
Sorry, we've misplaced that URL or it's pointing to something that doesn't exist.
Head back Home to try finding it again, or search for it on the Archives page.
Sorry, we've misplaced that URL or it's pointing to something that doesn't exist.
Head back Home to try finding it again, or search for it on the Archives page.
사내에서 패키지 구조 변경 작업을 하고 배포를 했는데 갑자기 특정 API에서 transaction silently rolled back이 발생했었습니다. 관련해서 확인해보니 DB조회 값을 Dto 객체로 변환해 캐싱한 값을 역직렬화하는 과정에서 문제가 발생했었습니다. 해당 캐시는 월마다 한번씩 바뀌는 주기를 갖는 값으로, 조회가 많은 비율을 차지합니다...
실무에서 MySQL 데이터베이스를 활용하면서 커넥션, I/O 연산, 잠금에 대해 더 유심히 살펴보게 되었다. 요 세가지 자원이 중요하다고 배웠는데 실제로 사용해보면서 정말 그렇다는걸 느낄 수 있었다. 그렇기에 이를 통해 배운점들을 다시 상기해고자 한다. 커넥션 데이터베이스를 사용하면서 가장 중요한 자원을 꼽는다면 커넥션이다. 커넥션이 부족해지는 순...
우리 회사를 포함해 많은 회사는 RDBMS를 사용할 때 MySQL Amazon Aurora DB(이하 오로라)를 사용하는 경우가 존재한다. 왜 오로라를 사용하는 지 궁금했는데 기존 전통적인 MySQL보다 가용성, 확장성, 연산 비용 등이 더 싸서 대규모 처리 작업에 용이해서 사용한다고 들었다. 또, 오로라는 컴퓨팅과 스토리지 인스턴스가 각각 분리되어 ...
문제 상황 회사에서 모든 환불은 어드민 서버를 거쳐 환불 서버에 환불 요청을 보내 환불 프로세스가 진행된다. 하지만 환불 서버에서 요청을 제대로 보내고 환불을 완료했지만, 어드민 서버에서 히스토리를 DB에 기록하는 작업이 제대로 이뤄지지 않았다. 그렇기에 어드민 히스토리와 환불 기록의 불일치가 발생했고, 이 운영 이슈를 해결하는 과정을 남기려고 한다...
근래에 감정적인 결정과 발언이 늘었다. 가진 환경에 대한 불만족 때문이었다. 모든 환경에는 장단이 존재하지만 비교와 기대 불일치로 인한 스트레스는 감정적인 결정을 유발했다. 이유를 분석해보고 왜 그랬는 지에 대해 생각해보자. The Conscious Discipline Brain State Model The Conscious Discipline...
중요한 일에 집중하기 샘 알트만과 폴 그레이엄은 공통적으로 인생은 짧다라는 말을 자주 한다. 인생이 짧다라는 의미는 결국 본인에게 중요하지 않은 일보다 중요한 일에 더 집중하게 만들기 때문이다. 그렇다면, 중요한 일은 무엇일까? 여러 방면으로 존재하겠지만, 근래에 가장 많이 시간을 사용하는 업무적인 부분에서 고민해보자. 진부하지만, 우선순위가 높은...
Spring boot에서 Domain Event 활용해 도메인 간의 결합도 낮추기 Goal 업적 달성 시, 데이터베이스에 유저의 업적 달성을 기록한다. 업적 달성은 편지 송신, 좋아요와 같은 유저의 행위가 발생한 후 조건을 만족하면 이뤄진다. 본 글에서는 유저가 편지를 작성할 떄, 이벤트를 발행해 유저의 업적을 달성하는 상황에 대한 코...
Testing에 관한 고찰 일반적으로 스프링으로 테스트를 작성할 때, @SpringBootTest를 이용해 통합테스트와 인수테스트를 진행했습니다. 이를 이용해 테스트를 진행하면, 개별적으로 테스트를 실행하기에도, 전체를 테스트를 실행하기에도 너무 속도가 느리다는 단점이 있었습니다. 뿐만 아니라, 테스트 간의 격리성을 확보하기 위해서 모든 데이터를 지...
지난 6월 말부터 8월 중순까지 두달 간 UC Berkeley에서 교환학생으로 학업을 진행했다. UC Berkeley에서 UI Development 수업(CS160)과 Operating System and System Programming(CS162) 수업을 수강했다. 두 수업다 upper division, 주로 junior ~ senior 학생들이 ...
문제 @Test void retrieveInboxAllLettersTest() { Letter letter = new Letter("content", user); letter.send(user1); letterRepository.save(letter); letterRepository.s...
SW 마에스트로 과정에서 너무나도 영광스럽게 조대협 멘토님의 k8s 멘토링을 4회 가량을 듣게 되었다. 오늘이 첫번째 강의였고 들으면서 기술에 대한 깨달음이 꽤나 커서 글을 작성한다. 뿐만 아니라 블로그에 좋은 글을 써야 한다는 강박이 계속되어 지금이라도 작은 글들을 조금씩 써나가는 연습을 해보려 한다. k8s를 배우기 앞서 k8s가 가장 잘 활용될...
Spring bulk Insertion 문제 상황 설문 조사 플랫폼을 만들던 와중에, 질문에 대한 응답 문항과, 응답 문항에 응답할 때 결과들을 insert하는 과정에서 문제가 발생했다. 질문에 상응하는 응답 문항 만큼 insert 쿼리가 날라간다는 점과 응답 문항에 상응하는 점이 문제이다. question -< answer answ...
배포 링크: Gijol BE 배경 GIST 청원 프로젝트를 진행하면서 크게 제품의 코드 작성법과 테스트, Operation, Git flow 등을 배울 수 있었다. 이를 청원팀의 팀원으로서 배웠던 점이 많은데 과연 이 배운 것들을 내가 스스로 해나갈 수 있을지에 대해서 의문이 들었다. 이에 대한 중요성과 필요성이 너무나도 중요하게 느껴졌기에...
삶의 가치 셀리 케이건의 “죽음이란 무엇인가”에서 삶의 가치에 대해 논할 때, 삶-그릇 이론을 정의하고 내용을 전개한다. 삶-그릇 이론이란, 삶은 우리가 스스로 정의한 좋은 것과 나쁜 것들을 채워넣을 수 있는 그릇이라는 것이다. 그렇다면 삶이 얼마나 가치 있는지, 좋은지에 대해 평가하려면 그릇에 담긴 좋은 것과 나쁜 것들의 합을 구해 평가를 하는 ...
서브 모듈을 통해 민감 정보 관리 3줄 요약 민감정보 데이터를 담을 private repo 생성 민감정보가 담긴 private 레포지토리를 public 레포지토리의 서브모듈로 git add submodule ${서브 모듈로 등록할 github repository의 주소} 을 사용해 등록한다. 원격 서브모듈 레포지토리에 있는 파일들을 g...
Log4j 이슈로 인해 우리 프로젝트에서 log4j를 버전을 확인해봤는데 2.14.1 버전을 사용하고 있었다. 이는 Intellij에서 External Library에서 확인할 수 있다. log4j 2.14.1 버전은 CVE-2021-44228 에서 나와있듯, 보안취약점에 영향을 받는 버전이다. 다음 사진에서 나와있듯, 2.15.0 버전으로 변경...
이번 우아한테크코스 프리코스 4기에 함께 성장하는 방법을 배워보려 지원했다. 그러기 위해서는 함께 사용할 수 있는 코드(객체지향적 코드)를 작성해야 했고 이를 프리코스라는 과정을 통해 간접적으로 경험해볼 수 있었다. 1주차 과제는 숫자야구게임으로, 1주차 피드백만으로도 충분히 받아들일 수 있었고, 고통스럽게 하는 고민은 없었다. 다만, 2주차 과제에...
팀원분께서 예전에 aws key를 yml파일에 넣으셨다. 이때 문제를 인식하고 커밋이 안 쌓였을 때 지웠어야 하는데 이런저런 핑계를 대며 지우지 않았는데 오늘 레포를 public으로 변경했는데 문제가 터졌다. 보통 가장 최근 커밋은 git reset HEAD 로 지울 수 있는데 한참 전 기록이 발목을 잡았던 것이다. 이를 해결하는데 겪은 고난을 ...
지난 6월 말부터 8월 중순까지 두달 간 UC Berkeley에서 교환학생으로 학업을 진행했다. UC Berkeley에서 UI Development 수업(CS160)과 Operating System and System Programming(CS162) 수업을 수강했다. 두 수업다 upper division, 주로 junior ~ senior 학생들이 많이 듣는 수업이었는데, 도전을 해보자는 목적으로 조금 빡빡하게 과목을 신청했다. 실제로 수업 로드도 빡세고 영어라는 언어적 장벽으로 다른 사람들이 사용하는 시간보다 1.5배는 적어도 더 사용해야 원활하게 업무를 진행할 수 있었다.
학습적인 측면에서도 부족함을 많이 느꼈지만, 특히나 팀 프로젝트에서 느낀 점이 너무 많았다. 우선, 너무나도 성장 속도가 빠르다는 점이었다. 팀적으로는 이점이지만, 내 개인과 비교했을 때 배우는 속도가 적어도 1.5배 가량 차이가 났다. 이 뿐만 아니라 질문도 굉장히 뛰어나며, 두려움이 없다. 분위기 또한, 누구나 모를 수 있다는게 기본 전제였다. 이를 통해 이후에는 본인의 이해를 바탕으로 명쾌하게 설명까지 할 수 있었으며, 팀적인 기여에도 좋은 퍼포먼스를 보였다. 22년 동안 모르는 것을 혼자 찾아보며 해결한 나에게는 속도적인 측면이건, 방법론적인 측면이건 충격으로 다가왔다. 한 번도 그래보지 못했기 때문이다.
프로젝트 경험을 통해 코드를 어느 정도 잘 짠다고 생각했었고, GIST에서 System Programming 수업을 들어 OS적인 내용도 미리 많이 사전에 준비해 간다고 생각했었다. 뿐만 아니라, 버클리에서도 열심히 수업듣고 여가 시간 없이 하루의 대부분을 투자했음에도, 버클리 학생들이 훨씬 더 잘했다. 내가 학기 동안 아무리 열심히해도 이들에게 닿기 어려웠다. 너무나도 우물 안의 개구리였다고 느꼈고, 잘한다고 생각했던 것 조차 부끄럽게 다가왔다.
이 경험은 내게 너무나도 충격적으로 다가왔고, 자신감을 크게 잃었으며 근 몇달간 고민으로 이어졌다. 다행히도 이 고민을 먼저 느끼셨던 여러 멘토님들이 존재했었고, 그 답변들은 고민을 해결하는데 큰 도움이 되었다.
먼저, 미국에서 SW마에스트로 활동을 통해 실리콘밸리에서 커리어를 이어오셨던 한기용 멘토님께서 흔쾌히 산호세에서 만나주셨다. 관련된 상황을 말씀드렸고, 비교가 나를 갉아먹을 정도 가면 너무나도 불행해지고 과거의 본인과 비교하는게 중요하다고 하셨다. 그리고 분명히 내가 가진 강점이 있을거기 때문에 이를 빨리 찾아내고 발전해서 임팩트(결과)를 내는 것이 중요하다고 말씀주셨다. 일을 잘하는 것과 학습을 잘하는 것은 다르기 때문이다. 관련해서도 글을 작성해주셨다.
이 글을 통해 다시 한번 이야기를 나눴던 것을 상기할 수 있었고, 위로받을 수 있었다. 너무나도 멘토님께 감사드리며, 이 기억은 아마 평생 잊지 못할 듯 싶다.
재학 중인 심리학 교수님께서도 수업시간에 지능에 관해 이야기를 해주시면서, 미국에 가면 주변의 동기들 때문에 자괴감을 많이 느끼셨다고 하셨다. 정확히 나와 일치해 질문을 드렸다. 답변은 결국에는 조금 더 많이 준비하고 시간을 사용했고, 그러다보니 조금 익숙해지면서 3~4년차부터는 어느 정도 맞춰나가실 수 있으셨다고 말씀주셨다. 이 답변은 굉장히 정직하고 명확했기 때문에 와닿았다. 부족하면, 간단하게 조금씩 더 하면 되는 것이다.
뿐만 아니라, 조대협 멘토님께도 우연히 질문할 기회가 생겨 내 경험에 비추어 질문을 드렸었는데 비슷한 경험을 인생에서 두 번 느끼셨고 그 경험들은 평생 못잊으실 경험이라고 말씀주셨다. 실제로 멘토님께서도 자바 커뮤니티를 운영하셨고, 자바를 어느 정도 잘하신다고 생각하셨는데 외국계 회사에 커리어를 진행하시면서, 주변 사람들의 굉장히 높은 수준에 좌절감을 느끼셨다고 하셨다. 너무나도 분함을 느끼셨다고 하셨는데 너무나도 공감이 많이 되었다.
그래서 그 상황에서 멘토님께서 생각하셨던 강점을 찾으려 하셨고 그 강점은 더 많이 시간을 사용하는 것이었다. 그로 인해, 멘토님께서는 기존보다 더 많은 업무를 먼저 도맡아 진행하셨고, 이를 바탕으로 회사에서 시스템 장애를 가장 많이 해결하신 사람이 되셨다고 하셨다. 구글에서도 세계에서 탑급 인재들을 보면서 생각을 많이 들으셨다고 하셨는데, 기존에 해결하신 방법과 동일하게, 강점을 바탕으로 입지를 다져나가셨다고 하셨다.
결국 이에 관해 고찰해본 결과, 현재 위치와 무관하게 누구나 다 느끼는 감정이며, 극복 방법도 대부분 비슷하다는게 가장 놀라웠다. 이 감정은 좋든 나쁘던 인생에 중요한 영향을 누구에게나 주었다. 결국 극복해야 하고, 극복하기 위해서는 본인의 강점을 잘 살려 그 강점을 바탕으로 자신감을 찾아야한다. 분명히 사람마다 본인이 가진 강점이 있을 것이고 그 강점을 최대한 경쟁력있게 가져갈 수 있는 사람이 되는게 중요하다고 느꼈다. 이를 통해 작은 자신감을 더 찾아나가고, 더 좋은 결과를 내면 된다.
이와 더불어 결국 잘한다는 기준은 끝도 없기에 비교에도 끝이 없다. 특히 나는 압도되는 격차에 좌절감을 많이 느껴 자신감을 많이 잃었다. 하지만 시간이 지나고 조금 나아졌고, 끝없는 성장의 필요성과 겸손함을 배웠다. 그렇기에 부족함을 느끼는 데에 적당한 동기부여로서 활용하는 것은 성장에 도움이 될 수 있지만, 나를 갉아먹을 때까지 가는 것은 위험다고 느꼈다.
결국에는 지금 가진 것들에 대한 감사함, 그리고 잘할 수 있는게 무엇인지 찾아가는게 중요하다. 굳이 따지면, 항상 노력으로 성취를 이뤄왔기 때문에 조대협 멘토님과 비슷하게 무언가에 대한 집착과 몰입이 지금 갖고 있는 나의 강점이라고 생각한다. 아직 모호한 부분이지만 이를 바탕으로 가시적인 강점까지 이어질 수 있기를 바라며, 지금까지 노력해온 나에게 감사하다고 말하고 싶다.
SW 마에스트로 과정에서 너무나도 영광스럽게 조대협 멘토님의 k8s 멘토링을 4회 가량을 듣게 되었다. 오늘이 첫번째 강의였고 들으면서 기술에 대한 깨달음이 꽤나 커서 글을 작성한다. 뿐만 아니라 블로그에 좋은 글을 써야 한다는 강박이 계속되어 지금이라도 작은 글들을 조금씩 써나가는 연습을 해보려 한다.
k8s를 배우기 앞서 k8s가 가장 잘 활용될 수 있는 구조인 MSA와 그 기반이 되는 Container에 대해서 먼저 다뤘다. 여기서 누차 강조하는 것은 기술을 배우기 전에 그 Background를 알고 그 기술을 왜 사용하는지에 대한 의문을 꾸준히 제기해야 한다는 것이다.
먼저 MSA를 왜 사용하는가?에 대한 질문을 답한다면, 조직마다 사용하는 이유는 각기 다르겠지만 기능 단위로 나눈다는 점이었다. 나는 기능 단위로 나눈다는 것을 통해 가용성을 높이는 것(어떤 단위의 서비스가 죽어도 다른 서비스는 정상적으로 작동한다는 의미)로서 가장 크게 받아들였다. 이를 통해 서비스를 최대한 안정적으로 돌릴 수 있다는 장점이 가장 먼저 떠오르는 이유였다. 나름 타당한 이유이지만, 멘토링 시간에 들은 내용으로는 기능 단위로 독립적으로 분리함을 통해 그 기능을 구현하는 조직의 의사결정을 명확히 위임할 수 있다는 측면이었다. 이는 곧 의사결정의 속도가 빨라진다는 것이고, 생산성 향상으로 이어져 소프트웨어를 개발하는 방법론으로서 굉장히 좋은 방법일 수 있었다.
관련한 법칙으로 Conway’s Law도 소개해주셨다. 이는 다음과 같다.
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
조직의 communication structure가 곧 조직의 system의 design에서 나타난다는 것이다. 만약 조직의 커뮤니케이션 구조가 복잡하다면 조직의 system design도 복잡해진다는 의미이다. 즉, 위계 조직과 같이 복잡한 커뮤니케이션 구조에서는 MSA를 사용한다고 하더라도 그 의미에 맞고 적합하게 사용하고 있지 못할 수 있다는 말이다. 결국 아키텍쳐의 가장 큰 원칙은 DDD와 같이 MSA를 잘 만드는 방법론보다도 팀의 구조에 맞춰 설계를 하는 것이 가장 중요함을 느낄 수 있었다.
이런 생산성 증대에 있어 궁금한 점이 있어 “그렇다면 MSA를 진행하는데 생산성 향상에 이를 수 있을 정도의 팀의 규모는 어느 정도인가?”에 대한 질문을 드렸다. 기능이 independent적인 관점에서 혼자 진행할 수도 있다고 했고 실제로 미국의 많은 스타트업에서는 작은 스타트업들도 MSA를 사용한다고 한다. 현업에서는 일반적으로 2-pizza 법칙으로 팀당 8명 내외로 꾸리고 여러 팀들을 묶어 30~40명 가량으로 운영할 수 있다고 한다. 그래서 팀마다 한달에 한번 릴리즈를 한다고 해도 4주에 4번 릴리즈가 되어 굉장히 빠르게 릴리즈를 가능하다고 하셨다.
하지만, MSA가 꼭 정답만은 아니다. 팀의 이해관계가 맞지 않는다면 오히려 학습하는데에도 시간을 낭비하고 맞지 않는 옷을 입으려니 생산성이 저하될 수도 있다. 그렇기 때문에 비즈니스에 맞지 않는 맹목적인 기술에 대한 맹신과 오버엔지니어링은 엔지니어로서 좋은 자세는 아닌 것 같다.
일반적으로 스프링으로 테스트를 작성할 때, @SpringBootTest를 이용해 통합테스트와 인수테스트를 진행했습니다. 이를 이용해 테스트를 진행하면, 개별적으로 테스트를 실행하기에도, 전체를 테스트를 실행하기에도 너무 속도가 느리다는 단점이 있었습니다. 뿐만 아니라, 테스트 간의 격리성을 확보하기 위해서 모든 데이터를 지우는 과정에서 DataIntegrityException 이 자주 발생해 어려움이 있었습니다.
이를 위해서 격리가 쉽고 빠른 테스트를 진행할 수 있는 테스트 방법에 대해 알아보았고, 마침 Mock을 이용한 Service Layer에 대한 단위테스트를 진행해보고 느낀 경험을 공유합니다.
저희의 ArgumentResolver에서 로그인한 유저를 조회하기 위해 사용하는 Service의 메소드 중 하나는 다음과 같습니다. jwtProvider를 통해 decode를 진행한 후에, email을 통해 user를 조회하게 됩니다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+
@Service
+@RequiredArgsConstructor
+public class UserService {
+
+ private final UserRepository userRepository;
+ private final JWTProvider jwtProvider;
+
+ ...
+
+ public User loginUser(String token) {
+ String email = jwtProvider.decodeJWTToSubject(token);
+ returnuserRepository.findUserByEmail(email).orElseThrow(NoSuchRecordException::new);
+ }
+}
+
이를 Mockito를 사용해 Service Layer의 의존성을 격리해 테스팅을 진행하면 코드는 다음과 같습니다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+
@ExtendWith(MockitoExtension.class)
+public class UserServiceMockTest {
+
+ private static final String ACCESS_TOKEN = "accessToken";
+ private static final String EMAIL = "swm.team.goyukkuri@gmail.com";
+ private static final String TOKEN = "token";
+
+ @Mock
+ private UserRepository userRepository;
+
+ @Mock
+ private JWTProvider jwtProvider;
+
+ @InjectMocks
+ private UserService userService;
+
+ private User googleUser;
+
+ @BeforeEach
+ void setup(){
+ googleUser = Fixtures.UserStub.defaultGoogleUser(EMAIL);
+ }
+
+ ...
+
+ @Test
+ void user_google_login_test() {
+ when(userRepository.findUserByEmail(anyString())).thenReturn(Optional.of(googleUser));
+ when(jwtProvider.decodeJWTToSubject(TOKEN)).thenReturn(EMAIL);
+
+ User user = userService.loginUser(TOKEN);
+
+ assertThat(user.getEmail()).isEqualTo(EMAIL);
+ verify(userRepository, times(1)).findUserByEmail(anyString());
+ verifyNoMoreInteractions(userRepository);
+ }
+}
+
UserService를 위한 의존관계인 UserRepository와 jwtProvider를 주입하려면, 먼저 Mocking을 진행해야 합니다. @Mock를 통해 가짜 빈을 넣어줄 수 있으며, 실제 구현된 객체와 무관하게 작동하게 됩니다. 다시말해 userRepository의 메서드들이 껍데기만 존재할 뿐, 구현체가 없게 됩니다. 만약 실제 객체를 주입하고 싶으면 @Spy 를 이용하면 됩니다.
의존 관계를 다 Mocking을 했다면, @InjectMock 을 통해 의존관계를 주입할 수 있습니다. 이를 통해 격리의 주체를 userService로만 둘 수 있게 되고, 다른 실제 객체들의 의존성이 모두 제거됩니다.
이후 when() 을 이용해서 Mock 객체의 메소드의 결과를 어떻게 설정할 것인지 정해준 후, userService.loginUser 메소드를 실행하게 됩니다. 만약 jwtProvider 혹은 userRepository 같은 Mock 객체의 메소드를 정의를 안해준 것이 있다면, 실행할 수 없게 됩니다.
이후 verify 를 통해 Mock 객체의 행위에 대해 검증해볼 수도 있습니다. 뿐만 아니라, when() 으로 설정한 것 이외의 행위가 있었는 지도 verifyNoMoreInteractions 를 통해 확인해볼 수 있었습니다.
SpringBootTest보다 압도적으로 속도가 빠르다는 점은 비교 불가한 장점이었습니다. 이를 통해 피드백을 더 빨리 받을 수 있었고, 빌드 시간도 단축할 수 있을 것이라는 생각이 들었습니다. 이는 곧 개발 생산성 향상으로 이어질 것입니다.
Mock을 사용해 다른 의존성들을 테스트 대역으로 사용하니, 내부 구현에 대해서 모두 Mocking을 진행해야 했습니다. 이는 내부 구현을 한번 더 확인해보게 되었으며, unit testing이 어려워지는 객체는 Mocking을 많이 진행해야 하고 고려해야 할 부분이 많아졌습니다. 이는, 메소드의 결합도가 높아졌다는 것을 알 수 있었습니다. 이는 통합테스트만으로는 알기 어려웠습니다.
Mockito를 통해 빈으로 주입받는 의존성을 모두 Mocking을 통해 테스트 대역을 편리하게 만들 수 있었습니다. @SpringBootTest도 @MockBean 을 통해 가능했지만, 이는 통합테스트 환경에서 특별한 의존성이 아닌 것들을 Mocking을 하는 것은 시스템 간의 상호작용을 확인하기 어려워지기 때문에 적절치 못하다고 생각했습니다.
모든 repository가 무엇이 사용되는 지 알아야 하고 이에 대한 return 값을 일일히 정해줘야 합니다. 이 부분은 관리 포인트가 많아진다는 단점을 지니고 있습니다. 뿐만 아니라, 인가 정책이 바뀌어 jwt가 아닌 session으로 바뀐다면, 테스트에 jwtProvider 절을 변경해야 할 것입니다. 이는 통합테스트에 비해 변경에 취약하게 됩니다.
저희 프로젝트의 도메인 서비스 로직에서 프로필 정보를 입력하는 다음과 같은 로직이 존재합니다.
1
+2
+3
+4
+5
+6
+
@Transactional
+public voidupdateUserProfile(User user, ProfileRequest request) {
+ Profile profile =newProfile(request.getNickname(), request.getGender(), request.getAge(), request.getJob(), user);
+ profile.addPsychologicalExam(request.getPsychologicalExams());
+ user.updateProfile(profile);
+}
+
본 로직은 영속성 전이(CASCADE.ALL)를 통해 프로필 정보에 대한 생명주기를 하나로 뒀습니다. 이는 Repository를 구현해 save를 하는 것은 객체 지향적이지 못하다고 생각해 위와 같이 구현했습니다. 이 같은 경우, 실제 쿼리가 어떻게 나가는 지에 대해 확인이 필요하다고 생각합니다. 다만, Mockito를 통해 unit testing을 진행한다면, 영속성 전이가 잘 이뤄졌는지에 대해서 확인이 어려울 것입니다. 뿐만 아니라, 전반적인 트랜잭션에 대한 테스트도 어려울 듯 싶습니다.
결론적으로 은탄환은 없다고, Mocking을 이용한 방법이 속도는 빠르지만 여러 단점이 존재했던 것 같습니다. 결국 각각의 장단점을 명확하게 인식하고 문제 상황에 맞게 조직에서 합의한 기준을 바탕으로 테스트를 잘 작성하는 것이 중요한 것 같습니다. 마지막으로, Mocking에 대한 여러 견해가 존재하는데 특히 테스트의 고전파와 런던파에 대한 마틴 파울러의 글(본 글의 테스트는 런던파에 해당합니다)을 읽어보는 것도 좋을 듯 합니다.
Mock Test 작성에 도움이 된 글
Unit Testing the Service Layer of Spring boot Application
책
블라디미르 코리코프, 단위테스트, 생산성과 품질을 위한 단위테스트 원칙과 패턴
설문 조사 플랫폼을 만들던 와중에, 질문에 대한 응답 문항과, 응답 문항에 응답할 때 결과들을 insert하는 과정에서 문제가 발생했다. 질문에 상응하는 응답 문항 만큼 insert 쿼리가 날라간다는 점과 응답 문항에 상응하는 점이 문제이다.
question -< answer
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+
@DataJpaTest
+public class AnswerTest {
+
+ @Autowired private SurveyRepository surveyRepository;
+ @Autowired private AnswerRepository answerRepository;
+ @Autowired private QuestionRepository questionRepository;
+
+ @Test
+ void answerBulkInsertTest(){
+ Survey survey = surveyRepository.save(new Survey("지방 선거 관련 설문", "2022 6월 1일에 시행되는 지방선거 관련 설문입니다.", Instant.now(), Instant.now().plusSeconds(100L), "pw"));
+ Question question1 = new Question("윤석열 정부에 대해 긍정적이십니까?", 5, 1, survey);
+
+ List<Answer> answerList = new ArrayList<>();
+ for (int i=0; i<100; i++){
+ Answer answer = new Answer("ans", question1);
+ answerList.add(answer);
+ }
+
+ question1.addAnswer(answerList);
+ questionRepository.save(question1);
+ answerRepository.saveAll(answerList);
+ }
+}
+
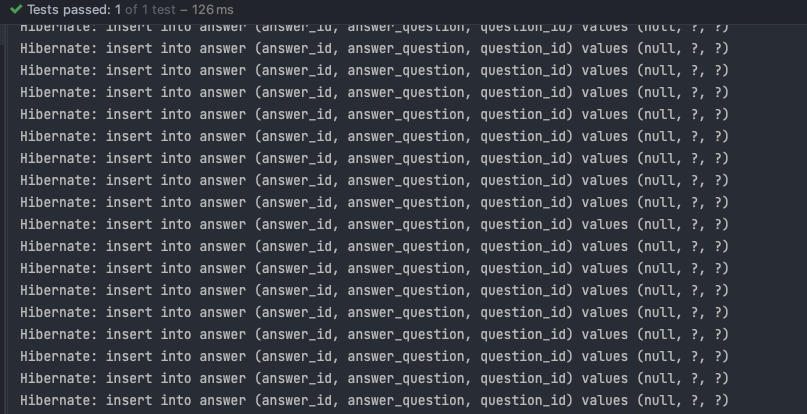
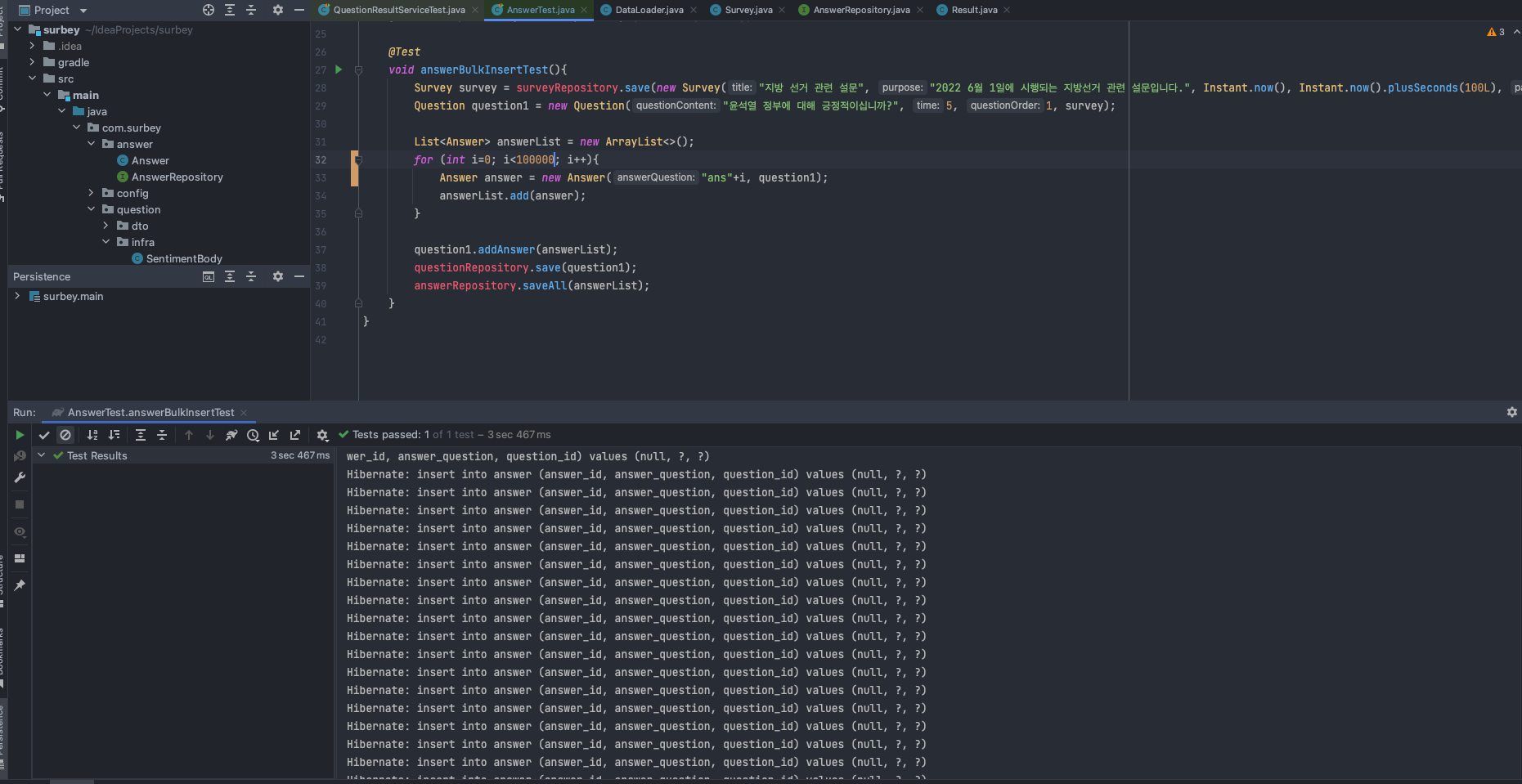
관련해서 실제로 프로젝트를 진행할 때, Navi Project를 진행할 때 Spring DATA JPA를 이용해 5000건 가량의 데이터를 insert했는데 속도도 13초 가량 걸릴 뿐더러 annotation 지정 방식이 굉장히 번거로웠다.
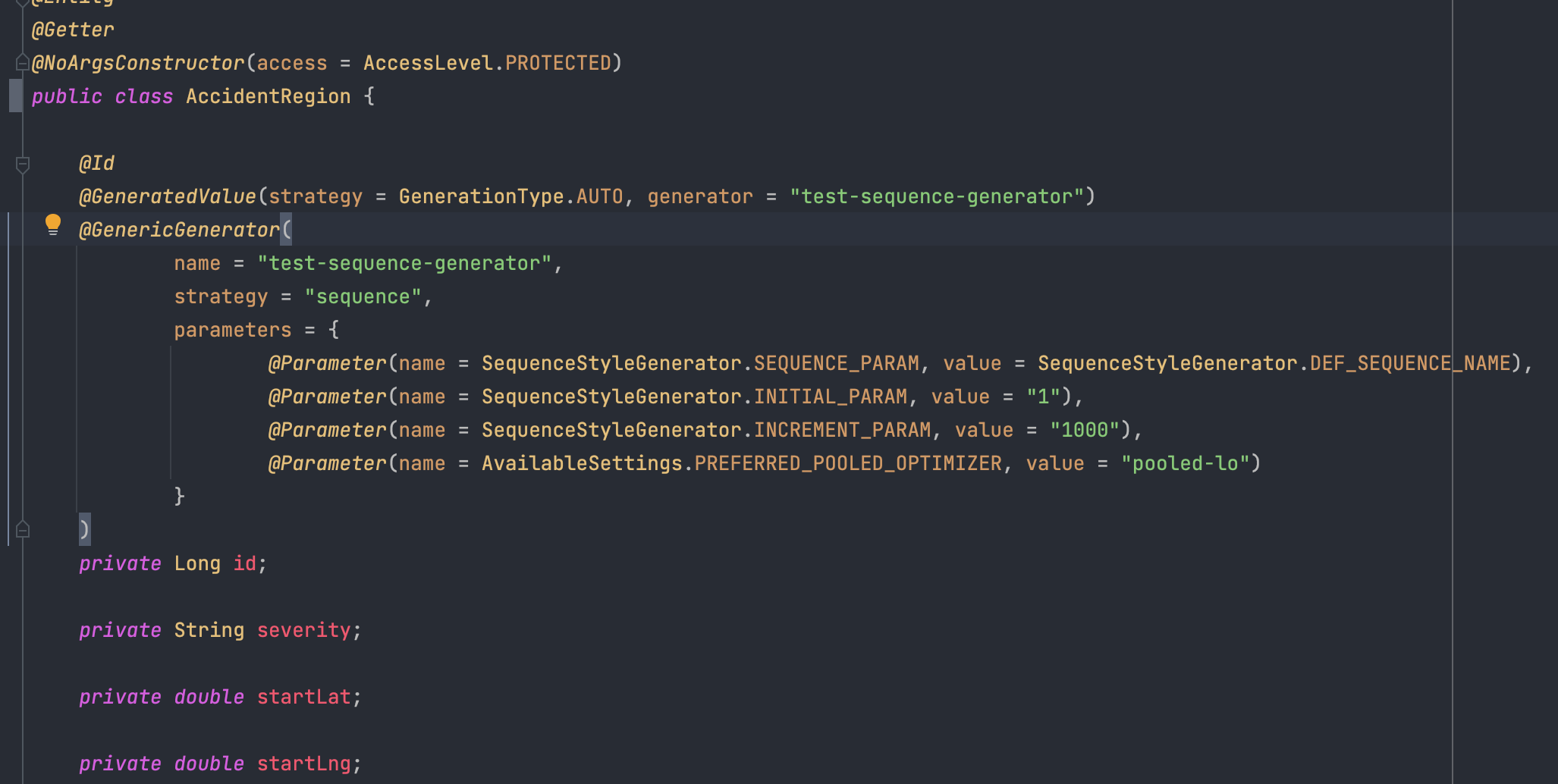

