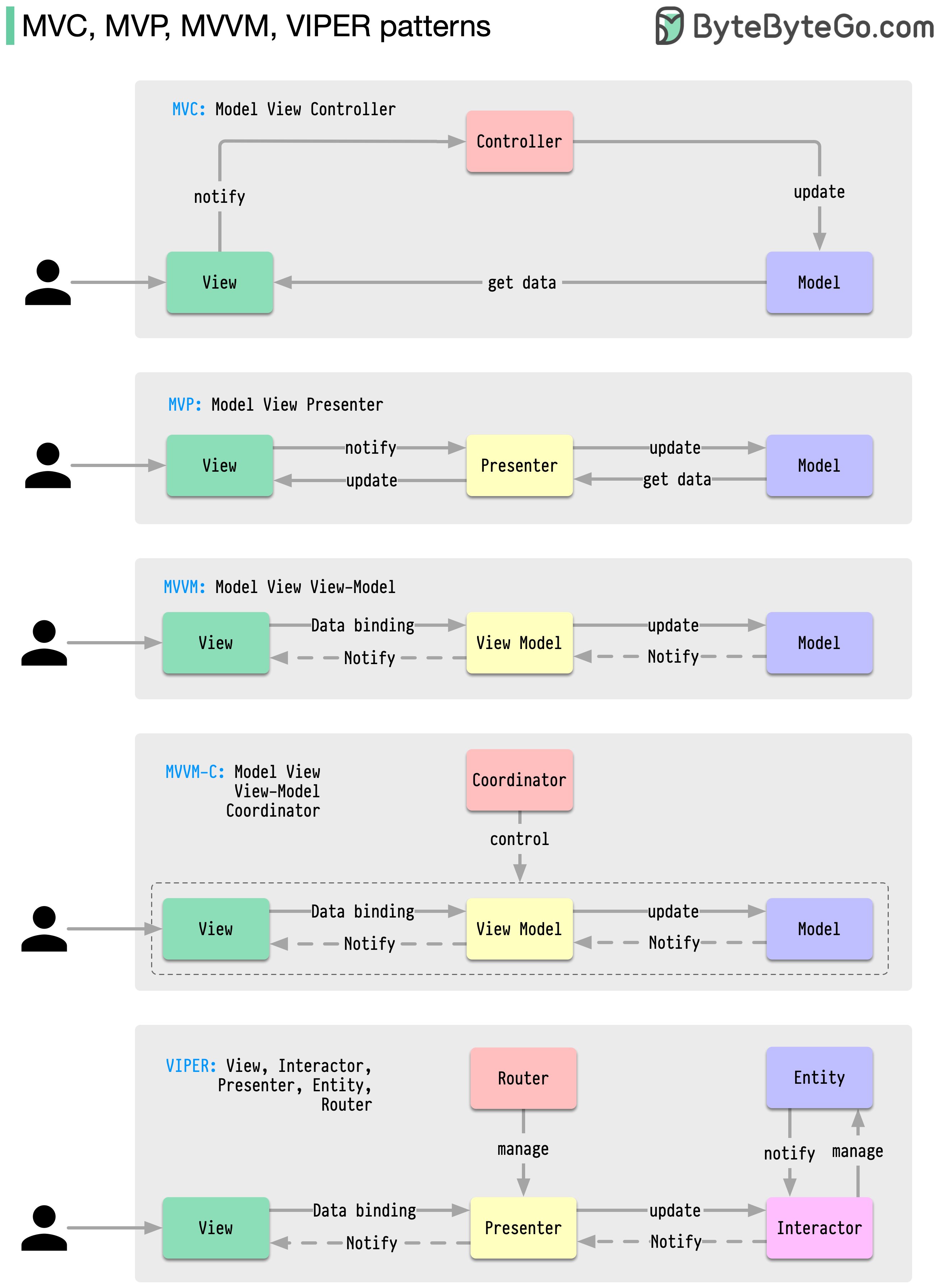
- Book System Design Interview – An insider's guide
- Book System Design Interview – An Insider's Guide: Volume 2
- ByteByteGo.com
- YouTube - ByteByteGo
- https://blog.levelupcoding.com/
- https://c4model.com/
- https://www.drawio.com/
- https://excalidraw.com/
- https://miro.com/
- https://lucid.co/
- https://creately.com/
-
References:
-
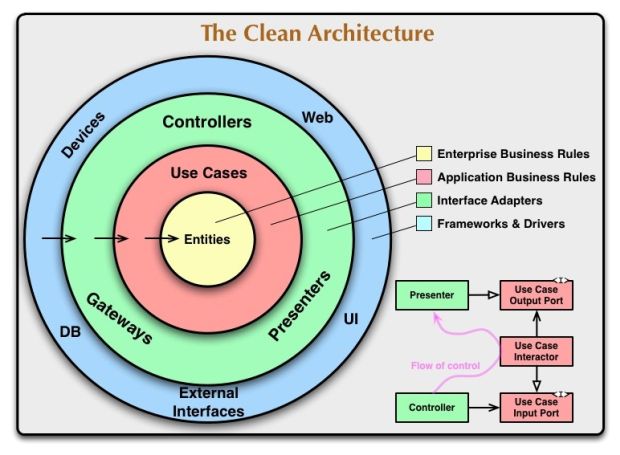
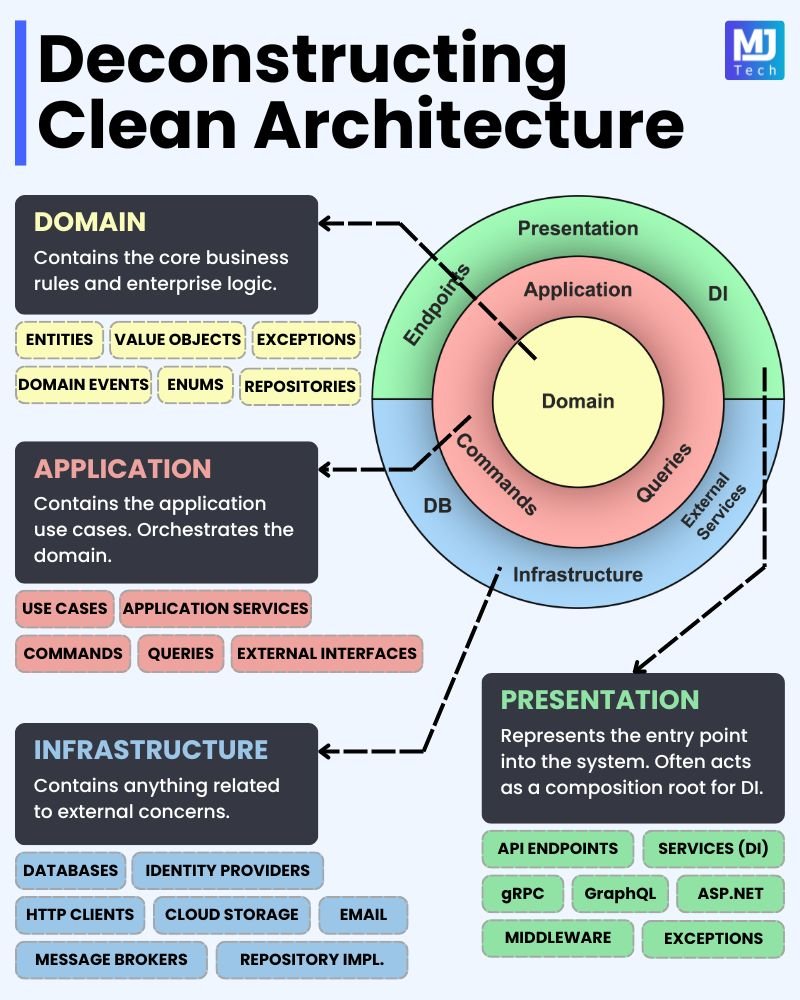
Clean Architecture, proposed by Robert C. Martin (known as Uncle Bob), is a software development approach that aims to create highly testable, scalable, and maintainable systems. The main idea is to separate business logic from implementation details, such as databases, frameworks, and user interfaces.
