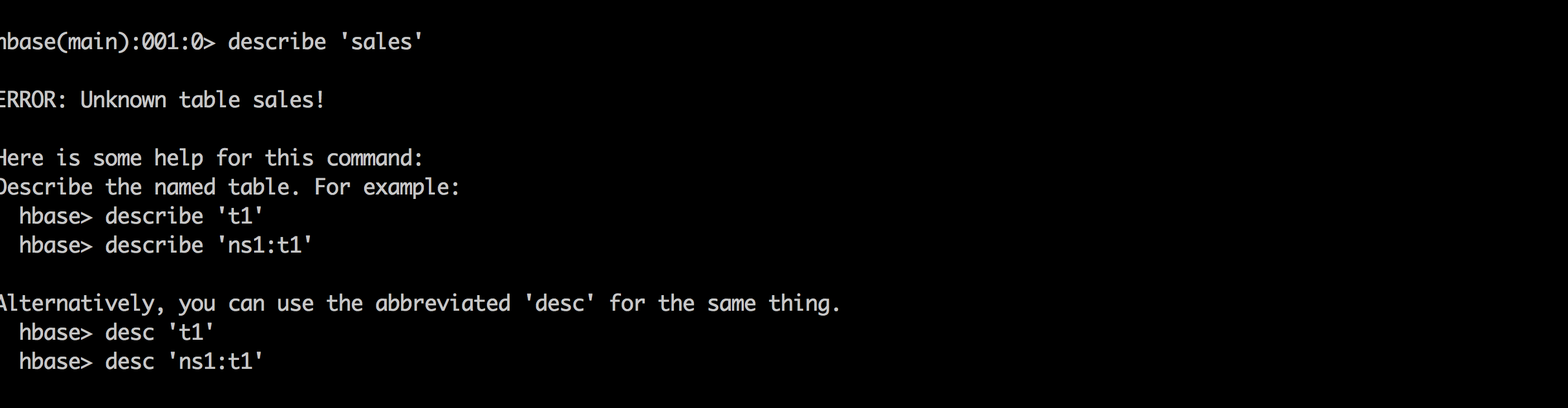
Now try to create a table called
saleswith column family calledcf
hbase> create 'sales', 'cf'
-
Now it fails with authorization error:
org.apache.hadoop.hbase.security.AccessDeniedException: Insufficient permissions for user '[email protected]' (action=create)- Note: there will be a lot of output from above. The error will be on the line right after your create command
-
Login into Ranger UI e.g. at http://RANGER_HOST_PUBLIC_IP:6080/index.html as admin/admin
-
In Ranger, click on 'Audit' to open the Audits page and filter by below.
- Service Type:
Hbase - User:
sales1
- Service Type:
-
Notice that Ranger captured the access attempt and since there is currently no policy to allow the access, it was
Denied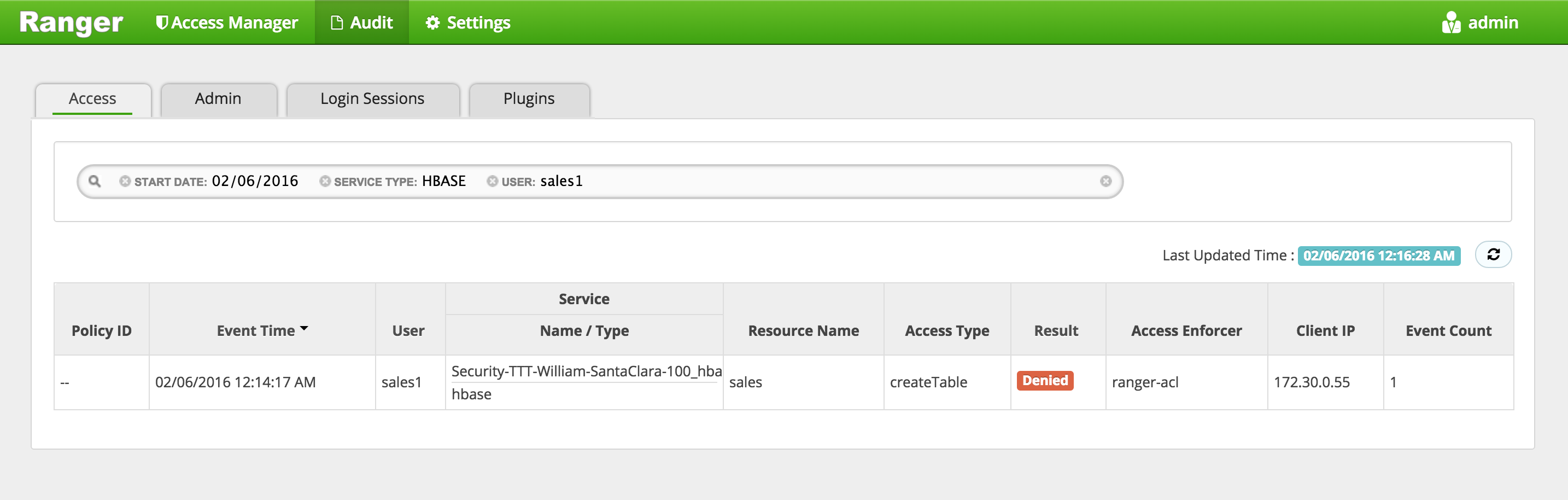
-
To create an HBASE Policy in Ranger, follow below steps:
- On the 'Access Manager' tab click HBASE > (clustername)_hbase
- This will open the list of HBASE policies
- Click 'Add New Policy' button to create a new one allowing
salesgroup users access tosalestable in HBase:- Policy Name:
sales - Hbase Table:
sales - Hbase Column Family:
* - Hbase Column:
* - Group :
sales - Permissions :
AdminCreateReadWrite - Add
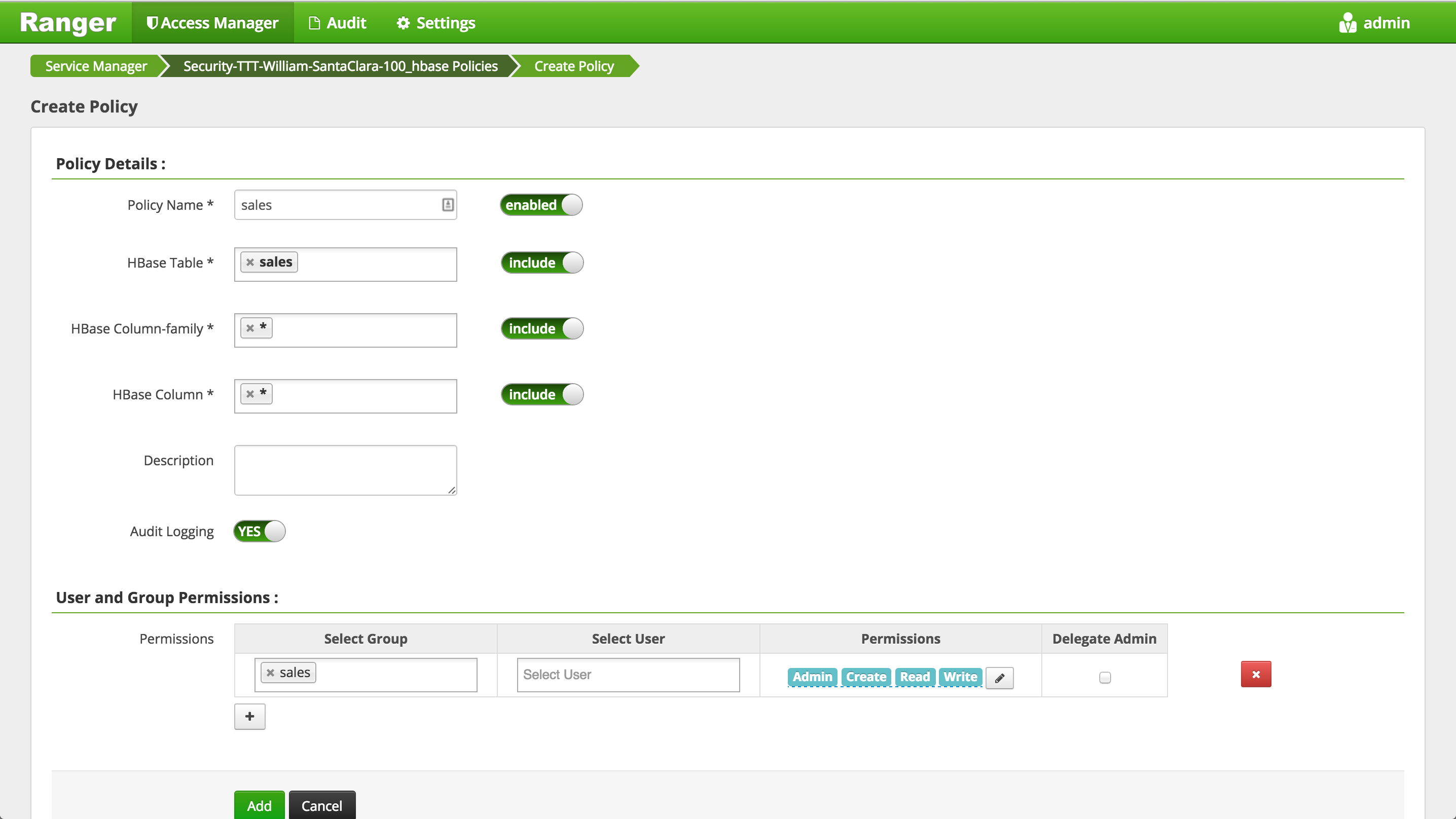
- Policy Name:
- On the 'Access Manager' tab click HBASE > (clustername)_hbase
-
Wait 30s for policy to take effect
-
Now try creating the table and now it works
hbase> create 'sales', 'cf'
-
In Ranger, click on 'Audit' to open the Audits page and filter by below:
- Service Type: HBASE
- User: sales1
-
Notice that Ranger captured the access attempt and since this time there is a policy to allow the access, it was
Allowed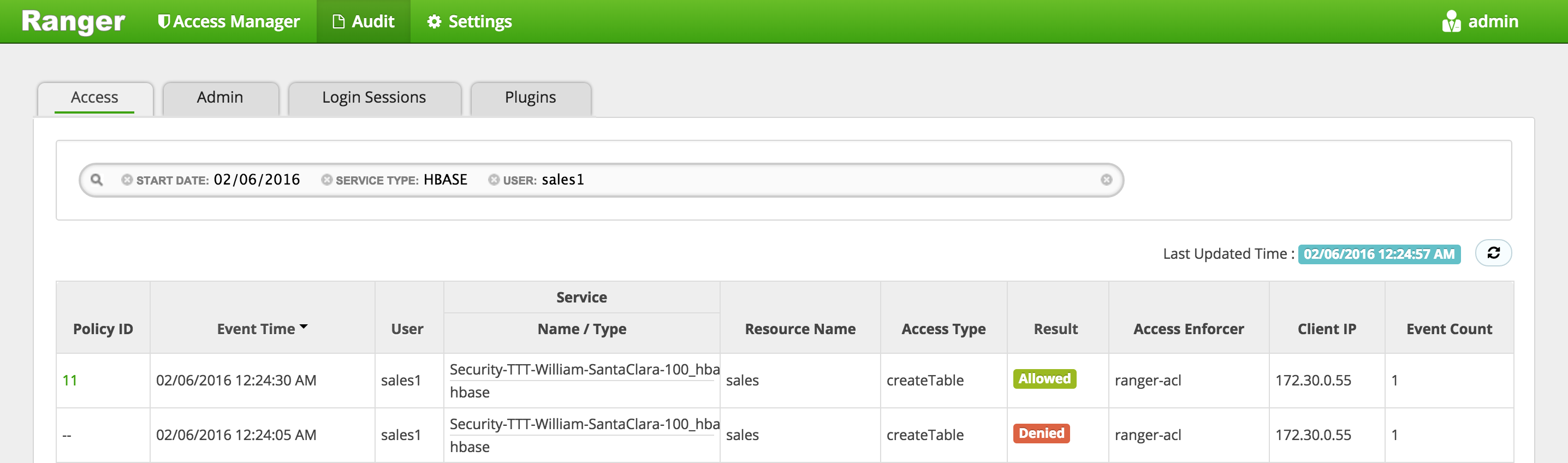
- You can also see the details that were captured for each request:
- Policy that allowed the access
- Time
- Requesting user
- Service type (e.g. hdfs, hive, hbase etc)
- Resource name
- Access type (e.g. read, write, execute)
- Result (e.g. allowed or denied)
- Access enforcer (i.e. whether native acl or ranger acls were used)
- Client IP
- Event count
- You can also see the details that were captured for each request:
-
For any allowed requests, notice that you can quickly check the details of the policy that allowed the access by clicking on the policy number in the 'Policy ID' column
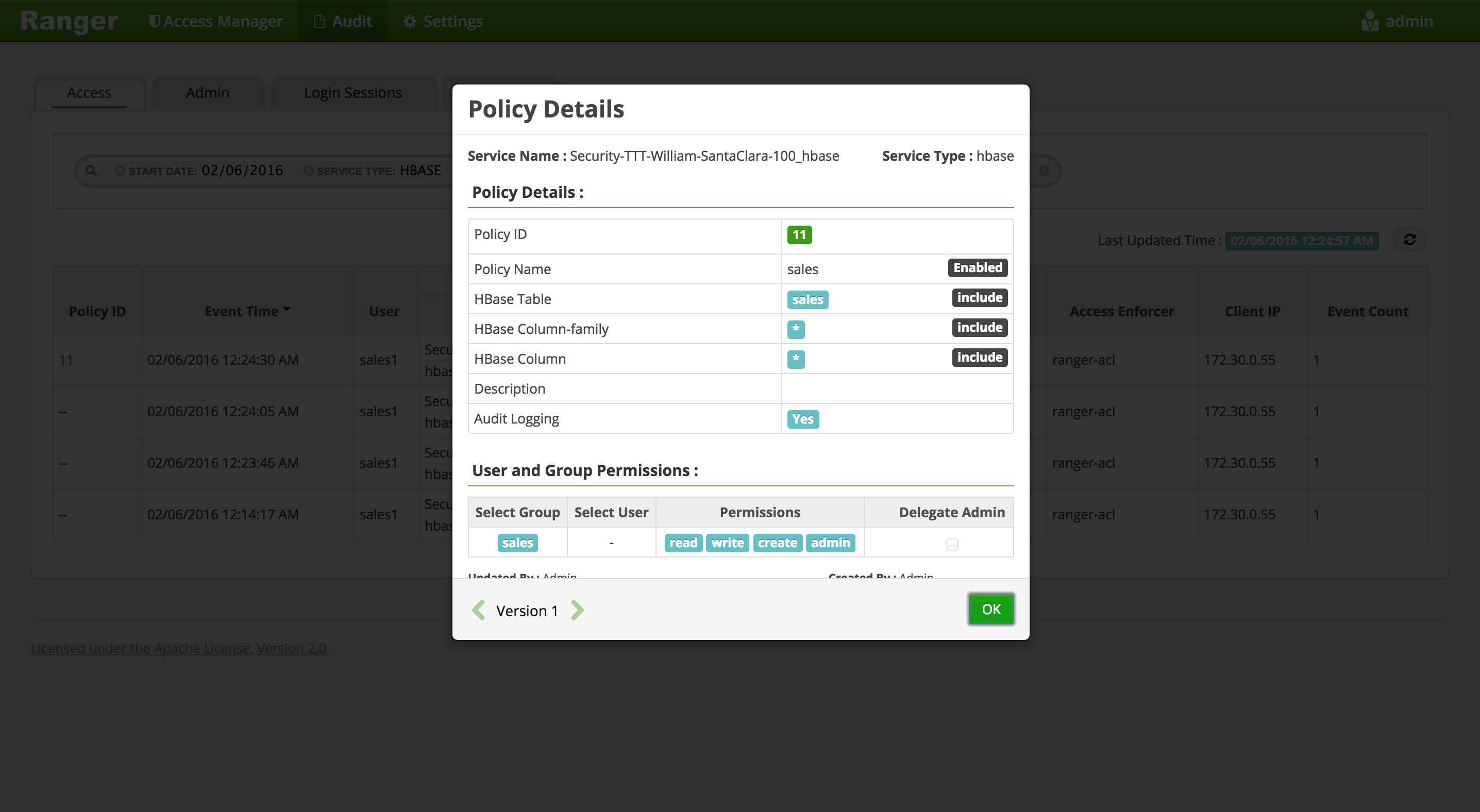
-
Exit hbase shell
hbase> exit
-
Now let's check whether non-sales users can access the table
-
Logout as sales1 and log back in as hr1
#logout as sales1
logout
#login as hr1 and authenticate using password: BadPass#1
su - hr1
klist
## Default principal: [email protected]
- Try to access the same dir as hr1 and notice this user does not even see the table