MySQL Docs에서 many rows에 insert할 때 다음과 같이 조언을 했다.
If you are inserting many rows from the same client at the same time, use
[INSERT]statements with multipleVALUESlists to insert several rows at a time. This is considerably faster (many times faster in some cases) than using separate single-row[INSERT]statements.
다중으로 값을 넣을 예정이라면, 한번에 쿼리로 넣으라는 말이다. 관련해서 구체적인 테스팅은 다음 글을 참고해도 좋을 듯하다.
그렇기에 bulk insert에 대한 sql문을로작성할 수 있으면 되는 것이다. 이는 Spirng에 내장된 jdbcTemplate 의 batchUpdate 이용하면 쉽게 bulk insert query를 작성할 수 있었다. Bult insert가 필요한 도메인에 대한 Repository에 공통적으로 사용할 수 있도록 BulkRepository 를 만들고 이에 대한 구현체인 BulkRepositoryImpl를 Bean으로 등록했다.
JdbcTemplate을 이용해 batchUpdate를 통해 batchsize를 100으로 설정하고 Answer 도메인에 대한 query를 날리는 코드는 다음과 같이 구현할 수 있다. .
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+
@Repository
+@RequiredArgsConstructor
+public class BulkRepositoryImpl implements BulkRepository {
+
+ private final JdbcTemplate jdbcTemplate;
+
+ @Override
+ public void answerBatchInsert(List<Answer> answers){
+ String sql = "INSERT INTO survey_answer"
+ + "(answer_question, question_id) values (?, ?)";
+
+ jdbcTemplate.batchUpdate(sql, answers, 100, (ps, argument) -> {
+ ps.setString(1, argument.getAnswerQuestion());
+ ps.setLong(2, argument.getQuestionId());
+ });
+ };
+
+}
+
이를 통해 최종적인 성능 비교를 하면 다음과 같다.
saveAll() - 20.892초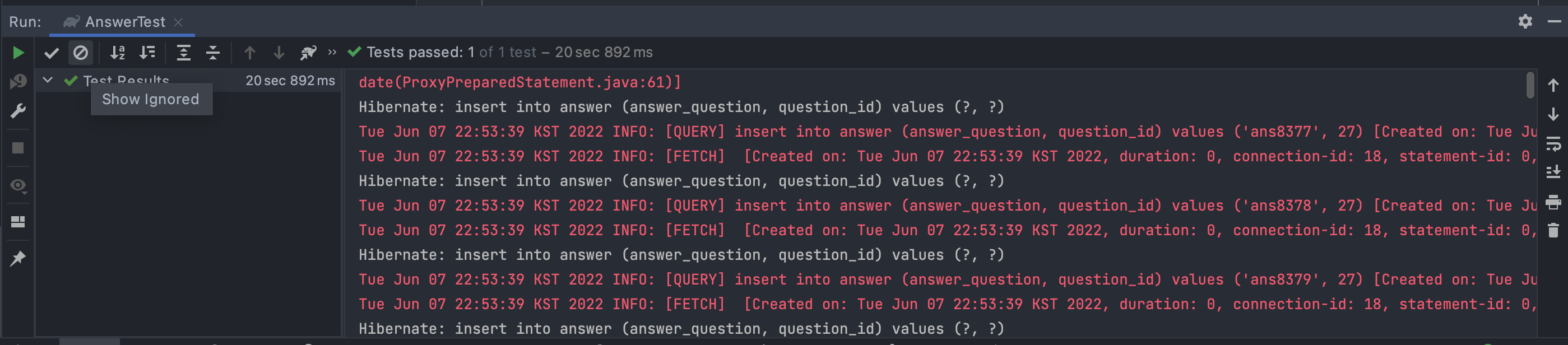
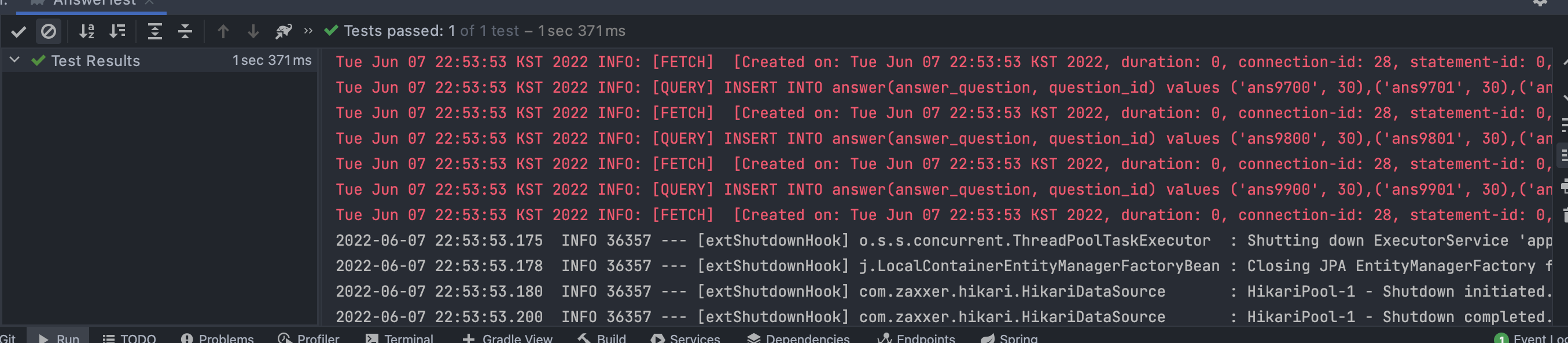
batchsize를 정해준 것은 insert query가 너무 크다면 mysql의 max_allowed_packet 을 초과할 수 있기 때문이다. Mysql8.0은 64MB를 디폴드인 것으로 알고 있으며, 이를 변경할 수 있지만 너무 커지면 세션 당 부하가 커질 수 있다.
만약 Bulk Insert한 것들에 대한 PK(id)값이 필요하다면 다음 글을 참고해보도록 하면 좋을듯 하다.
rewriteBatchedStatements=true 을 넣어줘야 작동한다!참고 문헌 및 래포
https://github.com/ChoiEungi/surbey-server
https://sabarada.tistory.com/195
https://kapentaz.github.io/jpa/JPA-Batch-Insert-with-MySQL/#
[https://homoefficio.github.io/2020/01/25/Spring-Data에서-Batch-Insert-최적화/#about](
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+
@Test
+ void retrieveInboxAllLettersTest() {
+ Letter letter = new Letter("content", user);
+ letter.send(user1);
+ letterRepository.save(letter);
+ letterRepository.save(letter);
+ letterRepository.save(letter);
+ List<InboxLetterResponse> inboxLetterResponses = letterService.retrieveInboxAllLetters(user1.getId());
+ assertThat(inboxLetterResponses.size()).isEqualTo(3);
+ }
+
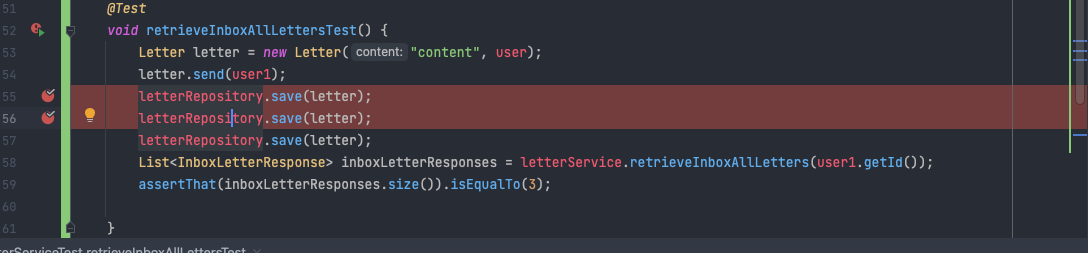
전체 편지를 조회하는 로직에서 3개를 insert한 후 이를 전체 조회해서 size를 비교하는 테스트코드를 작성하던 중 실패했습니다. 결과는 다음과 같이 나왔는데 편지에 대해서 insert쿼리가 1번만 발생한 것으로 보입니다. 실제로 전체 조회 후 size를 조회하면 1개가 나왔습니다.
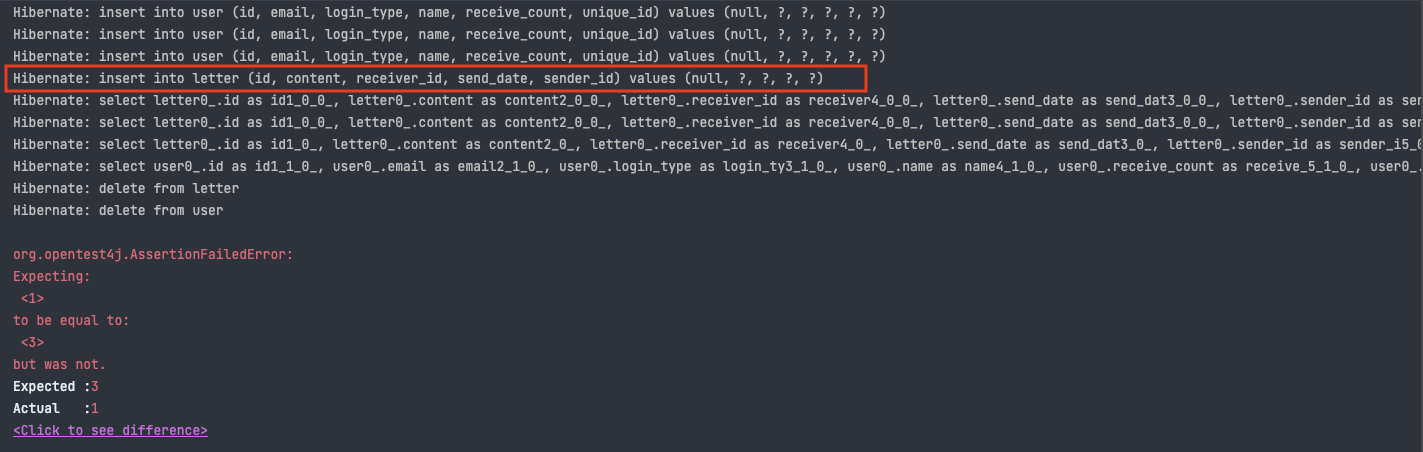
기본적으로 save가 identical하게 작동하고, flush를 진행하지 않아 발생한 것으로 유추되었는데 계속 실수가 발생하는 부분이기에 내부 동작 원리를 직접 확인해보겠습니다.
기본적으로 JpaRepository 는 다음과 같은 구조를 갖고 있습니다. 여기서 save는 CrudRepository 에서 인터페이스를 제공합니다. 참고로 PagingAndSortingRepository는 docs에서 나와있듯 CrudRepository 의 Extension으로, pagination과 sorting을 이용한 조회 method를 제공합니다.
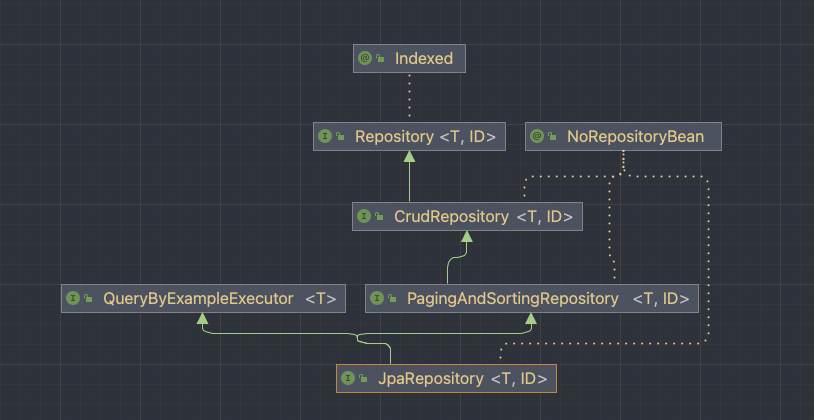
CrudRepository에서 save는 다음과 같이 인터페이스를 제공합니다. 여기서 docs의 설명이 굉장히 중요한데, 인스턴스가 변했을 수 있으므로, 저장 작업(insert query)이 save에서 return된 인스턴스를 사용한다고 되어있습니다. 제가 겪은 이슈에서는 이 return된 instance가 중복된 것으로 유추할 수 있습니다.