-
How Clean Architecture Works
- Is often represented as a set of concentric circles:
- Entities: Contains the most fundamental business rules. These classes can be reused in different systems without major changes.
- Use Cases: Defines the specific business logic of the application, including workflows and specific rules that should be applied.
- Interface Adapters: Contains the adapters and interfaces that convert the data from the use cases to the format used by external interfaces (such as APIs, UIs, etc.).
- Frameworks and Drivers: Contains the code specific to frameworks, libraries, and technologies. This layer deals with implementation details such as databases, user interfaces, etc.
- Is often represented as a set of concentric circles:
-
Fundamental Principles
- Framework Independence: The architecture should not depend on specific frameworks. They are tools, not part of the structure.
- Testability: The system should be easily testable.
- User Interface Independence: Business logic should be separated from the user interface.
- Database Independence: Business logic should not be coupled to the database.
- External Agent Independence: Business rules should not depend on external systems.
-
Use Cases
- Large-Scale Systems: In large and complex projects, Clean Architecture helps maintain organization and facilitates system maintenance and evolution.
- Applications with High Testability Requirements: For systems that require a lot of automated testing, the clear separation of responsibilities makes it easier to create and maintain tests.
- Systems with Multiple User Interfaces: If the application needs to support different user interfaces (such as web, mobile, desktop), Clean Architecture allows you to add or modify interfaces without changing the business logic.
- Legacy System Migration: When refactoring legacy systems, Clean Architecture can help separate business logic from legacy code, making modernization easier.
-
Practical Examples
- E-commerce: In an e-commerce system, entities might be products and orders, use cases might include processing orders and calculating shipping, interface adapters might handle REST APIs and web interfaces, and frameworks might include ORM for database access.
- Banking: In a banking system, entities might be accounts and transactions, use cases might include money transfers and statement generation, and adapters might include communication with legacy systems and external APIs.
- Healthcare Application: For a healthcare application, entities might be patients and medical records, use cases might include appointment scheduling and prescription processing, and adapters might handle user interfaces and electronic health record systems.
-
Summary
- Clean Architecture promotes the creation of modular, scalable, and maintainable systems through clear separation of responsibilities and independence from specific technologies. It is especially useful in large-scale projects with high testability requirements and the need to support multiple user interfaces.

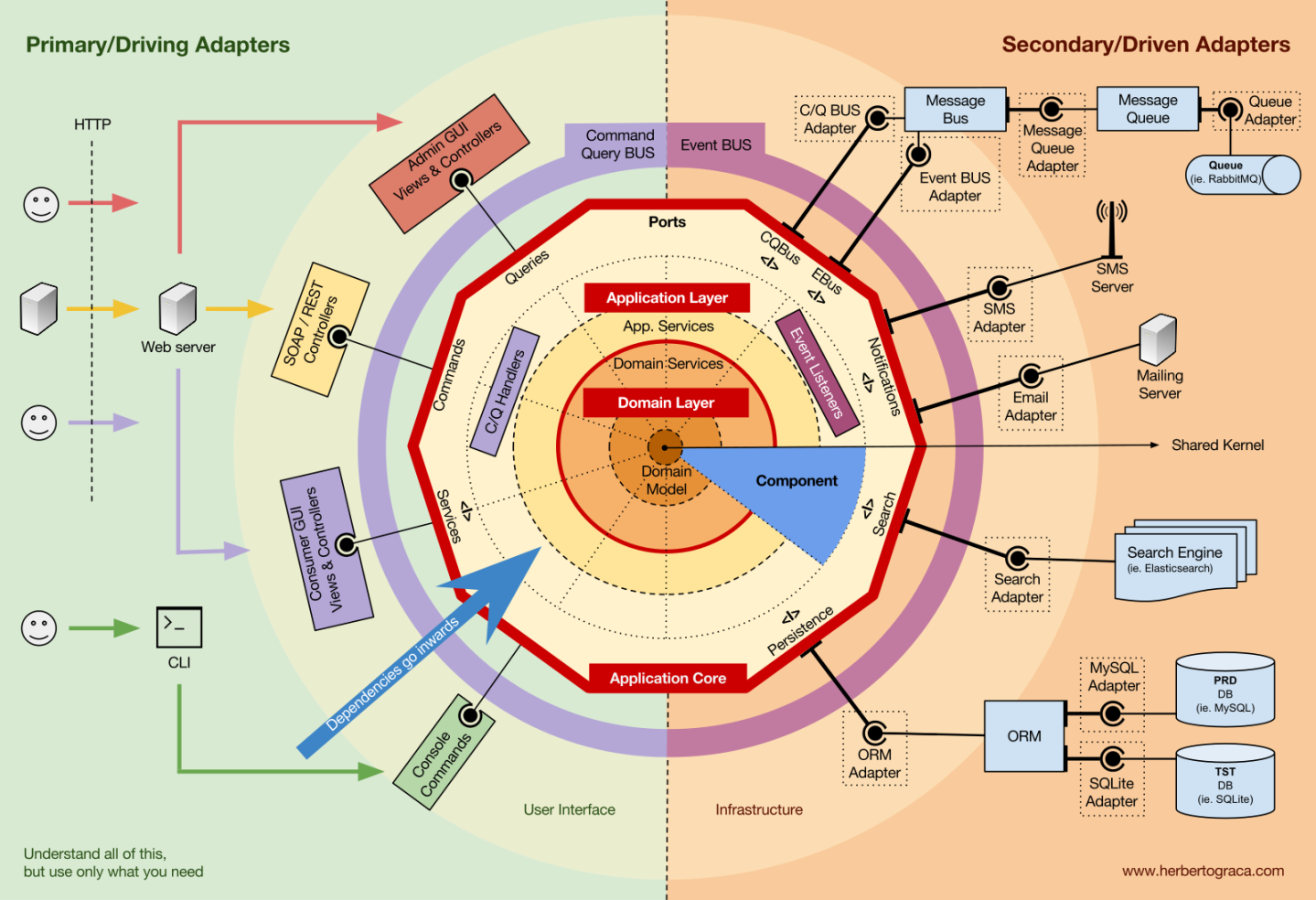

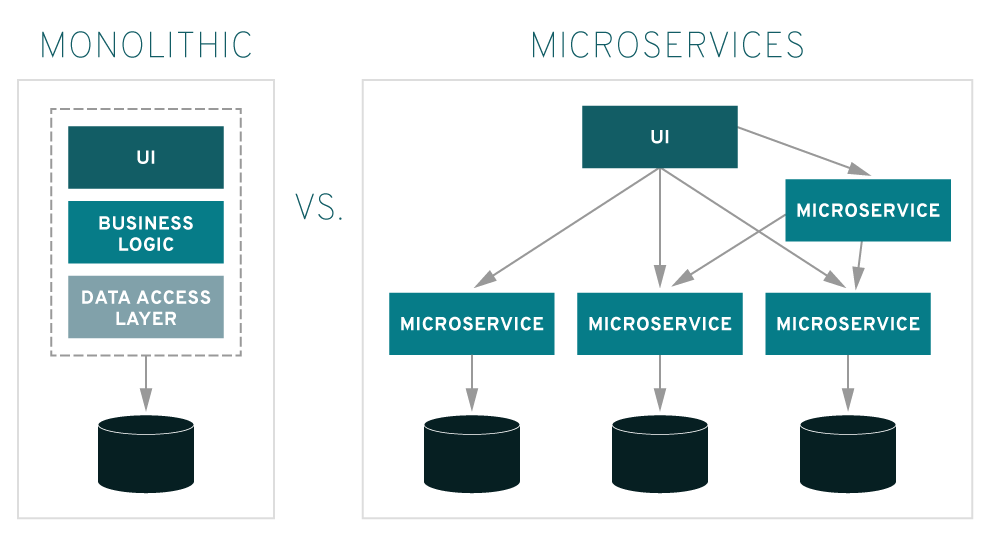
Microservices are an architectural approach to creating applications. What differentiates microservices architecture from traditional monolithic approaches is how it breaks down the application into basic functions. Each function is called a service and can be created and deployed independently. This means that each individual service can work or fail without compromising the others.
