专栏原创出处:github-源笔记文件 ,github-源码 ,欢迎 Star,转载请附上原文出处链接和本声明。
Java JVM-虚拟机专栏系列笔记,系统性学习可访问个人复盘笔记-技术博客 Java JVM-虚拟机
[toc]
介绍 Oracle HotSpot 虚拟机技术的性能增强部分案例。
优化技术手段非常之多,可参考官方列出 openjdk-优化技术概览
字符串压缩功能( JEP 254: Compact Strings )是为了节省内部空间。
字符串是 Java 堆用法的主要组成部分,并且大多数 String 对象仅包含 Latin-1 字符。此类字符仅需要存储一个字节。 结果,String 没有使用对象内部字符数组中一半的空间。JDK 9 中引入的压缩字符串功能减少了内存占用,并减少了垃圾回收活动。如果您在应用程序中发现性能下降问题,则可以禁用此功能。
它将 String 类的内部表示形式从 UTF-16(两个字节)字符数组修改为带有附加字段以标识字符编码的字节数组。其他字符串相关的类,如 AbstractStringBuilder,StringBuilder 和 StringBuffer 更新使用类似的内部表示。
在 JDK 9 中,默认情况下启用了压缩字符串功能。因此,String 该类将每个字符的字符存储为一个字节,编码为 Latin-1。附加字符编码字段指示所使用的编码。HotSpot VM 字符串内在函数已更新和优化以支持内部表示。
可以通过 -XX:-CompactStrings 在 java 命令行中使用该标志来禁用紧凑字符串功能。禁用此功能后,String 该类将字符存储为两个字节(编码为 UTF-16),并且将 HotSpot VM 字符串内部函数存储为使用 UTF-16 编码。
由于即时编译器编译本地代码需要占用程序运行时间,通常要编译出优化程度越高的代码,所花费的时间便会越长;而且想要编译出优化程度更高的代码,解释器可能还要替编译器收集性能监控信息,这对解释执行阶段的速度也有所影响。
为了在程序启动响应速度与运行效率之间达到最佳平衡,HotSpot 虚拟机在编译子系统中加入了分层编译的功能:
-
第 0 层。程序纯解释执行,并且解释器不开启性能监控功能(Profiling)。
-
第 1 层。使用客户端编译器将字节码编译为本地代码来运行,进行简单可靠的稳定优化,不开启性能监控功能。
-
第 2 层。仍然使用客户端编译器执行,仅开启方法及回边次数统计等有限的性能监控功能。
-
第 3 层。仍然使用客户端编译器执行,开启全部性能监控,除了第 2 层的统计信息外,还会收集如分支跳转、虚方法调用版本等全部的统计信息。
-
第 4 层。使用服务端编译器将字节码编译为本地代码,相比起客户端编译器,服务端编译器会启用更多编译耗时更长的优化,还会根据性能监控信息进行一些不可靠的激进优化。
以上层次并不是固定不变的,根据不同的运行参数和版本,虚拟机可以调整分层的数量。
通过 -XX:-TieredCompilation 在 java 命令中使用该标志来禁用分层编译。
Graal 是用 Java 编写的高性能优化的即时的编译器,与 Java HotSpot VM 集成在一起。是一个可自定义的动态编译器,我们可以从 Java 调用它。
要启用 Graal 作为 JIT 编译器,VM 参数配置:
-XX:+UnlockExperimentalVMOptions -XX:+UseJVMCICompiler
注意:Graal 是一项实验性功能,仅在 Linux-x64 上受支持。
提前(AOT,JEP 295: Ahead-of-Time Compilation )编译通过在启动虚拟机之前将 Java 类编译为本地代码来缩短大小型 Java 应用程序的启动时间。
尽管即时(JIT)编译器速度很快,但是编译大型 Java 程序仍需要时间。此外,当反复解释某些未编译的 Java 方法时,性能会受到影响。AOT 解决了这些问题。
语法如下:
jaotc <options> <list of classes or jar files>
jaotc <options> <--module name>
示例:
jaotc --output libHelloWorld.so HelloWorld.class
jaotc --output libjava.base.so --module java.base
java -XX:AOTLibrary=./libHelloWorld.so,./libjava.base.so HelloWorld ————执行应用程序时指定生成的 AOT 库
注意:提前(AOT)编译是一项实验性功能,仅在 Linux-x64 上受支持。
在 HotSpot 中,oop 或普通对象指针是指向对象的托管指针。openjdk-CompressedOops
1. 为什么要进行指针压缩?