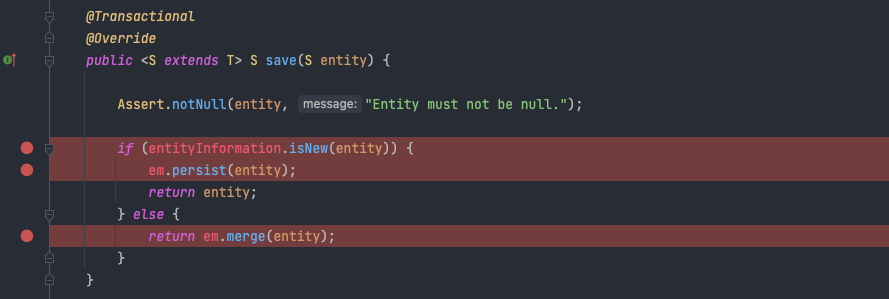
구현체인 SimpleJpaRepository로 들어가보면 다음과 같습니다.

만약 identity가 새로운 entity라면 persist한 후 entity를 리턴하는데, 그렇지 않다면 merge를 진행하게 됩니다. merge를 진행하면 Persistent Context에 객체가 추가되지 않기 때문에 이후에 save가 진행되는 객체가 insert되지 않게됩니다.
실제로 문제를 파악하기 위해서 디버깅을 진행해보면. 먼저 save가 실행 지점에 breakpoint를 잡고 이후 내부 동작을 확인하기 위해 Spring-data-jpa의 jar에 들어가서 SimpleJpaReposiotry 에서 breakpoint를 잡으면 다음과 같습니다.
디버깅을 실행하면 다음과 같습니다.
save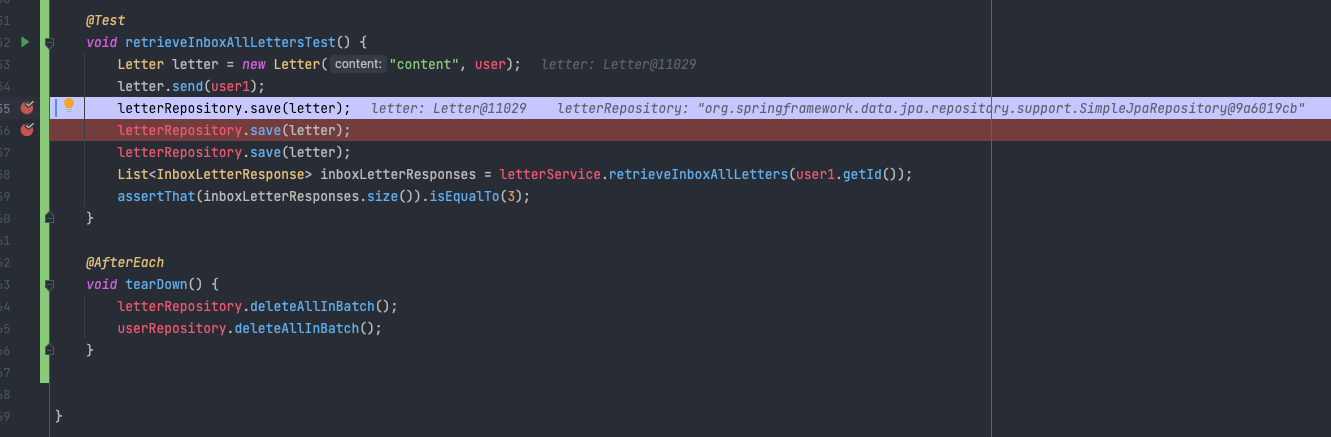

save두번 째에 대해서는 Persistent Context에 이미 존재하기 때문에 merge를 진행하게 됩니다. 이는 곧 identity가 똑같은 객체가 변경되었을 때 Persistent Context에 적용되고 이후 flush를 진행하면 쿼리가 발생하게 됩니다.