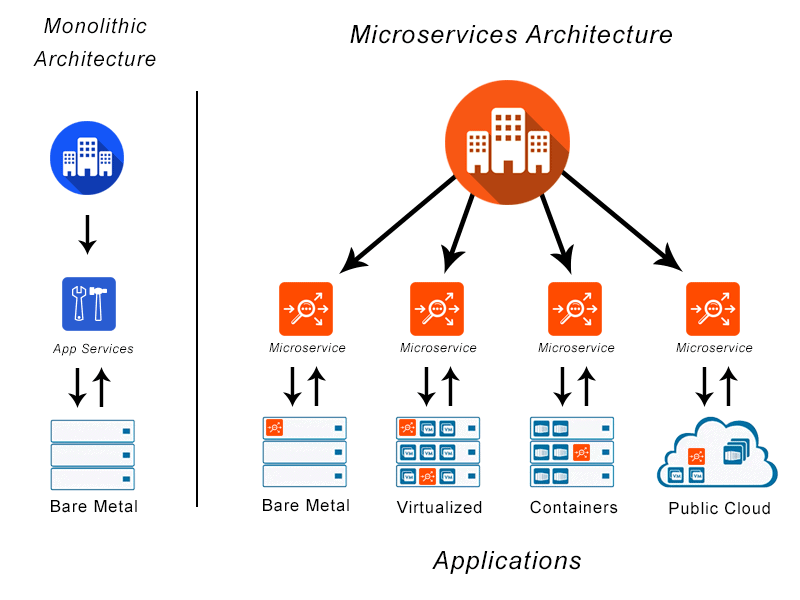
Think about the last time you visited a store's website. You've probably used the site's search bar to search for products. This research represents a service. You may also have seen related product recommendations pulled from a database of shoppers' preferences. This is also a service. Have you added any items to the shopping cart? That's right, this is another service.
- With microservices, your teams and routine tasks can become more efficient through distributed development.
- Furthermore, it is possible to develop several microservices at the same time.
- This means you can have more developers working simultaneously on the same application, which results in less time spent on development.
- Go to market faster because development cycles are shortened, microservices architecture supports more agile deployments and updates.
- Highly scalable
- As demand for certain services increases, you can deploy across multiple servers and infrastructures to meet your needs.
- Resilient
- Independent services, if built correctly, do not affect each other.
- This means that if one element fails, the rest of the application remains operational, unlike the monolithic model.
- Easy to implement
- Because microservices-based applications are more modular and smaller than traditional monolithic applications, concerns arising from these deployments are invalidated.
- This requires greater coordination, but the rewards can be extraordinary.
- Accessible
- As the larger application is decomposed into smaller parts, developers have an easier time understanding, updating and improving these parts.
- This results in faster development cycles, especially when agile development technologies are also employed.
- More open source
- Due to the use of multilingual APIs, developers have the freedom to choose the best language and technology for the required function.
- I. Code Base -> A code base with tracking using revision control, many deploys
- II. Dependencies -> Declare and isolate dependencies
- III. Settings -> Store settings in the environment
- IV. Support Services -> Treat support services as linked resources
- V. Build, release, run -> Strictly separate builds and run in stages
- VI. Processes -> Run the application as one or more processes that do not store state
- VII. Port Binding -> Export services by port binding
- VIII. Competition -> Scale by a process model
- IX. Disposability -> Maximize robustness with quick startup and shutdown
- X. Dev/prod similar -> Keep dev, test, production as similar as possible
- XI. Logs -> Treat logs as stream of events
- XII. Admin Processes -> Perform administration/management tasks as point processes
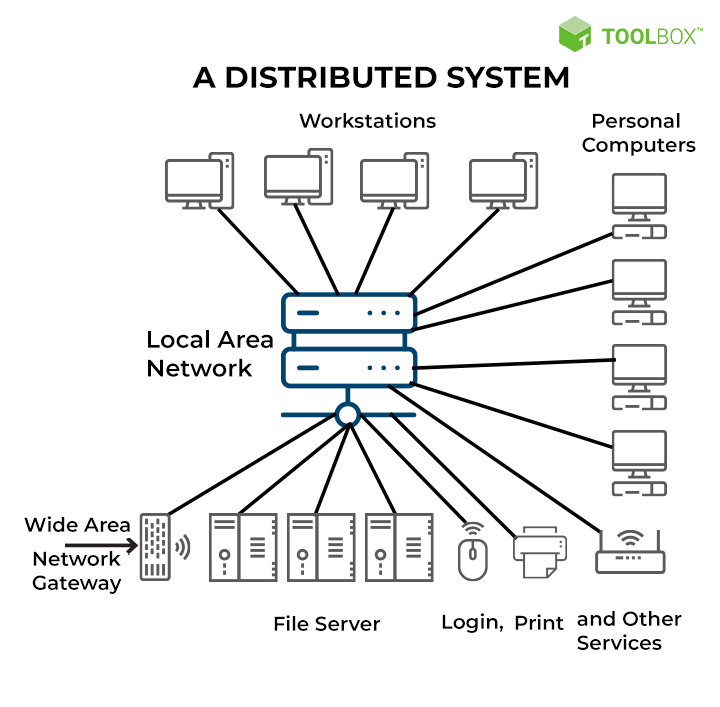
-
A distributed system is a set of independent computers that communicate with each other and collaborate to perform a task.
-
These computers are connected through a network (such as the Internet) and work in a coordinated manner to achieve a shared goal.
-
How Does a Distributed System Work?
- Communication: Computers (nodes) communicate with each other through messages. This can be done through various techniques, such as RPC (Remote Procedure Call) or message queues.