hbase shell
hbase> describe 'sales'
hbase> list 'default'
- Try to create a table as hr1 and it fails with
org.apache.hadoop.hbase.security.AccessDeniedException: Insufficient permissions
hbase> create 'sales', 'cf'
-
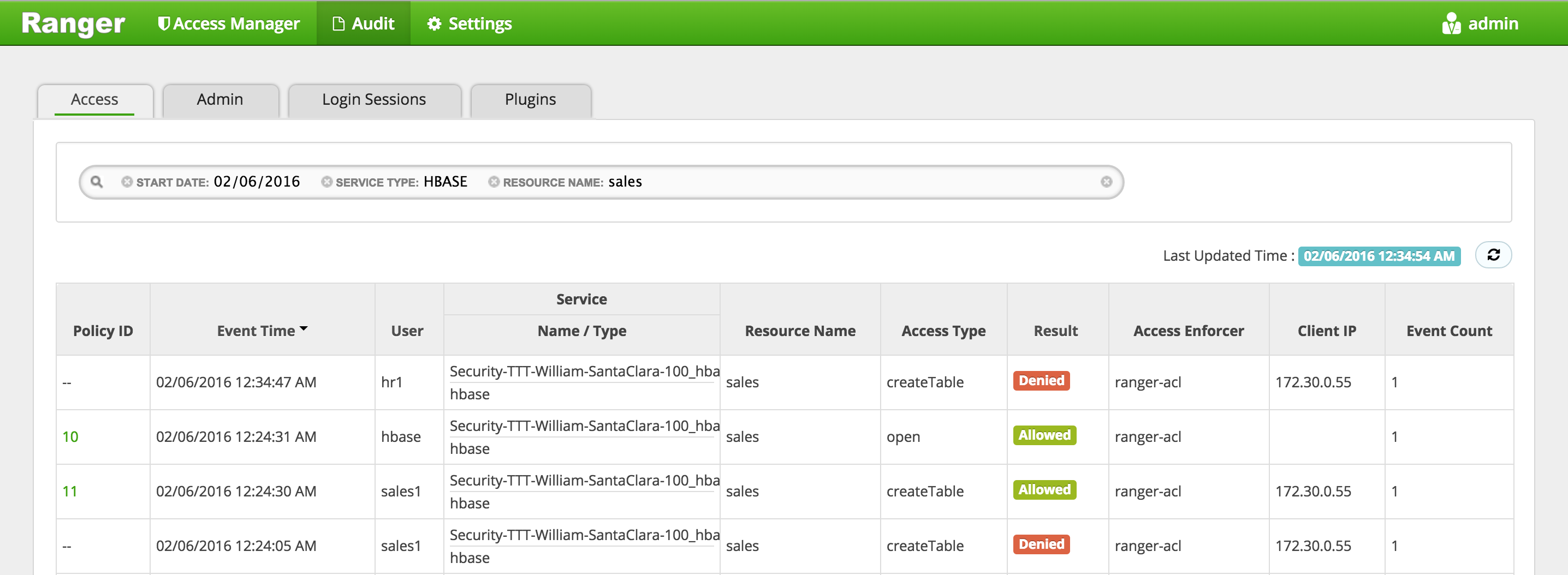
In Ranger, click on 'Audit' to open the Audits page and filter by:
- Service Type:
HBASE - Resource Name:
sales
- Service Type:
-
Here you can see the request by sales1 was allowed but hr1 was denied
- Exit hbase shell
hbase> exit
- Logout as hr1
logout
-
We have successfully created a table called 'sales' in HBase and setup authorization policies to ensure only sales users have access to the table
-
This shows how you can interact with Hadoop components on kerberized cluster and use Ranger to manage authorization policies and audits
-
If Sqoop is not already installed, install it via Ambari on same node where Mysql/Hive are installed:
- Admin > Stacks and Versions > Sqoop > Add service > select node where Mysql/Hive are installed and accept all defaults and finally click "Proceed Anyway"
- You will be asked to enter admin principal/password:
[email protected]- BadPass#1
-
On the host running Mysql: change user to root and download a sample csv and login to Mysql
sudo su -
wget https://raw.githubusercontent.com/HortonworksUniversity/Security_Labs/master/labdata/PII_data_small.csv
mysql -u root -pBadPass#1
- At the
mysql>prompt run below to:- create a table in Mysql
- give access to sales1
- import the data from csv
- test that table was created
create database people;
use people;
create table persons (people_id INT PRIMARY KEY, sex text, bdate DATE, firstname text, lastname text, addresslineone text, addresslinetwo text, city text, postalcode text, ssn text, id2 text, email text, id3 text);
GRANT ALL PRIVILEGES ON people.* to 'sales1'@'%' IDENTIFIED BY 'BadPass#1';
LOAD DATA LOCAL INFILE '~/PII_data_small.csv' REPLACE INTO TABLE persons FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n';
select people_id, firstname, lastname, city from persons where lastname='SMITH';
exit
- logoff as root
logout
-
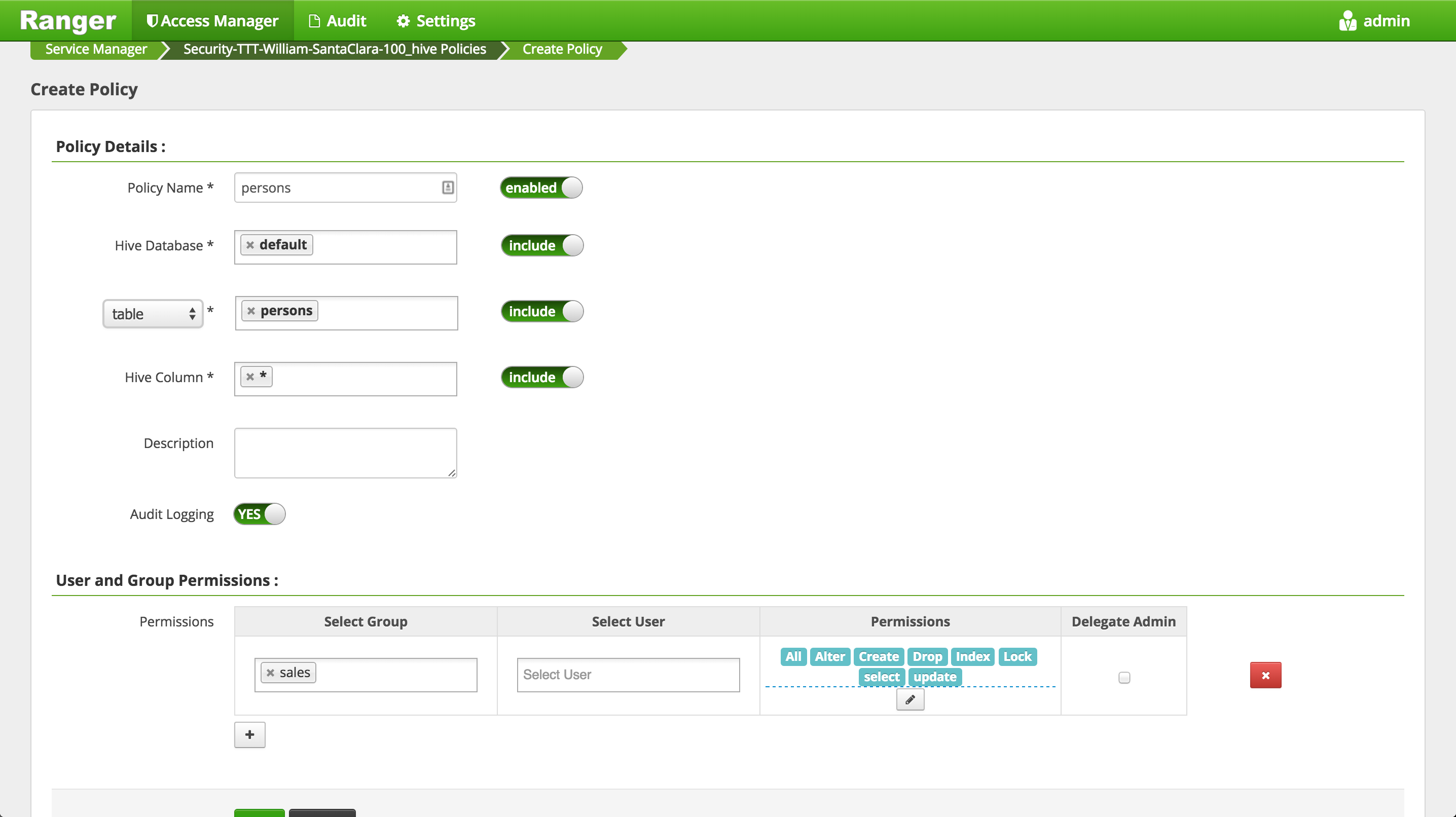
Create Ranger policy to allow
salesgroupall permissionsonpersonstable in Hive- Access Manager > Hive > (cluster)_hive > Add new policy
- Create new policy as below and click Add:
- Log out of Ranger
-
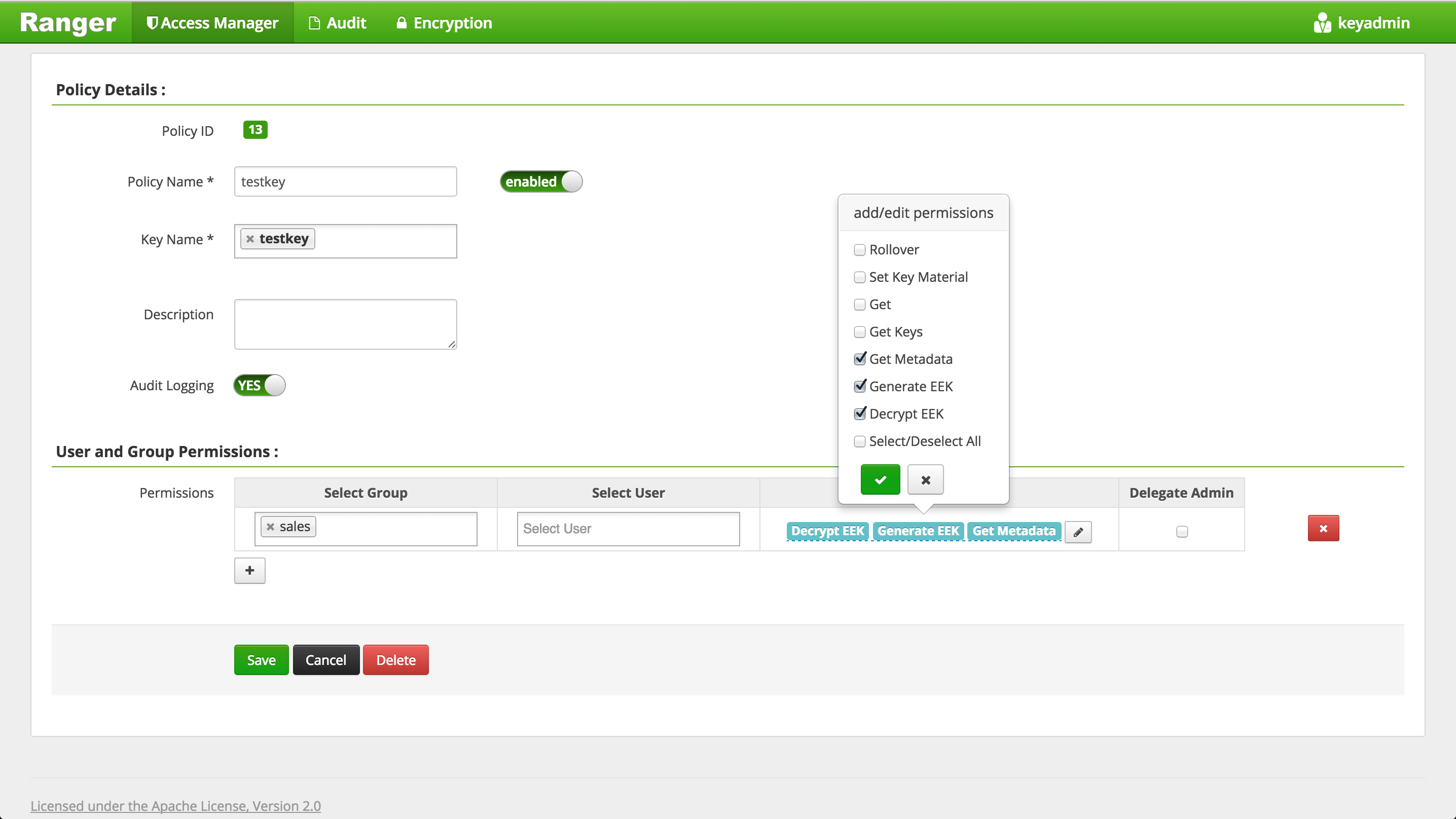
Create Ranger policy to allow
salesgroupGet MetadataGenerateEEKDecryptEEKpermissions ontestkey(i.e. the key used to encrypt Hive warehouse directories)- Login to Ranger http://RANGER_PUBLIC_IP:6080 with keyadmin/keyadmin
- Access Manager > KMS > (cluster)_KMS > Add new policy