뿐만 아니라 해결책으로 saveAndFlush 를 사용하면 되지 않나? 싶어서 진행했는데도 통과하지 않았습니다. 이는 flush는 Persistent Context를 지우는 것이 아니라, Persistent Context의 내용을 DB에 쿼리를 날려 반영하는 것인 것도 놓쳤던 것 같습니다. 결국에는 identity가 다른 객체를 각각 만들어 save를 진행해 해결할 수 있었습니다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+
@Test
+void retrieveInboxAllLettersTest() {
+
+ for (int i = 0; i < 3; i++) {
+ Letter letter = new Letter("content", user);
+ letter.send(user1);
+ letterRepository.save(letter);
+ }
+ List<InboxLetterResponse> inboxLetterResponses = letterService.retrieveInboxAllLetters(user1.getId());
+ assertThat(inboxLetterResponses.size()).isEqualTo(3);
+}
+
굉장히 기본적인 내용인데 생각보다 놓치기 쉬운 부분이기에 글을 작성합니다. JPA에서는 객체의 Identity(객체의 id값)를 통해 새로운 객체임을 구분하고 save메소드에서는 이를 기준으로 insert가 작동하기 때문에 이를 유의해야 할 것 같습니다.
우리 회사를 포함해 많은 회사는 RDBMS를 사용할 때 MySQL Amazon Aurora DB(이하 오로라)를 사용하는 경우가 존재한다. 왜 오로라를 사용하는 지 궁금했는데 기존 전통적인 MySQL보다 가용성, 확장성, 연산 비용 등이 더 싸서 대규모 처리 작업에 용이해서 사용한다고 들었다. 또, 오로라는 컴퓨팅과 스토리지 인스턴스가 각각 분리되어 있다. 여기서 오로라 스토리지 엔진이 기존 MySQL 스토리지 엔진인 InnoDB와 큰 차이가 있는지도 궁금했었다.
마침 Real MySQL 스터디에서 MySQL에서 대체로 쓰이는 스토리지 엔진인 InnoDB 스토리지 엔진의 구조에 대해 공부하면서, 영속성을 제공하는 DoubleWrite buffer 기능이 흥미로웠다. 언뜻보면 비효율적으로 보일 수 있는 연산으로 보였기 때문이다. 물론 옵션을 끌 수 있겠지만, 정합성 측면에서 끄는 것을 권장하지 않아 사용한다고 가정했을 때 더 효율적인 방법이 있을 지도 궁금했다. 그렇기에 스토리지 엔진을 개선한 오로라는 어떻게 효율적으로 처리하는 지 알아보자.
오로라같은 경우 기존 전통적인 MySQL에 비해 더 좋은 퍼포먼스, 확장성, 가용성과 내구성을 제공한다. 이는 컴퓨팅과 스토리지 엔진을 분리해서 제공함을 통해 제공하며, 기존 MySQL 엔진과 InnoDB 스토리지 엔진을 커스터마이징해서 Aurora로 제공한다. Aurora Storage 엔진에서 더 좋은 퍼포먼스를 이야기할 때 특히나 I/O 연산 최적화를 다음과 같이 언급한다.
Aurora는 비용을 절감하고 읽기/쓰기 트래픽을 위해 사용할 수 있는 리소스를 확보하기 위해 불필요한 I/O를 제거하도록 설계되었습니다. 쓰기 I/O는 안정적인 쓰기를 위해 트랜잭션 로그 기록을 스토리지 계층으로 푸시할 때만 사용됩니다. (중략) 기존 데이터베이스 엔진과는 달리 Amazon Aurora는 변경된 데이터베이스 페이지를 스토리지 계층으로 푸시하지 않으므로 I/O 사용을 좀 더 줄일 수 있습니다. 링크
트랜잭션 로그 기록을 스토리지 계층으로 푸시한다는 의미는 무엇이고, 기존 InnoDB는 그렇다면 데이터를 스토리지 엔진으로 푸시하는 것일까? 이 두 개의 관점을 비교하면서 알아보자.
InnoDB 스토리지 엔진은 RDBMS에서 말 그대로 스토리지 디스크로부터 데이터를 잘 가져오는 역할을 한다. InnoDB 스토리지 엔진은 트랜잭션, 장애 복구, 락, 백업 등 여러가지 스토리지와 관련된 기능을 제공한다. 공식 문서에 나와있는 아키텍쳐는 다음과 같다.
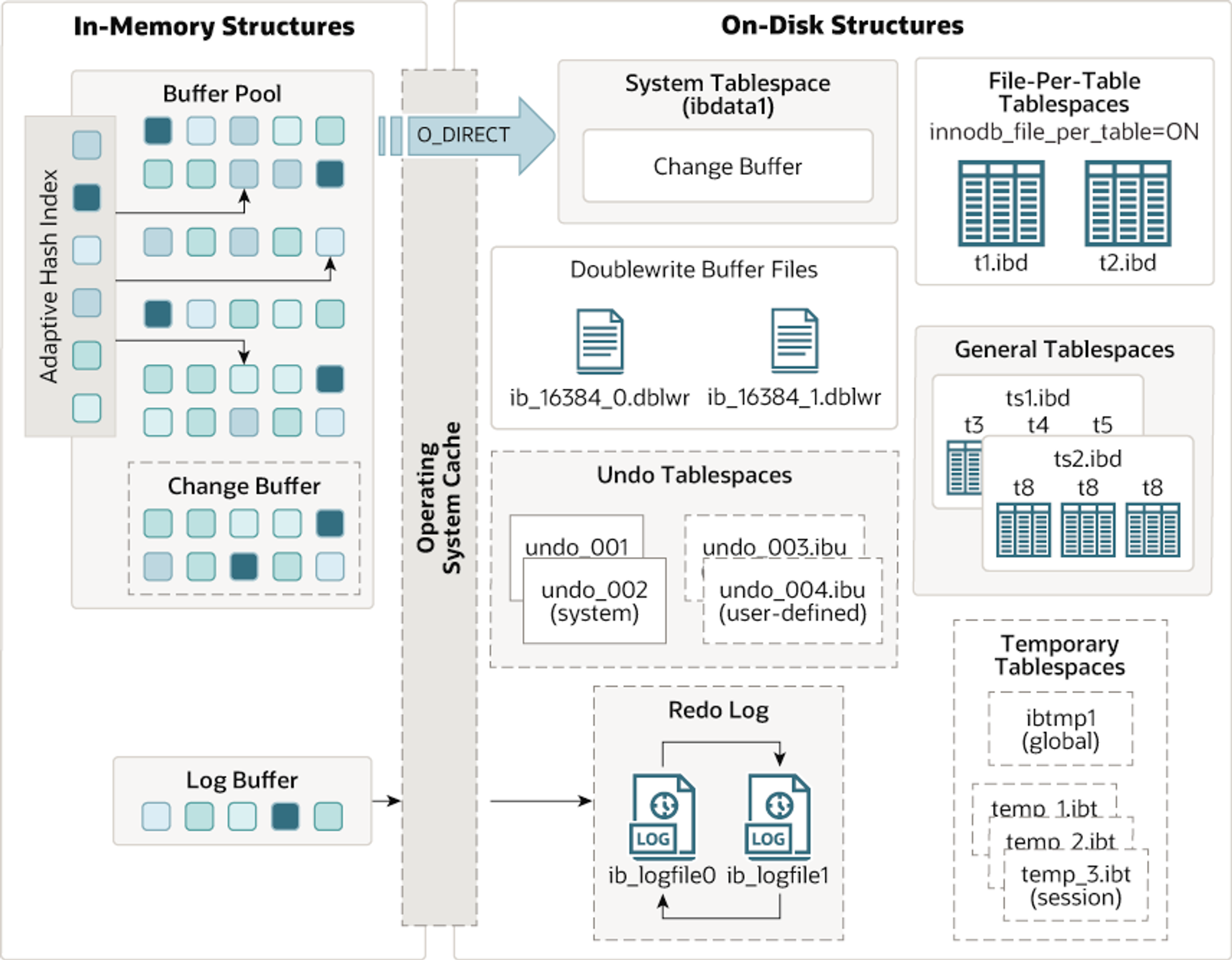
여기서 주의 깊게 봐야할 것은 DoubleWrite Buffer와 Buffer Pool이다. 여러 기능을 제공하지만, 버퍼 풀은 쓰기 지연 작업과 데이터 파일을 캐싱하는 역할을 하며, DoubleWrite Buffer는 데이터 정합성을 위해 버퍼풀에서 데이터 파일에 쓰기 작업을 하기 직전에 디스크에 따로 작성하는 로그이다.
innodb의 버퍼 풀에서는 기본적으로 데이터 파일에 flush하기 전에 doublewrite buffer를 스토리지에 저장한다. 이는 데이터의 무결성을 위함으로, 버퍼 풀에서 데이터 파일로 쓰기 작업 실패가 발생할 때를 사용된다. 실패가 나게 되면, doublewrite buffer의 내용과 데이터 파일을 비교해서 다른 내용을 담고 있는 페이지가 존재하면 doublewrite buffer의 내용을 데이터 파일의 페이지로 복사하게 된다. 이를 통해 시스템의 비정상적 종료에도 무결성을 보장할 수 있게된다.
예를 들어 다음 그림에서 innodb 버퍼 풀에서 데이터 파일에 쓰기 전에 먼저 DoubleWrite Buffer에 페이지를 작성하게 된다. 그 이후 버퍼 풀에서 flush를 진행해 데이터 파일에 쓰기를 진행한다. 만약 여기서 C 데이터 파일에 쓰는 과정에서 MySQL 서버가 종료되었다고 하면, 재시작할 때 forcing recovery로 인해 Doublewrite buffer의 내용이 해당 데이터 파일로 쓰기 작업이 일어난다.이를 통해 데이터 무결성을 보장할 수 있게된다.
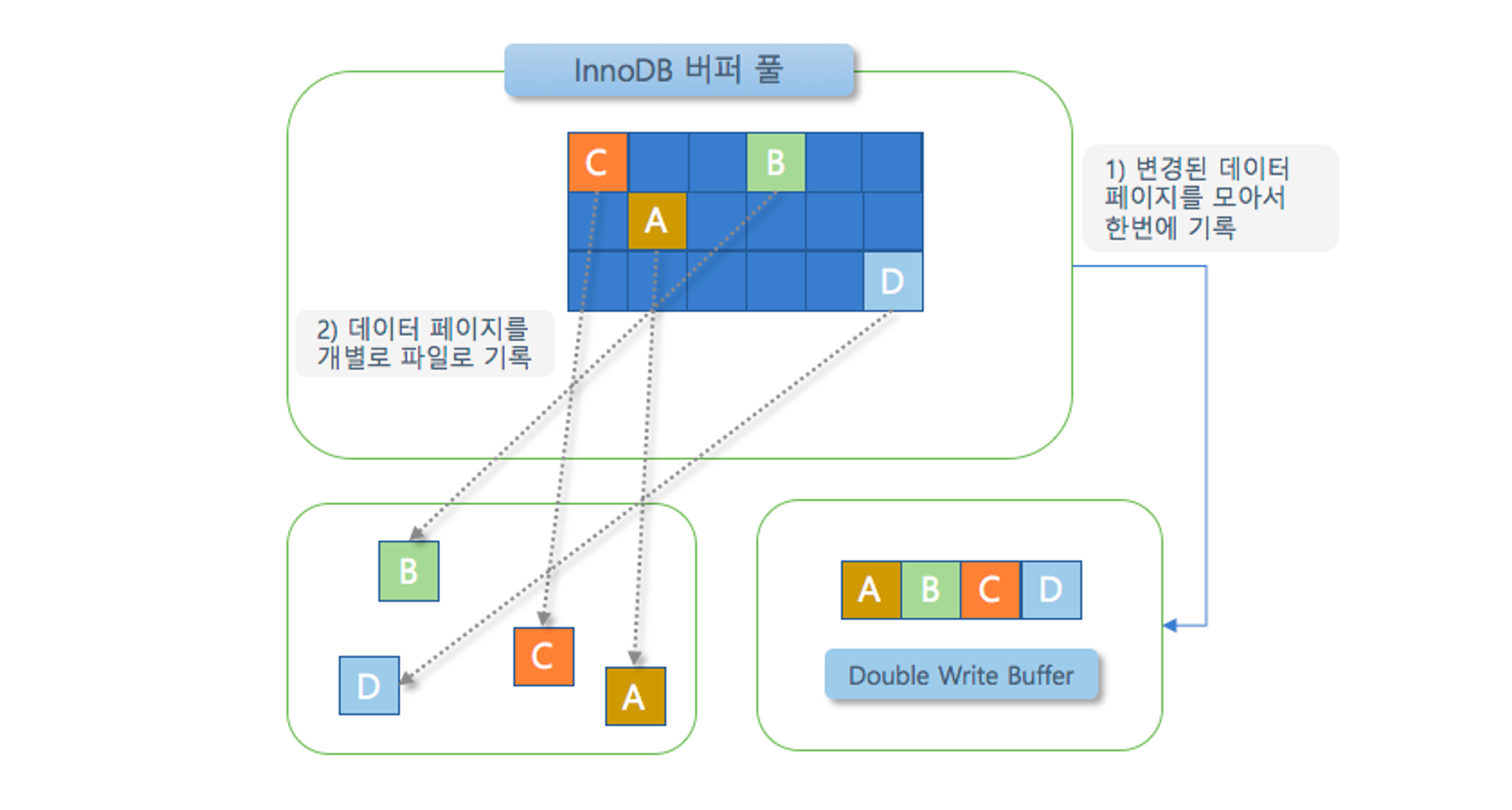
Doublewrite buffer 작업은 디스크에 실질적으로 쓰기 작업을 두 번 진행하는 것으로 볼 수 있다. 이에 대해 공식 문서에서는 2번의 쓰기 작업 I/O가 발생하지만 오버헤드는 2번 만큼 발생하지 않는다고 언급했다. 하지만 오로라는 이 Doublewrite buffer를 배제하는 방법으로 쓰기 작업을 진행한다. 즉, Doublewrite buffer를 작업하지 않으기에 표면적으로 봤을 떄 연산이 더 적다고 볼 수 있다.
다음 그림에서 볼 수 있듯이, insert를 진행할 때 MySQL은 doublewrite buffer과 Datafile에 쓰기 작업을 진행하지만, Aurora 같은 경우에는 스토리지에 로그를 쌓는 것이 전부이다. 그 이후의 작업은 오로라 스토리지 내부적으로 작업을 진행하게 된다.
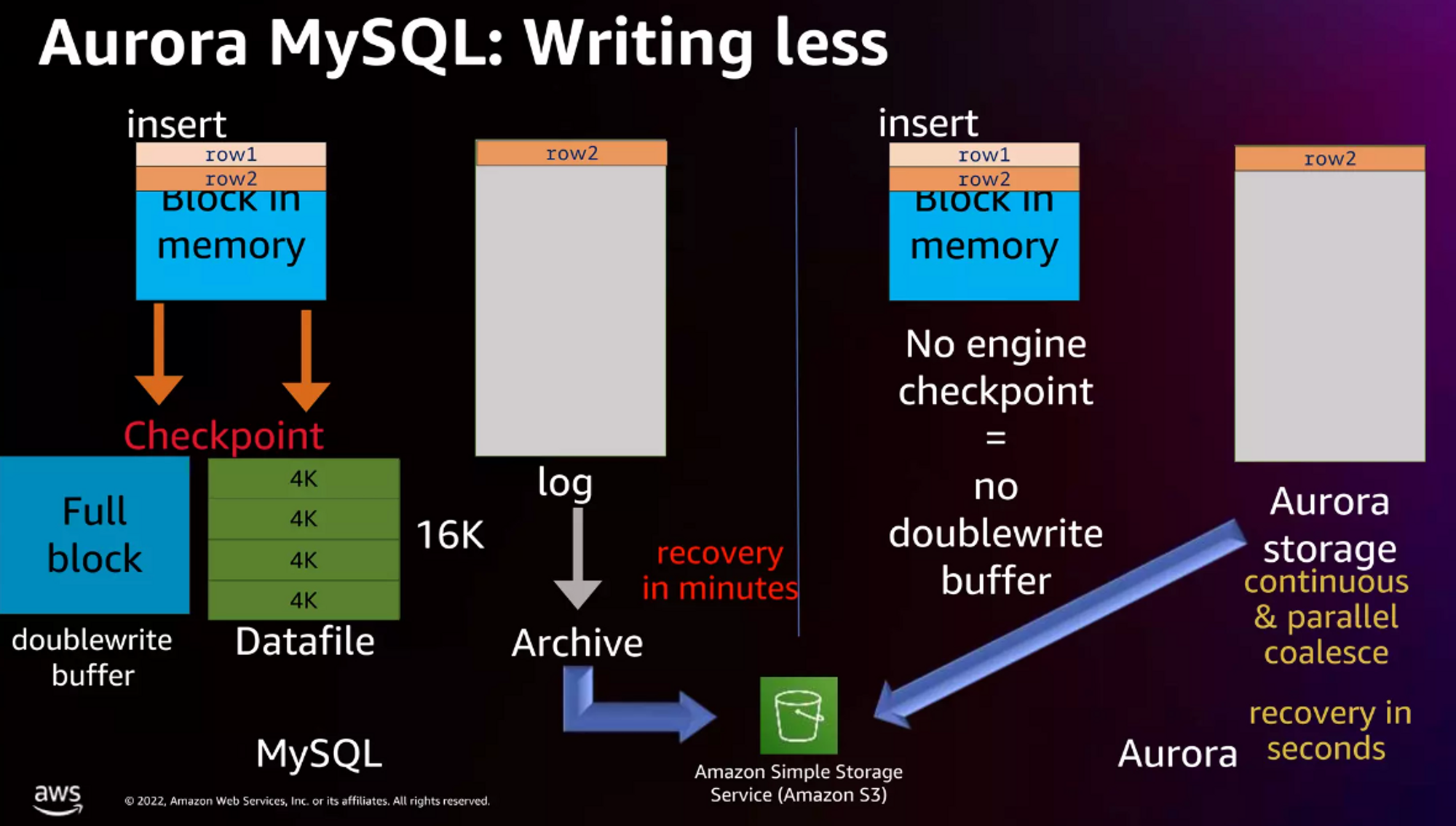
Aurora같은 경우에는 스토리지 구조가 log-structured storage이다. 위 그림에서 볼 수 있듯 오로라 스토리지에 로그만 쌓고 쓰기 작업이 끝난다. 그렇기에 오로라의 스토리지 쓰기 작업은 위에서 인용구에서 언급했듯, 트랜잭션 로그 기록(리두 로그)을 스토리지 계층으로 푸시할 때만 쓰기 I/O가 발생한다. 그렇기에 DoubleWrite buffer가 없을 뿐더러 데이터 파일도 직접 쓰기 연산을 하지 않는다. 이는 리두 로그(WAL)만을 디스크에 쓰기 연산함으로 I/O 연산을 극단적으로 줄일 수 있다. 또, 로그 파일은 데이터 파일에 비해 상대적으로 데이터 크기가 작을 것이기 때문에 실질적으로 더 많은 데이터 파일을 적은 I/O로 쓸 수 있게 되는 것이다.
언뜻 생각해보면 MySQL에서 리두 로그(WAL)를 모두 쌓지 않는 이유는 로그를 모두 쌓아서 연산함으로 데이터를 기록하게 되면 디스크 연산이 많아져 너무 느려져서라고 생각했었다. 하지만 오로라는 이를 Log Stream과 병렬 연산을 통해 연산 속도 문제를 해결했으며 그 관련 구조는 다음과 같다.
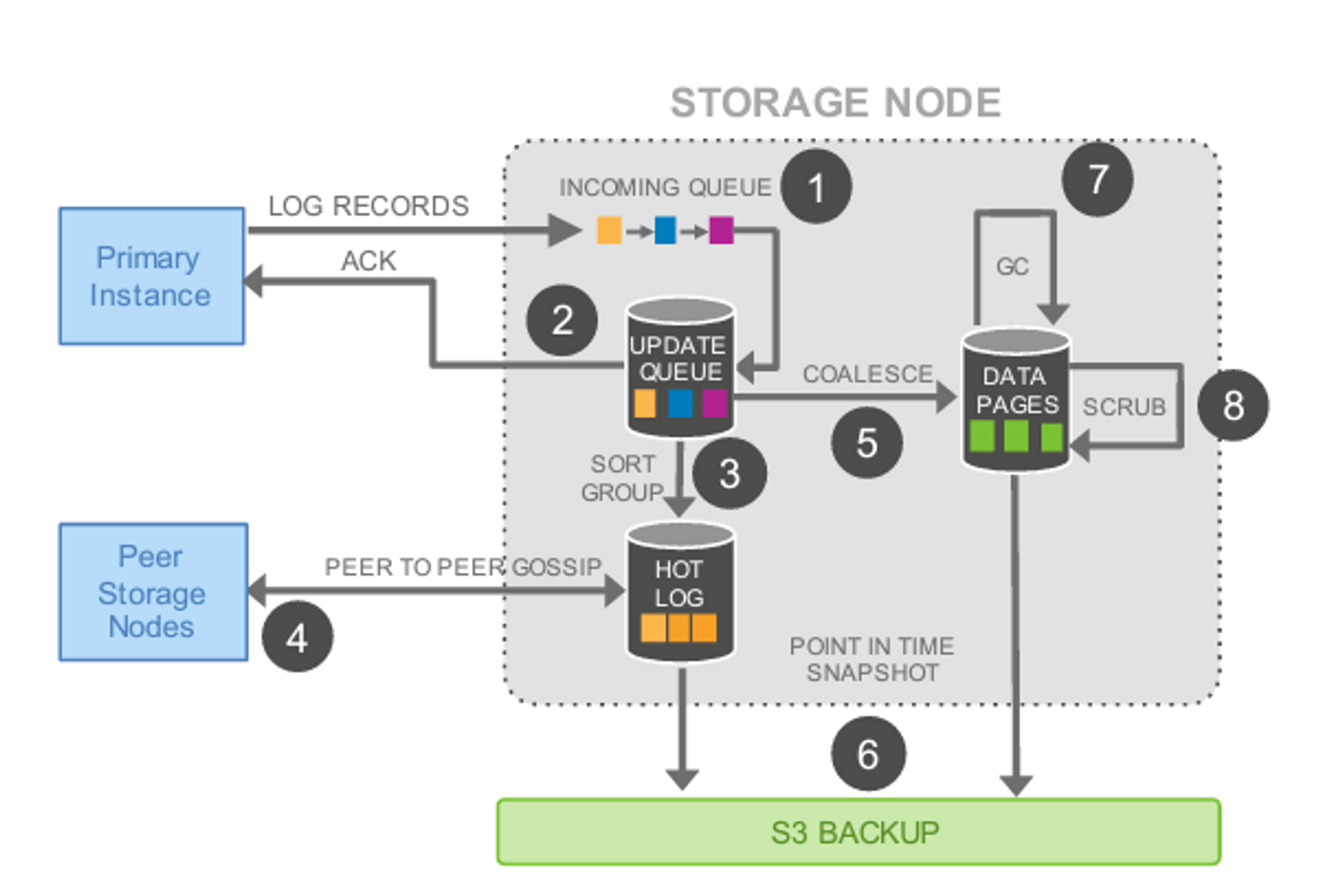
글에 요지에 벗어나서 구체적으로 다루지는 않지만, 로그 데이터를 incoming queue에서 받아 update queue로 동기식으로 전달하고 그 이후는 비동기 및 병렬로 처리해 데이터 파일에 쓰기 작업이 일어나게 된다. 또, 이렇게 작업된 것들은 S3에 저장함으로 손쉽게 백업을 구현한다. 이를 통해 오로라가 I/O를 기존 RDS MySQL에 비해 더 좋은 성능을 낼 수 있게 되었다.
디스크 I/O는 상대적으로 비싼 작업인 만큼 이는 수백, 수천만 I/O가 발생하는 서비스에서는 엄청난 차이를 만드며, 장기적인 관점으로 봤을 때 엄청난 비용 절감을 가져올 수 있다. 하지만 적은 I/O가 발생할 때는 오히려 RDS를 활용하는게 좋을 수 있다. 실제로 오로라의 최소 인스턴스(의 비용은 0.073 USD/h지만, RDS는 0.016USD/h이다. 또, DBMS가 AWS에 의존도가 높아진다는 단점이 존재한다. 결국 모든 기술에는 정답이 없는 만큼 현재 문제 상황에 맞는 데이터베이스를 적절히 고르는게 무엇보다도 중요할 것이다.
###
업적 달성은 데이터베이스의 유저의 정보 변경이 일어날 때 발생한다. 이는 곧, 유저 테이블에서 Insert와 Update 작업이 발생할 때, 업적 달성이 이뤄진다. 그렇기에 이 작업들에 대해 추적을 해야할 것이다. 여러가지 방법이 존재하겠지만, 이를 코드에서 추적할 수 있다면 좋겠다고 생각했고, 본 프로젝트에서는 Spring data를 사용하고 있어 관련된 해결책을 모색했다.
가장 첫 번째로 생각이 들었던건 단순히 비즈니스 로직을 처리하는 서비스 레이어에서 업적이 일어날 때마다 분기를 넣어 해결하는 방법인데, 이는 서로 다른 도메인의 강결합이 일어나는 문제가 존재했다. 편지 서비스 계층에서 편지 도메인의 편지라는 엔티티가 생성될 때, 유저 도메인의 유저 업적 엔티티를 생성하게 된다면 편지 도메인과 유저 업적 도메인이 강결합을 갖게 된다. 이렇게 다른 컨텍스트에 존재하는 도메인의 결합이 된다면, 추후 편지 작성이 아닌 다른 도메인에 해당하는 행위에 대한 업적을 생성할 때도 해당하는 엔티티와 유저 업적 엔티티는 강결합을 갖게 된다. 이는 극단적으로 유저 도메인과 다른 모든 도메인이 의존관계를 갖게 되는 잠재적 위험성이 있다.
그렇기 때문에 이러한 결합을 끊고, 스프링에서 제공하는 좋은 기능인 Domain Event를 발행해 해결한 사례를 공유합니다.
도메인 객체에서 어떤 작업이 실행됬을 때, 발행할 수 있는 이벤트를 의미한다. 이를 통해 객체의 생성이나 변경을 다른 객체와 결합 없이 Event Linstener를 통해 추적할 수 있다. 이를 통해 얻을 수 있는 장점은 다음과 같다.
스프링에서 기본적으로 제공하는 ApplicationContext는 이벤트를 발행할 수 있기 때문에, 이를 활용해 만들어진 도메인 이벤트를 활용하는데 어렵지 않게 사용할 수 있다.
먼저, spring data에서 제공하는 AbstractAggregateRoot<A> 를 활용한다면, 도메인 이벤트를 어렵지 않게 구현할 수 있다. AbstractAggregateRoot 는 domain event를 간편하게 발행할 수 있도록 만든 모듈이다. 이는 이름에서 볼 수 있듯, 도메인 이벤트를 발행하는 주체는 DDD의 AggregateRoot가 된다는 의미를 내포하고 있다.
Aggregate는 관련 객체를 하나로 묶은 군집을 의미하며, AggregateRoot는 군집 내에서 여러 객체들을 관리하는 루트 엔티티이다. 일반적으로 하나의 엔티티와 여러 개의 Value Object(값 객체)를 지니고 있으며, 하나의 Aggregate에 속한 객체는 같은 라이프사이클을 지닌다. Aggregate를 통해 간의 관계를 확인한다면, 더 상위 수준에서 도메인 간의 관계를 파악하는데 수월해진다.
본론으로 AbstractAggregateRoot<A> 를 이벤트를 발행할 Entity에 상속시키면 된다. 여기서 제너릭 타입(<A>)은 Entity의 타입이 된다. 이를 통해 registerEvent(event) 메소드를 상속받을 수 있으며 이 메소드를 통해 이벤트를 등록할 수 있다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+
public class AbstractAggregateRoot<A extends AbstractAggregateRoot<A>> {
+
+ private transient final @Transient List<Object> domainEvents = new ArrayList<>();
+
+ /**
+ * Registers the given event object for publication on a call to a Spring Data repository's save methods.
+ *
+ * @param event must not be {@literal null}.
+ * @return the event that has been added.
+ * @see #andEvent(Object)
+ */
+ protected <T> T registerEvent(T event) {
+
+ Assert.notNull(event, "Domain event must not be null!");
+
+ this.domainEvents.add(event);
+ return event;
+ }
+
+ ...
+}
+
이를 통해 편지 도메인 코드에 반영을 하면, 다음과 같다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+
@Entity
+@NoArgsConstructor(access = AccessLevel.PROTECTED)
+@Getter
+public class Letter extends AbstractAggregateRoot<Letter> {
+
+ @Id
+ @GeneratedValue(strategy = GenerationType.IDENTITY)
+ private Long id;
+
+ @Lob
+ private String content;
+
+ private LocalDate sendDate;
+
+ private boolean isRead;
+
+ @ManyToOne(fetch = FetchType.LAZY)
+ private User sender;
+
+ ...
+
+ @PostPersist
+ public void created() {
+ this.registerEvent(new LetterCreatedEvent(this.id, this.sender.getId(), this.sender.getUserAchievement().getSendLetterCountValue(), this.receiver.getReceiveCount()));
+ }
+}
+
여기서 @PostPersist 를 통해 이벤트를 발행했는데, 이는 JPA 엔티티의 라이프사이클에서 영속화가 된 이후에 이벤트를 등록하려 했기 때문에 다음과 같이 진행했다. 이는 서비스 계층에서 특별히 호출을 안해도 될 뿐더러, PK값 정책이 IDENTITY이기 때문에 영속화가 된 이후에 키 값을 받은 상태로 이벤트를 발행할 수 있다.
@EventListener를 통해 선언적으로 이벤트를 처리할 수 있다. 이를 통해 이벤트를 받는 코드를 작성하면 다음과 같다. 뿐만 아니라, 특정 조건을 만족하려 한다면 @EventListener(condition) 을 사용한다면 간편하게 활용할 수 있다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+
@Component
+@RequiredArgsConstructor
+public class AchievementPolicy {
+
+ private final UserRepository userRepository;
+ private final AchievementRepository achievementRepository;
+ private final LetterRepository letterRepository;
+
+ ...
+
+ @EventListener
+ public void achieveLevelTwo(LetterCreatedEvent letterCreatedEvent) {
+ Long userId = letterCreatedEvent.getUserId();
+ if (userRepository.existsById(userId) && letterRepository.existsById(letterCreatedEvent.getId())) {
+ achievementRepository.save(new Achievement(LEVEL_TWO.getLevel(), LEVEL_TWO.getName(), LEVEL_TWO.getTag(), userId));
+ userRepository.increaseUserPoint(userId, LEVEL_TWO.getPoint());
+ }
+ }
+
+ @EventListener(condition = "#letterReadEvent.read == true")
+ public void achieveLevelThree(LetterReadEvent letterReadEvent) {
+ Long userId = letterReadEvent.getUserId();
+ if (userRepository.existsById(userId) && letterRepository.existsById(letterReadEvent.getId())) {
+ achievementRepository.save(new Achievement(LEVEL_THREE.getLevel(), LEVEL_THREE.getName(), LEVEL_THREE.getTag(), userId));
+ userRepository.increaseUserPoint(userId, LEVEL_THREE.getPoint());
+ }
+ }
+}
+
이벤트 발행에 대한 테스트는 @*RecordApplicationEvents* 옵션을 활용할 수 있다. 이는 단일 테스트 실행 시 발행되는 어플리케이션 이벤트를 ApplicationEvents 라는 객체에 저장된다. 공식 문서에는 다음과 같이 나타나 있다.
@RecordApplicationEvents is a class-level annotation that is used to instruct the Spring TestContext Framework to record all application events that are published in the ApplicationContext during the execution of a single test. The recorded events can be accessed via the ApplicationEvents API within your tests.
이에 대한 코드를 작성하면 다음과 같다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+
@RecordApplicationEvents
+@SpringBootTest
+@ActiveProfiles("test")
+public class LetterEventTest {
+
+ @Autowired
+ private ApplicationEvents applicationEvents;
+
+ @Autowired
+ private LetterService letterService;
+
+ @Autowired
+ private UserRepository userRepository;
+
+ private User sender;
+ private User receiver;
+
+ @BeforeEach
+ void setup(){
+ sender = userRepository.save(Fixtures.UserStub.defaultGoogleUser("gmail@gmail.com"));
+ receiver = userRepository.save(Fixtures.UserStub.defaultGoogleUser("receiver@gmail.com"));
+ }
+
+ @Test
+ void letter_created_event_test(){
+ letterService.writeLetter(new LetterRequest("content", List.of()), sender);
+ letterService.writeLetter(new LetterRequest("content", List.of()), sender);
+ assertThat(applicationEvents.stream(LetterCreatedEvent.class).count()).isEqualTo(2);
+ }
+}
+
하나의 편지를 작성할 떄(DB에 편지를 저장할 떄) 정상적으로 이벤트가 발행되는 것을 볼 수 있다.
현재 EventListener 내 작업은 트렌젝션이 보장되어야 한다. 이에 대해 이벤트 리스너의 트랜잭션을 어떻게 처리할 지 알아보면 좋을 듯 싶다.
배포 링크: Gijol
GIST 청원 프로젝트를 진행하면서 크게 제품의 코드 작성법과 테스트, Operation, Git flow 등을 배울 수 있었다. 이를 청원팀의 팀원으로서 배웠던 점이 많은데 과연 이 배운 것들을 내가 스스로 해나갈 수 있을지에 대해서 의문이 들었다. 이에 대한 중요성과 필요성이 너무나도 중요하게 느껴졌기에 프로젝트에서 사용하면 좋은 부가적인 것들이 아니라, 필수적인 것들로 느껴졌다. 그렇기에 새로운 프로젝트를 진행하면서 배운 방법론적인 부분을 적용해보고 싶었다.
Gijol 프로젝트는 기존에 진행하던 프로젝트를 완성하지 못해 아쉬움이 남아 진행한 프로젝트이다. 학교 졸업요건을 특별히 확인할 수 있는 서비스가 아직 없기 때문에 이를 학사편람과 직접 비교와 대조하면서 졸업요건을 확인해야 했고, 이 부분에서 졸업요건 확인을 심지어 놓쳐 한 과목 때문에 졸업을 못하는 사례도 발생했다. 이 부분에서 Pain Point는 확실하다고 느꼈고 본격 프로젝트를 진행하게 되었다.
뿐만 아니라 내가 생각하는 좋은 팀이라는 기준에 맞아서 진심으로 몰입해보고 싶다는 생각이 들었다. 팀 상태는 한 명은 운영은 아니지만, 기본적인 FE 개발 경험이 있었고. 한 팀원는 개발을 처음 진행해봤지만, 몰입의 중요성을 너무나도 잘 알고 현 상황에서 팀에 도움이 되는 본인이 할 수 있는 최선을 다했었다. 그에 따라 개발적인 성장도 놓치지 않으면서 최대한 도움을 받을 수 있는 부분을 활용하면서 성장을 해나갔다. 그 결과 React + Typescript를 2달 가량만에 코드적인 부분에 기여를 할 수 있었다.
이 팀원의 성장은 크게 모르는 것과 대해 투명하게 공유한다는 점에서 기인했다고 생각한다. 처음 개발을 해보는 팀원이 본인이 겪는 어려움에 대해 우연히 말을 하다가 겪었던 어려움을 들었다. 이에 대한 어려움을 호소할 때 혼자 고민했던 부분, 병목이 되었던 부분, 그로 인한 본인이 느끼는 감정을 공유함으로 충분히 공감이 되었다. 이를 통해 우리 프로젝트를 진행하는데 학습에 대한 시간이 더 필요하다고 판단해 일정 조율을 하는 현실적인 대안을 세울 수 있었다. 그 결과 팀원이 성공적으로 코드를 기여하고 자신감을 되찾을 수 있었다. 뿐만 아니라 팀의 전체적인 생산성도 높였다. 이를 통해 같은 팀원과 투명한 의사소통을 통해 발생할 수 있는 위험을 줄일 수 있었다. 이후 현업에서 나도 같은 상황에 놓일 수 있는데, 일정에 영향이 갈 정도의 정말 어려운 부분에 대해 부끄럽다고 느껴 위축되고 문제를 만들기보다 투명한 공유가 필요할 수 있겠다는 생각이 들었다.
개인적으로 반성하게 되는 점이 나는 무언가를 잘못한다는 생각이 들때 마다 너무나도 부끄러워 위축되는 경향이 있다. 항상 거기서 현실적인 대안으로 한 걸음 더 발전해나가려 생각해보지는 못하는 것 같다. 이에 대한 의식적인 개선이 필요하고 적용해나가야 한다.
내가 진행하고 고민한 부분들을 요약하면 다음과 같다.
함께 일하는 것은 효율을 극대화하기 위해 진행하다는 것을 배울 수 있었다. 기존에 토이프로젝트는 여러번 리딩을 진행해봤지만, 실제로 런칭할 프로젝트를 리딩해본 경험은 처음이었다. 프로젝트를 진행해보면서 어느 정도 서로가 일적인 가치가 맞는 팀원이었기에 방법론 도입에 대한 공감대 형성이 잘 되었던 것 같다.
SW 마에스트로를 진행하면서 에자일, 스크럼, 협업에 관한 특강을 관심을 갖고 열심히 들었다. 이를 Gijol 프로젝트에서 바로바로 사용할 수 있었던 점이 굉장히 체화하기 좋았었다. 이 경험을 바탕으로 SW마에스트로 과정도 비슷하게 운영해나갈 계획이다.
졸업요건은 전공, 교양, 기초과학, 기타과목과 같은 각각 분야에 대한 조건을 맞춰야 충족할 수 있다. 이를 하나의 객체에 모두 책임을 지게하는 것은 데이터 주도적인 설계로 느껴 각각 분야를 하나의 객체로 둬서 책임을 분할했다. 예를 들어, 전공은 Major라는 객체로, 기초과학은 BasicScience 라는 객체로 분리했다. 이는 각각의 책임이 명확해질 뿐더러 각 기능에 대한 테스트도 용이했다.
특별히 데이터베이스를 사용하지 않기 때문에 비즈니스로직이라고 할 것들이 크게 없었다. 다만, 졸업요건을 확인하는 알고리즘을 짜는데 시간이 걸렸다. 처음에는 단순 알고리즘이기에 테스트를 미뤘다. 이는 굉장히 오만했음을 느낄 수 있었다. 테스트를 안짜고 변경에 취약한 부분들이 테스트를 통해 오류가 너무나도 많이 발견되었다. 이는 결국 운영서버에 배포까지 오류가 생겼고, 결국 각각 전공에 대한 유닛테스트를 모두 작성하게 되었고 기본적이고 중요한 기능에 대한 기능은 유닛테스트를 반드시 해야된다는 것을 느꼈다.
TMI로 jar 빌드에서 classResource를 getFile() 하게 되면 빌드가 깨진다. 이는 jar에서는 File://와 같은 프로토콜을 제공하지 않아서라고 한다. 이는 getInputStream() 을 사용해야된다는 것을 느끼게 해줬다.
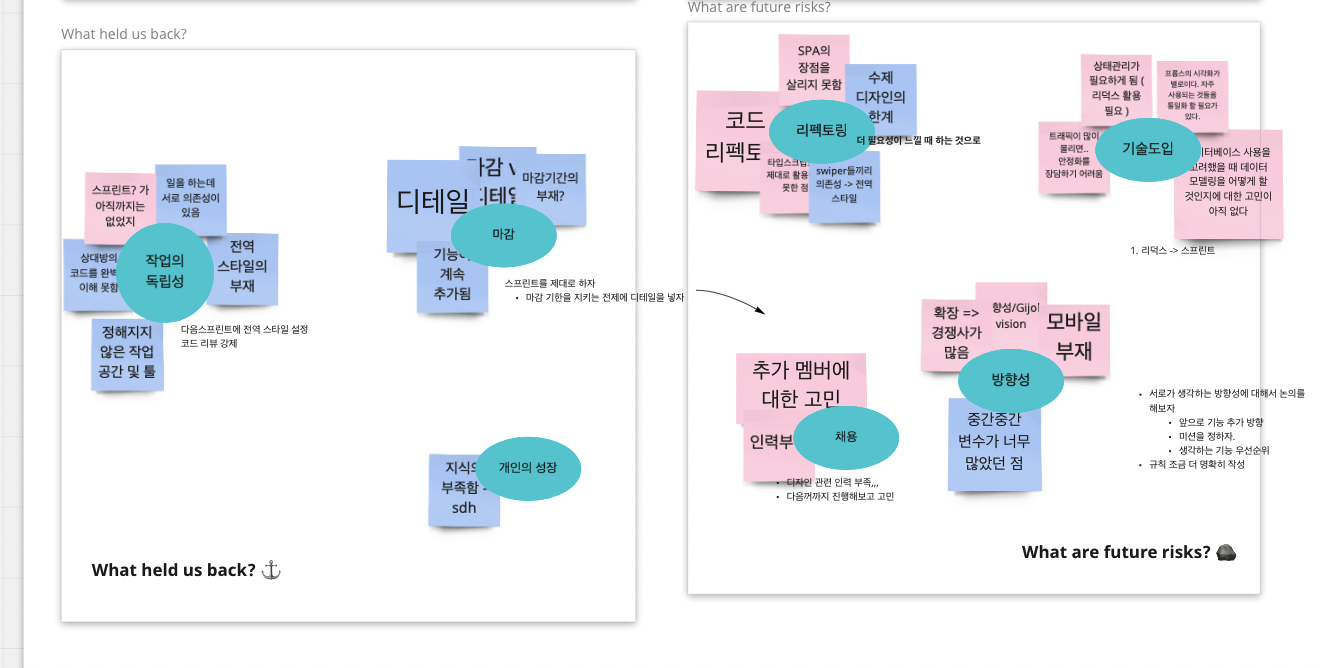
회고를 진행했을 때, 코드적인 부분의 투명한 공유가 부족했다는 점이 우리팀의 합의안 중 하나였다. 그렇기에 코드리뷰 문화를 일의 진행에 차질이 생기지 않는 선에서 강제하기로 Working Agreement를 추가했다. 나는 Java Spring 기반의 코드를 주로 작성하기에 FE 부분에 코드리뷰에 관여를 하기 어려웠다. 다만, 팀원들 스스로 객체 지향 설계의 필요성과 코드 개선에 대한 필요성을 너무 느끼고 있는 상황에서 내가 할 수 있는 것을 생각해보게 되었다.
Spring은 SOLID를 어느정도 Framework에서 강제한다. 그렇기 때문에 객체지향 설계에 대해 꾸준히 고민하게 된다. 뿐만 아니라, 우아한테크코스 프리코스 과정을 통해 객체지향 설계에 대한 고민을 진행해봤고, 최근에 객체지향 프로그래밍 수업에서 프로젝트(프로젝트는 객체지향과 사실과 오해라는 책에 소개한 객체 지향을 입각해 진행했다)를 진행하면서 객체 지향 설계에 대한 설명을 가장 잘할 수 있을 때가 아닌가라는 생각을 하게되었다. 뿐만 아니라 기존에 나는 데이터 주도 설계를 진행해보고 이는 객체 지향적이지 못하다는 것을 느꼈고 이 경험을 공유해주면 팀적으로 너무나도 좋을 것 같다는 생각이 들었다.
이러한 생각을 바탕으로 React를 코드리뷰가 가능한 선에서 공부해보기로 결심했다. 이는 장기적인 팀적 성장으로 봤을 때 팀적 생산성이 복리로 돌아올 수 있을거라 느껴 공부를 시작한 것이다. 또한, 새로운 것에 대한 학습으로 받아들일 수도 있겠다 내가 생각하는 학습이 맞는지에 대한 검증을 할 수도 있겠다. 이를 바탕으로 최대한 빠른 시간으로 React라는 것에대해 공부를 해보고 코드를 어느 정도 작성해보면서 Gijol 팀의 리뷰 문화를 개선하는 것을 목표로 두고있다.
벡엔드 개발자로서 역량도 향상에 힘쓸 생각이다. Gijol MVP는 DB 사용이 필수는 아니라는 것이 결론이었기 때문에, 아직 DB를 사용하지 않는다. 다만, 졸업요건 확인의 상태 유지를 할 계획이라는 점과 강의평가 기능을 추가한다는 점으로 사용자의 uniqueness를 검증해야 한다. 그렇기 때문에 다음 스프린트부터는 DB 도입을 진행할 계획이다. 그렇기에 DB와 설계에 대한 고민과 JPA 도입을 염두하고 있다.
아직 부족하게 많은 프로젝트였지만, Gijol 첫 MVP는 개발자로서 내가 중요하게 여기는 가치, 개발자를 너머 삶의 가치까지 생각해보게 되는 뜻깊은 시간이었다. 생각했던 것이 실현되는 것만큼 기쁘고 자아실현에 도움을 주는 것은 없는 것 같다. 물론 이 기대가 너무 커지면 불행으로 다가오는 것을 항상 인지해야 한다. 기대가 너무 크면 실망도 그에 상응한다.
공동 목표를 지닌 팀원들과 함께 정말 진심어린 몰입을 통해 기대 이상의 가치를 느끼는 것은 어떤 가치와도 맞바꾸기 어려운 것같다.
프로젝트는 본 링크에서 확인하실 수 있습니다.
git add submodule ${서브 모듈로 등록할 github repository의 주소} 을 사용해 등록한다.git submodule update --remote을 이용해 로컬에 있는 서브모듈 폴더로 가져 온다.++ gradle이나 github action으로 서브모듈을 잘 사용한다.
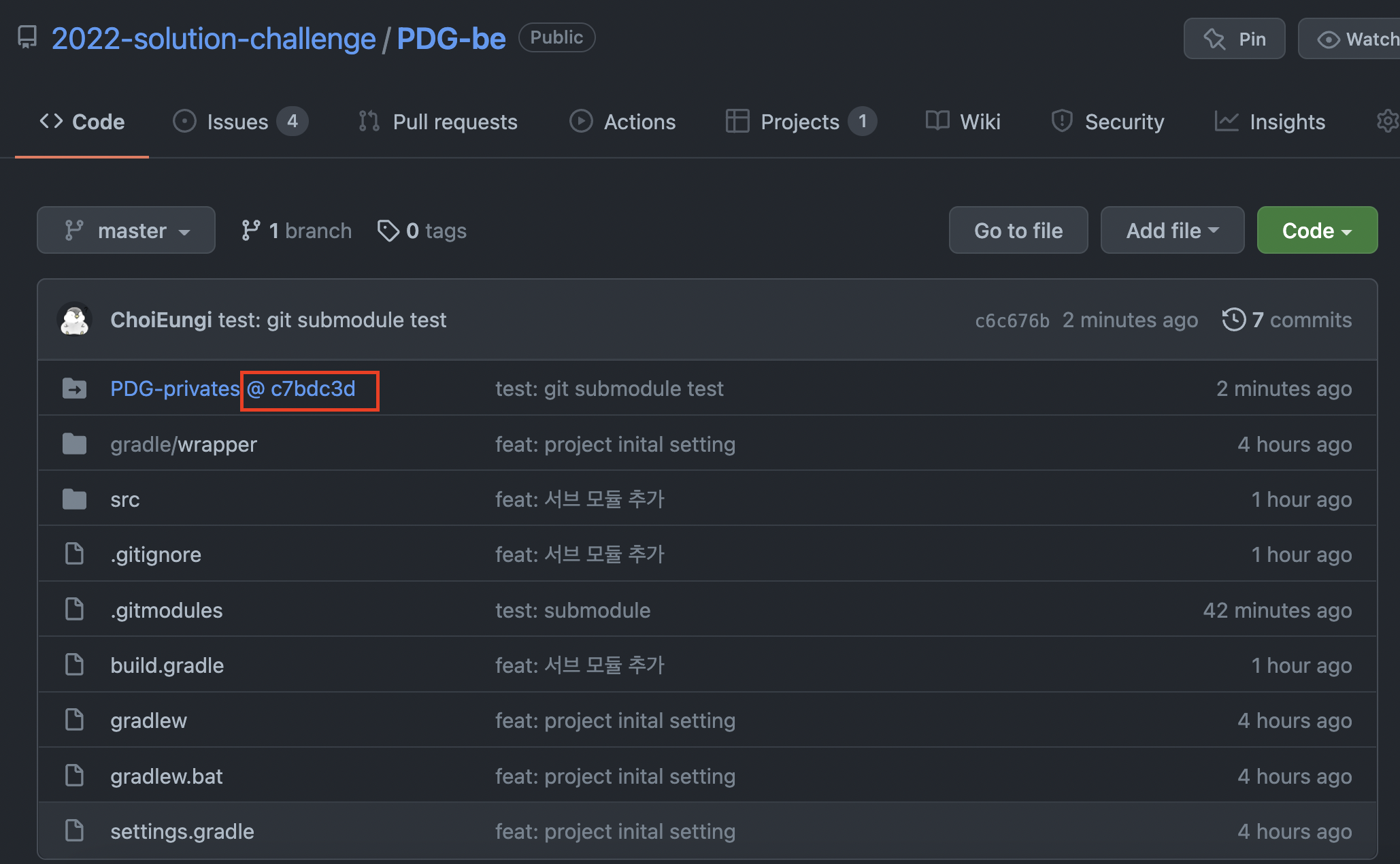
그렇다면 다음 나와있듯 /be 경로(프로젝트의 최상단 경로)에 PDG-privates(submodule repo 이름)라는 폴더가 생성된다.(submodule의 내용들)
git add submodule ${서브 모듈로 등록할 github repository의 주소}