- Coordination: Nodes need to coordinate their actions to avoid conflicts and ensure that the system works correctly. This can be done through consensus algorithms, where nodes agree on a common value or decision.
- Redundancy and Fault Tolerance: Distributed systems are designed to be redundant, that is, if one node fails, others can take over its function. This makes the system more robust and reliable.
- Scalability: Because several computers work together, it is easy to add more nodes to increase the system's capacity.
-
Distributed Systems Use Cases
- Cloud Services: Platforms such as AWS, Google Cloud, and Azure use distributed systems to provide scalable and highly available services.
- Social Networks: Networks such as Facebook and Twitter use distributed systems to manage large volumes of data and allow millions of users to interact simultaneously.
- E-commerce: Online stores such as Amazon use distributed systems to manage inventory, process payments, and provide personalized recommendations.
- Distributed Databases: Systems such as Apache Cassandra and MongoDB are used to store large volumes of data in a distributed manner, allowing for fast access and high availability.
- High Performance Computing (HPC): For tasks that require a lot of computing power, such as scientific simulations and big data analysis, distributed systems are used to divide the workload among multiple computers.
-
Benefits
- High Availability: Because data and processes are distributed, the system continues to function even if some nodes fail.
- Scalability: Easy to expand by adding more computers to the network.
- Performance: Ability to process large volumes of data quickly by dividing the workload.
-
Challenges
- Complexity: Designing and managing distributed systems is more complex due to the need to coordinate multiple nodes.
- Network Latency and Reliability: Communication between nodes can be slow or fail, which needs to be managed.
- Security: Securing data distributed across multiple nodes is more challenging.
-
Can we say that the Bitcoin blockchain is a distributed system?
- Yes, we can say that the Bitcoin blockchain is a distributed system. Let's explore how the Bitcoin blockchain fits into the definition of distributed systems:
-
What is the Bitcoin Blockchain?
- The Bitcoin blockchain is a decentralized digital ledger that records all transactions made with Bitcoin. It is maintained by a network of computers (or nodes) distributed globally.
-
How does the Bitcoin Blockchain work?
- Distribution: The blockchain is maintained by a network of distributed nodes, each of which has a complete copy of the ledger. No node has a central authority, and all nodes work together to validate and record transactions.
- Transaction Validation: When a transaction is made, it is broadcast to all nodes in the network. These nodes verify the validity of the transaction (for example, whether the sender has sufficient funds) using pre-defined consensus rules.
- Consensus: Bitcoin uses a consensus algorithm called Proof of Work (PoW). Nodes, called miners, compete to solve a complex mathematical problem. The first node to solve the problem validates the block of transactions and adds it to the blockchain. Other nodes verify the validity of the new block and accept it, maintaining the integrity of the chain.
- Immutability: Once a block is added to the blockchain, it is virtually impossible to change it, as this would require recalculating the PoW for all subsequent blocks, which is computationally infeasible.