- Create new policy as below and click Add:
- Log out of Ranger and re-login as admin/admin
-
Login as sales1 using password: BadPass#1
su - sales1
- As sales1 user, run sqoop job to create persons table in Hive (in ORC format) and import data from MySQL. Below are the details of the arguments passed in:
- Table: MySQL table name
- username: Mysql username
- password: Mysql password
- hcatalog-table: Hive table name
- create-hcatalog-table: hive table should be created first
- driver: classname for Mysql driver
- m: number of mappers
sqoop import --verbose --connect "jdbc:mysql://$(hostname -f)/people" --table persons --username sales1 --password BadPass#1 --hcatalog-table persons --hcatalog-storage-stanza "stored as orc" -m 1 --create-hcatalog-table --driver com.mysql.jdbc.Driver
-
This will start a mapreduce job to import the data from Mysql to Hive in ORC format
-
Note: if the mapreduce job fails with below, most likely you have not given sales group all the permissions needed on the EK used to encrypt Hive directories
java.lang.RuntimeException: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
-
Also note: if the mapreduce job fails saying sales user does not have write access to /apps/hive/warehouse, you will need to create HDFS policy allowing sales1 user and hive access on /apps/hive/warehouse dir
-
Login to beeline
beeline -u "jdbc:hive2://localhost:10000/default;principal=hive/$(hostname -f)@LAB.HORTONWORKS.NET"
- Query persons table in beeline
beeline> select * from persons;
-
Since the authorization policy is in place, the query should work
-
Ranger audit should show the request was allowed:
- Under Ranger > Audit > query for
- Service type: HIVE
- Service type: HIVE
- Under Ranger > Audit > query for
- From beeline, try to drop the persons table.
beeline> drop table persons;
- You will get error similar to below
message:Unable to drop default.persons because it is in an encryption zone and trash is enabled. Use PURGE option to skip trash.
- To drop a Hive table (when Hive directories are located in EncryptionZone), you need to include
purgeas below:
beeline> drop table persons purge;
- Destroy the ticket and logout as sales1
kdestroy
logout
- This completes the lab. You have now interacted with Hadoop components in secured mode and used Ranger to manage authorization policies and audits
Goal: In this lab we will explore how Atlas and Ranger integrate to enhance data access and authorization through tags
To create Tag-Based Policies, we will first need to create tags in Atlas and associate them to entities
-
Go to https://localhost:21000 and login to the Atlas UI using admin/admin for the username and pass