.gitmodules 추가submodule의 path(file 명)와 url(github url)을 추가해준다. 단 여기서 submodule의 default branch가 master가 아니라면 반드시 branch
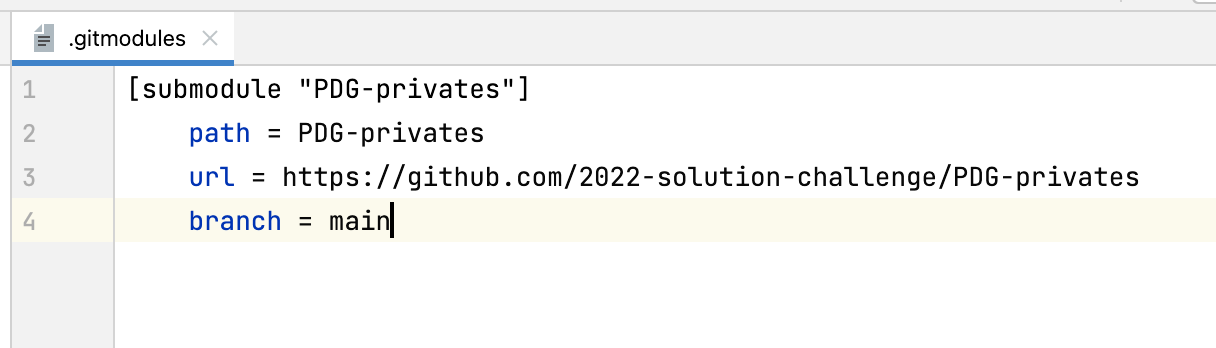
git submodule update --remote git submodule 방식은 branch의 hash를 작성하는 방식이다. 그렇기 때문에 git submodule update --remote 을 진행하면 submodule의 내용이 update 된다. 본 프로젝트에는 hash가 변경 된다. 이후 반드시 본 프로젝트의 git commit을 진행해야 hash가 제대로 업데이트 된다. 다시 말해, git commit -am "message" 를 진행하고 Push를 해야 한다!
현재 프로젝트는 다음과 같이 설정돼 있다.

이후 협업을 진행하거나 외부에서 submodule을 수정했다는 것을 가정하고 Remote에서 다음과 같이 변경한다.
이후 다음 커맨드를 입력한다.
1
+
git submodule update --remote
+
그렇다면 다음과 같이 hash 값이 checkout 됐다고 나온다.
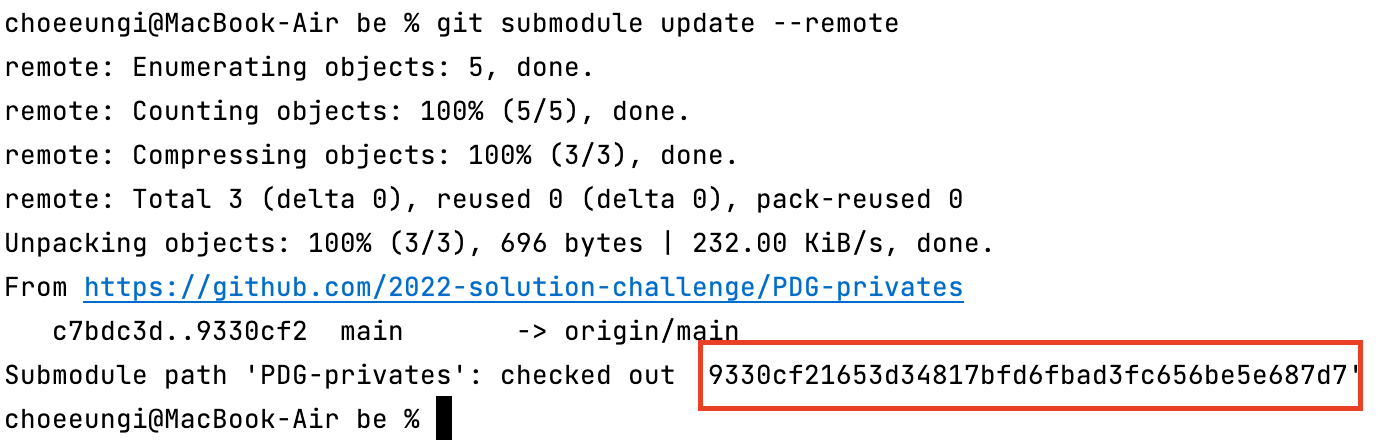
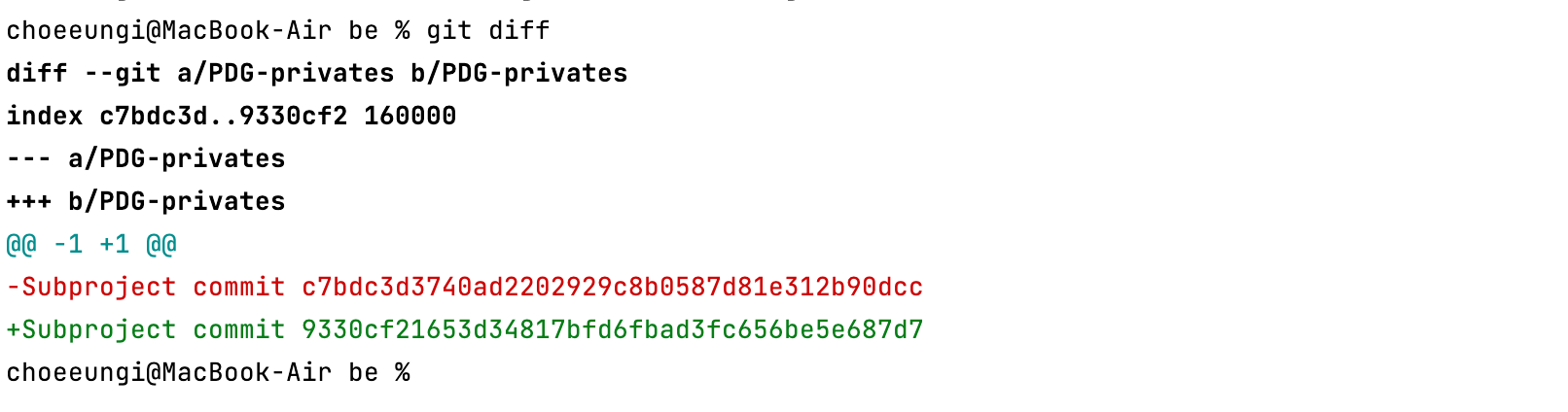
실제로 PDG-privates 폴더 안의 내용이 remote와 같이 변경된다. git diff 를 통해 hash를 확인해봐도 9330cf ~로 변경된 것을 볼 수 있다.
이를 커밋하고 push하면

로컬 privates 를 받아올 때, gradle를 사용하면 편리하게 submodule의 내용을 가져올 수 있다.
1
+2
+3
+4
+5
+6
+7
+
task copyPrivate(type: Copy) {
+ copy {
+ from './PDG-privates'
+ include "*.yml"
+ into 'src/main/resources/privates'
+ }
+}
+
이를 설정하고 build시 submodule의 yml파일들을 ‘src/main/resources/privates’로 가져온다. 이 때, 반드시 ‘src/main/resources/privates’를 .gitignore에 추가해줘야 한다.
1
+2
+3
+4
+5
+
- name: Checkout
+ uses: actions/checkout@v1
+ with:
+ token: $
+ submodules: true
+
를 workflow file에 추가해주면 된다.
Problem
1
+2
+
fatal: Needed a single revision
+Unable to find current origin/HEAD revision in submodule path 'PDG-privates'
+
Solution
.gitmodule에서 branch를 main으로 변경해줬더니 성공했다.1
+2
+3
+4
+
[submodule "PDG-privates"]
+ path = PDG-privates
+ url = <https://github.com/2022-solution-challenge/PDG-privates>
+ branch=main
+
팀원분께서 예전에 aws key를 yml파일에 넣으셨다. 이때 문제를 인식하고 커밋이 안 쌓였을 때 지웠어야 하는데 이런저런 핑계를 대며 지우지 않았는데 오늘 레포를 public으로 변경했는데 문제가 터졌다.
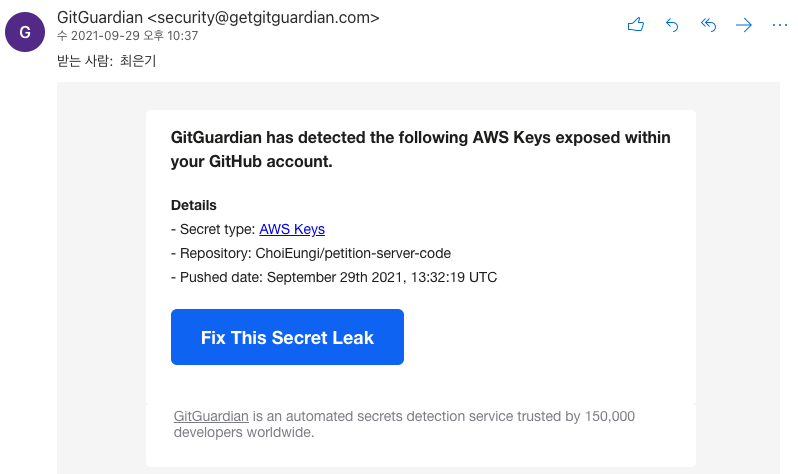
보통 가장 최근 커밋은 git reset HEAD 로 지울 수 있는데 한참 전 기록이 발목을 잡았던 것이다. 이를 해결하는데 겪은 고난을 소개하고자 한다.
민감 정보를 지우는데는 2가지 방법이 있다.
1번은 개인적으로 커밋한 흔적은 어떻게보면 버전인데 버전을 모두 지우기에 risk가 너무 크다는 생각이 들었다.(고생한 흔적도 지워지고) 그렇기에 2번을 이용해 커밋 기록을 그대로 남기면서 어떻게 민감 정보를 변경했는지 소개하고자 한다.
brew를 사용할 수 있다는 가정하에 작성한다.
bfg는 git-filter-branch의 대안으로 나온 repo cleaner이다. scala로 작성돼 git filter branch보다 빠를 뿐더러 사용하기 매우 간편하다.
mac의 경우 brew를 이용해 간편히 설치할 수 있다.
1
+
brew install bfg
+
지우려는 기록은 다음과 같다.