- Security: The decentralization of the network and the use of PoW make the blockchain resistant to attacks. To compromise the network, an attacker would need to control more than 50% of the network's computing power (51% attack), which is extremely difficult and expensive.
-
Distributed System Characteristics in the Bitcoin Blockchain
- Decentralization: There is no single point of control. All nodes have equal responsibilities and decision-making power.
- Coordination and Consensus: PoW is used to coordinate and achieve consensus among nodes, ensuring that everyone agrees on the current state of the blockchain.
- Fault Tolerance: If some nodes fail or become malicious, the network as a whole continues to function properly.
- Data Distribution: The blockchain is replicated across all nodes, providing redundancy and data security.
-
Use Cases for the Bitcoin Blockchain as a Distributed System
- Financial Transactions: Facilitates Bitcoin transactions without the need for intermediaries such as banks.
- Security and Transparency: Provides a transparent and secure record of all transactions, which is accessible to anyone.
- Smart Contracts: Although more common in other blockchains, the ability to execute programmable contracts in a decentralized manner is a related concept.
-
Benefits:
- Security: High resistance to fraud and attacks due to decentralization and PoW.
- Transparency: Anyone can verify transactions on the blockchain.
- Decentralization: Eliminates the need for a central authority.
-
Challenges:
- Scalability: Transaction processing capacity is limited.
- Energy Consumption: PoW requires a large amount of energy. - Latency: The time it takes to add a new block can be relatively long.
In short, the Bitcoin blockchain is an excellent example of a distributed system, combining decentralization, consensus, security, and immutability to create a robust and reliable system for recording financial transactions.
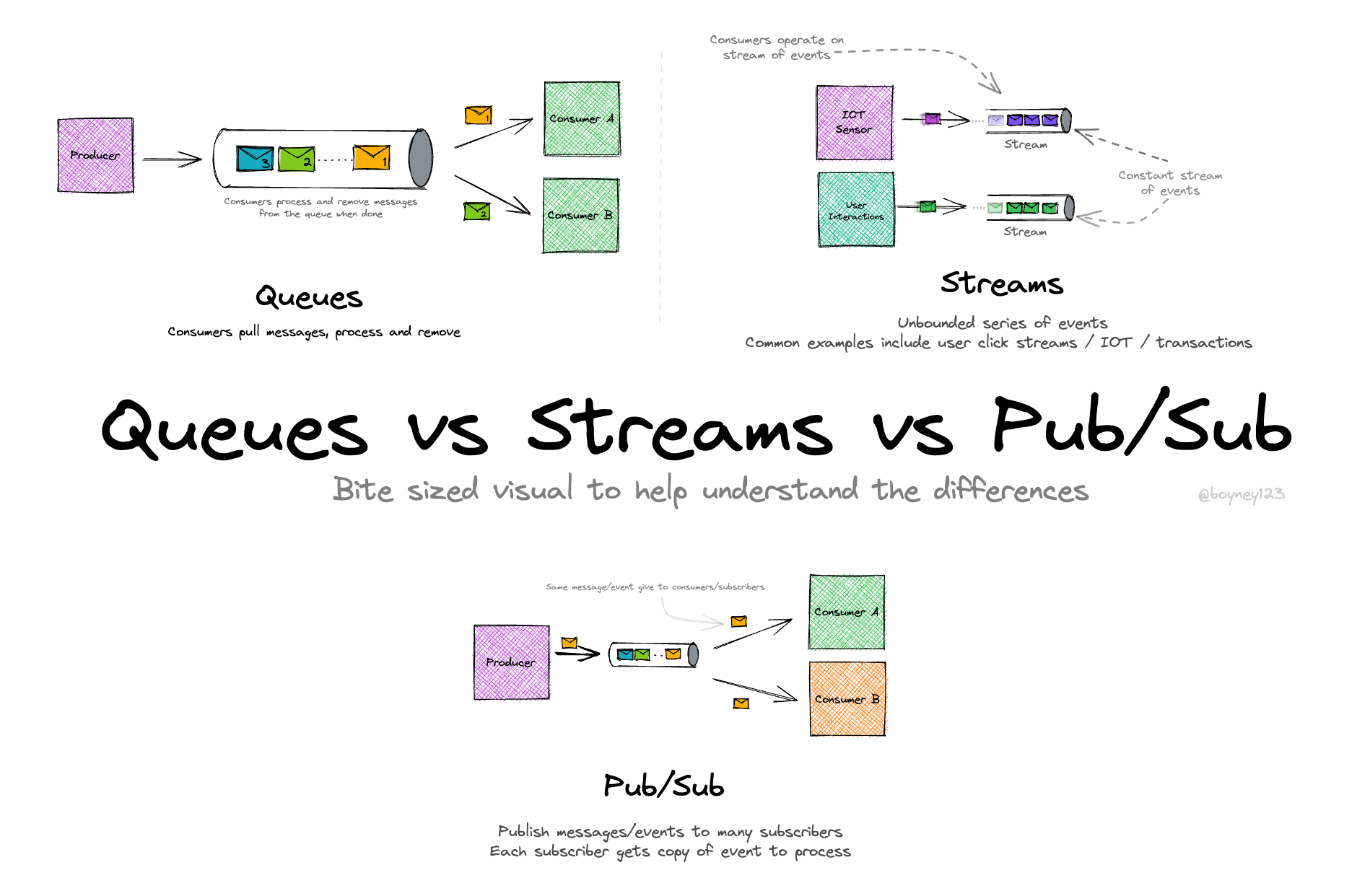
- References:
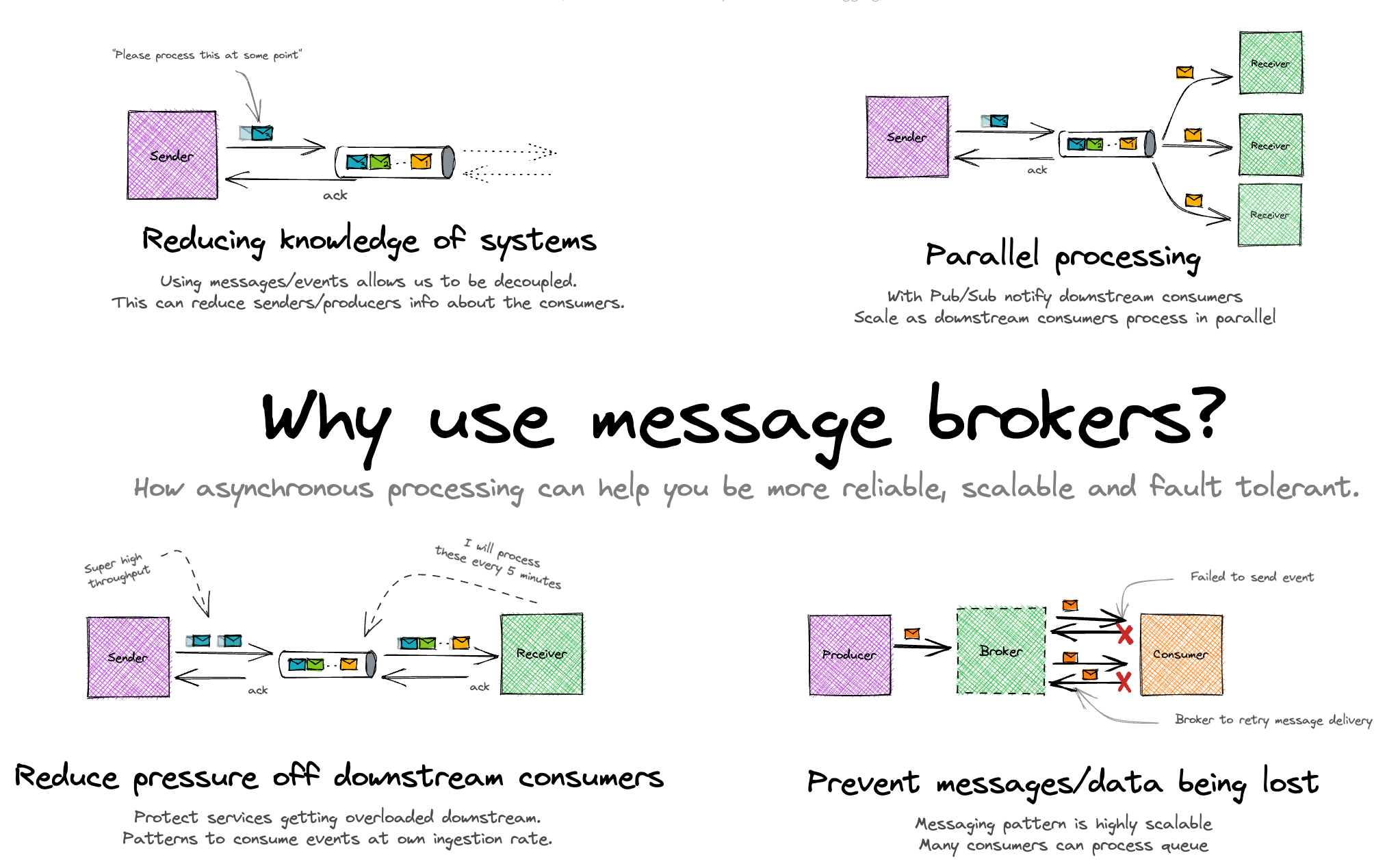
-
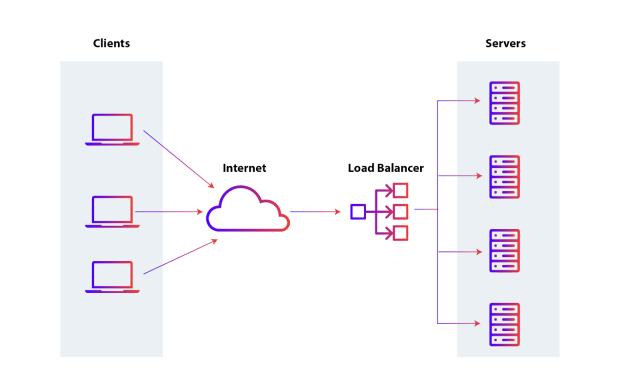
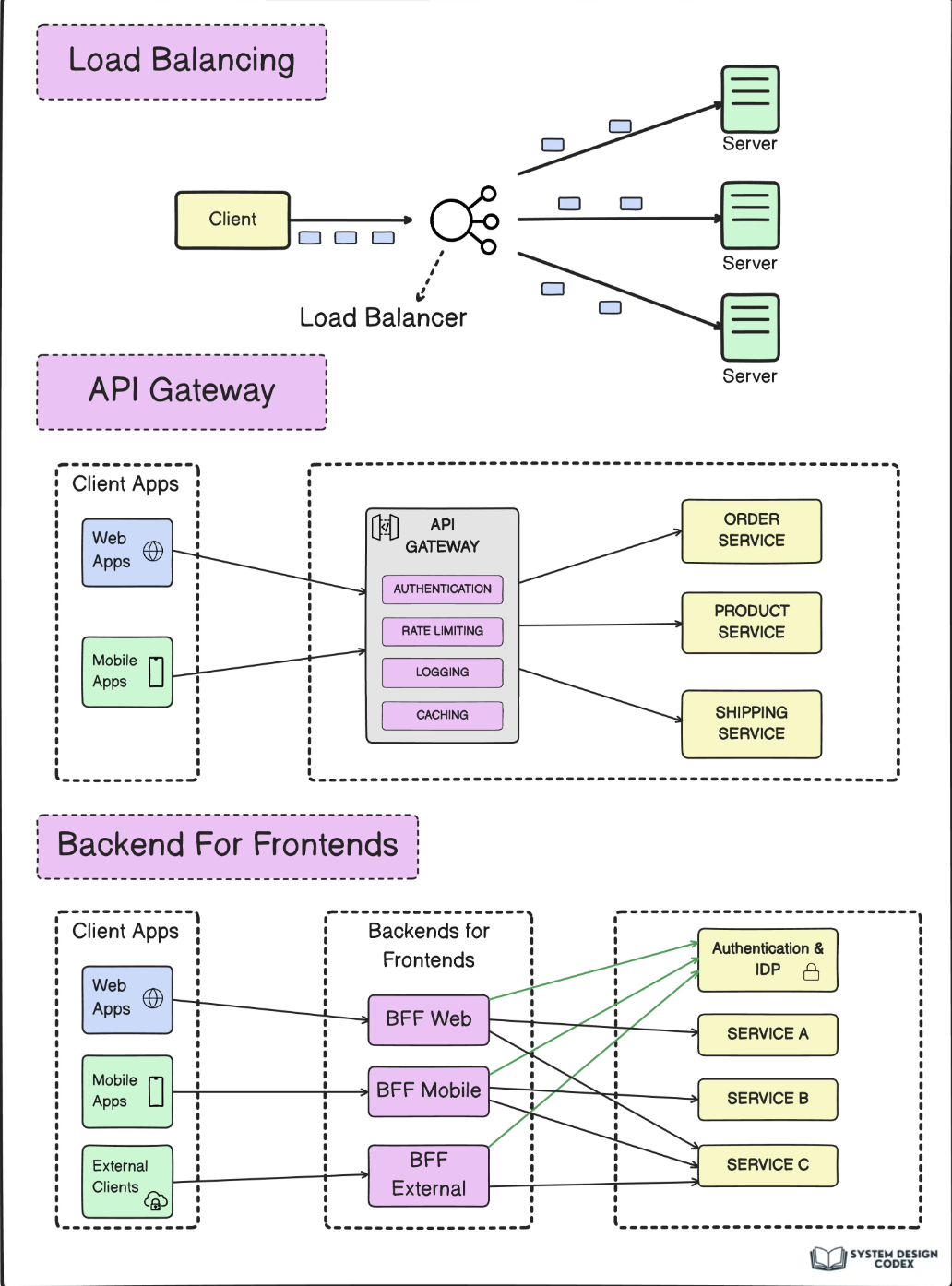
Is a device or software that distributes network or application traffic across multiple servers. The main idea is to ensure that no server is overloaded while others are underutilized, thus improving the efficiency, availability, and responsiveness of systems.
-
How does a Load Balancer work?
- Request Reception: The Load Balancer receives all incoming requests from clients, such as web page requests, database queries, etc.
- Request Distribution: It then distributes these requests across multiple available servers, called backend servers or nodes. There are several strategies for this distribution:
- Round Robin: Requests are distributed sequentially across servers.
- Least Connections: Requests are sent to the server with the least active connections at the time.
- IP Hash: The server is chosen based on the hash of the client's IP.
- Server Monitoring: The Load Balancer continuously monitors the health of the servers. If it detects that a server is down or overloaded, it redirects traffic to other active servers.
-
Load Balancer Use Cases
- High Availability Web Services: Websites and web applications that require high availability and performance. For example, online stores, social media platforms, and streaming services.
- Email Systems: Email services that need to distribute email traffic across multiple servers to ensure that all emails are processed efficiently.
- Business Critical Applications: Enterprise applications that require high availability and cannot afford downtime, such as banking and financial systems.