-
Select the "TAGS" tab and click on "Create Tag"

-
Create a new tag by inputing
- Name:
Private - Create

- Name:
-
Repeat the tag creation process above and create an additional tag named "Restricted"
-
Create a third tag named "Sensitive", however, during creation, click on "Add New Attributes" and input:
- Attribute Name:
level - Type:
int
- Attribute Name:
-
Create a fourth tag named "EXPIRES_ON", and during creation, click on "Add New Attributes" and input:
- Attribute Name:
expiry_date - Type:
int
- Attribute Name:
-
Under the "Tags" tab in the main screen you should see the list of newly created tags

-
In the search tab search using the following:
- Search By Type:
hive_table - Search By Text:
sample_08 - Search

- Search By Type:
-
To associate a tag to the "sample_08" table, click on the "+" under the Tags column in the search results for "sample_08"

-
From the dropdown select
Privateand clickAdd
-
You should see that the "Private" tag has been associated to the "sample_08" table

-
Now, in the same manner, associate the "EXPIRES_ON" tag to the "sample_08" table When prompted, select a date in the past for "expiry_date"

-
In the search results panel, click on the "sample_08" link
-
Scroll down and select the "Schema" tab

-
Select the "+" button under the Tag column for "salary" and associate the
Restrictedtag to it -
Select the "+" button under the Tag column for "total_emp" and associate the
Sensitivetag to it- When prompted, input
5for the "level"
- When prompted, input
-
On the "sample_08" table schema page you should see the table columns with the associated tags















We have now completed our preparation work in Atlas and have created the following tags and associations: - "Private" tag associated to "sample_08" table - "Sensitive" tag with a "level" of '5', associated to "sample_08.total_emp" column - "Restricted" tag associated to "sample_08.salary" column
To enable Ranger for Tag-Based Policies complete the following:
-
Select "Access Manager" and then "Tag Based Policies" from the upper left hand corner of the main Ranger UI page

-
Click on the "+" to create a new tag service

-
In the tag service page input:
- Service Name:
tags - Save

- Service Name:
-
On the Ranger UI main page, select the edit button next to your (clustername)_hive service

-
In the Edit Service page add the below and then click save
- Select Tag Service:
tags
- Select Tag Service:





We should now be able to create Tag-Based Policies for Hive
Goal: Create a Tag-Based policy for sales to access all entities tagged as "Private"
-
Select "Access Manager" and then "Tag Based Policies" from the upper left hand corner of the main Ranger UI page
-
Select the "tags" service that you had previously created
-
On the "tags Policies" page, click on "Add New Policy"

-
Input the following to create the new policy
- Policy Name:
Private Data Access - TAG:
Private - Under "Allow Conditions"
- Select Group:
sales - Component Permissions: (select
Hiveand enable all actions)
- Select Group:
- Add


- Policy Name:
-
Run these steps from node where Hive (or client) is installed
-
From node where Hive (or client) is installed, login as sales1 and connect to beeline:



su - sales1
klist
## Default principal: [email protected]
beeline -u "jdbc:hive2://localhost:10000/default;principal=hive/$(hostname -f)@LAB.HORTONWORKS.NET"
- Now try accessing table "sample_08" and notice how you have access to all the contents of the table
beeline> select * from sample_08;
Goal: Disallow everybody's access to data tagged as "Sensitive" and has an attribute "level" 5 or above
-
Return to the Ranger "tags Policies" page and "Add New Policy" with the below parameters
- Policy Name:
Sensitive Data Access - TAG:
Sensitive - Under "Deny Conditions"
- Select Group:
public - Policy Conditions/Enter boolean expression:
level>=5- Note: Boolean expressions are written in Javascript
- Component Permissions: (select
Hiveand enable all actions)
- Select Group:
- Add


- Policy Name:
-
Wait 30 seconds before trying to access the "total_emp" column in table "sample_08" and notice how you are denied access


beeline> select total_emp from sample_08;
- Now try to access the other columns and notice how you are allowed access to them access
beeline> select code, description, salary from sample_08;
Goal: Mask data tagged as "Restricted"
-
Return to the Ranger "tags Policies" page, click on the "Masking" tab in the upper right hand

-
Click on "Add New Policy" and input the below parameters
- Policy Name:
Restricted Data Access - TAG:
Restricted - Under "Mask Conditions"
- Select Group:
public - Component Permissions: (select
Hiveand enable all actions) - Select Masking Option:
Redact
- Select Group:
- Add
- Policy Name:
-
Wait 30 seconds and try run the below query. Notice how salary data has been masked

beeline> select code, description, salary from sample_08;
Goal: Restrict access to data based on a user's physical location at the time.
-
Return to the Ranger "tags Policies" page ("Access" tab) and "Add New Policy" with the below parameters
- Policy Name:
Geo-Location Access - TAG:
Restricted - Under "Deny Conditions"
- Select Group:
public - Policy Conditions/Enter boolean expression:
country_code=='USA'- If you are outside of USA use
country_code!='USA'instead
- If you are outside of USA use
- Component Permissions: (select
Hiveand enable all actions)
- Select Group:
- Add


- Policy Name:
-
Wait 30 seconds and try run the below query. Notice how you are now denied access to the "salary" column because of your location


beeline> select code, description, salary from sample_08;
Goal: To place an expiry date on sales' access policy to data tagged as "Private" after which access will be denied
-
Return to the Ranger "tags Policies" page ("Access" tab)and "Add New Policy" with the below parameters. You may already have default policy named "EXPIRES_ON", if so, please delete it before clicking "Add New Policy"
- Policy Name:
EXPIRES_ON - TAG:
EXPIRES_ON - Under "Deny Conditions"
- Select Group:
public - Policy Conditions/Accessed after expiry_date:
yes - Component Permissions: (select
Hiveand enable all actions)
- Select Group:
- Add


- Policy Name:
-
Wait 30 seconds and try run the below query. Notice how you are now denied access to the entire "sample_08" table because it is accessed after the expiry date tagged in Atlas


{kind=link}
beeline> select code, description from sample_08;
- Exit beeline
!q
- Logoff as sales1
logout
Notice how in the policies above, ones that deny access always take precedence over ones that allow access. For example, even though sales had access to "Private" data in the Tag-Based Access Control section, they were gradually disallowed access over the following sections as we set up "Deny" policies. This applies to both, Tag-Based as well as Resource-Based policies. To understand better the sequence of policy evaluation, take a look at the following flow-chart.