이후 project의 root directory에서 password.txt라는 파일을 만든다.(다른 이름도 괜찮다.) regex 문법을 이용하는데, regex를 크게 몰라도 간편하게 사용할 수 있다. 다음과 같은 형식을 사용하면 된다.
1
+
{민감정보}==>{변경정보}
+
관련해서 구체적인 예시는 다음 사이트를 보면 이해가 더 잘된다.

이 때 yml파일 같은 경우 앞의 공백이 생기기 때문에 이를 맞춰주려면 공백도 그대로 포함해야 한다.
이를 저장하고 다음과 같은 커멘드를 입력한다.
1
+
bfg --replace-text password.txt
+
성공적으로 진행되면 다음과 같이 나온다.
 민감 정보가 들어있는 yml 파일이 변경됬다고 잘 나온다. 그리고 마지막에 있는 command를 입력한다.
민감 정보가 들어있는 yml 파일이 변경됬다고 잘 나온다. 그리고 마지막에 있는 command를 입력한다.
1
+
git reflog expire --expire=now --all && git gc --prune=now --aggressive
+
이후 다른 repo를 새로 만들어서 git push하면 된다.

Log4j 이슈로 인해 우리 프로젝트에서 log4j를 버전을 확인해봤는데 2.14.1 버전을 사용하고 있었다. 이는 Intellij에서 External Library에서 확인할 수 있다.

log4j 2.14.1 버전은 CVE-2021-44228 에서 나와있듯, 보안취약점에 영향을 받는 버전이다. 다음 사진에서 나와있듯, 2.15.0 버전으로 변경해야 한다.
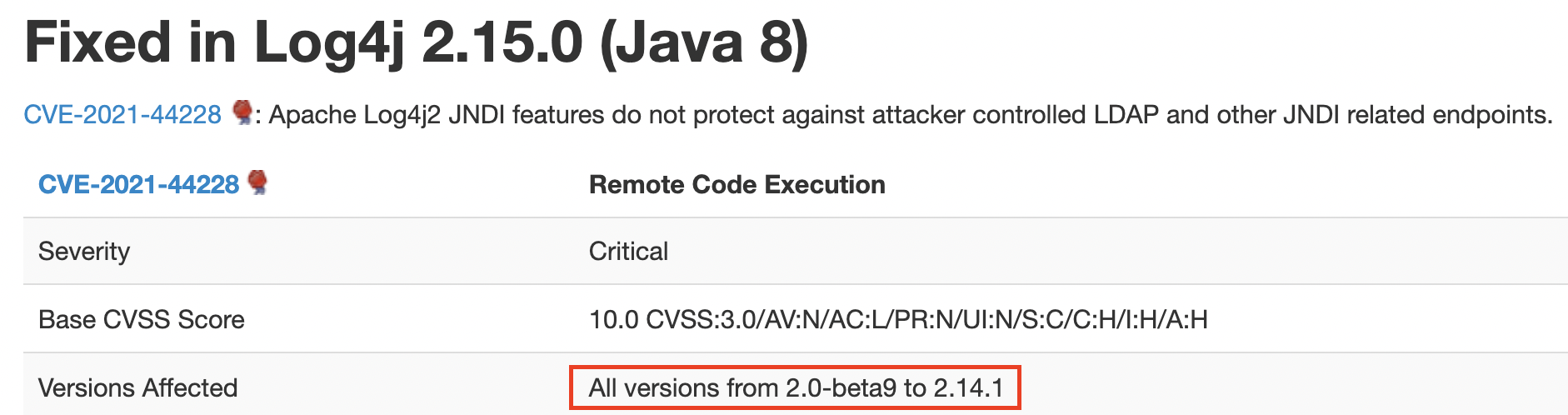
하지만 CVE-2021-44832 에서 2022년 1월 16일 기준으로 log4j에 대한 보안 취약점이 Java8 이상을 기준으로 2.17.0 버전까지 발견됐다. 관련해서는 다음 사진에 나와있다.

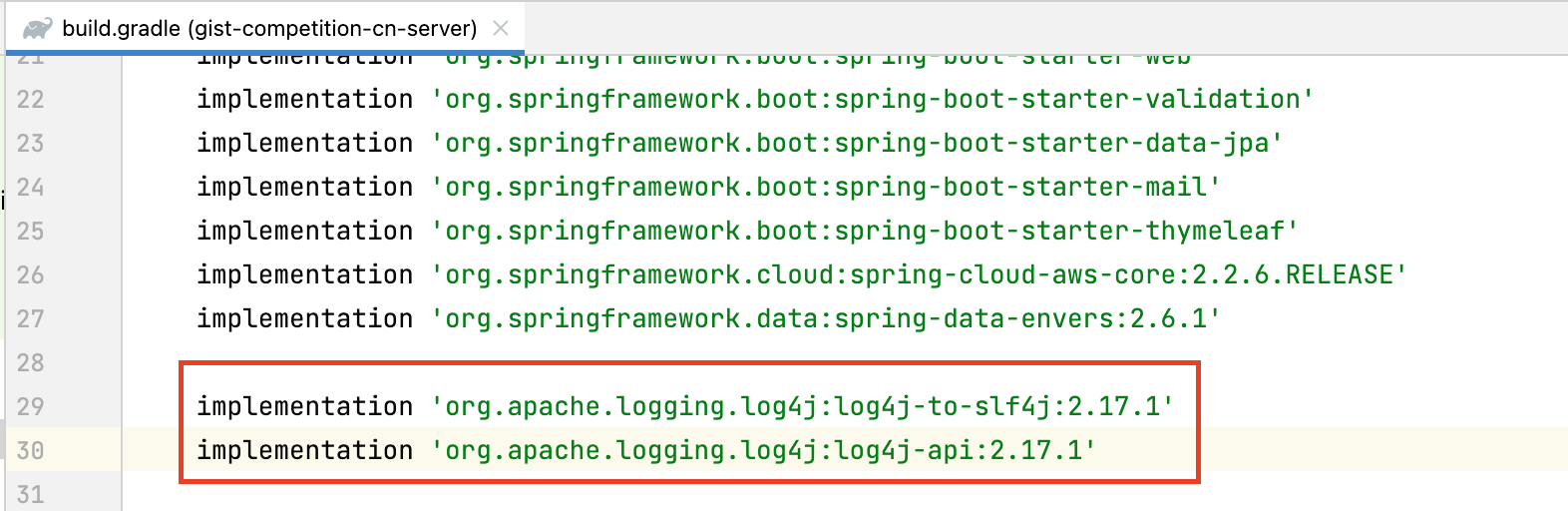
따라서 우리 프로젝트는 Java11을 사용하기 때문에 log4j 2.17.1로 변경했다. gradle(build.gradle)에서 사용하는 log4j에 대한 dependency를 다음과 같이 추가하면 된다.
implementation 'org.apache.logging.log4j:log4j-to-slf4j:2.17.1'
implementation 'org.apache.logging.log4j:log4j-api:2.17.1'
구체적인 것은 다음 PR에서 확인할 수 있습니다.
https://github.com/GIST-Petition-Site-Project/GIST-petition-server/pull/167
실무에서 MySQL 데이터베이스를 활용하면서 커넥션, I/O 연산, 잠금에 대해 더 유심히 살펴보게 되었다. 요 세가지 자원이 중요하다고 배웠는데 실제로 사용해보면서 정말 그렇다는걸 느낄 수 있었다. 그렇기에 이를 통해 배운점들을 다시 상기해고자 한다.
데이터베이스를 사용하면서 가장 중요한 자원을 꼽는다면 커넥션이다. 커넥션이 부족해지는 순간 쿼리를 날릴 수 없다는 의미이며, 이는 곧 장애로 이어진다. 그렇기에 데이터베이스 커넥션 개수를 원활하게 모니터링하고 관리하는 부분은 굉장히 중요하다.
커넥션이 부족해지게 만드는 요소로는 트래픽 증가로 서버의 스케일링으로 커넥션이 부족해질 때가 존재한다. 또, 트랜잭션이 길어져 해당 작업이 커넥션을 계속 잡고 있으면 db 커넥션이 부족해질 수 있다. 혹은 어플리케이션에서 커넥션을 제대로 반환하지 않는 경우도 존재할 수 있다.
항상 예상치 못한 상황이 발생하기에 db 커넥션 수를 잘 모니터링하고 제대로된 알람을 받는게 가장 중요하다. 이외에도 각 구성요소의 커넥션 풀과 timeout을 잘 설정해 db 커넥션이 부족하지 않도록 신경써야 한다. 부하테스트를 통해 선제적으로 방지하는 것도 방법이 될 수 있다.
커넥션을 적절히 확보한다면, I/O에 대해서 고민해볼 것 같다. DBMS는 결국 데이터를 HDD나 SSD에 읽기와 쓰기 에 대한 I/O를 진행해야 한다. 이 I/O는 사소한 차이에 성능이 천차만별 만큼 차이가 나기 때문에, I/O 연산이 정확한 수치까지는 아니더라도 대략적으로 얼마나 나오는 지 알아두는 건 굉장히 중요하다.
조회 I/O 최적화는 조인과 인덱스가 큰 영향을 준다. 조인을 잘못하면 테이블 간의 레코드 개수의 곱만큼의 순차 I/O가 발생할 수 있으며, 인덱스가 없는 컬럼의 테이블을 조회하면 레코드 수만큼의 순차 I/O가 발생할 수 있다. 그렇기에 인덱스를 활용해 대량의 순차 I/O를 소량의 랜덤 I/O로 변경하면 유의미하게 성능이 향상된다. 하지만 인덱스를 생성하는 I/O로 인해 insert, update, delete query의 성능을 저하시킬 수 있으며, 데이터 분포도가 고르지 않을 때 인덱스를 활용하면 조회 성능 마저 기존보다 느려질 수 있다.
또, 인덱스를 제대로 활용하지 않고 다량의 데이터를 조회하는 쿼리가 여러개가 작동하게 되면 CPU 사용량이 급증하게 된다. 이 역시 상황에 맞게 적절히 인덱스를 활용하고 조인문을 적절히 활용하는게 좋겠다. 실제로 나는 조인절 인덱스를 고려하지 않아 슬로 쿼리를 만들어 CPU를 높이는 실수한 경험이 있다..
커멘드 작업에도 I/O에 대해 고민해보는게 좋다. insert문과 update문을 사용할 때, 다량의 데이터를 넣을 때에는 단건의 쿼리를 고려해보는 것도 방법이다. 이는 서버와 db 간 네트워크 I/O와 인덱스 업데이트 과정의 Disk I/O를 줄일 수 있게된다. 실제로 mysql 공식 문서에서도 insert 속도 성능 향상을 위해 여러 단건 insert문보다 하나의 bulk insert문을 활용하라고 권장한다.
물론 bulk insert가 orm에서 기본적으로 제공하지 않을 수도 있다. 예를 들어 현재 회사에서 활용하는 spring jpa에서 컬렉션 타입에 대해 insert 혹은 update를 진행하게 되면 기본적으로 단건으로 여러 쿼리가 발생하는데, 수십~수백건에 대해서는 문제 없이 작동하지만 수천건이 넘어가는 순간부터 유의미하게 속도가 느려진다. 이 상황에서 jdbcTemplate 등을 활용해 raw query를 만드는 방법 등을 통해 bulk insert를 구현해 문제를 해결할 수도 있다.
하지만 모든 상황에서 이를 활용하는게 정답은 아니다. 저장해야할 데이터가 수천건이 넘어가 비즈니스 로직에 문제가 생긴다면 bulk insert를 구현해 성능을 최적화 할 수도 있을 것이고, 이 구현 역시 비용이 될 수 있으므로 단순히 spring data jpa의 saveAll()이나 변경 감지를 활용해 간단하게 처리할 수도 있다. 결국 상황에 맞게 적절히 활용해야 한다.
I/O를 잘 진행하면 그다음 고려할 것은 잠금이다. MySQL은 MVCC를 제공하기에 여러 잠금 레벨을 제공하며, 잠금에 따라 성능이 천차만별이다. 잠금은 데이터 정합을 위한 장치이다. 따라서 성능과 데이터 정합은 반비례한다고 보면 된다. 정합을 중요시해서 잠금을 높은 수준(길게)으로 설정한다면 성능에 이슈가 발생할 수 있다. 반면 정합이 상황에 따라 조금씩 틀리더라도 잠금을 낮은 수준으로 설정하면 성능에 큰 이점을 가져올 수 있다.
실제로 잠금을 직접 건드릴 일이 크게 많지는 않았지만, 이로 인한 문제가 발생할 때가 종종 있엇고 어떤 잠금이 문제를 일으키는 지 확인하는 과정은 중요했던 것 같다. 작업을 하면서 고려해야 할 잠금은 여러 개가 존재하겠지만 몇몇 사례를 소개한다.
결국 쿼리든, 잠금이든 정답은 존재하지 않는다. 도메인과 풀어야 하는 문제 상황에 맞게 적절히 쿼리를 작성하고 잠금 수준을 고려하는게 중요하다. 결제 정보와 같이 정합이 중요하다면 잠금을 직접 걸거나 고려해볼 수도 있으며, 가볍게 여러번 조회하는 타임라인, 목록과 같은 정보의 경우 조회 결과가 조금씩 달라도 큰 문제가 없다면 잠금 수준을 낮게 설정하는 것도 방법이다. 이 상황에서 오히려 정합을 위해 잠금 수준을 높게 두어 속도가 느리다면 고객 경험 측면에서 더 손해일 수도 있다.
잠금이나 쿼리에 대해서 최적화를 할 때 꼭 RDBMS에만 의존해야할 필요가 없을 수도 있다. 조회를 위해 인덱스를 거는 대신에 key-value db, document db로 캐싱을 고려하는 것도 방법이며, 어떤 작업에 대한 잠금이 필요할 때 Redis로 분산 락을 거는 것도 방법이다. 결국 방법은 여러 개이기에 지금 상황의 문제에 맞게 팀원과 합의해 최선의 방법으로 해결하는게 가장 중요하다.
회사에서 모든 환불은 어드민 서버를 거쳐 환불 서버에 환불 요청을 보내 환불 프로세스가 진행된다. 하지만 환불 서버에서 요청을 제대로 보내고 환불을 완료했지만, 어드민 서버에서 히스토리를 DB에 기록하는 작업이 제대로 이뤄지지 않았다. 그렇기에 어드민 히스토리와 환불 기록의 불일치가 발생했고, 이 운영 이슈를 해결하는 과정을 남기려고 한다.
실제로 핀포인트 로그는 다음과 같이 나타났다.
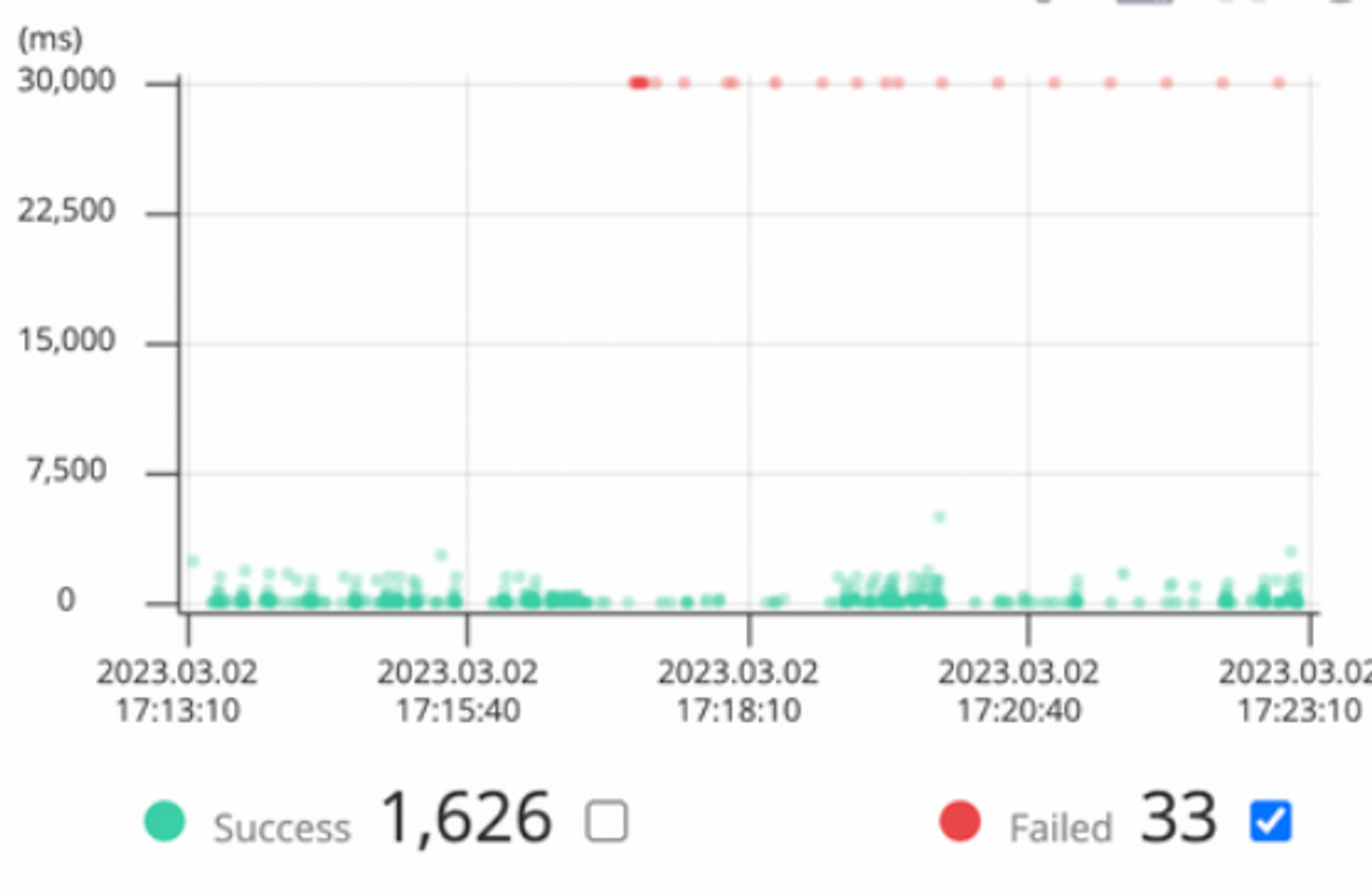
대략적으로 보면 알듯, 모두 30초(혹은 그 이상)에서 오류가 발생한 이력이 있는데 이는 어딘가에서 Timeout이 발생했음을 알 수 있다. 더 구체적으로 들어가서 확인해보면 에러가 다음과 같이 발생했다.
HikariPool-1 - Connection is not available, request timed out after 30000ms.
처음에 생각한 문제는 슬로우 쿼리가 커넥션을 오래 잡거나 배포 중 ECS 오토스케일링이 활성화되어 DB 커넥션이 부족해진 이유인 줄 알았다. 하지만 AWS 로그를 직접 확인해본 결과 당시 배포가 이뤄지지 않았으며 DB 커넥션 개수는 넉넉했었고 쿼리들도 문제가 없었다.
그렇기에 인프라적 문제보다는 어플리케이션 서버의 문제라고 생각했고, 어플리케이션 로그와 코드를 살펴봤다. 그 결과 문제는 querydsl에서 transform() 메서드를 잘못 사용하고 있어 발생했음을 확인할 수 있었다. 실제로 문제 상황과 비슷한 상황을 개발 서버에서 재현했을 때 transform() 메서드를 동시에 호출할 때 여러 요청들이 쿼리가 실행된 이후에도 커넥션을 계속 물고 있었으며 hikari의 모든 커넥션을 물게 되면, 다른 요청들은 hikari로부터 커넥션을 대기하게 되고 타임 아웃(30초)가 발생했다.
querydsl에서 transform() 메서드는 쿼리 결과를 grouping해서 Map으로 변환해주는 기능을 제공한다. 하지만 querydsl에서 query가 종료될 때 사용되는 메서드들이 queryTerminatingMehtods에 존재하는 메서드들이라면 JPA EntityManager를 close해준다. queryTerminatingMehtods에 존재하는 항목은 다음과 같다.
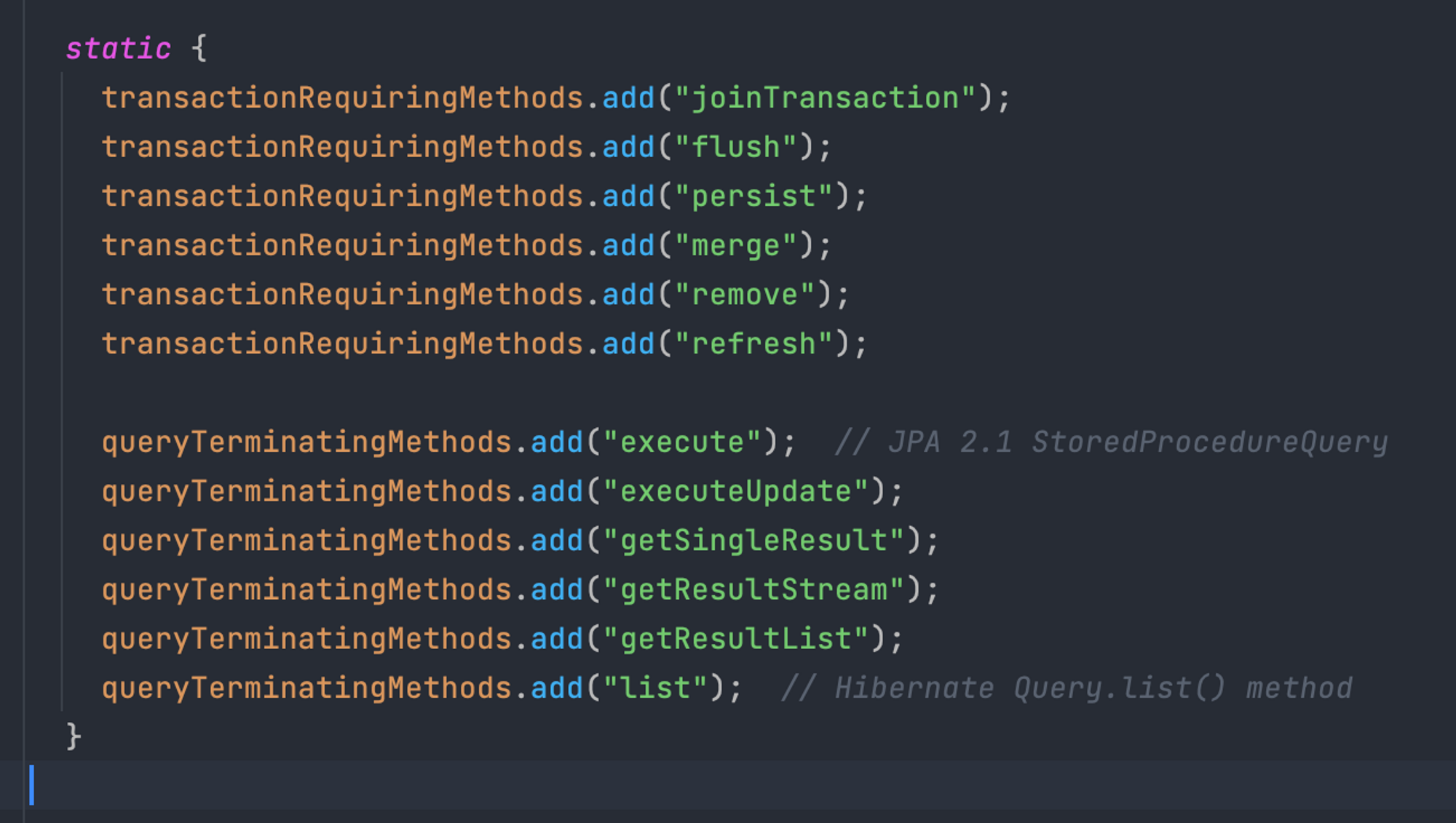
querydsl에서 자주 쓰는 fetch()나 fetchOne()같은 메서드는 queryTerminationMethods가 위의 메서드 리스트에 존재한다.
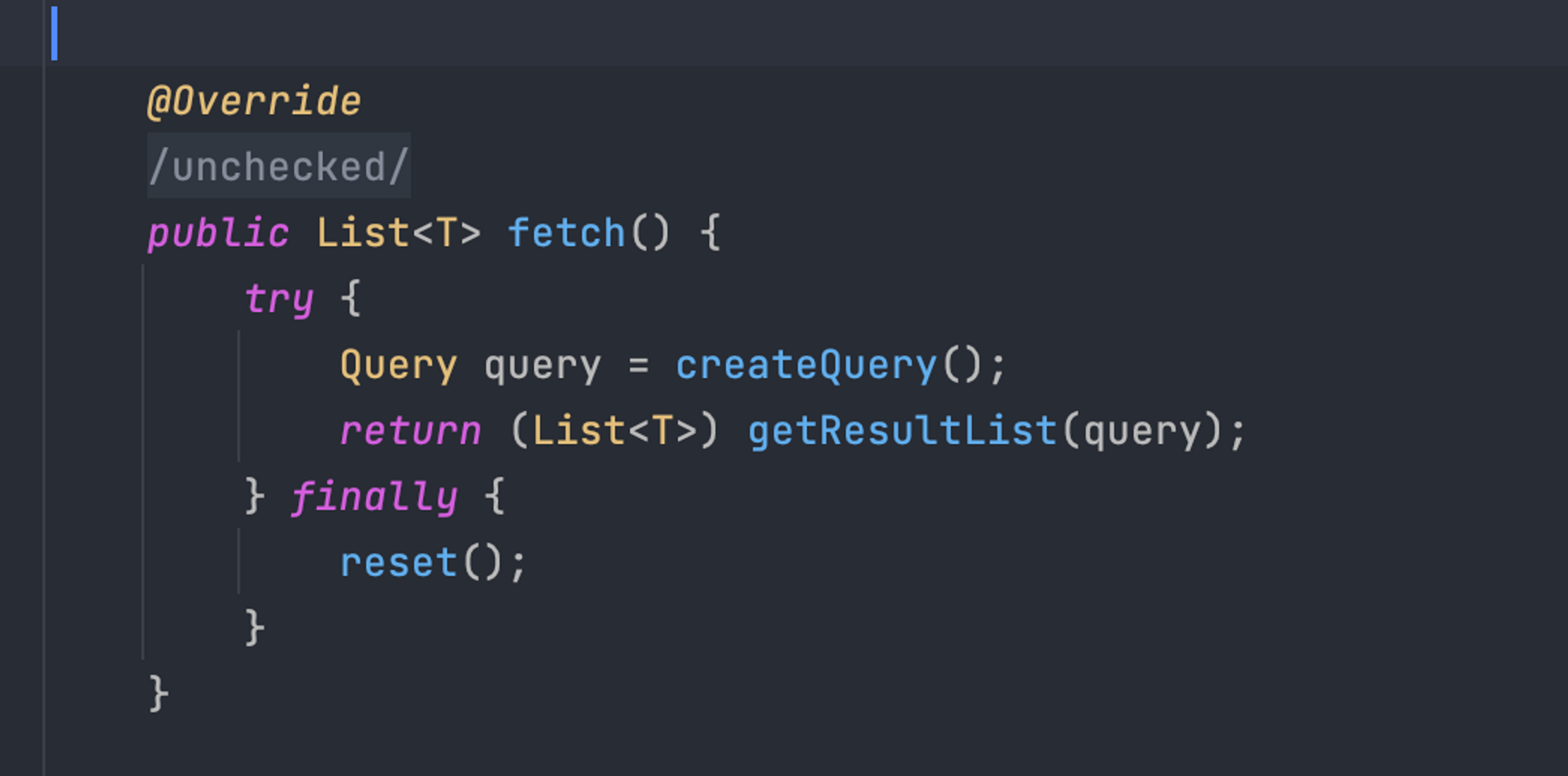
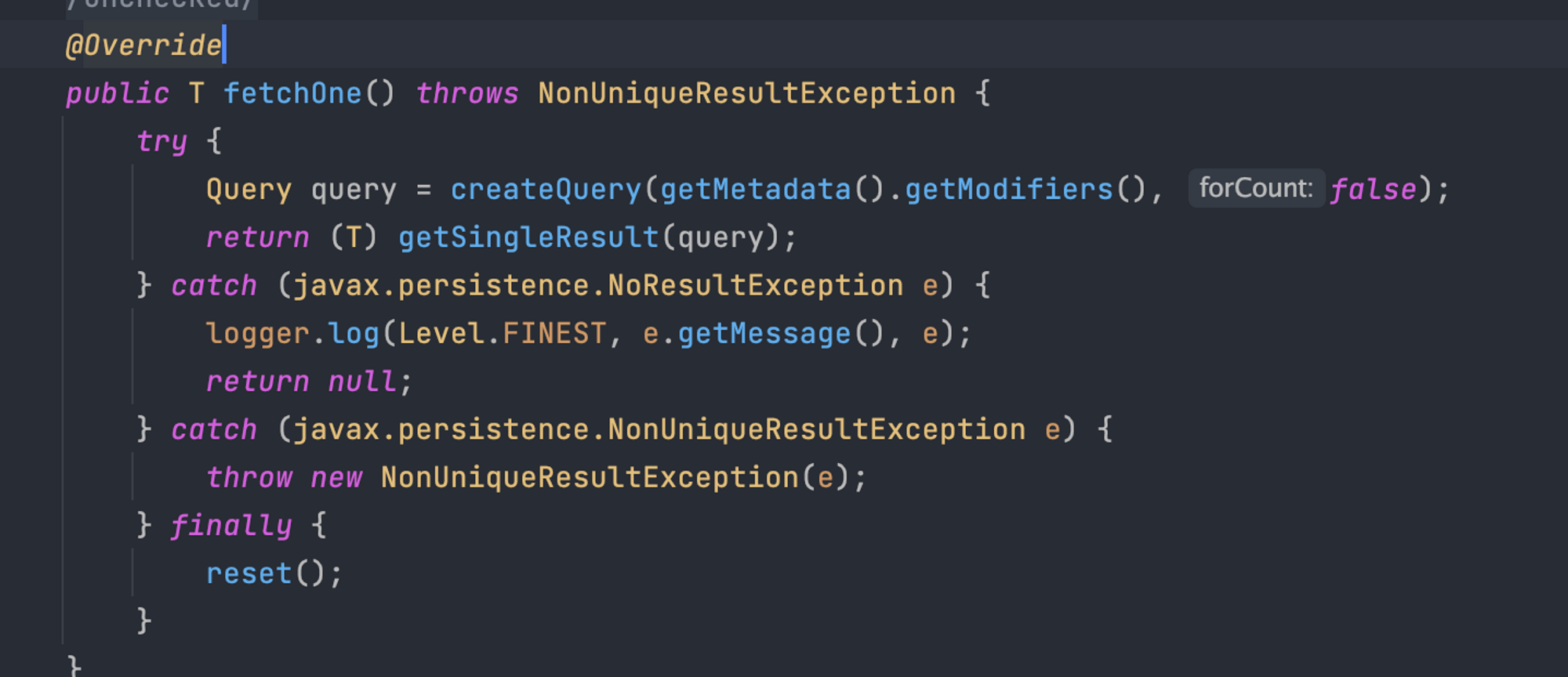
반면, 쿼리가 종료되는 메서드가 존재하는 ResultTransformer 인터페이스의 transfrom 메서드가 사용하는 query는 모두 iterate()로 종료된다. 따라서 queryTerminationMethods의 메서드가 아니며, EntityManager가 제대로 커넥션을 닫히지 않게 된다.
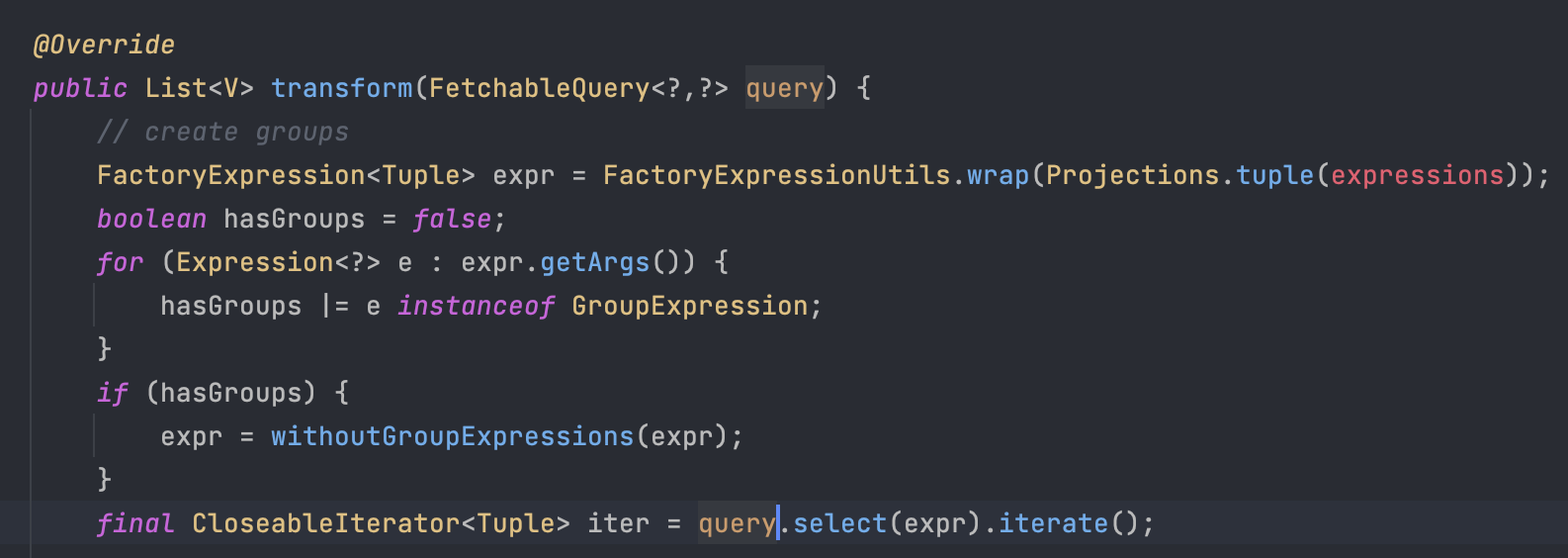
문제를 찾는 데에 비해 해결하는 방법은 굉장히 간단했다. querydsl transform() 메서드를 사용하는 쿼리에 @Transactional(readOnly=true)를 붙여주면 된다. querydsl도 결국 JPA를 기반으로 만들어진 라이브러리이며, @Transactional 을 갖는 메서드가 끝날 때 JpaTransactionManager 의 doCleanupAfterCompletion()을 통해 커넥션을 모두 정리해준다.
transform이 connection을 계속 물고 있어 오류가 발생하는 부분은 이해했지만, 결국에는 Hikari pool로 커넥션을 언젠가 돌려주게 된다. 이 돌려주는 원리가 hikari의 max-lifetime(기본 180초)로 인해 돌려주는 것인지, OS에 의해 좀비 스레드가 정리되는 것인 지 명확히 알아내지는 못했다.
또, querydsl 5.0.0 기준으로 transform() 메서드에서 커넥션이 왜 반납이 안되는 지 내부 원리를 구체적이고 명확히 알아보려 한다. 관련해서는 다음 글에서 풀어내 보자.
사내에서 패키지 구조 변경 작업을 하고 배포를 했는데 갑자기 특정 API에서 transaction silently rolled back이 발생했었습니다. 관련해서 확인해보니 DB조회 값을 Dto 객체로 변환해 캐싱한 값을 역직렬화하는 과정에서 문제가 발생했었습니다. 해당 캐시는 월마다 한번씩 바뀌는 주기를 갖는 값으로, 조회가 많은 비율을 차지합니다. 캐시로 사용하는 정보가 DB에서 열거형으로 관리되고 있어 이를 자바 Dto 객체로 직렬화해서 redis에 저장해 캐시로 활용하고 있었습니다.
코드를 확인해보면 다음과 같습니다.
설정 값들
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+39
+40
+41
+42
+43
+44
+
// package com.example.redisinactions.api;
+@Getter
+@AllArgsConstructor(access = AccessLevel.PRIVATE)
+@NoArgsConstructor(access = AccessLevel.PROTECTED)
+public class ProductResponse implements Serializable {
+ private String description;
+ private BigDecimal price;
+
+ private static ProductResponse of(Product product) {
+ return new ProductResponse(product.getDescription(), product.getPrice());
+ }
+
+ public static List<ProductResponse> listOf(List<Product> productList) {
+ return productList.stream()
+ .map(ProductResponse::of)
+ .toList();
+ }
+}
+
+@Configuration
+@EnableCaching
+public class CacheConfig {
+
+ @Bean
+ public RedisCacheConfiguration cacheConfiguration() {
+ return RedisCacheConfiguration.defaultCacheConfig()
+ .entryTtl(Duration.ofMinutes(60))
+ .disableCachingNullValues()
+ .serializeKeysWith(SerializationPair.fromSerializer(new StringRedisSerializer()))
+ .serializeValuesWith(SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
+ }
+
+ @Bean
+ public RedisCacheManagerBuilderCustomizer redisCacheManagerBuilderCustomizer() {
+ return (builder) -> builder
+ .withCacheConfiguration(PRODUCT_CACHE,
+ RedisCacheConfiguration.defaultCacheConfig().entryTtl(Duration.ofMinutes(10)));
+ }
+
+ public static class CacheName {
+ public static final String PRODUCT_CACHE = "productCache";
+ }
+}
+
+
레디스 캐시를 사용하는 서비스
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+39
+40
+41
+42
+
@Service
+@Slf4j
+@RequiredArgsConstructor
+public class ProductService {
+
+ private final ProductRepository productRepository;
+
+ @PostConstruct
+ void initProducts() {
+ productRepository.saveAll(List.of(
+ new Product("box", new BigDecimal(1000)),
+ new Product("snack", new BigDecimal(4000)),
+ new Product("chicken", new BigDecimal(20000))
+ )
+ );
+ }
+
+ @Cacheable(cacheNames = PRODUCT_CACHE, key = "'top10'")
+ public List<ProductResponse> getTenProduct() {
+ log.warn("NO CACHE - find top 10 products from DB");
+ return ProductResponse.listOf(productRepository.findTop10By());
+ }
+
+ @CacheEvict(cacheNames = PRODUCT_CACHE, key = "'top10'")
+ public void evict() {
+ log.warn("Cache Evicted");
+ }
+
+}
+
+@RestController
+@RequestMapping("/api/v1")
+@RequiredArgsConstructor
+public class ProductController {
+
+ private final ProductService productService;
+
+ @GetMapping("/products/top10")
+ public ResponseEntity<?> getTop10Products() {
+ return ResponseEntity.ok(productService.getTenProduct());
+ }
+}
+
해당 코드에서 getTenProduct()를 먼저 호출하면 다음과 같은 응답이 오며 redis에 잘 쌓이게 됩니다.