- Cloud Applications: Services and applications hosted in the cloud that need to scale dynamically to handle changes in user traffic.
-
Load Balancer Advantages
- Improved Performance: Distributes the workload evenly across servers, avoiding overloading a single server and improving response time.
- High Availability and Resilience: If a server fails, the Load Balancer redirects traffic to the remaining servers, ensuring that the service remains available.
- Scalability: Makes it easy to add new servers to handle increases in demand without interrupting service.
-
Disadvantages of Load Balancers
- Additional Cost: Implementing a Load Balancer can involve additional costs, both in terms of hardware and software licenses.
- Complexity: Setting up and managing a Load Balancer can add complexity to your infrastructure.
- Single Point of Failure: Although Load Balancers are designed for high availability, they can themselves become a single point of failure if not configured with redundancy.
-
Practical Examples
- Amazon Web Services (AWS): AWS Elastic Load Balancer automatically distributes incoming application traffic across multiple Amazon EC2 instances.
- Google Cloud Platform: Google Cloud Load Balancing distributes traffic across multiple backends, such as virtual machine instances, and can balance the load globally.
In summary, a Load Balancer is an essential tool for efficiently distributing traffic across multiple servers, ensuring that services are fast, reliable, and scalable.
The Round Robin algorithm is a simple and efficient method of process management in operating systems and networks. Let's understand it in two main areas:
-
In Operating Systems:
- Objective: Manage the execution of processes (running programs) in a fair and efficient manner.
- How it Works: Imagine that we have several processes waiting to be executed. Round Robin distributes CPU time among these processes equally.
-
Steps:
- Process Queue: Processes are placed in a circular queue (imagine a wheel where each process occupies a position).
- Time Quantum: A fixed period of time (quantum) is defined that each process can use the CPU.
- Execution: The first process in the queue is executed by the CPU for a time equal to the quantum.
- Context Switching: If the process does not finish within the quantum, it is placed at the end of the queue and the CPU moves on to execute the next process.
- Repetition: This continues, ensuring that each process has the same opportunity to execute.
-
Benefits:
- Fairness: All processes receive an equal share of CPU time.
- Simplicity: Easy to implement.
- Responsiveness: Useful in time-sharing systems where many users interact with the system.
-
In Networks:
- Goal: Distribute network requests (e.g., on web servers) evenly across multiple servers.
- How it Works: When multiple requests arrive, they are distributed in a circular fashion among a list of available servers.
-
Steps:
- Server List: Keep a list of servers that can handle the requests.
- Distribution: The first request is sent to the first server, the second to the second server, and so on.
- Restart: When the list of servers is completely traversed, the process restarts from the first server.
-
Benefits:
- Load Balancing: Requests are distributed evenly, avoiding overloading a single server.
- Simplicity: Easy to implement and configure.
In short, the Round Robin algorithm is a fair and simple way to manage processes or distribute tasks, whether in an operating system or in a network environment, ensuring that everyone receives attention equitably.