Goal: In this lab we will configure Apache Knox for AD authentication and make WebHDFS, Hive requests over Knox (after setting the appropriate Ranger authorization polices for access)
-
Run these steps on the node where Knox was installed earlier
-
To configure Knox for AD authentication we need to enter AD related properties in topology xml via Ambari
-
The problem is it requires us to enter LDAP bind password, but we do not want it exposed as plain text in the Ambari configs
-
The solution? Create keystore alias for the ldap manager user (which you will later pass in to the topology via the 'systemUsername' property)
- Read password for use in following command (this will prompt you for a password and save it in knoxpass environment variable). Enter BadPass#1:
read -s -p "Password: " knoxpass-
This is a handy way to set an env var without storing the command in your history
-
Create password alias for Knox called knoxLdapSystemPassword
sudo -u knox /usr/hdp/current/knox-server/bin/knoxcli.sh create-alias knoxLdapSystemPassword --cluster default --value ${knoxpass} unset knoxpass -
Now lets configure Knox to use our AD for authentication. Replace below content in Ambari > Knox > Config > Advanced topology.
- How to tell what configs were changed from defaults?
- Default configs remain indented below
- Configurations that were added/modified are not indented
- How to tell what configs were changed from defaults?
<topology>
<gateway>
<provider>
<role>authentication</role>
<name>ShiroProvider</name>
<enabled>true</enabled>
<param>
<name>sessionTimeout</name>
<value>30</value>
</param>
<param>
<name>main.ldapRealm</name>
<value>org.apache.hadoop.gateway.shirorealm.KnoxLdapRealm</value>
</param>
<!-- changes for AD/user sync -->
<param>
<name>main.ldapContextFactory</name>
<value>org.apache.hadoop.gateway.shirorealm.KnoxLdapContextFactory</value>
</param>
<!-- main.ldapRealm.contextFactory needs to be placed before other main.ldapRealm.contextFactory* entries -->
<param>
<name>main.ldapRealm.contextFactory</name>
<value>$ldapContextFactory</value>
</param>
<!-- AD url -->
<param>
<name>main.ldapRealm.contextFactory.url</name>
<value>ldap://ad01.lab.hortonworks.net:389</value>
</param>
<!-- system user -->
<param>
<name>main.ldapRealm.contextFactory.systemUsername</name>
<value>cn=ldap-reader,ou=ServiceUsers,dc=lab,dc=hortonworks,dc=net</value>
</param>
<!-- pass in the password using the alias created earlier -->
<param>
<name>main.ldapRealm.contextFactory.systemPassword</name>
<value>${ALIAS=knoxLdapSystemPassword}</value>
</param>
<param>
<name>main.ldapRealm.contextFactory.authenticationMechanism</name>
<value>simple</value>
</param>
<param>
<name>urls./**</name>
<value>authcBasic</value>
</param>
<!-- AD groups of users to allow -->
<param>
<name>main.ldapRealm.searchBase</name>
<value>ou=CorpUsers,dc=lab,dc=hortonworks,dc=net</value>
</param>
<param>
<name>main.ldapRealm.userObjectClass</name>
<value>person</value>
</param>
<param>
<name>main.ldapRealm.userSearchAttributeName</name>
<value>sAMAccountName</value>
</param>
<!-- changes needed for group sync-->
<param>
<name>main.ldapRealm.authorizationEnabled</name>
<value>true</value>
</param>
<param>
<name>main.ldapRealm.groupSearchBase</name>
<value>ou=CorpUsers,dc=lab,dc=hortonworks,dc=net</value>
</param>
<param>
<name>main.ldapRealm.groupObjectClass</name>
<value>group</value>
</param>
<param>
<name>main.ldapRealm.groupIdAttribute</name>
<value>cn</value>
</param>
</provider>
<provider>
<role>identity-assertion</role>
<name>Default</name>
<enabled>true</enabled>
</provider>
<provider>
<role>authorization</role>
<name>XASecurePDPKnox</name>
<enabled>true</enabled>
</provider>
</gateway>
<service>
<role>NAMENODE</role>
<url>hdfs://{{namenode_host}}:{{namenode_rpc_port}}</url>
</service>
<service>
<role>JOBTRACKER</role>
<url>rpc://{{rm_host}}:{{jt_rpc_port}}</url>
</service>
<service>
<role>WEBHDFS</role>
<url>http://{{namenode_host}}:{{namenode_http_port}}/webhdfs</url>
</service>
<service>
<role>WEBHCAT</role>
<url>http://{{webhcat_server_host}}:{{templeton_port}}/templeton</url>
</service>
<service>
<role>OOZIE</role>
<url>http://{{oozie_server_host}}:{{oozie_server_port}}/oozie</url>
</service>
<service>
<role>WEBHBASE</role>
<url>http://{{hbase_master_host}}:{{hbase_master_port}}</url>
</service>
<service>
<role>HIVE</role>
<url>http://{{hive_server_host}}:{{hive_http_port}}/{{hive_http_path}}</url>
</service>
<service>
<role>RESOURCEMANAGER</role>
<url>http://{{rm_host}}:{{rm_port}}/ws</url>
</service>
<service>
<role>DRUID-COORDINATOR-UI</role>
{{druid_coordinator_urls}}
</service>
<service>
<role>DRUID-COORDINATOR</role>