해당 상황을 도식화 하면 다음과 같습니다.

이후 ProductResponse를 v2 패키지로 변경한 이후 어플리케이션을 재실행해서 동일한 API를 호출하면 SerializationException이 발생합니다.
1
+2
+3
+4
+5
+6
+7
+
// package com.example.redisinactions.api.v2;
+@Getter
+@AllArgsConstructor(access = AccessLevel.PRIVATE)
+@NoArgsConstructor(access = AccessLevel.PROTECTED)
+public class ProductResponse implements Serializable {
+ ...
+}
+

Exception의 cause를 확인해보면 ClassNotFountException이 발생합니다. com.example.redisinactions.api.ProductResponse 클래스를 역직렬화해야 하는데 해당 클래스가 com.example.redisinactions.api.v2.ProductResponse로 변경되어 발생한 현상입니다.
1
+2
+3
+
Caused by: java.lang.ClassNotFoundException: com.example.redisinactions.api.ProductResponse
+ at java.base/jdk.internal.loader.BuiltinClassLoader.loadClass(BuiltinClassLoader.java:641) ~[na:na]
+ ...
+

해당 문제를 해결하기 위해서 @Cacheable에서 키값 deserialization에서 오류가 나는 것이므로 키값을 바꿔줘서 해결할 수 있습니다. 기존에 저장된 캐시를 재사용하는 부분에서 문제가 발생하는 것이기에 새로운 캐시를 다시 저장하고 이를 활용하면 됩니다. 기존 키값에 해당하는 값은 역직렬화할 수 없으므로 자연스럽게 TTL로 인해 사라지게 됩니다. 이를 통해 서비스에 지장 없이 안정적으로 캐시를 변경해서 사용할 수 있습니다. 코드로 나타나면 다음과 같습니다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+
@Configuration
+@EnableCaching
+public class CacheConfig {
+ ...
+
+ public static class CacheName {
+ public static final String PRODUCT_CACHE = "V2_productCache"; // as-is: productCache
+ }
+}
+