32 位内最多可以表示 4GB,64 位地址分为堆的基地址+偏移量,当堆内存 <32GB 时候,在压缩过程中,把偏移量/8 后保存到 32 位地址。在解压再把 32 位地址放大 8 倍,所以启用 CompressedOops 的条件是堆内存要在 4GB*8=32GB 以内。
所以压缩指针之所以能改善性能,是因为它通过对齐(Alignment),还有偏移量(Offset)将 64 位指针压缩成 32 位。换言之,性能提高是因为使用了更小更节省空间的压缩指针而不是完整长度的 64 位指针,CPU 缓存使用率得到改善,应用程序也能执行得更快。
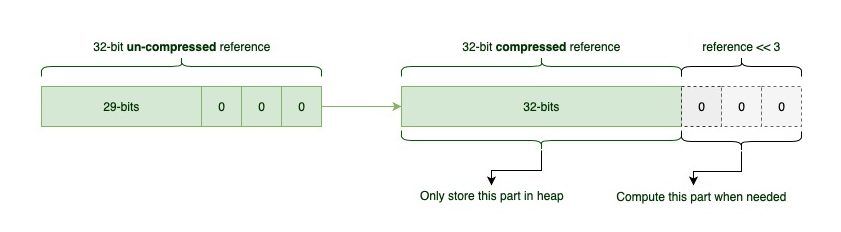
压缩与解压过程,指针向右移动 3 位放大 8 倍解压。因此 oops 最后 3 位始终为 0
2. 哪些信息不会被压缩?
压缩也不是万能的,针对一些特殊类型的指针,JVM 是不会优化的。 比如指向 PermGen 的 Class 对象指针,本地变量,堆栈元素,入参,返回值,NULL 指针不会被压缩。
3. 零基压缩优化:
零基压缩是针对压解压动作的进一步优化。 它通过改变正常指针的随机地址分配特性,强制堆地址从零开始分配(需要 OS 支持),进一步提高了压解压效率。
要启用零基压缩,你分配给 JVM 的内存大小必须控制在 4G 以上,32G 以下。如果 GC 堆大小在 4G 以下,直接砍掉高 32 位。
4. 指针压缩配置及版本支持 Java SE 6u23 和更高版本默认情况下支持并启用压缩的 oops。
在 Java SE 7 中,默认情况下,-Xmx 未指定时对 64 位 JVM 进程以及-Xmx 小于 32 GB 的值启用压缩 oop 。
对于早于 6u23 发行版的 JDK 版本,将该 -XX:+UseCompressedOops 标志与 java 命令一起使用以启用压缩的 oops。
逃逸分析( openjdk-EscapeAnalysis )的基本原理是:
- 分析对象动态作用域,当一个对象在方法里面被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,这种称为方法逃逸;
- 甚至还有可能被外部线程访问到,譬如赋值给可以在其他线程中访问的实例变量,这种称为线程逃逸;
根据不同的逃逸程度使用不同的优化手段:
- 栈上分配:直接在栈帧上进行对象分配。(不支持线程逃逸)
- 标量替换:类似 java 里面的基础类型不能进一步分解了,被称为标量,如果还能被分解称为聚量。
- 同步状态消除:如果确定一个变量仅被一个线程访问,直接取消同步状态。
@Data
class Person {
private String name;
private int age;
public Person(String personName, int personAge) {
name = personName;
age = personAge;
}
public Person(Person p) {
this(p.getName(), p.getAge());
}
}
class Employee {
private Person person;
// person 可能被修改,如果进一步分析调用没有修改 person ,可以直接使用原始的对象
public Person getPerson() {
return new Person(person);
}
public void printEmployeeDetail(Employee emp) {
Person person = emp.getPerson();
// person 不会被修改,我们只需要 person.name/age 两个变量即可
System.out.println("Employee's name: " + person.getName() + "; age: " + person.getAge());
}
public void printEmployeeDetail() {
Person person = new Person("name", 18);
String name = person.getName();
// person 不会逃逸出方法,可以直接优化为 String name = "name"
}
}public static void foo(Object obj) {
if (obj != null) {
System.out.println("do something");
}
}
public static void testInline(String[] args) {
Object obj = null;
foo(obj);
}我们可以看到 testInline 方法里面的都是无用的代码,但是单独看两个方法时他们又是有意思的。
有关内联的实现此处不进行叙述,感兴趣的可以参考文章末位《参考内容》
int d = (c * b) * 12 + a + (a + b * c); -- 原始表达式
int d = E * 12 + a + (a + E); -- 优化为
int d = E * 13 + a + a; -- 另一种优化(代数简化)if (foo != null) {
return foo.value;
} else {
throw new NullPointException();
}
// 可能优化为
try {
return foo.value;
} catch (segment_fault) {
uncommon_trap();
}虚拟机会注册一个 Segment Fault 信号的异常处理器(伪代码中的 uncommon_trap(),务必注意这里是指进程层面的异常处理器,并非真的 Java 的 try-catch 语句的异常处理器), 这样当 foo 不为空的时候,对 value 的访问是不会有任何额外对 foo 判空的开销的,而代价就是当 foo 真的为空时,必须转到异常处理器中恢复中断并抛出 NullPointException 异常。
进入异常处理器的过程涉及进程从用户态转到内核态中处理的过程,结束后会再回到用户态,速度远比一次判空检查要慢得多。当 foo 极少为空的时候,隐式异常优化是值得的,但假如 foo 经常为空,这样的优化反而会让程序更慢。 幸好 HotSpot 虚拟机足够聪明,它会根据运行期收集到的性能监控信息自动选择最合适的方案。
-
Oracl 官方虚拟机性能优化介绍-Java HotSpot Virtual Machine Performance Enhancements
-
《深入理解 Java 虚拟机:JVM 高级特性与最佳实践(第 3 版)》周志明 著
-
Oracle 官方对编译器的介绍-Understanding JIT Compilation and Optimizations