{{druid_coordinator_urls}}
</service>
<service>
<role>DRUID-OVERLORD-UI</role>
{{druid_overlord_urls}}
</service>
<service>
<role>DRUID-OVERLORD</role>
{{druid_overlord_urls}}
</service>
<service>
<role>DRUID-ROUTER</role>
{{druid_router_urls}}
</service>
<service>
<role>DRUID-BROKER</role>
{{druid_broker_urls}}
</service>
<service>
<role>ZEPPELINUI</role>
{{zeppelin_ui_urls}}
</service>
<service>
<role>ZEPPELINWS</role>
{{zeppelin_ws_urls}}
</service>
</topology>
- Then restart Knox via Ambari
- Tell Hadoop to allow our users to access Knox from any node of the cluster. Modify the below properties under Ambari > HDFS > Config > Custom core-site ('users' group should already part of the groups so just add the rest)
- hadoop.proxyuser.knox.groups=users,hadoop-admins,sales,hr,legal
- hadoop.proxyuser.knox.hosts=*
- (better would be to put a comma separated list of the FQDNs of the hosts)
- Now restart HDFS
- Without this step you will see an error like below when you run the WebHDFS request later on:
org.apache.hadoop.security.authorize.AuthorizationException: User: knox is not allowed to impersonate sales1"
-
Setup a Knox policy for sales group for WEBHDFS by:
-
Login to Ranger > Access Manager > KNOX > click the cluster name link > Add new policy
- Policy name: webhdfs
- Topology name: default
- Service name: WEBHDFS
- Group permissions: sales
- Permission: check Allow
- Add
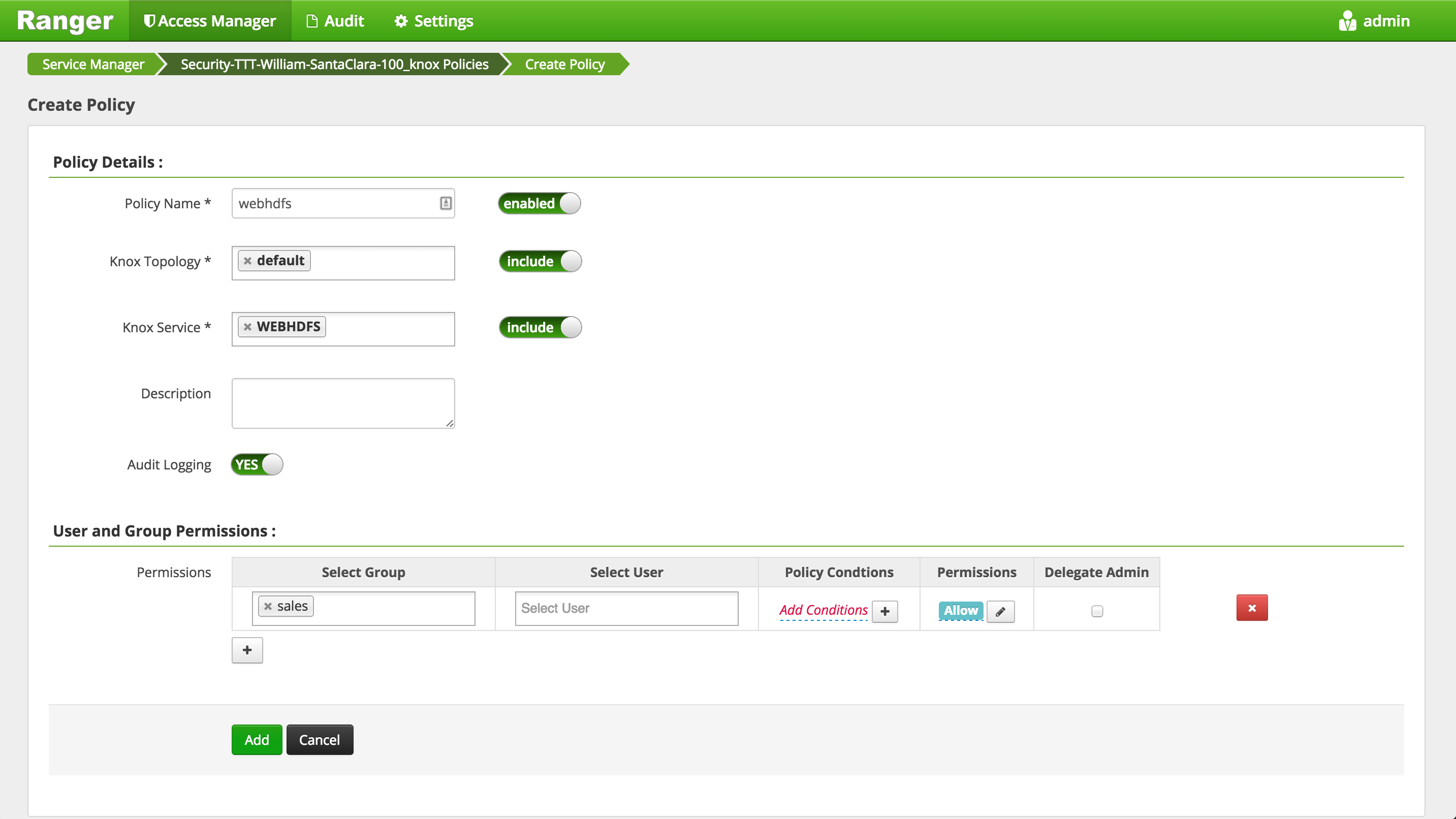
-
Now we can post some requests to WebHDFS over Knox to check its working. We will use curl with following arguments:
- -i (aka –include): used to output HTTP response header information. This will be important when the content of the HTTP Location header is required for subsequent requests.
- -k (aka –insecure) is used to avoid any issues resulting from the use of demonstration SSL certificates.
- -u (aka –user) is used to provide the credentials to be used when the client is challenged by the gateway.
- Note that most of the samples do not use the cookie features of cURL for the sake of simplicity. Therefore we will pass in user credentials with each curl request to authenticate.
-
From the host where Knox is running, send the below curl request to 8443 port where Knox is running to run
lscommand on/dir in HDFS:
curl -ik -u sales1:BadPass#1 https://localhost:8443/gateway/default/webhdfs/v1/?op=LISTSTATUS
-
This should return json object containing list of dirs/files located in root dir and their attributes
-
To avoid passing password on command prompt you can pass in just the username (to avoid having the password captured in the shell history). In this case, you will be prompted for the password
curl -ik -u sales1 https://localhost:8443/gateway/default/webhdfs/v1/?op=LISTSTATUS
## enter BadPass#1
-
For the remaining examples below, for simplicity, we are passing in the password on the command line, but feel free to remove the password and enter it in manually when prompted
-
Try the same request as hr1 and notice it fails with
Error 403 Forbidden:- This is expected since in the policy above, we only allowed sales group to access WebHDFS over Knox
curl -ik -u hr1:BadPass#1 https://localhost:8443/gateway/default/webhdfs/v1/?op=LISTSTATUS
-
Notice that to make the requests over Knox, a kerberos ticket is not needed - the user authenticates by passing in AD/LDAP credentials
-
Check in Ranger Audits to confirm the requests were audited:
- Ranger > Audit > Service type: KNOX
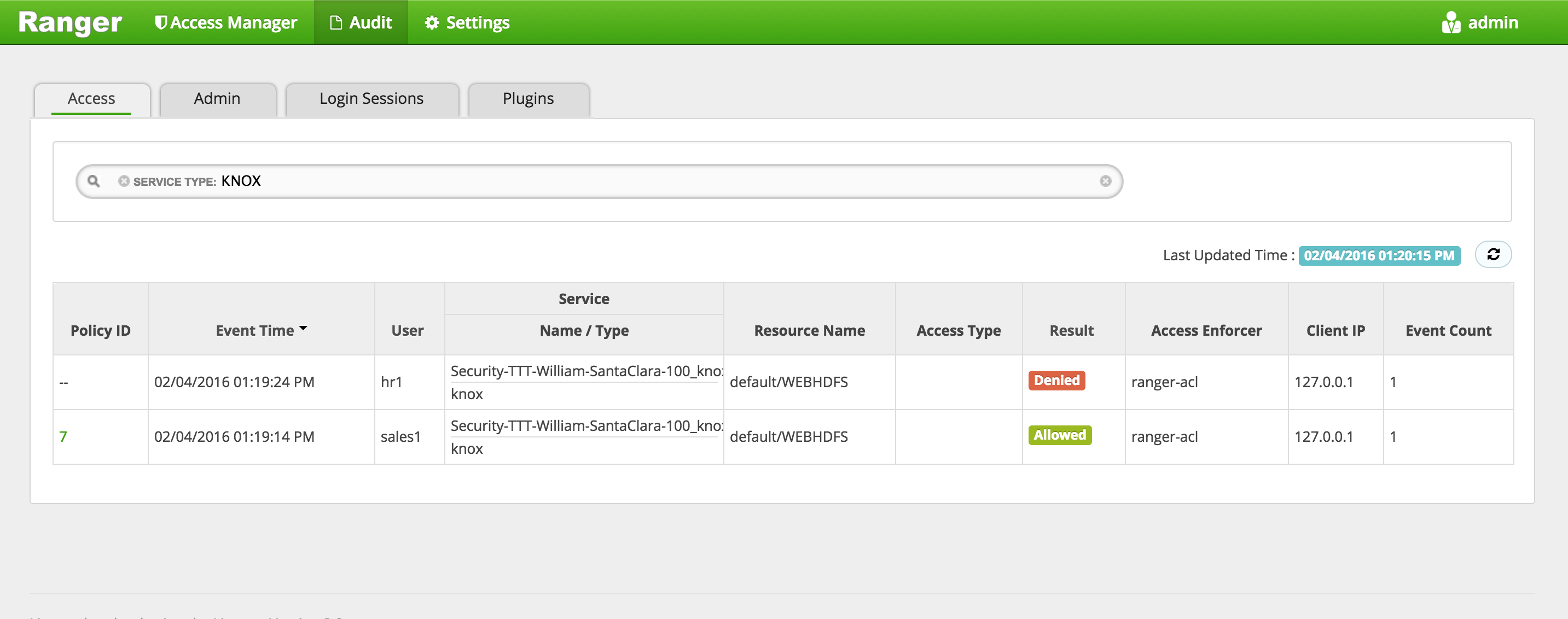
-
Other things to access WebHDFS with Knox
- A. Use cookie to make request without passing in credentials
- When you ran the previous curl request it would have listed HTTP headers as part of output. One of the headers will be 'Set Cookie'
- e.g.
Set-Cookie: JSESSIONID=xxxxxxxxxxxxxxx;Path=/gateway/default;Secure;HttpOnly - You can pass in the value from your setup and make the request without passing in credentials:
- Make sure you copy the JSESSIONID from a request that worked (i.e the one from sales1 not hr1)
curl -ik --cookie "JSESSIONID=xxxxxxxxxxxxxxx;Path=/gateway/default;Secure;HttpOnly" -X GET https://localhost:8443/gateway/default/webhdfs/v1/?op=LISTSTATUS-
B. Open file via WebHDFS
- Sample command to list files under /tmp:
curl -ik -u sales1:BadPass#1 https://localhost:8443/gateway/default/webhdfs/v1/tmp?op=LISTSTATUS- You can run below command to create a test file into /tmp as sales1
echo "Test file" > /tmp/testfile.txt su - sales1 ## enter BadPass#1 hdfs dfs -put /tmp/testfile.txt /tmp logout- Open this file via WebHDFS
curl -ik -u sales1:BadPass#1 -X GET https://localhost:8443/gateway/default/webhdfs/v1/tmp/testfile.txt?op=OPEN-