-
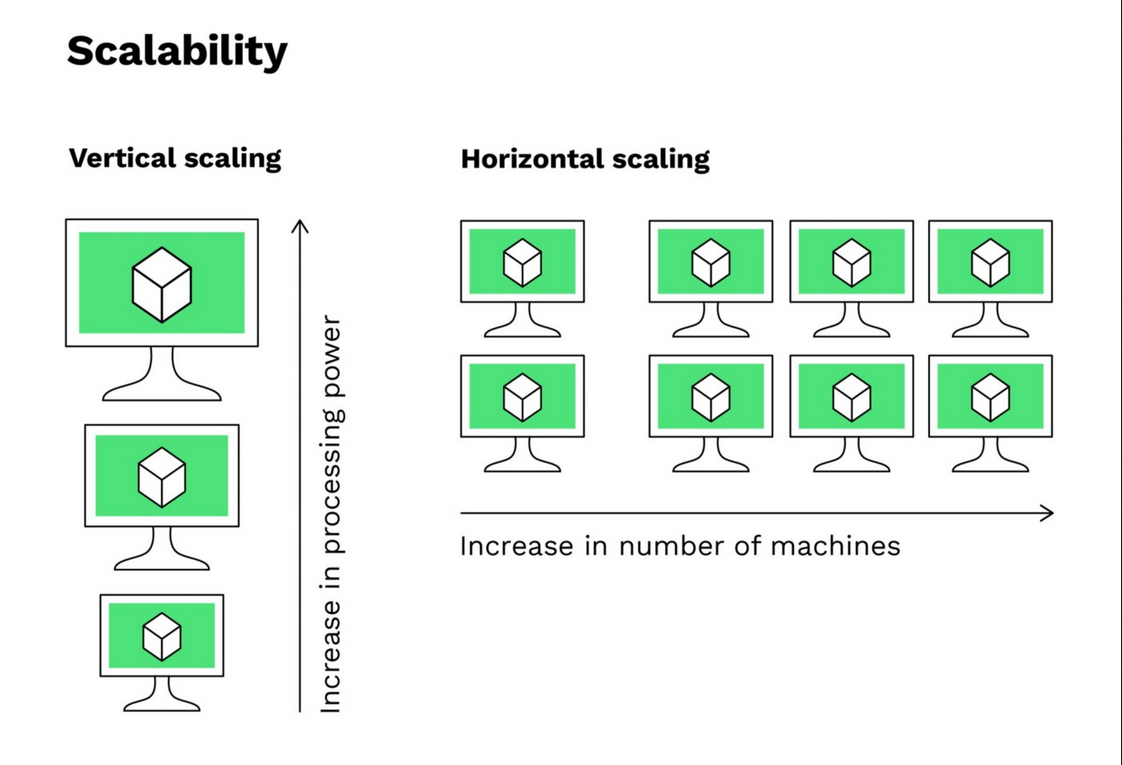
Horizontal Scaling (or "Scaling Out") is a technique for increasing the capacity of a system by adding more units or servers to the resource pool, rather than increasing the capacity of a single server (which would be vertical scaling).
-
How does Horizontal Scaling work?
- Adding Servers: When the system needs to handle more traffic or a larger workload, new servers are added to the existing infrastructure. Each new server can handle part of the total load.
- Load Distribution: A mechanism, such as a Load Balancer, distributes requests and tasks across multiple servers. This helps ensure that no server is overloaded.
- Server Independence: Each server operates independently, although they all work together to provide a cohesive service. This means that if one server fails, the others continue to function, ensuring high availability.
- State Management: In many applications, especially web-based ones, it is necessary to manage user state (such as sessions). In horizontal scaling, this can be done using shared caches, distributed databases, or centralized session stores.
-
Horizontal Scaling Use Cases
- High-Traffic Web Applications: Websites that receive large volumes of traffic, such as online stores during promotions, social networks, and media platforms.
- Streaming Services: Platforms that deliver videos or music to millions of users simultaneously, such as Netflix and Spotify.
- Database Systems: Distributed databases that store large volumes of data and require high availability, such as those used by financial services or healthcare.
- Online Gaming Platforms: Multiplayer games that need to handle a large number of players connected at the same time.
-
Advantages of Horizontal Scaling
- Infinite Scalability: In theory, you can continue to add more servers to meet increased demand.
- High Availability: If one server fails, the others can continue to operate, providing a more resilient service. []
- Cost-Effectiveness: It is often cheaper to add smaller, cheaper servers than to invest in a single, very powerful server.
-
Disadvantages of Horizontal Scaling
- Complexity: Setting up and managing a horizontally scaled environment can be more complex, requiring tools for orchestration and monitoring.
- Data Consistency: Ensuring that data is consistent across servers can be challenging, especially in distributed systems.
- Load Balancer Dependency: The effectiveness of horizontal scaling often depends on an efficient load balancer, which can become a single point of failure if not configured with redundancy.
-
Practical Examples
- Amazon Web Services (AWS): Using AWS Auto Scaling to automatically add EC2 instances when demand increases.
- Google Cloud Platform: Using Google Kubernetes Engine (GKE) to scale pods horizontally in response to increased load.
- Microsoft Azure: Implementing automatic scaling of services with Azure Virtual Machine Scale Sets.
In summary, Horizontal Scaling is a powerful strategy for increasing the capacity and resilience of software systems, especially useful for applications that need to handle large volumes of traffic and high availability.
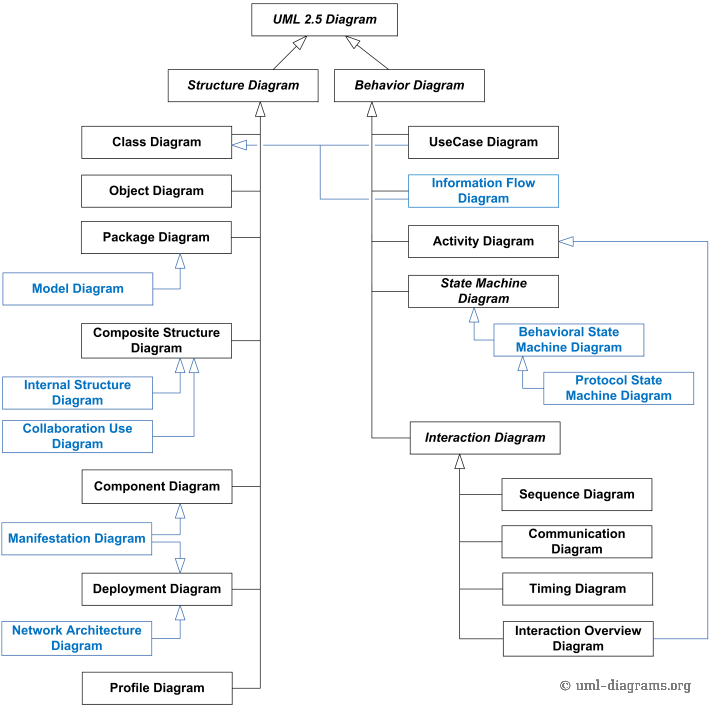
It is a notation language (a way of writing, illustrating, communicating) for use in systems projects.
This language is expressed through diagrams. Each diagram is made up of elements (graphic shapes used for drawings) that are related to each other.
UML diagrams are divided into two large groups: structural diagrams and behavioral diagrams.
Structural diagrams should be used to specify details of the system structure (static part), for example: classes, methods, interfaces, namespaces, services, how components should be installed, what the system architecture should be like, etc.
Behavioral diagrams should be used to specify details of the system's behavior (dynamic part), for example: how functionalities should work, how a business process should be handled by the system, how structural components exchange messages and how they respond to calls etc.
"João wants A, explains to the team something “similar” to B. Marcos understands that João wants C, and explains to Claudia that he should do D. Claudia makes a “D that looks more like an E”, and delivers a “half E” for João. And João wanted an A…”
UML is like a universal language for software production professionals, it is a “Google Translate” that greatly helps clear and objective communication between people involved in the production process (Business Analysts, Product Owner, Scrum Master, Architects , Developers, Project/Product Managers and other interested parties). The objective of a UML diagram is to convey a message in a standardized way, where all recipients of this message understand the pattern used. It's the famous: “Do you understand or do you want me to draw?”