사실 해당 값을 캐싱하는 부분에서 꼭 Redis를 이용해야 하는 부분에 대해서도 고민해볼 필요가 있습니다. Redis가 아니더라도 LocalCache를 이용한다면 빈을 주입할 때 값을 DB에서 조회해서 캐싱해서 사용하는 방법도 좋은 방법이라고 생각합니다.
본래 문제는 이로 인한 트랜잭션의 실패였습니다. 더 생각해볼 점은 @Cacheable은 Cahce aside pattern을 사용하는데 해당 전략은 캐시 조회가 실패한다면 원본 데이터에서 가져오는 전략입니다. 따라서 해당 작업이 트랜잭션에서 캐시 조회에서 오류가 발생한다고 롤백 마크로 인해 전체 트랜잭션이 실패하면 안된다고 생각합니다. 이는 트랜잭션을 사용할 때 두고두고 고민해야 하는 부분이라고 생각합니다.
관련 소스 코드는 다음 링크에서 확인할 수 있습니다. https://github.com/ChoiEungi/redis-in-actions/tree/feature/redis-cacheable
근래에 감정적인 결정과 발언이 늘었다. 가진 환경에 대한 불만족 때문이었다. 모든 환경에는 장단이 존재하지만 비교와 기대 불일치로 인한 스트레스는 감정적인 결정을 유발했다. 이유를 분석해보고 왜 그랬는 지에 대해 생각해보자.
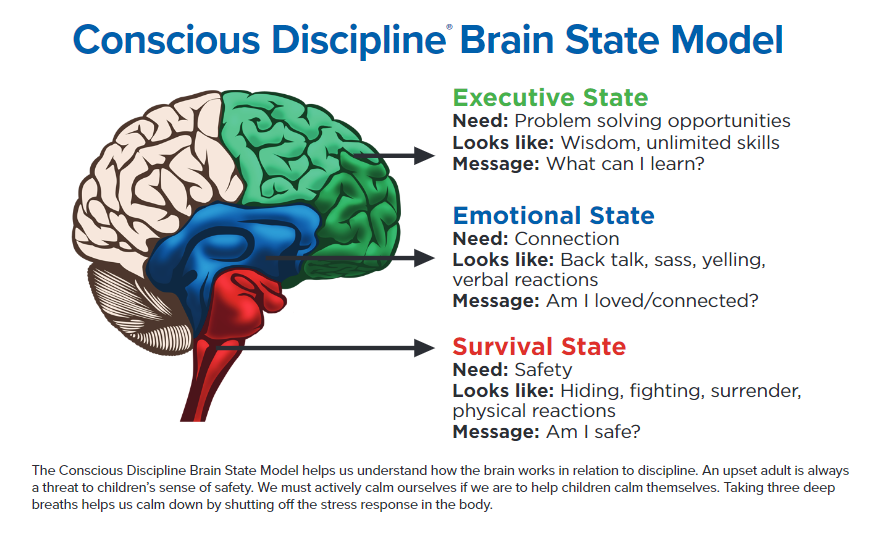
The Conscious Discipline Brain State Model에 따르면, 사람의 뇌는 Executive, Emotional, Survival로 세가지 활성 상태가 존재한다. Executive 상태는 문제 해결 능력과 학습을 할 때 활성화되는 영역이며, 이성적인 판단을 할 때 주로 사용한다. Emotional와 Survival 상태는 말 그대로 감정적인 상태에 돌입하게 되며 보호 본능이 발생하게 된다. 다시 말해, 흑백 논리와 극단적 사고를 하는 감정적인 판단을 하게 된다. 이는 생존을 위한 본능으로 생각할 수 있다.
여기서 사람이 스트레스나 충격을 받기 시작하면 판단을 할 때 Executive 상태(전두엽)가 비활성화 된다. 이는 Emotional 상태와 Survival 상태가 활성화되어 사람이 감정적이고 이분법적으로 판단해 생각이 짧아지기 시작한다. 이러한 상태가 1달이넘게 지속되었으며 이를 스스로 빠져나오기 어려웠던 것 같다.
내가 처한 상황에 대해 감정적으로 접근하기 시작했다. 상황에 대한 단순히 좋고 나쁨을 판단하는 이분법적 접근이 늘었으며, 문제 상황을 해결할 수 있다는 낙관보다는 회의가 더 늘었다. 그러다보니 자연스럽게 책임을 상황으로 돌리기 시작했으며 이는 너무나도 스스로를 불행하게 만들었다. 또, 자기객관화 마저 잊어버리며 주변에서 이유를 찾았다.
개인적인 성격으로는 욕심이 많은 편이다. 기왕 하는거 조금 더 잘하고 싶어 스스로 동기부여를 많이한다. 이로 인해 내가 생각했던 기대하던 바가 컸다. 다만 현실은 생각한 것보다 우아하지는 못했고 투박했다. 내가 기대했던 것들과는 너무나도 달랐다. 그렇기에 타인의 “좋아보이는” 환경에 더 집중하고 이와 비교하게 되었으며 내 억한 감정은 더 커져갔다. 가장 아쉬운건 불행의 원인이 비교와 기대 관리에서 온다는 걸 스스로 알고도 계속 기대 관리를 실패하고 비교를 해나갔다는 점이다.
이러한 요인으로 하지 말아야 할 실수와 당연한 실수를 반복하게 되었다. 이는 스스로를 불행하게 만들었고 성장에는 전혀 도움이 되지 않았다. 그리고 타인에게 많은 회의적이고 부정적인 감정을 노출했으며 나 뿐만 아니라 타인의 시간을 낭비하도록 만들었다.
성장에 대한 욕심으로 상황을 탓하는 건 정말 좋지 못하다. 얻을 결과에 대해만 집중하면 가진 것보다 부족한 부분에 집중하게 된다. 그렇다면 내가 처한 환경이 어떤지 확인하고 지금 집중해야 할 중요한 것들을 파악해보는건 어떨까? 이를 통해 상황을 개선하는 방법에 대해 고민할 수 있으며 얻을 수 있는 점에 집중해볼 수 있다.
예를 들어 회사의 레거시 코드에 아쉬움을 느낀다면 이 상황에서 어떤 점을 개선하면 좋을 지 함께 고민해보고 해결해나갈 수 있다. 이는 시스템 개선을 해본 성장할 수 있으며 팀에서 신뢰를 얻는데 도움이 된다. 또, 비슷한 상황에 대한 다른 관점도 찾아보는 점도 방법 중 하나이다. 하지만 상황에 대해 안 좋은 부분에만 집중하고 불평만 늘여놓는다면, 오히려 상황 귀인을 통해 스스로가 정체된다.
좋아하는 웹툰인 찌질의 역사에서 실수에 대한 구절이 인상적이었는데
어른이 되어서도 여전히 실수를 하고 잘못을 저지르고 누군가에게 상처를 입히고…그럴 수 있어.그렇다고 그게 찌질한 게 아니야.
실수를 합리화하고 정당화하고…
권위와 노련함으로 약한 사람에게 뒤집어 씌우고…
자신은 고결한 척, 완벽한 척. 잘못을 부정하고 외면하고
그게 찌질한 거야
잘못을 저지른 기억은 괴롭지. 하지만 잘못을 고치려는 노력조차 하지 않았던 기억은
훨씬 더 너를 괴롭힐 거야.
항상 부족함을 느끼지만, 본인의 잘못과 실수 인정할 수 있는 성숙한 어른이 되는건 정말 어려운 것 같다. 말로만 하는건 쉬우니 행동으로 옮길 수 있도록 스스로 꾸준하게 인지하자.
참고 문헌
https://consciousdiscipline.com/methodology/brain-state-model/
https://carmelmountainpreschool.com/conscious-discipline-the-three-brain-states/
셀리 케이건의 “죽음이란 무엇인가”에서 삶의 가치에 대해 논할 때, 삶-그릇 이론을 정의하고 내용을 전개한다. 삶-그릇 이론이란, 삶은 우리가 스스로 정의한 좋은 것과 나쁜 것들을 채워넣을 수 있는 그릇이라는 것이다. 그렇다면 삶이 얼마나 가치 있는지, 좋은지에 대해 평가하려면 그릇에 담긴 좋은 것과 나쁜 것들의 합을 구해 평가를 하는 것이다. 여기서 삶은 결국 그릇에 불과한 것이며, 그것 자체로는 아무런 가치가 없다고 볼 수 있다. 그렇다고 살아있음을 안좋다고 느끼는 것은 아니다.
이는 결국 내가 살아가는 가치는 내가 스스로 정의할 수 있다는 것이고, 내가 정한 기간 동안에 인생을 구성하게 될 가치물을 정하는 것이 중요하다는 말이다. 결국 내가 원하는 것들, 하고싶은 것들을 찾는 과정이라는 것은 내 삶의 가치물을 무엇인지 찾아가는 과정이라는 것이다. 이는 내 삶에 담을 그릇에 넣을, 내가 정의한 가치들이기 때문이다.
삶은 내가 정의한 가치 죽음이라는게 나쁜 것이라고 하자.(살아있음에 감사함과 기쁨을 느끼고 행복한 것들이 좋은 것들이라고 나는 느끼고 있다) 반면에 내 삶에 정의한 가치들이 아무 것도 없다면, 그 삶은 가치가 없어진다고 볼 수 있다는 것다. 그렇기 때문에 하고 싶은 것들을 스스로 정의하고 내가 정의한 가치들로 채워나가는게 중요하고 가치 있는 삶이지 않을까 싶다. 또한, 그 과정에서 느끼는 살아있음의 가치와 소중함을 느끼고 남아있는 여생에 최선을 다하고 싶을 따름이다.
그렇기에 내 삶에서 나는 가치를 1개월, 1년, 5년 등 단위로 내리고 그 기간동안 이 가치들로 채우는데 최선을 다하고 있는 중이다. 지금으로서 내 삶의 가치는 어떤 문제든 잘 해결하고 싶으며, 작은 부분에서라도 문제를 잘 찾아내는 것이다. 모든 상황을 부정적으로 본다는게 아니다. 그보다는 살아가면서 느낀 다수에게 pain point가 되는 부분이면서 해결할 때 피해가 없는(극 소수인) 부분에 대해 소프트웨어를 통해 해결하고 싶다.
이번 우아한테크코스 프리코스 4기에 함께 성장하는 방법을 배워보려 지원했다. 그러기 위해서는 함께 사용할 수 있는 코드(객체지향적 코드)를 작성해야 했고 이를 프리코스라는 과정을 통해 간접적으로 경험해볼 수 있었다.
1주차 과제는 숫자야구게임으로, 1주차 피드백만으로도 충분히 받아들일 수 있었고, 고통스럽게 하는 고민은 없었다. 다만, 2주차 과제에 고민이 있어 객체지향에 대해 고민을 더 많이 해본 선배님께 피드백을 받고 포스팅으로 고민을 공유하려한다. 1, 2주차 래포는 다음과 같다.
1주차
https://github.com/ChoiEungi/java-baseball-precourse
2주차
https://github.com/ChoiEungi/java-racingcar-precourse
본래 코드는 다음과 같았다. 본 코드에서 고민은 크게 2가지 였다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+
public class InputRole {
+ private String[] nameList;
+ private Integer trialNmber;
+ public void inputStart() {
+ while (true) {
+ try {
+ inputNames();
+ break;
+ } catch (IllegalArgumentException e) {
+ System.out.println(e.getMessage());
+ }
+ }
+ while (true) {
+ try {
+ inputTrialNumber();
+ break;
+ } catch (IllegalArgumentException e) {
+ System.out.println(e.getMessage());
+ }
+ }
+ }
+
+ public String[] getNameList() {
+ return nameList;
+ }
+
+ public int getTrialNmber() {
+ return trialNmber;
+ }
+...
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+
public class GameController {
+ public void gameStart() {
+ InputRole inputRole = new InputRole();
+ OutputRole outputRole = new OutputRole();
+ inputRole.inputStart();
+ changeInputToCar(inputRole);
+
+ outputRole.pirntResultInstruction();
+ for (int i = 0; i < inputRole.getTrialNmber(); i++) {
+ tryGameOnce();
+ outputRole.printOneGame(carList);
+ }
+ findWinner();
+ outputRole.printWinner(winnersList);
+ }
+}
+
+
우선 1번 고민에 대해서는 try-catch 문의 기능적으로 크게 좋은 솔루션이 없어, 단순히 메서드를 분리하려 했다. 이는 캡슐화가 제대로 이뤄진다고 보기는 어렵지만, 지금 현실적인 상황에서 가장 최선의 방법이었다. 그리고 인풋을 받는 것이 극단적인 스케일인 몇 만개 이런 식으로 늘어나는 변화는 현실적으로 어렵기 때문에, 단순히 메서드를 분리하는 것으로 해결했다. 그러다보니 class 멤버 변수를 크게 사용할 이유가 없었고 inputStart() 메서드에 구애 받기 보다는 Util로서의 Input을 설정했다.
InputRole 이 단순히 인스턴스로서 상태를 갖는 객체일 수 있는데, 어디서든 특정 역할에 대한 인풋을 받고 싶으면 상태를 갖는 것이 아니라, 필요할 때 마다 필요한 인풋을 받아서 인풋의 결과값을 출력해주면 여러 클래스에서 여러 인스턴스를 선언 하지 않고 사용할 수 있게 된다.
고민 후 수정한 코드는 다음과 같다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+39
+
public String[] getNameList() {
+ while (true) {
+ try {
+ return inputNames();
+ } catch (IllegalArgumentException e) {
+ System.out.println(e.getMessage());
+ }
+ }
+ }
+
+ public Integer getTrialNmber() {
+ while (true) {
+ try {
+ return inputTrialNumber();
+ } catch (IllegalArgumentException e) {
+ System.out.println(e.getMessage());
+ }
+ }
+ }
+
+private String[] inputNames() {
+ System.out.println(NAME_INPUT_INSTRUCTION);
+ String inputNames = Console.readLine();
+ String[] nameList = inputNames.split(",");
+ for (String name : nameList) {
+ checkNameWhiteSpaceValid(name);
+ checkNameLengthValid(name);
+ }
+ return nameList;
+ }
+
+private Integer inputTrialNumber() {
+ System.out.println(TRIAL_NUMBER_INPUT_INSTRUCTION);
+ String inputNumber = Console.readLine();
+ checkTrialNumberValid(inputNumber);
+ return Integer.valueOf(inputNumber);
+ }
+
+...
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+
public class GameController {
+ private static final InputRole inputRole = new InputRole();
+
+ public void gameStart() {
+ OutputRole outputRole = new OutputRole();
+ changeInputToCar(inputRole.getNameList());
+
+ outputRole.pirntResultInstruction();
+ for (int i = 0; i < inputRole.getTrialNmber(); i++) {
+ tryGameOnce();
+ outputRole.printOneGame(carList);
+ }
+ findWinner();
+ outputRole.printWinner(winnersList);
+ }
+
이 코드를 보면 inputRole을 더 유연하게 사용할 수 있다는 점과 코드가 간결해진 점에서 크게 유용할 수 있었다.
이러한 방식으로 역할이 나뉘었는데, 1번 2번은 같은 역할로서 볼 수 있겠지만, 3번은 충분히 분리해도 좋을 법할 것 같다는 생각을 해볼 수 있었다. 3번을 분리하기 전에 원래 코드를 보면 다음과 같다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+39
+40
+41
+42
+43
+44
+45
+46
+47
+48
+49
+50
+51
+52
+53
+54
+55
+56
+57
+58
+59
+60
+61
+62
+63
+
public class GameController {
+ private static final InputRole inputRole = new InputRole();
+ private static final int MAX_PICK_NUMBER = 9;
+ private static final int MIN_PICK_NUMBER = 0;
+ private static final int MOVE_FORWARD_CONTION_NUMBER = 4;
+ private final ArrayList<Car> carList = new ArrayList<>();
+ private final ArrayList<String> winnersList = new ArrayList<>();
+
+ public void gameStart() {
+ OutputRole outputRole = new OutputRole();
+ changeInputToCar(inputRole.getNameList());
+
+ outputRole.pirntResultInstruction();
+ for (int i = 0; i < inputRole.getTrialNmber(); i++) {
+ tryGameOnce();
+ outputRole.printOneGame(carList);
+ }
+ findWinner();
+ outputRole.printWinner(winnersList);
+ }
+
+ private void changeInputToCar(String[] nameList) {
+ for (String name : nameList) {
+ this.carList.add(new Car(name));
+ }
+ }
+
+ private int getRandomNumber() {
+ int randomNumber = Randoms.pickNumberInRange(MIN_PICK_NUMBER, MAX_PICK_NUMBER);
+ return randomNumber;
+ }
+
+ private boolean checkMoveForward(int randomNumber) {
+ return randomNumber >= MOVE_FORWARD_CONTION_NUMBER;
+ }
+
+ private void tryGameOnce() {
+ for (Car car : carList) {
+ int randomNumber = getRandomNumber();
+ if (checkMoveForward(randomNumber)) {
+ car.moveForward();
+ }
+ }
+ }
+
+ private void findWinner() {
+ int maxValue = findMaxInCarList(carList);
+ for (Car car : carList) {
+ if (car.getPosition() == maxValue) {
+ winnersList.add(car.getName());
+ }
+ }
+ }
+
+ private int findMaxInCarList(ArrayList<Car> carList) {
+ int maxValue = -1;
+ for (Car car : carList) {
+ if (maxValue < car.getPosition()) {
+ maxValue = car.getPosition();
+ }
+ }
+ return maxValue;
+ }
+
코드가 너무나도 길다. 그리고 역할이 너무 많다. 이후 확장할 때 코드를 작성하는데 점점 부담이 커질 수 밖에 없는 구조인 것이다. 그렇기 때문에 이를 분리해보면 다음과 같이 코드를 깔끔하게 변경해볼 수 있었다.
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+25
+26
+27
+28
+29
+30
+31
+32
+33
+34
+35
+36
+37
+38
+39
+40
+41
+42
+43
+44
+
public class Game {
+ private static final int MOVE_FORWARD_CONTION_NUMBER = 4;
+ private static final int MAX_PICK_NUMBER = 9;
+ private static final int MIN_PICK_NUMBER = 0;
+
+ public void startOnce(List<Car> carList) {
+ for (Car car : carList) {
+ int randomNumber = getRandomNumber();
+ if (checkMoveForward(randomNumber)) {
+ car.moveForward();
+ }
+ }
+ }
+
+ public List<String> winner(List<Car> carList) {
+ int maxValue = findMaxInCarList(carList);
+ List<String> winnersList = new ArrayList<>();
+ for (Car car : carList) {
+ if (car.getPosition() == maxValue) {
+ winnersList.add(car.getName());
+ }
+ }
+ return winnersList;
+ }
+
+ private int getRandomNumber() {
+ int randomNumber = Randoms.pickNumberInRange(MIN_PICK_NUMBER, MAX_PICK_NUMBER);
+ return randomNumber;
+ }
+
+ private boolean checkMoveForward(int randomNumber) {
+ return randomNumber >= MOVE_FORWARD_CONTION_NUMBER;
+ }
+
+ private int findMaxInCarList(List<Car> carList) {
+ int maxValue = -1;
+ for (Car car : carList) {
+ if (maxValue < car.getPosition()) {
+ maxValue = car.getPosition();
+ }
+ }
+ return maxValue;
+ }
+
+
1
+2
+3
+4
+5
+6
+7
+8
+9
+10
+11
+12
+13
+14
+15
+16
+17
+18
+19
+20
+21
+22
+23
+24
+
public class GameController {
+ private static final InputRole inputRole = new InputRole();
+ private final List<Car> carList = new ArrayList<>();
+
+ public void gameStart() {
+ Game game = new Game();
+ OutputRole outputRole = new OutputRole();
+ changeInputToCar(inputRole.getNameList());
+ Integer trialNumber = inputRole.getTrialNmber();
+
+ outputRole.pirntResultInstruction();
+ for (int i = 0; i < trialNumber; i++) {
+ game.startOnce(carList);
+ outputRole.printOneGame(carList);
+ }
+ outputRole.printWinner(game.winner(carList));
+ }
+
+ private void changeInputToCar(String[] nameList) {
+ for (String name : nameList) {
+ this.carList.add(new Car(name));
+ }
+ }
+}
+
이렇게 역할(클래스)가 명확하게 분리돼 더 보기 좋고 확장성이 좋은 코드를 작성해볼 수 있었다. 리펙토링한 코드는 choieungi_refactor branch에서 확인해볼 수 있다.
객체지향적으로 코드를 변경하려 하니 클래스를 매개변수로 쓰는 것이 아닌, 클래스의 멤버 변수 하나를 매개변수로 쓸 수 있는 등 놓칠 수 있는 부분을 개선하게 되는 계기가 될 수 있었다. 이처럼 코드에 대해 고민을 계속하다보면 정말 필요한 코드만 작성할 수 있을 것이라 느낄 수 있었다.
코드 이외에는 2주차 피드백에서 다른 사람의 코드를 보고 함께 성장할 수 있기에 코드를 작성하면서 느낀 소감을 PR에 올리면 좋을 것 같다는 피드백이 굉장히 인상적이었고 다른 의미로 기뻤다. 나는 1, 2주차 PR에 모두 소감을 올렸는데, 내가 느낀 것들을 다른 사람도 볼 수 있으면 같이 성장할 수 있겠다 느꼈기 때문이다.
프리코스를 통해 단순히 시험의 과정이 아닌, 성장의 과정으로 느낄 수 있었던 뜻깊던 시간이 아닐까 싶다. 그렇기에 프리코스 과정이 굉장히 몰입감을 주고 재미도 있다. 다만, 자만은 하면 안된다. 아직 부족한 점이 많고, 생각해볼 여지가 많은 부분이 있는 코드이므로 3주차 과제에서는 더 큰 고통을 느껴보고 성장해나갈 것이다.
개인적으로는 피드백을 통해 고민해볼 수 있는 기회가 많아졌다. 그렇기 때문에 프리코스 과정 피드백에서 이런 부분을 구현해보면 어떻게 될까요? 와 같이 challenging해볼 수 있는 여지를 줘도 재밌을 것 같다는 느낌이 든다.
샘 알트만과 폴 그레이엄은 공통적으로 인생은 짧다라는 말을 자주 한다. 인생이 짧다라는 의미는 결국 본인에게 중요하지 않은 일보다 중요한 일에 더 집중하게 만들기 때문이다.
그렇다면, 중요한 일은 무엇일까? 여러 방면으로 존재하겠지만, 근래에 가장 많이 시간을 사용하는 업무적인 부분에서 고민해보자. 진부하지만, 우선순위가 높은 일들과 임팩트가 큰 일들이라 생각한다. 그를 위한 역량으로는 결정은 시시각각 변하는 복잡한 시스템에서 최적의 결정을 할 수 있는거라 생각한다. 폴 그레이엄의 말을 조금 더 빌려보자면,
당신은 진짜 일이 어떤 것인지를 이해해야 하고, 당신이 어떤 일에 적합한지를 파악해야 하고, 그 일의 핵심에 가능한한 가깝게 접근해야 하고, 매 순간 당신이 할 수 있는 노력을 다하는지와 당신이 얼마나 잘하고 있는지를 정확하게 판단해야 하고, 결과를 해치지 않는 선에서 하루 몇 시간을 투자해야 하는지를 판단해야 합니다. 이는 모든 것이 연결된 매우 복잡한 방정식입니다. 하지만 매 순간 당신이 스스로에게 정직하고 스스로를 잘 판단할 수 있다면, 당신은 저절로 최적의 상태에 돌입하게 되며, 이 세상에 얼마 없는 생산적인 사람이 될 수 있을 것입니다.
무엇보다 중요한 건, 이 우선순위 내에서 맡은 일을 차질 없이 꾸준하게 “잘” 해내고 팀의 신뢰를 쌓아나가는 거라고 생각한다.
꾸준히 열심히 하는 점도 중요하지만, 잘하려고 노력하는 부분도 중요하다. 그렇기 때문에 개인적인 성장을 해야한다고 생각한다. 그리고 복리 효과(Compound Effect)를 나는 강력하게 믿고 있기 때문에 지금 더 많이, 그리고 이전의 나보다 훨씬 더 나아지려 최선을 다하고 있다.
업무 외적으로 중요한 부분은 소중한 관계, 여유, 업무 외 이뤄보고 싶은 성취 같은 것들이라 생각한다. 개인적으로는 주변에 있었던 좋은 사람들 덕분에 취업을 할 수 있었고, 금전적 여유를 통해 더 많은 자유가 생겼다. 그렇기에 20대 초반까지는 금전적인 고민을 줄이면서, 스스로에게 투자를 많이 해보고 싶다. 이를 바탕으로 주변 사람들에게 더 많은걸 배풀고 싶다. 좋은 사람이 되는 것은 너무나도 어렵지만, 더 많은 것들을 배우고 시행착오를 겪어보며 더 많은 사람에게 선한 영향력을 줄 수 있도록, 그리고 조금 더 낙관적이고 싶다.
또, 바쁘다라는 이유로 주변에 소중한 사람들에 소홀해지는 것도 다시 생각해보면, 정말 나에게 중요하지 않은 일을 하고 있을 때도 있었던 것 같다. 하루에 할 수 있는 가용성은 제한되어 있으며, 가용성을 넘어서 비효율적이더라도 무언가를 하려는 습관에 대해 되돌아 볼 필요성을 느끼게 되는 대목이다.
아직 하고 싶은 것과 나에게 잘 맞는 게 무엇인 지 구체적으로 모르겠지만, 분명히 온전히 몰입하고 성취하고 싶은게 생길거라 생각한다. 그게 우연이든, 필연이든 기회가 왔을 때 잘 소화하기 위해서는 복리 효과로 쌓아놓은 자산들(학습 능력, 네트워크 등)이라고 생각한다. 그렇기에 더 최선을 다할 것이며, 더 성장하고 싶다.
또, 성장의 일환으로 글또 활동을 참여하게 되었다. 글을 작성할 때 가장 큰 어려움은 꾸준함과 피드백 받기이다. 이를 글또 활동을 통해 잘 보완할 것이라 생각한다. 글또에 지원 동기에서, 감명받는 글을 더 많이 접하고 싶어서도 있었다. 나에게는, 샘 알트만, 폴 그레이엄, 샌드버드 김동신님의 블로그가 있다. 실제로 글또 슬랙에 올라오는 글 중에 인사이트가 많은 글들도 있어 너무 감사하며, 글또 활동을 꾸준히 이어나가고 싶다.