Look at value of Location header. This will contain a long url
-
Access contents of file /tmp/testfile.txt by passing the value from the above Location header
curl -ik -u sales1:BadPass#1 -X GET '{https://localhost:8443/gateway/default/webhdfs/data/v1/webhdfs/v1/tmp/testfile.txt?_=AAAACAAAABAAAAEwvyZNDLGGNwahMYZKvaHHaxymBy1YEoe4UCQOqLC7o8fg0z6845kTvMQN_uULGUYGoINYhH5qafY_HjozUseNfkxyrEo313-Fwq8ISt6MKEvLqas1VEwC07-ihmK65Uac8wT-Cmj2BDab5b7EZx9QXv29BONUuzStCGzBYCqD_OIgesHLkhAM6VNOlkgpumr6EBTuTnPTt2mYN6YqBSTX6cc6OhX73WWE6atHy-lv7aSCJ2I98z2btp8XLWWHQDmwKWSmEvtQW6Aj-JGInJQzoDAMnU2eNosdcXaiYH856zC16IfEucdb7SA_mqAymZuhm8lUCvL25hd-bd8p6mn1AZlOn92VySGp2TaaVYGwX-6L9by73bC6sIdi9iKPl3Iv13GEQZEKsTm1a96Bh6ilScmrctk3zmY4vBYp2SjHG9JRJvQgr2XzgA}' -
C. Use groovy scripts to access WebHDFS
- Edit the groovy script to set:
- gateway = "https://localhost:8443/gateway/default"
sudo vi /usr/hdp/current/knox-server/samples/ExampleWebHdfsLs.groovy- Run the script and enter credentials when prompted username: sales1 and password: BadPass#1
sudo java -jar /usr/hdp/current/knox-server/bin/shell.jar /usr/hdp/current/knox-server/samples/ExampleWebHdfsLs.groovy-
TODO fix error
Caused by: javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target -
Notice output show list of dirs in HDFS
[app-logs, apps, ats, hdp, mapred, mr-history, ranger, tmp, user, zone_encr] - Edit the groovy script to set:
-
D. Access via browser
- Take the same url we have been hitting via curl and replace localhost with public IP of Knox node (remember to use https!) e.g. https://PUBLIC_IP_OF_KNOX_HOST:8443/gateway/default/webhdfs/v1?op=LISTSTATUS
- Open the URL via browser
- Login as sales1/BadPass#1
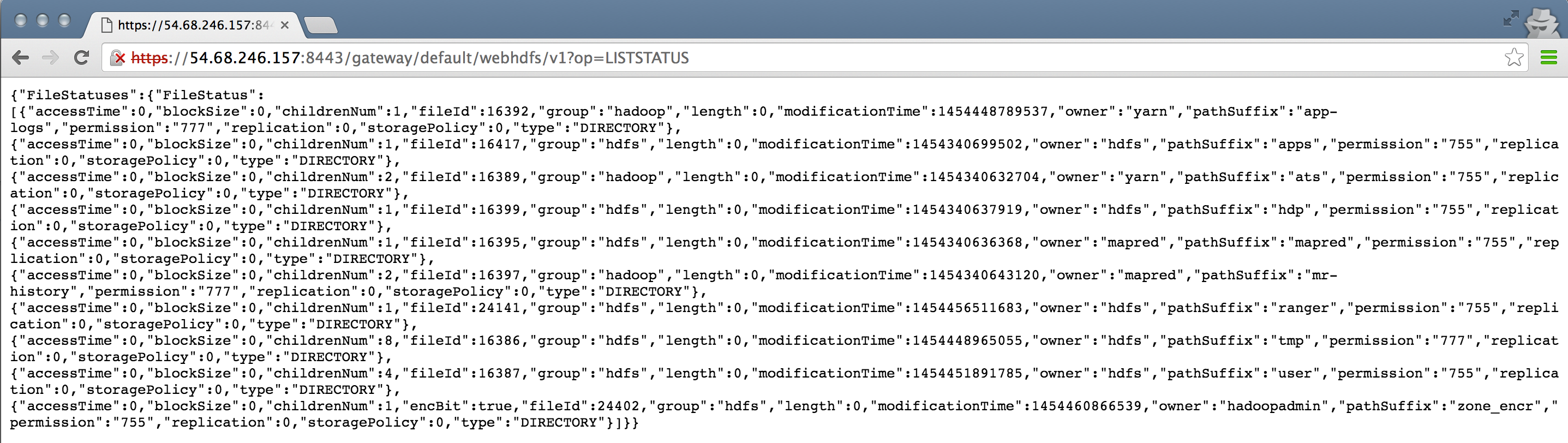
- A. Use cookie to make request without passing in credentials
-
We have shown how you can use Knox to avoid the end user from having to know about internal details of cluster
- whether its kerberized or not
- what the cluster topology is (e.g. what node WebHDFS was running)
- In Ambari, under Hive > Configs > set the below and restart Hive component.
- hive.server2.transport.mode = http
- Give users access to jks file.
- This is only for testing since we are using a self-signed cert.
- This only exposes the truststore, not the keys.
sudo chmod o+x /usr/hdp/current/knox-server /usr/hdp/current/knox-server/data /usr/hdp/current/knox-server/data/security /usr/hdp/current/knox-server/data/security/keystores
sudo chmod o+r /usr/hdp/current/knox-server/data/security/keystores/gateway.jks
-
Setup a Knox policy for sales group for HIVE by:
-
Login to Ranger > Access Manager > KNOX > click the cluster name link > Add new policy
- Policy name: hive
- Topology name: default
- Service name: HIVE
- Group permissions: sales
- Permission: check Allow
- Add
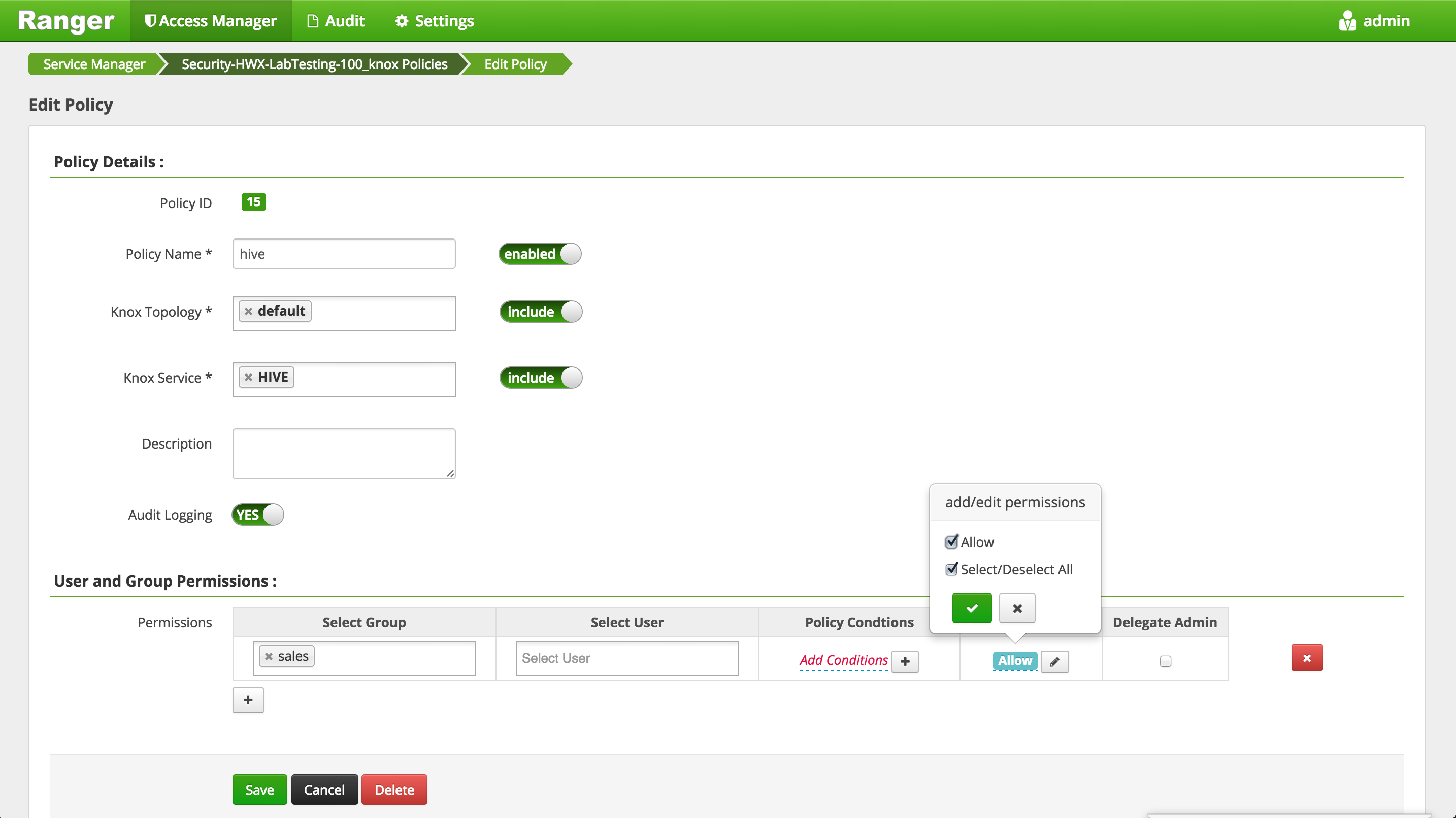
-
By default Knox will use a self-signed (untrusted) certificate. To trust the certificate:
- First on Knox node, create the /tmp/knox.crt certificate
knoxserver=$(hostname -f)
openssl s_client -connect ${knoxserver}:8443 <<<'' | openssl x509 -out /tmp/knox.crt
- On node where beeline will be run from (e.g. Hive node):
- copy over the /tmp/knox.crt
- easiest option is to just open it in
viand copy/paste the contents over:vi /tmp/knox.crt
- easiest option is to just open it in
- trust the certificate by running the command below
- copy over the /tmp/knox.crt
sudo keytool -import -trustcacerts -keystore /etc/pki/java/cacerts -storepass changeit -noprompt -alias knox -file /tmp/knox.crt
- Now connect via beeline, making sure to replace KnoxserverInternalHostName first below, and run a query:
beeline -u "jdbc:hive2://KnoxserverInternalHostName:8443/;ssl=true;transportMode=http;httpPath=gateway/default/hive" -n sales1 -p BadPass#1
select code, description from sample_07;
-
Notice that in the JDBC connect string for connecting to an secured Hive running in http transport mode:
- port changes to Knox's port 8443
- traffic between client and Knox is over HTTPS
- a kerberos principal not longer needs to be passed in
- we can run the query as any user by passing their AD credentials
-
Test these users:
- sales1/BadPass#1 should work
- hr1/BadPass#1 should not work
- Will fail with:
Could not create http connection to jdbc:hive2://hostname:8443/;ssl=true;transportMode=http;httpPath=gateway/default/hive. HTTP Response code: 403 (state=08S01,code=0)
-
Check in Ranger Audits to confirm the requests were audited:
- Ranger > Audit > Service type: KNOX
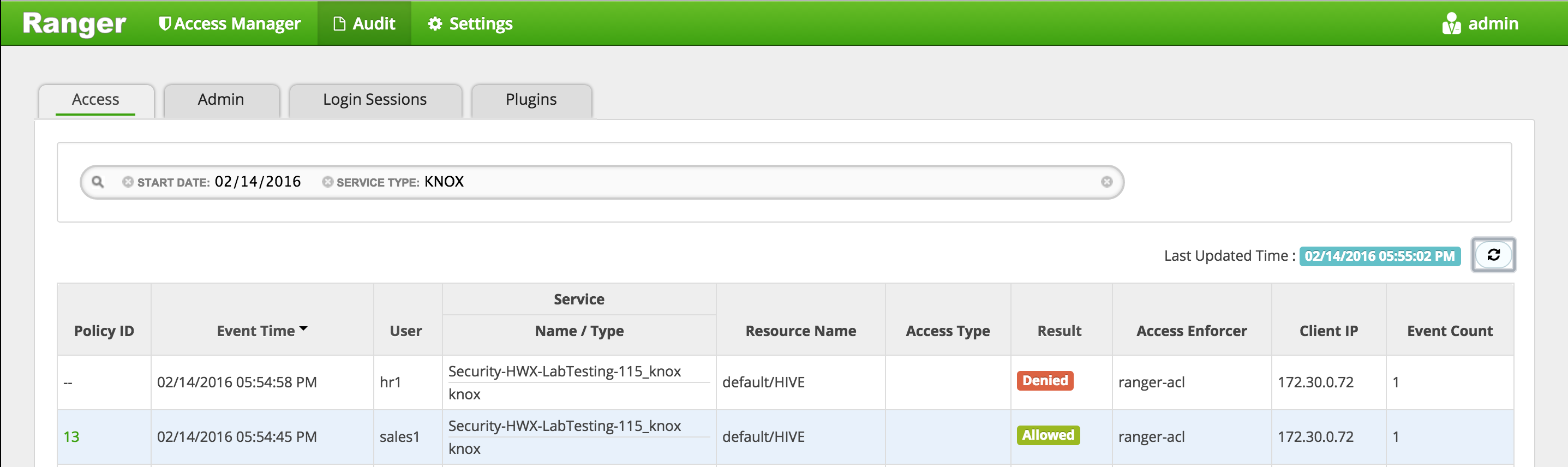
- Ranger > Audit > Service type: KNOX
-
This shows how Knox helps end users access Hive securely over HTTPS using Ranger to set authorization policies and for audits