Imagine that in the same room, without internet or telephone, there are three people who only speak their native language: a Chinese, a French, and a Brazilian.
In this room there is only paper and pencil. The Frenchman wants a coffee.
What will be the most efficient way, considering the resources available in the room, for the French person to convey the message “I want a coffee”?
Maybe drawing a picture of a cup of coffee!
Making this clear, in a simple, objective, transparent and pragmatic way, is communicating well.
Taking the above reasoning to software projects, UML must be used to communicate what you want and/or how you want, in an efficient way.
-
Domain-Driven Design: Tackling Complexity in the Heart of Software
-
What is most important in software?
- The code and technology used, the developer would say.
- The tests, the tester would say.
- The project plan, the manager would say.
- The architecture used, the architect would say.
-
Is there anything missing?
- The customer failed to respond, the most important thing being that the software solved their problem.
- Conclusion: The most important thing is the business rule and the value that the software adds to the customer.
Domain-Driven Design (DDD) is a software development approach that brings together a set of concepts, principles and techniques that focus on the domain and domain logic with the objective of creating a Domain Model or (domain model).
Using DDD means developing software according to the domain related to the problem we are proposing to solve.
Note: In this context, domain is what the software program models and the problem it proposes to solve = business rules.
Knowing the domain is fundamental and creating a model and adopting an application architecture that best reflects the concepts of the domain is not an easy task nor a task only for the analyst.
DDD suggests a standard architecture so that we can focus on the domain.
The following is a suggestion for a layered architecture that can be used in the domain model
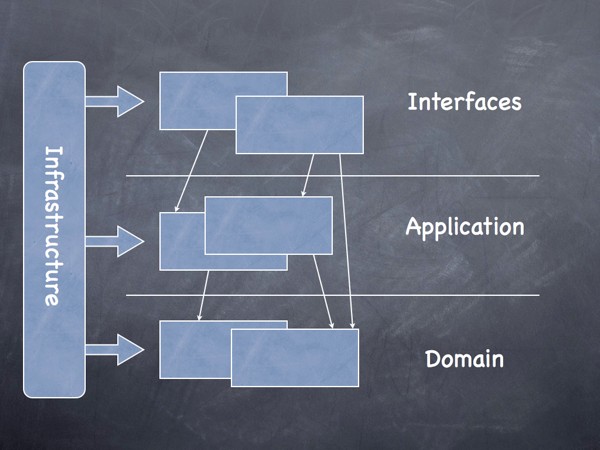
User Interface - Presents information to the user and interprets their commands. Application - Layer that coordinates application activity. Does not contain business logic. Domain - Contains information about the domain. It's the heart of the business. Infrastructure - Acts as a support library for the other layers. Performs communication between layers. Implements the persistence of business objects.
The focus of the approach is to create a domain that “speaks the language” of the user using what is known as a Ubiquitous language.
Ubiquitous language (common language) means that when working with DDD we must speak using the same language, in a single model, so that it is understood by the client, analyst, designer, designer, tester, manager, etc. in this language, which would be the language used in everyday life.
What are the advantages of using DDD?
- The code becomes less coupled and more cohesive.
- The business is better understood by everyone on the team, which facilitates development.
- DDD is not a 'silver bullet' nor a universal architecture, but an approach that should be considered and applied or not to your problem after you think and study a lot about its applications and consequences.
Remember, you don't have to go around applying (trying to apply) DDD to all types of projects.
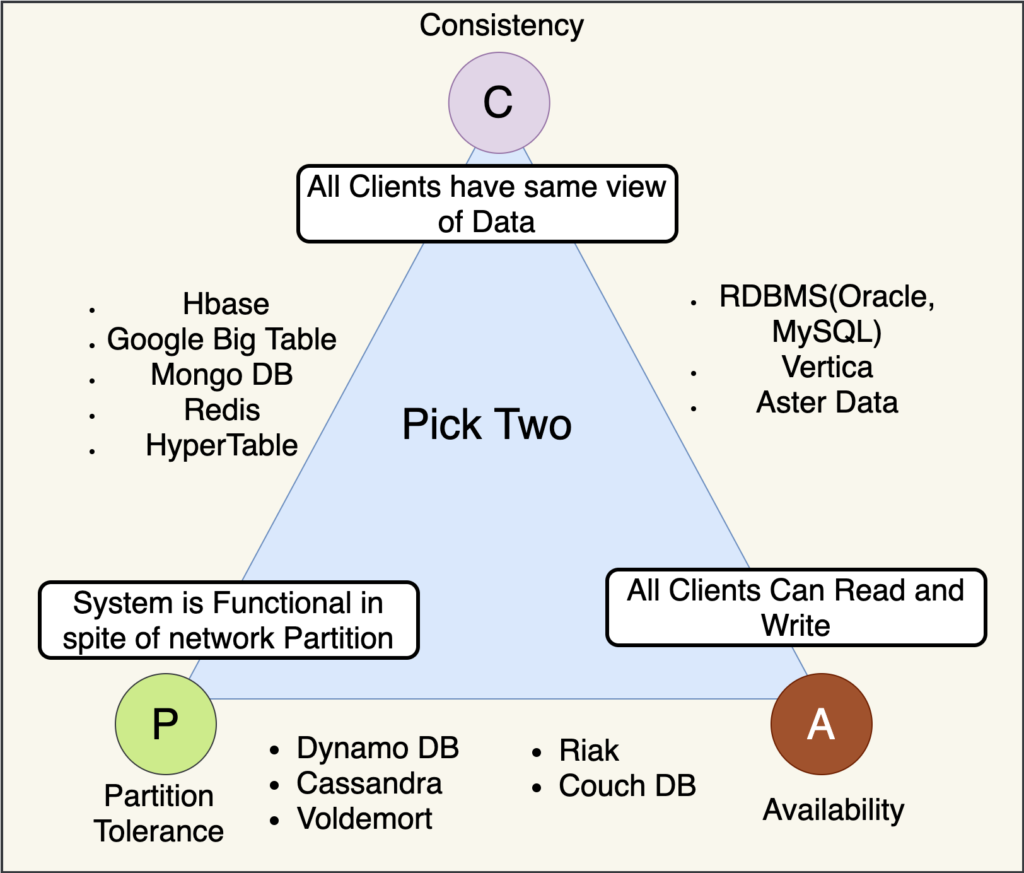
Also called Brewer's Theorem, it states that it is impossible that distributed data storage simultaneously provides more than two of the following three guarantees:</pca
- Consistency: Each read receives the most recent write or an error
- Availability: Each request receives a response (without error) - no guarantee that it contains the most recent writing
- Partition tolerance: The system continues to function despite an arbitrary number of messages being discarded (or delayed) by the network between nodes
No distributed system is protected from network failures, so partition must generally be tolerated. In the presence of partitions, two options are given: consistency or availability.
When choosing consistency over availability, the system will return an error or timeout if specific information cannot be guaranteed to be updated due to its sharing on the network.
When choosing availability over consistency, the system will always process the query and attempt to return the most recent available version of the information, even if it cannot guarantee that it is up to date due to partitions.
Super short version: databases can only choose 2 of the 3 elements. It is mathematically impossible to have all 3.